lcxfs1991 / blog Goto Github PK
View Code? Open in Web Editor NEWleehey's blog -- 请star或者watch
Home Page: https://docschina.org/blog
License: Creative Commons Attribution 4.0 International
leehey's blog -- 请star或者watch
Home Page: https://docschina.org/blog
License: Creative Commons Attribution 4.0 International








































































































































































































李成熙,Shopee Airpay 前端 Leader。2014年毕业加入腾讯AlloyTeam,先后负责过QQ群、花样直播、腾讯文档等项目。后于2018年加入腾讯云云开发团队。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
到了新公司之后,发现居然也是用企业微信。但可惜的是,外部的企业微信居然没有机器人。这对以前在鹅厂里习惯用企业微信做提醒的我觉得很不方便。终于,7月一开始企业微信终于上线机器人功能。
右击群聊天卡片,可以添加群机器人。
悬浮在机器人的头像上,会显示出 Webhook 地址。点击这个地址,会跳到机器人的开发文档。
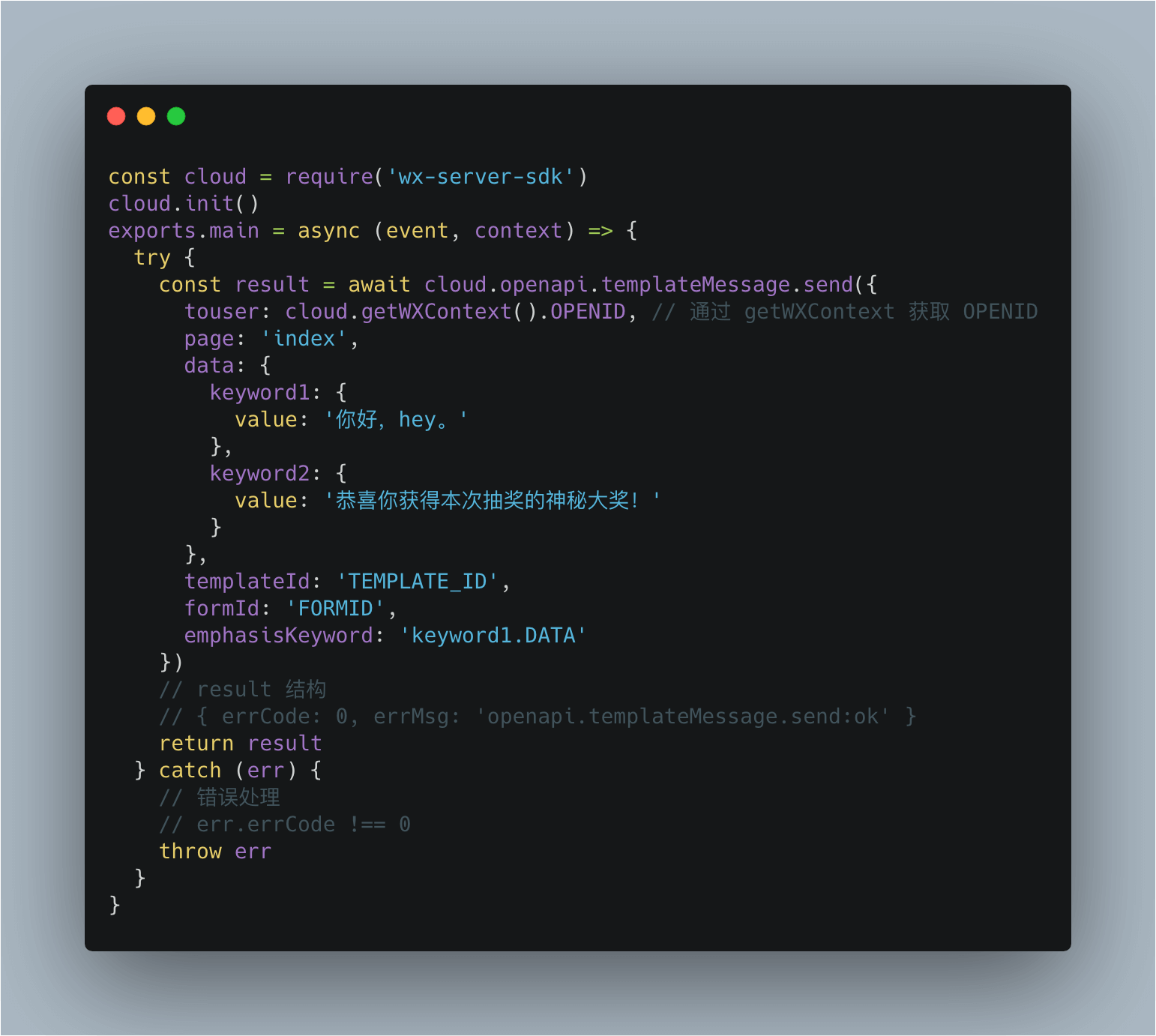
提醒机器人的开发其实很简单,其实就是向这个webhook地址,按文档提供的格式发送请求,就可以实现消息推送了。最简单的示例,可以用 Node.js 的 axios 类库:
const axios = require('axios')
async function bookLunch() {
let result = await axios.post(baseUrl, {
msgtype: 'text',
text: {
content: '大佬,订午餐啦!',
mentioned_list: ['@all'] // 可以使用邮箱或者手机号码
}
})
return result.data
}
bookLunch.then((res) => {
console.log(res)
})
以上是最简单的例子。除了普通文本内容,还可以发送 markdown,图文等内容,大家可以自行去看文档。
但问题来了:一般来说提醒,都是需要定时的,比如说每早提醒大家写计划,每周五傍晚提醒大家写周报,怎么可以让机器人在这些时间点出现提醒大家呢?你可能会想到买一台服务器,然后在上面部署 cronjob 服务,定时去调度服务。没错,这固然是最通俗的做法。但是买一台服务器要花钱呀,便宜的也得几十块钱一台虚拟机,而且只在上面跑一个这么简单的服务显然是不值的。有没有性价比高的做法呢?有,用云函数!
我个人的理解,云函数跟传统的服务主要的区别有几点,一个是它是一种事件型的服务,由不同的事件触发(HTTP、数据更改、对象存储的变更等),第二个它是非长驻的,运行一定时间后会冷却或者销毁,第三个由于以上两种特性,对于一些负载不是很高的服务,用云函数比较省钱。而对于这种提醒机器人,正正是一种负载不是很高的服务,非常合适。对小型团队的这种提醒服务,在最近各大厂商都在推广的时期,真的可以做到不要钱。
这里我对腾讯云的云函数最为熟悉,因此就用它来做实践。
首先为了方便,我们可以用腾讯云提供的 SCF CLI 来初始化我们的云函数和配置文件。我用的电脑是 Macbook,可以直接安装以下的命令进行安装:
pip install scf
如果不是Macbook可以先自行安装 python 和 pip
然后就是进行配置:
scf configure set --region ap-guangzhou --appid 1253970223 --secret-id AKIxxxxxxxxxx --secret-key uxxlxxxxxxxx
appid, secret-id 和 secret-key 可以在访问密钥页面里拿到。至于 region,则是你想部署云函数的区域,比方说在云函数的控制台首页,就能看到顶部的区域。选广州就是 ap-guangzhou,选香港的就是 ap-hongkong。基本上是 ap- 加上国内市场的拼音或国外城市的英文。
然后咱们初始化好项目(用node.js 8.9版本写云函数):
# 初始化云函数
scf init --runtime nodejs8.9 --name wework-robot
cd wework-robot
# 初始化 node 项目
npm init -y
然后就能得到该云函数:
这次要用到 axios,那我们就安装这个依赖:
npm i --save axios
打开 index.js 是如下一段代码,async 表示该函数可以用 Node.js 的新特性 async/await。
'use strict';
exports.main_handler = async (event, context, callback) => {
console.log("%j", event);
return "hello shopee!"
};
我进行一些删减后,成这样。将函数名字改为 main,而且由于用 async/await 就可以不用 callback 处理异步了。但改了名字也要改 template.yaml,将 main_handler 改为 main
exports.main = async (event, context) => {
return "hello shopee!"
};
好了。是时候来写提醒逻辑了。逻辑并不难,但主要注意的一点是时间。经过试验,云函数这里的时间统一使用了标准的国际时间,也就是北京时间要比它晚8小时,详细逻辑可以看以下代码的注释:
const axios = require('axios')
const baseUrl =
'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=7f399641-40aa-45c8-ad3d-c46e1ee085a7'
async function bookLunch() {
let result = await axios.post(baseUrl, {
msgtype: 'text',
text: {
content: '大佬,订午餐啦!',
mentioned_list: ['@all'] // 提醒所有人
}
})
return result.data
}
async function bookTaxi() {
let result = await axios.post(baseUrl, {
msgtype: 'text',
text: {
content: '辛苦了,早点回家休息吧。9点打车可以报销哦。',
mentioned_list: ['@all']
}
})
return result.data
}
async function remindWeeklyReport() {
let result = await axios.post(baseUrl, {
msgtype: 'text',
text: {
content: '周五了,记得写周报看看你这周有没偷懒!',
mentioned_list: ['@all']
}
})
return result.data
}
async function remindGoHome() {
let result = await axios.post(baseUrl, {
msgtype: 'text',
text: {
content: '11点半了,早点休息吧!'
}
})
return result.data
}
// 是否周五
function isFriday(day) {
return day === 5
}
// 是否工作日
function isWeekDay(day) {
return day > 0 && day < 6
}
// 是否30分,多预留1分钟以防云函数延迟启动或执行
function isHalfHour(min) {
return min >= 30 && min <= 31
}
// 是否正点,多预留1分钟以防云函数延迟启动或执行
function isSharp(min) {
return min >= 0 && min <= 1
}
exports.main = async (event, context) => {
let d = new Date() // js 时间对象
let day = d.getDay() // 获取今天是星期几,0 表示周日
let hour = d.getHours() // 获取当前的 时
let min = d.getMinutes() // 获取当前的 分
let hourGap = 8 // 咱们在东8区
hour += hourGap // 获取当前准确的时间数
// 打一下 log 看看具体时间
console.log(`day: ${day} hour: ${hour} min: ${min} hourGap: ${hourGap}`)
// 每周五4点到4点半通知写周报
if (isFriday(day) && hour === 4 && isHalfHour(min)) {
return await remindWeeklyReport()
}
// 工作日每天11点提醒订餐
if (isWeekDay(day) && hour === 11 && isSharp(min)) {
return await bookLunch()
}
// 工作日每天晚上9点提醒打车可以报销
if (isWeekDay(day) && hour === 21 && isSharp(min)) {
return await bookTaxi()
}
// 工作日每天晚上11点半提醒休息
if (isWeekDay(day) && hour === 23 && isHalfHour(min)) {
return await remindGoHome()
}
return 'hi shopee!'
}
逻辑都写好了,但是,我们需要让它定时执行,比如每30分钟执行一次。这个时候,我们就需要添加“定时触发器” 了。定时触发我们可以在 template.yaml 里面添加,可以把注释去掉,然后修改得到:
CronExpression 具体可以参考这个文档:https://cloud.tencent.com/document/product/583/9708
请使用推荐的写法:
这里有些参考的示例,直接套用即可:
我这里写的:0 */30 * * * MON-FRI *,表示每周一到周五,每30分钟会触发一次云函数的调用。
当然,我们还想开启一下 HTTP 触发器,来用地址直接访问该云函数进行一些逻辑的调试,看看是否真的能成功发消息。
我们可以再到 template.yaml 里添加这样的 HTTP 触发器:
好了,万事俱备,我们只需要再用 SCF CLI 发布即可。
# 打包
scf package -t template.yaml
Generate deploy file 'deploy.yaml' success
# 发布
scf deploy -t deploy.yaml
Deploy function 'wework-robot' success
发布完成后,我们可以到腾讯云的控制台看下,已经存在了:
点进去看看触发方式,发现分别有一个定时触发器,一个API网关触发器(HTTP触发)
如此,便大功告成了!看看效果:
最近由于用着html-webpack-plugin觉得很不爽,于是乎想自己动手写一个插件。原以为像gulp插件一样半天上手一天写完,但令人郁闷的是完全找不到相关的文章。一进官方文档却是被吓傻了。首先是进入how to write a plugin看了一页简单的介绍。然后教程会告诉你,你需要去了解compiler和compilation这两个对象,才能更好地写webpack的插件,然后作者给了github的链接给你,让你去看源代码,我晕。不过幸好最后给了一个plugins的API文档,才让我开发的过程中稍微有点头绪。
how to write a plugin这个教程还是可以好好看看的,尤其是那个simple example,它会教你在compilation的emit事件或之前,将你需要生成的文件放到webpack的compilation.assets里,这样就可以借助webpack的力量帮你生成文件,而不需要自己手动去写fs.writeFileSync。
主要就是这段代码
compilation.assets['filelist.md'] = {
source: function() {
return filelist;
},
size: function() {
return filelist.length;
}
};
首先,定义一个函数func,用户设置的options基本就在这里处理。
其次,需要设一个func.prototype.apply函数。这个函数是提供给webpack运行时调用的。webpack会在这里注入compiler对象。
输出complier对象,你会看到这一长串的内容(如下面代码),初步一看,我看出了两大类(有补充的可以告诉我)。一个webpack运行时的参数,例如_plugins,这些数组里的函数应该是webpack内置的函数,用于在compiltion,this-compilation和should-emit事件触发时调用的。另一个是用户写在webpack.config.js里的参数。隐约觉得这里好多未来都可能会是webpack暴露给用户的接口,使webpack的定制化功能更强大。
Compiler {
_plugins:
{ compilation: [ [Function], [Function], [Function], [Function] ],
'this-compilation': [ [Function: bound ] ],
'should-emit': [ [Function] ] },
outputPath: '',
outputFileSystem: null,
inputFileSystem: null,
recordsInputPath: null,
recordsOutputPath: null,
records: {},
fileTimestamps: {},
contextTimestamps: {},
resolvers:
{ normal: Tapable { _plugins: {}, fileSystem: null },
loader: Tapable { _plugins: {}, fileSystem: null },
context: Tapable { _plugins: {}, fileSystem: null } },
parser:
Parser {
_plugins:
{ 'evaluate Literal': [Object],
'evaluate LogicalExpression': [Object],
'evaluate BinaryExpression': [Object],
'evaluate UnaryExpression': [Object],
'evaluate typeof undefined': [Object],
'evaluate Identifier': [Object],
'evaluate MemberExpression': [Object],
'evaluate CallExpression': [Object],
'evaluate CallExpression .replace': [Object],
'evaluate CallExpression .substr': [Object],
'evaluate CallExpression .substring': [Object],
'evaluate CallExpression .split': [Object],
'evaluate ConditionalExpression': [Object],
'evaluate ArrayExpression': [Object],
'expression Spinner': [Object],
'expression ScreenMod': [Object] },
options: undefined },
options:
{ entry:
{
'index': '/Users/mac/web/src/page/index/main.js' },
output:
{ publicPath: '/homework/features/model/',
path: '/Users/mac/web/dist',
filename: 'js/[name].js',
libraryTarget: 'var',
sourceMapFilename: '[file].map[query]',
hotUpdateChunkFilename: '[id].[hash].hot-update.js',
hotUpdateMainFilename: '[hash].hot-update.json',
crossOriginLoading: false,
hashFunction: 'md5',
hashDigest: 'hex',
hashDigestLength: 20,
sourcePrefix: '\t',
devtoolLineToLine: false },
externals: { react: 'React' },
module:
{ loaders: [Object],
unknownContextRequest: '.',
unknownContextRecursive: true,
unknownContextRegExp: /^\.\/.*$/,
unknownContextCritical: true,
exprContextRequest: '.',
exprContextRegExp: /^\.\/.*$/,
exprContextRecursive: true,
exprContextCritical: true,
wrappedContextRegExp: /.*/,
wrappedContextRecursive: true,
wrappedContextCritical: false },
resolve:
{ extensions: [Object],
alias: [Object],
fastUnsafe: [],
packageAlias: 'browser',
modulesDirectories: [Object],
packageMains: [Object] },
plugins:
[ [Object],
[Object],
[Object],
[Object],
NoErrorsPlugin {},
[Object],
[Object] ],
devServer: { port: 8081, contentBase: './dist' },
context: '/Users/mac/web/',
watch: true,
debug: false,
devtool: false,
cache: true,
target: 'web',
node:
{ console: false,
process: true,
global: true,
setImmediate: true,
__filename: 'mock',
__dirname: 'mock' },
resolveLoader:
{ fastUnsafe: [],
alias: {},
modulesDirectories: [Object],
packageMains: [Object],
extensions: [Object],
moduleTemplates: [Object] },
optimize: { occurenceOrderPreferEntry: true } },
context: '/Users/mac/web/' }
除此以外,compiler还有一些如run, watch-run的方法以及compilation, normal-module-factory对象。我目前用到的,主要是compilation。其它的等下一篇有机会再说。
compiler还有compiler.plugin函数。这个相当于是插件可以进行处理的webpack的运行中的一些任务点,webpack就是完成一个又一个任务而完成整个打包构建过程的。如下图:

其它的任务点如invalid, after-plugins, after-resolvers具体可参考 compiler对象。
至于compilation,它继承于compiler,所以能拿到一切compiler的内容(所以你也会看到webpack的options),而且也有plugin函数来接入任务点。在compiler.plugin('emit')任务点输出compilation,会得到大致下面的对象数据,因为实在太长,我只保留了最重要的assets部份,如下
assetsCompilation {
assets:
{ 'js/index/main.js':
CachedSource {
_source: [Object],
_cachedSource: undefined,
_cachedSize: undefined,
_cachedMaps: {} } },
errors: [],
warnings: [],
children: [],
dependencyFactories:
ArrayMap {
keys:
[ [Object],
[Function: MultiEntryDependency],
[Function: SingleEntryDependency],
[Function: LoaderDependency],
[Object],
[Function: ContextElementDependency],
values:
[ NullFactory {},
[Object],
NullFactory {} ] },
dependencyTemplates:
ArrayMap {
keys:
[ [Object],
[Object],
[Object] ],
values:
[ ConstDependencyTemplate {},
RequireIncludeDependencyTemplate {},
NullDependencyTemplate {},
RequireEnsureDependencyTemplate {},
ModuleDependencyTemplateAsRequireId {},
AMDRequireDependencyTemplate {},
ModuleDependencyTemplateAsRequireId {},
AMDRequireArrayDependencyTemplate {},
ContextDependencyTemplateAsRequireCall {},
AMDRequireDependencyTemplate {},
LocalModuleDependencyTemplate {},
ModuleDependencyTemplateAsId {},
ContextDependencyTemplateAsRequireCall {},
ModuleDependencyTemplateAsId {},
ContextDependencyTemplateAsId {},
RequireResolveHeaderDependencyTemplate {},
RequireHeaderDependencyTemplate {} ] },
fileTimestamps: {},
contextTimestamps: {},
name: undefined,
_currentPluginApply: undefined,
fullHash: 'f4030c2aeb811dd6c345ea11a92f4f57',
hash: 'f4030c2aeb811dd6c345',
fileDependencies: [ '/Users/mac/web/src/js/index/main.js' ],
contextDependencies: [],
missingDependencies: [] }
assets部份重要是因为如果你想借助webpack帮你生成文件,你需要像官方教程how to write a plugin在assets上写上对应的文件信息。
除此以外,compilation.getStats()这个函数也相当重要,能得到生产文件以及chunkhash的一些信息,如下:
assets{ errors: [],
warnings: [],
version: '1.12.9',
hash: '5a5c71cb2accb8970bc3',
publicPath: 'xxxxxxxxxx',
assetsByChunkName: { 'index/main': 'js/index/index-4c0c16.js' },
assets:
[ { name: 'js/index/index-4c0c16.js',
size: 453,
chunks: [Object],
chunkNames: [Object],
emitted: undefined } ],
chunks:
[ { id: 0,
rendered: true,
initial: true,
entry: true,
extraAsync: false,
size: 221,
names: [Object],
files: [Object],
hash: '4c0c16e8af4d497b90ad',
parents: [],
origins: [Object] } ],
modules:
[ { id: 0,
identifier: 'multi index/main',
name: 'multi index/main',
index: 0,
index2: 1,
size: 28,
cacheable: true,
built: true,
optional: false,
prefetched: false,
chunks: [Object],
assets: [],
issuer: null,
profile: undefined,
failed: false,
errors: 0,
warnings: 0,
reasons: [] },
{ id: 1,
identifier: '/Users/mac/web/node_modules/babel-loader/index.js?presets[]=es2015&presets[]=react!/Users/mac/web/src/js/main/index.js',
name: './src/js/index/main.js',
index: 1,
index2: 0,
size: 193,
cacheable: true,
built: true,
optional: false,
prefetched: false,
chunks: [Object],
assets: [],
issuer: 'multi index/main',
profile: undefined,
failed: false,
errors: 0,
warnings: 0,
reasons: [Object],
source: '' // 具体文件内容}
],
filteredModules: 0,
children: [] }
这里的chunks数组里,是对应会生成的文件,以及md5之后的文件名和路径,里面还有文件对应的chunkhash(每个文件不同,但如果你使用ExtractTextPlugin将css文件独立出来的话,它会与require它的js入口文件共享相同的chunkhash),而assets.hash则是统一的hash,对每个文件都一样。值得关注的是chunks里的每个文件,都有source这一项目,提供给开发者直接拿到源文件内容(主要是js,如果是css且使用ExtractTextPlugin,则请自行打印出来参考)。
接下来,会以最近我写的一个插件html-res-webpack-plugin作为引子,来介绍基本的写插件原理。插件的逻辑就写在index.js里。
首先,将用户输入的参数在定好的函数中处理,HtmlResWebpackPlugin。
function HtmlResWebpackPlugin(opt) {
// 进行参数的处理
}
然后,新增apply函数,在里面写好插件需要切入的webpack任务点。目前HtmlResWebpackPlugin插件只用到emit这个任务点,其它几个仅作为演示。
HtmlResWebpackPlugin.prototype.apply = function(compiler, callback) {
// some code here
compiler.plugin("make", function(compilation, callback) {
// some code here
callback(); // 异步回调,跟gulp类似
});
compiler.plugin("emit", function(compilation, callback) {
// 对即将生成的文件进行处理
_this.options.basename = _this.addFileToWebpackAsset(compilation, _this.options.template, true);
if (_this.options.favicon) {
_this.options.faviconBaseName = _this.addFileToWebpackAsset(compilation, _this.options.favicon);
}
_this.findAssets(compilation);
if (!_this.options.isWatch) {
_this.processHashFormat();
}
_this.addAssets(compilation);
// other codes
callback();
});
}
第三步,调用addFileToWebpackAsset方法,写compilation.assets,借助webpack生成html文件(项目里最新版本新增了添加favicon的功能,因此有2个addFileToWebpackAsset的方法)。这里的核心就是本文一开始那段给compilation.assets添加source和size的代码。
第四步,在开发模式下(isWatch = true),直接生成html,但在生产模式下(isWatch = true),插件会开始对静态资源(js,css)进行md5或者内联。项目用了_this.options.isWatch去进行判断。
第五步,调用findAssets方法是为了通过compilation.getStats()拿到的数据,去匹配对应的静态资源,还有找到对应的哈希(是chunkhash还是hash)。
最六步,调用addAssets方法,对静态资源分别做内联或者md5文件处理。内联资源的函数是inlineRes,你会看到我使用了compilation.assets[hashFile].source() 及 compilation.assets[hashFile].children[1]._value。前者是针对于js的,后者是针对使用了ExtractTextPlugin的css资源。
最后一步,即是内联和md5完成后,再更新一下compilation.assets中对应生成html的source内容,才能正确地生成内联和md5后的内容。这一步在addAssets方法里有一处代码如下:
compilation.assets[this.options.basename].source = function() {
return htmlContent;
};
有兴趣可以试用一下html-res-webpack-plugin这个插件(为什么要写一个新的html生成插件,我在readme里写了,此处不赘述),看看有哪些用得不爽之处。目前只是第一版,还不适合用于生产环境。希望第二版的时候能适用于更多的场景,以及性能更好。到是,我也会写第二篇插件开发文章,将本文还没提到的地方一一补充完整。也欢迎大家在这里发贴,或者指出本人的谬误之处。
李成熙,腾讯文档前端Leader,负责DOC业务前端研发。2014年度毕业加入腾讯AlloyTeam,先后负责过QQ群、花样直播、腾讯文档等项目。2018年加入腾讯云云开发团队。2019年加入Shopee金融前端团队任一线前端Leader。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
这是一篇由内部分享转成的文章。因为最近有一些新的感悟,因此加入了一些新的内容。为什么还是想将一次分享铸成这篇文章呢?因为在日常工作中,还是能感受到很多同事一心只扑在技术上,对业务、对产品的关注过少,更有甚者是不想做业务需求,只求做艰涩的技术需求。
这并不是一个技术人正确的产品观。错误的产品观,会让技术人在技术上只求深入,不问业务,业务与技术的脱轨会让钻研的技术前功尽弃,也会让业务发展停滞。在商业公司里面从事技术,离不开商业世界基本的运行逻辑:收入 - 成本 = 利润。技术人就是要做功能将收入做得多多的,成本降得低低的,获得利润。当然你可以选择自己干,像两位马爸爸一样当创始人;或者做开源,像Vue、Redis、Nnginx 等开源应用的作者那样既做开源又做商业。只有通过技术手段获得利润,并且利润可持续,我们作为技术人的职业生涯才是可持续的。君不见,Webpack的作者由于拿不到足够的赞助又去上班了。连自己都养不活,更不要说烧些钱去探索星辰大海了。
那怎么样才是技术人良好的产品观,以及可以怎么树立呢?接下来我从四个常见的反面的思维为阐述。

在日常闲聊中,还是有很多同事对自己的产品数据不甚清楚,尤其许多前端的同事。可能后台经常要为机器发愁,生怕服务撑不起用户的并发,所以会经常问产品相关的产品数据。但前端的同事总觉得将页面切完接口调完就完事儿了。许多新的前端同事可能没想到,其实我们的HTML页面、其它静态资源部署,都是要考虑流量问题。一旦用户量很大,还需要要求云服务商给我们的服务、静态资源扩容。
下面列举了一些技术人最关注的数据。这些数据跟我们日常工作都是最息息相关的。有经验的技术人一般都会有所了解,新同事可能并不熟悉,本文只是做一个全面的列举,有兴趣可以专门学习,每一种类都有比较深的学问。
| 英语名称 | 作用 | 平台 |
|---|---|---|
| Metrics | 聚合数据/事件(比纯粹的Event更复杂) | Prometheus + Grafana |
| Event | 事件 | 腾讯云RUM |
| Tracing | 链路跟踪 | 如Jaeger |
| Logging | 日志 | 腾讯云CLS |
| Error | 错误栈信息 | 如Sentry |
| Performance | 性能 | 腾讯云RUM |
接下来我会列举一些跟产品更紧密关联的数据种类,这些连许多工程师都会忽略其重要性。一般来说,这类数据可以分为行为数据与业务数据。关注这些产品的数据有什么意义呢?
一般来说,行为数据最常见的埋点有以下三种:
| 名称 | 英文 | 含义 |
|---|---|---|
| 页面查看 | Page View | 统计页面的查看量 |
| 元素曝光 | Element Impression | 统计元素出现在屏幕可视区的量 |
| 元素点击 | Element Click | 统计元素点击量 |
基于上面埋点数量进行一些计算,常见可以得出行为数据三种最常见的指标:
| 名称 | 英文 | 含义 |
|---|---|---|
| (日/月)活跃用户 | Active User, DAU/MAU | 统计日/月活跃的用户,活跃的标准不同的产品有不同的选择,可以是查看,也可以是操作。也非常严格的比如查看多少分钟才纳入统计的 |
| 跳失率 | Bounce Rate | 统计通过某入口访问了一个页面就离开的的访问占总访问的比例 |
| 留存率 | Retention Rate | 统计前一周期访问但后一周期不再访问的用户占总用户的比例 |
一般来说,产品都会告知开发人员,尤其是前端或客户端帮忙做以上行为数据的一些埋点,再将数据导入数据仓库进行清洗后再加以分析。开发人员往往做完埋点就觉得工作完成了,在此也是希望开发人员可以要求产品人员提供相关功能、运营活动的行为指标,来看到自己做的功能是否受到用户青睐、运营活动是否带来用户的增长或留存。如果数据好当然可喜可贺,如果不好也没关系,可以用于复盘,为下一个爆款的功能和活动打好基础。至于如何做好埋点、如何分析复盘,这将是一个非常庞大的议题,但是有了以上数据埋点与指标的基本概念,才能做好复盘。
除了前端和客户端经常关心的行为数据,还有后台和数据同事经常打交道的业务数据。不同细分领域关注的业务数据可能不太一样,初创公司可能更关注用户规模,而电商金额公司则更看着实实在在的金额。以下列举一些常见的业务数据指标和比较关注这些指标的细分领域:
| 名称 | 英文 | 领域 |
|---|---|---|
| 注册用户 | Registered Users | 社交软件、效率工具 |
| 活跃用户 | Daily/Monthly Active Users(DAU/MAU) | 社交软件、效率工具 |
| 客单价 | Per Customer Transaction | 电子商务 |
| 订单数 | Transaction Volume | 电子商务 |
| 调用量 | API Call | 云服务 |
这些业务相关的数据,即使平时没有关注,如果你有投资科技领域的股票,这些数据相信也是经常见诸于财报,这些数据对这些公司的股价有实质性的影响。既然你用“真金白银”投资科技股会关注这些指标,而你“肉身”投资到某个业务,何不也多多关注这些业务的核心指标呢——这毕竟关乎你的前途和钱途。

这是一个典型的需求工具人思维。“产品说啥,我就干啥”;“为什么产品说这么干,背后的产品逻辑是啥,我不清楚”。抱有这种心态的技术人,很难真正投入到产品的研发中,往往敷衍了事,也无法将根据产品的特性与逻辑提供最适合的技术手段进行支持。更正确的想法应该是:让产品因你存在而大不同!让“技术”和“业务”互相成就彼此,共同成长。业务发展倒逼技术改进,技术改进成就业务,相佐相成。
那要怎么样才可以践行这样的理念呢?可以尝试以下的几条:

这也是一种常见的思维误区,只管自己的一亩三分地,总觉得多干一点自己就吃亏了。只关注自己“端”的技术,会导致:
没法从宏观、全链路的技术角度,去设计技术方案,做出用户体验最好的功能。
一个典型的反面案例,导出导入任务用户等待时间长,容易超时,最差劲的做法就是前端只管将页面和提示做好,后台只将导入导出接口写好,两边的衔接、中间通路的超时配置、用户体验完全忽略,很典型的只关注单点技术产生的问题。
解决问题慢或者无法解决。
有不少的技术疑难杂症会出在前后台交叉的领域。如果不能从全局出去,想办法,建立更好的日志监控、设计更好的工具用以快速定位并解决问题,问题则会迟迟得不到解决影响更广泛的用户。而且最后很可能沦落到互相推诿责任。
在这些年的研发过程中,认识到许多优秀的技术前辈、老板,他们的技术视野都是非常广阔的,他们一般都是先从某项技术专精起家,有机会涉猎其它领域的技术并通过快速学习的能力掌握,这样他们才具备统领涵盖多项技术的跨技术团队的能力。另外我觉得有一点尤为重要,即较为复杂、牵涉各端的需求,最好都由一位对各项技术都有所了解的技术同事作为技术Owner,总领各方的整体的技术方案更为妥当,并且这位技术人也需要对产品特性逻辑比较清楚,才能领导设计出符合产品与用户要求的技术方案并将其落地。

为了更好地论证这个**是偏见,有必要先定义一下通用技术与领域技术。这里的通用是指编程语言、数据结构、算法、设计模式等通用的计算机知识,如果是前端工程师可能会扩展到浏览器、V8等的一些相关知识。而业务领域技术,则专指该业务领域特别所需而其它业务领域可能不太需要的技术,比如直播行业需要直播录播、视频编解码等相关知识和技术;金融行业需要学习相应的股票、债券等知识,在国内券商甚至需要考证券从业人员资格证书;支付行业需要学习央行相关的法律规定还有支付的相关模型(读了内网的跨境金融技术深深感叹)还有各种数据库和各种锁保证交易和金额的一致性等等。
刚入行的年轻技术人总是希望学习更多的通用技术知识,但对业务领域的知识则表示抗拒,还发出灵魂一问:学了这些我到别的公司能用上嘛?我的回答是:有的用得上,有的用不上。比如视频技术,如果不在直播行业打工了,去长视频混口饭吃是绝对没问题的,但你说一旦跳槽到金融行业则完全用不上了。
有这样的想法很正常嘛,年轻的小伙未来的路还很长,可以尝试更多自己的兴趣,有很多转变赛道的机会,但你有没有想过,如果你成为某个业务领域的技术专家,这个支付模型整个公司只有几个人懂,核心视频编解码优化技术只有你能消化得了,办公文档的标准你了如指掌,你何愁不会成为业务的骨干与带头人呢?通用技术习得的人非常多,可替代性也比较强,但业务领域的技术知识,则还是需要沉浸在业务中,多年的摸爬滚打才能积累起来。通用技术与领域技术并不是互斥的,在修炼通用技术的同时,何不把自己所在业务所需要的业务领域技术与知识也一同学习,来个齐头并进呢?而且我相信,随着信息技术从消费互联网走向工业互联网,从新经济走向传统行业,我们所需要学习的业务知识、领域技术将会越来越多。而这类知识技术也将是技术人延长我们职业寿命非常重要的一环。
文章写得比较曲折,并没有直接陈述什么才是正确的技术人产品观,而是通过四个大家常见的一些误区或者偏见,逐一阐述和批判从而得到个人认为比较正确的产品观。以上均为经验心得,如有冒犯或谬误,恳请原谅或斧正,也欢迎大家留言进行讨论。

印记中文的成立主要是为了协助社区更好地翻译与部署文档。最近联合腾讯云一起设计了一套有效提升访问速度及降低流量消耗成本的方案,即 cos 对象存储服务 及 cdn 加速方案。本文主要描述方案大体的实现过程,如果你是技术文档的管理者,苦于没有优秀的文档部署方案,可以联系印记中文(docschina),我们会提供接入服务。如果你遇到性能问题,我们也可以提供免费的技术咨询服务
** QQ群:492361223 **
也可以关注我们的公众号:

一般而言,对公有代码,一般采用 Github + Travis-CI 存放及构建方式。而对于私有代码来说,则会直接使用 Bitbucket + Pipeline (Bitbucket自有的构建服务)。(点击以下标题展开详细内容)

在代码仓库方面,我们需要两个分支,一个是 master 分支,用于存放文档源码,另一个是 gh-pages 分支,用于存放生成的文档文件。
然后,我们需要配置 .travis.yml 文件,用于 Travis-CI 构建和部署我们的项目,下面是求全配置,表示仅在在 master 分支有 push 或者 pull request 事件的时候,才会触发构建,使用语言是 node.js,版本是 6.x,首先运行完安装依赖的 npm install 之后,再运行 bash ./scripts/deploy.sh。
branches:
only:
- master
language: node_js
node_js:
- "6"
script:
- bash ./scripts/deploy.sh
sudo: required
install:
- npm install那么 ./scripts/deploy.sh 脚本中,主要就是承担构建、鉴权,以及代码推送的功能。
// deploy.sh 第一部份,用于构建代码
npm run dist// deploy.sh 第二部份,用于与github鉴权
REPO=`git config remote.origin.url`
SSH_REPO=${REPO}
git config --global user.name "Travis CI"
git config --global user.email "[email protected]"
git remote set-url origin "${SSH_REPO}"
openssl aes-256-cbc -K $encrypted_7562052d3e34_key -iv $encrypted_7562052d3e34_iv -in scripts/deploy_key.enc -out scripts/deploy_key -d
chmod 600 scripts/deploy_key
eval `ssh-agent -s`
ssh-add scripts/deploy_key// deploy.sh 第三部份,用于向github推送代码
chmod -R 777 node_modules/gh-pages/
npm run deploy // dist是生产代码目录,deploy 所跑脚本是 gh-pages -d dist,最终将代码推送到gh-pages 分支那第二部份的 ssh key 怎么生成呢?其实整个 github 的鉴权原理不难,用工具成生 ssh key 公钥与私钥,然后将公钥存放到 github 的 repository 中,将私钥存放到代码库中,在Travis-CI 推送代码之前添加私钥,那么推送的时候就可以顺利鉴权成功。
那具体怎么生成 ssh key呢,具体可以参考这个文档Generating a new SSH key to generate SSH Key。
然后,到你的文档本地代码仓库键入以下示例命令:
ssh-keygen -t rsa -b 4096 -C ci@travis-ci.org
Enter file in which to save the key (/var/root/.ssh/id_rsa): deploy_key当有以下问题的时候,可 enter 跳过。
Enter passphrase (empty for no passphrase):
打开 deploy_key.pub 文件,将内容复制,然后到线上代码仓库https://github.com/<your name>/<your repo>/settings/keys中,添加 ssh public key。

