团队博客项目
每篇文章以本项目 ISSUES 形式发布。
文章需要注意:
- 文章内请不要出现项目相关信息、人员名称、账号密码等敏感信息;
- 翻转载文章请注明作者、链接;
- 不要大段大段贴代码或者图片 :)
芦叶满汀洲,寒沙带浅流。二十年重过南楼。柳下系船犹未稳,能几日,又中秋。 黄鹤断矶头,故人今在否?旧江山浑是新愁。欲买桂花同载酒,终不似,少年游。
团队博客项目
每篇文章以本项目 ISSUES 形式发布。
文章需要注意:




















All of the below properties or methods, when requested/called in JavaScript, will trigger the browser to synchronously calculate the style and layout*. This is also called reflow or layout thrashing, and is common performance bottleneck.
elem.offsetLeft, elem.offsetTop, elem.offsetWidth, elem.offsetHeight, elem.offsetParentelem.clientLeft, elem.clientTop, elem.clientWidth, elem.clientHeightelem.getClientRects(), elem.getBoundingClientRect()elem.scrollBy(), elem.scrollTo()elem.scrollIntoView(), elem.scrollIntoViewIfNeeded()elem.scrollWidth, elem.scrollHeightelem.scrollLeft, elem.scrollTop also, setting themelem.focus() can trigger a double forced layout (source&l=2923)elem.computedRole, elem.computedNameelem.innerText (source&l=3440))window.getComputedStyle() will typically force style recalc
window.getComputedStyle() will force layout, as well, if any of the following is true:
min-width, min-height, max-width, max-height, width, heightaspect-ratio, min-aspect-ratio, max-aspect-ratiodevice-pixel-ratio, resolution, orientation , min-device-pixel-ratio, max-device-pixel-ratioheight, widthtop, right, bottom, leftmargin [-top, -right, -bottom, -left, or shorthand] only if the margin is fixed.padding [-top, -right, -bottom, -left, or shorthand] only if the padding is fixed.transform, transform-origin, perspective-origintranslate, rotate, scalegrid, grid-template, grid-template-columns, grid-template-rowsperspective-originmotion-path, motion-offset, motion-rotation, x, y, rx, rywindow.scrollX, window.scrollYwindow.innerHeight, window.innerWidthwindow.getMatchedCSSRules() only forces styleinputElem.focus()inputElem.select(), textareaElem.select()mouseEvt.layerX, mouseEvt.layerY, mouseEvt.offsetX, mouseEvt.offsetY (source)doc.scrollingElement only forces stylerange.getClientRects(), range.getBoundingClientRect()More on forced layout section below covers everything in more detail, but the short version is:
for loops that force layout & change the DOM are the worst, avoid them.rAF, scroll handler, etc), when the numbers are still identical to the last time layout was done.
updateLayoutIgnorePendingStylesheets - GitHub search - WebKit/WebKit FrameNeedsReflow - mozilla-central searchUpdateStyleAndLayoutIgnorePendingStylesheets - Chromium Code SearchUpdateStyleAndLayoutTreeIgnorePendingStylesheets - Chromium Code SearchCSS Triggers is a related resource and all about what operations are required to happen in the browser lifecycle as a result of setting/changing a given CSS value. It's a great resource. The above list, however, are all about what forces the purple/green/darkgreen circles synchronously from JavaScript.
Updated slightly Feb 2018. Codesearch links and a few changes to relevant element properties.
float 属性设计的目的就是为了实现文字环绕效果。这种文字环绕,主要就是指文字环绕图片显示的效果。所以 float 并不是用来实现复杂的页面布局的,况且,使用 float 会带来一些意想不到的结果。例如 导致父元素的高度塌陷。
float 具有哪些特性这里的包裹性由两部分组成:“包裹” 和 “自适应性”。也就是说 float 元素的宽度就是 border-box(包裹),同时这个宽度总是小于等于父容器的宽度(自适应)。但是有一种情况比较例外,就是 float 元素内部都是一连串的数字或英文字母,那么这个时候元素的宽度就会超过父容器的宽度
<div class="demo">
<span>xsdhdfdsfdsfdsfdsfdsfdsfdsfsdfdsfdsfdsfdsfdsfdsfg</span>
</div> .demo {
width: 200px;
height: 100px;
margin: 30px;
font-size: 14px;
line-height: 1.5;
border: 1px solid #ddd;
}
.demo span {
float: left;
} <div class="demo">
<img src="./static/img/timg.jpg" alt="" height="50">
<span>对双方都十分舒服的沙发舒服的沙发都十分的是非得失</span>
</div> .demo {
width: 200px;
height: 100px;
margin: 30px;
font-size: 14px;
line-height: 1.5;
border: 1px solid #ddd;
}
.demo span {
float: left;
}会将元素的 display 变成 block 或者 table
会将元素从正常的文档流中脱离,float 元素的布局和正常元素布局是一样的,但是不会占据空间位置
<div class="demo">
<div style="height: 50px; background: #ccc"></div>
<div class="float"></div>
</div>
<div class="demo">
<div class="float"></div>
<div style="height: 50px; background: #ccc"></div>
</div>第一个 demo 中,float 元素在正常元素的后面,表现为 float 在下面,和正常布局一样
第二个 demo 中,float 元素在正常元素的前面,表现为 float 和正常元素重合了,这是因为 float 元素不占据流的空间位置导致的。
margin 合并float 作用机制我们知道 float 属性设计的目的就是为了实现文字环绕效果。但是又该如何实现这种效果呢??父元素的高度塌陷??对,就是这个特性。但这只是其中的一个,还有另外一个条件,我们先看看下面的 demo
<div>
<img src="./static/img/timg.jpg" alt="" class="float">
</div>
<p>房间划分为花椒粉胡椒粉看韩剧晚饭后恢复可望恢复肌肤健康护肤课和我分开和晚饭健康无烦恼接口和方法尽快恢复健康护肤</p>“高度塌陷” 只是让跟随的内容可以和浮动的元素在一个水平线上,但这只是实现 “环绕效果” 的条件之一,想要实现正真的 “环绕效果”,就需要另外一个条件 “行框盒子和浮动元素的不可重叠性”,也就是 “行框盒子如果和浮动元素的垂直高度有重叠,则行框盒子在正常定位状态下只会跟随浮动元素,而不会发生重叠”
<div class="demo">
<div class="float">
</div>
<div style="background: #ccc">sdhjfhfh搜附近的健身房回复是否会尽快回复空间划分双方还将恢复健康回复快回复快回复客户</div>
</div> .demo {
width: 200px;
height: 100px;
margin: 30px;
font-size: 14px;
line-height: 1.5;
border: 1px solid #ddd;
}
.float {
float: left;
width: 100px;
height: 40px;
background: #f80;
opacity: .1;
}从上面的这个 demo 的表现来看,完全符合 “行框盒子和浮动元素的不可重叠性”,同样实现了文字环绕。
注意: 只有行框盒子和浮动元素不发生重叠,行框盒子外部的父元素 (“块级元素”)完全和浮动元素重叠了。
还有一种情况就是 “父元素的高度塌陷”,那么如果我们设置父元素的 height 呢,不就可以避免这种情况了吗??答案是:可以的,但是必须要保证父元素的高度必须完全大于等于 float 的元素,否则还是没有办法避免
<div style="height: 35px;">
<img src="./static/img/timg.jpg" alt="" class="float">
</div>
<div>房间划分为花椒粉胡椒粉看韩剧晚饭后恢复可望恢复肌肤健康护肤课和我分开和晚饭健康无烦恼接口和方法尽快恢复健康护肤</div>上面的 demo 就完全解释了这中现象
有种情况,就是和浮动元素相邻的是 "内联元素" 的时候,而且内联元素还存在换行的情况,那么这个时候 float 元素如何定位??
<div style="height: 35px;">
房间划分为花椒粉胡椒粉看韩剧晚饭后恢复可望恢复肌肤健康护肤课和我分开和晚饭健康无烦恼接口和方法尽快恢复健康护肤
<span class="float">xxxx</span>
</div>
<div style="height: 35px;">
<span class="float">xxxx</span>
房间划分为花椒粉胡椒粉看韩剧晚饭后恢复可望恢复肌肤健康护肤课和我分开和晚饭健康无烦恼接口和方法尽快恢复健康护肤
</div>在 CSS 世界中, float 元素的 “浮动参考” 是 “行框盒子”,也就说 float 元素在当前 “行框盒子” 内定位。在强调一遍,是 “行框盒子”,不是外面的包含块盒子之类的东西,因为 CSS 浮动设计的初衷仅仅是实现文字环绕效果。
none - 默认值
left - 左侧抗浮动
right - 右侧抗浮动
both - 两侧抗浮动
官方对 clear 的解释是: 元素盒子的边不能和前面的浮动元素相邻。
对于设置了 clear 属性的元素只是对自身产生影响,而不是让其他的元素如何如何
<div style="height: 200px;">
<div class="float">1</div>
<div class="float">2</div>
<div class="float clear">3</div>
<div class="float">4</div>
<div class="float">5</div>
<div class="float">6</div>
<div class="float">7</div>
<div class="float">8</div>
</div> .float {
float: left;
width: 50px;
height: 40px;
background: #f80;
opacity: 1;
margin-left: 10px;
}
.clear {
clear: both;
}上面的这个 demo 表现为两行显示,第三个元素设置了 clear。但是这只能让自身不能和前面的浮动元素相邻,注意这里 “前面的” 三个字,也就是说,他对后面的浮动元素是不影响的。
clear 属性只有在块级元素中才能有效,而 ::after 等伪元素默认都是内联水平,这就是为什么需要借助伪元素清楚浮动时需要设置 display: table | block 的原因。
如果一个元素具有 BFC,那么它内部的子元素再怎么翻江倒海,都不会影响到外部的元素。所以,BFC 元素是不可能发生 margin 合并的,应为 margin 的合并会影响到外面的元素;BFC 元素还可以用来清除浮动的影响,因为如果不清楚,字元素浮动,则父元素高度塌陷,也会影响到外面元素的布局。
<html> 根元素
float 值不为 none
overflow 值不为 visible
display 值为 table-cess、table-caption、inline-block 中的任何一个
postion 值为 fixed 或 absolute
我们在之前的章节就已经使用过 BFC 了。比如说 双飞翼布局/左边自适应/右边自适应
<div style="height: 100px; background: #455">
<img src="./img/timg.jpg" alt="" style="width: 100px; float: right">
<div style="overflow: auto; background: #ccc">左边自适应</div>
</div>
<div style="height: 100px; background: #455">
<img src="./img/timg.jpg" alt="" style="width: 100px; float: left">
<div style="overflow: auto; background: #ccc">右边自适应</div>
</div>overflow了解 overflow-x 和 overflow-y
visible - 默认值
hidden - 剪切
scroll - 滚动区域一直存在
auto - 不足以滚动时没有滚动条,可以滚动时滚动条出现
注意: 如果 overflow-x、overflow-y 属性值中有一个是 visible,而另一个是 scroll/hidden/auto 其中的一个 。则 visible 的样式就会变成 auto。也就是说,除非 overflow-x | overflow-y 的属性值都是 visible,否则 visible 会当成 auto 来解析。
简单说就是,永远不可能实现一个方向溢出剪切或者滚动,另一个方向内容溢出显示的效果
::-webkit-scrollbar { // 血槽宽度
width: 8px;
height: 8px;
}
::-webkit-scrollbar-thumb { // 滚动条样式
background: rgba(0, 0, 0, .3);
border-radius: 6px;
}
::-webkit-scrollbar-track { // 背景槽样式
background: #ddd;
border-radius: 6px;
}
// 实现多行的 ...
.clamp {
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 2;
overflow: hidden;
}
// 实现单行的 ...
.clamp {
font-size: 14px;
text-overflow: ellipsis;
white-space: nowrap;
overflow: hidden;
}overflow 与 锚点定位锚点定位有两种情况
URL 地址中的锚链与锚点元素对应并有交互行为 <a href="#">top</a>点击的按钮就可以回到页面定位,这种 “#” 默认就直接回到顶部了。当然这种滚动行为没有过度效果,但是好处就是不依赖 JS 就可以实现。但是这种定位每次都是定位到浏览器可视区窗口的上边缘。
focus 的锚点元素处于 focus 状态 document.querySelector(‘.input’).focus();这种输入框在得到焦点的时候会自动定位到屏幕合适的位置(屏幕可视区之内摸个位置)
锚点定位也可以发生在普通的元素中,而且定位发生的行为是 “由内而外” 的。
<div style="overflow: auto; height: 150px; border: 1px solid #ddd">
<div style="height: 300px; background: red"></div>
<div id="title">title</div>
</div>
<a href="#title">title</a>“由内而外” 的意思是,如果我们点击了 title 按钮,<div> 元素内部先开始滚动,当元素 title 滚动到父元素可视区顶部的位置的时候,文档开始滚动,滚动到 title 元素的上边缘和屏幕上边缘对齐,这个时候就完成了。
注意: 元素设置了 overflow: hidden 也是可以 “滚动” 的,只是这个时候无法手动滑动滚动,而只能通过 JS 控制,或者锚点定位。
下面这个 demo 就是通过锚点实现的,每次定位都要滚动到可视区顶部。
<div class="wrapper">
<div class="list" id="list_1">1</div>
<div class="list" id="list_2">2</div>
<div class="list" id="list_3">3</div>
<div class="list" id="list_4">4</div>
</div>
<a href="#list_1">1</a>
<a href="#list_2">2</a>
<a href="#list_3">3</a>
<a href="#list_4">4</a> .wrapper {
width: 300px;
height: 200px;
background: #ccc;
white-space: nowrap;
overflow: hidden;
font-size: 0;
}
.list {
font-size: 14px;
display: inline-block;
width: 100%;
height: 200px;
background: #666;
}使用下面这种方式就可以完全避免上面的问题了
<div class="wrapper">
<div class="list">
<input type="text" class="input" id="list_1">
1111
</div>
<div class="list">
<input type="text" class="input" id="list_2">
2222
</div>
<div class="list">
<input type="text" class="input" id="list_3">
3333
</div>
<div class="list">
<input type="text" class="input" id="list_4">
4444
</div>
</div>
<label for="list_1">1</label>
<label for="list_2">2</label>
<label for="list_3">3</label>
<label for="list_4">4</label> .wrapper {
width: 300px;
height: 200px;
background: #ccc;
white-space: nowrap;
overflow: hidden;
font-size: 0;
}
.list {
font-size: 14px;
display: inline-block;
width: 100%;
height: 200px;
background: #666;
position: relative;
}
.input {
width: 100%;
border: none;
outline: none;
padding: 0;
position: absolute;
clip: rect(0 0 0 0);
}position: absolute当 absolute 和 float 同时存在时,float 属性就会失效。而且没有任何理由 absolute 和 float 同时使用。
absolute 和 float 存在很多共性,可以说是一对兄弟属性
块状化 - 和 float 一样,致使元素的 display 变成 block 或者 table
破坏性 - 这里指的是破坏正常的文档流特性。虽然 absolute 通过破坏正常的流来实现自己的特性,但是本身还是受普通的流体布局、位置甚至一些内联相关的 CSS 属性影响的
会计格式化上下文 BFC
包裹性
absolute 的包含块对于设置了绝对定位的元素而言,其 “包含块” 就是相对于第一个设置了 position 不为 static 的祖先元素计算的。实际上,“包含块” 应用的很多,不仅仅存在于绝对定位中
跟元素 <html> - 被称为 “初始包含块”,其尺寸等同于浏览器可是窗口的大小
对于其他元素,如果该元素的 position 是 relative 或者 static ,则 “包含块” 由其最近的块级父容器盒子的 content box 的大小
如果元素 position: fixed,则 “包含块” 就是 “初始包含块”
如果元素 position: absolute,则 “包含块” 由最近的 position 不为 static 的祖先元素建立
absolute 包含块有几个明显的差异内联元素可以作为 “包含块”
“包含块” 所在的元素不是父级块级元素,而是最近的 position 不为 static 的祖先元素或根元素
边界是 padding box 而不是 content box
一个绝对定位元素,没有任何 left/top/right/bottom 属性设置,并且其祖先元素全部都是非定位元素,其位置在什么地方??
absolute 是非常独立的 CSS 属性值,其样式和行为表现不依赖其他任何 CSS 属性就可以完成
<div style="width: 300px; height: 250px; background: url(./img/timg.jpg) no-repeat">
<img src="./img/timg.jpg" alt="" style="height: 50px; position: absolute;">
</div>上面的这个 demo 中 img 元素就处于左上角顶部位置
absolute 定位效果实现完全不需要父元素设置 position 就可以实现。我们把这种没有设置 left/right/top/bottom 属性值的绝对定位称为 “无依赖绝对定位”。很多场景下,“无依赖绝对定位” 要比使用 left/top 之类属性定位适用和强大。其除了代码简洁外,还有一个很棒的特性就是 “相对定位特性”。
<div class="wrapper">
<div class="item">
<label class="left">
<span class="red-icon">*</span>
邮箱
</label>
<div class="right">
<input type="text" class="input">
<span class="remark">xxxooo</span>
</div>
</div>
<div class="item">
<label class="left">
<span class="red-icon">*</span>
密码
</label>
<div class="right">
<input type="password" class="input">
<span class="remark">xxxooo</span>
</div>
</div>
<div class="item">
<label class="left">
<span class="red-icon">*</span>
手机号码
</label>
<div class="right">
<input type="password" class="input">
<span class="remark">xxxooo</span>
</div>
</div>
</div> .wrapper {
width: 300px;
margin: 20px auto 0;
}
.item {
height: 34px;
font-size: 14px;
line-height: 34px;
}
.item + .item {
margin-top: 10px;
}
.left {
float: left;
width: 70px;
}
.red-icon {
position: absolute;
width: 20px;
margin-left: -20px;
text-align: center;
color: red;
}
.right {
overflow: hidden;
}
.input {
display: inline-block;
width: 95%;
height: 34px;
box-sizing: border-box;
line-height: 20px;
padding: 6px 5px;
border: 1px solid #ddd;
border-radius: 4px;
background: #fff;
outline: none;
-webkit-appearance: none;
vertical-align: top;
}
.remark {
position: absolute;
color: red;
margin-left: 20px;
}注意: 上面的 input 宽度不能占满父容器,否则 remark 元素就会换行
虽然说元素 position: absolute 后的 display 计算值都是块状的,但是其定位的位置和没有设置 position: absolute 时候的位置相关。
<h1>
标题
<span class="follow">span</span>
</h1>
<h1>
标题
<div class="follow">div</span>
</h1> .follow {
position: absolute;
}
上面两个差别在于 “标题” 后面跟随的一个是 内联元素,一个是 块状元素。这个时候 span 显示在 “标题” 后面,div 显示在 “标题” 的下一行。
虽然此时无论是内联还是块级元素,display 计算值都是 bloc。但是它们的位置和没有设置 position: absolute 的时候一样,一个在前面一个在下面。
absolute 和 text-align <div style="height: 200px; background: #ccc; text-align: center">
<img src="./img/timg.jpg" alt="" style="height: 100px; position: absolute">
</div>实例中的图片确实收到了 text-align 的影响,但并不是 text-align 和 absolute 元素直接发生关系。其实这个时候 text-align 作用的是 “幽灵空白节点”。致使 “幽灵空白节点” 在容器盒子中居中展示,那么由于 <img> 是跟随 “幽灵空白节点” 的,所以图片的左边缘是和水平中线在一条线上对齐的。
overflow 和 absolute 元素的剪裁规则就是:绝对定位元素不总是被父级 overflow 属性剪裁,尤其是当 overflow 在绝对定位元素和其包含块之间的时候。"包含块" 在设置 overflow 元素之内或者就是设置 overflow 元素,绝对定位元素就会进行剪裁
包含块不在 overflow 元素之内,绝对定位元素就不会进行剪裁
注意:上面的这些限制对 position: fixed 都没有用。因为 fixed 的包含块是 <html>。除非是文档滚动
absolute 和 clipclip: rect(20px 30px 40px 50px)
意思就是:
距离画布上边缘 20px 的地方剪切一刀
距离画布左边缘 30px 的地方剪切一刀
距离画布上边缘 40px 的地方剪切一刀
距离画布左边缘 50px 的地方剪切一刀
中间的剪切区域就是最后我们看到的。如果要把一个元素全部剪切掉,参数全部设置为 0 ,就可以了
clip 还有一个好处就是,被剪切掉的元素还可以被爬虫给搜索到,这一点非常适合 SEO 优化。
absolute 流体特性当 absolute 遇到 left/right/top/bottom 属性的时候,absolute 元素才能真正变成绝对定位元素。
当我们只设置了一个方向的绝对定位时,另一个方向依然保持 “相对特性”
absolute 的流体特性,当一个绝对定位元素,其对立定位方向属性同时存在时,流体特性就会发生。
.fixed {
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
width: 200px;
height: 200px;
margin: auto;
}当元素具有流体特性的时候其 margin/border/padding/content 自动充满容器。所以这个时候 margin 设置 auto,就可以使上下左右平分两个方向的剩余空间了,从而实现了 水平垂直居中。
position: relative虽然说 relative/absolute/fixed 都能对 absolute 的 “包裹性” 以及 “定位” 产生限制,但只有 relative 可以让元素依然保持在正常的文档流中
relative 具有两大特性:一是相对自身;二是无侵入 <div class="relative"></div> .relative {
position: relative;
top: 0;
left: 0;
width: 200px;
height: 200px;
background: #f80;
}relative 的定位还有另外两点值得提相对定位元素的 left/right/top/bottom 的百分比值时相对于包含块计算的,而不是自身。这里的 “包含块” 其实就是父级块级元素。
top 和 bottom 这两个垂直方向的百分比值计算根 height 的百分比值是一样的,都是相对高度计算的。同时,如果包含块的高度是 auto,那么计算值是 0,偏移无效。也就是说,如果如元素没有设置高度或者不是 “格式化高度”,那么 relative 类似 top: 20% 的代码等同于 top: 0。
注意: relative 在使用时需要注意一个很重的问题,就是设置的元素会产生一个 “层叠上下文”,影响元素在层叠位置展现。所以使用时应该格外注意。
position: fixedfixed 定位,只说一点。就是“无依赖固定定位”。“无依赖固定定位” 和 “无依赖绝对定位” 相似。
fixed 后的 display 计算值都是块状的,其定位的位置和没有设置 position: fixed 时候的位置一样。
当元素的布局在首屏内,那么当文档滚动时,元素的不会随着屏幕滚动
当元素的布局不在首屏内,那么这个元素不可见,在屏幕之外。
symbol是js中7种基础数据类型之一(基础数据类型包括:number, string, boolean, null, undefined, bigint, symbol),symbol是在ECMAScript 2015 / ES6中新加入的。在JavaScript运行环境中,调用函数Symbol()可以动态地返回一个匿名且唯一的symbol类型的值。接下来,这篇文章会简单介绍一下Symbol构造函数,well-known symbols,全局symbol注册表这三部分内容。
Symbol()函数:构造一个symbol类型值并返回,该值唯一。
返回值:symbol类型值
它类似于内置的Object类,但不完全是一个构造器,因为它不支持new Symbol()这样的语法。
每一个从Symbol()函数返回的symbol值都是独一无二的,因为其唯一性,适合用作对象属性的标识符,使用Object.getOwnPropertySymbols() 以symbol数组的形式返回某个对象的所有symbol属性。
// Symbol()函数使用
const symbol1 = Symbol();
const symbol2 = Symbol(42);
const symbol3 = Symbol('foo');
console.log(typeof symbol1);
// expected output: "symbol"
console.log(symbol3.toString());
// expected output: "Symbol(foo)"
// 唯一性
console.log(Symbol('foo') === Symbol('foo'));
// expected output: false
const object1 = {};
// symbol用作对象属性的标识
object1[symbol1] = 'this is symbol1.';
object1[symbol2] = 'this is symbol2.';
object1[symbol3] = 'this is symbol3.';
// 获取某对象中所有的symbol属性
const objectSymbols = Object.getOwnPropertySymbols(object1);
console.log(objectSymbols.length);
// expected output: 3即内置symbol,用来表示内部语言行为,分为3种:迭代symbol,正则symbol,其他symbol。
Symbol.iterator是内置的迭代symbol,用来访问对象的@@iterator方法,该方法是对象默认迭代器的方法,可用于for...of循环,也可以说@@iterator为我们提供了重载of的方法。可迭代对象(String, Array, TypedArray, Map, Set, arguments对象等)拥有默认的@@iterator方法。对于不可迭代的Object,通过实现Object的@@iterator方法,就可以把不可迭代的对象转变为可迭代的对象。const iterable1 = new Object();
iterable1[Symbol.iterator] = function* () {
yield 1;
yield 2;
yield 3;
};
console.log([...iterable1]); // [1, 2, 3]Symbol.asyncIterator是内置的迭代symbol,用来访问对象的@@asyncIterator方法,该方法实现的是对象默认异步迭代器的方法,可用于for await...of循环。Symbol.match是内置的正则symbol,用于访问对象的@@match方法,该方法用来判断给定的值是否和某个字符串匹配,在使用String.prototype.match()时被调用。也就是说我们可以用@@match方法来实现自定义的匹配方法。class MyMatcher {
constructor(value) {
this.value = value;
}
[Symbol.match](string) {
var index = string.indexOf(this.value);
if (index === -1) {
return null;
}
return [this.value];
}
}
var fooMatcher = 'foobar'.match(new MyMatcher('foo')); // ['foo']
var barMatcher = 'foobar'.match(new MyMatcher('bar')); // ['bar']Symbol.matchAll是内置的正则symbol,用于访问对象的@@matchAll方法,该方法返回一个包括了所有匹配值的迭代器,在使用String.prototype.matchAll()时被调用。Symbol.replace是内置的正则symbol,用于访问对象的@@replace方法,该方法用来替换和某个字符串的子串匹配的部分,在使用String.prototype.replace()时被调用。class MyReplacer {
constructor(value) {
this.value = value;
}
[Symbol.replace](string, replacer) {
var index = string.indexOf(this.value);
if (index === -1) {
return string;
}
if (typeof replacer === 'function') {
replacer = replacer.call(undefined, this.value, string);
}
return `${string.slice(0, index)}${replacer}${string.slice(index + this.value.length)}`;
}
}
var fooReplaced = 'foobar'.replace(new MyReplacer('foo'), 'baz'); // 'bazbar'
var barMatcher = 'foobar'.replace(new MyReplacer('bar'), function () { return 'baz' }); // 'foobaz'Symbol.search用于访问对象的@@search方法,在使用String.prototype.search()时被调用。Symbol.split用于访问对象的@@split方法,在使用String.prototype.split()时被调用。Symbol.hasInstance用于判断某个对象是否为某个构造器的实例,通过instanceof被调用。class Array1 {
static [Symbol.hasInstance](instance) {
return Array.isArray(instance);
}
}
console.log([] instanceof Array1);
// expected output: trueSymbol.isConcatSpreadable用来访问对象的@@isConcatSpreadable属性,该属性为布尔值,用来配置一个数组对象在作为Array.prototype.concat()方法的参数时是否应该展开它的元素。var alpha = ['a', 'b', 'c'],
numeric = [1, 2, 3];
var alphaNumeric = alpha.concat(numeric);
console.log(alphaNumeric); // 结果: ['a', 'b', 'c', 1, 2, 3]
numeric[Symbol.isConcatSpreadable] = false;
alphaNumeric = alpha.concat(numeric);
console.log(alphaNumeric); // 结果: ['a', 'b', 'c', [1, 2, 3] ]Symbol.unscopables用来访问对象的@@unscopables属性,该属性为对象值,通过设置某个对象的这个属性,就可以把对象的自有属性及继承属性排除在with作用域之外。const object1 = {
property1: 42
};
object1[Symbol.unscopables] = {
property1: true
};
with (object1) {
console.log(property1);
// expected output: Error: property1 is not defined
}Symbol.species用来访问对象的@@species方法,该属性值为函数,该函数会在创建派生对象 (derived object) 时作为其构造函数。派生对象是相对于原始对象而言的,原始对象在某些具体的操作(如map)之后得到的对象被称为派生对象。一般情况下,派生对象和原始对象有着相同的构造器。而如果我们想为派生对象自定义一个构造器时,@@species方法就派上用场了。举个例子,我希望给Array类添加一些其他的方法,那么我可以基于父类Array继承得到子类MyArray。之后,MyArray的某个实例使用了map()方法,如果我希望map()方法返回的新对象是Array类的实例而不是MyArray类的实例,通过实现MyArray类的@@species方法可以达到目的。class MyArray extends Array {
isEmpty() {
return this.length === 0;
}
static get [Symbol.species]() {
return Array;
}
}
let array = new MyArray(3, 5, 4);
array.isEmpty(); // => false
let odds = array.filter(item => item % 2 === 1);
odds instanceof Array; // => true
odds instanceof MyArray; // => falseSymbol.toPrimitive用来访问对象的@@toPrimitive方法,当对象需要转化为基本数据类型的时候就会调用该方法。举个例子,在做+obj运算时js会调用obj[Symbol.toPrimitive]('number');在做'obj'运算时js会调用obj[Symbol.toPrimitive]('string')。var obj = {
[Symbol.toPrimitive](hint) {
if (hint == 'number') {
return 10;
}
if (hint == 'string') {
return 'hello';
}
return true;
}
};
console.log(+obj); // 10 -- hint is "number"
console.log(`${obj}`); // "hello" -- hint is "string"
console.log(obj + ''); // "true" -- hint is "default"Symbol.toStringTag用来访问对象的@@toStringTag属性,该属性返回一个字符串,用于设置对象默认的字符串描述。在使用Object.prototype.toString()方法时,Object.prototype.toString()方法首先会检查作为参数传入的对象是否存在@@toStringTag属性,如果有则用于最后返回的字符串中。class Collection {
get [Symbol.toStringTag]() {
return 'Collection';
}
}
var x = new Collection();
Object.prototype.toString.call(x) === '[object Collection]' // true即全局symbol注册表,表中的每一项称之为Record,每个record包含两个字段:key(字符串类型,用作symbol的标识), symbol(symbol类型,存储的symbol值)。在全局symbol注册表中的symbol可在全局访问到。
Symbol.for(key)函数,在全局symbol注册表中根据key值查询对应的symbol并返回;查询不到则创建一个可在全局symbol注册表中访问到的symbol。Symbol.keyFor(sym)函数,返回symbol在全局symbol注册表中对应的key值;没有对应的key值则返回undefined。symbol是ES6中新引入的基本数据类型,可通过Symbol构造函数创建得到唯一的symbol值,well-known symbols可以让开发人员自定义类及对象的行为,如迭代、字符串匹配查找等。
浏览器的常驻线程有哪些,他们的工作职责是什么??
这个线程的作用就是用来控制交互,响应用户的行为。
当一个鼠标事件被触发时该线程会把事件添加到任务队列的队尾,等待JS引擎的处理。这个任务队列中可以包含定时器任务、AJAX异步请求回调任务等,由于JS的单线程关系所有这些任务都得排队等待JS引擎处理。
当我们在代码中使用 setTimeout 或者 setInterval 的时候,并不是由JavaScript引擎来进行计数的,因为JavaScript引擎是单线程的,如果处于阻塞线程状态就计不了时,它必须依赖外部来计时并触发定时,所以当代码运行时发现 setTimeout 或者 setInterval,这个时候就会将这个任务交给浏览器定时器触发线程,由它来进行计时,当时间达到程序给定的时间时,这个时候就会将对应的任务添加到任务队列的队尾。
ps:W3C的HTML标准中规定,setTimeout中低与4ms的时间间隔算为4ms,IE9及以上,chrome都是4ms,IE8及以下都是15.6ms。
这里说的就是所有的网络请求,包含 <link> ,ajax请求和 medial 资源的请求等,当一个网络请求开始发起到成功返回结果的这个阶段都是由该线程控制, 当检测到状态变更时,如果设置有回调函数,该线程就将状态变更事件放到任务队列的队尾。
需要注意的地方: js引擎执行的时候会是一个阻塞的行为,会挂起GUI渲染线程。事件触发线程,定时器触发线程,http异步请求线程所产生的事件都会按照产生的顺序先压到队列中,采用先进先出的方式运行。再不断的从事件队列的对头取出事件,压入执行栈,由js主线程去执行,当事件执行完成以后再推出执行栈并重复这个过程,这就是事件循环javascript-event-loop。
在Javascript引擎运行脚本期间,GUI渲染线程都是处于挂起状态的,GUI更新会被保存在一个队列中等到js引擎线程空闲时立即被执行。 因为JavaScript脚本是可以操纵DOM元素,如果在修改这些元素属性的同时渲染界面,那么渲染线程前后获得的元素数据就可能不一致了。所以当我们通过js来修改dom样式的时候,界面并不会立即重新渲染,而是将这些操作放在一个ui队列中等待执行。
如果JS引擎正在进行CPU密集型计算,那么JS引擎将会阻塞,长时间不空闲,页面一直不能执行渲染,页面就会看起来卡顿卡顿的,渲染不连贯,所以,要尽量避免JS执行时间过长。
但是,并不是所有的js 对DOM操作时,GUI线程都会被挂起,等待js引擎执行完再进行GUI渲染,比如说获取元素的位置,宽高等,
js语言设定js引擎与GUI引擎是互斥的,也就是说GUI引擎在渲染时会阻塞js引擎计算。原因很简单,如果在GUI渲染的时候,js改变了dom,那么就会造成渲染不同步。
渲染引擎,也被称为浏览器内核,在线程方面又称为 GUI 线程。它是由各大浏览器厂商依照 W3C标准自行研发的,常见的浏览器内核可以分这四种:Trident 、Gecko、Blink、Webkit、Presto。
俗称 IE 内核,也被叫做 MSHTML 引擎,目前在使用的浏览器有 IE11 -,以及各种国产多核浏览器中的 IE 兼容模块。另外微软的 Edge 浏览器不再使用 MSHTML 引擎,而是使用类全新的引擎 EdgeHTML。
俗称 Firefox 内核,Netscape6 开始采用的内核,后来的 Mozilla FireFox(火狐浏览器)也采用了该内核,Gecko 的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。
Presto 是挪威产浏览器 opera 的 “前任” 内核,最新的 opera 浏览器内核现为 Blink。
Safari , Chrome 内核原型,主要是 Safari 浏览器在使用的内核,也是特性上表现较好的浏览器内核。也被大量使用在移动端浏览器上。
由 Google 和 Opera Software 开发,在Chrome(28及往后版本)、Opera(15及往后版本)和Yandex浏览器中使用。Blink 其实是 Webkit 的一个分支,添加了一些优化的新特性,例如跨进程的 iframe,将 DOM 移入 JavaScript 中来提高 JavaScript 对 DOM 的访问速度等,目前较多的移动端应用内嵌的浏览器内核也渐渐开始采用 Blink。
移动设备上浏览器内核
单一数据源,即项目的数据源只有一个,整个应用的数据都保存在一个js对象中,这样我们的页面之间或者不同组件之间可以进行数据的共享。redux的核心就是store,redux中的 createStore 方法会根据 reducer 返回store,而且 createStore 暴露出一些方法方便我们使用
getState 获取store中的数据dispatch 触发一个actionsubscribe 注册一个监听,当store发生变化的时候调用replaceReducer 更新当前store中的reducer直接上源码,已经在源码中做了注释
function createStore(reducer, preloadedState, enhancer) {
var _ref2;
// 判断,如果只有两个参数,且第二个参数还是一个function
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState;
preloadedState = undefined;
}
// 如果三个参数都传了,且第三个参数还是一个function
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.');
}
return enhancer(createStore)(reducer, preloadedState);
}
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.');
}
// ... 省略
// subscribe 注册一个监听,注意 listener 必须是一个function
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.');
}
var isSubscribed = true;
ensureCanMutateNextListeners();
// 将 监听方法添加到 nextListeners 队列中
nextListeners.push(listener);
// 返回了一个 unsubscribe 的方法,如果我们要取消订阅,那么就可以调用这个 unsubscribe
return function unsubscribe() {
if (!isSubscribed) {
return;
}
isSubscribed = false;
ensureCanMutateNextListeners();
var index = nextListeners.indexOf(listener);
nextListeners.splice(index, 1);
};
}
function dispatch(action) {
// ... 省略
try {
isDispatching = true;
currentState = currentReducer(currentState, action);
} finally {
isDispatching = false;
}
// 执行注册的每一个监听事件
var listeners = currentListeners = nextListeners;
for (var i = 0; i < listeners.length; i++) {
var listener = listeners[i];
listener();
}
return action;
}
// createStore 在初始化的时候就会执行一次 dispatch ,
// When a store is created, an "INIT" action is dispatched so that every
// reducer returns their initial state. This effectively populates
// the initial state tree.
dispatch({ type: ActionTypes.INIT });
// ... 省略其实createStore 在初始化的时候就会执行一次 dispatch,这也是为什么我们可以不传 preloadedState 这个参数,createStore还可以构建出state的结构。
但是这需要一个前提条件:在定义reduer函数的是的时候,在没有匹配到action后,仍然需要返回一个state的默认值(不能位undefined)。如果我们没有返回默认状态的系统会给我们报一个错,让我们必须返回默认状态的state,
看下面实例
info = (state = {}, action) => {
const { type } = action;
switch (type) {
case: 'increase':
return { ...state, count: state.count + 1 };
break;
case: 'decrease':
return { ...state, count: state.count - 1 };
break;
// 这里必须返回默认状态 state
default:
return state;
break;
}
}我们来看看applyMiddleware.js的源码
function applyMiddleware() {
for (var _len = arguments.length, middlewares = Array(_len), _key = 0; _key < _len; _key++) {
middlewares[_key] = arguments[_key];
}
return function (createStore) {
return function (reducer, preloadedState, enhancer) {
var store = createStore(reducer, preloadedState, enhancer);
var _dispatch = store.dispatch;
var chain = [];
var middlewareAPI = {
getState: store.getState,
// 这么写是有特殊用意的,因为在最后会将合成的dispatch重新赋值给_dispatch
// 这样中间件接受的middlewareAPI中的dispatch方法返回的就是最新合成dispatch
dispatch: function dispatch(action) {
return _dispatch(action);
}
};
// 每个中间件都是这种模型 ({dispatch, getState}) => (next) => action
chain = middlewares.map(function (middleware) {
return middleware(middlewareAPI);
});
// 注意这里,其实是将_dispatch重新赋值了,
// 所以中间件中只要是调用的middlewareAPI中的dispatch其实就是新合成的_dispatch
_dispatch = _compose2['default'].apply(undefined, chain)(store.dispatch);
return _extends({}, store, {
dispatch: _dispatch
});
};
};
}我们注意看上面的代码中middlewareAPI里面的 dispatch 方法,该方法又返回了一个 _dispatch 函数,也就是说当中间中使用middlewareAPI.dispatch时候,最后调用的还是 _dispatch 函数 。这就像是一个闭包一样。
接下来在看看compose.js的源码
function compose() {
// ...
if (funcs.length === 1) {
return funcs[0];
}
return funcs.reduce(function (a, b) {
return function () {
return a(b.apply(undefined, arguments));
};
});
}其实compose函数中最重要最难懂的地方就是 reduce 高阶函数了。可以点这里学习一下。每个中间件都是这种模型 ({dispatch, getState}) => (next) => action ,在applyMiddleware方法中每个中间件都会接受 middlewareAPI 作为第一个参数返回一个新的函数(接下来我用one,two,three这三个函数来模拟返回的函数),并作为变量 chain 集合中的一个元素,最后传给compose函数。
// 注意我这里只是模拟的中间件接受middlewareAPI后返回的函数部分
function one(next) {
// 函数foo 在这里只是我作为一个例子,用来说明的。实际的中间件中并不一定这样
return function foo(action) {
console.log('one:' + action);
return next(action);
};
};
function two(next) {
return function bar(action) {
console.log('two:' + action);
return next(action);
};
};
function three(next) {
return function baz(action) {
console.log('three:' + action);
return next(action);
};
};
// 模拟redux中的compose函数
function compose(...middleware) {
return middleware.reduce((a,b) => {
return function() {
return a(b.apply(undefined, arguments));
};
});
};
// 模拟 store.dispatch 方法
function dispatch(action) {
console.log('dispatch:' + action);
};
// 看下面的解释
var disp = compose(one, two, three)(dispatch);
disp('shen') // one:shen; two:shen; three:shen; dispatch: shen;compose(one, two, three)(dispatch) 方法合成以后,返回 one(two(three.apply(undefined, dispatch)))baz 的函数,且函数中的 next 其实就是我们传递的 dispatch 参数bar 的函数,且函数中的 next 其实就是three返回的 baz 函数foo 的函数,且函数中的 next 其实就是two返回的 bar 函数最后disp其实就是函数 foo ,且函数接受 action 作为参数,中间件执行的原理就是这样,action会从在中间件之间传递,一直传达到store.dispatch,然后触发action。
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
// 判断如果action是一个方法那么就直接执行
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
// 否则就执行下一个中间件,并将action传给这个中间件,这个时候action就是一个对象{type, data,…}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;我们再看看,如何定义action行为
// 同步
export function addCount() {
return {type: ADD_COUNT}
}
// 发送一个异步的请求
export function addCountAsync() {
// 上面的红色部分就是在执行下面的方法,参数就是中间件提供的 dispatch, getState, extraArgument
return dispatch => {
setTimeout( () => { dispatch(addCount()) },2000)
}
}this.props.dispatch(addCountAsync(...args)) 。在dispatch的时候action执行了,并返回了一个函数,我们暂且将这个返回函数命名为funcreturn action(dispatch, getState, extraArgument) (并不再往下一个中间件传递action),那不就等于 func(dispatch, getState, extraArgument),dispatch,而这个dispatch就是中间件接收的middlewareAPI参数中的dispatch属性,最终还是调用的中间件合成的_dispatch函数,那么ation就会继续往下执行了,直到传到store.dispatch。注意上面有个问题,就是action想要在中间件之间依次传递,那么必须是由中间件合成的dispatch触发的action才可以。否则就会立即出发这个action行为(注意:传递给store.dispatch函数的action必须是一个简单对象)。
我们先来看看它是怎么使用的
reducers = combineReducers({
users: function getUsersReducer(){},
userInfo: function getUserInfoReducer(){}
});
const store = createStore(reducers);也就是说combineReducers可以将多个子reducers合并成一个reducer,现在我们来看看它的源码
const combineReducers = (reducers) => {
const finalReducers = {};
// 这里可以看出来参数 reducers 是一个对象
const reducerKey = Object.keys(reducers);
reducerKey.forEach((item) => {
// 重新刷选出有用的reducer,reducer必须是一个function
if (typeof reducers[item] !== 'function') throw new TypeError('reducer is must be a function');
finalReducers[item] = reducers[item];
});
// 返回一个函数 其实combineReducers函数返回就是一个reducer,而且这个reducer返回一个新的state
return (state = {}, action) => {
// 创建一个新的state
const nextState = {};
// 标记新的nextState和原先的state是否相等
let hasChanged = false;
const finalReducersKey = Object.keys(finalReducers);
finalReducersKey.forEach((item) => {
// 遍历每一个子reducer
// 获取当前的这个reducer
const reducer = finalReducers[item];
// 获取当前这个reducer对应的initState下的属性
const prevStateForKey = state[item];
// 重新获取这个initState下属性的值
const nextStateForKey = reducer(prevStateForKey = {}, action);
if (typeof nextStateForKey === 'undefined') throw new TypeError(
'reducer is must a pure function and must return a result'
);
// 重新赋值
nextState[item] = nextStateForKey;
// 如果前后不相等,hasChanged就为true 否则就是false
// 一旦 hasChanged 为true,那么就一直为true
hasChanged = hasChanged || nextStateForKey !== prevStateForKey;
});
// 重新返回state
return hasChanged ? nextState : state;
};
}var bindActionCreator = (action, dispatch) => {
return (...args) => dispatch(action(...args));
};
var bindActionCreators = (actionCreators, dispatch) => {
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch);
}
// 判断action是不是一个undefined
if (typeof actionCreators !== 'object' || actionCreators === null) {
throw new Error('bindActionCreators expected an object or a function, instead received ' + (actionCreators === null ? 'null' : typeof actionCreators) + '. ' + 'Did you write "import ActionCreators from" instead of "import * as ActionCreators from"?');
}
var keys = Object.keys(actionCreators);
var boundActionCreators = {};
for (var i = 0; i < keys.length; i++) {
var key = keys[i];
var actionCreator = actionCreators[key];
if (typeof actionCreator === 'function') {
// key 其实就是 我们定义的action的方法名
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch);
}
}
// 最后返回一个对象
return boundActionCreators;
}
首先声明class组件App,由图可知App内的this方法继承了Component的方法
从react import Component之后可以console.log看出component在react文件夹开发文件react.development.js中
function PureComponent(props, context, updater) {
this.props = props;
this.context = context;
// If a component has string refs, we will assign a different object later.
this.refs = emptyObject;
this.updater = updater || ReactNoopUpdateQueue;
}
setState的方法写在了Component的prototype上
Component.prototype.setState = function (partialState, callback) {
!(typeof partialState === 'object' || typeof partialState === 'function' || partialState == null) ? invariant(false, 'setState(...): takes an object of state variables to update or a function which returns an object of state variables.') : void 0;
this.updater.enqueueSetState(this, partialState, callback, 'setState');
};
然后又调用了来自react-dom.development.js的enqueueSetState
enqueueSetState: function (inst, payload, callback) {
var fiber = get(inst);
var currentTime = requestCurrentTime();
var expirationTime = computeExpirationForFiber(currentTime, fiber);
var update = createUpdate(expirationTime);
update.payload = payload;
if (callback !== undefined && callback !== null) {
{
warnOnInvalidCallback$1(callback, 'setState');
}
update.callback = callback;
}
flushPassiveEffects();
enqueueUpdate(fiber, update);
scheduleWork(fiber, expirationTime);
}
react-dom中的get方法再将App的this转换成fiber
function get(key) {
return key._reactInternalFiber;
}
调度程序调用requestCurrentTime来计算到期时间 ,到期时间决定了批量更新的方式,
追踪两个时间"renderer time" "scheduler time","renderer time"随时更新(就是最小化渲染), "scheduler time"在没有没有pending work时更新。
flushPassiveEffects方法取消被动的方法保证追踪的正常
enqueueUpdate来创建更新队列
scheduleWork是最后的渲染,清空执行队列更新子节点的expiration time
跨平台的优势:
真正的原生应用:产生的不是网页应用,不是混合应用,而是一个原生的移动应用。快速开发应用:相比原生漫长的编译过程,Hot Reload简直不要太爽。可随时呼叫原生外援:完美兼容Java/Swift/OC的组件,一部分用原生一部分用RN来做完全可以。跨平台:一套业务逻辑代码可以稳定运行在两个平台。节省劳动力:为企业节省劳动力。。。(不知道算不算好事儿)。
可以看出RN和Flutter还是呈五五开的发展态势。
github:
但是Flutter是在18年底才发行了以第一个稳定版,而React Native是15年就已经推出。这么一看,Flutter突然🔥起来,就1年的时间就挤掉了RN的大半市场,今天我们一起看一下,这两个跨平台的框架究竟有什么神奇的地方。
React Native是带着React的光环出生的一个跨平台框架,具备React的一切新特性,让从Ionic与HBuilder的时代走过的Hybrid的开发欲罢不能。因为他能通过React的代码与通用的业务逻辑,编写一套完全原生的App应用,而且APP的使用感受与OC/JAVA编写的Native APP完全一致。
react-native init demo
React Native和React的基本业务逻辑与项目结构是相通的,除了组件是从react-native的包里引用,样式是css的子集,其他的都是页面的生命周期,渲染逻辑,diff都与React无异。

