kaindy7633 / blog Goto Github PK
View Code? Open in Web Editor NEW一个Web开发者的自我修养
一个Web开发者的自我修养































Table of Contents generated with DocToc
对象的声明,如下代码直接定义一个对象:
//定义对象
var Person = {
name: 'LiuZhen', //对象属性
age: 30, //对象属性
eat: function(){ //对象方法
alert('正在吃...');
}
}我们可以为对象添加属性:
Person.height = 100; //添加身高属性也可以调用对象中的属性:
console.log(Person.name); //调用对象属性面向对象编程在小型项目中并没有优势,但随着项目的不断的迭代,越来越大,管理成了很大的问题,这时面向对象的代码构建方式就显现出它的优势。
定义一个空对象:
function Person() {
}在对象的原型上添加对象属性和方法:
Person.prototype = {
name: 'liuzhne',
age: 30,
eat: function(){
alert('我正在吃...');
}
}接下来,实例化一个对象:
var p = new Person();然后我们就可以调用对象的属性和方法了:
p.name;
p.age;
p.eat();JS的 new 关键字与Java、C++里的完全是两回事,不可混淆。
Java、C++等纯面向对象语言里有Class(类)概念,但在JS中没有(最新发布的ES6已加入),这里,我们可以使用 Function 来模拟类的实现,看下面的代码:
首先,我们创建一个函数(或者可以叫JS的类),并为它添加两个属性,name和age
function People(name, age) {
this._name = name;
this._age = age;
}接着,我们在这个函数的原型上添加一个方法:
People.prototype.say = function(){
alert('say something ...');
}面向对象是可以实现继承的,现在我们来实现这个功能,我们在添加一个函数叫Student
function Student() {
}实现继承:
Student.prototype = new People();实例化一个对象,调用say方法:
var s = new Student();
s.say();完整代码如下:
//定义父类
function People(name, age) {
this._name = name;
this._age= age;
}
//为父类添加公用方法
People.prototype.say = function(){
alert('say something...');
}
//定义子类
function Student(name, age){
this._name = name;
this._age = age;
}
//实现继承
Student.prototype = new People();
//实例化对象
var s = new Student('Liuzhen');
//调用say方法
s.say();下面,我们来来子类添加一个方法,也叫say
//定义父类
function People(name, age) {
this._name = name;
this._age= age;
}
//为父类添加公用方法
People.prototype.say = function(){
alert('say something...');
}
//定义子类
function Student(name, age){
this._name = name;
this._age = age;
}
//实现继承
Student.prototype = new People();
/**********************************
* 为子类Student添加say方法
*********************************/
Student.prototype.say = function(){
alert('我是子类Student里定义的say方法');
}
//实例化对象
var s = new Student('Liuzhen');
//调用say方法
s.say();调用之后发现,我们已复写了父类中的say方法,执行的结果是子类中的say。
那我们如何来调用父类中的say方法呢?
我们可以在重写父类say方法之前,重新定义一个对象,把say方法指定过去,如下代码:
//定义父类
function People(name, age) {
this._name = name;
this._age= age;
}
//为父类添加公用方法
People.prototype.say = function(){
alert('say something...');
}
//定义子类
function Student(name, age){
this._name = name;
this._age = age;
}
//实现继承
Student.prototype = new People();
/**********************************
* 定义一个对象将say方法赋值过去
*********************************/
var ParentSay = Student.prototype.say;
/**********************************
* 为子类Student添加say方法
*********************************/
Student.prototype.say = function(){
//在子类重写父类方法中测试调用父类的say方法
ParentSay.call(this);
alert('我是子类Student里定义的say方法');
}
//实例化对象
var s = new Student('Liuzhen');
//调用say方法
s.say();下面,我们来把两个Function封装起来,达到信息隐藏的目的。
//定义父类
(function(){
var n = "Kaindy"; //这里定义的变量n,只能在这个函数中访问
function People(name, age) {
this._name = name;
this._age= age;
}
//为父类添加公用方法
People.prototype.say = function(){
alert('say something...');
}
window.People = People; //把函数赋值给顶级窗口
}());
//定义子类
function Student(name, age){
this._name = name;
this._age = age;
}
//实现继承
Student.prototype = new People();
/**********************************
* 定义一个对象将say方法赋值过去
*********************************/
var ParentSay = Student.prototype.say;
/**********************************
* 为子类Student添加say方法
*********************************/
Student.prototype.say = function(){
//在子类重写父类方法中测试调用父类的say方法
ParentSay.call(this);
alert('我是子类Student里定义的say方法');
}
//实例化对象
var s = new Student('Liuzhen');
//调用say方法
s.say();---------------------- 豪华滴分割线 ------------------------------------
现在我们来重写下上面的面向对象,采用对象赋值的方法
//定义一个父类Function
function Person() {
//定义一个空对象
var _this = {};
//在这里个空对象上定义一个sayHello方法
_this.sayHello = function() {
alert('Hello');
}
//返回这个对象
return _this;
}
//定义一个子类Function
function Teacher() {
//定义一个对象,把父类赋值给此对象
var _this = Person();
//返回此对象
return _this;
}
//实例化
var t = Teacher();
t.sayHello();好了,这种构建方法更简单明了,代码看上去更简洁,下面我们来实现对父类方法的重写
//定义一个父类Function
function Person() {
//定义一个空对象
var _this = {};
//在这里个空对象上定义一个sayHello方法
_this.sayHello = function() {
alert('Hello');
}
//返回这个对象
return _this;
}
//定义一个子类Function
function Teacher() {
//定义一个对象,把父类赋值给此对象
var _this = Person();
/*****************************************/
//重写父类的sayHello方法
_this.sayHello = function(){
alert('T-Hello');
}
/*****************************************/
//返回此对象
return _this;
}
//实例化
var t = Teacher();
t.sayHello();
调用父类的sayHello方法
//定义一个父类Function
function Person() {
//定义一个空对象
var _this = {};
//在这里个空对象上定义一个sayHello方法
_this.sayHello = function() {
alert('Hello');
}
//返回这个对象
return _this;
}
//定义一个子类Function
function Teacher() {
//定义一个对象,把父类赋值给此对象
var _this = Person();
/*****************************************/
//调用父类的sayHello方法
var ParentSay = _this.sayHello;
ParentSay.call(_this);
/*****************************************/
/*****************************************/
//重写父类的sayHello方法
_this.sayHello = function(){
alert('T-Hello');
}
/*****************************************/
//返回此对象
return _this;
}
//实例化
var t = Teacher();
t.sayHello();在
Java中,反射指的是在程序运行期间,根据类的字节码文件对象来获取类中的成员并使用的一项技术

反射的主要内容:

什么是反射呢? 反射就是在程序运行过程中分析类的一种能力

将上图中的流程反过来,无需实例化类,即可访问类中的构造方法、成员属性以及成员方法

那反射能做些什么呢?
分析类:通过类加载器加载并初始化一个类,查看类的所有属性和方法
查看并使用对象:查看一个对象的所有属性和方法并使用它们
反射的应用场景一般是:
构建通用的工具
搭建具有高度灵活性和扩展性的系统框架
类加载器(ClassLoader)
类加载器负责将类的字节码文件(.class文件)加载到内存中,并生成对应的Class对象
那Class对象又是什么呢? Class对象就是java.lang.Class类的对象,也叫字节码文件对象,每个Class对象对应一个字节码文件

类的加载时机
创建类的实例,如: Student stu = new Student(),只会加载一次
访问类的静态成员时,如:Calendar.getInstance()
初始化子类时,会优先加载其父类
class User extends Person {};
User user = new User(); // 先加载父类Person通过反射方式创建类的Class对象,如:Class clazz = Class.forName("类名称")
类名称包含包名 + 类名,如:cn.itcast.demo1.Student
获取Class对象的三种方式
通过Object类中的getClass()方法,所有类都具有该方法,如:Class clazz = 对象名.getClass()
通过类的静态属性,如:Class clazz = 类名.class
通过Class类的静态方法,如:Class clazz = Class.forName("类名称")
public class ReflectDemo1 {
public static void main(String[] args) throws ClassNotFoundException {
// 通过Object类中的getClass方法获取
Student stu = new Student();
Class clazz1 = stu.getClass();
// 通过类的静态属性获取
Class clazz2 = Student.class;
// 通过Class类的静态方法
Class clazz3 = Class.forName("com.todever.demo17.Student");
System.out.println(clazz1 == clazz2); // true
System.out.println(clazz3 == clazz3); // true
}
}
class Student {};在Java中,Constructor<T>属于构造器对象,它属于java.base模块,位于java.lang.reflect包,我们可以通过Class对象获取构造器对象,常用的获取方式有三种
getConstructor(Class<?>...parameterTypes),该方法返回一个Constructor对象,但仅是公共的构造函数
getDeclaredConstructor(Class<?>...parameterTypes),该方法同样返回一个Constructor对象,但它可以获取私有的构造函数
getConstructors(),该方法返回此类的所有构造函数组成的数组,但不含私有构造方法
此时我们有了构造器对象,就可以使用其内部的方法,常用的方法有两个:
String getName(),该方法返回构造函数名
T newInstance(Object... initargs),使用返回的构造函数和参数一起创建并初始化对象
public class ReflectDemo2 {
public static void main(String[] args) throws Exception {
// 获取Student类的字节码文件
Class clazz1 = Class.forName("com.todever.demo17.Person");
// 通过字节码文件获取无参构造
Constructor con1 = clazz1.getConstructor();
System.out.println(con1); // public com.todever.demo17.Person()
// 通过字节码文件获取有参构造
Constructor con2 = clazz1.getConstructor(String.class);
System.out.println(con2); // public com.todever.demo17.Person(java.lang.String)
// 通过字节码文件获取私有构造
Constructor con3 = clazz1.getDeclaredConstructor(int.class);
System.out.println(con3); // private com.todever.demo17.Person(int)
// 获取Person类所有的构造方法数组(私有除外)
Constructor[] cons = clazz1.getConstructors();
for (Constructor con : cons) {
System.out.println(con);
// public com.todever.demo17.Person()
// public com.todever.demo17.Person(java.lang.String)
}
// 通过getName获取类名
String _name = con2.getName();
System.out.println(_name); // com.todever.demo17.Person
// 通过newInstance方法获取到Student类的对象
Person p = (Person) con2.newInstance("张三");
System.out.println(p);
// name: 张三
// com.todever.demo17.Person@27973e9b
}
}
class Person {
// 公共无参构造
public Person() {}
// 公共有参构造
public Person(String name) {
System.out.println("name: " + name);
}
// 私有有参构造
private Person(int age) {
System.out.println("age: " + age);
}
}Method对象,即方法对象,属于java.base模块,java.lang.reflect包
它通过Class对象获取方法
getMethod(String name, Class<?>... parameterTypes),该方法返回一个Method对象,仅包含公共成员方法,name是方法名,parameterTypes是方法的参数列表
getDeclaredMethod(String name, Class<?>... parameterTypes),该方法返回一个Method对象,可以获取私有成员方法
getMethods(),该方法返回该类中所有方法的数组,但不包含私有方法
Method对象的常用方法:
String getName(),该方法返回方法名
Object invoke(Object obj, Object... args),在指定对象上调用此方法,参数为args
public class Test {
public static void main(String[] args) throws Exception {
// 获取Person类的字节码文件对象
Class clazz = Class.forName("com.todever.demo18.Person");
// 获取该类的构造器对象
Constructor con = clazz.getConstructor();
// 调用newInstance方法获取该类的实例对象,需要返回一个Person类型的
Person person = (Person) con.newInstance();
System.out.println(person); // com.todever.demo18.Person@10f87f48
// 调用公共的空参方法
Method show1 = clazz.getMethod("show1");
System.out.println(show1); // public void com.todever.demo18.Person.show1()
// 如果只想看方法名,可以使用getName方法
System.out.println(show1.getName()); // show1
// 通过invoke调用方法
show1.invoke(person); // 我是公共的空参方法
// 获取公共的带参方法
Method show2 = clazz.getMethod("show2", int.class);
// 调用方法
show2.invoke(person, 100); // 我是公共的带参方法,传入的参数是a, 其值为: 100
// 获取私有带参方法
Method show3 = clazz.getDeclaredMethod("show3", int.class, int.class);
// 调用私有方法,必须做向下转型,invoke返回Object类型
// 但这样调用会失败,因为目标方法是私有的
//int sum = (int) show3.invoke(person, 10, 20);
// 我们可以通过开启暴力反射,打开对私有方法的调用
show3.setAccessible(true);
int sum = (int) show3.invoke(person, 10, 20);
System.out.println(sum); // 30
// 获取类中所有的成员方法,但不包含私有方法
Method[] methods = clazz.getMethods();
for (Method method : methods) {
System.out.println(method);
}
// public void com.todever.demo18.Person.show1()
// public void com.todever.demo18.Person.show2(int)
// public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
// public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
// public final void java.lang.Object.wait() throws java.lang.InterruptedException
// public boolean java.lang.Object.equals(java.lang.Object)
// public java.lang.String java.lang.Object.toString()
// public native int java.lang.Object.hashCode()
// public final native java.lang.Class java.lang.Object.getClass()
// public final native void java.lang.Object.notify()
// public final native void java.lang.Object.notifyAll()
}
}
class Person {
public Person() {}
// 公共的空参方法
public void show1() {
System.out.println("我是公共的空参方法");
}
// 公共的带参方法
public void show2(int a) {
System.out.println("我是公共的带参方法,传入的参数是a, 其值为: " + a);
}
// 私有的带参方法
private int show3(int a, int b) {
System.out.println("我是私有的带参方法");
return a + b;
}
}通过反射我们可以获取类的setter方法,并使用该方法为属性赋值
setter方法的方法名由set和属性名(首字母大写)组成,如:setName,setAge
setter方法有且只有一个参数,参数类型为属性的类型,如:setName(String name)
setter方法为public修饰的方法,发射获取该方法可以使用getMethod(String, Class<?>...)
public class Test {
public static void main(String[] args) throws Exception {
// 获取Person类的字节码文件
Class clazz = Class.forName("com.todever.demo19.Person");
// 通过反射获取Person类的构造方法,并创建该类的对象
Constructor constructor = clazz.getConstructor();
// 需要转型到Person
Person person = (Person) constructor.newInstance();
// 通过getMethod方法获取setter方法
Method setName = clazz.getMethod("setName", String.class);
setName.invoke(person, "Kaindy");
System.out.println(person.getName()); // kaindy
}
}
class Person {
// 成员变量
private String name;
// 空参构造方法
public Person() {};
// 带参构造方法
public Person(String name) {
this.name = name;
}
// getter和setter
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
// 重写toString
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
'}';
}
}Field对象是域(属性、成员变量)对象,属于java.base模块下的java.lang.reflect包
我们可以通过Class对象获取属性
getField(String name) 该方法返回一个Field对象,但仅仅包含公共属性,参数为想要获取的属性名
getDeclaredField(String name) 该方法返回一个Field对象,它可以获取私有属性
getDeclaredFields() 该方法返回类的所有属性组成的数组,它可以返回私有属性
Field常用的方法:
void set(Object obj, Object value) 该方法设置obj对象的指定属性值为value
void setAccessible(boolean flag) 该方法可以将属性的可访问性设置为指定的布尔值,即开启暴力反射
public class Test {
public static void main(String[] args) throws Exception {
// 获取Person类的字节码文件对象
Class clazz = Class.forName("com.todever.demo20.Person");
// 获取空参构造方法
// Constructor con = clazz.getConstructor();
// 创建对象
// Person person = (Person) con.newInstance();
// 上面的两行代码可以合并成一行,我们叫做链式编程
Person person = (Person) clazz.getConstructor().newInstance();
// 获取name属性
Field name = clazz.getField("name");
// 通过set方法设置值
name.set(person, "Kaindy");
// 设置年龄,它是私有属性
Field age = clazz.getDeclaredField("age");
// 私有属性赋值需要开启暴力反射
age.setAccessible(true);
// 设置值
age.set(person, 100);
System.out.println(person); // Person{name='Kaindy', age=100}
}
}
class Person {
// 公共属性
public String name;
// 私有属性
private int age;
// 空参构造方法
public Person() {};
// 重写toString方法
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}shadowsocks,是个什么我就不多解释了,最近想把自己的vps弄一下,重装了系统,结果在跟新的时候出现问题了,更新源连接成功,但是更新不了,报了很多404,下面来看下如何解决。
我用了很多网上的方法,都么有成功,比如说替换源地址啊等等,发现几乎国内的都有问题,后来看到一篇文章,写的还是替换成官方的地址,只是不是最新的,而是这个:old-releases.ubuntu.com,所以就有了下面的操作。
首先执行下面的操作:
sudo sed -i -e 's/archive.ubuntu.com\|security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
请注意:我的原来的 sources.list 文件里的源地址是有个us开头的,也就是这个:us.archive.ubuntu.com,所以要根据源文件里的地址来改,所以就有了下面的操作
sudo sed -i -e 's/us.archive.ubuntu.com\|security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
搞完之后,直接上:
sudo apt-get update && sudo apt-get upgrade
最后成功更新
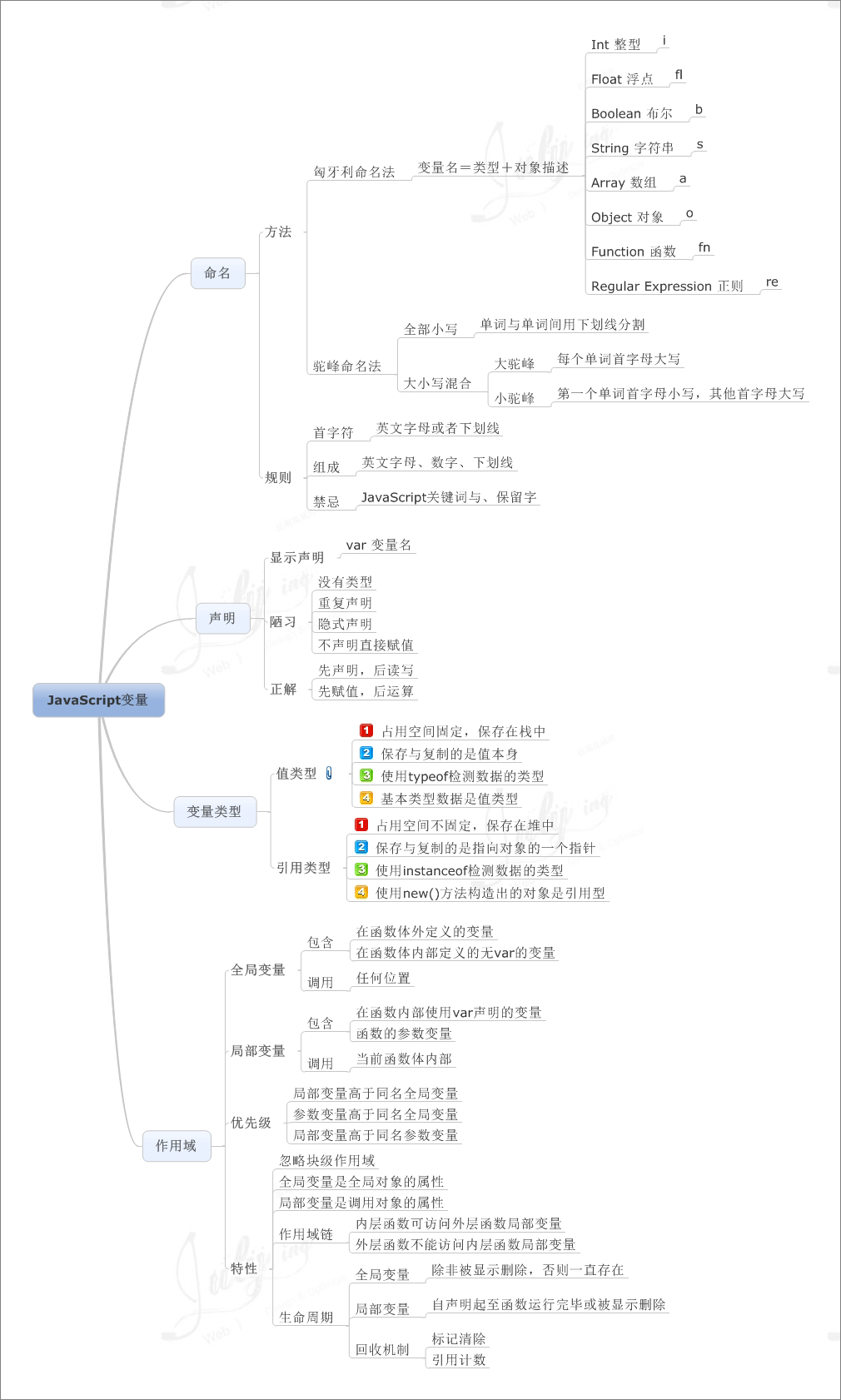
对象就是世间万物,面向对象**就是把关注点放在一件事或一个活动中涉及的人或事物上的**(思维方式)
除了面向对象,我们还有一种**就是面向过程,它是把关注点放在一件事或一个活动中涉及到的步骤(过程)。
面向对象**特点:
面向对象的程序开发,就是不断的找对象、使用对象、指挥对象做事情的过程,如果没有对象,那就创建一个。它有三大特征:封装、继承和多态
在Java中通过"类"来描述事物,它由属性和行为(方法)构成。
类,就是分类,是一系列具有相同属性和行为的事物的统称,把一系列相关事物的共同属性和行为提取出来的过程,我们称之为抽象
对象时某一类事物的某个具体存在,类是属性和行为的集合,是一个抽象的概念。
定义类的过程,就是把一系列相关事物共同的属性和行为抽取出来的过程。
事物的属性在类中叫成员属性,事物的行为在类中叫成员方法
如何创建一个对象呢?
类名 对象名 = new 类名();
// 使用属性
对象名.属性名
// 调用方法
对象名.方法名public class Student {
// 成员属性 姓名
String name;
// 成员属性 年龄
int age;
// 成员方法 学习
public void study() {
System.out.println(name + "正在学习...");
}
}
// Test
public class TestStudent {
public static void main(String[] args) {
// 创建学生类对象
Student stu = new Student();
// 给成员属性赋值
stu.name = "张三丰";
stu.age = 141;
// 调用成员方法
stu.study();
}
}成员变量与局部变量
public static void main(String[] args) {
Student stu = new Student();
stu.name = "张三丰"; // 成员变量
stu.age = 141;
stu.study();
}
public class Student {
String name;
int age;
public void study() {
String name = "小黑"; // 局部变量
System.out.println(name + "正在努力学习!");
}
}成员变量定义在类中,方法之外,而局部变量定义在方法中,或存在于形式参数中。
成员变量有默认的初始化值,而局部变量没有默认初始化值,必须先赋值后使用
成员变量可以作用于类中的任何位置,而局部变量只能在方法中使用
内存中,成员变量定义在堆内存中,而局部变量定义在栈内存中,成员变量的声明周期随着对象的创建而存在,随着对象的销毁而销毁,局部变量则随着方法的调用而存在,随着方法的调用完毕而销毁。
如果成员变量和局部变量重名,则采用就近原则,如果方法内有局部变量,则使用局部变量,如果没有,则使用类中的成员变量,如果没有找到,则报错。
引申义:封装就是把一系列功能打包到一台设备里,提供使用这些功能的界面,比如汽车、电脑、洗衣机...
封装的好处:
在Java中,类和方法都提供了封装的体现
方法:
类:
private关键字
private表示私有的,是一种访问权限修饰符,用来修饰类的成员,被它修饰的成员只能在本类中访问
用法:
private 数据类型 变量名; // 修饰成员
private 返回值类型 方法名(参数列表) {}; // 修饰方法private修饰的成员无法被外部访问,所以必须为其提供相应的访问(修改)的公共方法,即getter或setter方法
public Student {
private String name;
private int age;
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return this.age;
}
public void setAge(int age) {
this.age = age;
}
}this关键字
this表示本类对象的引用,本质是一个对象
每一个普通方法都有一个this,谁调用该方法,this就指向谁,调用:this.属性名
JavaBean
构造方法的概念:构造,创造,也叫构造器,它用来帮助创建对象的方法,构造方法也是用来初始化对象的。
在Java中通过new关键字来创建对象,并在内存中开辟空间,然后使用构造方法(构造器)完成对象的初始化工作
构造方法的格式:
修饰符 构造方法名(参数列表) {
// 方法体
}public class Student {
public Student() {} // 构造方法
private String name;
...
}构造方法注意事项:
示例:
public class Student {
// 无参构造方法
public Student() {}
// 有参构造方法
public Student(String name, int age) {
this.name = name;
this.age = age;
}
private String name;
private int age;
...
}在Java中编写类的规范,符合JavaBean标准的类,必须是具体的、公共的、并且具有无参数的构造方法,提供又来操作成员变量的set和get方法。
Java中的注释分为单行注释和多行注释
/**
* 多行注释1...
* 多行注释2...
*/
// 我是单行注释关键字是被Java语言赋予特定含义的单词,定义变量时不允许使用Java已定义的关键字,它们都是使用小写字母定义的。
如,用于定义数据类型的关键字:
|class|interface|enum|@interface|byte|short|int|long|char|float|double|boolean|void|
用于定义数据类型的关键字:
|true|false|null|
用于定义流程控制的关键字:
|if|else|switch|case|default|for|while|do|break|continue|return|
用于定义访问权限修饰符的关键字:
|public|protected|private|
用于定义类、函数、变量修饰符的关键字:
|abstarct|final|staic|synchronized|
用于定义类与类之间关系的关键字:
|extends|implements|
用于定义建立实例、引用实例和判断实例的关键字:
|new|this|super|intanceof|
用于处理异常的关键字:
|try|catch|finally|throw|throws|
用于包的关键字:
|package|import|
其他关键字:
|native|strictfp|transient|volatile|assert|
Java中的常量是指在程序执行过程中,其值不可以发生改变的量。
Java中的常量分为两种,分别是字面值常量和自定义常量
字面值常量又分为以下几种类型:
true和false,它只有两个值nullJava中的变量就是在程序执行过程中,其值可以在某个范围内发生改变的量,本质上,是内存中的一小块区域。
在Java中定义变量的格式如下:
数据类型 变量名 = 初始化值;
变量的使用可以直接通过调用变量名的操作
int num = 12;
System.out.println(num);Java中数据类型分为基本类型和引用类型两种。
所以,Java一共有八种基本数据类型,它们分别是:
byte、short、int、long、float、double、char和boolean
定义变量时,需要注意以下几点:
int类型,定义long类型变量时需要在值后面加上字母L(大小写均可,一般使用大写)double类型,定义float类型变量时需要在值后面加上字母F(大小写均可,一般使用大写)类型转换,在Java中,不同类型的数据之间可能会进行运算,而这些数据的取值范围不同,存储方式不同,直接运算可能会造成数据丢失,所以需要将一种类型转换成另外一种类型再进行运算。
Java中的类型转换分为自动(隐式)类型转换和强制(显式)类型转换两种
隐式类型转换时小转大的关系,它们的范围从小到大的顺序如下:
byte、short、char --> int --> long --> float --> double
boolean类型不参与比较,它的值只有 true和false两个
强制类型转换时大转小的关系,形式如下:
目标类型 变量名 = (目标类型) 要转换的值
注意: 强制类型转换在使用时可能会出现精度丢失的问题
// byte、short和char类型做转换时都会默认提升为int类型, 布尔类型不参与转换
int a = 10;
byte b = 20;
int c1 = a + b; // 没问题
byte c2 = a + b; // 报错..结果类型不能为byte
// 如果确实需要将结果定义为byte类型,我们可以使用强制类型转换
byte c3 = (byte) (a + b); // 强制类型转换 标识符就是给类、方法、变量、常量等起名字的字符序列,它可以由英文大小写字母、数字、下划线(_)和美元符号($)组成。
它有如下规则:
在进行标识符命名时应遵循如下规范:
HelloWorld,StudentgetName, studyJava_) 如 MAX_VALUE.)隔开,遵循域名反写的格式,如 com.todever.demo多态即多种状态,是指同一对象在不同情况下表现出不同的状态或行为
Java中实现多态,要有继承(或实现)关系,要有方法重写,父类引用指向子类对象
/**
* 定义父类
*/
public class Animal {
// 姓名
private String name;
// 空参构造
public Animal() {
}
// 全参构造
public Animal(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
// 成员方法
public void eat() {
System.out.println("吃东西");
}
}
/**
* Dog类,Animal的子类
*/
public class Dog extends Animal {
/**
* 重写 eat 方法
*/
@Override
public void eat() {
System.out.println(this.getName() + "吃骨头...");
}
}
/**
* Test Class
* 1、存在继承关系
* 2、重写了eat方法
* 3、父类引用指向子类对象
*/
public class Test {
public static void main(String[] args) {
Animal dog = new Dog(); // 多态的表现
}
}多态的使用场景,父类类型可以作为形参的数据类型,这样,方法可以接收其任意的子类对象
/**
* 定义父类
*/
public class Animal {
// 姓名
private String name;
// 空参构造
public Animal() {
}
// 全参构造
public Animal(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
// 成员方法
public void eat() {
System.out.println("吃东西");
}
}
/**
* Dog类,Animal的子类
*/
public class Dog extends Animal {
/**
* 重写 eat 方法
*/
@Override
public void eat() {
System.out.println(this.getName() + "吃骨头...");
}
}
/**
* 子类 继承 Animal父类
*/
public class Mouse extends Animal {
@Override
public void eat() {
System.out.println(this.getName() + "吃奶酪");
}
}
/**
* 测试类
*/
public class Test {
public static void main(String[] args) {
Dog d = new Dog();
d.setName("哈士奇");
showAnimal(d); // 同一个方法传入不同的子类对象,返回不同的结果
Mouse m = new Mouse();
m.setName("Jerry");
showAnimal(m); // 同一个方法传入不同的子类对象,返回不同的结果
}
public static void showAnimal(Animal an) {
an.eat();
}
}在类继承中,如果父类和子类有同名的成员变量,那么在多态中,它们的结果不同,并且成员变量是不能被重写的
public class Test {
public static void main(String[] args) {
Animal animal = new Dog();
System.out.println(animal.name); // Animal
Dog dog = new Dog();
System.out.println(dog.name); // Dog
}
}
class Animal {
String name = "Animal";
}
class Dog extends Animal {
String name = "Dog";
}多态的好处与弊端
那多态有哪些弊端呢?
不能使用子类特定的成员,但可以通过类型转换来使用子类特定功能
这种类型转换分为两种:
Animal animal = new Dog()Dog dog = (Dog) animal使用类型转换时应注意:
ClassCastException异常instanceof进行检查public static void main(String[] args) {
Dog dog = new Dog();
dog.setName("布鲁斯");
showAnimal(dog);
}
public static void showAnimal(Animal animal) {
if (animal instanceof Dog) {
Dog dog = (Dog) animal;
god.watch(); // 调用Dog类种特有的方法watch
}
animal.eat();
}类和方法都可以被抽象,包含抽象方法的类就是抽象类,抽象用abstract关键字修饰
如果方法只有声明,没有方法体,并且用abstract修饰,那么它就是一个抽象方法
// 定义抽象类
public abstract class Animal {
private String name;
// 定义抽象方法
public abstract void eat();
}
public class Mouse extends Animal {
public void eat() {
System.out.println(getName() + "吃奶酪");
}
}
public class Dog extends Animal {
public void eat() {
System.out.println(getName() + "啃骨头");
}
}当需要实现一个方法,但在父类中还不明确方法的具体实现时,可以将方法定义为abstract,具体的实现到子类中完成
抽象类有以下特点:
类和方法都必须使用abstract关键字进行修饰
修饰符 abstract class 类名 {}
修饰符 abstract 返回值类型 方法名() {}抽象类不能被实例化,只能创建子类对象
抽象类子类要么重写父类所有抽象方法,要么也定义成抽象类
抽象类中可以有普通的成员变量,也可以有成员常量(用final修饰的),成员方法可以是普通方法,也可以是抽象方法,所以,抽象类不一定有抽象方法,但又抽象方法的类一定是抽象类或者接口
另外关于构造方法,抽象类可以像普通类一样可以又构造方法,且可以被重载
/**
* 抽象类
*/
abstract class Animal {
// 抽象方法
public abstract void eat();
// 抽象方法
public abstract void sleep();
}
/**
* 子类继承抽象父类,必须重写所有抽象方法
*/
class Cat extends Animal {
@Override
public void eat() {
System.out.println("猫吃鱼");
}
@Override
public void sleep() {
System.out.println("猫躺着睡");
}
}
/**
* 定义抽象子类,继承抽象父类,无需重写抽象方法
*/
abstract class Dog extends Animal {}final的意思是最终、最后的
使用final修饰的类,该类不能被继承,比如系统内置的String类、System类等
父类中使用final修饰的方法,在子类中是不能被重写的,所以final和abstract两个关键字是不能同时出现的
使用final修饰的变量,表示最终值,即常量,只能赋值一次。这里需要注意,不建议使用final来修饰引用类型数据,因为仍然可以通过引用修改对象的内部数据,其意义不大。
/**
* 员工类
*/
public final class Employee {}
/**
* 程序猿类
*/
public Coder extends Employee {} // 报错..Person类不能被继承,因为被final关键字修饰/**
* 人类
*/
public class Person {}
/**
* 员工类
*/
public final class Employee extends Person {} // 被final修饰的类不能被继承,但它可以继承其他的类/**
* 员工类
*/
public class Employee {
// 使用final修饰方法
public final void show() {
System.out.println("被final修饰的方法不能被子类重写");
}
}
/**
* 程序猿类
*/
public Coder extends Employee {
// 试图重写父类的show方法,会报错
public void show() { // Exception...
// ...
}
}public class FinalTest {
final int MAX_NUM = 30;
// 试图修改被final修饰的常量值,报异常
// MAX_NUM = 100; // Exception
}static关键字的意思是静态的,它可以用来修饰类的成员,包括成员变量和成员方法,这些成员变量或成员方法被称为类变量或类方法,它们属于类,而不是实例(对象)
调用这些被static修饰的成员变量和成员方法,可以通过类名.成员变量名或类名.成员方法名(参数)的方式
public class Test {
public static void main(String[] args) {
Developer d1 = new Developer();
d1.name = "小黑";
d1.work = "写代码";
Developer d2 = new Developer();
d2.name = "媛媛";
d2.work = "鼓励师";
d1.selfIntroduction(); // 我是研发部的小黑,我的工作内容是写代码
d2.selfIntroduction(); // 我是研发部的媛媛,我的工作内容是鼓励师
}
}
class Developer {
String name;
String work;
// 使用static关键字修饰,它是一个公共的常量值
public final static String DEPARTMENT_NAME = "研发部";
public void selfIntroduction() {
System.out.println("我是" + DEPARTMENT_NAME + "的" + name + ",我的工作内容是" + work);
}
}当使用static修饰成员方法时,由于静态方法中没有this,所以不能访问非静态成员。
它的使用场景主要在值需要访问静态成员时,或者不需要访问对象状态,所需参数都由参数列表显式提供
public class Test {
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
// 调用ReverseArray类中的静态方法反转数组元素
ReverseArray.reverse(arr); // [5, 4, 3, 2, 1]
}
}
class ReverseArray {
/**
* 静态方法,反转一个数组
*/
public static void reverse(int[] arr) {
for (int i = 0; i < arr.length / 2; i++) {
int temp = arr[i];
arr[i] = arr[arr.length - 1 - i];
arr[arr.length - 1 -i] = temp;
}
}
}接口技术用于描述类具有什么功能,但并不给出具体实现,类要遵从接口描述的统一规则进行定义,所以,接口是对外提供的一组规则、标准
接口的定义时通过关键字 interface 来实现的, interface 接口名 {}
类需要实现接口,实现使用关键字implements表示,class 类名 implements 接口名
// 定义接口
public interface IMyInterface {
// 定义成员方法myMethod
public abstract void myMethod();
}
// 定义实现类
public class MyInterface implements IMyInterface {
@Override
public void myMethod() {
System.out.println("实现接口中定义的方法");
}
}
// 测试实现
public class Test {
public static void main(String[] args) {
// 多态实现
IMyInterface mf = new MyInterface();
mf.myMethod();
}
}接口的特点
接口是不能被实例化的,如果要实现它,必须通过多态的方式实例化子类对象
接口的子类(也就是实现类),它可以是抽象类(无需重写其方法),也可以是普通类(必须重写所有方法)
类与接口之间是实现的关系(implements),而接口与接口之间是继承的关系,也就是接口之间可以实现父子关系(extends),并且接口之间支持单继承和多继承,如:接口 extends 接口1, 接口2, 接口3, ...
