jingzhimo / jingzhimo.github.io Goto Github PK
View Code? Open in Web Editor NEWhttp://jingzhimo.github.io/
http://jingzhimo.github.io/

















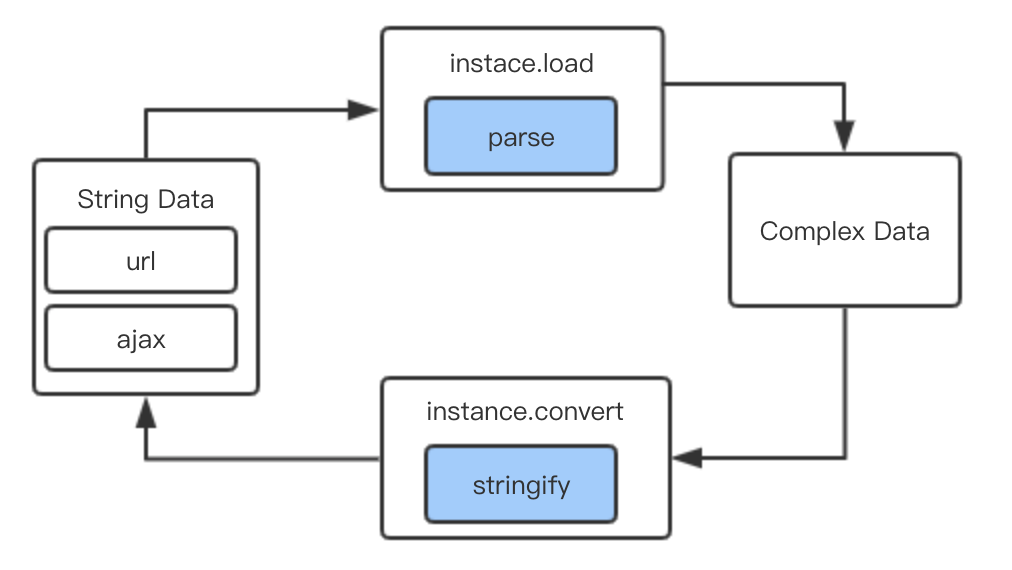
在使用 vue 的时候,了解到计算属性很好用,可以延迟计算直到调用才返回真实的数据,而且计算属性依赖的值没有发生改变的情况,就不会重新执行函数计算;比较好奇是怎么实现的,但是没有去了解原理性相关,最近去看一下源码实现,大概直到具体的实现。下面就是根据自己的了解,手动实现一个简单的计算属性:
我们知道 vue2.x 是基于Object.defineProperty来劫持数据的,那么挂载到vm.data的属性值就很好理解,在getter与setter的函数里面做一层简单的代理,那么计算属性为啥可以从一个函数变成一个数值,而且可以知道依赖的数据值?大概是因为计算属性的函数执行的时候,会触发到data属性的getter,那么我们就可以在这里做手脚,就知道当前的计算属性依赖了多少data数据了。
我们来看一段的代码,声明data与computed数据,劫持data数据方法,初始化计算属性方法等
// data 数据
var data = {
foo: 123,
bar: 'bar'
}
// data 的代理对象
var _data = {}
// 计算属性数据
var computedData = {
fooMap () {
return data.foo + 1
},
barMap () {
return data.bar + ' baz'
}
}
// 是否在收集数据
var isDep = false
// 当前收集的回调函数
var notify
// foo 的回调函数列表
var fooNotify = []
// 回调函数对应的字段
var notifyProp
// 劫持数据方法
function defineProperty (obj) {
for (let key in obj) {
// 缓存原有的数据
_data[key] = obj[key]
Object.defineProperty(obj, key, {
get () {
// 判断当前调用方法是否在收集当中
if (isDep) {
// 计算属性对应的方法与计算属性对应的key值加入到缓存
fooNotify.push([notify, notifyProp])
}
return _data[key]
},
set (value) {
// 更改缓存的数值
_data[key] = value
// 计算属性对应的方法重新计算,重新赋值
fooNotify.forEach(item => {
computedData[item[1]] = item[0]()
})
}
})
}
return obj
}
// 初始化计算属性
function initComputed (computed) {
// 依赖收集开始
isDep = true
for (let key in computed) {
let method = computed[key]
// 把当前的计算属性方法赋值到全局变量
notify = method
notifyProp = key
// 通过函数计算获取数据,获得计算属性的值
computed[key] = method()
}
// 依赖收集结束
isDep = false
}定义好方法与数据,我们可以尝试着使用:
// 1. 劫持数据
defineProperty(data)
// 2. 初始化计算属性
initComputed(computedData)
// 执行完这一步,computedData 的数据就变成了:{ fooMap: 124, barMap: 'bar baz' }
// 3. 更改 data.foo 的值
data.foo = 1234
// 执行完这一步,computedData 为: {fooMap: 1235, barMap: 'bar baz'}从上面的结果得到,可以实现计算属性一个很重要的一个特点:依赖数据发生改变,则计算属性发生改变;但是缺点也是很明显的,变量都是全局变量;依赖数据发生改变的回调的方法也是放到全局的数组;我们在接下来的v2版本修好这种情况。现在我们大概看到computed与data的观察者关系:
这一个版本我们主要 fix 部分全局变量,把计算属性与数据归类到同一个对象,这个版本改动不多:
// 是否在收集数据
var isDep = false
// 当前收集的回调函数
var notify
// foo 的回调函数列表
var fooNotify = []
// 回调函数对应的字段
var notifyProp
var instance = {
data: {
foo: 123,
bar: 'bar'
},
computed: {
fooMap () {
return instance.data.foo + 1
},
barMap () {
return instance.data.bar + ' baz'
}
}
}
// 劫持对象
function defineProperty (vm) {
let data = vm.data
vm._data = {}
for (let key in data) {
// 缓存原有的数据
vm._data[key] = data[key]
Object.defineProperty(data, key, {
get () {
if (isDep) {
fooNotify.push([notify, notifyProp])
}
return vm._data[key]
},
set (value) {
vm._data[key] = value
fooNotify.forEach(item => {
vm.computed[item[1]] = item[0]()
})
}
})
}
return data
}
// 初始化计算属性
function initComputed (vm) {
// 依赖收集开始
isDep = true
for (let key in vm.computed) {
let method = vm.computed[key]
notify = method
notifyProp = key
// 通过函数计算获取数据
vm.computed[key] = method()
}
// 依赖收集结束
isDep = false
}
// 劫持 data 数据
defineProperty(instance)
// 初始化计算属性
initComputed(instance)在完成v2.0版本之后,我们把计算属性与数据合成到一个对象;但是只能实现一个计算属性的应用,如果有多个计算属性的话,就控制不了,因为存放计算属性的数组只有一个,在v3版本,需要处理这种情况。
// 观察者列表
class ObserverList {
constructor () {
this.list = []
}
add (item) {
this.list.push(item)
}
count () {
return this.list.length
}
getByIndex (index) {
return this.list[index]
}
}
// 被观察者
class Watcher {
constructor () {
this.observer = new ObserverList()
}
addObserver (observer) {
this.observer.add(observer)
}
notify () {
let len = this.observer.count()
for (let i = 0; i < len; i++) {
this.observer.getByIndex(i).update()
}
}
}
// 观察者
class Observer {
constructor (update) {
this.update = update
}
}
// 数据依赖
class Dep {}
Dep.target = ''
// 劫持对象
function defineProperty (vm) {
let data = vm.data
vm._data = {}
for (let key in data) {
// 缓存原有的数据
vm._data[key] = data[key]
Object.defineProperty(data, key, {
get () {
// 只有在依赖收集的时候,才需要添加 watcher,普通数据调用不需要添加 watcher
if (Dep.target) {
// 当前数据字段还没有 watcher ,则新建一个
let watcher = vm._watcher[key] || new Watcher()
// 加入到依赖数组
watcher.addObserver(Dep.target)
vm._watcher[key] = watcher
}
return vm._data[key]
},
set (value) {
vm._data[key] = value
// 有对应的 watcher 那么则提示更新,调用watcher的notify方法
if (vm._watcher[key]) {
vm._watcher[key].notify()
}
}
})
}
return data
}
// 初始化计算属性
function initComputed (vm) {
vm._watcher = {}
for (let key in vm.computed) {
let method = vm.computed[key]
// 新建 observer,并标识收集依赖开始
Dep.target = new Observer(() => {
vm.computed[key] = method()
})
// 通过函数初始化计算数据,并且获取到所有依赖
vm.computed[key] = method()
// 依赖收集结束
Dep.target = undefined
}
}
var instance = {
data: {
foo: 123,
bar: 'bar',
baz: 'bazbaz'
},
computed: {
fooMap () {
let num = instance.data.foo + 1
let str = instance.data.bar + '...str'
return num + str
},
barMap () {
return instance.data.bar + ' baz'
}
}
}
// 劫持 data 数据
defineProperty(instance)
// 初始化计算属性
initComputed(instance)
// 验证处理:
console.log(instance.computed.fooMap) // 124bar...str
console.log(instance.computed.barMap) // bar baz
// 赋值数据
instance.data.bar = 'new bar value'
console.log(instance.computed.fooMap) // 124new bar value...str
console.log(instance.computed.barMap) // new bar value baz
// done.这个版本更改的地方比较多,加入观察者模式的处理;
在初始化计算属性的时候,为每个计算属性新建一个观察者,新建一个观察者传入的参数是一个函数,这个函数会在依赖的数据发生改变的时候执行;函数的内容就是为计算属性的值重新计算:
// 新建 observer,并标识收集依赖开始
Dep.target = new Observer(() => {
vm.computed[key] = method() // method 是指计算属性对应的方法
})在劫持数据的时候,数据的get触发的时候,如果是在依赖收集的过程中(也就是数据被计算属性调用),那么就会为这个数据添加watcher;并且把当前正在收集依赖的计算属性对应的observer实例加入到watcher中
if (Dep.target) {
// 当前数据字段还没有 watcher ,则新建一个
let watcher = vm._watcher[key] || new Watcher()
// 加入到依赖数组
watcher.addObserver(Dep.target)
vm._watcher[key] = watcher
}数据的set触发的时候,那么就需要通知对应观察者,计算属性对应的值就可以更新。
// 有对应的 watcher 那么则提示更新,调用watcher的notify方法
if (vm._watcher[key]) {
vm._watcher[key].notify()
}通过引入观察者的类别,处理多个计算属性;现在我们基本完善好v1.0版本全局变量的问题;除此之外,计算属性也有一个比较重要的特点是:惰性求值。当没有调用计算属性的时候,是不会触发计算;而且如果单个计算属性调用数据多次的时候,会存在watcher添加多次observer,这些下一个版本继续增加或优化。
// 观察者列表
class ObserverList {
constructor () {
this.list = []
}
add (item) {
this.list.push(item)
}
count () {
return this.list.length
}
getByIndex (index) {
return this.list[index]
}
}
// 被观察者
class Watcher {
constructor () {
this.dep = new Set()
this.observer = new ObserverList()
}
addObserver (observer) {
// 已经加入了到依赖,返回,不做处理
if (!this.dep.has(observer.id)) {
this.observer.add(observer)
this.dep.add(observer.id)
}
}
notify () {
let len = this.observer.count()
for (let i = 0; i < len; i++) {
let ob = this.observer.getByIndex(i)
ob.dirty = true
ob.update()
}
}
}
// 观察者
let _uid = 0
class Observer {
constructor (update) {
this.id = _uid++
this.update = update
}
}
// 数据依赖
class Dep {}
Dep.target = ''
// 劫持对象
function defineProperty (vm) {
let data = vm.data
vm._data = {}
vm._watcher = {}
for (let key in data) {
// 缓存原有的数据
vm._data[key] = data[key]
Object.defineProperty(data, key, {
get () {
if (Dep.target) {
// 当前数据字段还没有 watcher ,则新建一个
let watcher = vm._watcher[key] || new Watcher()
// 加入到依赖数组
watcher.addObserver(Dep.target)
vm._watcher[key] = watcher
}
return vm._data[key]
},
set (value) {
vm._data[key] = value
// 有 watcher 那么则提示更新
if (vm._watcher[key]) {
vm._watcher[key].notify()
}
}
})
}
return data
}
// 初始化计算属性
function initComputed (vm) {
vm._computedWatcher = {}
for (let key in vm.computed) {
let method = vm.computed[key]
vm._computedWatcher[key] = {
dirty: true,
value: undefined,
getter: method,
// 这个属性的观察者
ob: undefined
}
Object.defineProperty(vm.computed, key, {
get () {
let cache = vm._computedWatcher[key]
if (!cache.dirty) {
return cache.value
} else {
// 该属性没有指定的观察者,则新建
if (!cache.ob) {
// 新建 observer,并标识收集依赖开始
Dep.target = cache.ob = new Observer(() => {
cache.value = cache.getter()
})
}
cache.dirty = false
cache.value = cache.getter()
}
console.log('calc new cache')
return cache.value
}
})
// 通过函数初始化计算数据,并且获取到所有依赖
vm.computed[key] = method()
// 依赖收集结束
Dep.target = undefined
}
}
var instance = {
data: {
foo: 123,
bar: 'bar',
baz: 'bazbaz'
},
computed: {
fooMap () {
let num = instance.data.foo + 1
let str = instance.data.bar + '...str'
return num + str
},
barMap () {
return instance.data.bar + ' baz'
}
}
}在这一个版本,主要新增了,vm._computedWatcher,缓存每一个计算属性的一些记录,结构如下:
vm._computedWatcher[key] = {
dirty: true, // 表示当前数据是否为“脏”,当为“脏”的时候,则需要重新计算
value: undefined, // 缓存计算属性的返回值
getter: method, // 计算属性对应的计算方法
ob: undefined // 这个属性的观察者
}dirty为true的情况主要是两种,一种初始化的时候,另外一个种是依赖的数据已经发生了改变。为了验证这种情况,我们在计算属性的get方法打log,如果被调用的时候就会log出来:
// 劫持 data 数据
defineProperty(instance)
// 初始化计算属性
initComputed(instance) // 这个时候并没有 log:calc new cache
// 获取计算属性
instance.computed.fooMap
// calc new cache
// return 124bar...str由此可以看出,惰性求值是可以的。另外可以注意到为每个观察者的实例添加一个id,在watcher添加观察者的时候判断观察者列表是否已经包含当前观察者,可以实现简单的观察者去重。
至此,一个简单的计算属性就可以实现起来,虽然使用起来与vue有区别,例如数据与计算属性都挂载到vm对象;并且例子的健壮性也需要提高,没有考虑到一些特殊的情况,例如如何监听数组的变化,这些也需要实现;还有一些例如sync特性没有实现;但是大部分常用功能都能够实现,而且思路上理解清晰就完成了部分任务;这个时候再去看 vue 的源码应该会理解起来更加快。end.
前阵子去回顾一下tree-shaking的简单原理,然后顺藤摸瓜,逐步把之前不清晰或者不明白的打包基础工具梳理了一遍。
tree-shaking 就是可以把一些没有用到的代码在打包的过程剔除,进而减少最终的代码体积,例如:
// a.js
export const foo = () => {}
export const bar = () => {}
// b.js
import { foo } from './a.js'因为b.js不包含bar函数,所以最后会被剔除,具体可以看webpack 这篇文章;但是实现tree-shaking的基础是使用ES Module;平常nodeJs所用到的CommonJs的模块定义方式暂时是不能够应用到tree-shaking。ES Module 能实现的主要原因有三个:
import,export语句只能在模块顶层的语句出现第一点大概意思是,在模块中,import 与 export 语句不能够嵌套在其他块当中
// ES Module
// correctly
import { foo } from './a.js'
// error
if (value) {
import { foo } from './a.js'
}
// CommonJs
// correctly
var foo = require('./a.js').foo
// correctly too
if (value) {
var foo = require('./a.js').foo
}第二点的大概意思是,导入模块的时候,不能够使用变量进行拼接,只能是字符串常量:
// correctly
import foo from './a.js'
// error
import foo from 'some_module' + SUFFIX第三点原因,可以结合对模块循环引用的处理不同,来说明一下;
CommonJs对模块的处理是:在遇到require的时候,就进入到对应模块,然后执行依赖模块的代码,引用的模块只会执行一次,后续再依赖相同模块的时候,就不会执行依赖模块的代码;
ES Module在遇到import的时候并不会去马上执行依赖模块代码,而至拿到依赖模块的变量引用,当本模块对依赖模块的变量进行计算的时候,才会根据引用去拿数据。
直接文字说明没有代码可能比较晦涩,具体可以参考阮一峰的文章解释循环引用问题。
另外对于ES Module想了解更多的,可以查看exploringjs的文章,讲解得十分清晰,而且带有例子代码。
tree-shaking大概情况就是这样子了,但是实际上,很多依赖的库为了兼容大多数情况,最后都是打包成CommonJs,所以发现很多都没什么用...当然,有部分库会分不同的入口文件,例如main就是CommonJs打包模块的入口,module表示ES Module打包的入口:
// package.json
{
name: "package-name",
main: "dist/index-cmd.js",
module: "dist/index-esm.js"
}这个时候我们需要在webpack设置优先规则:
// webpack.config.js
module.exports = {
// ...
resolve: {
// 这是默认配置,可以根据需要进行更改
// 解析路径的时候解析顺序从左往右优先级降低
mainFields: ['module', 'main']
}
}这样子就能够处理那些导出包括ES Module 的库了。
ok,现在再回头看一下webpack的处理过程:babel => tree-shaking => 压缩;我们先从压缩的看起,无意中发现现在webpack默认的压缩工具改了!!!现在默认是:terser与对应的terser plugin,我对压缩工具的处理还停留在uglifyJs...简单看了一下terser的描述,大概意思就是,uglify-es已经停止维护了,uglify-js又不支持对ES6+的处理,所以就forkuglify-es,新建的一个库:
uglify-es is no longer maintained and uglify-js does not support ES6+.
terser is a fork of uglify-es that mostly retains API and CLI compatibility with uglify-es and uglify-js@3.
模块一开始就被babel来处理,但是默认babel会处理为CommonJs,所以配置需要更改。然后也顺便熟悉一下babel的部分插件,此处用@babel/preset-env为例:
// babel.config.js
module.exports = {
presets: ['@babel/env', {
modules: false // 不转换代码中的模块处理方式
}]
}看到这里,也顺便熟悉一下babel的@babel/preset-env和@babel/plugin-transform-runtime;
@babel/preset-env 是一堆插件的组合,通常能够支持最新稳定的 js 语法,而不需要手动去配置;如果对于一些还没有完全确定的js语法,暂时不支持
It is important to note that @babel/preset-env does not support stage-x plugins.
需要注意的是,babel默认是不处理API,只支持语法,例如class语法,箭头函数语法;一些API,例如Promise(ie: ???),Set,String.prototype.includes这些,默认不会转义,需要使用polyfill,这个后面就讲到。
@babel/plugin-transform-runtime能够把一部分helper函数,使用模块引入的方式。
A plugin that enables the re-use of Babel's injected helper code to save on codesize.
例如在不使用的情况下(这里用class语法的helper函数作为例子):
function _createClass(Constructor, protoProps, staticProps) { if (protoProps) _defineProperties(Constructor.prototype, protoProps); if (staticProps) _defineProperties(Constructor, staticProps); return Constructor; }如果不使用@babel/plugin-transform-runtime插件的时候,这个_createClass函数,在转换的时候,每个包含class文件都会引入这个helper,到最后webpack打包的时候就会有多个这样子的函数,而最后打包的命名规则通常与文件夹与文件名有关系,例如:
// 使用前
// index.js
function index_createClass () {}
// util.js
function util_createClass () {}最后打包出来就很多个这样类似函数,@babel/plugin-transform-runtime就是处理这种情况,能够统一引入,而不是直接把函数内容复制到文件:
// 使用后
var createClass = __webpack.require__(0) // 在文件顶部引入,0 是 webpack 定义模块的id默认的情况下,@babel/plugin-transform-runtime插件是通过CommonJs方式引用,我们也可以改成ES Module的方式:
// babel.config.js
module.exports = {
// ...
plugins: [
['@babel/plugin-transform-runtime', {
useESModules: true
}]
]
}从babel7.4.0开始就放弃了@babel/polyfill的使用,取而代之的是使用core-js来实现polyfill,例子:
// babel.config.js
module.exports = {
// ...
presets: [
['@babel/env', {
modules: false,
corejs: 2,
useBuiltIns: 'usage'
}]
]
}corejs与useBuiltIns需要配合使用,corejs通常可以指定两个版本2/3;corejs@3版本比corejs@2厉害的地方在于,可以把实例的方法也处理了,例如String.prototype.includes,这个方法属于字符串实例的方法,如果用corejs@2是不能够对这种方法处理的,只能处理一些全局的API,例如Set,Map这些;在@babel/preset-env通过配合corejs + useBuiltIns实现的polyfill,能够根据所需要支持的浏览器(通常是.browserslistrc的内容)与浏览器不支持的API引入对应的polyfill。
例如,支持的浏览器列表中有一项是:safari > 9,而且代码中用到了Set相关,那么就会引入Set的polyfill;如果支持的浏览器列表都是非常新的chrome,那么就不会引入Set的polyfill。还有一个地方需要注意的是,preset中引入的polyfill是会污染全局的API,例如上面所说到的includes方法,会直接在原有的原型链中添加该方法。能否不污染原有的API而引入polyfill?
使用@babel/plugin-transform-runtime插件:
// babel.config.js
module.exports = {
// ...
presets: [
['@babel/env', {
modules: false
}]
]
plugins: [
['@babel/plugin-transform-runtime', {
corejs: 3, // 使用polyfill
useESModules: true
}]
]
}处理完之后,原有的API会发生改变,例如:
// 18 只是一个模块的id,会随打包代码不同而改变
var set = __webpack_require__(18)
var set_default = __webpack_require.n(set)
var set = new Set(['foo'])
// 会转义为:
var set = new set_default.a(['foo']) // 这里举个例子,可能 a 变量会根据环境不同改变可以看出,原有的代码,使用新的变量进行代替了,在文件顶部,则会引入对应的模块,这样子只是局部更改,没有污染全局变量;那么有什么不好的?
那就是不能根据.browserslistrc的浏览器进行按需引入,无论浏览器支持与否,都会进行引入对应的模块;假设应用只支持较新版本chrome,当使用@babel/plugin-transform-runtime配合corejs的时候,也会把已支持的API打包到最终的文件...因此有可能使得打包文件变大,所以需要根据情况进行取舍。这个issue的回答也有给到一些关于使用@babel/preset-env与@babel/plugin-transform-runtime的一些建议,可以看一下。
为了减少打包后的体积,首先想到到tree-shaking,但是发现现实的骨干使得情况不能那么简单,还需要配合webpack, terser, babel来处理,每一层都必不可少,了解整个打包流程才使得得到最终的减少打包体积效果...
自从工作之后就极少写文章了,因为空闲时间没这么多,到了周末又想轻松两天,但是周末其实并不轻松,或许归根到底最后就是一个字:懒!这周回家之后,感觉总算可以静下心来做点东西,把之前在项目用ng1.x按需加载的实现整理一下。
最近工作用到angularJs,也就是ng1.x版本开发一个网站,这个项目其中用ui-router来控制路由,webpack来构建项目。有个比较致命的痛点,ng1.x官方不支持懒加载!
这个项目经过webpack打包之后主要形成两个js文件,一个是vendor.js,是引入的node_modules的公用文件,另外一个是app.js,是自己写的js文件。
处理之前项目的js入口文件大概是这样子的;
// 引入主要工具和框架
import angular from './angular'
import 'angular-ui-router'
// 引入一些工具库
import tool1 from './tool1'
// 引入ng的一些指令,组件,service等等
import aComponent from './a.component'
import aService from './a.service'
import aDirective from './a.directive'
// 引入路由
import router from './router'
// 项目模块
angular.module('app', [
'ui.router',
// ... 其他一些依赖
])
.config(router)
.component('aComponent', aComponent)
// ...从这个入口文件就可以看出,现在所有依赖的外部工具库和自己编写的内容都是一次性引入进来,尽管通过webpack来分开了两个文件,但是在入口的html文件还是一次引入了。特别是进入首页介绍页面的时候,逻辑功能比较少,但是却要加载全部功能。
因为项目通过一级url分工明显,每个url可以分离成一个模块,处理起来就更直观,例如:
/foo
/bar
/baz
// ...因此需要从ui-router先下手,能够指定一级url之后,交给对应的模块处理,对应的模块内部再处理子url,这样子每个模块之间就更加明确。从ui-router官网参考的例子如下:
var contactsFutureState = {
name: 'contacts.**',
url: '/contacts',
lazyLoad: function() {
// lazy load the contacts module here
}
}这里的例子大概意思是url为/contact的命名是contact.**,然后通过layLoad的函数加载对应的模块逻辑处理。这里要引入一个概念,叫futureState,字面上的意思是未来的状态,就是预先定义的。在配置页面全局路由的时候,大概就是这样子:
angular.module('app', ['ui-router'])
.config(['$stateProvider', function ($stateProvider) {
let states = [
{
name: 'foo.**',
url: '/foo',
lazyLoad: function() {
// 引入对应的模块
}
},
{
name: 'bar.**',
url: '/bar',
lazyLoad: function() {
// 引入对应的模块
}
}
// ...
]
// 定义相关url
states.forEach(state => $stateProvider.state(state))
}])然后具体foo模块就定义对应的二级url:
angular.module('foo', ['ui-router'])
.config(['$stateProvider', function ($stateProvider) {
let states = [
{
name: 'foo',
url: '/foo',
component: 'foo'
},
{
name: 'foo.second',
// 实际访问的url是 /foo/second
url: '/second',
component: 'fooSecond'
}
// ...
]
// 定义相关url
states.forEach(state => $stateProvider.state(state))
}])
// foo和fooSecond也是在该模块引入,这里没有写出
.component('foo', foo)
.component('fooSecond', fooSecond)但是,这样子并跑不通,会报一个multiple define的多重定义的错,然而ui-router官方并没有给出相关例子,刚才的foo模块定义是根据之前定义全局模块的定义。直到后来在stackflow找到了ui-router注入对象$stateRegistry,替换子模块的$stateProvider,因此子模块定义url的时候,就变成了:
// 注册相关url,依赖的注入也要修改
states.forEach(state => $stateRegistry.state(state))路由处理完毕之后,就要考虑一下怎么把刚才的子模块在对应路由触发的时候,动态注入,这个在ui-router给出了一个参考,就是利用第三方的ocLazyLoad来支撑,在定义全局路由的时候,表明懒加载,例如:
[{
name: 'foo.**',
url: '/foo',
lazyLoad: function ($transition$) {
return $transition$.injector().get('$ocLazyLoad').load('./fooModule.js');
}
}
}]动态注入ok了,然后就是用webpack工具来打包分离代码,分离比较简单,教程在这里,有使用import和require.ensure的方法,这里就使用了import的方法,修改lazyLoad的动态注入方法:
[{
name: 'foo.**',
url: '/foo',
lazyLoad: function ($transition$) {
return import(/* webpackChunkName: "foo" */ './fooModule.js')
.then(mod => {
// mod.defatut 是因为fooModule.js export default ...
