Fall: Not Yet Another Parser Generator
This is a work in progress hobby project. If you are looking for a production ready parser generator for Rust, consider pest, lalrpop or nom. If you are looking for a production grade IDE-ready parser generator, take a look at Grammar Kit or Papa Carlo. You might also find tree-sitter to be interesting.
Scope
The ambitious goal is to create a parsing framework, suitable for tools interacting with the source code, such as editors, IDEs, refactoring tools or code formatters.
Design constraints
The syntax tree must not be abstract, it should include all the whitespace and comments and be a lossless representation of the original text.
All the languages should share the same syntax tree data structure. That is, it should be possible to write non-generic code for processing syntax of any language. It should also be possible to provide a single C API to interact with a syntax tree of any language.
Parser should be able to deal with incomplete input gracefully. It should be able to recognize syntactic constructs even if some required elements are missing and it should attempt to resynchronize input after an error.
Non goals
Parser need not guarantee that the input grammar is unambiguous.
Parser need not guarantee sane worse case performance for any grammar. Nevertheless, it is expected that most sane programming languages could be parsed efficiently.
Nice to haves
Implementing parsers should be interactive: user should see the grammar, the example input and the parse tree simultaneously.
Parsing should be incremental: changing something inside the code block should cause only the block to be reparsed.
Parsing should be fast: even with incrementally, there are certain bad cases (unclosed quote), where one has to reparse the whole input.
Code structure
Tree Model
The entry point is fall/tree/src/node/mod.rs. It defines the structure of the syntax tree which roughly looks like this:
type NodeType = 32;
struct File { ... }
#[derive(Clone, Copy)]
struct Node<'f> {
file: &'f File,
...
}
impl<'f> Node<'f'> {
fn ty(&self) -> NodeType { ... }
fn parent(&self) -> Node<'f> { ... }
fn children(&self) -> impl Iterator<Item=Node<'f'>> { ... }
fn text_range(&self) -> (usize, usize) { ... }
fn text(&self) -> &str { ... }
}The main element is a non-generic Node which is a Copy handle representing some range in the input text, together
with its type (which is just an integer constant) and subranges. It is the main API that the consumers of the syntax
tree would use.
While having an untyped API is needed for working with several different languages together, for each particular language a typed API is easier to work with. You can layer a typed API on top of Nodes easily, using the following pattern
struct RustFunction {
node: Node
}
impl RustFunction {
fn new(node: Node) -> RustFunction {
assert_eq!(node.ty(), RUST_FUNCTION);
RustFunction { node: node }
}
fn name(&self) -> &str {
let ident_child = child_of_type_exn(self.node, IDENT);
ident_child.text()
}
}Such typed wrappers are generated automatically. See fall/tree/src/ast.rs and fall/tree/visitor.rs for a generic
implementation of this pattern and how it can be used to travers trees in a type-safe manner (imo, this is the most
beautiful piece of code here so far:) ). It's also interesting that you can create a single typed wrapper around
several node types, which allows to express an arbitrary [non-]hierarchy of node types. See AstClass for details.
Parsing
By itself, fall_tree does not impose any particular way of constructing trees. It should be possible to connect it to
a hand written, a generated or an external parser. Currently a specific parser generator is the main way to create
trees. fall/parse contains runtime for the parser (currently, parser is mostly interpreted), and fall_/gen
contains the corresponding generator, which generates a lexer, a parser and the AST. The parser is roughly a
"hand-written recursive descent" plus (to be implemented) Pratt parser for expressions. Some call this style
of parsing PEG.
Grammar
To learn the details of the grammar spec, it's best to read the (literalish) grammar of the fall language itself
Other examples are also in the lang subdirectory, look for the *.fall files.
Here are some interesting highlights of the grammar.
The <commit> specifier allows parser to recognize incomplete syntactic constructs. For example, for the
rule function {
'fn' ident <commit> '(' fn_args ')' '->' type expr
}
the parser would recognize fn foo as an incomplete function, and would give the following tree:
FUNCTION
FN
IDENT "foo"
ERROR '(' expected
The <with_skip to_skip rule> function allows to skip some tokens to resynchronize input. For example,
<with_skip 'fn' function> would skip the tokens (creating an error node) until the fn keyword, and then launch
function parser.
