Since IgBlast documentation does not have great details on the database setup, and there are a lot of questions on the forum regarding to the issue internal_data could not be found or the Germline annotation database...could not be found in [internal_data] directory, I wrote this short guide to in case it might be helpful.
This first part of this guide applies to installation of IgBlast and IMGT human germline sequence database. The second part applies to calling the IgBlast executable inside Jupyter notebook and converting some of the results to Pandas dataframe.
This repository contains executables and data files from ncbi-igblast-1.17.0-x64-macosx.tar.gz (latest Mac version as of Jan 9, 2021). It also has the IGHV, IGKV, and IGLV germline protein database obtained from IMGT (latest as of Jan 9, 2021).
Download executable here: ftp://ftp.ncbi.nih.gov/blast/executables/igblast/release/LATEST
Mac: Download the ncbi-igblast-1.17.0-x64-macosx.tar.gz or the latest version(NOT the dmg file) and unzip it in your destination folder.
Then:
- Create jupyter notebook inside the igblast folder.
- Create an empty folder called database inside the igblast folder
It should have a structure similar to what's shown below:
----igblast
--bin
--internal_data
--optional_file
--ChangeLog
--LICENSE
--ncbi_pakacage_info
--README
--database
--Using IgBlast.ipynb
- Germline seuqence can be found here. Both nucleic acid and protein sequences are available. If you
Note that the for blastp (protein blast), only V region alignment is provided by IgBlast.
For example, if you want to download the amino acid germline sequence for human IgHV, you can move to this section on the page, and click on Human under F+ORF+in-frame P. Note that that you can also select Human under F+ORF+in-frame P with IMGT gaps (sequence with gaps), but after cleaning the results will be the same.

- Once you click on the species in the page above, you will be directed to a page with a list of fasta sequences. Copy the fasta sequences.
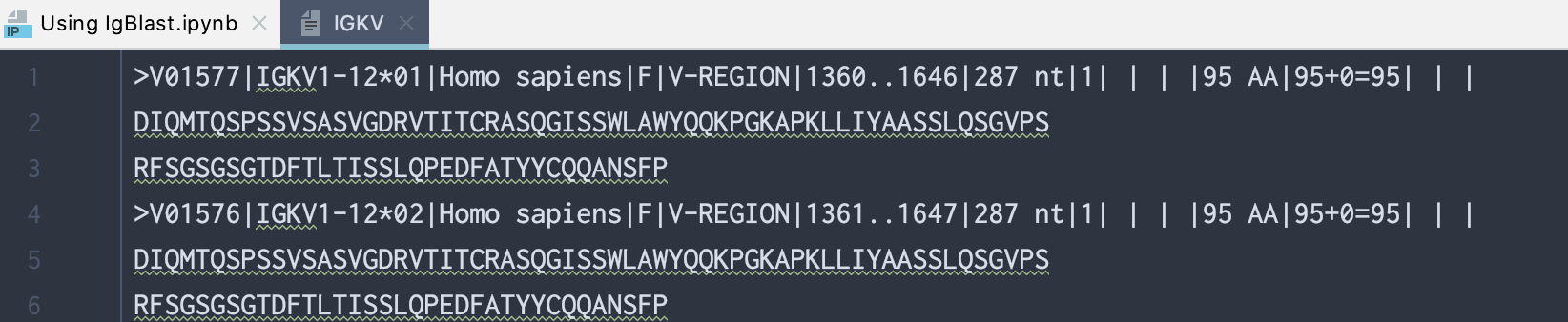
For example, if we want to set up a database for human IGKV germline sequence, we would copy all fasta sequences by locating IGKV row and column F+ORF+in-frame P in table above, then click on the Human link. As of now, there is 108 sequences (example of the first 2 are shown below), and you need to copy all of them.
>V01577|IGKV1-12*01|Homo sapiens|F|V-REGION|1360..1646|287 nt|1| | | |95 AA|95+0=95| | |
DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYAASSLQSGVPS
RFSGSGSGTDFTLTISSLQPEDFATYYCQQANSFP
>V01576|IGKV1-12*02|Homo sapiens|F|V-REGION|1361..1647|287 nt|1| | | |95 AA|95+0=95| | |
DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYAASSLQSGVPS
......
......
