luoyetx / mini-caffe Goto Github PK
View Code? Open in Web Editor NEWMinimal runtime core of Caffe, Forward only, GPU support and Memory efficiency.
License: BSD 3-Clause "New" or "Revised" License
Minimal runtime core of Caffe, Forward only, GPU support and Memory efficiency.
License: BSD 3-Clause "New" or "Revised" License






































































































































@luoyetx 如果要多线程运行,在编译和运行的时候怎么设置,谢谢!!
Hi:
Add matlab interface.
There is a message "BNParameter" in caffe.proto file but it's never used in any .cpp filed.So what's the role of this message ?
作者您好:
在caffe里面基本上所有的类都是模板类,但是在minicaffe的实现中,把模板都去掉了,采用的是float的数据类型。所以我想请教下:为什么要去模板化?c++的模板是编译时的多态,因此模板的存在不会影响程序运行时的性能。minicaffe应该算是caffe的前向传播版本,去掉模板本身也是一项工作,但是这个工作好像也不能带来性能的提升。所以想问下您,去模板是出于一个什么样的想法?
最后,非常感谢您在前面几次的耐心回答!
We need a python binding to run python code with caffe
hello:
I builded a .so file which linked against minicaffe of android version. And I also have written a JNI file. But when I invoke the JAVA class in android studio ,a error was occurred:
A/libc:Fatal signal 6 (SIGABRT),code -6 in aid 28981.
I located the question in one sentence:caffe::Net net_ = new caffe::Net("..."). It seems like the the caffe's construct function was not invoked at all. So I doubt the size of stack was overflow or the program was failed to link against the libcaffe.so.
Could you give me some advice ? Thank you a lot !
您好 有个问题想请教一下您, 就是我使用您的提供API的实现了对视频进行检测模型的修改 开始也可以正常的运行 但是过一段时间内存会突然增加 然后就检测不到目标了 未修改之前使用原版caffe是没有内存问题的。问一下您提供的API除了destory那个函数之外 还有其他地方需要的手动释放内存的吗? 谢谢。
I Know caffe could be installed in TK1, but when I install mini-caffe hit this issue:
/usr/lib/gcc/arm-linux-gnueabihf/4.8/include/stddef.h(432): error: identifier "nullptr" is undefined
I tried to solve this problem by add : list(APPEND CUDA_NVCC_FLAGS --compiler-options "-std=c++03")
to Cuda.cmake but hit this issue:
/usr/include/c++/4.8/bits/c++0x_warning.h:32:2: error: #error This file requires compiler and library support for the ISO C++ 2011 standard. This support is currently experimental, and must be enabled with the -std=c++11 or -std=gnu++11 compiler options.
When using minicaffe in my program, it continuously print LOG(INFO) message like this
"""
[18:07:54] ~/GitHub/mini-caffe/src/util/upgrade_proto.cpp:35: Attempting to upgrade input file specified using deprecated input fields: ./config/deploy.prototxt
[18:07:54] ~/GitHub/mini-caffe/src/util/upgrade_proto.cpp:38: Successfully upgraded file specified using deprecated input fields.
[18:07:54] ~/GitHub/mini-caffe/src/util/upgrade_proto.cpp:40: Note that future Caffe releases will only support input layers and not input fields.
"""
These messages are not useful for me now, and slow down the whole program running.
I have tried some methods to change GLOG level, such as set GLOG_minloglevel to 2, etc
But the printing is still the same.
So I wonder how to forbid this print screen, without modifying src code of mini-caffe.
I compile the minicaffe as below:
mkdir build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release -DUSE_CUDA=ON -DUSE_CUDNN=ON
make
And I have already intsalled the cudnn.But a problem was occured:
[ 0%] Building NVCC (Device) object CMakeFiles/cuda_compile.dir/src/layers/cudnn/cuda_compile_generated_cudnn_bn_layer.cu.o
/home/lgz/mini-caffe/src/layers/cudnn/././cudnn.hpp(97): error: too few arguments in function call
1 error detected in the compilation of "/tmp/tmpxft_00003fb4_00000000-7_cudnn_bn_layer.cpp1.ii".
CMake Error at cuda_compile_generated_cudnn_bn_layer.cu.o.cmake:266 (message):
Error generating file
/home/lgz/mini-caffe/build/CMakeFiles/cuda_compile.dir/src/layers/cudnn/./cuda_compile_generated_cudnn_bn_layer.cu.o
What's the matter ?
