一只前端切图仔,略懂Node.js Amateur programming enthusiast
一只前端切图仔,略懂Node.js Amateur programming enthusiast

JS 中七种内置类型(null,undefined,boolean,number,string,symbol,object)又分为两大类型
简记(nubnsso)
null,undefined,boolean,number,string,symbolArray ,Function, Date, RegExp等
//基本数据类型
var str = "abc";
console.log(str[1]="f"); // f
console.log(str); // abc
//引用数据类型
var a = [1,2,3];
a[1] = 5;
console.log(a[1]); // 5//基本数据类型
var a = 1;
var b = 1;
console.log(a === b);//true
//引用数据类型
var a = [1,2,3];
var b = [1,2,3];
console.log(a === b); // false
//虽然变量 a 和变量 b 都是表示一个内容为 1,2,3 的数组,
//但是其在内存中的位置不一样,也就是说变量 a 和变量 b 指向的不是同一个对象,所以他们是不相等的typeof 对于基本类型,除了 null 都可以显示正确的类型,对于 null 来说,虽然它是基本类型,但是会显示 object,这是一个存在很久了的 Bug, 这与JavaScript的历史有关,null被设计成可以自动转为0
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof b // b 没有声明,但是还会显示 undefined
typeof null // 'object'
// typeof` 对于对象,除了函数都会显示 `object
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'获得一个变量的正确类型,可以通过 Object.prototype.toString.call(xx)。这样我们就可以获得类似 [object Type] 的字符串。
Object.prototype.toString.call(22) //"[object Number]"
Object.prototype.toString.call('22') //"[object String]"
Object.prototype.toString.call(null) //"[object Null]"
Object.prototype.toString.call(undefined) //"[object Undefined]"
Object.prototype.toString.call(a) //"[object Undefined]"
Object.prototype.toString.call(true) //"[object Boolean]"
Object.prototype.toString.call({a:1}) //"[object Object]"typeof的安全防范机制
检查 DEBUG 变量是否已被声明
if (DEBUG) {
console.log('Debugging is starting');
}
// 报错 ReferenceError 错误
if (typeof DEBUG !== 'undefined') {
console.log('Debugging is starting');
}常见问题:null 和 undefined 的区别?
null表示"没有对象",即该处不应该有值。典型用法是:
Object.getPrototypeOf(Object.prototype)
// nullundefined表示"缺少值",就是此处应该有一个值,但是还没有定义。典型用法是:
(1)变量被声明了,但没有赋值时,就等于undefined。
(2)调用函数时,应该提供的参数没有提供,该参数等于undefined。
(3)对象没有赋值的属性,该属性的值为undefined。
(4)函数没有返回值时,默认返回undefined。
//变量被声明了,但没有赋值时,就等于undefined。
var i;
i // undefined
//调用函数时,应该提供的参数没有提供,该参数等于undefined。
function f(x){console.log(x)}
f() // undefined
//对象没有赋值的属性,该属性的值为undefined。
var o = new Object();
o.p // undefined
//函数没有返回值时,默认返回undefined。
var x = f();
x // undefined常见问题:为什么有的编程规范要求用 void 0 代替 undefined?
因为 JavaScript 的代码 undefined 是一个变量,而并非是一个关键字,这是 JavaScript 语言公认的设计失误之一,所以,我们为了避免无意中被篡改,建议使用 void 0 来获取 undefined 值,void 后面随便跟上一个变量,组成表达式,返回就是 undefined
let a
a === undefined //true
a //undefined
void 0 //undefined void 后面随便跟上一个组成表达式返回就是 undefined
a === void 0 //trueBoolean 类型有两个值, true 和 false
JavaScript 中的 Number 类型基本符合 IEEE 754-2008 规定的双精度浮点数规则,但是 JavaScript 为了表达几个额外的语言场景(比如不让除以 0 出错,而引入了无穷大的概念),规定了几个例外情况:
常见问题:0.1 + 0.2 不是等于 0.3 么?为什么 JavaScript 里不是这样的?
这里错误的不是结论,而是比较的方法,正确的比较方法是使用 JavaScript 提供的最小精度值:
console.log( Math.abs(0.1 + 0.2 - 0.3) <= Number.EPSILON);检查等式左右两边差的绝对值是否小于最小精度,才是正确的比较浮点数的方法。这段代码结果就是 true 了。
string常见问题:
Symbol 是 ES6 中引入的新类型,它是一切非字符串的对象 key 的集合,在 ES6 规范中,整个对象系统被用 Symbol 重塑。
//创建
var mySymbol = Symbol("my symbol");Object 表示对象的意思,它是一切有形和无形物体的总称。在 JavaScript 中,对象的定义是“属性的集合”。
属性分为数据属性和访问器属性,二者都是 key-value 结构,key 可以是字符串或者 Symbol 类型
加法
其他运算符
1 + '1' // '11'
true + true // 2
4 + [1,2,3] // "41,2,3"
4 * '3' // 12
4 * [] // 0
4 * [1, 2] // NaN== 操作符JavaScript 中的“ == ”运算,因为试图实现跨类型的比较,它的规则复杂到几乎没人可以记住, 它属于设计失误,并非语言中有价值的部分,很多实践中推荐禁止使用“ ==”,而要求程序员进行显式地类型转换后,用 === 比较
unicode字符索引来比较'10'.charCodeAt() //49
'厉害'.charCodeAt() //21385
'10' < '厉害' //true
'10' > '厉害' //false对象在转换类型的时候,会调用内置的[[ToPrimitive]]函数
转换流程:
Symbol.toPrimitive)Symbol.toPrimitive 方法时则只调用该方法,优先级最高toString方法,转换为基础类型的话就返回转换的值valueOf方法,结果不是基础类型的话再调用toString方法var a = {
valueOf() {
return 0;
},
toString() {
return '1';
},
[Symbol.toPrimitive]() {
return 2;
}
}
var b = {
valueOf() {
return 0;
},
toString() {
return '1';
},
}
console.log(`abc${b}`) // => 'abc1'
console.log(1 + a) // => 3
console.log('1' + a) // => '12'JS引擎有意去模糊“对象”和“基本类型”之间的关系, 遇到"."时,JS引擎会临时帮我们做一层“装箱转换”,这里就是 new String() 生成一个“临时对象”,这个临时对象是基本类型对应的包装类型。
装箱转换,正是把基本类型对象转换为对应的包装类型对象,它是类型转换中一种相当重要的种类
// Number
1
new Number(1)
// String
'aaa'
new String('aaa')
// Boolean
true
new Boolean(true)Symbol不能new,我们用特殊的方法把它new出来
Object(Symbol('aaa'))
// 或者
(function(){return this}).call(Symbol('aaa'))JS中拆箱转换是调用了对象的toPrimitive方法来拆箱,它会依次尝试使用valueOf, toString来转换,如果没有valueOf, toString方法,或者这2个方法转换出来的都是非基本类型,则报错
webpack配置中需要理解几个核心的概念Entry 、Output、Loaders 、Plugins、 Chunk
Entry:指定webpack开始构建的入口模块,从该模块开始构建并计算出直接或间接依赖的模块或者库
Output:告诉webpack如何命名输出的文件以及输出的目录
Loaders:由于webpack只能处理javascript,所以我们需要对一些非js文件处理成webpack能够处理的模块,比如sass文件
Plugins:Loaders将各类型的文件处理成webpack能够处理的模块,plugins有着很强的能力。插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量。但也是最复杂的一个。比如对js文件进行压缩优化的UglifyJsPlugin插件
Chunk:coding split的产物,我们可以对一些代码打包成一个单独的chunk,比如某些公共模块,去重,更好的利用缓存。或者按需加载某些功能模块,优化加载时间。在webpack3及以前我们都利用CommonsChunkPlugin将一些公共代码分割成一个chunk,实现单独加载。在webpack4 中CommonsChunkPlugin被废弃,使用SplitChunksPlugin
position是CSS中非常重要的一个属性,通过position属性,我们可以让元素相对于其正常位置,父元素或者浏览器窗口进行偏移。
CSS的很多其他属性大多容易理解,比如字体,文本,背景等。有些CSS书籍、博客或网站也会对这些简单的属性进行大张旗鼓的介绍,而偏偏忽略了对一些难缠的属性讲解,有避重就轻的嫌疑。CSS中主要难以理解的属性包括盒型结构,各种垂直居中问题、弹性布局以及定位。
正如position is everything.
position属性值:
position的属性值共有四个常用的:static、relative、absolute、fixed。
还有三个不常用的:inherit、initial、sticky
所有元素在默认的情况下position属性均为static,而我们在布局上经常会用到的相对定位和绝对定位常用的属性top、bottom、left、right 或者 z-index 声明在position为static的情况下无效。其用法为:在改变了元素的position属性后可以将元素重置为static让其回归到页面默认的文档流中。
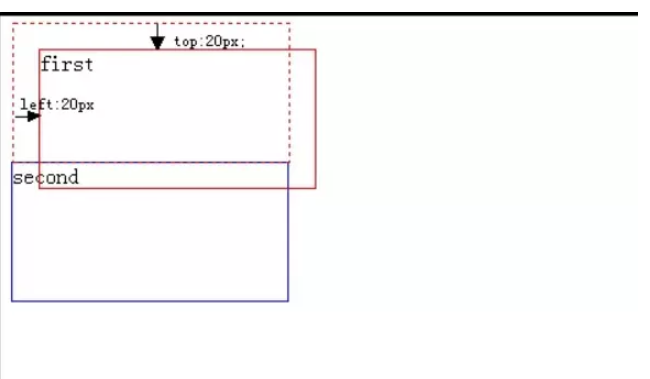
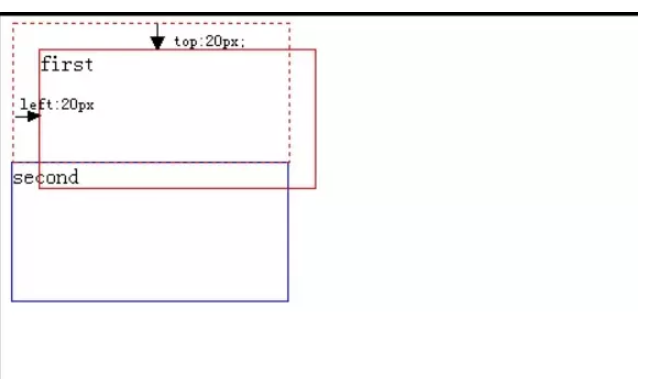
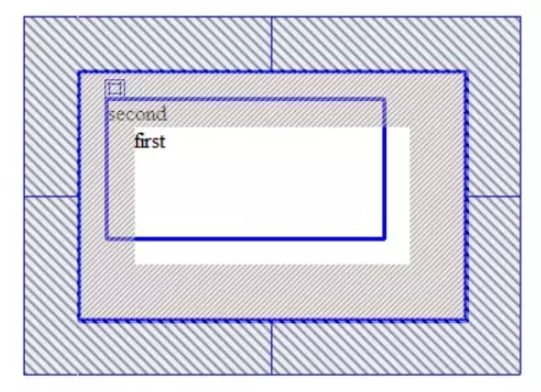
relative定位,又称为相对定位,从字面上来解析,我们就可以看出该属性的主要特性:相对。但是它相对的又是相对于什么地方而言的呢?这个是个重点,也是最让我在学习CSS中迷糊的一个地方,现在让我们来做个测试,我想大家都会明白的:
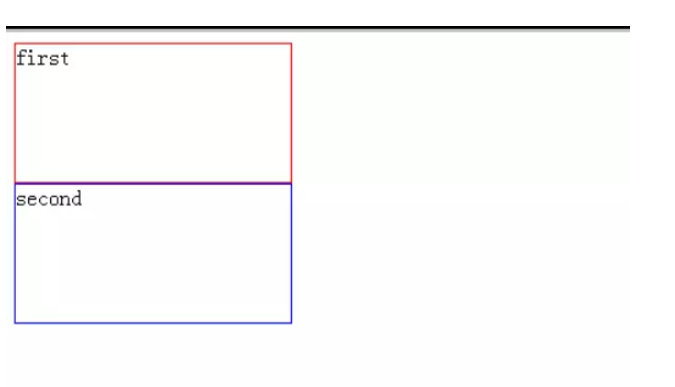
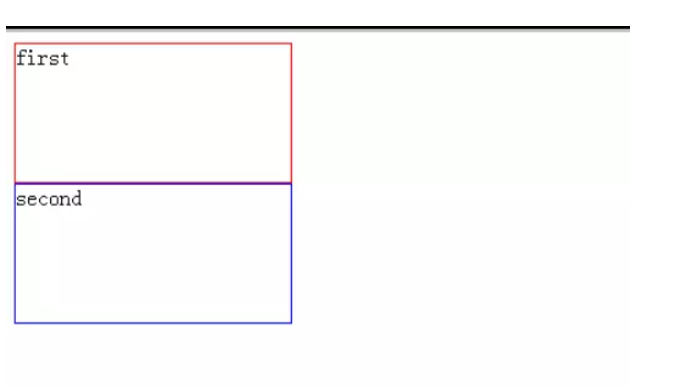
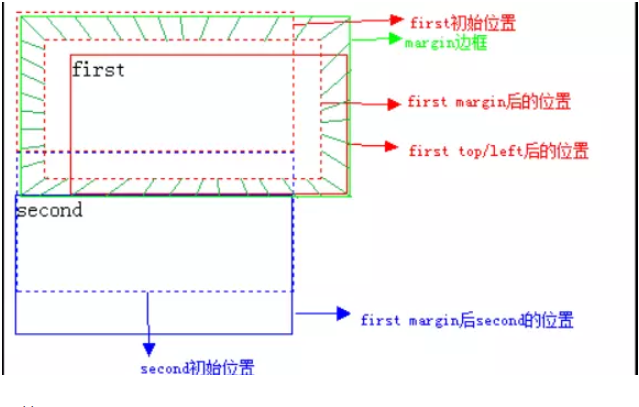
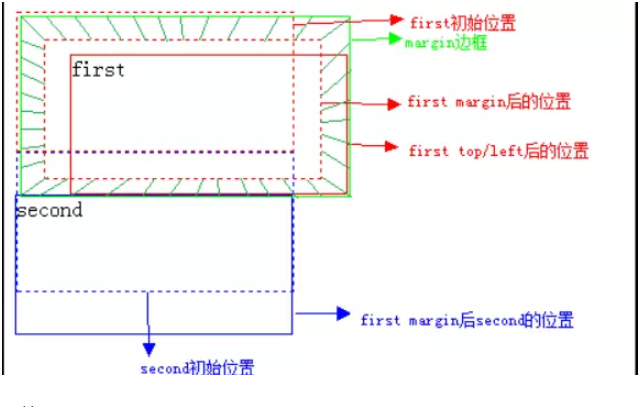
(1) 初始未定位
(2) 我们修改first元素的position属性:
相对偏移20px后:
已经很明显了,相对定位相对的是它原本在文档流中的位置而进行的偏移,而我们也知道relative定位也是遵循正常的文档流,它没有脱离文档流,但是它的top/left/right/bottom属性是生效的,可以说它是static到absoult的一个中间过渡属性,最重要的是它还占有文档空间,而且占据的文档空间不会随top / right / left / bottom 等属性的偏移而发生变动,也就是说它后面的元素是依据虚线位置( top / left / right / bottom等属性生效之前)进行的定位,这点一定要理解。
小扩展
那好,我们知道了top / right / left / bottom 属性是不会对relative定位的元素所占据的文档空间产生偏移,那么margin /
padding属性会让该文档空间产生偏移吗?
答案是肯定的,我们一起来做个试验吧:
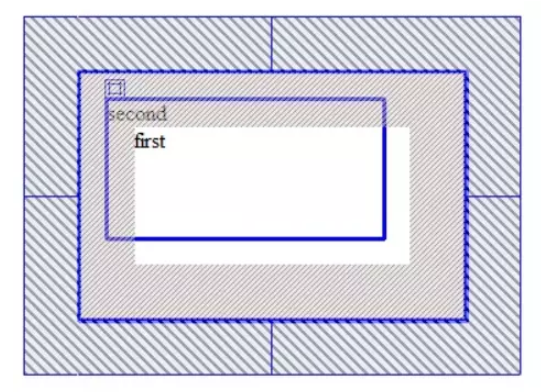
(3) 添加margin属性:
设置margin:20px后:
对比一下,答案一目了然,我们先将first元素外边距设为20px,那么second元素就得向下偏移40px,所以margin是占据文档空间!
同理,大家可以自己动手测下padding的效果!
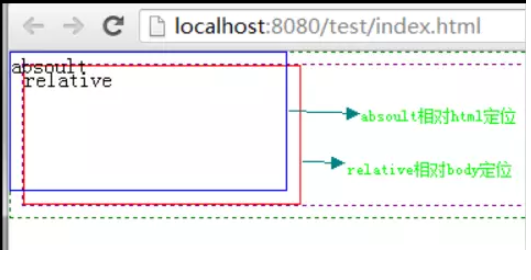
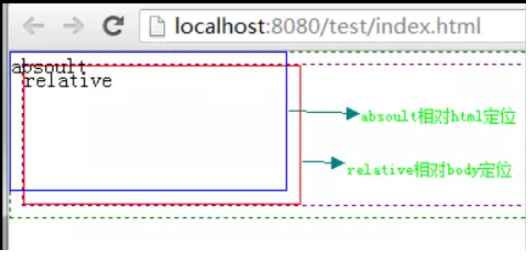
absolute定位,也称为绝对定位,虽然它的名字号曰“绝对”,但是它的功能却更接近于"相对"一词,为什么这么讲呢?原来,使用absolut定位的元素脱离文档流后,就只能根据祖先类元素(父类以上)进行定位,而这个祖先类还必须是以position非static方式定位的,
举个例子,a元素使用absolute定位,它会从父类开始找起,寻找以position非static方式定位的祖先类元素(Note!一定要是直系祖先才算.),直到html根标签为止。
这里还需要注意的是,relative和static方式在最外层时是以body标签为定位原点的,而absolute方式在没有position属性值等于非static的父级时是以html作为原点定位。
但是呢,我们都知道html和body元素相差大概有9px左右。我们来看下效果:
(4) 添加absolute属性:
position: absolute;top :0;left : 0
看了上面的信息后,细心的同学肯定要问了,为什么absolute定位要加 top:0; left:0; 属性,这不是多此一举吗?
其实我们加上这两个属性是完全必要的,因为我们如果使用absolute或fixed定位的话,必须指定 left、right、 top、 bottom属性中的至少一个,否则left/right/top/bottom属性会使用它们的默认值 auto,这将导致对象遵从正常的HTML布局规则,在前一个对象之后立即被呈递,简单讲就是都变成relative,会占用文档空间,这点非常重要,很多人使用absolute定位后发现没有脱离文档流就是这个原因,这里要特别注意~~~
小扩展
既然absolute是根据祖先类中的position非static元素进行定位的,那么祖先类中的margin/padding会不会对position产生影响呢?看个例子先:
(5) 在absolute定位中添加margin / padding属性:
结果很明朗了,祖先类的margin会让子类的absolute跟着偏移,而padding却不会让子类的absolute发生偏移。
总结一下,就是absolute是根据祖先类的border进行的定位。
Note : 充分了解relative和absolute的区别后,我们可以分析得出这个结论:(absolute)定位对象在可视区域之外会导致滚动条出现。而放置(relative)定位对象在可视区域之外,滚动条不会出现。这点在我们的前端页面制作中需要多加注意~~~
在很长的时间里,这个属性值因为兼容性问题,并没有得到非常广泛的应用(IE6未实现该属性值)。fixed和absolute有很多共同点:
fixed与absolute最大的区别在于:absolute的”根元素“是可以被设置的,而fixed则其”根元素“固定为浏览器窗口。即当你滚动网页,其元素与浏览器窗口之间的距离是恒定不变的。
不常用的属性值
inherit: 规定应该从父元素继承 position 属性的值。ie7及以下版本不支持此属性
sticky:css3新属性,磁贴定位。它的表现就像position:relative和position:fixed的合体:
initial:设置positon的值为默认值(static)。ie不支持此属性。initial 关键字可用于任何 HTML 元素上的任何 CSS 属性,不是postion特有的。
unset:设置positon的值为不设置:
当把一个元素position属性设置为absolute或fixed的时候,会发生三件事:
z-index属性:
z-index,又称为对象的层叠顺序,它用一个整数来定义堆叠的层次,整数值越大,则被层叠在越上面,当然这是指同级元素间的堆叠,如果两个对象的此属性具有同样的值,那么将依据它们在HTML文档中流的顺序层叠,写在后面的将会覆盖前面的。需要注意的是,父子关系是无法用z-index来设定上下关系的,一定是子级在上父级在下。
Note:使用static 定位或无position定位的元素z-index属性是无效的。
什么是文档流?
