juliaocean / aibecs.jl Goto Github PK
View Code? Open in Web Editor NEWThe ideal tool for exploring global marine biogeochemical cycles.
License: MIT License
The ideal tool for exploring global marine biogeochemical cycles.
License: MIT License

![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")






































Probably mostly a cleaning-up task.
Hi @briochemc,
I was going through the AIBECS model with the example provided by the documentation. In the Radiocarbon dating example, I noticed that plotting function was not working as expected: It throws an error whenever I wanted to plot the horizontal slice graph:
plothorizontalslice(age_in_yrs, grd, depth=2000u"m", color=:magma)
ERROR: MethodError: no method matching plot(::AIBECS.HorizontalPlane; color=:magma)
Similar error is encountered in the horizontal mean plot. Do you know what when wrong there?
Thanks
This would allow me to spot the failing runs quicker.
"thgus" and age restoring in LaTeX is incorrect.
Specifically, refactor these to allow the user to provide transpose(o) * W * o instead of recalculating it every time:
Lines 321 to 355 in 960ecad
That would allow for a less painful devlopment experience.
Some of the plots in the docs that have two maps concatenated in the same plot object have disproportionately large subplot frames/bboxes. Probably just setting size in the last plot call fixes it.
JLD2 not being actively maintained is an issue. BSON.jl has been suggested a couple times already as being offering similar functionality, but is actively maintained, so I should use that instead.
This issue is used to trigger TagBot; feel free to unsubscribe.
If you haven't already, you should update your TagBot.yml to include issue comment triggers.
Please see this post on Discourse for instructions and more details.
Leveraging MakieLayout, Makie seems posed to become the default plotting package for publication quality figures, so it would be great to add some Makie plot recipes, add tests, and some tutorials/how-to's that showcase these recipes.
Saving the OCIM2 grd and T using JLD2 with the {compress=true} flag reduces the file size from about 75 to 28 MB.
I think in the long run it will be good to somehow merge the solving functionality of this package (the solver(s) in particular) with the well maintained packages of DifferentialEquations and/or NLSolve. This would provide lots of added functionality (e.g., for #4, #5, etc.). Also this might help to provide a DSL as suggested in #18
Right now I do this via
const iDIP = 1:nb
const iDOP = iDIP .+ nb
const iPOP = iDOP .+ nb
function unpack_state(x)
DIP = x[iDIP]
DOP = x[iDOP]
POP = x[iPOP]
return DIP, DOP, POP
end
and
DIP, DOP, POP = unpack_state(x)
and
DIP_3d = NaN * wet3d; DIP_3d[iwet] = DIP
Probably good to have a unpack_state and vector_to_3D functions in AIBECS
Let's try to add some diagnostic functionality to AIBECS that generalizes the work done in Pasquier and Holzer, 2018.
Let's start from the generic equation
(∂ₜ + T) x = G(x).
x could represent a multitude of tracers and processes. Within x, there may be separate groups of tracers with a group per compound or element. E.g., one could be tracking many elements including, e.g., phosphorus, whose group could be composed of three pools, like PO4, DOP, and POP. For the diagnostics that I am interested in, we will assume for simplicity and without any loss of generality, that there is only one element (one group) here.
We can then express the group's system without loss of generality as a bunch of
Mathematically, that means we can write
G(x) = ∑p sp(x) + ∑ij Ji→j(x) + ∑q dq(x).
We construct the LEM by first creating linear-equivalent terms for Ji→j(x) and dq(x), evaluated at the steady-state solution x given by
T x = G(x)
In other words, the LEM is built such that
G(x) = ∑p sp + ∑ij Li→j x + ∑q Lq x
when x is the steady-state, and where
We then construct the LEM simply as
(∂ₜ + H) x = ∑p sp
where
H = T - ∑ij Li→j - ∑q Lq
