
📣 Clone your voice with a single click on 🐸Coqui.ai
🐸TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. 🐸TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
📰 Subscribe to 🐸Coqui.ai Newsletter
📢 English Voice Samples and SoundCloud playlist
📄 Text-to-Speech paper collection

Please use our dedicated channels for questions and discussion. Help is much more valuable if it's shared publicly so that more people can benefit from it.
| Type | Platforms |
|---|---|
| 🚨 Bug Reports | GitHub Issue Tracker |
| 🎁 Feature Requests & Ideas | GitHub Issue Tracker |
| 👩💻 Usage Questions | GitHub Discussions |
| 🗯 General Discussion | GitHub Discussions or Discord |
| Type | Links |
|---|---|
| 💼 Documentation | ReadTheDocs |
| 💾 Installation | TTS/README.md |
| 👩💻 Contributing | CONTRIBUTING.md |
| 📌 Road Map | Main Development Plans |
| 🚀 Released Models | TTS Releases and Experimental Models |
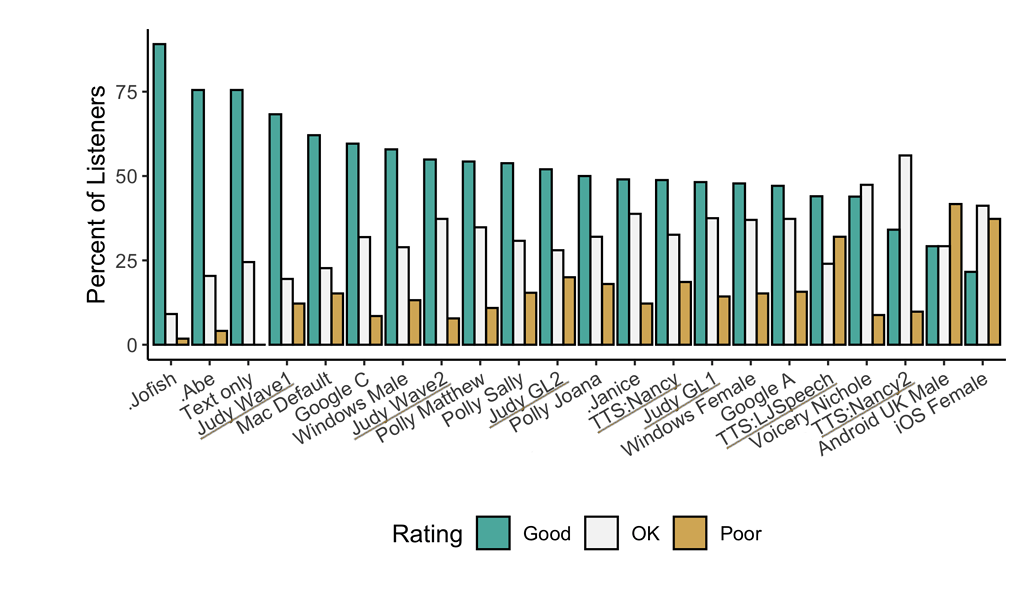
Underlined "TTS*" and "Judy*" are 🐸TTS models
- High-performance Deep Learning models for Text2Speech tasks.
- Text2Spec models (Tacotron, Tacotron2, Glow-TTS, SpeedySpeech).
- Speaker Encoder to compute speaker embeddings efficiently.
- Vocoder models (MelGAN, Multiband-MelGAN, GAN-TTS, ParallelWaveGAN, WaveGrad, WaveRNN)
- Fast and efficient model training.
- Detailed training logs on the terminal and Tensorboard.
- Support for Multi-speaker TTS.
- Efficient, flexible, lightweight but feature complete
Trainer API. - Released and ready-to-use models.
- Tools to curate Text2Speech datasets under
dataset_analysis. - Utilities to use and test your models.
- Modular (but not too much) code base enabling easy implementation of new ideas.
- Tacotron: paper
- Tacotron2: paper
- Glow-TTS: paper
- Speedy-Speech: paper
- Align-TTS: paper
- FastPitch: paper
- FastSpeech: paper
- FastSpeech2: paper
- SC-GlowTTS: paper
- Capacitron: paper
- OverFlow: paper
- Neural HMM TTS: paper
- Guided Attention: paper
- Forward Backward Decoding: paper
- Graves Attention: paper
- Double Decoder Consistency: blog
- Dynamic Convolutional Attention: paper
- Alignment Network: paper
- MelGAN: paper
- MultiBandMelGAN: paper
- ParallelWaveGAN: paper
- GAN-TTS discriminators: paper
- WaveRNN: origin
- WaveGrad: paper
- HiFiGAN: paper
- UnivNet: paper
You can also help us implement more models.