继承和实现的区别:
继承体现的是"is a"的关系,父类中定义共性内容
实现体现的是"like a"的关系,接口中定义扩展功能
// 定义接口USB
public interface USB {
// 连接
public abstract void open();
// 关闭
public abstract void close();
}
/**
* 鼠标类
* 实现USB接口
* 需要实现所有的接口方法,包含open和close
*/
public class Mouse implements USB {
@Override
public void open() {
System.out.println("连接鼠标");
}
@Override
public void close() {
System.out.println("断开鼠标");
}
}
/**
* 类 KeyBoard 定义为抽象类,可以不实现接口中的方法
*/
public abstract class KeyBoard implements USB {
}
public class Test {
public static void main(String[] args) {
// 测试鼠标类
// USB usb = new USB(); --> 报错,接口不能被实例化
USB usb = new Mouse();
usb.open(); // 连接鼠标
usb.close(); // 断开鼠标
}
}接口中成员的特点
在接口中没有成员变量,只有共有的、静态的常量,如:public static final 常量名 = 常量值
成员方法,在JDK7以前,接口中只有共有的、抽象方法,如:public abstract 返回值类型 方法名()
在JDK8以后,接口可以有默认方法和静态方法,如:public default 返回值类型 方法名() {},静态方法,如:static 返回值类型 方法名() {}
在JDK9以后,接口中可以有私有方法,如:private 返回值类型 方法名() {}
构造方法,接口不能被实例化,也没有需要初始化的成员,所以接口没有构造方法
public interface IMyInterface {
/**
* 接口中只能定义静态常量,其值不能修改
* public static final 可以省略,如果不写,系统会自动加上
*/
public static final int NUM = 10;
/**
* 成员方法
* JDK 7 及其之前的写法
*/
public abstract void methodForJDK7();
/**
* JDK 8 之后多了两种写法
* 静态写法和默认写法
*/
public static void staticMethod() {
System.out.println("我是JDK8的新特性,书写静态方法");
}
public default void defaultMethod() {
System.out.println("我是JDK8的新特性,书写默认方法");
}
/**
* JDK 9 之后多了私有方法
*/
private void privateMethod() {
System.out.println("我是JDK9的新特性,私有的接口成员方法");
}
}异常,即非正常情况,通俗的说,异常就是程序出现的错误
异常的顶层是Throwable类,它分为Exception和Error
Exception 表示合理的应用程序可能需要捕获的问题,它是可预料的,如:NullPointerException空指针异常
Error 表示合理的应用程序不应该试图捕获的问题,也就是不可预料的,如:StackOverFlowError栈内存溢出

在JVM中有默认的异常处理方式,即在控制台打印错误信息,并终止程序运行
在开发中,处理异常有两种方式:
try...catch 捕获,自己处理
try {
// 尝试执行的代码
} catch (Exception e) {
// 出现异常之后的处理代码
} finally {
// 无论是否出现异常都会执行的代码 一般用于关闭资源等
}throws 抛出,交给调用者处理
// 会抛出异常的方法,调用者必须处理它抛出的异常
public static void show() throws Exception {
// 要执行的代码
}

IO流即流入(Input)输出(Output),IO流指的是数据像连绵的流体一样进行传输,在Java中,IO流就是数据传输的方式
IO流按数据流向分为输入流和输出流两种,如果按照操作方式,就分为字节流和字符流两种
字节流分为InputStream和OutputStream,字符流分为Reader和Writer,它们都是抽象类
字符流
字符流即按字符读写数据的IO流,它分为Reader和Writer。
Reader字符流有两个子类,一个是FileReader,它是一种普通的字符流读取方式,另一种是BufferedReader,它是一种高效的字符流读取方式
Writer字符流有两个子类,一个是FileWriter,它是一种普通的字符流写入方式,另一种是BufferedWriter,它是一种高效的字符流写入方式

字节流
字节流即按字节读写数据的IO流,它分为InputStream和OutputStream,它们都是抽象类
InputStream有两个子类,一个是FileInputStream,另一个是高效的BufferedInputStream
OutputStream有两个子类,一个是FileOutputStream,另一个是高效的BufferedOutputStream

在Java中,一个File对象代表磁盘上的某个文件或文件夹
它的构造方法主要有三个:
File(String pathname) 传入文件路径
File(String parent, String child) 分别传入父目录和子目录
File(File parent, String child) 先将父目录转为File对象,然后再跟子目录字符串一起传入
有了File对象之后我们就可以调用其方法:
/**
* 创建文件对象的三种方式
*/
import java.io.File;
// 全路径写法
File file = new File("E:\\test\\test.txt"); // 全路径写法 \\ 表示路径分隔符,需要使用\来转义
File file2 = new File("E:/test/test.txt"); // 使用正斜杠方式
// 文件路径 + 文件名的写法
File file2 = new File("E/test/", "test.txt");
// 文件路径对象 + 文件名写法
File file3 = new File("E/test/");
File file4 = new File(file3, "test.txt");File类中创建的方法
createNewFile() 创建文件// 创建对象
File file = new File("E:/test.txt");
// 调用createNewFile()方法创建此文件,返回一个布尔值,表示是否成功创建
// 如果创建的文件不存在则创建,如果存在则返回false
boolean b1 = file.createNewFile();mkdir() 或 mkdirs() 创建目录// 创建对象
File file6 = new File("E:/NewDir");
// 调用mkdir()方法创建目录,返回一个布尔值,表示是否创建成功
// mkdir只能创建单级目录
boolean b2 = file6.mkdir();
// 创建对象
File file7 = new File("E:/NewDir1/a/b/c");
// mkdirs()可以创建多级目录,当然也可以创建单级目录,所以它使用的比较多一些
boolean b3 = file7.mkdirs();isDirectory() 判断File对象是否为目录// 创建对象
File file = new File("E:/NewDir");
// 判断是否为目录
boolean flag = file.isDirectory(); // true || falseisFile() 判断File对象是否为文件// 创建对象
File file = new File("E:/NewDir");
// 判断是否为文件
boolean flag = file.isFile(); // true || falseexists() 判断对象是否存在// 创建对象
File file = new File("E:/NewDir");
// 判断是否存在
boolean flag = file.exists(); // true || falseFile类中获取功能的方法
getAbsolutePath() 获取文件对象的绝对路径,即以盘符开头的路径,如:D:/test.txt
getPath() 获取文件的相对路径,即一般是相对于当前项目路径,如:test.txt
getName() 获取文件名
list() 获取指定目录下所有文件或文件夹的名称,返回的是一个数组
listFiles() 获取指定目录下所有文件或文件夹的File对象数组
字符流读取的顶层类是Reader,但它是一个抽象类,所以实例化对象必须使用它的子类FileReader
按单个字符读取
创建字符流读文件对象
Reader reader = new FileReader("readme.txt");
调用read()方法读取数据,该方法每次读取一个字符,返回该字符代表的整数,若到达流的末尾,则返回-1,这里需要异常处理,通常可以使用try...catch或throws IOException的方式,最后需要调用close()方法关闭读取流
public static void main(String[] args) throws IOException {
Reader reader = new FileReader("lib/test.txt");
// int ch1 = reader.read(); // 97 -> a
while ((ch = reader.read()) != -1) {
System.out.println(ch);
}
reader.close();
}读取字符数组
public static void main(String[] args) throws IOException {
Reader reader = new FileReader("lib/test.txt");
// 定义字符数组
char[] chs = new char[3];
int len1 = reader.read(chs);
System.out.println(chs); // abc
System.out.println(len1); // 3
reader.close();
}字符流写数据
第一种写法,写入单个字符
创建字符流写文件对象,Writer writer = new FileWrite("dest.txt")
调用write()方法写入字符 writer.write("中")
异常处理: try...catch 或 throws IOException
关闭资源:writer.close()
第二种写法,写入字符数组
创建字符流写文件对象,Writer writer = new FileWriter("dest.txt")
调用方法写入数据:
char[] chs = { '中', '国', '人' };
writer.write(chs);异常处理:throw IOException
关闭资源:writer.close()
第三种写法,直接写入一个字符串 writer.write("我是**人");
实现文件内容拷贝
// 按单个字符进行读写
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("lib/1.txt");
FileWriter fw = new FileWriter("lib/2.txt");
int len;
while((len = fr.read()) != -1) {
fw.write(len);
}
fr.close();
fw.close();
}
// 按字符数组进行读写
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("lib/1.txt");
FileWriter fw = new FileWriter("lib/2.txt");
char[] chs = new char[1024];
int len;
while((len = fr.read()) != -1) {
fw.write(chs, 0, len);
}
fr.close();
fw.close();
}通过字符缓冲流拷贝文件
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("lib/1.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("lib/2.txt"));
int len;
while((len = br.read()) != -1) {
bw.write(len);
}
br.close();
bw.close();
}读取一行数据
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("lib/1.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("lib/2.txt"));
String str;
// readline() 读取一行数据
while((str = br.readline()) != null) {
bw.write(str);
bw.newLine(); // 跨平台写入换行符
}
br.close();
bw.close();
}在字节流中有两个关键类:InputStream和OutputStream,分别是字节输入流和字节输出流,它们都是抽象类,在实际应用中,必须使用它们的实现类,即FileInputStream和FileOutputStream,它们是普通字节流读写
普通字节流-按单个字节读写
按单个字节进行读写流程如下:
创建字节流读文件对象:
InputStream is = new FileInputStream("abc.jpg");创建字节流写文件对象:
OutputStream os = new FileOutputStream("D:\\abc_copy.jpg");使用while循环读写数据:
int b;
while((b = is.read()) != -1) {
os.write(b);
}添加异常处理: throws IOException
关闭资源:
is.close();
os.close();利用字节流读写完成图片的拷贝,代码如下:
public static void main(String[] args) throws IOException {
// 创建字节流读对象
FileInputStream fis = new FileInputStream("lib/abc.jpg");
// 创建字节流写对象
FileOutputStream fos = new FileOutputStream("lib/abc_copy.jpg");
// 循环读取字节并写入新文件
int len;
while ((len = fis.read()) != -1) {
fos.write(len);
}
// 关闭资源
fis.close();
fos.close();
}普通字节流-按字节数组读写
字节流按字节数组进行读写的操作与上面按单字节进行读写的操作有两点不同
需要额外创建一个字节数组,如: byte[] b = new byte[2048],字节数组的长度必须是1024的整数倍
在进行写操作调用目标对象的write方法时,必须传入3个参数,分别是定义的字节数组,如上面的b,从哪一个索引位置开始写,这里是0,写入的终止位置,即读写到的len
int len;
while ((len = is.read(bys)) != -1) {
os.wirte(bys, 0, len);
}其他操作都是一样的,演示代码如下:
public static void main(String[] args) throws IOException {
// 创建字节流读对象
FileInputStream fis = new FileInputStream("lib/abc.jpg");
// 创建字节流写对象
FileOutputStream fos = new FileOutputStream("lib/abc_copy.jpg");
// 创建字节数组
byte[] bys = new byte[1024];
// 循环读取并写入新文件
int len;
while ((len = fis.read(bys)) != -1) {
fos.write(bys, 0, len);
}
// 关闭资源
fis.close();
fos.close();
}高效字节流-字节缓冲流读写
字节缓冲流读写操作,使用的是InputSteam和OutputStream的实现类BufferedInputSteam和BufferedOutputStream,此方式与上面不同的是,创建新文件是根据目标文件动态生成的,且是高效的
与上面的创建方式不同的在于创建读写对象:
创建字节缓冲流读读文件对象:
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("lib/abc.jpg");
)创建字节缓冲流写文件对象:
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("lib/abc_copy.jpg");
)演示如下:
public static void main(String[] args) throws IOException {
// 创建字节缓冲流读对象
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("lib/abc.jpg")
);
// 创建字节缓冲流写对象
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("lib/abc_copy.jpg")
);
// 循环读写文件
int len;
while ((len = bis.read()) != -1) {
bos.write(len);
}
// 关闭资源
bis.close();
bos.close();
}这是一个学习AngularJS中的一个栗子,todoList,把学习过程记录下来,便于以后练习。
首先,我们来创建html,为了美化我使用了BootStrap,代码如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>todoList</title>
<link rel="stylesheet" href="http://cdn.bootcss.com/bootstrap/3.3.6/css/bootstrap.min.css">
</head>
<body style="padding: 10px;">
<div class="input-group">
<input type="text" class="form-control">
<span class="input-group-btn">
<button class="btn btn-default">提交</button>
</span>
</div>
<h4>任务列表</h4>
<ul class="list-group">
<li class="list-group-item">1</li>
<li class="list-group-item">2</li>
<li class="list-group-item">3</li>
</ul>
</body>
<script src="http://cdn.bootcss.com/angular.js/1.5.5/angular.min.js"></script>
<script src="app.js"></script>
</html>为了养成良好的习惯,我吧AngularJS的代码写在app.js文件里
我们先在html里使用ng-app来声明AngularJS的管理边界,并指定这个模块的名称todoList
<html lang="zh-CN" ng-app="todoList">app.js:
'use strict';
angular.module('todoList', []) // 使用angular的module方法声明模块todoList
.controller('TaskCtrl', function($scope){ //生成控制器TaskCtrl
$scope.task = ''; //在$scope上定义变量task
$scope.tasks = []; //在$scope上定义空数组变量tasks
})接着,我们在body标签中加入定义的控制器TaskCtrl
<body ng-controller="TaskCtrl">在input标签中使用ng-model指令绑定输入,也就是把输入与变量task绑定起来
<input type="text" class="form-control" ng-model="task">现在我们为提交按钮添加一个添加列表事件,在button里使用ng-click添加事件
<button class="btn btn-default" ng-click="addItem()">提交</button>在app.js里响应这个事件
'use strict';
angular.module('todoList', []) // 使用angular的module方法声明模块todoList
.controller('TaskCtrl', function($scope){ //生成控制器TaskCtrl
$scope.task = ''; //在$scope上定义变量task
$scope.tasks = []; //在$scope上定义空数组变量tasks
$scope.addItem = function() {
$scope.tasks.push($scope.task);
}
})最后我们在html里使用指令ng-repeat来遍历用户输入,并把他们显示到下面的列表当中
<ul class="list-group">
<li class="list-group-item" ng-repeat="item in tasks track by $index">
{{item}}
</li>
</ul> ng-repeat指令里的内容表示,使用项目下标来遍历并输入列表项
至此我们就完成了一个简单的Angular应用,todoList,但是有两个问题我们来完善下,一是项目列表可以添加一个删除,还有就是那个
我们先来隐藏这个
ng-hide和ng-if都可以实现
<h4 ng-hide="tasks.length==0">任务列表</h4>
// 列表项数组长度为0时,将此标签隐藏<h4 ng-if="tasks.length > 0">任务列表</h4>
// 列表项数组长度大于0时才显示这个标签在实际应用中推荐使用ng-if指令,因为这个指令不会在DOM中创建对应的标签,而ng-hide不管对应的标签是否隐藏或显示,都会创建。
而另外一个,在列表项中创建一个删除
<ul class="list-group">
<li class="list-group-item" ng-repeat="item in tasks track by $index">
{{item}} <a ng-click="tasks.splice($index,1)">删除</a>
</li>
</ul>这个练习小项目我放在了github上,有兴趣的同学可以fork下。
错误表示程序中出现了异常情况。比如当我们试图打开一个文件时,文件系统里却并没有这个文件。这就是异常情况,它用一个错误来表示。
在 Go 中,错误一直是很常见的。错误用内建的 error 类型来表示。
就像其他的内建类型(如 int、float64 等),错误值可以存储在变量里、作为函数的返回值等等。
现在我们开始编写一个示例,该程序试图打开一个并不存在的文件。
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(f.Name(), "opened successfully")
}在程序的第 9 行,我们试图打开路径为 /test.txt 的文件。os 包里的 Open 函数有如下签名:
func Open(name string) (file *File, err error)如果成功打开文件,Open 函数会返回一个文件句柄(File Handler)和一个值为 nil 的错误。而如果打开文件时发生了错误,会返回一个不等于 nil 的错误。
如果一个函数或方法返回了错误,按照惯例,错误会作为最后一个值返回。于是 Open 函数也是将 err 作为最后一个返回值。
按照 Go 的惯例,在处理错误时,通常都是将返回的错误与 nil 比较。nil 值表示了没有错误发生,而非 nil 值表示出现了错误。在这里,我们第 10 行检查了错误值是否为 nil。如果不是 nil,我们会简单地打印出错误,并在 main 函数中返回。
运行该程序会输出:
// open /test.txt: No such file or directory很棒!我们得到了一个错误,它指出该文件并不存在。
让我们进一步深入,理解 error 类型是如何定义的。error 是一个接口类型,定义如下:
type error interface {
Error() string
}error 有了一个签名为 Error() string 的方法。所有实现该接口的类型都可以当作一个错误类型。Error() 方法给出了错误的描述。
fmt.Println 在打印错误时,会在内部调用 Error() string 方法来得到该错误的描述。上一节示例中的第 11 行,就是这样打印出错误的描述的。
现在,我们知道了 error 是一个接口类型,让我们看看如何从一个错误获取更多信息。
在前面的示例里,我们只是打印出错误的描述。如果我们想知道这个错误的文件路径,该怎么做呢?一种选择是直接解析错误的字符串。这是前面示例的输出:
// open /test.txt: No such file or directory我们解析了这条错误信息,虽然获取了发生错误的文件路径,但是这种方法很不优雅。随着语言版本的更新,这条错误的描述随时都有可能变化,使我们程序出错。
有没有更加可靠的方法来获取文件名呢?答案是肯定的,这是可以做到的,Go 标准库给出了各种提取错误相关信息的方法。我们一个个来看看吧。
如果你仔细阅读了 Open 函数的文档,你可以看见它返回的错误类型是 *PathError。PathError 是结构体类型,它在标准库中的实现如下:
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }通过上面的代码,你就知道了 *PathError 通过声明 Error() string 方法,实现了 error 接口。Error() string 将文件操作、路径和实际错误拼接,并返回该字符串。于是我们得到该错误信息:
// open /test.txt: No such file or directory结构体 PathError 的 Path 字段,就有导致错误的文件路径。我们修改前面写的程序,打印出该路径。
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err, ok := err.(*os.PathError); ok {
fmt.Println("File at path", err.Path, "failed to open")
return
}
fmt.Println(f.Name(), "opened successfully")
}在上面的程序里,我们在第 10 行使用了类型断言(Type Assertion)来获取 error 接口的底层值(Underlying Value)。接下来在第 11 行,我们使用 err.Path 来打印该路径。该程序会输出:
// File at path /test.txt failed to open很棒!我们已经使用类型断言成功获取到了该错误的文件路径。
第二种获取更多错误信息的方法,也是对底层类型进行断言,然后通过调用该结构体类型的方法,来获取更多的信息。
我们通过一个实例来理解这一点。
标准库中的 DNSError 结构体类型定义如下:
type DNSError struct {
...
}
func (e *DNSError) Error() string {
...
}
func (e *DNSError) Timeout() bool {
...
}
func (e *DNSError) Temporary() bool {
...
}从上述代码可以看到,DNSError 结构体还有 Timeout() bool 和 Temporary() bool 两个方法,它们返回一个布尔值,指出该错误是由超时引起的,还是临时性错误。
接下来我们编写一个程序,断言 *DNSError 类型,并调用这些方法来确定该错误是临时性错误,还是由超时导致的。
package main
import (
"fmt"
"net"
)
func main() {
addr, err := net.LookupHost("golangbot123.com")
if err, ok := err.(*net.DNSError); ok {
if err.Timeout() {
fmt.Println("operation timed out")
} else if err.Temporary() {
fmt.Println("temporary error")
} else {
fmt.Println("generic error: ", err)
}
return
}
fmt.Println(addr)
}在上述程序中,我们在第 9 行,试图获取 golangbot123.com(无效的域名) 的 ip。在第 10 行,我们通过 *net.DNSError 的类型断言,获取到了错误的底层值。接下来的第 11 行和第 13 行,我们分别检查了该错误是由超时引起的,还是一个临时性错误。
在本例中,我们的错误既不是临时性错误,也不是由超时引起的,因此该程序输出:
// generic error: lookup golangbot123.com: no such host如果该错误是临时性错误,或是由超时引发的,那么对应的 if 语句会执行,于是我们就可以适当地处理它们。
第三种获取错误的更多信息的方式,是与 error 类型的变量直接比较。我们通过一个示例来理解。
filepath 包中的 Glob 用于返回满足 glob 模式的所有文件名。如果模式写的不对,该函数会返回一个错误 ErrBadPattern。
filepath 包中的 ErrBadPattern 定义如下:
var ErrBadPattern = errors.New("syntax error in pattern")errors.New() 用于创建一个新的错误。我们会在下一教程中详细讨论它。
当模式不正确时,Glob 函数会返回 ErrBadPattern。
我们来写一个小程序来看看这个错误。
package main
import (
"fmt"
"path/filepath"
)
func main() {
files, error := filepath.Glob("[")
if error != nil && error == filepath.ErrBadPattern {
fmt.Println(error)
return
}
fmt.Println("matched files", files)
}在上述程序里,我们查询了模式为 [ 的文件,然而这个模式写的不正确。我们检查了该错误是否为 nil。为了获取该错误的更多信息,我们在第 10 行将 error 直接与 filepath.ErrBadPattern 相比较。如果该条件满足,那么该错误就是由模式错误导致的。该程序会输出:
// syntax error in pattern标准库在提供错误的详细信息时,使用到了上述提到的三种方法。在下一教程里,我们会通过这些方法来创建我们自己的自定义错误。
绝不要忽略错误。忽视错误会带来问题。接下来我重写上面的示例,在列出所有满足模式的文件名时,我省略了错误处理的代码。
package main
import (
"fmt"
"path/filepath"
)
func main() {
files, _ := filepath.Glob("[")
fmt.Println("matched files", files)
}我们已经从前面的示例知道了这个模式是错误的。在第 9 行,通过使用 _ 空白标识符,我忽略了 Glob 函数返回的错误。我在第 10 行简单打印了所有匹配的文件。该程序会输出:
// matched files []由于我忽略了错误,输出看起来就像是没有任何匹配了 glob 模式的文件,但实际上这是因为模式的写法不对。所以绝不要忽略错误。
this、call和apply在Javascript编程中应用非常广泛,所以,我们必须先了解它们。
Javascript中的 this 总是指向一个对象,而它又是基于执行环境动态绑定,而非函数被声明时的环境。以下有4中情况可以用来分析。
当函数作为对象的方法时,this 指向该对象,看下面的代码:
var obj = {
a: 1,
getA: function(){
alert(this === obj); //true
alert(this.a); //1
}
};
obj.getA();当作为普通函数调用时,此时的this总是指向全局对象window
window.name = 'globalName';
var getName = function(){
return this.name;
};
console.log(getName()); //globalName下面来一个实际的例子,我们在一个div节点内部,定义一个局部的callback方法,当这个方法被当做普通函数调用时,callback内部的this就指向了window,如下代码:
<html>
<body>
<div id="div1">我是一个Div</div>
</body>
<script>
window.id = 'window';
document.getElementById('div1').onclick = function(){
alert(this.id); //div1
var callback = function(){
alert(this.id); //window
}
callback();
};
</script>
</html>我们可以将callback函数分别写成 alert(this === callback) 和 alert(this === window) 来测试下。
那我们如何来解决这个问题呢,我们可以使用一个变量来保存div节点的引用
<html>
<body>
<div id="div1">我是一个Div</div>
</body>
<script>
window.id = 'window';
document.getElementById('div1').onclick = function(){
var that = this;
alert(that.id); //div1
var callback = function(){
alert(that.id); //div1
}
callback();
};
</script>
</html>在ES5的 strict 模式,这种 this 不会再指向window,而是 undefined
function func(){
"use strict";
alert(this); //undefined
}
func();构造器的调用,当我们使用 new 运算符调用函数时,总会返回一个对象,那么构造器里的 this 就指向这个对象
var myClass = function(){
this.name = 'Kaindy';
};
var obj = new myClass();
alert(obj.name); //KaindyFunction.prototype.call 或 Function.prototype.apply 调用,可以动态的改变传入函数的 this
var obj1 = {
name: 'Kaindy',
getName: function(){
return this.name;
}
};
var obj2 = {
name: 'anne';
}
console.log(obj1.getName()); //Kaindy
console.log(obj1.getName.call(obj2)); //anneOK,我们再来看下下面的例子,丢失的 this :
var obj = {
myName: 'Kaindy',
getName: function(){
return this.myName;
}
};
console.log(obj.getName()); //Kaindy
var getName2 = obj.getName;
console.log(getName2()); //undefined当obj调用其方法getName时,此时的this指向obj对象,所以打印出obj对象的myName属性值,然后当把对象obj的getName方法赋值给对象getName2时,此时是普通函数调用,this 就指向了全局 window 对象,所以会打印出undefined。
下面我们来分析下 call 和 apply,它们是ES3为 Function 的原型定义的两个方法,它们的作用一样,区别只是在传入的参数的不同。
apply 接受两个参数,第一个指定函数体内 this 对象的指向,第二个是集合,可以是数组也可以是类数组,apply 方法把集合中的元素作为参数传递给被调用的函数
var func = function(a, b, c){
alert([a, b, c]); //[1, 2, 3]
};
func.apply(null, [1, 2, 3]);call 传入的参数不是固定的,第一个参数与 apply 相同,代表函数体内的 this 指向,从第二个参数开始,每个参数被依次传入函数
var func = function(a, b, c){
alert([a, b, c]); //[1, 2, 3]
};
func.call(null, 1, 2, 3);在Javascript内部,参数是用数组来表示的,所以,apply 比 call 的使用率更高,如果我们明确参数的数量,想一目了然的表达形参与实参的对应关系,那么我们就使用 call 。
在使用 apply 或者 call 时,如果第一个参数使用 null,那么函数体内的 this 会指向默认的宿主对象,在浏览器中就是window,但在严格模式下,仍然为 null。
下面我们来看看apply和call的实际用途
var obj1 = {
name: 'sven';
};
var obj2 = {
name: 'anne';
};
window.name = 'window';
var getName = function(){
alert(this.name);
};
getName(); //window
getName.call(obj1); //sven
getName.call(obj2); //anne当执行 getName.call(obj1) 的时候,getName() 函数体内的 this 就指向了 obj1 对象
我们再来看一个在实际开发中可能会遇到的例子,如页面中有一个id为div1的区块
document.getElementById('div1').onclick = function(){
alert(this.id); //此处的this指向document.getElementById('div1')产生对象,输出div1
var func = function(){
alert(this.id); //此处的this就指向全局对象window了,故输出undefined
};
func();
}上面的代码中,事件函数有一个内部函数func,调用此函数时,this 就指向了 window,我们可以用 call 来修正它
document.getElementById('div1').onclick = function(){
alert(this.id); //div1
var func = function(){
alert(this.id); //div1
};
func.call(this);
}Function.prototype.bind大部分浏览器都实现了内置的 Function.prototype.bind ,用来指定函数内部的 this 指向。(这个内容不知道为什么要写,所以就略掉)
借用方法的第一种场景是“借用构造函数”,通过它可以实现一些类似继承的效果
var A = function(name){
this.name = name;
};
var B = function(){
A.apply(this, arguments);
};
B.prototype.getName = function(){
return this.name;
};
var b = new B('sven');
console.log(b.getName()); //sven第二种场景是对函数的参数列表 arguments 进行一些操作,arguments 并非真正的数组,如果我们想往arguments 中添加一些元素,就可以借用 Array.prototype.push 方法
(function(){
Array.prototpye.push.call(argumets, 3);
console.log(arguments); [1,2,3]
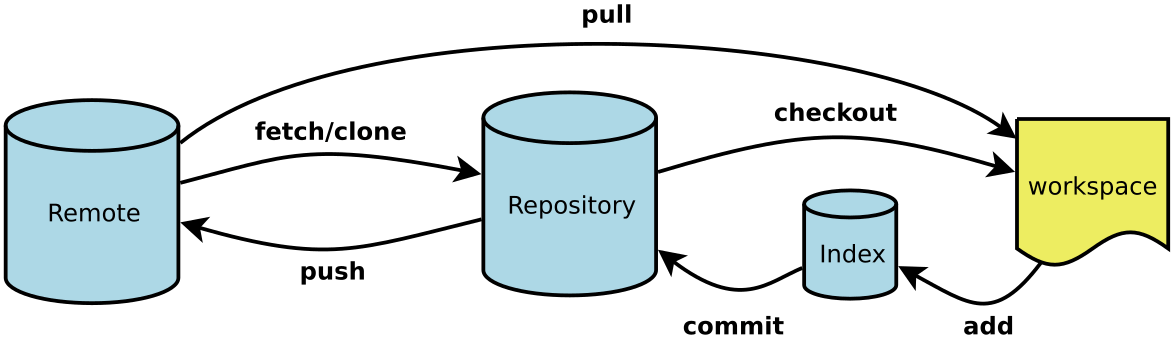
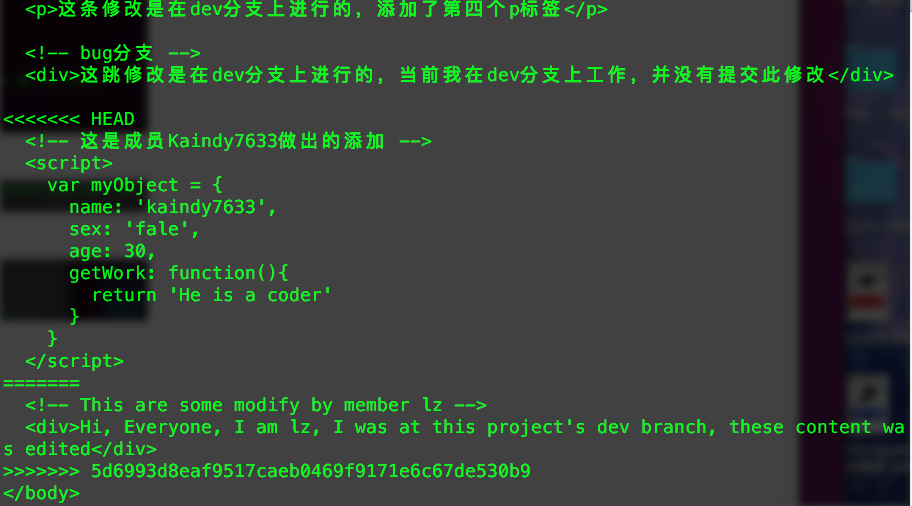
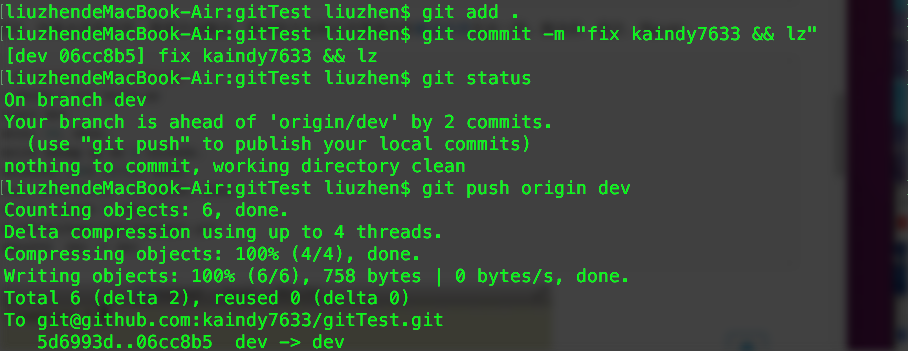
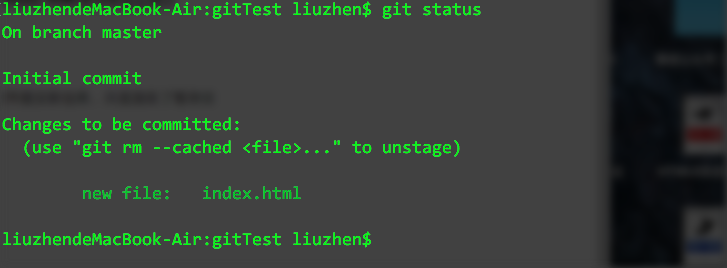
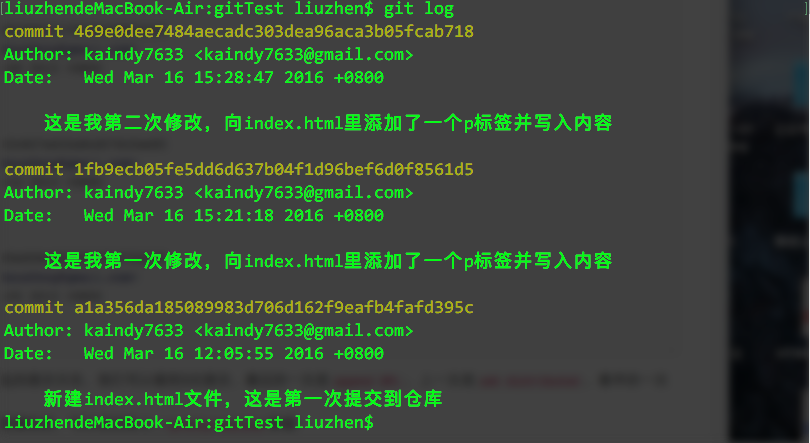
})(1, 2);通常我们在软件开发使用的版本控制系统有两种,一种是集中式版本控制,如SVN,另一种就是分布式版本控制系统,如GIT。Git的特点就是分布式,不但可以在本地机器上做版本仓库,还可以将代码上传至远程Git服务器,方便团队协作,也实现了另外一个远程代码备份。
git服务器我们可以自己搭建,但那是没有必要的,因为有github这样的网站为我们提供了,而且只要不是必须的,你不需要去付费使用。
首先我们需要在github上去注册一个自己的账号,因为本地git仓库与github仓库之间的数据传输是加密的,所以我们需要先创建 SSH KEY.
在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有 id_rsa 和 id_rsa.pub 这两个文件,如果没有,打开终端,创建SSH Key。
在终端使用命令创建这个KEY:
ssh-keygen -t rsa -C "[email protected]"后面引号里的Email地址填写自己的,应该为在github上注册Email地址。一路回车之后,就创建成功了。
其中id_rsa为私钥,这个不能泄露出去,而id_rsa.pub为公钥,可以放心的告诉别人。
接下来,我们登录github.com,在账号设置中,点击左边菜单栏中的SSH keys。
点击右上角的 “New SSH key”
在Title中填写标题,可随意填写,建议使用有意义的名称,比如这个项目的简称,然后将id_rsa.pub的内容粘贴到下面的key里,成功后显示如下:
OK,到现在,我们就可以正常使用github了。我们有了本地仓库,也有了github这样的远程仓库,就可以同步了,这样既可以有一个远程的代码备份,也方便团队进行协作开发。
现在我们需要在github上创建一个仓库,首先登陆github,在右上角点击 “+” 号,在弹出的菜单中选择 “New repository”。
在"Repository name" 中填写仓库名称,这里我填了gitTest,其他默认,然后点击下方的Create repository。
现在这个gitTest仓库是空的,我们可以将已有的本地仓库与之关联,然后将本地仓库推送到远程仓库,也可以从远程仓库克隆项目到本地仓库。
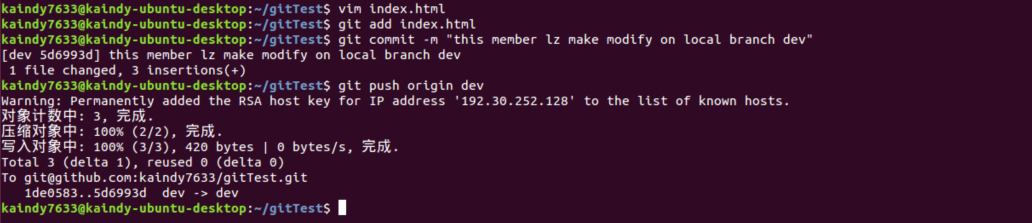
我们现在将上一节的gitTest项目推送到这个远程仓库,首先使用下面的命令让本地git与远程github进行关联
$ git remote add origin [email protected]:kaindy733/gitTest.git完成后没有提示错误,下一步我们使用下面的命令,将本地项目推送上去
$ git push -u origin master中间会有提示是否继续,输入yes即可。
下面我们来看下github上的项目情况
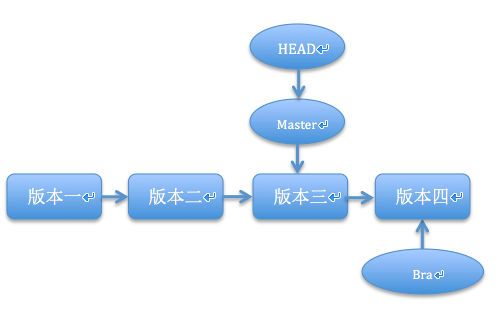
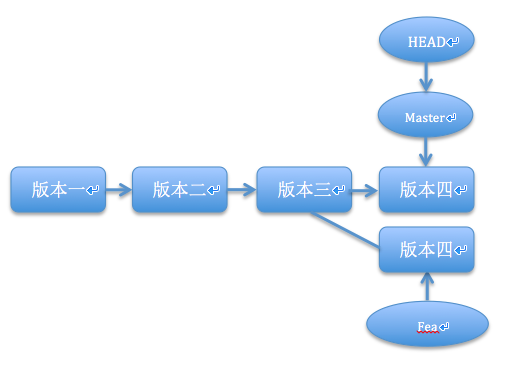
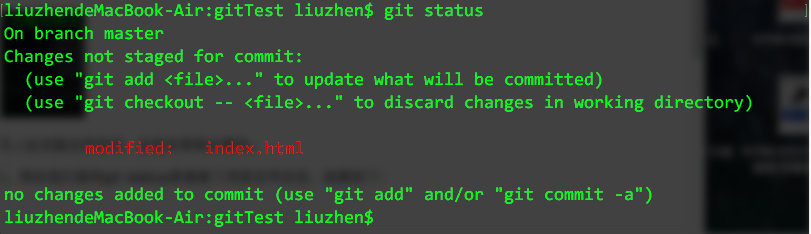
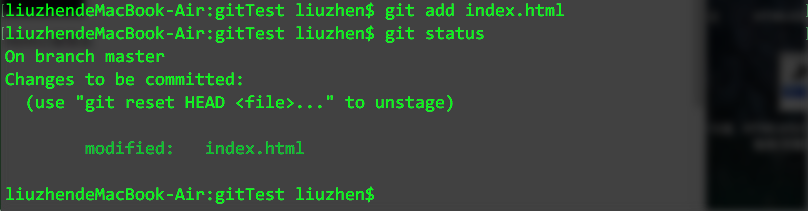
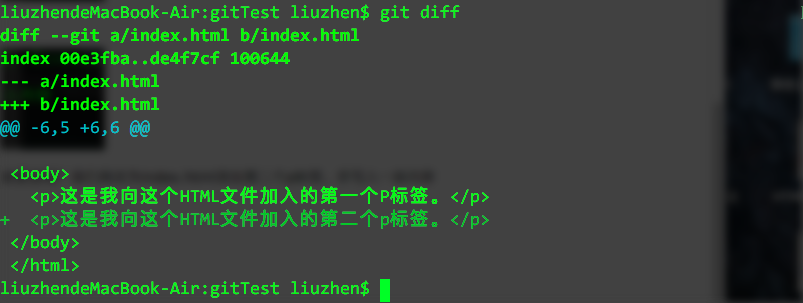
可以看到,我们的项目已经推送到了github上,把本地仓库的内容推送到远程,我们使用 git push命令,也就是把当前分支 master 推送到远程。由于远程仓库是空的,我们第一次推送 master 分支时加上了 -u 参数,git不但把本地的master分支内容推送到远程新的master分支,还会把两者关联,在以后的推送或拉取时就可以简化命令。
好了,从现在起,如果本地做了代码修改,就可以直接使用下面的命令将项目推送到github上。
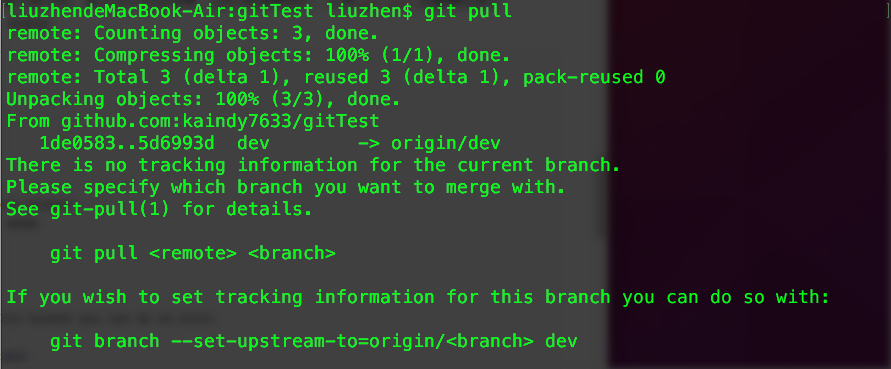
$ git push origin master分布式版本系统的最大好处之一是在本地工作完全不需要考虑远程库的存在,也就是有没有联网都可以正常工作,而SVN在没有联网的时候是拒绝干活的!当有网络的时候,再把本地提交推送一下就完成了同步
上面介绍的是从本地仓库推送项目到远程仓库,我们还可以从远程仓库克隆项目到本地,以方便团队开发。首先,我们在github上创建项目仓库
填写仓库名称,勾选下面的Initialize this repository with a README,这个操作会为我们的项目自动创建一个README文件,然后点击下面的创建按钮。
我们可以编辑README.md文件,为项目添加说明
好了,现在远程库已准备好,我们可以使用 git clone 从远程库克隆项目到本地
$ git clone [email protected]:kaindy7633/myProjectTest.git克隆成功,我们打开这个项目目录看下
我们先来看一个完整的项目实例,这是AngularJS官方为我们提供的Phonecat项目。在AngularJS的官方网站上有详细的指导,有兴趣的朋友可以去看看,地址:http://docs.angularjs.org/tutorial。
Phonecat项目源码托管在GitHub上,我们通过git来下载源码:
git clone --depth=14 https://github.com/angular/angular-phonecat.git如果不能下载,请将命令中的https替换成ssh。
Phonecat项目运行在Nodejs上,请确保你的系统里有NodeJS环境,下载完成后我们进入Phonecat目录,运行下面的命令安装项目依赖。
npm install运行该命令后,会在angular-phonecat项目路径下安装以下依赖包:
Bower . 包管理器
Http-Server . 轻量级Web服务器
Karma . 用于运行单元测试
Protractor . 用于运行端到端测试
完成上述操作之后,我们在angular-phonecat目录里执行下面的命令
npm startPhoneCat运行后,可以在浏览器中打开 http://localhost:8000/app/index.html 来访问该Web应用
OK,现在我们可以通过protractor来自动运行测试,protractor是一款自动测试工具,它可以自动打开本机的浏览器,运行当前项目,模拟用户的选择、输入、滑动等操作来测试项目。
npm run protractor通过这个项目我们可以看出自动化的构建和测试对前端来说尤其重要,但有时我们在想,我们到底需要一个什么样的前端开发环境呢?
1、首先我们需要一个款强大的代码编辑工具
2、一款易用的断点调试工具,尤其是在做JS调试时
3、一款拉风的版本管理工具,说到这里大家会想到的是就是Git,像SVN就不要了吧
4、一款代码合并和混淆工具
5、依赖管理工具
6、单元测试工具,以前我们的代码只能在浏览器环境里跑,所以每次的测试都离不开浏览器,过程也很繁琐,现在我们可以依赖NodeJS环境,来跑单元测试,这样就脱离的浏览器,做到自动的单元测试
7、集成测试工具,当我们完成整个项目的开发后,进入测试阶段,我们需要一款足够强大的全面的测试工具来帮我们完成整个项目的测试。
1、代码编辑工具:
说到代码编辑工具,前端的朋友都会推荐Sublime了,是的,这是一款前端轻量级的强大的代码编辑工具,支持多种编程语言,其使用方法和插件的安装在百度上会找的很多。
代码编辑工具除了上面说到的Sublime之外呢,还有一款重量级的,Webstorm,这款工具比较大,但功能确实很强大,插件里首先就支持了AngularJS,如果你的电脑比较好,可以考虑使用这款工具。
2、断点调试工具:
chrome插件Batarang,我们可以在chrome的设置里安装这个断点调试工具
3、版本管理工具
在这个技术日新月异的年代,我们当然要用上比较高大上的工具,版本管理,自然我们会使用Git这样强大的分布式版本管理工具,具体使用方法,在我的博客里有比较详细的讲解。
4、开发和调试工具:
我们用的很多这样的工具都依赖一个环境,这就是NodeJS,所以首先我们需要在自己的电脑上安装并配置好NodeJS,其次就是npm,这是NodeJS的一个包管理器,使用npm我们可以解决很多依赖包的安装和配置工作。
5、代码合并和混淆工具:
Grunt,这款工具也是在NodeJS环境下安装的,我们可以使用npm来安装grunt,然后我们在项目中,使用npm来安装一些grunt会使用到的插件,基本的包括uglify(代码混淆)、concat(合并文件)、watch(监控文件变化)。
6、依赖管理工具
Bower,这款工具可以自动安装依赖的组建,包括对这些依赖的检测和版本之间兼容性的检测,关于Bower的具体使用可以参考百度。
7、轻量级Server
http-server,这是一款基于NodeJS的http-server工具,它可以把你电脑上的任意一个目录变成Web服务目录。我们可以通过npm把它安装到全局,然后在需要测试的项目目录里运行http-server即可。
8、单元测试runner
我们先来看下单元测试神器:Karma,它只是用来跑测试用例的容器,并没有提供一套用来编写测试用例的语法,所以我们需要另外一款工具来配合,那就是Jasmine,它提供了一套比较简洁的语法,来编写测试用例。
Jasmine的四个核心概念:分组、用例、期望、匹配,它们分别对应Jasmine的四个函数:
describe(string,function) 这个函数表示分组,也就是一组测试用例
it(string,function) 这个表示单个的测试用例
expect(expression) 表示期望expression这个表达式会返回某个值或具有某种行为
to***(arg) 这个表示匹配
下面我们通过一个例子来看下这个单元测试的过程。首先我们需要在测试目录里安装必要的模块,这里我们新建并进入karmaTets目录,在此目录下通过npm或cnpm安装karma、karma-chrome-launcher、karma-coverage和karma-jasmine,安装过程这里就不再赘述了。
上述的安装完成之后,我们在目录中新建src目录,在这里个目录里新建一个index.js文件,写上一个简单的函数,这个函数的作用是把传入的参数字符串进行反转,如abc返回cba,js代码如下:
function reverse(name) {
return name.split("").reverse().join("");
}接下来我们再新建一个目录test,表示是测试目录,里面分别有两个目录,一个是unit,单元测试,一个是e2e,表示是集成测试目录。我们在unit目录新建一个测试文件,叫testCase.js,输入以下内容
describe("A suite", function(){
it("contains spec with an expectation", funtion(){
console.log("This is msg from log...");
expect(true).toBe(true);
});
});
describe("A suite of basic functions", function(){
it("reverse word", function(){
expect("DCBA").toEqual(reverse("ABCD"));
expect("damo").toEqual(reverse("omad"));
});
});然后我们在命令行下,执行karma init来初始化karma,并配置karma.conf.js文件,完成之后我们就可以使用karma start来启动测试,结果会在命令行打印出来。
9、专为AngularJS定制的测试工具 -- Protractor
Protractor是一款集成测试工具,专门为ANgularJS应用而设计的,它是基于WebDriverJS的,原理就是利用WebDriverJS,借助NodeJS直接调用浏览器的接口。我们可以通过下面的地址去了解这款工具
AngularJS是由Misko Hevery 和 Adam Abrons 两个人共同创建的,在2009年卖给了Google,它是一个构建动态Web应用的一个Javascript框架,目的是为了克服HTML在构建Web应用程序上的不足而设计的。
其中指令系统和双向数据绑定是AngularJS特有的,主要区别于其他的前端MVC框架,如BackBone
MVC是在1979年由Trygve Reenskaug第一次提出
Model:数据模型层
View:视图层,负责展示,一般我们能在页面上看到的都是
Controller:业务逻辑和控制逻辑
MVC的好处是职责很清晰,代码模块化,下面我们来看一段代码
<!DOCTYPE html>
<html ng-app="MyAngular">
<head>
<meta charset="UTF-8">
<title>AngularJS MVC</title>
</head>
<body>
<div ng-controller="HelloAngular">
<p>{{greeting.text}}, AngularJS</p>
</div>
</body>
<script src="js/angular-1.4.6.min.js"></script>
<script>
angular.module('MyAngular', [])
.controller('HelloAngular', function($scope){
$scope.greeting = {
text: 'Hello'
}
})
</script>
</html>从上面代码可以看出,在html标签里,使用ng-app定义了AngularJS的管理边界,也就是说,AngularJS可以管理整个html。
在body中的div里面定义了ng-controller,这就是MVC中的控制器,也就是C,而整个p标签就是我们的视图层,也就是V。
在最下面的script里,我们首先定义了一个AngularJS的模块MyAngular,然后在这个模块上定了控制器HelloAngular,里面的text:'Hello',就是我们的M层。
其实在上面的代码中,我们已经使用了AngularJS的模块化,下面我们来用另外一种方式来重写上面的JS代码部分
var myModule = angular.module('MyAngular', []); //定义模块
myModule.controller('HelloAngular', ['$scope', //在模块上定义一个控制器方法helloAngular
function helloAngular($scope) {
$scope.greeting = {
text: 'Hello'
}
}
]);上面第一排的代码为我们定义了一个模块myModel,然后我们利用该模块的controller方法生成一个控制器。请注意,我们在定义controller控制器时,第一个参数是控制器名称,而第二个是在一个方括号里,方括号里的第一个成员是一个变量$scope,第二个成员是一个Function,这个Function的参数也叫$scope,也就是说,这里的代码告诉Angular,请把第一个成员$scope注入到下面的方法中,这里也体现了Angular的依赖注入特性。
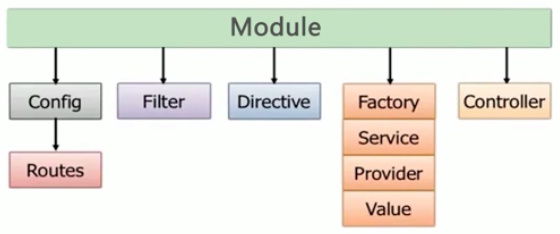
下面我们用一张图来说明下AngularJS的模块化
在AngularJS中,一切都是从模块开始的,创建了模块,我们就可以在这个模块上调用各种方法,如Filter、Directive、Controller等。
首先我们来看下下面的代码
<!DOCTYPE html>
<html ng-app="MyModule">
<head>
<meta charset="utf-8" />
<title>AngularJS - 指令系统</title>
</head>
<body>
<hello></hello>
</body>
<script src="js/angular-1.4.6.min.js"></script>
<script>
var MyModule = angular.module('MyModule', []);
MyModule.directive('hello', function(){
return {
restrict: 'E',
template: '<div>Hi Everyone!</div>',
replace: true
}
});
</script>
</html>上面的HTML代码中,我们可以看到<hello></hello>这样的标签,但是在HTML里,没有定义这杨的标签,浏览器引擎是不认识它的,这时,浏览器会忽略掉这个标签,Angular怎么做呢?在下面的JS代码中,Angular在已定义的模块MyModule上,使用了directive方法,在这个方法中,第一个参数就定义了hello这个标识符,用来说明在HTML中,hello标签的意义,在返回的属性中有一个template,它的作用就是说明这个标签会显示什么样的内容。
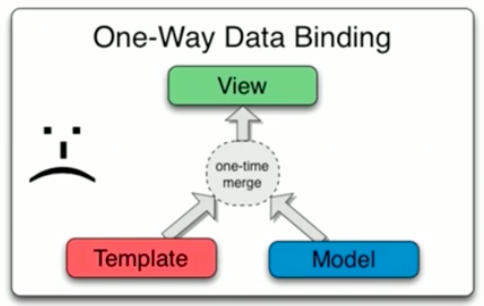
目前大多数的前端框架都是单向数据绑定,如jQueryUI、Backbone、Flex等。单向数据绑定是怎么做的呢?一般的做法是我们先生成模板(template),然后从后台获取数据(Model),通过绑定机制,将模板和数据结合起来生成HTML标签插入到文档流中(View)。
这样的单向数据绑定有什么问题吗?如果我们的数据有变化,那么按照这种流程,我们不得不重新将模板和新的数据再次生成HTML插入到文档流中,也就是需要重构HMTL页面。
那么AngularJS中的双向数据绑定又是怎么回事呢?