and we can then exploit this for powerful diagnostics as in Pasquier and Holzer, 2018. Fractions that came from source sp, or fraction that will be removed via process dq, are available from a single backslash with H. One can also further partition according to each i→j passage by removing Ji→j from H into a F operator and iteratively reapplying the source term. Direct computations leveraging the classical identities ∑n xn and ∑n n xn also allow for direct computations of, e.g., the number of i→j passages.
Maybe I can create a new name at each call of initialize_Parameters? E.g., Parameters_1, Parameters_2, etc.
I.e., the partition of the tracer equation into local sources and sinks and transport.
Probably a good idea to bundle them into a submodule to control what's exported.
Also better to bring the factor out the computation part into OceanGrids. That is, have a zonalaverage function in OceanGrids, or maybe even an overload of StatsBase/Statistics' likemean(::ZonalAverage, x, grd) or sum(::ZonalIntegral, x, grd) to just spit out the array, and then have the recipes use those functions directly instead.
It might be beneficial performance-wise to memoize some functions with a single memory cache when running optimizations, especially if I can keep a lot in memory :) Memoize.jl seems to be able to do just that... From its ReadMe:
using Memoize
using LRUCache
@memoize LRU{Tuple{Any,Any},Any}(maxsize=2) function x(a, b)
println("Running")
a + b
endThis might allow me to use LogitNormal as a prior.
Assume p has a D(p) = a + (b-a) * LogitNormal() prior. λ = subfun⁻¹(p) = logit((p - a) / (b - a)) (or is it the reverse) is then Normal() distributed in the sense that obj(λ) contains a -gradlogpdf(Normal(), λ) penalty. This is a priori great for Optim because this function is log-convex, real-valued — it's a quadratic afterall. However, when obj(λ) and its derivatives are computed, and subsequently λ is updated by Optim, if λ has been pushed a bit too far to one side, it may very well be that p = subfun(λ) is floating-arithmetic-rounded to be exactly a (or b), i.e., one of the bounds of the support of the prior. Then mismatch(p) = -gradlogpdf(D(p), a) evaluates to +Inf and everything falls apart. In reality, however, I don't think the mismatch should be that big, since it should just be -gradlogpdf(D(p), λ), and the penalty should ensure that this is not even close to +Inf. The solution could be to always evaluate the mismatch in λ space.
Side note/issue: Toying with TransformVariables, Bijectors, and what AIBECS does (in a local Pluto notebook that I should probably save as a gist and reference here), I noticed that I don't recover exactly what I'm supposed to going from p-space to λ-space in terms of gradlogpdf, so it would be good to elucidate that first before diving into this potential rabbit hole.
Here is the schematic made by @louisprimeau
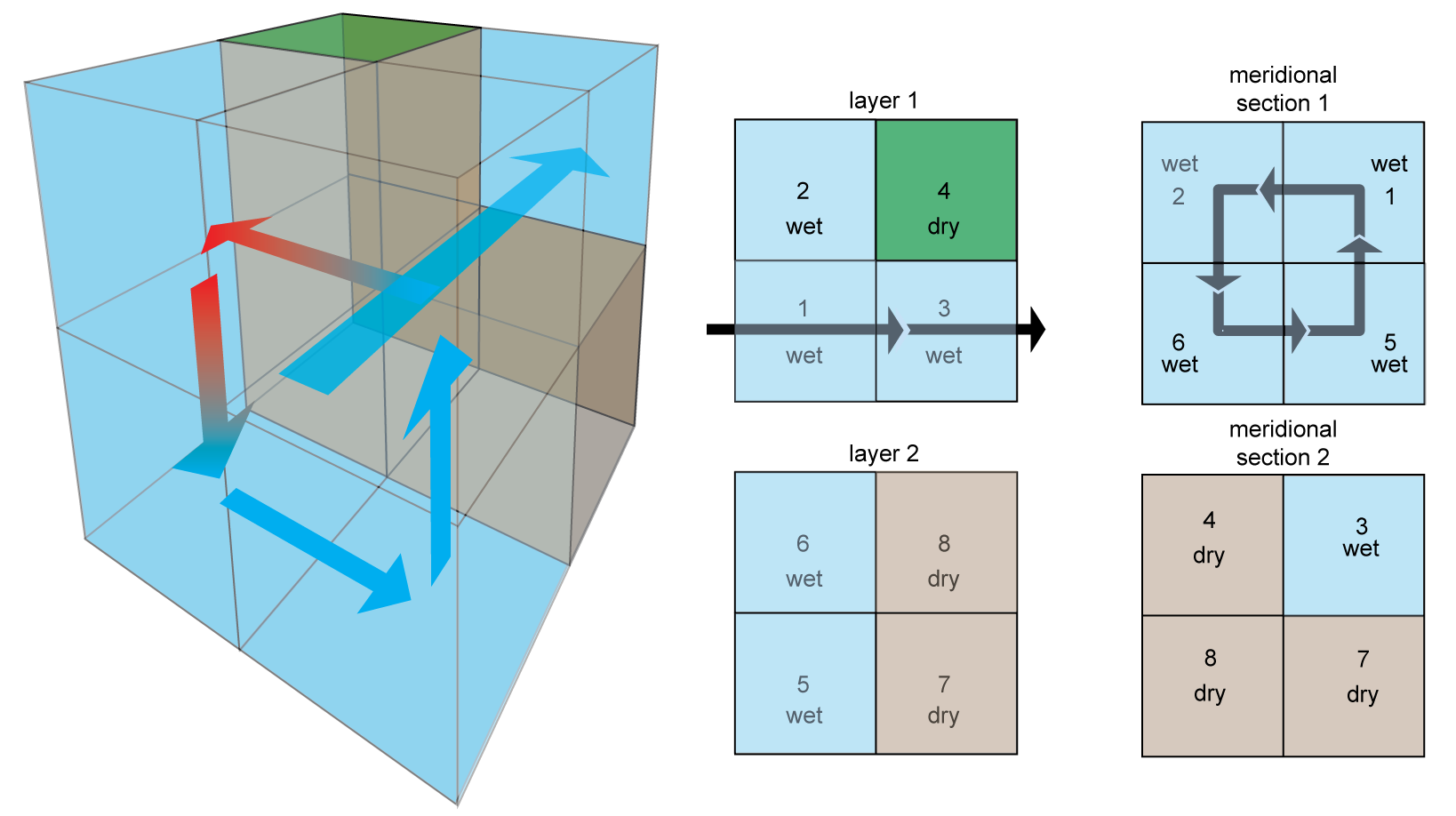
saved here for to be added to the corresponding notebook. (@fprimeau or @louisprimeau let me know if you want me to take it away from here.)
It would be great to be able to coarse-grain any given matrix to allow for quick testing.
Not sure how to do this easily. In particular, making this generic might not be possible, in particular, if the fine grid has a non-easily divisible size in one dimension (e.g., OCIM2 has size 91 in latitude, which is divisible by 7 🤷), or if the coarse grid would bundle separate boxes together (e.g., boxes originally separated by land diagonally).
See rafaqz/ModelParameters.jl#8 (comment) for reference.
Maybe try by building a small example AIBECS model manually and go from there.
Current OCIM2 files were built with UnitfulAstro's yr. While I don't think this is a problem for T and grd, it is one for the He fluxes, which are in mol/m^3/yr.
Todo list:
It would make for a cleanar API to just do
julia> grid, T = OCIM1.load()and have the wet point indices or the mask wet3D inside of grid.
This would mean breaking changes for
In the river tutorial, if I change the first solution plot to
cmap = :RdYlBu_4
plothorizontalslice(s, grd, zunit=u"μmol/m^3", depth=0, color=cmap, clim=(-1,1))I get to see numerical noise at the Amazon outlet and other major rivers at the surface.
With OCIM2:

OCIM1:

OCCA:

See doi: 10.1029/GB001i001p00015
I find I could sometimes use a very simple 2-box model, so let's make one. Should probably go with the values in the Sarmiento and Gruber book or the reference therein, if any.
Probably add something like
print_type(io, f, val::Float64, ppu, s, n) = @printf io "%$(n)s = %8.2e [%s] %s\n" f val ppu swhere n is the maximum length of all the symbols?
Maybe worth reworking the interface to be simpler and yielding more efficient code.
I was thinking of something along the lines of
Define tracers, e.g., DIP, DOP, POP, DFe, DO₂, maybe with a macro like
@define_tracers DIP DOP POP DFe DO₂Then define functions and who they apply to, maybe something like
@add_BGC_sink DIP → uptake : 1 / τ * DIP^2 / (DIP + k) * (z ≤ zₑ)
@add_BGC_source POP : σ * uptake
@add_BGC_source DOP : (1-σ) * uptake
@add_BGC_transfer DOP → DIP : kDOP * DOP
@add_BGC_transfer POP → DOP : kPOP * POP
@add_restoring DIP : DIPgeo τgeo
@add_external_source DFe : aeolian_DFe_source
etc.Then be able to pack/unpack the tracers and also create efficient inplace F (as suggested in #10)
Maybe try to figure out what CLIMA peeps are doing and use that? Otherwise AxisArrays?
This tutorial needs a few improvements
A worthy successor to the AWESOME OCIM (AO) should include all the functionality of the AO.
I try to reuse the AO nomenclature for reference, and will update with AIBECS names if I change them.
Thi issue will serve me as a check/TODO list to incorporate things one can do in the AO into AIBECS:
grd, T, He3, He4 = OCIM2.load().
regrid function. See tutorials.bioalpha.mbiobeta.mfbiobeta.m 👮♀bioredfield.mboundcon.m (sort of natural to implement in AIBECS with a fast relaxation term)conc.m (with a slow relaxation term)decay.m 👮♀ (with a decay term)dust.m 👮♀hydrothermal.mnephloid.m 👮♀nonrevscavPOC.mrevscav.m (using a transport operator and reaction constant)revscavPOC.mfrevscavPOC.m 👮♀river.m 👮♀photoout.m 👮♀I might want to change all the examples to use the depth at the bottom of the box to define w(p) instead of depthvec(grd).
Assuming one wants to simulate two independent tracers at the same time, there is no need to construct the full matrix. A better approach is to split the model into separate sub-models. Maybe a good solution is to raise a warning if some tracers are independent. The user can then think of it as separate models with separate inputs and outputs, that can be combined after the fact if needed.
I'm unsure at this stage but it seems to me that I should revisit the transport operator function to accommodate for the OCCA matrix because its cell volumes already account for subgrid topography (and the transport too?) and I think this causes mass-conservation problems for DIP–POP-like systems.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
