jchehe / blog Goto Github PK
View Code? Open in Web Editor NEW🌈 原创&翻译 🌈
🌈 原创&翻译 🌈










































































































































原文:How to Create an Interactive 3D Character with Three.js
在本长篇教程中,你将学会如何创建一个头部朝向鼠标和点击执行随机动画的交互式 3D 模型。
你是否曾经拥有一个展示职业生涯的个人网站,并且里面放着一张个人照片?最近我想更进一步,往里面添加一个完全交互式 3D 版本的自己,它能注视用户的光标。当然这还不够,你甚至可以点击“我”,然后我会作出动作进行响应。本篇教程将讲述如何基于名为 Stacy 的模型实现这件事。
以下就是体验案例(点击 Stacy,同时移动鼠标观察它的动作)。
由于是基于 Three.js 实现,我假设你已掌握了 JavaScript。
See the Pen Character Tutorial - Final by Kyle Wetton (@kylewetton) on CodePen.
该 模型 带有 10 个动画。而在本教程的最后一节,我将会阐述如何为模型添加多个动画。简言而之,模型是基于 Blender,动画是来自 Adobe 的免费动画网站——Mixamo。
以下这个 pen(译者注:CodePen 的一个实例)包含了项目所有的 HTML 和 CSS。你可以 Fork 这个 pen 或从这里复制 HTML 和 CSS 到一个新项目。
See the Pen Character Tutorial - Blank by Kyle Wetton (@kylewetton) on CodePen.
HTML 含有一个加载动画(目前已注释,需要时再恢复)、一个包装(wrapper)div 和最重要的 canvas 标签。该 canvas 是 Three.js 拿来渲染场景的,另外 CSS 将其设为视口 100% 宽高大小。在 HTML 底部加载了两个依赖:Three.js 和 GLTFLoader(GLTF 是本教程引用的 3D 模型格式)。当然,这两个依赖都可作为 npm 模块使用。
CSS 含有一小部分“居中”样式,其余是 loading 动画。现在,你可以折叠 HTML 和 CSS 代码,我会在需要的时候再深入讲解。
在 上一篇教程(译文:《【译】基于 Three.js 实现 3D 模型换肤》),我的做法是在用到全局变量时再回到文件顶部添加。而这次,我要把所有这些都预先定义,在需要时再讲解它们的作用。当然,每行都带有注释以满足你的好奇心。将这些全局变量放在一个函数内:
(function() {
// Set our main variables
let scene,
renderer,
camera,
model, // Our character
neck, // Reference to the neck bone in the skeleton
waist, // Reference to the waist bone in the skeleton
possibleAnims, // Animations found in our file
mixer, // THREE.js animations mixer
idle, // Idle, the default state our character returns to
clock = new THREE.Clock(), // Used for anims, which run to a clock instead of frame rate
currentlyAnimating = false, // Used to check whether characters neck is being used in another anim
raycaster = new THREE.Raycaster(), // Used to detect the click on our character
loaderAnim = document.getElementById('js-loader');
})(); // Don't add anything below this line初始化 Three.js 的工作包含场景(scene)、渲染器(renderer)、摄像机(camera)、光(lights)和一个更新函数(每帧执行)。
以上这些工作都在 init() 函数内完成。在声明变量后(仍在函数作用域内)添加该初始化函数:
init();
function init() {
}在初始化函数内,先引用 canvas 元素和声明背景色(淡灰色)。需要注意的是,Three.js 不能使用字符串格式的颜色值,如 '#f1f1f1',而使用十六机制的整数,如 0xf1f1f1。
const canvas = document.querySelector('#c');
const backgroundColor = 0xf1f1f1;接着,创建场景,并设置背景色和添加雾化效果。但在本教程中,你并不能看出有雾化效果,因为地板和背景色是一致的。若两者不一致,则能明显看到雾化的模糊效果。
// Init the scene
scene = new THREE.Scene();
scene.background = new THREE.Color(backgroundColor);
scene.fog = new THREE.Fog(backgroundColor, 60, 100);接着是渲染器(renderer),向渲染器的构造函数传入 canvas 引用和其它可选项。这里唯一一个可选项是启用抗齿距。另外,启用了 shadowMap,使得人物对象能投射阴影;基于设备设置了像素比,使得移动端的渲染效果更清晰,否则 canvas 会在高分度屏幕上呈现像素化。最后,将渲染器添加到 document.body(译者注:此行代码可省略)。
// Init the renderer
renderer = new THREE.WebGLRenderer({ canvas, antialias: true });
renderer.shadowMap.enabled = true;
renderer.setPixelRatio(window.devicePixelRatio);
document.body.appendChild(renderer.domElement);这就完成了 Three.js 初始化工作的前两个。接下来是摄像机(camera)。创建一个透视摄像机,并设置其视场(field of view, fov)为 50,横纵向比例为视口宽高比,默认的前后边界裁剪区域。然后,将其往后 30 个单位和往下 3 个单位位移。后续你会明白为何这么做。这些参数都可以尝试更改,但建议目前就使用这些参数。
// Add a camera
camera = new THREE.PerspectiveCamera(
50,
window.innerWidth / window.innerHeight,
0.1,
1000
);
camera.position.z = 30
camera.position.x = 0;
camera.position.y = -3;scene、renderer 和 camera 变量均已在项目顶部声明。
缺少光,摄像机就不能看到任何东西。那就现在创建两个光——环境光和定向光。然后,通过 scene.add(light) 将它们加到场景中。
将光相关的代码放在摄像机下方,后面我会解释这具体做了什么:
// Add lights
let hemiLight = new THREE.HemisphereLight(0xffffff, 0xffffff, 0.61);
hemiLight.position.set(0, 50, 0);
// Add hemisphere light to scene
scene.add(hemiLight);
let d = 8.25;
let dirLight = new THREE.DirectionalLight(0xffffff, 0.54);
dirLight.position.set(-8, 12, 8);
dirLight.castShadow = true;
dirLight.shadow.mapSize = new THREE.Vector2(1024, 1024);
dirLight.shadow.camera.near = 0.1;
dirLight.shadow.camera.far = 1500;
dirLight.shadow.camera.left = d * -1;
dirLight.shadow.camera.right = d;
dirLight.shadow.camera.top = d;
dirLight.shadow.camera.bottom = d * -1;
// Add directional Light to scene
scene.add(dirLight);环境光为强度 0.61 的白光,然后将其放置在中心点上方 50 单位。你也可以在后续尝试更改数值。
我根据个人感觉将定向光放置在一个适当的位置。随后,启用其投射阴影的能力并设置了阴影的分辨率。阴影的其余设置则与光的视场相关(译者注:定向光是使用正交摄像机计算阴影,参考 DirectionalLightShadow),这概念对我来说也有些模糊,但只要清晰知道:可通过调整变量 d 以确保阴影不被裁剪。
与此同时,在 init 函数内添加地板:
// Floor
let floorGeometry = new THREE.PlaneGeometry(5000, 5000, 1, 1);
let floorMaterial = new THREE.MeshPhongMaterial({
color: 0xeeeeee,
shininess: 0,
});
let floor = new THREE.Mesh(floorGeometry, floorMaterial);
floor.rotation.x = -0.5 * Math.PI; // This is 90 degrees by the way
floor.receiveShadow = true;
floor.position.y = -11;
scene.add(floor);首先,创建一个二维平面,它足够大:5000 个单位(确保无缝背景)。
然后创建一个材质(整篇教程中,我们只创建了两种不同的材质),并将它与几何图形结合为网格(mesh),最后将该网格添加到场景中。该网格足够大,被平放作为地面。网格的颜色是 0xeeeeee,虽然比背景色稍暗,但在灯光的作用下,与不受灯光影响的背景融为一体。
地板是由几何图形和材质结合而成的网格。通读一下我们刚添加的代码,我想你会发现一切都是不言自明。为了配合后续添加的人物模型,我们将地板向下移动 11 个单位。
这就是 init() 函数目前的内容。
Three.js 应用一般都会依赖于一个每帧都会执行的更新函数,如果你有涉猎过 Unity,那么它与游戏引擎的工作方式类似。该函数需要放在 init() 函数后,而不是其内部。在更新函数内,renderer 会渲染摄像机下的场景,并立刻再次调用自身。
function update() {
renderer.render(scene, camera);
requestAnimationFrame(update);
}
update();场景由此正式打开。canvas 目前看到的是亮灰色,实际是背景和地板。你可以更改地板的材质颜色为 0xff0000 进行测试,但记得改回来哦。
我们将在下一节加载模型。在此之前,还需要为场景做一件事。canvas 作为一个 HMTL 元素,其 CSS 属性 width 和 height 均被设为 100%,这使得它能基于其容器良好地适配尺寸大小。但场景也需要同步调整大小以保持比例。因此,在调用 update 函数下方(非其定义内部)添加这个功能。其所做的事情是:不断检查 renderer 的尺寸是否与 canvas 相等,若不等则设置 renderer 的尺寸,最后返回布尔值变量 needResize(译者注:建议通过监听 window resize 事件处理)。
function resizeRendererToDisplaySize(renderer) {
const canvas = renderer.domElement;
let width = window.innerWidth;
let height = window.innerHeight;
let canvasPixelWidth = canvas.width / window.devicePixelRatio;
let canvasPixelHeight = canvas.height / window.devicePixelRatio;
const needResize =
canvasPixelWidth !== width || canvasPixelHeight !== height;
if (needResize) {
renderer.setSize(width, height, false);
}
return needResize;
}在 update 函数内找到这几行代码:
renderer.render(scene, camera);
requestAnimationFrame(update);在这几行代码的上方,我们会调用该函数以检查是否需要调整大小,并在需要时更新摄像机的横纵向比例以适应新尺寸。
if (resizeRendererToDisplaySize(renderer)) {
const canvas = renderer.domElement;
camera.aspect = canvas.clientWidth / canvas.clientHeight;
camera.updateProjectionMatrix();
}完整的 update 函数如下:
function update() {
if (resizeRendererToDisplaySize(renderer)) {
const canvas = renderer.domElement;
camera.aspect = canvas.clientWidth / canvas.clientHeight;
camera.updateProjectionMatrix();
}
renderer.render(scene, camera);
requestAnimationFrame(update);
}
update();
function resizeRendererToDisplaySize(renderer) { ... }至此,我们整个项目如下。下一节是加载模型。
See the Pen Character Tutorial - Round 1 by Kyle Wetton (@kylewetton) on CodePen.
尽管场景目前十分空旷,但该有的配置都准备好了,如自适应大小、光和摄像机。现在就开始添加模型吧。
在 init() 函数顶部的 canvas 变量前引用模型。这是 GLTF 格式(.glb),尽管 Three.js 支持多种 3D 模型格式,但这是推荐的格式。我们将使用 GLTFLoader 加载模型。
const MODEL_PATH = 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/stacy_lightweight.glb';在 init() 函数的 camera 下方,创建一个 loader:
var loader = new THREE.GLTFLoader();然后使用该 loader 的 load 方法,它接受 4 个参数,分别是:模型路径、模型加载成功后的回调函数、模型加载中的回调函数、报错的回调函数。
var loader = new THREE.GLTFLoader();
loader.load(
MODEL_PATH,
function(gltf) {
// A lot is going to happen here
},
undefined, // We don't need this function
function(error) {
console.error(error);
}
);请注意注释“A lot is going to happen here”,这里是模型加载后会执行的地方。除非特别声明,否则接下来所有东西都放在该函数内。
GLTF 文件本身(即传入该回调函数的形参 gltf)由两部分组成,场景(gltf.scene,【译者注:即模型】)和动画(gltf.animations)。在该函数顶部引用它们,并将该模型添加到场景中:
model = gltf.scene;
let fileAnimations = gltf.animations;
scene.add(model);至此,完整的 loader.load 函数如下:
loader.load(
MODEL_PATH,
function(gltf) {
// A lot is going to happen here
model = gltf.scene;
let fileAnimations = gltf.animations;
scene.add(model);
},
undefined, // We don't need this function
function(error) {
console.error(error);
}
);注意:model 变量早已在项目顶部声明。
现在你会看到场景中有一个小人物。
有几件事需要说明:
- 模型很小;3D 模型如同矢量图形,支持不失真缩放;Mixamo 输出的模型很小,因此,我们需要对它进行放大。(译者注:可尝试调整摄像机的距离)
- GLTF 模型支持包含纹理,但我不这样做的原因有几点:1. 解耦可以拥有更小的文件大小;2. 关于色彩空间,对于这点我会在本教程的最后一节——如何构建 3D 模型中详细讨论。
将模型添加到场景前,我们需要做几件事。
首先,使用模型的 traverse 方法遍历所有网格(mesh)以启用投射和接收阴影的能力。该操作需要在 scene.add(model) 前完成。
model.traverse(o => {
if (o.isMesh) {
o.castShadow = true;
o.receiveShadow = true;
}
});然后,将模型在原来大小的基础上放大 7 倍。该操作在 traverse 方法下方添加:
// Set the models initial scale
model.scale.set(7, 7, 7);最后,将模型向下移动 11 个单位,以保证它是站在地板上的。
model.position.y = -11;完美,我们已成功加载模型。接着,我们加载并应用纹理。该模型带有纹理,并在 Blender 中已对模型进行贴图(map)。该过程被称为 UV mapping。你可以下载该图片进行观察,如果你想尝试制作属于自己的模型,可以学习更多关于 UV mapping 的知识。
之前我们已声明 loader 变量;在该声明的上方创建一个新纹理和材质:
let stacy_txt = new THREE.TextureLoader().load('https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/stacy.jpg');
stacy_txt.flipY = false; // we flip the texture so that its the right way up
const stacy_mtl = new THREE.MeshPhongMaterial({
map: stacy_txt,
color: 0xffffff,
skinning: true
});
// We've loaded this earlier
var loader = new THREE.GLTFLoader()纹理不仅是一张图片的 URL,它要作为一个新纹理,需要通过 TextureLoader 加载。我们将其赋值给 stacy_txt 变量。
在前面,我们已使用过材质。这个颜色为 0xeeeeee 的材质被用于地板。在这里,我们将为模型的材质使用一些新选项:1. 将 stacy_txt 纹理赋值给 map 属性;2. 将 skinning 设置为 true,这对动画模型至关重要。最后将该材质赋值给 stacy_mtl。
现在我们有了纹理材质。因为模型(gltf.scene)仅有一个对象,所以我们直接在 traverse 方法的阴影相关代码下方增添一行代码:
model.traverse(o => {
if (o.isMesh) {
o.castShadow = true;
o.receiveShadow = true;
o.material = stacy_mtl; // Add this line
}
});就这样,模型就成为了一个可辨识的角色——Stacy。
不过她有点死气沉沉,下一节我们将处理动画。现在你已接触过几何体和材质,就让我们用这些所学到的知识让场景变得更有趣。
在地板代码下方(即 init() 函数的最后一行代码),添加一个圆符。这是一个很大但远离我们的 3D 球体,并使用 BasicMaterial 材质。该材质不具备先前使用的 PhongMaterial 材质所拥有的光泽和投射并接收阴影的特性。因此,它在该场景中能作为一个平面圆,很好地衬托着 Stacy。
let geometry = new THREE.SphereGeometry(8, 32, 32);
let material = new THREE.MeshBasicMaterial({ color: 0x9bffaf }); // 0xf2ce2e
let sphere = new THREE.Mesh(geometry, material);
sphere.position.z = -15;
sphere.position.y = -2.5;
sphere.position.x = -0.25;
scene.add(sphere);可以改成你喜欢的颜色!
在进入本节主题前,你可能注意到 Stacy 的加载需要一段时间。显然,白屏对用户并不友好。我曾提及到:在 HTML 中我们有一个 loading 元素被注释。现在回到那里取消这个注释。
<!-- The loading element overlays everything else until the model is loaded, at which point we remove this element from the DOM -->
<div class="loading" id="js-loader"><div class="loader"></div></div>再次回到 loader 函数。
loaderAnim.remove();一旦将 Stacy 添加至场景,就删除 loading 动画遮罩层。保存更改并刷新浏览器,在看到 Stacy 前会有一个加载动画。若模型已被缓存,则可能会因太快而看不到加载动画。
是时候进入模型动画了!
仍在 loader 函数,我们将创建一个 AnimationMixer,它是用于播放场景中特定对象动画的播放器。它看来有些陌生,也超出本教程的范围。若想了解更多,可阅读 Three.js 文档的 AnimationMixer。而本文并不要求你知道关于它的更多内容。
在删除 loading 动画下方添加这行代码,其中传入的参数是我们的模型:
mixer = new THREE.AnimationMixer(model);注意 mixer 已在项目顶部声明。
在这行代码下方,我们创建 AnimationClip,并通过 fileAnimations 查找一个名为 idle(空闲)的动画。这个名字是在 Blender 中设置的。
let idleAnim = THREE.AnimationClip.findByName(fileAnimations, 'idle');然后,使用 mixer 的 clipAction 方法,并传入 idleAnim 参数。我们将这个 clipAction 命名为 idle。
最后,调用 idle 的 play 方法:
idle = mixer.clipAction(idleAnim);
idle.play();其实这还不能让动画执行起来,我们还需要做一件事。为了让动画持续运行,mixer 需要不断更新。因此,我们需要让它在 update() 函数内进行更新。我们将它放在判断是否需要调整尺寸的代码上方:
if (mixer) {
mixer.update(clock.getDelta());
}mixer 的 update 方法以 clock(已在项目顶部定义)作为参数。因为是基于时间(增量)进行更新,所以动画并不会因帧率下降而变慢。如果是基于帧率执行动画,则动画的快慢取决于帧率的高低,这应该不是你想要的。
至此,Stacy 应该能快乐的摇摆着身体!真棒!这仅是加载模型内的 10 个动画之一,我们将很快实现点击 Stacy 随机播放一个动画的效果。但接下来,我们先让模型变得更生动:让她的头部和身体朝向光标。
也许你不太了解 3D(大多数情况下甚至是 2D 动画),它其实是一个被网格(mesh)包裹着的骨架(skeleton)(即骨头数组)。更改骨头的位置、比例和旋转角度,就能以有趣的方式扭曲和移动网格。进入 Stacy 的骨架,找到脖子骨头和下脊柱骨头。以视口中点为基准,这两个骨头将朝向光标进行旋转。为了实现这一点,我们需要告诉当前的“空闲”动画忽略这两个骨头。现在就让我们开始实现吧。
还记得在模型方法 traverse 里运行这段代码 if (o.isMesh) { … set shadows ..} 的那部分吗?在该 traverse 方法内,我利用 o.isBone console 所有骨头,并找到脖子和脊柱(即名字)。对于你自己制作的角色,亦可通过该方式找到骨头的准确名字。
model.traverse(o => {
if (o.isBone) {
console.log(o.name);
}
if (o.isMesh) {
o.castShadow = true;
o.receiveShadow = true;
o.material = stacy_mtl;
}实际输出了一堆骨头,但以下才是我们想要找到的(粘贴自我的 console):
...
...
mixamorigSpine
...
mixamorigNeck
...
...现在我们知道了脊柱(从现在开始,我们称之为腰部)和脖子的名字。
在模型的 traverse 方法,将这两个骨头赋值给相应变量(已在项目顶部声明)。
model.traverse(o => {
if (o.isMesh) {
o.castShadow = true;
o.receiveShadow = true;
o.material = stacy_mtl;
}
// Reference the neck and waist bones
if (o.isBone && o.name === 'mixamorigNeck') {
neck = o;
}
if (o.isBone && o.name === 'mixamorigSpine') {
waist = o;
}
});现在,我们还需要做更多探究性工作。先前,我们创建了一个名为 idleAnim 的 AnimationClip,并将其放置在 mixer 播放。现在,我们想将脖子和腰部从这个动画中剥离,否则“空闲”动画将覆盖我们为模型创建的自定义动作。
因此,第一件需要做的是 console.log idleAnim。它是一个对象,并带有一个名为 tracks 的属性。该属性对应的值是一个长度为 156 的数组,其中,每 3 个子项代表一个骨头的动画。这 3 项分别表示骨头的位置、四元数(旋转)和比例。前三个子项是髋部位置、旋转和比例。
我们要找的是这些(粘贴自我的 console):
3: ad {name: "mixamorigSpine.position", ...
4: ke {name: "mixamorigSpine.quaternion", ...
5: ad {name: "mixamorigSpine.scale", ...…和这些:
12: ad {name: "mixamorigNeck.position", ...
13: ke {name: "mixamorigNeck.quaternion", ...
14: ad {name: "mixamorigNeck.scale", ...因此,在动画中,我需要通过 splice 方法移除第 3,4,5 和 12,13,14 个子项。
然而,一旦移除 3,4,5,脖子就变成了 9,10,11。这是需要注意的地方。
现在就通过代码实现以上需求。在 loader 函数的 idleAnim 下方,添加以下几行代码:
let idleAnim = THREE.AnimationClip.findByName(fileAnimations, 'idle');
// Add these:
idleAnim.tracks.splice(3, 3);
idleAnim.tracks.splice(9, 3);我们会在后续对所有动画执行同样的操作。添加以上代码后,就意味着无论她执行何种动画,我们都拥有腰部和脖子的控制权,这使得我们能实时修改动画(为了让角色在玩空气吉时摇头,我花费了 3 小时)。
在项目底部,添加返回鼠标位置的事件。
document.addEventListener('mousemove', function(e) {
var mousecoords = getMousePos(e);
});
function getMousePos(e) {
return { x: e.clientX, y: e.clientY };
}接着,我们创建 moveJoint 函数。
function moveJoint(mouse, joint, degreeLimit) {
let degrees = getMouseDegrees(mouse.x, mouse.y, degreeLimit);
joint.rotation.y = THREE.Math.degToRad(degrees.x);
joint.rotation.x = THREE.Math.degToRad(degrees.y);
}moveJoint 函数接收 3 个参数,分别是:当前鼠标的位置,需要移动的关节和允许关节旋转的角度范围。
我们在该函数顶部定义了一个名为 degrees 的变量,该变量的值来自于返回对象为 {x, y} 的 getMouseDegrees 函数。然后,基于这个值对关节分别在 x、y 轴进行旋转。
在实现 getMouseDegrees 前,我先讲解它的实现思路。
getMouseDegress 做了这些事:判断鼠标位于视口上半部、下半部、左半部和右半部的具体位置。
例如,当鼠标在视口中点与右边界的中间,该函数会得到right = 50%;当鼠标在视口中点与上边界的四分之一位置,该函数会得到为up = 25%(译者注:以视口中点为起始点)。一旦函数得到这些百分比,它会返回基于 degreelimit 的百分比。
所以,当该函数确定鼠标的位置为 75% right 和 50% up,那么会返回 x 轴 75% 的角度限值和 y 轴 50% 的角度限值。其余同理。
图示如下:
尽管我很想详细讲解这个看起来比较复杂的函数,但我怕逐行讲解会十分无聊。所以如果你感兴趣,可以结合注释进行理解。
在项目底部添加该函数:
function getMouseDegrees(x, y, degreeLimit) {
let dx = 0,
dy = 0,
xdiff,
xPercentage,
ydiff,
yPercentage;
let w = { x: window.innerWidth, y: window.innerHeight };
// Left (Rotates neck left between 0 and -degreeLimit)
// 1. If cursor is in the left half of screen
if (x <= w.x / 2) {
// 2. Get the difference between middle of screen and cursor position
xdiff = w.x / 2 - x;
// 3. Find the percentage of that difference (percentage toward edge of screen)
xPercentage = (xdiff / (w.x / 2)) * 100;
// 4. Convert that to a percentage of the maximum rotation we allow for the neck
dx = ((degreeLimit * xPercentage) / 100) * -1; }
// Right (Rotates neck right between 0 and degreeLimit)
if (x >= w.x / 2) {
xdiff = x - w.x / 2;
xPercentage = (xdiff / (w.x / 2)) * 100;
dx = (degreeLimit * xPercentage) / 100;
}
// Up (Rotates neck up between 0 and -degreeLimit)
if (y <= w.y / 2) {
ydiff = w.y / 2 - y;
yPercentage = (ydiff / (w.y / 2)) * 100;
// Note that I cut degreeLimit in half when she looks up
dy = (((degreeLimit * 0.5) * yPercentage) / 100) * -1;
}
// Down (Rotates neck down between 0 and degreeLimit)
if (y >= w.y / 2) {
ydiff = y - w.y / 2;
yPercentage = (ydiff / (w.y / 2)) * 100;
dy = (degreeLimit * yPercentage) / 100;
}
return { x: dx, y: dy };
}一旦完成该函数的定义,我们就能使用 moveJoint。根据实际情况,我们将脖子的角度限值设为 50°,腰部的角度限值设为 30°。
更新 mousemove 事件回调函数,以包含 moveJoints:
document.addEventListener('mousemove', function(e) {
var mousecoords = getMousePos(e);
if (neck && waist) {
moveJoint(mousecoords, neck, 50);
moveJoint(mousecoords, waist, 30);
}
});现在,在视口范围内移动鼠标,Stacy 就会不断盯着光标!注意,“空闲”动画仍在同时执行,这是因为我们将脖子和脊柱骨头从中剥离,从而拥有了对它们的独立控制权。
这可能不是在科学上最准确的实现方式,但出来的效果却很有说服力。以上就是我们的进展,如果你遗漏了什么或者效果不一致,请仔细看看这个 pen。
See the Pen Character Tutorial - Round 2 by Kyle Wetton (@kylewetton) on CodePen.
如前面提及,Stacy 的文件内实际上有 10 个动画,而我们仅用了其中一个。现在让我们回到 loader 函数,并找到这行代码。
mixer = new THREE.AnimationMixer(model);在这行代码下方,我们获得除“空闲(idle)”外的 AnimationClip 列表(因为我们并不想在点击 Stacy 时随机播放的动画中包含“空闲”)。
let clips = fileAnimations.filter(val => val.name !== 'idle');接着,与“idle”相同,将所有这些 clip 转为 Three.js AnimationClip。同时,将脖子和脊柱骨头从中剔除。最后将这些 AnimationClip 赋值给 possibleAnims(已在项目顶部定义)。
possibleAnims = clips.map(val => {
let clip = THREE.AnimationClip.findByName(clips, val.name);
clip.tracks.splice(3, 3);
clip.tracks.splice(9, 3);
clip = mixer.clipAction(clip);
return clip;
}
);现在,我们拥有了能播放动画的 clipAction 数组(点击 Stacy 时)。这里需要注意的是,我们并不能简单地为 Stacy 添加一个点击事件,毕竟她不是 DOM 的一部分。这里采用射线(raycasting)实现点击,即向指定方向发射激光束,然后返回被击中的对象集合。在该案例中,激光线是从摄像机射向光标。
在 mousemove 事件上方添加该函数:
// We will add raycasting here
document.addEventListener('mousemove', function(e) {...}window.addEventListener('click', e => raycast(e));
window.addEventListener('touchend', e => raycast(e, true));
function raycast(e, touch = false) {
var mouse = {};
if (touch) {
mouse.x = 2 * (e.changedTouches[0].clientX / window.innerWidth) - 1;
mouse.y = 1 - 2 * (e.changedTouches[0].clientY / window.innerHeight);
} else {
mouse.x = 2 * (e.clientX / window.innerWidth) - 1;
mouse.y = 1 - 2 * (e.clientY / window.innerHeight);
}
// update the picking ray with the camera and mouse position
raycaster.setFromCamera(mouse, camera);
// calculate objects intersecting the picking ray
var intersects = raycaster.intersectObjects(scene.children, true);
if (intersects[0]) {
var object = intersects[0].object;
if (object.name === 'stacy') {
if (!currentlyAnimating) {
currentlyAnimating = true;
playOnClick();
}
}
}
}我们添加了两个事件,分别对应 PC 和触屏。我们将 event 传入 raycast() 函数,并在触屏情况下,将 touch 参数设为 true。
在 raycast() 函数内,我们有一个 mouse 变量。若 touch 为 true,mouse.x 和 mouse.y 则被设为 changedTouches[0] 的坐标,反之被设为鼠标的坐标。(译者注:WebGL,坐标轴的原点在画布中心,坐标轴的范围是 -1 至 1)。
接着调用 raycaster (已在项目顶部声明为 new Raycaster 实例)的 setFromCamera 方法。这行代码表示光线从摄像机射向鼠标。
然后得到被射中的对象数组。若数组不为空,那么即可认为第一个子项就是被选中的对象。
如果选中对象的名字为 stacy,那么会执行 playOnClick()。注意,我们同时也会判断 currentlyAnimating 是否为 false,即当有动画正在执行(idle 除外)时,不会执行新动画。
在 raycast 函数下方,定义 playOnClick 函数。
// Get a random animation, and play it
function playOnClick() {
let anim = Math.floor(Math.random() * possibleAnims.length) + 0;
playModifierAnimation(idle, 0.25, possibleAnims[anim], 0.25);
}基于 possibleAnims 数组长度创建一个随机数,然后调用另一个函数 playModifierAnimation。该函数接收的参数有:idle(from,即从 idle 开始),从 idle 到新动画(possibleAnims[anim])的过渡时间;最后一个参数是从当前动画回到 idle 的过渡时间。在 playOnClick 函数下方,我们添加 playModifierAnimation。
function playModifierAnimation(from, fSpeed, to, tSpeed) {
to.setLoop(THREE.LoopOnce);
to.reset();
to.play();
from.crossFadeTo(to, fSpeed, true);
setTimeout(function() {
from.enabled = true;
to.crossFadeTo(from, tSpeed, true);
currentlyAnimating = false;
}, to._clip.duration * 1000 - ((tSpeed + fSpeed) * 1000));
}该函数做的第一件事是 重置 to 动画,即将要播放的动画。同时,我们将其 播放次数 设为 1 次,因为一旦动画播放完成(也许我们之前已播放过),它需要重置后才能再次播放。然后,调用 play 方法。
每个 clipAction 实例都有一个 crossFadeTo 方法,我们使用它来实现 from(idle) 到新动画的过渡,并且过渡时间为 fSpeed(即 from speed)。
至此,函数已有拥有了从 idle 过渡到新动画的能力。
接着,我们开启了一个定时器,用于将当前动画恢复到 from 动画(即 idle),同时将 currentlyAnimating 设置 false(这样就允许再次点击 Stacy)。setTimeout 的时间计算方法为:动画长度(* 1000 是因为过渡时间以秒而不是毫秒为单位)减去动画切入和切出的过渡时间(同样以秒为单位设置,所以需要 * 1000)来得到。
注意,脖子和脊柱骨头均不受动画控制,这使得我们能够在动画过程中旋转它们。
本教程到此已算结束,若遇到问题,请参考以下完整项目。
See the Pen Character Tutorial - Final by Kyle Wetton (@kylewetton) on CodePen.
如果你对模型和动画本身的工作感兴趣,那么我将在最后一节介绍一些基础知识,希望能拓展你的视野。
以下操作均基于最新稳定版 Blender 2.8。
在开始之前,请记住我曾经提到过的,尽管可以在 GLTF 文件(从 Blender 导出的格式)中包含纹理文件,但我遇到的问题是 Stacy 的纹理确实很暗。这与 GLTF 需要 sRGB 格式有关,尽管我尝试在 Photoshop 中进行转换,但这仍不起作用。在不能保证该文件格式的纹理质量下,我的做法是导出没有纹理的文件,然后再通过 Three.js 添加。除非你的项目非常复杂,否则我建议这样做。
不管怎样,一个 T 姿势的标准角色网格(mesh)就是我们在 Blender 起始点。之所以要让角色摆成 T 姿势,是因为 Mixamo 会基于此生成骨架,敬请期待。
然后以 FBX 格式导出模型。
然后可以离开 Blender 一阵子。
www.mixamo.com 网站提供了许多免费动画,可用于各种场景,而浏览者以独立游戏开发者居多。另外,该 Adobe 服务与 Adobe Fuse 关系密切,后者实际上是角色创建软件。该网站是免费使用的,但需要一个 Adobe 帐户(免费是指你不需要订阅 Creative Cloud)。因此,创建账号并登录。
你要做的第一件事是上传角色。这是我们从 Blender 导出的 FBX 文件。上传完成后,Mixamo 将自动启用 Auto-Rigger。
按照说明将标记放置在模型的关键位置上。一旦 Auto-Rigger 完成,你将会在面板上看到你的角色在运动。
Mixamo 已为你的模型创建骨架了,这就是本教程所谈及的骨架。
点击 “Next”,然后在左上方导航条中选择 “Animations”。让我们搜索 “idle” 动画作为开始,使用搜索框并输入 "idle"。本教程使用的是 “Happy idle”。
点击任意动画进行预览。当然该网站还有很多有趣的动画。对于本项目,结束动作与衔接动作的脚部位置尽可能相同,即其位置与空闲动画基本类似。因为结束姿势与下一个动画的开始姿势相似时,过渡会看起来更自然。
对 “idle” 动画感到满意后,请点击 “Downlod Character”。格式应为 FBX,并且 skin 应设置为 “With Skin”。其余设置保留为默认值。下载此文件,并保持 Mixamo 的打开状态。
返回到 Blender 中,将该文件导入到一个新空会话中(删除新会话附带的光源,摄像机和立方体)。
点击 play 按钮(如果未看到时间轴(timeline),将任意一个面板的 Editor Type 切换为 Timeline,若仍不懂,建议看看 Blender 的 界面介绍。
此时,若想重命名动画,则将 Editor Type 更改为 “Dope Sheet”,并将二级菜单设置为 “Action Editor”。
点击 “+ New” 旁的下拉框,选择从 Mixamo 得到动画。此时可以在输入框内重命名,我们将它改为 “idle”。
点击 “x” 可看到 “+ select” 标识
如果现在将该文件导出为 GLTF,那么在 gltf.animations 内就有一个名为 idle 的动画。记住,该文件同时拥有 gltf.animations 和 gltf.scene。
在导出之前,我们需要对角色对象进行重命名。设置如下所示。
请注意,在下方的子节点 stacy 是 JavaScript 中引用的对象名称。
现在我们仍不进行导出,相反,我将快速向你展示如何添加新动画。回到 Mixamo,我选择了 “Shake Fist”(挥拳)动画。下载此文件,我们仍保留皮肤,可能有人会说这次不需要保留皮肤。但我发现如果不保留皮肤会出现奇怪的状况。
将其导入 Blender。
此时,我们有两个 Stacy,一个叫 Armature,另一个是我们想保留的 Stacy。我们将删除 Armature,但首先要将其 Shake Fist 动画移至 Stacy。让我们回到 “Dope Sheet” > “Animation Editor”。
现在,你会看到在 idle 旁有一个新动画,让我们选择它,并将其重命名为 shakefist。
保持当前面板的 “Dope Sheet” > “Action Editor”,并将另一个未使用的面板(或拆分屏幕以创建一个新的面板。同样,阅读 Blender 界面介绍教程有助于理解这段话)设置 Editor Type 为非线性动画(NLA)。
点击 stacy,然后点击 idle 动画旁边的 “PUSH DOWN” 按钮。这样就能在已添加了 idle 动画基础上,创建新轨道以添加 shakefist 动画。
处理前,再次点击 stacy 名字:
回到 Animation Editor 面板,并从下拉列表中选择 “shaffist”。
最后,在 NLA 面板中点击 shaffist 旁边的 “Push Down” 按钮。
应该留下这些元素:
我们已经将动画从 Armature 转移到 Stacy,现在可以删除 Armature 了。
烦人的是,Armature 会将其子网格物体落到场景中,也将其删除。
重复以上步骤添加新动画(我相信做得越多,疑惑越少,效率越高)。
导出文件:
这是使用新模型的 pen!(需要注意的是:Stacy 的缩放比例与之前有所不同,所以在该 pen 中进行了调整。尽管到现在我对那些经 Mixamo 添加骨架并从 Blender 导出的模型的缩放比例仍琢磨不透,但在 Three.js 中能轻易地解决这个问题)。
See the Pen Character Tutorial - Remix by Kyle Wetton (@kylewetton) on CodePen.
完!
本文首发于 凹凸实验室
最近被分配到移动端开发组,支持某活动的页面页面制作。这算是我第一次真正接触移动端页面制作,下面就谈谈个人总结和思考。
开会大体讲解、讨论与排期 -> 交互设计 -> 视觉设计 -> 页面页面制作 -> 前端开发 -> 测试
每个步骤环环相扣,每个职位都需要和其前后的人沟通协调。
测试遇到问题则会反馈到相应环节负责人。
当然,涉及的职位也不仅于此,还有法务同事审核内容是否符合当前法规等等。
前端开发离不开构建工具,除了敲代码,其余都交给构建工具(如组件开发、CSS 兼容处理、图片 Base64、图片雪碧图和压缩处理等)。
在 Athena 中,文件层级结构如下:项目 project -> 模块 module(具体每个活动) -> 页面 page -> 部件 widget。
举例: 某项目 -> X、Y 活动 -> 预热页和高潮页 -> 头部、弹框等 widget。一般文件目录如下:
Xproject
- gb (公共部分,如初始化样式和一些常用 widget)
- X活动
- page
- 预热页
- 高潮页
- widget
- header
- footer
- diglog
- Y 活动
- ...
刚开始接触时,存在这样的一个疑惑:什么是 widget,一个不可复用的页面头部可以作为 widget 吗?
答:我最初的想法是:“错误地把 widget 当成 component,component 一直被强调的 特性之一是可复用性。对于不可复用的部分就不应该抽出为一个widget了?”**其实对于一个相对独立的功能,我们就可把它抽出来。**这无疑会增强程序的可维护性。
对于一个项目,一般一个模块由一个人负责。但考虑到每个模块间可能存在(或未来存在)可复用的 widget,需要规范命名以形成命名空间,防止冲突(具体会在下面的规范-命名中阐述)。
Component 与 Widget 的区别
Component 是更加广义抽象的概念,而Widget是更加具体现实的概念。所以Component的范围要比Widget大得多,通常 Component 是由多个 Widget 组成。
举个例子,可能不是很恰当,希望帮助你的理解,比如家是由床,柜子等多个 Component 组成,柜子是由多个抽屉 Widget 组成的。
而 Component 和 Widget 的目的都是为了模块化开发。
其实,在这里并没有对 widget 和 component 做这么细的区分。
正如上面讨论的,一个页面由多个 widget 组成。因此,一个页面看起来如下:
<body ontouchstart>
<div class="wrapper">
<!-- S 主会场头部 -->
<%= widget.load("app_market_main_header") %>
<!-- E 主会场头部 -->
<!-- S 达人问答区 -->
<%= widget.load("app_market_answer") %>
<!-- E 达人问答区 -->
<!-- S 优惠券 -->
<%= widget.load("app_market_coupons") %>
<!-- E 优惠券 -->
<!-- S 达人集中营 -->
<%= widget.load("app_market_camp") %>
<!-- E 达人集中营 -->
<!-- S 达人穿搭公式 -->
<%= widget.load("app_market_collocation") %>
<!-- E 达人穿搭公式 -->
<!-- S 卡券相关弹框 -->
<%= widget.load("app_market_dialog") %>
<!-- E 卡券相关弹框 -->
</div>
widget 一般存在可复用性。但如何控制细粒度呢?分得越细代码就越简洁,但工作量和维护难度可能会上升,因此需要权衡你当时的情况。
由于一个项目中,一个模块由某一个人负责,但模块之间的 widget 存在或未来存在可复用的可能(而且开发可能会为你的页面添加已有的组件,如页面会嵌在某 APP 内,该 APP 已有现成的一些提示框)。因此,需要命名空间将其它们进行区分以防止冲突。由于 CSS 不存在命名空间,因此只能通过类似 BEM 的方式(具体根据团队的规范),如:app_market_header、app_market_list_item。app_market 是模块(即某个活动)的标识,在该项目下,它是唯一的。
另外,还有一点:类名是否要按照 html 层级关系层层添加呢?如:
div.app_market_header
div.app_market_header_icon
div.app_market_header_**
对于 app_market_header_icon,尽管在 header 中,但 icon 并不只属于 header,而属于整个模块(活动),那么我们就可以改为 app_market_icon。
老司机 Code review 后,讲了以下内容:
反面教材:
<div class="app_market_answer">
<div class="app_market_secheader"></div>
<div class="app_market_answer_list">
<div class="app_market_answer_item">
<div class="app_market_answer_item_top"></div>
<div class="app_market_answer_item_middle"></div>
<a href="javascript:;" class="app_market_answer_item_bottom">去围观</a>
</div>
</div>
存在的问题是:嵌套层级越深,类名就越长。
较好的解决方案:
<div class="app_market_answer">
<div class="app_market_secheader"></div>
<div class="app_market_answer_list">
<div class="app_market_answer_item">
<div class="app_market_answer_itop"></div>***
<div class="app_market_answer_imid"></div>***
<a href="javascript:;" class="app_market_answer_ibtm">去围观</a>***
</div>
</div>
这是基于『姓名』原理进行优化的,举例:app_market_answer_item 是姓名(库日天),那么它的子元素只需继承它的『姓』(库姆斯) app_market_answer_itop,而不是它的姓名(库日天姆斯) app_market_answer_item_top。每当类名达到三到四个单词长时,就要考虑简化名字。
进一步优化,app_market 可以看成是『复姓』,有时为了书写便利,可以以两个单词的首字母结合形成一个新的『新姓』- 『am』。当然,追求便利的副作用是牺牲了代码的可读性。如果你负责的项目或页面没有太大的二次维护或者交叉维护的可能性,推荐做此简化。
BTW:此简化后的『姓』可以在代码中稍加注释说明,如下代码所示:
<!-- am = app_market -->
<div class="am_answer">
<div class="am_secheader"></div>
<div class="am_answer_list">
<div class="am_answer_item">
<div class="am_answer_itop"></div>
<div class="am_answer_imid"></div>
<a href="javascript:;" class="am_answer_ibtm">去围观</a>
</div>
</div>
<div>
<a href="javascript:;">...</a>
</div>
至少加一个类名,任何时候都尽量要『针对类名书写样式,而不是针对元素书写样式』,除非你能预判元素是末级元素。
因此对于以下 CSS:
.app_market_coupons > div {
...
}
可优化成:
.app_market_coupons > .xxx {
...
}
移动端采用 rem 布局方式。通过动态修改 html 的 font-size 实现自适应。
REM 布局有两种实现方式:CSS 媒介查询和 JavaScript 动态修改。由于 JavaScript 更为灵活,因此现在更多地采用此方式。
凹凸的实现方式是:在 head 标签末加入以下代码
<script type="text/javascript">
!function(){
var maxWidth=750;
document.write('<style id="o2HtmlFontSize"></style>');
var o2_resize=function(){
var cw,ch;
if(document&&document.documentElement){
cw=document.documentElement.clientWidth,ch=document.documentElement.clientHeight;
}
if(!cw||!ch){
if(window.localStorage["o2-cw"]&&window.localStorage["o2-ch"]){
cw=parseInt(window.localStorage["o2-cw"]),ch=parseInt(window.localStorage["o2-ch"]);
}else{
chk_cw();//定时检查
return ;//出错了
}
}
var zoom=maxWidth&&maxWidth<cw?maxWidth/375:cw/375,zoomY=ch/603;//由ip6 weChat
window.localStorage["o2-cw"]=cw,window.localStorage["o2-ch"]=ch;
//zoom=Math.min(zoom,zoomY);//保证ip6 wechat的显示比率
window.zoom=window.o2Zoom=zoom;
document.getElementById("o2HtmlFontSize").innerHTML='html{font-size:'+(zoom*20)+'px;}.o2-zoom,.zoom{zoom:'+(zoom/2)+';}.o2-scale{-webkit-transform: scale('+zoom/2+'); transform: scale('+zoom/2+');} .sq_sns_pic_item,.sq_sns_picmod_erea_img{-webkit-transform-origin: 0 0;transform-origin: 0 0;-webkit-transform: scale('+zoom/2+');transform: scale('+zoom/2+');}';
},
siv,
chk_cw=function(){
if(siv)return ;//已经存在
siv=setInterval(function(){
//定时检查
document&&document.documentElement&&document.documentElement.clientWidth&&document.documentElement.clientHeight&&(o2_resize(),clearInterval(siv),siv=undefined);
},100);
};
o2_resize();//立即初始化
window.addEventListener("resize",o2_resize);
}();
</script>
从以上代码可得出以下信息:
zoom 为 1有人说 rem 布局是 vw 和 vh 的替换方案,当 vw 和 vh 成熟时,两者可能会各司其职吧。
vw 的兼容性:在安卓 4.3 及以下是不支持的。
由于 rem 布局是相对于视口宽度,因此任何需要根据屏幕大小进行变化的元素(width、height、position 等)都可以用 rem 单位。
但 rem 也有它的缺点——不精细(在下一节阐述),其实这涉及到了浏览器渲染引擎的处理。因此,对于需要精细处理的地方(如通过 CSS 实现的 icon),可以用 px 等绝对单位,然后再通过 transform: scale() 方法等比缩放。
那 font-size 是否也要用 rem 单位呢? 这也是我曾经纠结的地方。如果不等比缩放,对不起设计师,而且对于小屏幕,一些元素内的字体会换行或溢出。当然这可以通过 CSS3 媒介查询解决这种状况。
字体不采用 rem 的好处是:在大屏手机下,能显示更多字体。
看到 网易新闻 和 聚划算 的字体大小都采用 rem 单位,我就不纠结了。当然,也有其它网站是采用绝对单位的,两者没有绝对的对与错,取决于你的实际情况。
由于 rem 布局是基于某一设备实现的(目前一般采用 iPhone6),对于 375 倍数宽的设备无疑会拥有最佳的显示效果。而对于非 375 倍数宽的设备,zoom 就可能是拥有除不尽的小数,根元素的字体大小也相应会有小数。而浏览器对小数的处理方式不一致,导致该居中的地方没完全居中,但你又不能为此设置特定样式(如 margin-top: *px;),因为浏览器多如牛毛,这个浏览器微调居中了,而原本居中的浏览器变得不居中了。
对于图标 icon,rem 的不精细导致通过多个元素(伪元素)组合而成的 icon 会形成错位/偏差。因此,在这种情况下,需要权衡是否需要使用 CSS 实现了。
SASS 无疑增强了原本声明式的 CSS,为 CSS 注入了可编程等能力。在这次项目,算是我第一次使用 SASS,由于构建工具和基础库的完善,只需通过查看/模仿已有项目的 SASS 用法,就能快速上手。后续还是要系统地学习,以更合理地使用 SASS。
使用 SASS 的最大问题是:层级嵌套过深,这也是对 SASS 理解不深入的原因。可以关注一下转译后的 CSS。
这次项目的 APP 采用手机自带浏览器内核,而这些浏览器内核依赖于系统版本等因素。另外,国产机也会对这些内核进行定制和修改。特别是华为、OPPO。
下面列出我所遇到的兼容性问题(不列具体机型,因为这些兼容性处理终会过时,不必死记硬背,遇到了能解决就好(要求基础扎实)):
auto = img.Height * (screen.Width/img.Width)】,导致图片未显示)。另外,需要注意的是:透明的色标在iOS 默认是黑色的,即 transparent 等于 rgba(0,0,0,0)。因此即使是完全透明的色标,也要指定颜色。否则后果如下:
function getStyle(ele, style) {
return document.defaultView.getComputedStyle(ele, null)[style]
}
;(function fixFontSize() {
var target = window.o2Zoom * 20
var cur = parseInt(getStyle(document.documentElement, "fontSize"))
while(cur - target >= 1) {
document.documentElement.style["fontSize"] = target - (cur - target) + "px"
cur = parseInt(getStyle(document.documentElement, "fontSize"))
}
})();
有网友提供这个方法 <meta name="wap-font-scale" content="no">,经测试不可行。此方法是针对 UC 浏览器的。
上面主要列出了对使用有影响的兼容性问题,有些由于浏览器渲染引擎导致的问题(不影响使用),若无法通过 transform、z-index 等解决,也许只能通过 JavaScript 解决或进行取舍了。
图片占位元素:对于宽高比例固定的坑位(如商品列表项),通过将图片放置在占位元素中,可避免图片加载时引起的页面抖动和图片尺寸不一致而导致的页面布局错乱。代码实现:
.img_placeholder {
position: relative;
height: 0;
overflow: hidden;
padding-top: placeholder 的高/宽%; // padding-top/bottom: 百分比; 是基于父元素的宽度
img {
width: 100%;
height: auto;
position: absolute;
left: 0;
top: 0;
}
}
1px:在 retina 屏幕下,1 CSS像素是用 4 个物理像素表示,为了在该屏幕下显示更精细,通过为 ::after 应用以下代码(以上边框为例):
div {
position: relative;
&::after {
content: '';
position: absolute;
z-index: 1;
pointer-events: none;
background: $borderColor;
height: 1px;left: 0;right: 0;top: 0;
@media only screen and (-webkit-min-device-pixel-ratio:2) {
&{
-webkit-transform: scaleY(0.5);
-webkit-transform-origin: 50% 0%;
}
}
}
}
根据元素个数应用特定样式:
/* one item */
li:first-child:nth-last-child(1) {
width: 100%;
}
/* two items */
li:first-child:nth-last-child(2),
li:first-child:nth-last-child(2) ~ li {
width: 50%;
}
/* three items */
li:first-child:nth-last-child(3),
li:first-child:nth-last-child(3) ~ li {
width: 33.3333%;
}
/* four items */
li:first-child:nth-last-child(4),
li:first-child:nth-last-child(4) ~ li {
width: 25%;
}
应用样例有:根据元素个数自适应标签样式。
而对于反方向标签,可先首先对整体 transform: scale(-1),然后再对字体 transform: scale(-1) 恢复从左向右的方向。效果如下:
卡券:『带孔且背景是渐变的卡券』在复杂背景中的实现。由于背景是复杂的(非纯色),因此孔不能简单地通过覆盖(与背景同色)产生。这里可以应用径向渐变 background-image: radial-gradient(rem(189/2) 100%, circle, transparent 0, transparent 3px, #fa2c66 3px);,其中 3px 是孔的半径。另外,卡券的上下部分是线性渐变的,因此可以在上下部分分别通过伪类元素添加 background-image: linear-gradient(to top, #fa2e67 0, #fb5584 100%);,当然,要从离外上/下边界 3px 的地方开始。虽然这不能完美地从最边界开始,但效果还是可以的。但由于径向渐变的兼容性问题,我最终还是用图片替换了这种实现。🙄
多行文本的多行padding:让背景只出现在有文字的地方,可直接设置 display: inline;,但还会存在一个问题是:padding 只会出现在多行文本的首和尾,对于需要为每行文本的首尾都需要相同的 padding,可以参考这篇文章:《multi-line-padded-text》 。该文章提供了多种实现方式,根据具体情况选择一种即可。另外,对于每行的间距,可通过设置 line-height 和 padding-top/bottom 实现,其中 line-height 要大于(字体高度+padding-top/bottom)。
最小字体限制:PC上最小字体是 12px、移动端最小是 8px,当然可通过 transform:scale() 突破限制。
由于工具的成熟,我不需要考虑构建工具的搭建。
由于发布方式的成熟,页面制作和开发能更好地分离,页面制作者负责输出 HTML、CSS,开发负责 copy html 代码和引入 CSS 页面片。CSS 页面片由页面制作者更新发布,开发无需关心。这达到了互不干扰、多线程并行的效果。
成熟的基础设施让我们免除了非代码相关的烦恼,但这也让我担心:假如有一天我脱离了这些基础设施,我该如何保持高效。
CSS 页面片
<!-- #include virtual="/folder/branch.shtml" -->
<link combofile="/folder/branch.shtml" rel="stylesheet" href="//website/folder/gb.min_1151b5b0.css,/folder/branch.min_925332fc.css" />
JS 页面片
<!-- #include virtual="/folder/branch_js.shtml" -->
<script combofile="/folder/branch.shtml" src="//website/path/branch.min_8971778a.js"></script>
Combo Handler是Yahoo!开发的一个Apache模块,它实现了开发人员简单方便地通过URL来合并JavaScript和CSS文件,从而大大减少文件请求数。 http://www.cnblogs.com/zhengyun_ustc/archive/2012/07/18/combo.html
这就是我的第一次...🙈 学习很多,完!
以上仅是我个人完成某项目页面制作的思考和总结,不小心暴露了团队下限。🌚
bug: readme里面 《用Mocha和Chai对JavaScript进行单元测试》链接错误
本文首发于 凹凸实验室
XCEL 是由京东用户体验设计部凹凸实验室推出的一个 Excel 数据清洗工具,其通过可视化的方式让用户轻松地对 Excel 数据进行筛选。
XCEL 基于 Electron 和 Vue 2.x,它不仅跨平台(windows 7+、Mac 和 Linux),而且充分利用 Electron 多进程任务处理等功能,使其性能优异。
落地页:https://xcel.aotu.io/ ✨✨✨
项目地址:https://github.com/o2team/xcel ✨✨✨
用户研究的定量研究和轻量级数据处理中,均需对数据进行清洗处理,以剔除异常数据,保证数据结果的信度和效度。目前因调研数据和轻量级数据的多变性,对轻量级数据清洗往往采取人工清洗,缺少统一、标准的清洗流程,但对于调研和轻量级的数据往往是需要保证数据稳定性的,因此,在对数据进行清洗时最好有标准化的清洗方式。
基于用研组的需求,利用 Electron 和 Vue 的特性对该工具进行开发。
纸上得来终觉浅,绝知此事要躬行
如果对某项技术比较熟悉,则可略读/跳过。
Electron 是一个可以用 JavaScript、HTML 和 CSS 构建桌面应用程序的库。这些应用程序能打包到 Mac、Windows 和 Linux 系统上运行,也能上架到 Mac 和 Windows 的 App Store。
通常来说,每个操作系统的桌面应用都由各自的原生语言进行编写,这意味着需要 3 个团队分别为该应用编写相应版本。而 Electron 则允许你用 Web 语言编写一次即可。
Electron 结合了 Chromium、Node.js 和用于调用操作系统本地功能的 API(如打开文件窗口、通知、图标等)。
基于 Electron 的开发就像在开发网页,而且能够无缝地 使用 Node。或者说:在构建一个 Node 应用的同时,通过 HTML 和 CSS 构建界面。另外,你只需为一个浏览器(最新的 Chrome)进行设计(即无需考虑兼容性等)。
Electron 有两种进程:『主进程』和『渲染进程』。部分模块只能在两者之一上运行,而有些则无限制。主进程更多地充当幕后角色,而渲染进程则是应用程序的各个窗口。
注:可通过任务管理器(PC)/活动监视器(Mac)查看进程的相关信息。
dialog 模块拥有所有原生 dialog 的 API,如打开文件、保存文件和警告等弹窗。主进程,通常是一个命名为 main.js 的文件,该文件是每个 Electron 应用的入口。它控制了应用的生命周期(从打开到关闭)。它既能调用原生元素,也能创建新的(多个)渲染进程。另外,Node API 是内置其中的。
渲染进程是应用的一个浏览器窗口。与主进程不同,它能存在多个(注:一个 Electron 应用只能存在一个主进程)并且相互独立(它也能是隐藏的)。主窗口通常被命名为 index.html。它们就像典型的 HTML 文件,但 Electron 赋予了它们完整的 Node API。因此,这也是它与浏览器的区别。
Chrome(或其他浏览器)的每个标签页(tab)及其页面,就好比 Electron 中的一个单独渲染进程。即使关闭所有标签页,Chrome 依然存在。这好比 Electron 的主进程,能打开新的窗口或关闭这个应用。
注:在 Chrome 浏览器中,一个标签页(tab)中的页面(即除了浏览器本身部分,如搜索框、工具栏等)就是一个渲染进程。
由于主进程和渲染进程各自负责不同的任务,而对于需要协同完成的任务,它们需要相互通讯。IPC就为此而生,它提供了进程间的通讯。但它只能在主进程与渲染进程之间传递信息(即渲染进程之间不能进行直接通讯)。
Electron 应用就像 Node 应用,它也依赖一个 package.json 文件。该文件定义了哪个文件作为主进程,并因此让 Electron 知道从何启动应用。然后主进程能创建渲染进程,并能使用 IPC 让两者间进行消息传递。
至此,Electron 的基础部分介绍完毕。该部分是基于笔者之前翻译的一篇文章《Essential Electron》,译文可点击 这里。
该工具使用了 Vue、Vuex、Vuex-router。在工具基本定型阶段,由 1.x 升级到了 2.x。
对于笔者来说:
Vue 1.x -> Vue 2.0 的版本迁移用 vue-migration-helper 即可分析出大部分需要更改的地方。
网上已有很多关于 Vue 的教程,故在此不再赘述。至此,Vue 部分介绍完毕。
该库支持各种电子表格格式的解析与生成。它由 JavaScript 实现,适用于前端和 Node。详情>>
目前支持读入的格式有(不断更新):
支持写出的格式有:
目前该库提供的 sheet_to_json 方法能将读入的 Excel 数据转为 JSON 格式。而对于导出操作,我们需要为 js-xlsx 提供指定的 JSON 格式。
更多关于 Excel 在 JavaScript 中处理的知识可查看凹凸实验室的《Node读写Excel文件探究实践》。但该文章存在两处问题(均在 js-xlsx 实战的导出表格部分):
String.fromCharCode(65+j) 生成。当列大于 26 时会出现问题。这个问题会在后面章节中给出解决方案;原来的:
var result = 某数组.reduce((prev, next) => Object.assign({}, prev, {[next.position]: {v: next.v}}), {});
改为:
var result = 某数组.forEach((v, i) => data[v.position]= {v: v.v})
实践是检验真理的唯一标准
在理解上述知识后,下面就谈谈在该项目实践中总结出来的技巧、难点和重点。
Excel 单元格采用 table 标签展示。在 Excel 中,被选中的单元格会高亮相应的『行』和『列』,以提醒用户。在该应用中也有做相应的处理,横向高亮采用 tr:hover 实现,而纵向呢?这里所采用的一个技巧是:
假设 HTML 结构如下:
div.container
table
tr
td
CSS 代码如下:
.container { overflow:hidden; }
td { position: relative; }
td:hover::after {
position: absolute;
left: 0;
right: 0;
top: -1个亿px; // 小目标达成,不过是负的😭
bottom: -1个亿px;
z-index: -1; // 避免遮住自身和同列 td 的内容、border 等
}
如图:
分割线可以通过 ::after/::before 伪类元素实现一条直线,然后通过 transform:rotate(); 旋转特定角度实现。但这种实现的一个问题是:由于宽度是不定的,因此需要通过 JavaScript 运算才能得到准确的对角分割线。
因此,这里可以通过 CSS 线性渐变 linear-gradient(to top right, transparent, transparent calc(50% - .5px), #d3d6db calc(50% - .5px), #d3d6db calc(50% + .5px), transparent calc(50% + .5px)) 实现。无论宽高如何变,依然妥妥地自适应。
26 列 时就会产生问题(如:第 27 列,String.fromCharCode(65+26) 得到的是 [,而不是 AA)。因此,这需要通过『十进制和 26 进制转换』算法来实现。// 将传入的自然数转换为26进制表示。映射关系:[0-25] -> [A-Z]。
function getCharCol (n) {
let s = ''
let m = 0
while (n >= 0) {
m = (n % 26) + 1
s = String.fromCharCode(m + 64) + s
n = (n - m) / 26
}
return s
}// 将传入的26进制转换为自然数。映射关系:[A-Z] ->[0-25]。
function getNumCol (s) {
if (!s) return 0
let n = 0
for (let i = s.length - 1, j = 1; i >= 0; i--, j *= 26) {
const c = s[i].toUpperCase()
if (c < 'A' || c > 'Z') return 0
n += (c.charCodeAt() - 64) * j
}
return n - 1
}Electron 为 File 对象额外增了 path 属性,该属性可得到文件在文件系统上的真实路径。因此,你可以利用 Node 为所欲为😈。应用场景有:拖拽文件后,通过 Node 提供的 File API 读取文件等。
Electron 应用在 MacOS 中默认不支持『复制』『粘贴』等常见编辑功能,因此需要为 MacOS 显式地设置复制粘贴等编辑功能的菜单栏,并为此设置相应的快捷键。
// darwin 就是 MacOS
if (process.platform === 'darwin') {
var template = [{
label: 'FromScratch',
submenu: [{
label: 'Quit',
accelerator: 'CmdOrCtrl+Q',
click: function() { app.quit(); }
}]
}, {
label: 'Edit',
submenu: [{
label: 'Undo',
accelerator: 'CmdOrCtrl+Z',
selector: 'undo:'
}, {
label: 'Redo',
accelerator: 'Shift+CmdOrCtrl+Z',
selector: 'redo:'
}, {
type: 'separator'
}, {
label: 'Cut',
accelerator: 'CmdOrCtrl+X',
selector: 'cut:'
}, {
label: 'Copy',
accelerator: 'CmdOrCtrl+C',
selector: 'copy:'
}, {
label: 'Paste',
accelerator: 'CmdOrCtrl+V',
selector: 'paste:'
}, {
label: 'Select All',
accelerator: 'CmdOrCtrl+A',
selector: 'selectAll:'
}]
}];
var osxMenu = menu.buildFromTemplate(template);
menu.setApplicationMenu(osxMenu);
}Electron 的一个缺点是:即使你的应用是一个简单的时钟,但它也不得不包含完整的基础设施(如 Chromium、Node 等)。因此,一般情况下,打包后的程序至少会达到几十兆(根据系统类型进行浮动)。当你的应用越复杂,就越可以忽略文件体积问题。
众所周知,页面的渲染难免会导致『白屏』,而且这里采用了 Vue 这类框架,情况就更加糟糕了。另外,Electron 应用也避免不了『先打开浏览器,再渲染页面』的步骤。下面提供几种方法来减轻这种情况,以让程序更贴近原生应用。
对于第一点,若应用的背景不是纯白(#fff)的,那么可指定窗口的背景颜色与其一致,以避免渲染后的突变。
mainWindow = new BrowserWindow({
title: 'XCel',
backgroundColor: '#f5f5f5',
};对于第二点,由于 Electron 本质是一个浏览器,需要加载非网页部分的资源。因此,我们可以先隐藏窗口。
var mainWindow = new BrowserWindow({
title: 'ElectronApp',
show: false,
};等到渲染进程开始渲染页面的那一刻,在 ready-to-show 的回调函数中显示窗口。
mainWindow.on('ready-to-show', function() {
mainWindow.show();
mainWindow.focus();
});对于第三点,笔者并没有实现,原因如下:
其实现方式,可参考《4 must-know tips for building cross platform Electron apps》。
在渲染进程中调用原本专属于主进程中的 API (如弹框)的方式有两种:
ipcMain 进行监听,然后在渲染进程通过 ipcRenderer 进行触发;对于第二种方式,在渲染进程中,运行以下代码即可:
const remote = require('electron').remote
remote.dialog.showMessageBox({
type: 'question',
buttons: ['不告诉你', '没有梦想'],
defaultId: 0,
title: 'XCel',
message: '你的梦想是什么?'
}如果 Electron 应用没有提供自动更新功能,那么就意味着用户想体验新开发的功能或用上修复 Bug 后的新版本,只能靠用户自己主动地去官网下载,这无疑是糟糕的体验。Electron 提供的 autoUpdater 模块可实现自动更新功能,该模块提供了第三方框架 Squirrel 的接口,但 Electron 目前只内置了 Squirrel.Mac,且它与 Squirrel.Windows(需要额外引入)的处理方式也不一致(在客户端与服务器端两方面)。因此如果对该模块不熟悉,处理起来会相对比较繁琐。具体可以参考笔者的另一篇译文《Electron 自动更新的完整教程(Windows 和 OSX)》。
目前 Electron 的 autoUpdater 模块不支持 Linux 系统。
另外,XCel 目前并没有采用 autoUpdater 模块实现自动更新功能,而是利用 Electron 的 DownloadItem 模块实现,而服务器端则采用了 Nuts。
通过 electron-builder 可直接生成常见的 MacOS 安装包,但它生成的 Windows 的安装包却略显简洁(默认选项时)。
Mac 常见的安装模式,将“左侧的应用图标”拖拽到“右侧的 Applications”即可
通过 electron-builder 生成的 Windows 安装包与我们在 Windows 上常见的软件安装界面不太一样,它没有安装向导和点击“下一步”的按钮,只有一个安装时的 gif 动画(默认的 gif 动画如下图,当然你也可以指定特定的 gif 动画),因此也就关闭了用户选择安装路径等权利。
Windows 安装时 默认显示的 gif 动画
如果你想为打包后的 Electron 应用(即通过 electron-packager/electron-builder 生成的,可直接运行的程序目录)生成拥有点击“下一步”按钮和可让用户指定安装路径的常见安装包,可以尝试 NSIS 程序,具体可看这篇教程 《[教學]只要10分鐘學會使用 NSIS 包裝您的桌面軟體–安裝程式打包。完全免費。》。
注:electron-builder 也提供了生成安装包的配置项,具体查看>>。
NSIS(Nullsoft Scriptable Install System)是一个开源的 Windows 系统下安装程序制作程序。它提供了安装、卸载、系统设置、文件解压缩等功能。正如其名字所描述的那样,NSIS 是通过它的脚本语言来描述安装程序的行为和逻辑的。NSIS 的脚本语言和常见的编程语言有类似的结构和语法,但它是为安装程序这类应用所设计的。
至此,CSS、JavaScript 和 Electron 相关的知识和技巧部分阐述完毕。
下面谈谈『性能优化』,这部分涉及到运行效率和内存占用量。
注:以下内容均基于 Excel 样例文件(数据量为:1913 行 x 180 列)得出的结论。
Vue 一直标榜着自己性能优异,但当数据量上升到一定量级时(如 1913 x 180 ≈ 34 万个数据单元),会出现严重的性能问题(未做相应优化的前提下)。
如直接通过列表渲染 v-for 渲染数据时,会导致程序卡死。
答:通过查阅相关资料可得, v-for 在初次渲染时,需要对每个子项进行初始化(如数据绑定等操作,以便拥有更快的更新速度),这对于数据量较大时,无疑会造成严重的性能问题。
当时,我想到了两种解决思路:
最终,我选择了第二条,理由是:
将原本繁重的 DOM 操作(Vue)转换为 JavaScript 的拼接字符串后,性能得到了很大提升(不会导致程序卡死而渲染不出视图)。这种优化方式难道不就是 Vue、React 等框架解决的问题之一吗?只不过框架考虑的场景更广,有些地方需要我们自己根据实际情况进行优化而已。
在浏览器当中,JavaScript 的运算在现代的引擎中非常快,但 DOM 本身是非常缓慢的东西。当你调用原生 DOM API 的时候,浏览器需要在 JavaScript 引擎的语境下去接触原生的 DOM 的实现,这个过程有相当的性能损耗。所以,本质的考量是,要把耗费时间的操作尽量放在纯粹的计算中去做,保证最后计算出来的需要实际接触真实 DOM 的操作是最少的。 —— 《Vue 2.0——渐进式前端解决方案》
当然,由于 JavaScript 天生单线程,即使执行数速度再快,也难免会导致页面有短暂的时间拒绝用户的输入。此时可通过 Web Worker 或其它方式解决,这也将是我们后续讲到的问题。
也有网友提供了优化大量列表的方法:https://clusterize.js.org/。但在此案例中笔者并没有采用此方式。
将拼接的字符串插入 DOM 后,出现了另外一个问题:滚动会很卡。猜想这是渲染问题,毕竟 34 万个单元格同时存在于界面中。
添加 transform: translate3d(0, 0, 0) / translateZ(0) 属性启动 GPU 渲染,即可解决这个渲染性能问题。再次感叹该属性的强大。🐂
后来,考虑到用户并不需要查看全部数据,只需展示部分数据让用户进行参考即可。我们对此只渲染前 30/50 行数据。这样即可提升用户体验,也能进一步优化性能。
另外,由于自己学艺不精和粗心大意,忘记在生产环境关闭 Vuex 的『严格模式』。
Vuex 的严格模式要在生产环境中关闭,否则会对 state 树进行一个深观察 (deep watch),产生不必要的性能损耗。也许在数据量少时,不会注意到这个问题。
还原当时的场景:导入 Excel 数据后,再进行交互(涉及 Vuex 的读写操作),需要等几秒才会响应,而直接通过纯 DOM 监听的事件则无此问题。由此,判断出是 Vuex 问题。
const store = new Vuex.Store({
// ...
strict: process.env.NODE_ENV !== 'production'
})前面说道,JavaScript 天生单线程,即使再快,对于数据量较大时,也会出现拒绝响应的问题。因此需要 Web Worker 或类似的方案去解决。
在这里我不选择 Web worker 的原因有如下几点:
Electron 作者在 2014.11.7 在《state of web worker support?》 issue 中回复了以下这一段:
Node integration doesn't work in web workers, and there is no plan to do. Workers in Chromium are implemented by starting a new thread, and Node is not thread safe. Back in past we had tried to add node integration to web workers in Atom, but it crashed too easily so we gave up on it.
因此,我们最终采用了创建一个新的渲染进程 background process 进行处理数据。由 Electron 章节可知,每个 Electron 渲染进程是独立的,因此它们不会互相影响。但这也带来了一个问题:它们不能相互通讯?
错!下面有 3 种方式进行通讯:
background process 是 B,那么 A 先将 Excel 数据传递到主进程,然后主进程再转发到 B。B 处理完后再原路返回,具体如下图。当然,也可以将数据存储在主进程中,然后在多个渲染进程中使用 remote 模块来访问它。该工具采用了第三种方式的第一种情况:
1、主页面渲染进程 A 的代码如下:
//①
ipcRenderer.send('filter-start', {
filterTagList: this.filterTagList,
filterWay: this.filterWay,
curActiveSheetName: this.activeSheet.name
})
// ⑥ 在某处接收 filter-response 事件
ipcRenderer.on("filter-response", (arg) => {
// 得到处理数据
})2、作为中转站的主进程的代码如下:
//②
ipcMain.on("filter-start", (event, arg) => {
// webContents 用于渲染和控制 web page
backgroundWindow.webContents.send("filter-start", arg)
})
// ⑤ 用于接收返回事件
ipcMain.on("filter-response", (event, arg) => {
mainWindow.webContents.send("filter-response", arg)
})3、处理繁重数据的 background process 渲染进程 B 的代码如下:
// ③
ipcRenderer.on('filter-start', (event, arg) => {
// 进行运算
...
// ④ 运算完毕后,再通过 IPC 原路返回。主进程和渲染进程 A 也要建立相应的监听事件
ipcRenderer.send('filter-response', {
filRow: tempFilRow
})
})
至此,我们将『读取文件』、『过滤数据』和『导出文件』三大耗时的数据操作均转移到了 background process 中处理。
这里,我们只创建了一个 background process,如果想要做得更极致,我们可以新建『CPU 线程数- 1 』 个的 background process 同时对数据进行处理,然后在主进程对处理后数据进行拼接,最后再将拼接后的数据返回到主页面的渲染进程。这样就可以充分榨干 CPU 了。当然,在此笔者不会进行这个优化。
不要为了优化而优化,否则得不偿失。 —— 某网友
解决了执行效率和渲染问题后,发现也存在内存占用量过大的问题。当时猜测是以下几个原因:
background process 处理。在通讯传递数据的过程中,由于不是共享内存(因为 IPC 是基于 Socket 的),导致出现多份数据副本(在写这篇文章时才有了这相对确切的答案)。null,然后等待 GC 回收。由于 Chromium 采用多进程架构,因此会涉及到进程间通信问题。Browser 进程在启动 Render 进程的过程中会建立一个以 UNIX Socket 为基础的 IPC 通道。有了 IPC 通道之后,接下来 Browser 进程与 Render 进程就以消息的形式进行通信。我们将这种消息称为 IPC 消息,以区别于线程消息循环中的消息。
——《Chromium的IPC消息发送、接收和分发机制分析》
定义:为了易于理解,以下『Excel 数据』均指 Excel 的全部有效单元格转为 JSON 格式后的数据。
最容易处理的无疑是第三点,手动将不再需要的变量及时设置为 null,但效果并不明显。
后来,通过操作系统的『活动监视器』(Windows 上是任务管理器)对该工具的每阶段(打开时、导入文件时、筛选时和导出时)进行粗略的内存分析,得到以下报告:
---------------- S:报告分割线 ----------------
经观察,主要耗内存的是页面渲染进程。下面通过截图说明:
PID 15243 是主进程
PID 15246 是页面渲染进程
PID 15248 是 background 渲染进程
a、首次启动程序时(第 4 行是主进程;第 1 行是页面渲染进程;第 3 行是 background 渲染进程 )
b、导入文件(第 5 行是主进程;第 2 行是页面渲染进程;第 4 行是 background 渲染进程 )
c、筛选数据(第 4 行是主进程;第 1 行是页面渲染进程;第 3 行是 background 渲染进程 )
由于 JavaScript 目前不具有主动回收资源的功能,所以只能主动将对象设置为 null,然后等待 GC 回收。
因此,经过一段时间等待后,内存占用如下:
d、一段时间后(第 4 行是主进程;第 1 行是页面渲染进程;第 3 行是 background 渲染进程 )
由上述可得,页面渲染进程由于页面元素和 Vue 等 UI 相关资源是固定的,占用内存较大且不能回收。主进程占用资源也不能得到很好释放,暂时不知道原因,而 background 渲染进程则较好地释放资源。
---------------- E:报告分割线 ----------------
根据报告,初步得出的结论是 Vue 和通讯时占用资源较大。
根据该工具的实际应用场景:Excel 数据只在『导入』和『过滤后』两个阶段需要展示,而且展示的是通过 JavaScript 拼接的 HTML 字符串所构成的 DOM 而已。因此将表格数据放置在 Vuex 中,有点滥用资源的嫌疑。
另外,在 background process 中也有存有一份 Excel 数据副本。因此,索性只在 background process 存储一份 Excel 数据,然后每当数据变化时,通过 IPC 让 background process 返回拼接好的 HTML 字符串即可。这样一来,内存占有量立刻下降许多。另外,这也是一个一举多得的优化:
background process,页面渲染进程进一步减少耗时的操作;其实,这也有点像 Vuex 的『全局单例模式管理』,一份数据就好。
当然,对于 Excel 的基本信息,如行列数、SheetName、标题组等均依然保存在 Vuex。
优化后的内存占有量如下图。与上述报告的第三张图相比(同一阶段),内存占有量下降了 44.419%:
另外,对于不需要响应的数据,可通过 Object.freeze() 冻结起来。这也是一种优化手段。但该工具目前并没有应用到。
至此,优化部分也阐述完毕了!
该工具目前是开源的,欢迎大家使用或推荐给用研组等有需要的人。
你们的反馈(可提交 issues / pull request)能让这个工具在使用和功能上不断完善。
最后,感谢 LV 在产品规划、界面设计和优化上的强力支持。全文完!
原文:Debouncing and Throttling Explained Through Examples
Debounce 和 Throttle 两者很类似(但不同!),均用于控制函数在一定时间范围内的执行频率。
将 debounce 或 throttle 后的函数用于 DOM 事件绑定是非常有用的。为什么?因为这让我们在事件和函数调用之间拥有了控制权。毕竟我们不能控制 DOM 事件的触发频率,却可以控制回调函数的执行频率。
例如,以下是 scroll 事件:
See the Pen Scroll events counter by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>当通过触摸板、鼠标滚轮或拖拽滚动条时,事件在 1 秒内的触发次数能轻松达到 30 次。智能手机就更甚了,在我们的测试中,缓慢滚动也能在 1 秒内触发事件次数到 100 次。而你的滚动回调函数是否已对此执行频率做好准备呢?
在 2011 年,Twitter 网站出现了一个问题:当往下滚动信息流时,网站的响应速度会变慢,甚至是拒绝响应。John Resig 写了一篇 关于该问题的文章,其阐述了直接为 scroll 事件绑定耗时函数的严重性。
John 的建议(五年前)是:onScroll 事件的回调函数应该每 250ms 执行一次。这样回调函数就不会直接耦合到事件。使用这种简单的技术就可以避免破坏用户体验。
如今,处理事件的方式需要变得更复杂一些。接下来,我会结合案例向大家介绍 Debounce、Throttle 和 requestAnimationFrame。
Debounce 技术让多次序列调用“结合”为一次。
假如你在电梯里,门开始关闭,突然有人想进来。此时,电梯不会开始执行改变楼层的功能,门再次打开。当再有另一个进来则会重复这个步骤。尽管电梯延迟了上下移动的行为,但却优化了电梯资源。
亲自尝试一下吧,点击或在按钮上移动:
See the Pen Debounce. Trailing by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>你可以看到快速连续触发的事件是如何结合为一个的 debounce 事件呈现。但如果事件的触发间隔较大,则呈现不出 debounce 的效果。
提前(或称为立刻)执行 debounce 的案例
在 underscore.js,该选项叫 immediate 而不是 leading
亲自尝试一下:
See the Pen Debounce. Leading by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>我第一次看到 debounce 的 JavaScript 实现是在 2009 年的 John Hann 文章(他也是该术语的创造者)。
不久之后,Ben Alman 开发了一个 jQuery 插件(不再维护)。一年后,Jeremy Ashkenas 将 其添加到了 underscore.js。而 underscore 的替代方案 Lodash 也随后添加。
这 3 种实现均有一些不同,但接口几乎一致。
有一段时间,underscore 采用了 Lodash 的 debounce/throttle 的实现,但随后我在 2013 年发现了 _.debounce 的一个 Bug。从那时起,两者就分开各自实现了。
Lodash 为 _.debounce 和 _.throttle 函数 添加了更多特性。原来的 immediate 标识被替换成 leading 和 trailing 可选项。该两个选项可开启一项或同时开启。默认情况下,仅 trailing 开启。
新可选项 maxWait(当时仅 Lodash 支持)并未在本文涵盖,但它十分有用。实际上,throttle 函数是通过 _.debounce 和 maxWait 实现的,详情可查看 Lodash 源码。
当拖拽改变浏览器窗口尺寸时,会触发非常多次 resize 事件。
如以下案例:
See the Pen Debounce Resize Event Example by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>如你所见,我们为 resize 事件使用了默认的 trailing 选项。毕竟,我们只对最后的值感兴趣(用户停止调整浏览器尺寸)。
有什么理由在用户仍在输入时每隔 50ms 发起 Ajax 请求呢?_.debounce 能帮助我们避免额外的操作,仅在用户停止输入时发起请求。
对于这个案例,leading 标识是没意义的,毕竟我们只想等到输入的最后一个字母结束。
See the Pen Debouncing keystrokes Example by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>类似的案例是等到用户停止键入时进行校验,然后弹出诸如“您的密码太短”的消息提示。
编写属于自己的 debounce/throttle 函数看似很诱人,或者随便从博客文章中复制使用。而我个人的推荐是直接使用 underscore 或 Lodash。如果你仅需要 _.debounce 和 _.throttle 函数,那么可以使用 Lodash 的自定义构建方式生成 2KB 的库。通过以下简单的命令行构建:
npm i -g lodash-cli
lodash include = debounce, throttle结合 webpack/browserify/rollup 构建工具,引入相应模块: loadsh/throttle 和 lodash/debounce 或者 lodash.throttle 和 lodash.debounce。
一个常见的陷阱是多次调用 _.debounce 函数:
// WRONG
$(window).on('scroll', function() {
_.debounce(doSomething, 300);
});
// RIGHT
$(window).on('scroll', _.debounce(doSomething, 200));将 debounce 后的函数赋值到一个变量,即可在需要的时候调用私有方法 debounced_version.cancel()。这适用于 lodash 和 underscore.js。
var debounced_version = _.debounce(doSomething, 200);
$(window).on('scroll', debounced_version);
// 需要的时候
debounced_version.cancel();通过使用 _.throttle,我们可以避免函数的执行频率过高(即每 X 秒大于一次)。
这与 debounce 的最大区别是:throttle 能保证函数能定期执行。即 X 毫秒内至少一次,而对于 debounce,只要一直保持高频繁触发事件,那么回调函数就一直不会被执行。
与 debounce 相同的是,throttle 技术均在 Ben 的插件、underscore.js 和 lodash 上提供。
这是一个十分常见的案例。用户在可无限滚动的页面中往下滚动时,你需要检测用户当前距离底部的距离。如果接近底部,那么就应该通过 Ajax 请求更多的内容,并将内容插入到页面中。
对于这种情况,_.debounce 并不能帮上忙,这是因为它只能等到用户停止滚动时才能调用回调函数。而我们这里需要在用户到达底部前就开始获取内容了。
通过 _.throttle,我们能保证不间断地检查用户到底部的距离。
See the Pen Infinite scrolling throttled by Corbacho (@dcorb) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>requestAnimationFrame 是另一种限制函数执行频率的方式。
它可以被看作为 _.throttle(dosomething, 16)。但其拥有更高的精确性,毕竟它是旨在提供更高精度的浏览器原生 API。
综合其优缺点,我们可以使用 rAF API 作为 throttle 的替代方案:
.debounce 或 .throttle 不同的是,我们只能对 rAF 发出 启动/取消的指令,但其终归浏览器内部管理。根据经验,如果 JavaScript 函数是用于“绘制”或直接过渡动画属性,那么就用 requestAnimationFrame。总之,在涉及重新计算元素位置的时候就该使用它。
对于 Ajax 请求或决定是否添加/删除类名(用于触发 CSS 动画)时,我会偏向于 _.debounce 或 _.throttle,毕竟能设置更低的执行频率(比如 200ms,而不是 16ms)。
你可能会想到:rAF 应该集成到 underscore 或 lodash 中,但他们均拒绝了这个想法。毕竟它更多是作为一个特定案例,并且很容易被直接调用。
我仅讨论以下这个案例:在滚动时使用 requestAnimationframe。这个案例的灵感来自 Paul Lewis 的文章,这篇文章细致地解释了这个案例的逻辑。
我将 rAF 与 16ms 的 _.throttle 并排比较。尽管性能看似相近,但 rAF 能在更复杂的场景中为你提供更佳的性能。
我见过使用该技术的一个更高级的例子是:headroom.js 库。它的实现 逻辑被解耦 包装在一个对象中。
使用 debounce、throttle 和 requestAnimationFrame 能优化事件回调函数。尽管三种技术略有不同,但它们都十分有用并相互补充。
总的来说:
难得一见的好书,无论深度还是文笔。本文几乎原样摘抄书本上个人认为相对重要的段落,方便日后回顾。
Chrome 浏览器和 Node 的组件构成
除了 HTML、WebKit 和显卡这些 UI 相关技术没有支持外,Node 的结构与 Chrome 十分相似。它们都是基于事件驱动的异步架构,浏览器通过事件驱动来服务界面上的交互,Node 通过事件驱动来服务 I/O。
异步 I/O
经典的异步调用
在 Node 中,绝大多数的操作都以异步的方式进行调用。Ryan Dahl 排除万难,在底层构建了很多异步 I/O 的 API,从文件读取到网络请求等,均是如此。这样的意义在于,在 Node 中,我们可以从语言层面很自然地进行并行 I/O 操作。每个调用之间无须等待之前的 I/O 调用结束。在编程模型上可以极大提升效率。
事件与回调函数
单线程
Node 保持了 JavaScript 在浏览器总单线程的特点。而且在 Node 中,JavaScript 与其余线程是无法共享任何状态的。
单线程的好处:
单线程的弱点:
像浏览器中 JavaScript 与 UI 共用一个线程一样,JavaScript 长时间执行会导致 UI 的渲染和响应被中断。在 Node 中,长时间的 CPU 占用也会导致后续的异步 I/O 发不出调用,已完成的异步 I/O 的回调函数也会得不到及时执行。
HTML5 的 Web Workers 能够创建工作线程来进行计算,以解决 JavaScript 大计算阻塞 UI 渲染的问题。工作线程为了不阻塞主线程,通过消息传递的方式来传递运行结果,这也使得工作线程不能访问到主线程中的 UI。
Node 采用了与 Web Workers 相同的思路来解决单线程中大计算量的问题:child_process。
子进程的出现,意味着 Node 可以从容地应对单线程在健壮性和无法利用多核 CPU 方面的问题。通过将计算分发到各个子进程,可以将大量计算分解掉,然后再通过进程之间的事件消息来传递结果,这可以很好地保持应用模型的简单和低依赖。通过 Master-Worker 的管理方式,也可以很好地管理各个工作进程,以达到更高的健壮性。
跨平台
基于 libuv 实现跨平台的架构示意图
兼容 Windows 和 *nix 平台主要得益于 Node 在架构层面的改动,它在操作系统与 Node 上层模块系统之间构建了一层平台架构,即 libuv。
关于 Node,探讨得较多的主要有 I/O 密集型和 CPU 密集型。
I/O 密集型
Node 面向网络且擅长并行 I/O,能够有效地组织起更多的硬件资源,从而提供更多好的服务。
I/O 密集的优势主要在于 Node 利用事件循环的处理能力,而不是启动每一个线程为每一个请求服务,资源占用极少。
是否不擅长 CPU 密集型业务
Node 是足够高效的,它优秀的运算能力主要来自 V8 的深度性能优化。
CPU 密集型应用给 Node 带来的挑战主要是:由于 JavaScript 单线程的原因,如果有长时间运行的计算(比如大循环),将会导致 CPU 时间片不能释放,使得后续 I/O 无法发起。但是适当调整和分解大型运算任务为多个小任务,使得运算能够适时释放,不阻塞 I/O 调用的发起,这样既可同时享受到并行异步 I/O 的好处,又能充分利用 CPU。
关于 CPU 密集型应用,Node 的异步 I/O 已经解决了在单线程上 CPU 与 I/O 之间阻塞无法重叠利用的问题,I/O 阻塞造成的性能浪费远比 CPU 的影响小。对于长时间运行的计算,如果它的耗时超过普通阻塞 I/O 的耗时,那么应用场景就需要重新评估,因为这类计算比阻塞 I/O 还影响效率,甚至说就是一个纯计算的场景,根本没有 I/O。此类应用场景或许采用多线程的方式进行计算。Node 虽然没有提供多线程用于计算支持,但是还是有以下两个方式来充分利用 CPU。
CPU 密集不可怕,如何合理调度是诀窍。
社区提出的 CommonJS 规范涵盖了模块、二进制、Buffer、字符集编码、I/O 流、进程环境、文件系统、套接字、单元测试、Web 服务器网关接口、包管理等。
理论和实践总是相互影响和促进的,Node 能以一种比较成熟的姿态出现,离不开 CommonJS 规范的影响。在服务器端,CommonJS 能以一种寻常的姿态写进各个公司的项目代码中,离不开 Node 优异的表现。实现的优良表现离不开规范最初优秀的设计,规范因实现的推广而得以普及。
Node 与浏览器以及 W3C 组织、CommonJS 组织、ECMAScript 之间的关系
CommonJS 对模块的定义十分简单,主要分为模块引用、模块定义和模块标识 3 个部分。
模块引用
模块引用的示例代码如下:
var math = require('math');在 CommonJS 规范中,存在 require() 方法,这个方法接受模块标识,以此引入一个模块的 API 到当前上下文中。
模块定义
在模块中,上下文提供 require() 方法来引入外部模块。对应引入的功能,上下文提供了 exports 对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个 module 对象,它代表模块自身,而 exports 是 module 的属性。在 Node 中,一个文件就是一个模块,将方法挂载在 exports 对象上作为属性即可定义导出的方式:
// math.js
exports.add = function () {
var sum = 0,
i = 0,
args = arguments,
l = args.length;
while (i < l) {
sum += args[i++];
}
return sum;
}在另一个文件中,我们通过 require() 方法引入模块后,就能调用定义的属性或方法了:
// program.js
var math = require('math');
exports.increment = function (val) {
return math.add(val, 1);
}模块标识
模块标识其实就是传递给 require() 方法的参数,它必须是符合小驼峰命名的字符串,或者以 .、.. 开头的相对路径,或者绝对路径。它可以没有文件名后缀 .js。
模块的定义十分简单,接口也十分简洁。它的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。如下图所示,每个模块具有独立的空间,它们互不干扰,在引用时也显得干净利落。
模块定义
CommonJS 构建的这套模块导出和导入机制使得用户完全不必考虑变量污染,命名空间等方案与之相比相形见绌。
Node 在实现中并非完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。
在 Node 中引入模块,需要经历如下 3 个步骤。
在 Node 中,模块分为两类:
Node 对引入过的模块都会进行缓存,以减少二次引入时的开销。与浏览器仅仅缓存文件相比,Node 缓存的是编译和执行之后的对象。
不论是核心模块还是文件模块,require() 方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。不同之处在于核心模块的缓存检查先于文件模块的缓存检查。
因为标识符有几种形式,对于不同的标识符,模块的查找和定位有不同程度上的差异。
模块标识符分析
模块标识符在 Node 中主要分为以下几类。
. 或 .. 开始的相对路径文件模块。/ 开始的绝对路径文件模块。connect 模块。核心模块
核心模块的优先级仅次于缓存加载,它在 Node 的源代码编译过程中已经编译为二进制代码,其加载过程最快。
如果试图加载一个与核心模块标识符相同的自定义模块,那是不会成功的。如果自己编写了一个 http 模块,想要加载成功,必须选择一个不同的标识符或者换用路径的方式。
路径形式的文件模块
以 .、..和 / 开始的标识符,这里都被当做文件模块来处理。在分析路径模块时,require() 方法会将路径转为真实路径,并以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。
由于文件模块给 Node 指明了确切的文件路径,所以在查找过程中可以节约大量时间,其加载速度慢于核心模块。
自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式。这类模块的查找是最费时的,也是所有方式中最慢的一种。
模块路径是 Node 在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组。关于这个路径的生称规则,我们可以手动尝试一番。
console.log(module.paths);。node module_path.js。在 Linux 下,你可能得到的是这样一个数组输出:
[ '/home/jackson/research/node_modules',
'/home/jackson/node_modules',
'/home/node_modules',
'/node_modules' ]而在 Windows 下,也许是这样:
[ 'c:\\nodejs\\node_modules', 'c:\\node_modules' ]可以看出,模块路径的生成规则如下所示。
在加载的过程中,Node 会逐个尝试模块路径中的路径,直到找到目标文件为止。可以看到,当前文件的路径越深,模块查找耗时会越多,这是自定义模块的加载速度是最慢的原因。
文件定位
从缓存加载的优化策略使得二次引入时不需要路径分析、文件定位和编译执行的过程,大大提高了再次加载模块时的效率。
但在文件的定位过程中,还有一些细节需要注意,这主要包括文件扩展名的分析、目录和包的处理。
文件扩展名分析
require() 在分析标识符的过程中,会出现标识符中不包含文件扩展名的情况。CommonJS 模块规范也允许在标识符中不包含文件扩展名,这种情况下,Node 会按 .js、.json、.node 的次序补足扩展名,依次尝试。
在尝试的过程中,需要调用 fs 模块同步阻塞式地判断文件是否存在。因为 Node 是单线程的,所以这里是一个会引起性能问题的地方。小诀窍是:如果是 .node 和 .json 文件,在传递给 require() 的标识符中带上扩展名,会加快一点速度。另一个诀窍是:同步配合缓存,可以大幅度缓解 Node 单线程中阻塞式调用的缺陷。
目录分析和包
在分析标识符的过程中,require() 通过分析文件扩展名之后,可能没有查到对应文件,但却得到一个目录,这在引入自定义模块和逐个模块路径进行查找时经常会出现,此时 Node 会将目录当作一个包来处理。
在这个过程中,Node 对 CommonJS 包规范进行了一定程度的支持。首先,Node 在当前目录下查找 package.json(CommonJS 包规范定义的包描述文件),通过 JSON.parse() 解析包描述对象,从中取出 main 属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。
而如果 main 属性指定的文件名错误,或者压根没有 package.json 文件,Node 会将 index 当作默认文件名,然后依次查找 index.js、index.json、index.node。
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完毕,依然没有查找到目标文件,则会抛出查找失败的异常。
模块编译
在 Node 中,每个文件模块都是一个对象,它的定义如下:
function Module (id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node 会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同,具体如下所示。
每一个编译成功的模块都会将其文件路径作为索引缓存在 Module._cache 对象上,以提高二次引入的性能。
根据不同的文件扩展名,Node 会调用不同的读取方法,如 .json 文件的调用如下:
// Native extension for .json
Module._extensions['.json'] = function (module, filename) {
var content = NativeModule.require('fs').readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};其中,Module._extensions 会被赋值给 require() 的 extensions 属性,所以通过在代码中访问 require.extensions 可以知道系统中已有的扩展加载方式。编写如下代码测试一下:
console.log(require.extensions);得到的执行结果如下:
{ '.js': [Function], '.json': [Function], '.node': [Function] } 如果想对自定义的扩展名进行特殊的加载,可以通过类似 require.extensions['.ext'] 的方式实现。
在确定文件的扩展名之后,Node 将调用具体的编译方式来将文件执行后返回给调用者。
JavaScript 模块的编译
回到 CommonJS 模块规范,我们知道每个模块文件中存在着 require、exports、module 这 3 个变量,但是它们在模块文件中没有定义,那么从何而来呢?甚至在 Node 的 API 文档中,我们知道每个模块中还有 __filename、__dirname 这两个变量的存在,它们又是从何而来的呢?如果我们把直接定义模块的过程放诸在浏览器端,会存在污染全局变量的情况。
事实上,在编译的过程中,Node 对获取的 JavaScript 文件内容进行了头尾包装。在头部添加了 (function (exports, require, module, __filename, __dirname) {\n,在尾部添加了 \n})。一个正常的 JavaScript 文件会被包装成如下的样子:
(function (exports, require, module, __filename, __dirname) {
var math = require('math');
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过 vm 原生模块的 runInThisContext() 方法执行(类似 eval,只是具有明确上下文,不污染全局),返回一个具体的 function 对象。最后,将当前模块对象的 exports 属性、require() 方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个 function() 执行。
这就是这些变量并没有定义在每个模块文件中却存在的原因。在执行之后,模块的 exports 属性被返回给了调用方。exports 属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。
至此,require、exports、module 的流程已经完整,这就是 Node 对 CommonJS 模块规范的实现。
此外,许多初学者都曾经纠结过为何存在 exports 的情况下,还存在 module.exports。理想情况下,只要赋值给 exports 即可:
exports = function () {
// My Class
};但是通过会得到一个失败的结果。其原因在于,exports 对象是通过形参的方式传入的,直接赋值形参会改变形参的引用,但并不能改变作用域外的值。测试代码如下:
var change = function (a) {
a = { a: 2 };
console.log(a); // => {a: 2}
}
var a = { a: 1 };
change(a);
console.log(a); // => {a: 1}如果要达到 require 引入一个类的效果,请赋值给 module.exports 对象。这个迂回的方案不改变形参的引用。
C/C++ 模块的编译
Node 调用 process.dlopen() 方法进行加载和执行。在 Node 的架构下,dlopen() 方法在 Windows 和 *nix 平台下分别有不同的实现,通过 libuv 兼容层进行了封装。
实际上,.node 的模块文件并不需要编译,因为它是编写 C/C++ 模块之后编译生成的,所以这里只有加载和执行的过程。在执行的过程中,模块的 exports 对象与 .node 模块产生联系,然后返回给调用者。
C/C++ 模块给 Node 使用者带来的优势主要是执行效率方面的,劣势则是 C/C++ 模块的编写门槛比 JavaScript 高。
JSON 文件的编译
.json 文件的编译是 3 种编译方式中最简单的。Node 利用 fs 模块同步读取 JSON 文件的内容之后,调用 JSON.parse() 方法得到对象,然后将它赋给模块对象的 exports,以供外部调用。
JSON 文件在用作项目的配置文件时比较有用。如果你定义了一个 JSON 文件作为配置,那就不必调用 fs 模块去异步读取和解析,直接调用 require() 引入即可。此外,还可以享受到模块缓存的便利,并且二次引入时也没有性能影响。
这里我们提到的模块编译都是指文件模块,即用户自己编写的模块。
Node 的核心模块在编译成可执行文件的过程中被编译进了二进制文件。核心模块其实分为 C/C++ 编写的和 JavaScript 编写的两部分,其中 C/C++ 文件存放在 Node 项目的 src 目录下,JavaScript 文件存放在 lib 目录下。
在编译所有 C/C++ 文件之前,编译程序需要将所有的 JavaScript 模块文件编译为 C/C++ 代码,此时是否直接将其编译为可执行代码了呢?其实不是。
转存为 C/C++ 代码
Node 采用了 V8 附带的 js2c.py 工具,将所有内置的 JavaScript 代码(src/node.js 和 lib/*.js)转换成 C++ 里的数组,生成 node_natives.h 头文件,相关代码如下:
namespace node {
const char node_native[] = { 47, 47, ..};
const char dgram_native[] = { 47, 47, ..};
const char console_native[] = { 47, 47, ..};
const char buffer_native[] = { 47, 47, ..};
const char querystring_native[] = { 47, 47, ..};
const char punycode_native[] = { 47, 42, ..};
...
struct _native {
const char* name;
const char* source;
size_t source_len;
};
static const struct _native natives[] = {
{ "node", node_native, sizeof(node_native)-1 },
{ "dgram", dgram_native, sizeof(dgram_native)-1 },
...
};
} 在这个过程中,JavaScript 代码以字符串的形式存储在 node 命名空间中,是不可直接执行的。在启动 Node 进程时,JavaScript 代码直接加载进内存中。在加载的过程中,JavaScript 核心模块经历标识符分析后直接定位到内存中,比普通的文件模块从磁盘中一处一处查找要快很多。
编译 JavaScript 核心模块
lib 目录下的所有模块文件也没有定义 require、module、exports 这些变量。在引入 JavaScript 核心模块的过程中,也经历了头尾包装的过程,然后才执行和导出了 exports 对象。与文件模块有区别的地方在于:获取源代码的方式(核心模块是从内存中加载的)以及缓存执行结果的位置。
JavaScript 核心模块的定义如下面的代码所示,源文件通过 process.binding('natives') 取出,编译成功的模块缓存到 NativeModule._cache 对象上,文件模块则缓存到 Module._cache 对象上:
function NativeModule(id) {
this.filename = id + '.js';
this.id = id;
this.exports = {};
this.loaded = false;
}
NativeModule._source = process.binding('natives');
NativeModule._cache = {}; 在核心模块中,有些模块全部由 C/C++ 编写,有些模块则由 C/C++ 完成核心部分,其他部分则由 JavaScript 实现包装或向外导出,以满足性能需求。后者这种 C++ 模块主内完成核心,JavaScript 主外实现封装的模块是 Node 能够提高性能的常见方式。通常,脚本语言的开发速度优于静态语言,但是其性能则弱于静态语言。而 Node 的这种复合模块可以在开发速度和性能之间找到平衡点。
这里我们将那些由纯 C/C++ 编写的部分统一称为内建模块,因为它们通常不被用户直接调用。Node 的 buffer、crypto、evals、fs、os 等模块都是部分通过 C/C++ 编写的。
在 Node 的所有模块类型中,存在如下图所示的一种依赖层级关系,即文件模块可能会依赖核心模块,核心模块可能会依赖内建模块。
依赖层级关系
通常,不推荐文件模块直接调用内建模块。如需调用,直接调用核心模块即可,因为核心模块中基本都封装了内建模块。
如下图所示的 os 原生模块的引入流程可以看到,为了符合 CommonJS 模块规范,从 JavaScript 到 C/C++ 的过程是相当复杂的,它要经历 C/C++ 层面的内建模块定义、(JavaScript)核心模块的定义和引入以及(JavaScript)文件模块层面的引入。但是对于用户而言,require() 十分简洁、友好。
os 原生模块的引入流程
JavaScript 的一个典型弱点就是位运算。JavaScript 的位运算参照 Java 的位运算实现,但是 Java 位运算是在 int 型数字的基础上进行的,而 JavaScript 中只有 double 型的数据类型,在进行位运算的过程中,需要将 double 类型转为 int 型,然后再进行。所以在 JavaScript 层面上做位运算的效率不高。
在应用中,会频繁出现位运算的需求,包括转码、编码等过程,如果通过 JavaScript 来实现,CPU 资源将会耗费很多,这时编写 C/C++ 扩展模块来提升性能的机会来了。
C/C++ 扩展模块属于文件模块中的一类。
C/C++ 扩展模块与 JavaScript 模块的区別在于加载之后不需要编译,直接执行之后就可以被外部调用了,其加载速度比 JavaScript 模块略快。
使用 C/C++ 扩展模块的一个好处在于可以更灵活和动态地加载它们,保持 Node 模块自身简单性的同时,给予 Node 无限的可扩展性。
C/C++ 内建模块属于最底层的模块,它属于核心模块,主要提供 API 给 JavaScript 核心模块和第三方 JavaScript 文件模块调用。
JavaScript 核心模块主要扮演的职责有两类:
模块之间的调用关系
Node 对模块规范的实现,一定程度上解决了变量依赖、依赖关系等代码组织性问题。包的出现,则是在模块的基础上进一步组织 JavaScript 代码。下图为包组织模块示意图。
包组织模块示意图
CommonJS 的包规范的定义其实十分简单,它由包结构和包描述文件两个部分组成,前者组织包中的各种文件,后者则用于描述包的相关信息,以供外部读取分析。
AMD 规范是 CommonJS 模块规范的一个延伸,它的模块定义如下:
define(id?, dependencies?, factory); 它的模块 id 和依赖是可选的,与 Node 模块相似的地方在于 factory 的内容就是实际代码的内容。下面的代码定义了一个简单的模块:
define(function() {
var exports = {};
exports.sayHello = function() {
alert('Hello from module: ' + module.id);
};
return exports;
}); 不同之处在于 AMD 模块需要用 define 来明确定义一个模块,而 Node 实现中是隐式包装的。另一个区别则是内容需要通过返回的方式实现导出。
与 AMD 规范的主要区别在于定义模块和依赖引入的部分。AMD 需要在声明模块时指定所有的依赖,通过形参传递依赖到模块内容中:
define(['dep1', 'dep2'], function (dep1, dep2) {
return function () {};
}); 与 AMD 模块规范相比,CMD 模块更接近于 Node 对 CommonJS 规范的定义:
define(factory);在依赖部分,CMD 支持动态引入,示例如下:
define(function(require, exports, module) {
// The module code goes here
}); require、exports 和 module 通过形参传递给模块,在需要依赖模块时,随时调用 require() 引入即可。
为了保持前后端的一致性,类库开发者需要将类库代码包装在一个闭包内。以下代码演示如何将 hello() 方法定义到不同的运行环境中,它能够兼容 Node、AMD、CMD 以及常见的浏览器环境中:
;(function (name, definition) {
// 检测上下文环境是否为 AMD 或 CMD
var hasDefine = typeof define === 'function',
// 检查上下文环境是否为 Node
hasExports = typeof module !== 'undefined' && module.exports;
if (hasDefine) {
// AMD 环境 或 CMD 环境
define(definition);
} else if (hasExports) {
// 定义为普通 Node 模块
module.exports = definition();
} else {
// 将模块的执行结果挂在 window 变量中,在浏览器中 this 指向 window 对象
this[name] = definition();
}
})('hello', function () {
var hello = function () {};
return hello;
});
不同的 I/O 类型及其对应的开销
I/O 是昂贵的,分布式 I/O 是更昂贵的。
Node 利用单线程,远离多线程死锁、状态同步等问题;利用异步 I/O,让单线程远离阻塞,以更好地使用 CPU。
为弥补单线程无法利用多核 CPU 的缺点,Node 提供了子进程,该子进程可以通过工作进程高效地利用 CPU 和 I/O。
从计算机内核 I/O 而言,异步/同步和阻塞/非阻塞实际上是两回事。
操作系统内核对于 I/O 只有两种方式:阻塞与非阻塞。
阻塞 I/O 的一个特点是调用之后一定要等到系统内核层面完成所有操作后,调用才结束。以读取硬盘上的一段文件为例,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才结束。
调用阻塞 I/O 的过程
阻塞 I/O 造成 CPU 等待 I/O,浪费等待时间,CPU 的处理能力不能得到充分利用。为了提高性能,内核提供了非阻塞 I/O。非阻塞 I/O 跟阻塞 I/O 的差别为调用之后会立即返回。
操作系统对计算机进行了抽象,将所有输入输出设备抽象为文件。内核在进行文件 I/O 操作时,通过文件描述符进行管理,而文件描述符类似于应用程序与系统内核之间的凭证。应用程序如果需要进行 I/O 调用,需要先打开文件描述符,然后再根据文件描述符去实现文件的数据读写。此处非阻塞 I/O 与阻塞 I/O 的区别在于阻塞 I/O 完成整个获取数据的过程,而非阻塞 I/O 则不带数据直接返回,要获取数据,还需要通过文件描述符再次读取。
调用非阻塞 I/O 的过程
非阻塞 I/O 返回之后,CPU 的时间片可以用来处理其他事务,此时的性能提升是明显的。
但非阻塞 I/O 也存在一些问题。由于完整的 I/O 并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。为了获取完整的数据,应用程序需要重复调用 I/O 操作来确认是否完成。这种重复调用判断操作是否完成的技术叫轮询。
阻塞 I/O 造成 CPU 等待浪费,非阻塞带来的麻烦却是需要轮询去确认是否完全完成数据获取,它会让 CPU 处理状态判断,是对 CPU 资源的浪费。这里我们且看轮询技术是如何演进的,以减少 I/O 状态判断的 CPU 损耗。
现存的轮询技术主要有以下这些。
通过 read 进行轮询的示意图
通过 select 进行轮询的示意图
select 轮询具有一个较弱的限制,那就是由于它采用一个 1024 长度的数组来存储状态,所以它最多可以同时检查 1024 个文件描述符。
通过 poll 实现轮询的示意图
通过 epoll 方式实现轮询的示意图
轮询技术满足了非阻塞 I/O 确保获取完整数据的需求,但是对于应用程序而言,它仍然只能算是一种同步,因为应用程序仍然需要等待 I/O 完全返回,依旧花费了很多时间来等待。等待期间,CPU 要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。结论是它不够好。
尽管 epoll 已经利用了事件来降低 CPU 的耗用,但是休眠期间 CPU 几乎是闲置的,对于当前线程而言利用率不够。
我们期望的完美的异步 I/O 应该是应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在 I/O 完成后通过信号或回调将数据传递给应用程序即可。下图为理想中的异步 I/O 示意图。
理想中的异步 I/O 示意图
幸运的是,在 Linux 下存在这样一种方式,它原生提供的一种异步 I/O 方式(AIO)就是通过信号或回调来传递数据的。但不幸的是,只有 Linux 下有,而且它还有缺陷——AIO 仅支持内核 I/O 中的 0_DIRECT 方式读取,导致无法利用系统缓存。
现实比理想要骨感一些,但是要达成异步 I/O 的目标,并非难事。前面我们将场景限定在了单线程的状况下,多线程的方式会是另一番风景。通过让部分线程进行阻塞 I/O 或者非阻塞 I/O 加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将 I/O 得到的数据进行传递,这就轻松实现了异步 I/O(尽管它是模拟的),如下图所示。
异步 I/O
glibc 的 AIO 便是典型的线程池模拟异步 I/O。然而遗憾的是,它存在一些难以忍受的缺陷和 bug,不推荐采用。libev 的作者 Marc Alexander Lehmann 重新实现了一个异步 I/O 的库: libeio。libeio 实质上依然是采用线程池与阻塞 I/O 模拟异步 I/O。最初,Node 在 *nix 平台下采用了 libeio 配合 libev
实现 I/O 部分,实现了异步 I/O。在 Node v0.9.3 中,自行实现了线程池来完成异步 I/O。
另一种我迟迟没有透露的异步 I/O 方案则是 Windows 下的 IOCP,它在某种程度上提供了理想的异步 I/O:调用异步方法,等待 I/O 完成之后的通知,执行回调,用户无须考虑轮询。但是它的内部其实仍然是线程池原理,不同之处在于这些线程池由系统内核接手管理。
IOCP 的异步 I/O 模型与 Node 的异步调用模型十分近似。在 Windows 平台下采用了 IOCP 实现异步 I/O。
由于 Windows 平台和 *nix 平台的差异,Node 提供了 libuv 作为抽象封装层,使得所有平台兼容性的判断都由这一层来完成,并保证上层的 Node 与下层的自定义线程池及 IOCP 之间各自独立。Node 在编译期间会判断平台条件,选择性编译 unix 目录或是 win 目录下的源文件到目标程序中,其架构如下图所示。
基于 libuv 的构架示意图
需要强调一点的是,这里的 *I/O 不仅仅只限于磁盘文件的读写。nix 将计算机抽象了一番,磁盘文件、硬件、套接字等几乎所有计算机资源都被抽象为了文件,因此这里描述的阻塞和非阻塞的情况同样能适用于套接字等。
另一个需要强调的地方在于我们时常提到 *Node 是单线程的,这里的单线程仅仅只是 JavaScript 执行在单线程中罢了。在 Node 中,无论是 nix 还是 Windows 平台,内部完成 I/O 任务的另有线程池。
介绍完系统对异步 I/O 的支持后,我们将继续介绍 Node 是如何实现异步 I/O 的。这里我们除了介绍异步 I/O 的实现外,还将讨论 Node 的执行模型。完成整个异步 I/O 环节的有事件循环、观察者和请求对象等。
首先,我们着重强调一下 Node 自身的执行模型——事件循环,正是它使得回调函数十分普遍。
在进程启动时,Node 便会创建一个类似于 while(true) 的循环,每执行一次循环体的过程我们称为 Tick。每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。流程图如下图所示。
Tick 流程图
在每个 Tick 的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。
每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
浏览器采用了类似的机制。事件可能来自用户的点击或者加载某些文件时产生,而这些产生的事件都有对应的观察者。在 Node 中,事件主要来源于网络请求、文件 I/O 等,这些事件对应的观察者有文件 I/O 观察者、网络 I/O 观察者等。观察者将事件进行了分类。
事件循环是一个典型的生产者/消费者模型。异步 I/O、网络请求等则是事件的生产者,源源不断为 Node 提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
在 Windows 下,这个循环基于 IOCP 创建,而在 *nix 下则基于多线程创建。
在这一节中,我们将通过解释 Windows 下异步 I/O(利用 IOCP 实现)的简单例子来探寻从 JavaScript 代码到系统内核之间都发生了什么。
对于一般的(非异步)回调函数,函数由我们自行调用,如下所示:
var forEach = function (list, callback) {
for (var i = 0; i < list.length; i++) {
callback(list[i], i, list);
}
};对于 Node 中的异步 I/O 调用而言,回调函数却不由开发者来调用。那么从我们发出调用后,到回调函数被执行,中间发生了什么呢?事实上,从 JavaScript 发起调用到内核执行完 I/O 操作的过渡过程中,存在一种中间产物,它叫做请求对象。
下面我们以最简单的 fs.open() 方法来作为例子,探素 Node 与底层之间是如何执行异步 I/O 调用以及回调函数究竟是如何被调用执行的:
fs.open = function(path, flags, mode, callback) {
// ...
binding.open(pathModule._makeLong(path),
stringToFlags(flags),
mode,
callback);
};fs.open() 的作用是根据指定路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有 I/O 操作的初始操作。从前面的代码中可以看到,JavaScript 层面的代码通过调用 C++ 核心模块进行下层的操作。下图为调用示意图。
调用示意图
从 JavaScript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用,这是 Node 里经典的调用方式。这里 libuv 作为封装层,有两个平台的实现,实质上是调用了 uv_fs_open() 方法。在 uv_fs_open() 的调用过程中,我们创建了一个 FSReqWrap 请求对象。从 JavaScript 层传入的参数和当前方法都被封装在这个请求对象中,其中我们最为关注的回调函数则被设置在这个对象的 uncomplete_sym 属性上:
req_wrap->object_->Set(oncomplete_sym, callback);对象包装完毕后,在 Windows 下,则调用 QueueUserWorkItem() 方法将这个 FSReqWrap 对象推入线程池中等待执行,该方法的代码如下所示:
QueueUserWorkItem(&uv_fs_thread_proc, \
req, \
WT_EXECUTEDEFAULT) QueueUserWorkItem() 方法接受 3 个参数:第一个参数是将要执行的方法的引用,这里引用的是 uv_fs_thread_proc,第二个参数是 uv_fs_thread_proc 方法运行时所需要的参数;第三个参数是执行的标志。当线程池中有可用线程时,我们会调用 uv_fs_thread_proc() 方法。uv_fs_thread_proc() 方法会根据传入参数的类型调用相应的底层函数。以 uv_fs_open() 为例,实际上调用 fs_open() 方法。
至此,JavaScript 调用立即这回,由 JavaScript 层面发起的异步调用的第一阶段就此结束。JavaScript 线程可以继续执行当前任务的后续操作。当前的 I/O 操作在线程池中等待执行,不管它是否阻塞 I/O,都不会影响到 JavaScript 线程的后续执行,如此就达到了异步的目的。
请求对象是异步 I/O 过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及 I/O 操作完毕后的回调处理。
组装好请求对象、送入 I/O 线程池等待执行,实际上完成了异步 I/O 的第一部分,回调通知是第二部分。
线程池中的 I/O 操作调用完毕之后,会将获取的结果储存在 req->result 属性上,然后调用 PostQueuedCompletionStatus() 通知 IOCP,告知当前对象操作已经完成:
PostQueuedCompletionStatus((loop)->iocp, 0, 0, &((req)->overlapped))PostQueuedCompletionStatus() 方法的作用是向 IOCP 提交执行状态,并将线程归还线程池。通过 PostQueuedCompletionStatus() 方法提交的状态,可以通过 GetQueuedCompletionStatus() 提取。
在这个过程中,我们其实还动用了事件循环的 I/O 观察者。在每次 Tick 的执行中,它会调用 IOCP 相关的 GetQueuedCompletionStatus() 方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到 I/O 观察者的队列中,然后将其当做事件处理。
I/O 观察者回调函数的行为就是取出请求对象的 result 属性作为参数,取出 oncomplete_sym 属性作为方法,然后调用执行,以此达到调用 JavaScript 中传入的回调函数的目的。
至此,整个异步 I/O 的流程完全结東,如下图所示。
整个异步 I/O 的流程
事件循环、观察者、请求对象、I/O 线程池这四者共同构成了 Node 异步 I/O 模型的基本要素。
Windows 下主要通过 IOCP 来向系统内核发送 I/O 调用和从内核获取已完成的 I/O 操作,配以事件循环,以此完成异步 I/O 的过程。在 Linux 下通过 epoll 实现这个过程,FreeBSD 下通过 kqueue 实现,Solaris 下通过 Event ports 实现。不同的是线程池在 Windows 下由内核(IOCP)直接提供,*nix 系列下由 libuv 自行实现。
从前面实现异步 I/O 的过程描述中,我们可以提取出异步 I/O 的几个关键词:单线程、事件循环、观察者和 I/O 线程池。这里单线程与 I/O 线程池之间看起来有些悖论的样子。由于我们知道 JavaScript 是单线程的,所以按常识很容易理解为它不能充分利用多核 CPU。事实上,在 Node 中除了 JavaScript 是单线程外,Node 自身其实是多线程的,只是 I/O 线程使用的 CPU 较少。另一个需要重视的观点则是,除了用户代码无法并行执行外,所有的 I/O(磁盘 I/O 和网络 I/O 等)则是可以并行起来的。
除了异步 I/O,Node 中还存在一些与 I/O 无关的异步 API,它们分别是:
setTimeout() 和 setInterval() 与浏览器中的 API 是一致的,分别用于单次和多次定时执行任务。它们的实现原理与异步 I/O 比较类似,只是不需要 I/O 线程池的参与。调用 setTimeout() 或者 setInterval() 创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次Tick 执行时,会从该红黑树中迭代取出定时器对象,检査是否超过定时时间,如果超过,就形成一个事件,它的回调函数将立即执行。
下图提到的主要是 setTimeout() 的行为。setInterval() 与之相同,区别在于后者是重复性的检测和执行。
setTimeout() 的行为
定时器的问题在于,它并非精确的(在容忍范围内)。尽管事件循环十分快,但是如果某一次循环占用的时间较多,那么下次循环时,它也许已经超时很久了。譬如通过 setTimeout() 设定一个任务在 10 毫秒后执行,但是在 9 毫秒后,有一个任务占用了 5 毫秒的 CPU 时间片,再次轮到定时器执行时,时间就已经过期 4 毫秒。
在未了解 process.nextTick() 之前,很多人也许为了立即异步执行一个任务,会这样调用 setTimeout() 来达到所需的效果:
setTimeout(function () {
// TODO
}, 0);由于事件循环自身的特点,定时器的精确度不够。而事实上,采用定时器需要动用红黑树创建定时器对象和迭代等操作,而 setTimeout(fn,0) 的方式较为浪费性能。实际上,process.nextTick() 方法的操作相对较为轻量,具体代码如下:
process.nextTick = function(callback) {
// on the way out, don't bother.
// it won't get fired anyway
if (process._exiting) return;
if (tickDepth >= process.maxTickDepth)
maxTickWarn();
var tock = { callback: callback };
if (process.domain) tock.domain = process.domain;
nextTickQueue.push(tock);
if (nextTickQueue.length) {
process._needTickCallback();
}
}; 每次调用 process.nextTick() 方法,只会将回调函数放入队列中,在下一轮 Tick 时取出执行。定时器中采用红黑树的操作时间复杂度为 O(lg(n)),nextTick() 的时间复杂度为 O(1)。相较之下,process.nextTick() 更高效。
setImmediate() 方法与 process.nextTick() 方法十分类似,都是将回调函数延迟执行。该方法的代码如下所示:
process.nextTick(function () {
console.log('延迟执行');
});
console.log('正常执行');上述代码的输出结果如下:
正常执行
廷迟执行而用 setImmediate() 实现时,相关代码如下:
setImmediate(function () {
console.log('延迟执行');
});
console.log('正常执行'); 其结果完全一样:
正常执行
廷迟执行但是两者之间其实是有细微差别的。将它们放在一起时,又会是怎样的优先级呢。示例代码如下:
process.nextTick(function () {
console.log('nextTick延迟执行');
});
setImmediate(function () {
console.log('setImmediate延迟执行');
});
console.log('正常执行');其结果如下:
正常执行
nextTick延迟执行
setImmediate延迟执行从结果里可以看到,process.nextTick() 中的回调函数执行的优先级要高于 setImmediate()。这里的原因在于事件循环对观察者的检查是有先后顺序的,process.nextTick() 属于 idle 观察者,setImmediate() 属于 check 观察者。在每一个轮循环检査中,idle 观察者先于 I/O 观察者,I/O 观察者先于 check 观察者。
在具体实现上,**process.nextTick() 的回调函数保存在一个数组中,setImmediate() 的结果则是保存在链表中。在行为上,process.nextTick() 在每轮循环中会将数组中的回调函数全部执行完,而 setImmediate() 在每轮循环中执行链表中的一个回调函数。**如下的示例代码可以佐证:
// 加入两个nextTick()的回调函数
process.nextTick(function () {
console.log('nextTick延迟执行1');
});
process.nextTick(function () {
console.log('nextTick延迟执行2');
});
// 加入两个setImmediate()的回调函数
setImmediate(function () {
console.log('setImmediate延迟执行1');
// 进入下次循环
process.nextTick(function () {
console.log('强势插入');
});
});
setImmediate(function () {
console.log('setImmediate延迟执行2');
});
console.log('正常执行');其执行结果如下:
正常执行
nextTick廷迟执行1
nextTick廷迟执行2
setImmediate廷迟执行1
强势插入
setImmediate延迟执行2从执行结果上可以看出,当第一个 setImmediate() 的回调函数执行后,并没有立即执行第二个,而是进入了下一轮循环,再次按 process.nextTick() 优先、setImmediate() 次后的顺序执行。之所以这样设计,是为了保证每轮循环能够较快地执行结束,防止 CPU 占用过多而阻塞后续 I/O 调用的情况。
建议对 CPU 的耗用不要超过 10ms,或者将大量的计算分解为诸多的小量计算,通过 setImmediate() 进行调度。
笔者补充来自网络更复杂的案例:
setImmediate(() => {
console.log(1);
setTimeout(() => {
console.log(2);
}, 100);
setImmediate(() => {
console.log(3);
});
process.nextTick(() => {
console.log(4);
});
});
process.nextTick(() => {
console.log(5);
setTimeout(() => {
console.log(6);
}, 100);
setImmediate(() => {
console.log(7);
});
process.nextTick(() => {
console.log(8);
});
});
console.log(9);
// 9 5 8 1 4 7 3 6 2前面主要介绍了异步的实现原理,在这个过程中,我们也基本勾勒出了事件驱动的实质,即通过主循环加事件触发的方式来运行程序。
尽管本章只用了 fs.open() 方法作为例子来阐述 Node 如何实现异步 I/O。而实质上,异步 I/O 不仅仅应用在文件操作中。对于网络套接字的处理,Node 也应用到了异步 I/O,网络套接字上侦听到的请求都会形成事件交给 I/O 观察者。事件循环会不停地处理这些网络 I/O 事件。如果 JavaScript 有传入回调函数,这些事件将会最终传递到业务逻辑层进行处理。利用 Node 构建 Web 服务器,正是在这样一个基础上实现的,其流程图如下图所示。
利用 Node 构建 Web 服务器的流程图
本章主要讲解 JavaScript 异步编程中遇到的难题,并介绍了当时主流的几种异步编程解决方案。至今已有 async/await 这种更优雅的解决方案,故本章不记录异步编程解决方案。
在 Node 中,我们可以十分方便地利用异步发起并行调用。使用下面的代码,我们可以轻松发起 100 次异步调用:
for (var i = 0, i < 100; i++) {
async();
}但是如果并发量过大,我们的下层服务器将会吃不消。如果是对文件系统进行大量并发调用,操作系统的文件描述符数量将会被瞬间用光,抛出如下错误:
Error: EMFILE, too many open files可以看出,异步 I/O 与同步 I/O 的显著差距:同步 I/O 因为每个 I/O 都是彼此阻塞的,在循环体中,总是一个接着一个调用,不会出现耗用文件描述符太多的情况,同时性能也是低下的;对于异步 I/O,虽然并发容易实现,但是由于太容易实现,依然需要控制。换言之,尽管是要压榨底层系统的性能,但还是需要给予一定的过载保护,以防止过犹不及。
bagpipe 的解决思路:
async 的 parallelLimit()。
Node 在 JavaScript 的执行上直接受益于 V8,可以随着 V8 的升级就能享受到更好的性能或新的语言特性(如 ES5 和 ES6)等,同时也受到 V8 的一些限制,尤其是本章要重点讨论的内存限制。
在一般的后端开发语言中,在基本的内存使用上没有什么限制,然而在 Node 中通过 JavaScript 使用内存时就会发现只能使用部分内存(64位系统下约为 1.4GB【1464MB】,32位系统下约为 0.7GB【732MB】)。在这样的限制下,将会导致 Node 无法直接操作大内存对象,比如无法将一个 2GB 的文件读入内存中进行字符串分析处理,即使物理内存有 32GB。这样在单个 Node 进程的情况下,计算机的内存资源无法得到充足的使用。
造成这个问题的主要原因在于 Node 基于 V8 构建,所以在 Node 中使用的 JavaScript,对象基本上都是通过 V8 自己的方式来进行分配和管理的。
在 V8 中,所有的 JavaScript 对象都是通过堆来进行分配的。Node 提供了 V8 中内存使用量的查看方式,执行下面的代码,将得到输出的内存信息:
$ node
> process.memoryUsage();
{ rss: 14958592,
heapTotal: 7195904,
heapUsed: 2821496 }单位均为字节:
V8 的堆示意图
当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过 V8 的限制为止。
至于 V8 为何要限制堆的大小,
Node 在启动时可传递 --max-old-space-size 或 --max-new-space-size 来调整内存限制的大小,如下所示:
node --max-old-space-size=1700 test.js // 单位为MB
// 或者
node --max-new-space-size=1024 test.js // 单位为KB上述参数在 V8 初始化时生效,一旦生效就不能再动态改变。
V8 用到的各种垃圾回收算法。
V8 的垃圾回收策略主要基于分代式垃圾回收机制。现代的垃圾回收算法中按对象的存活时间将内存的垃圾回收进行不同的分代,然后分别对不同分代的内存施以更高效的算法。
V8 的内存分代
V8 的分代示意图
V8 堆的整体大小就是新生代所用内存空间加上老生代的内存空间。前面我们提及的 --max-old-space-size 命令行参数可以用于设置老生代内存空间的最大值,--max-new-space-size 命令行参数则用于设置新生代内存空间的大小的。这两个值需要在启动时就指定。这意味着 V8 使用的内存无法根据使用情况自动扩充,当内存分配过程中超过极限值时,就会引起进程出错。
Scavenge 算法
在分代的基础上,新生代中的对象主要通过 Scavenge 算法进行垃圾回收。在 Scavenge 的具体实现中,主要采用了 Cheney 算法。
Cheney 算法是一种采用复制的方式实现的垃圾回收算法。它将堆内存一分为二,每一部分空间称为 semispace。在这两个 semispace 空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的 semispace 空间称为 From 空间,处于闲置状态的空间称为 To 空间。当我们分配对象时,先是在 From 空间中进行分配。当开始进行垃圾回收时,会检查 From 空间中的存活对象,这些存活对象将被复制到 To 空间中,而非存活对象占用的空间将会被释放。完成复制后,From 空间和 To 空间的角色发生对换。简而言之,在垃圾回收的过程中,就是通过将存活对象在两个 semispace 空间之间进行复制。
Scavenge 的缺点是只能使用堆内存中的一半,这是由划分空间和复制机制所决定的。但 Scavenge 由于只复制存活的对象,并且对于生命周期短的场景存活对象只占少部分,所以它在时间效率上有优异的表现。
由于 Scavenge 是典型的牺牲空间换取时间的算法,所以无法大规模地应用到所有的垃圾回收中。但可以发现,Scavenge 非常适合应用在新生代中,因为新生代中对象的生命周期较短,恰恰适合这个算法。
V8 的堆内存示意图
当一个对象经过多次复制依然存活时,它将会被认为是生命周期较长的对象。这种较长生命周期的对象随后会被移动到老生代中,采用新的算法进行管理。对象从新生代中移动到老生代中的过程称为晋升。
在单纯的 Scavenge 过程中,From 空间中的存活对象会被复制到 To 空间中去,然后对 From 空间和 To 空间进行角色对换(又称翻转)。但在分代式垃圾回收的前提下,From 空间中的存活对象在复制到 To 空间之前需要进行检査。在一定条件下,需要将存活周期长的对象移动到老生代中,也就是完成对象晋升。
对象晋升的条件主要有两个:
在默认情况下,V8 的对象分配主要集中在 From 空间中。对象从 From 空间中复制到 To 空间时会检査它的内存地址来判断这个对象是否已经经历过一次 Scavenge 回收。如果已经经历过了,会将该对象从 From 空间复制到老生代空间中,如果没有,则复制到 To 空间中。这个晋升流程如下图所示。
晋升过程
另一个判断条件是 To 空间的内存占用比。当要从 From 空间复制一个对象到 To 空间时,如果 To 空间已经使用了超过 25%,则这个对象直接晋升到老生代空间中,这个晋升的判断示意图如下图所示。
晋升的判断示意图
设置 25% 这个限制值的原因是当这次 Scavenge 回收完成后,这个 To 空间将变成 From 空间,接下来的内存分配将在这个空间中进行。如果占比过高,会影响后续的内存分配。
对象晋升后,将会在老生代空间中作为存活周期较长的对象来对待,接受新的回收算法处理。
Mark-Sweep & Mark-Compact
对于老生代中的对象,由于存活对象占较大比重,再采用 Scavenge 的方式会有两个问题:
为此,V8 在老生代中主要采用了 Mark-Sweep 和 Mark-Compact 相结合的方式进行垃圾回收。
Mark-Sweep 是标记清除的意思,它分为标记和清除两个阶段。与 Scavenge 相比,Mark-Sweep 并不将内存空间划分为两半,所以不存在浪费一半空间的行为。与 Scavenge 复制活着的对象不同,Mark-Sweep 在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以看出, Scavenge 中只复制活着的对象,而 Mark-Sweep 只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因。
Mark-Sweep 在老生代空间中标记后的示意图(黑色部分标记为死亡的对象)
Mark-Sweep 最大的问题是在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
为了解决 Mark-Sweep 的内存碎片问题,Mark-Compact 被提出来。Mark-Compact 是标记整理的意思,是在 Mark-Sweep 的基础上演变而来的。它们的差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。
完成标记并移动存活对象后的示意图(白色格子为存活对象,深色格子为死亡对象,浅色格子为存活对象移动后留下的空洞)
完成移动后,就可以直接清除最右边的存活对象后面的内存区域完成回收。
这里将 Mark-Sweep 和 Mark-Compact 结合着介绍不仅仅是因为两种策略是递进关系,在 V8 的回收策略中两者是结合使用的。下表是目前介绍到的 3 种主要垃圾回收算法的简单对比。
3 种垃圾回收算法的简单对比
从上表中可以看到,在 Mark-Sweep 和 Mark-compact 之间,由于 Mark-Compact 需要移动对象,所以它的执行速度不可能很快,所以在取舍上,V8 主要使用 Mark-Sweep,在空间不足以对从新生代中晋升过来的对象进行分配时才使用 Mark-Compact。
Incremental Marking
为了避免出现 JavaScript 应用逻辑与垃圾回收器看到的不一致的情况,垃圾回收的 3 种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为被称为“全停顿”(stop-the-world)。在 V8 的分代式垃圾回收中,一次小垃圾回收只收集新生代,由于新生代默认配置得较小,且其中存活对象通常较少,所以即便它是全停顿的影响也不大。但 V8 的老生代通常配置得较大,且存活对象较多,全堆垃圾回收(full 垃圾回收)的标记、清理、整理等动作造成的停顿就会比较可怕,需要设法改善。
增量标记示意图
V8 在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的 1/6 左右。
V8 后续还引入了延迟清理(lazy sweeping)与增量式整理( incremental compaction),让清理与整理动作也変成增量式的。同时还计划引入并行标记与并行清理,进一步利用多核性能降低每次停顿的时间。鉴于篇幅有限,此处不再深入讲解了。
查看垃圾回收日志的方式主要是在启动时添加 --trace_gc 参数。
通过在 Node 启动时使用 --prof 参数,可以得到 V8 执行时的性能分析数据。
如果需要释放常驻内存的对象,可以通过 delete 操作来删除引用关系。或者将变量重新赋值,让旧的对象脱离引用关系。在接下来的老生代内存清除和整理的过程中,会被回收释放。
虽然 delete 操作和重新赋值具有相同的效果,但是在 V8 中通过 delete 删除对象的属性有可能干扰 V8 的优化,所以通过赋值方式解除引用更好。
在正常的 JavaScript 执行中,无法立即回收的内存有闭包和全局变量引用这两种情况。由于 V8 的内存限制,要十分小心此类变量是否无限制地增加,因为它会导致老生代中的对象増多。
除了上述提到的 process.memoryUsage(),os 模块中的 totalmem() 和 freemem() 方法也可以查看内存使用的情况。
通过 process.momoryUsage() 的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量,这意味着 Node 中的内存使用并非都是通过 V8 进行分配的。我们将那些不是通过 V8 分配的内存称为堆外内存。
Buffer 对象不同于其他对象,它不经过 V8 的内存分配机制,所以也不会有堆内存的大小限制。
这意味着利用堆外内存可以突破内存限制的问题。
为何 Buffer 对象并非通过 V8 分配?这在于 Node 并不同于浏览器的应用场景。在浏览器中 JavaScript 直接处理字符串即可满足绝大多数的业务需求,而 Node 则需要处理网络流和文件 I/O 流,操作字符串远远不能满足传输的性能需求。
Node 的内存构成主要由通过 V8 进行分配的部分和 Node 自行分配的部分。受 V8 的垃圾回收限制的主要是 V8 的堆内存。
Node 对内存泄漏十分敏感,一旦线上应用有成千上万的流量,那怕是一个字节的内存泄漏也会造成堆积,垃圾回收过程中将会耗费更多时间进行对象扫描,应用响应缓慢,直到进程内存溢出,应用崩溃。
尽管内存泄漏的情况不尽相同,但其实质只有一个,那就是应当回收的对象出现意外而没有被回收,变成了常驻在老生代中的对象。
通常,造成内存泄漏的原因有如下几个。
缓存限制策略
需要增加完善的过期策略,防止内存(作为缓存)无限增长
模块机制
为了加速模块的引入,所有模块都会通过编译执行,然后被缓存起来。由于通过 exports 导出的函数,可以访问文件模块中的私有变量,这样每个文件模块在编译执行后形成的作用域因为模块缓存的原因,不会被释放。示例代码如下所示:
(function (exports, require, module, __filename, __dirname) {
var local = "局部变量";
exports.get = function () {
return local;
};
});由于模块的缓存机制,模块是常驻老生代的。在设计模块时,要十分小心内存泄漏的出现。在下面的代码,每次调用 leak() 方法时,都导致局部变量 leakArray 不停增加内存的占用,且不被释放:
var leakArray = [];
exports.leak = function () {
leakArray.push("leak" + Math.random());
}; 如果模块不可避免地需要这么设计,那么请添加清空队列的相应接口,以供调用者释放内存。
缓存的解决方案
直接将内存作为缓存的方案要十分慎重。除了限制缓存的大小外,另外要考虑的事情是,进程之间无法共享内存。如果在进程内使用缓存,这些缓存不可避免地有重复,对物理内存的使用是一种浪费。
解决方案:采用进程外的缓存。
解决以下两个问题:
在解决了缓存带来的内存泄漏问题后,另一个不经意产生的内存泄漏则是队列。在大多数应用场景下,队列的消费的速度远远大于生产的速度,内存泄漏不易产生。但是一旦消费速度低于生产速度,将会形成堆积。
举个实际的例子,有的应用会收集日志。如果欠缺考虑,也许会采用数据库来记录日志。日志通常会是海量的,数据库构建在文件系统之上,写入效率远远低于文件直接写入,于是会形成数据库写入操作的堆积,而 JavaScript 中相关的作用域也不会得到释放,内存占用不会回落,从而出现内存泄漏。
遇到这种场景,表层的解决方案是换用消费速度更高的技术。在日志收集的案例中,换用文件写入日志的方式会更高效。需要注意的是,如果生产速度因为某些原因突然激增,或者消费速度因为突然的系统故障降低,内存泄漏还是可能出现的。
深度的解决方案应该是监控队列的长度,一旦堆积,应当通过监控系统产生报警并通知相关人员。另一个解决方案是任意异步调用都应该包含超时机制,一旦在限定的时间内未完成响应通过回调函数传递超时异常,使得任意异步调用的回调都具备可控的响应时间,给消费速度一个下限值。
常见工具:
在 Node 中,不可避免地还是会存在操作大文件的场景。由于 Node 的内存限制,操作大文件也需要小心,好在 Node 提供了 stream 模块用于处理大文件。
stream 模块是 Node 的原生模块,直接引用即可。stream 继承自 EventEmitter,具备基本的自定义事件功能,同时抽象出标准的事件和方法。它分可读和可写两种。Node 中的大多数模块都有 stream 的应用,比如 fs 的 createReadStream() 和 createWriteStream() 方法可以分别用于创建文件的可读流和可写流,process 模块中的 stdin 和 stdout 则分别是可读流和可写流的示例。
由于 V8 的内存限制,我们无法通过 fs.readFile() 和 fs.writeFile() 直接进行大文件的操作,而改用 fs.createReadStream() 和 fs.createWriteStream() 方法通过流的方式实现对大文件的操作。下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.on('data', function (chunk) {
writer.write(chunk);
});
reader.on('end', function () {
writer.end();
});由于读写模型固定,上述方法有更简洁的方式,具体如下所示:
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.pipe(writer); 可读流提供了管道方法 pipe(),封装了 data 事件和写入操作。通过流的方式,上述代码不会受到 V8 内存限制的影响,有效地提高了程序的健壮性。
如果不需要进行字符串层面的操作,则不需要借助 V8 来处理,可以尝试进行纯粹的 Buffer 操作,这不会受到 V8 堆内存的限制。但是这种大片使用内存的情况依然要小心,即使 V8 不限制堆内存的大小,物理内存依然有限制。
在 Node 中,应用需要处理网络协议、操作数据库、处理图片、接收上传文件等,在网络流和文件的操作中,要处理大量二进制数据,JavaScript 自有的字符串远远不能满足这些需求,于是 Buffer 对象应运而生。
Buffer 是一个像 Array 的对象,但它主要用于操作字节。下面我们从模块结构和对象结构的层面上来认识它。
Buffer 是一个典型的 JavaScript 与 C++ 结合的模块,它将性能相关部分用 C++ 实现,将非性能相关的部分用 JavaScript 实现,如下图所示。
Buffer 所占用的内存不是通过 V8 分配的,属于堆外内存。
Buffer 对象类似于数组,它的元素为 16 进制的两位数,即 0 到 255 的数值。示例代码如下所示:
var str = "深入浅出node.js";
var buf = new Buffer(str, 'utf-8');
console.log(buf);
// => <Buffer e6 b7 b1 e5 85 a5 e6 b5 85 e5 87 ba 6e 6f 64 65 2e 6a 73>由上面的示例可见,不同编码的字符串占用的元素个数各不相同,上面代码中的中文字在 UTF-8 编码下占用 3 个元素,字母和半角标点符号占用 1 个元素。
Buffer 受 Array 类型的影响很大,可以访问 length 属性得到长度,也可以通过下标访问元素,在构造对象时也十分相似。
给元素的赋值如果小于 0,就将该值逐次加 256,直到得到一个 0 到 255 之间的整数。如果得到的数值大于 255,就逐次减 256,直到得到 0 ~ 255 区间内的数值。如果是小数,舍弃小数部分,只保留整数部分。
Buffer 对象的内存分配不是在 V8 的堆内存中,而是在 Node 的 C++ 层面实现内存的申请的。因为处理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式,这可能造成大量的内存申请的系统调用,对操作系统有一定压力。为此 Node 在内存的使用上应用的是在 C++ 层面申请内存、在 JavaScript 中分配内存的策略。
为了高效地使用申请来的内存,Node 采用了 slab 分配机制。 slab 是一种动态内存管理机制,最早延生于 SunOS 操作系统( Solaris)中,目前在一些 *nix 操作系统中有广泛的应用,如 FreeBSD 和 Linux。
简单而言,slab 就是一块申请好的固定大小的内存区域。slab 具有如下 3 种状态。
当我们需要一个 Buffer 对象,可以通过以下方式分配指定大小的 Buffer 对象:
new Buffer(size); Node 以 8KB 为界限来区分 Buffer 是大对象还是小对象:
Buffer.poolSize = 8 * 1024;这个 8KB 的值也就是每个 slab 的大小值,在 JavaScript 层面,以它作为单位单元进行内存的分配。
分配小 Buffer 对象
如果指定 Buffer 的大小少于 8KB,Node 会按照小对象的方式进行分配。
当再次创建一个 Buffer 对象时,构造过程中将会判断这个 slab 的剩余空间是否足够。如果足够,使用剩余空间,并更新 slab 的分配状态。
如果 slab 剩余的空间不够,将会构造新的 slab,原 slab 中剩余的空间会造成浪费。
这里要注意的事项是,由于同一个 slab 可能分配给多个 Buffer 对象使用,只有这些小 Buffer 对象在作用域释放并都可以回收时,slab 的 8KB 空间オ会被回收。尽管创建了 1 个字节的 Buffer 对象,但是如果不释放它,实际可能是 8KB 的内存没有释放。
分配大 Buffer 对象
如果需要超过 8KB 的 Buffer 对象,将会直接分配一个 SlowBuffer 对象作为 slab 单元,这个 slab 单元将会被这个大 Buffer 对象独占。
Buffer 对象可以与字符串之间相互转换。目前支持的字符串编码类型有如下这几种。
字符串转 Buffer 对象主要是通过构造函数完成的:
new Buffer(str, [encoding]);通过构造函数转换的 Buffer 对象,存储的只能是一种编码类型。encoding 默认值为 UTF-8 编码。
一个 Buffer 对象可以存储不同编码类型的字符串转码的值,调用 write() 方法可以实现该目的,代码如下:
buf.write(string, [offset], [length], [encoding]) 由于可以不断写入内容到 Buffer 对象中,并且每次写入可以指定编码,所以 Buffer 对象中可以存在多种编码转化后的内容。需要小心的是,每种编码所用的字节长度不同,将 Buffer 反转回字符串时需要谨慎处理。
Buffer 对象的 toString() 可以将 Buffer 对象转换为字符串,代码如下:
buf.toString([encoding], [start], [end])比较精巧的是,可以设置 encoding(默认为 UTF-8)、start、end 这 3 个参数实现整体或局部的转换。如果 Buffer 对象由多种编码写入,就需要在局部指定不同的编码,才能转换回正常的编码。
Buffer 提供了一个 isEncoding() 函数来判断编码是否支持转换:
Buffer.isEncoding(encoding)对于不支持的编码类型,可以借助 Node 生态圈中的模块完成转换。
Buffer 在使用场景中,通常是以一段一段的方式传输。以下是常见的从输入流中读取内容的示例代码:
var fs = require('fs');
var rs = fs.createReadStream('test.md');
var data = '';
rs.on("data", function (chunk){
data += chunk;
});
rs.on("end", function () {
console.log(data);
}); 上面这段代码常见于国外,用于流读取的示范,data 事件中获取的 chunk 对象即是 Buffer 对象。
一旦输入流中有宽字节编码时,问题就会暴露出来。如果你在通过 Node 开发的网站上看到 � 乱码符号,那么该问题的起源多半来自于这里。
这里潜藏的问题在于如下这句代码:
data += chunk;这句代码里隐藏了 toString() 操作,它等价于如下的代码:
data = data.toString() + chunk.toString();英文环境下,toString() 不会造成任何问题。但对于宽字节的中文,却会形成问题。这是因为 toString() 方法默认以 UTF-8 为编码,中文字在 UTF-8 下占 3 个字节,这使得宽字节存在被截断的可能性。
可读流还有一个设置编码的方法 setEncoding(),该方法的作用是让 data 事件中传递的不再是一个 Buffer 对象,而是编码后的字符串。
var rs = fs.createReadStream('test.md', { highWaterMark: 11});
rs.setEncoding('utf8'); 要知道,无论如何设置编码,触发 data 事件的次数依旧相同,这意味着设置编码并未改变按段读取的基本方式。
事实上,在调用 setEncoding() 时,可读流对象在内部设置了一个 decoder 对象。每次 data 事件都通过该 decoder 对象进行 Buffer 到字符串的解码,然后传递给调用者。是故设置编码后,data 不再收到原始的 Buffer 对象。但是这依旧无法解释为何设置编码后乱码问题被解决掉了,因为在前述分析中,无论如何转码,总是存在宽字节字符串被截断的问题。
最终乱码问题得以解决,还是在于 decoder 的神奇之处。decoder 对象来自于 string_decoder 模块 StringDecoder 的实例对象。它神奇的原理是什么,下面我们以代码来说明:
var StringDecoder = require('string_decoder').StringDecoder;
var decoder = new StringDecoder('utf8');
var buf1 = new Buffer([0xE5, 0xBA, 0x8A, 0xE5, 0x89, 0x8D, 0xE6, 0x98, 0x8E, 0xE6, 0x9C]);
console.log(decoder.write(buf1));
// => 床前明
var buf2 = new Buffer([0x88, 0xE5, 0x85, 0x89, 0xEF, 0xBC, 0x8C, 0xE7, 0x96, 0x91, 0xE6]);
console.log(decoder.write(buf2));
// => 月光,疑我将前文提到的前两个 Buffer 对象写入 decoder 中。奇怪的地方在于“月”的转码并没有如平常一样在两个部分分开输出。StringDecoder 在得到编码后,知道宽字节字符串在 UTF-8 编码下是以 3 个字节的方式存储的,所以第一次 write() 时,只输出前 9 个字节转码形成的字符,“月”字的前两个字节被保留在 StringDecoder 实例内部。第二次 write() 时,会将这 2 个剩余字节和后续 11 个字节组合在一起,再次用 3 的整数倍字节进行转码。于是乱码问题通过这种中间形式被解决了。
虽然 string_decoder 模块很奇妙,但是它也并非万能药,它目前只能处理 UTF-8、Base64 和 UCS-2/UTF-16LE 这 3 种编码。所以,通过 setEncoding() 的方式不可否认能解決大部分的乱码问题,但并不能从根本上解决该问题。
淘汰掉 setEncoding() 方法后,剩下的解决方案只有将多个小 Buffer 对象拼接为一个 Buffer 对象,然后通过 iconv-lite 一类的模块来转码这种方式。+= 的方式显然不行,那么正确的 Buffer 拼接方法应该如下面展示的形式:
var chunks = [];
var size = 0;
res.on('data', function (chunk) {
chunks.push(chunk);
size += chunk.length;
});
res.on('end', function () {
var buf = Buffer.concat(chunks, size);
var str = iconv.decode(buf, 'utf8');
console.log(str);
}); 正确的拼接方式是用一个数组来存储接收到的所有 Buffer() 片段并记录下所有片段的总长度,然后调用 Buffer.concat() 方法生成一个合并的 Buffer 对象。
Buffer 在文件 I/O 和网络 I/O 中运用广泛,尤其在网络传输中,它的性能举足轻重。在应用中,我们通常会操作字符串,但一旦在网络中传输,都需要转换为 Buffer,以进行二进制数据传输。在 Web 应用中,字符串转换到 Buffer 是时时刻刻发生的,提高字符串到 Buffer 的转换效率,可以很大程度地提高网络吞吐率。
通过预先转换静态内容为 Buffer 对象,可以有效地减少 CPU 的重复使用,节省服务器资源。在 Node 构建的 Web 应用中,可以选择将页面中的动态内容和静态内容分离,静态内容部分可以通过预先转换为 Buffer 的方式,使性能得到提升。由于文件自身是二进制数据,所以在不需要改变内容的场景下,尽量只读取 Buffer,然后直接传输,不做额外的转换,避免损耗。
Node 提供了 net、dgram、http、https 这 4 个模块,分别用于处理 TCP、UDP、HTTP、HTTPS,适用于服务器端和客户端。
TCP 全名为传输控制协议,在 OSI 模型(由七层组成,分别为物理层、数据链结层、网络层、传输层、会话层、表示层、应用层)中属于传输层协议。许多应用层协议基于 TCP 构建,典型的是 HTTP、SMTP、IMAP 等协议。七层协议示意图如下图所示。
OSI 模型(七层协议)
TCP 是面向连接的协议,其显著的特征是在传输之前需要 3 次握手形成会话,如下图所示。
TCP 在传输之前的 3 次握手
只有会话形成之后,服务器端和客户端之间才能互相发送数据。在创建会话的过程中,服务器端和客户端分别提供一个套接字,这两个套接字共同形成一个连接。服务器端与客户端则通过套接字实现两者之间连接的操作。
服务器可以同时与多个客户端保持连接,对于每个连接而言是典型的可写可读 Stream 对象。Stream 对象可以用于服务器端和客户端之间的通信,既可以通过 data 事件从一端读取另一端发来的数据,也可以通过 write() 方法从一端向另一端发送数据。
另外,由于 TCP 套接字是可写可读的 Stream 对象,可以利用 pipe() 方法巧妙地实现管道操作。
UDP 与 TCP 一样同属于网络传输层。UDP 与 TCP 最大的不同是 UDP 不是面向连接的。TCP 中连接一旦建立,所有的会话都基于连接完成,客户端如果要与另一个 TCP 服务通信,需要另创建一个套接字来完成连接。但在 UDP 中,一个套接字可以与多个 UDP 服务通信,它虽然提供面向事务的简单不可靠信息传输服务,在网络差的情况下存在丢包严重的问题,但是由于它无须连接,资源消耗低,处理快速且灵活,所以常常应用在那种偶尔丢一两个数据包也不会产生重大影响的场景,比如音频、视频等。UDP 目前应用很广泛,DNS 服务即是基于它实现的。
UDP 套接字相对 TCP 套接字使用起来更简单,它只是一个 EventEmitter 的实例,而非 Stream 的实例。
TCP 与 UDP 都属于网络传输层协议,如果要构造高效的网络应用,就应该从传输层进行着手。但是对于经典的应用场景,则无须从传输层协议入手构造自己的应用,比如 HTTP 或 SMTP 等,这些经典的应用层协议对于普通应用而言绰绰有余。
HTTP 构建在 TCP 之上,属于应用层协议。
HTTP 报文
$ curl -v http://127.0.0.1:1337
# TCP 的 3 次握手过程
* About to connect() to 127.0.0.1 port 1337 (#0)
* Trying 127.0.0.1...
* connected
* Connected to 127.0.0.1 (127.0.0.1) port 1337 (#0)
# TCP 的 3 次握手过程
# 客户端向服务器发送请求报文
> GET / HTTP/1.1
> User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8r zlib/1.2.5
> Host: 127.0.0.1:1337
> Accept: */*
>
# 客户端向服务器发送请求报文
# 服务器端完成处理后,向客户端发送响应内容
< HTTP/1.1 200 OK
< Content-Type: text/plain
< Date: Sat, 06 Apr 2013 08:01:44 GMT
< Connection: keep-alive
< Transfer-Encoding: chunked
<
Hello World
# 服务器端完成处理后,向客户端发送响应内容
# 结束会话的消息
* Connection #0 to host 127.0.0.1 left intact
* Closing connection #0
# 结束会话的消息从上述的报文信息中可以看出 HTTP 的特点,它是基于请求响应式的,以一问一答的方式实现服务,虽然基于 TCP 会话,但是本身却并无会话的特点。
Node 的 http 模块包含对 HTTP 处理的封装。在 Node 中 HTTP 服务继承自 TCP 服务器(net 模块),它能够与多个客户端保持连接,由于其采用事件驱动的形式,并不为每一个连接创建额外的线程或进程,保持很低的内存占用,所以能实现高并发。HTTP 服务与 TCP 服务模型有区别的地方在于,在开启 keepalive 后,一个 TCP 会话可以用于多次请求和响应。TCP 服务以 connection 为单位进行服务,HTTP 服务以 request 为单位进行服务,HTTP 模块即是将 connection 到 request 的过程进行了封装,示意图下图所示。
http 模块将 connection 到 request 的过程进行了封装
除此之外,HTTP 模块将连接所用套接字的读写抽象为 ServerRequest 和 ServerResponse 对象,它们分别对应请求和响应操作。在请求产生的过程中 HTTP 模块拿到连接中传来的数据,调用二进制模块 http_parser 进行解析,在解析完请求报文的报头后,触发 request 事件,调用用户的业务逻辑。该流程的示意图下图所示。
http 模块产生请求的流程
响应结東后,HTTP 服务器可能会将当前的连接用于下一个请求,或者关闭连接。值得注意的是,报头是在报文体发送前发送的,一旦开始了数据的发送,whiteHead() 和 setHeader() 将不再生效。这由协议的特性决定。
另外,无论服务器端在处理业务逻辑时是否发生异常,务必在结束时调用 res.end() 结束请求,否则客户端将一直处于等待的状态。当然,也可以通过延迟 res.end() 的方式实现客户端与服务器端之间的长连接,但结束时务必关闭连接。
WebScoket 与传统 HTTP 有如下好处。
WebSocket 协议主要分为两个部分:握手和数据传输。
客户端建立连接时,通过 HTTP 发起请求报文。
服务器端在处理完请求后,返回报文告知客户端正在更换协议,更新应用层协议为 WebSocket 协议,并在当前的套接字连接上应用新协议。
一旦 WebSocket 握手成功,服务器端与客户端将会呈现对等的效果,都能接收和发送消息。
在握手顺利完成后,当前连接将不再进行 HTTP 的交互,而是开始 WebSocket 的数据帧协议,实现客户端与服务器端的数据交换。下图为协议升级过程示意图。
协议升级过程示意图
暂略。
暂略。
从严格的意义上而言,Node 并非真正的单线程架构,Node 自身还有一定的 I/O 线程存在,这些 I/O 线程由底层 libuv 处理,这部分线程对于 JavaScript 开发者而言是透明的,只在 C++ 扩展开发时才会关注到。JavaScript 代码永远运行在 V8 上,是单线程的。本章将围绕 JavaScript 部分展开,所以屏蔽底层细节的讨论。
假设每次响应服务耗用的时间稳定为 N 秒。进程数上限为 M。线程所占用的资源为进程的 1/L。
同步:QPS 为 1/N。
复制进程:QPS 为 M/N。
在进程复制的过程中,需要复制进程内部的状态,对于每个连接都进行这样的复制的话,相同的状态将会在内存中存在很多份,造成浪费。并且这个过程由于要复制较多的数据,启动是较为缓慢的。
为了解决启动缓慢的问题,预复制( prefork)被引入服务模型中,即预先复制一定数量的进程。同时将进程复用,避免进程创建、销毁带来的开销。但是这个模型并不具备伸缩性,一旦并发请求过高,内存使用随着进程数的增长将会被耗尽。
多线程:QPS 为 M*L/N。
为了解决进程复制中的浪费问题,多线程被引入服务模型,让一个线程服务一个请求。线程相对进程的开销要小许多,并且线程之间可以共享数据,内存浪费的问题可以得到解决,并且利用线程池可以减少创建和销毁线程的开销。但是多线程所面临的并发问题只能说比多进程略好,因为每个线程都拥有自己独立的堆栈,这个堆栈都需要占用一定的内存空间。另外,由于一个 CPU 核心在一个时刻只能做一件事情,操作系统只能通过将 CPU 切分为时间片的方法,让线程可以较为均匀地使用 CPU 资源,但是操作系统内核在切换线程的同时也要切换线程的上下文,当线程数量过多时时间将会被耗用在上下文切换中。所以在大并发量时,多线程结构还是无法做到强大的伸缩性。
事件驱动:
多线程的服务模型服役了很长一段时间,Apache 就是采用多线程/多进程模型实现的,当并发増长到上万时,内存耗用的问题将会暴露出来,这即是著名的 C10k 问题。
为了解决高并发问题,基于事件驱动的服务模型出现了,像 Node 与 Nginx 均是基于事件驱动的方式实现的,采用单线程避免了不必要的内存开销和上下文切换开销。
基于事件的服务模型存在的两个问题:CPU 的利用率和进程的健壮性。单线程的架构并不少见,其中尤以 PHP 最为知名——在 PHP 中没有线程的支持。它的健壮性是由它给每个请求都建立独立的上下文来实现的。但是对于 Node 来说,所有请求的上下文都是统一的,它的稳定性是亟需解决的问题。
由于所有处理都在单线程上进行,影响事件驱动服务模型性能的点在于 CPU 的计算能力,它的上限决定这类服务模型的性能上限,但它不受多进程或多线程模式中资源上限的影响,可伸缩性远比前两者高。如果解决掉多核 CPU 的利用问题,带来的性能上提升是可观的。
child_process 模块提供了 4 个方法用于创建子进程。
以一个寻常命令为例,node worker.js 分别用上述 4 种方法实现,如下所示:
var cp = require('child_process');
cp.spawn('node', ['worker.js']);
cp.exec('node worker.js', function (err, stdout, stderr) {
// some code
});
cp.execFile('worker.js', function (err, stdout, stderr) {
// some code
});
cp.fork('./worker.js'); 以上 4 个方法在创建子进程之后均会返回子进程对象。
4 个方法的差别如下表所示。
4 种方法的差别
在 Master-Worker 模式中,要实现主进程管理和调度工作进程的功能,需要主进程和工作进程之间的通信。
子进程对象由 send() 方法实现主进程向子进程发送数据,message 事件实现收听子进程发来的数据。
// parent.js
var cp = require('child_process');
var n = cp.fork(__dirname + '/sub.js');
n.on('message', function (m) {
console.log('PARENT got message:', m);
});
n.send({hello: 'world'});
// sub.js
process.on('message', function (m) {
console.log('CHILD got message:', m);
});
process.send({foo: 'bar'});通过 fork() 或者其他 API,创建子进程之后,为了实现父子进程之间的通信,父进程与子进程之间将会创建 IPC 通道。通过 IPC 通道,父子进程之间才能通过 message 和 send() 传递消息。
IPC 的全称是 Inter-Process Communication,即进程间通信。进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。实现进程间通信的技术有很多,如命名管道、匿名管道、 socket、信号量、共享内存、消息队列、Domain Socket 等。Node 中实现 IPC 通道的是管道(pipe)技术。但此管道非彼管道,在 Node 中管道是个抽象层面的称呼,具体细节实现由 libuv 提供,在 Windows 下由命名管道(named pipe)实现,*nix 系统则采用 Unix Domain Socket 实现。表现在应用层上的进程间通信只有简单的 message 事件和 send() 方法,接口十分简洁和消息化。下图为 IPC 创建和实现的示意图。
IPC 创建和实现示意图
父进程在实际创建子进程之前,会创建 IPC 通道并监听它,然后オ真正创建出子进程,并通过环境变量( NODE_CHANNEL_FD)告诉子进程这个 IPC 通道的文件描述符。子进程在启动的过程中,根据文件描述符去连接这个已存在的 IPC 通道,从而完成父子进程之间的连接。下图为创建 IPC 管道的步骤示意图。
创建 IPC 管道的步骤示意图
建立连接之后的父子进程就可以自由地通信了。由于 IPC 通道是用命名管道或 Domain Socket 创建的,它们与网络 socket 的行为比较类似,属于双向通信。不同的是它们在系统内核中就完成了进程间的通信,而不用经过实际的网络层,非常高效。在 Node 中,IPC 通道被抽象为 Stream 对象,在调用 send() 时发送数据(类似于 write()),接收到的消息会通过 message 事件(类似于 data)触发给应用层。
注意:只有启动的子进程是 Node 进程时,子进程才会根据环境变量去连接 IPC 通道,对于其他类的子进程则无法实现进程间通信,除非其他进程也按约定去连接这个已经创建好的 IPC 通道。
建立好进程之间的 IPC 后,如果仅仅只用来发送一些简单的数据,显然不够我们的实际应用使用。
如果让服务都监听到相同的端口,会导致只有一个工作进程能够监听到该端口上,其余的进程在监听的过程中都抛出了 EADDRINUSE 异常,这是端口被占用的情况,新的进程不能继续监听该端口了。
要解决这个问题,通常的做法是让每个进程监听不同的端口,其中主进程监听主端口(如 80),主进程对外接收所有的网络请求,再将这些请求分别代理到不同的端口的进程上。示意图如下图所示。
主进程接收、分配网络请求的示意图
通过代理,可以避免端口不能重复监听的问题,甚至可以在代理进程上做适当的负载均衡,使得每个子进程可以较为均衡地执行任务。由于进程每接收到一个连接,将会用掉一个文件描述符,因此代理方案中客户端连接到代理进程,代理进程连接到工作进程的过程需要用掉两个文件描述符。操作系统的文件描述符是有限的,代理方案浪费掉一倍数量的文件描述符的做法影响了系统的扩展能力。
为了解决上述这样的问题,Node 在版本 v0.5.9 引入了进程间发送句柄的功能。send() 方法除了能通过 IPC 发送数据外,还能发送句柄,第二个可选参数就是句柄,如下所示:
child.send(message, [sendHandle])句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。比如句柄可以用来标识一个服务器端 socket 对象、一个客户端 socket 对象、一个 UDP 套接字、一个管道等。
发送句柄意味着什么?在前一个问题中,我们可以去掉代理这种方案,使主进程接收到 socket 请求后,将这个 socket 直接发送给工作进程,而不是重新与工作进程之间建立新的 socket 连接来转发数据。文件描述符浪费的问题可以通过这样的方式轻松解决。来看看我们的示例代码。
主进程代码如下所示:
var child = require('child_process').fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
server.on('connection', function (socket) {
socket.end('handled by parent\n');
});
server.listen(1337, function () {
child.send('server', server);
}); 子进程代码如下所示:
process.on('message', function (m, server) {
if (m === 'server') {
server.on('connection', function (socket) {
socket.end('handled by child\n');
});
}
}); 这里子进程和父进程都有可能处理我们客户端发起的请求。
以上是在 TCP 层面上完成的事情,我们尝试将其转化到 HTTP 层面来试试。对于主进程而言,我们甚至想要它更轻量一点,那么是否将服务器句柄发送给子进程之后,就可以关掉服务器的监听,让子进程来处理请求呢?
我们对主进程进行改动,如下所示:
// parent.js
var cp = require('child_process');
var child1 = cp.fork('child.js');
var child2 = cp.fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
server.listen(1337, function () {
child1.send('server', server);
child2.send('server', server);
// 关掉
server.close();
}); 然后对子进程进行改动,如下所示:
// child.js
var http = require('http');
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
});
process.on('message', function (m, tcp) {
if (m === 'server') {
tcp.on('connection', function (socket) {
server.emit('connection', socket);
});
}
}); 这样一来,所有的请求都是由子进程处理了。整个过程中,服务的过程发生了一次改变,如下图所示。
主进程将请求发送给工作进程
主进程发送完句柄并关闭监听之后,成为了下图所示的结构。
主进程发送完句柄并关闭监听后的结构
我们神奇地发现,多个子进程可以同时监听相同端口,再没有 EADDRINUSE 异常发生了。
句柄发送与还原
目前子进程对象 send() 方法可以发送的句柄类型包括如下几种。
send() 方法在将消息发送到 IPC 管道前,将消息组装成两个对象,一个参数是 handle,另一个是 message。message 参数如下所示:
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}发送到 IPC 管道中的实际上是我们要发送的句柄文件描述符,文件描述符实际上是一个整数值。这个 message 对象在写入到 IPC 管道时也会通过 JSON.stringify() 进行序列化。所以最终发送到 IPC 通道中的信息都是字符串,send() 方法能发送消息和句柄并不意味着它能发送任意对象。
连接了 IPC 通道的子进程可以读取到父进程发来的消息,将字符串通过 JSON.parse() 解析还原为对象后,才触发 message 事件将消息体传递给应用层使用。在这个过程中,消息对象还要被进行过滤处理,message.cmd 的值如果以 NODE_ 为前缀,它将响应一个内部事件 internalMessage。如果 message.cmd 值为 NODE_HANDLE,它将取出 message.type 值和得到的文件描述符一起还原出一个对应的对象。这个过程的示意图如下图所示。
句柄的发送与还原示意图
以发送的 TCP 服务器句柄为例,子进程收到消息后的还原过程如下所示:
function(message, handle, emit) {
var self = this;
var server = new net.Server();
server.listen(handle, function() {
emit(server);
});
} 上面的代码中,子进程根据 message.type 创建对应 TCP 服务器对象,然后监听到文件描述符上。由于底层细节不被应用层感知,所以在子进程中,开发者会有一种服务器就是从父进程中直接传递过来的错觉。值得注意的是,Node 进程之间只有消息传递,不会真正地传递对象,这种错觉是抽象封装的结果。
目前 Node 只支持上述提到的几种句柄,并非任意类型的句柄都能在进程之间传递,除非它有完整的发送和还原的过程。
端口共同监听
在了解了句柄传递背后的原理后,我们继续探究为何通过发送句柄后,多个进程可以监听到相同的端口而不引起 EADDRINUSE 异常。其答案也很简单,我们独立启动的进程中,TCP 服务器端 socket 套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。
Node 底层对每个端口监听都设置了 SO_REUSEADDR 选项,这个选项的涵义是不同进程可以就相同的网卡和端口进行监听,这个服务器端套接字可以被不同的进程复用,如下所示:
setsockopt(tcp->io_watcher.fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on)) 由于独立启动的进程互相之间并不知道文件描述符,所以监听相同端口时就会失败。但对于 send() 发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。
多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用。换言之就是网络请求向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务。这些进程服务是抢占式的。
搭建好了集群,充分利用了多核 CPU 资源,似乎就可以迎接客户端大量的请求了。但请等等,我们还有一些细节需要考虑。
虽然我们创建了很多工作进程,但每个工作进程依然是在单线程上执行的,它的稳定性还不能得到完全的保障。我们需要建立起一个健全的机制来保障 Node 应用的健壮性。
上述这些事件是父进程能监听到的与子进程相关的事件。除了send() 外,还能通过 kill() 方法给子进程发送消息。kill() 方法并不能真正地将通过 IPC 相连的子进程杀死,它只是给子进程发送了一个系统信号。默认情况下,父进程将通过 kill() 方法给子进程发送一个 SIGTERM 信号。它与进程默认的 kill() 方法类似,如下所示:
// 子进程
child.kill([signal]);
// 当前进程
process.kill(pid, [signal]);它们一个发给子进程,一个发给目标进程。在 POSIX 标准中,有一套完备的信号系统,在命令行中执行 kill -l 可以看到详细的信号列表,如下所示:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGEMT 8) SIGFPE
9) SIGKILL 10) SIGBUS 11) SIGSEGV 12) SIGSYS
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGURG
17) SIGSTOP 18) SIGTSTP 19) SIGCONT 20) SIGCHLD
21) SIGTTIN 22) SIGTTOU 23) SIGIO 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGINFO 30) SIGUSR1 31) SIGUSR2 Node 提供了这些信号对应的信号事件,每个进程都可以监听这些信号事件。这些信号事件是用来通知进程的,每个信号事件有不同的含义,进程在收到响应信号时,应当做出约定的行为,如 SIGTERM 是软件终止信号,进程收到该信号时应当退出。示例代码如下所示:
process.on('SIGTERM', function() {
console.log('Got a SIGTERM, exiting...');
process.exit(1);
});
console.log('server running with PID:', process.pid);
process.kill(process.pid, 'SIGTERM');
主进程加入子进程管理机制的示意图
// master.js
var fork = require('child_process').fork;
var cpus = require('os').cpus();
var server = require('net').createServer();
server.listen(1337);
var workers = {};
var createWorker = function () {
var worker = fork(__dirname + '/worker.js');
// 退出时重新启动新的进程
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
createWorker();
});
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
};
for (var i = 0; i < cpus.length; i++) {
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', function () {
for (var pid in workers) {
workers[pid].kill();
}
}); 在实际业务中,可能有隐藏的 bug 导致工作进程退出,那么我们需要仔细地处理这种异常,如下所示:
// worker.js
var http = require('http');
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
});
var worker;
process.on('message', function (m, tcp) {
if (m === 'server') {
worker = tcp;
worker.on('connection', function (socket) {
server.emit('connection', socket);
});
}
});
process.on('uncaughtException', function () {
// 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
}); 上述代码的处理流程是,一旦有未捕获的异常出现,工作进程就会立即停止接收新的连接;当所有连接断开后,退出进程。主进程在侦听到工作进程的 exit 后,将会立即启动新的进程服务,以此保证整个集群中总是有进程在为用户服务的。
自杀信号
当然上述代码存在的问题是要等到已有的所有连接断开后进程才退出,在极端的情况下,所有工作进程都停止接收新的连接,全处在等待退出的状态。但在等到进程完全退出才重启的过程中,所有新来的请求可能存在没有工作进程为新用户服务的情景,这会丢掉大部分请求。
为此需要改进这个过程,不能等到工作进程退出后才重启新的工作进程。当然也不能暴力退出进程,因为这样会导致已连接的用户直接断开。于是我们在退出的流程中增加一个自杀(suicide)信号。工作进程在得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。代码改动如下所示:
// worker.js
process.on('uncaughtException', function (err) {
process.send({act: 'suicide'});
// 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
}); 主进程将重启工作进程的任务,从 exit 事件的处理函数中转移到 message 事件的处理函数中,如下所示:
var createWorker = function () {
var worker = fork(__dirname + '/worker.js');
// 启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
});
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
delete workers[worker.pid];
});与前一种方案相比,创建新工作进程在前,退出异常进程在后。在这个可怜的异常进程退出之前,总是有新的工作进程来替上它的岗位。至此我们完成了进程的平滑重启,一旦有异常出现,主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。整个过程使得我们的应用的稳定性和健壮性大大提高。
这里存在问题的是有可能我们的连接是长连接,不是 HTTP 服务的这种短连接,等待长连接断开可能需要较久的时间。为此为已有连接的断开设置一个超时时间是必要的,在限定时间里强制退出的设置如下所示:
process.on('uncaughtException', function (err) {
process.send({act: 'suicide'});
// 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
// 5秒后退出进程
setTimeout(function () {
process.exit(1);
}, 5000);
}); 进程中如果出现未能捕获的异常,就意味着有那么一段代码在健壮性上是不合格的。为此退出进程前,通过日志记录下问题所在是必须要做的事情,它可以帮我们很好地定位和追踪代码异常出现的位置,如下所示:
process.on('uncaughtException', function (err) {
// 记录日志
logger.error(err);
// 发送自杀信号
process.send({act: 'suicide'});
// 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
// 5秒后退出进程
setTimeout(function () {
process.exit(1);
}, 5000);
}); 限量重启
通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然还是有极端的情况。工作进程不能无限制地被重启,如果启动的过程中就发生了错误,或者启动后接到连接就收到错误会导致工作进程被频繁重启,这种频繁重启不属于我们捕捉未知异常的情况,因为这种短时间内频繁重启已经不符合预期的设置,极有可能是程序编写的错误。
为了消除这种无意义的重启,在满足一定规则的限制下,不应当反复重启。比如在单位时间内规定只能重启多少次,超过限制就触发 giveup 事件,告知放弃重启工作进程这个重要事件。
为了完成限量重启的统计,我们引入一个队列来做标记,在每次重启工作进程之间进行打点并判断重启是否太过频繁,如下所示:
// 重启次ْ数
var limit = 10;
// 时间单位
var during = 60000;
var restart = [];
var isTooFrequently = function () {
// 记录重启时间
var time = Date.now();
var length = restart.push(time);
if (length > limit) {
// 取出最后10个记录
restart = restart.slice(limit * -1);
}
// 最后一次重启到前10次重启之间的时间间隔
return restart.length >= limit && restart[restart.length - 1] - restart[0] < during;
};
var workers = {};
var createWorker = function () {
// 检查是否太过频繁
if (isTooFrequently()) {
// 触发 giveup 事件后,不再重启
process.emit('giveup', length, during);
return;
}
var worker = fork(__dirname + '/worker.js');
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
});
// 重新启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
}; giveup 事件是比 uncaughtException 更严重的异常事件。uncaughtException 只代表集群中某个工作进程退出,在整体性保证下,不会出现用户得不到服务的情况,但是这个 giveup 事件则表示集群中没有任何进程服务了,十分危险。为了健壮性考虑,我们应在 giveup 事件中添加重要日志,并让监控系统监视到这个严重错误,进而报警等。
Node 默认提供的机制是采用操作系统的抢占式策略。所谓的抢占式就是在一堆工作进程中闲着的进程对到来的请求进行争抢,谁抢到谁服务。
一般而言,这种抢占式策略对大家是公平的,各个进程可以根据自己的繁忙度来进行抢占。但是对于 Node 而言,需要分清的是它的繁忙是由 CPU、I/O 两个部分构成的,影响抢占的是 CPU 的繁忙度。对不同的业务,可能存在 I/O 繁忙,而 CPU 较为空闲的情况,这可能造成某个进程能够抢到较多请求,形成负载不均衡的情况。
为此 Node 在 v0.11 中提供了一种新的策略使得负载均衡更合理,这种新的策略叫 Round-Robin,又叫轮叫调度。轮叫调度的工作方式是由主进程接受连接,将其依次分发给工作进程。分发的策略是在 N 个工作进程中,每次选择第 i=(i+1) mod n 个进程来发送连接。在 cluster 模块中启用它的方式如下:
// 启用Round-Robin
cluster.schedulingPolicy = cluster.SCHED_RR
// 不启用Round-Robin
cluster.schedulingPolicy = cluster.SCHED_NONE或者在环境变量中设置 NODE_CLUSTER_SCHED_POLICYE 的值,如下所示:
export NODE_CLUSTER_SCHED_POLICY=rr
export NODE_CLUSTER_SCHED_POLICY=none Round-Robin 非常简单,可以避免 CPU 和 I/O 繁忙差异导致的负载不均衡。Round-Robin 策略也可以通过代理服务器来实现,但是它会导致服务器上消耗的文件描述符是平常方式的两倍。
实现状态同步的机制有两种,一种是各个子进程去向第三方进行定时轮询,示意图如下图所示。
定时轮询示意图
定时轮询带来的问题是轮询时间不能过密,如果子进程过多,会形成并发处理,如果数据没有发生改变,这些轮询会没有意义,白白增加查询状态的开销。如果轮询时间过长,数据发生改变时,不能及时更新到子进程中,会有一定的延迟。
一种改进的方式是当数据发生更新时,主动通知子进程。当然,即使是主动通知,也需要种机制来及时获取数据的改变。这个过程仍然不能脱离轮询,但我们可以减少轮询的进程数量,我们将这种用来发送通知和查询状态是否更改的进程叫做通知进程。为了不混合业务逻辑,可以将这个进程设计为只进行轮询和通知,不处理任何业务逻辑,示意图如下图所示。
主动通知示意图
这种推送机制如果按进程间信号传递,在跨多台服务器时会无效,是故可以考虑采用 TCP 或 UDP 的方案。进程在启动时从通知服务处除了读取第一次数据外,还将进程信息注册到通知服务处。一旦通过轮询发现有数据更新后,根据注册信息,将更新后的数据发送给工作进程。由于不涉及太多进程去向同一地方进行状态査询,状态响应处的压力不至于太过巨大,单一的通知服务轮询带来的压力并不大,所以可以将轮询时间调整得较短,一旦发现更新,就能实时地推送到各个子进程中。
Node 在 v0.8 版本时新增的 Cluster 模块就能解决。在 v0.8 版本之前,实现多进程架构必须通过 child_process 来实现,要创建单机 Node 集群,由于有这么多细节需要处理,对普通工程师而言是一件相对较难的工作,于是 v0.8 时直接引入了 Cluster 模块,用以解决多核 CPU 的利用率问题,同时也提供了较完善的 API,用以处理进程的健壮性问题。
通过 cluster 创建 Node 进程集群
// cluster.js
var cluster = require('cluster');
cluster.setupMaster({
exec: "worker.js"
});
var cpus = require('os').cpus();
for (var i = 0; i < cpus.length; i++) {
cluster.fork();
} 在进程中判断是主进程还是工作进程,主要取决于环境变量中是否有 NODE_UNIQUE_ID,如下所示:
cluster.isWorker = ('NODE_UNIQUE_ID' in process.env);
cluster.isMaster = (cluster.isWorker === false);事实上 cluster 模块就是 child_process 和 net 模块的组合应用。cluster 启动时,如同我们在【句柄传递】小节里的代码一样,它会在内部启动 TCP 服务器,在 cluster.fork() 子进程时,将这个 TCP 服务器端 socket 的文件描述符发送给工作进程。如果进程是通过 cluster.fork() 复制出来的,那么它的环境变量里就存在 NODE_UNIQUE_ID,如果工作进程中存在 listen() 侦听网络端口的调用,它将拿到该文件描述符,通过 SO_REUSEADDR 端口重用,从而实现多个子进程共享端口。对于普通方式启动的进程,则不存在文件描述符传递共享等事情。
在 cluster 内部隐式创建 TCP 服务器的方式对使用者来说十分透明,但也正是这种方式使得它无法如直接使用 child_process 那样灵活。在 cluster 模块应用中,一个主进程只能管理一组工作进程,如下图所示。
在 cluster 模块应用中,一个主进程只能管理一组工作进程
对于自行通过 child_process 来操作时,则可以更灵活地控制工作进程,甚至控制多组工作进程。其原因在于自行通过 child_process 操作子进程时,可以隐式地创建多个 TCP 服务器,使得子进程可以共享多个的服务器端 socket,如下图所示。
自行通过 child_process 控制多组工作进程
对于健壮性处理,Cluster 模块也暴露了相当多的事件。
这些事件大多跟 child_process 模块的事件相关,在进程间消息传递的基础上完成的封装这些事件对于增强应用的健壮性已经足够了。
尽管 Node 从单线程的角度来讲它有够脆弱的:既不能充分利用多核 CPU 资源,稳定性也无法得到保障。但是群体的力量是强大的,通过简单的主从模式,就可以将应用的质量提升一个档次。在实际的复杂业务中,我们可能要启动很多子进程来处理任务,结构甚至远比主从模式复杂,但是每个子进程应当是简单到只做好一件事,然后通过进程间通信技术将它们连接起来即可。这符合 Unix 的设计理念,每个进程只做一件事,并做好一件事,将复杂分解为简单,将简单组合成强大。
尽管通过 child_process 模块可以大幅提升 Node 的稳定性,但是一旦主进程出现问题,所有子进程将会失去管理。在 Node 的进程管理之外,还需要用监听进程数量或监听日志的方式确保整个系统的稳定性,即使主进程出错退出,也能及时得到监控警报,使得开发者可以及时处理故障。
测试风格:TDD(测试驱动开发)、BDD(行为驱动开发)。它们的差别如下:
基准测试要统计的就是在多少时间内执行了多少次某个方法。为了増强可比性,一般会以次数作为参照物,然后比较时间,此来判别性能的差距。
对网络接口进行压力测试以判断网络接口的性能。对网络接口做压力测试需要考査的几个指标有吞吐率、响应时间和并发数,这些指标反映了服务器的并发处理能力。
笔者个人补充:
负载测试
是通过逐步增加系统负载,测试系统性能的变化,并在满足最终确定性能指标的情况下,系统所能承受的最大负载量。
负载测试的重点是:在系统正常工作情况下的性能指标,发现系统能够承受最大负载量的测试,属于正常范围的测试;
压力测试的重点是:确定在什么负载下系统的性能处于失效状态,发现系统性能的拐点,来获得系统能提供的最大服务级别的测试,属于异常范围的测试。
所谓的工程化,可以理解为项目的组织能力。体现在文件上,就是文件的组织能力。对于不同类型的项目,其组织方式也有所不同。
部署流程图
动静分离
动静分离示意图
启用缓存
多进程架构
读写分离
日志
监控报警
稳定性
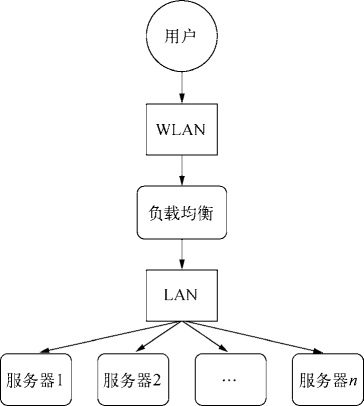
异构共存
编程语言与服务通过网络协议进行调用的示意图
呃~貌似好久没写文章了,感觉有点奇怪。废话不多说,但还是加点前戏吧。
不想听废话,直入主题>>
为何要写这篇文章
接下来因工作调整,应该就很少接触 H5 开发了。借此机会总结个人对动画的一些思考。
本文贴合实战,会结合笔者为数不多的开发案例进行讲解🤣。文章结尾也会提供相应文件让读者进行实践。
同一份设计稿给到不同开发者,结果可能千差万别。而结果主要由两部分体现——内在与外在。『内在』指的是代码质量、性能优化,『外在』则指的是视觉还原度和动效(交互)。
其中对于更直观的『外在』来说,视觉还原度高是前提,真正体现差距的是『动效』。因为设计师一般只给到“静态”的视觉稿,而无动画演示,更不用说提供动效搞(如 AE)了。
在这种情况下,页面的动效更多是由前端开发者自由发挥。因此对动效有钻研的同学优势尽显。我也曾问过这些同学,他们大多回答是:“多试多调”。因此,在设计师无『动效稿』提供的情况下,都需要花时间慢慢调整,以达到各方(本人、设计师、产品和需求方等)满意。若没有设计、动效等相关知识的学习与积累,恐怕是一只『没头苍蝇』。
关于动画的理论方面,笔者并没有积累,但推荐一些不错的资料(或许需要梯子)。同时也希望得到读者们的有效补充:
大多数前端开发者在设计和动效方面并没有太多积累,因而难以做出令人拍手称赞的效果。其实,这是设计师(和动效设计师)所擅长的领域。下表给出两者的对比:
| * | 设计师 | 前端开发 | 备注 |
|---|---|---|---|
| 是否擅长动画 | 大部分 | 少部分 | |
| 如何生产动画 | GUI 工具,如 AE | 编写代码 | |
| 效益 | 高 | 低 | 体现在以下几个方面: 1. 专业度 2. 实现效率:可视化 > 编写代码 3. 沟通成本 4. 各方满意度 5. ... |
从上表可看出,将『动效设计』交给设计师能显著提高效益。
而在实际工作流程上:
 |
 |
|---|---|
| 补间动画——Apple | 逐帧动画——洗衣机 |
设计师输出的动效演示
注:全文『动效稿』均基于 Adobe After Effects(简称 AE)设计。
其实,与『制造业』一样,实现方式就两种:
两者的优缺点比较:
| * | 机械 | 手工 |
|---|---|---|
| 效率 | 高 | 低 |
| 精度 | 高 | 视情况而定 |
| 定制化 | 低 | 高 |
| 情怀 | 无 | 因人而异 |
机械代表着“未来、高效”。业界出现了很多优秀的工具,使得在浏览器渲染复杂动效成为了可能,且极大地提高了效率。
代表工具有:
可是『世界上本来就没有十全十美的东西』。机械化生产可能未必满足所有要求,生产环境上的要求就更加苛刻了。主要体现在:机械化生产导致介入难度高。若出现以下问题就比较棘手:
无论如何,『机械化』是未来,期待它早日以完美的姿态到来。
手工代表着“自定义、可控性”。无论世界如何工具化,总有一些人保持着对『手工』的热爱。
『手工』意味着从无到有的过程。需要我们参与这个过程的每一步。这也就使得我们拥有很强的自定义能力。这恰恰是『机械化』目前所不具备的特性。这也是本文重点阐述的内容。
基于 AE 手工实现 Web 动画的主要工作有两点:
显然,对于取参操作来说,逐帧动画比补间动画的工作量要大得多,但两者操作一致。所以下面以 补间动画 Apple 为例:
打开 apple.aep 文件,AE 界面如下:
AE 界面
点击『信息模块』预览面板的播放按钮或拖动『时间轴模块』的
标记3即可预览动画。
根据 CSS3 animation 属性,我们需要获取以下信息:
animation-durationanimation-timing-functionanimation-delay为了方便阐述,我们选取整个 Apple 动画中一个小圆圈(共 60 个)为代表,其余元素同理。
另外,由于该动画是一次性的,无需获取/设置动画的重复次数(animation-iteration-count)、运动方向(animation-direction)。
现在我们把目光投向『图层、运动模块』的 标记1:
标记1——FPS
由上图可得,FPS 为 12,即 1 秒 12 帧, 1 帧 0.0833 秒。
由上面 Apple 动画 可看出,每个圆的延时时间(animation-delay)、缓动函数(animation-timing-function)和持续时间(animation-duration)均不相同。换句话说,每个圈都是一个独立的补间动画,所有元素组合起来才是一个完整的补间动画。
双击『标记 2』,进入编组以查看每个圆的信息。
子元素——圆
在『查看器』或『图层、运动模块』任意选中一个圆,展开其 变换 属性并单击 位置(标记1),即可在其右侧显示元素运动路径(标记2)。同时这也反映了属性的变化速率(即缓动函数(animation-timing-function),这方面会在后续详解。
位置前面的时钟图标为蓝色时,代表有过渡动画。
结合上面知识,可从上图得出以下信息点:
因此,我们基于 CSS3 animation 实现该元素的补间动画:
<div class="circle-29"></div>/* 默认将该园定位在第 2(或 3)关键帧的位置,以让元素默认显示屏幕内,便于开发调试。 */
.circle-29 {
width: 60px;
height: 60px;
background-color: rgba(0, 224, 93, .7);
position: absolute;
left: 473px;
top: 348px;
border-radius: 50%;
animation-name: circle29;
animation-duration: 3.5s; /* 42 * (1 / 12) */
animation-delay: 0.0833s; /* 1 * (1 / 12) */
animation-fill-mode: both;
animation-timing-function: ease-in-out;
}
@keyframes circle29 {
0% {
transform: translate3d(0, 1175px, 0);
}
61.90% { /* (2 * 12 + 3 - 1) / 42,注意要减去延时时间(1 帧)。下同。*/
transform: translate3d(0, 0, 0);
}
64.29% { /* (2 * 12 + 4 - 1) / 42 */
transform: translate3d(0, 0, 0);
}
100% {
transform: translate3d(0, -1225px, 0);
}
}这样就完成了某个圆的补间动画了。虽然繁琐,但省去了反复试验的时间,基本做到一次开发,各方满意的效果。
See the Pen ae2web-circle by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>其余元素按照以上步骤即可完成整个动画。
假设没有动画演示和动效稿,仅凭个人感觉,编码完成一个由 60 多个元素组成的动画,简直难于上青天(对于笔者来说)。
animation-timing-function 存在误解细心的读者可能发现:如果第 1、2 关键帧和第 3、4 关键帧的缓动函数不相同时,该怎么办?
首先部分人可能对 animation-timing-function 存在误解:它是作用于整个 @keyframes 规则的。❌
其实缓动函数是作用于 @keyframes 规则内的关键帧。若未为关键帧指定 animation-timing-function,则从其元素取得 animation-timing-function。
更严格地说,缓动函数是应用在属性上。当关键帧有指定 animation-timing-function 时,则该缓动函数会影响该关键帧内所有属性,而每个受影响的属性,其缓动效果会结束在下一个有指定同样属性的关键帧。
举个例子:
.box {
width: 100px;
height: 100px;
background-color: #6190e8;
animation: move 2s ease both;
}
@keyframes move {
0% {
animation-timing-function: linear;
transform: translateX(0);
opacity: 1;
}
50% {
opacity: .5;
}
100% {
transform: translateX(100px);
opacity: 1;
animation-timing-function: ease-in-out; /* 无用多余 */
}
}在 0% 关键帧中指定的 animation-timing-function: linear 会对 transform 和 opacity 属性有效。但因为 50% 关键帧未指定 transform 属性,所以 animation-timing-function: linear 对它生效至有指定 transform 属性的关键帧,即 100% 关键帧。
对于 opacity 属性,因为 50% 关键帧未指定 animation-timing-function,所以它会取 .box 元素上指定的 ease 缓动函数。
简言而之:
综上所述,可在关键帧上指定不同的缓动函数,以满足属性在各个关键帧间不同的变化速率。
细心的读者可能又发现:缓动函数碰巧是 预定义的关键字 还好,但如果是以下这种情况呢?
显然浏览器预定义的关键字无法还原这些类型的缓动函数,但浏览器提供了强大的 cubic-bezier() 方法。翻译过来就是三次贝塞尔曲线。因此,我们可以通过该方法自定义缓动函数。
想了解贝塞尔曲线的更多知识,可阅读 《贝塞尔曲线扫盲》。
AE 时间轴 上呈现的是属性的变化路径,其未必与变化速率(即缓动函数)完全一致。因为它们的 X/Y 轴含义不同。
如上图所示,AE 是属性随着时间而变,CSS3 animation 是动画进度随着时间而变。然而属性的变化是有方向的,动画进度是永远向前的。
举个例子:
AE:
AE 属性变化是有方向的
对应 CSS3 animation-timing-function:
动画进度永远是向前的
如上面二图所示,下图是上图的速率变化(缓动函数)。理清 AE 与 CSS3 animation 的对应关系后,剩下的问题就是:如何通过 cubic-bezier() 表示图中的 CurveA 与 CurveB。
也许有工具可从 AE 直接导出(欢迎读者们提供链接),但本文为了简单起见,推荐使用 Ceasar 或 Cubic-Bezier.com 这类可视化工具直接模拟生成。
因此,上述补间动画的缓动函数可表示为:
@keyframes ae2css {
0% {
animation-timing-function: ease-out;
}
23% {
animation-timing-function: ease-in;
}
50% {
animation-timing-function: cubic-bezier(0.5, 0, 0.5, 1.5);
}
76% {
animation-timing-function: cubic-bezier(0, 0, 0, 1);
}
100% {
}
}
本文基于实际案例总结出 AE 到 Web 动画的实现方法。相对于『无动效稿』的反复编码尝试,该方法无疑能提高效益。当然,『手工』不能胜任复杂的动画(如 SVG 的变形动画(Morphing)),并且低效。因此,业界在『机械/工具化』方面不断推陈出新,涌现出许多优秀的工具,让复杂动画在各终端上得以展现。无论如何,学习更多知识总没错!
最后,感谢你的阅读!
Apple 补间动画整体效果演示(一次性动画,请点击 "RERUN" 按钮重播):
See the Pen ae2css-apple by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>| 项目 | Apple | Joy&Apple | 洗衣机 |
|---|---|---|---|
| 动画类型 | 补间动画 | 补间动画 | 逐帧动画(APP 背景图) |
| 体验链接 | Apple | Joy&Apple | 洗衣机 |
| 效果展示 |  |
 |
 |
| 视频外链(若 gif 加载失败,可点击视频外链) | Apple | Joy&Apple | 洗衣机 |
曲线运动是指运动轨迹为曲线的运动。当物体运动的的速度与其所受到的合外力不在同一直线上时,物体便做曲线运动。典型的曲线运动有:平抛运动、斜抛运动、圆周运动等。——维基百科
在 Web 页面中,直线运动很普遍,因为它实现简单的同时,也符合大多数场景。但是总有一些情况需要用到曲线运动。本文将曲线运动分为两种:「随机曲线运动」和「曲线路径运动」,后者是本文讲述的重点。而为了控制篇幅,部分章节以案例+外链的形式进行讲解。
在阐述曲线运动前,我们先看看直线运动。
在二维的直角坐标系中,速度矢量 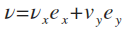
See the Pen 直线运动 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>当物体运动的的速度与其所受到的合外力不在同一直线上时,物体便做曲线运动。典型的曲线运动有:平抛运动、斜抛运动和圆周运动。
See the Pen 典型的曲线运动 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>然而在网页动画中,元素并不一定符合物理世界的规律。因此,对设计稿中的曲线运动可选择以下实现方式:
实现方法肯定不止于此,更多的方法由大家去探索,欢迎大家留言分享。至于动画库,每个人的习惯或喜爱各不相同,本文就不再展开细说。
三角函数看似简单,却在各类动画实现中承当了重要角色。比如:
See the Pen Lissajous by Jake Albaugh (@jakealbaugh) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>在 直线运动 章节,我们知道:在二维的直角坐标系中,速度由 x 轴和 y 轴两个速度分量组成。因此通过 CSS 亦可实现曲线运动,具体可阅读 《【译】使用 CSS 分层动画实现曲线运动》 。
分享一下笔者之前基于该方式实现的背景氛围动效:
See the Pen css-curve-final by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>然而,有些自定义的路径并不能简单地通过三角函数或 CSS 分层动画实现。假如设计师有提供 AE 稿,那么我们就可以考虑使用逐帧法去实现曲线路径运动。
See the Pen 逐帧曲线 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>上述案例存在两个曲线路径运动。因为曲线路径范围较小且无转向要求(物体是圆),采用逐帧的方式也能实现。
当然,逐帧并不是要求以 60 帧率去读取曲线信息,而是根据具体案例,以固定帧数间距取值作为关键帧,然后关键帧间使用线性过渡(animation-timing-function: linear;)即可。
因此,将光滑的曲线路径离散成固定帧数间距的点时,在视觉上也能提供曲线路径运动的效果。
「逐帧法」的确适用于小范围使用的案例,但显然不适用于复杂(或长距离)的曲线运动场景。
上述案例是从 AE 动画中提取曲线路径信息的,关于如何从 AE 中提取动画信息,可阅读 《动画:从 AE 到 Web》。
在 Web 浏览器上,Canvas 和 SVG 都提供了绘制贝塞尔曲线的 API(二次与三次贝塞尔曲线)。但 SVG 比 Canvas 更贴心地提供了 animateMotion 路径动画。
SVG 路径动画:
See the Pen SVG Path motion by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>要想在 Canvas 上实现与 SVG 一样的路径动画,本质是要实时获取路径在某时刻的 (x, y) 坐标。
以下图为例,路径由多段线段/曲线(以颜色区分)组成。
红色和金色为直线、绿色为二次贝塞尔曲线、蓝色为三次贝塞尔曲线
See the Pen 曲线路径运动 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>以下代码以百分比为参数(0.00 ~ 1.00)返回路径的 (x, y) 坐标。比如:
以下代码是获取线段(直线)特定位置的 (x, y) 坐标:
function getLineXYatPercent(startPt, endPt, percent) {
const dx = endPt.x - startPt.x
const dy = endPt.y - startPt.y
const X = startPt.x + dx * percent
const Y = startPt.y + dy * percent
return { x: X, y: Y }
}以下代码是获取二次贝塞尔曲线特定位置的 (x, y) 坐标:
function getQuadraticBezierXYatPercent(startPt, controlPt, endPt, percent) {
const x = Math.pow(1 - percent, 2) * startPt.x + 2 * (1 - percent) * percent * controlPt.x + Math.pow(percent, 2) * endPt.x
const y = Math.pow(1 - percent, 2) * startPt.y + 2 * (1 - percent) * percent * controlPt.y + Math.pow(percent, 2) * endPt.y
return { x: x, y: y }
}以下代码是获取三次贝塞尔曲线特定位置的 (x, y) 坐标:
function getCubicBezierXYatPercent(startPt, controlPt1, controlPt2, endPt, percent){
const x = CubicN(percent, startPt.x, controlPt1.x, controlPt2.x, endPt.x)
const y = CubicN(percent, startPt.y, controlPt1.y, controlPt2.y, endPt.y)
return { x: x, y: y }
}
// 三次贝塞尔曲线的辅助函数
function CubicN(pct, a, b, c, d) {
const t2 = pct * pct
const t3 = t2 * pct
return a + (-a * 3 + pct * (3 * a - a * pct)) * pct
+ (3 * b + pct * (-6 * b + b * 3 * pct)) * pct
+ (c * 3 - c * 3 * pct) * t2
+ d * t3
}将以上获取 (x, y) 坐标的方法结合在一起后,就可以实现图中的路径动画。
// 计算路径上特定位置的 (x, y) 坐标
if (pathPercent < 25) {
const line1percent = pathPercent / 24
xy = getLineXYatPercent({x: 100, y: 20}, {x: 200, y: 160}, line1percent)
}
else if (pathPercent < 50) {
const quadPercent = (pathPercent - 25) / 24
xy = getQuadraticBezierXYatPercent({x: 200, y: 160}, {x: 230, y: 200}, {x: 250, y: 120}, quadPercent)
}
else if (pathPercent < 75) {
const cubicPercent = (pathPercent - 50) / 24
xy = getCubicBezierXYatPercent({x: 250, y: 120}, {x: 290, y: -40}, {x: 300, y: 200}, {x: 400, y: 150}, cubicPercent)
}
else {
const line2percent = (pathPercent - 75) / 25
xy = getLineXYatPercent({x: 400, y: 150}, {x: 500, y: 90}, line2percent)
}
// 绘制物体(矩形)
drawRect(xy)由于贝塞尔曲线的特性,百分比参数得到的点并没有拥有相同的弧长。如以下所示:
贝塞尔曲线的点间距问题
左侧是二次贝塞尔曲线,右侧是三次贝塞尔曲线。通过 0, 0.1, 0.2,..., 1 间距打点后会发现曲线两端点比中间点的间距要大。想要达到两点间距相等的效果,可 点击这里 阅读了解。
See the Pen 曲线路径运动(带转向) by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>SVG 的路径动画还支持物体实时跟随路径方向转向。为 animateMotion 标签指定 rotate="auto" 即可让物体指向即时速度方向(即点 P 的切线方向)。
在曲线运动中,物体在某点的速度方向就是该点的切线方向(指向前进一侧)
既然我们能得到路径任意位置的坐标,那么我们就可以通过「当前位置」与「相邻位置」的坐标计算出该点的斜率,然后再根据斜率对物体进行旋转。
斜率,亦称“角系数”,表示一条直线相对于横轴的倾斜程度。一条直线与某平面直角坐标系横轴正半轴方向的夹角的正切值即该直线相对于该坐标系的斜率。 如果直线与x轴垂直,直角的正切值无穷大,故此直线不存在斜率。——百度百科
// 获取两点之间的角度(弧度)
function getAngleOfTwoPoints (point1, point2) {
return Math.atan2(point2.y - point1.y, point2.x - point1.x) // [-Math.PI, Math.PI]
}See the Pen 两点角度 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>得到切线与 x 轴的夹角后,即可通过 context.translate() 与 context.rotate() 对物体旋转至切线方向。关于如何在 Canvas 中以物体为中心进行旋转的问题,建议读者阅读 《canvas 图像旋转与翻转姿势解锁》 ,以深入了解 Canvas 的坐标系及相关知识。
细心的同学可能发现 JavaScript 还有 Math.atan() 这个 API。Math.atan2() 与 Math.atan() 都是正切 tan(θ) 的反函数。
在 MDN 文档中可知两者有以下区别:
Math.atan2() 接受单独的 y 和 x 参数(注意参数顺序),而 Math.atan() 接受两个参数的比值(dy/dx);Math.atan() 仅返回半圆区间的值 (-Math.PI / 2, Math.PI / 2](正 x 轴为 0),而 Math.atan2() 则返回整个圆的值 (-Math.PI ~ Math.PI];Math.atan2() 能正确处理 x = 0 而 y = 0 的情况,而 Math.atan() 不能 。Math.atan(0 / 0); // NaN, (0 / 0) 本来就是 NaN
Math.atan2(0, 0); // 0
// Math.atan2(y, x) 表示 (0, 0) 到 (x, y) 的直线与正 x 轴形成的夹角
Math.atan2(-1, 1); // -Math.PI / 4,即 -45°
Math.atan2(1, 1); // Math.PI / 4,即 45°因此在一般情况下更推荐使用 Math.atan2(y, x)。
Math.atan2() 返回的角度为何是这样?
Math.atan2() 返回的角度如下图左侧所示,这似乎与平时课本上的不一样。
在 MDN 上对 Math.atan2() 有这样的描述——"This is the counterclockwise angle, measured in radians, between the positive X axis, and the point (x, y)."。重点是“This is the counterclockwise angle”,翻译过来是“这是一个逆时针角度”。
其实,课本中的角度正是“逆时针角度”。既然两者均是“逆时针角度”,为何表现得不一致呢?
逆时针角度:逆时针为正,顺时针为负
其实,两者是一致的。之所以表现不一致,是因为 Canvas 坐标系的 y 轴往下为正(x 轴往右为正)。
Canvas 坐标系的历史背景是:电子枪是从左往右,从上往下扫描屏幕的。——《HTML5 + JavaScript 动画基础》
因此,只需将坐标系沿 x 轴翻转 180° 即可使 Math.atan2 还原成课本中的样子。
当然,在 Canvas 中涉及角度的方法无需还原成课本上的样子,因为它们所处环境是一致的,比如:Math.atan2() 得到的角度可让 context.rotate() 方法直接使用。所以,我们并不需要将坐标系进行翻转,只需理解为什么在 Canvas 中正角度表现为“顺时针”即可。
context.rotate(angle)
另外,笔者在搜索“逆时针角度”的资料时,顺便填充了生活常识的一个空白:一般情况下,时钟指针是顺时针走的,水龙头是顺时针关闭的,螺丝是顺时针拧紧的,罗盘方位是顺时针走的,但角度是逆时针测量的。
贝塞尔曲线 案例中,四段子路径的运动时间相同。倘若想让物体在整个路径中速度保持不变,那么就需要得到每段子路径的路径长度,以分配与路径长度成比例的帧数(时间)。
下面是计算线段、二次贝塞尔曲线和三次贝塞尔曲线长度的计算方法:
设两个点 A、B 以及坐标分别为 A(x1, y1)、B(x2, y2)
以下代码是获取线段长度:
function getLineLength (startPt, endPt) {
return Math.sqrt(Math.pow(startPt.x - endPt.x, 2) + Math.pow(startPt.y - endPt.y, 2))
}以下代码是获取二次贝塞尔曲线长度:
// 来自:https://gist.github.com/tunght13488/6744e77c242cc7a94859
function getQuadraticBezierLength(p0, p1, p2) {
var ax = p0.x - 2 * p1.x + p2.x
var ay = p0.y - 2 * p1.y + p2.y
var bx = 2 * p1.x - 2 * p0.x
var by = 2 * p1.y - 2 * p0.y
var A = 4 * (ax * ax + ay * ay)
var B = 4 * (ax * bx + ay * by)
var C = bx * bx + by * by
var Sabc = 2 * sqrt(A+B+C)
var A_2 = sqrt(A)
var A_32 = 2 * A * A_2
var C_2 = 2 * sqrt(C)
var BA = B / A_2
return (A_32 * Sabc + A_2 * B * (Sabc - C_2) + (4 * C * A - B * B) * log((2 * A_2 + BA + Sabc) / (BA + C_2))) / (4 * A_32)
}See the Pen 二次贝塞尔曲线的路径长度 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>目前没有一个简单的公式能直接获取三次贝塞尔曲线的长度,所以建议将曲线分为 N 段,然后将每段作为线段(直线)进行累加长度。所谓的分段,就是通过百分比参数获取路径上的值,然后再计算相邻两点的距离。当然,N 越大结果就越精准。
See the Pen 三次贝塞尔曲线的路径长度 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>以下代码是获取三次贝塞尔曲线长度:
function getCubicBezierLength(startPt, controlPt1, controlPt2, endPt, steps) {
const points = []
let sum = 0
for (let i = 0; i < steps + 1; i++) {
const percent = i * (1 / steps)
const xy = getCubicBezierXYatPercent(startPt, controlPt1, controlPt2, endPt, percent)
points.push(xy)
