liheyoung / st-plusplus Goto Github PK
View Code? Open in Web Editor NEW[CVPR 2022] ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
Home Page: https://arxiv.org/abs/2106.05095
License: MIT License
[CVPR 2022] ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
Home Page: https://arxiv.org/abs/2106.05095
License: MIT License









































































































Hi! Thanks a lot for your great work!
In Algo2, after computing score
Does it mean to re-initialize the weight of the student model to the initialized random parameters? Why the re-initialization is needed? I think I did not find the relevant words in the text.
Thanks!
https://github.com/LiheYoung/ST-PlusPlus/tree/master/dataset/splits/pascal/92/split_0
https://github.com/LiheYoung/ST-PlusPlus/tree/master/dataset/splits/pascal/92/split_1
https://github.com/LiheYoung/ST-PlusPlus/tree/master/dataset/splits/pascal/92/split_2
Three different versions of split, which exist at the same time, quite confused me.
Hi, @LiheYoung
Thanks for your nice work.
Btw, I encountered error like below.
It seems like kinda cuDNN error, but I have no idea to deal with.
How can I fix it?
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/container.py", line 117, in forward
input = module(input)
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/d1/daeun/semi/ST-PlusPlus/model/backbone/resnet.py", line 78, in forward
out = self.conv1(x)
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 423, in forward
return self._conv_forward(input, self.weight)
File "/home/daeun/anaconda3/envs/cuda114/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 419, in _conv_forward
return F.conv2d(input, weight, self.bias, self.stride,
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
It seems that in "Supervised training on labeled images (SupOnly)" stage, you double the dataset when the number of images is less than 200. So in some setting as "92 labeled images", the actual training epoch is 160 rather than 80?

作者你好,我在windos下pycharm复现您代码的时候,无论在VOC还是自己数据集下都无法生成伪标签, pred = Image.fromarray(pred.squeeze(0).numpy().astype(np.uint8), mode='P')会报维度3>2的错误。我的pytorch版本为1.6.0 , python=3.6.13,pillow=8.3.1,numpy=1.16.3,下面是完整信息: 很感激期待您的回复!
Namespace(backbone='resnet101', batch_size=2, crop_size=321, data_root='./ywDataset/', dataset='pascal', epochs=2, labeled_id_path='./dataset/splits/pascal/1_8/split_1/labeled.txt', lr=0.000125, model='deeplabv3plus', plus=None, pseudo_mask_path='./outdir/pseudo_masks/pascal/1_8/split_1', reliable_id_path='./outdir/pseudo_masks/1_8/split_1', save_path='./outdir/models/pascal/1_8/split_1', unlabeled_id_path='./dataset/splits/pascal/1_8/split_1/unlabeled.txt')
================> Total stage 1/3: Supervised training on labeled images (SupOnly)
Params: 59.3M
==> Epoch 0, learning rate = 0.0001 previous best = 0.00
Loss: 0.712: 100%|██████████| 5/5 [00:44<00:00, 8.92s/it]
mIOU: 33.15: 100%|██████████| 10/10 [00:05<00:00, 1.99it/s]
==> Epoch 1, learning rate = 0.0001 previous best = 33.15
Loss: 0.589: 100%|██████████| 5/5 [00:42<00:00, 8.56s/it]
mIOU: 33.15: 100%|██████████| 10/10 [00:05<00:00, 1.79it/s]
================> Total stage 2/3: Pseudo labeling all unlabeled images
0%| | 0/25 [00:07<?, ?it/s]
Traceback (most recent call last):
File "D:/ST-PlusPlus-master/main.py", line 359, in
main(args)
File "D:/ST-PlusPlus-master/main.py", line 94, in main
label(best_model, dataloader, args)
File "D:/ST-PlusPlus-master/main.py", line 331, in label
pred = Image.fromarray(pred.squeeze(0).numpy().astype(np.uint8), mode='P')
File "C:\Users\admin\anaconda3\envs\pytorch\lib\site-packages\PIL\Image.py", line 2840, in fromarray
raise ValueError(f"Too many dimensions: {ndim} > {ndmax}.")
ValueError: Too many dimensions: 3 > 2.
We use your code to reproduce the experimental results in your paper.
Our settings are pascal_batchsize_16_resnet50_deeplabv3plus_pascal_1_16_split_0
but get 55.17mAP
In your paper, it's about 73 mAP with ST++
你好,谢谢你的工作。我有个小问题,请问pseudo- labels生成,是实时就加入 原来的labelled data里面,保持一直的训练模式,还是人为地需要把生成的pseudo- labels 放入原来的labelled data,再开始重新训练模型。
那如果是人为地加入pseudo-labels, 是不是就应该可以理解成分阶段循环训练模型。ô
请问是不是有end-to-end, 就是pseudo-labels generating 和 re-train模型合并的,就不分阶段,实时地进行生成伪标签和重新训练模型
Congrats on CVPR first, nice work!
The detailed results about the cityscapes are not reported in the preprint. I wonder that have you compared your results with other sota methods on the cityscapes dataset?
Line 16 in 4b0f5ba
Forget to ignore class 255 in caculating mIoU?
你好,我想用这个模型训练灰度图像,请问可以实现吗
老师您好,我想请问一下--unlabeled-id-path 应该怎样设置,如果按照readme.md的设置,代码会在Total stage 2/3: Pseudo labeling all unlabeled images过程中会终端训练并报错找不到VOC2012文件下缺少图片。在unlabeled.txt中无标签图像名称和标签名称一一对应,但数据集中并没有这些无标记图像的标签,不懂为什么这样设置,请老师为我解惑。
Hello, thank you very much for your work!
I'd like to ask what is the purpose of doubling the training ids when the number of labeled images is less than 200?