双向数据绑定认为,视图和数据是对应的,借助事件机制,当视图发生变化时,数据模型也会发生相应的变化,而当数据模型发生变化时,视图会自动更新,这种场景应用最典型的就是我们的表单,当用户在表单中完成输入后,数据模型就会立刻拿到用户输入,下面我们用一段代码来说明下
<!DOCTYPE html>
<html ng-app>
<head>
<meta charset="utf-8">
</head>
<body>
<div>
<input type="text" ng-model="greeting.text">
<p>{{greeting.text}}, AngularJS</p>
</div>
</body>
<script src="js/angular-1.4.6.min.js"></script>
</html>当我们在表单中任意输入后,下面的p标签会马上显示出用户输入,代码中的双大括号表示一个取值表达式。
最近在系统的复习ES6、ES7的知识,发现了尾调用优化这块的内容,感觉很有趣,也非常实用,所以把这块记录下来方便后期查看。
我们先来看下,什么是尾调用 ?
尾调用 (Tail Call) 是函数式编程的一个重要概念,其本身也比较简单,就是指某个函数的最后一步是调用另一个函数。
function f(x) {
return g(x)
}上面的示例代码中,函数f的最后一步调用函数g,这就是尾调用
下面的情况,就不属于尾调用了
function f(x) {
let y = g(x)
return y
}
// 调用函数g之后还有其他的赋值操作,所以上面的不是尾调用function f(x) {
return g(x) + 1
}
// 调用后还有进一步的操作,这里是 +1 ,所以上面的函数也不是尾调用function f(x) {
g(x)
}
// 如果没有显式的指定函数的返回值,则函数会返回一个undefined,所以上面的代码最后一步实际上是 return undefined那么,尾调用优化又是什么呢?我们来看看原因:
我们知道,函数调用会在内存中形成一个调用记录,又称为调用帧(call frame),它保存着调用位置和内部变量等信息,如果在函数A的内部调用函数B,那么在A的调用帧上方还会形成一个B的调用帧,等到B执行完毕,将结果返回给A,B的调用帧才会消失,如果函数B内部还调用了函数C,那么就还有一个C的调用帧,以此类推,所有的调用帧就形成了一个调用栈(call stack)
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,直接用内层函数的调用帧取代外层函数的即可。
function f() {
let m = 1
let n = 2
return g(m + n)
}
f()
// 等同于
function f() {
return g(3)
}
f()
// 等同于
g(3)上面的代码中,如果函数 g 不是尾调用,函数 f 就需要保存内部变量 m 和 n 的值、g 的调用位置等信息,但由于调用了 g 之后,函数 f 就结束了,所以执行到最后一步,完全可以删除 f(x) 的调用帧,只保留 g(3) 的调用帧。
这就叫做尾调用优化(Tail Call Optimization) ,即只保留内层函数的调用帧。如果所有的函数都是尾调用,那么就可以做到每次执行时调用帧只有一项,这将大大节省内存。
函数调用自身就称为递归,如果尾调用自身就成为尾递归。
递归是非常耗内存的,如果需要同时保存成百上千个调用帧,很容易发生栈溢出错误,但尾递归可以解决这个问题,因为它始终只有一个调用帧,永远也不会发生栈溢出。我们先来看一个没有使用尾递归的例子:
// 阶乘,没有使用尾递归
function factorial(n) {
if (n === 1) return 1
return n * factorial(n - 1)
}
factorial(5) // 120上面的代码是一个阶乘函数,计算 n 的阶乘,最多需要保存 n 个调用记录,复杂度为 O(n),如果改写成尾递归,只保留一个调用记录,则复杂度为 O(1)
// 使用尾递归
function factorial(n, total) {
if (n === 1) return total
return factorial(n - 1, n * total)
}
factorial(5, 1) // 120下面再来看一个比较经典的例子,斐波拉契数列(Fibonacci),没有使用尾递归的代码如下:
// 斐波拉契数列,没有使用尾递归的实现
function Fibonacci (n) {
if (n <= 1) return 1
return Fibonacci(n - 1) + Fibonacci(n - 2)
}
Fibonacci(10) // 89
Fibonacci(100) // 堆栈溢出
Fibonacci(500) // 堆栈溢出尾递归优化的 Fibonacci 数列实现如下:
// 斐波拉契数列,使用了尾递归的实现
function Fibonacci (n, ac1 = 1, ac2 = 1) {
if (n <= 1) return ac2
return Fibonacci(n - 1, ac2, ac1 + ac2)
}
Fibonacci(100) // 573147844013817200000
Fibonacci(1000) // 7.0330367711422765e+208ES6明确规定,所有的ECMAScript的实现都必须部署 "尾调用优化",所以在ES6中,只要使用尾递归,就不会发生栈溢出,相当节省内存。
尾递归的实现需要改写递归函数,确保最后一步只调用自身,要做到这一点,就要把所有用到的内部变量改写成函数的参数,比如上面的例子,阶乘函数 factorial 需要用到一个中间变量 total,就把这个中间变量改写的函数参数,不过这样做不太直观,为什么计算5的阶乘需要传入两个参数?
解决这个问题有两个方法。方法一就是在尾递归函数之外再提供一个函数
function tailFactorial (n ,total) {
if (n === 1) return total
return tailFactorial(n - 1, n * total)
}
function factorial (n) {
return tailFactorial(n, 1)
}
factorial(5) // 120另外在函数式编程中还有一个概念,叫柯里化 (currying) ,意思是将多参数的函数转换成单参数的形式,这里也可以使用柯里化
function currying (fn, n) {
return function (m) {
return fn.call(this, m, n)
}
}
function tailFactorial (n, total) {
if (n === 1) return total
return tailFactorial(n - 1, n * total)
}
const factorial = currying(tailFactorial, 1)
factorial(5) // 120方法二就简单多了,那就是使用ES6的函数参数默认值
function factorial (n, total = 1) {
if (n === 1) return total
return factorial(n - 1, n * total)
}
factorial(5) // 120上面的代码中,参数 total 有默认值 1,所以调用时不用提供这个参数
ES6的尾调用优化只在严格模式下开启,正常模式下是无效的。
在正常模式下函数内部有两个变量,可以跟踪函数的调用栈:
func.arguments:返回调用时函数的参数func.caller:返回调用当前函数的那个函数尾调用优化发生时,函数的调用栈会改写,因此上面的两个变量会失真,严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
上面讲到了尾调用优化只能在严格模式下进行,那么在正常模式下,如何实现尾递归优化呢?
我们知道,之所以尾递归需要优化,是因为调用栈太多造成了栈溢出,那么只要减少调用栈就不溢出了,那如何减少调用栈呢?我们采用"循环"来替换"递归"
// 下面是一个正常的递归函数
function sum (x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
} else {
return x
}
}
sum(1, 100000) // 发生栈溢出,提示超出调用栈的最大次数我们可以使用蹦床函数(trampoline)来将递归执行转为循环执行
// 下面是一个蹦床函数
function trampoline (f) {
while (f && f instanceof Function) {
f = f()
}
return f
}上面的蹦床函数返回一个函数,而不是在函数里调用函数,这样就避免了递归执行,从而消除了调用栈过大的问题
接下来,我们将原来的递归函数改写为每一步返回另一个函数
// 下面的函数,没执行一次,sum都会返回另一个版本的自己
function sum (x, y) {
if (y > 0) {
return sum.bind(null, x + 1, y - 1)
} else {
return x
}
}使用 trampoline 函数执行 sum 就不会发生调用栈溢出了
trampoline(sum(1, 100000)) // 100001然而,蹦床函数并不是真正的尾递归优化,下面来实现一个真正的:
function tco (f) {
var value
var active = false
var accumulated = []
return function accumulator () {
accumulated.push(arguments)
if (!active) {
active = true
while (acumulated.length) {
value = f.apply(this, accumulated.shift())
}
active = false
return value
}
}
}
var sum = tco(function (x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
} else {
return x
}
})
sum(1, 100000) // 100001tco 函数是尾递归优化的实现,状态变量 active 默认情况下是不被激活的,一旦进入尾递归优化过程,这个变量就被激活了,然后每一轮递归 sum 返回的都是 undefined ,所以就避免了递归执行。
纯CSS3制作3D导航栏,带立体效果和分隔
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSS制作立体导航</title>
<link rel="stylesheet" href="http://www.w3cplus.com/demo/css3/base.css">
<style>
body{
background: #ebebeb;
}
.nav{
width:560px;
height: 50px;
font:bold 0/50px Arial;
text-align:center;
margin:40px auto 0;
background: #f65f57;
border-radius:10px;
box-shadow:0px 8px 0px #900;
}
.nav a{
display: inline-block;
-webkit-transition: all 0.2s ease-in;
-moz-transition: all 0.2s ease-in;
-o-transition: all 0.2s ease-in;
-ms-transition: all 0.2s ease-in;
transition: all 0.2s ease-in;
}
.nav a:hover{
-webkit-transform:rotate(10deg);
-moz-transform:rotate(10deg);
-o-transform:rotate(10deg);
-ms-transform:rotate(10deg);
transform:rotate(10deg);
}
.nav li{
position:relative;
display:inline-block;
padding:0 16px;
font-size: 13px;
text-shadow:1px 2px 4px rgba(0,0,0,.5);
list-style: none outside none;
}
.nav li::before,.nav li::after{
content:"";
position:absolute;
top:14px;
height: 25px;
width: 1px;
}
.nav li::after{
right: 0;
background: -webkit-linear-gradient(rgba(255,255,255,0), rgba(255,255,255,.2) 50%, rgba(255,255,255,0));
background: -o-linear-gradient(rgba(255,255,255,0), rgba(255,255,255,.2) 50%, rgba(255,255,255,0));
background: linear-gradient(rgba(255,255,255,0), rgba(255,255,255,.2) 50%, rgba(255,255,255,0));
}
.nav li::before{
left: 0;
background: -moz-linear-gradient(top, #ff625a, #9e3e3a 50%, #ff625a);
background: -webkit-linear-gradient(top, #ff625a, #9e3e3a 50%, #ff625a);
background: -o-linear-gradient(top, #ff625a, #9e3e3a 50%, #ff625a);
background: -ms-linear-gradient(top, #ff625a, #9e3e3a 50%, #ff625a);
background: linear-gradient(top, #ff625a, #9e3e3a 50%, #ff625a);
}
.nav li:first-child::before{
background: none;
}
.nav li:last-child::after{
background: none;
}
.nav a,
.nav a:hover{
color:#fff;
text-decoration: none;
}
</style>
</head>
<body>
<ul class="nav">
<li><a href="">Home</a></li>
<li><a href="">About Me</a></li>
<li><a href="">Portfolio</a></li>
<li><a href="">Blog</a></li>
<li><a href="">Resources</a></li>
<li><a href="">Contact Me</a></li>
</ul>
</body>
</html>本文介绍一些JavaScript事件绑定的常用方法及其优缺点,同时在最后展示一个由 Dean Edwards 写的一个比较完美的事件绑定方案。
element.onclick = function(e){ // ... };非常简单和稳定,可以确保它在你使用的不同浏览器中运作一致
处理事件时,this 关键字引用的是当前元素,这很有帮组
传统方法只会在事件冒泡中运行,而非捕获和冒泡
一个元素一次只能绑定一个事件处理函数。新绑定的事件处理函数会覆盖旧的事件处理函数
事件对象参数(e)仅非IE浏览器可用
element.addEventListener('click', function(e){ // ... }, false);该方法同时支持事件处理的捕获和冒泡阶段。事件阶段取决于 addEventListener 最后的参数设置:false (冒泡) 或 true (捕获)。
在事件处理函数内部,this关键字引用当前元素。
事件对象总是可以通过处理函数的第一个参数(e)捕获。
可以为同一个元素绑定你所希望的多个事件,同时并不会覆盖先前绑定的事件
attachEvent 函数替代。element.attachEvent('onclick', function(){ // ... });IE仅支持事件捕获的冒泡阶段
事件监听函数内的 this 关键字指向了 window 对象,而不是当前元素(IE的一个巨大缺点)
事件对象仅存在与1window.event`参数中
事件必须以 ontype 的形式命名,比如,onclick 而非 click
仅IE可用。你必须在非IE浏览器中使用W3C的 addEventListener
function addEvent(elementment, type, handler) {
// 为每个事件处理函数赋予一个独立的ID
if(!handler.$$guid) handler.$$guid = addEvent.guid++;
// 为元素建立一个事件类型的散列表
if(!elementment.events) elementment.events = {};
// 为每对元素/事件建立一个事件处理函数的散列表
var handlers = elementment.events[type];
if(!handlers) {
handlers = elementment.events[type] = {};
// 存储已有的事件处理函数(如果已存在一个)
if(elementment["on" + type]) {
handlers[0] = elementment["on" + type];
}
}
// 在散列表中存储该事件函数
handlers[handler.$$guid] = handler;
// 赋予一个全局事件处理函数来出来所有工作
elementment["on" + type] = handleEvent;
}
// 创建独立ID的计数器
addEvent.guid = 1;
function removeEvent(elementment, type, handler) {
// 从散列表中删除事件处理函数
if(elementment.events && elementment.events[type]) {
delementte elementment.events[type][handler.$$guid];
}
}
function handleEvent(event) {
var returnValue = true;
// 获取事件对象(IE使用全局的事件对象)
event = event || fixEvent(window.event);
// 获取事件处理函数散列表的引用
var handlers = this.events[event.type];
// 依次执行每个事件处理函数
for(var i in handlers) {
this.$$handerEvent = handlers[i];
if(this.$$handlerEvent(event) === fasle) {
returnValue = false;
}
}
return returnValue;
}
// 增加一些IE事件对象缺乏的方法
function fixEvent(event) {
event.preventDefault = fixEvent.preventDefault;
event.stopPropagation = fixEvent.stopPropagation;
return event;
}
fixEvent.preventDefault = function() {
this.returnValue = false;
}
fixEvent.stopPropagation = function() {
this.cancelBubble = true;
}addEvent 的优点可以在所有浏览器中工作,就算是更古老无任何支持的浏览器
this 关键字可以在所有的绑定函数中使用,指向的是当前元素
中和了所有防止浏览器默认行为和阻止事件冒泡的各种浏览器特定函数
不管浏览器类型,事件对象总是作为第一个对象传入
addEvent 的缺点JavaScript没有提供传统面向对象语言中的类式继承,而是通过原型委托的方式来实现对象与对象之间的继承。JavaScript也咩有在语言层面提供对抽象类和接口的支持
编程语言按数据类型分类,大致可以分为静态类型语言和动态类型语言。
静态类型语言在编译时已确定变量类型,而动态语言类型的变量类型要到程序运行时被赋值后才能确定。
�静态类型语言的优点是在编译时就能发现类型不匹配的错误,且明确了数据类型,执行速度较快,而动态类型语言的优点就是代码量少,且比较灵活,但在运行时可能会发生类型相关的错误
Javascript是一门典型的动态类型语言。
鸭子类型(duck typing),关于这个有一个故事:从前有个国王,他觉得这个世界上鸭子的叫声很美妙,于是召集大臣要组建一个1000只鸭子组成的合唱团,大臣们找遍了全国却只有999只,最后大臣们发现有一只鸡,它的叫声跟鸭子一模一样,于是这只鸡成为了鸭子合唱团的最后一员。
鸭子类型指导我们只关注对象的行为,而非对象本身,下面我们用代码来模拟上面的这个故事:
var duck = {
duckSinging: function() {
console.log('嘎嘎嘎');
}
};
var chicken = {
duckSinging: function() {
console.log('咯咯咯');
}
};
var choir = []; //合唱团
var joinChoir = function(animal) {
if(animal && typeof animal.duckSinging === 'function') {
choir.push(animal);
console.log('恭喜加入合唱团');
console.log('合唱团已有成员数量:' + choir.length);
}
};
joinChoir(duck); //恭喜加入合唱团
joinChoir(chicken); //恭喜加入合唱团鸭子类型的概念在动态类型语言的面向对象设计中非常重要,利用它我们可以在动态类型语言中实现“面向接口编程”,而不是“面向实现编程”。
多态(polymorphism),它的含义是同一操作作用于不同的对象上,可以产生不同的解释和不同的执行效果,换句话说,给不同的对象发送同一消息时,这些对象会根据这个消息分别给出不同的反馈,下面举个栗子:
有一只鸭和一只鸡,它们都会叫,当主人向它们发出“叫”的指令时,鸭会“嘎嘎嘎”的叫,而鸡会“咯咯咯”的叫,两只动物会根据主人发出的同一指令,发出各自不同的声音。
下面我们来看一段多态的Javascript代码:
var makeSound = function(animal) {
if(animal instanceof Duck) {
console.log('嘎嘎嘎');
}else if(animal instanceof Chicken) {
console.log('咯咯咯');
}
};
var Duck = funcdtion(){};
var Chicken = function(){};
makeSound(new Duck()); //嘎嘎嘎
makeSound(new Chicken()); //咯咯咯多态背后的**就是把“做什么”和“谁去做及怎样去做”分离开,也就是将“不变的事”和“可能改变的事”分离开。很显然,上面的代码有问题,如果我们再增加一只狗,就要改动makeSound函数,修改代码是危险且不可取的,我们要让代码变得可扩展,我们将上面的代码进行改动,如下:
//将不变的部分分离出来,这里就是所有的动物都会叫
var makeSound = function(animal) {
animal.sound();
};
//将可变的部分封装起来
var Duck = function(){};
Duck.prototype.sound = function(){
console.log('嘎嘎嘎');
}
var Chicken = function(){};
Chicken.prototype.sound = function(){
console.log('咯咯咯');
}
makeSound(new Duck()); //嘎嘎嘎
makeSound(new Chicken()); //咯咯咯如果我们需要增加一只动物,那么我们只需要增加代码即可,而不需要去改动 makeSound函数
var Dog = function(){};
Dog.prototype.sound = function(){
console.log('汪汪汪');
}
makeSound(new Dog()); //汪汪汪由此可见,Javascript的多态性是与生俱来的,它作为一门动态类型语言,既不会检查对象类型,也不会检查参数类型,从上面的例子看出,我们既可以往 makeSound 函数里传递 duck 参数,也可以传递 chicken 参数,所以,一种动物是否能发出声音,只取决于它有没有 makeSound 方法,而不取决于它是否是某种类型的对象。
下面我们再来看一个在实际项目中可能会遇到的例子,假设我们要编写一个地图应用,有两家地图API可供选择,他们都提供了show方法,代码如下:
var googleMap = {
show: function(){
console.log('开始渲染谷歌地图');
}
};
var renderMap = function(){
googleMap.show();
};
renderMap(); //开始渲染谷歌地图现在我们需要把谷歌地图换成百度地图
var googleMap = {
show: function(){
console.log('开始渲染谷歌地图');
}
};
var baiduMap = {
show: function(){
console.log('开始渲染百度地图');
}
};
var renderMap = function(type) {
if(type === 'google') {
googleMap.show();
}else if(type === 'baidu'){
baiduMap.show();
}
};
renderMap('google'); //开始渲染谷歌地图
renderMap('baidu'); //开始渲染百度地图OK,现在问题来了,如果我再增加一个搜搜地图呢?那就要改动 renderMap 函数,继续在里面添加条件分支语句,所以,看下面的代码:
var googleMap = {
show: function(){
console.log('开始渲染谷歌地图');
}
};
var baiduMap = {
show: function(){
console.log('开始渲染百度地图');
}
};
//把相同的部分抽象出来,也就是显示地图
var renderMap = function(map){
if(map.show instanceof Function){
map.show();
}
};
renderMap(googleMap); //开始渲染谷歌地图
renderMap(baiduMap); //开始渲染百度地图这时,我们如果需要添加其他的地图API
var sosoMap = {
show: function(){
console.log('开始渲染搜搜地图');
}
};
renderMap(sosoMap);在Javascript中,函数是一等对象,函数本身也是对象,函数用来封装行为并能被四处传递,当我们向函数发出“调用”消息时,这些函数会返回不同的执行结果。
封装的目的就是将信息隐藏,一般我们讨论的是对数据和实现进行封装,除此之外更广泛的是对封装类型和封装变化。
在其他许多编程语言中提供了 private 、public、protected 等关键字来实现封装,但Javascript没有,我们只有依靠变量的作用域来实现,而且只能模拟出 public和 private 这两种封装特性
var myObject = (function(){
var _name = 'sven'; //私有(private)变量
return {
getName: function(){ //公开(public)方法
return _name;
}
}
})();
console.log(myObject.getName()); //sven
console.log(myObject._name); //undefined另外,在ES6中,可以通过 Symbol 来创建私有属性。
封装的目的是将信息隐藏,封装应被视为"任何形式的封装",也就是说,封装不仅仅是隐藏数据,还包括隐藏实现细节、设计细节以及隐藏对象的类型
封装实现使得对象内部的变化对于其他对象而言是透明的,是不可见的,这使得对象之间的耦合变得松散,对象之间只通过对外暴露的API接口�来通信
封装类型就是把对象的真正类型隐藏在抽象类或接口之后,相比对象类型,客户更关心对象的行为。
在JavaScript中并没有对抽象类和接口的支持,所以JavaScript没有能力,也没有必要去做到这点。
从设计模式的角度上看,封装在更重要的层面�体现为封装变化
通过封装变化的方式,把系统中稳定不变的部分和容易变化的部分隔离开来,找到变化并封装。
�在以类为中心的面向对象编程语言中,类和对象的关系可以想象成铸模和铸件的关系,对象总是从�类中创建而来,而在原型编程**中,类并不是必需的,对象未必需要从类中创建而来,一个对象是通过克隆另外一个对象所得到的。
原型模式不单是一种设计模式,也被称为一种编程泛型
Javascript中继承是基于原型模式的,而像Java、C++等这些是基于类的的面向对象语言,我们要创建一个对象,必须先定义一个Class,然后从这个Class里实例化一个对象出来。然而Javascript中并没有类,所以,在JavaScript中对象是被克隆出来的,也就是一个对象通过克隆另一个对象来创建自己。
原型模式是用于创建对象的一种模式,它并不关心对象的具体类型,而是找到一个对象,然后通过克隆来创建一个一模一样的对象。
原型模式的实现关键,是语言本身是否提供了 clone 方法,假设我们需要编写一个网页版的飞机大战游戏,这个飞机拥有分身技能,当使用这个技能时,页面上会出现多个同样的飞机,这时我们就需要使用到原型模式来克隆飞机。ES5提供了 Object.create 方法来克隆对象
var Plane = function () {
this.blood = 100;
this.attackLevel = 1;
this.defenseLevel = 1;
};
var plane = new Plane();
plane.blood = 500;
plane.attackLevel = 10;
plane.defenseLevel = 7;
var clonePlane = Object.create(plane);
console.log(clonePlane); // Object {blood: 500, attackLevel: 10, defenseLevel: 7}在不支持 Object.create 方法的浏览器中,可以使用以下代码
Object.create = Object.create || function (obj) {
var F = function () {};
F.prototype = obj;
return new F();
}原型模式的真正�目的并非在于得到一个一模一样的对象,而是提供了一种便捷的方式去创建某个类型的对象,克隆只是创建对象的过程和手段
�所有的对象都有一个原型对象,那么可想而知,必定会有一个�根对象,这个根对象就是 Object, �我们可以从 Object 去克隆一个对象A,那么� Object 就是对象A的原型,如果再�从对象A克隆一个对象B,那么对象A就是对象B的原型对象,它们之间就形成了一条原型链,基于原型链的委托机制就是原型继承的本质
原型继承遵循以下原则,Javascript也不例外:
Javascript中存在一个根对象 Object.prototype,它是一个空对象,所有的对象都是从这个根对象中克隆而来的,Object.prototype 就是它们的原型。
var obj1 = new Object();
var obj2 = {};
//利用ES5提供的Object.getPrototypeOf方法来查看它们的原型
console.log(Object.getPrototypeOf(obj1) === Object.prototype); //true
console.log(Object.getPrototypeOf(obj2) === Object.prototype); //true通过 new 运算符从构造器中得到一个对象,看下面的代码:
function Person(name){
this.name = name;
};
Person.prototype.getName = function(){
return this.name;
};
var a = new Person('Kaindy');
console.log(a.name); //Kaindy
console.log(a.getName()); //Kaindy
console.log(Object.getPrototypeOf(a) === Person.prototype); //true上面代码中的Person并不是一个类,而是函数构造器,Javascript的函数既可以作为普通函数使用,也可以作为构造器调用,当使用 new 运算符时,函数就成了构造器,这个创建对象的过程,也就是先克隆了 Object.prototype,然后再做其他的一些操作。
在Javascript中,每个对象都会记住它的原型,准确的说,应该是对象的构造器有原型。每个对象都有一个名为 __proto__ 的隐藏属性,这个属性会指向它的构造器的原型对象
var a = new Object();
console.log(a.__proto__ === Object.prototype); //true实际上,每个对象就是通过自身隐藏的 __proto__ 属性来记住自己的构造器原型.
如果对象无法响应请求,它会把这个请求委托给它的构造器的原型,我们来看下面的代码:
var obj = {name: 'Kaindy'};
var A = function(){};
A.prototype = obj;
var a = new A();
console.log(a.name); //Kaindy我们来看下引擎做了什么,
首先,我们需要打印出对象a的name属性,尝试遍历对象a的所有属性,但没找到name
接着,对象a把查找name属性这个请求委托给了它自己的构造器原型,也就是 a.__proto__ ,而 a.__proto__ 指向了 A.prototype ,A.prototype 被设置为了对象obj。
最后在obj中找到了name属性,并返回它的值。
结束:Object.create 是原型模式的天然实现,目前大多数主流浏览器都支持此方法,但它效率并不高,比通过构造函数创建对象要慢,最新的ES6带来了 Class 语法,看起来像一门基于类的语言,但原理还是通过原型机制来创建对象,看下面的代码:
class Animal {
constructor(name) {
this.name = name;
}
getName() {
return this.name;
}
}
class Dog extends Animal {
constructor(name) {
super(name);
}
speak() {
return "woof";
}
}
var dog = new Dog("Scamp");
console.log(dog.geName() + ' says ' + dog.speak());继承,泛指把前人的作风、文化、知识、财产等接收过来的过程。
Java中的继承,就是让类与类之间产生父子关系,被继承的类叫做父类(基类、超类), 继承的类叫做子类(派生类)
我们可以通过关键字extends来实现这种继承关系
// 父类
class Parent {}
// 子类
class Children extends Parent {
// ...
}当两个类发生了继承关系后,子类就拥有了父类的非私有成员,包括成员属性和成员方法
// 父类
public class Parent {
// 成员变量
private String name;
private int age;
// 构造方法
public Parent() {
}
public Parent(String name, int age) {
this.name = name;
this.age = age;
}
// Getter & Setter
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
// 子类继续父类
class Child extends Parent {
}在多个类中,存在相同的属性和行为时,可以将这些内容提取出来放到一个新类当中,让这些类和新类产生父子关系,以便实现代码复用。
Java中使用变量,遵循就近原则,局部位置有则使用,如果没有,则去本类的成员位置找,否则就去父类中找
如果想要在子类方法使用使用类变量,可以使用this关键字,如果想使用父类变量,可以使用super关键字
class Fruit {
int price = 20;
}
class Apple extends Fruit {
int price = 10;
public void showPrice() {
int price = 5;
System.out.println(price); // 5
System.out.println(this.price); // 10
System.out.println(super.price); // 20
}
}子类继续父类,实例化子类后,如果父类中定义了无参构造,则会自动执行父类的无参构造,系统会在子类构造中加入super(),意思就是调用父类的构造方法,调用父类构造方法的super()语句必须在子类构造方法的第一行
class Person {
public Person() {
System.out.println("Person类的无参构造方法");
}
}
class Worker extends Person {
public Worker() {
// super(); 这行代码系统会自动加上
System.out.println("Worker子类的无参构造方法");
}
}但如果父类没有无参构造方法,则子类构造方法会报错,比如我们在父类中指定了一个有参构造方法
class Person {
// 有参构造方法
public Person(String name) {
System.out.println("Person类的无参构造方法");
}
}
class Worker extends Person {
public Worker() {
super("阿振sc"); // 这时必须手动调用父类构造方法并传入参数
System.out.println("Worker子类的无参构造方法");
}
}Java中的方法重写(Override)是指子类中出现和父类方法定义相同的方法的现象。方法重写也叫方法的复写、覆盖,它要求方法名、参数列表、返回值类型都要相同
class Parent {
public void pMethod() {
System.out.println("父类中的pMethod方法");
}
}
class Child extends Parent {
// 重写父类中的同名方法
@Override
public void pMethod() {
System.out.println("子类中的pMethod方法");
}
}注意:
private 强调的是给自己来使用protected 强调的是给子类使用的public 强调的是给所有类所有的单继承, Java中只支持类的单继承,但支持多层(重)继承
Java中是支持接口的多继承的,比如:接口A extends 接口B, 接口C, 接口D, ...
父类的私有成员是不能被继承的,私有成员包含成员变量和成员方法
构造方法不能被继承,构造方法用于初始化本类对象,创建子类对象时,需要调用父类构造方法进行初始化
继承体现了一种 is a的关系,子类符合is a父类的情况下,才使用继承
ECMAScript6(简称ES6),是JavaScript的下一代标准,因为ES6是在2015年发布的,所以又称ECMAScript2015(ES6 === ECMAScript2015)
目前不是所有的浏览器都完全兼容ES6,但很多程序猿已经开始使用ES6了,所以了解并逐步掌握ES6,甚至在你的项目中使用ES6,是非常有必要的,至少也要看得懂小伙伴写的ES6代码吧?
在说ES6之前,我们先来了解下Babel,这是个什么鬼?它是一个广泛使用的ES6转码器,可以将我们写的ES6代码转换成能在当前所有浏览器中执行的ES5代码。你可以在你习惯使用的工具中集成Babel,方便它来工作,具体使用请查看Babel官网(http://babeljs.io)
下面我们来看下最常用的一些ES6特性:
let是用来声明变量的,与var相似,const是定义常量的。我们先来看下面的例子
while (true) {
var name = 'obama';
console.log(name); //obama
break;
}
console.log(name); //obama在ES5中只有全局作用域和函数作用域,没有块级作用域,所以上面的代码中,while循环体内的name变量覆盖了上面声明的全局name变量,最后输出的就是被覆盖的变量值。而let为JavaScript增加了块级作用域,用它声明的变量只在当前的代码块内有效。
let name = 'zach';
while (true) {
let name = 'obama';
console.log(name); //obama
break;
}
console.log(name); //zach另外一个问题,就是计数循环
var a = [];
for (var i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
}
}
a[6](); //10用var定义的i值,成了全局变量,会导致最后的i值是最后一轮循环完成后的值,而使用let就不会有这个问题。
var a = [];
for (let i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
}
}
a[6](); //6下面我们再来看个例子,页面上有5个类名相同的元素,我们通过点击这些元素,分别弹出他们在集合中的序号
var clickBoxs = documnet.querySelectorAll('clickBox');
for (var i = 0; i < clickBoxs.length; i++) {
clickBoxs[i].onclick = function () {
alert(i);
}
}很不幸,每次弹出的都是5.for循环中用var定义的i,已经是全局变量,在执行弹出时,实际上i已经累加到了5,如果我们将var换成let,就可以在每次点击的时候得到我们想要的结果。
再来想想如何使用闭包来解决这个问题呢?
function iteratorFactory (i) {
var onclick = function (e) {
alert(i);
}
return onclick;
}
var clickBoxs = document.querySelectorAll('clickBox');
for (var i = 0; i < clickBoxs.length; i++) {
clickBoxs[i].onclick = iteratorFactory(i);
}const用来声明常量,一旦声明,常量的值是不能被改变的。
const PI = Math.PI;这三个特性让我们从JavaScript的原型面向对象中解脱出来,它们让�JavaScript具有了像传统高级编程语言那样的写法。
class Animal {
constructor () {
this.type = 'animal';
}
says (message) {
console.log(this.type + ' says ' + message);
}
}
let animal = new Animal();
animal.says('hello'); //animal says hello
class Cat extends Animal {
constructor () {
super();
this.type = 'cat';
}
}
let cat = new Cat();
cat.says('hello'); //cat says hello上面的代码首先定义了一个class,里面有个constructor,这是构造函数,this关键字指向当前类的实例对象。 class之间可以通过extends关键字实现继承,上面的代码中,Cat类通过extends继承了Animal类的所有属性和方法。 在子类中的constructor中,必须调用super方法,这是为了继承父类中的this。
箭头函数,这是�ES6最常用的特性,用它来写function比ES5的更加简介和清晰。
function(i){return i + 1;} //ES5
(i) => i + 1; //ES6如果有多行代码或代码比较复杂的,需要使用{}把代码包裹起来
function (x, y) {
x++;
y--;
return x + y;
}
(x, y) => {x++; y--; return x + y;}箭头函数除了在写法上更加简洁之外,还有一个功能,更加明确了this的指向
class Animal {
constructor () {
this.type = 'animal';
}
says (message) {
setTimeout (function () {
console.log(this.type + ' says ' + message);
},1000);
}
}
var animal = new Animal();
animal.says('hi'); //undefined says hi上面的例子运行后,得到的结果是undefined says hi,跟我们预想的不一样,是因为在setTimeout中,this已经指向了全局。现在,我们有两个传统的方法来解决
第一种,将this传递给self,也就是将this对象缓存起来
says (message) {
var self = this;
setTimeout(function () {
console.log(self.type + ' says ' + message);
}, 1000);
}第二种,使用bind(this)
says (message) {
setTimeout(function () {
console.log(this.type + ' says ' + message);
}.bind(this), 1000);
}OK,现在我们有了箭头函数,就不用这么麻烦了。
class Animal {
constructor () {
this.type = 'animal';
}
says (message) {
setTimeout(() => {
console.log(this.type + ' says ' + message);
}, 1000);
}
}
var animal = new Animal();
animal.says('hi'); //animal says hi使用箭头函数时,函数体内的this就是定义时所在的对象,而不是使用时的对象。
这玩意叫模板变量,它有什么用呢? 当我们需要在JS中插入大量的html内容时,传统的写法很麻烦,所以我们经常会引入一些模板工具库,我们先来看下下面的代码
$('#result').append(
"There are <b>" + basket.count + "</b>" +
"items in your basket, " +
"<em>" + basket.onSale +
"</em> are on sale!"
);我们需要用一大堆的‘+’来链接文本和变量,而有了ES6的模板变量后,我们可以这样写
$("#result").append(`
There are <b>${basket.count}</b> items
in your basket, <em>${basket.onSale}</em>
are on sale!
`);我们用反引号" ` "来标示起始和结束,用" ${} "来引用变量,而且所有的空格和缩进都会被保留。
ES6允许按照一定的模式,从数组和对象中取值,对变量进行赋值,这被称为解构(Destructuring)。
let cat = 'ken';
let dog = 'lili';
let zoo = {cat: cat, dog: dog};
console.log(zoo); //Object {cat: "ken", dog: "lili"}在ES6中,我们可以这样写
let cat = 'ken';
let dog = 'lili';
let zoo = {cat, dog};
console.log(zoo); //Object {cat: "ken", dog: "lili"}反过来可以这么写
let dog = {type: 'animal', many: 2};
let {type, many} = dog;
console.log(type, many); //animal 2default就是默认值的意思,如果在调用函数时候没有传参数,传统做法是加上这么一句,type = type || 'cat' 来指定默认值
function animal (type) {
type = type || 'cat';
console.log(type);
}
animal(); //cat如果用ES6,就可以这样写
function animal (type = 'cat') {
console.log(type);
}
animal();rest的语法也很简单,看例子
function animals(...types) {
console.log(types)
}
animals('cat', 'dog', 'fish'); //['cat', 'dog', 'fish']如果不适用ES6的语法,那么我们必须使用ES5的arguments
以上就是ES6中最常用的语法,可以说这20%的语法在使用中占了80%的使用率。
利用gulp搭建本地服务器,实现自动打开页面,自动刷新,模拟ajax操作
用到的模块如下:
package.jsonnpm initnpm install gulp --save-dev
npm install gulp-webserver --save-dev
npm install gulp-livereload --save-devgulpfile.js文件var url = require('url');
var fs = require('fs');
var path = require('path');
gulp = require('gulp');
livereload = require('gulp-livereload');
webserver = require('gulp-webserver');
//web服务器
gulp.task('webserver', function() {
gulp.src('./www') // 服务器目录(./代表根目录)
.pipe(webserver({ // 运行gulp-webserver
port: 8000, //端口,默认8000
livereload: true, // 启用LiveReload
open: true, // 服务器启动时自动打开网页
directoryListing: {
enable: true,
path: './www'
},
middleware: function(req, res, next) {
//mock local data
var urlObj = url.parse(req.url, true),
method = req.method;
if (!urlObj.pathname.match(/^\/api/)) { //不是api开头的数据,直接next
next();
return;
}
var mockDataFile = path.join(__dirname, urlObj.pathname) + ".js";
//file exist or not
fs.access(mockDataFile, fs.F_OK, function(err) {
if (err) {
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify({
"status": "没有找到此文件",
"notFound": mockDataFile
}));
return;
}
var data = fs.readFileSync(mockDataFile, 'utf-8');
res.setHeader('Content-Type', 'application/json');
res.end(data);
});
next();
},
proxies: []
}));
});
// 默认任务
gulp.task('default', ['webserver']);前面我们学习了 Go 中的错误是如何表示的,并学习了如何处理标准库里的错误。我们还学习了从标准库的错误中提取更多的信息。
在本教程中,我们会学习如何创建我们自己的自定义错误,并在我们创建的函数和包中使用它。我们会使用与标准库中相同的技术,来提供自定义错误的更多细节信息。
创建自定义错误最简单的方法是使用 errors 包中的 New 函数。
在使用 New 函数创建自定义错误之前,我们先来看看 New 是如何实现的。如下所示,是 errors 包中的 New 函数的实现。
// Package errors implements functions to manipulate errors.
package errors
// New returns an error that formats as the given text.
