Go 依赖管理
Go 引用的包,可以分为两类:内部包和外部包,对于内部包,因为是项目内部自己写的,管理起来比较简单;但是,对于外部包,因为是开源的,一般由第三方维护管理,可能会版本不一致,出现非预期的情况,导致编译错误,或者出现程序 BUG,有经验的程序员应该都知道,这种由于第三方包引起的问题,定位和解决往往都是很烦人的。所以,目前所谓的依赖包管理工具,都是针对外部包的管理。
大部分编程语言都是将项目代码目录作为单独的工作目录(workspace),但 Go 只有一个工作目录 ——
$GOPATH,因为 Go 自身提供了很多工具,固定的工作目录,便于这些工具的运行。因此,需要强调一点是,我们应该在 $GOPATH/src 下,创建自己的项目目录。因为,项目构建时,就是从这个路径下开始的(即作为环境路径)。
其实,对于 Go 本身来说,是不区分内部包和外部包的,因为 go get 下载的包,也都放在 $GOPATH/src 目录下,因此,当我们 import 依赖包时,只要直接路径指定就行了,类似 github.com/xx/x。又因为 $GOPATH 目录下可能创建了多个项目,因此下载在这里的依赖包,也可能会被多个项目引用,随时可能会被其他项目更新修改。
所以,在最开始的时候(Go 1.5 之前),go 项目包的依赖管理是很简陋的,为了保证外部包的安全,就必须要把外部包拷贝到项目内部,变成“内部包”。此时,包的查找顺序是: $GOROOT --> $GOPATH.
在 Go 1.5 时,为了解决这个问题,引入了 vendor 这一特殊目录,该目录在项目内创建,这就相当于,每个项目有了自己独立的 GOPATH,此时,包的查找顺序是:离引用代码最近的 vendor --> $GOROOT --> $GOPATH.
项目内的每个目录下都能创建自己的 vendor 目录,引用时,使用的是最近一层的 vendor。但是,最好只在根目录创建 vendor,便于管理,也避免同样的包,出现在同一项目内的多个 vendor 目录下。
基于 vendor 能够实现真正意义的依赖包管理,而告别简陋的拷贝操作。
内部包管理
内部包管理其实很简单,但是有一个特性需要说明,那就是 internal 目录,位于 internal 目录下的包,只能被同父目录下的包引用,否则会编译报错。 这里需要说明的是,父目录的父目录也算,即位于项目根目录下 internal 里面的包,是可以被项目内所有包引用的。
与 vendor 类似,项目内也可以有多个 internal 目录,但是建议在项目根目录创建一个就够了。
internal 目录的目的是保护该目录下的包被其他项目所引用,例如某个包还不太成熟,不想被其他项目使用。很明显,这只是一种简单的“警告”机制。
外部包管理
基于 vendor 实现的依赖包管理工具,比较流行的有 dep, Godep, Glide, Govendor 等,实现原理大同小异。官网这里对这几个工具进行了分类说明,建议使用 dep 作为项目的依赖管理工具,原因主要有两点:
dep 是官方推出的管理工具,虽然目前还是处于 official experiment. 状态,但是已经可以作为正式工具使用了;Godep 已经是 Gopher 比较常用的依赖工具了,但是可以看到,其官网已经声明后面只会进行维护性的开发工作,建议大家使用 dep 或其他工具代替:Please use dep or another tool instead.
dep 使用
dep 的使用,官方有较详细的说明文档:dep introduction.
