jobrunr / jobrunr Goto Github PK
View Code? Open in Web Editor NEWAn extremely easy way to perform background processing in Java. Backed by persistent storage. Open and free for commercial use.
Home Page: https://www.jobrunr.io/en/
License: Other
An extremely easy way to perform background processing in Java. Backed by persistent storage. Open and free for commercial use.
Home Page: https://www.jobrunr.io/en/
License: Other




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





























































































































































Describe the bug
If server exists during processing, job gets stuck in that state
Environment
I'm using version 0.9.7
I'm running on JRE / JDK 11
To Reproduce
Start long running job (in my case something that times out) and just stop the server during execution.
Expected behavior
Should requeue the job.
My case is like this:
1- I have an unreachable database IP so it times out after 30 seconds.
2- Before it times out (i.e. Hikari pool is starting), stop the server.
3- Job is stuck at processing state
Describe the bug
I see these exceptions in the logs when shutting down the server:
2020-09-25 09:49:10,202 ERROR [org.job.sto.AbstractStorageProvider] (Timer-0) Error notifying JobStorageChangeListeners - please create a bug report (with the stacktrace attached): org.jobrunr.JobRunrException: JobRunr encountered a problematic exception. Please create a bug report (if possible, provide the code to reproduce this and the stacktrace)
at org.jobrunr.JobRunrException.shouldNotHappenException(JobRunrException.java:43)
at org.jobrunr.storage.sql.common.db.dialect.DialectFactory.forDataSource(DialectFactory.java:25)
at org.jobrunr.storage.sql.common.db.Sql.using(Sql.java:49)
at org.jobrunr.storage.sql.common.BackgroundJobServerTable.<init>(BackgroundJobServerTable.java:33)
at org.jobrunr.storage.sql.common.DefaultSqlStorageProvider.backgroundJobServerTable(DefaultSqlStorageProvider.java:236)
at org.jobrunr.storage.sql.common.DefaultSqlStorageProvider.getBackgroundJobServers(DefaultSqlStorageProvider.java:86)
at org.jobrunr.storage.AbstractStorageProvider.notifyBackgroundJobServerStatusChangeListeners(AbstractStorageProvider.java:120)
at org.jobrunr.storage.AbstractStorageProvider.access$100(AbstractStorageProvider.java:21)
at org.jobrunr.storage.AbstractStorageProvider$SendJobStatsUpdate.run(AbstractStorageProvider.java:163)
at java.util.TimerThread.mainLoop(Timer.java:555)
at java.util.TimerThread.run(Timer.java:505)
Caused by: java.sql.SQLException: This pool is closed and does not handle any more connections!
at io.agroal.pool.ConnectionPool.getConnection(ConnectionPool.java:192)
at io.agroal.pool.DataSource.getConnection(DataSource.java:81)
at org.jobrunr.storage.sql.common.db.dialect.DialectFactory.forDataSource(DialectFactory.java:18)
... 9 moreEnvironment
I'm using version 1.0.0
I'm running on JRE / JDK Quarkus
Describe the bug
@ConditionalOnProperty should refer to a property in kebab case and the auto-configuration currently uses camel case. See this example.
Check the Javadoc of @ConditionalOnProperty for more details.
Environment
n/a
Describe the bug
The enqueue code is being done in a spring rest controller such as this:
@RestController
public class ReportStorageController {
@GetMapping("/test")
public String test() {
BackgroundJob.enqueue(r -> r.test());
return "ok";
}
}
ReportService is an interface defined in the spring context and has one @component (DefaultReportService.class) registered
The exception is
java.lang.NoSuchMethodException: com.adswizz.ds.swiss.ui.report.storage.ReportStorageController.lambda$test$87095d82$1()
So it seems that when resolving the lambda, it strangely thinks the test call should be made on the controller and not the r instance
Any idea ?
I think it will be better to rename:
scheduleRecurringly -> scheduleRecurring
deleteRecurringly -> remove
Hangfire names are also similar. Especially deleteRecurringly sounds like it will repeat deleting the job.
Describe the bug
Adding @ConditionalOnClass on a bean method to guard a bean to be created if the class is not on the classpath won't work as the JVM will load the class and parse method signature.
Here is an example.
See the Javadoc of @ConditionalOnClass for more details.