}
for (let i = 0; i < points.length - 1; i++) {
const curPt = points[i]
const nextPt = points[i + 1]
sum += getLineLength(curPt, nextPt)
}
return sum
}
// 根据 percent 获取三次贝塞尔曲线的 (x, y) 坐标
function getCubicBezierXYatPercent(startPt, controlPt1, controlPt2, endPt, percent) {
var x = CubicN(percent, startPt.x, controlPt1.x, controlPt2.x, endPt.x);
var y = CubicN(percent, startPt.y, controlPt1.y, controlPt2.y, endPt.y);
return ({
x: x,
y: y
});
}
// 三次贝塞尔曲线的辅助函数
function CubicN(pct, a, b, c, d) {
var t2 = pct * pct;
var t3 = t2 * pct;
return a + (-a * 3 + pct * (3 * a - a * pct)) * pct + (3 * b + pct * (-6 * b + b * 3 * pct)) * pct + (c * 3 - c * 3 * pct) * t2 + d * t3;
}
function getLineLength(startPt, endPt) {
return Math.sqrt(Math.pow(startPt.x - endPt.x, 2) + Math.pow(startPt.y - endPt.y, 2))
}其实本文是笔者一直想写的主题,毕竟很多有趣的动画或多或少都会拥有曲线(路径)运动。当然,很多成熟的动画库都已经可以轻松实现曲线(路径)运动,但这也不妨碍笔者去学习总结相关知识。尽管,很多公式都是搜索来的。
原文:Vue Authentication And Route Handling Using Vue-router
Vue 是一个渐进式 JavaScript 框架,它使得前端应用的构建变得简单。搭配 vue-router 就能构建拥有复杂动态路由的高性能应用。vue-router 是一个高效的工具,它能在 Vue 应用中无缝地处理用户认证。在本教程中,我们将看到如何使用 vue-router 处理用户认证和应用各部分的访问控制。
通过 Vue cli 创建一个 Vue 应用:
$ npm install -g @vue/cli
$ npm install -g @vue/cli-init
$ vue init webpack vue-router-auth根据安装提示完成应用的安装。如果某个选项不确定,可敲 return 键(既 enter 键)输入默认值以进行下一步。当询问是否安装 vue-router 时,就确认安装。
1. 开始 - Getting Started
2. 启动 Node.js 服务 - Setup Node.js Server
3. 更新 Vue-router 文件 - Updating The Vue-router File
4. 定义组件 - Define Some Components
5. 全局安装 Axios - Setting Up Axios Globally
6. 运行应用 - Running The Application
7. 总结 - Conclusion
下一步是启动 Node.js 服务以处理用户认证功能。我们将使用 SQLite 作为数据库。通过以下命令安装 SQLite 驱动:
$ npm install --save sqlite3因为需要与密码打交道,所以需要对密码进行哈希加密。我们将使用 bcrypt 完成哈希加密操作。通过以下命令安装:
$ npm install --save bcrypt当用户向应用需要认证的部分发送请求时,我们如何进行用户认证呢?对此,我们将使用 JWT 解决这个问题。通过以下命令安装 JWT 模块:
$ npm install jsonwebtoken --save为了能读取 json 请求数据,我们需要 body-parser 模块。通过以下命令安装:
$ npm install --save body-parser现在万事俱备,让我们创建一个简单的 Node.js 服务以处理用户认证。创建名为 server 的新目录,它将存放所有 Node.js 后端文件。在该目录下,创建名为 app.js 文件,其内容如下:
const express = require('express')
const DB = require('./db')
const config = require('./config')
const bcrypt = require('bcrypt')
const jwt = require('jsonwebtoken')
const bodyParser = require('body-parser')
const db = new DB('sqlitedb')
const app = express()
const router = express.Router()
router.use(bodyParser.urlencoded({ extended: false }))
router.use(bodyParser.json())引入应用所需的所有模块、定义数据库、创建一个 express 服务和一个 express 路由。
现在,让我们定义 CORS 中间件,以确保不陷入任何跨域问题:
// CORS middleware
const allowCrossDomain = function (req, res, next) {
res.header('Access-Control-Allow-Origin', '*')
res.header('Access-Control-Allow-Methods', '*')
res.header('Access-Control-Allow-Headers', '*')
next()
}
app.use(allowCrossDomain)很多开发者都会使用 CORS 库,但我们并没有任何复杂的配置,所以适合就好。
接下来,定义注册新用户的路由:
router.post('/register', (req, res) => {
db.insert([
req.body.name,
req.body.email,
bcrypt.hashSync(req.body.password, 8)
], err => {
if (err) {
return res.status(500).send('There was a problem registering the user.')
}
db.selectByEmail(req.body.email, (err, user) => {
if (err) {
return res.status(500).send('There was a problem getting user')
}
let token = jwt.sign(
{ id: user.id },
config.secret,
{ expiresIn: 86400 }
)
res.status(200).send({
auth: true,
token,
user,
})
})
})
})上述代码做了以下事情:向数据库方法(后续定义)传递了请求体(request body)和一个用于处理数据库响应的回调函数。同时,也定义了错误检查,以确保能向用户提供精确的反馈信息。
当用户成功注册时,我们通过 email 选择用户,并通过 jwt 模块为其创建用户认证 token。而 config 文件内的 secret key 则用于对用户认证进行签名。这样,我们就能验证发送到服务器的 token,避免伪造身份。
现在,定义用于注册管理员和登录的路由,两者与上述的注册逻辑类似:
router.post('/register-admin', (req, res) => {
db.insertAdmin([
req.body.name,
req.body.email,
bcrypt.hashSync(req.body.password, 8),
1,
], err => {
if (err) {
return res.status(500).send('There was a problem registering the user.')
}
db.selectByEmail(req.body.email, (err, user) => {
if (err) {
return res.status(500).send('There was a problem getting user.')
}
let token = jwt.sign(
{ id: user.id },
config.secret,
{ expiresIn: 86400 }
)
res.status(200).send({
auth: true,
token,
user,
})
})
})
})
router.post('/login', (req, res) => {
db.selectByEmail(req.body.email, (err, user) => {
if (err) {
return res.status(500).send('Error on the server.')
}
if (!user) {
return res.status(404).send('No user Found.')
}
let passwordIsValid = bcrypt.compareSync(req.body.password, user.user_pass)
if (!passwordIsValid) {
return res.status(401).send({
auth: false,
token: null
})
}
let token = jwt.sign(
{ id: user.id },
config.secret,
{ expiresIn: 86400 }
)
res.status(200).send({
auth: true,
token,
user,
})
})
})对于登录,我们使用 bcrypt 模块对哈希后的密码和用户提供的密码进行比较。若两者相同,则登录成功。反之,则登录失败,并向用户进行反馈。
通过 express 服务器让应用可响应请求:
app.use(router)
let port = process.env.PORT || 3000
let server = app.listen(port, () => {
console.log(`Express server listening on port ${port}`)
})我们在 port: 3000 创建了一个服务,任意动态生成的端口亦可(heroku 提供 生成动态端口服务)。
然后,在同样目录下创建 config.js 文件:
module.exports = {
'secret': 'supersecret'
}最后,创建 db.js 文件:
const sqlite3 = require('sqlite3').verbose()
class DB {
constructor(file) {
this.db = new sqlite3.Database(file)
this.createTable()
}
createTable() {
const sql = `
CREATE TABLE IF NOT EXISTS user (
id integer PRIMARY KEY,
name text,
email text UNIQUE,
user_pass text,
is_admin integer)`
return this.db.run(sql);
}
selectByEmail(email, callback) {
return this.db.get(
`SELECT * FROM user WHERE email = ?`,
[email], function (err, row) {
callback(err, row)
})
}
insertAdmin(user, callback) {
return this.db.run(
'INSERT INTO user (name,email,user_pass,is_admin) VALUES (?,?,?,?)',
user, (err) => {
callback(err)
})
}
selectAll(callback) {
return this.db.all(`SELECT * FROM user`, function (err, rows) {
callback(err, rows)
})
}
insert(user, callback) {
return this.db.run(
'INSERT INTO user (name,email,user_pass) VALUES (?,?,?)',
user, (err) => {
callback(err)
})
}
}
module.exports = DB为数据库创建一个类以抽象出所需的基本函数。你可能希望在此使用更通用和可复用的方法来进行数据库操作,甚至是使用 promise 来提高其效率。既需要一个所有类可共用的库(特别是使用 MVC 架构的应用)。
服务器端已完成开发,接下来让我们看看 Vue 应用。
该 vue-router 文件在 ./src/router 目录下。我们将在 index.js 文件定义应用的所有路由。这与服务器不同,切记混淆。
打开该文件并添加以下内容:
import Vue from 'vue'
import Router from 'vue-router'
import HelloWorld from '@/components/HelloWorld'
import Login from '@/components/Login'
import Register from '@/components/Register'
import UserBoard from '@/components/UserBoard'
import Admin from '@/components/Admin'
Vue.use(Router)引入所有组件,这些组件将在后续创建。
定义应用的路由:
let router = new Router({
mode: 'history',
routes: [
{
path: '/',
name: 'HelloWorld',
component: HelloWorld
},
{
path: '/login',
name: 'login',
component: Login,
meta: {
guest: true
}
},
{
path: '/register',
name: 'register',
component: Register,
meta: {
guest: true
}
},
{
path: '/dashboard',
name: 'userboard',
component: UserBoard,
meta: {
requiresAuth: true
}
},
{
path: '/admin',
name: 'admin',
component: Admin,
meta: {
requiresAuth: true,
is_admin : true
}
},
]
})Vue router 可定义元数据(meta),可基于此指定额外行为。上述代码,我们分别定义了 访客(未认证用户可见)、认证用户(认证用户可见)和管理员的路由。
基于元数据(meta)处理路由请求:
router.beforeEach((to, from, next) => {
if (to.matched.some(record => record.meta.requiresAuth)) {
if (localStorage.getItem('jwt') === null) {
next({
path: '/login',
query: { nextUrl: to.fullPath },
})
} else {
const user = JSON.parse(localStorage.getItem('user'))
if (to.matched.some(record => record.meta.is_admin)) {
if (user.is_admin === 1) {
next()
} else {
next({ name: 'userboard' })
}
} else {
next()
}
}
} else if (to.matched.some(record => record.meta.guest)) {
if (localStorage.getItem('jwt') === null) {
next()
} else {
next({ name: 'userboard' })
}
} else {
next()
}
})
export default routerVue-router 拥有一个 beforeEach 方法,其在每个路由处理前调用。可利用此特性定义检查条件并限制用户访问权限。该方法共接收 3 个参数——to、from 和 next。其中,to 是用户将去哪、from 是用户来自哪、next 是一个继续用户请求处理的回调函数。因此,检查操作将在 to 对象上进行。
我们将进行以下几点检查:
requireAuth,则检查 jwt token,以表明用户是否已登录。requireAuth 且要求是管理员,则检查已登录用户是否是管理员。guest,则检查用户是否已登录。我们根据检查内容对用户请求进行重定向。由于上述代码使用路由的 name 属性进行重定向,需确保应用拥有该 name 属性的路由。
重要:始终确保检查的每个条件语句末尾均调用
next()函数,以防止应用存在检查遗漏。
下面将定义一些组件,用于测试上面构建的内容。在 ./src/components/ 目录下,打开 HelloWorld.vue 文件并输入以下内容:
<template>
<div class="hello">
<h1>This is homepage</h1>
<h2>{{msg}}</h2>
</div>
</template>
<script>
export default {
data () {
return {
msg: 'Hello World!'
}
}
}
</script>
<!-- Add "scoped" attribute to limit CSS to this component only -->
<style scoped>
h1, h2 {
font-weight: normal;
}
ul {
list-style-type: none;
padding: 0;
}
li {
display: inline-block;
margin: 0 10px;
}
a {
color: #42b983;
}
</style>在同样目录下,创建 Login.vue 文件并输入以下内容:
<template>
<div>
<h4>Login</h4>
<form>
<label for="email" >E-Mail Address</label>
<div>
<input id="email" type="email" v-model="email" required autofocus>
</div>
<div>
<label for="password" >Password</label>
<div>
<input id="password" type="password" v-model="password" required>
</div>
</div>
<div>
<button type="submit" @click="handleSubmit">
Login
</button>
</div>
</form>
</div>
</template>上面是 HTML 模板,下面将为其定义处理登录的脚本:
<script>
export default {
data(){
return {
email : '',
password : ''
}
},
methods : {
handleSubmit(e){
e.preventDefault()
if (this.password.length > 0) {
this.$http.post('http://localhost:3000/login', {
email: this.email,
password: this.password
})
.then(response => {
})
.catch(function (error) {
console.error(error.response);
});
}
}
}
}
</script>此时,我们将 email 和 password 数据绑定到表单域以收集用户输入的信息。最终,将用户提供的信息发送到服务器以验证凭证。
处理服务器返回的信息:
[...]
methods : {
handleSubmit(e){
[...]
.then(response => {
let is_admin = response.data.user.is_admin
localStorage.setItem('user',JSON.stringify(response.data.user))
localStorage.setItem('jwt',response.data.token)
if (localStorage.getItem('jwt') !== null){
this.$emit('loggedIn')
if(this.$route.query.nextUrl){
this.$router.push(this.$route.query.nextUrl)
}
else {
if(is_admin === 1){
this.$router.push('admin')
}
else {
this.$router.push('dashboard')
}
}
}
})
[...]
}
}
}
}将 jwt token 和 user 信息存储到 localStorage,以便在应用随时获取。当然,我们还会将认证处理后的用户重定向至认证前的路由。若用户来自登录路由,则取决于用户类型。
接下来,创建 Register.vue 文件并添加以下内容:
<template>
<div>
<h4>Register</h4>
<form>
<label for="name">Name</label>
<div>
<input id="name" type="text" v-model="name" required autofocus>
</div>
<label for="email" >E-Mail Address</label>
<div>
<input id="email" type="email" v-model="email" required>
</div>
<label for="password">Password</label>
<div>
<input id="password" type="password" v-model="password" required>
</div>
<label for="password-confirm">Confirm Password</label>
<div>
<input id="password-confirm" type="password" v-model="password_confirmation" required>
</div>
<label for="password-confirm">Is this an administrator account?</label>
<div>
<select v-model="is_admin">
<option value=1>Yes</option>
<option value=0>No</option>
</select>
</div>
<div>
<button type="submit" @click="handleSubmit">
Register
</button>
</div>
</form>
</div>
</template>定义处理注册的脚本:
<script>
export default {
props : ['nextUrl'],
data(){
return {
name : '',
email : '',
password : '',
password_confirmation : '',
is_admin : null
}
},
methods : {
handleSubmit(e) {
e.preventDefault()
if (this.password === this.password_confirmation && this.password.length > 0) {
let url = 'http://localhost:3000/register'
if (this.is_admin !== null || this.is_admin === 1) url = 'http://localhost:3000/register-admin'
this.$http.post(url, {
name: this.name,
email: this.email,
password: this.password,
is_admin: this.is_admin
})
.then(response => {
localStorage.setItem('user',JSON.stringify(response.data.user))
localStorage.setItem('jwt',response.data.token)
if (localStorage.getItem('jwt') !== null) {
this.$emit('loggedIn')
if (this.$route.query.nextUrl) {
this.$router.push(this.$route.query.nextUrl)
} else {
this.$router.push('/')
}
}
})
.catch(error => {
console.error(error)
})
} else {
this.password = ''
this.passwordConfirm = ''
return alert('Passwords do not match')
}
}
}
}
</script>这与 Login.vue 文件结构类似。
创建 Admin.vue 并添加以下内容:
<template>
<div class="hello">
<h1>Welcome to administrator page</h1>
<h2>{{msg}}</h2>
</div>
</template>
<script>
export default {
data () {
return {
msg: 'The superheros'
}
}
}
</script>
<style scoped>
h1, h2 {
font-weight: normal;
}
ul {
list-style-type: none;
padding: 0;
}
li {
display: inline-block;
margin: 0 10px;
}
a {
color: #42b983;
}
</style>以上是当用户访问管理员页面时挂载的组件。
最后,创建 UserBoard.vue 文件并添加以下内容:
<template>
<div class="hello">
<h1>Welcome to regular users page</h1>
<h2>{{msg}}</h2>
</div>
</template>
<script>
export default {
data () {
return {
msg: 'The commoners'
}
}
}
</script>
<!-- Add "scoped" attribute to limit CSS to this component only -->
<style scoped>
h1, h2 {
font-weight: normal;
}
ul {
list-style-type: none;
padding: 0;
}
li {
display: inline-block;
margin: 0 10px;
}
a {
color: #42b983;
}
</style>以上是当用户访问 dashboard 页面看到组件。
以上就是所需的所有组件。
对于服务端请求,我们将使用 axios。axios 是一个基于 promise 的 HTTP 库,适用于浏览器和 Node.js。使用以下命令安装 axios:
$ npm install --save axios为了让所有组件获取它,打开 ./src/main.js 文件并添加以下内容:
import Vue from 'vue'
import App from './App'
import router from './router'
import Axios from 'axios'
Vue.prototype.$http = Axios
Vue.config.productionTip = false
new Vue({
el: '#app',
router,
components: { App },
template: '<App/>'
})通过定义 Vue.prototype.$http = Axios 改变 Vue 以添加 axios。这样我们就能在所有组件通过 this.$http 使用 axios。
至此已完成整个应用的开发。由于 Node.js 服务器与 Vue 应用相互依存,需要同时运行。
通过添加脚本,方便启动 Node.js 服务器。打开 package.json 文件并添加以下内容:
[...]
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"server": "node server/app",
"build": "node build/build.js"
},
[...]server 脚本是为了便于启动 Node.js 服务器。现在执行以下命令以启动服务器:
$ npm run server可看到以下类似内容:
创建另一个终端实例并运行 Vue 应用:
$ npm run dev这将会构建所有资源并启动应用。
在本教程中,我们学到了如何使用 vue-router 为路由定义检查条件,防止用户访问特定路由,也学到了如何根据认证状态进行重定向。当然,用户认证是通过我们建立的小型 Node.js 服务器进行处理。
其实,我们所做的访问控制与 Laravel 之类的框架类似。你可以看看 vue-router 还有什么有趣的事情可做。
最近为基于 Egg.js 的项目编写单元测试用例。写得七七八八后,想了解一下单元测试的覆盖率。由于第一次接触测试覆盖率报告,对其中一些细节存在疑惑。
经查阅资料后,整理出这篇文章,希望能解答大家一些关于测试覆盖率报告的疑问。
注:以下内容是基于 Istanbul 覆盖率引擎。不同覆盖率引擎可能会存在一些差异。
通过 Istanbul 得到的测试覆盖率报告
四个测量维度
理解以上四个测量维度并没什么大问题,但还是有些细节可以深究。
“行覆盖率”中的行是指可执行代码行(Lines of Executable Code),而不是源文件中所有的行(含空行)——(Lines of Source Code)。
可执行代码行:
一般来说,包含语句的每一行都应被视为可执行行。而复合语句(简称为语句块,用 {} 括起来)会被忽略(但其内容除外)。
注:对于可执行行的定义,不同覆盖率引擎可能会存在一些差异。
因此:
function doTheThing () // +0
{ // +0
const num = 1; // +1
console.log(num); // +1
} // +0具体以下东西会被忽略(即视为非可执行行,+0):
一些覆盖率引擎会将以下两点视为可执行行,而 Istanbul 会忽略它们:
import { isEqual } from 'lodash'; // +0
const path = require('path'); // +1
require('jquery') // +1
let filePath // +0
const fileName = 'a.txt'; // +1 注:不仅是声明,还有赋值
class Person { // +0
constructor (name) { // +0
this.name = name; // +1
} // +0
static sayHello () { // +0
console.log('hello'); // +1
} // +0
walk () {} // +0
} // +0
function doTheThing () // +0
{ // +0
const num = 1; // +1
console.log(num); // +1
} // +0
import、声明都被视为非可执行行(+0),require、赋值等语句视为可执行行(+1)
如果某行存在可执行代码,则这一整行会被视为可执行代码行。
而如果一个语句被拆分为多行,则该可执行代码块中,仅第一行被会视为可执行行。
因此:
'use strict';
for // +1
( // +0
let i=0; // +1
i < 10; // +0
i++ // +0
) // +0
{ // +0
} // +0
console.log({ // +1
a: 1, // +0
b: 2, // +0
}) // +0
function func () { // +0
return { // +1
a: 1, // +0
b: 2, // +0
} // +0
} // +0另外,不管嵌套语句横跨多少行,可执行行的数目仅会加 1。
foo(1, bar()); // +1
foo(1, // +1
bar()); // +0细心的读者可能会发现,注释 // +1 的那些行,其左侧都是 Nx 或粉色色块(即这两者与底色——灰色不同)。所以
可以不管以上那些概念,通过颜色的不同(非底色——灰色)即可看出哪些是可执行代码行:
绿色方框的是 Lines of Source Code、红色红框内与底色不同的色块是 Lines of Executable Code
关于可执行行的更多信息,可查阅:《sonarqube——Executable Lines》。
一般情况下,如果我们遵守良好的代码规范,可执行代码行和语句的表现是一致的。然而当我们将两个语句放一行时,就会得到不同的结果。
// 2 lines、2 statements
const x = 1;
console.log(x);// 1 line、2 statements
const x = 1; console.log(x);
左图是 2 lines、2 statements,右图是 1 line、2 statements
JavaScript 的 流程控制语句 有:
运算符:
condition ? exprIfTrue : exprIfFalse)我们需要确保流程控制的每个边界情况(即分支)都被执行(覆盖)。
测试覆盖率报告出现的标识有:
if(含 else if)分支已测试,而 else 分支未测试。if(含 else if) 分支未测试。代码中的某些分支可能很难,甚至无法测试。故 Istanbul 提供 注释语法,使得某些代码不计入覆盖率。
// 忽略一个 else 分支
/* istanbul ignore else */
if (foo.hasOwnProperty('bar')) {
// do something
}// 忽略一个 if 分支
/* istanbul ignore if */
if (hardToReproduceError)) {
return callback(hardToReproduceError);
}// 忽略默认值 {}
var object = parameter || /* istanbul ignore next */ {};
通过注释语法,将 funB 的 if 分支排除。故 Branches 由 2/4 变为 2/3,即总分支数由 4 减为 3。
关于 Istanbul 注释语法的更多信息,请查阅《Ignoring code for coverage purposes》。
圆形填充是一个非常神奇的效果。蕴含数学魅力的它,看似非常复杂。在本教程中,我们将创建一个有趣的圆形填充效果。尽管它实现起来并不特别高效,但仍然很快。
老规矩,初始化 canvas。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;
context.lineWidth = 2;现在,我将阐述一下实现流程,并因此而确定需要哪些变量。该实现流程并不是最高效的,但能完成工作。
流程如下:
因此,需要一个 circles 数组、totalCircles、最小与最大半径和 createCircleAttempts 变量。
var circles = []; // 存放合格的圆形
var minRadius = 2; // 最小半径
var maxRadius = 100; // 最大半径
var totalCircles = 500; // 调用创建圆形函数的次数
var createCircleAttempts = 500; // 创建一个圆时,所需尝试的最大次数现在,我们将通过代码描绘整体实现流程。创建函数 createCircle 和 doesCircleHaveACollision 函数,然后根据要求逐步填充实现细节。其中,包括调用 createAndDrawCircle 函数 totalCircles 次。
function createAndDrawCircle() {
// 从 0 开始遍历至 createCircleAttempts
// 尝试创建一个圆
// 创建单位圆后,将其尺寸不断增大,直至碰到另一个圆。此时达到最大值
// 绘制圆形
}
function doesCircleHaveACollision(circle) {
// 根据当前圆形是否与另一个圆形发生碰撞,返回 true 或 false
// 但现在一直返回 false
return false;
}
for( var i = 0; i < totalCircles; i++ ) {
createAndDrawCircle();
}创建带有 x、y 和 radius 属性的圆形对象。
var newCircle = {
x: Math.floor(Math.random() * size),
y: Math.floor(Math.random() * size),
radius: minRadius
}并将圆形对象填充到 circles 数组中,并进行绘制。尽管实际并不需要执行这一步,但这有助于了解代码流程。
circles.push(newCircle);
context.beginPath();
context.arc(newCircle.x, newCircle.y, newCircle.radius, 0, 2*Math.PI);
context.stroke(); 现在 canvas 上充满了小圆圈。接着,让圆形每次增长 1 单位大小,直至发生碰撞。当发生碰撞时,半径大小减少 1,并退出循环。
for(var radiusSize = minRadius; radiusSize < maxRadius; radiusSize++) {
newCircle.radius = radiusSize;
if(doesCircleHaveACollision(newCircle)){
newCircle.radius--
break;
}
}哇,超级乱!原因是 doesCircleHaveACollision 一直返回 false。
判断圆形之间是否发生碰撞,需要涉及一些三角学。我们需要遍历所有已绘制在 canvas 上的圆形,并将当前圆形与它们进行比较。若两者半径之和大于两者圆心距离,则发生碰撞。
通过勾股定理可计算出两圆心距离(哇,高中数学派上用场!)。
译者注:在国内,初中就已经学习勾股定理了。
for(var i = 0; i < circles.length; i++) {
var otherCircle = circles[i];
var a = circle.radius + otherCircle.radius;
var x = circle.x - otherCircle.x;
var y = circle.y - otherCircle.y;
if (a >= Math.sqrt((x*x) + (y*y))) {
return true;
}
}还有另一个小难题。当我们创建圆时,有可能出现在已有圆形内。
这就需要在创建圆形的循环内增加碰撞检测,尽管随机生成的位置会导致不那么高效。其实,除非要创建百万以上的圆形,否则不会看到任何迟缓的现象。
如果圆形找不到安全区域,那就放弃当次尝试。
var newCircle;
var circleSafeToDraw = false;
for( var tries = 0; tries < createCircleAttempts; tries++) {
newCircle = {
x: Math.floor(Math.random() * size),
y: Math.floor(Math.random() * size),
radius: minRadius
}
if(doesCircleHaveACollision(newCircle)) {
continue;
} else {
circleSafeToDraw = true;
break;
}
}
if(!circleSafeToDraw) {
return;
}哇,现在拥有了漂亮圆形的效果。尽管整个 canvas 被圆圈填满,但还剩一个小步骤要做,那就是增加圆形与边界的碰撞检测。我们将该工作拆分为两个判断语句,一个是检查上下边界,另一个是检查左右边界。
if ( circle.x + circle.radius >= size ||
circle.x - circle.radius <= 0 ) {
return true;
}
if (circle.y + circle.radius >= size ||
circle.y-circle.radius <= 0 ) {
return true;
}我们终于实现了!尽管这不是最完美的代码,但它是一个说明如何通过相对简单的数学来推理、思考并逐步完成较为复杂工作的好案例。
微信小程序是赋能开发者微信生态能力、改善 Web 用户体验、对 Web 开发者友好的特定应用。
最近参与了一个新项目,涉及到微信小程序。鉴于第一次接触小程序和对小程序的期望,借此谈谈本次项目的总结与思考。
笔者之前也编写了《我的第一次移动端页面制作 — 总结与思考》。
在微信的《2018 年数据报告》中提到:
在**市场有如此高的占用率,无疑是一个不可忽视的场景。
尽管在浏览器不断提高性能和赋予网页更多原生应用权限的今天,多年被诟病的浏览器兼容性和差异性等依然是开发者难以跨越的鸿沟。
而微信正是看到了网页体验的种种痛点,于 2016 年正式推出了小程序。
小程序不仅改善了“触摸体验”,更融合了微信的整体生态。如更早前为普通网页提供微信原生能力的 JS-SDK(涵盖拍摄、录音、语音识别、二维码、地图、支付、分享、卡券等几十个 API)。
小程序带来了贴近原生应用的特性和微信的生态能力,使得开发者能相对轻松地拥有“完整”的应用。
网页开发者需要面对的环境是各式各样的浏览器,PC 端需要面对 IE、Chrome、QQ 浏览器等,在移动端需要面对 Safari、Chrome 以及 iOS、Android 系统中的各式 WebView 。而小程序需要面对的是两大操作系统 iOS 和 Android 的微信客户端,以及用于辅助开发的小程序开发者工具,小程序中三大运行环境也是有所区别的,如下表所示:
| 运行环境 | 逻辑层 | 渲染层 |
|---|---|---|
| iOS | JavaScriptCore | WKWebView |
| 安卓 | X5 JSCore | X5 浏览器 |
| 小程序开发者工具 | NWJS | Chrome WebView |
关于小程序更多知识,更推荐官方文档——《小程序开发指南》。笔者阅读后整理了以下一幅思维导图。当然,这是基于笔者个人理解和需求整理而成。理解实现原理,才能更好地应对开发中遇到的疑问和编写出更合适的代码。
笔者作为后来者,更像是站在巨人肩膀上。而老东家则是微信小程序的第一批尝鲜者,躺过无数坑。
现在开发框架百花争放,让开发体验不断往相对完善的 Web 靠拢。WePY、Taro 等便是其中的佼佼者。基于团队的技术栈,我们此次选择了更像 Vue 的 WePY。
尽管 WePY 的风格像 Vue,但在开发的过程仍有部分不完善的地方,需要通过 Hack 的方式规避一些问题。至于具体哪些问题,本文也不会列举太多。毕竟这不是技术原理/本质的东西,说不定过一阵子就会被抹掉(WePY 2.0 正在路上)。
WePY(1.7.x)版本存在以下问题:
页面(或组件)中非 data 内的属性需要在 onUnload 重置,否则下次打开该页面仍是上一次的值。
// 本文称该区域的变量为:页面局部变量
const height = 100
export default Class Index extends wepy.page {
data = {
name: 'Jack'
}
methods = {
changeHandle () {
height = 120
this.name = 'Amy'
this.age = 18
}
}
// 本文称该区域的变量为:页面属性
age = 10
onLoad () {
// 假设第一次进来触发了 changeHandle,那么第二次进来会分别输出
console.log(this.age) // 18
console.log(this.name) // 'Jack'
console.log(height) // 120
}
}与 Vue 相比,有以下异同:
age);height)。data 内属性会在组件销毁时重置。对此,笔者有以下建议:
data 内属性,要在 onUnload 内进行重置;$apply() 的触发都会导致 computed 属性内所有值都运行一次,即使 computed 属性所依赖的属性未变更。
与 Vue 相比,有以下不同:
computed 属性仅在其所依赖的属性发生变化时才重新计算优化方法:
$apply()$apply() 触发脏检测。computed 属性,可声明为 data 属性,然后 watch 其所依赖的属性,这样就能仅在所依赖的属性变化时才会重新计算。methods 属性提供的 onPageScroll 方法是 WePY 封装过的,其内置 $apply() 会导致频繁触发脏检测问题。
...
methods = {
onPageScroll () {} // 即使函数体为空,只要定义了该方法,页面滚动就会触发该方法,从而导致频繁调用 $apply()
}
...其实在页面属性定义 onPageScroll 即可使用微信小程序提供的原生方法,这样就可将其 throttle/debounce 化。
onPgaeScroll () {
this.pageScrollThrottled()
}
onLoad () {
this.pageScrollThrottled = throttle(() => {
this.isScrolling = true
this.$apply()
}, 3000)
}WePY 1.7.x 对于自定义组件是静态编译的,所以对于 repeat 里放置自定义组件是存在一些问题的:
<repeat for="{{list}}">
/* 向自定义组件的 anyProp 属性传 item.someKey,并在 customComponent 里对 anyProp 属性衍生出 computed 属性,结果该 computed 属性输出却是 undefined */
<customComponent :anyProp.sync="item.someKey" />
/* 直接将 item 传入,但该 repeat 内所有 customComponent 的 anyProp 都指向 list 的第一个 item */
<customComponent :anyProp.sync="item" />
</repeat>
除了上述两个问题,还存在 repeat 嵌套 wx:for 循环等其他问题。因此,在 WePY 解决这些问题前,暂时可通过以下方法规避以上问题:
repeat 内的自定义组件,只支持直接渲染 props 属性,不支持其他诸如 computed 后处理。repeat 封装为一个组件,而不是将 item 封装为一个组件。repeat 列表的自定义子组件存在列表渲染时,使用 repeat 而不是 wx:for。以上自定义组件的问题相信在即将到来的 WePY 2.0 会得到有效解决。
除了耳熟能详的 《雅虎前端优化 35 条规则》 和《小程序开发指南》的第七章 性能优化,针对 WePY 也有一些需要注意的地方。
小程序支持“分包”,即小程序的代码包可以被划分为几个:一个是“主包”,包含小程序启动时会马上打开的页面代码和相关资源;其余是“分包”,包含剩余模块的代码和资源。这样,小程序启动时,只需要先将主包下载完成,就可以立刻启动小程序,从而显著降低小程序代码包的下载时间。
在 WePY 中,当项目结构是将页面的业务组件放在 src/components/{pageName} 下,那么 WePY 在构建时会把所有页面的业务组件均放置在主包内,导致主包冗余,影响小程序首次加载时间。
├── app.wpy
├── components
│ ├── article
│ │ └── comA.wpy
│ ├── common
│ │ ├── table.wpy
│ │ └── tabs.wpy
│ └── index
│ ├── vfooter.wpy
│ └── vheader.wpy
├── pages
│ ├── article
│ │ ├── article.wpy
│ │ └── list.wpy
│ └── index.wpy
为了避免主包含有其他分包的组件,需要将页面的业务组件放置在 src/pages/{pageName}/components 下:
├── app.wpy
├── components
│ └── common
│ ├── table.wpy
│ └── tabs.wpy
├── pages
│ ├── article
│ │ ├── article.wpy
│ │ ├── components
│ │ │ └── comA.wpy
│ │ └── list.wpy
│ └── index.wpy
另外,微信开发者工作中提供了“体验评分”插件,它是一项给小程序的体验好坏打分的功能,会在小程序运行过程中实时检查,分析出一些可能导致体验不好的地方,并且定位出哪里有问题,以及给出一些优化建议。
关于对小程序的思考,我想脱离开发者的角度,以产品/运营角度看。所以待笔者有属于自己的产品时再回头补充。
任何新生事物的发展都不会是一帆风顺的,都要经历一个从小到大、由弱到强的曲折发展过程。
微信小程序的出现,为大家带来了比 Web 更好的使用体验。而小程序的火爆,也促使社区诞生出对开发者更友好的开发框架和工具。
显然,小程序仍在快速迭代中,难免出现一些问题或不足的地方。希望大家在享受小程序红利的同时,也耐心地向微信官方反馈遇到的问题,共同成长。
最后,希望属于自己的“小程序”也早日落地。
本文首发于 凹凸实验室
“目镜在他眼前涂上了一抹朦胧的淡色,映射着一幅弯曲的广角画面:一条灯火辉煌的大街,伸向无尽的黑暗。但这大街其实并不存在,它只是电脑绘出的一片虚拟的空间。”——《Snow Crash》,Neal Stephenson 1992年
VR(Virtual Reality)是利用电脑模拟产生一个三维空间的虚拟世界,提供用户关于视觉等感官的模拟,让用户感觉仿佛身历其境,可以及时、没有限制地观察三维空间内的事物。用户进行位置移动时,电脑可以立即进行复杂的运算,将精确的三维世界视频传回产生临场感。—— 维基百科
了解 VR 显示原理前,先了解我们人眼的立体视觉的成像原理:
人眼的视觉是可以感觉出深度的,也就是深度知觉(depth perception)。而有了深度的信息后,才能判断出立体空间的相对位置。
另外,由于两个眼睛的位置不一样(一般人两眼相距 5~7 厘米),所以看到的东西会有两眼视差(binocular parallax),大脑再将这两个图像做融合处理,从而产生立体的感觉(即所谓的 binocular cues)。
立体视觉
头戴式显示器(HMD)是 VR 目前最常见的一种体验方式。它的原理是将小型二维显示器所产生的图像经由光学系统放大。具体而言,小型显示器所发射的光线经过凸状透镜使图像因折射产生类似远方效果。利用此效果将近处物体放大至远处观赏,从而达到所谓的全息视觉(Hologram)。另外,显示器被分为左右两个部分,分别显示左右眼看到的图像。大脑再将左右眼所看到的图像(两眼视差)做融合处理,从而产生 3D 效果。同时,HMD 会根据头部运动让视角与之同步。综合上述特性,用户通过 HMD 体验 VR 时就如同在现实中观看一样,这种体验也被称为沉浸式体验。
HMD 原理示意图
目前市场上主要有以下 3 种 HMD 设备:
对于想初步体验或入门 VR 的用户,推荐谷歌的 Carboard 或国内的性价比高的滑配式设备。
Google Carboard
VR 是最具科幻色彩以及梦幻体验的东西,单独一个 HMD 并不能发挥 VR 的最大效果,加上“属性加成”的周边才能体验极致的 VR。
2015 年,澳大利亚开设了世界首家 VR 沉浸式竞技游戏店—— Zero Latency。 这家店拥有 4300 平方英尺,安装有 129 台 PlayStation Eye 摄像头,用于捕捉玩家的动作。整套系统可以最多同时供 6 名玩家进行游戏。
现实与虚拟
当然,各式各样的 VR 周边设备也越来越多,如 Virtuix Omni 跑步机:
Virtuix Omni
这些设备无疑会增强了 VR 的体验,给用户带来更加刺激与逼真的体验。
上文说了这么多关于 VR 的东西,视乎还没有入正题(⊙﹏⊙))
许多 VR 体验是以应用程序的形式呈现的,这意味着你在体验 VR 前,必须进行搜索与下载。而 Web VR 则改变了这种形式,它将 VR 体验搬进了浏览器,Web + VR = WebVR。
下面根据我目前的见解,分析一下 WebVR 的现状。
WebVR 是早期和实验性的 JavaScript API,它提供了访问如 Oculus Rift 和 Google Cardboard 等 VR 设备功能的 API。
VR 应用需要高精度、低延迟的接口,才能传递一个可接受的体验。而对于类似 Device Orientation Event 接口,虽然能获取浅层的 VR 输入,但这并不能为高品质的 VR 提供必要的精度要求。WebVR 提供了专门访问 VR 硬件的接口,让开发者能构建舒适的 VR 体验。
WebVR API 目前可用于安装了 Firefox nightly 的 Oculus Rift、Chrome 的实验性版本和 Samsung Gear VR 的浏览器。当然,如果你现在就想在你的移动端浏览器体验 WebVR,可以使用 WebVR Polyfill。
在 Web 上开发 VR 应用,有下面三种(潜在)方式:
由于 WebVR 仍处于草案阶段并可能会有所改变,所以建议你基于 webvr-boilerplate 进行 WebVR 开发。
上面说道,在 Web 上开发 VR 应用有 3 种(潜在)方式,前两种都离不开直接接触 Three.js,而第三种方式则为时尚早。对于没接触过 Three.js,但又想体验一把 WebVR 开发的同学们来说,无疑会存在一定的门槛。
如果你想以较低的门槛体验一把 WebVR 开发,那么可以试试 MozVR 团队 开发的 A-Frame 框架。
PS:写着写着,A-Frame 的版本从 v0.2 升到到 v0.3(这很前端),但文档等各方面变得更加完善了。
A-Frame 是一个通过 HTML 创建 VR 体验的开源 WebVR 框架。通过该框架构建的 VR 场景能兼容智能手机、PC、 Oculus Rift 和 HTC Vive。
MozVR 团队开发的 A-Frame 框架的目的是:让构建 3D/VR 场景变得更易更快,以吸引 web 开发社区进入 WebVR 的生态。WebVR 要成功,需要有内容。但目前只有很少一部分 WebGL 开发者,却有数以百万的 Web 开发者与设计师。A-Frame 要把 3D/VR 内容的创造权力赋予给每个人。
<a-scene> 标签。
减少冗余复杂的代码
talk is cheap,show me the c... hello world.
A-Frame 的 Hello world
在手机的浏览器(如:Chrome、QQ浏览器)中呈现的效果
实现代码如下:
// 引入aframe框架
<script src="./aframe.min.js"></script>
<a-scene>
<!-- 球体 -->
<a-sphere position="0 1 -1" radius="1" color="#EF2D5E"></a-sphere>
<!-- 盒(此处是立方体) -->
<a-box width="1" height="1" rotation="0 45 0" depth="1" color="#4CC3D9" position="-1 0.5 1"></a-box>
<!-- 圆柱 -->
<a-cylinder position="1 0.75 1" radius="0.5" height="1.5" color="#FFC65D"></a-cylinder>
<!-- 平面 -->
<a-plane rotation="-90 0 0" width="4" height="4" color="#7BC8A4"></a-plane>
<!-- sky元用于为场景添加背景图或显示360度的全景图 -->
<a-sky color="#ECECEC"></a-sky>
<!-- 用于指定摄像机的位置 -->
<a-entity position="0 0 4">
<a-camera></a-camera>
</a-entity>
</a-scene>
基本概念(以 v0.3 版本为参考):
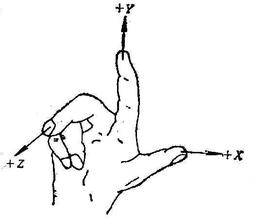
当然,上述案例只是 A-Frame 的 Hello World demo。若你感兴趣,可以深入学习,再结合自己的想法,相信你能作出让人拍手称赞的作品。
下面就列举一些 WebVR 的相关案例,如果你已具备了 VR 的体验环境,不妨体验一下。
更多 WebVR 内容等着你们发现
许多人将 2016 年称为 VR 元年。VR 的前景有人看好,也有人看衰。但无论如何,新技术的出现都值得我们去体验一番。当然,作为一名开发者,也可以从代码的角度体验一番。
想详细了解更多关于 VR 的行业报告,可以阅读 《VR与AR:解读下一个通用计算平台》。
Redis 的单线程特性是指执行命令的线程,从任意个客户端接收到的命令都会被一个接一个执行。而事务(MULTI 和 EXEC)则会在 Redis 接收到 EXEC 命令时,将存储在事务队列的命令依次执行,执行期间不会被其他客户端的命令插入打断,即 Redis 事务是原子性的。
MULTI 和 EXEC 组成的事务在执行时不会被其他客户端打断,决解了“竞争条件”的问题。而 WATCH 命令则保证了:在任意个客户端连接的情况下,WATCH 到 EXEC 的整个代码逻辑(事务只是其中一部分)在执行期间数据的正确性(被 watch 的键未被改动)。
Redis 的原子性操作:
a. 把多个操作在 Redis 中实现成一个操作,即单命令操作;
b. 事务(Redis 更推荐 Lua,并在开发者都使用 Lua 脚本替代事务时,删除事务)。
c. 把多个操作写到一个 Lua 脚本中,以原子性方式执行单个 Lua 脚本。
参考资料:
本文涉及多个 Codepen 案例,若想获得更佳体验,请到 凹凸实验室博客 阅读,谢谢。
本文将阐述如何通过 Web 技术实现简易的移动监测效果,并附上一些有意思的案例。
移动侦测,英文翻译为“Motion detection technology”,一般也叫运动检测,常用于无人值守监控录像和自动报警。通过摄像头按照不同帧率采集得到的图像会被 CPU 按照一定算法进行计算和比较,当画面有变化时,如有人走过,镜头被移动,计算比较结果得出的数字会超过阈值并指示系统能自动作出相应的处理。——百度百科
由上述引用语句可得出“移动监测”需要以下要素:
注:本文涉及的所有案例均基于 PC/Mac 较新版本的 Chrome / Firefox 浏览器,部分案例需配合摄像头完成,所有截图均保存在本地。
对方不想和你说话,并向你扔来一个链接:
综合案例
该案例有以下两个功能:
上述案例也许并不能直接体现出『移动监测』的实际效果和原理,下面再看看这个案例。
像素差异
案例的左侧是视频源,而右侧则是移动后的像素处理(像素化、判断移动和只保留绿色等)。
因为是基于 Web 技术,所以视频源采用 WebRTC,像素处理则采用 Canvas。
不依赖 Flash 或 Silverlight,我们使用 WebRTC (Web Real-Time Communications) 中的 navigator.getUserMedia() API,该 API 允许 Web 应用获取用户的摄像头与麦克风流(stream)。
示例代码如下:
<!-- 若不加 autoplay,则会停留在第一帧 -->
<video id="video" autoplay></video>
// 具体参数含义可看相关文档。
const constraints = {
audio: false,
video: {
width: 640,
height: 480
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(stream => {
// 将视频源展示在 video 中
video.srcObject = stream
})
.catch(err => {
console.log(err)
})
对于兼容性问题,Safari 11 开始支持 WebRTC 了。具体可查看 caniuse。
在得到视频源后,我们就有了判断物体是否移动的素材。当然,这里并没有采用什么高深的识别算法,只是利用连续两帧截图的像素差异来判断物体是否发生移动(严格来说,是画面的变化)。
获取视频源截图的示例代码:
const video = document.getElementById('video')
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = 640
canvas.height = 480
// 获取视频中的一帧
function capture () {
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
// ...其它操作
}
对于两张图的像素差异,在 凹凸实验室 的 《“等一下,我碰!”——常见的2D碰撞检测》 这篇博文中所提及的“像素检测”碰撞算法是解决办法之一。该算法是通过遍历两个离屏画布(offscreen canvas)同一位置的像素点的透明度是否同时大于 0,来判断碰撞与否。当然,这里要改为『同一位置的像素点是否不同(或差异小于某阈值)』来判断移动与否。
但上述方式稍显麻烦和低效,这里我们采用 ctx.globalCompositeOperation = 'difference' 指定画布新增元素(即第二张截图与第一张截图)的合成方式,得出两张截图的差异部分。
示例代码:
function diffTwoImage () {
// 设置新增元素的合成方式
ctx.globalCompositeOperation = 'difference'
// 清除画布
ctx.clearRect(0, 0, canvas.width, canvas.height)
// 假设两张图像尺寸相等
ctx.drawImage(firstImg, 0, 0)
ctx.drawImage(secondImg, 0, 0)
}
两张图的差异
体验上述案例后,是否有种当年玩“QQ游戏《大家来找茬》”的感觉。另外,这个案例可能还适用于以下两种情况:
由上述“两张图像差异”的案例中可得:黑色代表该位置上的像素未发生改变,而像素越明亮则代表该点的“动作”越大。因此,当连续两帧截图合成后有明亮的像素存在时,即为一个“动作”的产生。但为了让程序不那么“敏感”,我们可以设定一个阈值。当明亮像素的个数大于该阈值时,才认为产生了一个“动作”。当然,我们也可以剔除“不足够明亮”的像素,以尽可能避免外界环境(如灯光等)的影响。
想要获取 Canvas 的像素信息,需要通过 ctx.getImageData(sx, sy, sw, sh),该 API 会返回你所指定画布区域的像素对象。该对象包含 data、width、height。其中 data 是一个含有每个像素点 RGBA 信息的一维数组,如下图所示。
含有 RGBA 信息的一维数组
获取到特定区域的像素后,我们就能对每个像素进行处理(如各种滤镜效果)。处理完后,则可通过 ctx.putImageData() 将其渲染在指定的 Canvas 上。
扩展:由于 Canvas 目前没有提供“历史记录”的功能,如需实现“返回上一步”操作,则可通过 getImageData 保存上一步操作,当需要时则可通过 putImageData 进行复原。
示例代码:
let imageScore = 0
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
const r = rgba[i] / 3
const g = rgba[i + 1] / 3
const b = rgba[i + 2] / 3
const pixelScore = r + g + b
// 如果该像素足够明亮
if (pixelScore >= PIXEL_SCORE_THRESHOLD) {
imageScore++
}
}
// 如果明亮的像素数量满足一定条件
if (imageScore >= IMAGE_SCORE_THRESHOLD) {
// 产生了移动
}
在上述案例中,你也许会注意到画面是『绿色』的。其实,我们只需将每个像素的红和蓝设置为 0,即将 RGBA 的 r = 0; b = 0 即可。这样就会像电影的某些镜头一样,增加了科技感和神秘感。
示例代码:
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
rgba[i] = 0 // red
rgba[i + 2] = 0 // blue
}
ctx.putImageData(imageData, 0, 0)
将 RGBA 中的 R 和 B 置为 0
有了明亮的像素后,我们就要找出其 x 坐标的最小值与 y 坐标的最小值,以表示跟踪矩形的左上角。同理,x 坐标的最大值与 y 坐标的最大值则表示跟踪矩形的右下角。至此,我们就能绘制出一个能包围所有明亮像素的矩形,从而实现跟踪移动物体的效果。
找出跟踪矩形的左上角和右下角
示例代码:
function processDiff (imageData) {
const rgba = imageData.data
let score = 0
let pixelScore = 0
let motionBox = 0
// 遍历整个 canvas 的像素,以找出明亮的点
for (let i = 0; i < rgba.length; i += 4) {
pixelScore = (rgba[i] + rgba[i+1] + rgba[i+2]) / 3
// 若该像素足够明亮
if (pixelScore >= 80) {
score++
coord = calcCoord(i)
motionBox = calcMotionBox(montionBox, coord.x, coord.y)
}
}
return {
score,
motionBox
}
}
// 得到左上角和右下角两个坐标值
function calcMotionBox (curMotionBox, x, y) {
const motionBox = curMotionBox || {
x: { min: coord.x, max: x },
y: { min: coord.y, max: y }
}
motionBox.x.min = Math.min(motionBox.x.min, x)
motionBox.x.max = Math.max(motionBox.x.max, x)
motionBox.y.min = Math.min(motionBox.y.min, y)
motionBox.y.max = Math.max(motionBox.y.max, y)
return motionBox
}
// imageData.data 是一个含有每个像素点 rgba 信息的一维数组。
// 该函数是将上述一维数组的任意下标转为 (x,y) 二维坐标。
function calcCoord(i) {
return {
x: (i / 4) % diffWidth,
y: Math.floor((i / 4) / diffWidth)
}
}
在得到跟踪矩形的左上角和右下角的坐标值后,通过 ctx.strokeRect(x, y, width, height) API 绘制出矩形即可。
ctx.lineWidth = 6
ctx.strokeRect(
diff.motionBox.x.min + 0.5,
diff.motionBox.y.min + 0.5,
diff.motionBox.x.max - diff.motionBox.x.min,
diff.motionBox.y.max - diff.motionBox.y.min
)
这是理想效果,实际效果请打开 体验链接
扩展:为什么上述绘制矩形的代码中的
x、y要加0.5呢?一图胜千言:
在上一个章节提到,我们需要通过对 Canvas 每个像素进行处理,假设 Canvas 的宽为 640,高为 480,那么就需要遍历 640 * 480 = 307200 个像素。而在监测效果可接受的前提下,我们可以将需要进行像素处理的 Canvas 缩小尺寸,如缩小 10 倍。这样需要遍历的像素数量就降低 100 倍,从而提升性能。
示例代码:
const motionCanvas // 展示给用户看
const backgroundCanvas // offscreen canvas 背后处理数据
motionCanvas.width = 640
motionCanvas.height = 480
backgroundCanvas.width = 64
backgroundCanvas.height = 48
尺寸缩小 10 倍
我们都知道,当游戏以『每秒60帧』运行时才能保证一定的体验。但对于我们目前的案例来说,帧率并不是我们追求的第一位。因此,每 100 毫秒(具体数值取决于实际情况)取当前帧与前一帧进行比较即可。
另外,因为我们的动作一般具有连贯性,所以可取该连贯动作中幅度最大的(即“分数”最高)或最后一帧动作进行处理即可(如存储到本地或分享到朋友圈)。
至此,用 Web 技术实现简易的“移动监测”效果已基本讲述完毕。由于算法、设备等因素的限制,该效果只能以 2D 画面为基础来判断物体是否发生“移动”。而微软的 Xbox、索尼的 PS、任天堂的 Wii 等游戏设备上的体感游戏则依赖于硬件。以微软的 Kinect 为例,它为开发者提供了可跟踪最多六个完整骨骼和每人 25 个关节等强大功能。利用这些详细的人体参数,我们就能实现各种隔空的『手势操作』,如画圈圈诅咒某人。
下面几个是通过 Web 使用 Kinect 的库:
通过 Node-Kinect2 获取骨骼数据
文章至此就真的要结束了,如果你想知道更多玩法,请关注 凹凸实验室。同时,也希望大家发掘更多玩法。
原文:Exploring Animation And Interaction Techniques With WebGL (A Case Study)
两年前,我决定在 Codepen 上开始一系列小型 WebGL 实验。今年早些时候,我终于抽出时间将它们放在一个名为 “Moments of Happiness” 的网站上。经过这些实验后,我已经找到了如何探索和学习不同 动画 和交互技术的方法,并在这些互动玩具中得以体现。
正如你将看到的,每个玩具的互动方式是非常不同的,但所有实验都有一个原则:每个角色的行为都以编程的方式响应用户的输入。没有预先计算的动画 —— 每个运动都在运行时定义。而赋予角色生命力的代码只有数行,但这也是我们的主要挑战。
定义动画和解释其意图
当一个动画与功能目的不匹配时,它常会让用户感到尴尬和懊恼。既然如此,这里有九个有助于验证功能性动画的逻辑目的。查看更多 ->
这些实验主要基于 Three.js 和 GreenSock 库开发,完全手工编码,未使用任何 3D 或动画软件。
这个过程包括了以编程的方式将方块逐个组合成独特的角色。当然,我的大部分精力用在修改代码的值上,以调整比例、位置和整体渲染效果。然后,最终根据用户的输入(鼠标移动、点击和拖动等)移动角色的各个部分。
这个过程的优势并不明显。但这允许我能只使用文本编辑器来完成整个实验,从而避免导出资源和通过各个工具调整角色属性的麻烦。利用 Codepen 提供的实时预览功能,使整个过程非常灵活。
话虽如此,这个过程仍需要一套用于保证可管理性的自身约束:
注意:要明确的是,这个过程对我很有用,但如果你习惯于 3D 软件,那么你就应当用它来制作模型。即在你所掌握的技能中寻找适当的平衡,以尽可能高效。而当我将所有流程都放在一个工具中时,无疑会更高效。
Moments of Happiness 是一个会让你快乐的 WebGL 实验系列。
这个过程所需的极简主义,为寻找出最能精确描述每个表现(舒适、快乐、失望等)的动作提供了可能。
每个立方体和动作都会受到质疑:我真的需要它吗?它能让体验更佳,还仅仅是一个自封角色设计师的念头?
我最后得到的是非常简单的玩具,并且它们都生活在安静和简约的环境中。
这些角色主要由立方体组成——即使是火焰和烟雾!
然而,这里最大的挑战可能是以编程方式让物体动起来。我们该如何在不使用动画软件或可视化时间轴的前提下构建自然生动的动作呢?我们该如何以动画的形式在响应用户输入的同时,保持动作自然呢?
在开始这些实验前,我花费了一些时间去观察、记录并思考传达何种情感。
受寒狮子的主要灵感来源是在我抚摸狗狗时产生的。我观察它在开心时是如何闭上眼睛,如何伸出脖子请求挠痒。然后寻找适当的算法以编程的方式翻译将这些动作,这就是情感与基础数学技能的融合。
噢,就是这种感觉!
对于“偏执鸟”(下图),我记得是模仿一个看起来不舒服的家伙,他拥有快速的眼神。为了让动作看起来更自然,我需要弄清楚它的眼睛和头部运动的时间差。
要捕捉这种尴尬的动作也只是生活经验上的问题
但有时候,你不能只依赖于自身经验。视觉灵感有时是捕捉特征的必要条件。幸运的是,Giphy 上可以找到任意一种细微表情。我也花费了很多时间在 Youtube 和 Vimeo 上寻找适当的动作。
我们来看一个例子。
“Moments of Happiness” 中最棘手的动画之一是 兔子逃出狼的魔爪。
有多少种逃跑方法就有多少种奔跑方式
要实现这个动作,首先要理解一个奔跑循环的运行方式。我在 Giphy 上看了一些令人激动的慢动作 GIF,直到我遇到了这一张:
(图片来源: Giphy)
在该 GIF 中有趣的是,奔跑循环不仅是关于腿部的移动。它跟整个身体有关,也包括身体的最小部分,各个部分完全同步协调地动起来。耳朵,嘴巴,甚至是舌头的参与,无疑增强了速度和重力带来的效果。
事实上,动物种类和奔跑的原因都是决定奔跑循环的因素。如果你想深入研究奔跑循环,阅读其他更准确的参考资料也是个不错的想法。下面提供两个有用的资源:Pinteresr 上的 Run Cycle” collection 和 “Quadruped Locomotion Tutorial” 视频。
如果你有看过这些资料,那么每个奔跑循环的背后结构将会变得更加清晰。而且你的大脑会不自觉地开始捕捉身体各个部分之间的关系,而奔跑的顺序和节奏将以一种循环、可重复和可复用的形式展示。
现在,我们需要一个技术方案去实现它。
自动玩具 十分让人着迷,只需旋转一个手柄就能让这些机械玩具进行复杂的运动。我想尝试类似的技术,并探索一种更适合我们且基于代码的解决方案,而不是时间轴和关键帧。
该方案的实现思路是:无论循环动作简单与否,它都是完全依赖于主循环的处理。
一个通过旋转手柄驱动自身运动的自动玩具,图片来自 Brinquedos Autômatos。
对于奔跑循环,每条腿、耳朵、眼睛、身体和头部的运动都是由同一个主循环驱动。在某些情况下,所产生的旋转会被转换成水平运动或垂直运动(译者注:如圆周运动转换为半圆运动)。
当需要将圆周运动转为线性运动时,三角学似乎是最佳选择。
别走!这里所需的三角学种类是非常基础的。大多数公式就像这样:
x = cos(angle)*distance;
y = sin(angle)*distance;
这就是将点(angle, distance)的极坐标转换为笛卡尔坐标(x, y)的基础用法。
通过改变角度,可使点围绕着中心旋转。
将极坐标转换为笛卡尔坐标
只需修改公式的值,三角学就可让我们做更多复杂的运动。这种技术的美妙之处在于让运动变得平滑。
举个例子:
通过三角学原理制作的动画案例
为了理解三角学,你必须亲自实践。没有实践的理论仅仅只是智力游戏。
为了实践上述公式,我们需要一个基本环境。你可以选用 Canvas、SVG 或任何具有图像 API 的库,如 Three.js、 PixiJS 或 BabylonJS.
让我们看看 Three.js 基础框架:
首先,下载最新版本的 Three.js,并将其在 html 的 head 引入:
<script type="text/javascript" src="js/three.js"></script>
然后添加整个实验的容器:
<div id="world"></div>
通过 CSS 样式将该容器覆盖浏览器视口:
#world {
position: absolute;
width: 100%;
height: 100%;
overflow: hidden;
background: #ffffff;
}
JavaScript 部分有点长,但并不复杂:
// 初始化变量
var scene, camera, renderer, WIDTH, HEIGHT;
var PI = Math.PI;
var angle = 0;
var radius = 10;
var cube;
var cos = Math.cos;
var sin = Math.sin;
function init(event) {
// 获取承载整个动画的容器
var container = document.getElementById('world');
// 获取窗口大小
HEIGHT = window.innerHeight;
WIDTH = window.innerWidth;
// 创建 Three.js 场景,并设置摄像机和渲染器
scene = new THREE.Scene();
camera = new THREE.PerspectiveCamera( 50, WIDTH / HEIGHT, 1, 2000 );
camera.position.z = 100;
renderer = new THREE.WebGLRenderer({ alpha: true, antialias: true });
renderer.setSize(WIDTH, HEIGHT);
renderer.setPixelRatio(window.devicePixelRatio ? window.devicePixelRatio : 1);
container.appendChild(renderer.domElement);
// 创建立方体
var geom = new THREE.CubeGeometry(16,8,8, 1);
var material = new THREE.MeshStandardMaterial({
color: 0x401A07
});
cube = new THREE.Mesh(geom, material);
// 将立方器放置在场景中
scene.add(cube);
// 创建并添加光源
var globalLight = new THREE.AmbientLight(0xffffff, 1);
scene.add(globalLight);
// 监听 window 的 resize 事件
window.addEventListener('resize', handleWindowResize, false);
// 开启渲染每帧动画的循环
loop();
}
function handleWindowResize() {
// 如果 window 尺寸发生更改,就更新摄像机的长宽比
HEIGHT = window.innerHeight;
WIDTH = window.innerWidth;
renderer.setSize(WIDTH, HEIGHT);
camera.aspect = WIDTH / HEIGHT;
camera.updateProjectionMatrix();
}
function loop(){
// 每帧循环都会调用更新立方体位置的 update 函数
update();
// 渲染每帧场景
renderer.render(scene, camera);
// 调用下一帧 loop 函数
requestAnimationFrame(loop);
}
// 页面加载后初始化案例
window.addEventListener('load', init, false);
现在我们创建了场景、摄像机、灯光和立方体。然后在循环中更新立方体的位置。
现在我们需要添加 update() 函数,并向函数体内添加一些三角公式:
function update(){
// angle 每帧自增 0.1。值越大运动速度越高
angle += .1;
// 尝试修改 angle 和 radius,以获得不一样的动画
cube.position.x = cos(angle) * radius;
cube.position.y = sin(angle) * radius;
// 如果你想看同样的原理放在对象的 rotation 属性上的效果,请取消下一句的注释
//cube.rotation.z = cos(angle) * PI/4;
// 或者修改 scale。注意加 1 是为了避免计算结果为负值
//cube.scale.y = 1 + cos(angle) * .5;
/*
轮到你!你可能想:
- 注释或取消注释上面的某行代码,以产生新的组合
- 用 sin 替换 cos,或相反
- 用其他周期函数替换 radius
*/
例如:
cube.position.x = cos(angle) * (sin(angle) * radius)
...
}
如果存在疑惑,可以看看 Codepen。正弦和余弦函数让立方体以不同方式进行移动。希望通过该案例,能让你更好地了解如何在动画中使用三角学。
或者你可以查看下一个案例,并将其作为步行循环或奔跑循环的入门案例。
利用之前通过代码移动立方体的三角学知识,我们接下来将一步步地制作一个简单的步行循环。
与之前代码基本一致,主要不同的地方在于需要更多的立方体组成身体的各个部分。
Three.js 可以将对象组嵌入到其他对象组中。例如,我们可以创建一个含有腿部、手臂和头部的 body 组。
看看角色的制作过程:
Hero = function() {
// 用于循环的旋转角度变量,每帧自增
this.runningCycle = 0;
// 创建放置 body 的网格(mesh)
this.mesh = new THREE.Group();
this.body = new THREE.Group();
this.mesh.add(this.body);
// 创建并放置在 body 的各个肢体
var torsoGeom = new THREE.CubeGeometry(8,8,8, 1);
this.torso = new THREE.Mesh(torsoGeom, blueMat);
this.torso.position.y = 8;
this.torso.castShadow = true;
this.body.add(this.torso);
var handGeom = new THREE.CubeGeometry(3,3,3, 1);
this.handR = new THREE.Mesh(handGeom, brownMat);
this.handR.position.z=7;
this.handR.position.y=8;
this.body.add(this.handR);
this.handL = this.handR.clone();
this.handL.position.z = - this.handR.position.z;
this.body.add(this.handL);
var headGeom = new THREE.CubeGeometry(16,16,16, 1);
this.head = new THREE.Mesh(headGeom, blueMat);
this.head.position.y = 21;
this.head.castShadow = true;
this.body.add(this.head);
var legGeom = new THREE.CubeGeometry(8,3,5, 1);
this.legR = new THREE.Mesh(legGeom, brownMat);
this.legR.position.x = 0;
this.legR.position.z = 7;
this.legR.position.y = 0;
this.legR.castShadow = true;
this.body.add(this.legR);
this.legL = this.legR.clone();
this.legL.position.z = - this.legR.position.z;
this.legL.castShadow = true;
this.body.add(this.legL);
// 确保各个肢体能投射和接收阴影
this.body.traverse(function(object) {
if (object instanceof THREE.Mesh) {
object.castShadow = true;
object.receiveShadow = true;
}
});
}
将这个角色放置在场景(scene)中:
function createHero() {
hero = new Hero();
scene.add(hero.mesh);
}
这是通过 Three.js 制作的简易角色。如果你想了解有关使用 Three.js 制作角色的更多信息,请阅读我在 Codrops 上编写的详细教程。
完成 body 的构建后,我们将逐步地为每个肢体添加动画,直至形成一个简单的步行循环。
整个逻辑都放在 Hero 对象的 run 函数中:
Hero.prototype.run = function(){
// angle 自增
this.runningCycle += .03;
var t = this.runningCycle;
// 确保 angle 在 0 ~ 2PI 的区间内
t = t % (2*PI);
// 幅度(Amplitude)用作腿部移动的主要半径
var amp = 4;
// 更新各个肢体的位置和旋转
this.legR.position.x = Math.cos(t) * amp;
this.legR.position.y = Math.max (0, - Math.sin(t) * amp);
this.legL.position.x = Math.cos(t + PI) * amp;
this.legL.position.y = Math.max (0, - Math.sin(t + PI) * amp);
if (t<PI){
this.legR.rotation.z = Math.cos(t * 2 + PI/2) * PI/4;
this.legL.rotation.z = 0;
} else{
this.legR.rotation.z = 0;
this.legL.rotation.z = Math.cos(t * 2 + PI/2) * PI/4;
}
this.torso.position.y = 8 - Math.cos( t * 2 ) * amp * .2;
this.torso.rotation.y = -Math.cos( t + PI ) * amp * .05;
this.head.position.y = 21 - Math.cos( t * 2 ) * amp * .3;
this.head.rotation.x = Math.cos( t ) * amp * .02;
this.head.rotation.y = Math.cos( t ) * amp * .01;
this.handR.position.x = -Math.cos( t ) * amp;
this.handR.rotation.z = -Math.cos( t ) * PI/8;
this.handL.position.x = -Math.cos( t + PI) * amp;
this.handL.rotation.z = -Math.cos( t + PI) * PI/8;
}
每行代码都十分有趣,你可以在 Codepen 上找到步行循环的完整代码。
为了让它更易理解,我制作了以下案例,它将步行循环进行分解,突出显示身体被移动的部分,及其每一步所使用的公式。
See the Pen Walking cycle breakdown by Karim Maaloul (@Yakudoo) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>一旦你对正弦、余弦、距离和频率运用自如,那么各类循环(如跑步、游泳、飞行,甚至是月球漫步)的制作就变得轻而易举了。
我不会让你没有兔子玩。
下面的 Codepen 能让你对身体的各个部分应用不同的 angle 增量和幅度(amplitude)。你还可以修改循环速率,以获得更疯狂的效果。
你能为这个家伙想出不同的奔跑循环吗?玩得开心!
See the Pen Run bunny run by Karim Maaloul (@Yakudoo) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>人们可能认为基于代码的动画会导致动作不自然。相反,我相信这大大提高了调整动作的灵活性。同时,这也让角色更容易实现令人欣赏的动作。
Moments of Happiness 是各个实验的集合,而每个实验都具有其挑战性。在本文中,我已详细地介绍了制作奔跑循环的解决方案。另外,在我的 Codepen 页面 中,都可以找到这些实验,并且代码可任意使用。尽情创造属于你的互动玩具吧。
本文首发于 凹凸实验室
本文记录了笔者对 Web 游戏的一些疑问,也许你也恰巧曾经遇到过。
习大大说道:“不忘历史才能开辟未来,善于继承才能善于创新”。对于新生一代(如 00 后和我🙄 ),由于 Web 新标准的快速推进,有些旧事物也许未接触就已经被新事物取代了。如曾经如日中天的 Flash,现在被 HTML5 逐渐蚕食。
由于我未曾学习过 Flash 编程,所以通过查阅资料发现了一个网站——Waste Creative 公司的《Flash vs HTML5》,它对 Flash 与 HTML5 作出了比较**(具体数据也许已过时,但整体趋势不变)**。
| Flash | HTML5 Canvas | |
|---|---|---|
| 运行平台 | 桌面端 | 桌面端、移动端 |
| 桌面端浏览器支持率 | 99% | 82% |
| 3D 硬件加速支持率 | Flash Player 11(stage3D)81% | WebGL 53% |
| 文件&资源目录 | 可编译的 SWFs 意味着 Flash 可作为单个文件共享和重新托管(re-hosted)。这对于 Flash 游戏非常重要。 | HTML5 的本质意味着它的基础资源会作为独立的文件加载。因此,HTML5 的托管需要更谨慎。 |
| 可视化创作 | Flash IDE 对于设计师和新开发者来说是非常友好的,它拥有一个庞大的用户群体和社区。 | 相较于前者,HTML5 创作工具(Animate CC)目前还处于起步阶段,没有明确的“工业标准”。 |
| 移动端浏览器 | 目前的浏览器不再有 Flash 插件,Adobe 已经停止对先前移动端 player 的支持与迭代。 | Canvas 几乎已得到所有浏览器的支持,而 WebGL 的支持程度也逐渐提高。 |
在移动端早就不支持 Flash 的情况下,现在越来越多桌面端现代浏览器默认不启动 Flash 了。在可预见的未来,HTML5 (Canvas 2D 与 WebGL)的支持度会越来越高。
尽管 HTML5 的支持度越来越高,但是对于很多未接触 Flash 开发而直接着手于 HTML5 开发的新人来说,前辈们的经验无疑是非常宝贵的。在 2014 年有将近 30 万的 Flash 开发者,其中 90% 是和游戏相关的,他们对 Web 游戏的开发和理解都胜于任何使用其他 Web 前端技术进行开发游戏的群体。
基于这点,很多 HTML5 游戏引擎在 API 设计等方面都会考虑 Flash 这个开发群体。另外 Adobe Animate CC(前身是 Flash Professinal)在支持 Flash SWF 文件的基础上,加入了对 HTML5 的支持。因此,熟悉 Flash 的设计师/开发者就能通过 Animate CC 进行可视化创作,然后导出基于 Canvas 的游戏/动画。
我们常常听到有人说:“3D 场景用 WebGL”。
这句话对于未深入学习相关知识的人来说,会潜移默化地在脑中留下这样的刻板印象:“WebGL 就是 3D,3D 就是 WebGL”。
其实不然,因为我们也能在三维空间里绘制二维物体嘛。因此,我们能看到很多 2D 游戏引擎(如 PixiJS,Egret)会提供两种渲染模式:Canvas 2D 和 WebGL。但由于两者 API 不相同,游戏引擎会对两者进行一定抽象封装,为开发者提供一致的 API。
注:PixiJS 的定位是渲染器。而为了方便描述,在本文中我们暂且称它为游戏引擎。
另外,我们可以看到在支持上述两种渲染模式的游戏引擎中,都会优先启用 WebGL,若不兼容则回退至 Canvas 2D。游戏引擎之所以采取这种策略,目的之一是获取更高的性能。
那为什么 WebGL 的性能比 Canvas 2D 高?
在回答上述问题前,我们先了解 Canvas 2D 与 WebGL 的基本信息。
我们都知道 <canvas> 元素提供一个了空白区域,让特定的 JavaScript API 进行绘制。其中,绘制 API 取决于用户所指定的绘制上下文,如 Canvas 2D 或 WebGL。
对于 Chrome,其 Canvas 2D 的底层实现是 Skia 图形库。其实不止于 Chrome,该库还服务于 Chrome OS、 Android、Mozilla Firefox 和 Firefox OS 等众多产品。
通过在 Chrome 地址栏输入 about:gpu 可看到,Canvas 2D 是支持硬件加速的。若未启用,则在地址栏输入 about:flags,然后启用 Accelerated 2D canvas 选项并重启浏览器即可。
Graphics Feature Status
Canvas: Hardware accelerated ***
Flash: Hardware accelerated
Flash Stage3D: Hardware accelerated
Flash Stage3D Baseline profile: Hardware accelerated
Compositing: Hardware accelerated
Multiple Raster Threads: Enabled
Native GpuMemoryBuffers: Hardware accelerated
Rasterization: Hardware accelerated
Video Decode: Hardware accelerated
Video Encode: Hardware accelerated
WebGL: Hardware accelerated
WebGL2: Hardware accelerated
什么是 WebGL(Web Graphics Library)?简而言之,它允许 JavaScript 对图形硬件进行低阶编程。这无疑让 Web 页面能更好地利用显卡的优势,如 3D、着色器和卓越性能。
另外,目前 WebGL 有两个版本,其中 WebGL 1.0 是基于 OpenGL ES 2.0,WebGL 2.0 是基于 OpenGL ES 3.0。
在了解了 Canvas 2D 和 WebGL 的基本信息后,我们再看看 GPU 是如何渲染 2D 图像的。
首先,我们先介绍渲染处理,以便你了解测试中发生了什么。尽管有点简化,但它能让你有一个基本的认识。要在低阶渲染器(如 WebGL 和 DirectX)中绘制 2D 图像,首先需要一个能包围该图像的四边形。因此,我们需要提供该四边形每个角的坐标(x, y)。这里的每个角都被称为顶点(vertex),如下图的红点所示:
包围着图像的四边形
为了高效地绘制大量的 2D 图像,我们需要有一个能装载每个图像所有顶点的列表。该列表存储在顶点缓冲区,显卡会进行读取绘制。下图中有 5 个海盗公主,有的旋转,有的缩放,共有 20 个顶点。
多个图像时的顶点
显卡是非常先进的技术,它已被庞大的 3D 游戏行业推动多年。现在它的运算速度非常快,渲染 2D 图像的速度更是快得难以形容。因为它的渲染速度甚至比你告诉它渲染哪张图更快。换句话说,计算每个顶点的位置并将其发送到显卡的这个过程可能需要 2 微秒,但显卡完成其工作只需 1 微秒,然后空闲地等待下一个指令。
由此可看出,2D 游戏的性能主要受限于顶点缓冲区的填充速度。所以这里的问题是:计算顶点的位置和将其填充到缓冲区的速度能有多快?
下面我们将分别对 Canvas 2D 和 WebGL 进行测试。
为了测试两个渲染器的性能,我们编写了一个标准测试。首先,我们有一个蓝色正方形图像,然后在其基础上绘制足够多的图像,直至让帧率降至 30FPS。这样做是为了最大限度地减少每帧中不必要的计算量,确保我们能得出顶点的填充速度。另外,图像是具有透明度的,因此我们能看到它们不断地堆叠起来,如下图:
测试示例图
我们可在各个浏览器上进行测试,以查看它们的实际渲染速度:
在 Early 2013 MacBook Pro(系统为 macOS 10.12.5,硬件配置为 i7 2.4GHz 处理器、8G 1600 MHz DDR3 内存、GT 650M 显卡)上测试可得出以下数据:
注:对于 Windows,可能还需要修改独显对测试浏览器的支持(默认可能是集显)。
Chrome 59.0.3071.115(正式版本)(64 位)测试数据如下:
Chrome Canvas 2D——分数为 2415
Chrome WebGL——分数为 13711
Safari 10.1.1(12603.2.4)测试数据如下:
Safari Canvas 2D——分数 7481
Safari WebGL——分数 52061
Firfox 54.0.1(64位) 测试数据如下:
Firfox Canvas 2D——分数 5992
Firfox WebGL——分数 66291
由上述数据可得:3 款浏览器的 WebGL 性能都优于 Canvas 2D,Chrome 是 5.6 倍、Safari 是 6.95 倍、Firfox 是 11 倍。而且由分数可看出:Safari 和 Firfox 无论是 Canvas 2D 还是 WebGL 都远强于 Chrome。
为何 WebGL 普遍比 Canvas 2D 性能要高呢?
对于 Canvas 2D,其 API 相对于 WebGL 更高阶。即它实际并没有直接发送顶点信息到顶点缓冲区,而只是描述了在某个位置上绘制一个 2D 图像,然后再让浏览器计算出具体的顶点信息。
对于 WebGL,它直接给出所有对象的顶点信息。这意味着无需再进行任何计算来确定顶点的信息。这样就可以消除浏览器对顶点处理的开销,从而直接复制到顶点缓冲区。另外,从上面我们的实际测试结果可知,WebGL 的性能提升效果是非常明显的。当然,上述只是简单的测试,实际应用中还是需要考虑实际情况。
综上所述,影响两者性能的因素有很多,如操作系统、硬件、浏览器的底层实现与优化和项目代码质量等。在实际测试中,现代浏览器的 WebGL 性能在整体上优于 Canvas 2D。
也许有人认为:性能够用就好,再高也就是过剩。其实不然,因为除了保证画面流畅外,性能高还有以下好处:
一般来说,要达到流畅的体验,电影需要 24FPS,而游戏却要 60FPS。
概括来说,造成两者差异的主要原因有:
更详细的解答请看以下两个链接(此刻,我不生产内容,只是内容的搬运工):
其实原来文章的大纲不止于以上几点(还有 TypeScript、WebAssembly、脏矩形、骨骼动画等),但由于笔者深知自己能力和经验上的不足,所以把模棱两可或不确定的点都取消了。但笔者会在后续的学习中不断完善,甚至增加新的知识点。所以这是一篇不定时更新的博文,请持续关注 凹凸实验室。
看了以上几个心中疑问后,是否觉得离『游戏入门』的门近了一点呢?
最后,希望大家能在评论区提出更多关于 Web 游戏的疑问,说不定可以收录至本文哦👏。
参考资料:
本书的目录就激起了笔者强烈的阅读欲望。每阅读一章或一节,几乎都能解答之前遇到的疑惑,也开阔了知识面,是一本难得的好书,相见恨晚。笔者也相信,丰富的随书案例能在创作时激发灵感。
本文仅记录了部分知识点,感兴趣的读者可以深入阅读书本。
用于直角三角形,直角两条边的平方和等于斜边的平方。
a^2 + b^2 = c^2
在直角三角形中,
sinθ = a / c(对边/斜边)
cosθ = b / c(邻边/斜边)
tanθ = a / b(对边/邻边)
cotθ = b / a(领边/对边)
另外,一个角的正弦值等于另一个角的余弦值。
是三角函数的逆运算。换句话说,输入一个比率,获得对应的夹角(弧度)。
反正切函数 用于计算夹角(弧度)。
2PI弧度 = 360度
1弧度 = 57.2958度
function degToRad (deg) {
return deg * Math.PI / 180
}
function radToDeg (rad) {
return rad * 180 / Math.PI
}
直角坐标系(又叫笛卡尔坐标系) (x, y)
极坐标系 (r, θ)
其中:
r = Math.sqrt(x^2 + y^2)
θ = Math.atan2(y, x)
余弦定理是描述三角形中三边长度与一个角的余弦值关系的数学定理,是勾股定理在一般三角形情形下的推广,勾股定理是余弦定理的特例。余弦定理是揭示三角形边角关系的重要定理,直接运用它可解决一类已知三角形两边及夹角求第三边或者是已知三个边求三角的问题。——百度百科
对于任意三角形,任何一边的平方等于其他两边平方的和减去这两边与它们夹角的余弦的积的两倍。
a² = b² + c² - 2bc x cosA
b² = a² + c² - 2ac x cosB
c² = a² + b² - 2ab x cosC
二次贝塞尔曲线
context.quadraticCurveTo(cpx, cpy, x, y)
第一个是控制点,第二个是终点。
该函数会计算出从一个点到另一个点的一条曲线。该曲线会弯向但永远不触及控制点,就好像它被控制点的引力所吸引。
假设起点为 (x0, y0)、终点为 (x2, y2),控制点为 (x1, y1)。假如我们希望曲线穿过的点为 (xt, yt),那么 (x1, y1) 应该设为什么值呢?下面是计算公式:
x1 = xt * 2 - (x0 + x2) / 2
y1 = yt * 2 - (y0 + y2) / 2简单来说,将目标点的坐标乘以 2 再减去起点和终点坐标的平均值。
开始一条新路径,把画笔移到第一个点的位置。接下来 for 循环从 1 开始以 2 为步长递增,绘制一条曲线经过点 1 到达点 2,然后经过点 3 到达点 4,在经过点 5 到达点 6,最后经过点 7 到达点 8,而它恰好是最后一个点(注:点 0 为第一个点)。在该案例中,至少要包含三个点,而且点的个数必须为奇数。
...
for (let i = 0; i < numPoints; i++) {
points.push({
x: Math.random() * canvas.width,
y: Math.random() * canvas.height
})
}
context.beginPath()
context.moveTo(points[0].x, points[1].y)
for (let i = 0; i < numPoints; i += 2) {
context.quadraticCurveTo(points[i].x, points[i].y, points[i + 1].x, points[y + 1].y)
}
context.stroke()
...如上图所示,它根本就不像一条平滑的曲线,而且在某些地方看上去还很尖锐。问题在于在连续两条曲线间并没有协调好它们的走向,而只是简单地穿过了同一个点。
需插入一些更多的点让它看上去更像曲线。在每两个点之间,加入一个恰好位于它们中间的新点,并使用它们作为每条曲线的起点和终点,而将原始点作为曲线的控制点。
...
context.beginPath()
context.moveTo(points[0].x, points[1].y)
//curve through the rest, stopping at each midpoint
for (i = 1; i < numPoints - 2; i++) {
ctrlPoint.x = (points[i].x + points[i+1].x) / 2
ctrlPoint.y = (points[i].y + points[i+1].y) / 2
context.quadraticCurveTo(points[i].x, points[i].y,
ctrlPoint.x, ctrlPoint.y)
}
//curve through the last two points
context.quadraticCurveTo(points[i].x, points[i].y,
points[i+1].x, points[i+1].y)
context.stroke()
...Smoothly Joined Multiple Curves
上述代码中,for 循环从 1 开始到 numPoints - 2 结束,这也就略过第一个和最后一个点。在循环中创建一个新的控制点,其 x、y 坐标分别设置为循环中当前点和后续点的 x、y 坐标的平均值。然后绘制一条穿过当前点并以控制点结尾的曲线,重复此过程直到循环结束。当循环结束时,索引 i 指向倒数第二个点,此时绘制一条曲线穿过它到达最后一个点。
此方法并不限制点的个数是否为奇数,只需点的个数等于或大于 3 个即可。
闭合的平滑曲线
与上面方法相同。它计算初始中点,即第一个点和最后一个点的平均值,并移动到该位置,然后遍历剩下的点,获得接下来每两个相邻点的中点,最终将最后一条曲线画回到初始的中点。
...
for (let i = 0; i < numPoints; i++) {
points.push({
x: Math.random() * canvas.width,
y: Math.random() * canvas.height
})
}
//find the first midpoint and move to it
ctrlPoint1.x = (points[0].x + points[numPoints-1].x) / 2
ctrlPoint1.y = (points[0].y + points[numPoints-1].y) / 2
context.beginPath()
context.moveTo(ctrlPoint1.x, ctrlPoint1.y)
//curve through the rest, stopping at each midpoint
for (i = 0; i < numPoints - 1; i++) {
ctrlPoint.x = (points[i].x + points[i+1].x) / 2
ctrlPoint.y = (points[i].y + points[i+1].y) / 2
context.quadraticCurveTo(points[i].x, points[i].y,
ctrlPoint.x, ctrlPoint.y)
}
//curve through the last point, back to the first midpoint
context.quadraticCurveTo(points[i].x, points[i].y,
ctrlPoint1.x, ctrlPoint1.y)
context.stroke()
...Smoothly Joined Multiple Curves in Closed Path
bezierCurveTo(cp1x, co1y, cp2x, cp2y, x, y) 三次贝塞尔曲线arcTo(cp1x, cp1y, cp2x, cp2y, radius) 根据控制点和半径绘制圆弧路径,使用当前的描点(前一个moveTo或lineTo等函数的止点)。根据当前描点与给定的控制点1连接的直线,和控制点1与控制点2连接的直线,作为使用指定半径的圆的切线,画出两条切线之间的弧线路径。arc(x, y, radius, startAngle, endAngle[, antiClockwise]) 圆。处理多个合力:只需将每个力产生的加速度叠加到速度向量上即可,其中并不涉及复杂的加权平均或因式分解计算。
vx = v * Math.cos(angle)
vy = v * Math.sin(angle)ax = force * Math.cos(angle)
ay = force * Math.sin(angle)vx += ax
vy += ayx += vx
y += vy摩擦力:(又称为阻力、阻尼)只会改变速度向量的大小而不会改变它的方向。换句话说,摩擦力只能将物体的速度降至零,但它无法让物体掉头向相反的方向移动。
speed = Math.sqrt(vx * vx + vy * vy)
angle = Math.atan2(vy, vx)
if (speed > friction) {
speed -= friction
} else {
speed = 0
}
vx = Math.cos(angle) * speed
vy = Math.sin(angle) * speedvx *= friction
vy *= friction可基于 Spaceship Simulation with Friction Applied 案例做一款可漂移的小车游戏。
缓动和弹动关系紧密,这两种技术都是把对象从已有位置移动到目标位置的方法。缓动指物体滑动到目标点就停下来。弹动是指物体来回反弹一会,最终停在目标点的运动。
两种技术的共同点:
缓动和弹动的不同点:
缓动有多种类型,下面主要讨论“缓出(ease out)”。
延伸:ease in、ease out、ease in out、ease 有何不同?
linear:没有任何缓动。
ease in:即缓动发生在入口处,也就是刚开始的时候。
ease out:即缓动发生在出口处,也就是结束之前。
ease in out:入口和出口处都有缓动,但中间是匀速。
ease:入口和出口处都有缓动,但中间是加速。
实现策略:
实现代码:
object.x += (targetX - object.x) * easing甚至也可以移动目标点,如鼠标。
缓动不仅于运动
object.rotation += (targetRotation - rotation) * easing高级缓动
罗伯特·皮诺(Robert Penner)收集了许多缓动公式并加以分类,同时在 Flash 中实现。可在 http://robertpenner.com/easing/ 中找到他的这些缓动公式。这里有书作者整理的 JavaScript 版本:http://lamberta.github.io/html5-animation/xtras/easing-equations/click-to-ease.html。
弹动是动画编程中最重要和最强大的物理概念之一。
生活案例
在橡皮筋的一头系上一个小球,另一头固定起来。小球的目标点就是它静止悬空的那个点。将小球拉开一小段距离然后松开,刚松手那一瞬间,它的速度为零,但是橡皮筋给它施加了外力,把它拉向目标点。如果将小球拉得越远,橡皮筋对它施加的外力就越大。松手后,小球会急速飞过目标点,这时它的速度很高。但是,当它飞过目标点后,橡皮筋又把它往回拉,使其速度减小。它飞得越远,橡皮筋施加的力就越大。最终,它的速度降为零,又掉头往回飞。反复几次后,小球逐渐慢下来,停在目标点上。
实现代码:
const ax = (targetX - object.x) * spring
const ay = (targetY - object.y) * spring
vx += ax
vy += ay
// 增加摩擦力,否则一直来回弹动,永远停不下来
vx *= friction
vy *= friction
object.x += vx
object.y += vyconst dx = object.x - targetX
const dy = object.y - targetY
const angle = Math.atan2(dy, dx)
const targetX = targetX + Math.cos(angle) * springLength
const targetY = targetY + Math.sin(angle) * springLength
// 与以上代码相同
基础的多物体碰撞检测
多物体碰撞并不是直接的两层 for 循环,因为这其中含有不必要,甚至是重复的判断。
objects.forEach((objectA, i) => {
for (let j = 0; j < objects.length; j++) {
const objectB = objects[j]
if (hitTestObject(objectA, objectB)) {
// do something
}
}
})以上碰撞检测存在以下问题:
i 与 j 相等时。这浪费了 objects.length 次。(objects.length * objects.length) - objects.length 次,而且由于重复判断可能会导致不可预料的结果,难以调试。优化后的算法:
objects.forEach((objectA, i) => {
for (let j = i + 1; j < objects.length; j++) {
const objectB = objects[j]
if (hitTestObject(objectA, objectB)) {
// do something
}
}
})快速计算多个物体的检测次数,其实是一个阶加。
因此,当有 n 个物体进行碰撞检测,那么判断的次数为 (n - 1)?。如 6 个物体,则判断 15 次。
阶加的概念:所有小于及等于该数的正整数之和,记作 n? 或 Σ(n)。
举例来说:5? = 1+2+3+4+5 = 15
阶加的计算方法:
n? = n(n+1) / 2
通过增减角度,用基本的三角函数计算位置,就能使物体围绕中心点旋转。可以设置一个变量 vr(旋转速度)来控制角度的变化量。
vr = 0.1
angle = 0
radius = 100
centerX = 0
centerY = 0
// 在动画循环中做以下计算:
object.x = centerX + cos(angle) * radius
object.y = centerY + sin(angle) * radius可见,这种方式需要知道角度和半径。
对于只知道物体位置和中心点位置的情况,也可以通过以下方式得到上述两个变量:
const dx = ball.x - centerX
const dy = ball.y - centerY
const angle = Math.atan2(dy, dx)
const radius = Math.sqrt(dx * dx + dy * dy)这种方式并不适用于需要旋转多个物体,且它们相对于中心点的位置各不相同的情况。因为,要在每帧中计算每个物体的距离、角度和半径,然后再把 vr 累加在角度上,最后计算新的 x、y 坐标。显然,这既不是一个优雅的方案,也并不高效。
如果物体围绕一个点旋转,你只知道它们的坐标,那么下面这个公式非常适合这种情况。这个方式只需要知道物体相对于中心点的 x、y 坐标和旋转角度,就能算出物体旋转后的 x、y 位置。公式如下:
x1 = x * cos(rotation) - y * sin(rotation)
y1 = y * cos(rotation) + x * sin(rotation)公式的结果如下图所示:正在旋转 x、y 坐标,更具体地说,是旋转物体相对于中心点的坐标。所以,也可以把公式写成这样:
x1 = (x - centerX) * cos(rotation) - (y - centerY) * sin(rotation)
y1 = (y - centerY) * cos(rotation) + (x - centerY) * sin(rotation)旋转角度(rotation)就是物体在这一步的旋转量,而不是当前角度,也不是旋转后的角度,而是两者的差值。因此,该公式不用知道和关心起始角度和旋转后的角度,只需要关心旋转角度即可。
上述公式的推导过程:
// 中心点为 (0, 0),即 centerX 和 centerY 为 0
x = radius * cos(angle) + centerX
y = radius * sin(angle) + centerY
x1 = radius * cos(angle + rotation)
y1 = radius * sin(angle + rotation)
又因为两角之和的余弦值和正弦值:
cos(a + b) = cos(a) * cos(b) + sin(a) * sin(b)
sin(a + b) = sin(a) * cos(b) + cos(a) * sin(b)
把 x1、y1 的公式展开,得到:
x1 = radius * cos(angle) * cos(rotation) - radius * sin(angle) * sin(rotation)
y1 = radius * sin(angle) * cos(rotation) + radius * cos(angle) * sin(rotation)
把上面的 x、y 变量带入公式,得到:
x1 = x * cos(rotation) - y * sin(rotation)
y1 = y * cos(rotation) + x * sin(rotation)
以旋转多个物体为例,对比两者的情况:
简单坐标旋转
balls.forEach((ball) => {
const dx = ball.x - centerX
const dy = ball.y - centerY
const angle = Math.atan2(dy, dx)
const dist = Math.sqrt(dx * dx + dy * dy)
angle += vr
ball.x = centerX + Math.cos(angle) * dist
ball.y = centerY + Math.sin(angle) * dist
})高级坐标旋转
const cos = Math.cos(vr)
const sin = Math.sin(vr)
balls.forEach((ball) => {
const x1 = ball.x - centerX
const y1 = ball.y - centerY
const x2 = x1 * cos - y1 * sin
const y2 = y1 * cos + x1 * sin
ball.x = centerX + x2
ball.y = centerY + y2
})前者在每次循环中调用了 4 次 Math 方法,而后者全程只调用了 2 次,且无论多少个对象。当然这是在旋转速度不变的前提下。
对于斜面,我们要做的是:旋转整个系统使反弹面水平,然后做反弹,最后再旋转回来。这意味着反弹面、物体的坐标位置和速度向量都旋转了。
旋转速度可能听起来很复杂,但是你已经把速度存储在 vx 和 vy 变量中。vx 和 vy 确定了一个包含了角度(方向)和大小(长度)的向量。如果你知道角度,就可以直接旋转它。但是如果你只知道 vx 和 vy,就可以使用高级坐标旋转公式得到同样的效果。
从图 10-5 来看,实现反弹非常简单。只需调整小球的位置,改变 y 轴上的速度,如图 10-6 所示。
现在小球的位置和速度都发生了变化。接下来,再把整个场景旋转回到最初的角度,如图 10-7 所示。
以上就是斜面碰撞背后的理论。
执行旋转
在开始之前,首先需要一个东西来充当斜面。这只是为了让你能看到,而不是数学计算上的需要。对于平面反弹,可以使用 canvas 的边界。但是对于斜面反弹,可以画一条斜线,这样你就能看到小球在哪里反弹。
因此,新建一个 Line 类,可以用来画一条直线。它还提供了一个相当完善的 getBounds 方法用来做碰撞检测——即使旋转了也能正常工作。
function Line (x1, y1, x2, y2) {
this.x = 0
this.y = 0
this.x1 = (x1 === undefined) ? 0 : x1
this.y1 = (y1 === undefined) ? 0 : y1
this.x2 = (x2 === undefined) ? 0 : x2
this.y2 = (y2 === undefined) ? 0 : y2
this.rotation = 0
this.scaleX = 1
this.scaleY = 1
this.lineWidth = 1
}
Line.prototype.draw = function (context) {
context.save()
context.translate(this.x, this.y)
context.rotate(this.rotation)
context.scale(this.scaleX, this.scaleY)
context.beginPath()
context.moveTo(this.x1, this.y1)
context.lineTo(this.x2, this.y2)
context.closePath()
context.stroke()
context.restore()
}
Line.prototype.getBounds = function () {
if (this.rotation === 0) {
const minX = Math.min(this.x1, this.x2)
const minY = Math.min(this.y1, this.y2)
const maxX = Math.max(this.x1, this.x2)
const maxY = Math.max(this.y1, this.y2)
return {
x: this.x + minX,
y: this.y + minY,
width: maxX - minX,
height: maxY - minY
}
} else {
const sin = Math.sin(this.rotation)
const cos = Math.cos(this.rotation)
const x1r = cos * this.x1 - sin * this.y1 // 注:书本上是 +,本案例中,结果一致
const x2r = cos * this.x2 - sin * this.y2 // 注:书本上是 +,本案例中,结果一致
const y1r = cos * this.y1 + sin * this.x1
const y2r = cos * this.y2 + sin * this.x2
return {
x: this.x + Math.min(x1r, x2r),
y: this.y + Math.min(y1r, y2r),
width: Math.max(x1r, x2r) - Math.min(x1r, x2r),
height: Math.max(y1r, y2r) - Math.min(y1r, y2r)
}
}
}继续使用 Ball 类,确保小球位于直线的上方,这样它就能落在直线上。
const canvas = document.getElementById('canvas')
const context = canvas.getContext('2d')
const ball = new Ball()
const line = new Line(0, 0, 300, 0)
const gravity = 0.2
const bounce = -0.6
ball.x = 100
ball.y = 100
line.x = 50
line.y = 200
line.rotation = 10 * Math.PI / 180 // 10° 的弧度
// 计算角度的 sine 和 cosine
const cos = Math.cos(line.rotation)
const sin = Math.sin(line.rotation)
(function drawFrame () {
window.requestAnimationFrame(drawFrame, canvas)
context.clearRect(0, 0, canvas.width, canvas.height)
// 常规的运动代码
ball.vy += gravity
ball.x += ball.vx
ball.y += ball.vy
// 以 line 为参考,获取 ball 的位置
let x1 = ball.x - line.x
let y1 = ball.y - line.y
// 旋转坐标
const x2 = cos * x1 + sin * y1
const y2 = cos * y1 - sin * x1
// 旋转速度
const vx1 = cos * ball.vx + sin * ball.vy
const vy1 = cos * ball.vy - sin * ball.vx
// 执行旋转后的反弹
if (y2 > -ball.radius) {
y2 = -ball.radius
vy1 *= bounce
}
// 恢复旋转前
x1 = cos * x2 - sin * y2
y1 = cos * y2 + sin * x2
ball.vx = cos * vx1 - sin * vy1
ball.vy = cos * vy1 + sin * vx1
ball.x = line.x + x1
ball.y = line.y + y1
ball.draw(context)
line.draw(context)
}())你可能注意到这两行代码(加减号与公式相反):
// 旋转坐标
x2 = x1 * cos + y1 * sin
y2 = y1 * cos - x1 * sin要让直线水平,需要旋转 -10°,但最后需要整个系统旋转归位,还需要计算原始角度(10°)的正余弦值。为了减少计算量,只需简单调换一下加减号即可。注:因为一四(或二三)象限 cos 一致,sin 取反。
不必旋转 line 实例,因为它只是用来让你看到反弹面,而且它还是保存斜面角度和位置的好地方。
接下来可以使用位置 x2、y2 和速度 vx1、vy1 来执行反弹。因为 y2 是相对于 line 实例的位置,所以“底边”就是 line 自己,也就是 0。考虑到小球的大小,需要判断 y2 是否大于 0 - ball.radius,即:
if (y2 > -ball.radius) {
// do bounce
}最后把所有东西都旋转归位,用最初的公式计算 x1、y1、ball.vx 和 ball.vy,并把 x1、y1 和 line.x、line.y 相加得到 ball 实例的绝对位置。
优化代码
其实有很多代码并不需要在每帧中都执行。许多代码仅在小球碰到直线后才需要执行。其余大多数时间,只需要执行基本的运动代码以及小球与直线的碰撞检测。这样就节省了很多计算量。随着动画越来越复杂,类似这样的优化就显得愈发重要。
优化后的代码:
(function () {
window.requestAnimationFrame(drawFrame, canvas)
context.clearRect(0, 0, canvas.width, canvas.height)
// 常规的运动代码
ball.vy += gravity
ball.x += ball.vx
ball.y += ball.vy
// 以 line 为参考,获取 ball 的位置
let x1 = ball.x - line.x
let y1 = ball.y - line.y
// 旋转坐标
let y2 = y1 * cos - x1 * sin
// 执行旋转后的反弹
if (y2 > -ball.radius) {
// 旋转坐标
let x2 = x1 * cos + y1 * sin
// 旋转速度
let vx1 = ball.vx * cos + ball.vy * sin
let vy1 = ball.vy * cos - ball.vx * sin
y2 = -ball.radius
vy1 *= bounce
// 恢复旋转前
x1 = x2 * cos - y2 * sin
y1 = y2 * cos + x2 * sin
ball.vx = vx1 * cos - vy1 * sin
ball.vy = vy1 * cos + vx1 * sin
ball.x = line.x + x1
ball.y = line.y + y1
}
ball.draw(context)
line.draw(context)
})()修复“不从边缘落下”的问题
你可能注意到,即使小球到了直线的边缘,它还是会沿着直线方向滚动。这看起来很奇怪,但是别忘了小球并不是真的与 line 对象交互,运动都是通过数学算出来的。因此,需要通过碰撞检测或边界框检测来让小球知道线的位置。
修复“线下”问题
在检测碰撞时,首先要判断小球是否在直线附近,然后进行坐标旋转,得到旋转后的位置和速度。接着,判断小球旋转后的纵坐标 y2 是否越过了直线,如果是,则执行反弹。
但是如果小球位于直线下方该怎么办呢?比如碰撞检测和边界框检测都返回 true,程序会认为小球在直线上反弹,它就会把小球从直线下移到直线上。
有一个解决方案是比较 vy1 和 y2,仅当 vy1 大于 y2 的时候才执行反弹。如下图所示。
左边小球在 y 轴上的速度大于它与直线的相对距离,这意味着,它刚刚从直线上穿越下来。右边小球的速度向量小于它和直线的相对距离,也就是说,它在这一帧和上一帧中都位于线下,因此它只是在线下运动。
笔者注:可通过距离公式 y = y0 + v 推导理解。
// 需要把 y2 < vy1 加入到 if 语句中:
if (y2 > -ball.radius && y2 < vy1) {
}本章重要公式
x1 = x * Math.cos(rotation) - y * Math.sin(rotation)
y1 = y * Math.cos(rotation) + x * Math.sin(rotation)x1 = x * Math.cos(rotation) + y * Math.sin(rotation)
y1 = y * Math.cos(rotation) - x * Math.sin(rotation)两个物体碰撞后动量如何变化,动量守恒定理,以及如何将动量守恒应用在动画中。
在地球上,我们通常认为质量就代表物体有多重。它们的确关系紧密,因为重量与质量成正比。实际上,我们用同样的单位来测量质量和重量。但从严格意义上说,质量是指物体保持运动速度的能力。因此物体的质量越大,就越难以改变物体的运动状态(加减速或方向)。而重量是指带有一定质量的物体在引力场中所受的力。
质量、加速度和外力的关系:
F = m x a
动量是物体质量与速度的乘积。
p = m x v
因为速度是向量,所以动量也是向量,其方向与速度向量的方向相同。
动量守恒是制作真实的碰撞效果的基本原理。
使用动量守恒定理,可以确定两个物体碰撞后如何反应。因此你可以说:“碰撞前,一个物体以速度 A 运动,另一个物体以速度 B 运动;碰撞后,一个物体速度变成了 C,另一个物体的速度变成了 D”。进一步分解来看,因为速度由大小的方向组成,如果已知两个物体碰撞前的速度大小和运动方向,就能计算出碰撞后的速度大小和运动方向。
当然前提是已知每个物体的质量。
动量守恒定理是一个基本的物理概念:系统在碰撞前的总动量等于系统在碰撞后的总动量。
(m0 x v0) + (m1 x v1) = (m0 x v0Final) + (m1 x v1Final)
解一个有两个未知数方程的方法,就是找出另一个含有相同两个未知数的方程。物理学中恰好有这么一个方程——动能。
KE = 0.5m x v²
动能不是向量,所有 v 仅表示速度的大小,与方向无关。
碰撞前后动能相同:
KE0 + KE1 = KE0Final + KE1Final
根据“代入消元法”可以得到两个未知数的公式:
if (Math.abs(dist) < ball0.radius + ball1.radius) {
const vx0Final = ((ball0.mass - ball1.mass) * ball0.vx + 2 * ball1.mass * ball1.vx) / (ball0.mass + ball1.mass),
const vx1Final = ((ball1.mass - ball0.mass) * ball1.vx + 2 * ball0.mass * ball0.vx) / (ball0.mass + ball1.mass);
ball0.vx = vx0Final;
ball1.vx = vx1Final;
ball0.x += ball0.vx;
ball1.y += ball1.vx;
}调整物体位置
避免出现两个物体嵌在一起,可以把一个物体调整到另一个小球的边缘上。但无论移动哪个都会看起来跳帧,在速度较慢时尤其明显。
方法很多,这里有一种比较简单的方法:把新速度加在物体的位置上,再次让它们弹开。如上面代码块的最后两行所示。
优化代码
以上代码出现两次几乎同样的方程,所以我们需要消除一个。
首先需要得到两个物体的相对速度,就是它们的叠加总速度。然后,当你计算出一个物体的最终速度后,再根据前面得到的相对速度,就能计算出另一个物体的最终速度。
两个物体的速度相减就能得到相对速度(注:带方向)。
在碰撞前,用 ball0.vx 减去 ball1.vx 来计算出总速度:
const vxTotal = ball0.vx - ball1.vx然后在计算出 vx0Final 后,把它与 vxTotal 相加等到 vx1Final。
vx1Final = vxTotal + vx0Final简化后的代码:
if (Math.abs(dist) < ball0.radius + ball1.radius) {
const vxTotal = ball0.vx - ball1.vx;
const ball0.vx = ((ball0.mass - ball1.mass) * ball0.vx + 2 * ball1.mass * ball1.vx) / (ball0.mass + ball1.mass);
ball1.vx = vxTotal + ball0.vx
ball0.x += ball0.vx;
ball1.y += ball1.vx;
}注:当两个相同质量的物体碰撞时,有更简单的做法:沿着碰撞的方向,物体简单地交换它们的速度。尽管仍然使用坐标旋转来确定碰撞角度与物体在这个角度上的速度,不过省去了复杂的动量守恒。
假设两物体质量相同,那么上述代码将可以改为:
// 旋转 ball0 的速度
vel0 = rotate(ball0.vx, ball0.vy, sin, cos)
// 旋转 ball1 的速度
vel1 = rotate(ball1.vx, ball1.vy, sin, cos)
const temp = vel0
vel0 = vel1
vel1 = temp二维空间中的碰撞,因为速度方向不在 x 轴上,所以不能直接把速度带入动量守恒公式。因此需要将整个场景旋转至与一维空间一样(位置和速度)。与第 10 章斜面反弹的做法完全一样。
两球间的角度很重要,这是碰撞角度。你只需关心小球的位于碰撞角度上的速度分量——vx。
这就和单轴的情况一样,使用公式得到两个新的 vx 值,而 vy 的值永远不变,即 vx 的变化单独影响了总体速度。
最后把所有东西后旋转回原位后,就得到了每个球最终真实的 vx 和 vy。
多球时的潜在问题
如果屏幕上有三个小球——ball0、ball1 和 ball2,它们恰好离得很近。下面是要发生的事情:
注意,这种情况最容易发生在空间小、物体多并且移动速度高的情况下。这也会发生在物体一开始就接触的情况下。
问题出现在以下两行代码:
// 更新位置
pos0.x += vel0.x
pos1.x += vel1.x这个假设碰撞只是由两个小球自己的速度引起的,然后把它们新的速度加回去以分开它们。大多数情况下,这是对的。但是在我们刚才说的那个场景例外。所以需要在移动之前更加严谨地确保两个物体是分离的。
// 更新位置
const absV = Math.abs(vel0.x) + Math.abs(vel1.x)
const overlap = (ball0.radius + ball.radius) - Math.abs(pos0.x - pos1.x)
pos0.x += vel0.x / absV * overlap
pos1.x += vel1.x / absV * overlap这不是数学中最精确的方法,但看起来工作得很好,其思路是:
第 5 章介绍的过万有引力(重力),但那是从微观角度来看的重力。站在地球上,重力的描述很简单:它把物体向下拉。实际上,它以特定的速率把物体向下拉。
当你往后退时,离一个星球或者很大的物体越远,受到的引力就越小。这对于地球和其他行星来说是个很好的现象,避免了被吸进太阳里捣得粉碎。从遥远的、宏观的视角看太阳系,你可以把行星看作例子,它们间的距离会影响万有引力。
距离与万有引力的关系很容易描述:万有引力与距离的平方成反比。另外,引力与质量关系紧密,一个物体的质量越大,它对其他物体的引力就越大,它受到其他物体的引力同样也越大(注:力是相互的,另外,根据 F=ma,质量小的能获得更大的加速度)。
force = G x m1 x m2 / distance²
G 是万有引力常数,等于 6.674 x 10^-11 x m³ x kg^-1 x S^-2
若需要对宇宙建模,用牛顿作为计量单位,就需要带上 G。而对于动画,将其设置为 1 省去。
计算两粒子的引力作用:
function gravitate (partA, partB) {
const dx = partB.x - partA.x
const dy = partB.y - partA.y
const distSQ = dx * dx + dy * dy
const dist = Math.sqrt(distSQ)
const force = partA.mass * partB.mass / distSQ
const forceX = force * dx / dist // cos
const forceY = force * dy / dist // sin
// 加减取决于计算 dx 和 dy 的相减顺序
partA.vx += forceX / partA.mass
partA.vy += forceY / partA.mass
partB.vx -= forceX / partB.mass
partB.vy -= forceY / partB.mass
}这些粒子一开始静止,然后相互吸引。偶尔两个粒子会相互绕圈,但是大多数情况下,这些粒子相互接近,然后向相反方向飞出。
这样碰撞后高速飞出是代码中的 bug 吗?并不是,这正是期望的效果。这个行为叫做弹弓效应(slingshot effect),NASA 就是使用这种效应把探测器发射到外太空去。随着一个物体与一个星球越来越近,它的加速度越来越大,速度会越来越高。如果你瞄得恰到好处,物体就会掠过星球,以足够大的速度摆脱星球的引力,进入太空。
在程序中,当两个物体距离很小的时候——几乎是零距离,它们之间的引力变得非常大,几乎是无限大。这样在数学上是对的。不过,从模拟的角度看,这并不真实。应该发生的结果是:在两个物体足够接近时,我们来控制碰撞。如果你把空间探测器瞄准一个星球,它就不能以无限大的速度接近,这样只能撞出一个火山口。
碰撞检测及反应
碰撞后的反应,可以是爆炸或者消失,或者可以让一个粒子消失,然后把它的质量加在另一个上,就像是两个融合了。
碰撞弹开则用到上一章节——撞球物体的知识。
其实这也许是 https://tendril.ca/ 网站,多个小人追随目标地的实现原理。
轨道运动
为了演示轨道运动,我们建立一个简单的行星系,其中有一个太阳和一个行星。设置太阳的质量为 10000,行星的质量为 1。让行星距离太阳一段距离,然后给它一个沿太阳切线方向的初速度。
如果设置了合适的质量、距离和速度,你就能让行星进入轨道(经过一些试验)。
如果你观察万有引力和弹力,就会发现它们相似但几乎完全相反。它们都是在两个物体上施加加速度使它们接近。但是对于万有引力,两个物体距离越大,加速度越小;对于弹力,两个物体距离越大,加速度越大。
可以用弹力来替换水上一个例子的万有引力的代码,但结果并不有趣。例子最终会黏成一团——弹力不能容忍距离。
这是一个两难的处境,你既想让粒子间通过弹力相互吸引,又想让它们保持一定距离,不黏在一起。我们可以设置一个最小距离来解决这个问题,如果两个粒子间的距离大于这个最小距离,则忽略对方。
function spring (partA, partB) {
const dx = partB.x - partA.x
const dy = partB.y - partA.y
const dist = Math.sqrt(dx * dx, dy * dy)
if (dist < minDist) {
const ax = dx * springAmount
const ay = dy * springAmount
partA.vx += ax
partA.vy += ay
partB.vx -= ax
partB.vy -= ay
}
}这样粒子都聚成一团,就像一群苍蝇围着垃圾堆嗡嗡叫。这些团也会移动,散开,与其他团结合,这是一个有趣的自然行为。
运动学:是一个数学分支,用来处理物体的运动,但不关心质量和外力,因此它关心速度、方向。
当计算机科学、图形学、游戏领域的人说起运动学时,他们通常涉及运动学的两个特殊分支:正向运动学和反向运动学。
正向和反向运动学通常与多个部件组合而成的系统相关,比如,一个链条或者一个由关节组成的手臂。它们来解决整个系统如何运动,以及每个部件相对于其他部件和整个系统如何运动。
通常,一个运动学系统有两个端点:基础端和自由端。由关节组成的手臂通常一端固定,另一端可以随意伸出去拿一个东西。链条可能有一端或者两端固定,或者都不固定。
正向运动学(Forward Kinematics, FK)的动作起源于固定端,移动自由端。
反向运动学(Inverse Kinematics, FK)的动作开始于,或者决定于自由端,移动向固定端(若有)。
用例子区分它们的区别。
大多数情况下,在行走时,四肢的运动是正向运动学。大腿带动小腿,小腿带动脚。脚不决定其他任何东西,它的运动取决于大腿和小腿的运动。
反向运动学的例子是去拉一个人的手,这时力量施加在自由端(那个人的手),移动手的位置就能移动小臂、最终影响到整个身体。
拖拽和伸手去拿一般是反向运动学,但是一个重复周期的运动,如行走,往往是正向运动学。
编写两种运动学的程序都包含以下一些基本元素:
每个节段都有一端是轴心点,它可以围绕轴心点旋转。如果一个节段的一端有子阶段,那么它的轴心点在另一端。比如,上臂的轴心点在肩膀,前臂的轴心点在肩膀,前臂的轴心点在肘部,手的轴心点在腕部。
当然,在很多真实的系统中,节段可能在多个方向上围绕轴心点旋转。如转动手腕。
function Segment(width, height, color) {
this.x = 0
this.y = 0
this.width = width
this.height = height
this.vx = 0
this.vy = 0
this.rotation = 0
this.scaleX = 1
this.scaleY = 1
this.color = (color === undefined) ? "#ffffff" : utils.parseColor(color)
this.lineWidth = 1
}
Segment.prototype.draw = function (context) {
const h = this.height
const d = this.width + h // 包含两端半圆的半径
const cr = h / 2 // 圆角半径
context.save()
context.translate(this.x, this.y)
context.rotate(this.rotation)
context.scale(this.scaleX, this.scaleY)
context.lineWidth = this.lineWidth
context.fillStyle = this.color
context.beginPath()
context.moveTo(0, -cr)
context.lineTo(d - 2 * cr, -cr)
context.quadraticCurveTo(-cr + d, -cr, -cr + d, 0)
context.lineTo(-cr + d, h - 2 * cr)
context.quadraticCurveTo(-cr + d, -cr + h, d - 2 * cr, -cr + h)
context.lineTo(0, -cr + h)
context.quadraticCurveTo(-cr, -cr + h, -cr, h - 2 * cr)
context.lineTo(-cr, 0)
context.quadraticCurveTo(-cr, -cr, 0, -cr)
context.closePath()
context.fill()
if (this.lineWidth > 0) {
context.stroke()
}
// 绘制两个插销点
context.beginPath()
context.arc(0, 0, 2, 0, (Math.PI * 2), true)
context.closePath()
context.stroke()
context.beginPath()
context.arc(this.width, 0, 2, 0, (Math.PI * 2), true)
context.closePath()
context.stroke()
context.restore()
}
// 右边插销点的位置
Segment.prototype.getPin = function () {
return {
x: this.x + Math.cos(this.rotation) * this.width,
y: this.y + Math.sin(this.rotation) * this.width
}
}本章只记录一小部分,更多内容请阅读书本。
伸出:当系统的自由端伸向一个目标时,系统的另一端(基础端)可能是固定的。所以,如果目标超出范围,自由端有可能永远够不到它。反向运动学会告诉你如何调整位置以实现最佳的伸出效果。
拖拽:自由端被外力拖动。无论它被拖到哪里,系统的其他部分都跟随其后,位置由物理原理决定。反向运动学告诉你如何当各个部件被拖动时位置如何变化。
对于伸出而言,所有节段都要向目标旋转。
const dx = mouse.x - segment0.x
const dy = mouse.y - segment0.y
segment0.rotation = Math.atan2(dy, dx)
segment0.draw(context)拖拽方法的开始部分与伸出方法相同:向鼠标指针方向旋转节段。其次要把节段的第二个轴心点移动到鼠标位置。这需要知道两个轴心点在 x、y 轴上的距离——可以叫做 w 和 h,它们可以通过节段的位置以及 getPin() 方法的返回值计算得到。然后从当前鼠标指针位置中再减去 w 和 h,这就是节段要移动到的位置。
const dx = mouse.x - segment0.x
const dy = mouse.y - segment0.y
segment0.rotation = Math.atan2(dy, dx)
// S 相对上列新增部分
const w = segment0.getPin().x - segment0.x
const h = segment0.getPin().y - segment0.y
segment0.x = mouse.x - w
segment0.y = mouse.y - h
// E 相对上列新增部分
segment0.draw(context)
本章只记录一小部分,更多内容请阅读书本。
另外,网易的 《睡姿大比拼》 应该就是基于反向运动学的伸出实现。
三维背后的主要概念就是存在一个除了 x、y 轴之外的维度。这个维度表示深度,它通常叫做 z。
接下里的案例均使用右手坐标系统。
有很多技术可以用来表示透视图,但是我们只关心两种:
所以,当在 z 轴上移动物体时,要做两件事:
在二维系统中,可以使用屏幕的 x、y 坐标作为物体的 x、y 坐标,因为它们是一一对应的。但是这在三维系统中行不通,因为两个物体可能拥有相同的 x、y 坐标,但是由于它们的深度不同,它们在屏幕上的位置就不一样。在三维系统中的任何一个物体都有自己的 x、y 和 z 坐标,这个坐标描述在虚拟空间内的位置。透视图的计算告诉我们应该把物体放在屏幕上的哪个位置。注:还有正视图等。
透视图公式
基本**:随着物体的远离(z 坐标增加),它的大小缩小到 0,同时 x、y 坐标向消失点移动。因为缩放的比例和接近消失点的比例相同,所以只需根据距离计算出缩放比例,然后两个地方都能使用这个比例进行计算。
在这里,有一个正在远离你的物体,一个观察点(相机)和一个成像面(即屏幕)。物体和成像面之间有一段距离,z 值。观察点到成像面也有一段距离,这与照相机镜头的焦距相似,所以用变量 f1 表示。长焦距可以比作长焦镜头,它可以拉近远处的物体,但视野比较小。短焦距就像是广角镜头,视野很大,但是有些变形。中等的焦距类似人类的眼睛,f1 为 200~300 之间的值。透视图公式:
scale = f1 / (f1 + z)
公式通常会产生 0.0~1.0 之间的值,这就是用来缩放和靠近消失点的比例。当 z 小于或等于 -f1 时,我们可以让物体消失,避免出现 scale 为负数,当把它应用到 canvas 的上下文中,会导致图像坐标系翻转,从而看到小球变大然后变小。
if (z > -f1) {
const scale = f1 / (f1 + z)
x = mouse.x - vpX // vpX 为消失点 x,值为 canvas.width / 2
y = mouse.y - vpY
ball.scaleX = ball.scaleY = scale
ball.x = vpX + xpos * scale
ball.y = vpY + ypos * scale
ball.visible = true
} else {
ball.visible = false
}
if (ball.visible) {
ball.draw(context)
}Z 排序是指物体在 z 轴上如何排序,或者表示物体哪个在前,哪个在后。
function zSort (a, b) {
return (b.z - a.z)
}
balls.sort(zSort)这个排序基于每个元素的 z 属性,依照数字的反序排列,换句话说,就是从高到低。得到的结果是,最远的物体(z 值最大)处于数组中首位,因为第一个被绘制在 canvas 上。最近的小球是数组中的最后一个元素,它被绘制在所有其他小球之上。
三维系统能对之前章节的各种动画效果进行延伸,如重力反弹、屏幕环绕等等。
重力反弹
屏幕环绕(如三维赛车类游戏)
Running Through a Forest with Screen-Wrapping
在二维坐标旋转中,坐标点是绕着 z 轴旋转。只有 x 坐标和 y 坐标在改变。
在三维系统中,也可以绕 x 轴或 y 轴旋转。点绕着 x 轴旋转并且只改变其 y 坐标和 z 坐标。
绕 y 轴旋转,改变其 x 坐标和 z 坐标。
因此,在三维系统中,当物体绕着某一条轴旋转时,它在其他两条轴上的坐标发生变化。与第十章中的二维坐标旋转基本相同,但是要指定绕哪条轴旋转:x、y 或 z。这样就得到以下三组公式:
x1 = x * cos(angleZ) - y * sin(angleZ)
y1 = y * cos(angleZ) + x * sin(angleZ)
x1 = x * cos(angleY) - z * sin(angleY)
z1 = z * cos(angleY) + x * sin(angleY)
y1 = y * cos(angleX) - z * sin(angleX)
z1 = z * cos(angleX) + y * sin(angleX)
上一章节只是通过计算物体的大小和屏幕位置把它们至于三维空间中,但物体本身仍然是二维的。
function Point3d(x, y, z) {
// x、y、z 是实际位置,会导致物体围绕着三维空间的中心旋转
this.x = (x === undefined) ? 0 : x
this.y = (y === undefined) ? 0 : y
this.z = (z === undefined) ? 0 : z
this.fl = 250 // 焦距
this.vpX = 0 // 消失点
this.vpY = 0
this.cX = 0 // 中心点,移动整个模型,同时绕着自己的中心旋转
this.cY = 0
this.cZ = 0
}
Point3d.prototype.setVanishingPoint = function (vpX, vpY) {
this.vpX = vpX
this.vpY = vpY
}
Point3d.prototype.setCenter = function (cX, cY, cZ) {
this.cX = cX
this.cY = cY
this.cZ = cZ
}
Point3d.prototype.rotateX = function (angleX) {
const cosX = Math.cos(angleX)
const sinX = Math.sin(angleX)
const y1 = this.y * cosX - this.z * sinX
const z1 = this.z * cosX + this.y * sinX
this.y = y1
this.z = z1
}
Point3d.prototype.rotateY = function (angleY) {
const cosY = Math.cos(angleY)
const sinY = Math.sin(angleY)
const x1 = this.x * cosY - this.z * sinY
const z1 = this.z * cosY + this.x * sinY
this.x = x1
this.z = z1
}
Point3d.prototype.rotateZ = function (angleZ) {
const cosZ = Math.cos(angleZ)
const sinZ = Math.sin(angleZ)
const x1 = this.x * cosZ - this.y * sinZ
const y1 = this.y * cosZ + this.x * sinZ
this.x = x1
this.y = y1
}
Point3d.prototype.getScreenX = function () {
const scale = this.fl / (this.fl + this.z + this.cZ)
return this.vpX + (this.cX + this.x) * scale
}
Point3d.prototype.getScreenY = function () {
const scale = this.fl / (this.fl + this.z + this.cZ)
return this.vpY + (this.cY + this.y) * scale
}与其他三维系统类似,模型都有点、线、三角形组成。
而三角形的顶点都是按照顺时针方向排序,其法向量是面的指向方向,用于背面剔除(backface culling)。
我们使用屏幕坐标来判断一个多边形的顶点是顺时针还是逆时针方向。不是三维 x、y、z 坐标,而是调用 getScreenX()、getScreen() 得到的经过透视计算的 canvas 坐标。
Triangle.prototype.isBackface = function () {
const cax = this.pointC.getScreenX() - this.pointA.getScreenX()
const cay = this.pointC.getScreenY() - this.pointA.getScreenY()
const bcx = this.pointB.getScreenX() - this.pointC.getScreenX()
const bcy = this.pointB.getScreenY() - this.pointC.getScreenY()
return cax * bcy > cay * bcx
}我们将 A,B 和 A,C 做一条向量,这两条向量为:U = B - A,V = C - A
因为都在 X,Y 平面,所以有:U = (Ux, Uy, 0), V = (Vx, Vy, 0)
然后使用叉积计算 U 和 V:U × V = (0, 0, UxVy - UyVx)
然后通过判断 UxVy - UyVx 的符号来判断三角形的朝向。
负值:用左手判断 3 个顶点的方向是顺时针方向;
正值:为逆时针方向。
来自:三角形正面判断
深度排序,或者 z 排序,已经在第 15 章中介绍透视图时讨论过了。在那个例子中,依据一个数组中三维物体的 z 属性对它们进行排序。
但是现在,你并不是在处理多个物体。所以需要对组成模型的三角形数组进行排序。这里依据的是三角形的深度,这个值是组成三角形的三个顶点的 z 坐标的最小值。
Triangle.prototype.getDepth = function () {
return Math.min(this.pointA.z, this.pointB.z, this.pointC.z)
}然后对三角形对象数组进行排序,确定三角形绘制的先后顺序。要按升序排列,要让最远的那个排在第一位。
function depth (a, b) {
return (b.getDepth() - a.getDepth())
}矩阵被大量应用于 3D 系统中,以实现旋转、缩放以及平移 3D 坐标的功能。它也常用语各种 2D 图形的变换。
矩阵的下标都是从 1 开始计数,如下图中,M2,3(下标)是 6。
矩阵的一个常见用途是操作 3D 空间中的点,这样一个点分别包含 x、y 与 z 轴上的坐标。可以将其简单地视为一个 1 x 3 的矩阵。
x y z
为了实现点在空间中的移动,也称为点的平移,需要知道它在每条轴上的移动距离。可以将每条轴上的移动距离填充到一个平移矩阵中,就像下面这个 1 x 3 的矩阵:
dx dy dz
这里,dx、dy 与 dz 分别为 x、y 与 z 轴上的移动距离。现在要通过矩阵加法将平移矩阵作作用于 3D 点上。只需将每个对应的单元格的数值加在一起就可以创造出一个包含每个单元格之和的新矩阵。只有两个同样大小的矩阵才能相加。点的平移如下所示:
x y z + dx dy dz = (x + dx) (y + dy) (z + dz)
矩阵乘法是 3D 转化的计算中更为常用的一种方法,它通常用于缩放和旋转。
使用矩阵进行缩放
首先,需要知道一个物体现有的宽度、高度与深度,换句话说,也就是它在三条轴上每个分量的大小。
w h d
然后要用到像下面这样的一个缩放矩阵:
sx 0 0
0 sy 0
0 0 sz
在这个矩阵中,sx、sy 与 sz 分别为对应轴上的缩放比例。它们都是以分数或小数的形式出现,1.0 表示 100%,0.5 则表示 50% 等。
sx 0 0
w h d * 0 sy 0
0 0 sz
计算结果如下:
(w * sx) (h * sy) (d * sz)
矩阵乘法有一个必要条件,第一个矩阵的列数必须等同于第二个矩阵的行数,只要符合这个标准,无论第一个矩阵有多少行,第二个矩阵有多少列,它们都可以相乘,否则它们无法进行乘法运算。
a b c
u v w * d e f
g h i
等于 (u * a + v * d + w * g) (u * b + v * e + w * h) (u * c + v * f + w * i)
矩阵相乘后得到的新矩阵的大小的行列数分别由第一个矩阵的行数和第二个矩阵的列数决定。
使用矩阵进行坐标旋转
首先,我们将再次用到 3D 空间中一个点的矩阵:
x y z
它持有待旋转点的三维坐标。现在,我们需要一个旋转矩阵,通过它我们可以在三条轴中任意一条轴上进行旋转。我们将分别为每种类型的旋转创建一个矩阵。先从 x 轴的旋转矩阵开始:
1 0 0
0 cos sin
0 -sin cos
计算得出:
(x * 1 + y * 0 + z * 0) (x * 0 + y * cos - z * sin) (x * 0 + y * sin + z * cos)
整理后结果如下:
(x) (y * cos - z * sin) (z * cos + y * sin)
与之对应的 JavaScript 代码如下:
x = x
y = y * Math.cos(rotation) - z * Math.sin(rotation)
z = z * Math.cos(rotation) + y * Math.sin(rotation)这里的方法与之前介绍的围绕 x 轴的旋转方法完全一致。这并没有什么值得惊奇的,因为矩阵数据仅仅是组织各种公式与方程的另一种方法而已。
围绕 y 轴旋转的矩阵:
cos 0 sin
0 1 0
-sin 0 cos
围绕 z 轴旋转的矩阵:
cos sin 0
-sin cos 0
0 0 1
矩阵的另一个重要功能是用于操纵 canvas 上显示的图形。通过应用一个变换矩阵,可以实现图形的旋转、缩放以及平移,进而改变他们的形状、大小与位置。
canvas 上下文在内容使用像下面这样一个 3x3 的变换矩阵:
a c dx
b d dy
u v w
该变换也称为仿射变换,这意味着,为了能应用仿射变换,二维向量 (x, y) 需要改写为三维向量 (x, y, 1)。由于 (u, v, w) 并不会用到,他们会直接设为 (0, 0, 1),并保持不变。所以你不用管它们。
可以通过调用以下函数设置 canvas 上下文的变换矩阵:
context.setTransform(a, b, c, d, dx, dy)
要将当前的 canvas 上下文中的变换矩阵再乘上一个新的变换矩阵(注:即累计),可以调用以下函数:
context.transform(a, b, c, d, dx, dy)
如果没有为 canvas 设置任何变换矩阵,那么 canvas 会认为我们使用了一个单位矩阵(identity matrix)或一个空矩阵,就是类似下面这样一个矩阵:
1 0 0
0 1 0
0 0 1
为 canvas 上下文应用该矩阵不会产生任何变换。所以,每当你希望重置 canvas 上下文时,可以将它的变换矩阵设置为单位矩阵,如下所示:
context.setTransform(1, 0, 0, 1, 0, 0)
变化矩阵的那些字母元素的含义:
dx 和 dy 控制 canvas 上下文将要在 x 与 y 轴上平移的距离。注意,坐标 (0, 0) 位于 canvas 的左上角。
而 a、b、c、d 则有点复杂,它们之间的联系非常紧密。如果将 b 与 c 设为 0,则可以借助 a 与 d 实现物体在 x 轴与 y 轴上的缩放。而如果将 a 与 d 设为 1,则可以通过 b 与 c 让物体在 y 轴 与 x 轴上倾斜。甚至可以将 a、b、c、d 联合起来设置成下面这个我们熟悉的矩阵:
cos -sin dx
sin cos dy
u v w
这里包含一个旋转矩阵。很容易想到,这里的 cos 与 sin 代表 canvas 上下文将要旋转的角度(以弧度为单位)的余弦和正弦值。
倾斜,倾斜是将物体沿着某条轴拉伸使得物体的两端沿着两个相反的方向运动。这种变换想要通过某个公式实现是非常复杂的,而借助变换矩阵就变得很容易。
将矩阵中的 a 与 d 设为 1,剩下的 b 可用于指定物体在 y 轴上的倾斜程度,而 c 则用于指定物体在 x 轴上的倾斜程度。
注:正值是往左/上(以左上角为参考点)
切斜效果经常用于实现伪 3D。
在计算机图形学的各种应用中都能找到矩阵的身影。它广泛应用于计算机视觉过滤器、图像处理(比如边缘检测)、锐化以及模糊变换。随着你不断地深入到更加高级的计算图形编程中,你会发现更多有关矩阵的应用。
布朗运动:虽然水看起来是静止的,但是一滴水中有无数水分子,它们在不断地运动。一些分子与花粉或灰尘发生碰撞,这样就会把动量传递给它们。
模拟效果:在每一帧中,计算随机数并累加给移动物体的 x、y 速度上,随机数有正有负,并且非常小,比如在 -0.1~0.1 之间。
function draw (dot) {
dot.vx += Math.random() * 0.2 - 0.1
dot.vy += Math.random() * 0.2 - 0.1
dot.x += dot.vx
dot.y += dot.vy
dot.vx *= friction // 摩擦力,避免速度过渡累积,产生不自然的效果
dot.vy *= friction
}运动轨迹的生成
以 rgba(255, 255, 255, 0.01) 绘制一个矩形来替换 context.clearRect。这样每一帧中都不会擦除粒子的运动轨迹,只会逐步地让图形越来越淡。
笔者认为绘制 100 次后会完全变白,但实际并不会。相关讨论:rgba fillStyle with alpha does not get fully opaque if applied multiple times
通过计算随机数的平方根(偏向 1,远离 0),可以让分布更加平滑。
while (numDots--) {
const radius = Math.sqrt(Math.random()) * maxRadius
const angle = Math.random() * (Math.PI * 2)
const x = canvas.width / 2 + Math.cos(angle) * radius
const y = canvas.height / 2 + Math.sin(angle) * radius
}让小圆点随机分布在整个 canvas 上,但让它们趋向分布在中心区域。即有一些在边缘附近,但越接近中心,分布得越多。这与第一个圆形分布的例子相似,但这次是在矩形区域内。
通过给为每一个位置产生多个随机数并计算它们的平均值来实现。
while (numDots--) {
for (let i = 0, xpos = 0; i < iterations; i++) {
xpos += Math.random() * canvas.width
}
const x = xpos / iterations
}在某些场景中,正态分布比随机分布更能还原自然现象。本文将阐述正态分布的相关知识,并结合案例讲解如何在动画中使用正态分布。
其实,大家都熟知随机数,通过 Math.random() 就能返回一个 [0, 1) 区间内的 伪随机数。例如:当抛硬币的次数足够大时,正/反面的出现概率均为 50%。对于这种均匀随机数的情况是可以通过 Math.random() 模拟实现的。然而,自然界中有很多变量是服从或近似服从正态分布的。
正态分布,又名高斯分布
正态分布是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
一般地,如果对于任何实数 a, b(a < b),随机变量 X 满足:
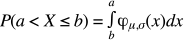
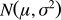
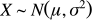
正态分布的函数表达式:
当期望值 μ 为 0(即正态曲线关于 Y 轴对称),标准差 σ 为 1 时,则为标准正态分布,记作 N(0, 1)。
因为正态分布完全由 μ 和 σ 确定,所以可以通过研究 μ 和 σ 对正态曲线的影响来认识正态曲线的特点。
(1)先确定 σ 值,μ 取不同值的图像如下:
当 σ 一定时,曲线随着 μ 的变化而沿 x 轴平移。
(2)再固定 μ 值,σ 取不同值的图像如下:
当 μ 一定时,曲线的形状由 σ 决定。σ 越少,曲线越“瘦高”,表示总体的分布越集中;σ 越大,曲线越“矮胖”,表示总体的分布越分散。
关于正态分布的基础知识,本文介绍至此。更多知识和实际应用的资料,读者可自行搜索。
显然,想要在程序中实现期望值为 μ、标准差为 σ 的正态分布并不是件容易的事。ECMAScript 目前也没有提供一个直接生成服从正态分布的随机数的函数。但已有前人给出了实现算法,其中 Box-Muller transform 算法是一个能根据均匀分布的随机数来产生服从正态分布的随机数算法。
当然,也有其他生成服从正态分布随机数的算法:
因为 Box-Muller transform 算法效率较高,并且计算过程比较简单,在很长时间内都是生成服从正态分布随机数的“标准”算法,所以本文就结合此算法进行阐述。
根据 Box-Muller 算法,假设 a、b 是两个服从均匀分布并且取值范围在 [0, 1] 的随机数,我们就可以通过下面的公式得到两个满足标准正态分布(均数 μ 为 0,标准差 σ 为 1)的随机数 Z1 和 Z2。
等式中的
ln(x)代表自然对数函数,即以 e(=2.71828) 为底的对数函数。
得到的 Z1 和 Z2 是独立的、服从标准正态分布的随机数。因此,读者只要将 Z1 和 Z2 作为两个没有任何关联的随机数去使用即可。
下面看看“撒金币”分别在均匀随机和正态分布下的表现,看看哪个更能俘获你的心。
See the Pen 均匀分布的随机数 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>See the Pen 服从正态分布的随机数 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>“撒金币”案例主要对每个金币的水平速度 vx 和垂直速度 vy 应用独立的随机数。
对于均匀分布的随机数,我们直接使用 Math.random() 实现。而对于服从正态分布的随机数,则通过 Box-Muller 算法,其大概过程如下:
// 因为 Math.random() 返回 [0, 1),1 - Math.random() 得到 (0, 1],避免出现 ln(0) = -infinite
const rand = 1 - Math.random()
const randR = Math.sqrt(-2 * Math.log(rand))
const randT = 2 * Math.PI * Math.random()
Z1 = randR * Math.cos(randT)
Z2 = randR * Math.sin(randT)对于“撒金币”案例,正态分布是否比随机分布更好,也许见仁见智。但使用正确的方式还原自然现象,无疑能给用户带来更真实的体验。
“碰乜鬼嘢啊,碰走晒我滴靓牌”。想到“碰”笔者就自然联想到“麻将”这一伟大发明。当然除了“碰”,洗牌的时候也充满了大量『碰撞』。
好了,不废话。直入主题——碰撞检测。
在 2D 环境下,常见的碰撞检测方法有如下几种:
下文将以由易到难的顺序介绍上述各种碰撞检测方法:外接图形判别法 > 其他 > 光线投射法 > 分离轴定理。
另外,有一些场景只需约定好限定条件,也能实现我们想要的碰撞,如下面的碰壁反弹:
See the Pen Boundary collision detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>当球碰到边框就反弹(如x/y轴方向速度取反)。
if(ball.left < 0 || ball.right > rect.width) ball.velocityX = -ball.velocityX
if(ball.top < 0 || ball.bottom > rect.height) ball.velocityY = -ball.velocityY再例如当一个人走到 100px 位置时不进行跳跃,就会碰到石头等等。
因此,某些场景只需通过设定适当的限制即可实现碰撞检测。
概念:判断任意两个(无旋转)矩形在每个轴上是否重叠,若都重叠则为碰撞。
算法:
rect1.x < rect2.x + rect2.width &&
rect1.x + rect1.width > rect2.x &&
rect1.y < rect2.y + rect2.height &&
rect1.height + rect1.y > rect2.y两矩形间碰撞的各种情况:
在线运行示例(先点击运行示例以获取焦点,下同):
See the Pen AxisAlignedBoundingBox collision detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>概念:通过判断任意两个圆形的圆心距离是否小于两圆半径之和,若小于则为碰撞。
计算两点距离的公式:
判断两圆心距离是否小于两半径之和:
Math.sqrt(Math.pow(circleA.x - circleB.x, 2)
+ Math.pow(circleA.y - circleB.y, 2))
< circleA.radius + circleB.radius图例:
在线运行示例:
See the Pen EZrorG by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>概念:通过找出矩形上离圆心最近的点,然后通过判断该点与圆心的距离是否小于圆的半径,若小于则为碰撞。
那如何找出矩形上离圆心最近的点呢?下面我们从 x 轴、y 轴两个方向分别进行寻找。为了方便描述,我们先约定以下变量:
矩形上离圆心最近的点为变量:closestPoint = {x, y};
矩形 rect = {x, y, w, h}; // 左上角与宽高
圆形 circle = {x, y, r}; // 圆心与半径
首先是 x 轴:
如果圆心在矩形的左侧(if(circle.x < rect.x)),那么 closestPoint.x = rect.x。
如果圆心在矩形的右侧(else if(circle.x > rect.x + rect.w)),那么 closestPoint.x = rect.x + rect.w。
如果圆心在矩形的正上下方(else),那么 closestPoint.x = circle.x。
同理,对于 y 轴(此处不列举图例):
如果圆心在矩形的上方(if(circle.y < rect.y)),那么 closestPoint.y = rect.y。
如果圆心在矩形的下方(else if(circle.y > rect.y + rect.h)),那么 closestPoint.y = rect.y + rect.h。
圆心在矩形的正左右两侧(else),那么 closestPoint.y = circle.y。
因此,通过上述方法即可找出矩形上离圆心最近的点了,然后通过『两点距离公式』得出『最近点』与『圆心』的距离,最后将其与圆的半径相比,即可判断两者是否发生碰撞。
var distance = Math.sqrt(Math.pow(closestPoint.x - circle.x, 2) + Math.pow(closestPoint.y - circle.y, 2))
if(distance < circle.r) return true // 发生碰撞
else return false // 未发生碰撞
在线运行示例:
See the Pen Circle and Rectangle by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>概念:即使矩形以其中心为旋转轴进行了旋转,但是判断它与圆形是否发生碰撞的本质还是找出矩形上离圆心的最近点。
对于旋转后的矩形,要找出其离圆心最近的点,似乎有些困难。其实,我们可以将矩形的旋转看作是整个画布的旋转。那么我们将画布(即 Canvas)反向旋转『矩形旋转的角度』后,所看到的结果就是上一个方法“圆形与矩形(无旋转)”的情形。因此,我们只需计算画布旋转后的圆心位置,即可使用『圆形与矩形(无旋转)』的判断方法了。
先给出可直接套用的公式,计算反向旋转后的圆心坐标:
x’ = cos(β) * (cx – centerX) – sin(β) * (cy – centerY) + centerX
y’ = sin(β) * (cx – centerX) + cos(β) * (cy – centerY) + centerY
下面给出该公式的推导过程:
根据下图,计算某个点绕另外一个点旋转一定角度后的坐标。我们设 A(x,y) 绕 B(a,b) 旋转 β 度后的位置为 C(c,d)。
由上述公式推导后可得:旋转后的坐标 (c,d) 只与旋转前的坐标 (x,y) 及旋转的角度 β 有关。
当然,(c,d) 是旋转一定角度后『相对于旋转点(轴)的坐标』。因此,前面提到的『可直接套用的公式』中加上了矩形中心点的坐标值。
从图中也可以得出以下结论:由 A 点旋转后得到的 C 点总是在圆周(半径为 |AB|)上运动,利用这点可让物体绕旋转点(轴)做圆周运动。
得到旋转后的圆心坐标值后,即可使用『圆形与矩形(无旋转)』方法进行碰撞检测了。
在线运行案例:
See the Pen Circle and Rotated Rectangle Collision Detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>概念:将地图(场景)划分为一个个格子。地图中参与检测的对象都存储着自身所在格子的坐标,那么可认为当两个物体在相邻格子时即为碰撞,或者两个物体在同一格时才为碰撞。另外,采用此方法的前提是:地图中所有参与碰撞的物体大小都须为格子的整数倍。
蓝色X 为障碍物:
实现方法:
// 通过特定标识指定(非)可行区域
map = [
[0, 0, 1, 1, 1, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 1, 1, 1, 1, 1, 0, 0]
],
// 设定角色的初始位置
player = {left: 2, top: 2}
// 移动前(后)判断角色的下一步动作(如不能前行)
...在线运行示例:
See the Pen map cell collision detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>适用案例:
概念:以像素级别检测物体之间是否存在像素重叠,若存在则为碰撞。
实现方法有多种,下面列举在 Canvas 中的两种实现方式:
globalCompositeOperation = 'destination-in' 属性。该属性会使得两者重叠部分保留,其余区域变成透明。因此,若存在非透明像素,则为碰撞。注意,当待检测碰撞物体为两个时,第一种方法需要两个 offscreen canvas,而第二种只需一个。
offscreen canvas:与之相关的是 offscreen rendering。正如其名,它会在某个地方进行渲染,但不是屏幕。“某个地方”其实是内存。渲染到内存比渲染到屏幕更快。—— Offscreen Rendering
当然,我们这里并不是利用 offscreen render 的性能优势,而是利用 offscreen canvas 保存独立物体的像素。换句话说:onscreen canvas 只是起展示作用,碰撞检测是在 offscreen canvas 中进行。
另外,由于需要逐像素判断,若对整个 Canvas 内所有像素都进行此操作,无疑会浪费很多资源。因此,我们可以先通过运算得到两者相交区域,然后只对该区域内的像素进行检测即可。
图例:
下面示例展示了第一种实现方式:
See the Pen pixel collision detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>缺点:
概念:通过检测两个物体的速度矢量是否存在交点,且该交点满足一定条件。
对于下述抛小球入桶的案例:画一条与物体速度向量相重合的线(#1),然后再以另一个待检测物体为始点,连线到前一个物体,绘制第二条线(#2),最后根据两条线的交点位置来判定是否发生碰撞。
抛球进桶图例:
在小球飞行的过程中,需要不断计算两直线的交点。
当满足以下两个条件时,那么就可以判定小球已落入桶中:
#2)下方在线运行示例:
See the Pen ray casting collision detection by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>概念:通过判断任意两个 凸多边形 在任意角度下的投影是否均存在重叠,来判断是否发生碰撞。若在某一角度光源下,两物体的投影存在间隙,则为不碰撞。
图例:
在程序中,遍历所有角度是不现实的。那如何确定 投影轴 呢?其实投影轴的数量与多边形的边数相等即可。
注:数字标号的含义,在下面“投影轴”章节了解。
以较高抽象层次判断两个凸多边形是否碰撞:
function polygonsCollide(polygon1, polygon2) {
var axes, projection1, projection2
// 根据多边形获取所有投影轴
axes = polygon1.getAxes()
axes.push(polygon2.getAxes())
// 遍历所有投影轴,获取多边形在每条投影轴上的投影
for(each axis in axes) {
projection1 = polygon1.project(axis)
projection2 = polygon2.project(axis)
// 判断投影轴上的投影是否存在重叠,若检测到存在间隙则立刻退出判断,节省不必要的运算。
if(!projection1.overlaps(projection2))
return false
}
return true
}上述代码有几个需要解决的地方:
如下图所示,我们使用一条从 p1 指向 p2 的向量来表示多边形的某条边,我们称之为边缘向量。在分离轴定理中,还需要确定一条垂直于边缘向量的法向量,我们称之为“边缘法向量”。
投影轴平行于边缘法向量。投影轴的位置不限,因为其长度是无限的。该轴的方向才是关键的。
// 以原点(0,0)为始,顶点为末。最后通过向量减法得到边缘向量。
var v1 = new Vector(p1.x, p1.y)
v2 = new Vector(p2.x, p2.y)
// 首先得到边缘向量,然后再通过边缘向量获得相应边缘法向量(单位向量)。
// 两向量相减得到边缘向量 p2p1。
// 设向量 p2p1 为(A,B),那么其法向量通过 x1x2+y1y2 = 0 可得:(-B,A) 或 (B,-A)。
axis = v1.edge(v2).normal()以下是向量对象的部分实现,具体可看源码。
var Vector = function(x, y) {
this.x = x
this.y = y
}
Vector.prototype = {
// 获取向量大小(即向量的模),即两点间距离
getMagnitude: function() {
return Math.sqrt(Math.pow(this.x, 2),
Math.pow(this.y, 2))
},
// 点积的几何意义之一是:一个向量在另一个向量方向上的投影长度。
// 后续将会用其计算出投影的长度
dotProduct: function(vector) {
return this.x * vector.x + this.y + vector.y
},
// 向量相减得到边向量
subtarct: function(vector) {
var v = new Vector()
v.x = this.x - vector.x
v.y = this.y - vector.y
return v
},
edge: function(vector) {
return this.substract(vector)
},
// 获取当前向量的法向量(垂直)
perpendicular: function() {
var v = new Vector()
v.x = this.y
v.y = 0 - this.x
return v
},
// 获取单位向量(即向量大小为 1,用于表示向量方向),一个非零向量除以它的模即可得到单位向量
normalize: function() {
var v = new Vector(0, 0)
m = this.getMagnitude()
if(m !== 0) {
v.x = this.x / m
v.y = this.y /m
}
return v
},
// 获取边缘法向量的单位向量,即投影轴
normal: function() {
var p = this.perpendicular()
return p .normalize()
}
}
向量相减
关于向量的更多知识可通过其它渠道学习。
投影的大小:通过将一个多边形上的每个顶点与原点(0,0)组成的向量,投影在某一投影轴上,然后保留该多边形在该投影轴上所有投影中的最大值和最小值,即可表示一个多边形在某投影轴上的投影了。
判断两多边形的投影是否重合:projection1.max > projection2.min && project2.max > projection.min
为了易于理解,示例图将坐标轴原点(0,0)放置于三角形边1投影轴的适当位置。
由上述可得投影对象:
// 用最大和最小值表示某一凸多边形在某一投影轴上的投影位置
var Projection = function (min, max) {
this.min
this.max
}
projection.prototype = {
// 判断两投影是否重叠
overlaps: function(projection) {
return this.max > projection.min && projection.max > this.min
}
}如何得到向量在投影轴上的长度?
向量点积的几何含义之一是:一个向量在另一个向量方向上的投影长度。
故投影的长度为 x1 * x2 + y1 * y2。
// 根据多边形的每个定点,得到投影的最大和最小值,以表示投影。
function project = function (axis) {
var scalars = [], v = new Vector()
this.points.forEach(function (point) {
v.x = point.x
v.y = point.y
scalars.push(v.dotProduct(axis))
})
return new Projection(Math.min.apply(Math, scalars),
Math.max.apply(Math, scalars))
}尽管圆形可看成一个有无数条边组成的正多边形,但我们不可能按照这些边一一进行投影和判断。我们只需将圆形投影到一条投影轴上即可,这条轴就是圆心与多边形顶点中最近一点的连线,如图所示:
因此,该投影轴和多边形自身的投影轴就组成了一组待检测的投影轴数组了。
而对于圆形与圆形之间的碰撞检测依然是两圆心距离是否小于两半径之和。
分离轴定理的整体代码实现,可查看以下案例:
See the Pen SeparatingAxisTheorem by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>缺点:
关于分离轴定理的更多资料:
通常来说,如果碰撞之后,碰撞双方依然存在,那么就需要将两者分开。可以使原来相撞的两物体彼此弹开,也可以让他们黏在一起,还可以根据具体需要来实现其他行为。不过首先要做的还是将两者分开,这就需要用到最小平移向量(Minimum Translation Vector, MIT)。
若每个周期都对全部物体进行两两判断,会造成浪费(因为物体分布在不同区域,不同区域的物体根本不会发生碰撞)。所以,更优的方案是将碰撞分为两个阶段:粗略和精细(broad/narrow)。
粗略阶段能为你提供有可能碰撞的实体列表。这可通过一些特殊的数据结构实现,它们能为你提供这些信息:实体存在哪里和哪些实体在其周围。这些数据结构可以是:四叉树(Quad Trees)、R树(R-Trees)或空间哈希映射(Spatial Hashmap)等。
读者若感兴趣,可以自行查阅相关资料。
当有了较小范围的实体列表,再通过精细阶段的算法(即上述碰撞算法)得到一个确切的答案(是否发生碰撞)。
碰撞检测有多种,选择合适最重要。
完!
原文:How to Build a Color Customizer App for a 3D Model with Three.js
本文将阐述如何基于 Three.js 创建一个完整的 3D 模型(椅子)颜色自定义应用。
马上体验:3D Model Color Customizer App with Three.js
该工具的灵感来源于 Vans shoe customizer,并采用优秀的 JavaScript 3D 库 Three.js 实现。
阅读本文的前提是已掌握 JavaScript、HTML 和 CSS。
为了能让你确切学到东西,而不是单纯地粘贴/复制。本文不按常规出牌,在一开始就给出全部 CSS。CSS 起到装扮应用的作用,即仅专注于 UI。每当我们粘贴部分 HTML 时,都会讲解相应 CSS 的作用。
你可以完全跳过本节,但它可以让你对这一切有更深入的了解。
这不是一篇关于 3D 建模的教程,但我将阐述如何在 Blender 中设置模型,这有助于你创建属于自己的模型、修改网上的免费模型或指点他人调试。以下是创作 3D 模型——椅子的一些经验。
模型需设置为符合真实世界的尺寸。我也不知道这是否重要,但感觉没问题,为什么不这样做呢?
这部分很重要:物体中每个需要独立控制的元素都必须是 3D 场景中独立的对象。这些对象也必须拥有唯一的名字。这里有 back(背部)、base(底座)、cushions(坐垫)、legs(椅腿)和 supports(支架)。若有三个元素都命名为 supports,那么 Blender 会将它们命名为 supports、supports.001、supports.002。这没问题,因为我们可以在 JavaScript 中使用 includes("supports") 找到它们。
模型应放置在场景的原点,并落在地板上。另外,最好能面向正确的方向,但这可通过 JavaScript 旋转易实现。
导出前,要使用 Blender 的 Smart UV unwrap。在此不深入细节,总之这会让纹理可以保持宽高比不变,保证不会在包裹模型中因各类形状而产生怪异的拉伸(建议你制作自己的模型时才仔细研究它)。
确保所有对象应用 transformations(译者注:即将缩放转为对象实际尺寸)。
显然 Three.js 支持很多 3D 对象文件格式,但它推荐的格式之一是 glTF(.glb)。而且 Blender 也支持导出该格式。
Fork 这个 pen(译者注:即 codepen 的一个案例),或创建一个 pen 并从其中复制 CSS。这是一个含有本教程所有 CSS 的空白 pen。
3D Chair Customizer Tutorial - Blank
若不选择 fork,也需要复制 HTML。这包含响应式 meta 标签和 Google 字体。
本教程使用了 3 个依赖,我在它们各自上方写有描述用途的注释。
<!-- The main Three.js file -->
<script src='https://cdnjs.cloudflare.com/ajax/libs/three.js/108/three.min.js'></script>
<!-- This brings in the ability to load custom 3D objects in the .gltf file format. Blender allows the ability to export to this format out the box -->
<script src='https://cdn.jsdelivr.net/gh/mrdoob/Three.js@r92/examples/js/loaders/GLTFLoader.js'></script>
<!-- This is a simple to use extension for Three.js that activates all the rotating, dragging and zooming controls we need for both mouse and touch, there isn't a clear CDN for this that I can find -->
<script src='https://threejs.org/examples/js/controls/OrbitControls.js'></script>引入 canvas 标签。整个 3D 体验将渲染于此,而其余 HTML 标签作为 UI 辅助于它。将 canvas 放在 HTML 底部(脚本前)。
<!-- The canvas element is used to draw the 3D scene -->
<canvas id="c"></canvas>
现在为 Three.js 创建一个 scene。
// Init the scene
const scene = new THREE.Scene();接着引用 canvas 元素:
const canvas = document.querySelector('#c');Three.js 需要具备一些元素才能跑起来。第一个是 scene,第二个是 renderer。在 canvas 变量下方添加它。创建一个 WebGLRenderer,传入 canvas 和选项参数(抗齿距,使 3D 模型的边缘更光滑)。
// Init the renderer
const renderer = new THREE.WebGLRenderer({canvas, antialias: true});然后将 renderer 插入到 body 元素(译者注:此行代码可省略)。:
document.body.appendChild(renderer.domElement);为 canvas 编写的 CSS 仅是将其拉伸至 body 的 100% 宽高,因此整个页面目前是黑色的(即 canvas 现在是黑色)。
虽然场景目前漆黑一片,但我们走在正确的道路上。
接着 Three.js 需要一个更新循环,这是一个在每帧都会执行的函数,对运行我们的应用程序起到重要作用。我们将更新函数命名为 animate(),并将其放置在 JavaScript 代码的最底部。
function animate() {
renderer.render(scene, camera);
requestAnimationFrame(animate);
}
animate();请注意,上面代码了引用摄像机(camera),但我们仍未添加它。
在 JavaScript 代码顶部,添加一个名为 cameraFar 的变量。当我们添加 camera 到 scene 时,其默认位置是 0,0,0。但这可是椅子的位置!因此 cameraFar 变量是告诉 camera 应离此多远,以确保能看到椅子。
var cameraFar = 5;在 animate() 函数上方添加 camera。
// Add a camera
var camera = new THREE.PerspectiveCamera( 50, window.innerWidth / window.innerHeight, 0.1, 1000);
camera.position.z = cameraFar;
camera.position.x = 0;这是一个透视摄像机,其参数为 50 视场(field of view,fov),宽高比和默认的裁剪区域。裁剪区域指定了可视区域的前后边界。当然,这些都不是本应用关心的事情。(译者注:可参考《Three.js 现学现卖》)
我们的场景仍然是黑色,下面设置背景色。
在顶部的 scene 变量上方,添加背景色变量 BACKGROUND_COLOR。
const BACKGROUND_COLOR = 0xf1f1f1;注意我们这里的十六进制是使用 0x 而不是 #。这不是字符串,而是以 0x 开头的整数。
在 scence 变量下方,更新 scene 的背景色,并在远处添加同样颜色的雾,旨在隐藏地板的边界。
const BACKGROUND_COLOR = 0xf1f1f1;
// Init the scene
const scene = new THREE.Scene();
// Set background
scene.background = new THREE.Color(BACKGROUND_COLOR );
scene.fog = new THREE.Fog(BACKGROUND_COLOR, 20, 100);现在仍是一个空白的世界,没有东西,没有投影。是时候加载模型了。
我们将使用第二个依赖来加载模型。
在此之前,我们先声明引用模型的变量,该变量会被频繁使用。我们将其放在 JavaScript 顶部的 BACKGROUND_COLOR 前。同时,添加该模型的路径。我已对其进行托管,供大家使用。它有 1Mb 左右的大小。
var theModel;
const MODEL_PATH = "https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/chair.glb";现在创建一个 loader,并使用其 load 方法。theModel 就是整个场景的 3D 模型。将其设置合适的尺寸大小,这里设为原大小的 2 倍。接着,设置其 y 轴偏移量为 -1,使其往下移动。最后将其添加到场景中。
load 函数的第一个参数是模型的路径,第二个参数是资源加载成功后的回调函数,第三个参数目前是 undefined,但它其实是资源加载期间的回调函数,最后一个参数是报错回调函数。
将这部分代码放在 camera 下方。
// Init the object loader
var loader = new THREE.GLTFLoader();
loader.load(MODEL_PATH, function(gltf) {
theModel = gltf.scene;
// Set the models initial scale
theModel.scale.set(2,2,2);
// Offset the y position a bit
theModel.position.y = -1;
// Add the model to the scene
scene.add(theModel);
}, undefined, function(error) {
console.error(error)
});此时,你应该看到的是一张被拉伸、黑色且像素化的椅子。看起来很糟糕,但这是正常的,别担心!
除了摄像机,我们还需要光。背景不受光影响,但如果此时添加地板,那么它依然会是黑色。Three.js 有几种类型的光且有丰富的选项可供调整。这里我们添加两种:环境光和定向光。两者的设置是专门适配该应用的,其中包括位置和强度。如果你对它们有使用经验,可以尝试更改。但现在就使用我提供的参数吧。将光放在 loader 下方。
// Add lights
var hemiLight = new THREE.HemisphereLight( 0xffffff, 0xffffff, 0.61 );
hemiLight.position.set( 0, 50, 0 );
// Add hemisphere light to scene
scene.add( hemiLight );
var dirLight = new THREE.DirectionalLight( 0xffffff, 0.54 );
dirLight.position.set( -8, 12, 8 );
dirLight.castShadow = true;
dirLight.shadow.mapSize = new THREE.Vector2(1024, 1024);
// Add directional Light to scene
scene.add( dirLight );此时,椅子看起来稍微好一些!到目前为止,JavaScript 如下:
var cameraFar = 5;
var theModel;
const MODEL_PATH = "https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/chair.glb";
const BACKGROUND_COLOR = 0xf1f1f1;
// Init the scene
const scene = new THREE.Scene();
// Set background
scene.background = new THREE.Color(BACKGROUND_COLOR );
scene.fog = new THREE.Fog(BACKGROUND_COLOR, 20, 100);
const canvas = document.querySelector('#c');
// Init the renderer
const renderer = new THREE.WebGLRenderer({canvas, antialias: true});
document.body.appendChild(renderer.domElement);
// Add a camerra
var camera = new THREE.PerspectiveCamera( 50, window.innerWidth / window.innerHeight, 0.1, 1000);
camera.position.z = cameraFar;
camera.position.x = 0;
// Init the object loader
var loader = new THREE.GLTFLoader();
loader.load(MODEL_PATH, function(gltf) {
theModel = gltf.scene;
// Set the models initial scale
theModel.scale.set(2,2,2);
// Offset the y position a bit
theModel.position.y = -1;
// Add the model to the scene
scene.add(theModel);
}, undefined, function(error) {
console.error(error)
});
// Add lights
var hemiLight = new THREE.HemisphereLight( 0xffffff, 0xffffff, 0.61 );
hemiLight.position.set( 0, 50, 0 );
// Add hemisphere light to scene
scene.add( hemiLight );
var dirLight = new THREE.DirectionalLight( 0xffffff, 0.54 );
dirLight.position.set( -8, 12, 8 );
dirLight.castShadow = true;
dirLight.shadow.mapSize = new THREE.Vector2(1024, 1024);
// Add directional Light to scene
scene.add( dirLight );
function animate() {
renderer.render(scene, camera);
requestAnimationFrame(animate);
}
animate();现在看起来如下:
让我们解决像素化和拉伸的问题。Three.js 需要在(视口)改变时更新 canvas 尺寸,其内部分辨率需依赖于 canvas 尺寸和设备屏幕像素比(手机的像素比一般比较高)。
在 JavaScript 代码底部,即调用 animate() 的下方添加该函数。该函数会监听 canvas 的尺寸和 window 的尺寸,并返回一个判断两者是否相同的布尔值。我们将会在 animate 函数内使用该函数,以决定是否需要重新渲染场景(设置场景大小)。该函数还会考虑设备像素比,以确保 canvas 在手机上也清晰。(译者注:建议通过监听 window resize 事件进行判断,且设备像素比上限为 2)
在 JavaScript 底部添加该函数:
function resizeRendererToDisplaySize(renderer) {
const canvas = renderer.domElement;
var width = window.innerWidth;
var height = window.innerHeight;
var canvasPixelWidth = canvas.width / window.devicePixelRatio;
var canvasPixelHeight = canvas.height / window.devicePixelRatio;
const needResize = canvasPixelWidth !== width || canvasPixelHeight !== height;
if (needResize) {
renderer.setSize(width, height, false);
}
return needResize;
}现在更新 animate 函数后看起来如下:
function animate() {
renderer.render(scene, camera);
requestAnimationFrame(animate);
if (resizeRendererToDisplaySize(renderer)) {
const canvas = renderer.domElement;
camera.aspect = canvas.clientWidth / canvas.clientHeight;
camera.updateProjectionMatrix();
}
}椅子看起来好多了。
我需要提醒两点:
跳到 loader 方法,还记得设置缩放比例的地方吗 theModal.scale.set(2,2,2)?我们将调整的旋转角度添加在它下方:
// Set the models initial scale
theModel.scale.set(2,2,2);
theModel.rotation.y = Math.PI;哇哦,看起来好多了。还有一件事是:据我所知,Three.js 目前仍不支持角度(deg)单位。因此,这里使用 Math.PI,即 180 度,如果想旋转至 45 度角,那么就设置 Math.PI / 4。
我们还需要一块地板,不然怎么产生投影呢?
创建一个平面(二维平面,或高度为 0 的三维体)作为地板。
在光的下方添加:
// Floor
var floorGeometry = new THREE.PlaneGeometry(5000, 5000, 1, 1);
var floorMaterial = new THREE.MeshPhongMaterial({
color: 0xff0000,
shininess: 0
});
var floor = new THREE.Mesh(floorGeometry, floorMaterial);
floor.rotation.x = -0.5 * Math.PI;
floor.receiveShadow = true;
floor.position.y = -1;
scene.add(floor);下面讲解一下这里发生了什么。
首先,我们创建了一个几何图形。这是本文创建的唯一一个几何图形,你可以进行各种参数的调整。
第二,我们使用了 MeshPhongMaterial,为其设置了颜色和反光度(shininess)。在讲 Three.js 其他材质前,我们先看看 Phong。我们能调整它的反光度(reflectiveness)和镜面高光(specular highlights)。另外,还有 MeshStandardMaterial,其支持更多的纹理特性,如金属(metallic)和环境光遮蔽(ambient occlusion);另外,还有不支持阴影的 MeshBasicMaterial。本文仅用到 Phong 材质。
我们创建了变量 floor,并将 geometry 和 material 合为 Mesh。
我们还对地板进行了以下操作:旋转至平坦状态,使其能接收阴影、往下移至椅子的位置。最后将其添加至场景。
现在看起来如下:
我们暂时将地板设为红色,但阴影在哪?为此,我们还需要做几件事。首先在 const renderer 下方添加这几行代码:
// Init the renderer
const renderer = new THREE.WebGLRenderer({canvas, antialias: true});
renderer.shadowMap.enabled = true;
renderer.setPixelRatio(window.devicePixelRatio); 我们同时设置了设备像素比,这与阴影无关,恰巧是适当的位置。我们启用了 shadowMap,但仍没有阴影?
在 loader 函数内,我们能遍历 3D 模型(的组成元素)。因此,跳到 loader 函数,在 theModel = gltf.scene; 下添加以下操作:为 3D 模型的每一个元素(椅腿、坐垫等)启用投射和接收阴影的选项。该遍历方法会在后续再次使用。
在 theModel = gltf.scene; 下方添加:
theModel.traverse((o) => {
if (o.isMesh) {
o.castShadow = true;
o.receiveShadow = true;
}
});这看起来比以前更糟,但起码能在地板上产生阴影!之所以不好看,是因为模型仍使用 Blender 带来的材质。下面我们将所有这些材质都替换为普通的 PhongMaterial。
在 loader 函数上方创建另一个 PhongMaterial:
// Initial material
const INITIAL_MTL = new THREE.MeshPhongMaterial( { color: 0xf1f1f1, shininess: 10 } );这是一个不错的起始材质,灰白色和略带光泽。
虽然目前只有一种材质,但为了后续方便为椅子各个部分设置不同颜色或加载的纹理,我们将材质的数据结构声明为一个数组。
// Initial material
const INITIAL_MTL = new THREE.MeshPhongMaterial( { color: 0xf1f1f1, shininess: 10 } );
const INITIAL_MAP = [
{childID: "back", mtl: INITIAL_MTL},
{childID: "base", mtl: INITIAL_MTL},
{childID: "cushions", mtl: INITIAL_MTL},
{childID: "legs", mtl: INITIAL_MTL},
{childID: "supports", mtl: INITIAL_MTL},
];再次遍历 3D 模型(的组成元素),并使用 childID 查找椅子的不同部分,然后设置相应材质(mtl 属性)。模型每个元素的名字都是在 Blender 中设置的,这在第一节讲到。
在 loader 函数下方,添加一个参数为模型、模型的哪部分(type)和材质的函数。我们还为模型的组成元素添加了一个后续会用到的新属性 nameID。
// Function - Add the textures to the models
function initColor(parent, type, mtl) {
parent.traverse((o) => {
if (o.isMesh) {
if (o.name.includes(type)) {
o.material = mtl;
o.nameID = type; // Set a new property to identify this object
}
}
});
}在 loader 函数内的 scene.add(theModel) 前遍历 INITIAL_MAP 数组,并执行该函数,:
// Set initial textures
for (let object of INITIAL_MAP) {
initColor(theModel, object.childID, object.mtl);
}最后,回到地板,将其颜色从红色(0xff0000)改为亮灰色(0xeeeeee)。
// Floor
var floorGeometry = new THREE.PlaneGeometry(5000, 5000, 1, 1);
var floorMaterial = new THREE.MeshPhongMaterial({
color: 0xeeeeee, // <------- Here
shininess: 0
});这里值得注意的是:0xeeeeee 与背景色不同。但在光的作用下,它们看起来一致。
3D Chair Customizer Tutorial - Part 1
恭喜,越来越像样了!如果你卡在某一节点,可以 fork 这个 pen 或参考它,直至找到问题所在。
实际上,本章节很短,这得益于第三个依赖——OrbitControls.js,让一切变得十分简单。
在声明 animate 函数上方,添加以下控制代码:
// Add controls
var controls = new THREE.OrbitControls( camera, renderer.domElement );
controls.maxPolarAngle = Math.PI / 2;
controls.minPolarAngle = Math.PI / 3;
controls.enableDamping = true;
controls.enablePan = false;
controls.dampingFactor = 0.1;
controls.autoRotate = false; // Toggle this if you'd like the chair to automatically rotate
controls.autoRotateSpeed = 0.2; // 30在 animate 函数内的顶部,添加:
controls.update();controls 是 OrbitControls 的实例。你可以随意更改其参数,其中包括允许用户旋转椅子(上下)、禁用拖拽以使椅子保持在中心、启用了阻尼使其过渡更自然,还有自动旋转功能(根据个人情况启用与否),但目前是关闭状态。
用你的鼠标或触摸屏进行体验吧!
到现在,我们的程序还没进入主题,所以接下来会专注于更改颜色(纹理)。
在 canvas 标签下方添加:
<div class="controls">
<!-- This tray will be filled with colors via JS, and the ability to slide this panel will be added in with a lightweight slider script (no dependency used for this) -->
<div id="js-tray" class="tray">
<div id="js-tray-slide" class="tray__slide"></div>
</div>
</div>.controls DIV 标签吸附在视口底部,.tray 设为 100%(相对于 body),其子元素 .tray__slide 作为色板,色板可根据需要进行补充。
首先添加几种颜色。在 JavaScript 顶部,添加含有 5 个对象的数组,每个对象都带有 color 属性。
const colors = [
{
color: '66533C'
},
{
color: '173A2F'
},
{
color: '153944'
},
{
color: '27548D'
},
{
color: '438AAC'
}
]注意:以上十六进制颜色值既没有 #,也没有 0x。这是因为它的使用场景不止一种(CSS 和 Three.js)。另外,之所以使用对象,是因为能添加其他属性,如亮度(shininess)、图片纹理。
使用这些颜色制作色板!
首先在 JavaScript 顶部引用滑块:
const TRAY = document.getElementById('js-tray-slide');在 JavaScript 底部添加一个名为 buildColors 的函数,并立即调用它。
// Function - Build Colors
function buildColors(colors) {
for (let [i, color] of colors.entries()) {
let swatch = document.createElement('div');
swatch.classList.add('tray__swatch');
swatch.style.background = "#" + color.color;
swatch.setAttribute('data-key', i);
TRAY.append(swatch);
}
}
buildColors(colors);上面是我们基于 colors 数组创建的色板列表!注意我们同时为它们设置了 data-key 属性,这是用于查找生成材质的颜色值。
在 buildColors 函数下方,为色板添加事件处理函数:
// Swatches
const swatches = document.querySelectorAll(".tray__swatch");
for (const swatch of swatches) {
swatch.addEventListener('click', selectSwatch);
}点击事件的处理函数命名为 selectSwatch。它会基于色值创建新的 PhongMaterial,并调用另一个函数来遍历 3D 模型(的组成元素),对匹配的部分更换材质!
function selectSwatch(e) {
let color = colors[parseInt(e.target.dataset.key)];
let new_mtl;
new_mtl = new THREE.MeshPhongMaterial({
color: parseInt('0x' + color.color),
shininess: color.shininess ? color.shininess : 10
});
setMaterial(theModel, 'legs', new_mtl);
}该函数通过 data-key 属性匹配颜色,并基于该颜色创建新材质。
该函数仍不能工作,需要添加 setMaterial 函数。
注意:
setMaterial(theModel, 'legs', new_mtl);第二个参数目前暂且传入'legs',很快我们就有指定不同部分的能力。目前,首先要实现 setMaterial 函数。
在该函数下方,添加 setMaterial 函数:
function setMaterial(parent, type, mtl) {
parent.traverse((o) => {
if (o.isMesh && o.nameID != null) {
if (o.nameID == type) {
o.material = mtl;
}
}
});
}这与 initColor 函数大同小异。nameID 属性来自 initColor,若它与参数 type 相等,就为它添加材质。
现在我们的色板能创建新材质,并更改椅腿的颜色,快来试一试!
Swatches change the legs color!
我们已经能更改椅腿的颜色。现在就让我们添加指定更改哪部分颜色的能力。在 body 标签内的顶部添加以下 HTML:
<!-- These toggle the the different parts of the chair that can be edited, note data-option is the key that links to the name of the part in the 3D file -->
<div class="options">
<div class="option --is-active" data-option="legs">
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/legs.svg" alt=""/>
</div>
<div class="option" data-option="cushions">
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/cushions.svg" alt=""/>
</div>
<div class="option" data-option="base">
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/base.svg" alt=""/>
</div>
<div class="option" data-option="supports">
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/supports.svg" alt=""/>
</div>
<div class="option" data-option="back">
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/back.svg" alt=""/>
</div>
</div>这是带有自定义图标的按钮集合。.option DIV 吸附在视口一侧(另外,通过 CSS 的媒介查询还会使其随着视口大小而进行调整)。每个 .option DIV 都是白色正方形,而带有 --is-active 类名的还会有红色边框。另外,还带有用于匹配 nameID data-option 属性。最后,image 元素拥有 pointer-events 属性,即使点击了 image,点击事件的触发始终保留在其父元素。
在 JavaScript 顶部添加另一个变量 activeOptions,其默认值为 legs:
var activeOption = 'legs';回到 selectSwatch 函数,更改硬编码的 legs 参数为 activeOption:
setMaterial(theModel, activeOption, new_mtl);现在我们需要做的是创建事件处理函数,当点击 .option 时更改 activeOption。
在 const swtaches 和 selectSwatch 函数上方添加:
// Select Option
const options = document.querySelectorAll(".option");
for (const option of options) {
option.addEventListener('click',selectOption);
}
function selectOption(e) {
let option = e.target;
activeOption = e.target.dataset.option;
for (const otherOption of options) {
otherOption.classList.remove('--is-active');
}
option.classList.add('--is-active');
}该函数会将 event.target 的 data-option 值设为 activeOption,并切换 --is-active 类。
体验一下
止步于此?物体全是一种材质类型时,难免乏味。下面就增加木和纺织布材质:
const colors = [
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/wood_.jpg',
size: [2,2,2],
shininess: 60
},
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/denim_.jpg',
size: [3, 3, 3],
shininess: 0
},
{
color: '66533C'
},
{
color: '173A2F'
},
{
color: '153944'
},
{
color: '27548D'
},
{
color: '438AAC'
}
]前两个是纹理,分别是木和牛仔布。另外,还增加了两个新属性——size 和 shininess。size 表示重复图案的频率,所以数值越大图案越密集。
现在我们要更新两个函数以支持该特性。首先将 buildColors 更新为:
// Function - Build Colors
function buildColors(colors) {
for (let [i, color] of colors.entries()) {
let swatch = document.createElement('div');
swatch.classList.add('tray__swatch');
if (color.texture)
{
swatch.style.backgroundImage = "url(" + color.texture + ")";
} else
{
swatch.style.background = "#" + color.color;
}
swatch.setAttribute('data-key', i);
TRAY.append(swatch);
}
}现在它会检查是否存在 texture 属性,若存在,则将色板的背景设为该纹理。
注意到第 5、6 块色板之间的间距了吗?我通过 CSS 将每 5 个色板作为一组,这对于拥有更多色板数量时显得尤为重要。
第二个需要更新的函数是 selectSwatch:
function selectSwatch(e) {
let color = colors[parseInt(e.target.dataset.key)];
let new_mtl;
if (color.texture) {
let txt = new THREE.TextureLoader().load(color.texture);
txt.repeat.set( color.size[0], color.size[1], color.size[2]);
txt.wrapS = THREE.RepeatWrapping;
txt.wrapT = THREE.RepeatWrapping;
new_mtl = new THREE.MeshPhongMaterial( {
map: txt,
shininess: color.shininess ? color.shininess : 10
});
}
else {
new_mtl = new THREE.MeshPhongMaterial({
color: parseInt('0x' + color.color),
shininess: color.shininess ? color.shininess : 10
});
}
setMaterial(theModel, activeOption, new_mtl);
}该函数会检查当前色板是不是纹理,若是,则通过 Three.js 的 TextureLoader 方法创建新纹理,并将该纹理的 repeat 设为色板 size 值。另外,还为纹理设置 wrapping(经试验后得出效果最佳的 wrapping 值),然后为 PhongMaterial 的 map 属性设置为当前纹理,最后设置 shininess 值。
如果当前色板无 texture 属性,则使用老方法。请注意,你也可以为了纯色的材质设置 shininess 值。
重要:如果添加纹理后椅子表现为黑色,请查看 console,判断是否是跨域导致的问题?这也是 CodePen 的问题,建议注册 Cloudinary 并使用其免费套餐存放图片。
这里带有纹理的 pen:
我曾有个项目交付给客户验收,这个项目有一个大按钮去祈求被按,甚至在 hover 时闪闪发光,然而客户及其同事(会计部的 Dave)却反馈他们不知道要按什么(去你的,Dave)。
在 canvas 标签上方添加一些号召性语句:
<!-- Just a quick notice to the user that it can be interacted with -->
<span class="drag-notice" id="js-drag-notice">Drag to rotate 360°</span>通过 CSS 将其放在椅子前方,用于指示用户可拖拽旋转椅子。但椅子仅仅呆滞不动?
让椅子在首次加载后进行旋转,旋转完毕后隐藏引导语。
首先在 JavaScript 上方添加 loaded 变量,并设为 false:
var loaded = false;在 JavaScript 底部添加该函数:
// Function - Opening rotate
let initRotate = 0;
function initialRotation() {
initRotate++;
if (initRotate <= 120) {
theModel.rotation.y += Math.PI / 60;
} else {
loaded = true;
}
}模型需要在 120 帧内线性旋转 360 度(约 2 秒,60fps),所以我们将在 animate 函数中运行该函数 120 次,一旦完成则将 loaded 设为 true。代码如下:
function animate() {
controls.update();
renderer.render(scene, camera);
requestAnimationFrame(animate);
if (resizeRendererToDisplaySize(renderer)) {
const canvas = renderer.domElement;
camera.aspect = canvas.clientWidth / canvas.clientHeight;
camera.updateProjectionMatrix();
}
if (theModel != null && loaded == false) {
initialRotation();
}
}
animate();我们判断 theModel 是否不等于 null 且 loaded 是否为 false,若符合条件,则调用该函数 120 次,然后将 loaded 设为 true,使得 animate 函数最终忽略它。
这就拥有了自旋转的椅子。椅子停止的这一刻是删除引导语的好时机。
在 CSS 中,为引导语添加一个带有隐藏动画的类,该动画的延迟时间为 3 秒,所以,在开始旋转椅子的同时为引导语添加该类。
在 JavaScript 顶部引用引导语:
const DRAG_NOTICE = document.getElementById('js-drag-notice');更新 animate 函数:
if (theModel != null && loaded == false) {
initialRotation();
DRAG_NOTICE.classList.add('start');
}好极了!这里有更丰富的颜色供你选择。同时,下方也提供了轻量无依赖的滑动功能(用于拖拽滑动色板列表):
const colors = [
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/wood_.jpg',
size: [2,2,2],
shininess: 60
},
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/fabric_.jpg',
size: [4, 4, 4],
shininess: 0
},
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/pattern_.jpg',
size: [8, 8, 8],
shininess: 10
},
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/denim_.jpg',
size: [3, 3, 3],
shininess: 0
},
{
texture: 'https://s3-us-west-2.amazonaws.com/s.cdpn.io/1376484/quilt_.jpg',
size: [6, 6, 6],
shininess: 0
},
{
color: '131417'
},
{
color: '374047'
},
{
color: '5f6e78'
},
{
color: '7f8a93'
},
{
color: '97a1a7'
},
{
color: 'acb4b9'
},
{
color: 'DF9998',
},
{
color: '7C6862'
},
{
color: 'A3AB84'
},
{
color: 'D6CCB1'
},
{
color: 'F8D5C4'
},
{
color: 'A3AE99'
},
{
color: 'EFF2F2'
},
{
color: 'B0C5C1'
},
{
color: '8B8C8C'
},
{
color: '565F59'
},
{
color: 'CB304A'
},
{
color: 'FED7C8'
},
{
color: 'C7BDBD'
},
{
color: '3DCBBE'
},
{
color: '264B4F'
},
{
color: '389389'
},
{
color: '85BEAE'
},
{
color: 'F2DABA'
},
{
color: 'F2A97F'
},
{
color: 'D85F52'
},
{
color: 'D92E37'
},
{
color: 'FC9736'
},
{
color: 'F7BD69'
},
{
color: 'A4D09C'
},
{
color: '4C8A67'
},
{
color: '25608A'
},
{
color: '75C8C6'
},
{
color: 'F5E4B7'
},
{
color: 'E69041'
},
{
color: 'E56013'
},
{
color: '11101D'
},
{
color: '630609'
},
{
color: 'C9240E'
},
{
color: 'EC4B17'
},
{
color: '281A1C'
},
{
color: '4F556F'
},
{
color: '64739B'
},
{
color: 'CDBAC7'
},
{
color: '946F43'
},
{
color: '66533C'
},
{
color: '173A2F'
},
{
color: '153944'
},
{
color: '27548D'
},
{
color: '438AAC'
}
]在 JavaScript 底部添加 slider 函数,它将使你拥有可通过鼠标或触摸屏拖拽色板的能力。为了紧扣主题,这里就不过多研究其工作原理。
var slider = document.getElementById('js-tray'), sliderItems = document.getElementById('js-tray-slide'), difference;
function slide(wrapper, items) {
var posX1 = 0,
posX2 = 0,
posInitial,
threshold = 20,
posFinal,
slides = items.getElementsByClassName('tray__swatch');
// Mouse events
items.onmousedown = dragStart;
// Touch events
items.addEventListener('touchstart', dragStart);
items.addEventListener('touchend', dragEnd);
items.addEventListener('touchmove', dragAction);
function dragStart (e) {
e = e || window.event;
posInitial = items.offsetLeft;
difference = sliderItems.offsetWidth - slider.offsetWidth;
difference = difference * -1;
if (e.type == 'touchstart') {
posX1 = e.touches[0].clientX;
} else {
posX1 = e.clientX;
document.onmouseup = dragEnd;
document.onmousemove = dragAction;
}
}
function dragAction (e) {
e = e || window.event;
if (e.type == 'touchmove') {
posX2 = posX1 - e.touches[0].clientX;
posX1 = e.touches[0].clientX;
} else {
posX2 = posX1 - e.clientX;
posX1 = e.clientX;
}
if (items.offsetLeft - posX2 <= 0 && items.offsetLeft - posX2 >= difference) {
items.style.left = (items.offsetLeft - posX2) + "px";
}
}
function dragEnd (e) {
posFinal = items.offsetLeft;
if (posFinal - posInitial < -threshold) { } else if (posFinal - posInitial > threshold) {
} else {
items.style.left = (posInitial) + "px";
}
document.onmouseup = null;
document.onmousemove = null;
}
}
slide(slider, sliderItems);现在,将 CSS 内的 .tray__slider 小动画注释掉:
/* transform: translateX(-50%);
animation: wheelin 1s 2s ease-in-out forwards; */剩下最后两步收尾工作就完成了!
更新 .controls div,让其包含引导语:
<div class="controls">
<div class="info">
<div class="info__message">
<p><strong> Grab </strong> to rotate chair. <strong> Scroll </strong> to zoom. <strong> Drag </strong> swatches to view more.</p>
</div>
</div>
<!-- This tray will be filled with colors via JS, and the ability to slide this panel will be added in with a lightweight slider script (no dependency used for this) -->
<div id="js-tray" class="tray">
<div id="js-tray-slide" class="tray__slide"></div>
</div>
</div>现在我们拥有了一个新的信息块,其包含描述如何控制应用的一些说明。
最后,增加一个 loading 遮罩层,以确保在应用加载期间页面是干净的,并在模型加载后将其删除。
在 body 内的顶部增加以下 HTML。
<!-- The loading element overlays all else until the model is loaded, at which point we remove this element from the DOM -->
<div class="loading" id="js-loader"><div class="loader"></div></div>为了使其优先加载,我们将这些 CSS 单独放在 head 标签内,而不是链接式的 CSS 中。所以,在 head 闭合标签上方添加以下 CSS。
<style>
.loading {
position: fixed;
z-index: 50;
width: 100%;
height: 100%;
top: 0; left: 0;
background: #f1f1f1;
display: flex;
justify-content: center;
align-items: center;
}
.loader{
-webkit-perspective: 120px;
-moz-perspective: 120px;
-ms-perspective: 120px;
perspective: 120px;
width: 100px;
height: 100px;
}
.loader:before{
content: "";
position: absolute;
left: 25px;
top: 25px;
width: 50px;
height: 50px;
background-color: #ff0000;
animation: flip 1s infinite;
}
@keyframes flip {
0% {
transform: rotate(0);
}
50% {
transform: rotateY(180deg);
}
100% {
transform: rotateY(180deg) rotateX(180deg);
}
}
</style>快好了!在加载模型后将其删除。
在 JavaScript 顶部引用它:
const LOADER = document.getElementById('js-loader');在 loader 函数中,在 scene.add(theModel) 后放置以下代码:
// Remove the loader
LOADER.remove();现在,模型会在该 DIV 背后加载:
就这样!以下就是完整的 pen,仅供参考!
See the Pen 3D Chair Customizer Tutorial - Part 4 by Kyle Wetton (@kylewetton) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>你还可以体验托管在 Codrops 上的 案例。
感谢您的支持!
这是一篇长篇教程。如果你发现错误,请在评论告诉我。
Georg Ness 的奇妙作品是生成艺术的真正灵感来源。在本教程中,我们将实现他的作品之一:无序方块。
<canvas> 是页面中唯一的元素,其大小为 300x300 像素。
老规矩,下面是初始步骤,里面没有任何渲染操作。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
context.lineWidth = 2;
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;
var squareSize = 30;squareSize 变量用于指定方块的尺寸大小。
现在,创建一个用于绘制方块的函数。该函数十分简单,仅接受 width 和 height 参数。方块位置由另一个循环处理。
function draw(width, height) {
context.beginPath();
context.rect(-width/2, -height/2, width, height);
context.stroke();
}通过循环将屏幕填满方块。这里我们使用上下文 context 的 save、translate 和 restore 方法移动上下文坐标系,然后调用上面定义的 draw 方法进行绘制。
for( var i = squareSize; i <= size - squareSize; i += squareSize) {
for( var j = squareSize; j <= size - squareSize; j+= squareSize ) {
context.save();
context.translate(i, j);
draw(squareSize, squareSize);
context.restore();
}
}现在屏幕铺整整齐齐地铺满了方块,为“无序”打下了基础。
引入随机是十分简单的:首先定义变量,一个用于指定方块的相对位移距离,另一个是旋转角度。
var randomDisplacement = 15;
var rotateMultiplier = 20;这样我们就可以利用这些变量创建随机的位移和旋转值,并且越靠近 canvas 底部值越大。
var plusOrMinus = Math.random() < 0.5 ? -1 : 1;
var rotateAmt = j / size * Math.PI / 180 * plusOrMinus * Math.random() * rotateMultiplier;
plusOrMinus = Math.random() < 0.5 ? -1 : 1;
var translateAmt = j / size * plusOrMinus * Math.random() * randomDisplacement;然后应用位移和旋转值。
context.translate( i + translateAmt, j)
context.rotate(rotateAmt);这就是我们拥有的:无序方块!
本文由才华横溢的 maxwellito 撰写。如果你对编写文章感兴趣,可以像他一样提交一份 提案。
这种三角网格效果常出现库和 SVG 中。今天我们将用 canvas 实现它!同时,这也是一个说明坐标系和替换细节而得到漂亮效果的案例。
老规矩,首先是初始化得到一个方形 canvas。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;创建点网格的常规方式是通过行和列。这些点将会被绘制在 canvas 上,并被存储在一个数组中,以便后续使用。
点是由一个含有 x、y 属性的对象表示。
行列之间的间距通过 gap 变量表示。我们将点绘制成圆后,便看到网格在 canvas 上的样子。
var line,
lines = [],
gap = size / 7;
for (var y = gap / 2; y <= size; y+= gap) {
line = []
for (var x = gap / 2; x <= size; x+= gap) {
line.push({x: x, y: y})
context.beginPath();
context.arc(x, y, 1, 0, 2 * Math.PI, true);
context.fill();
}
lines.push(line)
}然后替换隔行的 x 坐标。这里我们通过 odd 变量交替赋值 true 或 false 实现。
一个正三角网格将在新坐标下形成。
var line, dot,
odd = false,
lines = [],
gap = size / 8;
for (var y = gap / 2; y <= size; y+= gap) {
odd = !odd
line = []
for (var x = gap / 4; x <= size; x+= gap) {
dot = {x: x + (odd ? gap/2 : 0), y: y}
line.push(dot)
context.beginPath();
context.arc(dot.x, dot.y, 1, 0, 2 * Math.PI, true);
context.fill();
}
lines.push(line)
}下一步是使用点绘制三角形。
创建一个接收三角形三个坐标,并连接绘制它们的函数。
function drawTriangle(pointA, pointB, pointC) {
context.beginPath();
context.moveTo(pointA.x, pointA.y);
context.lineTo(pointB.x, pointB.y);
context.lineTo(pointC.x, pointC.y);
context.lineTo(pointA.x, pointA.y);
context.closePath();
context.stroke();
}现在,结合 drawTriangle 函数和点数组绘制所有三角形。
这部分也许会有点难以理解。脚本会遍历所有线,并组合相邻线的点以形成三角形。为了便于理解,我们将相邻的两条线分别称为 a 和 b。然后将两线符合要求的点合并到一个数组中,使其看起来像“之”字型:a1、b1、a2、b2、a3 以此类推。
这将为我们提供了一个含有三角形所有坐标的数组。如:[a1, b1, a2]、[b1, a2, b2], [a2, b2, a3] 等。
var dotLine;
odd = true;
for (var y = 0; y < lines.length - 1; y++) {
odd = !odd
dotLine = []
for (var i = 0; i < lines[y].length; i++) {
dotLine.push(odd ? lines[y][i] : lines[y+1][i])
dotLine.push(odd ? lines[y+1][i] : lines[y][i])
}
for (var i = 0; i < dotLine.length - 2; i++) {
drawTriangle(dotLine[i], dotLine[i+1], dotLine[i+2])
}
}至此,我们得到一个正三角网格。接着,我们为一个细节赋予魔法。
现在每个点与相邻点之间的间距相同。其实,我们可以将点在该区域内进行位移,而避免与其它点发生重叠(译者注:每个点的安全位移区域是点间距的一半)。利用 Math.random() 对点进行位移。
line.push({
x: x + (Math.random()*.8 - .4) * gap + (odd ? gap/2 : 0),
y: y + (Math.random()*.8 - .4) * gap,
})另外,还可以增加一些生成艺术的乐趣。比如填充只有 16 种色调的灰色!
var gray = Math.floor(Math.random()*16).toString(16);
context.fillStyle = '#' + gray + gray + gray;
context.fill();如果想探索该效果的更多实现细节,可看看我的库:triangulr。
原文:Displaying Content in Full Screen using the Fullscreen API in JavaScript
译者注:若想直接应用 Fullscreen API,可直接使用 screenfull.js。
另外,iOS 上 video 元素可能不兼容 Fullscreen API,但 iOS 有特定的方法处理,具体可查看 Apple Developer 相关文档。如:video 请求进入全屏video.webkitEnterFullscreen()。此方法目前在 iOS 微信上有效。
大多数情况下,网站上的图片或视频等一些内容比较适合于全屏展示。而本文所指的全屏:是指占用用户整个屏幕,没有多余的浏览器边框和其他应用。Fullscreen API 的出现,让我们只需数行 JavaScript 代码即可使网站的任意一片内容成为焦点。如发布在你旅游博客上,并引以为豪的海岸景观(图片来自:PixaBay):

