技术博客&工作记录存档,较为完整的记录放置在issue中
- js event loop机制
- Angular组件库脚手架搭建过程及背后原理 Angular
- Angular的单向数据流 Angular
- Angular6 升级指南
- 波浪动画效果
- [Angular API] NgTemplateOutlet 理解
- Angular可拖拽应用的实现
- npm--优秀包管理器的发展历程
- Angular4升级到Angular5的升级记录
- Flume的使用
- rsyslog的使用
见目录
Blog,Algorithms,Record,etc.
Home Page: https://github.com/jkhhuse/imgRepo/issues







在学习javascript的Event loop时,通常会遇到task、asynchronous、microtasks、runtime、message queue等等一系列概念,本文将针对浏览器端的Event loop做出整理,一一拨开这些概念的“谜团”。
首先是javascript运行时的状态表述,现代javascript引擎实现了类似于下图的模型,包含栈(Stack)、堆(Heap)、队列(callback Queue/下文也会称之为task队列)、WebAPI等机制:
参考(Philip Reberts)演讲演示文档中的一张图:

首先是栈结构,函数调用会形成一个栈帧,以“后进先出”的顺序执行,例如一段函数:
function foo(b) {
var a = 10;
return a + b + 11;
}
function bar(x) {
var y = 3;
return foo(x * y);
}
console.log(bar(7));调用bar时,创建了第一个帧,帧中包含了bar的参数和局部变量,压入栈的底部。当bar调用foo时,第二个帧会被创建,并压入栈中第一个帧之上。执行完后则会弹出栈,直至栈为空。这样一系列函数调用形成的栈的形式大致如下:

对象被分配在一个堆中,用以表示一个大部分非结构化的内存区域。
task任务队列(Queue)这个队列包含了javascript运行过程中待处理的任务,也可以称之为“task任务队列”,在Event loop的某个时刻,任务队列中的函数会以先进先出的方式被移出队列,创建栈帧,并当栈为空时压入栈底部。
通常指浏览器提供的能力,也可以把它理解为异步事件,例如SetTimeout、DOM option,如click事件、XHR等。当js程序处理异步调用时,会执行异步调用,异步调用结束后,则把回调函数添加到task任务队列中。
javascript是一个单线程语言,在处理类似上一个代码片段时,函数顺序压入栈中执行。那么遇到异步任务时,函数执行不可能陷入停顿,等待异步任务执行完毕后再继续执行。处理这种情况的技术正是Event loop机制。
所以,Event loop是一个持续处理的过程,用于判断栈中是否为空,如果栈为空,那么从task任务队列中获取一个任务放入栈中执行。
首先,先想一下下面程序的运行过程:
console.log("Hi!");
setTimeout(function timeout() {
console.log("Click the button!");
}, 5000);
console.log("Welcome to loupe.");依据之前的解释,函数被调用执行,以栈帧的方式压入栈中执行。异步调用进入Web APIs中执行,执行结束后回调函数进行任务队列。当栈为空时,从task任务队列中取出第一个函数,压入栈中执行,周而复始,直至队列为空。
得出的结果即为:
Hi
Welcome to loupe.
Click the button!那么,为了验证这个过程,可以使用Philip Reberts写的工具来验证,它可视化模拟javascript事件循环的工具。

在日常编程中,经常会遇到setTimeout(fn, ms)这样的黑魔法,使用的时候只是简单的理解为提前到某个时间去执行,如果ms为0呢?是否是立即执行呢?在理解事件循环机制之前,确实有这样的困扰。
其实,setTimeout(fn, 0)与其他setTimeout执行过程相同,它在执行时,会在0ms(不过通常情况下,不会是0ms,会有一定的延迟,例如chrome下是4ms等)后将fn加入到任务队列之中,当栈为空时,执行fn。那么setTimeout(fn, 0)的作用是:在下一个执行周期开始时,且栈为空时,执行该函数。
setTimeout(fn, 0)的存在并不是扰乱大家的视线,它在某些场景下确实有其用武之地,但是不建议滥用它,否则你的程序的维护性会大大降低。
在浏览器端开发网页应用时,事件会由最具体的元素逐级向上冒泡,参考如下示例,input click事件会冒泡到body节点,从而也会触发body.onclick事件,如果没有setTimeout,那么执行结果为:
button中的value变化
buton -> input -> body<input type="button" value="buton"/>
------------------
var input = document.getElementsByTagName('input')[0];
input.onclick = function inputClick() {
//setTimeout(function defer() {
input.value = 'input';
//}, 0)
};
document.body.onclick = function C() {
input.value = 'body'
};如果用户想要先执行body click,那么则在input click事件中添加setTimeout,把它放到任务队列中,在下一次执行周期中再去执行它。
当用户在页面渲染的过程中,存在一个耗时的渲染流程,那么页面渲染会在这个阶段停留很久,从而阻碍页面继续渲染,通过setTimeout把这个耗时流程延后执行,则一定程度上可以改善页面渲染的速度。
考虑一下以下代码的执行顺序:
console.log('script start');
setTimeout(function timer() {
console.log('setTimeout');
}, 0);
new Promise(function(resolve, reject) {
console.log('promise');
resolve();
}).then(function() {
console.log('then');
});
console.log('script end');这段代码的执行结果为:
script start
promise
script end
then
setTimeout这样的执行结果可能与预想的有些出入,产生疑问的地方主要是Promise执行顺序。
其实,隐藏在背后的的原因就是,事件循环中的microtask,的确,js运行时环境中除了task队列外,还存在着一个microtask队列。
task和MicroTask分别对应的行为是:
task:XHR、setTimeout/setinterval/setImmediate、requestAnimationFrame、UI交互事件等microtask: Promise、process.nextTick、Object.observe(已废弃)、MutationObserver等因而带有microtask队列的Event loop的运行机制如下图所示:

微任务的执行流程为:
task队列和microtask队列中task任务task任务执行完毕,执行microtask任务执行流程用伪代码表示如下:
while (eventLoop.waitForTask()) {
const taskQueue = eventLoop.selectTaskQueue();
while (taskQueue.hasNextTask()) {
taskQueue.processNextTask();
}
const microtaskQueue = eventLoop.microTaskQueue;
while (microtaskQueue.hasNextMicrotask()) {
microtaskQueue.processNextMicrotask();
}
}回到本节开头的示例,套用微任务执行流程:
script作为第一个task任务执行,执行输出script startsetTimeout,进入task队列Promise直接执行,输出promise,then()进入microtask任务队列script endtask任务执行完毕microtask任务,输出thentask队列中,移入timer()函数至栈中执行,输出setTimeout本篇文章参考和总结了一些互联网中的优秀的介绍事件循环的资料,在文末中列举了这些引用,读者若有不明白的地方可以直接参考这些一手资料得到更确切的表述。此外本篇文章也是本人学习Event loop概念的一个总结,因个人理解以及水平限制,文中难免会存在表述错误的地方,望给予指正。
最后,文中介绍的事件循环机制只是brower端的情况,javascript世界涉及的事件循环不止于此,例如服务端的nodejs执行环境的事件循环机制,以及html5提出的web worker标准之后,javascript就不再仅仅是单线程运行了,事件机制也与本文介绍的情况不尽相同,后续将继续学习、探究这些内容。
js并发模型及事件循环
Philip Roberts早期分享的Event loop内容
针对Philip Roberts分享内容的总结
microtask介绍
轻快愉悦的Event loop介绍
你所不知道的setTimeout
source、sink、channel等
# 解压
> gzip -d apache-flume-1.5.2-bin.tar.gz
> tar xvf apache-flume-1.5.2-bin.tar
# conf中配置logs输出地址
# 修改配置文件
# 设置flume-ng的执行权限
> chmod +x flume-ng
# 设置flume-ng的字符集
> vim flume-ng
> :set ff=unix
# 启动命令
> bin/flume-ng agent --conf conf --conf-file test.conf --name a1 -Dflume.root.logger=INFO,consolersyslog配置
> vim /etc/rsyslog.conf
# 添加udp或者tcp配置
> *.* @192.168.174.132:514
> *.* @@192.168.174.132:10514flume配置:
# 创建一个配置文件,启动flume
> touch test.conf
# 编辑文件
> vim test.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#a1.sources.r1.type = syslogudp
#a1.sources.r1.port = 514
#a1.sources.r1.host = localhost
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 10514
a1.sources.r1.host = 192.168.174.132
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# 启动flume测试;
# 查看端口是否连通
> telnet ip port
# 端口侦听(-l表示长时间监听)
> nc -l ip port
# 抓包工具,查看指定IP与端口的网络内容,并输出到cap文件
> tcpdump tcp port xx and host xx -w xx.cap
# 查看网络连接状态
> netstat -apn
# 例子
[root@promote bcstream]# netstat -natpl | grep 131
tcp 0 0 192.168.174.131:22 192.168.174.1:60794 ESTABLISHED 2661/sshd
tcp 0 52 192.168.174.131:22 192.168.174.1:61562 ESTABLISHED 2741/sshd
tcp 0 0 192.168.174.131:36401 192.168.174.132:514 ESTABLISHED 1874/rsyslogd
#监控
命令行添加-Dflume.monitoring.type=http -Dflume.monitoring.port=34545
#往本地端口发送UDP数据
> echo "test1" > /dev/udp/192.168.174.132/10514
#往远程UDP端口发送数据
> echo "test" | socat - udp4-datagram:192.168.1.80:5060tcpdump的使用:http://www.cnblogs.com/ggjucheng/archive/2012/01/14/2322659.html
https://angular-update-guide.firebaseapp.com/
主要涉及:
主要涉及以下部分:
ng serve后出现错误: No module factory available for dependency type: ContextElementDependency
解决方法:
breaking changes:
https://blog.angular.io/version-7-of-angular-cli-prompts-virtual-scroll-drag-and-drop-and-more-c594e22e7b8c
https://medium.com/@jeroenouw/upgrade-to-angular-7-beta-within-10-minutes-c14fc380edd
Angular 升级是越来越方便了,具体可以参考上面的两个链接,一个是 Angular new feature 的介绍,另一个是 10 分钟升级指南。当然,10 分钟升级肯定是有点夸张了(毕竟安装 npm 依赖受机器配置和网络环境影响)。
框架、Material、CLI现在版本号统一为 v7。
@angular/core 依赖
首先更新一下CLI: npm i -g @angular/cli
然后更新 npm 包至最新版(参考十分钟升级那篇)
随后按照下面指南进行更新:
yarn global add rxjs-tslint
rxjs-5-to-6-migrate -p src/tsconfig.app.json Angular 6.x 升级至 7.x 总体来说挺顺利,也没遇到什么问题,经历过两次升级(v5->v6,v4->v5)后,也对 Angular 的升级有了一个大概的预期(不会引发 break change,且升级之后项目平稳),所以这次升级遇到的阻力和心理包袱也很少。
这次升级唯一遇到的问题就是:
运行时,报了下面的错误:
ERROR in node_modules/@types/jquery/index.d.ts(6316,66): error TS2344: Type '"timeout" | "onreadystatechange" | "responseType" | "withCredentials" | "msCaching"' does not satisfy the constraint '"abort" | "open" | "timeout" | "response" | "status" | "getAllResponseHeaders" | "getResponseHeader" | "overrideMimeType" | "readyState" | "responseText" | "setRequestHeader" | ... 22 more ... | "dispatchEvent"'.
Type '"msCaching"' is not assignable to type '"abort" | "open" | "timeout" | "response" | "status" | "getAllResponseHeaders" | "getResponseHeader" | "overrideMimeType" | "readyState" |
"responseText" | "setRequestHeader" | ... 22 more ... | "dispatchEvent"'.
发现是 @types/jquery/index.d.ts 中类型定义的问题,从 yarn.lock 中看到:
"@types/html2canvas@^0.0.33":
version "0.0.33"
resolved "http://registry.npm.taobao.org/@types/html2canvas/download/@types/html2canvas-0.0.33.tgz#e4076f0ea664d3cd6e1460c82e48b177774052fe"
integrity sha1-5AdvDqZk081uFGDILkixd3dAUv4=
dependencies:
"@types/jquery" "*"
是 html2canvas 包引用了 jquery,又去翻看 html2canvas 是否有更新的版本(更新了依赖),发现这个包没有最新的更新。
npm 搜索 @types/jquery 检查有没有最新的包,发现这个包一直在更新,遂打开 @types/jquery 的package.json 看一下:
...
"typeScriptVersion": "2.3"
...原来是 typescript 的版本不兼容导致的,所以升级 @types/jquery 包至最新,问题解决。
需要v8.9+
原先的angular-cli.json现已变更为angular.json
使用命令来升级CLI:
npm install -g @angular/cli@latest
npm install @angular/cli@latest
ng update @angular/cli

