multiprocessio / datastation Goto Github PK
View Code? Open in Web Editor NEWApp to easily query, script, and visualize data from every database, file, and API.
Home Page: https://datastation.multiprocess.io
License: Other
App to easily query, script, and visualize data from every database, file, and API.
Home Page: https://datastation.multiprocess.io
License: Other


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





































































































































User reported it would be more convenient to reference panels by name: DM_getPanelByName("Untitled Panel #0"). This is an improvement on fetching by integer index because the name doesn't change as panels are added/moved and because it contains more info in the function call than just fetching an integer.
https://discord.com/channels/852998104931631115/852998104931631118/892793099460419635
The only concern with doing this is making sure that the panel names are unique. Or maybe it doesn't matter and we just fetch the first one by that name if fetched by name.
Right now you need to manually script unarchiving these files. It would be better if DataStation could unarchive them and deal with a particular interior file directly in the workflow.
Dealing with the interior file could be solved in a similar manner as when solving the particular Excel sheet problem when there is more than one Excel sheet since that is not handled well right now.
The user will need to pick a paging methodology, the couple that should be supported up front are:
result.next_url)For a beginner read ARCHITECTURE.md, HACKING.md and git grep snowflake or git grep prometheus and copy the basics from one of these existing systems.
Now that all panels are run in a subprocess this should be even easier.
The tricky part here is that streaming data back will work differently in server mode vs desktop mode. In desktop mode you just have to work around the rpc library in desktop/rpc.ts and desktop/preload.ts. But for server mode this might mean using websockets. Except that the streaming is only in one direction. So maybe SSE is ok in this case which may be simpler than websockets. Not sure.
I am just introduced to https://datastation.multiprocess.io/.
This seems to be a really cool approach and I like that it supports mix and match between data sources and scripting languages.
I just thought it would be pretty cool if this project supports Prometheus and PromQL, https://prometheus.io/docs/prometheus/latest/querying/basics/ down the road.
For the DSQ tool:
Seems like this tool would be a lot more useful if I could pass multiple files, naming each of them as a "table" name, and then doing joins on the data. Would be especially useful if one could do this with different datatype, maybe I have a couple of Excel documents, a csv and some json data coming from different datasources and I'd like to run a query over all of them.
Current workflows involves writing data importers to get all of the data into a proper SQL database server, and then running queries against to generate a report.
Tutorials:
Currently any objects pulled into database panels have nested fields skipped. That's not ideal since there are plenty of good reasons for nested structures.
This will require bringing the Go port of shape completely up to date with the original JavaScript implementation since the Go shape library completely skips nested fields while the JS one does not.
Once we know about nested fields in the shape the DB panels can do the collapse when they ingest panels.
This means you'd be able to query like SELECT "x.y.z" FROM DM_getPanel('My JSON rows'). You'll need to quote the field though with dots in it because the column name will literally have dots in it which would conflict with the natural SQL parser unless the column is escaped.
Required for multiprocessio/dsq#10
This happened during dark mode addition, I forgot to fix it.
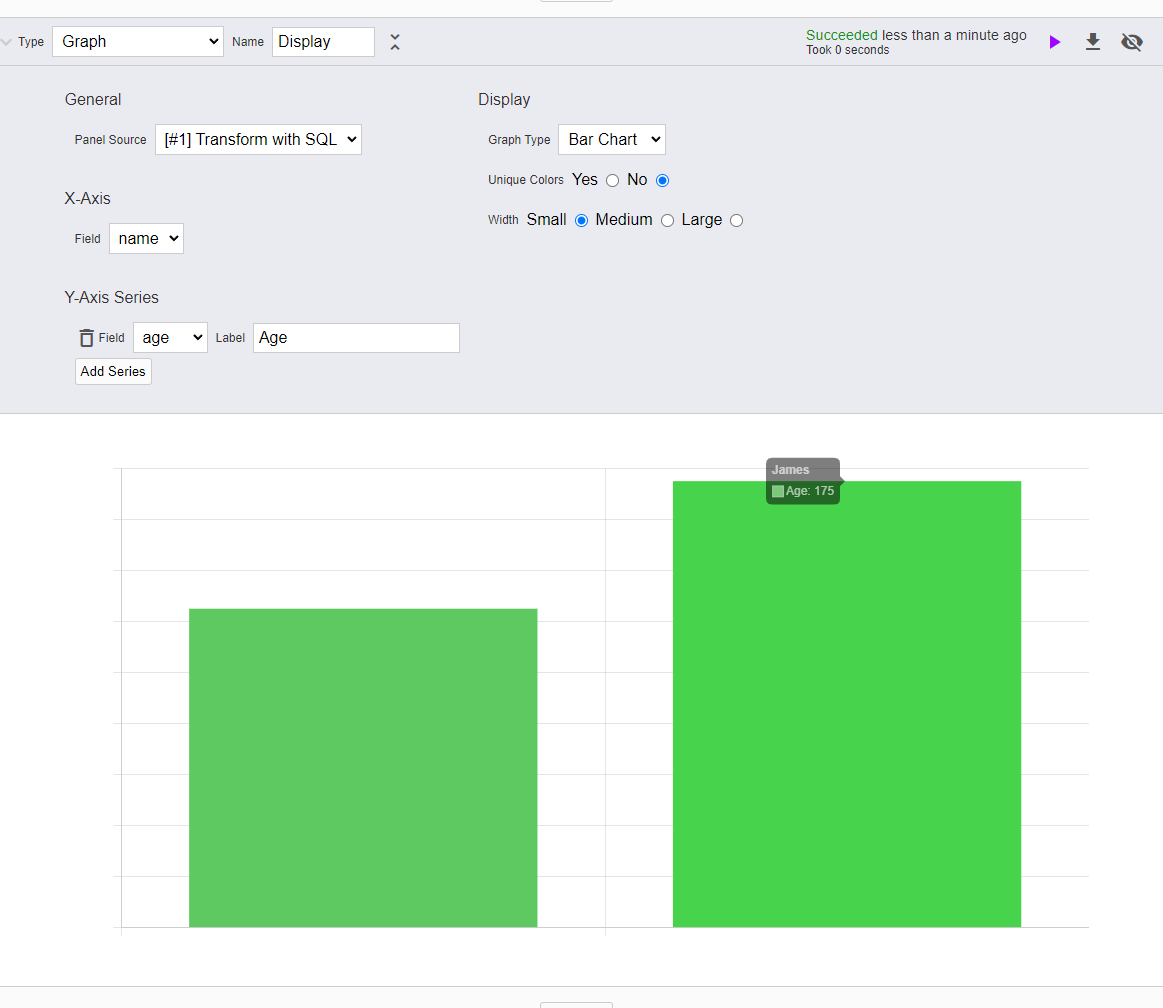
Everywhere that a panel references another one in configuration (table, graph, and visual transform panels) they use the index of the panel. This is fragile and I can't remember any reason for it to be like this. Instead these panels should reference panel.id, a uuid, instead of the panel index. This way when panels are reordered or added/removed the reference stays constant.