$transition$.injector().get('$ocLazyLoad').load(mod.default)
})
}
}
}]这样子webpack打包文件的时候会分割代码,当该模块触发的时候,再请求该模块的文件,然后给到ocLazyLoad来动态注入,实现按需加载,当访问过该模块的时候,下次进入已加载过的模块,也不会再次发出请求模块文件
到这里,整个流程就跑通了,回顾一下几个关键点:
$stateRegistry来注册路由;ocLazyLoad实现动态注入;这次也是在填ng1.x的一些坑,使用相对较旧的框架实现一些看起来比较简单的需求,有时候也是挺折腾的。或许像同事所说的这是旧框架与人民日益增长的需求之间的矛盾。
回顾之前用hexo写文章的时候,换了电脑之后,源文件又要重新找,而且过程搭建也是挺麻烦的,所以这次写博客用到同事贡献自动化博客,安利一下地址,仅仅用github的issue就可以写了,而且不怕丢失了,而且一次配置,绝无手尾,写完issue就能更新到我们的博客了。END
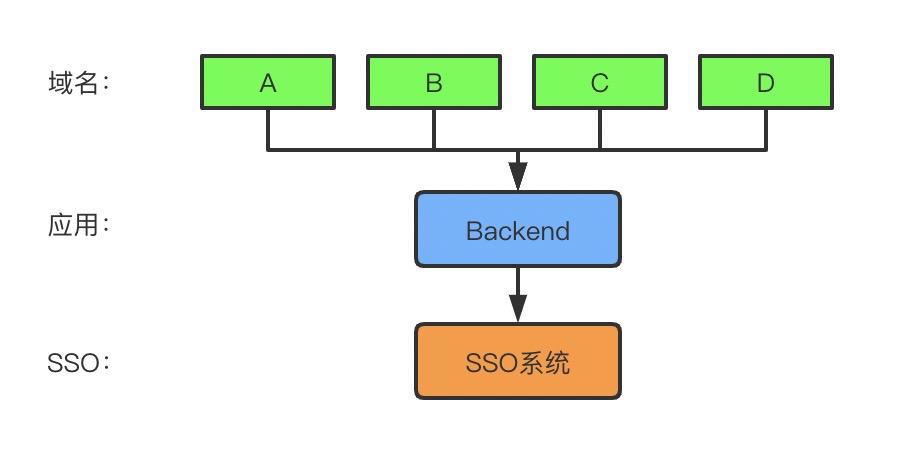
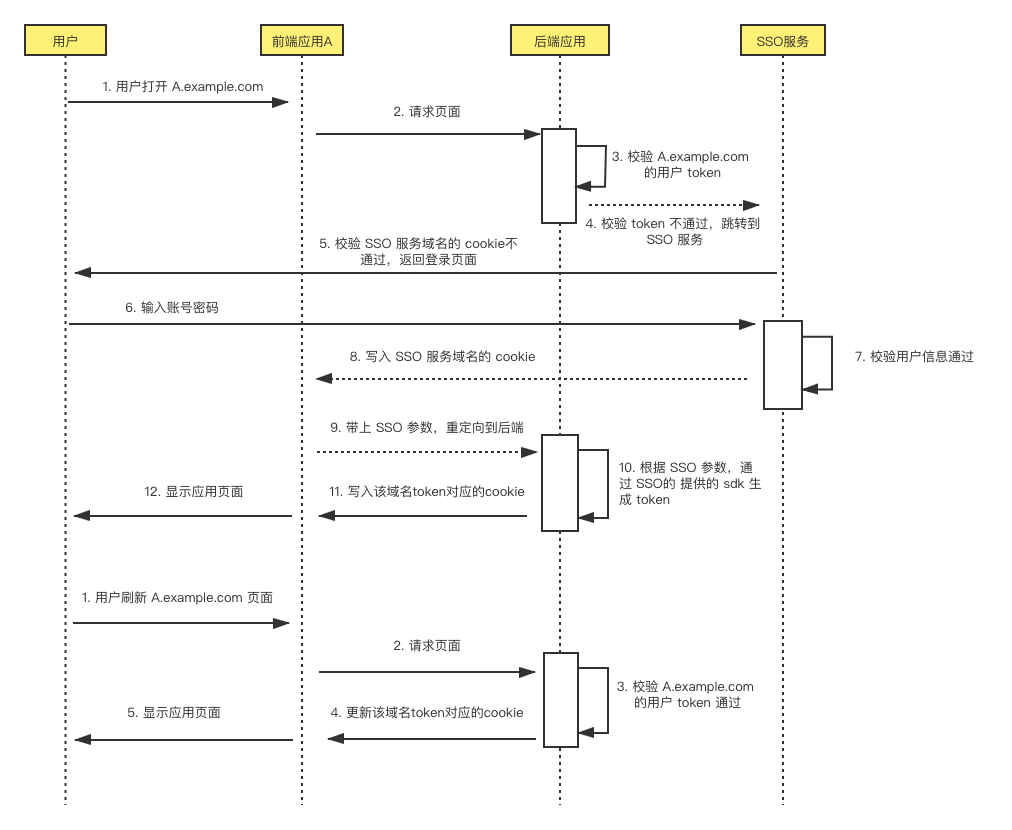
这篇文章主要梳理一下现在http缓存相关的header,还有http2的特点与简单原理分析。
先讲一下缓存,用于协商缓存的请求头有很多个,其中比较常用是以下几个:
通用首部指既能够在请求首部出现,也可以在响应首部出现
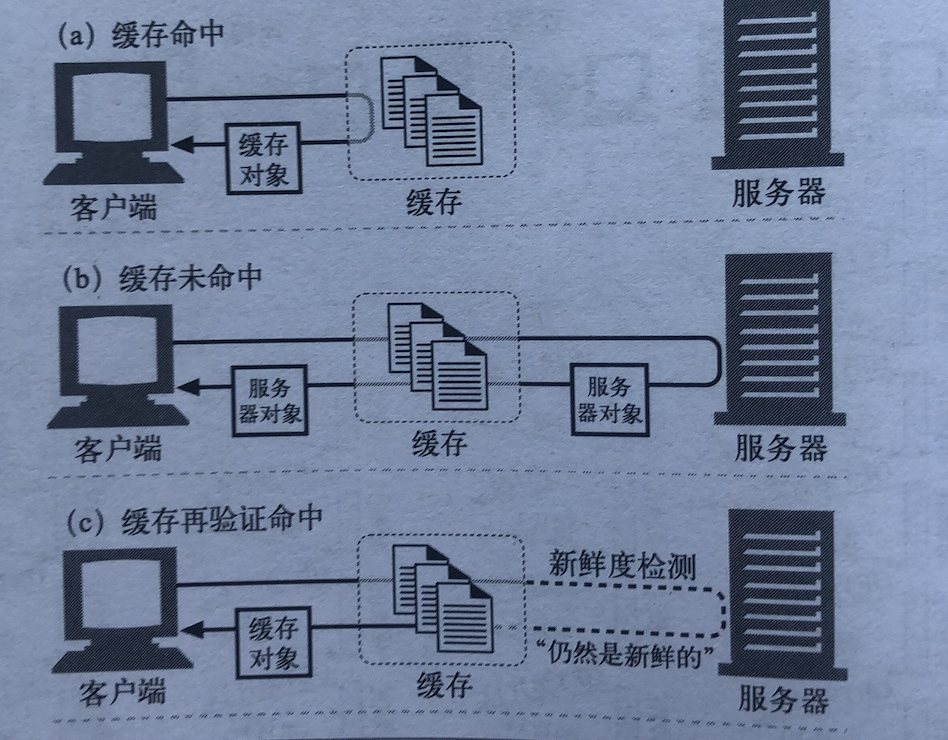
这里先说以下浏览器缓存判断逻辑
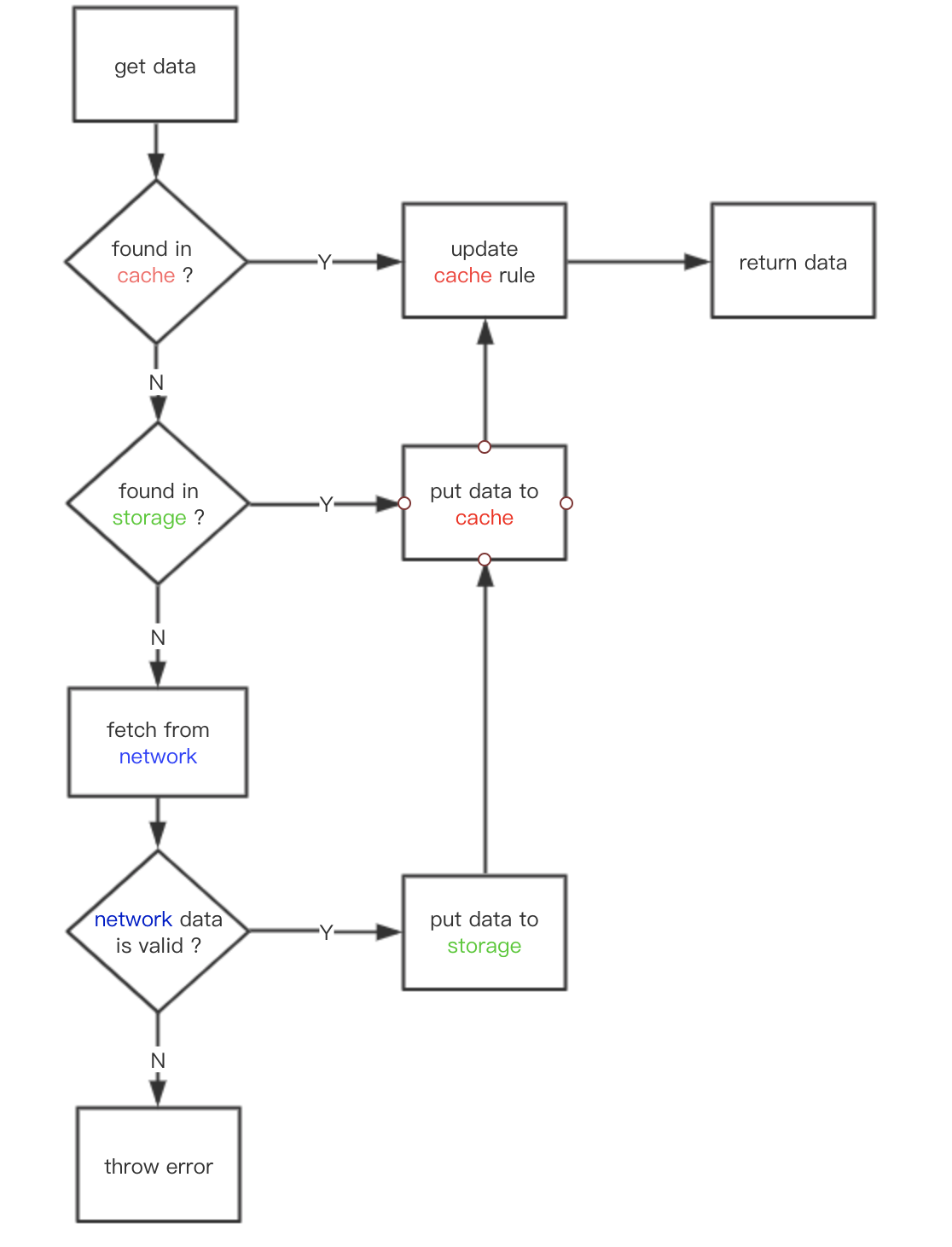
function mockCache () {
// 浏览器本地缓存命中
if (cacheHit) {
return cache
}
// 缓存没命中,去检测新鲜度
if (checkFreshness) {
// 缓存仍然有效
return cache
}
return newResponse
}
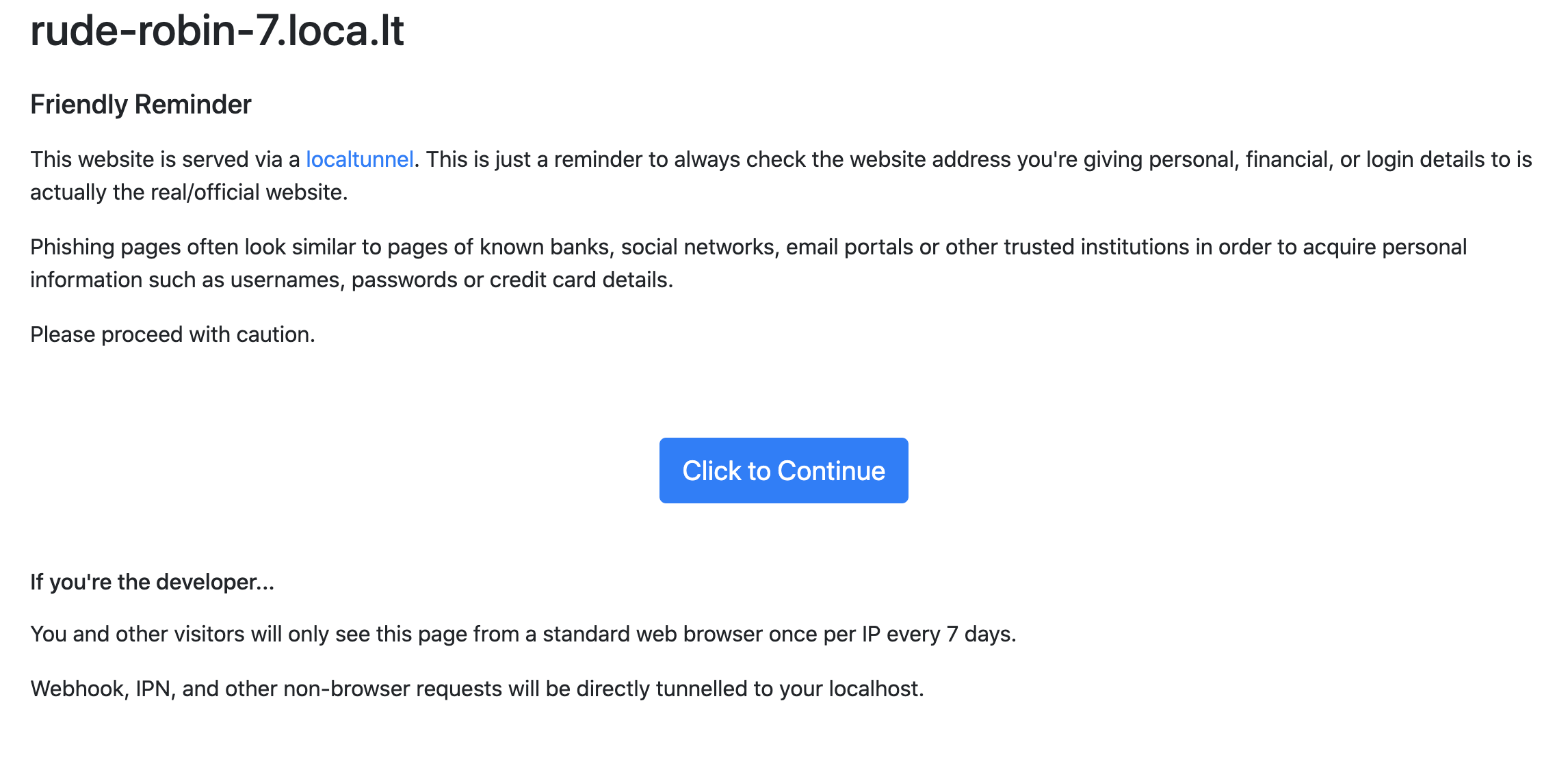
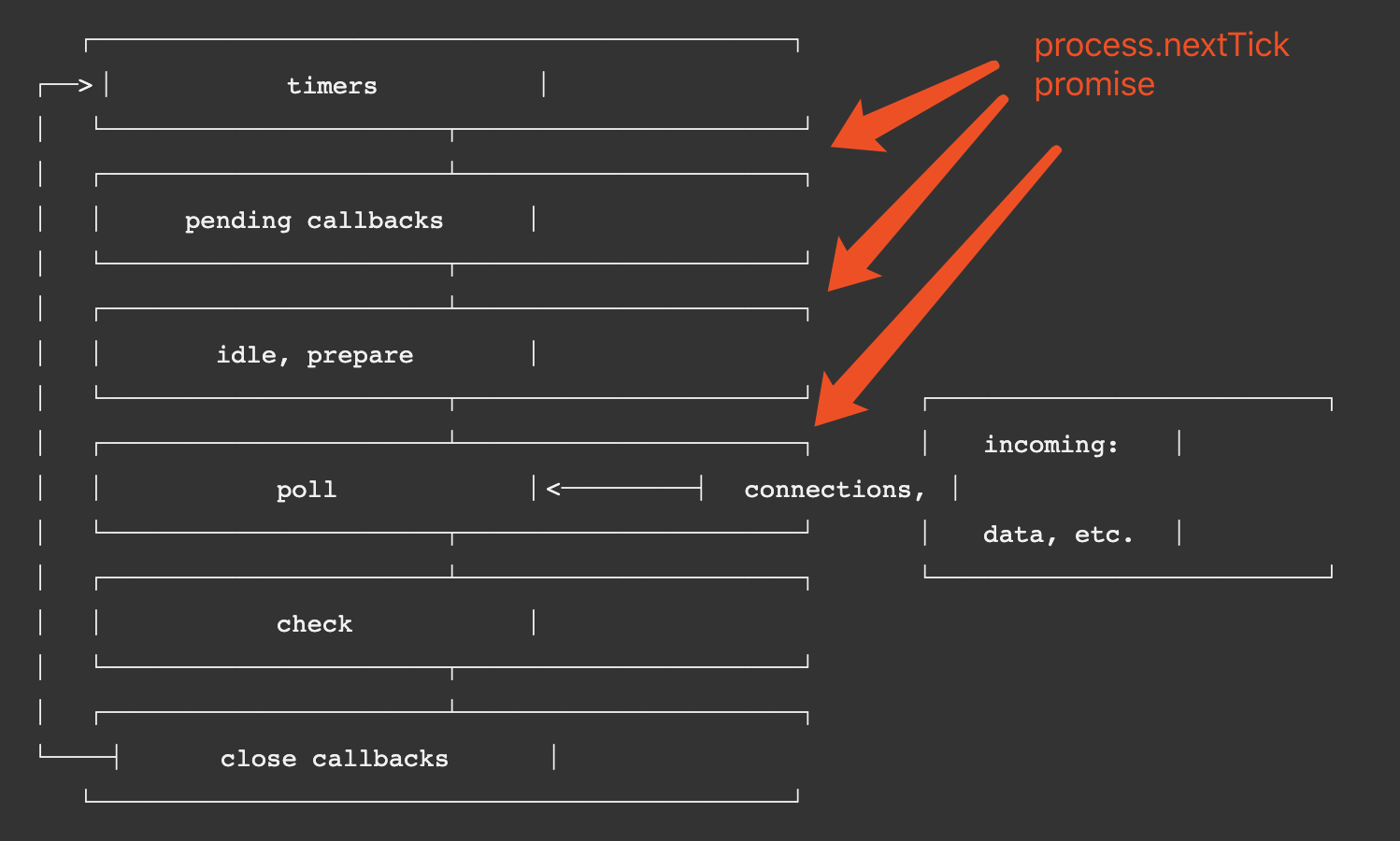
图片来源:http权威指南
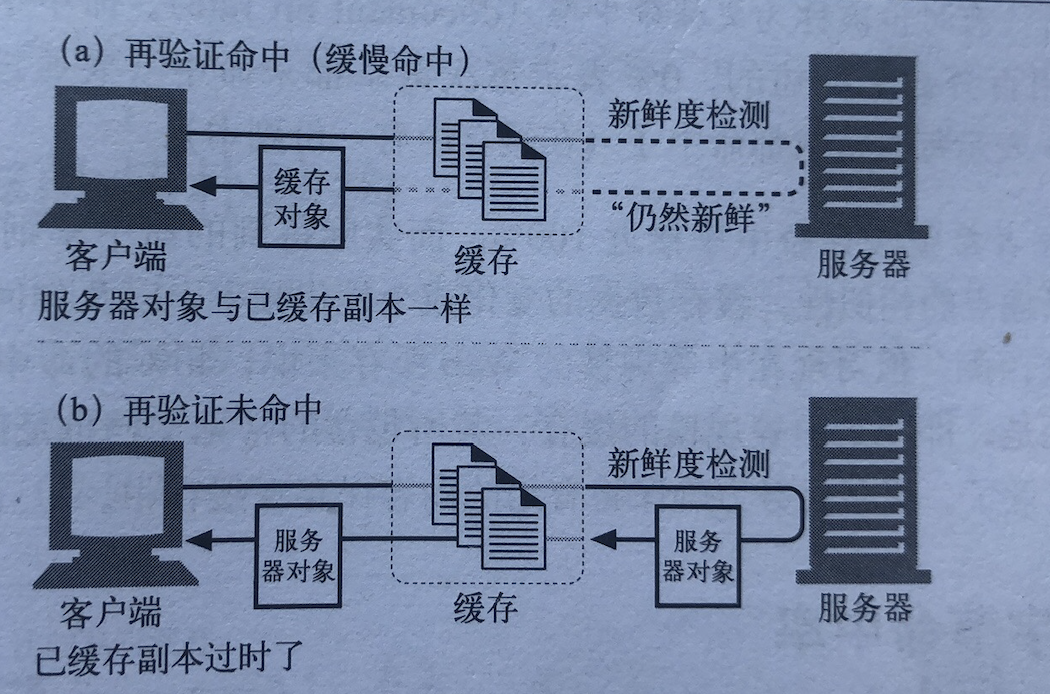
浏览器会先查看请求是否命中本地缓存,若命中,则直接使用本地缓存,这个请求返回的http状态码是200,而响应的内容与该请求上一次有效返回一致,常见的有:from memory cached,from disk cached
若缓存在本地没有命中,则会去检测新鲜度,也叫协商缓存,通常是etag && if-none-match与last-modify && if-modified-since这两对组合去判断,前者优先级更高;如果缓存仍然有效,则响应的http状态码是304;如果缓存已经失效,那么响应的http状态码是200,服务器返回最新的内容。
用于判断缓存是否命中的优先级为:
pragma > cache-control > expired
2019.11.03更新cache-control字段
这里需要特别说一下cache-control的值,no-cache,no-store,must-revalidate;当服务器响应的中的header包含no-cahce的时候,表示,下次该请求再次发出的时候,需要再次校验本地保存的缓存是否正确才能够使用,这里所说的校验,通常是通过etag, last-modified等的协商缓存进行协商;
当服务器返回的响应中header中包含:cache-control: no-store,则表示浏览器不会存储该请求响应的内容,所以下次浏览器再次发出请求的时候,则不会带上etag的内容,相当于是一个新的请求
当服务器返回的响应中header中包含:cache-control: must-revalidate,则表示当缓存过期(max-age: 0)的时候,需要需要重新进行校验,当返回must-revalidate, max-age=0的效果,相当于cache-control: no-cache.
用于判断新鲜度的优先级为:
etag > last-modified
options请求的缓存这里需要特别说明一下options请求的缓存:Access-Control-Max-Age: seconds;主要用来缓存预检(Preflight)请求options。
什么情况下会出现预检options请求?在设置跨域cors的时候,对于“复杂”请求,则会先发出预检;若对于“简单”请求,则不会发出。
Access-Control-Max-Age表示对该options预检请求进行缓存,在指定时间内,同一个请求则不再发出预检;该时间单位为秒;若返回-1,则表示,该请求不需要缓存,每次请求都需要预检。但是这个时间的最大值可能不一定受用于影响,据谷歌得到结果所知,chromium浏览器的最大缓存时间是10分钟(10 * 60s),而firefox则是最大缓存时间是24小时(24 * 60 * 60s)。
接下来说一下http2的相关特点,主要有以下三点:
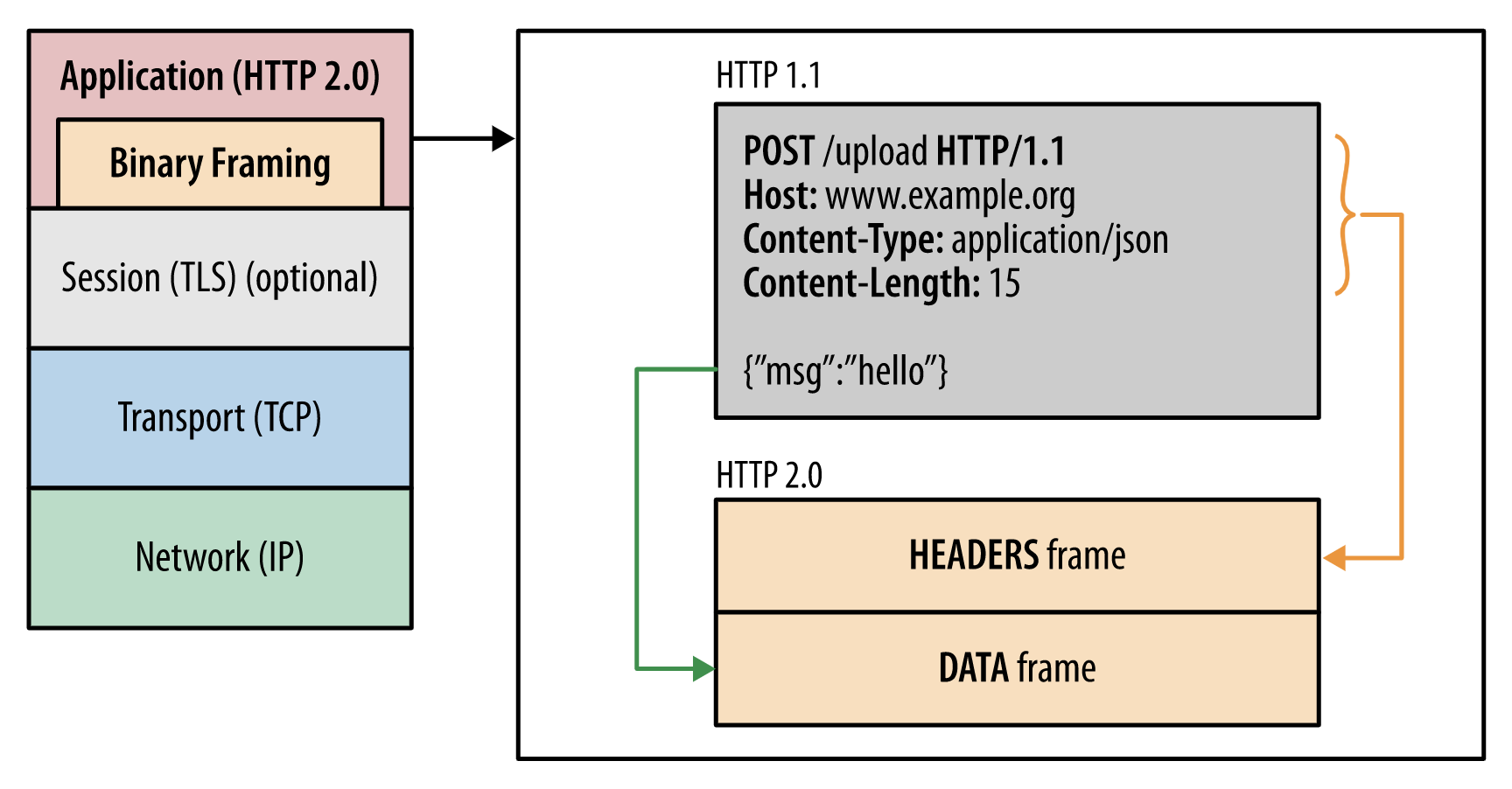
http1.1的请求头与内容等是已字符串的形式传输,以空行为分隔符;而http2是以二进制的方式传输,把请求头与请求内容都封装成帧;
对与新的二进制分帧的数据传输模式,需要熟悉几个概念:
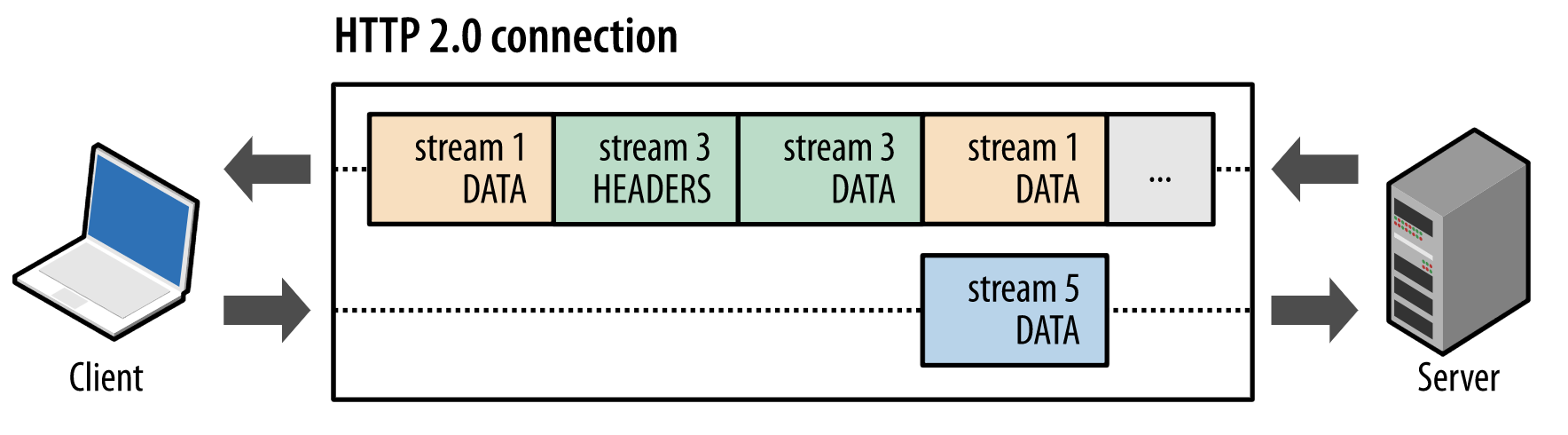
从图上我们可以看出,发送的时候,很多时候都是并非按顺序的传输,帧与帧之间不需要等待,这样子可以达到快速的传输目的。
不会,因为每一个帧都带有头部信息,这些头部信息能够给到接收的一端重新组装。
能,数据流与帧都能够设置优先级,优先级使用1到256之间的整数表示,数字越大,处理的优先级越高。
对于有依赖关系的数据流来说,会优先把依赖的资源优先获得分配,然后再对原有资源进行整理。
例如左一情况,数据流A的优先级比数据流B优先级高,从weight数值知道,数据流 B 获得的资源是 A 所获资源的三分之一。
例如左而情况,数据流C依赖与数据流D,尽管C比D优先级高,但是还是数据流D优先获取完整数据,再到C获取。
从上面的二进制分帧的处理可以看出,多个http请求可以利用一个tcp进行数据传输,形成多路复用;而http1.1,只能够一个tcp对应一个http,而浏览器对同时建立的tcp连接数通常限制为6;尽管在keep-alive的加持下,能够复用已存在的tcp链接,但是总体并发请求的效率不如http2。
http1.1都是基于“请求-响应”来处理数据,而http2,服务器可以主动发送资源到客户端,客户端下次需要数据的时候,就可以直接使用,不需要重新发起请求。例如请求index.html,index.html包含style.css与app.js文件;当允许server push的时候,浏览器请求index.html的同时,也返回了style.css与app.js,等到浏览器解析html文件的时候,需要对应的资源文件,就可以快速获取。
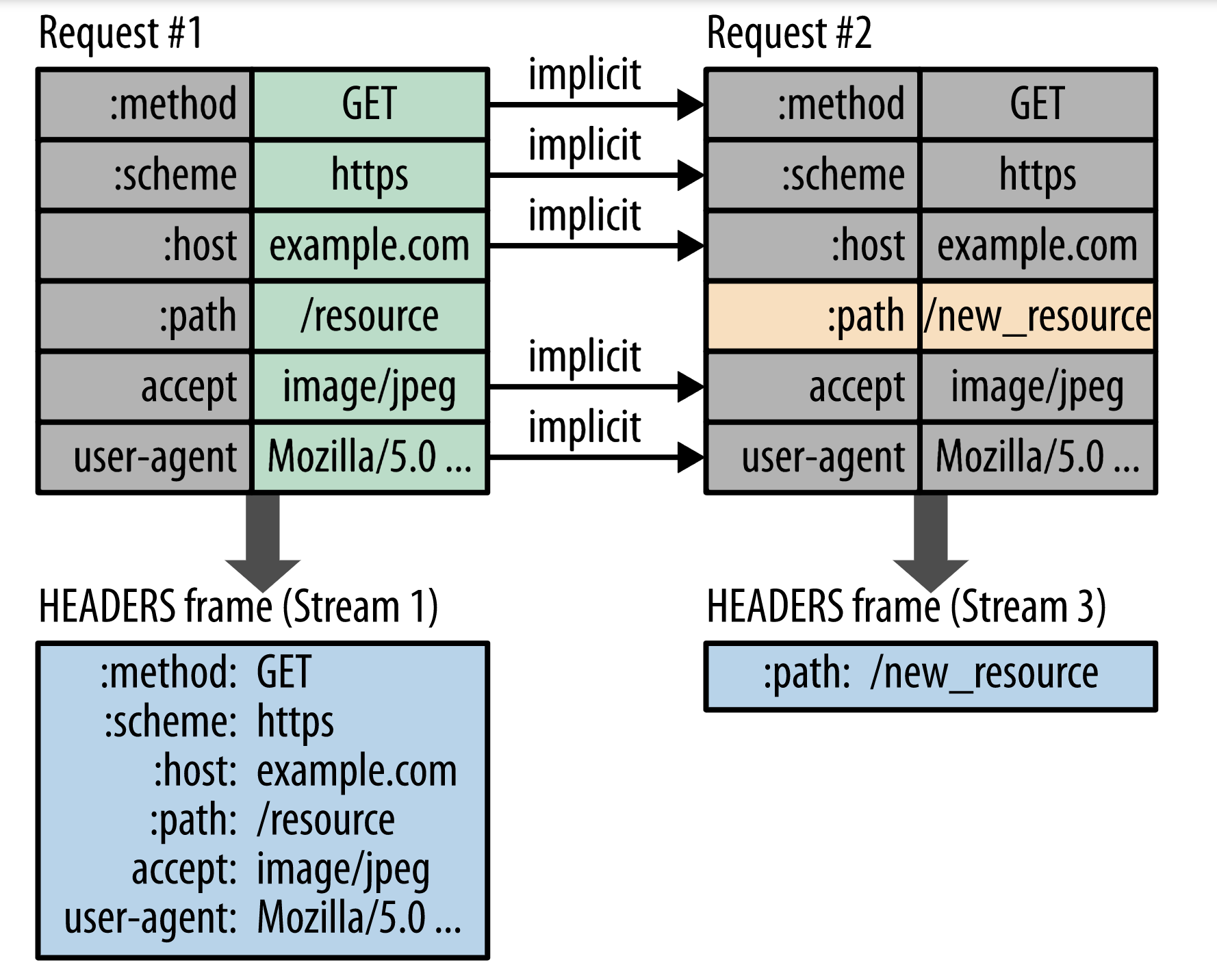
很多情况下,当我们连续发出多个http请求的时候,请求的header信息会重复,例如cookie,http method,scheme等。如果请求的body内容越少,那么相当于header的内容大小在这次请求的占比越高,利用率就变得更低了。
而http2,可以把重复相同的请求头不发送,只发送与之前曾经发过不同的请求头,具体例子如图
图片来源
第二次请求与第一次请求相比,只是:path的值发生了改变,那么第二次请求的时候,只需要发出:path: /new_resource的请求头;通常的情况也适用于响应头。http2使用hpack的算法来实现这种"diff header",下面会简单说一下实现的过程:
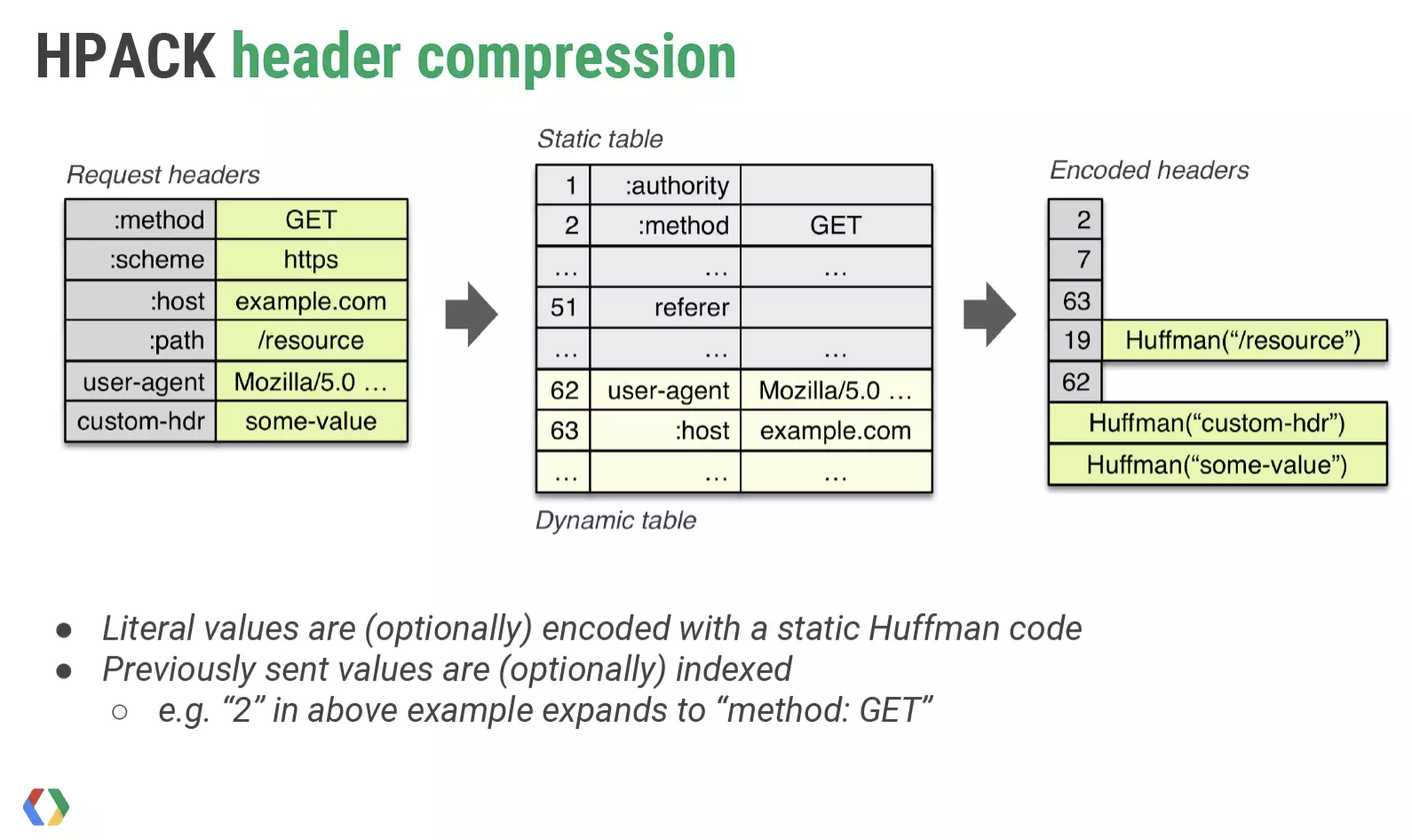
客户端只传不同的header,那么服务器是怎么拿到完整的header?