Environment
n/a
Is your feature request related to a problem? Please describe.
When a new version of the code is deployed, and there are scheduled jobs that have another class/method/method signature, they will fail with a JobClassNotFoundException or a JobMethodNotFoundException. 😒
Describe the solution you'd like
I would like to see in the logs that there are incompatible scheduled jobs.
I would like to see in the dashboard that there are incompatible scheduled jobs.
Additional context
This feature request is related to #40 - Upcasting of lambda method.
I need to customize the Dashboard ,do you has plan to support ?
Describe the bug
Even though two jobs are registered, only one works.
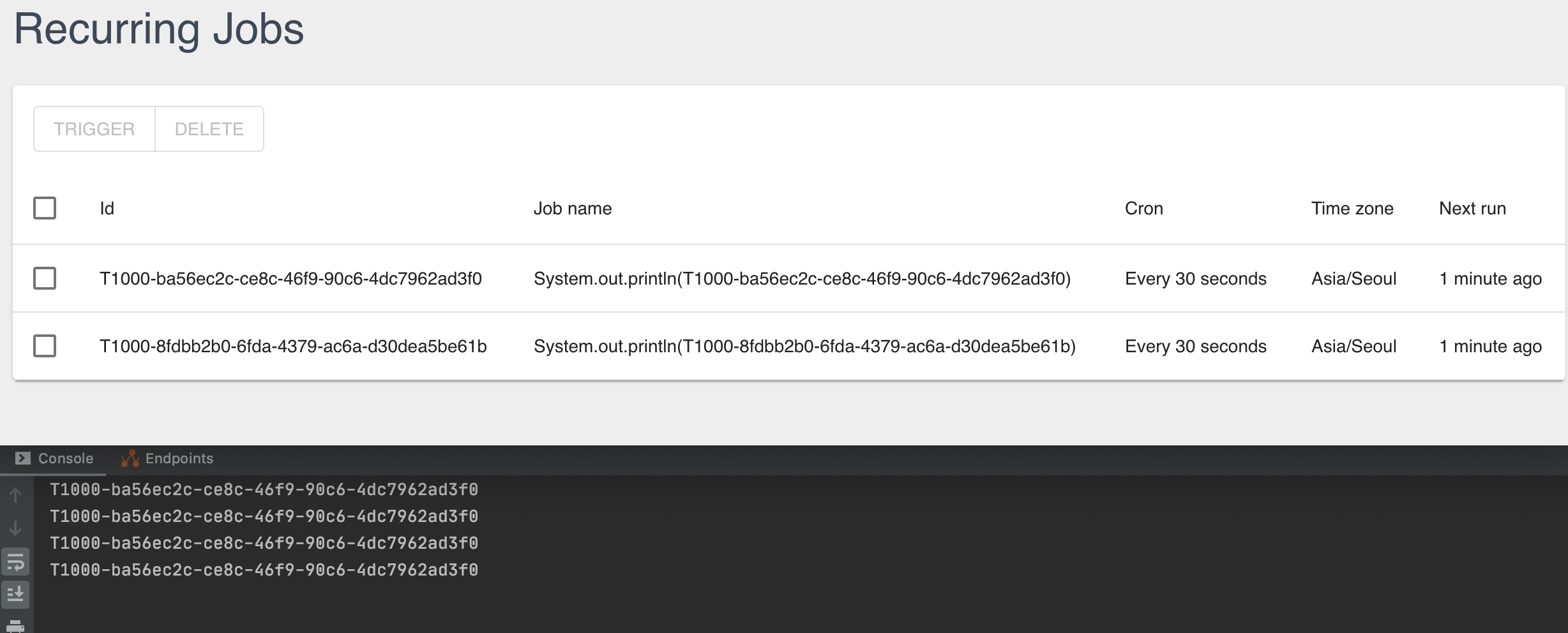
Environment
I'm using version 1.0.0
I'm running on JRE / JDK 11
To Reproduce
Provide a simple project or code fragment which shows how to reproduce the issue.
BackgroundJob.enqueue(() -> service.helpMe());Expected behavior
All recurring jobs are executed at same cron expression.
Additional context
Add any other context about the problem here.
Describe the bug
Instead of scheduleRecurringly we should use scheduleRecurrently as it is grammatical more correct
Environment
I'm using version 0.9.19
Is your feature request related to a problem? Please describe.
We have some jobs that are failing for reasons that won't be solved after any number of retries (e.g. underlying logic crashes for whatever reason).
Describe the solution you'd like
Some way to stop mark the job failed after 1 or 2 retries.
