
![]()
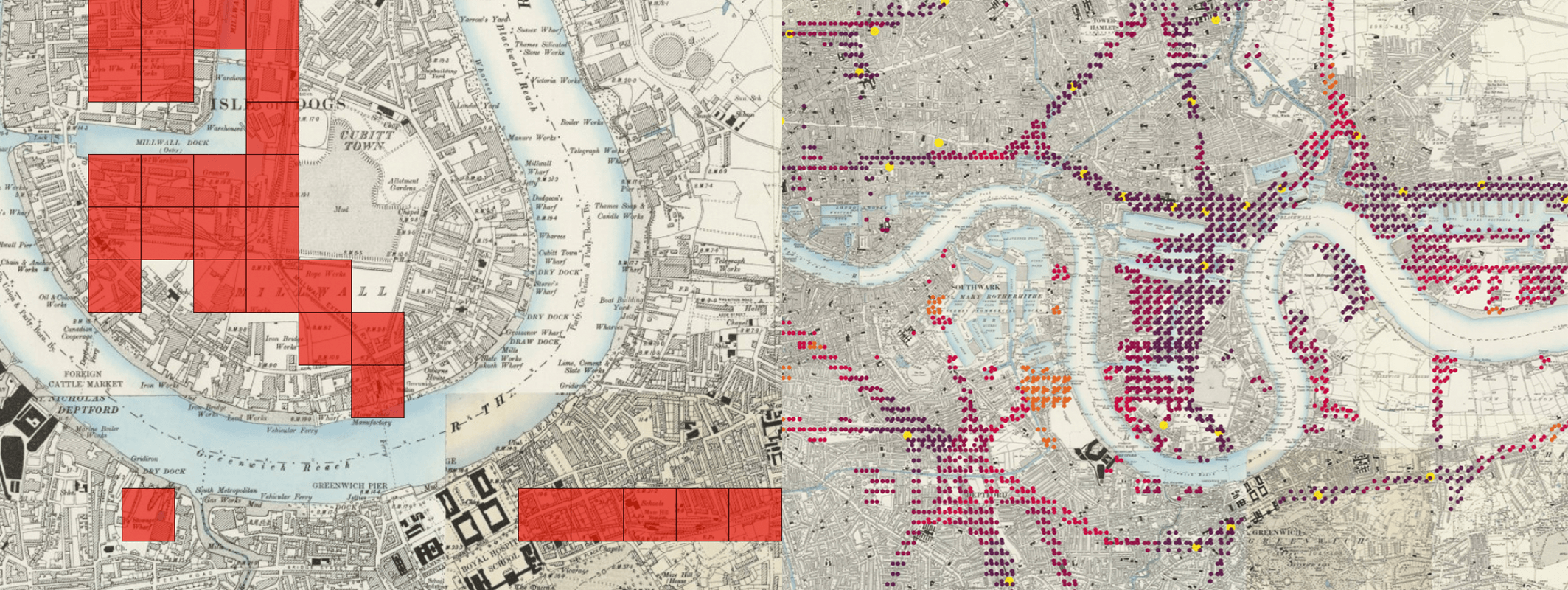
MapReader is an end-to-end computer vision (CV) pipeline for exploring and analyzing images at scale.
MapReader was developed in the Living with Machines project to analyze large collections of historical maps but is a generalizable computer vision pipeline which can be applied to any images in a wide variety of domains.
MapReader is a groundbreaking interdisciplinary tool that emerged from a specific set of geospatial historical research questions. It was inspired by methods in biomedical imaging and geographic information science, which were adapted for use by historians, for example in our Journal of Victorian Culture and Geospatial Humanities 2022 SIGSPATIAL workshop papers. The success of the tool subsequently generated interest from plant phenotype researchers working with large image datasets, and so MapReader is an example of cross-pollination between the humanities and the sciences made possible by reproducible data science.