客户端与服务器都需要会维护一个静态字典(static table)与一个动态字典(dynamic table);静态字典是包含常见的头部名称与值的组合,例如:scheme: http,:method: GET,:status: 200,更多静态字典可见这里。而动态字典是由双方来协定添加。字典的内容,是通过哈夫曼编码(Huffman Coding)处理后,再添加到字典中。我们看一个例子:
在请求发送前的请求头为:
:method: GET
:scheme: https
:host: example.com
:path: /resource
user-agent: Mozilla/5.0 ...
custom-hdr: some-value
经过静态字典的编码之后:
:method: GET => 2
:sheme: https => 7
...
:path: /resouce => 19: Huffman("/resource")
这里的2和7是静态字典中的索引值,通过索引值的发送,可以大大降低header内容的大小;而对于:path,因为:path也在静态字典中,所以key值就是索引值,而/resource因为不在静态字典用,使用哈夫曼编码处理:Huffman("/resource");对于自定义的custom-hdr,key与value值都是用哈夫曼编码。这次使用哈夫曼编码处理的值,会加入到对应的动态字典里面中,当下一个请求发出的时候,就可以利用动态字典中的索引来表示,也大大减少了header的内容大小。
咳咳...2019年叫觉醒之年好像有点夸张,接下来是今年一年的小总结或者概览吧,逻辑比较乱。大家不嫌弃的话,可以当讲故事那样子看一下。
2019年对于我个人来说,注定是一个失败的年份。年前定下的目标,大部分都没有达成,最主线的目标也是在一次又一次的失败当中渐渐错过。或者说因为最主线的目标没有达成,导致其他可能已经实现的小目标也变得暗然。
在工作方面,2019前半年都一直处于一个不断迭代的过程;着手一个新开的项目,这个项目算是我第一个完全主导的项目中,从最开始的技术选型、基础搭建、研发推进、上线部署整一个过程都在努力推动中。也算是在之前的工作中的一个提高吧。
在这个项目的初期,我也是挺有冲劲的,毕竟vue的技术栈在这之前没有做过一个完整的项目,在这个9102年里面,说出去真的惭愧。因为在这个项目之前,我都是使用ng1.x的框架,所以已经感觉到已经跟主流的技术栈脱节了。但是因为之前实在太安逸了,导致对自己的思考不足。回头看2018年,这一年基本我都是在为了公司的业务而奋斗,在技术上面的提升真的很少,学习的方向也是十分的不定向。差不多这里学一下,那里学一下,最后真的是没有一个是学得好的。
当然,如果往好的方向想的话,2018年的软能力提高还是不错的,例如一些沟通协作的处理方式。但是好像这种能力并没有得到“人们”的重视。还是这种能力很容易就能学得到呢?或许看起来很虚吧,很难说服别人;又或者这对于程序员来说只是一个小的加分项?好了,这里又感叹了一下2018年的不好;说回来19年;当我推动完这个项目的时候,发现到后期并没有什么特别厉害的东西可以弄;而个人也是在慢慢的在准备去更好的平台的过程,补充一些平常忽略的知识。在这个过程也是通过列一些计划,强有目的性去学习;所以在这里也感受到有计划有目的的学习,大大的增强了效率(为什么之前就没有这样子去做...)。到了某个时间点,我觉得我已经达到一个计划完成90%的时候,这个时候我也有去做一些尝试;而这些尝试,都失败了;尽管这些尝试都是选比较困难的来,这样子对我的打击是非常非常的大;因为有好些机会对于我来说,只是差了毫厘;到成功真的只差一点点,而这一点点让我感到非常的不甘。在这里除了核心竞争力之外,我觉得我缺少的是一个表达自己能力的一个能力;对于有些会的,因为表达的问题,没有表达清楚而导致最后的失败;但是日常对于这些会的问题,简直就是易如反掌;或许这种表达自己所拥有的能力(当然不是通过吹牛)也是一种需要不断提升的能力。对于这些失败,也是在不断的反思;这个反思促成了今年比较靠后的时间不断去完善自己的学习计划与学习能力;而且最重要的是,通过这些失败,知道自己要的是什么,懂得如何去分解这个问题,然后寻找破解方法。一扫之前的迷茫感觉;并且对于身边的抗压能力也懂得如何去化解。对于自己的短期内的职业生涯规划,还有生活规划也有一定的计划。所以对今年称之为觉醒之年,哈哈,感觉自己有点中二了。
今年也参加过前端的conf,从这个conf可以说是受益匪浅;因为conf的内容基本都是一些别人沉淀过,得到不错的成果才用来展现,而通过参加聆听,可以站在他们的肩膀上面获取知识,对于工作中的启发非常明显。并且对业界的一些发展方向也有一定的了解,希望今后可以尽量参加部分质量高的conf,对于眼界的提高十分有帮助。对了,今年还有做的还不错的是,开始慢慢对外输出一些技术文章还有开源的工具,尽管文章质量可能不算非常高,但是对于日常的总结能力和调研能力提高都不错的;对于开源的工具来说,或许现在解决的情景还不算非常多,不过更多接触的话,会慢慢发现,以前不知道写什么工具的想法是因为做的太少,只要写的越多,发掘的东西也越多。毕竟talk is cheap. show me the code.
当然,生活上不止只有工作,也有多方面发展。今年年初定的其中一个目标就是:保持身体健康。但是实际上今年身体状况反而变得不好了,各种小毛病都找上门来,尽管每周都保持一定的运动量。或许因为今年在很长一段时间内,整个人都处于一个高压的状态,每天对于自己的压力都很大,所以个人精神方面经常都是比较低迷,之前一直都保持不错的午觉,现在一周能够两天睡着就不错了;头发掉的速度也相应的增快了。。。好惨。现在慢慢逐渐沉浸在紧凑的学习计划,焦虑感也有一点降低。想起今天去一趟医院检查一下,因为最近发现血压好像不太正常。然后医生说了一些东西,查过血压和心电图;得出的结论是:不适与疲劳。内心看了真是一个苦笑。或许真的是这样子,也是一件好事吧,后面好好休息一下。除了这些不好的,也有一个还不错的,就是学会了游泳;这个总体来说还是挺满意的;解决了20多年来的一个难题,算是今年在生活上一个为数不多的闪光点吧。
展望,还记得上一年发了朋友圈说希望2019能够变得好一点。那是因为上一年是真的没有底气,所以变得那么的卑微。通过2019年觉醒,我觉得今年不是“2020年,请对我好一点”。而是“2020年,我会对你好一点。”。经过长时间的积累,相信也必须今年能够得到想要结果;工作与生活都需要运行在期望的轨道上。工作中找到一个比较top的平台,维持自己的写blog与开源的习惯;持续提升技术,主要提升深度,成为“砖家”。体重希望可以突破并维持55kg。保持运动状态,保持健康的体魄。学习一定理财计划。
简简单单写了一下,也不算是什么总结吧,只是把最近的感受写一下。给自己立个flag。
完。明年的目标终将实现。
msn-cache是最近弄的一个小工具,用于处理memory,storage,netword数据,msn也就是这三个单词的首字母。获取缓存数据处理过程的优先级是memory => storage => network。至于怎样降级获取数据的详细处理,可以往下看一下
在降级处理过程,主要有两个难点:
目前支持的算法有LRU与FIFO那么怎么验证这个算法是正确的?LRU算法相对比较复杂,这边是通过在leetcode提交验证,若通过leetcode的验证,则表明通过。leetcode 题目地址,但是leetcode暂时不支持ts语法,因此要把ts转换为js,再粘贴到leetcode运行。LRU的运行效率对比同语言还算不错。FIFO算法在leetcode没有找到相关题目,暂时只能手工测试,后续考虑加上单元测试。
简单使用例子:
import MCache from 'msn-cache'
const mc = new MCache({
name: 'LRU', // FIFO
capacity: 2,
storage: 'sessionStorage'
})
// get value from cache
mc.get('key', () => { /* request function */ })
// put new key-value in cache
mc.put('key', value)在实例化的时候,只需要指定cache算法的名称则可,而不同算法的具体实现对于实例调用mc.get,mc.put都是透明的。
算法说明:
在工具的使用,可以选用localStorage,sessionStorage两种。由于这两种的存储方法不能存储对象类型的数据。在put data in storage的过程中,会执行JSON.stringify(data)方法对数据进行转换;而从storage提取数据的过程,会执行JSON.parse(string)方法转换:
let storage = 'sessionStorage'
let data = {
foo: 'foo'
}
window[storage].setItem(JSON.stringify(data))
data = JSON.parse(window[storage].getItem())因此,如果数据无法转换,则不能够使用,例如: JSON.parse(undefined),不能转换成功;不过程序目前已针对undefined的情况进行处理。
localStorage相对sessionStorage很好理解,只要用户不删除,是一直存在的;但有时候缓存的数据会失效;而msn-cache从localStorage能够拿到旧数据,就不会发出新的请求更新数据;针对这种情况,目前提供clearStorage用于清除存在storage的数据,用户可以选择需要的时候,对storage数据进行清理,具体API可以看API文档。
sessionStorage的定义是,在会话过程中,一直存在;那么怎么定义“会话”?
用户在初始状态: A;sessionStorage数据为:foo: 'foo'
foo: 'foo'foo: 'foo';原有属于A的session storage数据也带过去了;bar: 'bar';此时切换到A页面tab,A页面不能拿到bar: 'bar'ctrl,点击超链接C,该链接从新tab打开,C页面不能拿到foo: 'foo'foo: 'foo'注意,页面之间跳转均属于同一个域名
由此,我们可以知道sessionStorage的规则:
因此用户需要根据上述规则,需要根据情况是否对数据进行清除或初始化。
说了这么久,好像都没有跟network有关系?实际上msn-cache确实没有对network做缓存,只是把network请求当成最后一个找不到缓存的获取途径,使用的方法如下:
let mc = new MCache({/* ... */})
mc.get('key', () => {
return fetch('/api/foo')
})mc.get方法第二参数是一个方法,如果从storage也获取不到数据,就会执行该方法,获取该方法返回的值,作为mc.get的数据。从network数据缓存,我们延伸到service worker。
service worker是什么?
是worker的一种,不能操作DOM,与主线程的通信是利用postMessage方法;能够拦截请求,配合cache storage,能够做到离线缓存。
在应用部署service worker,需要应用使用https,若在本地开发使用localhost则不需要
下面看一个简单的例子:页面中注册一个service worker,这个sw在安装成功之后,主动缓存/cat.svg;当页面请求/dog.svg的时候,返回/cat.svg。caches是指cacheStorage,与localStorage这些属于storage类型。
// 例子1:
// index.js
navigator.serviceWorker.register('/sw.js').then(function(registration) {
console.log('register successful.')
}, function(err) {
console.log('register failed.', err)
});
setTimeout(() => {
let img = new Image()
img.src = '/dog.svg'
img.onload = () => {
document.getElementById('img').src = '/dog.svg'
}
}, 3000)// sw.js
self.addEventListener('install', event => {
// sw 已安装
console.log('sw installed')
event.waitUntil(caches.open('v1').then(cache => {
cache.add('/cat.svg')
}))
})
self.addEventListener('activate', event => {
// sw 已激活
console.log('sw activated')
})
// 拦截fetch事件
self.addEventListener('fetch', event => {
const url = new URL(event.request.url);
// 拦截dog.svg请求,对这个请求返回cat.svg
if (url.pathname == '/dog.svg') {
event.respondWith(caches.match('/cat.svg'));
}
});从上述例子中,当初始值进入页面的时候,经过3秒之后(假定sw已经安装并激活完毕),会去请求/dog.svg,但是会发现,这个时候返回的图片,还是/dog.svg原图,并不是我们在fetch事件拦截,预计返回的/cat.svg;而当我们重新刷新页面的时候,请求/dog.svg才按照预计返回/cat.svg内容。
这是因为第一次进入页面,sw激活完毕的时候,并没有马上拿到应用的控制权,在请求/dog.svg中,请求并没有被拦截到,这是sw默认的处理方式;而如果第一次sw加载即马上控制页面,则需要调用clients.claim()方法。
self.addEventListener('activate', event => {
// 主动获取控制权
clients.claim()
// sw 已激活
console.log('sw activated')
})注:我看到很多人添加 clients.claim() 作为样板文件,但我自己很少这么做。该事件只是在首次加载时非常重要,由于渐进式增强,即使没有 Service Worker,页面也能顺利运行。
在主线程监听到sw的变化:
navigator.serviceWorker.register('/sw.js').then(registration => {
var serviceWorker;
if (registration.installing) {
console.log('init state is installing')
serviceWorker = registration.installing;
} else if (registration.installed) {
serviceWorker = registration.installed;
console.log('init state is installed')
} else if (registration.waiting) {
serviceWorker = registration.waiting;
console.log('init state is waiting')
} else if (registration.active) {
serviceWorker = registration.active;
console.log('init state is active')
}
serviceWorker.addEventListener('statechange', function (e) {
console.log('状态变化为', e.target.state)
});
}).catch(err => {
console.log('register sw error', err)
})在主线程中,监听首次加载sw的状态变化为:
而在sw中,首次加载的主要事件变化是两个:
installed sw已经安装成功,通常会在这个时候主动缓存资源,而且installed事件在一个sw中,只会触发一次activate sw 已经正常激活,准备好去处理fetch等事件那么,如果有需要更新到新的sw,状态是怎么发生变化?例如sw.js资源发生变化,然后主动刷新页面,新的sw中的install事件会进行触发,而activate事件不会马上触发;那么再次刷新呢?还是不会触发新的sw的activate事件,而在主线程的log中,发现初始状态为waiting;无论刷新多少次,都是这样子...
事实上,如果sw对应的文件发生变化,旧的worker还是会继续控制浏览器;同时新的worker会进行加载,加载完毕后(sw线程的install事件触发)不会把原有的控制权抢过去,而是处于waiting,这个时候拿到的缓存,也是旧worker对应的缓存;fetch事件的拦截也是旧worker处理。
等待旧的worker控制的所有页面都被关闭(是的,你没看错,是控制的所有页面),待下次打开该页面的时候,新的worker才会接收新的控制权;这样子的处理逻辑,是保证只有一个worker控制资源。
图片来源:https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle
那么,如果真的有需求是需要获取到新的worker的时候,马上让新的worker控制所有缓存数据,怎么处理?
使用skipWaiting()方法跳过等待;从上面的描述可以知道,新的worker安装完毕之后,就会进入等待状态,当所有由旧worker控制的页面退出则接受控制;这个阶段,新的worker一直处于waiting状态;
const cacheVersion = 'v2'
const urlCache = [
'/cat.svg',
'/dog.svg',
'/cow.svg'
]
self.addEventListener('install', event => {
// 跳过等待,安装完毕之后马上由新的worker控制
self.skipWaiting()
// 缓存新版本数据
event.waitUntil(caches.open('v2')
.then(cache => cache.addAll(urlCache)))
})
self.addEventListener('activate', event => {
// 新的worker激活完成
event.waitUntil(caches.keys().then(keys => {
return Promise.all(keys.map(item => {
// 删除旧版本数据
if (cacheVersion !== item) {
return caches.delete(item)
}
}))
}))
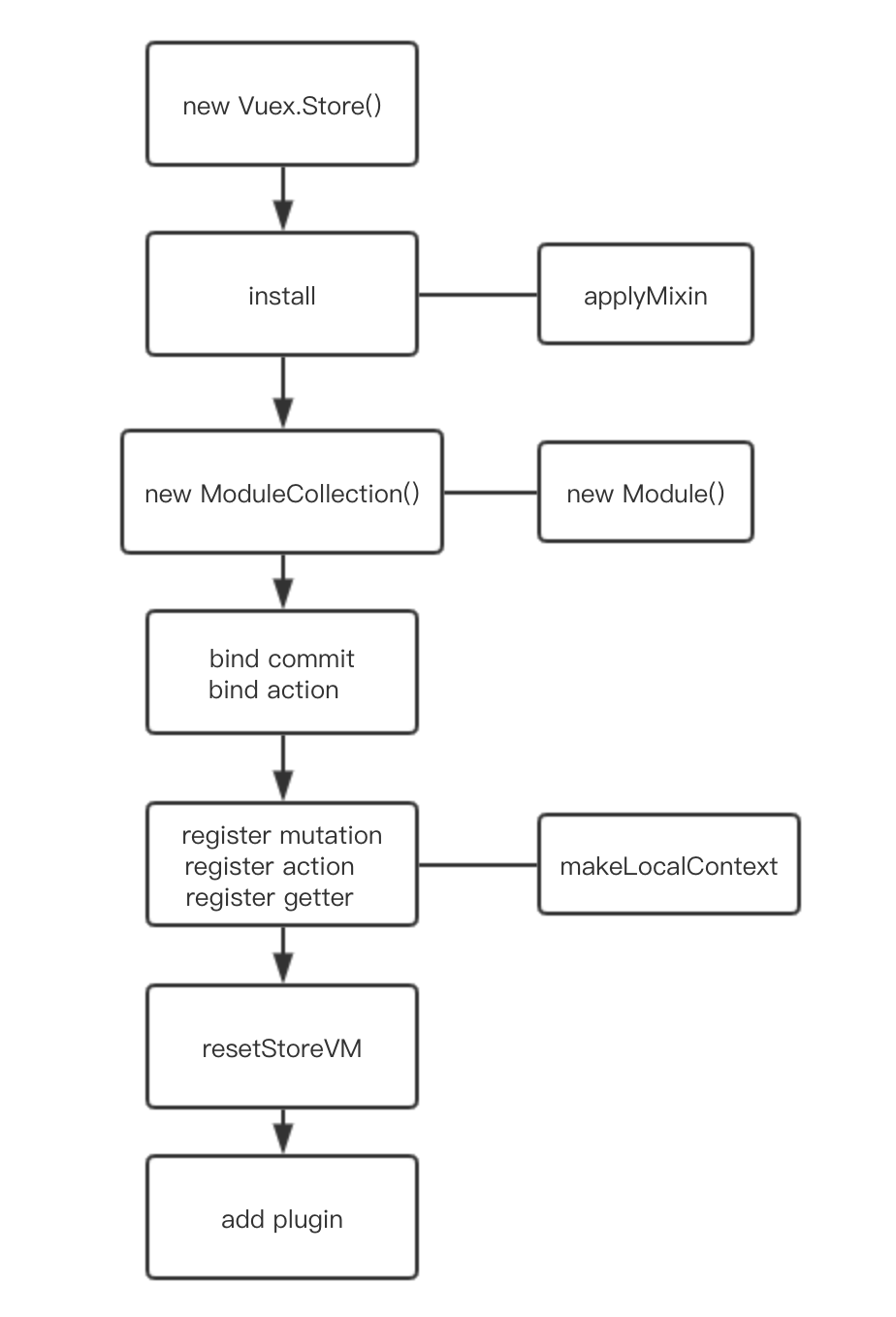
})这次阅读的redux的版本是4.x的版本,为啥不是最新的呢?因为最新的redux使用typescript来重写了,变化不是特别大,而typescript会有很多的函数类型定义;另一方面,对js的熟练度肯定比ts要好,理解起来也会相对容易一点,还有这次阅读源码的目的是为了了解整个redux的工作流程。redux的源码非常精简,很适合源码的阅读与学习。在阅读之前,对redux有一定的使用会带来更好的效果,一边看一边反思平常所写的内容。下面就开始吧:
下面的内容是项目的src目录结构
# src
-- utils/
-- actionTypes.js
-- isPlainObject.js
-- warning.js
-- applyMiddleware.js
-- bindActionCreators.js
-- combineReducers.js
-- compose.js
-- createStore.js
-- index.js
项目的文件非常的少,主要逻辑也是在src直接目录下的文件,先做个热身,对简单的utils文件夹入手,这是一些通用的工具方法:
在看源码的过程中,对一些工具方法的使用效果保持一定的记忆,对流程的理解上挺有帮助
const ActionTypes = {
INIT: `@@redux/INIT${randomString()}`,
REPLACE: `@@redux/REPLACE${randomString()}`,
PROBE_UNKNOWN_ACTION: () => `@@redux/PROBE_UNKNOWN_ACTION${randomString()}`
}actionTypes.js主要定义一些redux内部使用的action,randomString函数是生成一些随机字符串,保证内部使用的action不会冲突
export default function isPlainObject(obj) {
if (typeof obj !== 'object' || obj === null) return false
let proto = obj
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
return Object.getPrototypeOf(obj) === proto
}该方法用于判断参数是否是一个“纯对象”。什么是“纯对象”,就是直接继承Object.prototype的对象,例如直接声明的对象:const obj = {};如果const objSub = Object.create(obj),那么objSub就不是这里说的“纯对象”。
export default function warning(message) {
if (typeof console !== 'undefined' && typeof console.error === 'function') {
console.error(message)
}
try {
throw new Error(message)
} catch (e) {} // eslint-disable-line no-empty
}warning.js逻辑比较简单:先把错误的详细信息打印出来,再抛出错误。
热身完之后,我们来看一下redux的核心,入口在:src/index.js:
export {
createStore,
combineReducers,
bindActionCreators,
applyMiddleware,
compose,
__DO_NOT_USE__ActionTypes
}这个是index.js的暴露对象,都是从外部引入;除此之外,还有一个叫空函数isCrushed:
function isCrushed() {}这个空函数的作用是啥?因为在代码压缩的时候,会对该函数进行重命名,变成function a(){},这样子的函数;这个函数的作用就是,判断如果redux代码被压缩了,而且redux不是运行在production环境,就会报错,提示使用开发版本。
redux 的核心是createStore,这个核心我们先放一下,后面再处理,先了解一些辅助该核心的方法:
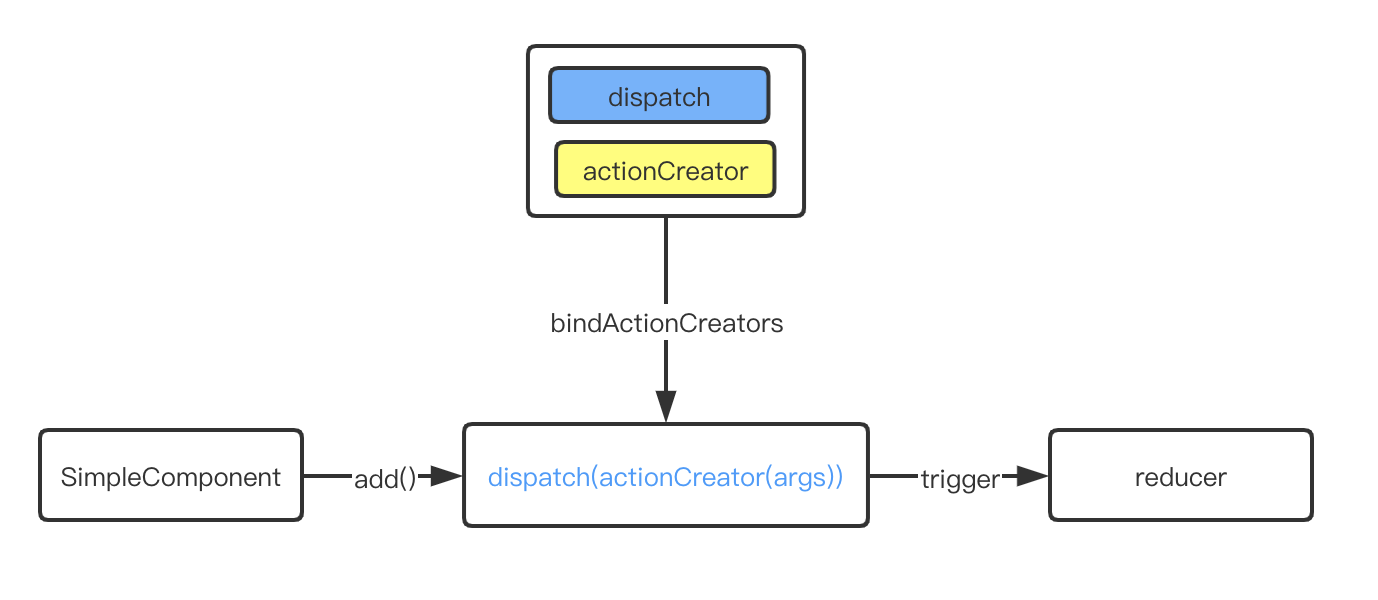
这个方法出场率有时候不是很高,那么它的作用是啥?
首先我们知道一个词汇actionCreator,这个actionCreator就如命名那样,是用于创建action类型的函数。那bindActionCreators的目的又是什么?这里可能要结合react-redux的connect方法与“容器组件”、“展示组件”(容器组件 vs 展示组件)来说明会更好。
通常情况下,如果要让当前组件是用redux,我们会使用react-redux的connect方法,把我们的组件通过connect包裹为一个高级组件,而包裹的过程拿到dispatch与我们指定的store数据:
// Container.jsx
import { connect } from 'react-redux'
class Container extends React.Component {
// ...
render () {
return <SimpleComponent />
}
}
export default connect(state => ({ todo: state.todo }))(Container)而这个Container组件我们可以称之为“容器组件”,因为里面包含了一些复杂的处理逻辑,例如与redux的连接;而如果SimpleComponent组件也有一些操作,这些操作需要更改到redux的内容,这样子的话,处理方法有两个:
SimpleComponent也使用connect处理为高级组件Container把redux的dispatch方法显示传递到SimpleComponent这两个方法都不是很好,第一方法会让组件更加复杂,可能与我们的容器组件-展示组件的姿势有点不同;第二种方法也可以,但是会让组件变得耦合度高。那能不能让SimpleComponent组件给Container的反馈也通过平常props-event的形式来处理呢,让SimpleComponent感知不到redux的存在?
这个时候就可以使用bindActionCreators了;例如有一个action为:{ type: 'increment', value: 1},通常如果Container组件触发可以通过:
// actions.js
const Add = (value) => { type: 'increment', value }// Container.jsx
import Add from './actions.js'
// Container.jsx 某个事件触发触发更新
class Container extends React.Component {
onClick() {
dispatch(Add(1))
}
}利用bindActionCreators处理后,给到SimpleComponent使用则可以这样:
// Container.jsx
import Add from './actions.js'
class Container extends React.Component {
render () {
const { dispatch } = this.props // 通过 react-redux 的 connect 方法组件可以获取到
const actions = bindActionCreator({
add: Add
}, dispatch)
return <SimpleComponent {...actions} />
}
}
// SimpleComponent.jsx
function SimpleComponent({ add }) {
return <button onClick={() => add(1)}>click</button>
}通过bindActionCreators处理后的函数,add,直接调用,就可以触发dispatch来更新,而这个时候SimpleComponent并没有感知到有redux,只是当是一个事件函数那样子调用。
了解到bindActionCreators的作用之后,我们再来看一下源码就很好理解了:
function bindActionCreator(actionCreator, dispatch) {
// 使用闭包来屏蔽 dispatch 与 actionCreator
return function() {
return dispatch(actionCreator.apply(this, arguments))
}
}
export default function bindActionCreators(actionCreators, dispatch) {
// 当 actionCreators 只有一个的时候,直接返回该函数的打包结果
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
// 省略参数类型判断
// ...
const boundActionCreators = {}
for (const key in actionCreators) {
const actionCreator = actionCreators[key]
// 只对 { key: actionCreator } 中的函数处理;actionCreators 中的其他数据类型被忽略
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
return boundActionCreators
}接下来说一下combineReducers,这个方法理解起来比较简单,就是把多个reducer合并到一起,因为在开发过程中,大多数的数据不会只有一个reducer这么简单,需要多个联合起来,组成复杂的数据。
// () => {} 为每个对应的reducer
const state = {
count: () => {},
userData: () => {},
oeherData: () => {}
}通常使用compineReducer可以让我们规避一些问题,例如对reducer的传入参数的判断等,保证reduce流程的运转,简化核心代码如下,去掉一部分开发代码,但是会注释作用:
export default function combineReducers(reducers) {
const reducerKeys = Object.keys(reducers)
const finalReducers = {}
// 检查所有reducer的key值是否合法,reducer是一个函数,则加入到finalReducers
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
// 这里有个判断,如果reducers对象的某个key值的value为undefined,则报错
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
const finalReducerKeys = Object.keys(finalReducers)
// 这里有个判断(assertReducerShape),判断是否有 reducer 返回是 undefined
// 如果有,则先保留这个错误,我们定义为错误 A
// 这个 combination 函数,每次dispatch都会执行一次
return function combination(state = {}, action) {
// 这里有个判断,如果错误A存在,则抛出异常
// 这里有个判断(getUnexpectedStateShapeWarningMessage),会对数据进行多重判断,
// 判断有错,则抛出异常,判断的规则有:
// 1. reducers的数量是否为0
// 2. 对每次执行reducer传入的state(state的来源后面讲到)是否是“纯对象”(上面有提到)
// 3. 对每次执行reducer传入的state对象判断,是否该对象所有的字段都是“自己的”(hasOwnProperty),
// 也就是没有一些从父对象继承,toString ?