Describe alternatives you've considered
Looked at the source code trying to find a way to change the retry count of RetryFilter, but that would require setting up the whole machinery manually, i.e. without using JobRunr.configure().
Describe the bug
When i start my application within docker container im not able to open dashboard.
It looks like redirect from / to /dashboard works but it results with 404.
Environment
I'm using version 0.9.11
I'm running on JRE / JDK 1.8.0
To Reproduce
Try to run jobrunr within docker
Expected behavior
Dashboard is accessible when its run within docker container
Additional context
Edit:
After spending some time on debugging i notice the problem is placed within StaticFileHttpHandler.java.
When i start my application from my IDE the path
final Path toServe = rootDir.resolve(requestUri.substring((contextPath + "/").length()));
is accessible. When i create jar file for my whole application, then the ZipFilesSystem changed and setup us my application jar name and it need firstly extract jobrunr jar from my application jar, and theres no way to extract jar which is already inside jar.
Hi @rdehuyss,
Thanks a lot for your work on this tool!
I'm now in the evaluation phase on whether JobRunr would fit our needs or not.
There are a few different use-cases, but here I'll focus only on one.
Is there a way to run specific jobs on a particular worker? Some examples:
I looked at the source code, and it seems that the only way to achieve this at the moment is to implement custom WorkDistributionStrategy and somehow inject it into the places where it is relevant.
I would appreciate it if you can share your thoughts on the subject and give some comments on whether such features are planned in the future, or it's entirely out of scope.
Thank you,
Alex.
P.S. I might be approaching the problem in a wrong way, so if you have better suggestions - please do not hesitate to share them :)
Describe the bug
I'm trying to schedule a job, but hitting the following exception:
Caused by: java.lang.IllegalStateException: Unknown INVOKESPECIAL instruction: javaTarJob
at org.jobrunr.JobRunrException.shouldNotHappenException(JobRunrException.java:32) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.instructions.InvokeSpecialInstruction.invokeInstruction(InvokeSpecialInstruction.java:27) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.instructions.AbstractJVMInstruction.invokeInstructionAndPushOnStack(AbstractJVMInstruction.java:16) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.JobDetailsFinderContext.invokeInstructions(JobDetailsFinderContext.java:78) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.JobDetailsFinderContext.getJobDetails(JobDetailsFinderContext.java:71) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator$JobDetailsFinder.getJobDetails(JobDetailsAsmGenerator.java:135) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator.findJobDetailsInByteCode(JobDetailsAsmGenerator.java:59) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator.toJobDetails(JobDetailsAsmGenerator.java:38) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.scheduling.JobScheduler.enqueue(JobScheduler.java:81) ~[jobrunr-0.9.11.jar:?]
at org.jobrunr.scheduling.BackgroundJob.enqueue(BackgroundJob.java:41) ~[jobrunr-0.9.11.jar:?]
at jobs.JobService.analyzeJavaTar(JobService.scala:12) ~[?:?]
The JobService.scala looks like this:
class JobService {
def analyzeJavaTar(tarPath: String): UUID = {
BackgroundJob.enqueue(() => javaTarJob(JobContext.Null, tarPath)).asUUID
}
private def javaTarJob(ctx: JobContext, tarPath: String): Unit = {
/// omitted
}
}Environment
I'm using version 0.9.11.
I'm running on JRE / JDK adoptopenjdk-13.jdk on macOS.
To Reproduce
The snippet causing the issue is above. Here is the initialization code:
val dataSource = new SQLiteDataSource
dataSource.setUrl("jdbc:sqlite:/tmp/annotation-server.sqlite")
val storageProvider = new DefaultSqlStorageProvider(dataSource)
JobRunr.configure()
.useStorageProvider(storageProvider)
.useDefaultBackgroundJobServer()
.useDashboard()
.initialize()Expected behavior
I expect the job to be scheduled :)
Additional context
I'm using JobRunr as part of the PlayFramework app written in Scala.
Is your feature request related to a problem? Please describe.
In case of a JobRunr shouldNotHappenException, a lot of information is needed from users/developers to pinpoint the actual problem:
Describe the solution you'd like
We could create a diagnostics report in the tmp directory which contains all relevant information in case such an exception occurs. The actual exception would then print a log message asking the user to attach the information to the ticket.
JobRunr looks great and I found it when searching for a "command scheduling library" that can be used together with Occurrent.
The one drawback I can see with the library this:
Important: all your servers must run the same version of your code! If your webapp server has a newer version with a method signature that is not compatible with the server that processes your background jobs, a NoSuchMethod Exception will be thrown and job processing will fail!
This is of course understandable, but I'm lacking documentation on what's happening when a NoSuchMethodException is thrown. Will the method be retried forever in this case so that one has a chance to fix it and deploy a new version?