- Inside the database folder you created in the 1st step, create another folder called Homo_sapiens and Homo_sapiens_clean Inside each of these 2 folders, create a folder called IG_dna and a folder called IG_prot. See screenshot below:
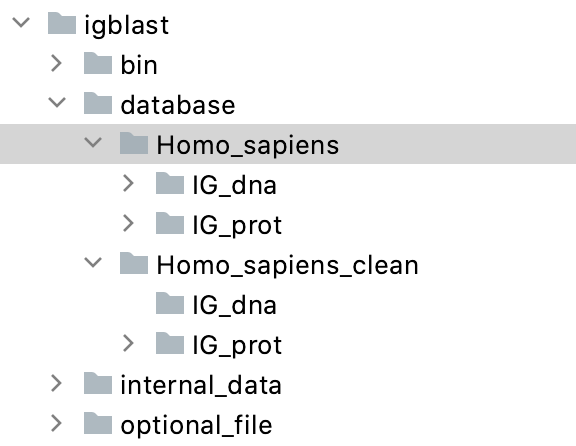
These folders are empty for now.
- Inside the IG_prot folder under Homo_sapiens folder, create a text file and paste the fasta sequences of IGKV in there.
Do NOT keep the .txt or .fasta extension for the text file. (otherwise Igblast automatically adds other extensions after your current extension, and your database name will look weird).
Here is what the directory structure looks like. Note that the text files do not have any extension (.txt or .fasta)
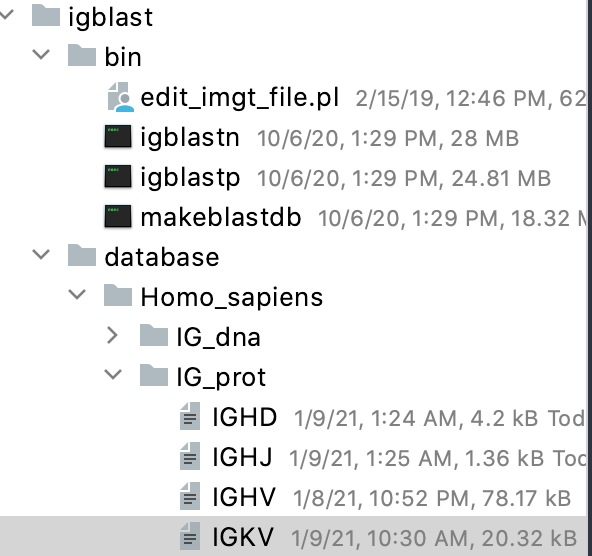
Here is a screenshot of what the IGKV text file looks like:
- If you have any DNA germline sequence, you can use similar method and copy them to IG_dna folder
You can execute the command through terminal, or using the python script below.
Open a terminal at the igblast folder. Then type
bin/edit_imgt_file.pl database/Homo_sapiens/IG_prot/IGKV > database/Homo_sapiens_clean/IG_prot/IGHV_clean
The above line cleans up the IGKV text file you just made, and save the cleaned file inside Homo_sapiens_clean/IG_prot folder.
After cleaning, the id, name, and description of the original IMGT fasta sequences are truncated to keep only the allele type. An example of cleaned sequence:

# cleaning up IGKV IMGT germline sequence file
input_imgt_ref = 'database/Homo_sapiens/IG_prot/IGKV'
output_imgt_ref = 'database/Homo_sapiens_clean/IG_prot/IGKV_clean'
cmd = ['bin/edit_imgt_file.pl', input_imgt_ref , '>', output_imgt_ref]
# display result (and any error) in notebook. No file will be saved
# subprocess.run(cmd.split(), capture_output=True)
# save cmd output to file
fh = open(output_imgt_ref, 'w')
subprocess.Popen(cmd, stdout=fh)We need to parse the cleaned germline sequence file to database. There are 2 ways to do it. In terminal or in Python.
The basic syntax for DNA and protein seuqence is:
bin/makeblastdb -parse_seqids -dbtype nucl -in my_seq_file
bin/makeblastdb -parse_seqids -dbtype prot -in my_seq_file
To parse the IGKV protein germline seuqences, open a terminal at the igblast folder. Then type
bin/makeblastdb -parse_seqids -dbtype prot -in database/Homo_sapiens_clean/IG_prot/IGKV_clean
Igblast will create a variety of files in the same directory as the cleaned germline sequence text file. A screenshot is shown below:
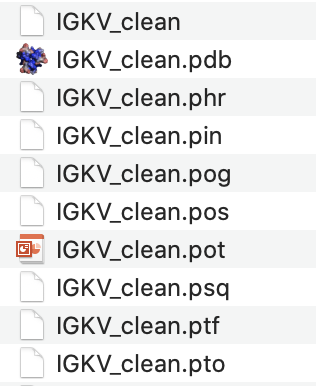
cmd = ['bin/makeblastdb', '-parse_seqids', '-dbtype', 'prot', '-in', output_imgt_ref]
subprocess.Popen(cmd, stdout=subprocess.PIPE)Repeat the process for other germline sequence database. Create one database for VH, one for VL, one for VK...