从截图中看,update命令自动地做了一些事情,例如更新了一些文件,创建angular.json文件,删除angular-cli.json文件等。
命令的使用方式统一使用'--'来指定,例如ng build --prod --source-map,需要把不符合的部分做变更
使用命令ng update @angular/core 可以更新Angular框架内置的包至V6,包括rxjs及typescript。
此外,如果其他第三方包也支持ng update,那么也会一并更新。
这里遇到了一个小问题:
Package "codelyzer" has an incompatible peer dependency to "@angular/core" (requires "^2.3.1 || >=4.0.0-beta <5.0.0" (extended), would install "6.1.1").
Package "codelyzer" has an incompatible peer dependency to "@angular/compiler" (requires "^2.3.1 || >=4.0.0-beta <5.0.0" (extended), would install "6.1.1").这是npm中的peer dependency问题,即@angular/core与@angular/compiler中期望其运行在codelyzer的x版本之上,但是codelyzer会被install为y版本。
其实,在npm3中peer dependency并不会报错,只是控制台中给予提示。
peer dependency提示大部分情况下不会存在问题,例如codelyzer也有对应版本被安装,codelyzer也会向下兼容,那么引用它的模块也不会存在问题。
所以官方建议在使用peer dependency时尽量把语义版本区间设置更为宽泛。
所以这个问题,可以使用force命令来解决:ng update @angular/core --latest --force。
v6版本下的rxjs不再像以前那样难用,常常会需要google去寻找rxjs各类方法的引入方式。
现在的方式更为友好:
例如操作符的引用:
import 'rxjs/add/observable/of';
import 'rxjs/add/operator/map';在rxjs6中引入方式变更为:
import { of } from 'rxjs';
import { map } from 'rxjs/operators';例如Subject、Observable等方法引入:
import { Subject } from 'rxjs/Subject'
import { Observable } from 'rxjs/Observable'在rxjs6中引入方式变为:
import { Subject, Observable } from 'rxjs'升级之后,再也不用担心import rxjs的各种烦恼了。
此外Angular官方也贴心地准备了一个rxjs migrate工具,解决了绝大部分rxjs的升级问题,它能够直接重构项目中引用rxjs的代码,省时省力。
例如,原有项目中存在如下写法:
return next.handle(req).do(event => {...});rxjs migrate工具会帮你自动修改为:
return next.handle(req).pipe(tap(event => {...}));这个升级至rxjs6的命令如下:
npm install -g rxjs-tslint
rxjs-5-to-6-migrate -p src/tsconfig.app.json此外在升级过程中会产生一个兼容的rxjs-compat包,当所有第三方包依赖的rxjs升级至v6版本之后,可以删除它。
在Angular6中,Service可以自己进行注册,不用再显示地把Service加入到providers列表中:
@Injectable({
providedIn: 'root' // 注册到app bootstrap中
})
@Injectable({
providedIn: MainModule // 注册到MainModule模块中
})这样的改变,使得Service更加独立,方便于单元测试,不过原有的写法在Angular6中依然可用。
解决方法:升级postcss-loader版本,webpack-contrib/postcss-loader#319
ERROR in ./src/app/app.component.scss
Module build failed: TypeError: loader._compilation.applyPluginsWaterfall is not a function
at D:\HSmart-0.3\0.3\HSmart\hsmart-web\node_modules\postcss-loader\index.js:122:43
at <anonymous>
at process._tickCallback (internal/process/next_tick.js:188:7)
原因:CLI工具处理lazyloading模块引发的错误
解决方法:一直在各个CLI版本中断断续续出现,目前可以在ng serve命令后添加--aot来解决,更推荐的方式是在angular.json中增加aot:true选项。
在v5中,行内元素如果写法如下,两个span元素之间会存在一个间隙,如果并排写则无间隙:
<span>1</span>
<span>2</span>在升级到了v6后,即使换行写,间隙也不会存在。
v5的时候,带有lazyloading的RouteModule的顺序不会有影响,不过在v6需要注意在AppModule中带有lazyloading Module的顺序。
如果只存在AppRoutingModule,那么需要在imports中把AppRoutingModule置于列表最后。
如果存在其他LazyLoading Module,则需要把它们置于AppRoutingModule之后。
@NgModule({
declarations: [ ... ],
imports: [
BrowserModule,
CoreModule,
...,
AppRoutingModule,
MainModule(该模块中配置有LazyLoading Module)
]...Angular6的这次升级,给Angular带来了重大变革,优化了性能/发布包,工具链更加成熟,生态圈更加紧密,版本发布更为顺畅,简而言之就是用户会用的更爽:
ng add @angular/pwang generate library [name]https://nodejs.org/en/blog/npm/peer-dependencies/
https://update.angular.io/
https://blog.angular.io/version-6-of-angular-now-available-cc56b0efa7a4
看了egg.js文档以及issues中的各种解决方法,都没能解决egg.js在vscode下的调试,偶然间尝试成功,记录一下:
首先安装vscode-egg.js debug插件
按下F1,选择auto attach
在package.json scripts中找到scripts中的debug选项:
"debug": "egg-bin-dev"运行debug命令npm run debug
出现下图中的提示信息

该提示信息要求:可以直接attach进行debug。
过去一年中,收获和失望参半,技术有一定程度的成长,也可以说是从后端转为前端以来最能直观感受到自己成长的一年。失望的是自己的心态,越来越少地以产品的视角来审视工程以及追踪产品的走向。这些因因果果有很多,自己也该有个总结来审视下自己。
18 年主要投入学习的框架还是 Angular,不过今年对 Angular 的整体视角有了一个变化,开始在设计层面理解 Angular 解决问题的思路,知晓了其原理,并能够顺畅地使用 Angular 提供的方案来解决问题。也投入了一些精力在 Angular 周边技术上,例如 rxjs、CDK、Typescript。此外,也看了一些书籍,练了些算法,不过投入精力较少。
本年度大致的收获如下:
本年度 2/3 时间还是能沉稳投入到技术掌握中去的,不过也多了些浮躁与疑惑,主要是自身技术的困惑、产品、个人职业发展、技术投入方向等。
首先是自身技术的困惑:
由于自身掌握的主要框架是 Angular,市场中匹配的 HC 也比较少,前端技术日新月异,技术上的忧虑感也会更多些。于是在年初的时候,花了一周学习 React,并能简单写一些示例(全家桶未能掌握),不过此次学习纯粹是应付自己的忧虑感。年末由于需要帮助朋友面试 Vue 技术栈的同学,一个周末入门了 Vue (全家桶),并写了一个小功能,此时由于自身对 Angular 理解的深入,反倒是让我理解 Vue 中的很多概念很快。至此,也算是对 AVR 有一个简单的认识了,有了认识也就有了感悟:其实深耕一门框架就好了,框架之间的切换成本或许没有表面上看起来这么大,而自己也渐渐不会再有这种莫名的忧虑感。
当然,对于我目前的工作场景,我仍然认为 Angular 是最合适的:2B 业务、大部分项目维护周期在 2-3 年以上甚至更久、同时投入到一个项目中的人不会很多、由于项目进度因素,可能会存在人员的临时加入。原因就是:Angular 的代码组织结构分明、Typescript 加成(IDE友好、类型安全、代码提示等)都会让维护成本更小;不同人员(前提是负责任、具备一定经验)写出来的代码差异性较小,不会存在 React 那种多路技术栈的情况;Angular 未来两三年的技术栈稳定性可见,对于企业级的应用来说,也是免去了一定的折腾成本,毕竟搭建/维护一个工具/技术链也是一个耗费精力的事情。
第二,产品视角:
由于参与的是部门预研性质的产品(关键词:AI、运维、大数据),在集团内部实用场景很难把握,产品基本上都是处于摸着石头过河的阶段,在落地的过程中,也很难真正帮助客户解决一些实际的问题,这样也导致产品演进比较困难,虽然堆叠了一些功能,但是产品也要不断经历重塑阶段,从工程师角度,甚至一度不知道下一步要做的功能是什么。
产品处在这个状态下,研发的质量把控、付出的心血、投入的精力也很难展示出来,势必也会影响整个团队的士气。马洛斯需要层次理论中提到的偏中上层的需要为:尊重需要与自我实现需要。的确,人都是追求着做有意义的事情,希望能尽到自己的努力,把事情做得更好,否则还在坚持什么呢?
第三,个人职业发展:
工作进入了第四年了,以往职业规划和接触项目/技术,更多的是补足自己的不足,到了第四年,工作上遇到的“难题”,似乎也不再那么难,工作中遇到的挑战也似乎越来越少。身处在当前职位,能接触到的技能也似乎到了“天花板”,移动端/图形学等等一系列前端新兴的方向,都未深入实践,这些都是自己要思考的问题。
最后,还是要立立 flag,希望自己今年能有个改变,继续向前~
最后的最后,祝愿自己明年一月份能够收获这些吧~~
Angular项目组提供了一个脚手架工具:@angular/cli用于帮助用户在web-app场景下快速组织Angular的项目结构。@angular/cli工具集成了测试、tsc编译、css预处理、AOT、npm等开发、测试、构建环境,并且提供了一系列快速可用的命令来运行这一套脚手架提供的功能。然而对于通用组件库开发而言,只使用@angular/cli来构建组件库开发的脚手架是不够的。
针对Angular组件的开发与发布,Angular项目组发布了一系列文档:
讲解了@angular/meterial所使用的代码组织结构,并给出了Angular组件库构建的一套“规范”,这套“规范”给出了组件库打包依赖的环境:

此外社区也有一些针对Angular组件打包的方案,例如:
generator-angular-library,该方法使用Yeoman作为基础的构建环境,对于Yeoman可能存在几个问题,如被墙、脚手架维护不方便、在各个框架的CLI流行下,使用Yeoman生成项目框架的行为在逐渐变少;
angular-library-starter,该方法也未使用Angular的CLI工具,使用systemJs作为构建环境,该环境虽然集成了组件库的单元测试,但是未提供组件的doc或demo支持;
angular-quickstart-lib,这个工具所未由Angular官方发布,但是由@angular/cli工具组的成员开源,它使用systemJs来作为构建平台,提供了完整的打包、测试、发布命令,也提供了demo支持,是一个比较理想的seed目标。
由于@angular/cli提供了完整的web-app开发环境,而组件库的doc/demo非常适合使用@angular/cli来构建。组件库部分的代码完全则可以与doc/demo代码隔离开,单独集成一套构建环境来为组件库独立打包,此外还可以在package.json中为组件库设置一些打包、构建、测试命令。
从上文中可以了解到搭建一个Angular组件库的主要构成部分:UMD bundle、代码压缩、Typescript编译、rollup、npm scripts支持,此外为了满足组件库的开发、测试,通常还需考虑scss解析、doc/demo生成等。下面将对构建过程中涉及到的术语名词作出解释:
Typescript编译:Typescript为es2015的超集,本身并不能被浏览器直接解析执行,因而需要对Typescirpt进行解析、转换为浏览器可识别的代码。
Rollup: Angular使用Typescript来组织代码之间的联系,即使用es2015规范中的import与export语句构成的js模块化。而使用npm的angular工程,在执行npm install后形成的项目依赖包node_modules往往规模很大,此时的项目规模不太适用于线上部署。Rollup支持一种tree-shaking的技术,可以分析静态代码中的import引用,并排除任何未实际使用的代码,从而可以优化npm工程的大小。
Module Bundle:虽然Angular的代码以ESM的方式进行模块化,但是很多浏览器并不支持,因而需要对模块进行module bundler或者module loader处理,即代码的执行方式为AOT或者JIT执行。通常情况下JIT可以帮助用户快速查看到代码的执行效果,但是AOT相比JIT而言,工程包体积更大,执行性能更优,因而目前生产环境中仍以AOT方式更佳。Angular使用rollup.js来对工程执行bundles操作,把各个Angular文件合并为一个或者多个文件,并且转译为UMD格式。
AOT:AOT不仅包含了bundles操作,还包含inline resources操作,通过把HTML模板和CSS样式内联到js文件中,可以降低源文件的数量,达到优化网络请求的目的。在AOT过程中,能够在编译阶段及发现错误,防止在生产环境使用时才发现问题。
支持模块化的形式:ESM、UMD。
Metadata.json:描述了Angular的组织形式,告诉Angular如何构建应用及在运行时各个类之间的交互关系,metadata.json结构如下图:

使用Promise.then形式同步执行如下操作:
Setp1:css预处理
Setp2:资源内联
Setp3:编译typescript、生成metadata.json
Setp4:rollup
Setp5:构建生成UMD、uglify、ES、ES2015形式的源码
Setp6:拷贝metadata.json及package.json到dist目录
具体形式如下:
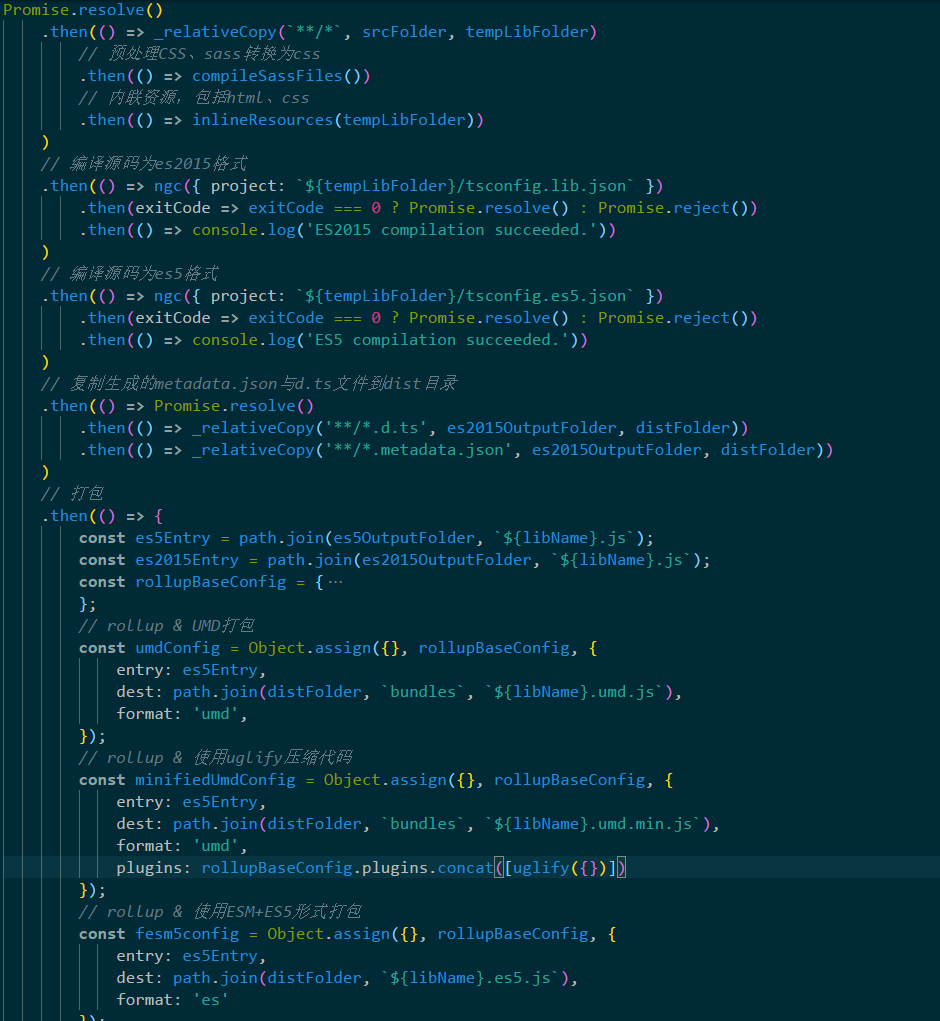


上面两张图为组件库的代码组成部分,其中左图为@angular/cli生成的代码结构,右图为对src目录结构的改造。
其中src下分三个部分:asserts、demo和lib:
@angular/cli指导一致;npm publish也是针对lib build之后的dist目录进行;assets作为公用资源的目的是,lib组件在发布的时候不希望带有额外的css与icon资源,以此可以减小发布包的大小以及符合单一职责设计目标。因而在使用组件库时可以从npm中分别获取css样式库、icon资源库和lib组件库的方式来构建一个工程。
相比传统开发web-app的方式,编写组件的方式需要作出一些改变:在组件的根目录需要添加index.ts文件,在文件中添加service及module的export代码:

发布还需要注意以下几点:
package.json中version的变化,否则npm不会接收发布的包npm账号,在发布前先npm loginpackage.json中设置private:true根据业务需要及参考开源项目,总结和改进了angular组件库的脚手架,并结合了@angular/cli对lib包独立构建、打包、发布,能够较为方便的测试lib库和形成一个完整的doc页面。
谈到包管理器,大家一定不陌生,例如大名鼎鼎的rpm、maven。前端也有包管理器,不过与服务端不同的是,前端的包管理器有点让人眼花缭乱:bower、npm、yarn、cnpm、jspm、component、spm等。在搭建新项目的seed时,这么多包管理器该怎么选择?其实,本文的标题已经告诉你答案了。
下面简单介绍一下上述包管理都分别有哪些特性。
bower:
首先是包安装机制,由于从bower install的包,理想状态下都是已经构建过的资源,这些包之间不会有依赖关系,从而实现了扁平化的特点。其次,在bower中注册包,开发者首先要先在github中创建一个项目,随后使用bower register命令在bower注册这个github项目,由于github项目中通常都是存放源码,众多项目通常会把构建后的资源重新整理为一个仓库,用来为bower提供服务。此外,bower未提供构建功能,不过可以通过grunt、gulp类似工具提供构建支持。最后,bower是一个中立的包管理器,最初实现时没有对bower管理的包做模块化的限制。
bower最初的设计使得bower更像是一个包地址的存放中心,当然现在的bower在github作为下载的目标源外,也提供了自身的仓库。bower看似简单易用,但是由于未限制前端的模块化方式,导致使用bower的开发者仍要考虑bower install后的模块化的种种问题。bower在后续演进过程中增加了UMD、ES6、yui等模块化方案的支持,残酷的是bower已不再“流行”。
jspm:
设计之初就考虑到了前端的众多模块化的支持,包括ES6、AMD、commonjs和globals等模块化方案,jspm作为SystemJS的包管理器,依赖于SystemJS可以方便地加载各类模块化写的包。此外jspm还提供了npm与github等多种源来安装包。综合来看,jspm提供多模块化方案的加载、构建、集成了多种仓库,是一个完备的包管理工具。但是相比于commonjs模块化方案的npm生态圈,jspm的比较明显的优势是提供多种模块化方案的支持,随着commonjs方案下的Webpack广泛应用,并且CommonJS转换为ES5的早已不是难题。从这个角度来看,jspm代替npm的可能性非常低。
component、spm已然不在包管理器舞台活跃了,此处不再比较。
npm:
npm最初是用于服务端nodejs的包管理器,遵循node.js的commonjs标准,但是随着前端社区的发展,bowers端也开始使用npm作为包管理。
前端开发者们可以自由地在npm上获取和上传包,应用可以在package.json中定义依赖包的元数据信息。npm中的包通常都设计用来解决单一的问题,这样设计的好处是开发者当需要某种功能时,只需要在npm中找到对应功能的包并安装它,这使得团队协助更加便捷。npm支持scripts、语义化版本、包管理仓库、丰富的命令,涵盖了包管理器必须具备的功能。
yarn与cnpm:
yarn与cnpm都为npm的一个变种,或者可以说都是基于npm开发,解决npm使用过程中的某个“痛点”。例如,yarn解决了npm cache及版本锁定等问题;cnpm是淘宝同步了npm镜像源的一个npm替代工具,解决国内用户使用npm下载依赖中超时等问题,cnpm支持了npm中除了publish外的绝大部分命令。
小结:
目前npm已经超越maven等包管理器成为世界上注册最多包及下载量最多的软件仓库,npm也成为前端包管理解决方案中“事实上”的标准。npm功能齐全,且伴随着webpack等工具的发展,使用npm几乎没有各种后顾之忧。所以推荐在项目中切换为使用npm/yarn/cnpm作为唯一的包管理器。
下文将对npm的使用、配置项、缓存、yarn、依赖等做一个概述。
npm install package [--save | --save-dev]在本地安装包,--save表示把该包作为本项目用于开发/生产环境的依赖,执行命令后会把包信息放在package.json中的dependencies项下。--save-dev把该包作为本项目中的开发/测试环境下的依赖,执行命令后会把包信息放在package.json中的devDependencies项下。最新的v5中npm install package --save 不再为必须项了。
npm install -g package-g表示在全局安装包,类似于把当前包添加到系统环境变量中,例如npm install -g gulp,那么在使用gulp命令时,则简化为gulp xx。不过全局安装并非必须,用户仍然本地安装,并在本地项目下node_modules中找到指定工具路径来执行命令,例如node_modules/gulp xx。
npm uninstall package 卸载包
npm update package 更新包
npm ls - depth=0 -g 查看全局安装的包
npm init 新建一个npm项目,会生成一个package.jsonpackage.json是包依赖的管理文件,它包含了当前项目的基本信息如name、version、description、author、license等;依赖包的语义化版本信息;脚本定义等。
简化的package.json如下:
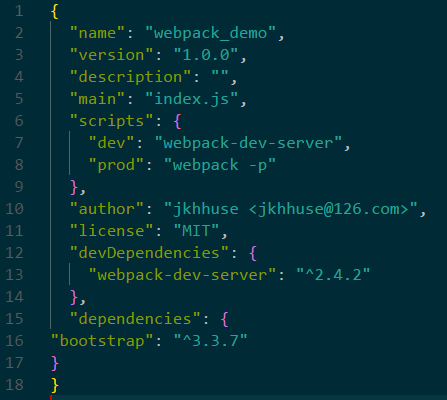
其中scripts用于定义npm中的可执行脚本,用户可以自定义一些测试、构建、语法检查等命令。例如本例npm run prod可以执行webpack -p命令。
在查看项目中的package.json时,经常看到如下属性:dependencies、devDependencies、peerDependencies、bundledDependencies、optionalDependencies等各类dependencies,下面将介绍一下各类dependencies的用途:
在package.json中的dependencies项下,通常可以看到包名后带上了版本号,这个版本号的书写方式则称之为语义化版本。
npm的语义化版本规定为:
| 名称 | 解释 | 示例 |
|---|---|---|
| patch | 代表此次更新为修复bug | 1.0、1.0.x、~1.0.4 |
| minor | 代表此次更新新增了新的特性 | 1、1.x、^1.0.4 |
| major | 代表重大升级,此次更新可能会破坏向后兼容性 | *、x、2.0.0 |
语义化版本一方面引导npm包开发者的迭代发布流程不会颠覆现有用户的使用习惯,另一方便也给用户提供了灵活的升级习惯,保守的用户在package.json中可以定义包的语义化版本为patch,那么执行npm update不会再担心某个依赖包的升级导致整个项目运行异常;同时勇于尝试的用户则希望使用最新的功能,那么他们可以使用minor甚至major。
语义化版本带来的“副作用”就是版本锁定问题,5.2节将描述版本锁定问题的由来及解决方法。
npm作为使用次数最多的包管理器,管理着最庞大的包,但是npm发展之路却颇为曲折,甚至可以说npm很差劲。本节将分析npm的诸多弊端,以及社区做出的改进:
上文提到package.json记录了当前npm包的依赖信息,一个npm包通常会有多个依赖包。而依赖的npm包也会存在package.json文件,因而npm install之后的node_modules是一个层次很深树状依赖结构,带来例如维护、更新等一系列的“并发症”,导致node_modules体积膨胀严重,更新性能底下,此外国内用户连接npm仓库不太稳定,都给npm造成一种“低端、难用、不可靠”的映象。针对此种情况,npm及开源社区做出了一系列的解决方法:
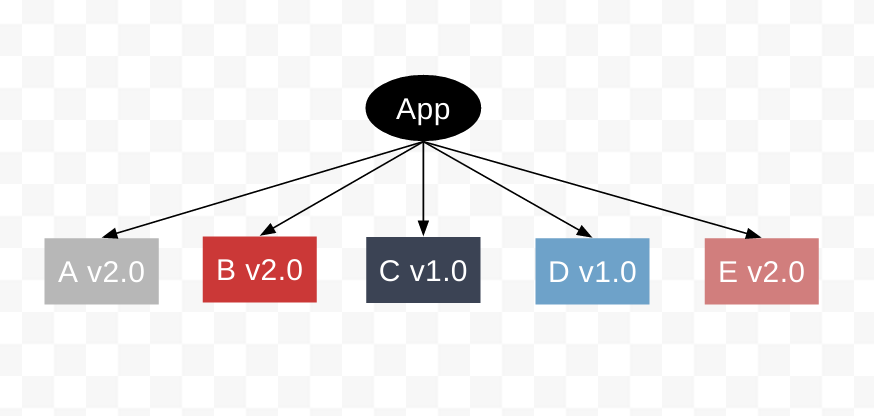
最主要的是npm V3做出的扁平化依赖处理,主要**可以从下图看出:
图1为App项目的包依赖关系;图2为npm install一个E依赖包,并且E自身依赖于B v1.0;图3为install之后的包依赖关系图。从图3可以看出B v1.0已经存在于node_modules中,那么npm不会再在E包添加一个B依赖。
图4为一个更新操作,用户把项目中A依赖包从v1.0升级到v2.0,A v2.0依赖了B v2.0;图5为更新后的依赖关系;图6把E升级到v2.0,E v2.0依赖于B v2.0;图7此时的B v1.0没有依赖会被移除,而B v2.0会被移入第一层。

