To use the matrix version of the least squares solution
Calculating least squares weights
reading data on dist to return Pandas DataFrame
select data by column
implement column cutoffs
This cell imports the necessary modules and sets a few plotting parameters for display
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (20.0, 10.0)
Read in the data
Shift + Enter, or press the play button above ^^^
tr_path =r'C:\Users\hp\Downloads\train.csv'
test_path =r'C:\Users\hp\Downloads\test.csv'
data = pd.read_csv(tr_path)
The .head() function shows the first few lines of data for perspecitve
data.head()
-------------------------------------------------------------------------------------------------------
We can plot the data as follows
Price v. living area
with matplotlib
Y = data['SalePrice']
X = data['GrLivArea']
plt.scatter(X, Y, marker = "x")
Annotations
plt.title("Sales Price vs. Living Area (excl. basement)")
plt.xlabel("GrLivArea")
plt.ylabel("SalePrice");
price v. year
Using Pandas
data.plot('YearBuilt', 'SalePrice', kind = 'scatter', marker = 'x');
-------------------------------------------------------------------------------------------------------
Build a function that takes as input a matrix
return the inverse of that matrix
assign function to "inverse_of_matrix"
def inverse_of_matrix(mat):
matrix_inverse = np.linalg.inv(mat)
return matrix_inverse
Testing function:
print("test:\n",inverse_of_matrix([[1,2],[3,4]]), "\n")
print("From Data:\n", inverse_of_matrix(data.iloc[:2,:2]))
In order to create any model it is necessary to read in data
Build a function called "read_to_df" that takes the file_path of a .csv file.
Use a pandas functions appropriate for .csv files to turn that path into a DataFrame
Use pandas function defaults for reading in file
Return that DataFrame
the returned item is of type "DataFrame" and the dimensions should be correct
import pandas as pd
def read_to_df(file_path):
"""Read on-disk data and return a dataframe."""
tr_path =r'C:\Users\hp\Downloads\train.csv'
data = pd.read_csv(tr_path) # making dataframe from the csv file
return data
Testing function:
print(type(data))
print(data[:10])
-------------------------------------------------------------------------------------------------------
Build a function called "select_columns"
As inputs, take a DataFrame and a list of column names.
Return a DataFrame that only has the columns specified in the list of column names
check type of object, dimensions of object, and column names
def select_columns(data_frame, column_names):
tr_path =r'C:\Users\hp\Downloads\train.csv'
data = pd.read_csv(tr_path)
#selected_columns = data.iloc[:,lambda data:data.columns.str.contains('SalePrice|GrLivArea|YearBuilt',case=False)].head()
#fields=['SalePrice','GrLivArea','YearBuilt']
#data2=pd.read_csv(r'C:\Users\hp\Downloads\train.csv', skipinitialspace=True, usecols=fields)
selected_columns = data.loc[:,['SalePrice', 'GrLivArea', 'YearBuilt']]
sub_df = select_columns(data, selected_columns)
return sub_df
#print(data.columns)
#print(data['SalePrice'],data['GrLivArea'],data['YearBuilt'])
-------------------------------------------------------------------------------------------------------
Build a function called "column_cutoff"
As inputs, accept a Pandas Dataframe and a list of tuples.
Tuples in format (column_name, min_value, max_value)
Return a DataFrame which excludes rows where the value in specified column exceeds "max_value"
or is less than "min_value".
### NB: DO NOT remove rows if the column value is equal to the min/max value
def column_cutoff(data_frame, cutoffs):
"""Subset data frame by cutting off limits on column values.
Positional arguments:
data -- pandas DataFrame object
cutoffs -- list of tuples in the format:
(column_name, min_value, max_value)
Example:
data_frame = read_into_data_frame('train.csv')
Remove data points with SalePrice < $50,000
Remove data points with GrLiveAre > 4,000 square feet
cutoffs = [('SalePrice', 50000, 1e10), ('GrLivArea', 0, 4000)]
selected_data = column_cutoff(data_frame, cutoffs)
"""
cutoffs = [('SalePrice', 50000, 1e10), ('GrLivArea', 0, 4000)]
selected_data = column_cutoff(data_frame, cutoffs)
return ''
-------------------------------------------------------------------------------------------------------
Build a function called "least_squares_weights"
take as input two matricies corresponding to the X inputs and y target
assume the matricies are of the correct dimensions
Step 1: ensure that the number of rows of each matrix is greater than or equal to the number
of columns.
### If not, transpose the matricies.
In particular, the y input should end up as a n-by-1 matrix, and the x input as a n-by-p matrix
Step 2: prepend an n-by-1 column of ones to the input_x matrix
Step 3: Use the above equation to calculate the least squares weights.