Details of different parameters and options can be found using:
bin/iglbastp -help
bin/igblastn -help
Below is an example output of bin/igblastp -help
USAGE
igblastp [-h] [-help] [-germline_db_V germline_database_name]
[-num_alignments_V int_value] [-germline_db_V_seqidlist filename]
[-organism germline_origin] [-domain_system domain_system]
[-ig_seqtype sequence_type] [-focus_on_V_segment] [-extend_align5end]
[-extend_align3end] [-min_V_length Min_V_Length] [-db database_name]
[-dbsize num_letters] [-entrez_query entrez_query] [-query input_file]
[-out output_file] [-evalue evalue] [-word_size int_value]
[-gapopen open_penalty] [-gapextend extend_penalty] [-searchsp int_value]
[-sum_stats bool_value] [-matrix matrix_name] [-threshold float_value]
[-ungapped] [-lcase_masking] [-query_loc range] [-parse_deflines]
[-outfmt format] [-show_gis] [-num_descriptions int_value]
[-num_alignments int_value] [-line_length line_length]
[-num_threads int_value] [-remote] [-version]
DESCRIPTION
BLAST for Ig and TCR sequences
OPTIONAL ARGUMENTS
-h
Print USAGE and DESCRIPTION; ignore all other parameters
-help
Print USAGE, DESCRIPTION and ARGUMENTS; ignore all other parameters
-version
Print version number; ignore other arguments
*** Input query options
-query <File_In>
Input file name
Default = `-'
-query_loc <String>
Location on the query sequence in 1-based offsets (Format: start-stop)
*** General search options
-db <String>
Optional additional database name
-out <File_Out>
Output file name
Default = `-'
-evalue <Real>
Expectation value (E) threshold for saving hits
Default = `1'
-word_size <Integer, >=2>
Word size for wordfinder algorithm
-gapopen <Integer>
Cost to open a gap
-gapextend <Integer>
Cost to extend a gap
-matrix <String>
Scoring matrix name (normally BLOSUM62)
-threshold <Real, >=0>
Minimum word score such that the word is added to the BLAST lookup table
*** Formatting options
-outfmt <String>
alignment view options:
3 = Flat query-anchored, show identities,
4 = Flat query-anchored, no identities,
7 = Tabular with comment lines
19 = Rearrangement summary report (AIRR format)
Options 7 can be additionally configured to produce
a custom format specified by space delimited format specifiers.
The supported format specifiers are:
qseqid means Query Seq-id
qgi means Query GI
qacc means Query accesion
qaccver means Query accesion.version
qlen means Query sequence length
sseqid means Subject Seq-id
sallseqid means All subject Seq-id(s), separated by a ';'
sgi means Subject GI
sallgi means All subject GIs
sacc means Subject accession
saccver means Subject accession.version
sallacc means All subject accessions
slen means Subject sequence length
qstart means Start of alignment in query
qend means End of alignment in query
sstart means Start of alignment in subject
send means End of alignment in subject
qseq means Aligned part of query sequence
sseq means Aligned part of subject sequence
evalue means Expect value
bitscore means Bit score
score means Raw score
length means Alignment length
pident means Percentage of identical matches
nident means Number of identical matches
mismatch means Number of mismatches
positive means Number of positive-scoring matches
gapopen means Number of gap openings
gaps means Total number of gaps
ppos means Percentage of positive-scoring matches
frames means Query and subject frames separated by a '/'
qframe means Query frame
sframe means Subject frame
btop means Blast traceback operations (BTOP)
staxid means Subject Taxonomy ID
ssciname means Subject Scientific Name
scomname means Subject Common Name
sblastname means Subject Blast Name
sskingdom means Subject Super Kingdom
staxids means unique Subject Taxonomy ID(s), separated by a ';'
(in numerical order)
sscinames means unique Subject Scientific Name(s), separated by a ';'
scomnames means unique Subject Common Name(s), separated by a ';'
sblastnames means unique Subject Blast Name(s), separated by a ';'
(in alphabetical order)
sskingdoms means unique Subject Super Kingdom(s), separated by a ';'
(in alphabetical order)
stitle means Subject Title
salltitles means All Subject Title(s), separated by a '<>'
sstrand means Subject Strand
qcovs means Query Coverage Per Subject
qcovhsp means Query Coverage Per HSP
qcovus means Query Coverage Per Unique Subject (blastn only)
When not provided, the default value is:
'qseqid sseqid pident length mismatch gapopen gaps qstart qend sstart send
evalue bitscore', which is equivalent to the keyword 'std'
Default = `3'
-show_gis
Show NCBI GIs in deflines?