将窗体自上而下分成一行行, 并在每行中按从左至右的顺序排放元素,即为文档流。
只有三种情况会使得元素脱离文档流,分别是:浮动、绝对定位和和fixed,相对定位不脱离文档流。
这篇文章主要讲一下JS中面向对象以及 __proto__,ptototype和constructor,这几个概念都是相关的,所以一起讲了。
在讲这个之前我们先来说说类,了解面向对象的朋友应该都知道,如果我要定义一个通用的类型我可以使用类(class)。比如在java中我们可以这样定义一个类:
public class Puppy{
int puppyAge;
public Puppy(age){
puppyAge = age;
}
public void say() {
System.out.println("汪汪汪");
}
}上述代码我们定义了一个Puppy类,这个类有一个属性是puppyAge,也就是小狗的年龄,然后有一个构造函数Puppy(),这个构造函数接收一个参数,可以设置小狗的年龄,另外还有一个说话的函数say。这是一个通用的类,当我们需要一个两岁的小狗实例是直接这样写,这个实例同时具有父类的方法:
Puppy myPuppy = new Puppy( 2 );
myPuppy.say(); // 汪汪汪但是早期的JS没有class关键字啊(以下说JS没有class关键字都是指ES6之前的JS,主要帮助大家理解概念),JS为了支持面向对象,使用了一种比较曲折的方式,这也是导致大家迷惑的地方,其实我们将这种方式跟一般的面向对象类比起来就很清晰了。下面我们来看看JS为了支持面向对象需要解决哪些问题,都用了什么曲折的方式来解决。
首先JS连class关键字都没有,怎么办呢?用函数代替,JS中最不缺的就是函数,函数不仅能够执行普通功能,还能当class使用。比如我们要用JS建一个小狗的类怎么写呢?直接写一个函数就行:
function Puppy() {}这个函数可以直接用new关键字生成实例:
const myPuppy = new Puppy();这样我们也有了一个小狗实例,但是我们没有构造函数,不能设置小狗年龄啊。
当做类用的函数本身也是一个函数,而且他就是默认的构造函数。我们想让Puppy函数能够设置实例的年龄,只要让他接收参数就行了。
function Puppy(age) {
this.puppyAge = age;
}
// 实例化时可以传年龄参数了
const myPuppy = new Puppy(2);注意上面代码的this,被作为类使用的函数里面this总是指向实例化对象,也就是myPuppy。这么设计的目的就是让使用者可以通过构造函数给实例对象设置属性,这时候console出来看myPuppy.puppyAge就是2。
console.log(myPuppy.puppyAge); // 输出是 2上面我们实现了类和构造函数,但是类方法呢?Java版小狗还可以“汪汪汪”叫呢,JS版怎么办呢?JS给出的解决方案是给方法添加一个prototype属性,挂载在这上面的方法,在实例化的时候会给到实例对象。我们想要myPuppy能说话,就需要往Puppy.prototype添加说话的方法。
Puppy.prototype.say = function() {
console.log("汪汪汪");
}使用new关键字产生的实例都有类的prototype上的属性和方法,我们在Puppy.prototype上添加了say方法,myPuppy就可以说话了,我么来试一下:
myPuppy.say(); // 汪汪汪__proto__那myPuppy怎么就能够调用say方法了呢,我们把他打印出来看下,这个对象上并没有say啊,这是从哪里来的呢?
这就该__proto__上场了,当你访问一个对象上没有的属性时,比如myPuppy.say,对象会去__proto__查找。__proto__的值就等于父类的prototype, myPuppy.__proto__指向了Puppy.prototype。
如果你访问的属性在Puppy.prototype也不存在,那又会继续往Puppy.prototype.__proto__上找,这时候其实就找到了Object.prototype了,Object.prototype再往上找就没有了,也就是null,这其实就是原型链。
我们说的constructor一般指类的prototype.constructor。prototype.constructor是prototype上的一个保留属性,这个属性就指向构造函数本身。
既然prototype.constructor是指向构造函数的一个指针,那我们是不是可以通过它来修改构造函数呢?我们来试试就知道了。我们先修改下这个函数,然后新建一个实例看看效果:
function Puppy(age) {
this.puppyAge = age;
}
Puppy.prototype.constructor = function myConstructor(age) {
this.puppyAge = age + 1;
}
const myPuppy2 = new Puppy(2);
console.log(myPuppy2.puppyAge); // 输出是2上例说明,我们修改prototype.constructor只是修改了这个指针而已,并没有修改真正的构造函数。
可能有的朋友会说我打印myPuppy2.constructor也有值啊,那constructor是不是也是对象本身的一个属性呢?其实不是的,之所以你能打印出这个值,是因为你打印的时候,发现myPuppy2本身并不具有这个属性,又去原型链上找了,找到了prototype.constructor。我们可以用hasOwnProperty看一下就知道了:
上面我们其实已经说清楚了prototype,__proto__,constructor几者之间的关系,下面画一张图来更直观的看下:
我们知道很多面向对象有静态方法这个概念,比如Java直接是加一个static关键字就能将一个方法定义为静态方法。JS中定义一个静态方法更简单,直接将它作为类函数的属性就行:
Puppy.statciFunc = function() { // statciFunc就是一个静态方法
console.log('我是静态方法,this拿不到实例对象');}
Puppy.statciFunc(); // 直接通过类名调用静态方法和实例方法最主要的区别就是实例方法可以访问到实例,可以对实例进行操作,而静态方法一般用于跟实例无关的操作。这两种方法在jQuery中有大量应用,在jQuery中$(selector)其实拿到的就是实例对象,通过$(selector)进行操作的方法就是实例方法。比如$(selector).append(),这会往这个实例DOM添加新元素,他需要这个DOM实例才知道怎么操作,将append作为一个实例方法,他里面的this就会指向这个实例,就可以通过this操作DOM实例。那什么方法适合作为静态方法呢?比如$.ajax,这里的ajax跟DOM实例没关系,不需要这个this,可以直接挂载在$上作为静态方法。关于jQuery实例方法和静态方法更详细的介绍,可以看这里。
面向对象怎么能没有继承呢,根据前面所讲的知识,我们其实已经能够自己写一个继承了。所谓继承不就是子类能够继承父类的属性和方法吗?换句话说就是子类能够找到父类的显式原型prototype,最简单的方法就是子类隐式原型的__proto__指向父类显式原型prototype就行了。
function Parent() {}
function Child() {}
Child.prototype.__proto__ = Parent.prototype;
const obj = new Child();
console.log(obj instanceof Child ); // true
console.log(obj instanceof Parent ); // true上述继承方法只是让Child访问到了Parent原型链,但是没有执行Parent的构造函数:
function Parent() {
this.parentAge = 50;
}
function Child() {}
Child.prototype.__proto__ = Parent.prototype;
const obj = new Child();
console.log(obj.parentAge); // undefined为了解决这个问题,我们不能单纯的修改Child.prototype.__proto__指向,还需要用new执行下Parent的构造函数,也就是将子类的隐式原型指向父类的实例:
function Parent() {
this.parentAge = 50;
}
function Child() {}
Child.prototype.__proto__ = new Parent();
const obj = new Child();
console.log(obj.parentAge); // 50上述方法会多一个__proto__层级,可以换成修改Child.prototype的指向来解决,注意将Child.prototype.constructor重置回来:
function Parent() {
this.parentAge = 50;
}
function Child() {}
Child.prototype = new Parent();
Child.prototype.constructor = Child; // 注意重置constructor
const obj = new Child();
console.log(obj.parentAge); // 50
// parentAge 属性的查找顺序是:-> obj -> obj.__proto__=Child.prototype=new Parent()
// 而 (new Parent()).parentAge=50当然还有很多其他的继承方式,他们的原理都差不多,只是实现方式不一样,核心都是让子类拥有父类的方法和属性,感兴趣的朋友可以自行查阅。
结合上面讲的,我们知道new其实就是生成了一个对象,这个对象能够访问类的原型,知道了原理,我们就可以自己实现一个new了。
function myNew(func, ...args) {
const obj = {}; // 新建一个空对象
const result = func.call(obj, ...args); // 执行构造函数
obj.__proto__ = func.prototype; // 设置原型链
// 注意如果原构造函数有Object类型的返回值,包括Functoin, Array, Date, RegExg, Error
// 那么应该返回这个返回值
const isObject = typeof result === 'object' && result !== null;
const isFunction = typeof result === 'function';
if(isObject || isFunction) {
return result;
}
// 原构造函数没有Object类型的返回值,返回我们的新对象
return obj;
}
function Puppy(age) {
this.puppyAge = age;
}
Puppy.prototype.say = function() {
console.log("汪汪汪");
}
const myPuppy3 = myNew(Puppy, 2);
console.log(myPuppy3.puppyAge); // 2
console.log(myPuppy3.say()); // 汪汪汪知道了原理,其实我们也知道了instanceof是干啥的。instanceof不就是检查一个对象是不是某个类的实例吗?换句话说就是检查一个对象的的原型链上有没有这个类的prototype,知道了这个我们就可以自己实现一个了:
function myInstanceof(targetObj, targetClass) {
// 参数检查
if(!targetObj || !targetClass || !targetObj.__proto__ || !targetClass.prototype){
return false;
}
let current = targetObj;
while(current) { // 一直往原型链上面找
if(current.__proto__ === targetClass.prototype) {
return true; // 找到了返回true
}
current = current.__proto__;
}
return false; // 没找到返回false
}
// 用我们前面的继承实验下
function Parent() {}
function Child() {}
Child.prototype.__proto__ = Parent.prototype;
const obj = new Child();
console.log(myInstanceof(obj, Child) ); // true
console.log(myInstanceof(obj, Parent) ); // true
console.log(myInstanceof({}, Parent) ); // false最后还是提一嘴ES6的class,其实ES6的class就是前面说的函数类的语法糖,比如我们的Puppy用ES6的class写就是这样:
class Puppy {
// 构造函数
constructor(age) {
this.puppyAge = age;
}
// 实例方法
say() {
console.log("汪汪汪")
}
// 静态方法
static statciFunc() {
console.log('我是静态方法,this拿不到实例对象');
}
}
const myPuppy = new Puppy(2);
console.log(myPuppy.puppyAge); // 2
console.log(myPuppy.say()); // 汪汪汪
console.log(Puppy.statciFunc()); // 我是静态方法,this拿不到实例对象使用class可以让我们的代码看起来更像标准的面向对象,构造函数,实例方法,静态方法都有明确的标识。但是他本质只是改变了一种写法,所以可以看做是一种语法糖,如果你去看babel编译后的代码,你会发现他其实也是把class编译成了我们前面的函数类,extends关键字也是使用我们前面的原型继承的方式实现的。
最后来个总结,其实前面小节的标题就是核心了,我们再来总结下:
prototype属性。prototype上的属性和方法,实例对象的__proto__指向了类的prototype。所以prototype是函数的属性,不是对象的。对象拥有的是__proto__,是用来查找prototype的。prototype.constructor指向的是构造函数,也就是类函数本身。改变这个指针并不能改变构造函数。constructor属性,你访问到的是原型链上的prototype.constructor。__proto__,他指向的是JS内置对象Function的原型Function.prototype。所以你才能调用func.call,func.apply这些方法,你调用的其实是Function.prototype.call和Function.prototype.apply。prototype本身也是对象,所以他也有__proto__,指向了他父级的prototype。__proto__和prototype的这种链式指向构成了JS的原型链。原型链的最终指向是Object的原型。Object上面原型链是null,即Object.prototype.__proto__ === null。Function.__proto__ === Function.prototype。这是因为JS中所有函数的原型都是Function.prototype,也就是说所有函数都是Function的实例。Function本身也是可以作为函数使用的----Function(),所以他也是Function的一个实例。类似的还有Object,Array等,他们也可以作为函数使用:Object(), Array()。所以他们本身的原型也是Function.prototype,即Object.__proto__ === Function.prototype。换句话说,这些可以new的内置对象其实都是一个类,就像我们的Puppy类一样。再来看一下完整图:
https://juejin.cn/post/6844903487323504653
优化http请求方面的:
<head>里面、js放到</body>前面,以及js的异步加载(async、defer)等gzip压缩https://juejin.cn/post/6844904055790125064
MVC
MVC 全名是 Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范
MVC 的**:一句话描述就是 Controller 负责将 Model 的数据用 View 显示出来,换句话说就是在 Controller 里面把 Model 的数据赋值给 View。
MVVM
MVVM 新增了 VM 类
MVVM 与 MVC 最大的区别就是:它实现了 View 和 Model 的自动同步,也就是当 Model 的属性改变时,我们不用再自己手动操作 Dom 元素,来改变 View 的显示,而是改变属性后该属性对应 View 层显示会自动改变(对应 Vue 数据驱动的**)
整体看来,MVVM 比 MVC 精简很多,不仅简化了业务与界面的依赖,还解决了数据频繁更新的问题,不用再用选择器操作 DOM 元素。因为在 MVVM 中,View 不知道 Model 的存在,Model 和 ViewModel 也观察不到 View,这种低耦合模式提高代码的可重用性
那么问题来了 为什么官方要说 Vue 没有完全遵循 MVVM **呢?
- 严格的 MVVM 要求 View 不能和 Model 直接通信,而 Vue 提供了$refs 这个属性,让 Model 可以直接操作 View,违反了这一规定,所以说 Vue 没有完全遵循 MVVM。
组件中的 data 写成一个函数,数据以函数返回值形式定义,这样每复用一次组件,就会返回一份新的 data,类似于给每个组件实例创建一个私有的数据空间,让各个组件实例维护各自的数据。而单纯的写成对象形式,就使得所有组件实例共用了一份 data,就会造成一个变了全都会变的结果
beforeCreate 在实例初始化之后,数据观测(data observer) 和 event/watcher 事件配置之前被调用。在当前阶段 data、methods、computed 以及 watch 上的数据和方法都不能被访问
created 实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。这里没有$el,如果非要想与 Dom 进行交互,可以通过 vm.$nextTick 来访问 Dom
beforeMount 在挂载开始之前被调用:相关的 render 函数首次被调用。
mounted 在挂载完成后发生,在当前阶段,真实的 Dom 挂载完毕,数据完成双向绑定,可以访问到 Dom 节点
beforeUpdate 数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁(patch)之前。可以在这个钩子中进一步地更改状态,这不会触发附加的重渲染过程
updated 发生在更新完成之后,当前阶段组件 Dom 已完成更新。要注意的是避免在此期间更改数据,因为这可能会导致无限循环的更新,该钩子在服务器端渲染期间不被调用。
beforeDestroy 实例销毁之前调用。在这一步,实例仍然完全可用。我们可以在这时进行善后收尾工作,比如清除计时器。
destroyed Vue 实例销毁后调用。调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。
activated keep-alive 专属,组件被激活时调用
deactivated keep-alive 专属,组件被销毁时调用
异步请求在哪一步发起?
可以在钩子函数 created、beforeMount、mounted 中进行异步请求,因为在这三个钩子函数中,data 已经创建,可以将服务端返回的数据进行赋值。
如果异步请求不需要依赖 Dom 推荐在 created 钩子函数中调用异步请求,因为在 created 钩子函数中调用异步请求有以下优点:
(3)生命周期示意图
v-if 在编译过程中会被转化成三元表达式,条件不满足时不渲染此节点。
v-show 会被编译成指令,条件不满足时控制样式将对应节点隐藏 (display:none)
使用场景
v-if 适用于在运行时很少改变条件,不需要频繁切换条件的场景
v-show 适用于需要非常频繁切换条件的场景
扩展补充:display:none、visibility:hidden 和 opacity:0 之间的区别?
数据总是从父组件传到子组件,子组件没有权利修改父组件传过来的数据,只能请求父组件对原始数据进行修改。这样会防止从子组件意外改变父级组件的状态,从而导致你的应用的数据流向难以理解。
注意:在子组件直接用 v-model 绑定父组件传过来的 prop 这样是不规范的写法 开发环境会报警告
如果实在要改变父组件的 prop 值 可以再 data 里面定义一个变量 并用 prop 的值初始化它 之后用$emit 通知父组件去修改
computed 是计算属性,依赖其他属性计算值,并且 computed 的值有缓存,只有当计算值变化才会返回内容,它可以设置 getter 和 setter。
watch 监听到值的变化就会执行回调,在回调中可以进行一些逻辑操作。
计算属性一般用在模板渲染中,某个值是依赖了其它的响应式对象甚至是计算属性计算而来;而侦听属性适用于观测某个值的变化去完成一段复杂的业务逻辑
计算属性原理详解 传送门
侦听属性原理详解 传送门
v-for 和 v-if 不要在同一个标签中使用,因为解析时先解析 v-for 再解析 v-if。如果遇到需要同时使用时可以考虑写成计算属性的方式。
整体思路是数据劫持+观察者模式
对象内部通过 defineReactive 方法,使用 Object.defineProperty 将属性进行劫持(只会劫持已经存在的属性),数组则是通过重写数组方法来实现。当页面使用对应属性时,每个属性都拥有自己的 dep 属性,存放他所依赖的 watcher(依赖收集),当属性变化后会通知自己对应的 watcher 去更新(派发更新)。
相关代码如下
class Observer {
// 观测值
constructor(value) {
this.walk(value);
}
walk(data) {
// 对象上的所有属性依次进行观测
let keys = Object.keys(data);
for (let i = 0; i < keys.length; i++) {
let key = keys[i];
let value = data[key];
defineReactive(data, key, value);
}
}
}
// Object.defineProperty数据劫持核心 兼容性在ie9以及以上
function defineReactive(data, key, value) {
observe(value); // 递归关键
// --如果value还是一个对象会继续走一遍odefineReactive 层层遍历一直到value不是对象才停止
// 思考?如果Vue数据嵌套层级过深 >>性能会受影响
Object.defineProperty(data, key, {
get() {
console.log("获取值");
//需要做依赖收集过程 这里代码没写出来
return value;
},
set(newValue) {
if (newValue === value) return;
console.log("设置值");
//需要做派发更新过程 这里代码没写出来
value = newValue;
},
});
}
export function observe(value) {
// 如果传过来的是对象或者数组 进行属性劫持
if (
Object.prototype.toString.call(value) === "[object Object]" ||
Array.isArray(value)
) {
return new Observer(value);
}
}响应式数据原理详解 传送门
数组考虑性能原因没有用 defineProperty 对数组的每一项进行拦截,而是选择对 7 种数组(push,shift,pop,splice,unshift,sort,reverse)方法进行重写(AOP 切片**)
所以在 Vue 中修改数组的索引和长度是无法监控到的。需要通过以上 7 种变异方法修改数组才会触发数组对应的 watcher 进行更新
相关代码如下
// src/obserber/array.js
// 先保留数组原型
const arrayProto = Array.prototype;
// 然后将arrayMethods继承自数组原型
// 这里是面向切片编程**(AOP)--不破坏封装的前提下,动态的扩展功能
export const arrayMethods = Object.create(arrayProto);
let methodsToPatch = [
"push",
"pop",
"shift",
"unshift",
"splice",
"reverse",
"sort",
];
methodsToPatch.forEach((method) => {
arrayMethods[method] = function (...args) {
// 这里保留原型方法的执行结果
const result = arrayProto[method].apply(this, args);
// 这句话是关键
// this代表的就是数据本身 比如数据是{a:[1,2,3]} 那么我们使用a.push(4) this就是a ob就是a.__ob__ 这个属性就是上段代码增加的 代表的是该数据已经被响应式观察过了指向Observer实例
const ob = this.__ob__;
// 这里的标志就是代表数组有新增操作
let inserted;
switch (method) {
case "push":
case "unshift":
inserted = args;
break;
case "splice":
inserted = args.slice(2);
default:
break;
}
// 如果有新增的元素 inserted是一个数组 调用Observer实例的observeArray对数组每一项进行观测
if (inserted) ob.observeArray(inserted);
// 之后咱们还可以在这里检测到数组改变了之后从而触发视图更新的操作--后续源码会揭晓
return result;
};
});数组的观测原理详解 传送门
Vue3.0 新特性以及使用经验总结 传送门
Vue3.x 改用 Proxy 替代 Object.defineProperty。因为 Proxy 可以直接监听对象和数组的变化,并且有多达 13 种拦截方法。
相关代码如下
import { mutableHandlers } from "./baseHandlers"; // 代理相关逻辑
import { isObject } from "./util"; // 工具方法
export function reactive(target) {
// 根据不同参数创建不同响应式对象
return createReactiveObject(target, mutableHandlers);
}
function createReactiveObject(target, baseHandler) {
if (!isObject(target)) {
return target;
}
const observed = new Proxy(target, baseHandler);
return observed;
}
const get = createGetter();
const set = createSetter();
function createGetter() {
return function get(target, key, receiver) {
// 对获取的值进行放射
const res = Reflect.get(target, key, receiver);
console.log("属性获取", key);
if (isObject(res)) {
// 如果获取的值是对象类型,则返回当前对象的代理对象
return reactive(res);
}
return res;
};
}
function createSetter() {
return function set(target, key, value, receiver) {
const oldValue = target[key];
const hadKey = hasOwn(target, key);
const result = Reflect.set(target, key, value, receiver);
if (!hadKey) {
console.log("属性新增", key, value);
} else if (hasChanged(value, oldValue)) {
console.log("属性值被修改", key, value);
}
return result;
};
}
export const mutableHandlers = {
get, // 当获取属性时调用此方法
set, // 当修改属性时调用此方法
};Vue.js 3.0 放弃defineProperty, 使用Proxy的原因
Object.defineProperty缺陷
父 beforeCreate->父 created->父 beforeMount->子 beforeCreate->子 created->子 beforeMount->子 mounted->父 mounted
父 beforeUpdate->子 beforeUpdate->子 updated->父 updated
父 beforeUpdate->父 updated
父 beforeDestroy->子 beforeDestroy->子 destroyed->父 destroyed
由于在浏览器中操作 DOM 是很昂贵的。频繁的操作 DOM,会产生一定的性能问题。这就是虚拟 Dom 的产生原因。Virtual DOM 本质就是用一个原生的 JS 对象去描述一个 DOM 节点,是对真实 DOM 的一层抽象。
优点:
缺点:
v-model 只是语法糖而已
v-model 在内部为不同的输入元素使用不同的 property 并抛出不同的事件:
注意:对于需要使用输入法 (如中文、日文、韩文等) 的语言,你会发现 v-model 不会在输入法组合文字过程中得到更新。
在普通标签上
<input v-model="sth" /> //这一行等于下一行
<input v-bind:value="sth" v-on:input="sth = $event.target.value" />在组件上
<currency-input v-model="price"></currentcy-input>
<!--上行代码是下行的语法糖
<currency-input :value="price" @input="price = arguments[0]"></currency-input>
-->
<!-- 子组件定义 -->
Vue.component('currency-input', {
template: `
<span>
<input
ref="input"
:value="value"
@input="$emit('input', $event.target.value)"
>
</span>
`,
props: ['value'],
})如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
更准确:因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确。
更快速:利用 key 的唯一性生成 map 对象来获取对应节点,比遍历方式更快
相关代码如下
// 判断两个vnode的标签和key是否相同 如果相同 就可以认为是同一节点就地复用
function isSameVnode(oldVnode, newVnode) {
return oldVnode.tag === newVnode.tag && oldVnode.key === newVnode.key;
}
// 根据key来创建老的儿子的index映射表 类似 {'a':0,'b':1} 代表key为'a'的节点在第一个位置 key为'b'的节点在第二个位置
function makeIndexByKey(children) {
let map = {};
children.forEach((item, index) => {
map[item.key] = index;
});
return map;
}
// 生成的映射表
let map = makeIndexByKey(oldCh);diff 算法详解 传送门
原生事件绑定是通过 addEventListener 绑定给真实元素的,组件事件绑定是通过 Vue 自定义的$on 实现的。如果要在组件上使用原生事件,需要加.native 修饰符,这样就相当于在父组件中把子组件当做普通 html 标签,然后加上原生事件。
$on、$emit 是基于发布订阅模式的,维护一个事件中心,on 的时候将事件按名称存在事件中心里,称之为订阅者,然后 emit 将对应的事件进行发布,去执行事件中心里的对应的监听器
手写发布订阅原理 传送门
路由钩子(导航钩子)的执行流程, 钩子函数种类有:全局守卫、路由守卫、组件守卫
完整的导航解析流程:
我们经常需要把某种模式匹配到的所有路由,全都映射到同个组件。例如,我们有一个 User 组件,对于所有 ID 各不相同的用户,都要使用这个组件来渲染。那么,我们可以在 vue-router 的路由路径中使用“动态路径参数”(dynamic segment) 来达到这个效果:
const User = {
template: "<div>User</div>",
};
const router = new VueRouter({
routes: [
// 动态路径参数 以冒号开头
{ path: "/user/:id", component: User },
],
});问题:vue-router 组件复用导致路由参数失效怎么办?