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
New 函数的实现很简单。errorString 是一个结构体[7]类型,只有一个字符串字段 s。第 14 行使用了 errorString 指针接受者(Pointer Receiver),来实现 error 接口的 Error() string 方法[8]。
第 5 行的 New 函数有一个字符串参数,通过这个参数创建了 errorString 类型的变量,并返回了它的地址。于是它就创建并返回了一个新的错误。
现在我们已经知道了 New 函数是如何工作的,我们开始在程序里使用 New 来创建自定义错误吧。
我们将创建一个计算圆半径的简单程序,如果半径为负,它会返回一个错误。
package main
import (
"errors"
"fmt"
"math"
)
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, errors.New("Area calculation failed, radius is less than zero")
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("Area of circle %0.2f", area)
}
在 glayground 上运行[9]
在上面的程序中,我们检查半径是否小于零(第 10 行)。如果半径小于零,我们会返回等于 0 的面积,以及相应的错误信息。如果半径大于零,则会计算出面积,并返回值为 nil 的错误(第 13 行)。
在 main 函数里,我们在第 19 行检查错误是否等于 nil。如果不是 nil,我们会打印出错误并返回,否则我们会打印出圆的面积。
在我们的程序中,半径小于零,因此打印出:
Area calculation failed, radius is less than zero
使用 Errorf 给错误添加更多信息
上面的程序效果不错,但是如果我们能够打印出当前圆的半径,那就更好了。这就要用到 fmt[10] 包中的 Errorf[11] 函数了。Errorf 函数会根据格式说明符,规定错误的格式,并返回一个符合该错误的字符串[12]。
接下来我们使用 Errorf 函数来改进我们的程序。
package main
import (
"fmt"
"math"
)
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, fmt.Errorf("Area calculation failed, radius %0.2f is less than zero", radius)
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("Area of circle %0.2f", area)
}
在 playground 上运行[13]
在上面的程序中,我们使用 Errorf(第 10 行)打印了发生错误的半径。程序运行后会输出:
Area calculation failed, radius -20.00 is less than zero
使用结构体类型和字段提供错误的更多信息
错误还可以用实现了 error 接口[14]的结构体来表示。这种方式可以更加灵活地处理错误。在上面例子中,如果我们希望访问引发错误的半径,现在唯一的方法就是解析错误的描述信息 Area calculation failed, radius -20.00 is less than zero。这样做不太好,因为一旦描述信息发生变化,程序就会出错。
我们会使用标准库里采用的方法,在上一教程中“断言底层结构体类型,使用结构体字段获取更多信息”这一节,我们讲解了这一方法,可以使用结构体字段来访问引发错误的半径。我们会创建一个实现 error 接口的结构体类型,并使用它的字段来提供关于错误的更多信息。
第一步就是创建一个表示错误的结构体类型。错误类型的命名约定是名称以 Error 结尾。因此我们不妨把结构体类型命名为 areaError。
type areaError struct {
err string
radius float64
}
上面的结构体类型有一个 radius 字段,它存储了与错误有关的半径,而 err 字段存储了实际的错误信息。
下一步是实现 error 接口。
func (e *areaError) Error() string {
return fmt.Sprintf("radius %0.2f: %s", e.radius, e.err)
}
在上面的代码中,我们使用指针接收者 *areaError,实现了 error 接口的 Error() string 方法。该方法打印出半径和关于错误的描述。
现在我们来编写 main 函数和 circleArea 函数来完成整个程序。
package main
import (
"fmt"
"math"
)
type areaError struct {
err string
radius float64
}
func (e *areaError) Error() string {
return fmt.Sprintf("radius %0.2f: %s", e.radius, e.err)
}
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, &areaError{"radius is negative", radius}
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
if err, ok := err.(*areaError); ok {
fmt.Printf("Radius %0.2f is less than zero", err.radius)
return
}
fmt.Println(err)
return
}
fmt.Printf("Area of rectangle1 %0.2f", area)
}
在 playground 上运行[15]
在上面的程序中,circleArea(第 17 行)用于计算圆的面积。该函数首先检查半径是否小于零,如果小于零,它会通过错误半径和对应错误信息,创建一个 areaError 类型的值,然后返回 areaError 值的地址,与此同时 area 等于 0(第 19 行)。于是我们提供了更多的错误信息(即导致错误的半径),我们使用了自定义错误的结构体字段来定义它。
如果半径是非负数,该函数会在第 21 行计算并返回面积,同时错误值为 nil。
在 main 函数的 26 行,我们试图计算半径为 -20 的圆的面积。由于半径小于零,因此会导致一个错误。
我们在第 27 行检查了错误是否为 nil,并在下一行断言了 *areaError 类型。如果错误是 *areaError 类型,我们就可以用 err.radius 来获取错误的半径(第 29 行),打印出自定义错误的消息,最后程序返回退出。
如果断言错误,我们就在第 32 行打印该错误,并返回。如果没有发生错误,在第 35 行会打印出面积。
该程序会输出:
Radius -20.00 is less than zero
下面我们来使用上一教程提到的第二种方法[16],使用自定义错误类型的方法来提供错误的更多信息。
使用结构体类型的方法来提供错误的更多信息
在本节里,我们会编写一个计算矩形面积的程序。如果长或宽小于零,程序就会打印出错误。
第一步就是创建一个表示错误的结构体。
type areaError struct {
err string //error description
length float64 //length which caused the error
width float64 //width which caused the error
}
上面的结构体类型除了有一个错误描述字段,还有可能引发错误的宽和高。
现在我们有了错误类型,我们来实现 error 接口,并给该错误类型添加两个方法,使它提供了更多的错误信息。
func (e *areaError) Error() string {
return e.err
}
func (e *areaError) lengthNegative() bool {
return e.length < 0
}
func (e *areaError) widthNegative() bool {
return e.width < 0
}
在上面的代码片段中,我们从 Error() string 方法中返回了关于错误的描述。当 length 小于零时,lengthNegative() bool 方法返回 true,而当 width 小于零时,widthNegative() bool 方法返回 true。这两个方法都提供了关于错误的更多信息,在这里,它提示我们计算面积失败的原因(长度为负数或者宽度为负数)。于是我们就有了两个错误类型结构体的方法,来提供更多的错误信息。
下一步就是编写计算面积的函数。
func rectArea(length, width float64) (float64, error) {
err := ""
if length < 0 {
err += "length is less than zero"
}
if width < 0 {
if err == "" {
err = "width is less than zero"
} else {
err += ", width is less than zero"
}
}
if err != "" {
return 0, &areaError{err, length, width}
}
return length * width, nil
}
上面的 rectArea 函数检查了长或宽是否小于零,如果小于零,rectArea 会返回一个错误信息,否则 rectArea 会返回矩形的面积和一个值为 nil 的错误。
让我们创建 main 函数来完成整个程序。
func main() {
length, width := -5.0, -9.0
area, err := rectArea(length, width)
if err != nil {
if err, ok := err.(*areaError); ok {
if err.lengthNegative() {
fmt.Printf("error: length %0.2f is less than zero\n", err.length)
}
if err.widthNegative() {
fmt.Printf("error: width %0.2f is less than zero\n", err.width)
}
return
}
fmt.Println(err)
return
}
fmt.Println("area of rect", area)
}
在 main 程序中,我们检查了错误是否为 nil(第 4 行)。如果错误值不是 nil,我们会在下一行断言 *areaError 类型。然后,我们使用 lengthNegative() 和 widthNegative() 方法,检查错误的原因是长度小于零还是宽度小于零。这样我们就使用了错误结构体类型的方法,来提供更多的错误信息。
如果没有错误发生,就会打印矩形的面积。
下面是整个程序的代码供你参考。
package main
import "fmt"
type areaError struct {
err string //error description
length float64 //length which caused the error
width float64 //width which caused the error
}
func (e *areaError) Error() string {
return e.err
}
func (e *areaError) lengthNegative() bool {
return e.length < 0
}
func (e *areaError) widthNegative() bool {
return e.width < 0
}
func rectArea(length, width float64) (float64, error) {
err := ""
if length < 0 {
err += "length is less than zero"
}
if width < 0 {
if err == "" {
err = "width is less than zero"
} else {
err += ", width is less than zero"
}
}
if err != "" {
return 0, &areaError{err, length, width}
}
return length * width, nil
}
func main() {
length, width := -5.0, -9.0
area, err := rectArea(length, width)
if err != nil {
if err, ok := err.(*areaError); ok {
if err.lengthNegative() {
fmt.Printf("error: length %0.2f is less than zero\n", err.length)
}
if err.widthNegative() {
fmt.Printf("error: width %0.2f is less than zero\n", err.width)
}
return
}
fmt.Println(err)
return
}
fmt.Println("area of rect", area)
}
在 playground 上运行[17]
该程序会打印输出:
error: length -5.00 is less than zero
error: width -9.00 is less than zero
在上一教程错误处理[18]中,我们介绍了三种提供更多错误信息的方法,现在我们已经看了其中两个示例。
第三种方法使用的是直接比较,比较简单。我留给读者作为练习,你们可以试着使用这种方法来给出自定义错误的更多信息。
本教程到此结束。
简单概括一下本教程讨论的内容:
使用 New 函数创建自定义错误
使用 Error 添加更多错误信息
使用结构体类型和字段,提供更多错误信息
使用结构体类型和方法,提供更多错误信息
思维导图又叫心智图,是表达发射性思维的有效的图形思维工具 ,它简单却又极其有效,是一种革命性的思维工具。
思维导图运用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来,把主题关键词与图像、颜色等建立记忆链接,思维导图充分运用左右脑的机能,利用记忆、阅读、思维的规律,协助人们在科学与艺术、逻辑与想象之间平衡发展,从而开启人类大脑的无限潜能。思维导图因此具有人类思维的强大功能。
分别归类为:
能够认真看完就是一次对javascript的回顾与提升,可以很好的检验基础。
Table of Contents generated with DocToc
很早之前在搭建这个博客的时候就使用了免费的https证书访问,当然申请的是 Let's Encrypt 的,这个证书有3个月的有效期,3个月之后就失效了。前两天突然访问的时候就发现证书无效了,弄了一两个小时才OK,所以把这个过程记录下来,给有需要的朋友参考。
以前是用的是一种手动方式来搭建https,今天要介绍了是使用certbot自动获取证书,并实现脚本自动两个月之后更新证书
第一步很简单,直接从github上下载certbot
git clone https://github.com/certbot/certbot进入其目录,你也可以执行命令来查看其提供的功能
cd certbot
./certbot-auto --help直接执行下面的命令:
./certbot-auto certonly --webroot --agree-tos -v -t --email 邮箱地址 -w 网站根目录 -d 网站域名我的是这样的:
./certbot-auto certonly --webroot --agree-tos -v -t --email [email protected] -w /home/www/todever -d www.todever.com注意 这里会自动生成一个文件夹:/.well-known/acme-challenge,默认生成到 /网站根目录/.well-known/acme-challenge,然后 shell 脚本会对应的访问 网站域名/.well-known/acme-challenge 是否存在来确定你对网站的所属权
比如:我的域名是 www.todever.com 那我就得保证域名下面的 .well-known/acme-challenge/ 目录是可访问的
如果返回正常就确认了你对这个网站的所有权,就能顺利生成,完成后这个目录会被清空
如果这面的 shell 执行完毕后显示如下信息:
- Congratulations! Your certificate and chain have been saved at
/etc/letsencrypt/live/网站域名/fullchain.pem
...恭喜你,已完成一大半工作啦...
dhparams使用 openssl 工具生成 dhparams,这个过程时间可能会有点长
openssl dhparam -out /etc/ssl/certs/dhparams.pem 2048你也可以随意指定生成目录,当然,后面配置 nginx 的时候会用到这个目录
Nginx打开 nginx server 配置文件加入如下设置:
ssl on;
ssl_certificate /etc/letsencrypt/live/网站域名/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/网站域名/privkey.pem;
ssl_dhparam /etc/ssl/certs/dhparams.pem;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;接着重启Nginx就好了
systemctl restart nginx.servicehttpshttps 默认是监听 443 端口的,没开启 https 访问的话一般默认是 80 端口。如果你确定网站 80 端口上的站点都支持 https 的话加入下面的配件可以自动重定向到 https
server {
listen 80;
server_name todever.com www.todever.com;
rewrite ^(.*)$ https://$host$1 permanent;
}免费证书只有 90 天的有效期,到时需要手动更新 renew。 我们可以去 Let’s monitor 免费注册账号添加域名监控,系统会在证书马上到期时发出提醒邮件,非常方便。收到邮件后去后台执行 renew 即可
./certbot-auto renew新建文件 renew_cert.sh,写入下面的脚本:
#!/bin/bash
rm -rf /etc/letsencrypt/live/*.*
~/certbot/certbot-auto renew && systemctl restart nginx.service如果这里有同名的域名文件夹,certbot 会自动创建 域名+0001 的其他文件夹,这样我们就需要更改 nginx 配置了,所以在生成之前删除原来的
再次说明我的Centos版本是7.1
Table of Contents generated with DocToc
Git是一款免费、开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git是一个开源的分布式版本控制系统,用以有效、高速的处理从很小到非常大的项目版本管理。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Torvalds 开始着手开发 Git 是为了作为一种过渡方案来替代 BitKeeper,后者之前一直是 Linux 内核开发人员在全球使用的主要源代码工具。开放源码社区中的有些人觉得 BitKeeper 的许可证并不适合开放源码社区的工作,因此 Torvalds 决定着手研究许可证更为灵活的版本控制系统。尽管最初 Git 的开发是为了辅助 Linux 内核开发的过程,但是我们已经发现在很多其他自由软件项目中也使用了 Git。例如 最近就迁移到 Git 上来了,很多 Freedesktop 的项目也迁移到了 Git 上。
(以上内容摘自百度百科,有兴趣的朋友可以移步到百度进行搜索)
Git是什么?
Git是目前世界上最先进的分布式版本控制系统(没有之一)。
Git有什么特点?简单来说就是:高端大气上档次!
那什么是版本控制系统?
如果你用Microsoft Word写过长篇大论,那你一定有这样的经历:
想删除一个段落,又怕将来想恢复找不回来怎么办?有办法,先把当前文件“另存为……”一个新的Word文件,再接着改,改到一定程度,再“另存为……”一个新文件,这样一直改下去,最后你的Word文档变成了这样:
过了一周,你想找回被删除的文字,但是已经记不清删除前保存在哪个文件里了,只好一个一个文件去找,真麻烦。
看着一堆乱七八糟的文件,想保留最新的一个,然后把其他的删掉,又怕哪天会用上,还不敢删,真郁闷。
更要命的是,有些部分需要你的财务同事帮助填写,于是你把文件Copy到U盘里给她(也可能通过Email发送一份给她),然后,你继续修改Word文件。一天后,同事再把Word文件传给你,此时,你必须想想,发给她之后到你收到她的文件期间,你作了哪些改动,得把你的改动和她的部分合并,真困难。
于是你想,如果有一个软件,不但能自动帮我记录每次文件的改动,还可以让同事协作编辑,这样就不用自己管理一堆类似的文件了,也不需要把文件传来传去。如果想查看某次改动,只需要在软件里瞄一眼就可以,岂不是很方便?
这个软件用起来就应该像这个样子,能记录每次文件的改动:
| 版本 | 用户 | 说明 | 日期 |
|---|---|---|---|
| 1 | 张三 | 删除了软件服务条款 | 57/12 10:38 |
| 2 | 张三 | 增加了License人数限制 | 7/12 18:09 |
| 3 | 李四 | 财务部门调整了合同金额 | 7/13 9:51 |
| 4 | 张三 | 延长了免费升级周期 | 7/14 15:17 |
这样,你就结束了手动管理多个“版本”的史前时代,进入到版本控制的20世纪。
(以上内容摘自廖雪峰的博客网站,地址是:http://www.liaoxuefeng.com/,有兴趣的朋友可以去查看他的git教程)
OK,我以自己的MAC为准,来记录我的学习过程。
首先,MAC自带了 git,我们在命令行下输入git,会跳出一大堆帮助命令,再次输入 git --version,就会显示当前git版本。
接着我们从git的官方网站(git-scm.com)下载最新的git版本,官网会自动提示您下载当前您的系统适应版本,下载完成后直接安装,这里就不再赘述。
我们在命令行窗口输入命令来查看当前系统安装的git
localhost:~ liuzhen$ which -a git
/usr/local/git/bin/git
/usr/local/bin/git
/usr/bin/git
localhost:~ liuzhen$我们看到有3个版本的git,那么我们如何来使用这些版本的git呢?在命令行窗口使用vim打开并编辑.bash_profile文件
并输入以下命令:
export PATH=/usr/local/git/bin:$PATH保存、退出,并输入命令连接:
source .bash_profile再次输入git --version命令来查看当前使用的git版本
localhost:~ liuzhen$ git --version
git version 2.6.4git有自动完成功能,当我们记不住完整的命令时,可以使用tab键来完成输入,如果是在windows下,这个功能是集成的。但在Mac下需要进行配置
从github.com/git/git这个地址里下载git源码,解压缩后,进入contrib/completion目录,找到git-completion.bash和git-prompt.sh文件,将他们拷贝到根目录下即可,最后source一下
git的基本配置很简单,需要配置用户名和Email,命令如下:
git config --global user.name kaindy1976
git config --global user.email [email protected]这两个配置用来说明提交代码的人是谁,用来识别作者。
git配置的三个级别分别是git config --system、git config --global、 git config --local,从优先级来说,local级别最高,其次是global,最低是system
git文档的查看,git的命令很多,我们也不可能每个都记得,最好的方式就是学会查看git的文档,查看git文档有三种方式:
git config --help
git help config
man git-configgit添加,比如我们想给git添加一个user,那么我们可以像这样做
git config --global --add user.name lz接下来我们可以使用下面的命令来获取
git config user.name也可以这样获取
git config --get user.nameOK,如果我们需要获取所有的键值对信息呢?可以这样
git config --list --global在git中,同一个键可以对应多个值,比如,我们可以再次指定一个user.name的值
git config --global --add user.name liuzhen这时当我们需要删除时可以键入下面的命令
git config --global --unset user.name但如果有多个值时,系统会提示user.name这个键有多个值,需要单独指定,这时,我们就可以指定要删除的值
git config --global --unset user.name liuzhen那么我们如何来修改这些键值对呢?
git config --global user.name liuzhen我们只需要像上面一样,重新指定键的值即可
下面我们来看看给git命令起别名
git config --global alias.co checkout
git config --global alias.br branch
git config --global alias.st status
git config --global alias.ci commit以后我们就可以使用这些别名来启动git的命令了
Table of Contents generated with DocToc
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>使用CSS3美化按钮</title>
</head>
<body>
<div class="download-info">
[View Project On GitHub](#)
</div>
</body>
</html>CSS部分:
body {
padding-top: 50px;
}
.download-info {
text-align: center;
}
/* 默认状态下的按钮效果 */
.btn {
background-color: #0074cc;
*background-color: #0055cc; /* IE6,7 */
/* CSS3渐变制作背景图片 */
background-image: -webkit-gradient(linear, 0 0, 0 100%, from(#0088cc), to(#0055cc));
background-image: -webkit-linear-gradient(top, #0088cc, #0055cc);
background-image: -ms-linear-gradient(top, #0088cc, #0055cc);
background-image: -o-linear-gradient(top, #0088cc, #0055cc);
background-image: -moz-linear-gradient(top, #0088cc, #0055cc);
background-image: linear-gradient(top, #0088cc, #0055cc);
background-repeat: repeat-x;
display: inline-block;
*display: inline; /* IE6,7 */
border: 1px solid #ccc;
*border: 0; /* IE6,7 */
border-color: #ccc;
/* CSS3色彩模块 */
border-color: rgba(0, 0, 0, 0.1) rgba(0, 0, 0, 0.1) rgba(0, 0, 0, 0.25);
border-radius: 6px;
color: #fff;
cursor: pointer;
font-size: 20px;
font-weight: normal;
filter: progid:dximagetransform.microsoft.gradient(startColorstr='#0088cc', endColorstr='#0055cc', GradientType=0);
filter: progid:dximagetransform.microsoft.gradient(enabled=false);
line-height: normal;
padding: 14px 24px;
text-align: center;
/* CSS3文字阴影特性 */
text-shadow: 0 -1px 0 rgba(0, 0, 0, 0.25);
text-decoration: none;
vertical-align: middle;
*zoom: 1;
}
/* 悬浮状态下按钮效果 */
.btn:hover {
background-position: 0 -15px;
background-color: #0055cc;
*background-color: #004ab3;
color: #fff;
text-decoration: none;
text-shadow: 0 -1px 0 rgba(0, 0, 0, 0.25);
/* CSS3动画效果 */
-webkit-transition: background-position 0.1s linear;
-moz-transition: background-position 0.1s linear;
-ms-transition: background-position 0.1s linear;
-o-transition: background-position 0.1s linear;
transition: background-position 0.1s linear;
}
/* 点击时按钮效果 */
.btn:active {
background-color: #0055cc;
*background-color: #004ab3;
background-color: #004099 \9;
background-image: none;
outline: 0;
/* CSS3盒子阴影特性 */
box-shadow: inset 0 2px 4px rgba(0, 0, 0, 0.15), 0 1px 2px rgba(0, 0, 0, 0.15);
color: rgba(255, 255, 255, 0.75);
}
/* 获取焦点按钮效果 */
.btn:focus {
outline: thin dotted #333;
outline: 5px auto -webkit-focus-ring-color;
outline-offset: -2px;
}Table of Contents generated with DocToc
我每天使用
Git,但是很多命令记不住。
一般来说,日常使用只要记住下图6个命令,就可以了。但是熟练使用,恐怕要记住60~100个命令。
下面是我整理的常用 Git 命令清单。几个专用名词的译名如下。
Workspace:工作区Index/Stage:暂存区Repository:仓库区(或本地仓库)Remote:远程仓库# 在当前目录新建一个Git代码库
$ git init
# 新建一个目录,将其初始化为Git代码库
$ git init [project-name]
# 下载一个项目和它的整个代码历史
$ git clone [url]Git的设置文件为.gitconfig,它可以在用户主目录下(全局配置),也可以在项目目录下(项目配置)。
# 显示当前的Git配置
$ git config --list
# 编辑Git配置文件
$ git config -e [--global]
# 设置提交代码时的用户信息
$ git config [--global] user.name "[name]"
$ git config [--global] user.email "[email address]"# 添加指定文件到暂存区
$ git add [file1] [file2] ...
# 添加指定目录到暂存区,包括子目录
$ git add [dir]
# 添加当前目录的所有文件到暂存区
$ git add .
# 添加每个变化前,都会要求确认
# 对于同一个文件的多处变化,可以实现分次提交
$ git add -p
# 删除工作区文件,并且将这次删除放入暂存区
$ git rm [file1] [file2] ...
# 停止追踪指定文件,但该文件会保留在工作区
$ git rm --cached [file]
# 改名文件,并且将这个改名放入暂存区
$ git mv [file-original] [file-renamed]# 提交暂存区到仓库区
$ git commit -m [message]
# 提交暂存区的指定文件到仓库区
$ git commit [file1] [file2] ... -m [message]
# 提交工作区自上次commit之后的变化,直接到仓库区
$ git commit -a
# 提交时显示所有diff信息
$ git commit -v
# 使用一次新的commit,替代上一次提交
# 如果代码没有任何新变化,则用来改写上一次commit的提交信息
$ git commit --amend -m [message]
# 重做上一次commit,并包括指定文件的新变化
$ git commit --amend [file1] [file2] ...# 列出所有本地分支
$ git branch
# 列出所有远程分支
$ git branch -r
# 列出所有本地分支和远程分支
$ git branch -a
# 新建一个分支,但依然停留在当前分支
$ git branch [branch-name]
# 新建一个分支,并切换到该分支
$ git checkout -b [branch]
# 新建一个分支,指向指定commit
$ git branch [branch] [commit]
# 新建一个分支,与指定的远程分支建立追踪关系
$ git branch --track [branch] [remote-branch]
# 切换到指定分支,并更新工作区
$ git checkout [branch-name]
# 切换到上一个分支
$ git checkout -
# 建立追踪关系,在现有分支与指定的远程分支之间
$ git branch --set-upstream [branch] [remote-branch]
# 合并指定分支到当前分支
$ git merge [branch]
# 选择一个commit,合并进当前分支
$ git cherry-pick [commit]
# 删除分支
$ git branch -d [branch-name]
# 删除远程分支
$ git push origin --delete [branch-name]
$ git branch -dr [remote/branch]# 列出所有tag
$ git tag
# 新建一个tag在当前commit
$ git tag [tag]
# 新建一个tag在指定commit
$ git tag [tag] [commit]
# 删除本地tag
$ git tag -d [tag]
# 删除远程tag
$ git push origin :refs/tags/[tagName]
# 查看tag信息
$ git show [tag]
# 提交指定tag
$ git push [remote] [tag]
# 提交所有tag
$ git push [remote] --tags
# 新建一个分支,指向某个tag
$ git checkout -b [branch] [tag]# 显示有变更的文件
$ git status
# 显示当前分支的版本历史
$ git log
# 显示commit历史,以及每次commit发生变更的文件
$ git log --stat
# 搜索提交历史,根据关键词
$ git log -S [keyword]
# 显示某个commit之后的所有变动,每个commit占据一行
$ git log [tag] HEAD --pretty=format:%s
# 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
$ git log [tag] HEAD --grep feature
# 显示某个文件的版本历史,包括文件改名
$ git log --follow [file]
$ git whatchanged [file]
# 显示指定文件相关的每一次diff
$ git log -p [file]
# 显示过去5次提交
$ git log -5 --pretty --oneline
# 显示所有提交过的用户,按提交次数排序
$ git shortlog -sn
# 显示指定文件是什么人在什么时间修改过
$ git blame [file]
# 显示暂存区和工作区的差异
$ git diff
# 显示暂存区和上一个commit的差异
$ git diff --cached [file]
# 显示工作区与当前分支最新commit之间的差异
$ git diff HEAD
# 显示两次提交之间的差异
$ git diff [first-branch]...[second-branch]
# 显示今天你写了多少行代码
$ git diff --shortstat "@{0 day ago}"
# 显示某次提交的元数据和内容变化
$ git show [commit]
# 显示某次提交发生变化的文件
$ git show --name-only [commit]
# 显示某次提交时,某个文件的内容
$ git show [commit]:[filename]
# 显示当前分支的最近几次提交
$ git reflog# 下载远程仓库的所有变动
$ git fetch [remote]
# 显示所有远程仓库
$ git remote -v
# 显示某个远程仓库的信息
$ git remote show [remote]
# 增加一个新的远程仓库,并命名
$ git remote add [shortname] [url]
# 取回远程仓库的变化,并与本地分支合并
$ git pull [remote] [branch]
# 上传本地指定分支到远程仓库
$ git push [remote] [branch]
# 强行推送当前分支到远程仓库,即使有冲突
$ git push [remote] --force
# 推送所有分支到远程仓库
$ git push [remote] --all# 恢复暂存区的指定文件到工作区
$ git checkout [file]
# 恢复某个commit的指定文件到暂存区和工作区
$ git checkout [commit] [file]
# 恢复暂存区的所有文件到工作区
$ git checkout .
# 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变
$ git reset [file]
# 重置暂存区与工作区,与上一次commit保持一致
$ git reset --hard
# 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变
$ git reset [commit]
# 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致
$ git reset --hard [commit]
# 重置当前HEAD为指定commit,但保持暂存区和工作区不变
$ git reset --keep [commit]
# 新建一个commit,用来撤销指定commit
# 后者的所有变化都将被前者抵消,并且应用到当前分支
$ git revert [commit]
# 暂时将未提交的变化移除,稍后再移入
$ git stash
$ git stash pop# 生成一个可供发布的压缩包
$ git archiveApplication Programming Interface,即应用程序编程接口,这里指的是API文档,通常叫:"Java文档",是Java种提供的类的使用说明书
学习API文档,发挥面向对象**,找到Java提供的对象来实现功能,学习API就是学习Java中的类的使用方法
Java中组件的层次结构如下:
模块(Module) --> 包(Package) --> 类或接口(Class/Interface)

什么是模块
模块(Module),是从Java9起提供的一种新的Java基础组件,在包(Package)的基础上又进行了一层封装,是包的容器
JavaSE Modules 是Java语言的核心类库,其下的模块名多以java开头
JDK Modules 是Java开发工具相关内容,其下的模块名多以jdk开头
Object类是类层次结构中最顶层的基类,所有类都直接或间接继承自Object类,所以,所有的类都是一个Object(对象)
Object类位于java.base模块 --> java.lang包 --> Object
构造方法
Object类只有一个空参构造方法,Object() {},构造一个对象,所有子类对象初始化时都会优先调用该方法
成员方法
Object类中有很多成员方法,其中最常用的以下4种:
hashCode()
int hashCode() 该方法返回对象的哈希码值,该方法通过对象的地址值进行计算,不同对象的返回值不同
/**
* Object类位于 java.lang 包下,这个包会被默认导入,无需手动导入
* Object类下的方法都是非静态方法
* 所以这些方法必须使用创建的对象调用
*/
Object obj1 = new Object();
Object obj2 = new Object();
/**
* hashCode方法
* 不同的对象,返回的hashCode不一样
*/
int code1 = obj1.hashCode();
int code2 = obj2.hashCode();
System.out.println(code1); // 1915910607
System.out.println(code2); // 284720968getClass()
Class<?> getClass() 该方法返回调用此方法对象的运行时对象(调用者的字节码文件对象)
/**
* Class<?> getClass() 返回该调用者的字节码文件对象
* 一个类只有一个字节码文件对象
* 也就是通过该类创建的所有对象调用此方法返回的值都是一样的
*/
Class cls1 = obj1.getClass();
Class cls2 = obj2.getClass();
System.out.println(cls1); // class java.lang.Object
System.out.println(cls2); // class java.lang.ObjecttoString()
String toString() 该方法返回该对象的字符串表示
/**
* String toString() 该方法返回对象的字符串表示
* 默认返回的是地址值,不同的对象地址值不一样
*/
String str1 = obj1.toString();
String str2 = obj2.toString();
System.out.println(str1); // java.lang.Object@723279cf
System.out.println(str2); // java.lang.Object@10f87f48equals()
boolean equals() 该方法返回其他某个对象是否与此对象"相等",默认情况下比较两个对象的引用,建议重写
/**
* boolean equals() 该方法比较两个对象是否相等
* 该方法比较的是对象在内存种的地址值,但不同对象的地址值都不一样
* 所以一般子类都会重写该方法
*/
boolean b1 = obj1.equals(obj2);
System.out.println(b1); // false重写Object类的方法
一般在开发种通常需要将对象转成字符串形式进行传输,或者需要对即将使用的对象进行相等的判断,所以我们需要重写toString方法和equals方法
public class Student {
private int id;
private String name;
private int score;
public Student() {
}
public Student(int id, String name, int score) {
this.id = id;
this.name = name;
this.score = score;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
// 重写 toString 方法,用来将对象转换成对应的字符串形式
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", score=" + score +
'}';
}
// 重写 equals 方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id == student.id &&
score == student.score &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name, score);
}
}Scanner类就是一个扫描器,能够解析字符串和基本数据类型的数据,它读取用户再设备上的输入,然后将输入值读取到指定的变量中
Scanner类的构造方法很多,最常见的是Scanner(InputStream),它构建一个扫描器对象,从指定输入流中获取数据参数System.in,对应键盘输入
Scanner类的成员方法有:
hasNextXxx() 这是一种泛指的写法,比如:hasNextInt()、hasNextDouble等,它们用来判断是否还有下一个输入项,其中Xxx表示基本数据类型,返回结果为布尔类型
nextXxx() 有判断,就有接收,此方法用来获取下一个输入项,其中Xxx表示任意基本数据类型,返回对应类型的数据,如:nextInt()、nextFloat()等
String nextLine() 用于接收字符串类型的输入,意思是获取下一行数据,以换行符作为分隔符
String next() 也是用于接收字符串类型的输入,意思是获取下一个输入项,以空白字符作为分隔符,空白字符包括空格、tab,回车等。
// 创建Scanner对象
// System.in为标准输入流,意为键盘
Scanner sc = new Scanner(System.in);
// 接收整数
if (sc.hasNextInt()) { // 判断录入的是否为整数
int num = sc.nextInt();
System.out.println(num);
}
// 接收字符串
String str = sc.nextLine();
System.out.println(str);String类表示字符串,每一个字符串对象都时常量。在Java中,常量分为自定义常量和字面值常量,自定义常量通过final关键字定义,字面值常量包含六种,其中就有String类
String类位于:java.base模块 --> java.lang包 --> String
String类中的构造方法常用的有两种:
String(byte[]) 构造一个String对象,将指定字节数组中的数据转化成字符串
String(char[]) 构造一个String对象,将指定字符数组中的数据转化成字符串
/**
* 使用字节数组构建字符串
*/
byte[] bytes = { 97, 98, 99 };
String s1 = new String(bytes);
System.out.println(s1); // abc
/**
* 使用字符数组构建字符串
*/
char[] chars = { 'h', 'e', 'l', 'l', 'o' };
String s2 = new String(chars);
System.out.println(s2); // hello
/**
* 在实际开发中,一般可以直接定义字符串对象
*/
String str = "Hello World";String类的常用成员方法
boolean equals(String) 判断当前字符串与给定字符串是否相同,区分大小写
boolean equalsIgnoreCase(String) 判断当前字符串与给定字符串是否形同,它时不区分大小写的
boolean startsWith(String) 判断字符串是否以给定的字符串开头
boolean isEmpty(String) 判断给定字符串是否为空
更多String类方法可以查看官方API文档 String类文档
/**
* 判断两个字符串对象是否相同
*/
String str1 = "abc";
String str2 = "ABC";
boolean b1 = str1.equals(str2); // 区分大小写 返回false
boolean b2 = str1.equalsIgnoreCase(str2); // 不区分大小写 返回true
/**
* 判断字符串对象是否以特定字符串开头
*/
boolean b3 = str1.startsWith("a"); // 是否以a开头,返回 true
/**
* 判断字符串是否为空
*/
boolean b4 = str1.isEmpty(); // falseString类中包含获取功能的成员方法
int length() 获取字符串的长度
char charAt(int index) 获取指定索引位置的字符
int indexOf(String) 获取指定字符或字符串在当前字符串中第一次出现的索引,未找到返回-1
int lastIndexOf(String) 获取指定字符或字符串在当前字符串中最后一次出现的索引,未找到返回-1
String substring(int) 获取指定索引位置(含)之后的字符串
String substring(int, int) 获取从索引start位置(含)起至索引end位置(不含)的字符串
String类中操作字符串的成员方法
byte[] getByte() 将字符串转换成字节数组
char[] toCharArray() 将字符串转换成字符数组
static String valueOf() 将指定类型数据转换成字符串
String replace(old, new) 将指定字符(串)替换成新的字符(串)
String[] split(String) 切割字符串,返回切割后的字符串数据,源字符串不变
String trim() 去除字符串两端的空白字符
StringBuilder和StringBuffer类都是可变字符序列,用于构造字符串对象,它们内部使用自动扩容的数组操作字符串数据,它们也使用相同的API
在实际应用场景中,StringBuilder由于效率更高,所以一般都使用StringBuilder
构造方法
StringBuidler() 空参构造方法,构造一个空的StringBuilder容器
StringBuidler(String) 构造一个StringBuilder容器,并添加指定字符串
/**
* 创建StringBuilder容器
*/
StringBuilder sb = new StringBuilder();
sb.append("abc"); // 返回自身
/**
* 使用带参构造
*/
StringBuilder sb2 = new StringBuilder("abc");
System.out.println(sb2); // abc成员方法
StringBuidler append(...) 将任意数据添加到StringBuilder容器中
String toString() 将当前StringBuilder容器转换成字符串
Date类和Calendar类分别用于处理日期和日历,都是用于操作日期相关信息的
Date类的构造方法
Date() 空参构造,构造一个日期对象,值为系统时间,精确到毫秒
Date(long) 带参构造,构造一个日期对象,值为自"1970年1月1日 00:00:00"起至指定参数的毫秒数
Date类和Caleander类的成员方法
long getTime() 该方法将日期对象转换成对应时间的毫秒值
static Calendar getInstance() 该方法根据当前系统时区和语言环境获取日历对象
int get(int field) 该方法返回给定日历字段的值
void set(int field, int value) 该方法将给定的日历字段设置为指定的值
/**
* Date类
*/
Date date = new Date();
System.out.println(date); // Tue May 17 19:07:31 CST 2015
// 获取毫秒值
System.out.println(date.getTime()); // 1431860869000
/**
* 指定时间
*/
Date l = new Date(1431860869000L);
System.out.println(l); // Sun May 17 19:07:49 CST 2015/**
* 通过静态方法getInstance创建Caleandar对象
*/
Calendar cd = Calendar.getInstance();
// 通过get方法获取年月日等信息
int year = cd.get(Calendar.YEAR);
int month = cd.get(Calendar.MONTH);
int day = cd.get(Calendar.DATE);由于基本类型不是对象,不能通过它来调用方法,所以Java针对基本类型提供了对应的包装类,以对象的形式来使用
| 基本类型 | 所对应包装类 |
|---|---|
byte |
Byte |
short |
Short |
int |
Integer |
long |
Long |
char |
Character |
float |
Float |
double |
Double |
boolean |
Boolean |
包装类有两个概念要了解:
装箱: 装箱就是把基本类型转换成包装类型(对象类型)
拆箱: 拆箱就是把包装类型转换成基本类型
成员方法
包装类的功能就是将字符串类型的数据转换成对应的基本类型,如:static 基本类型 parseXxx(String)
/**
* 装箱操作,将基本数据类型转换成引用类型
*/
// Integer it = new Integer(100); 此方式已过时,使用下面的方式
Integer it = 100;
/**
* 拆箱操作
*/
int newIt = it.intValue(); // 100
/**
* 将字符串类型的值转换成整数
*/
String s = "100";
int num = Integer.parseInt(s);Table of Contents generated with DocToc
在目前的团队开发中,前端团队的代码规范问题是很让人头痛的。如果让你去看一个你不熟悉的代码风格,其实是非常耗时且效率低下的事。那有什么方法可以规范团队中每个成员的代码书写风格呢?答案是肯定的,使用ESLint可以很方便的,或者说可以强制性的规范每个人的代码书写风格,在中小团队中,我们可以不去自定义风格,而去使用ESLint官方推荐的代码风格(Standard),这篇博文简单的介绍了如何使用ESLint去做这些事,甚至我们可以通过一些方法在Git中加入钩子,强制不规范的代码不能提交。
在这里,我在Vue代码中做一些例子的示范,其他的如React,可参照网上其他的教程做相应的修改,或参看官方推荐。
在我们的项目中加入ESLint,好处不言而喻,首先可以防止一些低级的错误,导致在编译时出现一些莫名其妙的问题,其次就是在团队协作时,能保持所有成员的开发风格一致,这样在参看别人的代码时就显得非常的方便,从而提高效率。
首先,我们应该在自己的项目中安装ESLint及其相关的依赖包,ESLint是遵循一定的规则的,在中小团队中,就没有必要去自定义了,可以使用官方的 Standard 标准,当然,其配置文件中也可以对部分规则进行修改,以满足团队的特殊需求.
下面来看看需要安装的包:
eslinteslint-config-standardeslint-plugin-standardeslint-plugin-promiseeslint-plugin-importeslint-plugin-nodenpm i -D eslint eslint-config-standard eslint-plugin-standard eslint-plugin-promise eslint-plugin-import eslint-plugin-node安装完成后,在项目根目录下创建文件 .eslintrc
这是ESLint的配置文件,它是一个JSON格式的文件
{
"extends": "standard"
}这里有个问题,因为我们的JS代码都写在了Vue中,ESLint是无法识别Vue文件的,所以这里还需要安装一个工具包 eslint-plugin-html
npm i -D eslint-plugin-html安装完成后,在配置文件 .eslintrc 中加入 plugins 选项
{
"extends": "standard",
"plugins": [
"html"
]
}上述的安装和配置完成之后,我们就可以在 package.json 中增加 script 选项来使用ESLint了。
{
"scripts": {
"lint": "eslint --ext .js --ext .jsx --ext .vue src/"
}
}这里解释一下上面的 lint 命令,运行的是 npm run lint 来检查当前开发目录 src 中所有的需要检查的文件代码。 --ext 参数指定我们需要检查哪些后缀名的文件,最后的 src/ 表示要检查那个目录里的文件。
如果当项目一开始没有使用ESLint来规范代码书写的话,这时候会在控制台打印出很多错误,如果一条一条的去修复很麻烦,很幸运的是,ESLint为我们提供了修复的命令:
{
"scripts": {
"lint": "eslint --ext .js --ext .jsx --ext .vue src/",
"lint-fix": "eslint --fix --ext .js --ext .jsx --ext .vue src/"
}
}上面在 scripts 中加入了另外一条命令 lint-fix, 这条命令里增加了一个 --fix 的参数,表示运行此命令,如果遇到错误就自动修复。
通过上面的操作,我们可以发现并修复我们代码中不符合ESLint规范的错误,但这种方法并不好,因为这样团队成员就无法养成规范书写的习惯,每次都要去重新修复一次,所以我们希望的是在书写代码的时候能即时发现错误并提示修改。
要做到这一点,我们还需要安装两个包,eslint-loader 和 babel-eslint
npm i -D eslint-loader babel-eslint安装完成后,首先要去修改 .eslintrc 这个配置文件,增加 parser 选项
{
"extends": "standard",
"plugins": [
"html"
],
"parser": "babel-eslint"
}那为什么我们需要增加这个选项呢? 因为我们的项目都是经过Webpack进行打包的,代码是通过 babel 进行处理的,在这个过程中,babel可能会与ESLint有所冲突,所以使用这个方法来解决这些问题。
然后,我们就可以修改我们的 Webpack 的配置文件
{
module: {
rules: [
{
test: /\.(vue|js|jsx)$/,
loader: 'eslint-loader',
exclude: /node_modules/,
enforce: 'pre'
}
]
}
}上面的配置中,需要特别注意是最后一项 enforce, 为什么要配置它呢? 是因为在 rules 中会有其他的配置选项,比如单独对 vue 文件进行处理的 vue-loader, 所以这里需要指定,预先对vue文件使用 eslint-loader 进行代码风格检查,如果这里都过不了,就无需进行下去,直接报错并提示。
通过上述的安装和配置,我们就可以在实际的代码开发中,当发现有不符合ESLint规则的时候就会报错。这样,团队成员都会按照既定的风格进行代码书写,以达到统一开发的目的。
在编辑器方面,我们还可以配置 editorconfig 来进一步规范代码书写,首先我们的编辑器要安装相应的插件,在vscode中,直接搜索并安装 EditorConfig for VS Code
然后在项目根目录下新建 editorconfig 文件,并写入配置项
root = true
[*]
charset = utf-8
end_of_line = lf
indent_size = 2
indent_style = space
insert_final_newline = true
trim_trailing_whitespace = true
通过上面的配置,我们基本上可以做到统一团队的代码开发风格了,那还有没有更进一步的优化呢? 是有的。 我们还可以在 Git 中使用钩子,在成员进行代码提交时对代码风格进行检查,如果不符合则禁止其提交代码。
首先我们需要安装一个包 husky
npm i -D husky注意:在安装之前,我们要使用 git init初始化本地仓库,因为在安装完这个包之后,会在本地 git 目录下生成一个hook,如果没有 git 目录,就会初始化失败。这个hook会读取我们的 package.json 文件里的内容。
随后,我们就可以在 scripts 里添加一个选项 precommit,内容就是进行 ESLint 代码检查
{
"scripts": {
"lint": "eslint --ext .js --ext .jsx --ext .vue src/",
"lint-fix": "eslint --fix --ext .js --ext .jsx --ext .vue src/",
"precommit": "npm run lint"
}
}每次当我们进行代码提交时,这个hook都会自动调用 precommit ,进行代码检查,如果有错误,则停止后面的提交,并显示错误.
先来看看Scanner类吧,使用Scanner可以从外部接收用户在控制台输入的数据,它就像一个扫描器,并将扫描到的数据存入我们定义的变量中。
使用Scanner类一般分为三步:
// 第一步:导入包
import java.util.Scanner;
public class ScannerDemo {
public static void main(String[] args) {
// 第二步:创建scanner对象
Scanner sc = new Scanner(System.in);
// 第三步:接收数据
int i = sc.nextInt(); // nextInt只能接收整数类型的值
}
}程序的结果跟代码的执行顺序紧密相关,通过使用一些特定的语句控制代码的执行顺序从而完成特定的功能,这就是流程控制结构。
流程控制结构的分类:
顺序结构
顺序结构按照代码的顺序从上往下、从左往右一次执行代码结构,它是最简单的流程控制结构,不需要特定的语句,大多数代码都是这样执行的。
选择(判断)结构
循环结构
选择结构根据不同的条件选择不同的代码来执行代码结构,它需要先判断条件是否成立,如果成立执行一部分代码,反之执行另外一段代码,所以,选择结构也称为判断结构。
选择结构的分类:
if 做区间值得判断
// 第一种格式
if(关系表达式) {
// 语句体1
}
// 第二种格式
if(关系表达式) {
// 语句体1
} else {
// 语句体2
}
// 第三种格式
if(关系表达式1) {
// 语句体1
} else if(关系表达式2) {
// 语句体2
}
...
else {
// 语句体n+1
}switch 做固定值的判断
switch(表达式) {
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
default:
语句体n+1;
break;
}Table of Contents generated with DocToc
这篇博文总结了近期我去面试高级前端工程师遇到的各种问题,基本上大部分题在网上都能找到答案,部分题比较少见,这里总结一部分高级前端可能会遇到的一个问题。此篇博文会持续更新!