请问最终的IOU就是最后一轮最后一张图片的mIOU吗?还是最后一轮的平均IOU?是我操作的不对吗,最后的输出只到这了
mIOU: 74.82: 100%|██████████| 1449/1449 [01:13<00:00, 19.79it/s]
mIOU: 74.82: 100%|██████████| 1449/1449 [01:13<00:00, 19.77it/s]
老师您好,请问这个数据集的文件结构怎么放置的??
Hello,
I am wondering if it would be possible for you to share the final model weights (and training logs) on either of the CityScapes and Pascal splits?
I have some class-wise comparisons and visualizations to perform, and I am unable to do them at this point.
Thank you.
Hi! I really appreciate your jobs, that is awesome! But I' m new to SSL, and I have some questions about experiments.
Hi thanks for your work.
I noticed that you use the best checkpoint to do the pseudo labeling
Line 129 in 561d68f
The best model is selected by the evaluation on the val set with ground truth label. Do you think this cause an information leaking?
Although the ground truth doesn’t explicitly involve in the training. it does provide some information for the model checkpoint selection.
When we train our model, we should make sure that we can touch nothing about the val set.
Have you tried to train your method without this selection? Say just use the final checkpoint?
thanks.
作者您好,deeplap v2的预训练模型无法下载,可以重新发送吗
Excuse me, What is the version of pytorch used in your project?
Hi, Lihe. I'm a littble bit confused of the number of images in each epoch.
As you mentioned `over-sampler' in Algorithm 1.

Take the split 1464+9118 as example. Then, one epoch would contain 2*9118 images. Or, following previous definition, one epoch only contains 10582 images?
Thanks for your excellent work~
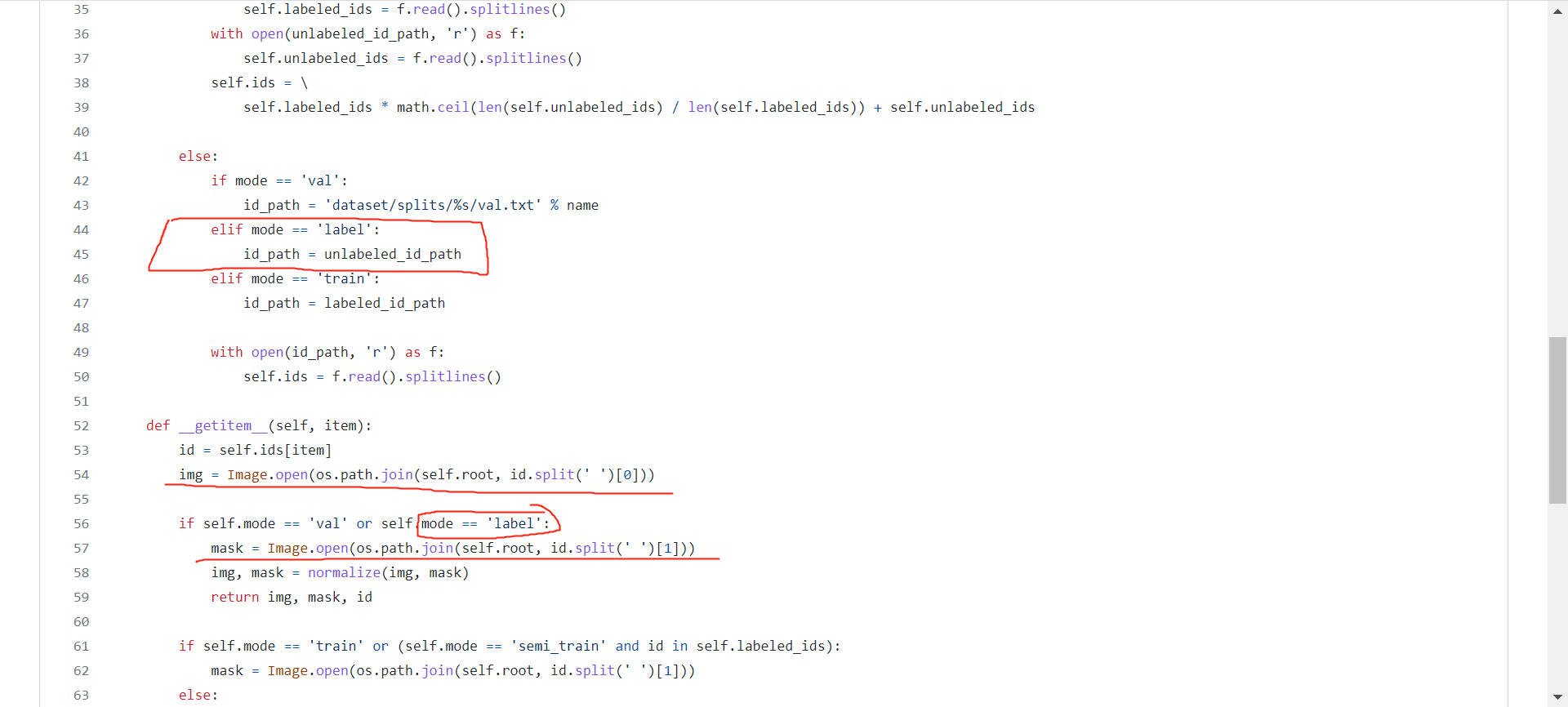
Hello, I have a confusion hope can be helped, why when mode== label, and can get the mask of unlabeled.
作者你好,我想问一下unlable.txt的文件怎么来的。unlable的标签不应该是没有的吗?
Hi,
I'm a beginner of the semi-supervised segmentation, and I'm actually very confused of the settings that the recent paper use. For example, in you Table 1,