import React from 'react';
import {
SafeAreaView,
StyleSheet,
ScrollView,
View,
Text,
StatusBar,
} from 'react-native';
import {
Header,
LearnMoreLinks,
Colors,
DebugInstructions,
ReloadInstructions,
} from 'react-native/Libraries/NewAppScreen';
const App = () => {
return (
<>
<StatusBar barStyle="dark-content" />
<SafeAreaView>
<ScrollView
contentInsetAdjustmentBehavior="automatic"
style={styles.scrollView}>
<Header />
{global.HermesInternal == null ? null : (
<View style={styles.engine}>
<Text style={styles.footer}>Engine: Hermes</Text>
</View>
)}
<View style={styles.body}>
<View style={styles.sectionContainer}>
<Text style={styles.sectionTitle}>Step One</Text>
<Text style={styles.sectionDescription}>
Edit <Text style={styles.highlight}>App.js</Text> to change this
screen and then come back to see your edits.
</Text>
</View>
<View style={styles.sectionContainer}>
<Text style={styles.sectionTitle}>See Your Changes</Text>
<Text style={styles.sectionDescription}>
<ReloadInstructions />
</Text>
</View>
<View style={styles.sectionContainer}>
<Text style={styles.sectionTitle}>Debug</Text>
<Text style={styles.sectionDescription}>
<DebugInstructions />
</Text>
</View>
<View style={styles.sectionContainer}>
<Text style={styles.sectionTitle}>Learn More</Text>
<Text style={styles.sectionDescription}>
Read the docs to discover what to do next:
</Text>
</View>
<LearnMoreLinks />
</View>
</ScrollView>
</SafeAreaView>
</>
);
};
const styles = StyleSheet.create({
scrollView: {
backgroundColor: Colors.lighter,
},
engine: {
position: 'absolute',
right: 0,
},
body: {
backgroundColor: Colors.white,
},
sectionContainer: {
marginTop: 32,
paddingHorizontal: 24,
},
sectionTitle: {
fontSize: 24,
fontWeight: '600',
color: Colors.black,
},
sectionDescription: {
marginTop: 8,
fontSize: 18,
fontWeight: '400',
color: Colors.dark,
},
highlight: {
fontWeight: '700',
},
footer: {
color: Colors.dark,
fontSize: 12,
fontWeight: '600',
padding: 4,
paddingRight: 12,
textAlign: 'right',
},
});
export default App;
Android/IOS目录分别承载这各自应用架构与bundle入口,src部分会打包成jsbundle,然后通过Native的入口注入。
看到这里会有这样的一个疑问为什么js代码可以运行在APP中?
是因为RN有两个核心
干货 | 加载速度提升15%,携程对RN新一代JS引擎Hermes的调研
所以:JSC/Hermes会将作为JS的运行环境(解释器),JS层通过JSI获取到对应的C++层的module对象的代理,最终通过JNI回调Java层的module,在通过JNI映射到Native的函数。
所以,RN中所有的标签其实都不是真是的控件,js代码中所有的控件,都是一个“Map对中的key”,JS通过这个key组合的DOM,放到VDOM的js数据结构中,然后通过JSBridge代理到Native,Native端会解析这个DOM,从而获得对应的Native的控件。
例子:实现判断应用是否开启通知,如果未打开通知则进入设置页面开启通知。
5.1 IOS端
#import <Foundation/Foundation.h>
#import <React/RCTEventEmitter.h>
@interface RNDataTransferManager : RCTEventEmitter <RCTBridgeModule>
@end
#import "RNDataTransferManager.h"
@implementation RNDataTransferManager
RCT_EXPORT_MODULE();
// 判断notification是否开启
RCT_EXPORT_METHOD(isNotificationEnabled:(RCTPromiseResolveBlock)resolve
rejecter:(RCTPromiseRejectBlock)reject) {
BOOL isEnable = NO;
UIUserNotificationSettings *setting = [[UIApplication sharedApplication] currentUserNotificationSettings];
isEnable = (UIUserNotificationTypeNone == setting.types) ? NO : YES;
return resolve(@(isEnable));
}
// 进入设置开启Notification
RCT_EXPORT_METHOD(gotoOpenNotification) {
[self goToAppSystemSetting];
}
注意两个宏:
RCT_EXPORT_METHOD :用来设置给JS导出的Native Module名字。
RCT_EXPORT_MODULE :给JS提供的方法通过RCT_EXPORT_METHOD()宏实现,必须明确的声明要给 JavaScript 导出的方法,否则 React Native 不会导出任何方法。
5.2 Android端
首先新建一个JavaModule类继承ReactContextBaseJavaModule。
public class RNDataTransferManager extends ReactContextBaseJavaModule {
private static ReactApplicationContext reactContext;
public static RNDataTransferManager rnDataTransferManager;
public static String currentBindAlias = "";
public RNDataTransferManager(@Nonnull ReactApplicationContext reactContext) {
super(reactContext);
this.reactContext = reactContext;
}
public static RNDataTransferManager getInstance() {
if (null == rnDataTransferManager) {
rnDataTransferManager = new RNDataTransferManager(reactContext);
}
return rnDataTransferManager;
}
@Nonnull
@Override
public String getName() {
return "RNDataTransferManager";
}
@ReactMethod
public void isNotificationEnabled(Promise promise) {
if (promise != null) {
if (MainApplication.getContext() != null) {
if (NotificationManagerCompat.from(MainApplication.getContext())
.areNotificationsEnabled()) {
Log.e("push", "推送开启 isNotificationEnabled -> true");
promise.resolve(true);
} else {
Log.e("push", "推送未开启 isNotificationEnabled -> false");
promise.resolve(false);
}
} else {
promise.resolve(false);
}
}
}
@ReactMethod
public boolean gotoOpenNotification() {
if (MainApplication.getContext() == null) {
return false;
}
Intent intent = getSetIntent(MainApplication.getContext());
PackageManager packageManager = MainApplication.getContext().getPackageManager();
List<ResolveInfo> list = packageManager.queryIntentActivities(intent, 0);
if (list != null && list.size() > 0) {
try {
MainApplication.getContext().startActivity(intent);
return true;
} catch (Exception e) {
return false;
}
}
return false;
}
}
写好了Native Module之后需要注册模块。
1)首先通过ReactPackage的createNativeModules来注册模块。
package com.mengtuiapp.mms.bridge;
import com.facebook.react.ReactPackage;
import com.facebook.react.bridge.NativeModule;
import com.facebook.react.bridge.ReactApplicationContext;
import com.facebook.react.uimanager.ViewManager;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import javax.annotation.Nonnull;
public class DataTransferPackage implements ReactPackage {
private RNDataTransferManager transferModule;
@Nonnull
@Override
public List<NativeModule> createNativeModules(@Nonnull ReactApplicationContext reactContext) {
List<NativeModule> nativeModules = new ArrayList<>();
transferModule = new RNDataTransferManager(reactContext);
RNDataTransferManager.rnDataTransferManager = transferModule;
nativeModules.add(transferModule);
return nativeModules;
}
@Nonnull
@Override
public List<ViewManager> createViewManagers(@Nonnull ReactApplicationContext reactContext) {
return Collections.emptyList();
}
}
2)然后让你的应用拿到注册到的package,需要在Application的getPackages方法中提供。
@Override
protected List<ReactPackage> getPackages() {
List<ReactPackage> packages = new PackageList(this).getPackages();
packages.add(new DataTransferPackage());
packages.add(new RNInstallApkPackage());
packages.add(new RNUserAgentPackage());
packages.add(new RNKeyboardAdjustPackage());
packages.add(new CodePush(mContext.getString(R.string.InnotechCodepushKey), mContext, this.moduleId, BuildConfig.DEBUG, mContext.getString(R.string.InnotechCodepushServerUrl)));
return packages;
}
5.3 JS端调用
NativeModules.RNDataTransferManager.gotoOpenNotification()
就可以前往应用设置页面打开通知。
- 相比Hybrid性能更高、因为都是原生组件的渲染。
- 从render到virtual dom的过程都是React驱动,具备React的一切优秀特性,可以使用React的社区优秀工具。
- 项目搭建起来了,用JS写APP又具有原生的渲染效率简直爽,一份代码Android、IOS、web都可以适配(毕竟vDom层是一样的,jsbridge就随你魔改了)。
- 相比原生的编译速度,开发JS使用HotReload简直太爽了。
- 跨平台,但是Android、IOS毕竟是不同的系统与生态,组件与功能都有一些跨平台的差异,RN的原生组件的平台差异性很大。
- 性能问题:动画性能不好、列表数据量大性能不好,主要集中在低端机,大数据列表快速滑动会有白屏,动画层级多在Android低于30fps的情况频繁。
- 白屏问题,加载bundle的时间会有一个白屏出现,需要手动改Native代码。
- 开发业务功能不需要原生能力,但是开发一个完整的跨平台项目,是需要具备一定的双端原生能力(有很多要写Native的,许多功能和组件也需要自己封装)
- 这也是RN做的不好的地方,版本迭代太慢,不痛不痒的迭代了5年了,很多问题还是没有解决。这也是Flutter为什么这么火的原因。
Flutter使用Dart作为开发语言,作为一个AOT框架,Flutter是在运行时直接将Dart转化成客户端的可执行文件,然后通过Skia渲染引擎直接渲染到硬件平台。如果说RN是为开发者做了平台兼容,那Flutter更像是为开发者屏蔽了平台的概念。RN需要被转译为本地对应的组件,而Flutter是直接编译成可执行文件并渲染到设备。Flutter可以直接控制屏幕上的每一个像素,这样就可以避免由于使用JSBridge导致的性能问题。
三要素:

直接演示。
今天我们主要看了一下两个框架开发时的代码结构,与代码书写形式,还有简单了解了一下它是怎么运行。那之后如果小伙伴想继续去学习,或做一个自己的应用,还有以下几个方面需要注意:
1. APP初始化与生命周期状态。
2. 数据持久化 - 数据管理、SP、本地数据库。
3. 碎片化处理。
4. 打包三要素:Android(混淆、签名、加固),IOS(生成证书、导入证书、使用证书)。
5. 拆包、热更新、原生集成。
Flutter因为自带了渲染引擎,理论上是要比RN渲染效率要高,但是其实实际使用上,在性能过剩的移动端设备中,并没有出现特别大的差异,而Facebook的团队在Flutter的持续施压之下也决定重构底层,并在最近几个版本有了一些进步,所以大家有兴趣的都可以研究一下。
在 APP 开发中,通常都会使用
webview组件承载一个网页应用。最近 Chrome 团队宣称安卓 APP 可以直接使用 Chrome 浏览器全屏打开一个网页了。这种技术被称为TWA (Trusted Web Activity)
TWA 基于安卓应用程序和网页站点属于同一开发者的信任前提,提供在应用内贡献 Chrome 浏览器中站点的资源,包括 cookie 等。
也就是当用户登陆了 Chrome 下的站点后,进入 APP 内打开站点可以获取到之前在 Chrome 中存储的状态。
这会给用户带来更好的一致性体验,而且,使用 TWA 的站点,可以全屏在 APP 内展示,没有浏览器的用户界面,但是同样享有 Chrome 浏览器的表单自动填充、共享 API 等功能。这些都是 Webview 无法提供的。
TWA 还具有一些特别的功能,比如发送网络推送通知、后台同步、媒体源扩展(MSE)和共享 API 等。
TWA 中的所有内容都必须符合 Play 商店政策,包括付款应用内购买和其他数字商品的政策。
TWA 必须符合安装 PWA 的标准,并且能够快速加载(Lighthouse性能评分 80 分以上)。也就是说,适用于 TWA 的站点首先是一个合格的 PWA 化的应用。
TWA 的内容受到保护,安卓应用程序无法读取或者修改其中内容。这也意味着只有应用程序通过查询字符串参数初始化站点时,可以将状态从应用程序共享至 TWA,而应用程序无法将内容插入 TWA。
在安装了 Chrome 的设备上可以使用 TWA,如果用户设备上的 Chrome 由于关闭更新是一个过期版本,那么 TWA 会自动替换成 Chrome 自定义标签(CCT)。因为本身 TWA 是一个 CCT 的特例(比 CCT 更好的使用 Chrome 的能力)。
如果站点的质量要求或者 Play 商店的政策修改都可能使 TWA 下架或者被拒绝入境。
TWA 通过数字资产链(DAL)认证用户是否可信任。
在测试的过程中可以设置设备上的 Chrome 跳过认证环节以便快速开发和测试。
chrome://flags。搜索 Enable commmand line on non-rooted devices 并设置为启用(enable),然后多重启几次浏览器;/data/local/tmp/chrome-command-line,加入一份文件,内容为 _ --disable-digital-asset-link-verification-for-url="https://xxx.com",注意命令结尾处不要产生新行,不然会打开浏览器失败。这样设置后启动 xxx.com 这个站点就会跳过受信认证了。
首页我们需要了解,TWA 应用首先是一个合格的 PWA 应用,所以应该在浏览器下得到充分的测试后才被用于 TWA。
安卓开发者需要确定使用的 SDK API 版本必须等于或高于 16。
要创建一个 TWA 应用,可以按如下步骤。
打开 Android Studio,创建一个 Android Studio project,点击下一步后会询问应用名称等,注意这里必须将最小 API 版本一项设置成不低于 API Level 16。
支持 TWA 的类库目前需要在 build.gradle 文件中配置 jitpack,
allprojects {
repositories {
google()
jcenter()
maven { url "https://jitpack.io" }
}
}
以后 TWA 类库会集成在 Jetpack 中,就不再需要上述的步骤了。
TWA 类库依赖 Java 8 的功能,所以需要确保在 Module 中启用 Java 8。在 Module 层级的 build.gradle 中加入 compileOptions 字段:
android {
...
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}
然后就可以将 TWA 类库作为依赖项加入 dependencies 字段:
dependencies {
implementation 'com.github.GoogleChrome.custom-tabs-client:customtabs:3a71a75c9f'
}
在应用的 AndroidManifest.xml 文件中添加一个 TWA Activity。
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
package="com.example.twa.myapplication">
<application
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/AppTheme"
tools:ignore="GoogleAppIndexingWarning">
<activity
android:name="android.support.customtabs.trusted.LauncherActivity">
<!-- Edit android:value to change the url opened by the TWA -->
<meta-data
android:name="android.support.customtabs.trusted.DEFAULT_URL"
android:value="https://xxx.com" />
<!-- This intent-filter adds the TWA to the Android Launcher -->
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
<!--
This intent-filter allows the TWA to handle Intents to open
airhorner.com.
-->
<intent-filter>
<action android:name="android.intent.action.VIEW"/>
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE"/>
<!-- Edit android:host to handle links to the target URL-->
<data
android:scheme="https"
android:host="xxx.com"/>
</intent-filter>
</activity>
</application>
</manifest>这份 XML 文件中,有两个需要注意的地方:
meta-data 标签用来描述 TWA 需要打开站点,可以通过修改 android:value 属性改变你需要打开的站点。intent-filter 标签允许 TWA 拦截打开 https://xxx.com 的 intent。确保这里 data 标签的 android:host 属性是 TWA 要打开的站点域名。TWA 需要和站点进行关联才能消除地址栏。
通过数字资产链(DAL),可以建立起应用程序和站点之间的关联。
上面已经叙述了如何跳过受信认证,这里讲一下如何设置 DAL。
在项目资源文件中打开 app > res > values > strings.xml,加上 DAL 声明:
<resources>
<string name="app_name">XXX TWA</string>
<string name="asset_statements">
[{
\"relation\": [\"delegate_permission/common.handle_all_urls\"],
\"target\": {
\"namespace\": \"web\",
\"site\": \"https://xxx.com\"}
}]
</string>
</resources>打开 AndroidManifest.xml 文件,在 application 标签内增加一个新的 meta-tag。
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.twa.myapplication">
<application
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/AppTheme">
<meta-data
android:name="asset_statements"
android:resource="@string/asset_statements" />
<activity>
...
</activity>
</application>
</manifest>这样我们建立起了应用程序和站点的关联。
接下来还需要建立站点和应用程序的关联,这里需要 2 个步骤。
build.gradle 文件中找到。完成这 2 步后就可以进入 DAL 生成器,填写字段并点击生成声明。复制生成的语句,确保可以在站点根目录下的 /.well-known/assetlinks.json 访问到。
建立应用程序和站点的双向关联后,接下来就可以生成一个独立的 APP 了。
可以通过 adb 在一台连接的设备上安装应用。
adb install app-release.apk
如果发生错误,可以通过调试工具进行检查。
TWA 在 PWA 基础上更加强化了用户体验一致性,即在 APP 内和浏览器内可以同步状态。而且 APP 内的站点还可以直接使用 Chrome 作为载体,享受比 webview 更多的特性。
在未来,如果 PWA 站点都可以十分方便的和 APP 进行集成的话,无疑会更加模糊 APP 和网页应用直接的边界。
// main.js
const { BrowserWindow, app } = require("electron")
app.on("ready", () => {
const bw = new BrowserWindow()
bw.loadURL("https://www.mengtuiapp.com/#/")
})每个 Electron 中的 web 页面运行在它的叫渲染进程的进程中。
Electron 的用户在 Node.js 的 API 支持下可以在页面中和操作系统进行一些底层交互。
主进程使用 BrowserWindow 实例创建页面。 每个 BrowserWindow 实例都在自己的渲染进程里运行页面。 当一个 BrowserWindow 实例被销毁后,相应的渲染进程也会被终止。
https://www.electronjs.org/docs/api/ipc-main
https://www.electronjs.org/docs/api/ipc-renderer
https://www.electronjs.org/docs/api/remote
Electron同时对主进程和渲染进程暴露了Node.js 所有的接口
https://www.electronjs.org/docs/tutorial/application-architecture#using-nodejs-apis
壳工具主要功能
https://www.electronjs.org/docs/api/ipc-renderer
https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Structured_clone_algorithm
remote 重构
https://www.electronjs.org/docs/api/remote#remote
// 注册
__electronBridge__.registerScreenshots((res)=>{console.log("res ",res)})
// 调用
__electronBridge__.screenshots()
https://juejin.im/post/5bbac5cee51d450e7042ad2c
__electronBridge__.sendNotification({title:"title-test",body:"<body><h2 style='background:red;color:white'>"+Date.now()+"</h2></body>"})https://blog.csdn.net/weixin_33936401/article/details/88722952
https://www.electron.build/
https://github.com/electron/electron-packager
https://baike.baidu.com/item/OpenSSH/1137789?fr=aladdin
https://baike.baidu.com/item/Jenkins/10917210?fr=aladdin
https://www.npmjs.com/package/http-server
rewrite config.js
上一篇文章我们提到了 localStorage 和 localForage,我们了解了 LS 的问题所在,以及社区中通常使用的替代 LS 的解决方案。现在,由 WICG(Web Incubator Community Group)提出了一个新的提案,一起来看看这份“真香”。
KV Storage (Key Value Storage 简称,文章且称之为 KVS) 的出现是因为目前越来越多的应用都在依赖和使用 localForage 等基于 IndexedDB 的存储解决方案。为了能够更好的满足开发者的需求,KVS 的提案应允而生,它的目的是旨在提供一套方便、高效的浏览器内建 API 帮助开发者摆脱第三方组件库的依赖。
在 KVS 的规范中提到的 KVS 的基本功能是提供开发者一套简单易用的异步存储 API,同时它还有一些额外的目标:
localForage 的方式创建一个新的有别于默认的存储区域;<p>
You have viewed this page
<span id="count">an untold number of</span>
time(s).
</p>
<script type="module">
import { storage } from "std:kv-storage";
(async () => {
let pageLoadCount = await storage.get("pageLoadCount") || 0;
++pageLoadCount;
document.querySelector("#count").textContent = pageLoadCount;
await storage.set("pageLoadCount", pageLoadCount);
})();
</script>KVS 提供 storage 和 StorageArea 两个对象,其中 storage 提供一个默认的 StorageArea 对象实例,而 StorageArea 则提供开发者创建不同储存区域的能力。
import { storage, StorageArea } from "std:kv-storage";storage 对象是一个 StorageArea 类的实例,我们这里就只介绍一下 StorageArea 类。
class StorageArea {
constructor(name)
set(key, value) // 设置
get(key) // 获取
delete(key) // 删除
clear() // 清除
keys() // 返回 key 集合
values() // 返回 value 集合
entries() // 成员遍历器,返回存储条目集合,数组类型
get backingStore() // 返回一个 BackingStore 对象
}首先,在构造函数中,需要传参 name,它会被用于创建一个 kv-storage:${name} 为名称的 IndexedDB 数据库。如果 name 传入了一个非字符串,那么会进行 toString 强制转换为字符串。
其他的方法和 Map 对象所提供的方法基本一致,不同的是,get、set、delete 和 clear 方法最终都会返回一个 Promise 对象。
比较需要注意的是,如果 set 方法的第二个参数是 undefined 将会导致这个 key 被删除。
我们可以通过 storage.backingStore 的方式获得 BackingStore 对象,该对象包含了数据库名称等信息,可以被用于 IndexedDB 操作。
const { database, store, version } = storage.backingStore;
const request = indexedDB.open(database, version);
request.onsuccess = () => {
const db = request.result;
bulbasaurEvolve.onclick = () => {
const transaction = db.transaction(store, "readwrite");
const store = transaction.objectStore(store);
store.put("bulbasaur", false);
store.put("ivysaur", true);
db.close();
};
};上面的例子展示了从 KVS 降级到 IndexedDB 的操作方法。
KVS 规范从浏览器层面为我们打造一套更加高效简单的存储方案,接下来就看各大浏览器厂商的实现计划了。
在开发过程中,我们向服务端发送请求,一般会使用三种方式, XMLHttpRequest(XHR),Fetch ,jQuery实现的AJAX。其中, XMLHttpRequest(XHR)和Fetch是浏览器的原生API,它们都是全局的方法。jquery的ajax其实是封装了XHR。接下来我们来看看Fetch如何使用。
Fetch 是基于 Promise 实现的,所以它的返回值是一个 Promise 对象。当请求返回一个代表错误的 HTTP 状态码时,从 fetch() 返回的 Promise 不会被标记为 reject, 即使该 HTTP 响应的状态码是 404 或 500。相反,它会将 Promise 状态标记为 resolve (但是会将 resolve 的返回值的 ok 属性设置为 false ),仅当网络故障时或请求被阻止时,才会标记为 reject。
默认情况下,fetch 不会从服务端发送或接收任何 cookies, 如果站点依赖于用户 session,则会导致未经认证的请求(要发送 cookies,必须设置 credentials 选项)。

