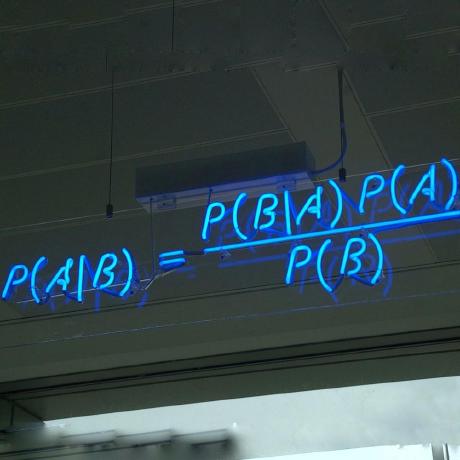This project implements a minimal server that can perform federated learning with differential privacy and accepts messages from clients.
We are using Miniconda to manage the environment. It can be installed using one of the installers available here. For MacOS, the bash installer is recommended.
Make sure to have conda init run during conda installation so that
your PATH is set properly.
To install and run the tests for this project you can run:
# Set up the environment.
$ make setup_conda
$ conda activate mozfldp
# Run tests
$ make pytestYou can run the server locally, serving requests on port 8000, using:
$ python -m mozfldp.serverpython setup.py sdistThe server can also be built and run as a Docker container. First, install Docker.
Once you have Docker installed, you can build the container and run tests using:
$ make build_image
$ make docker_testsTo run the service in the container, use:
$ make upNote that in the above command, we are exposing the container's port 8000 by binding it to port 8090 on the host computer.
You can submit arbitrary JSON blobs to the server using HTTP POST.
A sample curl invocation that will work is:
curl -X POST http://127.0.0.1:8000/api/v1/compute_new_weights
{"result":"ok","weights":[[[0.0,0.0,0.0,.... }Note: If you are running locally, the port will be 8000. Port 8090 is used if you are running in a docker container.