I try to access a resource through HTTPS using a certificate signed by my compagny. This certificate authority (CA) is not known by datastation. I fails
Error evaluating panel:
Error: [ERROR] 2021-12-22T09:11:31.713Z request to https://internal.server/resource failed, reason: unable to get local issuer certificate
at ClientRequest.<anonymous> (...\datastation-win32-x64-0.4.0\resources\app.asar\node_modules\node-fetch\src\index.js:95:4)
at ClientRequest.emit (node:events:394:28)
at TLSSocket.socketErrorListener (node:_http_client:447:9)
at TLSSocket.emit (node:events:394:28)
at emitErrorNT (node:internal/streams/destroy:157:8)
at emitErrorCloseNT (node:internal/streams/destroy:122:3)
at processTicksAndRejections (node:internal/process/task_queues:83:21)
at ChildProcess.<anonymous> (...\datastation-win32-x64-0.4.0\resources\app.asar\desktop\panel\eval.ts:120:28)
at ChildProcess.emit (node:events:394:28)
at Process.ChildProcess._handle.onexit (node:internal/child_process:290:12)
A solution could be to allow to bypass server certificate verification or better, to be able to add the CA in the tool.
The runner already supports tsv and ods but they don't show up in the UI dropdown for file type selector. These should both be added there: https://github.com/multiprocessio/datastation/blob/main/ui/components/ContentTypePicker.tsx.
Maybe:
Because of Node's default 4GB limits and the 1GB string limit. Need to find some ways around this.
One solution would be to build a fuzzy JSON parser for large data files where individual rows are less than 1GB but there are millions/billions of rows. The fuzzy parser could be aware of only the outer array and pass the internal objects to regular JSON.parse.
Or maybe we could store arrays as json newline.
For a beginner read ARCHITECTURE.md, HACKING.md and git grep snowflake or git grep prometheus and copy the basics from one of these existing systems.
For example running CREATE TABLE or INSERT will succeed but the panel will still show an error.
Array of
Object with
'baum_id' of
number,
'anlage' of
string,
'anlage_id' of
number,
'lateinischer_name' of
string or
null,
'deutscher_name' of
string or
null,
'alter' of
number or
null
Reported by schmidt_fu on Discord.
There are missing integration tests for:
Right now this will just generate a stack trace. If instead all these errors are caught with an error registered in here then in the UI it will show up as just a message in a warning box not a stacktrace in an error box.
Hopefully, this can be easily integration tested in desktop/panel/program.test.js by running the program panel with PATH="" on the parent so that no programs can be found.
Databases
General