Fullscreen API 的核心是 requestFullscreen() 方法,它能被文档上任意元素所调用,使自身沿四周展开,直至屏幕边界。
var featuredImg = document.getElementById('rockyshot')
if (featuredImg.requestFullscreen) {
featuredImg.requestFullscreen()
}
IE 11+(含 11) 和桌面端 Chrome、Firefox 的所有较新版本均支持 Fullscreen API。需要注意的是,在编写本文时,仍需要添加内核前缀以获取被支持的相关方法和事件处理函数。以主要方法 requestFullscreen() 方法为例,最下面的三个版本是为了迎合三大主流浏览器:
| requestFullscreen() (标准版本) |
|---|
| webkitRequestFullscreen() |
| mozRequestFullScreen() // 注意:Screen 的 S 为大写 |
| msRequestFullscreen() |
跨浏览器 Full Screen 函数:下面就创建一个跨浏览器版本的 requestFullscreen(),该函数能被页面上任何元素所使用,因此不必每次使用该函数时都进行 if/else 判断:
译者注:Fullscreen 的所有兼容性写法可引用或参考 screenfull.js。
// 译者注:缺少对完全不兼容 requestFullscreen 的处理,下同。
function getReqFullscreen () {
var root = document.documentElement
return root.requestFullscreen || root.webkitRequestFullscreen || root.mozRequestFullScreen || root.msRequestFullscreen
}
// 用法:getRequestFullscreen().call(targetElement)
当每次调用 getRequestFullscreen() 时,我们都会得到浏览器支持的 requestFullscreen() 函数。而实际调用则需要通过 call() 指定上下文。即向 call() 传入我们想全屏展示的元素。
**案例:**页面中所有拥有 CSS 类名 canfullscreen 的图片被点击时都会全屏展示(图片来自 PixaBay):
var globalReqFullscreen = getReqFullscreen()
document.addEventListener('click', function (e) {
var target = e.target
if (target.tagName === 'IMG' && target.classList.contains('canfullscreen')) {
globalReqFullscreen.call(target)
}
})
易如反掌!
**注意:**若想让 document 自身全屏,则可使用 document.documentElement.requestFullscreen(),或通过跨浏览器函数:globalReqFullscreen.call(document.documentElement)。
当有元素处于全屏状态时,用户有默认退出全屏的选项,即通过按 "esc" 或 "f11"。当然,你也可以通过 document.exitFullscreen() 实现同样的需求,其兼容性写法如下:
| document.exitFullscreen() (标准方法) |
|---|
| document.webkitExitFullscreen() |
| document.mozCancelFullScreen() // 注意:Screen 的 S 为大写 |
| document.msExitFullscreen() |
需要注意的是:不像 requestFullscreen() 方法会存在于每个 DOM 元素上,以指定哪个元素进入全屏状态。而 exitFullscreen() 方法仅定义在 document 对象上。当它被调用时,会让全屏元素恢复到原有的位置上。
跨浏览器的 Exit 函数 :与上一章节相同,我们将会创建一个返回浏览器支持的 document.exitFullscreen() 函数,以便后续使用。
function getExitFullscreen() {
return document.exitFullscreen || document.webkitExitFullscreen || document.mozCancelFullScreen || document.msExitFullscreen
}
// 用法: getExitFullscreen.call(document)
**案例:**将下面代码添加到上一个案例中,双击任何带有 CSS 类名 canfullscreen 的图片都会从全屏返回到正常状态。
var globalExitFullscreen = getExitFullscreen()
document.addEventListener('dblclick', function (e) {
var target = e.target
if (target.tagName === 'IMG' && target.classList.contains('canfullscreen')) {
globalExitFullscreen.call(document)
}
}, false)
每当浏览器进入全屏模式时,document.fullscreenElement 对象(只读)都会引用当前展示的元素。否则,该对象返回 null。
使用 document.fullscreenElement,我们能:
document.fullscreenElement 和其它 Fullscreen API 方法类似,都需要添加浏览器内核前缀:
| document.fullscreenElement (标准方法) |
|---|
| document.webkitFullscreenElement |
| document.mozFullScreenElement // 注意:Screen 的 S 为大写 |
| document.msFullscreenElement |
**获取全屏元素的函数:**下面函数将会返回被支持的 document.fullscreenElement 对象:
function getFullscreenElement() {
return document.fullscreenElement || document.webkitFullscreenElement || document.mozFullScreenElement || document.msFullscreenElement
}
// 用法:getFullscreenElement()
下面是检查浏览器目前是否处于全屏状态,并且全屏展示的元素是图片:
if (getFullscreenElement() && getFullscreenElement().tagName === 'IMG') {
console.log('An image is currently being shown full screen')
}
document.fullscreenElement 对象的常见用法是动态切换元素的全屏与常规状态。
案例:下面通过单击操作切换图片的全屏状态。
var globalReqFullscreen = getReqFullscreen()
var globalExitFullscreen = getExitFullscreen()
document.addEventListener('click', function (e) {
var target = e.target
if (target.tagName === 'IMG' && target.classList.contains('canfullscreen')) {
if (getFullscreenElement() === null) {
globalReqFullscreen.call(target)
} else {
globalExitFullscreen.call(document)
}
}
}, false)
再补充剩余的一些对象和事件处理函数则是完整的 Fullscreen API。它们分别是:
document.fullscreenEnabled:如果页面可用于全屏模式,则返回 true。若没有为窗口插件或 <iframe> 元素显示设置 allowfullscreen 属性,则会在尝试全屏展示它们时返回失败。document.onfullscreenerror 事件也会被相应触发。document.onfullscreenchange:每当浏览器进入或退出全屏模式时触发的事件处理函数。document.onfullscreenerror:当请求全屏模式失败时触发的事件处理函数。当然,以上属性或方法均需要加上内核前缀以获得被支持的版本。它们分别是:
| document.fullscreenEnabled(标准方法) | document.onfullscreenchange (标准方法) | document.onfullscreenerror (标准方法) |
|---|---|---|
| document.webkitFullscreenEnabled | document.onwebkitfullscreenchange | document.onwebkitfullscreenerror |
| document.mozFullScreenEnabled | document.onmozfullscreenchange | document.onmozfullscreenerror |
| document.msFullscreenEnabled | document.onmsfullscreenchange | document.onmsfullscreenerror |
要创建跨浏览器兼容的 document.onfullscreenchange 和 document.onfullscreenerror,可根据浏览器对 requestFullscreen() 的兼容版本,映射支持的相应事件处理函数。
跨浏览器的 onfullscreenchange 事件: 下面是创建 document.onfullscreenchange 的一种方式:
function getOnFullscreenEvent() {
var root = document.documentElement
var fullscreenEvents = {
'requestFullscreen': 'onfullscreenchange',
'webkitRequestFullscreen': 'onwebkitfullscreenchange',
'mozRequestFullScreen': 'onmozfullscreenchange',
'msRequestFullscreen': 'onmsfullscreenchange'
}
for (var method in fullscreenEvents) {
if (root[method]) {
return fullscreenEvents[method]
}
}
return undefined
}
// 用法:var globalOnFullscreenChange = getOnFullscreenEvent()
// document[globalOnFullscreenChange] = function(){...}
当调用 getOnFullscreenEvent 时,我们会得到被支持的 "onfullscreenchange" 字符串,如 "onwebkitfullscreenchange"。然后,将其绑定在 document 对象上:
var globalOnFullscreenChange = getOnFullscreenEvent()
document[globalOnFullscreenChange] = function () {
console.log('You just entered or exit full screen')
}
需要注意的是,返回的字符串(如 "onfullscreenchange" 或 "onwebkitfullscreenchange")并不适用于 document.addEventListener(),其只适用于直接绑定在 document 对象上。
可通过 :fullscreen 伪选择器及其内核前缀修改元素在全屏模式下的样式:
:-webkit-full-screen {
/*style for full screen element */
}
:-moz-full-screen {
/*style for full screen element */
}
:-ms-fullscreen {
/*style for full screen element */
}
:fullscreen { /* official selector */
/*style for full screen element */
}
这对于创建目标元素及其后代元素全屏模式下的样式与常规模式下的不同,如 figure 元素含有一张可全屏查看的图片:
这对于目标元素及其后代元素在全屏与常规模式下展示不同的样式是非常有用的。如待全屏且含有图片的 figure:
案例:
figure 默认是 300px 宽,其子元素 img 则是 100% 宽。在全屏模式下,figure 的宽度伸展至 100%,而其子元素 img 的高度为 90vh(剩余空间留给下面的 caption 元素)。实现该功能的 CSS 如下:
<style>
figure{
width: 300px;
background: #eee;
padding: 5px;
cursor: pointer;
}
figure img{
width: 100%;
height: auto;
}
figure:-webkit-full-screen {
width: 100%;
text-align: center;
}
figure:-moz-full-screen {
width: 100%;
text-align: center;
}
figure:-ms-fullscreen {
width: 100%;
text-align: center;
}
figure:fullscreen { /* 标准选择器 */
width: 100%;
text-align: center;
}
figure:-webkit-full-screen img{
width: auto;
height: 90vh;
}
figure:-moz-full-screen img{
width: auto;
height: 90vh;
}
figure:-ms-fullscreen img{
width: auto;
height: 90vh;
}
figure:fullscreen img{
width: auto;
height: 90vh;
}
</style>
以全屏方式展示某些内容,可作为加深印象和吸引用户的一个额外“补充”。如电子商务网站上的产品图片。
而 Fullscreen API 可帮助你实现这一点。
原文:Joy Division
欢乐分队的专辑封面有一段非常有趣的历史。同时也是一个数据驱动艺术的惊艳案例。
欢乐分队的《Unknown Pleasures》专辑封面
这里我们打算使用 canvas 实现,没有额外 API。只需在 HTML 中放置一个 300x300 像素的 元素。
首先进行初始化,没有任何渲染操作。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;这为我们提供了在页面上绘制的 context 上下文。
首先,在 canvas 上绘制由一系列点组成的线段。然后,将每个点替换成随机数,以达到期待的效果。
定义一些基本变量:
var step = 10;
var lines = [];下面编写函数来生成线。线由一系列点(拥有 x、y 属性的对象)组成。
// Create the lines
for( var i = step; i <= size - step; i += step) {
var line = [];
for( var j = step; j <= size - step; j+= step ) {
var point = {x: j, y: i};
line.push(point)
}
lines.push(line);
}下一步是绘制线段。和 上篇教程 一样,我们先绘制简单的东西,然后再进行扩展。
// Do the drawing
for(var i = 0; i < lines.length; i++) {
context.beginPath();
context.moveTo(lines[i][0].x, lines[i][0].y)
for( var j = 0; j < lines[i].length; j++) {
context.lineTo(lines[i][j].x, lines[i][j].y);
}
context.stroke();
}现在,canvas 上就拥有多条线段。下一步是替换线段里的点。该操作将在第一层循环(创建点的时候)里执行。
var random = Math.random() * 10;
var point = {x: j, y: i + random};噢,现在线的每个点都发生了跳动。但我们期望这些变化集中在线的中间区域,即越靠近线中心的点变化幅度越大,两侧越小。下面通过一个独立函数实现。
var distanceToCenter = Math.abs(j - size / 2);
var variance = Math.max(size / 2 - 50 - distanceToCenter, 0);
var random = Math.random() * variance / 2 * -1;现在看起来有点混乱,每条线都存在交叉重叠。这里使用 fill 方法进行覆盖。
首先,设置填充的样式。
context.fillStyle = '#f9f9f9';
context.lineWidth = 2;然后在每条线绘制后执行 fill 方法,这将会覆盖每个图层下面混乱的线。
译者注:当路径是非封闭图形时,canvas 会直接连接始点和终点,从而形成封闭图形。
context.fill()快要完成了,唯一剩下的事情是让线看起来更圆滑。二次贝塞尔曲线可以做到这点,只需在两点之间创建一个控制点即可。quadraticCurveTo 就是最后一步。
for( var j = 0; j < lines[i].length - 2; j++) {
var xc = (lines[i][j].x + lines[i][j + 1].x) / 2;
var yc = (lines[i][j].y + lines[i][j + 1].y) / 2;
context.quadraticCurveTo(lines[i][j].x, lines[i][j].y, xc, yc);
}
context.quadraticCurveTo(lines[i][j].x, lines[i][j].y, lines[i][j + 1].x, lines[i][j + 1].y);我们最终得到它了!你可以对每个步骤进行调整,或者更改样式和颜色,从而得到不同效果。一切都令人兴奋!
本文翻译自 http://jlord.us/essential-electron/
本文将简明扼要地讲解 Electron。
| Background | Development | Development Con't |
|---|---|---|
| What is Electron | Prereqs | Stay in touch |
| Why is this important | Two Processes | Put it all Together |
| How,even? | Main Process | Packaging |
| What is developing like? | Renderer Process | More resources |
| / | Think of it like this | / |
Electron 是一个可以用 JavaScript、HTML 和 CSS 构建桌面应用程序的库。这些应用程序能打包到 Mac、Windows 和 Linux 系统上运行,也能上架到 Mac 和 Windows 的 App Store。
Next:为什么它如此重要?
定义:
相关资源:
Apps built on Electron
Electron API Demos(看看你能通过 Electron 实现什么功能)
通常来说,每个操作系统的桌面应用都由各自的原生语言进行编写,这意味着需要 3 个团队分别为该应用编写相应版本。而 Electron 则允许你用 Web 语言编写一次即可。
Next:它由什么组成?
定义:
Electron 结合了 Chromium、Node.js 和用于调用操作系统本地功能的 API(如打开文件窗口、通知、图标等)。
Next:开发体验如何?
定义:
相关资源:
基于 Electron 的开发就像在开发网页,而且能够无缝地 使用 Node。或者说:在构建一个 Node 应用的同时,通过 HTML 和 CSS 构建界面。另外,你只需为一个浏览器(最新的 Chrome)进行设计(即无需考虑兼容性等)。
Next:具备条件(开发方面)
定义:
相关资源:
因为 Electron 应用的两个组成部分是网站(译者注:UI)和 JavaScript(译者注:功能),所以在开发 Electron 应用前,你需要拥有这两方面的经验。你可以搜索 HTML、CSS 和 JS 的教程,并在你的电脑上安装 Node。
定义:
Next:两个进程
相关资源:
Electron 有两种进程:『主进程』和『渲染进程』。部分模块只能在两者之一上运行,而有些则无限制。主进程更多地充当幕后角色,而渲染进程则是应用程序的各个窗口。
定义:
dialog 模块拥有所有原生 dialog 的 API,如打开文件、保存文件和警告等弹窗。相关资源:
主进程,通常是一个命名为 main.js 的文件,该文件是每个 Electron 应用的入口。它控制了应用的生命周期(从打开到关闭)。它既能调用原生元素,也能创建新的(多个)渲染进程。另外,Node API 是内置其中的。
定义:
Next:渲染进程
相关资源:
渲染进程是应用的一个浏览器窗口。与主进程不同,它能存在多个(注:一个 Electron 应用只能存在一个主进程)并且相互独立(它也能是隐藏的)。主窗口通常被命名为 index.html。它们就像典型的 HTML 文件,但 Electron 赋予了它们完整的 Node API。因此,这也是它与浏览器的区别。
定义:
Next:把它想象成这样
相关资源:
Chrome(或其他浏览器)的每个标签页(tab)及其页面,就好比 Electron 中的一个单独渲染进程。即使关闭所有标签页,Chrome 依然存在。这好比 Electron 的主进程,能打开新的窗口或关闭这个应用。
相关资源:
Next: 相互通讯
由于主进程和渲染进程各自负责不同的任务,而对于需要协同完成的任务,它们需要相互通讯。IPC就为此而生,它提供了进程间的通讯。但它只能在主进程与渲染进程之间传递信息(即渲染进程之间不能进行直接通讯)。
定义:
Next:汇成一句话
Electron 应用就像 Node 应用,它也依赖一个 package.json 文件。该文件定义了哪个文件作为主进程,并因此让 Electron 知道从何启动应用。然后主进程能创建渲染进程,并能使用 IPC 让两者间进行消息传递。
定义:
package.json 文件: 这是一个常见的 Node 应用文件,它包含了关于项目的元数据和一系列依赖。Next:快速开始
Electron Quick Start 代码库是一个 Electron 应用的基本骨架,拥有前文提及的 package.json、main.js 和 index.html。这是你了解和学习 Electron 的好开头!当然,查看下面资源中的 Boilerplates,在里面选择适合你的模板。
Next: 打包
相关资源:
应用构建完成后,可以通过 命令行工具 electron-packager 对其打包为适用于 Mac、Windows 和 Linux 的应用。当然,你可以在 package.json 添加该命令行。查看下面相关资源,学习如何将应用发布到 Mac 和 Windows 的 App Store。
Next:更多资源
定义:
相关资源:
这里提供更多资料供你更深入且全面地学习 Electron。
相关资源:
用代码复现皮特·蒙德里安的艺术作品并不是件简单的事情。老实说,我认为没有方法能复现他的作品,毕竟它们都是手绘的。但我们可以尝试复现皮特作品的部分工作,这也是本教程要阐述的部分。当然,我们也会进行上色。
老规矩,以下是初始化代码,其中包括设置 canvas 大小和使用 window.devicePixelRatio 缩放 canvas 以适配视网膜屏幕。而页面中仅有一个 <canvas> 元素。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
var dpr = window.devicePixelRatio;
canvas.width = size * dpr;
canvas.height = size * dpr;
context.scale(dpr, dpr);
context.lineWidth = 8;我采取的方法并不是完美的。首先创建一个大方块(canvas),然后将它进行分割。我会选择一条线(水平或竖直)将其分为多个方块,后续会为分割操作添加随机因子,而不是将所有方块都进行分割,这样应该能呈现出蒙德里安的风格,尽管会有数学上死板的感觉。
创建一组方块。
var squares = [{
x: 0,
y: 0,
width: size,
height: size
}];一如既往地创建 “draw” 函数并进行调用。这样就能我们所做的东西。
function draw() {
for (var i = 0; i < squares.length; i++) {
context.beginPath();
context.rect(
squares[i].x,
squares[i].y,
squares[i].width,
squares[i].height
);
context.stroke();
}
}
draw()这会遍历所有方块(目前仅有一个方块,并绘制在 canvas 上)。
现在,创建一个用于寻找在哪个方块进行分割的函数,该函数会在我们指定的方向上对方块进行分割。
function splitSquaresWith(coordinates) {
// 遍历找出需要进行分割的方块
}
function splitOnX(square, splitAt) {
// 基于提供的 x 坐标,创建两个新方块
}
function splitOnY(square, splitAt) {
// 基于提供的 y 坐标,创建两个方块
}
splitSquaresWith({x: 160})
splitSquaresWith({y: 160})代码末尾调用了分割方块的函数,分别在 x、y 的中间位置。若代码能正常运行,我们就可以做更多的分裂操作。但就目前而言,更适合试验。
splitSquaresWith 函数:
const { x, y } = coordinates;
for (var i = squares.length - 1; i >= 0; i--) {
const square = squares[i];
if (x && x > square.x && x < square.x + square.width) {
squares.splice(i, 1);
splitOnX(square, x);
}
if (y && y > square.y && y < square.y + square.height) {
squares.splice(i, 1);
splitOnY(square, y);
}
}这里使用了一些小技巧:
const { x, y } = coordinates 会提取对象的 x 和 y 变量,如 {x: 160} 或 {y: 160}。(var i = squares.length - 1; i >= 0; i--) 逆序遍历方块,是为了让新元素剔除出循环(分割操作会将一个方块替换为两个)。逆序遍历意味着在遍历下标无需调整的同时,避免新方块不会被再次分割。当然,现在还是仅有一个方块,这是因为 splitOn 函数还未实现。实质上两者(splitOnX 和 splitOnY)非常相似。
splitOnX
var squareA = {
x: square.x,
y: square.y,
width: square.width - (square.width - splitAt + square.x),
height: square.height
};
var squareB = {
x: splitAt,
y: square.y,
width: square.width - splitAt + square.x,
height: square.height
};
squares.push(squareA);
squares.push(squareB);和
splitOnY
var squareA = {
x: square.x,
y: square.y,
width: square.width,
height: square.height - (square.height - splitAt + square.y)
};
var squareB = {
x: square.x,
y: splitAt,
width: square.width,
height: square.height - splitAt + square.y
};
squares.push(squareA);
squares.push(squareB);这两个函数均将先前的一个方块分割成两个方块,并将创建的方块添加到 squares 数组中。通过两次居中分割,最终形成了一个窗口。
取消两次硬编码的分割调用,通过 step 变量,遍历多次进行分割。
var step = size / 6;然后循环遍历。
for (var i = 0; i < size; i += step) {
splitSquaresWith({ y: i });
splitSquaresWith({ x: i });
}这就有了多个方块。通过添加随机因子,将原来每次 100% 分割变为 50% 的机会进行分割。
if(Math.random() > 0.5) {
squares.splice(i, 1);
splitOnX(square, x);
}哇喔,看起来不错。y 轴同理。
if(Math.random() > 0.5) {
squares.splice(i, 1);
splitOnY(square, y);
}这就是我们想要的形状和结构!与往常一样,所有教程均可点击编辑器与案例之间的小箭头,让代码重新运行(译者注:原文可体验)。每次点击均可看到不同形状的蒙德里安结构。
现在,让我们为它赋予色彩。首先,定义变量。使用漂亮的红蓝黄色。
var white = '#F2F5F1';
var colors = ['#D40920', '#1356A2', '#F7D842']我们随机选择三个方块,为它们各自赋予一种颜色。你可能会看到仅有 1 或 2 种颜色,这是因为同一个方块被随机选中了两次以上。
for (var i = 0; i < colors.length; i++) {
squares[Math.floor(Math.random() * squares.length)].color = colors[i];
}当然,还需要确保在 draw 函数内进行填充操作。
if(squares[i].color) {
context.fillStyle = squares[i].color;
} else {
context.fillStyle = white
}
context.fill()美丽的色彩!
基于网格,你可以轻松增加或减少复杂性。
var step = size / 20;var step = size / 4;var step = size / 7;这就是我们拥有的蒙德里安作品。
《Nginx 高性能 Web 服务器详解》于 2018 年购买,两年有余。印象中是看了一下就看不下去了,毕竟当时没有实际应用。现在终于使用上了,也遇到一些问题,所以有动力看了,并整理了笔记。
书评:相对于官方文档,书本扩充了很多相关知识面,这对于第一次接触 Nginx 的人来说,无疑更易掌握知识点。然而,本书存在不少拖沓冗余,甚至让人一头雾水的描述,错词错字也不少。另外,因为基于 Nginx 版本非最新,存在过时的描述。综上所述,笔者建议本书与官方文档一起阅读,效果更佳。
本书基于 Nginx 1.2.3。书本有些表述不清晰的地方,笔者会结合官方文档进行完善,同时会附上链接。另外,本文是基于笔者个人情况进行选择性记录,建议大家通过官网文档获取最新、最全的信息。
Nginx(engine-x)的开发工作从 2002 年开始,于 2004.10.04 发布正式版本,版本号为 0.1.0。Nginx 最早开发的目的之一是邮件代理服务器。
本书将 Nginx 提供的基本功能服务归纳为基本 HTTP 服务、高级 HTTP 服务和邮件服务等三大类。
在 Nginx 提供的基本 HTTP 服务中,主要包含以下功能特性:
在 Nginx 提供的高级 HTTP 服务中,主要包含以下功能特性:
Nginx 提供邮件代理服务也是基本开发需求之一,主要包含以下功能特性:
HTTP 代理和反向代理
负载均衡
Web 缓存
本文忽略安装部分,具体请参考其他教程。
Nginx 服务器的安装目录主要包括了 conf、html、logs 和 sbin 等 4 个目录。
在 Linux 平台下,控制 Nginx 服务的启停有不止一种方法。
信号机制是实现启停 Nginx 服务的方法之一。
Nginx 服务在运行时,会保持一个主进程和一个或多个 worker process 工作进程。我们通过给 Nginx 服务的主进程发送信号就可以控制服务的启停了,其步骤如下:
获取 PID 有两个途径:
a:在 Nginx 服务启动以后,默认在 Nginx 服务器安装目录下的 logs 目录中会产生文件名为 nginx.pid 的文件,此文件中保持的就是 Nginx 服务主进程的 PID。此文件的存放路径和文件名都可以在 Nginx 服务器的配置文件中进行设置。
$ cat nginx.pid
4136b: 使用 Linux 平台下查看进程的工具 ps,其使用方法是:
$ ps -ef | grep nginx
root 4136 1 0 01:05 ? 00:00:00 nginx: master process ./nginx
nobody 4137 4136 0 01:05 ? 00:00:00 nginx: worker process
nobody 4138 4136 0 01:05 ? 00:00:00 nginx: worker process
nobody 4139 4136 0 01:05 ? 00:00:00 nginx: worker process
root 4160 4062 0 02:44 pts/0 00:00:00 grep Nginx表2.2 Nginx 服务可接受的信号
| 信号 | 作用 |
|---|---|
| TERM 或 INT | 快速停止 Nginx 服务 |
| QUIT | 平缓停止 Nginx 服务 |
| HUP | 使用新的配置文件启动进程,之后平缓停止原有进程,也就是所谓的“平滑重启” |
| USR1 | 重新打开日志文件,常用于日志切割 |
| USR2 | 使用新版本的 Nginx 文件启动服务,之后平缓停止原有 Nginx 进程,也就是所谓的“平滑升级” |
| WINCH | 平缓停止 worker process,用于 Nginx 服务器平滑升级 |
a. 使用 nginx 二进制文件,如 $ ./sbin/nginx -g <SIGNAL>
b. 使用 kill 命令发送信号,其语法:kill <SIGNAL> PID,SIGNAL 用于指定信号(即表 2.2);PID 为 Nginx 服务主进程的 PID,也可以使用 nginx.pid 动态获取 PID 号:kill <SIGNAL> 'filepath',其中,filepath 为 nginx.pid 路径。
启动 Nginx 服务:在 Linux 平台下,直接运行安装目录下 sbin 目录中的二进制文件即可。
停止 Nginx 服务有两种方式:
a. 快速停止:立即停止当前 Nginx 服务正在处理的所有网络请求和丢弃连接,停止工作。
b. 平缓停止:允许 Nginx 服务将当前正在处理的网络请求处理完成,但不再接收新的请求,之后关闭连接,停止工作。
平滑重启的过程(如更改 Nginx 服务器的配置文件和加入新模块):Nginx 服务进程接收到信号后,首先读取新的 Nginx 配置文件,如果配置语法正确,则启动新的 Nginx 服务,然后平缓关闭旧的服务进程;如果新的 Nginx 配置有问题,将显示错误,仍然使用旧的 Nginx 进程提供服务。
平滑升级的过程(如 Nginx 服务器进行版本升级、应用新模块):Nginx 服务接收到 USR2 信号后,首先将旧的 nginx.pid 文件(如果在配置文件中更改过这个文件的名字,也是相同的过程)添加后缀 .oldbin,变为 nginx.pid.oldbin 文件;然后执行新版本 Nginx 服务器的二进制文件重启服务。如果新的服务器启动成功,系统中将有新旧两个 Nginx 服务共同提供 Web 服务。之后,需要向旧的 Nginx 服务进程发送 WINCH 信号,使旧的 Nginx 服务平滑停止,并删除 nginx.pid.oldbin 文件。在发送 WINCH 信号之前,可以随时停止新的 Nginx 服务。
Nginx 启动后,就能通过使用 -s 参数调用可执行文件来对其进行控制。语法如下:
nginx -s <signal>signal 的取值:
什么叫重新打开日志文件?
内容来自:https://developer.aliyun.com/article/316188
先移动日志文件
mv /usr/local/openresty/nginx/logs/access.log /usr/local/openresty/nginx/logs/access.log.20161024发送信号重新打开日志文件
kill -USR1 $(cat /usr/local/openresty/nginx/logs/nginx.pid)简单说明一下:
kill -USR1 cat ${pid_path} 之前,即便已经对文件执行了 mv 命令也只是改变了文件的名称,Nginx 还是会向新命名的文件 “access.log.20161024” 中照常写入日志数据。原因在于 Linux 系统中,内核是根据文件描述符来找文件的。默认的 Nginx 服务器配置文件都存放在安装目录 conf 中,主配置文件为 nginx.conf。
nginx.conf(展示各条语句的生效范围)
worker_processes 1; # 全局生效
events { # 在 events 部分中生效
worker_connections 1024;
}
http { # 以下指令在 http 部分中生效
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server { # 以下指令在 http 的 server 部分中生效
listen 80;
server_name localhost;
location / { # 以下指令在 http/server 的 location 中生效
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}... # 全局块
events { # events 块
...
}
http { # http 块
... # http 全局块
server { # server 块
... # server 全局块
location [PATTERN] { # location 块
...
}
location [PATTERN] { # location 块
...
}
}
server { # server 块
...
}
... # http 全局块
}nginx.conf 一共由三部分组成,分别为全局块、events 块和 http 块。在 http 块中,又包含 http 全局块、多个 server 块。每个 server 块中,可以包含 server 全局块和多个 location 块。在同一配置块中嵌套的配置块,各个之间不存在次序关系。
配置文件支持大量可配置的指令,绝大多数指令不是特定属于某一个块。同一个指令放在不同层级的块中,其作用域也不同。一般情况下,高一级块中的指令可作用于自身所在的块和此块包含的所有低层级块。若某个指令同时出现在两个不同层级的块中,则以较低层级块中的配置为准。
各个块的作用:
用于配置运行 Nginx 服务器用户(组)的指令是 user,其语法格式为:
user <user> [group];只有被设置的用户或者用户组成员才有权限启动 Nginx 进程,如果是其他用户(如 test_user)尝试启动 Nginx 进程,将会报错:
nginx: [emerg] getpwnam("test_user") failed (2: No such file or directory) in /Nginx/conf/nginx.conf:2可以从错误信息中看到,Nginx 无法运行的原因是查找 test_user 失败,引起错误的原因是 nginx.conf 的第二行内容,即配置 Nginx 服务器用户(组)的内容。
如果希望所有用户都可以启动 Nginx 进程,有两种办法:
a. 将此指令注释掉:
# user <user> [group];或者将用户(和用户组)设置为 nobody:
user nobody nobody;
这也是 user 指令的默认配置。user 指令只能用在全局块。
在 Nginx 配置文件中,每一条指令配置都必须以分号结束。
worker process 是 Nginx 服务器实现并发处理的关键所在。
worker_processes 指令用于配置允许生成的 worker process 数,其语法格式为:
worker_processes <number | auto>;在默认配置文件中,number = 1。
此指令只能在全局块中设置。
Nginx 进程作为系统的守护进程运行,我们需要在某文件中保存当前运行程序的主进程号。Nginx 支持对它的存放路径进行自定义配置,指令是 pid,其语法格式为:
pid <file>;配置文件默认将此文件存放在 Nginx 安装目录 logs 下,名为 nginx.pid。支持绝对路径和以 Nginx 安装目录为根目录的相对路径。
此指令只能在全局块中设置。
使用 error_log 指令,其语法结构是:
error_log <file | stderr> [ debug | info | notice | warn | error | crit | alert | emerg ];Nginx 服务器的日志支持输出到特定文件 file 或者标准错误输出 stderr;日志的级别是可选项,由低到高分别为 debug(需要在编译时使用 --with-debug 开启 debug 开关)、info、notice、warn、error、crit、alert、emerg。需要注意的是,设置某一级别后,比该级别高的日志也会被记录。
Nginx 日志存放和级别的默认设置为:
error_log logs/eror.log error;Nginx 进程的用户需要对指定文件具有写权限,否则报错。
此指令可以在全局块、http 块、server 块以及 location 块中配置。
通过 include 指令将其他 Nginx 配置或者第三方模块的配置引入到主配置文件中。其语法结构:
include <file>;Nginx 进程的用户需要对引入的文件具有写入权限,并且符合 Nginx 配置文件的语法结构。
此指令可放在配置文件的任何地方。
在《UNIX 网络编程》第 1 卷里提到过一个叫“惊群”的问题(Thundering herd problem),大致意思是,当某一时刻只有一个网络连接到来时,多个睡眠进程会被同时唤醒,但只有一个进程可获得连接。如果每次唤醒的进程数目太多,会影响系统性能。在 Nginx 服务器的多进程下,就有可能出现这样的问题。
为了解决这样的问题,Nginx 配置中包含了这样一条指令 accept_mutex,当其设置为开启时,多个 Nginx 进程会序列化地接收连接,从而防止多个进程争抢连接。其语法结构为:
accept_mutex <on | off>;此指令默认为开启(on)状态。
此指令只能在 events 块中进行配置。
每个 Nginx 服务器的 worker_process 都有能力同时接收多个新到达的网络连接,但这需要在配置文件中进行设置,其指令为 multi_accept,语法结构为:
multi_accept <on | off>;此指令默认为关闭(off)状态,即每个 worker process 一次只能接收一个新到达的网络连接。
此指令只能在 events 块中进行配置。
Nginx 服务器提供了多种事件驱动模型来处理网络消息。配置文件为我们提供了相关的指令来强制 Nginx 服务器选择哪种事件驱动模型进行消息处理,指令为 use,其语法结构为:
use <method>;其中,method 可选择的内容有:select、poll、kqueue、epoll、rtsig、/dev/poll 以及 eventport。
此指令只能在 events 块中进行配置。
worker_connections 指令用于设置一个 worker process 可同时打开的最大连接数(注意,该连接数包含所有连接,如与代理服务器的连接等,而不仅是与客户端的连接)。其语法结构为:
worker_connections <number>;此指令的默认设置为 512。
number 不能大于操作系统支持打开的最大文件句柄数量。
此指令只能在 events 块中进行配置。
MIME Type 是网络资源的媒体类型。Nginx 服务器作为 Web 服务器,必须能够识别客户端请求的资源类型。
在默认的 Nginx 配置文件中,我们看到在 http 全局块中有以下两行配置:
include mime.types;
default_type application/octet-stream;第一行从外部引用了 mime_types 文件,其内容片段如下:
$ cat mime.types
types {
text/html html htm shtml;
...
image/gif gif;
...
application/x-javascript js;
...
video/3gpp 3gpp 3gp;
...
}从 mime_types 文件的内容片段可以看到,其中定义了一个 types 结构,结构中包含了浏览器能够识别的 MIME 类型以及对应于相关类型的文件后缀名。由于 mime_types 文件是主配置文件引入的第三方文件,因此,types 也是 Nginx 配置文件中的一个配置块,我们可称之为 types 块,其用于定义 MIME 类型。
第二行中使用指令 default_type 配置了用于处理客户端请求的 MIME 类型,其语法结构为:
default_type <mime-type>;其中,mime-type 为 types 块中定义的 MIME-type。该指令的默认值为 text/plain。
此指令可以在 http 块、server 块或者 location 块中进行配置。
在全局块中,我们介绍过 error_log 指令,其用于配置 Nginx 进程运行时的日志存放文件和级别。而服务日志是指记录 Nginx 服务器提供服务过程中客户端的请求日志。
Nginx 服务器支持对服务日志的格式、大小、输出等进行配置。这涉及两个指令,分别是 access_log 和 log_format 指令。
access_log 指令的语法结构为:
access_log <path> [format [buffer=size]];此指令的默认配置为:
access_log logs/access.log combined;其中,combined 为 log_format 指令默认定义的日志格式字符串名称。
若要取消记录服务日志的功能,则使用:
access_log off;此指令可以在 http 块、server 块或者 location 块中进行设置。
log_format 指令是用于定义服务日志的格式,并且可以为格式字符串定义名字,以便 access_log 指令直接调用。其语法格式为:
log_format <name> <string ...>;例子:
log_format exampleLog '$remote_addr - [$time_local] $request '
'$status $body_bytes_sent $http_referer '
'$http_user_agent';此指令只能在 http 块中进行配置。
在 Apache、lighttd 等 Web 服务器配置总,都有和 sendfile 相关的配置。配置 sendfile 传输方式的相关指令 sendfile 和 sendfile_max_chunk 的语法结构:
sendfile <on | off>;用于开启或关闭使用 sendfile() 传输文件,默认值为 off。
此指令可以在 http 块、server 块或者 location 块中配置。
sendfile_max_chunk <size>;若 size 大于 0,则 Nginx 进程的每个 worker process 每次调用 sendfile() 传输的数据量最大不能超过这个值;若设置为 0,则无限制。默认值为 0。
例子:
sendfile_max_chunk 128k;此指令可以在 http 块、server 块或 location 块中配置。
与用户建立连接后,Nginx 服务器可以保持这些连接打开一段时间,此时间段通过指令 keepalive_timeout 设置,其语法结构:
keepalive_timeout <timeout> [header_timeout];例子:
keepalive_timeout 120s 100s;其含义是:在服务器端保持连接的时间设置为 120s,发给用户端的响应报文头部中 Keep-Alive 域的超时时间设置为 100s。
此指令可以在 http 块、server 块或者 location 块中配置。
Nginx 服务器端和用户端建立会话连接后,用户端通过此连接发送请求。指令 keepalive_requests 用于限制用户通过某一连接向 Nginx 服务器发送请求的次数。其语法结构为:
keepalive_requests <number>;此指令可以出现在 http 块、server 块和 location 块。
listen 指令看来起来比较复杂,但其实在一般的使用过程中,相对来说比较简单,其默认设置为:
listen *:80 | *:8000;即监听所有 80 端口和 8000 端口。
案例:
listen 192.168.1.10:8000; # 监听指定 IP 和端口上的请求
listen 192.168.1.10; # 监听指定 IP 的所有端口上的请求
listen 8000; # 监听指定端口的所有 IP 请求,等同于 listen *:8000;
笔者注:关于 Nginx 如何具体处理一个请求,请查看官方文档:《How nginx processes a request》。
“主机”是指 server 块对外提供的虚拟主机。设置了主机的名称并配置好 DNS,用户就可以使用这个名称向此虚拟主机发送请求了。配置主机名称的指令为 server_name,其语法结构为:
server_name <name> ...;name 支持设置多个名称,它们之间用空格隔开。Nginx 服务器规定,第一个名称作为此虚拟主机的主要名称。
name 支持三种形式:
对于通配符名称,通配符只能出现在名称的前后两侧,并且是 . 边上。例如,www.*.example.org 和 w*.example.org 都是无效的,但它们可用在“正则表达式名称”,如 ~^www\..+\.example\.org$ 和 ~^w.*\.example\.org$。一个通配符能匹配多个片段(即 . 分隔的字符串),如 *.example.org 不仅能匹配 www.example.org,还能匹配 www.sub.example.org。
对于正则表达式名称,Nginx 使用的正则表达式与 Perl 编程语言(PCRE)的正则表达式兼容。要使用正则表达式,服务器名称必须以 ~ 字符开头。
server_name ~^www\d+\.example\.net$;否则将被视为“确切名称”,或者如果表达式中包含星号,则被视为“通配符名称”(而且很可能是无效的名称)。不要忘记设置 ^ 和 $,虽然它们不是语法要求,但逻辑上需要。
同时注意,域名的 . 应该用反斜杠转义。包含字符 { 和 } 的正则表达式应加双引号。
server_name "~^(?<name>\w\d{1,3}+)\.example\.net$";否则 Nginx 将无法启动并显示错误信息。
directive "server_name" is not terminated by ";" in ...对于正则表达式,支持几种方式的字符串捕获,并在稍后用作变量:
server {
server_name ~^(www\.)?(?<domain>.+)$;
location / {
root /sites/$domain;
}
}
server {
server_name ~^(www\.)?(.+)$;
location / {
root /sites/$2;
}
}当通过 name 搜索虚拟主机,并且 name 被多个虚拟主机的 server_name 匹配,那么会根据以下规则决定该请求交给哪个虚拟主机处理(注:按 1 ~ 4 的优先顺序):
* 开头的最长通配符名称,如 *.example.com* 结尾的最长通配符名称,如 mail.*笔者注:关于 server name 更详细的描述,请查看官网《server names》。
location 的语法结构为:
location [ = | ~ | ~* | ^~ ] uri { ... }以一个典型且简单的 PHP 网站为例:
server {
listen 80;
server_name example.org www.example.org;
root /data/www;
location / {
index index.html index.php;
}
location ~* \.(gif|jpg|png)$ {
expires 30d;
}
location ~ \.php$ {
fastcgi_pass localhost:9000;
fastcgi_param SCRIPT_FILENAME
$document_root$fastcgi_script_name;
include fastcgi_params;
}
}Nginx 是如何选择一个 location 去处理请求的:
为了方便描述,我们约定:
Nginx 首先不考虑定义顺序,搜索与请求字符串最匹配的 prefix location(笔者注:此处匹配是指 startsWith,而不是 includes,这就是 prefix 所指的意思)。在上述配置中,只有 / 一个 prefix location,因为它与任意请求都匹配,所以它作为兜底选择。然后 Nginx 按照配置文件中含“正则 uri”的 location 的定义顺序,寻找第一个与请求字符串匹配的 location。若找到第一个匹配的“正则 uri”,则停止搜索并使用该 location。若最终找不到匹配的“正则 uri”,Nginx 则使用先前找到的最匹配 prefix location。
需要注意的是,请求字符串的参数(即查询字符串)不参与所有类型的 location 的匹配。这是因为查询字符串中的参数能以多种方式给出,例如:
/index.php?user=john&page=1
/index.php?page=1&user=john了解以上内容后,下面解释可选项中各个标识的含义:
=:用于“标准 uri”前,要求请求字符串与 uri 严格相等才能匹配。如果匹配成功,则停止继续搜索并使用此 location 处理此请求。如果经常请求 “ /”,则定义 “location = /” 能加快该请求的处理速度。~:用于表示 uri 包含正则表达式,并且区分大小写。~*:用于表示 uri 包含正则表达式,并且不区分大小写。^~:用于“标准 uri”前,表示搜索到与请求字符串最匹配的 prefix location 后,就停止搜索并使用此 location 处理此请求。我们看看以上 PHP 网站如何处理请求:
/logo.gif 请求首先与 prefix location / 匹配,然后与“正则 uri” \.(gif|jpg|png)$ 匹配。因此,该请求会被后者 location 处理。使用指令 root /data/www 将请求映射到文件 /data/www/logo.gif,然后该文件会被 Nginx 发送到客户端。/index.php 请求同样首先与 prefix location / 匹配,然后与“正则 uri” \.(php)$ 匹配。因此,该请求会被后者 location 处理。该 location 会将该请求传递给在 localhost:9000 监听的 FastCGI 服务器。fastcgi_param 指令设置 FastCGI 参数 SCRIPT_FILENAME 为 /data/www/index.php,从而 FastCGI 服务器会执行该文件。其中,变量 $document_root 等同于 root 指令的值,变量 $fastcgi_script_name 等同于请求 URI,如 /index.php。/about.html 请求只与 prefix location / 匹配,因此,该请求由该 location 处理。使用指令 root /data/www 将请求映射到文件 /data/www/about.html,然后该文件会被 Nginx 发送到客户端。/ 请求的处理会复杂一些。它只与 prefix location / 匹配,因此,请请求由该 location 处理。指令 index 会根据其参数和 root /data/www 指令检查 index file 是否存在。若文件 /data/www/index.html 不存在,而 /data/www/index.php 存在,则该指令会内部重定向到 index.php,即就像从客户端发送过来的请求一样,Nginx 会再次搜索 location。正如我们之前看到的那样,重定向后的请求最终会被 FastCGI 服务器处理。基于官方文档补充以下知识点:
location 块支持嵌套。显然,严格相等的 location(即 = uri)显然不支持嵌套 location。
还有一种以 @ 为前缀的命名 location(named location),它不用于常规的请求处理,而是用于内部重定向请求。它不支持被嵌套和嵌套 location。
可结合 try_files、error_page 指令使用:
location / {
try_files /system/maintenance.html
$uri $uri/index.html $uri.html
@mongrel;
}
location @mongrel {
proxy_pass http://mongrel;
}location / {
error_page 404 = @fallback;
}
location @fallback {
proxy_pass http://backend;
}如果 prefix location 以 / 结尾,并且请求由 proxy_pass、fastcgi_pass、uwsgi_pass、scgi_pass、memcached_pass、grpc_pass 中的一个指令处理,则会执行一个特殊处理。对于无 / 结尾的请求,会以 301 永久重定向至追加 / 后的 URI。如果这不是你想要的处理方式,请使用严格相等的 location,如下所示:
location /user/ {
proxy_pass http://user.example.com;
}
location = /user {
proxy_pass http://logion.example.com;
}注:location 的部分内容摘抄自描述更清晰的官方文档:《How nginx processes a request》。
Web 服务器接收到网络请求之后,首先要在服务器端指定目录中寻找请求资源。在 Nginx 服务器中,指令 root 就是用来配置这个根目录的,其语法结构为:
root <path>;$document_root 和 $realpath_root 不可使用。此指令可以在 http 块、server 块 和 location 块中配置。
注意:经笔者测试,如果当前 location [root + uri(index)] 找不到相应目录的文件,则会再次匹配 location,如 /。如果最后匹配的 location 内(如 /)仍找不到文件,这时才返回 404。
在 location 块中,除了用 root 指令指明处理请求的根目录,还可以用 alias 指令改变 location 接收到的 URI 的请求路径,其语法结构为:
alias <path>;$document_root 和 $realpath_root 不可使用。为指定 location 定义一个替换值。如:
location /i/ {
alias /data/w3/images/;
}对于请求 /i/top.gif,会向客户端返回 /data/w3/images/top.gif 文件。
当在“正则 uri”的 location 使用 alias,该“正则 uri”应该包含捕获(captures),然后在 alias 引用这些捕获,例如:
location ~ ^/users/(.+\.html)$ {
alias /var/www/$1;
}否则会出现意想不到的问题。
当 location 与 alias 指令的末段一致:
location /images/ {
alias /data/w3/images/;
}则更推荐使用 root 指令:
location /images/ {
root /data/w3;
}另外,经笔者测试:
对于 prefix location,若 loaction 的 uri 末尾含 /,而 alias 指令值的末尾不含 /,会返回 403。
location /test/ { # 末尾含 '/'
alias /var/www; # 末尾不含 '/'
}因此,对于 prefix location 内的 alias 指令值的末尾应该始终含 /。
alias 指令部分内容摘抄自官方文档:《Module ngx_http_core_module》。
指令 index 用于设置网站的默认首页。它一般有两个作用:
其语法结构为:
index <file ...>;index.html。案例:
location ~ ^/data/(.+)/web/$ {
index index.$1.html index.my1.html index.html;
}当 location 块接收到 /data/locationtest/web/ 请求时,匹配成功,它首先将预置变量 $1 置为 locationtest,然后在 /data/locationtest/web/ 路径下按照 index 的配置次序依次寻找 index.locationtest.html 页、index.my1.html 页和 index.html 页,将找到的页面作为请求响应。
Nginx 服务器设置网站错误页面的指令为 error_page,其语法结构为:
error_page <code ...> [=<response>] uri案例:
设置 Nginx 服务器使用“Nginx 安装路径/html/404.html”页面响应 404 错误:
error_page 404 /404.html;设置 Nginx 服务器使用 http://somewebsite.com/forbidden.html 页面响应 403 错误:
error_page 403 http://somewebsite.com/forbidden.html;设置 Nginx 服务器产生 410 的 HTTP 消息时,使用“Nginx 安装路径/html/empty.gif” 返回给用户端 301 消息。
error_page 410 =310 /empty.gif;从以上案例看到,变量 uri 实际上是一个相对于 Nginx 安装路径的相对路径。如果我们不想将错误页面放到 Nginx 服务器的安装路径下,那么只需新增一个 location 指令将错误页面指向新的路径下即可。
error_page 404 /404.html
location /404.html {
root /myserser/errorpage/;
}error_page 指令可以在 http 块、server 块和 location 块中配置。
Nginx 通过两种途径支持基本的访问权限控制,其中一种是由 HTTP 标准模块 ngx_http_access_module 支持的,其通过 IP 来判断客户端是否拥有对 Nginx 的访问权限,这里涉及两个指令。
allow 指令,用于设置允许访问 Nginx 的客户端 IP,语法结构为:
allow <address | CIDR | all>;deny 指令,用于设置禁止访问 Nginx 的客户端 IP,语法结构为:
deny <address | CIDR | all>;在同时使用这两个指令时,需要注意设置为 all 的用法。
案例:
location / {
deny 192.168.1.1;
allow 192.168.1.0/24;
deny all;
}对于 deny 或 allow 指令,Nginx 是按顺序对当前客户端的连接进行访问权限检查的,当遇到匹配配置就停止向下搜索。因此,当 192.168.1.0/24 客户端访问时,Nginx 在第 3 行解析配置时发现允许该客户端访问,就不会继续寻找了,即允许该客户端访问。
这两个指令可以在 http 块、server 块或者 location 块中配置。
Nginx 支持基于 HTTP Basic Authentication 协议的认证。该协议是一种 HTTP 性质的认证办法,需要识别用户名和密码。认证成功的客户端才拥有访问 Nginx 服务器的权限。该功能由 HTTP 标准模块 ngx_http_auth_basic_module 支持,这里涉及两个指令。
auth_basic 指令,用于开启或关闭该认证功能,语法结构为:
auth_basic <string | off>;auth_basic_user_file 指令,用于设置包含用户名和密码信息的文件路径,语法结构为:
auth_basic_user_file <file>;密码文件支持明文或密码加密后的文件。明文的格式如下:
name1:password1
name2:password2:comment
name3:password3加密密码可以使用 crypt() 函数进行密码加密的格式,在 Linux 平台上可以使用 htpassword 命令生成。使用 htpassword 命令的一个示例为:
$ htpassword -c -d /nginx/conf/pass_file username运行后输入密码即可。
一般来说,实现并行处理请求的方式有三种:
服务器每当接收到一个客户端请求时,就由服务器主进程生成一个子进程和该客户端建立连接进行交互,直到连接断开,该子进程就结束。
服务器每当接收到一个客户端请求时,会由服务器主进程派生一个线程出来和该客户端进行交互。
Nginx 结合多进程机制和异步机制对外提供服务。
Nginx 服务器启动后,会产生一个主进程(master process)和多个工作进程(worker process),其中可以在配置文件中指定产生的工作进程数量。Nginx 服务器的所有工作进程都用于接收和处理客户端的请求。这类似于 Apache 使用的改进后的多进程机制,预生成多个工作进程,等待处理客户端请求。
Master-Worker 模型实际上被更广泛地称为 Master-Slave 模型。
每个工作进程都使用了异步非阻塞方式,可以处理多个客户端请求。当某个工作进程接收到客户端的请求后调用 I/O 进行处理,如果不能立即得到结果,就去处理其他的请求;而客户端在此期间也无需等待响应,可以去处理其他事情;当 I/O 调用返回结果时就会通知此工作进程;该进程得到通知,暂时挂起当前处理的事务,去响应客户端请求。
客户端请求数量增加、网络负载繁重时,Nginx 服务器使用多进程机制能够保证不增长对系统资源的压力;同时使用异步非阻塞方式避免了工作进程在 I/O 调用上的阻塞延迟,保证了不降低对请求的处理能力。
I/O 调用是如何把自己的状态通知到工作进程的呢?
一般解决这个问题的方案有两种:
显然,前者不断地检查在时间和资源上会导致不小的开销,最理想的解决方案是第二种。
select/poll/epoll/kqueue 等事件驱动模型就是用来支持第二种解决方案的。它们提供了一种机制,让进程可以同时处理多个并发请求,不用关心 I/O 调用的具体状态。I/O 调用完全由事件驱动模型来管理,事件准备好后就通知工作进程事件已经就绪。
事件驱动模型一般由事件收集器、事件发送器和事件处理器三个基本单元组成。
“目标对象”中的“事件处理器”可以有以下几种实现办法:
以上三种处理方式,各自优缺点如下:
事件驱动处理库又被称为多路 I/O 复用方法。
Nginx 服务器针对不同的 Linux 或 Unix 衍生平台提供了多种事件驱动模型的处理,尽量发挥系统平台本身的优势,最大程度地提供处理客户端请求事件的能力。在实际工作中,我们需要根据具体情况和应用场景选择使用不同的事件驱动模型,以保证 Nginx 服务器的高效运行。
Nginx 服务器启动后,产生一个主进程(master process),主进程执行一系列工作后生成一个或多个工作进程(worker process)。主进程主要进行 Nginx 配置文件解析、数据结构初始化、模块配置和注册、信号处理、网络监听生成、工作进程生成和管理等工作;工作进程主要进行进程初始化、模块调用和请求处理等工作,是 Nginx 服务器提供服务的主体。
在客户端请求动态站点的过程中,Nginx 服务器还涉及和后端服务器的通信。Nginx 服务器将接收到的 Web 请求通过代理转发到后端服务器,由后端服务器进行数据处理和页面组织,然后将结果返回。
另外,Nginx 服务器为了提高对请求的响应效率,进一步降低网络压力,采用了缓存机制,将历史响应数据缓存到本地。在每次 Nginx 服务器启动后的一段时间内,会启动专门的进程对本地缓存的内容重建索引,保证对缓存文件的快速访问。
Nginx 服务器架构示意图
到目前为止,我们一共提到 Nginx 服务器的三大类进程:主进程、由主进程生成的工作进程和刚提到的用于为缓存文件建立索引的进程。
主进程(Master Process)
Nginx 服务器启动时运行的主要进程。它的主要功能是与外界通信和内部对其他进程进行管理,具体来说有以下几点:
工作进程(Worker Process)
由主进程生成,生成数量由 Nginx 配置文件指定,正常情况下会存在于主进程的整个生命周期。该进程的主要工作有以下几项:
工作进程是 Nginx 服务器提供 Web 服务、处理客户端请求的主要进程,完成了 Nginx 服务器的主体工作。因此,我们应该重点监视工作进程的运行状态,保证 Nginx 服务器能向外提供稳定的 Web 服务。
缓存索引重建及管理进程(Cache Loader & Cache Manager)
上图的 Cache 模块,主要由缓存索引重建(Cache Loader)和缓存索引管理(Cache Manager)两类进程来完成工作。缓存索引重建进程是在 Nginx 服务启动一段时间之后(默认是 1 分钟)由主进程生成,在缓存元数据重建完成后就自动退出;缓存索引管理进程一般存在于主进程的整个生命周期,负责对缓存索引进行管理。
这两个进程维护的内存索引元数据库,为工作进程对缓存数据的快速查询提供了便利。
Nginx 服务器在使用 Master-Worker 模型时,会涉及主进程与工作进程(Master-Worker)之间的交互和工作进程(Worker-Worker)之间的交互。这两类交互都依赖于管道(channel)机制,交互的准备工作都在工作进程生成时完成的。
上文已记录部分常用配置,其余配置暂忽略。
相关指令可在 http 块、server 块或者 location 块中配置。
ngx_http_gzip_module 模块主要负责 Gzip 功能的开启和设置,对响应数据进行在线实时压缩。该功能模块包含以下主要指令。
gzip <on | off>;默认设置为 off。
gzip_buffers <number> <size>;根据该配置项,Nginx 服务器在对响应数据进行 Gzip 压缩时需向系统申请 number * size 大小的空间用于存储压缩数据。从 Nginx 0.7.28 开始,默认情况下 number * size 的值为 128,其中 size 的值取系统内存页一页的大小,为 4KB 或者 8KB,即:
gzip_buffers 32 4k | 16 8k;gzip_comp_level <level>;默认设置为 1。
gzip_disable <regex ...>;示例:
gzip_disable MSIE [4-6]\.;表示来自 User-Agent 字符串中包含 MSIE4 - 6 的请求,Nginx 都不进行 Gzip 压缩。
gzip_http_version <1.0 | 1.1>;默认设置为 1.1,即只有客户端使用 1.1 及以上版本的 HTTP 协议时,才使用 Gzip 功能。
gzip_min_length <length>;gzip_proxied <off | expired | no-cache | no-store | private | no_last_modified | no_etag | auth | any ...>;gzip_types <mime-type ...>;mime-type 变量的默认值为 text/html。值 * 表示对所有 MIME 类型的数据进行 Gzip 压缩。
Vary: Accept-Encoding 域的响应头部,该域的主要功能是告诉接收方:发送的数据经过了压缩处理。开启后的效果是在响应头部添加 Accept-Encoding: gzip。其语法结构为:gzip_vary <on | off>;默认设置为 off。事实上,我们可通过 Nginx 配置的 add_header 指令强制 Nginx 服务器在响应头部添加 Vary: Accept-Encoding 域,以达到同样的效果:
add_header Vary Accept-Encoding gzip;ngx_http_gzip_static_module 模块主要负责搜索和发送经过 Gzip 功能预压缩的数据。这些数据以 .gz 后缀名存储在服务器上。如果客户端请求的数据在之前已被压缩,且客户端支持 Gzip 压缩,就直接返回压缩后的数据。
该模块与 ngx_http_gzip_module 模块的不同之处主要在于,该模块使用的是静态压缩,在 HTTP 响应头部包含 Content-Length 域来指明报文体的长度,用于服务器可缺点响应数据长度的情况;而后者默认使用 Chunked 编码的动态压缩,其主要适用于服务器无法确定响应数据长度的情况,比如大文件下载的情形,这时需要实时生成数据长度。
gzip_static 指令,用于开启和关闭该模块的功能,其语法结构:
gzip_static <on | off | always>;Nginx 服务器支持对响应数据进行 Gzip 压缩,这对客户端来说,需要有能力解压和处理 Gzip 压缩数据,但如果客户端本身不支持该功能,就需要 Nginx 服务器在向其发送数据之前先将该数据解压。压缩数据可能来自后端服务器压缩产生或 Nginx 服务器预压缩产生。ngx_http_gunzip_module 模块便是用来针对不支持 Gzip 压缩数据处理的客户端。
gunzip_static <on | off>;默认设置为 off。当功能开启时,如果客户端不支持 Gzip 处理,Nginx 服务器将返回解压后的数据;如果客户端支持 Gzip 处理,Nginx 服务器忽略该指令的设置,返回压缩数据。
当客户端不支持 Gzip 数据处理时,使用该模块可以解决数据解析的问题,同时保证 Nginx 服务器与后端服务器传输数据或本身存储数据时仍然使用压缩数据,从而减少服务器之间的数据传输量,降低本地存储空间和缓存的使用率。
gunzip_buffers <number> <size>;根据该配置项,Nginx 服务器在对 Gzip 数据进行解压时需向系统申请 number * size 大小的空间。默认情况下 number * size 的值为 128,其中 size 的值取系统内存页一页的大小,为 4KB 或者 8KB,即:
gunzip_buffers 32 4k | 16 8k;gzip on; # 启用 gzip
gzip_min_length 1024; # 设置文件被压缩的最低大小门槛
gzip_buffers 16 8k; # 压缩数据的缓冲区大小
gzip_comp_level 2; # 压缩级别
gzip_types text/plain text/css text/xml text/html application/javascript; # 压缩文件 MIME
gzip_vary on; # 添加响应头部 Accept-Encoding: gzip
gzip_proxied any; # 对代理请求的响应进行 Gzip 压缩
gzip_static on; # 启用 Gzip 预压缩功能
gunzip_static on; # 对于不支持 Gzip 的客户端返回解压后的数据
Rewrite 功能是大多数 Web 服务器支持的一项功能,其在提供重定向服务时起到主要作用。
Nginx 服务器支持设置一组服务器作为后端服务器,在学习 Nginx 服务器的反向代理、负载均衡等重要功能时会经常涉及后端服务器。
服务器组的指令由标准 HTTP 模块 ngx_http_upstream_module 进行解析和处理。
upstream <name> {
...
}name 是给后端服务器组起的名字。花括号中列出后端服务器组中包含的服务器,其中可以使用下面介绍到的指令。
默认情况下,某个服务器组接收到请求以后,按照轮叫调度(Round-Robin,RR)策略顺序选择组内服务器处理请求,如果一个服务器在处理请求的过程中出现错误,请求会被依次交给组内下一个服务器进行处理,以此类推,直到返回正常响应。当所有组内服务器出错,则返回最后一个服务器的处理结果。当然,我们可以根据各个服务器处理能力或者资源配置情况的不同,给各个服务器配置不同的权重,让能力强的服务器多处理请求,能力弱的少处理。配置权重的变量包含在 server 指令中。
server <address> [parameters];unix: 为前缀的 Unix Domain Socket(用于进程间通信)。示例:
upstream backend {
server backend1.example.com weight=5;
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server unix:/tmp/backend3;
}在该示例中,我们设置了一个名为 backend 的服务器组,组内包含三台服务器,分别是基于域名的 backend1.example.com、基于 IP 地址的 127.0.0.1:8080 和用于进程间通信的 Unix Domain Socket。backend1.example.com 的权重设置为 5,为组内最大,优先接收和处理请求;对本地服务器 127.0.0.1:8080 的状态检查设置为:如果在 30s 内产生 3 次请求失败,则该服务器在之后 30s 内被认为是无效(down)状态。
ip_hash;好处:
注意:
示例:
upstream backend {
ip_hash;
server myback1.proxy.com;
server myback2.proxy.com;
}该示例中配置了一个名为 backend 的服务器组,包含两台后端服务器 myback1.proxy.com 和 myback2.proxy.com。在添加 ip_hash 指令后,我们使用同一个客户端向 Nginx 服务器发送请求。我们会看到一直是由同一台服务器响应。如果注释 ip_hash 指令后进行相同的操作,请求会由两台服务器轮流响应。
激活到 upstream 服务器的连接缓存。
connections 参数:用于设置每工作进程在缓存中保持的到 upstream 服务器的空闲 keepalive 连接的最大数量。当超过该数量时,最近使用最少的连接将会被关闭。
特别提醒:keepalive 指令不会限制 Nginx 的一个工作进程到 upstream 服务器的连接总数。connections 参数应该设置为一个足够小的数值来让 upstream 服务器来处理新进来的连接。
笔者注:该指令描述摘抄自官方文档《Module ngx_http_upstream_module》。关于该指令的更详细描述,请读者自行查阅资料。
conns/weight,选取该值最小的服务器。如果有多个服务器的 conns/weight 值同为最小,那么对它们采用加权轮询算法。least_conn;地址重写与地址转发是两个不同的概念。
地址重写:是为了实现地址的标准化,比如我们可以在地址栏中中输入 www.baidu.com. 我们也可以输入 www.baidu.cn. 最后都会被重写到 www.baidu.com 上。浏览器的地址栏也会显示 www.baidu.com。
地址转发:“转发”是指在网络数据传输过程中数据分组到达路由器或桥接器后,该设备通过检查分组地址并将数据转发到最近局域网的过程。后来该概念被用在 Web 上,出现了“地址转发”的说法,是指将一个域名指到另一个已有站点的过程。
因此地址重写和地址转发有以下不同点:
该指令可在 server 块或 location 块中使用。其语法结构为:
if (<condition>) {
...
}condition 为判断条件,它支持以下几种设置方法:
false,其余情况认为是 true:~ 判断变量是否与正则表达式(大小写敏感)匹配,~* 是大小写不敏感。正则表达式可包含捕获(capture),可在后续通过 $1...$9 变量引用这些捕获。反运算符 !~ 和 !~* 均可用。若正则表达式包含 } 或 ; 符号,则整个表达式应使用单引号或双引号包围。-f 和 !-f 检查文件是否存在。-d 和 !-d 检查目录是否存在。-e 和 !-e 检查文件、目录或符号链接(symbolic link)是否存在。-x 和 !-x 判断文件是否为可执行文件。(笔者注:Linux 中文件 x 属性表示文件可执行)if ($http_user_agent ~ MSIE) {
rewrite ^(.*)$ /msie/$1 break;
}
if ($http_cookie ~* "id=([^;]+)(?:;|$)") {
set $id $1;
}
if ($request_method = POST) {
return 405;
}
if ($slow) {
limit_rate 10k;
}
if ($invalid_referer) {
return 403;
}该指令用于中断当前相同作用域的其他 Nginx 配置。与该指令处于同一作用域的 Nginx 配置中,位于它前面的指令配置生效,位于它后面的指令配置无效。Nginx 服务器在根据配置处理请求的过程中,遇到该指令会回到上一层作用域,然后继续向下读取配置。
该指令可以在 server 块、location 块和 if 块中使用。
该指令用于完成对请求的处理,直接向客户端返回响应状态码。处于该指令后的所有 Nginx 配置都是无效的。其语法结构为:
return code [text];
return code URL;
return URL;从 0.8.42 起,可为 301、302、303、307 和 308 状态码指定 URL,为其他状态码返回文本 text。URL 和 text 均支持变量。
该指令可以在 server 块、location 块和 if 块中使用。
笔者注:该指令描述部分摘抄自《官网文档》。
rewrite <regex> <replacement> [flag];该指令可用在 server、location、if 块。
若指定的正则表达式匹配请求 URI 部分(即不包含 HTTP 协议和域名,如 www.baidu.com/abc?arg=1 中的 /abc),则 URI 部分会被替换为 replacement 字符串。rewrite 指令会按配置文件的出现次序依次执行(即可指定多个 rewrite 指令)。可通过使用 flag 中止后续 rewrite 指令的执行。若 replacement 字符串以 http://、https:// 或 $scheme 开头,处理就会到此为止,并将重定向给客户端。
可选项 flag 可以为以下之一:
replacement 不是以 http://、https:// 或 $scheme 开头,但又要实现同样的效果,则可以使用该 flag。该指令用于是否开启 URL 重写日志的输出功能,其语法结构为:
rewrite_log <on | off>;默认设置为 off。若开启,URL 重写的相关日志将以 notice 级别输出到 error_log 指令配置的日志文件中。
该指令用于设置一个新变量,其语法结构为:
set <var> <value>;$ 开头,且不能与 Nginx 服务器预设的全局变量同名。该指令用于配置使用未初始化的变量时,是否记录警告日志,其语法结构为:
uninitialized_variable_warn <on | off>;默认设置为开启 on。
忽略。
请到官网查看 Nginx 的所有变量:http://nginx.org/en/docs/varindex.html
通过 Rewrite 功能可以实现一级和多级域名跳转。在 server 块中配置 Rewrite 功能即可。
# 例1
# 客户端访问 http://jump.myweb.name 时,URL 将被 Nginx 服务器重写为 http://jump.myweb.info,客户端得到的数据其实是由 http://jump.myweb.info 响应的。
...
server {
listen 80;
server_name jump.myweb.name;
rewrite ^/ http://www.myweb.info/; # 域名跳转
...
}
...
# 例2
# 客户端访问 http://jump.myweb.info/reqsource 时,URL 将被 Nginx 服务器重写为 http://jump.myweb.name/reqsource,客户端得到的数据实际上是由 http://jump.myweb.name 响应的。
...
server {
listen 80;
server_name jump.myweb.name jump.myweb.info;
if ($host ~ myweb\.info) { # 注意正则表达式中对点号“.”要用 “\” 进行转义
rewrite ^(.*) http://jump.myweb.name$1 permanent; # 多域名跳转
}
...
}
...
# 例3
# 客户端访问 http://jump1.myweb.name/reqsource 或者 http://jump2.myweb.name/reqsource,URL 都将被 Nginx 服务器重写为 http://jump.myweb.name/reqsource,实现了三级域名的跳转。
...
server {
listen 80;
server_name jump1.myweb.name jump2.myweb.name;
if ($http_host ~* ^(.*)\.myweb\.name$) {
rewrite ^(.*) http://jump.myweb.name$1; # 三级域名跳转
}
}
...镜像网站是指将一个完全相同的网站分别放置到几个服务器上,并分别使用独立的 URL,其中一个服务器上的网站叫主站,其他为镜像网站。镜像网站和主站没有太大区别,或者可算是主站的后备。可以通过镜像网站提高网站在不同地区的响应速度。镜像网站可以平衡网站的流量负载,可以解决网络带宽限制、封锁等。
使用 Nginx 服务器的 Rewrite 功能可以轻松地实现域名镜像的跳转。在 server 块中配置 Rewrite 功能,将不同的镜像 URL 重写到指定的 URL 即可。
...
server {
...
listen 80;
server_name mirror1.myweb.name;
rewrite ^(.*) http://jump1.myweb.name$1 last;
}
server {
...
listen 81;
server_name mirror2.myweb.name;
rewrite ^(.*) http://jump2.myweb.name$1 last;
}
...若不想将整个网站做镜像,只想为某一个子目录下的资源做镜像,我们可以在 location 块中配置 Rewrite 功能,原理和上面一样。
...
server {
listen 80;
server_name jump.myweb.com;
location ^~ /source1 {
...
rewrite ^/source1(.*) http://jump.myweb.name/websrc2$1 last;
break;
}
location ^~ /source2 {
...
rewrite ^/source2(.*) http://jump.myweb.name/websrc2$1 last;
break;
}
...
}
...当一个网站包含多个板块时,可以为其中某些板块设置独立域名。其原理和设置某个子目录镜像的原理相同。
...
server {
...
listen 80;
server_name bbs.myweb.name;
rewrite ^(.*) http://www.myweb.name/bbs$1 last;
break;
}
server {
...
listen 81;
server_name home.myweb.name;
rewrite ^(.*) http://www.myweb.name/home$1 last;
break;
}
...如果网站设定了默认资源文件,那么当客户端使用 URL 访问时可以不加具体的资源文件名称。比如,在访问 www.myweb.name 站点时,应该在浏览器地址中输入http://www.myweb.name/index.htm 这样的 URL,如果我们设置了 www.myweb.name 站点的首页为 index.htm,那么直接在地址栏中输入 http://www.myweb.name 即可访问成功,/index.htm 可以忽略不写。
但如果请求的资源文件在二级目录下,这样的习惯可以会造成无法正常访问资源。比如,在访问 http://www.myweb.name/bbs/index.htm 时,如果将 URL 省略为 http://www.myweb.name/bbs/ 可以进行正常访问,但是如果将 URL 写为 http://www.myweb.name/bbs,将末尾的斜杠 / 也省略,那么就无法访问。我们可以使用 Rewrite 功能为末尾没有斜杠“/”的 URL 自动添加一个斜杠 /:
...
server {
listen 81;
server_name www.myweb.name;
location ^~ /bbs {
...
if (-d $request_filename) { # 若指定目录存在
rewrite ^/(.*)([^/])$ http://$host/$1$2/ permanent;
}
}
}
...使用 if 指令判断请求的“/bbs”是目录后,匹配接收到的 URI,并将各部分的值截取出来重新组装,并在末尾添加斜杠“/”。
目录合并用于增强 SEO 的一个方法,它将多级目录下的资源文件转化为看上去是对目录级数很少的资源访问。
比如将 /server/12/34/56/78/9.htm 目录变为 /server/12-34-56-78-9.htm 的 URL。
...
server {
...
listen 80;
server_name www.myweb.name;
location ^~ /server {
...
rewrite ^/server-([0-9]+)-([0-9]+)-([0-9]+)-([0-9]+)-([0-9]+)\.htm$ /server/$1/$2/$3/$4/$5.htm last;
break;
}
}通过检测 Referer 域的值是否是自身网站的 URL,并采取措施,从而实现防盗链。但由于 Referer 域的值可被更改,因此该方法并不是完美的。
Nginx 配置中有一个指令 valid_referers,它会根据指定值来判断 Referer 值是否符合要求,并为 Nginx 变量(Embedded Variables) $invalid_referer 赋值。如果 Referer 不符合 valid_referers 指令配置的值,$invalid_referer 变量会被赋值为 "1",反之为空字符串。valid_referers 指令的语法结构为:
valid_referers none | blocked | server_names | string ...;*。检测期间,Referer 值的端口号会被忽略。~。应当注意:正则表达式会与“http://”或“https://”后的字符串进行匹配。案例:
valid_referers none blocked server_names
*.example.com example.* www.example.org/galleries/
~\.google\.;有了 valid_referers 指令和 $invalid_referer 变量,就能通过 Rewrite 功能实现防盗链。有两种方案:1. 根据请求资源的类型;2. 根据请求目录。
根据文件类型实现防盗链:
server {
...
listen 80;
server_name www.myweb.name;
location ~* ^.+\.(gif|jpg|png|swf|flv|rar|zip)$ {
...
valid_referers none blocked server_names *.myweb.name;
if ($invalid_referer) {
rewrite ^/ http://www.myweb.com/images/forbidden.png; # 或者直接返回 403。
}
}
}根据请求目录实现防盗链(原理一致,只是改变 location 块的 uri。):
server {
...
listen 80;
server_name www.myweb.name;
location /file/ {
valid_referers none blocked server_names *.myweb.name;
if ($invalid_referer) {
rewrite ^/ http://www.myweb.com/images/forbidden.png;
}
}
}代理(Proxy)服务,通常也称为正向代理服务。局域网内的机器借助代理服务器访问局域网外的网站,这主要是为了增强局域网内部网络的安全性,使得网外的威胁因素不容易影响到网内,这里的代理服务器起到了一部分防火墙的功能。同时,利用代理服务器可以对局域网对外网的访问进行必要的监控和管理。正向代理服务器不支持外部对内部网络的访问请求。
正向代理服务器示意图
与正向代理服务相反,如果局域网向 Internet 提供资源,让 Internet 上的其他用户可以访问局域网内的资源,也可以设置使用一个代理服务器,它提供的服务就叫做反向代理(Reverse Proxy)服务。
反向代理服务器示意图
正向代理服务器让局域网客户机接入外网以访问外网资源,反向代理服务器让外网的客户端接入局域网中的站点以访问站点中的资源。理解这两个概念的关键是明白我们当前的角色和目的是什么,在正向代理服务器中,我们的角色是客户端,目的是要访问外网的资源;在反向代理服务器中,我们的角色是站点,目的是把站点的资源发布出去让其他客户端能访问。
resovler <address ...> [valid=time];该指令用于设置 DNS 服务器域名解析的超时时间,语法结构为:
resolver_timeout <time>;该指令用于设置代理服务器的协议和地址。其语法结构为:
proxy_pass <URL>;在代理服务器配置中,该指令的设置是相对固定的:
proxy_pass http://$http_host$request_uri;其中,代理服务器协议设置为 HTTP,$http_host 和 $request_uri 两个变量是获取主机和 URI(含参数) 的变量。
server {
resolver 8.8.8.8;
listen 82;
location / {
proxy_pass http://$http_request$request_uri;
}
}设置 DNS 服务器地址为 8.8.8.8,使用默认的 53 端口,代理服务器的监听端口设置为 82 端口,Nginx 服务器接收到的所有请求都由第 5 行的 location 块进行处理。
需要注意:设置 Nginx 的代理服务器,一般是配置到一个 server 块中。该 server 块中不要出现 server_name 指令,即不要设置虚拟主机的名称或 IP。而 resolver 指令是必须的。若无该指令,Nginx 服务器无法处理接收到的域名。
该指令用于设置被代理服务器的地址。支持主机名称、IP 地址加端口号、服务器组名称。
该指令的值可以包含变量。在这种情况下,如果将地址指定为域名,首先在服务器组中搜索。在找不到的情况下使用 resolver 指令解析该域名。
对于服务器组,若组内的各个服务器都指明了传输协议 http://,那么在 proxy_pass 指令就无要指明。反之则反之。
请求 URI 按如下方式传递到被被代理服务器:
location /name/ {
proxy_pass http://127.0.0.1/remote/;
}客户端请求 http://192.168.1.10/name/path/index.html 会被代理到 http://127.0.0.1/remote/path/index.html。即 location URI:/name/ 被替换为 proxy_pass 指定的 URI:/remote/
注意:经笔者测试,若改为
proxy_pass http://127.0.0.1/remote(即去掉末尾/),则会被代理到http://127.0.0.1/remotepath/index.html。
location /some/path {
proxy_pass http://127.0.0.1;
}客户端请求 http://192.168.1.10/some/path/index.html 会被代理到 http://127.0.0.1/some/path/index.html。URI 保持不变。
在某些情况下,请求 URI 无法确定替换后的值:
对于正则表达式和命名 location,proxy_pass 不应该带有 URI。
当 URI 被 location 内 rewrite 指令更改时,传递给被代理服务器的 URI 是更改后的,且行为与 location URI 一致(即上述两种情况)。
location /name/ {
rewrite /name/([^/]+) /users?name=$1 break;
proxy_pass http://127.0.0.1;
}在该案例中,proxy_pass 无 URI,所以 rewrite 后的 URI 会原样传递给被代理服务器。
当 proxy_pass 使用变量:
location /name/ {
proxy_pass http://127.0.0.1$request_uri;
}在该案例中,proxy_pass 指定的 URI 会传递给被代理服务器,即替换掉原始请求的 URI。
笔者注:proxy_pass 描述摘抄自:《官方文档》。
该指令用于设置 Nginx 服务器在发送 HTTP 响应时,需要隐藏的一些头部域信息。其语法结构为:
proxy_hide_header <field>;proxy_pass_header <field>;proxy_pass_request_body <on | off>;默认设置为 on。
proxy_pass_request_headers: <on | off>;默认设置为 on。
proxy_set_header <filed> <value>;默认设置为:
proxy_set_header Host $proxy_host;
proxy_set_header Connection close; proxy_set_body <value>;proxy_bind <address>;proxy_connect_timeout 指令
proxy_read_timeout 指令
proxy_send_timeout 指令
proxy_http_version 指令
proxy_method 指令
该指令用于设置 Nginx 服务器请求被代理服务器时使用的请求方法。设置该指令后,会覆盖客户端的请求方法。
proxy_ignore_client_abort 指令
proxy_ignore_headers 指令
proxy_redirect 指令
proxy_intercept_errors 指令
开始状态下,如果被代理服务器返回的 HTTP 状态码为 300 或大于 300,则 Nginx 服务器使用自己定义的错误页(使用 error_page 指令);关闭状态下,Nginx 服务器直接将被代理服务器返回的 HTTP 状态码返回给客户端。其语法结构为:
proxy_intercept_errors <on | off>;默认值为 off。
proxy_headers_hash_max_size 指令
proxy_headers_hash_bucket_size 指令
proxy_next_upstream 指令
在配置 Nginx 服务器反向代理功能时,如果使用 upstream 指令配置了一组服务器作为被代理服务器,服务器组中各服务器的访问规则遵循 upstream 指令配置的轮询规则,同时可以使用该指令配置在发生哪些异常情况时,将请求顺次交由组内下一个服务器处理。该指令的语法结构为:
proxy_next_upstream <status ...>;proxy_ssl_session_reuse <on | off>;默认设置为 on。
Proxy Buffer 启用后,Nginx 服务器会异步地将被代理服务器的响应数据传递给客户端。
Nginx 服务器首先尽可能地从被代理服务器接收响应数据,并放置在 Proxy Buffer 中,Buffer 大小由 proxy_buffer_size 指令和 proxy_buffers 指令决定。在接收过程中,如果发现 Buffer 没有足够空间接收一次响应的数据,Nginx 服务器会将部分接收到的数据临时存放在磁盘的临时文件中,磁盘上的临时文件路径可通过 proxy_temp_path 设置,临时文件的大小由 proxy_max_temp_file_size 和 proxy_temp_file_write_size 决定。一次响应数据被接收完成或 Buffer 已经装满后,Nginx 服务器开始向客户端传输数据。
每个 Proxy Buffer 装满数据后,在从开始向客户端发送一直到 Proxy Buffer 中的数据全部传输给客户端的过程中,它都处于 BUSY 状态,期间对它进行的其他操作都会失败。同时处于 BUSY 状态的 Proxy Buffer 总大小由 proxy_busy_buffers_size 限制。
在 Nginx 服务器中,Proxy Buffer 和 Proxy Cache 都与代理服务相关,它们主要用来提高客户端与被代理服务器之间的交互效率。Proxy Buffer 实现了被代理服务器响应数据的异步传输,Proxy Cache 实现了 Nginx 服务器对客户端请求的快速响应。Nginx 服务器在接收到被代理服务器的响应数据之后,一方面通过 Proxy Buffer 机制将数据传递给客户端,另一方面根据 Proxy Cache 的配置将这些数据缓存到本地磁盘。当客户端下次访问相同数据时,Nginx 服务器会直接从硬盘检索到相应的数据返回给用户。
Proxy Cache 机制依赖于 Proxy Buffer 机制,只有在 Proxy Buffer 机制开启的情况下 Proxy Cache 的配置才发挥作用。
Nginx 服务器还提供另一种将被代理服务器数据缓存到本地的方法 Proxy Store,与 Proxy Cache 的区别是,它对来自被代理服务器的响应数据,尤其是静态数据只进行简单的缓存,不支持缓存过期更新、内存索引建立等功能,但支持设置用户或用户组对缓存数据的访问权限。
Nginx 反向代理服务的一个重要用途是实现负载均衡。
负载均衡主要通过专门的硬件设备实现或通过软件算法实现。通过硬件设备实现的负载均衡效果好、效率高、性能稳定,但成本较高。通过软件实现的负载均衡主要依赖于均衡算法的选择和程序的健壮性。均衡算法常见有两类:静态负载均衡算法和动态负载均衡算法。
静态算法实现比较简单,在一般网络环境下也能达到比较好的效果,主要有:
动态负载在较为复杂的网络环境中适应性更强,效果更好,主要有:
以下 5 个配置案例展示了 Nginx 服务器实现不同情况下负载均衡的基本方法。由于 Nginx 服务器的功能在结构上是增量式的,我们可以在这些配置的基础上继续添加更多功能,比如 Web 缓存、Gzip、身份认证、权限管理等。同时在使用 upstream 指令配置服务器组时,可以充分发挥各个指令的功能,配置出满足需求,高效稳定的 Nginx 服务器。
在以下案例片段中,backend 服务器组中所有服务器的优先级全部配置为默认的 weight=1,这样它们会按照一般轮询策略依次接收请求任务。该配置是一个最简单的实现 Nginx 服务器负载均衡的配置。所有访问 www.myweb.com 的请求都会在 backend 服务器组中实现负载均衡。
...
upstream backend { # 配置后端服务器组
server 192.168.1.2:80;
server 192.168.1.3:80;
server 192.168.1.4:80; # 默认 weight=1
}
server {
listen 80;
server_name: www.myweb.com;
index index.html index.htm;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
...
}
...
}...
upstream backend { # 配置后端服务器组
server 192.168.1.2:80 weight=5;
server 192.168.1.3:80 weight=2;
server 192.168.1.4:80; # 默认 weight=1
}
server {
listen 80;
server_name: www.myweb.com;
index index.html index.htm;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
...
}
...
}在该实例片段中,我们设置了两组被代理的服务器组。其中,名为 “videobackend” 的一组用于对请求 video 资源的客户端请求进行负载均衡,另一组名为 filebackend 的用于对请求 file 资源的客户端请求进行负载均衡。通过对 location 块 uri 的不同配置,我们就很轻易地实现了对特定资源的负载均衡。所有对 http://www.myweb.name/video/* 的请求都会在 videobackend 服务器组中获得均衡效果,所有对 http://www.myweb.name/file/* 的请求都会在 filebackend 服务器组中获得均衡效果。在该实例中展示的是实现一般负载均衡的配置,对于加权负载均衡的配置可以参考“配置实例二”。
在 location /file/ {...} 块中,我们将客户端的真实信息分别填充到了请求头中的 “Host”、“X-Real-IP” 和 “X-Forwarded-For” 域,这样后端服务器组收到的请求中保留了客户端的真实信息,而不是 Nginx 服务器的信息。实例代码如下:
... # 其他配置
upstream videobackend {
server 192.168.1.2:80;
server 192.168.1.3:80;
server 192.168.1.4:80;
}
upstream filebackend {
server 192.168.1.5:80;
server 192.168.1.6:80;
server 192.168.1.7:80;
}
server {
listen 80;
server_name: www.myweb.name;
index index.html index.htm;
location /video/ {
proxy_pass http://videobackend;
proxy_set_header Host $host;
...
}
location /file/ {
proxy_pass http://filebackend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x-Forwarded-For $proxy_add_x_forwarded_for;
...
}
...
}在该实例片段中,我们设置了两个虚拟服务器和两组后端被代理的服务器组,分别用来接收不同域名的请求,并对这些请求进行负载均衡处理。如果客户端请求域名为 “home.myweb.name”,则由服务器 server 1 接收并转向 homebackend 服务器组进行负载均衡处理;如果客户端请求域名为 “bbs.myweb.name”,则由服务器 server 2 接收并转向 bbsbackend 服务器组进行负载均衡处理。这样就实现了对不同域名的负载均衡。
需要注意两组后端服务器组中有一台服务器 server 192.168.1.4:80 是公用的。在该服务器上需要部署两个域名下的所有资源才能保证客户端请求不会出现问题。实现代码如下:
...
upstream bbsbackend {
server 192.168.1.2:80 weight=2;
server 192.168.1.3:80 weight=2;
server 192.168.1.4:80;
}
upstream homebackend {
server 192.168.1.4:80;
server 192.168.1.5:80;
server 192.168.1.6:80;
}
server { # server 1
listen 80;
server_name home.myweb.name;
index index.html index.htm;
location / {
proxy_pass http://homebackend;
proxy_set_header Host $host;
...
}
...
}
server { # server 2
listen 80;
server_name bbs.myweb.com;
index index.html index.htm;
location / {
proxy_pass http://bbsbackend;
proxy_set_header Host $host;
...
}
...
}首先,我们来看具体的源码实现,这是在实例一的基础上做的修改:
...
upstream backend {
server 192.168.1.2:80;
server 192.168.1.3:80;
server 192.168.1.4:80;
}
server {
listen 80;
server_name www.myweb.name;
index index.html index.htm;
location /file/ {
rewrite ^(/file/.*)/media/(.*)\.*$ $1/mp3/$2.mp3 last;
}
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
...
}
...
}该实例片段与“配置实例一”相比,增加了对 URI 包含 "/file/" 的 URL 重写功能。例如客户端的请求 URL 为 http://www.myweb.name/file/download/media/1.mp3 时,该虚拟服务器首先使用 location /file/ {...} 块将该 URL 进行重写为 http://www.myweb.name/file/download/mp3/1.mp3 时,然后新的 URL 再由 location / {...} 块转发到后端的 backend 服务器组中实现负载均衡。在该配置方案中,一定要掌握清楚 rewrite 指令中 last 标记和 break 标记的区别,才能达到预期效果。
忽略。
解压 Linux 版本的 Nginx 压缩包后,有一个 src 目录,其中存放了 Nginx 软件的所有源代码。
$ cd src
$ ls
core event http mail misc osngx_cpp_test_module.cpp 文件实现的功能是测试程序中引用的头文件是否与 C++ 兼容。ngx_google_perftools_module.c 文件是用来支持 Google PerfTools 的使用。Google PerfTools 包含四个工具,用于优化内存分配的效率和速度,帮助在高并发的情况下控制内存的使用,对 Nginx 服务器的运行做出进一步优化。忽略。
Nginx 初始化过程的主要工作
Nginx 服务器程序完成初始化工作后,就会开始启动进程的工作。Nginx 服务器程序的进程模型分为 Single 和 Master 两种,其中 Single 模型是以单进程方式工作的,一般不会在实际应用中使用;Master 模型是以 Master-Worker 多进程方式进行工作的,它是实际应用中使用的主要模式。
启动多进程的过程和执行一般的多进程程序是一样的,主要使用 fork() 函数产生子进程。主进程通过一个 for 循环来接收和处理外部信息,对 Nginx 服务器的启停进行控制;产生的子进程就是工作进程,每个工作进程执行一个 for 循环来实现 Nginx 服务器对事件的接收和处理,以提供 Nginx 服务器的各项功能。
Master 模型下多进程的启动过程
忽略。
忽略。
忽略。
忽略。
忽略。
原文链接:Auto-updating apps for Windows and OSX using Electron: The complete guide
2017.11.06 更新:electron-builder 提供了 electron-updater 模块,具体请查阅:《Quick and painless automatic updates in Electron》。
由于我之前也调研了 Electron 的自动更新方面的知识,所以我会在保留原文所有信息的前提下,加入了一些备注(如作者的一些错误信息和补充了我个人的一些认识)。
通过 Electron,你可能只需一眨眼的时间就完成了一个不错的桌面应用,并分发到用户手中。当你觉得自己能像一个侥幸的坏蛋一样轻松时,你可能会意识到你遗漏了一个重要的点:用户如何获取下一个版本呢?甚至该新版本新增了一些优秀的功能。当然,他们能删除后再重新安装该应用,但这难道不蹩脚吗?
快速浏览 Electron 文档 时,你会注意到该文档中含有 auto-updater 模块,它仅仅是另一个框架——Squirrel 的接口。Squirrel 会在背后检测(或你主动触发)是否有新版本、下载新版本,并在你启动或重启应用时自动更新应用。
但悲伤的是:实际实现起来并不是文档上写的这么简单。因为自动更新在 OSX 和 Windows 上的工作方式并不相同(目前并不支持 Linux),并且这两者的文档是分散在多个库(repository)中。我已经花费了大量的时间把该功能实现了。所以我觉得将我所学习到的知识总结成一篇教程是值得的,希望它能节省你的时间。
虽然这里所讲的一切应该均能在 Windows 和 OSX 上运行,但为了减少异议,我先声明我是在 Mac OSX 10.11 上执行的操作,除了为 Windows 系统构建安装包(在虚拟机上)。
如对该篇教程有任何改善或更新的建议,可在 twitter 联系我!
在实现自动更新之前,有一个重要的步骤 —— 打包。我假设大多数人已经知道如何通过 electron-packager 实现该操作,但有两件事是时常被忽略的。
{
"name": "MyApp",
"main": "app.js",
"private": true,
"productName": "MyApp",
"version": "1.0.0",
"author": "My Company Ltd",
"description": "MyApp",
"devDependencies": {
"electron-installer-squirrel-windows": "^1.3.0",
"electron-packager": "^5.1.1",
"electron-prebuilt": "0.36.7"
},
"scripts": {
"start": "NODE_ENV=development ./node_modules/.bin/electron .",
"pack:osx": "./node_modules/.bin/electron-packager . $npm_package_productName --app-version=$npm_package_version --version=0.36.7 --out=builds --ignore='^/builds$' --platform=darwin --arch=x64 --sign='Developer ID Application: My Company Ltd (ABCDEFGH10)' --icon=icon.icns --overwrite",
"pack:win": "./node_modules/.bin/electron-packager . $npm_package_productName --app-version=$npm_package_version --version=0.36.7 --out=builds --ignore='^/builds$' --platform=win32 --arch=ia32 --version-string.CompanyName='My Company Ltd' --version-string.LegalCopyright='Copyright (C) 2016 My Company Ltd' --version-string.FileDescription=$npm_package_productName --version-string.OriginalFilename='MyApp.exe' --version-string.InternalName=$npm_package_productName --version-string.ProductName=$npm_package_productName --version-string.ProductVersion=$npm_package_version --asar=true --icon=logo.ico --overwrite"
}
}
package.json
注意 package.json 的额外字段 —— productName、author 和 description,虽然这几个字段并不是打包必备的,但它们会在 Windows 的 Squirrel 安装包中使用到。
为应用执行代码签名(Code-signing)的这部操作并不是自动更新的必备步骤(译者注:也许作者当时的 Electron 版本的自动更新模块不必进行代码签名,但当前版本是必须要进行这部操作的,官方文档中写道:Your application must be signed for automatic updates on macOS. This is a requirement of Squirrel.Mac. ),但这是非常可取的操作。对于 OSX,你需要一个 Apple 的开发者认证,然后在 script 字段的 pack:osx 替换以下参数即可:
--sign='Developer ID Application: My Company Ltd (ABCDEFGH10)'
在 OSX 中,你可以通过 Keychain Access > My Certificates 查看(应用程序 -> 钥匙串 > 我的证书,如果有的话)。
我并没有在 Windows 上执行代码签名这项操作,但你可以看看该主题相关的优秀教程。
对于 Windows,推荐为 electron-packager 传递 version-string 的所有可选参数,如 company name、product name 等。因为一旦我们生成 Windows 的 Squirrel 安装包,该应用就能在 Windows 的『开始』菜单显示正确的元信息(metadata),而不是 Atom 的默认信息。
Atom Shell is now called Electron。
所以,让我们开始吧!
在 OSX 中,自动更新是通过 Squirrel.Mac 处理的,它是内置于 Electron 中。这意味着你只需打包你的应用,然后照常运行就好!
恩,其实不完全是。
Squirrel.Mac 的工作方式是通过访问一个你所提供的 API 『路径』(endpoint),判断是否有新版本。如果没有新版本,那么该路径应该返回 HTTP 204。如果有新版本,则它会期待接收一个 HTTP 200、且是 JSON 格式 的响应,其中包含一个 能获取 .zip 文件的 url。
PS:『路径』又称"终点"(endpoint),表示API的具体网址。
{
"url": "http://mysite.com/path/to/zip/MyApp.zip"
}
在得到该 url 后,Squirrel 会构造一个 application/zip 的请求去访问该 url,下载相应文件,然后触发最终事件(下载完成)让你知道更新包即将安装。对于你来说,所有事情的处理都是自动化的。
如果你不十分确定服务器程序应该长什么样,可看看下面的一个超级小型的 Node.js/Express 服务,假定它的目录结构如下:
└── releases
├── darwin
│ ├── 1.0.0
│ ├── 1.0.2
│ └── 1.0.3
└── win32
{
"name": "squirrel-version-checker",
"version": "0.0.0",
"private": true,
"scripts": {
"start": "PORT=80 node app.js",
"dev": "./node_modules/.bin/nodemon app.js"
},
"dependencies": {
"express": "^4.9.8",
"morgan": "^1.3.2"
},
"devDependencies": {
"nodemon": "^1.8.1"
}
}
基于 Node 的更新服务 package.json
'use strict';
const fs = require('fs');
const express = require('express');
const path = require('path');
const app = express();
app.use(require('morgan')('dev'));
app.use('/updates/releases', express.static(path.join(__dirname, 'releases')));
app.get('/updates/latest', (req, res) => {
const latest = getLatestRelease();
const clientVersion = req.query.v;
if (clientVersion === latest) {
res.status(204).end();
} else {
res.json({
url: `${getBaseUrl()}/releases/darwin/${latest}/MyApp.zip`
});
}
});
let getLatestRelease = () => {
const dir = `${__dirname}/releases/darwin`;
const versionsDesc = fs.readdirSync(dir).filter((file) => {
const filePath = path.join(dir, file);
return fs.statSync(filePath).isDirectory();
}).reverse();
return versionsDesc[0];
}
let getBaseUrl = () => {
if (process.env.NODE_ENV === 'development') {
return 'http://localhost:3000';
} else {
return 'http://download.mydomain.com'
}
}
app.listen(process.env.PORT, () => {
console.log(`Express server listening on port ${process.env.PORT}`);
});
一个简单地、用于测试 Squirrel.Mac 自动更新的 Express 服务器
这将会从本地的文件系统进行分发文件,但这不是理想的处理方式。我的建议是:将这些文件放置在 Amazon S3。
Amazon S3:Amazon Simple Storage Service
然后你可以在开发环境下,通过 Electron 访问该路径:
http://localhost:3000/updates/latest?v=1.0.1
?v=1.0.1 是你当前应用的版本。
现在你已经拥有了服务器程序和路径了,那么在应用中处理更新操作就十分简单了。
在 Electron 的主进程文件中,引入 auto-updater 模块,然后获取当前系统和应用的版本:
const autoUpdater = require('auto-updater');
const appVersion = require('./package.json').version;
const os = require('os').platform();
然后配置路径,该路径会因系统(Windows 和 Mac)不同而有所差异(至于原因,会在 Windows 章节看到):
var updateFeed = 'http://localhost:3000/updates/latest';
if (process.env.NODE_ENV !== 'development') {
updateFeed = os === 'darwin' ?
'https://mysite.com/updates/latest' :
'http://download.mysite.com/releases/win32';
}
autoUpdater.setFeedURL(updateFeed + '?v=' + appVersion);
告诉 Electron 到哪里检测新版本
autoUpdater 模块提供了一些事件,你可通过渲染进程触发它们(译者注:通过 IPC 通讯模块),想获取更多信息,可查阅 auto-Updater 文档页面 。相关交互的实现决定取决于你如何处理这些事件(如发生错误等),并通知用户。但你最后一步应该做的是:
autoUpdater.quitAndInstall();
将上述语句放在主进程文件后,应用会以新本版的形式重启。赞!
如你想象的那样,在 Windows 上实现自动更新是通过 Squirrel.Windows。但它的处理方式与 OSX 完全不同。
与 Squirrel.Mac 不同的点在于:Squirrel.Windows 并不需要一个用于检测新版本的 API 路径,它需要的是一个文件服务器,所以你可以简单地将文件拖拽到 Amazon S3 bucket 上。另外,该 Squirrel 更新器并不内置于 Electron,它是一个第三方依赖。这意味着你需要为你所打包的 Windows 应用生成一个安装器,这样它才会包含 Squirrel 更新器。
Amazon S3 bucket:S3 的数据存储结构非常简单,就是一个扁平化的两层结构:一层是存储桶(Bucket,又称存储段),另一层是存储对象(Object,又称数据元)。具体信息可查看 《亚马逊S3服务介绍》
好消息是:Windows 的安装包和更新器的运行过程顺滑的。因为当你启动 Setup.exe 时,你会发现安装和启动该应用是迅速的。没有无聊的安装向导和一直按“下一步”、最后按“完成”的步骤,不然与大多数 Windows 安装器如出一辙。当然,它也能生成 delta packages,这让你在执行更新时,不必下载整个应用,这真的是一流啊。
译者注:我通过 electron-builder 生成的 Windows 安装包与我们常见的软件安装界面不太一样,他没有安装向导和点击“下一步”,只有一个安装时的 gif 动画(默认的 gif 动画如下图),因此也就没有让用户选择安装路径等权利。也许作者习惯了 Mac 的安装方式(即下面第二幅图),所以会觉得 Windows 的安装包比较繁琐。
Windows 安装时 默认显示的 gif 动画
Mac 常见的安装模式,将“左侧的应用图标”拖拽到“右侧的 Applications”即可
如果你想为 Windows 应用生成常见的、需要点击“下一步”的(即用户可自定义的)安装包,可以通过 NSIS 程序,具体可看这篇教程《[教學]只要10分鐘學會使用 NSIS 包裝您的桌面軟體–安裝程式打包。完全免費。》。当然,前提还是通过 electron-packager 打包程序。
NSIS(Nullsoft Scriptable Install System)是一个开源的 Windows 系统下安装程序制作程序。它提供了安装、卸载、系统设置、文件解压缩等功能。这如其名字所指出的那样,NSIS 是通过它的脚本语言来描述安装程序的行为和逻辑的。NSIS 的脚本语言和通常的编程语言有类似的结构和语法,但它是为安装程序这类应用所设计的。
坏消息是(至少对于 Mac 用户):我不能在 OSX 上正确地生成安装包,所以我建议你下载一个 Windows 虚拟机(如 VirtualBox、parallels),并安装 Node.js。
译者注:我通过 electron-builder,可在 MacOS 中直接(即不通过虚拟机)生成 Windows 安装包(即Setup.exe)。具体可 查看这里。
假设你已经配置好并设置了正确的更新源,那么在上述 OSX 章节的代码基础上,还需要处理一些 Squirrel.Windows 事件,这些事件与 OSX 上的不同。你可以查看该 案例。然而,这里提供一个更简单的方式,仅需安装 electron-squirrel-startup npm 模块:
npm install electron-squirrel-startup --save-dev
然后在 Electron 的主进程文件顶部添加以下一行语句:
if (require('electron-squirrel-startup')) return;
Squirrel.Windows 事件应该被尽早处理,显然,这是要走的路。
最后,为了生成安装包,我们会使用 Atom 的 grunt-electron-installer。为什么它是一个 grunt 插件,而不是一个简单的命令行工具——我不知道,但它就是解决方法。
更新:Electron 团队开发了一个独立的安装器打包工具——electron-winstaller,它拥有与 grunt task 同样的 API
将 Electron-packager 生成的 win32 文件夹打包压缩(zip),然后将其复制到虚拟机上。在该文件夹外(译者注:在解压后),你需要配置 grunt task,该 task 会生成安装包,因此你应该首先安装所有依赖:
npm install -g grunt-cli
npm install grunt grunt-electron-installer --save-dev
假设 Windows 编译后的包放置在一个称为 MyApp-win32-ia32 的文件夹下。下面展示 Gruntfile 的样子:
module.exports = function(grunt) {
grunt.initConfig({
'create-windows-installer': {
ia32: {
appDirectory: './MyApp-win32-ia32',
outputDirectory: './dist',
name: 'MyApp',
description: 'MyApp',
authors: 'My Company Ltd',
exe: 'MyApp.exe'
}
}
});
grunt.loadNpmTasks('grunt-electron-installer');
};
需要注意的是:如果你想为你的文件和安装包进行代码签名(code-sign)操作,你也需要为该 task 配置提供所有参数。
运行该 grunt task 后,会在 ./dist 目录下产生一堆文件:
grunt create-windows-installer
你预期看到的与下面类似:
└── dist
├── MyApp.1.0.0.nupkg
├── MyApp-1.0.0-full.nupkg
├── RELEASES
├── Setup.exe
在下一次发布时,该安装器也会自动生成一个 delta packages。
现在进行最简单的一步 —— 拖拽这些文件到 S3 bucket 进行上传。然后 url 指向该文件夹(包含 RELEASES 和 nupkg 文件)。当应用运行在 Windows 系统上时,它会将该 url 设置到 updateFeed 参数上(因为我们在先前的 OSX 章节处已实现)。
注意:目前有一个与安装器的 node-rcedit 模块相关的问题,该模块会在你尝试去修改 .exe 文件的一些元信息和替换默认图标(icon)时抛出错误。你可以在 这里查看该 issue。因此,目前如果你想为安装器文件修改 icon 或为其赋予实际数据,你可能不得不手动地通过 ResHacker 进行修改。
希望这篇文章能作为一个好的起点,能帮助和服务每一个正在为 Electron 应用实现自动更新的朋友们。如果你发现任何我遗漏的点,或有任何改善的建议,欢迎在 twitter 告诉我!另外,请记住 Electron 是一个快速发展的框架,所以要确保你阅读的是你当前版本的文档。Electron 的 API 也是更新十分频繁的。
本文涉及多个 Codepen 案例,若想获得更佳体验,请到 凹凸实验室博客 阅读,谢谢。
三维计算机图形和二维计算机图形的不同之处在于计算机存储了几何数据的三维表示,其用于计算和绘制最终的二维图像。——《3D computer graphics》
随着 WebGL 标准的快速推进,越来越多团队尝试在浏览器上推出可交互的 3D 作品。相较于二维场景,它更能为用户带来真实和沉浸的体验。
然而 OpenGL 和 WebGL(基于 OpenGL ES) 都比较复杂,Three.js 则更适合初学者。本文将分享一些 Three.js 的基础知识,希望能让你能有所收获。
当然,分享的知识点也不会面面俱到,想更深入的学习,还得靠大家多看多实践。另外,为了控制篇幅,本文更倾向于通过案例中的代码和注释进行阐述一些细节。
若想系统学习,笔者认为看书是一个不错的选择:
Three.js开发指南(原书第2版) 购买链接>>
尽管由于 Three.js 的不断迭代,书本上的某些 API 已改变(或弃用),甚至难免还有一些错误,但这些并不影响整体的阅读。
如引言中说道,3D 图像在计算机中最终以 2D 图像呈现。因此,渲染模式只是作为一个载体。下面我们用 JavaScript(无依赖) 在 Canvas 2D 渲染一个在正视图/透视图中的立方体。
正视图中的立方体:
See the Pen 3D Orthographic View by SitePoint (@SitePoint) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>透视图中的立方体:
See the Pen 3D Perspective View by SitePoint (@SitePoint) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>若要将三维图形渲染在二维屏幕上,需要将三维坐标以某种方式转为二维坐标。但对于更复杂的场景,大量坐标的转换和阴影等耗性能操作无疑需要 Web 提供更高效的渲染模式。
另外,想了解上述两个案例的实现原理,可查看译文:《用 JavaScript 构建一个3D引擎》。
WebGL(Web Graphics Library)在 GPU 中运行。因此需要使用能够在 GPU 上运行的代码。这样的代码需要提供成对的方法(其中一个叫顶点着色器, 另一个叫片段着色器),并且使用一种类 C/C++ 的强类型语言 GLSL(OpenGL Shading Language)。 每一对方法组合起来称为一个 program(着色程序)。
顶点着色器的作用是计算顶点的位置。根据计算出的一系列顶点位置,WebGL 可以对点、线和三角形在内的一些图元进行光栅化处理。当对这些图元进行光栅化处理时需要使用片段着色器方法。片段着色器的作用是计算出当前绘制图元中每个像素的颜色值。
用 WebGL 绘制一个三角形:
See the Pen WebGL - Fundamentals by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>查看上述案例的代码实现后,我们发现绘制一个看似简单的三角形其实并不简单,它需要我们学习更多额外的知识。
因此,对于刚入门的开发者来说,直接使用 WebGL 来绘制并拼装出几何体是不现实的。但我们可以在了解 WebGL 的基础知识后,再通过 Three.js 这类封装后的库来现实我们的需求。
打开 Three.js 官方文档 并阅览左侧的目录,发现该文档对初学者并不友好。但相对于其他资料,它提供了最新的 API 说明,尽管有些描述并不详细(甚至需要在懂 WebGL 等其他知识的前提下,才能了解某个术语的意思)。下面提供两个 Three.js 的相关图片资料,希望它们能让你对 Three.js 有个整体的认识:
Three.js 文档结构:图片来自>>
Three.js 核心对象结构和基本的渲染流程:图片来自>>
我们先通过一个简单但完整的案例来了解 Three.js 的基本使用:
// 引入 Three.js 库
<script src="https://unpkg.com/three"></script>
function init () {
// 获取浏览器窗口的宽高,后续会用
var width = window.innerWidth
var height = window.innerHeight
// 创建一个场景
var scene = new THREE.Scene()
// 创建一个具有透视效果的摄像机
var camera = new THREE.PerspectiveCamera(45, width / height, 0.1, 800)
// 设置摄像机位置,并将其朝向场景中心
camera.position.x = 10
camera.position.y = 10
camera.position.z = 30
camera.lookAt(scene.position)
// 创建一个 WebGL 渲染器,Three.js 还提供 <canvas>, <svg>, CSS3D 渲染器。
var renderer = new THREE.WebGLRenderer()
// 设置渲染器的清除颜色(即背景色)和尺寸。
// 若想用 body 作为背景,则可以不设置 clearColor,然后在创建渲染器时设置 alpha: true,即 new THREE.WebGLRenderer({ alpha: true })
renderer.setClearColor(0xffffff)
renderer.setSize(width, height)
// 创建一个长宽高均为 4 个单位长度的立方体(几何体)
var cubeGeometry = new THREE.BoxGeometry(4, 4, 4)
// 创建材质(该材质不受光源影响)
var cubeMaterial = new THREE.MeshBasicMaterial({
color: 0xff0000
})
// 创建一个立方体网格(mesh):将材质包裹在几何体上
var cube = new THREE.Mesh(cubeGeometry, cubeMaterial)
// 设置网格的位置
cube.position.x = 0
cube.position.y = -2
cube.position.z = 0
// 将立方体网格加入到场景中
scene.add(cube)
// 将渲染器的输出(此处是 canvas 元素)插入到 body 中
document.body.appendChild(renderer.domElement)
// 渲染,即摄像机拍下此刻的场景
renderer.render(scene, camera)
}
init()
在线案例:
See the Pen threejs-blog-01-hello-world by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>看完上述案例代码后,你可能会产生以下几个疑问:
下面我们逐一回答:
答:Three.js 基于 OpenGL,那我们从 OpenGL 文档看到这么一句话:
"The preceding paragraph mentions inches and millimeters - do these really have anything to do with OpenGL? The answer is, in a word, no. The projection and other transformations are inherently unitless. If you want to think of the near and far clipping planes as located at 1.0 and 20.0 meters, inches, kilometers, or leagues, it's up to you. The only rule is that you have to use a consistent unit of measurement. Then the resulting image is drawn to scale." ——《OpenGL Programming Guide》
中文:前面段落提及的英寸和毫米真的和 OpenGL 有关系吗?没有。投影和其它变换在本质上都是无单位的。如果你想把近距离和远距离的裁剪平面分别放置在 1.0 和 20.0 米/英寸/千米/里格,这取决于你。这里唯一的要求是你必须使用统一的测量单位,然后按比例绘制最终图像。
答:Three.js 的坐标系是遵循右手坐标系,如下图:
右手坐标系
坐标系的原点在画布中心(canvas.width / 2, canvas.height / 2)。我们可以通过 Three.js 提供的 THREE.AxisHelper() 辅助方法将坐标系可视化。
RGB颜色分别代表 XYZ 轴:
See the Pen threejs-blog-02-axis by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>另外,补充一点:对于旋转 cube.rotation 正值是逆时针旋转,负值是顺时针旋转。
答: THREE.PerspectiveCamera(fov, aspect, near, far) 具有 4 个参数,具体解释如下:
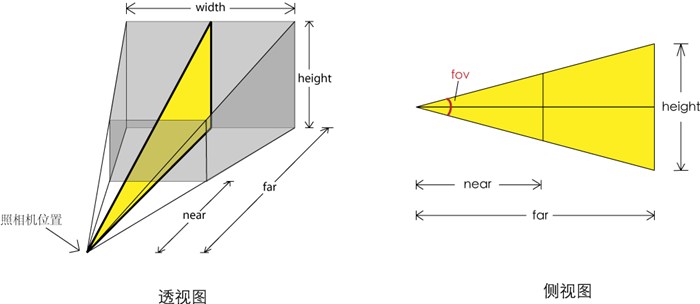
透视图中,灰色的部分是视景体,是可能被渲染的物体所在的区域。
Three.js 还提供了其他 3 种摄像机:CubeCamera、OrthographicCamera、StereoCamera。
其中 OrthographicCamera 是正交投影摄像机,他不具有透视效果,即物体的大小不受远近距离的影响。
切换正交投影摄像机和透视摄像机:
See the Pen switchCamera by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>答:Mesh 好比一个包装工,它将『可视化的材质』粘合在一个『数学世界里的几何体』上,形成一个『可添加到场景的对象』。
当然,创建的材质和几何体可以多次使用(若需要)。而且,包装工不止一种,还有 Points(点集)、Line(线/虚线) 等。
同一个几何体的多种表现形式:
See the Pen multi-appearance by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>从 Three.js 文档目录的 Geometries 可看到,Three.js 已为我们提供了很多现成的几何体,但如果对几何知识不常接触,可能就很难从它的英文名字联想到其实际的形状。下面我们将它们一次性罗列出来:
Three.js 提供的 18 个几何体:
See the Pen all-the-geometry by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>目前 Three.js 一共提供了 22 个 Geometry,除了 EdgesGeometry、ExtrudeGeometry、TextGeometry、WireframeGeometry,上面涵盖 18 个,它们分别是底层的 planeGeometry 和以下 17 种(顺序与上述案例一一对应,下同):
| BoxGeometry(长方体) | CircleGeometry(圆形) | ConeGeometry(圆锥体) | CylinderGeometry(圆柱体) |
|---|---|---|---|
| DodecahedronGeometry(十二面体) | IcosahedronGeometry(二十面体) | LatheGeometry(让任意曲线绕 y 轴旋转生成一个形状,如花瓶) | OctahedronGeometry(八面体) |
| ParametricGeometry(根据参数生成形状) | PolyhedronGeometry(多面体) | RingGeometry(环形) | ShapeGeometry(二维形状) |
| SphereGeometry(球体) | TetrahedronGeometry(四面体) | TorusGeometry(圆环体) | TorusKnotGeometry(换面纽结体) |
| TubeGeometry(管道) | \ | \ | \ |
剩余的 TextGeometry、EdgesGeometry、WireframeGeometry、ExtrudeGeometry 我们单独拿出来解释:
See the Pen the-remaining-geomtry by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>| / | TextGeometry | / |
|---|---|---|
| EdgesGeometry | WireframeGeometry | ExtrudeGeometry |
如案例所示,EdgesGeometry 和 WireframeGeometry 更多地可能作为辅助功能去查看几何体的边和线框(三角形图元)。
ExtrudeGeometry 则是按照指定参数将一个二维图形沿 z 轴拉伸出一个三维图形。
TextGeometry 则需要从外部加载特定格式的字体文件(可在 typeface.js 网站上进行转换)进行渲染,其内部依然使用 ExtrudeGeometry 对字体进行拉伸,从而形成三维字体。另外,该类字体的本质是一系列类似 SVG 的指令。所以,字体越简单(如直线越多),就越容易被正确渲染。
以上就是目前 Three.js 提供的几何体,当然,这些几何体的形状也不仅于此,通过改变参数即能生成更多种类的形状,如 THREE.CircleGeometry 可生成扇形。
另外,通过 console.log 查看任意一个 geometry 对象可发现,在 Three.js 中的几何体基本上是三维空间中的点集(即顶点)和这些顶点连接起来的面组成的。以立方体为例(widthSegments、heightSegments、depthSegments 均为 1 时):
对于 Three.js 提供的几何体,我们不需要自己定义这些几何体的顶点和面,只需提供 API 指定的参数即可(如长方体的长宽高)。当然,你仍然可以通过定义顶点和面来创建自定义的几何体。如:
var vertices = [
new THREE.Vector3(1, 3, 1),
new THREE.Vector3(1, 3, -1),
new THREE.Vector3(1, -1, 1),
new THREE.Vector3(1, -1, -1),
new THREE.Vector3(-1, 3, -1),
new THREE.Vector3(-1, 3, 1),
new THREE.Vector3(-1, -1, -1),
new THREE.Vector3(-1, -1, 1)
]
var faces = [
new THREE.Face3(0, 2, 1),
new THREE.Face3(2, 3, 1),
new THREE.Face3(4, 6, 5),
new THREE.Face3(6, 7, 5),
new THREE.Face3(4, 5, 1),
new THREE.Face3(5, 0, 1),
new THREE.Face3(7, 6, 2),
new THREE.Face3(6, 3, 2),
new THREE.Face3(5, 7, 0),
new THREE.Face3(7, 2, 0),
new THREE.Face3(1, 3, 4),
new THREE.Face3(3, 6, 4)
]
var geometry = new THREE.Geometry()
geometry.vertices = vertices
geometry.faces = faces
geomtry.computeFaceNormals()
上述代码需要注意的点有:
geometry.verticesNeedUpdate = true。更多关于需要主动设置变量来开启更新的事项,可查看官方文档的 How to update things。我们从文档目录中竟然发现有 Audio 音频对象,为什么 Three.js 不是游戏引擎,却带个音频组件呢?原来这个音频也是 3D 的,它会受到摄像机的距离影响:
我们可以到 官方案例 亲自体验一下 Audio 的效果。
在 Three.js 的官方案例中,你几乎都能看到左右上角的两个常驻控件,它们分别是:JavaScript 性能监测器 stats.js 和可视化调参插件 dat.GUI。
stats.js 为开发者提供了易用的性能监测功能,它目前支持四种模式:

dat.GUI 为开发者提供了可视化调参的面板,对参数调整的操作提供了极大的便利。
关于这两个插件的使用,请查看他们的官方文档或 Three.js 官方案例中的代码。
window.addEventListener('resize', onResize, false)
function onResize () {
// 设置透视摄像机的长宽比
camera.aspect = window.innerWidth / window.innerHeight
// 摄像机的 position 和 target 是自动更新的,而 fov、aspect、near、far 的修改则需要重新计算投影矩阵(projection matrix)
camera.updateProjectionMatrix()
// 设置渲染器输出的 canvas 的大小
renderer.setSize(window.innerWidth, window.innerHeight)
}
阴影是增强三维场景效果的重要因素,但 Three.js 出于性能考虑,默认关闭阴影。下面我们来看看如何开启阴影的。
renderer.shadowMap.enabled = true
// 并不是所有类型的光源能产生投影,不能产生投影的光源有:环境光(AmbientLight)、半球光(HemisphereLight)
spotLight.castShadow = true
// 平面和立方体都能接受阴影
plane.receiveShadow = true
cube.receiveShadow = true
// 球体的阴影可以投射到平面和球体上
sphere.castShadow = true
// 更改渲染器的投影类型,默认值是 THREE.PCFShadowMap
renderer.shadowMap.type = THREE.PCFSoftShadowMap
// 更改光源的阴影质量,默认值是 512
spotLight.shadow.mapSize.width = 1024
spotLight.shadow.mapSize.height = 1024
产生阴影:
See the Pen shadow by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>雾化效果是指:场景中的物体离摄像机越远就会变得越模糊。
目前,Three.js 提供两种雾化效果:
// Fog( hex, near, far ),线性雾化。
// near 表示哪里开始应用雾化效果(摄像机为 0)
// far 表示哪里的雾化浓度为 1。若某物体在该距离后,则其表现为雾的颜色。当雾的颜色和渲染器的背景色相同时,则表现为消失(实为颜色相同)。
scene.fog = new THREE.Fog( 0xffffff, 0.015, 100 )
// FogExp2( hex, density ),指数雾化
// density 是雾化强度
scene.fog = new THREE.FogExp2( 0xffffff, 0.01 )
// 雾化效果默认是全局影响的,若某个材质不受雾化效果影响,则可为材质的 fog 属性设置为 false(默认值 true)
var material = new THREE.Material({
fog: false
})
查看不同位置的立方体:
See the Pen fog by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>其实,对于前端开发来说,能做到用代码实现就要尽量不用外部加载的图片(纹理)来装饰物体就最好了。对于前面提及的几何体,其实只要发挥我们的创意,就能将不起眼的它们变得有魅力,如 Low Poly。
圣诞树:
See the Pen Step Five by Matt Agar (@agar) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>更多关于 Low Poly 风格的案例和学习资料:
CSS3 有一个 backface-visibility 属性,它指定当元素背面朝向用户时,该元素是否可见。因为元素背面的背景颜色是透明的,所以当其可见时,就会显示元素正面的镜像。
而在 Three.js 中,材质默认只应用在正面(THREE.FrontSide),即当你旋转物体(或摄像机)查看物体的背面时,它会因为未被应用材质而变得透明(即效果与 CSS3 backface-visibility: hidden 一样)。因此,当你想让物体正反两面均应用材质,则需要在创建材质时声明 side 属性为 THREE.DoubleSide:
var material = new THREE.MeshBasicMaterial({
side: THREE.DoubleSide // 其他值:THREE.FrontSide(默认值)、THREE.BackSide
})
当然,为几何体正反两面均应用材质时,会让渲染器做更多工作,从而影响性能。同理,对于 CSS3,若对动画性能有更高的追求,则可以尝试显示地为 transform 动画元素设置其背面不可见 backface-visibility: hidden;,这样也许能提高性能。
可你是否见过或想到过这样的一个应用场景:
3D 看房
当你旋转时,面向用户的墙都会变得透明,从而实现 360 度查看房子内部结构的效果。
剔除外部立方体正面:
See the Pen Face culling by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>上述案例会实时剔除外层立方体的正面,从而保证其内部可见。
这里其实涉及到 OpenGL 的 Face culling 的知识点。出于性能的考虑,Three.js 默认开启 Face culling 特性,且将剔除模式设置为 CullFaceBack(默认值),这样就可剔除对于观察者不可见的反面 。
因此,当我们将剔除模式设置为 CullFaceFront(剔除正面) 时,就会发生以上效果。一切看起来都是这么自然。其实仔细想想,就会发现有点不对劲。
side: THREE.BackSide 或 THREE.DoubleSide),那它不应该也是不可见的吗?关于 OpenGL 的 Face culling 更多知识,可阅读:《Learn OpenGL》。
对于粒子化效果,相信大家都不陌生。前段时间的 《腾讯的 UP2017》 就是应用 Three.js 实现粒子化效果的精彩案例。
对于 Three.js,实现粒子效果的方法有两种:THREE.Sprite( material ) 和 THREE.Points( geometry, material )。而且这两者都会一直面向摄像机(无论你旋转摄像机还是设置粒子的 rotation 属性)。
下面基于 THREE.Sprite 实现一个简单的 10 x 10 粒子效果(可拖拽旋转):
See the Pen sprite by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>当粒子数量较小时,一般不会存在性能问题。但随着数量的增长,就会很快遇到性能瓶颈。此时,使用 THREE.Points 更为合适。因为 Three.js 不再需要管理大量 THREE.Sprite 对象,而只需管理一个 THREE.Points 对象。
下面我们用 THREE.Points 实现上一个案例的效果:
See the Pen points by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>从上述两个案例可看到,粒子默认形状是正方形。若想改变它的形状,则需要用到纹理。样式化粒子的纹理一般有两种方式:加载外部图片和 Canvas 2D 画布。
Canvas 2D 画布:
See the Pen points-canvas by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>加载外部图片:
See the Pen points-img by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>上一个案例中,我们加载了两个不同的纹理。由于 THREE.Points 的局限性(一个材质只能对应一种纹理),若想添加多个纹理,则需要创建相应个数的 THREE.Points 实例,而 THREE.Sprite 在此方面显得更灵活一些。
上述粒子效果都是我们手动设置各个粒子的具体位置,若想将特定形状通过粒子效果显示,则可以直接将该几何体(geometry)传入 THREE.Points( geometry, material ) 的第一个参数即可。
See the Pen points-models by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>鼠标作为 PC 端(移动端中的触摸)的主要交互方式,我们经常会通过它来选择页面上的元素。而对于 Three.js,它没有类似 DOM 的层级关系,并且处于三维环境中,那么我们则需要通过以下方式来判断某对象是否被选中。
function onDocumentMouseDown(event) {
var vector = new THREE.Vector3(( event.clientX / window.innerWidth ) * 2 - 1, -( event.clientY / window.innerHeight ) * 2 + 1, 0.5);
vector = vector.unproject(camera);
var raycaster = new THREE.Raycaster(camera.position, vector.sub(camera.position).normalize());
var intersects = raycaster.intersectObjects([sphere, cylinder, cube]);
if (intersects.length > 0) {
console.log(intersects[0]);
intersects[0].object.material.transparent = true;
intersects[0].object.material.opacity = 0.1;
}
}
当点击鼠标时,上述代码会发生以下处理:
上述最后一步会返回包含了所有被光线照射到的对象信息的数组(根据距离摄像机距离,由短到长排序)。数组的子项的信息包括有:
distance: 49.90470
face: THREE.Face3
faceIndex: 4
object: THREE.Mesh
point: THREE.Vector3
点击物体后改变其透明度:
See the Pen mouse-select by Jc (@JChehe) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>最后,乱七八糟地整理了自己最近学 Three.js 的相关知识,其中难免出现一些自己理解不透彻,甚至是错误的观点,希望大家能积极提出来。当然,笔者也会捉紧学习,不断完善文章。希望大家多多关注 凹凸实验室。感谢~👏
URI 是否短小且容易输入
在表示的信息量相同的情况下,使用短小、简单的表述方式更易于理解和记忆,并能减少输入时的错误。
案例
http://api.example.com/service/api/search
=>
http://api.example.com/search
URI 是否能让人一眼看懂
即使没有其他提示,也能理解其用途。
能将某个 URI 非常容易地修改为另一个 URI
服务器端的处理均在服务器内部完成,而无需用户费心
案例
// 直观地看到 12345 是 item 的 ID,因此便于修改
http://api.example.com/v1/items/12345
// 极端案例
1~3000 http://api.example.com/v1/items/alpah/:id
4000~6000 http://api.example.com/v1/items/beta/:id
URI 是否反映了服务器端的架构
规则统一的 URI
指 URI 所用的词汇和结构等。
案例:①查询字符串与URI路径 ②单复数
http://api.example.com/friends?id=100
http://api.example.com/friend/100/message
=>
http://api.example.com/friends/100
http://api.example.com/friends/100/message
有没有使用合适的 HTTP 方法
| 方法名 | 说明 |
|---|---|
| GET | 获取资源 |
| POST | 新增资源 |
| PUT | 更新已有资源 |
| DELETE | 删除资源 |
| PATCH | 更新部分资源 |
| HEAD | 获取资源的元信息 |
表示获取信息。一般不会修改服务器上的已有资源(当然,已读/未读、最后访问日期等资源会因为 GET 操作而自我更新,属于例外)。
用于向服务器注册新建的资源,如新用户注册、发布新的博文等。
用于更新资源。PUT 会用发送的资源完全替换原有的资源信息。如果只是更新资源的某部分数据,可以使用 PATCH。
用于删除指定的资源。
用于更新原有资源中的部分信息。
使用连接符来连接多个单词
为什么是连字符(-)而不是下划线等呢?因为 URI 的主机名(域名)允许使用连字符而禁止使用下划线,且不区分大小写。其次点字符具有特殊含义。
其实最好的方法是尽量避免在 URI 中使用多个单词。比如,不用 popular_users,而用 users/popular,或者用查询字符串的方式。
分页的设计是否恰当
① 获取数据量和获取位置的查询参数: 通过 per_page=50&page=3 或 limit=50&offset=100 组合。page 一般从1开始计数,offet 则从 0 开始计数。但这种使用相对位置的方法存在以下几个问题:(1) 性能问题(为了获取第2302条开始的数据,也需要从首条数据开发计数) (2) 如果数据更新的频率很高,会导致当前获取的数据出现一定的偏差(如数据重复)。
② 使用绝对位置来获取数据。如“某个 ID 之前”或“某个日期之前”等条件。
登录有没有使用 OAuth 2.0
响应数据格式有没有使用 JSON 作为默认格式
越来越多公司只支持 JSON,而不支持 XML。
是否支持通过查询参数来指定数据格式
若希望支持或者必须支持其他数据格式,则通过查询参数(推荐键值为 format)来指定。
是否支持不必要的 JSONP
通过查询参数 callback 指定回调函数名字,另外由于 JSONP 是 JavaScript 而不是 JSON, Content-type 不是 application/json,而使用 application/javascript。
使用 JSONP 最大的问题在于服务器返回错误时无法正确应对。当返回错误的状态码(400等)时,script 元素就会终止脚本的载入。换言之,如果在处理 JSONP 时发生错误,返回了 4、5 字头的状态码,客户端方面就完全无法知晓当前发生了什么。
于是在使用 JSONP 时,即便发生了错误,也要求服务器依旧返回 200 这样的状态码,并在响应体里显示具体的错误内容。
案例——将原本置于首部的状态码等信息放到消息体里进行处理。
{
status_code: 404,
error_message: 'User Not Found'
}
http://api.example.com/v1/users/12345?fields=name,age
{} 部分在 JavaScript 语言里会被解释器识别为语法块(block),因此其中单独的部分并不符合正确的语法(user: {})。{
"errors": [
{
"messages": "Bad Authentication data",
"code": 215
}
]
}
另外,对于“详细的错误代码”是指 API 提供者针对各个错误自定义的代码。这些代码的清单应该和 API 一起以联机文档的方式提供。对于这个代码,建议和 HTTP 状态码一样,如用4位数表示,1字头表示通用错误,2字头表示用户信息错误等。
另外,有时会在错误的提示信息里同时包含面向非开发人员的信息和面向开发人员的信息。
{
"errors": {
"developerMessage": "面向开发人员的信息",
"userMessage": "面向用户的信息",
"code": 2013,
"info": "http://docs.example.com/api/v1/authentication"
}
}
通过首位数字即可了解状态的大概含义
| 状态码 | 含义 |
|---|---|
| 1字头 | 消息 |
| 2字头 | 成功 |
| 3字头 | 重定向 |
| 4字头 | 客户端原因引起的错误 |
| 5字头 | 服务器端原因引起的错误 |
主要的 HTTP 状态码
| 状态码 | 名称 | 说明 |
|---|---|---|
| 200 | OK | 请求成功 |
| 201 | Created | 请求成功,新的资源已创建。这也就是 POST 的场景。在数据库的数据表里添加了新的项目等场景中,都可以返回 201。 |
| 202 | Accepted | 请求成功。在异步处理客户端请求时,它用来表示服务器端已接受了来自客户端的请求,但处理尚未结束。在文件转换、处理远程通知,如(Apple Push Notification)这类很耗时的场景中,如果等所有处理都结束后才向客户端返回响应消息,就会花费相当长的时间。这时所采用的方法是服务器端向客户端返回一次响应消息,随后立即开始异步处理。202 状态码就被用于告知客户端:服务器端已开始处理请求,但整个处理过程尚未结束。 |
| 204 | No Conent | 没有内容。当响应信息为空时会返回该状态码 |
| 300 | Multiple Choices | 存在多个资源 |
| 301 | Moved Permanently | 资源被永久转移 |
| 302 | Found | 请求的资源被暂时转移 |
| 303 | See Other | 引用它处 |
| 304 | Not Modified | 自上一次访问后没有发生更新 |
| 307 | Teamporary Redirect | 请求的资源被暂时转移 |
| 400 | Bad Request | 请求不正确 |
| 401 | Unauthorized | 需要认证 |
| 403 | Forbidden | 禁止访问 |
| 404 | Not Found | 没有找到指定的资源 |
| 405 | Method Not Allowed | 无法使用指定的方法 |
| 406 | Not Acceptable | 同 Accept 相关联的首部里含有无法处理的内容。API 不支持客户端指定的数据格式时服务器端所返回的状态码。比如只支持 JSON 和 XML 输出的 API 被指定返回 YAML 的数据格式时,服务器端就会返回 406 状态码。HTTP 协议一般通过 Accept 请求首部来指定数据格式,但 API 里有时会用其他方式来指定。 |
| 408 | Request Timeout | 请求在规定时间内没有处理结束。当客户端发送请求至服务器所需的时间过长时,就会触发服务器端的超时处理。 |
| 409 | Conflict | 资源存在冲突。在使用邮箱地址及 FackBook ID 等信息进行新用户注册时,如果该邮箱地址或 ID 已被其他用户注册,就会引起冲突。 |
| 410 | Gone | 指定的资源已不存在。与 404 同表示资源不存在。但 410 还进一步表示该资源曾经存在但目前已经消失了。但这会让客户端知道服务器端知道不必要的信息。 |
| 413 | Request Entity Too Large | 请求消息体太大 |
| 414 | Request-URI Too Long | 请求的 URI 太长 |
| 415 | Unsupported Media Type | 不支持所指定的媒体类型 |
| 429 | Too Many Requests | 请求次数过多 |
| 500 | Internal Server Error | 服务器端发生错误 |
| 503 | Service Unavailable | 服务器暂时停止运行 |
对于爱好生成艺术的人来说,Vera Molnár 是他们的灵感来源。因为她是最早创作数字艺术的人之一,并且作品十分引人注目。在本教程中,我们将仿造她的作品之一——一二三。
毫无疑问,我们将使用几乎称为“标准”的初始化代码,即获取用于绘制的 canvas 和上下文 context,同时设置 canvas 的尺寸大小。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;为 context 设置一些变量。前两行是指定线的粗细和样式。后两行是指定遍历 canvas 次数和用于绘制效果的变量。
context.lineWidth = 4;
context.lineCap = 'round';
var step = 20;
var aThirdOfHeight = size/3;定义用于绘制的函数,其接收 x & y 坐标、width & height 和数组类型的 positions。其中,positions 是指定所绘制线的位置。
function draw(x, y, width, height, positions) {
context.save();
context.translate(x, y)
for(var i = 0; i <= positions.length; i++) {
context.beginPath();
context.moveTo(positions[i] * width, 0);
context.lineTo(positions[i] * width, height);
context.stroke();
}
context.restore();
}这里将使用 context.translate 方法来移动 canvas 的坐标系,然后再结合传入的 positions 参数,进而设置线的位置。
for( var y = step; y < size - step; y += step) {
for( var x = step; x < size - step; x+= step ) {
draw(x, y, step, step, [0.5]);
}
}现在每个方块的中间都绘制了一个细线(译者注:二层嵌套循环形成一个方块)。但若要复制 Vera 的作品,我们还要变得更复杂一些。这就用到了先前定义的 aThirdOfHeight 变量,使得可在方块内绘制 2 或 3 条线。
if( y < aThirdOfHeight) {
draw(x, y, step, step, [0.5]);
} else if ( y < aThirdOfHeight * 2) {
draw(x, y, step, step, [0.2, 0.8]);
} else {
draw(x, y, step, step, [0.1, 0.5, 0.9]);
}真棒!沿着页面向下,以一、二、三的区间逐步增加复杂性。剩下的工作就是添加随机旋转角度的魔法。使用 context.rotate(Math.random() * 5) 得到随机旋转角度值。当然,首先要改变 translate 位移值,以确保旋转中心在每个方块的中心。
context.translate(x + width/2, y + height/2)
context.rotate(Math.random() * 5);
context.translate(-width/2, -height/2)漂亮!这就拥有了《一二三》效果。如果你想探索更多可能性,可以尝试大于 3 行的效果,甚至是赋予颜色。记住,生成艺术的乐趣在于添加更多更能性和创造性,直至让自己都为之惊叹。
原文:Leaf Notes – An Interactive Web Toy
在浏览器上体验 https://tendril.ca/
我最近为多伦多的设计动画工作室 Tendril 推出了一个可互动的 Web 小玩具。你可以在其 官网首页 亲自体验。该网站会轮流展示数个不同的 Web 玩具,所以可能需要刷新一到两次才能看到它。
<iframe src="https://player.vimeo.com/video/261147357" width="640" height="367" frameborder="0" allowfullscreen></iframe>玩法非常简单:用鼠标划过植物就能使它们开花,并发出相应音调。
该项目十分有趣,我对目前结果也非常满意。Twitter 和 Instagram 上的热烈反应使我备受鼓舞,其中最让我暖心的是一位年仅四岁的小孩在平板上进行了体验。
本文将阐述我与优秀团队 Tendril 如何创造这个 Web 玩具,并讨论期间遇到的一些技术挑战。
在前一段时间,Tendril 已在其官网推出了独具一格的交互动画(案例:1、2)。他们想让我创造一种全新的体验,且要体现生殖生长和程序化几何。
译者注:
生殖生长:当植物生长到一定时期以后,便开始分化形成花芽,以后开花、授粉、受精、结果(实),形成种子。——百度百科
程序化几何:通过程序生成的几何图形。
Tendril 先前的一个 Web 玩具
这个想法十分开放:为 Tendril 官网开发一个可互动的有趣玩具。它与已有的 Web 玩具共存,所以设计要适中、使用要简单、加载速度要快。总的来说:交互方式要轻易上手,整体体验要与 Tendril 的网站一致。
一个充满创作自由的想法对我来说可是一个挑战。在过去几个月里,我一直逼自己在开发前进行更多的搜索、头脑风暴、艺术指导和设计思考和构思。我发现铅笔和笔记本确实是最好的工具,不过像 Pinterest 和 Behance 这类平台则有助于管理参考文献和寻找灵感来源。
在讨论了几个不同想法后,我们选定了“与热带植物交互”的这个方向。
早期 情绪板
我早期的情绪板更倾向于单色而鲜明的视觉方向。这些信息反映出了项目在迭代开发中的变化区间。
💡相关说明:我希望有一个开源工具能将一组图片生成砌体结构风格的情绪板。虽然 InVision Boards 的用户体验很棒,但它是一个付费服务。
早期程序化生化的植物几何体 Canvas2D 原型
最初,我使用 Canvas2D 的线来进行植物结构的原型设计。这无疑是快速验证想法和几何实现的好方法,因为这无需关心 WebGL 和 GPU 的复杂性。
我使用了简单的线段和二次贝塞尔曲线建立了植物的程序结构。二次贝塞尔曲线如下图所示,它由起点、控制点和终点构成。
使用简单的基本图形和参数函数(如线、曲线)能让事情变得更可控,如动画、GPU 的快速渲染、鼠标的碰撞检测、甚至是声音设计等。例如:定义变量 t,它是 [0, 1] 区间的数字,然后使用参数函数高效地计算出该值所代表的 2D 点。
为每棵植物定义一个起点(如屏幕边界)和一个终点(如接近屏幕中点的某个位置)。然后,再放置一个稍微偏离两端点间中点的控制点,以形成一种弯曲植物茎的感觉。
为生成叶子,需按固定间隔遍历曲线,确定每个位置上的垂直法向量,并使用一些函数对法向量进行缩放 & 旋转操作,最终形成像“羽毛”一样的叶子。在最终案例中,我并未使用垂直法向量,而是使用了斜接的法向量(mitered normal)【译者注:mitered normal 翻译有误】。
我提取部分代码到以下 Canvas2D 案例中,你可以在 这里 查看/修改。点击以下案例可修改曲线结构。
在 2D 原型设计阶段,我犯了两个错误。在后续原型设计中应尽量避免:
在几何植物的顶点上使用简单的弹簧效果,而不是使用复杂且 CPU 密集型的物理系统。这使得植物看起来有点像果冻,但不失为一个有趣好玩的互动。
对植物茎和叶子上的顶点,我都指定了 target(即顶点应该弹向的目标位置)、position(即顶点的实时位置)和 velocity(速度和运动方向)。基础物理系统的伪代码如下:
// 1. 为速度 velocity 添加鼠标力
if (鼠标足够靠近顶点) {
velocity += mouseVelocity * mouseStrength;
}
// 2. 弹向目标位置
const delta = target - position;
velocity += delta * spring;
// 一直存在的且不变的“空气阻力”
velocity *= friction;
// 累加得出顶点位置
position += velocity;以下是顶点弹簧效果的交互案例,它展示了如何让二次贝塞尔曲线与鼠标产生弹簧的效果。尝试一下案例吧,也可以 点击这里 阅读完整代码:
对于碰撞,我使用了 point within radius 模块判断顶点是否与鼠标发生碰撞。该碰撞检测的运算速度很快,但并非完美:叶子上存在部分“盲点”,即不会产于交互。为了在划动叶子时产生更精确的声音效果,我在小树叶上使用 point to line segment distance 进行碰撞检测。使用后者能产生更佳的互动体验,但在最终案例中,较大的鼠标半径和较多的植物数量使得难以发现两者差异。
尽管 Canvas2D 能很好地完成原型阶段的处理,但却不能胜任诸如逐像素着色的工作。
感谢 ThreeJs 及其 OrthographicCamera,它们使得所有 canvas 代码迁移至 WebGL 变得不会太难。每根植物茎由一个 PlaneGeometry(可复用)和一个自定义顶点着色器(vertex shader)组成。顶点着色器将平面几何段(plane segments)沿曲线(或线段,即植物茎或叶子)放置。
译者注:OrthographicCamera:正交相机,即镜头下所有东西均不会产生近大远小的透视效果,尺寸保持一致。
可通过我之前编写的笔记 《2D Quadratic Curves on the GPU》 了解更多该技术相关的知识点。通过该方法能生成每棵植物所需的曲线和线段。最终效果如下:
在顶点着色器中,我添加了参数函数,以实现沿 t 弧长变化的线宽。例如:thickness = sin(t * PI) 会压缩曲线的开始和结束部分。有了这些函数,平面几何的轮廓开始变得更像锥形叶子。
最后,添加颜色和外观细节——每片叶子在亮度、色相、饱和度、叶脉密度和旋转角度等方面均有了细微变化。所有这些计算均在片段着色器(fragment shader)完成。例如:每片叶子的叶脉和中线是基于纹理坐标计算得到的,并使用 fwidth() 计算出抗齿锯 2~3 像素的平滑曲线。
在开发期间,我使用 dat.gui 作为可视化滑块,并使用 surge.sh 与团队的其他成员共享迭代。这些工具使得我们能够尝试许多不同的想法和方向。而这种开发迭代的方式也让我们能想出一些有趣的特性:直到项目后期我们才引入了在黑色“手绘”状态下添加动画的想法(译者注:此句原文为:it wasn’t until later in the project that we introduced the idea of animating plants in from a black “hand-drawn” state)。
为了让项目更加生意盎然,我在小细节上花费了许多时间。实际上,叶子的核心结构和弹簧般的交互效果是最简单的部分,而大部分时间则花在了提升视觉效果、制作动画和修复各种跨浏览器问题上。
部分细节如下:
和一般交互式 Web 项目一样,项目的最后阶段通常需要小调整,以确保能在各类浏览器和设备上顺利运行。
对此,我使用了几个过去用于处理常见跨浏览器问题的模块,如用于统一鼠标和触摸事件的 touches 和兼容 iOS WebAudio 的 web-audio-player。
还有其他一些浏览器问题,以下是我处理的方案:
setTimeout 不能及时触发回调函数。因此,我认为它是不精确的,而且我也不可能为此等待 2~3 秒之久。于是选择 timeout-raf 修复它。audioContext.resume()。window.innerWidth 值。为了修复该问题,我最终为 canvas 设置 position:fixed 且宽高 100% 的样式。感谢 Tendril 团队,名单如下:
本文和交互案例的源码均可在以下链接找到:
try {
// 可能会导致错误的代码
} catch (err) {
// 在错误发生时怎么处理
} finally {
// 无论是否报错都会执行
}try-catch 是针对可能抛出错误代码,避免因报错而中断整体代码的运行。
try 不能单独使用,必须搭配 catch 或 finally 使用。
当 try 代码块内抛出错误时,则从该代码行起后续代码将不会执行(当前代码块),直接进入 catch。若 try 没有抛出错误,则会跳过 catch。
当 try 代码块内抛出错误时,但未定义 catch,即只定义了 finally,那么仍会中断整体代码的运行。
throw语句用来抛出一个用户自定义的异常。当前函数的执行将被停止(throw之后的语句将不会执行),并且控制权将被传递到调用堆栈中的第一个catch块。如果调用者函数中没有catch块,程序将会终止。
延伸:return throw new Error() 是错误的语法
Uncaught SyntaxError: Illegal return statement。MDN 上return [[expression]];return 后面接的是表达式而不是语句,而 throw 是语句。另外,throw 本身也会中断当前代码块后续代码的运行。
无论是否抛出异常 finally 子句都会执行。即使没有 catch 子句处理异常。
当发生异常时,可以使用 finally 子句使您的脚本以更优雅的方式处理错误的情况。例如,释放已经绑定的资源等。
openMyFile()
try {
// tie up a resource
writeMyFile(theData)
}
finally {
closeMyFile() // always close the resource
}try 可以嵌套,当内部 try 没有对应的 catch,则抛出的错误被最近且有定义 catch 的上层所捕获。
try {
console.log(1)
throw new Error('err')
} finally {
console.log(2)
}
// 由于未定义 catch,抛出的错误会导致中断整体代码的运行
// 另外,这里的输出是:1 2 Error。至于 finally 为何先于 try 抛出的 Error,目前笔者没有深入考究。假如以上代码块的 finally 也抛出错误,即如下:
try {
console.log(1)
throw new Error('a')
} finally {
throw new Error('b')
console.log(2)
}
// 那么输出 1 Error('b')。即 finally 里抛出的错误已经导致整体流程的中断(或取代了 Error('a'))。function test () {
try {
console.log(1);
return 'from_try';
} catch (e) {
// TODO
} finally {
console.log(2);
}
}
console.log(test()); // 1 2 from_try从以上输出结果可看出,return 与上一小节 throw 情况类似,即 finally 优先于 try 的 throw 和 return。
function test () {
try {
console.log(1)
return 'from_try'
} catch (e) {
// TODO
} finally {
console.log(2)
return 'from_finally'
}
}
console.log(test()); // 1 2 from_finally同上,与上一小节 throw 情况类似,finally 的 return 优先于(或取代了) try 的 return(上一小节是 throw)。
function test () {
try {
console.log(1);
throw new Error('from_try')
} catch (e) {
console.log(e.message)
return 'from_catch'
} finally {
console.log(2)
}
}
console.log(test()) // 1 from_try 2 from_catch从以上结果可看出,try 和 catch 的 return 都需要先经过 finally,与 throw 类似。
将 return 改为 throw 进行验证:
function test () {
try {
console.log(1)
throw new Error('from_try')
} catch (e) {
console.log(e.message)
throw new Error('from_catch')
} finally {
console.log(2)
}
}
test() // 1 from_try 2 from_catch可见,throw 与 return 对代码执行流程的控制是一样的。
外链:https://www.jianshu.com/p/f4cca5ce055a
是指一个程序运行所需内存的空间大小,利用程序的空间复杂度可以对程序运行所需要的内存大多少有个预估判断。一个程序的执行除了存储空间和存储本身所使用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为现实计算所需信息的辅助空间。程序执行时所需存储空间包括两部分:
原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
代码(注:实例代码主要体现算法思路,不进行验证等额外操作):
function bucketSort(arr) {
const buckets = []
const result = []
const max = Math.max(...arr)
// 初始化每个桶为 0
for (let i = 0; i <= max; i++) {
buckets[i] = 0
}
// 计数
for (let i = 0; i <= max; i++) {
buckets[arr[i]] += 1
}
// 根据每个桶的次数进行输出
for (let i = 0; i <= max; i++) {
const bucket = buckets[i]
for (let j = 0; j < bucket; j++) {
result.push(i)
}
}
return result
}
let arr = [2, 3, 1, 2, 4, 8]
console.log(bucketSort(arr))基本**:每次比较两个相邻元素,如果它们的顺序错误则把对它们进行交换。若有 n 个数进行排序,只需将 n-1 个数归位。也就是说要进行 n-1 趟操作。而每趟都需要从第 1 位开始进行相邻两个数的比较,将较小(大)的数往后挪一位,两两比较与挪位,直至最后一个尚未归位的数。
代码:
function bubbleSort(arr, direction = 1) {
let didSwap = false // 若未发生交换,则直接判定为排序完成
for (let i = 0; i < arr.length - 1; i++) {
didSwap = false
for (let j = 0; j < arr.length - i; j++) {
let curVal = arr[j]
let nextVal = arr[j + 1]
if (curVal < nextVal) {
arr[j] = nextVal
arr[j + 1] = curVal
didSwap = true
}
}
if (!didSwap) {
return
}
}
}快排之所以比冒泡快,是因为每次交换都是跳跃式的。每次排序的时候设置一个基准点,将小于或等于基准点的数全部放到基准点的左边,将大于或等于基准点的数全部放到基准点的右边。由于总的比较次数与交换次数较少,速度自然就提高了。当然,最坏情况下,仍可能是相邻的两个数进行交换。快速排序是基于“二分”的**。
代码:
function quickSort(arr, left, right) {
if (left > right) {
return
}
let temp = arr[left]
let i = left
let j = right
while (i !== j) {
// 顺序很重要,要从右往左找
while (arr[j] >= temp && i < j) {
j--
}
// 再从左往右找
while (arr[i] <= temp && i < j) {
i++
}
// 当哨兵i和哨兵j没有相遇时,交换两个数在数组中的位置
if (i < j) {
let t = arr[i]
arr[i] = arr[j]
arr[j] = t
}
}
// 将基准数归位
arr[left] = arr[i]
arr[i] = temp
quickSort(arr, left, i - 1) // 继续处理左边,这是一个递归的过程
quickSort(arr, i + 1, right) // 继续处理右边,这是一个递归的过程
}
const arr = [1, 5, 8, 4, 2, 10]
quickSort(arr, 0, arr.length - 1)队列是一种特殊的线性结构,它只允许在队列的首部(head)进行删除操作,称为“出队”,在队列的尾部(tail)进行插入操作,称为“入队”。当队列中没有元素时(即head==tail),称为空队列。即遵循“先进先出”(First In First Out)原则。
数据结构
struct queue {
int data[100]; // 队列的主体,用于存储内容
int head; // 队首
int tail; // 队尾
}栈限定为只能在一端进行插入和删除操作的数据结构。
栈的实现只需要一个一维数组和一个指向栈顶的变量 top。我们通过 top 来对栈进行插入和删除操作。
案例:回文。
回文:正读反读均相同的字符序列。
判断是否是回文:将当前栈中的字符依次出栈,看看是否与 mid 之后的字符一一匹配。
栈还可以用来进行验证括号的匹配。
采用暴力枚举的时候也需要仔细分析问题,我们只是将枚举 C 改为通过 A + B 来算出 C,就将 O(N^3) 的算法优化到了 O(N^2)。
关健在于解决“当下该如何做”。至于“下一步如何做”则与“当下该如何做”是一样的。
深度优先搜索的基本模型:
void dfs(int step) {
判断边界
尝试每一种可能 for (i = 0; i < n; i++) {
继续下一步 dfs(step + 1)
}
返回
}以某个点为源点对其邻近的点进行着色。
问:地图红有多少个独立的小岛?
答:只需对地图上的每个大于 0 的点都进行一遍深度优先搜索即可。其实这就是求一个图中独立子图的个数。这个算法就是鼎鼎大名的 Floodfill 漫水填充法(也称种子填充法)。
Floodfill 在计算机图形学中有着非常广泛的应用,比如图像分割、物体识别等等。实际应用:Windows 的“画图”软件的油漆桶工具、Photoshop 魔法棒选择工具等。
图的存储
图的邻接矩阵存储法:数组中第 i 行第 j 列表示的就是顶点 i 到顶点 j 是否有边。1 表示有边,∞ 表示没有边,这里我们将自己到自己(即 i 等于 j)设为 0。该二维数组沿主对角线对称,因为这个图是无向图。
图的邻接矩阵存储法
深度优先遍历的主要**:首先以一个未被访问过的顶点作为起始点,沿当前顶点的边做到未访问过的顶点;当没有未访问过的顶点时,则回到上一个顶点,继续试探访问别的顶点,直到所有顶点都被访问过。
广度优先遍历的主要**:首先以一个未被访问过的顶点作为起始点,访问其所有相邻的顶点,然后对每个相邻的顶点,再访问它们相邻的未被访问过的顶点,直到所有顶点都被访问过,遍历结束。
树和图的区别?
树其实就是不包含回路的连通无向图。
树的特性:
术语:
树的应用场景:足球世界杯的晋级图、家族的族谱图、公司的组织结构图、书的目录、操作系统(Windows、Linux、Mac)的目录。
二叉树:每个结点最多有两个子结点。
满二叉树:一棵深度为 h 且有 2^h - 1 个结点的二叉树。二叉树中每个内部结点都有两个子结点。所有叶结点均有同样的深度。
完全二叉树:若设二叉树的高度为 h,除第 h 层外,其他各层(1~h-1)的结点都达到最大个数,第 h 层从右向左连续缺若干个结点。也就是说如果一个结点有右子结点,那么它一定也有左子结点。
原文链接:《A Complete Guide to Grid》
Grid 是 CSS 目前最强的布局系统。与 flexbox 这类一维系统不同,它是二维系统,能同时处理行与列。Grid 布局需要对父元素(作为 Grid 容器)及其子元素(作为 Grid 子项)应用 CSS。
CSS Grid Layout(简称“Grid”) 是一个基于网格的二维布局系统,旨在完全改变基于网格设计的用户界面。CSS 一直被用于 Web 页面布局,却从未很好地解决这个问题。在一开始,我们使用 table,然后使用 float、position 和 inline-block。但所有这些方法本质都是 Hack,并落下了很多重要的功能(如垂直居中)。Flexbox 在一定程度上解决了这些问题,但其主要针对的是一维布局,对于复杂的二维布局则显得力不从心(当然 Flexbox 与 Grid 结合使用效果更佳)。Grid 是首个专门用于解决布局问题而创建的 CSS 模块。
有两个主要因素驱动我编写这篇教程。第一个是 Rachel Andrew 的书 《Get Ready for CSS Grid Layout》,该书清晰且彻底地介绍了 Grid,这也是本文的基础。我强烈推荐你购买阅读此书。另一个重要因素是 Chris Coyier 的 《A Complete Guide to Flexbox》,这是我查阅所有关于 Flexbox 知识的地方,它也帮助了很多开发者,在 Google 关键词 "Flebox" 当之无愧地排名第一 。你也将会发现本文与它有很多相似之处,这难道不应该向最佳榜样学习吗?
本文的意图是介绍最新规范中的 Grid 概念。因此,我不会覆盖过时的 IE 语法,并尽最大努力紧跟规范并更新本文。
首先需要通过 display: grid 定义 Grid 的容器元素,然后设置行与列的尺寸 grid-template-rows 与 grid-template-columns,最后通过 grid-row 与 grid-column 将子元素放置在 grid 中。与 Flexbox 类似,grid 子项的编写顺序与实际顺序并不是绝对一致的,通过 CSS 即可将子元素以任意顺序摆放,结合媒介查询语句调整子项顺序就变得轻而易举了。想象一下:对于整个页面的布局,只需数行 CSS 即可针对不同屏幕宽度进行重排。Grid 无疑是 CSS 有史以来最强大的模块之一。
截止 2017 年 3 月,大部分浏览器兼容了无浏览器内核标识前缀的原生 Grid 语法,其中包括 Chrome(含 Android)、Firefox、Safari(含 iOS)和 Opera。而 Internet Explorer 10 与 11 则以过时的语法实现老旧规范。Edge 已宣布支持,但目前还未真正实现。
浏览器的兼容性来自于 Caniuse,它提供了更详细的数据。数字代表浏览器从该版本起支持该特性。
| Chrome: 57 | Opera: 44 | Firefox: 52 | IE: 11* | Edge: 16 | Safari: 10.1 |
|---|
| iOS Safari: 10.3 | Opera Mobile: No | Opera Mini: No | Android: 62 | Android: 62 | Android Firefox: 57 |
|---|
除了 Microsoft,其余浏览器厂家都等到规范成熟后再实现标准规范。这无疑是一件好事,因为这意味着我们不必兼顾多种语法。
在生产环境中使用 Grid 只是时间问题,但是现在正是学习它的时候了。
在深入学习 Grid 概念前,理解术语是关键的。由于这里涉及的术语在概念上较为相似,如果不先记住它们在 Grid 规范中的定义,则很容易彼此混淆。但不必因此而担心,因为它们并不多。
应用 display: grid 的元素。它是所有 Grid 子项的直接父元素。下面案例中,container 是 Grid 容器。
<div class="container">
<div class="item item-1"></div>
<div class="item item-2"></div>
<div class="item item-3"></div>
</div>
Grid 容器的直系子元素。item 元素是 Grid 子项,但 sub-item 不是。
<div class="container">
<div class="item"></div>
<div class="item">
<p class="sub-item">
</div>
<div class="item"></div>
</div>
构成 Grid 结构的分界线。它们要不垂直(“Grid 列”),要不水平(“Grid 行”),彼此交叉或平行。下图黄线就是 Grid 列。
相邻 Grid 线之间的空间。你可以认为它们是 Grid 的行或列。下图是第二条与第三条水平 Grid 线之间的 Grid 轨道。
相邻行与相邻列同时围住的空间。这是 Grid 的一个“单元”。下图中第一二行和第二三列围住的空间就是 Grid 单元格。
由四条 Grid 线围住的空间。一个 Grid 区域可由任意个 Grid 单元格组成。下图中的 Grid Area 由第一三行与第一三列围成。
将元素定义为 Grid 容器,即为其内容建立一个新的 Grid 格式上下文(grid formatting context)。
取值:
.container {
display: grid | inline-grid | subgrid;
}
注意:column、float、clear 和 vertical-align 对 Grid 容器无效。
使用空格符分隔的值列表指定网格的行和列。这些值表示轨道的大小,即相邻 Grid line 之间的空间。
取值:
<track-size> :可以是长度值、百分比或 Grid 剩余空间的占比(使用 fr 单位)<line-name>:可填写任意名字.container {
grid-template-columns: <track-size> ... | <line-name> <track-size> ...;
grid-template-rows: <track-size> ... | <line-name> <track-size> ...;
}
案例:
当轨道值之间只有一个空白字符时,Grid 线会被自动分配数字类型的名字:
.container {
grid-template-columns: 40px 50px auto 50px 40px;
grid-template-row: 25% 100px auot;
}
但你可以明确指定 Grid 线的名字。注意 Grid 线名字的括号语法:
.container {
grid-template-columns: [first] 40px [line2] 50px [line3] auto [col4-start] 50px [five] 40px [end];
grid-template-rows: [row1-start] 25% [row1-end] 100px [third-line] auto [last-line];
}
需要注意的是:可以为 Grid 线指定多个名字。例如,下面的第二条 Grid 线就拥有两个名字:row1-end 和 row2-start:
.container {
grid-template-rows: [row1-start] 25% [row1-end row2-start] 25% [row2-end];
}
如果值有重复部分,可以使用 repeat() 让值变得精简:
.container {
grid-template-columns: repeat(3, 20px [col-start]) 5%;
}
fr 单位能让我们根据 Grid 容器剩余空间的比例设置轨道大小。例如,设置每个 Grid 子项占 Grid 容器的 1/3。
.container {
grid-template-columns: 1fr 1fr 1fr;
}
剩余空间即减去非伸缩 Grid 子项后的空间。例如下面案例的总可利用剩余空间是减去 50px 后的:
.container {
grid-template-columns: 1fr 50px 1fr 1fr;
}
通过引用 Grid 区域名字定义 Grid 模板,而 Grid 区域通过 grid-area 属性指定。多个 Grid 区域名字则代表内容跨越多个 Grid 单元格。而 . 则代表一个空 Grid 单元格。而语法本身则提供了可视化的 Grid 结构。
取值:
<grid-area-name>:通过 grid-area 属性指定的 Grid 区域名字。.:指定空 Grid 单元格.container {
grid-template-areas: "<grid-area-name> | . | none | ..."
"...";
}
案例:
.item-a {
grid-area: header;
}
.item-b {
grid-area: main;
}
.item-c {
grid-area: sidebar;
}
.item-d {
grid-area: footer;
}
.container {
grid-template-columns: 50px 50px 50px 50px;
grid-template-rows: auto;
grid-template-areas:
"header header header header"
"main main . sidebar"
"footer footer footer footer";
}
这将会创建一个 3 行 x 4 列的 Grid。整个顶行由 header 区域组成。中间行由两个 main 区域、一个空单元格和一个 sidebar 区域组成。底行是整个 footer。
声明中的每行需要拥有相同数量的单元格。
你可以使用任意数量无间距的 . 去声明一个空单元格。因为多个 . 之间无空格时则仍表示为一个单元格。
注意,该语法并没有命名 Grid 线,只是命名了区域。其实,当使用该语法时,区域各端的边界线都是自动命名的。如果 Grid 区域的名字为 foo,那么该区域的起始行和起始列将会被命名为 foo-start,相应地,其最后一行和最后一列将会被命名为 foo-end。这就意味着线可能拥有多个名字,例如上述案例中的最左侧线拥有了 header-start、main-start 和 footer-start 三个名字。
是 grid-template-rows、grid-template-columns 和 grid-template-areas 的简写。
取值:
grid-template-rows 和 grid-template-columns 为 subgrid,而 grid-template-areas 为默认值<grid-template-rows> / <grid-template-columns>:分别设置 grid-template-rows 和 [grid-template-columns] 为指定值,而 grid-template-areas 为 none.container {
grid-template: none | subgrid | <grid-template-rows> / <grid-template-columns>;
}
它还接受一个更复杂但非常便捷的语法来指定三个属性。例如:
.container {
grid-template:
[row1-start] "header header header" 25px [row1-end]
[row2-start] "footer footer footer" 25px [row2-end]
/ auto 50px auto;
}
这等同于:
.container {
grid-template-rows: [row1-start] 25px [row1-end row2-start] 25px [row2-end];
grid-template-columns: auto 50px auto;
grid-template-areas:
"header header header"
"footer footer footer";
}
grid-template 不会重置隐式 Grid 属性(grid-auto-columns、grid-auto-rows 和 grid-auto-flow),因为这可能满足你大多数情况的需要,但还是建议你使用 grid 属性,而不是 grid-template。
指定 Grid 线的粗细。你可以把它想象成在行/列之间的间隙宽度。
取值:
<line-size>:长度值。.container {
grid-column-gap: <line-size>;
grid-row-gap: <line-size>;
}
案例:
.container {
grid-template-columns: 100px 50px 100px;
grid-template-rows: 80px auto 80px;
grid-column-gap: 10px;
grid-row-gap: 15px;
}
间隙只存在于行/列之间,而不存在于外层边界。
是 grid-row-gap 和 grid-column-gap 的简写。
取值:
<grid-row-gap> <grid-column-gap>:长度值.container {
grid-gap: <grid-row-gap> <grid-column-gap>
}
案例:
.container {
grid-template-columns: 100px 50px 100px;
grid-template-rows: 80px auto 80px;
grid-gap: 10px 15px;
}
若未指定 grid-column-gap,则其值与 grid-row-gap 相同。
定义 Grid 子项内容在行轴的对齐方式(相应地,align-items 定义了在列轴上的对齐方式)。对 Grid 容器内的所有 Grid 子项有效。
取值:
案例:
.container {
justify-items: start;
}
.container {
justify-items: end;
}
.container {
justify-items: center;
}
.container {
justify-items: stretch;
}
可通过 justify-self 属性为某个 Grid 子项单独设置同样的行为。
定义 Grid 子项内容在列轴的对齐方式(相应地,justify-items 定义了在行轴上的对齐方式)。对 Grid 容器内的所有 Grid 子项有效。
取值:
.container {
align-items: start | end | center | stretch;
}
案例:
.container {
align-items: start;
}
.container {
align-items: end;
}
.container {
align-items: center;
}
.container {
align-items: stretch;
}
可通过 align-self 属性为某个 Grid 子项单独设置同样的行为。
当 Grid 子项都以非可伸缩单位(如 px)指定尺寸时,Grid 的实际尺寸可能会小于其 Grid 容器的尺寸。在这种情况下,你可以设置 Grid 在 Grid 容器内的对齐方式。该属性是指定沿行轴上的对齐方式(相应地,align-content 是沿列轴上的对齐方式)。
取值:
.container {
justify-content: start | end | center | stretch | space-around | space-between | space-evenly;
}
案例:
.container {
justify-content: start;
}
.container {
justify-content: end;
}
.container {
justify-content: center;
}
.container {
justify-content: stretch;
}
.container {
justify-content: space-around;
}
.container {
justify-content: space-between;
}
.container {
justify-content: space-evenly;
}
当 Grid 子项都以非可伸缩单位(如 px)指定尺寸时,Grid 的实际尺寸可能会小于其 Grid 容器的尺寸。在这种情况下,你可以设置 Grid 在 Grid 容器内的对齐方式。该属性是指定沿列轴上的对齐方式(相应地,justify-content 是沿列轴上的对齐方式)。
取值:
.container {
align-content: start | end | center | stretch | space-around | space-between | space-evenly;
}
案例:
.container {
align-content: start;
}
.container {
align-content: end;
}
.container {
align-content: center;
}
.container {
align-content: stretch;
}
.container {
align-content: space-around;
}
.container {
align-content: space-between;
}
.container {
align-content: space-evenly;
}
指定自动生成的 Grid 轨道大小(又称“隐式 Grid 轨道”)。隐式 Grid 轨道会在指定 Grid 子项行列位置超出定义的 Grid 范围时(通过 grid-template-rows 和 grid-template-columns)创建。
取值:
<track-size>:长度值、百分比或 Grid 剩余空间占比(使用 fr 单位)。.container {
grid-auto-columns: <track-size> ...;
grid-auto-rows: <track-size> ...;
}
为了说明隐式 Grid 轨道是如何创建的,请思考一下:
.container {
grid-template-columns: 60px 60px;
grid-template-rows: 90px 90px
}
创建了一个 2x2 的 Grid
但现在假设你使用 grid-row 和 grid-column 指定 Grid 子项:
.item-a {
grid-column: 1 / 2;
grid-row: 2 / 3;
}
.item-b {
grid-column: 5 / 6;
grid-row: 2 / 3;
}
我们告诉 .item-b 在第五列开始,并在第六列结束,但我们并未定义第五和第六列。因为我们引用的列并不存在,所以会以宽度为 0 的隐式轨道填充缺口。我们可以使用 grid-auto-rows 和 grid-auto-columns 指定这些隐式轨道的宽度:
.container {
grid-auto-columns: 60px;
}
当有 Grid 子项未在 Grid 中明确设置位置时,自动放置算法(auto-placement-algorithm)会自动将其放置在相应位置。所以该属性是控制自动放置算法的工作方式。
取值:
.container {
grid-auto-flow: row | column | row dense | column dense
}
需要注意的是,dense 可能会导致子项乱序。
案例:
考虑以下 HTML:
<section class="container">
<div class="item-a">item-a</div>
<div class="item-b">item-b</div>
<div class="item-c">item-c</div>
<div class="item-d">item-d</div>
<div class="item-e">item-e</div>
</section>
定义一个二行五列的 Grid,并设置 grid-auto-flow 为 row(默认值):
.container {
display: grid;
grid-template-columns: 60px 60px 60px 60px 60px;
grid-template-rows: 30px 30px;
grid-auto-flow: row;
}
只指定两个 Grid 子项:
.item-a {
grid-column: 1;
grid-row: 1 / 3;
}
.item-e {
grid-column: 5;
grid-row: 1 / 3;
}
由于 grid-auto-flow 设置为 row,Grid 看起来如下图。未被显示定位的三个子项(item-b、item-c 和 item-d)会横向流动在空余行空间:
如果将 grid-auto-flow 设置为 column,item-b、item-c 和 item-d 会沿空余列空间向下流动:
.container {
display: grid;
grid-template-columns: 60px 60px 60px 60px 60px;
grid-template-rows: 30px 30px;
grid-auto-flow: column;
}
是 grid-template-rows、grid-template-columns、grid-template-areas、grid-auto-rows、grid-auto-columns 和 grid-auto-flow 的简写。它会将 grid-row-gap 和 grid-column-gap 设为初始值,尽管不能通过该属性明确设置它们。
取值:
<grid-template-rows> / <grid-template-columns>:分别设置 grid-template-rows 和 grid-template-columns 为指定值。其余子属性均为初始值<grid-auto-flow> [<grid-auto-rows> / <grid-auto-columns>]:分别指定 grid-auto-flow、grid-auto-rows、grid-auto-columns 三个属性。如果 grid-auto-columns 缺省,则其值为 grid-auto-rows 的值。如果两者均缺省,则均为初始值。.container {
grid: none | <grid-template-rows> / <grid-template-columns> | <grid-auto-flow> [<grid-auto-rows> [/ <grid-auto-columns>]];
}
案例:
下面两段代码是等价的:
.container {
grid: 200px auto / 1fr auto 1fr;
}
.container {
grid-template-rows: 200px auto;
grid-template-columns: 1fr auto 1fr;
grid-template-areas: none;
}
下面两段代码也是等价的:
.container {
grid: column 1fr / auto;
}
.container {
grid-auto-flow: column;
grid-auto-rows: 1fr;
grid-auto-columns: auto;
}
它还可以接受一次性设置所有子属性的语法,复杂却便捷。指定 grid-template-areas、grid-template-rows 和 grid-template-columns 值时,其余子属性均被设置相应的初始值。你需要做的是:行内指定 Grid 线名字、轨道大小和各自 Grid 区域。最简单的说明案例:
.container {
grid: [row1-start] "header header header" 1fr [row1-end]
[row2-start] "footer footer footer" 25px [row2-end]
/ auto 50px auto;
}
等同于:
.container {
grid-template-areas:
"header header header"
"footer footer footer";
grid-template-rows: [row1-start] 1fr [row1-end row2-start] 25px [row2-end];
grid-template-columns: auto 50px auto;
}
通过引用特定的 Grid 线来确定 Grid 子项在 Grid 内的位置。grid-column-start / grid-row-start 指定了 Grid 子项的起始线,grid-column-end / grid-row-end 指定了 Grid 子项的结束线。
取值:
<line>:数字引用已编号的 Grid 线,名字引用已命名的 Grid 线span <number>:该子项会跨越 <number> 个 Grid 轨道span <name>:该子项会跨越至 <name> Grid 线auto:表示自动放置,自动跨越或默认跨度为 1.item {
grid-column-start: <number> | <name> | span <number> | span <name> | auto
grid-column-end: <number> | <name> | span <number> | span <name> | auto
grid-row-start: <number> | <name> | span <number> | span <name> | auto
grid-row-end: <number> | <name> | span <number> | span <name> | auto
}
案例:
.item-a {
grid-column-start: 2;
grid-column-end: five;
grid-row-start: row1-start;
grid-row-end: 3;
}
.item-b {
grid-column-start: 1;
grid-column-end: span col4-start;
grid-row-start: 2
grid-row-end: span 2
}
如果未声明 grid-column-end / grid-row-end,Grid 子项会默认跨越一个轨道。
Grid 子项会相互覆盖,这时可通过 z-index 控制它们的层叠顺序。
分别是 grid-column-start + grid-column-end 和 grid-row-start + grid-row-end 的简写。
取值:
<start-line> / <end-lune>:各自取值与非简写时一致,也就包括 span.item {
grid-column: <start-line> / <end-line> | <start-line> / span <value>;
grid-row: <start-line> / <end-line> | <start-line> / span <value>;
}
案例:
.item-c {
grid-column: 3 / span 2;
grid-row: third-line / 4;
}
若未声明结束线(end line),则 Grid 子项默认跨度为 1。
通过赋予 Grid 子项名字,引用 grid-template-areas 属性创建的模板。另外,该属性可用作 grid-row-start + grid-column-start + grid-row-end + grid-column-end 的简写。
取值:
<name>:你选择的名字<grid-start> / <column-start> / <row-end> / <column-end>:代表线的数值或名字.item {
grid-area: <name> | <row-start> / <column-start> / <row-end> / <column-end>;
}
案例:
为 Grid 子项分配名字:
.item-d {
grid-area: header
}
作为 grid-row-start + grid-column-start + grid-row-end + grid-column-end 的简写:
.item-d {
grid-area: 1 / col4-start / last-line / 6
}
设置 Grid 子项沿行轴的对齐方式(相应地,align-self 沿列轴)。该属性值仅对当前子项有效。
取值:
.item {
justify-self: start | end | center | stretch;
}
案例:
.item-a {
justify-self: start;
}
.item-a {
justify-self: end;
}
.item-a {
justify-self: center;
}
.item-a {
justify-self: stretch;
}
要对 Grid 内所有子项设置沿行轴的对齐方式,可对 Grid 容器设置 justify-items 属性。
设置 Grid 子项沿列轴的对齐方式(相应地,align-self 沿行轴)。该属性值仅对当前子项有效。
取值:
.item {
align-self: start | end | center | stretch;
}
案例:
.item-a {
align-self: start;
}
.item-a {
align-self: end;
}
.item-a {
align-self: center;
}
.item-a {
align-self: stretch;
}
要对 Grid 内所有子项设置沿列轴的对齐方式,可对 Grid 容器设置 align-items 属性。
年纪大了,写不动文字笔记了(写到一半)😭。出思维导图,方便自己快速回顾及查阅。
2019.10.25 补充:
Git 2.23.0 (发布于2019.08.16)新增两个实验性命令:
参考地址:《Git 2.23.0: Forget about checkout, and switch to restore.》
本文涉及多个 Codepen 案例,若想获得更佳体验,请到 凹凸实验室博客 阅读,谢谢。
增强现实(Augmented Reality,简称AR):是一种实时地计算摄影机影像的位置及角度并加上相应图像、视频、3D模型的技术,这种技术的目标是在屏幕上把虚拟世界套在现实世界并进行互动。
本文将让你了解“如何通过 Web 技术实现一个简单但有趣的 AR 效果”。
正如文章开头说道:AR 是将真实环境与虚拟物体实时地叠加到一个画面。因此我们需要通过摄像头实时获取真实环境,并通过识别算法识别与分析真实环境中特定的物体,然后结合得到的数据,将虚拟物体以某种方式结合到画面中。
结合我们的案例,可得出以下步骤:
下面我们就根据以上步骤逐点分析。
不依赖 Flash 或 Silverlight,我们使用 navigator.getUserMedia() API,该 API 允许 web 应用获取用户的摄像头与麦克风流(stream)。
<!-- 若不加 autoplay,则会停留在第一帧 -->
<video autoplay></video>
navigator.getUserMedia = navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia ||
navigator.msGetUserMedia;
var video = document.querySelector('video');
var constraints = {
video: true
}
function successCallback(stream) {
// 此处利用该 window.URL 对象的 createObjectURL 方法将 blob 转为 url。
if (window.URL) {
video.src = window.URL.createObjectURL(stream); // 用来创建 video 可以播放的 src
} else {
video.src = stream;
}
}
function errorCallback(error) {
console.log('navigator.getUserMedia error: ', error);
}
if (navigator.getUserMedia) {
navigator.getUserMedia({video: true}, successCallback, errorCallback);
} else {
console.log('getUserMedia() is not supported in your browser')
video.src = 'somevideo.webm'; // fallback.
}上述 API 已不被推荐,建议使用新标准 API:navigator.mediaDevices.getUserMedia()。
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
/* use the stream */
}).catch(function(err) {
/* handle the error */
});另外,可通过 constraints 参数设置以下选项:
目前 IOS 设备的微信和 Safari 均不支持,较新的安卓和桌面端浏览器均支持。
另外,出于安全问题考虑,Chrome 只支持 HTTPS 页面启用摄像头。因此,我们可以用 Firefox,或者借助一些线上编辑器,如 jsbin、jsFiddle 等进行开发测试。
得到视频源后,我们需要对图像中的物体(本案例是 Marker)进行实时识别。下面提供两个可实现识别的库:
正如其名,它们是 aruco 和 artoolkit 的 JavaScript 版本。本文仅对第一个库进行介绍。
OpenCV(Open Source Computer Vision Library):是一个跨平台的计算机视觉库。它可用于开发实时的图像处理、计算机视觉以及模式识别程序。
jsaruco 能识别视频每帧画面中的 Marker 位置(含 4 个角坐标)。获取坐标后,我们就能将虚拟物体放在真实环境的适当位置了。关于 jsaruco 的介绍和用法,可到 这里 查看。
对图像的处理,Canvas(WebGL) 无疑是目前 Web 的最佳选择。
虚拟对象若是 2D 的,则直接利用 Canvas 2D API 在相应坐标上进行绘制。若虚拟对象是 3D 的,则可使用 Three.js 或 A-Frame 等 3D 库(当然,你也可以直接用 WebGL)。
如果你对 Three.js 还不了解,可以看看 《Three.js入门指南》。
另外,使用 A-Frame 可让你更快和更轻易地体验到 3D 的乐趣,仅需 10 行代码即可实现 AR,具体可阅读这篇文章 《Augmented Reality in 10 Lines of HTML》。
每个识别库都有其自身的实现方式。因此,一些 Marker 可能只适用于某个库。对于 jsaruco,它对 Marker 的要求如下:
一个 7x7 的正方形,其外层是“不用”的黑边。内部 5x5 单元格则组成了 ID 信息。其中,每行需要遵循以下模式:
white - black - black - black - black
white - black - white - white - white
black - white - black - black - white
black - white - white - white - black
因此,根据上述信息,我们可以得出该库最多可识别 1024(4的5次方) 个 Marker。也就是说:每个 Marker 对应唯一一个 ID,然后我们可以利用 ID 指定显示的虚拟对象。
一个合格的 Marker 应该是这样子:
可通过这个 链接,获取 jsaruco 的更多 Marker。
当然,更先进的图像识别库不仅能识别 Marker,也可以识别你指定的图片,甚至是自然特征跟踪( Natural Feature Tracking)和 SLAM(Simultaneous Localization and Mapping,即时定位与地图构建)。
自然特征跟踪
SLAM
建议使用带有摄像头的电脑体验以下案例(注意不要被自己的头像惊艳到~)。
另外,由于以下案例均未要求特定 ID 的 Marker,因此你可以选择以下 Marker(拍照或打印),或者在 这里 挑选一个进行体验。