然后安装 travis client tool,用于上传 SSH Key 信息到 Travis-CI 服务器。上传完后,运行以下命令:
travis encrypt-file deploy_key
使用,将以下代码复制到 deploy.sh 中,并且将 deploy_key.enc 文件复制到 scripts 目录下。记得千万不要上传 deploy_key.pub 文件。
openssl aes-256-cbc -K $encrypted_7562052d3e34_key -iv $encrypted_7562052d3e34_iv -in scripts/deploy_key.enc -out scripts/deploy_key -d然后使用以下命令进行登陆:
travis loginBitbucket + Pipeline 与 Github + Travis-CI 的流程是大体相似的,你可以稍微参考一下上一节的架构图。只是个别流程有细微出入。
生成 SSH Key 与 Github 的办法一样,可参考Generating a new SSH key。
然后前往 https://bitbucket.org/account/user/username/ssh-keys/,或者点击网站左下角头像,进入 Bitbucket Setting,Security,SSH keys,进行公钥添加。

至于 deploy.sh 脚本,也略有一些出入。
// deploy.sh 第一部份,用于构建代码
npm run dist// deploy.sh 第二部份,用于与github鉴权
REPO=`git config remote.origin.url`
SSH_REPO=${REPO}
git config --global --replace-all user.name "xxxxxx"
git config --global --replace-all user.email "[email protected]"
git remote set-url origin "${SSH_REPO}"
chmod 600 scripts/id_rsa
eval `ssh-agent -s`
ssh-add scripts/id_rsa
ssh -T git@bitbucket.org// deploy.sh 第三部份,用于向github推送代码
chmod -R 777 node_modules/gh-pages/
npm run deploy // dist是生产代码目录,deploy 所跑脚本是 gh-pages -d dist,最终将代码推送到gh-pages 分支设置 Webhook,是用于在构建完毕后,向部署服务器发起请求,触发自动部署的脚本。只要跟部署服务器约定好 url 路径,然后根据需要配置好 webhook 即可。



首先,创建一个 Bucket,没有备案的域名请选择海外的节点,同时选择 CDN 加速(后面需要用):

创建后,会进入 Vue Bucket 的文件列表页面,目前是空的。到 基础配置,中开启**静态网站配置。

然后进入域名管理,添加域名。

然后到你的域名管理提供商,配置一下 CNAME 解析。直接用上图的域名和 CNAME 值。

如果需要开启 HTTP2,还可以去申请 HTTPS 证书,腾讯云可以申请免费的 HTTPS 证书。

进入 缓存配置,添加一些缓存规则,如 js, css, png, jpg 等带有 md5 的资源可以长久缓存,而 html 等资源则不宜缓存。

然后进入 高级配置,在当中配置 HTTPS 证书 和 开启 HTTP2。
技术方案可大体如下实行。
监听请求方面, koa + pm2 部署一个小型服务,根据参考运行腾讯云 COS 文件上传脚本,然后用 nginx 反向代理技术将请求代理到此小型服务中。
至于 腾讯云 COS 文件上传脚本,本人推荐 Java 与 Python 版本的,尤其是 Python 版本的比较容易安装部署。
小型服务根据请求参考,先到本地部署好的文档 gh-pages 分支代码处,先行更新代码,然后再运行文件上传工具,将文件依次上传到 COS 服务中。
以下是使用 COSCMD 工具的一个简单示例:
const execSync = require("child_process").execSync,
moment = require("moment"),
fs = require("fs-extra"),
path = require("path");
// COSCMD 基本配置
const config = {
"appid": "xxx",
"secret_id": "xxx",
"secret_key": "xxx",
"timeout": 60,
"max_thread": 20,
};
// 执行命令方法
function exeCmd(cmd) {
var result = execSync(cmd);
console.log(`[${moment().format('YYYY-MM-DD HH:mm:ss')}]${result}`);
}
exports.index = function* () {
// 从请求 url 参数中获得 project 和 cos 部署节点区域的值
const project = this.params.project || '',
region = this.params.region || 'cn-east';
console.log(`[${moment().format('YYYY-MM-DD HH:mm:ss')}],${project} is starting to update. The region is ${region}!`);
// gh-pages 分支代码存放位置
const codePath = path.join(`/docs/files/${project}`);
if (!fs.existsSync(codePath)) {
this.response.status = 400;
console.log(`${codePath} does not exist`);
return;
}
// 更新 gh-pages 文件
const updateCommand = `cd ${codePath};sudo git pull origin gh-pages;sudo git reset --hard gh-pages;`;
exeCmd(updateCommand);
// 更新 COSCMD 配置
const configCommand = `coscmd config -a ${config.secret_id} -s ${config.secret_key} -u ${config.appid} -b ${project} -r ${region} -m ${config.max_thread}`;
exeCmd(configCommand);
// 筛选要上传的文件或文件夹
let info = fs.readdirSync(`/docs/files/${project}`, 'utf-8');
info = info.filter((item) => {
if (item.indexOf('.') === 0) {
return false;
}
return true;
});
// COSCMD 上传文件
info.forEach((item) => {
let syncCommand = '';
let stat = fs.statSync(path.join(`/docs/files/${project}/${item}`));
if (stat.isDirectory()) {
syncCommand = `sudo coscmd upload -r /docs/files/${project}/${item} ${item}/`;
}
else {
syncCommand = `sudo coscmd upload /docs/files/${project}/${item} ${item}`;
}
exeCmd(syncCommand);
});
this.body = "success";李成熙,腾讯云高级工程师。2014年度毕业加入腾讯AlloyTeam,先后负责过QQ群、花样直播、腾讯文档等项目。2018年加入腾讯云云开发团队。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
小程序诞生以来,业界关注小程序前端的技术演进较多,因此众多小程序前端的框架、工具也应运而生,前端开发效率大大提高,而后台的开发技术则关注不多,痛点不少,具体痛在哪里呢?
第一个是脑袋瓜疼,怎么疼呢?
随着像腾讯云等的云服务商提供的云服务越来越便捷,业务上云已经是大势所趋。但是从简单地在云虚拟机上部署页面,到实现真正全面地上云,还是有很多区别。要真正实现全面的上云,要了解的东西非常多,当你第一次接触这些概念的时候,学的这些东西是一个接一个,让你应接不暇,往往分散了你的对业务的专注力。比如我自己,来腾讯云之后,为了对云服务有更好地了解,就去报了个腾讯云的课程。这课程系列分云架构师、云开发、云运维三门课程,还分初级、中级、高级,需要花费大量时间才能理清这些知识概念,并且还要花大量的时间去上机做实验。所以对于开发来说,要彻底搞清楚,还真的不是件容易事,绝对让你的脑袋疼。
第二是肉疼,尤其是你老板肉疼。
最开始当互联网还没有云服务商的时候,公司都得自己搭服务,不仅花大价钱买机器、买宽带流量,还得请人过来维护。如果在这种情况下要搞小程序开发,公司得请一个维护服务器硬件的、一个维护网络的,一个数据工程师,一个后台还有一个前端,刚好五个人。当云服务商开始进入变革整个市场的时候,我们就不用再自己维护硬件了,由云服务商来维护,因此我们可以少请一个维护硬件的,但还是得有一个运维去维护云服务。当云服务商将数据库、容器服务都抽象出来上云之后,咱们连专业的数据库维护都可以不请了,由后台或者云维兼岗就行。云服务商的不断发展,确实是让云服务的成本不断下降,但投入的钱还是很多呀,要投入的人还是不少,这几年生意难做,作为老板肯定是想投入成本、试错成本越少越好。
第三个是肾疼。
大家都知道,开发是一个走肾的工作。比如,这些年流行的前后端分离,虽然让专人专项,但却引入了联调这个事,所以也增加了肾的负担。
这里列出了三个前后端分离带来的麻烦。
正因为小程序后台开发的麻烦重重,因此业内都想出了各种各样的开发方案,其中一种方案,“无服务开发小程序”,我们认为,将会是未来的趋势。但这个未来,其实今天已经到来了。
那什么是无服务开发呢?无服务,又称为 Serverless。Serverless 还处在一个比较初期的阶段,目前也没有权威和官方的定义,不同人不同公司有不同说法,今天我也不打算讲太复杂。顾名思义, Serverless 就是指应用的开发不再需要考虑服务器这样的硬件基础设施,基于 Serverless 架构的应用主要依赖于像腾讯云这样的云服务商提供的后台服务。比如说无服务云函数、云数据库、对象存储服务等等。简单来说,相当于你现在要开个水果店卖水果,以前你还得要租店面,搞水电、装修门面。现在这些都不用了,你就在一个已经搭好各种各样设施的超市里,租一个已经帮你搞好门面的架子或者箱子,卖得好你就租大一点,卖不好就租小一点,随时随地随你的心意,非常灵活。
为什么说无服务化开发是趋势呢?因为云服务的进程,已经从物理机,演进到 IAAS,再到 PAAS。IAA�S 就是包括像云虚拟机、私有网络、网络专线、负载均衡等等的基础服务;PAAS 则更抽象一些,比如像云数据库、网络防护等等。基于 IAAS、PAAS,云服务商发展出 Serverless 这类更高级的开发服务。因此呢,无服务开发就会是今后开发类似小程序这类轻量应用的新的开发趋势。
一句话概括就是说,有了无服务开发之后,你就不用再处理安装、运维,底层了,只管写接口、写逻辑就好。总得来说,虽然你管的东西越来越少,但开发效率却越来越高,开发出来的轻应用、小程序却是具备高性能、高可用、高扩展的特性。
那无服务开发,具体怎么去解决刚刚提到的后台开发痛点呢?
第一是让你更加关注你的业务逻辑。云服务许多好用但难理解的概念,什么冷备热备、弹性伸缩、负载均衡等等,通通都不用管,你只需要写好你的业务,服务好用户就行。
第二,更省人力更省资金,老板不再肉疼。因为有了无服务开发,运维工作也不用操心了,像小程序这类的轻应用,有一个全栈开发,或者一个前端,半个后台就可以轻松应付了,资金和人力的需求可谓大大节省。
第三,就是前端工程师向全栈工程师的转变。有了无服务开发,前端工程师其实也可以安全、高性能地去操作一些以前只有后台才敢操作的数据和逻辑,如果要开发的应用是像小程序一样轻量的、简单的,完全可以由前端工程师完成,除非是特别复杂的,可能才需要后台的介入。这样也省缺了先前提到的前后端联调的麻烦。
说了这么多无服务开发的概念、优点,在小程序无服务开发这一块,腾讯云有什么样的作品呢。这就是今天要重点介绍的,小程序·云开发,这就是腾讯云与微信联合研发后,交出的答卷。
云开发,一共提供了三大能力,分别是存储、数据库、云函数。简而言之,就是提供了存文件、存数据和运行业务逻辑的能力。接下来,我会采取前后对比的方式,从方方面面去对比云开发和旧有的开发模式的不同。
首先是开发模式与架构上的对比。在云开发模式出来之前,旧的小程序后台开发模式就是上面这幅图,在小程序端发请求,往往你得引入额外封装好的 SDK,然后你需要在云服务这边配置大量的运维产品才能做出性能、可用性非常好的产品。开发者要关心的内容,从前端、后台一直关心到运维这块。
而云开发的全新模式,只要调用小程序原生的接口,就可以操作最基本的三大资源,而云开发背后又有腾讯云的基础服务作为支撑,本身就高可用、高性能、可扩展,你要关心的事情是大大减少了。
其次是资源管理平台的对比。以前你需要管理云资源,你需要在腾讯云的面板里,几十上百的产品里找到你需要的产品。
而云开发呢,你在小程序开发工具里,就可以找到云开发的控制面板入口。进入后,我们将你要关注的产品,做成一个独立面板供你使用,极为简洁方便。
第三,我们对比一下在小程序端调用资源。以上传文件为例,旧的开发模式,小程序端,你需要用 wx.chooseImage 还有 wx.uploadFile 小程序接口,后台要部署业务框架、路由,还有写逻辑上传到腾讯云的对象存储,你还要考虑这个后台服务的性能与安全,万一用户量峰值很大怎么办,有黑客攻击怎么办。
而云开发的例子,则极为简单,十几行代码,就可以写出安全、性能好的代码上传逻辑!
假设开发者是一个菜鸟,只懂 JavaScript 基础,对比下来,传统的开发模式,前端耗时2分钟开发,1小时联调,后台框架、逻辑和联调一共8小时,运维,要花一整天时间去学,总共要花1142分钟,对比只要写2分钟就能完成的云开发模式,足足是云开发耗时的571倍!
最后,我们来对比在服务端里插入数据。这里的服务端里指的包括有云函数、还有你自己买的服务器。旧模式下,小程序端要用一个 wx.request 发送请求到后台,后台搭建好框架、路由等服务之后,开始写插入数据到腾讯云MongoDB实例的逻辑,自然也是需要考虑服务的性能与安全。
而云开发的新模式,十几行代码,就可以开发出性能好、安全性高的插入数据逻辑。
假设开发者是一个菜鸟,对比下来,传统的开发模式,前端要花31分钟进行开发与联调,后台要用6小时部署服务开发逻辑还要30分钟联调,而运维的话从学习到会用大概也得10小时,基本上是云开发模式耗时的1000多倍。
从代码、耗时等多个方面去对比新旧两种开发模式,我们可以发现,云开发是绝对的碾压。
大家现在知道了无服务开发是未来的开发新趋势,带有无服务特性的小程序云开发带来的各种各样的好处,那么腾讯云在背后,做了些什么技术进行支撑呢?
架构上,一个请求操作从小程序端,通过微信后台,一直到腾讯云这边的云开发服务层,云开发服务层调用的这些数据库、存储、云函数,其实都是基于腾讯云的各种基础服务。在这个请求通路上面,微信会将小程序的用户 openid, 小程序 appid 直接带过来,将用户的信息写到云函数、数据和文件元信息里面,为更方便的权限控制打下基础。
另外,既然是复用了腾讯云的基础资源,那自然是具备了云资源的特性。比如存储自动接入了 CDN 加速, 数据库天然就带有自动备份、无损恢复等功能,云函数有弹性伸缩、多地可用的特性,能响应峰值不同的服务。而云开发服务层,我们也做了负载均衡、并且与微信后台进行就近接入,让性能更好。
目前云开发正式上线5天(注:9月10日深夜发布,掘金技术大会是在9月16日),我们的服务所支撑的 API 日调用量最大的单个小程序,已经达到 1000W+ 的调用量了,这个调用量是什么概念呢?一般只有BAT,一些高频使用的独角兽开发的小程序才能达到这个调用量级。因此90%以上的小程序用我们这个服务都是没有问题的。
讲一项技术,除了讲功能、讲底层,其实更重要地说讲怎么去用这门技术去实践。接下来,我会介绍一些我们推荐的实践方式,但我只会是点到为止,我们其实更希望社区能基于云开发,做出更多更好的实践。
第一点是资源操作的推荐实践。
在小程序端操作资源方面,我们是使用小程序的原生接口进行操作,而在小程序端操作资源,由于安全的考虑问题,基本上操作存储、数据库等的资源只能写用户自己的数据,而读数据则根据规则来判断是否有权限。在服务端操作资源方面,我们使用 wx-server-sdk 或者 tcb-admin-node 来处理,前者是基于后者的能力进行了封装。在服务端使用这两个 SDK 去操作资源,所拥有的权限是管理级的,就是意味着可以操作一切的资源。
左边的图是数据库的权限控制,右边的图是存储的权限控制。这两个控制面板都有各自不同权限的一些推荐的使用场景,大家可以打开控制去读下面每个权限的灰色的解释。
第二点,是数据库的推荐实践。这里以腾讯乘车码为例,像这种交通的小程序,可能会面对弱网或者无网的情况,开发初期为了省事,将大量的配置信息都写在小程序端中。但随着向更多城市的推进,配置文件越来越大,小程序的包体积越来越大。正好这个时候云开发推出了,腾讯乘车码就采用云开发的数据库,将一些不一定要在离线环境使用的配置迁移到云开发,另外还采用云开发的存储服务来存放静态资源。这就大大压缩了乘车码小程序的体积,为其它新增功能腾挪了空间。
第三点,推荐使用云开发的存储存放小程序中所需要的静态资源。因为云开发的存储天然自带 CDN 加速。比如在控制面版的存储中,文件的详情里获取的下载地址,就是 CDN 已经加速的地址。
第四点,是云函数的使用。目前云函数暂时不支持过于耗时、太复杂的操作,目前的超时时间为20s,函数包大小控制在20M左右。但其实这也已经能满足超过80%的需求,随着服务的逐步稳定,我们会考虑将这些限制进一步放宽。
云函数另一种用法就是,我们可以将相同的一些操作,比如用户管理、支付逻辑,按照业务的相似性,归类到一个云函数里,这样比较方便管理、排查问题以及逻辑的共享。甚至如果你的小程序的后台逻辑不复杂,请求量不是特别大,完全可以在云函数里面做一个单一的微服务,根据路由来处理任务。
比如这里就是传统的云函数用法,一个云函数处理一个任务,高度解耦。
第二幅架构图就是尝试将请求归类,一个云函数处理某一类的请求,比如有专门负责处理用户的,或者专门处理支付的云函数。
最后一幅图显示这里只有一个云函数,云函数里有一个分派任务的路由管理,将不同的任务分配给不同的本地函数处理。
云函数还有一种用法就是,可以作为中间路由,然后将 appid, openid,转发给原有的服务。这里以腾讯相册为例。具体怎么操作呢。比如腾讯相册之前将评论功能接入了云开发,但一些敏感操作,像删除、编辑评论,这个请求发送到云函数,然后云函数会将用户信息转发给相册原本的后台,然后再将该用户是否有权限返回来告诉云函数,如果有权限,就在云函数里删除评论。
最后,如果你们想在云函数调用 AI 服务,还有一些微信相关的操作,可以使用我封装的这两个 SDK。第一个 image-node-sdk 覆盖面比较全,覆盖了全部的腾讯云智能图像服务,下面的 wx-js-utils,也提供了微信支付、模板消息、用户信息获取等几个常用的接口。
可以关注我的微博或者 Github 获取最新云开发的�资讯或者技术资料。
李成熙,腾讯云高级工程师。2014年度毕业加入腾讯AlloyTeam,先后负责过QQ群、花样直播、腾讯文档等项目。2018年加入腾讯云云开发团队。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
在掘金开发者大会上,在推荐实践那里,我有提到一种云函数的用法,我们可以将相同的一些操作,比如用户管理、支付逻辑,按照业务的相似性,归类到一个云函数里,这样比较方便管理、排查问题以及逻辑的共享。甚至如果你的小程序的后台逻辑不复杂,请求量不是特别大,完全可以在云函数里面做一个单一的微服务,根据路由来处理任务。
用下面三幅图可以概括,我们来回顾一下:
比如这里就是传统的云函数用法,一个云函数处理一个任务,高度解耦。
第二幅架构图就是尝试将请求归类,一个云函数处理某一类的请求,比如有专门负责处理用户的,或者专门处理支付的云函数。
最后一幅图显示这里只有一个云函数,云函数里有一个分派任务的路由管理,将不同的任务分配给不同的本地函数处理。
tcb-router 介绍及用法为了方便大家试用,咱们腾讯云 Tencent Cloud Base 团队开发了 tcb-router,云函数路由管理库方便大家使用。
那具体怎么使用 tcb-router 去实现上面提到的架构呢?下面我会逐一举例子。
架构一:一个云函数处理一个任务
这种架构下,其实不需要用到 tcb-router,像普通那样写好云函数,然后在小程序端调用就可以了。
// 函数 router
exports.main = (event, context) => {
return {
code: 0,
message: 'success'
};
};wx.cloud.callFunction({
name: 'router',
data: {
name: 'tcb',
company: 'Tencent'
}
}).then((res) => {
console.log(res);
}).catch((e) => {
console.log(e);
});架构二: 按请求给云函数归类
此类架构就是将相似的请求归类到同一个云函数处理,比如可以分为用户管理、支付等等的云函数。
// 函数 user
const TcbRouter = require('tcb-router');
exports.main = async (event, context) => {
const app = new TcbRouter({ event });
app.router('register', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'register success'
}
});
app.router('login', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'login success'
}
});
return app.serve();
};
// 函数 pay
const TcbRouter = require('tcb-router');
exports.main = async (event, context) => {
const app = new TcbRouter({ event });
app.router('makeOrder', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'make order success'
}
});
app.router('pay', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'pay success'
}
});
return app.serve();
};// 注册用户
wx.cloud.callFunction({
name: 'user',
data: {
$url: 'register',
name: 'tcb',
password: '09876'
}
}).then((res) => {
console.log(res);
}).catch((e) => {
console.log(e);
});
// 下单商品
wx.cloud.callFunction({
name: 'pay',
data: {
$url: 'makeOrder',
id: 'xxxx',
amount: '3'
}
}).then((res) => {
console.log(res);
}).catch((e) => {
console.log(e);
});架构三: 由一个云函数处理所有服务
// 函数 router
const TcbRouter = require('tcb-router');
exports.main = async (event, context) => {
const app = new TcbRouter({ event });
app.router('user/register', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'register success'
}
});
app.router('user/login', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'login success'
}
});
app.router('pay/makeOrder', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'make order success'
}
});
app.router('pay/pay', async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx) => {
ctx.body = {
code: 0,
message: 'pay success'
}
});
return app.serve();
};// 注册用户
wx.cloud.callFunction({
name: 'router',
data: {
$url: 'user/register',
name: 'tcb',
password: '09876'
}
}).then((res) => {
console.log(res);
}).catch((e) => {
console.log(e);
});
// 下单商品
wx.cloud.callFunction({
name: 'router',
data: {
$url: 'pay/makeOrder',
id: 'xxxx',
amount: '3'
}
}).then((res) => {
console.log(res);
}).catch((e) => {
console.log(e);
});小程序·云开发的云函数目前更推荐 async/await 的玩法来处理异步操作,因此这里也参考了同样是基于 async/await 的 Koa2 的中间件实现机制。
从上面的一些例子我们可以看出,主要是通过 use 和 router 两种方法传入路由以及相关处理的中间件。
use 只能传入一个中间件,路由也只能是字符串,通常用于 use 一些所有路由都得使用的中间件
// 不写路由表示该中间件应用于所有的路由
app.use(async (ctx, next) => {
});
app.use('router', async (ctx, next) => {
});router 可以传一个或多个中间件,路由也可以传入一个或者多个。
app.router('router', async (ctx, next) => {
});
app.router(['router', 'timer'], async (ctx, next) => {
await next();
}, async (ctx, next) => {
await next();
}, async (ctx, next) => {
});不过,无论是 use 还是 router,都只是将路由和中间件信息,通过 _addMiddleware 和 _addRoute 两个方法,录入到 _routerMiddlewares 该对象中,用于后续调用 serve 的时候,层层去执行中间件。
最重要的运行中间件逻辑,则是在 serve 和 compose 两个方法里。
serve 里主要的作用是做路由的匹配以及将中间件组合好之后,通过 compose 进行下一步的操作。比如以下这段节选的代码,其实是将匹配到的路由的中间件,以及 * 这个通配路由的中间件合并到一起,最后依次执行。
let middlewares = (_routerMiddlewares[url]) ? _routerMiddlewares[url].middlewares : [];
// put * path middlewares on the queue head
if (_routerMiddlewares['*']) {
middlewares = [].concat(_routerMiddlewares['*'].middlewares, middlewares);
}组合好中间件后,执行这一段,将中间件 compose 后并返回一个函数,传入上下文 this 后,最后将 this.body 的值 resolve,即一般在最后一个中间件里,通过对 ctx.body 的赋值,实现云函数的对小程序端的返回:
const fn = compose(middlewares);
return new Promise((resolve, reject) => {
fn(this).then((res) => {
resolve(this.body);
}).catch(reject);
});那么 compose 是怎么组合好这些中间件的呢?这里截取部份代码进行分析
function compose(middleware) {
/**
* ... 其它代码
*/
return function (context, next) {
// 这里的 next,如果是在主流程里,一般 next 都是空。
let index = -1;
// 在这里开始处理处理第一个中间件
return dispatch(0);
// dispatch 是核心的方法,通过不断地调用 dispatch 来处理所有的中间件
function dispatch(i) {
if (i <= index) {
return Promise.reject(new Error('next() called multiple times'));
}
index = i;
// 获取中间件函数
let handler = middleware[i];
// 处理完最后一个中间件,返回 Proimse.resolve
if (i === middleware.length) {
handler = next;
}
if (!handler) {
return Promise.resolve();
}
try {
// 在这里不断地调用 dispatch, 同时增加 i 的数值处理中间件
return Promise.resolve(handler(context, dispatch.bind(null, i + 1)));
}
catch (err) {
return Promise.reject(err);
}
}
}
}看完这里的代码,其实有点疑惑,怎么通过 Promise.resolve(handler(xxxx)) 这样的代码逻辑可以推进中间件的调用呢?
首先,我们知道,handler 其实就是一个 async function,next,就是 dispatch.bind(null, i + 1) 比如这个:
async (ctx, next) => {
await next();
}而我们知道,dispatch 是返回一个 Promise.resolve 或者一个 Promise.reject,因此在 async function 里执行 await next(),就相当于触发下一个中间件的调用。
当 compose 完成后,还是会返回一个 function (context, next),于是就走到下面这个逻辑,执行 fn 并传入上下文 this 后,再将在中间件中赋值的 this.body resolve 出来,最终就成为云函数数要返回的值。
const fn = compose(middlewares);
return new Promise((resolve, reject) => {
fn(this).then((res) => {
resolve(this.body);
}).catch(reject);
});看到 Promise.resolve 一个 async function,许多人都会很困惑。其实撇除 next 这个往下调用中间件的逻辑,我们可以很好地将逻辑简化成下面这段示例:
let a = async () => {
console.log(1);
};
let b = async () => {
console.log(2);
return 3;
};
let fn = async () => {
await a();
return b();
};
Promise.resolve(fn()).then((res) => {
console.log(res);
});
// 输出
// 1
// 2
// 3互联网的应用,大大小小,不同的场景,都离不开鉴权,从简单的可被用户感知的登录的鉴权,到技术侧不给感知的各种技术参数鉴权,都有着形形色色的鉴权方式和表现形式。其实本质上来讲,鉴权就是要证明你就是你,你可以做哪些事情。
所以鉴权分为两部分,一部分是鉴别身份,一部分是确定权力。而现代网络设计中,权力的分配一般都是预先分配好的,在鉴别身份之后,拿着身份信息,去权限中心确定权力范围,就完成了用户的鉴权过程。
身份证是现代社会用于鉴别身份的一种方式,说起身份证, 据相关史实考证,我国的身份证最早出现在战国时期,在商鞅在秦国变法,发明了照身帖。照身帖由官府发放,是一块打磨光滑细密的竹板, 上面刻有持有人的头像和籍贯信息。 国人必须持有, 如若没有就被认为是黑户, 或者间谍之类的。这可能是早期身份证的雏形, 在隋唐时期,我国出现了最早的“身份证”,当时的朝廷发给官员一种类似身份证的“鱼符”,他是用木头或者金属所作,形状像鱼,分左右两片,上有小孔,并可有官员姓名、任职衙门、官员品级等。那时,凡亲王、三品以上官员“鱼符”用黄金制作;五品以上用白银;六品以下为铜制。五品以上官员,还备有存放鱼符的专用袋子,称为“鱼袋”。
从秦朝到清朝的这个阶段, 出现的这些身份的标识, 形式多样性, 但总体来说,都是属于身份证明的这一范畴。然而,这样的身份证, 在核验其身份的真实性, 只能凭眼观, 造假很容易蒙混过关, 没有人 能真正的证明其真实性。 这种核验身份方法, 是最初级最原始的方法。 现代身份证雏形的阶段。
而身份证这种鉴权方式由如密码鉴权一样,属于一种固定密钥鉴权方式。密钥要不被私有不公开,要不很难伪造。
同样,在武侠小说中的令牌,也是如此。最近热播的倚天屠龙记,明教的圣火令,见之如见教主。而圣火令就是令牌的一种方式,使一种固定的密钥鉴权方式。
我这有一把锁,我把钥匙发给你,你使用资源的时候过来开锁使用就好了。可以形象的比喻现代互联网中使用的密码鉴权体系。资源管理者只信任密码凭证,无论谁持有了密码,就可以使用对应的权利资源。比如不管谁持有圣火令,就可以使用明教教主的权利资源。那么密钥鉴权体系的特点:
1.简单
2.密码成本,不公开或伪造有门槛
想象一种场景,持有圣火令的教主,每次施号发令,都要将圣火令从自己藏的密道里取出来才能发令?如果自己心爱的人正在被屠杀,取个圣火令回来可能人就没了,所以这里应该是有一个简单的方式来优化这一过程。
互联网密码鉴权体系中,常常在通过身份验证后,将通过认证的信息保持一段时间,同样,实际武侠江湖中,大家都是有记忆的,圣火令持有者亮出圣火令的一段时间后,看到的人就能记下他已经是圣火令的持有者了,下次发号施令,就不必取来圣火令了。
在web认证体系下,http协议是一种无状态的协议,用户通过输入密码后获得身份认证,这种状态是无法保持下来的,为了保持这种状态,客户端和服务端可以一起想办法把鉴权状态保留一段时间。比如客户端可以记下用户的密码,下次只需要把密码自动带入到服务端,但这种方式是极为不安全的。客户端和传输端的可能泄漏密码。为了避免这种风险的发生,客户端和服务端通过其他的约定来保持这种状态,比如通过一种临时密码来降低这种风险发生的危害,这种临时规则可以是session + cookie,可以是token等等。
密码鉴权体系一般都是发生在两方之间的鉴权方案。但是回归到武侠世界中,如果一个人拿了伪造的圣火令来发号施令,那不是对明教的危害很大?怎么解决这个问题?这就需要一个可以被信任的人,能够先先甄别圣火令的真假,然后其他的人信任这个人,最终完成身份的验证。
所以这就引入了一个可信任的第三方代为鉴别令牌的,然后告知鉴别结果。
比如第三方登录场景下, 平台需要第三方平台代为身份验证后告知平台此人的身份是什么。这就是我们常见到的oAuth鉴权,现在被广泛应用再第三方登录平台中,比如微信登录、QQ登录等等。
oAuth 2.0分为客户端鉴权和服务器端鉴权两种方式。拿比较常见的qq登录来举例,第三方平台需要在QQ互联平台申请一个appid, 互联平台同时会分配一个私密的appkey(密钥,始终不公开)
下面以web版 服务端oAuth鉴权方式举例:
1.用户: 点击使用QQ登录按钮(平台方页面)
2.浏览器: 跳转到QQ互联登录页面(第三方平台页面)
> url参数:平台方appid和平台方回调地址(用于接收第三方的校验信息)
> 第三方平台会校验appid和回调地址对应情况
3.浏览器: 用户和第三方平台鉴权(第三方平台)
4.浏览器: 第三方平台跳回回调页面(平台方)
url参数: 第三方平台颁发的临时token
5.服务器:第三方通过token加appkey来获取用户信息(服务端发起,避免appkey暴露)
通过上述过程完成了第三方平台的鉴权,获取到了第三方平台提供的临时密钥token,平台之后就可以通过这些信息向第三方索取更多的数据和权力,比如获取用户的openid和基本信息等等。
说了这么多广而全的鉴权方式,我们看看小程序开发中的鉴权是如何实现的
有过小程序开发经验的开发者,都会或多或少地用上小程序的开放能力,其中为数不少的能力是通过服务端 API 接口的方式提供给广大的开发者。比如我们常用来发送通知用户给用户的模板消息能力:
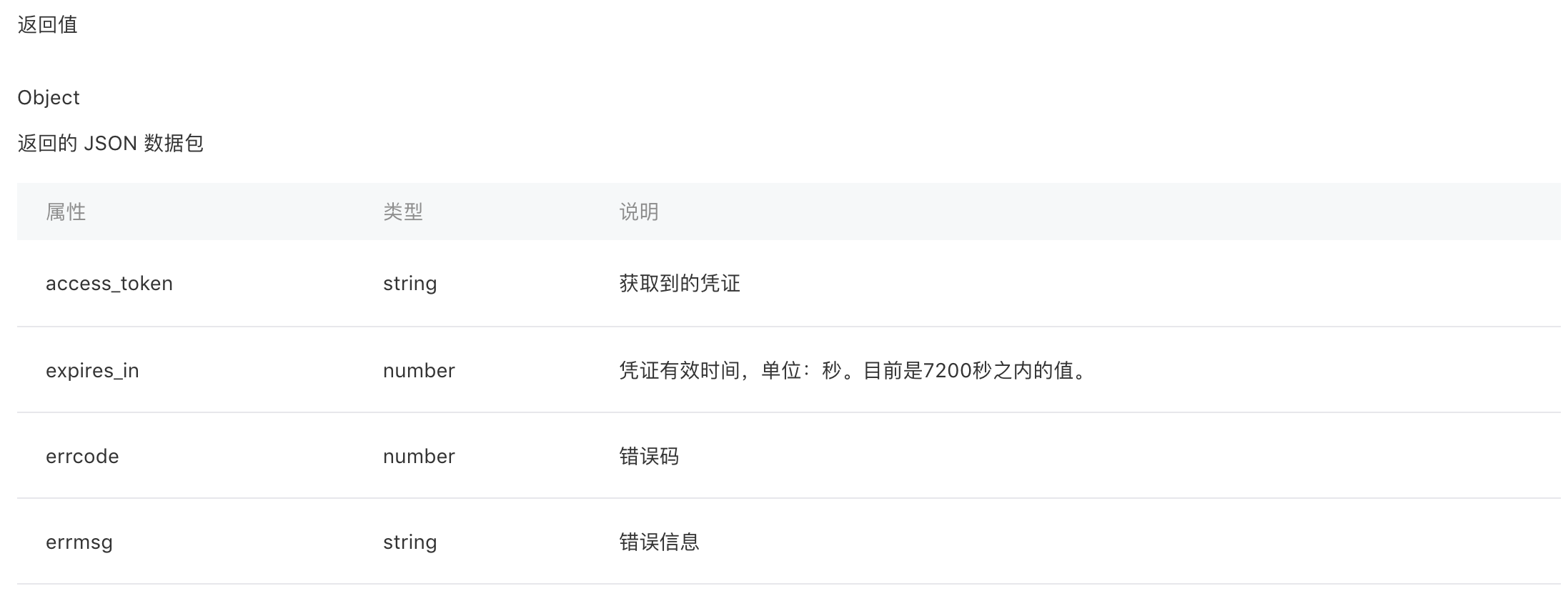
然后如果你查阅这些开放的服务端 API ,会发现几乎每个 API 都需要填一个参数,那就是 access_token。这个参数主要是用于微信侧的服务器鉴权。微信侧的服务器拿到 access_token 后,就会知道该小程序有没有权限可以替用户进行开放能力的操作。那么这个参数是怎么获取的呢?它是通过一个auth.getAccessToken 的接口来获取的,它具体的入参出参如下:
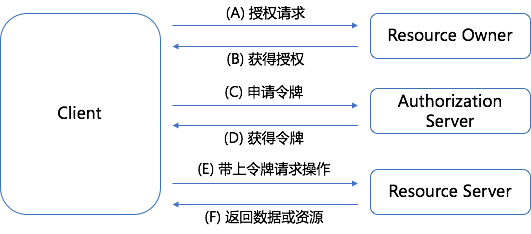
这种调用方式,基本上的思路跟 OAuth 2.0 的客户端模式很类似。OAuth 2.0 比较完整的模型如下图:
上图有一些主体概念,我们以微信小程序这个场景来解释一下:
整个流程其很显而易见:
(A) 小程序的后台向 Resource Owner 发送授权请求
(B) Resource Owner 获得授权
(C) 小程序的后台向 Authorization Server 根据上一步获得的授权,向 Authorization Server 申请令牌
(D) 获取令牌 Access Token
(E) 小程序的后台带上 Access Token 向 Resource Server 发请求,申请操作开放数据及资源
(D) Resource Server 返回数据或操作结果
实际上,微信将这个流程简化成下图,具体的步骤是:
(A) 小程序带上 appid 和 secret 向 Authorization Server 申请鉴权及获取令牌
(B) Authorization Server 确认 appid 和 secret 密钥对无误后,会返回一个临时密钥 Access Token (一般是2小时)
(C) 带上 Access Token,就可以向 Resource Server 发请求,申请操作开放数据及资源
(D) Resource Server 返回数据或操作结果
其中步骤 A 里,grant_type 表示授权类型,小程序这里的固定值是 client_credentials。外面有的服务还需要填一个 scope 字段,表示 Access Token 的适用获围,这里则省略了,表示适用所有的服务端 API。
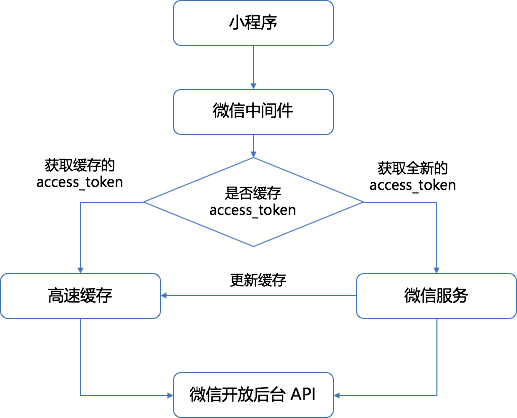
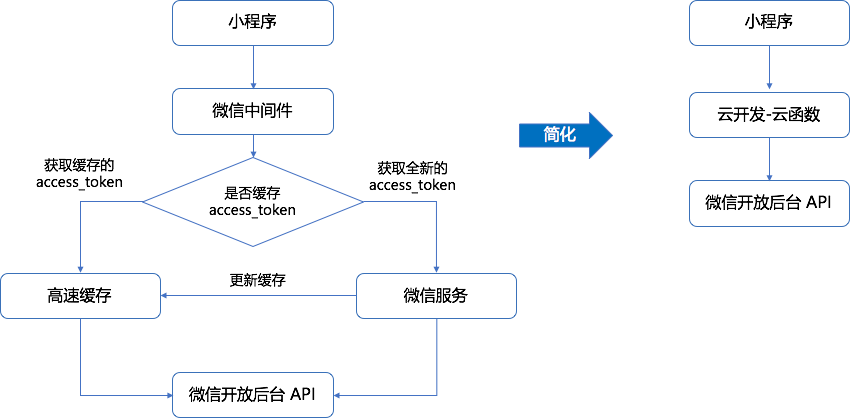
基于这种 OAuth 2.0 的开发模式,很多公司都会多搭建一个中间服务层,或者直接用中间件,去获取类似 Access Token 这种跟小程序相关的信息,因为这个令牌是有一定时效性,而且每天都有接口调用的限制,因此不可能每个用户操作的时候,都调用接口获取新的 Access Token。
这种开发模式有一定的局限性,那就是在开发微信相关业务的时候,需要额外部署缓存或数据服务,而存储的数据量其实很少,造成了资源的浪费和抬高了维护成本。
安全性与便利性就像一对互有恩怨情仇的侠侣,总是无法很好地调和。如果希望系统更安全,多设几道防御屏障,用加密级数更高的算法,那便利性、性能等方面就会承受一定的折损。而如果想用户更方便,少设几道安全关卡,那安全方面自然就会大打折扣。
因此,如果需要自己搭建一套微信小程序的服务,首先微信开放平台的鉴权服务是自然跑不掉的,需要按照文档规范逐一落实。而这套服务跟小程序前端的鉴权,也自然是个棘手的问题。简单一点的,用 JWT (JSON Web Token) 实现去中心化的鉴权,缺点是无法保证用户端的泄漏风险以及过期时间。而高级一点的是自己维护一套有过期时间的中心化 Cookie/Session 体系,看起来是安全些,但对服务的平行扩容却又并不太友好。
看起来,真的没有既安全,又便利的小程序鉴权服务体系了吗?
小程序最近推出的云调用能力,则是对原有的这种鉴权模式的巨大优化。官方对云调用的描述是这样的:
云调用是云开发提供的基于云函数使用小程序开放接口的能力。云调用需要在云函数中通过
wx-server-sdk使用。在云函数中使用云调用调用服务端接口无需换取access_token,只要是在从小程序端触发的云函数中发起的云调用都经过微信自动鉴权,可以在登记权限后直接调用如发送模板消息等开放接口。
主要是有几个关键点:
我们来看一下云调用如何在云函数中发送模板消息。
从这个例子看出,其实入参并无差异,只是不需要再去获取 access_token。那意味着整个开发的架构,可以简化成这样,架构的复杂度大大降低:
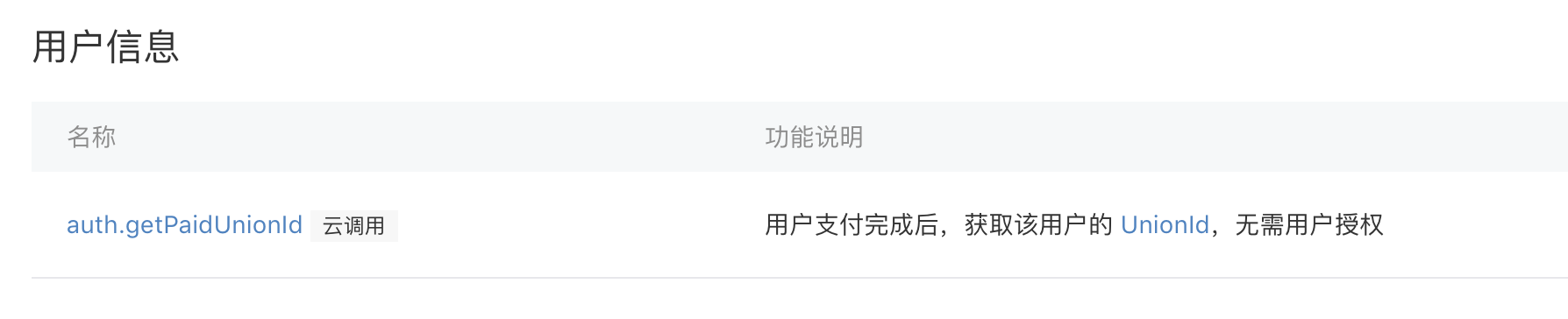
那目前有哪些的小程序使用场景可以用上云调用呢?统计了一下,主要用户信息获取、访问留存、消息(模板、统一服务、动态)、小程序码、内容安全等十几个大类几十个开放接口已经支持云调用。具体可以参考小程序服务端接口列表,如果接口旁边有一个"云调用"的标签,表明该接口支持云调用。
但总得来说,这种使用方式已经算是给小程序开发效率的提高,带为质的飞跃。
总之,鉴权场景从古至今都是一个高频场景,从古代的鱼符号,现代的身份证,都是一种令牌凭证的鉴权方式,到了线上的系统中,大部分场景也是基于密码鉴权体系,除此之外,基于生物特征的鉴权,比如基于指纹、基于面容ID等等也都在广泛使用起来。第三方鉴权体系也随着各大平台的开放而逐渐发展起来,单看小程序体系下鉴权也是无处不在,小程序云开发推出了免鉴权体系,为小程序的开发带来了极大的方便。
更进一步,未来是否可以有一种不基于密码的授权方式?比如基于机器学习和区块链模式下的鉴权,区块链的信任是去中心化的一种实现方式,未来的鉴权能否也可以做到去中心化的鉴权?
原文发表于:CSDN
作者: 腾讯AlloyTeam, 李成熙LeeHey
"每18至24个月,前端都会难一倍"(注:2015深JS大会上,赫门在《前端服务化之路》主题演讲中说的一句话)。难,是前端发展史偶然中的必然。但难,也造就着前端当下的繁荣。
Ryan Dah之所以选择用Javascript作为Node.js的基础语言,主要是因为它是单线程的,没有服务器I/O,没有历史包袱,有较低的门槛和比较良好的社区1。这看似是偶然,但实际上正正是Javascript的这些优秀的特性必然被历史选择,承担推动web技术发展的使命。(注:Node.js Interview: 4 Questions with Creator Ryan Dahl, http://bostinno.streetwise.co/2011/01/31/node-js-interview-4-questions-with-creator-ryan-dahl/)
本届的深JS大会,我们看见的是在Node.js的推动下,前端技术大放异彩,逐渐告别"石器时代",走向"工业时代"。而通过推动前端"工业时代"的离不开"三化"的建设,分别是自动化、实时化与服务化。
前端的自动化技术已经发展了好几年,之前涌现的grunt, gulp都已经帮助前端很好地解决代码压缩,生成md5,合图等的功能。自动化属于"三化"中的基础,它的发展极大释放了前端的手脚,让前端有更多的时候专注于实时化与服务化的发展。大会带来与前端相关的主题是前端的测试自动化。这相信是前端自动化比较棘手的问题。
马逸清给我们展示了七牛存储在前端测试上的一些尝试。但目前来看成果还是相当有限的。其一,他们的做法主要是针对于Javascript的逻辑,或者是一些基本的UI交互的测试,浏览器兼容性的测试、前端页面与设计稿的对齐方面的测试,基本都是空白。其二,即使他们现在可以对Javascript的逻辑进行测试,但比较好的切入条件是对DOM的隔离,所以,如果业务使用的是View与Model的框架如Angular的话,测试是比较友好的。但如果使用到的是web component这种将Javascript, CSS和HTML模块化地放在一起的元素,则比较麻烦。
对于前端页面与设计稿对齐的测试,我们团队AlloyTeam也有一些尝试,曾开发过一个AlloyDesigner的工具。而对于浏览器兼容性测试,在IE流行的时代,为了兼容IE,很多人喜欢用一个叫IE Tester的工具。但这些都只属于测试的工具化,离自动化还有很长的距离。