// 第三点其实有点不太了解,因为第二步纯对象已经过滤了?
// 下面这个就是 combineReducers 的核心代码
let hasChanged = false
const nextState = {}
// 遍历所有的函数reducer,获取返回值,通过判断前后值的不同,判断是否发生了变化,有变化,则返回新的state
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
// 不允许 reducer 返回的值为 undefined,否则报错
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
// 这里判断是否改变,是通过判断 reducer 返回的值与之前的值是否一致
// 所以就突出了“不可变对象”的重要性
// 如果reducer每次返回的对象是在旧对象上面更改数据
// 而对象地址没改变,那么 redux 就认为,这次改变是无效的
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state
}
}讲完上面两个辅助方法之后,来讲一下创建store的核心createStore的方法;因为createStore方法比较长,下面先看一下概览:
export default function createStore(reducer, preloadState, enhancer) {
// 判断是否传入各种参数是否符合要求
// 对于增强器(enhancer)的调用会提前返回
// 创建store的过程被延后到增强器中
// ...
// 当前最新的 reducer 与 state
// listeners 是通过 store实例subscribe的函数数组
let currentReducer = reducer
let currentState = preloadedState
let currentListeners = []
let nextListeners = currentListeners
// 当前的reducer是否在执行当中
let isDispatching = false
// 用于防止 listeners 数组出错,后面讲到
function ensureCanMutateNextListeners() {}
// 返回当前最新的 state,给外部函数调用获取内部数据
function getState() {
return currentState
}
// store.subscribe的方法,用于添加 listener,后面有详细讲解
// 监听 state 的变化
function subscribe(listener) {}
// 触发 reducer 执行,返回新的 state
function dispatch(action) {}
// 使用新的 reducer 替换当前的 currentReducer
// 通常在两种情况下使用:
// 1. 部分 reducer 异步加载,加载完毕后添加
// 2. 用于开发时候用,热更新
function replaceReducer(nextReducer) {
currentReducer = nextReducer
}
// TODO 这个了解不多
function observable () {}
// 触发第一个更新。拿到第一次初始化的 state
dispatch({ type: ActionTypes.INIT })
}在没有enhancer处理的过程,createStore的过程,都是一些声明的函数与变量,唯一开始执行的是dispatch,现在就从这个dispatch开始讲解:
function dispatch (action) {
// 判断 action 是否是“纯”函数
// 判断 action.type 是否存在
// ...
// 判断当前的dispatch是否在执行中,多次触发,则报错
if (isDispatching) { throw new Error() }
try {
isDispatching = true
// 尝试去执行 reducer,把返回的 state 作为最新的 state
// 如果 我们的 reducer 是使用 combineReducers 方法包裹的话
// 这里的 currentReducer 为 comineReducer的combination方法
// 这里回答了之前所说的 combination 方法拿到的第一个参数 state
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// 更新完 state 之后,就会把监听的函数全都执行一遍
// 注意这里的 currentListeners 被赋值为 nextListeners
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}整个 dispatch 就结束了,很简单,就是把所有reducer都执行一遍,返回最新的 reducer;如果使用combineReducer来联合所有的reducer的话,相当于执行combination方法,该方法会把被联合的所有reducer都执行一遍,所以这里能解释说,为什么在reducer方法的时候,在switch...case要保留一个default选项,因为有可能执行当前reducer的action,是用于触发其他reducer的;这种情况就把当前reducer对应的state返回即可
function reducer(state, action) {
switch (action.type) {
case '':
// ...
break
case '':
// ...
break
default:
return state
}
}当state通过reducer更新之后,就会把加入监听的listener逐个执行;循环的listeners是currentListeners,这里要圆一下之前说的ensureCanMutateNextListeners函数与subscribe的行为,函数代码为:
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
function subscribe(listener) {
// 省略部分参数与进程判断
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) {
return
}
// 省略部分进程可行性判断
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}我们看到subscribe与unsubscribe的过程,只是一个很简单的数组处理添加与删除listeners的过程,但是这两个过程都有执行ensureCanMutateNextListeners的函数。这个函数的作用是:
保证当次触发listeners的过程不受影响
这句话怎么理解呢?可以看到触发listeners也只是把listeners的函数循环执行一遍。但如果listeners由此至终都只是一个数组,那么如果某个listeners执行的内容,再次添加/删除listener,那么这个循环过程就有可能出现问题:
const { dispatch, subscribe } = createStore(/* ... */)
subscribe(() => {
log('state change')
// 在 listeners 添加监听方法
subscribe(() => {
})
// 或者 移除之前监听的部分方法
unsubscribe(/* ... */)
})
所以ensureCanMutateNextListeners把listeners区分为两个数组,一个是当前循环的数组,另一个是下次循环的数组。每次触发dispatch都是最近更新的一次listeners快照。
了解完核心createStore之后,我们再了解一下增强核心功能的函数:applyMiddleware,因为applyMiddleware与compose关联很密切,applyMiddleware的实现依赖compose。
compose是一个函数,先看一下compose的代码:
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}非常的精简;compose的代码的作用是简化代码:
(...args) => f(g(h(...args)))
// 等同于
compose(f, g, h)(...args)
// compose使用例子
function foo (str) {
return str + '_foo'
}
function bar (str) {
return str + '_bar'
}
function baz (str) {
return str + '_baz'
}
compose(baz, bar, foo)('base') // "base_foo_bar_baz"compose方法就是把上一个函数执行的结果作为下一个函数执行的参数,执行顺序从后往前,传入参数的最后一个函数先被执行。
middleware就是一个中间件的概念,简化如下:
数据经过每个中间件的处理,会对数据,或者保留一些数据的痕迹,例如写入日志等
applyMiddleware的用法也是类似:
const store = createStore(rootReducer, {}, applyMiddleware(middleware1, middleware2))// applyMiddleware 源码
export default function applyMiddleware(...middlewares) {
// createStore方法作为参数传入
// 相当于延迟一步初始化 store
return createStore => (...args) => {
const store = createStore(...args)
let dispatch = () => {/* ... */}
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// 把传入的 middleware 先执行了一遍
// 把 getState 与 dispatch 方法传入
// 让 middleware 能够获取到当前 store 的 state与有触发新的 dispatch 能力
const chain = middlewares.map(middleware => middleware(middlewareAPI))
// 这个时候的 dispatch 不是原有的 createStore 函数中的方法
// 而是一个经过 middleware 集成的新方法
// 而原有的 dispatch 方法作为参数,传入到不同的middleware
dispatch = compose(...chain)(store.dispatch)
return {
...store,
// 使用当前的 dispatch 覆盖 createStore 的 dispatch 方法
dispatch
}
}
}redux-thunk是一个对于了解middleware很好的例子,下面参照redux-thunk弄一个自定义的middleware, 源码如下:
function customeMiddleware({ dispatch, getState }) {
return next => {
return action => {
if (typeof action === 'function') {
return action(dispatch, getState)
}
return next(action)
}
}
}为什么会函数嵌套那么多层呢?其实每一层都是有原因的;第一层:
function customeMiddleware ({dispatch, getState}) {
// ...
}dispatch是能够触发一个完整流程更改state的方法,getState方法用于获取整个reducer的state数据;这两个方法都是给到middleware需要获取完整state的方法。从上面applyMiddleware的方法可以知道,applyMiddleware执行的时候,就先把middleware函数都执行了一遍,返回chains数组:
const chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)看到这里,会有一个疑问compose执行的顺序是从后面往前执行,但是我们定义middleware是从前往后的。
chains数组的方法相当于middleware的next方法(接收参数为next函数,暂时这样子命名),compose执行的时候,相当于next已经执行,并且返回一个新的函数,这个函数是接收一个叫action的函数(暂命名为action函数);因为每个middleware的接收next函数执行后都是action函数;next函数的next参数就是上一个函数的返回值。执行到最后,dispatch = compose(...)(store.dispatch),dispatch函数其实是第一个middleware的action函数
// chain0 表示 chain 数组中的第一个函数,chain1表示第二个,以此类推
// compose 执行顺序为倒序
const action2 = chain2(store.dispatch) // store.dispatch的值是compose()(store.dispatch)传入的
const action1 = chain1(action2)
const action0 = chain0(action1)action0就是最终返回到dispatch函数;当我们在组件中执行dispatch()的时候,实际上是调用action0函数,action0函数可以通过next调用下一个middleware
// action0
action0(action)
const result = next(action) // 这个 next 的函数为 action1
// action1
action1(action)
const result = next(action) // 这个 next 的函数为action2
// action2
action2(action)
const result = next(action) // 这个 next 的函数为 store.dispatch就这样子层层嵌套,把每个middleware都执行完,最终去到store.dispatch,最终更改好reducer,返回一个全新的state;而这个state也层层冒泡传到最顶层的middleware;middleware执行顺序的疑问由此解开。
redux的源码不多,使用起来也很简单,但是里面运用的知识不少,特别是在middleware的时候,需要很细心的看且有较好的基础,不然看起来还是有点吃力的。另外一些用闭包来缓存变量、保存函数执行状态等,用得很精妙。Get.~
最近在看一本比较经典的书《你的灯还亮着吗?》这本书讲述一些对问题的发现,还有对问题的定义等等。对问题的各个方面进行分析,分析的时候都带上生动的例子。下面是对书的一些语句进行摘录。
有些摘录或许要多次看,而且有实际经历,才会认识更加深刻。
这篇文章是Dan Abramov 在github上面的一个issue的讨论回答,虽然并不是一个正式发的文章,但是我觉得对于理解也是很重要,能够了解到设计的原因,这样子比大部分搜索到的“复制-粘贴”资料更深入。
原文链接在这里,大家有兴趣可以去看一下原版,以下是我渣渣英语的翻译:
这里有几个想法,在某种意义上,这不是一个完整的回答,但仍然比不回答任何东西有帮助。
第一点,我认为我们为了批量更新而延迟调度(reconciliation)是很有利的。我们认同setState触发同步重新渲染在很多情况下是低效的,如果我们知道我们将要执行几个任务,那么批量更新是一个更好的选择。
举个例子,如果我们在浏览器点击的回调方法中,子组件(Child)与父组件(Parent)都调用了setState,我们不想去重新渲染两次子组件(Child),而是去标识这两个组件都是脏的(dirty),然后在退出浏览器事件(click)之前,把父子组件都重新渲染。
你提出一个问题:为什么我们不能够做同样的事情(批量更新),而是在调度(reconciliation)的最后来通过setState来马上更新this.state.我想目前没有一个明确的答案(两种解决方法(指同步和异步)都有权衡),但是下面是我想到的几个原因:
尽管state的更新是同步的,但是props不是(你不知道props值,除非你重新渲染父组件;如果使用同步的方法更新这些数据(译注:props和state),批量更新就会超出处理窗口(batching goes out of the window))。
现在React提供的对象props,state,refs,在它们互相看到是内部一致的。这样子就意味着,如果你只使用这些对象,这些对象数据能够根据调度树来保证互相对比(尽管这是一个旧版本的调度树)。为什么这样子做很重要?
当你使用以下的state,如果它同步更新(正如你所想),这种模式是可行的:
console.log(this.state.value) // 0
this.setState({ value: this.state.value + 1 });
console.log(this.state.value) // 1
this.setState({ value: this.state.value + 1 });
console.log(this.state.value) // 2然而,假设需要提升数据状态来给到几个组件之间进行共享,你需要把该操作移动到父组件:
-this.setState({ value: this.state.value + 1 });
+this.props.onIncrement(); // Does the same thing in a parent我想强调的是,在React app中,app依赖的setState()是React最通用的设计标准类型;在平常中你能够经常调用它。
然而,这让我们的代码无法正确运行:
console.log(this.props.value) // 0
this.props.onIncrement();
console.log(this.props.value) // 0
this.props.onIncrement();
console.log(this.props.value) // 0这是因为,在你提出的代码中(指上面同步的操作),this.state应该是马上刷新(更新数据),但是this.props不会。我们在没有重新渲染父组件的时候,不能够马上更新this.props,因为这样子(同步)就意味着我们我们就要放弃批量更新(对于一些情况来说,会明显降低表现性能)。
这里也有一些小的例子,说明同步是不能够正常运行。例如,如果你把this.props(还没更新)与this.state(提议马上更新)混合一起,创建一个新的state:#122(comment),使用Refs也会有这个问题:#122(comment)。
上面这些例子不是所有的理论假设。 事实上,React Redux的绑定通常明确会有这些问题,因为他们把React props与不是React的state数据混合在一起: reduxjs/react-redux#86, reduxjs/react-redux#99, reduxjs/react-redux#292, reduxjs/redux#1415, reduxjs/react-redux#525。
我不知道为什么Mobx的使用者们没有碰到这个问题,但是我的直觉是,他们可能在某些情景遇到这个问题,但是他们认为是他们自己的错。或者有可能他们没有直接从props读取数据,而是直接读取MobX变化的数据。
所以现在React是怎么解决的?在React中,this.state与this.props只在调度与刷新完成后才更新。所以你将会看到,在重构完的例子中,执行前后都是打印出0。这样子可以让状态提升的state变得安全。
是的,这样子的调用可能会在某些情况不方便。特别是对于人们以 OO 为背景,仅想通过更改几次state,而不是思考怎样在一处地方去完整更新state。我对这种处理也有同感,但我认为保持集中更新state对于调试debugger过程是非常清晰的。
你仍然有其他一些方法来更改state,通过一些有副作用的可变的对象(mutable object),为了马上能够读取到state。特别是当你不想使用该数据作为渲染的源数据的时候。就如MobX让你做的那样。🙂
如果你知道你所做的目的,你也可以有方法去更新整棵树。这个API为ReactDOM.flushSync(fn)。我认为我们还没有相关的文档关于它,但我们肯定会在16.x的release中加入这个文档。需要注意的是,这个API实际上被调用的时候,在数据更改后强制重新渲染,所以你需要很谨慎的使用它。这种方法不会打破props,state,refs之间内部数据的一致性。
总结一下,React这种模式不能够总是让代码变得简洁,但是是为了在React内部保持数据一致性,还有保证状态提升变得安全。
从概念上面讲,React的行为就好像在每个组件中有一个单一的更新队列。这就是为什么这个讨论是有意义的:我们讨论是否应该马上更新this.state,因为我们对这些更新的应用顺序毫无疑问。然而,事实上并不是这样。haha。
最近我们经常讨论“异步渲染”。我认为我们在沟通这方便做得不是很好,但这是技术(R&D)的本质:你在追求一个似乎很有希望的概念,但是你只有花很多时间下去,才能够真正的了解到它的含义。
其中一个解释“异步渲染”的是:React 会在setState()的时候,根据它们的数据来源分配不同的优先级,这些数据来源有:事件回调句柄,网络相应,动画效果等。
例如,如果你在输入一个信息,setState在TextBox组件被调用的时候需要马上刷新。然而,如果你在输入的时候,在接收一个新的信息,这样子可能更好的做法是:一定程度的延迟渲染新的信息冒泡更新,而不是因为进程的阻塞导致这个输入过程变得卡顿。
如果我们让某些更新变得“低优先级”,我们可以把这些渲染分割几个小的任务,在几毫秒内执行;这样子就不会让用户察觉到。
我知道像这样子的性能优化听起来很激动人心或有说服力。你可能会说:“我们在使用MobX不需要性能优化,我们更新跟踪是能够足够快仅为了避免重新渲染”。我认为这个说法不是在所有的情况都是对的(例如:无论 MobX 有多快,你仍然需要创建DOM节点并且在一个新的视图中挂载渲染)。尽管,假设这种情况是对的,并且如果你决定,总是使用一个特殊的JavaScript库包裹着对象是没问题的,用来跟踪数据读取与写入,可能你在这些优化中没有获得收益。
但是异步渲染不只为了性能优化。我们认为这是React组件的模式能做到的根本性转变。
例如,考虑这种情景,当你从一个页面跳转到另外一个。通常是你会在新个页面中显示一个spinner。
然而,如果这个跳转是足够快的(在一秒钟左右),刷新与马上隐藏一个spinner会导致用户体验的下降。更糟糕的事,如果你有多个组件层级,这些组件有不同的异步依赖(数据,代码,图片),最终你会在很短时间内,spinner一个一个地闪烁。这种情况会让app在视觉效果变得不好,让app实际上运行变慢,因为所有的DOM都重排了(reflow)。这也会出现在很多模版代码中。
如果当你执行一个简单的setState来渲染一个不同的视图,这不是很好吗,我们能够"开始"渲染更新视图的时候是在“后台”执行?想象一下你自己没有编写任何协调(coordination)的代码,就能够选择展示一个spinner,如果这次更新需要超过了某个阈值(例如:一秒),否则当异步依赖在整个子树中已完成,React会呈现无缝的过度。而且,当我们在“等待”,旧页面还保持可响应(例如:所以你能够选择另外一个不同的元素(item)去过度),如果这次更新耗费时间很长,React强制让你显示一个spinner。
结果发现,通过现在React的模式还有一个生命周期的调整,我们实际上能够实现(上面说的更新过度)。@acdlite 在过去几周内研究这个功能,也快要发一个RFC。
需要注意的是,这是唯一的可能,因为this.state不是马上更新。如果this.state是马上更新,当目前“旧版本”也能够看到和响应的时候,我们就没有办法在后台去开始渲染一个“新版本”视图。他们那些独立的状态更新就会崩溃。
我不想从 @acdlite 中抢先发布这个内容,但是我希望这听起来有点激动。我想这仍然像蒸汽那样去不断了解这想法。或者像我们不能够真的认识到我们所做的事情。我希望我们能够在接下来几个月说服你,并且你会欣赏React这种灵活的模式。据我所知,由于不是马上刷新state,至少在某种程度上,这种灵活性是可行的。
这篇文章会先从最基础的vue组件的生命周期开始阐述,后续结合keep-alive与vue-router来梳理一下平常用到的生命周期hook,加强印象。
这是一个老生常谈的问题,有时候回顾一下,会有另外的收获;先引用官方的图:
图片引用地址: https://cn.vuejs.org
vue的生命周期分几类:
图中简单描述了生命周期过程,我们从代码上面看一下初始化的过程
// https://github.com/vuejs/vue/blob/dev/src/core/instance/init.js
// 截一段相对关键的代码,加上简单的注释
// @function initMixin
vm._self = vm
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate')
initInjections(vm) // resolve injections before data/props
initState(vm)
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created')
// ...
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}在beforeCreate之前,主要做了三个动作:initLifeCycle, initEvents, initRender;这三个动作完成之后再执行beforeCreate的hook函数,这三个函数分别做的事情:
TL;DR
vm.$parent, vm.$refs, vm.$root等$slot、$attr、$listener// 1. initLifecycle (src/core/instance/lifecycle.js)
// @function initLifecycle
export function initLifecycle (vm: Component) {
const options = vm.$options
// 建立父子组件的关系
let parent = options.parent
if (parent && !options.abstract) {
// 对于抽象的组件,不断往上找父组件,找到不是抽象的父组件为止
while (parent.$options.abstract && parent.$parent) {
parent = parent.$parent
}
parent.$children.push(vm)
}
// balabala 初始化很多数据
vm.$parent = parent
vm.$root = parent ? parent.$root : vm
vm.$children = []
vm.$refs = {}
vm._watcher = null
vm._inactive = null
vm._directInactive = false
vm._isMounted = false
vm._isDestroyed = false
vm._isBeingDestroyed = false
}
// 2. initEvents (src/core/instance/events.js)
// @function initEvents
export function initEvents (vm: Component) {
vm._events = Object.create(null)
vm._hasHookEvent = false
// init parent attached events
// 初始化组件监听的事件
const listeners = vm.$options._parentListeners
if (listeners) {
updateComponentListeners(vm, listeners)
}
}
// 3. initRender (src/core/instance/render.js)
// @function initRender
// 中间去掉一些声明变量,主要保留一些赋值到vm的数据
export function initRender (vm: Component) {
vm._vnode = null // the root of the child tree
vm._staticTrees = null // v-once cached trees
//...
// 赋值 slot 的值与对应的 slot 对应的数据
vm.$slots = resolveSlots(options._renderChildren, renderContext)
vm.$scopedSlots = emptyObject
//...
// 赋值从组件传过来的属性值与没有显式被组件监听的事件,分别赋值到$attr与$listener
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
defineReactive(vm, '$attrs', parentData && parentData.attrs || emptyObject, () => {
!isUpdatingChildComponent && warn(`$attrs is readonly.`, vm)
}, true)
defineReactive(vm, '$listeners', options._parentListeners || emptyObject, () => {
!isUpdatingChildComponent && warn(`$listeners is readonly.`, vm)
}, true)
} else {
defineReactive(vm, '$attrs', parentData && parentData.attrs || emptyObject, null, true)
defineReactive(vm, '$listeners', options._parentListeners || emptyObject, null, true)
}
}执行完这三个初始化函数,就可以触发beforeCreate的hook函数,可以看到还没有初始化$data的相关数据;在beforeCreate与created之间,执行的函数有:initInjections, initState, initProvide;
TL;DR
data, computed, methods, watcher_provided字段// 1. initInjections (src/core/instance/inject.js)
// @function initInjections
export function initInjections (vm: Component) {
// 拿到注入的数据
const result = resolveInject(vm.$options.inject, vm)
if (result) {
// 标识inject的属性与方法在当前组件不需要成为 observer,不用监听变化进行响应
toggleObserving(false)
Object.keys(result).forEach(key => {
// ...
// 绑定注入的数据到当前组件
defineReactive(vm, key, result[key])
})
// 把 observer 的标识位置为 true
toggleObserving(true)
}
}
// 2. initState (src/core/instance/state.js)
// @function initState
export function initState (vm: Component) {
// 初始化依赖的props,methods
vm._watchers = []
const opts = vm.$options
if (opts.props) initProps(vm, opts.props)
if (opts.methods) initMethods(vm, opts.methods)
// 初始化 data
if (opts.data) {
initData(vm)
} else {
observe(vm._data = {}, true /* asRootData */)
}
// 初始化计算属性
if (opts.computed) initComputed(vm, opts.computed)
// 初始化 watch 的数据
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch)
}
}
// 3. initProvide (src/core/instance/inject.js)
// @function initProvide
export function initProvide (vm: Component) {
const provide = vm.$options.provide
if (provide) {
// 对 provide 是函数的情况,执行函数赋值到 _provided;否则直接赋值
vm._provided = typeof provide === 'function'
? provide.call(vm)
: provide
}
}执行完这个三个函数之后,就会触发created的hook函数,这个时候就可以拿到data与methods等数据;现在再回去initMixin函数:
// 忽略已分析代码
callHook(vm, 'created')
// ...
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}当有el的元素的时候,就触发$mount方法,否则到后面主动调用方法再触发;这个$mount方法在:src/core/instance/lifecycle.js
// 定义挂载组件的方法
// mountComponent (src/core/instance/lifecycle.js)
// @function mountComponent
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 没有 render 函数
if (!vm.$options.render) {
vm.$options.render = createEmptyVNode
// ...
}
// 触发 beforeMount hook 函数
callHook(vm, 'beforeMount')
// ...
// 定义数据发生变化的回调方法
updateComponent = () => {
// 调用该方法更新当前的组件,执行完毕之后,需要通过 scheduler 来触发 updated 的 hook,为什么不是马上触发hook,是因为需要保证子组件都更新了,才调用当前组件的 updated,详细可以看一下源码,位置如下
// src/core/instance/lifecycle.js
// @function Vue.prototype._update
vm._update(vm._render(), hydrating)
}
// we set this to vm._watcher inside the watcher's constructor
// since the watcher's initial patch may call $forceUpdate (e.g. inside child
// component's mounted hook), which relies on vm._watcher being already defined
// 新建一个 watcher,用来监听数据发生变化
// 注意 beforeUpdate 的hook也是在这里进行监听调用
new Watcher(vm, updateComponent, noop, {
// 在执行 updateComponent 之前先执行 before 函数,也就是触发 beforeUpdate
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
// 挂载的对象如果不是为空,则触发 mounted 回调方法
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
return vm
}TL;DR
_isBeingDestroyed更改$el与$vnode引用// src/core/instance/lifecycle.js
// @function Vue.prototype.$destroy
Vue.prototype.$destroy = function () {
const vm: Component = this
if (vm._isBeingDestroyed) {
return
}
// 触发 beforeDestroy 的 hook
callHook(vm, 'beforeDestroy')
vm._isBeingDestroyed = true
// remove self from parent
// 移除父组件与当前组件的关系
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// teardown watchers
// 移除所有watcher
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove reference from data ob
// frozen object may not have observer.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// call the last hook...
vm._isDestroyed = true
// invoke destroy hooks on current rendered tree
// 移除 vnode 内容
vm.__patch__(vm._vnode, null)
// fire destroyed hook
callHook(vm, 'destroyed')
// turn off all instance listeners.
vm.$off()
// remove __vue__ reference
if (vm.$el) {
vm.$el.__vue__ = null
}
// release circular reference (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
}
}至此,基本的声明周期就差不多了,后续的内容主要是对hook的触发顺序进行一个巩固记忆
当从一个组件a切换到组件b的时候,执行的顺序是:
b-component beforeCreateb-component createdb-component beforeMounta-component beforeDestroya-component destroyedb-component mounted注意从a切换到b的时候,并不是a的destroy的相关方法马上执行,而是等到b组件的beforeMount函数执行后再调用之前的destroy的相关方法;当旧的组件被销毁之后,再执行新的组件的mounted的挂载方法,因为挂载完毕之后就会显示组件对应的内容
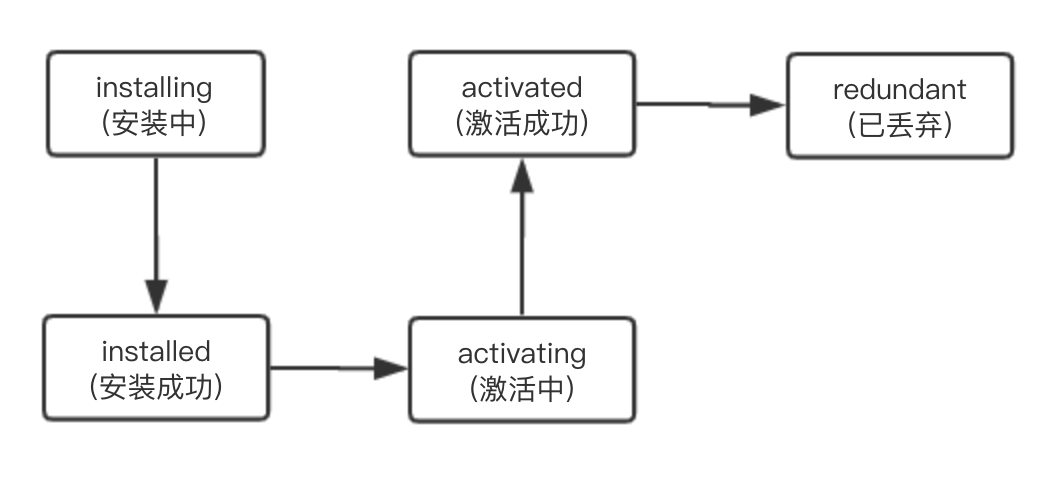
当使用 keep-alive 来缓存组件的时候,keep-alive里面的生命周期会有点不一样;
<keep-alive>
<component-a v-if="componentName === 'component-a'"></component-a>
<component-b v-if="componentName === 'component-b'"></component-b>
</keep-alive>当切换不同的componentName变量的时候,在没有使用keep-alive的时候,触发周期如前面所说的;但使用keep-alive之后,一个组件进入的周期就变成了:
注意这里多了一个activated的hook调用,这一个hook是仅在keep-alive中使用的,表示当前组件被激活;对应这另外一个hook就是,deactivated,表示当前组件被停用,那么从component-a切换到component-b的过程中,生命周期hook调用顺序就变成了:
component-a初始化:
从component-a切换到:component-b:
component-b beforeCreatecomponent-b createdcomponent-b beforeMountcomponent-a deactivatedcomponent-b mountedcomponent-b activated可以注意到,这个时候没有了之前看到的destroy类的触发,而是deactivated;mounted之后,也是跟之前类似,也会调用activated方法
然后从component-b再切换到: component-a:
component-b deactivatedcomponent-a activated因为这个时候component-a已经初始化了,所以没有触发create与mount类的hook,而是先component-b停用,再component-a激活;后续不断切换也是只反复调用这两个hook...
keep-alive可以设置一个最大缓存的数量,当超出设置的最大缓存的数量,则最久没有被访问到的实例会被销毁:
<keep-alive :max="2">
<component-a v-if="componentName === 'component-a'"></component-a>
<component-b v-if="componentName === 'component-b'"></component-b>
<component-c v-if="componentName === 'component-c'"></component-c>
</keep-alive>从component-a切换到component-b的hook调用顺序与没有设置max类似;再从component-b切换到component-c的时候,调用顺序为:
component-a beforeDestroycomponent-a destroyedcomponent-c beforeCreatecomponent-c createdcomponent-c beforeMountcomponent-b deactivatedcomponent-c mountedcomponent-c activated由于设置了最大的缓存数量为2,当切换到component-c的时候,首先触发的是component-a的destroy的相关方法;再执行初始化component-c,然后component-b失活
component-a => component-b: 与没有max一致component-b => component-c:首先component-a的destroy相关hook被调用,后续的调用顺序是先初始化component-c,再让component-b失活component-c => component-b: 仅执行deactivated与activated的方法component-b => component-a;首先componet-c的destroy相关hook被调用,后续hook调用顺序是先初始化component-a,再让component-b失活在vue-router当中,定义了好多hook,称之为导航守卫,现在简单结合一下组件的生命周期梳理一下:
实验例子:
<ul>
<li>
<router-link :to="{name: 'foo'}">jump to foo</router-link>
</li>
<li>
<router-link :to="{name: 'bar'}">jump to bar</router-link>
</li>
</ul>
<router-view></router-view>当点击跳转到/foo的时候,foo组件的生命周期与路由钩子触发顺序为:
需要注意的是,有时候我们在beforeRouteEnter的钩子做一些处理,例如判断用户是否有权限进入该组件,没有权限就跳转去别的页面,有权限则进入页面,伪代码如下:
import router from 'router' // vue-router object
export default {
beforeRouteEnter (to, from, next) {
console.log('beforeRouteEnter')
requestPermission().then(allowAccessed => {
if (allowAccessed) {
next(vm => {
console.log('beforeRouteEnter next')
vm.allow = true
})
} else {
router.push({ name: 'homepage' })
}
})
}
}那么这个时候触发的顺序为:
next回调函数是最后才执行;因为在next所传的函数里面,已经可以拿到当前组件的实例
ok,回到之前的例子,然后点击从foo跳转到/bar,foo与bar组件的生命周期与路由钩子触发顺序为:
可以看到先触发foo beforeRouteLeave再到bar beforeRouteEnter;而后续3-8点,与之前组件切换类似
实验代码更改为:
<ul>
<li>
<router-link :to="{name: 'foo'}">jump to foo</router-link>
</li>
<li>
<router-link :to="{name: 'bar'}">jump to bar</router-link>
</li>
</ul>
<keep-alive>
<router-view></router-view>
</keep-alive>首次进入/foo路由
进入的顺序没有特别,最后多了一个activated的调用,与之前使用keep-alive类似
然后从/foo进入/bar:
再从/bar进入/foo:
路由的优先级始终是在最高级别,然后再到组件的初始化过程;若组件已经初始化且在缓存当中,则到keep-alive的activated的相关hook
这篇文章主要是调研 module federation的时候. 对 webpack 异步加载代码分割文件与加载远端组件的流程简述.前半部分是流程与部分代码分析, 后半部分是webpack代码的注释笔记.