需要支持的话,我们可以在项目中引入isomorphic-fetch,isomorphic-fetch 是对 whatwg-fetch和node-fetch的一种封装,你一份代码就可以在两种环境下跑起来了。
第一个参数是一个请求的url。第二个参数是一个可选参数,可以控制不同配置的 init 对象。方法返回一个 promise 对象。
如果要在请求中携带凭据,请添加credentials: 'include'。如果你只想在请求URL与调用脚本位于同一起源处时发送凭据(cookie),请添加credentials: 'same-origin'。要确保浏览器不在请求中包含凭据,请使用 credentials: 'omit',这个也是默认值
var formData = new FormData();
var photos = document.querySelector("input[type='file'][multiple]");
formData.append('title', 'My Vegas Vacation');
// 注意这里上传的是多个文件
formData.append('photos', photos.files);
fetch(url, {
method: 'POST',
body: formData
})
.then(response => {
if (response.ok) {
return response.json();
}
throw 'the qequest failed';
})
.then(response => console.log('Success:', response))
.catch(error => console.error('Error:', error)); fetch(url, {
method: 'POST',
body: JSON.stringify(query),
})
.then(response => {
if (response.ok) {
return response.blob();
}
throw 'the qequest failed';
})
.then(data => {
const blobURL = window.URL.createObjectURL(data);
download(blobURL);
})
.catch(error => console.error('Error:', error));
function download(url) {
const a = document.createElement('a');
a.style.display = 'none';
a.download = '<文件名>';
a.href = url;
a.click();
document.body.appendChild(a);
document.body.removeChild(a);
}fetch 的兼容性较差,所以不得不使用第三方插件,这里推荐 isomorphic-fetch。http 状态下如400 | 500等不会 reject,相反它会被 resolveexport default function withFoo(WrappedComponent) {
function WithFoo(props) {
return <WrappedComponent {...props} foo />;
};
const wrappedComponentName = WrappedComponent.displayName
|| WrappedComponent.name
|| 'Component';
WithFoo.displayName = `withFoo(${wrappedComponentName})`;
return WithFoo;
}class 的 demo: (hooks 的 demo就不写了 都差不多 )
/*
* @Author: your name
* @ModuleName: 2020-01-09 11:26:03
* @Date: 2020-01-09 11:26:03
* @Last Modified by: name
* @Last Modified time: 2020-01-09 11:26:03
*/
import React from "react";
import PropTypes from "prop-types";
const propTypes = {
id: PropTypes.number.isRequired,
url: PropTypes.string.isRequired,
text: PropTypes.string
};
const defaultProps = {
text: "Hello World"
};
class Link extends React.PureComponent {
static methodsAreOk() {
return true;
}
componentWillMount() {}
// 数据请求一般写在这里
componentDidMount() {}
// 更改状态
toggleVisible() {}
// 监听的events用on开头
onChange = () => {};
// 事件回掉类型的event用handle 开头
handleClick = () => {};
getFooterContent = () => {
return this.state.content;
};
renderNavigation = text => {
return <div>{text}</div>;
};
render() {
return (
<a href={this.props.url} data-id={this.props.id} show>
{this.props.text}
</a>
)
}
}
Link.propTypes = propTypes;
Link.defaultProps = defaultProps;
export default Link;编码
预先进行的工作 编码时进行的工作
名称 注释 代码格式 等 编码约定
错误处理 可重用代码遵循标准 性能因素思考
质量保证
代码流程跟踪
集成测试
review代码
工具
版本控制
重构工具 编辑器 调试器 语法检查器
先对软件构建进行设计。设计就是把需求分析和编码调试联系在一起的活动。好的高层次设计可以提供一个可以稳妥容纳多个低层次设计的结构。
要考虑产品迭代的频率。对于高频率改动或觉得不合理后期会改动的点,我们要考虑逻辑抽象。在抽象的过程中要保证代码的完整性和单一性。争取一块代码只做一件事。让逻辑简单明了。
要预测产品设计后期可能会改动的点。如果不知道可以考虑问产品,只有了解产品的需求设计的目的才能为此次迭代做出更合理的解决方案。写代码的时候为这些点主动留出空位。要将这些预测加入进设计内。
如果不确定的话可以考虑写一下思维导图。在组建设计中可以考虑画uml类图。这里推荐一个chorme扩展程序 Gliffy Diagrams,命名可以使用Code Spell Checker 。在复杂判断处写注释。 代码格式 prettier
例如下面是我准备写的刮刮卡的 粗糙画图 可以看得出来简单明了
理想的设计特征
最小的复杂度,标准技术 要用标准化的,常用的方法给人熟悉的感觉,将复杂度降到最低
易于维护 把同事当作自己的听众,要写出别人听起来更能理解的代码。要对于一些逻辑进行隐藏,减少改动所带来的代码量。例如 should,is,can,have等都可以用来命名 bool类型的判断。
handle,toggle,change等都可以用来命名函数,名字一看就是回调。
松散耦合
设计时让程序的各个组成部分之间的关联最小,即SOLID原则。通过应用类的接口中的合理抽象、封装性及信息隐藏等原则,设计出相互关联尽可能少的类。减少关联,保持子程序的短小精悍,减少思考的负担,既能写出更让人容易裂解的代码,让人更容易着手,专注在更小的问题上写出更少错误性能更好的代码。
例如Object1 和 Object2的联系要传入Object3。那么Object2 肯定会对Object3 进行校验。 如果这个时候 Object4想要使用Object2 是不是就要传入整个Object1 传出的 Object3格式的代码呢?这个时候Object2 的代码就紧紧的和Object1耦合在一起。这个时候 可以考虑对bject2 的接口定义固定字段A。把Object1返回的Object3 放入另一块代码中进行数据处理返回Object2需要的数据格式A.这个时候 Object2就可以达到通用了。降低耦合。
对于耦合度高,过度依赖 入参的代码,代码的健壮性和可维护性肯定的会降低的
可扩展性 增强系统功能的同时尽量不破坏底层代码。
可重用性
可移植性 代码很方便的移植到其他环境中。后期维护可能会舍弃一部分功能保留一部分功能,代码可移植性高就会更方便。
精简性 每次都要思考 代码的修改在于不能加入东西的时候可以删除什么。越多的代码需要越多的开发测试复审,可能会产生越多的bug。
层次性 对于需要重构的代码,处理旧代码的兼容和新代码的书写,两个层次的剥离 Hoc实际上就是一种层次的剥离
怎样写出来的代码利于维护
写代码之前思考下我可以隐藏什么?
对于多次引用和操作的具名常量,我们可以用字面两代替。例如整数 20 要在代码里引用。这个引用要使用100次。那我们以后万一要改这个引用值是不是就要改100个地方呢?我们可以在刚开始的时候用具名常量 MAX_LENGTH 代替字面量,就只用改变一次了。
但是如果后期我们要对 MAX_LENGTH 进行 ++ 的操作,同时还想使用非连续的 MAX_LENGTH 或保留旧的 MAX_LENGTH 进行操作,我们要命名一个 PREVIOS_MAX_LENGTH 吗?随着需求的迭代MAX_LENGTH操作越来越多,旧的迭代代码被保留,代码会越来越多,以后改bug根本不知道哪些操作是有用的。后期对 MAX_LENGTH 的 操作越多维护起来就越复杂。
如果我们刚开始在 MAX_LENGTH 要进行操作更改的时候,意识到 把它放在子程序中 return MAX_LENGTH 。后续的维护就会变得很容易。
找出容易变化的点,把容易变化点抽离,把可能变化的点隔离
简易版本 Enum
const Color = {
RED: 0,
GREEN: 1,
BLUE: 2
}
Object.freeze(Color);
Color.RED === Color.RED // true
Color.RED = 4; // error 不能修改枚举常量简易实现 Enum
const createEnum = enumObj => {
const forEach = (target) =>{
console.log('forEach')
}
const handler = {
get: function(target, key) {
switch(key){
// 增加foreach 方法
case 'forEach':
return () => forEach(target)
// 获取 详细描述
case 'descs':
return 'descs'
// entries
// valuas
// keys
default:
break;
}
if (target[key]) {
if (
typeof target[key] === "object" &&
target[key].hasOwnProperty("value")
) {
return target[key].value;
} else if (
typeof target[key] === "object" &&
!target[key].hasOwnProperty("value")
) {
return key;
}
return target[key];
}
throw new Error(`No such enumerator: ${key}`);
}
};
return new Proxy(enumObj, handler)
};
const httpMethods = createEnum({
DELETE: {
value: "DELETE",
desc: "删除"
},
GET: {
value: "GET",
desc: "获取"
},
OPTIONS: {
desc: "获取"
},
PATCH: "PATCH",
POST: "POST",
PUT: "PUT"
});
console.log(httpMethods.GET); // GET
console.log(httpMethods.OPTIONS); // OPTIONS
console.log(httpMethods.PATCH); // PATCH
httpMethods.forEach() // console.log('forEach') 使用访问器子程序取代状态变量的直接检查
class GetState {
constructor(originState){
this.state = originState;
}
// 使用子程序访问 变量
get State () {
return this.state
}
setState(result){
this.state = result
}
increase(){
this.setState(this.state ++)
}
}function demo(handle){
if( !handle || (handle && typeof handle !== 'function')){
return false
}
handle()
}
// 参数的不可能存在的范围
function demo(number){
if(number < 3 || number > 10){
return false
}
console.log(number)
}function demo(status){
status = status.toUpperCase()
if(status === 'LOADING'){
return
}
}async function (){
try {
const data = await PromiseDemo();
} catch (e) {
utils.info(e.message || e)
}
}function demo(props){
return (<div>
{
( props.list || []).map(item=>(
<div key={item.id}>{item.text}</div>
)
}
</div>)
}本文旨在通过代码分析让读者了解基于神经网络进化的机器学习实现方法。
之前 G 家的 Alpha Go 打败人类围棋冠军的事件将人工智能推上了人民群众议论的焦点。人工智能的热潮随之扑面而来,无论是手机、摄像、点外卖,无不标榜自己具有人工智能加成。一时间人工智能成为了时代的宠儿。
前不久在逛 github 的时候,偶然发现了一个叫 Neuroevolution.js 的文件,项目作者用它实现了一个人工智能玩游戏的 Demo
【游戏截图】
我认真的读了代码,结合有限的知识,下面尝试将代码讲解下,看看 Neuroevolution 是如何实现机器学习方式之一 —— 神经网络的。
首先介绍一下神经网络。神经网络的研究很早就已出现,今天“神经网络”已经是一个相当大的、多学科交叉的学科领域。神经网络的定义也多种多样,这里我们采用如下定义:
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络中最基本的成分是“神经元”模型,即上述定义中的“简单单元”。神经元互相相连,当有一个神经元接受外部信息并被“激活”,那么它会向相连神经元发送“化学物质”,改变它们的电位。如果某神经元的电位超过一个“阈值”,那么它也会向相连神经元发送“化学物质”。经过一系列的连锁反应,根据最后的神经元输出,就能得到相应的反馈,比如“跳”、“咬”等动作。
神经网络进化是指通过一代又一代“优胜劣汰”方式筛选出适应“生存规则”的个体,这些个体所具备的“基因”含有能够使其作出对外部环境正确反应的神经网络。
神经网络进化的方式特点在于其越来越“智能”的进化过程无需人工干预,理想情况下仅依靠自身的逻辑就可产生趋于最优的解。
以 Demo 游戏为例,游戏中每一代会若干个个体,小鸟。每一代的个体全部死亡后会依据得分最高的一部分,使它们的基因延续给下一代(过程略复杂,后文有详解),如此往复,最后得到了一个或者多个能够持续穿越管道的个体。
如果你有足够耐心,可以看到存活个体已经掌握游戏生存规则,达到了人类难以企及的分数。

【难以企及】
Neuroevolution 文件中我们可以很清晰的看到它的代码结构,除 Neuroevolution 对象本身的属性和方法外,其中还包括 Generations、Generation、Genome、Network、Layer、Neuron 类(JS 的类可以通过 prototype 模拟的,所以虽然没使用 class 关键字,但本文也称之为“类”)。
下面我们分析下 Neuroevolution 对象和这些类的作用。
Neuroevolution 对象(其实是个方法,但是 JS 中方法也是对象,姑且称之为对象)提供了一些基础配置,如下:
| 配置项 | 描述 |
|---|---|
| activation | 激活函数,经典 S(Sigmoid)函数 |
| randomClamped | 随机值函数,返回一个 -1 到 1 的浮点数 |
| network | 神经网络层配置 |
| population | 人口,每一代产生的个体数量 |
| elitism | 上一代最优基因的延续比例 |
| randomBehaviour | 下一代随机基因的比例 |
| mutationRate | 神经元的突触异变率 |
| mutationRange | 神经元的突触异变量 |
| historic | 上一代的存活人口 |
| lowHistoric | 是否不存储上一代神经网络 |
| scoreSort | 分数升降序,即声明分数越高越好还是越低越好 |
| nbChild | 生育数,上一代 2 个体繁殖的后代数量 |
这里的配置参数 network 如何配置?Demo 中使用的值 [2, [2], 1] 如何理解?
Neuvol = new Neuroevolution({
population:50,
network:[2, [2], 1],
});network 配置项第一和第三个参数表示输入层和输出层的神经元个数,第一层我们称之为输入层,第三层我们称之为输出层。输入层和输出层就构成了一个感知机。
感知机能够轻易的实现逻辑与或非运算。
比如输入层有两个值 x1, x2,输出层为 y
y = x1 && x2 // 与运算
y = x1 || x2 // 或运算
y = !x1 // 非运算感知机如果只有输入和输出层,且仅输出层有激活函数处理,功能是十分有限的,即使简单的异或问题也难以解决。
所以一般情况下,神经网络除了输入和输出层外,还会有若干的隐藏层,即 network 值第二项。
network 值第二项值为数组,数组项的个数表示隐藏层个数,每一项的数值表示该隐藏层的神经元个数。比如配置:
network: [2, [2, 2, 2], 1]表示有 3 层隐藏层,每一层含有 2 个神经元。
通常情况下,我们称含有 1 个隐藏层的神经网络为单层神经网络,多个隐藏层的神经网络为多层神经网络。
隐藏层的主要工作是对输入层传过来的数据进行加工,然后传递给下一层网络,最终传递给输出层,如图:

【单层网络神经图片】
理论上隐藏层越多,神经网络的学习成本就越高。深度学习的神经网络其隐藏层数量是十分庞大的,可能会涉及上亿个参数需要调试。而神经网络进化是基于自身逻辑进行微调,从而产生足够”智能“的神经网络。
重新回到 Neuroevolution 对象,它具有如下方法:
| 方法 | 描述 |
|---|---|
| set | 覆盖默认配置参数 |
| generations | Generations 实例 |
| restart | 重新开始生成后代 |
| nextGeneration | 返回下一代所有神经网络 |
| networkScore | 用于神经网络计分 |
其中 networkScore 方法用于为神经网络计分,通过配置参数 scoreSort 和其得分可以确定该神经网络在当代所有神经网络中的排名顺序。
下面我们看看其他的类。
var Neuron = function () {
this.value = 0;
this.weights = [];
}
/**
* Initialize number of neuron weights to random clamped values.
*
* @param {nb} Number of neuron weights (number of inputs).
* @return void
*/
Neuron.prototype.populate = function (nb) {
this.weights = [];
for (var i = 0; i < nb; i++) {
this.weights.push(self.options.randomClamped());
}
}Neuron 类很简单,它的实例由 value 和 weights 属性和一个 populate 方法组成。
value 即神经元的值,该值通过系列计算后由激活函数输出weights 为神经元的突触,其个数等于输入层神经元个数populate 方法可以向神经元突触填充随机值/**
* Neural Network Layer class.
*
* @constructor
* @param {index} Index of this Layer in the Network.
*/
var Layer = function (index) {
this.id = index || 0;
this.neurons = [];
}
/**
* Populate the Layer with a set of randomly weighted Neurons.
*
* Each Neuron be initialied with nbInputs inputs with a random clamped
* value.
*
* @param {nbNeurons} Number of neurons.
* @param {nbInputs} Number of inputs.
* @return void
*/
Layer.prototype.populate = function (nbNeurons, nbInputs) {
this.neurons = [];
for (var i = 0; i < nbNeurons; i++) {
var n = new Neuron();
n.populate(nbInputs);
this.neurons.push(n);
}
}Layer 类负责管理神经网络中的层。每个 Layer 实例需要确定它在整个网络中的位置 index,和它含有的神经元 neurons 数组。它提供的 populate 方法可以为实例填充神经元。
Network 类负责管理神经网络,它的实例具有一个 layers 数组存放 Layer 实例。我们再看看 Network 实例的方法。
perceptronGeneration 方法该方法会通过调用 Layer 和 Neuron 实例的填充方法将神经网络填充完整。它的填充过程如图:

【神经网络填充图】
一个完整神经网络包含相应的层,每一层包含相应的神经元,而神经元包含值和突触。
值得注意的是,第一层输入层是没有突触的,之后的所有层包括最后的输出层的神经元都会拥有和输入神经元个数相同的突触数量。
那么突触具体的作用是什么呢?
compute 方法从 compute 方法中可以解读到,突触其实就是用以对神经元的值进行微调的一种参数,当神经元接收到前一层神经元传递的值,接着和突触发生“反应”,然后根据所有突触的值,通过激活函数,成为当前神经元新的 value 值。
/**
* Compute the output of an input.
*
* @param {inputs} Set of inputs.
* @return Network output.
*/
Network.prototype.compute = function (inputs) {
// Set the value of each Neuron in the input layer.
for (var i in inputs) {
if (this.layers[0] && this.layers[0].neurons[i]) {
this.layers[0].neurons[i].value = inputs[i];
}
}
var prevLayer = this.layers[0]; // Previous layer is input layer.
for (var i = 1; i < this.layers.length; i++) {
for (var j in this.layers[i].neurons) {
// For each Neuron in each layer.
var sum = 0;
for (var k in prevLayer.neurons) {
// Every Neuron in the previous layer is an input to each Neuron in
// the next layer.
sum += prevLayer.neurons[k].value *
this.layers[i].neurons[j].weights[k];
}
// Compute the activation of the Neuron.
this.layers[i].neurons[j].value = self.options.activation(sum);
}
prevLayer = this.layers[i];
}
// All outputs of the Network.
var out = [];
var lastLayer = this.layers[this.layers.length - 1];
for (var i in lastLayer.neurons) {
out.push(lastLayer.neurons[i].value);
}
return out;
}前文提到了很多次的激活函数,这里解释下。框架使用的激活函数代码如下:
/**
* Logistic activation function.
*
* @param {a} Input value.
* @return Logistic function output.
*/
activation: function (a) {
ap = (-a) / 1;
return (1 / (1 + Math.exp(ap)))
}通过激活函数,我们可以将一个值使用约束在 0 到 1 的范围内,且当参数 a 等于 0 时,激活函数取值为 0.5。
激活函数在坐标系中呈现为 S 形连续图像,如图:
【S函数图像】
连续的图像能够确保在微小的修改下,得到的值是相近的,有利于参数微调(如果参数调整的幅度过大,就会产生”震荡“,使最优解难以被归纳得过)。
getSave 方法和 setSave 方法这对方法中,getSave 方法是将神经网络的神经元和突触保存为一种结构,包含所有层的神经元个数和所有神经元突触的值。这种结构将神经网络中的层以数组的形式表示,这为复制神经网络的逻辑提供了方便。
setSave 方法正好相反,可以将上述的数据结构写入一个神经网络中,即将层和突触数据填充入新的神经网络。
Generation 类Genome 类负责将神经网络和外部环境因素关联,起到纽带的作用。每一个基因包含一个神经网络。
Generation 类负责管理 Genome 实例,直觉上我们会认为所有存活的基因都在 Generation 示例下,但实际上 Generation 仅仅负责记录存活失败的基因并为它们排序。它具有如下方法:
| 方法 | 描述 |
|---|---|
| addGenome | 往最新一代中添加一个 Genome 实例 |
| breed | 通过两个 Genome 实例繁殖出新一代的 Genome 实例 |
| generateNextGeneration | 生成新一代个体 |
addGenome 方法被用于生成新一代基因,并且该方法会对基因的“生存能力”进行排序。Demo 中每阵亡一个小鸟,就会生成新的基因。
generateNextGeneration 方法是比较核心的方法。当游戏中的个体全部存活失败,就会执行 generateNextGeneration 方法。新一代个体的生成逻辑是:
elitism 比例的当代基因,然后复制该部分基因的神经网络用于下一代;randomBehaviour 比例的基因,随机初始化后用于下一代;/**
* Generate the next generation.
*
* @return Next generation data array.
*/
Generation.prototype.generateNextGeneration = function () {
var nexts = [];
for (var i = 0; i < Math.round(self.options.elitism *
self.options.population); i++) {
if (nexts.length < self.options.population) {
// Push a deep copy of ith Genome's Nethwork.
nexts.push(JSON.parse(JSON.stringify(this.genomes[i].network)));
}
}
for (var i = 0; i < Math.round(self.options.randomBehaviour *
self.options.population); i++) {
var n = JSON.parse(JSON.stringify(this.genomes[0].network));
for (var k in n.weights) {
n.weights[k] = self.options.randomClamped();
}
if (nexts.length < self.options.population) {
nexts.push(n);
}
}
var max = 0;
while (true) {
for (var i = 0; i < max; i++) {
// Create the children and push them to the nexts array.
var childs = this.breed(this.genomes[i], this.genomes[max],
(self.options.nbChild > 0 ? self.options.nbChild : 1));
for (var c in childs) {
nexts.push(childs[c].network);
if (nexts.length >= self.options.population) {
// Return once number of children is equal to the
// population by generatino value.
return nexts;
}
}
}
max++;
if (max >= this.genomes.length - 1) {
max = 0;
}
}
}在基因繁殖过程中,新基因的每个神经元会获得两个父基因提供的神经元的突触,并且基于 mutationRate 配置参数,可能会使突触产生变化。
/**
* Breed to genomes to produce offspring(s).
*
* @param {g1} Genome 1.
* @param {g2} Genome 2.
* @param {nbChilds} Number of offspring (children).
*/
Generation.prototype.breed = function (g1, g2, nbChilds) {
var datas = [];
for (var nb = 0; nb < nbChilds; nb++) {
// Deep clone of genome 1.
var data = JSON.parse(JSON.stringify(g1));
for (var i in g2.network.weights) {
// Genetic crossover
// 0.5 is the crossover factor.
// FIXME Really should be a predefined constant.
if (Math.random() <= 0.5) {
data.network.weights[i] = g2.network.weights[i];
}
}
// Perform mutation on some weights.
for (var i in data.network.weights) {
if (Math.random() <= self.options.mutationRate) {
data.network.weights[i] += Math.random() *
self.options.mutationRange *
2 -
self.options.mutationRange;
}
}
datas.push(data);
}
return datas;
}以 mutationRange 为 0.5 为例,突触的变化范围在 (-0.5, 0.5)。
Generations 负责记录当代个体和生成下一代所有个体,它具有如下几个方法:
| 方法 | 描述 |
|---|---|
| firstGeneration | 生成初代 |
| nextGeneration | 生成下一代 |
| addGenome | 往最新一代中添加基因(个体) |
另外 Generations 还有一个同名的属性 generations,是一个数组,用于存放当代个体的最终状态。
每一代生成后,同时会向 generations 数组中插入一个空的 Generation 实例。在当代的个体存活失败时,通过 addGenome 方法生成新的基因,该基因保存了传入的神经网络数据,然后根据 score 值排序候放入 Generation 实例的 genomes 数组中。
由于使用了多处同名函数,这里的逻辑是有点绕的,可以仔细阅读代码辅助理解。
最后我们再看下游戏是如何和框架集成的。
从 game.js 文件看,首先是初始化 Neuroevolution 框架。
Neuvol = new Neuroevolution({
population:50,
network:[2, [2], 1],
});游戏中每一代生成 50 个个体,输入层 2 个神经元,1 层隐藏层,含有 2 个神经元,输出层 1 个神经元。
游戏开始时,会调用 nextGeneration 方法生成个体,然后根据个体数量产生对应游戏中的 bird 实例(游戏中一个鸟配一个神经网络)。
游戏过程中,会不断调用 bird 对应 network 实例的 compute 方法,根据输出值判断是否需要执行 flap 方法。也就是鸟会根据其神经网络的输出值判断是否进行跳跃。
然后在判断存活失败时,会对鸟的神经网络打分(当前的游戏分数),用以在当代个体中排序。
最后当当代个体全部失败后,游戏会重新调用 start 方法,使用游戏重新开始。但是这时的神经网络已经完成了一代的进化。
if(this.birds[i].isDead(this.height, this.pipes)){
this.birds[i].alive = false;
this.alives--;
//console.log(this.alives);
Neuvol.networkScore(this.gen[i], this.score);
if(this.isItEnd()){
this.start();
}
}神经网络进化只是机器学习中的一种实现方式,还有很多实现方式,包括强化学习、规则学习、计算学习等,而仅就神经网络形式而言,也有 RBF (Radial Basis Function,径向基函数)网络、ART (Adaptive Resonance Theory,自适应谐振理论)网络、深度学习等常见的神经网络。
如果大家有兴趣,推荐阅读周志华教授编著的《机器学习》一书。
如果用过 less\scss\stylus 等预处理 CSS 语言,那么你就不会对使用变量来简化我们的 CSS 开发工作感到陌生。但是你知道吗?CSS 现在也支持原生的变量了: var()。
CSS 原生的变量如何使用?我们来看下:
.selector {
--size: 16px;
font-size: var(--size)
}这个简单的例子中,.selector 的 fontSize 值就是 16px。但是这么简单的例子凸显不出 CSS 变量的价值,我们来看个更能体现变量价值的例子:
body {--bg: #fff}
p {background: var(--bg)}
a {color: var(--bg)}
span {border: 1px solid var(--bg)}这个例子中,我们在 body 元素中定义了变量 --bg,并在其他三个标签上应用了变量,而且用于不同的 CSS 属性。变量无疑给我们开发 CSS 带来了便利和更好的维护性,简单修改变量值即可同时在不同 selector 和不同属性上生效。那么我们接下来再仔细看看 CSS 变量的一些特性。
--* 格式CSS 变量有一个很明显的特点就是必须以 -- 起始,看起来很奇怪。早期的规范是以 var- 作为起始,所以在一些老版本浏览器中可能需要定义 var- 起始(firefox 31 以下 bug 985838)的变量名才能生效。
我个人感觉有一个好处就是官方钦定了 CSS 变量名的烤肉串风格(Kebabs Style)写法(人都给你两个 - 了)。
和普通的 CSS 属性忽略大小写不同,变量名对大小写是敏感的。
body {
--color: #f90;
--Color: #f00;
background: var(--color); /* #f90 */
}建议变量名全小写,原因就是上面我们提到的,变量名使用烤肉串风格声明。
不同于预处理语法直接声明变量,CSS 变量必须声明在样式规则中,包括条件化规则 @media 等。
--size: 20px; /* 语法错误 */
body {
--size: 20px; /* 正确声明 */
}但是在 @keyframes 中定义的变量会被作为动画属性。因为规范规定变量是 Animatable: no 的,不可以作为动画属性的。一旦在 @keyframes 中定义了变量,且有动画属性使用了该变量,那么这个属性将会受到影响,导致动画失效。
@keyframe test {
from { --color: #f00; background: var(--color)}
to { --color: #fff; background: var(--color)}
}这种方式的写法,背景色不会出现变化哦。那该怎么做呢?一种方式就是多定义几个变量,比如:
@keyframe test {
from { background: var(--color-start)}
to { background: var(--color-end)}
}变量必须通过将变量名放入 var() 中进行引用,否则会被忽略。
body {
--color: #f90;
background: --color; /* 语法错误 */
background: var(--color) /* 正确 */
}CSS 变量也遵循 CSS 的继承规则和级联优先级规则。比如,当一个规则使用了变量,但是自身没有定义该变量时,CSS 解析器会向上查找变量,试图使用父级、祖父级的变量。
.parent {--size: 20px}
.parent .current {font-size: var(--size)} /* current 的规则并没有定义 --szie 变量,使用的是继承到的变量 */当多条规则中有重复定义的变量时,解析器会按样式级联优先级来确定使用哪个值:
.current.more {--size: 20px;} /* 这条规则权重大,所以 --size 变量取值为 20px */
.current {--size: 10px}注意没有继承关系时,可以存在多个同名变量。
<div class="one"></div>
<div class="two"></div>
<div class="three"></div>.one {--size: 10px; font-size: var(--size)}
.two {--size: 20px; font-size: var(--size)}
.three {--size: 30px; font-size: var(--size)}
/*等同于*/
.one {font-size: 10px}
.two {font-size: 20px}
.three {font-size: 30px}如果需要默认值,可以在 var 方法中传入哦。
body {background: var(--bg, #f00)}如果没有找到 --bg 变量,那么 #f00 会生效。
需要注意的是,在使用变量时可能出现非法值的情况:
body {--bg: 20px; background: var(--bg, #f00)}这种情况下,规则会被解析为:
body {background: 20px}最终 body 的背景色是透明,而不是我们在 var 中设置的默认值。也就是说,CSS 变量的默认值只在变量未声明的情况下生效,不会影响值与属性非法组合情况。
和 JS 中定义变量类似,CSS 变量也拥有变量提升的效果,但是也有差异。
console.log(a) // undefined
var a = 1;
console.log(a) // 1
//等同于
var a;
console.log(a)
a = 1;
console.log(a)JS 中变量只有声明会被提升,值还是按照正常的代码流程进行赋值。而 CSS 变量不仅声明被提升,值也会被提升。
body {background: var(--color); --color: #f00}
/* 等同于 */
body {--color: #f00; background: var(--color)}在定义变量之前使用变量,和定义变量之后使用变量效果相同。
上面的例子中我们都在 CSS 属性值的位置使用变量,那么我们可以将变量作为 CSS 属性吗?比如:
--prop : font-size;
var(--prop): 12px答案是:不可以。
虽然CSS 变量不能作为属性名,但是它可以使用另一个变量进行赋值或表达式计算:
body {
--size: 10px;
--big-size: calc(var(--size) * 2);
}此处,--big-size 变量的值为 20px。
赋值的时候我们需要注意给变量带上单位,如果在引用之后加上单位是不能正确解析的,如:
body {
--size: 10;
font-size: var(--size)px; /* 会被解析成 font-size: 10 px,数字 10 与 px 之间有一个空格 */
}这种写法等同于给 CSS 属性设置了一个非法值。
规范中有提到可以使用 CSSOM 进行变量的获取与设置:
element.style.setProperty('--foo', '10px')
element.style.setProperty('height', 'var(--foo)') // 设置元素 height 为 10px
element.style.getPropertyValue('--foo') // 获取变量值,返回 10px我们可以通过 DOM 对象的 style 属性进行 CSS 变量的取值和设置。
需要注意的事,只有 inline 到 DOM 对象的 CSS 变量能通过这种方式获取,写在 CSS 文件或 style 元素中的 CSS 变量的获取方式尚未找到,有知晓的朋友欢迎留言相告,感谢。
目前来看,CSS 变量在 PC 浏览器兼容性比较好,只有 IE 尚未实现。而移动端 IOS safari 已经实现了,安卓需要再等等就可以在生产使用。
当你看到这篇文章的时候可能有所变化,请前往 can i use 查看实时数据。
加载的过程分为下面的4歌步骤:
资源分类 ===> 资源安全策略检查 ===> 资源优先级计算 ===> 根据优先级下载资源
接下来按照这个顺序给大家解说。
将常见的资源类型分为下面的10种:
HTMLcssfont(也就是Icon字体库)scriptimagexhrsvgmedia: 多媒体资源: vedio, audio, TextTrack(video的字幕)manifest: 应用程序缓存资源perfetch:预读取资源| type | introduction |
|---|---|
| kMainResource | html |
| kImage | image |
| kCSSStyleSheet | css |
| kScript | js |
| kFont | font |
| kRaw | ajax |
| kSVGDocument | SVG |
| kXSLStyleSheet | XSLT |
| kLinkPrefetch | Link prefetch, dns-prefetch |
| kTextTrack | TextTrack |
| kImportResource | HTML Imports |
| kMedia | media |
| kManifest | HTML5 application resource cache |
| kMock | test type |
也就是我们所说的网络白名单,限制浏览器对各类资源的加载,提高网站的安全性。一种常用的应用就是通过限制非信任域名的脚本加载来预防XSS攻击
白名单的设置可以分为两种:
<meta> 标签来设置 <meta http-equiv="Content-Security-Policy" content="script-src 'self'; style-src nos.netease.com kaola.com;">script-src 和 style-src 是资源的类型,常见的还有 img-src;
self 表示当前网页的域名
nos.netease.com kaola.com 表示信任的域名 多个域名可以使用空格连接
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">设置这个meta标签以后,浏览器会将https页面中的所有htttp请求自动升级到https;例如:当我们将全站中的http转成https时,对于原有的http强制转成https的形式发送,且不会报错。当然这是时候是需要服务器端支持的。
<meta http-equiv="Content-Security-Policy" content="block-all-mixed-content">混合内容 Mixed Content 就是指https页面中含有http的请求,这种在安全链接中混合了非安全请求内容就叫做混合内容(一般出现这种情况的时候可以在控制台中看到警告信息)
通过上面的标签来阻止所有类型的非安全链接请求,这样包括图片、音频、视频等资源也将会被拦截报错。
从浏览器内核考虑将资源分为5个等级(不同浏览器的等级名称可能不一样):
VeryHigh ===> High ===> Medium ===> Low ===> VeryLow
VeryHigh: html、css、font这三类资源的优先级最高
High: HTML Imports(将一个HTML文件导入到其他HTML文档中,)、script、xhr请求
Medium: manifest 程序应用缓存资源
Low: 图片、音频、视频、SVG、TextTrack(video的字幕)
VeryLow: perfetch预读取的资源
初始优先级设置好以后,浏览器会根据资源的实际属性和位于文档中的位置等方面,对优先级进行调整,来确定出最终的加载优先级顺序
对于XHR请求资源:将同步XHR请求的优先级调整为最高。 XHR请求可以分为同步请求和异步请求,浏览器会把同步请求的优先级提升到最高级,以便尽早获取数据、加快页面的显示
对于图片资源:会根据图片是否在可见视图之内来改变优先级。
图片资源的默认优先级为Low。现代浏览器为了提高用户首屏的体验,在页面渲染时会计算图片资源是否在首屏可见视区以内,在的话,会将这部分可见图片(Image in viewport)资源的优先级提升为High。
对于脚本资源:浏览器会将根据脚本所处的位置和属性标签分为三类:
A:添加了 defer/async 属性标签的脚本的优先级会全部降为Low
B:没有添加 defer/async 属性的脚本,且页面是否已经加载了一张非 preload 图片,来判断脚本在文档中的位置。如果页面已经加载了一张图片就认为这个script是页面偏底部的位置, 就把它的优先级调成medium
C:否则就设置为high
通过上面的安全策略和优先级的设置来加载和阻塞资源,我们可以通过优化资源的加载优先级顺序,来有效提高页面的加载响应速度。我们可以通过下面的技术来进行优化。
preload 和 prefetch它们都属于预加载性能优化技术。预先告知浏览器某些资源可能在将来会被使用到,让浏览器对这部分资源进行提前加载
<link rel="preload" href="xxxx.js">
<link rel="preload" href="xxx.jpg">Prefetch包括资源预加载、DNS预解析、http预连接和页面预渲染。
<link rel="prefetch" href="test.css">
<link rel="dns-prefetch" href="//haitao.nos.netease.com">
<link rel="prefetch" href="//www.kaola.com">
<link rel="prerender" href="//m.kaola.com">最后两个分别是:http预连接和页面预渲染。
preload 和 prefetch 的区别preload 告诉浏览器预先请求当前页需要的资源,提高这些资源请求的优先级。对于那些本来请求优先级较低的关键请求,我们可以通过设置 preload 来提升这些请求的优先级。prefetch 告诉浏览器将来可能在其他页面(非本页面)或将来摸个时候可能使用到的资源,那么浏览器会在空闲时,就去加载这些资源,最常见的 dns-prefetch。
看看浏览器对 preload 和 prefetch 的兼容性如何



通常可以利用LocalStorage来对部分请求的数据和结果进行缓存,省去发送http请求所消耗的时间,从而提高网页的响应速度。 这类做法在移动端应用已经十分广泛。
通过上面的分析,我们已经知道了浏览器对资源加载的过程,和如何进行优化。最后那么来捋一捋js和css资源放在文档不同位置时对其他资源的阻塞情况

上面的三种情况,很明显第一种和最后一种更优。那 <script> 放在头部位置和尾部有什么不一样。通过观察css的位置可以知道,第三种情况下留给用户的白屏的时间更短,因为在相同的情况下css越靠前那么就会越早完成解析,页面就也早呈现给用户。这就是为什么很多项目都将js资源放在文档底部的原因。
之前自己看了些资料和代码,这里尝试通过实现一个类react的框架,来理解下react的工作流程,写文章也是对自己思路的一个整理,如有谬误还请大家帮忙指出。
根据Dan在React Components, Elements, and Instances里的讲解,react element是指
An element is not an actual instance. Rather, it is a way to tell React what you want to see on the screen. You can’t call any methods on the element. It’s just an immutable description object with two fields: type: (string | Component) and props: Object.*
简单来说,react element是我们要绘制的页面结构的javascript描述
举个例子,下方这样的页面结构
<div class="container">
<span class="item">hello</span>
<span class="item">world</span>
</div>
所对应的react element如下
{
type: "div",
props: {
className: "container",
children: [{
type: "span",
props: {
className: "item",
children: "hello"
}
}, {
type: "span",
props: {
className: "item",
children: "world"
}
}]
}
}
可以看出react element是一个典型的树状结构。而React初次渲染的过程就是把react element转换为dom节点的过程,假设我们已经有了一个上面这样的react element对象,下面来看下ReactDom.render是如何把react element转换为dom树的。
我们需要做的是遍历react element树来生成dom节点,对于树状结构最容易想到的遍历方式就是递归,于是有了下面的伪代码:
/**
* 把react elements渲染成dom节点
* @param {MiniReactElement} element
* @param {HTMLElement} container
* @return {void}
*/
const render = (element, container) => {
// 如果element为文本元素
if (!element.type) {
const node = createTextNode();
container.appendChild(node);
return;
}
const node = document.createElement(element.type);
// 添加properties
addPropertiesForNode(node);
// 添加event listener
addEventListenerForNode(node);
// 递归遍历children, 生成子树
children.forEach(child => {
render(child, node);
});
container.appendChild(node);
}
渲染函数有了,那react element又是如何生成的呢,我们知道在react里是通过jsx来描述react elements的,那来看下jsx到底做了哪些工作?
下面是babel repl中的截图

可以看到babel其实是把jsx转换成了对React.createElement方法的调用
通过查看@babel/plugin-transform-react-jsx的说明,看到可以通过给jsx加注释的方式来自定义转换后的函数

现在只要我们实现了MiniReact.createElement方法,就可以直接在代码里通过jsx来描述react elements了
因为它做的工作只是返回一个javascript对象,所以实现起来还是比较简单
/**
* 生成MiniReact Element
* @param {string} type 组件类型,e.g. div, section, span
* @param {object} config 组件需要接收的props
* @param {[]} args 组件的children
*/
const createElement = (type, config, ...args) => {
const props = Object.assign({}, config, {
children: flattenArray(args),
})
return {
type,
props,
}
}
到目前为止基本实现了,从『数据』到『dom节点』的初始渲染过程

那当数据更新时,我们可以重新生成新的elements,然后调用render生成新的dom树。再把root container的innerHTML改为新生成的dom树就完成了页面的更新。
但这样做有两个问题:
先来解决第一个问题,我们在update的过程中引入reconcile。
于是引入一个新的数据结构instance:
/**
* @typedef {Object} Instance
* @property {MiniReactElement} element
* @property {HTMLElement} dom
* @property {Instance[]} childrenInstances
* instance是MiniReactElement渲染到dom后的一种表示
*/