The <layer cover contents> rule allows to "approximately" parse a fragment of input, which helps with error recovery
and incremental and lazy reparsing. Let's look at the concrete example:
pub rule block_expr {
'{' <layer block_body {seq_expr? {'|' seq_expr}*}> '}'
}
rule block_body { <rep balanced> }
rule balanced {
'{' <commit> block_body '}'
| <not '}'>
}
Here, block_body parses an arbitrary sequence of tokens with the sole restriction that { and } are balanced. When
parsing the innards of block_expr, the parser would first find the borders of the bock_body, and than it would parse
the contents of the block_body with the more detailed {<opt seq_expr> <rep {'|' seq_expr}>}. Crucially, if the
detailed rule fails, than all the remaining tokens inside the block body will be marked as an errors, but the parsing
outside of the blocks will continue as usual. Moreover, if the user types anything inside the block, the parser will
check if the block's borders do not change (this would be the case unless { or } is typed) and if it is the case,
it will only reparse the block itself.
The test blocks allow to quickly get feedback about the current grammar. You can write something like
pub rule struct_def {
<opt 'pub'> 'struct' <commit> ident
'{' <layer block_body struct_field*>'}'
}
test r"
struct Foo {
a: A,
pub b: B,
}
"
and then run cargo run --bin gen --example rust.fall to render the syntax tree of the example block. watch.sh
wraps this into convenient "rerender example on save" script. In the VS Code plugin, you can place cursor on the example
and run a Quick Fix (Ctrl+. by default) to render the syntax tree of the test.
VS Code plugin
There is a VS Code plugin in the code director, which demonstrates how fall can be used from an editor. The plugin
currently supports only the fall language itself. All features are implemented in Rust in an editor agnostic way in
lang/fall/src/editor_api.rs. It should be possible to hook up this code with any editor, by either dynamically or
statically linking in the Rust crate, or by wrapping it into an RPC.
Current status
Something works :)
Using fall, I've implemented a more-or-less complete Rust parser (see lang/rust/syntax) and a library with various IDE
features implemented (see lang/rust). This library is then used to implement a VS code plugin for rust (see code/rust,
install by running just code-rust). Features include
- extend selection (pressing
ctrl+shift+rightwill expand selection precisely, covering larger syntactic structures, and not just braced blocks) - parse-tree based syntax highlighting
- breadcrumbs (at the bottom of the screen, current function/impl/mod etc are shown)
- file struture (
ctrl+shift+oshows a list of symbols in files) - navigate to symbol (
ctrl+Tshows the list of symbols in the current project. This is CTAGS done right, with parser instead of regex, and with incremental update on editing. Indexingrust-lang/rustrepo takes about 30 seconds, using single core). - rudimentary postfix templates (
foo().pd$expands toeprintln!("foo() = {:?}", foo)) - rudimentary code-actions support (
ctrl+.on a struct defintion suggests adding animplwith all generics and lifetimes filled-in)
In general the plugin is definitely unpolished, but is workable. Reliable symbol navigation, breadcrumbs and extend selection are particularly useful features! However, if you like them, just use IntelliJ Rust plugin ;)
And of course the VS code plugin for fall is implemented in fall itself. See lang/fall/syntax for parser,
lang/fall/src/analysis for "brains", lang/fall/src/editor for IDE library and code/fall for the actual plugin.
just code-fall installs the plugin.