What version of cudnn are you using? I can't compile mini-caffe on the TX2
error:
mini-caffe/src/layers/cudnn/././cudnn.hpp(97): error: too few arguments in function call
Hi:
I run a program which linked against mini-caffe and I compiled the mini-caffe in both cpu and gpu sytles. But the result is weird. It cost 47ms to finish the task in cpu version but cost 170ms in gpu version.Besides , some log message were printed to screen like:
[14:05:15] /home/lgz/mini-caffe/src/syncedmem.cpp:275: [CPU] Requested 36.8 K, Get 49 K
[14:05:15] /home/lgz/mini-caffe/src/syncedmem.cpp:275: [CPU] Requested 73.5 K, Get 98 K
although they get the same result,the performance of gpu version made me puzzled. is it normal ? I know much parallelism is needed to use gpu.If the scale of my problem is too small ?? how to explain this ?
In minicaffe I couldn't find c++ API like this: net->input_blobs() , net->output_blobs(). In fact, I need this API;
你好我遇到的错误如下:>LINK : fatal error LNK1104: 无法打开文件“Debug\caffe.lib”。
不应该是编译生成caffe.lib么?为什么在编译过程中需要调用caffe.lib这个库呢。谢谢~~
Hi, I get a problem when I run your mini caffe example on arm(raspberry pi 3 b):
./ex
detection time: 346.662
face1 keypoints time: 88.37
face2 keypoints time: 83.353
face3 keypoints time: 83.481
face4 keypoints time: 83.531
face5 keypoints time: 83.623
detect number: 5
sleep time: 3000.29
*** Error in `./ex': double free or corruption (!prev): 0x019fc6f0 ***
Aborted
it occurs in main function when return;
I also have ran MTCNN with your mini caffe, but facing the same problem:
pi@raspberrypi:~/MTSrc/build $ ./MTCNN ../ ../test2.jpg
Detect 431X450 Time Using CPU: 2597.32
*** Error in `./MTCNN': double free or corruption (!prev): 0x00de2b60 ***
Aborted
How to solve it?
Hello,
Generally, page-locked host memory has higher bandwidth than pageable host memory when transferring between CPU and GPU. However, in the current implementation of SyncedMemory, host memory is allocated as pageable. Is there any reason for not using page-locked host memory? Thank you!
page-locked host memory references:
In the blob.cpp: reshape function,we should allocate shape.sizesizeof(int) instead of KMaxBlobAxessizeof(int).
Is that right ?
mtcnn need net_input_blobs_ and net_output_blobs_ but minicaffe not include, how change to mtcnn?
您好:
minicafffe默认的好像只是编译了一种计算能力的nv代码,我希望指定的或者全部的nv代码应该怎么修改cmake ?
hello:
I have read your examples and almost all the nets were created in the stack instead of heap. But I alloc the net in the heap memory。Actually,it's ok worked on X86 linux,but the segmentation fault was occurred when destruct the net worked on arm linux. The code is totally same,what make this different ?
Successfully built rfc executable file, but when runing throw this error. What is this about?
Hello, I'm a fresher in android develop and I have developed some neural networks used c++ program language in x86\ubuntu OS. Now I have build mini-caffe to android, I want to know if my c++ programs needed modify.
Thank you!
在CPU上运行SSD MobileNet内存占用900多M,而用Opencv的DNN模块来运行,内存200多M,差别为什么这么大呢
I compare the resnet from your run_test.cpp.
But the performance is like below. The speed drop down than caffe.
Any ideas?
I'm useing the newest caffe with cudnn 5.1.5.
Thanks
你好。
我已经按你的说明,在vs工具编译文件:
cpu的编译成功。
cuda的编译成功。
cuda+cudnn的编译出现如下错误:

版本为cuda8.0 + cudnn 5.1
请问这是什么情况??
你好,问下在mini-caffe中common.hpp中有Caffe这个类,为什么找了半天没看到在哪里有用啊,还有这个mini-caffe的多线程是怎么样的啊?就是在不同的线程中调用用CaffeNetCreate初始化了的net会怎么样,会和BVLC/caffe#4595 中一样吗?
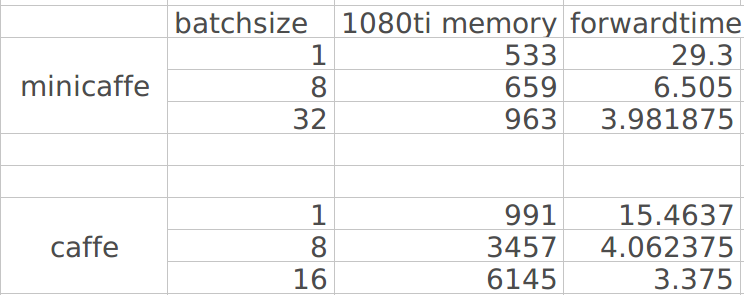
Caffe currently consumes too much memory during the Forward phase. It's mainly because the internal temporary buffer held by the Layer. e.g Convolution Layer need to cache im2col result for gemm operation. These temporary buffer is not shared between layers which causing too much memory usage. Second, since we don't perform backward operation, network internal buffer can also be reused or freed as long as no other layer needs it.