-num_descriptions <Integer, >=0>
Number of database sequences to show one-line descriptions for
Not applicable for outfmt > 4
Default = `10'
-num_alignments <Integer, >=0>
Number of database sequences to show alignments for
Default = `10'
-line_length <Integer, >=1>
Line length for formatting alignments
Not applicable for outfmt > 4
Default = `60'
*** Query filtering options
-lcase_masking
Use lower case filtering in query and subject sequence(s)?
*** Restrict search or results
-entrez_query <String>
Restrict search with the given Entrez query
* Requires: remote
*** Statistical options
-dbsize <Int8>
Effective length of the database
-searchsp <Int8, >=0>
Effective length of the search space
-sum_stats <Boolean>
Use sum statistics
*** Extension options
-ungapped
Perform ungapped alignment only?
*** Ig-BLAST options
-germline_db_V <String>
Germline database name
-num_alignments_V <Integer>
Number of Germline sequences to show alignments for
Default = `3'
-germline_db_V_seqidlist <String>
Restrict search of germline database to list of SeqIds's
-organism <String>
The organism for your query sequence. Supported organisms include human,
mouse, rat, rabbit and rhesus_monkey for Ig and human and mouse for TCR.
Custom organism is also supported but you need to supply your own germline
annotations (see IgBLAST web site for details)
Default = `human'
-domain_system <String, `imgt', `kabat'>
Domain system to be used for segment annotation
Default = `imgt'
-ig_seqtype <String, `Ig', `TCR'>
Specify Ig or T cell receptor sequence
Default = `Ig'
-focus_on_V_segment
Should the search only be for V segment (effective only for non-germline
database search using -db option)?
-extend_align5end
Extend V gene alignment at 5' end
-extend_align3end
Extend J gene alignment at 3' end
-min_V_length <Integer, >=9>
Minimal required V gene length
Default = `9'
*** Miscellaneous options
-parse_deflines
Should the query and subject defline(s) be parsed?
-num_threads <Integer, >=1>
Number of threads (CPUs) to use in the BLAST search
Default = `4'
* Incompatible with: remote
-remote
Execute search remotely?
* Incompatible with: num_threads
This will help to solve the issue of [internal_data] cannot be found. THe IGDATA should:
- point to the bin folder, not the internal_data folder.
- use the full path (e.g. in mac /Users/mightycamole/Desktop/DataScience/Python/Work/igblast/bin) and NOT a relative path
- The path should not contain any spaces (change your directory name if it does). You might as well avoid
_and-in any of the folder names as well. - Use the
exportoption to assign the environment variable. If you use conda, don't create environment variable inside a specific conda enviroment or modify the envsstatefile. Directly use theexportoption described below.
Method: Open a terminal at the igblast folder. Then type
export IGDATA=/Users/mightycamole/Desktop/DataScience/Python/Work/igblast/bin
Replace the file path with your file path
Suppose you have a folder called test inside igblast. The folder contains Rituximab VH and VL sequence in fasta format. Below are 3 examples of parsing:
- In Example 1, we parse query seuqence in terminal.
- In Example 2, the code will parse the closest germline matching hits into pandas dataframe.
Example:
df, top_germ_allele, top_identity = blastp_get_top_hits_v(
input_fp = 'scratch/Rituximab-VH.fasta',
db_fp= 'database/Homo_sapiens_clean/IG_prot/IGHV_clean'
)
print('best match germline: ', top_germ_allele)
print('identity %: ', top_identity)
dfOutput:
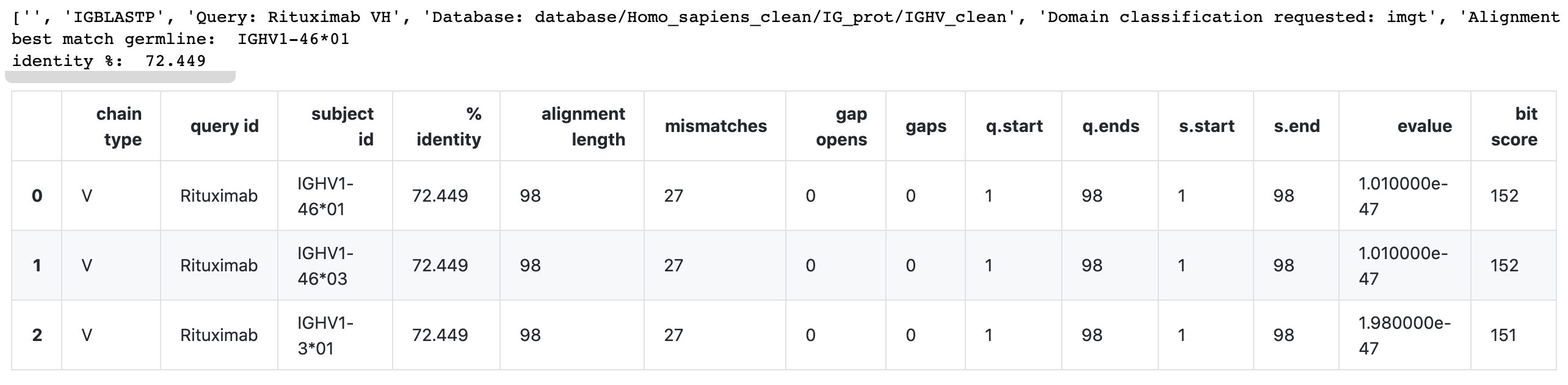
- In Example 3, the code will try to determine if a light chain sequence is a kappa or lambda type.