另外,马逸清还提到,写这些测试代码要增加约20%至30%的工作时间。这对于人手不足、业务时间急、需求迭代快的团队,是一个不少的挑战。而且这个幅度的时间增加,对这些团队来说,可能有违自动化的核心理念——效率的提高。
因此,前端的自动化下一步需要关注的是,拓展测试可覆盖的场景,以及减少额外的时间开销。
所谓服务化,即使用者只需调用,而毋须知道内部的实现,说白了就是标准化(注:《前端服务化之路》赫门, 2015深JS)。Node.js的出现使前端服务化成为可能。Node.js开发的系统可以作为接入层,调用Java, C++等提供的基础功能,处理数据库,然后将数据吐给浏览器进行渲染。简易言之,就是用Node.js代替Java, C++这一层。最后造就的成果是,不仅Java, C++可以放弃业务逻辑,更专注于数据处理的基础服务,而且Node.js能更专注于业务逻辑,挺供API服务给浏览器端的代码进行调用。
用Node.js作为接入层,让前端涉足"后台"的业务成为可能,而且能提高开发效率,还能更方便地使用最新Web技术,如Big Pipe, WebSocket等对页面进行优化。早前淘宝进行的前后端分离,腾讯AlloyTeam正在进行的玄武框架,都是在推动前端服务化做出努力。
除了Node.js作为 接入层提供服务以外,淘宝的赫门还提出了将前端Web Component作为一种服务,提供给后台使用。Javascript的AMD与CommonJS规范的订立使Javascript的模块化开发成为可能,也就自然而然地推动了前端的组件化。但赫门认为组件化的web component是散乱的,并没有办法一统江湖(如果Angular, React这类框架),而他的理念就是希望帮助Web Component重新定位,也就是将其标准化。他在演讲中举出一个应用场景:使用React开发了一个组件,给前端用直接使用React,而给后端用的时候则先用Flipper输出成web component再用。赫门的这个Flipper在技术上并没有太大的新意,有创新之处在于,他基于Flipper提出的服务化理念。
AlloyTeam内部其实有类似的更完善的方案—— MVVM框架Q.js 及Ques组件方案。赫门的Flipper只管将代码转成标准化Web Component,而Ques组件方案不仅在开发过程中可以用标准化Web Component,而且建基于构建,开发的过程中就已经可以将HTML, CSS及JS模块化,更好地组织代码。而Q.js则一个类Vue.js的的MVVM框架,它可以使用Ques组件方案,结合MVVM框架的特性,能够轻松驾驭一个项目的开发(注:Q.js, https://github.com/imweb/Q.js; Ques, https://github.com/miniflycn/Ques)。
我不确定用实时化这个词形容是否恰当,但不可否认的是,web技术的发展使网页获得更好的响应。目前比较流行的方案就是前端SPA(单页应用)技术结合后台的API服务,他们的桥梁是诞生刚满10年的Ajax。 未来,这种趋势会得到强化,而且web的体验会越来越贴近应用。
会上,前Googler尤雨溪带来的Meteor正致力于完善这件事。一般的单页应用都如下图,UI、客户端数据、和服务器数据相互沟通,达到状态的更新。而Meteor则希望将客户端数据这一层变薄甚至直接去掉,以减少性能的损耗,因此他们引入一种叫Minimongo的数据库驱动,它遵守DDP(分布式数据协议),根据Meteor的说法,是一种简易的结构化数据获取及数据更新协议。它的特色是,可以在客户端直接定制想要订阅的数据格式,服务器根据请求对订阅者进行推送。Meteor的另一个特色是使用了WebSocket技术。如果你打开TeleScope(使用Meteor技术的一个BBS应用),你能发现它是通过WebSocket获取数据的实时应用。也正因为Meteor使用WebSocket这个HTML5新特性,Meteor将DDP亲切地称为WebSocket的REST。

(图片来源:Database Everywhere: a Reactive Data Architecture for JavaScript Frontends, 尤雨溪, 深JS, [http://slides.com/evanyou/shenjs#/)][3]
另一个讲者,Strikingly的CTO郭达峰提到Facebook最近打算开源的一种新技术,GraphQL,结合Relay和Reactive,是最新比较热门的web开发方案。这种方案跟Meteor相比其实有异曲同工之妙。在通信结构方案,这种方案遵循上图,React负责UI状态,Relay负责客户端数据状态,而GraphQL则负责服务器数据状态。在通信协议方案,与Meteor不同,它并不限于使用WebSocket,它其实更着眼于解决REST的问题。GraphQL在服务器端发布一个类型系统,Relay通过客户端发送一些比较结构化的查询请求来获取数据,如下图。这套解决方案简化了服务器端,以统一的GraphQL接口提供给Relay这一层,Relay会自动获取数据并统一进行数据变更的处理,使数据获取和处理更加高效。

(图片来源:郭达峰,GraphQL and Relay https://speakerdeck.com/dfguo/lightning-talk-at-jsconf-2015)
在实时化应用方面,业界前10年(Ajax诞生10周年)的发展是致力于前端的交互与设计方面的优化,例如Ajax的诞生,Angular, React一类框架使单页应用更为普及。又如AlloyTeam的AlloyKit离线包系统(注:《AK(AlloyKit)——手机QQ Hybrid app 优化新思路》陈桂鸿,http://www.infoq.com/cn/presentations/alloykit-qq-hybrid-app-optimizing-ideas),使HybridApp体验更为完美。而看这次大会,站在10年这个分水岭上发表的演讲,像Facebook这样的巨头和Meteor这样的创新型公司正开始着眼于使前后端的数据通信更快更好。
前端的自动化、服务化和实时化是前端开发中正在发生的变化,是一系列深刻的变革。这些变革使前端的能务更加丰富、创造的应用更加完美。在深圳举办的这次**Javascript大会上的讲座,都相当精彩,有意无意地反应出业界的这些变化。希望下一届的大会能够少一点安利,少一点使用性的介绍,多一点实用的干货。
看到腾讯云提供了这么多 AI 图像服务,跃跃欲试!
结果发现,只有 Java, Python, C++ 几款 SDK。
为了前端工程师的福祉,撸了一款 Node 的 SDK,如下:
一共支持6大类(信息认证、人脸识别、文字识别、图片识别、人脸核身和人脸融合),35个接口,有些接口是提供了大量免费调用的机会,而有些可会要收费。
共提供两种调用方式。
外链
读取本地文件
欢迎试用以及给我提Issue或PR!
手Q群成员分布页面。每天PV约260万,约60万人点击活跃群成员头像,点击申请加群14万人,转化率约5%。
示例连接,需要QQ登录态,可到腾讯网门户进行登录:
链接

这次的构建优化主要带来的思考是,一个基本的构建、优秀的构建分别是怎么样的。
我们应该引入怎么样的评判标准呢? 市面上还没有人做过标准的回答。一般而方,作为构建,它的使命是提高开发人员的效率,并能对项目进行足够的性能优化。也就是说, 开发效率及性能优化应该作为两个最基本的评判标准。
对于一个前端项目而言,基本的构建功能应该包括下面的功能。
(1) 文件复制
(2) 文件压缩
(3) 文件md5
(4) 文件打包及合并
(5) 文件内联
(6) 合图
在构建工具的选择的时候,如果包含这些功能的话,那么称得上是“合格”的构建工具。它的目标,是为前端的项目带来最为基本的优化和开发效率。如果结合手Q的业务来说,那么离线包和cdn路径替换也应该作为第7和第8点的基本功能。
那么什么算是优秀的构建呢。优秀构建应该比基本的构建带来更进一步的开发效率和项目性能优化方面的提升。一些比较好的构建特性可能会被包含在内,例如图片压缩、实时刷新、性能上报打点生成、自动化测试、代码性能优化检测等等。除此之外,更优秀的构建会做的是,结合自己业务的需求,将打包、部署测试、发布等一系列流程打通,形成整个开发的闭环。

根据学习需要,参考了Simple,我写了一个基本的构建工具,steamer-gulp(蒸汽机的意思,第一次工业革命的动力之源。寓意给前端带来自动化)。这个构建代码大约300多行,由于学习需要,代码会稍有冗余之处,但比较便于新人学习及修改。

对于构建的功能来说,第三方插件有时候是你非常重要扩展功能的重要途径,而且功能插件化,能使你的构建更加精炼,代码更为优雅。但有时候你并不能找到令人满意的插件,这时候你就需要动手自己写。grunt的插件并不能开发,因为只是文件的操作,而gulp的插件在开发之前,你要首先理解清楚stream和buffer的概念,并阅读一下官方的文档和例子。下面三个链接提供了中文官方文档和两个笔者开发用于steamer-gulp的插件例子:
(1) 插件开发
(2) gulp-bigpipe-template (bigpipe模板生成)
(3) gulp-inline-res (内联js, css和html)
使用构建的时候,你会发现会被约束各种文件应该放的位置,以及文件名的命名。Simple和steamer-gulp采用的是常用的约束方式,同类型的文件就放在相同的文件夹下,我们不妨将之称为同类文件约束方式。但在组件化的大潮下面,越来越多的工程师可能会采用组件化的思维的约定方式。与同一组件相关的文件归到组件的文件夹下面。UC浏览器的张云龙,以及旁边组的Q.js框架的构建,都推崇后一种的思路。这种思维我们可将之称为组件化约束方式。
同类文件的约束方式对开发模式的采用并没有很大的限制,你可以自由选择喜欢的开发模式。至于组件化的约束方式,它推荐,并且很大程度限制于使用组件化的开发思路,在js开发的时候喜欢采用观察者模式或者中介者模式。例如Q.js喜欢采用emit和on分发和监听事件,React目前的最佳实践是类flux框架(flux采用观察者模式,redux采用中介者模式)。
手Q群成员分布一开始就采用了同类文件约束方式。在搭建steamer-gulp的时候,也曾考虑过使用组件化的约束方式。但一旦选择这类约束方式立即就会面临问题。其一,组件化约束方式看来无法脱离组件化的开发方式,如果新人对这种开发方式不熟悉,开发起来会比较痛苦。其二,即使熟悉组件化的开发方式,你也要面临组件化开发框架的选择问题。例如,如果你选择还未成熟的Q.js框架(期待逐渐成熟),开发效率并没有带来提升,倒不如使用兴趣部落的老王模型结合同类文件约束方式开发得爽。
性能会与预期一样更好,但做这些基本的优化也跟预期一样,并不会带来非常大的优化。性能其实不算是这次成果的重点。另外,离线包大小通过构建离线包由原来的423kb,减少到247kb。节约了带宽成本,加快了用户下载离线包的速度。

通过构建,我们可以达成开发效率的提升,以及对项目最基本的优化。因此,能够通过构建自动化做到的优化和效率提升,请尽量做足。这样才能让我们有更多时间将优化花在更为精辟独到、难以自动化的优化层面上。
但仅仅通过构建达到的优化其实还是有限的,更大范围的优化还需要建立于前端的工程化之上。前端工程化是一个很广阔与高深的话题就不在本文篇幅里面,作为新人,在用好构建工具之后,可以对前端工程化作进一步的探讨与尝试。
写这篇文章也是为了引起新人对构建的重视。作为新人,仅仅信手拿别人的构建使用并不足够,我们还需要有能力动手搭建或完善我们使用的构建工具。
webpack:
一小时包教会 —— webpack 入门指南
Webpack 和 React 小书
webpack-demos
webpack 教程大全

最近几个月一直有些事情没有想通,但可幸的是,有些问题的答案逐渐开始明朗起来了。好久没写文章,籍此献上一篇短文。
当初准备毕业的时候,其实并没有想过要当前端工程师,毕竟当时基本都是全栈(PHP + jQuery)。但由于并不是科班出身(大学读Business),自信心不足,以及机缘巧合,就成为了一名前端工程师。
选择这份职业,其实也领略到它所拥有的魅力,更快捷的开发方式,更紧贴时代的发展,跨端的兼容等等,可以算是享受了前端这几年飞速发展的红利。但工作三年之后,也逐渐发现只是围绕前端来发展,有很大的局限性。
大约是有那么两件事触动到我吧。
第一件事是, React Native, Weex, Node.js 这事技术的发展,仿佛是给前端铺平了进入客户端和后台的道路。但真正开发过的人才知道,在这些技术里玩得溜的,其实还是从安卓、IOS转过来的客户端开发或者从JAVA, C++转过来的后台工程师。
第二件事是,如果未来,需要你带技术团队,只懂前端技术足够吗?其实是不够的,精通前端技术,然后懂点后台、客户端皮毛呢?我觉得也是不够的。就这样,能与后台和客户端达到更良好的技术沟通与理解吗?能在他们给出非最佳方案的时候提出自己的见解吗?万一部门的前端人力富余了,有能力带团队做后台吗?做些客户端的东西呢?能做,但能做得优秀吗?如果没有技术储备,我觉得上述的问题完全解决不了。

所以,未来一两年,希望自己能朝着软件工程师方向发展,而不仅仅是将自己局限为前端工程师。不过,一个人的精力真的有限,未必能把各方面的技术都学得很透彻。但我对自己的要求是,精通一门端技术和一门后台技术应该是比较好的搭配,这样整个产品的技术开发都基本能 Hold 得住。不过,具体怎么搭配,可能还是跟自己的职业发展和兴趣爱好有关,同时掌握端两门端技术、后台 + AI 技术、等等,我觉得这些搭配也不差。
技术能力拓宽之后,你未必能马上能管理团队、更好地掌握一些跨端技术,尽管如此,你在前端领域的一些想法,可能会有更不一样的转变。

比如说,如果公司内的团队,每个人都至少掌握一门端技术和一门后台技术,好多时候人力都可以动态调配,联调的时候也能减少。某个需求,如果后台人力太紧,导致联调时间滞后,之前前端团队最喜欢的做法是,我们来写个数据Mock平台,自己在上面写一些假数据,调完之后,后台好了,再跟后台调。但如果我本身就会这门技术,我直接把接口写好就行了,在接口传假数据,虽然可能还要跟后台的数据对接,但总体来说,实质上还是少了些Mock的功夫。

由于动态调配带来的好处除了节省开发时间,其实是更有利于技术部门组建 feature team。国内许多大公司主要都是将技术分得很细很细,每个组的成员,几乎就只会一门技术。如果一个部门里缺少了某种技术的组,或者尽管有但人力不足,要孵化的新项目需要这项技术,估计就因找不到合适的人才而难产了。
看完我所说之后,结合自身的发展,不知道是否也有所感触呢?
如有谬误,恳请斧正。
原文链接
本文使用starter-kit:steamer-react react分支。此分支已集成react与preact。
最近接手了互动视频的项目,做了一个月的运营活动。跟基础功能不同,运营活动更为轻量。因此许多同事并不想用那么“重”的React。但同时,大家由于之前度过React的上手痛苦期后,开始体会到React的许多好处,裸写运营活动的时候,又开始对React的好处念念不忘记:良好的组件化、解放js能力的jsx等。
因此,寻找轻量化的类React解决方案便提上日程。
选型的时候,首先有几个考量:
基本上以上几点,Preact都能够很好的满足,因此最终选定为团队的类React轻量化框架进行使用和研究。
相比起react-lite,Deku, Virtual-DOM,Preact虽然不是最多的star,但也能排第2,也具备测试用例,且作者开通了gitter chat跟开发者保持联系,某天在上面留言,作者也是回复得很迅速。

性能方面,Preact也不俗。加载性能方面,由于本身的bundle在gzip后大概只有3kb,跟React相比小太多,自由就有优势。渲染性能方面,参考了一篇JS WEB FRAMEWORKS BENCHMARK系列测评文章,发现Preact在创建、更新、删除节点等方面,都有良好的表现。
第一次性能测试:

第二次性能测试:

包大小:
| framework | version | minimized size |
|---|---|---|
| React | 0.14.3 | 136.0kb |
| React-lite | 0.15.6 | 25kb |
| Preact | 5.6.0 | 10kb |
| Deku | 2.0.0-rc16 | 51.2kb |
| Virtual Dom | 2.1.1 | 50.5kb |
除了性能的良好表现,此框架的浏览器兼容性也不错,能兼容目前的主流浏览器,并且在添加polyfill的情况下,能够兼容在国内还有不少份额的IE8,确实是不少还需要兼容IE8开发者的福音。
Preact的常用api基本跟React一致,这使得对React熟悉的开发者,完全没有上手的难度,Preact作者单独开辟了一个文档Differences to React,介绍React与Preact的异同。Preact主要缺少的React Api有PropType,Children, 和 Synthetic Events(合成事件)。作者解释道,PropType其实许多人都不使用,并不影响开发; Children其实是数组,所以也并不是必须的;而合成事件,由于不需要过度考虑不同浏览器对事件处理的异同,所以也并没有做过度封装。如果真的想使用以上这些缺失的React Api,作者也提供了preact-compat,使用的时候,在Webpack上的external这样替换便可:
{
// ...
resolve: {
alias: {
'react': 'preact-compat',
'react-dom': 'preact-compat'
}
}
// ...
}
对于React开发者来说,最常用的就是redux, router这些周边的插件。而Preact也有提供preact-redux和preact-router,甚至还有帮助Preact做同构直出的preact-render-to-string。
Preact项目的框架小而美,合并成的dist文件也只有500行左右,比较容易学习和维护。若团队选择此框架作为React的轻量解决方案的话,我们最好能具备维护和开发此框架的能力,这能够在遇到bug的时候第一时间修复,而且能够很好地开发一些组件,提升框架的开发效率。
作者在Getting Started里有比较好的介绍。其实不外乎就2点差异:
import preact, { h, render, Component } from 'preact';
而引入react的时候,大概是这样的:
import React, { Component, PropTypes } from 'react';
import { render } from 'react-dom';
如果你想在一个构建里面同时使用React和Preact(有的页面使用React,有的用Preact),你可以通过Webapck的loader include或者exclude,然后凭路径区分。而我在steamer-react的react-preact分支里的处理是直接用文件名后缀。如果是有React相关引入的,则用.js后缀,而有Preact相关引入的,则用.jsx后缀。
补充自@zbinlin的答案:
babel-preset-react 也是依赖于 babel-plugin-transform-react-jsx,而 babel-plugin-transform-react-jsx 在将 jsx 编译成 js 代码时,提供了一个选项 pragma 来选择 react(默认)还是其他的 Virtual-DOM。该选项可以通过在 .babelrc 中指定,或者直接在 jsx 的源文件里通过 /** @jsx XXX */ pragma 来指定。
因此如果混合使用 react 和 preact,可以在使用 preact 的 jsx 文件里添加 /** @jsx h /(或者 /* @jsx preact.h */,如果你只 import preact,而没有 import h 的话)来处理。
粗略看了一下Preact的实现,简单介绍一下。
Virtual Dom算是类React框架的最大卖点。Preac作者写了一篇WTF is JSX。主要就是借助babel-plugin-transform-react-jsx的能力,里面有个pragma参数,用于设定用什么函数来做virtual dom的转换。此处定义的是preact.h
["transform-react-jsx", { "pragma":"preact.h" }]
所以,你会看到编译后,有类似的代码:
_preact2.default.h(
'p',
{ className: 'info-content' },
item.des
)
查看源码,preac定义了h的函数,用于将传入的值转换成virtual dom:
function h(nodeName, attributes, firstChild) {
// some code here
}
所以,如果传入上面的p和对应属性,则会转换成下面的对象:
VNode {nodeName: "p", attributes: {class:"info-content"}, children: undefined, key: undefined}
但virtual dom需要转换成真实的dom,还需要一个函数进行转换。在Preact中,大体是通过这个流程,然后最终转换成真实dom:
render (类似于react-dom里的render,主入口,触发渲染) => diff => idiff (看起来应该是做dom diff) => createNode (生成真实dom)
组件化也是类React框架的一大特色。Preact的组件化,主要是通过Component这一方法来实现的。主要包括,setState,render以及一众生命周期。主要的渲染,生命周期的触发,也主要定义在renderComponent和setComponentProps方法内。用户的自定义组件只需要继承Component就可以自由使用Preact组件化的能力。
Preact并没有像React那样自己实现了一套事件机制,主要还是用浏览器自带的能力。因此,在给生成真实dom并通过setAccessor给dom插入属性的时候,有这么一段代码:
else if ('o' === name[0] && 'n' === name[1]) {
var l = node._listeners || (node._listeners = {});
name = toLowerCase(name.substring(2));
if (value) {
if (!l[name]) node.addEventListener(name, eventProxy);
} else if (l[name]) node.removeEventListener(name, eventProxy);
l[name] = value;
}
判断属性中是否含有o和n,也就是在看,有没有on开头的属性(一般就是事件)。然后就进行addEventListener或者removeEventListener。看起来跟我们写原生js的事件绑定没有什么区别。
有兴趣的童鞋可先参考 steamer-kit-�library
李成熙,腾讯云高级工程师。2014年度毕业加入腾讯AlloyTeam,先后负责过QQ群、花样直播、腾讯文档等项目。2018年加入腾讯云云开发团队。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
小程序·云开发是微信团队和腾讯云团队共同研发的一套小程序基础能力,简言之就是:云能力将会成为小程序的基础能力。整套功能是基于腾讯云全新推出的云开发(Tencent Cloud Base)所研发出来的一套完备的小程序后台开发方案。
小程序·云开发为开发者提供完整的云端流程,简化后端开发和运维概念,无需搭建服务器,使用平台提供的 API 进行核心业务开发,即可实现快速上线和迭代。
该解决方案目前提供三大基础能力支持:
存储:在小程序前端直接上传/下载云端文件,在小程序云控制台可视化管理
数据库:一个既可在小程序前端操作,也能在云函数中读写的文档型数据库
云函数:在云端运行的代码,微信私有协议天然鉴权,开发者只需编写业务逻辑代码
未来,我们还会集成更多的服务能力,为小程序提供更强有力的云端支持。
上面就是小程序·云开发简单的使用图谱:在小程序端,直接用官方提供的接口,在云函数端,直接用官方提供的 Node SDK,就可以操作你云的资源。以前开发小程序所担忧的数据库搭建、文件系统部署,通通没有。
你只需要有在小程序开发 IDE 里面的 云开发,开通一下,填写环境 ID,便可以拥有小程序的云能力!
当然,其实用云开发,并不排斥原有的后台架构,通过下面的架构,你也可以无缝与原有的后台服务兼容,也简化了一些小程序鉴权的逻辑:
接下来,我会分别从小程序端、服务端讲述如何使用这些云资源。
客户端,这里是指在小程序端中。如果要使用云开发能力,请做以下配置:
app.json / game.json 中, 中增加字段 "cloud": true//app.js
App({
onLaunch: function () {
wx.cloud.init({
traceUser: true // 用户信息会显示在云开发控制台的用户面板中
});
}
});在用户管理中会显示使用云能力的小程序的访问用户列表,默认以访问时间倒叙排列,访问时间的触发点是在小程序端调用 wx.cloud.init 方法,且其中的 traceUser 参数传值为 true。
如果你想在云函数中,操作文件、数据库和云函数资源,你可以使用我们提供的服务端 SDK 进行操作。首先,进入到你的某个云函数中,安装以下依赖包:
npm i --save tcb-admin-node在云函数中初始化
// 初始化示例
const app = require('tcb-admin-node');
// 初始化资源
// 云函数下不需要secretId和secretKey。
// env如果不指定将使用默认环境
app.init({
secretId: 'xxxxx',
secretKey: 'xxxx',
env: 'xxx'
});
//云函数下使用默认环境
app.init()
//云函数下指定环境
app.init({
env: 'xxx'
});云开发提供存储空间、上传文件、下载文件、CDN加速文件访问等能力,开发者可以在小程序端与服务端通过 API 使用这些能力。
// 选择图片
wx.chooseImage({
success: dRes => {
// 上传图片
const uploadTask = wx.cloud.uploadFile({
cloudPath: `${Date.now()}-${Math.floor(Math.random(0, 1) * 10000000)}.png`, // 随机图片名
filePath: dRes.tempFilePaths[0], // 本地的图片路径
success: console.log,
fail: console.error
});
},
fail: console.error,
});const app = require('tcb-admin-node');
app.init();
app.uploadFile({
cloudPath: "cover.png",
fileContent: fs.createReadStream(`${__dirname}/cover.png`)
}).then((res) => {
console.log(res);
}).catch((err) => {
console.error(err);
});;上传好的文件,就会出现在控制台中,如下图。你可以在控制台里删除、下载或者查看图片的详情。
你还可以控文件整体的权限,这里还有一些具体的介绍。
小程序云提供文档型数据库 ( document-oriented database ),数据库包含多个集合(相当于关系型数据中的表),集合近似于一个 JSON 数组,数组中的每个对象就是一条记录,记录的格式是 JSON 文档。
每条记录都有一个 _id 字段用以唯一标志这条记录、一个 _openid 字段用以标志记录的创建者,即小程序的用户。开发者可以自定义 _id,但不可在小程序端自定义(在服务端可以) _openid 。_openid 是在文档创建时由系统根据小程序用户默认创建的,开发者可使用其来标识和定位文档。
数据库 API 分为小程序端和服务端两部分,小程序端 API 拥有严格的调用权限控制,开发者可在小程序内直接调用 API 进行非敏感数据的操作。对于有更高安全要求的数据,可在云函数内通过服务端 API 进行操作。云函数的环境是与客户端完全隔离的,在云函数上可以私密且安全的操作数据库。
数据库 API 包含增删改查的能力,使用 API 操作数据库只需三步:获取数据库引用、构造查询/更新条件、发出请求。切记,在操作数据库前,请先在控制台中创建 collection。
const db = wx.cloud.database();
// 插入数据
db.collection('photo').add({
data: {
photo: 'cloud://tcb-xxx/05ca1d38f86f90d66d4751a730379dfa6584dde05ab4-Ma9vMN_fw658.jpg',
title: '风景'
}
});
// 提取数据
db.collection('photo').get().then((res) => {
let data = res.data;
console.log(data);
});
// 输出
// 在小程序端, _openid 会自动插入到数据库中
{
photo: 'cloud://tcb-xxx/05ca1d38f86f90d66d4751a730379dfa6584dde05ab4-Ma9vMN_fw658.jpg',
title: '风景',
_openid: 'oLlMr5FICCQJV-QgVLVzKu1212341'
}const app = require('tcb-admin-node');
app.init();
const db = app.database();
db.collection('photo').limit(10).get().then((res) => {
console.log(res);
}).catch((err) => {
console.error(err);
});
// 输出
// 因为是在服务端,其它用户的也可以提取出来
{
photo: 'cloud://tcb-xxx/05ca1d38f86f90d66d4751a730379dfa6584dde05ab4-Ma9vMN_fw658.jpg',
title: '风景',
_openid: 'oLlMr5FICCQJV-QgVLVzKu1342121'
}
{
photo: 'cloud://tcb-xxx/0dc3e66fd6b53641e328e091ccb3b9c4e53874232e6bf-ZxSfee_fw658.jpg',
title: '美女',
_openid: 'DFDFEX343xxdf-QgVLVzKu12452121'
}
{
photo: 'cloud://tcb-xxx/104b27e339bdc93c0da15a47aa546b6e9c0e3359c315-L8Px2Y_fw658.jpg',
title: '动物',
_openid: 'DFDFEX343xxdf-QgVLVzKu1342121'
}可以在控制台里,看到用户操作的数据,你也可以自己在控制台上添加、更新或删除数据。
如果数据量庞大,可以设置索引提供查询的效率。
数据库也可以通过设置权限,管控每个 collection。
云函数是一段运行在云端的代码,无需管理服务器,在开发工具内一键上传部署即可运行后端代码。
开发者可以在云函数内获取到每次调用的上下文(appid、openid 等),无需维护复杂的鉴权机制,即可获取天然可信任的用户登录态(openid)。
wx.cloud.callFunction({
name: 'addblog', // 云函数名称
data: { // 传到云函数处理的参数
title: '云开发 TCB',
content: '存储、数据库存、云函数'
}
}).then(res => {
console.log(res)
}).catch((err) => {
console.error(err);
});const app = require("tcb-admin-node");
app.init();
app.callFunction({
name: 'addblog', // 云函数名称
data: { // 传到云函数处理的参数
title: '云开发 TCB',
content: '存储、数据库存、云函数'
}
}).then((res) => {
console.log(res);
}).catch((err) => {
console.error(err);
});上传好之后的云函数,都会在这里罗列出来。
每次调用云函数,都可以在这里看到日志,还可以构造测试的参数,用于调试。
大部份的接口,目前都支持两种写法,分别是Promise 和 Async/Await,本节以 callFunction 作为例子,在云函数中介绍这两种写法。 Async/Await 本质上是基于 Promise 的一种语法糖,它只是把 Promise 转换成同步的写法而已。
const app = require("tcb-admin-node");
app.init();
exports.main = (event, context, callback) => {
app.callFunction({
name: 'addblog', // 云函数名称
data: { // 传到云函数处理的参数
title: '云开发 TCB',
content: '存储、数据库存、云函数'
}
}).then((res) => {
console.log(res);
callback(null, res.data);
}).catch((err) => {
callback(err);
});
};const app = require("tcb-admin-node");
app.init();
exports.main = async (event, context) => {
let result = null;
try {
result = await app.callFunction({
name: 'addblog', // 云函数名称
data: { // 传到云函数处理的参数
title: '云开发 TCB',
content: '存储、数据库存、云函数'
}
});
}
catch (e) {
return e;
}
return result;
};在云函数里使用,由于是 Node 8.9 或以上的环境,因此天然支持 Async/Await 诘法,但在小程端要使用的话,需要额外引入 Polyfill,比如这个开源的项目:regenerator
由于小程序·云开发是基于腾讯云的云开发开发的功能,因此在腾讯云与小程序两边都有不少的开发者资源,这里供大家参阅读:
2018年暑假,有幸参加了首次腾讯 SNG MINI 项目 的改版试验——导师制 + 定向命题。MINI 项目是在短时间内通过组队、设计并独立完成一个完整产品的培训项目,我觉得除了能通过实习生的实践来验证最近做的技术项目之外,还深感这还是一次独立带队的好机会,于是欣然答应。
以往的 MINI 项目都是由新人们自主想题目,这次是由各位导师预先根据自身任务或者项目,让新人来选择。虽然这次参与,有业务压力在身,但考虑到MINI项目本身的性质,以及希望童鞋都是带着兴趣来的,因此还是花了不少心血认真选材出题。
对所选组的要求是使用最近即将推出的与小程序相关的技术,并可以做出一个准上线级别的小程序。除了这点限制,可以在产品方向上做些发挥。
为了更好地完成任务,必须吸引优秀的人才。吸引人才无非三方面:钱、理想、兴趣。MINI项目不谈钱也不谈理想,兴趣便是首要吸引人才的关键。因此产品上,我初步设计了 toB 和 toC 的业务,涵盖两至三个方向的产品。除了可以从不同产品形态检阅腾讯云的技术,也能多给童鞋选择,招揽更多人才。
下图是我制定的两个产品方向,一个是比较实用的家庭相册,一个是紧追热点的偶像粉丝小程序。