把之前生成dom树的render函数重命名为instantiate, 返回值为instance类型
/**
* 返回instance对象
* @param {MiniReactElement} element
* @return {Instance}
*/
const instatiate = (element) => {
const instance = {
element,
}
// 处理文本节点
if (!element.type) {...}
const node = document.createElement(element.type);
// 设置attributes和listener
updateDomProperties(node, [], props);
const childInstances = props.children.map(instatiate);
const childDoms = childInstances.map(instance => instance.dom);
childDoms.forEach(dom => node.appendChild(dom));
return Object.assign({}, instance, { dom: node, childInstances });
}
保存之前生成的instance对象
/**
* 保存上次渲染生成的instance对象
* @type {Instance}
*/
let rootInstance = null;
/**
* @param {MiniReactElement} element
* @param {HTMLElement} container
*/
const render = (element, container) => {
const preRootInstance = rootInstance;
rootInstance = reconcile(container, preRootInstance, element);
}
/**
* 对比新老instance,完成dom树的更新
* @param {HTMLElement} container
* @param {Instance} preInstance
* @param {MiniReactElement} element
* @return {Instance} newInstance
*/
const reconcile = (container, preInstance, element) => {
// 旧的节点需要删除
if (!element) {
container.removeChild(preInstance.dom);
return null;
}
// 新增节点
if (!preInstance) {
const newInstance = instatiate(element);
container.appendChild(newInstance.dom);
return newInstance;
}
// 类型不一致,替换节点
if (preInstance.element.type !== element.type) {
const newInstance = instatiate(element);
container.replaceChild(preInstance.dom, newInstance.dom);
return newInstance;
}
const newInstance = {
element,
};
if (preInstance.element.type === element.type) {
// 类型一致,复用节点
newInstance.dom = preInstance.dom;
updateDomProperties(preInstance.dom, preInstance.element.props, element.props);
}
// 递归调用reconcile, 生成childInstance
newInstance.childInstances = reconcileChildren(preInstance, newInstance);
return newInstance;
}
/**
* 递归调用reconcile生成childInstances
* @param {Instance} preInstance
* @param {MiniReactElement} element
* @return {Instance[]}
*/
const reconcileChildren = (preInstance, newInstance) => {
const element = newInstance.element;
const count = Math.max((preInstance && preInstance.childInstances.length) || 0, (element.props && element.props.children.length) || 0);
const newChildrenInstances = [];
for (let i = 0; i < count; i++) {
const preChildInstance = (preInstance && preInstance.childInstances[i]) || null;
const child = element.props && element.props.children[i];
const childInstance = reconcile(newInstance.dom, preChildInstance, child);
newChildrenInstances.push(childInstance);
}
return newChildrenInstances;
}
添加了reconcile之后发现,只有被影响到的节点会更新啦~, 那全局state的问题怎么解决呢,我们知道react 16之前只有react的类组件是可以有自己的state的,那现在我们来引入Component
首先,我们需要有一个Component基类来供自定义组件继承
class Component {
constructor(props) {
this.props = props;
this.state = this.state || {};
}
setState(partialState) {
this.state = Object.assign({}, this.state, partialState);
/**
* reconcile的过程,我们需要在当前实例上能访问到,
* 之前的instance。我们把它保存在实例的__internalInstance上,为了把类组件的实例和instance
* 区分开,这里我们把类组件的实例叫做publicInstance
* /
const instance = this.__internalInstance;
reconcile(instance.dom.parentNode, instance, instance.element);
}
render() {
return null;
}
}
当在elements中引入自定义的Component后,意为着element.type可以是一个function, 而不再只能是dom节点的tagName, 我们来更改instatiate函数的实现
/**
* 返回instance对象
* @param {MiniReactElement} element
* @return {Instance}
*/
const instatiate = (element) => {
let { type, props } = element;
if (typeof type === "function") {
const newInstance = {
element,
};
if (typeof type.prototype.render === "function") {
// 类组件
const publicInstance = createPublicInstance(element, newInstance);
const childElement = publicInstance.render();
const childInstance = instatiate(childElement);
Object.assign(newInstance, {
dom: childInstance.dom,
childInstance, publicInstance
});
return newInstance;
}
// 函数组件
const childElement = type(props);
const childInstance = instatiate(childElement);
Object.assign(newInstance, { childInstance, dom: childInstance.dom });
return newInstance;
}
// 原有逻辑 {...}
}
/**
* 创建与Component相关的publicInstance
* @param {MiniReactElement} element
*/
const createPublicInstance = (element, newInstance) => {
const { type, props } = element;
const publicInstance = new type(props);
publicInstance.__internalInstance = newInstance;
return publicInstance;
}
另外reconcile的过程也需要少许更改
/**
* 对比新老instance,完成dom树的更新
* @param {HTMLElement} container
* @param {Instance} preInstance
* @param {MiniReactElement} element
* @return {Instance} newInstance
*/
export const reconcile = (container, preInstance, element) => {
// 旧的节点需要删除 {...}
// 新增节点 {...}
// 类型不一致,替换节点 {...}
// 类型一致
if (typeof preInstance.element.type === "function") {
let childElement;
if (typeof element.type.prototype.render === "function") {
// 类组件
preInstance.publicInstance.props = element.props;
childElement = preInstance.publicInstance.render();
} else {
// 函数组件
childElement = element.type(element.props);
}
const childInstance = reconcile(
container,
preInstance.childInstance,
childElement
);
Object.assign(preInstance, { childInstance, })
return preInstance;
}
// 原有处理dom更新逻辑 {...}
}
至此,我们引入了component从而支持了局部的state, 页面现在可以进行部分刷新了~
上面列举的内容,与React 16之前的结构还是基本类似的,React 16主要的不同是它引入了fiber架构,那啥是fiber呢?
Fiber是React 16以后引入的新的reconciliation算法,它的名称来自于React实现中的Fiber数据组构。
引入Fiber的目的是实现增量渲染:
把渲染工作分段并可以插入到多个帧内的能力
通俗的讲就是reconciliation的过程在16之后是可中断/暂停/继续的,它带来的优势主要是渲染任务现在支持区分优先级了。e.g.像用户交互类的渲染会更优先得到响应,而像从服务器读取数据这种IO操作就会被安排一个较低的优先级。
具体差异可以参见这个triangle动画的例子:Fiber vs Stack Demo

有了fiber结构,我们可以把之前基于callstack的数据结构切换到链表,这样就有了暂停的先决条件, 那怎么判断何时暂停呢?
借助requestIdleCallback, 它提供了一种在浏览器空闲的情况下执行代码的机会
浏览器一帧的周期内所做的工作:
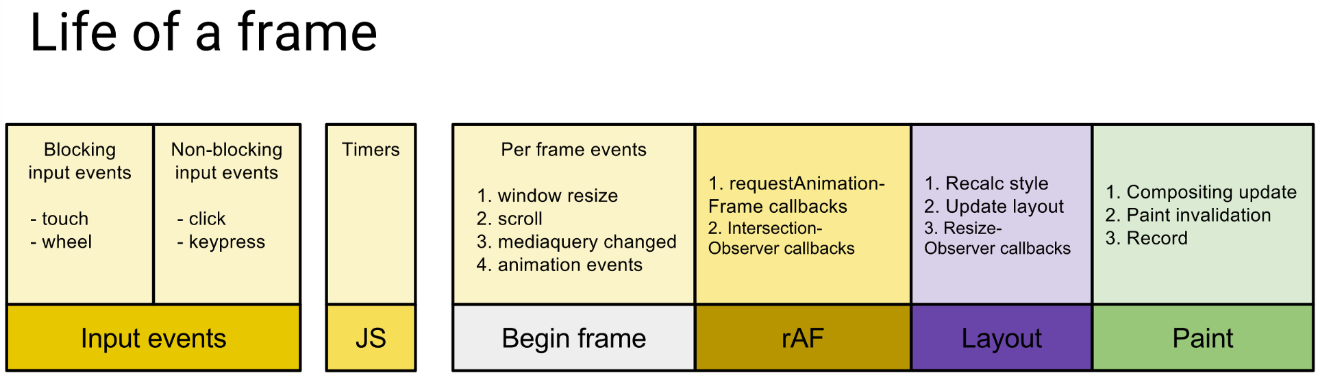
requestIdleCallback的执行时机:
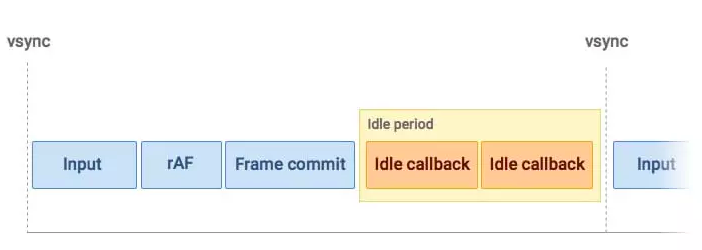
下面来看下循环遍历fiber tree的伪代码:
let wipRoot = {
dom: container,
props: {
children: [element],
},
alternate: currentRoot,
}
let nextUnitWork = wipRoot;
window.requestIdleCallback(workLoop);
function workLoop(idleDeadline) {
while (idleDeadline.timeRemaining() > 1 || idleDeadline.didTimeout) {
nextUnitWork = performUnitWork(nextUnitWork);
}
if (nextUnitWork) {
window.requestIdleCallback(workLoop);
}
}
performUnitWork做的工作主要如下:
/**
* 1. 创建dom节点
* 2. 返回nextUnitWork
* @return {Fiber}
*/
const performUnitWork = (fiber) => {
if (typeof fiber.type === "function") {
if (typeof fiber.type.prototype.render === "function") {
// 类组件
} else {
wipFiber = fiber;
hooksIdx = 0;
fiber.props.children = [fiber.type(fiber.props)]
}
}
reconcileChildren(fiber);
if (fiber.child) {
return fiber.child;
}
if (fiber.sibling) {
return fiber.sibling;
}
let parent = fiber.return;
while (!parent.sibling && parent.return) {
parent = parent.return;
}
if (parent.sibling) {
return parent.sibling;
}
return null;
}
reconcileChildren的作用主要是
const reconcileChildren = (wipFiber) => {
const elements = wipFiber.props.children;
let oldFiber = wipFiber.alternate && wipFiber.alternate.child;
let index = 0;
let prevSibling = null;
while (index < elements.length || oldFiber) {
if (index < elements.length) {
const element = elements[index];
const newFiber = {
type: element.type,
props: element.props || {},
return: wipFiber,
alternate: oldFiber,
dom: null,
hooks: [],
};
// 新增节点
if (!oldFiber) {
newFiber.effectTag = EFFECT_TAG.NEW;
effectList.push(newFiber);
}else if (oldFiber.type !== newFiber.type) {
newFiber.alternate = null;
oldFiber.effectTag = EFFECT_TAG.DELETE;
effectList.push(oldFiber);
} else if (oldFiber.type === newFiber.type) {
newFiber.dom = oldFiber.dom;
newFiber.stateNode = oldFiber.stateNode;
const changeNeeded = Array.from(new Set([...getKeys(newFiber.props), ...getKeys(oldFiber.props)]))
.some(key => newFiber.props[key] !== oldFiber.props[key])
if (changeNeeded) {
newFiber.effectTag = EFFECT_TAG.UPDATE;
effectList.push(newFiber);
}
}
if (!wipFiber.child) {
wipFiber.child = newFiber;
}
if (prevSibling) {
prevSibling.sibling = newFiber;
}
prevSibling = newFiber;
index++;
} else {
// 需删除节点
oldFiber.effectTag = EFFECT_TAG.DELETE;
effectList.push(oldFiber);
}
if (oldFiber) {
oldFiber = oldFiber.sibling || null;
}
}
}
最后生成提交渲染的过程放在commitRoot函数中,它做的工作主要是通过遍历effectlist来生成dom树,这个过程不贴代码了,感觉兴趣的同学可以自己实现下,需要注意的地方是commitRoot的过程是不可中断的。
这里主要再介绍下hooks的实现,从上面的代码可以看到fiber对象上有一个叫做hooks的数组,performUnitWork生成当前节点的elements时,会重设一个叫做hooksIdx的变量,而useState所做的工作是
export const useState = (initV) => {
const oldHook = wipFiber.alternate &&
wipFiber.alternate.hooks &&
wipFiber.alternate.hooks[hooksIdx];
const hook = {
state: oldHook ? oldHook.state : initV,
queue: [],
};
wipFiber.hooks.push(hook);
hooksIdx++;
const actions = oldHook ? oldHook.queue : [];
actions.forEach(action => {
hook.state = typeof action === "function" ? action(hook.state) : action;
});
const setState = (newV) => {
hook.queue.push(newV);
wipRoot = {
dom: currentRoot.dom,
alternate: currentRoot,
props: currentRoot.props,
}
nextUnitWork = wipRoot;
window.requestIdleCallback(workLoop);
}
return [hook.state, setState];
}
其他用于保存数据的hooks的实现原理,应该也基本类似。。
想介绍的内容大概就是这些,肯定有写的不准确的地方,希望大家帮忙指正,我这边会进行修改的,
一边写文档一边犯懒癌😂,还是得多写吧,anyway, 希望对大家理解react工作原理有所帮助, 2020新年快乐🎉🎉🎉
CSS 规定,小写的字母 x 的下边缘 就是基线(baseline)。字母 x 的高度就是 x-height。x-height 就是术语描述的 "基线" 和 "等分线" 之间的距离。
line-height对于非替换元素的纯内联元素来说,line-height 就是计算高度的基石,更准确一点的说就是:指定了用来计算行框盒子高度的基础。内联盒子的 padding 、border 不包含在行框盒子高度内(这一点很重要)
<div class="container">
<span style="padding: 10px; line-height: 32px;">我是谁x</span>
<img src="./static/img/timg.jpg" alt="" style="height: 20px; vertical-align: top">
</div> .container {
height: 100px;
font-size: 24px;
background: #ccc;
}行距 = lineheight - fontsize。 有了行距,在一分为二就是 “半行距”,分别加在 "em-box" 上面和下面就构成了文字的完整高度了
由于文字具有明显的下沉现象,且 font-size 值越大下沉越明显。所以当尺寸标注的是距离文字上边距的话就,半行距就向下取整。否则就向上取整。假如设计师标注了文字上边距距离图片下边缘的距离是 20px,文字的 line-height: 21px, font-size: 14px 那么这个时候 半行距:(21 - 14)/ 2 = 3.5 再向下取整所以这个时候半行距为 3px。
大多数情况下,内容区域和 em-box 是不一样的,内容区域高度受 font-family 和 font-size 的双重影响,而 em-box 只受到 font-size 影响,通常内容区域高度会高一些。
当字体是 “simsun” 的时候,内容区域和 em-box 是等高的。因为 “simsun” 字体是等宽等高的。这里我们可以理解为在 Firefix 浏览器下,文本选中的背景颜色区域就是 “内容区域”
<div class="test">
<span>spinx</span>
</div> .test {
font-family: simsun;
font-size: 24px;
line-height: 36px;
background: yellow;
}
.test span {
background: white;
}实际开发中图文混合的场景很多,那么这种内联替换元素和内联非替换元素在一起时候的高度表现如何呢??
<div style="border: 1px solid #ddd">
<img src="./static/img/timg.jpg" alt="" height="100px">
</div>思考:为什么父容器底部和 img 底部由间隙呢??
这是因为 “幽灵空白节点” 在作祟。默认情况下 <img> 的 baseline 就是自己的下边缘,和文字的 baseline 对齐。所以多出来的距离就是 “幽灵空白节点” 的 baseline 到内容区域底部的距离。
<div style="border: 1px solid #ddd; line-height: 50px;">
xxxxs<img src="./static/img/timg.jpg" alt="" height="100px">
</div>思考:这个时候图片和文字如何呈现??父元素的高度是多少??
从上面的 demo 中,我们可以看出来,父元素的行高要大于自身设置的 line-height。那么这个时候 line-height 就不能决定容器高度了(只有当设置的行高大于任何子元素的高度时,line-height 才会起到决定容器高度的作用)。
normal(默认值):不同的浏览器下数值不一样,一般在 1.32-1.41 之间(大致就是这个值)。
数值:一般采用 1.5 。好算
百分比: 相对 font-size 计算
长度值(px)
line-heightHTML 中的很多替换元素,尤其是表单类的替换元素,如输入框、按钮之类的,很多具有继承特性的 CSS 属性其自己也有一套,如 font-family、font-size、font-weight、font 以及 line-height 。由于继承的权重是最弱的,所以 body 中设置的 line-height 是无法影响到这些替换元素的,但是 * 作为一个选择器,就不一样了,直接会重置这些替换元素默认的 line-height。但是如果考虑到性能或者其他问题,一般情况下很少使用 通配符选择器。
body {
line-height: 1.5;
}
input, button {
line-height: inherit;
}line-height 的 “大值特性” <div style="line-height: 50px; background: #444; width: 200px">
<span style="line-height: 20px">dhfhsfjh解放军互粉可好尽快发货的康师傅尽快发货的复活节岛上</span>
</div>
<div style="line-height: 20px; background: #444; width: 200px">
<span style="line-height: 50px">dhfhsfjh解放军互粉可好尽快发货的康师傅尽快发货的复活节岛上</span>
</div>看看上面的两个 demo 有没有什么区别??
其实上面的两个 demo 没有啥区别,样式都是一样的。这是为什么呢??
因为 "行框盒子" 的高度是由这一行最高的那个内联元素决定的,第一个 demo 中,<span> 和 “幽灵空白节点” 组合为一个行框盒子,高度由 “幽灵空白节点” 的高度决定,因为父元素的 line-height 比 <span> 的 line-height 要大。
第二个 demo 和第一个一样,只不过这个时候 "行框盒子" 的高度是由 <span> 的 line-height 决定的。所以两个 demo 的呈现样式都是一样的。
vertical-align <div style="line-height: 32px;">
<span style="font-size: 24px;">都是废话话费放胡椒粉</span>
</div>思考:父元素表现出来的高度是多少??注意:这里需要考略 vertical-align 和字体下沉。
vertical-algin 的属性值baseline、top、middle、bottom
text-top、text-bottom
sub、sup
数值(px)、百分比(相对 line-height 计算)
上面的 “数值、百分比” 应该是两类,分别是 “数值类” 和 “百分比类”。放在一起是因为两者有很多的共性。根据计算值的不同相对于基线往上或往下偏移。当为正值时往上移动,为负值时往下偏移。
<div style="border: 1px solid #ddd; line-height: 50px;">
xxxxs<img src="./static/img/timg.jpg" alt="" style=“height: 100px; vertical-align: 10px”>
</div>注意: 当 vertical-align: 0 时,其实和 vertical-align: baseline 是一样的。
vertical-align 百分比值 相对于 line-height 进行计算的。line-height 的百分比值则相对于 font-size 进行计算的。
vertical-algin 起作用的条件只能适用于 内联元素以及 display 为 table-cell、inline-block、inline-table、table-cell 的元素上。
看下面这个 demo ,我们想让这个图片垂直居中显示
<div class="mid">
<img src="./static/img/timg.jpg" alt="" style="height: 100px; vertical-align: middle;">
</div> .mid {
height: 200px;
border: 1px solid #ddd;
}但是,最终显示的效果却没有达到我们的预期。为什么??
因为容器的高度是 200,图片的高度时 100,正常的 CSS 布局是默认左上方排列对齐,所以图片的顶部和父容器的顶部对齐。
再者就是 <img> 此时是一个内联元素,所以在它的前面会有一个 “幽灵空白节点”。在这一行构成一个行框盒子,
当给 <img> 元素设置 vertical-align: middle 后,希望图片的垂直中心点和 "行框盒子" 的基线往上二分之一处 x-heighter 对齐。我们可以在 <img> 前面添加一个字母x,方便我们观察。
这个时候的 "行框盒子" 的 baseline 在什么地方?? 就是图片的下边缘,又因为当前字符 x 的高度很小,所以当前 "行框盒子" 的高度是由图片的高度决定的(由 height 最大的那个内联盒子决定)。
所以这个时候图片是不会发生偏移的,实际偏移的是字符 x。所以才会出现 vertical-align: middle 无效的情况
我们加入一些代码,做个修改。通过下面的修改后,就ok了。达到我们的目的了。这又是为什么???
.mid:after {
content: '';
display: inline-block;
height: 100%;
vertical-align: middle;
}为什么会这样呢?其实还是因为行框盒子的高度影响到。在元素中添加了一个为元素,并设置了它的高度就是容器的高度。这个时候 after 就和 <img> 、“幽灵空白节点” 一起组成了当前行的 "行框盒子" 。所以当前行框盒子的高度就是 after 高度,其实这个时候字符 x 和 after 还有图片都是底部对齐的(不设置 vertical-align: middle 的情况下)。所以 after 需要设置 vertical-align: middle,这样字符 x 就垂直居中了。
这个时候 <img> 设置了 vertical-align: middle 同样 <img> 的垂直中心点和字符x往上二分之一处 x-heighter 对齐,所以这个时候 图片就居中了。
vertical-align 和 font-size 的关系因为文字具有下沉的现象,所以当 font-size 越大的时候 文字下沉的越明显。默认情况下,文字都是基线对齐的,所以当字号大小不一样的两个文字在一起的时候,彼此就会发生上下位移。
<div class="demo1">
<span style="background: #ccc">xxxxx</span>
<span style="background: #444; font-size: 24px;">xxxxx</span>
</div> .demo1 {
margin: 30px;
line-height: 100px;
background: #ddd;
position: relative;
}
.demo1:after {
content: '';
position: absolute;
top: 0;
left: 50px;
width: 5px;
height: 50%;
background: #f80;
}当第二个 <span> 元素的 font-size 逐渐变大时,会发现两个元素会发生上下位移。父元素中设置了 line-height: 100px。所以两个元素的高度就是100px;当两个元素发生错位的时候 高度就会变大。那么我们的父元素的高度就随着变大了。
我们来看下面这个demo,为什么容器底部有间隙?
<div class="demo">
<span style=" background: #444">xsdhg</span>
<img src="./img/timg.jpg" alt="" style="height: 100px;">
</div> .demo {
font-family: simsun;
font-size: 20px;
margin: 30px;
line-height: 1;
border: 1px solid #ddd;
}间隙的大小就等于字体的 baseline 到字体下边缘的距离。
因为 line-height 存在继承,即使我们没有设置 line-height,他仍然存在。
准确的来说,字符 x 的高度其实要小于 font-size。所以当我们将 line-height 设置为 1 的时候,这个间隙刚好就是文字体基线到字体下边缘的距离了,这个距离我们定义为 x。line-height: 1 的时候其实是没有行距的,或者说行距为0,如果这个时候 line-height: 2,那么半行距刚好等于 0.5 个 font-size 的大小,这个距离定义为 y。所以这个时候间隙的大小就等于 x + y。
line-height 设置为足够小,当 line-height 小于等于1时,半行距就小于等于0了。font-size 设置为 0,这种情况下,就不存在 height 了vertical-align: middle 这个时候字符 x 就垂直居中了。上面的 demo 已经讨论过了vertical: baseline 给限定死了。 <div class="demo3">
x<img src="./static/img/timg.jpg" alt="" style="height: 100px; margin-top: -100px">
</div> .demo3 {
border: 1px solid #ddd;
}inline-block 和 baseline我们现在知道了 baseline 就是文本之类的内联元素字符 x 的下边缘,对于替换元素就是替换元素的下边缘。但是,如果是 inline-block 元素,则规则就要复杂了。
如果元素内部没有内联元素,或者设置了 overflow(不能是 visible),则该元素的 baseline 就是元素的 margin-bottom 的下边缘。否则就是元素内最后一行内联元素的基线
<div class="demo4">
xxx
<div class="demo4-con">的废话废话废话少放胡椒粉和客户反馈复活节肯定很舒服</div>
</div> .demo4 {
width: 300px;
line-height: 120px;
border: 1px solid #ddd;
}
.demo4-con {
width: 200px;
overflow: auto;
margin-bottom: 10px;
display: inline-block;
line-height: 20px;
background: #ccc;
}vertical-align: top / bottom元素顶部和当前行框盒子的顶部 / 底部 对齐
<div class="demo5">
x
<img src="./static/img/timg.jpg" alt="" style="height: 80px; vertical-align: top">
<img src="./static/img/timg.jpg" alt="" style="height: 80px; vertical-align: bottom">
</div> .demo5 {
height: 100px;
line-height: 100px;
border: 1px solid #ddd;
}vertical-align: middle元素的垂直中心点和行框盒子基线往上 二分之一 x-height 处对齐
vertical-align: text-top / text-bottomtext-top: 元素的顶部和父元素的内容区域顶部对齐
text-bottom: 元素的底部和父元素的内容区域底部对齐
<div class="demo6">
xgh
<img src="./img/timg.jpg" alt="" style="height: 80px; vertical-align: text-top">
<img src="./img/timg.jpg" alt="" style="height: 80px; vertical-align: text-bottom">
</div> .demo6 {
height: 100px;
line-height: 100px;
font-size: 32px;
border: 1px solid #ddd;
}vertical-align 实现一个水平垂直居中 <div class="container">
<div class="dialog"></div>
</div> .container {
position: fixed;
top: 0;
bottom: 0;
left: 0;
right: 0;
font-size: 0;
text-align: center;
background: rgba(0,0,0,.6);
white-space: nowrap;
overflow: hidden;
}
.container:after {
content: 'x';
display: inline-block;
height: 100%;
width: 0px;
vertical-align: middle;
}
.dialog {
display: inline-block;
vertical-align: middle;
width: 200px;
height: 200px;
background: #fff;
}萌推项目的采集上报规范在立项之初基本已经定义完备,在后续业务迭代过程中也得到了充分的验证。
萌推的采集上报基于集团的采集上报工具,为了区分集团采集上报的预留字段,所有萌推项目上报的字段都以字母 x 开头。比如 type 字段,在原始报表中是 xtype 字段。
萌推所有业务上报字段的值,均为字符串格式或者 NULL。这个的缘由是原始数据落库处理时会将值根据其数据类型放入不同的字段,比如 a= 123,最终落库的数据为 a={int_type=123, long_type=0, float_type=0.0, string_type=0},如果是 a="xyz",落库后成了 a={int_type=0, long_type=0, float_type=0.0, string_type=xyz}。为了清洗数据方便,我们规定所有上报字段都用字符串格式。
萌推项目每次上报都使用一些通用字段,通用字段中部分来自集团使用的字段,部分来自项目自定义字段,枚举如下:
| 字段 | 含义 |
|---|---|
| member_id | 用户 id,值为萌推 uid 的 hash 值 |
| kuid | 反作弊侧提供的设备识别码 |
| ua | 浏览器 ua 信息 |
| ref | HTTP Referrer 信息 |
| xtype | 上报类型,有 pv、mt、res.imp 等 |
| xpage_name | 当前页 page name,比如商详页 goods_detail |
| xpage_id | 当前页 page id |
| xkey_param | 当前页的细分参数,不同页面,其所表述的内容含义不同 |
| xref_page_name | 来源页 page name |
| xref_page_id | 来源页 page id |
| xref_key_param | 来源页 key param 值 |
| xref_pos_id | 来源页位置 id |
| xplatform | 平台信息 微信商城 2,小程序 4,iOS 30,安卓 40,QTT 导量 110 |
| xe_time | 上报产生时间点,同步服务器时间 |
| xapp_ver | APP 版本号 |
| xenv | 环境信息,取值只有 NULL 和 test,test 表示非生产环境,一般清洗数据需要剔除 test 数据 |
关于 kuid,kuid 在 iOS 和安卓下可以被解析为有效的 tuid,在其他非 APP 环境下皆无法正确解析为 tuid。
另外,萌推 H5 页面在 APP 环境下是使用 APP kuid 进行上报,所以无需区分 APP 下是 H5 还是原生上报。
集团上报 SDK 是收集上报机制,会在一个时间跨度之后将收集的上报一次性全部发送,即 N 条上报信息到达服务器的时间相同,所以上报产生时间需要通过 xe_time 字段记录。
上报的类型种类比较繁多,理论上是可以无限扩展的,常用的有 pv、action.click 等,这里先枚举一些常用的类型:
| xtype 取值 | 表达类型 |
|---|---|
| action.click | 点击事件 |
| launch | 启动页上报,仅安卓 APP 有该上报 |
| login | 登陆上报 |
| action.order | 下单行为 |
| action.order.pay | 订单支付行为 |
| action.click.cart | 购物车行为 |
| action.share | 分享行为 |
| action.search | 搜索行为 |
| action.download | 下载行为,一般发生在站外 |
还有一些常用上报类型下面细述。
pv 上报一般指用户访问一个页面之初的上报,用来记录该页面的 page view,进而可以得到 user view 等数据。
pv 上报的 xtype 字段值为 pv。每个页面都设有独有的 page name 值。
可以查阅 km 文档:http://km.innotechx.com/pages/viewpage.action?pageId=76903202
另,每一次 pv 上报都使用不同的 page id。为了防止 page id 重复,其生成规则采用了时间和空间维度双重保障,具体规则如下:
page_name + 时间戳 + 10 位随机字符串
page id 的生命周期可以理解为页面访问到页面退出,可以合理用在比如路径查找、订单归因等数据清洗过程中。
在 qe 平台上有清洗的实时 pv 表:mengtuidw.dwd_bhv_pv_rt
曝光上报包含商品曝光上报、页面模块曝光上报等,其 xtype 值为 res.imp。
曝光上报一般伴随两个特别字段 pos_id 和 res_id。其含义如下:
| 字段 | 含义 |
|---|---|
| pos_id | 位置 id |
| res_id | 资源 id |
可以通过这两个字段精确到页面具体位置的上报,其知晓上报内容。比如 pos_id = 'recommend.1',res_id = 'goods?id=1002832',表示来源于页面的推荐列表,曝光的商品 id 是 1002832。
相关 pos_id 及 res_id 定义可以查看文档:http://km.innotechx.com/pages/viewpage.action?pageId=40140937
在 qe 平台上有清洗的实时曝光表:mengtuidw.dwd_bhv_exposure_rt
tdata 字段是推荐这边比较关注的一个字段,它不仅限于一个特定类型的上报中,而是结合在包括 pv、res.imp 等上报中,通常以 xtdata 字段标识其值。
xtdata 字段值是一个 JSON String,其中包含了业务方需要的信息。
tdata 上报拥有一条包含曝光到下单,比较完整的上报链路,如下所示:
算法推荐 -> GO 商品列表接口 -> 客户端曝光 -> 用户点击至商详 -> 用户下单
通过这个路径,能够保障 tdata 字段可以最终关联上商品产生的订单。
在上述路径中,tdata 字段值会被一直透传,直至后续路径断开。该过程中,对 tdata 字段值一律不作处理,所以最终上报内容是等于下发内容的。了解这一点有助于快速排出问题。
另外,tdata 字段目前有 2 个业务在使用,一个是算法推荐,另一个是广告系统。算法推荐使用 5 个 key,分别是 req_id, p_score, o_score, from, s_score,目前除了 req_id 字段,其他几个字段比较鲜见;广告系统使用 1 个 key: ads_report。
所以在调整 tdata 字段时需要注意不影响其他业务,并且及时通知维护文档:http://km.innotechx.com/pages/viewpage.action?pageId=97708332
session 上报是在发生和商品相关的上报时,增加的一种冗余上报,
session 上报的 type 值为 session。该上报中使用 xsession 字段表达上报内容,xsession 字段值是一个 JSON String,其中 key 枚举如下:
| 字段 | 含义 |
|---|---|
| member_id | 用户 id |
| opid | kuid |
| gid | goods id |
| time | 上报时间 |
| from_page_id | 来源页 page id |
| page_id | 当前页 page id |
| action_type | session 上报的前置上报类型 |
| page_name | 当前页 page name |
| from_page_name | 来源页 page name |
| key_param | 当前页 key param |
| from_pos_id | 来源页位置 id |
| ext | 额外信息,JSON String |
在任何上报中含有 goods_id 字段时,即产生 session 上报。
产生 session 上报的重要来源有:
业务迭代过程中,为了减少清洗数据带来的人力和资源成本,所以增加了字段含义更为抽象的 mt 上报。
| 字段 | 含义 |
|---|---|
| xtype | 类型,值为 mt |
| xaction | 描述具体行为 |
| xaction2 | 更细化的行为描述 |
| xext1 | 通用字段,视具体上报内容而定 |
| ... | ... |
| xext10 | 通用字段,视具体上报内容而定 |
mt 上报中,ext1 到 ext10 这 10 个字段都是根据具体上报定其含义。
这带来的好处是清洗一次表后,任何上报都可以在 mt 上报中得到表达。不便之处是具体上报中 ext 字段含义需要对照文档进行识别。
萌推 APP 在测试版 APP 中增加了一些辅助工具帮助数分及其他同学可以方便查看上报信息。
首页是下载测试版 APP,
下载地址:
iOS 版本的安装需要在 plist 中增加手机设备识别号,需要联系 杰伦、女巫 进行步骤指导和安装
安装完成后需要设置一下 APP,
进入 我的 - 设置
进入 调试工程模式
切换环境 正式环境
开启 H5 DEBUG 模式
开启 强制关闭HTML本地资源包映射
点击顶部 保存重启
如提示 “当前环境,无需切换”,可以手动杀死 APP,再次打开生效
进入 Debug
切换环境 线上环境
开启 是否强制使用远程资源包
开启 是否使用H5Debug
点击顶部 立即生效
如点击 立即生效 无反馈,可以手动杀死 APP,再次打开生效
设置完成后,进入 H5 页面会发现右上角多了一个 toggle 按钮,表示已经生效。
点击 toggle 按钮可以切换可视化数据显示/隐藏。

一般的 PV 信息和曝光信息会在页面上直观呈现。
设置完成后,H5 页面的右下角会多一个绿色的原型按钮。通过该按钮,可以直接查看商品数据。
具体操作是,先点击按钮,按钮此时会变成红色,表示进入选区模式。
在选区模式时,手指滑动屏幕,会出现一个选区。将选区选定一个商品名称,此时会出现一个遮罩层,展示出该商品相关的原始数据。