Marker
想体验以下案例,需要先对某一个 Marker 拍下或打印,然后将其展示在摄像头前。
另外,为了保持文章的简洁,在此就不直接展示以下案例的实现代码。若需要,则直接查看案例源码。
再次提醒:以下案例均在电脑上进行开发测试,未针对移动端设备进行优化测试。
除了第一个案例,其余均以动画的方式展示虚拟元素。
当你展示团队 Logo 时,链接>>。
当你看到“男神/女神”时,链接>>。
当需要展示某个人的身份信息时,链接>>。
当展示我们的地球母亲时,链接>>。
当展示我们的商品时,链接>>。
由于笔者才疏学浅,实现的案例未必完全符合 AR 的要求。但希望通过本文,让大家能对 Web AR 有一定的了解。
原文:Moving along a curved path in CSS with layered animation
CSS animation 和 transition 均能很好地实现 A 到 B 的过渡,但这仅限于直线运动。无论你如何调整元素的 animation 或 transition 的 贝塞尔曲线(*-timing-function),均不能使其沿曲线运动。当然也包括自定义过渡函数,如弹簧效果。这是因为 X 轴与 Y 轴的相对位移总是相等的。
无疑 JavaScript 能轻易实现曲线运动,但这里有一个简单方法能突破这个限制:分层动画。通过使用两个或以上的元素去驱动一个动画,即对元素的路径进行细粒度的控制,分别为 X 轴和 Y 轴应用不同的过渡函数(*-timing-function)。
See the Pen css-curve-1 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>在深入研究解决方案前,先仔细研究一个问题。CSS animation 和 transition 限制着元素仅能沿直线运动,即总是执行 A 到 B 的最短路径,这很适合大多数情况。但却缺乏一种方式告诉 CSS 应使用“更佳路径”而不是“最短路径”。
在 CSS 中,两点位移过渡的最直接方式是使用 transform 的 translate 属性,但这仅能产生直线运动。在以下 @keyframes 中,元素会在 (0, 0) 和 (100, -100) 间来回移动:
@keyframes straightLine {
50% {
transform: translate3D(100px, -100px, 0);
}
}
.dot {
animation: straightLine 2.5s infinite linear;
}这并不复杂。为了得到问题的解决方案,我们需要将动画进行拆分(至少在视觉上)。
我们从 0% 的 (0, 0) 开始,并在 50% 使用 translate3d(100px, -100px, 0) 将元素位移至 (100, -100),最后原路返回。换一种思考方式,元素分别向右位移 100px 和向上位移 100px,两者一结合就会产生一定角度的直线位移。
See the Pen css-curve-2 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>那么我们如何创建前面案例提及的曲线运动呢?要创建非直线运动,需要为 X 轴与 Y 轴指定不同的运动速度。
前面案例均使用 linear 过渡函数。但这里我们要为元素添加一个父元素,并为父元素 X 轴与 Y 轴分别应用不同的过渡函数。下面将为 X 轴应用 ease-in,为 Y 轴应用 ease-out:
See the Pen css-curve-3 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>不幸的是,CSS 不支持为 transform 叠加多个 animation,否则仅最后声明的 animation 有效。那么我们该如何组合两个 animation 呢?首先,先将一个元素放在另一个元素中,然后对容器元素指定一个 animation,再对子元素指定另一个不同的 animation 即可。
在上述所有曲线运动中,我们均能看到两个分离的元素在运动,而(曲线运动的)容器元素(即父元素)则完全透明。为了能清楚看到两个元素如何结合得到曲线运动,我们为容器元素添加边框:
See the Pen css-curve-4 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>dot 元素是边框元素的子元素。边框元素沿 X 轴水平运动,而 dot 自身沿 Y 轴上下竖直运动。移除父元素的边框后,就可得到我们预期中的曲线运动。利用伪元素则无需在 HTML 中创建两个元素。
译者注:部分移动设备中,animation / transition 对伪元素无效。
假设有以下 HTML 代码:
<div class="dot"></div>那么可以像下面那样添加伪元素:
.dot {
/* Container. Animate along the X-axis */
}
.dot::after {
/* Render dot, and animate along Y-axis */
}然后添加两个独立的 animation 代码块:一个用于 X 轴,一个用于 Y 轴。其中第一个使用 ease-in,第二个使用 ease-out:
.dot {
/* Some layout code… */
animation: xAxis 2.5s infinite ease-in;
}
.dot::after {
/* Render dot */
animation: yAxis 2.5s infinite ease-out;
}
@keyframes xAxis {
50% {
animation-timing-function: ease-in;
transform: translateX(100px);
}
}
@keyframes yAxis {
50% {
animation-timing-function: ease-out;
transform: translateY(-100px);
}
}带上 WebKit 内核前缀,并使用自定义贝塞尔曲线替换 ease-in 和 ease-out,就能得到文章最开始的效果:
.demo-dot {
-webkit-animation: xAxis 2.5s infinite cubic-bezier(0.02, 0.01, 0.21, 1);
animation: xAxis 2.5s infinite cubic-bezier(0.02, 0.01, 0.21, 1);
}
.demo-dot::after {
content: '';
display: block;
width: 20px;
height: 20px;
border-radius: 20px;
background-color: #fff;
-webkit-animation: yAxis 2.5s infinite cubic-bezier(0.3, 0.27, 0.07, 1.64);
animation: yAxis 2.5s infinite cubic-bezier(0.3, 0.27, 0.07, 1.64);
}
@-webkit-keyframes yAxis {
50% {
-webkit-animation-timing-function: cubic-bezier(0.02, 0.01, 0.21, 1);
animation-timing-function: cubic-bezier(0.02, 0.01, 0.21, 1);
-webkit-transform: translateY(-100px);
transform: translateY(-100px);
}
}
@keyframes yAxis {
50% {
-webkit-animation-timing-function: cubic-bezier(0.02, 0.01, 0.21, 1);
animation-timing-function: cubic-bezier(0.02, 0.01, 0.21, 1);
-webkit-transform: translateY(-100px);
transform: translateY(-100px);
}
}
@-webkit-keyframes xAxis {
50% {
-webkit-animation-timing-function: cubic-bezier(0.3, 0.27, 0.07, 1.64);
animation-timing-function: cubic-bezier(0.3, 0.27, 0.07, 1.64);
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}
@keyframes xAxis {
50% {
-webkit-animation-timing-function: cubic-bezier(0.3, 0.27, 0.07, 1.64);
animation-timing-function: cubic-bezier(0.3, 0.27, 0.07, 1.64);
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}这就是文章最开始的效果:
See the Pen css-curve-5 by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>你可能注意到:目前所有案例均使用了 @keyframes 代码块,但这纯粹是因为需要几个关键帧来实现来回移动的动画。换句话说,分层动画也适用于 transition 属性,特别是 A 到 B 的这类动画。
对于绝对定位的元素,你可以通过设置单个元素的 left 和 bottom 属性实现曲线运动,从而避免使用容器元素。但这并不推荐,因为动画的每一帧均会触发重绘,导致性能低下。使用具有伪元素的分层动画,能利用硬件加速的 translate 属性产生漂亮丝滑的动画。
译者基于本文实现了以下效果:
See the Pen css-curve-final by Jc (@JChehe) on CodePen.
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>阅读体验更佳:https://jchehe.gitbook.io/mysql_data_types_cn/
目录(译者注:目录跳转可能无效,请直接搜索文字)
MySQL 支持几种类别的 SQL 数据类型:数值类型、“日期和时间”类型、字符串(字符和字节)类型、空间类型和 JSON 数据类型。本章阐述了每个类别所含类型的属性,以及总结了数据类型的存储要求。
数据类型的描述使用了以下约定:
M 表示最大的显示宽度(display width);对于浮点型(floating-point)和定点型(fixed-point)类型,M 表示可被存储数字的总个数(the precision);对于字符串类型,M 是最大长度。另外,M 的最大允许值取决于具体的数据类型。D 应用于浮点型和定点型,它表示小数点后可存在多少个数字(the scale)。可能的最大值为 30,但不应大于 M-2。fsp 应用于 TIME、DATETIME 和 TIMESTAMP 类型,它表示小数的精度(即毫秒、微秒),即小数点后数字的个数。fsp 的取值范围为 [0, 6],其中 0 表示没有小数。若缺省(即不传递该参数),默认精度为 0(与 SQL 标准的默认值 6 不同,主要为了兼容 MySQL 旧版本)。MySQL 支持 SQL 标准中所有数值数据类型,其中包括精确数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),也包括近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。关键字 INT 是 INTEGER 的代名词,关键字 DEC 和 FIXED 是 DECIMAL 的代名词。MySQL 将 DOUBLE 视为 DOUBLE PRECISION 的代名词(一种非标准扩展)。除非启用 SQL 的 REAL_AS_FLOAT 模式,否则 MySQL 也把 REAL 视为 DOUBLE PRECISION 的代名词(一种非标准变体)。
BIT 数据类型用于存储 bit 值,MyISAM、MEMORY、InnoDB 和 NDB 数据库表支持该数据类型。
关于 MySQL 如何处理超出范围和溢出的数值的更多信息,请查看 “Out-of-Range and Overflow Handling”。
关于数值数据类型的存储要求的信息,请查看 Section 11.7, “Data Type Storage Requirements”。
关于处理数值函数的说明,请查看 Section 12.5, “Numeric Functions and Operators”。数值运算结果的数据类型是取决于运算值的类型及对它们执行的操作。详情请看 Section 12.5.1, “Arithmetic Operators”。
对于整型数据类型,M 表示最大的显示宽度,其最大值为 255。显示宽度与类型可存储的值的范围无关,如 Section 11.1.6, “Numeric Type Attributes” 中所述。
对于浮点型和定点型数据类型,M 表示可存储数字的总个数。
从 MySQL 8.0.17 开始,不建议使用整型数据类型的“显示宽度”属性,并将在未来的 MySQL 版本中移除它。
若为一个数值类型的列指定 ZEROFILL,MySQL 将会为该列自动添加 UNSIGNED 属性。
从 MySQL 8.0.17 开始,不建议使用数值数据类型的 ZEROFILL 属性,并将在未来的 MySQL 版本中移除它。可考虑使用替代方法实现同样的效果。例如,在程序中使用 LPAD() 函数将数字 0 填充至所需宽度,或存储格式化后的数值到 CHAR 类型的列中。
数值数据类型即允许 UNSIGNED 属性,也允许 SIGNED 属性。然而,SIGNED 是默认值,因此 SIGNED 并没有什么用。
从 MySQL 8.0.17 开始,不建议数据类型为 FLOAT、DOUBLE 和 DECIMAL(及它们的代名词)的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
(译者注:UNSIGNED 并不影响它们的取值范围,而是表明该列不接受负数)
SERIAL 是 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE 的别名。
在整型列的定义中, SERIAL DEFAULT VALUE 是 NOT NULL AUTO_INCREMENT UNIQUE 的别名。
注意:当两个整型进行减法运算,且其中一个是 UNSIGNED,则结果是无符号的(unsigned),除非启用 SQL 的 NO_UNSIGNED_SUBTRACTION 模式。详情请看 Section 12.10, “Cast Functions and Operators”。
BIT[(M)]
bit 值类型。M 表示值含有 bit 的数量,取值范围为 [1, 64],默认值为 1(M 缺省时)。
TINYINT[(M)] [UNSIGNED] [ZEROFILL]
微小整型。有符号的取值范围是 [-128, 127],无符号的取值范围是 [0, 255]。
BOOL, BOOLEAN
是 TINYINT(1) 的代名词。值为 0 时表示 false,非零时表示 true:
mysql> SELECT IF(0, 'true', 'false');
+------------------------+
| IF(0, 'true', 'false') |
+------------------------+
| false |
+------------------------+
mysql> SELECT IF(1, 'true', 'false');
+------------------------+
| IF(1, 'true', 'false') |
+------------------------+
| true |
+------------------------+
mysql> SELECT IF(2, 'true', 'false');
+------------------------+
| IF(2, 'true', 'false') |
+------------------------+
| true |
+------------------------+然而,TRUE 和 FALSE 值仅仅分别是 1 和 0 的别名,如下所示:
mysql> SELECT IF(0 = FALSE, 'true', 'false');
+--------------------------------+
| IF(0 = FALSE, 'true', 'false') |
+--------------------------------+
| true |
+--------------------------------+
mysql> SELECT IF(1 = TRUE, 'true', 'false');
+-------------------------------+
| IF(1 = TRUE, 'true', 'false') |
+-------------------------------+
| true |
+-------------------------------+
mysql> SELECT IF(2 = TRUE, 'true', 'false');
+-------------------------------+
| IF(2 = TRUE, 'true', 'false') |
+-------------------------------+
| false |
+-------------------------------+
mysql> SELECT IF(2 = FALSE, 'true', 'false');
+--------------------------------+
| IF(2 = FALSE, 'true', 'false') |
+--------------------------------+
| false |
+--------------------------------+倒数两个语句的执行结果表明,2 既不等于 1 也不等于 0。
SMALLINT[(M)] [UNSIGNED] [ZEROFILL]
小整型。有符号的取值范围是 [-32768, 32767],无符号的取值范围是 [0, 65535]。
MEDIUMINT[(M)] [UNSIGNED] [ZEROFILL]
中整型。有符号的取值范围是 [-8388608, 8388607],无符号的取值范围是 [0, 16777215]。
INT[(M)] [UNSIGNED] [ZEROFILL]
常规尺寸的整型。有符号的取值范围是 [-2147483648, 2147483647],无符号的取值范围是 [0, 4294967295]。
INTEGER[(M)] [UNSIGNED] [ZEROFILL]
INT 的代名词。
BIGINT[(M)] [UNSIGNED] [ZEROFILL]
大整型。有符号的取值范围是 [-9223372036854775808, 9223372036854775807],无符号的取值范围是 [0, 18446744073709551615]。
SERIAL 是 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE 的别名。
关于 BIGINT 列,需要注意以下几点:
所有算术运算都是使用带符号(signed)的 BIGINT 或 DOUBLE 值完成。因此,除位函数(bit function)外,不要使用大于 9223372036854775807(63 bit)的无符号大整型(big integer)!如果这样做,会因为将 BITINT 值转换为 DOUBLE 时的四舍五入错误,导致结果中的最后几位可能出错。
在以下情况下,MySQL 可处理 BIGINT:
向 BIGINT 列存储较大的无符号整数。
在 MIN(col_name) 或 MAX(col_name) 中,其中 col_name 是引用 BIGINT 列。
当使用操作符(+、-、* 等)时,两个操作数均为整型。
你始终可以通过使用字符串将精确的整型值存储在 BIGINT 列中。在这种情况下,MySQL 会执行 string-to-number 的转换,期间不涉及双精度表示形式。
当两个操作数均为整数值时,+、-、* 操作符会使用 BIGINT 进行算术运算。这意味着,如果将两个较大的整数相乘(或函数返回的整数),则当结果大于 9223372036854775807 时,会得到意想不到的结果。
DECIMAL[(M[,D])] [UNSIGNED] [ZEROFILL]
经过包装的“精确”定点数。M 表示数字的总个数(the precision),D 表示小数点后数字的个数(the scale)。其中,M 不包含小数点和负号 -(对于负数)。如果 D 为 0,则值没有小数点(即小数部分)。M(即数字个数)的最大值为 65,D(即小数部分的数字个数)的最大值是 30。D 的默认值为 0(缺省时),M 的默认值是 10(缺省时)。
UNSIGNED 属性表示不接受负值。从 MySQL 8.0.17 开始,不建议 DECIMAL(及其代名词)数据类型的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
DECIMAL 列的所有基础运算(+、-、*、/)均以 65 位数字的精度完成。
DEC[(M[,D])] [UNSIGNED] [ZEROFILL], NUMERIC[(M[,D])] [UNSIGNED] [ZEROFILL], FIXED[(M[,D])] [UNSIGNED] [ZEROFILL]
这些类型均是 DECIMAL 的代名词。其中 FIXED 代名词与其他数据库系统兼容。
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数,其取值范围是 [-3.402823466E+38, -1.175494351E-38]、0、[1.175494351E-38, 3.402823466E+38]。这些是基于 IEEE 标准的理论极限。实际范围可能会略微缩小,这具体取决于你的硬件或操作系统。
M 表示数字总个数,D 表示小数点后的数字个数。若 M 和 D 都缺省,则会将值存储为硬件允许的极限。单精度浮点数的精度约为小数点后 7 位。
FLOAT(M, D) 是非标准的 MySQL 扩展。从 MySQL 8.0.17 开始,不建议使用该句法,并将在未来的 MySQL 版本中移除它。
UNSIGNED 属性表示不接受负值。从 MySQL 8.0.17 开始,不建议 FLOAT(及其代名词)数据类型的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
使用 FLOAT 可能会带来意想不到的问题,因为在 MySQL 中所有计算均以双精度完成的。详情请看 Section B.4.4.7, “Solving Problems with No Matching Rows”。
FLOAT(p) [UNSIGNED] [ZEROFILL]
浮点数。p 表示以 bit 为单位的精度,但 MySQL 仅用此值来确定对最终数据类型是 FLOAT 还是 DOUBLE。若 p 值位于 [0, 24],则数据类型实际为不带 M 和 D 的 FLOAT 类型;若 p 值位于 [25, 53],则数据类型实际为不带 M 和 D 的 DOUBLE 类型。列的最终取值范围与本节前面提到的单精度 FLOAT 和双精度 DOUBLE 数据类型一致。
UNSIGNED 属性表示不接受负值。从 MySQL 8.0.17 开始,不建议 FLOAT(及其代名词) 数据类型的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
提供 FLOAT(p) 句法是为了兼容 ODBC。
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
正常大小的(双精度)浮点数。其取值范围是 [-1.7976931348623157E+308, -2.2250738585072014E-308]、0、[2.2250738585072014E-308, 1.7976931348623157E+308]。这些是基于 IEEE 标准的理论极限。实际范围可能会略微缩小,这具体取决于你的硬件或操作系统。
M 表示总数字个数,D 表示小数点后的数字个数。若 M 和 D 都缺省,则会将值存储为硬件允许的极限。双精度浮点数的精度约为小数点后 15 位。
DOUBLE(M, D) 是非标准的 MySQL 扩展。从 MySQL 8.0.17 开始,不建议使用该句法,并将在未来的 MySQL 版本中移除它。
UNSIGNED 属性表示不接受负值。从 MySQL 8.0.17 开始,不建议 DOUBLE(及其代名词) 数据类型的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
DOUBLE PRECISION[(M,D)] [UNSIGNED] [ZEROFILL], REAL[(M,D)] [UNSIGNED] [ZEROFILL]
两者都是 DOUBLE 的代名词。例外:如果启用 SQL 的 REAL_AS_FLOAT 模式,那么 REAL 是 FLOAT 的代名词,而不是 DOUBLE 的代名词。
MySQL 支持 SQL 标准的整型类型:INTEGER(或 INT)和 SMALLINT。作为标准的扩展,MySQL 也支持这些整型类型:TINYINT、MEDIUMINT 和 BIGINT。以下表格展示了每种整型类型所需的存储空间和取值范围。
Table 11.1 Required Storage and Range for Integer Types Supported by MySQL
| Type | Storage (Bytes) | Minimum Value Signed | Maximum Value Signed | Minimum Value Unsigned | Maximum Value Unsigned |
|---|---|---|---|---|---|
| TINYINT | 1 | -128 | 127 | 0 | 255 |
| SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
| MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
| INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
| BIGINT | 8 | -2^63 | 2^63-1 | 0 | 2^64-1 |
DECIMAL 和 NUMERIC 类型能存储精确的数值数据。这些类型适用于重视精确度的需求,如货币数据。在 MySQL 中,NUMERIC 被实现为 DECIMAL,因此以下有关 DECIMAL 的说明同样适用于 NUMERIC。
MySQL 以二进制格式存储 DECIMAL。详情请看 See Section 12.25, “Precision Math”。
在 DECIMAL 列的声明中,通常都会指定 M(the precision)和 D(the scale)。如:
salary DECIMAL(5, 2)以上案例,M 是 5,D 是 2。M 表示可存储多少个有效数字,D 表示可存储小数点后多少个数字。
SQL 标准要求 DECIMAL(5, 2) 能存储任何由 5 个数字(其中 2 个是小数)组成的数值。因此,salary 列的存储范围是 [-999.99, 999.99]。
在 SQL 标准中,DECIMAL(M) 等同于 DECIMAL(M, 0)。类似地,DECIMAL 等同于 DECIMAL(M, 0),其具体表现则取决于 M 值。MySQL 支持以上 DECIMAL 的两种不同形式,且 M 的默认值为 10。
若 D 为 0,则 DECIMAL 值不包含小数点(或小数部分)。
DECIMAL 支持最多 65 个数字,但 DECIMAL 列的实际存储范围受 M 和 D 的约束。当值的小数部分的数字个数大于指定的 D,则会将小数部分的数字个数限制为 D 个。(这种明确的行为是特定于操作系统,但通常的处理方式为裁剪至 D 长度。【译者注:FLOAT 等近似值数据类型一般采取四舍五入】)
FLOAT 和 DOUBLE 类型表示近似值。MySQL 用 4 字节存储单精度值,用 8 字节存储双精度值。
对于 FLOAT,SQL 标准允许 FLOAT 关键字后的小括号() 内指定一个可选的、以 bit 为单位的精度参数—— FLOAT(p)。MySQL 也支持此可选精度的语法,但该精度参数仅用于确定存储大小。当 p 位于 [0, 23],则该列是 4 字节的单精度 FLOAT 列;当 p 位于 [24, 53],则该列是 8 字节的双精度 DOUBLE 列。
MySQL 支持一种非标准句法:FLOAT(M, D) 或 REAL(M, D) 或 DOUBLE PRECISION(M, D)。在这里,(M, D) 表示值可以最大存储 M 个数字,其中 D 个数字位于小数点后。例如,一个定义为 FLOAT(7, 4) 的列,其值显示为 -999.9999。MySQL 会在存储值时执行四舍五入操作,所以当你插入 999.00009 到 FLOAT(7, 4) 列时,其实际结果为近似值 999.0001。
从 MySQL 8.0.17 开始,不建议使用非标准句法 FLOAT(M, D) 和 DOUBLE(M, D),并将在未来的 MySQL 版本中移除它们。
由于浮点数是近似值,不能作为精确值存储,当将它们视为精确值进行比较时,可能会出现问题。另外,它们还受平台或实现依赖的约束。详情请看 Section B.4.4.8, “Problems with Floating-Point Values”。
为了获得最大可移植性,存储近似值数据时,应使用无 M 和 D 的 FLOAT 或 DOUBLE PRECISION 类型。
BIT 数据类型用于存储 bit 值。BIT(M) 表示可允许存储 M-bit 大小的值。M 的取值范围是 [1, 64]。
要指定 bit 值,可使用 b'value' 表示法。value 是由 0 和 1 组成的二进制值。如:b'111' 和 b'10000000' 分别表示 7 和 128。详情请看 Section 9.1.5, “Bit-Value Literals”。
如果指定的值的长度小于 BIT(M) 列要求的 M 位,则该值会在左侧填充 0。例如,向 BIT(6) 列指定 b'101' 值,实际相当于指定 b'000101'。
NBD 集群。一个 NDB 表中所有 BIT 列的总大小不能超过 4096 bit。
MySQL 支持在整型数据类型后的括号内指定一个可选的显示宽度属性。如:INT(4) 指定 INT 列的显示宽度为 4 个数字。应用程序可使用此可选的显示宽度来显示整型数据,当该数值的宽度小于指定宽度时,会在其左侧填充空格。(也就是说,此宽度存在于返回结果集的元数据中,是否使用该宽度则取决于应用程序。)
显示宽度不会限制值的存储范围,也不会影响比显示宽度长的值的正确显示。例如,数据类型为 SMALLINT(3) 的列,通常其存储范围是 [-32768, 32767],对于大于显示宽度的值也能显示完整。
当同时使用可选(非标准)的 ZEROFILL 属性时,填充左侧的空格将会被替换为 0。例如,数据类型为 INT(4) ZEROFILL 的列,检索值 5 时会得到 0005。
注意:对于表达式或 UNION 查询中涉及的列,会忽略 ZEROFILL 属性。
如果将大于显示宽度的值存储在具有 ZEROFILL 属性的整型列中,则当 MySQL 为某些复杂的联结(join)生成临时表时,你可能会遇到问题。在这种情况下,MySQL 会假定值已满足列的显示宽度。
从 MySQL 8.0.17 开始,不建议数值数据类型使用 ZEROFILL 属性,对于整型数据类型,则不建议使用显示宽度属性,并将在未来的 MySQL 版本中移除整型数据类型的 ZEROFILL 和显示宽度属性。可考虑使用替代方法实现同样的效果。例如,在程序中使用 LPAD() 函数将数字 0 填充至所需宽度,或存储格式化后的数值到 CHAR 类型的列中。
所有整型数据类型均拥有可选的(非标准)UNSIGNED 属性。一个 unsigned 类型可实现非负数的存储,或者你希望拥有更大的数值范围。例如,如果 INT 列是 UNSIGNED 的,虽然范围的长度不变,但端点是往正数方向移动,即从 [-2147483648, 2147483647] 变到 [0, 4294967295]。
浮点型和定点型也可使用 UNSIGNED 属性,和整型一样,unsigned 属性能实现非负数的存储。但与整型不一样的地方是,它并不能改变取值范围,即保持不变。从 MySQL 8.0.17 开始,不建议 FLOAT、DOUBLE 和 DECIMAL(及其代名词) 数据类型的列使用 UNSIGNED 属性,并将在未来的 MySQL 版本中移除它。可考虑对这些列使用简单的 CHECK 进行约束。
若为数值类型的列指定 ZEROFILL,MySQL 则自动为其添加 UNSIGNED 属性。
整型和浮点型数据类型的列可使用 AUTO_INCREMENT 属性。当你向 AUTO_INCREMENT 索引列插入 NULL 值时,该列会将其设为下一个序列值。通常为 value+1,其中 value 是列目前的最大值。(AUTO_INCREMENT 序列从 1 开始。)
向 AUTO_INCREMENT 列存储 0 时,效果和存储 NULL 一样,除非启用 SQL 的 NO_AUTO_VALUE_ON_ZERO 模式。
插入 NULL 以生成 AUTO_INCREMENT 值的前提是该列已声明为 NOT NULL。如果该列声明为 NULL,那么在插入 NULL 时就会存为 NULL。当向 AUTO_INCREMENT 列插入其他值,那么就会直接存储该值,并重置序列值,以使得下次能自动生成以该插入值为起始值的序列值。
AUTO_INCREMENT 列不支持负值。
CHECK 约束不能引用具有 AUTO_INCREMENT 属性的列,也不能将 AUTO_INCREMENT 属性添加到 已使用 CHECK 约束的列。
从 MySQL 8.0.17 开始,不建议为 FLOAT、DOUBLE 列使用 AUTO_INCREMENT,并将在未来的 MySQL 版本中移除它。可考虑移除这些列的 AUTO_INCREMENT 属性,或将它们转为整型。
当 MySQL 向数值类型的列存储超出列数据类型允许范围的值时,处理结果取决于当时的 SQL 模式。
如果启用 SQL 严格模式,MySQL 则按照 SQL 标准处理——以报错的方式拒绝超出范围的值,即插入失败。
如果未启用任何限制模式,MySQL 会将值裁剪为列数据类型取值范围内的相应端点,并作为结果值存储。
当为整型列插入一个超出范围的值时,MySQL 会存储为列数据类型取值范围内的相应端点。
当为浮点型和定点型列插入一个超过指定(或默认)M 和 D 所表示的范围时,MySQL 会存储该取值范围内的相应端点的值。
假设表 t1 定义如下:
CREATE TABLE t1 (i1 TINYINT, i2 TINYINT UNSIGNED);在启用 SQL 严格模式下,会报超出范围的错误:
mysql> SET sql_mode = 'TRADITIONAL';
mysql> INSERT INTO t1 (i1, i2) VALUES(256, 256);
ERROR 1264 (22003): Out of range value for column 'i1' at row 1
mysql> SELECT * FROM t1;
Empty set (0.00 sec)当未启用 SQL 严格模式,会进行裁剪并产生警告(warning):
mysql> SET sql_mode = '';
mysql> INSERT INTO t1 (i1, i2) VALUES(256, 256);
mysql> SHOW WARNINGS;
+---------+------+---------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------+
| Warning | 1264 | Out of range value for column 'i1' at row 1 |
| Warning | 1264 | Out of range value for column 'i2' at row 1 |
+---------+------+---------------------------------------------+
mysql> SELECT * FROM t1;
+------+------+
| i1 | i2 |
+------+------+
| 127 | 255 |
+------+------+如果未启用 SQL 严格模式,列赋值转换(column-assignment conversion)会因裁剪而发生,并会产生警告(warning),以上这些会发生在 ALTER TABLE、LOAD DATA、UPDATE 和多行 INSERT 语句中。在严格模式下,这些语句均会执行失败,并且某些、甚至所有值都不会被插入或更改,这取决于该表是否为事务表或其他一些因素。详情请看 Section 5.1.11, “Server SQL Modes”。
数值表达式求值期间可能会产生溢出而导致错误。例如,有符号 BIGINT 的最大值是 9223372036854775807,则以下表达式会报错:
mysql> SELECT 9223372036854775807 + 1;
ERROR 1690 (22003): BIGINT value is out of range in '(9223372036854775807 + 1)'要想以上表达式顺利运行,需要将值转为无符号:
mysql> SELECT CAST(9223372036854775807 AS UNSIGNED) + 1;
+-------------------------------------------+
| CAST(9223372036854775807 AS UNSIGNED) + 1 |
+-------------------------------------------+
| 9223372036854775808 |
+-------------------------------------------+是否发生溢出是取决于操作数的取值范围,因此处理上面表达式的另一种方法是使用精确算术法,因为 DECIMAL 的取值范围比整型大。
mysql> SELECT 9223372036854775807.0 + 1;
+---------------------------+
| 9223372036854775807.0 + 1 |
+---------------------------+
| 9223372036854775808.0 |
+---------------------------+在整型的减法中,当其中一个操作数是 UNSIGNED,则默认会产生一个 UNSIGNED 结果值。如果结果是负数值,则会报错:
mysql> SET sql_mode = '';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT CAST(0 AS UNSIGNED) - 1;
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(cast(0 as unsigned) - 1)'如果启用 SQL 的 NO_UNSIGNED_SUBTRACTION 模式,则结果为负数:
mysql> SET sql_mode = 'NO_UNSIGNED_SUBTRACTION';
mysql> SELECT CAST(0 AS UNSIGNED) - 1;
+-------------------------+
| CAST(0 AS UNSIGNED) - 1 |
+-------------------------+
| -1 |
+-------------------------+如果将这个表达式的结果值用于更新一个 UNSIGNED 整型列,则会被裁剪为该列数据类型的取值范围的最大值,或当启用 NO_UNSIGNED_SUBTRACTION 时,会裁剪为 0。如果开启 SQL 严格模式,则会报错,且该列的值保持不变。
译者注:
用于表示时间值的“日期和时间”数据类型有:DATE、TIME、DATETIME、TIMESTAMP、YEAR。每个时间类型均拥有各自合法的取值范围,以及一个“零”值,即当你指定一个 MySQL 无法表达的非法值时会被替换为该值。TIMESTAMP 和 DATETIME 数据类型拥有特殊的自动更新能力。详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
关于时间值的存储要求,请看 Section 11.7, “Data Type Storage Requirements”。
关于对时间值进行运算的函数说明,请看 Section 12.6, “Date and Time Functions”。
使用“日期和时间”数据类型时,请记住以下一般注意事项:
MySQL 以标准输出格式检索指定的“日期和时间”类型的值。对于提供的各种格式的输入值,MySQL 也会尝试去解析(例如,将一个值赋值给“日期和时间”类型或与“日期和时间”进行比较)。这时可能会产生不可预测的结果,所以建议你提供有效的值。关于“日期和时间”类型允许格式的说明,请看 Section 9.1.3, “Date and Time Literals”。
尽管 MySQL 会尝试以几种格式去解析值,但日期部分请务必以 year-month-day 的顺序提供(如 '98-09-04'),而不是别处常用的 month-day-year 或 day-month-year 顺序(如 '09-04-98'、'04-09-98')。STR_TO_DATE() 函数能将其他顺序的字符串转化为 year-month-day 顺序。
2 位数年份的日期是不明确的,因为世纪未知。MySQL 会使用以下规则解析 2 位数的年份值:
年份值 [70, 99] 内的会变为 [1970, 1999]。
年份值 [00, 69] 内的会变为 [2000, 2069]。
两个不同类型的时间值的转换规则,请查看 Section 11.2.7, “Conversion Between Date and Time Types”。
如果在数值类型的上下文中使用“日期和时间”,MySQL 会自动将“日期和时间” 转为数值,反之亦然。
默认情况下,MySQL 会将超出“日期和时间”类型 取值范围的值或非法值转为相应数据类型的“零”值。唯一例外是:TIME 对超出取值范围的值裁剪到 TIME 取值范围的相应端点。
通过将 SQL 模式设置为适当的值,可以让 MySQL 去支持你想要的日期类型。(详情请看 Section 5.1.11, “Server SQL Modes”)通过启用 SQL 的 ALLOW_INVALID_DATES 模式,可以使得 MySQL 接受某些值,如 '2009-11-31'(译者注:11 月只有 30 日)。如果要在数据库中存储用户指定(如,以 Web 表单)的,且“可能错误”的值,并在将来再对这些值进行处理时,那么这个模式就起到了作用。在这个模式下,MySQL 仅进行以下校验:month 是否在 [1, 12],day 是否在 [1, 31]。
MySQL 允许 DATE 或 DATETIME 列存储 day 或 month 与 day 为 0 的日期值。这对需要存储生日,但可能不知道精确日期的应用程序有用。在这种情况下,你只需将日期存储为 '2009-00-00' 或 '2009-01-00'。然而,对于这样的日期值,你并不能从诸如 DATE_SUB() 或 DATE_ADD() 之类需要完整日期参数的函数中得到正确的结果。可通过启用 NO_ZERO_IN_DATE 模式,实现禁止日期值出现 month 或 day 为 0 的情况。
MySQL 允许你将 '0000-00-00' 这样的“零”值作为“虚拟日期”(dummy date)进行存储。在某些情况下,这比使用 NULL 值更方便,并且使用更少的数据和索引空间。可通过启用 NO_ZERO_DATE 模式来禁止 '0000-00-00'。
通过 Connector/ODBC 使用“日期和时间”类型的“零”值时,会自动转换为 NULL,因为 ODBC 无法处理这类的值。
下面表格展示了每种数据类型对应的“零”值。“零”值是特殊的,但可以用表中展示的值显式地存储或引用它们。另外,你也可以使用更容易编写的值——'0' 或 0 来实现同样的操作。对于含有日期的时间类型(DATE、DATETIME 和 TIMESTAMP),使用这些值可能会产生警告(warning)或错误(error)。这种明确的行为取决于严格模式的启用与否和 NO_ZERO_DATE 模式中的哪一个。详情请看 Section 5.1.11, “Server SQL Modes”。
| Data Type | "Zero" Value |
|---|---|
| DATE | '0000-00-00' |
| TIME | '00:00:00' |
| DATETIME | '0000-00-00 00:00:00' |
| TIMESTAMP | '0000-00-00 00:00:00' |
| YEAR | 0000 |
用于表示时间值的“日期和时间”数据类型有:DATE、TIME、DATETIME、TIMESTAMP 和 YEAR。
对于 DATE 和 DATETIME 取值范围的描述,“支持(supported)”表示尽管较早的值可能有效,但并不保证。
MySQL 允许 TIME、DATETIME 和 TIMESTAMP 拥有小数,精度最大为微秒(6 位数)。为了定义拥有小数的列,需要使用 type_name(fsp) 句法,其中 type_name 是 TIME、DATETIME 或 TIMESTAMP 中的一个,fsp 是小数的精度。例如:
CREATE TABLE t1 (t TIME(3), dt DATETIME(6), ts TIMESTAMP(0));fsp 的取值范围是 [0, 6]。0 表示没有小数部分。默认值是 0(缺省时)。(与 SQL 标准的默认值 6 不同,主要为了兼容 MySQL 旧版本。)
表中任意 TIMESTAMP 和 DATETIME 列都可具有自动初始化和更新的属性,详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
DATE
日期。支持(supported)的取值范围是 ['1000-01-01', '9999-12-31']。MySQL 以 'YYYY-MM-DD' 的形式展示 DATE 值,但允许将字符串和数值赋值给 DATE 列。
DATETIME[(fsp)]
日期和时间的结合体。支持(supported)的取值范围是 ['1000-01-01 00:00:00.000000', '9999-12-31 23:59:59.999999']。MySQL 以 'YYYY-MM-DD hh:mm:ss[.fraction]' 的形式展示 DATETIME 的值,但允许将字符串和数值赋值给 DATETIME 列。
可选参数 fsp 的取值范围是 [0, 6],它用于指定小数部分的精度。0 表示没有小数部分,若缺省,默认值为 0。
可在 DATETIME 列定义语句中通过 DEFAULT 和 ON UPDATE 子句启用自动初始化和更新为当前日期时间值的特性。详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
TIMESTAMP[(fsp)]
时间戳。取值范围是 ['1970-01-01 00:00:01.000000' UTC, '2038-01-19 03:14:07.999999' UTC]。TIMESTAMP 可存储自纪元(epoch,'1970-01-01 00:00:00' UTC)以来的秒数。TIMESTAMP 不能表示 '1970-01-01 00:00:00',因为它相当于自纪元开始的第 0 秒,而保留值 0 表示 TIMESTAMP 的“零”值——'0000-00-00 00:00:00'。
可选参数 fsp 的取值范围是 [0, 6],它用于指定小数部分的精度。0 表示没有小数部分,若缺省,默认值为 0。
服务器处理 TIMESTAMP 定义的方式取决于 explicit_defaults_for_timestamp 系统变量(详情请看 Section 5.1.8, “Server System Variables”)。
若启用 explicit_defaults_for_timestamp,则不会将 DEFAULT_CURRENT_TIMESTAMP 或 ON UPDATE CURRENT_TIMESTAMP 属性自动分配给任何 TIMESTAMP 列。它们必须明确包含在列定义中。另外,任何 TIMESTAMP 未明确声明为 NOT NULL,则允许 NULL 值。
若未启用 explicit_defaults_for_timestamp,服务器会按照以下规则处理 TIMESTAMP:
除非另有说明,否则表中的第一个 TIMESTAMP 列会被定义为:若未明确赋值,则会被自动设置为最近修改的日期和时间。这对用于记录 INSERT 或 UPDATE 操作时的时间戳非常有用。你也可以为任意 TIMESTAMP 列赋值 NULL,以取得当前 日期和时间,除非该列定义为允许为 NULL。
可在定义时包含 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 子句,以获得自动初始化和更新为当前日期和时间的能力。如上一段所述,默认情况下,第一个 TIMESTAMP 列会自动拥有这些属性。当然,你也可以为表中任意 TIMESTAMP 列定义这些属性。
TIME[(fsp)]
时间。取值范围是 ['-838:59:59.000000', '838:59:59.000000']。MySQL 以 'hh:mm:ss[.fraction]' 的形式展示 TIME 值,但允许将字符串或数值赋值给 TIME 列。
可选参数 fsp 的取值范围是 [0, 6],它用于指定小数部分的精度。0 表示没有小数部分,若缺省,默认值为 0。
YEAR[(4)]
4 位数的年份。MySQL 以 YYYY 的形式显示 YEAR 值,但允许将字符串或数值赋值给 YEAR 列。它的取值范围是 [1901, 2155] 或 0000。
有关 YEAR 显示格式和输入值解析的更多信息,请看 Section 11.2.4, “The YEAR Type”。
注意:从 MySQL 8.0.19 开始,不建议使用明确设定显示宽度的 YEAR(4) 数据类型,并将在未来的 MySQL 版本中移除它。而且,无显示宽度的 YEAR 与它的含义相同。
MySQL 8.0 不支持旧版 MySQL 中允许的 2 位数 YEAR(2)。有关转换为 4 位数 YEAR 的说明,请看 MySQL 5.7 Reference Manual 的 2-Digit YEAR(2) Limitations and Migrating to 4-Digit YEAR。
聚集函数 SUM() 和 AVG() 不适用于时间值(它们将时间值转换为数值时,会丢失掉自第一个非数值字符后的所有信息)。为了解决该问题,可先将时间值转为数值单位后再执行聚集操作,最后再转回为时间值。如:
SELECT SEC_TO_TIME(SUM(TIME_TO_SEC(time_col))) FROM tbl_name;
SELECT FROM_DAYS(SUM(TO_DAYS(date_col))) FROM tbl_name;DATE、DATETIME 和 TIMESTAMP 三者是相关的。本节描述了它们的特征,包括它们的相似与不同。MySQL 能以几种形式识别 DATE、DATETIME 和 TIMESTAMP 的值,于 Section 9.1.3, “Date and Time Literals” 进行了详细描述。对于 DATE 和 TIMESTAMP 的取值范围描述,“支持(supported)”表示尽管较早的值可能有效,但并不保证。
DATE 类型适用于仅有日期但无时间的值。MySQL 以 'YYYY-MM-DD' 格式进行检索和显示。支持(supported)的取值范围是 ['1000-01-01', '9999-12-31']。
DATETIME 类型适用于同时含日期和时间的值。MySQL 以 'YYYY-MM-DD hh:mm:ss' 格式进行检索和显示。支持(supported)的取值范围是 ['1000-01-01 00:00:00', '9999-12-31 23:59:59']。
TIMESTAMP 类型适用于同时含有日期和时间的值。TIMESTAMP 的取值范围是 ['1970-01-01 00:00:01' UTC, '2038-01-19 03:14:07' UTC]。
DATETIME 和 TIMESTAMP 值能拥有小数部分,精度达到微秒(6 位数)。插入到 DATETIME 或 TIMESTAMP 列中的值的小数部分都会被存储而不是被丢弃。包括小数部分在内,这些值的格式是 'YYYY-MM-DD hh:mm:ss[.fraction]'。相应地,DATETIME 的取值范围 ['1000-01-01 00:00:00.000000', '9999-12-31 23:59:59.999999'];TIMESTAMP 的取值范围是 ['1970-01-01 00:00:01.000000', '2038-01-19 03:14:07.999999']。小数部分应始终与时间的其它部分用小数点分隔。除小数点外,任何标识符都不能作为小数的分隔符。关于 MySQL 对小数秒的支持信息,请看 see Section 11.2.6, “Fractional Seconds in Time Values”。
TIMESTAMP 和 DATETIME 数据类型提供了自动初始化和更新为当前日期和时间的特性。详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
MySQL 会将 TIMESTAMP 的值从当前时区转化为 UTC 进行存储。相应地也会在检索时从 UTC 转化为当前时区。(对于其他类型,如 DATETIME,则不会发生这种情况)。默认情况下,每个连接(connection)的当前时区就是服务器的时间。可以在每个预连接(pre-connection)的基础上设置时区。只要时区设置保持不变,你就能获得与存储相同的值。如果存储了一个 TIMESTAMP 值,然后在改变时区后再检索该值,则检索的值就与存储的值不同。发生这种情况是因为存储与检索的时区不一致。当前时区可用作 time_zone 系统变量的值。详情请看 Section 5.1.14, “MySQL Server Time Zone Support”。
从 MySQL 8.0.19 开始,你可以在插入 TIMESTAMP 或 DATETIME 值时,指定时区偏移量。该偏移量追加在日期时间字面量的日期部分后,且中间没有空格。另外,同样格式也可用在 time_zone 系统变量。时区需要注意以下几点:
插入带有时区偏移量的日期时间到 TIMESTAMP 和 DATETIME 列时,使用不同的 time_zone 设置,会造成什么影响呢?(观察检索结果):
mysql> CREATE TABLE ts (
-> id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> col TIMESTAMP NOT NULL
-> ) AUTO_INCREMENT = 1;
mysql> CREATE TABLE dt (
-> id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> col DATETIME NOT NULL
-> ) AUTO_INCREMENT = 1;
mysql> SET @@time_zone = 'SYSTEM';
mysql> INSERT INTO ts (col) VALUES ('2020-01-01 10:10:10'),
-> ('2020-01-01 10:10:10+05:30'), ('2020-01-01 10:10:10-08:00');
mysql> SET @@time_zone = '+00:00';
mysql> INSERT INTO ts (col) VALUES ('2020-01-01 10:10:10'),
-> ('2020-01-01 10:10:10+05:30'), ('2020-01-01 10:10:10-08:00');
mysql> SET @@time_zone = 'SYSTEM';
mysql> INSERT INTO dt (col) VALUES ('2020-01-01 10:10:10'),
-> ('2020-01-01 10:10:10+05:30'), ('2020-01-01 10:10:10-08:00');
mysql> SET @@time_zone = '+00:00';
mysql> INSERT INTO dt (col) VALUES ('2020-01-01 10:10:10'),
-> ('2020-01-01 10:10:10+05:30'), ('2020-01-01 10:10:10-08:00');
mysql> SET @@time_zone = 'SYSTEM';
mysql> SELECT @@system_time_zone;
+--------------------+
| @@system_time_zone |
+--------------------+
| EST |
+--------------------+
mysql> SELECT col, UNIX_TIMESTAMP(col) FROM dt ORDER BY id;
+---------------------+---------------------+
| col | UNIX_TIMESTAMP(col) |
+---------------------+---------------------+
| 2020-01-01 10:10:10 | 1577891410 |
| 2019-12-31 23:40:10 | 1577853610 |
| 2020-01-01 13:10:10 | 1577902210 |
| 2020-01-01 10:10:10 | 1577891410 |
| 2020-01-01 04:40:10 | 1577871610 |
| 2020-01-01 18:10:10 | 1577920210 |
+---------------------+---------------------+
mysql> SELECT col, UNIX_TIMESTAMP(col) FROM ts ORDER BY id;
+---------------------+---------------------+
| col | UNIX_TIMESTAMP(col) |
+---------------------+---------------------+
| 2020-01-01 10:10:10 | 1577891410 |
| 2019-12-31 23:40:10 | 1577853610 |
| 2020-01-01 13:10:10 | 1577902210 |
| 2020-01-01 05:10:10 | 1577873410 |
| 2019-12-31 23:40:10 | 1577853610 |
| 2020-01-01 13:10:10 | 1577902210 |
+---------------------+---------------------+检索时并不会显示日期时间值的偏移量,尽管在插入时有一个值带有偏移量。
偏移量支持(supported)的取值范围是 [-14:00, +14:00]。
带有时区偏移量的日期时间字面量可通过参数化查询(prepared statements)指定参数。
非法的 DATE、DATETIME 和 TIMESTAMP 值会被转化为相应类型的“零”值('0000-00-00' 或 '0000-00-00 00:00:00'),但前提是 SQL 模式允许此转换。这种明确的行为取决于严格模式的启用是否和 NO_ZERO_DATE 模式中的哪一个。详情请看 Section 5.1.11, “Server SQL Modes”。
注意 MySQL 对日期值的各个组成部分的解析规则:
MySQL 对字符串类型的值采用“宽松”格式,任何标点符号均可作为日期或时间组成部分的分隔符。在某些情况下,这种语法是具有欺骗性的。例如,值 '10:11:12' 会因为冒号(:)被看作是 时间,但在日期上下文中会被解析为 '2010-11-12'。值 '10:45:15' 会被转为 '0000-00-00',因为 '45' 是非法的月份。
“日期和时间”与小数之间唯一能被识别的分隔符是小数点。
服务器要求 month 和 day 的组合值是合法的,而不仅仅局限于在各自范围 [1, 12]、[1, 31] 合法即可。当关闭严格模式,非法日期,如 '2004-04-31' 会被转为 '0000-00-00',并产生一个警告。当启用严格模式,非法日期会报错。若要存储非法日期,需要启用 ALLOW_INVAILD_DATES。详情请看 Section 5.1.11, “Server SQL Modes”。
MySQL 不接受 day 或 month 是 0 及其他非法日期值的 TIMESTAMP。该规则的唯一例外是特殊值——“零”值 '0000-00-00 00:00:00',当然前提是 SQL 模式允许该特殊值。这种明确的行为取决于严格模式的启用与否和 NO_ZERO_DATE 模式中的哪一个。详情请看 Section 5.1.11, “Server SQL Modes”。
2 位数年份的日期是不明确的,因为世纪未知。MySQL 会使用以下规则解析 2 位数的年份值:
年份值 [70, 99] 内的会变为 [1970, 1999]。
年份值 [00, 69] 内的会变为 [2000, 2069]。
详情请看 Section 11.2.8, “2-Digit Years in Dates”。
MySQL 以 'hh:mm:ss'(或 hhh:mm:ss 格式,用于小时数较大的值)格式进行检索和显示。TIME 的取值范围是 ['-838:59:59', '838:59:59']。小时部分可能会很大,因为 TIME 不仅用于存储一天内的时间(这肯定小于 24 小时),而且还能存储消耗的时间或两事件之间的时间间隔(这可能远大于 24 小时,甚至是负数)。
MySQL 可识别几种格式的 TIME 值,其中包括小数部分,其精度最大达到微秒(6位数)。详情请看 Section 9.1.3, “Date and Time Literals”。有关 MySQL 对小数的支持信息,请看 Section 11.2.6, “Fractional Seconds in Time Values”。插入到 TIME 列中的值的小数部分都会被存储而不是被丢弃。当含有小数部分时,TIME 的取值范围是 ['-838:59:59.000000', '838:59:59.000000']。
将省略值赋值给 TIME 列时要小心。因为 MySQL 解析带有冒号(:)的省略 TIME 值时,会优先作为一天中的时间进行解析。也就是说,'11:12' 表示的是 '11:12:00',而不是 '00:11:12'。MySQL 解析不带有冒号(:)的简写 TIME 值时,最右侧的两位数会被解析为秒(也就是说,会优先解析为消耗的时间,而不是一天中的时间)。例如,你可能认为 '1112' 和 1112 表示 '11:12:00'(11 时 12 分),其实 MySQL 将它们解析为 '00:11:12'(11 分 12 秒)。如此类推,'12' 和 12 会被解析为 '00:00:12'。
时间与小数之间唯一能被识别的分隔符是小数点。
默认情况下,位于 TIME 取值范围之外,但有效(译者注:指格式)的值将会被裁剪为最靠近端点的值。例如,'-850:00:00' 和 '850:00:00' 会被分别转为 '-838:59:59' 和 '838:59:59'。非法的 TIME 值会被转为 '00:00:00'。需要注意的是,因为 '00:00:00' 本身就是 TIME 的有效值,所以无法判断表中的 '00:00:00' 值是主动存储还是非法值转化而来的。
为了更严格地处理非法的 TIME 值(对此会产生一个错误),可启动 SQL 的严格模式。详情请看 Section 5.1.11, “Server SQL Modes”。
YEAR 是用来表示年份值的类型,其大小为 1 字节。可隐式声明为显示宽度为 4 字符的 YEAR,即与显式声明的 YEAR(4) 等效。
注意:从 MySQL 8.0.19 开始,不建议使用明确设定显示宽度的 YEAR(4) 数据类型,并将在未来的 MySQL 版本中移除它。而且,无显示宽度的 YEAR 与它的含义相同。
MySQL 8.0 不支持旧版 MySQL 中允许的 2 位数 YEAR(2)。有关转换为 4 位数 YEAR 的说明,请看 MySQL 5.7 Reference Manual 的 2-Digit YEAR(2) Limitations and Migrating to 4-Digit YEAR 。
MySQL 以 YYYY 的形式显示 YEAR 值。其取值范围是 [1901, 2155] 和 0000。
YEAR 接受以下几种格式的输入值:
位于 ['1901', '2155'] 的 4 位数的字符串。
位于 [1901, 2155] 的 4 位数的数值。
位于 ['0', '99'] 的 1 ~ 2 位数的字符串。MySQL 会对这些值进行转换,['0', '69'] 和 ['70', '99'] 会被分别转为 ['2000', '2069'], ['1970', '1999']。
位于 [0, 99] 的 1 ~ 2 位数的数值。MySQL 会对这些值进行转换,[1, 69] 和 [70, 99] 会被分别转为 [2001, 2069], [1970, 1999]。
插入数值 0 的结果:显示值和内部值均为 0000。为了让 0 解析为 2000,需要指定为字符串 '0' 或 '00'。
返回值含有 YEAR 上下文的函数,如 NOW()。
若未开启 SQL 严格模式,MySQL 会将非法的 YEAR 值转为 0000。反之,插入一个非法的 YEAR 值时会报错。
另请查看 Section 11.2.8, “2-Digit Years in Dates”。
TIMESTAMP 和 DATETIME 列拥有自动初始化和更新到当前日期和时间(即当前时间戳)的能力。
表中任意 TIMESTAMP 和 DATETIME 列都可以将当前时间戳作为默认值和自动更新的值(两者可同时存在):
对于自动初始化的列,当插入未指定该列值的行时,会被自动设置为当前时间戳。
对于自动更新的列,当行的其他任意列值发生改变时,它会被自动更新为当前时间戳。当行的其他任意列设置同样的值时,它会保持不变。当你想实现其他列更新时,自动更新列保持不变,那么就需要明确地设置为现有值。当你想让自动更新列在其他列值未发生变化时而进行更新,那么就需要明确地将其设置为目标值(如,设置为 CURRENT_TIMESTAMP)。
此外,若系统变量 explicit_defaults_for_timestamp 被禁用,那么可通过为 TIMESTAMP 列(不包括 DATETIME 类型)赋值 NULL,实现初始化或更新为当前日期和时间。除非该列声明时允许 NULL 值。
要指定自动化属性,需要在列定义中使用 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 子句。这两个子句的顺序无关紧要。如果定义中同时存在这两者,则任意一个都可以先出现。与 CURRENT_TIMESTAP 等价的有:CURRENT_TIMESTAMP()、NOW()、LOCALTIME、LOCALTIME()、LOCALTIMESTAMP 和 LOCALTIMESTAMP()。
DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 只能用于 TIMESTAMP 和 DATETIME。DEFAULT 子句可指定一个常量(即保持不变)作为默认值(如 DEFAULT 0 或 DEFAULT '2000-01-01 00:00:00')。
注意:以下案例使用 DEFAULT 0,该默认值会产生警告或错误,这取决于是否开启严格模式或 NO_ZERO_DATE。需要注意的是,SQL 模式 TRADITIONAL 是包含严格模式和 NO_ZERO_DATE 的。详情请看 Section 5.1.11, “Server SQL Modes”。
在 TIMESTAMP 或 DATETIME 列的定义中,可指定当前时间戳(同时、任一、均不)作为默认值和自动更新值。不同的列能指定不同的自动属性组合。以下案例展示了可能性:
对于同时拥有 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 的列,默认值为当前时间戳和拥有自动更新为当前时间戳的能力。
CREATE TABLE t1 (
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
dt DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);拥有 DEFAULT 子句,但没有 ON UPDATE CURRENT_TIMESTAMP 子句的列,默认值为指定的值,但不具备自动更新为当前时间戳的能力。
默认值是由 DEFAULT 子句指定的,可以是 CURRENT_TIMESTAMP 或常量。为 CURRENT_TIMESTAMP 时,默认值是当前时间戳。
CREATE TABLE t1 (
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
dt DATETIME DEFAULT CURRENT_TIMESTAMP
);默认值为常量时,那么列就不再具有自动属性(译者注:即默认值保持不变)。
CREATE TABLE t1 (
ts TIMESTAMP DEFAULT 0,
dt DATETIME DEFAULT 0
);带有 ON UPDATE CURRENT_TIMESTAMP 子句和默认值为常量的子句的列,拥有自动更新为当前时间戳的能力和默认值为指定常量。
CREATE TABLE t1 (
ts TIMESTAMP DEFAULT 0 ON UPDATE CURRENT_TIMESTAMP,
dt DATETIME DEFAULT 0 ON UPDATE CURRENT_TIMESTAMP
);带有 ON UPDATE CURRENT_TIMESTAMP 子句,但没 DEFAULT 子句的列,拥有自动更新为当前时间戳的能力,但没有将当前时间戳作为它的默认值。
这种情况下,默认值取决于具体类型。对于 TIMESTAMP,除非声明了 NULL 属性(此时默认值为 NULL),否则默认值为 0。
CREATE TABLE t1 (
ts1 TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, -- default 0
ts2 TIMESTAMP NULL ON UPDATE CURRENT_TIMESTAMP -- default NULL
);对于 DATETIME,除非声明了 NOT NULL 属性(此时默认值为 0),否则默认值为 NULL。
CREATE TABLE t1 (
dt1 DATETIME ON UPDATE CURRENT_TIMESTAMP, -- default NULL
dt2 DATETIME NOT NULL ON UPDATE CURRENT_TIMESTAMP -- default 0
);除非明确指定,否则 TIMESTAMP 和 DATETIME 列不具备自动属性。唯一例外是:如果禁用 explicit_defaults_for_timestamp 系统变量,且第一个 TIMESTAMP 列未明确声明两者,那么该列就会同时拥有 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 属性。要想取消第一个 TIMESTAMP 列拥有自动属性的特性,可使用以下策略之一:
启用 explicit_defaults_for_timestamp 系统变量。这种情况下,可通过声明 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP 子句实现自动初始化和更新。也就是说,除非明确在列声明中包含它们,否则不会自动分配给任何 TIMESTAMP 列。
或者,如果禁用 explicit_defaults_for_timestamp,请执行以下任一操作:
定义列时,请指定默认值为常量的 DEFAULT 子句。
指定 NULL 属性。这使得列允许为 NULL 值,这也就意味着不能通过为列赋值 NULL 而得到当前时间戳。即赋值为 NULL 就是 NULL,而不会被转为当前时间戳。想要得到当前时间戳,则需要指定为 CURRENT_TIMESTAMP 或其代名词,如 NOW()。
请考虑以下表定义:
CREATE TABLE t1 (
ts1 TIMESTAMP DEFAULT 0,
ts2 TIMESTAMP DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);
CREATE TABLE t2 (
ts1 TIMESTAMP NULL,
ts2 TIMESTAMP DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);
CREATE TABLE t3 (
ts1 TIMESTAMP NULL DEFAULT 0,
ts2 TIMESTAMP DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);这些表具有以下属性:
在每个表的定义中,第一个 TIMESTAMP 列没有自动初始化和更新的能力。
这些表在 ts1 列对处理 NULL 值的方式上有所不同。对于 t1 表,ts1 列是 NOT NULL,当赋值为 NULL 时,会被转为当前时间戳。对于 t2 和 t3 表,ts1 列是允许为 NULL,当赋值为 NULL 时,存储的就是 NULL。
t2 和 t3 表的 ts1 列的默认值不同。对于 t2 表,ts1 列允许为 NULL,因此在没有显示声明 DEFAULT 子句下,默认值也为 NULL。对于 t3 表,ts1 列允许为 NULL,但同时明确声明默认值为 0。
如果 TIMESTAMP 和 DATETIME 列定义中的任意地方含有明确的小数秒精度参数,那么该列定义中所有该参数的值都必须一致。这是允许的情况:
CREATE TABLE t1 (
ts TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6)
);这是不允许的情况:
CREATE TABLE t1 (
ts TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(3)
);TIMESTAMP 初始化和 NULL 属性
若禁用 explicit_defaults_for_timestamp 系统变量,则 TIMESTAMP 列默认为 NOT NULL,即不能保存 NULL 值,当赋值 NULL 时,实际赋值为当前时间戳。为了允许 TIMESTAMP 列能保存 NULL 值,需要明确声明 NULL 属性。这种情况下,默认值变成了 NULL,除非通过指定不同值的 DEFAULT 子句进行覆盖。DEFAULT NULL 用于明确指定 NULL 为默认值(对于不声明 NULL 属性的 TIMESTAMP 列来说,NULL 是非法值)。如果 TIMESTAMP 列允许 NULL 值,那么赋值 NULL 就是 NULL,而不会转为当前时间戳。
以下表包含多个允许为 NULL 的 TIMESTAMP 列:
CREATE TABLE t
(
ts1 TIMESTAMP NULL DEFAULT NULL,
ts2 TIMESTAMP NULL DEFAULT 0,
ts3 TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP
);允许为 NULL 的 TIMESTAMP 列不会在插入时使用当前时间戳,除非符合以下任一条件:
默认值为 CURRENT_TIMESTAMP,且在插入时该列未指定值。
在插入时,明确指定值为 CURRENT_TIMESTAMP 或其代名词(如 NOW())。
换句话说,dui'yu允许为 NULL 的 TIMESTAMP 列仅在其定时中包含 DEFAULT CURRENT_TIMESTAMP 时才会被自动初始化:
CREATE TABLE t (ts TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP);如果 TIMESTAMP 列允许为 NULL,但定义时不包含 DEFAULT CURRENT_TIMESTAMP,那么在插入时必须明确为当前日期和时间。假设表 t1 和 t2 的定义如下:
CREATE TABLE t1 (ts TIMESTAMP NULL DEFAULT '0000-00-00 00:00:00');
CREATE TABLE t2 (ts TIMESTAMP NULL DEFAULT NULL);要让任一表中的 TIMESTAMP 列设置为插入时的当前时间戳,需要明确赋值。如:
INSERT INTO t2 VALUES (CURRENT_TIMESTAMP);
INSERT INTO t1 VALUES (NOW());如果启用 explicit_defaults_for_timestamp 系统变量,那么只有在声明时包含 NULL 属性,TIMESTAMP 列才允许为 NULL。此外,无论声明 NULL 或 NOT NULL 属性,TIMESTAMP 列均不会因赋值为 NULL 而被转为当前时间戳。只有赋值为 CURRTENT_TIMESTAMP 或其代名词(如 NOW())时,该列才为当前时间戳。
MySQL 的 TIME、DATETIME 和 TIMESTAMP 均支持小数,精度最高可达 6 位数(微秒):
使用 type_name(fsp) 句法定义带有小数的列,其中 type_name 可以为 TIME、DATETIME 或 TIMESTAMP。另外,fsp 表示小数的精度。如:
CREATE TABLE t1 (t TIME(3), dt DATETIME(6));fsp 的取值范围为 [0, 6]。0 表示没小数。若缺省,默认值为 0(与 SQL 标准的默认值 6 不同,主要为了兼容 MySQL 旧版本)。
向 TIME、DATE 和 TIMESTAMP 列插入对应类型且带有小数部分的值时,实际可能会得到四舍五入后更少位数的值。考虑如下创建和填充表:
CREATE TABLE fractest( c1 TIME(2), c2 DATETIME(2), c3 TIMESTAMP(2) );
INSERT INTO fractest VALUES
('17:51:04.777', '2018-09-08 17:51:04.777', '2018-09-08 17:51:04.777');时间值被四舍五入后插入表中:
mysql> SELECT * FROM fractest;
+-------------+------------------------+------------------------+
| c1 | c2 | c3 |
+-------------+------------------------+------------------------+
| 17:51:04.78 | 2018-09-08 17:51:04.78 | 2018-09-08 17:51:04.78 |
+-------------+------------------------+------------------------+四舍五入并没有产生警告或错误。因为这个行为符合 SQL 标准。
当你想要被裁剪而不是四舍五入时,请启用 SQL 模式的 TIME_TRUNCATE_FRACTIONAL:
SET @@sql_mode = sys.list_add(@@sql_mode, 'TIME_TRUNCATE_FRACTIONAL');当启用该 SQL 模式后,将以裁剪的方式插入时间值:
mysql> SELECT * FROM fractest;
+-------------+------------------------+------------------------+
| c1 | c2 | c3 |
+-------------+------------------------+------------------------+
| 17:51:04.77 | 2018-09-08 17:51:04.77 | 2018-09-08 17:51:04.77 |
+-------------+------------------------+------------------------+对于拥有时间参数的函数来说,它接收带有小数的时间值时,返回值也会包括适当的小数。例如,不带参数的 NOW() 会返回不带有小数的日期和时间,当指定可选参数为 0 到 6 之间 的值时,返回值也会含有指定位数的小数。
通过时间字面量句法得到时间值:DATE 'str'、TIME 'str'、TIMESTAMP 'str' 和 ODBD 语法的等效项。结果值的小数可通过指定得到。在以前,时间类型关键字会被忽略,从而这些构造体会变成字符串值。详情请看 Standard SQL and ODBC Date and Time Literals。
在某种程度上,你能将值从一种时间类型转换为另一种时间类型。但是,值可能会有所变化或丢失信息。在所有情况下,时间类型之间的转换都取决于目标类型的有效值范围。例如,尽管 DATE、DATETIME 和 TIMESTAMP 的值可以使用相同格式的值指定,但这些类型的取值范围并不相同。TIMESTAMP 的值不能早于 1970 UTC 或晚于 '2038-01-19 03:14:07' UTC。这意味着日期 '1968-01-01' 对 DATE 和 DATETIME 来说是合法的,但对 TIMESTAMP 来说是不合法的,并会转换为 0。
转换 DATE 值:
转换为 DATETIME 或 TIMESTAMP 值时,会补充 '00:00:00'。因为 DATE 值不包含时间信息。
转换为 TIME 是无用的,结果为 '00:00:00'。
转换 DATETIME 和 TIMESTAMP 值:
转换为 DATE 值时,会对时间小数进行四舍五入。例如,'1999-12-31 23:59:59.499' 转换得到 '1999-12-31',而 '1999-12-31 23:59:59.500' 转换得到 '2000-01-01'。
转换为 TIME 值时,会丢掉日期部分,因为 TIME 类型不包含日期信息。
转换 TIME 值到其他时间类型时,会将 CURRENT_DATE() 的值作为日期部分。TIME 类型作为消耗时间(而不是一天中的时间)进行解析(译者注:即不局限于 24 小时内,且有可能是负数),然后与日期相加。这意味着,如果时间不在 ['00:00:00', '23:59:59'] 范围内时,则转换结果的日期与当前时间的日期是不同的。
假设,此时日期为 '2012-01-01'。TIME 类型的值分别是 '12:00:00'、'24:00:00' 和 '-12:00:00',当它们转换为 DATETIME 或 TIMESTAMP 值时,得到结果分别是:'2012-01-01 12:00:00'、'2012-01-02 00:00:00' 和 '2011-12-13 12:00:00'。
从 TIME 转换为 DATE 时也与之类似,但会丢掉时间部分:'2012-01-01'、'2012-01-02' 和 '2011-12-31'。
可用显式转换替代隐式转换。例如,对于 DATE 和 DATETIME,DATE 值可通过添加时间部分——'00:00:00' 强行得到 DATETIME 类型。相反地,可通过忽略 DATETIME 的时间部分得到 DATE 类型,这可通过 CAST() 函数实现:
date_col = CAST(datetime_col AS DATE)将 TIME 和 DATETIME 转换为数值形式(如通过加 +0)时,得到的结果类型取决于值是否含有小数部分。对于 TIME(N) 或 DATETIME(N),当 N 为 0(或缺省)时,会转换为整型;当 N 大于 0 时,则转换为 DECIMAL 型:
mysql> SELECT CURTIME(), CURTIME()+0, CURTIME(3)+0;
+-----------+-------------+--------------+
| CURTIME() | CURTIME()+0 | CURTIME(3)+0 |
+-----------+-------------+--------------+
| 09:28:00 | 92800 | 92800.887 |
+-----------+-------------+--------------+
mysql> SELECT NOW(), NOW()+0, NOW(3)+0;
+---------------------+----------------+--------------------+
| NOW() | NOW()+0 | NOW(3)+0 |
+---------------------+----------------+--------------------+
| 2012-08-15 09:28:00 | 20120815092800 | 20120815092800.889 |
+---------------------+----------------+--------------------+2 位数年份的日期是不明确的,因为世纪未知。由于 MySQL 内部使用 4 位数字存储年份,因此必须将这些解析为 4 位数字格式。
对于 DATETIME、DATE 和 TIMESTAMP,MySQL 会使用以下规则解析 2 位数的年份值:
年份值 [70, 99] 内的会变为 [1970, 1999]。
年份值 [00, 69] 内的会变为 [2000, 2069]。
对于 YEAR 类型,规则与上面一致,但有一个例外:当将数值 00 插入到 YEAR 时,会得到 0000 而不是 2000。要想 YEAR 将 0 解析为 2000,则需要指定为字符串类型的 '0' 或 '00' 。
请记住,这些规则只是对你想要的值进行合理猜测。如果 MySQL 使用这些规则未能产生你所需的值,那么请你提供明确的 4 位数年份值。
ORDER BY 可以正确排序 2 位数年份的 YEAR 值。
诸如 MIN() 和 MAX() 这些会将 YEAR 转为数值的函数,它们不能正确处理 2 位数年份。在这种情况下,需要将 YEAR 转为 4 位数的形式。
字符串数据类型有:CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET。
有关字符串数据类型的存储要求的信息,请看 Section 11.7, “Data Type Storage Requirements”。
关于处理字符串函数的说明,请查看 Section 12.7, “String Functions and Operators”。
字符串数据类型有:CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET。
在某些情况下,MySQL 可能会对 CREATE TABLE 和 ALTER TABLE 语句中的字符串类型列进行类型更改。有关信息请看 Section 13.1.20.7, “Silent Column Specification Changes”。
对于字符类字符串列(CHAR、VARCHAR 和 TEXT 类型),MySQL 以字符为单位解析长度规格。对于二进制类字符串列(BINARY、VARBINARY 和 BLOB 类型),MySQL 以字节为单位解析长度规格。
定义字符类字符串列使,可指定列的字符集和排序规则:
CHARACTER SET 指定字符集。若需要,也可通过 COLLATE 属性指定字符集的排序规则。如:
CREATE TABLE t
(
c1 VARCHAR(20) CHARACTER SET utf8,
c2 TEXT CHARACTER SET latin1 COLLATE latin1_general_cs
);以上表定义创建了名为 c1 的列,该列的字符集为 utf8,并采用默认的字符集排序规则。c2 列的字符集为 latin1,并采用大小写敏感(_cs)的排序规则。
Section 10.3.5, “Column Character Set and Collation” 介绍了在缺少 CHARACTER SET 和 COLLATE 属性(之一或全部)时,如何分配字符集和排序规则。
CHARSET 是 CHARACTER SET 的代名词。
为字符类字符串列指定 CHARACTER SET binary 属性时,会使该列创建为相应的二进制类字符串类型:CHAR 变为 BINARY,VARCHAR 变为 VARBINARY,TEXT 变成 BLOB。对于 ENUM 和 SET 数据类型,这种情况不会发生,它们依然按声明语句进行创建。假设这样定义表:
CREATE TABLE t
(
c1 VARCHAR(10) CHARACTER SET binary,
c2 TEXT CHARACTER SET binary,
c3 ENUM('a','b','c') CHARACTER SET binary
);实际表定义变成:
CREATE TABLE t
(
c1 VARBINARY(10),
c2 BLOB,
c3 ENUM('a','b','c') CHARACTER SET binary
);BINARY 属性是一种非标准的 MySQL 扩展,它是列字符集(若列未指定字符集,则取表的默认字符集)的二进制(_bin)排序规则的简写。这种情况下,比较排序是基于 numeric character code 值(译者注:应该是字符编码值?)。假设这样定义表:
CREATE TABLE t
(
c1 VARCHAR(10) CHARACTER SET latin1 BINARY,
c2 TEXT BINARY
) CHARACTER SET utf8mb4;实际表定义变成:
CREATE TABLE t (
c1 VARCHAR(10) CHARACTER SET latin1 COLLATE latin1_bin,
c2 TEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin
) CHARACTER SET utf8mb4;在 MySQL 8.0,由于 utf8mb4 字符集具有多个 _bin 排序规则,因此这种对 BINARY 属性的非标准用法是不明确的。从 MySQL 8.0.17 开始,不建议这样使用 BINARY 属性,并将在未来的 MySQL 版本中移除它。应用程序应该调整为一个明确的 _bin 排序规则。
使用 BINARY 指定数据类型或字符集的用法保持不变。
ASCII 属性是 CHARACTER SET latin1 的缩写。
UNICODE 属性是 CHARACTER SET ucs2 的缩写。
字符列的比较排序是基于分配给该列的排序规则。对于 CHAR、VARCHAR、TEXT、ENUM 和 SET 数据类型,你可以在声明时带上二进制(_bin)排序规则或 BINARY 属性,让比较排序是基于 underlying character code(字符编码) 而不是 lexical ordering(字典序)。
有关在 MySQL 中使用字符集的更多信息,请看 Chapter 10, Character Sets, Collations, Unicode。
[NATIONAL] CHAR[(M)] [CHARACTER SET charset_name] [COLLATE collation_name]
定长字符串。在存储时总是会在右侧填充空格至指定长度。M 表示列的字符长度,其取值范围为 [0, 255]。若 M 缺省,则默认为 1。
注意:检索时会移除尾随空格,除非启用 SQL 模式 PAD_CHAR_TO_FULL_LENGTH。
CHAR 是 CHARACTER 的缩写。NOTIONAL CHAR(或 NCHAR 缩写)是使用某些预定义字符集定义 CHAR 列的标准 SQL 方式。MySQL 使用 utf8 作为预定义字符集。Section 10.3.7, “The National Character Set”。
CHAR BYTE 数据类型是 BINARY 数据类型是别名。这是一项兼容性功能。
MySQL 允许创建 CHAR(0) 列。这主要用于你必须兼容“依赖该列存在但实际无用的旧应用程序”的场景。CHAR(0) 也可用于只能接受两个值的列:对于 CHAR(0) 列,NULL 只占用 1 bit 空间,它也只能接受 NULL 和 ''(空字符串)。
[NATIONAL] VARCHAR(M) [CHARACTER SET charset_name] [COLLATE collation_name]
可变长字符串。M 表示列的最大字符长度,其取值范围为 [0, 65535]。VARCHAR 的有效最大长度是取决于行的最大大小(65535 字节,所有列组成)和所使用的字符集。例如,字符集 utf8 的每个字符最多需要 3 字节,因此使用 utf8 字符集的 VARCHAR 列可声明的最大值为 21844 个字符。详情请看 Section 8.4.7, “Limits on Table Column Count and Row Size”。
MySQL 将 VARCHAR 值存储为:1 字节或 2 字节长度前缀 + 实际数据。长度前缀是用来表示值的字节数。如果 VARCHAR 列需要少于或等于 255 字节时使用 1 字节,如果值可能需要超过 255 字节时使用 2 字节。
注意:MySQL 遵循 SQL 标准规范,并不会移除 VARCHAR 值的尾随空格。
VARCHAR 是 CHARACTER VARYING 的缩写,NATIONAL VARCHAR 是使用某些预定义字符集定义 VARCHAR 列的标准 SQL 方式。MySQL 使用 utf8 作为预定义字符集。Section 10.3.7, “The National Character Set”。NVARCHAR 是 NATIONAL VARCHAR 的缩写。
BINARY[(M)]
BINARY 类型与 CHAR 类型类似,不同的地方在于:它是存储二进制字节字符串,而不是非二进制的字符类字符串。可选的 M 表示以字节为单位的列长。若 M 缺省,则默认为 1。
VARBINARY(M)
VARBINARY 类型与 VARCHAR 类型类似,不同的地方在于:它是存储二进制字节字符串,而不是非二进制的字符类字符串。M 表示以字节为单位的最大列长。
TINYBLOB
BLOB 列的最大长度为 255 字节(2^8 - 1)。存储每个 TINYBLOB 值时,都会带有 1 字节长度前缀,它表示这个值的长度为多少字节。
TINYTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
TEXT 列的最大长度为 255 字符(2^8 - 1)。若值包含多字节字符,则有效的最大长度会变小。存储每个 TINYTEXT 值时,都会带有 1 字节长度前缀,它表示这个值的长度为多少字节。
BLOB[(M)]
BLOB 列的最大长度为 65535 字节(2^16 - 1)。存储每个 BLOB 值时,都会带有 2 字节长度前缀,它表示这个值的长度为多少字节。
该类型有可选的长度参数 M。若指定该参数,则 MySQL 会将列创建为最小的 BLOB 类型,但其大小足以存放 M 字节长的值。
TEXT[(M)] [CHARACTER SET charset_name] [COLLATE collation_name]
TEXT 列的最大长度为 65535 字符(2^16 - 1)。若值包含多字节字符,则有效的最大长度会变小。存储每个 TEXT 值时,都会带有 2 字节长度前缀,它表示这个值的长度为多少字节。
该类型有可选的长度参数 M。若指定该参数,则 MySQL 会将列创建为最小的 TEXT 类型,但其大小足以存放 M 字符长的值。
MEDIUMBLOB
BLOB 列的最大长度为 16777215 字节(2^24 - 1)。存储每个 MEDIUMBLOB 值时,都会带有 3 字节长度前缀,它表示这个值的长度为多少字节。
MEDIUMTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
TEXT 列的最大长度为 16777215 字符(2^24 - 1)。若值包含多字节字符,则有效的最大长度会变小。存储每个 MEDIUMTEXT 值时,都会带有 3 字节长度前缀,它表示这个值的长度为多少字节。
LONGBLOB
LONGBLOB 列的最大长度为 4294967295 或 4GB(2^32 - 1)字节。LONGBLOB 列的有效最大长度是取决于客户端/服务器协议中配置的最大数据包大小和可用内存。存储每个 LONGBLOB 值时,都会带有 4 字节长度前缀,它表示这个值的长度为多少字节。
LONGTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
TEXT 列的最大长度为 4294967295 或 4GB(2^32 - 1)字符。若值包含多字节字符,则有效的最大长度会变小。LONGTEXT 列的有效最大长度也取决于客户端/服务器协议中配置的最大数据包大小和可用内存。存储每个 LONGTEXT 值时,都会带有 4 字节长度前缀,它表示这个值的长度为多少字节。
ENUM('value1','value2',...) [CHARACTER SET charset_name] [COLLATE collation_name]
枚举。只能拥有一个值的字符串对象,且该值可从 'value1'、'value2'、...、NULL 或特殊错误值 '' 中选择。ENUM 类型在内部以整型表示。
一个 ENUM 列最多可包含 65535 个不同元素。
单个 ENUM 元素支持(supported)的最大长度是 M <= 255 和 (M x w) <= 1020,其中 M 是元素字面量长度,w 是字符集中最长字符所需的字节数。
SET('value1','value2',...) [CHARACTER SET charset_name] [COLLATE collation_name]
set。能拥有 0 个或以上值的字符串对象,其中每个值须从 'value1', 'value2', ... 中选择。SET 类型在内部以整型表示。
SET 列最多可包含 64 个不同元素。
单个 SET 元素支持(supported)的最大长度是 M <= 255 和 (M x w) <= 1020,其中 M 是元素字面量长度,w 是字符集中最长字符所需的字节数。
CHAR 和 VARCHAR 类型是类似的,不同点在于存储和检索。另外,它们支持的最大长度和是否保留尾随空格也不同。
CHAR 和 VARCHAR 类型均可在声明时指定长度,该长度表示打算存储的最大字符数。例如, CHAR(30) 最多可放 30 个字符。
CHAR 列长度是固定的,该长度是在表声明时指定。长度的取值为 [0, 255]。当存储 CHAR 值时,会在右侧填充空格至指定长度。当检索 CAHR 值时,尾随空格会被移除,除非启用 SQL 模式 PAD_CHAR_TO_FULL_LENGTH。
VARCAR 列是可变长字符串。长度的取值范围为 [0, 65535]。VARCHAR 的有效最大长度是取决于行的最大大小(65535 字节,所有列组成)和所使用的字符集。详情请看 Section 8.4.7, “Limits on Table Column Count and Row Size”。
与 CHAR 不同,VARCHAR 值存储为: 1 字节或 2 字节长度前缀 + 实际数据。长度前缀是用来表示实际值的字节数。如果值需要少于或等于 255 字节时使用 1 字节,如果值可能需要大于 255 字节时使用 2 字节。
如果未启用 SQL 严格模式,并且为 CHAR 或 VARCHAR 列分配的值超过了该列的最大长度,则该值会被裁剪至合适长度(译者注:裁剪末端)并产生警告。如果开启 SQL 严格模式,那么当裁剪非空格字符时(译者注:若裁剪末端空格后符合长度要求,则不报错),会导致报错(而不是警告),并插入值失败。详情请看 Section 5.1.11, “Server SQL Modes”。
对于 VARCHAR 列,无论使用哪种 SQL 模式,插入前都会裁剪超出列长度的尾随空格并产生警告。对于 CHAR 列,无论使用哪种 SQL 模式,插入前都会静默地裁剪超出列长度的尾随空格(译者注:即不会产生警告)。
存储 VARCHAR 值时不会对其进行填充。根据 SQL 标准,在存储和检索时都会保留尾随空格。
下表通过显示将各种字符串值存储到 CHAR(4) 和 VARCHAR(4) 列中的结果来说明 CHAR 和 VARCHAR 之间的不同(假设该列使用单字节字符集,如 latin1):
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
|---|---|---|---|---|
| '' | ' ' | 4 bytes | '' | 1 byte |
| 'ab' | 'ab ' | 4 bytes | 'ab' | 3 bytes |
| 'abcd' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
| 'abcdefgh' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
表格最后一行的值仅在不启用严格模式时适用;若开启严格模式,超出列长度的值都不会被存储,并报错。
InnoDB 会将大于或等于 768 字节的定长字段(Field)编码为可存在 off-page 的可变长字段。例如,CHAR(255) 列可能会超过 768 字节,因为存在最大字节长度大于 3 的字符集,如 utf8mb4。
当将一个值分别存在 CHAR(4) 和 VARCHAR(4) 列时,检索出的值并不总是一样的。因为 CHAR 列在检索时会删除尾随空格。以下案例说明了这种差异:
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO vc VALUES ('ab ', 'ab ');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;
+---------------------+---------------------+
| CONCAT('(', v, ')') | CONCAT('(', c, ')') |
+---------------------+---------------------+
| (ab ) | (ab) |
+---------------------+---------------------+
1 row in set (0.06 sec)CHAR(4) 和 VARCHAR(4) 列的比较排序是基于列设置的字符集排序规则。
大多数 MySQL 排序规则拥有填充属性 PAD SPACE。例外是基于 UCA 9.0.0 或更高版本的 Unicode 排序规则,其填充属性为 NO PAD。详情请看 Section 10.10.1, “Unicode Character Sets”。
通过 INFORMATION_SCHEMA 的 COLLATIONS 表可查看特定排序规则的填充属性。
填充属性决定了非二进制字符串(CHAR、VARCHAR 和 TEXT 值)在比较时如何处理尾随空格。NO PAD 排序规则将尾随空格视为与其他字符一样。而 PAD SPACE 排序规则是不在意尾随空格的。即在字符串比较时,会忽略任何尾随空格。在此上下文中的“比较”,是不包括 LIKE 模式匹配操作符,即它是在意尾随空格的。案例如下:
mysql> CREATE TABLE names (myname CHAR(10));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO names VALUES ('Jones');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT myname = 'Jones', myname = 'Jones ' FROM names;
+--------------------+--------------------+
| myname = 'Jones' | myname = 'Jones ' |
+--------------------+--------------------+
| 1 | 1 |
+--------------------+--------------------+
1 row in set (0.00 sec)
mysql> SELECT myname LIKE 'Jones', myname LIKE 'Jones ' FROM names;
+-----------------------+-----------------------+
| myname LIKE 'Jones' | myname LIKE 'Jones ' |
+-----------------------+-----------------------+
| 1 | 0 |
+-----------------------+-----------------------+
1 row in set (0.00 sec)对于所有 MySQL 版本均是如此,并且不受服务器 SQL 模式影响。
注意:关于 MySQL 字符集和排序规则的更多信息,请查看 Chapter 10, Character Sets, Collations, Unicode。
关于存储要求的其他信息,请查看 Section 11.7, “Data Type Storage Requirements”。
对于移除尾随字符或在比较时忽略它们的情况,如果列具有唯一索引(要求值唯一),则将仅尾随字符数不同的值插入列时,会出现 duplicate-key 错误。例如,如果表已有 'a' 的情况下,再尝试存储 'a ' 时,会导致 duplicate-key 错误。
“BINARY 和 VARBINARY 类型”与“CAHR 和 VARCHAR 类型”类似,不同点在于前者存储的是二进制字符串,而后者存储的是非二进制字符串。换句话说,存的是字节字符串而不是字符类字符串。这意味着他们拥有 binary 字符集和排序规则,且比较排序是基于字节的字符编码(numeric values of the bytes in the values)。
“BINARY 和 VARBINARY”的最大长度与“CHAR 和 VARCHAR”相同,但测量单位是字节而不是字符。
BINARY 和 VARBINARY 数据类型与 CHAR BINARY 和 VARCHAR BINARY 数据类型不同。后者的 BINARY 属性不会导致该列被视为二进制字符串列,而是让该列使用列字符集的二进制(_bin)排序规则(若未指定列字符集,则采用表的默认字符集),并且该列本身不会存储二进制字符串,而是依然会存储非二进制字符串。例如,如果默认字符集是 utf8mb4,CHAR(5) BINARY 就会被视为 CHAR(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin。这显然与 binary 字符集和排序规则的,且能存储 5 字节二进制字符串的 BINARY(5) 不同。关于 binary 字符集的 binary 排序规则与非二进制字符集的 _bin 排序规则不同之处,请查看 Section 10.8.5, “The binary Collation Compared to _bin Collations”。
如果未启用 SQL 严格模式,并且为 BINARY 和 VARBINARY 列分配的值超过了该列的最大长度,则该值会被裁剪至合适长度并产生警告。反之,裁剪会导致报错(而非警告),并且插入值失败。详情请看 Section 5.1.11, “Server SQL Modes”。
存储 BINARY 值时,会在右侧填充指定的值至指定长度。填充值是 0x00(the zero byte)。插入时会右侧填充 0x00,且在检索时不会删除尾随字节。所有字节在比较(含 ORDER BY 和 DISTINCT)时均有效。0x00 与空格在比较操作中是不同的,其中 0x00 排在空格之前。
案例:对于 BINARY(3) 列,插入 'a ' 时,实际变成插入 'a \0';同样地,'a\0' 变成 'a\0\0'。在检索时,插入的两个值均保持不变。
对于 VARBINARY,插入不会填充,检索不会移除字节。所有字节在比较(含 ORDER BY 和 DISTINCT)时均有效。0x00 与空格在比较操作中是不同的,0x00 排在空格之前。
对于移除尾随填充字节或在比较时忽略它们的情况,如果列具有唯一索引(要求值唯一),则将仅尾随填充字节数不同的值插入列时,会出现 duplicate-key 错误。例如,如果表已有 'a' 的情况下,再尝试存储 'a\0' 时,会导致 duplicate-key 错误。
如果打算使用 BINARY 数据类型存储二进制数据,并且要求检索的值与存储的值完全相同,则应仔细考虑上述填充和移除的特性。以下案例说了 BINARY 值填充的 0x00 如何影响列值的比较:
mysql> CREATE TABLE t (c BINARY(3));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO t SET c = 'a';
Query OK, 1 row affected (0.01 sec)
mysql> SELECT HEX(c), c = 'a', c = 'a\0\0' from t;
+--------+---------+-------------+
| HEX(c) | c = 'a' | c = 'a\0\0' |
+--------+---------+-------------+
| 610000 | 0 | 1 |
+--------+---------+-------------+
1 row in set (0.09 sec)若想检索值与存储值一致(即无填充),则最好使用 VARBINARY 或 BLOB 之类的数据类型。
BLOB 是一个二进制大对象,能承载可变数量的数据。有 4 种 BLOB 类型,分别是:TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB。它们仅在值的最大长度上有所不同。TEXT 类型也有 4 种,分别是:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。它们分别对应 4 种 BLOB 类型,并具有相同的最大长度和存储要求。详情请看 Section 11.7, “Data Type Storage Requirements”。
BLOB 值被视为二进制字符串(字节字符串),拥有 binary 字符集和排序规则,比较排序均基于字节的数值(the numeric values of the bytes);TEXT 指被视为非二进制字符串(字符类字符串),拥有二进制以外的字符集,比较排序基于字符集的排序规则。
若未开启 SQL 严格模式,向 BLOB 或 TEXT 列指定超过列最大长度的值,那么会将值裁剪至合适长度,并产生一个警告。如果开启严格的 SQL 模式,那么裁剪非空格字符时(译者注:若裁剪末端空格后符合长度要求则不报错),会导致报错(而不是警告),并插入值失败。详情请看 Section 5.1.11, “Server SQL Modes”。
对于 TEXT 列裁剪超出范围的尾随空格时,总会产生一个警告,而不管 SQL 模式。
对于 TEXT 和 BLOB 列,插入不会填充,检索不会移除字节。
如果对 TEXT 列建立索引,则索引条目的比较会在末尾填充空格。这意味着,如果索引要求值唯一,则将仅尾随空格数不同的值插入列时,则会导致 duplicate-key 错误。例如,如果表已有 'a' 的情况下,再尝试存储 'a ' 时,会导致 duplicate-key 错误。
在大部分情况下,你可将 BLOB 列视为能设置任意大小 VARBINARY 列。类似地,你可将 TEXT 列视为 VARCHAR 列。“BLOB 和 TEXT”与“VARBINARY 和 VARCHAR”不同的点如下:
BLOB 和 TEXT 的索引必须指定索引前缀长度(index prefix length)。而对 CHAR 和 VARCHAR 来说,前缀长度是可选的。详情请看 Section 8.3.5, “Column Indexes”。
BLOB 和 TEXT 不能拥有默认值(DEFAULT)。
若对 TEXT 数据类型使用 BINARY 属性,则该列会被指定为当前字符集的二进制排序规则(_bin)。
LONG 和 LONG VARCHAR 映射为 MEDIUMTEXT 数据类型,这是一项兼容性功能。
MySQL Connector/ODBC 将 BLOB 值定义为 LONGVARBINARY,将 TEXT 值定义为 LONGVARCHAR。
因为 BLOB 和 TEXT 值可能会非常长,因此在使用时可能会遇到一些限制:
排序时仅使用该列的前 max_sort_length 个字节。max_sort_length 的默认值为 1024。可通过在服务器启动或运行时增大 max_sort_length 的值,使得在排序或分组时有更多字节参与。任意客户端都可以更改其 session 的 max_sort_length 变量值:
mysql> SET max_sort_length = 2000;
mysql> SELECT id, comment FROM t
-> ORDER BY comment;使用临时表处理的查询结果中,若含有 BLOB 或 TEXT 实例,则会导致服务器使用磁盘上的表而不是内存中的表,因为 MEMORY 存储引擎不支持这些数据类型(详情请看 Section 8.4.4, “Internal Temporary Table Use in MySQL”)。使用磁盘会导致性能下降,因此仅在查询结果确实需要 BLOB 或 TEXT 列时才包含它们。例如,避免使用 SELECT *,它会选择所有列。
BLOB 和 TEXT 对象的最大大小由其类型决定,但实际上可以在客户端和服务器之间传输的最大值是由可用内存和通信缓冲区的大小决定。可以通过更改 max_allowed_packet 变量的值来更改通信缓冲区,且服务器和客户端程序均须设置。例如,mysql 和 mysqldump 均允许更改客户端的 max_allowed_packet 值。详情请看 Section 5.1.1, “Configuring the Server”、Section 4.5.1, “mysql — The MySQL Command-Line Client” 和 Section 4.5.4, “mysqldump — A Database Backup Program”。你可能还需要将数据包大小与要存储的数据对象(的存储要求)进行比较,详情请看 Section 11.7, “Data Type Storage Requirements”
每个 BLOB 和 TEXT 值在内部都由单独分配的对象表示。这与所有其他数据类型不同,其他数据类型都在表打开时为每列分配一次存储空间。
在某些情况下,你可能希望将二进制数据(例如媒体文件)存储在 BLOB 或 TEXT 列中。你可能发现 MySQL 的字符串处理函数对处理此类数据很有用。详情请看 Section 12.7, “String Functions and Operators”。出于安全和其他原因,通常建议使用应用程序代码完成这样的功能而不是为程序用户提供 FILE 权限。你可以在 MySQL 论坛 中讨论各种语言和平台的细节。
ENUM 是一个字符串对象,其值是从允许值列表中选择,而允许值列表是在创建表的列定义中明确枚举。该类型具有以下优点:
有限个允许值,利于压缩数据存储空间。作为输入值的字符串会自动编码为数值。关于 ENUM 类型的存储要求,请看 Section 11.7, “Data Type Storage Requirements”。
可读的查询和输出。在查询结果中,数值会转换回为对应的字符串。
同时,也要考虑以下潜在问题:
如果枚举值与数值相近,则很容易将字面量值和相应的内部索引值混淆,如 Enumeration Limitations 所述。
在 ORDER BY 子句中使用 ENUM 列时,要格外小心,如 Enumeration Sorting 所述。
本章目录
枚举值必须是带引号的字符串字面量。创建一个含有 ENUM 列的表:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),
('polo shirt','small');
SELECT name, size FROM shirts WHERE size = 'medium';
+---------+--------+
| name | size |
+---------+--------+
| t-shirt | medium |
+---------+--------+
UPDATE shirts SET size = 'small' WHERE size = 'large';
COMMIT;向该表插入 1 百万行 'medium' 值,需要 1 百万字节存储空间。而如果存储实际字符串 'medium' 到 VARCHAR 列,则需要 600 百万字节。(译者注:应该是 700 百万字节?因为 VARCHAR 的值有 1 或 2 字节长度前缀)
每个枚举值都有一个索引值:
列上的元素列表均分配有索引值,从 1 开始。
空字符串(错误值)的索引值为 0。这意味着可以使用以下 SELECT 语句找出所有分配了无效 ENUM 值的行:
mysql> SELECT * FROM tbl_name WHERE enum_col=0;NULL 的索引值为 NULL。
术语“index”在这里是指枚举值列表的位置,与表的索引无关。
例如,指定为 ENUM('Mercury','Venus','Earth') 的列具有如下值,每个值对应的索引值也有展示。
| Value | Index |
|---|---|
| NULL | NULL |
| '' | 0 |
| 'Mercury' | 1 |
| 'Venus' | 2 |
| 'Earth' | 3 |
ENUM 列最多拥有 65535 个不同值。
若以数值上下文检索 ENUM 值,则返回该值的索引值。例如,你这样检索 ENUM 列的索引值:
mysql> SELECT enum_col+0 FROM tbl_name;期望参数为数值的函数,如 SUM() 或 AVG(),会在必要时将参数转为数值。对于 ENUM 值,在计算中会使用索引值。
在创建表时,会自动删除 ENUM 成员值的尾随空格。
检索时,ENUM 列的值会以列定义中的大小字母进行显示。注意,ENUM 列可指定字符集和排序规则。对于二进制或大小写敏感的排序规则,在为列赋值时会考虑字母大小写。
若向 ENUM 列存储数值时,该数值会被看作索引值,并且存储的值是该索引值对应的枚举成员。(然而,这不适用于将所有输入都视为字符串的 LOAD_DATA)。如果数值被引号包起来,则在没有与枚举值列表匹配的情况下,依然会被解析为索引值。出于这个原因,不建议在 ENUM 列定义中使用与数值相近的枚举值,毕竟很容易造成混淆。例如,以下列拥有枚举成员 '0'、'1'、'2',但对应的索引值是 1、2、3:
numbers ENUM('0','1','2')当存储 2 时,会被解析为索引值,即实际存储为 '1' (对应索引值为 2)。当存储 '2' 时,因匹配枚举值,所以存为 '2'。当存储 '3' 时,因未匹配任何枚举值,所以会被视为索引值,实际存储为 '2'(对应索引值为 3)。
mysql> INSERT INTO t (numbers) VALUES(2),('2'),('3');
mysql> SELECT * FROM t;
+---------+
| numbers |
+---------+
| 1 |
| 2 |
| 2 |
+---------+要确定 ENUM 列所有可能值,请使用 SHOW COLUMNS FROM tbl_name LIKE 'enum_col',并在输出的 Type 列中分析 ENUM 定义。
在 C API 中,ENUM 值以字符串形式返回。有关使用结果集元数据区分它与其他字符串的信息,请看 Section 28.7.4, “C API Data Structures”。
在某些情况下,枚举值可为空字符串('')或 NULL:
向 ENUM 插入一个非法值(即允许值列表里不存在的字符串)时,会被替换为空字符串(作为一个特殊错误值)。该字符串与“常规”的空字符串不同,因为它拥有索引值 0。想更详细了解枚举值对应的索引值,请看 Index Values for Enumeration Literals。
若开启严格模式,则尝试插入非法枚举值会报错。
如果声明 ENUM 列允许 NULL,那么 NULL 就是该列的合法值,且默认值为 NULL。若声明 ENUM 列为 NOT NULL,则默认值为允许值列表的第一个元素。
ENUM 值根据其索引值进行排序,该索引值取决于在列声明中枚举成员列表的顺序。例如,对于 ENUM('b', 'a'),'b' 排在 'a' 前。空字符串排在非空字符串前,NULL 排在所有其它枚举值前。
为了防止在 ENUM 列上使用 ORDER BY 子句时出现意外结果,请使用以下技术之一:
以字母顺序指定 ENUM 列表。
通过 ORDER BY CAST(col AS CHAR) 或 ORDER BY CONCAT(col) 子句确保该列的排序是基于字典而不是索引值。
枚举值不能是表达式,即使求值结果是字符串。
例如,以下 CREATE TABLE 语句会执行失败,因为 CONCAT 函数不能用于构建枚举值:
CREATE TABLE sizes (
size ENUM('small', CONCAT('med','ium'), 'large')
);而且不能将用户变量作为枚举值。以下语句会执行失败:
SET @mysize = 'medium';
CREATE TABLE sizes (
size ENUM('small', @mysize, 'large')
);强烈建议不要使用数值作为枚举值,因为它不会在适当的 TINYINT 或 SMALLINT 类型上节省存储空间,并且很容易造成字符串与对应索引值的混淆(两者可能不相等)。如果确实要使用数值作为枚举值,请始终将其用引号包起来。若省略引号,则会将该数值视为索引值。关于如何将一个数值字符串被错误地用作索引值,请查看 Handling of Enumeration Literals。
定义中存在重复值会导致产生警告。若开启 SQL 严格模式,则会导致错误。
SET 是字符串对象,能拥有 0 个或多个值,每个值都必须从创建表时指定的允许值列表中选取。由多个 set 成员组成的 SET 的值,须用逗号(,)分隔成员值。SET 成员值本身不应该包含逗号。
例如,SET('one', 'two') NOT NULL 列的值可以为以下任意一个:
''
'one'
'two'
'one,two'SET 列最多能拥有 64 个不同的成员。
若定义中含有重复值时,则会产生警告。若开启严格模式,则会报错。
在创建表时,会自动删除 SET 成员值的尾随空格。
检索时,显示的 SET 列值就是定义时的大小写字母。注意,SET 列可指定字符集和排序规则。对于二进制或大小写敏感的排序规则,在为列分配值时会考虑字母大小写。
MySQL 以数值形式存储 SET 的值,而存储值的最低位(bit)对应第一个 set 成员。若在数值上下文中检索 SET 值,则检索到的值为组成该列值的 set 成员相对应的 bit 集合。例如,这样可以从 SET 列中检索出数值:
mysql> SELECT set_col+0 FROM tbl_name;如果将数值存储到 SET 列中,则用数值的二进制表示形式的位(bit)确定列值中的 set 成员。对于指定为 SET('a','b','c','d') 的列,set 成员具有以下十进制和二进制的值。
| SET Member | Decimal Value | Binary Value |
|---|---|---|
| 'a' | 1 | 0001 |
| 'b' | 2 | 0010 |
| 'c' | 4 | 0100 |
| 'd' | 8 | 1000 |
若向该列赋值为 9(对应二进制是 1001),那么第一和第四个 SET 值成员会被选中,所以最终结果值为 'a,d'。
插入包含多个 SET 元素的值时,这些元素可以以任意顺序排列,另外也不会关心元素的出现次数。而检索该值时,值的每个元素均只会出现一次,并且元素是根据创建表时指定的顺序进行排序。假设列指定为 SET('a', 'b', 'c', 'd'):
mysql> CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));如果你插入这些值 'a,d'、'd,a'、'a,d,d'、'a,d,a' 和 'd,a,d':
mysql> INSERT INTO myset (col) VALUES
-> ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
Query OK, 5 rows affected (0.01 sec)
Records: 5 Duplicates: 0 Warnings: 0所有这些值在检索时都会呈现为 'a,d':
mysql> SELECT col FROM myset;
+------+
| col |
+------+
| a,d |
| a,d |
| a,d |
| a,d |
| a,d |
+------+
5 rows in set (0.04 sec)当向 SET 列插入一个不支持的值,这个值会被忽略,并产生一个警告:
mysql> INSERT INTO myset (col) VALUES ('a,d,d,s');
Query OK, 1 row affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+---------+------+------------------------------------------+
| Level | Code | Message |
+---------+------+------------------------------------------+
| Warning | 1265 | Data truncated for column 'col' at row 1 |
+---------+------+------------------------------------------+
1 row in set (0.04 sec)
mysql> SELECT col FROM myset;
+------+
| col |
+------+
| a,d |
| a,d |
| a,d |
| a,d |
| a,d |
| a,d |
+------+
6 rows in set (0.01 sec)若开启 SQL 严格模式,则尝试插入一个非法 SET 值时会报错。
SET 列值按数值排序。NULL 值排在所有非 NULL 的 SET 值前。
期望参数为数值的函数,如 SUM() 或 AVG(),会在必要时将参数转为数值。对于 SET 值,会将其转换为数值后使用。
通常,使用 FIND_IN_SET() 函数或 LIKE 操作符搜索 SET 值:
mysql> SELECT * FROM tbl_name WHERE FIND_IN_SET('value',set_col)>0;
mysql> SELECT * FROM tbl_name WHERE set_col LIKE '%value%';第一句是查找那些 set_col 包含 set 成员 value 的行。第二句相似,但不相同:查找那些 set_col 任意地方包含 value,甚至作为一个 set 成员的子字符串的行。
也允许使用以下语句:
mysql> SELECT * FROM tbl_name WHERE set_col & 1;
mysql> SELECT * FROM tbl_name WHERE set_col = 'val1,val2';第一句查找的是包含第一个 set 成员的值。第二句是精确匹配。注意第二句的比较,将 'var1,var2' 与 'var2,var1' 分别与 set 值进行比较,会得到不同的比较结果。应该按照列定义中列出的顺序指定值。
要确定 SET 列所有可能值,请使用 SHOW COLUMNS FROM tbl_name LIKE 'set_col',并在输出的 Type 列分析 SET 定义。
在 C API 中,SET 值以字符串形式返回。有关使用结果集元数据区分它与其他字符串的信息,请看 Section 28.7.4, “C API Data Structures”。
暂未涉及该领域数据,故暂不翻译。
MySQL 支持 RFC 7159 定义的原生 JSON 数据类型,该类型可以有效访问 JSON(JavaScript Object Notation)文档中的数据。与存储在字符串列的 JSON 序列化字符串相比,JSON 数据类型具有以下优点:
自动校验存储在 JSON 列中的 JSON 文档。非法文档会报错。
优化存储格式。存储在 JSON 列的 JSON 文档会被转为允许快速读取文档元素的内部格式。当服务器读取以二进制格式存储的 JSON 值时,则无需从文本形式解析该值。二进制格式的结构使得服务器能够直接通过键值或数组下标查找子对象或嵌套值,而无需读取它们在文档中的上下文。
MySQL 8.0 还支持 RFC 7396 定义的 JSON Merge Path 格式,可通过 JSON_MERGE_PATH() 函数进行使用。有关示例和更多信息,请查看此函数的描述以及 Normalization, Merging, and Autowrapping of JSON Values。
注意:本讨论中,使用 monotype 字体的
JSON是专门表示 JSON 数据类型的,而使用常规字体的 “JSON” 通常表示 JSON 数据。(译者注:前者用代码标识符 `` 表示)
暂未涉及该领域数据,故暂不翻译。
数据类型的默认值可以是显式或隐式的。
可通过 DEFAULT value 子句显式指定列的默认值。例如:
CREATE TABLE t1 (
i INT DEFAULT -1,
c VARCHAR(10) DEFAULT '',
price DOUBLE(16,2) DEFAULT 0.00
);SERIAL DEFAULT VALUE 是一种特殊情况。在整型列的定义中,它是 NOT NULL AUTO_INCREMENT UNIQUE 的别名。
显式 DEFAULT 子句处理的某些方面受版本影响,如下所述。
MySQL 8.0.13 起的显式默认值的情况
MySQL 8.0.13 前的显式默认值的情况
隐式默认值的情况
DEFAULT 子句指定的默认值可以是字面量常量或表达式。后者需要放在括号内,以将其与字面量常量默认值进行区分。例如:
CREATE TABLE t1 (
-- literal defaults
i INT DEFAULT 0,
c VARCHAR(10) DEFAULT '',
-- expression defaults
f FLOAT DEFAULT (RAND() * RAND()),
b BINARY(16) DEFAULT (UUID_TO_BIN(UUID())),
d DATE DEFAULT (CURRENT_DATE + INTERVAL 1 YEAR),
p POINT DEFAULT (Point(0,0)),
j JSON DEFAULT (JSON_ARRAY())
);特例情况是:对于 TIMESTAMP 和 DATETIME 列,你可以将无括号包围的 CURRENT_TIMESTAMP 函数作为默认值。详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
仅当值作为表达式编写时,才可为 BLOB、TEXT、GEOMETRY 和 JSON 数据类型指定默认值,即使表达式值是字面量:
这是允许的(字面量默认值指定为表达式):
CREATE TABLE t2 (b BLOB DEFAULT ('abc'));这会报错(字面量默认值未指定为表达式):
CREATE TABLE t2 (b BLOB DEFAULT 'abc');表达式默认值必须遵守以下规则。如果表达式包含不允许的部分,则会报错。
允许使用字面量、内置函数(确定性和非确定性均可)和操作符。
不允许使用子查询、参数、存储函数和用户定义的函数。
表达式默认值不能依赖于具有 AUTO_INCREMENT 属性的列。
列的表达式默认值可以引用其他表的列,但对于引用生成列(generated column)或拥有表达式默认值的列,必须出现在表定义前。也就是说,表达式默认值不能包含生成列或拥有表达式默认值的列的前向引用(forward reference)。
forward refercene:Forward reference vs. forward declaration(译者注)
这种顺序约束也适用于使用 ALTER TABLE 重新排序表列的情况。如果结果表拥有的表达式默认值包含对生成列或具有表达式默认值的列的前向引用,则该语句将失败。
注意:如果表达式默认值的任意组成部分依赖 SQL 模式,则表的不同用法可能会产生不同的结果,除非在所有用法中 SQL 模式保持一致。
对于 CREATE TABLE ... LIKE 和 CREATE TABLE ... SELECT,目标表会保留原始表的表达式默认值。
如果表达式默认值引用一个非确定性函数,那么任何能导致表达式求值的语句对于基于语句复制来说都是不安全的。这包括 INSERT、UPDATE 和 ALTER TABLE 等语句。在这种情况下,如果禁用了二进制日志记录,则语句将正常执行。如果启用了二进制日志记录,且将 binlog_format 设置为 STATEMENT,则会记录并执行该语句,但会向错误日志写入一条警告消息,因为复制从属节点可能会出现分歧。当 binlog_format 设置为 MIXED 或 ROW 时,将不执行该语句,并向错误日志写入一条错误消息。
插入新行时,可通过省略列名或将列指定为 DEFAULT 来插入具有表达式默认值的列的默认值:
mysql> CREATE TABLE t4 (uid BINARY(16) DEFAULT (UUID_TO_BIN(UUID())));
mysql> INSERT INTO t4 () VALUES();
mysql> INSERT INTO t4 () VALUES(DEFAULT);
mysql> SELECT BIN_TO_UUID(uid) AS uid FROM t4;
+--------------------------------------+
| uid |
+--------------------------------------+
| f1109174-94c9-11e8-971d-3bf1095aa633 |
| f110cf9a-94c9-11e8-971d-3bf1095aa633 |
+--------------------------------------+但是,仅允许对具有字面量默认值的列使用 DEFAULT(col_name) 指定指名列的默认值,而不允许对具有表达式默认值的列使用。
并非所有存储引擎都支持表达式默认值,对于那些不支持的,会出现 ER_UNSUPPORTED_ACTION_ON_DEFAULT_VAL_GENERATED 错误。
如果默认值的数据类型与列声明的类型不同,则会根据 MySQL 常规的类型转换规则将其隐式转换为声明类型。详情请看 Section 12.2, “Type Conversion in Expression Evaluation”。
DEFAULT 子句定义的默认值必须是字面量常量,即不能是函数或表达式。例如,不能为日期列的默认值设置为函数,如 NOW() 或 CURRENT_DATE。唯一例外是:对于 TIMESTAMP 和 DATETIME 列,可以指定 CURRENT_TIMESTAMP 作为默认值。详情请看 Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”。
无法为 BLOB、TEXT GEOMETRY 和 JSON 数据类型指定默认值。
如果默认值的数据类型与列声明的类型不同,则会根据 MySQL 常规的类型转换规则将其隐式转换为声明类型。详情请看 Section 12.2, “Type Conversion in Expression Evaluation”。
如果无显式的 DEFAULT 值,则 MySQL 按照以下方式确定默认值:
如果列可接受 NULL 值,则使用显式 DEFAULT NULL 子句定义该列。
如果列不接受 NULL 值,则 MySQL 定义该列时不使用显式 DEFAULT 子句(译者注:不理解这句话)。例外:若列定义为 PRIMARY KEY 但无显式声明 NOT NULL,则 MySQL 将其创建为 NOT NULL 列(因为 PRIMARY KEY 必须为 NOT NULL)。
向没有显式 DEFAULT 子句的 NOT NULL 列输入数据时,如果 INSERT 或 REPLACES 语句不包含该列的值,或 UPDATE 语句设置该列为 NULL,则 MySQL 会根据当时的 SQL 模式处理该列:
若开启 SQL 严格模式,则事务表会报错,并且回滚该语句。对于非事务表,也会报错,但如果此报错发生在多行语句(multiple-row statement,译者注:即一条语句影响多行数据)的第二行或更后的行中,则依然会插入前面的行。
若未开启 SQL 严格模式,则 MySQL 将列设置为该列数据类型的隐式默认值。
假设表 t 定义如下:
CREATE TABLE t (i INT NOT NULL);在这种情况下,i 没有明确的默认值,因此在严格模式下,下面的每条语句均会报错,并且不会插入行。当不开启严格模式,前两句会插入隐式默认值,第三句会报错,因为 DEFAULT(i) 无法产生值:
INSERT INTO t VALUES();
INSERT INTO t VALUES(DEFAULT);
INSERT INTO t VALUES(DEFAULT(i));详情请看 Section 5.1.11, “Server SQL Modes”。
SHOW CREATE TABLE 语句能显示指定表的哪些列具有显式的 DEFAULT 子句。
隐式默认值的定义如下:
对于数值类型,默认值是 0。但对于具有 AUTO_INCREMENT 属性的整型或浮点型列,默认值是序列的下一个值。
对于 TIMESTAMP 以外的“日期和时间”类型,默认值是对应类型的“零”值。如果启用 explicit_defaults_for_timestamp 系统变量(详情请看 Section 5.1.8, “Server System Variables”),则 TIMESTAMP 亦是如此。否则,对于表中的第一个 TIMESTAMP 列,默认值为当前日期和时间。详情请看 Section 11.2, “Date and Time Data Types”。
对于 ENUM 以外的字符串类型,默认值是空字符串。对于 ENUM 类型,默认值是第一个枚举值。
目录:
磁盘上表数据的存储要求取决于几个因素。不同存储引擎表示的数据类型和存储的原始数据均不同。表数据可能会被压缩,无论是针对列还是整行,都会使得表或列的存储要求的计算复杂化。
尽管磁盘上的存储布局有所不同,但 MySQL 内部 API(用于通信和交换表行信息) 使用的是适用于所有存储引擎的一致性数据结构。
本节讲述 MySQL 支持的每种数据类型的存储要求的信息,包括使用固定大小表示的数据类型在存储引擎的内部格式和大小。这些信息按类别或存储引擎列出。
表的内部表示形式的最大行大小是 65535 字节,即使存储引擎能够支持更大的行。以上表述不包括 BLOB 和 TEXT 列,它们仅占用该大小的 9 到 12 字节。对于 BLOB 和 TEXT 数据,该信息存储在与行缓冲区不同的内存区域中。不同存储引擎以不同方式处理此数据的分配和存储。有关更多信息,请查看 Chapter 16, Alternative Storage Engines 和 Section 8.4.7, “Limits on Table Column Count and Row Size”。
关于 InnoDB 表的存储要求,请看 Section 15.10, “InnoDB Row Formats”。
重要:NDB 表使用 4 字节对齐;所有 NBD 数据存储均以 4 字节的倍数完成。因此,通常需要 15 字节的列值在 NDB 表中则需要 16 字节。例如,在 NDB 表中,由于对齐的因素,TINTINT、SMALLINT、MEDIUMINT 和 INTEGER(INT) 类型列的每条记录都需要 4 字节。
每个 BIT(M) 列需要 M bit 的存储空间。尽管单个 BIT 列无需对齐 4 字节,但是 NDB 为每行所有的 BIT 列的前 1-32 bit 保留 4 字节(32 bit),然后为 33-64 bit 保留另外的 4 字节,以此类推。
尽管 NULL 本身不需要任何存储空间,但如果表定义包含允许为 NULL 的任意列(最多 32 个 NULL 列),则 NDB 为每行保留 4 字节。(如果定义的 NDB 集群表拥有超过 32 个 NULL 列(最多 64 个 NULL 列),则为每行保留 8 字节。)
使用 NDB 存储引擎的每个表都需要一个主键。若未定义主键,则 NDB 会创建一个“隐藏”主键。该隐藏主键消耗每行 31 - 35 字节。
可使用 ndb_size.pl Perl 脚本来估计 NDB 的存储要求。它会连接到当前的 MySQL 数据库(不是 NDB 集群),并创建有关使用 NDB 存储引擎时数据库需要多少空间的报告。有关更多信息,请看 Section 22.4.28, “ndb_size.pl — NDBCLUSTER Size Requirement Estimator”。
| Data Type | Storage Required |
|---|---|
| TINYINT | 1 byte |
| SMALLINT | 2 bytes |
| MEDIUMINT | 3 bytes |
| INT, INTEGER | 4 bytes |
| BIGINT | 8 bytes |
| FLOAT(p) | 4 bytes(p [0, 24]), 8 bytes(p [25, 53]) |
| FLOAT | 4 bytes |
| DOUBLE [PERCISION], REAL | 8 bytes |
| DECIMAL(M,D),NUMERIC(M,D) | 不定,看下面讨论 |
| BIT(M) | 大约 (M+7)/8 bytes |
DECIMAL(和 NUMERIC)列值使用二进制格式表示,它将 9 个十进制(基数 10)数字打包为 4 字节。每个值的整数和小数部分(的存储)需要分别独立确定。每 9 位数字需要 4 字节,而“剩余”数字需要小于或等于 4 字节。下表给出了多余数字的存储要求。
| Leftover Digits | Number of Bytes |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 2 |
| 5 | 3 |
| 6 | 3 |
| 7 | 4 |
| 8 | 4 |
从 MySQL 5.6.4 开始,TIME、DATETIME 和 TIMESTAMP 列允许拥有小数部分,这部分需要额外 0 到 3 字节。
| Data Type | Storage Required Before MySQL 5.6.4 | Storage Required as of MySQL 5.6.4 |
|---|---|---|
| YEAR | 1 byte | 1 byte |
| DATE | 3 bytes | 3 bytes |
| TIME | 3 bytes | 3 bytes + 小数部分的存储空间 |
| DATETIME | 8 bytes | 5 bytes + 小数部分的存储空间 |
| TIMESTAMP | 4 bytes | 4 bytes + 小数部分的存储空间 |
从 MySQL 5.6.4 开始,YEAR 和 DATE 的存储需求保存不变,但 TIME、DATETIME 和 TIMESTAMP 的表示形式变得不同。DATETIME 的存储效率更高,非小数部分从 8 字节变为 5 字节,并且这三者的小数部分需要 0 到 3 字节,这具体取决于存储值的小数精度。
| 小数部分的精度 | Storage Required |
|---|---|
| 0 | 0 bytes |
| 1,2 | 1 byte |
| 3,4 | 2 bytes |
| 5,6 | 3 bytes |
例如,TIME(0)、TIME(2)、TIME(4) 和 TIME(6) 分别需要 3、4、5 和 6 字节。TIME 和 TIME(0) 是等价的,故需要相同的存储空间。
有关时间值内部表示的详情信息,请看 MySQL Internals: Important Algorithms and Structures。
在下表中,M 表示列声明的长度,对于非二进制字符串,以字符为单位;对于二进制字符串,以字节为单位。L 表示指定字符串值的实际字节长度。
| Data Type | Storage Required |
|---|---|
| CAHR(M) | 紧凑的 InnoDB 行格式优化了拥有不同长度字符集的存储。详情请看 StartFragment COMPACT Row Format Storage CharacteristicsEndFragment。除此之外,就是 M x w 字节,M 的取值范围为 [0, 255],w 是字符集中最长字符所需的字节数。 |
| BINARY(M) | M 字节,M 的取值范围为 [0,255]。 |
| VARCHAR(M),VARBINARY(M) | 若列值需要 [0,255] 字节,则共需要 L + 1 字节;若列值需要大于 255 字节,则共需要 L + 2 字节。 |
| TINYCHAR,TINYTEXT | L + 1 字节,其中 L < 2^8 |
| BLOB,TEXT | L + 2 字节,其中 L < 2^16 |
| MEDIUMBLOB,MEDIUMTEXT | L + 3 字节,其中 L < 2^24 |
| LONGGLOB,LONGTEXT | L + 4 字节,其中 L < 2^32 |
| ENUM('value1','value2',...) | 1 或 2 字节,取决于枚举值的数量(最多为 65535 个值) |
| SET('value1', 'value2',...) | 1、2、3、4 或 8 字节,取决于 set 成员的数量(最多 64 个成员) |
可变长字符串类型存储的是:长度前缀 + 实际数据。长度前缀需要 [1, 4] 字节,这具体取决于数据类型,并且前缀的值为 L(字符串的字节长度)。例如,存储 MEDIUMTEXT 值需要 L 字节存储实际值,再加上 3 字节存储实际值的长度。
要计算用于存储特定 CHAR、VARCHAR 或 TEXT 列值的字节数,必须要考虑该列的字符集以及该值是否含有多字节字符。特别是 utf8 Unicode 字符集,因为它并非所有字符都使用相同数量的字节。utf8mb3 和 utf8mb4 字符集的每个字符分别最多需要 3 和 4 字节。有关用于不同类别的 utf8mb3 或 utf8mb4 字符的存储的详细信息,请看 Section 10.9, “Unicode Support”。
VARCHAR、VARBINARY、BLOB 和 TEXT 类型都是可变长类型。对于各自的存储要求,取决于以下因素:
列值的实际长度
列的最大可能长度
列的字符集,因为某些字符集包含多字节字符。
例如,VARCHAR(255) 列可容纳最大长度为 255 个字符的字符串。假设该列使用 latin1 字符集(每个字符均为 1 字节),则实际需要的存储空间是字符串长度(L)+ 用于记录字符串长度的 1 字节。对于字符串 'abcd',L 是 4,所以存储要求为 5 字节。如果该列更改声明为 2 字节的 ucs2 字符集,则存储要求是 10 字节:'abcd' 的长度为 8 字节,并且需要 2 字节存储长度,因为最大长度大于 255 字节(最大为 510 个字节)。
VARCHAR 或 VARBINARY 列可存储的有效最大字节数取决于 65535 字节的最大行大小(row size),该大小是所有列之间共享。对于存储多字节字符的 VARCHAR 列,最大有效字符数会变少。例如,utf8mb4 字符集的每个字符最多需要 4 字节,因此使用 utf8mb4 字符集的 VARCHAR 列可声明为最多 16383 个字符。详情请看 Section 8.4.7, “Limits on Table Column Count and Row Size”。
InnoDB 会将大于或等于 768 字节的定长字段(Field)编码为可存储在 off-page 的可变长字段。例如,CHAR(255) 列可能会超过 768 字节,因为存在最大字节长度大于 3 的字符集,如 utf8mb4。
NDB 存储引擎支持可变宽列。这意味着 NDB 集群中的 VARCHAR 列和其他存储引擎一样,需要相同大小的存储空间,然而这些值是 4 字节对齐的。因此,对于存储在字符集为 latin1 的 VARCHAR(50) 列的 'abcd' 字符串,需要 8 字节(在相同条件下,MyISAM 表则需 5 字节)。
TEXT 和 BLOB 列在 NBD 中的实现方式有所不同;TEXT 列中的每一行(译者注:即 TEXT 列的每个值)都是由两个独立的部分组成。其中一部分是固定大小(256 字节),并且实际存储在原始表中,另一部分是存储在隐藏表中的,超出 256 字节的数据。第二个表的行大小始终为 2000 字节。这意味着,如果 size <= 256(size 表示行的大小),则 TEXT 列大小是 256;否则大小为 256 + size + (2000 × (size − 256) % 2000)。
ENUM 对象的大小由不同枚举值的数量决定。1 字节用于最多 255 个枚举值;2 字节用于 [256, 65535] 个枚举值。详情请看 See Section 11.3.5, “The ENUM Type”。
SET 对象的大小由不同 set 成员的数量决定。如果 set 大小为 N(译者注:要理解这个“大小”,需要先了解 SET 值的内部表示。1 个 set 成员占 1 bit,64 个成员,则占 64 bit),则对象占用 (N + 7)/8 字节,向上取整为 1、2、3、4 或 8 字节。一个 SET 最多可拥有 64 个成员。详情请看 Section 11.3.6, “The SET Type”。
暂未涉及,后续再翻译。
通常,JSON 列的存储需求与 LONGBLOB 或 LONGTEXT 列存储要求大致相同。也就是说,JSON 文档占用的空间与将该文档序列化后(译者注:即将 JSON 字符串表现形式)存储在这些类型中所用的空间大致相同。然而,存储在 JSON 文档的各个值的二进制编码会产生额外的开销,这其中包括需要查找的元数据和字典。例如,存储在 JSON 文档中的字符串需要 4 到 10 字节的额外存储空间,这具体取决于字符串的长度和存储该字符串的对象或数组的大小。
另外,MySQL 对存储在 JSON 列中的 JSON 文档的大小施加了限制,以使其不能大于 max_allowed_packet 的值。
为了获得最佳存储,在所有情况下都应该尽量使用最精确的类型。例如,如果一个整型列的取值范围是 [1, 99999],那么 MEDIUMINT UNSIGNED 是最佳的类型。因为在所有符合要求的类型中,该类型占用存储空间最少。
在 DECIMAL 列中,所有基础计算(+、-、*、/)都以 65 个十进制数字的精度完成,详情请看 Section 11.1.1, “Numeric Data Type Syntax”。
如果精度不太重要,或速度是最高优先级,则 DOUBLE 类型可能就足够了。为了获得高精度,可以始终将其转换为存储在 BITINT 中的定点类型。这使得你能够使用 64 位整数进行所有计算,然后根据需要将结果转换回浮点数。
为了便于使用为其他供应商的 SQL 实现编写的代码,MySQL 映射了数据类型,如下表所示。这些映射使得从其他数据库系统导入表定义到 MySQL 变得更加简单。
| Other Vendor Type | MySQL Type |
|---|---|
| BOOL | TINYINT |
| BOOLEAN | TINYINT |
| CHARACTER VARYING(M) | VARCHAR(M) |
| FIXED | DECIMAL |
| FLOAT4 | FLOAT |
| FLOAT8 | BOUBLE |
| INT1 | TINYINT |
| INT2 | SMALLINT |
| INT3 | MEDIUMINT |
| INT4 | INT |
| INT8 | BIGINT |
| LONG VARBINARY | MEDIUMBLOB |
| LONG VARCHAR | MEDIUMTEXT |
| LONG | MEDIUMTEXT |
| MIDDLEINT | MEDIUMINT |
| NUMERIC | DECIMAL |
数据类型映射在创建表时发生,此后原始类型就会失效。如果使用其他供应商的类型创建表,然后执行 DESCRIBE tbl_name 语句,MySQL 会使用等效的 MySQL 类型报告表的结构。例如:
mysql> CREATE TABLE t (a BOOL, b FLOAT8, c LONG VARCHAR, d NUMERIC);
Query OK, 0 rows affected (0.00 sec)
mysql> DESCRIBE t;
+-------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------------+------+-----+---------+-------+
| a | tinyint(1) | YES | | NULL | |
| b | double | YES | | NULL | |
| c | mediumtext | YES | | NULL | |
| d | decimal(10,0) | YES | | NULL | |
+-------+---------------+------+-----+---------+-------+
4 rows in set (0.01 sec)设计模式的定义:在面向对象软件设计过程中针对特定问题的简洁而优雅的解决方案。
JavaScript 没有提供传统面向对象语言中的类式继承,而是通过原型委托的方式来实现对象与对象之间的继承。JavaScript 也没有在语言层面提供对抽象类和接口的支持。正因为存在这些跟传统面向对象语言不一致的地方,我们在用设计模式编写代码的时候,更要跟传统面向对象语言加以区别。
“多态”一词源于希腊文 polymorphism,拆开来看是 poly(复数) + morph(形态) + sim,从字面上我们可以理解为复数形式。
多态的实际含义是:同一操作作用于不同的对象上面,可以产生不同的解释和不同的执行结果。换句话说,给不同的对象发送同一个消息时,这些对象会根据这个消息分别给出不同的反馈。
/*
* 多态
* 一段“多态”的 JavaScript 代码
* 问题:随着动物总类的增加会导致 makeSound 函数臃肿
*/
var makeSound = function (animal) {
if (animal instanceof Duck) {
console.log('嘎嘎嘎')
} else if (animal instanceof Chicken) {
console.log('咯咯咯')
}
}
var Duck = function () {}
var Chicken = function () {}
makeSound(new Duck()) // 嘎嘎嘎
makeSound(new Chicken()) // 咯咯咯
/*
* 对象的多态性
* 改进:将不变的部分抽离出来(所有动画都会叫 makeSound),然后把可变的部分各自封装起来
*/
var makeSound = function (animal) {
animal.sound()
}
var Duck = function () {}
Duck.prototype.sound = function () {
console.log('嘎嘎嘎')
}
var Chicken = function () {}
Chicken.prototype.sound = function () {
console.log('咯咯咯')
}
makeSound(new Duck())
makeSound(new Chicken())多态最根本的作用就是通过把过程化的条件分支语句转化为对象的多态性,从而消除这些条件分支语句。
将行为分布在各个对象中,并将这些对象各自负责自己的行为,这正是面向对象设计的优点。
/*
* 优化前
*/
var googleMap = {
show: function () {
console.log('开始渲染谷歌地图')
}
}
var baiduMap = {
show: function () {
console.log('开始渲染百度地图')
}
}
var renderMap = function (type) {
if (type === 'google') {
googleMap.show()
} else if (type === 'baidu') {
baiduMap.show()
}
}
renderMap('google') // 输出:开始渲染谷歌地图
renderMap('baidu') // 输出:开始渲染百度地图
/*
* 优化后
* 对象的多态性提示我们:“做什么”和“怎么去做”是可以分开的
*/
var googleMap = {
show: function () {
console.log('开始渲染谷歌地图')
}
}
var baiduMap = {
show: function () {
console.log('开始渲染百度地图')
}
}
/*
* 后续增加soso地图,renderMap 函数不需要做出任何改变
*/
var sosoMap = {
show: function () {
console.log('开始渲染soso地图')
}
}
var renderMap = function (map) {
if (map.show instanceof Function) {
map.show()
}
}
renderMap(googleMap) // 输出:开始渲染谷歌地图
renderMap(baiduMap) // 输出:开始渲染百度地图JavaScript 的函数既可以普通函数被调用,也可以作为构造函数被调用。当使用 new 运算符来调用函数时,此时的函数就是一个构造器。用 new 运算符来创建对象的过程,实际上也只是先克隆 Object.prototype 对象,在进行一些其他额外操作的过程。
在 Chrome 和 Firefox 等向外暴露了对象 __proto__ 属性的浏览器下,我们可以通过下面这段代码来理解 new 运算符的过程:
function Person(name) {
this.name = name
}
Person.prototype.getName = function () {
return this.name
}
var objectFactory = function () {
var obj = new Object() // 从 Object.prototype 上克隆一个空的对象
var Constructor = [].shift.call(arguments) // 取得外部传入的构造器,此例是 Person
obj.__proto__ = Constructor.prototype // 指向正确的原型 Person.prototype 而不是原来的 Object.prototype
var ret = Constructor.apply(obj, arguments) // 借用外部传入的构造器给 obj 设置属性
return typeof ret === 'object' ? ret : obj // 确保构造器总是会返回一个对象
}
var a = objectFactory(Person, 'sven')
console.log(a.name) // sven
console.log(a.getName()) // sven
console.log(Object.getPrototypeOf(a) === Person.prototype) // true
// 我们看到,分别调用下面两句代码产生了一样的结果:
var a = objectFactory(A, 'sven')
var a = new Person('sven')JavaScript 给对象提供了一个名为 __proto__ 的隐藏属性,对象的 __proto__ 属性默认会指向它的构造函数的原型对象。
var a = new Object()
console.log(a.__proto__ === Object.prototype) // true实际上,__proto__ 就是对象跟“对象构造函数的原型”联系起来的纽带。
虽然 JavaScript 的对象最初都是由 Object.prototype 对象克隆而来,但对象构造函数的原型并不仅限于 Object.prototype 上,而是可以动态指向其他对象。
最常用的原型继承方式:
var obj = {name: 'sven'}
var A = function () {}
A.prototype = obj
var a = new A()
console.log(a.name) // sven使用 Object.create 来完成原型继承看起来更能体现原型模式的精髓。通过 Object.create(null) 可以创建出没有原型的对象。
另外,ECMAScript 6 带来了新的 Class 语法。但其背后仍是通过原型机制来创建对象。
JavaScript 的 this 总是指向一个对象,而具体指向哪个对象时运行时基于函数的执行环境动态绑定的,而非函数被声明时的环境。
除去不常用的 with 和 eval 的情况,具体到实际应用中,this 的指向大致可以分为以下 4 种。
Math.max.apply(null, [1, 2, 3])大部分高级浏览器都实现了内置的 Function.prototype.bind。但我们也可以模拟一个:
// bind 的一个特性是 bind 之后不能再次更改 this,这里也实现了。
Function.prototype.bind = function (context) {
var self = this
return function () {
return self.apply(context, arguments)
}
}高阶函数是指至少满足下列条件之一的函数:
AOP(面向切面编程)的主要作用是把一些跟核心业务逻辑模块无关的功能抽离出来,这些跟业务逻辑无关的功能通常包括日记统计、安全控制、异常处理等。把这些功能抽离出来之后,再通过“动态织入”的方式掺入业务逻辑模块中。这样可以保持业务逻辑模块的纯净和高内聚性,其次是方便复用日志统计等功能模块。
通常,在 JavaScript 中实现 AOP 都是指把一个函数“动态织入”到另外一个函数中,具体的实现技术有很多,这里通过扩展 Function.prototype 来做到这一点。
Function.prototype.before = function (beforefn) {
var __self = this // 保持原函数的引用
return function () { // 返回包含了原函数和新函数的“代理”函数
beforefn.apply(this, arguments) // 执行新函数,修正 this
return __self.apply(this, arguments) // 执行原函数
}
}
Function.prototype.after = function (afterfn) {
var __self = this
return function () {
var ret = __self.apply(this, arguments)
afterfn.apply(this, arguments)
return ret
}
}
var func = function () {
console.log(2)
}
func = func.before(function () {
console.log(1)
}).after(function () {
console.log(3)
})
func() // 1 2 3这种使用 AOP 的方式来给函数添加职责,也是 JavaScript 语言中一种非常特别和巧妙的装饰者模式实现。
currying 又称部分求值。一个 currying 的函数首先会接受一些参数,接受了这些参数之后,该函数并不会立即求值,而是继续返回另外一个函数,刚才传入的参数在函数形成的闭包中被保存起来。待到函数被真正需要求值的时候,之前传入的所有参数都会被一次性用于求值。
/*
* 通用的 function currying() {}
*/
var currying = function (fn) {
var args = []
return function () {
if (arguments.length === 0) {
return fn.apply(this, args)
} else {
[].push.apply(args, arguments)
return arguments.callee
}
}
}
/*
* 月底计算本月花了多少钱,并不需要每天计算,只需最后求值即可。
*/
var cost = (function () {
var money = 0
return function () {
for (var i = 0, l = arguments.length; i < l; i++) {
money += arguments[i]
}
return money
}
})()
var cost = currying(cost) // 转化为 currying 函数
cost(100) // 未真正求值
cost(200) // 未真正求值
cost(300) // 未真正求值
alert(cost()) // 求值并输出 600/*
* throttle
*/
var throttle = function (fn, interval) {
var __self = fn // 保存需要被延迟执行的函数引用
var timer // 定时器
var firstTime = true // 是否是第一次调用
return function () {
var args = arguments
var __me = this
if (firstTime) { // 如果是第一次调用,不需延迟执行
__self.apply(__me, args)
return firstTime = false
}
if (timer) { // 如果定时器还在,说明前一次延迟执行还没有完成
return false
}
timer = setTimeout(function () { // 延迟一段时间执行
clearTimeout(timer)
timer = null
__self.apply(__me, args)
}, interval || 500)
}
}
window.onresize = throttle(function () {
console.log(1)
}, 500)对于耗时函数的解决方案之一是下面的 timeChunk 函数,timeChunk 函数让创建节点的工作分批进行。
timeChunk 函数接受 3 个函数,第 1 个参数是总数据,第 2 个参数是封装了处理逻辑的函数,第 3 个参数是每一批处理的数量。
/*
* 分时函数
* ary 总数据
* fn 每个数据的处理函数
* count 每批处理的数据量
*/
var timeChunk = function (ary, fn, count) {
var obj
var t
var len = ary.length
var start = function () {
for (var i = 0; i < Math.min(count || 1, ary.length); i++) {
var obj = ary.shift()
fn(obj)
}
}
return function () {
t = setInterval(function () {
if (ary.length === 0) { // 如果全部数据已处理完
return clearInterval(t)
}
start()
}, 200) // 分批执行的时间间隔,也可以用参数的形式传入
}
}在 Web 开发中,因为浏览器之间的实现差异,一些嗅探工作总是不可避免。比如我们需要一个在各个浏览器中能够实现通用的事件绑定函数 addEvent。
// 方案一:常见的写法
// 缺点:每次被调用都会执行条件分支
var addEvent = function (elem, type, handler) {
if (window.addEventListener) {
return elem.addEventListener(type, handler, false)
}
if (window.attachEvent) {
return elem.attachEvent('on' + type, handler)
}
}
// 方案二:在代码加载时就进行一次判断,让 addEvent 返回一个包裹正确逻辑的函数
// 缺点:当从头到尾都未用过,形成冗余操作
var addEvent = (function () {
if (window.addEventListener) {
return function (elem, type, handler) {
elem.addEventListener(type, handler, false)
}
}
if (window.attachEvent) {
return function (elem, type, handler) {
elem.attachEvent('on' + type, handler)
}
}
})()
// 方案三:惰性载入函数
var addEvent = function (elem, type, handler) {
if (window.addEventListener) {
addEvent = function (elem, type, handler) {
elem.addEventListener(type, handler, false)
}
} else if (window.attachEvent) {
addEvent = function (elem, type, handler) {
elem.attachEvent('on' + type, handler)
}
}
addEvent(elem, type, handler)
}本书并没有涵盖 GoF 所提出的 23 种设计模式,而是选择了在 JavaScript 开发中更常见的 14 种设计模式。
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
// 通用的惰性单例
var getSingle = function (fn) {
var result
return function () {
return result || (result = fn.apply(this, arguments))
}
}
var createLoginLayer = function () {
var div = document.createElement('div')
div.innerHTML = '我是登录浮窗'
div.style.display = 'none'
document.body.appendChild(div)
return div
}
var createSingleLoginLayer = getSingle(createLoginLayer)
document.getElementById('loginBtn').onclick = function () {
var loginLayer = createSingleLoginLayer()
loginLayer.style.display = 'block'
}定义:定义一系列算法,把它们一个个封装起来,并且使它们可以相互替换。
案例:
// 计算奖金
// 最初的代码实现
var calculateBouns = function (performanceLevel, salary) {
if (performanceLevel === 'S') {
return salary * 4
}
if (performanceLevel === 'A') {
return salary * 3
}
if (performanceLevel === 'B') {
return salary * 2
}
}
calculateBouns('B', 2000) // 40000
calculateBouns('S', 6000) // 24000
// JavaScript 版本的策略模式
var strategies = {
S: function (salary) {
return salary * 4
},
A: function (salary) {
return salary * 3
},
B: function (salary) {
return salary * 2
}
}
var calculateBouns = function (level, salary) {
return strategies[level](salary)
}
console.log(calculateBouns('S', 20000)) // 80000
console.log(calculateBouns('A', 30000)) // 30000通常会把算法的含义扩散开来,使用策略模式也可以用来封装一系列的“业务规则”。只要这些业务规则指向的目标一致,并且可以被替换使用,我们就可以用策略模式来封装它们。
/*
* 缺点和计算奖金的最初版本一样
* 1.registerForm.onsubmit 函数比较庞大,包含了很多 if-else 语句
* 2.registerForm.onsubmit 缺乏弹性,增加或修改规则需深入内部,违反开发-封闭原则
* 3.算法复用性差
*/
var registerForm = document.getElementById('registerForm')
registerForm.onsubmit = function () {
if (registerForm.userName.value === '') {
alert('用户名不能为空')
return false
}
if (registerForm.password.value.length < 6) {
alert('密码长度不能少于6位')
return false
}
if (!/(^1[3|5|8][0-9]{9})/.test(registerForm.phoneNumber.value)) {
alert('手机号码格式不正确')
return false
}
}
/*
* 用策略模式重构表单校验
* 第一步:将校验逻辑封装成策略对象
* 第二步:实现 Validator 类。Validator 类在这里作为 Context,负责接收用户的请求并委托给 strategy 对象。
* 第三步:客户调用代码
*/
var strategies = {
isNotEmpty: function (value, errorMsg) {
if (value === '') {
return errorMsg
}
},
minLength: function (value, length, errorMsg) {
if (value.length < length) {
return errorMsg
}
},
isMobile: function (value, errorMsg) {
if (!/(^1[3|5|8][0-9]{9})/.test(value)) {
return errorMsg
}
}
}
var Validator = function () {
this.cache = []
}
// 支持对同一个 dom 添加多种校验规则
Validator.prototype.add = function (dom, rules) {
var self = this
for (var i = 0, rule; rule = rules[i++]; ) {
(function (rule) {
var strategyAry = rule.strategy.split(':') // 把 strategy 和参数分开
var errorMsg = rule.errorMsg
self.cache.push(function () { // 把校验的步骤用空函数包装起来,并且放入 cache
var strategy = strategyAry.shift() // 用户挑选的 strategy
strategyAry.unshift(dom.value) // 把 input 的 value 添加进参数列表
strategyAry.push(errorMsg) // 用 errorMsg 添加进参数列表
return strategies[strategy].apply(dom, strategyAry)
})
})(rule)
}
}
Validator.prototype.start = function () {
for (var i = 0, ValidatorFunc; ValidatorFunc = this.cache[i++]; ) {
var errorMsg = ValidatorFunc() // 开始校验,并取得校验后的返回信息
if (errorMsg) { // 如果没有确切的返回值,说明校验没有通过
return errorMsg
}
}
}
// 客户调用代码
var registerForm = document.getElementById('registerForm')
var validatorFunc = function () {
var validator = new Validator()
validator.add(registerForm.userName, [{
strategy: 'isNotEmpty',
errorMsg: '用户名不能为空'
}, {
strategy: 'minLength:6',
errorMsg: '用户名长度不能少于6位'
}])
var errorMsg = validator.start()
return errorMsg
}
registerForm.onsubmit = function () {
var errorMsg = validatorFunc()
if (errorMsg) {
alert(errorMsg)
return false
}
}代理模式的关键是,当客户不方便直接访问一个对象或不满足需要的时候,提供一个替身对象来控制对这个对象的访问,客户实际上访问的是替身对象。替身对象对请求做出一些处理之后,再把请求转交给本体对象。
两种代理模式:保护代理和虚拟代理。
保护代理:用于控制不同权限的对象对目标对象的访问,但在 JavaScript 并不容易实现保护代理,因为我们无法判断谁访问了对象。
虚拟代理:把一些开销很大的对象,延迟到真正需要它的时候才创建。
/*
* 无代理,更常见的情况
*/
var MyImage = (function () {
var imgNode = document.createElement('img')
document.body.appendChild(imgNode)
var img = new Image
img.onload = function () {
imgNode.src = img.src
}
return {
setSrc: function (src) {
imgNode.src = '***.gif'
img.src = src
}
}
})
/*
* 引入代码
*/
var myImage = (function () {
var imgNode = document.createElement('img')
document.body.appendChild(imgNode)
return {
setSrc: function (src) {
imgNode.src = src
}
}
})()
var proxyImage = (function () {
var img = new Image
img.onload = function () {
myImage.setSrc(this.src)
}
return {
setSrc: function (src) {
myImage.setSrc('***.gif')
img.src = src
}
}
})()
proxyImage.setSrc('***.JPG')单一职责原则指的是,就一个类(通常也包括对象和函数等)而言,应该仅有一个引起它变化的原因。如果一个对象承担了多项职责,就意味着这个对象将变得巨大,引起它变化的原因可能会有多个。而面向对象设计鼓励奖行为分布到细粒度和低内聚的设计。
在面向对象的程序设计中,大多数情况下,若违反其他任何原则,同时将违反开放-封闭原则。
因此,代理负责预加载图片,预加载的操作完成之后,把请求体重新交给本体 MyImage。
/*
* 点击 checkbox 即同步文件
* 反面例子
*/
var syncFile = function (id) {
console.log('开始同步文件,id 为' + id)
}
var checkbox = document.getElementsByTagName('input')
for (var i = 0, c; c = checkbox[i++]; ) {
c.onclick = function () {
if (this.checked === true) {
syncFile(this.id)
}
}
}
// 使用代理
var syncFile = function (id) {
console.log('开始同步文件,id 为' + id)
}
var proxySyncFile = (function () {
var cache = []
var timer
return function (id) {
cache.push(id)
if (timer) {
return
}
timer = setTimeout(function () {
syncFile(cache.join(',')) // 2 秒后向本体发送需要同步的 ID 集合。
clearTimeout(timer)
timer = null
cache.length = 0
}, 2000)
}
})()
var checkbox = document.getElementsByTagName('input')
for (var i = 0, c; c = checkbox[i++]; ) {
c.onclick = function () {
if (this.checked === true) {
proxySyncFile(this.id)
}
}
}缓存代理可以为一些开销大的运算结果提供暂时的存储,在下次运算时,如果传递进来的参数跟之前一直,则可以直接返回前面存储的运算结果。
/*
* 通过增加缓存代理的方式,mult 函数可以继续专注于自身的职责——计算乘积
* 缓存的功能由代理对象实现
*/
var mult = function () {
console.log('开始计算乘积')
var a = 1
for (var i = 0, l = arguments.length; i < l; i++) {
a *= arguments[i]
}
return a
}
var proxyMult = (function () {
var cache = {}
return function () {
var args = Array.prototype.join.call(arguments, ',')
if (args in cache) {
return cache[args]
}
return cache[args] = mult.apply(this, arguments)
}
})()
proxyMult(1, 2, 3, 4) // 24
proxyMult(1, 2, 3, 4) // 24缓存代理用于 Ajax 异步请求数据:与计算乘积不同的是,请求数据是个异步操作,无法直接把计算结果放到代理对象的缓存中,而是要通过回调的方式。
var pageProxy = (function () {
var cache = {}
return function (fn) { // fn 作为处理页码数据的函数
var pageData = cache[page]
if (pageData) {
return fn(pageData) //返回制定页码的数据
}
http.getPage(page) // 获取制定页码的数据
.then((data) => {
cache[page] = data //存放数据
fn(data)
})
}
})()通过传入高阶函数这种更加灵活的方式,可以为各种计算方法创建缓存代理。
/*
* 创建缓存代理的工厂
*/
var createProxyFactory = function (fn) {
var cache = {}
return function () {
var args = Array.prototype.join.call(arguments, ',')
if (args in cache) {
return cache[args]
}
return cache[args] = fn.apply(this, arguments)
}
}
var proxyMult = createProxyFactory(mult)
proxyMult(1, 2, 3, 4)防火墙代理、远程代理、保护代理、智能引用代理、写时复制代理
迭代器模式是指提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
/*
* 根据不同浏览器获取相应的上传组件对象
*/
/*
* 缺点:难以阅读
* 严重违反开发-封闭原则
* 不便增加新的上传方式,如 HTML5 上传
*/
var getUploadObj = function () {
try {
} catch (e) {
if (supportFlash()) {
var str = '<object type="application/x-shockwave-flash"></object>'
return $(str).appendTo($('body'))
} else {
var str = '<input name="file" type="file" />>'
return $(str).appendTo($('body'))
}
}
}
/*
* 迭代器
* 三个函数有同一个约定:upload 对象可用就返回,否则返回 false,提示迭代器继续往后迭代
*/
var getActiveUploadObj = function () {
try {
return new ActiveXObject('TXFTNActiveX.FTNUpload')
} catch(e) {
return false
}
}
var getFlashUploadObj = function () {
if (supportFlash()) {
var str = '<object type="application/x-shockwave-flash"></object>'
return $(str).appendTo($('body'))
}
return false
}
var getFormUploadObj = function () {
var str = '<input name="file" type="file" />>'
return $(str).appendTo($('body'))
}
var iteratorUploadObj = function () {
for (var i = 0, fn; fn = arguments[i]; ) {
var uploadObj = fn()
if (uploadObj !== false) {
return uploadObj
}
}
}
var uploadObj = iteratorUploadObj(getActiveUploadObj, getFlashUploadObj, getFormUploadObj)迭代器模式是一种相对简单的模式,简单到很多时候我们都不认为它是一种设计模式。目前绝大部分语言都内置了迭代器,如 Array.prototype.forEach。
又称观察者模式,定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都将得到通知。
/*
* 全局的 Event 对象
*/
var Event = (function () {
var clientList = {}
var listen
var trigger
var remove
listen = function (key, fn) {
if (!clientList[key]) {
clientList[key] = []
}
clientList[key].push(fn)
}
trigger = function () {
var key = Array.prototype.shift.call(arguments)
var fns = clientList[key]
if (!fns || fns.length === 0) {
return false
}
for (var i, fn; fn = fns[i]; ) {
fn.apply(this, arguments)
}
}
remove = function (key, fn) {
var fns = clientList[key]
if (!fns) {
return false
}
if (!fn) {
fns && (fns.length = 0)
} else {
for (var l = fns.length - 1; l >=0; l --) {
var _fn = fns[l]
if (_fn === fn) {
fns.splice(l, 1)
}
}
}
}
return {
listen: listen,
trigger: trigger,
remove: remove
}
})()
Event.listen('squareMeter88', function (price) {
console.log('价格=' + price)
})
Event.trigger('squareMeter88', 200000)优点:
缺点:
对于书中解释仍不太理解,后续再补充。
/*
*
* 打开空调
* 打开电视和音响
* 关门、开电脑、登录 QQ
* 宏命令:执行该宏命令时,会一次遍历执行它所包含的子命令
*/
var MacroCommand = function () {
return {
commandList: [],
add: function (command) {
this.commandList.push(command)
},
execute: function () {
for (var i = 0, command; command = this.commandList[i++]; ) {
command.execute()
}
}
}
}
var openAcCommand = {
execute: function () {
console.log('打开空调')
}
}
/*
* 加里的电视和音响是链接在一起的,所有可以用一个宏命令来组合打开它们
*/
var openTvCommand = {
execute: function () {
console.log('打开电视')
}
}
var openSoundCommand = {
execute: function () {
console.log('打开音响')
}
}
var macroCommand1 = MacroCommand()
macroCommand1.add(openTvCommand)
macroCommand1.add(openSoundCommand)
/*
* 关门、打开电脑和登录QQ 的宏命令
*/
var closeDoorCommand = {
execute: function () {
console.log('关门')
}
}
var openPcCommand = {
execute: function () {
console.log('打开电脑')
}
}
var openQQCommand = {
execute: function () {
console.log('登录 QQ')
}
}
var macroCommand2 = MacroCommand()
macroCommand2.add(closeDoorCommand)
macroCommand2.add(openPcCommand)
macroCommand2.add(openQQCommand)
/*
* 把所有的命令组合成一个“超级命令”
*/
var macroCommand = MacroCommand()
macroCommand.add(openAcCommand)
macroCommand.add(macroCommand1)
macroCommand.add(macroCommand2)
/*
* 给遥控器绑定“超级命令”
*/
var setCommand = (function (command) {
document.getElementById('button').onclick = function () {
command.execute()
}
})(macroCommand)组合模式适用于以下两种情况:
模板方法模式由两部分结构组成,第一部分是抽象父类,第二部分是具体的实现子类。通常在抽象父类中封装了子类的算法框架,包括实现一些公共方法和封装子类中所有方法的执行顺序。子类通过继承这个抽象类,也继承了整个算法结构,并且可以选择重写父类的方法。
用 Java 实现 Coffee or Tea 的例子
/*
* 用 Java 实现 Coffee or Tea 的例子
*/
public abstract class Beverage { // 饮料抽象类
final void init () { // 模板方法
boilWater();
brew();
pourInCup();
addCondiments();
}
void boilWater () { // 具体方法 boilWater
System.out.println('把水煮沸');
}
abstract void brew(); // 抽象方法 brew
abstract void addCondiments(); // 抽象方法 addCondiments
abstract void pourInCup(); // 抽象方法 pourInCup
}
public class Coffee extends Beverage { // coffee 类
@Override
void brew () { // 子类中重写 brew 方法
System.out.println('用沸水冲泡咖啡');
}
@Override
void pourInCup () { // 子类中重写 pourInCup 方法
System.out.println('把咖啡倒进杯子');
}
@Override
void addCondiments () { // 子类中重写 addCondiments 方法
System.out.println('加糖和牛奶');
}
}
public class Tea extends Beverage { // Tea 类
@Override
void brew () { // 子类中重写 brew 方法
System.out.println('用沸水冲泡茶叶');
}
@Override
void pourInCup () { // 子类中重写 pourInCup 方法
System.out.println('把茶叶倒进杯子');
}
@Override
void addCondiments () { // 子类中重写 addCondiments 方法
System.out.println('加柠檬');
}
}
public class Test {
private static void prepareRecipe(Beverage beverage) {
beverage.init();
}
public static void main (String args[]) {
Beverage coffee = new Coffee(); // 创建 coffee 对象
prepareRecipe(coffee); // 开始泡咖啡
// 把水煮沸
// 用沸水冲泡咖啡
// 把咖啡倒进杯子
// 加糖和牛奶
Beverage tea = new Tea(); // 创建 tea 对象
prepareRecipe(tea); // 开始泡茶叶
// 把水煮沸
// 用沸水冲泡茶叶
// 把茶叶倒进杯子
// 加柠檬
}
}我们知道 Beverage.prototype.init 方法作为模板方法,已经规定了子类的算法框架。
Beverage.prototype.init = function () {
this.boldWater()
this.brew()
this.pourInCup()
this.addCondiments()
}然而,JavaScript 没有抽象类,也没 Java 编辑器会保证子类会重写父类中的抽象方法。因此需要其他变通的解决方案。
让 Beverage.prototype.brew 等方法直接抛出一个异常。至少让程序运行时得到一个错误:
Beverage.prototype.brew = function () {
throw new Error('子类必须重写 brew 方法')
}
// ...钩子方法让子类不受某些约束。放置钩子是隔离变化的一种常见手段。我们在父类中容易变化的地方放置钩子,钩子可以有一个默认的实现,究竟要不要“挂钩”,这由子类自行决定。钩子方法的返回结果决定了模板方法方面部分的执行步骤,也就是程序接下来的走向。这样一来,程序就拥有了变化的可能。
var Beverage = function () {}
Beverage.prototype.boilWater = function () {
console.log('把水煮沸')
}
Beverage.prototype.brew = function () {
throw new Error('子类必须重写 brew 方法')
}
Beverage.prototype.pourInCup = function () {
throw new Error('子类必须重写 pourInCup 方法')
}
Beverage.prototype.addCondiments = function () {
throw new Error('子类必须重写 addCondiments 方法')
}
Beverage.prototype.customerWantsCondiments = function () {
return true // 默认需要调料
}
Beverage.prototype.init = function () {
this.boilWater()
this.brew()
this.pourInCup()
if (this.customerWantsCondiments()) { // 如果挂钩默认返回 true,则需要调料
this.addCondiments()
}
}模板方法模式是基于继承的一种设计模式,父类封装了子类的算法框架和方法的执行顺序。子类继承父类之后,父类通知子类执行这些方法,好莱坞原则很好地诠释了这种设计技巧,即高层组件调用底层组件。
然而 JavaScript 语言实际上没有提供真正的类似继承,继承是通过对象与对象之前的委托来实现的。虽然,我们在形式上借鉴了提供类似继承的语言,但本章学习到的模板方法并不十分正宗。在 JavaScript 通过高阶函数也能实现。
var Beverage = function (param) {
var boilWater = function () {
console.log('把水煮沸')
}
var brew = param.brew || function () {
throw new Error('必须传递 brew 方法')
}
var pourInCup = param.pourInCup || function () {
throw new Error('必须传递 pourInCup 方法')
}
var addCondiments = param.addCondiments || function () {
throw new Error('必须传递 addCondiments 方法')
}
var F = function () {}
F.prototype.init = function () {
boilWater()
brew()
pourInCup()
addCondiments()
}
return F
}
var Coffee = Beverage ({
brew: function () {
console.log('用沸水冲泡咖啡')
},
pourInCup: function () {
console.log('把咖啡倒进杯子')
},
addCondiments: function () {
console.log('加糖和咖啡')
}
})
var coffee = new Coffee()
coffee.init()模板方法模式是一种典型的通过封装变化提供系统扩展性的设计模式。在传统的面向对象语言中,一个运用了模板方法模式的程序中,子类的方法种类和执行顺序都是不变的,所以我们把这部分逻辑抽象到父类的模板方法里面。而子类的方法具体怎么实现则是可变的,于是我们把这部分的逻辑封装到子类中。通过增加新的子类,我们便能给系统增加新的功能,并需要改动抽象父类及其他子类,这也符合开发-封闭原则。
享元模式是一种用于性能优化的模式。其核心是用共享技术来支持大量细粒度的对象。
享元模式要求将对象的属性划分为内部状态和外部状态(通常指属性)。享元模式的目标是尽量减少共享对象的数量。
如何划分内部状态和外部状态,下面的几条经验提供了一些指引:
这样一来,我们便可以把所有内部状态相同的对象都指定为同一个共享对象。而外部状态可以从对象身上剥离出来,并存储在外部。
剥离了外部状态的对象成为共享对象,外部状态在必要时被传入共享对象来组装成一个完整的对象。虽然组装外部状态成为一个完整对象的过程需要花费一定的时间,但却可以大大减少系统中的对象数量。因此,享元模式是一种时间换空间的优化模式。
通常来讲,内部状态有多少种组合,系统中便最多存在多少个对象。
使用享元模式的关键是如何区别内部状态和外部状态。可以被对象共享的属性通常被划分为内部状态。
案例:不管什么样式的衣服,都可以按照性别不同,穿在同一个男模特或者女模特身上,模特的性别就可以作为内部状态存储在共享对象的内部。而外部状态取决于具体的场景,并根据场景而变化,就像例子中每件衣服都是不同的,它们不能被一些对象共享,因此只能被划分为外部状态。
每个上传文件对应一个 upload 对象。对于同时上传多个文件时会创建大量对象。
/*
* 对象爆炸
*/
var id = 0
var startUpload = function (uploadType, files) { // uploadType 区分是控件还是 Flash
for (var i = 0, file; file = files[i++]; ) {
var uploadObj = new Upload(uploadType, file.fileName, file.fileSize)
uploadObj.init(id++) // 给 upload 对象设置一个唯一的 id
}
}
var Upload = function (uploadType, fileName, fileSize) {
this.uploadType = uploadType
this.fileName = fileName
this.fileSize = fileSize
this.dom = null
}
Upload.prototype.init = function (id) {
var that = this
this.id = id
this.dom = document.createElement('div')
this.dom.innerHTML =
'<span>文件名称:'+ this.fileName +', 文件大小:'+ this.fileSize +'</span>' +
'<button class="delFile">删除</button>'
this.dom.querySelector('.delFile').onclick = function () {
this.delFile()
}
document.body.appendChild(this.dom)
}
Upload.prototype.delFile = function () {
if (this.fileSize < 3000) {
return this.dom.parentNode.removeChild(this.dom)
}
if (window.confirm('确定要删除该文件吗?' + this.fileName)) {
return this.dom.parentNode.removeChild(this.dom)
}
}
startUpload('plugin', [{
fileName: '1.txt',
fileSize: 1000
}, {
fileName: '2.txt',
fileSize: 3000
}])
startUpload('flash', [{
fileName: '3.txt',
fileSize: 1000
}, {
fileName: '4.txt',
fileSize: 3000
}])/*
* 享元模式重构文件上传
* uploadType 为内部状态
* fileName、fileSize 是根据场景而变,无法被共享,所以为外部状态
*/
var Upload = function (uploadType) {
this.uploadType = uploadType
}
Upload.prototype.delFile = function (id) {
uploadManager.setExternalState(id, this)
if (this.fileSize < 3000) {
return this.dom.parentNode.removeChild(this.dom)
}
if (window.confirm('确定需要删除该文件吗?' + this.fileName)) {
return this.dom.parentNode.removeChild(this.dom)
}
}
/*
* 工厂进行对象实例化
* 如果某种内部状态对应的共享对象已经被创建过,则直接返回该对象,否则创建一个新的对象。
*/
var UploadFactory = (function () {
var createdFlyWeightObjs = {}
return {
create: function (uploadType) {
if (createdFlyWeightObjs[uploadType]) {
return createdFlyWeightObjs[uploadType]
}
return createdFlyWeightObjs[uploadType] = new Upload(uploadType)
}
}
})
/*
* 管理器封装外部状态
* 负责向 UploadFactory 提交创建对象的请求,
* 并用 uploadDatabase 对象保存所有 upload 对象的外部状态,
* 以便在程序运行过程中给 upload 共享对象设置外部状态
*/
var uploadManager = (function () {
var uploadDatabase = {}
return {
add: function (id, uploadType, fileName, fileSize) {
var flyWeightObj = UploadFactory.create(uploadType)
var dom = document.createElement('div')
dom.innerHTML =
'<span>文件名称:'+ this.fileName +', 文件大小:'+ this.fileSize +'</span>' +
'<button class="delFile">删除</button>'
dom.querySelector('.delFile').onclick = function () {
flyWeightObj.delFile(id)
}
document.body.appendChild(dom)
uploadDatabase[id] = {
fileName: fileName,
fileSize: fileSize,
dom: dom
}
return flyWeightObj
},
setExternalState: function (id, flyWeightObj) {
var uploadData = uploadDatabase[id]
for (var i in uploadData) {
flyWeightObj[i] = uploadData[i]
}
}
}
})()
var id = 0
window.startUpload = function (uploadType, files) {
for (var i = 0, file; file = files[i++]; ) {
var uploadObj = uploadManager.add(++id, uploadType, file.fileName, file.fileSize)
}
}
/*
* 无论上传多少文件,需要创建的 upload 对象的最大数量为 2
*/
startUpload('plugin', [{
fileName: '1.txt',
fileSize: 1000
}, {
fileName: '2.txt',
fileSize: 3000
}])
startUpload('flash', [{
fileName: '3.txt',
fileSize: 1000
}, {
fileName: '4.txt',
fileSize: 3000
}])一般来说,以下情况发生时便可以使用享元模式。
对于无内部状态的情况下,依然使用享元模式时,构造函数 Upload 就变成了无参数的形式:
var Upload = function () {}其他属性如 fileName、fileSize、dom 依然可以做为外部状态保存在共享对象外部。现在已经没有了内部状态,意味着只需要唯一的一个共享对象。现在我们需要改写创建享元对象的工厂:
var UploadFactory = (function () {
var uploadObj
return {
create: function () {
if (uploadObj) {
return uploadObj
}
return uploadObj = new Upload()
}
}
})()管理器部分的代码不需要改动,还是负责剥离和组装外部状态。当对象没有内部状态时,生成共享对象的工厂实际上变成了一个单例工厂。
对象池维护一个装载空闲对象的池子,如果需要对象时,不是直接 new,而是转从对象池里获取。如果对象池里没有空闲对象,则创建一个新的对象,当获取出的对象完成它的职责后,再进入池子等待下次被获取。
对象池技术的应用非常广泛,HTTP 连接池和数据库连接池都是其代表应用。在 Web 前端开发中,对象池使用最多的场景大概就是跟 DOM 有关的操作。
/*
* 对象池的通用实现
*/
var objectPoolFactory = function (createObjFn) {
var objectPool = []
return {
create: function () {
var obj = objectPool.length === 0 ?
createObjFn.apply(this, arguments) : objectPool.shift()
},
recover: function (obj) {
objectPool.push(obj)
}
}
}
var iframeFactory = objectPoolFactory(function () {
var iframe = document.createElement('iframe')
document.body.appendChild(iframe)
iframe.onload = function () {
iframe.onload = null // 防止 iframe 重复加载的 bug
iframeFactory.recover(iframe) // iframe 加载完成之后回收节点
}
return iframe
})
var iframe1 = iframeFactory.create()
iframe1.src = 'http://baidu.com'
var iframe2 = iframeFactory.create()
iframe2.src = 'http://qq.com'
setTimeout(function () {
var iframe3 = iframeFactory.create()
iframe3.src = 'http://163.com'
}, 3000)对象池是另外一种性能优化方案,它跟享元模式有一些相似,但没有分离内部状态和外部状态这个过程。上述的文件上传案例用对象池+事件委托来代替实现。
职责链模式的定义是:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
现实案例:1. 高峰时期递公交卡 2. 作弊传纸条
最大优点:请求发送者只需要直到链中的第一个节点,从而弱化了发送者和一组接收者之间的强联系。如果不使用职责链模式,那么在公交车上,需要先搞清楚谁是售票员后,才能把硬币递给他。同样在考试中,也许就要先了解同学中有哪些可以解答这道题。
/*
* 预定抢购活动:根据定金得优惠券
* orderType 表示订单类型(500定金用户、200定金用户、无优惠券用户)
* pay 表示用户是否已经支付定金
* stock 表示当前手机库存数量
*/
var order = function (orderType, pay, stock) {
if (orderType === 1) {
if (pay === true) {
console.log('500 元定金预约,得到100优惠券')
} else { // 未交付定金,降级到普通购买模式
if (stock > 0) { // 用于普通购买的手机还有库存
console.log('普通购买,无优惠券')
} else {
console.log('手机库存不足')
}
}
} else if (orderType === 2) { // 200 元定金购买模式
if (pay === true) {
console.log('200元定金预约,得到 50 优惠券')
} else {
if (stock > 0) {
console.log('普通购买,无优惠券')
} else {
console.log('手机库存不足')
}
}
} else if (orderType === 3) {
if (stock > 0) {
console.log('普通购买,无优惠券')
} else {
console.log('手机库存不足')
}
}
}
order(1, true, 500) // 500 元定金预约,得到100优惠券
/*
* 灵活可拆分的职责链节点
* 约定某个节点不能处理请求,则返回一个特定的字符串 'nextSuccessor'
* 来表示该请求需要继续往后面传递
*/
var order500 = function (orderType, pay, stock) {
if (orderType === 1 && pay === true) {
console.log('500 元定金预购,得到100优惠券')
} else {
return 'nextSuccessor' // 不知道下一个节点是谁,反正把请求往后面传递
}
}
var order200 = function (orderType, pay, stock) {
if (orderType === 2 && pay === true) {
console.log('200元定金预购,得到50优惠券')
} else {
return 'nextSuccessor' // 不知道下一个节点是谁,反正把请求往后面传递
}
}
var orderNormal = function (orderType, pay, stock) {
if (stock > 0) {
console.log('普通购买,无优惠券')
} else {
console.log('手机库存不足')
}
}
// 接下来需要将函数包装进职责链节点。
var Chain = function (fn) {
this.fn = fn
this.successor = null
}
Chain.prototype.setNextSuccessor = function (successor) {
return this.successor = successor
}
Chain.prototype.passRequest = function () {
var ret = this.fn.apply(this, arguments)
if (ret === 'nextSuccessor') {
return this.successor && this.successor.passRequest.apply(this.successor, arguments)
}
return ret
}
var chainOrder500 = new Chain(order500)
var chainOrder200 = new Chain(order200)
var chainOrderNormal = new Chain(orderNormal)
chainOrder500.setNextSuccessor(chainOrder200)
chainOrder200.setNextSuccessor(chainOrderNormal)
chainOrder500.passRequest(1, true, 500) // 500元定金预购,得到100优惠券
chainOrder500.passRequest(2, true, 500) // 200元定金预购,得到50优惠券
chainOrder500.passRequest(3, true, 500) // 普通购买,无优惠券
chainOrder500.passRequest(1, false, 0) // 手机库存不足
// 现在就可以自由灵活地添加、移除和修改链中的节点顺序
// 下面增加300元定金的案例
var order300 = function () {
// ...
}
chainOrder300 = new Chain(order300)
chainOrder500.setNextSuccessor(chainOrder300)
chainOrder300.setNextSuccessor(chainOrder200)/*
* 异步的职责链
* 增加 next 方法表示手动传递请求给职责链中的下一个节点
*/
Chain.prototype.next = function () {
return this.successor && this.successor.passRequest.apply(this.successor, arguments)
}
var fn1 = new Chain(function () {
console.log(1)
return 'nextSuccessor'
})
var fn2 = new Chain(function () {
console.log(2)
var self = this
setTimeout(function () {
self.next()
}, 1000)
})
var fn3 = new Chain(function () {
console.log(3)
})
fn1.setNextSuccessor(fn2).setNextSuccessor(fn3)
fn1.passRequest()解耦了请求者和 N 个接收者之间的复杂关系,由于链中的哪个节点可以处理你发出的请求,所以只需把请求传递给第一个节点即可。
其他优点:
缺点:
Function.prototype.after = function (fn) {
var self = this
return function () {
var ret = self.apply(this, arguments)
if (ret === 'nextSuccessor') {
return fn.apply(this, arguments)
}
return ret
}
}
var order = order500.after(order200).after(orderNormal)
order(1, true, 500) // 500定金购买,得到100优惠券
order(2, true, 500) // 200元定金购买,得到50优惠券
order(1, true, 500) // 普通购买,无优惠券第七章有一个用迭代器获取文件上传对象的例子,其实这里用职责链实现更简单:
var getActiveUploadObj = function () {
try {
return new ActiveXObject('TXFTNActiveX.FTMUpload') // IE 上传控件
} catch (e) {
return 'nextSuccessor'
}
}
var getFlashUploadObj = function () {
if (supportFlash()) {
var str = '<object type="application/x-shockwave-flash"></object>'
return $(str).appendTo($('body'))
}
return 'nextSuccessor'
}
var getFormUploadObj = function () {
return $('<form><input name="file" type="file" /></form>').appendTo($('body'))
}
var getUploadObj = getActiveUploadObj.after(getFlashUploadObj).after(getFormUploadObj)
console.log(getUploadObj())职责链可以帮助我们管理代码,降低发起请求的对象和处理请求对象之间的耦合性。职责链中的节点数量和顺序是可以自由变化的,我们可以在运行时决定链中包含哪些节点。
无论是作用域链、原型链,还是 DOM 节点中的事件冒泡,我们都能从中找到职责链模式的影子。
面向对象设计鼓励将行为分布到各个对象中,把对象划分成更小的粒度,有助于增强对象的可复用性,但由于这些细粒度对象之间的联系激增,又有可能会反过来降低它们的可复用性。
中介者模式的作用就是解除对象与对象之间的耦合关系。增加一个中介者对象后,所有的相关对象都通过中介者对象来通信,而不是相互作用,所以当一个对象发生改变时,只需要通知中介者对象即可。中介者使各对象之间耦合松散,而且可以独立地改变它们之间的交互。中介者模式使网状的多对多关系变成了相对简单的一对多关系。
对于前者,如果对象 A 发生了改变,则需要同时通知跟 A 发生引用关系的 B、D、E、F 这 4 个对象;而后者则只需通知中介者对象即可。
/*
* 每个玩家都是紧密耦合
* 每个玩家对象都有两个属性:this.partners 和 this.enemies
* 用来保存其他玩家对象的引用,但每个对象的状态发生改变时,
* 比如角色移动、吃到道具或者死亡时,都必须显示遍历通知所有玩家
*/
function Player (name) {
this.partners = [] // 队友列表
this.enemies = [] // 敌人列表
this.state = 'live' // 玩家状态
this.name = name // 角色名字
this.teamColor = teamColor // 队伍颜色
}
Player.prototype.win = function () {
console.log(this.name + 'won ')
}
Player.prototype.lose = function () {
console.log(this.name + 'lost ')
}
// 在每个玩家死亡的时候,都需要遍历其他队友的生存状况,若全死则游戏结束
Player.prototype.die = function () {
var all_dead = true
this.state = 'dead'
// 遍历队友列表
for (var i = 0, partner; partner = this.partners[i++]; ) {
if (partner.state !== 'dead') {
all_dead = false
break
}
}
if (all_dead === true) {
this.lose()
// 通知所有队友玩家游戏失败
for (var i = 0, partner; partner = this.partners[i++]; ) {
partner.lose()
}
// 通知所有敌人游戏胜利
for (var i = 0, enemy; enemy = this.enemies[i++]; ) {
enemy.win()
}
}
}
var playerFactory = function (name, teamColor) {
var newPlayer = new Player(name, teamColor)
// 通知所有玩家有新角色加入
for (var i = 0, player; player === players[i++]; ) {
// 如果是同一队,则相互添加队友列表
if (player.teamColor === newPlayer.teamColor) {
player.partners.push(newPlayer)
newPlayer.partners.push(player)
} else {
// 相互添加敌人列表
player.enemies.push(newPlayer)
newPlayer.enemies.push(player)
}
}
players.push(newPlayer)
return newPlayer
}
var players = []
var player1 = playerFactory('皮蛋1', 'red')
var player2 = playerFactory('皮蛋2', 'red')
var player3 = playerFactory('皮蛋3', 'red')
var player4 = playerFactory('皮蛋4', 'red')
var player5 = playerFactory('黑妞1', 'blue')
var player6 = playerFactory('黑妞2', 'blue')
var player7 = playerFactory('黑妞3', 'blue')
var player8 = playerFactory('黑妞4', 'blue')
// 让红队所有玩家死亡
player1.die()
player2.die()
player3.die()
player4.die()
/*
* 用中介者模式改造
* 首先定义 Player 构造函数和 player 对象的原型方法
* 在 player 对象的这些原型方法中,不再负责具体的执行逻辑,
* 而是吧操作转交给中介者对象 PlayDirector
*/
function Player (name, teamColor) {
this.name = name
this.teamColor = teamColor
this.state = 'alive'
}
Player.prototype.win = function () {
console.log(this.name + ' won')
}
Player.prototype.lose = function () {
console.log(this.name + ' lost')
}
// 玩家死亡
Player.prototype.die = function () {
this.state = 'dead'
// 给中介者发送消息,玩家死亡
playerDirector.ReceiveMessage('playerDead', this)
}
// 移除玩家
Player.prototype.remove = function () {
// 给中介者发送消息,移除一个玩家
playerDirector.ReceiveMessage('removePlayer', this)
}
// 玩家换队
Player.prototype.changeTeam = function (color) {
// 给中介者发送消息,玩家换队
playerDirector.ReceiveMessage('changeTeam', this, color)
}
var playerFactory = function (name, teamColor) {
var newPlayer = new Player(name, teamColor)
// 向中介者发送消息,新增玩家
playerDirector.ReceiveMessage('addPlayer', newPlayer)
return newPlayer
}
/*
* 实现中介者 playerDirector 对象一般有以下两种方式:
* 1. 发布-订阅模式,将 playerDirector 实现为订阅者,各 player 作为发布者,
* 一旦 player 的状态发生改变,便推送消息给 playerDirector,
* playerDirector 处理消息后将反馈发送给其他 player
* 2. 在 playerDirector 中开发一些接收信息的接口,各 player 可以直接调用该接口
* 来给 playerDirector 发送消息, player 只需传递一个参数给 playerDirector,
* 这个参数的目的是使 playerDirector 可以识别发送者。同样,playerDirector 接收
* 到信息之后会将处理结果反馈给其他 player。
*
* 这两种方式的实现没什么本质上的区别。以下采用第二种方式。
* 对外暴露 ReceiveMessage,负责接收 player 对象发送的消息,
* player 对象发送消息的时候,总是把自身 this 作为参数发送给 playerDirector,
* 以便 playerDirector 识别消息来自于哪个玩家对象
*/
var playerDirector = (function () {
var players = {} // 保存所有玩家
var operations = {} // 中介者可以执行的操作
// 新增一个玩家
operations.addPlayer = function (player) {
var teamColor = player.teamColor
players[teamColor] = players[teamColor] || []
players[teamColor].push(player)
}
// 移除一个玩家
operations.removePlayer = function (player) {
var teamColor = player.teamColor
var teamPlayers = players[teamColor] || []
for (var i = teamPlayers.length - 1; i >= 0; i++) {
if (teamPlayers[i] === player) {
teamPlayers.splice(i, 1)
}
}
}
// 玩家换队
operations.changeTeam = function (player, newTeamColor) {
operations.removePlayer(player)
player.teamColor = newTeamColor
operations.addPlayer(player)
}
operations.playerDead = function (player) {
var teamColor = player.teamColor
var teamPlayers = players[teamColor]
var all_dead = true
for (var i = 0, player; player = teamPlayers[i++]; ) {
if (player.state !== 'dead') {
all_dead = false
break
}
}
if (all_dead === true) {
for (var i = 0, player; player = teamPlayers[i++]; ) {
player.lose()
}
for (var color in players) {
if (color !== teamColor) {
var teamPlayers = players[color]
for (var i = 0, player; player = teamPlayers[i++];) {
player.win()
}
}
}
}
}
var ReceiveMessage = function () {
// arguments 的第一个参数作为消息名称
var message = Array.prototype.shift.call(arguments)
operations[message].apply(this, arguments)
}
return {
ReceiveMessage
}
})()中介者模式是迎合迪米特法则的一种实现。迪米特法则也叫最小知识原则,是指一个对象应该尽可能少地了解另外的对象。如果对象之间的耦合性太高,一个对象发生改变后,难免会影响到其他对象。而在中介者模式里,对象之间几乎不知道彼此的存在,它们只能通过中介者对象来相互影响对方。
因此,中介者模式使各个对象之间得以解耦,以中介者和对象之间的一对多关系取代了对象之间的网状多对多关系。各个对象只需关注自身功能的实现,对象之间的交互关系交给了中介者对象来实现和维护。
中介者模式存在的最大缺点是:新增一个中介者对象,因为对象之间交付的复杂性,转移成了中介者对象的复杂性,使得中介者对象经常是巨大的,中介者对象自身往往就是一个难以维护的对象。
一般来说,如果对象之间的复杂耦合确实导致调用和维护出现了困难,而且这些耦合度随项目的变化呈指数增长,那我们就可以考虑用中介者模式来重构代码。
装饰者模式可以动态地给某个对象添加一些额外的职责,而不会影响从这个类中派生的其他对象。
又称为包装器模式。
想要为函数添加一些功能,最简单粗暴的方式就是直接改写该函数,但这是最差的办法,直接违反了开发-封闭原则:
var a = function () {
alert(1)
}
// 改成:
var a = function () {
alert(1)
alert(2)
}很多时候我们不想碰原函数。现在需要一个方法,在不改变函数源代码的情况下,给函数增加功能,这正是开发-封闭原则给我们指出的光明道路。
var a = function () {
alert(1)
}
var _a = a
var a = function () {
_a()
alert(2)
}
a()这是实际开发中很常见的一种做法,比如我们想给 window 绑定 onload 事件,但又不确定这个事件是否已经被其他人绑定过,为了避免覆盖之前的 window.onload 函数中的行为,我们一般都会先保存好原先的 window.onload,把它放入新的 window.onload 里执行。
window.onload = function () {
alert(1)
}
var _onload = window.onload || function () {}
window.load = function () {
_onload()
alert(2)
}Function.prototype.before = function (beforefn) {
var __self = this // 保存原函数的引用
return function () { // 返回包含了元函数和新函数的“代理”函数
// 执行新函数,且保证 this 不被劫持,新函数接受的参数
// 也会被原封不动地传入原函数,新函数在原函数之前执行
beforefn.apply(this, arguments)
// 执行原函数并返回原函数的执行结果,并保证 this 不被劫持
return __self.apply(this, arguments)
}
}
Function.prototype.after = function (afterfn) {
var __self = this
return function () {
var ret = __self.apply(this, arguments)
afterfn.apply(this, arguments)
return ret
}
}
// 之前的 window.onload 例子
window.onload = function () {
alert(1)
}
window.onload = (window.onload || function () {}).after(function () {
alert(2)
}).after(function () {
alert(3)
}).after(function () {
alert(4)
})不污染原型的方式:把原函数和新函数都作为参数传入 before 或 after 方法:
var before = function (fn, beforefn) {
return function () {
beforefn.apply(this, arguments)
return fn.apply(this, arguments)
}
}
var a = before(
function () {alert(3)},
function () {alert(2)}
)
a = before(a, function () {alert(1)})
a()分离业务代码和数据统计代码,无论在什么语言中,都是 AOP 的经典应用之一。在项目开发的结尾开阶段难免要加上很多统计数据的代码,这些过程可能让我们被迫改动早已封装好的函数。
/*
<html>
<button tag="login" id="button">点击打开登录浮层</button>
</html>
*/
var showLogin = function () {
console.log('打开登录浮层')
log(this.getAttribute('tag'))
}
var log = function (tag) {
console.log(`上报标签为:${tag}`)
// (new Image).src = `http://xxx.com/report?tag=${tag}` // 真正的上报代码略
}
document.getElementById('button').onclick = showLoginshowLogin 函数里既要负责打开登录图层,又要负责数据上报,这是两个层面的功能,在此处却要被耦合在一个函数里。使用 AOP 分离之后,代码如下:
/*
<html>
<button tag="login" id="button">点击打开登录浮层</button>
</html>
*/
Function.prototype.after = function (afterfn) {
var __self = this
return function () {
var ret = __self.apply(__self, arguments)
afterfn.apply(this, arguments)
return ret
}
}
var showLogin = function () {
console.log('打开登录浮层')
}
var log = function () {
console.log('上报标签为:', this.getAttribute('tag'))
}
showLogin = showLogin.after(log) // 打开登录浮层之后上传数据
document.getElementById('button').onclick = showLogin观察 Function.prototype.before 方法:
Function.prototype.before = function (beforefn) {
var __self = this
return function () {
beforefn.apply(this, arguments)
return __self.apply(this, arguments)
}
}var func = function (param) {
console.log(param) // { a: 'a', b: 'b' }
}
func = func.before(function (param) {
param.b = 'b'
})
func({ a: 'a' })
var ajax = function (type, url, param) {
console.dir(param)
// 发送 ajax 请求的代码略
}
ajax('get', 'http://xxx.com/userinfo', { name: 'sven' })
// 由于受到 CSRF 攻击,最简单的办法是在 HTTP 请求中带上一个 Token 参数。
var getToken = function () {
return 'token'
}
var ajax = function (type, url, param) {
param = param || {}
param.Token = getToken()
}用 AOP 的方式给 ajax 函数动态装饰上 Token 参数,保证了 ajax 函数是一个相对纯净的函数,提高了 ajax 函数的可复用性,它在被迁往其他项目的时候,不需要做任何修改。
var ajax = function (type, url, param) {
console.dir(param)
}
// 把 Token 参数通过 Function.prototype.before 装饰到 ajax 函数的参数 param 对象中:
var getToken = function () {
return 'Token'
}
ajax = ajax.before(function (type, url, param) {
param.token = getToken()
})
ajax('get', 'http://xxx.com/userinfo', { name: 'sven' })
// 从 ajax 函数打印的 log 可以看到,Token 参数已经被附加到了 ajax 请求的参数中:
{ name: 'sven', Token: 'token' }formSubmit 函数在此处承担了两个职责,除了提交 ajax 请求之外,还要验证用户输入的合法性。这种代码以来会造成函数臃肿,职责混乱,二来谈不上任何可复用性。代码如下:
var username = document.getElementById('username')
var password = document.getElementById('password')
var submitBtn = document.getElementById('submitBtn')
var formSubmit = function () {
if (username.value === '') {
return alert('用户名不能为空')
}
if (password.value === '') {
return alert('密码不能为空')
}
var param = {
username: username.value,
password: password.value
}
ajax('http://xxx.com/login', param)
}
submitBtn.onclick = function () {
formSubmit()
}现在的代码有一些改进,把校验的逻辑都放到了 validate 函数中,但 formSubmit 函数内部还要计算 validate 函数的返回值,因为返回的结果表明了是否通过校验。代码如下:
var validate = function () {
if (username.value === '') {
alert('用户名不能为空')
return false
}
if (password.value === '') {
alert('密码不能为空')
return false
}
}
var formSubmit = function () {
if (validate() === false) {
return
}
var param = {
username: username.value,
password: password.value
}
ajax('http://xxx.com/login', param)
}
submitBtn.onclick = function () {
formSubmit()
}校验输入和提交表单的代码完全分离开开来,不再有任何耦合关系。代码如下:
Function.prototype.before = function (beforefn) {
var __self = this
return function () {
// beforefn 返回 false 的情况直接 return,不再执行后面的函数
if (beforefn.apply(this, arguments) === false) {
return
}
return __self.apply(this, arguments)
}
}
var validate = function () {
if (username.value === '') {
alert('用户名不能为空')
return false
}
if (password.value === '') {
alert('密码不能为空')
return false
}
}
var formSubmit = function () {
var param = {
username: username.value,
password: password.value
}
ajax('http://xxx.com', param)
}
formSubmit.before(validate)
submitBtn.onclick = function () {
formSubmit()
}函数通过 Function.prototype.before 或 Function.prototype.after 被装饰之后,返回的实际上是一个新的函数,如果在原函数保存了一些属性,那么这些属性会丢失。另外,装饰方式也叠加了函数的作用域,如果装饰的链条过长,性能上也会受到一些影响。
两者的机构看起来非常相像,都描述了怎样为对象提供一定程度上的间接引用,它们的实现部分都保留了对另外一个对象的引用,并且向那个对象发送请求。
代理模式和装饰者模式最重要的区别在于它们的意图和目的。
代理模式的目的是:当直接访问本体不方便或者不符合需求时,为这个本体提供一个替代者。本体定义了关键功能,而代理提供货拒绝对它的访问,或者在访问本体之前做一些额外的事情。
装饰者模式的作用就是为对象动态加入行为。
换句话说,代理模式强调一种关系(Proxy 与它的实体之间的关系),这种关系可以静态的表达,也就是说,这种关系在一开始就可以被确定。而装饰者模式用于一开始不能确定对象的全部功能时。代理模式通常只有一层代理-本体的引用,而装饰者模式经常会形成一条常常的装饰链。
在虚拟代理实现突破预加载的例子中,本体负责设置 img 节点的 src,代理则提供了预加载的功能,这看起来也是“加入行为”的一种方式,但这种加入行为的方式和装饰者模式的偏重点是不一样的。装饰者模式是实实在在的为对象增加新的职责和行为,而代理做的事情还是跟本体一样,最终都是设置 src。但代理可以加入一些“聪明”的功能,比如在图片真正加载好之前,先使用一张站位的 loading 图片。
除了上述提到的例子,装饰者模式在框架开发中也十分有用。作为框架坐着,我们希望框架里的函数提供的是一些稳定而方便移植的功能,那些个性化的功能可以在框架之外动态装饰上去,这可以避免为了让框架拥有更多功能,而去使用一些 if、else 语句预测用户的实际需要。
状态模式的关键是区分事物内部的状态,事物内部状态的改变往往会带来事物的行为改变。
/**
* 同一个开关切换灯的状态。
* 然而灯的种类有多种,如:强弱关状态的灯。
* 因此不能不改造 buttonWasPressed 方法
* 这有以下几点缺点:
* 1. buttonWasPressed 违反开发-封闭原则
* 2. 所有状态有关的行为都被封装在 buttonWasPressed 方法里,会随着迭代不能膨胀
* 3. 状态的切换不明显,需看完 buttonWasPressed 方法才能知道有多少种状态
* 4. 状态之间的切换状态,不过是往 buttonWasPressed 里堆砌 if、else 语句,难以阅读和维护
*/
var Light = function () {
this.state = 'off'
this.button = null
}
Light.prototype.init = function () {
var button = document.createElement('button')
var self = this
button.innerHTML = '开关'
this.button = document.body.appendChild(button)
this.button.onclick = function () {
self.buttonWasPressed()
}
}
Light.prototype.buttonWasPressed = function () {
if (this.state === 'off') {
console.log('开灯')
this.state = 'on'
} else if (this.state === 'on') {
console.log('关灯')
this.state = 'off'
}
}
var light = new Light()
light.init()通常我们谈到封装,一般都会优先封装对象的行为,而不是对象的状态。但在状态模式中刚好相反,状态模式的关键是把事物的每种状态都封装成单独的类,跟此种状态有关的行为都被封装在这个类的内部,所以 button 被按下的时候,只需要在上下文中,把这个请求委托给当前的状态对象即可,该状态对象会负责执行它自身的行为,如下图所示:
同时我们还可以把状态的切换规则事先分布在状态类中,这样就有效地消除了原本存在的大量条件分支语句,如下图所示:
/**
* 状态模式改进电灯程序
* 首先定义 3 个状态类,分别是 OffLightState、WeakLightState、StrongLightState
* 这三个类都有一个原型方法 buttonWasPressed,代表各自状态下,按钮被按下时将发生的行为
*/
// OffLightState
var OffLightState = function (light) {
this.light = light
}
OffLightState.prototype.buttonWasPressed = function () {
console.log('弱光') // offLightState 对应的行为
this.light.setState(this.light.weakLightState) // 切换状态到 weakLightState
}
// WeakLightState
var WeakLightState = function (light) {
this.light = light
}
WeakLightState.prototype.buttonWasPressed = function () {
console.log('强光')
this.light.setState(this.light.strongLightState)
}
// WeakLightState
var StrongLightState = function (light) {
this.light = light
}
StrongLightState.prototype.buttonWasPressed = function () {
console.log('关灯')
this.light.setState(this.light.offLightState)
}
/**
* 改写 Light 类
* 不使用字符串记录当前状态,而是使用更加立体化的状态对象。
* 在构造函数里为每个状态都创建一个状态对象,这样对多少种状态一目了然
*/
var Light = function () {
this.offLightState = new OffLightState(this)
this.weakLightState = new WeakLightState(this)
this.strongLightState = new StrongLightState(this)
this.button = null
}
Light.prototype.init = function () {
var button = document.createElement('button')
var self = this
this.button = document.body.append(button)
this.button.innerHTML = '开关'
this.currState = this.offLightState // 设置当前状态
this.button.onclick = function () {
self.currState.buttonWasPressed()
}
}
Light.prototype.setState = function (newState) {
this.currState = newState
}
var light = new Light()
light.init()状态模式使得每一种状态和它对应的行为之间的关系局部化,这些行为被分散和封装在各自对应的状态类之中,便于阅读和管理代码。
当需要增加一种新状态时,只需增加一个新的状态类,再更改与之相关联的状态即可。
我们看到,在状态类中将定义一些共同的行为方法,Context 最终会将请求委托给状态对象的这些方法。在上述例子中,这个方法就是 buttonWasPressed。无论增加了多少种状态类,它们都必须实现 buttonWasPressed 方法。
由于 JavaScript 既不支持抽象类,也没有接口的概念,所以难以避免出现状态类未定义 buttonWasPressed 方法,导致在状态切换时抛出异常。
var State = function () {}
State.prototype.buttonWasPressed = function () {
throw new Error('父类的 buttonWasPressed 方法必须被重写')
}
var SuperStrongLightState = function (light) {
this.light = light
}
SuperStrongLightState.prototype = new State() // 继承抽象父类
SuperStrongLightState.prototype.buttonWasPressed = function () { // 重写 buttonWasPressed 方法
console.log('关灯')
this.light.setState(this.light.offLightState)
}实际上,不论是文件上传,还是音乐,视频播放器,都可以找到一些明显的状态区分。比如文件上传程序中有扫描、正在上传、暂停、上传成功、上传失败这几种状态,音乐播放器可以分为加载中、正在播放、暂停、播放完毕这几种状态。点击同一个按钮,在上传中和暂停状态下的行为表现是不一样的。
相对于电灯的例子,文件上传不同的地方在于,现在我们将面临更加复杂的条件切换关系。电灯的状态总是循规蹈矩的 A->B->C->A,所以即使不使用状态模式来编写电灯的程序,而是使用原始的 if、else 来控制状态切换也能胜任。
而文件上传的状态切换相比要复杂得多,有暂停/继续上传与删除文件两个按钮:
在本例子中,上传是一个异步的过程,所以控件会不停地调用 JavaScript 提供的一个全局函数 window.external.upload,来通知 JavaScript 目前的上传进度,控件会把当前的文件状态作为参数 state 塞进 window.external.upload。这里我们简单地用 setTimeout 来模拟文件的上传进度,window.external.upload 函数在此例也只负责打印一些 log。
/**
* 反例:与电灯第一个案例一样
* 充斥着 if、else 条件语句,状态与行为都被耦合成一个巨大的方法里
* 难以修改和扩展这个状态机。
*/
/* S 保持不变:上传插件及 window.external.upload 函数 */
window.external.upload = function (state) {
console.log(state) // 可能为 sign、uploading、done、error
}
// 用于上传的插件对象
var plugin = (function () {
var plugin = document.createElement('embed')
plugin.style.display = 'none'
plugin.type = 'application/txfn-webkit'
plugin.sign = function () {
console.log('开始文件扫描')
}
plugin.pause = function () {
console.log('暂停文件上传')
}
plugin.uploading = function () {
console.log('开始文件上传')
}
plugin.del = function () {
console.log('删除文件上传')
}
plugin.done = function () {
console.log('文件上传完成')
}
plugin.body.appendChild(plugin)
return plugin
})()
/* E 保持不变:上传插件及 window.external.upload 函数 */
var Upload = function (fileName) {
this.plugin = plugin
this.fileName = fileName
this.button1 = null
this.button2 = null
this.state = 'sign' // 设置初始状态为 waiting
}
Upload.prototype.init = function () {
var that = this
this.dom = document.createElement('div')
this.dom.innerHTML =
'<span>文件名称:'+ this.fileName +'</span>\
<button data-action="button1">扫描中</button>\
<button data-action="button2">删除</button>'
document.body.appendChild(this.dom)
this.button1 = this.dom.querySelector('[data-action="button1"]')
this.button2 = this.dom.querySelector('[data-action="button2"]')
this.bindEvent()
}
Upload.prototype.bindEvent = function () {
var self = this
this.button1.onclick = function () {
if (self.state === 'sign') {
console.log('扫描中,点击无效...')
} else if (self.state === 'uploading') {
this.changeState('pause')
} else if (self.state === 'pause') {
this.changeState('uploading')
} else if (self.state === 'done') {
console.log('文件已完成上传,点击无效')
} else if (self.state === 'error') {
console.log('文件上传失败,点击无效')
}
}
this.button2.onclick = function () {
if (self.state === 'done' ||
self.state === 'error' ||
self.state === 'pause') {
self.changeState('del')
} else if (self.state === 'sign') {
console.log('文件正在扫描中,不能删除')
} else if (self.state === 'uploading') {
console.log('文件正在上传中,不能删除')
}
}
}
Upload.prototype.changeState = function (state) {
switch (state) {
case 'sign':
this.plugin.sign()
this.button1.innerHTML = '扫描中,任何操作无效'
break
case 'uploading':
this.plugin.uploading()
this.button1.innerHTML = '正在上传,点击暂停'
break
case 'pause':
this.plugin.pause()
this.button1.innerHTML = '已暂停,点击继续上传'
break
case 'done':
this.plugin.done()
this.button1.innerHTML = '上传完成'
break
case 'error':
this.plugin.error()
this.button1.innerHTML = '上传失败'
break
case 'del':
this.plugin.del()
this.dom.parentNode.removeChild(this.dom)
console.log('删除完成')
break
}
this.state = state
}
var uploadObj = new Upload('uploader')
uploadObj.init()
// 插件调用 JavaScript 的方法
window.external.upload = function (state) {
uploadObj.changeState(state)
}
// 文件开始扫描
window.external.upload('sign')
// 1 秒后开始上传
setTimeout(() => {
window.external.upload('uploading')
}, 1000)
// 5 秒后上传完成
setTimeout(() => {
window.external.upload('done')
}, 5000)/**
* 状态模式重构文件上传程序
*/
var Upload = function (fileName) {
this.plugin = plugin
this.fileName = fileName
this.button1 = null
this.button2 = null
this.signState = new SignState(this)
this.uploadingState = new UploadingState(this)
this.pauseState = new PauseState(this)
this.doneState = new DoneState(this)
this.errorState = new ErrorState(this)
this.currState = this.signState
}
// 保持不变,仍负责往页面中创建跟上传流程有关的 DOM 节点,并开始绑定按钮事件
Upload.prototype.init = function () {
var that = this
this.dom = document.createElement('div')
this.dom.innerHTML =
'<span>文件名称:'+ this.fileName +'</span>\
<button data-action="button1">扫描中</button>\
<button data-action="button2">删除</button>'
document.body.appendChild(this.dom)
this.button1 = this.dom.querySelector('[data-action="button1"]')
this.button2 = this.dom.querySelector('[data-action="button2"]')
this.bindEvent()
}
// 负责具体的按钮事件实现,在点击按钮后,Context 并不做任何具体的操作,
// 而是把请求委托给当前的状态类来执行
Upload.prototype.bindEvent = function () {
var self = this
this.button1.onclick = function () {
self.currState.clickHandler1()
}
this.button2.onclick = function () {
self.currState.clickHandler2()
}
}
// 把状态对应的逻辑放在 Upload 类中
Upload.prototype.sign = function () {
this.plugin.sign()
this.currState = this.signState
}
Upload.prototype.uploading = function () {
this.button1.innerHTML = '正在上传,点击暂停'
this.plugin.uploading()
this.currState = this.uploadingState
}
Upload.prototype.pause = function () {
this.button1.innerHTML = '已暂停,点击继续上传'
this.plugin.pause()
this.currState = this.pauseState
}
Upload.prototype.done = function () {
this.button1.innerHTML = '上传完成'
this.plugin.done()
this.currState = this.doneState
}
Upload.prototype.error = function () {
this.button1.innerHTML = '上传失败'
this.currState = this.errorState
}
Upload.prototype.del = function () {
this.plugin.del()
this.dom.parentNode.removeChild(this.dom)
}
// 编写各个状态类的实现。这里使用 StateFactory 来避免因 JavaScript 中午抽象类所带来的问题
var StateFactory = (function () {
var state = function () {}
State.prototype.clickHandler1 = function () {
throw new Error('子类必须重写父类的 clickHandle1 方法')
}
State.prototype.clickHandler2 = function () {
throw new Error('子类必须重写父类的 clickHandle2 方法')
}
return function (param) {
var F = function (uploadObj) {
this.uploadObj = uploadObj
}
F.prototype = new State()
for (var key in param) {
F.prototype[key] = param[key]
}
return F
}
})
var SignState = StateFactory({
clickHandler1 () {
console.log('扫描中,点击无效...')
},
clickHandler2 () {
console.log('文件正在上传中,不能删除')
}
})
var UploadingState = StateFactory({
clickHandler1 () {
this.uploadObj.pause()
},
clickHandler2 () {
console.log('文件正在上传中,不能删除')
}
})
var PauseState = StateFactory({
clickHandler1 () {
this.uploadObj.uploading()
},
clickHandler2 () {
this.uploadObj.del()
}
})
var DoneState = StateFactory({
clickHandler1 () {
console.log('文件已完成上传,点击无效')
},
clickHandler2 () {
this.uploadObj.del()
}
})
var ErrorState = StateFactory({
clickHandler1 () {
console.log('文件上传失败,点击无效')
},
clickHandler2 () {
this.uploadObj.del()
}
})
// 测试
var uploadObj = new Upload('uploader')
uploadObj.init()
window.external.upload = function (state) {
uploadObj[state]()
}
window.external.upload('sign')
// 1 秒后开始上传
setTimeout(() => {
window.external.upload('uploading')
}, 1000)
// 5 秒后上传完成
setTimeout(() => {
window.external.upload('done')
}, 5000)优点:
缺点:
两者像是一对双胞胎,都封装了一系列算法或行为。它们的类图看起来几乎一致,但在意图上有很大不同。
两者相同点是:它们都有一个上下文、一些策略或状态类,上下文把请求委托给这些类来执行。
它们之间的区别是:
前面两个示例都是模拟传统面向对象语言的状态模式实现,我们为每种状态都定义一个状态之类,然后在 Context 中持有这些状态对象的引用,以便把 currState 设置为当前的状态对象。
状态模式是状态机的实现之一。JavaScript 可以非常方便地使用委托技术,并不需要事先让一个对象持有另一个对象。下面的状态机选择了通过 Function.prototype.call 方法直接把请求委托给某个字面量对象来执行。
/**
* JavaScript 版本的状态机
* 1. 利用 Function.prototype.call
* 2. 用闭包替代面向对象
*/
// 1. 利用 Function.prototype.call
var Light = function () {
this.currState = FSM.off
this.button = null
}
Light.prototype.init = function () {
var button = document.createElement('button')
var self = this
button.innerHTML = '已关灯'
this.button = document.body.appendChild(button)
this.button.onclick = function () {
// 把请求委托给 FSM 状态机
self.currState.buttonWasPressed.call(self)
}
}
var FSM = {
off: {
buttonWasPressed () {
console.log('关灯')
this.button.innerHTML = '下一次按我是开灯'
this.currState = FSM.on
}
},
on: {
buttonWasPressed () {
console.log('开灯')
this.button.innerHTML = '下一次按我是关灯'
this.currState = FSM.off
}
}
}
var light = new Light()
light.init()
// 2. 闭包代替面向对象
var delegate = function (client, delegation) {
return {
buttonWasPressed () {
return delegation.buttonWasPressed.apply(client, arguments)
}
}
}
var FSM = {
off: {
buttonWasPressed () {
console.log('关灯')
this.button.innerHTML = '下一次按我是开灯'
this.currState = this.onState
}
},
on: {
buttonWasPressed () {
console.log('开灯')
this.button.innerHTML = '下一次按我是关灯'
this.currState = this.offState
}
}
}
var Light = function () {
this.offState = delegate(this, FSM.off)
this.onState = delegate(this, FSM.on)
this.currState = this.offState
this.button = null
}
Light.prototype.init = function () {
var button = document.createElement('button')
var self = this
button.innerHTML = '已关灯'
this.button = document.body.appendChild(button)
this.button.onclick = function () {
self.currState.buttonWasPressed()
}
}
var light = new Light()
light.init()基于表驱动的是实现状态机的另一种方式。我们可以在表中很清楚地看到下一个状态是由当前状态和行为共同决定。这样一来,我们就可以在表中查找状态,而不必定义很多条件分支。
| 状态转移表 | |||
|---|---|---|---|
| 当前状态→条件 ↓ | 状态A | 状态B | 状态C |
| 条件X | ... | ... | ... |
| 条件Y | ... | 状态C | ... |
| 条件Z | ... | ... | ... |
Github 上有个对应的库实现,通过这个库,可以很方便地创建出 FSM:
var fsm = StateMachine.create({
initial: 'off',
events: [
{ name: 'buttonWasPressed', from: 'off', to: 'on' },
{ name: 'buttonWasPressed', from: 'on', to: 'off' }
],
callbacks: {
onbuttonWasPressed (event, from, to) {
console.log(arguments)
}
},
error (eventName, from, to, args, errorCode, errorMessage) {
// 从一种状态试图切换到一种不可能到达的状态的时候
console.log(arguments)
}
})库地址:https://github.com/jakesgordon/javascript-state-machine
适配器模式的作用是解决两个软件实体间的接口不兼容的问题。使用适配器模式之后,原本由于接口不兼容而不能工作的两个软件实体可以一起工作。
适配器的别名是包装器(wrapper)。
适配器是一种“亡羊补牢”的模式,我们不会在程序设计之初就使用它。
/**
* 对于最初的地图案例,假如百度的展示不叫 show 而叫 display。
* 由于百度是第三方对象,正常情况下我们都不应该去改动它。
* 此时我们可以通过增加适配器来解决这个问题
*/
var googleMap = {
show () {
console.log('开始渲染谷歌地图')
}
}
var baiduMap = {
display () {
console.log('开始渲染百度地图')
}
}
var baiduMapAdapter = {
show () {
return baiduMap.display()
}
}
renderMap(googleMap) // 输出:开始渲染谷歌地图
renderMap(baiduMapAdapter) // 输出:开始渲染百度地图适配器模式是一种相对简单的模式。在本书提及的设计模式中,有一些模式跟适配器模式的结构非常相似,如装饰者模式、代理模式和外观模式(第十九章提及)。这几种模式都属于“包装模式”,都是由一个对象来包装另一个对象。区别它们的关键仍是模式的意图。
设计原则通常指单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、合成复用原则和最少知识原则。
单一原则的职责被定义为“引起变化的原因”。如果我们有两个动机去改写一个方法,那么这个方法就具有两个职责。职责越多,那么在需求的变迁过程中,需要改写这个方法的可能性就越大。
SRP 的原则体现为:一个对象(方法)只能做一件事。
SRP 原则在很多设计模式中都有着广泛的应用,如代理模式、迭代器模式、单例模式和装饰者模式。
最少知识原则说的是一个软件实体应当尽可能少地与其他实体发生相互作用。这里的软件实体是一个广义的概念,不仅包括对象,还包括系统、类、模块、函数、变量等。
单一职责原则指导我们把对象划分成较小的粒度,这样可以提高对象的可复用性。但越来越多的对象之间可能会产生错综复杂的关系,如果修改了其中一个对象,很可能会影响到跟它相互引用的其他对象。
最少知识原则要求我们在设计程序时,应该尽量减少对象之间的交互。如果两个对象之间不必彼此直接通信,那么这两个对象就不要发生直接的互相联系。常见的做法是引入一个第三者对象来承担这些对象之间的通信作用。
最少知识原则在设计模式中体现得最多的地方是中介者模式和外观模式。
外观模式
外观模式主要是为子系统的一组接口提供一个一致的界面,外观模式定义了一个高层接口,使得子系统更佳容易使用。
外观模式的作用是对客户屏蔽一组子系统的复杂性。外观模式对客户提供了一个简单易用的高层接口,高层接口会把客户的请求转发给子系统来完成具体的功能实现。请求外观并不是强制的,如果外观不能满足客户的个性化需求,那么客户也可以选择越过外观来直接访问子系统。
全自动洗衣机的一键洗衣按钮就是一个外观。
定义:软件实体(类、模块、函数)等应该是可以扩展的,但是不可修改。
为 window.onload 新增需求,我们往往是直接在原来函数内进行修改。但修改代码是一种危险的行为。因此,这里我们可以通过装饰者模式在不修改原代码的情况下,新增函数。新增代码和原代码可以进水不犯河水。
开放-封闭原则的**:当需要改变一个程序的功能或者给这个程序增加新功能时,可以使用增加代码的方式,但是不允许改动程序的源代码。
过多的条件分支语句是造成程序违反开放-封闭原则的一个常见原因。每当增加一个新的 if 语句时,都要被迫改动原函数。把 if 换成 switch-case 是没用的,这是换汤不换药的做法。实际上,每当我们看到一大片的 if 或者 switch-case 语句时第一时间就应该考虑能否利用对象的多态性来重构它们。
利用对象的多态性来让程序遵守开放-封闭原则是一个常用的技巧。
开放-封闭原则并没有实际的模板教导我们怎样亦步亦趋地实现它。但我们还是能找到一些让程序尽量遵守开放-封闭原则的规律,最明显的就是找出程序中将要发生变化的地方,然后把变化封装起来。
其他可以帮助我们编写遵守开发-封闭原则代码的方式还有:放置挂钩(第十一章——模板方法模式)、使用回调函数。
几乎所有的设计模式都遵守开放-封闭原则。可以这么说,开放-封闭原则是编写一个好程序的目标,其他设计原则都是达到这个目标的过程。
读书笔记至此完毕!
William Kolomyjec 的工作让我们再次想起一些以前(old school)的生成艺术,专注于简单图形、平铺和递归。
今天我们要复现他的作品之一——催眠方块。
页面中仅有一个 320x320 像素的 <canvas>。
老规矩,以下是初始化代码,其中包括设置 canvas 大小和使用 window.devicePixelRatio 缩放 canvas 以适配视网膜屏幕。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
var dpr = window.devicePixelRatio;
canvas.width = size * dpr;
canvas.height = size * dpr;
context.scale(dpr, dpr);
context.lineWidth = 2;现在,需要定义一些变量和创建 draw 函数。该函数会被递归调用,不断在方块内绘制方块,直至方块达到指定的最小尺寸。
如果对递归不太了解也没关系,后续会讲解。
var finalSize = 10;
var startSize = size;
var startSteps = 5;
function draw(x, y, width, height, xMovement, yMovement, steps) {
// We will fill this in
}
draw(0, 0, startSize, startSize, 0, 0, startSteps);draw 函数内的 steps 参数 代表方块递归的次数。目前是固定值,但随后我们会赋予它一些随机性。
finalSize 是绘制方块的最小尺寸,即当方块达到此尺寸时,我们将停止绘制。
startSteps 在递归时用于计算越来越小的方块尺寸。
我们先在 draw 函数内单纯画一个方块。
context.beginPath();
context.rect(x, y, width, height);
context.stroke();现在有了一个方块,接着进行递归操作,即 draw 函数会调用自身多次,直至满足某个条件。该条件非常重要,否则会造成死循环。这里我们使用 steps 作为倒数的开始点。
if(steps >= 0) {
var newSize = (startSize) * (steps / startSteps) + finalSize;
var newX = x + (width - newSize) / 2
var newY = y + (height - newSize) / 2
draw(newX, newY, newSize, newSize, xMovement, yMovement, steps - 1);
}哇喔,这就是递归!下面让我解释一下上述代码。
不同的 startSteps 就会有不同的递归程度。
var startSteps = 8或
var startSteps = 4当为该值赋予随机数时会有不同的效果。但现在先让我们添加其他效果。xMovement 和 yMovement 两个变量是用于将方块放置在特定方向上。
先更改 draw 函数的调用参数,即 xMovement 和 yMovement 均置为 1。此举是为了让方块放置在右下方。
draw(0, 0, startSize, startSize, 1, 1, startSteps);然后计算下方变量。
newX = newX - ((x - newX) / (steps + 2)) * xMovement
newY = newY - ((y - newY) / (steps + 2)) * yMovement这看起来有点复杂。我们计算了相邻方块的间距,然后将其按照剩步数(译者注:代码中是 steps + 2)切分。+2 是为了确保新方块永远不会触碰到上一个方块的边界(译者注:若 + 1,则当 steps 最后为 0 时,会导致发生碰撞)。
依次更改 draw 函数的 xMovement 和 yMovement 两个参数,你将会看到它是如何移动的。
draw(0, 0, startSize, startSize, 1, 0, startSteps);draw(0, 0, startSize, startSize, 1, -1, startSteps);draw(0, 0, startSize, startSize, 0, -1, startSteps);draw(0, 0, startSize, startSize, -1, -1, startSteps);接着我们需要做先前 瓷砖线 教程的事了——将其作为一个瓷砖,然后平铺。
首先定义变量,如方块的平铺密度、方块的偏移量等。我们会将最终尺寸变得更小,并根据 canvas 宽度减去 offset 后的大小分割成想要的份数(7)。directions 数组存储着所有可能的方向:-1, 0 & 1。
var finalSize = 3;
var startSteps;
var offset = 2;
var tileStep = (size - offset * 2) / 7;
var startSize = tileStep;
var directions = [-1, 0, 1];现在也许看起来有点奇怪,因为我们还没将这些变量应用上。
for( var x = offset; x < size - offset; x += tileStep) {
for( var y = offset; y < size - offset; y += tileStep) {
startSteps = 3
draw(x, y, startSize, startSize, 1, 1, startSteps - 1);
}
}现在可以开始玩耍啦,可以为 steps 赋予随机数。
startSteps = 2 + Math.ceil(Math.random() * 3)再设置随机方向!
var xDirection = directions[Math.floor(Math.random() * directions.length)]
var yDirection = directions[Math.floor(Math.random() * directions.length)]
draw(x, y, startSize, startSize, xDirection, yDirection, startSteps - 1);这就是最终效果——催眠方块。这是使用递归的好例子,也是一副易于上色的艺术作品,特别是在较大的 canvas 上。
原文链接:
译者注:本文由两章节组成。
嘿,读者们! 👋
如果说哪样东西是我的真爱,那么它应该就是隧道动画 😍
不懂我的意思?那看看我之前创建的案例吧:
我甚至使用这种动画作为我们团队的 2017 愿望卡 🎆。
我将在本文阐述上述案例的基本实现。其中,第一步是创建一个隧道(管道),并在其内部执行摄像机动画。接下来,我们看看如何自定义隧道。
对于该案例,我会使用 Three.js 实现 WebGL 部分。如果对此不熟悉,你可以看看 Rachel Smith 的 相关文章。
第一步,搭建用于初始化 Three.js 场景的基本要素。
别忘了在页面中引入 Three.js 库
See the Pen Setup the scene by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>如果你能看到一个红色立方体在旋转,那么这就意味着我们可以继续往下走啦 📦 !
想要在 Three.js 中创建管道,首先需要创建一条路径(path)。THREE.CatmullRomCurve3() 构建函数能实现这个需求,它能基于一个顶点数组创建一条平滑的曲线。
在案例中,我硬编码了一个点(point)数组,并将每个点转为 Vector3()。
当拥有了顶点数组后,就能使用上述构造函数创建路径。
// 硬编码点数组
var points = [
[0, 2],
[2, 10],
[-1, 15],
[-3, 20],
[0, 25]
];
// 将点转为顶点
for (var i = 0; i < points.length; i++) {
var x = points[i][0];
var y = 0;
var z = points[i][10];
points[i] = new THREE.Vector3(x, y, z);
}
// 根据顶点创建路径
var path = new THREE.CatmullRomCurve3(points);
在得到路径后,我们就能基于它创建管道了。
// 基于路径创建管道几何体
// 第一个参数是路径
// 第二个参数是组成管道的片段(segment)数量
// 第三个参数是管道半径
// 第四个参数是沿半径的片段数
// 第五个参数是指定管道是否闭合
var geometry = new THREE.TubeGeometry( path, 64, 2, 8, false );
// 红色基础材质(译者注:不受光影响)
var material = new THREE.MeshBasicMaterial( { color: 0xff0000 } );
// 创建网格(mesh)
var tube = new THREE.Mesh( geometry, material );
// 将管道网格添加至场景中
scene.add( tube );
See the Pen Create a tube geometry by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>这时应该能看到一个红色管道在场景中旋转 😊。
在大多数情况下,我们并不希望硬编码路径上的点。其实我们可以通过一些随机算法生成一系列点。但对于下一个案例,我们将从由 Adobe Illustrator 创建的 SVG 上获取点的值。
如果不在路径上设置任何贝塞尔曲线,Illustrator 会将路径作为多边形导出,如:
<svg viewBox="0 0 346.4 282.4">
<polygon points="68.5,185.5 1,262.5 270.9,281.9 345.5,212.8 178,155.7 240.3,72.3 153.4,0.6 52.6,53.3 "/>
</svg>
我们手动地将多边形的点转化为一个数组:
var points = [
[68.5,185.5],
[1,262.5],
[270.9,281.9],
[345.5,212.8],
[178,155.7],
[240.3,72.3],
[153.4,0.6],
[52.6,53.3],
[68.5,185.5]
];
// 切记要将最后一个参数设置为 true,否则管道不闭合
var geometry = new THREE.TubeGeometry( path, 300, 2, 20, true );
如果感兴趣,你可以创建一个动态将 SVG 字符串转为数组的函数 😉
See the Pen Create a tube from a SVG polygon by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>你也可以看到左侧是 SVG 多边形,右侧则是根据多边形的点创建的管道。
有了管道后,剩余的主要部分就是动画了!
我们会使用 path 非常有用的函数 path.getPointAt(t)。
该函数会基于所指定的参数值,返回路径上的任意一点。参数的取值范围为 0 至 1。0 是路径的第一个点,1 是路径的最后一个点。
我们会在每帧中调用此函数,以让摄像机沿着路径移动。另外,我们还需要在每帧中增大该函数的参数值以获得意想不到的效果。
// 参数值由 0 开始
var percentage = 0;
function render(){
// 参数值自增
percentage += 0.001;
// 根据参数值获取路径上的点
var p1 = path.getPointAt(percentage%1);
// 将摄像机放置在该点上
camera.position.set(p1.x,p1.y,p1.z);
renderer.render(scene, camera);
requestAnimationFrame(render);
}
requestAnimationFrame(render);
由于 .getPointAt() 函数只接受 [0, 1] 区间内的值,我们需要对该值进行“取余”运算,以确保它不会大于 1。
目前摄像机的位置设定没有任何问题,但摄像机的朝向始终不变。为了解决该问题,我们需要将摄像机的朝向设置在比自身位置更前一点的地方。因此,在每帧中,我们不仅需要计算摄像机的自身位置,还要计算比该位置更靠前的朝向坐标。
var percentage = 0;
function render(){
percentage += 0.001;
var p1 = path.getPointAt(percentage%1);
// 获取路径上更靠前的点
var p2 = path.getPointAt((percentage + 0.01)%1);
camera.position.set(p1.x,p1.y,p1.z);
// 让摄像机朝向第二个点
camera.lookAt(p2);
renderer.render(scene, camera);
requestAnimationFrame(render);
}
另外,材质还提供了其他可选参数。目前,管道的材质是 MeshBasicMaterial,但其只渲染了管道外层(译者注:默认情况下),而摄像机是置于管道内的,因此只需要渲染管道材质背面即可。另外,由于我们并未在场景中添加任何光源,将材质设置为**线框(wireframe)**时,才能清楚看到具体效果。
var material = new THREE.MeshBasicMaterial({
color: 0xff0000, // 红色
side : THREE.BackSide, // 渲染背面材质
wireframe:true // 以线框的形式展示管道
});
瞧,现在摄像机在管道内动起来了!🎉
See the Pen Move the camera inside the tube by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>我并不打算在本文详细讲解光源,但会告诉你如何在管道中设置基础的光源效果。
其原理与摄像机的运动相同。我们将光源放置在摄像机的朝向位置。
// 为场景创建一个点光源
var light = new THREE.PointLight(0xffffff,1, 50);
scene.add(light);
var material = new THREE.MeshLambertMaterial({
color: 0xff0000,
side : THREE.BackSide
});
var percentage = 0;
function render(){
percentage += 0.0003;
var p1 = path.getPointAt(percentage%1);
var p2 = path.getPointAt((percentage + 0.02)%1);
camera.position.set(p1.x,p1.y,p1.z);
camera.lookAt(p2);
light.position.set(p2.x, p2.y, p2.z);
renderer.render(scene, camera);
requestAnimationFrame(render);
}
这就是具体效果啦!
See the Pen Add a light by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>基于最后一步(译者注:即上一步),我通过一些参数的变换,创建出新的动画类型。若感兴趣可以查看源代码。 😉
对于该案例,我为每个面设置了不同颜色。这样就得到了一个有趣的马赛克效果啦。
See the Pen Crazy 1 by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>In this one, I'm playing with the Y position of the points to generate my path. That way the tube is not only on one plane, but in three dimensions.
在该案例中,路径的生成加入了 Y 坐标(即不再为 0)。这使得管道不仅是在一个平面上,而是在三维空间上穿梭了。
See the Pen Crazy 2 by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>对于最后一个案例,我创建了 5 个半径和颜色均不相同的隧道。而为了得到更佳的显示效果,它们均被设置了不同的透明度。
See the Pen Crazy 3 by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>这就是第一章节的结尾了。而在下一章节,我将阐述如何在不使用 TubeGeometry 的情况下创建粒子管道。
若想一次性体验上述所有案例,你可以看看该 集合。
我希望你能从中学习到一些东西!如果遇到任何问题,请毫不犹豫地通过 Twitter 告诉我。
正如我在上一章节的结尾说道,我们将看到如何在不使用 TubeGeometry() 的情况下创建粒子管道。
你最终能创建这种类型的动画
为了达到想要的效果,我们需要沿着路径生成粒子。其实,Three.js 也是使用相同的方式生成管道几何体,其中不同的一点是:它加入了面(face),以形成一个常见的管道。
首先明确的细节是管道的构建元素及其半径。
这些细节由两个值设定:
// 组成管道的圆圈数量
var segments = 500;
// 组成每个圆的粒子数量
var circlesDetail = 10;
// 管道的半径
var radius = 5;
现在我们或许已经知道粒子的总数了(剧透:segments * circleDetails),而此刻则需要我们计算 佛莱纳标架(Frenet frame)。
我并不是这个领域的专家,但需要我们明白的是,佛莱纳标架(Frenet frame)是为管道所有片段(segments)计算出来的值。而每个值则由单位切向量、主法向量和副法向量组成。换句话说,这些值指定了每个片段的旋转角度及其朝向。
如果你想了解更多关于佛莱纳标架的计算过程,可以看看这篇文章。
多亏了 Three.js,我们不必理解上述任何知识即可让我们继续进行下去。使用 path 的内置函数即可:
var frames = path.computeFrenetFrames(segments, true);
// true 表明是否让路径闭合,在该案例中需要路径闭合
该函数返回的是三个由 Vector3() 组成的数组。
现在我们拥有每个片段所需的所有信息,能开始沿着每个片段生成粒子了。
我们将每个粒子以 Vector3() 形式存储在 Geometry() 中,以便后续复用。
// 创建一个用于插入粒子的空几何体
var geometry = new THREE.Geometry();
现在需要为每块片段放置粒子。这就是通过循环遍历所有片段的原因。
我不打算在这里阐述该函数是如何工作的,查看下面代码,你会发现所有细节都在注释中!⬇
// 循环遍历所有片段
for (var i = 0; i < segments; i++) {
// 从佛莱纳标架获取片段的主法向量
var normal = frames.normals[i];
// 从佛莱纳标架获取片段的副法向量
var binormal = frames.binormals[i];
// 计算片段的索引(0 至 1)
var index = i / segments;
// 获取片段中心点的坐标
// 在第一章节用于沿路径移动摄像机的函数
var p = path.getPointAt(index);
// Loop for the amount of particles we want along each circle
// 循环每个圆所需的粒子数量
for (var j = 0; j < circlesDetail; j++) {
// 复制圆心的位置
var position = p.clone();
// 需要将每个点基于角度 0 至 Pi*2 进行定位
// 如果只想要半个管道(如水滑梯),你可以从 0 至 Pi。
var angle = (j / circlesDetail) * Math.PI * 2;
// 计算当前角度的 sine 值
var sin = Math.sin(angle);
//计算当前角度的负 cosine 值
var cos = -Math.cos(angle);
// 根据每个点的角度、片段的主法向量与副法向量,计算出每个点的法向量
var normalPoint = new THREE.Vector3(0,0,0);
normalPoint.x = (cos * normal.x + sin * binormal.x);
normalPoint.y = (cos * normal.y + sin * binormal.y);
normalPoint.z = (cos * normal.z + sin * binormal.z);
// 法向量乘以半径长度,因为我们所需的管道的半径不是 1。
normalPoint.multiplyScalar(radius);
// 圆心位置与法向量相加
position.add(normalPoint);
// 将该向量放到几何体中
geometry.vertices.push(position);
}
}
唷,这段代码并不是那么容易理解。我阅读了 Three.js 的源码后才将其编写出来。
通过下面这个案例,你可以看到粒子是如何逐个计算出来的。
(如果管道已完全显示,请点击 “Rerun”)
See the Pen Calculate the positions of the particles by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>现在已经拥有填充顶点后的几何体对象了。通过 Three.js 的 Points 构造函数,你能创建精妙的粒子案例。而且对于简单的点,其渲染性能优异。可以通过纹理或不同的颜色自定义点的样式。
与创建 网格(Mesh) 的方式相同,我们需要两个元素才能创建 Points 对象,这两者是材质(material)与几何体(geometry)。因为在第一步中几何体已被创建,所以这里需要定义的是材质。
var material = new THREE.PointsMaterial({
size: 1, // 每个点的尺寸
sizeAttenuation: true, // 点的大小是否依赖于其与摄像机的距离(译者注:即近大远小)
color: 0xff0000 // 点的颜色
});
最后,创建点对象(Points),并将其添加至场景中:
var tube = new THREE.Points(geometry, material);
scene.add(tube);
See the Pen Create the tube by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>为了让所有东西动起来,我们将复用前面动画案例的代码。
var percentage = 0;
function render() {
// 变量自增
percentage += 0.0005;
// 获取摄像机该去的位置
var p1 = path.getPointAt(percentage % 1);
// 获取摄像机该朝向的位置
var p2 = path.getPointAt((percentage + 0.01) % 1);
camera.position.set(p1.x, p1.y, p1.z);
camera.lookAt(p2);
// 渲染场景
renderer.render(scene, camera);
// 动画循环
requestAnimationFrame(render);
}
🎉 欢呼吧,我们有一个由粒子构成的基础隧道了 🎉
See the Pen Moving particle tunnel by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>经过第二章节的学习后,现在的你可以接触到无数个不同的隧道了!可以在下面三个案例中体验到基于上述知识构建的自定义隧道。
在该案例中,我为每个点应用了自定义颜色。另外,也在场景中添加了雾化效果,让隧道产生渐隐效果。
See the Pen Crazy 4 by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>// 首先基于顶点索引创建新颜色
var color = new THREE.Color("hsl(" + (index * 360 * 4) + ", 100%, 50%)");
// 将该颜色添加到几何体对象的 colors 数组内
geometry.colors.push(color);
var material = new THREE.PointsMaterial({
size: 0.2,
vertexColors: THREE.VertexColors // 指定颜色应当来自几何体
});
// 为场景添加雾化效果
scene.fog = new THREE.Fog(0x000000, 30, 150);
See the Pen Crazy 5 by Louis Hoebregts (@Mamboleoo) on CodePen.
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>该隧道仅由立方体组成。我在每个顶点的位置创建新的网格(Mesh),以替换 Points 对象。另外,颜色是基于柏林噪声算法生成。
<p data-height="265" data-theme-id="0" data-slug-hash="EmaReQ" data-default-tab="result" data-user="Mamboleoo" data-embed-version="2" data-pen-title="Crazy 6" class="codepen">See the Pen <a href="https://codepen.io/Mamboleoo/pen/EmaReQ/">Crazy 6</a> by Louis Hoebregts (<a href="https://codepen.io/Mamboleoo">@Mamboleoo</a>) on <a href="https://codepen.io">CodePen</a>.</p>
<script async src="https://production-assets.codepen.io/assets/embed/ei.js"></script>
对于该案例,我将每个圆的顶点连接起来。而且调整了顶点的角度及其颜色以创造出旋转的幻觉。
for (var i = 0; i < tubeDetail; i++) {
// 为每个圆创建新的几何体
var circle = new THREE.Geometry();
for (var j = 0; j < circlesDetail; j++) {
// 将点添加到圆的顶点数组
circle.vertices.push(position);
}
// 再次将第一个点的添加到圆的顶点数组,以保证圆是闭合的
circle.vertices.push(circle.vertices[0]);
// 以自定义颜色创建新材质
var material = new THREE.LineBasicMaterial({
color: new THREE.Color("hsl("+(noise.simplex2(index*10,0)*60 + 300)+",50%,50%)")
});
// 创建线(Line)对象
var line = new THREE.Line(circle, material);
// 将其添加到场景中
scene.add(line);
感谢你阅读我这篇关于隧道动画的文章!
若你想一次性体验上述所有案例(第二章节),你可以看看该 集合。
希望你会对这篇文章感兴趣!如果你创造出了漂亮的隧道,请与我分享 --> Twitter。如果遇到任何问题,请毫不犹豫地告诉我。 😉
原文:Tiled Lines
今天,我打算在这里讲一个很早期却很简单的编程艺术。它就是最初在 Commodore 64 编码实现的 10 PRINT。
Commodore 64:Commodore 64,也称为C64、CBM 64或在瑞典被称作VIC-64,是由Commodore(康懋达国际)公司于1982年1月推出的8位家用电脑。——百度百科
由于其简单而惊艳,已被多次实现。
这里我们打算使用 canvas 实现,没有额外 API。只需在 HTML 中放置一个 300x300 像素的 <canvas> 元素。
首先进行初始化,没有任何渲染操作。
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
var size = window.innerWidth;
canvas.width = size;
canvas.height = size;以上代码将 canvas 设置为方形,并为我们提供了用于绘制的 context 上下文。
现在,再创建一个用于绘制的 draw 函数,其接收 x、y、width 和 height 参数。随后调用,尽管函数为空。
function draw(x, y, width, height) {
// TODO: Functionality here
}
draw(0, 0, size, size);现在,我们将使用 draw 函数绘制一些从 (0, 0) 坐标到 canvas 宽高坐标的东西。
至于绘制什么东西,那从一条简单的线开始。
context.moveTo(x, y);
context.lineTo(x + width, y + height);
context.stroke();这样我们就拥有一条从 canvas 左上角至右下角的对角线,而且是不可变的。
为了使其具有“活性”,我们需要对它进行更改,既 50% 的概率将其替换成从右上角至左下角的对角线。总的来说,就是将“艺术”从我们双手释放给计算机完成。
从代码实现上,我们将添加一个随机布尔值,并将其放置在 if 语句中:
var leftToRight = Math.random() >= 0.5;
if( leftToRight ) {
context.moveTo(x, y);
context.lineTo(x + width, y + height);
} else {
context.moveTo(x + width, y);
context.lineTo(x, y + height);
}
context.stroke();Math.random() 将返回一个 0~1 的数字,这给予了我们二选一的概率。
最后一步是“分而治之”。因为,100 条线比 1 条线有趣多了。
添加 step 变量:
var step = 100该变量表示“步伐距离”。在本案例中,width 是 400,step 是 100,既需要填充 4 次(译者注:横向 4 次,纵向 4 次,共 16 次)。
for( var x = 0; x < size; x += step) {
for( var y = 0; y < size; y+= step ) {
draw(x, y, step, step);
}
}效果怎么样?我们还可以缩短"步伐距离":
var step = 20现在,我们拥有一个更复杂漂亮的作品了。
没错,这就是本教程的全部!
你可以随意调整代码中的任意变量,如起始点 x, y 等。当然,step 应该是最有趣的地方。另外,draw 函数可以绘制比对角线更复杂的东西。
本文首发于 凹凸实验室
3D 全景并不是什么新鲜事物了,但以前我们在 Web 上看到的 3D 全景一般是通过 Flash 实现的。若我们能将 CSS3 Transform 的相关知识运用得当,也是能实现类似的效果。
在实现 CSS3 3D 全景之前,我们先理清部分 CSS3 Transform 相关的属性:
z=0 平面的距离,使具有三维变换的元素产生透视效果。(默认值:none,值只能是绝对长度,即负数是非法值)。perspective 的元素,默认值:50% 50%,即正视物体。值为 50% 100% 时,即仰视物体)。下面我们对上述的一些点进行更深入的分析:
对于 perspective 对元素大小的影响:
根据 相似三角形 的性质可计算出被前移的元素最终在屏幕上显示的实际大小
另外,对于在“眼睛”背后的元素(即元素的 z 轴坐标值大于 perspective 的值),浏览器是不会将其渲染出来的。
对于 transform-style,该属性指定其子元素是处于 3D 场景还是 2D 场景。对于 2D 场景,子元素位于元素本身的平面内,即使旋转也不会穿透其他子元素;对于 3D 场景,子元素以真实 3D 空间进行定位展示。
另外,由于 transform-style 是非继承属性,对于中间节点需再次指定。
对于 transform 属性:下图整理了 rotate3d、translate3d 的变换方向:
需要注意的是:transform 中的变换属性是有顺序的,如 translateX(10px) rotate(30deg) 与 rotate(30deg) translateX(10px) 是不等价的。
另外,如果 scale 值为负数,则该方向会 180 度翻转;
再另外,transform 可能会导致元素(字体)模糊,如 translate 的数值存在小数、通过 translateZ 或 scale 放大元素等等。每个浏览器都有其不同的表现。
理清了 CSS Transform 相关的知识点后,下面就讲讲如何实现 CSS 3D 全景 :
想象一下,当我们站在十字路口中间,身体旋转 360°,这个过程中所看到的画面就是一幅以你为中心的全景图。其实,当焦距不变时,我们就等同于站在一个圆柱体的中心。
但是,虚拟世界与现实世界最大的不同点是:没有东西是连续的,即所有东西都是离散的。例如,你无法在屏幕上显示一个完美的圆。你只能以一个正多边形表示圆:边越多,圆就越“完美”。
同理,在三维空间中,每个 3D 模型都是一个多面体(即 3D 模型由不可弯曲的平面组成)。当我们讨论一个本身就是多面体(如立方体)的模型时并不足以为奇,但对于其它模型,如球体,就需要意识这个原理。
淘宝造物节的活动页 是一个基于 CSS 3D 实现的全景页面。它将全景图分割成 20 等份,为一个正 20 棱柱。需要注意的是:我们要确保每个元素的正面是指向棱柱中心。所以要计算好每等份的旋转角度值后,再将元素向外(即 Z 轴方向)平移 r px。对于立方体的 r 就是 边长/2,而对于其他正棱柱呢?
举例:对于正九棱柱,每个元素的宽为 210px,对应的圆心角为 40°,即如下图:
图片来自:https://desandro.github.io/3dtransforms/docs/carousel.html
正九棱柱的俯视图
计算过程
由此可得到一个通用函数,只需传入含有元素的宽度和元素数量的对象,即可得到 r 值:
function calTranslateZ(opts) {
return Math.round(opts.width / (2 * Math.tan(Math.PI / opts.number)))
}
calTranlateZ({
width: 210,
number: 9
}); // 288
俯视所看到的元素外移动画
另外,为了让下文易于理解,我们约定 HTML 的结构:
#view(perspective: 420px)
#cube(transform-style: preserve-3d)
.face // 组成立方体的面
正棱柱构建完成后,就需要将我们的“眼睛”放置在正棱柱内。由于浏览器不会渲染在“眼睛”后的元素(与 .face 元素 是否设置 backface-visibility: hidden; 无关),且保证 .face 元素 的正面均指向正棱柱中心,这样就形成 360° 被环绕的效果了。
根据上述知识,笔者粗略地模仿了“造物节”的效果:https://css3dpanorama-1251477229.cos.ap-guangzhou.myqcloud.com/index.html
另外,只需 6 幅图即可实现一个常见的无死角全景图效果:https://css3dpanorama-1251477229.cos.ap-guangzhou.myqcloud.com/street.html
可由下图看出,将水平的 4 张图片合成后就是一张全景图:
以上就是我们通过 CSS3 Transform 相关属性实现的可交互全景效果了。当然,交互效果可以是拖拽,也可以是重力感应等。
将全景图制作分为设计类与实景类:
要制作类似 《淘宝造物节》 的全景页面,设计稿有以下要求。
注:下面提及的具体数据均基于《造物节》,可根据自身要求进行调整(若发现欠缺,欢迎作出补充)。
整体背景设计图如下(2580*1170px,被分成 20 等份):
基本要求:
为了增强立体感,可添加能形成视差效果的小物体(与背景图不同的运动速度、延迟时间),如:
小物体元素(虚线用于参考,造物节**有 21 个小物体)
如上图虚线所示,每个小物体也会被等分成 M 份,且每份宽度应与背景元素宽度相等。
如果想制作实景的全景效果,可以看看 Google 街景:
Google 街景 推荐的设备如下:
如上图,最实惠的方式就是最后一个选项——Google 街景 APP,该应用提供了全景相机功能。但正如图片介绍所说,这是需要练习的,因此对操作要求比较高。
补充:
上周六(2016.8.20)参加了 TGDC 的分享会,嘉宾分享了他们处理全景的方式:
其中 Web 技术有以下 3 种可选方式:
现场快速制作的 会议现场全景。
可见,优秀硬件设备的出现,大大减少了后期处理的时间,而 Web 则提供了一个优秀的展现平台。
随着终端设备的软硬件不断完善与提高,Web 在 3D 领域也不甘落后,如果你玩腻了 2D 的 H5 或者想为用户提供更加新颖真实的体验,全景也许是一种选择。
最后,如有不清晰或不明白的地方,可以留言,我会尽可能解决的。谢谢谢~
原文:How to better organize your React applications?
在过去的几年,我一直在开发超大型的 Web 应用。与数十名开发者从零开始,使其现在达到服务数百万用户的规模。如果一开始就没有一个好的文件目录结构,就很难维持代码的组织性。
Nathanael Beisiegel 写了一篇有趣的文章,阐述了他在组织大型 React 项目的策略。但我对其想法并不十分赞同。因此,我决定花些时间找出将来组织 React 项目的最佳方式。
注意 1:在本文提及的所有案例均使用了 Redux。如果你还未了解 Redux,可以阅读 此文档。
注意 2:所有案例均基于 ReactJS,但你可以在 React-Native 应用上使用相同的结构。
写于 2018.04:如果想改善代码结构,那么你应该对我最近写的这篇文章感兴趣——《为何 React 开发者应该懂得模块化》
绝大多数开发者会(或将会)碰到以下场景:
每当客户决定向程序添加新功能时,新代码都会与复杂的遗留代码混合在一起,使得可维护性越来越低。而导致这一切问题的根源在于程序从一开始就没有正确设计。
在刚开始学习 React 时, ,我找了几篇关于如何创建 Todo List 或简单游戏的优秀文章。这些文章让我很好地理解了 React 的基础知识。但与此同时,我很快发现这并没有告诉我如何使用 React 构建真实项目,即包含数十个页面和数百个组件的项目。
在搜索过后,我发现 Github 上所有 React 模板项目均是相类似的结构——根据文件类型组织项目。大概如下:
/src
/actions
/notifications.js
/components
/Header
/Footer
/Notifications
/index.js
/containers
/Home
/Login
/Notifications
/index.js
/images
/logo.png
/reducers
/login.js
/notifications.js
/styles
/app.scss
/header.scss
/home.scss
/footer.scss
/notifications.scss
/utils
index.js
这样的文件结构对于构建个人网站或应用应该没多大的问题,但我相信这并不是最佳的目录结构。
当以文件类型组织时,无疑会随着应用的迭代而变得愈发难以维护。当你意识到这一点时已为时已晚,你不得不花费大量的时间和金钱去更改所有东西,或者在接下来的时间忍受着这一问题。
使用 React 的好处是你可以随心所欲地组织项目,而不会强制你按照特定的文件结构。毕竟 React 就是一个简单的 JavaScript 库。
在金融机构工作的那几年,我们将 Ember 作为主要的 JavaScript 框架去构建所有新的 Web 应用。而 Ember 有趣的一点是:能够按照功能组织项目,而不是文件类型。但这足以改变这一切。
Ember 的 Pods 结构很优秀,但仍有局限性,所以我想为其赋予更多的灵活性。在经过数次实验以试图寻找出最佳的目录结构后,我得出这一结论:将所有相关功能组合在一起,然后按需嵌套。以下就是我正在使用的结构:
/src
/components
/Button
/Notifications
/components
/ButtonDismiss
/images
/locales
/specs
/index.js
/styles.scss
/index.js
/styles.scss
/scenes
/Home
/components
/ButtonLike
/services
/processData
/index.js
/styles.scss
/Sign
/components
/FormField
/scenes
/Login
/Register
/locales
/specs
/index.js
/styles.scss
/services
/api
/geolocation
/session
/actions.js
/index.js
/reducer.js
/users
/actions.js
/api.js
/reducer.js
index.js
store.js
每个组件、场景(译者注:一般为页面,但也可将登陆和注册两个页面视为一个场景)或服务(功能)均含有供自己使用的所有东西,如自身的样式、图片、译文(译者注:国际化)、actions(译者注:应该指 Redux 相关)和单元/集成测试。即将一项功能视为应用中的一个独立代码段(有点类似 Node 模块)。
为了运行良好,需遵循以下规则:
注意:父级不局限于直系父级,还包含祖先级。不能使用“堂兄弟”的功能,只能将其移到父级内再使用。
下面听我分点阐述。
大家都知道组件是什么。但在此文件结构中,是允许组件嵌套组件。
在项目根目录的 components 文件夹内定义的组件是全局的,即可在应用中的任意位置使用。当在一个组件内定义一个新组件(即嵌套)时,则该新组件就仅能被其直系父级使用。
当开发一个大型应用时,你经常需要创建组件。你明确知道它不会在其他地方复用,但确实需要它。如果你将其放到根目录的 components 文件夹下,久而久之,里面就会填满数百个组件。此时,你意识到需要将它们进行分类,但早已忘了其用途和在哪些地方使用。
如果仅在里面放应用的主要组件,如 button、form field、thumbnail 甚至是一些更复杂的组件,如 listComment、formComposer 及其子组件,那么就能提高查找它们的效率。
案例:
/src
/components
/Button
/index.js
/Notifications
/components
/ButtonDismiss
/index.js
/actions.js
/index.js
/reducer.js
场景就是应用中的一个页面。场景其实也是一个组件,但我更乐意将它们放到单独一个文件夹中。
如果有使用 React-Router 或 React Native Router,那么你可以将所有场景引入到 index.js 应用入口文件中,并将它们与路由进行匹配。
既然是组件,那么场景也是可嵌套的,即场景内嵌套场景。当然,也可以在场景内定义组件或服务。但需要记住的是:场景内定义的东西,仅供该场景使用。
案例:
/src
/scenes
/Home
/components
/ButtonShare
/index.js
/index.js
/Sign
/components
/ButtonHelp
/index.js
/scenes
/Login
/components
/Form
/index.js
/ButtonFacebookLogin
/index.js
/index.js
/Register
/index.js
/index.js
并不是所有东西都能作为组件。你需要创建一个独立的模块,以供组件和场景使用。
你可以将一项服务看作是独立的模块。它定义了应用的核心业务逻辑,最终可供多个场景,甚至是多个应用(web 与 native 版本 的应用)共享使用。
/src
/services
/api
/services
/handleError
/index.js
/index.js
/geolocation
/session
/actions.js
/index.js
/reducer.js
我建议你创建一个服务去管理所有 API 请求。即将其作为服务器 API 与视图层(场景和组件)的桥梁/适配器。它可以处理应用发起的网络请求、获取或发布内容、在发送或存储在应用的 store(如 Redux) 前按需处理负载。而场景和组件只需 dispatch actions、读取 store 数据和更新视图即可。
在过去几个月,我已经根据此目录结构开发了一个 React-Native 个人项目,并因此节省了大量时间。所以,将所有相关实体放在一起会让事件变得更简单和更易处理。
这种目录结构只是无数种组织项目的方式之一。但这就是我现在喜欢的方式,希望它能提升你的工作效率!
如果你想查看使用该文件结构的实际工作项目,可查看我 Github 账号:
若有任何疑问,请随时评论或直接与我联系,我将非常乐意提供帮助。
Have fun!
大家好,我是 Alexis!我是一名拥有 14 年开发经验的全栈开发者。我自小就对技术充满激情。现专注于 JavaScript 开发。乐意花费无数时间去学习和使用新技术,并将其用于我们下一个项目中。我最近开始使用 Twitter,欢迎关注我:@alexmngn
原文:Machine Learning For Front-End Developers With Tensorflow.js——Charlie Gerard
摘要:结合 JavaScript 和诸如 Tensorflow.js 等框架是入门机器学习的好办法。本文将涵盖 Tensorflow.js 目前提供的三大主要功能,并阐明了在前端使用机器学习的局限性。
机器学习常给人的感觉是属于数据科学家和 Python 开发者的领域。然而,在过去数年,开源框架的涌现使得语言不再成为限制,JavaScript 就是其一。在本文,我们将使用 Tensorflow.js 并结合示例项目去探索在浏览器中使用机器学习的不同可能性。
在开始深入代码前,我们先简单讲解机器学习是什么,及其核心概念和术语。
通用定义是赋予计算机从数据中获得学习能力而没有显式编程的能力。
人工智能领域的先驱者,Arthur Samuel 在 1959 年创造“机器学习”这个概念时,对它下的定义:“Field of study that gives computers the ability to learn without being explicitly programmed”。
如果将其与传统编程相比,意味着让计算机去识别数据中的模式,然后拥有预测能力,而无需我们明确它该做什么。
以欺诈检测为例。这显然没有固定的标准来判断交易是否存在欺诈行为;欺诈可以发生在任何国家/地区、任何账户、任何客户、任何时刻。手动跟踪所有这一切几乎是不可能的。
然而,我们可以利用所收集的欺诈相关数据去训练一个机器学习算法,使其理解数据中的模式,最终生成一个能预测任何新交易是否为诈骗的模型(model)。
为理解后续代码案例,我们还需要先学习一些常用术语。
当使用数据集训练机器学习算法时,模型就是该训练的输出(结果)。它有点类似函数,将新数据作为输入,产生一个预测作为输出。
标签和特征是与你在训练过程中向算法提供的数据有关。
标签是指如何对数据集中每个样本进行分类,以及如何对其打标签。例如,数据集是描述不同动物的 CSV 文件,那么我们的标签可以是 “cat”、“dog” 或 “snake” 之类的词语。
特征是数据集中每个样本的特征。以上述动物为例,它可以是“胡须、喵叫”、“顽皮、犬吠”、“爬行动物、猖獗”等。
这样,机器学习算法就能够找到特征与其标签之间的联系,并用于将来的预测。
神经网络是一组机器学习算法,其试图通过使用人工神经元层来模仿大脑的工作方式。
本文并不需要你深入了解它的工作方式,但如果想了解更多,下面有一个非常棒的视频:
But what is a Neural Network? | Deep learning, chapter 1
至此,我们已经定义了一些机器学习的常用术语。下面让我们谈谈使用 JavaScript 和 Tensorflow.js 框架能做些什么。
目前支持三大功能:
我们先从最简单的一个说起。
对于你打算解决的问题,可能存在已使用特定数据集训练过的模型,那么你就可以在代码中导入并使用它。
比如说,我们将构建一个用于预测图片是否是猫的网站。那么流行的图像分类模型 MobileNet 可作为 Tensorflow.js 的预训练模型来使用。
实现代码如下:(译者注:mobilenet 需要全局翻墙才能加载成功)
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cat detection</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]"> </script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]"> </script>
</head>
<body>
<img id="image" alt="cat laying down" src="cat.jpeg"/>
<script>
const img = document.getElementById('image');
const predictImage = async () => {
console.log("Model loading...");
const model = await mobilenet.load();
console.log("Model is loaded!")
const predictions = await model.classify(img);
console.log('Predictions: ', predictions);
}
predictImage();
</script>
</body>
</html>首先在 HTML 头部引入 Tensorflow.js 和 MobileNet 模型:
<script src="https://cdnjs.cloudflare.com/ajax/libs/tensorflow/1.0.1/tf.js"> </script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]"> </script>然后,在 body 内放置一张用于预测的 img 元素:
<img id="image" alt="cat laying down" src="cat.jpeg"/>最后,在 script 标签内加载预训练 MobileNet 模型,并对 #image 元素进行分类。该分类会返回一个含有 3 个预测结果的数组,并根据概率分数进行排序(分数最高的排第一位)。
const predictImage = async () => {
console.log("Model loading...");
const model = await mobilenet.load();
console.log("Model is loaded!")
const predictions = await model.classify(img);
console.log('Predictions: ', predictions);
}
predictImage();以上就是在浏览器上使用预训练模型和 Tensorflow.js 的方式。
Note:如果你想知道 MobileNet 模型还能进行哪些分类,可以在 Github 的 这里 寻找。
需要引起注意的是:在浏览器中加载一个预训练模型会比较耗时(可能超过 10 秒),所以你需要做预加载或调整界面交互以减轻对用户的影响。
如果你更倾向于将 Tensorflow.js 视为一个 NPM 模块,那么可通过以下方式导入:
import * as mobilenet from '@tensorflow-models/mobilenet';点击 CodeSandbox 可以随意玩耍这个案例。
现在我们已经学会了如何使用预训练模型,下面我们看看第二个功能:迁移学习。
迁移学习是一种将预训练模型和自定义训练数据相结合的能力。换句话说,你可以利用模型的功能并添加自己的样例,而无需从零开始创建所有内容。
例如,现在有一个图片分类模型,它由一个已被数千张训练过的算法得到。此时你无需从零开始,因为迁移学习允许你将新的自定义图片样本与预训练模型组合得到一个新的图片分类器。
为了更好地说明,我们在原来代码的基础上进行了调整,以对新图像进行分类:
Note:下面就是最终实验结果,可以点击 这里 体验。
下面是该案例中最重要的代码段,可在 CodeSandbox 查看完整代码。
开始部分仍需要引入 Tensorflow.js 和 MobileNet,但这次还需要加上 KNN(k-nearest neighbor) 分类器:
<!-- Load TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<!-- Load MobileNet -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/mobilenet"></script>
<!-- Load KNN Classifier -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/knn-classifier"></script>需要分类器(而不只是使用 MobileNet 模块)的原因是:我们加入了先前没有的自定义样本数据。所以 KNN 分类器的作用是:将所有东西结合在一起,从而能基于结合后的数据作出预测行为。
然后,我们用 video 标签替换掉猫的图像,即从摄像头获取图像。
<video autoplay id="webcam" width="227" height="227"></video>最后,需要在页面上添加几个按钮,用于记录一些视频样本作为标签和启动预测。
<section>
<button class="button">Left</button>
<button class="button">Right</button>
<button class="test-predictions">Test</button>
</section>现在,开始编写 JavaScript 文件。首先,定义一些重要的变量:
// 类别的数量
const NUM_CLASSES = 2;
// 类别的标签
const classes = ["Left", "Right"];
// 网络摄像头的图片尺寸,必须为 227
const IMAGE_SIZE = 227;
// KNN 的 K 值
const TOPK = 10;
const video = document.getElementById("webcam");本案例要对摄像头中的用户头部向左/右倾斜进行分类,所以需要两个类别标签 left 和 right。
之所以将图片尺寸设置为 227 像素,是为了匹配已训练过 MobileNet 模型的数据的格式。即后者必须采用相同格式才能对新数据进行分类。
如果样本确实较大,就需要在输入 KNN 分类器前对数据进行大小调整。
接着,我们将 K 值设为 10。K 值对于 KNN 算法很重要,它表示对新输入进行分类时考虑多少实例。
在该案例中,10 表示在预测新数据的标签时,将从训练数据中最邻近的 10 个数据查找。
最后,获取 video 元素。
对于实现逻辑,我们从加载模型和分类器开始:
async load() {
const knn = knnClassifier.create();
const mobilenetModule = await mobilenet.load();
console.log("model loaded");
}然后,获取视频源:
navigator.mediaDevices
.getUserMedia({ video: true, audio: false })
.then(stream => {
video.srcObject = stream;
video.width = IMAGE_SIZE;
video.height = IMAGE_SIZE;
});紧接着,为按钮绑定事件,以记录样例数据:
setupButtonEvents() {
for (let i = 0; i < NUM_CLASSES; i++) {
let button = document.getElementsByClassName("button")[i];
button.onmousedown = () => {
this.training = i;
this.recordSamples = true;
};
button.onmouseup = () => (this.training = -1);
}
}获取摄像头的图像样例,并重新格式化它们,最后将它们结合到 MobileNet 模块:
// 从 video 元素获取图像数据
const image = tf.browser.fromPixels(video);
let logits;
// 'conv_preds' 是 MobileNet 的对数激活(logits activation)
const infer = () => this.mobilenetModule.infer(image, "conv_preds");
// 当其中一个按钮按下时,则训练类别
if (this.training != -1) {
logits = infer();
// 添加当前图像到分类器
this.knn.addExample(logits, this.training);
}最后,一旦我们收集到一些摄像头图像,我们就可以使用以下代码进行预测:
logits = infer();
const res = await this.knn.predictClass(logits, TOPK);
const prediction = classes[res.classIndex];当不再需要摄像头数据时,我们可以将其释放:
image.dispose();
if (logits != null) {
logits.dispose();
}再次提醒,如果想查看完整代码,请点击 CodeSandbox。
最后一个功能是完全在浏览器上定义、训练并使用模型。我们将通过构建一个识别鸢尾花种类的案例来阐述。
为此,我们将基于开源数据集创建一个能对鸢尾花进行分类(三种类别,分别是:Setosa、Virginica 和 Versicolor)的神经网络。
每个机器学习项目的核心是数据集。项目初期首先要做的事情之一是将数据集拆分为训练集和测试集。
这样做的原因是我们将用训练集训练算法,用测试集检查预测的准确性,以验证模型是可用还是需要调整。
Note:为了让事情变简单,我已将训练集和测试集拆分为两个 JSON 文件,可以在 CodeSanbox 找到。
训练集含有 130 项,测试集含有 14 项。数据看起来像这样:
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2,
"species": "setosa"
}如你所见,萼片(sepal)和花瓣(petal)的长宽是四个不同的特征,以及作为标签的物种(species)。
为了能被 Tensorflow.js 所用,我们需要将数据转成框架能理解的数据格式。对于本例,训练数据的 [130, 4] 表示有 130 个带有 4 个特征的鸢尾花。
import * as trainingSet from "training.json";
import * as testSet from "testing.json";
const trainingData = tf.tensor2d(
trainingSet.map(item => [
item.sepal_length,
item.sepal_width,
item.petal_length,
item.petal_width
]),
[130, 4]
);
const testData = tf.tensor2d(
testSet.map(item => [
item.sepal_length,
item.sepal_width,
item.petal_length,
item.petal_width
]),
[14, 4]
);接着,我们需要将输出数据进行转换:
const output = tf.tensor2d(trainingSet.map(item => [
item.species === 'setosa' ? 1 : 0,
item.species === 'virginica' ? 1 : 0,
item.species === 'versicolor' ? 1 : 0
]), [130,3])然后,一旦数据准备就绪就可以开始创建模型:
const model = tf.sequential();
model.add(tf.layers.dense(
{
inputShape: 4,
activation: 'sigmoid',
units: 10
}
));
model.add(tf.layers.dense(
{
inputShape: 10,
units: 3,
activation: 'softmax'
}
));上述代码中,我们首先实例化一个序列模型,添加一个输入层和输出层。
对于参数(inputShapre,activation 和 units),它们超出了本文的叙述范围。它们取决于你所创建的模型、数据的类型等。
一旦模型就绪,我们将能使用测试数据进行验证:
async function train_data(){
for(let i=0;i<15;i++){
const res = await model.fit(trainingData, outputData,{epochs: 40});
}
}
async function main() {
await train_data();
model.predict(testSet).print();
}验证通过后,我们就可以供用户使用。
每次调用 main 函数,预测的输出大概像这样:
[1,0,0] // Setosa
[0,1,0] // Virginica
[0,0,1] // Versicolor预测返回的结果是一个含有 3 个数值的数组,它们分别表示属于三个种类之一的概率。即数值越接近 1 ,概率越高。
如果分类的输出结果是 [0.0002, 0.9494, 0.0503],数组的第二个数值最大,那么该模型预测新输入大概率是 Virginica。
这就是 Tensorflow.js 的一个简单神经网络!
在这里,我们仅讨论了一个关于鸢尾花的小数据集,但对于更大的数据集或图像,步骤是一致的:
如果你想分享该模型到另一个应用,那么可以保存它:
await model.save('file:///path/to/my-model'); // in Node.jsNote:关于保存模型的更多可选项,可看 这里。
是的!我们刚刚介绍了 Tensorflow.js 目前提供的三大功能。
在文章结尾之前,我认为有必要简单提一下在前端使用机器学习的局限性。
导入一个预训练的模型会对应用产生性能问题。例如,一些对象检测模型超过 10MB,这无疑会显著减慢网站的加载速度。所以,请务必考虑用户体验,并优化资源的加载,以改善感知性能。
感知性能(Perceived Performance):计算机工程中的感知性能是指软件功能在执行其任务时的速度。该概念主要适用于用户接受方面。 通过显示启动屏幕或文件进度对话框,应用程序启动或下载文件所需的时间不会更快。但是,它满足了一些人的需求:它对用户来说似乎更快,并提供了一个视觉提示,让他们知道系统正在处理他们的请求。——维基百科
如果从零开始构建模型,那么必须要自己收集数据或从一些开源的数据集中寻找。
在进行任何类型的数据处理或尝试不同的算法之前,请务必检查输入数据的质量。举例来说,你尝试构建一个用于识别文本情感的情感分析模型,那么就需要确保数据的准确性和多样性。如果使用的数据质量较低,那么训练的结果将毫无用处。
使用开源的预训练模型无疑是简单快速的。然而,这也意味着你可能不知道它如何生成、数据集由什么构成,甚至使用了何种算法。有些模型被称为“黑盒子”,这意味着你并不知道它们是如何预测某种输出。
对于部分构建意图,这可能存在一定问题。例如,假设你使用一个基于扫描影象的机器学习模型来帮助人们检查患癌可能性。万一发生假阴性(模型预测病人未患癌,但实际已患癌),这可能牵涉到法律责任。此时,你必须能够解释为何该模型作出这一预测。
总的来说,结合 JavaScript 和诸如 Tensorflow.js 等框架是入门机器学习的好办法。尽管生产环境的应用程序应该使用 Python 之类的语言,但 JavaScript 降低了门槛,让开发者能体验各种功能和理解基础概念。这无疑降低了在决定投入精力学习另一种语言前的成本。
本教程仅介绍了 Tensorflow.js 的可能性,但其他库和工具的生态正在成长。更多特定领域的框架能让你结合机器学习进行探索,例如音乐方面的 Magenta.js,或预测网站用户浏览行为的 guess.js!
随着工具越来越高效,使得构建支持机器学习的 JavaScript 应用成为了可能,这无疑令人兴奋。现在就是学习它的好时机,因为社区正努力改善其可用性。
如果想学习更多,下面提供一些资源:
感谢阅读!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