待所有导师的产品方案都出来之后,发现其他导师大部份的出题是 toB 的或者是技术类项目,我初步估计可能由于我的选题较丰富,能吸引不少人才。
MINI 项目启动会当天,几大选题讲完之后,报名参加我这边命题的人数远超我的预期。一堆人将我团团围住。可能由于出乎意料以及缺乏经验,在选人的环节处理得不太好。我采用了逐个微信加的办法,然后按顺序筛选,这导致后面分组有些混乱。

后来回顾经负责项目的HR提点,应该让所有人通过微信面对面建群,并给出理想的岗位人数搭配,然后组长组好队伍之后再次申请加入我的战队。
虽然组队方式有些不足,但凭借选题的优势,基本垄断了最优秀的产品、设计、前后台工程师,还意外收获一枚算法特厉害的小鲜肉。
在制定选题的时候,我自己也有策划一些产品的功能点与方向,但我并不想将这些内容强加在组员身上,而是先给些时间发挥他们的主观能动性。毕竟这批刚出校门的实习生,虽然经验不足,但应该还是创意满满的。要是最终他们出不了好的产品方案,我再用我自己的方案兜底。
但是,创意归创意,脑暴归脑暴,太天马行空的想法,是无法落地成产品的。根据游戏规则,产品的完成度会影响整体分数。因此我担心太庞杂的产品,不仅会导致失分,而且可能无法完成业务上的任务。于是,尽管我给各组一定的自由度,但复杂性较高的需求,极容易导致延期又不是必要的功能点,一律砍掉或者优先级调低。
组队结束当天晚上,我就给他们传递我的产品要求与理念:
具体产品暂时不放,等有机会这些产品能面世的时候再更新到这里。:)
原计划我只带两组人,但由于报名情况火爆,共有五组人,综合权衡了一下,觉得首次加入MINI项目就带五组人,风险还是蛮大的,但为了照顾更多对项目感兴趣的童鞋,我多带了一组。
三组共17人,负责三条业务线,带队压力还是不小,在腾讯相当于一个小组长的带队人数了。
技上方面,由于是使用咱们组研发的技术,因此事前我和产品先制定了一个支撑MINI项目的迭代计划,从功能完成度、文档等方面列出了一个 checklist。然后跟组内同事并肩作战,在MINI项目启动前将所有 checklist的任务完成。但由于这是技术第一次对外体验,我对稳定性有所担忧,于是跟同事们沟通,争取大家在周末的时候,也能响应一些遇到的 Bug,我也需要驻场,亲自指导或者解决一些疑难杂症,这样才能保障所有业务的顺利完成。基础技术、疑难诊断解答以及支持支援,是一个架构师日常需要承担的任务。有时候虽然方法论重要,但可能不如亲自上阵诊断和写code来得实在。
另外一个管理者需要做的就是培训教育。事前,我学习了本次MINI项目负责人 Ben 总的方法,针对提供的技术以及小程序开发的一些重点,提前做了培训,虽然并不指望课堂上能马上消化所有内容,但至少给技术们一个概念,回去对照PPT再进行练习。
当我们提供技术的真正下场接受实习生们检验的时候,也要因应不同产品形态,实施不同的技术架构。
比如偶像粉丝的小程序,基本上全栈 JavaScript + Node 就可以搞定,用上我亲自写的 image-node-sdk 便可以实现人脸融合。
又如相册的小程序,其实整体难点不多,只是涉及权限管理方面有一定的复杂度,用全栈 JavaScript + Node 再结合云这边的数据库也可以搞定。实施的时候,我也给后台稍微点拨了一下如何更好地设计数据库结构和做权限管理。
另一组的项目就稍微有些棘手了,他们是做动物小视频识别,算法部份是用python + tensorflow写的。因此,还需要实施一个中台的接口服务来给前台吐数据。这边也采用了Node做中台。虽然 Node 对并发需求并不一定做得非常好,但如果能做好负载均衡应该也能抗住很大部需求,公司的业务也有不少实践。另外异构系统也比较少。我后来评审其它组的时候发现,有的组用django做后台数据读写,用Node又做中台,感觉就增加了系统复杂度了。因此那个组没有部署起上来,而我们组基本部署服务,都相当轻松。

MINI项目参与的都是初出校门的实习生,处事经验未成熟,工作能力与经验都欠缺,而且并非全职做 MINI项目,自身业务可能也相当繁忙。有了这样的预期,作为导师,从先期的产品设计(上文已提到)到后期的进度把握,我逐步摸索了自己的方法论。
进度把握方面,确实有实习生由于前端组内业务繁忙,早期投入度不够的情况。这时,我并非第一个去做推动,而是先交由产品经理,去锻炼与考察产品经理带队方面的能力。
不过在此过程中,我首先打了助攻:由于我每天都会盯进度,适当的时候,我会把进度跟大家同步,并且会暗示其它部份都完成得很好,并婉转地表达还差某部份功能就能拿到多少分了,以此来激励还没投入的同学也能尽快投入进来。
助攻之后,其中一位产品经理处理得较好,能争取到两位业务繁重同学当下的立即反馈,评估工作量后表示能在周末如期完成。另一位产品经理比较腼腆,正好那位组员也比较腼腆,初次争取并没有得来很快的反馈。后来我发现他们每天都会实习邮件给导师和组长,于是我就发了封鼓励性质的邮件,第二天我就见到那位组员出现,并且当天晚上把90%的任务都完成妥当,效率和质量之高让人吃惊(组团组到厉害的人意味着成功了一半)。
来到了最后一个周末,产品验收环节,主要的得分点在产品完成度、架构性能以及代码规范与错误三大块。各组都围绕这些得分点不断去迭代优化。
对基层管理比较高的要求就在于执行力与细节把控上面。我也以这样的准则来要求自己,为了让三组的得分都尽量高,初期的进度把握需要比较精准,遇到一些差错影响进度了,也需要自己上阵,或者想办法调动资源来让进度赶上。到了冲刺前两天,主要是求稳,尽量不要加太多太重的功能了,否则容易出BUG,即使是业务上的产品,基本也是这么管理。
这里有点特殊的是,三组的产品要同时上线,所以较早完成的组,当天我就放少些时间,差临门一脚就完成但遇到难题的组,我投入精力尽力扶一扶,但我亲自帮扶的准则是,非到我出手才能解决的问题,不去解决,让实习生多试试,否则他们会形成依赖,日后难以独当一面。
当天做得稍有不足的地方就是,由于时间不足,没有对每个产品在各方面做好测试,虽然有提醒边界情况有处理好,但还是有产品因为BUG扣了分,略为遗憾。这个应该在培训的时候,多提点技术和产品,最好能把测试路径也简单写一份文档,后续可以反复测试。
这次除了产品,还要考察大家的代码质量,于是要求代码一律接入CodeDog做检测。最后一天,我逐个组帮忙review了代码,提出修改意见,抓住他们一个一个把问题改好,还有让组内负责 CodeDog 接入的童鞋,追着 CodeDog 的接口人,报错的问题,一直改到接近满分为止。最后的结果就是我带的三组全部 CodeDog 分数并列第一。
”基层抓细节,高层争资源“ 说的是不同层级管理者的侧重点,但其实也不是绝对的,基层干部有些时候也要为团队争取资源支持,高层像咱们的老板小马哥,时不时都要体验自家产品。在 MINI 项目中,我也得到了如何跟自己上级以及平级争取人才与成绩的经验。
MINI 项目一开始就来了一场”人才争夺战“,过程还是挺有意思的。由于我和另一个导师吸引的组员较多,开始打乱了另外组导师的计划。于是导师之间就开始讨论与协调,希望为自己争取更多的人才。由于MINI项目主要还是为了培训新人,并非你死我活的斗争,基本都是在新人兴趣与自己任务中间拿捏平衡点,实现一些妥协,因此我将招收的5组缩减为3组,也希望是次的妥协能为后续其它的争论赢得一些空间。
最后当然就是成绩的争夺。我在冲刺的前两天评分的时候预感到,目前的许多打分环节,都是由导师操刀的,每个导师,都希望为自己的组争取到最好的成绩,尽量往高分打。本着这个想法,我逆向而为,我并不先为自己的团队打高分,而是从低分打起,适当做些分数的鼓励。我还将得分纬度细化,每一个做得不足的地方,先把分扣了,先把问题写了,然后滚动实时让组员们不断优化改进。
我的出发点很简单,一定需要让自己带的产品经得挑战与考验。面对老板,需要把本职工作做好了,才有底气争取更好的成绩、更好的薪酬,否则自己都不好意思了。
在得分初步出来之后,我带的其中一组骑绝尘,折得桂冠,另外有两组和其他导师的三组,五组共同争夺一个银奖和两个铜奖。我这边相册组与其他导师的一组由于BUG偏多率先出局了,另一组视频识别的组,在算法公示的环节里,由于算法报告详尽细致,将另外一组PK掉,勇夺铜奖。幸好最后MINI项目负责人争取到每个导师可以颁发一个导师特别奖,让我带的三组都抱奖而归。

这次带队MINI项目组,收获真的是很多,欢迎更多年轻的,升上高工的工程师们参与 SNG MINI项目的定向命题,除了能带领实习生们一起闯关打怪完成你自己分配的任务以外,还能让你得到不少管理上的收获。也希望各部门的负责人可以多多推荐这些高工们参与哈。
最后奉上我与三个组的合照:



// webpack.config.js
module.exports = {
entry: {
index: "./main.js",
},
output: {
path: __dirname + '/dist',
filename: '[name].js'
},
};// main.js, entry chunk
import { chunk2, chunk3 } from './main1';
import chunk5, { C1, C2, C3 } from './main2';
var chunk1 = 1;
exports.chunk1 = chunk1;
exports.chunk4 = {
a: 1,
b: 2
};
console.log(C1);
console.log(chunk3);// main1.js
var chunk2 = 2;
exports.chunk2 = chunk2;
var chunk3 = 3;
exports.chunk3 = chunk3;
export function f1() {
return 'f1';
}
export function f2() {
return 'f2';
}// main2.js
export function f3() {
return 'f3';
}
export default class C3 {
constructor() {
}
f1() {
console.log("f1")
}
f2() {
console.log("f2");
}
}
export const C1 = 'c1';
export const C2 = 'c2';// result file, index.js
(function(modules) {
// modules在webpack1的时候是数组,现在变成了key值是数字的对象
// module的缓存
var installedModules = {};
// require方法,转义成此
function __webpack_require__(moduleId) {
// 若module已被缓存,直接返回
if(installedModules[moduleId])
return installedModules[moduleId].exports;
// 创建一个新的module,被放入缓存中
// webpack1的时候都是全称,现在估计为了省点空间,都变成了id => i, load => l
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// 执行module
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 标明此module已被加载
module.l = true;
// module.exports通过在执行module的时候,作为参数存进去,然后会保存module中暴露给外界的接口,
// 如函数、变量等
return module.exports;
}
// 在源文件中,直接使用__webpack_modules__,生成文件用__webpack_require__.m替换
__webpack_require__.m = modules;
// 暴露module缓存
__webpack_require__.c = installedModules;
// identity function for calling harmory imports with the correct context
__webpack_require__.i = function(value) { return value; };
// 为harmory exports 定义 getter function, configurable=false表明,此属性不能修改
// 例如export const,由于是常量,需要用__webpack_require__.d进行定义
__webpack_require__.d = function(exports, name, getter) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter
});
};
// 兼容 non-harmony 模块,这些模块如果设了__esModule属性,则被标记为non-harmony
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};
// Object.prototype.hasOwnProperty.call polyfill
__webpack_require__.o = function(object, property) { return Object.prototype.hasOwnProperty.call(object, property); };
// 使用__webpack_public_path__,则会替换__webpack_require__.p
__webpack_require__.p = "//localhost:8000/";
// 加载入口模块,并返回exports
return __webpack_require__(__webpack_require__.s = 143);
})
/************************************************************************/
({
143: // 入口模块
function(module, exports, __webpack_require__) {
module.exports = __webpack_require__(64);
},
64: // main.js
function(module, exports, __webpack_require__) {
"use strict";
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__main1__ = __webpack_require__(72);
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_1__main2__ = __webpack_require__(73);
var chunk1 = 1;
exports.chunk1 = chunk1;
exports.chunk4 = {
a: 1,
b: 2
};
// 此如由于引用了C1,而C1又是常用,它事先定义成属性a,此处直接引用对象的属性a
console.log(__WEBPACK_IMPORTED_MODULE_1__main2__["a" /* C1 */]);
console.log(__WEBPACK_IMPORTED_MODULE_0__main1__["chunk3"]);
},
72: // main1.js
function(module, exports, __webpack_require__) {
"use strict";
/* unused harmony export f1 */
/* unused harmony export f2 */
// 此处注释表示,这两个harmony export模块没有被使用,后续如果使用unglify插件,f1与f2会被去掉
// 这个就是著名的tree-shaking
var chunk2 = 2;
exports.chunk2 = chunk2;
var chunk3 = 3;
exports.chunk3 = chunk3;
function f1() {
return 'f1';
}
function f2() {
return 'f2';
}
},
73: // main2.js
function(module, exports, __webpack_require__) {
"use strict";
/* unused harmony export f3 */
/* unused harmony export default */
/* harmony export (binding) */ __webpack_require__.d(exports, "a", function() { return C1; });
/* unused harmony export C2 */
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
function f3() {
return 'f3';
}
var C3 = function () {
function C3() {
_classCallCheck(this, C3);
}
C3.prototype.f1 = function f1() {
console.log("f1");
};
C3.prototype.f2 = function f2() {
console.log("f2");
};
return C3;
}();
var C1 = 'c1';
var C2 = 'c2';
}
});整个立即执行函数,主要是webpack_require, webpack_require.n, webpack_require.d起作用。installedModules是用于缓存已经加载的模块。
// webpack.config.js
module.exports = {
entry: {
index: "./main.js",
},
output: {
path: __dirname + '/dist',
filename: '[name].js',
chunkFilename: "js/[name].js",
},
};// main.js
var chunk1 = 1;
exports.chunk1 = chunk1;
function errorLoading(err) {
console.error('Dynamic page loading failed', err);
}
function loadRoute(cb) {
console.log("dynamic loading success");
return (module) => cb(null, module.default);
}
// 符合es6规范的异步加载模块方法
System.import('./main1')
.then(loadRoute(cb))
.catch(errorLoading);// main1.js
var chunk2 = 2;
exports.chunk2 = chunk2;
var chunk3 = 3;
exports.chunk3 = chunk3;
export function f1() {
return 'f1';
}
export function f2() {
return 'f2';
}
export default function f3() {
return 'f3';
}// result file, index.js// result file, 0.js
webpackJsonp([0],{
144:
function(module, exports, __webpack_require__) {
"use strict";
/* harmony export (immutable) */ exports["f1"] = f1;
/* harmony export (immutable) */ exports["f2"] = f2;
/* harmony export (immutable) */ exports["default"] = f3;
var chunk2 = 2;
exports.chunk2 = chunk2;
var chunk3 = 3;
exports.chunk3 = chunk3;
function f1() {
return 'f1';
}
function f2() {
return 'f2';
}
function f3() {
return 'f3';
}
}
});// result file index.js
(function(modules) { // webpackBootstrap
// install a JSONP callback for chunk loading
var parentJsonpFunction = window["webpackJsonp"];
// 全局定义webpackJsonp,让chunk加载的时候,直接可调用
window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules, executeModules) {
// 将异加载的moreModules,添加到entry chunk的modules里面
// 然后使所有chunk标记为已加载,并触发回调函数
var moduleId, chunkId, i = 0, resolves = [], result;
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
installedChunks[chunkId] = 0;
}
// 将moreModules存入modules中
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if(parentJsonpFunction) {
parentJsonpFunction(chunkIds, moreModules, executeModules);
}
// resolves就是需要触发的回调
while(resolves.length) {
resolves.shift()();
}
};
// The module cache
var installedModules = {};
// objects to store loaded and loading chunks
var installedChunks = {
3: 0
};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if(installedModules[moduleId])
return installedModules[moduleId].exports;
// Create a new module (and put it into the cache)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
module.l = true;
// Return the exports of the module
return module.exports;
}
// 异步加载函数,返回promise对象
__webpack_require__.e = function requireEnsure(chunkId) {
// 如果已经加载,则返回Promise.resolve
if(installedChunks[chunkId] === 0)
return Promise.resolve();
// an Promise means "currently loading".
if(installedChunks[chunkId]) {
return installedChunks[chunkId][2];
}
// 开始加载
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.timeout = 120000;
// 加载的资源位置
script.src = __webpack_require__.p + "js/chunk/" + ({}[chunkId]||chunkId) + ".js";
var timeout = setTimeout(onScriptComplete, 120000);
script.onerror = script.onload = onScriptComplete;
function onScriptComplete() {
// avoid mem leaks in IE.
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) chunk[1](new Error('Loading chunk ' + chunkId + ' failed.'));
installedChunks[chunkId] = undefined;
}
};
head.appendChild(script);
var promise = new Promise(function(resolve, reject) {
// resolve与reject,属于installedChunks[chunkId]的回调函数,
// 在webpackJsonpCallback函数中,有可能被调用
installedChunks[chunkId] = [resolve, reject];
console.log(installedChunks[chunkId]);
});
return installedChunks[chunkId][2] = promise;
};
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// identity function for calling harmory imports with the correct context
__webpack_require__.i = function(value) { return value; };
// define getter function for harmory exports
__webpack_require__.d = function(exports, name, getter) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter
});
};
// getDefaultExport function for compatibility with non-harmony modules
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};
// Object.prototype.hasOwnProperty.call
__webpack_require__.o = function(object, property) { return Object.prototype.hasOwnProperty.call(object, property); };
// __webpack_public_path__
__webpack_require__.p = "//localhost:8000/";
// on error function for async loading
__webpack_require__.oe = function(err) { console.error(err); throw err; };
// Load entry module and return exports
return __webpack_require__(__webpack_require__.s = 141);
})
/************************************************************************/
({
141:
function(module, exports, __webpack_require__) {
module.exports = __webpack_require__(64);
},
64:
function(module, exports, __webpack_require__) {
var chunk1 = 1;
exports.chunk1 = chunk1;
function errorLoading(err) {
console.error('Dynamic page loading failed', err);
}
function loadRoute() {
console.log("dynamic loading success");
return function (module) {
console.log(module.default);
};
}
// 符合es6规范的异步加载模块
__webpack_require__.e/* System.import */(0).then(__webpack_require__.bind(null, 144)).then(loadRoute()).catch(errorLoading);
}
});异步加载,主要是多了webpackJsonp全局函数,以及webpack_require.e作为加载script的函数。
// webpack.config.js
module.exports = {
entry: {
index: "./main.js",
spa: "./spamain.js"
},
output: {
path: __dirname + '/dist',
filename: '[name].js',
chunkFilename: "js/[name].js",
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: "commons",
filename: "commons.js",
chunks: ['index', 'spa'],
}),
]
};// result file, index.js
(function(modules) { // webpackBootstrap
// install a JSONP callback for chunk loading
var parentJsonpFunction = window["webpackJsonp"];
window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules, executeModules) {
// add "moreModules" to the modules object,
// then flag all "chunkIds" as loaded and fire callback
var moduleId, chunkId, i = 0, resolves = [], result;
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(installedChunks[chunkId])
resolves.push(installedChunks[chunkId][0]);
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if(parentJsonpFunction) parentJsonpFunction(chunkIds, moreModules, executeModules);
while(resolves.length)
resolves.shift()();
// 这里比异步加载相同的函数多了一段执行逻辑,主要用于执行entry chunk
if(executeModules) {
for(i=0; i < executeModules.length; i++) {
result = __webpack_require__(__webpack_require__.s = executeModules[i]);
}
}
return result;
};
// The module cache
var installedModules = {};
// objects to store loaded and loading chunks
var installedChunks = {
3: 0
};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if(installedModules[moduleId])
return installedModules[moduleId].exports;
// Create a new module (and put it into the cache)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
module.l = true;
// Return the exports of the module
return module.exports;
}
// This file contains only the entry chunk.
// The chunk loading function for additional chunks
__webpack_require__.e = function requireEnsure(chunkId) {
if(installedChunks[chunkId] === 0)
return Promise.resolve();
// an Promise means "currently loading".
if(installedChunks[chunkId]) {
return installedChunks[chunkId][2];
}
// start chunk loading
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.timeout = 120000;
script.src = __webpack_require__.p + "js/chunk/" + ({"0":"index","1":"spa"}[chunkId]||chunkId) + ".js";
var timeout = setTimeout(onScriptComplete, 120000);
script.onerror = script.onload = onScriptComplete;
function onScriptComplete() {
// avoid mem leaks in IE.
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) chunk[1](new Error('Loading chunk ' + chunkId + ' failed.'));
installedChunks[chunkId] = undefined;
}
};
head.appendChild(script);
var promise = new Promise(function(resolve, reject) {
installedChunks[chunkId] = [resolve, reject];
});
return installedChunks[chunkId][2] = promise;
};
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// identity function for calling harmory imports with the correct context
__webpack_require__.i = function(value) { return value; };
// define getter function for harmory exports
__webpack_require__.d = function(exports, name, getter) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter
});
};
// getDefaultExport function for compatibility with non-harmony modules
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};
// Object.prototype.hasOwnProperty.call
__webpack_require__.o = function(object, property) { return Object.prototype.hasOwnProperty.call(object, property); };
// __webpack_public_path__
__webpack_require__.p = "//localhost:8000/";
// on error function for async loading
__webpack_require__.oe = function(err) { console.error(err); throw err; };
})
/************************************************************************/
({
8:
function(module, exports, __webpack_require__) {
"use strict";
/* unused harmony export f1 */
/* unused harmony export f2 */
/* unused harmony export default */
var chunk2 = 2;
exports.chunk2 = chunk2;
var chunk3 = 3;
exports.chunk3 = chunk3;
function f1() {
return 'f1';
}
function f2() {
return 'f2';
}
function f3() {
return 'f3';
}
}
});// main.js
webpackJsonp([0],{
14:
function(module, exports, __webpack_require__) {
"use strict";
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__main1__ = __webpack_require__(8);
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_1__main2__ = __webpack_require__(24);
var chunk1 = 1;
exports.chunk1 = chunk1;
exports.chunk4 = {
a: 1,
b: 2
};
},
24:
function(module, exports, __webpack_require__) {
"use strict";
/* unused harmony export f3 */
/* unused harmony export default */
/* unused harmony export C1 */
/* unused harmony export C2 */
/* unused harmony export C4 */
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
function f3() {
return 'f3';
}
var C3 = function () {
function C3() {
_classCallCheck(this, C3);
}
C3.prototype.f1 = function f1() {
console.log("f1");
};
C3.prototype.f2 = function f2() {
console.log("f2");
};
return C3;
}();
var C1 = 'c1';
var C2 = 'c2';
var C4 = 'c4';
},
41:
function(module, exports, __webpack_require__) {
module.exports = __webpack_require__(14);
}
},[41]);// spamain.js
webpackJsonp([1],{
16:
function(module, exports, __webpack_require__) {
"use strict";
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__index_main1__ = __webpack_require__(8);
console.log(__WEBPACK_IMPORTED_MODULE_0__index_main1__["chunk2"]);
},
43:
function(module, exports, __webpack_require__) {
module.exports = __webpack_require__(16);
}
},[43]);提取公共包的这种情况,跟异步加载很类似,不过它将主要的功能函数都提取到common.js中,并且新增了执行module的逻辑。但主要入口的chunk都在主要逻辑的index.js与spa.js中。
webpack2使用了一些低端浏览器并不支持的接口,因此如果需要支持这些低端浏览器的业务,需要谨慎使用。

昨晚,搞Babel翻译的李其昌微信我,说在掘金上看到云谦的这篇介绍一个新打包工具的文章:

我读了一遍后,再看了下项目文档。忽觉此打包工具让人眼前一亮。李其昌说不如搞一波翻译,说完他这边就买了个域名。
我看文档其实并不多,加上印记中文目前成熟的翻译规范,快速的工程化部署流程,感觉可以挑战下能否在24小时之内将文档翻译并部署出来。
结果,不到24小时,文档已经部署好了,临时地址在 https://parceljs.docschina.org,刚买的域名也可以通过 http://www.parceljs.io访问,不过可能有点慢。连核心成员之一的 James Kyle 都震惊了。

文档翻译完成,不过仍希望有意翻译的朋友可以继续参与后续的维护,以及帮助我们进行第一版本的校对。地址奉上:https://github.com/docschina/parceljs.io。
印记中文希望有更多好的项目进驻,无论是前端、后台、客户端、AI等等,我们尊崇谁推动、谁负责、谁主导的原则,印记中文会作为你强大的服务器资源及工程化流程支持,助你更好地进行技术文档的翻译或者社区的搭建。
参考文章:
印记中文联合腾讯云推出文档CDN + COS部署方案
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan
腾讯 Web 前端大会完美落幕。希望大家能收获满满干货。博主负责大会部份的讲师的遴选。虽然我全程都没怎么听(基本都在安排展位和发微博),但我希望通过选题的角度,以及PPT的内容,给大家分享一点思路和分享的导读。

第一位讲师是在 Elastic Search 工作的 Nicolas Bevacqua,他同时也是知名书作者和博主。
他所分享的这个主题,是跟W3C的标准制定相关。对于大神们说,这个知识都已经有所涉猎,但对于新入行几年的新人来说,可能相对陌生。Nicolas 出了与 ES6 有关的书籍,是这方面的专家,因此邀请他过来分享非常合适,也考虑到他是做英文分享,因此通过分享W3C标准制定流程、W3C标准的新特性这类知识性的分享,不会太艰涩难懂,但又对引起国内对W3C关注也起到一定的效果。毕竟国人在技术上,太过关注业务,大会还是希望通过引起大家对“标准”的关注,让越来越多的国人能花时间精力投身到“标准”的制定上去,比方说腾讯前端第一人“黄老师” Stone Huang 就是W3C**信息无障碍社区组的主席。
本分享主要介绍的有,TC39是什么,以及他们制定规范的流程是怎么样的。关于这方面,我曾经阅读过一篇不错的介绍性文章《JavaScript(ECMAScript) 语言标准历史及标准制定过程介绍》,我就不再赘述了。Nicolas 在分享的时候,只点到了TC39是制定标准的委员会,不过没提到的是其实每个开发者都有机会成为一份子。另外,从Stage 0 到 Stage 4,整个标准制定过程从提案、审阅、算法规划、Polyfill到测试用例,这一切保证了整个流程的更加快速可靠。让W3C标准在这两年的进展一下子加快了不少。Nicolas 还提供了比较有趣的故事就是,之前W3C都是用着老旧的Microsoft Word来建设文档,是后来使用了Github之后,让整个流程更公开快捷,由于扭转了W3C标准指定落伍的局面。Nicolas 自己还专门建了个网站,用来监察 W3C 标准制定的进展。TC39 proposals。
我觉得最需要理解W3C的时候,是使用 Babel 的时候。因为 Babel 会通过不同的 preset 或者 plugin 帮你去编译不同的新特性。
Babel 的 plugin 通过只支持某一种特性的编译,而 preset 则是指一系列的 plugins 。因此我们常见到 es2015, es2016 这些 preset,而偶尔会见到 transform-decorators-legacy 这一类 plugin。通常来说,进入 stage4 的特性基本笃定能进入标准当中,一般可以通过 Babel 放心使用(不过不排除会有性能的问题),但之前的 stage,随时有可能回炉重做,因此要慎重使用。
分享最后稍微介绍了一些现代的前端工具,
npm,Javascript 包管理工具,打败了 bower
webpack,JavaScript 打包工具,击败了 gulp,require.js
babel,JavaScript 编译工具
rollup,新一代 JavaScript 的打包工具,在类库开发中颇受欢迎
eslint,JavaScript 代码质量检查工具
prettier,JavaScript 新一代代码质量检查工具,大有取代eslint之势
node,JavaScript V8 运行环境

本分享有幸邀请到的是前端业内工程化的大神张云龙,之前是FIS的核心开发者,目前在全**播担任CTO。办大会的时候,一直就想着要在主会场安排一场工程化的分享,一定要请张云龙过来分享,没想到愿望达成(擦当天太忙还没空跟他合照!!!)。
我一直是想推动业内前端工程化的,让所有程序员都因为工程化让性能优化、持续集成、测试部署、发布监控更为得心应手。我看到的反面教材是当今国内的电影业,拍摄太过随意,完全不讲流程,前期拍不好就由后期来擦屁股(详参《《择天记》收官在即,“5毛特效”背后的故事你不能不知道》)。但反观国外,电影已经是一项成熟工业了,“工程化”做得很好,各方面都控制得相当规范,因此即使我们有时候觉得情节方面有缺陷,但总体来说能达到所谓的6分“工业水准”,不至于强差人意,偶尔情节不错,也能来个8分9分的爆款。而国内电影由于“工程化”缺失,3分4分的脑残片、5毛特效片比比皆是。从国产电影这个反面教材,我深知如果让国内的页面水平也能保持相当好的工业水准,工程化是绕不开的一道槛。
云龙大神选的这个题还是蛮有实用价值的,毕竟在大公司工作的人是少数,不少开发者还是在中小企业里工作的,没有专门的人负责帮你搭建好所有的工具。因此,云龙大神选的这个“初创公司”的切入点,不仅直接与他当前工作的经验相关联,也能引起在座许多开发者的共鸣。
分享开篇就先点出了讲者自身所处的业务环境与团队规模,业务复杂,但团队不大,因此得出来希望工程化提高效率的同时,却面临不少现实问题的尴尬局面。
然后作者开始直接抛出解决问题的方案。我先把总结放上来:
这里提到的与架构相关的是组件化开发,同时点出其背后的核心概念,即“分治”。这部份提到一个有意思的点,便是服务端模板里也用到了组件化的方式。如下图,通过资源表来管理静态资源,require 引入 js/css, widget 引入组件(可能是html加上js/css?)。这是以往不用Node开发后台的方式。而以现在我们常见的 Node + Webpack + React,则是直接在服务器运行JavaScript 生成 HTML 字串再吐出来。有点可惜是的可能由于篇幅和时间关系,具体技术细节并没有展开,还是很希望可以对比一下两种方式在SEO、维护效率、性能(QPS每秒查询率)等方面一些数据的比较。

持续集成一言以蔽之,就是键帮你将测试部署都跑通,有条件的团队可以弄一下,极大地提高生产效率。云龙大神这里是以Gitlab做例子,我之前也写过一篇文章,是以Github做例子,希望大家在做开源项目的时候也能极大提高效率(Deploy Using Travis-CI And Github Webhook — webpack doc as an example )。
前端部署多个环境也是蛮有意思的,这个应该在Node开发的时候比较有帮助,而单纯是页面,用Fiddler, Charles一类的代码软件,也可以达到同样的效果。
至于ESlint嘛,我建议如果可以在IDE里集成最好在里面先集成了,然后在commit的时候检测,可以在集成机里省掉这一步。
分享里的思路,看起来是基于云龙大神之前的一个开源项目page-monitor。还没使用过,希望有人可以写写对比的文章,对比一下这个思路跟基本测试方案的优劣。
云龙大神这里分享的物理看板,是我觉得最有意思的地方。在一直提倡电子化的今天,重新使用物理看板,在外人看来是不可思议的。分享中点出了电子看板的一些问题:
而物理看板有这样一些优势:
我觉得其实采用哪种方式没什么问题,但我觉得能够从采纳的方式中,不断优化项目的开发效率,积淀中一套好的牙慧管理方式,才是最好的方案。不过随着公司规模的不断增长,电子化好像是无法逆转的趋势,因为电子化了,以前的数据可以保存下来,后续可用各种数据、算法进行分析。期待云龙后面在团队不断扩张中关于敏捷开快这一块的演进。

谜渡大神这次分享的内容有不少的难度,我特意找他推荐了几篇V8入门级的文章,让大家先读一下。有问题,可以到TFC大会互动群里提问。平时前端开发者主要只是关注写好自己的JavaScript就行了,但对JavaScript背后的引擎好像比较陌生。希望是次分享可以给大家带来有关JavaScript引擎优化的相关知识,使得日后写JavaScript代码的时候,能够更容易让引擎进行优化。
如有谬误,恳请斧正!
原文地址
本文starter kit: steamer-react
就是为了“性能”!!!
按照经验来说,直出,能够减少20% - 50%不等的首屏时间,因此尽管增加一定维护成本,前端们还是前赴后继地在搞直出。
除此之外,有些特定的业务做直出能够弥补前后端分离带来的SEO问题。像这次选取的腾讯新闻,大多数页面首屏其实都是直出的(但肯定不是React直出)。
刚提到的首屏时间,只是单纯内容的渲染,另外还有首屏可交互时间,即除了内容渲染之余,还能够让用户能够对首屏的内容进行交互,如点击、滚动等等。现在市面上有关React的性能报告,尤其是那些截了Chrome渲染映像的,都归到首屏时间。
由于只是实验,数据都是拉取腾讯新闻现网提供的,而样式简单地仿照了一下,做得略粗糙,请见谅。
做这次实践阅读了不少文章,文章提到过的内容我这里就不再赘述了,后文主要是做补充。
这次同构直出实践,我们使用的是脱胎于手Q家校群的react start kit,名曰steamer-react。目前可以试用。它有2个分支,一个是react分支,目前只是提供纯前端的boilerplate。另一个是react-isomorphic,同时包括前端和后台的boilerplate。有什么问题可以给我提issue。
文章:
这次我们选取的是腾讯新闻的列表页、详情页和评论页。平时我们浏览腾讯新闻的时候,都会发现从列表页进详情页,或者从详情页进入评论页,都需要跳转,就像steamer-react中,访问index.html页一样。这样对于用户体验欠佳,因此我做了另外一版,spa.html,使用react + react-router做了一版无跳转的单页面应用。



可是单页面应用在SEO的优化方面,处于略势,因此对于新闻类业务来说,需要做直出来弥补。下面我们逐步来拆解React同构直出的步骤。
AlloyTeam团队目前以Koa为基础搭建了玄武直出平台,目前不少手Q基础的web业务也有接入,包括早前做过同构优化的手Q家校群列表页。是次实践,在steamer-react下面新建了一个node文件夹,存放后台服务。后台服务包括返回数据的api,还有直出的controller层。controller层仿照玄武的写法,对于腾讯内的同事,做适当修改便可以快速接入玄武直出平台,对于腾讯外的,也可以作有用的参照,嵌入自己的业务也不费什么功夫。
那直出的controller层具体怎么写呢?
直出controller层和数据返回的api都一律写在controller.js里面,然后去require存放在node/asset/下面具体直出逻辑文件,然后将yield出来的值直接吐出来:
exports.spa = function* () {
let dir = path.dirname(path.resolve()),
appPath = path.join(dir, '/pub/node/index.js');
if (fs.existsSync(appPath)) { // 若asset中无此文件,则输出其它值
var ReactRender = require(appPath);
yield ReactRender(this.request, this.response); // 给ReactRender函数传入request和response
this.body = this.response.body;
}
else {
this.body = "spa list";
}
};
而ReactRender函数,大概长这样,其实就是一个generator function,具体拉取数据和React同构渲染的逻辑都写在这里面。
module.exports = function* (req, res) {
// some code
}
你直接写好的逻辑,有不少可能node并不识别,例如import, window对象等,这些需要构建去处理,后文会有论述。
其实整个直出过程非常简单。基本就是三部曲,拉数据、存数据和吐内容。
拉数据这里封装了一个requestSync的库,可以直接通过yield对request库做同步的写法:
// requestSync.js
var request = require('request');
exports.requestSync = function(option) {
return function(callback) {
request(option, function (error, response, body) {
callback(error, response);
});
};
} ;
// 拉数据逻辑
var response = yield requestSync.requestSync({
uri: CGI_PATH['GET_TOP_NEWS'] + urlParam,
method: 'GET'
});
// 在编译的时候,你可能会发现require('request')报错,这是因为你缺少了一些babel插件。但也有另外一个办法让你去寻找一个不知名的babel插件。我改用plugin('requestSync')而不是require。因为require会直接去读取node_modules包的内容,plugin并不会编译,它会保留原样,等Koa读取的时候再实时运行。plugin实质是定义在global全局变量里的一个函数,然后将它nodeUtils在controller.js中require进来,就能达到保留原样的效果。
// 直出逻辑
var requestSync = plugin('requestSync');
// nodeUtils.js
global.plugin = function(pkg) {
return require('./' + pkg);
}
// controller.js
var nodeUtils = require('../common/nodeUtils');
由于我们采用redux做统一数据的处理,因此我们需要将数据存一份到store里,以便后面吐内容。
const store = configureStore();
store.dispatch({
type: 'xxx action',
data: response.body,
param:{
}
});
如果我们没有使用react-router,我们直接将store存给最主要的React Component,然后就可以开始直出了,像这样:
import { renderToString } from 'react-dom/server';
var Root = React.createFactory(require('Root').default);
ren html = renderToString(Root(store.getState()));
但如果我们使用了react-router,我们就需要引用react-router比较底层的match来做路径匹配和内容吐出。
import { match, RouterContext } from 'react-router';
import { routeConfig } from 'routes';
match({ routes: routeConfig, location: req.url }, (error, redirectLocation, renderProps) => {
if (renderProps) {
reactHtml = renderToString(
<Provider store={store}>
<RouterContext {...renderProps} />
</Provider>
);
}
else {
res.body = "404";
}
});
客户端也需要做类似的写法,且我们不采用hashHistory,而是browserHistory
let history = syncHistoryWithStore(browserHistory, store);
const { pathname, search, hash } = window.location;
const location = `${pathname}${search}${hash}`;
match({ routes: routeConfig, location: location }, () => {
render(
<Provider store={store}> // Redux相关
<div>
<Router routes={routeConfig} history={history} /> // Router 相关
</div>
</Provider>,
document.getElementById('pages')
)
});
在吐内容(html)的同时,请记得将store也吐一份到<script>标签里,因为客户端的js中也需要用到。
在首次吐出内容之后,你会发现还不能马上进行交互,需要客户端再次执行一行Root.js里面的代码,才能够将可交互的事件绑定。
前端的代码改动不大,不过前端这里主要完成最后关键的一步,事件挂载。
后台渲染完后,给客户端吐出html字符串,这时还没有任何事件的绑定,需要客户端的代码进行事件挂载,这里需要注意2点:
react-isomorphic比react的分支多了一个webpack.node.js,用于设置直出的相关构建内容。一些需要留意的配置如下:
target: 'node', // 构建输出node可以识别的内容
node: {
__filename: true,
__dirname: true
},
{
test: /\.js?$/,
loader: 'babel',
query: {
cacheDirectory: '/webpack_cache/',
plugins: [
'transform-decorators-legacy',
[
"transform-runtime", {
"polyfill": false,
"regenerator": true // 识别regenerator
}
]
],
presets: [
'es2015-loose',
'react',
]
},
exclude: /node_modules/,
},
{
test: /\.css$/,
loader: "ignore-loader", // ignore-loader对css/scss输出空内容
},
plugins: [
new webpack.BannerPlugin("module.exports = ", {entryOnly : true, raw: true}),
// react/node/asset/下的文件生产到/react/pub/node/之后,需要在最前面注入module.exports,
// 这样Koa才能正常引用
]
如下面两图,是直出前后的Chrome映像对比图,直出要比非直出快400ms,近40%的性能提升。除了直出之外,还采用了react-router,使页面可以无缝切换,大大提高了用户的体验。你可能还会担心这么多页面的逻辑放在一个js bundle会让js很大,如果js bundle膨胀到一定程度,你可以考虑使用webpack和react-router的特性进行拆包。


可能你会惊诧于习惯写长文的我居然只写这么少,但React同构下出真的就是这么简单,而借助脱胎于手Q家校群,验证于腾讯新闻的steamer-react start kit,你会更事半功倍。
如有错误,恳请斧正。
For beginners, webpack building performance is sometimes annoying. However, this will not stop webpack from becoming the best web building tool in the world. Once you master the following skills, you can soon boost the building performance and save your team a lot of time.