埋点规则:http://km.innotechx.com/pages/viewpage.action?pageId=34799684
page name 一览:http://km.innotechx.com/pages/viewpage.action?pageId=76903202
mt 上报一览:http://km.innotechx.com/pages/viewpage.action?pageId=72857273
session 上报规则:http://km.innotechx.com/pages/viewpage.action?pageId=69748056
pos_id/res_id 规则及一览:http://km.innotechx.com/pages/viewpage.action?pageId=40140937
字段解释:http://km.innotechx.com/pages/viewpage.action?pageId=69731721
APP 采集上报文档:http://km.innotechx.com/pages/viewpage.action?pageId=82251637
QE 平台:http://dataplatform.qutoutiao.net/qe_vue/#/search
浏览器在 XMLHttpRequest 类上定义了他们的 HTTP API。这个类的每一个实例都表示一个独立的请求/响应,并且这个对象的属性和方法允许指定请求细节和提取响应数据。W3C在 XMLHttpRequest 规范的基础上制定了2级 XMLHttpRequest (下文简称 XHR2 )标准草案,且大部分浏览器都已经支持了。
XMLHttpRequest 之前,我想先简单说一下HTTP请求组成部分和响应的组成部分HTTP 请求的各部分有指定的顺序:请求方法和URL首先到达,然后是请求头,最后是主体。XHMLHttpRequest 实现通常直到调用send()方法才开始启动网络。但 XMLHttpRequest API的设计似乎使每个方法都将写入网络流。这意味着调用 XMLHttpRequest 上的方法的顺序必须匹配 HTTP 请求的架构。例如,setRequestHeader() 方法的调用必须在调用 open() 之前但是在 send() 之后,否则就会跑出异常。下面我门会按照这个顺序来介绍。
使用 XMLHttpRequest API的第一件事就是先实例化;
var request = new XMLHttpRequest();我们也能重用已经存在的 XMLHttpRequest对象,但是这将会中止之前通过该对象发起的任何请求,但一般不会这么用
request.open('POST', url);第一个参数指定HTTP方法或动作,注意: 不区分大小写,但通常都是使用大写来匹配HTTP协议。
第二个参数是URL,这个URL可以是相对url也可以是绝对的url。
第三个参数用来设置请求的异步还是同步
如果请求一个受保护的URL,把用户和密码作为第4和第5个参数传递。
request.setRequestheader('Content-Type': 'text/plain');如果对相同的头调用 setRequestHeader() 多次,新值不会取代之前指定的值,相反,HTTP请求将包含这个头的多个副本或这个头将指定多个值。
setRequestHeader() 没有办法设置下面的 header,XMLHttpRequest 将自动添加这些头而防止伪造他们。类似的,XMLHttpRequest 对象自动处理 cookie,连接时间,字符集和编码判断,所以无法向 setRequestHeader() 传递这些头:
| Accept-Charset | Accept-Encoding | Connection | Content-Length | Cookie |
| Cookie2 | Content-Transfer-Encoding | Date | Expect | Host |
| Keep-Live | Referer | TE | Trailer | Transfer-Encoding |
| Upgrage | User-Agent | Via |
当 send() 方法传入 XML 文档时,没有指定 Content-Type,XMLHttpRequest 会自动设置一个合适的头。类似的如果给 send() 传入一个字符串但没有指定 Content-Type,那么 XMLHttpRequest 将会自动添加 text/plain; charset=utf-8 头。
当使用 GET 方法时,不需要调用 setRequestHeader() 这个方法,因为 GET 请求只能进行 url编码(application/x-www-form-urlencoded),而如果使用 POST 方法且传递的参数是以 ‘&’ 和 ‘=’ 符号进行键值连接时,Content-Type 头必须设置 application/x-www-form-urlencoded。
使用 XMLHttpRequest 发起HTTP请求的最后一步就是指定可选的请求主体并向服务器发送它:
request.send(null);setRequestHeader() 指定的 Content-type 头。XMLHttpRequest 属性readystatechangeXMLHttpRequest 对象通常异步使用:发送请求后,send() 方法立即返回,直到响应返回。为了在响应准备就绪的时候得到通知,必须监听 XMLHttpRequest 对象上的 readystatechange 事件。
readyState它是一个整数, 他指定了 HTTP 请求的状态。
abort() 方法重置。open() 方法已调用,请求连接已经建立。但是 send() 方法未调用,请求数据未发送。send() 方法已调用,HTTP 请求已发送到 Web 服务器。接收到头信息HTTP 响应已经完全接收status服务器返回的http状态码,当 readyState 小于 3 的时候读取这一属性会导致一个异常。
statusText以数字和文字的形式返回 HTTP 状态码。
getRequestHeader()/getAllRequestHeaders()使用这两个方法都可以查询到响应头。XMLHttpRequest 会自动处理 cookie,他会从 getAllRequestHeaders() 头返回集中过滤掉 cookie 头。而如果给 getRequestHeader() 传递 Set-Cookie 和 Set-Cookie2 则会返回 null。
responseTextresponseText 接受到服务器的相应数据 返回的值是一个json字符串 通过 JSON.parse(xhr.responseText) 可以得到数据对象
responseXMLresponseXML属性可以得到 XML 的 Document形式的数据。
XHR2规范定义了很多有用的事件集,在这个新的事件模型中,XMLHttpRequest 对象在请求的不同阶段触发不同类型的事件,所以它不再需要检查 readyState 属性
。
onloadstart : 当调用 send() 时,触发单个 loadstart 事件
onprogress : xhr对象会发生 progress 事件,通常每隔50ms左右触发一次,所以可以使用这个事件给用户反馈请求的进度。如果请求快速完成,他可能不会触发 progress 事件。注意这里的 progress 是下载的进度,xhr2 额外的定义了上传 upload 属性,用来定义上传的相关事件。
onload : 当事件完成时,触发 load 事件,load 事件的处理程序应该检查xhr对象的 status 状态码来确定收到的是 200 还是 404
ontimeout : 如果请求超时,会触发 timeout 事件。
onerror : 大多重定向这样的网络错误会阻止请求的完成,但这些情况发生时会触发 error 事件。
onabort : 如果请求中止,会触发 abort 事件。
onloadend : 对于任何具体的请求,浏览器将只会触发 load/abort/timeout/error 事件中的一个。一旦这些事件触发以后,浏览器将会触发 loadend 事件。
loaded : 目前传输的字节数值total : 传输的数据的整体长度(单位字节),Content-Length == total,如果不知道内容的长度则 total == 0;lengthComputable : 如果知道内容的长度则 lengthComputable == true, 否则 false xhr.onprogress = function(event) {
if (event.lengthComputable) {
const progress = event.loaded / event.total * 100;
}
}XHR2 新增的 upload 属性XHR2 中新增了一个 upload 属性,这个属性值是一个对象,他定义了 addEventListener() 和 整个 progress 事件集合,比如说 onprogress 和 onload。(但 upload 没有定义 onreadystatechange 属性,upload 仅能触发新的事件类型)。
onloadstart : 和 XMLHttpRequest 中的 loadstart 事件一样。
onprogress : 和 XMLHttpRequest 中的 progress 事件一样。
onload : 和 XMLHttpRequest 中的 load 事件一样。
ontimeout : 和 XMLHttpRequest 中的 timeout 事件一样。
onerror : 和 XMLHttpRequest 中的 error 事件一样。
onabort : 和 XMLHttpRequest 中的 abort 事件一样。
onloadend : 和 XMLHttpRequest 中的 loadend 事件一样。
upload 属性上定义的事件主要用在上传文件时。我们可以使用 upload 上的 onloadstart,onprogress 分别监听文件开始上传和上传过程中进度的变化。
const input = document.getElementsByTagName('input')[0];
input.addEventListener('change', function() {
var file = this.files[0];
if (!file) return;
var xhr = new XMLHttpRequest();
xhr.open('POST', url);
xhr.send(file);
}, false);文件类型是更普通的二进制大对象 Blob 类型中的一个字类型。XHR2 允许向 send() 方法传入任何 Blob 对象。如果没有显示的设置 Content-Type 头,这个 Blob 对象的 type 属性用于设置待上传的 Content-Type 头。
XHR2 定义了新的 FormData API, 它容易实现多部分请求主体。首先,使用 FormData() 构造函数创建 FormData 对象,然后按需多次调用这个对象的 append() 方法把个体部分(string/File/Blob对象) 添加到请求中。最后把 FormData 对象传递给 send() 方法。send() 方法将对请求定义合适的边界字符串和设置 Content-Type 头。
通过调用 XMLHttpRequest 对象的 abort() 方法来取消正在进行的 HTTP 请求。当调用 abort() 方法后会触发 xhr 对象的 onabort 事件。
XHR2 定义了 timeout 属性来指定请求自动终止的毫秒数。同时也定义了 timeout 事件,当超时发生时触发。
// 封装一个request方法
const request = (url, formData, cb) => {
// 初始化
const xhr = new XMLHttpRequest();
// 定义请求的方法/动作和url
xhr.open('POST', url);
// 设置超时时间,单位是毫秒
xhr.timeout = 2000;
xhr.ontimeout = function() {
console.log('timeout');
};
// 开始上传
xhr.upload.onloadstart = function() {
console.log('开始上传');
};
// 上传的进度
xhr.upload.onprogress = function(event) {
// 只有当 lengthComputable 为true是,loaded 才有值
if (event.lengthComputable) {
const value = Math.ceil((event.loaded / event.total) * 100);
cb && cb({
status: 'loading',
progress: value,
data: null,
});
}
};
// 监听事件完成, 完成并不一定代表请求成功,所以需要判断 status 状态码
xhr.onload = function() {
const resp: Response = {
status: 'success',
progress: 100,
data: null,
};
if (xhr.status === 200) {
resp.data = JSON.parse(xhr.responseText);
cb && cb(resp);
} else {
resp.status = 'error';
cb && cb(resp);
}
};
xhr.onerror = function() {
cb && cb({
status: 'error',
progress: 0,
data: null,
});
};
xhr.onabort = function() {
console.log('onabort');
};
xhr.onloadend = function() {
console.log('上传结束');
};
xhr.send(formData);
return xhr;
};作为同源策略的一部分,XMLHttpRequest 对象通常仅可以发起和文档具有相同服务器的 HTTP 请求。这个限制关闭了安全里漏洞,但同时也阻止了大量可使用的跨域请求。好在 XHR2 通过在 HTTP 响应中选择发送合适的 CORS(Cross-Origin Resource Sharing,跨域资源共享) 允许跨域访问网站。在日常开发中使用跨域请求并不需要进行的额外的其他设置,只要浏览器支持 CORS 跨域请求就行。
虽然实现 CORS 支持跨域的请求工作不需要做任务的事情,但有一些安全细节需要了解:
xhr.open() 方法传入第四和第五个参数(用户名和密码)时,将不会通过跨域请求发送cookie 的。如果需要携带 cookie,那么可以在调用 send() 方法之前设置 XMLHttpRequest 的withCredentials属性为 trueCORS 跨域请求,可以直接通过检测 XMLHttpRequest 的 withCredentials 的属性是否存在即可。XMLHttpRequest 的跨域请求同样包含简单请求和非简单请求,非简单请求又会进行预检请求,具体 CORS 的相关知识可以查看之前的分享的文章点击这里。XMLHttpRequest API非常的好用,而且目前市面上的主浏览器也基本上都支持。相比 fetch 而言,兼容性肯定是更胜一筹,唯一不足的是不支持 Promise,但是这也难不倒我们程序员,自己封装一层就可以了。更为重要的是 XMLHttpRequest 支持超时设置和中止请求,还有进度事件,这些都是 'fetch' 所不具备的。
作为一名合格的前端开发工程师,了解并掌握正则表达式是非常有必要的。多年的项目经验告诉我,学好正则表达式可以让我们少写很多的代码。这篇文章非常适合哪些初中级和对正则表达式掌握不是很清楚的同学,废话不多少,我门开始吧。。。
js中的正则表达式用 RegExp 对象表示,可以使用 RegExp() 构造函数来创建 RegExp 对象,不过更多情况下我们使用一种特殊的直接量语法来创建,举个例子:
// 使用直接量的形式
var pattern = /\d$/;
// 使用构造函数的形式
var pattern = new RegExp('\d$');但是如果需要我们动态的生成一个正则表达式呢,那么这个时候就需要使用构造函数形式了, 看下面的这个例子
var fmt = 'MM-dd hh:mm:ss';
var date = new Date();
var fmtObj = {
'M+': date.getMonth() + 1,
'd+': date.getDate(),
'h+': date.getHours(),
'm+': date.getMinutes(),
's+': date.getSeconds(),
}
for(let key in fmtObj) {
if (new RegExp(`(${key})`).test(fmt)) {
fmt = fmt.replace(RegExp.$1, RegExp.$1.lengt === 1 ? fmtObj[key] : ('00' + fmtObj[key]).substr((fmtObj[key] + '').length))
}
}正则表达式中所有的字母和数字都是按照字面量的含义进行匹配的,js的正则表达式也支持非字母的字符匹配,这些字符需要功过反斜杠 \ 进行转译。下表中列举了转译字符
| \o | NUL字符(\u0000) |
| \t | 制表符(\u0009) |
| \n | 换行符 (\u000A) |
| \v | 垂直制表符(\u000B) |
| \f | 换页符(\u000C) |
| \r | 回车符(\u000D) |
| \xnn | 由16进制数nn指定的拉丁字符,例如,\x0A等价于\n |
| \uxxxx | 由16进制数xxxx指定的unicode字符,例如\u0009等价于\t |
| \cX | 控制字符^X,\cJ等价于换行符\n |
| 字母和数字字符 | 匹配自身 |
在正则表达式中,许多标点符号具有特殊的含义,他们是:^ $ . * + ? = ! : | \ / ( ) { } [ ]
某些符号只能在正则表达式的某些上下文中才具有某种特殊含义,在其他上下文中则会被当成直接量处理。如果想要在正则表达式中使用这些符号的直接量进行匹配,则必须使用前缀 \ ,这是一条通用的规则,其他标点符号(例如@和引号)没有特殊含义,在正则表达式中按照字面量含义进行匹配,如果不记得哪些标点符号需要反斜杆转义,可以在每一个标点符号前面都加上转义符 \ 。另外需要注意,许多字母和数字在有反斜杆做前缀时会有特殊含义,所以对于想按照直接量进行匹配的数字和字母,尽量不要用 \ 进行转义
将直接量字符单独放进方括号内就组成了字符类。一个字符类可以匹配它所包含的任意字符,因此表达式 /[abc]/ 就和字母a,b,c中的任意一个都匹配
var reg = /[a-z0-9]/;上面的正则表达式可以匹配任意一个字母或数字,其中 a-z 表示a到z的所有字母,0-9 表示0到9之间的数字
就是匹配字符类中不含有的字符,用 ^ 符号开头
var reg = /[^a-z0-9]/;上面的正则表达式的意思就是匹配任意一个不含有字母和数字的字符
| [...] | 字符类 |
| [^...] | 反字符类 |
| . | 除换行符和其他unicode行终止符之外的任意字符 |
| \w | 数字,字母和下划线, 等价于[a-z0-9_] |
| \W | 非数字,字母和下划线, 等价于[^a-z0-9_] |
| \s | 任何unicode 空白符 |
| \S | 非任何unicode 空白符 |
| \d | 数字 |
| \D | 非数字 |
| \b | 单词边界 |
| \B | 非单词边界 |
| {n, m} | 最少匹配n次,最多匹配m次 |
| {n, } | 至少匹配n次或更多 |
| {n} | 匹配n次 |
| ? | 匹配0次或一次 |
| + | 最少匹配一次 |
| * | 匹配0次或多次 |
上面我们列举出了匹配重复字符是尽可能多的匹配,而且允许后续的正则表达式继续匹配。因此我们称之为'贪婪'匹配模式。我们同样可以使用的正则表达式进行非贪婪匹配。只需要在待匹配的字符后跟随一个问号即可: '??', '+?', '*?' 或者'{1, 5}?'
var a = /[a-z0-9]+?/
a.exec('sdfff900') // ["s", index: 0, input: "sdfff900", groups: undefined]
// 使用非贪婪模式匹配得到的结果可能和期望并不一样,可以来看看看下面的这个例子:
var b = /a+?b/;
b.exec('aaab') // ["aaab", index: 0, input: "aaab", groups: undefined]
// 下面这样的匹配结果你想到了吗??
var c = /shen(ab)+?/;
b.exec('shenababab'); // ["shenab", "ab", index: 0, input: "shenababab", groups: undefined]这是因为正则表达式的模式匹配总是会寻找字符串中第一个可能匹配的位置,由于这个匹配是从字符串的第一个字符开始的,因此在这里不考虑他的子串中更短的匹配
正则表达式语法还包括指定选择项,子表达分组和引用前一子表达式的特殊字符,我们分别来看一下
| 用于分隔供选择的字符。/ab|cd|ef/,可以匹配字符串ab,也可以匹配cd或者是ef。
注意选择项的尝试匹配的次序是从左到右,直到发现了匹配的项。如果左边的选择项匹配,就忽略右边的选择项,即使产生更好的匹配。
所以,当正则表达式 /a|ab/ 匹配字符串 ab 时,他只能匹配第一个字符串 a
正则表达式中的圆括号有多种作用。
| * + ? 等来对单元内的项进行处理。 var a = /java(script)?/; // 可以匹配字符串 'java',其后可以有'script'也可以没有。
var b = /(ab|cd)+|ef/; // 可以匹配字符串ef, 也可以匹配ab或者cd的一次或多次重复 var a = /[a-z]+(\d+)/; // 那么这个时候我们可以从检索到的匹配中拿到和圆括号中子模式相匹配的数字() 表示捕获分组,() 会把每个分组里的匹配的值保存起来,使用 $n (n是一个数字,表示第n个捕获组的内容)
var reg = /\b(shen(sxx))/;
reg.test('shensxx');
console.log(RegExp.$1, RegExp.$2) // shensxx sxx
reg.exec('shensxx');
// ["shensxx", "shensxx", "sxx", index: 0, input: "shensxx", groups: undefined](?:) 表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
var reg = /\b(shen(?:sxx))/;
reg.test('shensxx');
console.log(RegExp.$1, RegExp.$2) // shensxx
reg.exec('shensxx');
// ["shensxx", "shensxx", index: 0, input: "shensxx", groups: undefined]这是通过在字符 \ 后面加一位数字或多位数字来实现的,这个数字指定了圆括号的子表达式在正则表达式中的位置。\1, \3 分别表示正则表达式中的第一个圆括号的子表达式和第三个子表达式(注意这里指的是自表达式中匹配的文本的引用,并不是指子表达式)
注意: 因为子表达式可以嵌套另一个子表达式,所以他们的位置是参与计数的左括号的位置
var a = /([Jj]ava([Ss]cript)?)\sis\s(fun\w*)/; // \2 则是代表的([Ss]sript)
var b = /(['"])[^'"]*\1/; // 只能匹配单引号或者双引号是成对出现的,不允许出现一个单引号一个双引号有一些正则表达式匹配的是字符串之间的位置,而不是实际的字符。例如 \b 匹配一个单词边界,即位于 \w 和 \W 之间的边界,或者是一个字符串开始或结束的位置。像 \b 这样的元素不匹配某个可见的字符,他们指定匹配发生的合法位置。还有一些锚元素 ^ $, 分表表示匹配字符串开始和结束的位置
\b 匹配一个单词边界,即位于 \w 和 \W 之间的边界,或者是一个字符串开始或结束的位置。 var reg = /xx\b/;
reg.test('sxx shen') // true
reg.test('xxs shen') // false
var reg = /\bsx/;
reg.test('sxx shen') // true
reg.test('xsx shen') // false
var reg = /\b\d+/;
reg.test('.123') // true
reg.test('sxx124') // false\B 匹配非单词边界。er\B 能匹配 verb 中的 er,但不能匹配 never 中的 er。x(?=y) :正向先行断言,匹配 x 仅仅当 x 后面不跟着 yx(?!y) :负向先行断言, 匹配 x 仅仅当 x 后面不跟着 y我们看下面的正则表达式,意思就是非单词边界后面跟这三个数字字符串,而且三个数字字符串后面不再跟数字
var reg = /\B(?=(\d{3})+(?!\d))/g;
'123456789.123456'.replace(reg, ',') // "123,456,789.123,456"(?<=y)x :正向后行断言,匹配 x 仅仅当 x 前面跟着 y var reg = /(?<=95|98|NT|2000)Windows/;
'3.1Windows'.replace(reg, 'aaaa'); // '3.1Windows'没有匹配到
'2000Windows'.replace(reg, 'aaaa'); // '2000aaaa'(?<!y)x :负向后行断言,匹配 x 仅仅当 x 前面跟的不是 y var reg = /(?<!95|98|NT|2000)Windows/;
'3.1Windows'.replace(reg, 'aaaa'); // '3.1aaaa'
'2000Windows'.replace(reg, 'aaaa'); // '2000Windows' 没有匹配到 var reg = /(?<!\.\d*)\B(?=(\d{3})+(?!\d))/g
'123456789.98764525437'.replace(reg, ',')
// "123,456,789.98764525437"i: 执行时不区分大小写
g: 执行一个全局匹配,简而言之,就是找到所有的匹配,而不是在找到第一个之后就停止
m: 多行匹配模式,^ 匹配一行的开头和字符串的开头,$ 匹配行的结束和字符串的结束
使用字面量形式时: /\bjavascript\b/ig
构造函数形式: new RegExp('\bjavascript\b', 'ig')
@params: 一个正则表达式,如果参数不是一个正则表达式,那么会通过 `RegExp` 构造函数转成正则表达式
@return: 第一个与之匹配的字符串的起始位置,若是没有发生匹配就返回数字 `-1`
var a = 'javascript'
'fsfsdjavsssjavasdfsfsjfjhhshh3r98u'.search(a) // 11
var a = /[Jj]ava([Ss]crit)*/g;
'012345javascript 67890'.search(a) // 6@params: RegExp | string (正则表达式,可以设置修饰符)
@params: function | string
@return: 返回一个新的字符串,不改变源对象
如果第一个参数是一个string,那么 replace() 将直接搜索这个字符串然后进行替换(注意这里指替换第一个搜索到的结果),并不会先转成 RegExp 进行匹配。
如果第一个参数是一个 RegExp,那么 replace() 将会进行正则匹配,将第一次匹配到结果进行替换,这里正则表达式可以设置修饰符。g 会进行全局多次匹配,将所有匹配到的结果进行替换
如果第二个参数是一个 string,那么 replace() 将匹配的结果直接用这个字符串替换
如果第二个参数是一个 function,我们看看可以有哪些参数:
@params: 完整模式匹配到的结果
@params: 完整模式下的子模式匹配到的结果,看正则表达式中有多少个圆括号,那么这里就可以有多少个这样的参数,每个参数表示对应的子模式匹配的结果
@return: 使用 return 的返回值替换匹配到的值
var a = /([Jj]ava([Ss]cript))\sis\s(fun\w*)/g;
var b = 'ffhfhjavascript is functionsdfffsff';
b.replace(a, function(match) {
// 打印的结果就是 javascript is functionsdfffsff 123
console.log(match, 123);
return '@@@@'
});
// ffhfh@@@@
b.replace(a, function(match, v1, v2, v3) {
// 打印的结果就是 javascript is functionsdfffsff 123
console.log(match, 123);
// javascript
console.log(v1);
// script
console.log(v2);
// functionsdfffsff
console.log(v3);
return '@@@@'
});
// ffhfh@@@@@params: 正则表达式 | string(通过 `RegExp` 的构造函数转化成正则表达式)
@return: 数组,
如果这个正则表达式没有设置修饰符 g,match() 就不会进行全局检索,只检索第一个匹配。在这种情况下:数组的第一个元素就是就是完整模式匹配的结果,其余的元素则是正则表达式中圆括号的子表达式匹配的结果(如果没有圆括号就不会有这些元素)。index 表示匹配的位置,input 表示目标字符串
var a = /([Jj]ava([Ss]cript))\sis\s(fun\w*)/;
var b = 'ffhfhjavascript is functionsdfffsff';
b.match(a)
// ["javascript is functionsdfffsff", "javascript", "script", "functionsdfffsff", index: 5, input: "ffhfhjavascript is functionsdfffsff", groups: undefined]
如果添加了修饰符g,那么返回的数组中就是多次全局模式匹配的结果
var a = /123(sxx)456(hello)/g;
var b ='123sxx456helloffffjfljfj123sxx456hellojjweww123456hello123sxx456hello';
b.match(a)
// ["123sxx456hello", "123sxx456hello", "123sxx456hello"]@params: string
@return: 数组 | null
如果匹配到结果就返回一个数组,结果和字符串的 match() 方法的非全局匹配返回的结果一样。但是有一点和 match() 不一样,就是不管式全局还是非全局都是一样的结构。如果没有匹配到结果就返回 null
var a = /123(sxx)456(hello)/g;
var b ='123sxx456helloffffjfljfj123sxx456hellojjweww123456hello123sxx456hello';
a.exec(b);
// [“123sxx456hello", "sxx", "hello", index: 0, input: "123sxx456helloffffjfljfj123sxx456hellojjweww123456hello123sxx456hello", groups: undefined]@params: string
@return: boolean
这个方法很简,匹配成功就返回true,否则就返回false
javascript权威指南
我们认为浏览器存在一个缓存的数据库,用来存储一些不经常变化的静态文件(img,css,js文件等),一般将缓存分为强制缓存和协商缓存。强制缓存和协商缓存可以同时存在,且强制缓存的优先级大于协商缓存。
如果缓存数据库中已经存在所请求的数据,那么直接从缓存数据库中去获取数据,当缓存数据库中没有所请求的的数据,
客户端会先去缓存数据库中去获取缓存数据的标识,然后一起发送给服务端,服务端会去验证缓存是否已经失效,如果失效就重新返回新的数据,否则就返回304,客户端直接去缓存数据库中获取数据。
response header 部分的某些字段来判断Expires、Cache-ControExpires它的值是服务器返回的数据有效到期时间,当再次请求时的时间在这个时间以内,那么直接使用缓存。但是服务器时间和客户端时间是有误差的,而且 `Expires` 是http1.0的产物,所以一般使用Cache-Control代替。
Cache-Control 有很多的属性ETag,Last-Modifide (将其值作为缓存数据的标识的值,发送给服务器去验证)如果一个资源被修改了,但是他的内容却没有发生变化 Last-Modified也会发生改变
Etag 服务器返回的,表示当前资源在服务器生成的唯一标识ETag的计算是通过计算方法得出来的,算法会占用一定的资源,每一次资源发生变化以后就会重新生成ETag。所以一般很少使用ETag
服务器根据文件的一些信息会计算出ETag:
* 文件的索引节 inode
* 最后一次修改时间 mtime 和大小 size
Nginx官方默认的ETag计算方式是为文件最后修改时间16进制-文件长度16进制。例:ETag: “59e72c84-2404”
自定义:
// 这里额stat是通过nodejs的 fs.statSync 或者 fs.stats发放读取到的文件信息
function stattag (stat) {
var mtime = stat.mtime.getTime().toString(16);
var size = stat.size.toString(16);
return '"' + size + '-' + mtime + '"';
}ETag 和 last-modified 的优先级* 如果缓存的资源中两者都有的话,就将两者一起发送给服务器;服务器在判断时会会先判断ETag
如果 `if-non-match` 和 `ETag` 不一样那么重新返回资源 `status=200`,否则就返回304;这个时候不会再去判断 `last-modified`。
* 只存在 `last-modified` :如果 `if-modified-since` 和 `last-modified` 不一样,那么就重新返回资源 `status=200` 否则返回304。
Last-Modified,If-Modified-Since 和 ETag、If-None-Match 一般都是同时启用,这是为了处理Last-Modified不可靠的情况。有一种场景需 要注意:* 分布式系统里多台机器间文件的 `Last-Modified` 必须保持一致,以免负载均衡到不同机器导致比对失败;
* 分布式系统尽量关闭掉ETag(每台机器生成的ETag都会不一样);
* 减少不必要的请求,减轻服务器的压力,提升网站的性能
* 加快客户端网页加载的速度
关于js,css等文件需要更新,但是设置的缓存时间比较长怎么办???
Cross-Origin 跨域jsonp 跨域postMessagedocument.domainCross-Origin和 jsonp 这两种方式。postMessage 和 document.domain 使用的不是很多。下面我会介绍他们如何使用和使用的场景还有一些不常见的问题。我们先看看浏览器的兼容性,如下图:

注意: 所以要使用Cross-Origin进行跨域的话,必须注意客户端和服务器必须同时支持。
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request),我们看看如何区分
1.请求方法是以下三种方法之一:
HEADGETPOST2.HTTP的头信息不超出以下几种字段:
AcceptAccept-LanguageContent-LanguageLast-Event-IDContent-Type :只限于三个值 application/x-www-form-urlencoded 、multipart/form-data、text/plain对于简单请求,浏览器直接发出CORS请求。具体来说,就是在头信息之中,增加一个Origin字段。Origin字段用来说明,本次请求来自哪个源(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意这次请求。
如果Origin指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应。浏览器发现,这个回应的头信息没有包含 Access-Control-Allow-Origin 字段(详见下文),就知道出错了,从而抛出一个错误,被 XMLHttpRequest 的 onerror 回调函数捕获。注意,这种错误无法通过状态码识别,因为HTTP回应的状态码有可能是200。(如果我们使用的fetch,那么fetch会自动触发一个错误,那么这个时候我们可以通过promise可捕获这个错误信息)。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段
// 该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求
Access-Control-Allow-Origin: http://api.bob.com
// 该字段可选。它的值是一个布尔值,表示是否允许发送Cookie,如果需要发送cookie那么就设置为true,否则不会含有这个字段
// 如果要发送cookie,那么还需要设置 var xhr = new XMLHttpRequest(); xhr.withCredentials = true;
Access-Control-Allow-Credentials: true
// 该字段可选。CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:
// Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma
// 如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。上面的例子指定
// getResponseHeader('FooBar')可以返回FooBar字段的值。
Access-Control-Expose-Headers: FooBar需要注意的是,如果要发送 Cookie,Access-Control-Allow-Origin就不能设为*,必须指定明确的、与请求网页的域名一致。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为 预检请求(preflight)。
预检请求 用的请求方法是OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是Origin,表示请求来自哪个源。
除了Origin字段,"预检"请求的头信息包括两个特殊字段
// 该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法,上例是PUT。
Access-Control-Request-Method: PUT
// 该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段
Access-Control-Request-Headers:X-Custom-Header // 该字段必需, 字段也可以设为星号,表示同意任意跨源请求
Access-Control-Allow-Origin: *
// 该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法。
// 注意,返回的是所有支持的方法,而不单是浏览器请求的那个方法。这是为了避免多次"预检"请求。
Access-Control-Allow-Methods: GET, POST, PUT
// 如果浏览器请求包括Access-Control-Request-Headers字段,则Access-Control-Allow-Headers字段是必需的。
// 它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段,不限于浏览器在"预检"中请求的字段。
Access-Control-Allow-Headers: X-Custom-Header
// 该字段可选
// 该字段与简单请求时的含义相同
Access-Control-Allow-Credentials: true
// 该字段可选,用来指定本次预检请求的有效期,单位为秒。
// 即允许缓存该条回应1728000秒(即20天),在此期间,不用发出另一条预检请求。
Access-Control-Max-Age: 1728000一旦服务器通过了"预检"请求,以后每次浏览器正常的CORS请求,就都跟简单请求一样,会有一个Origin头信息字段。服务器的回应,也都会有一个 Access-Control-Allow-Origin 头信息字段。
我们以 koa为列,在demo中这么设置就可以了
// 下面是对cors进行的设置,在返回的headers中添加如下字段,也可以使用 koa2-cors
app.use(async (ctx, next) => {
// 允许来自所有域名请求,请求携带了cookie就不能设置为 *
ctx.set("Access-Control-Allow-Origin", "http://10.105.16.162:3000");
// 设置所允许的HTTP请求方法
ctx.set("Access-Control-Allow-Methods", "GET,POST");
// 它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段.
ctx.set("Access-Control-Allow-Headers", "x-requested-with,accept,origin,content-type");
// 该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认情况下,Cookie不包括在CORS请求之中。
// 当设置成允许请求携带cookie时,需要保证"Access-Control-Allow-Origin"是服务器有的域名,而不能是"*";
ctx.set("Access-Control-Allow-Credentials", true);
await next();
}); jonsp跨域的原理是通过动态创建script的标签的形式来实现跨域的,因为script不受同源策略的影响。但是jsonp只能接受get方法。
看看下面的代码是如何封装的,并做了超时设置。
const defaultOptions = {
timeout: 15000,
uid: 0,
perfix: '_jsp',
name: 'callBack',
}
const jsp = (url, params, options = {}) => {
let timer = null;
const options = Object.assign({}, defaultOptions, options);
const callBackName = `${options.perfix}_${options.name}_${options.uid++}`;
const paramsKeys = Object.entries(params);
url += `?${callback}=${callBackName}`;
url = paramsKeys.reduce((initUrl, [k, v]) => {
return `${initUrl}&${k}=${v}`;
}, url);
const body = document.getElementByTagName(body)[0];
const script = document.createElement('script');
script.src = url;
body.appendChild(script);
const clean = () => {
if (timer) {
clearInterval(timer);
timer = null;
body.removeChild(script);
window[callBackName] = null;
}
};
return new Promise((resolve, reject) => {
window[callBackName] = function(data) {
clear();
return resolve(data);
};
timer = setTimeout(() => {
clear();
return reject('请求超时了');
}, options.time);
});
}它可用于解决以下方面的问题:
使用方法:postMessage(data, origin) 方法接受两个参数
data html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用 JSON.stringify()序列化。IE10才开始支持对象形式。
origin 协议+主机+端口号,也可以设置为 *,表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为 /。
// 发送窗口代码:
const ifr = document.createElement('iframe');
ifr.src = 'http://localhost:3001';
ifr.display = 'none';
document.body.append(ifr);
ifr.onload = function() {
const doc = ifr.contentWindow;
// 目标源 可以限定具体的 协议 + 域名 + 端口 或者是 *
const targetOrigin = 'http://localhost:3001';
// 发送消息 doc可以是window.open() 也可以是嵌套的iframe
// 发送的消息可以是 string 或者 object(IE10才支持)
doc.postMessage('hello world', targetOrigin);
}
// 接收窗口代码:
window.addEventListener('message', (e)=> { // 必须是window不能是document监听
// 数据
const data = e.data;
// 消息是从哪个源发送来的
const origin = e.origin;
// 发送消息窗口
const source = e.source;
// 通过source回传消息 同样在发送消息的窗口也需要监听
source.postMessage('hi shenxuxiang', 'http://localhost:3000');
},false)此方案仅限主域相同,子域不同的跨域应用场景。实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
之后就可以共享window下的属性。
// www.a.com/a.html页面中的代码
document.domain = 'a.com';
const ifr = document.createElement('iframe');
ifr.src = 'http://www.script.a.com/b.html';
ifr.display = 'none';
document.body.append(ifr);
ifr.onload = function() {
const doc = ifr.contentWindow;
console.log(doc.name); // shenxuxiang
}
// www.script.a.com/b.html页面中的代码
document.domain = 'a.com';
window.name = 'shenxuxiang';上面一共介绍了4种前端跨域的方法,jsonp 和 cors 可以和后台进行跨域,而 postMessage 和 domain 适合页面间的通讯。页面间的跨域还有可以使用 window.name | location.hash。如果想了解的可以点击这里
首先我们要弄清楚 reduxjs 的**、作用是什么,这样我们才能开始下一步的构思。在我看来 reduxjs 核心就是一种单一数据源的概念,数据存储在一个函数的 state 变量中,只能通过固定的方法去修改和获取 dispatch()、getState()。
在 SPA 应用中,reduxjs 被广泛使用。对数据进行统一管理、实现数据共享,通常组件和组件之间、页面和页面之间可以数据共享。在 react 开发中,我经常将共用的数据和异步请求数据存放在 state 中。通过 props 的形式存在,只要在一个组件中对数据源进行了修改,其他共享的组件都会及时得到更新和渲染UI界面。
现在我们知道了关于 redux 的关键**和用途,接下来我们一步一步实现它。我会按照下面这个列表的顺序给大家详细说明:
function createStore(reducer, initState) {
// 声明一个初始化用的 action
const INIT_ACTION = undefined;
// 绑定监听事件的集合
const listeners = [];
// 这就是我们一直说的那个【数据源】
// 参数 initState 可以有,也可以没有。一般情况下不需要传递
let state = initState ? initState : {};
function dispatch(action) {
// action 必须是一个纯对象,不能是其他的类型
if (Object.prototype.toString.call(action) === '[object Object]') {
throw new Error('Actions must be plain objects');
}
// 注意:这里是最终还是通过调用 reducer 方法
state = reducer(state, action);
// 遍历 listeners
for (let i = 0; i < listeners.length; i++) {
listeners[i]();
}
}
// 获取 state 数据
function getState() {
return state;
}
// 绑定监听事件
function subscription(listener) {
listeners.push(listener);
// 取消监听,将事件从 listeners 中移除
return function() {
const idx = listeners.indexOf(listener);
if (idx >= 0) {
listeners.splice(idx, 1);
}
}
}
// 这是啥意思了,其实这是在调用 createStore() 时,就初始化了一个 state
dispatch(INIT_ACTION);
// 通过对象,将这些内部函数传递到外部。不要怀疑,这就是一个典型的闭包
return {
dispatch,
getState,
subscription,
};
}从 createStore 方法中我们可以看出来,其实他就是 js模块。利用了局部变量和闭包的特性,将 state 隐藏起来,只能通过闭包的形式进行访问和修改。
首先 reduce 它是一个函数,我们可以自己定义。我们可以把我们的项目想像成如下的一个场景,修改用户的信息:
function userName(state = {}, action = {}) {
switch (action.type) {
case 'name':
return { ...state, name: action.data };
case 'age':
return { ...state, age: action.data };
case 'sex':
return { ...state, sex: action.data };
// 必须设置 default,直接返回 state
default:
return state;
}
}如果我们的项目中只需要这一种交互场景,那么定义 userName() 就够了。这个时候 我们把 userName 传递给 createStore
const { getState } = createStore(userName);
// 返回的是一个 {}
console.log(getState());上面的代码在执行 createStore(userName) 时,内部执行一次 dispatch(INIT_ACTION) ,从而在 dispatch 方法内部调用了 userName({}, undefined)。所以打印的结果是一个空对象。
如果交互场景比较多的时候呢,一个 reducer 肯定不够用啊,那么这个时候我们可能会定义多个类似 userName 这个的 reducer 函数,所以我们还需要定义一个工具函数 combineReducers,将多个 reducer 函数组合成一个 reducer 函数。
function combineReducers(reducers) {
const keys = Object.keys(reducers);
const finallyKeys = [];
for (let i = 0; i < keys.length; i++) {
if (typeof reducers[keys[i]] !== 'function') throw Error('reducer must be a function');
finallyKeys.push(keys[i]);
}
// 看,最后返回的还是一个 function
return function(state = {}, action) {
let hasChange = false;
const newState = {};
// 遍历所有的 reducer 函数
finallyKeys.forEach(key => {
// 获取这个 reducer 函数对应的 state。注意它可能是一个 undefined
// 没错,在 createStore() 中执行 dispatch(INIT_ACTION),这个时候 prevState_key 可能就是一个 unudefined
const prevState_key = state[key];
const reducer = reducers[key];
// 调用该 reducer,返回一个新的 state
const nextState_key = reducer(prevState_key, action);
// 注意这里,如果 reducer 函数返回的是一个 undefined。那么这里就会报错了
// 所以我们在定义 reducer 函数时,应该有一个限制:如果没有匹配到 action 的 type 。应该默认返回 previous state。
if (typeOf nextState_key === 'undefined') {
throw Error('to ignore an action, you must explicitly return the previous state');
}
// 当 reducer 执行完成时,会在 newState 上添加一个新属性,属性值就是 nextState_key
// 其实,从这个地方我们就应该可以猜测到,最终得到的 state【数据源】,它的结果应该和我们传入的 reducers 结构是一样的
newState[key] = nextState_key;
hasChange = hasChange || nextState_key !== prevState_key;
});
return hasChange ? newState : state;
}
}结合之前的 createStore,我们看看下面的 demo:
function menu(state = {}, action = {}) {
switch (action.type) {
case 'home':
return { ...state, home: action.data };
case 'list':
return { ...state, list: action.data };
case 'detail':
return { ...state, detail: action.data };
default:
return state;
}
}
const reducer = combineReducers({ userName, menu });
const { getState } = createStore(userName);
// 返回的是一个 { userName: {}, menu: {} }
// 这里和我们传递给 combineReducers() 中的参数的结构是一致的。
console.log(getState());上面的 reducer 是 userName, menu 的一个组合体,所以每次调用 dispatch(action) 时,都会遍历所有的 reducers。还有一个很重要的地方就是,每个 reducer 函数在没有匹配到 action.type 时,必须把 reducer() 的参数 state 作为返回值,否则就报错。
reduxjs 还有一个非常厉害的功能,就是可以利用中间件,做很多事情。比如说,我们比较常用的 redux-thunk、redux-logger 等。
// 这里先不考虑参数为空的情况
function compose() {
const middleware = [...arguments];
// 这里利用了redux 高阶函数
// 第一次执行时,将 middleware 中的第一个和第二个元素赋值给 a、b。然后将返回的结果函数 fn 赋值给 a。
// 第二次执行时,a 就是上一次的执行结果,这个时候将 middleware 中的第三个元素赋值给 b。然后将返回的结果函数 fn 赋值给 a。
// 第三次,第四次。依次类推。。。
return middleware.reduce(function(a, b) {
return function fn () {
return a(b.apply(null, arguments));
}
});
}
function applyMiddlyWare(createStore) {
return function(reducer) {
// 接收中间件作为参数
return function(...middlewares) {
const { dispatch, getState, subscription } = createStore(reducer);
// 将 dispatch 赋值给变量 _dispatch
let _dispatch = dispatch;
const disp = (...args) => {
_dispatch(...args);
}
// 将上面定义 disp 内部函数,传递给每一个中间件函数
// 所以上面的 disp 就构成了一个闭包
const chain = middlewares.map(middleware => middleware({ dispatch: disp, getState }));
// 这里又对变量 _dispatch 进行了赋值。这里理解可能有点绕,后面再详细介绍
// 注意这里是一个科里化函数的调用, 参数 dispatch 是原始,没有进过改造的
_dispatch = compose(...chain)(dispatch);
return {
dispatch: _dispatch,
getState,
subscription,
}
}
}
}到这里为止,reduxjs 就基本实现了。但是我们的探讨还没有结束,继续往下看
从上面的代码我们可以看出来,applyMiddlyWare 函数其实就是对 createStore 的一层封装,最终输出的 dispatch 是经过中间件改造过的。现在我们来看看这个 dispatch 到底是什么,它和我们传入的中间件有什么关系???
const chain = middlewares.map(middleware => middleware({ dispatch: disp, getState }));
_dispatch = compose(...chain)(dispatch);上面的两行代码,先遍历执行中间件,再将变量 chain 传递给 compose 函数。所以我们应该可以猜测到,表达式 middleware({ dispatch: disp, getState }) 应该返回一个函数,不然 compose 中的 reduce 就没有办法执行了。
这里还要考虑到中间件执行的策略,所有的中间件必须串联起来,挨个往下执行。所以中间件应该还应该接收另一个中间件作为参数。所以现在我们可以大致的猜测到一个中间件应该是这样的:
function middleware({ dispatch, getState }) {
return function (nextMiddleware) {
return function () {
// 这里应该先执行一些任务,然后再去执行下一个中间件
...
nextMiddleware();
}
}
}这个时候其实中间件的模型还不够完整,少了一些东西。少了什么了,就是 action 呀!applyMiddlyWare 函数通过中间件对 dispatch 进行改造。所以还是要接收 action 才能对 state 进行修改。所以这下我们清楚了
function middleware({ dispatch, getState }) {
return function (nextMiddleware) {
return function (action) {
// 在调用 nextMiddleware 之前可以进行一些操作
console.log(1111);
// 必须将 action 传递给下一个中间件
const result = nextMiddleware(action);
// 在调用 nextMiddleware 之后可以进行一些操作
console.log(222);
return result;
}
}
}现在我们清楚了中间件的模型了,可以来专门研究一下 applyMiddlyWare 函数返回的 dispatch 是啥玩意了
function compose() {
const middleware = [...arguments];
return middleware.reduce(function(a, b) {
return function fn () {
return a(b.apply(null, arguments));
}
});
}
function one(next) {
console.log('one');
return function one_(action) {
console.log('这是中间件one,你可以在这里做很多事情', action);
return next(action)
}
}
function two(next) {
console.log('two');
return function two_(action) {
console.log('这是中间件two,你可以在next调用之前做一些事情', action);
const result = next(action);
console.log('这是中间件two,也可以在next调用之后做一些事情', action);
return result;
}
}
function three(next) {
console.log('three');
return function three_(action) {
console.log('这是中间件three,你可以在这里做很多事情', action);
return next(action)
}
}
// 可以把它当作 createStore 函数返回的 dispatch 方法
function dispatch(action) {
console.log(action);
}
// 我这么写,大家应该可以理解哈。因为 compose 函数接收到的其实是 middleware({ dispatch, getState }) 返回的结果
// 所以这里的 one, two, three 可以理解为是 middleware({ dispatch, getState }) 返回的结果
// 这里只是做一个简单的 demo,用不到 dispatch, getState。
var disp = compose(one, two, three)(dispatch);我们把 compose(one, two, three)(dispatch) 这段代码用我们自己的代码实现一下,大致就是下面这样的效果:
var fn = (function(one, two, three) {
var first = function() {
return one(two.apply(null, arguments));
};
var next = function() {
return first(three.apply(null, arguments));
};
return next
})(one, two, three);
var disp = fn(dispatch);当调用 fn(dispatch) 时,three.apply(null, dispatch) 开始执行,返回一个 three_ 函数。继续往下执行。
first(three_) 开始执行,然后执行 two.apply(null, three_),two 执行完成,返回一个 two_ 函数。继续往下执行。
one(two_) 开始执行,并返回一个 one_ 函数,这个函数最终作为 fn(dispatch) 执行的最终结果,并赋值给变量 disp。
disp(action) 执行时,先调用 one_(action) 然后是 two_(action) 最后是 three_(action)。注意最后一个中间件接收的参数不是中间件参数了,而是原始的 dispatch 方法。所以会在最后一个中间件中执行 dispatch(action),从而调用 rducer 函数修改数据源【state】。
执行 disp({data: 1200, type: 'username'})这段代码,看下打印的结果是啥
这下我们就非常清楚了,原来经过 applyMiddlyWare 改造后输出的 dispatch 方法,在调用时,会挨个执行每一个传入 applyMiddlyWare 函数的中间件,并在最后一个中间件中调用原始的 dispatch() 方法。
// 中间件1
function thunk ({dispatch, getState}) {
return function (next) {
return function(action) {
if (typeof action === 'function') {
action({dispatch, getState});
} else {
return next(action);
}
}
}
}
// 中间件2
function dialog ({dispatch, getState}) {
return function (next) {
return function(action) {
console.log('prevstate:', getState());
const result = next(action);
console.log('nextstate:', getState());
return result;
}
}
} // 模拟用户http请求
function getUserName(name) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'name', data: name})
}, 0);
}
}
function getUserAge(age) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'age', data: age})
}, 0);
}
}
function getUserSex(sex) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'sex', data: sex})
}, 0);
}
}
function getHome(value) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'home', data: value})
}, 0);
}
}
function getList(value) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'list', data: value})
}, 0);
}
}
function getDetail(value) {
return ({dispatch}) => {
setTimeout(() => {
dispatch({type: 'detail', data: value})
}, 0);
}
} // userName, menu 直接复制前面的代码
var reducer = combineReducers({ userName, menu });
var { dispatch, getState, subscription } = applyMiddlyWare(store)(reducer)(thunk, dialog);
console.log(getState(), 'initState');
const name_button = document.querySelector('.name');
const age_button = document.querySelector('.age');
const sex_button = document.querySelector('.sex');
const home_button = document.querySelector('.home');
const list_button = document.querySelector('.list');
const detail_button = document.querySelector('.detail');
const addListener = document.querySelector('.addListener');
const removeListener = document.querySelector('.removeListener');
name_button.onclick = function() {
dispatch(getUserName('shenxuxiang'))
};
age_button.onclick = function() {
dispatch(getUserAge('29'))
};
sex_button.onclick = function() {
dispatch(getUserSex('man'))
};
home_button.onclick = function() {
dispatch(getHome('home_page'))
};
list_button.onclick = function() {
dispatch(getList('list_page'))
};
detail_button.onclick = function() {
dispatch(getDetail('detail_page'))
};
let removeListen;
addListener.onclick = function() {
removeListen = subscription(function() {
console.log('我们添加了一个事件监听器', getState())
})
};
removeListener.onclick = function() {
removeListen && removeListen();
};项目是为创造独特的产品、服务或成果而进行的临时性工作。