Example:
df, top_germ_allele, top_identity = blastp_multiple_hits_v(
input_fp = 'scratch/Rituximab-VL.fasta',
db_lst= ['database/Homo_sapiens_clean/IG_prot/IGKV_clean','database/Homo_sapiens_clean/IG_prot/IGLV_clean']
)
print('best match germline: ', top_germ_allele)
print('identity %: ', top_identity)
dfOutput:
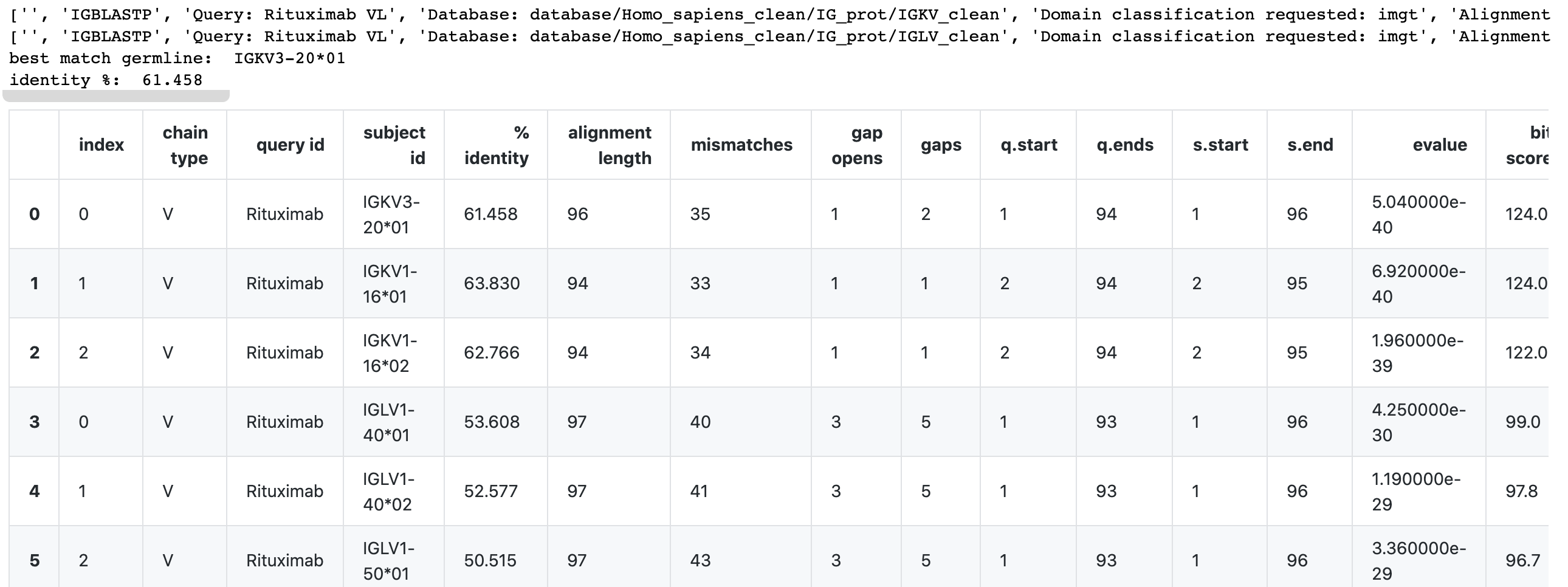
See jupyter notebook for details on the examples