This brings me to the actual feature request. It would be great to be able to configure "upcasting" or conversion functions that can be applied to the JobRunr configuration. For example, if I have scheduled a job like this:
BackgroundJob.enqueue(() -> SomeClass.something("Hello, world!"));but I change something to take two strings before the job is executed, e.g. something(String, String), I assume I will run into a NoSuchMethodException. Then it would be great to be able to configure upcasting functions like this:
JobRunr.configure()
.upcasting(document -> {
if (document.isTargeting(SomeClass::something) && document.hasParameterCount(1)) {
return document.addParameter("default for second param");
} else {
return document;
}
})Where document is a (potentially immutable) class that is wrapping the serialized data:
{
"lambdaType": "org.jobrunr.jobs.lambdas.JobLambda",
"className": "org.something.Something",
"methodName": "somehing",
"jobParameters": [
{
"className": "java.lang.String",
"object": "a test"
}
]
}
WDYT?
I am using JobRunr to create multiple recurring jobs to fetch all user's data every 10 min, using same method and just changing the user id, and of course, I provide a unique id for each recurring job based on user id.
But jobrunr seems to ignore the provided job id, and it considers all jobs as one job because they have the same method name and type.
jobScheduler.scheduleRecurrently("One",() -> System.out.println("One"), Cron.minutely());
jobScheduler.scheduleRecurrently("Two", () -> System.out.println("Two"), Cron.minutely());
Different recurring jobs get added successfully:

But only executes the job with id = "Two" over and over :

A step further, I changed the called printing method for the job with id = "One" ;
from print("One") to println("Two"), and repeated the test,
after this change jobrunr was able to run both jobs recurrently because the job method was changed
jobScheduler.scheduleRecurrently("One",() -> System.out.print("One"), Cron.minutely());
jobScheduler.scheduleRecurrently("Two", () -> System.out.println("Two"), Cron.minutely());


Describe the bug
Job is stuck in the "ENQUEUED" state.
Environment
I'm using version 0.9.11.
I'm running on JRE / JDK 8
To Reproduce
Not sure I can provide easy steps to reproduce. Some more details are below.
Expected behavior
The job starts after being enqueued.
Additional context
I was just using JobRunr jobs for a couple of days and everything worked fine. One of the jobs has failed some days ago and I deleted it. Today, I fixed the underlying issue and re-queued the deleted job, however, it didn't start. I deleted it again and created another job - it didn't start as well. I was away for a couple of hours, when I got back it's still in the "enqueued" state.
I'm not sure where to start the debugging, so any hints are much appreciated.
Let me know if I can provide more information.
Thanks,
Alex.
Is your feature request related to a problem? Please describe.
The auto-configuration currently access the environment directly for configuration options of this starter. See this mapping.
Describe the solution you'd like
A @ConfigurationProperties annotated type with proper documentation and the annotation processor configured to generated metadata should be used instead. This allows auto-completion for those keys in an IDE.
Is your feature request related to a problem? Please describe.
I want to run the database scripts outside of JobRunr as I don't want to give the user with which JobRunr is running DDL rights
Describe the solution you'd like
Is your feature request related to a problem? Please describe.
This is hard coded in the JobZooKeeper.
Can this made be configurable?
Describe the solution you'd like
Add an option to the class BackgroundJobServerConfiguration called
=> keep the same defaults in the BackgroundJobServerConfiguration as before (36 hours and 72 hours).
=> use the values given in the BackgroundJobServerConfiguration in the zookeeper.
HI @rdehuyss,
Just curious whether using UUID (as opposed to a String) is intentional?
I.e. shouldn't this
job.getId().toString().
While the current implementation is working fine, I've never seen a binary object used as an ID, and I'm wondering whether it may cause any issues with other queries such as aggregate.
The JobDetailsAsmGenerator is one of the backbones of JobRunr, it parses the java bytecode of your project to find the exact lambda you are passing.
The JobDetailsAsmGenerator is using a MethodVisitor of ASM to visit all the methods in the class file until it finds INVOKEVIRTUAL call which typically is your lambda. The score of this class in SonarCloud isn't the greatest due to the cyclomatic complexity.
How can this class be improved so that the cyclomatic complexity descends?
Exception happened when execute query:
select * from jobrunr_jobs_stats ORDER BY total ASC OFFSET ? ROWS FETCH NEXT ? ROWS ONLY
The OFFSET syntax is not support in Oracle 11g.
First of all, thanks sincerely for using and supporting JobRunr. I will try my best to make JobRunr better, and keep the community and eco-system growing.