Webpack 5 新增一个 module federation 的特性, 详情可以看 官方文档. 这个特性大概的作用是:
多个独立的构建可以组成一个应用程序,这些独立的构建之间不应该存在依赖关系,因此可以单独开发和部署它们。
这通常被称作微前端,但并不仅限于此。
例如在 A 应用上运行的 组件 FOO , B 应用也会有类似的需求, 需要复用组件 FOO , 通常我们可能会把 FOO 组件抽离到一个 npm 包, 然后发布到 npm 平台, 那么在 A, B 两个应用都进行引入对应的 npm 包, 后续的维护,会独立在 npm 包中进行发布. 如果 npm 包发生更新, 那么对应 A, B 两个应用都进行重新打包. 这一种维护组件的模式,会有点在“编译时”的味道.
而 module federation 的插件主要针对应用“运行时”. 就如上面的例子, A 应用可以通过 webpack 配置 ModuleFederationPlugin的插件, 在构建A应用的时候, 把 FOO 组件顺便打包为一个远端组件包,通常为 remoteEntry.js. B 应用想使用 FOO 组件, 则通过在入口 html 文件中, 引入 A 应用地址下的remoteEntry.js文件(这一步通常也由ModuleFederationPlugin 完成 ), 并通过 import 关键词引入即可. 后续FOO组件的发布与维护,都在 A 应用进行处理. A 发布新的包, B应用可以不重新构建代码,就可以引用最新的代码. 简单如下图所示:
但是要有一个前提条件,A, B两个应用都是使用 webpack 5 来打包, 否则无法识别,
看到这个远端加载组件的方法还挺有趣,于是乎想看一下具体的实现.后面会贴一些源代码的实现.后续的所有例子,都是基于 module-federation-examples/basic-host-remote 例子来调研.
我们先了解一下 webpack 打包出来的产物的两个概念:
chunk
module
chunk 是文件级别, 利用 Code Splitting 分割的代码,每个文件都是一个 chunk, 通常一个 chunk 中包含一个或者多个 module. 而实际webpack代码运行的时候, 是根据 module id 进行定位.
这里对三种文件类型文件源码结构进行分析:
会先从普通 Code Splitting 的文件加载说起, 然后对 remoteEntry 类文件进行分析.
(() => {
// 定义变量
var __webpack_modules__ = {}
var __webpack_module_cache__ = {}
function __webpack_require__() {}
// 往 __webpack_require__ 对象挂载各种数据、函数等
__webpack_require__.m = __webpack_modules__
__webpack_require__.n = function() {}
// ...
// 定义 jsonp 的回调函数,后面会说到:
function webpackJsonpCallback() {}
// 对指定对象数组的 push 方法进行劫持, 后面会说到
var chunkLoadingGlobal = self["webpackChunk_basic_host_remote_app1"] = self["webpackChunk_basic_host_remote_app1"] || [];
chunkLoadingGlobal.forEach(webpackJsonpCallback.bind(null, 0));
chunkLoadingGlobal.push = webpackJsonpCallback.bind(null, chunkLoadingGlobal.push.bind(chunkLoadingGlobal));
// 加载并执行对应模块
Promise.all([
__webpack_require__.e(558),
__webpack_require__.e(165)
]).then(__webpack_require__.bind(__webpack_require__, 165))
})()从主文件结构开始分析, 在 Promise.all函数执行之前, 都是一些变量与函数的定义, 正式启动是调用 __webpack_require__.e 接着是 __webpack_require__ 函数的执行.
__webpack_require__.e 这种挂载的函数或者变量很多,前缀很长...后面会用__.e 来代替
__.e函数,是一个统一异步加载 chunk 的入口,
__webpack_require__ 是一个对 module 进行引入的工具函数, 如果第一次执行,还会对该 module 进行执行, 返回内容挂载在 exports 中.
所以主文件的处理方式就是: 加载 chunk id 为558, 165 的 chunk 文件, 然后执行 module id 为 165 的 module.
那么问题来了, moduleId: 165 是位于 异步加载的 chunkId: 165 中, 怎样可以让局部变量 __webpack_require__来加载呢?
(self["webpackChunk_basic_host_remote_app1"] = self["webpackChunk_basic_host_remote_app1"] || []).push(
[165], // 这是这个文件对应的 chunkId
// 以下这两个是 moduleId, 对应的模块内容的函数
{
165: () => {},
408: () => {}
}
)被代码分割出来的文件比较简单, 直接往 webpackChunk_basic_host_remote_app1 的全局变量数组push 两个变量[165, { 165: '', 408: 'xx'}], 该类型文件并没有一些调用的函数.
这里的关键点, 在于主文件对变量 webpackChunk_basic_host_remote_app1 的 push 函数进行了劫持:
var chunkLoadingGlobal = self["webpackChunk_basic_host_remote_app1"] = self["webpackChunk_basic_host_remote_app1"] || [];
chunkLoadingGlobal.forEach(webpackJsonpCallback.bind(null, 0));
chunkLoadingGlobal.push = webpackJsonpCallback.bind(null, chunkLoadingGlobal.push.bind(chunkLoadingGlobal));当该全局变量数组执行 push 函数的之后, 并不是执行正常数组把数据添加到数组, 而是执行 webpackJsonpCallback函数, 这个函数的作用是负责把对应 chunk 标识为已加载成功, 并把加载到的 chunk 中的 module, 逐个注册到 __.m 变量中, 这样子后续主文件的代码,就能够拿到异步加载的 module. 简要如下图:
// 定义全局变量, 这个全局变量是在 ModuleFederationPlugin 插件中定义
var app2; app2 = (() => {
// 这个函数的内容,与主文件类似, 定义一部分变量
var __webpack_modules__ = {
677: () => {
// ... 还有其他代码
__webpack_require__.d(exports, {
// get 方法是用于, 根据组件名称获取相关组件内容
get: () => get,
// init 方法是用于初始化当前分离打包组件需要依赖包的版本这部分
init: () => init
});
}
}
var __webpack_module_cache__ = {}
function __webpack_require__() {}
// 后续就不详细展开,也有定义 jsonp 的回调函数等
function webpackJsonpCallback() {}
// 与主文件不一致的地方, 给全局变量返回对应的数据
return __webpack_require__(677);
})()由 module federation 插件打包出来的 remoteEntry 的文件结构,与普通代码分割的 chunk 文件不一致, 所以不能用类似的方法进行加载, remoteEntry 类文件加载会相对复杂一点点.
这里需要看一下 __.e 函数的作用, 之前说过, __.e 函数是用于加载异步的 chunk, 而实际上, 加载异步的 chunk 会有几种类型, 这几种类型分别都有独自的处理方法, 分别是:
__.f.j 处理普通代码分割的 chunk__.f.remotes 处理需要从远端获取的组件__.f.consumes 处理加载 remoteEntry 相关 chunk__.e 只是一个壳, 每次执行,都会依次把这三个函数执行一遍. 这三种处理方法,通常如何辨别, 一个 chunk id 过来,是否符合当前处理的类型?
假设一个 chunkId: 165, 的文件需要加载, 这种文件只是一种普通的代码分割的 chunk, __.f.remotes & __.f.consumes 这两个函数不需要实际上发起请求. 针对这种情况, 处理函数通常会维护一份 chunkMapping, 通过判断 chunkId 在 chunkMapping 来确认继续, 例如
// __.f.consumes
const chunkMapping = {
160: xx
}对于__.f.consumes 函数来说,只有 chunkId: 160, 是有效的, 对于其他无效 chunkId, 会跳过实际处理环节.
说完 __.f相关函数的加载简要描述, 接下来说 remoteEntry 的加载过程:
__.f.consumes 执行, 对module federation插件配置的 share 相关包进行版本注册(通常是一些公共基础包, 例如 react, react-dom 等). 配置 share, 可以减少重复加载基础包init 方法(上述: remoteEntry 文件结构中的 init 函数), 把主应用的公共基础包与 remoteEntry 基础包的版本进行对比, 根据x.y.z版本号的方式, 看双方版本是否适配. 如果适配, 加载同一份公共基础包, 否则, 各自加载.__.f.remotes__.f.remotes 加载对应远端组件, 调用 remoteEntry 暴露的 get 方法(上述: remoteEntry 文件结构中的 get 函数), 根据组件名称,获取到对应的组件, 挂载到 __webpack_modules__ 变量下, 后续会被 __webpack_require__ 方法所使用下图对版本处理,做了简化,只显示加载与调用的过程
remoteEntry 类的文件, 也需要使用全局变量做为其中一个中介来传递数据, 与webpackJsonpCallback有一部分相同之处, 但是 remoteEntry 多了版本的判断, 这一部分其实非常复杂,上面只是简要对过程进行了分析, 远端版本控制没有做深入的讲解.
webpack实现异步加载的方法都很巧妙,无论是利用劫持全局变量方法,还是通过“伪”全局变量来做数据中转.函数设计分工精细. 例如在 __.e 与 __.f.j & __.f.remotes & __f.consumes 之间的联动, 还是底层工具方法的定义, 对日常开发思路都有比较不错的参考.后续的部分,是在调研过程中,对部分代码的分析做的一部分笔记, 也做为简要的 api 文档来查阅. 需要可以往后查看. (完)
function __webpack_require__(moduleId) {
// 判断该模块是否已经缓存,已缓存直接返回该模块
if(__webpack_module_cache__[moduleId]) {
return __webpack_module_cache__[moduleId].exports;
}
// 没有缓存,根据 moduleId 创建一个缓存模块
var module = __webpack_module_cache__[moduleId] = {
// no module.id needed
// no module.loaded needed
exports: {}
};
/******/
// Execute the module function
// 执行目标模块
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
// 执行完毕之后,module 这个对象就被挂上目标模块了,
// 因为module对象内存地址是同一个,在执行模块的时候,已被赋值
return module.exports;
}// hasOwnProperty 的简写
__webpack_require__.o = (obj, prop) => Object.prototype.hasOwnProperty.call(obj, prop)// 获取 __webpack_modules__ 对象
__webpack_require__.m = __webpack_modules__// 对 webpack 的模块进行数据劫持,类似 vue 的数据劫持
// 但是直接获取模块的值的时候进行劫持,不会对 set 进行赋值
// 能够保证模块暴露(module.exports)的值,不会被外部模块重写
__webpack_require__.d = (exports, definition) => {
for(var key in definition) {
if(__webpack_require__.o(definition, key) && !__webpack_require__.o(exports, key)) {
Object.defineProperty(exports, key, { enumerable: true, get: definition[key] });
}
}
};// 返回当前的全局变量,例如 nodeJs 中的 globalThis、浏览器中的 window 变量
__webpack_require__.g = (function() {
if (typeof globalThis === 'object') return globalThis;
try {
return this || new Function('return this')();
} catch (e) {
if (typeof window === 'object') return window;
}
})();// 兼容获取 只进行 export default 的es模块打包,提取 export default 的模快
// 通常是针对引入的模块的获取进行劫持
// 但是这里 对 getter 的 a 变量的 get 劫持,不是十分了解
__webpack_require__.n = (module) => {
var getter = module && module.__esModule ?
() => module['default'] :
() => module;
__webpack_require__.d(getter, { a: getter });
return getter;
};// 这个对象下,挂载需要拆分打包(import() 或 require.ensure)的模块函数, 例如:
// f.j, 入口文件 entry 的依赖
// f.consumes, f.remotes module federation的依赖
__webpack_require__.f = {};// 对 entry 入口文件中依赖的 chunk, 按顺序,进行加载并执行
__webpack_require__.e = (chunkId) => {
return Promise.all(Object.keys(__webpack_require__.f).reduce((promises, key) => {
__webpack_require__.f[key](chunkId, promises);
return promises;
}, []));
};// 拼接 chunk 的文件名称(根据 webpack 配置的 basename?)
__webpack_require__.u = (chunkId) => {
// return url for filenames based on template
return "" + chunkId + ".js";
};// 用于通过 scripts 标签加载 js 文件
// 限制加载 js 文件超时时间为 120s
// 加载 js 文件完毕之后,会删除 scripts 标签
(() => {
var inProgress = {};
// loadScript function to load a script via script tag
/**
* @params url 请求 js 文件的 url
* @params done 请求完毕之后的回调函数
* @params key 带有 chunk 的 id 的字符串,例如 chunk-1
*/
__webpack_require__.l = (url, done, key) => {
if(inProgress[url]) { inProgress[url].push(done); return; }
var script, needAttach;
if(key !== undefined) {
// 通过以下循环,判断当前该 js 文件是否已经加载
// 若已加载,则不会通过创建 scripts 标签加载 js 文件
var scripts = document.getElementsByTagName("script");
for(var i = 0; i < scripts.length; i++) {
var s = scripts[i];
if(s.getAttribute("src") == url || s.getAttribute("data-webpack") == key) { script = s; break; }
}
}
if(!script) {
needAttach = true;
script = document.createElement('script');
script.charset = 'utf-8';
script.timeout = 120;
if (__webpack_require__.nc) {
script.setAttribute("nonce", __webpack_require__.nc);
}
script.setAttribute("data-webpack", key);
script.src = url;
}
inProgress[url] = [done];
var onScriptComplete = (event) => {
onScriptComplete = () => {
}
// 避免在 IE 中内存泄漏
script.onerror = script.onload = null;
clearTimeout(timeout);
var doneFns = inProgress[url];
delete inProgress[url];
script.parentNode.removeChild(script);
doneFns && doneFns.forEach((fn) => fn(event));
}
;
var timeout = setTimeout(() => {
onScriptComplete({ type: 'timeout', target: script })
}, 120000);
script.onerror = script.onload = onScriptComplete;
needAttach && document.head.appendChild(script);
};
})();// 通过 Object.defineProperty 来劫持 es 模块的 exports 对象
// 使得 es 模块的 __esModule 字段返回是 true 或
// es 模块的 Symbol.toStringTag 字段,返回固定值 "Module"
__webpack_require__.r = (exports) => {
if(typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};// 固定返回 webpack 设置的 publicPath
__webpack_require__.p = "http://localhost:3001/";// 加载 chunk 文件
// 用于处理所有 chunk 文件的状态
// key 为 chunkId, value 是该 chunk 文件的状态,分别有
// * undefined 不会进行加载
// * null 为该 chunk 是 preloaded/prefetched 的类型
// * Promise 为该 chunk 还在加载当中
// * 0 为该 chunk 已经加载完毕
var installedChunks = {
179: 0
};
__webpack_require__.f.j = (chunkId, promises) => {
// JSONP chunk loading for javascript
var installedChunkData = __webpack_require__.o(installedChunks, chunkId)
? installedChunks[chunkId]
: undefined;
// 判断是否已经安装过,若已安装,则直接返回
if(installedChunkData !== 0) { // 0 means "already installed".
// a Promise means "currently loading".
if(installedChunkData) {
promises.push(installedChunkData[2]);
} else {
if(true) { // all chunks have JS
// setup Promise in chunk cache
var promise = new Promise((resolve, reject) => {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
promises.push(installedChunkData[2] = promise);
// start chunk loading
// 拼接需要请求的 js 文件链接
var url = __webpack_require__.p + __webpack_require__.u(chunkId);
// create error before stack unwound to get useful stacktrace later
var error = new Error();
var loadingEnded = (event) => {
// 加载 js 文件完毕之后的回调函数
// 执行的时机,可以看 __webpack_require__.l 的函数
if(__webpack_require__.o(installedChunks, chunkId)) {
installedChunkData = installedChunks[chunkId];
// 重点关注:这个时候,如果正常加载完毕的话,installedChunkData[chunkId] = 0
if(installedChunkData !== 0) installedChunks[chunkId] = undefined;
if(installedChunkData) {
var errorType = event && (event.type === 'load' ? 'missing' : event.type);
var realSrc = event && event.target && event.target.src;
error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')';
error.name = 'ChunkLoadError';
error.type = errorType;
error.request = realSrc;
installedChunkData[1](error);
}
}
};
__webpack_require__.l(url, loadingEnded, "chunk-" + chunkId);
} else installedChunks[chunkId] = 0;
}
}
};在说,webpackJsonpCallback函数之前,先讲一下之前的函数列表。
main.js文件底部,会直接执行__webpack_require__.e函数用于启动获取主函数。
入口文件先启动的函数顺序是
__webpack_require__.e => __webpack_require__.f.j => __webpack_require__.l
来加载 js 文件。__webpack_require__.f.j 函数里面有一个 loadingEnded 的回调函数,这个函数是在 js 文件加载完之后,onload 触发的。但是,判断加载的 chunk 文件是否成功,是根据 installedChunkData 这个变量来确定的。只有 installedChunkData 的值为 0 的时候,才算成功。从函数调用顺序来看,没有看到什么时候对 installedChunkData 的值进行赋值,而这个赋值,就是在 webpackJsonpCallback来进行处理的。webpackJsonpCallback代码如下:
webpack 在全局中定义变量webpackJsonpmodule_federation_starter(webapck 5以下是:webpackJsonp 变量),该变量是一个数组,劫持了该数组的 push 方法,当有新的元素 push 到该数组,就先调用 webpackJsonpCallback 方法。
在 webpackJsonpCallback 方法中,主要做两件事:
__webpack_require__.f.j 中能够识别已加载成功__webpack_require__.m(__webpack_modules__)中,其他 module 依赖就可以直接获取// install a JSONP callback for chunk loading
function webpackJsonpCallback(data) {
var chunkIds = data[0];
var moreModules = data[1];
var runtime = data[3];
// add "moreModules" to the modules object,
// then flag all "chunkIds" as loaded and fire callback
var moduleId, chunkId, i = 0, resolves = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(__webpack_require__.o(installedChunks, chunkId) && installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
// 关键点
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(__webpack_require__.o(moreModules, moduleId)) {
// 关键点
__webpack_require__.m[moduleId] = moreModules[moduleId];
}
}
if(runtime) runtime(__webpack_require__);
if(parentJsonpFunction) parentJsonpFunction(data);
while(resolves.length) {
resolves.shift()();
}
};
// 关键点
var jsonpArray = window["webpackJsonpmodule_federation_starter"] = window["webpackJsonpmodule_federation_starter"] || [];
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
jsonpArray.push = webpackJsonpCallback;
var parentJsonpFunction = oldJsonpFunction;// 需要被处理的 chunkId
var chunkMapping = {
"164": [
164
]
};
var idToExternalAndNameMapping = {
"164": [
"default",
"./Button",
980
]
};
__webpack_require__.f.remotes = (chunkId, promises) => {
if(__webpack_require__.o(chunkMapping, chunkId)) {
chunkMapping[chunkId].forEach((id) => {
var getScope = __webpack_require__.R;
if(!getScope) getScope = [];
var data = idToExternalAndNameMapping[id];
if(getScope.indexOf(data) >= 0) return;
getScope.push(data);
if(data.p) return promises.push(data.p);
var onError = (error) => {
if(!error) error = new Error("Container missing");
if(typeof error.message === "string")
error.message += '\nwhile loading "' + data[1] + '" from ' + data[2];
__webpack_modules__[id] = () => {
throw error;
}
data.p = 0;
};
// 处理回调的工厂方法
var handleFunction = (fn, arg1, arg2, d, next, first) => {
try {
var promise = fn(arg1, arg2);
if(promise && promise.then) {
var p = promise.then((result) =>
(next(result, d)),
onError
);
if(first) promises.push(data.p = p); else return p;
} else {
return next(promise, d, first);
}
} catch(error) {
onError(error);
}
}
// 判断是否已经请求远端 remoteEntry 文件, 若未请求, __webpack_require__.I 会发出请求
var onExternal = (external, _, first) => (external
? handleFunction(
__webpack_require__.I,
data[0],
0,
external,
onInitialized,
first
)
: onError()
);
// 调用 remoteEntry 中暴露的 get 焊方法
var onInitialized = (_, external, first) => (
handleFunction(
external.get,
data[1],
getScope,
0,
onFactory,
first
)
);
// 往 __webpack_modules__ 中挂载 moduleId, 后续给到 __webpack_require__ 所调用
var onFactory = (factory) => {
// chunk 加载中
data.p = 1;
__webpack_modules__[id] = (module) => {
module.exports = factory();
}
};
// 执行顺序 __webpack_require__ => remoteEntry.get => __webpack_module__.m => __webpack_require__
handleFunction(__webpack_require__, data[2], 0, 0, onExternal, 1);
});
}
}
})();在使用 ModuleFederationPlugin 的时候,配置 shared 依赖包的加载处理,例如配置为:
new ModuleFederationPlugin({
// ... 其他的配置
// 共享模块的配置 f.consumes 函数就是处理这些依赖
shared: ["react", "react-dom"],
}),// 定义 chunkId 需要依赖的 chunk 的关系
// 例如 801 这个 chunk 是需要把 module id 为 250, 138 的依赖进行加载
// 该关系,在 webpack 打包的时候,自动生成
var chunkMapping = {
"591": [
591
],
"801": [
250,
138
]
};
// 定义share 依赖包进行加载的方法,与对应的版本
// 版本用来在其他 webpack 应用共享的时候,进行是否复用判断
var moduleToHandlerMapping = {
250: () => loadStrictVersionCheckFallback("default", "react-dom", ["16",13,0], () => Promise.all([__webpack_require__.e(338), __webpack_require__.e(591)]).then(() => () => __webpack_require__(338))),
138: () => loadStrictVersionCheckFallback("default", "react", ["16",13,0], () => __webpack_require__.e(162).then(() => () => __webpack_require__(162))),
591: () => loadStrictVersionCheckFallback("default", "react", ["16",14,0], () => __webpack_require__.e(764).then(() => () => __webpack_require__(162)))
};
__webpack_require__.f.consumes = (chunkId, promises) => {
// 需要判断 chunkId 是否在配置中
if(__webpack_require__.o(chunkMapping, chunkId)) {
chunkMapping[chunkId].forEach((id) => {
if(__webpack_require__.o(installedModules, id)) return promises.push(installedModules[id]);
// chunk 加载成功,加入到对应 __webpack_module__ 中,模块后续不需要重新加载
var onFactory = (factory) => {
installedModules[id] = 0;
__webpack_modules__[id] = (module) => {
delete __webpack_module_cache__[id];
module.exports = factory();
}
};
var onError = (error) => {
delete installedModules[id];
__webpack_modules__[id] = (module) => {
delete __webpack_module_cache__[id];
throw error;
}
};
try {
// 调用方法,进行加载对应的 chunk
var promise = moduleToHandlerMapping[id]();
if(promise.then) {
promises.push(installedModules[id] = promise.then(onFactory).catch(onError));
} else onFactory(promise);
} catch(e) { onError(e); }
});
}
}// 定义分享模块的 scope , 例如 default, default 里面会挂载依赖包的版本
__webpack_require__.S = {} // 初始化为空对象
// __webpack_require__.S = {
// default: {
// react: xxx,
// react-dom: xxx
// }
// }
// name 就是 scope 的 name
// __webpack_require__.I 函数就是为 scope 注册对应的依赖版本
// 注册完,挂载到 __webpack_require__.S 中
__webpack_require__.I = (name) => {
// only runs once
if(initPromises[name]) return initPromises[name];
// handling circular init calls
initPromises[name] = 1;
// creates a new share scope if needed
if(!__webpack_require__.o(__webpack_require__.S, name)) __webpack_require__.S[name] = {};
// runs all init snippets from all modules reachable
var scope = __webpack_require__.S[name];
var warn = (msg) => typeof console !== "undefined" && console.warn && console.warn(msg);;
// 为当前的包的所有版本都注册到 default 这个 scope 中
// 并对版本进行判断
// 通常版本号是 x.y.z 的,webpack 会把三个版本都进行注册,例如 react 16.14.0
// 分别注册为
// react`16, react`16`4, react`16`4`0
// 这三个版本都挂载到 scope 下,也就是
// __webpack_require__.S['default'] = {
// react`16: { get: , factory: },
// react`16`14: { get: , factory: },
// react`16`14`0: { get: , factory: },
// }
var register = (name, version, factory, currentName) => {
// ...
};
var initExternal = (id) => {}
var promises = [];
switch(name) {
case "default": {
register(
"react",
[16,14,0],
// 定义获取当前库的方法, webpack 常用手段
// 先通过 .e 函数来加载,然后通过 __webpack_require__ 来包装对象
() => __webpack_require__.e(162).then(() => () => __webpack_require__(162))
);
register(
"react-dom",
[16,14,0],
() => Promise.all([
__webpack_require__.e(338),
__webpack_require__.e(591)
]).then(() => () => __webpack_require__(338))
);
}
break;
}
return promises.length && (initPromises[name] = Promise.all(promises).then(() => initPromises[name] = 1));
};这篇文章主要是读 ts 入门教程 与 ts 中文网 所记下来的一些笔记,作为后面学习的一个参考点;看完文章后,对知识点做一定的提取;但是描述起来比较简单,主要针对部分关键知识点;如果需要系统的学习的话,就需要把教程看了。
// 声明数字
let num: number
num = 1
num = 'str' // error
// 声明字符串
let str: string = 'str'
// 声明多种类型
let value: number | string
value = 1
value = 'str'
// 声明任意数据类型;若声明函数没有指明类型,也是 any 类型
let value: any
value = true
value = { foo: 'foo' }
// 声明函数返回的类型
// 函数参数支持类型也是与声明变量类似
function foo (bar: string | number): boolean {
var flag:boolean = true
console.log(bar.length) // length 属性只在 string 类型存在,number 类型不存在;因为编译器会报错
console.log(bar.toString()) // 两种类型都有的方法,能够正常运行,因此当声明变量为多个类型的时候,访问的属性需要两个类型都具有的方法或者属性
return flag
}interface Person {
name: string,
age: number
}
let person: Person = {
name: 'kyrie',
age: 20
}
// 当有属性是不确定添加,部分对象包含,部分对象不包含的情况,可以使用这样子来表示:
interface Person {
name: string,
nickName?: string,
age: number,
id?: number,
}
let person: Person = {
name: 'kyrie',
age: 20,
id: 10
}
// 当一个对象需要一些不确定名称的值,可以使用任意属性的定义方法,但是已知的属性必须是任意属性类型的子集;例如已知属性全部都是 string 类型;那么任意属性可以定义为 string, 但不能够定义为 number;如果已知属性有number, string,那么任意属性定义为 string 也不正确
interface: Person {
readonly id: number,
name: string,
age: number,
[propName: string]: any // 所以这里可以定义为 any 类型;那么 string 与 number 就是 any 的子集
}
// 注意上面的接口有一个是 readonly 关键词,表示只读,也就是第一次赋值,不能二次赋值
let person: Person = {
id: 10,
name: 'kyrie',
age: 20
}
person.id = 11 // error// 1. 类型 + 方括号表示方法,类型包括 any 的定义
let arr: number[] = [1, 2, 3] // 数组元素只能是数字
// 2. 泛形(后面会说到泛型的详细信息)
let arr: Array<number> = [1, 2, 3]
// 3. 接口类型
interface NumberArray {
[index: number]: number
}
let arr: NumberArray = [1, 2] // successful
let arr2: NumberArray = [1, 2, '3'] // error
// 4. 内置对象,常见的有:IArguments(普通函数的参数), NodeList, HTMLCollection
function foo () {
// let args: number[] = arguments // error
let args: IArguments = arguments
console.log(args)
console.log(typeof args)
}// 通常函数定义分两种,一种是函数声明,另外一种是函数表达式
function foo () {} // 函数声明
let foo = function () {} // 函数表达式
// 对于普通函数声明:
function foo (id: number, name: string = 'anonymous', age?: number, address?: string) {}
// 上面这个函数表示,id 这个参数比必选的,name 参数有默认值,如果不传的值是 'anonymous', age 参数是可选的,不传就没有值了;
// 可选参数且没有默认值的参数,只能在函数声明的最后,可以有多个可选没默认值参数;有默认值的参数,后面可以接必须参数
// 剩余参数的处理;实际上剩余参数是数组,我们可以声明数组的方式来处理
function foo (id: number, name: string, ...msg: any[]) {
console.log(msg)
}
// 对于函数表达式
let foo = function (id: number, name: string): any {
// 这样子定义是ok的,能够通过编译
}
// 实际上只是对右边的匿名函数进行声明类型,没有对 foo 的变量的类型声明,完整的声明方式应该是这样子的:
// 注意区分箭头函数的区别
let foo: (id: number, name: string) => any = function (id: number, name: string): any {
// xxx
}
// 另外一种为函数表达式变量定义类型的方式可以使用接口形式
interface fooFunction {
(id: number, name: string): boolean
}
let foo: fooFunction = function (id: number, name: string): boolean {
return !!id
}
// 函数重载,需求:假设对传的参数是number,则扩大十倍,是字符串则添加前缀:
function calc (value: number | string): number | string {
if (typeof value === 'number') {
return value * 10
} else {
return '_' + value
}
}
// 实际上是应该对参数是number 则返回值是 number; 参数是 string ,则返回值是 string
function calc (value: number): number;
function calc (value: string): string;
function calc (value: number | string): number | string {
if (typeof value === 'number') {
return value * 10
} else {
return '_' + value
}
}
// 前两次声明是函数的定义,最后的声明是函数的实现;ts 会从最开始声明的进行匹配function getLength (value: string | number): void {
// 断言方式有两种
// 第一种是 <type> 的方式
console.log((<string>value).length)
// 第二种是 值 as 类型
console.log((value as string).length)
// 因为第一种方式在 jsx 里面会存在误区,所以在 jsx 语法里面,只能使用第二种
}简要解释一下上面的函数,因为接收的参数有string与number两种类型,而number类型是没有length属性,前面说到,需要两个类型共有的方法或者属性才能使用;而我们这里强制断言为string,因此编译的时候不会报错。
就例如上面的getLength方法,有些时候我们需要定义多个类型的时候,如果经常要重复编写就会很麻烦,我们可以自定义一个类型:
// 使用 type 关键词
type numStr = string | number
type numStrFun = numStr | () => string
function getLength (value: numStr) {
// ...