🐸TTS is tested on Ubuntu 18.04 with python >= 3.7, < 3.11..
If you are only interested in synthesizing speech with the released 🐸TTS models, installing from PyPI is the easiest option.
pip install TTSIf you plan to code or train models, clone 🐸TTS and install it locally.
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks] # Select the relevant extrasIf you are on Ubuntu (Debian), you can also run following commands for installation.
$ make system-deps # intended to be used on Ubuntu (Debian). Let us know if you have a different OS.
$ make installIf you are on Windows, 👑@GuyPaddock wrote installation instructions here.
You can also try TTS without install with the docker image. Simply run the following command and you will be able to run TTS without installing it.
docker run --rm -it -p 5002:5002 --entrypoint /bin/bash ghcr.io/coqui-ai/tts-cpu
python3 TTS/server/server.py --list_models #To get the list of available models
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits # To start a serverYou can then enjoy the TTS server here More details about the docker images (like GPU support) can be found here
from TTS.api import TTS
# Running a multi-speaker and multi-lingual model
# List available 🐸TTS models and choose the first one
model_name = TTS.list_models()[0]
# Init TTS
tts = TTS(model_name)
# Run TTS
# ❗ Since this model is multi-speaker and multi-lingual, we must set the target speaker and the language
# Text to speech with a numpy output
wav = tts.tts("This is a test! This is also a test!!", speaker=tts.speakers[0], language=tts.languages[0])
# Text to speech to a file
tts.tts_to_file(text="Hello world!", speaker=tts.speakers[0], language=tts.languages[0], file_path="output.wav")
# Running a single speaker model
# Init TTS with the target model name
tts = TTS(model_name="tts_models/de/thorsten/tacotron2-DDC", progress_bar=False, gpu=False)
# Run TTS
tts.tts_to_file(text="Ich bin eine Testnachricht.", file_path=OUTPUT_PATH)
# Example voice cloning with YourTTS in English, French and Portuguese:
tts = TTS(model_name="tts_models/multilingual/multi-dataset/your_tts", progress_bar=False, gpu=True)
tts.tts_to_file("This is voice cloning.", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav")
tts.tts_to_file("C'est le clonage de la voix.", speaker_wav="my/cloning/audio.wav", language="fr", file_path="output.wav")
tts.tts_to_file("Isso é clonagem de voz.", speaker_wav="my/cloning/audio.wav", language="pt", file_path="output.wav")-
List provided models:
$ tts --list_models -
Get model info (for both tts_models and vocoder_models):
-
Query by type/name: The model_info_by_name uses the name as it from the --list_models.
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"For example:
$ tts --model_info_by_name tts_models/tr/common-voice/glow-tts$ tts --model_info_by_name vocoder_models/en/ljspeech/hifigan_v2 -
Query by type/idx: The model_query_idx uses the corresponding idx from --list_models.
$ tts --model_info_by_idx "<model_type>/<model_query_idx>"For example:
$ tts --model_info_by_idx tts_models/3
-
-
Run TTS with default models:
$ tts --text "Text for TTS" --out_path output/path/speech.wav -
Run a TTS model with its default vocoder model:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wavFor example:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --out_path output/path/speech.wav -
Run with specific TTS and vocoder models from the list:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --vocoder_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wavFor example:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --vocoder_name "vocoder_models/en/ljspeech/univnet" --out_path output/path/speech.wav -
Run your own TTS model (Using Griffin-Lim Vocoder):
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav -
Run your own TTS and Vocoder models:
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav --vocoder_path path/to/vocoder.pth --vocoder_config_path path/to/vocoder_config.json
-
List the available speakers and choose as <speaker_id> among them:
$ tts --model_name "<language>/<dataset>/<model_name>" --list_speaker_idxs -
Run the multi-speaker TTS model with the target speaker ID:
$ tts --text "Text for TTS." --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --speaker_idx <speaker_id> -
Run your own multi-speaker TTS model:
$ tts --text "Text for TTS" --out_path output/path/speech.wav --model_path path/to/model.pth --config_path path/to/config.json --speakers_file_path path/to/speaker.json --speaker_idx <speaker_id>
|- notebooks/ (Jupyter Notebooks for model evaluation, parameter selection and data analysis.)
|- utils/ (common utilities.)
|- TTS
|- bin/ (folder for all the executables.)
|- train*.py (train your target model.)
|- ...
|- tts/ (text to speech models)
|- layers/ (model layer definitions)
|- models/ (model definitions)
|- utils/ (model specific utilities.)
|- speaker_encoder/ (Speaker Encoder models.)
|- (same)
|- vocoder/ (Vocoder models.)
|- (same)




























![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