Pls. submit a comment in this issue and include the following information:
You can refer to the following sample answer for the format:
* Organization: Rosoco
* Location: Leuven, Belgium
* Contact: [email protected]
* Purpose: used as cornerstone in a distributed service architecture for generating a large amount of documents.
Thanks again for your participation !
Describe the bug
I get a java.lang.IllegalStateException: Unknown INVOKESPECIAL instruction when scheduling a private method
Environment
I'm using version 0.9.19
I'm running on JRE / JDK unrelevant
Expected behavior
I would like to receive a clear exception.
I am trying to run the task below which gives the error:
@RestController
@RequestMapping("/v1/task/enqueue")
public class TaskController {
private final JobScheduler jobScheduler;
private final CsvExportService csv;
public TaskController(JobScheduler jobScheduler, CsvExportService csv) {
this.jobScheduler = jobScheduler;
this.csv = csv;
}
@PostMapping(value = "/")
public ResponseEntity findAll() {
jobScheduler.<CsvExportService>enqueue(c -> c.export(1, "select * from dual", Path.of("/")));
return ResponseEntity.ok().build();
}
} @Bean
public JobScheduler initJobRunr(ApplicationContext applicationContext) {
return JobRunr.configure()
.useStorageProvider(new MongoDBStorageProvider("localhost", 27017))
.useJobActivator(applicationContext::getBean)
.useDefaultBackgroundJobServer()
.useDashboard()
.initialize();
}java.lang.IllegalArgumentException: Instruction 87 not found
at org.jobrunr.jobs.details.instructions.AllJVMInstructions.get(AllJVMInstructions.java:56) ~[jobrunr-0.9.7.jar:?]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator$JobDetailsFinder$1.visitInsn(JobDetailsAsmGenerator.java:101) ~[jobrunr-0.9.7.jar:?]
at org.objectweb.asm.ClassReader.readCode(ClassReader.java:2188) ~[asm-7.3.1.jar:7.3.1]
at org.objectweb.asm.ClassReader.readMethod(ClassReader.java:1492) ~[asm-7.3.1.jar:7.3.1]
at org.objectweb.asm.ClassReader.accept(ClassReader.java:717) ~[asm-7.3.1.jar:7.3.1]
at org.objectweb.asm.ClassReader.accept(ClassReader.java:401) ~[asm-7.3.1.jar:7.3.1]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator.findJobDetailsInByteCode(JobDetailsAsmGenerator.java:58) ~[jobrunr-0.9.7.jar:?]
at org.jobrunr.jobs.details.JobDetailsAsmGenerator.toJobDetails(JobDetailsAsmGenerator.java:38) ~[jobrunr-0.9.7.jar:?]
at org.jobrunr.scheduling.JobScheduler.enqueue(JobScheduler.java:111) ~[jobrunr-0.9.7.jar:?]
at com.ttgint.myapp.controller.TaskController.findAll(TaskController.java:25) ~[classes/:?]
Is your feature request related to a problem? Please describe.
Usability: a succeeded job does not show it will be deleted automatically.
Describe the solution you'd like
I want to see in the dashboard when it will be deleted
Additional context
If a Job is deleted, I also want to see when it will be deleted permamently.
Hi,I want to get result when job execute finished in a Controller, but don't want to query database, Do you have any suggestions?
I am getting not found error when I go to http://localhost:8000/.

When falling asleep yesterday I came to think of an important thing that I don't think JobRunr currently supports, and that is idempotency of job scheduling/enqueueing.
For example, in event-based systems, it's common that I want to schedule something after an event has occurred. Take for example the order case. Let's say you an order was placed, i.e. an OrderWasPlaced event has been published. As a consequence of this I want to schedule a reminder to be sent if the order has not been paid in 1 week. Thus I'd like to create a policy that listens to OrderWasPlaced and schedules a future action (pseudo-code since I don't have the API in front of me :)):
OrderWasPlaced e = ..
BackgroundJob.schedule(() -> Order.sendReminder(..), e.getPlacedAt().plus(1, WEEK));But if the application crash after the call to BackgroundJob.schedule(..) but before the method returns and ack's that the OrderWasPlaced has been handled correctly, then two jobs will be registered since the method will be retried by the broker infrastructure (RabbitMQ, Kafka etc).
Instead, I would like the client to also be able to generate a unique UUID. For example:
OrderWasPlaced e = ..
BackgroundJob.schedule(settings().jobId(e.getEventUUID()), () -> Order.sendReminder(..), e.getPlacedAt().plus(1, WEEK));settings() could also host more options, such as the ability to specify a parallel property as discussed in issue #43.