}
// type 关键词除了可以定义类型之外,还可以字符串字面量
type top3 = 'first' | 'second' | 'third'
function typeFun (value: top3) {
console.log(value)
}
typeFun('first')
typeFun('fourth') // 报错,因为参数 fourth 不在定义的字符串字面量中var multiType: [string, number]
multiType = ['1', 1]
// 元组与数组比较类似,可以通过下标用来赋值或者取值,但是赋值的时候,这个值需要下标对应类型一致,否则会出错
multiType[0] = 2 // error,类型对不上
// 可以使用 push 添加属性,也可以使用 slice 来获取不同值
multiType.push('2') // 注意使用 push 的时候,需要初始化值之后才能使用
multiType.push(2)
multiType.slice(0) // [ '1', 1, '2', 2 ]
multiType.push(true) // error 类型对不上通常是用于取值在一定范围的场景,例如一周7天,颜色固定红绿蓝三个颜色
enum Color {
red,
green,
blue
}
// 取值
Color['red'] // 0
Color[1] // 'green'
// 上面的枚举类型,转换到js之后是这样子的:
var Color;
(function (Color) {
Color[Color["red"] = 0] = "red";
Color[Color["green"] = 1] = "green";
Color[Color["blue"] = 2] = "blue";
})(Color || (Color = {}));
// 执行后相当于:
var Color = {
0: 'red',
1: 'green',
2: 'blue',
'red': 0,
'green': 1,
'blue': 2
}
// 通过下标与字符串都能够访问到对应数据实际上枚举的步长每次增加1;如果我们设置初始的值是1,例如:
enum Color {
red = 1,
green,
blue
}
Color[2] // 'green'
Color[3] // 'blue'
// 所以这个数可以是负数或者是小数,每次增加步长都是1;也可以是计算所得值:
enum Color {
red,
green,
blue = 'blue'.length
}
// 需要注意的是,这个计算所得值对应的枚举项需要是最后的值;如果不是最后的值,那么计算所得值后面的枚举项将不能每次步长+1;无法获取确切的初始值而报错。// 1. 类的属性与方法添加修饰符:public(默认值,任何对象都能够访问到), private(只能在当前类的方法访问), protected(只能在当前类或者子类访问)
class Animal {
public name
private nickName
constructor (name: string, nickName: string) {
this.name = name
this.nickName = nickName
}
// 默认是 public,实例对象可以访问
getName () {
return this.name
}
// 私有方法,只能在当前类访问
private getNickName () {
return this.nickName
}
// 保护方法,只能在当前类或者子类中访问
protected getFullName () {
return this.name + ':' + this.nickName
}
}
// 2. 抽象类,使用 abstract 关键词声明的类;抽象类是不能够直接实例化,只能通过有子类继承,并由子类实现所有抽象类的抽象方法
abstract class Eat {
abstract eatFood ()
}
class Animal {
public food
constructor (food: string) {
this.food = food
}
eatFood () {
console.log('eat food:', this.food)
}
}通常类大多数都是继承关系,子类通过继承父类,然后加多一些特有的方法属性等;但有时候继承类并不能实现所有方法,子类(假设为A)可能有些方法需要在别的类(假设为B类)实现;而且这个B类也为其他类别(假设为C类)提供;B类就有点公共类的意思了,同时为A,C类提供;
例如一个场景:
举例来说,门是一个类,防盗门是门的子类。如果防盗门有一个报警器的功能,我们可以简单的给防盗门添加一个报警方法。这时候如果有另一个类,车,也有报警器的功能,就可以考虑把报警器提取出来,作为一个接口,防盗门和车都去实现它:
interface Alarm {
alert ()
}
class Door {
}
class SecurityDoor extends Door implements Alarm {
alert () {
console.log('SecurityDoor alert')
}
}
class Car implements Alarm {
alert () {
console.log('Car alert')
}
}
// 并且一个类可以实现多个接口:
interface Alarm {
alert()
}
interface Light {
lightOn ()
lightOff ()
}
class Car implements Alarm, Light {
alert() {
console.log('Car alert')
}
lightOn() {
console.log('Car light on')
}
lightOff() {
console.log('Car light off')
}
}
上例中,Car 实现了 Alarm 和 Light 接口,既能报警,也能开关车灯
这样子在使用 class 语法的时候,能够提高类的灵活性;容易添加部分公共类方法,扩充对象
通常在定义函数、接口、类的时候,会定义一些类型;但有时候有些类型是函数执行的时候才能确定,并且是根据传入参数的类型,返回的类型也要一致;那样子就有点存在动态类型的意思了;而泛型的作用是可以在定义的时候不预先指定类型,在运行的时候再确定好数据的类型:
function repeatValue<T> (value: T): T[] {
var arr: T[] = []
for (var i = 0; i < 3; i++) {
arr.push(value)
}
return arr
}
repeatValue('str') // ['str', 'str', 'str']
repeatValue(1) // [1, 1, 1]
// 泛型中的类型可以是 interface 的类型,也可以是基础的数据类型
// 可以在函数中定义多个泛型的类型
function reverse<T, U> (v1: T, v2: U): [U, T] {
return [v2, v1]
}
reverse('1', 2) // [2, '1']
// 由于泛型定义的变量并不知道是什么类型,因此如果调用变量的一些属性的时候,因为类型不确定的关系,系统会报错
// 这个泛型的默认类型为 string; 可以在函数使用的时候,传的参数没有指定确切类型的时候使用
function getLen<T = string> (value: T): number {
return value.length // error
}
// 但是我们的泛型也是可以添加约束的,那么在约束范围内使用方法或者属性就可以了:
interface lengthInterface {
length: number
}
function getLen<T extends lengthInterface> (value: T): number {
return value.length
}
// 泛型接口 interface
// 没有使用泛型定义的接口,根据接口定义函数表达式的函数
interface includeFunction {
(str: string, subStr: string): boolean
}
let isInclude: includeFunction
isInclude = function (str: string, subString): boolean {
return str.indexOf(subStr) > -1
}
// 使用泛型定义接口的话
interface repeatFunction {
<T>(value: T, len: number): Array<T>
}
let repeatByLen: repeatFunction
repeatByLen = function<T> (value: T, len: number): Array<T> {
let arr: Array<T> = []
for (let i = 0; i < len; i++) {
arr.push(value)
}
return arr
}
repeatByLen('foo', 3) // ['foo', 'foo', 'foo']
// 在类中添加泛型
class NumberClass<T> {
value: T,
add: (x: T, y: T) => T
}
let num = new NumberClass()
num.value = 10
num.add = function (x, y) { return x + y }最近在折腾一下微信公众号的开发,在这个过程中还是遇到挺多麻烦的事,当然,每一件麻烦的事情,在 goole 下都能找到对应的解决方案,这次是把整个过程记录一下,从开始到放弃。
这次文章的目标是,在本地能够启动 node.js 服务,并能够接收用户发送给公众号的消息,进行响应处理。
(废话,下一个)
最开始的时候,是选中 koa 来作为本地开发的,因为研发手写的代码简单,就那么几行,就可以在一个完全空白的项目跑起来了。但是后面发现,koa虽简单,但是功能也比较简单,如果要进行完整的服务端开发,还需自己搭建非常多的内容。于是选中 egg 作为开发的框架。
# 下面命令是初始化 egg 相关项目,并启动
$ mkdir egg-example && cd egg-example
$ npm init egg --type=simple
$ npm i
$ npm run dev运行完上面的命令之后,打开本地链接 http://localhost:7001 即可看到 egg 启动的界面了。
要让微信公众号的信息正确发到本地服务,这些东西还不够,要暴露一个外部的 ip,让微信把公众号接收到的消息发送到这个 外部 ip。这个时候需要一个代理工具:localtunnel
localtunnel 可以把本地的接口,生成一个暴露对外的域名地址;当外部进行发送消息的时候,把发送到该域名的地址,转发到本地的服务。简单如图:
下面是安装的简单过程
# 也可以使用 npx localtunnel --port 7001,不过通常后续会多次执行,还是全局安装之后,后面执行起来比较快
$ npm install -g localtunnel
# 7001 这个端口就是使用 egg 启动占用的端口
$ lt --port 7001
# 执行完命令,会返回url,例如下面的地址。如果处理出错,重复多两次一般就可以
your url is: https://rude-robin-7.loca.lt拿到这个url之后,就需要复制到浏览器打开,通常会出现下面的界面:
然后点击按钮,就能看到访问http://localhost:7001内容一致。后续刷新,就不会出现以上界面,而是直接返回本地服务的内容。
执行完上一步之后,本地开发的服务,就可以通过域名访问了。然后去到微信公众号后台修改配置,没有开启,则需要开启:开发 => 基本配置 => 服务器配置。
URL 那一栏就填写通过 localtunnel 获取的域名;Token 那一栏现在可以随便填一下,具体后面的使用待会说到。然后点击,提交,会发现,出错。因为我们的服务还没有按照微信的要求,对请求进行验证。
微信要求设定的URL需要进行验证,否则不能作为公众号接收的服务,简要的验证逻辑如下。官方对于验证的文档在这里。
知道验证的方法之后,就可以着手进行处理,就按照初始化的 egg 文件内容来处理,修改 app/controller/home.js 的 index() 方法:
// 需要依赖该加密工具
const sha1 = require('sha1')
class HomeController extends Controller {
async index() {
const { ctx } = this;
const { query } = ctx
// 在微信公众号后台的配置
const token = 'testtoken'
const { signature, echostr, timestamp, nonce } = query
if (!echostr) return
const newSignature = sha1([token, timestamp, nonce].sort().join(''))
ctx.body = newSignature === signature
? echostr
: 'error'
}
}确认服务重启之后,回去到公众号后台配置的地方,再次点击“提交”。什么?还是出错,那大概率是 localtunnel 的问题,因为这个服务不太稳定,导致微信那边访问也会有波动。点多两次提交就可以了。
当我们发送消息到公众号的时候,公众号后台会对信息进行处理,然后以一个 post 方法的 http 请求,发送到刚才在公众号后台配置的链接中,请求的内容是以 xml 为格式的内容。官方关于接收消息文档如下。
上面我们的 egg 应用只是对 GET 请求进行处理,还没有对 POST 请求进行响应,所以做了以下两步处理:
// app/router.js 新增处理
module.exports = app => {
const { router, controller } = app;
router.get('/', controller.home.index);
// 下面这一行为新增
router.post('/', controller.home.post);
};在官方文档中可以知道,需要对 XML 的文件格式进行处理,而 POST 请求是基于事件,类似流式接收二进制数据;且针对 XML,需要 xml2js 的工具,进行转换为常用的 js 对象。
const xml2js = require('xml2js');
class HomeController extends Controller {
// 为之前处理 GET 请求的方法
async index() {}
async post() {
let data = '';
const { req } = this.ctx;
// 马上对响应进行返回,让公众号后台能够收到请求已收到,避免公众号后台进行重试
this.ctx.body = 'success';
req.setEncoding('utf8');
req.on('data', function (chunk) {
data += chunk;
});
req.on('end', function () {
xml2js.parseString(data, { explicitArray: false }, function (err, json) {
if (err) {
// TODO
return
}
// 拿到后台发送过来的数据
console.log(json.xml)
});
});
}
}以上的两个文件更改,即可接收 POST 请求了;但是 egg 默认对 POST 请求做了 csrf 防御的处理,如果需要快速解决这个问题,可以先把配置关掉:
// /config/config.default.js
const config = exports = {
// ...
security: {
csrf: false
},
}完成以上步骤之后,用户发送到微信公众号的数据,本地服务基本就可以接收到了。
为什么会有优化版?因为 localtunnel 实在太不稳定了,经常会掉线;掉线之后,重新获取域名之后,域名再次发生更改,还需要在公众号后台更改对应的域名。
所以优化版是针对有远端服务器进行处理,代理部分,从 localtunnel 改为 云服务器。
接下来,需要对原来 localtunnel 实现转发这一步,改为我们手动来实现。而有一个需要注意的是,微信后台配置的链接,只能配置 http/https,分别对应 80/443 端口。因为没有证书,所以只能够在 80 端口下手了。而 80 端口,第一时间想到 nginx。通常来说,使用 nginx 进行反向代理,通过一定的规则,把访问 80 端口的一部分流量代理到其他端口。
另外,为了把线上的流量代理到本地,可以使用 ssh 的功能进行转发。ssh 命令为:
$ ssh -NfR 8080:localhost:7001 [email protected] -i ./my.pem上面这句命令的意思是,把服务器端口为 8080 的流量代理到本地 7001 端口,i- ./my.pem 是使用对应的密钥进行登录;如果没有,则使用密码进行处理。
为什么是 8080 端口,而不是 80 端口呢。因为 80 端口已经被 nginx 占用了。会提示出错。所以,还需要配合ngxin,把针对微信的流量进行转发,更改配置如下:
# /etc/nginx/sites-enabled/default
server {
# 其他配置...
# 把微信的请求,代理到 8080 端口
location /wxapi/ {
proxy_pass http://127.0.0.1:8080/;
}
}
这个时候,就需要更改公众号后台的开发者接口配置
上面填写的 URL 的ip地址就是云服务器的地址,/wxapi/ 就是 ngxin 设置的地址。
所以总体来说,自己搭建代理的方式如下:
通过这个优化之后,后续只需要本地启动 egg 服务,然后至少上述 ssh 的命令即可;ssh 代理命令也可以设置为开机启动,那样子就可以再继续减少一步。
整体流程其实并不复杂,但是需要把各个知识点都串联起来,各种工具、配置的简要知识都需要了解一下。完。
最近打算给WEB应用收集一些打开的相关数据,所以需要对performance的api进行熟悉。收集完数据之后,后续有什么故障或者优化的手段,就可以使用数据说话,而不是说,“加入了XX的优化,快了很多”,“服务器负载过高,影响了XX的部分的解析时间”。
接下来主要分析performance.timing对象所在属性,对于performance对象的其他属性不做详细处理。这篇文章的也没什么特别的地方,只是在面向谷歌研究的时候,发现很多关于performance.timing的描述都很模棱两可,而且比较简单,对于实际情况应用与影响因素不明确,所以做了部分测试。
performance.timing对象的数据是什么?该对象下包含页面打开的各种的时间戳,例如:DNS 耗费时间,TCP 连接时间等;这些时间不通过performance的api,暂时无法获取这些相对底层的时间。这个包含以下字段:
navigationStart
unloadEventStart
unloadEventEnd
redirectStart
redirectEnd
fetchStart
domainLookupStart
domainLookupEnd
connectStart
connectEnd
secureConnectionStart
requestStart
responseStart
responseEnd
domLoading
domInteractive
domContentLoadedEventStart
domContentLoadedEventEnd
domComplete
loadEventStart
loadEventEnd
这些字段顺序触发是怎样的?参考alloyteam抄回来的这张图:
所以调整以下,整体顺序是这样子的:
{
// unload 事件触发的开始与结束时间
// unload 事件指的是上一个页面(跳转到当前页面)或者当前页面(刷新页面)监听的事件: window.addEventListener('unload', () => {})
// 这个通常是这个事件的回调函数所耗费的事件,感觉不太重要?
unloadEventStart,
unloadEventEnd,
// 比较好理解,重定向所花的时间,若中途包含多次重定向才能确定最终的地址,则耗费的时间随之上升
redirectStart,
redirectEnd,
// alloyteam描述:在同一个浏览器上下文中,前一个网页(与当前页面不一定同域)unload 的时间戳,如果无前一个网页 unload ,则与 fetchStart 值相等
// 个人理解,当有 unload 事件的时候,与unloadEventStart时间一致,否则与 fetchStart 时间一致
navigationStart,
// 已找到目标地址,开始获取文档
fetchStart,
// DNS 解析时间
domainLookupStart,
domainLookupEnd,
// DNS 解析到对应的ip,开始建立TCP
connectStart,
// 如果是加密https,则TCP加密有这一步,如果是http协议,则这个值为0
secureConnectionStart,
connectEnd,
// TCP 已建立,准备发出http请求
requestStart
// 接收文档数据
responseStart
responseEnd
// dom 解析
domLoading
// dom 解析完毕
domInteractive
// 触发 DOMConctentLoaded 事件
domContentLoadedEventStart
domContentLoadedEventEnd
// dom 已准备好,对应的资源也已经ok
domComplete
// 触发 load 事件
loadEventStart
loadEventEnd
}对应unloadEventStart,unloadEventEnd, 这个是unload时间的执行整个时间;有时候从别的页面跳转过来,控制权不在自己所在应用,通常来说意义不是很大。
影响因素:上一次unload事件处理任务
对应redirectStart,redirectEnd, 这个比较明显,在达到最终域名之前,重定向所花的时间;通常重定向收集部分数据或者链接更改。
影响因素:redirect 次数
对应domainLookupStart,domainLookupEnd, 这个通常是指该链接文档对应的'index.html'所在链接的DNS解析时间,不是页面所有链接的DNS所花时间
影响因素:域名供应商?[狗头]
对应connectStart,connectEnd,secureConnectionStart事件,建立TCP链接所耗费时间
影响因素:服务器对请求响应速度
对应requestStart,responseStart,responseEnd事件;从requestStart到responseStart这段时间,是服务器处理生成文档的过程;而responseStart到responseEnd的时间,是客户端下载整个文档所花的时间;
影响因素:1. 确认文档:服务器处理文档的时间;2. 下载过程:客户端与服务端的网络速度;
以上几个因素对于基础网络研究不深入,所以只能点一些皮毛,比较浅显的影响因素
对应domLoading, domInteractive;从dom开始解析到dom解析完毕;这里的domInteractive响应,已经包含了对应的静态资源;这里的静态资源指的是index.html所在的包含的同步css,js等。不包含图片。同步js文件发出新的请求加入的js文件,这些文件加载不影响这个过程的时间
<head>
<!-- 同步 css 加载时间影响 -->
<link rel="stylesheet" href="index.css">
</head>
<body>
<!-- 图片加载时间不影响 -->
<img src="/big.jpg" />
<!-- 同步js影响 domInteractive 时间 -->
<script src="index.js"></script>
<!-- 异步 js 文件加载时间不影响 -->
<script src="defer.js" defer></script>
<script src="async.js" async></script>
</body>// index.js
var script = document.createElement('script')
// 后续加入的js文件加载时间不影响这个过程
script.src = '/append-by-index.js'
document.head.appendChild(script)影响因素:
css, js文件的大小与加载时间;对应domInteractive, domContentLoadedEventStart;这个时候dom已经解析完毕,按道理来说应该马上进入domContentLoadedEventStart事件,还有其他影响吗?也是我们上面提到的,标识为defer的script标签如果在domInteractive触发后还没加载好,那么这个时候就会影响到。
这是因为defer的特性,defer的js文件会在DOMContentLoaded事件触发前执行,执行完毕再触发DOMContentLoaded事件。
与defer类似的async异步script,async的js文件没有这个限制,而是在下载完毕后,马上执行,与DOMContentLoaded事件没有关系。
影响因素:
defer的js文件加载速度对应domContentLoadedEventStart与domContentLoadedEventEnd,这个比较简单,就是DOMContentLoaded回调事件函数执行的时长。
影响因素:
DOMContentLoaded事件回调函数执行时间对应domComplete事件;这里有点疑惑,dom在上面不是已经完成了,这里怎么还有一个domComplete事件。因为这个domComplete事件是应用中所有的资源,包括图片等都已经加载完了,才会触发domComplete事件
影响因素:
这个与DOMContentLoaded类似,是load事件的执行时间:
window.addEventListener('load', () => {})影响因素:
load回调函数的执行时长通过上面可以知道哪些因素影响哪一部分的效果,通常来说,收集的指标有以下几种:
// 后续的performance.timing都是使用这个变量代替
var timing = performance.timingtiming.domainLookupEnd - timing.domainLookupStarttiming.connectEnd - timing.connectStarttiming.redirectEnd - timing.redirectStarttiming.responseStart - timing.requestStart 有些统计会把DNS解析或者TCP连接都归类到ttfb的时间,但是从chrome开发者工具看到,ttfb只包含从请求发起到收到的时间,所以这里也是选用了这种 ttfb wikitiming.responseEnd - timing.responseStart ,反映该请求文档的下载时间,服务器是否处理过长timing.domInteractive - timing.domLoading;若时间过长,则考虑 DOM 节点的问题与基础静态文件体积大小,是否对入口文件进行拆分,使用懒加载功能;是否对静态文件加入到CDN,是否改成http2等timing.domComplete - timing.domContentLoadedEventEnd;图片资源是否过大,非必要进页面展现的图片使用懒加载占位等,图片资源是否也加入cdn,http2等.....在domLoading事件之前的指标都是只与html文档有关系。对于SPA应用来说,实际上DOM元素没多少个,大部分元素都是后面进行渲染,所以是否需要对后续渲染的过程再做一层处理,收集app启动的时间?收集的启动时间没有对应在timing对象,需要通过performance.measure来处理,下面以vue与react为例子进行一个简单例子:
// vue main.js
import xx from 'xx'
// ...
performance.mark('appBootStart')
new Vue({
el: '#app',
mounted() {
// 使用 setTimeout 是使用宏任务保证可交互状态
setTimeout(() => {
performance.mark('appBootEnd')
performance.measure('bootDuration', 'appBootStart', 'appBootEnd')
const { duration } = performance.getEntriesByName('bootDuration')[0]
// upload duration time
})
}
})// react main.js
import xx from 'xx'
// ...
performance.mark('appBootStart')
const app = () => {
// componentDidMounted hook
useEffect(() => {
setTimeout(() => {
performance.mark('appBootEnd')
performance.measure('bootDuration', 'appBootStart', 'appBootEnd')
const { duration } = performance.getEntriesByName('bootDuration')[0]
// upload duration time
})
}, [])
}如果根节点的mount事件并不能充分展现应用的实际情况,那么需要更改到其他组件下进行处理,才能记录真实应用的情况;反馈有内容的第一次可交互时间。
参考文章:
在之前一段时间中,我这边在补充 React 的技术栈(不会 React 都不好意思说自己搞前端了?)。下面分享一下我这边的学习的过程,还有一些学习过程中觉得不错的学习文章。主要是 React 技术栈与 Typescript 的应用。
在决定系统学习 React 的技术栈之前,其实对 React 的使用也有比较一些低层级的使用,所以是有一些比较浅的认识。因为也工作了不短时间了,在工作的工程中,在前端框架方面使用,前期是ng1.x,后面主用vue了。所以对前端框架的使用也是有一定经验。而对 Typescript 的使用,之前也有完整学习了一遍并做了一些简要的学习笔记。所以基于之前零散的学习,现在就开始系统学习一波吧,整理之前的知识。
先定个小目标,这次学习的目的是:系统整合 React 技术栈与 Typescript 的使用。
学习的载体:选一个自己熟悉项目,用这个项目来重构;或者选一个需求明确的产品。我觉得这个挺重要的,如果在开发过程中还要纠结各种需求问题,就与我们目标有偏移。我是选择了一个熟悉的产品并重构部分,一来可以反思之前的问题,二来因为熟悉需求,减少在上面耗费的其他精力。
开始需要列一下学习路线图roadmap,可能不需要很精确,主线清晰就ok了,学习的过程中有时候需要不断调整。下面是我这边前期的学习路线:
create-react-app --typescript 创建项目这里列的都是一些基本点,每一个基本点展开都是非常多的。所以在这个过程中,建议多阅读 React 官方文档,通常开始会对一些方法与使用姿势不对。通过多阅读文档,可以在涉猎对应场景之前,就能够提前有个认知;因为长时间使用其他的框架,容易造成把不同框架的使用姿势强行结合,导致使用不当,先忘记之前所学的。
如果完成上述的基本路线图,就基本把 React 的常见使用入门了。这就完了?不不
通常你在上面每个阶段都会遇到各种问题;而且需要对每一步的处理进行反思,记录下来之后,需要进一步深入。
例如在第一步进行创建的时候,使用create-react-app的时候,可能会想到,这个工具是怎么实现的,怎么做到开箱即用,具体原理可以看文章create-react-app原理。还有结合第 6 步,如果加入mockServer的话,增加配置不容易,那么通过eject命令把配置都导出,自己重新去更改?还是通过react-app-rewired工具去更改cra的流程呢?这些在实际项目中可能得根据具体情况进行不同处理。
在使用redux的时候,是否有思考内部是怎样实现的,还有与vuex进行区别。如果仅使用redux,不使用辅助工具的话,项目会很困难,所以又有了react-redux的官方工具库,用于把 React 与 redux 连结起来。并内置部分优化,那是否也看一下react-redux内置的优化是什么呢?
在接入react-router的时候,通常会涉及一些懒加载的处理,除了路由层面对页面懒加载,是否也有一些对组件进行懒加载?另外,对路由的实现是否也需要看一下呢?对于history与hash的兼容是怎样的?不同路由组件间怎么同步相同的路由数据?
hook的使用相对会与之前的生命周期钩子有点不太一样,当尝试复用自己写的hook的时候,你可能会发现,一个名为react-use的工具库非常实用,里面涵盖了非常的常见工具hook,当没有思路编写自己的业务hook,不妨上去找一下代码与灵感。可能不写过几个死循环,都很难把hook使用到点,对于掌握hook,可能真的需要“把之前学到的都忘掉”。才能发挥更好的效果。
结合 Typescript 来使用,把两个不太熟练的东西一起使用也会大大增大难度;可能会发现,使用 js 就搞定了,但是使用 ts 的时候,在类型定义,还有引用第三方库会非常难理解,在这里有可能浪费挺多时间。这通常源于对 ts 的类型系统与部分默认定义类型的不熟悉;解决几个相似的提示之后,到后面解决起来就会很快了。
下面是一些解决部分问题比较不错的文章与回答,在这个学习过程所记录:
useEffect完整指南useRef与typescript的使用例子代码:
个人部分写的文章,见笑了:
这次的文章比较短,大多数是在描述一些在学习过程产生的一些疑问,与带入的一些解决方法。这些疑问是我们在学习的时候深究的来源。最开始的时候我也尝试过直接去阅读源码,但是发现 React 的源码实在太多了,如果没有一定的使用基础还有对一些常见概念熟悉的话,根本看不下去;为了看源码而看源码得不偿失。当在开发过程遇到部分问题之后,带着这些小问题,再去局部局部的深入;然后对之前所学的知识点作归纳,知识梳理起来就会有条理。那样子解决问题起来才能够得心应手。完!
之前一段时间就大概把这个轮子弄好了,但是一直没有整理成文章。今天完善一下使用这个轮子的例子,顺便发现之前的几个bug,一同修复。看来后面还是需要把测试用例补充,否则很难避免使用起来遗漏的地方。目前这个工具托管在friendly-query,欢迎大家尝试使用并提issue。
通常路由库可以处理从:/path1 => path2的跳转切换不同的页面;但是对/path1?foo=1切换到/path2?foo=2这种情况支持不是很好。如果页面对应的参数不增加到url中,用户在页面更改部分参数后,刷新页面,用户之前选择的这一部分参数就会被重置而不会选中后的页面处理。
在开发的过程中,想实现页面的部分表单参数同步到url的query参数;
popstate的事件,然后根据回调事件来监听参数发生变化,根据更改后的url参数,再进行处理;参数发生改变可能只影响一部分,通常只需要触发该部分的回调就可以了;总体来说,这个工具就是解决以上两个问题
上面图主要描述了三种情况:
enter pageupdate datapopstatefriendly-query的init方法生成实例instance.load()方法,该方法会从url上获取所有参数,并根据初始化传入的转换的数据类型,进行处理;返回的数据则为我们定义的数据类型storeinstance.convert方法,把原有复杂的数据类型转换为字符串类型,把参数发送到后端通常这一步是用户触发更改不同的参数,前端根据不同的参数请求相应的数据
instance.convert方法,获取新的数据转换后的字符串参数history添加记录;添加记录这一步可能部分路由已支持;若不支持,则需要手动调用:history.pushState()添加记录popstate事件(监听事件这一步,在init的时候进行了绑定)callback函数;这个callback函数为初始化init传入的参数;若对参数进行分多组处理,则改变的参数对应的分组回调才被调用,例如:init([{
type: {
foo: {}
},
callback () {}
}, {
type: {
bar: {}
},
callback () {}
}])若在popstate事件发生的时候,foo参数相比旧url发生了改变,则foo对应分组的callback会调用;bar对应的分组的callback不会被调用;这种情况适用于页面有多个不同请求,并且这些请求都需要更新到url。
从图可以看出,核心方法是load与convert的处理,是字符串数据与复杂数据之间桥梁。
instance.load方法的核心是parse的方法,parse不是只有一个,而是对于多种不同的数据类型,从字符串转换为需要类型的转换函数,例如:Int与Array的parse过程是不同的,parse函数主要接收三个参数:
{String} str url 对应参数的数据{Any} value 初始化传入该参数的默认数据{Object} option 该参数对应的数据类型的配置与parse对应的处理函数stringify,在instance.convert()实现,则是把不同的数据类型转换为字符串,例如把数组:['foo', 'bar']转换为字符串:'foo,bar',该函数主要接收两个参数:
{Array|Object} groupQuery 需要从设定的数据类型转换为url参数所用的字符串类型{Boolean} isMerged 对转换后的数组字符串数据合并到一个对象中,默认合并默认支持的类型有:
IntFloatStringDateBooleanArrayIntArrayFloatArray每种类型都有自己的处理规则,例如Array的配置当中,默认分隔符是逗号:separator: ',';在parse的时候,会根据逗号,来分割字符串,在stringify的时候,会根据逗号,来拼接字符串。如果想更改为别的分隔符,例如更改为连接符号-,则可以在init的时候,传入第二个参数,对需要更改的规则进行处理:
init([
// ...
], {
Array: {
separator: '-'
},
IntArray: {
// ...