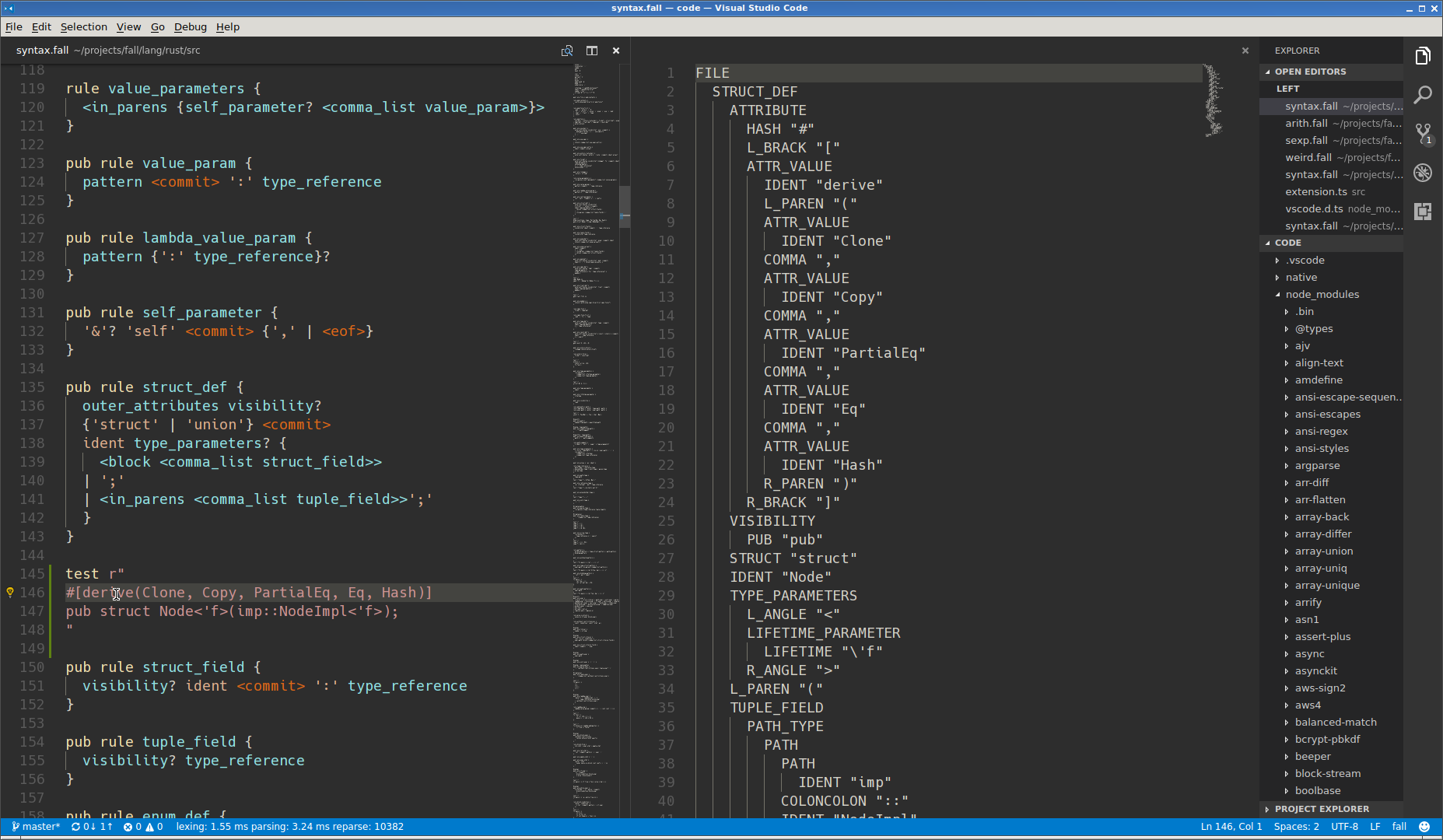
Here's a screenshoot showing Rust grammar, inline test and the resulting syntax tree.
Contributing
At the moment, there's no clear plan and set of issues to work on, however there's a lot of interesting projects to do :)
-
Writing grammars and tests for more languages
-
Actually exposing a C-API and integrating parser with Emacs and Vim
-
Using xi-rope instead of string
-
Implementing incremental relexing
-
Improving the VS Code plugin
We use just to automate code generation tasks:
-
generate-parsers-- updates the generated parser code -
update-test-data-- fixes expected syntax trees in tests after grammar update -
code-rust,code-fall-- builds VS Code extension