预测型:在生命早期阶段确定项目范围,时间和成本
增量型:在预定的时间区间内渐进增加产品功能
迭代型:是通过一系列重复活动来开发产品
敏捷型:结合迭代和增量的特点,频繁细化需求,交付产品功能子集
五大过程组,10大领域,49个过程

ITTO流程示意图:

项目整合管理内容:

制定项目章程:输入、工具与技术和输出

头脑风暴(集思广益)
用于在短时间内获得大量创意,适用于团队环境,需要引导者进行引导
头脑风暴由两个部分构成:创意产生和创意分析
特点:面对面,无拘无束,快速,不求最后结果
名义小组技术
名义小组技术是用于促进头脑风暴的一种技术,通过投票排列最有用的创意,以便进一步开展头脑风暴或优先排序。
名义小组技术是一种结构化的头脑风暴形式,由四个步骤组成:
焦点小组
焦点小组召集相关方和主题专家讨论项目风险、成功标准和其他议题
访谈
访谈是指通过与相关方直接交谈来了解高层级需求、假设条件、制约因素、审批标准以及其他信息
通常一对一,有时也可以多对多
关键路径法
关键路径法用于在进度模型中估算项目最短工期,确定逻辑网络路径的进度灵活性大小
关键路径法示例:

进度压缩
进度压缩技术是指在不缩减项目范围的前提下,缩短或加快进度工期,以满足进度制约因素、强制日期或其他进度目标
赶工
通过增加资源,以最小的成本代价来压缩进度工期的一种技术。
赶工的例子包括:批准加班、增加额外资源或支付加急费用,来加快关键路径上的活动。
赶工只适用于那些通过增加资源就能缩短持续时间的,且位于关键路径上的活动。
但赶工并非总是切实可行的,因它可能导致风险和/或成本的增加。
快速跟进
一种进度压缩技术,将正常情况下按顺序进行的活动或阶段改为至少是部分并行开展。
例如,在大楼的建筑图纸尚未全部完成前就开始建地基。
快速跟进可能造成返工和风险增加,所以它只适用于能够通过并行活动来缩短关键路径上的项目工期的情况。以防进度加快而使用提前量通常增加相关活动之间的协调工作,并增加质量风险。
快速跟进还有可能增加项目成本。

识别相关方 — 识别相关方是定期识别项目相关方,分析和记录他们的利益、参与度、相互依
赖性、影响力和对项目成功的潜在影响的过程。

规划相关方参与 — 规划相关方参与是根据相关方的需求、期望、利益和对项目的潜在影响,
制定项目相关方参与项目的方法的过程。
管理相关方参与 — 管理相关方参与是与相关方进行沟通和协作,以满足其需求与期望,处理
问题,并促进相关方合理参与的过程。
监督相关方参与 — 监督项目相关方关系,并通过修订参与策略和计划来引导相关方合理参与
项目的过程
用于在项目相关方之间传递信息的方法很多。信息交换和协作的常见方法包括对话、会议、书面
文件、数据库、社交媒体和网站。
可能影响沟通技术选择的因素包括:
形成阶段
开始认识,了解项目和职责
不开诚布公,相互独立
震荡阶段
团队开始从事项目工作、制定技术决策和讨论项目管理方法
磨合期,没有凝聚力,相互独立,彼此竞争
规范阶段
团队成员开始协同工作,并调整各自的工作习惯和行为来支持团队,团队成员会学习相互信任
协同工作,相互信任,集体决策,共同解决问题
成熟阶段
团队就像一个组织有序的单位那样工作,团队成员之间相互依靠,平稳高效地解决问题
相互依靠,完善阶段,彼此坦诚,高效解决问题
解散阶段
通常在项目可交付成果完成之后,或者,在结束项目或阶段过程中,释放人员,解散团队
团队完成所有工作,团队成员离开项目

线性表是最简单、最常用的一种数据结构,它是n个数据元素的有限集合。实现线性表一般有数组和链表两种方式,数组用一组连续的存储单元依次存储线性表的数据元素,链表用一组任意的存储单元存储线性表的数据元素(存储单元可连续也可不连续)。
数组是一种大小固定的数据结构,当数组不能再存储线性表中的新元素时,我们可以创建一个新的大的数组来替换当前数组,这样就可以使用数组实现动态的数据结构。前面基于静态类型的语言,动态类型的语言,如javascript,就不同。二分查找的例子:
// 二分查找数组中的数,适用于不经常变动而查找频繁的有序列表
function binarySearch(data, arr, start, end) {
if (start > end) {
return -1;
}
var mid = Math.floor((end + start) / 2);
if (data == arr[mid]) {
return mid;
} else if (data < arr[mid]) {
return binarySearch(data, arr, start, mid - 1);
} else {
return binarySearch(data, arr, mid + 1, end);
}
}二分查找的时间复杂度为O(logn),比顺序查找的链表(O(n))更快,但插入、删除效率低。
链表是一种物理存储单元上非连续、非顺序的存储结构,逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,这些节点不必在内存中相连。每个节点由数据部分Data和链部分Next,Next指向下一个节点,添加或者删除时,只需要改变相关节点的Next的指向,效率很高。
// 删除节点
var deleteNode = function (head, node) {
// 当前节点是不是尾节点
if (node.next) {
node.val = node.next.val;
node.next = node.next.next;
// 当前只有一个节点
} else if (node === head) {
node = null;
head = null;
} else {
// 删除的是尾节点
node = head;
while (node.next.next) {
node = node.next;
}
node.next = null;
node = null;
}
return node;
};
// 删除重复节点
function deleteDuplication(pHead) {
const map = {};
if (pHead && pHead.next) {
let current = pHead;
// 计数
while (current) {
const val = map[current.val];
map[current.val] = val ? val + 1 : 1;
current = current.next;
}
current = pHead;
while (current) {
const val = map[current.val];
if (val > 1) {
// 删除节点
console.log(val);
if (current.next) {
current.val = current.next.val;
current.next = current.next.next;
} else if (current === pHead) {
current = null;
pHead = null;
} else {
current = pHead;
while (current.next.next) {
current = current.next;
}
current.next = null;
current = null;
}
} else {
current = current.next;
}
}
}
return pHead;
}数组链表的区别:
下面是数组与链表插入操作对比:
var arrInsert = [1, 2, 3];
var arrSplice = [1, 2, 3];
var arrList = new LinkedList();
arrList.append(1);
arrList.append(2);
arrList.append(3);
console.time("insert");
for(var i = 0; i < 10000; i++) {
arrInsert = insert(2, 5, arrInsert);
}
console.timeEnd("insert");
console.log(arrInsert.length);
console.time("splice");
for(var j = 0; j < 10000; j++) {
arrSplice.splice(2, 0, 5);
}
console.timeEnd("splice");
console.log(arrInsert.length);
console.time("arrList");
for(var k = 0; k < 10000; k++) {
arrList.insert(2, 5);
}
console.timeEnd("arrList");
console.log(arrList.size());
// 普通插入操作
function insert(index, e, arr) {
var curIndex = arr.length;
while(curIndex > index) {
arr[curIndex--] = arr[curIndex];
}
arr[curIndex] = e;
return arr;
}
function LinkedList() {
var Node = function(element){
this.element = element;
this.next = null;
};
var length = 0;
var head = null;
this.append = function(element){
var node = new Node(element),
current;
if (head === null){
head = node;
} else {
current = head;
while(current.next){
current = current.next;
}
current.next = node;
}
length++;
};
// 链表插入操作
this.insert = function(position, element){
if (position >= 0 && position <= length){
var node = new Node(element),
current = head,
previous,
index = 0;
if (position === 0){
node.next = current;
head = node;
} else {
while (index++ < position){
previous = current;
current = current.next;
}
node.next = current;
previous.next = node;
}
length++;
return true;
} else {
return false;
}
};
this.getHead = function(){
return head;
};
this.size = function() {
return length;
};
}运行结果:
栈是一种比较特殊的线性表,访问、插入和删除元素只能在栈顶进行。
如图:
class Stack {
constructor () {
this.items = [];
}
push (element) {
this.items.push(element);
}
pop () {
return this.items.pop();
}
peek () {
return this.items[this.items.length - 1];
}
isEmpty () {
return this.items.length === 0;
}
size () {
return this.items.length;
}
clear () {
this.items = [];
}
print () {
console.log(this.items.toString());
}
}
let stack = new Stack();
console.log(stack.isEmpty());十进制转二进制例子:
let divideBy2 = function (decNumber) {
let remStack = new Stack();
let rem = 0;
let binaryString = '';
while (decNumber > 0) {
rem = decNumber % 2 // 记录当前余数是多少
remStack.push(rem); // 存入栈中
decNumber = parseInt(decNumber / 2); // 与2除取整
}
while (!remStack.isEmpty()) {
binaryString += remStack.pop().toString();
}
return binaryString;
};队列是一种特殊的线性表,先进先出的原则,队列也有顺序队列和链式队列两种实现。数据量已知就使用数组实现队列,未知的话就使用链表实现队列。
如图:
//单链表实现
function LinkedQueue () {
//节点结构定义
var Node = function(element){
this.element = element;
this.next = null;
}
var length = 0,
front,//队首指针
rear;//队尾指针
//入队操作
this.push = function(element){
var node = new Node(element),
current;
if(length == 0){
front = node;
rear = node;
length++;
return true;
}else{
current = rear;
current.next = node;
rear = node;
length++;
return true;
}
}
//出队操作
this.pop = function(){
if(!front){
return 'Queue is null';
}else{
var current = front;
front = current.next;
current.next = null;
length--;
return current;
}
}
//获取队长
this.size = function(){
return length;
}
//获取队首
this.getFront = function(){
return front;
}
//获取队尾
this.getRear = function(){
return rear;
}
this.toString = function(){
var str = '',
current = front;
while(current){
str += current.element;
current = current.next;
}
return str;
}
//清除队列
this.clear = function(){
front = null;
rear = null;
length = 0;
return true;
}
}树型结构是一类非常重要的非线性数据结构,二叉树是每个节点最多有两棵子树的树结构。通常子树被称作“左子树”和“右子树”。
三种遍历方式:
如图:
二叉搜索树的实现及遍历:
//定义节点
class Node {
constructor(data){
this.root = this;
this.data = data;
this.left = null;
this.right = null
}
}
//创建二叉搜索树(BST))
class BinarySearchTree {
constructor(){
this.root = null
}
//插入节点
insert(data){
const newNode = new Node(data);
const insertNode = (node,newNode) => {
if (newNode.data < node.data){
if(node.left === null){
node.left = newNode
}else {
insertNode(node.left,newNode)
}
}else {
if(node.right === null){
node.right = newNode
}else{
insertNode(node.right,newNode)
}
}
};
if(!this.root){
this.root = newNode
}else {
insertNode(this.root,newNode)
}
}
//删除节点
remove(data){
const removeNode = (node,data) => {
if(node === null) return null;
// 找到节点
if(node.data === data){
// 没有左右子节点
if(node.left === null && node.right === null) return null;
// 没有左子节点,用右子节点覆盖
if(node.left === null) return node.right;
// 没有右子节点,用左子节点覆盖
if(node.right === null) return node.left;
// 有左右子节点,取右子树的最小节点来覆盖删除的节点并删除最小节点,而不改变树的排序
if(node.left !==null && node.right !==null){
let _node = this.getMin(node.right);
node.data = _node.data;
node.right = removeNode(node.right,_node.data);
return node
}
} else if(data < node.data){
// 递归左子树
node.left=removeNode(node.left,data);
return node
} else {
// 递归右子树
node.right=removeNode(node.right,data);
return node
}
};
return removeNode(this.root,data)
}
//中序遍历
inOrder(){
let backs = [];
const inOrderNode = (node,callback) => {
if(node !== null){
inOrderNode(node.left,callback);
backs.push(callback(node.data));
inOrderNode(node.right,callback)
}
};
inOrderNode(this.root,callback);
function callback(v){
return v
}
return backs
}
//前序遍历
preOrder(){
let backs = [];
const preOrderNode = (node,callback) => {
if(node !== null){
backs.push(callback(node.data));
preOrderNode(node.left,callback);
preOrderNode(node.right,callback)
}
};
preOrderNode(this.root,callback);
function callback(v){
return v
}
return backs
}
//后序遍历
postOrder(){
let backs = [];
const postOrderNode = (node,callback) => {
if(node !== null){
postOrderNode(node.left,callback);
postOrderNode(node.right,callback);
backs.push(callback(node.data))
}
};
postOrderNode(this.root,callback);
function callback(v){
return v
}
return backs
}
}数组、链表和二叉树的比较:
| 操作 | 数组 | 链表 | 二叉树 |
|---|---|---|---|
| 插入、删除 | O(n) | O(1) | O(logn) |
| 查找 | O(1) | O(n) | O(logn) |
堆就是用数组实现的二叉树,所有它没有使用父指针或者子指针,分为最大堆和最小堆。
堆的特点:
堆与树的区别:
例子:
例如数组[10, 7, 2, 5, 1]
堆的实现:
function MaxHeap(initDataArray, maxSize = 9999) {
let arr=initDataArray || [];
let currSize=arr.length;
// 填充heap,目前还不是一个堆
let heap=new Array(arr.length);
function init() {
for(let i=0; i<currSize;i++){
heap[i]=arr[i];
}
// 最后一个分支节点的父节点
le currPos=Math.floor((currSize-2)/2);
while (currPos>=0){
// 局部自上向下下滑调整
shif_down(currPos, currSize-1);
// 调整下一个分支节点
currPos--;
}
}
function shif_down(start,m) {
// 父节点
let parentIndex=start,
// 左子节点
maxChildIndex=parentIndex*2+1;
while (maxChildIndex<=m){
if(maxChildIndex<m && heap[maxChildIndex]<heap[maxChildIndex+1]){
// 一直指向最大关键码最大的那个子节点
maxChildIndex=maxChildIndex+1;
}
if(heap[parentIndex]>=heap[maxChildIndex]){
break;
}else {
// 交换
let temp=heap[parentIndex];
heap[parentIndex]=heap[maxChildIndex];
heap[maxChildIndex]=temp;
// 调整它的子节点
parentIndex=maxChildIndex;
maxChildIndex=maxChildIndex*2+1
}
}
}
/**
* 插入一个数据
*
* @param {*} data 数据值
* @returns {boolean} isSuccess 返回插入是否成功
*/
this.insert = function (data) {
// 如果当前大小等于最大容量
if(currSize===maxSize){
return false
}
heap[currSize]=data;
shif_up(currSize);
currSize++;
return true;
};
function shif_up(start) {
let childIndex=start; //当前叶节点
let parentIndex=Math.floor((childIndex-1)/2); //父节点
while (childIndex>0){
// 如果大就不交换
if(heap[parentIndex]>=heap[childIndex]){
break;
}else {
let temp=heap[parentIndex];
heap[parentIndex]=heap[childIndex];
heap[childIndex]=temp;
// 调整它的父节点
childIndex=parentIndex;
parentIndex=Math.floor((parentIndex-1)/2);
}
}
}
}堆的应用:
图由边的集合及顶点的集合组成。边是有方向的是有序图(有向图),否则就是无序图(无向图)。可以用邻接表和邻接矩阵来表示边,邻接表是一个二维数组。
如图邻接表:
定义:
// 构造图类
function Graph(v) {
this.vertices = v; //顶点的数量
this.edges = 0;
this.adj = [];
for (var i = 0; i < this.vertices; i++) {
this.adj[i] = []; //保存与顶点 i 相邻的顶点列表
}
this.addEdge = addEdge;
this.showGraph = showGraph;
this.dfs = dfs;
this.bfs = bfs;
this.marked = []; //保存未访问过的顶点
for (var i = 0; i < this.vertices; i++) {
this.marked[i] = false;
}
}
// 添加边
function addEdge(v, w) {
this.adj[v].push(w);
this.adj[w].push(v);
this.edges++;
}
// 展示图
function showGraph() {
for (var i = 0; i < this.vertices; i++) {
var str = '';
str += i + " -> ";
for (var j = 0; j < this.vertices; j++) {
if (this.adj[i][j] != undefined) {
str += this.adj[i][j] + ' ';
}
}
console.log(str);
}
}
// 深度优先算法
function dfs(v) {
this.marked[v] = true;
if (this.adj[v] != undefined) {
console.log("Visited vertex: " + v);
}
for(var w of this.adj[v]) {
if (!this.marked[w]) {
this.dfs(w);
}
}
}
// 广度优先算法
function bfs(s) {
var queue = [];
this.marked[s] = true;
queue.push(s); // 添加到队尾
while (queue.length > 0) {
var v = queue.shift(); // 从队首移除
if (v != undefined) {
console.log("Visisted vertex: " + v);
}
for(var w of this.adj[v]) {
if (!this.marked[w]) {this.marked[w] = true;
queue.push(w);
}
}
}
}
// 调用
g = new Graph(5);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(1, 4);
g.addEdge(2, 4);
g.showGraph();
g.dfs(0);Hook是React 16.8中的新增功能。它们允许您在不编写类的情况下使用状态和其他React功能。HOOKS只能在函数组件中使用
React.memo 是一个高阶的组件。它类似于React.PureComponent 也就是说如果组件的 props 没有改变,是不会被重新渲染的。
function Foo (props) {
...
}
export default React.memo(Foo)类似于类组件中的state,不同的是 useState 接受一个任意类型的值 string, array, object, bool... 作为参数并返回一个数组,且 useState 只会在组件初始化的时候执行。
// 初始化的时候,age的值就是useState中参数的值
const [ age, setAge ] = useState(20);
const [ visible, setVisible ] = useState(props.visible);数组中的第一个元素是状态值,组件在运行过程中会保留这个状态值,类似于this.state
数组中的第二个元素是改变这个状体值的函数,类似于this.setState()
function Hooks(props) {
const [ age, setAge ] = useState(20);
const [ visible, setVisible ] = useState(props.visible);
return (
<div className="">
<p>我的年龄是{age}岁</p>
<button onClick={() => setAge(age + 1)}>点击</button>
<p>{`${visible}`}</p>
</div>
);
};这个类似类组件中的 componentDidMount 和 componentDidUpdate。每次当函数组件挂载成功或者重新渲染完成后都会调用 useEffect 。 之所以说类似,是因为 useEffect 不完全同类组件中的 componentDidMount 和 componentDidUpdate生命周期函数一样,useEffect 有延迟,在父组件didMount或didUpdate后,但在任何新渲染之前触发。useEffect可以在组件中使用多次。
useEffect 还可以返回一个函数,并在组件即将销毁时调用这个返回函数,没错,就是和类组件的 componentWillUnmount 一样。