}
})不同数据类型详细的配置,可以看这里
如果上述默认的类型都不能支持项目所用,可以使用extend的全局方法来扩充所需要的类型,下面这个例子是扩充一个DateArray的类型:
// dateformat 为一个日期格式类型处理的库
import dateformat from 'dateformat'
extend({
DateArray: {
// 从字符串转换为 Array 的方法
parse (str, value, option) {
if (!str) return value
return str.split(option.separator).map(item => {
return new Date(item)
})
},
// 从 Array 转换为字符串的方法
stringify (value, option) {
if (!value.length) return ''
return value.map(item => dateformat(item, option.format)).join(option.separator)
},
option: {
// 分隔符
separator: ',',
// 转换的时间格式
format: 'yyyy/mm/dd hh:MM'
}
}
})需要注意的是,使用extend扩充的类型,会全局影响,因此最好在项目入口定义新的类型
目前暂时只支持HTML5 history的模式,暂还没支持hash的路由模式
更详细的API可以查看这里
最近弄了一个轮子,是用来统计 git 代码行数还有文件数目的一些占比,把这部分数据可视化到图表。仓库链接
在造这个轮子之前,曾经在 gitlab 上面看到一部分统计的数据,发现只是统计了 commit 的提交数量、文件占比的比例;对于代码行数的纬度统计比较少。因此基本的需求就出来了。
因为需要分析到每个文件行数的修改细节,因此这一部分一定需要 git 相关命令进行统计,目的是统计文件的每一个用户的提交行数;面向谷歌编程的我,找到以下命令:
$ git ls-files ${fileName} | while read f; do git blame --line-porcelain $f | grep '^author '; done | sort -f | uniq -ic | sort -n
# 将 ${fileName} 替换为 README.md
$ git ls-files README.md | while read f; do git blame --line-porcelain $f | grep '^author '; done | sort -f | uniq -ic | sort -n输出结果:
10 author Not Committed Yet # 表示当前文件有10行还没有提交。Not Committed Yet 表示没有 commit 到仓库
43 author jingzhiMo # 表示这个文件有43行是作者 jingzhiMo 提交的然后需要对仓库的所有文件进行遍历,这里选择了深度优先遍历来处理,把最底部的文件节点不断往上统计;这样可以统计到每个文件夹的详细信息。
通常项目文件会有部分外部依赖文件或者部分不在 git 的跟踪下,这部分文件就不需要统计;最开始的思路是想通过项目的.gitignore判断文件是否在 git 跟踪下,不在就不进行统计,但是这个方法需要遍历.gitignore的规则,可能会判断出错。如果直接通过git判断就可以保证万无一失,利用git ls-files命令:
$ git ls-files no-track-file.js # 命令行输出为空除此之外,默认会去除lock文件与一些图片媒体文件,例如: package-lock.json与yarn.lock等。
呈现数据主要使用的工具是 echarts;本地开发使用create-react-app来搭建基础开发环境;左侧文件夹显示使用树状组件呈现,找了一圈找不到大概适合的,于是自己写一个简单的树状组件。树状组件大体思路是利用递归组件实现,组件内部包含自己组件:
<!-- <Tree> 组件对应的渲染元素 -->
<div>
<!-- 当前节点名称 -->
<span>file name or folder name</span>
<!-- children 当前文件夹对应的子文件夹-->
<Tree data={children} />
<!-- leaf 当前文件夹对应的文件-->
<Tree data={leaf} />
</div>每个节点都需要渲染自己的节点名称与直接子文件与直接文件夹;然后把对应子节点的数据继续传递到Tree组件,做到逐层数据展开,增强复用性。
为了节俭用户运行命令的时间与运行复杂度,所以把静态资源构建那一步需要在本地执行,生成好build的文件夹;但是因为生成的分析文件是动态生成的,所以暂时的处理方式是固定动态引入的文件名称,通过脚本生成的文件覆盖原有资源文件:
<!-- html入口文件 -->
<!DOCTYPE html>
<html>
<head>
<script src="source.js"></script>
</head>
</html>// source.js 运行文件调用该变量
window._source = {
// ...
}由于build文件夹是不需要git跟踪,而需要上传到npm包,因此需要.npmignore与.gitignore配合使用才可以。
$ cd git-repository /* 进入需要统计的 git 仓库文件夹 */
$ npx visualize-commit
$ cd commit-analyze /* 打开文件夹的 index.html 文件即可 */$ cd git-repository
$ npm install visualize-commit --save-dev
# or
$ yarn add visualize-commit --dev在package.json加入对应的脚本:
{
"scripts": {
"vsz": "vsz-commit"
}
}执行命令:
$ npm run vsz
# or
$ yarn add vsz
$ cd commit-analyze /* 打开文件夹的 index.html 文件即可 */现在这个代码统计功能还比较简单,希望看到文章的小伙伴可以提issue,使得统计的纬度更加多样化。现在给到自己将要做的功能可能有以下这些:
网站的首页和部分介绍页面需要预渲染,为了更好的SEO;而网站的dashboard的相关页面则保持原来的SPA处理。后续生产环境的文件构建需要放到ci统一处理。
现在使用prerender-spa-plugin的插件用来把部分静态页面预渲染,这个插件是依赖puppeteer的工具,puppeteer工具是需要下载一个chromium的浏览器。如果没有梯子是没办法下载的,下载安装包的大小大概在70M左右。
puppeteer从1.7.0版本开始就把puppeteer-core的包分离出来,如果需要单独测试的话,仅下载这个包就好了。但是prerender-spa-plugin插件是依赖puppeteer的包,所以需要设置npm的环境变量才能能够跳过下载浏览器,在安装npm install之前,需要在项目的根目录新建文件.npmrc或者往里面追加内容,内容是:
puppeteer_skip_chromium_download=true后面所使用的代码,均基于官方的例子进行更改
在webpack的配置当中,生产环境的plugins的数组需要加入下面的实例:
// 引入对应的插件
const PrerenderSPAPlugin = require('prerender-spa-plugin')
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer
module.exports = {
// ...
plugins: [
// ...
new PrerenderSPAPlugin({
staticDir: path.join(__dirname, 'dist'),
routes: [ '/', '/about', '/contact' ],
renderer: new Renderer({
inject: {
foo: 'bar'
},
headless: false,
// 这个事件名称需要与网站的事件名称一直,具体可以参考官方例子:
// https://github.com/chrisvfritz/prerender-spa-plugin/tree/master/examples/vue2-webpack-router
renderAfterDocumentEvent: 'render-event',
// 这个是macos下chrome的调用路径
executablePath: '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
// chromium的调用路径
// executablePath: '/Applications/Chromium.app/Contents/MacOS/Chromium'
})
})
]
}如果使用vue-cli进行配置,需要更改vue.config.js,可以通过configureWebpack的函数进行处理:
// vue.config.js
module.exports = {
configureWebpack: () => {
// 针对生产环境进行处理
if (process.env.NODE_ENV === 'production') {
return {
plugins: [
new PrerenderSPAPlugin({
// ...
})
]
}
}
}
}在使用本地系统安装浏览器的时候,推荐使用chromium,由于部分情况chrome可能会出现问题。linux通常chrome和chromium的安装路径分别是:
/usr/bin/chromium-browser
/usr/bin/google-chrome
部分chrome版本是stable版本,所以可能是/usr/bin/google-chrome-stable;在linux可以通过which命令查看对应路径,然后把得到的路径填入executablePath字段即可。
在linux系统执行的时候,有可能会出现依赖没有装完,导致无法启动chromium,这个问题可以查看这个解决方案;也有可能会提示配置不需要沙箱环境,需要改动配置如下:
new PrerenderSPAPlugin({
staticDir: path.join(__dirname, 'dist'),
routes: [ '/', '/about', '/contact' ],
renderer: new Renderer({
inject: {
foo: 'bar'
},
headless: false,
renderAfterDocumentEvent: 'render-event',
// 这个是macos下chrome的调用路径
executablePath: '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
// 配置这行
args: ['--no-sandbox']
})
})如果需要在ci环境部署,浏览器的安装也是一个问题,浏览器的安装包体积也不小,这里想到的几个方案有:
node_modules安装的时候,把浏览器安装包也下载了;然后ci的cache把node_modules加上;cache需要把node_modules和浏览器下载路径都缓存;chromium的docker的image,就可以避免安装chromium。缺点:
1、2两点都能够通过不同方法安装浏览器,但是通常浏览器依赖包还是缺失,需要自行安装对应的依赖;
第3点应该是比较好的解决方案,但需要选中一个比较好且稳定的image,dockerhub
最近项目组的的后端业务开始拆分,把部分用户与业务需求拆分;在原来的时候,用户的请求与业务请求都是由同一个后端项目支持;现在由于子项目不断扩充,不同的子项目之间的账号信息需要同步。
步骤:
request user, 前端向后端请求用户信息(忽略登录过程)response token,后端返回用户的token;前端拿到token存储到 storagereq/res 前后端进行业务数据的交流步骤:
request user 前端a.example 向user.example用户后端请求 用户信息(忽略登录过程)response token,用户后端返回用户的token,设置到 cookie;req/res data 前端与业务后端b.example.com进行数据交流这次更改的不同点主要是:
由于涉及多个域名,因此原有使用 storage 的方案没有 cookie 那么灵活。OK,涉及多个域名,那么最常见的 CORS 跨域的手段必不可少;前端在这个过程处理不多,只需要设置 xhr 的withCredentials: true;则浏览器会在请求跨域的时候,把对应域名的 cookie 带上到请求。
但是在开发的时候,尽管后端同学已经允许请求跨域;但是看到 network 会出现部分 OPTIONS 请求;然后再发出真正的请求;在这之前,有了解过,这是浏览器的安全机制,先发出 OPTIONS 的预检请求,如果服务器允许的话,才发出真正的请求,这个过程对前端来说是透明的。但是观察到,只是部分请求有预检,并不是所有请求都有预检,那么对于哪些请求才需要呢?然后找到了 mdn cors 相关文章,文章对于情况说的比较明白,这里简单总结几点;
GET, POST, HEAD 这三种user-Agent,referer等, 白名单的请求头有:
到现在为止,请求就能够正常发出了,用户的登录与业务数据交流也完成了;但实际上也遗留了一个问题:线上环境的业务请求不是跨域的,只是本地与后端同学调试才是,那么能不能本地也不做跨域的请求呢?
本地测试前置条件:
http://localhost:8080user.local.coma.local.com由于本地开发的时候,本地通常是访问http://localhost:8080;因此在请求完user.local.com的时候,后端返回的用户信息 cookie 是存在域名 *.local.com;所以当我们请求业务数据的时候a.local.com的时候,浏览器自动把 cookie 带过去。
因此想在请求业务数据a.local.com的时候不跨域而又需要a.local.com;那么本地访问的地址也是要*.local.com;顺理成章,我们把本地的host配一下,a.local.com:8080,这个时候有个疑问,因为不同协议(http/https),不同域名,不同端口的情况下,都属于跨域,那么实际上 cookie 还是不会发过去...
But, 对于我这种面向google的,还是去查一下,因为之前只停留在印象阶段,没有去实际应用;在stackoverflow 的回答中,指出 cookie 的传输不受端口的跨域限制。
至此,我们前端开发的域名就与后端一致了;那么后端的接口怎么发送到后端同学那边呢,这里我们可以使用webpack-dev-server代理我们的请求;webpack dev-server的简略配置:
devServer: {
proxy: {
// 通常针对特定规则的请求
'^/backend': {
// 后端同学的ip地址
target: '172.x.x.x'
}
}
}总体起来是两点:
这次解决的问题实际上也比较简单;但是对一些之前认知的知识只停留在理论阶段,在实际应用上并没有实践好;顺便也巩固之前一些模棱两可的答案。end...
最近在开发的过程中,发现部署的过程非常非常的慢,可能一个跑完完整的任务理想情况下都需要10分钟左右,如果同时任务多一点,甚至到20分钟,非常影响工作效率;尽管可以在部署任务的时候摸鱼,当然这个时候可以切换去做其他任~但是长此下去不行鸭。
ci/cd中有很多job,得分析这些job的过程,卡在哪一步,才能针对过程进行优化。通常来说,一个job的“主任务”,也就是任务的核心过程,例如通过webpack构建网站资源,连接到服务器,发送文件等;这部分处理本身“主任务”之外,可能还跟对应服务器硬件资源较大关联,暂时这些就不列在这次的优化方向。
那么除了这些主任务之外,还涉及一些通用的,例如cache与artifacts,这些也是比较影响job的速度,所以这次处理方向也是这个。
提前说一下优化的结果:
优化前,job数量2-3个的时候,大概10-20分钟;job数量在5-6的时候,需要25分钟左右;
优化后,job数量2-3个的时候,大概2-3分钟;job数量在5-6个的时候,大概5分钟左右;
可以对比,大概下降的达到**70%到90%**左右,极大提高开发效率。
cache影响范围这个其中一个原因是原有的cache策略设置不好,设置了全局的cache策略:
# .gitlab-ci.yml
cache:
key: xx
path:
- node_modules
# job1
job1:
# job2
job2:
# job3
job3:因为设置了全局的cache,这个cache的内容是node_modules, 而且job之间并没有对策略(policy)进行更改,所以每个job执行的时候,开始都拉取cache(pull cache),然后提取node_modules;然后开始执行“主任务”,执行完任务之后,再把node_modules打包压缩为cache.zip,再进行上传:
download cache.zip
extract node_modules
// ...
tar node_modules
upload cache.zip
所以每个job都至少执行了“下载-上传”的过程;但是有些任务可能并不需要node_modules;所以整个node_modules连下载都没必要,通常下载是从docker对应的云盘进行下载;这些io也会很耗费时间,所以这个时候就需要看任务对cache的使用情况;
node_modules缓存,只有少部分job不需要,则可以仍然设置全局cache,对部分job显式更改策略:job1:
# 不需要cache
cache: {}cache,那么则不设置全局cache,只对job进行设定cache:job1:
cache:
key: "node_modules"
path:
- node_modules/
job2:
script:
- echo "this is job2"
job3:
script:
- echo "this is job3"
job4:
cache:
key: "node_modules"
path:
- node_modules/不同的job可以使用相同的缓存,通过key值来确定,例如上面的设置node_modules为cache的id值,job1与job4都会使用并且更新同一份cache。
通过上面第一点的优化,可以把不需要cache的任务过滤掉;但是有些地方还是会有重复,例如上面例子的job1与job4,两个job都对cache进行下载与更新,但是是否需要更新这么频繁呢?是否另外的任务是不需要对cahce进行更新,只需要获取就ok了?
对于这种情况,可以设置一个任务需要“下载-上传”cache,而其他需要到相同的cache,只进行下载,那么就可以省了“上传”的步骤;可以通过设置policy: pull配置该策略;policy的值有三个:
pull只下载push只上传,不下载pull-push下载-上传(不设置的默认值)假设上面提到job1总是比job4要先,所以job4的策略可以做更改,删除job4的 npm install过程
job4:
cache:
key: "node_modules"
path:
- node_modules/
policy: pull而为了保证这种顺序,job1我们可以设置为一个独立的stage,在执行job4的之前,必须执行:
stage:
- first
- second
job1:
stage: first
cache:
key: "node_modules"
path:
- node_modules/
job2:
job3:
job4:
cache:
key: "node_modules"
path:
- node_modules/
policy: pull所以我们可以把stage: first的过程定义为获取node_modules,也就是npm install的过程,作为其他依赖node_modules最基础的一个job。这就完了?还有优化方向吗?
通常来说,node_modules的变化次数不会特别多,所以尽管把npm install的过程抽离出来,但是每次提交都执行npm install,还要把巨大的cache.zip上传一遍;耗费的时间也是不少。所以我们可以设置当npm包发生更改的时候再执行npm install的job;也就是package.json发生改变,所以job1可以更改为:
job1:
stage: first
cache:
key: "node_modules"
path:
- node_modules/
rules:
- changes:
- package.json
- yarn.lock # 或者 package-lock.json 等
when: always
- if: $YOUR_CUSTOME_VARIABLE
when: always上面的changes数组表示,如果package.json或者yarn.lock发生改变之后,再运行job1;细心的朋友可能发现rules的数组还有一个规则,if: $YOUR_CUSTOME_VARIABLE,这个规则作用是啥?
因为cache是不稳定的,有可能被删除;这个时候package.json并没有更新,job4就不能够获取cache,job4就不能跑起来(上面提到,job4去掉npm install过程);而这个if: $YOUR_CUSTOME_VARIABLE规则就是加入可以人为主动控制触发job1,用于下载npm install;而这个变量是存在于gitlab仓库的ci variable,或者主动触发pipeline的时候加入。这样子整个流程就能完整保证运行起来。
实际上运用起来更改比较简单,但是效果确实非常明显,对于上面的方法,小结如下:
cache影响范围,不适用的选择跳过cache的更新次数,通常node_modules不需要多个任务更新,独立到一个任务即可cache的更新策略,并有人工干预手段进行处理,保证程序可用性实际上,之前旧的规则每次耗费这么多的时间,除了cache控制不好之外,也有另外一个非常重要的原因。从上面可以知道,在没优化cache策略之前,每个job都有对cache进行pull-push的过程;在push之前,ci会显示打包涉及的文件数量:node_modules/: found ${xxx} matching files,其中${xxx}为需要压缩为cache.zip的文件数量;通过观察发现,跑的pipeline越多,打包的文件数量越来越多;最终导致cache.zip体积也越来越大;甚至已经达到了30w+的文件数量,这是非常恐怖的数字。要知道,项目初始化安装完node_modules的时候,文件数量才3w+,为什么文件数量的数量级会直接加了一个数量级?
因为npm安装的文件也不会每次更改,已经有lock的相关文件,所以剔除涉及的npm包问题;那么node_modules除了npm包之外还有什么哪些文件?.bin与.cache。.bin的数量也是不变的;所以只能落到.cache文件夹变化了。
node_modules/.cache文件夹内容通常是cache-loader存储缓存文件的地方,通过统计开发机的该文件夹的文件数量,惊人的发现,居然也有将近20w的文件。其中.cache/vue-loader的最多,达到10几w,其次是.cache/babel-loader。
那么为啥.cache文件夹的数量,因为我们在开发或者部署过程中,更改文件之后,就会生成新的一些cache,逐渐逐渐的,.cahce文件就越来越多。而优化前的cache规则,是全局的,而且每次都会push,所以就每次跑完pipeline都会把该次所更新的.cache增加文件,最后就导致文件非常庞大.....
cache-loader的目标是为了加快构建速度,下面做了一个测试,大家可以观察一下:
| # | cache | no-cache |
|---|---|---|
| first run dev-serve | 40s | 38s |
| second run dev-serve | 20s | 29s |
| third run dev-serve | 20s | 28s |
| add line | 5s | 5s |
| trigger eslint error | 3s | 3.1s |
| stop & restart dev-serve | 21s | 29s |
| stop & update element & restart dev-serve | 25s | 30s |
| first build | 62s | 60s |
| second build | 23s | 30s |
| update element & build | 30s | 33s |
测试顺序从上到下,cache为使用cache-loader,no-cache没有使用,测试流程解析如下:
first run dev-serve首次启动本地开发,通常是npm run servesecond run dev-serve文件没有更改,再次启动本地开发third run dev-serve与上一步一致add line添加一行代码,添加的这行代码一致trigger eslint error,这里也是添加一行代码,但是这行代码会触发eslint的报错,例如执行一个不存在的函数stop && restart dev-serve,关掉本地开发的serve,然后再次启动stop && update element & restart dev-serve,关掉serve,然后更新部分元素,两次更新一致;然后再次启动servefirst build,第一次执行build任务,生产环境构建second build,没有更改文件,再次执行build任务update element & build,更改部分元素,再次执行构建从上面可以发现,cache-loader没有什么优势;只在两次构建文件没变化的时候,有一定的提升;但是这种情况比较少,所以是否利用也是值得商榷。当然也有可能测试不够严谨,大家也可以测试过程。
End.
参考文章:
最近在弄一个项目的模版,之前是以fork的方式新建;这种方式不太友好,所以想着参考cra,用cli的方式创建模版;也趁这个机会了解cra创建项目的过程。如果想了解概要过程,直接拉到页面底部即可。
先大概了解cra所用到的工具,在入口文件可以看到,下面写一些简单工具的简单描述与使用目的,对所使用工具熟悉,看源码起来会比较有帮助。熟悉的话可以跳过...
// chalk 是一个美化终端输出文字,通常可以更改文字的颜色与背景色
const chalk = require('chalk');
// commander 是一个对终端的参数输入进行处理工具,让输入参数更容易处理
const commander = require('commander');
// 原生 dns 模块,emm,作用就是对域名相关dns解析吧
const dns = require('dns');
// eninfo 获取系统的信息,设备信息,浏览器,node版本等;在debug的时候用到
const envinfo = require('envinfo');
// execSync 调用子进程的一个方法
const execSync = require('child_process').execSync;
// fs-extra 增强型 fs,提供一些更友好调用方法
const fs = require('fs-extra');
// hyperquest 将http请求应答过程变成stream形式返回
const hyperquest = require('hyperquest');
// inquirer 用于在终端与用户交互的输入工具,例如,提问,y/N等
const inquirer = require('inquirer');
// 原生 os 模块,用于获取不同系统的结束标识:os.EOL
const os = require('os');
// 原生 path 模块,用于路径拼接等处理
const path = require('path');
// semver 用于对版本的大小判断, 通常基于 x.y.z
const semver = require('semver');
// cross-spawn 与child_process的spawn类似,增强型,兼容多系统
const spawn = require('cross-spawn');
// tmp 获取系统的临时文件夹等 https://github.com/raszi/node-tmp
const tmp = require('tmp');
// tar-pack 解压tar压缩包
const unpack = require('tar-pack').unpack;
// 原生 url 模块,对url进行处理,返回对象形式等
const url = require('url');
// validateProjectName 判断 npm 包名称是否合法
const validateProjectName = require('validate-npm-package-name');const program = new commander.Command(packageJson.name)
.arguments('<project-directory>')
.option('--typescript')
// ...可以看到处理输入的文件夹名称与部分配置等;通过commander的处理转换成对象形式,更容易操作
当判断输入已经没问题之后,就执行createApp函数,
函数执行首先是判断node版本,对于低版本进行提醒或退出,这个取决于是否用到typescript;这里判断node版本信息通过semver处理,需要node版本>=8.10.0。
检查node版本之后,就会检测输入的文件夹名称是否负责npm包名称的规范,检测的方法为:checkAppName,其中利用到的工具库是validateProjectName;
接着处理目标文件夹,fs.ensureDirSync(name),这里的fs是指fs-extra模块;fs.ensureDirSync方法的作用是:如果目标文件夹不存在,则创建对应的文件夹;
那如果目标文件夹存在怎么办?cra会对目标文件夹的文件进行判断,如果目标文件夹的文件不影响新建项目,则还是可以继续进行;cra会维护一些文件的白名单还有部分规则,具体可以看isSafeToCreateProjectIn函数
文件夹准备完成之后,就会往目标文件夹写入一个简单的package.json文件
{
name: appName, // appName 就是目标文件夹的名称
version: '0.1.0',
private: true,
}然后判断使用哪一个依赖管理器,默认是yarn,也可以指定npm和pnpm;依赖的npm版本需要大于5,yarn版本需要大于1.12.0;当处理完管理器之后;如果确定使用yarn且没有更改yarn的仓库地址(默认是:https://registry.yarnpkg.com);则会拷贝yarn.lock.cache当作yarn.lock,用于保证安装依赖是正确的;如果不是指定yarn或者指定了别的仓库地址,则按最新版本安装。
这里简单说一下pnpm,npm和yarn会熟悉一点,但是这个pnpm用得比较少。这个管理器号称速度比yarn和npm都要快3倍(2017年数据),而且省空间;因为yarn不同项目如果依赖相同版本的npm包,如果本地已安装,是通过复制文件到不同的项目中去;而pnpm是通过硬链接代替复制。具体更详细可以看这篇文章why-should-we-use-pnpm?。
准备的工具和文件夹都ok了,就开始安装依赖~
run函数最开始是获取react-scripts与cra-template的安装路径与对应版本。源码在这。需要注意的是,cra-template是从v3.3.0版本开始才增加,之前的版本中,cra-template的内容也是在react-scripts中。
为什么要获取安装的路径呢?因为这两个安装包的安装路径,cra支持多种方式:
file://),猜测是为了更方便的debug过程tar.gz)文件,本地或http链接。获取完依赖包的信息之后,就开始下载
react
react-dom
react-scripts
cra-template
如果指定是typescript的环境,则还会增加相应的包:
@types/node
@types/react
@types/react-dom
@types/jest
typescript
当确认好使用的包管理工具,依赖的包版本与地址信息之后;进入install方法后,还需要对当前网络环境进行判断;因为使用yarn是支持离线下载的;这个判断就使用到dns模块,对registry.yarnpkg.com域名进行解析,若解析成功则为在线,反之则是离线。
一切就绪就开始进行下载,执行下载的命令需要对上述工具与信息拼接,然后使用spawn方法调用起子进程,让子进程去执行我们的安装命令,例如我们平常的安装命令yarn add lodash。到这里会有一个疑问,看到文件顶部引入的execSync与spawn都是子进程的执行方法,这两个方法会有什么区别?
这两个方法最主要的两个区别是:
spawn()返回的是一个流stream,stream会触发data和end等事件,通过触发事件返回数据;文章中称之为"异步的异步"exec()返回是一个buffer,也就是对执行命令的输出一次性返回,这个buffer默认是200k;如果输出超过这个值,就会报错。文章中称之为"同步的异步"所以通常对于输出数据比较大的选用spawn 输出数据比较简单的,选用exec。更详细可以看这篇文章,difference-between-spawn-and-exec
回到install函数,spawn执行安装,当安装完毕后,通过close事件确认是否安装成功:
// https://github.com/facebook/create-react-app/blob/9a817dd0d780ec401afb1f99dbc0f3bdbcd51683/packages/create-react-app/createReactApp.js#L402
const child = spawn(command, args, { stdio: 'inherit' });
child.on('close', code => {
if (code !== 0) {
reject({
command: `${command} ${args.join(' ')}`,
});
return;
}
resolve();
});安装完毕之后,会回到原来的run函数,接着还有对环境进行检查:checkNodeVersion,检查当前node的环境版本是否符合react-scripts最低的node版本要求;
环境检查完毕后,对所依赖的包react-scripts的版本修正:setCaretRangeForRuntimeDeps,例如下载react-scripts的时候指定v3.3.0版本,则在新建的项目中的package.json的dependencies修正为:^3.3.0。
检查都通过之后,准备对模版文件进行处理;因为安装的cra-template已经包含了我们需要的源文件,是直接拷贝到目标文件就可以了?这个时候执行另外一段命令,地址:
await executeNodeScript(
{
cwd: process.cwd(),
args: nodeArgs,
},
[root, appName, verbose, originalDirectory, templateName],
`
var init = require('${packageName}/scripts/init.js');
init.apply(null, JSON.parse(process.argv[1]));
`
);这段命令是执行react-scripts/scripts/init.js的方法。后续的操作就交给init方法处理,这个暂时先放一下,后面再展开;再看一下如果该段代码执行出错,或者在install过程中出错,就会跳到最后的catch方法:这个方法主要是对已生成的文件进行删除,错误代码处理过程:源码
package.json
yarn.lock
node_modules
如果在目标文件夹已生成上面的文件列表,则会对这些文件移除;若移除后文件夹为空,则会对文件夹也删除。
到这一步的时候,新建的项目中主动安装的依赖有:react,react-dom,react-scripts,cra-template
这个方法主要是对cra-template的项目的模版文件进行处理,安装一些缺失的额外依赖与更改新建项目的package.json进行优化处理。
// appPackage为package.json的内容,初始化为,后续安装依赖会有改变
// {
// name: appName,
// version: '0.1.0',
// private: true,
// }
// 设置npm script命令
appPackage.scripts = Object.assign(
{
start: 'react-scripts start',
build: 'react-scripts build',
test: 'react-scripts test',
eject: 'react-scripts eject',
},
templateScripts
);
appPackage.eslintConfig = {
extends: 'react-app',
};
appPackage.browserslist = defaultBrowsers;
// ...
// 再次更新写入文件
fs.writeFileSync(
path.join(appPath, 'package.json'),
JSON.stringify(appPackage, null, 2) + os.EOL
);cra-template/template文件到新建项目目录:// Copy the files for the user
const templateDir = path.join(templatePath, 'template');
if (fs.existsSync(templateDir)) {
fs.copySync(templateDir, appPath);
} else {
console.error(
`Could not locate supplied template: ${chalk.green(templateDir)}`
);
return;
}cra-template/template.jsontemplate.json内容为:
{
"dependencies": {
"@testing-library/react": "^9.3.2",
"@testing-library/jest-dom": "^4.2.4",
"@testing-library/user-event": "^7.1.2"
}
}由于这些依赖没有在react-scripts中,因为需要在这里需要再次安装该部分依赖。
cra-template前面可以知道我们安装的时候会包含这个cra-template的依赖,而这个依赖的作用是提供模版文件,现在已经复制到目标文件夹了,因此可以执行命令删除:
$ yarn remove cra-templategit init初始化新建项目文件夹为git仓库,并把初始化的文件加入到commitInitial commit from Create React App至此整个流程已经安装完毕
安装的过程梳理为以下几点:
typescript等package.jsonreact,react-dom,react-scripts,cra-templatecra-template到目标文件夹,更改package.json内容cra-template指定额外依赖commit上述过程实现起来并不困难,但是需要兼顾到非常多的环境问题与版本处理等比较零碎的边界值等。需要对文件系统的操作了解很多,对于优化用户提示与用户交互所用到工具也要较为熟悉。整体流程需要十分严谨,才能在各种环境中处理正常。
react-scripts是项目的核心处理,包括npm script命令,还有项目的依赖。还有一些该项目的其他问题要处理,例如:
cra-template项目如何维护?yarn.lock.cached如何更新处理?这些问题解决方式都可以从create-react-app根目录的tasks文件夹与根目录的package.json中找到。
test
.
.
.
.
.
..
..
有运营同学反馈,在我们的系统上的用户信息不同步。在其他系统的用户信息会同步...
这位运营同学有两种账号:
通常来说,一般人都只有一个个人账号;但是运营需要切换为公共账号,使用该账号的权限来统一发布东西。而他遇到的情况就是,在系统 A 上从个人账号切换公共账号,然后打开我们的系统 B;发现系统 B 上看到的用户信息还是个人账号。而这个时候,他打开系统 C、D 看到的账号信息,却是公共账号。
上面说的A,B,C,D这些系统,都是由同一个后端应用来处理,每个系统的域名是一级域名相同,二级域名不同,例如:
https://a.example.com
https://b.example.com
https://c.example.com
https://d.example.com我这边后面也申请了一个公共账号,也是按运营同学的执行步骤来执行:
从这个现象发现,并不是只有 B 系统才会出现的问题,其他系统应该也会有一定概率会出现账号信息不同步;通过附近另外一个同学也来验证,系统账号信息同步具有“随机性”。也就是说,这几个系统之间,都有可能出现不同步的情况。
在当时想的推测方向:用户信息校验不同步。但是导致这个不同步是服务器(多台服务器) session 之间没共享?还是客户端 cookie 不同?还没解决。
从上面的背景可以了解到系统架构简略图如下:
不同应用的域名都解析到同一个后端应用,而后端应用对接 SSO 系统。
从上面“问题重现”中说到的推测:
但是导致这个不同步是服务器(多台服务器) session 之间没共享?还是客户端 cookie 不同?还没解决。
假设由于 session 是因为服务器之间没有同步,应该会在一段时间内进行同步完毕;但即使过了两三分钟,账户信息还是没同步。从这个粗暴的观察方法,这个假设成立度很低。
那就剩下一个原因:cookie 不同,导致服务端在认证用户的时候,辨别到不同的用户。通过调查发现,后端应用会通过解析 cookie 的其中一个字段(token) 来提取用户的信息。这一个 cookie 是挂在具体二级域名下面的,也就是:A.example.com,不是泛一级域名*.example.com。
所以实际上,A,B,C,D 这些系统之间的用户信息其实都是隔离的,只是有些“局部现象”误导了我们,这些系统之间是互通。那么这些“局部现象”应该怎么解释呢?