解决方法:
1.通过 watch 监听路由参数再发请求
watch: { //通过watch来监听路由变化
"$route": function(){
this.getData(this.$route.params.xxx);
}
}2.用 :key 来阻止“复用”
<router-view :key="$route.fullPath" />vuex 是专门为 vue 提供的全局状态管理系统,用于多个组件中数据共享、数据缓存等。(无法持久化、内部核心原理是通过创造一个全局实例 new Vue)
主要包括以下几个模块:
需要做 vuex 数据持久化 一般使用本地存储的方案来保存数据 可以自己设计存储方案 也可以使用第三方插件
推荐使用 vuex-persist 插件,它就是为 Vuex 持久化存储而生的一个插件。不需要你手动存取 storage ,而是直接将状态保存至 cookie 或者 localStorage 中
模块:由于使用单一状态树,应用的所有状态会集中到一个比较大的对象。当应用变得非常复杂时,store 对象就有可能变得相当臃肿。为了解决以上问题,Vuex 允许我们将 store 分割成模块(module)。每个模块拥有自己的 state、mutation、action、getter、甚至是嵌套子模块。
命名空间:默认情况下,模块内部的 action、mutation 和 getter 是注册在全局命名空间的——这样使得多个模块能够对同一 mutation 或 action 作出响应。如果希望你的模块具有更高的封装度和复用性,你可以通过添加 namespaced: true 的方式使其成为带命名空间的模块。当模块被注册后,它的所有 getter、action 及 mutation 都会自动根据模块注册的路径调整命名。
SSR 也就是服务端渲染,也就是将 Vue 在客户端把标签渲染成 HTML 的工作放在服务端完成,然后再把 html 直接返回给客户端。
优点:
SSR 有着更好的 SEO、并且首屏加载速度更快
缺点: 开发条件会受到限制,服务器端渲染只支持 beforeCreate 和 created 两个钩子,当我们需要一些外部扩展库时需要特殊处理,服务端渲染应用程序也需要处于 Node.js 的运行环境。
服务器会有更大的负载需求
1.工厂模式 - 传入参数即可创建实例
虚拟 DOM 根据参数的不同返回基础标签的 Vnode 和组件 Vnode
2.单例模式 - 整个程序有且仅有一个实例
vuex 和 vue-router 的插件注册方法 install 判断如果系统存在实例就直接返回掉
3.发布-订阅模式 (vue 事件机制)
4.观察者模式 (响应式数据原理)
5.装饰模式: (@装饰器的用法)
6.策略模式 策略模式指对象有某个行为,但是在不同的场景中,该行为有不同的实现方案-比如选项的合并策略
...其他模式欢迎补充
这里只列举针对 Vue 的性能优化 整个项目的性能优化是一个大工程 可以另写一篇性能优化的文章 哈哈
在日常的开发中,我们经常会遇到在不同的组件中经常会需要用到一些相同或者相似的代码,这些代码的功能相对独立,可以通过 Vue 的 mixin 功能抽离公共的业务逻辑,原理类似“对象的继承”,当组件初始化时会调用 mergeOptions 方法进行合并,采用策略模式针对不同的属性进行合并。当组件和混入对象含有同名选项时,这些选项将以恰当的方式进行“合并”。
相关代码如下
export default function initMixin(Vue){
Vue.mixin = function (mixin) {
// 合并对象
this.options=mergeOptions(this.options,mixin)
};
}
};
// src/util/index.js
// 定义生命周期
export const LIFECYCLE_HOOKS = [
"beforeCreate",
"created",
"beforeMount",
"mounted",
"beforeUpdate",
"updated",
"beforeDestroy",
"destroyed",
];
// 合并策略
const strats = {};
// mixin核心方法
export function mergeOptions(parent, child) {
const options = {};
// 遍历父亲
for (let k in parent) {
mergeFiled(k);
}
// 父亲没有 儿子有
for (let k in child) {
if (!parent.hasOwnProperty(k)) {
mergeFiled(k);
}
}
//真正合并字段方法
function mergeFiled(k) {
if (strats[k]) {
options[k] = strats[k](parent[k], child[k]);
} else {
// 默认策略
options[k] = child[k] ? child[k] : parent[k];
}
}
return options;
}Vue.mixin 原理详解 传送门
nextTick 中的回调是在下次 DOM 更新循环结束之后执行的延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。主要思路就是采用微任务优先的方式调用异步方法去执行 nextTick 包装的方法
相关代码如下
let callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false; //把标志还原为false
// 依次执行回调
for (let i = 0; i < callbacks.length; i++) {
callbacks[i]();
}
}
let timerFunc; //定义异步方法 采用优雅降级
if (typeof Promise !== "undefined") {
// 如果支持promise
const p = Promise.resolve();
timerFunc = () => {
p.then(flushCallbacks);
};
} else if (typeof MutationObserver !== "undefined") {
// MutationObserver 主要是监听dom变化 也是一个异步方法
let counter = 1;
const observer = new MutationObserver(flushCallbacks);
const textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true,
});
timerFunc = () => {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
} else if (typeof setImmediate !== "undefined") {
// 如果前面都不支持 判断setImmediate
timerFunc = () => {
setImmediate(flushCallbacks);
};
} else {
// 最后降级采用setTimeout
timerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}
export function nextTick(cb) {
// 除了渲染watcher 还有用户自己手动调用的nextTick 一起被收集到数组
callbacks.push(cb);
if (!pending) {
// 如果多次调用nextTick 只会执行一次异步 等异步队列清空之后再把标志变为false
pending = true;
timerFunc();
}
}nextTick 原理详解 传送门
keep-alive 是 Vue 内置的一个组件,可以实现组件缓存,当组件切换时不会对当前组件进行卸载。
相关代码如下
export default {
name: "keep-alive",
abstract: true, //抽象组件
props: {
include: patternTypes, //要缓存的组件
exclude: patternTypes, //要排除的组件
max: [String, Number], //最大缓存数
},
created() {
this.cache = Object.create(null); //缓存对象 {a:vNode,b:vNode}
this.keys = []; //缓存组件的key集合 [a,b]
},
destroyed() {
for (const key in this.cache) {
pruneCacheEntry(this.cache, key, this.keys);
}
},
mounted() {
//动态监听include exclude
this.$watch("include", (val) => {
pruneCache(this, (name) => matches(val, name));
});
this.$watch("exclude", (val) => {
pruneCache(this, (name) => !matches(val, name));
});
},
render() {
const slot = this.$slots.default; //获取包裹的插槽默认值
const vnode: VNode = getFirstComponentChild(slot); //获取第一个子组件
const componentOptions: ?VNodeComponentOptions =
vnode && vnode.componentOptions;
if (componentOptions) {
// check pattern
const name: ?string = getComponentName(componentOptions);
const { include, exclude } = this;
// 不走缓存
if (
// not included 不包含
(include && (!name || !matches(include, name))) ||
// excluded 排除里面
(exclude && name && matches(exclude, name))
) {
//返回虚拟节点
return vnode;
}
const { cache, keys } = this;
const key: ?string =
vnode.key == null
? // same constructor may get registered as different local components
// so cid alone is not enough (#3269)
componentOptions.Ctor.cid +
(componentOptions.tag ? `::${componentOptions.tag}` : "")
: vnode.key;
if (cache[key]) {
//通过key 找到缓存 获取实例
vnode.componentInstance = cache[key].componentInstance;
// make current key freshest
remove(keys, key); //通过LRU算法把数组里面的key删掉
keys.push(key); //把它放在数组末尾
} else {
cache[key] = vnode; //没找到就换存下来
keys.push(key); //把它放在数组末尾
// prune oldest entry //如果超过最大值就把数组第0项删掉
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode);
}
}
vnode.data.keepAlive = true; //标记虚拟节点已经被缓存
}
// 返回虚拟节点
return vnode || (slot && slot[0]);
},
};扩展补充:LRU 算法是什么?
LRU 的核心**是如果数据最近被访问过,那么将来被访问的几率也更高,所以我们将命中缓存的组件 key 重新插入到 this.keys 的尾部,这样一来,this.keys 中越往头部的数据即将来被访问几率越低,所以当缓存数量达到最大值时,我们就删除将来被访问几率最低的数据,即 this.keys 中第一个缓存的组件。
了解 Vue 响应式原理的同学都知道在两种情况下修改数据 Vue 是不会触发视图更新的
1.在实例创建之后添加新的属性到实例上(给响应式对象新增属性)
2.直接更改数组下标来修改数组的值
Vue.set 或者说是$set 原理如下
因为响应式数据 我们给对象和数组本身都增加了ob属性,代表的是 Observer 实例。当给对象新增不存在的属性 首先会把新的属性进行响应式跟踪 然后会触发对象ob的 dep 收集到的 watcher 去更新,当修改数组索引时我们调用数组本身的 splice 方法去更新数组
相关代码如下
export function set(target: Array | Object, key: any, val: any): any {
// 如果是数组 调用我们重写的splice方法 (这样可以更新视图)
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val;
}
// 如果是对象本身的属性,则直接添加即可
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val;
}
const ob = (target: any).__ob__;
// 如果不是响应式的也不需要将其定义成响应式属性
if (!ob) {
target[key] = val;
return val;
}
// 将属性定义成响应式的
defineReactive(ob.value, key, val);
// 通知视图更新
ob.dep.notify();
return val;
}响应式数据原理详解 传送门
官方解释:Vue.extend 使用基础 Vue 构造器,创建一个“子类”。参数是一个包含组件选项的对象。
其实就是一个子类构造器 是 Vue 组件的核心 api 实现思路就是使用原型继承的方法返回了 Vue 的子类 并且利用 mergeOptions 把传入组件的 options 和父类的 options 进行了合并
相关代码如下
export default function initExtend(Vue) {
let cid = 0; //组件的唯一标识
// 创建子类继承Vue父类 便于属性扩展
Vue.extend = function (extendOptions) {
// 创建子类的构造函数 并且调用初始化方法
const Sub = function VueComponent(options) {
this._init(options); //调用Vue初始化方法
};
Sub.cid = cid++;
Sub.prototype = Object.create(this.prototype); // 子类原型指向父类
Sub.prototype.constructor = Sub; //constructor指向自己
Sub.options = mergeOptions(this.options, extendOptions); //合并自己的options和父类的options
return Sub;
};
}Vue 组件原理详解 传送门
指令本质上是装饰器,是 vue 对 HTML 元素的扩展,给 HTML 元素增加自定义功能。vue 编译 DOM 时,会找到指令对象,执行指令的相关方法。
自定义指令有五个生命周期(也叫钩子函数),分别是 bind、inserted、update、componentUpdated、unbind
1. bind:只调用一次,指令第一次绑定到元素时调用。在这里可以进行一次性的初始化设置。
2. inserted:被绑定元素插入父节点时调用 (仅保证父节点存在,但不一定已被插入文档中)。
3. update:被绑定于元素所在的模板更新时调用,而无论绑定值是否变化。通过比较更新前后的绑定值,可以忽略不必要的模板更新。
4. componentUpdated:被绑定元素所在模板完成一次更新周期时调用。
5. unbind:只调用一次,指令与元素解绑时调用。
原理
1.在生成 ast 语法树时,遇到指令会给当前元素添加 directives 属性
2.通过 genDirectives 生成指令代码
3.在 patch 前将指令的钩子提取到 cbs 中,在 patch 过程中调用对应的钩子
4.当执行指令对应钩子函数时,调用对应指令定义的方法
事件修饰符
v-model 的修饰符
键盘事件的修饰符
系统修饰键
鼠标按钮修饰符
Vue 的编译过程就是将 template 转化为 render 函数的过程 分为以下三步
第一步是将 模板字符串 转换成 element ASTs(解析器)
第二步是对 AST 进行静态节点标记,主要用来做虚拟DOM的渲染优化(优化器)
第三步是 使用 element ASTs 生成 render 函数代码字符串(代码生成器)
相关代码如下
export function compileToFunctions(template) {
// 我们需要把html字符串变成render函数
// 1.把html代码转成ast语法树 ast用来描述代码本身形成树结构 不仅可以描述html 也能描述css以及js语法
// 很多库都运用到了ast 比如 webpack babel eslint等等
let ast = parse(template);
// 2.优化静态节点
// 这个有兴趣的可以去看源码 不影响核心功能就不实现了
// if (options.optimize !== false) {
// optimize(ast, options);
// }
// 3.通过ast 重新生成代码
// 我们最后生成的代码需要和render函数一样
// 类似_c('div',{id:"app"},_c('div',undefined,_v("hello"+_s(name)),_c('span',undefined,_v("world"))))
// _c代表创建元素 _v代表创建文本 _s代表文Json.stringify--把对象解析成文本
let code = generate(ast);
// 使用with语法改变作用域为this 之后调用render函数可以使用call改变this 方便code里面的变量取值
let renderFn = new Function(`with(this){return ${code}}`);
return renderFn;
}模板编译原理详解 传送门
Vue 的生命周期钩子核心实现是利用发布订阅模式先把用户传入的的生命周期钩子订阅好(内部采用数组的方式存储)然后在创建组件实例的过程中会一次执行对应的钩子方法(发布)
相关代码如下
export function callHook(vm, hook) {
// 依次执行生命周期对应的方法
const handlers = vm.$options[hook];
if (handlers) {
for (let i = 0; i < handlers.length; i++) {
handlers[i].call(vm); //生命周期里面的this指向当前实例
}
}
}
// 调用的时候
Vue.prototype._init = function (options) {
const vm = this;
vm.$options = mergeOptions(vm.constructor.options, options);
callHook(vm, "beforeCreate"); //初始化数据之前
// 初始化状态
initState(vm);
callHook(vm, "created"); //初始化数据之后
if (vm.$options.el) {
vm.$mount(vm.$options.el);
}
};生命周期实现详解 传送门
函数式组件与普通组件的区别
1.函数式组件需要在声明组件是指定 functional:true
2.不需要实例化,所以没有this,this通过render函数的第二个参数context来代替
3.没有生命周期钩子函数,不能使用计算属性,watch
4.不能通过$emit 对外暴露事件,调用事件只能通过context.listeners.click的方式调用外部传入的事件
5.因为函数式组件是没有实例化的,所以在外部通过ref去引用组件时,实际引用的是HTMLElement
6.函数式组件的props可以不用显示声明,所以没有在props里面声明的属性都会被自动隐式解析为prop,而普通组件所有未声明的属性都解析到$attrs里面,并自动挂载到组件根元素上面(可以通过inheritAttrs属性禁止)
优点 1.由于函数式组件不需要实例化,无状态,没有生命周期,所以渲染性能要好于普通组件 2.函数式组件结构比较简单,代码结构更清晰
使用场景:
一个简单的展示组件,作为容器组件使用 比如 router-view 就是一个函数式组件
“高阶组件”——用于接收一个组件作为参数,返回一个被包装过的组件
相关代码如下
if (isTrue(Ctor.options.functional)) {
// 带有functional的属性的就是函数式组件
return createFunctionalComponent(Ctor, propsData, data, context, children);
}
const listeners = data.on;
data.on = data.nativeOn;
installComponentHooks(data); // 安装组件相关钩子 (函数式组件没有调用此方法,从而性能高于普通组件)vue-router中默认使用的是hash模式
hash 模式
window.addEventListener("hashchange", funcRef, false);每一次改变 hash(window.location.hash),都会在浏览器的访问历史中增加一个记录利用 hash 的以上特点,就可以来实现前端路由“更新视图但不重新请求页面”的功能了
特点:兼容性好但是不美观
history 模式
利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。
这两个方法应用于浏览器的历史记录站,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。这两个方法有个共同的特点:当调用他们修改浏览器历史记录栈后,虽然当前 URL 改变了,但浏览器不会刷新页面,这就为单页应用前端路由“更新视图但不重新请求页面”提供了基础。
特点:虽然美观,但是刷新会出现 404 需要后端进行配置
建议直接看 diff 算法详解 传送门
如何让 CSS 旨在当前组件中起作用?