Otherwise these fields are basically impossible to reach by SQL calls to DM_getPanel().
Keep the on disk format private.
Each panel stores its resulting shape. This should be usable in CodeEditor components to fill autocomplete information from previous panel results.
Hi,
Upon attempting to query an ElasticSearch server configured to only support HTTPS (no protocol specified in the Host config value for the data source):
Error:
[INFO] 2022-01-13T19:05:20.118Z DataStation Community Edition Panel Runner 0.5.0 DEBUG
[INFO] 2022-01-13T19:05:20.273Z Connecting to http://xyz.us-east-1.aws.found.io:9243 for elasticsearch query
[INFO] 2022-01-13T19:05:20.275Z Elasticsearch request: {"size":1000,"index":["par_document_promoted_stag"],"q":"","body":{}}
[ERROR] 2022-01-13T19:05:20.431Z Client sent an HTTP request to an HTTPS server.
Upon attempting to query an ElasticSearch server configured to only support HTTPS (https:// specified in the Host config value for the data source):
Error:
[INFO] 2022-01-13T19:08:17.683Z DataStation Community Edition Panel Runner 0.5.0 DEBUG
[INFO] 2022-01-13T19:08:17.837Z Connecting to https://64c5f893d5fc400f9d3354820a0dbe81.us-east-1.aws.found.io:9243 for elasticsearch query
[INFO] 2022-01-13T19:08:17.838Z Elasticsearch request: {"size":1000,"index":["par_document_promoted_stag"],"q":"","body":{}}
[ERROR] 2022-01-13T19:08:17.950Z Client sent an HTTP request to an HTTPS server.
When you create a new project, it keeps the same size as the create project dialog window. It should grow to be the normal default size once the project is created.
The window size is defined here: https://github.com/multiprocessio/datastation/blob/master/desktop/project.ts#L103.
The make project handler is here: https://github.com/multiprocessio/datastation/blob/master/desktop/store.ts#L122.
Simon Willison has some good notes here https://til.simonwillison.net/electron/sign-notarize-electron-macos.
I don't think this is something an external contributor can help with because most of it is me signing up for all the stuff and putting keys in Github Actions.
For a beginner read ARCHITECTURE.md, HACKING.md and git grep snowflake or git grep prometheus and copy the basics from one of these existing systems.
Unlike all the existing charts that graph a string (most likely) against a number, this graphs numbers on both axises. So in addition to the configuration changes needed for passing the right field to chartjs, the PR for this should also change the "preferred type" to "number" for the x axis when the chart type is scatter plot.

Right now the runner runs through Electron which makes panel evaluation take way longer than it needs to.
I did this in 0.2.0 because I wasn't sure if there was a real Node process bundled with Electron. But it is way too slow this way.
Also, breaking the runner into its own directory/package and bundling with pkg may significantly reduce the time to unzip on Windows since the deps will be bundled into a binary.
In the feature list of the datastation.multiprocess.io, the link to app.datastation.multiprocess.io os broken.
The href of the <a>-tag starts with https//app... (note the missing colon), and should be replaced with https://app...


Definitely:
Maybe?
Bugs
Right now the inMemoryEval for Python uses pyodide. It takes 10-20 seconds to load though. All python panels fail while it's loading.
I just heard about https://github.com/plasticityai/coldbrew so it might be worth comparing load times of coldbrew and pyodide.
Importantly, you must still be able to pass JavaScript objects to the python panel reasonably and send Python objects to JavaScript reasonably (i.e. with DM_getPanel, DM_setPanel). Pyodide improved on Brython which didn't allow you to do obj['x'] in Python from DM_getPanel objects it only allowed you to do obj.x which is not very Pythonic so a bad user experience.
Please add open office format
For a beginner read ARCHITECTURE.md, HACKING.md and git grep snowflake or git grep prometheus and copy the basics from one of these existing systems.