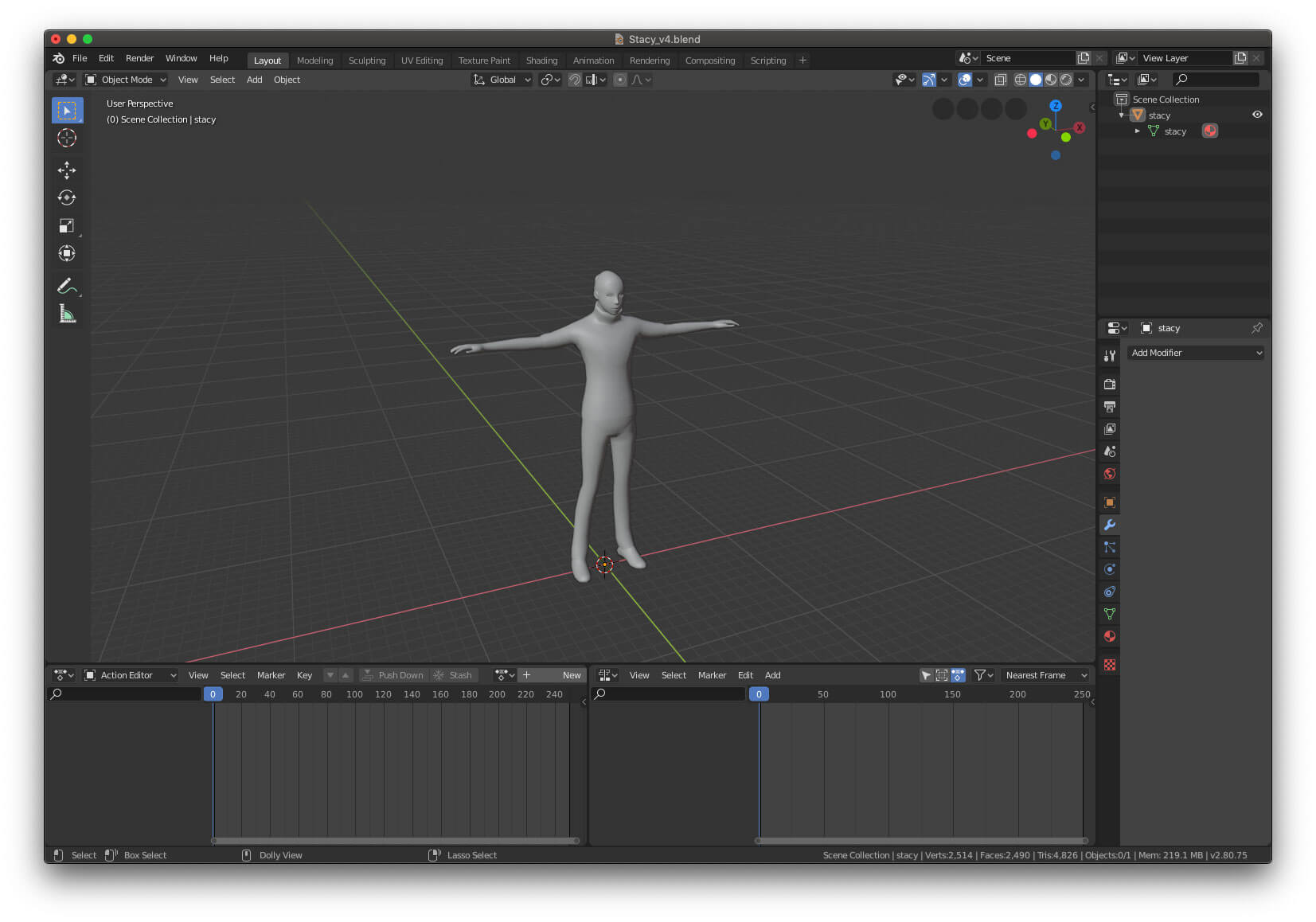
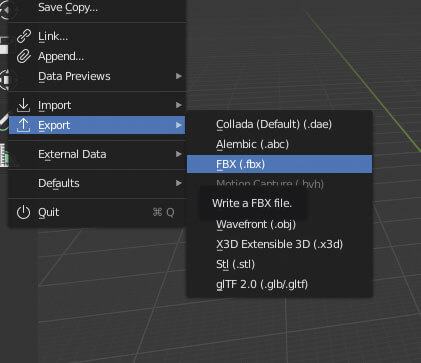
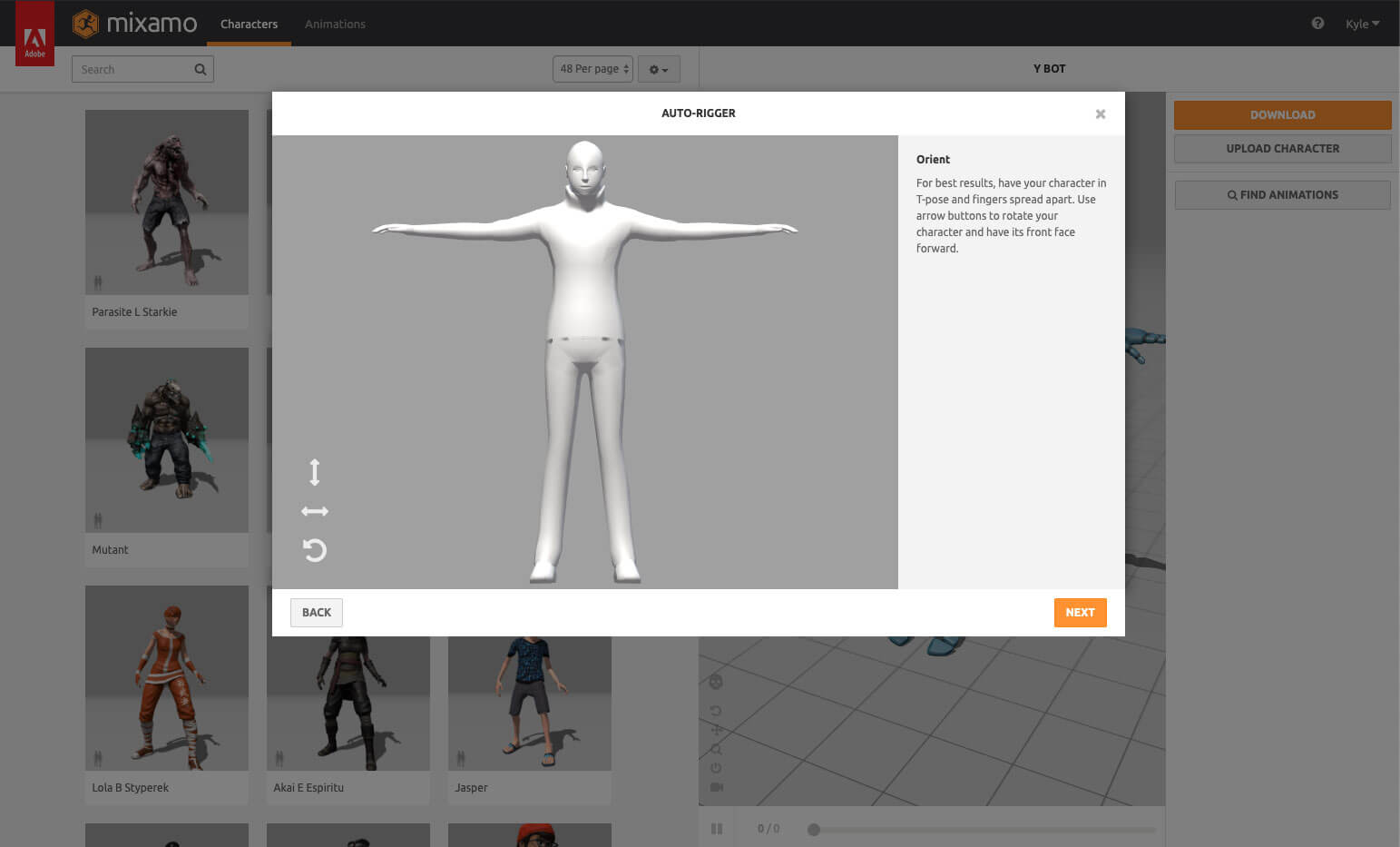
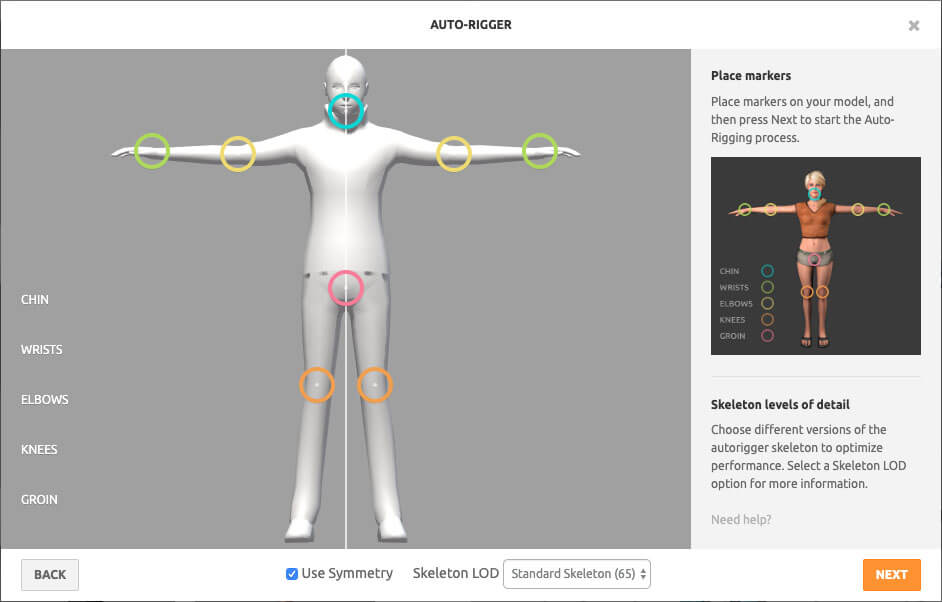
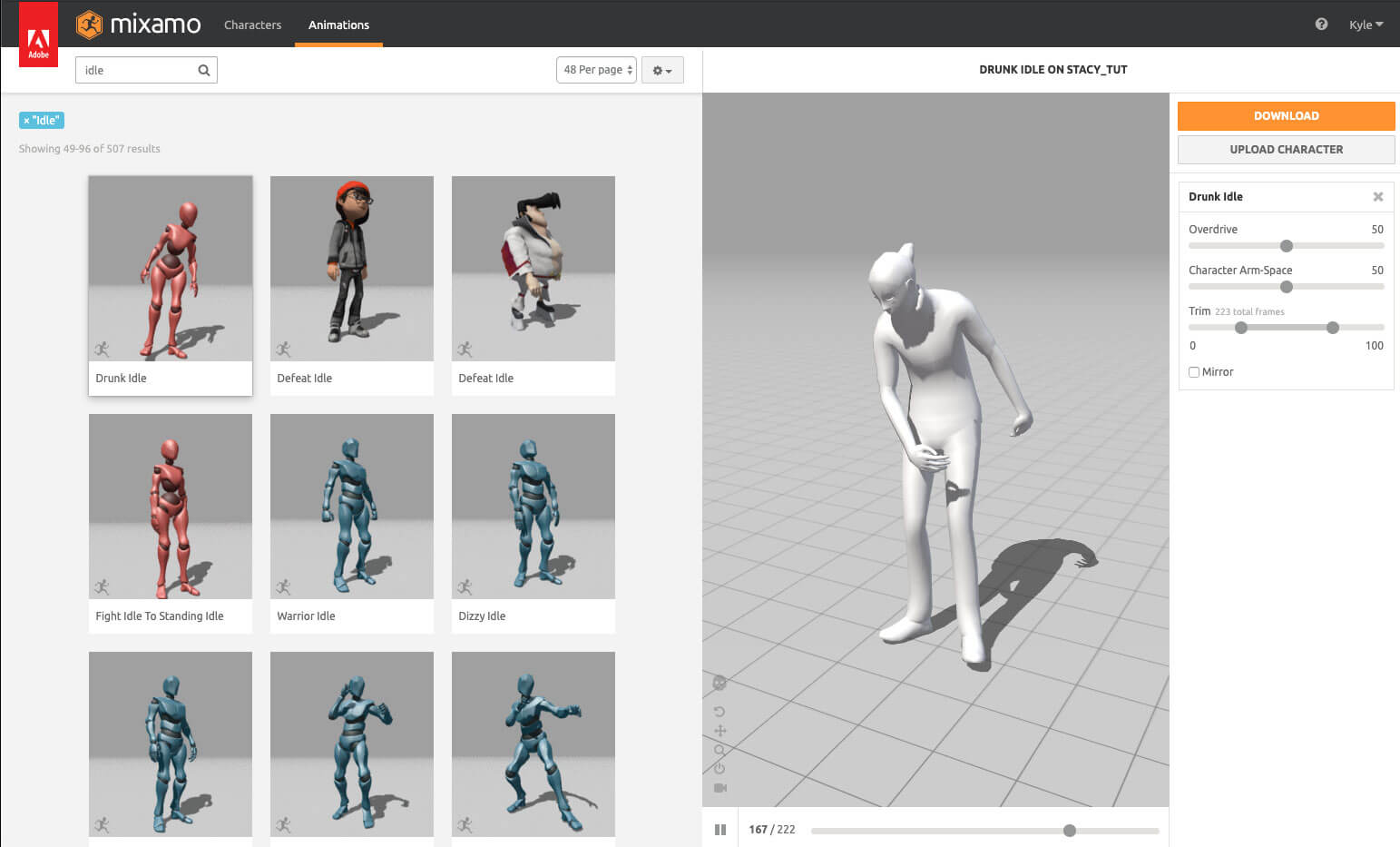
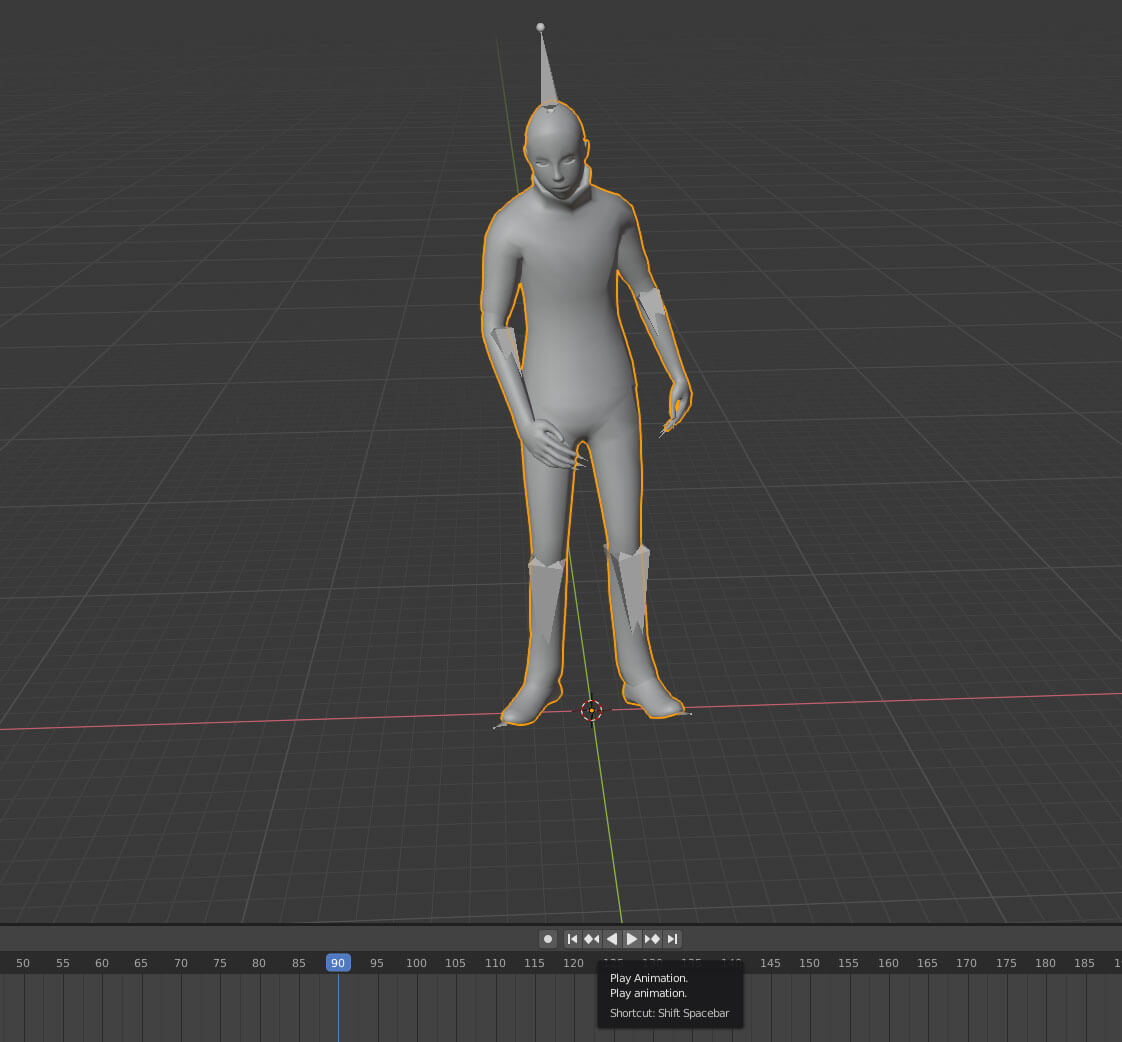
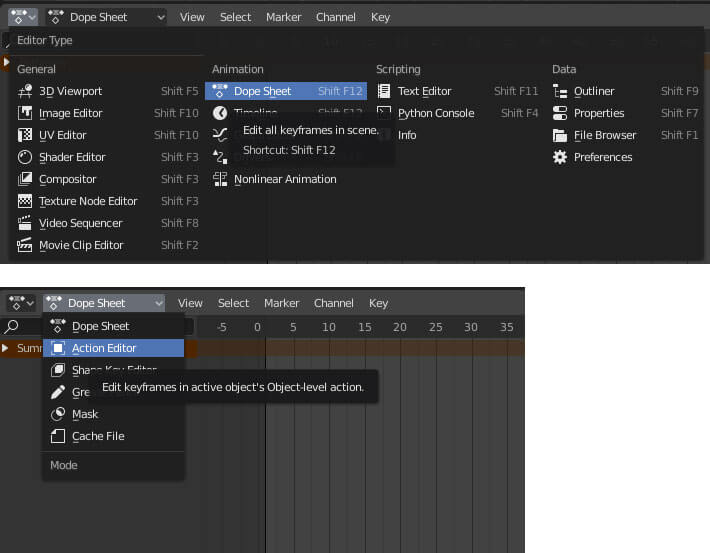
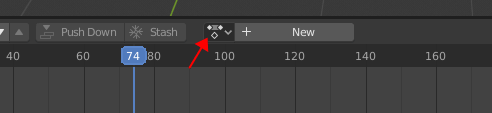
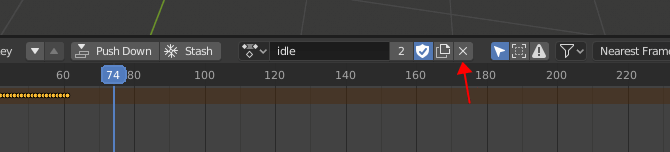