0.1 + 0.2 === 0.3吗? 请阐述原因并给出解决方案这道题在网上有很多答案,解决方法也大相径庭,不过我在工作中就曾经遇到过,在前端对订单的各种数额进行计算,并与后端的结果进行对比,保证计算结果精度正确。
当然,问这道题,答案肯定是否,为什么呢? 难道 0.1 + 0.2 不等于 0.3 吗?是的,在JS中,这道题的答案确实是 false ,而 0.2 + 0.3 的结果却是 0.5, 原因在于JS采用IEEE 754标准定义的64位浮点格式表示数字,所以JS中的所有数字都是浮点数。按照JS的数字格式,整数有的范围是-2^53 ~ 2^53,而且只能表示有限个浮点数,能表示的个数为2^64 − 2^53 + 3个,浮点数的个数是无限的,这就导致了JS不能精确表达所有的浮点数,而只能是一个近似值。并且所有采用IEEE 754标准的语言都会有这个问题,只是它们已经在其标准库中解决了这个问题。而很遗憾的是JS却没有。下面我们来分析一下运算过程:
1.1001100110011001100110011001100110011001100110011001 1(0011)+ * 2^-4;round to nearest, tie to even的舍入模式,因此0.1实际存储时的位模式是0-01111111011-1001100110011001100110011001100110011001100110011010;1.1001100110011001100110011001100110011001100110011001 1(0011)+ * 2^-3;round to nearest, tie to even的舍入模式,因此0.2实际存储时的位模式是0-01111111100-1001100110011001100110011001100110011001100110011010;0-01111111101-0011001100110011001100110011001100110011001100110100。转换为十进制即为0.30000000000000004。那如何来解决这个问题呢??原生的解决方法如下:
parseFloat((0.1 + 0.2).toFixed(10))更精确的解决方案如下:
function accAdd (arg1, arg2) {
var r1, r2, m;
try{
r1 = arg1.toString().split(".")[1].length
} catch (e) {
r1 = 0
}
try{
r2 = arg2.toString().split(".")[1].length
} catch (e) {
r2 = 0
}
m = Math.pow(10, Math.max(r1,r2))
return (parseInt(arg1*m, 10) + parseInt(arg2*m, 10)) / m
}可以按此原理抽象成自己的标准计算库,在各个项目中使用。
说到这个概念,我不得不建议大家先去看看大神阮一峰老师的博客:传送门
先说说概念吧,JS是一种单线程语言,所谓单线程,意思就是一次只能执行一个任务,如果有多个任务,那么就排队,执行完一个再执行下一个(还有其他方案,比如多线程或多进程)。这样的模式势必会造成资源浪费,也就是说,下一个任务必须等待,造成一种"假死"的情况,从而无法响应用户的行为。那为什么JS从一开始不设计为一个多线程语言呢? 这是历史原因造成的,JS本身被创造出来就是为了解决一些简单问题的,并且JS没有锁机制,如果存在多线程,DOM操作将会变得复杂且不可控。当然,现在可以使用Web Worker API来实现多线程。
当这种等待机制运行时,会造成阻塞,这也就是同步机制,Event Loop就是为了解决这个问题而生的。
Event Loop是一个程序结构,用于等待和发送消息和事件
简单说,就是在程序中设置两个线程:一个负责程序本身的运行,称为"主线程";另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为"Event Loop线程"(可以译为"消息线程")。
每当遇到I/O的时候,主线程就让Event Loop线程去通知相应的I/O程序,然后接着往后运行,等到I/O程序完成操作,Event Loop线程再把结果返回主线程。主线程就调用事先设定的回调函数,完成整个任务。
上面介绍的这种运行模式,就被称为"异步模式",或者"非阻塞模式"。
下面我们再用几个例子来说明Event Loop中的几个概念。
JS 在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到 Task(有多种 task) 队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
// script start -> script end -> setTimeout不同的任务源会被分配到不同的 Task 队列中,任务源可以分为微任务(microtask)和宏任务(macrotask)。在 ES6 规范中,microtask 称为 jobs,macrotask 称为 task。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout微任务包括 process.nextTick ,promise ,Object.observe ,MutationObserver
宏任务包括 script , setTimeout ,setInterval ,setImmediate ,I/O ,UI rendering
所以正确的一次 Event loop 顺序是这样的
除此之外,这里不得不提一下,Node中也存在Event Loop机制,并且与浏览器中的不一样。
Node 的 Event loop 分为6个阶段,它们会按照顺序反复运行
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
timers 阶段会执行 setTimeout 和 setInterval
一个 timer 指定的时间并不是准确时间,而是在达到这个时间后尽快执行回调,可能会因为系统正在执行别的事务而延迟。
下限的时间有一个范围:[1, 2147483647] ,如果设定的时间不在这个范围,将被设置为1。
I/O 阶段会执行除了 close 事件,定时器和 setImmediate 的回调
idle, prepare 阶段内部实现
poll 阶段很重要,这一阶段中,系统会做两件事情
poll 队列中的事件并且当 poll 中没有定时器的情况下,会发现以下两件事情
poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者系统限制poll 队列为空,会有两件事发生如果有 setImmediate 需要执行,poll 阶段会停止并且进入到 check 阶段执行 setImmediate
如果没有 setImmediate 需要执行,会等待回调被加入到队列中并立即执行回调
如果有别的定时器需要被执行,会回到 timer 阶段执行回调。
check 阶段执行 setImmediate
close callbacks 阶段执行 close 事件
并且在 Node 中,有些情况下的定时器执行顺序是随机的
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate
// 可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 1 毫秒,这时候会执行 setImmediate
// 否则会执行 setTimeout当然在这种情况下,执行顺序是相同的
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// 因为 readFile 的回调在 poll 中执行
// 发现有 setImmediate ,所以会立即跳到 check 阶段执行回调
// 再去 timer 阶段执行 setTimeout
// 所以以上输出一定是 setImmediate,setTimeout上面介绍的都是 macrotask 的执行情况,microtask 会在以上每个阶段完成后立即执行。
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// 以上代码在浏览器和 node 中打印情况是不同的
// 浏览器中打印 timer1, promise1, timer2, promise2
// node 中打印 timer1, timer2, promise1, promise2Node 中的 process.nextTick 会先于其他 microtask 执行。
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick, timer1, promise1这个问题很经典,也是很多面试高级前端时必问的问题。我也在面试时遇到过,只不过不同的是,面试官在这之前还问了一个问题,那就是从打开一个浏览器标签页开始,发生了什么。
也就是说,考察的是面试者对浏览器进程与线程的认知程度。下面是浏览器中进程的相关概念:
也就是说,新打开一个TAB页,实际上就创建了一个浏览器进程,但是有时候会有不同,为了性能考虑,浏览器的优化策略会将多个空的TAB页进程合并成一个,在有输入内容之后才分离出来创建另一个新的浏览器进程。
下面来说说当输入url之后,到底发生了什么。总体来说分为以下几个过程:
这个过程实际上是浏览器将输入的url发送到DNS服务器进行查询,DNS服务器会返回当前查询url的IP地址。它实际上充当了一个翻译的角色,实现了网址到IP地址的转换
DNS解析是一个递归查询的过程。
上图中演示的过程经历了8个步骤,如果每次都是这样,必然会损耗大量的资源,所以我们必须对DNS解析进行优化。
HTTP协议是使用TCP作为其传输层协议的,当TCP出现瓶颈时,HTTP也会受到影响。HTTP报文是包裹在TCP报文中发送的,服务器端收到TCP报文时会解包提取出HTTP报文。但是这个过程中存在一定的风险,HTTP报文是明文,如果中间被截取的话会存在一些信息泄露的风险。那么在进入TCP报文之前对HTTP做一次加密就可以解决这个问题了。HTTPS协议的本质就是HTTP + SSL(or TLS)。在HTTP报文进入TCP报文之前,先使用SSL对HTTP报文进行加密。从网络的层级结构看它位于HTTP协议与TCP协议之间。
HTTPS在传输数据之前需要客户端与服务器进行一个握手(TLS/SSL握手),在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL使用了非对称加密,对称加密以及hash等
发送HTTP请求的过程就是构建HTTP请求报文并通过TCP协议中发送到服务器指定端口(HTTP协议80/8080, HTTPS协议443)。HTTP请求报文是由三部分组成: 请求行, 请求报头和请求正文。
请求行的格式如下:
Method Request-URL HTTP-Version CRLF
例如:
eg: GET index.html HTTP/1.1
常用的方法有: GET, POST, PUT, DELETE, OPTIONS, HEAD。
请求报头:请求报头允许客户端向服务器传递请求的附加信息和客户端自身的信息。常见的请求报头有: Accept, Accept-Charset, Accept-Encoding, Accept-Language, Content-Type, Authorization, Cookie, User-Agent等。
Accept用于指定客户端用于接受哪些类型的信息,Accept-Encoding与Accept类似,它用于指定接受的编码方式。Connection设置为Keep-alive用于告诉客户端本次HTTP请求结束之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP连接建立的时间。
请求正文: 当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中。在请求包头中有一些与请求正文相关的信息,例如: 现在的Web应用通常采用Rest架构,请求的数据格式一般为json。这时就需要设置Content-Type: application/json。
后端从在固定的端口接收到TCP报文开始,这一部分对应于编程语言中的socket。它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。这一部分工作一般是由Web服务器去进行
HTTP响应报文也是由三部分组成: 状态码, 响应报头和响应报文。
状态码是由3位数组成,第一个数字定义了响应的类别,且有五种可能取值:
平时遇到比较常见的状态码有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500
响应报头:常见的响应报头字段有: Server, Connection...。
响应报文:服务器返回给浏览器的文本信息,通常HTML, CSS, JS, 图片等文件就放在这一部分
浏览器在收到HTML,CSS,JS文件后,它是如何把页面呈现到屏幕上的
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上,这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。
reflow: DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为reflowrepain当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。
JS的执行机制就可以看做是一个主线程加上一个任务队列(task queue)。同步任务就是放在主线程上执行的任务,异步任务是放在任务队列中的任务。所有的同步任务在主线程上执行,形成一个执行栈;异步任务有了运行结果就会在任务队列中放置一个事件;脚本运行时先依次运行执行栈,然后会从任务队列里提取事件,运行任务队列中的任务,这个过程是不断重复的,所以又叫做事件循环(Event loop)。
浏览器在解析过程中,如果遇到请求外部资源时,如图像,iconfont,JS等。浏览器将重复上面的过程下载该资源。请求过程是异步的,并不会影响HTML文档进行加载,但是当文档加载过程中遇到JS文件,HTML文档会挂起渲染过程,不仅要等到文档中JS文件加载完毕还要等待解析执行完毕,才会继续HTML的渲染过程。原因是因为JS有可能修改DOM结构,这就意味着JS执行完成前,后续所有资源的下载是没有必要的,这就是JS阻塞后续资源下载的根本原因。CSS文件的加载不影响JS文件的加载,但是却影响JS文件的执行。JS代码执行前浏览器必须保证CSS文件已经下载并加载完毕
TCP/IP协议栈主要分为四层:应用层、传输层、网络层、数据链路层, 每层都有相应的协议,如下图:
其实重要的在TCP和UDP,那它们有什么区别呢?
TCP(传输控制协议,Transmission Control Protocol):(类似打电话)
面向连接、传输可靠(保证数据正确性)、有序(保证数据顺序)、传输大量数据(流模式)、速度慢、对系统资源的要求多,程序结构较复杂,每一条TCP连接只能是点到点的,TCP首部开销20字节。
UDP(用户数据报协议,User Data Protocol):(类似发短信)
面向非连接 、传输不可靠(可能丢包)、无序、传输少量数据(数据报模式)、速度快,对系统资源的要求少,程序结构较简单 , UDP支持一对一,一对多,多对一和多对多的交互通信,UDP的首部开销小,只有8个字节。
TCP建立连接需要三次握手:
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去
结论:
HTTP协议是建立在请求/响应模型上的。首先由客户建立一条与服务器的TCP链接,并发送一个请求到服务器,请求中包含请求方法、URI、协议版本以及相关的MIME样式的消息。服务器响应一个状态行,包含消息的协议版本、一个成功和失败码以及相关的MIME式样的消息
虽然HTTP本身是一个协议,但其最终还是基于TCP的
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。
HTTPS加密、加密、及验证过程,如下图所示:
简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
先看下面的第一问,下列代码打印出什么 ?
for (var i = 0; i < 10; i++) {
setTimeout(function() {
console.log(i)
}, 1000);
}好了,是不是很经典?很多人在面试的时候都会被问到这个问题,OK,可能80%的同学都知道,它会打印出 10 个 10 来,为什么?
这就考到作用域的问题了。实际上,var 定义的变量在 for 循环之外是可以访问到的,也就是说,在执行 setTimeout 这个类似异步的操作之前,循环就已经结束了。这时的 i 已经为 10,所以最后打印出来的也就是 10个 10 了
这就完了?呵呵,刚刚开始。
下面来接着问,如何解决这个问题呢? 有经验的同学都会想到使用 IIFE,这也考察了面试者对闭包的理解。
for (var i = 0; i < 10; i++) {
(function(i) {
setTimeout(function() {
console.log(i);
})
})(i)
}这样,就可以顺利的打印出 0 ~ 9的结果了。如果还想考察,可以进一步问还有其他的解决方案吗? 可以提示:让每次循环的代码块都能正常的拿到 i 值即可。
var output = function(i) {
setTimeout(function() {
console.log(i);
}, 1000);
}
for (var i = 0; i < 10; i++) {
output(i);
}当然,最快的解决方案,有面试者可能会直接说出,利用ES6的 let 就可以,因为 let 可以定义一个块级作用域嘛。
for (let i = 0; i < 10; i++) {
setTimeout(function() {
console.log(i)
}, 1000)
}进一步,问利用ES6的 Promise 如何解决这个呢? 下面给出答案,如果面试者能大概写出来,那么是一个大大的加分。
const tasks = [];
for (var i = 0; i < 10; i++) {
(function(i) {
tasks.push(new Promise((resolve) => {
setTimeout(() => {
console.log(i);
resolve()
})
}))
})(i)
}
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(i)
}, 1000)
})这里实际上考察了面试者对ES6的 Promise 的理解程度。下面是一种更简洁的写法:
const tasks = [];
const output = (i) => new Promise(resolve => {
setTimeout(() => {
console.log(i);
resolve()
}, 1000)
})
for (var i = 0; i < 10; i++) {
tasks.push(output(i))
}
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(i)
}, 1000)
})
// 最简洁写法:
new Promise((resolve) => {
for (var i = 0; i < 10; i++) {
console.log(i);
resolve()
}
})最后再来看下,更"变态"的,可以进一步使用ES7的 async/await 来解决,下面的代码摘自网上,不得不说,太牛掰了。
const sleep = (timeout) => new Promise((resolve) => {
setTimeout(resolve, timeout);
});
(async () => {
for (var i = 0; i < 10; i++) {
await sleep(1000);
console.log(i);
};
})();
// 这里也有个最简洁写法:
(async () => {
for (var i = 0; i < 10; i++) {
console.log(i)
}
})();什么是防抖?
如果我们页面上有一个事件会被用户操作触发,而如果用户反复操作,就会被反复触发,这样带来的后果是性能低下和资源浪费。比如,页面有一个鼠标移入则会发送 ajax 请求的事件,如果用户反复的操作,就会浪费网络资源,不停的去请求。这时,我们就需要防抖。
防抖的原理就是:当执行一个事件函数时,会等待一个阈(yu)值,可以设置为 n 秒,只有在 n 秒之后不再有操作,事件才会真正被触发。这样就不会引起页面抖动。
function debounce(func, wait) {
var timeout;
return function () {
var context = this;
var args = arguments;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
}节流的概念比较简单,就是当触发某个事件,每隔一段时间,只执行一次该事件。实现方式有两种:时间戳和定时器
// 时间戳方式实现:
function throttle(func, wait) {
var context, args;
var previous = 0;
return function() {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}
// 定时器方式:
function throttle(func, wait) {
var timeout;
var previous = 0;
return function() {
context = this;
args = arguments;
if (!timeout) {
timeout = setTimeout(function(){
timeout = null;
func.apply(context, args)
}, wait)
}
}
}说说你了解并掌握的设计模式在JavaScript中的实现。
保证一个类只有一个实例,并提供一个访问它的全局访问点(调用一个类,任何时候返回的都是同一个实例)
实现方法:使用一个变量来标志当前是否已经为某个类创建过对象,如果创建了,则在下一次获取该类的实例时,直接返回之前创建的对象,否则就创建一个对象。
class Singleton {
constructor(name) {
this.name = name
this.instance = null
}
getName() {
alert(this.name)
}
static getInstance(name) {
if (!this.instance) {
this.instance = new Singleton(name)
}
return this.instance
}
}工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类。该模式使一个类的实例化延迟到了子类。而子类可以重写接口方法以便创建的时候指定自己的对象类型。
简单说:假如我们想在网页面里插入一些元素,而这些元素类型不固定,可能是图片、链接、文本,根据工厂模式的定义,在工厂模式下,工厂函数只需接受我们要创建的元素的类型,其他的工厂函数帮我们处理。
// 文本工厂
class Text {
constructor(text) {
this.text = text
}
insert(where) {
const txt = document.createTextNode(this.text)
where.appendChild(txt)
}
}
// 链接工厂
class Link {
constructor(url) {
this.url = url
}
insert(where) {
const link = document.createElement('a')
link.href = this.url
link.appendChild(document.createTextNode(this.url))
where.appendChild(link)
}
}
// 图片工厂
class Image {
constructor(url) {
this.url = url
}
insert(where) {
const img = document.createElement('img')
img.src = this.url
where.appendChild(img)
}
}
// DOM工厂
class DomFactory {
constructor(type) {
return new (this[type]())
}
// 各流水线
link() { return Link }
text() { return Text }
image() { return Image }
}
// 创建工厂
const linkFactory = new DomFactory('link')
const textFactory = new DomFactory('text')
linkFactory.url = 'https://surmon.me'
linkFactory.insert(document.body)
textFactory.text = 'HI! I am surmon.'
textFactory.insert(document.body)let str = 'asdfghjklaqwertyuiopiaia';
const strChar = str => {
let string = [...str],
maxValue = '',
obj = {},
max = 0;
string.forEach(value => {
obj[value] = obj[value] == undefined ? 1 : obj[value] + 1
if (obj[value] > max) {
max = obj[value]
maxValue = value
}
})
return maxValue;
}// forEach
let arr = ['1', '2', '3', '1', 'a', 'b', 'b']
const unique = arr => {
let obj = {}
arr.forEach(value => {
obj[value] = 0
})
return Object.keys(obj)
}
// filter
let arr = ['1', '2', '3', '1', 'a', 'b', 'b']
const unique = arr => {
return arr.filter((ele, index, array) => {
return index === array.indexOf(ele)
})
}
// set
let arr = ['1', '2', '3', '1', 'a', 'b', 'b']
const unique = arr => {
return [...new Set(arr)]
}================================= 分割线 =================================
未完待续,持续更新面试题
在MAC中使用ssh连接远程服务器:
打开终端,输入:
ssh -p 9011 [email protected]
回车后输入密码,提示登录成功....
切换到需要存放文件的目录,在命令行下输入:
prompt off (回车) /* 不用每次都输入Y来确认是否下载 */
接下来输入:
wget ftp://ip:port/子目录/* --ftp-user=你的用户名 --ftp-password=你的FTP密码 -r
示例:
wget ftp://192.168.20.249:8081/htdocs/* --ftp-user=lzadmin --ftp-password=123456 -r
注意:-r 的意思是下载所有文件包括文件夹
grunt 简介grunt 是什么?
grunt 是Javascript世界的构建工具,我们的项目在创建初期,会很小,但经过很多版本的迭代,越来越大,CSS和JS都不太好管理了,这时我们需要工具来帮助我们管理,grunt 就是做这个的。它主要的工具就是编译、压缩、单元测试等,以减少我们的工作量。
grunt 已有很多可供我们使用的插件,帮助我们实现各种工业自动化,那如何使用 grunt 呢?
grunt 和其插件都是通过 npm 安装的,所以,系统中必须安装 npm ,npm 是NodeJS的包管理器。
liuzhendeMacBook-Air:gruntTest liuzhen$ npm -v
2.14.12安装 grunt 之前必须先将 grunt-cli 安装到全局中(我这里使用了sudo命令来安装)
liuzhendeMacBook-Air:gruntTest liuzhen$ sudo npm install -g grunt-cli
Password:
npm WARN deprecated [email protected]: lodash@<3.0.0 is no longer maintained. Upgrade to lodash@^4.0.0
/usr/local/bin/grunt -> /usr/local/lib/node_modules/grunt-cli/bin/grunt
[email protected] /usr/local/lib/node_modules/grunt-cli
├── [email protected]
├── [email protected] ([email protected])
└── [email protected] ([email protected], [email protected])
liuzhendeMacBook-Air:gruntTest liuzhen$安装好 grunt-cli 并不是安装了 grunt ,grunt-cli 的作用就是调用与 grunfile 同目录的 grunt,这样做的好处就是不同的项目里可以存放不同版本的 grunt。
package.json和 gruntfile在项目中安装 grunt 之前,一般都需要两个文件,package.json 和 gruntfile
package.json:
此文件被 npm 用于存储项目的元数据,以便将此项目发布为 npm 模块进入项目目录,使用 npm init 命令来创建一个基本的 package.json,在创建完 gruntfile 之后,就可以在项目目录中使用
sudo npm install grunt --save-dev来安装项目 grunt,也可以使用
sudo npm install grunt-contrib-jshint --save-dev来安装grunt插件
gruntfile:
此文件可被定义为 gruntfile.js 或者 gruntfile.coffee,用来配置或定义任务(task),并加载 grunt 插件。
一般它可以由以下几个部分组成:
“wrapper”函数,它包含整个grunt配置信息
module.exports = function(grunt) {}在这个函数中初始化 configuration 对象
grunt.initConfig({});
接下来就可以从 package.json 中读取配置信息,并存入pkg属性中
pkg:grunt.file.readJSON('package.json')好了,到目前为止我们可以看到如下的代码:
module.exports = function(grunt) {
grunt.initConfig({
pkg: grunt.file.readJSON('package.json')
});
}接下来,我们就可以为每个任务定义相应的配置
项目与任务配置
首先,我们来配置 concat,也就是文件合并任务,如下代码:
concat: {
options: {
//定义一个用于插入合并输出文件之间的字符
separator: ';';
},
dist: {
//将要被合并的文件
src: ['src/**/*.js'],
//合并后的JS文件的存放位置
dest: 'dist/<%= pkg.name %>.js'
}
}接下来,我们配置 uglify 插件,也就是文件压缩
uglify: {
options: {
//此处定义的banner注释将插入到输出文件的顶部
banner: '/* <%= pkg.name %> <%= grunt.template.today("dd-mm-yyyy") %> */\n'
},
dist: {
files: {
'dist/<%= pkg.name %>.min.js': ['<%= concat.dist.dest %>']
}
}
}QUnit 插件用于测试文件,只要提供文件位置即可
qunit: {
files: ['test/**/*.html']
},JShint 插件用于检查JS代码的合法性,配置也很简单
jshint: {
//定义需要检查的文件的位置
files: ['gruntfile.js', 'src/**/*.js', 'test/**/*.js'],
//JSHint默认配置
options: {
globals: {
jQuery: true,
console: true,
module: true
}
}
}最后,来配置 watch 插件,它是用来监视当前文件变化,如果有变化,则grunt会自动执行代码检查
watch: {
files: ['<%= jshint.files %>'],
tasks: ['jshint', 'qunit']
}加载grunt插件和任务
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-qunit');
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-contrib-concat');以上的 grunt 插件需要通过npm进行安装,如以下代码:
sudo npm install grunt-contrib-jshint --save-dev最后,我们需要设置 task ,重要的是 default 任务:
//在命令行输入“grunt test”,test task就会被执行
grunt.registerTask('test', ['jshint', 'qunit']);
//在命令行上输入“grunt”,就会被执行的default task
grunt.resisterTask('default', ['jshint', 'qunit', 'concat', 'uglify']);下面,是最终完成的 gruntfile 文件代码:
module.exports = function(grunt) {
//初始化
grunt.initConfig({
//读取配置信息
pkg: grunt.file.readJSON('package.json'),
//定义文件合并
concat: {
options: {
separator: ';'
},
dist: {
src: ['src/**/*.js'],
dest: 'dist/<%= pkg.name %>.js'
}
},
//文件压缩
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("dd-mm-yyyy") %> */\n'
},
dist: {
files: {
'dist/<%= pkg.name %>.min.js': ['<%= concat.dist.dest %>']
}
}
},
//文件测试
qunit: {
files: ['test/**/*.html']
},
//JS代码检查
jshint: {
files: ['gruntfile.js', 'src/**/*.js', 'test/**/*js'],
options: {
//这里覆盖JSHint默认配置选项
globals: {
jQuery: true,
console: true,
module: true,
document: true
}
}
},
//文件变化监听
watch: {
files: ['<%= jshint.files %>'],
tasks: ['jshint', 'qunit']
}
});
//加载插件
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-qunit');
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-contrib-concat');
//设置任务
grunt.registerTask('test', ['jshint', 'qunit']);
grunt.registerTask('default', ['jshint', 'qunit', 'concat', 'uglify']);
};
$apply()和$digest()在AngularJS中是两个核心概念,但是有时候它们又让人困惑。而为了了解AngularJS的工作方式,首先需要了解$apply()和$digest()是如何工作的。这篇文章旨在解释$apply()和$digest()是什么,以及在日常的编码中如何应用它们。
$apply()和$digest()AngularJS提供了一个非常酷的特性叫做双向数据绑定(Two-way Data Binding),这个特性大大简化了我们的代码编写方式。
数据绑定意味着当View中有任何数据发生了变化,那么这个变化也会自动地反馈到scope的数据上,也即意味着scope模型会自动地更新。
类似地,当scope模型发生变化时,view中的数据也会更新到最新的值。那么AngularJS是如何做到这一点的呢?
当你写下表达式如{{ aModel }}时,AngularJS在幕后会为你在scope模型上设置一个watcher,它用来在数据发生变化的时候更新view。这里的watcher和你会在AngularJS中设置的watcher是一样的:
$scope.$watch(‘aModel’, function(newValue, oldValue) {
//update the DOM with newValue
}); 传入到$watch()中的第二个参数是一个回调函数,该函数在aModel的值发生变化的时候会被调用。
当aModel发生变化的时候,这个回调函数会被调用来更新view,这一点不难理解,但是,还存在一个很重要的问题!AngularJS是如何知道什么时候要调用这个回调函数呢?换句话说,AngularJS是如何知晓aModel发生了变化,才调用了对应的回调函数呢?它会周期性的运行一个函数来检查scope模型中的数据是否发生了变化吗?好吧,这就是$digest循环的用武之地了。
在$digest循环中,watchers会被触发。当一个watcher被触发时,AngularJS会检测scope模型,如果它发生了变化那么关联到该watcher的回调函数就会被调用。OK,下一个问题就是$digest循环是在什么时候以各种方式开始的?
在调用了$scope.$digest()后,$digest循环就开始了。
假设你在一个ng-click指令对应的handler函数中更改了scope中的一条数据,此时AngularJS会自动地通过调用$digest()来触发一轮$digest循环。当$digest循环开始后,它会触发每个watcher。这些watchers会检查scope中的当前model值是否和上一次计算得到的model值不同。如果不同,那么对应的回调函数会被执行。调用该函数的结果,就是view中的表达式内容(译注:诸如{{ aModel }})会被更新。除了ng-click指令,还有一些其它的built-in指令以及服务来让你更改models(比如ng-model,$timeout等)和自动触发一次$digest循环。
目前为止还不错!但是,有一个小问题。在上面的例子中,AngularJS并不直接调用$digest(),而是调用$scope.$apply(),后者会调用$rootScope.$digest()。因此,一轮$digest循环在$rootScope开始,随后会访问到所有的children scope中的watchers。
现在,假设你将ng-click指令关联到了一个button上,并传入了一个function名到ng-click上。当该button被点击时,AngularJS会将此function包装到一个wrapping function中,然后传入到$scope.$apply()。因此,你的function会正常被执行,修改models(如果需要的话),此时一轮$digest循环也会被触发,用来确保view也会被更新。
Note: $scope.$apply()会自动地调用$rootScope.$digest()。$apply()方法有两种形式。第一种会接受一个function作为参数,执行该function并且触发一轮$digest循环。第二种会不接受任何参数,只是触发一轮$digest循环。我们马上会看到为什么第一种形式更好。
$apply()方法?如果AngularJS总是将我们的代码wrap到一个function中并传入$apply(),以此来开始一轮$digest循环,那么什么时候才需要我们手动地调用$apply()方法呢?
实际上,AngularJS对此有着非常明确的要求,就是它只负责对发生于AngularJS上下文环境中的变更会做出自动地响应(即,在$apply()方法中发生的对于models的更改)。
AngularJS的built-in指令就是这样做的,所以任何的model变更都会被反映到view中。但是,如果你在AngularJS上下文之外的任何地方修改了model,那么你就需要通过手动调用$apply()来通知AngularJS。这就像告诉AngularJS,你修改了一些models,希望AngularJS帮你触发watchers来做出正确的响应。
比如,如果你使用了JavaScript中的setTimeout()来更新一个scope model,那么AngularJS就没有办法知道你更改了什么。这种情况下,调用$apply()就是你的责任了,通过调用它来触发一轮$digest循环。类似地,如果你有一个指令用来设置一个DOM事件listener并且在该listener中修改了一些models,那么你也需要通过手动调用$apply()来确保变更会被正确的反映到view中。
让我们来看一个例子。加入你有一个页面,一旦该页面加载完毕了,你希望在两秒钟之后显示一条信息。你的实现可能是下面这个样子的:
<body ng-app=“myApp”>
<div ng-controller=“MessageController”>
Delayed Message: {{message}}
</div>
</body> /* What happens without an $apply() */
angular.module(‘myApp’,[])
.controller(‘MessageController’, function($scope) {
$scope.getMessage = function() {
setTimeout(function() {
$scope.message = ‘Fetched after 3 seconds';
console.log(‘message:’+$scope.message);
}, 2000);
}
$scope.getMessage();
}); 通过运行这个例子,你会看到过了两秒钟之后,控制台确实会显示出已经更新的model,然而,view并没有更新。原因也许你已经知道了,就是我们忘了调用$apply()方法。因此,我们需要修改getMessage(),如下所示:
/* What happens with $apply */
angular.module(‘myApp’,[]).controller(‘MessageController’, function($scope) {
$scope.getMessage = function() {
setTimeout(function() {
$scope.$apply(function() {
//wrapped this within $apply
$scope.message = ‘Fetched after 3 seconds';
console.log(‘message:’ + $scope.message);
});
}, 2000);
}
$scope.getMessage();
}); 如果你运行了上面的例子,你会看到view在两秒钟之后也会更新。唯一的变化是我们的代码现在被wrapped到了$scope.$apply()中,它会自动触发$rootScope.$digest(),从而让watchers被触发用以更新view。
Note:顺便提一下,你应该使用$timeout service来代替setTimeout(),因为前者会帮你调用$apply(),让你不需要手动地调用它。
而且,注意在以上的代码中你也可以在修改了model之后手动调用没有参数的$apply(),就像下面这样:
$scope.getMessage = function() {
setTimeout(function() {
$scope.message = ‘Fetched after two seconds';
console.log(‘message:’ + $scope.message);
$scope.$apply(); //this triggers a $digest
}, 2000);
}; 以上的代码使用了$apply()的第二种形式,也就是没有参数的形式。需要记住的是你总是应该使用接受一个function作为参数的$apply()方法。这是因为当你传入一个function到$apply()中的时候,这个function会被包装到一个try…catch块中,所以一旦有异常发生,该异常会被$exceptionHandler service处理。
$digest循环会运行多少次?当一个$digest循环运行时,watchers会被执行来检查scope中的models是否发生了变化。如果发生了变化,那么相应的listener函数就会被执行。这涉及到一个重要的问题。如果listener函数本身会修改一个scope model呢?AngularJS会怎么处理这种情况?
答案是$digest循环不会只运行一次。在当前的一次循环结束后,它会再执行一次循环用来检查是否有models发生了变化。这就是脏检查(Dirty Checking),它用来处理在listener函数被执行时可能引起的model变化。因此,$digest循环会持续运行直到model不再发生变化,或者$digest循环的次数达到了10次。因此,尽可能地不要在listener函数中修改model。
Note: $digest循环最少也会运行两次,即使在listener函数中并没有改变任何model。正如上面讨论的那样,它会多运行一次来确保models没有变化。
我希望这篇文章解释清楚了$apply和$digest。需要记住的最重要的是AngularJS是否能检测到你对于model的修改。如果它不能检测到,那么你就需要手动地调用$apply()。
在上一节中,我们在本地创建了一个Git仓库,但只有一个分支,就是 master 分支,它是主分支,HEAD指向 master ,master指向当前提交,所以,HEAD指向的就是当前分支。
每次提交,master都会向前移动一步,随着不断的提交,这条分支线会越来越长
当我们创建了新的分支,比如叫 myBranch ,git就会新建一个指针叫 myBranch,指向 master 相同的提交,在把HEAD指向 myBranch,就表示当前分支在 myBranch 上。
从现在开始,对工作区的修改和提交都是针对 myBranch 分支了,如果我们修改后再提交一次,myBranch指针就会向前移动一步,而master指针不变
当我们在myBranch分支上的工作完成后,就可以把myBranch合并到master,也就是把master指针移动到myBranch的当前提交。
当合并完成后,我们就可以删除掉myBranch分支,也就是把myBranch指针删除掉,然后我们就只剩下master分支了
OK,我们现在通过实际的例子来说明上面分支的使用。我们先看看当前分支:
$ git branch //查看分支可以看到,目前我们只有一个master主分支,我们来创建一个bra分支:
$ git checkout -b bragit checkout 命令加上-b参数,表示创建分支并切换,它相当于下面的两个命令:
$ git branch dev //创建分支
$ git checkout dev //切换到创建的分支我们再次查看下当前分支情况
我们可以看到有两个分支,分别是master和bra,当前在bra分支上。
git branch命令会列出所有分支,当前分支前面会标注一个 * 号,现在我们在bra分支上对index.html做一些修改
保存退出后,我们进行提交
现在我们在bra分支上的工作完成,切换到master分支:
$ git checkout master我们发现,刚才添加的第三个P标签不见了,这是因为刚才的提交时在bra分支上,而master分支此刻的提交点没有变化
现在我们可以使用 git merge 命令来将bra分支上的更改合并到master分支上:
$ git merge bra然后我们再次查看index.html的内容
OK,在bra分支上添加的第三个P标签回来了,而当前我们是在master主分支上。大家可能注意到了在我们合并时,出现了 'Fast-forward',它告诉我们这次合并是'快进模式',也就是将master指针直接指向bra分支的提交,所以速度很快,当然除了这种模式,还有其他模式。
合并完成后,我们就可以删除bra分支了
$ git branch -d bra然后我们再次查看分支情况
现在只剩下master分支了。GIT鼓励我们使用分支来进行开发,下面我们来总结下上面使用过的命令:
查看分支: git branch
创建分支: git branch "branch name"
切换分支: git checkout "branch name"
创建并切换分支: git checkout -b "branch name"
合并某分支到当前分支: git merge "branch name"
删除分支: git branch -d "branch name"
有时候我们在进行分支合并时,会遇到各种各样的问题,下面我们用实例来说明下。
我们先创建一个新的分支fea,在这个分支上对index.html再添加一个p标签,然后在这个分支上提交。
$ git checkout -b fea //创建并切换到fea分支
//对index.html做出修改
$ git add index.html //提交
$ git commit -m "modifyed and commit on fea branch"切换到master分支上
$ git checkout master上面的代码还提示我们当前的master分支比远程的master还要多2个提交,可以使用 git push 命令推送本地的提交
接下来,我们在master分支上对index.html做出修改,并提交修改
现在,master分支和fea分支都有了各自的提交
这个时候,git是无法进行快速合并的,只能把各自的修改合并起来,但这种合并可能会造成冲突。下面我们尝试着合并一下
看到了吗? Automatic merge failed,合并失败了。git告诉我们文件有冲突,必须手动解决,我们用 git status 来看下,也提示有问题
查看文件内容,也有提示
我们进入index.html进行修改,保存退出后,提交。
最后,我们删除fea分支
当git无法自动合并分支时,就必须手动去解决问题,再进行合并。我们还可以使用 git log --graph 来查看分支合并图
上面我们了解了合并分支,git会使用 Fast forward 模式,在这种模式下合并,删除分支后,会丢失分支信息,所以我们强制禁用 Fast forward 模式,在合并分支的时候使用 --on--ff
现在我们新建并切换到dev分支上
修改index.html文件并提交
切换到master分支
OK,关键在这里,我们合并dev分支, 使用--no--ff参数,表示禁用 Fast forward
$ git merge --no-ff -m "merge with no-ff" dev合并后,我们使用 git log 查看分支历史
在实际的开发中,master分支是主分支,是非常稳定的,仅仅只能用来发布新的版本,平时不能在它上面工作。
在一个项目开始的时候,我们可以在git上新建一个dev分支,那么如果团队有3个人,分别是A,B,C,那么他们都分别会有自己的分支,大家都在自己的分支上干活,完成之后都提交到dev分支上,但这是不稳定的,经过多次的测试,发现bug,修改,再次合并到dev分支,经过很多次的迭代,版本稳定了,OK,现在可以把dev分支合并到master上进行发布了。
我们在工作时会遇到各种各样的BUG,有时候,有些bug需要立刻修复,但是你手上的任务还没有完成,怎么办?这时,Git为我们提供了 stash 功能,它可以将我们当前分支上的任务存储起来,放在另外一个地方,我们就可以放心的切换到有bug的分支去进行修复。
当前有如下的情景,我在dev分支上工作,写了一些代码,但并没有提交
这时,有任务来了,需要去Fix一个编号为88的bug,我们可以在master分支上创建一个临时的分支来修复这个bug,OK,我们利用 stash 功能将当前的工作保存起来。
我们在利用 status 来查看下当前工作区状态
我们看到当前在dev分支上,而且工作区是干净的,而刚刚我们在dev分支上做的工作并没有提交。
好了,我们现在需要去master分支上创建一个fix88分支来修复bug,先切换到master分支
创建fix88分支来修复bug
我们进入index.html修复bug,并提交
切换到master分支,合并修改,并删除fix88分支
修复bug后的index.html内容如下,我们在最后一个p标签里,把原来的内容加上了一个span标签,并添加了另外一个span标签,插入了一些说明的内容
然后我们再来看看当前的分支状态和工作区状态
切换到我们原来的工作分支dev上,并查看工作区状态
工作区是干净的,下面我们使用 git stash list 命令来查看下刚刚我们隐藏的工作场景
OK,我们来恢复我们在dev分支上的工作场景 ,这里有两个方法可以来恢复
一是使用 git stash apply,这个方法恢复之后,并不会删除stash里的内容,还需要使用 git stash drop来删除 stash 里的内容
二是使用 git stash pop ,这个方法恢复之后,会直接删除stash里的内容
可以看到工作场景恢复了,我们再来看看stash里的内容,git stash list
没有了。
我们还可以多次使用stash,最后需要恢复的时候,使用下面的命令:
git stash apply stash@{0}修复bug可能是我们会长期做的事,它会随时出现,而bug需要立刻解决,这时,我们就需要把现有的手上的工作stash 下,然后创建一个新的分支去修复bug,提交合并后删除这个分支,最后再使用 git stash pop 来恢复我们的工作场景。
我们在开发的过程中,可能随时会接到新的任务,为整个工程添加新的功能,这时,我们最好的做法就是新建一个feature分支,在这个分支上开发,合并,最后删除该分支
假设有这样一个场景,我们接到了Boss的一个任务,要在当前工程上开发一个新的功能,命名为feature-new01,ok, let's go work...