For one thing before kickoff, webpack.js.org is now the official site for webpack. I browsed the documentation and soon found out that this one is much better than the old doc. Though it is not yet finished, it deserves half an hour reading.

Here is the overall configuration for webpack.
entry is for setting up source code file.output is for setting up output cdn, destination and filename.loader is the config for loaders to compile files from certain format to the format which can be recognized by the browser.plugins: via plugin, developer can utilize more webpack apis.resolve is the guide for webpack to search files before real compilationAs gulp fans, many developers highly rely on the work flow of gulp. So they tend to use gulp as the core to control the building flow, and only use webpack to pack js files. Based on this habbit, they usually use webpack-stream which I think, is a bad idea at most cases.
Since they usually use gulp.watch at developing mode, once they modify a file, the whole gulp building process will rerun which takes time. Of course, you can write some building logic to prevent some building process from being invoked, however, it is far from good.
I used to test this idea using a big project with, it takes 13 seconds for incremental build under developing mode.

Based on my experience, webpack is more than just a packing tool, as the community grows and the number of plugins and loaders flourishes, it becomes a solid competitor agains gulp and grunt.
I intend to use webpack as the core of the whold building tool for the project. gulp or grunt is used only for some tasks which webpack is still not good at, like multiple sprites. For flow control, you can use package.json to manage.
& is for serial&& is for parallelexport is used in Mac or Linux for injecting environment variableset is used in Windows for injecting environment variable
I use a react project of 10 js files as an example. I run the test in a machine with 2 CPU cores and 8G ram. For a very basic configuration (without file uglification), it takes 26seconds.

Let me summarize the tips first.


Put the big libraries like react, zepto in script tag directly, and use external config to tell webpack, it is fine to use the external link as the source, don't build it. It saves 8 seconds.

In this case, we are trying to pre-build some files before we really start the main building flow.
webpack.dll.js in which we use DllPlugin. Please see the following pic, we use DllPlugin to pre-build react, react-dom, redux, react-redux, redux-thunk and loadash.merge as a new vendor called lib.js. At the same time, a dependencies file ./tool/manifest.json is created for next-step usage.
In main webpack config, we now use DllReferencePlugn to reference the dependencies.

noParse
Once you have some files which are in ES5 format, you don't have to parse it.

PrefetchPlugin
This plugin maybe strange to most developers. I do not completely master it either. For this plugin, it cost extra analysis since it varies from project to project.
Firstly, stats-webpack-plugin is used for generating a work flow file, stats.json.

Secondly, enter this site http://webpack.github.io/analyse/ and upload stats.json. If you concern about code security, you can checkout this project to your local machine and do the analysis work in local environment.

Thirdly, click hint and locate long module build chains part. If this part exists, you can prefetch part of the long building chain like the following:

Due to conflict of external and dll, I don't use external config this time. However it also saves much time. Reduce from 26 seconds to 16.8 seconds.

Before webpack compiles files, it needs to locate each file. Searching files is also a time-consuming job. Please cut it when necessary.
babel-loader can skip node_modules.
resolve.aliasresolve.alias.
resolve.unsafeCacheresolve.unsafeCache to save the file location in webpack so that next time, webpack does not need to search again. Set it as true. Once the a library changes its location, please disable it and make webpack search agagin.resolve.root, resolve.modulesDirectory and resolve.fallbackAfter these optimization, it further reduce the building time from 18 seconds to 15 seconds.

We can make a big progress using cache. For example, babel-loader has a cache option. As JavaScript takes up the majority of compilation time when we enable it, it nearly reduces half of the compilation time, from 15 seconds to 8 seconds.


In this section, I introduce a famous parallel packing tool, happypack for webpack.
For js, please just directly copy the options from loader config.


For css, you can use it only in developing mode since it does not support extract-text-webpack-plugin.


3 more seconds are decreased.

So far, we have reduce the total compilation time from 26 seconds to 5 seconds, a remarkable result.
What about the compilation time after uglification?
If we use the basic config with webpack.optimize.UglifyJsPlugin, it takes 66 seconds to finish the whole process. However, if we use webpack-uglify-parallel, another parallel uglification tool and combine suitable optimazation tips introduced above, it takes only 19.5 seconds.


《React移动web极致优化》也提到了,构建工具是前端优化的重要一环。而React的推荐构建工具则是Webpack。这篇文章我们就来聊聊如何在Webpack构建的过程中如何针对React的应用做一些优化。
如果还没看过《webpack使用优化(基本篇)》这篇文章,建议去看看,因为针对React的优化往往也离不开Webpack那些最基本的优化点。此外,在这里将Webpack视作构建可能招来一些人的反对,他们会将Webpack定位成打包的工具。但实际项目中,除了合图以外,家校群项目已将Webpack将为最核心的构建工具。
本篇文章的成果最终都会转化成一个开源的boilerplate, steamer-react(暂时设为私有项目)。

构建工具离不开目录的设计,我们需要安排号文件存放的位置才便于构建工程的开展。在src目录下一级的文件,除了page文件夹是react的主体逻辑文件之外,其它的像img, js, css, libs,都属于各个页面都会用到的公共文件,如utils, 上报等。
page目录下,common文件夹主要旋转跟React相关的一些公共的文件,如公共的component,中间件等。而其它的文件夹就是每个页面的主体逻辑和资源,另外就是页面对应的html文件。
由于家校群采用的是React+ Redux这套方案,我们文件夹的名字也很能体现这套方案的特色。首先组件Component方面,我们比较认同Redux推崇的smart component(container)和dump component,因此它们分别放置在container和component文件夹下。那container和component文件夹下面放在什么呢?我们放置了组件相关的逻辑js和样式scss文件。我们暂时没将图片放在组件这一层,而是放在页面这一层,是因为我们业务不同组件间共用了不少图片,因此放在更上一层更为合适。
而store, reducer, action, connect都是跟Redux这个数据处理框架相关。像root这样的文件夹则是项目的主入口,里面有root.dev.js和root.prod.js,用于区分开发环境与生产环境对应需要引入的组件。
如果你还用到React-Router,可能你还需要多加一个route的文件夹,里面用存放项目route的配置文件。
这套文件架构比较传统的gulp和grunt复杂,但却更符合React + Redux这套方案的开发思路。
Webpack跟Gulp和Grunt不同,前者属于配置型构建(当然也可以通过插件去做一些流程),后两者属于任务型的构建。以前在用Gulp开发的时候,也会写一些任务专门针对开发或者生产的环境,分别再建两条任务流,分别去处理开发与生产环境的构建。同理Webpack也需要去处理开发与生产环境的构建,因此也需要两套配置去实现。
如果搞不清楚什么任务应该放在开发环境,什么应该放在生产环境,可以参考《性能优化三部曲之一——构建篇》,里有有详情参考;如果不知道如何去区分开发与生产环境,可以参考《webpack使用优化(基本篇)》(https://github.com/lcxfs1991/blog/issues/2)。
这里想提出来说的有2点:
devConfig.addPlugins = function(plugin, opt) {
devConfig.plugins.push(new plugin(opt));
};
ES2015近2年很火热,我们也来尝尝鲜。用ES2015的最大好处就是可以使用许多方便的特性,但有一个小小的坏处就是,你可能忽略ES5的写法,而ES5的写法很多时候能够清楚地表示出React的实现方式,对理解框架和原理更有帮助。
另外就是,用这些新的特性,会有一些不稳定的因素,就是不知道转换之后会成什么样子,转换后的代码兼容性如何(具体可参《babel到底将代码转换成什么鸟样?》])。果不其然,我们发布列表页之后发现一个报错:
Uncaught TypeError: Cannot assign to read only property '__esModule' of #<Object>。
解决办法,就是babel编译使用ES2015-Loose而不是ES2015的preset。具体转换的代码如下:

具体在Webpack的loaders里可以这样写你的编译配置
{
test: /\.js?$/,
loader: 'babel',
query: {
plugins: ['transform-decorators-legacy'], /// 使用decorator写法
presets: [
'es2015-loose', // ES2015 loose mode
'react',
]
},
exclude: /node_modules/,
}
除此之外,我们也发现每个Webpack打包的模块,最终编译都会生成一堆类似的代码:
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
......
这些是Babel对ES2015转义生成的代码片段。多的时候,每个模块生成的这些代码都接近1kb。如果你的component多,例如像家校群有超过20组件,后面的详情页的组件可能更多,这么多组件合起来重复的代码可能就近20kb。在PC端20kb没有所谓,但到移动端却对bundle的大小锱铢必较。建议写一个Webpack plugin/loader对这些代码进行去重(反正没看到Webpack有插件,机会就留给你们了)。
打包css的时候,我们习惯使用ExtractTextPlugin让css单独生成一个文件。但如果你想让css也能够热替换,在开发环境的时候请去掉这个插件让样式内联。
使用此模式会内联一大段便于定位bug的字符串,查错时可以开启,不是查错时建议
关闭,否则开发时加载的包会非常大。
如果不使用devtools查错,你看到的会是合成之后的bundle,上万行代码,也不知道是哪个文件:
 。
。
使用了之后,你就很很清晰是在哪个文件,哪一行了:

webpack的bug导致如果本地开发目录路径不一致,编译出来的md5会不一致。所以推荐使用服务器构建。
在搭项目构建的时候,曾经尝试过用Webpack一个合图插件,但因不够成熟而弃用,转而考虑转投向gulp的合图插件的怀抱。由于家校群功能页面是一个多页项目,每个页面都会有合图,因此我们选用了gulp.spritesmith-multi。
以前使用gulp的构建项目,css都同一放在一层,引用图片的路径都放在一个css里面。但面对React的项目,我们每一个component都有自己对应的index.js(处理逻辑)和index.scss(处理样式),由于这个合图插件只能标出一个图片路径,因此如果合图的引用发生在不同层次的component,绝对会发生找不到文件的报错,因此我们统一将引用放在container的样式文件中,权宜地解决这个问题,以下是大致gulpfile写法:
gulp.task('sprites', function (cb) {
var spriteData = gulp.src(Config.filePath.src + 'img/sprites/**/*.png')
.pipe(spritesmith({
spritesmith: function(options) {
options.imgPath = Config.sprites.imgPath + options.imgName;
options.cssName = options.cssName.replace('.css', '.scss');
// customized generated css template
options.cssTemplate = './config/scss.template.handlebars';
}
}));
// Pipe image stream through image optimizer and onto disk
var imgStream = spriteData.img
// DEV: We must buffer our stream into a Buffer for `imagemin`
.pipe(gulp.dest(Config.sprites.imgDest));
// Pipe CSS stream through CSS optimizer and onto disk
var cssStream = spriteData.css
.pipe(gulp.dest(Config.sprites.cssDest));
// Return a merged stream to handle both `end` events
return merge(imgStream, cssStream);
});
以下是样式引用办法:
@import"../../../css/sprites/list_s";
......
.info-right.tiku-status3 {
@include sprite($remark);
}
如有错误,恳请斧正!
将babel捧作前端一个划时代的工具一定也不为过,它的出现让许多程序员幸福地用上了es6新语法。但你就这么放心地让babel跑在外网?反正我是不放心,我就曾经过被坑过,于是萌生了研究babel代码转换的想法。本文不是分析babel源码,仅仅是看看babel转换的最终产物。
es6在babel中又称为es2015。由于es2015语法众多,本文仅挑选了较为常用的一些语法点,而且主要是分析babel-preset-2015这个插件(react开发的时候,常在webpack中用到这个preset)。
打开babel-preset2015插件一看,一共20个插件。熟悉es2015语法的同志一看,多多少少能从字面意思知道某个插件是用于哪种语法的转换
const和let现在一律转换成var。那const到底如何保证不变呢?如果你在源码中第二次修改const常量的值,babel编译会直接报错。
转换前
var a = 1;
let b = 2;
const c = 3;
转换后:
var a = 1;
var b = 2;
var c = 3;
那let的块级作用怎么体现呢?来看看下面例子,实质就是在块级作用改变一下变量名,使之与外层不同。
转换前:
let a1 = 1;
let a2 = 6;
{
let a1 = 2;
let a2 = 5;
{
let a1 = 4;
let a2 = 5;
}
}
a1 = 3;
转换后:
var a1 = 1;
var a2 = 6;
{
var _a = 2;
var _a2 = 5;
{
var _a3 = 4;
var _a4 = 5;
}
}
a1 = 3;
写react的时候,我们使用负值解构去取对象的值,用起来非常爽,像这样:
var props = {
name: "heyli",
getName: function() {
},
setName: function() {
}
};
let { name, getName, setName } = this.props;
我们来看看转换的结果:
var props = {
name: "heyli",
getName: function getName() {},
setName: function setName() {}
};
var name = props.name;
var getName = props.getName;
var setName = props.setName;
至于数组呢?如果是一个匿名数组,则babel会帮你先定义一个变量存放这个数组,然后再对需要赋值的变量进行赋值。
转换前:
var [ a1, a2 ] = [1, 2, 3];
转换后:
var _ref = [1, 2, 3];
var a1 = _ref[0];
var a2 = _ref[1];
看到这个,感觉转换结果跟我们想的还蛮一致。哈哈,使用的噩梦还没开始。
如果使用匿名对象直接进行赋值解构会怎样呢?如下。babel为了使接收的变量唯一,直接就将匿名对象里的属性拼在一起,组成接收这个匿名对象的变量,吓得我赶紧检查一下项目里有没有这种写法。
转换前:
var { abc, bcd, cde, def } = { "abc": "abc", "bcd": "bcd", "cde": "cde", "def": "def", "efg": "efg", "fgh": "fgh" };
转换后:
var _abc$bcd$cde$def$efg$ = { "abc": "abc", "bcd": "bcd", "cde": "cde", "def": "def", "efg": "efg", "fgh": "fgh" };
var abc = _abc$bcd$cde$def$efg$.abc;
var bcd = _abc$bcd$cde$def$efg$.bcd;
var cde = _abc$bcd$cde$def$efg$.cde;
var def = _abc$bcd$cde$def$efg$.def;
还有一种对象深层次的解构赋值:
转换前:
var obj = {
p1: [
"Hello",
{ p2: "World" }
]
};
var { p1: [s1, { p2 }] } = obj;
转换后:
// 为解释本人将代码美化了
var _slicedToArray = (function() {
function sliceIterator(arr, i) {
var _arr = [];
var _n = true;
var _d = false;
var _e = undefined;
try {
// 用Symbol.iterator造了一个可遍历对象,然后进去遍历。
for (var _i = arr[Symbol.iterator](), _s; !(_n = (_s = _i.next()).done); _n = true) {
_arr.push(_s.value);
if (i && _arr.length === i) break;
}
} catch (err) {
_d = true;
_e = err;
} finally {
try {
if (!_n && _i["return"]) _i["return"]();
} finally {
if (_d) throw _e;
}
}
return _arr;
}
return function(arr, i) {
if (Array.isArray(arr)) {
return arr;
} else if (Symbol.iterator in Object(arr)) {
return sliceIterator(arr, i);
} else {
throw new TypeError("Invalid attempt to destructure non-iterable instance");
}
};
})();
var obj = {
p1: ["Hello", { p2: "World" }]
};
var _obj$p = _slicedToArray(obj.p1, 2);
var s1 = _obj$p[0];
var p2 = _obj$p[1].p2;
babel在代码顶部生产了一个公共的代码_slicedToArray。大概就是将对象里面的一些属性转换成数组,方便解构赋值的进行。但Symbol.iterator的兼容性并不好(如下图),还是谨慎使用为妙。

另外,下面这种对字符串进行赋值解构也同样使用到_slicedToArray方法:
const [a, b, c, d, e] = 'hello';
在es5的年代,一般我们写参数的默认值都会这么写:
function func(x, y) {
var x = x || 1;
var y = y || 2;
}
我们来看看babel的转换办法:
function func({x, y} = { x: 0, y: 0 }) {
return [x, y];
}
function func1(x = 1, y = 2) {
return [x, y];
}
function func() {
var _ref = arguments.length <= 0 || arguments[0] === undefined ? { x: 0, y: 0 } : arguments[0];
var x = _ref.x;
var y = _ref.y;
return [x, y];
}
function func1() {
var x = arguments.length <= 0 || arguments[0] === undefined ? 1 : arguments[0];
var y = arguments.length <= 1 || arguments[1] === undefined ? 2 : arguments[1];
return [x, y];
}
babel这里使有了arguments来做判。第一种情况涉及解构赋值,因此x和y的值还是有可能是undefined的。至于第二种情况,则会保证2个参数的默认值分别是1和2.
再来看一种。...y代表它接收了剩下的参数。也就是arguments除了第一个标号的参数之外剩余的参数。
转换前:
function func(x, ...y) {
console.log(x);
console.log(y);
return x * y.length;
}
转换后:
function func(x) {
console.log(x);
for (var _len = arguments.length, y = Array(_len > 1 ? _len - 1 : 0), _key = 1; _key < _len; _key++) {
y[_key - 1] = arguments[_key];
}
console.log(y);
return x * y.length;
}
剪头函数其实主要是省了写函数的代码,同时能够直接用使外层的this而不用担心context切换的问题。以前我们一般都要在外层多写一个_this/self直向this。babel的转换办法其实跟我们的处理无异。
转换前:
var obj = {
prop: 1,
func: function() {
var _this = this;
var innerFunc = () => {
this.prop = 1;
};
var innerFunc1 = function() {
this.prop = 1;
};
},
};
转换后:
var obj = {
prop: 1,
func: function func() {
var _this2 = this;
var _this = this;
var innerFunc = function innerFunc() {
_this2.prop = 1;
};
var innerFunc1 = function innerFunc1() {
this.prop = 1;
};
}
};
转换前:
var a = 1,
b = "2",
c = function() {
console.log('c');
};
var obj = {a, b, c};
转换后:
var a = 1,
b = "2",
c = function c() {
console.log('c');
};
var obj = { a: a, b: b, c: c };
es2015开始新增了在对象中用中括号解释属性的功能,这对变量、常量等当对象属性尤其有用。
转换前:
const prop2 = "PROP2";
var obj = {
['prop']: 1,
['func']: function() {
console.log('func');
},
[prop2]: 3
};
转换后:
var _obj;
// 已美化
function _defineProperty(obj, key, value) {
if (key in obj) {
Object.defineProperty(obj, key, {
value: value,
enumerable: true,
configurable: true,
writable: true
});
} else {
obj[key] = value;
}
return obj;
}
var prop2 = "PROP2";
var obj = (_obj = {}, _defineProperty(_obj, 'prop', 1), _defineProperty(_obj, 'func', function func() {
console.log('func');
}), _defineProperty(_obj, prop2, 3), _obj);
看似简单的属性,babel却大动干戈。新增了一个_defineProperty函数,给新建的_obj = {}进行属性定义。除此之外使用小括号包住一系列从左到右的运算使整个定义更简洁。
以前我们一般都用obj.prototype或者尝试用this去往上寻找prototype上面的方法。而babel则自己写了一套在prototype链上寻找方法/属性的算法。
转换前
var obj = {
toString() {
// Super calls
return "d " + super.toString();
},
};
转换后:
var _obj;
// 已美化
var _get = function get(object, property, receiver) {
// 如果prototype为空,则往Function的prototype上寻找
if (object === null) object = Function.prototype;
var desc = Object.getOwnPropertyDescriptor(object, property);
if (desc === undefined) {
var parent = Object.getPrototypeOf(object);
// 如果在本层prototype找不到,再往更深层的prototype上找
if (parent === null) {
return undefined;
} else {
return get(parent, property, receiver);
}
}
// 如果是属性,则直接返回
else if ("value" in desc) {
return desc.value;
}
// 如果是方法,则用call来调用,receiver是调用的对象
else {
var getter = desc.get; // getOwnPropertyDescriptor返回的getter方法
if (getter === undefined) {
return undefined;
}
return getter.call(receiver);
}
};
var obj = _obj = {
toString: function toString() {
// Super calls
return "d " + _get(Object.getPrototypeOf(_obj), "toString", this).call(this);
}
};
es6新增的Object.assign极大方便了对象的克隆复制。但babel的es2015 preset并不支持,所以没对其进入转换,这会使得一些移动端机子遇到这种写法会报错。所以一般开发者都会使用object-assign这个npm的库做兼容。
Object.is用于比较对象的值与类型,es2015 preset同样不支持编译。
转换前:
console.log(`string text line 1
string text line 2`);
转换后:
console.log("string text line 1\nstring text line 2");
转换前:
var a = 5;
var b = 10;
console.log(`Fifteen is ${a + b} and not ${2 * a + b}.`);
转换后:
var a = 5;
var b = 10;
console.log("Fifteen is " + (a + b) + " and not " + (2 * a + b) + ".");
es6的这种新特性给模板处理赋予更强大的功能,一改以往对模板进行各种replace的处理办法,用一个统一的handler去处理。babel的转换主要是添加了2个属性,因此看起来也并不算比较工程浩大的编译。
转换前:
var a = 5;
var b = 10;
function tag(strings, ...values) {
console.log(strings[0]); // "Hello "
console.log(strings[1]); // " world "
console.log(values[0]); // 15
console.log(values[1]); // 50
return "Bazinga!";
}
tag`Hello ${ a + b } world ${ a * b }`;
转换后:
var _templateObject = _taggedTemplateLiteral(["Hello ", " world ", ""], ["Hello ", " world ", ""]);
// 已美化
function _taggedTemplateLiteral(strings, raw) {
return Object.freeze(Object.defineProperties(strings, {
raw: {
value: Object.freeze(raw)
}
}));
}
// 给传入的object定义strings和raw两个不可变的属性。
var a = 5;
var b = 10;
function tag(strings) {
console.log(strings[0]); // "Hello "
console.log(strings[1]); // " world "
console.log(arguments.length <= 1 ? undefined : arguments[1]); // 15
console.log(arguments.length <= 2 ? undefined : arguments[2]); // 50
return "Bazinga!";
}
tag(_templateObject, a + b, a * b);
javascript实现oo一直是非常热门的话题。从最原始时代需要手动维护在构造函数里调用父类构造函数,到后来封装好函数进行extend继承,再到babel出现之后可以像其它面向对象的语言一样直接写class。es2015的类方案仍然算是过渡方案,它所支持的特性仍然没有涵盖类的所有特性。目前主要支持的有:
转换前:
class Animal {
constructor(name, type) {
this.name = name;
this.type = type;
}
walk() {
console.log('walk');
}
run() {
console.log('run')
}
static getType() {
return this.type;
}
get getName() {
return this.name;
}
set setName(name) {
this.name = name;
}
}
class Dog extends Animal {
constructor(name, type) {
super(name, type);
}
get getName() {
return super.getName();
}
}
转换后(由于代码太长,先省略辅助的方法):
/**
......一堆辅助方法,后文详述
**/
var Animal = (function () {
function Animal(name, type) {
// 此处是constructor的实现,用_classCallCheck来判定constructor正确与否
_classCallCheck(this, Animal);
this.name = name;
this.type = type;
}
// _creatClass用于创建类及其对应的方法
_createClass(Animal, [{
key: 'walk',
value: function walk() {
console.log('walk');
}
}, {
key: 'run',
value: function run() {
console.log('run');
}
}, {
key: 'getName',
get: function get() {
return this.name;
}
}, {
key: 'setName',
set: function set(name) {
this.name = name;
}
}], [{
key: 'getType',
value: function getType() {
return this.type;
}
}]);
return Animal;
})();
var Dog = (function (_Animal) {
// 子类继承父类
_inherits(Dog, _Animal);
function Dog(name, type) {
_classCallCheck(this, Dog);
// 子类实现constructor
// babel会强制子类在constructor中使用super,否则编译会报错
return _possibleConstructorReturn(this, Object.getPrototypeOf(Dog).call(this, name, type));
}
_createClass(Dog, [{
key: 'getName',
get: function get() {
// 跟上文使用super调用原型链的super编译解析的方法一致,
// 也是自己写了一个回溯prototype原型链
return _get(Object.getPrototypeOf(Dog.prototype), 'getName', this).call(this);
}
}]);
return Dog;
})(Animal);
// 检测constructor正确与否
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
// 创建类
var _createClass = (function() {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
// es6规范要求类方法为non-enumerable
descriptor.enumerable = descriptor.enumerable || false;
descriptor.configurable = true;
// 对于setter和getter方法,writable为false
if ("value" in descriptor) descriptor.writable = true;
Object.defineProperty(target, descriptor.key, descriptor);
}
}
return function(Constructor, protoProps, staticProps) {
// 非静态方法定义在原型链上
if (protoProps) defineProperties(Constructor.prototype, protoProps);
// 静态方法直接定义在constructor函数上
if (staticProps) defineProperties(Constructor, staticProps);
return Constructor;
};
})();
// 继承类
function _inherits(subClass, superClass) {
// 父类一定要是function类型
if (typeof superClass !== "function" && superClass !== null) {
throw new TypeError("Super expression must either be null or a function, not " + typeof superClass);
}
// 使原型链subClass.prototype.__proto__指向父类superClass,同时保证constructor是subClass自己
subClass.prototype = Object.create(superClass && superClass.prototype, {
constructor: {
value: subClass,
enumerable: false,
writable: true,
configurable: true
}
});
// 保证subClass.__proto__指向父类superClass
if (superClass)
Object.setPrototypeOf ?
Object.setPrototypeOf(subClass, superClass) : subClass.__proto__ = superClass;
}
// 子类实现constructor
function _possibleConstructorReturn(self, call) {
if (!self) {
throw new ReferenceError("this hasn't been initialised - super() hasn't been called");
}
// 若call是函数/对象则返回
return call && (typeof call === "object" || typeof call === "function") ? call : self;
}
先前在用react重构项目的时候,所有的react组件都已经摒弃了es5的写法,一律采用了es6。用类的好处写继续更加方便,但无法用mixin,需要借助更新的es7语法中的decorator才能够实现类mixin的功能(例如pureRender)。但这次分析完babel源码之后,才发现原来babel在实现class特性的时候,定义了许多方法,尽管看起来并不太优雅。
在开发react的时候,我们往往用webpack搭配babel的es2015和react两个preset进行构建。之前看了一篇文章对babel此处的模块加载有些启发(《分析 Babel 转换 ES6 module 的原理》)。
示例:
// test.js
import { Animal as Ani, catwalk } from "./t1";
import * as All from "./t2";
class Cat extends Ani {
constructor() {
super();
}
}
class Dog extends Ani {
constructor() {
super();
}
}
// t1.js
export class Animal {
constructor() {
}
}
export function catwal() {
console.log('cat walk');
};
// t2.js
export class Person {
constructor() {
}
}
export class Plane {
constructor() {
}
}
通过webpack与babel编译后:
// t1.js的模块
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.catwal = catwal;
// 省略一些类继承的方法
var Animal = exports.Animal = function Animal() {
_classCallCheck(this, Animal);
};
function catwal() {
console.log('cat walk');
};
// t2.js的模块
Object.defineProperty(exports, "__esModule", {
value: true
});
// 省略一些类继承的方法
var Person = exports.Person = function Person() {
_classCallCheck(this, Person);
};
var Plane = exports.Plane = function Plane() {
_classCallCheck(this, Plane);
};
// test.js的模块
var _t = __webpack_require__(1);
var _t2 = __webpack_require__(3); // 返回的都是exports上返回的对象属性
var All = _interopRequireWildcard(_t2);
function _interopRequireWildcard(obj) {
// 发现是babel编译的, 直接返回
if (obj && obj.__esModule) {
return obj;
}
// 非babel编译, 猜测可能是第三方模块,为了不报错,让default指向它自己
else {
var newObj = {};
if (obj != null) {
for (var key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) newObj[key] = obj[key];
}
}
newObj.default = obj;
return newObj;
}
}
// 省略一些类继承的方法
var Cat = (function (_Ani) {
_inherits(Cat, _Ani);
function Cat() {
_classCallCheck(this, Cat);
return _possibleConstructorReturn(this, Object.getPrototypeOf(Cat).call(this));
}
return Cat;
})(_t.Animal);
var Dog = (function (_Ani2) {
_inherits(Dog, _Ani2);
function Dog() {
_classCallCheck(this, Dog);
return _possibleConstructorReturn(this, Object.getPrototypeOf(Dog).call(this));
}
return Dog;
})(_t.Animal);
es6的模块加载是属于多对象多加载,而commonjs则属于单对象单加载。babel需要做一些手脚才能将es6的模块写法写成commonjs的写法。主要是通过定义__esModule这个属性来判断这个模块是否经过babel的编译。然后通过_interopRequireWildcard对各个模块的引用进行相应的处理。
另一个发现是,通过webpack打包babel编译后的代码,每一个模块里面都包含了相同的类继承帮助方法,这是开发时忽略的。由此可看,在开发react的时候用es5的语法可能会比使用es6的class能使js bundle更小。
开发家校群的时候,在android4.0下面报esModule错误的问题,如下:
Uncaught TypeError: Cannot assign to read only property '__esModule' of #<Object>。
经查证,发现是构建中babel-es2015 loader的模式问题,会导致Android4.0的用户有报错。只需要使用loose mode就可以解决问题。下面是相关的stackoverflow issue以及对应解决问题的npm包。
那么es2015和normal mode和loose mode有什么区别呢,这个出名的博客略有介绍:Babel 6: loose mode。
实质就是(作者总结)normal mode的转换更贴近es6的写法,许多的property都是通过Object.defineProperty进行的。而loose mode则更贴近es5的写法,性能更好一些,兼容性更好一些,但将这部份代码再转换成native es6的话会比较麻烦一些(感觉这一点并不是缺点,有源码就可以了)。
上面esModule解决的办法,实质就是将
Object.defineProperty(exports, "__esModule", {
value: true
});
改成
exports.__esModule = true;
再举个例子,如下面的Cat类定义:
class Cat extends Ani {
constructor() {
super();
}
miao() {
console.log('miao');
}
}
正常模式会编译为:
var Cat = (function (_Ani) {
_inherits(Cat, _Ani);
function Cat() {
_classCallCheck(this, Cat);
return _possibleConstructorReturn(this, Object.getPrototypeOf(Cat).call(this));
}
_createClass(Cat, [{
key: "miao",
value: function miao() {
console.log('miao');
}
}]);
return Cat;
})(_t.Animal);
loose mode模式会编译为:
var Cat = (function (_Ani) {
_inherits(Cat, _Ani);
function Cat() {
_classCallCheck(this, Cat);
return _possibleConstructorReturn(this, _Ani.call(this));
}
Cat.prototype.miao = function miao() {
console.log('miao');
};
return Cat;
})(_t.Animal);
babel es2015中loose模式主要是针对下面几个plugin:
每一种的转换方式在此就不再赘述了,大家可以回家自己试。
如有错误,恳请斧正!
最近公司某业务有个事故,在用户使用高峰的时候页面打开白屏,大概20多分钟才恢复。复盘后发现根本的原因是由于在整个网络链路上云厂商提供的专线网络带宽打满,导致页面静态资源加载过慢或无法加载,进而引发的事故。
有鉴于此,在部门内组织各业务梳理,看看有没有业务有类似的带宽风险。让大家梳理的过程中,发现大家对前端服务中间通过的通路、带宽基本都没什么概念。前端团队如果没人懂网络、懂带宽,感觉是比较危险的,不仅业务的可用性风险无人洞悉,对如何控制成本也没有概念,在现在互联网的大环境来说这是比较难接受的。
一般来说,后台的网络架构论述的较多,实际上前端也有网络的架构,一般的前端网络架构分两种,一种是全部资源部署在服务器,另一种是将部份静态资源放到CDN,架构如下:


上面是常见的两种前端的部署架构,负载均衡到K8S服务的网络要比上面描述的更复杂,这里为了易于理解做了简化。此外,如果没有运维能力或者服务并不需要建设K8S,也可以更换成普通的虚拟机。
你会发现,在K8S和CDN双部署架构中,CDN有可能需要回源。CDN通常将静态资源部署在靠近用户的服务器上,以加快加载速度。但如果靠近用户的服务器尚未缓存这些资源,则这些资源的请求将直接发送到源站,这被称为回源。
源站可以是在云服务厂商处购买的对象存储,也可以是存储在K8s中的资源。至于采用哪种,主要是看诉求和预算。如果预算较低,可以直接部将源站设置到服务的K8S中,与html资源放在一起。如果是预算充足,还需要一些比如鉴黄、自动压缩、自动缩放裁剪等功能,那大可以使用对象存储。
当我们对部署架构有所了解,下一步就需要知道部署架构中所经过的网络带宽的上限是多少了,因为带宽的上限深刻地影响着服务的质量。一般来说,所有的网络通路都会有带宽的限制,但网部的网络由于上限较高,很多时候都会被忽略。
带宽的单位一般用Mbps(每秒Mb)或Gbps(每秒Gb),分为上行与下行,上行会影响资源的上传速度,下行则会影响资源的下载速度,对前端资源来说,下行的带宽影响最为深刻。
那我们在哪里可以获取带宽的信息呢?一种是可以在购买云资源的时候,设备规格的时候获取,比如当你买一台云虚拟机,以下是购买虚拟机时,内网带宽与外网带宽的信息:


也可以在购买的云资源里,找到相应的带宽信息:


细心的你会发现,无论是购买云服务器,还是CDN,都会有两种经典的收费模式,一种是按带宽计费,一直是按流量计费。如果您不确定如何选择,可以查看云厂商的说明文档。他们通常会根据不同场景提供推荐。譬如他们会推荐有一定访问量但流量较为稳定的个人博客使用按带宽计费,而那些电商的大促活动有一定的性能要求的,大部份时间用按带宽计费,而重大活动为了保证性能而按流量计费。
选择的模式可能并不是最开始就能够选到最优解,可以在相同业务的反复尝试中发现对业务成本最低的计费方式,最终进行选择即可。
对于那些按流量计费的云资源而言,主要的瓶颈就是云资源的预算。而对于那些按下行带宽计费的云资源,主要的瓶颈就是业务下行的带宽峰值远超云资源自身的带宽上限。既然我们能够查询到云资源的带宽上限,那如何判断业务目前是否有瓶颈呢?
第一个办法是可以通过云服务厂商的监控,找到业务带宽的峰值,如下图。如果外网出带宽使用率长时间达到90% - 100%,那表示目前的带宽可能会对业务造成瓶颈,需要适当加大带宽。
如果没有这种监控或者比较难找到,那该怎么办呢?可以通过在Chrome浏览器的Network面板中粗略估算:

首先需要禁用缓存,然后加载一遍页面,筛选出想统一的域名资源,再剔除Fetch/XHR请求,剩下的主要就是静态资源。这里10.6MB就是静态资源Gzip后实际的传输值,12.35s表示目前所显示的资源的加载时间,那平均每秒的传输值就约为 10.6MB / 12.35s 约为 0.86MBps = 0.86 * 8 = 6.88 Mbps 。如果服务的带宽小于 6.88Mbps,那服务器的带宽就会比较有压力了。这个数据实际上可能有一定的高估,因为许多用户访问过站点之后,就会有缓存,因此实际并不会加载这么多网络的资源。
如有谬误,恳请斧正
MB和Mb、MB/s和Mb/s是有区别的。
其中大B代表Byte(字节),小b代表bit(位)。
1 Kb = 1024 bit
1 KB = 1024 Byte
1 Mb = 1024 Kb
1 MB = 1024 KB
1 Byte = 8 bit
1 MB = 8Mb
Some friends and I have been running webpack-china for a few months.
After a few months effort, most doc translation job have also been done. We keep tracking the master and you will see Chinese version does not lag behind too much.