当前组件的 < style>标签修改为< style scoped>
vue data 中某一个属性的值发生改变后,视图不会立即同步执行重新渲染。
Vue 实现响应式并不是数据发生变化之后 DOM 立即变化,而是按一定的策略进行 DOM 的更新。
Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化, Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个watcher被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环”tick”中,Vue 刷新队列并执行实际(已去重的)工作,从而避免不必要的计算和 DOM 操作。
通过children 数组:
const router = new VueRouter({
routes: [
{
path: "/parentPage",
component: testPage,
children: [
{
path: "/childrenA",
component: childrenComponentA,
},
{
path: "/childrenB",
component: childrenComponentB,
},
],
},
{
// 其他和parentPage平级的路由
},
],
});路由之间跳转的方式
active-class是哪个组件的属性
vue-router 模块 的router-link组件
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
缺点:
Class 可以通过对象语法和数组语法进行动态绑定:
<div v-bind:class="{ active: isActive, 'text-danger': hasError }"></div>
data: {
isActive: true,
hasError: false
}<div v-bind:class="[isActive ? activeClass : '', errorClass]"></div>
data: {
activeClass: 'active',
errorClass: 'text-danger'
}Style 也可以通过对象语法和数组语法进行动态绑定:
<div v-bind:style="{ color: activeColor, fontSize: fontSize + 'px' }"></div>
data: {
activeColor: 'red',
fontSize: 30
}<div v-bind:style="[styleColor, styleSize]"></div>
data: {
styleColor: {
color: 'red'
},
styleSize:{
fontSize:'23px'
}
}由于 JavaScript 的限制,Vue 不能检测到以下数组的变动:
vm.items[indexOfItem] = newValuevm.items.length = newLength为了解决第一个问题,Vue 提供了以下操作方法:
// Vue.set
Vue.set(vm.items, indexOfItem, newValue)
// vm.$set,Vue.set的一个别名
vm.$set(vm.items, indexOfItem, newValue)
// Array.prototype.splice
vm.items.splice(indexOfItem, 1, newValue)为了解决第二个问题,Vue 提供了以下操作方法:
// Array.prototype.splice
vm.items.splice(newLength)参考链接:
在两数相加时,十进制数会先转换成二进制,不是所有的十进制分数都能够非常精确的表示,0.1(十进制) 和 0.2(十进制)没有相应的二进制数与其对应,他们 转换成二进制的时候造成精度丢失,因此最终的运算结果也会有精度丢失。
所以总结:精度丢失可能出现在进制转换和对阶运算中
参考链接
参考链接
随着移动网络的发展与演化,我们手机上现在除了有原生 App,还能跑“WebApp”——它即开即用,用完即走。一个优秀的 WebApp 甚至可以拥有和原生 App 媲美的功能和体验。WebApp 优异的性能表现,有一部分原因要归功于浏览器存储技术的提升。cookie存储数据的功能已经很难满足开发所需,逐渐被WebStorage、IndexedDB所取代,本文将介绍这几种存储方式的差异和优缺点。
Cookie 的本职工作并非本地存储,而是“维持状态”。 因为HTTP协议是无状态的,HTTP协议自身不对请求和响应之间的通信状态进行保存,通俗来说,服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两瓶饮料。最后结帐时,由于HTTP的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么,于是就诞生了Cookie。它就是用来绕开HTTP的无状态性的“额外手段”之一。服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
我们可以把Cookie 理解为一个存储在浏览器里的一个小小的文本文件,它附着在 HTTP 请求上,在浏览器和服务器之间“飞来飞去”。它可以携带用户信息,当服务器检查 Cookie 的时候,便可以获取到客户端的状态。
在刚才的购物场景中,当用户选购了第一项商品,服务器在向用户发送网页的同时,还发送了一段Cookie,记录着那项商品的信息。当用户访问另一个页面,浏览器会把Cookie发送给服务器,于是服务器知道他之前选购了什么。用户继续选购饮料,服务器就在原来那段Cookie里追加新的商品信息。结帐时,服务器读取发送来的Cookie就行了。
Cookie指某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。 cookie是服务端生成,客户端进行维护和存储。通过cookie,可以让服务器知道请求是来源哪个客户端,就可以进行客户端状态的维护,比如登陆后刷新,请求头就会携带登陆时response header中的set-cookie,Web服务器接到请求时也能读出cookie的值,根据cookie值的内容就可以判断和恢复一些用户的信息状态。
如上图所示,Cookie 以键值对的形式存在。
典型的应用场景有:
Cookie的原理
第一次访问网站的时候,浏览器发出请求,服务器响应请求后,会在响应头里面添加一个Set-Cookie选项,将cookie放入到响应请求中,在浏览器第二次发请求的时候,会通过Cookie请求头部将Cookie信息发送给服务器,服务端会辨别用户身份,另外,Cookie的过期时间、域、路径、有效期、适用站点都可以根据需要来指定。
Cookie的生成方式主要有两种:
我们可以通过响应头里的 Set-Cookie 指定要存储的 Cookie 值。默认情况下,domain 被设置为设置 Cookie 页面的主机名,我们也可以手动设置 domain 的值。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2018 07:28:00 GMT;//可以指定一个特定的过期时间(Expires)或有效期(Max-Age)
当Cookie的过期时间被设定时,设定的日期和时间只与客户端相关,而不是服务端。
例如我们在掘金社区控制台输入以下三句代码,便可以在Chrome 的 Application 面板查看生成的cookie:
document.cookie="userName=hello"
document.cookie="gender=male"
document.cookie='age=20;domain=.baidu.com'从上图中我们可以得出:
Domain 标识指定了哪些域名可以接受Cookie。如果没有设置domain,就会自动绑定到执行语句的当前域。 如果设置为”.baidu.com”,则所有以”baidu.com”结尾的域名都可以访问该Cookie,所以在掘金社区上读取不到第三条代码存储Cookie值。
Cookie的大小限制在4KB左右,对于复杂的存储需求来说是不够用的。当 Cookie 超过 4KB 时,它将面临被裁切的命运。这样看来,Cookie 只能用来存取少量的信息。此外很多浏览器对一个站点的cookie个数也是有限制的。
这里需注意:各浏览器的cookie每一个name=value的value值大概在4k,所以4k并不是一个域名下所有的cookie共享的,而是一个name的大小。
Cookie 是紧跟域名的。同一个域名下的所有请求,都会携带 Cookie。大家试想,如果我们此刻仅仅是请求一张图片或者一个 CSS 文件,我们也要携带一个 Cookie 跑来跑去(关键是 Cookie 里存储的信息并不需要),这是一件多么劳民伤财的事情。Cookie 虽然小,请求却可以有很多,随着请求的叠加,这样的不必要的 Cookie 带来的开销将是无法想象的。
cookie是用来维护用户信息的,而域名(domain)下所有请求都会携带cookie,但对于静态文件的请求,携带cookie信息根本没有用,此时可以通过cdn(存储静态文件的)的域名和主站的域名分开来解决。
对于 cookie 来说,我们还需要注意安全性。
HttpOnly 不支持读写,浏览器不允许脚本操作document.cookie去更改cookie, 所以为避免跨域脚本 (XSS) 攻击,通过JavaScript的 Document.cookie API无法访问带有 HttpOnly 标记的Cookie,它们只应该发送给服务端。如果包含服务端 Session 信息的 Cookie 不想被客户端 JavaScript 脚本调用,那么就应该为其设置 HttpOnly 标记。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
标记为 Secure 的Cookie只应通过被HTTPS协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过Cookie传输,因为Cookie有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
为了弥补 Cookie 的局限性,让“专业的人做专业的事情”,Web Storage 出现了。
HTML5中新增了本地存储的解决方案----Web Storage,它分成两类:sessionStorage和localStorage。这样有了WebStorage后,cookie能只做它应该做的事情了——作为客户端与服务器交互的通道,保持客户端状态。
基于上面的特点,LocalStorage可以作为浏览器本地缓存方案,用来提升网页首屏渲染速度(根据第一请求返回时,将一些不变信息直接存储在本地)。
localStorage保存的数据,以“键值对”的形式存在。也就是说,每一项数据都有一个键名和对应的值。所有的数据都是以文本格式保存。 存入数据使用setItem方法。它接受两个参数,第一个是键名,第二个是保存的数据。 localStorage.setItem("key","value"); 读取数据使用getItem方法。它只有一个参数,就是键名。 var valueLocal = localStorage.getItem("key");
具体步骤,请看下面的例子:
<script>
if(window.localStorage){
localStorage.setItem('name','world')
localStorage.setItem('gender','female')
}
</script>
<body>
<div id="name"></div>
<div id="gender"></div>
<script>
var name=localStorage.getItem('name')
var gender=localStorage.getItem('gender')
document.getElementById('name').innerHTML=name
document.getElementById('gender').innerHTML=gender
</script>
</body>
LocalStorage在存储方面没有什么特别的限制,理论上 Cookie 无法胜任的、可以用简单的键值对来存取的数据存储任务,都可以交给 LocalStorage 来做。
这里给大家举个例子,考虑到 LocalStorage 的特点之一是持久,有时我们更倾向于用它来存储一些内容稳定的资源。比如图片内容丰富的电商网站会用它来存储 Base64 格式的图片字符串:
sessionStorage保存的数据用于浏览器的一次会话,当会话结束(通常是该窗口关闭),数据被清空;sessionStorage 特别的一点在于,即便是相同域名下的两个页面,只要它们不在同一个浏览器窗口中打开,那么它们的 sessionStorage 内容便无法共享;localStorage 在所有同源窗口中都是共享的;cookie也是在所有同源窗口中都是共享的。除了保存期限的长短不同,SessionStorage的属性和方法与LocalStorage完全一样。
基于上面的特点,sessionStorage 可以有效对表单信息进行维护,比如刷新时,表单信息不丢失。
sessionStorage 更适合用来存储生命周期和它同步的会话级别的信息。这些信息只适用于当前会话,当你开启新的会话时,它也需要相应的更新或释放。比如微博的 sessionStorage就主要是存储你本次会话的浏览足迹:
lasturl 对应的就是你上一次访问的 URL 地址,这个地址是即时的。当你切换 URL 时,它随之更新,当你关闭页面时,留着它也确实没有什么意义了,干脆释放吧。这样的数据用 sessionStorage 来处理再合适不过。
作用域:localStorage只要在相同的协议、相同的主机名、相同的端口下,就能读取/修改到同一份localStorage数据。sessionStorage比localStorage更严苛一点,除了协议、主机名、端口外,还要求在同一窗口(也就是浏览器的标签页)下
生命周期:localStorage 是持久化的本地存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除;而 sessionStorage 是临时性的本地存储,它是会话级别的存储,当会话结束(页面被关闭)时,存储内容也随之被释放。
Web Storage 是一个从定义到使用都非常简单的东西。它使用键值对的形式进行存储,这种模式有点类似于对象,却甚至连对象都不是——它只能存储字符串,要想得到对象,我们还需要先对字符串进行一轮解析。
说到底,Web Storage 是对 Cookie 的拓展,它只能用于存储少量的简单数据。当遇到大规模的、结构复杂的数据时,Web Storage 也爱莫能助了。这时候我们就要清楚我们的终极大 boss——IndexedDB!
IndexedDB 是一种低级API,用于客户端存储大量结构化数据(包括文件和blobs)。该API使用索引来实现对该数据的高性能搜索。IndexedDB 是一个运行在浏览器上的非关系型数据库。既然是数据库了,那就不是 5M、10M 这样小打小闹级别了。理论上来说,IndexedDB 是没有存储上限的(一般来说不会小于 250M)。它不仅可以存储字符串,还可以存储二进制数据。
IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
在IndexedDB大部分操作并不是我们常用的调用方法,返回结果的模式,而是请求——响应的模式。
window.indexedDB.open("testDB")这条指令并不会返回一个DB对象的句柄,我们得到的是一个IDBOpenDBRequest对象,而我们希望得到的DB对象在其result属性中
除了result,IDBOpenDBRequest接口定义了几个重要属性:
onerror: 请求失败的回调函数句柄
onsuccess:请求成功的回调函数句柄
onupgradeneeded:请求数据库版本变化句柄
<script>
function openDB(name){
var request=window.indexedDB.open(name)//建立打开IndexedDB
request.onerror=function (e){
console.log('open indexdb error')
}
request.onsuccess=function (e){
myDB.db=e.target.result//这是一个 IDBDatabase对象,这就是IndexedDB对象
console.log(myDB.db)//此处就可以获取到db实例
}
}
var myDB={
name:'testDB',
version:'1',
db:null
}
openDB(myDB.name)
</script>控制台得到一个 IDBDatabase对象,这就是IndexedDB对象
indexdb.close()function closeDB(db){
db.close();
}window.indexedDB.deleteDatabase(indexdb)function deleteDB(name) {
indexedDB.deleteDatabase(name)
} 从上表可以看到,cookie 已经不建议用于存储。如果没有大量数据存储需求的话,可以使用 localStorage 和 sessionStorage 。对于不怎么改变的数据尽量使用 localStorage 存储,否则可以用 sessionStorage 存储。
正是浏览器存储、缓存技术的出现和发展,为我们的前端应用带来了无限的转机。近年来基于存储、缓存技术的第三方库层出不绝,此外还衍生出了 PWA 这样优秀的 Web 应用模型。总结下本文几个核心观点:
前端缓存主要是分为HTTP缓存和浏览器缓存。其中HTTP缓存是在HTTP请求传输时用到的缓存,主要在服务器代码上设置;而浏览器缓存则主要由前端开发在前端js上进行设置。

在了解http缓存之前我们要先了解http请求流程:

在流程图中发起请求后判断是否已缓存这里我们需要了解http报文。
通过网络获取内容既缓慢,成本很高:大的响应需要在客户端和服务器之间进行多次往返通信,这拖延了浏览器可以使用和处理内容的时间,同时也增加了访问者的数据成本。使用http缓存能节约带宽,能降低后端服务器的访问压力,极大的加快响应的速度。
http缓存分为强缓存和协商缓存
如果强缓存是新鲜的,优先强缓存。 如果强缓存是不新鲜的,判断有无协商缓存
强制缓存的含义是,当客户端发起请求前,会先访问缓存数据库看缓存是否存在。如果存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库。
强制缓存直接减少请求数,是提升最大的缓存策略。 它的优化覆盖了请求、处理、响应的三个步骤。如果考虑使用缓存来优化网页性能的话,强制缓存应该是首先被考虑的。
可以造成强制缓存的字段是Pragma、 Cache-control 和 Expires。
Pragma: no-cache当该字段值为“no-cache”的时候,告诉客户端不要读取缓存,这个报文已经很少用了但需要知道Pragma的优先级是高于Cache-Control 。
Cache-control: max-age=2592000为当前主流浏览器通用的强缓存识别报文,下面列举一些 Cache-control 字段常用的值
max-age:即最大有效时间,在上面的例子中我们可以看到must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。no-cache:虽然字面意思是“不要缓存”,但实际上还是要求客户端缓存内容的,只是是否使用这个内容由后续的对比来决定。no-store: 真正意义上的“不要缓存”。所有内容都不走缓存,包括强制和对比。public:所有的内容都可以被缓存 (包括客户端和代理服务器, 如 CDN)private:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。表示缓存到期时间
Expires: Thu, 10 Nov 2017 08:45:11 GMT在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
但是,这个字段设置时有两个缺点:
若强缓存失效,则浏览器会将请求发送至服务器。服务器根据http头信息中的Last-Modify/If-Modify-Since或Etag/If-None-Match来判断缓存是否失效。如果未失效,则http返回码为304,浏览器从缓存中加载资源。
(1)服务器通过 Last-Modified 字段告知客户端,资源最后一次被修改的时间,例如
Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT(2)浏览器将这个值和内容一起记录在缓存数据库中。
(3)下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的 Last-Modified 的值写入到请求头的 If-Modified-Since 字段
(4)服务器会将 If-Modified-Since 的值与 Last-Modified 字段进行对比。如果相等,则表示未修改,响应 304;反之,则表示修改了,响应 200 状态码,并返回数据。
但是他还是有一定缺陷的:
1.如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
2.如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
为了解决上述问题,出现了一组新的字段 Etag 和 If-None-Match
If-None-Match: "56fcccc8-1699"Etag 存储的是文件的特殊标识(一般都是 hash 生成的),服务器存储着文件的 Etag 字段。之后的流程和 Last-Modified 一致,只是 Last-Modified 字段和它所表示的更新时间改变成了 Etag 字段和它所表示的文件 hash,把 If-Modified-Since 变成了 If-None-Match。服务器同样进行比较,命中返回 304, 不命中返回新资源和 200。
Etag 的优先级高于 Last-Modified。
// 1.原生 node 实现
app.use(async (ctx, next) => {
ctx.set("Access-Control-Allow-Origin", ctx.headers.origin);
ctx.set("Access-Control-Allow-Credentials", true);
ctx.set("Access-Control-Request-Method", "PUT,POST,GET,DELETE,OPTIONS");
ctx.set(
"Access-Control-Allow-Headers",
"Origin, X-Requested-With, Content-Type, Accept, cc"
);
if (ctx.method === "OPTIONS") {
ctx.status = 204;
return;
}
await next();
});// 2.使用第三方中间件
const cors = require("koa-cors");
app.use(cors());
// 3.使用 node 正向代理,比如
webpackConfig.devServer.proxy
// 4.使用 nginx 反向代理// 5.jsonp
<script>
window.jsonpCallback = function(res) {
console.log(res);
};
</script>
<script
src="http://localhost:8080/api/jsonp?msg=hello&cb=jsonpCallback"
type="text/javascript"
></script>
<script>
jsonpCallback({ a: 1 });
</script>
// 6.window.postMessage
// index.html
<iframe
src="http://localhost:8080"
frameborder="0"
id="iframe"
onload="load()"
></iframe>
<script>
function load() {
iframe.contentWindow.postMessage("秋风的笔记", "http://localhost:8080");
window.onmessage = e => {
console.log(e.data);
};
}
</script>
// another.html
<div>hello</div>
<script>
window.onmessage = e => {
console.log(e.data); // 秋风的笔记
e.source.postMessage(e.data, e.origin);
};
</script>常见的语义化标签:
<header>有两种用法,第一是标注内容的标题,第二是标注网页的页眉语义元素均有一个共同特点——他们均不做任何事情。换句话说,语义元素仅仅是页面结构的规范化,并不会对内容有本质的影响。
下图展示了一个典型的页面结构。

<header>元素有两种用法,第一是标注内容的标题,第二是标注网页的页眉,如上图你看到的那样。除非必要(内容标题附带其它信息的情况下:发布时间、作者等),一般不在内容中使用<header>。因而,网页中可以包含多个<header>元素。按照 HTML5 的规定,<header>都应包含某个级别的标题,所以应隐式或显式地包含标题,通常将不希望显示的标题设置为display: none;,一方面遵守规范,另一方面则提供了无障碍阅读而不至于影响到页面设计。
导航栏使用<nav>看起来是理所当然的,进一步,它也用于一组文章的链接。一个页面可以包含多个<nav>元素,但通常仅仅在页面的主要导航部分使用它。
《HTML5:The Missing Manual》中指出了在侧栏使用<nav>标签的两个案例:
<!-- 案例一 -->
<nav>
<!-- 此处是链接 -->
<aside></aside>
<aside></aside>
</nav>
<!-- 案例二 -->
<aside>
<nav>
<!-- 此处是链接 -->
</nav>
<section></section>
<div></div>
</aside>
如果侧栏中包含其它不同于链接的其它区块,那么,使用第二种方案显然更为合适。
导航通常包含一组链接,普遍认为,链接使用列表来组织。
<nav>
<ul>
<li><a href="#" title="链接">链接</a></li>
<li><a href="#" title="链接">链接</a></li>
<li><a href="#" title="链接">链接</a></li>
</ul>
</nav>
<aside>元素并不仅仅是侧栏,它表示与它周围文本没有密切关系的内容。文章中同样可以使用<aside>元素,来说明文章的附加内容、解释说明某个观点、相关内容链接等等。
当<aside>用于侧栏时,其表示整个网页的附加内容。通常的广告区域、搜索、分享链接则位于侧栏。侧栏中的<section>元素规定了一个区域,通常是带有标题的内容。
<section>标签适合标记的内容区块:
<div> 标签依然是可用的,当你觉得使用其它标签都不太合适的时候。新的语义元素出现之前,我们总是这么干的!
