Deep Learning of Comic Strips of XKCD to extract text
Images from XKCD, and transcript text scraped from ExplainXKCD
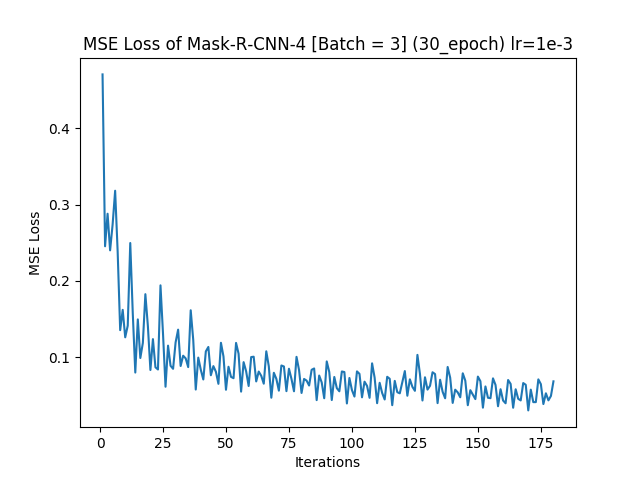
OpenCV was used to manually label regions of text in 18 images. Out of many trial and errors, the following is the loss of the best model trained on the images for 30 epochs.
Phase 0: Preprocess Image into a 512 x 512 image and make it be grayscaled

Phase 1: Use trained model to predict areas of text

Phase 2: Use iterative graph search in order to find the top left and bottom right bounding regions to extract
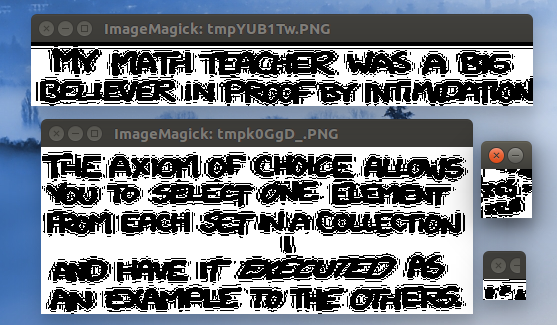
This can then be further used to then mask the text from the original comic image

- Train a CNN-LSTM model to "caption" extracted text into a transcript.
- Manual label characters as well, and find a way to relate characters to the text they said.
- Have more labeled images (>100)