NB: .shape, np.matmul, np.linalg.inv, np.ones and np.transpose will be valuable.
If those above functions are used, the weights should be accessable as below:
weights = least_squares_weights(train_x, train_y)
weight1 = weights[0][0]; weight2 = weights[1][0];... weight<n+1> = weights[n][0]
def least_squares_weights(input_x, target_y):
training input
X=np.array([[1710, 1262, 1786,
1717, 2198, 1362,
1694, 2090, 1774,
1077],
[2003, 1976, 2001,
1915, 2000, 1993,
2004, 1973, 1931,
1939]])
column vector form
X=X.T
print(" The shape of the training input matrix:\n", X.shape)
training label
Y=np.array([[208500, 181500, 223500,
140000, 250000, 143000,
307000, 200000, 129900,
118000]])
column vector form
Y=Y.T
print(" The shape of the training label matrix:\n", Y.shape)
print("There are {} numbers of samples".format(X.shape[0]))
print("There are {} numbers of features".format(X.shape[1]))
#Fetching the input data to include bias
X_tilde=np.c_[np.ones([num_samples,1]),X]
print("X_tilde is:\n", X_tilde)
transpose of the input data
X_tilde_T=X_tilde.T
solving the normal equation (using pseudo-inverse instead of inverse because you cannot guarantee
#that the inverse actually exists)
param_tilde= np.linalg.pinv(X_tilde_T.dot(X_tilde)).dot(X_tilde_T).dot(Y)
the optimised parameter (bias + weights)
print("The optimised parameter:\n", param_tilde)
-------------------------------------------------------------------------------------------------------
df = read_to_df(tr_path)
df_sub = select_columns(df, ['SalePrice', 'GrLivArea', 'YearBuilt'])
cutoffs = [('SalePrice', 50000, 1e10), ('GrLivArea', 0, 4000)]
df_sub_cutoff = column_cutoff(df_sub, cutoffs)
X = df_sub_cutoff['GrLivArea'].values
Y = df_sub_cutoff['SalePrice'].values
reshaping for input into function
training_y = np.array([Y])
training_x = np.array([X])
weights = least_squares_weights(training_x, training_y)
print(weights)