创建新功能分支feature-new01
在当前新功能分支上,我们对index.html添加一个新的东西
提交修改
切换回dev分支,并准备进行合并。(新功能合并到dev工作分支上)
这时,Boss说新能取消,不再开发,所以我们必须删除,如果我们使用 git branch -d feature-new01 ,这时git会提示我们,这个分支的内容还没有被合并,不能删除,所以,我们需要使用 git branch -D feature-new01 来强行删除这个分支。
如果团队需要在现有工程上开发新的功能,请新建一个分支进行,完成后,提交,并切换回团队工作分支(不是master),进行合并,如果在合并之前需要删除,使用 git branch -D <branch name> 来强行删除,如果已合并,请参考前面的版本回退。
当我们从远程仓库克隆项目时,实际上是把本地master分支和远程master分支对应起来了,远程仓库的默认名称是 origin ,要查看远程仓库的信息,使用 git remote
或者我们可以使用 git remote -v 来显示更详细的信息
推送分支,就是把该分支上的所有本地提交都推送到远程仓库,推送时,需要指定本地分支,比如我们需要推送master分支,使用 git push origin master
如果要推送其他分支,如dev,则可以使用 git push origin dev
但不是所有的本地分支都需要推送到远程仓库
master分支是主分支,它是需要推送到远程的。
dev分支作为开发分支,也是需要推送到远程分支的。
处理bug的某些分支,因为处理完成之后会被删除,所以就么有必要了,除非团队需要,比如可以查看那些人在什么时候处理了哪些bug
新功能的开发分支,如feature分支,视自己的团队情况而定。
所以,我们自己在本地的分支,是否推送,完全取决于我们自己,某些分支完全就可以放在自己的本地电脑上玩。
多人团队开发时,团队成员都会往master和dev分支上推送自己的修改,下面我们来模拟一个2人的团队开发,我在自己的Mac上的虚拟机中装了一个Ubuntu,我们在这里来模拟。
在Ubuntu上装好git,然后从github上克隆gitTest项目。(注意:在这之前必须把当前机器的SSH Key添加到github)。
创建用户
当前,我们在远程仓库中有两个分支,分别是mastet主分支和dev开发分支,但其他开发成员从远程克隆项目下来之后,会发现只有master分支,看刚才我们在Ubuntu上克隆的项目
我们看到只有一个master分支,如果团队成员lz需要在dev分支上进行开发,那么必须创建远程的dev分支到本地,可以使用 git checkout -b dev origin/dev 命令创建
现在,团队成员lz就可以在dev分支上进行开发,并提交,push到远程。我们来试试
修改完成,最后一行的div是团队成员lz在本地dev分支上添加的。我们保存退出并提交,最后push到远程仓库
OK,现在团队成员lz对index.html做了添加并推送到了远程,当另外一个成员也对这个文件做了修改,并推送,是一个怎么样的情况呢?我们来试试
呀,提示推送失败了,原因是刚才lz已经对index.html文件做除了修改并推送到了dev分支,我再提交推送就会出现冲突,这时我们需要先把最新的修改pull下来到我的本地,合并修改后再推送
pull也失败了,原因是我们需要将本地dev和远程的origin/dev建立链接
再次pull
成功了,我们打开inex.html看看
看到了吗?刚才成员lz的代码和我刚才写入的代码都在里面了,而且git也给我们做出了提示,如果现在合并会起冲突,我们需要手动调整代码,然后再提交推送
通常情况下,在团队协作开发中,我们可以先推送自己的修改,使用 git push origin <branch name>
如果推送失败,说明远程的分支比本地更新,我们需要使用 git pull 来合并
如果 git pull 提示 “no tracking information”, 说明我们本地的分支没有和远程进行关联,我们需要使用
git branch --set-upstream-to=origin/dev dev 来进行关联,之后再次使用 git pull
如果存在冲突,在本地解决冲突的代码,最后 git push origin <branch name>。
集合简称集,它是用来存储多个元素的容器
集合跟数组很相似,他们的区别如下:
集合只能存储引用类型的元素,如果是基本类型会自动装箱,将基本类型转换成对应的包装类,而数组既可以存储基本类型,也可以存储引用类型
集合的元素个数(容量)是不固定的,可以任意扩容,而数组从定义之时起就固定了,不能改变容量
集合的优势在于不受容器大小的限制,可以随时添加、删除元素,并提供了大量操作元素的方法,如判断、获取等
Java的集合体系
在Java中,集合分为单列集合(Collection)和多列集合(Ma)两种

List属于单列集合,它的特点就是元素可重复、有序(存取顺序相同)
List集合属于接口,要使用它必须创建其子类对象,如: List list = new ArrayList()
/**
* 1. 创建集合对象
* 2. 创建元素对象
* 3. 将元素对象添加到集合对象中
* 4. 遍历集合
*/
List list = new ArrayList();
Student stu1 = new Student("乔峰", 41);
Student stu2 = new Student("乔峰", 41);
Student stu3 = new Student("虚竹", 38);
Student stu4 = new Student("段誉", 26);
// 添加元素对象到List集合中
list.add(stu1);
list.add(stu2);
list.add(stu3);
list.add(stu4);
// 获取List集合中的元素
Object obj = list.get(2); // Student{name='虚竹', age=38}
// 通过for循环遍历List集合
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}增强for循环用来简化数组和集合的遍历操作,格式如下:
for (数据类型 变量名 : 数组或集合对象) {
// 循环体
}...
for (Object o : list) {
System.out.println(o);
}
...迭代器
迭代就是对过程的重复,迭代器是遍历Collection集合的通用方式,可以在对集合遍历的同时进行添加、删除等操作
迭代器中一般有两个常用方法:
next() 该方法返回迭代的下一个元素对象
hasNext() 该方法判断是否仍有元素可以迭代,有则返回true,否则返回false
// 1. 创建集合对象
List list = new ArrayList();
// 2. 创建元素对象并添加到集合对象中
list.add("a"); // 自动装箱
list.add("b"); // 自动装箱
list.add("c"); // 自动装箱
// 使用迭代器遍历List
Iterator it = list.iterator();
while(it.hasNext()) {
String s = (String) it.next(); // 向下转型
System.out.println(s);
}这里有一个开发中常见的需求,需要判断遍历中是否有某个特定的字符,如果有,则进行一系列的操作,比如这里需要判断是否有字符串b,如果有则往List中插入另外一个字符串
// 在while循环中判断
...
while(it.hasNext()) {
String s = (String) it.next();
// 重点:这里的s是个变量,一般使用常量和变量进行比较时,通常我们将它们反转过来
// 意思就是用常量去调用equals方法
// if (s.equals("b")) {
// // 执行一些操作
// }
// 应该这样写:
// 好处时可以规避空指针异常的问题
if ("b".equals(s)) {
// 执行一些操作
}
}
...当我们进行以上操作时,比如在迭代List的同时,还要进行添加、删除等操作,会报并发异常,意思就是说迭代的同时不能做其他的操作,这时我们就需要列表迭代器了
列表迭代器
它是List体系独有的遍历方式,可以在对集合进行遍历的同时,做添加、删除等操作,列表迭代器的方法是:listIterator()
...
ListIterator lit = list.listIterator();
while (lit.hasNext()) {
String s = (String) lit.next();
if ("b".equals(s)) {
lit.add("java");
}
}
System.out.println(list); // [a, b, java, c]
...总结:普通的迭代器在遍历集合的同时不能添加或删除元素,否则会报:并发修改异常,列表迭代器(
listIterator)在遍历集合的同时可以修改集合中的元素(添加、删除等),但必须使用列表迭代器中的方法
泛型即泛指任意类型,又叫参数化类型(ParameterizedType),对具体类型的使用起到辅助作用,类似于方法的参数
这里要了解一下集合类泛型,它表示该集合中存放指定类型的元素,比如,我们给一个List集合添加泛型String,表示该集合中,只能添加String类型的元素,如:
List<String> list = new ArrayList<String>();由此可以看出,集合类泛型的好处在于类型更安全,且避免了类型转换
// 1. 创建带有泛型的集合对象
List<String> list = new ArrayList<String>();
// 2. 创建元素对象并添加到集合对象中
list.add("a");
list.add("b");
list.add("c");
// list.add(10); 报错...
// 3. 遍历集合
for (String s : list) {
System.out.println(s); // a b c
}注意: 泛型一般只和集合类结合使用,它是JDK5的新特性,在JDK7之后,后面的泛型可以不写,如:
List<String> list = new ArrayList<>();
Collections工具类是针对集合进行操作的一系列工具类,使用它主要是使用它内置的各种方法,它们都是静态方法
sort(List<T>) 该方法根据元素的自然顺序,将指定列表按升序进行排列
max(Collection<T>) 该方法返回集合中的最大的元素
reverse(List<T>) 该方法反转List中的集合元素
shuffle(List<T>) 该方法使用默认的随机源随机置换指定的列表
// 1. 创建集合对象
List<Integer> list = new ArrayList<>();
// 2. 添加元素
list.add(1);
list.add(3);
list.add(3);
list.add(4);
list.add(8);
list.add(6);
list.add(9);
list.add(2);
System.out.println(list); // [1, 3, 3, 4, 8, 6, 9, 2]
// 获取集合中最大的元素
Integer max = Collections.max(list); // 9
// 对集合进行升序排列
Collections.sort(list); // [1, 2, 3, 3, 4, 6, 8, 9]
// 对集合元素进行翻转操作
Collections.reverse(list); // [2, 9, 6, 8, 4, 3, 3, 1]
// 随机置换,相当于洗牌操作
Collections.shuffle(list); // [2, 3, 4, 9, 8, 6, 3, 1]Set集合是单列集合,它的特点是元素不可重复,且是无序的
它是一个接口,所以若要使用它,必须创建其子类对象HashSet,如:Set<T> set = new HashSet<>()
当Set集合创建完成后,就可以使用add方法向集合中添加元素,并使用迭代器遍历集合
// 1. 创建Set集合对象
Set<Student> set = new HashSet<>();
// 2. 向Set集合中添加Student元素
set.add(new Student("1", "张三丰"));
set.add(new Student("2", "张无忌"));
set.add(new Student("3", "章子怡"));
// 3. 遍历集合
Iterator<Student> it = set.iterator();
while (it.hasNext()) {
Student stu = it.next();
System.out.println(stu);
}
/**
* Student{id='1', name='张三丰'}
* Student{id='3', name='章子怡'}
* Student{id='2', name='张无忌'}
*/Map是一种双列集合,元素由键值对(Entry)构成,包含了key和value,key是不能重复的,但value是可以重复的
Map是一个接口类型,所以使用时需要创建其子类对象HashMap,如:
Map<T1, T2> map = new HashMap<>();泛型T1表示键的类型,泛型T2表示值得类型
当创建完Map集合之后,就可以往集合中添加元素了,在Map中添加元素使用put()方法,遍历Map,需要先获取所有的key: keySet(),也就是由所有的键组成的单列集合,然后通过key,并使用方法get(),获取到对应的value
// 1. 创建Map集合
Map<Integer, Student> map = new HashMap<>();
// 2. 向map集合中添加元素
map.put(1, new Student("1", "张三"));
map.put(2, new Student("2", "李四"));
map.put(3, new Student("3", "王五"));
System.out.println(map); // {1=Student{id='1', name='张三'}, 2=Student{id='2', name='李四'}, 3=Student{id='3', name='王五'}}
// 根据键,获取值
Student s1 = map.get(2); // Student{id='2', name='李四'}
// 遍历Map集合,双列集合不能直接遍历,需要先把键转换成单列集合
Set<Integer> keys = map.keySet();
// 使用迭代器获取key组成的Set集合
Iterator<Integer> it = keys.iterator();
while (it.hasNext()) {
Integer key = it.next();
// 根据键获取值
Student stu = map.get(key);
System.out.println(stu);
/**
* Student{id='1', name='张三'}
* Student{id='2', name='李四'}
* Student{id='3', name='王五'}
*/
}import java.util.*;
public class SendPokerTest {
public static void main(String[] args) {
// 第一步: 创建一副牌
// 定义双列集合,键是编号,值是牌的名称
Map<Integer, String> pokers = new HashMap<>();
// 定义单列集合,用于存放所有牌的编号
List<Integer> list = new ArrayList<>();
// 定义牌的编号,从0开始
int num = 0;
// 创建具体的牌
String[] colors = { "♠", "♥", "♣", "♦" }; // 4种花色
String[] numbers = { "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2" };
// 通过嵌套循环,创建普通牌
for (String number : numbers) { // 外循环,获取所有的点数
for (String color : colors) { // 内循环,获取素有的花色
String poker = color + number;
// 将牌的编号和具体的牌放入双列集合种
pokers.put(num, poker);
// 将牌的编号放入单列集合中
list.add(num);
// 编号自增
num++;
}
}
// 添加小大王,并让num自增
pokers.put(num, "小王");
list.add(num++);
pokers.put(num, "大王");
list.add(num);
// 第二步:洗牌
// 使用集合类Collections中的shuffle方法,随机打乱list
Collections.shuffle(list);
// 第三步: 发牌
// 使用list集合中的元素的索引与3取余,如果是0,发给第1个玩家、如果是1发给第二个玩家,如果是3发给第三个玩家
// 创建4个List集合,分别存放玩家1、玩家2、玩家3和底牌
List<Integer> player1 = new ArrayList<>();
List<Integer> player2 = new ArrayList<>();
List<Integer> player3 = new ArrayList<>();
List<Integer> lastPocker = new ArrayList<>();
// 遍历pokers集合,根据索引进行发牌操作
for (int i = 0; i < list.size(); i++) {
Integer pokerNum = list.get(i);
if (i >= list.size() - 3) { // 最后三张牌
lastPocker.add(pokerNum);
} else if (i % 3 == 0) {
player1.add(pokerNum);
} else if (i % 3 == 1) {
player2.add(pokerNum);
} else if (i % 3 == 2) {
player3.add(pokerNum);
}
}
// 第四步:看牌
System.out.println("玩家1的牌面是: " + printPoker(player1, pokers));
System.out.println("玩家2的牌面是: " + printPoker(player2, pokers));
System.out.println("玩家3的牌面是: " + printPoker(player3, pokers));
System.out.println("底牌的牌面是: " + printPoker(lastPocker, pokers));
/**
* 玩家1的牌面是: ♥5 ♣5 ♦5 ♥6 ♣6 ♠7 ♦7 ♣8 ♠9 ♦9 ♣10 ♣J ♦J ♦Q ♣K ♣A 小王
* 玩家2的牌面是: ♥3 ♦3 ♥4 ♣4 ♥7 ♣7 ♥8 ♥9 ♣9 ♠10 ♦10 ♠J ♥K ♥A ♦A ♠2 ♦2
* 玩家3的牌面是: ♠3 ♣3 ♠4 ♦4 ♠5 ♦6 ♠8 ♦8 ♥10 ♥Q ♣Q ♠K ♦K ♠A ♥2 ♣2 大王
* 底牌的牌面是: ♠6 ♥J ♠Q
*/
}
/**
* 看牌方法
* @parmas List<Integer>
* @parmas Map<Integer, String>
* @return String
*/
public static String printPoker(List<Integer> nums, Map<Integer, String> pokers) {
//定义字符串序列,展示拿到的牌
StringBuilder pokerList = new StringBuilder();
// 对序号列表中元素进行升序排列
Collections.sort(nums);
// 遍历编号列表,在Map中查找
for (Integer num : nums) {
String poker = pokers.get(num);
pokerList.append(poker + " ");
}
String str = pokerList.toString();
return str.trim();
}
}Table of Contents generated with DocToc
我们在上一节介绍了
git及一些简单的配置,具体在各个平台上(如Linux、windows)的安装,可以参考廖雪峰老师的博客上的文章
版本库,又名仓库,英文名:repository,我们可以把它当做是一个目录,git能管理这个目录里的所有文件,包括对这些文件的修改、删除的跟踪。
创建版本库很简单,假设我们需要新开发一个项目,那么我们首先创建一个新的目录,作为这个项目的工作区
上面我们创建项目目录gitTest并进入这个目录。
执行 git init 命令,在当前工作目录创建git,那么在当前目录下就会有一个隐藏的.git目录,所有的记录都会在这个目录中。
接下来我们直接创建一个测试的html文件,并用vim进行编辑,写入html基本结构,保存后退出,现在这个index.html是没有被跟踪的
我们使用 git add index.html 命令来讲刚创建的index.html文件添加到暂存区,这时我们还没有将新建的文件提交到仓库,只是放在了暂存区
OK,接下来我们把这个新的文件提交到仓库
我们可以看到,index.html已成功提交到了仓库,在 git commit 后面加上了-m参数,后面写上此次提交的说明,这是非常有必要的。
好了,接下来我们对index.html做出修改,向HTML文件里添加一个p标签,并写入一些信息,然后我们使用 git status 来查看下当前文件状态,结果如下:
上面第一排的On branch master表示我们正在master分支上,下面的红色部分说明index.html已被修改
现在我们把修改添加到暂存区,之后再次查看下当前状态
红色部分没有了,这表示修改已提交到了暂存区,接着我们把它提交到仓库并附上说明
现在有个问题,如果我们对文件做了更改,但没有提交,而我们又想知道文件到底做了哪些更改呢?我们再次为index.html添加第二个p标签,并写入一些内容
当我们对index.html再次做出更改后,我们用 git diff 命令来查看最近有些更改
从上图可以看出,第二个p标签前面有个+号,表示这段代码是我们后面加入的,但并没有提交,好了我们知道了上次对文件做了哪些更改,就可以对更改后的文件做提交了
我们来试想下,上面显示了一个创建和两次对文件内容的更改(添加),而且内容都很少,如果我们在几个月内对一个或多个文件做了成百上千此更改呢?有谁会记得这些,好了,我们可以使用 git log 来查看历史修改记录
可以看到我们每次在修改之后提交到仓库的动作,都记录在这里,不过好像有点不太清楚,OK,我们在命令后面加上参数 --pretty=oneline
这样就舒服多了,现在我们来做回退的工作,如果最近一次的修改你并不满意,但修改量很大,而且也记不清是哪些地方做了修改,我们就使用 git reset 来回退到上一个版本,那么要回退,必须要让git知道我们需要回退到那个版本,在git中,HEAD 用来表示当前版本,上一个版本使用 HEAD^ 表示,上上一个版本使用HEAD^^表示,那100个呢?不是要写100个^?呵呵,像这样的情况我们使用 HEAD~100 来表示。好,我们现在来把index.html的内容回退到上一个版本,在做这个操作之前,我们先使用 cat index.html 来查看下当前index.html的内容是怎样的。
接着我们使用 git reset --hard HEAD^ 来回退到上一个版本
好了,没有错误提示,我们再次查看下index.html的内容,发现文件内容已回退到了上一个版本,也就是没有第二个P标签的时候
完成上面的操作后,我们回到了我们希望的版本,第二天一睡醒,完了,后悔了,这么办?这个好办,我们使用命令 git reflog 来查看我们的每次操作
可以看到,我们做的第三次操作的commitid是:469e0de,好了,有这个就好办了,我们再次执行 git reset --hard 469e0de
再次cat一下index.html的内容
看到了吗?刚刚的第二个p标签又回来啦!
就是你在电脑里能看到的目录,比如我的gitTest文件夹就是一个工作区
工作区有一个隐藏目录 .git,这个不算工作区,而是Git的版本库。
Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支 master,以及指向 master 的一个指针叫HEAD
我们把文件往Git版本库里添加的时候,是分两步执行的:
第一步是用 git add 把文件添加进去,实际上就是把文件修改添加到暂存区;
第二步是用 git commit 提交更改,实际上就是把暂存区的所有内容提交到当前分支。
因为我们创建Git版本库时,Git自动为我们创建了唯一一支 master 分支,所以,现在,git commit 就是往 master 分支上提交更改。
你可以简单理解为,需要提交的文件修改通通放到暂存区,然后,一次性提交暂存区的所有修改。
Git管理的是修改,而非文件,比如新增是一个修改,删除也是一个修改,更改了某些字符也是一个修改,删了一些又加了一些也是一个修改,甚至创建一个新文件也算一个修改。
比如有一个文件,我们第一次做了修改,然后 git add 了,这时我们再次做了一次修改,并没有add,而是直接 git commit 了,git diff 下就可以看到,git commit 是将暂存区的修改提交到了仓库,而第二次的修改并没有 add 到暂存区,所以看到的只是第一次修改的结果。
我们也可以使用 git diff -- index.html 这样的命令来查看工作区与仓库之间的文件差异,如果没有返回结果,那么这两处的结果是一样的。
当我们的工作量很大时,必须会在编写代码时出错,这时,我们来分析下下面的几种情况:
我们写错了代码,并没有提交到暂存区,也就是没有执行 git add 操作,这时你发现了错误,OK,我们执行 git checkout -- file 命令,撤销工作区的修改,返回到跟暂存区版本一致。
我们写错了代码,而且已经提交修改到了暂存区,但没有commit,这时,我们执行 git reset HEAD file ,丢弃暂存区的修改,这样就返回到了上面的阶段,然后再次执行上面的 git checkout -- file 就可以了。
我们写错了代码,不但提交到了暂存区,而且已经commit了,这时,可以参看上面的版本回退部分,不过前提是没有提交到远程仓库。
在Git中,删除也是一种修改操作,下面我们用一个实例来讨论下。首先我们创建一个test.txt文件,并把它提交到仓库
这时,我们直接在工作区将这个文件删除
我们使用 git status 来查看下
git 告诉我们,test.txt已被删除了,因为它发现了工作区和版本库的不一致了,这时,我们有两个选择,一是直接删除版本库里的test.txt ,另外一种就是删错了,要从版本库里恢复
下面,我们首先来恢复被误删的test.txt,使用 git checkout -- test.txt 命令
被删除后,项目目录里没有test.txt,当我们恢复文件后,就出现在目录里了
如果我们确定要删除,那么我们可以使用 git rm 命令来执行删除操作
在过去的几年中,jQuery一直是使用最为广泛的JavaScript脚本库。今天我们将为各位Web开发者提供10个最实用的jQuery代码片段,有需要的开发者可以保存起来。
当涉及到CSS设计时,对开发者和设计者而言Internet Explorer一直是个问题。尽管IE6的黑暗时代已经过去,IE也越来越不流行,它始终是一个能够容易检测的好东西。当然了,下面的代码也能用于检测别的浏览器。
$(document).ready(function() {
if (navigator.userAgent.match(/msie/i) ){
alert('I am an old fashioned Internet Explorer');
}
});这是一个最广泛使用的jQuery效果:对一个链接点击下会平稳地将页面移动到顶部。这里没什么新的内容,但是每个开发者必须要会偶尔编写一下类似函数
$("a[href='#top']").click(function() {
$("html, body").animate({ scrollTop: 0 }, "slow");
return false;
});非常有用的代码片段,它允许一个元素固定在顶部。对导航按钮、工具栏或重要信息框是超级有用的。
$(function(){
var $win = $(window);
var $nav = $('.mytoolbar');
var navTop = $('.mytoolbar').length && $('.mytoolbar').offset().top;
var isFixed=0;
processScroll()
$win.on('scroll', processScroll)
function processScroll() {
var i, scrollTop = $win.scrollTop();
if (scrollTop >= navTop && !isFixed) {
isFixed = 1
$nav.addClass('subnav-fixed')
} else if (scrollTop <= navTop && isFixed) {
isFixed = 0
$nav.removeClass('subnav-fixed')
}
}jQuery使得用另外一个东西取代html标志很简单。可以利用的余地无穷无尽。
$('li').replaceWith(function(){
return $("<div />").append($(this).contents());
});现在移动设备比过时的电脑更普遍,能够方便去检测一个更小的视窗宽度会很有帮助。幸运的是,用jQuery来做超级简单。
var responsive_viewport = $(window).width();
/* if is below 481px */
if (responsive_viewport < 481) {
alert('Viewport is smaller than 481px.');
} /* end smallest screen */如果你的站点比较大而且已经在线运行了好多年,你或多或少会遇到界面上某个地方有损坏的图片。这个有用的函数能够帮助检测损坏图片并用你中意的图片替换它,并会将此问题通知给访客。
$('img').error(function(){
$(this).attr('src', 'img/broken.png');
});使用jQuery可以很容易去根据你的要求去检测复制、粘贴和剪切的操作。
$("#textA").bind('copy', function() {
$('span').text('copy behaviour detected!')
});
$("#textA").bind('paste', function() {
$('span').text('paste behaviour detected!')
});
$("#textA").bind('cut', function() {
$('span').text('cut behaviour detected!')
});当链接到外部站点时,你可能使用target=”blank”的属性去在新界面中打开站点。问题在于target=”blank”属性并不是W3C有效的属性。让我们用jQuery来补救:下面这段代码将会检测是否链接是外链,如果是,会自动添加一个target=”blank”属性。
var root = location.protocol + '//' + location.host;
$('a').not(':contains(root)').click(function(){
this.target = "_blank";
});另一个“经典的”代码,它要放到你的工具箱里,因为你会不时地要实现它。
$(document).ready(function(){
$(".thumbs img").fadeTo("slow", 0.6); // This sets the opacity of the thumbs to fade down to 60% when the page loads
$(".thumbs img").hover(function(){
$(this).fadeTo("slow", 1.0); // This should set the opacity to 100% on hover
},function(){
$(this).fadeTo("slow", 0.6); // This should set the opacity back to 60% on mouseout
});
});在很多表格领域都不需要空格键,例如,电子邮件,用户名,密码等等等。这里是一个简单的技巧可以用于在选定输入中禁止空格键。
$('input.nospace').keydown(function(e) {
if (e.keyCode == 32) {
return false;
}
});使用CSS3制作手风琴效果
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
.accordionMenu {
background-color: #fff;
color: #424242;
font: 12px Arial, Verdana, sans-serif;
margin: 0 auto;
padding: 10px;
width: 500px;
}
.accordionMenu h2 {
margin: 5px 0;
padding: 0;
position: relative;
}
.accordionMenu h2:before {
border: 5px solid #fff;
border-color: #fff transparent transparent;
content: "";
height: 0;
position: absolute;
right: 10px;
top: 15px;
width: 0;
}
.accordionMenu h2 a {
background: #8f8f8f;
background: -moz-linear-gradient(top, #cecece, #8f8f8f);
background: -webkit-gradient(linear, left top, left bottom, from(#cecece), to(#8f8f8f));
background: -webkit-linear-gradient(top, #cecece, #8f8f8f);
background: -o-linear-gradient(top, #cecece, #8f8f8f);
background: linear-gradient(top, #cecece, #8f8f8f);
border-radius: 5px;
color: #424242;
display: block;
font-style: 13px;
font-weight: normal;
margin: 0;
padding: 10px 10px;
text-shadow: 2px 2px 2px #aeaeae;
text-decoration: none;
}
.accordionMenu :target h2 a,
.accordionMenu h2 a:focus,
.accordionMenu h2 a:hover,
.accordionMenu h2 a:active {
background: #2288dd;
background: -moz-linear-gradient(top, #6bb2ff, #2288dd);
background: -webkit-gradient(linear, left top, left bottom, from(#6bb2ff), to(#2288dd));
background: -webkit-linear-gradient(top, #6bb2ff, #2288dd);
background: -o-linear-gradient(top, #6bb2ff, #2288dd);
background: linear-gradient(top, #6bb2ff, #2288dd);
color: #fff;
}
.accordionMenu p {
margin: 0;
height: 0;
overflow: hidden;
padding: 0 10px;
-moz-transition: height 0.5s ease-in;
-webkit-transition: height 0.5s ease-in;
-o-transition: height 0.5s ease-in;
transition: height 0.5s ease-in;
}
.accordionMenu :target p {
height: 100px;
overflow: auto;
}
.accordionMenu :target h2:before {
border-color: transparent transparent transparent #fff;
}
</style>
</head>
<body>
<div class="accordionMenu">
<div class="menuSection" id="brand">
<h2><a href="#brand">Brand</a></h2>
<p>Lorem ipsum dolor...</p>
</div>
<div class="menuSection" id="promotion">
<h2><a href="#promotion">Promotion</a></h2>
<p>Lorem ipsum dolor sit amet...</p>
</div>
<div class="menuSection" id="event">
<h2><a href="#event">Event</a></h2>
<p>Lorem ipsum dolor sit amet...</p>
</div>
</div>
</body>
</html>循环就是事物周而复始的变化,循环结构使得一部分代码按照次数或一定条件反复执行。
循环结构一般分为三大类:
for循环while循环do...while循环for循环的格式如下:
for(初始化语句;判断条件语句;控制条件语句) {
// 循环体
}while循环语句的格式:
while(判断条件语句) {
循环体语句;
控制条件语句;
}do...while循环语句的格式:
do {
循环体语句;
控制条件语句;
} while(判断条件语句);注意: while小括号后的分号不可以省略,do...while循环至少会执行一次。
break表示中断语句执行,它可以直接跳出循环。
continue表示中断本次循环,直接进行下一次循环
apply 方法: 它能劫持另外一个对象的方法,继承另外一个对象的属性
Function.apply(obj,args) 能接受两个参数:
obj : 这个对象将代替 Function 类中的 this 对象
args: 这是个数组,它将作为参数传递给 Function 类
示例代码:
<script>
/* 定义一个人类 */
function Person(name, age){
this.name = name;
this.age = age;
}
/* 定义一个学生类 */
function Student(name, age, grade){
Person.apply(this, arguments);
this.grade = grade;
}
/* 创建一个学生对象 */
var student = new Student('LZ', 40, '一年级');
//测试
alert("name:"+student.name+"\n"+"age:"+student.age+"\n"+"grade:"+student.grade);
//大家可以看到测试结果name:LZ age:40 grade:一年级
//学生类里面我没有给name和age属性赋值啊,为什么又存在这两个属性的值呢,这个就
//是apply的神奇之处.
</script>Person.apply(this,arguments)
this : 在创建对象时这个代表 student
arguments : 是一个数组,也就是 [“LZ”,”40”,”一年级”]
用 student 去执行 Person 这个类里面的内容,在 Person 这个类里面存在 this.name 等之类的语句,这样就将属性创建到了 student 对象里面
apply的一些其他巧妙用法:
Math.max 可以实现得到数组中最大的一项, 因为 Math.max 参数里面不支持 Math.max([param1,param2]) 也就是数组
但是它支持 Math.max(param1,param2,param3…) ,所以可以根据刚才 apply 的特点来解决
var max=Math.max.apply(null,array), 这样轻易的可以得到一个数组中最大的一项
这块在调用的时候第一个参数给了一个null,这个是因为没有对象去调用这个方法,我只需要用这个方法帮我运算,得到返回的结果就行,.所以直接传递了一个null过去
Math.min 可以实现得到数组中最小的一项
同样和max是一个**
var min=Math.min.apply(null,array)
Array.prototype.push 可以实现两个数组合并
同样 push 方法没有提供 push 一个数组,但是它提供了
push(param1,param,…paramN) 所以同样也可以通过 apply 来装换一下这个数组,即:
var arr1 = new Array("1","2","3");
var arr2 = new Array("4","5","6");
Array.prototype.push.apply(arr1, arr2);也可以这样理解,arr1调用了push方法,参数是通过apply将数组装换为参数列表的集合
做了多年的桌面浏览器应用开发,到了新公司后,接触到了移动web,下面把一些心得记录下来,目前还不完整,待后续完善总结一篇更完整的
<meta content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0;" name="viewport" />这个想必大家都知道,当页面在手机上显示时,增加这个meta可以让页面强制让文档的宽度与设备的宽度保持1:1,并且文档最大的宽度比例是1.0,且不允许用户点击屏幕放大浏览。
<meta content="telephone=no" name="format-detection" />
<meta content="email=no" name="format-detection" />这两个属性分别对ios上自动识别电话和android上自动识别邮箱做了限制。
window.scrollX
window.scrollY 桌面浏览器中想要获取滚动条的值是通过document.scrollTop和document.scrollLeft得到的,但在iOS中你会发现这两个属性是未定义的,为什么呢?
因为在iOS中没有滚动条的概念,在Android中通过这两个属性可以正常获取到滚动条的值,那么在iOS中我们该如何获取滚动条的值呢?就是上面两个属性,但是事实证明android也支持这属性,所以索性都用woindow.scroll.
-webkit-user-select: none禁止用户选择文本,ios和android都支持
-webkit-appearance: none亲测,可以同时屏蔽输入框怪异的内阴影,解决iOS下无法修改按钮样式,测试还发现一个小问题就是,加了上面的属性后,iOS下默认还是带有圆角的,不过可以使用border-radius属性修改。
element {
width: 100%;
padding-left: 10px;
box-sizing: border-box;
-webkit-box-sizing: border-box;
border: 1px solid blue;
}那我想要一个元素100%显示,又必须有一个固定的padding-left/padding-right,还有1px的边框,怎么办?
这样编写代码必然导致出现横向滚动条,肿么办?
要相信问题就是用来解决的。这时候伟大的css3为我们提供了box-sizing属性,对于这个属性的具体解释不做赘述(想深入了解的同学可以到w3school查看,要知道自己动手会更容易记忆)
p {
overflow: hidden;
text-overflow: ellipsis;
display: - webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
}Webkit支持一个名为-webkit-line-clamp的属性,参见链接,也就是说这个属性并不是标准的一部分,可能是Webkit内部使用的,或者被弃用的属性。需要注意的是display需要设置成box,
-webkit-line-clamp表示需要显示几行。
selector {
background-image: url(no-image-set. png );
background: image-set(url(foo-lowres.png ) 1x, url(foo-highres.png ) 2x) center;
}image-set的语法,类似于不同的文本,图像也会显示成不同的:
不支持image-set:在不支持image-set的浏览器下,他会支持background-image图像,也就是说不支持image-set的浏览器下,他们解析background-image中的背景图像;
支持image-set:如果你的浏览器支持image-sete,而且是普通显屏下,此时浏览器会选择image-set中的@1x背景图像;
Retina屏幕下的image-set:如果你的浏览器支持image-set,而且是在Retina屏幕下,此时浏览器会选择image-set中的@2x背景图像。
if (window.DeviceMotionEven ) {
window.addEventListener('devicemotion', deviceMotionHandler, false );
}
var speed = 30; //speed
var x = y = z = lastX = lastY = lastZ = 0;
function deviceMotionHandler(eventData) {
var acceleration = event.accelerationIncludingGravity;
x = acceleration.x;
y = acceleration.y;
z = acceleration.z;
if (Math.abs(x - lastX) > speed || Math.abs(y - lastY) > speed || Math.abs (z - lastZ) > speed) {
//简单的摇一摇触发代码
alert(1);
}
lastX = x;
lastY = y;
lastZ = z;
}关于deviceMotionEvent是HTML5新增的事件,用来检测手机重力感应效果具体可参考http://w3c.github.io/deviceorientation/spec-source-orientation.html
touchstart // 当手指接触屏幕时触发
touchmove // 当已经接触屏幕的手指开始移动后触发
touchend // 当手指离开屏幕时触发
touchcancel // 当某种touch事件非正常结束时触发
这4个事件的触发顺序为:
touchstart -> touchmove -> touchend ->touchcancel
对于某些android系统touch的bug:
比如手指在屏幕由上向下拖动页面时,理论上是会触发一个 touchstart ,很多次 touchmove ,和最终的 touchend ,可是在android 4.0上,touchmove只被触发一次,触发时间和touchstart 差不多,而 touchend 直接没有被触发。
这是一个非常严重的bug,在google Issue已有不少人提出 ,这个很蛋疼的bug是在模拟下拉刷新是遇到的尤其当 touchmove 的dom节点数量变多时比出现,当时解决办法就是用settimeout来稀释touchmove。
click 事件因为要等待双击确认,会有 300ms 的延迟,体验并不是很好。
开发者大多数会使用封装的 tap 事件来代替 click 事件,所谓的 tap 事件由 touchstart 事件 + touchmove 判断 + touchend 事件封装组成。
<!DOCTYPE html>
<head>
<style>
input {
position: fixed;
top: 0;
left: 0;
}
</style>
</head>
<body>
<div class="header">
<form action="">
<label> Testfield :
<input type="text" />
</label>
</form>
</div>
</body>
</html>在ios里面,当一个文本框的样式为fixed时候,如果这个文本框获得焦点,它的位置就会乱掉,由于ios里面做了自适应居中,这个fixed的文本框会跑到页面中间。类似:
解决办法有两个:
可以在文本框获得焦点的时候将fixed改为absolute,失去焦点时在改回fixed,但是这样会让屏幕有上下滑动的体验不太好。
.fixfixed {
position: absolute;
}
$(document).on('focus', 'input', function(e) {
$this.addClass('fixfixed');
}).on('blur', 'input', function(e) {
$this.removeClass('fixfixed');
});还有一种就是用一个假的fixed的文本框放在页面顶部,一个absolute的文本框隐藏在页面顶部,当fixed的文本框获得焦点时候将其隐藏,然后显示absolute的文本框,当失去焦点时,在把absolute的文本框隐藏,fixed的文本框显示。
.fixfixed {
position: absolute;
}
$(document).on('focus', 'input', function(e) {
$absolute.show();
$this.hide();
}).on('blur', 'input', function(e) {
$fixed.show();
$this.hide();
});最后一种就是顶部的input不参与滚动,只让其下面滚动。
position:sticky是一个新的css3属性,它的表现类似position:relative和position:fixed的合体,在目标区域在屏幕中可见时,它的行为就像position:relative; 而当页面滚动超出目标区域时,它的表现就像position:fixed,它会固定在目标位置。
.sticky {
position: -webkit-sticky;
position: sticky;
top: 15px;
}浏览器兼容性:
由于这是一个全新的属性,以至于到现在都没有一个规范,W3C也刚刚开始讨论它,而现在只有webkit nightly版本和chrome 开发版(Chrome 23.0.1247.0+ Canary)才开始支持它。
另外需要注意的是,如果同时定义了left和right值,那么left生效,right会无效,同样,同时定义了top和bottom,top赢~~
简单的说,由于在移动端我们经常会使用tap(touchstart)事件来替换掉click事件,那么就会有一种场景是:
<div i ="mengceng"></div>
<a href="www.qq.com">www.qq.com</a>div是绝对定位的蒙层z-index高于a,而a标签是页面中的一个链接,我们给div绑定tap事件:
$('#mengceng').on('tap', function() {
$('#mengceng').hide();
});我们点击蒙层时 div正常消失,但是当我们在a标签上点击蒙层时,发现a链接被触发,这就是所谓的点透事件。
原因:
touchstart 早于 touchend 早于 click。亦即click的触发是有延迟的,这个时间大概在300ms左右,也就是说我们tap触发之后蒙层隐藏,此时click还没有触发,300ms之后由于蒙层隐藏,我们的click触发到了下面的a链接上。
解决办法:
touch事件来替换click事件。click的preventDefaultu在移动端,网络请求是很珍贵的资源,尤其在2g或者3g网络下,所以能不发请求的资源都尽量不要发,对于一些小图片icon之类的,可以将图片用base64编码,来减少网络请求。
<input type=”file”>的 accept 属性
<!-- 选择照片 -->
<input type=file accept="image/*">
<!-- 选择视频 -->
<input type=file accept="video/*">我们在制作动画效果时经常会想要改版元素的top或者left来让元素动起来,在pc端还好但是移动端就会有较大的卡顿感,这么我们需要使用css3的 transform: translate3d 来替换,
此效果可以让浏览器开启gpu加速,渲染更流畅,但是笔着实验时在ios上体验良好,但在一些低端android机型可能会出现意想不到的效果。
在iOS上如果你想让一个元素拥有像 Native 的滚动效果,你可以这样做:
.div {
overflow: auto;
-webkit-overflow-scrolling: touch;
}经笔着测试,此效果在不同的ios系统表现不一致,
对于局部滚动,ios8以上,不加此效果,滚动的超级慢,ios8一下,不加此效果,滚动还算比较流畅
对于body滚动,ios8以上,不加此效果同样拥有弹性滚动效果。
android
::-webkit-scrollbar {
opacity: 0;
}ios
使用一个稍微高一些div包裹住这个有滚动条的div然后设置 overflow:hidden 挡住之
.wrap {
height: 100px;
overflow: hidden;
}
.box {
width: 100 %;
height: -webkit-calc(100 % + 5px);
overflow-x: auto;
overflow-y: hidden;
- webkit-overflow-scrolling: touch;
}<div class="wrap" >
<div class="box"></div>
</div>input: focus
::-webkit-input-placeholder {
opacity: 0;
}终端用户响应的时间中,有80%用于下载各项内容。这部分时间包括下载页面中的图像、样式表、脚本、Flash等。通过减少页面中的元素可以减少HTTP请求的次数。这是提高网页速度的关键步骤。
减少页面组件的方法其实就是简化页面设计。那么有没有一种方法既能保持页面内容的丰富性又能达到加快响应时间的目的呢?这里有几条减少HTTP请求次数同时又可能保持页面内容丰富的技术。
合并文件是通过把所有的脚本放到一个文件中来减少HTTP请求的方法,如可以简单地把所有的CSS文件都放入一个样式表中。当脚本或者样式表在不同页面中使用时需要做不同的修改,这可能会相对麻烦点,但即便如此也要把这个方法作为改善页面性能的重要一步。
CSS Sprites是减少图像请求的有效方法。把所有的背景图像都放到一个图片文件中,然后通过CSS的 background-image 和 background-position 属性来显示图片的不同部分;
图片地图是把多张图片整合到一张图片中。虽然文件的总体大小不会改变,但是可以减少HTTP请求次数。图片地图只有在图片的所有组成部分在页面中是紧挨在一起的时候才能使用,如导航栏。确定图片的坐标和可能会比较繁琐且容易出错,同时使用图片地图导航也不具有可读性,因此不推荐这种方法;
内联图像是使用 data:URL scheme 的方法把图像数据加载页面中。这可能会增加页面的大小。把内联图像放到样式表(可缓存)中可以减少HTTP请求同时又避免增加页面文件的大小。但是内联图像现在还没有得到主流浏览器的支持。
减少页面的HTTP请求次数是你首先要做的一步。这是改进首次访问用户等待时间的最重要的方法。如同Tenni Theurer的他的博客Browser Cahe Usage - Exposed!中所说,HTTP请求在无缓存情况下占去了40%到60%的响应时间。让那些初次访问你网站的人获得更加快速的体验吧!
域名系统(DNS)提供了域名和IP的对应关系,就像本中人名和他们的的关系一样。当你在浏览器地址栏中输入www.dudo.org 时,DNS解析服务器就会返回这个域名对应的IP地址。DNS解析的过程同样也是需要时间的。一般情况下返回给定域名对应的IP地址会花费20到120毫秒的时间。而且在这个过程中浏览器什么都不会做直到DNS查找完毕。
缓存DNS查找可以改善页面性能。这种缓存需要一个特定的缓存服务器,这种服务器一般属于用户的ISP提供商或者本地局域网控制,但是它同样会在用户使用的计算机上产生缓存。DNS信息会保留在操作系统的DNS缓存中(微软Windows系统中DNS Client Service)。大多数浏览器有独立于操作系统以外的自己的缓存。由于浏览器有自己的缓存记录,因此在一次请求中它不会受到操作系统的影响。
Internet Explorer默认情况下对DNS查找记录的缓存时间为30分钟,它在注册表中的键值为DnsCacheTimeout。Firefox对DNS的查找记录缓存时间为1分钟,它在配置文件中的选项为network.dnsCacheExpiration(Fasterfox把这个选项改为了1小时)。
当客户端中的DNS缓存都为空时(浏览器和操作系统都为空),DNS查找的次数和页面中主机名的数量相同。这其中包括页面中URL、图片、脚本文件、样式表、Flash对象等包含的主机名。减少主机名的数量可以减少DNS查找次数。
减少主机名的数量还可以减少页面中并行下载的数量。减少DNS查找次数可以节省响应时间,但是减少并行下载却会增加响应时间。我的指导原则是把这些页面中的内容分割成至少两部分但不超过四部分。这种结果就是在减少DNS查找次数和保持较高程度并行下载两者之间的权衡了。
跳转是使用301和302代码实现的。下面是一个响应代码为301的HTTP头:
HTTP/1.1 301 Moved Permanently
Location: http://example.com/newuri
Content-Type: text/html
浏览器会把用户指向到Location中指定的URL。头文件中的所有信息在一次跳转中都是必需的,内容部分可以为空。不管他们的名称,301和302响应都不会被缓存除非增加一个额外的头选项,如Expires或者Cache-Control来指定它缓存。<meat /> 元素的刷新标签和JavaScript也可以实现URL的跳转,但是如果你必须要跳转的时候,最好的方法就是使用标准的3XXHTTP状态代码,这主要是为了确保“后退”按钮可以正确地使用。
但是要记住跳转会降低用户体验。在用户和HTML文档中间增加一个跳转,会拖延页面中所有元素的显示,因为在HTML文件被加载前任何文件(图像、Flash等)都不会被下载。
有一种经常被网页开发者忽略却往往十分浪费响应时间的跳转现象。这种现象发生在当URL本该有斜杠(/)却被忽略掉时。例如,当我们要访问 http://astrology.yahoo.com/astrology 时,实际上返回的是一个包含301代码的跳转,它指向的是 http://astrology.yahoo.com/astrology/ (注意末尾的斜杠)。在Apache服务器中可以使用 Alias 或者 mod_rewrite 或者 the DirectorySlash 来避免。
连接新网站和旧网站是跳转功能经常被用到的另一种情况。这种情况下往往要连接网站的不同内容然后根据用户的不同类型(如浏览器类型、用户账号所属类型)来进行跳转。使用跳转来实现两个网站的切换十分简单,需要的代码量也不多。尽管使用这种方法对于开发者来说可以降低复杂程度,但是它同样降低用户体验。一个可替代方法就是如果两者在同一台服务器上时使用 Alias 和 mod_rewrite 和实现。如果是因为域名的不同而采用跳转,那么可以通过使用 Alias 或者 mod_rewirte 建立CNAME(保存一个域名和另外一个域名之间关系的DNS记录)来替代。
Ajax经常被提及的一个好处就是由于其从后台服务器传输信息的异步性而为用户带来的反馈的即时性。但是,使用Ajax并不能保证用户不会在等待异步的JavaScript和XML响应上花费时间。在很多应用中,用户是否需要等待响应取决于Ajax如何来使用。例如,在一个基于Web的Email客户端中,用户必须等待Ajax返回符合他们条件的邮件查询结果。记住一点,“异步”并不异味着“即时”,这很重要。
为了提高性能,优化Ajax响应是很重要的。提高Ajxa性能的措施中最重要的方法就是使响应具有可缓存性,具体的讨论可以查看 Add an Expires or a Cache-Control Header。其它的几条规则也同样适用于Ajax:
让我们来看一个例子:一个Web2.0的Email客户端会使用Ajax来自动完成对用户地址薄的下载。如果用户在上次使用过Email web应用程序后没有对地址薄作任何的修改,而且Ajax响应通过 Expire 或者 Cacke-Control 头来实现缓存,那么就可以直接从上一次的缓存中读取地址薄了。必须告知浏览器是使用缓存中的地址薄还是发送一个新的请求。这可以通过为读取地址薄的Ajax URL增加一个含有上次编辑时间的时间戳来实现,例如,&t=11900241612等。如果地址薄在上次下载后没有被编辑过,时间戳就不变,则从浏览器的缓存中加载从而减少了一次HTTP请求过程。如果用户修改过地址薄,时间戳就会用来确定新的URL和缓存响应并不匹配,浏览器就会重要请求更新地址薄。
即使你的Ajxa响应是动态生成的,哪怕它只适用于一个用户,那么它也应该被缓存起来。这样做可以使你的Web2.0应用程序更加快捷。
你可以仔细看一下你的网页,问问自己“哪些内容是页面呈现时所必需首先加载的?哪些内容和结构可以稍后再加载?