Mini-Caffe should change this situation without breaking any high level API exposed in include (maybe add some APIs).
Some ideas.
Layer who needs temporary memory should requests memory from a global memory source manager. The Manager itself hold the data and borrow the memory buffer to which requests. A memory pool can be implemented or just reuse the same memory and resize if request is too big. The network internal buffer can also be requested through the manager but need to track the dependency of this named blob, return the memory to manager when no other layer needs it. This strategy comes within every Forward phase.
Since Caffe network graph is static, we can plan the memory before forwarding the graph. Some Layer API changes will be helpful. Layer itself should only gives network the memory size it needs and let network holds the memory and borrow it to the layer during Forward. This includes bottom, top and temporary memory. Change Reshape function of every layer. Counting the dependency of network internal blobs, plan the memory and reuse the internal blobs. This strategy comes before every Forward phase.
Hi:
用mini-caffe编译mobile-ssd时,遇到“caffe.LayerParameter has no field named"permute_param"错误,
请问怎么修改?
谢谢
I install the miniCaffe with the commends listed in readme.md and my OS is ubuntu.Then I encounter a problem like this:
[ 96%] Linking CXX executable run_net
/usr/bin/ld: CMakeFiles/run_net.dir/tests/run_net.cpp.o: undefined reference to symbol 'pthread_create@@GLIBC_2.2.5'
//lib/x86_64-linux-gnu/libpthread.so.0: error adding symbols: DSO missing from command line
collect2: error: ld returned 1 exit status
CMakeFiles/run_net.dir/build.make:95: recipe for target 'run_net' failed
make[2]: *** [run_net] Error 1
CMakeFiles/Makefile2:104: recipe for target 'CMakeFiles/run_net.dir/all' failed
make[1]: *** [CMakeFiles/run_net.dir/all] Error 2
Makefile:83: recipe for target 'all' failed
make: *** [all] Error 2
I know nothing about cmake. Could anyone help me to solve this problem ?

what is wrong with it?
I found that I cannot use release version of caffe.dll and caffe.lib when I try to debug my project. It is a good idea to set postfix d to distinguish them just like opencv does.
set(CMAKE_DEBUG_POSTFIX "d" CACHE STRING "Set debug library postfix")
@luoyetx thanks for your nice work!the code is really simplified for caffe inference.
and there is a question:
when I use the time count:
clock_t start = clock();
clock_t end = clock();
float time = (float)(end - start) / CLOCKS_PER_SEC;
the time I get is about 1000ms,but when I use profiler in the mini-caffe,the time I get is about 250ms,I know the clock() is not so accurate,and the time it get is about twice of profile,but why I get four times?
请问这个数学卷运算库,有没有32位的lib,和dll啊,能发我一份么,谢谢了。[email protected]
After I updated the mini-caffe, there is a strange thing:
How to reproduce:
I have tried to roll back it to "build with CUDA9 and cuDNN7", it will be ok, so this bug should be imported after this version, I will test other version if I have time.
Hello,
Why the GPU is used when I didn't invoke caffe::SetMode(caffe::GPU,0) in my program ? Although I complied it with options -DUSE_CUDA=ON -DUSE_CUDNN=ON, the value of mode_ is Caffe::CPU and it should work in CPU style (I get it from common.cpp). In my thought,even though I complied it with cuda and cudnn on, the mode is still Caffe::CPU if I didn't invoke the SetMode function and GPU should not be occupied (I check it with NVIDIA-SMI).
Hello,
I have a class like:
class A {
private:
caffe::Net* net_;
}
The constructor like:
A:A(){
net_ = new caffe::Net("**.prototxt");
}
A weird question was occurred:
When I use the class A like:
A = new A();
Everything is OK.
But when I use the class A like:
A a;
A crash happened ! After I run forward of net, I get a nan result.
Hello, I use command "cmake .. -DUSE_CUDA=ON -DUSE_CUDNN=ON" to use gpu, but only have a little speed up, not same as caffe. This is the result:
minicaffe cpu : 51 ms. gpu: 44ms
caffe cpu: 78ms gpu: 9ms
I know caffe to use gpu should add "caffe.set_mode_gpu()" in source file, how about minicaffe ?
Do you make opt in forward_cpu_gemm , why you program run fast than caffe ?
Thank you!
how to modify the cuda.cmake to find cuda10.
tks
I want to run the example in the example fold,But after compiled the program said no caffemodel.How can I download this caffemodel file?