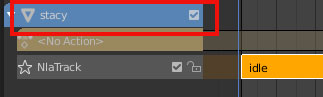
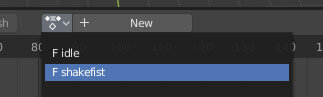
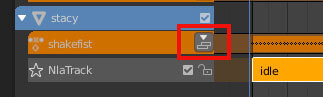
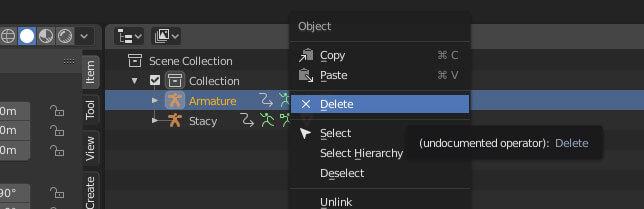
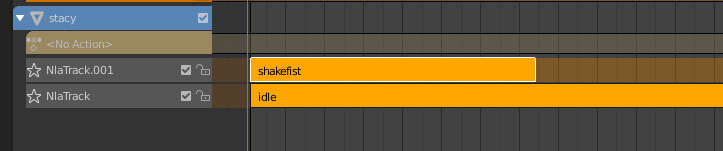
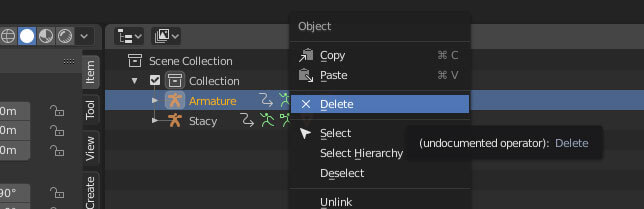







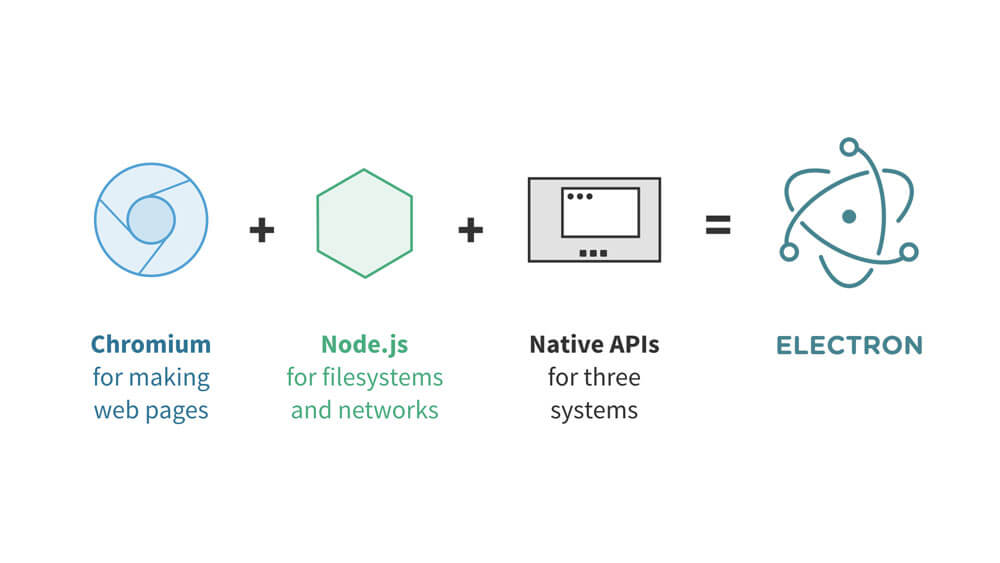

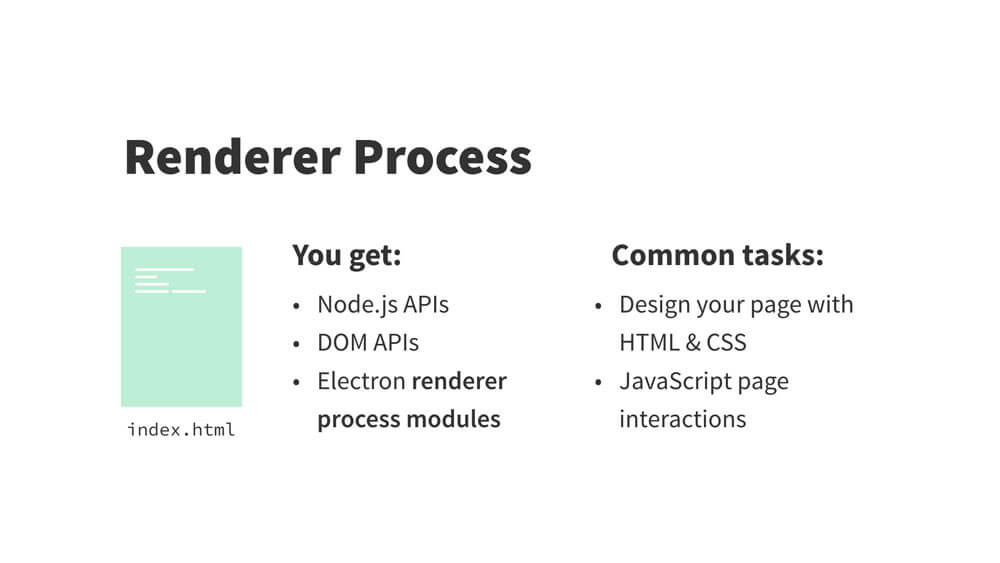
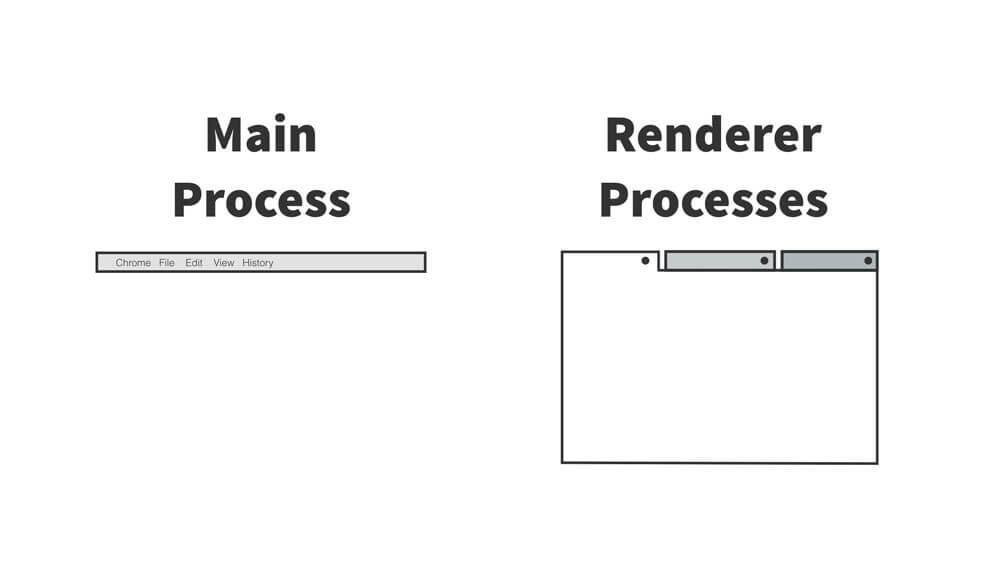
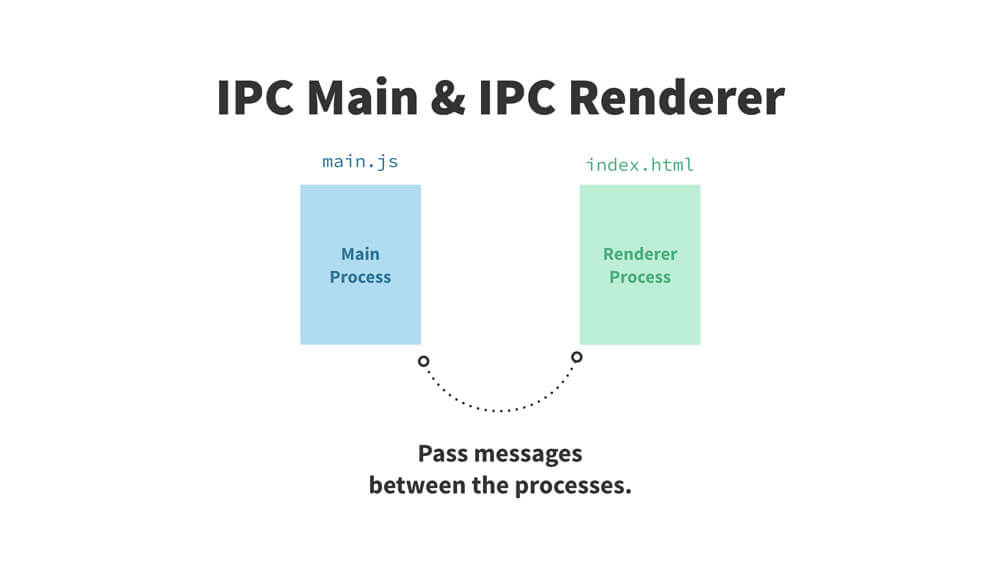
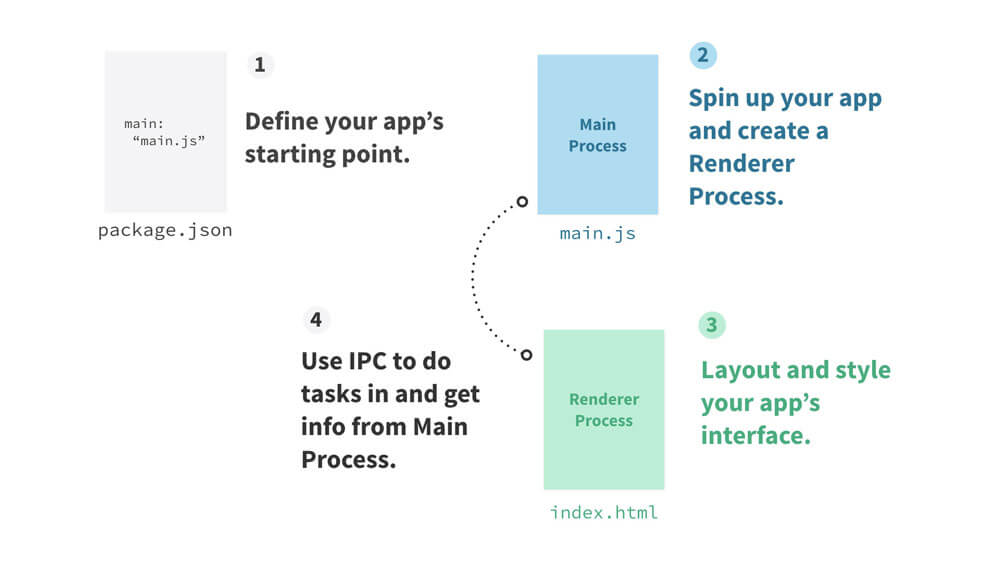


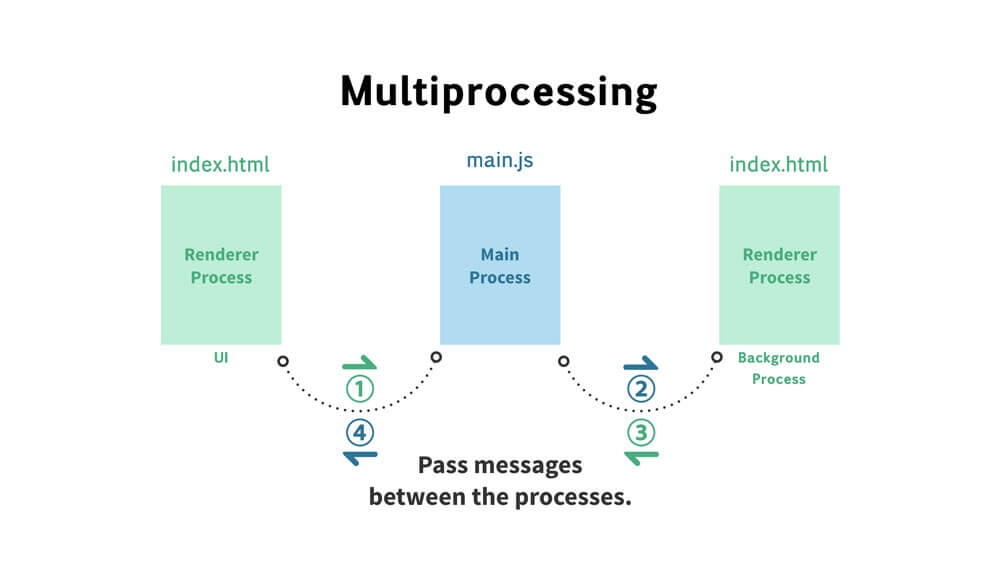
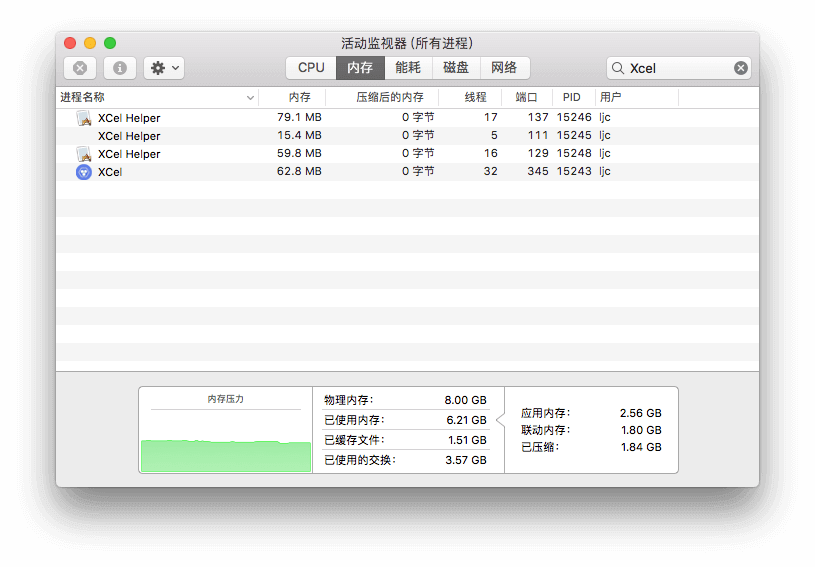
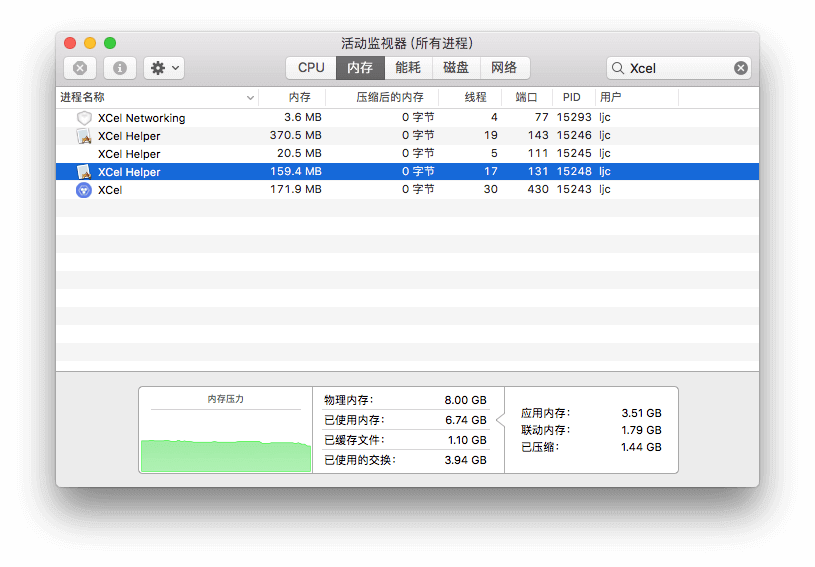
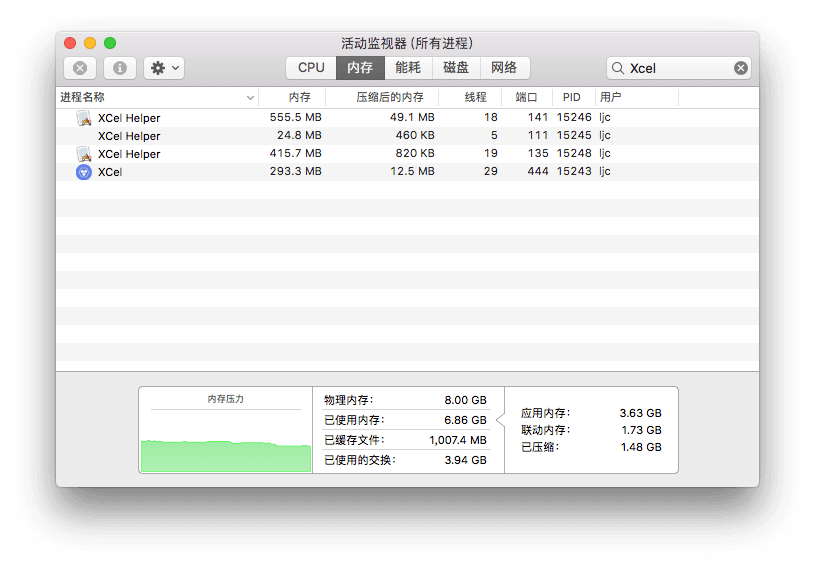
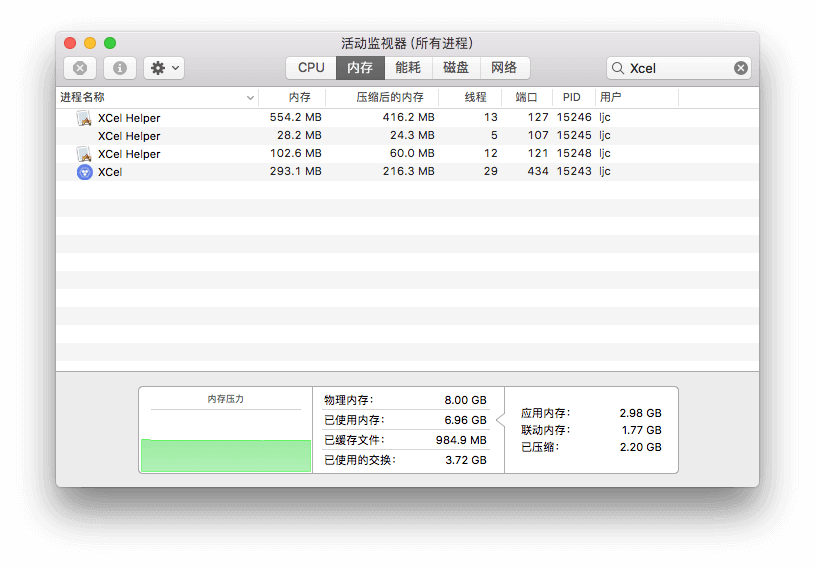
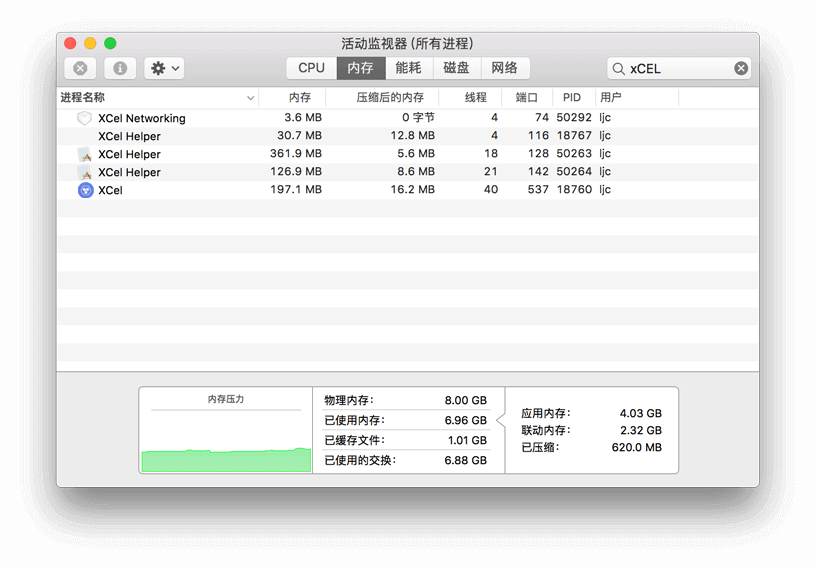
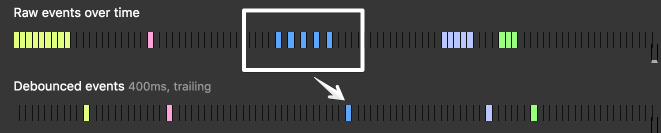
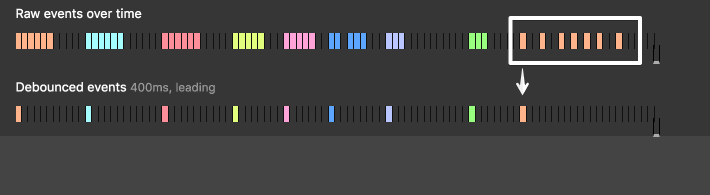
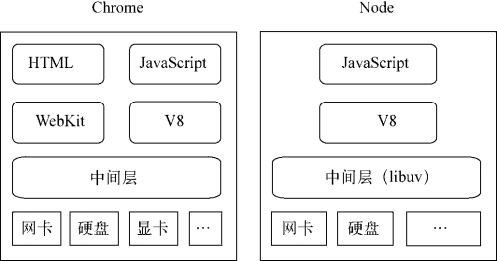
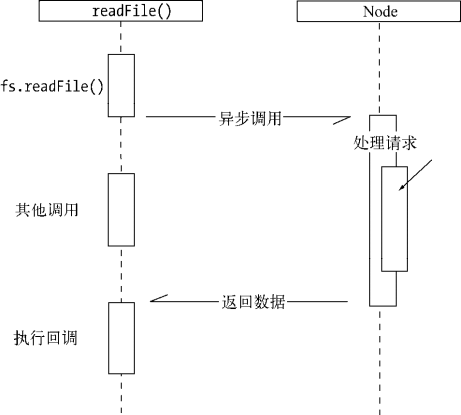
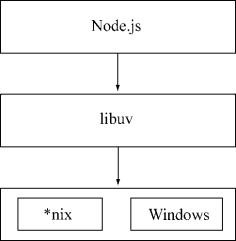
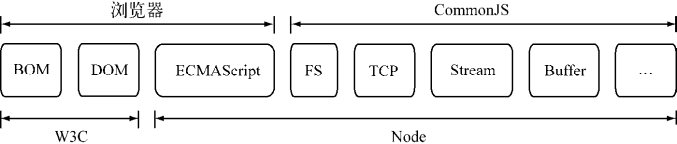
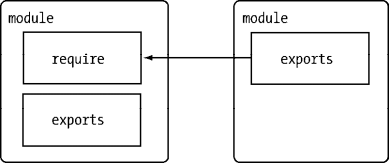
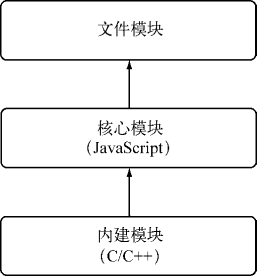
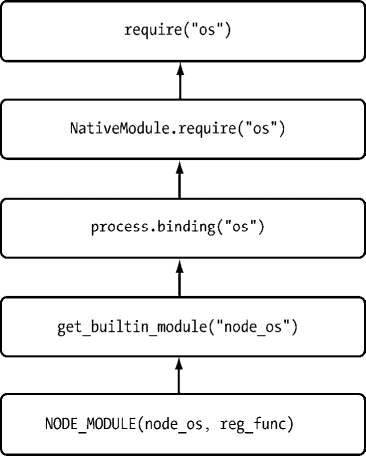
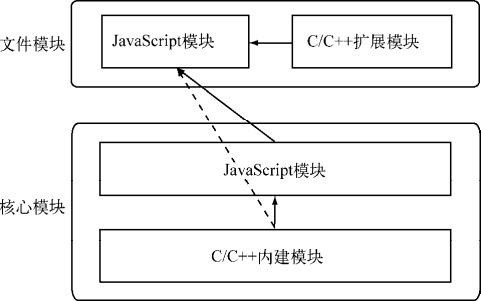
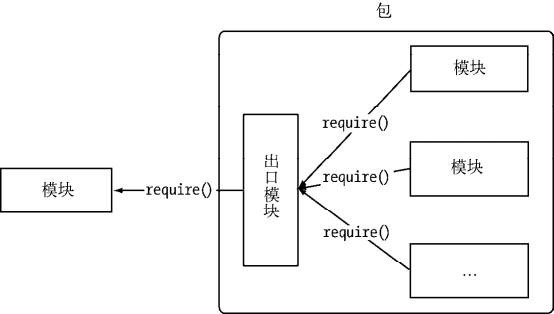