把整个过程按照 onload 事件分隔成两部分,JavaScript是一个理想的选择。例如,如果你有用于实现拖放和动画的JavaScript,那么它就以等待稍后加载,因为页面上的拖放元素是在初始化呈现之后才发生的。其它的例如隐藏部分的内容(用户操作之后才显现的内容)和处于折叠部分的图像也可以推迟加载
工具可以节省你的工作量:YUI Image Loader可以帮你推迟加载折叠部分的图片,YUI Get utility是包含JS和 CSS的便捷方法。比如你可以打开Firebug的Net选项卡看一下Yahoo的首页。
当性能目标和其它网站开发实践一致时就会相得益彰。这种情况下,通过程序提高网站性能的方法告诉我们,在支持JavaScript的情况下,可以先去除用户体验,不过这要保证你的网站在没有JavaScript也可以正常运行。在确定页面运行正常后,再加载脚本来实现如拖放和动画等更加花哨的效果。
预加载和后加载看起来似乎恰恰相反,但实际上预加载是为了实现另外一种目标。预加载是在浏览器空闲时请求将来可能会用到的页面内容(如图像、样式表和脚本)。使用这种方法,当用户要访问下一个页面时,页面中的内容大部分已经加载到缓存中了,因此可以大大改善访问速度。
下面提供了几种预加载方法:
无条件加载:触发onload事件时,直接加载额外的页面内容。以Google.com为例,你可以看一下它的spirit image图像是怎样在onload中加载的。这个spirit image图像在google.com主页中是不需要的,但是却可以在搜索结果页面中用到它。
有条件加载:根据用户的操作来有根据地判断用户下面可能去往的页面并相应的预加载页面内容。在search.yahoo.com中你可以看到如何在你输入内容时加载额外的页面内容。
有预期的加载:载入重新设计过的页面时使用预加载。这种情况经常出现在页面经过重新设计后用户抱怨“新的页面看起来很酷,但是却比以前慢”。问题可能出在用户对于你的旧站点建立了完整的缓存,而对于新站点却没有任何缓存内容。因此你可以在访问新站之前就加载一部内容来避免这种结果的出现。在你的旧站中利用浏览器的空余时间加载新站中用到的图像的和脚本来提高访问速度。
一个复杂的页面意味着需要下载更多数据,同时也意味着JavaScript遍历DOM的效率越慢。比如当你增加一个事件句柄时在500和5000个DOM元素中循环效果肯定是不一样的。
大量的DOM元素的存在意味着页面中有可以不用移除内容只需要替换元素标签就可以精简的部分。你在页面布局中使用表格了吗?你有没有仅仅为了布局而引入更多的 <div> 元素呢?也许会存在一个适合或者在语意是更贴切的标签可以供你使用。
YUI CSS utilities可以给你的布局带来巨大帮助:grids.css可以帮你实现整体布局,font.css和reset.css可以帮助你移除浏览器默认格式。它提供了一个重新审视你页面中标签的机会,比如只有在语意上有意义时才使用 <div>,而不是因为它具有换行效果才使用它。
DOM元素数量很容易计算出来,只需要在Firebug的控制台内输入:
document.getElementsByTagName('*').length 那么多少个DOM元素算是多呢?这可以对照有很好标记使用的类似页面。比如Yahoo!主页是一个内容非常多的页面,但是它只使用了700个元素(HTML标签)。
把页面内容划分成若干部分可以使你最大限度地实现平行下载。由于DNS查找带来的影响你首先要确保你使用的域名数量在2个到4个之间。例如,你可以把用到的HTML内容和动态内容放在www.example.org 上,而把页面各种组件(图片、脚本、CSS)分别存放在 statics1.example.org 和 statics.example.org 上。
你可在Tenni Theurer和Patty Chi合写的文章Maximizing Parallel Downloads in the Carpool Lane找到更多相关信息。
ifrmae元素可以在父文档中插入一个新的HTML文档。了解iframe的工作理然后才能更加有效地使用它,这一点很重要。
<iframe> 优点:
<iframe>的缺点:
HTTP请求时间消耗是很大的,因此使用HTTP请求来获得一个没有用处的响应(例如404没有找到页面)是完全没有必要的,它只会降低用户体验而不会有一点好处。
有些站点把404错误响应页面改为“你是不是要找***”,这虽然改进了用户体验但是同样也会浪费服务器资源(如数据库等)。最糟糕的情况是指向外部JavaScript的链接出现问题并返回404代码。首先,这种加载会破坏并行加载;其次浏览器会把试图在返回的404响应内容中找到可能有用的部分当作JavaScript代码来执行。
用户与你网站服务器的接近程度会影响响应时间的长短。把你的网站内容分散到多个、处于不同地域位置的服务器上可以加快下载速度。但是首先我们应该做些什么呢?
按地域布置网站内容的第一步并不是要尝试重新架构你的网站让他们在分发服务器上正常运行。根据应用的需求来改变网站结构,这可能会包括一些比较复杂的任务,如在服务器间同步Session状态和合并数据库更新等。要想缩短用户和内容服务器的距离,这些架构步骤可能是不可避免的。
要记住,在终端用户的响应时间中有80%到90%的响应时间用于下载图像、样式表、脚本、Flash等页面内容。这就是网站性能黄金守则。和重新设计你的应用程序架构这样比较困难的任务相比,首先来分布静态内容会更好一点。这不仅会缩短响应时间,而且对于内容分发网络来说它更容易实现。
内容分发网络(Content Delivery Network,CDN)是由一系列分散到各个不同地理位置上的Web服务器组成的,它提高了网站内容的传输速度。用于向用户传输内容的服务器主要是根据和用户在网络上的靠近程度来指定的。例如,拥有最少网络跳数(network hops)和响应速度最快的服务器会被选定。
一些大型的网络公司拥有自己的CDN,但是使用像Akamai Technologies,Mirror Image Internet, 或者Limelight Networks这样的CDN服务成本却非常高。对于刚刚起步的企业和个人网站来说,可能没有使用CDN的成本预算,但是随着目标用户群的不断扩大和更加全球化,CDN就是实现快速响应所必需的了。以Yahoo来说,他们转移到CDN上的网站程序静态内容节省了终端用户20%以上的响应时间。使用CDN是一个只需要相对简单地修改代码实现显著改善网站访问速度的方法。
Expires 或 Cache-Control这条守则包括两方面的内容:
对于静态内容:设置文件头过期时间 Expires 的值为 Never expire(永不过期)
对于动态内容:使用恰当的 Cache-Control 文件头来帮助浏览器进行有条件的请求
网页内容设计现在越来越丰富,这就意味着页面中要包含更多的脚本、样式表、图片和Flash。第一次访问你页面的用户就意味着进行多次的HTTP请求,但是通过使用 Expires 文件头就可以使这样内容具有缓存性。它避免了接下来的页面访问中不必要的HTTP请求。Expires 文件头经常用于图像文件,但是应该在所有的内容都使用他,包括脚本、样式表和Flash等。
浏览器(和代理)使用缓存来减少HTTP请求的大小和次数以加快页面访问速度。Web服务器在HTTP响应中使用Expires文件头来告诉客户端内容需要缓存多长时间。下面这个例子是一个较长时间的 Expires文件头,它告诉浏览器这个响应直到2010年4月15日才过期。
Expires: Thu, 15 Apr 2010 20:00:00 GMT 如果你使用的是Apache服务器,可以使用 ExpiresDefault 来设定相对当前日期的过期时间。下面这个例子是使用 ExpiresDefault 来设定请求时间后10年过期的文件头:
ExpiresDefault "access plus 10 years" 要切记,如果使用了 Expires 文件头,当页面内容改变时就必须改变内容的文件名。依Yahoo!来说我们经常使用这样的步骤:在内容的文件名中加上版本号,如yahoo_2.0.6.js。
使用Expires文件头只有会在用户已经访问过你的网站后才会起作用。当用户首次访问你的网站时这对减少HTTP请求次数来说是无效的,因为浏览器的缓存是空的。因此这种方法对于你网站性能的改进情况要依据他们“预缓存”存在时对你页面的点击频率(“预缓存”中已经包含了页面中的所有内容)。
Yahoo!建立了一套测量方法,我们发现所有的页面浏览量中有75~85%都有“预缓存”。通过使用 Expires 文件头,增加了缓存在浏览器中内容的数量,并且可以在用户接下来的请求中再次使用这些内容,这甚至都不需要通过用户发送一个字节的请求。
网络传输中的HTTP请求和应答时间可以通过前端机制得到显著改善。的确,终端用户的带宽、互联网提供者、与对等交换点的靠近程度等都不是网站开发者所能决定的。但是还有其他因素影响着响应时间。通过减小HTTP响应的大小可以节省HTTP响应时间。
从HTTP/1.1开始,web客户端都默认支持HTTP请求中有 Accept-Encoding 文件头的压缩格式:
Accept-Encoding: gzip, deflate 如果web服务器在请求的文件头中检测到上面的代码,就会以客户端列出的方式压缩响应内容。Web服务器把压缩方式通过响应文件头中的 Content-Encoding 来返回给浏览器。
Content-Encoding: gzip Gzip是目前最流行也是最有效的压缩方式。这是由GNU项目开发并通过RFC 1952来标准化的。另外仅有的一个压缩格式是deflate,但是它的使用范围有限效果也稍稍逊色。
Gzip大概可以减少70%的响应规模。目前大约有90%通过浏览器传输的互联网交换支持gzip格式。如果你使用的是Apache,gzip模块配置和你的版本有关:Apache 1.3使用mod_zip,而Apache 2.x使用moflate。
浏览器和代理都会存在这样的问题:浏览器期望收到的和实际接收到的内容会存在不匹配的现象。幸好,这种特殊情况随着旧式浏览器使用量的减少在减少。Apache模块会通过自动添加适当的Vary响应文件头来避免这种状况的出现。
服务器根据文件类型来选择需要进行gzip压缩的文件,但是这过于限制了可压缩的文件。大多数web服务器会压缩HTML文档。对脚本和样式表进行压缩同样也是值得做的事情,但是很多web服务器都没有这个功能。实际上,压缩任何一个文本类型的响应,包括XML和JSON,都值得的。图像和PDF文件由于已经压缩过了所以不能再进行gzip压缩。如果试图gizp压缩这些文件的话不但会浪费CPU资源还会增加文件的大小。
Gzip压缩所有可能的文件类型是减少文件体积增加用户体验的简单方法。
Entity tags(ETags)(实体标签)是web服务器和浏览器用于判断浏览器缓存中的内容和服务器中的原始内容是否匹配的一种机制(“实体”就是所说的“内容”,包括图片、脚本、样式表等)。增加ETag为实体的验证提供了一个比使用“last-modified date(上次编辑时间)”更加灵活的机制。Etag是一个识别内容版本号的唯一字符串。唯一的格式限制就是它必须包含在双引号内。原始服务器通过含有ETag文件头的响应指定页面内容的ETag。
HTTP/1.1 200 OK
Last-Modified: Tue, 12 Dec 2006 03:03:59 GMT
ETag: "10c24bc-4ab-457e1c1f"
Content-Length: 12195 稍后,如果浏览器要验证一个文件,它会使用 If-None-Match 文件头来把ETag传回给原始服务器。在这个例子中,如果ETag匹配,就会返回一个304状态码,这就节省了12195字节的响应。
GET /i/yahoo.gif HTTP/1.1
Host: us.yimg.com
If-Modified-Since: Tue, 12 Dec 2006 03:03:59 GMT
If-None-Match: "10c24bc-4ab-457e1c1f"
HTTP/1.1 304 Not Modified ETag的问题在于,它是根据可以辨别网站所在的服务器的具有唯一性的属性来生成的。当浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时ETag就会不匹配,这种情况对于使用服务器组和处理请求的网站来说是非常常见的。默认情况下,Apache和IIS都会把数据嵌入ETag中,这会显著减少多服务器间的文件验证冲突。
Apache 1.3和2.x中的ETag格式为 inode-size-timestamp。即使某个文件在不同的服务器上会处于相同的目录下,文件大小、权限、时间戳等都完全相同,但是在不同服务器上他们的内码也是不同的。
IIS 5.0和IIS 6.0处理ETag的机制相似。IIS中的ETag格式为 Filetimestamp:ChangeNumber 。用ChangeNumber来跟踪IIS配置的改变。网站所用的不同IIS服务器间ChangeNumber也不相同。 不同的服务器上的Apache和IIS即使对于完全相同的内容产生的ETag在也不相同,用户并不会接收到一个小而快的304响应;相反他们会接收一个正常的200响应并下载全部内容。如果你的网站只放在一台服务器上,就不会存在这个问题。但是如果你的网站是架设在多个服务器上,并且使用Apache和IIS产生默认的ETag配置,你的用户获得页面就会相对慢一点,服务器会传输更多的内容,占用更多的带宽,代理也不会有效地缓存你的网站内容。即使你的内容拥有Expires文件头,无论用户什么时候点击“刷新”或者“重载”按钮都会发送相应的GET请求。
如果你没有使用ETag提供的灵活的验证模式,那么干脆把所有的ETag都去掉会更好。Last-Modified文件头验证是基于内容的时间戳的。去掉ETag文件头会减少响应和下次请求中文件的大小。微软的这篇支持文稿讲述了如何去掉ETag。在Apache中,只需要在配置文件中简单添加下面一行代码就可以了:
FileETag none
当用户请求一个页面时,无论如何都会花费200到500毫秒用于后台组织HTML文件。在这期间,浏览器会一直空闲等待数据返回。在PHP中,你可以使用 flush() 方法,它允许你把已经编译的好的部分HTML响应文件先发送给浏览器,这时浏览器就会可以下载文件中的内容(脚本等)而后台同时处理剩余的HTML页面。这样做的效果会在后台烦恼或者前台较空闲时更加明显。
输出缓冲应用最好的一个地方就是紧跟在 <head /> 之后,因为HTML的头部分容易生成而且头部往往包含CSS和JavaScript文件,这样浏览器就可以在后台编译剩余HTML的同时并行下载它们。 例子:
<!-- css, js -->
</head>
<?php flush(); ?>
<body>
<!-- content -->为了证明使用这项技术的好处,Yahoo!搜索率先研究并完成了用户测试。
Yahoo!Mail团队发现,当使用 XMLHttpRequest 时,浏览器中的POST方法是一个“两步走”的过程:首先发送文件头,然后才发送数据。因此使用GET最为恰当,因为它只需发送一个TCP包(除非你有很多cookie)。IE中URL的最大长度为2K,因此如果你要发送一个超过2K的数据时就不能使用GET了。
一个有趣的不同就是POST并不像GET那样实际发送数据。根据HTTP规范,GET意味着“获取”数据,因此当你仅仅获取数据时使用GET更加有意义(从语意上讲也是如此),相反,发送并在服务端保存数据时使用POST。
在研究Yahoo!的性能表现时,我们发现把样式表放到文档的 <head /> 内部似乎会加快页面的下载速度。这是因为把样式表放到 <head /> 内会使页面有步骤的加载显示。
注重性能的前端服务器往往希望页面有秩序地加载。同时,我们也希望浏览器把已经接收到内容尽可能显示出来。这对于拥有较多内容的页面和网速较慢的用户来说特别重要。向用户返回可视化的反馈,比如进程指针,已经有了较好的研究并形成了正式文档。在我们的研究中HTML页面就是进程指针。当浏览器有序地加载文件头、导航栏、顶部的logo等对于等待页面加载的用户来说都可以作为可视化的反馈。这从整体上改善了用户体验。
把样式表放在文档底部的问题是在包括Internet Explorer在内的很多浏览器中这会中止内容的有序呈现。浏览器中止呈现是为了避免样式改变引起的页面元素重绘。用户不得不面对一个空白页面。
HTML规范清楚指出样式表要放包含在页面的 <head /> 区域内:“和 <a /> 不同, <link />只能出现在文档的 <head /> 区域内,尽管它可以多次使用它”。无论是引起白屏还是出现没有样式化的内容都不值得去尝试。最好的方案就是按照HTML规范在文档 <head /> 内加载你的样式表。
CSS表达式是动态设置CSS属性的强大(但危险)方法。Internet Explorer从第5个版本开始支持CSS表达式。下面的例子中,使用CSS表达式可以实现隔一个小时切换一次背景颜色:
background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" ); 如上所示,expression中使用了JavaScript表达式。CSS属性根据JavaScript表达式的计算结果来设置。expression方法在其它浏览器中不起作用,因此在跨浏览器的设计中单独针对Internet Explorer设置时会比较有用。
表达式的问题就在于它的计算频率要比我们想象的多。不仅仅是在页面显示和缩放时,就是在页面滚动、乃至移动鼠标时都会要重新计算一次。给CSS表达式增加一个计数器可以跟踪表达式的计算频率。在页面中随便移动鼠标都可以轻松达到10000次以上的计算量。
一个减少CSS表达式计算次数的方法就是使用一次性的表达式,它在第一次运行时将结果赋给指定的样式属性,并用这个属性来代替CSS表达式。如果样式属性必须在页面周期内动态地改变,使用事件句柄来代替CSS表达式是一个可行办法。如果必须使用CSS表达式,一定要记住它们要计算成千上万次并且可能会对你页面的性能产生影响。
很多性能规则都是关于如何处理外部文件的。但是,在你采取这些措施前你可能会问到一个更基本的问题:JavaScript和CSS是应该放在外部文件中呢还是把它们放在页面本身之内呢?
在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏览器中产生缓存。内置在HTML文档中的JavaScript和CSS则会在每次请求中随HTML文档重新下载。这虽然减少了HTTP请求的次数,却增加了HTML文档的大小。从另一方面来说,如果外部文件中的JavaScript和CSS被浏览器缓存,在没有增加HTTP请求次数的同时可以减少HTML文档的大小。
关键问题是,外部JavaScript和CSS文件缓存的频率和请求HTML文档的次数有关。虽然有一定的难度,但是仍然有一些指标可以一测量它。如果一个会话中用户会浏览你网站中的多个页面,并且这些页面中会重复使用相同的脚本和样式表,缓存外部文件就会带来更大的益处。
许多网站没有功能建立这些指标。对于这些网站来说,最好的坚决方法就是把JavaScript和CSS作为外部文件引用。比较适合使用内置代码的例外就是网站的主页,如Yahoo!主页和My Yahoo!。主页在一次会话中拥有较少(可能只有一次)的浏览量,你可以发现内置JavaScript和CSS对于终端用户来说会加快响应时间。
对于拥有较大浏览量的首页来说,有一种技术可以平衡内置代码带来的HTTP请求减少与通过使用外部文件进行缓存带来的好处。其中一个就是在首页中内置JavaScript和CSS,但是在页面下载完成后动态下载外部文件,在子页面中使用到这些文件时,它们已经缓存到浏览器了。
精简是指从去除代码不必要的字符减少文件大小从而节省下载时间。
消减代码时,所有的注释、不需要的空白字符(空格、换行、tab缩进)等都要去掉。在JavaScript中,由于需要下载的文件体积变小了从而节省了响应时间。精简JavaScript中目前用到的最广泛的两个工具是JSMin和YUI Compressor。YUI Compressor还可用于精简CSS。
混淆是另外一种可用于源代码优化的方法。这种方法要比精简复杂一些并且在混淆的过程更易产生问题。在对美国前10大网站的调查中发现,精简也可以缩小原来代码体积的21%,而混淆可以达到25%。尽管混淆法可以更好地缩减代码,但是对于JavaScript来说精简的风险更小。
除消减外部的脚本和样式表文件外, <script> 和 <style> 代码块也可以并且应该进行消减。即使你用Gzip压缩过脚本和样式表,精简这些文件仍然可以节省5%以上的空间。由于JavaScript和CSS的功能和体积的增加,消减代码将会获得益处。
<link> 代替@import前面的最佳实现中提到CSS应该放置在顶端以利于有序加载呈现。
在IE中,页面底部 @import 和使用 <link> 作用是一样的,因此最好不要使用它。
IE独有属性 AlphaImageLoader 用于修正7.0以下版本中显示PNG图片的半透明效果。这个滤镜的问题在于浏览器加载图片时它会终止内容的呈现并且冻结浏览器。在每一个元素(不仅仅是图片)它都会运算一次,增加了内存开支,因此它的问题是多方面的。
完全避免使用 AlphaImageLoader 的最好方法就是使用PNG8格式来代替,这种格式能在IE中很好地工作。如果你确实需要使用 AlphaImageLoader ,请使用下划线 _filter 又使之对IE7以上版本的用户无效。
脚本带来的问题就是它阻止了页面的平行下载。HTTP/1.1 规范建议,浏览器每个主机名的并行下载内容不超过两个。如果你的图片放在多个主机名上,你可以在每个并行下载中同时下载2个以上的文件。但是当下载脚本时,浏览器就不会同时下载其它文件了,即便是主机名不相同。
在某些情况下把脚本移到页面底部可能不太容易。比如说,如果脚本中使用了 document.write 来插入页面内容,它就不能被往下移动了。这里可能还会有作用域的问题。很多情况下,都会遇到这方面的问题。
一个经常用到的替代方法就是使用延迟脚本。 DEFER 属性表明脚本中没有包含 document.write ,它告诉浏览器继续显示。
不幸的是,Firefox并不支持DEFER属性。在Internet Explorer中,脚本可能会被延迟但效果也不会像我们所期望的那样。如果脚本可以被延迟,那么它就可以移到页面的底部。这会让你的页面加载的快一点。
在同一个页面中重复引用JavaScript文件会影响页面的性能。你可能会认为这种情况并不多见。对于美国前10大网站的调查显示其中有两家存在重复引用脚本的情况。有两种主要因素导致一个脚本被重复引用的奇怪现象发生:团队规模和脚本数量。如果真的存在这种情况,重复脚本会引起不必要的HTTP请求和无用的JavaScript运算,这降低了网站性能。
在Internet Explorer中会产生不必要的HTTP请求,而在Firefox却不会。在Internet Explorer中,如果一个脚本被引用两次而且它又不可缓存,它就会在页面加载过程中产生两次HTTP请求。即时脚本可以缓存,当用户重载页面时也会产生额外的HTTP请求。
除增加额外的HTTP请求外,多次运算脚本也会浪费时间。在Internet Explorer和Firefox中不管脚本是否可缓存,它们都存在重复运算JavaScript的问题。
一个避免偶尔发生的两次引用同一脚本的方法是在模板中使用脚本管理模块引用脚本。在HTML页面中使用<script /> 标签引用脚本的最常见方法就是:
<script type="text/javascript" src="menu_1.0.17.js"></script> 在PHP中可以通过创建名为 insertScript 的方法来替代:
<?php insertScript("menu.js") ?> 为了防止多次重复引用脚本,这个方法中还应该使用其它机制来处理脚本,如检查所属目录和为脚本文件名中增加版本号以用于Expire文件头等。
使用JavaScript访问DOM元素比较慢,因此为了获得更多的应该页面,应该做到:
有时候我们会感觉到页面反应迟钝,这是因为DOM树元素中附加了过多的事件句柄并且些事件句病被频繁地触发。这就是为什么说使用 event delegation(事件代理)是一种好方法了。
如果你在一个div中有10个按钮,你只需要在div上附加一次事件句柄就可以了,而不用去为每一个按钮增加一个句柄。事件冒泡时你可以捕捉到事件并判断出是哪个事件发出的。
你同样也不用为了操作DOM树而等待onload事件的发生。你需要做的就是等待树结构中你要访问的元素出现。你也不用等待所有图像都加载完毕。
你可能会希望用 DOMContentLoaded 事件来代替 onload,但是在所有浏览器都支持它之前你可使用YUI 事件应用程序中的 onAvailable 方法。
HTTP coockie可以用于权限验证和个性化身份等多种用途。coockie内的有关信息是通过HTTP文件头来在web服务器和浏览器之间进行交流的。因此保持coockie尽可能的小以减少用户的响应时间十分重要。
有关更多信息可以查看Tenni Theurer和Patty Chi的文章“When the Cookie Crumbles”。这们研究中主要包括:
当浏览器在请求中同时请求一张静态的图片和发送coockie时,服务器对于这些coockie不会做任何地使用。因此他们只是因为某些负面因素而创建的网络传输。所有你应该确定对于静态内容的请求是无coockie的请求。创建一个子域名并用他来存放所有静态内容。
如果你的域名是 www.example.org ,你可以在 static.example.org 上存在静态内容。但是,如果你不是在 www.example.org 上而是在顶级域名 example.org 设置了coockie,那么所有对于 static.example.org 的请求都包含coockie。在这种情况下,你可以再重新购买一个新的域名来存在静态内容,并且要保持这个域名是无coockie的。Yahoo!使用的是ymig.com,YouTube使用的是ytimg.com ,Amazon使用的是 images-anazon.com 等等。
使用无coockie域名存在静态内容的另外一个好处就是一些代理(服务器)可能会拒绝对coockie的内容请求进行缓存。一个相关的建议就是,如果你想确定应该使用 example.org 还是 www.example.org 作为你的一主页,你要考虑到coockie带来的影响。忽略掉www会使你除了把coockie设置到 *.example.org (*是泛域名解析,代表了所有子域名译者dudo注)外没有其它选择,因此出于性能方面的考虑最好是使用带有www的子域名并且在它上面设置coockie。
设计人员完成对页面的设计之后,不要急于将它们上传到web服务器,这里还需要做几件事:
你可以检查一下你的GIF图片中图像颜色的数量是否和调色板规格一致。 使用 imagemagick 中下面的命令行很容易检查:
identify -verbose image.gif 如果你发现图片中只用到了4种颜色,而在调色板的中显示的256色的颜色槽,那么这张图片就还有压缩的空间。
尝试把GIF格式转换成PNG格式,看看是否节省空间。大多数情况下是可以压缩的。由于浏览器支持有限,设计者们往往不太乐意使用PNG格式的图片,不过这都是过去的事情了。现在只有一个问题就是在真彩PNG格式中的alpha通道半透明问题,不过同样的,GIF也不是真彩格式也不支持半透明。因此GIF能做到的,PNG(PNG8)同样也能做到(除了动画)。
下面这条简单的命令可以安全地把GIF格式转换为PNG格式:
convert image.gif image.png “我们要说的是:给PNG一个施展身手的机会吧!”
在所有的PNG图片上运行pngcrush(或者其它PNG优化工具)。例如:
pngcrush image.png -rem alla -reduce -brute result.png 在所有的JPEG图片上运行 jpegtran。这个工具可以对图片中的出现的锯齿等做无损操作,同时它还可以用于优化和清除图片中的注释以及其它无用信息(如EXIF信息):
jpegtran -copy none -optimize -perfect src.jpg dest.jpg 不要为了在HTML中设置长宽而使用比实际需要大的图片。如果你需要:
<img width="100" height="100" src="mycat.jpg" alt="My Cat" /> 那么你的图片(mycat.jpg)就应该是100x100像素而不是把一个500x500像素的图片缩小使用。
favicon.ico 是位于服务器根目录下的一个图片文件。它是必定存在的,因为即使你不关心它是否有用,浏览器也会对它发出请求,因此最好不要返回一个404 Not Found的响应。
由于是在同一台服务器上,它每被请求一次coockie就会被发送一次。这个图片文件还会影响下载顺序,例如在IE中当你在onload中请求额外的文件时,favicon会在这些额外内容被加载前下载。
因此,为了减少 favicon.ico 带来的弊端,要做到:
这条限制主要是因为iPhone不能缓存大于25K的文件。注意这里指的是解压缩后的大小。由于单纯gizp压缩可能达不要求,因此精简文件就显得十分重要。
把页面内容打包成复合文本就如同带有多附件的Email,它能够使你在一个HTTP请求中取得多个组件(切记:HTTP请求是很奢侈的)。当你使用这条规则时,首先要确定用户代理是否支持(iPhone就不支持)。
Table of Contents generated with DocToc
为提高团队协作效率,便于后台人员添加功能及前端后期优化维护,输出高质量的文档,特制订此文档。本规范文档一经确认,前端开发人员必须按本文档规范进行前台页面开发。 本文档如有不对或者不合适的地方请及时提出,经讨论决定后方可更改。
基本准则:符合web标准,语义化html,结构表现行为分离,兼容性优良。页面性能方面,代码要求简洁明了有序,尽可能的减小服务器负载,保证最快的解析速度。
文件与目录命名约定:一律小写,必须是英文单词或产品名称的拼音,多个单词用下划线(_)连接。只能出现英文字母、数字和下划线,严禁出现中文;出现版本号时,需要用字母 v 做为前缀,小版本号用点号(.)隔开,比如 global_v8.js 或 detail_v2.2.js;该命名规范适用于 html, css, js, swf, xml, png, gif, jpg, ico 等前端维护的所有文件类型和相关目录。
文件编码约定:一律使用 UTF-8 编码.
id 和 class 命名约定:内容优先,表现为辅。首先根据内容来命名,比如 main-nav。如果根据内容找不到合适的命名,可以再结合表现来定,比如 skin-blue、 present-tab、col-main;用于样式的 id 和 class 名称一律小写,多个单词用连字符连接,比如 recommend-presents,名称中只能出现小写的 26 个英文字母、数字和连字符(-),任何其它字符都严禁出现;id 和 class 尽量用英文单词命名。确实找不到合适的单词时,可以考虑使用产品的中文拼音;在不影响语义的情况下, id 和 class 名称中可以适当采用英文单词缩写, 比如 col, nav, hd, bd, ft 等, 但切忌自造缩写; id 和 class 名称中的第一个词必须是单词全拼或语义非常清晰的单词缩写, 比如 present、col; 在 JavaScript 代码中当作 hook 用的 id 或 class, 命名规则为驼峰规则,比如:navSubMenu,tableForm。 注意:如果在 JavaScript 和 CSS 中都需要用到,则不用遵守本约定。
使用符合语义的标签书写 HTML 文档, 选择恰当的元素表达所需的含义
<!-- 不推荐 -->
<div onclick="goToRecommendations();">All recommendations</div>
<!-- 推荐 -->
<a href="recommendations/">All recommendations</a>元素的标签和属性名必须小写, 属性值必须加双引号; 例如:
<!-- 不推荐 -->
<A HREF='/'>Home</A>
<!-- 推荐 -->
<a href="/">Home</a>去除比不必要的空格; 例如:
<!-- 不推荐 -->
<p>test </p>
<!-- 推荐 -->
<p>test</p>元素嵌套遵循 (X)HTML Strict 嵌套规则;
正确区分自闭合元素和非自闭合元素. 非法闭合包括:<br>..</br>、<script />、<iframe />, 非法闭合会导致页面嵌套错误问题;
尽可能减少div嵌套层数。
通过给元素设置自定义属性来存放与 JavaScript 交互的数据, 属性名格式为 data-xx (例如:data-lazyload-url)。某些第三方插件自有数据不限此规范。
<!doctype html>
<meta charset="utf-8" /><div id="sample"> ... </div> <!-- #sample END -->
<div class="sample"> ... </div> <!-- .sample END --><!-- TODO(haovei): remove duplicate tag -->
<p><span>2</span></p>不要在 html 和模板中加入除了结构以外的东西,在文档中引入尽可能少的样式和脚本; 在页面中尽量避免使用style属性,即style="…"。
结构性元素 p 表示段落. 只能包含内联元素, 不能包含块级元素;
div 本身无特殊含义, 可用于布局. 几乎可以包含任何元素;
br 表示换行符;
hr 表示水平分割线;
h1-h6 表示标题. 其中 h1 用于表示当前页面最重要的内容的标题;
blockquote 表示引用, 可以包含多个段落. 请勿纯粹为了缩进而使用 blockquote, 大部分浏览器默认将blockquote 渲染为带有左右缩进;
pre 表示一段格式化好的文本。
头部元素 title 每个页面必须有且仅有一个 title 元素;
base 可用场景:首页、频道等大部分链接都为新窗口打开的页面;
link link 用于引入 css 资源时, 可省去 media(默认为all) 和 type(默认为text/css) 属性;
style type 默认为 text/css, 可以省去;
script type 属性可以省去;
不赞成使用lang属性;
不要使用古老的<!– //–>这种hack脚本, 它用于阻止第一代浏览器(Netscape 1和Mosaic)将脚本显示成文字;
noscript 在用户代理不支持 JavaScript 的情况下提供说明;。
<!-- 不推荐 -->
<link rel="stylesheet" href="//www.google.com/css/maia.css" type="text/css">
<script src="//www.google.com/js/gweb/analytics/autotrack.js" type="text/javascript"></script>
<!-- 推荐 -->
<link rel="stylesheet" href="//www.google.com/css/maia.css">
<script src="//www.google.com/js/gweb/analytics/autotrack.js"></script>文本元素 特殊符号使用: 尽可能使用代码替代:比如 < ( < )、> ( > ) 、空格 ( ) 、» ( » );
a a 存在 href 属性时表示链接, 无 href 属性但有 name 属性表示锚点;
em,strong em 表示句意强调, 加与不加会引起语义变化, 可用于表示不同的心情或语调;
strong 表示重要性强调, 可用于局部或全局, strong强调的是重要性, 不会改变句意;
abbr 表示缩写;
sub,sup 主要用于数学和化学公式, sup还可用于脚注;
span 本身无特殊含义;
ins,del 分别表示从文档中增加(插入)和删除。
img 请勿将img元素作为定位布局的工具, 不要用他显示空白图片;
给img元素增加alt属性 object/embed 可以用来插入Flash。
dl 表示关联列表,dd是对dt的解释;
dt和dd的对应关系比较随意: 一个dt对应多个dd、多个dt对应一个dd、多个dt对应多个dd, 都合法;
可用于名词/单词解释、日程列表、站点目录;
ul 表示无序列表;
ol 表示有序列表, 可用于排行榜等;
li 表示列表项, 必须是ul/ol的子元素。
推荐使用 button 代替 input, 但必须声明 type,不同浏览器的 type 值不一样;
推荐使用 fieldset, legend 组织表单;
单选或多选 input 建议使用 label 包含;
表单元素的 name 不能设定为 action, enctype, method, novalidate, target, submit 会导致表单提交混乱;
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Sample page</title>
<link rel="stylesheet" href="css_example_url" />
</head>
<body>
<div id="page">
<div id="header">
页头
</div>
<div id="content">
主体
</div>
<div id="footer">
页尾
</div>
</div>
<script src="js_example_url"></script>
<script>
// 你的代码
</script>
</body>
</html>使用小写字母,复合词以下划线(_)分隔;例如 nav.css,login_nav.css,login_page.css。
id 和 class 的命名总规则为: 内容优先,表现为辅.
首先根据内容来命名, 比如 main-nav. 如果根据内容找不到合适的命名, 可以再结合表现来定, 比如 skin-blue, present-tab, col-main;
用于样式的 id 和 class 名称一律小写, 多个单词用连字符连接, 比如 recommend-presents.,名称中只能出现小写的 26 个英文字母、数字和连字符(-), 任何其它字符都严禁出现;
id 和 class 尽量用英文单词命名 . 确实找不到合适的单词时, 可以考虑使用产品的中文拼音;
在不影响语义的情况下, id 和 class 名称中可以适当采用英文单词缩写, 比如 col, nav, hd, bd, ft 等, 但切忌自造缩写;
id 和 class 名称中的第一个词必须是单词全拼或语义非常清晰的单词缩写, 比如 present, col。
/* 不推荐 */
border-top-style: none;
font-family: palatino, georgia, serif;
font-size: 100%;
line-height: 1.6;
padding-bottom: 2em;
padding-left: 1em;
padding-right: 1em;
padding-top: 0;
/* 推荐 */
border-top: 0;
font: 100%/1.6 palatino, georgia, serif;
padding: 0 1em 2em;0、0前缀 和 单位 对属性值为 0 的情况省略单位,省略属性值中的 0 前缀。例如:
margin: 0;
padding: 0;
font-size: .8em;.selector {
-webkit-box-shadow: 0 0 5px rgba(200, 200,200, 0.8);
-moz-box-shadow: 0 0 5px rgba(200, 200,200, 0.8);
box-shadow: 0 0 5px rgba(200, 200,200, 0.8);
}成组的 css 规则间用块状注释和空行分离
/* Header */
#login-header {}
#login-header-below {}
/* Footer */
#login-footer {}
#login-footer-below {}
/* Gallery */
.login-gallery {}
.login-gallery-other {}(7) 特别注意
避免滥用CSS Hack;
使用after或overflow的方式清浮动,不要在html里增加多余的标签;
CSS尽可能的放在head里;
避免使用filter、expression、@import、!important;
避免直接定义标签的样式。如: div { ... }; 避免在标签上直接写样式;
绝对不要在CSS中使用“*”选择符;
内联和外联的CSS都必须放在页面的head里。
研究web前端优化时最多的建议就是不要使用 css @import 因为用这种方式加载css相当于把css放在了html底部
网上很多文章提及到的@import,其关注的问题是:
不要使用 css @import, 因为用这种方式加载css相当于把css放在了html底部。
那为什么用@import就等于把css放在了页面底部呢?在google developers看一篇文章时,无意间找到了这个原因,原文如下:
Avoid CSS @import Overview
Using CSS @import in an external stylesheet can add additional delays during the loading of a web page. Details
CSS @importallows stylesheets to import other stylesheets. When CSS @import isused from an external stylesheet, the browser is unable to downloadthe stylesheets in parallel, which adds additional round-trip timesto the overall page load. For instance, iffirst.css contains the following content:
@import url("second.css")
The browser must download, parse, andexecute first.css before it is able to discover that itneeds to downloadsecond.css. Recommendations
Use the <link> tag instead of CSS @import Instead of @import, use a <link> tag for each stylesheet. This allows the browser to download stylesheets in parallel, which results in faster page load times:
<link rel="stylesheet" href="first.css"> <link rel="stylesheet" href="second.css">
我们确实要避免使用css @import, 但原因却不是什么相当于放在了页面底部,而是这样做会导致css无法并行下载,因为使用@import引用的文件只有在引用它的那个css文件被下载、解析之后,浏览器才会知道还有另外一个css需要下载,这时才去下载,然后下载后开始解析、构建render tree等一系列操作。
浏览器在页面所有css下载并解析完成后才会开始渲染页面(Before a browser can begin to render a web page, it mustdownload and parse any stylesheets that are required to lay out thepage. Even if a stylesheet is in an external file that is cached,rendering is blocked until the browser loads the stylesheet from disk.)
因此css @import引起的css解析延迟会加长页面留白期。 所以,要尽量避免使用css @import而尽量采用link标签的方式引入。
运算符就是程序对常量和变量进行算术运算操作时使用的符号。它包含以下分类:
+ 加法运算- 减法运算* 乘法运算/ 除法运算% 取模(取余)运算++ 自增运算-- 自减运算特别注意:
/ 除法运算得到两个数据相除的商,在Java中整数除以整数的结果还是整数。% 取模(取余)运算得到两个数据相除的余数,可以用来判断两个数是否能整除。在Java中,+运算符有两个作用,当加号两边是数值型数据时,进行数学中的加法运算,而如果操作数是字符型时,则会调用当前字符所对应的ASCII码来进行运算
自增(++)和自减(--)运算
如果是对某个变量进行单独运算,那么这两个运算符放在变量前和变量后都是一样
但如果是参与运算就不同了
int a = 5;
a++; // 6
++a; // 6
int b = a++;
System.out.println(a); // 6
System.out.println(b); // 5
int b = ++a;
System.out.println(a); // 6
System.out.println(b); // 6赋值运算符就是用于给变量赋值的运算符,它可以分为基本赋值运算符和扩展赋值运算符
扩展赋值运算符的好处,就是省略了强制类型转换的操作,避免了一些因为类型问题引起的问题
int a = 10;
a += 20; // 相当于 a = a + 20
System.out.println(a); // 30关系运算符是用来描述两个变量之间关系的,它的运算结果都是布尔(boolean)值类型,要么是true,要么是false
int a = 10;
int b = 20;
int c = 10;
Systemout.out.println(a == b); // false
Systemout.out.println(a == c); // true
Systemout.out.println(a != b); // true
Systemout.out.println(a != c); // false逻辑运算符用于判断"并且"、"或者"、"除非"等逻辑关系,它的两端一般连接的是值为布尔类型的关系表达式
常见的逻辑运算符有:
&& 逻辑与 并且 表示所有表达式都为true时计算结果才为true,否则为false|| 逻辑或 或者 表示所有表达式中,任意一个表达式为true,则计算结果就为true! 逻辑非 表示否定 将当前运算表达式计算结果取反System.out.println(true && true); // true
System.out.println(true && false); // false
System.out.println(false && true); // false
System.out.println(false && false); // false
System.out.println(true || true); // true
System.out.println(true || false); // true
System.out.println(false || true); // true
System.out.println(false || false); // false
System.out.println(!true); // false
System.out.println(!false); // true三元运算符又叫"三目运算符",它由三部分组成,格式如下:
(关系表达式) ? 表达式1 : 表达式2;
运算流程是,如果关系表达式结果为true,则运算后的结果是表达式1,否则如果关系表达式结果为false,则运算后的结果是表达式2
// 计算两个整数的最大值
int a;
int b;
return a > b ? a : b;方法,也叫函数,它是完成特定功能的代码块。一个方法就是一个功能、一个动作或一种行为。
当一些代码被反复使用时,可以把它们提取出来,放到一个方法中,以方法的形式来使用这些代码,大大提高代码的复用性。
方法的格式如下:
修饰符 返回值类型 方法名(参数类型 参数名1, 参数类型 参数名2...) {
// 方法体语句;
return 返回值;
}那么如何来定义一个方法呢?
public class MethodDemo {
public static void main(String[] args) {
}
/**
求两个整数和的方法
*/
public static sum(int a, int b) {
// 方法体语句
int c = a + b;
return c;
}
}方法定义完成后就要调用它,直接通过方法名就可以调用方法,除此之外,还需要根据形式参数列表将实际参数传递给方法
public class MethodDemo {
public static void main(String[] args) {
/**
在main函数中调用方法
*/
int result = sum(10, 20);
System.out.println(result);
}
/**
求两个整数和的方法
*/
public static sum(int a, int b) {
// 方法体语句
int c = a + b;
return c;
}
}方法定义需要注意以下几点要求:
voidvoid时,可以省略return语句return语句后的数据类型必须和返回值类型匹配return语句之后不能再放置其他语句下面来看看在Java中非常重要的方法重载
方法重载是指在同一个类中的多个方法,它们的方法名相同,参数列表不同,且方法重载与返回值类型无关。
那为什么我们需要方法重载呢? 当实现的功能相同,但具体的实现方式不同时,我们可以通过定义名称相同、参数(条件)不同的方法,来更好的识别和管理类中的方法。
public static int sum(int a, int b) {
return a + b;
}
public static long sum(long a, long b) {
return a + b;
}
public static double sum(double a, float b, int c) {
return a + b + c;
}数组就是用来存储同一种数据类型的多个元素的容器,这里的数据类型可以是基本类型,也可以是引用类型
在Java中,定义数组的格式有三种:
数据类型[] 数组名 = new 数据类型[长度]
数据类型即数组中存储元素的数据类型,可以是基本类型或引用类型
[]表示是数组
new创建数组的关键字,通过new开辟内存空间
长度表示数组中最多能存储元素的个数,注意:数组长度在定义时指定,以后不可更改
int[] arr = new int(3);数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, 元素3, ...};
这种定义数组的格式,在定义时元素是确定的,避免了内存空间的浪费
int[] arr2 = new int[]{1, 2, 3};数据类型[] 数组名 = {元素1, 元素2, 元素3, ...};
这是上一种形式的一个简写
int[] arr3 = {1, 2, 3};那么我们如何访问数据中的元素呢?