这里根据自己的理解,做些说明。
安装
主要有两个安装方式:
mv dep-linux-amd64 $GOPATH/bin/dep
curl https://raw.githubusercontent.com/golang/dep/master/install.sh | sh
当然你也可以使用源码安装,但是,你最好不要这么干。安装完成后,执行 dep -h 查看帮助信息。
使用
dep init
首先进入需要 dep 管理依赖包的项目,以 dep-test 项目为例。执行命令 dep init
cd $GOPATH/src/dep-test
dep init
完成后,在项目根目录下会创建文件 Gopkg.lock, Gopkg.toml 和 vendor 目录,vendor 里面就是依赖的包源码了,前两个文件保存内保存了依赖包的规则类型信息,依赖包版本信息以及依赖关系描述,后面还会对 dep 实现原理进行简单说明。
实际应用中,提交代码时,我们可以将 vendor 目录一起提交,此时 其他开发者应该先使用 dep check 检验。
但是,一般 vendor 目录都比较大,这时可以只提交 Gopkg.toml 和 Gopkg.lock 文件,开发者在本地使用 dep ensure -vendor-only 自行下载依赖包。
实现模型
实现模型也有详细说明:Models and Mechanisms,dep 使用 four state system 模型,这是一种经典的包管理模型。这四个模块分别是:
Project source code 当前项目代码,即你的项目代码A manifest 依赖清单,这里就是指 Gopkg.toml 文件,最初由 dep init 生成,主要由用户编辑,来实现个性化需求。它包含几种类型的规则声明来管理 dep 的行为,可以实现灵活的下载依赖包,例如可以指定特定区间版本的依赖包。A lock 依赖描述文件,这里是指 Gopkg.lock 文件,里面详细记录了依赖包的地址,hash 值,版本等基本信息,根据描述能够复现完整的依赖图。这个文件完全是由 dep 根据 Gopkg.toml 和项目引用自动生成的。Source code of the dependences themselves 依赖包自身源码,这是就是指 vendor 目录下的代码。

dep 主要就是围绕对这四个模块进行输入输出管理实现。流程大概如下:
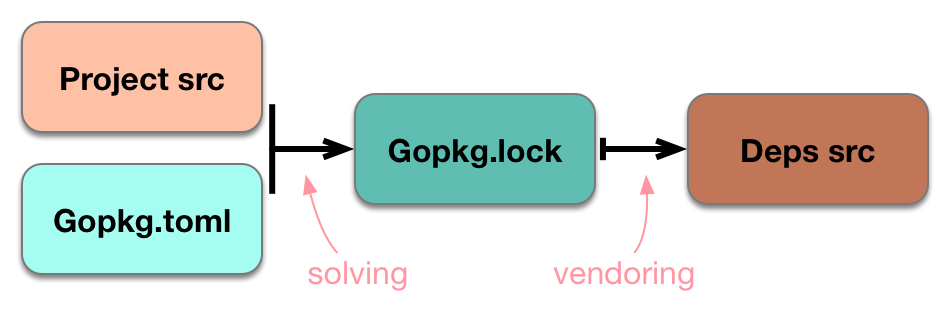
dep 根据项目引用代码和 Gopkg.toml 文件内的规则信息,计算自动生成 Gopkg.lock 文件,此时,依赖的包信息就确定了,然后根据这些信息将对应的包下载到 vendor 目录内。
踩过的坑
使用软链接问题
对于 go 这种必须将项目放在 $GOPATH/src 的约定,实际应用中可能并不灵活,于是有两个技巧:
- 动态指定 $GOPATH,也即将当前项目目录作为 $GOPATH,代码也放在 src 下,早期很多项目就是这么干的,要频繁的修改 $GOPATH,比较折腾;
- 使用软链接,这是个小技巧,即在
$GOPATH/src 下创建一个软链接,指向项目目录;
但是,当使用软链接这种方式的时候,vendor 目录会失效,变成普通的目录了,因为 vendor 目录只有位于 $GOPATH 路径下,Go 才会把它当作特殊目录处理。而符号链接只是创建了指向文件名的符号,实际的文件位置依然没变。
使用相对路径问题
实际上对于内部包,我们在引用时可以使用相对路径(相对 import 代码的路径,例如: ./a/b 或者 ../x/y 等),这可能是 go 命令的潜规则,这种方式相对较灵活而且直观,项目存放位置也可以很随意。所以对于简单项目,个人是比较喜欢使用这种方式的。
但是,这会影响 dep 生成依赖关系,导致 dep 误以为没有依赖的外部包,非常奇怪的问题。
其实,这两个坑都是因为我之前比较随意,没有按规范,将项目放在 $GOPATH/src 导致的。
Go Modules
dep 还没有应用推广,在 Go 1.11 中,又推出了全新的依赖包管理机制 Go Modules,原来叫 vgo ,在 Go 1.11 被采纳合并到了主分支,正式被发布,不出意外的话,后续版本应该都会将这个当作包依赖管理的官方解决方案。
模块为 GOPATH 提供了替代方案,用来为项目定位依赖和管理版本化。如果 go 命令在 $GOPATH/src 之外的目录中运行,并且该目录中有一个模块的话,那么模块功能就会启用,否则 go 将会使用 GOPATH(Go 1.11)。与 dep 不同,模块是集成在 go 命令的,可以使用 go mod init 创建。
小结
Go 作为比较新的语言,包依赖管理方式也在持续变动,主要分为三个阶段: 纯依赖包源码拷贝 --> 基于 vendor --> Go Modules。
每次变动都使管理变的更先进,这对于 Go 和 Gopher 都是有益的,特别是 Go Modules 据称使用了其它语言包管理工具不同的理念算法,看起来比较复杂。因为刚出来,有较多问题需要讨论,后续比较成熟了再研究,可能要等到 Go 1.12 版本吧。
所以,如果不想成为第一个吃螃蟹的人,目前,还是使用 dep 作为管理工具比较稳妥。




























































