当执行npm dedupe后,最终的依赖关系如下图所示,此时的App项目的依赖已经变为扁平的结构了:
上文提到了语义化带来的好处,但是语义化也带来了另外版本差异问题,即存在“我电脑上运行是没问题的”这样的不确定性。例如员工A机器中的package.json依赖为semver: ,npm install后semver版本为0.1。两年后,员工B接手了项目,npm install后,semver版本变成了6.2.0,这样就会导致两个员工的项目运行环境不一致。当然这个例子比较极端,事实上很多人都不会选择使用来定义语义化,然而实际项目中的npm包之间的依赖非常复杂,且npm v3后,依赖包安装顺序的不同,也会导致不同环境下依赖关系出现差异。好在社区早已有了解决方案:锁定版本,做法是记录当前环境中包的版本,以便于在其他环境中重新安装后可以完全复现原有环境下的包依赖环境。
锁定版本有三种方式:最初npm提供了shrinkwrap方案,不过需要工程师手动执行npm shrinkwrap来锁定版本,一旦工程师在改动后忘记执行该命令和上传shrinkwrap文件,那么可能导致文件与代码不同步。后来yarn提供了自动的版本锁定功能yarn.lock,最新的npm v5也通过默认package-lock.json来提供版本锁定支持。
npm的cache功能一直先天不足,主要包括:
离线安装问题,可以通过--cache-min设置从缓存中安装包,当指定包不存在缓存目录,npm会连接仓库。但是当指定包已经存在于缓存目录中,npm也会发出连接请求,并且当服务器返回304时,不会重新下载tarball。如果某个包已经存在于缓存,但是版本低于要求,npm不会选择去仓库下载符合要求的版本,而会直接报错。
包命中问题,npm只会从已解压的缓存目录中查询包,如果一个包的tarball版本已经存在于下载目录,npm也仍然需要重新去远程仓库下载。
yarn的开源最初就是为了解决npm cache的问题,因为fb内部CI环境为了安全考虑,是无法连接互联网的,而npm始终无法做到离线安装。
npm v5重写了cache模块,提供了--offline安装模式,提升了性能,添加了tarball的校验机制。由于重写了cache模块,在升级到v5后,需要执行npm clean cache来解决cache之间的不兼容问题。
yarn并不是npm的替代者,yarn install的源为npm。yarn瞄准npm的痛点,主要为版本锁定、性能、缓存、重试机制等痛点而开源,一定程度上推动了npm的发展。npm v5也参考了yarn做出了许多改进,解决了以往的大部分问题,甚至可以直接替代yarn。不过目前yarn仍然有其使用市场,社区有人对npm v5与yarn做了性能测试(github:npm-vs-yarn),npm v5的性能比起yarn还有一些差距,如下图。此外现存大量项目已经是yarn的忠实用户,所以短期之内yarn还是会一直演进,给npm用户带来更多的惊喜。

通过以上npm的介绍,大家一定觉得npm非常不靠谱,使用npm开发者都有同样的抱怨。然而随着yarn的开源以及npm v5的发布,npm正在成为一个优秀的包管理器,甚至是未来一定时期内“最佳的”的前端包管理器。不过,由于npm的历史问题,用户在使用npm的时候,推荐使用npm v3+和yarn混用或者直接使用npm v5版本。
首发在公司公众号:中移苏研大数据博客
rsyslog中主要存在:modules、templates、Actions、Filter等概念
modules通常包括Input、OutPut模块,有些是内置的,有些则需要另行安装;
rsyslog版本分为v5、v7、v8,v5比较陈旧,文档不是很完善,一般推荐使用v7或者v8;
rsyslog支持多种插件与协议:
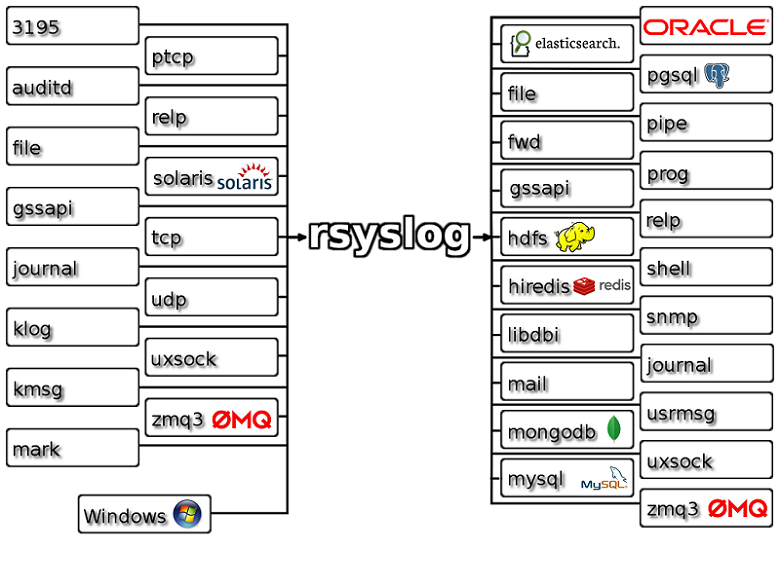
许多发行版linux都默认使用rsyslog,本次使用centos6.8来测试rsyslog的使用。
centos6.8默认安装了5.8x版本的rsyslog,rsyslog版本之间差异较大,可以选择安装比较新的版本。
#下载rsyslog.repo
> cd /etc/yum.repos.d/
> wget http://rpms.adiscon.com/v8-stable/rsyslog.repo
#安装rsyslog
> yum clean all
> yum makecache
> yum install rsyslog
#查看rsyslog版本号
> rsyslogd -v
#重启rsyslog
service rsyslog restartcat /etc/rsyslog.conf
默认配置文件如下:
#### MODULES ####
#默认支持logger命令和内核日志
module(load="imuxsock") # provides support for local system logging (e.g. via logger command)
module(load="imklog") # provides kernel logging support (previously done by rklogd)
#module(load"immark") # provides --MARK-- message capability
# 支持UDP日志转发,更多信息查看http://www.rsyslog.com/doc/imudp.html
#module(load="imudp") # needs to be done just once
#input(type="imudp" port="514")
# 支持TCP日志转发,更多信息查看http://www.rsyslog.com/doc/imtcp.html
#module(load="imtcp") # needs to be done just once
#input(type="imtcp" port="514")
#### GLOBAL DIRECTIVES ####
# 使用默认时间戳格式
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
# File syncing capability is disabled by default. This feature is usually not required,
# not useful and an extreme performance hit
#$ActionFileEnableSync on
# Include all config files in /etc/rsyslog.d/
$IncludeConfig /etc/rsyslog.d/*.conf
#### RULES ####
# Log all kernel messages to the console.
# Logging much else clutters up the screen.
#kern.* /dev/console
# Log anything (except mail) of level info or higher.
# Don't log private authentication messages!
*.info;mail.none;authpriv.none;cron.none /var/log/messages
# The authpriv file has restricted access.
authpriv.* /var/log/secure
# Log all the mail messages in one place.
mail.* /var/log/maillog
# Log cron stuff
cron.* /var/log/cron
# Everybody gets emergency messages
*.emerg :omusrmsg:*
# Save news errors of level crit and higher in a special file.
uucp,news.crit /var/log/spooler
# Save boot messages also to boot.log
local7.* /var/log/boot.log
# ### begin forwarding rule ###
# The statement between the begin ... end define a SINGLE forwarding
# rule. They belong together, do NOT split them. If you create multiple
# forwarding rules, duplicate the whole block!
# Remote Logging (we use TCP for reliable delivery)
#
# An on-disk queue is created for this action. If the remote host is
# down, messages are spooled to disk and sent when it is up again.
#$WorkDirectory /var/lib/rsyslog # where to place spool files
#$ActionQueueFileName fwdRule1 # unique name prefix for spool files
#$ActionQueueMaxDiskSpace 1g # 1gb space limit (use as much as possible)
#$ActionQueueSaveOnShutdown on # save messages to disk on shutdown
#$ActionQueueType LinkedList # run asynchronously
#$ActionResumeRetryCount -1 # infinite retries if host is down
# remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional
#*.* @@remote-host:514
# ### end of the forwarding rule ###远程地址中,UDP使用@,TCP使用@@
*.* @192.168.174.132:514
module(load="imuxsock")
module(load="imklog")
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
*.info;mail.none;authpriv.none;cron.none /var/log/messages
authpriv.* /var/log/secure
mail.* /var/log/maillog
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log配置两个input module,imudp、imtcp
module(load="imuxsock")
module(load="imklog")
module(load="imudp")
input(type="imudp" port="514")
module(load="imtcp")
input(type="imtcp" port="514")
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
*.info;mail.none;authpriv.none;cron.none /var/log/messages
authpriv.* /var/log/secure
mail.* /var/log/maillog
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log# A机器 使用tail -f查看日志输入
> tail -f /var/log/messages
> logger xxx
# B机器查看接收到的日志
> tail -f /var/log/messages$template myFormat,"%rawmsg%\n"
$ActionFileDefaultTemplate myFormataction(type="omfile" dirCreateMode="0700" FileCreateMode="0644"
File="/var/log/test123")建议使用较新版本的linux内核,因为其支持recvmmsg()调用,能够提升UDP接收的速度并减低CPU的利用率;
imptcp模式依赖于Linux支持TLS,否则使用imtcp代替;
使用buffered模式,保证缓冲区满后才写入,或者当写文件关闭后写入;
在使用过程中,调整threads在2-4之间与batchSize大小,来查看处理性能。
# load required modules
module(load="imudp" threads="2"
timeRequery="8" batchSize="128")
module(load="imptcp" threads="3")
# listeners
# repeat blocks if more listeners are needed
# alternatively, use array syntax:
# port=["514","515",...]
input(type="imudp" port="514"
ruleset="writeRemoteData")
input(type="imptcp" port="10514"
ruleset="writeRemoteData")
# now define our ruleset, which also includes
# threading and queue parameters.
ruleset(name="writeRemoteData"
queue.type="fixedArray"
queue.size="250000"
queue.dequeueBatchSize="4096"
queue.workerThreads="4"
queue.workerThreadMinimumMessages="60000"
) {
action(type="omfile" file="/var/log/remote.log"
ioBufferSize="64k" flushOnTXEnd="off"
asyncWriting="on")
}syslog output默认只会输出到一个日志文件中,rsyslog只能使用output cannel去轮询日志。也可以使用logrotate命令去轮询:
# 安装logrotate
> yum install logrotate crontabs
# 配置文件为/etc/logrotate.conf,通常轮询设置都放在/etc/logrotate.d目录下
> vim /etc/logrotate.d/log-file
/var/log/log-file {
monthly
rotate 5
compress
delaycompress
missingok
notifempty
create 644 root root
postrotate
/usr/bin/killall -HUP rsyslogd
endscript
}
# 测试
# 随机创建10M的日志数据
> touch /var/log/log-file
> head -c 10M < /dev/urandom > /var/log/log-file
# 模拟轮询
> logrotate -d /etc/logrotate.d/log-file monthly: 日志文件将按月轮循。其它可用值为‘daily’,‘weekly’或者‘yearly’。
rotate 5: 一次将存储5个归档日志。对于第六个归档,时间最久的归档将被删除。
compress: 在轮循任务完成后,已轮循的归档将使用gzip进行压缩。
delaycompress: 总是与compress选项一起用,delaycompress选项指示logrotate不要将最近的归档压缩,压缩将在下一次轮循周期进行。这在你或任何软件仍然需要读取最新归档时很有用。
missingok: 在日志轮循期间,任何错误将被忽略,例如“文件无法找到”之类的错误。
notifempty: 如果日志文件为空,轮循不会进行。
create 644 root root: 以指定的权限创建全新的日志文件,同时logrotate也会重命名原始日志文件。
postrotate/endscript: 在所有其它指令完成后,postrotate和endscript里面指定的命令将被执行。在这种情况下,rsyslogd 进程将立即再次读取其配置并继续运行。
#备份
> cd /etc/yum.repos.d
> mv ...repo ...repo.backup
#下载新的源,常见的如ali、sina、163
> wget ...
#更新yum
> yum makecache
> yum -y update[root@dsjtest-63 ~]# service rsyslog stop
Shutting down system logger: [FAILED]
[root@dsjtest-63 ~]# service rsyslog restart
Shutting down system logger: [FAILED]
Starting system logger: /bin/bash: line 1: 20943 Segmentation fault /sbin/rsyslogd -i /var/run/syslogd.pid [FAILED]解决方法:
在/etc/rs.d/
rsyslog启动失败 http://www.linuxquestions.org/questions/linux-general-1/system-logger-fails-when-restarting-syslog-106754/
最近有一个需求,考虑到有些私有化项目的分支较为混乱,某些情况下难以定位到当前运行的前端页面是从属哪个分支,溯源较为困难,所以想把当前分支的信息构建到前端构建物之中。
为啥不用 package.json,package.json 适合单向的版本记录,如果存在多个分支的情况下,package.json 则无法准确的获知真实的版本信息。
为啥不用现有的插件,例如 DefinePlugin,这个插件支持构建的时候,手动输入一些版本信息,从而在运行的时候能够打印出来,只是每次拉分支的时候都难免会忘记填写版本信息。
因而,如果能够从 git 自动获得当前的分支信息,那么可以解决如上的问题。
首先介绍一下 webpack 的插件机制,以 webpack@4 为例。
插件由以下几个部分构成:
apply 方法。webpack 的事件钩子。webpack 内部实例的特定数据。webpack 提供的 callback 方法。下面是一个 webpack 插件的模板代码:
// 插件代码
class MyExampleWebpackPlugin {
// 将 `apply` 定义为其原型方法,此方法以 compiler 作为参数
apply(compiler) {
// 指定要附加到的事件钩子函数
compiler.hooks.emit.tapAsync(
'MyExampleWebpackPlugin',
(compilation, callback) => {
console.log('This is an example plugin!');
console.log('Here’s the `compilation` object which represents a single build of assets:', compilation);
// 使用 webpack 提供的 plugin API 操作构建结果
compilation.addModule(/* ... */);
callback();
}
);
}
}
// webpack.config.js 插件的使用
var MyExampleWebpackPlugin = require('index');
module.exports = {
// ... 这里是其他配置 ...
plugins: [new MyExampleWebpackPlugin ()]
};Compiler 它扩展自 Tapable 类,设置了一系列事件钩子和各种配置参数,并定义了 webpack 诸如启动编译、观测文件变动、将编译结果文件写入本地等一系列核心方法。
常见对应的 Hooks 的生命周期顺序为:
Complication 可以理解为编译的对象,包含了模块、依赖、文件等信息。在开发模式下运行webpack 时,每修改一次文件都会产生一个新的 Compilation 对象,Plugin 可以访问到本次编译过程中的模块、依赖、文件内容等信息。
常见的编译过程需要用到的模块、依赖、文件的信息为:
除此之外,Complication 还可以触及一些钩子和其他方法,例如:
webpack 编译执行的生命周期可以参考下图:

所以,编写插件的原则即是在对应的生命周期内,对当前生命周期的输出物、关联物做对应的处理。例如读取输出物的资源:
那么代码可以这样写:
compiler.hooks.emit.tapAsync('MyWebpackPlugin', (compilation, callback) => {
console.log(compilation.chunks);
});介绍完 webpack 插件开发的基本原理后,下面来实现文章开头的小需求吧。
首先创建一个插件的基本目录结构,推荐目录结构如下:
- example # 插件使用样例代码, 也可以方便本地调试与验证
--- index.js
--- package.json
--- webpack.config.js # webpack 配置文件
- src # 插件代码
--- index.js
- package.json插件核心代码如下,代码较为简单不再详细介绍,具体也可以参考 github 中的源码 https://github.com/jkhhuse/git-version-webpack-plugin :
const child_process = require('child_process');
class GitVersionWebpackPlugin {
constructor(options) {
console.log('GitVersionWebpackPlugin', options);
}
apply(compiler) {
console.log(compiler);
const HtmlWebpackPlugin = compiler.options.plugins
.map(({ constructor }) => constructor)
.find(
constructor => constructor && constructor.name === 'HtmlWebpackPlugin'
);
const version = child_process.execSync('git branch --v', {
encoding: 'utf8'
});
compiler.hooks.compilation.tap('GitVersionWebpackPlugin', compilation => {
console.log('The compiler is starting a new compilation...');
HtmlWebpackPlugin.getHooks(compilation).beforeEmit.tapAsync(
'GitVersionWebpackPlugin',
(data, cb) => {
// Manipulate the content
data.html += `<script>console.log('current version: ${
version.split(' ')[1]
}')</script>`;
// Tell webpack to move on
cb(null, data);
}
);
});
}
}
module.exports = GitVersionWebpackPlugin;其实在编写插件的过程中,Debug 是最重要的技能,否则很难知道插件的执行周期、数据源、产生的目标数据等,也会导致插件的开发存在困难。
首先,需要在插件的源码处打上 debugger 断点,例如:
class GitVersionWebpackPlugin {
...
apply(compiler) {
debugger;
...随后,在 example 目录下执行:
node --inspect-brk ../node_modules/webpack/bin/webpack.js --progress打开浏览器,地址栏输入:
chrome://inspect/#devices

点击 “open dedicated DevTools for Node”,会出现调试控制台,通过断点即可进行插件调试:

最后看看插件应用的效果,在 example 中引入插件,执行命令:webpack。
构建时会在 index.html 下插入如下代码:
<script>console.log('current version: master')</script>先看一段代码:
const pipeLine = (...fns) => arg => fns.reduce((p, f) => f(p), arg)
pipeLine(x => x+1, x => x+2)(0)
当我初次接触此代码时,很难准确理解其含义,主要是因为对一些函数式编程及es6中的一些用法没能真正理解。本文是对相关概念的一次梳理,逐步解释此行代码的涵义及用途,在最终解释这段代码之前,先要理解箭头函数、柯里化和reduce的用法。
pipeLine代码中出现了很多的箭头函数,箭头函数是es6中定义函数的一种方式,例如:
var f = fucntion(v){
return v;
}可以使用es6语法简化为:
var f = v => v;箭头函数是常见的用法,不过在本例中,需要注意的是隐式return的用法,即:
var f = v => v;
// 等价于
var f = fucntion(v){
return v;
}
var f = v => {v;}
// 等价于
var f = fucntion(v){
v;
}首先看一下柯里化的定义:
柯里化是一种处理函数中附有多个参数的方法,并在只允许单一参数的框架中使用这些函数。
换种说法就是,柯里化只指把多个参数的方法转换为单次处理一个参数的手段,感觉这么说还是有些难理解,那么就以示例展开:
f(x, y) = x * y;
// 计算f(2,3),首先带入x=2,那么函数变为:
g(y) = f(2, y) = 2 * y;
// 再代入 y=3
g(3) = f(2, 3) = 2 * 3;
// 在柯里化过程中,每个参数与此类似,逐步代入再以js代码来描述:
const multiply = x => y => x * y;
const result = multiply(2)(3);
// 上面的multiply为简化写法,也可以写成下面形式,
const multiply = (x) => {
return (y) => {
return x * y;
}
}上面的代码,单次接收一个参数,并且可以把执行过程分开执行,分为(2)、(3)两段执行,这就是柯里化。
此外从代码中还可以看出,柯里化具备延迟执行(分两段执行)的好处,当然这个示例比较简单,实现的multiply只能接收两个函数,对于2*3*4*5这样的连续乘积操作则无法适配。要想做到这样一点,那么就需要下一个出场的Reduce函数了。
Reduce函数接收一个累加器函数和一个数组,对数组中的元素从左至右应用累加器函数,并最终返回一个值。
Reduce函数的定义如下(以Typescript方式描述):
Array<any>.reduce(callbackfn: (previousValue: any, currentValue: any, currentIndex: number, array: any[]) => any, initialValue: any): any
callbackfn为累加器函数,包含四个参数
- previousValue 上一次调用函数时的返回值
- currentValue 数组中正在处理的元素
- currentIndex 数组中正在处理的元素对应的下标
- array 调用reduce的数组
initialValue,第一次调用callbackfn函数时的第一个参数值,如果没有提供该值,则以数组中的第一个元素替代再看一下Reduce函数的实际应用:
[2,3,4,5].reduce((p, c) => p * c);
// 等同于
[2,3,4,5].reduce((p, c) => p * c, 1);理解了reduce用法后,就可以考虑利用Reduce来实现上一节中的连续乘积操作:
const multiply = (array) => {
return (initialValue) => {
return array.reduce((p, c) => p * c, initialValue);
}
}
multiply([2,3,4,5])(1);看完上面三个概念的解释再去理解文章开头的代码片段相信会很简单了,也可以把该段代码转换一下:
const pipeLine = (...fns) => {
return (arg) => {
return fns.reduce((p, f) => f(p), arg)
}
}
pipeLine(x => x+1, x => x+2)(0)这样看来,与上一节介绍reduce用法的代码相比,唯一不同之处就是reduce的累加器函数的实现,此处(p,f)=>f(p),p参数对应的是previousValue,f参数对应的是currentValue,而currentValue的值分别为两个函数x => x+1, x => x+2。
所以这个累积加器函数的执行过程是:
| callback | previousValue | currentValue | currentIndex | array | 返回值 |
|---|---|---|---|---|---|
| 第一次调用 | 0 | x => x + 1 | 0 | [x => x+1, x => x+2] | 1 |
| 第二次调用 | 1 | x => x + 2 | 1 | [x => x+1, x => x+2] | 3 |
pipeline代码在前端中颇为常见,例如rxjs中存在的pipe操作符,用于流式处理多个操作:
Observable.from([1,2,3]).pipe(
scan((acc, item) => acc += item, 1),
skip(1)
)虽然pipeline的实现过程已经掌握,但是在使用过程中累积器中的函数操作不可能一直是同步操作,那么为了让pipeline能够处理异步操作,那么则需要对上面的代码做出小小的改变:
const pipeLine = (...fns) => arg => fns.reduce((p, f) => p.then(f), Promise.resolve(arg))
pipeLine(
x => x+1,
x => new Promise(resolve => resolve(x+2)),
async x => await(x+3)
)(0).then(result => console.log(result));上述代码增加了对异步事件的处理,首先是initialValue使用Promise.resolve()方法封装为一个Promise对象,其次对累加器中的函数依此做then()链式调用,最后返回的也是一个Promise对象,并通过then拿到最终的值。
在使用一段时间 vue3.x 后,对 vue3 中的 Ref 还存在几个不明白之处,在开启下一轮学习之前,还是需要把 API 们捡过来再好好研究下。
先整理问题点:
1、flush 的 'pre' | 'post' | 'sync' 到底有什么区别,日常开发好像很少注意这些区别。
2、deep 属性控制到什么程度?子对象,子数组,对象的子数组是否都能控制到?
3、immediate 与 flush 之间的关系是什么?感觉功能上有些重复。
4、watch 与 watchEffect 的使用场景到底是什么样的,总感觉使用 watchEffect 工程容易陷入“失控”,遇到任意变化,都会触发 watchEffect 操作。
5、reactive 与 ref 的使用场景傻傻分不清楚,一直无脑使用 ref。
6、使用响应式函数,响应式好像莫名其妙丢失了,如何在使用响应式函数后仍然保留变量的响应式。
7、如果把异步事件编写在响应式函数中,对编程逻辑的组织总感觉有些奇怪,不如写在一个文件里来得简单痛快。
8、类型系统,什么时候传 Ref,什么时候传 T,编写子组件与响应式函数的时候,总感觉不对劲。
好了,问题点列出来了,好像 vue3 白使用这么久了,这明明是 0 基础,平时代码能写出来都是一种巧合 😆,为了继续搬砖,赶紧恶补一下自己的知识盲点。
先看下解释:
'pre' ,适用于在模板渲染前更新值。'post' 在渲染之后执行回调,适用于获取 DOM 或者子组件值。'sync' 在值发生变化后,同步调用回调,适用于需要获得多次更新值的情况。使用场景都说完了,下面使用 demo 的形式展示一下就都明白了:
<template>
<div id="app">
<button @click="exec()">执行</button>
change: <span id="span">{{count * 10}}</span>
</div>
</template>
<script>
import {reactive, watch, ref, watchEffect} from "vue";
import _ from 'lodash';
export default {
name: 'App',
components: {
},
setup(props, context) {
const count = ref(1)
watchEffect(
() => {
console.log("conut:" + count.value);
const spanValue = document.getElementById("span");
if(spanValue?.innerText) {
console.log("result:" + spanValue.innerText);
}
},
{
flush: 'pre' // TODO: post | sync
}
)
const exec = () => {
count.value++;
count.value++;
}
return {
exec,
count
}
}
}
</script>当 flush 的值分别变化为 'pre' | 'post' | 'sync',点击执行按钮,执行结果分别为:
-------pre-------
count:1
---> click button
count:3
result: 10
-------post-------
count:1
result: 10
---> click button
count:3
result: 30
-------sync-------
count:1
--- click button
count:2
result: 10
count:3
result: 10从执行结果来看,pre 获取的是模板渲染前的结果,post 获取的是模板渲染后的结果,sync 可以获得值的多次变化,但是仍然拿到的是模板渲染前的结果。
pre | post 与 sync 的区别则是 pre | post 使用了回调缓存,在同一执行周期内,watch 不会被多次触发。 sync 则可以同步检测值的变化,同步执行回调。
其实这个部分文档说的比较明确,只是需要和 vue2 的使用上做个区分即可。
deep 的使用规则:
deep: true 时,可以监测对象与数组的变化,但是回调函数中的 newValue 与 oldValue 都是指向同一个引用,并不会得到变化前的对象与数组。<template>
<div id="app">
<button @click="exec()">执行</button>
</div>
</template>
<script>
import {reactive, watch, ref, watchEffect, defineComponent} from "vue";
import _ from 'lodash';
export default defineComponent({
name: 'App',
components: {
},
setup(props, context) {
const stu = ref({
name: "1",
score: [1,2,3]
})
const exec = () => {
stu.value.score = stu.value.score.splice(1);
}
watch(() => stu.value, (newValue, preValue) => {
console.log(newValue);
console.log(preValue);
}, {
deep: true // TODO: false
})
return {
exec,
stu
}
}
})
</script>
-------deep: true-------
---> click 执行
{name: "1", score: Array[2]}
{name: "1", score: Array[2]}
-------deep: false-------
无输出deep: false 时,如果只 watch 对象本身,当对象被替换时,可以监测到,但是对象内的元素变动不会被监测到。// 可以监测到变化
const exec1 = () => {
// 重新对 stu 进行赋值操作
stu.value = {
name: "2",
score: [1,2,3]
}
}
// 无法监测到变化
const exec2 = () => {
// 只改变对象中的元素
stu.value.name = "2";
}
watch(() => stu.value, (newValue, preValue) => {
console.log(newValue);
console.log(preValue);
}, {
deep: false
})
-------exec1-------
{name: "2", score: Array[2]}
{name: "2", score: Array[2]}
-------exec2-------
无输出immediate 立即触发回调,flush 也是用于控制回调触发的时机,看起来有点冲突,其实这个问题是因为对文档阅读不够仔细形成的误解。
immediate: true 时,会立即得到监听的值变化,false 则不会得到:
watch(
() => stu.value.name,
() =>
{
console.log("change");
},
{
// 初始化就会打印一次 change, 设置为 false 后不会打印
immediate: true // TODO: false
}
)flush 是用于控制模板渲染与值变更的触发顺序问题,例子运行之后,也就能更清晰的指定两者的区别了,至于为什么产生这个混淆,分析之后,可能就是 watch 与 watchEffect 的错误使用导致形成这个错觉。
先回答下上一个问题中这两个方法使用错误的问题,使用的错觉大部分也是由于不清晰这两个方法的 options 参数设置而导致。所以先看下这两个方法的参数有什么不同:
// watchEffect 的 options
export declare interface WatchOptionsBase {
flush?: 'pre' | 'post' | 'sync';
}
// watch 的 options
export declare interface WatchOptions<Immediate = boolean> extends WatchOptionsBase {
immediate?: Immediate;
deep?: boolean;
}
declare type WatchCallback<V = any, OV = any> = (value: V, oldValue: OV, onInvalidate: InvalidateCbRegistrator) => any;
declare function watchEffect(effect: WatchEffect, options?: WatchOptionsBase): WatchStopHandle;
declare function watch<T extends Readonly<WatchSource<unknown>[]>, Immediate extends Readonly<boolean> = false>(sources: T, cb: WatchCallback<MapSources<T>, MapOldSources<T, Immediate>>, options?: WatchOptions<Immediate>): WatchStopHandle;从类型定义中可以看到,watch 比 watchEffect 多了几个属性, immediate 与 deep,那说明 watchEffect 不具备这两个属性带来的操作特征。其次,watch 入参多了一个 WatchCallback,再看下文档中的描述:
与 watchEffect 比较,watch 允许我们:
这个效果是 immediate 提供,watchEffect 不会初始化时触发回调。
<template>
<div id="app"></div>
</template>
<script>
import { watch, ref, watchEffect, defineComponent } from 'vue';
export default defineComponent({
name: 'App',
components: {},
setup(props, context) {
const count = ref(1);
watchEffect(() => {
console.log('watchEffect:' + count.value);
});
watch(
() => count.value,
() => {
console.log('watch:' + count.value);
},
// immediate value default false
);
return {
count,
};
},
});
</script>
--------初始化执行--------
watchEffect:1所以 immediate 控制了 watch 是否“懒惰执行”。
我理解这个指是监测变化的机制更加明确,在 watchEffect 中,是自动跟踪其回调函数中响应式变化,而 watch 显示地提供了 sources: T 与 deep: true| false 来明确监测目标:
const stu = ref({
name: "1",
score: [1,2,3]
})
const exec = () => {
stu.value.name = "2";
}
watchEffect(() => {
console.log(stu.value);
})
---------示例1---------------
// 执行 exec() 后**有输出**
const stu = ref({
name: "1",
score: [1,2,3]
})
const exec = () => {
stu.value.name = "name";
}
watchEffect(() => {
console.log(stu.value.score);
})
---------示例2---------------
// 执行 exec() 后**无输出**上述示例中,watchEffect 会自动监听 effect 参数的“动态”,因而在不注意的情况下,多多少少会让用户有些疑惑,所以直接使用 watch 则能相应的增加代码的可维护度,毕竟给到维护着的信息是明确的。
分析了一下容易混淆的几个概念点:
下面给出了 reactive 与 ref 间的转换关系,主要包含两类,一类是响应式状态保留下的转换,另一类是响应式丢失的情况下转换。通过图表形式可以对转换方法有个更为清晰的认识:

当然有些时候 isReactive 和 isRef 可能不会那么“准确”:
例如:
// 1. 包裹了 reactive 的 readonly 对象
const plain = readonly({
name: 'Mary'
})
console.log(isReactive(plain)) // -> false
const stateCopy = readonly(state)
console.log(isReactive(stateCopy)) // -> true
// 2. 包裹了 reactive/ref 的 reactive/ref 对象
const state = ref('Tom');
const _state = reactive(refState);
console.log(refState.value); // -> Tom
console.log(_state.value); // -> Tom第二种这样使用很容易弄混淆,所以建议就是尽量不要用 reactive 与 ref 套用响应对象。
reactive() ,什么时候用 ref() ?两个方法的使用区别:
reactive 只接收对象作为参数,ref 接收原语,如 string、boolean、number、symbol、null、undefined 等。ref 使用 .value 方式获得属性,reactive 可以直接获得属性。在使用过程中,响应式变量在两种方式之间来回转换,常常也会导致阅读干扰。在日常使用中,一些人对 reactive 心存不满,因为在它的用法显得不够灵活,例如,reactive 无法对完整的对象重新赋值:
const stu = ref({
name: "1",
score: [1,2,3]
})
stu.value = ({
name: "1",
score: [1,2,3]
}); // True
const stu = reactive({
name: "1",
score: [1,2,3]
})
stu = {
name: "1",
score: [1,2,3]
} // **ERROR!!!**也有使用者对 .value 的使用方式感到冗余,从而不喜欢使用 ref 方式,虽然 vue 源码中 ref 底层实现依赖于 reactive 。社区在针对是否改造 ref.value 使用方式而设计了一个新的语法糖,由于此语法糖违背了 js 的常用语法规范,看起来更像是一个泛型定义,所以社区也产生较大分歧:
<script setup>
// declaring a variable that compiles to a ref
ref: count = 1
function inc() {
// the variable can be used like a plain value
count++
}
// access the raw ref object by prefixing with $
console.log($count.value)
</script>
<template>
<button @click="inc">{{ count }}</button>
</template>感兴趣的同学也可以深入了解下:vuejs/rfcs#228。
以前写代码的时候,经常会发现写着写着就丢失了响应式。从上一章节,大概也可以发现响应式是如何丢失的,典型的一个丢失问题是对 reactive 进行解构导致的:
const data = reactive({
count: 1,
});
const { count } = data;
const exec = () => {
data.count++;
}
// obj.test 的改变不会促使 test 值的改变,即响应式丢失。当然这种情况的解决方法也很简单:
plan a:把 count 变成一个对象,那么解构后的对象仍然具备响应式。
plan b:使用 toRefs(data) 语法进行转换,转换后的 count 的类型为 Ref<string> ,具备响应式。
而在编写组合式函数(composition function)的时候更容易出现这个问题,比如下一章节中添加副作用的组合函数。
在官方文档中也有这样一个示例,编写合适的组合式函数来分拆工程的主逻辑。对于开发者来说,只需注意分拆后的逻辑的响应式传递问题。
首先我们来看一下 watch 的部分描述:
watch 需要侦听特定的数据源,并在单独的回调函数中执行副作用。
侦听器数据源可以是一个具有返回值的 getter 函数,也可以直接是一个 ref。
那我们可以得到一个信息:由 watch 监听数据的变化,并且在 watch 中执行副作用。
最后给出一个相对完整的 DEMO 辅助大家理解:
------------ App.vue ------------
<template>
<div>loading: {{ loading }}</div>
<div>result: <Result :arg="result" /></div>
<div>sync result: {{ plus }}</div>
</template>
<script lang="ts">
import { defineComponent, ref } from 'vue';
import useCount from './components/useCount';
import usePlus from './components/usePlus';
import Result from './components/Result.vue';
export default defineComponent({
name: 'App',
components: { Result },
setup() {
const count = ref(1);
const { loading, result } = useCount(count);
const { plus } = usePlus(result);
return {
loading,
result,
plus,
};
},
});
</script>
------------ useCount.ts ------------
import { ref, Ref, watch } from 'vue';
export default function useCount(count: Ref<number>) {
const loading = ref<boolean>(true);
const result = ref<string>('');
const fetchCount = () => {
let initValue = count.value;
setInterval(() => {
fetch('https://api.github.com/repos/vuejs/vue/pulls?per_page=1', {
method: 'GET',
headers: new Headers({
'Content-Type': 'application/json',
}),
})
.then((res: any) => res.json())
.catch((r) => {
console.log(r);
})
.then((response) => {
initValue++;
result.value = response[0].number + initValue;
loading.value = false;
console.log('Success:', result.value);
});
}, 2000);
};
watch(
() => count.value,
() => {
fetchCount();
},
{
immediate: true,
flush: 'post',
deep: true,
}
);
return {
loading,
result,
};
}
------------ usePlus.ts ------------
import { reactive, Ref, ref, toRefs, watch } from 'vue';
export default function usePlus(data: Ref<string>) {
const plus = ref<string>('0');
watch(
() => data.value,
() => {
setTimeout(() => {
plus.value = data.value + '^_^';
}, 1000);
}
);
return { plus };
}
------------ Result.vue ------------
<template>
{{ _arg }}
</template>
<script lang="ts">
import { computed, toRefs, SetupContext, defineComponent, isRef } from 'vue';
export default defineComponent({
name: 'Result',
components: {},
props: {
arg: String,
},
setup(props: any, context: SetupContext) {
const _arg = computed(() => props.arg);
return {
_arg: _arg,
};
},
});
</script>这个因为 vue3 做了几次改动,其中对 setup 中的 props 的改动了多次,props 与 context 的响应式涵义也略有不同。所以对早期入手 vue3 的人是会带来一定疑惑的。
在当前版本(v3.2)笔者整理了两种针对 setup 中 props 推导的推荐写法:
// 方法1
interface Props {
arg: string;
}
export default defineComponent({
props: ['arg'],
setup(props: Props, context: SetupContext) {
// 可以正确推导 props.arg
console.log(props.arg);
},
});
// 方法2
export default defineComponent({
props: {
arg: String,
},
// props 不设置类型
setup(props, context: SetupContext) {
// 可以正确推导 props.arg
console.log(props.arg);
},
});此外,除了上面写法中获取 props 子元素,也可以通过以下方式:
const { arg1, arg2 } = toRefs(props);
const arg1 = toRefs(props).arg1;用于向TemplateRef嵌入视图
它是一个指令:
@Directive({ selector: '[ngTemplateOutlet]' })
class NgTemplateOutlet implements OnChanges {
constructor(_viewContainerRef: ViewContainerRef)
ngTemplateOutletContext: Object
ngTemplateOutlet: TemplateRef<any>
ngOnChanges(changes: SimpleChanges)
}ngTemplateOutletContext 接收一个对象,通常为: templateRefExp; context: contextExp , context 变量用于接收组件中定义的对象,用于向 templateRefExp 模板中传值:
<ng-container *ngTemplateOutlet="templateRefExp; context: contextExp"></ng-container>ngTemplateOutlet 接收一个 <ng-template></ng-template> 模板,与 ngTemplateOutletContext 中的 templateRefExp 作用相同.
参考官方示例:
import {
Component,
EventEmitter,
Input,
Output,
TemplateRef,
ViewChild
} from '@angular/core';
@Component({
selector: 'ng-template-outlet-example',
template: `
<ng-container *ngTemplateOutlet="greet"></ng-container>
<hr>
<ng-container *ngTemplateOutlet="eng; context: myContext"></ng-container>
<hr>
<ng-container *ngTemplateOutlet="svk; context: myContext"></ng-container>
<hr>
<ng-template #greet><span>Hello</span></ng-template>
<ng-template #eng let-name><span>Hello {{name}}!</span></ng-template>
<ng-template #svk let-person="localSk"><span>Ahoj {{person}}!</span></ng-template>
`
})
export class NgTemplateOutletExample {
myContext = {$implicit: 'World', localSk: 'Svet'};
}运行结果如下:
Hello
----------------
Hello World!
----------------
Ahoj Svet!
----------------
Pagination 组件中大量应用了 ngTemplateOutlet 与 ngTemplateOutletContext, 主要使用在prev、page、next按钮的生成之中。
Zorro提取了他们的公共特征:都为一个个可点击的单元,不同之处是这个单元可以是页码或者是图标, 而页码或者图标的不同可以使用 ngTemplateOutletContext 来配置以及使用样式来提前设置好。
所以Zorro定义了他们的公共结构为:
<ng-template #renderItemTemplate let-type let-page="page">
<a class="ant-pagination-item-link" *ngIf="type!='page'"></a>
<a *ngIf="type=='page'">{{page}}</a>
</ng-template>其中type和page变量来决定该单元结构中显示的是页码还是图标。
prev按钮的生成是通过定义[ngTemplateOutletContext]="{ $implicit: 'prev'}", $implicit 代表默认,那么 type 的值为prev, 'prev'!='page', 再应用预先定义好的样式, 那么最终渲染出来上一页按钮。
若 ngTemplateOutletContext 的值为 { $implicit: 'page',page: page.index }, type 变量对应的值为 page, 渲染出page按钮。并且把 page 变量值通过 {{page}} 渲染到页面中。
对应代码如下:
<li
title="{{ 'Pagination.prev_page' | nzI18n }}"
class="ant-pagination-prev"
(click)="jumpPreOne()"
[class.ant-pagination-disabled]="isFirstIndex">
<ng-template [ngTemplateOutlet]="nzItemRender" [ngTemplateOutletContext]="{ $implicit: 'prev'}"></ng-template>
</li>
<li
*ngFor="let page of pages"
[attr.title]="page.index"
class="ant-pagination-item"
(click)="jumpPage(page.index)"
[class.ant-pagination-item-active]="nzPageIndex==page.index">
<ng-template [ngTemplateOutlet]="nzItemRender" [ngTemplateOutletContext]="{ $implicit: 'page',page: page.index }"></ng-template>
</li> &-prev {
.@{pagination-prefix-cls}-item-link:after {
content: "\e620";
display: block;
}
}
&-next {
.@{pagination-prefix-cls}-item-link:after {
content: "\e61f";
display: block;
}
}首先放出源码中的实现代码:
private _viewRef: EmbeddedViewRef<any>;
@Input() public ngTemplateOutletContext: Object;
@Input() public ngTemplateOutlet: TemplateRef<any>;
constructor(private _viewContainerRef: ViewContainerRef) {}
ngOnChanges(changes: SimpleChanges) {
const recreateView = this._shouldRecreateView(changes);
if (recreateView) {
if (this._viewRef) {
this._viewContainerRef.remove(this._viewContainerRef.indexOf(this._viewRef));
}
if (this.ngTemplateOutlet) {
this._viewRef = this._viewContainerRef.createEmbeddedView(
this.ngTemplateOutlet, this.ngTemplateOutletContext);
}
} else {
if (this._viewRef && this.ngTemplateOutletContext) {
this._updateExistingContext(this.ngTemplateOutletContext);
}
}
}在onchange中获得当前绑定的两个属性的状态检测情况,即changes中包含两个属性:ngTemplateOutletContext、ngTemplateOutlet。
首先需要判断是否需要重新进行view attach操作,通过this._shouldRecreateView(changes)方法判断。
private _shouldRecreateView(changes: SimpleChanges): boolean {
const ctxChange = changes['ngTemplateOutletContext'];
return !!changes['ngTemplateOutlet'] || (ctxChange && this._hasContextShapeChanged(ctxChange));
}
private _hasContextShapeChanged(ctxChange: SimpleChange): boolean {
const prevCtxKeys = Object.keys(ctxChange.previousValue || {});
const currCtxKeys = Object.keys(ctxChange.currentValue || {});
if (prevCtxKeys.length === currCtxKeys.length) {
for (let propName of currCtxKeys) {
if (prevCtxKeys.indexOf(propName) === -1) {
return true;
}
}
return false;
} else {
return true;
}
}在这个过程中存在几种情况:context对象的变化(值变化与Shape变化)、templateRef变化。
!!changes['ngTemplateOutlet'] 用于判断<ng-template></ng-template> 是否变化。
this._hasContextShapeChanged(ctxChange) 用于判断 context上下文对象是否发生变化,这个变化包括两种情况,值变化与Shape变化,如下所示:
<ng-template let-ctx #tpl>{{ctx.foo}}</ng-template>
<ng-container *ngTemplateOutlet="tpl; context: context"></ng-container>this.context = {$implicit: {foo: 'bar'}};
// 值变化为
this.context = {$implicit: {foo: 'bar1'}};
// Shape变化
this.context = {$implicit: {foo: 'bar1'}, $ctx: {foo: 'bar2'}};针对值变化,只需要更新ngTemplateOutletContext 对象中的属性值。
针对Shape变化,需要根据情况来从container中remove emberView,再重新create emberView。
最后,如果templateRef变化,也会与Shape的处理一样。
参考Luy-dragger的react实现,采用Angular来重新实现该示例。
源码:Adragger
在拖拽事件的控制中涉及到mousemove、mouseup、mouseup等事件。
Angular中可以使用rxjs来实现事件机制,例如fromEvent来创建一个事件:
// 发布一个document元素中的mousemove事件
source = fromEvent(document, 'mousemove');
// 当鼠标移动时,触发move方法
this.mouseEvent = this.source.pipe(
tap((event) => {
this.move(event);
})
);其中tap方法的解释如下:
Intercepts each emission on the source and runs a function, but returns an output which is identical to the source as long as errors don't occur.
因为tap函数返回数据流的镜像,所以tap函数通常用于处理流中的'副作用'。
在元素的click方法中实现元素拖拽的位移控制,其中使用transform的translate来控制2D位移:
this.bindMouseEvent = this.mouseEvent.subscribe(
() => {
this.style = Object.assign({
'user-select': 'none',
'transform': 'translate(' + this.state.x + 'px,' + this.state.y + 'px)'
}, this.dragStyle);
}
);拖拽行为可以分解为:mousedown(click) + mousemove。当前鼠标放置在元素中点击时,订阅事件流,此后移动鼠标,会触发move方法,move方法中会修改当前元素的位置信息state.x与state.y值。由于订阅事件中做了2D位移的控制,所以可以模拟出完整的拖拽行为。
在拖拽事件结束后,即需要及时注销。
使用HostListener事件绑定mouseup事件,unsubscribe事件流。
@HostListener('document:mouseup', ['$event'])
mouseUp(event: any): void {
event.stopPropagation();
if (this.bindMouseEvent) {
this.bindMouseEvent.unsubscribe();
}
}从原有demo来看,元素框中的内容是变化的,要想复用组件,那么可以使用投影:<ng-content></ng-content>,把元素框中变化的内容投影到组件中。
组件模板:
<div class="WrapDragger" [ngStyle]="style" (mousedown)="onDragStart($event)">
<ng-content></ng-content>
</div>元素框HTML代码:
<app-dragger [dragStyle]="{left: '50px'}">
<div>普通的拖拽组件</div>
</app-dragger>实现功能:拖拽元素框时,可以支持指定沿着X轴位移或者Y轴位移。
在move方法中实现如下逻辑,控制当前元素的位移state.x或者state.y值变化,从而在订阅事件流中的2D位移变换中做出相应控制:
if (this.draggerProps && this.draggerProps.allowX) {
deltaY = 0;
}
if (this.draggerProps && this.draggerProps.allowY) {
deltaX = 0;
}
this.state.x = deltaX;
this.state.y = deltaY;在this.mouseEvent.subscribe订阅中向外发送事件,从而在父组件中获得当前组件的状态信息。
发送事件:
this.dragMove.emit(this.state);父组件的事件处理,在onDrag方法中接收dragger组件的传值:
<app-dragger [dragStyle]="{left: '650px'}" (dragMove)="onDrag($event)">
<div>
位移
<div>x:{{ state.x }} px</div>
<div>y:{{ state.y }} px</div>
</div>
</app-dragger>state = {
x: 0,
y: 0
};
onDrag(e) {
this.state = {
x: e.x,
y: e.y
};
}只需要判断当前元素框是否具有把手标识(class="className"):
if (this.draggerProps && this.draggerProps.hasDraggerHandle) {
if (event.target.className !== 'handle') {
return;
}
}首先要确认当前元素离周围边框的距离,使用Position的left、right、top、bottom四个变量来表示,随后使用类似控制元素框的位移控制方式,来判断当前位移是否超出Position的规定范围。
最近花了180块钱,买了一个服务器(1核2G,1M带宽),实验发现,做个自用小站点或应用服务性能完全足够的,且不用做过多优化,前端的访问体验也较为流畅。虽然域名还是在备案中,但是主体的事情已经做完,所以最近这段“旅程”算是可以暂时告一段落了,简单总结一下翻篇,省得今后一段时间一直要在这个事情中耗费过多时间。
这里选用了阿里云作为云服务器,新客 180 元可以购买 3年,性价比较高,尤其是可以搭配免费的 Devops、镜像服务以及价格低廉的 OSS、域名等服务一起使用。可以说是一个非常低成本的开源小项目/个人博客的部署方案。
本篇文章的目的是为了让 Github 中托管的代码,最终可以部署在阿里云的 ESC 服务器之中,从而使得能够在互联网公网中使用部署的应用。为了快速开发与部署,集成了阿里云 Devops 工具云效,实现上传的代码能够自动的构建与使用 Docker 部署,下面将分几个章节记录了整个实践的过程。
为了后续部署与集成 Devops 环境更为方便,可以安装 nginx、docker、mysql 等基环境。
默认服务中会自带 nginx 服务,可以使用 rpm -ql nginx 来查看 nginx 的配置。
# 启停
/usr/sbin/nginx
# 配置文件
/etc/nginx/nginx.conf创建镜像仓库,配置访问凭证,方便后续可以登录仓库,推送镜像:


可以在阿里云的容器镜像服务配置自己的镜像加速服务:

# 配置镜像加速服务
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxx.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart dockeryum -y install docker-ce
systemctl start docker新建网络是为了实现同主机的多个容器间网络互通,走内网,类似于软件交换。
docker network create -d bridge --subnet 172.27.0.0/16 cloud-netd 参数指定 Docker 网络类型,有 bridge overlay。其中 overlay 网络类型用于 Swarm mode。subnet 参数表示新建了 172.27.0.0/255.255.0.0 的网络,名称为 cloud-net。# 搜索 mysql
docker search mysql
# 拉取镜像
docker pull mysql:latest
# 运行, 注意 mysql 需要配置一下持久化
# mysql 也需要加入到 network 中,这样在其他的 Docker 容器内可以直接通过 hostname 访问到
docker container run --name mysql -p 3306:3306 --network=cloud-net --hostname=mysql -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=xxx mysql日常管理在如 github 等开放平台中的代码,如果想自动构建与部署,则可以利用阿里云的云效与 ESC 云主机联动实现快速的接入 Devops。
分别以 vue 工程和 java 工程,部署在 Docker 的案例来展示。

vue 工程和 java 工程分别都部署在 Docker 之中,Vue 通过挂载的配置文件,设置访问的 http 请求中增加 base_url prefix。云主机中的 nginx 匹配到 base_url 并转发至 java docker 处。
部署结构已经梳理完毕,下面来梳理一下配置项。
vue 工程会添加一个 base_url(plans),可以通过挂载配置的方式,选择 base_url 的内容。
{
"base_url": "http://ip:8000/plans/"
}FROM nginx:latest
# 复制到指定目录
COPY dist /usr/share/nginx/dist/
# nginx.conf
http {
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_comp_level 8;
gzip_types text/plain application/x-javascript text/css application/xml application/javascript text/javascript image/jpeg image/gif image/x-icon image/png application/json application/octet-stream application/vnd.sun.wadl+xml;
gzip_vary on;
gzip_disable "MSIE [1-6]\.";
server {
# 监听 80 端口,并通过 docker port 对外暴露 80 端口
listen 80;
server_name localhost;
location / {
# 工程部署位置, 即 docker 镜像构建时 copy 的目标地址
root /usr/share/nginx/dist;
# 针对 history router 的配置
try_files $uri $uri/ /;
add_header Cache-Control "no-store, no-cache";
}
}
}docker container run --name plan-app --network=cloud-net --hostname=plan-app -p 80:80 -d -v /home/config/nginx.conf:/etc/nginx/nginx.conf -v /home/config/config.json:/usr/share/nginx/dist/config.json registry.cn-shanghai.aliyuncs.com/jkhhuse-plan/plan:plan-app# 环境
FROM adoptopenjdk/openjdk11
# 创建目录存放 jar 包与配置文件
RUN mkdir -p /home/server
# 拷贝jar
ADD target/plan-server-1.0.jar /home/server/plan-server.jar
# 设置暴露的端口号
EXPOSE 8080
# 设置工作目录
WORKDIR /home/server
# 执行命令
ENTRYPOINT ["java","-jar","/home/server/plan-server.jar"]docker container run --name plan-server -e TZ="Asia/Shanghai" --network=cloud-net --hostname=plan-server -v /home/config:/home/server/config -p 8080:8080 -d registry.cn-shanghai.aliyuncs.com/xxx/plan:plan-server# /etc/nginx/nginx.conf
# 代理服务器目的地址
upstream proxy_server {
ip_hash;
server ip:8080;
}
server {
listen 8000;
listen [::]:8000;
server_name plan;
# 对 /plans base_url 的请求做转发
location ^~/plans/ {
proxy_set_header Host $host;
# 移除 /plans => / 后再转发
rewrite ^/plans/(.*)$ /$1 break;
# 反向代理服务器配置
proxy_pass http://proxy_server;
}
}新建流水线

