Download pages from http://reserves.lib.tsinghua.edu.cn/
自动下载书籍每一页的原图。
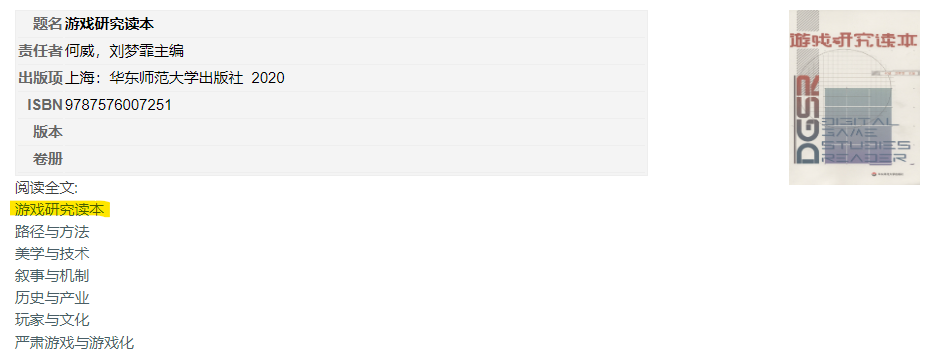
运行downloader.py(或调用函数claw),传入的参数为阅读全文下第一个链接(图中标黄的位置)。
程序会自动爬取每一章的每一页,保存在./clawed下。
Q: 如何生成教参的PDF?
A: 目前的解决方案是使用学校提供的正版福昕编辑器,将多个图片合成PDF,并可以进行OCR文字识别/图片压缩。 现在, 下载完成后会询问是否自动合并为 PDF 文件, 但是需要安装 img2pdf 库.
Q: 运行报错ModuleNotFoundError: No module named 'requests',怎么办?
A: 在命令行中运行pip install requests以安装此库。
Q: 运行报错No cookie data,怎么办?
A: 经测试,绝大部分教参无需cookie即可访问。少数教参需要cookie进行身份验证,请将网站cookie中,.ASPXAUTH和ASP.NET_SessionId的值依次写入cookie.txt中,每行一个。(我将会完善获取网站cookie的相关教程。若急需,请与我发邮件)
- CI/CD
- Async
欢迎Star/Issue/PR.
仅供学习编程,请勿用于非法用途!
更多清华常用信息/服务汇总请看这里。