Note that it would be benefitial if settings could be defined before the lamda expression if you take Kotlin friendliness into account since in Kotlin the last lambda expression can be moved outside the parenthesis:
BackgroundJob.enqueue(settings().jobId(UUID.randomUUID()) {
Application.doStuff(...)
}
Unfortunately, this won't work for the schedule method since it defines OffsetDateTime and ZoneDateTime as the last parameter. It's a minor thing, but maybe it's worth keeping in mind in the future :)
Describe the bug
A clear and concise description of what the bug is.
Background Job Server is not starting when using Spring Boot 2.3
Environment
I'm using version 1.1.0
I'm using the following StorageProvider MongoDBStorageProvider
To Reproduce
Run tests with latest MongoDB Driver
Expected behavior
Tests should pass
Extra information
Exception in thread "extShutdownHook" org.bson.codecs.configuration.CodecConfigurationException: The uuidRepresentation has not been specified, so the UUID cannot be encoded.
at org.bson.codecs.UuidCodec.encode(UuidCodec.java:72)
at org.bson.codecs.UuidCodec.encode(UuidCodec.java:37)
at com.mongodb.client.model.BuildersHelper.encodeValue(BuildersHelper.java:37)
at com.mongodb.client.model.Filters$SimpleEncodingFilter.toBsonDocument(Filters.java:1175)
at com.mongodb.internal.operation.Operations.toBsonDocument(Operations.java:514)
at com.mongodb.internal.operation.Operations.bulkWrite(Operations.java:406)
at com.mongodb.internal.operation.Operations.deleteOne(Operations.java:319)
at com.mongodb.internal.operation.SyncOperations.deleteOne(SyncOperations.java:173)
at com.mongodb.client.internal.MongoCollectionImpl.executeDelete(MongoCollectionImpl.java:982)
at com.mongodb.client.internal.MongoCollectionImpl.deleteOne(MongoCollectionImpl.java:507)
at com.mongodb.client.internal.MongoCollectionImpl.deleteOne(MongoCollectionImpl.java:502)
at org.jobrunr.storage.nosql.mongo.MongoDBStorageProvider.signalBackgroundJobServerStopped(MongoDBStorageProvider.java:137)
at org.jobrunr.storage.ThreadSafeStorageProvider.signalBackgroundJobServerStopped(ThreadSafeStorageProvider.java:53)
at org.jobrunr.server.ServerZooKeeper.stop(ServerZooKeeper.java:52)
at org.jobrunr.server.BackgroundJobServer.stopZooKeepers(BackgroundJobServer.java:187)
at org.jobrunr.server.BackgroundJobServer.stop(BackgroundJobServer.java:110)
at java.lang.Thread.run(Thread.java:748)
Describe the bug
A clear and concise description of what the bug is.
the 'awaitAll' method not found in LettuceRedisStorageProvider, LettuceRedisPipelinedStream classes

Environment
I'm using version 1.0.0
I'm running on JRE / JDK 11, lettuce-core 5.3.3.RELEASE
To Reproduce
Provide a simple project or code fragment which shows how to reproduce the issue.
BackgroundJob.enqueue(() -> service.helpMe());Expected behavior
A clear and concise description of what you expected to happen.
Additional context
Add any other context about the problem here.
changes Futures.awaitAll to LettuceFutures.awaitAll maybe?
The link http://localhost:8000/dashboard/overview does not work. The content appears but quickly disappears:

http://localhost:8000/dashboard/jobs and the rest of the tabs works fine however.
Once I enqueue some jobs, it starts to work
Describe the bug
org.jobrunr.storage.AbstractStorageProvider throw java.util.ConcurrentModificationException
this.onChangeListeners.forEach((listener) -> {
listener.onChange(jobStats);
});maybe onChangeListeners has changed when do foreach?
Environment
I'm using version 0.9.7
I'm running on JRE / JDK 1.8
To Reproduce
Provide a simple project or code fragment which shows how to reproduce the issue.
Exception in thread "Timer-0" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1429)
at java.util.HashMap$KeyIterator.next(HashMap.java:1453)
at java.lang.Iterable.forEach(Iterable.java:74)
at org.jobrunr.storage.AbstractStorageProvider.notifyOnChangeListeners(AbstractStorageProvider.java:61)
at org.jobrunr.storage.AbstractStorageProvider$SendJobStatsUpdate.run(AbstractStorageProvider.java:67)
at java.util.TimerThread.mainLoop(Timer.java:555)
at java.util.TimerThread.run(Timer.java:505)Describe the bug
Various auto-configurations are reacting to the fact another bit of infrastructure is present. For instance, the elasticsearch one checks if a HighLevelClient is defined. Yet, the auto-configuration does not declare anywhere it should be processed once the auto-configuration for elasticsearch has been processed.