同可“包罗万象”的<header>元素不同,标准规定<footer>标签仅仅可以包含版权、来源信息、法律限制等等之类的文本或链接信息。如果想要在页脚中包含其它内容,可以使用熟悉的<div>来帮忙。
<div>
<aside>
<!-- 其它内容 -->
</aside>
<footer>
<!-- 法律、版权、来源、联系信息等 -->
</footer>
</div>
在早先的 HTML5 版本中并没有规定页面主体的标签,相关的书中经常会说:除去头部、尾部、侧栏等其它部分,剩下的自然是主体部分。
然而,HTML5.1 中规定了一个<main>标签来标识主体内容。<main>标签不能包含在页面其它区块元素中,通常是<body>的子标签,或者是全局<div>的子标签。<main>标签可以帮助屏幕阅读工具识别页面的主体部分,从而让访问者迅速得到有用的信息。
<article>表示一个完整的、自成一体的内容块。如文章或新闻报道。<article>应包含完整的标题、文章署名、发布时间、正文。当语义与表现发生冲突,例如有时需要将文章分多个页面显示,那么需要把每个页面的文章区域都用<article>标记。
文章中包含插图时,使用新的语义元素<figure>标签。
<article>
<h1>标题</h1>
<p>
<!-- 内容 -->
</p>
<figure>
<img src="#" alt="插图">
<figcaption>这是一个插图</figcaption>
</figure>
</article>
上述情况下,<figcaption>包含了关于插图的详细解释,则<img>的alt属性可以略去。
网页布局(layout)是 CSS 的一个重点应用。
布局的传统解决方案,基于盒状模型,依赖 display 属性 + position属性 + float属性。它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现。
2009年,W3C 提出了一种新的方案----Flex 布局,可以简便、完整、响应式地实现各种页面布局。目前,它已经得到了所有浏览器的支持,这意味着,现在就能很安全地使用这项功能。
Flex 布局将成为未来布局的首选方案。本文介绍它的语法,下一篇文章给出常见布局的 Flex 写法。网友 JailBreak 为本文的所有示例制作了 Demo,也可以参考。
以下内容主要参考了下面两篇文章:A Complete Guide to Flexbox 和 A Visual Guide to CSS3 Flexbox Properties。
Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性。
任何一个容器都可以指定为 Flex 布局。
.box{
display: flex;
}行内元素也可以使用 Flex 布局。
.box{
display: inline-flex;
}Webkit 内核的浏览器,必须加上-webkit前缀。
.box{
display: -webkit-flex; /* Safari */
display: flex;
}注意,设为 Flex 布局以后,子元素的float、clear和vertical-align属性将失效。
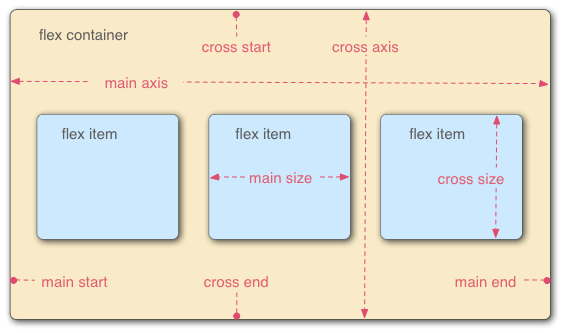
采用 Flex 布局的元素,称为 Flex 容器(flex container),简称"容器"。它的所有子元素自动成为容器成员,称为 Flex 项目(flex item),简称"项目"。
容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
以下6个属性设置在容器上。
flex-direction属性决定主轴的方向(即项目的排列方向)。
.box {
flex-direction: row | row-reverse | column | column-reverse;
}它可能有4个值。
row(默认值):主轴为水平方向,起点在左端。row-reverse:主轴为水平方向,起点在右端。column:主轴为垂直方向,起点在上沿。column-reverse:主轴为垂直方向,起点在下沿。默认情况下,项目都排在一条线(又称"轴线")上。flex-wrap属性定义,如果一条轴线排不下,如何换行。
.box{
flex-wrap: nowrap | wrap | wrap-reverse;
}它可能取三个值。
(1)nowrap(默认):不换行。
(2)wrap:换行,第一行在上方。
(3)wrap-reverse:换行,第一行在下方。
flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。
.box {
flex-flow: <flex-direction|| <flex-wrap>;
}justify-content属性定义了项目在主轴上的对齐方式。
.box {
justify-content: flex-start | flex-end | center | space-between | space-around;
}它可能取5个值,具体对齐方式与轴的方向有关。下面假设主轴为从左到右。
flex-start(默认值):左对齐flex-end:右对齐center: 居中space-between:两端对齐,项目之间的间隔都相等。space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。align-items属性定义项目在交叉轴上如何对齐。
.box {
align-items: flex-start | flex-end | center | baseline | stretch;
}它可能取5个值。具体的对齐方式与交叉轴的方向有关,下面假设交叉轴从上到下。
flex-start:交叉轴的起点对齐。flex-end:交叉轴的终点对齐。center:交叉轴的中点对齐。baseline: 项目的第一行文字的基线对齐。stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
.box {
align-content: flex-start | flex-end | center | space-between | space-around | stretch;
}该属性可能取6个值。
flex-start:与交叉轴的起点对齐。flex-end:与交叉轴的终点对齐。center:与交叉轴的中点对齐。space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。stretch(默认值):轴线占满整个交叉轴。以下6个属性设置在项目上。
orderflex-growflex-shrinkflex-basisflexalign-selforder属性定义项目的排列顺序。数值越小,排列越靠前,默认为0。
.item {
order: <integer>;
}flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
.item {
flex-grow: <number>; /* default 0 */
}如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
.item {
flex-shrink: <number>; /* default 1 */
}如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
负值对该属性无效。
flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。
.item {
flex-basis: <length| auto; /* default auto */
}它可以设为跟width或height属性一样的值(比如350px),则项目将占据固定空间。
flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。
.item {
flex: none | [ <'flex-grow'<'flex-shrink'>? || <'flex-basis']
}该属性有两个快捷值:auto (1 1 auto) 和 none (0 0 auto)。
建议优先使用这个属性,而不是单独写三个分离的属性,因为浏览器会推算相关值。
align-self属性允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch。
.item {
align-self: auto | flex-start | flex-end | center | baseline | stretch;
}该属性可能取6个值,除了auto,其他都与align-items属性完全一致。
大家的第一反应,可能就是 flex 了。因为它的写法够简单直观,兼容性也没什么问题。是手机端居中方式的首选。
<div class="wrapper flex-center">
<p>horizontal and vertical</p>
</div>
<style>
.wrapper {
width: 300px;
height: 300px;
border: 1px solid #ccc;
}
.flex-center {
display: flex;
justify-content: center;
align-items: center;
}
</style>利用到了 2 个关键属性:justify-content (水平方向居中)和 align-items(垂直方向居中),都设置为 center,即可实现居中。
需要注意的是,一定要把这里的 flex-center 挂在父级元素,才能使得其中 唯一的 子元素居中。
这是 flex 方法的变种。父级元素设置 flex,子元素设置 margin: auto;。可以理解为子元素被四周的 margin “挤” 到了中间。
<div class="wrapper">
<p>horizontal and vertical</p>
</div>
<style>
.wrapper {
width: 300px;
height: 300px;
border: 1px solid #ccc;
display: flex;
}
.wrapper > p {
margin: auto;
}
</style>常用于图片的居中显示。
<div class="wrapper">
<img src="test.png" />
</div>
<style>
.wrapper {
width: 200px;
height: 200px;
border: 1px solid #ccc;
position: relative;
background-color: green;
}
.wrapper > img {
position: relative;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
}
</style>
使用绝对定位布局,设置 margin:auto;,并设置 top、left、right、bottom 的 值相等即可(不一定要都是 0)。
<div class="wrapper">
<p>horizontal and vertical</p>
</div>
<style>
.wrapper {
width: 300px;
height: 300px;
border: 1px solid #ccc;
position: relative;
}
.wrapper > p {
width: 170px;
height: 20px;
margin: auto;
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
}
</style>这种方法一般用于弹出层,需要设置弹出层的宽高。
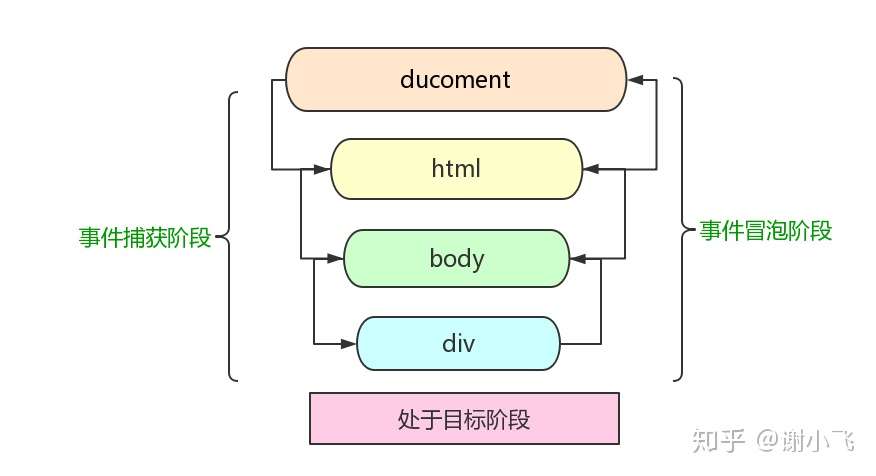
在JS事件循环中,我们接触了很多JS自己触发的事件。但是当我们在网页上进行某些类型的交互时,也会触发事件,比如在某些内容上的点击、鼠标经过某个特定元素或按下键盘上的某些按键。当一个节点产生一个事件时,该事件会在元素结点与根节点之间按特定的顺序传播,路径所经过的节点都会收到该事件,这个传播过程称为DOM事件流。
JavaScript和HTML之间的交互是通过事件实现的。事件,就是文档或浏览器窗口发生的一些特定的交互瞬间。可以使用监听器(或事件处理程序)来预定事件,以便事件发生时执行相应的代码。通俗的说,这种模型其实就是一个观察者模式。(事件是对象主题,而这一个个的监听器就是一个个观察者)
事件流描述的就是从页面中接收事件的顺序。而早期的IE和Netscape提出了完全相反的事件流概念,IE事件流是事件冒泡,而Netscape的事件流就是事件捕获。
事件流的执行顺序:
IE提出的事件流是事件冒泡,即从下至上,从目标触发的元素逐级向上传播,直到window对象。
而Netscape的事件流就是事件捕获,即从document逐级向下传播到目标元素。由于IE低版本浏览器不支持,所以很少使用事件捕获。
后来ECMAScript在DOM2中对事件流进行了进一步规范,基本上就是上述二者的结合。
DOM2级事件规定的事件流包括三个阶段: (1)事件捕获阶段 (2)处于目标阶段 (3)事件冒泡阶段
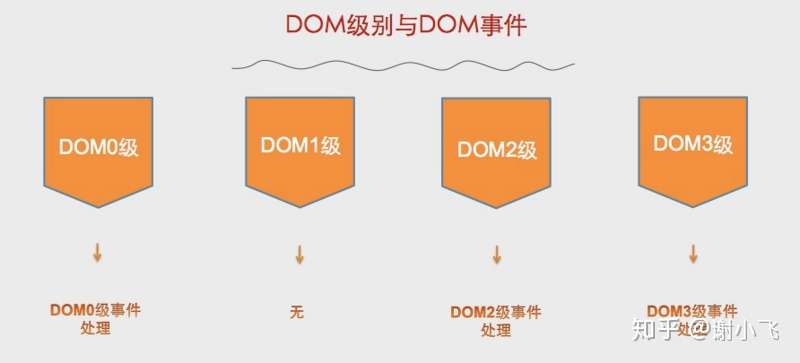
DOM节点中有了事件,那我们就需要对事件进行处理,而DOM事件处理分为4个级别:DOM0级事件处理,DOM1级事件处理,DOM2级事件处理和DOM3级事件处理。
其中DOM1级事件处理标准中并没有定义相关的内容,所以没有所谓的DOM1事件处理;DOM3级事件在DOM2级事件的基础上添加了更多的事件类型。
DOM0级事件具有极好的跨浏览器优势,会以最快的速度绑定。第一种方式是内联模型(行内绑定),将函数名直接作为html标签中属性的属性值。
<div onclick="btnClick()">click</div>
<script>
function btnClick(){
console.log("hello");
}
</script>内联模型的缺点是不符合w3c中关于内容与行为分离的基本规范。第二种方式是脚本模型(动态绑定),通过在JS中选中某个节点,然后给节点添加onclick属性。
<div id="btn">点击</div>
<script>
var btn=document.getElementById("btn");
btn.onclick=function(){
console.log("hello");
}
</script>点击输出hello,没有问题;如果我们给元素添加两个事件
<div id="btn">点击</div>
<script>
var btn=document.getElementById("btn");
btn.onclick=function(){
console.log("hello");
}
btn.onclick=function(){
console.log("hello again");
}
</script>这时候只有输出hello again,很明显,第一个事件函数被第二个事件函数给覆盖掉,所以脚本模型的缺点是同一个节点只能添加一次同类型事件。让我们把div扩展到3个。
<div id="btn3">
btn3
<div id="btn2">
btn2
<div id="btn1">
btn1
</div>
</div>
</div>
<script>
let btn1 = document.getElementById("btn1");
let btn2 = document.getElementById("btn2");
let btn3 = document.getElementById("btn3");
btn1.onclick=function(){
console.log(1)
}
btn2.onclick=function(){
console.log(2)
}
btn3.onclick=function(){
console.log(3)
}
</script>
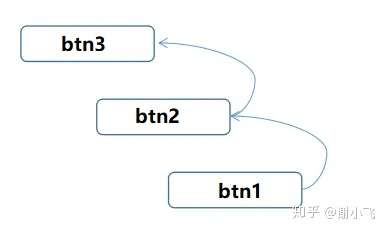
当我们点击btn3的时候输出3,那当我们点击btn1的时候呢?
我们发现最先触发的是最底层btn1的事件,最后才是顶层btn3的事件,因此很明显是事件冒泡。DOM0级只支持冒泡阶段。
进一步规范之后,有了DOM2级事件处理程序,其中定义了两个方法:
函数均有3个参数, 第一个参数是要处理的事件名 第二个参数是作为事件处理程序的函数 第三个参数是一个boolean值,默认false表示使用冒泡机制,true表示捕获机制。
<div id="btn">点击</div>
<script>
var btn=document.getElementById("btn");
btn.addEventListener("click",hello,false);
btn.addEventListener("click",helloagain,false);
function hello(){
console.log("hello");
}
function helloagain(){
console.log("hello again");
}
</script>这时候两个事件处理程序都能够成功触发,说明可以绑定多个事件处理程序,但是注意,如果定义了一摸一样时监听方法,是会发生覆盖的,即同样的事件和事件流机制下相同方法只会触发一次,
<div id="btn">点击</div>
<script>
var btn=document.getElementById("btn");
btn.addEventListener("click",hello,false);
btn.addEventListener("click",hello,false);
function hello(){
console.log("hello");
}
</script>这时候hello只会执行一次;让我们把div扩展到3个。
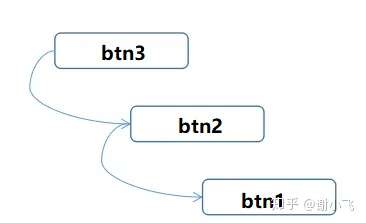
<div id="btn3">
btn3
<div id="btn2">
btn2
<div id="btn1">
btn1
</div>
</div>
</div>
<script>
let btn1 = document.getElementById('btn1');
let btn2 = document.getElementById('btn2');
let btn3 = document.getElementById('btn3');
btn1.addEventListener('click',function(){
console.log(1)
}, true)
btn2.addEventListener('click',function(){
console.log(2)
}, true)
btn3.addEventListener('click',function(){
console.log(3)
}, true)
</script>这时候看到顺序和DOM0中的顺序反过来了,最外层的btn最先触发,因为addEventListener最后一个参数是true,捕获阶段进行处理。
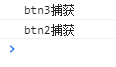
那么冒泡和捕获阶段谁先执行呢?我们给每个元素分别绑定了冒泡和捕获两个事件。
btn1.addEventListener('click',function(){
console.log('btn1捕获')
}, true)
btn1.addEventListener('click',function(){
console.log('btn1冒泡')
}, false)
btn2.addEventListener('click',function(){
console.log('btn2捕获')
}, true)
btn2.addEventListener('click',function(){
console.log('btn2冒泡')
}, false)
btn3.addEventListener('click',function(){
console.log('btn3捕获')
}, true)
btn3.addEventListener('click',function(){
console.log('btn2冒泡')
}, false)我们看到先执行捕获阶段的处理程序,后执行冒泡阶段的处理程序,我们把顺序换一下再看运行结果:
btn1.addEventListener('click',function(){
console.log('btn1冒泡')
}, false)
btn1.addEventListener('click',function(){
console.log('btn1捕获')
}, true)
btn2.addEventListener('click',function(){
console.log('btn2冒泡')
}, false)
btn2.addEventListener('click',function(){
console.log('btn2捕获')
}, true)
btn3.addEventListener('click',function(){
console.log('btn3冒泡')
}, false)
btn3.addEventListener('click',function(){
console.log('btn3捕获')
}, true)我们发现在触发的目标元素上不区分冒泡还是捕获,按绑定的顺序来执行。
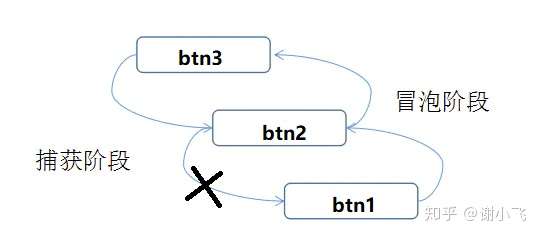
有时候我们需要点击事件不再继续向上冒泡,我们在btn2上加上stopPropagation函数,阻止程序冒泡。
btn1.addEventListener('click',function(){
console.log('btn1冒泡')
}, false)
btn1.addEventListener('click',function(){
console.log('btn1捕获')
}, true)
btn2.addEventListener('click',function(){
console.log('btn2冒泡')
}, false)
btn2.addEventListener('click',function(ev){
ev.stopPropagation();
console.log('btn2捕获')
}, true)
btn3.addEventListener('click',function(){
console.log('btn3冒泡')
}, false)
btn3.addEventListener('click',function(e){
console.log('btn3捕获')
}, true)可以看到btn2捕获阶段执行后不再继续往下执行。
如果有多个DOM节点需要监听事件的情况下,给每个DOM绑定监听函数,会极大的影响页面的性能,因为我们通过事件委托来进行优化,事件委托利用的就是冒泡的原理。
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<script>
var li_list = document.getElementsByTagName('li')
for(let index = 0;index<li_list.length;index++){
li_list[index].addEventListener('click', function(ev){
console.log(ev.currentTarget.innerHTML)
})
}
</script>正常情况我们给每一个li都会绑定一个事件,但是如果这时候li是动态渲染的,数据又特别大的时候,每次渲染后(有新增的情况)我们还需要重新来绑定,又繁琐又耗性能;这时候我们可以将绑定事件委托到li的父级元素,即ul。
var ul_dom = document.getElementsByTagName('ul')
ul_dom[0].addEventListener('click', function(ev){
console.log(ev.target.innerHTML)
})上面代码中我们使用了两种获取目标元素的方式,target和currentTarget,那么他们有什么区别呢:
不一定是绑定事件的元素因此我们总结一下事件委托的优点:
简述:
集合 与 字典 的区别:
ES6 新增的一种新的数据结构,类似于数组,成员唯一(内部元素没有重复的值)。且Set元素的遍历顺序就是插入顺序。
Set 本身是一个构造函数,用来生成 Set 对象。
Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
const s = new Set()
[1, 2, 3, 4, 3, 2, 1].forEach(x => s.add(x))
for (let i of s) {
console.log(i) // 1 2 3 4
}
// 去重数组的重复对象
let arr = [1, 2, 3, 2, 1, 1]
[... new Set(arr)] // [1, 2, 3]注意:向 Set 加入值的时候,不会发生类型转换,所以5和"5"是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是**NaN等于自身,而精确相等运算符认为NaN不等于自身。**
let set = new Set();
let a = NaN;
let b = NaN;
set.add(a);
set.add(b);
set // Set {NaN}
let set1 = new Set()
set1.add(5)
set1.add('5')
console.log([...set1]) // [5, "5"]操作方法:
遍历方法(遍历顺序为插入顺序)
WeakSet 对象允许你将弱引用对象储存在一个集合中。
WeakSet 与 Set 的区别:
方法:
是一组键值对的结构,具有极快的查找速度。
const m = new Map()
const o = {p: 'haha'}
m.set(o, 'content')
m.get(o) // content
m.has(o) // true
m.delete(o) // true
m.has(o) // false操作方法:
遍历方法:
WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意。
注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。
WeakMap 中,每个键对自己所引用对象的引用都是弱引用,在没有其他引用和该键引用同一对象,这个对象将会被垃圾回收(相应的key则变成无效的),所以,WeakMap 的 key 是不可枚举的。
方法:
Set:
WeakSet:
Map:
WeakMap:
平常我们对象的属性都是字符串
const obj = {
name: 'Sunshine_Lin',
age: 23
}
console.log(obj['name']) // 'Sunshine_Lin'
console.log(obj['age']) // 23其实也可以用Symbol来当做属性名
const gender = Symbol('gender')
const obj = {
name: 'Sunshine_Lin',
age: 23,
[gender]: '男'
}
console.log(obj['name']) // 'Sunshine_Lin'
console.log(obj['age']) // 23
console.log(obj[gender]) // 男但是Symbol作为属性的属性不会被枚举出来,这也是JSON.stringfy(obj)时,Symbol属性会被排除在外的原因
console.log(Object.keys(obj)) // [ 'name', 'age' ]
for(const key in obj) {
console.log(key) // name age
}
console.log(JSON.stringify(obj)) // {"name":"Sunshine_Lin","age":23}其实想获取Symbol属性也不是没办法。
// 方法一
console.log(Object.getOwnPropertySymbols(obj)) // [ Symbol(gender) ]
// 方法二
console.log(Reflect.ownKeys(obj)) // [ 'name', 'age', Symbol(gender) ]有以下场景
// 赋值
const one = 'oneXin'
const two = 'twoXin'
function fun(key) {
switch (key) {
case one:
return 'one'
break;
case two:
return 'two'
break;
}
}如果变量少的话还好,但是变量多的时候,赋值命名很烦,可以利用Symbol的唯一性
const one = Symbol()
const two = Symbol()以下例子,PASSWORD属性无法在实例里获取到
class Login {
constructor(username, password) {
const PASSWORD = Symbol()
this.username = username
this[PASSWORD] = password
}
checkPassword(pwd) { return this[PASSWORD] === pwd }
}
const login = new Login('123456', 'hahah')
console.log(login.PASSWORD) // 报错
console.log(login[PASSWORD]) // 报错
console.log(login[PASSWORD]) // 报错我们都知道,javascript从诞生之日起就是一门单线程的非阻塞的脚本语言。这是由其最初的用途来决定的:与浏览器交互。
单线程意味着,javascript代码在执行的任何时候,都只有一个主线程来处理所有的任务。
而非阻塞则是当代码需要进行一项异步任务(无法立刻返回结果,需要花一定时间才能返回的任务,如I/O事件)的时候,主线程会挂起(pending)这个任务,然后在异步任务返回结果的时候再根据一定规则去执行相应的回调。
单线程是必要的,也是javascript这门语言的基石,原因之一在其最初也是最主要的执行环境——浏览器中,我们需要进行各种各样的dom操作。试想一下 如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
当然,现如今人们也意识到,单线程在保证了执行顺序的同时也限制了javascript的效率,因此开发出了web worker技术。这项技术号称让javascript成为一门多线程语言。
然而,使用web worker技术开的多线程有着诸多限制,例如:所有新线程都受主线程的完全控制,不能独立执行。这意味着这些“线程” 实际上应属于主线程的子线程。另外,这些子线程并没有执行I/O操作的权限,只能为主线程分担一些诸如计算等任务。所以严格来讲这些线程并没有完整的功能,也因此这项技术并非改变了javascript语言的单线程本质。
可以预见,未来的javascript也会一直是一门单线程的语言。
话说回来,前面提到javascript的另一个特点是“非阻塞”,那么javascript引擎到底是如何实现的这一点呢?答案就是今天这篇文章的主角——event loop(事件循环)。
注:虽然nodejs中的也存在与传统浏览器环境下的相似的事件循环。然而两者间却有着诸多不同,故把两者分开,单独解释。
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
我们知道,当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。。这个过程反复进行,直到执行栈中的代码全部执行完毕。
下面这个图片非常直观的展示了这个过程,其中的global就是初次运行脚本时向执行栈中加入的代码:

从图片可知,一个方法执行会向执行栈中加入这个方法的执行环境,在这个执行环境中还可以调用其他方法,甚至是自己,其结果不过是在执行栈中再添加一个执行环境。这个过程可以是无限进行下去的,除非发生了栈溢出,即超过了所能使用内存的最大值。
以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?前文提过,js的另一大特点是非阻塞,实现这一点的关键在于下面要说的这项机制——事件队列(Task Queue)。
js引擎遇到一个异步事件后并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务。当一个异步事件返回结果后,js会将这个事件加入与当前执行栈不同的另一个队列,我们称之为事件队列。被放入事件队列不会立刻执行其回调,而是等待当前执行栈中的所有任务都执行完毕, 主线程处于闲置状态时,主线程会去查找事件队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件,并把这个事件对应的回调放入执行栈中,然后执行其中的同步代码...,如此反复,这样就形成了一个无限的循环。这就是这个过程被称为“事件循环(Event Loop)”的原因。
这里还有一张图来展示这个过程:

图中的stack表示我们所说的执行栈,web apis则是代表一些异步事件,而callback queue即事件队列。
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task)。
以下事件属于宏任务:
setInterval()setTimeout()以下事件属于微任务
new Promise()new MutaionObserver()前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈...如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。
这样就能解释下面这段代码的结果:
setTimeout(function () {
console.log(1);
});
new Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
结果为:
2
3
1
省略,请查看原文
以本文就浏览器渲染流程单独开篇讲解,希望大家都能有新的收获。
(浏览器主要组件)
Firefox使用Geoko——Mozilla自主研发的渲染引擎。
Safari和Chrome都使用webkit。Webkit是一款开源渲染引擎,它本来是为linux平台研发的,后来由Apple移植到Mac及Windows上。
本文我主要以webkit渲染引擎来讲解,尽管webkit和Gecko使用的术语稍有不同,他们的主要流程基本相同。
(webkit渲染引擎流程)
关键渲染路径是指浏览器从最初接收请求来的HTML、CSS、javascript等资源,然后解析、构建树、渲染布局、绘制,最后呈现给客户能看到的界面这整个过程。
所以浏览器的渲染过程主要包括以下几步:
当浏览器接收到服务器响应来的HTML文档后,会遍历文档节点,生成DOM树。
需要注意的是,DOM树的生成过程中可能会被CSS和JS的加载执行阻塞。渲染阻塞问题下文会讲。
浏览器解析CSS文件并生成CSS规则树,每个CSS文件都被分析成一个StyleSheet对象,每个对象都包含CSS规则。CSS规则对象包含对应于CSS语法的选择器和声明对象以及其他对象。
当浏览器遇到一个 script 标记时,DOM 构建将暂停,直至脚本完成执行,然后继续构建DOM。每次去执行JavaScript脚本都会严重地阻塞DOM树的构建,如果JavaScript脚本还操作了CSSOM,而正好这个CSSOM还没有下载和构建,浏览器甚至会延迟脚本执行和构建DOM,直至完成其CSSOM的下载和构建。
所以,script 标签的位置很重要。实际使用时,可以遵循下面两个原则:
CSS 优先:引入顺序上,CSS 资源先于 JavaScript 资源。
JS置后:我们通常把JS代码放到页面底部,且JavaScript 应尽量少影响 DOM 的构建。
当解析html的时候,会把新来的元素插入dom树里面,同时去查找css,然后把对应的样式规则应用到元素上,查找样式表是按照从右到左的顺序去匹配的。
例如: div p {font-size: 16px},会先寻找所有p标签并判断它的父标签是否为div之后才会决定要不要采用这个样式进行渲染)。
所以,我们平时写CSS时,尽量用id和class,千万不要过渡层叠。
通过DOM树和CSS规则树我们便可以构建渲染树。浏览器会先从DOM树的根节点开始遍历每个可见节点。对每个可见节点,找到其适配的CSS样式规则并应用。
渲染树构建完成后,每个节点都是可见节点并且都含有其内容和对应规则的样式。这也是渲染树与DOM树的最大区别所在。渲染树是用于显示,那些不可见的元素当然就不会在这棵树中出现了,譬如。除此之外,display等于none的也不会被显示在这棵树里头,但是visibility等于hidden的元素是会显示在这棵树里头的。
布局阶段会从渲染树的根节点开始遍历,然后确定每个节点对象在页面上的确切大小与位置,布局阶段的输出是一个盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小。
在绘制阶段,遍历渲染树,调用渲染器的paint()方法在屏幕上显示其内容。渲染树的绘制工作是由浏览器的UI后端组件完成的。
根据渲染树布局,计算CSS样式,即每个节点在页面中的大小和位置等几何信息。HTML默认是流式布局的,CSS和js会打破这种布局,改变DOM的外观样式以及大小和位置。这时就要提到两个重要概念:repaint和reflow。
repaint:屏幕的一部分重画,不影响整体布局,比如某个CSS的背景色变了,但元素的几何尺寸和位置不变。
reflow: 意味着元件的几何尺寸变了,我们需要重新验证并计算渲染树。是渲染树的一部分或全部发生了变化。这就是Reflow,或是Layout。
所以我们应该尽量减少reflow和repaint,我想这也是为什么现在很少有用table布局的原因之一。
display:none 会触发 reflow,visibility: hidden属性并不算是不可见属性,它的语义是隐藏元素,但元素仍然占据着布局空间,它会被渲染成一个空框,所以visibility:hidden 只会触发 repaint,因为没有发生位置变化。
有些情况下,比如修改了元素的样式,浏览器并不会立刻 reflow 或 repaint 一次,而是会把这样的操作积攒一批,然后做一次 reflow,这又叫异步 reflow 或增量异步 reflow。
有些情况下,比如 resize 窗口,改变了页面默认的字体等。对于这些操作,浏览器会马上进行 reflow。
Reflow 是不可避免的,只能将 Reflow 对性能的影响减到最小,给出下面几条建议:
// 不好的写法
var left = 10,
top = 10;
el.style.left = left + "px";
el.style.top = top + "px";
// 推荐写法
el.className += " theclassname";原理都是利用闭包保存变量。
防抖是任务频繁触发的情况下,只有任务触发的间隔超过指定间隔的时候,任务才会执行,一般用于输入框实时搜索;
节流是规定函数在指定的时间间隔内只执行一次,一般用于scroll事件。
// 防抖
function debounce(fn, time) {
let timer = null;
return function () {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.apply(this, arguments)
}, time)
}
}
// 节流
function throttle(fn, time) {
let canRun = true;
return function () {
if (!canRun) {
return
}
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, time)
}
}一般不用看 https://segmentfault.com/a/1190000018445196
一般不用看 https://www.cnblogs.com/c2016c/articles/9328725.html
// 1.