(pretty much the same and http2 is also applied)
However it has been a while that we need to manually deploy the site. With the help of Travis-Ci and Github webhook, we finally make it an auto process.
Travis-CI is used for building your code that you need to publish and push them to your gh-pages branch. Github webhook then takes over the job and sends a request to your hosting server. When your server gets the request, it would run a script to pull the latest code from gh-page. The site then finish all the updating steps.
(Sample process)
Here I will use webpack-china/webpack.js.org as an example. The repository is forked from webpack/webpack.js.org. But we have to modify it a bit.

(.travis.yml)
This file is the configuration for Travis-CI. Not much difference from other project, branches means which branches will be watched by Travis-Ci. Node.js is used as the major programing language. Node 6.0 environment will be set up. The most important file should be deploy.sh. This file contains the commands used for deployment.

(1st part of deploy.sh)
The 1st part of deploy.sh script is used for building the site. Ready releasing code will be put under build folder when you run
npm run build
(2nd part of deploy.sh)
The 2nd part of the script is aiming for pushing code to gh-pages branch. But how does Travis-CI know get the permission to access your repo?
SSH Key does the trick for you. Please follow this guide, Generating a new SSH key to generate SSH Key. (Please do it under your local repository folder)
example code:
ssh-keygen -t rsa -b 4096 -C ci@travis-ci.org
Enter file in which to save the key (/var/root/.ssh/id_rsa): deploy_keyWhen you are asked to enter passphrase, please type enter to skip.
Enter passphrase (empty for no passphrase):Then open deploy_key.pub and copy whole file content. Add that deploy key to your repository at https://github.com/<your name>/<your repo>/settings/keys.
(deploy keys in github)
Next, install travis client tool to upload SSH Key information to the Travis-CI.
After installation, run
travis encrypt-file deploy_key
(travis encrypt-file result)
Add the script to deploy.sh under scripts folder and also add deploy_key.enc to scripts folder. Append scripts/ to delopy_key and deploy_key in this script as follows,
openssl aes-256-cbc -K $encrypted_7562052d3e34_key -iv $encrypted_7562052d3e34_iv -in scripts/deploy_key.enc -out scripts/deploy_key -dPlease do not to upload deploy_key.pub.
If it prompts login info, try
travis loginThen you can push everything to the repository and Travis-CI will build and push things for you.
One more thing to note is that npm run deploy in deploy.sh is used here which use gh-pages library to push code to gh-pages.
(1st part Github Webhook)
(2nd part of Github Webhook)
Add a webhook in your project (1st part of Github Webhook) and you can specify when Github will send the request (2nd part of Github Webhook).

(app to receive Github Webhook Request)
Then you need to deploy a small app (pm2 is recommended to persist the app process) to respond to Github Webhook.
codePath is the path where accommodate production code from gh-pages branch.
updateCommand,
cd ${codePath};sudo git fetch — all;sudo git reset — hard origin/gh-pages;is to fetch all stuff from gh-pages branch and only show the latest record.
Don’t forget to configure your nginx/apache to serve your static files in codePath.
React 的开发也已经有2年时间了,先从QQ的家校群,转成做互动直播,主要是花样直播这一块。切换过来的时候,业务非常繁忙,接手过来的业务比较凌乱,也没有任何组件复用可言。
为了提高开发效率,去年10月份也开始有意识地私下封装一些组件,并且于今年年初在项目组里发起了百日效率提升计划,其中就包含组件化开发这一块。
本文并不是要谈如何去写一个 React 组件,这一块已经有不少精彩的文章。例如像这篇《重新设计 React 组件库》,里面涉及一个组件设计的各方面,如粒度控制、接口设计、数据处理等等(不排除后续也写一篇介绍组件设计理念哈)。
本文关键词是三个,工程化、快速和可靠。我们是希望利用工程化手段去保障快速地开发可靠的组件,工程化是手段和工具,快速和可靠,是我们希望达到的目标。
前端工程化不外乎两点,规范和自动化。
读文先看此图,能先有个大体概念:

规范,主要就是目录规范和代码规范。跟同事合作,经过将近20个的组件开发后,我们大概形成了一定的目录规范,以下是我们大致的目录约定。哪里放源码,哪里放生产代码,哪里是构建工具,哪里是例子等。有了这些的约定,日后开发和使用并一目了然。
__tests__ -- 测试用例
|
example -- 真实demo
|
dist -- 开发者使用代码
|
src -- 源代码
|
config -- 项目配置
|------project.js -- 项目配置,主要被 webpack,gulp 等使用
|
|
tools -- 构建工具
|
|——————start.js -- 开发环境执行命令
|——————start.code.js -- 开发环境生成编译后代码命令
|
package.json命令我们也进行了规范,如下,
// 开发环境,服务器编译
npm start 或者 npm run dev
// 开发环境,生成代码
npm run start.code
// 生产环境
npm run dist
// 测试
npm test
// 测试覆盖率
npm run coverage
// 检查你的代码是否符合规范
npm run lint代码规范,主要是写 js,css 和 html 的规范,基本我们都是沿用团队之前制定好的规范,如果之前并没有制定,例如 React 的 jsx 的写法,那么我们就参考业界比较优秀的标准,并进行微调,例如 airbnb 的 JavaScript 规范,是不错的参考。
规范是比较人性的东西,凭着人对之的熟悉就可以提高效率了,至于那些工作繁复的流程,单凭人的熟悉也会达到极限,那么我们就需要借助自动化的工具去突破这重极限。
例如代码规范,单凭人的肉眼难以识别所有不合规范的代码,而且效率低下,借助代码检测工具就可让人卸下这个重担。如 css ,我们推荐使用 stylelint ,js 则是 eslint。有这种自动化的工具协助开发者进行检查,能更好地保障我们的代码质量。
自动化最为重要的任务是,去保证开发过程良好的体验还有发布生产代码。实际上,开发和发布组件的整个过程跟平时开发一个任务很像,但却又略有差异。
首先是开发过程中,我们希望一边开发的时候,我们开发的功能能够显示出来,这时最好能搭建一个demo,我们把 demo 放到了 example 目录下,这点对 UI 组件(像toast, tips等组件) 尤为重要,逻辑组件(像ajax, utils等组件),可以有 demo,也可以采取测试驱动开发的方式,先制定部份测试用例,然后边开发边进行测试验证。
开发过程中的这个 demo, 跟平时开发项目基本一致,我们就是通过配置,把 html,js, css 都搭建好,而且我们是开发 React 组件,引入热替换的功能令整个开发流程非常流畅。这里分别是 webpack 和配合 `webpack 开发的静态资源服务器的两份配置: webpack & server。
但是发布组件的这个过程跟开发项目却又很不同。开发项目,我们需要把所有的依赖都打包好,然后一并发布。但对于组件来说,我们只需要单独将它的功能发布就好了,它的相关依赖可以在实际开发项目中引用时一并再打包。因此这里的 package.json 写的时候也要有所区分。跟只跟开发流程、构建、测试相关的,我们一律放在 devDependencies 中,组件实际依赖的库,则主要放在 dependencies 中。
鉴于我们项目一般采用 webpack 打包,因此我们一般只需要 es6 import 的引入方式,那我们直接用 babel 帮我们的项目进行生产代码的编译打包就可以了,这样能有效减少冗余代码。配置好 .babelrc,然后配置 package.json 的打包命令即可。要注意的是,你的组件可能含有样式文件,配置命令的时候要记得将样式文件也复制过去,像下面的命令,--copy-files 参数就是为了将样式文件直接拷贝到 dist 目录下。
babel src --out-dir dist --copy-files但有时候,你也想组件能兼容多种引用方式,即 umd,那 babel 的这种打包就不够了。这时你可以借助 webpack 打包 library 的能力。可参考此 配置。主要是配置 output.library 和 output.libraryTarget。
output: {
// other config
library: "lib", // 表示以什么名字输出,这里,会输出为如 exports["lib"]
libraryTarget: "umd", // 表示打包的方式
},另一点要注意的是,我们只需打包组件的逻辑就好了,那些依赖,可以等实际生产项目的时候再进行解析。但 webpack 默认会将依赖也打包进行,为了避免这点,你需要将这些依赖一一配置成为 external,这就告诉了 webpack 它们是外部引用的,可以不用打包进来。
打包完成之后,根据指引进行 npm publish 就可以了。这里大体总结了一下我们开发组件的一些流程和注意事项。
上述讲的都跟如何提升开发效率有关的,即满足 “快速” 这个目标,对 ”可靠“ 有一定帮助,如稳定的流程和良好的代码规范,但并没有非常好地保证组件地稳定可靠。需要 ”可靠“的组件,还需要测试来保证。
不少开发者做测试会使用 mocha,如果是 UI 组件可能会配置上 karma。而 React 组件测试还有一个更好的选择,就是官方推荐的 jest + enzyme。
jest 跟 jasmine 有点类似,将一个测试库的功能大部份集成好了(如断言等工具),一键安装 babel-jest 可以用 es6 直接写测试用例,搭配 jest-environment-jsdom 和 jsdom 能够模拟浏览器环境,结合 airbnb 写的 react 测试库 enzyme, 基本能满足大部份的 React 测试需求。确实符合官方的宣传语 painless,这是一个无痛的测试工具。
测试逻辑组件问题倒不大,UI组件对于大部份的情况都可以,许多事件都可以通过 enzyme 模拟事件进行测试。但这里举的例子, react-list-scroll 组件,一个 React 的滚动列表组件,碰巧遇到一种比较难模拟的情况,就是对 scroll 事件的模拟。这里想展开说一下。
对于 React 的 scroll 事件而言,必须要绑定在某个元素里才能进行模拟,不巧,对于安卓手机来说,大部份 scroll 事件都是绑定在 window 对象下的。这就非常尴尬了,需要借助到 jsdom 的功能。通过 jest-environment-jsdom,它能够将 jsdom 注入到 node 运行环境中,因此你可以在测试文件中直接使用 window 对象进行模拟。例如下面代码,模拟滚动到最底部:
test('scroll to bottom', (done) => {
const wrapper = mount(<Wrapper />);
window.addEventListener('scroll', function(e) {
setTimeout(() => {
try {
// expect 逻辑
done();
}
catch(err) {
done.fail(err);
}
}, 100);
jest.runAllTimers();
});
let scrollTop = 768;
window.document.body.scrollTop = scrollTop; // 指明当前 scrollTop到了哪个位置
window.dispatchEvent(new window.Event('scroll', {
scrollTop: scrollTop
}));
});细心的你会发现,上图还有一些定时器的逻辑。原因是在组件中会有一些截流的逻辑,滚动时间隔一段时间才去检测滚动的位置,避免性能问题,因此加一个定时器,等待数据的返回,而 jest.runAllTimers(); 则是用于告诉定时器马上跑完。
除此之外,定时器里还有个 try catch 的逻辑,主要是如果 expect 验证不通过,jest 会报告错误,这时需用错误捕获的办法将错误传给 done (异步测试的回调),这样才能正常退出这一个测试用例,否则会返回超时错误。
安卓测完了,那iPhone呢?iPhone 的 scroll 事件是绑定在具体某个元素里的,但我这里又不是通过 React 的 onScroll 来绑定。首先我们得通过 window.navigator.userAgent 来区分手机类型。但由于 userAgent 只有 getter 函数,直接设置值会报错,因此我们要添加一个 setter 函数给它,用这段示例代码:
Object.defineProperty(window.navigator, "userAgent", (function(_value){
return {
get: function _get() {
return _value;
},
set: function _set(v) {
_value = v;
}
};
})(window.navigator.userAgent));
let str = "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1";
window.navigator.userAgent = str;然后,去找到这个绑定的元素,进行事件监听和分发就好了:
const wrapper = mount(<Wrapper />),
scrollComp = wrapper.find(Scroll),
scrollContainer = scrollComp.nodes[0].scrollContainer;
scrollContainer.addEventListener('scroll', function(e) { //... });
scrollContainer.dispatchEvent(// ... );本文主要是提取了开发组件工程化的一些关键要点,具体的开发脚手架可以参考 steamer-react-component,里面主要举了pure-render-deepCompare-decorator 和 react-list-scroll,一个逻辑组件,一个UI组件,共两个示例,对照着脚手架的文档,从目录规范、开发流程、发布都写得较为清楚,大家开发组件的时候,可以根据情况做些调整。
如有谬误,恳请斧正。
本文不是webpack入门文章,如果对webpack还不了解,请前往题叶的Webpack入门,或者阮老师的Webpack-Demos。
第3点我想稍微论述一下,如果看过我之前写的《如何写一个webpack插件(一)》,会发现,webpack会将文件内容存在compilation这个大的object里面,方便各种插件,loader间的调用。虽然gulp也用到了流(pipe)这样的内存处理方式,但感觉webpack更进一步。gulp是每一个任务(task)用一个流,而webpack是共享一个流。

Webpack的配置主要为了这几大项目:
了解了以上介绍的Loaders和Plugins之后,基本就可以搭建一整套基于Webpack的构建(不需要gulp与grunt,合图除外)。下面让我来介绍一下在使用过程中的一些优化点。
"scripts": {
"publish-mac": "export NODE_ENV=prod&&webpack -p --progress --colors",
"publish-win": "set NODE_ENV=prod&&webpack -p --progress --colors"
}
使用代码热替换在开发的时候无需刷新页面即可看到更新,而且,它将构建的内容放入内在中,能够获得更快的构建编译性能,因此是官方非常推荐的一种构建方式。
1.将代码内联到入口js文件里

2.启动代码热替换的plugins

直接实现一个server.js,启动服务器(需要启动热替换plugin),下面是我在业务中用到的一个范例。具体的一些参数可以
var webpack = require('webpack');
var webpackDevMiddleware = require("webpack-dev-middleware");
var webpackDevServer = require('webpack-dev-server');
var config = require("./webpack.config.js");
config.entry.index.unshift("webpack-dev-server/client?http://localhost:9000"); // 将执替换js内联进去
config.entry.index.unshift("webpack/hot/only-dev-server");
var compiler = webpack(config);
var server = new webpackDevServer(compiler, {
hot: true,
historyApiFallback: false,
// noInfo: true,
stats: {
colors: true // 用颜色标识
},
proxy: {
"*": "http://localhost:9000" // 用于转发api数据,但webpack自己提供的并不太好用
},
});
server.listen(9000);
直接在webpack.config.js上配置。这个办法最简单,当然灵活性没有自己实现一个服务器好。

<script>单独将react引入

如果想将report数据上报组件放到全局,有两种办法:
在loader里使expose将report暴露到全局,然后就可以直接使用report进行上报
{
test: path.join(config.path.src, '/js/common/report'),
loader: 'expose?report'
},
如果想用R直接代表report,除了要用expose loader之外,还需要用ProvidePlugin帮助,指向report,这样在代码中直接用R.tdw, R.monitor这样就可以
new webpack.ProvidePlugin({
"R": "report",
}),
有些类库如utils, bootstrap之类的可能被多个页面共享,最好是可以合并成一个js,而非每个js单独去引用。这样能够节省一些空间。这时我们可以用到CommonsChunkPlugin,我们指定好生成文件的名字,以及想抽取哪些入口js文件的公共代码,webpack就会自动帮我们合并好。
new webpack.optimize.CommonsChunkPlugin({
name: "common",
filename: "js/common.js",
chunks: ['index', 'detail]
}),
resolve里面有一个alias的配置项目,能够让开发者指定一些模块的引用路径。对一些经常要被import或者require的库,如react,我们最好可以直接指定它们的位置,这样webpack可以省下不少搜索硬盘的时间。

有时候你的node_modules包可能会放在上层父文件夹中,这时你可以使用resolve.moduledirectories来扩张你的索引路径,例如我们给redux做一个alias:
resolve: {
moduledirectories:['node_modules', config.path.src],
extensions: [".js", ".jsx",],
alias: {
'redux': 'redux/dist/redux',
}
},
这样的话,它的索引路径会如下:
/a/b/node_module/redux/dist/redux
/a/node_module/redux/dist/redux
/node_module/redux/dist/redux
要注意的是多加索引路径可能会导致性能下降,所以除非项目复杂,否则慎用这个功能。
仅使用app作为注入的文件:
plugins: [
new HtmlWebpackPlugin({
chunks: ['app']
})
]
不使用dev-helper作为注入文件:
plugins: [
new HtmlWebpackPlugin({
excludeChunks: ['dev-helper']
})
]
如果你不想用inject模式,但又想使用html-webpack-plugin,那你需要在html里用<script>标签放入对应的js,以及用入对应的css。记住,这些资源的路径是在生成目录下的,写路径的时候请写生成目录下的相对路径。
当时我就给维护者提了一个issue--Add inline feature to the plugin。
然后维护者在开发的分支上加了这么一个特性(证明维护者不想在插件里加内联功能了,想让我来弄):
事件
允许其它插件去使用执行事件
html-webpack-plugin-before-html-processing
html-webpack-plugin-after-html-processing
html-webpack-plugin-after-emit
使用办法:
compilation.plugin('html-webpack-plugin-before-html-processing', function(htmlPluginData, callback) {
htmlPluginData.html += 'The magic footer';
callback();
});
不过我还是决定自己开发一个了一个插件
html-res-webpack-plugin,有中英文文档可以参考。其实html-webpack-plugin以js作为入口可能跟webpack的理念更为一致,但其实直接在html上放link和script更加方便直白一些。而且html-webpack-plugin局限性太多,如果我想在script上加attribute也是比较麻烦的事儿。所以我干脆开发一个可以允许在html上直接放link和script而且支持内联及md5的插件。
但相信我之后也会针对html-webpack-plugin再写一个内联及md5的插件,适配一直在用这个插件的人。

上图是初始化构建30个文件的用时,一共用了13秒。用了externals优化后,还有100多kb,比用纯webpack优化要大50多kb。而且,由于你用的是gulp-webpack,每次有文件改动,都必须全部重新编译一次。因此,跟react搭配建议还是不要用gulp-webpack。因为如果你使用webpack的话,即使初次启动时速度也并不快,但开发过程中,webpack会自动识别,只会重新编译有修改的文件,这大大加快了编译构建速度。
没办法,老项目改造,真的要用,乍办?我提供以下思路
(1)当非js文件改变的时候,不要去跑js打包的任务
(2)非公共的js发生改变的时候,只执行这个js的打包任务

下图是优化了之后,在开发过程中非公共文件修改后的编译速度。我的娘,纯webpack只需要100多200ms。建议还是用webpack吧。

这一点对于创业公司来说可能比较有用,它们的初期产品都需要快速上线,用一些比较成熟的UI框架会比较好。
这样,首先我们需要jquery文件,并且安装bootstrap(3.3.5) ,font-awesome(4.4.0),以及imports-loader(0.6.3)。还需要sass-loader(3.1.2)及less-loader(2.5.3)。
然后,在主要入口文件要这么引用下面的样式文件:
require('bootstrap/less/bootstrap.less');
require('font-awesome/scss/font-awesome.scss');
require('./index.scss');
在webpack.config.js的entry项目里,可以加上这个vendor:
common: ['jquery', 'bootstrap'],
在loaders里加入以下loader,将jQuery暴露到全局:
{
test: path.join(config.path.src, '/libs/jq/jquery-2.1.4.min'),
loader: 'expose?jQuery'
},
再添加以下loader,让webpack帮助复制font文件
{
test: /\.(woff|woff2|eot|ttf|svg)(\?.*$|$)/,
loader: 'url-loader?importLoaders=1&limit=1000&name=/fonts/[name].[ext]'
},
在plugins里添加ProvidePlugin,让$指向jQuery
new webpack.ProvidePlugin({
$: "jquery",
jQuery: "jquery"
}),
这样,就可以同时使用jQuery, Bootstrap和Fontawesome了。
目前有一个还没有成型的,我先放在这里,目前可以通过查看gulpfile.js和webpack.config.js文件进行学习
steamer_branch_v2。要成为boilerplate还待我花一周时间整理。

经过一个多月的奋战,webpack2的中文文档已经翻译好大部份,并且完成了核心内容“概念”和“指南”部份的校对。
这份文档比react, vue之类的文档都要庞大而且复杂。本文带你如何快速读懂这份文档。
首先是“概念”。这部份对于菜鸟或者老司机来说,都是值得一读的,由于webpack跟之前的grunt, gulp都有所不同,它是基于模块的配置型构建工具,许多理念对于前端玩家来说都是全新的,例如,什么是入口(entry),它有几种配置的方式,如何配置我们需要输出(output)的位置、文件名,加载器(loaders),和插件(plugins)是如何帮助我们编译文件和处理各种自动化任务的,webpack要打包的模块(module)到底是什么,它去哪里解析(resolve)文件等等,这里都会帮你一一解答。
在你了解了webpack的概念之后,接下来,可以看看“指南”。这里的内容都是实践经验之谈,例如前四篇文章主要是介绍怎么用webpack去初始化一个项目,并进行发布;《从v1迁移到v2》帮助你顺利从webpack1升级至webpack2。其它的文档,主要是介绍webpack一些比较精彩的特性,例如拆包、热替换等等,还有一些比较有趣的,像怎么用typescript写webpack配置,怎么用虚拟机跑webpack等等。
如果你对前两部份都了如指掌,那么恭喜你,你已经具备能力进入webpack的深水区了--更为细致的"文档"了。
点击”文档“,首先进入的是"配置",这里算是完整配置的介绍,要搭建一个更为完善的脚手架或者构建工具,需要仔细阅读这里的配置文档。
“API”主要介绍了像webpack命令行的使用、如何在Node.js中结合webpack来搭建构建工具。对比起webpack1,webpack2的命令行工具变得更为强大,而且可以对你的构建耗时进行分析。
API中另外的两部份,“加载器API”和“插件API”,可以结合“开发”部份来看,主要是帮助开发者更好地开发webpack的加载器和插件,借助webpack的能力去解决自身项目中遇到的构建问题。对比webpack1,这是一份更好的加载器和插件开发文档,因为它不仅介绍了推荐的写法,还把内部的事件、内部可调用的一些方法,都展现了出来,赋予了开发者更多的能力。
webpack2的文档,耗费了许多人大量的心血,尤其要感谢最开始启动这个翻译项目的dear-lizhihua 还有 dingyiming,webpack中文社区的几位筹办成员,还有许多贡献本项目的热心技术同仁。
如果想参与我们的翻译项目,请关注我们的官方文档翻译计划。
如果有webpack相关的技术文章,可以在awesome-webpack-cn给我们提pull request。
如果有兴趣参与社区筹办,请关注我们的harpers项目。
我们会持续关注webpack,关注前端工程化发展的方方面面。
By AlloyTeam LeeHey,
webpack-china首席打杂
于2017.2.25,一个寒冷的春夜
优化之前,并没有上报首屏时间,页面加载时间约为2.4秒。
研究认为[1],用户最满意的网页打开时间是2秒以内。作为一个相对简单的页面,我们就应该最可能将首屏时间甚至加载时间控制在2秒以内,让用户体验到最佳的页面体验。
首屏时间,英文称之为above the fold(首屏线之上)。我们以手Q群成员分布的页面作为例子。在iPhone5屏幕下,这个页面在没有往下滚动的时候,如上图。滚动到底部时,如下图。


我们所说的首屏时间,就是指用户在没有滚动时候看到的内容渲染完成并且可以交互的时间。至于加载时间,则是整个页面滚动到底部,所有内容加载完毕并可交互的时间。
在这个页面中,我们可以划分成四个部份,分别是活跃 群成员、男女比例、省市分布及年龄。我们将前三个部份归入首屏渲染时间。剩下的内容加载时间加上首屏加载时间即是页面加载时间。
另外值得一提的是,由于之前项目的开发将动画渲染时间也纳入统计,因此为了方便对比,我也将渲染时间纳入统计。实际上,如果除去动画渲染时间,首屏及加载时间会快300 - 500ms。
除非各种性能优化书籍提出的要点之外,在这篇优化之前已经做到的优化并值得简单提出来的有两点。

上图是项目旧有的加载模式,是比较通常的页面加载渲染模式。将css放在head标签内,为了避免阻塞将js放在底部。因此页面渲染完成后,还需要等待js的加载,js拉取数据以及js的渲染。 这便大大地减慢了首屏及加载时间。
从性能的角度看,将整个加载渲染模式换成下面的模式更有利于首屏的渲染,我们可以称之为首屏优先加载渲染模式。

根据上述的模型,我们可以将首屏优先模式总结为三个原则,一是首屏数据拉取逻辑置于顶部,二是首屏渲染css及js逻辑优先内联HTML,三是次屏逻辑延后处理和执行。
**原则一:**首屏数据拉取逻辑置于顶部,是为了数据能够第一时间返回,相比起将数据拉取逻辑放在外部资源会少了一个JS资源加载的往返时间。
**原则二:**首屏渲染css及js逻辑优先内联HTML,这是为了当HTML文档返回时CSS和JS能够立即执行。但要注意的是HTML文档最好不要超过14kb。这是由于,TCP协议里面有一个流控机制,被称为 slow start,也就是在连接建立过程中逐渐增加传输的分段(segments)大小[2],根据Paul Irish在他的演讲“Delivering the Goods”给出的结论是,一个Web应用最开始的 14kb 数据是最重要的[3]。
**原则三:**次屏逻辑延后处理和执行,各种数据上报最好是延时上报,这样可以减少阻塞。对于首屏的数据上报,可以先将数据存在变量里面,等上报组件report.js加载完毕后,再调用回调进行上报。
新人可能会问将这么多代码内联很不优雅,而且很麻烦呀。如果你用的构建是一个合格的构建,你大可以用构建帮你进行内联,这并不是很费时的事情(这也是为什么我将构建作为优化的第一篇章,构建给优化带来便利)。
经过优化以后,首屏时间方面,非离线包版本达到1400ms左右,离线包版本则达到850ms左右。


页面渲染完成时间方面,非离线包版本从平均2400ms左右,降至平均1600ms,性能提升33%。离线包版本从平均1350ms,降至平均970ms,性能提升28%。


[1] http://www.ruanyifeng.com/blog/2009/03/the_psychology_of_web_performance.html
[2] http://lenciel.cn/2014/11/7-principles-of-rich-web-applications/
[3] https://docs.google.com/presentation/d/1MtDBNTH1g7CZzhwlJ1raEJagA8qM3uoV7ta6i66bO2M/present?slide=id.g3eb97ca8f_1536
一毕业,我就进入鹅厂。在鹅厂经历了最顶峰的日子,也见证了鹅厂发展变慢,寻求变革。在这里有很多光环,大厂,技术牛,工资好。在外面参加各种场合的活动,作为小兵的我也时常被人捧上天。工作第3年的时候,我就开始陷入沉思。究竟这些光环,这些牛B,是鹅厂带给我的,还是我自己实实在在挣来的呢?如果我哪天离开了这里,没有这个大厂的光环,我的技术还能那么牛吗?我推动的事情还能这么顺利吗?招人还那么容易吗?
我是危机感比较强的人,希望可以挑战一下自己,跟随着一个快速发展的团队,不断打磨自己作为一个软件研发人员的工程能力和生存能力。正好19年5月份碰巧拿到一家腾讯系公司 Shopee 的 offer,有机会可以带团队。Shopee的规模没有鹅厂这么大,虽然全球也有几千人,但在深圳刚加入的时候只有几百人,但发展很迅猛,机会和挑战并存。总括来说,Shopee就是规模相对较小,但发展相当迅猛的公司,非常适合现阶段的自己,于是便希望去尝试挑战一下。
在大厂里,一切的流程,工具,系统,都已经有前人搭建好,你只需要做一口听话的螺丝钉,安心执行,等被人喂即可。但在小一点的平台,各方面都未完善,并没有人告诉你该怎么做,需要自己一步一个脚印把路给踩出来。
记得刚到 Shopee 的时候,需要将业务发布到CDN上。但当时一问之下,由于金融业务需要有特殊的合规要求,一直没有将业务发布到已有的CDN服务供应商上,而只能将业务发布到公司自己搭建的IDC上,成本比较高。在这个问题上,似乎并没有人可以帮到我,我只有选择作为喂别人的人,将这整个合规的流程给打通。搜索资料,拿出理据,说服老板,这三步很重要。
首先要搜索到市面上主要的CDN厂商的功能、性能以及合规的信息,然后在公司内网,想尽办法了解公司当前以及未来规划的架构策略,无意中发意其中一家符合要求的服务商,有一些海外的业务在试用了,我便把这些信息进行汇总后,誊写一份邮件,争取到老板的支持,把整个流程打通,为后续业务的顺利上线和更多业务接入降低成本铺好路。其实上面提到的这三步,在大公司里也适用,我们开展一个项目,达成一个目标,也需要拿出说服人的理据,来说服老板和同侪的支持。但由于大公司一切都很完善,很容易会养成惯性,自己翘起双手,什么也不管,虽然会慢点,但最后也会有人解决好前面的路障,让你可以坐享其成。但小平台不一样,可能有生存的压力,有盈利的压力,有发布新产品的压力,这个问题不解决,你们团队就可能面临丢饭碗的困境,因此选择喂饱你的战友,你的项目,养成这种意识,才能在不同环境之下都可以生存。
大平台经得起内部赛马,但小平台经不起过多的折腾。以前在鹅厂经常听老板说ROI,也就是所谓的投入产出比。但你会看到其实一起合力更实力,但旧东家还是很喜欢搞赛马——外部投了虎牙和斗鱼,内部一样还有企鹅电竞和NOW直播。大厂钱多人多,经得起消耗,但小一点的平台则不然,合力往往是解决问题的最好方式。
开发几个月后,业务就即将上线了,但对业务的监控还是没有很好的方案。这是每一个项目的技术带头人,都需要的决策,是自己搭一个,还是用别人的?经过询问之后,部门内部是有一套已经在用的Sentry,当时就答应下来,要马上接入。还有一套简单的性能上报平台,但功能还不是太完善,并且正在规划下一个版本的设计,接口可能完全不兼容,看起来不太符合当时的接入条件。在做产品上报的时候,我发现公司的数据平台,其实可以一定程度上充当这个上报的角色,经过简单的开发支持后,不仅可以将性能数据上报,经过打探,还可以做一些实时数据上报的事情。
于是我便决定下来,将我的需求整理成文档,然后花了两三周的时候,耐心地解释这个事情对业务的重要性(能让业务通过不断优化,提升性能,给用户更好地体验;有实时监控PV也可以大体监测业务是否掉量),以及对于数据平台的价值(除了上报产品数据外,还可以兼顾技术的数据,减少内部竞争者)。最终通过寻找共赢点,成功游说到数据平台对我们进行支持。这次的合作,看起来我只是一个推动者,但整个合作是由我发起,流程由我推动打通,看似是数据平台的能力在喂我,但其实是我跟数据平台打通了流程和开拓了能力和服务场景后,一起去喂其他的业务,也是对上一节讲解的呼应。
大平台钱多人多,最喜欢就是某一个领域专精的工程师,所以对某一方面非常专业,即可在大公司混上口饭上。但这样会导致知识面较窄,丧失广泛深习的能力。万一自己熟悉的技术落伍了,公司业绩不好,很容易被淘汰。比如目前鹅厂有些部门,前端再进行细分,就是将HTML和CSS单独列为重构。这样确实可以让重构的工程师专注于做体验,他们往往比同时写JS,HTML和CSS写的页面效果更好更精细。
但对于发展迅猛的业务来说,花60%的精力做到80分,可能比花90%的精力做到90分更符合ROI。并且业务多元快速发展,但人手不够,技术储备不够,便可能要求员工在切换业务的时候,也需要快速适应另一个技术栈,因此一专多长在小一点的平台里,显得难能可贵。可能并不是所有小厂都是这样要求的,但我对组内的兄弟的培养,都是这样的要求。譬如你可能写 React Native 是大神中的大神,但 React Native 需要挥快速更新的优势和分包,就需要研发一个热更新的服务,那对Node.js也需要有一些的了解,才可以研发出热更新的服务,而研发热更新的服务,就需要了解CDN技术,K8S技术,才可以将Node.js服务部署好,将React Native的Bundle存放好。在大厂里,这个流程每一小块都可以由一个人自己承担,但在我的项目组,只是由2个兄弟独力承担。他们虽然辛苦,但成长的速度远远要比在大厂快,并且由于将自己培养成一专多长的人才,经过一段时间的磨练,相信每个人都能初步具备当技术leader所需要的技术深度和广度。
来Shopee半年了,以上是我总结出来比较一些不成熟的经验,有了这些经验,在小厂生存下来不成问题,亦能跟业务一起成长,在大厂也能独当一面。是的,现在团队缺人,如果想尝试挑战自己,让自己更加独当一面,更具备国际化的视野,这里非常适合你。华人的企业跟真正站在国际的舞台,东南亚是一定要拿下的一个战场。在Shopee能够让你获得具备在国际舞台上跟欧美巨头一战的机会。即使你未必跟Shopee一起战到最后,但在这里收获的经验,一定能让你的职场路走得更远。
如果有兴趣加入我们Shopee金融前端团队,可以将简历发送至 [email protected]。
工作地址:深圳
岗位职责:
1、参与面向东南亚等地区的支付、信贷等金融产品的前端开发和交互实现,以及相关管理系统的实现;
2、负责对产品功能和性能不断优化,持续提升用户体验;
3、完善效率工具建设,提升研发效能;探索前沿技术,选择合适的新技术并运用到实际项目中。
岗位要求:
1、大学本科及以上学历,2年以上前端开发经验;
2、精通前端基础技能,熟练掌握ES Next、HTML5、CSS3新特性;
3、深入理解浏览器工作原理,熟悉各种性能优化手段;
4、熟悉主流MVVM框架和类库,了解业界最佳实践;熟悉React Native等新型混合应用框架并有实际使用经验者优先;
5、具备良好的编程能力,对常见算法有一定的了解;
6、熟悉服务端技术和至少一门后台语言, 有大型 Node.js项目开发经验者优先;
7、对PWA/WebAssembly/跨端统一方案等新技术有强烈兴趣并且有一定理解者优先。
[BG定期的新人培训]
[工位很大,横着竖着都能放下一张午休床]
[初次跟team member聚餐,被上来的盆栽惊呆了]
[team member自发地在讨论问题]
李成熙,某大型央企数字化架构师。先后在腾讯文档、腾讯云云开发、Shopee金融团队担任 Leader 和架构师。专注于性能优化、工程化和小程序服务。微博 | 知乎 | Github
做数字化转型业务已经有大半年,虽然以前在做智能表格类工具的时候,就有思考过如何通过智能表格类工具解决企业流程的问题,但远不如这大半年深更业务来得更真切。在这过程中也逐步习得了数字化转型的过程,并扫除了以前对数字化转型的一些误区,通过此文给大家分享。
数字化从字面意思看,就是要将业务都数字化,后面基于数据再开展一系列业务的降本增效提质。数据怎么来呢?那必须尽可能将业务线上化了。
初入门者看似很简单,实则深似水。从互联网公司转型过来的从业者会发现以前的经验都失效了,很多时候也难以站在一个用户的角度来审视如何线上化这个问题。譬如以前做社交产品,还能自己站在普通用户的角度,YY出不少看似说得通的需求,到了企业数字化领域,不能一头扎入业务中,多跟业务分析师、一线业务专家沟通,业务这潭深水就可以够呛一肚子水。
业务的线上化并非易事,需要遵循以下的步骤:

建立系统之间的关系,本质是建立了数据流动的链条。系统主要是承载企业的数据,将系统连接起来即是将他这些数据串联起来,产生1+1>2的价值。
作为数字化专家,比较少见可以在企业成立之初就参与数字化的建设。企业草创阶段更多是企业的负责人担当这一角色。数字化专家半路加入,往往可能是面对一系列外部采购的系统,如:存储员工信息的飞书,存储财务预算的飞书文档和财务经营数据的金蝶,存放客户资料和销售线索的纷享销客等等。如果有研发实力的企业,可能还养着一个小团队,自研搭建了一些简单的业务系统。
企业数字化的过程,就像在下一盘围棋一样,每通过外采/自研建设一个系统,就像在棋盘上下子,并且我们在下子的过程中都会寻求棋子之间的联系,比如每个系统的用户信息,都可以通过飞书获取;生产经营的信息导出成文档,基于这些文档的数据可以在飞书上做财务预算;生产系统可以基于客户资料和销售线索调整生产计划等等。这些系统只有像棋子一样联系起来,整盘棋才能盘货起来,在市场竞争中占据优势。如果所有系统都没有规划,各自为政,一盘散沙,那势必会被竞争对手吞掉。想象一下,如果每建设一个系统的员工信息都需要重新建设,那该多头疼。
至于这些系统是怎么串联起来,一般来说通过数据的导入导出、开放接口等技术手段,采用哪种基于成本考虑,在此就不作赘述。

在已有信息输入的基础上,我们建立了系统之间的联系,这些系统有的是已经存在的,有的是亟待规划落地的。良好的系统关系的梳理与建立,能够帮助企业高屋建瓴地做好后续信息化的规划,知道系统建设的优先级,毕竟数字化的资源(预算、人力)是有限的。
确认了规划,我们才好知道下一步该建设哪个系统,这时我们便进入了第二阶段,梳理标准作业流程。这一阶段,可能通过翻阅过往标准作业流程文档、与业务专家进行访谈等手段,全面地梳理清楚这些流程。有了标准作业流程,数字化专家才好去对这些流程做归类,形成系统的功能模块,并规划相应的功能模块将这些标准作业流程线上化。
系统的落地无非是通过自研或者采购。不过这个命题对于那些中小企业来说看来是无需烦恼的,采购只能是唯一划算的出路。
对于有自研能力的公司,这是个头疼的问题。即使自研能较强的互联网公司,也不可能所有的能力都由自己建设。最常见的代码仓库、发布系统等等,往往是“采购”自公司内部的研效团队。选择自研,无非是希望可以更灵活、更可控;选择采购无法是看种成本——资金成本、时间成本。基于这些考虑,公司对那些服务较为核心、战略级业务,且愿意花更多时间等待成长成熟的系统,更多倾向于自研。而那些非核心的,等太久公司会瘫痪的系统(时间成本),也不需要花大价钱(有许多同样采购的客户分摊了成本)购买的,如财税系统、办公软件,则更多倾向于采购。
自研与采购其实也并非一定要二选一。有些提供软件SAAS的厂商,也愿意将源码售卖给客户,更有甚者,越来越多的厂商会提供对自研更友好的PAAS产品。这可以看作是一个先采购后迭代自研的过程。
数字化过程中有一个常见的误区,就是只要我努力地将标准作业流程搬到线上,就可以一定能帮公司降本增效提质,能让公司发展红红火火。这里的误区其实是有两个重要的误区:

误区一: 数字化一定能公司降本增效提质,能让公司发展红红火火。再好的数字化建设也只是工具,如果使用者的意识没有跟上,可能达不到效果。比如强推系统而培训不足,那就会导致使用率不足,数据失真严重;有好的数据分析能力却没有很好使用的知识,那就无法帮公司提升做出正确决策的效率。作为数字化专家,有义务跟老板和团队沟通清楚数字化系统的能力范围,并采取相应的措施让人与系统的磨合做得更好。
误区二: 将标准作业流程搬到线上即大功告成。要达到降本增效的效果,只“搬”是远远不够的,还需要优化体验和流程。
优化体验应该是互联网人独有的优势,互联网业务中,多少工程师被设计师毒打,摁在电脑桌前一个个设计稿还原,天生自带好坏体验的滤镜。体验差相信是很多传统行业信息系统的通病,慢,卡,难用基本是一线用户想到的形容词。
如果说互联网产品体验不好用户可以逃走,那公司的系统用户是无法选择的。体验差造成的问题有很多,比如新系统推广难,老系统用户敷衍了事,造假应付导致数据失真。因此在设计产品的时候虽然我们多数侧重功能要先有,但体验也万万不能忽视。
交互体验在传统行业数字化转型中扮演着重要的角色。由于传统行业的一线人员往往对电子设备的使用水平不如IT从业人员,因此需要设计出更符合他们使用习惯的数字化产品,从而提高交互体验,降低使用难度。
以银行业为例,招行银行推出了“一网通”服务,通过简洁的界面设计、便捷的操作流程,大大提高了用户的使用体验。此外,该服务还提供了丰富的数字化工具,如在线客服、手机银行等,使得用户可以随时随地进行业务办理,提高了业务效率。
虽然体验对于互联网人而言驾轻就熟,但流程确实门外汉。往往在跟业务专家梳理和讨教流程的时候,惮于提出质疑和优化,这就损失了一个大好机会进行流程调整优化。
一个业务流程,线下和线上的操作可能大相径庭。以物业行业为例,一个巡逻的检查任务,以前只需要到每个巡逻点通过纸质签到即可,换成线上后,可能是扫码也可能是NFC近场检测,整个流程都会被颠覆、重塑。因此全新的流程理应跟业务专家、一线的代码员工沟通确认清楚再落地,那样对后续的推广都更为便利,反对的声音也自然更少。
细心的你可能还会发现,这里的(标准)被括弧括起来了,这表示流程的标准化是非常重要的,尤其对于上了规模的公司,如果同一性质的业务单元同一个作业流程完全不同,那将流程统一为一套标准就已经是生产效率的极大提升。但标准又不是必须的,如果公司的规模小,那标准化的工作可能并不是必须的,只针对流程做优化也是足够的,毕竟做流程的统一本身就非常费劲,而且在公司规模小、起步早期,过早统一标准也有可能束缚了业务单元自身的想象力。
那应该以什么样的标准来说明流程被优化了呢?目前主要是有两个,一个是能节省多少工时,另一个可以用最近比较流行的是否做到无纸化,前者是大部份老板都关注的可以节约的成本,后者除了成本的节约也可以更体验公司的社会责任与彰显社会形象,突显公司对节能减排方面的贡献。

如果说前两步的路径还尚算明确、既定,那智能化在大多数企业中还是在探索进行时。关于智能化我想到了个生动的形容:在智能化之前,信息系统是工具人士兵,使用者得思考、得指挥他们执行;在智能化之后,这些系统纷纷跃升为军师,可以给使用者出谋划策。
智能化的根基是数据。如果我们的终极目标是智能化,那么我们需要在智能化之前就要收集充分且质量高的数据。收集充分,首先种类要是充分的,人员数据、销售数据、库存数据、生产数据等等,一切与业务相关的数据都可以收集。其次是对象要充分,一切可以被智能化所斌能的都可以收集数据,人员、设备、流程均可进行收集。质量高,可以通过标准化管理,建立数据质量控制体系,确保数据的准确性、完整性和一致性,需要的时候可以对数据进行校验和清洗,确保数据的准确性。
那收集的数据如何存放呢?一般而言,我们需要建立数据中台,整合公司各部门的数据源,实现数据的互联互通,减少重复工作,提高数据共享和利用效率。数据中台除了存储,还可以提供加工、计算等能力,给予业务系统更好的数据能力支撑。
当数据达到充分、标准、高质量的状态,数据便可以在以下这些场景给业务赋能:
综上所述,智能化需要数据作为基础,在数据之上构建智能化能力,并可以在不同的场景给业务提供数据决策、个性化服务、自动化生产、智能化调度与优化等能力。只有这样,才能让智能化真正成为企业发展的助推器。
相信这篇文章能给初入数字化深水区的互联网人有比较清晰的实操脉络,也能避开不少坑。后续也会陆续出一系列关于数字化转型的关于产品思考、技术设计的系列文章,敬请期待!
差不多2年前,由于业务需要,了解各种各样不同的跨域方式。但由于各种方式千奇百怪,我觉得有必要将各种方法封装起来,方便使用,弄了个简单的跨域使用库,里面包含各种跨域的使用函数,都存放在steamer-cross v1.0分支里。但2年过后,IE8以下的浏览器已经逐渐淡出市场,基本上跨域的方案可以由postMessage一统天下,于是在MessengerJS启发下,自己写了一个steamer-cross v2.0版本,更灵活的用法,且兼顾父子窗口之间互相传递数据。
v1.0版本可能有bug,仅供学习参考,v2.0已写测试样例,可以test文件夹中看到,文档不清楚的地方,也可以参考test/index.html的写法。
本文主不会详细述说各种方法的具体实现,具体的办法可以点击后文参考资料里面的三篇文章。本文只会提及实现过程中的一些坑,以及框架的实现办法。具体的实现方法,可以参考steamer-cross v1.0版本中的文件,各种办法的实现,可以看对应文件夹里面的文件。
这是最直观的办法,只需要一个页面,在页面内包含一个指向数据页面的script tag,然后在src后面多加一个回调函数即可以获取数据。
这个办法前后端都涉及,因此前端的同学需要后端的配合。其实质只是一个ajax,可以接收除了post和get之后的其它服务器请求例如put。后端需要修改的是.htaccess文件。加入以下一句
Header set Access-Control-Allow-Origin *
符号*代表接收任意的HTTP请求,你也可以通过修改,限制接受请求的域名或者IP地址。
另外一个隐藏坑是,ie10以下的浏览器是不支持的。值得注意的是,ie8和ie9是通过XDomainRequest来进行CORS通信的。XDomainRequest同样支持get和post方法。对象详细内容请见参考资料。
XDomainRequest的另一个坑是,当发送POST请求的时候,无法设置Header,如
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlencoded");
这可能导致后台没法辨认POST数据。如果是PHP的话,后台需要特殊的处理,例如
if(isset($HTTP_RAW_POST_DATA))
{
parse_str($HTTP_RAW_POST_DATA, $output);
echo json_encode($output);
}
CORS支持情况:Chrome 4 , Firefox 3.5 , IE 8~9(XDomainRequest), IE 10+ , Opera 12 , Safari
这个办法坑比较多,网上的办法会有些问题。这个办法需要三个页面,分别是主调用页(index.html), 数据页(data.html),和代理页(proxy.html)。实质的结构是,index.html里有一个iframe指向data.html,而data.html里又有一个iframe指向proxy.html。要注意的是,index.html和proxy.html主域和子域都相同,只有data.html是异域,因此当data.html生成数据时,将数据放在proxy.html链接的hash(#)后面,然后再由proxy.html里的代码通过parent.parent这样的调用,将数据放到proxy.html的祖父index.html的链接上面。
大多数教程都是停留在这一步。这是不够的,还需要在index.html里面设置一个setInterval去监听index.html中#的变化,进而获取数据。据说有些高端浏览器里面可以直接用hashchange来监听,但低端的话最好还是用setInterval。因此框架里面用setInterval实现。
由于window.name在iframe的src的变化时不会改变,所以这个办法也可以用于跨域。这个方式虽然也需要跟location.hash也需要三个页面,但proxy.html的作用非常次要。由于data.html能够直接对window.name写值,因此写值完毕后,只需要将src改成与index.html主域和子域一致的页面,就可以让index.html直接调用了。也有不需要proxy页面的写法,将iframe的src写成"about:blank;"就可以了。
这个办法对于主调用页(index.html)和数据页(data.html)而言是双向的,即两个页面都可以得到对方的数据(主要是DOM元素)。实质就是index.html包含一个指向data.html的iframe,然后在data.html中改变document.domain,使之和index.html的document.domain是一样的,这样就可以使两个页面互相调用对方的数据。唯一的缺点是只能应用于子域不同,但主域相同的两个页面。
网上大部份教程都只教从index.html传数据到data.html。其实data.html也可以发数据到index.html。实现方法一样,只要在data.html里面发送的地址跟index.html的地址一样就可以了。否则浏览器会报错。这是比较优秀的一个办法,缺点是旧式浏览器并不支持。
这是ie6和ie7的一个安全bug。目前似乎还没有补丁打上,所以主页面和iframe页面之间可以自由调用。
上次写总结文章,是来 Shopee 刚好半年后,那时刚刚适应从个人贡献者到技术架构师和管理者的身份转变,有一些感悟与心得,拿出来与大家分享。
又一年过去了,来 Shopee 已经一年半,团队从刚开始时的 4 个人,到现在 18 人,公司股价,也从当初的 20 美金,到 180 美金。很有幸,公司在进步,我也在进步。
今天主要想分享三个作为前端,可能经历的瓶颈,然后讲讲我为了突破这些瓶颈,所做的一些思考与努力。这三个突破,分别是
其实这个可以从架构能力与管理能力两个层面讲。咱们先来讲一下架构能力。
所谓架构能力,简单地说就是将不同的模块、组件、系统组装起来,联动发挥作用,解决业务或技术需求的一个过程,网上可能有更详尽的解释,大家可以自行去了解。开发者在个人贡献者阶段,更多只是接受架构师指派的任务,完成自己一个小模块的设计与代码。而在架构师的阶段,要担负起的责任与工作则更多,而且既要兼顾全局,有时也要 Review 细节的落实,有时候是又当建筑设计师,又当工地监工。
作为架构师,首先要对需求的把握非常清晰,一个是需求要落实的功能点,另一个是要考虑一些特性,譬如性能,未来的扩展性等等。以最近我们计划要做的一个产品的官网为例,这个官网比较核心的特性,一个是发布新闻、一些推广活动还有常见问答,另一个是可以提供这些内容的相关搜索,还有对个别商家做一些排行榜。
由于后台的人力不足,我们是计划由前端完成大部份的前端与后台开发工作,这里就需要由一位既懂前端,又懂后台的架构师去设计把关这里的架构(当然分开架构也可以)。这里你可能会有疑问,为什么前端的架构师,有能力在这个需求里,对前后台做架构设计呢?前端的同事是何德何能可以承担这里的前后台开发呢?这里就涉及到技术管理的梯队建设与才能储备,咱们讲管理的时候再详聊。
基于该需求的特性,我们在做设计之前,还需要收集一下这个站点未来可能的访问量(数据),这些数据对我们的技术选型非常关键!没错,我们点出了架构第一个重要的环节,技术选型。据了解,该站点每天访问量,每秒的并发都不大,基本不需要上到一些应对高并发的手段。另外,由于要做内容的全文搜索,如果通过数据库的全文检索,尽管使用量不大,但随着内容越来越多(运营人员更新内容的频率还是很高的),查询性能会越来越慢。而且我们的数据库暂时跟一些核心交易数据放在同一个数据库集群里,这种耗时操作可能会加大对数据库集群的压力,因此我们可能需要用到ElasticSearch帮我们做切词与搜索。而对商家数据做排行榜,这个由于涉及到核心数据,我计划是让后台的微服务出一个 API,再由咱们 Node.js(由于是前端来实现后台能力,基于熟悉度的考量,用Node.js对于前端来说,开发与维护都相当方便) 服务层去调用。
在技术选型的基础上,架构师平时积累的一些经验、方法论、指标关注面,在架构设计中,也起到比较重要的作用。这里以团队做的热更新服务、配置中心、运营搭建页面这几个平台为例。刚组建团队的时候,我们亟需热更新平台来给React Native提供动态更新的能力。这里当时是采用了MySQL + Redis + Node.js + Serverless Function(做代码差分)的架构。

有了热更新服务的经验,后面在做配置中心和运营搭建页面的时候,也从中吸取了经验,用了类似的架构做数据的存储与缓存。但随着业务的发展,我们发现为了让系统的可用性更高、性能更好,在一些场景里,对数据量比较大的读取,经常会将数据放到内存里(Redis 读取大数据也会有瓶颈);另外在做差分的时候,为了保证准确性,设计了一个任务队列,保证任务不会被重复运行,也安排了一些失败重试、人工处理等的机制。在设计任务队列的时候,我们有考虑过引入 Kafka 这类中间件,但实质上用MySQL也能满足到诉求,那考虑到可移植性,因此咱们直接就用MySQL顶上。上面讲的这些例子,都是在业务发展过程中,架构的演进,并且在这种迭代的过程中,自己的架构经验与方法论也不断丰富,日后遇到类似的问题,就像砌积木那样子,搬出曾经用过、思考过、验证过的种种方案,构建成心目中的模样。你可能会说,架构师的工作难度蛮大的,时刻会遇到自己无知的领域,比如自己之前没有用过的一些中间件,在真正面临需求的时候,怎么会想得到?这里感觉并没有捷径,只有在日常工作中不断涉猎,打开自己的眼界,才能在不断变化的需求世界里更为从容。
小结一下,成为架构师需要做到的事情:
技术管理这个话题,可能讲几天几夜也讲不完,这里我只摘取我认为最为重要与关键的一些做法与理念。在理念上,我认为要让大家高效工作、快乐工作,在实施上,要想尽办法给团队、给成员赋能。
从业界的趋势来看,许多业务、技术领域也已经走到了深水区、国际比较前沿的阶段,不是简单的拼人力、拼时间就可以将事情做对、做漂亮的,让大家抱着快乐的心情,发挥自己的创造力地去做事情,比让大家拼尽一切时间,还时不时在工位摸鱼,更能可能将事情做好。毕竟我们是将要在国际舞台上跟巨头拼刺刀的公司,在找对方向后,跟时间赛跑是没问题的,但在找对方向之前盲目地虚耗大家的精力与创造力,可能会引发一将无能,累死三军的局面。
高效工作,可以从个人与团队两个角度进行赋能。
个人层面上,本质就是希望个人的能力不断提升,大家能够找到自己发展的目标,技能上做到一专多长,并且最终达成为一位自带“体系”的技术人。譬如今年我们团队来了一位 React Native 的大牛,自己的曾经的创业项目也是整体用 React Native 搭建 iOS和 Android 的 APP。但 React Native,有一个很重要的特性就是热更新,在他之前的项目里还没用到过,更别说自研了。来我们团队后,有契机让他参与热更新项目的研发,并且也让他多了解客户端实现这套体系的一些基本的逻辑。后续如果公司有新的业务有需要到 React Native,那这位同事就可以作为自带“体系”的架构师,去帮忙搭建业务的架构,促进业务的发展。

团队层面上,做好模块划分、流程优化、技术规划与梯队建设。
所谓模块划分,就是大家在相对稳定的模块中工作,当你比较熟悉业务逻辑的话,工作都相对容易。当然对相似工作内容产生倦怠人皆有之,这个又是可以开另一个专题阐述了。早期我在这里也踩过一些坑,也是由于团队早期的业务比较紧,尽管同事还是会尽量做他们熟悉的模块,奈何不同的版本,不同模块的业务压力大小不尽相同,会经常抽调同事去负责全新的模块,这样其实对工作的效率与质量都是不利的,花的时间长,产生的 BUG 也多。所以后续也尽量让人员相对更加固定,即使后续某个模块非常忙,也尽量由负责该模块的同事主导业务开发的工作,支援的同事需要在良好的指引下(文档一定要完备)开展工作。
流程优化,即使减少工作中的流程对研发人员带来的桎梏。工作流程有许多,创建新项目的流程,如Git 工作流、JIRA 工作单管理流程等等。如何优化流程我认为主要是识别反人性的流程,然后用工具优化之。这里以团队中的 JIRA 流程优化为例,在 Shopee,研发团队是用 JIRA 做研发流程的管理的,大家都会在 JIRA 上面记录工作量以及扭转状态。团队刚开始的时候人比较少,谁忙谁闲一目了然,但随着团队人员不断增加,单纯通过肉眼、心算去看看大家的忙闲程度,分配工作就变得极具挑战性了,在没有工作的帮助下,管理半径就会限制在 5 - 8 个人左右,而且为了分配工作会把自己忙死——要做大量的手动统计工作。于是为了提供管理的效率,我决定写了一个脚本,帮我统计 JIRA 的开放 API,将团队内成员的工作量,全部都拉下来放到 Excel 里被自动将工作量总量统计出来。这样分配工作,只需要跑一个脚本,就可以轻松统计出每个人的已经排的工作量。当然,如果能统计出甘特图是最完美的,但受限于个别数据团队没有要求填(比如工作开始时间),因此就无法画出来。

除此以外,由于项目经理一些研发统计的需要,对每个同事建 JIRA 单的要求、填字段的数量都越来越多。将心比己,即使是我本人作为 member,都可能会疏忽未能填写完成准确。这些措施对管理上可能会更加方便,但对每个研发来说都会增加负担与困扰。于是我们也计划做一些工具与平台,一方面方便管理者做统计,另一方面也减少研发人员在一些行政、流程上的事情浪费过多的时间。
技术规划,主要就是引领整个团队的技术方向,并努力将之落地,这个是技术管理者体现价值的非常重要的环节。因为模块划分、流程优化,有做导师带过小项目之后,都能得心应手,但技术规划,怎么顺应着业务的发展变化,提前做一些技术的储备与布局,怎么将团队的技术水平带到业界一流水平,这个是当上技术管理者之后才能得到的体会。
所谓的规划,不能是单点的突破,而是需要多点,并且点连成线面;不能只着重于一个个工具与平台的建设,而更要关注这些工具与平台如何有机地结合在一起,协同发挥作用,形成体系。当然,也需要这些技术与时俱进,在技术的规划前路上,也逐步识别并摘除一些技术债务。



梯队建设也是我认为非常重要的一环。能否规划与组建你的团队,是技术管理者与架构师非常重要的区别之一。梯队建设为什么重要,那是因为良好的梯队建设,一方面能让你的团队人员更稳固,毕竟大家都有成长的诉求,无论是当技术管理还是架构师,都或多或少需要带人完成更具挑战性的项目,单打独斗能成事者寥寥无几。今年年中的时候,大批校招生准备进场。当时分析自己的团队,有 5 - 6 个高级或者准高级工程师了,这些高级的工程师工作经验都比较丰富了,但一直没有带人的机会,同时也由于业务比较繁忙,于是我就趁机会要了足够数量的毕业生,让他们带带人。我是希望通过手把手带人,可以更好地激发他们的责任心,也可以让毕业生跟着他们去做一些技术规划里的项目,让这些高级工程师也多锻炼架构与管理能力。虽然早期难免会有阵痛,比如毕业生对流程不熟悉,研发质量可能会有下降,但经过三个月的试用期后,毕业生的工作都步入正规,有充足人力的情况下,许多的技术规划落地都比较顺利。
其次,梯队建设的好坏,能决定你之前的技术规划能否顺利落地。除了前面提到的不同职级与经验的人的比例要均衡,还需要在各个技术方向有技术储备,最好是有技术领头人,甚至能有技术小组,毕竟孤身一人去探索某个技术方案还是挺孤独寂寞的,也没有人一起做技术讨论。另外有这样的一个技术小组,也可以有备份人。在团队中,因应着定下的技术规划,基本上每个体系的建设都会成立一个技术小组,这些人可能在公司组织上并不是同一个组,但只要他们对这块感兴趣,或者在这块有建树,就可以参与到这块的建设中。比如在 Web 体系建设小组里面,有三位同事,这块需要负责的项目比较多,包括 Web 发布的自动化、精细化,Web 组件建设,Figma 组件生成自动化,同构渲染研究等都归属到这里,每个人都有自己主攻的方向,但每一个时期侧重点可能有不同,有可能会有有几个人共同参与到某一个项目的建设当中,快速将该项目先做成。

高效工作 如果落实得好,快乐工作其实也就达成一半以上了,因为高效工作可以让工作效率提高,加班减少,也能让大家有成长的快感,再加之以打造良好的技术氛围(技术分享、外出参与技术会议、内部开放的技术讨论),相信员工的工作满意度会相对较高。
小结一下,成为好的管理者,需要通过赋能做到:
高效工作
快乐工作
随着职级的提升,要跟跨团队的技术合作、甚至带跨技术的项目、同时带其它的技术组的情况会越来越多。如果倒推几年,前端要进入后台、客户端的领域,难度还是比较大的,这个是整个业界都存在的问题。但随着一些重要的技术的诞生与成熟,比如 Node.js,React Native, Electron 进入前端人的视野,前端有更多的机会可以参与到这些。所以从大局上、宏观上讲,我们要多支持这些技术的成长,无论是给这些开源项目贡献源码、布道、贡献最佳实践,最终都能让我们自己受益。所以我在团队里也比较鼓励大家贡献开源项目,或者通过造开源项目的周边小轮子练练手。
但从自己团队的业务与技术发展,这个微观的层面来看更着重看的是自己团队在某块跨领域技术的知识储备、人才储备与项目历练。举个例子,如果前端要能够承接个别的中后台业务,必需要团队里面的 Node.js 基建设施比较完善,并且要有相关的人才能够 Hold 得住,否则哪里报了 Node.js 的错误,哪里产生的性能瓶颈,哪里出现疑难杂症,没有人有思路解决,这就很可能会阻塞到业务的进展。
我个人的建议是,首先要让基建设施完备,譬如将 Node.js 部署到 K8S 的设施搭建起来,包括进程管理器、上报埋点的工具库、Node.js 的基础 Docker 镜像等等。基建完备后,我们先用一些技术项目练手,尤其是在许多跟客户端一起合作的项目里,由于有前端能写 Node.js 的缘故,一些大前端的公共平台,比如热更新发布平台、配置中心等的一些项目,都可以由前端来做主要推手,通过这些项目来积累一些高并发、高可用的后台开发与运维经验,从而获取后台开发的经验。如果不想如此的激进,也可以从一些偏管理后台的项目开始,这些老板们是比较放心让 Node.js 来实现的。当拥有了基础的 Node.js 开发与运维经验后,可以开始在业务中做一些尝试,尤其是那些中台的接口转发项目、或者是同构渲染提升性能的项目。只有跨越出来,能做一些用户侧业务的 Node.js 服务,这样才能更进一步通过解决用户侧的服务挑战来提升团队的实力。我们当时是选择了一个非常适合前端 Node.js 来实现的服务,就是用户购买商品后的订单详情页。这个页面,产品要求的动态化非常高,不同产品的字段不尽相同,而且可能时不时调整顺序或者添加字段。而且后台提供的定的接口,又不太好表现一些字段的分类、字段的排序、字段展示的格式等。于是我们就提出,用 Node.js 做一个中间服务,将这些商品的详情字段全部做成可配置化,并在 React Native 侧做了一个基础的展示引擎,基于后台返回的字段动态渲染。


有了不少的技术项目还有这次业务项目的实践成功,大大增强了前端的信心,等到后续后台由于人力原因无法投入太多精力到产品官网的开发,前端就顺其自然地接受了这个挑战,会去做全站的前后台开发任务,在业务中更深层次地使用 Node.js。
做一下小结,想突破目前单一技术的管理,如果以中后台为例的话,可以尝试走以下的步骤:
前端,乃至大部份的研发,被作为工具人,长久只是需求的实现机器,能真正突破从做技术到带业务的人少之又少。这个突破有两个层次,一个是成为这个业务模块的整体技术负责人,另一个层次是直接成为这个业务的总负责人。遗憾的是,本人都未能达到这些层次,目前只是粗略地谈一下我自己做的一些尝试,而且主要是第一个层次的尝试。
一个研发是不是关注业务,其实只要你问一下他,是否知道这个产品面向的用户,用户规模、活跃用户有多少,GMV 有多少等等的一些关键业务数据,如果他能答出一些,而不是完全不知道,那证明这位研发还是比较关心业务的。有这样良好的关心业务数据的习惯,相信更进一步,让这位研发不仅只了解自己模块的业务逻辑,可以将后台、客户端跟某个模块相关的业务逻辑都了解一遍还是比较容易的。并且老板、产品、测试人员来问的时候,都能比较清楚地做出解释,那这位研发熟悉业务的名声就已经远播了。
但是,有的时候尽管你可能对这些业务有所了解,但由于在前端这个岗位上,天然可能就比后台有一定的劣势——毕竟业务的最主要的流程是在后台实施的。这些对于金融、电商的行业尤其如此,可能相比之下,社交、内容、工具等平台,前端的话语权可能反倒更大一些。加上如果你做了大量的技术项目,尽管你对业务其实也了解,也可能会给别人留下过于关注技术,而忽略业务的印象——毕竟每次项目会上,需要解决的后台的问题,比前端和客户端高出一大截,我们也不太好去插话。因此,在重视技术建设的同时,也可以多对业务的流程提出一些优化,比如后续我就吸取一些经验教训,希望在一些商品上新的流程上做一些简化,减少每次上新投入的人力,使整个项目组的人力规划可以向其它更重要的事情上倾斜。
此外,我们也可以尝试针对业务当下或者未来的诉求做一些产品的孵化。比如作为金融电商平台,比较容易想到的就是一些常规运营页面的搭建工具,毕竟前端在产品做用户增长这块,还是可以发挥比较大的作用。于是断断续续,我们团队就搭建了一个可以跨多个 APP 运行的运营页面搭建工具。在做这些项目的孵化过程中,并不是一帆风顺的,比方说这些产品要从策略、设计到落地都需要团队的人从头做起,推动运营人员的使用也并非一帆风顺,也成就也有挫败。但经过这些历练之后,让自己对业务、产品的把握也会有另一番的见解。虽然目前的这些努力未有很明显的成效,但团队人员在产品设计、打磨、落地方面的能力得到了储备,正所谓养兵千日,用在一时,相信未来可能将会有这些产品、人员发挥的地方。

小结一下,从带技术到带业务的一些努力:
来 Shopee 一年半,变化翻天覆地,从来不敢想象自己会有机会去突破这些职业的界限,或者摸到这些职业界限的天花板。希望这些粗浅的经验能够对后来都有些启发,也希望一些同行、前辈可以多多指点,不吝赐教。同时感谢我团队的同事与老板,这一年多以来对我不遗余力的支持!
直出其实并不算是新概念。只不过在Web2.0单页应用流行的年代,一直被人遗忘在身后。其实在Web1.0时代,前后端没有分离的时候,程序员直接用后台程序渲染出模板,这便是直出。而到了今天,当Node大大提高了前端开发者的能力时,前端人员也可以做一些后台的事情,通过Node来实现模板的渲染和数据的吞吐。
由AlloyTeam开发的,建基于Koa之上的玄武直出框架。该框架的优势在于:
(1) 安装与本地开发简单:只需要几行命令安装和几行代码部署本地开发环境。
(2) 完善的文档和规范的开发实践:经过数个项目的试验,文档已经日臻完善,并总结出一套可供大部份业务使用的实践方案。
(3) 部署测试和发布成熟:目前已有兴趣部落、群搜索等数个项目成功发布。
(4) 较好的容错功能: 通过公司的L5负载均衡服务,完美兼容直出与非直出版本,即使直出挂了,也能顺利走非直出版本,让前端可以安心睡大觉。
玄武框架提供一个封装了开源request库的一个同名request框架,并且提供异步拉取数据方案。文档代码如下:
function(req, res, next) {
var hander = function(error,response,body){
var data = JSON.parse(body);
res.body = body;
next();
};
ajax.request(opt,hander);
}
也有不少人认为写异步比较不优雅,因此会使用promise, bluebird等第三方库。我在实践手Q群成员分布的时候,经过对generator的学习之后,探索出一个简易的同步写法,这种写法简单易懂,而且大大减少了对第三方库的依赖。如下面代码:
function*(req, res) {
var opt = {
url : 'xxxxxxxxx',
method: 'POST',
form: {
bkn: getBkn(skey),
gc: gc,
},
headers : {
'host' : 'web.qun.qq.com',
'Referer' : 'web.qun.qq.com'
}
};
function requestSync(opt) {
return function(callback) {
ajax.request(opt, function(error, response, body) {
callback(error, response);
});
}
}
var content = yield requestSync(opt);
}
只要像上面代码一样进行简单的封装,就可以写出同步的写法。具体代码的分析和理解可以看文章的附录一部份。
除了数据拉取,模板如何渲染也是直出的重要环节。下面有三种方案提供:
(1) 在服务器中搭建一个浏览器,渲染好所有东西然后传给前台
这种方案应该是最快的办法,但由于需要在服务器中搭建浏览器进行渲染,因此会消耗服务器大量性能,因此并不可取。
(2) 通过玄武写主要逻辑,然后吐给前台再渲染
这种方案的性能也是非常好的,但由于要将原本代码的部份逻辑放到服务器写,因此需要对后台和前台都做容错,会耗费一些开发时间。
(3)只给前台吐出数据,然后完全由前台渲染
这种方案的改动小,而且容错比较容易实现。例如,我在手Q群成员分布中,在html里加入如下代码:
<script>
{{'xw-data'}}
</script>
然后在直出入口文件做替换:
this.body = tpl.init().replace('{{'xw-data'}}', 'var xw_data = ' + body + ';');
然后在js文件里对xw_data做判断,如果有数据,直接去渲染,如果没数据,走旧有逻辑。
BigPipe是一个重新设计的动态网页服务体系。 将页面分解成一个个Pagelet,然后通过Web 服务器和浏览器之间建立管道,进行分段输出 (减少请求数)。BigPipe不需要改变现有的网络浏览器或服务器(百度百科)。

BigPipe实际上也可以算作出直的一种特殊方案,最先是由Facebook提出(2010 Velocity Conference),在国内由新浪微博最先进行大规模实践(2011 Velocity Conference)。
传统的渲染方式,用户所感知的页面延时如下图,从页面生成,网络延迟到页面渲染都是串行进行的。

而BigPipe使得整个用户感知流程变成并行,使页面首屏渲染时间更快。如下图:

BigPipe的渲染方式,首先是在页面头部添加一个全局的加载Pagelet的onPageletArrive函数,然后渲染出HTML各Pagelet的占位标签,等各标签的数据到达的时候,依次调用全局onPageletArrive加载函数进行渲染。如以下代码。
<html>
<head>
<!-- 全局 onPageletArrive function -->
<script>
window.onPageletArrive = function(obj){
// load css
// load js
// load html
};
</script>
</head>
<body>
<!-- Pagelet 占位 -->
<div id="pagelet1"></div>
<div id="pagelet2"></div>
….
<div id="pageletN"></div>
<!-- 后台返回的js代码,用于直接吐出执行全局onPageletArrive -->
<script>
onPageletArrive({
"id" : "pagelet1",
"css" : [ <list of css resources>],
"js" : [ <list of JavaScript resources>] "content" : <html>
"onload": [JavaScript init code]
});
</script>
…
<script>
// onPageletArrive for pageletN
</script>
</body>
</html>
从开发模式来说,BigPipe这种的写法比较适合组件化、模块化的前端开发模式。从网站规模来说,对于大型网站的优化效果会比较明显,毕竟分步吐出内容也是会有延时存在的,对于小型网站来说,有可能直接吐出所有内容会比分步吐出更快。
了解完基本的原理之后,我们来谈谈BigPipe在手Q群成员分布项目中用Node的具体实践。
(1) 对页面分模块并设计好占位符
首先要对页面尽可能地划分好不同的模块,亦即Pagelet。读过上一篇优化文章的人都记得,手Q群成员分布可以分为活跃群成员、男女比例、省市分布、年龄四大模块,如下面图片红框标框好的部份。



相应地,我们得出如下的占位符。
<section>
<!-- 活跃群成员 -->
<div id="active"></div>
<!-- 男女比例 -->
<div id="gender"></div>
<!-- 成员省份 -->
<div id="area"></div>
<!-- age -->
<div id="age"></div>
</section>
(2) 设计每个Pagelet需要渲染的内容,并对前后台的代码进行分工
根据Facebook的方式,每个Pagelet都有自己独立需要加载的样式,JS文件,模板文件。这对于小型项目来说,大可不必。如手Q群成员分布项目中,我已直接将样式内联,模板文件也存在变量当中。因此,前端全局渲染函数主要负责将内容嵌入占位符当中。因此在head标签内,我设定了一个componentRender的函数,用于负责将后台吐出的内容嵌入占位符。代码大概如下:
function componentRender(target, tplString) {
// targetObj.innerHTML = tplString
}
而后台的代码,则在拼好模板字符串之后,分步吐出内容,代码大体如下:
this.push("<script>componentRender(\"#active\," + tplString )</script>");
this.push("<script>componentRender(\"#gender\," + tplString )</script>");
this.push("<script>componentRender(\"#area\," + tplString )</script>");
this.push("<script>componentRender(\"#age\," + tplString )</script>");
对于后台的代码,尤其是使用Koa框架,可能会无从入手,大家可以参考Github上的BigPipe Example。大体的写法和解释如下:
// BigPipe需要的模块,用于flush内容到页面
var Readable = require('stream').Readable;
// 生成分片段页面内容函数
var createChunkedView = function(end) {
function noop() {};
typeof end === 'function' || (end = noop);
util.inherits(View, Readable);
function View(ctx) {
Readable.call(this);
ctx.type = 'text/html; charset=utf-8';
ctx.body = this;
this.app = ctx;
}
View.prototype._read = noop;
View.prototype.end = end;
return View;
};
function* end() {
// 页面主逻辑,这里也要以用各种yeild
// this.push(xxx)
// this.push(xxx)
// this.push(null) 最末尾请push空内容,通知框架内容flush结束
}
module.exports = function*() {
// 原本的koa view函数
const View = createChunkedView(end);
yield * new View(this).end();
}
首屏时间方面,直出方案比纯前端的方案有大概400ms的优化,提升约28.6%的性能。而BigPipe对比普通直出的优化有大约200ms,提升约16.7%。虽然实践的项目规模较小,模块数量也较少,但BigPipe的优化成果也算是比较令人满意的。

页面渲染完成时间方面,纯前端的的优化对比优化前有了质的飞跃(在前一篇文章也提到),性能提升33%。普通直出对纯前端的优化提升约200ms, 性能提升约13.3%。而BigPipe优化跟普通直出优化则没有非常明显的优劣,只快了几十毫秒。