See @AutoConfigureBefore, @AutoConfigureAfter for more details.
Environment
n/a
Describe the bug
when the SUCCEEDED job is DELETED, table jobrunr_jobs update the state column to DELETED,but table jobrunr_job_counters is not update the amount colum
Environment
I'm using version 0.9.7
I'm running on JRE / JDK 1.8
Additional context


Describe the bug
When I call my service call in try block it works fine, which means my service class is properly wired, but when I try to put it to BackgroundJob.enqueue or scheduleRecurrently it doesn't work.
Environment
I'm using version 1.1.0
I'm using SpringBoot 2.3.3.RELEASE
I'm running on JRE / JDK 14
I'm using the following StorageProvider InMemoryStorageProvider
To Reproduce
@Configuration
public class Runner {
private static final Logger log = LoggerFactory.getLogger(Runner.class);
@Autowired JobScheduler jobScheduler;
@Autowired FtpAccountService ftpAccountService;
@Bean
public void scheduleRecurrently() {
log.info("Configured");
try {
ftpAccountService.sweepFolders();
} catch (Exception e) {
e.printStackTrace();
}
BackgroundJob.enqueue(() -> ftpAccountService.sweepFolders());
}
}Error
org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.onlykalu.tn.edi.service.FtpAccountService' available
at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:352) ~[spring-beans-5.2.8.RELEASE.jar:5.2.8.RELEASE]
at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:343) ~[spring-beans-5.2.8.RELEASE.jar:5.2.8.RELEASE]
at org.springframework.context.support.AbstractApplicationContext.getBean(AbstractApplicationContext.java:1127) ~[spring-context-5.2.8.RELEASE.jar:5.2.8.RELEASE]
at org.jobrunr.server.runner.BackgroundJobWithIocRunner.supports(BackgroundJobWithIocRunner.java:21) ~[jobrunr-1.1.0.jar:na]
at org.jobrunr.server.BackgroundJobServer.lambda$getBackgroundJobRunner$0(BackgroundJobServer.java:133) ~[jobrunr-1.1.0.jar:na]
at java.base/java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:176) ~[na:na]
at java.base/java.util.Spliterators$ArraySpliterator.tryAdvance(Spliterators.java:958) ~[na:na]
at java.base/java.util.stream.ReferencePipeline.forEachWithCancel(ReferencePipeline.java:127) ~[na:na]
at java.base/java.util.stream.AbstractPipeline.copyIntoWithCancel(AbstractPipeline.java:502) ~[na:na]
Expected behavior
List down files
Currently you can provide id/name for recurring tasks like:
BackgroundJob.scheduleRecurringly("my-recurring-job", () -> service.doWork(), Cron.daily()); and you can also delete them.
However, for others (enqueue and schedule) you cannot provide a custom id/name or delete them. I think it will be a good enhancement to allow these two options.
Describe the bug
When i go to JobRunr dashboard and click on one of succeded job then appears white page with following error in console.
react_devtools_backend.js:2273 TypeError: t.latencyDuration.toFixed is not a function
at ra (succeeded-state.js:62)
at Xr (react-dom.production.min.js:153)
at ms (react-dom.production.min.js:261)
at cl (react-dom.production.min.js:246)
at sl (react-dom.production.min.js:246)
at Js (react-dom.production.min.js:239)
at react-dom.production.min.js:123
at t.unstable_runWithPriority (scheduler.production.min.js:19)
at Gn (react-dom.production.min.js:122)
at jn (react-dom.production.min.js:123)
overrideMethod @ react_devtools_backend.js:2273
es @ 2.144d0f26.chunk.js:2
i.callback @ 2.144d0f26.chunk.js:2
ur @ 2.144d0f26.chunk.js:2
rs @ 2.144d0f26.chunk.js:2
hl @ 2.144d0f26.chunk.js:2
t.unstable_runWithPriority @ 2.144d0f26.chunk.js:2
Gn @ 2.144d0f26.chunk.js:2
pl @ 2.144d0f26.chunk.js:2
Js @ 2.144d0f26.chunk.js:2
(anonymous) @ 2.144d0f26.chunk.js:2
t.unstable_runWithPriority @ 2.144d0f26.chunk.js:2
Gn @ 2.144d0f26.chunk.js:2
jn @ 2.144d0f26.chunk.js:2
Vn @ 2.144d0f26.chunk.js:2
L @ 2.144d0f26.chunk.js:2
$t @ 2.144d0f26.chunk.js:2
react-dom.production.min.js:123 Uncaught TypeError: t.latencyDuration.toFixed is not a function
at ra (succeeded-state.js:62)
at Xr (react-dom.production.min.js:153)
at ms (react-dom.production.min.js:261)
at cl (react-dom.production.min.js:246)
at sl (react-dom.production.min.js:246)
at Js (react-dom.production.min.js:239)
at react-dom.production.min.js:123
at t.unstable_runWithPriority (scheduler.production.min.js:19)
at Gn (react-dom.production.min.js:122)
at jn (react-dom.production.min.js:123)
Environment
I'm using version 0.9.11 JobRunr
I'm running on JRE / JDK 1.8.0_232
Dashboard has been setup to listen on custom port 8069
To Reproduce
Go to dashboard, click on Succeeded jobs and click one of entry (id or description)
Expected behavior
Details of selected job entry.