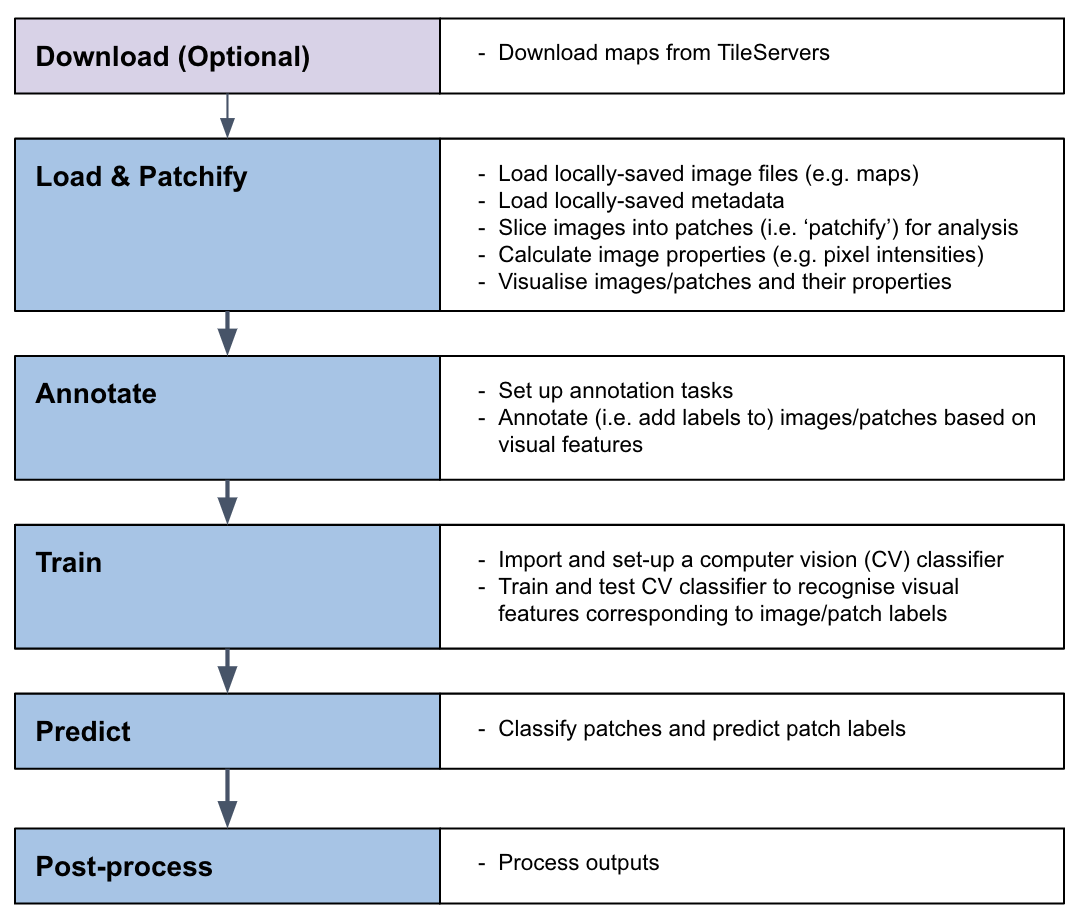
The MapReader pipeline consists of a linear sequence of tasks which, together, can be used to train a computer vision (CV) classifier to recognize visual features within maps and identify patches containing these features across entire map collections.
See our About MapReader page to learn more.
The MapReader documentation can be found at https://mapreader.readthedocs.io/en/latest/index.html.
New users should refer to the Installation instructions and Input guidance for help with the initial set up of MapReader.
All users should refer to our User Guide for guidance on how to use MapReader. This contains end-to-end instructions on how to use the MapReader pipeline, plus a number of worked examples illustrating use cases such as:
- Geospatial images (i.e. maps)
- Non-geospatial images
Developers and contributors may also want to refer to the API documentation and Contribution guide for guidance on how to contribute to the MapReader package.
Join our Slack workspace! Please fill out this form to receive an invitation to the Slack workspace.
The MapReader package provides a set of tools to:
- Download images/maps and metadata stored on web-servers (e.g. tileservers which can be used to retrieve maps from OpenStreetMap (OSM), the National Library of Scotland (NLS), or elsewhere).
- Load images/maps and metadata stored locally.
- Pre-process images/maps:
- patchify (create patches from a parent image),
- resample (use image transformations to alter pixel-dimensions/resolution/orientation/etc.),
- remove borders outside the neatline,
- reproject between coordinate reference systems (CRS).
- Annotate images/maps (or their patches) using an interactive annotation tool.
- Train or fine-tune Computer Vision (CV) models and use these to predict labels (i.e. model inference) on large sets of images/maps.
Various plotting and analysis functionalities are also included (based on packages such as matplotlib, cartopy, Google Earth, and kepler.gl).
If you use MapReader in your work, please cite both the MapReader repo and our SIGSPATIAL paper:
- Kasra Hosseini, Daniel C. S. Wilson, Kaspar Beelen, and Katherine McDonough. 2022. MapReader: a computer vision pipeline for the semantic exploration of maps at scale. In Proceedings of the 6th ACM SIGSPATIAL International Workshop on Geospatial Humanities (GeoHumanities '22). Association for Computing Machinery, New York, NY, USA, 8–19. https://doi.org/10.1145/3557919.3565812
- Kasra Hosseini, Rosie Wood, Andy Smith, Katie McDonough, Daniel C.S. Wilson, Christina Last, Kalle Westerling, and Evangeline Mae Corcoran. “Living-with-machines/mapreader: End of Lwm”. Zenodo, July 27, 2023. https://doi.org/10.5281/zenodo.8189653.
This work was supported by Living with Machines (AHRC grant AH/S01179X/1) and The Alan Turing Institute (EPSRC grant EP/N510129/1).
Living with Machines, funded by the UK Research and Innovation (UKRI) Strategic Priority Fund, is a multidisciplinary collaboration delivered by the Arts and Humanities Research Council (AHRC), with The Alan Turing Institute, the British Library and the Universities of Cambridge, East Anglia, Exeter, and Queen Mary University of London.
Maps above reproduced with the permission of the National Library of Scotland https://maps.nls.uk/index.html
 Katie McDonough 🔬 🤔 📖 📋 📆 👀 📢 ✅ |
 Daniel C.S. Wilson 🔬 🤔 📢 📖 📋 |
 Kasra Hosseini 💻 🤔 🔬 👀 📢 |
 Rosie Wood 💻 📖 🤔 📢 ✅ 👀 🚧 🔬 |
 Kalle Westerling 💻 📖 🚧 👀 📢 |
 Chris Fleet 🔣 |
 Kaspar Beelen 🤔 👀 🔬 |
 Andy Smith 💻 📖 🧑🏫 👀 |













































