SSO 登录系统用来解决多个应用统一的登录问题,减少用户在每个系统上都需要一套账号密码的麻烦程度,能够让各个系统统一登录状态。例如上面说的,有4个系统,通常只要在一个系统上面登录了,在另外几个系统就能够做到“免登”的效果。
下面的图是简单描述了一个系统通过 SSO 来进行登录的过程;
假设用户没有登录过 A.example.com的系统,而且输入的账号密码都是正确:
当用户已经在 A.example.com 登录过之后,再打开 B.example.com 流程如下图
对比以上两张图,对于用户操作来说,打开 B.example.com 就不需要输入账号密码这一步骤,用户信息状态也会进行同步。
*.example.com 的 token这里需要说一下,“过期时间”这个可能是几分钟,也有可能是几个小时,这个是后端应用进行配置。
B.example.com的时候,因为改应用域名校验是不通过的,这个时候应用跳转到 SSO 服务之后;而 SSO 服务拿到对应域名的 cookie,校验用户信息是正确的。就可以免去用户再次输入账号密码的过程。在步骤分析这一块,校验用户信息的时候,会优先对应用域名对应的 token 进行校验,如果 token 校验通过,则会返回这一个用户的信息。
假设:一开始 A,B,C,D 四个应用都是个人账号。
当用户在 A.example.com 域名下,从个人账号切换到公共账号的时候,再打开 B.example.com,有的用户是同步到公共账号,有的用户还是停留在个人账号。导致这一个现象是第三步校验的不同步。
B.example.com 这个域名下 token 校验不通过,然后跳转到 SSO 校验的时候,SSO 服务域名对应的 cookie 校验通过了,返回公共用户。B.example.com,在第三步校验 token 的时候通过,该 token 没有过期,所以返回还是个人账号。因为不同用户登录这几个系统的时间不一致,导致 token 的过期时间存在差异。导致,出现部分系统用户信息同步,部分用户信息不同步。
(完)。
这篇文章主要来聊一下事件循环;什么是事件循环?通常情况下,js是单线程处理主要任务,而除了同步逻辑之外,还有大部分异步逻辑;事件循环的规则就用于协调同步与异步任务的调用。js的事件循环在浏览器与nodejs不太一样,后面会展开说一下。
异步任务分类比较多,在浏览器端,有DOM事件,也有定时器,Promise等。在nodejs,也有process.nextTick与setImmediate等。下面会逐步介绍一下
先从一个比较简单的例子入手,该例子运行于浏览器端:
setTimeout(() => {
console.log('timeout')
}, 0)
new Promise((resolve) => {
console.log('before resolve')
resolve()
})
.then(() => {
console.log('after resolve')
})
const now = Date.now()
// 避免setTimeout受最小延迟4ms影响
while (Date.now() - now < 10) {}
console.log('end')输出结果是什么?
before resolve
end
after resolve
timeout
为什么是这样子的输出?这个例子大概是:先执行一个0ms延迟执行的定时器,紧接定义一个马上resolve的promise,然后就是一个10ms的循环block掉主线程;这个block是为了避免受定时器最小延迟因素影响。
首先输出的值是:before resolve,这是因为传入Promise的构造函数会被同步执行,至于为什么,可以查找一下Promise的实现原理。接下来输出的值是end,这也是同步的一部分,问题不大。
这里主要的疑惑是在定时器与Promise,按照最直观的感受是,定时器到时间而且先注册,Promise后面才注册,应该是先输出timeout,再输出after resolve。
对于这个处理,需要引入一个macro task(宏任务)与micro task(微任务)的概念;现在知道有这回事,js把异步任务分成两种;而这两种任务的优先级不同;事件循环的时候,可以想象:线程快速轮询,判断是否有这两种任务,有则执行;那么执行的时候,总是优先执行微任务,用代码简单描述:
let macroTaskQueue = []
let microTaskQueue = []
while (macroTaskQueue.length) {
// 执行宏任务,按照FIFO顺序执行
execute(macroTaskQueue[0])
// 执行完毕检查是否有微任务,也是按照FIFO顺序执行
while (microTaskQueue.length) {
execute(microTaskQueue[0])
microTaskQueue.shift()
}
// 执行完该宏任务,则从队列删除
macroTaskQueue.shift()
}宏任务会首先执行,因为主线程开始是属于宏任务;执行完同步任务后,检查是否有微任务,有则一直执行,直到把微任务的队列清空,然后再检查是否有宏任务,有则执行...一直轮询这个过程。
而promise属于微任务,setTimeout属于宏任务;回去刚才的例子,当执行完输出end之后,相当于第一个宏任务已经完成;而这个时候setTimeout也到了设定时间,需要加入到macroTaskQueue的队列中;promise也从pending变成resolved状态了,也需要加入到microTaskQueue队列中;因为microTaskQueue有任务,所以需要先执行,输出after resolve之后;microTaskQueue队列就为空了;然后就检查macroTaskQueue队列,发现有任务,这个时候就输出timeout。
浏览器中的微任务通常有:
宏任务通常除了以上的,基本都是,例如:
requestAnimationFrame简称为rAF,表示:
告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画
具体的api说明可以看mdn说明。
requestIdleCallback简称rIC,表示浏览器渲染一帧的空闲时间进行调用;若执行没有超过给定的时间,则不会影响浏览器关键事件,例如动画和输入响应的。具体的api说明可以看mdn说明。
我们来看一个稍微复杂一点的例子:
<!-- dom 结构-->
<div id="outer"></div>document.getElementById('outer').addEventListener('click', () => {
console.log('start')
requestIdleCallback(deadline => {
console.log('rIC', deadline.didTimeout)
})
requestAnimationFrame(() => {
console.log('rAF')
})
setTimeout(() => {
console.log('setTimeout')
}, 0)
Promise.resolve().then(() => {
console.log('promise')
})
console.log('end')
}大概的逻辑就是,对#outer的元素进行一个点击绑定,在点击的回调函数里面有各种异步操作,求输出的顺序。
按照我们之前的微/宏任务的划分,可以大概知道顺序是:
1. start
2. end
3. promise
?. rIC/rAF/setTimeout
输出顺序的1,2,3很好理解,主线的宏任务与微任务优先级比较高;但是rAF, rIC, setTimeout的输出是怎样的呢?按照之前我们的定义,这三个都属于宏任务,如果这三个按顺序进入macroTaskQueue的队列的话,也就是逐个输出;那么这个时候输出是:rIC => rAF => setTimeout吗?当多次点击触发的时候会发现,顺序并不固定。
这个时候就需要了解简单的原理:
图片来源
上面这张图会简单描述了,浏览器中刷新每一帧所做的事情;每一帧中,都会按顺序处理js事件,timer,rAF,渲染等。从这里我们可以看到,rAF是在Paint与Layout阶段之前处理的;
再看下一张图:
图片来源
在一帧当中,如果动画渲染完毕,就会进入这一帧的Idle阶段,这个时候就会回调我们的rIC函数,这个函数接收的参数就可以知道当前帧是否有空闲时间、剩余多少空闲时间。
从上面的图大概可以知道每一帧所处理的主要事情;这个时候我们回到输出代码的例子:
?. rIC/rAF/setTimeout
这个顺序的不确定性,与浏览器中每一帧的处理有关系;如果在下一帧开始之前,setTimeout已经加入到macroTaskQueue队列中,则这个时候,rAF与rIC也已经在这之后进入队列,这种情况所输出的顺序是:setTimeout => rAF => rIC;
如果在下一帧开始之前,setTimeout的回调还没有被加入队列中,但是rAF与rIC也已经进队了;这个时候就会先输出rAF => rIC;而setTimeout则在这一帧完成之后,才被加入到队列,所以会下一帧处理timer的过程输出值;这种情况最后的输出值为:rAF => rIC => setTimeout;
还有一种情况是,这一帧处理已经开始了,setTimeout的回调还没有加入到队列中,当执行完rAF之后,setTimeout才加入到队列,那么这个时候是会执行timer还是rIC;根据测试发现(chrome 77.0),这个时候会去执行timer,再执行rIC;这种情况最后的输出值为:rAF => setTimeout => rIC.
小结:
rAF与setTimeout的执行顺序取决于进入macroTaskQueue的顺序,而加入macroTaskQueue的顺序可能取决于这一帧的运行情况与setTimeout的时机;rIC之前,总是把队列中的任务都执行完,包括microTaskQueue与macroTaskQueue通常情况下,触发dom的回调事件除了在人工触发之外,还可以通过代码触发。例如点击事件,可以在元素上点击与主动触发$element.click();我们看下面的例子:
<!-- dom 结构 -->
<div id="outer">
<div id="inner"></div>
</div>function click (ev) {
console.log('start', ev.currentTarget.id)
Promise.resolve().then(() => {
console.log('promise', ev.currentTarget.id)
})
console.log('end', ev.currentTarget.id)
}
document.getElementById('outer').addEventListener('click', click)
document.getElementById('inner').addEventListener('click', click)当在界面点击#inner的时候,输出的顺序为:
1. start inner
2. end inner
3. promise inner
4. start outer
5. end outer
6. promise outer
上面输出问题不大,因为冒泡的事件触发也属于宏任务,Promise的触发属于微任务,队列变化的简单过程为:
// 0. 点击inner
macroTaskQueue = ['click(inner)', 'click(outer)']
microTaskQueue = []
// 1. inner的回调函数处理完毕,并出队
macroTaskQueue = ['click(outer)']
microTaskQueue = ['promise(inner)']
// 2. 微任务先执行,并出队
macroTaskQueue = ['click(outer)']
microTaskQueue = []
// 3. 再执行剩下outer,并出队
macroTaskQueue = []
microTaskQueue = ['promise(outer)']
// 4. 执行微任务
macroTaskQueue = []
micoTaskQueue = []如果使用代码主动触发:$inner.click(),输出的顺序为:
1. start inner
2. end inner
3. start outer
4. end outer
5. promise inner
6. promise outer
这个时候任务队列的初始情况就变成了:
macroTaskQueue = ['click(inner);click(outer);']
microTaskQueue = []冒泡的事件都变成到一个宏任务,具体为什么,就后续再做研究了...浏览器的事件循环就暂时到这里。
小结:
nodejs端的事件循环比浏览器会稍微复杂一点点,除了微/宏任务之外,还有不同的事件阶段,下面我们来看这张图
图片来源
nodejs中的事件分为6个阶段:
每个阶段都有一个 FIFO 队列来执行回调。虽然每个阶段都是特殊的,但通常情况下,当事件循环进入给定的阶段时,它将执行特定于该阶段的任何操作,然后在该阶段的队列中执行回调,直到队列用尽或最大回调数已执行。当该队列已用尽或达到回调限制,事件循环将移动到下一阶段,等等。
简单的说是,执行到每个阶段,都需要把该阶段的队列回调执行完或者达到最大的执行数量,所以nodejs的队列至少有6个。为什么说说至少呢,因为这个截图中没有把procese.nextTick()与Promise相关列出来;这两种情况都会在进行下一阶段执行之前执行,而nextTick的优先级要比Promise要高,因此这个图就变成了:
上图没有把所有都用箭头标出来,只是列举了前三个,实际上所有阶段都会有这个检查
nodejs把“宏任务”分成了6种情况,这6种分别对应:
timer 专门执行定时器相关的回调函数:setTimeout,setIntervalpending callbacks: 此阶段通常对系统操作执行回调(例如 TCP错误),例如,如果 TCP 套接字在尝试连接时接收到 ECONNREFUSED,则某些 *nix 的系统希望等待报告错误。这将被排队到这个阶段执行idle, prepare: 系统相关执行,不了解,忽略poll: 执行大部分I/O callback,除了process.nextTick,microtask,timer, pending callbacks, close event之外的所有回调都是在这里,例如,读取文件的回调等check: 专门执行setImmediate的回调close callback: 例如网络的socket close的回调事件在这里处理我们先看一个例子:
Promise.resolve().then(() => {
console.log('promise')
})
process.nextTick(() => {
console.log('nexttick')
})
setTimeout(() => {
console.log('timeout')
})
setImmediate(() => {
console.log('immediate')
})
console.log('finish')finish,这个问题不大,因为刚开始的同步执行nexttick,在进入timers阶段之前执行,可以认为是微任务promise,与nexttick类似,也属于微任务,但是优先级相对低一点timeout或immediate,这个输出不稳定,两个先后顺序不确定在上面的输出结果可以看出,前3个输出都每啥问题;而对于timeout与immediate,为什么会不稳定呢?
是因为js在准备进入检查队列的时候,timeout的回调函数不确定是否进入了timers阶段的队列;尽管设置了setTimeout的时间为0,实际上只至少1ms,因此有可能在1ms之后,js进程已经运行过了timers阶段,那么这个时候的输出结果就是immediate优先;若进入timers阶段已经耗费超过1ms,那么就会出现timeout的输出。
再看下一个例子:
const fs = require('fs');
fs.readFile('./file.js', () => {
console.log('file callback')
setImmediate(() => {
console.log('immediate')
})
setTiemout(() => {
console.log('timeout')
})
})输出顺序为:
因为fs.readFile的回调属于poll阶段,而在这个阶段中,把timeout与immediate都加入不同的队列中;当poll阶段完成之后,进入check阶段,这个时候刚才添加的immediate已经进入队列,所以输出是immediate;当事件循环下次经过timers的时候,再把timeout输出。
小结:
process.nextTick与Promise属于微任务,优先级相对较高,其中process.nextTick对于Promise优先级更高;在进入每个事件阶段之前,都先执行微任务下面从源码简单分析一下vuex的启动与使用过程,适合对vuex有使用经验看一下;适当回顾,也是对提高很有帮助。
先看一下简略初始化的流程,后面看完再回头过一遍:
图中左边是主要的流程,右边是对某个流程的重要关联,也属于主流程
在src目录下的index.js文件主要内容是:
export default {
Store,
install,
version: '__VERSION__',
mapState,
mapMutations,
mapGetters,
mapActions,
createNamespacedHelpers
}其中mapXxx这些是工具函数,暂不展开说明;vuex的主要内容是在Store中,就从这个文件为入口进行分析:
// store.js
export class Store {
constructor () {
if (!Vue && typeof window !== 'undefined' && window.Vue) {
install(window.Vue)
}
if (process.env.NODE_ENV !== 'production') {
assert(Vue, `must call Vue.use(Vuex) before creating a store instance.`)
assert(typeof Promise !== 'undefined', `vuex requires a Promise polyfill in this browser.`)
assert(this instanceof Store, `store must be called with the new operator.`)
}
// ...
}
}当调用new Store()的时候;先看第二个if,这里通过判断当前运行的环境,例如在开发环境中,不是通过new,不支持Promise等情况进行warning提示
在构造器的第一个if当中,帮助用户自动安装vuex到vue中,安装的主要函数是install,我们继续来看这个函数:
function install (_Vue) {
if (Vue && _Vue === Vue) {
if (process.env.NODE_ENV !== 'production') {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
}
return
}
Vue = _Vue
applyMixin(Vue)
}在install函数当中,在非生产环境当中,也会判断是否有重复安装;若没有重复安装,则调用applyMixin方法。
// applyMixin function
export default function (Vue) {
const version = Number(Vue.version.split('.')[0])
if (version >= 2) {
Vue.mixin({ beforeCreate: vuexInit })
} else {
const _init = Vue.prototype._init
Vue.prototype._init = function (options = {}) {
options.init = options.init
? [vuexInit].concat(options.init)
: vuexInit
_init.call(this, options)
}
}
/**
* Vuex init hook, injected into each instances init hooks list.
*/
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
this.$store = typeof options.store === 'function'
? options.store()
: options.store
} else if (options.parent && options.parent.$store) {
this.$store = options.parent.$store
}
}
}对于applyMixin的处理分两种情况,如果是大于[email protected]版本,会使用全局混入的方法处理,把初始化的过程加入到组件的beforeCreate钩子;而对于[email protected]版本,会在原型链中添加_init方法;这两种情况都是调用了vuexInit的函数;
vuexInit的函数的处理是把store挂载到每个组件的this.$store中;大概的逻辑是,每个组件调用的时候,都会从父组件(this.$options.parent)获取$store,那样子就可以做到把$store逐级往下传递:
root
|-- foo
|-- bar
|-- baz
组件渲染也是从上层往下层渲染,例如上面的结构,根组件是通过this.$options.store获取$store; foo组件的父组件是root,那么从root中获取$store的引用;而渲染到bar,baz的时候,就从foo组件中获取。
安装过程小结:在调用new Store()的时候,会判断当前环境支持情况,是否重复安装等情况进行判断,若不符合要求会报warning或error;安装的时候注入全局mixin或者更改Vue.prototype方法,对新增组件完成添加$store的过程。
通过上一步安装Store之后,之后就根据用户传入的配置进行初始化。下面的代码片段仍然属于Store的构造器
class Store {
constructor () {
// 安装Store...
this._committing = false
this._actions = Object.create(null)
this._actionSubscribers = []
this._mutations = Object.create(null)
this._wrappedGetters = Object.create(null)
// 生成模块
this._modules = new ModuleCollection(options)
this._modulesNamespaceMap = Object.create(null)
this._subscribers = []
this._watcherVM = new Vue()
}
}这一段的代码片段没什么特别,把一些属性挂载到this,也就是Store实例;其中有一段this._modules = new ModuleCollection(options)需要调用到外部class生成:
// module-collection.js
export default class ModuleCollection {
constructor (rawRootModule) {
// rawRootModule 为用户传入的配置,{ state, mutations, modules } 等
this.register([], rawRootModule, false)
}
register (path, rawModule, runtime = true) {
// balabala
if (process.env.NODE_ENV !== 'production') {
assertRawModule(path, rawModule)
}
const newModule = new Module(rawModule, runtime)
if (path.length === 0) {
this.root = newModule
} else {
// 绑定到对应的父模块
const parent = this.get(path.slice(0, -1))
parent.addChild(path[path.length - 1], newModule)
}
// register nested modules
if (rawModule.modules) {
forEachValue(rawModule.modules, (rawChildModule, key) => {
this.register(path.concat(key), rawChildModule, runtime)
})
}
}
}构造器中没什么特别,调用register方法,而传过去的方法是三个:
path = [] 模块的路径,根目录为空值 [],非根目录则为模块嵌套的路径:['foo', 'bar']rawModule = rawRootModule rawRootModule 为该模块的配置,根目录的配置为用户传入的所有配置runtime = false忽略掉环境的判断,可以看到还需要调用新模块方法:new Module();这一块我们暂时忽略,知道是根据当前的配置生成一个模块,后面回头再看;
由于初始化的path数组为空,因此只需要在ModuleCollection的实例的root属性添加新模块引用;执行到if (rawModule.modules),若根模块有modules,则表示有子模块,就会遍历所有的子模块,同样调用register;当子模块调用的时候,需要把子模块,挂载到父模块中。例如:
new Vuex.Store({
state: {},
mutations,
modules: {
foo: {
state: {},
modules: {
bar: {
state: {}
}
}
},
baz: {
state: {}
}
}
})对于这个配置,根目录下有foo与baz模块,foo模块有bar模块;对于这种结构生成的ModuleCollection实例简略信息为:
{
root: {
state: {},
_children: {
foo: {
state: {},
_children: {
bar: {}
}
},
baz: {
state: {}
}
}
}
}至此,ModuleCollection已完成;我们回头看一下刚才new Module()的处理:
class Module {
constructor (rawModule, runtime) {
this.runtime = runtime
this._children = Object.create(null)
this._rawModule = rawModule
const rawState = rawModule.state
this.state = (typeof rawState === 'function' ? rawState() : rawState) || {}
}
}只是把构造函数的参数挂载到实例,其中_rawModule是指该模块对应的配置,mutations,state这些。
小结:通过new ModuleCollection()传入用户的配置,调用register递归把子模块注册完毕,形成模块间的父子关系,最后挂载到store._modules属性中
对配置的模块关系处理完毕之后,就需要给store绑定commit与dispatch
class Store {
constructor () {
// ...
const store = this
const { dispatch, commit } = this
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
}
}这里先提取原型链的commit和dispatch方法,然后重新赋值,使用call方法保证了commit与dispatch方法执行的上下文为store的实例
// store.js
class Store {
constructor () {
// ..
const state = this._modules.root.state
// 递归把所有模块的mutations等注册
installModule(this, state, [], this._modules.root)
}
}
// installModule
function installModule (store, rootState, path, module, hot) {
const isRoot = !path.length
// 获取模块的路径,例如;['foo', 'bar'] => 生成 /foo/bar
const namespace = store._modules.getNamespace(path)
// register in namespace map
if (module.namespaced) {
if (store._modulesNamespaceMap[namespace] && process.env.NODE_ENV !== 'production') {
console.error(`[vuex] duplicate namespace ${namespace} for the namespaced module ${path.join('/')}`)
}
store._modulesNamespaceMap[namespace] = module
}
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
const local = module.context = makeLocalContext(store, namespace, path)
// 注册mutation
// 添加一个_mutation属性到store
// 把同名的mutation放到同一个数组
// store._mutations = [
// handler1,
// handler2
// ]
module.forEachMutation((mutation, key) => {
const namespacedType = namespace + key
registerMutation(store, namespacedType, mutation, local)
})
// 注册 action
// 添加一个 _action属性到store,与 mutation 类似
module.forEachAction((action, key) => {
const type = action.root ? key : namespace + key
const handler = action.handler || action
registerAction(store, type, handler, local)
})
// 注册 getters
// 添加一个 _wrappedGetters 属性到 store,与mutation和action有点不同
// 只能有一个getters
module.forEachGetter((getter, key) => {
const namespacedType = namespace + key
registerGetter(store, namespacedType, getter, local)
})
// 递归安装模块
module.forEachChild((child, key) => {
installModule(store, rootState, path.concat(key), child, hot)
})
}来分析一下installModule,部分有写注释到代码;if (module.namespaced)是用来判断是否有重名的模块,在非生产环境提示(真的很多提示...),然后来到关键一步:
const local = module.context = makeLocalContext(store, namespace, path)通过makeLocalContext函数,对当前模块对应的commit与dispatch再做一层处理,使得适配对子模块路径调用,例如commit('/foo/bar');对模块的state与getters做数据劫持处理;这个暂时先跳过,我们先知道这个函数的作用。
接下来installModule就对mutations,actions,getters进行注册,分别赋值到:
mutations => store._mutationsactions => store._actionsgetters => store._wrappedGetters那么store._actions里面是什么?这是一个hash数据,key是action的名称,value是这个action的handler调用函数。
为什么一个action对应多个handler?因为vuex对module处理的时候,如果模块没有明确声明namespaced: true,那么这个handler获取到的state也是'root'下的数据
这些handler有什么特别?为了传入更多的参数,例如我们调用的时候是:store.dispatch('type'),但在store的action,可以接收更多的参数;因为注册actions的时候,再套一层函数,设置handler在调用传入参数。
store: {
actions: {
type ({ commit, rootState }) {}
}
}mutations与actions比较相似,允许多个同名,但是getters只能允许有一个。
当注册完以上数据的时候,则对所有子模块递归处理,那么子模块的actions等也处理完毕;最后得到所有的actions;最终形成的数据:
store._actions = {
'action1': [fn1, fn2], // 重名action加入到数组
'foo/action1': [fn3] // 这个是因为有命名空间`foo`
}小结:通过installModule递归安装所有模块;通过makeLocalContext获取到对应模块的上下文,使得commit与dispatch能够获取到子模块的数据;根据命名空间的设定,生成带路径的调用type,分别挂载到store对应字段;并对handler的参数进行调整。
从上面可以知道,makeLocalContext是设定模块的上下文,处理过程如下:
function makeLocalContext (store, namespace, path) {
const noNamespace = namespace === ''
const local = {
// 没有指定命名空间,则使用与root根路径下的调用一致
dispatch: noNamespace ? store.dispatch : (_type, _payload, _options) => {
const args = unifyObjectStyle(_type, _payload, _options)
const { payload, options } = args
let { type } = args
// 子模块调用
if (!options || !options.root) {
// 拼接调用路径
type = namespace + type
if (process.env.NODE_ENV !== 'production' && !store._actions[type]) {
console.error(`[vuex] unknown local action type: ${args.type}, global type: ${type}`)
return
}
}
return store.dispatch(type, payload)
},
commit: noNamespace ? store.commit : (_type, _payload, _options) => {
// ...
}
}
// getters and state object must be gotten lazily
// because they will be changed by vm update
Object.defineProperties(local, {
getters: {
get: noNamespace
? () => store.getters
: () => makeLocalGetters(store, namespace)
},
state: {
get: () => getNestedState(store.state, path)
}
})
return local
}对dispatch的处理,如果没有指定命名空间,那么action接收到的state等是与root下一致;如果指定命名空间,则对原来调用的type进行拼接,加上对应的命名空间;对应上面所有的:store._actions的hash的key值;
对于commit的处理,与dispatch一致;而对getters和state的处理,需要对数据进行劫持,延迟更新。
至此,安装模块已经完毕,我们继续回到Store的构造函数
class Store {
constructor () {
// ...
resetStoreVM(this, state)
}
}
// resetStoreVm
function resetStoreVM (store, state, hot) {
const oldVm = store._vm
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
// 对 getters 进行计算属性的处理
forEachValue(wrappedGetters, (fn, key) => {
computed[key] = partial(fn, store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: {
$$state: state
},
computed
})
Vue.config.silent = silent
// 开启严格模式,不允许不通过commit修改数据
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
if (hot) {
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}
// enableStrictMode
function enableStrictMode (store) {
store._vm.$watch(function () { return this._data.$$state }, () => {
if (process.env.NODE_ENV !== 'production') {
assert(store._committing, `do not mutate vuex store state outside mutation handlers.`)
}
}, { deep: true, sync: true })
}resetStoreVM主要做的是:
getters转换为store._vm的计算方法;store的state数据进行深度监听;对于直接修改state数据的时候,进行错误提示。至此,new Store()的流程基本走完,还有插件的处理,这里就暂不展开说明。
上面说到,如果直接修改state的时候,会进行错误提示;那么为什么通过commit就不会呢?
commit (_type, _payload, _options) {
// check object-style commit
const {
type,
payload,
options
} = unifyObjectStyle(_type, _payload, _options)
const mutation = { type, payload }
// 获取调用的handler
const entry = this._mutations[type]
if (!entry) {
if (process.env.NODE_ENV !== 'production') {
console.error(`[vuex] unknown mutation type: ${type}`)
}
return
}
// 通过 _withCommit 方法调用handler
this._withCommit(() => {
entry.forEach(function commitIterator (handler) {
handler(payload)
})
})
// ...
}从上面看到,commit的流程,就是从store._mutation拿到对应的handler数组,然后逐个执行;而循环执行所有handler是包裹在_withCommit方法里面:
_withCommit (fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}因为调用_withCommit的时候,会把标识位this._committing设定为true,执行中,会触发前面resetStoreVM说到的,深度监听state回调函数;该回调函数判断this._committing为true,则为正确的调用;_withCommit把函数执行完毕之后把标识位重新设定为false;这样子就可以做到,对不通过commit调用的提示。
vuex的异步操作,是放到dispatch调用:
dispatch (_type, _payload) {
// check object-style dispatch
const {
type,
payload
} = unifyObjectStyle(_type, _payload)
const action = { type, payload }
const entry = this._actions[type]
if (!entry) {
if (process.env.NODE_ENV !== 'production') {
console.error(`[vuex] unknown action type: ${type}`)
}
return
}
// .. try catch subscriber
const result = entry.length > 1
? Promise.all(entry.map(handler => handler(payload)))
: entry[0](payload)
return result.then(res => {
// ... try catch subscriber
return res
})
}从代码可以看出,通过dispatch的type找到所有的handler,如果handler只有一个,则直接返回这个handler的调用处理;若有多个,则使用Promise.all包裹处理,最终作为一个Promise形式返回;用户设定的actions实际上并不会一定是Promise,这种情况,只有一个handler会出错吗?
不会,因为handler在registerAction的时候,对返回值进行判断,若不是Promise,则直接返回Promise.resolve(res),res为actions的返回值。
除了主流程的执行,还有执行前后对subscriber执行的try...catch处理
简单分析了一下vuex的源码的主要流程,发现其中很多处理都很巧妙;例如,上下文,执行参数的处理;值得学习...但是文章对插件的分析过程缺失,大家也可以去熟悉一下,END.
最近在看一下react-router的源码,看到react-rouer的功能分散到几个packages,也依赖基础包hisotry,如果完整源码分析,可能会有点多,所以这次就弄一个张图来说明一下react-router的使用。估计再过一阵子,v6版本就要发了,这个图是v5.x版本的,有点悲催。下面直接上图,主要说是在浏览器端运行的react-router:
图有点点长,先来简单说一下不同颜色的区域表示什么:
左边纵向的一列:
react-router,react-router-dom,history表示不同的库,而window就是浏览器。
下面就从对底层说起,捋一下这张图。
通常来说,路由库大部分基于两种:
一种是window.history对象来控制url的改变
另外一种是通过location.hash值来控制url的改变;
现在应该大部分都是用window.history,如果要兼容部分低版本浏览器,可能就需要到location.hash。而这两者都需要到location的支持,才能获取更详细的信息。
需要注意的是,这是一个库,并不是window.history的对象。
这个库是对页面路径的操作进行封装,目前是独立一个仓库,github 地址,支持上面所说的window.history与location.hash的两种路由情况;
分别对应BrowserHistory与HashHistory的创建函数,通过这两个创建函数创建出来的对象,都具有相同的API调用,因为history这个库对这两种情况的路由进行了适配。通常这些通用的方法包含:
history.push()
history.replace()
history.go()
history.back()
// ... 等等
除此之外,还有定义一些路由过度的`promot`的逻辑等。除此之外,还有还封装了MemoryHistory的创建方法,看起来,是给到react-router-native与部分测试的时候使用的。
这个是react-router的仓库其中一个package,是专门针对浏览器处理的路由封装。
通常我们是在这个库里面指定使用哪一种路由方式,BrowserHistory or hashHistory:
import { BrowserRouter as Router } from 'react-router-dom'
// or
import { HashRouter as Router } from 'react-router-dom'而指定路由方式的时候,则调用hisotry的两种不同createHistory方法;获取创建的hisotry返回对象。
react-router-dom处理指定路由方式之外,还提供Link与NavLink的组件;通常来说;这两个组件用于跳转到不同的路由,这个时候跳转也是调用createHistory返回对象的API,push或者replace
react-router通常是开发者直接调用的入口,例如路由组件的分发,当前参数获取等。
我们知道,从react-router-dom引入BrowserRouter或者HashRouter来指定路由方式;其实这个时候,也返回一个Router的组件,用于渲染页面路由的根组件。
Router的根组件是后面所有组件的基础;后续所有组件,必须在这个根组件下。Router,Switch等组件层层嵌套。在这个过程中,RouterContext是在整个组件过程中存在,这个context就是用于不同组件间的数据共享;通常这个context的数据为:
{
history, // createHistory 返回的对象
location, // 当前路径的信息
match // 当前路由匹配的信息
}嵌套路由之间也是共用这个context,从而达到路由数据之间的传递;而hooks的调用也是基于useContext来演变成不同的hooks,例如useHistory,useLocation等。
那react-router-dom的Link更改的路由,怎么通知到context更改呢?
在createHistory的时候,返回的history对象️监听方法listen;而根组件Router监听该方法,若发生改变,则更改RouterContext的内容;从而做到不同组件间的数据通信。
这篇文章对代码描述的不多,主要是对流程的处理进行梳理;了解到不同库之间的协作,与数据通信的技巧。具体实现还是得看源码。希望能够一图胜千言!!!喜欢给个star~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.