There is no reshape() before real layer to do forward.
This change does not support faster-rcnn because this kind of network will reshap top layer by down layer at runtime.
I think this feature should be considered. Thanks.
Thank you for sharing the code. Could you tell me how to add a new layer in min-caffe? Is it the same as caffe?
the cpu mode is oK; But the gpu mode gets much error:
.
.
.
.
/usr/include/c++/4.8/cmath(278): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(278): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(278): error: expected a ";"
/usr/include/c++/4.8/cmath(297): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(297): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(297): error: expected a ";"
/usr/include/c++/4.8/cmath(328): error: "constexpr" is not a function or static data member
/usr/include/c++/4.8/cmath(337): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(337): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(337): error: expected a ";"
/usr/include/c++/4.8/cmath(356): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(356): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(356): error: expected a ";"
/usr/include/c++/4.8/cmath(375): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(375): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(375): error: expected a ";"
/usr/include/c++/4.8/cmath(406): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(406): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(406): error: expected a ";"
/usr/include/c++/4.8/cmath(443): error: inline specifier allowed on function declarations only
/usr/include/c++/4.8/cmath(443): error: variable "std::constexpr" has already been defined
/usr/include/c++/4.8/cmath(443): error: expected a ";"
Error limit reached.
100 errors detected in the compilation of "/tmp/tmpxft_00005df7_00000000-7_math_functions.cpp1.ii".
Compilation terminated.
CMake Error at cuda_compile_generated_math_functions.cu.o.cmake:264 (message):
Error generating file
/home/methods/mini-caffe-master/build_gpu/CMakeFiles/cuda_compile.dir/src/util/./cuda_compile_generated_math_functions.cu.o
make[2]: *** [CMakeFiles/cuda_compile.dir/src/util/./cuda_compile_generated_math_functions.cu.o] Error 1
make[1]: *** [CMakeFiles/caffe.dir/all] Error 2
make: *** [all] Error 2
I found mini-caffe running speed is slower than speed of official version in CPU mode. It blame to conv layer in figure below. Can anyone give some tip that why conv layer will be slow?
left: mini-caffe time. right: official caffe time. run in win10 vs2013.

what is the error:
[100%] Linking CXX executable run_net
/usr/bin/ld: CMakeFiles/run_net.dir/tests/run_net.cpp.o: undefined reference to symbol 'pthread_create@@GLIBC_2.2.5'
//lib/x86_64-linux-gnu/libpthread.so.0: error adding symbols: DSO missing from command line
collect2: error: ld returned 1 exit status
CMakeFiles/run_net.dir/build.make:99: recipe for target 'run_net' failed
make[2]: *** [run_net] Error 1
CMakeFiles/Makefile2:141: recipe for target 'CMakeFiles/run_net.dir/all' failed
make[1]: *** [CMakeFiles/run_net.dir/all] Error 2
Makefile:83: recipe for target 'all' failed
I have the following error:
e:\Projects\DeepLearning\mini-caffe-master\src\caffe\util\upgrade_proto.cpp(196): error C2660: 'caffe::ConvolutionParameter::set_pad': Function does not accept one input argumente
Could you please help me?
你好,我有个问题很困惑:
[在新的版本中,在网络初始化的时候就规划好blobs_中的blob指针之间的关系,与forward过程中根据blob_life_time_动态回收MemBlock到MemPool中有什么区别啊?我用tools/parse_mem.py的分析结果好像都差不多的啊?
宏REGISTER_LAYER_GREATOR从定义上看好像是申明了一个静态的函数,但是我没有找到这个静态函数的具体实现,只是见到这个宏产生的静态函数会在层的creator创建后会被调用,百思不得其解,还请作者帮忙解答,谢谢!
D:\mini-caffe\include\caffe/logging.hpp:211: [17:22:10] D:\mini-caffe\src\syncedmem.cpp:148: Check failed: error == cudaSuccess (29 vs. 0) driver shutting down
Hi,
When i create a new caffe::Net object in a Thread the memory is not freed.
Below example without Thread works fine and frees memory:
int main()
{
for(int i=0;i<10;i++)
{
caffe::Net* cnn = new caffe::Net(("deploy.prototxt"));
delete cnn;
}
std::cin.ignore();
return 0;
}
The below example using Threads doesn't free memory
void threadWork()
{
caffe::Net* cnn = new caffe::Net(("deploy.prototxt"));
delete cnn;
}
int main()
{
for(int i=0;i<10;i++)
{
std::thread t1(threadWork);
t1.join();
}
std::cin.ignore();
return 0;
}
Do you know what is causing this?
Hi, guys. Are there any implementations of LSTM layer? I had tried to add the LSTM layer but failed.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.