function deepClone(obj) {
var result = Array.isArray(obj) ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
if (typeof obj[key] === 'object' && obj[key] !== null) {
result[key] = deepClone(obj[key]);
} else {
result[key] = obj[key];
}
}
}
return result;
}
//2.
function deepClone(arr){
return JSON.parse(JSON.stringify(arr))
}
// 浅拷贝
function shallowClone(obj) {
let cloneObj = {};
for (let i in obj) {
cloneObj[i] = obj[i];
}
return cloneObj;
}// 1.取巧的一种算法,但是每个位置乱序的概率不同
function mixArr(arr){
return arr.sort(() => {
return Math.random() - 0.5;
})
}
// 2.著名的Fisher–Yates shuffle 洗牌算法
function shuffle(arr){
let m = arr.length;
while(m > 1){
let index = parseInt(Math.random() * m--);
[arr[index],arr[m]] = [arr[m],arr[index]];
}
return arr;
}// 1.
let resultArr = [...new Set(originalArray)];
// 2.
let resultArr = Array.from(new Set(originalArray));
// 3.
const resultArr = new Array();
const originalArray = [1, 2, 3, 4, 1, 2, 4, 6]
originalArray.forEach(element => {
if (!resultArr.includes(element)) {
resultArr.push(element)
}
});
console.log(resultArr);
// 4.
console.log(_.uniq(originalArray));数组flat方法是ES6新增的一个特性,可以将多维数组展平为低维数组。如果不传参默认展平一层,传参可以规定展平的层级。
// 展平一级
function flat(arr) {
var result = [];
for (var i = 0; i < arr.length; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flat(arr[i]))
} else {
result.push(arr[i]);
}
}
return result;
}
//展平多层
function flattenByDeep(array, deep) {
var result = [];
for (var i = 0; i < array.length; i++) {
if (Array.isArray(array[i]) && deep >= 1) {
result = result.concat(flattenByDeep(array[i], deep - 1))
} else {
result.push(array[i])
}
}
return result;
}filter方法经常用,实现起来也比较容易。需要注意的就是filter接收的参数依次为数组当前元素、数组index、整个数组,并返回结果为ture的元素。
Array.prototype.filter = function (fn, context) {
console.log(`context`, context)
if (typeof fn != 'function') {
throw new TypeError(`${fn} is not a function`)
}
let arr = this;
let result = []
for (let i = 0; i < arr.length; i++) {
let temp = fn.call(context, arr[i], i, arr);
if (temp) {
result.push(arr[i]);
}
}
return result
}
const a = [1, 2, 3, 4, 0, 0, ""]
console.log(a.filter(Boolean))call,bind,apply 的用法及区别
call,bind,apply 都是用于改变函数的 this 的指向,三者第一个参数都是this要指向的对象,如果没有这个参数或参数为undefined或null,则默认 this 指向全局 window 或 global。区别:
// 手写 call
Function.prototype.myCall = function(context, ...args) {
// 判断是否是 undefined 和 null
// 从用户的视角,context 一般就是用户要传入的 this
if (typeof context === 'undefined' || context === null) {
context = globalThis
}
console.log(`globalThis`, globalThis)
const fnSymbol = Symbol()
// this 是 myCall 的调用者,就是 fn
context[fnSymbol] = this
console.log(`myCall this`, this)
// 这一步将 fn 的调用者改为了 context
const res = context[fnSymbol] (...args)
delete context[fnSymbol]
return res
}
const fn = function(m) {
console.log(`fn this`, this)
console.log(m)
return m + ` test`
}
const a = {
b: 'this is b'
}
console.log(`fn.myCall(a, "mmm")`, fn.myCall(a, "mmm"))核心思路是:
context扩展一个属性,将原函数指向这个属性context之外的所有参数全部传递给这个新属性,并将运行结果返回。一些细节:
…args)可以存储函数多余的参数context扩展参数扩展新属性使用了**Symbol()数据类型**,这样确保不会影响到传入的context,因为Symbol值一定是独一无二的。…)将原来是数组的args转发为逗号分隔一个个参数传入到函数中。为什么能找到this.name呢?因为方法context[fnSymbol]中的this指向的是context。// 手写 apply
Function.prototype.myApply = function(context, args) {
// 判断是否是undefined和null
if (typeof context === 'undefined' || context === null) {
context = globalThis
}
const fnSymbol = Symbol()
context[fnSymbol] = this
const res = context[fnSymbol] (...args)
delete context[fnSymbol]
return res
}思路和call是一样的只是传参不同方式而已
// 手写 bind
Function.prototype.myBind = function (context) {
// 判断是否是undefined和null
if (typeof context === "undefined" || context === null) {
context = globalThis;
}
const fnSymbol = Symbol()
context[fnSymbol] = this
return function (...args) {
const res = context[fnSymbol](...args)
delete context[fnSymbol]
return res
}
}
const fn = function (m) {
console.log(`this in fn`, this)
console.log(m)
}
const obj = { a: "this is obj.a" }
const _fn = fn.myBind(obj)
_fn(`this is message`)观察者模式是我们工作中经常能接触到的一种设计模式。用过 jquery 的应该对这种设计模式都不陌生。eventEmitter 是 node 中的核心,主要方法包括on、emit、off、once。
class EventEmitter {
constructor() {
this.events = {}
}
on(name, cb) {
this.events[name] = (this.events[name] || []);
this.events[name].push(cb)
}
emit(name, ...arg) {
if (this.events[name]) {
this.events[name].forEach(fn => {
fn.call(this, ...arg)
})
}
}
off(name, cb) {
if (this.events[name]) {
this.events[name] = this.events[name].filter(fn => {
return fn != cb
})
}
}
once(name, fn) {
var onlyOnce = () => {
console.log(`this`, this)
console.log(`arguments`, arguments)
fn.apply(this, arguments);
this.off(name, onlyOnce)
}
this.on(name, onlyOnce);
return this;
}
}
const fn = function () {
console.log(`arguments`, arguments)
}
const bus = new EventEmitter()
bus.once("a", fn)
bus.emit("a", 1, 2, 3)
/**
this EventEmitter { events: { a: [ [Function: onlyOnce] ] } }
arguments [Arguments] { '0': 'a', '1': [Function: fn] }
arguments [Arguments] { '0': 'a', '1': [Function: fn] }
*/// ES6
class Parent {
constructor(name, age) {
this.name = name;
this.age = age;
}
say() {
console.log(`this is parent`)
}
}
class Child extends Parent {
constructor(name, age, sex) {
super(name, age);
this.sex = sex; // 必须先调用super,才能使用this
}
}
const child = new Child()
child.say()实现一个LazyMan,可以按照以下方式调用:
LazyMan("Hank")输出:
Hi! This is Hank!
LazyMan("Hank").sleep(10).eat("dinner")输出
Hi! This is Hank!
//等待10秒..
Wake up after 10
Eat dinner~
LazyMan("Hank").eat("dinner").eat("supper")输出
Hi This is Hank!
Eat dinner~
Eat supper~
LazyMan("Hank").sleepFirst(5).eat("supper")输出
//等待5秒
Wake up after 5
Hi This is Hank!
Eat supper
以此类推。这道题主要考察的是链式调用、任务队列、流程控制等。关键是用手动调用next函数来进行下次事件的调用,类似express中间件和vue-router路由的执行过程。
class LazyMan {
constructor(name) {
this.nama = name;
this.queue = [];
this.queue.push(() => {
console.log("Hi! This is " + name + "!");
this.next();
})
setTimeout(() => {
this.next()
}, 0)
}
next() {
const fn = this.queue.shift();
fn && fn();
}
eat(name) {
this.queue.push(() => {
console.log("Eat " + name + "~");
this.next()
})
return this;
}
sleep(time) {
this.queue.push(() => {
setTimeout(() => {
console.log("Wake up after " + time + "s!");
this.next()
}, time * 1000)
})
return this;
}
sleepFirst(time) {
this.queue.unshift(() => {
setTimeout(() => {
console.log("Wake up after " + time + "s!");
this.next()
}, time * 1000)
})
return this;
}
}
function LazyManFactory(name) {
return new LazyMan(name)
}
let lazyMan = LazyManFactory("pengjie")
lazyMan = LazyManFactory("pengjie").sleep(10).eat("dinner")
lazyMan = LazyManFactory("pengjie").sleepFirst(5).eat("supper")函数柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术,是高阶函数的一种用法。比如求和函数add(1,2,3), 经过柯里化后变成add(1)(2)(3)
// 普通的add函数
function add(x, y) {
return x + y
}
// Currying后
function curryingAdd(x) {
return function (y) {
return x + y
}
}
add(1, 2) // 3
curryingAdd(1)(2) // 3// 正常正则验证字符串 reg.test(txt)
// 普通情况
function check(reg, txt) {
return reg.test(txt)
}
check(/\d+/g, 'test') //false
check(/[a-z]+/g, 'test') //true
// Currying后
function curryingCheck(reg) {
return function(txt) {
return reg.test(txt)
}
}
var hasNumber = curryingCheck(/\d+/g)
var hasLetter = curryingCheck(/[a-z]+/g)
hasNumber('test1') // true
hasNumber('testtest') // false
hasLetter('21212') // false其实Function.prototype.bind就是科里化的实现例子
function sayKey(key) {
console.log(this[key])
}
const person = {
name: 'Sunshine_Lin',
age: 23
}
// call不是科里化
sayKey.call(person, 'name') // 立即输出 Sunshine_Lin
sayKey.call(person, 'age') // 立即输出 23
// bind是科里化
const say = sayKey.bind(person) // 不执行
// 想执行再执行
say('name') // Sunshine_Lin
say('age') // 23function formatDate(t,str){
var obj ={
yyyy: t.getFullYear(),
yy: (t.getFullYear())%100,
M: t.getMonth() +1,
MM: ('0' + (t.getMonth() + 1)).slice(-2),
d:t.getDate(),
dd:('0' + t.getDate()).slice(-2),
HH:('0' + t.getHours()).slice(-2),
H:t.getHours(),
h:t.getHours()%12,
hh:('0' +t.getHours()%12).slice(-2),
mm:('0' + t.getMinutes()).slice(-2),
m:t.getMinutes(),
ss:('0' + t.getSeconds()).slice(-2),
s:t.getSeconds(),
w:['日', '一', '二', '三', '四', '五', '六'][t.getDay()]
}
return str.replace(/[a-z]+/ig,function($1){
return obj[$1]
})
}var isEmail = function (val) {
var pattern = /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/;
var domains= ["qq.com","163.com","vip.163.com","263.net","yeah.net","sohu.com","sina.cn","sina.com","eyou.com","gmail.com","hotmail.com","42du.cn"];
if(pattern.test(val)) {
var domain = val.substring(val.indexOf("@")+1);
for(var i = 0; i< domains.length; i++) {
if(domain == domains[i]) {
return true;
}
}
}
return false;
}
// 输出 true
isEmail("[email protected]");参考链接:
https://juejin.cn/post/6844903960495538189
https://zhuanlan.zhihu.com/p/69070129
promise是什么?
Promise是异步编程的一种解决方案,比传统的回调函数和事件更合理和强大。
所谓Promise,简单来说就是一个容器,里面保存着某个未来才会结束的事情(通常是一个异步操作)。
从语法上说,Promise是一个对象,从他可以获取异步操作的消息。
特点:
缺点:一旦创建promise就会立即执行
const newPromise = new promise((resolve, reject) => {
if (success) {
resolve()
} else {
reject()
}
}).then((data) => { console.log(data) }, (error) => { console.log(error) })
.catch(null, (error) => { console.log(error) })then方法可以接受两个回调函数作为参数,
第一个回调函数是promise对象的状态变为resolved的时候调用,
第二个回调函数是promise对象的状态变为rejected时调用。
其中第二个函数是可选的,不一定需要提供。
catch方法是.then(null, rejection)的别名,用于指定发生错误时的回调函数。
promise.all是什么?
Promise.all([p1, p2, p3]) 方法返回一个 Promise 实例,此实例在 p1,p2,p3 都“完成(resolved)”时回调完成(resolve);如果参数中 promise 有一个失败(rejected),此实例回调失败(reject),失败原因的是第一个失败 promise 的结果。
result = arr.map(i => {
const rowPromise = filtered
.sort({ create_time: -1 }) //-1降序 1升序
.skip(offset > -1 ? offset : 0)
.limit(limit <= 200000 ? limit : 200000)
.toArray()
return rowPromise
})
promise.all(result)
.then(total => resolve(total))
.catch(err => reject(err))promise.all中传入的result一定要是一个数组。返回的是个promise实例,机制与promise一致
promise.race 与 promise.all 类似,当 p1,p2,p3 中有一个 resolve 或 reject 时调用相应的 resolve/reject 回调
easy 难度的题毫无头绪。或者甚至看不懂别人的题解(没错我经常)相信我,这很正常,不能说明你不适合学习算法,只能说明算法确实是一个博大精深的领域,把自己在其他领域的沉淀抛开来,接受自己是新手这个事实,多看题解,多请教别人。接下来我会放出几个分类的经典题型,以及我对应的讲解,当做开胃菜,并且在文章的末尾我会给出获取每个分类推荐你去刷的题目的合集,记得看到底哦。
两个数组的交集 II-350
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]来源:力扣(LeetCode)
链接:leetcode-cn.com/problems/in…
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
为两个数组分别建立 map,用来存储 num -> count 的键值对,统计每个数字出现的数量。
然后对其中一个 map 进行遍历,查看这个数字在两个数组中分别出现的数量,取出现的最小的那个数量(比如数组 1 中出现了 1 次,数组 2 中出现了 2 次,那么交集应该取 1 次),push 到结果数组中即可。
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number[]}
*/
var intersect = function (nums1, nums2) {
let map1 = makeCountMap(nums1)
let map2 = makeCountMap(nums2)
const values = [...new Set(nums1.concat(nums2))]
const r = []
const common = values.filter(v => nums1.includes(v) && nums2.includes(v))
common.forEach(v => {
let min = Math.min(map1[v], map2[v])
while (min) {
r.push(v)
min--
}
})
return r
}
function makeCountMap(nums) {
let map = Object.create(null)
nums.forEach(v => {
map[v] = map[v] || 0
map[v]++
});
return map
}最接近的三数之和-16
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例:
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。提示:
3 <= nums.length <= 10^3` `-10^3 <= nums[i] <= 10^3` `-10^4 <= target <= 10^4来源:力扣(LeetCode)
链接:leetcode-cn.com/problems/3s…
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
先按照升序排序,然后分别从左往右依次选择一个基础点 i(0 <= i <= nums.length - 3),在基础点的右侧用双指针去不断的找最小的差值。
假设基础点是 i,初始化的时候,双指针分别是:
left:i + 1,基础点右边一位。right: nums.length - 1 数组最后一位。然后求此时的和,如果和大于 target,那么可以把右指针左移一位,去试试更小一点的值,反之则把左指针右移。
在这个过程中,不断更新全局的最小差值 min,和此时记录下来的和 res。
最后返回 res 即可。
/**
* @param {number[]} nums
* @param {number} target
* @return {number}
*/
let threeSumClosest = function (nums, target) {
let n = nums.length
if (n === 3) {
return getSum(nums)
}
// 先升序排序 此为解题的前置条件
nums.sort((a, b) => a - b)
let min = Infinity // 和 target 的最小差
let res
// 从左往右依次尝试定一个基础指针 右边至少再保留两位 否则无法凑成3个
for (let i = 0; i <= nums.length - 3; i++) {
let basic = nums[i]
let left = i + 1 // 左指针先从 i 右侧的第一位开始尝试
let right = n - 1 // 右指针先从数组最后一项开始尝试
while (left < right) {
let sum = basic + nums[left] + nums[right] // 三数求和
// 更新最小差
let diff = Math.abs(sum - target)
if (diff < min) {
min = diff
res = sum
}
if (sum < target) {
// 求出的和如果小于目标值的话 可以尝试把左指针右移 扩大值
left++
} else if (sum > target) {
// 反之则右指针左移
right--
} else {
// 相等的话 差就为0 一定是答案
return sum
}
}
}
return res
}
function getSum(nums) {
return nums.reduce((total, cur) => total + cur, 0)
}无重复字符的最长子串-3
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。来源:力扣(LeetCode) 链接:leetcode-cn.com/problems/lo… 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题是比较典型的滑动窗口问题,定义一个左边界 left 和一个右边界 right,形成一个窗口,并且在这个窗口中保证不出现重复的字符串。
/**
* @param {string} str
* @return {number}
*/
let lengthOfLongestSubstring = function (str) {
const len = str.length
let max = 0;
let i = 0; // 左指针
for (let j = 0; j < len; j++) {
const v = str[j]
let subStr = str.slice(i, j)
// 确保 subStr 是无重复子串
while (subStr.includes(v)) {
i++
subStr = str.slice(i, j)
}
max = Math.max(max, j - i + 1)
}
return max
}
let test = 'abcabcbcabbc'
console.log(lengthOfLongestSubstring(test))两两交换链表中的节点-24
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例:
给定 1->2->3->4, 你应该返回 2->1->4->3.来源:力扣(LeetCode)
链接:leetcode-cn.com/problems/sw…
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题本意比较简单,1 -> 2 -> 3 -> 4 的情况下可以定义一个递归的辅助函数 helper,这个辅助函数对于节点和它的下一个节点进行交换,比如 helper(1) 处理 1 -> 2,并且把交换变成 2 -> 1 的尾节点 1的next继续指向 helper(3)也就是交换后的 4 -> 3。
边界情况在于,1.第1第2一对节点与之后的节点对(3与4对,5与6对...)的处理不同,所以增加一个dummy node使1,2节点对与之后的处理保持一致;2.current或者current.next都可能为尾结点,需要特殊处理。
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
let swapPairs = function (head) {
let dummy = new ListNode(undefined, head)
let current = dummy
let n1 = current.next
let n2 = (n1 || {}).next