function Hooks(props) {
const [ age, setAge ] = useState(20);
// 当组件挂载成功后调用下面的函数
// 当props.visible 改变了,那么会在组件重新渲染完成以后调用下面的函数
// 当调用setAge,age发生改变,那么会在组件重新渲染完成以后调用下面的函数
useEffect(() => {
console.log(props);
// 会在组件willUnmount时候调用
return () => {...}
});
return (
<div className="">
<p>我的年龄是{age}岁</p>
<button onClick={() => setAge(age + 1)}>点击</button>
<p>{`${visible}`}</p>
</div>
);
};类似于类组件中的 componentDidUpdate(prevProps, prevState) ,这个生命周期,那么如何使用呢?
function Hooks(props) {
const [ age, setAge ] = useState(20);
const [ visible, setVisible ] = useState(props.visible);
// 当函数调用时发现props.visible发生了变化,类似于类组件中的componentDidUpdate(prevProps, prevState)
// 当prevProps.visible !== this.props.visible 那么就会执行useEffect的函数体
useEffect(() => {
console.log('visible is changed');
setVisible(props.visible);
}, [ props.visible ]);
// 当函数调用时发现age发生了变化,类似于类组件中的componentDidUpdate(prevProps, prevState)
// 当prevState.age !== this.state.age 那么就会执行useEffect的函数体
useEffect(() => {
console.log(age, 1111);
}, [ age ]);
return (
<div className="">
<p>我的年龄是{age}岁</p>
<button onClick={() => setAge(age + 1)}>点击</button>
<p>{`${visible}`}</p>
</div>
);
};如果参数中有多个元素 [ age, props.visible ] ,那么元素的关系是 age && props.visible ,通过比较后只要有一个元素发生变化,useEffect 就会执行。如果参数是一个空数组 [] ,那么这个时候 useEffect 就和类组件中的 componentDidMount 一样,只在组件刚刚挂载的时候调用一次。 useEffect 函数中return的函数,不受第二个参数的影响,仍在组件 WillUnmount 的时候调用。
不要在循环条件或嵌套函数中调用Hook。相反,始终在React函数的顶层使用Hooks。通过遵循此规则,您可以确保每次组件呈现时都以相同的顺序调用Hook。这就是React允许多个useState和useEffect调用之间正确保留Hook状态的原因。
和 useEffect 使用原理相同,但是唯一的区别在于 useLayoutEffect 不会延迟触发,和类组件的 componentDidMount 和 componentDidUpdate 这两个生命周期函数是同步的,其他没有区别。
自定义Hook是一个JavaScript函数,其名称以“use” 开头,可以调用其他Hook。构建自己的Hook可以将组件逻辑提取到可重用的函数中
,确保只在自定义Hook的顶层无条件地调用其他Hook。与React组件不同,自定义Hook不需要具有特定签名。我们可以决定它作为参数需要什么,以及它应该返回什么(如果有的话)
// useVisibleStatus是一个自定义的钩子,我们在函数中调用的useEffect
function useVisibleStatus(isShow) {
const [ visible, setVisible ] = useState(isShow);
useEffect(() => {
setVisible(isShow);
}, [ isShow ]);
return visible;
};
function Hooks(props) {
const [ count ] = useState(props.count);
const visible = useVisibleStatus(props.visible);
return (
<div className="">
<h2>{count}</h2>
<button onClick={() => setCount(count + 1)}>点击</button>
<h2>{`${visible} ${props.count}`}</h2>
</div>
);
};我们也可以将一些复杂或者重复的逻辑提取提取到自定义的hook函数中,从而简化我们的代码。其实自定义hook和函数组件没有多大区别。
当 useState 复杂的状态逻辑涉及多个子值或下一个状态取决于前一个状态时,通常useReducer更可取。useReducer还可以让您优化触发深度更新的组件的性能
const initialState = {count: 0};
function reducer(state, action) {
switch (action.type) {
case 'increment':
return {count: state.count + 1};
case 'decrement':
return {count: state.count - 1};
default:
throw new Error();
}
}
function Counter({initialState}) {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<>
Count: {state.count}
<button onClick={() => dispatch({type: 'increment'})}>+</button>
<button onClick={() => dispatch({type: 'decrement'})}>-</button>
</>
);
}我们看看 useReducer 具体的实现(和自定义hook没有差异):
function useReducer(reducer, initialState) {
const [state, setState] = useState(initialState);
function dispatch(action) {
const nextState = reducer(state, action);
setState(nextState);
}
return [state, dispatch];
}可以通过 useImperativeHandle ,给ref上绑定一些自定的事件,前提是我们必须使用 forwardRef ,注意所有的事件都是绑定在ref的 current 属性上。
看下面的例子
// hook.js
function Hooks(props, ref) {
const [ count, setCount ] = useState(props.count);
useImperativeHandle(ref, () => ({
// 自定义一些事件
click: () => {
setCount(count + 1);
},
}));
return (
<div className="">
<h2>{count}</h2>
<button onClick={() => setCount(count + 1)}>点击</button>
</div>
);
};
export default React.forwardRef(Hooks);
// Application.js
export default class App extends PureComponent {
componentDidMount() {
this.ref = React.createRef();
}
return (
<div
onClick={() => this.ref.current.click()}
>
// ...
<Hooks ref={this.ref} count={this.state.count} visible={this.state.visible}/>
// ...
</div>
);
}或者
function FancyInput(props, ref) {
// 获取真是DOM节点
const inputRef = useRef();
useImperativeHandle(ref, () => ({
// 自定义一些事件
focus: () => {
// 在DOM节点执行一些操作都可以
inputRef.current.focus();
}
}));
return <input ref={inputRef} />;
}
FancyInput = forwardRef(FancyInput);useRef 返回一个可变的ref对象,其 .current 属性值为初始化传递的参数(initialValue)。返回的对象将持续整个组件的生命周期。和class组件中的实例属性很像
const ref = usRef(20);
console.log(ref.current) // 20
// 可以重新赋值
ref.current = 200;当然最常见的就是访问一个元素节点
function TextInputWithFocusButton() {
const inputEl = useRef(null);
const onButtonClick = () => {
// `current` points to the mounted text input element
inputEl.current.focus();
};
return (
<>
<input ref={inputEl} type="text" />
<button onClick={onButtonClick}>Focus the input</button>
</>
);
}使用的场景:函数组件中,我们定义了一些方法,但是我们并不希望每次组件更新的时候都重新执行一次个函数,而是变成有条件的触发,那么这个时候我们就可以使用useMemo。有个地方需要注意点那就是,useMemo是在useLayoutEffect之前执行,这和类组件中的 componentWillMount 和 componentWillUpdate 类似。可以查看的我们demo
// 组件初始化的时候会调用Func,类似 componentWillMount
// 当数组中的元素的值发生改变,那么就会调用Func,这个条件 `a && b` 的关系
useMemo(() => Func(a, b), [a, b]);在看这个带返回值的
function Hooks(props) {
const [ count, setCount ] = useState(props.count);
useLayoutEffect(() => {
console.log('useLayoutEffect 后执行');
setCount(props.count);
}, [ props.count ]);
const dom = useMemo(() => {
console.log('useMemo 优先执行');
return <h2>{count * 10}</h2>;
}, [count]);
return (
<div className="">
<h2>{count}</h2>
<button onClick={() => setCount(count + 1)}>点击</button>
{dom}
</div>
);
};useCallback 的使用和 useMemo 是一样的,且 useCallback(fn, deps) 相当于 useMemo(() => fn, deps)。
这是我的demo
主要相关的两个属性:vertical-align, line-height
vertical-align主要了解两个方面
line-height我们主要了一个方面
由此解决幽灵空白
把内元素改为块即元素,即是解决vertical-align失效。
修改vertical-align为最后一跳线,vertical-align: bottom。
主动设置line-height: 为一个足够小的值,那么块级高度为小于行内高度,就没有足够空间留给‘幽灵’。
设置font-size:0,由于默认的normal是根据字体大小来相对计算的,如果font-size
所以下面会有一定的幽灵距离距离,所以也就得处vertical-align: bottom可以解决,把line-height设置很小也能解决,由于line-height相对于font-size而言的,所以设置font-size:0 其实也是变相把line-height设置为0.
不同设备的相对值,统一设备不同视口的绝对值
物理像素(设备像素)-device pixel:每个显示设备都是有一个一个的物理‘点’组成的,设备上俗称的分辨率就是这这些点的数量,比如1920*1080 就是宽高分别有1920个点和1080个点,在固定尺寸的显示设备上分辨率越高点的尺寸就越小,显示的就越清晰,手机里常说的PPI也就是单位像素密度也是说的这个物理像素点
由于各个设备像素和宽度不同,所以css像素是一个虚拟的相对值,相对的只是不同的设备而言,比如相同屏幕尺寸2k的和1k的1个css像素是不一样的,但是同一个显示设备内不管内容宽度是多少1个像素的值是常量。
@media
随着显示设备的升级以及移动端普及,固定常量的css像素已经很难满足市场显示需求,如果使用同样固定像素进行布局很难在多样的手机上展示一样的ui甚至都很难做到相似,样式bug自然出现,常见就是放不下,折行,溢出等诸多问题。
这期间媒体查询根据市面上常见的阈值来进行媒体查询虽然能解决一部分需求,但是手机尺寸型号越来越难以固定,这就导致媒体查询的代码越来越冗杂。
@media (max-width: 600px) { .h1 { font-size: 18px; } }
百分比'px'=>'%'
相对值就派上用场了,相对宽度值一开始流行于'px'=>'%'的转变,但是这样问题又来了,每一次html落地的时候,都得手动计算计,误差又会变大,且在高度的计算上又是偏差,出力不讨好,内部嵌套也存在隐患,同样不能完美解决,
比如设计图在320的基础上
h1{ width: 160px} => h1{ width: 50%}
em
em是以当前元素的字体为基准
h1{ font-size: 16px; height: 1em //16px }
但是由于em又继承的问题,如果嵌套不小心疏漏了很容易出错,这就相当于同意个变量名在不停的嵌套作用域被定义且被使用,很难想象不会出错,有种简单事情复杂化的感觉
.div1 { font-size: 100px } .div1 .div2 { font-size: 200px//一旦设置了次 宽度就可能不是想要的 width: 0.5em }
rem(root em)
rem同样是相对字体大小为基准的,字面翻译自然知道是为‘根’的字体大小,这个‘根’自然就是dom的顶节点标签,由于是顶点不依赖任何标签也不存在继承,除了主动修改外不会有其他干扰,这样1rem就是一个相对稳定的量,不管你在dom任何地方用到它都是固定的,可以把rem理解为em的升级版
html { font-size: 100px } .div1 { width: 0.2rem //20px }
固定了html的值那么rem其实也只是一个变相的px而已也没有做到自适应,那么我们只需要根据不同内容款低设置html font-size 把font-size改为动态就可以实现。
例如在宽屏font-size: 100px,窄屏幕font-size: 50px,相应的div也就成为动态的了。
所以使用rem之前首先得要定义动态rem 也就是html的根字体大小
方法一:
媒体查询,根据不同尺寸设置不同,
@media (max-width: 600px) {
html {
font-size: 100px
}
}
随着css预处理的加入我们可以像写js一样的去写媒体查询,写法虽然简单了,但是实质还是媒体查询
@each $width in 100px, 200px, 300px, 400px {
@media screen and (min-width: $width) {
html {
font-size: 100px * ($width / 375px)
//由于我们设计常用iphone6宽度375设计,所以我们把375当作一个基准点
}
}
}
这样不好的一点就是大面积的要涵盖各个尺寸容易疏漏,所以我们用js手动修改html字体大小
(function(doc, win) {
var docEl = doc.documentElement,
resizeEvt = 'orientationchange' in window ? 'orientationchange' : 'resize',
recalc = function() {
var clientWidth = docEl.clientWidth;
if (!clientWidth) return;
docEl.style.fontSize = 100 * (clientWidth / 375) + 'px';
};
if (!doc.addEventListener) return;
win.addEventListener(resizeEvt, recalc, false);
doc.addEventListener('DOMContentLoaded', recalc, false);
})(document, window);
其他字体问题
其他pc浏览器font-size最小是12px,虽然移动端可以显示小于12px的字体,但是根据安卓和ios浏览器对不同字体解释不通,导致留白不同,尤其是通过line-height进行垂直居中的时候出现无法居中的情况,鉴于这种情况推荐使用2倍再缩小0.5倍即可解决
常用与我们商品详情tag,name mark等
.div1 {
height: 11px
line-height: 11px
border: 1px solid #f60;
border-radius: 4px;
}
.div1 {
height: 22px
line-height: 22px
transform: scale(0.5);
transform-origin: 0 0;
border: 1px solid #f60;
border-radius: 4px;
}
通过修改某个属性值呈现的内容就可以被替换的元素就被称为 “替换元素”。<img>、<object>、<vedio>、<iframe>、<textarea>、<input> 等都是典型的替换元素
内容的外观不受页面上的 CSS 的影响
有自己的尺寸:在不设置尺寸的时候,这些元素会有一个默认的尺寸(300 * 150),如: <video>、<canvas>、<iframe>。<img> 图片默认展示的就是图片的原始尺寸。
在很多 CSS 属性上有自己的一套表现规则。比较有代表性的就是 vertical-align 属性。对于字符而言,vertical-align 的默认值就是 baseline,也就是字母 “x” 的下边缘。但是,对于替换元素而言就不一样了。对于图片来说 vertical-align 的默认值就是图片的下边缘。
可以将替换元素的尺寸从内到外分为:“固有尺寸”、“HTML尺寸”、“CSS尺寸”
固有尺寸:指的就是替换内容原本的尺寸。例如,图片、视频作为一个单独的文件存在的时候,都有着自己的宽度和高度,这个宽度和高度就是“固有尺寸”
HTML尺寸:一些替换元素存在 width 和 height 的 HTML 属性,例如 <img> 和 <canvas> 元素。这个称为 HTML 尺寸
CSS尺寸:指的是可以通过 CSS 的 width 和 height 或者 max-width/min-width 和 max-height/min-height 设置元素的尺寸。这种称为 CSS 尺寸
如果 ”固有尺寸“ 含有固有的宽度比例,同时仅设置了宽度或者仅设置了高度,则元素依然按照固有比例宽高显示
<div style="height: 32px; line-height: 32px; background: #444">
xxxx<span style="background: #999; padding: 20px 0; border: 5px solid #fff">我是谁</span>xxxx
</div>
<div style="height: 32px; line-height: 32px; background: #555">
xxxx的是非得失丰富的水分是我的
</div>先看看上面这个 demo,可以看出来,对于内联元素来说,padding 和 border 对内联元素的文字对齐没有影响。(其实内联元素的 padding/border 不计算在行框盒子的高度内)
注意:padding 不能出现负值
块级元素的 padding 的百分比值无论是水平方向和垂直方向都是相对于宽度进行计算的
内联元素的 padding 的计算规则就有一点点的差异了
<div style="width: 100px; border: 2px dashed #444">
<span style="background: #999; padding: 50% 0;">我是谁我是谁我是谁我是谁</span>
</div><ol>|<ul> 列表内置 padding-left,但是单位不是 px,而是 em。
表单元素内置的 padding
<input>、<textarea> 输入框内部内置 padding
<button> 按钮内置 padding
部分浏览器 <select> 下拉内置 padding
<radio>、<checkbox> 单选框和复选框无内置 padding
<div style="height: 300px; background: #ccc; margin: 20px">
<div class="circle"></div>
<div class="three-line"></div>
<div class="triangle"></div>
</div> .circle {
width: 20px;
height: 20px;
padding: 5px;
background: #fff;
background-clip: content-box;
border: 2px solid #fff;
border-radius: 50%;
}
.three-line {
width: 20px;
height: 25px;
border: 3px solid #fff;
border-left-width: 0;
border-right-width: 0;
padding: 8px 0;
background: #fff;
background-clip: content-box;
box-sizing: border-box;
}
.triangle {
display: inline-block;
background: transparent;
border: 10px solid transparent;
border-top-color: #333;
}先介绍几个概念术语
元素尺寸:包含 padding、borde、content 部分的尺寸,可以通过 offsetWidth、offsetHeight 获取。也被称为 “元素偏移尺寸”
元素内部尺寸:包含 padding 不包含 border ,也就是元素的 padding box 尺寸。通过 clientWidth、clientHeight 获取。同时也被称为 “元素可视尺寸”(不含滚动条的宽度)
元素外部尺寸:包含 padding、border、margin、content,也就是元素的 margin box 尺寸。
当元素设置了 width 属性或者当元素具有 “包裹性” 的时候,margin 对尺寸是没有影响的。只有当元素是 “充分利用可用空间” 的时候,margin 才可以改变元素的可视尺寸。
<div style="margin-left: 100px;">
<div style="background: #ccc">123</div>
</div>同样,垂直方向也是可以的
<div style="position: relative; width: 100px; height: 100px; background: #333">
<div style="background: #ccc; position: absolute; top: 0; bottom: 0; margin-top: 30px;">123</div>
</div>上面的 demo 可以看出来,当前元素表现为 “格式化宽高” 的时候,元素自动充满父容器的宽度和高度,这个时候 margin\border\padding\content 自动分配水平和垂直方向空间。当元素表现为正常流特性的时候,和 “格式化宽度” 是一样的。
看看下面的几个 demo
<div style="background: #ccc; overflow: hidden">
<img src="./static/images/timg.jpg" alt="" class="right">
<div class="left">1234567890</div>
</div> .left {
margin-right: 100px;
}
.right {
float: right;
width: 100px;
} <div style="background: #ccc; overflow: hidden">
<img src="./static/images/timg.jpg" alt="" class="left">
<div class="right">1234567890</div>
</div> .right {
margin-left: 100px;
}
.left {
float: left;
width: 100px;
} <div style="background: #ccc; overflow: hidden">
<div class="middle">
<div class="con">1234567890</div>
</div>
<img src="./static/images/timg.jpg" alt="" class="left">
<img src="./static/images/timg.jpg" alt="" class="right">
</div> .right {
float: left;
width: 100px;
margin-left: -100px;
}
.left {
float: left;
width: 100px;
margin-left: -100%;
}
.middle {
/*margin: 0 100px;*/
float: left;
width: 100%;
}
.con {
margin: 0 100px;
} <div style="background: #ccc; overflow: hidden">
<img src="./static/images/timg.jpg" alt="" class="left">
<img src="./static/images/timg.jpg" alt="" class="right">
<div class="middle">
<div class="con">1234567890</div>
</div>
</div> .right {
float: right;
width: 100px;
}
.left {
float: left;
width: 100px;
}
.middle {
width: 100%;
}
.con {
margin: 0 100px;
}注意: 这个时候当 margin 为负值的时候,容器的 width 会增加
<div style="margin-right: -30px; background: #333; text-align: right">1234567890</div>在 CSS 世界中很多棘手的问题都是需要借助 margin 的外部尺寸特性来实现的。比方说, FireFox 浏览器下,设置了 overflow: auto/scroll 的容器会忽略 padding-bottom 值。
<div style="padding: 50px; background: #ccc; height: 200px; overflow: scroll;">
<img src="./static/images/timg.jpg" alt="" height="300px">
</div>注意:如果 padding-bottom 属性的数值设置的过小,则看不出是否被忽略的效果,所以这里我设置的是 50px
那么对于上面的问题,我们可以在最后一个子元素中设置 margin-bootom 来替换就可以了。
当 margin 为负值的时候,“元素尺寸” 就会变大。这个时候,如果 padding/border 是固定的数值,那么 content (这里的 width 的值为 auto)就会随着 margin 负值的增加而变大,但对于 height 来说,没有任何影响(不会影响 height 值)。
注意:不是定位方向的 margin 是不会对元素的定位产生影响的,只能对该元素后面相邻的元素定位产生影响。
我们这里有一个需求是:一个盒子内部需要让左右两栏的背景高度一致,取最高那部分的高度。(使用 margin 和 padding 互补)
<div style="max-height: 200px; overflow: hidden;">
<div style="float: left; width: 50%;background: #ccc; padding-bottom: 500px; margin-bottom: -500px;">
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
<p>1213r</p>
</div>
<div style="float: left; width: 50%; background: #444; padding-bottom: 500px; margin-bottom: -500px;">
456
</div>
</div>padding 和 margin 互补部分的尺寸是不会计算到布局定位中的
margin 的百分比值 和 padding 一样都是相对于父容器的 width 进行计算的
块级元素的上、下外边距有时候是会发生合并的,发生 “margin合并” 必须满足两点重要信息
相邻兄弟元素 margin 合并
父容器和第一个字元素的 margin 合并(子元素大于1个,发生 margin-top 合并)
<div style="height: 200px; background: #444">
<div style="width: 50%; height: 50px; background: #ccc; margin-top: 100px">
</div>
</div>这个时候的 margin 会合并到父元素上,也就是说 margin-top 实际上是作用在父元素上
margin 合并(子元素大于1个,发生 margin-bottom 合并) <div style="background: #444">
<div style="width: 50%; height: 50px; background: #ccc; margin-bottom: 100px">
</div>
</div>这个时候的 margin 会合并到父元素上,也就是说 margin-bottom 实际上是作用在父元素上。注意:这个时候父元素不能设置 height 属性
height 属性,那么 margin-top、margin-bottom 都可能与父元素发生 “margin合并”。如果设置了 height 属性,那么就不会发生 margin-bottom 的合并。注意,这里的合并最终效果都是作用在了父元素身上。 <div style="background: #444">
<div style="width: 50%; height: 50px; background: #ccc; margin: 100px">
</div>
</div>父元素设置 BFC 块级格式化上下文
父元素设置 border-top
父元素设置 padding-top
在父元素和第一个字元素之间添加一个 内联元素 进行分隔
父元素设置 BFC 块级格式化上下文
父元素设置 height 、min-height 或者 max-height
父元素设置 border-bottom
父元素设置 padding-bottom
在父元素和最后一个字元素之间添加一个 内联元素 进行分隔
margin-top 和 margin-bottom。那么这个时候 margin-top 和 margin-bottom 是会发生合并的。所以实际定位时只计算一个 margin-top/margin-bottom 的值(谁的值大取谁)。如何消除这种情况的 margin 合并margin 都是正值,那么取最大的那个margin 一正一负,那么取正负相加后的值margin 都是负值,那么取最负的那个margin: auto 作用机制margin-left、margin-right,如果一侧定值一侧为 auto,那么 auto 为剩余空间大小 <div style="width: 100px; margin: 0 0 0 auto; background: #ccc">123</div>
<div style="width: 100px; margin: 0 auto 0 0; background: #444">123</div>** 对于 margin-left、margin-right,如果都为 auto,那么 平分剩余空间
<div style="width: 100px; margin: 0 auto; background: #444">123</div>格式化宽高
** margin-left、margin-right 或者 margin-top、margin-bottom,如果一侧定值一侧为 auto,那么 auto 为剩余空间大小
<div style="position: absolute; top: 0; left: 0; right: 0; bottom: 0; width: 200px; height: 200px; margin: 100px auto 0; background: #444">123</div>
<div style="position: absolute; top: 0; left: 0; right: 0; bottom: 0; width: 200px; height: 200px; margin: auto auto 0; background: #444">123</div>** 对于 margin-left、margin-right 或者 margin-top、margin-bottom,如果都为 auto,那么 auto 为剩余空间大小
<div style="position: absolute; top: 0; left: 0; right: 0; bottom: 0; width: 200px; height: 200px; margin: 0 auto; background: #444">123</div>
<div style="position: absolute; top: 0; left: 0; right: 0; bottom: 0; width: 200px; height: 200px; margin: auto auto; background: #444">123</div>下面的这个案例就可以完美的解释 margin: auto
<div style="width: 300px; background: #ccc">
<div style="width: 200px; margin-left: auto; margin-right: 80px; background: #455">123</div>
</div>margin 无效display 计算值为 inline 的非替换元素的 margin-top、margin-bottom。内联替换元素的垂直 margin 是有效的,并且没有 margin 合并的问题,所以图片不会发生 “margin合并”
表格中的 <tr>、<td> 元素或者设置 display: table-cell | table-row 的元素的 margin 都是无效的
margin 合并的时候,更改 margin 值可能是没有效果的(只有当更改的那个 margin 值大于另外一个 marin 值时才会生效)。
绝对定位元素非定位方位的 margin 值 “无效”。其实并不是 margin 没有生效,实际上,绝对定位元素任意方位的 margin 值无论在什么场景下都是一直有效的,比如下面的 demo 。这种情况,margin-bottom: 80px 其实增加了元素的外部尺寸。所以在元素的底部和父元素的底部间隔 80px。
<div style="width: 300px; height: 100px; background: #ccc; overflow: auto; position: relative;">
<div style="position: absolute; top: 0; left: 0; height: 100px; margin-top: 100px; margin-bottom: 80px; background: #455">123</div>
</div>margin-right 或者 margin-bottom 都是 “无效”。对元素的定位是不起作用的。但是这种情况和上面的 demo 一样,会增加元素的外部尺寸。 <div style="width: 300px; background: #ccc; overflow: auto;">
<div style="height: 100px; margin-top: 100px; margin-bottom: 80px; background: #455">123</div>
</div>这种情况也可以该改变。给元素设置 float: right 后,那么这个时候 right 就成了定位方向了,这个时候 margin-right 就起作用了。
border-widththin - 薄薄的,等于1px;
medium - 薄厚均匀,等于3px;默认值。
thick - 厚厚的,等于4px
border-style 默认值就是 none。所以当我们设置 border-width 和 border-color 没有显示边框的原因。但是当我们只设置 border-style: solid 就会出现边框。none - 无,默认值
solid - 实线边框
dashed - 虚线边框
dotted - 虚点边框
doubble - 双线边框:当 border-width 小于 3px 的时候,展示的只有一条边框线。
inset - 内凹槽
outset - 外凸槽
groove - 沟槽
ridge - 山脊
border-color 有一个很重要的特性就是 border-color 的默认值就是 color 色值。当没有设置 border-color 颜色值的时候,会使用当前元素的 `color 计算值作为边框色。前言:Javascript 是一门灵活的编程语言,吸引着全世界的程序员为其构建整个生态,在 Github 语言使用榜单上,JS 一直是名列前茅。如此热门的一门语言,它自身的演化又是如何的呢?今天我们就来聊一聊,JS 的演进之路。我们会聊到 JS 与 ES 的关系,ES 规范、规范的制订过程等。最后,希望大家能够通过本篇文章了解到 ECMAScript 的一些知识。
首先我们要了解到的是,ECMAScript 它是一套语言规范,即 ECMA-262 规范,制订该规范的组织叫 TC39。
它和 Javascript 的关系,通俗的讲,ECMAScript 就好像是自行车的基础构造,而 Javascript 则是使用了该基础构造的一个品牌产品,好比摩拜和 ofo,本质都是自行车,都是用了自行车的构造,有两个轮子,脚踏板,链子,刹车,龙头等,但是他们品牌不同,附加的装备也不同,比如车锁、车铃等。语言界和 Javascript 使用同样规范的有 ActionScript、JScript 和现在非常火的 NodeJS 等。
Javascript 除了 ECMAScript 提供的语法、API 和关键字等之外,还包括了宿主环境提供的 DOM 和 BOM,诸如 window 对象、XMLHttpRequest 对象、navigator 对象等。
谈到 ES 的版本,可能很多人都知道 ES 6 发布了,改名叫做 ES 2015。今年是 ES 2017 版本发布,在今年 6 月份。那么,ES 的版本是如何迭代的?版本号为何要改成年份呢?带着这两个问题,我们一起往下看。
首先,之前的名称如 ES5,这里的 5 代表的是 ECMA 262 规范的修订版本号,可以理解为第 5 版。即使现在都叫做 ES 201X,我们还是可以以这个数字作为版本号继续使用,ES 7、ES 8、ES 9...ES N。
接下来我们看下 ES 规范各个版本的发布时间:
| 版本 | 时间 | 间隔(年) |
|---|---|---|
| ES 1 | 1997 | 0 |
| ES 2 | 1998 | 1 |
| ES 3 | 1999 | 1 |
| ES 4 | - | - |
| ES 5 | 2009 | 10 |
| ES 6 | 2015 | 6 |
| ES 7 | 2016 | 1 |
| ES 8 | 2017 | 1 |
| ES 9 | 2018 | 1 |
这个表格上我们看到,ES3 到 ES5 之间间隔了 10年,而且有一个版本难产而死,并没有正式发布,那就是 ES4。这是为什么呢?
这是因为,在那个 10 年之初,IE6 作为浏览器王者,一统天下,之后的 IE7,IE8 都没有带来 IE6 如此的辉煌成就。IE6 当时的盛行,导致了浏览器演进趋于停止,这也就导致浏览器使用的脚本引擎一直停滞,即使开发新的规范,没有浏览器厂商的支持,就形同于一纸空文。ES4 当时希望能解决语言方面的诸多问题,class、namespace、package 等等。但是既没有大厂支持也没有社区的支持(写 JS 的同学大多数觉得这么搞太复杂太不“灵活”),这就最终导致 ES4 规范被取消(其中也有一些不和谐的政治因素)。
时间推移,在 Chrome 诞生后,采用了新的解析引擎 V8 ,成功瓜分了浏览器市场份额,浏览器大战终于再次打响(第一次是网景和微软之间,微软完胜)。各浏览器厂商为了争取更多的用户和开发者,开始争相实现新规范,进行性能竞赛。FireFox、Chrome、Safari 等也都出了各自的新特性实施版本,如果你是开发者,可以下载这些版本体验下最新的提案内容(文章最后有链接)。
09 年诞生的 ES5,其实只是 ES3.1 版本,当初 ES 4 在推进过程中停滞不前,微软和 Yahoo 的代表就干脆另起了一份 ES3.1 规范。规范内容相较 ES4 是相对保守的。
09 年之后,到 15 年,ES6 终于面世了,这其中隔了 6 年时间主要是因为 ES6 增加了很多新功能和新语法。ES6 可以称得上是一次大的版本迭代。这其实是有风险的,委员会成员也各自表达了对这种大版本迭代形式的担忧,大家都不希望再次看到一个 “ES4 事件” 出现。所以以后的 ES 规范会每年一版,并且改名以年份作为版本号。ES6 改名叫 ES 2015,以后每年的版本依次类推。迭代的内容则是将当年 1 月份进入 Stage 4 的提案 Merge 到规范中作为当年版本的新规范。如果一个提案在当年 1 月份还没进入 Satge 4,那么就后延至下一年的版本。
目前来看,每年一个版本增加的内容并不多,ES7 仅增加了几个新内容,ES8 增加了比较重要 async await 函数。对于开发者来说,学习成本还是很低的,比学习某些框架的成本低多了。
每个规范在成为规范之前,都是委员会里的一个提案。每个提案都需要走一个处理流程,称为 TC39 process。流程共分 Stage 0 到 Stage 4,5 个阶段。最终进入 Satge 4 的提案即会成为下一个版本的规范。
我们这里看下 Satge 0 到 Stage 4 阶段都代表什么:
自由形式提案,表述提案包含的 ECMAScript 演变思路,由 TC39 成员(member)或已注册成为 TC39 贡献者(contributor)的非会员提交。再由 TC39 会议审查后,将提案添加到 Satge 0 阶段。
正式提案,此时需要为提案指定一名 TC39 成员作为提案的带头人(champion)或联合带头人(co-champion)。进入第一阶段的提案要满足:
接下来,TC39 通过接受第一阶段的建议,声明其愿意审议,讨论并对该提案作出贡献。之后,预计将对该提案进行重大修改。
这是提案作为规范的第一个版本,与最终规范中包含的特性不会有太大差别。这一阶段要求提案必须:
满足这些条件后,提案才能正式进入第二阶段。
接下来,提案只能进行增量的修改。
进入这一阶段的提案已经属于基本完成了的。进入这一阶段需要满足的条件有:
接下来,只能在实施及使用过程中引起的关键问题上作出变更。
进入这一阶段标志着提案已经准备好纳入标准。在提案进入这一阶段之前,需要满足的条件有:
仅就当前看来,ES 规范很大程度上会考虑旧网页兼容性,换句话说,就是你写老代码,也依旧能行。比如在 ES 7 中新增了一个数组对象的方法,本来叫做 contains,用于返回数组中是否包含参数的值,可以说是十分贴切。但是由于老牌的脚本库 mootools 下会产生报错,所以提案最后将 contains 换成了 includes。还有如 typeof null 返回的值是 object,这些奇怪的问题也依旧在最新的规范版本中。
但是,那么多人辛苦制定的规范,是真的没什么用吗?那他们为何还要煞费苦心的指定新规范呢?
我们接下来看看,如果你不学习最新的规范,你会错过什么呢?
比如 ES6 的 Modules,它是静态的模块,可以提供静态分析,进而使用 Tree Sharking 技术可以起到为打包瘦身的效果。再比如使用 for of 可以直接遍历对象的值等等。
ES 8 加入了 async 和 await 规范(当然,你可能很早之前就用过了),它比 callback、Promise 或者 generator 都要让人更容易使用,也更容易读懂代码,是相当好的处理异步的方式。还有比如使用 let、const 定义变量,不会产生变量提升效果。
console.log(a); // 'undefined'
a = 1;
var a = 2;
console.log(b); // Uncaught ReferenceError: a is not defined
b = 1;
let b = 2;还有使用 Set 数据结构可以得到无重复项的数组等等。
那么我只学习最新规范是否就可以不学习老的一套的了呢?其实要这样理解新规范,每一版本的规范,并不是将老规范的推倒重来,可能之后有一天,所有的新规范可以覆盖 ES3 中所有内容了,那么你那时就可以不用再学习 ES3 了,但是目前来看,你或多或少还是要学习一些“老”的内容。
面试中基本上都会问新规范,但从面试技巧上讲,可能并不会那么直接的发问一些纯知识型的问题,比如:
你能告诉我一下 ES 7 中 Array 对象新增了哪些方法,又是怎么用的呢?
这种问题就比较无聊,而且容易使候选人产生一种 “我看一眼就知道了呀” 的抗拒心理。所以一般面试官会以场景出题,可能是这么问:
现在有一个巨大的数组,你有哪些方法可以告诉我,如何判断一个数字都否在该数组中?
这样问,候选人如果知道新规范的实现方法,那肯定是有加分的。
还有比如会问:
我们的 Node 项目中有特别多的异步请求,比如有一个请求需要在前置的请求完成之后发送,你能否帮我设计一下代码思路?
这个时候你会想到什么样的答案呢?
如果业务工作量很大,没那么多时间的话,建议半年或者一年学习一次最新规范,可以订阅一些业界名人的博客、论坛等。如果时间比较充裕,可以通过看 TC39 的 proposals 页面,了解到委员会最新的一些提案。
光看了文档,也需要有实现最新提案的浏览器,可以使用厂商推出的新规范实施版本进行尝试:
firefox nightly: https://www.mozilla.org/en-US/firefox/channel/desktop/#nightly
chrome canary: https://google-chrome-canary.en.softonic.com/
Safari Technology Preview: https://developer.apple.com/safari/download/
前端在 09 年之后,随着 ES5、NodeJS 的出现,发生了翻天覆地的变化。我们开发工具从 DW、notepad++ 换到了 Sublime、VS Code,我们发布过程加入了基于 grunt、gulp、webpack 等的工作流,我们样式书写也从简单的配置文件到程序编程,而最大的变化,莫过于我们所写的 JS。从 ES3 到 ES5,再到 ES2015、6、7、8、9,我们有理由相信,ES 的未来是美好的。
缓存对于我们前端来说是一个用于提高网页性能非常重要的工具。简单的“缓存”两字,其中包含了许多有趣的知识,其中对于缓存细粒度的讨论也一直不绝于耳。
目前见过的缓存细粒度分为三类:
以全部文件为最小单位;
以单独文件为最小单位;
以字符为最小单位。
下面让我们一起看看这三种方案的到底是如何处理生产环境下的缓存的。
这种做法相当的粗暴而且历史悠久,无论开发过程中的文件有多少个,整个打包成一个文件后在页面中引用。这样做带来的好处是可以最大的减少对资源的请求数,至今仍使用这种方法进行线上缓存处理的网站还有很多(特别是某些后端框架自带合并资源功能时)。然而这种方案的缺点也十分明显。
由于太粗暴,开发环境中的一个文件被修改,就会导致整个页面的资源都将失效。客户端不得不因为一小部分的修改,而重新下载所有的内容,这是移动互联网大环境下不能被容忍的(流量就是钱,客户也是,公司也是)。
另外一点是对于开发人员来说维护困难。由于每个页面的业务逻辑都不相同,所以每个页面引用的资源文件也不会相同。但是当一个整站共用的文件出现了修改,那么整站的资源内容都要重新打包上传,如果不是某些框架或者工具为你处理的话,相信大家都会疯掉。
针对上述两个硬伤,马上出现了方案的改良版。将整站通用的资源打包一份,页面级的资源打包一份。页面上引用的资源数不再是一,而是二了。
改良后的方案,在遇到整站共用的内容发生修改时,仅仅重新打包整站共用资源即可,大大降低了维护成本。而遇到页面级逻辑发生修改时,用户也仅仅是重新下载新的页面级资源,相比以前好得多了。
所谓的三层架构,即将资源划分成 通用底层 - 通用组件层 - 页面级逻辑层 三层。(这个叫法我是从一个特别老的前端写的书上看到的...)相比上面一分为二的做法,这种方案将细粒度稍微的多细分了一下,将整站通用资源分为了底层(不含 UI 逻辑)与组件层。这种方案在底层或组件层发生修改时可以更好的为用户节约流量。
上面的方案有点奔放,而这种方案就又稍显别致了。将可细分的功能全部做为文件,并通过 hash 命名等手段在页面中引用。一旦一个功能做出修改,用户也仅仅需要下载该功能相关的资源。这对于大公司来说是有其必要性的。主要是因为大公司的网站 PV 量比较大,一个文件的修改都可能会消耗很多 CDN 流量,所以要尽量控制所修改文件的大小。
这种方案是目前看过的最小细粒度的方案,已经到了字符级别了。通过向查询,当有内容发生修改时,服务器仅仅返回包裹修改内容的一些字符串,而并非整个文件。这个响应内容会被客户端接收并重新写入对应的修改处后生成新的本地缓存(基于 localStorage 方案)。
这个方案可以说是别致的让人诧异,最小化的减少因为功能逻辑修改而消耗的流量。但是这个方案的使用缺很少见过。
最早的该方案版本出现于腾讯(更早是不是国外有过就不得而知了),但是据传言该方案在分享后被人抢先申请了专利...
资源文件的命名,也影响到缓存效果。比如都是 a.png,更新前后一个名,那么 CDN 无法知道源站上文件是否是新的,都会向客户端返回节点命中的缓存。
现如今,基本上资源名都是以 文件名 + hash 的形式命名,这是历史发展的结果。
最早之前,前端工程化十分薄弱,需要依赖 Ruby、PHP 或者 JAVA 等后端语言进行工程化处理,所以在资源的使用上,刀耕火种的年代一般都是通过 URL 带上时间戳或者版本号参数进行资源更新。
这种使用版本号/时间戳更新资源的方式的问题很多,由于版本号/时间戳都通过打包生成,那么一个文件修改就会升级版本号/时间戳,这会导致无需更新的文件也被强迫失效,CDN 资源被浪费。
版本号/时间戳还有可能被放置在文件名 中,但也是换汤不换药(自然不同的形式有不同的特点,下面会讲到),依旧难以解决这个问题。
<img src="path/name.jpg?v=1.2.3" />
<img src="path/name.1.2.3.jpg" />
<!-- 升级成 -->
<img src="path/name.jpg?v=1.2.4" />
<img src="path/name.1.2.4.jpg" />后来就以文件的摘要作为版本号,就解决这个问题了,因为每个文件都是以自身内容的摘要进行版本管理。
所以还是有两种使用方案,URL 参数和文件名:
<img src="path/name.jpg?v=hash_code" /> <!-- 第一种方案 -->
<img src="path/name.hash_code.jpg" /> <!-- 第二种方案 -->第一种是摘要放在 URL 参数中的方案,由于 CDN 的回源机制,这种方案最起码的问题是不通用。
很多 CDN 回源机制会加入被动防御机制,即是不考虑 URL 参数的,也就是
<img src="path/name.jpg?v=hash_code1" />
<img src="path/name.jpg?v=hash_code2" />这两个请求都是同一个命中,这可以确保 CDN 不被恶意构造的请求刷流量或者程序错误导致的 CDN 长时间失效(比如:path/name.jpg?v=${Date.now()})。
第一种方案还会遇到同名文件覆盖后回退版本、同名文件更新提前被访问等问题,这里不多赘述。
第二种方案在文件名中带入摘要可以很好的解决上述所有问题。
还有将版本号放入 URL path 的方案,但这方案太小众,而且和目前流行的方案相比也没什么优势,弃之不谈。
待到 HTTP2.0 中的 service push 功能能够优雅的使用的时候,届时前端资源缓存方案都将会迎来一波革新。
最近在做一个热力图图像中显著性区域识别的需求,比如有如下一个图像:

需要识别出图像中高亮较集中的区域,即高亮集中的区域被认为是图像中的显著性区域,效果如下:

在没有原始数据情况下,需要对原始图像中的图像数据进行分析,然后可以通过射线法等方法得到显著性区域范围。
而在拥有原始数据的情况下,我们可以通过简单的操作原始数据获取图像显著性区域,十分方便。
这里通过一个例子,来介绍一下基于原始数据的图像显著性区域识别方法。
首先准备了一个页面用于渲染图像,内容如下:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
.box {width: 500px; height: 500px; border: 1px solid #bbb; position: relative;}
.item {width: 10px; height: 10px; border-radius: 5px; position: absolute; background: rgba(0, 0, 0, 0.4); transform: translate(-50%, -50%)}
.line {border: 1px solid red; position: absolute;}
</style>
</head>
<body>
<div class="box"></div>
<script></script>
</body>
</html>代码中预定义了样式,可以看出,box 元素将会是图像的"画布",item 元素是画布中的点,而 line 元素是包裹范围的选框。
本文提到的原始数据是指含有 x, y 坐标信息的数据集合,并且该数据集合被用于绘制图像,如:
var data = [
{x: 20, y: 31},
{x: 104, y: 99},
...
]这里通过随机数生成一个原始数据:
var items = [], max = 500, len = 1000, i = 0
// 生成 1000 个坐标点,范围 [0 - 500)
for (i; i < len; i++) {
items.push([Math.floor(Math.random() * max), Math.floor(Math.random() * max)])
}得到数据后,我们可以先在画布上绘制点。
var html = ''
items.map(function (item) {
html += '<div class="item" style="left: ' + item[0] + 'px; top: ' + item[1] + 'px"></div>'
})
document.querySelector('.box').innerHTML = html效果如图:
我们需要识别的范围,简单的说就是多个连续的数据点的集合所形成的范围。所以第一步,我们需要通过一个点来寻找它所在的连续数据点集合。
连续数据点集合的获取方法描述如下:
1 设定一个点作为起始点;
2 遍历数据寻找与起始点“连续”的点,即两点距离小于某一阈值;
3 对获取到的“连续”点集合进行遍历重复 1 - 3 步骤直到全部遍历完成。
完成一次连续数据点集合的获取即代表着获取到了一个数据范围。但是该数据范围是否“显著”,这个是需要判断的,例子中将仅以数据点的个数作为判断依据;实际应用中判断显著性应该还需要结合图像中的其他权重值,比如热力图中每个点的点击量值。
我们先定义一下获取两个点距离的方法:
// 十分熟悉的勾股定理
function getDistance (p1, p2) {
return Math.sqrt(Math.pow(p2[1] - p1[1], 2) + Math.pow(p2[0] - p1[0], 2))
}获取连续数据点的方法定义如下:
/**
* infect 通过一个起始点获取一个连续数据点集合
* @params {Array} startPoint 起始点
* @params {Array} restPoints 剩余待计算点的集合
* @params {Array} range 已计算所得的连续数据点集合
* @return {Array} 连续数据点集合
*/
function infect (startPoint, restPoints, range) {
var i = 0, temp = []
// 还有剩余待计算点时,对下一个待计算点进行连续判断(这里仅以距离作为判断依据),如果是连续点,则将该点加入数据集合并从剩余待计算点集合中剔除。
while (restPoints[i]) {
if (getDistance(startPoint, restPoints[i]) <= 5 * 2) {// 距离小于两圆半径之和表示“连续”
if (range.indexOf(restPoints[i]) === -1) {
temp.push(restPoints[i])
restPoints.splice(i, 1)
i--
}
}
i++
}
range = range.concat(temp)
// 上面一次遍历仅获得了起始点的连续点,接下来计算起始点的连续点的连续点,依此类推,直到没有剩余待计算点为止
i = 0
while (temp[i] && restPoints.length > 0) {
range = range.concat(infect(temp[i], restPoints, [temp[i]]))
i++
}
return range
}代码中通过对起始点的连续点中的每一个点进行连续点求值,获得最终一个范围内的所有数据点。
接下来,我们通过 infect 函数获得所有范围集合。
function findRangeAndDraw () {
var startPoint = null, i = 0, ranges = [], rest = items.slice(0)
// 获取到一个范围数据点集合后,如果还有剩余待计算点,继续进行范围获取。
while (rest.length) {
startPoint = rest.shift()
ranges.push(infect(startPoint, rest, [startPoint]))
}
// 绘制所有范围
draw(ranges)
}在最后的绘制方法中,需要对范围内的所有数据点进行遍历以确定范围的左上角顶点和长宽,代码如下:
function draw (ranges) {
var i = 0, points = ranges.shift(), maxX = 0, maxY = 0, minX = max, minY = max, width = 0, height = 0
if (points.length === 1) {
// 如果范围内仅一个点,继续绘制
if (ranges.length) {
draw(ranges)
return
}
} else {
// 获取左上角顶点和右下角顶点坐标
points.map(function (point) {
maxX = Math.max(point[0], maxX)
maxY = Math.max(point[1], maxY)
minX = Math.min(point[0], minX)
minY = Math.min(point[1], minY)
})
// 计算获取高宽,这里的数值 5 每个点的半径,见 CSS 中的属性
minX = minX - 5
minY = minY - 5
width = maxX - minX + 5
height = maxY - minY + 5
}
document.querySelector('.box').insertAdjacentHTML('afterBegin', '<div class="line" style="left: ' + minX + 'px; top: ' + minY + 'px; width: ' + width + 'px; height: ' + height + 'px;"></div>')
if (ranges.length) {
draw(ranges)
}
}所有代码完成,最后执行 findRangeAndDraw 方法,运行后效果如下:
[!ranges.jpg]
上述方法通过操作原始数据获取图像的显著性区域,还有很多方法可以不依靠原始数据获取图像显著性区域。
这里简单介绍两种方法。
射线法是不依靠原始数据而能得到显著性区域范围的一种方法。
它的获取范围的步骤是:
1 设定显著性区域的阈值并通过图像获得图像的像素数据;
2 遍历图像像素数据,获得显著点的集合;
3 遍历显著点集合,对每一个显著点,
3.1 依序发射 4 条直线,每条直线成45度夹角,最终形成一个“米”字;
3.2 依序遍历这 4 条直线,判断距离显著点最近的该线上背景色点坐标;
3.3 遍历完成 4 条线,获得一个具有 8 个点的集合;
3.4 确定该显著点的范围,并在下次遍历中跳过该范围内的所有点的计算;
4 重复步骤 3 中的所有小步骤直到没有显著点可计算;
5 绘制所有范围。
区块统计法是通过对图像进行 N 等分后获得 N 个区块,然后判断相邻区块是否含有显著性区块,最终获得显著性区域的一种方法。同样,该方法也不依靠原始数据。
它的步骤如下:
1 获得图像的像素数据;
2 将图像划分为 N 个区块,如以 5 * 5 的像素范围为一个区块;
3 遍历区块,判断在区块范围内的像素数据是否含有显著性像素,是则将区域标记为 1,否则为 0;
4 对标记为 1的区块进行遍历,并对相邻的标记为 1 的区块进行合并为一个范围;
5 绘制所有范围;
通过操作图像的原始数据,可以获取到图像的显著性区域范围。而当没有原始数据时,我们也可以通过分析图像的像素数据获得范围。
目前,分析图像的显著性区域技术使用的非常广阔。比如常见的二维码识别、条形码识别、商品识别、色情图像识别等等,当然每一个具体的场景对应的算法都会有所不同,希望本文能够对大家能够深入其中带来一点帮助。
js的一个特点是单线程,即浏览器中js引擎中负责解析执行js代码的线程只有一个。这是因为在浏览器环境中,我们常常需要对DOM做各种各样的操作。假设js是多线程的,那么当两个js线程同时对一个DOM进行一项操作,比如线程A希望删除这个DOM,而线程B希望改变其样式,这时就涉及到了复杂的同步问题。因此,为了保证不发生和上述场景类似的问题,js的执行只由一个线程完成。
而js中有许多原生的异步事件,诸如 setTimeout,setInterval,事件监听,Ajax请求等等。那么单线程的js是如何实现异步的呢?其核心在于js的事件循环机制。
每个js线程拥有独立的Event loop,大多数的代码会依据正常的函数调用规则来执行,而遇到特殊的任务源,如 setTimeout/setInterval 则由他们将不同的任务分发到对应的任务队列中。
任务又分为宏任务(Macrotask) 与 微任务(Microtask) 两种。在浏览器中,
宏任务:包括主代码块,setTimeout/setInterval回调,I/O,UI Rendering等;
如有必要,浏览器会在一个宏任务完成之后,下一个宏任务开始之前,重新渲染页面。
微任务:包括promise回调,MutationObserver回调。
事件循环的过程可以用下图来表示,概括起来,事件循环的一轮迭代主要包括3个步骤:

console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');首先,Macrotask队列中主代码块最先被执行,这里会首先输出 script start ,遇到 setTimeout 会将它的回调函数分发到Macrotask队列中,然后继续执行,遇到 Promise ,再将 Promise 的两个回调函数依次分发到Microtask队列中,接着向下执行输出 script end ,此时,主代码块执行结束。开始处理Microtask队列中的任务,即promise的两个回调函数,所以控制台接着输出 promise1 promise2 ,到目前为止Microtask队列为空,一轮事件循环完成。
然后开始第二轮事件循环,从Macrotask队列中取出setTimeout回调并执行,控制台输出 setTimeout ,Microtask队列仍为空,第二轮事件循环结束。至此,程序运行完毕,控制台的所有输出汇总如下:
script start
script end
promise1
promise2
setTimeout
我们再来看一个涉及到html 的例子,我们创建两个div,inner div嵌套在outer div里面,代码如下:
<div class="outer">
<div class="inner"></div>
</div>// 首先获取文档中的两个元素
var outer = document.querySelector('.outer');
var inner = document.querySelector('.inner');
// 创建MutationObserver监听outer div的属性改化,如果发生变化就调用函数
new MutationObserver(function() {
console.log('mutate');
}).observe(outer, {
attributes: true
});
// 声明一个事件监听器
function onClick() {
console.log('click');
setTimeout(function() {
console.log('timeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise');
});
outer.setAttribute('data-random', Math.random());
}
// 将监听器分别和两个div绑定
inner.addEventListener('click', onClick);
outer.addEventListener('click', onClick);那么现在我们点击内部的div,控制台会如何输出呢?
首先,点击inner div相当于一次I/O事件,会触发inner div绑定的 onClick 函数 ,同时由于event bubble也会触发和outer div绑定的 onClick 函数,两个onClick函数作为Macrotask分发至Macrotask队列中。
接着,从Macrotask中取出onClick函数执行,接下来就和上一个例子差不多了,控制台输出 click,setTimeout 将其回调函数分发至Macrotask队列,Promise将其回调函数分发至Microtask队列,然后执行到outer.setAttribute,注意它修改了outer div的属性,会触发MutationObserver绑定的回调函数,而该回调函数会分发至Microtask队列中。至此,inner div的事件监听器执行完毕。
此时,Macrotask队列和Microtask的情况分别是:
Macrotask队列:onClick | setTimeout callback
Microtask队列:Promise callback | Mutation observer
然后,开始处理所有的Microtask,控制台依次输出promise mutate,一轮事件循环结束。
此时,Macrotask队列和Microtask的情况分别是:
Macrotask队列:onClick | setTimeout callback
Microtask队列:空
第二轮事件循环开始执行第二个onClick函数,和上一个一样,控制台输出 click,setTimeout 将其回调函数分发至Macrotask队列,Promise将其回调函数分发至Microtask队列,然后outer.setAttribute 触发MutationObserver绑定的回调函数,而该回调函数会分发至Microtask队列中。
此时,Macrotask队列和Microtask的情况分别是:
Macrotask队列:setTimeout callback | setTimeout callback
Microtask队列:Promise callback | Mutation observer
然后,开始处理所有的Microtask,控制台依次输出promise mutate,第二轮事件循环结束。
此时,Macrotask队列和Microtask的情况分别是:
Macrotask队列:setTimeout callback | setTimeout callback
Microtask队列:空
接着继续执行setTimeout的回调函数,控制台输出timeout timeout。至此,程序运行完毕,控制台的所有输出汇总如下:
click
promise
mutate
click
promise
mutate
timeout
timeout
Tasks, microtasks, queues and schedules
深入理解js事件循环机制(浏览器篇)
《JavaScript核心技术开发揭秘》
很少有时间对于写过的代码重构 这次发现重构是真的很有意思的事情 所以就记录下来了
集卡属于互动类型的游戏,此页面有9个弹窗,其中有同时出现的5个弹窗的情况,且如果同时出现必须按照指定顺序弹出。
遇到复杂的交互逻辑,数据结构可以帮助理清思路,抽象逻辑,完成稳定可靠的代码。在这次交互中,弹框要一个个按照顺序弹出,可以虑有序队列。但是弹框的弹出和关闭属于事件。在上一个弹框弹出关闭后,触发下一个弹框弹出。可以考虑事件的发布订阅。
队列 是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(end)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队首。
队列的弹窗展示有三个状态
整体逻辑分析如下图
import { push } from "./utils"
push(MODAL_TYPE.GIVE_CARD)
push(MODAL_TYPE.ASSIST_CARD)
push(MODAL_TYPE.BUY_CARD)
push(MODAL_TYPE.TASK_CARD)
setTimeOut(()=>{
push(MODAL_TYPE.RECEIVE_CARD)
},1000)
setTimeOut(()=>{
push(MODAL_TYPE.ASSIST_CARD)
},4000)
游戏状态多意味着常量多,好的代码最好是不写注释也一目了然。如果可以把注释通过代码表示出来那就太棒了,限制维护者强制书写注释那就更好了。
优化后的代码index.js减少了500行左右的代码
我的处理是
写单测是和留下组建快照 是代码的一次快照缩影,以后维护中可以验证是否修改最后的html结构。用代码描述出最基本的功能,并进行验证。这样保证代码的设计合理性和容易理解的实用性。
使用stylelint检测css一些不和规则的书写
因为css里有一些属性会触发重绘 所以 按照一定的书写顺序可以减少重绘提高css加载速度
而使用简写等可以减少css的打包体积
npm install stylelint --save-dev
npm install stylelint-config-standard --save-dev
npm install stylelint-order --save-dev
npx stylelint "**/*.css" --fix // fix 是自动修改
下图 是stylelint检测的要修改的点 加入--fix就会自动修改了
对比 虽然很小 但是 量变产生质变 文件多了自然就减少的多了
const RedBagRain = React.lazy(() =>
import(
/* webpackPrefetch: true, webpackChunkName: 'RedBagRain.lazy'*/ "./components/red_bag_rain"
)
)
<React.Suspense fallback={null}>
<RedBagRain
dis_cold_start_selectors={[".mask", ".slidemodal"]}
visible={!showFinishPage}
/>
</React.Suspense>RedBagRain有155 kb ,组建单独打包,分包加载,最后显示分出来 我把modal,actionsheet等 需要点击才能显示出的组建分包加载。这样就达到了首要的包优先加载,其他的包懒加载。如果不需要立即加载的,延迟1000s加载的写法是
const RedBagRain = React.lazy(() => {
return new Promise(resolve => setTimeout(resolve, 10 * 100)).then(() =>
import(/*webpackChunkName: 'RedBagRain.lazy'*/ "./components/red_bag_rain")
)
})
点击进入tiny-图片压缩网站
webpack-bundle-analyzer 分析那些图片太大,如果不是主要图片就进行再次压缩
打包结果对比:
优化前
加载结果对比
文章将从 LocalStorage 开始讲起,聊到 localForage,在后续的篇章中将会说一说新的存储方案。
本地存储功能在我们站点应用中十分常见,LocalStorage,SessionStorage 等都是大家经常使用的。然后目前也有很多应用选择避免使用 LS、SS,而改用基于本地数据库(indexedDB, WebSQL 之类)的解决方案,这是为什么呢?
为什么好好的,大家都不使用 LocalStorage/SessionStorage 了?
LS 一推出就以其简单的 API 大受欢迎。基于 storage 规范(嗯,这个不是 HTML5 的内容),LS 拥有十分简单的 API:
localStorage.setItem( 'key', 'value' )
localStorage.getItem( 'key' ) // ===> 'value'不得不说 LS 给开发者带来的很多好处:
随着 LS 被广泛地使用,它的弊端也慢慢为人所熟知:
LS 本质上是一种同步的行为,这意味着它在执行时会阻塞渲染,影响你的应用的体验。
每次 LS 执行文件 IO 都意味着对本地硬盘的操作,这可能会需要很多的时间,具体取决于系统执行的操作。而且,为了显得流畅,应用在加载时会等待 LS 内容加载至内存中,这意味着 LS 使用的越多,应用加载就越慢。
LS 遵循规范中基于 Scheme、hostname、unique port 的三者隔离特性。但是由于 LS 是明文存储,在安全页面和非安全页面中都不应该将敏感数据存储于 LS,所以 HTTP 和 HTTPS 的站点本应该可以同享 LS 内容,但是实际上却并非如此。
LS 在隐私模式下会使用一个新的临时数据库,这意味着在隐私模式被关闭后,LS 的数据也将丢失。
LS 的存储限制一般仅 5Mb 左右,并没有太好的解决方案进行 LS 的扩容。
LS 存储值的过程中会自行将非字符串类型值转义成字符串,是一个容易被人忽略的问题,比如:
localStorage.setItem( 'key', 900 )
localStorage.getItem( 'key' ) === 900 // false, return '900'
localStorage.setItem( 'key', {toString: function () {return '100'}} )
localStorage.getItem( 'key' ) === '100' // true总之,大家都开始寻找更好的存储方案进行替代原来的 LS。
localForage 是一个快速的简单的 JS 存储工具。他使用的是异步存储(基于 IndexedDB 或者 WebSQL),并且它有一套类似 LS 的 API。
localforage.setItem('key', 'value', function (err) {
// if err is non-null, we got an error
localforage.getItem('key', function (err, value) {
// if err is non-null, we got an error. otherwise, value is the value
});
});由于 localForage 使用的是异步存储,所以提供的 API 是异步 API,localForage 同时提供了 Callback(Node-style,即回调第一个参数为 error) 和 Promise 的方式进行异步处理。
localforage.setItem('key', 'value', function (err) {
// if err is non-null, we got an error
localforage.getItem('key', function (err, value) {
// if err is non-null, we got an error. otherwise, value is the value
});
});
////
localforage.setItem('key', 'value').then(function () {
return localforage.getItem('key');
}).then(function (value) {
// we got our value
}).catch(function (err) {
// we got an error
});localForage 可以存储包括 Blobs、TypedArrays 和其他 JS 对象:
LS 无法同时存储同 key 的多个值,localForage 可以通过实例化加以解决。
var store = localforage.createInstance({
name: "nameHere"
});
var otherStore = localforage.createInstance({
name: "otherName"
});
// Setting the key on one of these doesn't affect the other.
store.setItem("key", "value");
otherStore.setItem("key", "value2");另外,由于 localforage 是基于 indexedDB 这类本地数据库的,所以没有存储限制,或者说在硬盘空间足够的情况下是不存在存储限制的。localforage 在数据存储的容量方面完胜 LS。
在 W3C 的 HTML4 规范中,已经明确把 HTML 元素划分为 “块级元素” 和 “内联元素”。
常见的块级元素有 <div>、<p>、<li>、<ul>、<table> 等。需要注意的是 “块级元素” 和 display 为 block 的元素不是一个概念。例如,<li> 元素默认的 display 为 list-item ,
display 为 table,但是它们都是 “块级元素”,因为它们都符合块级元素的基本特征,水平方向独占一行,多个块级元素之间换行显示正是由于 “块级元素” 具有换行的特性,因此理论上可以配合 clear 属性清除浮动带来的影响
.clear:after {
display: table;
clear: both;
content: ‘’;
}由于 list-item 会添加一个项目符号 【·】,所以不经常使用
display: inline-block为了方便理解,可以认为每个元素都有两个盒子组成,"外在盒子" 和 "内在盒子",外在盒子负责元素是否可以在一行显示还是换行显示,内在盒子负责元素的宽高和内容的呈现。按照 display 属性值的不同,
block 的元素的盒子实际是由外在的 “块级盒子” 和内在的 “块级盒子” 组成inline-block 的元素则由外在的 “内联盒子” 和内在的 “块级盒子” 组成inline 的元素则内外都是由 “内联盒子” 组成width: auto (默认值就是 auto,所以一般直接省略 width 这个属性,采用默认值),具有以下几种不同的表现
充分利用可用空间:块级元素的宽度默认是 100% 于父元素的。
收缩和包裹:如果元素设置了浮动或者绝对定位或者 display: inline-block/inline-table 后,宽度就等于其 “内容尺寸”,称之为 “包裹性”。
超出父容器宽度限制:如果元素设置了明确的 width,否则正常情况下是不会超出父容器的宽度的,但凡事总有例外。内容很长的连续的英文字符和数字,或者内联元素被设置了 white-space: nowrap,这个时候元素的 width 就会超过父容器
margin\padding\border\content 自动分配水平空间的机制。 <div class="nav">
<a href="" class="nav-a">导航1</a>
<a href="" class="nav-a">导航2</a>
<a href="" class="nav-a">导航3</a>
</div> .nav {
background-color: #ccc;
width: 300px;
height: 90px;
}
.nav-a {
display: block;
height: 29px;
width: 100%;
border-bottom: 1px solid;
padding: 0 10px;
}position 属性为 absolute 和 fixed 元素中。默认情况下,绝对定位元素的宽度表现为 “包裹性”,宽度由 “内部尺寸” 决定。但是。有一种情况下宽度是由 “外部尺寸” 决定的:对于非替换元素,当 left/right,或者 top/bottom 对立方位属性值同时存在时,元素的宽高表现为 “格式化宽高”,其宽高尺寸相对最近父元素的具有定位特性(position 属性值不是 static)的祖先元素计算。 <div class="fixed">
<div class="fixed-box"></div>
</div> .fixed {
position: relative;
width: 200px;
height: 200px;
background: #999;
}
.fixed-box {
position: absolute;
left: 0;
right: 0;
height: 50px;
margin-right: 50px;
border: 10px solid green;
background: #f80;
}float\绝对定位\inline-block 属性时,其宽度就表现为包裹性,但是具有 “包裹性” 的元素的宽度其实还是受到了父容器宽度的限制,始终小于等于父容器的 width,并自动换行显示。但是,如果父容器的尺寸小于 “首选最小宽度” 的时候,就不适用了。看上面的这个 demo ,内部尺寸大于容器尺寸。
<div style="width:5px; background: #666">我</div>如何实现文字只有一行的时候居中对其,大于一行的时候左对齐:
<div style="width: 300px; background: #ccc; text-align: center">
<div style="display: inline-block; text-align: left;">说的话就发货发货是否会回复 i 的回</div>
</div>首选最小宽度:在 CSS 世界中,图片和文字的权重要远大于布局,因此,CSS 设计者们不会让图文在 width: 0 时宽度变成 0 ,此时所表现的宽度就是 “首选最小宽度”。具体表现规则:
** 东亚文字(如汉子)最小宽度为单个汉子的宽度;
** 西方文字最小宽度由特定的连续的英文字符单元决定。并不是所有的英文字符都会组成连续单元,一般会终止于 空格、短横线、问号以及其他非英文字符等;
** 对于图片这样的替换元素,首选最小宽度就是该元素的内容的宽度。
<div style="width:5px; background: #666"><span>我</span></div>
<div style="width:5px; background: #666"><span>display:inline-block</span></div>white-space: nowrap; <div style="width: 300px; background: #999; white-space: nowrap">ABCjdsfhfhhfkdshjfhfkhfkhfhjfhfhfhkhfkhfkhfjkdhsfjkdhsfjkhfjkh</div>盒模型包含哪些部分:margin\padding\border\content
width 属性作用在 content 部分,不含 margin、padding 和 border 部分。通常我们可以设置 box-sizing 属性,来改变 wdit 作用的部分。
box-sizing 属性有三个属性值:border-box | content-box | padding-box (Firefox 曾今支持过,现在不支持了)
相比于 width: auto 要简单很多。一般情况下元素设置 height: auto 后,其高度受子元素 height 的影响。有一个地方需要说明一下,就是,height: auto 也有 “外部尺寸” 特性。仅存在于 “绝对定位模型” 中,称之为 “格式化高度”。
<div class="fixed">
<div class="fixed-box-1"></div>
</div> .fixed {
position: relative;
width: 200px;
height: 200px;
background: #999;
}
.fixed-box-1 {
position: absolute;
top: 0;
bottom: 0;
width: 100px;
height: auto;
border: 10px solid green;
background: #f80;
}注意:默认情况下块级元素的 height 的默认值就是 auto;
对于 width 属性,就算父元素 width 为 auto ,其百分比值也是支持的;但是,对于 height 属性,如果父元素 height 为 auto, 只要元素在文档中,其百分比值就完全被忽略。看看下面的 demo
<div>
<div style="height: 50px; background: #666;">1111</div>
<div style="height: 100%; background: #f80;">2222</div>
</div> <div style="height: 100px;">
<div style="height: 50px; background: #666;">1111</div>
<div style="height: 100%; background: #f80;">2222</div>
</div> <div style="position: relative;">
<div style="height: 50px; background: #666;">1111</div>
<div style="height: 100%; background: #f80; position: absolute;">2222</div>
</div>注意:使用绝对定位后的元素,其 height 百分比的值是相对于 “包含块” 的 padding box 进行计算的,而不是 content box
有一种情况,元素的 height 不是固定的一个数值,而是根据内容高度的变化而自适应,这个时候 height 就是默认值 auto。那么就不能通过 transitio 设置 height 的过渡动效。
<div class="transf">
<div style="height: 200px; background: #999" class="transf-con">max-height</div>
</div> .transf {
/*height: 100px;*/
max-height: 100px;
width: 100px;
/*transition: height 1s ease;*/
transition: max-height 1s ease;
overflow: hidden;
}
.transf:hover {
/*height: auto;*/
max-height: 220px;
}展开后的 max-height 值,我们只需要设定为保证比展开内容高度大的值就可以。max-height 值比 height 计算值大的时候,元素的高度就是 height 属性的计算高度。
注意: 虽然 max-height 值设置的越大越安全,但是对于我们这里的动效来说,如果 max-height 值太大,动效展开就无法达到预期的效果,总是比预期的要快,同时动画收起的时候有明显的 “延迟”。所以,一般建议 max-height 使用足够安全的最小值就可以了,即使我们的效果和预期不一样,但是也不会太大,用户一般情况下是无法察觉的。
这里不做详细的介绍,下面说说什么是 “内联盒子” 和 “行框盒子”
“内联盒子” 不会让内容成块显示,而是排成一行,这里的 “内联盒子” 实际指的就是元素的 “外在盒子”,用来决定元素是内联还是块级,该盒子可以分为 “内联盒子” 和 “匿名内联盒子”。简单的说其实就是,当 “外在盒子” 决定元素是在一行显示的时候,那么这个元素就是 “内联盒子”。比如说设置了 display: inline-block 属性的元素就是一个内联盒子。
<div style="color: red">
<span style="color: black">sfjjfhfjh</span>
会务费和返回份盒饭好烦好烦
<span style="color: black">fhhdfhfhfh</span>
</div>上面红色汉子的部分就是 “匿名内联盒子”
注意: 并不是所有文字的部分都是 “匿名内联盒子”。这个要看这段文字前后的标签类型,如果标签类型是块级元素,那么它就属于 “匿名块级盒子”。
如果当前行是由 “内联盒子” 所组成的,那么这一行就可以被称之为 “行框盒子”
“幽灵空白节点” 是内联盒模型中非常重要的一个概念,具体指的是:HTML5 文档声明中,内联元素的所有解析和渲染表现就如同每个行框盒子的前面有一个 “空白节点” 一样。这个空白节点透明、不占据任何宽度、看不见也无法通过脚本获取,就像幽灵一般。但是,它又确实存在,表现如同文本节点一样。
注意: 这里有一个前提条件。就是,文档声明必须是 HTML5 文档声明(<!doctype html>)
<div style="background: #ccc;">
<img src="https://demo.cssworld.cn/images/common/l/1.jpg" alt="" width="100">
</div>上面的这个 demo 显示 父元素的底部和图片的底部有间隙,这是为什么呢?。
什么是高阶组件
高阶组件是react中的一个概念,实质来讲,高阶组件就是一个高阶函数
什么是高阶函数,就是满足以下任意一个条件:
可以传入另一个函数作为参数(比如filter、map)
可以返回一个函数(比如bind)
日常工作中,我们在不知不觉中就已经使用了高阶函数
const arr = [1,2,3,4,5,6];
const square = d => d ** 2;
arr.map(square) // [1, 4, 9, 16, 25, 36];
在这个例子中,我们的map函数通过传入的方法square实现了数组的二次方。
另一个我们经常会用到的例子:
<ul>
{list ? list.map((item, index) => {
return <li>{item.name}</li>
})}
</ul>
由这些高阶函数我们可以明白,其实高阶组件是一种用于复用组件逻辑的高级技术,它并不是 React API的一部分,而是从React 演化而来的一种模式。具体地说,高阶组件就是:接收一个组件并返回另外一个新组件的函数,并且会继承传入组件(state,props,生命周期,render)。
用来做什么
简单来讲,提取重复代码,处理相同逻辑
高阶组件还有更多的功能:
// 操作props
// 可以对原组件的props进行增删改查,通常是查找和增加,删除和修改的话,需要考虑到`不能破坏原组件`。
function Hoc(WrappedComponent) {
return class extends React.Component {
render() {
const {userInfo,...otherprops} = this.props;
return <WrappedComponent {...otherprops} />
}
}
}
// 将组件包裹起来,为了封装样式、布局等目的
function HOC(WrappedComponent) {
return class PP extends React.Component {
render() {
return (
<div style={{display: 'block'}}>
<WrappedComponent {...this.props}/>
</div>
)
}
}
}
// 操纵组件的方法
function HOC(WrappedComponent) {
return class ExampleEnhance extends WrappedComponent {
...
componentDidMount() {
super.componentDidMount();
}
componentWillUnmount() {
super.componentWillUnmount();
}
render() {
...
return super.render();
}
}
}
这里我们可以看到,我们的高阶组件继承了传入组件(一般的高阶组件是继承react的component),并且在render函数中return的是super.render(),从而实现了继承反转。因此高阶组件就可以获取到传入组件的生命周期钩子和方法。
这里举一个简单的例子:
我们先创建一个被包裹的组件:
import React, { Component } from "react";
export default class ComponentChild extends Component {
constructor(props) {
super(props);
this.state = {
message: "我是ComponentChild中的message"
};
}
componentDidMount() {
console.log("ComponentChild Did Mount");
}
clickComponent() {
console.log("ComponentChild click");
}
render() {
return <div>{this.state.message}</div>;
}
}
这里我们会返回一个信息,信息存在组件的state中,并且有一个clickComponent方法和一个生命周期方法,会在控制台打印信息。
接下来实现具有继承反转能力的高阶组件:
import React from "react";
//这样的方式,外部组件的 state 可以将被继承组件的 state 和 钩子函数彻底覆盖掉。同时,外部组件也可以调用被继承组件的方法。
const messageOtherHoc = WrappedComponent => {
return class extends WrappedComponent {
constructor(props) {
super(props);
this.state = {
message: "我是messageOtherHoc中的message"
};
}
componentDidMount() {
console.log("messageOtherHoc componentDidMount");
this.clickComponent();
}
render() {
return (
<div>
<div onClick={this.clickComponent}>messageOtherHoc 点击我</div>
<div>
<div>{super.render()}</div>
</div>
</div>
);
}
};
};
export default messageOtherHoc;
高阶组件中,我们会定义state,生命周期函数,并且在div中设置点击事件,调用this.clickComponent方法,显然,我们高阶组件中并没有写这样的方法;最后我们会返回传入组件的render函数,通过super找到传入组件
然后我们去调用这个高阶组件:
const Message2 = MessageOtherHoc(ComponentChild);
<Message2 />
打印台信息:

显而易见,高阶组件覆盖了传入组件的生命周期方法并且调用了传入组件的clickComponent方法。
这就意味着这样的高阶组件可以访问到WrappedComponent的state,props,生命周期和render方法。如果在高阶组件中定义了与WrappedComponent同名方法,将会发生覆盖,如果需要调用他们,我们就必须手动通过super进行调用。就像例子中那样。
如何创建一个高阶组件
一个简单易懂的例子,命名和代码可能不是规范的写法,但是可以说明问题
用于返回Tips相同的展示:
import React, { Component } from "react";
function withToolTipsSubscription(WrappedComponent) {
return class withToolTipsSubscription extends Component {
render() {
const { tipsType, ...otherProps } = this.props;
return (
<fieldset>
<legend>我是一个 {tipsType.type} 组件</legend>
<p>
<span>提示时间:{tipsType.date}</span>
</p>
<p>
<span>提示:</span>
</p>
<span>WrappedComponent is:</span>
<WrappedComponent {...otherProps} />
</fieldset>
);
}
};
}
export default withToolTipsSubscription;
我们的Tip可以拥有一个共同的标题,提示时间和一些文字
在这里面我们用到了操纵props,并把props继续传递给了我们的参数组件:
const { tipsType, ...otherProps } = this.props;
<WrappedComponent {...otherProps} />
AskToolTip.js
用于展示一个一个带有两个按钮的Tips
两个按钮可以和父组件进行交互,直接调用 this.props 调用父组件方法即可,无需其他操纵
import React, { Component } from "react";
import ToolTips from "./ToolTips";
class AskToolTips extends Component {
constructor(props) {
super(props);
this.handleConfirm = this.handleConfirm.bind(this);
this.handleCancel = this.handleCancel.bind(this);
this.confirmIndex = 0;
this.cancelIndex = 0;
}
handleConfirm() {
this.props.onConfirm((this.confirmIndex += 1));
}
handleCancel() {
this.props.onCancel((this.cancelIndex += 1));
}
render() {
return (
<div
style={{
borderWidth: "1px",
borderColor: "#d3d3d3",
borderStyle: "solid"
}}
>
<div>
<span>There are somthing will ask with you:</span>
<p>
<span>[ ConfirmTimes:{this.props.confirmTimes} ]</span>
<span>[ ConfirmTimes:{this.props.cancelTimes} ]</span>
</p>
</div>
<button onClick={this.handleConfirm}>confirm</button>
<button onClick={this.handleCancel}>cancel</button>
</div>
);
}
}
export default ToolTips(AskToolTips);
这个组件的写法和平常的组件大致无二,唯一的的区别在于 export 的内容
export default ToolTips(AskToolTips);
引入并返回我们包裹的高阶组件
ErrorToolTips.js
和上面的组件类似,但是这里只接收父组件传递的内容进行展示:
import React, { Component } from "react";
import ToolTips from "./ToolTips";
class ErrorToolTips extends Component {
render() {
return (
<div
style={{
borderWidth: "1px",
borderColor: "#d3d3d3",
borderStyle: "solid"
}}
>
<span>{this.props.msg.str}</span>
</div>
);
}
}
export default ToolTips(ErrorToolTips);
HocExample.js
组件的具体调用:
import React, { Component } from "react";
import AskToolTips from "./HocEx/AskToolTips";
import ErrorToolTips from "./HocEx/ErrorToolTips";
export default class HocExample extends Component {
constructor(props) {
super(props);
this.handlerAskConfirm = this.handlerAskConfirm.bind(this);
this.handlerAskCancel = this.handlerAskCancel.bind(this);
this.state = {
confirmTimes: 0,
cancelTimes: 0,
date: new Date().toLocaleString(),
msg: "我是一个错误提示框"
};
}
handlerAskConfirm(index) {
console.log("handlerAskConfirm:" + index);
this.setState((state, props) => {
const msg =
"睡在我下铺的兄弟Ask我:" +
(state.cancelTimes + index) +
"次!,Confirm:" +
index +
"次!Cancel:" +
state.cancelTimes +
"次!";
return {
confirmTimes: index,
msg: msg,
date: new Date().toLocaleString()
};
});
}
handlerAskCancel(index) {
console.log("handlerAskCancel:" + index);
this.setState((state, props) => {
const msg =
"睡在我下铺的兄弟Ask我:" +
(state.confirmTimes + index) +
"次!,Confirm:" +
state.confirmTimes +
"次!Cancel:" +
index +
"次!";
return {
cancelTimes: index,
msg: msg,
date: new Date().toLocaleString()
};
});
}
render() {
return (
<fieldset>
<legend>高阶组件实例</legend>
<ErrorToolTips
tipsType={{
type: "ErrorToolTips",
date: this.state.date
}}
msg={{ str: this.state.msg }}
/>
<AskToolTips
tipsType={{
type: "AskToolTips",
date: this.state.date
}}
confirmTimes={this.state.confirmTimes}
cancelTimes={this.state.cancelTimes}
onConfirm={e => this.handlerAskConfirm(e)}
onCancel={e => this.handlerAskCancel(e)}
/>
</fieldset>
);
}
}
我们直接调用AskToolTips和ErrorToolTips,并且传递props的方式和普通的组件没有上面不同。
效果:


高阶函数的具体应用
这里我就结合我们的 ReactDOM.createPortal 具体说一下:
Portal是一种将子节点渲染到存在于父组件以外的 DOM 节点的方案,相信大家都有所了解,这里也不做赘述,主要是通过 ReactDOM.createPortal 方法,第一个参数是任何可以渲染的react元素或者组件。第二个参数是作为渲染第一个参数的容器DOM 元素,最终生成的节点将会挂载到此dom元素节点上,是为了解决dom层级的问题
import React, { Component } from "react";
import ReactDOM from "react-dom";
const withPortal = WrappedComponent => {
class AddPortal extends Component {
constructor(props) {
super(props);
this.el = this.getDiv();
}
componentWillUnmount() {
document.body.removeChild(this.el);
}
getDiv() {
const div = document.createElement("div");
const appendNode = this.props.appendNode || document.body;
appendNode.appendChild(div);
return div;
}
render() {
return ReactDOM.createPortal(
<WrappedComponent {...this.props} />,
this.el
);
}
}
return AddPortal;
};
export default withPortal;
总结:高阶组件是一个函数,传递一个组件作为参数,并且会返回一个组件;在高阶组件中我们会对组件中公共的部分进行提取、抽象,可以对props,state进行控制,可以调用组件的生命周期方法,render方法,可以赋予组件一些具有共性的信息,但是我们不能对作为参数的组件进行修改,要保持他的纯函数的特性;通过对一系列组件的加工处理,可以大大提高我们的开发速度和销量,提高代码质量和组件易用性。
纯函数:如果函数的调用参数相同,则永远返回相同的结果。它不依赖于程序执行期间函数外部任何状态或数据的变化,必须只依赖于其输入参数
tips:不要问我为什么不直接引用组件到高阶组件中,而不通过参数进行传递,如果这样的话,我们写每一个组件都要copy一份新的函数进行开发,何必呢
在介绍 Markdown 之前,我们先来看一下同样是标记语言的,广为人知的,万众瞩目的 HTML。
HTML 的全称是超文本标记语言 (Hypertext Markup Language),它以标记表示区块,可以承载文本、图片、流媒体等介质。一段普通的 HTML 段落,看起来是这样的:
<p>请继续往下看,千万不要<a href="http://xiaohuangwang.com" >离开</a>哦。</p>在非技术同学的眼里,虽然也能看得懂这段代码大致表达的意思,但是还是缺少一些可读性。所以在准备写一篇博客时,常见的是从 word 编写完后,将样式带进富文本编辑器中,而不是打开源码按钮直接进行编辑,因为大多数人对 HTML 还是觉得难以下手。针对这种情况,有一种更简单的方式可以推荐给这类人群,那就是 Markdown。同样实现上面的段落,Markdown 的语法看起来是这样的:
请继续往下看,千万不要[离开](http://xiaohuangwang.com)哦。
Markdown 就是这么简洁!通常我们在 Github 上写 issue、readme、comment 等时也都会用到 Markdown,下面我们来学习一下它的语法。
Markdown 的衍生版本众多,这里我们仅介绍 Github 中使用的语法 ![]() 。
。
# This is an <h1> tag
## This is an <h2> tag
###### This is an <h6> tag
效果
This is an <h1> tag
This is an <h2> tag
This is an <h6> tag
*一个星号包裹是斜体*
_一个下划线包裹也是斜体_
**两个星号包裹是粗体**
__两个下划线包裹也是粗体__
~~两个飘就是中划线了哦~~
效果
一个星号包裹是斜体
一个下划线包裹也是斜体
两个星号包裹是粗体
两个下划线包裹也是粗体
两个飘就是中划线了哦
你还可以混合使用它们,
_~~__斜体加粗中划线__~~_
效果
斜体加粗中划线
可以使用 *, - 或 数字+点 表示列表。
* 无序列表用星号
- 中划线也表示无序列表
1. 有序列表用数字+点
效果
- 无序列表项 1
- 无序列表项 2
- 无序列表项 3
- 有序列表项 1
- 有序列表项 2
- 有序列表项 3
链接以成对的方括号和圆括号组成。
[链接文案](链接地址)
效果
萌推大前端
类似链接,图片由感叹号、方括号和圆括号组成。

效果
使用前后成对的 3 个回勾号 (```) 包裹代码段,并且可以指定一些语言名称用以高亮显示代码内容,增加阅读体验
效果
let block = 'JS 语法高亮'.code {
/* CSS 语法高亮 */
display: none;
}Github 下的 Markdown 支持的语法高亮列表,请查收
使用大于号+空格表示引用
效果
引用的展示效果
不同于代码块,使用 2 个回勾号 (`) 包裹内容,例如 `code`
效果
行内代码的展示效果
- [x] 选中状态的项
- [ ] 未选中状态的项
效果
- 选中状态的项
- 未选中状态的项
表头1 | 表头2 | 表头3
---- | ---- | ----
项1 | 项2 | 项3
项4 | 项5 | 项6
效果
| 姓名 | 身高 | 体重 |
|---|---|---|
| 小明 | 179 | 140 |
| 小王 | 188 | 160 |
:[emoji name]:
效果
🚗
⭕
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.