为了让 github 上的项目可以加速,可以在网站后面添加 cnpmjs.org ,不然云效的 git clone 操作会超时。下面是
代码仓库的配置项:

接下来是配置构建步骤,首先配置 Node 的基础环境:
# input your command here
yarn config set registry http://registry.npm.taobao.org/
yarn install
yarn build
随后把构建产出物的 dist 包进行 Docker 镜像的构建:
这个步骤结束后,会把构建的镜像发送到之前配置的阿里云镜像仓库中,随后可以进行 Docker 镜像的部署工作:
选定好部署的主机与执行用户,填入执行的部署脚本完成。

docker login --username=xxx --password=xxx registry.cn-shanghai.aliyuncs.com
docker pull registry.cn-shanghai.aliyuncs.com/jkhhuse-plan/plan:plan-app
docker images
docker container stop plan-app
docker container rm plan-app
docker container run --name plan-app --network=cloud-net --hostname=plan-app -p 80:80 -d -v /home/config/nginx.conf:/etc/nginx/nginx.conf -v /home/config/config.json:/usr/share/nginx/dist/config.json registry.cn-shanghai.aliyuncs.com/xxx/plan:plan-app
docker container ls | grep plan-appJava 工程与 Vue 的工程类似,选用 Java 的构建模板即可。


在随后的 Docker 镜像的部署中,填入部署脚本:
docker login --username=xxx --password=xxx registry.cn-shanghai.aliyuncs.com
docker pull registry.cn-shanghai.aliyuncs.com/jkhhuse-plan/plan:plan-server
docker images
echo `docker images`
docker container stop plan-server
docker container rm plan-server
docker container run --name plan-server -e TZ="Asia/Shanghai" --network=cloud-net --hostname=plan-server -v /home/config:/home/server/config -p 8080:8080 -d registry.cn-shanghai.aliyuncs.com/jkhhuse-plan/plan:plan-server
docker container ls -a | grep plan-server保存流水线配置后,可以选择手动执行,也可以利用 webhook 功能让云效自己触发执行的时机。

Typescript 进阶知识分享与实践交流
2019年
Angular技术分享
2018年
之前见到波浪的效果觉得非常酷,但是一直没能详细理解其原理,今天google尝试后,记录下其原理(惊叹前辈们的想象力)。
其实波浪就是一个带radius的方块rotate的仿真效果,多层波浪就是使用不同的radius比例及透明度来制造层次感。

<div class="circle">
<div class="wave"></div>
</div>body{
margin: 0;
padding: 0;
}
.circle {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
width: 150px;
height: 150px;
background: #4973ff;
border: 5px solid #fff;
box-shadow: 0 0 0 5px #4973ff;
border-radius: 50%;
overflow: hidden;
}
.wave {
position: relative;
width: 100%;
height: 100%;
background: #4973ff;
border-radius: 50%;
box-shadow: inset 0 0 50px rgba(0,0,0,.5);
}
.wave:before,
.wave:after {
content: '';
position: absolute;
width: 200%;
height: 200%;
top: 0;
left: 50%;
transform: translate(-50%, -75%);
}
.wave:before {
border-radius: 45%;
background: rgba(255,255,255,1);
animation: animate 5s linear infinite;
}
.wave:after {
border-radius: 40%;
background: rgba(255,255,255,.5);
animation: animate 10s linear infinite;
}
@keyframes animate {
0% {
transform: translate(-50%, -75%) rotate(0deg);
}
100% {
transform: translate(-50%, -75%) rotate(360deg);
}
}大部分的架构的模式很难掌握,尤其资料缺乏的情况下。Angular的单向数据流便是其中之一。这个概念在官方文档中没有明确的解释,只零星存在于expression guidelines和template statements章节之中。作者在网上也没有找到详细描述单向数据流的文章,所以写下此篇文章。
在论及Angularjs与Angular之间的性能差异时,通常会提及单向数据流这一概念。单向数据流是Angular性能高于Angularjs的“秘诀”。
每个框架都存在利用绑定来实现组件之间通信的类似机制,例如在Anuglarjs中:
app.component('aComponent', {
controller: class ParentComponent() {
this.value = {name: 'initial'};
},
template: `
<b-component obj="$ctrl.value"></b-component>
`
});
----------------
app.component('bComponent', {
bindings: {
obj: '='
},父组件A向子组件B传递值的方式是使用obj输入绑定:
<b-component obj="$ctrl.value"></b-component>在Angular中也有着类似的方式:
@Component({
template: `
<b-component [obj]="value"></b-component>`
...
export class AppComponent {
value = {name: 'initial'};
}
----------------
export class BComponent {
@Input() obj;首先,最重要的事情是要理解Angular和Angularjs更新绑定是在变更检测(change detection)中进行的。在它们运行变更检测时,父组件A的值改变也会更新子组件B中的obj属性的值。
bComponentInstance.obj = aComponentInstance.value;这个过程演示了,双向绑定中的单向绑定或者单向数据流中的自顶向下。但是Angularjs不同之处是它更新了父组件中的值,也可以由子组件的值改变而改变。
app.component('parentComponent', {
controller: function ParentComponent($timeout) {
$timeout(()=>{
console.log(this.value); // logs {name: 'updated'}
}, 3000)
}
----------------
app.component('childComponent', {
controller: function ChildComponent($timeout) {
$timeout(()=>{
this.obj = { name: 'updated' };
}, 2000)在上面代码片段中存在两个带有回调函数的timeout函数,当子组件obj属性更新为{name: ‘updated’}。当Angularjs检测绑定在子组件属性的变更时,也会更新父组件的属性。这是Angularjs内置的双向绑定特性。而在Angular之中,子组件的值会变更,但是不会冒泡到父组件中。这是两者变更检测过程中的区别。
在Angular中,虽然没有双向绑定,但是仍然存在一种方式可以子组件操控父组件中值的更新,即组件中的Output绑定。
@Component({
template: `
<h1>Hello {{value.name}}</h1>
<a-comp (updateObj)="value = $event"></a-comp>`
...
export class AppComponent {
value = {name: 'initial'};
constructor() {
setTimeout(() => {
console.log(this.value); // logs {name: 'updated'}
}, 3000);
----------------
@Component({...})
export class AComponent {
@Output() updateObj = new EventEmitter();
constructor() {
setTimeout(() => {
this.updateObj.emit({name: 'updated'});
}, 2000);首先,需要说明的是,这种方式与Angularjs那种直接从子组件值改变来更新父组件的双向绑定不同。但是奇怪的是,这种方式为什么不能称之为双向绑定?毕竟子/父组件的交互是双向的。
这篇文章Two Phases of Angular Applications给出了一个解释:
(Angular 2 separates updating the application model and reflecting the state of the model in the view into two distinct phases. The developer is responsible for updating the application model. Angular, by means of change detection, is responsible for reflecting the state of the model in the view.)
Angular2 更新应用中model和解析model至view是位于两个不同的处理阶段。开发人员负责更新应用model,Angular通过变更检测,把model的变更映射到view层。
所以上述示例中,Angular父组件依赖于output绑定机制的更新,并不属于Angular的变更检测的一部分。
它是在变更检测开始之前,更新应用model的第一个阶段执行的。因此,单向数据流定义了变更检测期间的绑定更新体系结构。与Angularjs不同,Angular的变更检测机制下没有把子组件属性更新传播到父组件。output绑定处理位于变更检测之外,因此不会将单向数据流转变为双向绑定。
大部分的web应用都使用了分层设计,视图(view)层和服务(service)层。
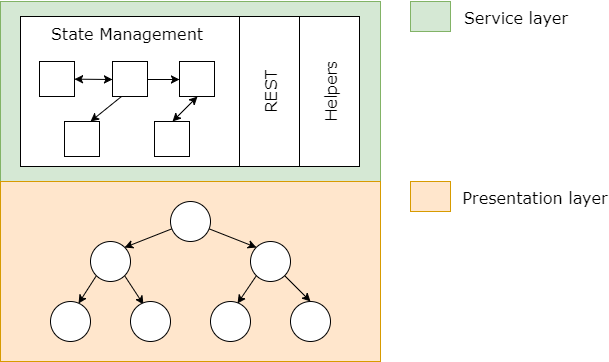
在web环境下,view层中为使用DOM等技术来展示用户数据,在Angular中view层则由组件实现。service层则负责处理与存储业务相关的数据。像上图所示,service层包含了状态管理、REST调用、可重用的通用工具服务等。
之前解释的单向数据流是与应用的view层相关,Angular中的view由组件呈现,所以单向数据流其实就可以表现为组件之间的数据流动。
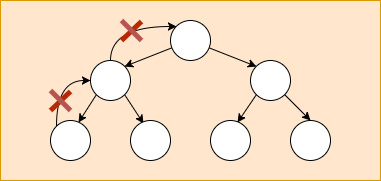
然而,当引入ngrx(实现了类似Redux的状态管理模式)之后,又会陷入另外一种困惑。Redux的文档中关于状态的描述:
Redux的架构围绕严格的单向数据流实现,这意味着应用程序中的所有数据都遵循着相同的生命周期,使你的应用程序逻辑更加可预测和可理解。
所以,这里的单向数据流是与service层相关,而不是view层。在引入类Redux模式时,要注意区别这两者的区别。Redux主要关注的是service层中的状态管理模块,引入Redux后,Web应用的架构则由
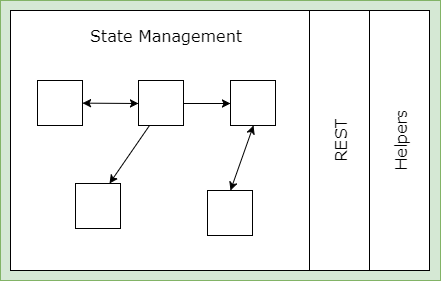
转变为:

Do you really know what unidirectional data flow means in Angular
这篇文章对Angualrjs与Angular的绑定机制做了对比,Angular的“双向绑定”通过指令ngModel实现(在表单中可以直接使用ngModel)或者由语法[()]来实现。
关于[()]其实是[]与()的集合,可以视作一种语法糖,参考一个示例:
import { Component, EventEmitter, Input, Output } from '@angular/core';
@Component({
selector: 'app-sizer',
template: `
<div>
<button (click)="dec()" title="smaller">-</button>
<button (click)="inc()" title="bigger">+</button>
<label [style.font-size.px]="size">FontSize: {{size}}px</label>
</div>`
})
export class SizerComponent {
@Input() size: number | string;
@Output() sizeChange = new EventEmitter<number>();
dec() { this.resize(-1); }
inc() { this.resize(+1); }
resize(delta: number) {
this.size = Math.min(40, Math.max(8, +this.size + delta));
this.sizeChange.emit(this.size);
}
}
---------------app.component.html
<app-sizer [(size)]="fontSizePx"></app-sizer>[(size)]其实是[size]与(sizeChange)的一个简写:
<app-sizer [size]="fontSizePx" (sizeChange)="fontSizePx=$event"></app-sizer>可以简写的原因就是这里其实目标是实现fontSizePx的双向绑定,即子组件app-sizer中的size的改动更新可以冒泡到父组件中。sizeChange则可以隐式emit出size值。
ngModel指令也是同样,它其实是可以分解为[ngModel]与(ngModelChange)两个部分。
最后,本篇文章着重讲了单向数据流的概念周边,为了进一步理解Angular的change detection机制及更多其他的知识点,我还将陆续翻译/写作一些文章或者资料帮助加深自己对Angular的理解。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.