while (n1 && n2) {
current.next = n2
n1.next = n2.next
n2.next = n1
current = n1
n1 = current.next
n2 = (n1 || {}).next
}
return dummy.next
}二叉树的所有路径-257
给定一个二叉树,返回所有从根节点到叶子节点的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
输入: root = [1,2,3,null,5]
1
/ \
2 3
\
5
输出: ["1->2->5", "1->3"]
解释: 所有根节点到叶子节点的路径为: 1->2->5, 1->3来源:力扣(LeetCode)
链接:leetcode-cn.com/problems/bi…
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
用当前节点的值去拼接左右子树递归调用当前函数获得的所有路径。
也就是根节点拼上以左子树为根节点得到的路径,加上根节点拼上以右子树为根节点得到的所有路径。
直到叶子节点,仅仅返回包含当前节点的值的数组。
let binaryTreePaths = function (root) {
let res = []
if (!root) {
return res
}
if (!root.left && !root.right) {
return [`${root.val}`]
}
let leftPaths = binaryTreePaths(root.left)
let rightPaths = binaryTreePaths(root.right)
leftPaths.forEach((leftPath) => {
res.push(`${root.val}->${leftPath}`)
})
rightPaths.forEach((rightPath) => {
res.push(`${root.val}->${rightPath}`)
})
return res
}在每个树行中找最大值-515
您需要在二叉树的每一行中找到最大的值。
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: [1, 3, 9]这是一道典型的 BFS 题目,BFS 的套路其实就是维护一个 queue 队列,在读取子节点的时候同时把发现的孙子节点 push 到队列中,但是先不处理,等到这一轮队列中的子节点处理完成以后,下一轮再继续处理的就是孙子节点了,这就实现了层序遍历,也就是一层层的去处理。
但是这里有一个问题卡住我了一会,就是如何知道当前处理的节点是哪个层级的,在最开始的时候我尝试写了一下二叉树求某个 index 所在层级的公式,但是发现这种公式只能处理「平衡二叉树」。
后面看题解发现他们都没有专门维护层级,再仔细一看才明白层级的思路:
其实就是在每一轮 while 循环里,再开一个 for 循环,这个 for 循环的终点是「提前缓存好的 length 快照」,也就是进入这轮 while 循环时,queue 的长度。其实这个长度就恰好代表了「一个层级的长度」。
缓存后,for 循环里可以安全的把子节点 push 到数组里而不影响缓存的当前层级长度。
另外有一个小 tips,在 for 循环处理完成后,应该要把 queue 的长度截取掉上述的缓存长度。一开始我使用的是 queue.splice(0, len),结果速度只击败了 33%的人。后面换成 for 循环中去一个一个shift来截取,速度就击败了 77%的人。
/**
* @param {TreeNode} root
* @return {number[]}
*/
let largestValues = function (root) {
if (!root) return []
let queue = [root]
let maximums = []
while (queue.length) {
let max = -Infinity
// 这里需要先缓存len 这个len最开始代表当前所处的层级
// 在循环开始后 会push新的节点 len就不稳定了
let len = queue.length
for (let i = 0; i < len; i++) {
let node = queue[i]
max = Math.max(node.val, max)
node.left && queue.push(node.left)
node.right && queue.push(node.right)
}
// 本「层级」处理完毕,截取掉。
while (len--) {
queue.shift()
}
// 这个for循环结束后 代表当前层级的节点全部处理完毕
// 直接把计算出来的最大值push到数组里即可。
maximums.push(max)
}
return maximums
}
const root = {
val: 1,
left: {
val: 3,
left: {
val: 5
},
right: {
val: 3
}
},
right: {
val: 2,
left: null,
right: {
val: 9
}
},
}
console.log(largestValues(root))有效的括号-20
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
示例 1:
输入: "()"
输出: true示例 2:
输入: "()[]{}"
输出: true示例 3:
输入: "(]"
输出: false示例 4:
输入: "([)]"
输出: false示例 5:
输入: "{[]}"
输出: true提前记录好左括号类型 (, {, [和右括号类型), }, ]的映射表,当遍历中遇到左括号的时候,就放入栈 stack 中(其实就是数组),当遇到右括号时,就把 stack 顶的元素 pop 出来,看一下是否是这个右括号所匹配的左括号(比如 ( 和 ) 是一对匹配的括号)。
当遍历结束后,栈中不应该剩下任何元素,返回成功,否则就是失败。
/**
* @param {string} s
* @return {boolean}
*/
const map = {
")": "(",
"]": "[",
"}": "{",
}
let isValid = function (str) {
const arr = []
if(str.length % 2) return false
return (str.split('').every(s => {
if (['(', '[', '{'].includes(s)) {
arr.push(s)
return true
} else {
if (arr.pop() === map[s]) return true
return false
}
}) && arr.length === 0);
}直接看我写的这两篇文章即可,递归与回溯甚至是平常业务开发中最常见的算法场景之一了,所以我重点总结了两篇文章。
《前端电商 sku 的全排列算法很难吗?学会这个套路,彻底掌握排列组合。》
打家劫舍 - 198
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。来源:力扣(LeetCode) 链接:leetcode-cn.com/problems/ho… 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
动态规划的一个很重要的过程就是找到「状态」和「状态转移方程」,在这个问题里,设 i 是当前屋子的下标,状态就是 以 i 为起点偷窃的最大价值
在某一个房子面前,盗贼只有两种选择:偷或者不偷。
在这两个值中,选择最大值记录在 dp[i]中,就得到了以 i 为起点所能偷窃的最大价值。。
动态规划的起手式,找基础状态,在这题中,以终点为起点的最大价值一定是最好找的,因为终点不可能再继续往后偷窃了,所以设 n 为房子的总数量, dp[n - 1] 就是 nums[n - 1],小偷只能选择偷窃这个房子,而不能跳过去选择下一个不存在的房子。
那么就找到了动态规划的状态转移方程:
// 抢劫当前房子
robNow = nums[i] + dp[i + 2] // 「当前房子的价值」 + 「i + 2 下标房子为起点的最大价值」
// 不抢当前房子,抢下一个房子
robNext = dp[i + 1] //「i + 1 下标房子为起点的最大价值」
// 两者选择最大值
dp[i] = Math.max(robNow, robNext)
,并且从后往前求解。
function (nums) {
if (!nums.length) {
return 0;
}
let dp = [];
for (let i = nums.length - 1; i >= 0; i--) {
let robNow = nums[i] + (dp[i + 2] || 0)
let robNext = dp[i + 1] || 0
dp[i] = Math.max(robNow, robNext)
}
return dp[0];
};
最后返回 以 0 为起点开始打劫的最大价值 即可。
分发饼干-455
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i ,都有一个胃口值 gi ,这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j ,都有一个尺寸 sj 。如果 sj >= gi ,我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
注意:
你可以假设胃口值为正。 一个小朋友最多只能拥有一块饼干。
示例 1:
输入: [1,2,3], [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: [1,2], [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
来源:力扣(LeetCode) 链接:leetcode-cn.com/problems/as… 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
把饼干和孩子的需求都排序好,然后从最小的饼干分配给需求最小的孩子开始,不断的尝试新的饼干和新的孩子,这样能保证每个分给孩子的饼干都恰到好处的不浪费,又满足需求。
利用双指针不断的更新 i 孩子的需求下标和 j饼干的值,直到两者有其一达到了终点位置:
j++ 寻找下一个饼干,不用担心这个饼干被浪费,因为这个饼干更不可能满足下一个孩子(胃口更大)。i++; j++; count++ 记录当前的成功数量,继续寻找下一个孩子和下一个饼干。/**
* @param {number[]} g
* @param {number[]} s
* @return {number}
*/
let findContentChildren = function (g, s) {
g.sort((a, b) => a - b)
s.sort((a, b) => a - b)
let i = 0
let j = 0
let count = 0
while (j < s.length && i < g.length) {
let need = g[i]
let cookie = s[j]
if (cookie >= need) {
count++
i++
j++
} else {
j++
}
}
return count
}
难度中等859收藏分享切换为英文接收动态反馈
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
/**
* @param {number} n
* @param {number} k
* @return {number[][]}
*/
var helper = function (arr, k) {
const result = []
const n = arr.length
if (k > 0) {
for (let i = 0; i < n; i++) {
const left = arr[i]
if (k === 1) {
result.push([left])
} else {
const rest = arr.slice(i + 1, n)
let temp = helper(rest, k - 1)
temp.forEach(arr1 => {
arr1.unshift(left)
result.push(arr1)
})
}
}
}
return result
};
const combine = function (n, k) {
const arr = Array.from({ length: n }, (v, k) => k + 1);
return helper(arr, k)
}
console.log(combine(4, 2))给定一个字符串,输出该字符串所有排列的可能。如输入“abc”,输出“abc,acb,bca,bac,cab,cba”。
实现过程
输入字符串,输出所有的组合,对js来说,用数组表示最恰当了 即:
function fullpermutate(str) {
var result = [];
return result;
}然后,用递归的形式解决。
基础情况应该是输入字符串为单个字符时的情况,此时返回的就是其本身,但不要忘记用数组的形式返回哦;
function fullpermutate(str) {
var result = [];
if (str.length > 1) {
//do something
} else if (str.length == 1) {
result.push(str);
}
return result;
}接下来,遍历字符串的每一个元素,并将字符串中除了该元素的其他元素进行全排列,如'abc',拿到a后,将bc再次进行全排列,返回的排列好的数组每一项再与a组合在一起得到最终的abc、acb;
function fullpermutate(str) {
var result = [];
if (str.length > 1) {
//遍历每一项
for (var m = 0; m < str.length; m++) {
//拿到当前的元素
var left = str[m];
//除当前元素的其他元素组合
var rest = str.slice(0, m) + str.slice(m + 1, str.length);
//上一次递归返回的全排列
var preResult = fullpermutate(rest);
//组合在一起
for (var i = 0; i < preResult.length; i++) {
var tmp = left + preResult[i]
result.push(tmp);
}
}
} else if (str.length == 1) {
result.push(str);
}
return result;
}var preorderTraversal = function(root) {
const res = [];
// 递归函数
function _preorder(node) {
if (!node) return;
res.push(node.val);
_preorder(node.left);
_preorder(node.right);
}
_preorder(root);
return res;
};通过栈数据结构(先进后出),我们可以将父节点压入栈,对栈执行出栈操作,每次将出栈的节点的右孩子先压入栈,其次压入左孩子。这样就可以做到先遍历父节点,再遍历左孩子部分,后遍历右孩子部分。
var preorderTraversal = function(root) {
if (!root) return [];
const stack = [root];
const res = [];
while(stack.length) {
// 出栈
const cur = stack.pop();
res.push(cur.val);
// 子节点存在压入栈中,先右再左
cur.right && stack.push(cur.right);
cur.left && stack.push(cur.left);
}
return res;
};var inorderTraversal = function(root) {
const res = [];
// 递归函数
function _inorder(node) {
if (!node) return;
_inorder(node.left);
res.push(node.val);
_inorder(node.right);
}
_inorder(root);
return res;
};我们同样可以使用栈结构来实现中序遍历,因为中序遍历左子树是优先遍历,所以父节点要先于子树的节点优先压入栈中,每当我们压入节点时,都要把节点的左子树的所有左节点压入栈中。
var inorderTraversal = function(root) {
if (!root) return [];
const stack = [];
let cur = root;
const res = [];
while (stack.length || cur) {
// 左节点都先压入栈
while (cur) {
stack.push(cur);
cur = cur.left;
}
const node = stack.pop();
res.push(node.val);
if (node.right != null) {
cur = node.right;
}
}
return res;
};var postorderTraversal = function(root) {
const res = [];
// 递归函数
function _postorder(node) {
if (!node) return;
_postorder(node.left);
_postorder(node.right);
res.push(node.val);
}
_postorder(root);
return res;
};后序遍历是父节点需要最后被遍历。但其实可以跟前序遍历的实现方式上差不多,只不过在插入数组中,我们总是在头部插入,这样先被插入的节点值一定是相对于左右孩子后面的。
var postorderTraversal = function(root) {
if (!root) return null;
const res = [];
const stack = [root];
while (stack.length) {
const cur = stack.pop();
// 总是头部插入,先被插入的在后面。
res.unshift(cur.val);
cur.left && stack.push(cur.left);
cur.right && stack.push(cur.right);
}
return res;
};var levelOrder = function(root) {
const res = [];
function _levelOrder(node, level) {
if (!node) return null;
// 当前层数组初始化
res[level] = res[level] || [];
res[level].push(node.val);
// 下一层 +1
_levelOrder(node.left, level + 1);
_levelOrder(node.right, level + 1);
}
_levelOrder(root, 0);
return res;
};我们使用队列来保存节点,每轮循环中,我们都取一层出来,将它们的左右孩子放入队列。
var levelOrder = function(root) {
if (root == null) return [];
const ans = [];
let level = 0;
const queue = [root];
while(queue.length) {
ans.push([]);
const len = queue.length;
// 通过遍历,提前执行完一层的所有元素,层级level就可以+1
for (let i = 0; i < len; i++) {
const node = queue.shift();
ans[level].push(node.val);
node.left && queue.push(node.left);
node.right && queue.push(node.right);
}
level++;
}
return ans;
};关于二叉树的前序、中序、后续遍历,使用递归的方法不用多说,主要是迭代方法,通过对栈的应用,对节点不同顺序的压入栈中,从而实现不同顺序的遍历。二叉树的层序遍历迭代方式则是通过对队列的应用。
本质上是一个斐波那契数列,详细 https://zhuanlan.zhihu.com/p/133870284
// 递归
var temp = []
var climbStairs = function(n) {
if(n <= 0){
return 0
}
if(n <= 2){
return n
}
if(temp[n]){
return temp[n]
}
temp[n] = climbStairs(n-2) + climbStairs(n-1)
return temp[n]
};
// 动态规划的解法
var climbStairs = function(n) {
if(n <= 2){
return n
}
var res = [0,1,2]
for(var i = 3 ; i <= n;i++){
res[i]=res[i-1]+res[i-2]
}
return res[n]
};打平的数据内容如下:
let arr = [
{id: 1, name: '部门1', pid: 0},
{id: 2, name: '部门2', pid: 1},
{id: 3, name: '部门3', pid: 1},
{id: 4, name: '部门4', pid: 3},
{id: 5, name: '部门5', pid: 4},
]输出结果
[
{
"id": 1,
"name": "部门1",
"pid": 0,
"children": [
{
"id": 2,
"name": "部门2",
"pid": 1,
"children": []
},
{
"id": 3,
"name": "部门3",
"pid": 1,
"children": [
// 结果 ,,,
]
}
]
}
]主要思路是提供一个递getChildren的方法,该方法递归去查找子集。
let arr = [
{ id: 1, name: '部门1', pid: 0 },
{ id: 2, name: '部门2', pid: 1 },
{ id: 3, name: '部门3', pid: 1 },
{ id: 4, name: '部门4', pid: 3 },
{ id: 5, name: '部门5', pid: 4 },
]
/**
* 递归查找,获取children
*/
const getChildren = (data, children, pid) => {
for (const item of data) {
if (item.pid === pid) {
const newItem = { ...item, children: [] };
children.push(newItem);
getChildren(data, newItem.children, item.id);
}
}
}
/**
* 转换方法
*/
const arrayToTree = (data, pid) => {
const result = [];
getChildren(data, result, pid)
return result;
}
console.log(arrayToTree(arr, 0))猴子吃香蕉, 分割数组(猴子吃香蕉可是掰成好几段来吃哦)
把一个数组arr按照指定的数组大小size分割成若干个数组块。
例如:chunk([1,2,3,4],2)=[[1,2],[3,4]];
chunk([1,2,3,4,5],2)=[[1,2],[3,4],[5]];
function chunk(arr, size) {
var newarr = [];
for (var i = 0; i < arr.length; i += size) {
newarr.push(arr.slice(i, i + size));
}
console.log(newarr);
return newarr;
}
chunk(["a", "b", "c", "d"], 2);function Palindromes(str) {
let reg = /[\W_]/g; // \w 匹配所有字母和数字以及下划线; \W与之相反; [\W_] 表示匹配下划线或者所有非字母非数字中的任意一个;/g全局匹配
let newStr = str.replace(reg, '').toLowerCase();
let reverseStr = newStr.split('').reverse().join('')
return reverseStr === newStr; // 与 newStr 对比
}实际上这里做了很多步对数组的操作,字符转数组 翻转数组 再转字符串,所以这里性能也不是很好。以为数组是引用类型,要改变这个数组,需要开辟新的堆地址空间。
// 写法1
function Palindromes(str) {
let reg = /[\W_]/g;
let newStr = str.replace(reg, '').toLowerCase();
for(let i = 0, len = Math.floor(newStr.length / 2); i < len; i++) {
if(newStr[i] !== newStr[newStr.length - 1 - i]) return false;
}
return true;
}
// 写法2
function Palindromes(str) {
let reg = /[\W_]/g;
let newStr = str.replace(reg, '').toLowerCase();
let len = newStr.length;
for(let i = 0, j = len - 1; i < j; i++, j--) { // i < j
console.log('---');
if(newStr[i] !== newStr[j]) return false;
}
return true;
}
// 写法3
function Palindromes(str) {
let reg = /[\W_]/g;
let newStr = str.replace(reg, '').toLowerCase();
let start= 0
let end = newStr.length -1
while(start < end) {
if (newStr[start] !== newStr[end]) {
return false
}
start++
end--
}
return true
}
const str1 = "abcdcba"
const str2 = "abcdcba1"
console.log(Palindromes(str1))
console.log(Palindromes(str2))function Palindromes(str) {
let reg = /[\W_]/g;
let newStr = str.replace(reg, '').toLowerCase();
let len = newStr.length;
while(len >= 1) {
console.log('--')
if(newStr[0] != newStr[len - 1]) {
// len = 0; // 为了终止 while 循环 否则会陷入死循环
return false;
} else {
return Palindromes(newStr.slice(1, len - 1));
// 截掉收尾字符 再次比较收尾字符是否相等
// 直到字符串剩下一个字符(奇数项)或者 0 个字符(偶数项)
}
}
return true;
}以12点为界限来计算角度,首先计算时针到12点的角度,就等于 h % 12 * 360 + 360 / 12 * m / 60。
再计算分钟到12点的角度,就是 m / 60 * 360。之后求这两个角度差的绝对值就是夹角,如果夹角大于180则再求一次补角返回即可。
/**
* @param {number} hour
* @param {number} minutes
* @return {number}
*/
var angleClock = function(h, m) {
// 分针移动的角度
let minutesAngle = m / 60 * 360
// 时针移动的角度 并且防止12点 所以 hour % 12
let hourAngle = h % 12 * 360 + 360 / 12 * m / 60
// 用时针的角度减去分针的角度,得其绝对值
let diff = Math.abs(hourAngle - minutesAngle)
// 返回最小值
return Math.min(diff, 360 - diff)
}其实写了这么多,以上分类所提到的题目,只是当前分类下比较适合作为例题来讲解的题目而已,在整个 LeetCode 学习过程中只是冰山一角。这些题可以作为你深入这个分类的一个入门例题,但是不可避免的是,你必须去下苦功夫刷每个分类下的其他经典题目。
如果你信任我,你也可以点击这里 获取各个分类下必做题目的详细题解(拿到了记得收藏),我跟着一个ACM 亚洲区奖牌获得者给出的提纲,整理了100+道必做题目的详细题解。
那么什么叫必做题目呢?
当然你也可以去知乎等平台搜索相关的问题,也会有很多人总结,但是比我总结的全的不多见。100 多题说多也不多,说少也不少。认真学习、解答、吸收这些题目大概要花费1 个月左右的时间。但是相信我,1 个月以后你在算法方面会脱胎换骨,应对国内大厂的算法面试也会变得游刃有余。
关于算法在工程方面有用与否的争论,已经是一个经久不衰的话题了。这里不讨论这个,我个人的观念是绝对有用的,只要你不是一个甘于只做简单需求的人,你一定会在后续开发架构、遇到难题的过程中或多或少的从你的算法学习中受益。
再说的功利点,就算是为了面试,刷算法能够进入大厂也是你职业生涯的一个起飞点,大厂给你带来的的环境、严格的 Code Review、完善的导师机制和协作流程也是你作为工程师所梦寐以求的。
希望这篇文章能让你不再继续害怕算法面试,跟着我一起攻下这座城堡吧,大家加油!