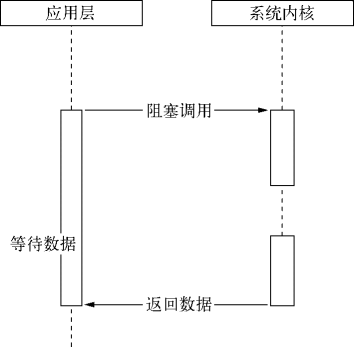
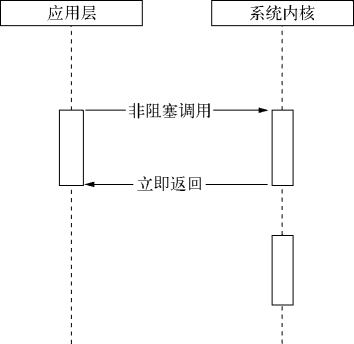
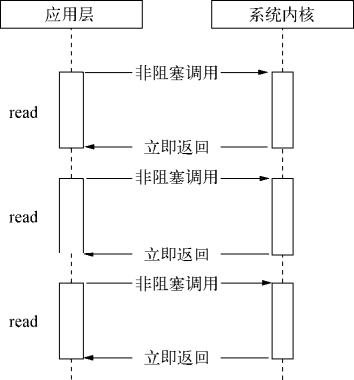
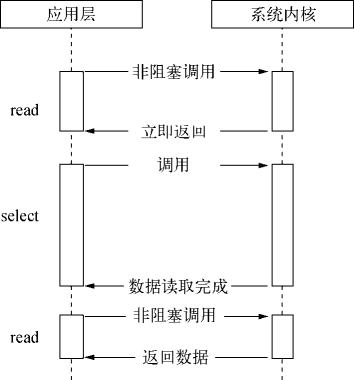
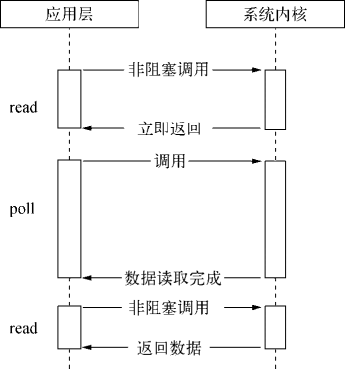
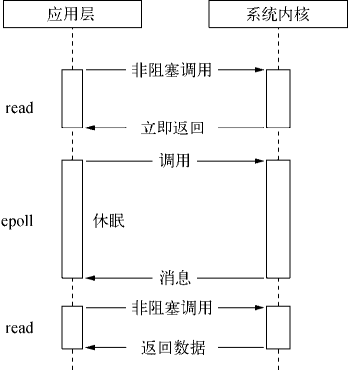
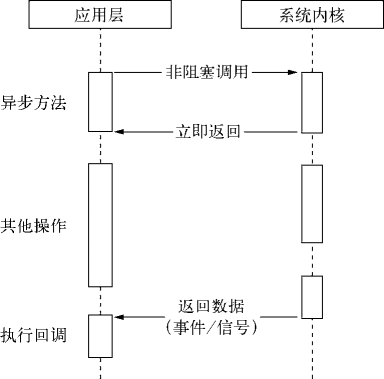
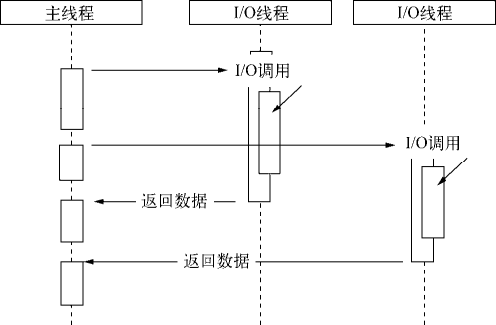
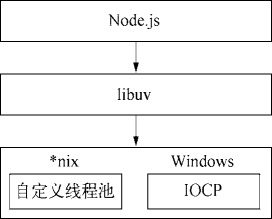
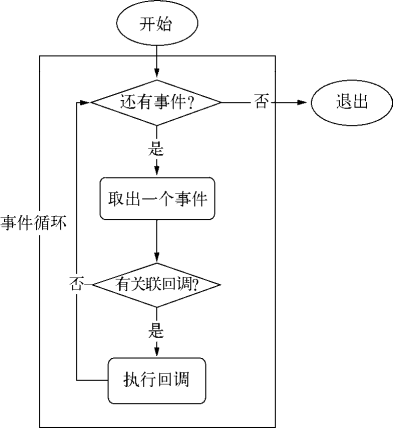
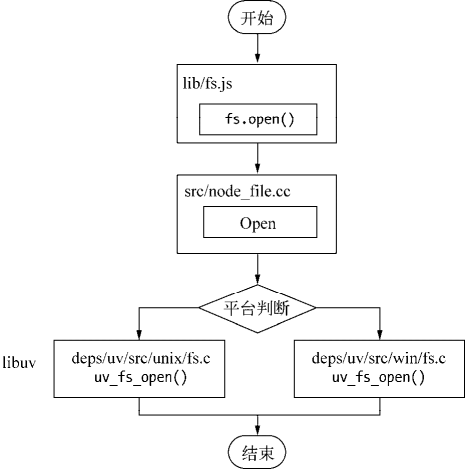
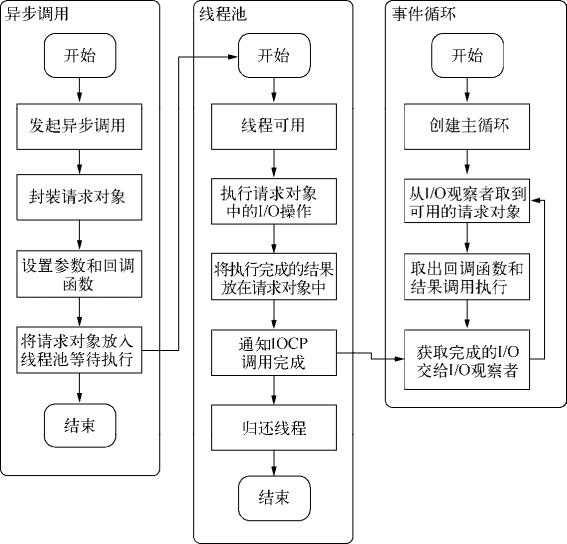
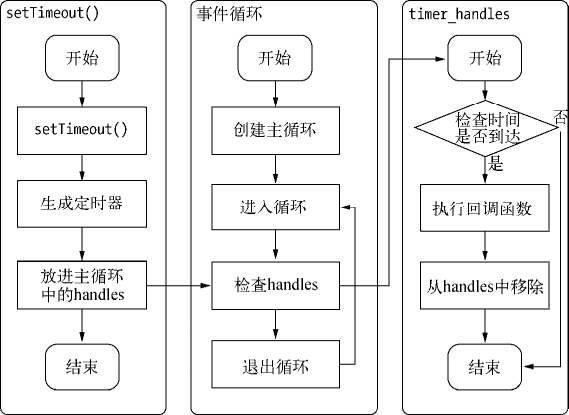
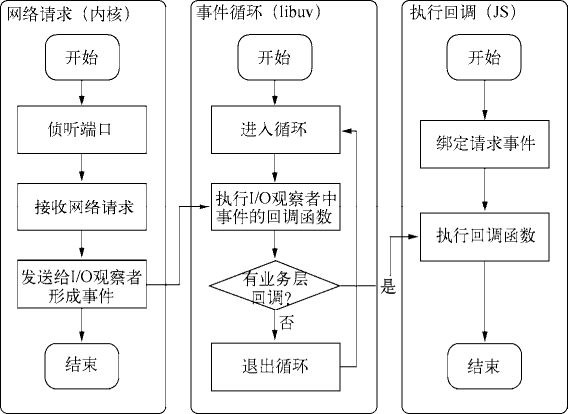



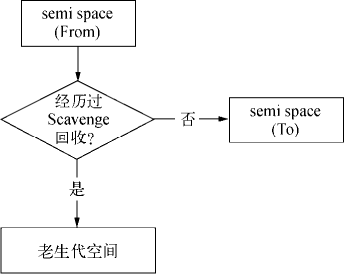
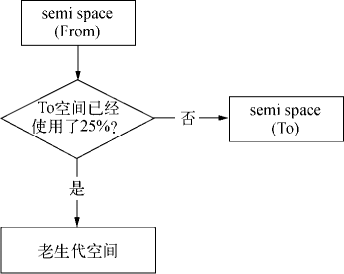

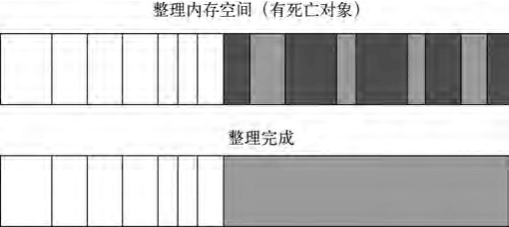

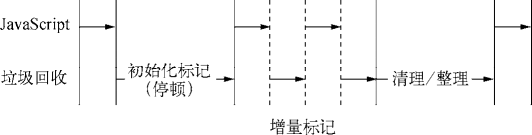
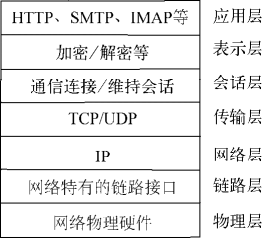
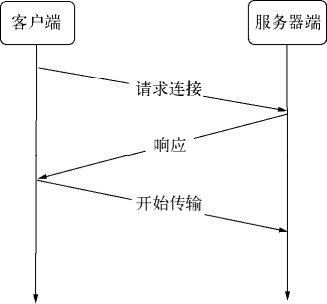
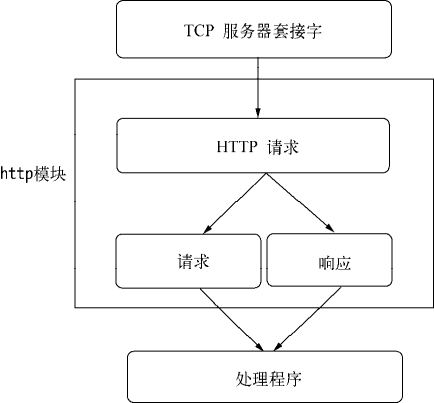
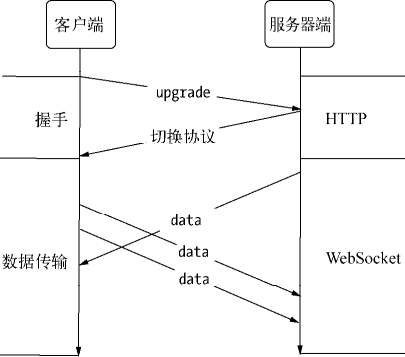

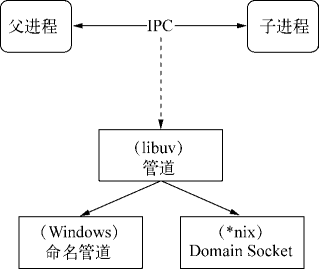
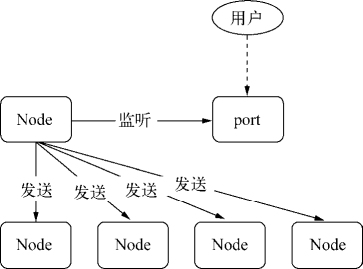
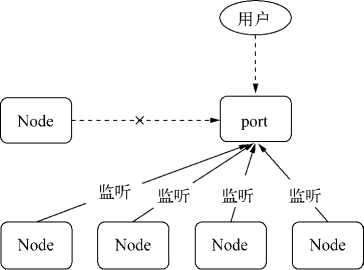

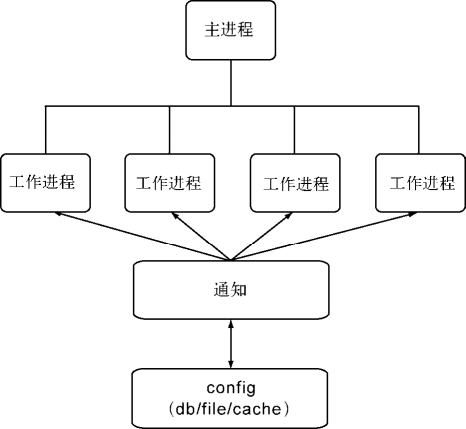

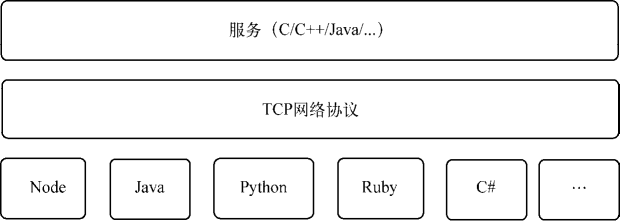

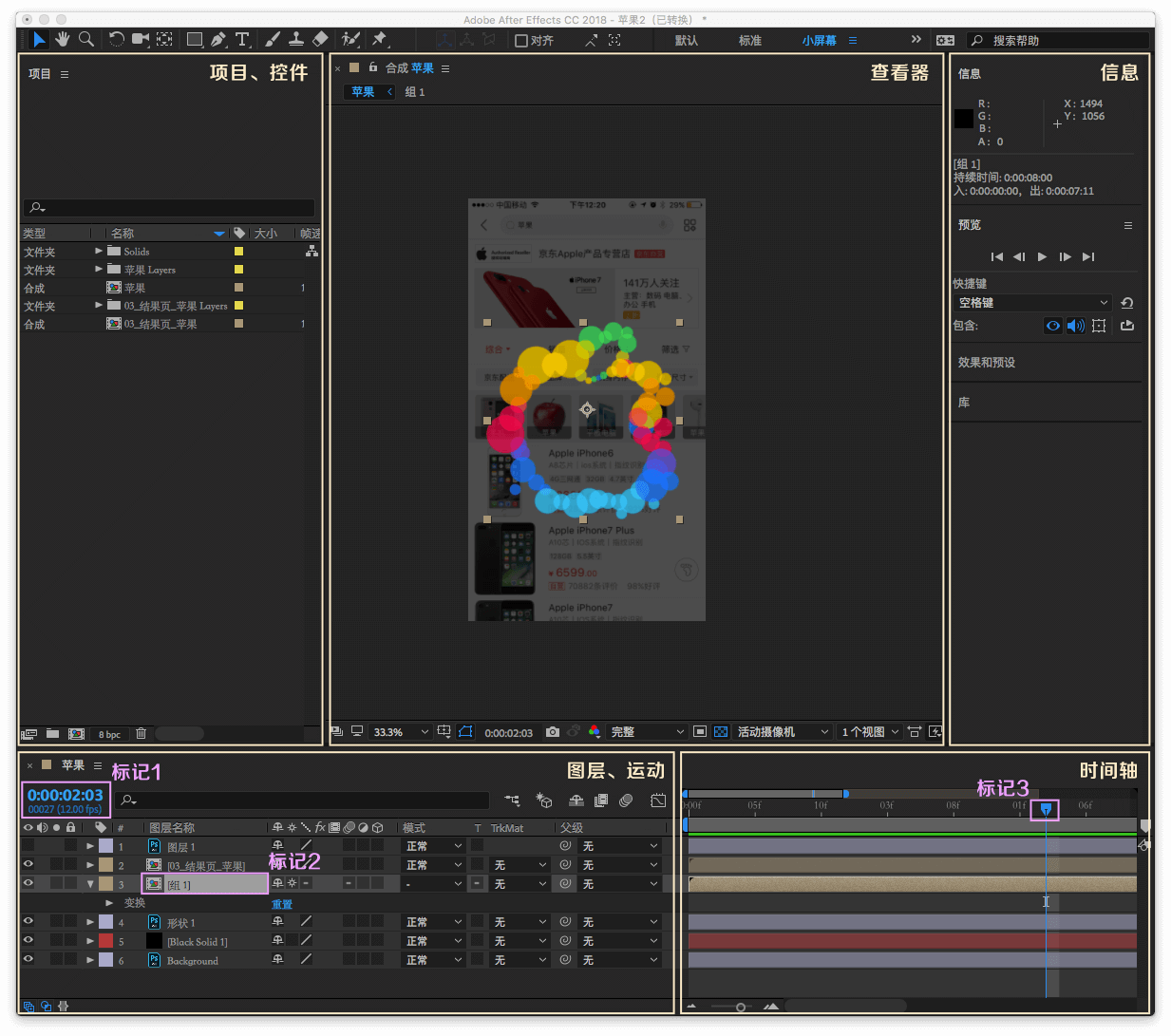
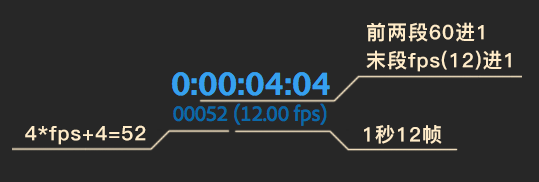
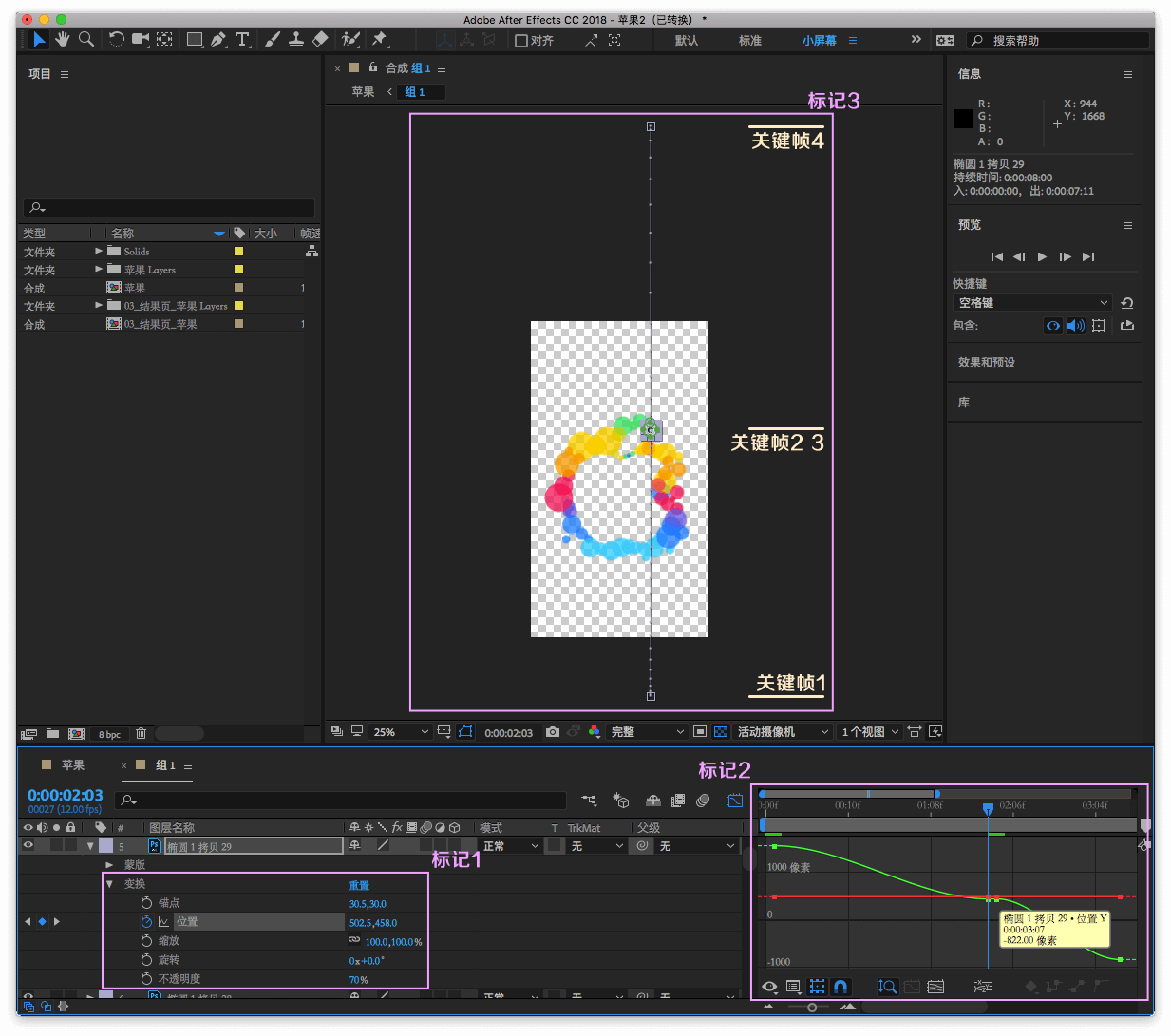
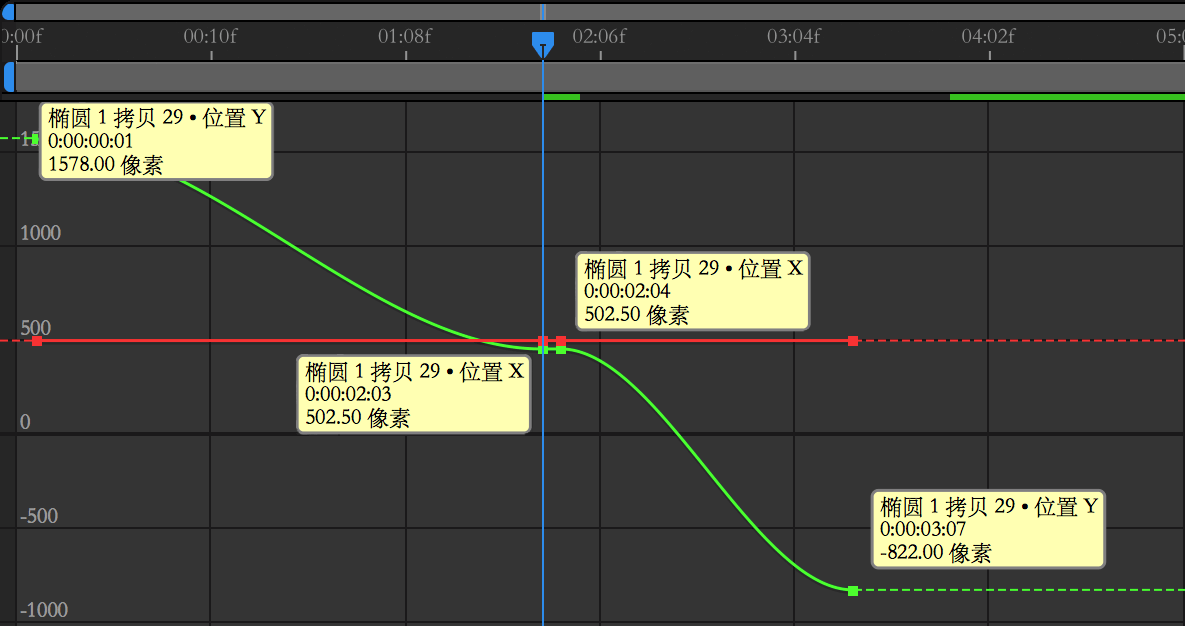
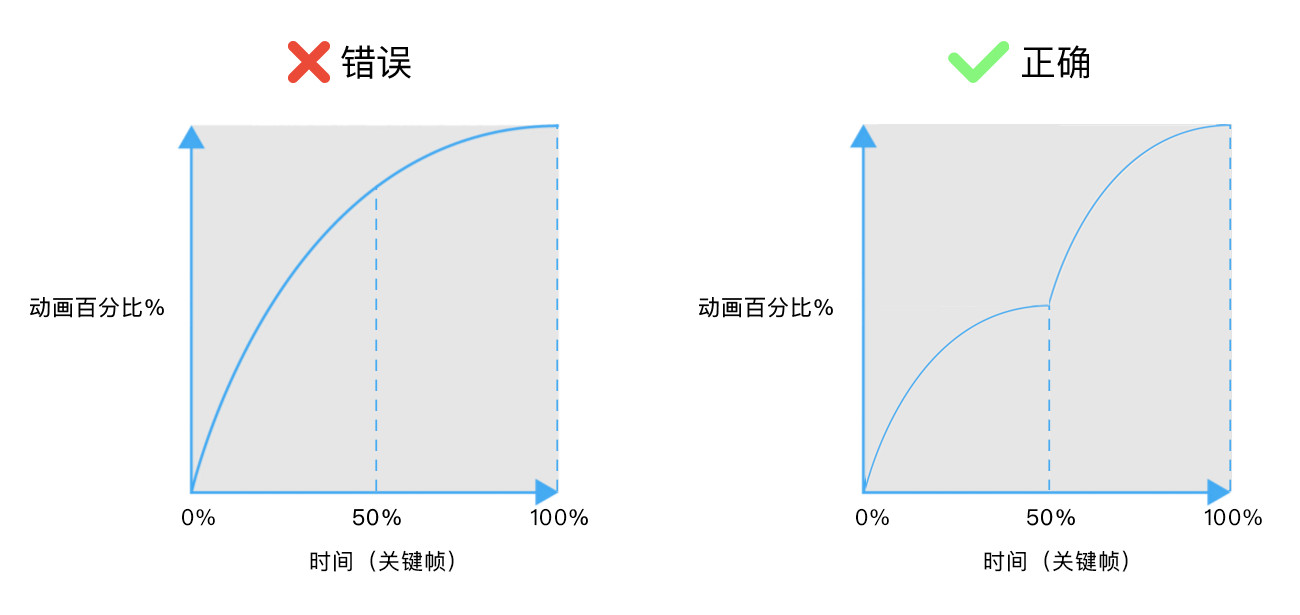
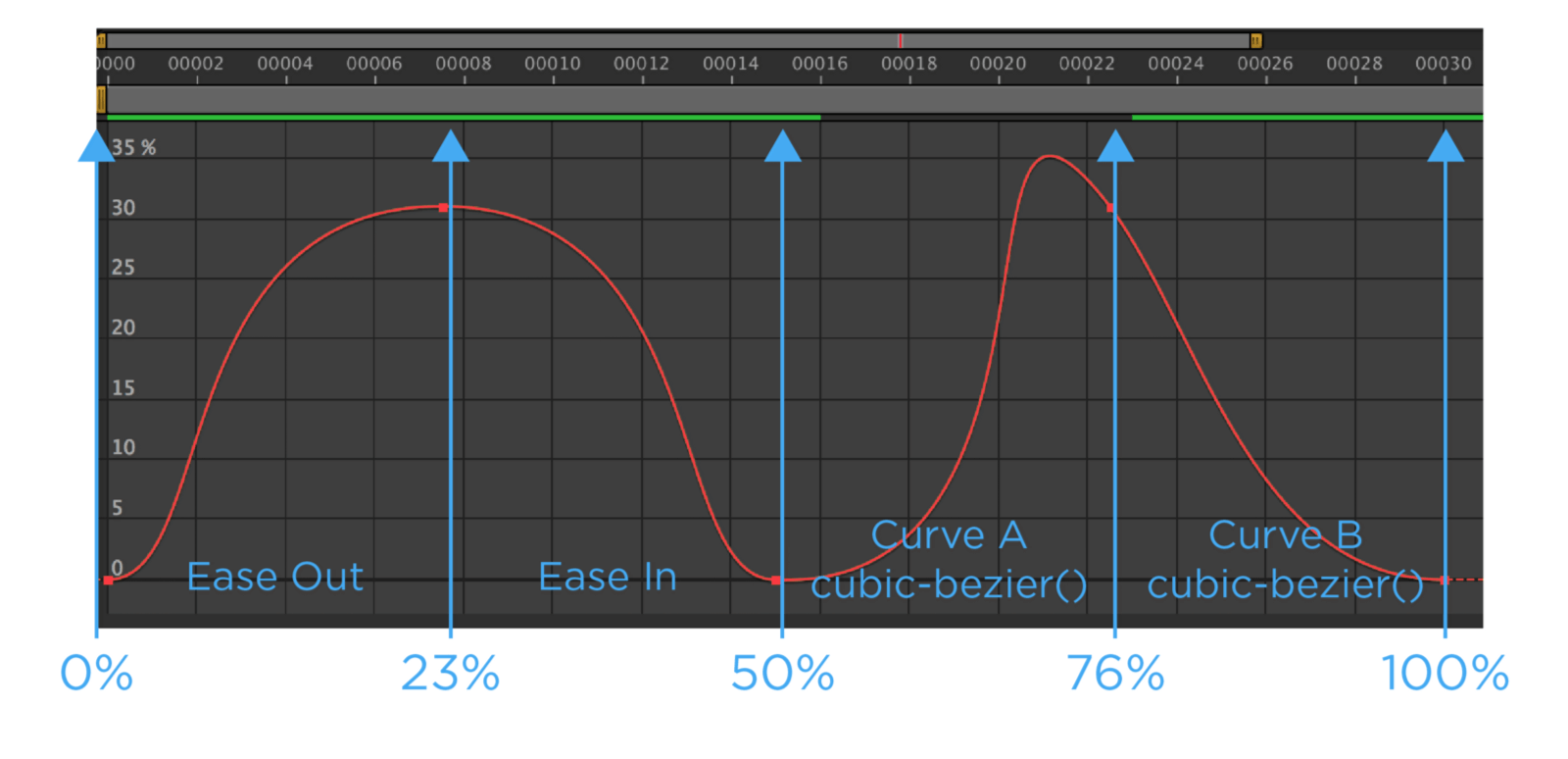
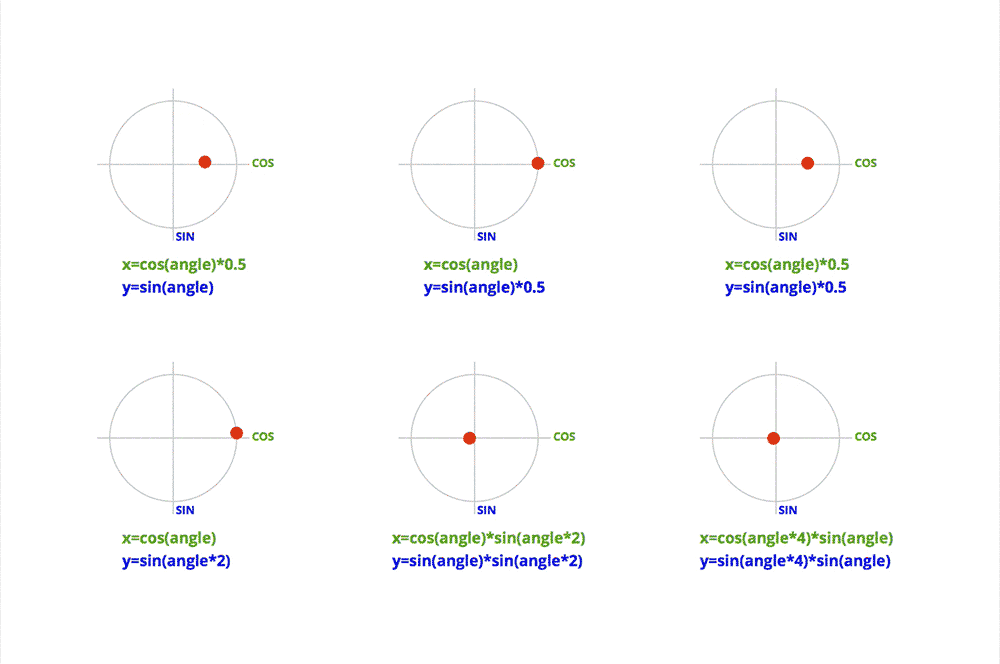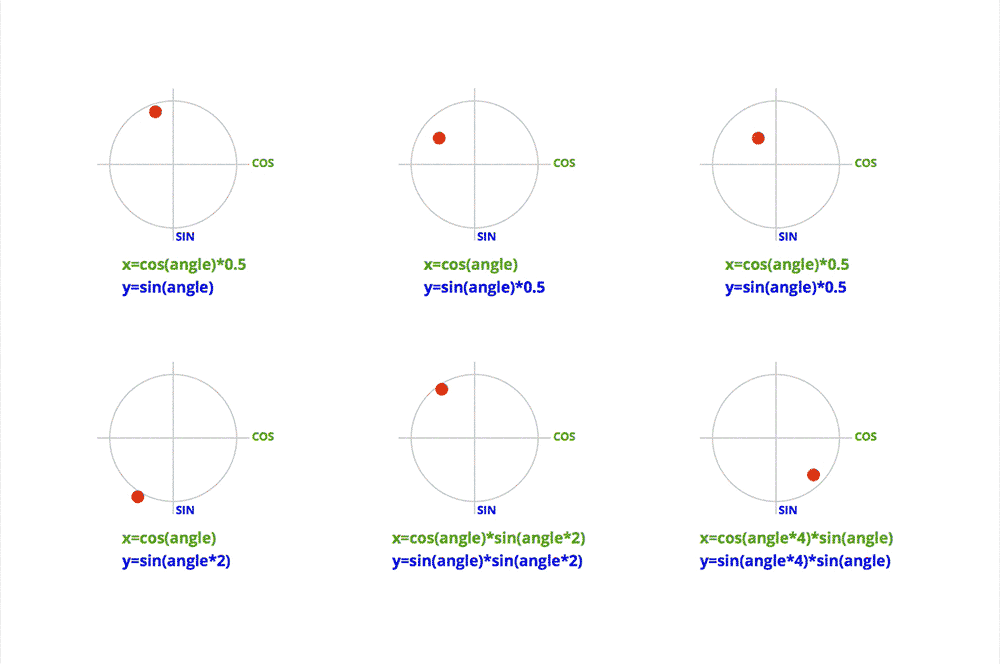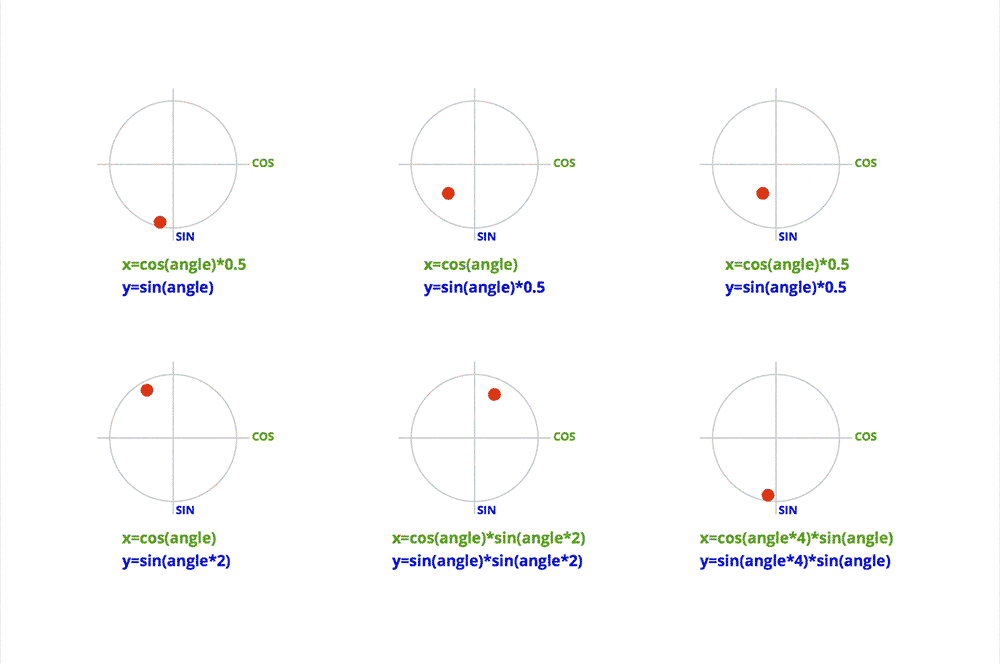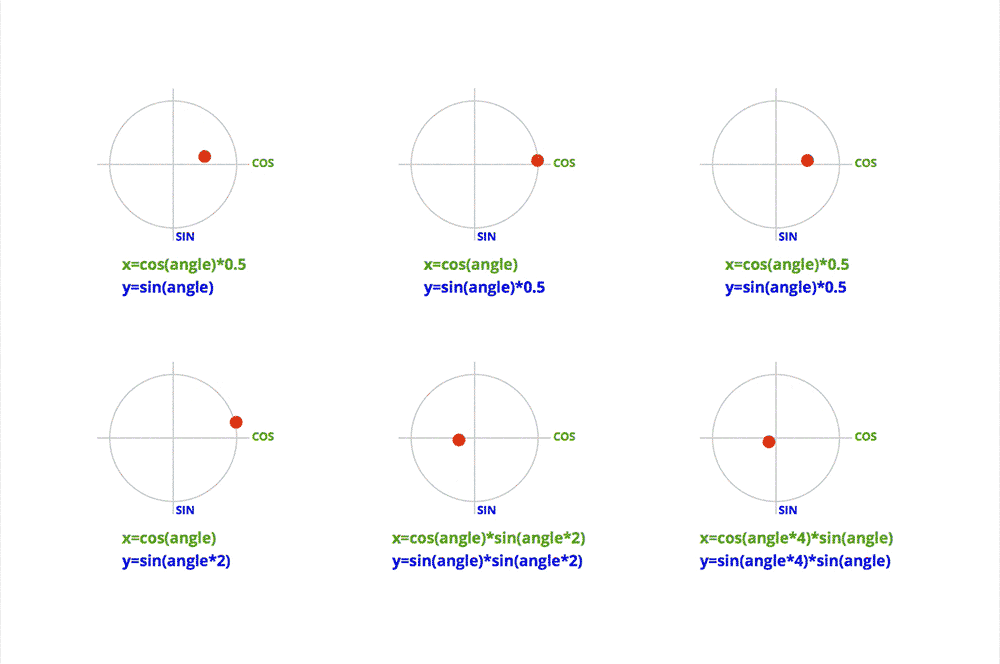
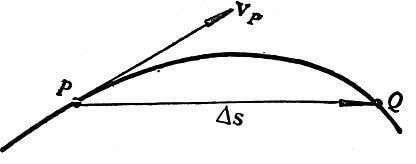
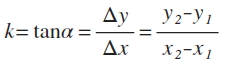

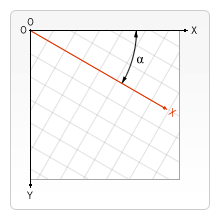



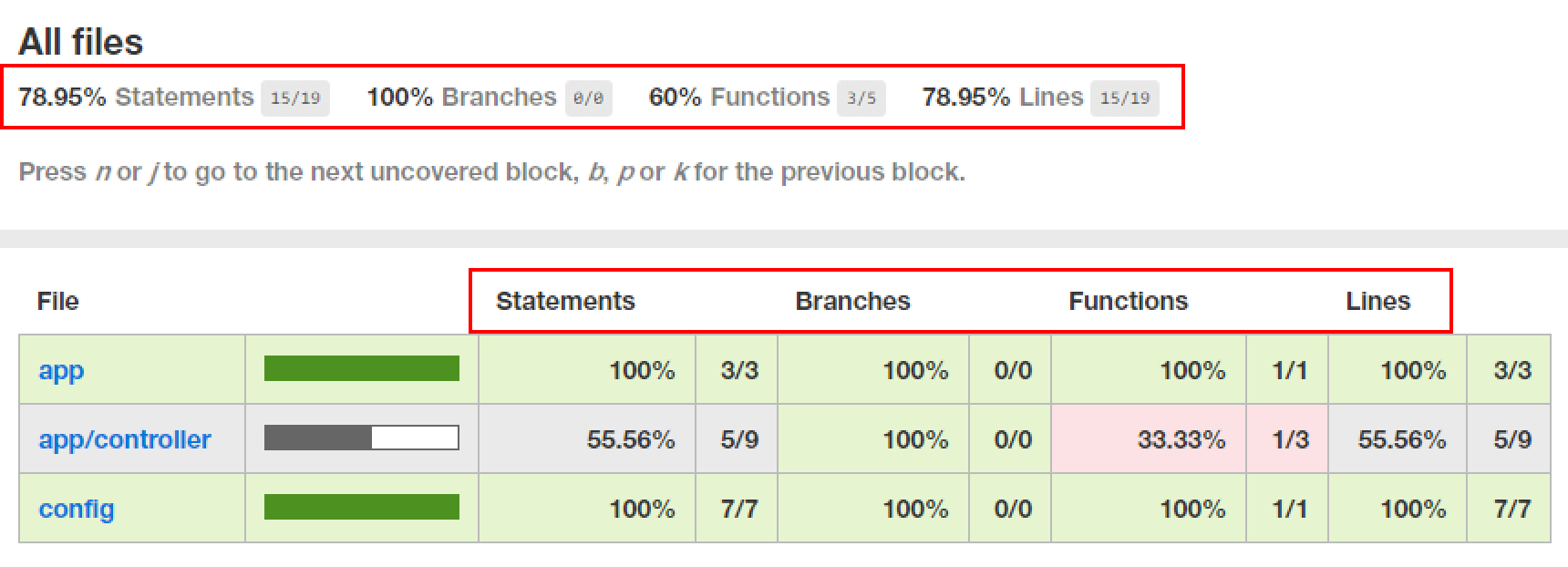
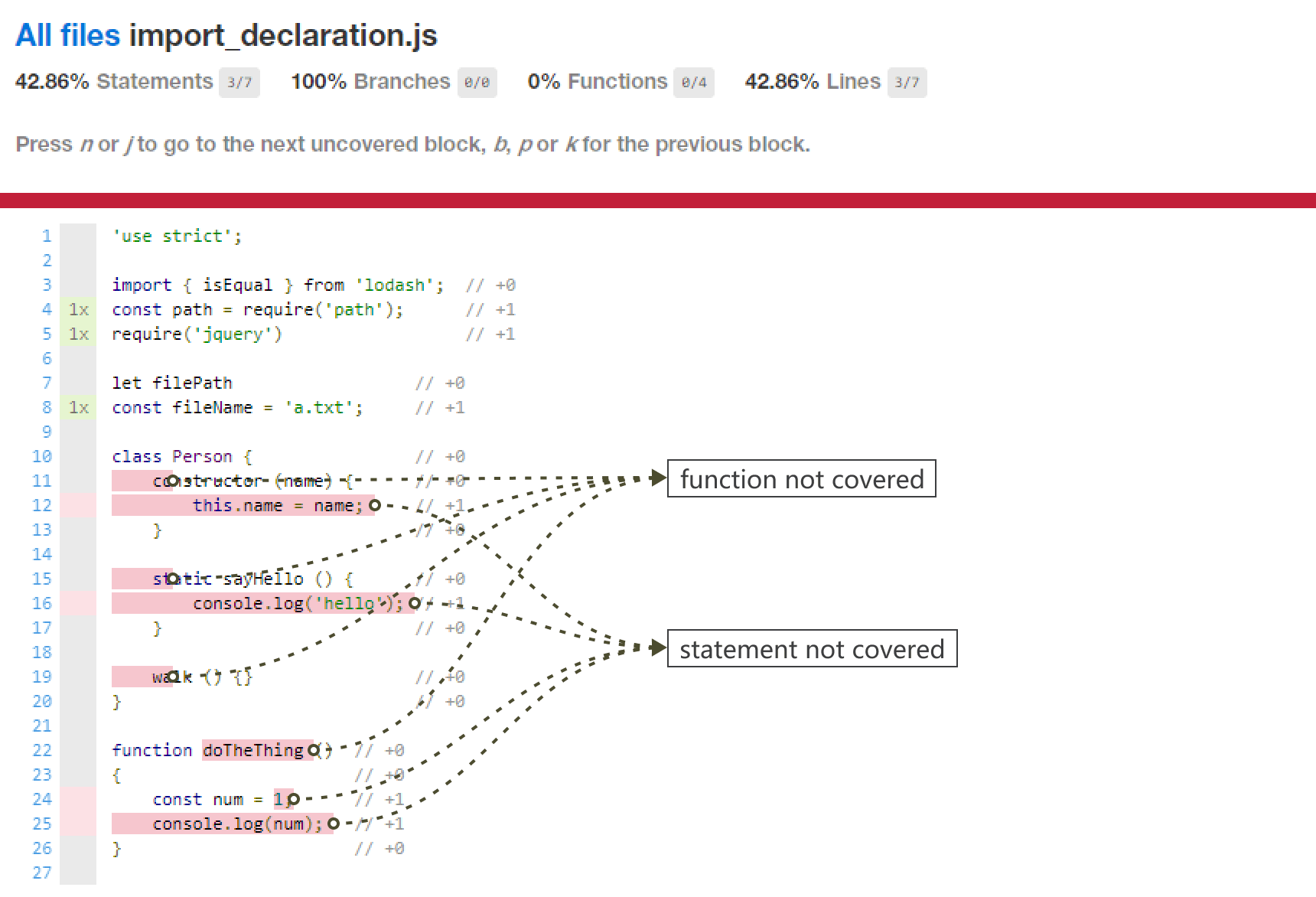
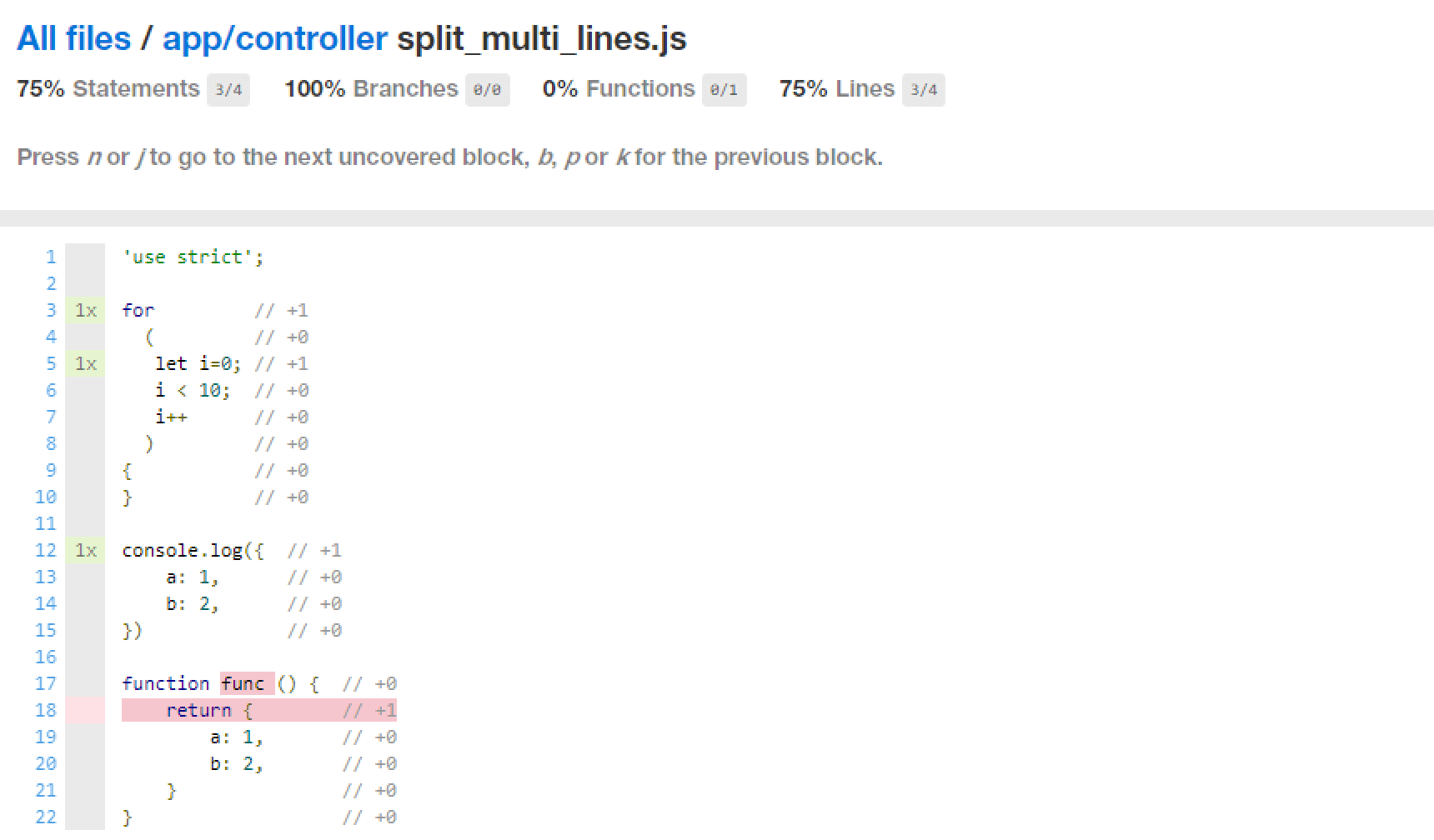
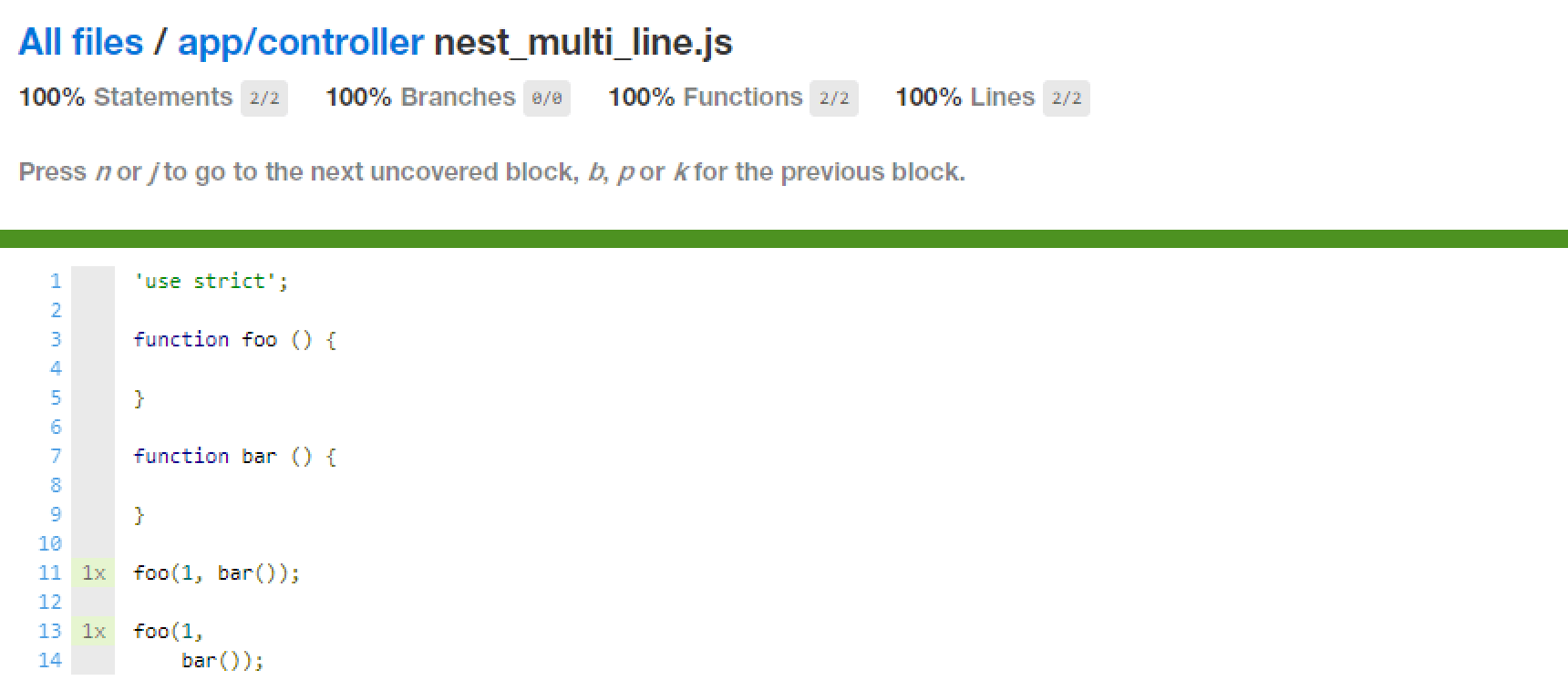


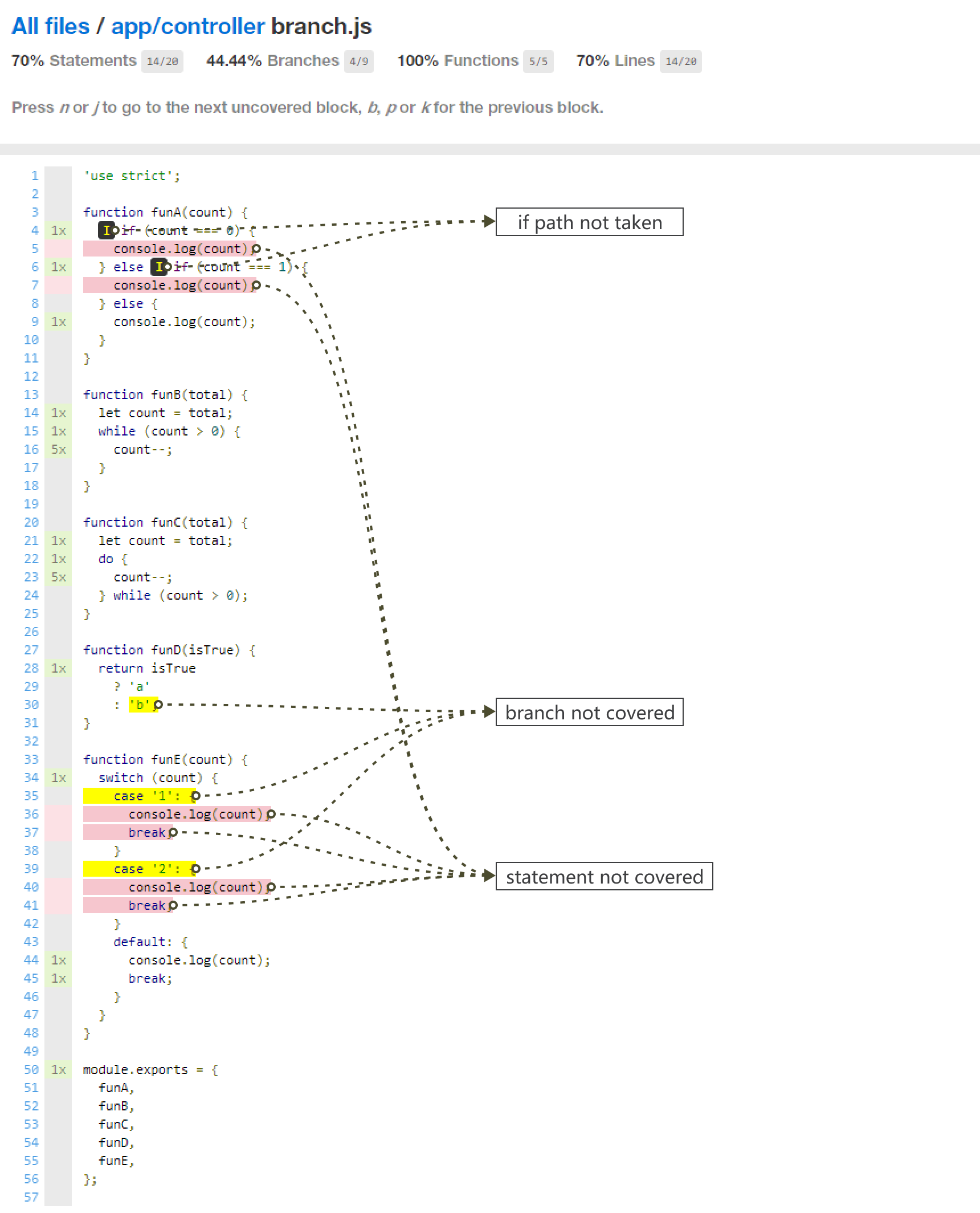





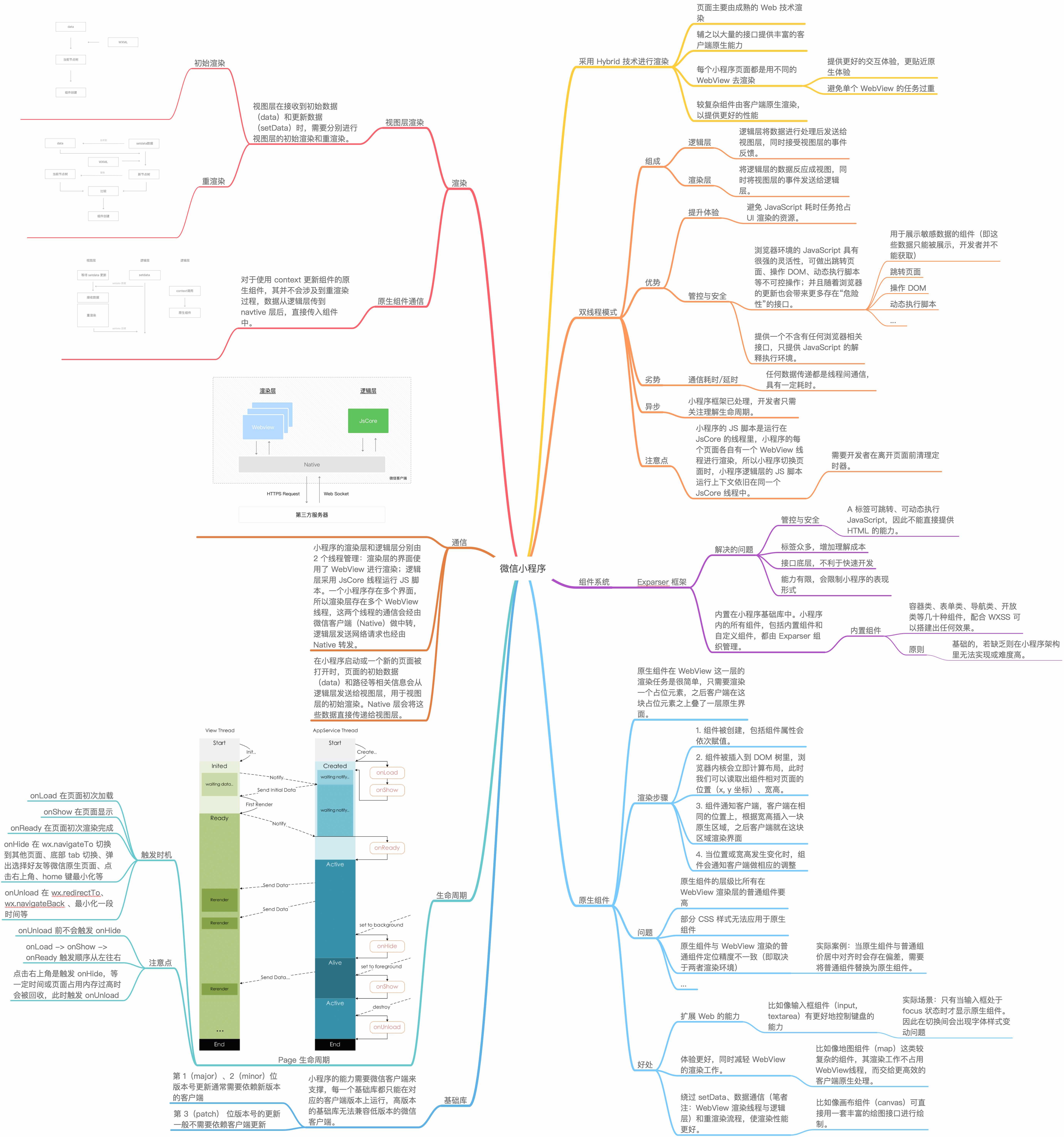







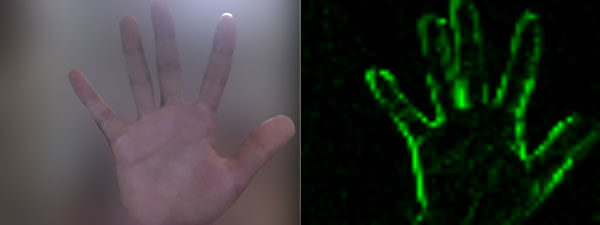


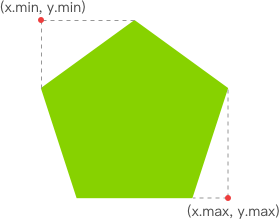







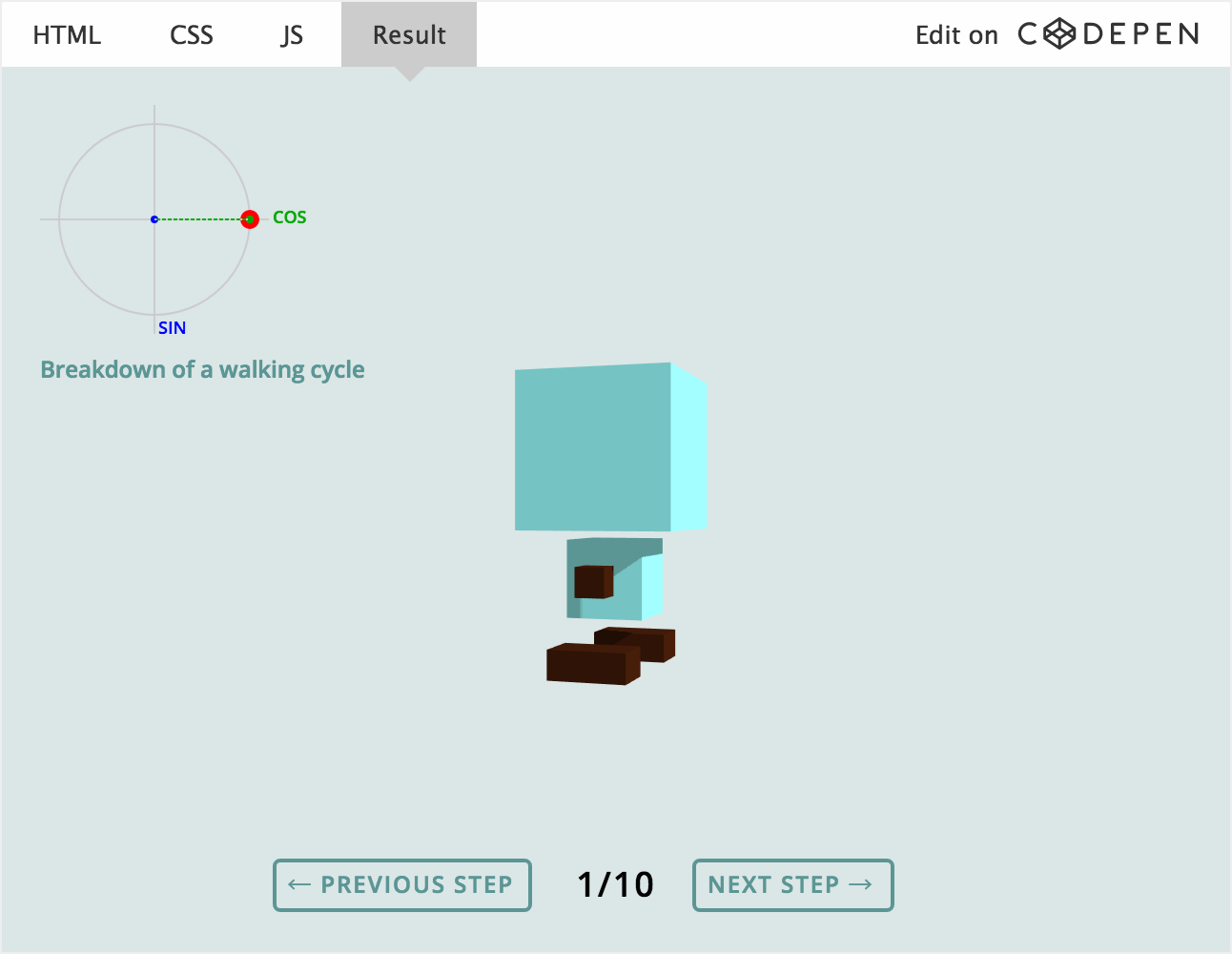
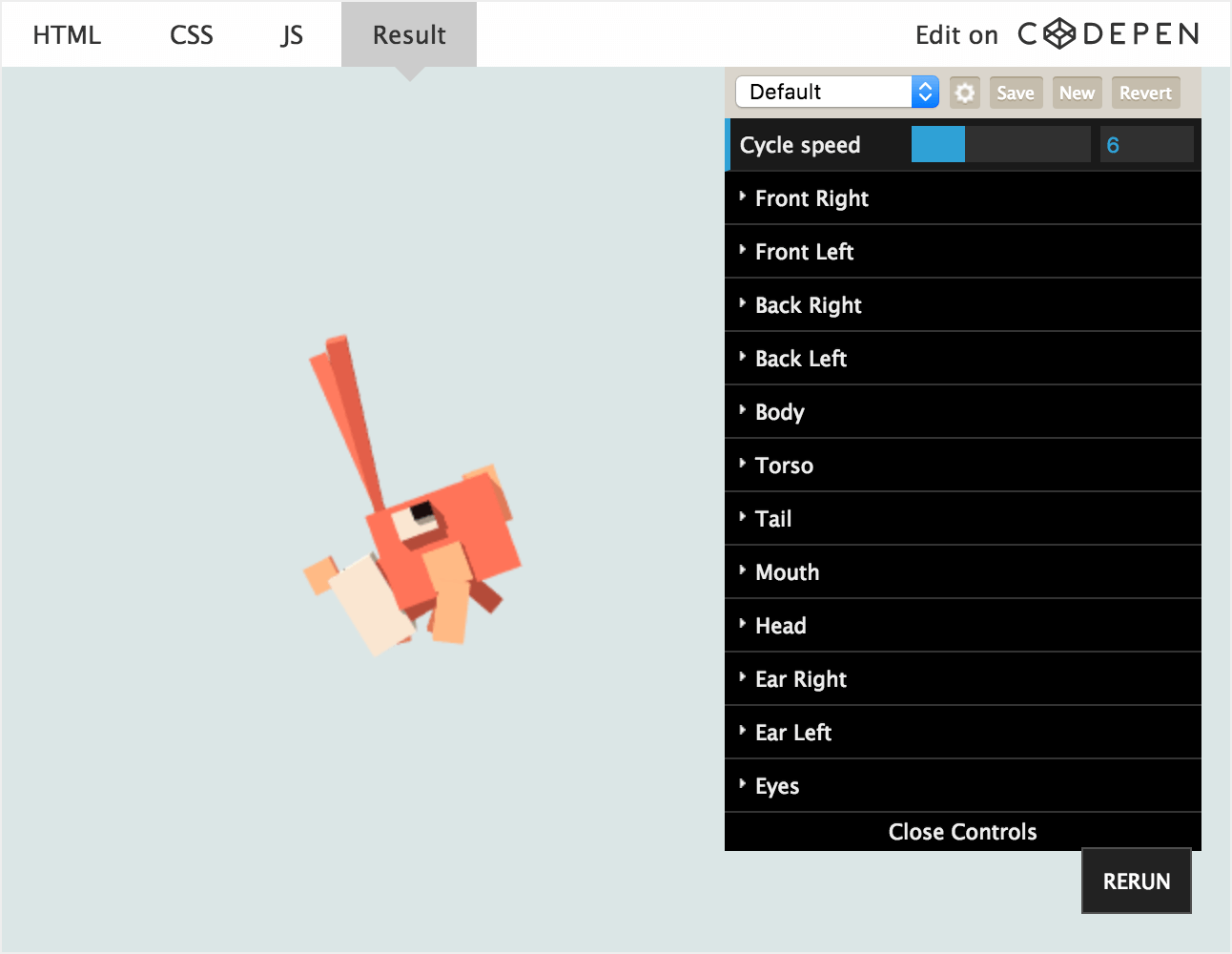








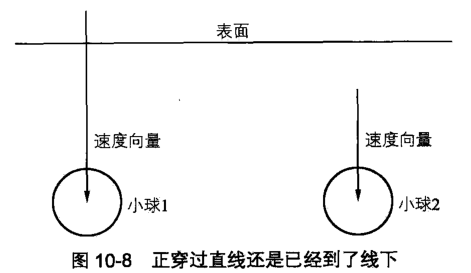
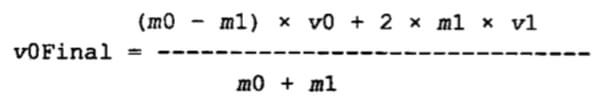
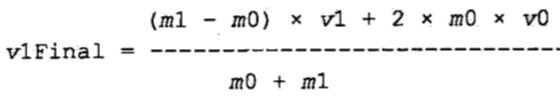
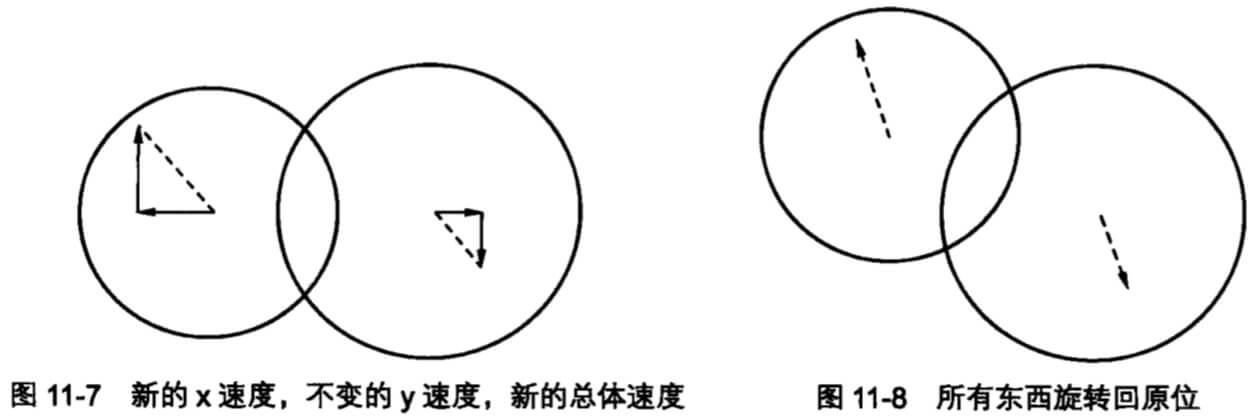
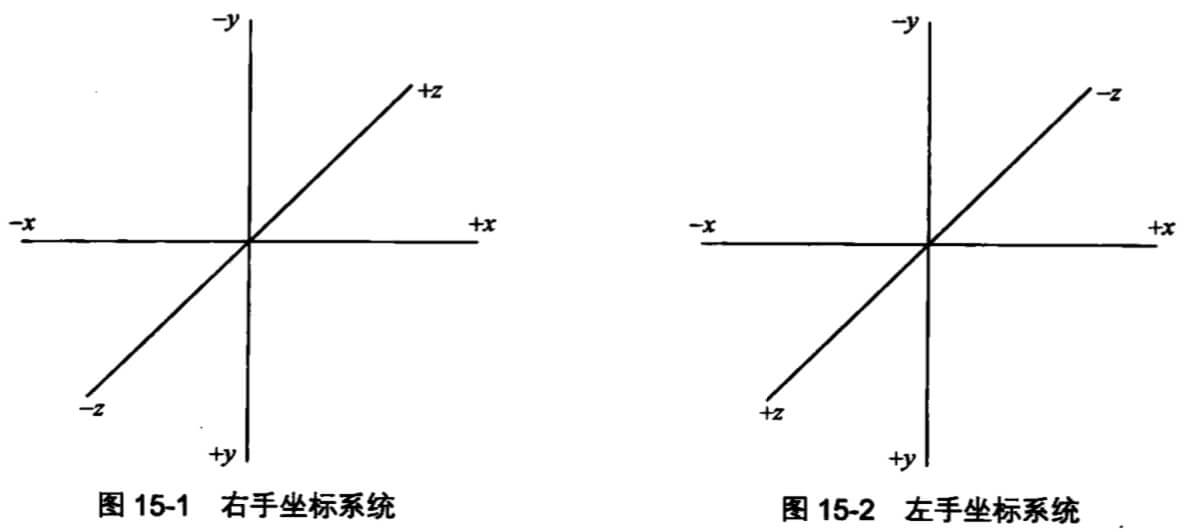

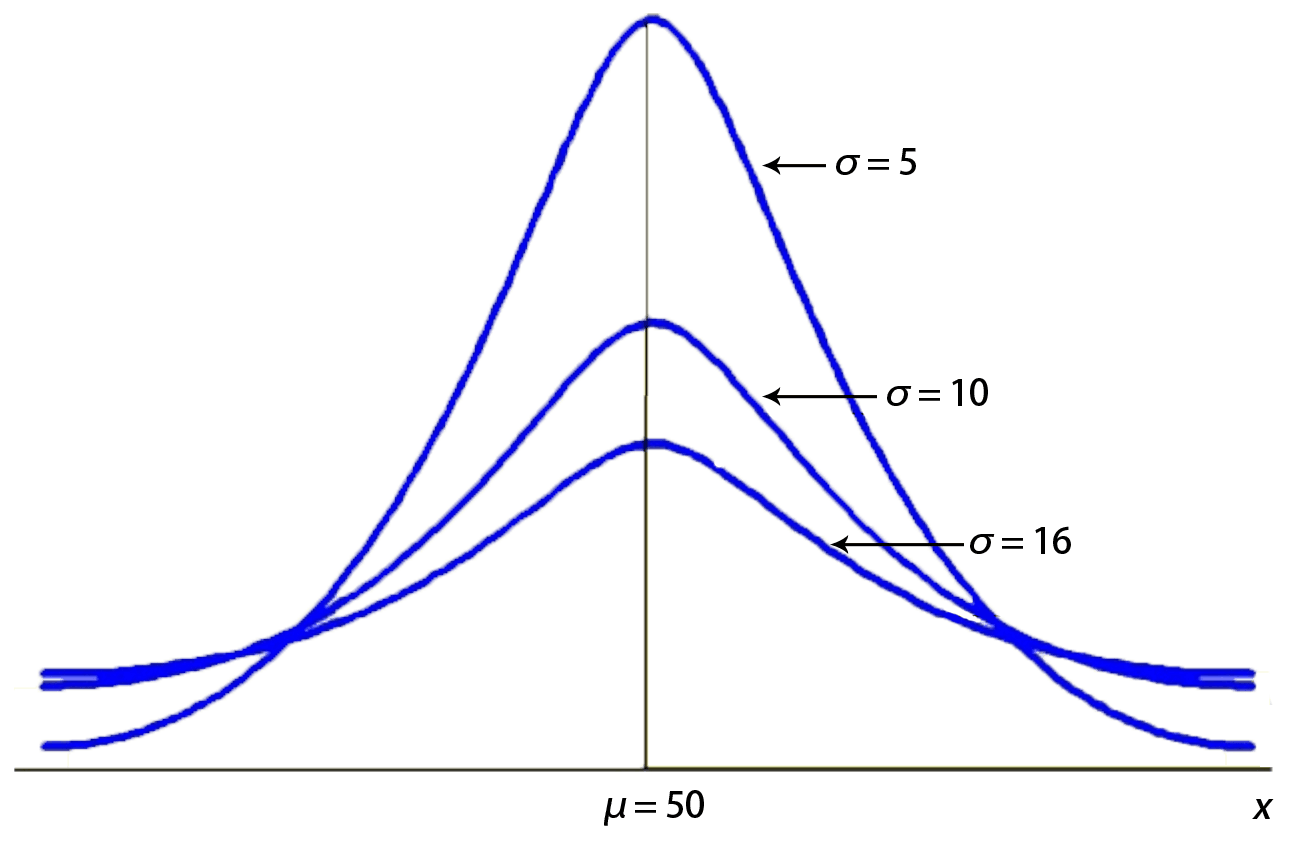
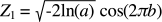
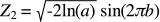
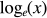

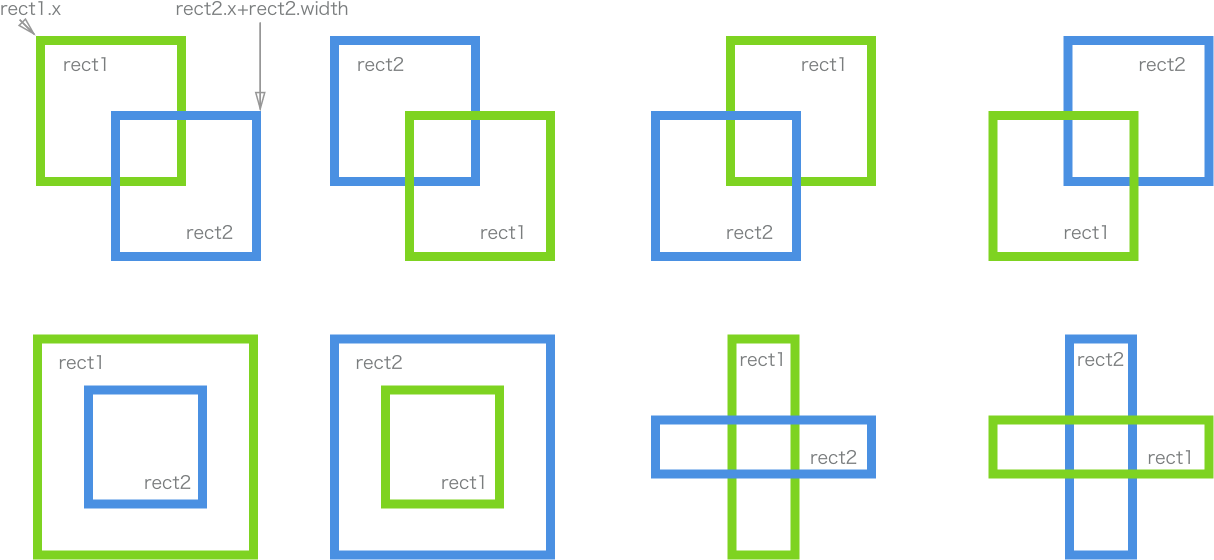
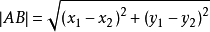
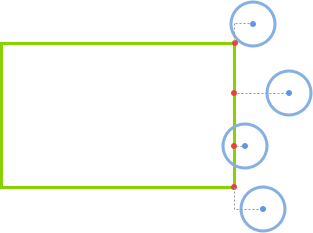
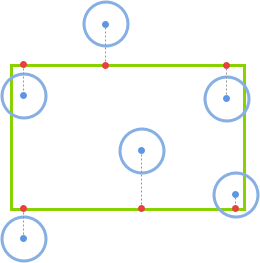

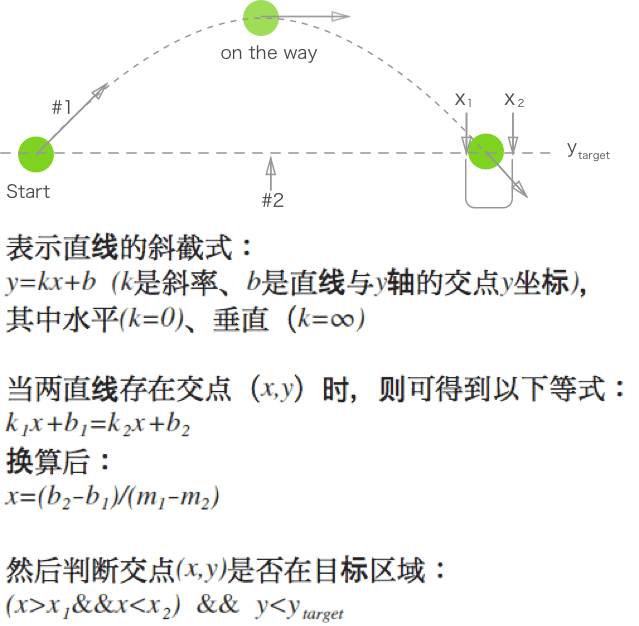
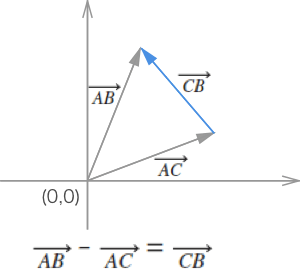
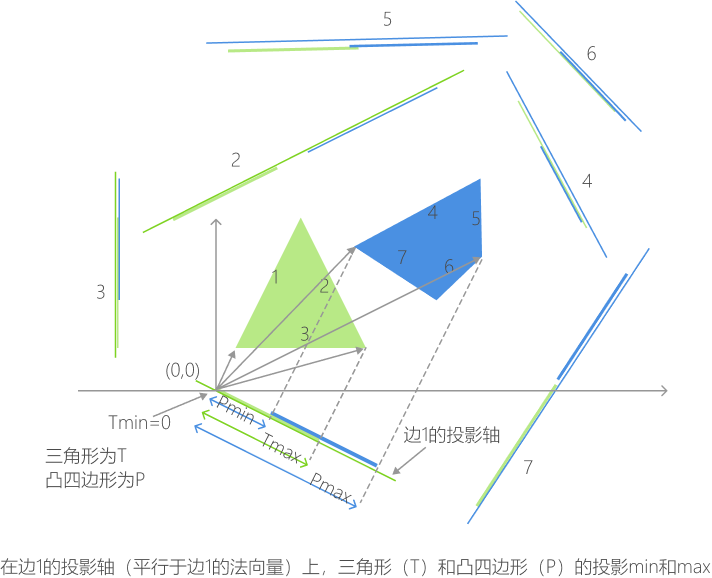
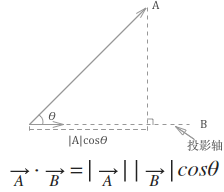
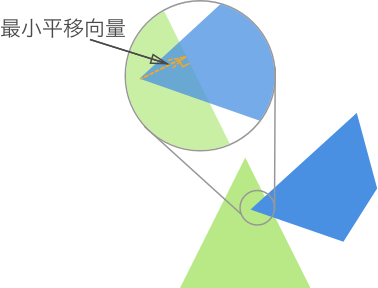


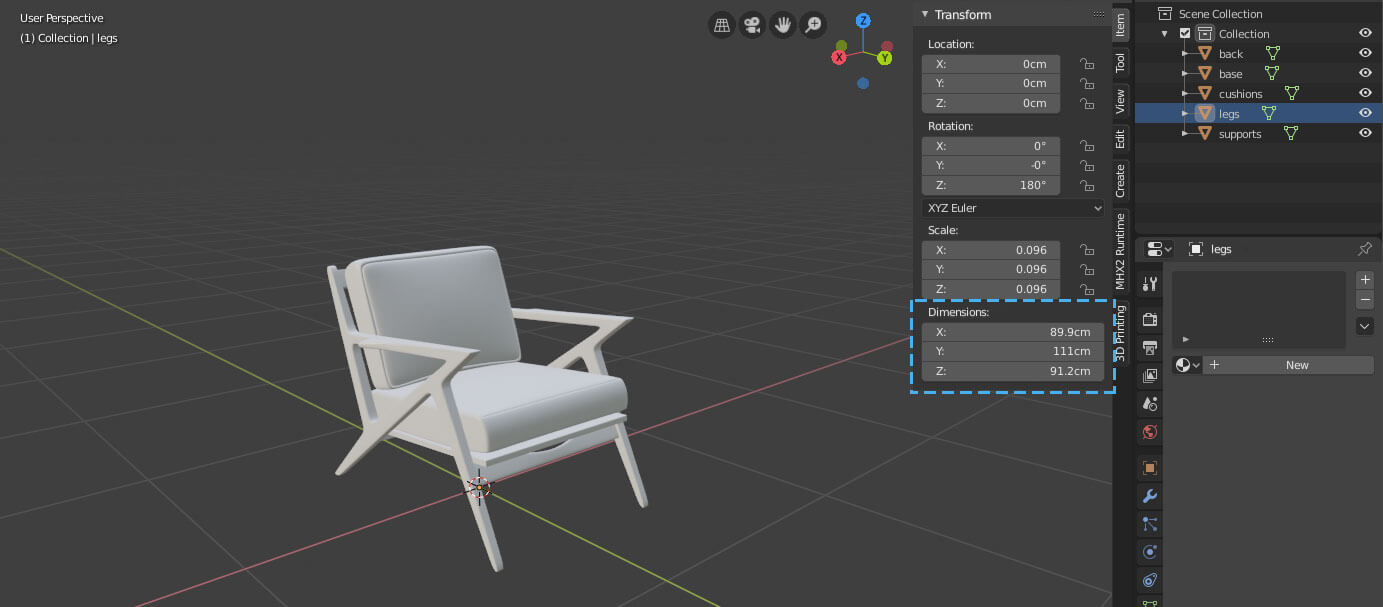




















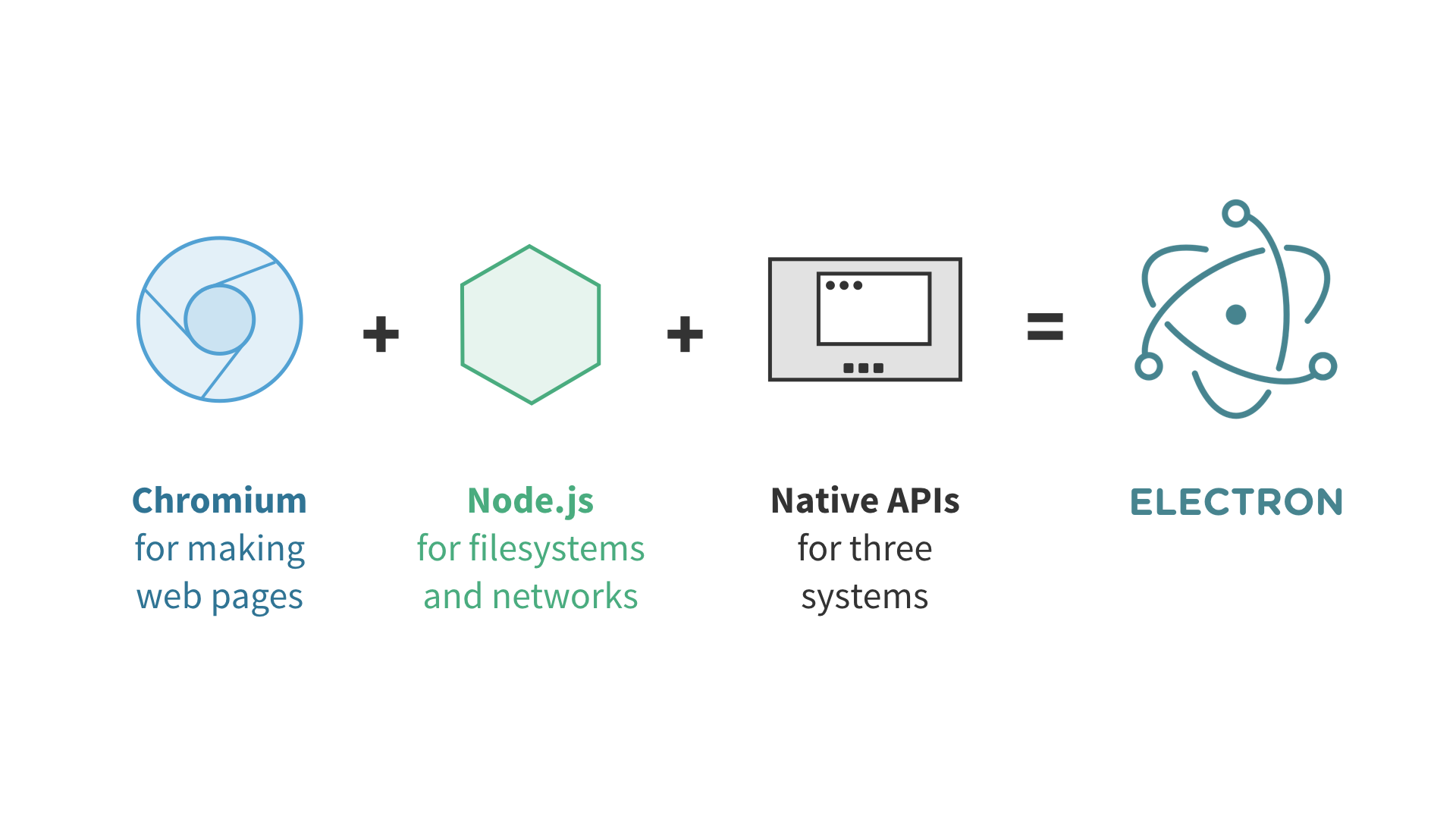

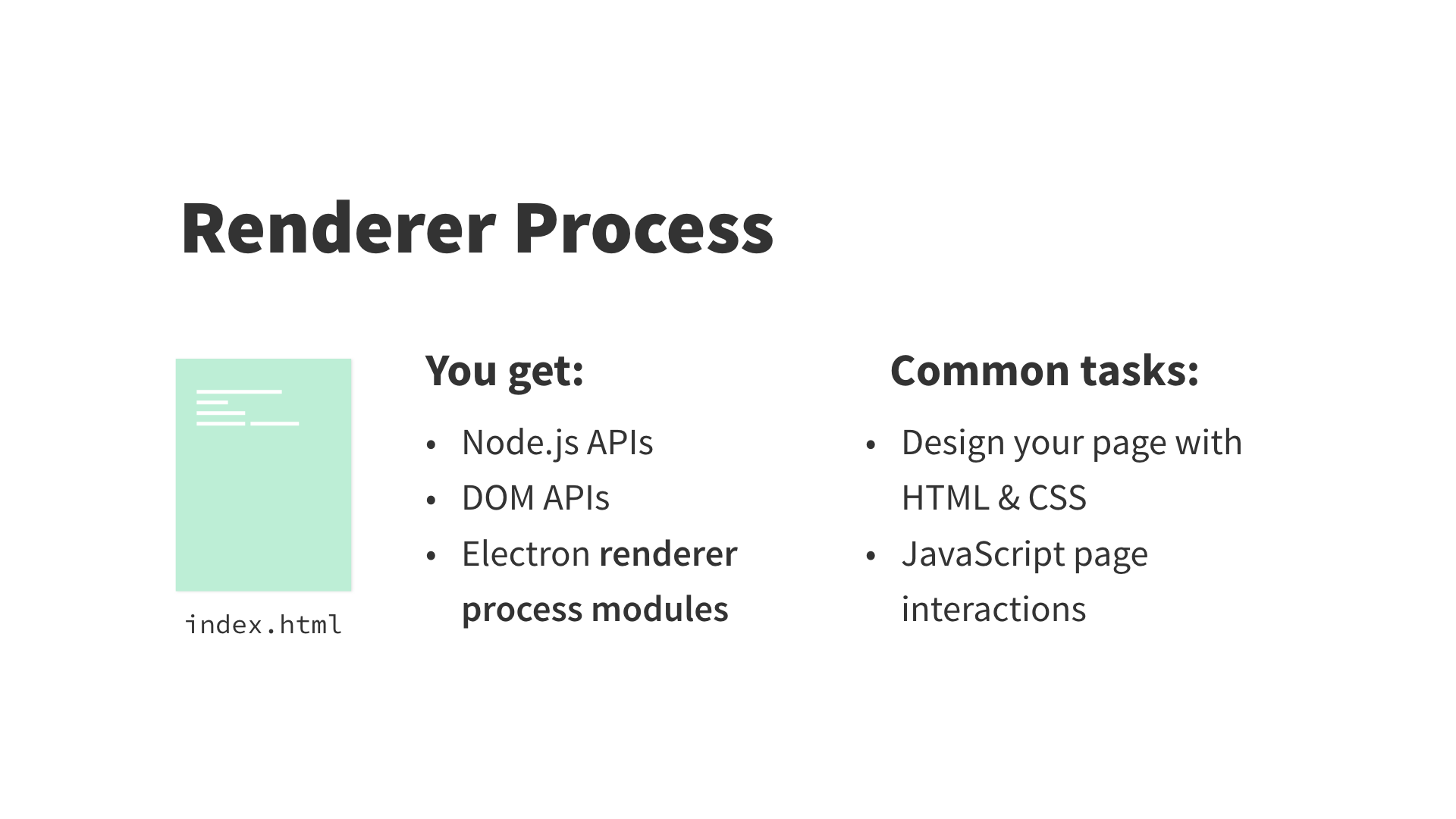
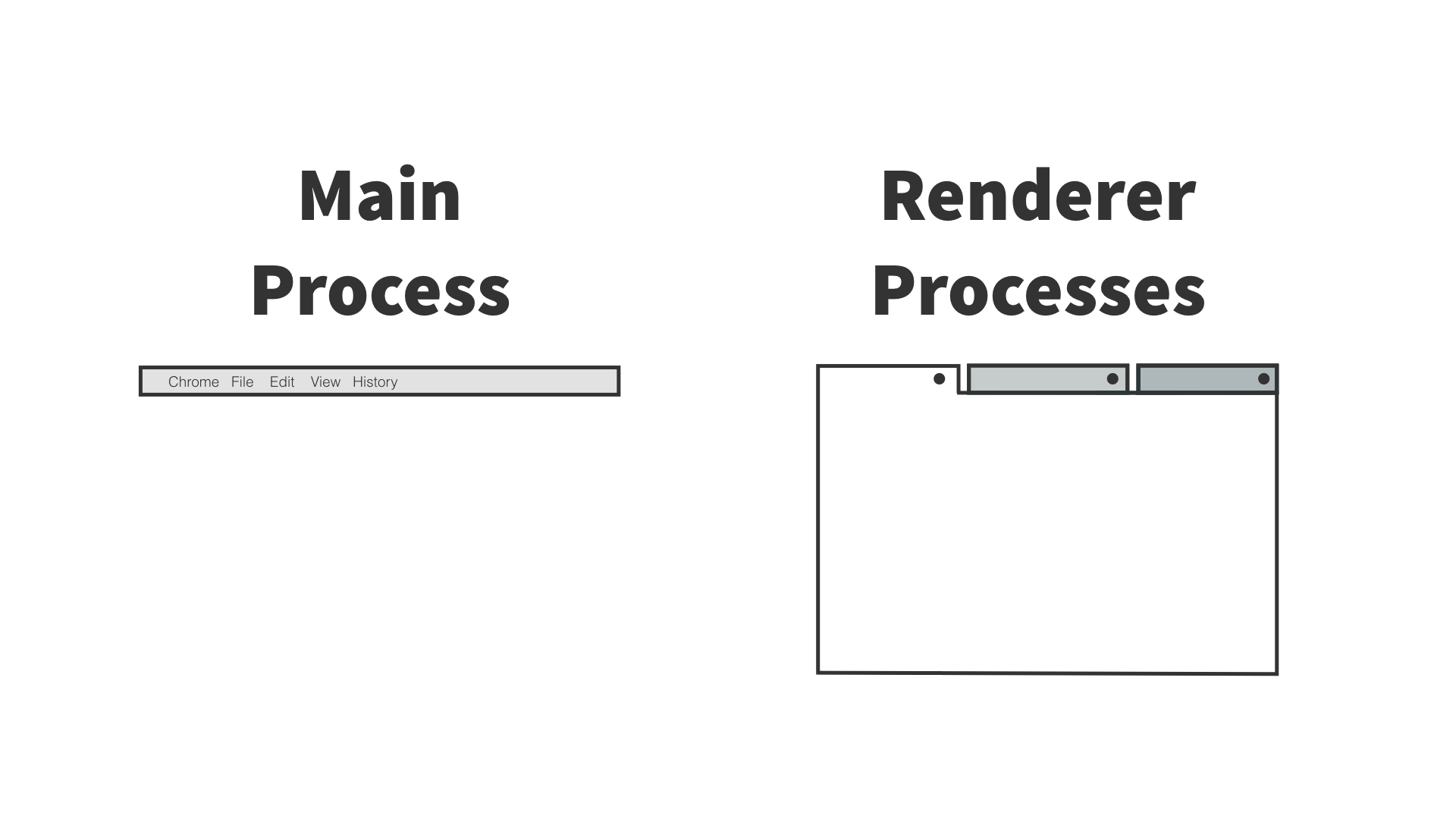
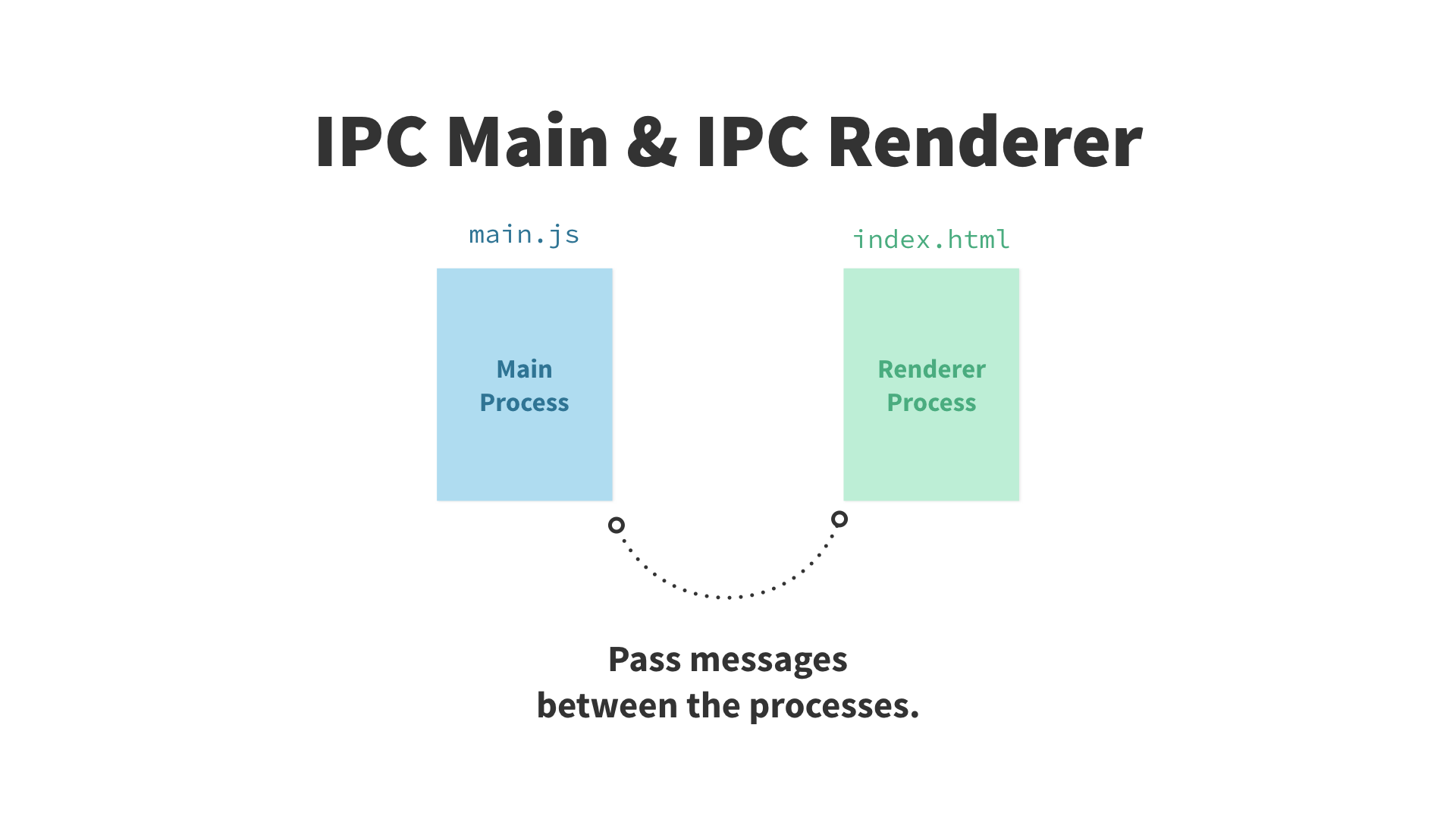
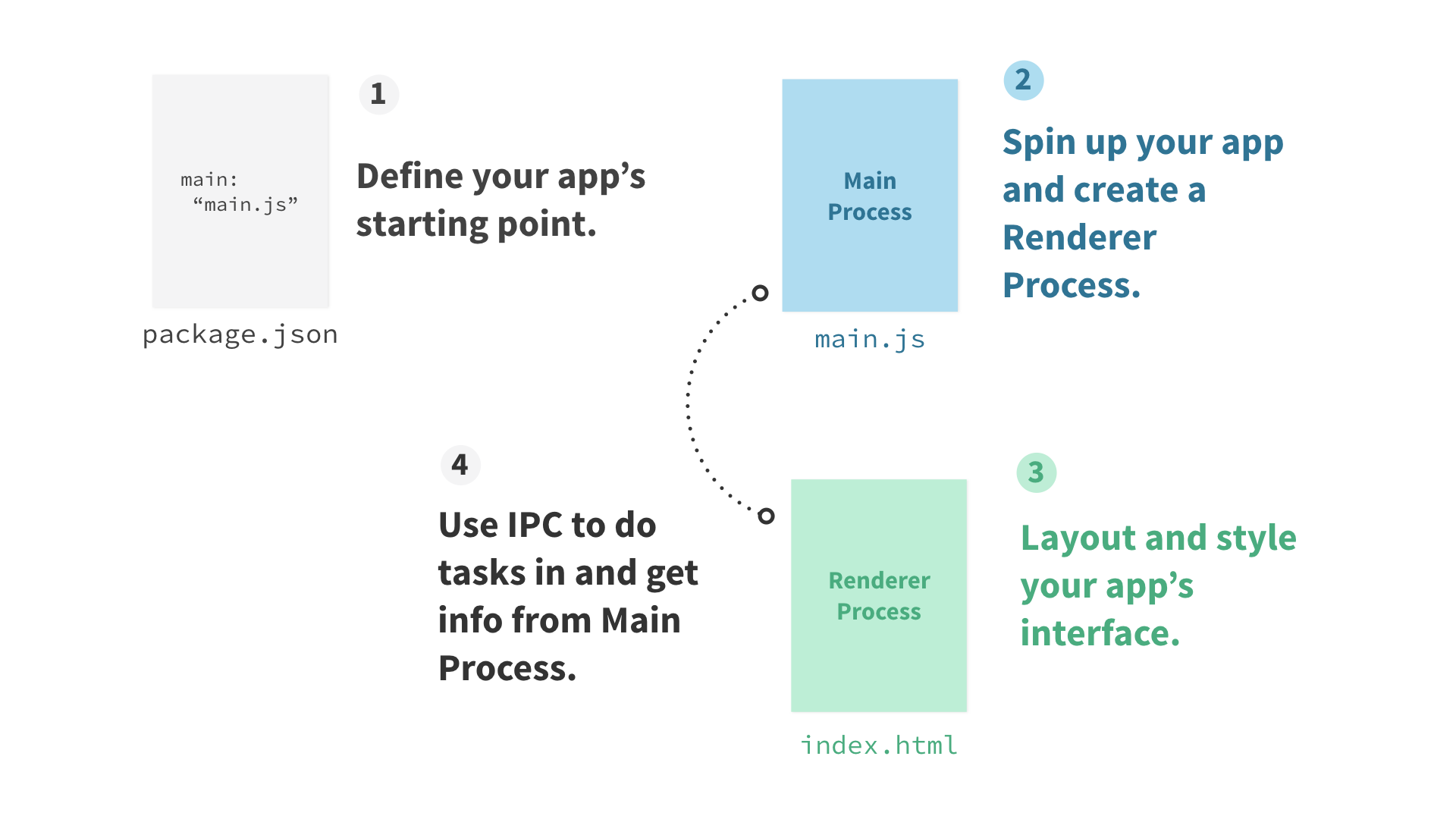







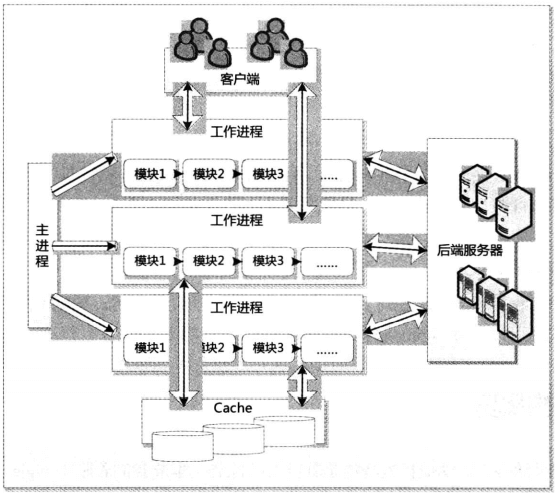
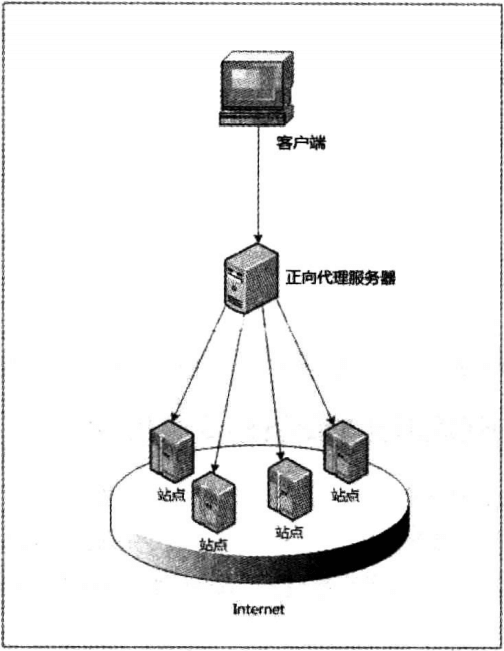
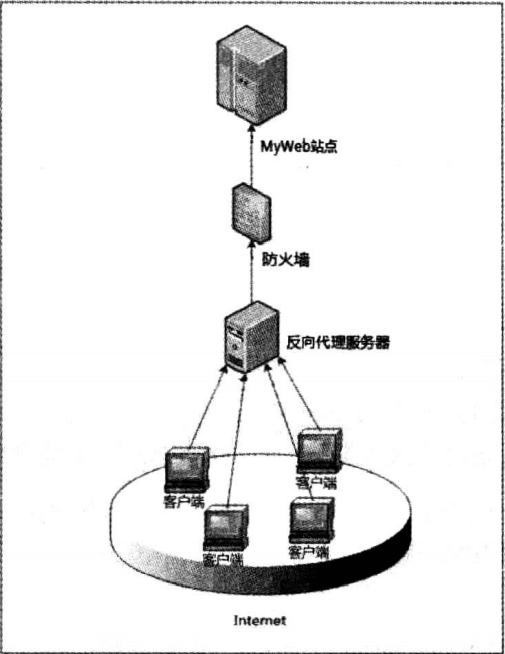
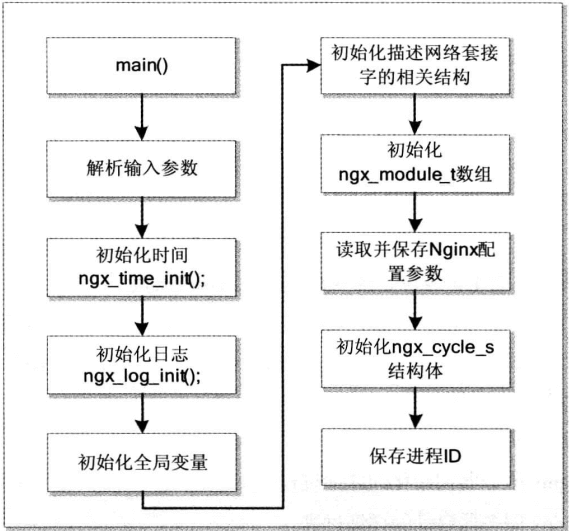
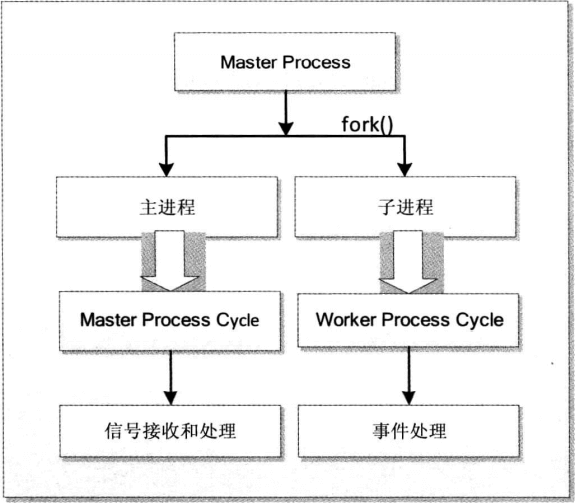














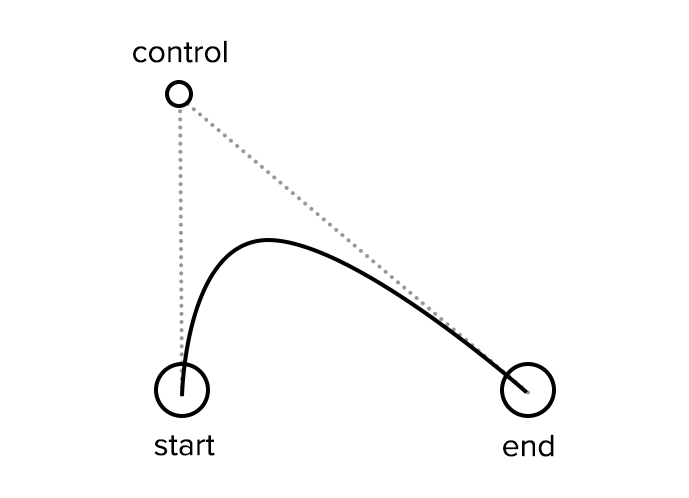





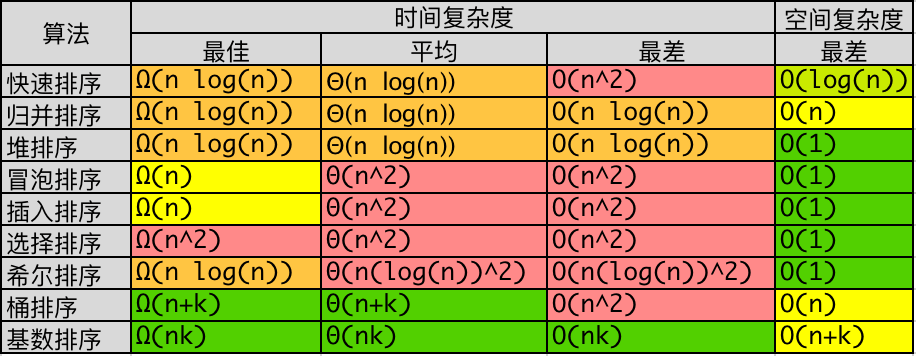
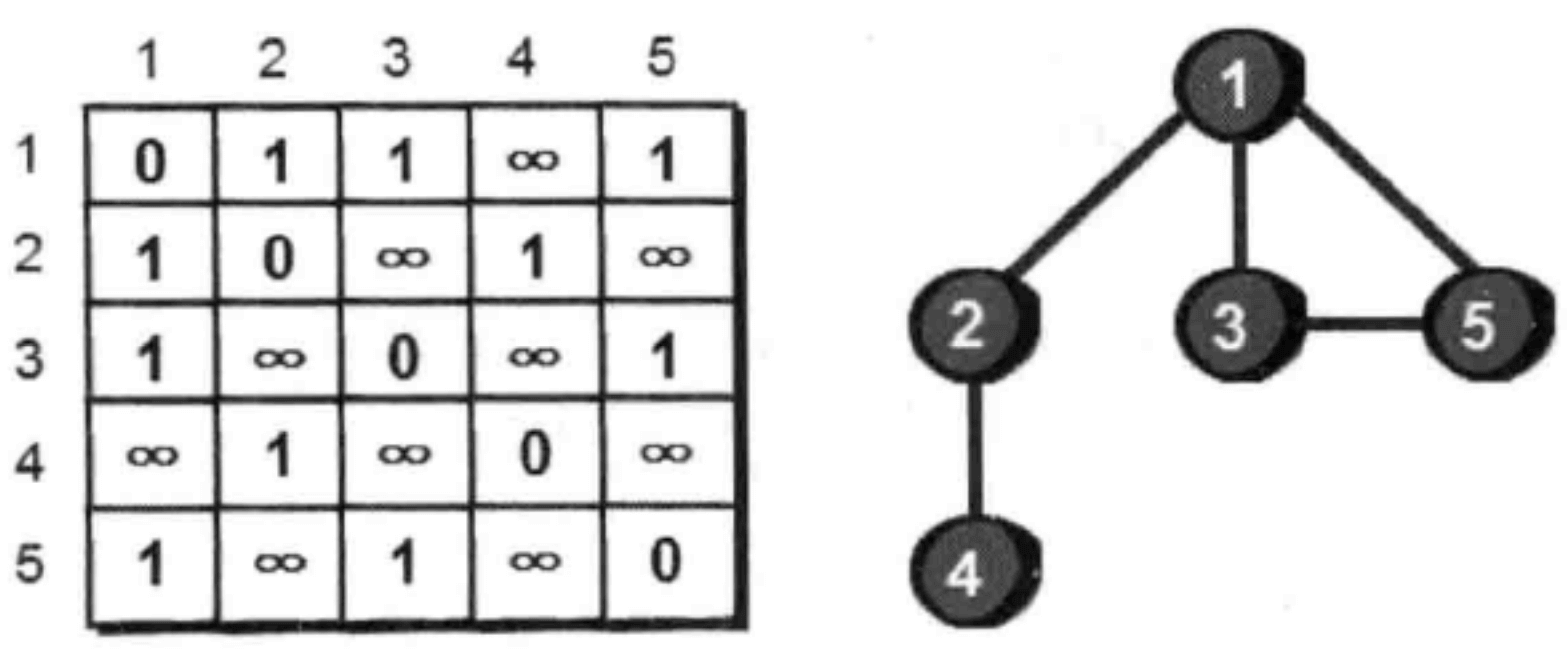
























































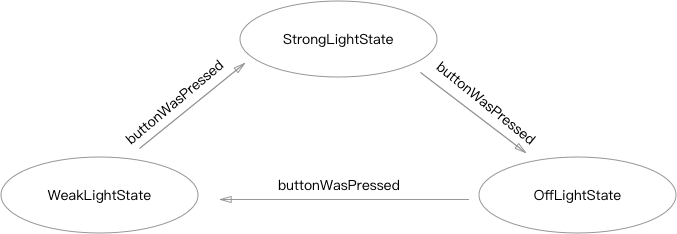
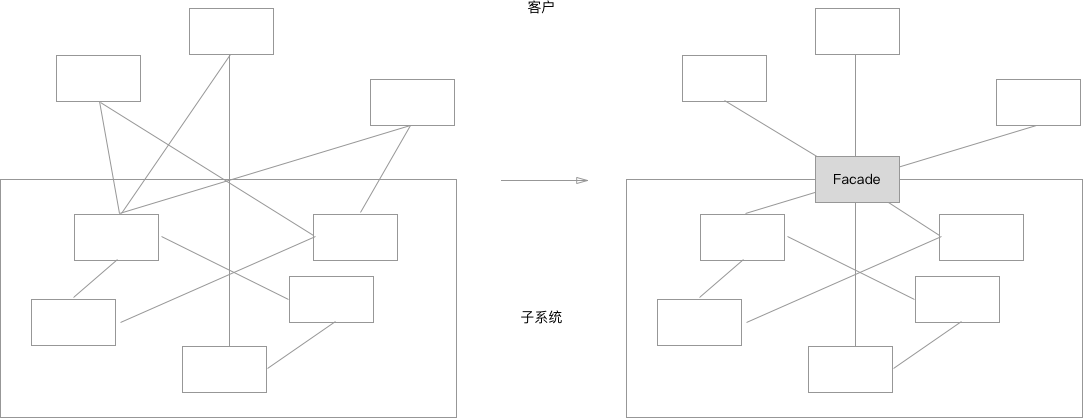

















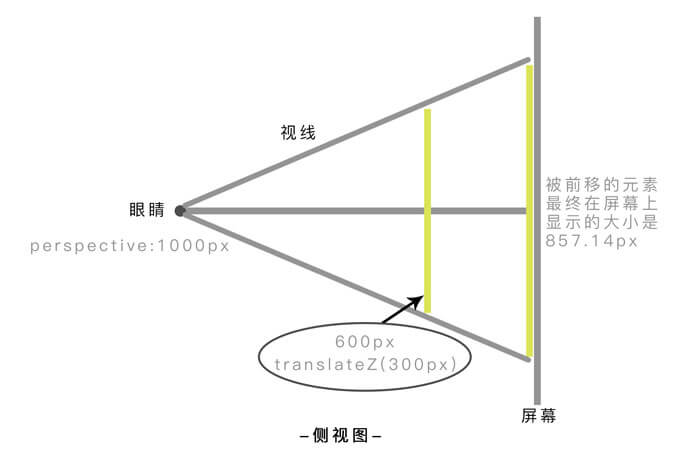
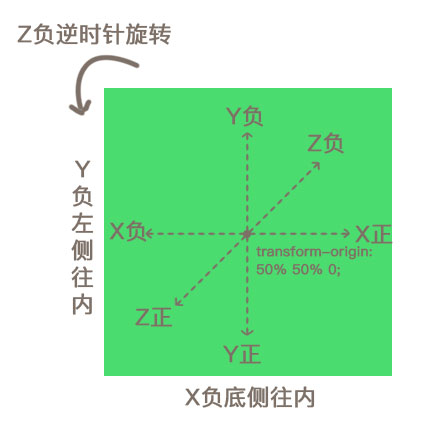
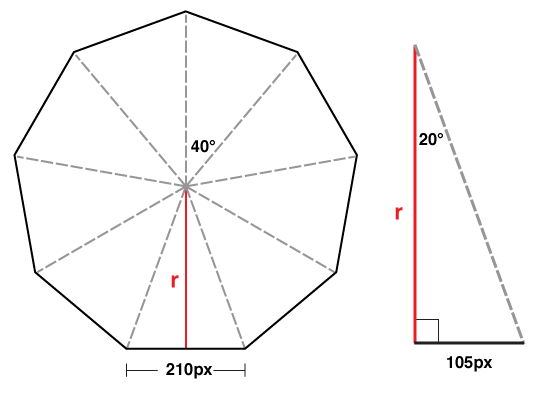





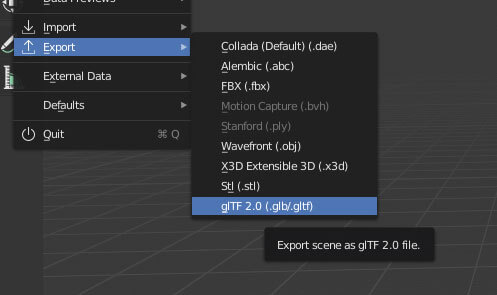{kind=link}
{kind=link}