一般我们通过数组的索引来访问数组的元素,索引,也叫下标,或者脚标,是数组元素起始位置的偏移量,第一个元素的偏移量为0,所以数组的索引是从0开始的。
取值:数组名[索引]
赋值:数组名[索引] = 值
int[] arr = {11, 22, 33};
arr[0] = 10; // 10 通过索引操作数组中的元素值数组最常见的操作就是遍历数组元素,遍历数组需要知道以下知识点:
数组名.length 来获取int,则默认值0下面来看下数组的相关知识点:
数组的初始化:它其实就是在内存中为数组开辟连续空间并为每个元素赋值的过程,连续空间就是数组元素在内存空间中的存放位置是连续的。
在Java中,数组的初始化分为两种,一种是动态初始化,也就是指定数据长度,由系统给出默认值
\u0000(空字符)falsenull另外一种就是静态初始化,由开发者给出初始化值,系统决定数组长度。
Java的内存分配
Java的内存分配分为以下几个区域:
class文件,包含方法、静态成员、常量等。new出来的数组或对象JVM在调用操作系统功能时使用,与开发无关数组类型:变量arr存储的是数组在堆空间中的地址值,而不是数组元素的值,变量arr通过内存地址引用堆内存中的数组,所以数组是引用类型。
数组的常见操作
先来看下数组使用中两个常见的问题
数组索引越界异常: ArrayIndexOutOfBoundsException
当访问了不存在的索引时会触发上面的异常
空指针异常: NullPointerException
数组引用存储的值为null而非数组的地址值时
我们经常使用Git来保存自己的工作,在我们迷迷糊糊的犯下错误之后,就可以使用Git将代码返回到之前的状态。通常,大部分时间我们都只会用到
add、commit、branch和push/pull这些命令。但如果自己往仓库中添加了错误的文件,或是将代码提交到了错误的分支,而且提交信息还写错了的话,自己怎样才能取消之前的操作?
下面这个命令可以让你编辑最近一次的提交信息
$ git commit --amend -m ”YOUR-NEW-COMMIT-MESSAGE”下面的命令强制推送这次的代码提交
$ git push <remote> <branch> --forcegit add如果你往暂存区(staging area)中加入了一些错误的文件,但是还没有提交代码。你可以使用一条简单的命令就可以撤销
$ git reset <文件名>或者如果你想从暂存区移除所有没有提交的修改:
$ git reset有时候你可能会不小心提交了错误的文件或一开始就遗漏了某些东西
$ git reset --soft HEAD~1
$ git add -A .
$ git commit -c ORIG_HEAD行第一个命令时,Git会将HEAD指针后移到此前的一次提交,之后你才能移动文件或作必要的修改。
然后你就可以添加所有的修改,而且当你执行最后的命令时,Git会打开你的默认文本编辑器,其中会包含上一次提交时的信息
“撤销”(revert)在许多情况下是非常有必要的——尤其是你把代码搞的一团糟的情况下
$ git checkout <SHA><SHA>是你想查看的提交拥有的哈希值(Hash Code)中前8至10个字符
这个命令会使<HEAD>指针脱离(detach),可以让你在不检出(check out)任何分支的情况下查看代码
要想撤销合并,你可能必须要使用恢复命令(HARD RESET)回到上一次提交的状态。“合并”所做的工作基本上就是重置索引,更新working tree(工作树)中的不同文件,即当前提交()代码中与HEAD游标所指向代码之间的不同文件;但是合并会保留索引与working tree之间的差异部分(例如那些没有被追踪的修改)
$ git checkout -b <SHA>假设你凑巧有一些未被追踪的文件(因为不再需要它们),不想每次使用git status命令时让它们显示出来
$ git clean -f -n #1 // 选项-n将显示执行下面的命令时将会移除哪些文件
$ git clean -f #2 // 该命令会移除所有上面的命令中显示的文件
$ git clean -fd #3 // 如果你还想移除文件件,请使用选项-d
$ git clean -fX #4 // 如果你只想移除已被忽略的文件,请使用选项-X
$ git clean -fx #5 // 如果你想移除已被忽略和未被忽略的文件,请使用选项-x$ git branch --delete --force <branchName> // 删除本地分支
$ git push origin --delete <branchName> // 删除远程分支gulp现在是越来越流行了。它可以做的事情实在是太多了,比如,拼接js文件,压缩图片。
在这个教程里,你会了解怎么使用gulp.js来实现一个应用了内置的livereload功能的本地web服务。
假设我们要开发一个单页应用。这个app的入口是index.html。我们的目标是可以让浏览器通过localhost来访问这个页面。以前,你需要安装一个Apache或者Nginx这样的服务器软件来实现这样的功能。
时至今日,javascript无所不能了,就要称霸天下了,甚至它都可以去实现一个web服务。这篇文章里,我们就要用一个gulp的插件,人称gulp-connect。用这个插件来实现一个WEB服务。
接下来的篇幅,我们就要来为我们的单页应用来配置一个本地服务。
开始下文之前,我假定你已经把准备工作都已经做好了,比如gulpfile文件已建好!
第一步,安装
第一步,我们要来安装下gulp-connect插件
安装的命令如下:
npm install --save-dev gulp-connect小提示:npm install --save-dev 可以简写为npm i -D
现在,我们来定义web服务,gulpfile.js的代码如下
var gulp = require('gulp'),
connect = require('gulp-connect');
gulp.task('webserver',function(){
connect.server();
})
gulp.task('default',['webserver']);只要在终端执行gulp命令,然后在浏览器地址栏输入localhost:8080就可以看到index.html啦。
localhost:8080所指向的就是gulpfile文件所在的那一级目录。
在终端输入ctrl+c会结束当前任务。
livereload的支持创建一个基础的web服务很简单,是不是?那现在我们继续来把livereload加入web服务中。
我们需要做两件事情:
首先,告诉web服务启动的时候运行livereload。
其次,在页面有更新的时候通知livereload刷新页面。
第一步很简单是不是,我们只要将livereload的属性设置为true,将webserver这个任务写成下面的样子。
gulp.task('webtask',function(){
connect.server({
livereload:true
});
});第二步的话就取决于你具体的实例了。比如说,我们要将less文件自动编译成css样式表,并让其被浏览器识别。
我们来将这个例子分步处理下:
首先,需要一个'watcher',用来监控less文件的变化,监控到变化后这个'watcher'就会去触发less的编译器,将其输出为一个css文件。之后这个css文件有更新了之后就会去通知livereload,让其刷新页面。
在这个例子里面,还需要用到gulp-less插件。
插件的安装命令如下
npm install --save-dev gulp-lessgulp里已经有了watch这个方法,可以来充当'watcher'
我们的文档结构大致可以如下:
.
├── node_modules
│ └── ...
├── styles
│ └── main.less
├── gulpfile.js
├── index.html
└── package.json
watch任务执行的时候,gulp.js监听styles文件夹里less文件的所有改动,当有改动的时候就会触发less任务。每一次编译之后,结果会自动返回给浏览器。
gulpfile.js文件的代码如下所示(作者允许将下列代码使用于你自己的项目):
var gulp = require('gulp'),
connect = require('gulp-connect'),
less = require('gulp-less');
gulp.task('webserver',function(){
connect.server({
livereload:true
});
});
gulp.task('less',function(){
gulp.src('styles/main.less')
.pipe(less())
.pipe(gulp.dest(styles))
.pipe(connect.reload());
});
gulp.task('watch',function(){
gulp.watch('style/*.less',['less']);
})
gulp.task('default',['less','webserver','watch']);现在我们重新在终端执行gulp,然后再在浏览器打开localhost:8080。
做完这些,我们就可以试着在style文件夹的less文件里做一些改动。它会立即编译并刷新浏览器。
看吧,这样我们并不需要依赖什么浏览器插件,就可以实现页面的自动刷新啦!
注意,我们之前写的gulpfile.js文件只是一个小小的示例用于示范怎么来实现一个运用了livereload的web服务。
我非常建议大家可以把将其他gulp插件一起玩起来。
你也可以试着重新修改下你写的各个task的结构,用一用不是gulp内置的watch方法,这个方法可以只监控有改动的文件。这个对于以后你如果使用更大的代码库来说尤为重要。
我们来看一看对于以上实现web服务的另一个方案。
gulp-connect插件本身有很多可选的配置。
比如说,你可以更改web服务的端口号或者hostname。你甚至可以用一个你习惯使用的hostname配上80端口(默认的是localhost:8080)
代码如下:
connect.server({
port:80,
host:'gulp.dev'
});进行了这个配置之后,我们要在hosts文件里面加上gulp.dev,然后运行sudo gulp,因为要使用80端口的话,是需要管理员权限的。
你可以同时启动多个web server。这个很有用的。比如说,如果你要同时启动一个开发和一个测试的服务。
gulp-connect也可以设置多个根目录。
比如,你要用coffeescript,然后将压缩过得js文件放到一个临时的文件夹,那就可以在根目录root中加上这个临时的文件夹而不去影响原来的源文件夹。
在GitHub上你可以获得更多的示例,链接如下:
https://github.com/AveVlad/gulp-connect
在以上的例子中,我们只是写了一个小小的将less编译成css文件,并让其立即体现在浏览器中的例子。
虽然它奏效了,但是我们可以做的更好。
当把编译和livereload混合起来用的时候,可能会有一些问题。
所以,我们将他们拆分开来并用watch来监控。
为此,就需要用到上面提到的gulp-watch插件。
我们可以再加入一个coffeeScript的编译步骤。这个增加的步骤会使我们的新结构更加清晰。
安装新插件的命令
npm install --save-dev gulp-watch gulp-coffee在gulpfile.js文件的最顶部引用这两个插件。在下面的步骤中,我假设你已经在scripts文件夹里有了以.coffee为后缀的文件。
重写的gulpfile文件,如下所示:
var gulp = require('gulp'),
connect = require('gulp-connect'),
watch = require('gulp-watch'),
coffee = require('gulp-coffee'),
less = require('gulp-less');
gulp.task('webserver',function(){
connect.server({
live reload:true,
root:['.','.tmp']
});
});
gulp.task('livereload',function(){
gulp.src(['.tmp/styles/*.css','.tmp/scripts/*.js'])
.pipe(watch()) //注意此处的watch是gulp-watch插件
.pipe(connect.reload());
});
gulp.task('coffee',function(){
gulp.src('scripts/*.coffee')
.pipe(coffee())
.pipe(dest('.tmp/scripts'));
});
gulp.task('less',function(){
gulp.src('styles/main.less')
.pipe(less())
.pipe(gulp.dest('.tmp/styles'));
});
gulp.task('watch',function(){
gulp.watch('style/*.less',['less']);
gulp.watch('scripts/*.coffee',['coffee']);
})
gulp.task('default',['less','coffee','watch','webserver','livereload']);最大的变化,是增加的livereload任务。这个任务仅仅是监听了编译之后的文件,然后如果有变化就刷新浏览器。
watch()方法可以仅仅只重新加载有变化的文件。
gulp自带的gulp.watch()会将整个项目都重新加载。
因为添加了livereload这个任务,我们就不需要在每一步的编译之后都加上.pipe(connect.reload())了。
所以,我们把每个任务按照他们各自关注的点分开定义,这样对于项目开发来说比较好。
同时,我们也发现,编译之后的文件不再保存至他们各自的文件夹去了。现在它们存储在一个临时文件夹.tmp中。文件夹的内容就是生成的文件,它们存储在临时文件夹,不再去污染scripts和styles文件夹。我们也建议不要将临时文件夹加入版本控制系统。
我们要做的就是把临时文件夹也视为一个根目录
代码如下
root:['.','.tmp']这边经过我的测试,经过编译之后会自动生成.tmp文件夹,这个文件夹里有一个styles文件夹存储css文件有一个scripts文件夹存储js文件。
然后我们的版本控制系统是git,那么在.gitignore文件里就要写上.tmp,不要让.tmp这个临时文件夹加入版本控制系统。
因为在本地预览,这样html就得要能获取到css和js文件,那么就在root里把.tmp也设置为根目录。这样gulp执行的时候,就能读取到css和js文件啦~
提交git的话,就提交html,styles folder,scripts folder.
协同开发者如果clone的话,再执行下gulp就会再次生成临时文件夹,进行预览。
现在,你已经可以用gulp来构建一个本地web服务了。
你也可以尝试和其他gulp插件配合使用,来构建或者测试一个单页应用。
这里的web服务仅仅是本地服务,如果你要作为生产,就得要用一些类似Nginx或者CDN这样的高效解决方案。
Grunt及类似的项目都可以实现以上的功能,gulp只是提供了一个比较简便的方法来实现这个功能。
CSS3是CSS2的升级版本,3只是版本号,它在CSS2.1的基础上增加了很多强大的新功能。 目前主流浏览器chrome、safari、firefox、opera、甚至360都已经支持了CSS3大部分功能了,IE10以后也开始全面支持CSS3了。
在编写CSS3样式时,不同的浏览器可能需要不同的前缀。它表示该CSS属性或规则尚未成为W3C标准的一部分,是浏览器的私有属性,虽然目前较新版本的浏览器都是不需要前缀的,但为了更好的向前兼容前缀还是少不了的。
| 前缀 | 浏览器 |
|---|---|
| -webkit | chrome和safari |
| -moz | firefox |
| -ms | IE |
| -o | opera |
CSS3给我们带来了什么好处呢?简单的说,CSS3把很多以前需要使用图片和脚本来实现的效果、甚至动画效果,只需要短短几行代码就能搞定。比如圆角,图片边框,文字阴影和盒阴影,过渡、动画等。
CSS3简化了前端开发工作人员的设计过程,加快页面载入速度。
CSS3都有哪些强大功能呢?
class、 ID 或 tagname 来选择HTML元素,CSS3的选择器强大的难以置信。它们可以减少在标签中的class和ID的数量更方便的维护样式表、更好的实现结构与表现的分离。border-radius 帮你轻松搞定。@Font-Face 轻松实现定制字体。border-radius 是向样式添加圆角边框,使用方法:
E {
border-radius: 10px; // 所有角都使用半径为10px的圆角
}E {
border-radius: 5px 4px 3px 2px; // 四个半径值分别是左上角、右上角、右下角和左下角,顺时针
}不要以为border-radius的值只能用px单位,你还可以用百分比或者em,但兼容性目前还不太好。
实心上半圆:把高度(height)设为宽度(width)的一半,并且只设置左上角和右上角的半径与元素的高度一致(大于也是可以的)
div {
height: 50px; // 是width的一半
width: 100px;
background: #9da;
border-radius: 50px 50px 0 0; // 半径至少设置为height的值
}实心圆:把宽度(width)与高度(height)值设置为一致(也就是正方形),并且四个圆角值都设置为它们值的一半
div {
height: 100px; // 与width设置一致
width: 100px;
background: #9da;
border-radius: 50px; // 四个圆角值都设置为宽度或高度的一半
}box-shadow是向盒子添加阴影。支持添加一个或者多个,用法如下:
box-shadow: X轴偏移量 Y轴偏移量 [阴影模糊半径] [阴影扩展半径] [阴影颜色] [投影方式];| 值 | 描述 |
|---|---|
| X轴偏移量 | 必需,水平阴影的位置,允许负值 |
| Y轴偏移量 | 必需,垂直阴影的位置,允许负值 |
| 阴影模糊半径 | 可选,模糊距离 |
| 阴影扩展半径 | 可选,阴影的尺寸 |
| 阴影颜色 | 可选,阴影的颜色,省略默认为黑色 |
| 投影方式 | 可选,设置inset时为内部阴影,省略则为外部阴影 |
.box_shadow {
box-shadow: 4px 2px 6px #333;
}
```css
## 为元素设置内阴影:
```css
.box_shadow {
box-shadow: 4px 2px 6px #333 inset;
}
```css
## 添加多个阴影,只需用逗号隔开即可
```css
.box_shadow {
box-shadow:4px 2px 6px #f00, -4px -2px 6px #000, 0px 0px 12px 5px #33CC00 inset;
}阴影模糊半径:此参数可选,其值只能是为正值,如果其值为0时,表示阴影不具有模糊效果,其值越大阴影的边缘就越模糊;
阴影扩展半径:此参数可选,其值可以是正负值,如果值为正,则整个阴影都延展扩大,反之值为负值时,则缩小;
.boxshadow-outset {
width:100px;
height:100px;
box-shadow:-4px 4px 6px #666;
}.boxshadow-outset{
width:100px;
height:100px;
box-shadow:4px -4px 6px #666;
}#border-image{
background:#F4FFFA;
width:210px; height:210px; border:70px solid #ddd;
border-image:url(borderimg.png) 70 repeat
}RGB是一种色彩标准,是由红(R)、绿(G)、蓝(B)的变化以及相互叠加来得到各式各样的颜色。RGBA是在RGB的基础上增加了控制alpha透明度的参数。
语法:
color:rgba(R,G,B,A)以上R、G、B三个参数,正整数值的取值范围为:0 - 255。百分数值的取值范围为:0.0% - 100.0%。超出范围的数值将被截至其最接近的取值极限。并非所有浏览器都支持使用百分数值。A为透明度参数,取值在0~1之间,不可为负值。
background-color:rgba(100,120,60,0.5);CSS3 Gradient 分为线性渐变(linear)和径向渐变(radial)。由于不同的渲染引擎实现渐变的语法不同,这里我们只针对线性渐变的 W3C 标准语法来分析其用法,其余大家可以查阅相关资料。W3C 语法已经得到了 IE10+、Firefox19.0+、Chrome26.0+ 和Opera12.1+等浏览器的支持。
linear-gradient(to bottom, #fff, #999);参数:
第一个参数:指定渐变方向,可以用“角度”的关键词或“英文”来表示:
| 角度 | 用英文表示 | 作用 |
|---|---|---|
| 0deg | to top | 从下向上 |
| 90deg | to right | 从左向右 |
| 180deg | to bottom | 从上向下 |
| 270deg | to left | 从右向左 |
| to top left | 右下角到左上角 | |
| to top right | 左下角到右上角 |
第一个参数省略时,默认为“180deg”,等同于“to bottom”。
第二个和第三个参数,表示颜色的起始点和结束点,可以有多个颜色值。
background-image:linear-gradient(to left, red, orange,yellow,green,blue,indigo,violet);
text-overflow用来设置是否使用一个省略标记(...)标示对象内文本的溢出。
语法:
// clip表示剪切, ellipsis表示显示省略标记
text-overflow: clip | ellipsis但是text-overflow只是用来说明文字溢出时用什么方式显示,要实现溢出时产生省略号的效果,还须定义强制文本在一行内显示(white-space:nowrap)及溢出内容为隐藏(overflow:hidden),只有这样才能实现溢出文本显示省略号的效果,代码如下:
div {
text-overflow:ellipsis;
overflow:hidden;
white-space:nowrap;
}同时,word-wrap也可以用来设置文本行为,当前行超过指定容器的边界时是否断开转行。
//normal表示控制连续文本换行, break-word表示内容将在边界内换行
word-wrap: normal | break-wordnormal为浏览器默认值,break-word设置在长单词或 URL地址内部进行换行,此属性不常用,用浏览器默认值即可。
@font-face能够加载服务器端的字体文件,让浏览器端可以显示用户电脑里没有安装的字体。
@font-face {
font-family: 字体名称;
src: 字体文件在服务器上的相对或绝对路径;
}这样设置之后,就可以像使用普通字体一样在(font-*)中设置字体样式。
p {
font-size :12px;
font-family : "My Font";
/*必须项,设置@font-face中font-family同样的值*/
}
text-shadow可以用来设置文本的阴影效果。
text-shadow: X-Offset Y-Offset blur color;X-Offset:表示阴影的水平偏移距离,其值为正值时阴影向右偏移,反之向左偏移;
Y-Offset:是指阴影的垂直偏移距离,如果其值是正值时,阴影向下偏移,反之向上偏移;
Blur:是指阴影的模糊程度,其值不能是负值,如果值越大,阴影越模糊,反之阴影越清晰,如果不需要阴影模糊可以将Blur值设置为0;
Color:是指阴影的颜色,其可以使用rgba色。
p {
text-shadow: 0 1px 1px #fff;
}
background-origin设置元素背景图片的原始起始位置。
background-origin: border-box | padding-box | content-box;参数分别表示背景图片是从边框,还是内边距(默认值),或者是内容区域开始显示。
需要注意的是,如果背景不是no-repeat,这个属性无效,它会从边框开始显示。
用来将背景图片做适当的裁剪以适应实际需要。
background-clip: border-box | padding-box | content-box | no-clip参数分别表示从边框、或内填充,或者内容区域向外裁剪背景。no-clip表示不裁切,和参数border-box显示同样的效果。backgroud-clip默认值为border-box。
设置背景图片的大小,以长度值或百分比显示,还可以通过cover和contain来对图片进行伸缩。
background-size: auto | <长度值> | <百分比> | cover | containauto:默认值,不改变背景图片的原始高度和宽度;
<长度值>:成对出现如200px 50px,将背景图片宽高依次设置为前面两个值,当设置一个值时,将其作为图片宽度值来等比缩放;
<百分比>:0%~100%之间的任何值,将背景图片宽高依次设置为所在元素宽高乘以前面百分比得出的数值,当设置一个值时同上;
cover:顾名思义为覆盖,即将背景图片等比缩放以填满整个容器;
contain:容纳,即将背景图片等比缩放至某一边紧贴容器边缘为止。
多重背景,也就是CSS2里background的属性外加origin、clip和size组成的新background的多次叠加,缩写时为用逗号隔开的每组值;用分解写法时,如果有多个背景图片,而其他属性只有一个(例如background-repeat只有一个),表明所有背景图片应用该属性值。
background : [background-color] | [background-image] | [background-position][/background-size] | [background-repeat] | [background-attachment] | [background-clip] | [background-origin],...可以把上面的缩写拆解成以下形式:
background-image:url1,url2,...,urlN;background-repeat : repeat1,repeat2,...,repeatN;
backround-position : position1,position2,...,positionN;
background-size : size1,size2,...,sizeN;
background-attachment : attachment1,attachment2,...,attachmentN;
background-clip : clip1,clip2,...,clipN;
background-origin : origin1,origin2,...,originN;
background-color : color;注意:
在HTML中,通过各种各样的属性可以给元素增加很多附加的信息。例如,通过id属性可以将不同div元素进行区分。
在CSS2中引入了一些属性选择器,而CSS3在CSS2的基础上对属性选择器进行了扩展,新增了3个属性选择器,使得属性选择器有了通配符的概念,这三个属性选择器与CSS2的属性选择器共同构成了CSS功能强大的属性选择器。如下表所示:
| 属性选择器 | 功能描述 |
|---|---|
| E[att^='val'] | 选择匹配元素E,且E元素定义了属性att,其属性值以val开头的任何字符串 |
| E[att$='val'] | 选择匹配元素E,且E元素定义了属性att,其属性值以val结尾的任何字符串 |
| E[att*='val'] | 选择匹配元素E,且E元素定义了属性att,其属性值的任意位置包含了val |
示例:
<a href="xxx.pdf">我链接的是PDF文件</a>
<a href="#" class="icon">我类名是icon</a>
<a href="#" title="我的title是more">我的title是more</a>a[class^=icon]{
background: green;
color:#fff;
}
a[href$=pdf]{
background: orange;
color: #fff;
}
a[title*=more]{
background: blue;
color: #fff;
}
:root选择器,从字面上我们就可以很清楚的理解是根选择器,他的意思就是匹配元素E所在文档的根元素。在HTML文档中,根元素始终是<html>
通过“:root”选择器设置背景颜色
:root {
background:orange;
}
:not选择器称为否定选择器,和jQuery中的:not选择器一模一样,可以选择除某个元素之外的所有元素。就拿form元素来说,比如说你想给表单中除submit按钮之外的input元素添加红色边框
form {
width: 200px;
margin: 20px auto;
}
div {
margin-bottom: 20px;
}
input:not([type="submit"]){
border:1px solid red;
}
:empty选择器表示的就是空。用来选择没有任何内容的元素,这里没有内容指的是一点内容都没有,哪怕是一个空格
比如说,你的文档中有三个段落p元素,你想把没有任何内容的P元素隐藏起来。我们就可以使用:empty选择器来控制
p{
background: orange;
min-height: 30px;
}
p:empty {
display: none;
}
:target选择器称为目标选择器,用来匹配文档(页面)的url的某个标志符的目标元素
点击链接显示隐藏的段落
html代码:
<h2><a href="#brand">Brand</a></h2>
<div class="menuSection" id="brand">
content for Brand
</div>css代码:
.menuSection{
display: none;
}
:target{ /*这里的:target就是指id="brand"的div对象*/
display:block;
}分析:
具体来说,触发元素的URL中的标志符通常会包含一个#号,后面带有一个标志符名称,上面代码中是:#brand
:target就是用来匹配id为brand的元素(id="brand"的元素),上面代码中是那个div元素。
多个url(多个target)的处理:
同一个页面上有很多的url的时候你可以取不同的名字,只要#号后对的名称与id=""中的名称对应就可以了
html代码:
<h2><a href="#brand">Brand</a></h2>
<div class="menuSection" id="brand">
content for Brand
</div>
<h2><a href="#jake">Brand</a></h2>
<div class="menuSection" id="jake">
content for jake
</div>
<h2><a href="#aron">Brand</a></h2>
<div class="menuSection" id="aron">
content for aron
</div>CSS代码:
#brand:target {
background: orange;
color: #fff;
}
#jake:target {
background: blue;
color: #fff;
}
#aron:target {
background: red;
color: #fff;
}:first-child选择器表示的是选择父元素的第一个子元素的元素E
示例演示:
通过:first-child选择器定位列表中的第一个列表项,并将序列号颜色变为红色。
html代码:
<ol>
<li><a href="##">Link1</a></li>
<li><a href="##">Link2</a></li>
<li><a href="##">link3</a></li>
</ol>CSS代码:
ol > li{
font-size:20px;
font-weight: bold;
margin-bottom: 10px;
}
ol a {
font-size: 16px;
font-weight: normal;
}
ol > li:first-child{
color: red;
}:last-child选择器选择的是元素的最后一个子元素
html代码:
<div class="post">
<p>第一段落</p>
<p>第二段落</p>
<p>第三段落</p>
<p>第四段落</p>
<p>第五段落</p>
</div>CSS代码:
.post {
padding: 10px;
border: 1px solid #ccc;
width: 200px;
margin: 20px auto;
}
.post p {
margin:0 0 15px 0;
}
.post p:last-child {
margin-bottom:0;
}:nth-child(n)选择器用来定位某个父元素的一个或多个特定的子元素。其中n是其参数,而且可以是整数值(1,2,3,4),也可以是表达式(2n+1、-n+5)和关键词(odd、even),但参数n的起始值始终是1,而不是0。也就是说,参数n的值为0时,选择器将选择不到任何匹配的元素。
html代码:
<ol>
<li>item1</li>
<li>item2</li>
<li>item3</li>
<li>item4</li>
<li>item5</li>
<li>item6</li>
<li>item7</li>
<li>item8</li>
<li>item9</li>
<li>item10</li>
</ol>CSS代码:
ol > li:nth-child(2n){
//将偶数行列表背景色设置为橙色
background: orange;
}:nth-last-child(n)选择器和前面的:nth-child(n)选择器非常的相似,只是这里多了一个last,所起的作用和:nth-child(n)选择器有所区别,从某父元素的最后一个子元素开始计算,来选择特定的元素。
html代码:
<ol>
<li>item1</li>
<li>item2</li>
<li>item3</li>
<li>item4</li>
<li>item5</li>
<li>item6</li>
<li>item7</li>
<li>item8</li>
<li>item9</li>
<li>item10</li>
<li>item11</li>
<li>item12</li>
<li>item13</li>
<li>item14</li>
<li>item15</li>
</ol>
CSS代码:
ol > li:nth-last-child(5){
background: orange;
}
:first-of-type选择器类似于:first-child选择器,不同之处就是指定了元素的类型,其主要用来定位一个父元素下的某个类型的第一个子元素。
html代码:
<div class="wrapper">
<div>我是一个块元素,我是.wrapper的第一个子元素</div>
<p>我是一个段落元素,我是不是.wrapper的第一个子元素,但是他的第一个段落元素</p>
<p>我是一个段落元素</p>
<div>我是一个块元素</div>
</div>
CSS代码:
.wrapper {
width: 500px;
margin: 20px auto;
padding: 10px;
border: 1px solid #ccc;
color: #fff;
}
.wrapper > div {
background: green;
}
.wrapper > p {
background: blue;
}
/*我要改变第一个段落的背景为橙色*/
.wrapper > p:first-of-type {
background: orange;
}
:nth-of-type(n)选择器和:nth-child(n)选择器非常类似,不同的是它只计算父元素中指定的某种类型的子元素。当某个元素中的子元素不单单是同一种类型的子元素时,使用:nth-of-type(n)选择器来定位于父元素中某种类型的子元素是非常方便和有用的。在:nth-of-type(n)选择器中的n和:nth-child(n)选择器中的n参数也一样,可以是具体的整数,也可以是表达式,还可以是关键词。
html代码:
<div class="wrapper">
<div>我是一个Div元素</div>
<p>我是一个段落元素</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
<p>我是一个段落</p>
</div>
CSS代码:
.wrapper > p:nth-of-type(2n){
background: orange;
}
:last-of-type选择器和:first-of-type选择器功能是一样的,不同的是他选择是父元素下的某个类型的最后一个子元素。
html代码:
<div class="wrapper">
<p>我是第一个段落</p>
<p>我是第二个段落</p>
<p>我是第三个段落</p>
<div>我是第一个Div元素</div>
<div>我是第二个Div元素</div>
<div>我是第三个Div元素</div>
</div>
CSS代码:
.wrapper > p:last-of-type{
background: orange;
}
:nth-last-of-type(n)选择器和:nth-of-type(n)选择器是一样的,选择父元素中指定的某种子元素类型,但它的起始方向是从最后一个子元素开始
html代码:
<div class="wrapper">
<p>我是第一个段落</p>
<p>我是第二个段落</p>
<p>我是第三个段落</p>
<p>我是第四个段落</p>
<p>我是第五个段落</p>
<div>我是一个Div元素</div>
<p>我是第六个段落</p>
<p>我是第七个段落</p>
</div>
CSS代码:
.wrapper > p:nth-last-of-type(3){
background: orange;
}
:only-child选择器选择的是父元素中只有一个子元素,而且只有唯一的一个子元素。也就是说,匹配的元素的父元素中仅有一个子元素,而且是一个唯一的子元素。
html代码:
<div class="post">
<p>我是一个段落</p>
<p>我是一个段落</p>
</div>
<div class="post">
<p>我是一个段落</p>
</div>
CSS代码:
.post p {
background: green;
color: #fff;
padding: 10px;
}
.post p:only-child {
background: orange;
}
:only-of-type选择器用来选择一个元素是它的父元素的唯一一个相同类型的子元素。这样说或许不太好理解,换一种说法。:only-of-type是表示一个元素他有很多个子元素,而其中只有一种类型的子元素是唯一的,使用:only-of-type选择器就可以选中这个元素中的唯一一个类型子元素。
html代码:
<div class="wrapper">
<p>我是一个段落</p>
<p>我是一个段落</p>
<p>我是一个段落</p>
<div>我是一个Div元素</div>
</div>
<div class="wrapper">
<div>我是一个Div</div>
<ul>
<li>我是一个列表项</li>
</ul>
<p>我是一个段落</p>
</div>
CSS代码:
.wrapper > div:only-of-type {
background: orange;
}
在Web的表单中,有些表单元素有可用:enabled和不可用:disabled状态,比如输入框,密码框,复选框等。在默认情况之下,这些表单元素都处在可用状态。那么我们可以通过伪选择器:enabled对这些表单元素设置样式。
html代码:
<form action="#">
<div>
<label for="name">Text Input:</label>
<input type="text" name="name" id="name" placeholder="可用输入框" />
</div>
<div>
<label for="name">Text Input:</label>
<input type="text" name="name" id="name" placeholder="禁用输入框" disabled="disabled" />
</div>
</form>
CSS代码:
div{
margin: 20px;
}
input[type="text"]:enabled {
background: #ccc;
border: 2px solid red;
}
:disabled选择器刚好与:enabled选择器相反,用来选择不可用表单元素。要正常使用:disabled选择器,需要在表单元素的HTML中设置disabled属性。
html代码:
<form action="#">
<div>
<input type="text" name="name" id="name" placeholder="我是可用输入框" />
</div>
<div>
<input type="text" name="name" id="name" placeholder="我是不可用输入框" disabled />
</div>
</form>
CSS代码:
form {
margin: 50px;
}
div {
margin-bottom: 20px;
}
input {
background: #fff;
padding: 10px;
border: 1px solid orange;
border-radius: 3px;
}
input[type="text"]:disabled {
background: rgba(0,0,0,.15);
border: 1px solid rgba(0,0,0,.15);
color: rgba(0,0,0,.15);
}
在表单元素中,单选按钮和复选按钮都具有选中和未选中状态。(大家都知道,要覆写这两个按钮默认样式比较困难)。在CSS3中,我们可以通过状态选择器:checked配合其他标签实现自定义样式,而:checked表示的是选中状态。
html代码:
<form action="#">
<div class="wrapper">
<div class="box">
<input type="checkbox" checked="checked" id="usename" /><span>√</span>
</div>
<lable for="usename">我是选中状态</lable>
</div>
<div class="wrapper">
<div class="box">
<input type="checkbox" id="usepwd" /><span>√</span>
</div>
<label for="usepwd">我是未选中状态</label>
</div>
</form>
CSS代码:
form {
border: 1px solid #ccc;
padding: 20px;
width: 300px;
margin: 30px auto;
}
.wrapper {
margin-bottom: 10px;
}
.box {
display: inline-block;
width: 20px;
height: 20px;
margin-right: 10px;
position: relative;
border: 2px solid orange;
vertical-align: middle;
}
.box input {
opacity: 0;
position: absolute;
top:0;
left:0;
}
.box span {
position: absolute;
top: -10px;
right: 3px;
font-size: 30px;
font-weight: bold;
font-family: Arial;
-webkit-transform: rotate(30deg);
transform: rotate(30deg);
color: orange;
}
input[type="checkbox"] + span {
opacity: 0;
}
input[type="checkbox"]:checked + span {
opacity: 1;
}
::selection伪元素是用来匹配突出显示的文本(用鼠标选择文本时的文本)
html代码:
<p>“::selection”伪元素是用来匹配突出显示的文本。浏览器默认情况下,选择网站文本是深蓝的背景,白色的字体,</p>
CSS代码:
::-moz-selection {
background: red;
color: green;
}
::selection {
background: red;
color: green;
}
:read-only伪类选择器用来指定处于只读状态元素的样式。简单点理解就是,元素中设置了readonly=’readonly’
html代码:
<form action="#">
<div>
<label for="name">姓名:</label>
<input type="text" name="name" id="name" placeholder="大漠" />
</div>
<div>
<label for="address">地址:</label>
<input type="text" name="address" id="address" placeholder="**上海" readonly="readonly" />
</div>
</form>
CSS代码:
form {
width: 300px;
padding: 10px;
border: 1px solid #ccc;
margin: 50px auto;
}
form > div {
margin-bottom: 10px;
}
input[type="text"]{
border: 1px solid orange;
padding: 5px;
background: #fff;
border-radius: 5px;
}
input[type="text"]:-moz-read-only{
border-color: #ccc;
}
input[type="text"]:read-only{
border-color: #ccc;
}
:read-write选择器刚好与:read-only选择器相反,主要用来指定当元素处于非只读状态时的样式。
html代码:
<form action="#">
<div>
<label for="name">姓名:</label>
<input type="text" name="name" id="name" placeholder="大漠" />
</div>
<div>
<label for="address">地址:</label>
<input type="text" name="address" id="address" placeholder="**上海" readonly="readonly" />
</div>
</form>
CSS代码:
form {
width: 300px;
padding: 10px;
border: 1px solid #ccc;
margin: 50px auto;
}
form > div {
margin-bottom: 10px;
}
input[type="text"]{
border: 1px solid orange;
padding: 5px;
background: #fff;
border-radius: 5px;
}
input[type="text"]:-moz-read-only{
border-color: #ccc;
}
input[type="text"]:read-only{
border-color: #ccc;
}
input[type="text"]:-moz-read-write{
border-color: #f36;
}
input[type="text"]:read-write{
border-color: #f36;
}
::before和::after这两个主要用来给元素的前面或后面插入内容,这两个常和content配合使用,使用的场景最多的就是清除浮动。
.clearfix::before,
.clearfix::after {
content: ".";
display: block;
height: 0;
visibility: hidden;
}
.clearfix:after {clear: both;}
.clearfix {zoom: 1;}
当然,我们还可以使用它们来实现阴影效果
.effect::before, .effect::after{
content:"";
position:absolute;
z-index:-1;
-webkit-box-shadow:0 0 20px rgba(0,0,0,0.8);
-moz-box-shadow:0 0 20px rgba(0,0,0,0.8);
box-shadow:0 0 20px rgba(0,0,0,0.8);
top:50%;
bottom:0;
left:10px;
right:10px;
-moz-border-radius:100px / 10px;
border-radius:100px / 10px;
}
上面代码作用在class名叫.effect上的div的前(before)后(after)都添加一个空元素,然后为这两个空元素添加阴影特效
当我们需要提交一个软件版本时,可以往这个版本上打一个标签,以后可以按照某个标签来取回某个版本的代码,实际上标签就是一个软件版本的快照。
标签实际上是一个指向某个commit的指针,跟分支很像,但分支可以移动,而标签却不能。
首先,我们应该切换到需要打标签的分支上
git branch
* dev
master
git checkout master
Switched to branch 'master'
Your branch is up-to-date with 'origin/master'.然后,我们可以使用git tag v1.0这样的命令来创建一个标签
git tag v1.0使用git tag命令来查看所有标签
git tag上面的操作是默认的,也就是当前最新的提交上,如果想要给历史版本打上标签,就必须找到历史提交的commit id
git log --pretty=oneline --abbrev-commit
4b2bea2 merge fix88 branch's modifyed
601da8d 在fix88分支上修复了一个bug
3d3cc43 merge with no-ff
a75a84c modifyed on dev branch
d057d79 conflict fixed
08ae6f3 modifyed on master branch
cec715d modifyed and commit on fea branch
8d4576f test on bra branch
62a6606 delete test.txt
96d9332 add test.txt
469e0de 这是我第二次修改,向index.html里添加了一个p标签并写入内容
1fb9ecb 这是我第一次修改,向index.html里添加了一个p标签并写入内容
a1a356d 新建index.html文件,这是第一次提交到仓库比如,我们想要在第二次修改的地方打上标签,那么它对应的commit id就是 469e0de,下面来敲入命令:
git tag v0.1 469e0de我们再次使用git tag命令来查看标签列表
git tag
v0.1
v1.0我们可以使用git show <tagname>命令来查看标签信息
git show v0.1
commit 469e0dee7484aecadc303dea96aca3b05fcab718
Author: kaindy7633 <[email protected]>
Date: Wed Mar 16 15:28:47 2016 +0800
这是我第二次修改,向index.html里添加了一个p标签并写入内容
diff --git a/index.html b/index.html
index 00e3fba..de4f7cf 100644
--- a/index.html
+++ b/index.html
@@ -6,5 +6,6 @@
<body>
<p>这是我向这个HTML文件加入的第一个P标签。</p>
+ <p>这是我向这个HTML文件加入的第二个p标签。</p>
</body>
</html>我们还可以为标签打上一段说明,使用-a参数指定标签名,-m参数指定标签说明
git tag -a v0.2 -m "add for fea branch" cec715d继续使用git show <tagname>查看
git show v0.2
tag v0.2
Tagger: kaindy7633 <[email protected]>
Date: Thu May 5 18:24:55 2016 +0800
add for fea branch
commit cec715de12320fe1169c083c722e572685750144
Author: kaindy7633 <[email protected]>
Date: Fri Mar 18 10:41:18 2016 +0800
modifyed and commit on fea branch
diff --git a/index.html b/index.html
index bf6b036..b7720b4 100644
--- a/index.html
+++ b/index.html
@@ -8,5 +8,6 @@
<p>这是我向这个HTML文件加入的第一个P标签。</p>
<p>这是我向这个HTML文件加入的第二个p标签。</p>
<p>这条修改是在bra分支上进行的,添加了第三个p标签</p>
+ <p>这条修改是在fea分支上进行的,添加了第四个p标签</p>
</body>
</html>如果标签打错了,也是可以删除的,标签都是存储在本地的
git tag -d v0.1
Deleted tag 'v0.1' (was 469e0de)如果想要把本地标签推送到远程,可以使用git push origin <tagname>命令
git push origin v1.0
Total 0 (delta 0), reused 0 (delta 0)
To [email protected]:kaindy7633/gitTest.git
* [new tag] v1.0 -> v1.0或者,我们可以一次把所有未推送到远程的标签推送到远程,使用命令git push origin --tags
git push origin --tags
Counting objects: 1, done.
Writing objects: 100% (1/1), 161 bytes | 0 bytes/s, done.
Total 1 (delta 0), reused 0 (delta 0)
To [email protected]:kaindy7633/gitTest.git
* [new tag] v0.2 -> v0.2如果标签已推送到远程,而又要删除,则会有点麻烦,先删除本地标签
git tag -d v0.2
Deleted tag 'v0.2' (was d6683cf)然后从远程删除,命令也是使用push
git push origin :refs/tags/v0.2
Warning: Permanently added the RSA host key for IP address '192.30.252.120' to the list of known hosts.
To [email protected]:kaindy7633/gitTest.git
- [deleted] v0.2A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.