用来控制元素的盒子模型的解析模式,默认为 content-box
CSS 选择符:id 选择器(#myid)、类选择器(.myclassname)、标签选择器(div, h1, p)、相邻选择器(h1 + p)、子选择器(ul > li)、后代选择器(li a)、通配符选择器(*)、属性选择器(a[rel="external"])、伪类选择器(a:hover, li:nth-child)
可继承的属性:font-size, font-family, color
不可继承的样式:border, padding, margin, width, height
优先级(就近原则):!important > [ id > class > tag ]
!important 比内联优先级高
元素选择符: 1
class 选择符: 10
id 选择符:100
元素标签:1000
p:first-of-type 选择属于其父元素的首个元素
p:last-of-type 选择属于其父元素的最后元素
p:only-of-type 选择属于其父元素唯一的元素
p:only-child 选择属于其父元素的唯一子元素
p:nth-child(2) 选择属于其父元素的第二个子元素
:enabled :disabled 表单控件的禁用状态。
:checked 单选框或复选框被选中。
div:
border: 1px solid red;
margin: 0 auto;
height: 50px;
width: 80px;绝对定位的左右居中:
border: 1px solid black;
position: absolute;
width: 200px;
height: 100px;
margin: 0 auto;
left: 0;
right: 0;还有更加优雅的居中方式就是用 flexbox,我以后会做整理。
inline(默认)--内联
none--隐藏
block--块显示
table--表格显示
list-item--项目列表
inline-block
首先,需要把元素的宽度、高度设为 0。然后设置边框样式。左上右边框都是三角形,且被隐藏了,下边框也是三角形,显示出来了。
div {
width: 0;
height: 0;
border-top: 40px solid transparent;
border-left: 40px solid transparent;
border-right: 40px solid transparent;
border-bottom: 40px solid #ff0000;
}
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>品字布局</title>
<style>
/* 使用 flex 布局 */
/* 去除所有元素默认的内外边距的值 */
* {
margin: 0;
padding: 0;
}
html,
body {
height: 100%;
width: 100%;
display: flex;
flex-wrap: wrap;
}
.header {
height: 50%;
width: 50%;
background-color: rgb(255, 2545, 167);
margin: 0 25%;
}
.main {
height: 50%;
width: 100%;
display: flex;
}
.main .left {
width: 50%;
height: 100%;
background-color: rgb(204, 255, 102);
}
.main .right {
width: 50%;
height: 100%;
background-color: red;
}
</style>
</head>
<body>
<div class="header"></div>
<div class="main">
<div class="left"></div>
<div class="right"></div>
</div>
</body>
</html>
不同浏览器的标签默认的 margin 和 padding 不一样。
*{margin:0;padding:0;}
IE6 双边距 bug:块属性标签 float 后,又有横行的 margin 情况下,在 IE6 显示 margin 比设置的大。hack:display:inline;将其转化为行内属性。
渐进识别的方式,从总体中逐渐排除局部。首先,巧妙的使用“9”这一标记,将 IE 浏览器从所有情况中分离出来。接着,再次使用“+”将 IE8 和 IE7、IE6 分离开来,这样 IE8 已经独立识别。
{
background-color: #f1ee18; /*所有识别*/
.background-color: #00deff\9; /*IE6、7、8识别*/
+background-color: #a200ff; /*IE6、7识别*/
_background-color: #1e0bd1; /*IE6识别*/
}设置较小高度标签(一般小于 10px),在 IE6,IE7 中高度超出自己设置高度。hack:给超出高度的标签设置 overflow:hidden;或者设置行高 line-height 小于你设置的高度。
IE 下,可以使用获取常规属性的方法来获取自定义属性,也可以使用 getAttribute()获取自定义属性;Firefox 下,只能使用 getAttribute()获取自定义属性。解决方法:统一通过 getAttribute()获取自定义属性。
Chrome 中文界面下默认会将小于 12px 的文本强制按照 12px 显示,解决方法:
p {
font-size: 10px;
-webkit-transform: scale(0.8);
} //
/* 0.8是缩放比例。或者:
-webkit-text-size-adjust: none; 解决。
*/因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对 CSS 初始化往往会出现浏览器之间的页面显示差异。
无论属于哪种,都要先找到其祖先元素中最近的 position 值不为 static 的元素,然后再判断:
如果都找不到,则为 initial containing block。
补充:
当一个元素的 visibility 属性被设置成 collapse 值后,对于一般的元素,它的表现跟 hidden 是一样的。
display:none 不显示对应的元素,在文档布局中不再分配空间(回流+重绘)
visibility:hidden 隐藏对应元素,在文档布局中仍保留原来的空间(重绘)
display 属性规定元素应该生成的框的类型;position 属性规定元素的定位类型;float 属性是一种布局方式,定义元素在哪个方向浮动。
类似于优先级机制:position:absolute/fixed 优先级最高,有他们在时,float 不起作用,display 值需要调整。float 或者 absolute 定位的元素,只能是块元素或表格。
BFC 规定了内部的 Block Box 如何布局。
定位方案:
满足下列条件之一就可触发 BFC
浮动元素碰到包含它的边框或者浮动元素的边框停留。由于浮动元素不在文档流中,所以文档流的块框表现得就像浮动框不存在一样。浮动元素会漂浮在文档流的块框上。
浮动带来的问题:
清除浮动的方式:
在重合元素外包裹一层容器,并触发该容器生成一个 BFC。
例子:
<div class="aside"></div>
<div class="text">
<div class="main"></div>
</div>
<!--下面是css代码-->
<style>
.aside {
margin-bottom: 100px;
width: 100px;
height: 150px;
background: #f66;
}
.main {
margin-top: 100px;
height: 200px;
background: #fcc;
}
.text {
/*盒子main的外面包一个div,通过改变此div的属性使两个盒子分属于两个不同的BFC,以此来阻止margin重叠*/
/* 此时已经触发了BFC属性。 */
overflow: hidden;
}
</style>通过媒体查询可以为不同大小和尺寸的媒体定义不同的 css,适应相应的设备的显示。
<head>里边
<link rel="stylesheet" type="text/css" href="xxx.css" media="only screen and (max-device-width:480px)">24 使用 CSS 预处理器吗?
Less sass
CSS 选择器的解析是从右向左解析的。若从左向右的匹配,发现不符合规则,需要进行回溯,会损失很多性能。若从右向左匹配,先找到所有的最右节点,对于每一个节点,向上寻找其父节点直到找到根元素或满足条件的匹配规则,则结束这个分支的遍历。两种匹配规则的性能差别很大,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点),而从左向右的匹配规则的性能都浪费在了失败的查找上面。
而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 Render Tree。
使用偶数字体。偶数字号相对更容易和 web 设计的其他部分构成比例关系。Windows 自带的点阵宋体(中易宋体)从 Vista 开始只提供 12、14、16 px 这三个大小的点阵,而 13、15、17 px 时用的是小一号的点。(即每个字占的空间大了 1 px,但点阵没变),于是略显稀疏。
何时使用 margin:
何时使用 padding:
兼容性的问题:在 IE5 IE6 中,为 float 的盒子指定 margin 时,左侧的 margin 可能会变成两倍的宽度。通过改变 padding 或者指定盒子的 display:inline 解决。
当按百分比设定一个元素的宽度时,它是相对于父容器的宽度计算的。对于一些表示竖向距离的属性,例如 padding-top , padding-bottom , margin-top , margin-bottom 等,当按百分比设定它们时,依据的也是父容器的宽度,而不是高度。
响应式网站设计(Responsive Web design)是一个网站能够兼容多个终端,而不是为每一个终端做一个特定的版本。
基本原理是通过媒体查询检测不同的设备屏幕尺寸做处理。页面头部必须有 meta 声明的 viewport。
<meta
name="viewport"
content="width=device-width, initial-scale=1. maximum-scale=1,user-scalable=no"
/>视差滚动(Parallax Scrolling)通过在网页向下滚动的时候,控制背景的移动速度比前景的移动速度慢来创建出令人惊叹的 3D 效果。访问这里查看示例
:before 和 :after 这两个伪元素,是在 CSS2.1 里新出现的。起初,伪元素的前缀使用的是单冒号语法,但随着 Web 的进化,在 CSS3 的规范里,伪元素的语法被修改成使用双冒号,成为::before ::after
行高是指一行文字的高度,具体说是两行文字间基线的距离。CSS 中起高度作用的是 height 和 line-height,没有定义 height 属性,最终其表现作用一定是 line-height。
单行文本垂直居中:把 line-height 值设置为 height 一样大小的值可以实现单行文字的垂直居中,其实也可以把 height 删除。
多行文本垂直居中:需要设置 display 属性为 inline-block。
-webkit-font-smoothing 在 window 系统下没有起作用,但是在 IOS 设备上起作用-webkit-font-smoothing:antialiased 是最佳的,灰度平滑。
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no"/>多数显示器默认频率是 60Hz,即 1 秒刷新 60 次,所以理论上最小间隔为 1/60*1000ms = 16.7ms。
行框的排列会受到中间空白(回车空格)等的影响,因为空格也属于字符,这些空白也会被应用样式,占据空间,所以会有间隔,把字符大小设为 0,就没有空格了。
解决方法:
外层 div 使用 position:relative;高度要求自适应的 div 使用 position: absolute; top: 100px; bottom: 0; left: 0
页面加载自上而下 当然是先加载样式。
写在 body 标签后由于浏览器以逐行方式对 HTML 文档进行解析,当解析到写在尾部的样式表(外联或写在 style 标签)会导致浏览器停止之前的渲染,等待加载且解析样式表完成之后重新渲染,在 windows 的 IE 下可能会出现 FOUC 现象(即样式失效导致的页面闪烁问题)
参数是 scroll 时候,必会出现滚动条。
参数是 auto 时候,子元素内容大于父元素时出现滚动条。
参数是 visible 时候,溢出的内容出现在父元素之外。
参数是 hidden 时候,溢出隐藏。
将一个页面涉及到的所有图片都包含到一张大图中去,然后利用 CSS 的 background-image,background- repeat,background-position 的组合进行背景定位。利用 CSS Sprites 能很好地减少网页的 http 请求,从而大大的提高页面的性能;CSS Sprites 能减少图片的字节。
javascript 中对象的属性只支持 字符串 和 Symbol 两种类型 ,如果我们使用的是其他类型值作为属性名,最后都会被转为字符串。
不过在 es6 中新增了一种数据结构 Map,它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
关于 Map 以后再介绍,本篇文章介绍的是获取对象属性(键值)的方法有哪些
Object.getOwnPropertyNames() 方法返回一个由指定对象的所有自身属性的属性名(包括不可枚举属性但不包括Symbol值作为名称的属性)组成的数组。
我们创建一个obj对象,里面包含了‘字符串属性’和‘Symbol属性’,接着给对象添加两个不可枚举属性,然后再在它的原型上定义一个属性。
var str = 'aaa'
var number = 111
var symbol = Symbol(111)
var obj = {
[str]: '这是一个‘字符串’属性',
[number]: '这也是一个‘字符串’属性',
[symbol]: '这是一个‘Symbol’属性'
}
// 在 obj 定义一个不可枚举属性
Object.defineProperty(obj, 'unenum', {
value: '这是字符串类型的不可枚举属性',
writeable: true,
enumerable: false,
configurable: true
})
Object.defineProperty(obj, Symbol('unenum'), {
value: '这是Symbol类型的不可枚举属性',
writeable: true,
enumerable: false,
configurable: true
})
// 在 obj 原型上定义一个属性
obj.__proto__.bbb = '这是obj原型上的属性'我们试着用 Object.getOwnPropertyNames() 方法看看会返回什么。
可以看到只返回了所有自身属性的键值(不包括 Symbol 类型)。
Object.getOwnPropertySymbols() 方法返回一个给定对象自身的所有 Symbol 属性(包括不可枚举的)的数组。
用上面的代码试一下这个方法
可以看到返回的是自身所有 Symbol 类型的属性。
for...in语句以任意顺序遍历一个对象的除 Symbol 以外的可枚举属性。是否属于可枚举属性我们可以通过对象的propertyIsEnumerable('property')方法来查看。
来试一下 for...in

可以看到返回了对象自身及所在原型链上的所有可枚举字符串属性(不包括 Symbol 类型)。
Object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和正常循环遍历该对象时返回的顺序一致 。
再来试一下 Object.keys()
可以看到只返回了自身的可枚举属性(不包括 Symbol 类型和原型上的)。
相当于 for...in 和 hasOwnProperty()结合。
Reflect.ownKeys 方法返回一个由目标对象自身的属性键组成的数组。它的返回值等同于 Object.getOwnPropertyNames(obj).concat(Object.getOwnPropertySymbols(obj))。
最后试一下 Reflect.ownKeys
可以看到返回了自身所有属性(包括 Symbol 类型,但不包括原型上的属性)。
实际开发中可能会将几种方法组合起来使用。为了方便记忆,将各种方法的特性写在一张表格里。
| 方法 | 能否返回不可枚举属性 | 能否返回Symbol属性 | 能否返回原型上的属性 |
|---|---|---|---|
| Object.getOwnPropertyNames() | 是 | 否 | 否 |
| Object.getOwnPropertySymbols() | 是 | 是 | 否 |
| for...in | 否 | 否 | 是 |
| Object.keys() | 否 | 否 | 否 |
| Reflect.ownKeys | 是 | 是 | 否 |
HTTP状态码分类:
常见的请求状态码
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点
他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
http://element-ui.cn/article/show-117322.aspx
webRequest 可以让插件监控 Chrome 的网络请求,甚至重定向请求。例如:临时替换hotfix分支的图片
// background.js
chrome.webRequest.onBeforeRequest.addListener(
function (details) {
const url = details.url;
if (url === 'http://n.sinaimg.cn/news/1_img/upload/7b577cec/576/w778h598/20180820/lSSg-hhxaafy9194151.jpg') {
console.log(22)
return {
redirectUrl: 'https://github.com/welearnmore/chrome-extension-book/raw/master/doc/images/logo_google_developers.png'
}
}
return {cancel: false}
},
{urls: ["<all_urls>"]},
["blocking"]
)闭包意味着内部函数始终可以访问外部函数的变量和参数,即使外部函数已经返回。
我们可以在 JavaScript 中创建嵌套函数。内部函数可以访问外部函数的变量和参数(但是,不能访问外部函数的参数对象arguments)。
看看下面这个例子:
function OuterFunction() {
var outerVariable = 1;
function InnerFunction() {
console.log(outerVariable);
}
InnerFunction(); // 1
}InnerFunction() 可以访问 outerVariable
function OuterFunction() {
var outerVariable = 100;
function InnerFunction() {
alert(outerVariable);
}
return InnerFunction;
}
var innerFunc = OuterFunction();
innerFunc(); // 100在上面的例子, 当调用 OuterFunction() 时,从 OuterFunction 返回InnerFunction 函数。变量 innerFunc 只引用InnerFunction(),而不是OuterFunction()。现在,当你调用 innerFunc() 时,它仍然可以访问在 OuterFunction() 中声明的 outerVariable。这就是闭包。
function Counter() {
var counter = 0;
function IncreaseCounter() {
return counter += 1;
};
return IncreaseCounter;
}
var counter = Counter();
console.log(counter()); // 1
console.log(counter()); // 2
console.log(counter()); // 3
console.log(counter()); // 4闭包的一个重要特征是外部变量可以在多次调用之间保持其状态。请记住,内部函数不保留外部变量的单独副本,但它引用外部变量,这意味着如果您使用内部函数改变它,外部变量的值将被改变。
在上面的例子中,外部函数 Counter 返回内部函数 IncreaseCounter。增加 IncreaseCounter 将外部变量 counter 加1。因此多次调用 IncreaseCounter 函数将使 counter 多次加1。
function Counter() {
var counter = 0;
setTimeout( function () {
var innerCounter = 0;
counter += 1;
console.log("counter = " + counter);
setTimeout( function () {
counter += 1;
innerCounter += 1;
console.log("counter = ", counter)
console.log("innerCounter = ", innerCounter)
}, 500);
}, 1000);
};
Counter();闭包在多层内部函数中是有效的。
什么时候使用闭包
var counter = (function() {
var privateCounter = 0;
function changeBy(val) {
privateCounter += val;
}
return {
increment: function() {
changeBy(1);
},
decrement: function() {
changeBy(-1);
},
value: function() {
return privateCounter;
}
};
})();
alert(counter.value()); // 0
counter.increment();
counter.increment();
alert(counter.value()); // 2
counter.decrement();
alert(counter.value()); // 1在上面的示例中,increment()、decrement() 和 value()成为公共函数,因为它们包含在返回对象中,而changeBy() 函数成为私有函数,因为它没有返回,只被 increment() 和 decrement() 内部使用。
window.onresize = function() {
debounce(fn, 1000);
};
var fn = function() {
console.log("fn");
};
function debounce(fn,time){
let timer = null;
return function(){
if(timer){
clearTimeout(timer)
}
timer = setTimeout(()=>{
fn.apply(this,arguments)
},time)
}
}比如要缩放窗口 触发onresize 事件 需要在这时候做一件事情,但是我们希望拖动的时候只触发一次,比如
window.onresize = function(){
console.log('onresize')//只想触发一次
}一般方法vs闭包
// 不使用闭包
window.onresize = function () {
debounce(fn, 1000)
}
var fn = function () {
console.log('fn')
}
var time = ''
function debounce(fn, timeLong) {
if (time) {
clearTimeout(time)
time = ''
}
time = setTimeout(function () {
fn()
}, timeLong)
}
// 使用闭包
window.onresize = debounce(fn, 500)
function debounce(fn) {
var timer = null
return function () {
if (timer) { //timer第一次执行后会保存在内存里 永远都是执行器 直到最后被触发
clearTimeout(timer)
timer = null
}
timer = setTimeout(function () {
fn()
}, 1000)
}
}
var fn = function () {
console.log('fn')
}class CreateUser {
constructor(name) {
this.name = name;
this.getName();
}
getName() {
return this.name;
}
}
// 代理实现单例模式
var ProxyMode = (function () {
var instance = null;
return function (name) {
if (!instance) {
instance = new CreateUser(name);
}
return instance;
}
})();
// 测试单体模式的实例
var a = ProxyMode("aaa");
var b = ProxyMode("bbb");
// 因为单体模式是只实例化一次,所以下面的实例是相等的
console.log(a === b); //true内部属性 在java里使用private就可以,但是js 还没有这个东东
let _width = Symbol();
class Private {
constructor(s) {
this[_width] = s
}
foo() {
console.log(this[_width])
}
}
var p = new Private("50");
p.foo();
console.log(p[_width]);//可以拿到
//使用闭包设置私有变量
let sque = (function () {
let _width = Symbol();
class Squery {
constructor(s) {
this[_width] = s
}
foo() {
console.log(this[_width])
}
}
return Squery
})();
let ss = new sque(20);
ss.foo();
console.log(ss[_width]) // Uncaught ReferenceError: _width is not definedfor (var i = 0; i < 10; i++) {
setTimeout(function () {
console.log(i)//10个10
}, 1000)
}遇到这种问题 如何用解决呢
for (var i = 0; i < 10; i++) {
((j) => {
setTimeout(function () {
console.log(j)//1-10
}, 1000)
})(i)
}原理是 声明了10个自执行函数,保存当时的值到内部
下面代码输出的结果?
for(var i = 0; i < 3; i++){
setTimeout(function(){
console.log(i);
},0);
};答案:3,3,3
解决方法
for(let i = 0; i < 3; i++){
setTimeout(function(){
console.log(i);
},0);
};
// 0 1 2
for (var i = 0; i < 3; i++) {
(function(i) {
setTimeout(function () {
console.log(i);
}, 0, i)
})(i)
};
// 0 1 2分析一下new的整个过程:
简单实现一下new:
function myNew (fn, ...args) {
// 第一步:创建一个空对象
const obj = {}
// 第二步:继承构造函数的原型
obj.__proto__ = fn.prototype
// 第三步:this指向obj,并调用构造函数
fn.apply(obj, args)
// 第四步:返回对象
return obj
}箭头函数和普通函数有啥区别?箭头函数能当构造函数吗?
普通函数通过 function 关键字定义, this 无法结合词法作用域使用,在运行时绑定,只取决于函数的调用方式,在哪里被调用,调用位置。(this 取决于调用者,和是否独立运行)
箭头函数使用被称为 “胖箭头” 的操作符 => 定义,箭头函数不应用普通函数 this 绑定的四种规则,而是根据外层(函数或全局)的作用域来决定 this,且箭头函数的 this 绑定无法被修改(new 也不行)。
function foo() {
return (a) => {
console.log(this.a);
}
}
var obj1 = {
a: 2
}
var obj2 = {
a: 3
}
var bar = foo.call(obj1);
bar.call(obj2);参考资料
// 数组排序
var arr=[3,4,100,9,2,16];
arr.sort(function(a,b){
return b-a; //降序排列,return a-b; ——>升序排列
}) //括号里不写回调函数,则默认按照字母逐位升序排列,结果为[2,3,4,9,16,100]var arr = [10, 44, 82, 50, 70, 74, 29, 1, 40, 36, 58, 21, 56, 44, 43, 61, 222, 48];
for (var i = 0; i < arr.length; i++) {
var n = i;
while (arr[n] > arr[n + 1] && n >= 0) {
var temp = arr[n];
arr[n] = arr[n + 1];
arr[n + 1] = temp;
n--;
}
}//性能一般
var arr=[10,44,82,50,70,74,29,1,40,36,58,21,56,44,43,61,222,48];
//冒泡排序,每一趟找出最大的,总共比较次数为arr.length-1次,每次的比较次数为arr.length-1次,依次递减
var temp;
for(var i=0;i<arr.length-1;i++){
for(var j=0;j<arr.length-1;j++){
if(arr[j]>arr[j+1]){
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}选择排序就是不断地从未排序的元素中选择最大(或最小)的元素放入已排好序的元素集合中,直到未排序中仅剩一个元素为止。
//性能一般
var arr=[10,44,82,50,70,74,29,1,40,36,58,21,56,44,43,61,222,48];
var temp;
for(var i=0;i<arr.length-1;i++){
for(var j=i+1;j<arr.length;j++){
if(arr[i]>arr[j]){
temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
}不重要 https://juejin.cn/post/6960226985926721567
var arr=[10,44,82,50,70,74,29,1,40,36,58,21,56,44,43,61,222,48];
var arr2=[];
for(var i=0;i<arr.length;i++){
var key=arr[i];
arr2[key]=1;
}
for(var j in arr2){
console.log(j);
}计数排序
//1. 定义需要排序的数组
let arr = [2, 6, 3, 8, 3];
//let arr = [9,5,8,7,2,3,5,1,7,2,3,5,7,6,8,9,2,1,3,5];
//2. 定义需要接受排序的数组
let arr1 = new Array(arr.length + 10);
//3. 把arr1的值全部置零
arr1.fill(0);
//4. 循环遍历arr
for (let i = 0; i < arr.length; i++) {
//5. 循环一次如果有值就+ 1,遇到重复的就再次 + 1
arr1[arr[i]] = arr1[arr[i]] + 1;
// 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 索引号
//[0, 0, 1, 2, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0]
}
//6.遍历接受排序的数组
//7.定义一个接受返回值的数组
let arr3 = [];
for (let i = 0; i < arr1.length; i++) {
//7.遍历接受排序的数组里面的元素
for (let j = 0; j < arr1[i]; j++) {
arr3.push(i);
}
}
console.log(arr3); //[2, 3, 3, 6, 8]function xier(arr){
var interval = parseInt(arr.length / 2); //分组间隔设置
while(interval > 0){
for(var i = 0 ; i < arr.length ; i ++){
var n = i;
while(arr[n] < arr[n - interval] && n > 0){
var temp = arr[n];
arr[n] = arr[n - interval];
arr[n - interval] = temp;
n = n - interval;
}
}
interval = parseInt(interval / 2);
}
return arr;
}
xier([10,44,82,50,70,74,29,1,40,36,58,21,56,44,43,61,222,48]);核心**:
1.在待排序的元素任取一个元素作为基准(通常选第一个元素,称为基准元素)
2.将待排序的元素进行分块,比基准元素大的元素移动到基准元素的右侧,比基准元素小的移动到作左侧,从而一趟排序过程,就可以锁定基准元素的最终位置
3.对左右两个分块重复以上步骤直到所有元素都是有序的(递归过程)
function quickSort(arr) {
if (arr.length <= 1) {
return arr;
}
var left = [];
var right = [];
var midIndex = parseInt(arr.length / 2);
var mid = arr[midIndex];
for (var i = 0; i < arr.length; i++) {
if (i == midIndex) continue;
if (arr[i] < mid) {
left.push(arr[i])
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat([mid], quickSort(right));
}
const mm = [4,2,0,9,8,3,1,9,9,2]
console.log(mm)
console.log(quickSort(mm))A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.