For each percentage of the annotated labels, larger number of labels yields better result which is totally make sense. However, in your Table 2,
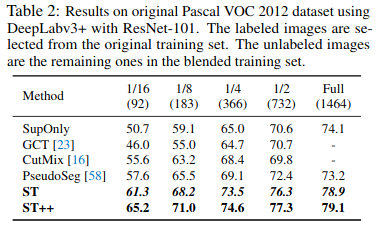
With only 1464 original annotated images you reach even higher result by compared with the
Cheers,
Hello, thanks for your great work first!
When I use your ST++ model in my dataset, the validation DICE of retraining on labeled and reliable data improved obviously. However, the validation DICE descreased in second retraining (on labeled and all unlabelled data). This situation wasn't accidental, and it happened in many experiments. I thought a lot and didnot find a good way to figure out. Could you help me? And have you met this situation ever? What did you do to solve this problem?
Thanks a lot.
Looking forward to your reply.
您好 我想问一下我的监督训练过程第一轮开始mIOU就是100% 损失为0的原因 还是说我的val有问题
@yyamx 你好,你使用的是Pasca VOC数据集吗?
Originally posted by @LiheYoung in #33 (comment)
我想用其他的数据集需要修改哪些内容
Although this work is very insightful, I have some questions about the report results. After running the code for several times, I found that the biggest gap in baseline(Stage 1)is 0.47 of mIoU. This value is even greater than the ST++'s improvement over ST in some data splits. So what is your principle for those reported results?

Hello author! I noticed that there is no test code given in github. I would like to know how to test on the test set when using a custom data set?
Hi, sorry for disturbing you again.
In your paper, you said that the batch size is 16 for both VOC and Cityscapes with 2 and 4 V100 respectively.
I wonder whether 16 is the batch size for each V100 or is the total batch size (i.e., for VOC, the batch size for each V100 is 8 and 4 for Cityscapes)?
感谢您精彩的工作。我有以下几个问题,希望可以得到您的解答。
erase_w = int(np.sqrt(size / ratio))
erase_h = int(np.sqrt(size * ratio))
Have you performed your ST with deeplab101 for cityscapes? Would you plan to report the results?
Hi, I'm a beginner in semantic segmentation, and thanks for your great work. It seems ST++ is the only method which select `reliable DT mask' for unlabeled images.
I'm interested in the `evaluation bug' metioned on Table.1

Could you give me a brief introduction about it?
In your code, when running "Total stage 1: Supervised training on labeled images (SupOnly)", it gets best model by evaluating on validate dataset. I want to know is it fair to use the information provided by validate dataset to select best model? I think in training stage all you have is labeled and unlabeled training dataset.
Sorry for bothering you again!
First, I have re-trained several models, i.e., CPS, U2PL, and AEL. But my results are far below their reported results. Among these SOTA methods with public codes, I can only reproduce expected results based on your ST++ (e.g. 74.15 for 1/16 pascal). Appreciate it!
I found there are several different settings within former methods, i.e., stronger backbone(resnet_stem), auxiliary decoders, larger crop_size, OHEM loss, Sync_bn, and several training tricks, which are extremely unfair for comparisons.
Then, I wonder whether the reviewers ask you to compare yours with these methods? Is it necessary to re-train your ST++ with the same settings? Just for curiosity.......
Hello, thank for your insightful and ingenious work. After thorough reading, I have a simple question that why CPS(Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision) is not compared with ST++, since CPS is a previous SOTA work?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.