纯前端的优化对其实也已经为项目带来比较好的提升。直出对于首屏的渲染也能带来不错的提升。另外,由于玄武框架只是一个简单的页面接入层,并不能直接对数据库进行操作,因此框架方面可以做的事情还有更多。
系列文章里面所介绍到的纯前端优化方案、直出方案,都属于过去数年的方案。随着直出框架、方案及优秀实践的不断完善,相信应该要成为每个项目的标配。
文中略略提到的离线包方案,属于腾讯手Q方面独立研发出来的针对手机端优化的方案,对于其它非腾讯业务也有一定借鉴的意义,具体要参考我导师2014年在InfoQ上有关离线包系统的讲解(链接)。至于未来数年,我们可以将希望寄放在websocket,当然还有即将普及的HTTP2.0身上。
数据拉取同步方案:
function*(req, res) {
var opt = {
url : 'xxxxxxxxx',
method: 'POST',
form: {
bkn: getBkn(skey),
gc: gc,
},
headers : {
'host' : 'web.qun.qq.com',
'Referer' : 'web.qun.qq.com'
}
};
function requestSync(opt) {
return function(callback) {
ajax.request(opt, function(error, response, body) {
callback(error, response);
});
}
}
var content = yield requestSync(opt);
}
如何理解?
简单的回调用法:
function* Hello() {
yield 1;
yield 2;
}
var hello = Hello() // hello 是一个generator
var a = hello.next() // a: Object {value: 1, done: false}
var b = hello.next() // b: Object {value: 2, done: false}
var c = hello.next() // c: Object {value: undefined, done: true}
在next中传入参数:
function* gen() {
while(true) {
var value = yield null;
console.log(value);
}
}
var g = gen();
g.next(1);
// "{ value: null, done: false }"
g.next(2);
// "{ value: null, done: false }"
// 2
// 在该示例中,调用 next 方法并传入了参数,请注意,首次调用 next 方法时没有出任何输出, 这是 因为初始状态时生成器通过yield 返回了null.
经典示例一,按顺序执行:
funciton delay(time, cb) {
setTimeout(function() {
cb && cb()
}, time)
}
delay(200, function() {
delay(1000, function() {
delay(500, function() {
console.log('finish')
})
})
})
function delay(time) {
return function(fn) {
setTimeout(function() {
fn()
}, time)
}
}
co(function* () {
yield delay(200);
yield delay(1000);
yield delay(500);
})(function() {
console.timeEnd(1) // print 1: 1702.000ms
})
function co(GenFunc) { // GenFunc → function*() { yield ……….}
return function(cb) { // function() { console.log.timeEnd(1); }
var gen = GenFunc()
next()
function next() {
if (gen.next) {
var ret = gen.next();
// {done: true/false, value=delay 返回的function}
if (ret.done) { // 如果结束就执行cb
cb && cb()
} else { // 继续next
ret.value(next)
}
}
}
}
}
经典示例二,按顺序执行并且下一个执行依赖于上一个执行的返回值:
function delay(time) {
return function(fn) {
setTimeout(function() {
fn(time) // time为回调参数
}, time)
}
}
co(function* () {
var a;
a = yield delay(200); // a: 200
a = yield delay(a + 100); // a: 300
a = yield delay(a + 100); // a: 400
return a;
})(function(data) {
console.log(data) // print 400, 最后的值被回调出来
});
function co(GenFunc) {
return function(cb) {
var gen = GenFunc();
next();
function next(args) { // 传入args
if (gen.next) {
var ret = gen.next(args) // 给next传入args
if (ret.done) {
cb && cb(args)
} else {
ret.value(next);
}
}
}
}
回到玄武直出代码:
module.exports = function*(req, res) {
}
co(function*(req, res){
// some code
function requestSync(opt) {
return function(callback) {
ajax.request(opt, function(error, response, body) {
callback(error, response);
});
}
}
var content = yield requestSync(opt);
// 在gen.next()之后,yield会返回值给content
// other code
});
参考:
http://www.alloyteam.com/2015/03/es6-generator-introduction/
http://www.alloyteam.com/2015/04/solve-callback-hell-with-generator/
http://www.html-js.com/article/Nodejs-commonly-used-modules-detailed-address-correction-in-Pyramid-Harmony-Generator-yield-ES6-CO-framework-of-learning
原文地址
本文start kit: steamer-react
PS: 要看效果得将一个QQ群组转换成家校群,可到此网址进行转换(手Q/PC都可以访问):
http://qun.qq.com/homework/。转换之后,可以通过QQ群的加号面板,或者群资料卡进入。
最近一个季度,我们都在为手Q家校群做重构优化,将原有那套问题不断的框架换掉。经过一些斟酌,决定使用react 进行重构。选择react,其实也主要是因为它具有下面的三大特性。
学习React的好处就是,学了一遍之后,能够写web, node直出,以及native,能够适应各种纷繁复杂的业务。需要轻量快捷的,直接可以用Reactjs;需要提升首屏时间的,可以结合React Server Render;需要更好的性能的,可以上React Native。
但是,这其实暗示学习的曲线非常陡峭。单单是Webpack+ React + Redux就已够一个入门者够呛,更何况还要兼顾直出和手机客户端。不是一般人能hold住所有端。
Virtual Dom(下称vd)算是React的一个重大的特色,因为Facebook宣称由于vd的帮助,React能够达到很好的性能。是的,Facebook说的没错,但只说了一半,它说漏的一半是:“除非你能正确的采用一系列优化手段”。
另一个被大家所推崇的React优势在于,它能令到你的代码组织更清晰,维护起来更容易。我们在写的时候也有同感,但那是直到我们踩了一些坑,并且渐渐熟悉React+ Redux所推崇的那套代码组织规范之后。
上面的描述不免有些先扬后抑的感觉,那是因为往往作为React的刚入门者,都会像我们初入的时候一样,对React满怀希望,指意它帮我们做好一切,但随着了解的深入,发现需要做一些额外的事情来达到我们的期待。
初学者对React可能满怀期待,觉得React可能完爆其它一切框架,甚至不切实际地认为React可能连原生的渲染都能完爆——对框架的狂热确实会出现这样的不切实际的期待。让我们来看看React的官方是怎么说的。React官方文档在Advanced Performanec这一节,这样写道:
One of the first questions people ask when considering React for a project is whether their application will be as fast and responsive as an equivalent non-React version
显然React自己也其实只是想尽量达到跟非React版本相若的性能。React在减少重复渲染方面确实是有一套独特的处理办法,那就是vd,但显示在首次渲染的时候React绝无可能超越原生的速度,或者一定能将其它的框架比下去。因此,我们在做优化的时候,可的期待的东西有:
手Q家校群功能页主要由三个页面构成,分别是列表页、布置页和详情页。列表页已经重构完成并已发布,布置页已重构完毕准备提测,详情页正在重构。与此同时我们已完成对列表页的同构直出优化,并已正在做React Native优化的铺垫。
这三个页面的重构其实覆盖了不少页面的案例,所以还是蛮有代表性的,我们会将重构之中遇到的一些经验穿插在文章里论述。
在手Q家校群重构之前,其实我们已经做了一版PC家校群。当时将native的页面全部web化,直接就采用了React比较常用的全家桶套装:
为什么我们在优化的时候主要讲手Q呢?毕竟PC的性能在大部份情况下已经很好,在PC上一些存在的问题都被PC良好的性能掩盖下去。手机的性能不如PC,因此有更多有价值的东西深挖。开发的时候我就跟同事开玩笑说:“没做过手机web优化的都真不好意思说自己做过性能优化啊“。
我在《性能优化三部曲之一——构建篇》提出,“通过构建,我们可以达成开发效率的提升,以及对项目最基本的优化”。在进行React重构优化的过程中,构建对项目的优化作用必不可少。在本文暂时不赘述,我另外开辟了一篇《webpack使用优化(react篇)》进行具体论述。

在PC端使用Redux的时候,我们都很喜欢使用Redux-Devtools来查看Redux触发的action,以及对应的数据变化。PC端使用的时候,我们习惯摆在右边。但移动端的屏幕较少,因此家校群项目使用的时候放在底部,而且由于性能问题,我们在constant里设一个debug参数,然后在chrome调试时打开,移动端非必须的时候关闭。否则,它会导致移动web的渲染比较低下。
这一部份算是重头戏吧。React作为View层的框架,已经通过vd帮助我们解决重复渲染的问题。但vd是通过看数据的前后差异去判断是否要重复渲染的,但React并没有帮助我们去做这层比较。因此我们需要使用一整套数据管理工具及对应的优化方法去达成。在这方法,我们选择了Redux。
Redux整个数据流大体可以用下图来描述:

Redux这个框架的好处在于能够统一在自己定义的reducer函数里面去进行数据处理,在View层中只需要通过事件去处触发一些action就可以改变地应的数据,这样能够使数据处理和dom渲染更好地分离,而避免手动地去设置state。
在重构的时候,我们倾向于将功能类似的数据归类到一起,并建立对应的reducer文件对数据进行处理。如下图,是手Q家校群布置页的数据结构。有些大型的SPA项目可能会将初始数据分开在不同的reducer文件里,但这里我们倾向于归到一个store文件,这样能够清晰地知道整个文件的数据结构,也符合Redux想统一管理数据的想法。然后数据的每个层级与reducer文件都是一一对应的关系。

这套React + Redux的东西在PC家校群页面上用得很欢乐, 以至于不用怎么写shouldComponentUpdate都没遇到过什么性能问题。但放到移动端上,我们在列表页重构的时候就马上遇到卡顿的问题了。
什么原因呢?是重复渲染导致的!!!!!!
说好的React vd可以减少重复渲染呢?!!!
请别忘记前提条件!!!!
你可以在每个component的render里,放一个console.log("xxx component")。然后触发一个action,在优化之前,几乎全部的component都打出这个log,表明都重复渲染了。
更正:可见后面yeatszhang同学的解释。
 (网图,引用的文章太多以致于不知道哪篇才是出处)
(网图,引用的文章太多以致于不知道哪篇才是出处)
上图是React的生命周期,还没熟悉的同学可以去熟悉一下。因为其中的shouldComponentUpdate是优化的关键。React的重复渲染优化的核心其实就是在shouldComponentUpdate里面做数据比较。在优化之前,shouldComponentUpdate是默认返回true的,这导致任何时候触发任何的数据变化都会使component重新渲染。这必然会导致资源的浪费和性能的低下——你可能会感觉比较原生的响应更慢。
这时你开始怀疑这世界——是不是Facebook在骗我。
当时遇到这个问题我的开始翻阅文档,也是在Facebook的Advanced Performance一节中找到答案:Immutablejs。这个框架已被吹了有一年多了吧,吹这些框架的人理解它的原理,但不一定实践过——因为作为一线移动端开发者,打开它的github主页看dist文件,50kb,我就已经打退堂鼓了。只是遇到了性能问题,我们才再认真地去了解一遍。
Immutable这个的意思就是不可变,Immutablejs就是一个生成数据不可变的框架。一开始你并不理解不可变有什么用。最开始的时候Immutable这种数据结构是为了解决数据锁的问题,而对于js,就可以借用来解决前后数据比较的问题——因为同时Immutablejs还提供了很好的数据比较方法——Immutable.is()。小结一下就是:
说到这里,已万事俱备了。那东风呢?我们还欠的东风就是应该在哪里写这个比较。答案就是shouldComponentUpdate。这个生命周期会传入nextProps和nextState,可以跟component当前的props和state直接比较。这个就可以参考pure-render的做法,去重写shouldComponentUpdate,在里面写数据比较的逻辑。
其中一位同事polarjiang利用Immutablejs的is方法,参考pure-render-decorator写了一个immutable-pure-render-decorator。
那具体怎么使用immutable + pure-render呢?
对于immutable,我们需要改写一下reducer functions里面的处理逻辑,一律换成Immutable的api。
至于pure-render,若是es5写法,可以用使mixin;若是es6/es7写法,需要使用decorator,在js的babel loader里面,新增plugins: [‘transform-decorators-legacy’]。其es6的写法是
@pureRender
export default class List extends Component { ... }
你可能会想到Immutable能减少无谓的重新渲染,但可能没想过会导致页面不能正确地重新渲染。目前列表页在老师进入的时候是有2个tab的,tab的切换会让列表也切换。目前手Q的列表页学习PC的列表页,两个列表共用一套dom结构(因为除了作业布置者名字之外,两个列表一模一样)。上了Immutablejs之后,当碰巧“我发布的“列表和”全部“列表开头的几个作业都是同一个人布置的时候,列表切换就不重新渲染了。
引入immutable和pureRender后,render里的JSX注意一定不要有同样的key(如两个列表,有重复的数据,此时以数据id来作为key就不太合适,应该要用数据id + 列表类型作为key),会造成不渲染新数据情况。列表页目前的处理办法是将key值换成id + listType。
 (列表页两个列表的切换)
(列表页两个列表的切换)
这样写除了保证在父元素那一层知晓数据(key值)不同需要重新渲染之外,也保证了React底层渲染知道这是两组不同的数据。在React源文件里有一个ReactChildReconciler.js主要是写children的渲染逻辑。其中的updateChildren里面有具体如何比较前后children,然后再决定是否要重新渲染。在比较的时候它调用了shouldUpdateReactComponent方法。我们看到它有对key值做比较。在两个列表中有不同的key,在数据相似的情况下,能保证两者切换的时候能重新渲染。
function shouldUpdateReactComponent(prevElement, nextElement) {
var prevEmpty = prevElement === null || prevElement === false;
var nextEmpty = nextElement === null || nextElement === false;
if (prevEmpty || nextEmpty) {
return prevEmpty === nextEmpty;
}
var prevType = typeof prevElement;
var nextType = typeof nextElement;
if (prevType === 'string' || prevType === 'number') {
return nextType === 'string' || nextType === 'number';
} else {
return nextType === 'object' && prevElement.type === nextElement.type && prevElement.key === nextElement.key;
}
}
上文也提到Immutablejs编译后的包也有50kb。对于PC端来说可能无所谓,网速足够快,但对于移动端来说压力就大了。有人写了个seamless-immutable,算是简易版的Immutablejs,只有2kb,只支持Object和Array。
但其实数据比较逻辑写起来也并不难,因此再去review代码的时候,我决定尝试自己写一个,也是这个决定让我发现了更多的奥秘。
针对React的这个数据比较的深比较deepCompare,要点有2个:
先上一下列表页的代码,如下图。这里当时是学习了PC家校群的做法,将component作为props传入。这里的<Scroll>封装的是滚动检测的逻辑,而<List>则是列表页的渲染,<Empty>是列表为空的时候展示的内容,<Loading>是列表底部加载的显示横条。

针对deepCompare的第1个要点,扁平化数据,我们很明显就能定位出其中一个问题了。例如<Empty>,我们传入了props.hw,这个props包括了两个列表的数据。但这样的结构就会是这样
props.hw = {
listMine: [
{...}, {...}, ...
],
listAll: [
{...}, {...}, ...
],
}
但如果我们提前在传入之前判断当前在哪个列表,然后传入对应列表的数量,则会像这样:
props.hw = 20;
两者比较起来,显示是后者简单得多。
针对deepCompare第2点,限制比较的条件。首先让我们想到的是比较的深度。一般而言,对于Object和Array数据,我们都需要递归去进行比较,出于性能的考虑,我们都会限制比较的深度。
除此之外,我们回顾一下上面的代码,我们将几个React component作为props传进去了,这会在shouldComponentUpdate里面显示出来。这些component的结构大概如下:

$$typeof // 类型
_owner // 父组件
_self: // 仅开发模式出现
_source: // 仅开发模式出现
_store // 仅开发模式出现
key // 组件的key属性值
props // 从传入的props
ref // 组件的ref属性值
type 本组件ReactComponent
因此,针对component的比较,有一些是可以忽略的,例如$$typeof, _store, _self, _source, _owner。type这个比较复杂,可以比较,但仅限于我们定好的比较深度。如果不做这些忽略,这个深比较将会比较消耗性能。关于这个deepCompare的代码,我放在了pure-render-deepCompare-decorator。
不过其实,将component当作props传入更为灵活,而且能够增加组件的复用性,但从上面看来,是比较消耗性能的。看了官方文档之后,我们尝试换种写法,主要就是采用<Scroll>包裹<List>的做法,然后用this.props.children在<Scroll>里面渲染,并将<Empty>, <Loading>抽出来。


本以为React可能会对children这个props有什么特殊处理,但它依然是将children当作props,传入shouldComponentUpdate,这就迫使父元素<Scroll>要去判断是否要重新渲染,进而跳到子无素<List>再去判断是否进一步进行渲染。
那<Scroll>究竟要不要去做这重判断呢?针对列表页这种情况,我们觉得可以暂时不做,由于<Scroll>包裹的元素不多,<Scroll>可以先重复渲染,然后再交由子元素<List>自己再去判断。这样我们对pure-render-deepCompare-decorator要进行一些修改,当轮到props.children判断的时候,我们要求父元素直接重新渲染,这样就能交给子元素去做下一步的处理。
如果<Scroll>包裹的只有<List>还好,如果还有像<Empty>, <Loading>甚至其它更多的子元素,那<Scroll>重新渲染会触发其它子元素去运算,判断自己是否要做重新渲染,这就造成了浪费。react的官方论坛上已经有人提出,React的将父子元素的重复渲染的决策都放在shouldComponentUpdate,可能导致了耦合Shouldcomponentupdate And Children。
此段更新于2016年6月30日
由于immutable的大小问题一直萦绕头上,久久不得散去,因此再去找寻其它的方案。后面决定尝试一下lodash.merge,并用上之前自己写的pureRender。在渲染性能上还可以接受,在仅比immutable差一点点(后面会披露具体数据),但却带来了30kb的减包。
这里归纳了一些其它性能优化的小Tips
既然将数据主要交给了Redux来管理,那就尽量使用Redux管理你的数据和状态state,除了少数情况外,别忘了shouldComponentUpdate也需要比较state。
Component的render里不动态bind方法,方法都在constructor里bind好,如果要动态传参,方法可使用闭包返回一个最终可执行函数。如:showDelBtn(item) { return (e) => {}; }。如果每次都在render里面的jsx去bind这个方法,每次都要绑定会消耗性能。
传得太多,或者层次传得太深,都会加重shouldComponentUpdate里面的数据比较负担,因此,也请慎用spread attributes(<Component {...props} />)。
这个用法是工业聚在React讨论微信群里教会的,我们可以将不怎么变动,或者不需要传入状态的component写成const element的形式,这样能加快这个element的初始渲染速度。
当项目变得更大规模与复杂的时候,我们需要设计成SPA,这时路由管理就非常重要了,这使特定url参数能够对应一个页面。

PC家校群整个设计是一个中型的SPA,当js bundle太大的时候,需要拆分成几个小的bundle,进行异步加载。这时可以用到webpack的异步加载打包功能,require。

在重构手Q家校群布置页的时候,我们有不少的浮层,列表有布置页内容主浮层、同步到多群浮层、科目管理浮层以及指定群成员浮层。这些完全可以使用react-router进行管理。但是由于当时一早使用了Immutablejs,js bundle已经比较大,我们就不打算使用react-router了。但后面仍然发现包比重构前要大一些,因此为了保证首屏时间不慢于重构前,我们希望在不用react-router的情况下进行分包,其实也并不难,如下面2幅图:


首先在切换浮层方法里面,使用require.ensure,指定要加载哪个包。
在setComponent方法里,将component存在state里面。
在父元素的渲染方法里,当state有值的时候,就会自动渲染加载回来的component。
目前只有列表页发布外网了,我们比较了优化前后的首屏可交互时间,分别有18%和5.3%的提升。


更新于2016年7月2日
React重构后第一版,当时还没做任何的优化,发现平均FPS只有22(虽然Android的肉眼感受不出来),而后面使用Immutable或者Lodash.merge都非常接近,能达到42或以上。而手机QQ可接受的FPS最少值是30FPS。因此使用Immutable和Lodash.merge的优化还是相当明显的。



在iOS上的fps差距尤为明显。重构后第一版,拉了大概5屏之后,肉眼会有卡顿的感觉,拉到了10屏之后,数据开始掉到了20多30。而Immutable和Lodash.merge则大部份时间保持在50fps以上,很多时候还能达到非常流畅的60fps。



用Chrome模拟器也能看出一些端倪。在Scripting方面,Immutable和Lodash.merge的耗时是最少的,约700多ms,而重构后的第一版则需要1220ms。Lodash.merge在rendering和painting上则没占到优势,但Immutable则要比其它两个要少30% - 40%。由于测试的时候是在PC端,PC端的性能又极好,所以不管是肉眼,还是数据,对于不是很复杂的需求,总体的渲染性能看不出非常明显的差距。



从上面的数据看来,在移动端使用Immutable和Lodash.merge相对于不用,会有较大的性能优势,但Immutable相对于Lodash.merge在我们需求情景下暂时没看出明显的优势,笔者估计可能是由于项目数据规模不大,结构不复杂,因此Immutable的算法优势并没有充分发挥出来。
Android端测试FPS是使用了腾讯开发的GT随身调。而iOS则使用了Macbook里xCode自带的instrument中的animation功能。Chrome模拟器则使用了Chrome的timeline。测试的方式是匀速滚动列表,拉出数据进行渲染。
我们在开发的过程中,将上面所论述的内容,总结成一个基本的军规,铭记于心,就可以保证React应用的性能不至于太差。
目前参考了这个项目的打包方案:
https://github.com/hartmamt/react-with-tap-events
Facebook官方issue: https://github.com/facebook/react/blob/bef45b0b1a98ea9b472ba664d955a039cf2f8068/src/renderers/dom/client/eventPlugins/TapEventPlugin.js
React-tap-event-plugin github:
https://github.com/zilverline/react-tap-event-plugin
var _extends = ...;
_extends(a, b);
如有错误,请斧正!
想请问下博主,都是实践在SPA的项目吗?
印记中文一直致力于为国内前端开发者提供技术文档的翻译服务,比如 React, Webpack, Node.js 等技术文档,都能有看到印记中文参与的影子。为了让文档的加载速度更好,我们都把文档全数部署在腾讯云国内的 CDN 服务上。不过这也带来了比较大的成本压力,做部署服务买的机器、每几个月要买 TB 级别的 CDN 流量包。
直到最近,腾讯云云开发推出的静态资源部署服务,对于许多文档站、静态个人官网,无论是在部署上,还是价格上,都非常的友好亲民。经过计算发现,比将站点部署在云服务器以及传统的 CDN 更加实惠。这么好的羊毛,不薅天理难容啊!

不过由于印记中文的文档种类多,情况各不相同,经过一番的研究之后,梳理出以下的需求,并且输出了对应的解决方案,希望开放出来给大家针对自身的情况使用。
由于印记中文的文档不少,至少有 10 个以上,部署的方案需要比较整齐划一才比较好地做维护。之前我们是通过 Node.js 写了一个部署服务,一定程度上减轻了部署的负担,但还是需要在每个文档里,新加入脚本做构建和触发部署。而 Github Action 推出后,完美解决了 Github 项目构建与部署问题,因此基于 Github Action 做一个部署方案是比较好的解决方案。
印记中文的文档是部署在子域下面的,之前是部署在腾讯云的 COS 和 CDN 服务上。有的文档的文件量非常大,像 react, webpack 的文档文件数,动辄上千,腾讯云平台的工具都只是提供全量的上传,这样不仅上传的速度慢,而且平台是会针对上传次数计费的,因此,我们要尽量减少每次发布的上传量,将性能提升并将成本降低。作为有追求的开发者,怎么可能在发布这个事情让云平台赚到我们的钱呢!
主站由于备案要求以及产品策略的关系,一般都需要部署在云服务器。因此印记中文的主站采取的策略是 HTML 文件部署在云服务器,其它的静态资源部署在云开发作为加速。
基于印记中文上述的需求,开放出一套解决方案,基本可以满足上述的需求。
首先我们要解决的是一个统一的发布方案,对代码入侵比较少的主要就是使用 Github Action。印记中文的部署 Github Action 同时能支持腾讯云对象存储(COS)还有云开发(Cloudbase),地址在:https://github.com/docschina/docschina-actions

下面代码是截取了印记中文主站部署的前半部份,主要的流程就是构建+部署。关于 Github Action 的语法推荐到技术社区搜索相关的帖子,本文主要是讲述部署的方案。
第一个 step(步骤)是 Checkout,主要就是拉取代码。
第二个 step 是 Build and Deploy,用于运行 npm run build 命令构建,并将构建到 build 目录的代码都上传到 gh-pages 分支做存档。
第三个 step 是 Check Build,用于检查 build 目录是否存在以及给它赋予可读写的权限。
第四个 step 是 Docschina Github Action,就是印记中文的核心部署 Github Action,在Setting的 Secrets里填写了腾讯云的密钥对 SECRET_ID, SECRET_KEY 和云开发发ENV_ID

name: Build CI For CloudBase
on:
push:
branches: [master]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [12.x]
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Build and Deploy
uses: JamesIves/github-pages-deploy-action@master
env:
ACCESS_TOKEN: ${{ secrets.ACCESS_TOKEN }}
BRANCH: gh-pages
FOLDER: build
BUILD_SCRIPT: npm install --unsafe-perm=true && npm run build
- name: Check Build
run: |
sudo -i
sudo chown -R $USER build
- name: Docschina Github Action
id: deployStatic
uses: docschina/docschina-actions@master
with:
secretId: ${{ secrets.SECRET_ID }}
secretKey: ${{ secrets.SECRET_KEY }}
staticSrcPath: ./build
isForce: ${{ secrets.ISFORCE }}
envId: ${{ secrets.ENV_ID }}那 docschina/docschina-actions@master 这个 Github Action 跟腾讯云的官方工具相比,提供了哪些其它的能力呢?官方的工具,主要是提供了全量的文件上传,而印记中文研发的工具,提供了增量发布、强制全量发布、忽略文件、支持 COS 和 Cloudbase 两种发布方式。
忽略文件,是通过 skipFiles 填入的数据参数实现的,而全量发布,可以通过给isForce传入true值达成。那究竟如何实现增量发布的呢?
一般来说,增量发布有两种方式,见下图:

方案一是最精确的做法,就是每次都去检测现网,看看资源是否存在,而对于 Web 入口的 HTML 文件还要多检测一次 MD5——那是为大多数非 HTML 资源,都会在文件名里加上 MD5 串,而 HTML 则不会。但这种求精确的方案会带来 CDN 资源的消耗,因为每次发布的时候都得检测,而且发布的速度也会被拖慢。
方案二则是选择用空间换时间,将已经发布过的文件信息都存在一个 manifest 的文件里,然后每次发布前都拉取一下这个文件,如果在该文件里出现过的就不再发布了,而且还会将本次发布的文件更新到该 manifest 文件中。这种方法的缺点是可能不精确,因为可能由于其它的原因,比如手动删除文件,服务中的文件可能不存在,但 manifest 中已经有该文件的发布信息了。基于这个方案,印记中文做了一些小优化,HTML文件会在 manifest 中记录其内容的 md5 值,非 HTML 文件则会记录是否发布的布尔型值,另外还提供了isForce参数,允许用户可以强制全量发布,避免有一些文件丢失的时候,可以全量先发布一次。
上面的方案已经能解决前两个需求了,那第三个需求呢?我们把印记中文主站最后部份的部署代码列出来。这里是使用了Pendect/action-rsyncer这个Github Action,将 HTML 文件,通过rsync命令传输到远端的服务器。
- name: Deploy To Server
uses: Pendect/[email protected]
env:
DEPLOY_KEY: ${{secrets.DEPLOY_KEY}}
with:
flags: '-avzr'
options: ''
ssh_options: ''
src: 'build/'
dest: '[email protected]:/data/docs/docschina'
SSH_PRIVATE_KEY: ${{ secrets.DEPLOY_KEY }}但Github Action如何可以连接远端的服务器呢?关键就是在于这个DEPLOY_KEY.首先,你得先得生成一个 SSH 私钥,这个生成跟你的 Github SSH 私钥生成的过程类似,可以自行搜索相关的文章。
然后,需要让你的服务器,加载该 SSH 私钥,如下图:
 。
。
然后,打开该私钥文件,拿到内容,给Github Action配置DEPLOY_KEY内容,这样在使用rsync的时候,就能自动连接上远端的服务器。
自此,通过组合自研的和别人的Github Action,基本实现了常见的不同情况的静态资源部署。要感谢腾讯云云开发研发团队给予的一些帮助,让我比较顺利地通过调用一些内部的 API 更好地实现定制的部署流程,让我更加任性地薅这波羊毛。这波的 9.9 元的包年活动据说截至到 7 月份,如果想把自己的静态站点迁移到云开发静态部署服务,可以尝试使用本文推荐的工具。
如有错误,恳请斧正!
requirejs 算是几年前一个比较经典的模块加载方案(AMD的代表)。虽然不曾用过,但它对 webpack, rollup 这些后起之秀有不少借鉴的意义,因此也决定大体分析一下它的源码进行学习。
requirejs 首先定义了一些基本的全局变量(在requirejs自执行函数里的全局),比方说版本号,对运行环境的判断、特殊浏览器(Opera)的判断等。
其次,是定义了一系列的 util 函数,如类型判断、迭代器、对象属性判断、Mixin(掺合函数)等等。(个人感觉这些函数在版本的浏览器都有,但这里定义主要是有兼容性的考虑)。
接下来出现下面几个判断,主要是判断 define, requirejs, require 三个关键函数是否已经被定义,如果已经被定义,则不进行重写。
if (typeof define !== 'undefined') {
//If a define is already in play via another AMD loader,
//do not overwrite.
return;
}
if (typeof requirejs !== 'undefined') {
if (isFunction(requirejs)) {
//Do not overwrite an existing requirejs instance.
return;
}
cfg = requirejs;
requirejs = undefined;
}
//Allow for a require config object
if (typeof require !== 'undefined' && !isFunction(require)) {
//assume it is a config object.
cfg = require;
require = undefined;
}然后,是一个横跨了几乎上千行的函数,newContext ,吓得我要报警了。大概浏览一下,根据注释的描述,它主要干了几件事:
trimDots, normalize 等。最后的部份,主要是定义了一些跟主入口 (main entry) 加载相关,及对外暴露的一些接口,如require, requirejs, define,分别用作加载配置、依赖加载、依赖(模块)定义。
在理解了整体的架构之后,我们从主入口开始,进行更深入的分析。我们可以写一个简单的 demo 进行分析,示例代码如下:
// index.html
<!DOCTYPE html>
<html>
<head>
<title>My Sample Project</title>
<!-- data-main attribute tells require.js to load
scripts/main.js after require.js loads. -->
<script data-main="index" src="require.js"></script>
</head>
<body>
<h1>My Sample Project</h1>
</body>
</html>// index.js
// 定义加载的配置
require.config({
paths: {
util: 'helper/util'
}
});
// 主入口的加载依赖定义
requirejs(["util"], function(util) {
console.log(util);
});正式加载主入口文件之前,requirejs 先初始化好资源的上下文 (context),而这个时候 newContext 粉墨登场。
req = requirejs = function (deps, callback, errback, optional) {
// some other code
if (!context) {
context = contexts[contextName] = req.s.newContext(contextName);
}
// some other code
}// 创建默认的上下文
req({});打开 Chrome Debug 面板,能看到这个上下文 (context) 包含了以下一些属性与函数,默认上下文是 _,因此推断这还可以进行上下文的自定义,这个与 requirejs 的多版本支持有关:

下面这段源码便是寻找这个主入口文件:
if (isBrowser && !cfg.skipDataMain) {
//Figure out baseUrl. Get it from the script tag with require.js in it.
eachReverse(scripts(), function(script) {
//Set the 'head' where we can append children by
//using the script's parent.
if (!head) {
head = script.parentNode;
}
//Look for a data-main attribute to set main script for the page
//to load. If it is there, the path to data main becomes the
//baseUrl, if it is not already set.
dataMain = script.getAttribute('data-main');
if (dataMain) {
//Preserve dataMain in case it is a path (i.e. contains '?')
mainScript = dataMain;
//Set final baseUrl if there is not already an explicit one,
//but only do so if the data-main value is not a loader plugin
//module ID.
if (!cfg.baseUrl && mainScript.indexOf('!') === -1) {
//Pull off the directory of data-main for use as the
//baseUrl.
src = mainScript.split('/');
mainScript = src.pop();
subPath = src.length ? src.join('/') + '/' : './';
cfg.baseUrl = subPath;
}
//Strip off any trailing .js since mainScript is now
//like a module name.
mainScript = mainScript.replace(jsSuffixRegExp, '');
//If mainScript is still a path, fall back to dataMain
if (req.jsExtRegExp.test(mainScript)) {
mainScript = dataMain;
}
//Put the data-main script in the files to load.
cfg.deps = cfg.deps ? cfg.deps.concat(mainScript) : [mainScript];
return true;
}
});
}呼应的是 html 文件里,有这么一段 js 的引用:
<script data-main="index" src="require.js"></script>这样写, requirejs 就会帮我们去自动加载主入口文件,而它需要去提取的是 data-main 属性里的 index 值。
在最底部,有下面这段调用,requirejs 正式开始处理加载。
//Set up with config info.
req(cfg);第二次调用 req 函数,之前的配置和上下文都已经配置过,因此不会再重复配置,而此时 config.deps 资源依赖已经放上了主入口文件。因此 requirejs 开始调用 context.require (localRequire) 函数进行加载。
localRequire 函数中关键用于寻找可加载模块的逻辑主要集中在这里:
//Grab defines waiting in the global queue.
intakeDefines();
//Mark all the dependencies as needing to be loaded.
context.nextTick(function() {
//Some defines could have been added since the
//require call, collect them.
intakeDefines();
requireMod = getModule(makeModuleMap(null, relMap));
//Store if map config should be applied to this require
//call for dependencies.
requireMod.skipMap = options.skipMap;
requireMod.init(deps, callback, errback, {
enabled: true
});
checkLoaded();
});intakeDefines 及里面的 takeGlobalQueue 函数,先针对 html 文件中 定义的模块进行加载,然后再调用主入口文件中定义的模块。
getModule 和 makeModuleMap 主要用于生成及获取模块相关的参数。
requireMod.init (Module.init) 表示需要加载的模块开始进行加载的初始化工作。在该函数里,通过 enable => check => fetch => load 几个函数之后,你会逐渐看见添加并加载 script 的逻辑。
对于主入口文件 index.js 加载 util 逻辑,原理也是大体类似。
除了主入口以外,其它模块都会采用 define 函数进行模块的定义,下面是例子中 util 及其相关依赖模块。
// helper/utils.js
define(["helper/cart", "helper/inventory"], function(cart, inventory) {
return {
color: "blue",
size: "large",
addToCart: function() {
inventory.decrement(this);
cart.add(this);
}
}
});// helper/inventory.js
define(function() {
return {
decrement: function() {
}
}
});// helper/cart.js
define(function() {
return {
add: function() {
}
}
});define 函数里面,还可以直接使用 require 进行异步加载,requirejs 除了通过第一个参数的依赖数组以外,还会通过匹配 cjsRequireRegExp 的值,进行依赖的分析,然后将相关的模块名、上下文都进行初始化:
/**
* The function that handles definitions of modules. Differs from
* require() in that a string for the module should be the first argument,
* and the function to execute after dependencies are loaded should
* return a value to define the module corresponding to the first argument's
* name.
*/
define = function(name, deps, callback) {
var node, context;
//Allow for anonymous modules
if (typeof name !== 'string') {
//Adjust args appropriately
callback = deps;
deps = name;
name = null;
}
//This module may not have dependencies
if (!isArray(deps)) {
callback = deps;
deps = null;
}
//If no name, and callback is a function, then figure out if it a
//CommonJS thing with dependencies.
if (!deps && isFunction(callback)) {
deps = [];
//Remove comments from the callback string,
//look for require calls, and pull them into the dependencies,
//but only if there are function args.
if (callback.length) {
callback
.toString()
.replace(commentRegExp, commentReplace)
.replace(cjsRequireRegExp, function(match, dep) {
deps.push(dep);
});
//May be a CommonJS thing even without require calls, but still
//could use exports, and module. Avoid doing exports and module
//work though if it just needs require.
//REQUIRES the function to expect the CommonJS variables in the
//order listed below.
deps = (callback.length === 1 ? ['require'] : ['require', 'exports', 'module']).concat(deps);
}
}
//If in IE 6-8 and hit an anonymous define() call, do the interactive
//work.
if (useInteractive) {
node = currentlyAddingScript || getInteractiveScript();
if (node) {
if (!name) {
name = node.getAttribute('data-requiremodule');
}
context = contexts[node.getAttribute('data-requirecontext')];
}
}
//Always save off evaluating the def call until the script onload handler.
//This allows multiple modules to be in a file without prematurely
//tracing dependencies, and allows for anonymous module support,
//where the module name is not known until the script onload event
//occurs. If no context, use the global queue, and get it processed
//in the onscript load callback.
if (context) {
context.defQueue.push([name, deps, callback]);
context.defQueueMap[name] = true;
} else {
globalDefQueue.push([name, deps, callback]);
}
};requirejs 加载完主入口文件之后,会开始依次加载这些依赖模块,并且也会逐个依赖模块进行依赖分析,以此类推。
不过 requirejs 的缺陷还是很明显的。如果纯粹使用 requirejs 这种 AMD 的异步加载,一旦依赖非常多,就会导致加载速度很慢。当然它也提供了 r.js 这样的下构建工具,通过将文件打包到一起来解决问题,但相起比 webpack 和 rollup,还是免不了许多手动的工作。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.