-------------------------------------------------------------------------------------------------------
max_X = np.max(X) + 500
min_X = np.min(X) - 500
Choose points evenly spaced between min_x in max_x
reg_x = np.linspace(min_X, max_X, 1000)
Use the equation for our line to calculate y values
reg_y = weights[0][0] + weights[1][0] * reg_x
plt.plot(reg_x, reg_y, color='#58b970', label='Regression Line')
plt.scatter(X, Y, c='k', label='Data')
plt.xlabel('GrLivArea')
plt.ylabel('SalePrice')
plt.legend()
plt.show()
-------------------------------------------------------------------------------------------------------
Calculating RMSE
rmse = 0
b0 = weights[0][0]
b1 = weights[1][0]
for i in range(len(Y)):
y_pred = b0 + b1 * X[i]
rmse += (Y[i] - y_pred) ** 2
rmse = np.sqrt(rmse/len(Y))
print(rmse)
-------------------------------------------------------------------------------------------------------
Calculating 𝑅2
ss_t = 0
ss_r = 0
mean_y = np.mean(Y)
for i in range(len(Y)):
y_pred = b0 + b1 * X[i]
ss_t += (Y[i] - mean_y) ** 2
ss_r += (Y[i] - y_pred) ** 2
r2 = 1 - (ss_r/ss_t)
print(r2)
-------------------------------------------------------------------------------------------------------
sklearn implementation
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
sklearn requires a 2-dimensional X and 1 dimensional y. The below yeilds shapes of:
skl_X = (n,1); skl_Y = (n,)
skl_X = df_sub_cutoff[['GrLivArea']]
skl_Y = df_sub_cutoff['SalePrice']
lr.fit(skl_X,skl_Y)
print("Intercept:", lr.intercept_)
print("Coefficient:", lr.coef_)


























































































































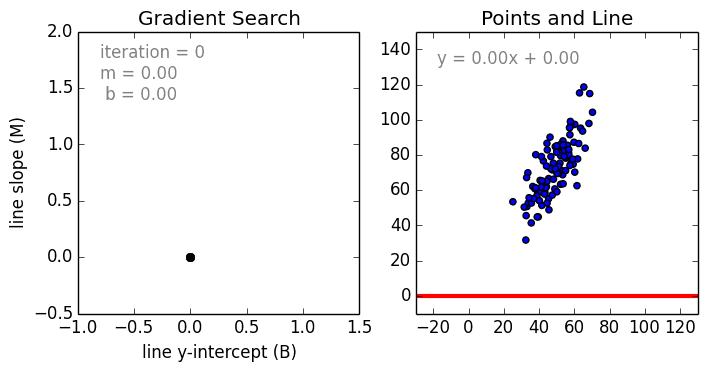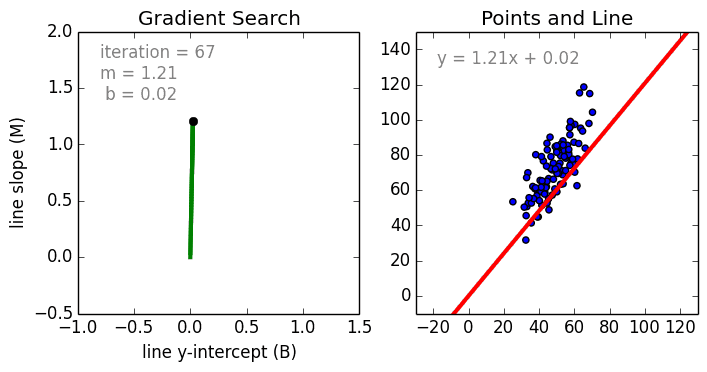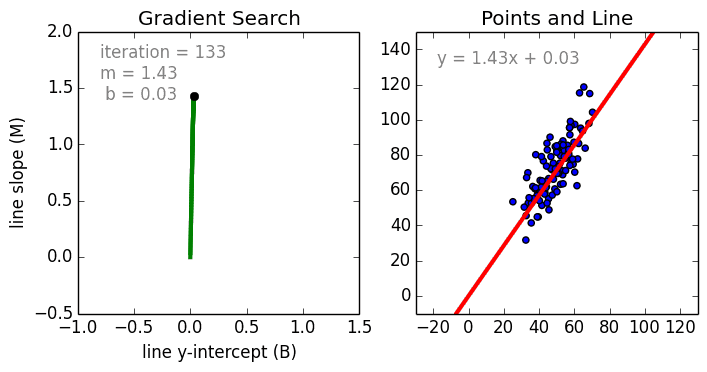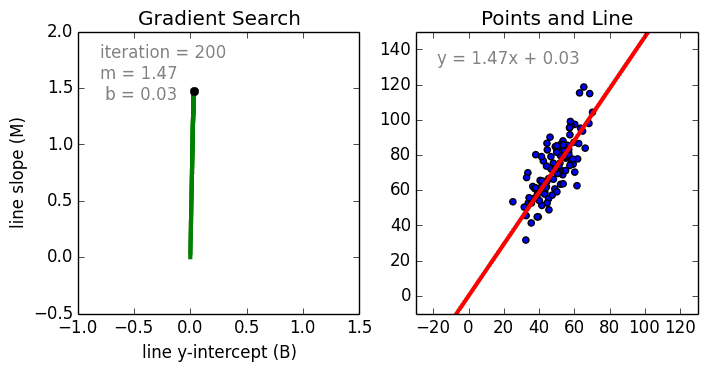{kind=link}
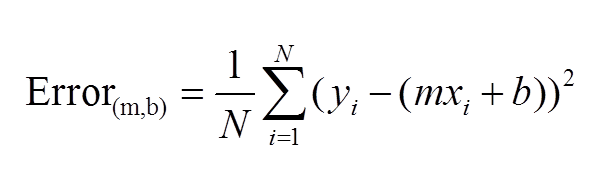{kind=link}
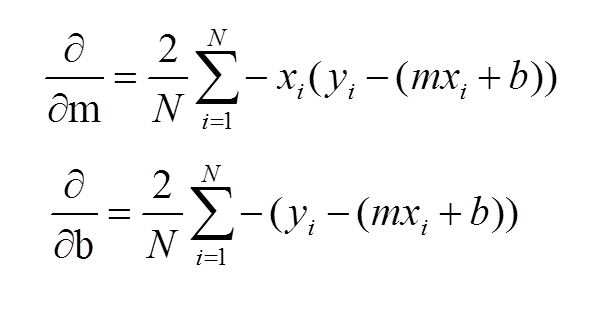{kind=link}