Additional context
I'm using Postgresql storage with configured my custom json mapper.
Describe the bug
Tests fail when upgrading Jackson to 2.11.3.
Further investigation is needed.
Describe the bug
Although the background job server says it started, it did not as registering in the MongoDB Storage Provider failed.
Environment
I'm using version 1.1.0
I'm using the following StorageProvider MongoDBStorageProvider
The job shows correctly only the detail of process in status "processing" while the others give a error in the console and a "white" page
Environment
I'm using version Jobrunr 0.9.17
I'm running on JRE / JDK 11
Chrome and Firefox
Jobrunr started with (processJob and dashboard are true)
MysqlDataSource da = new MysqlDataSource();
da.setURL(url);
da.setUser(user);
da.setPassword(pwd);
JobRunrConfiguration jr = JobRunr.configure()
.useStorageProvider(new DefaultSqlStorageProvider(da, DefaultSqlStorageProvider.DatabaseOptions.SKIP_CREATE))
.useJobActivator(applicationContext::getBean);
// start as a processor
if (processJob) {
jr.useDefaultBackgroundJobServer();
}
// web dashboard?
if (hasJobDashboard)
{
jr.useDashboard(8000);
}
jr.initialize();There is another processor running with both processJob and dashboard false.
The project add some job that are processed correctly but in the dashboard only the "processing" details are correctly displayed.
When you click on the link for the job:

you get an error in this js code:

with this log in the console:
react-dom.production.min.js:123 Uncaught TypeError: Cannot read property '1' of null
at $e (succeeded-state.js:45)
at Qe (succeeded-state.js:59)
at Xr (react-dom.production.min.js:153)
at ms (react-dom.production.min.js:261)
at cl (react-dom.production.min.js:246)
at sl (react-dom.production.min.js:246)
at Js (react-dom.production.min.js:239)
at react-dom.production.min.js:123
at t.unstable_runWithPriority (scheduler.production.min.js:19)
at Gn (react-dom.production.min.js:122)
Expected behavior
Display of the detail information
Additional context
We are in develop so the project has been restarted multiple times
Is your feature request related to a problem? Please describe.
I'm always frustrated when I need to add a lot of boiler plate code to add a new library.
Describe the solution you'd like
I would like a jobrunr-spring-boot-starter
Describe alternatives you've considered
Adding all the beans myself or using the fluent API
Describe the bug
The time displayed in latency and processing time are wrong.
Expected behavior
I expect the durations in the Succeeded State to be correct.
Describe the bug
The dashboard uptime sensor switches randomly between the available servers. It should show the value of the longest server running
Only happens when using Redis Storage Provider
Is it currently possible to set the maximum number of concurrent jobs a worker executes at a time? I would like to be able to limit the load on workers somehow.
Describe the bug
I try recurring jobs with 0.9.16 version. when I run recurring jobs with Cron.hourly, everything is perfect.
But run recurring jobs with Cron.daily, the jobs run repeatedly.
After job running, the next run of hourly job in dashboard displays xTime from now, but daily job is xTime ago.
Environment
I'm using version 0.9.16
I'm running on JRE / JDK 11.0.2
To Reproduce
jobScheduler.scheduleRecurringly("Daily", myService -> myService.doSimpleJob("Hello!"), Cron.daily());
Expected behavior
Daily job should be running daily. After job running, the next run of job should be xTime ago.
Is your feature request related to a problem? Please describe.
Not possible to use JobRunr on apps that use Cassandra, without introducing another storage layer.
Describe the solution you'd like
Allow Cassandra as a background job storage provider
Describe alternatives you've considered
Adding PgSQL to an existing Cassandra app. Possible, but cumbersome.
Additional context
You would probably need to use lightweight transactions in Cassandra.
For some jobs we have to supply a report template. These templates might be above 16MB document limit of mongodb. So is it possible to use the Binary type when storing the job on this line.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.