Right now I'm bundling the server and desktop code with tons of exceptions. It probably doesn't make any sense to do this.
I don't think this is something an external contributor can help with because most of it is me signing up for all the stuff and putting keys in Github Actions.
Right now you have to actually make a query to test if the connection was set up correctly. It would be more convenient if there were a signal in the connection area that showed that the connection was valid or not.
https://discord.com/channels/852998104931631115/852998104931631118/892791999097372682
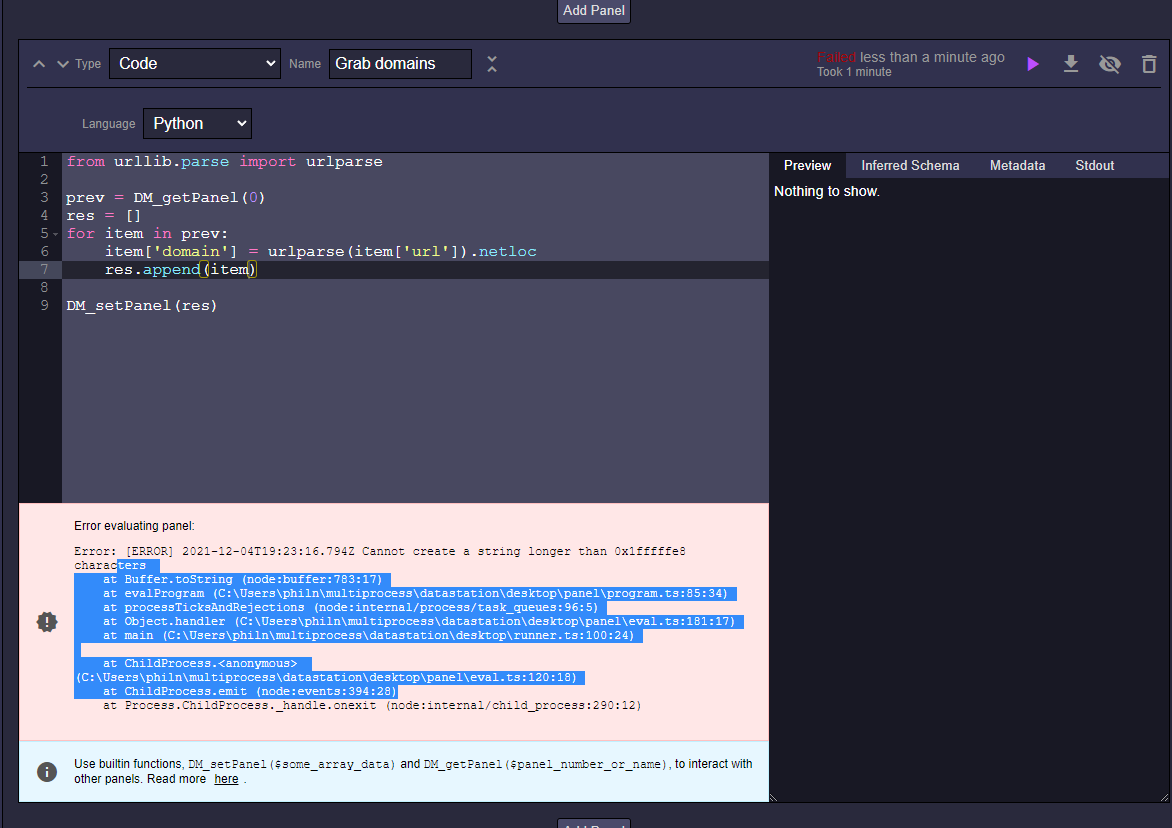
Error evaluating panel:
Error: [ERROR] 2021-12-04T19:23:16.794Z Cannot create a string longer than 0x1fffffe8 characters
at Buffer.toString (node:buffer:783:17)
at evalProgram (C:\Users\philn\multiprocess\datastation\desktop\panel\program.ts:85:34)
at processTicksAndRejections (node:internal/process/task_queues:96:5)
at Object.handler (C:\Users\philn\multiprocess\datastation\desktop\panel\eval.ts:181:17)
at main (C:\Users\philn\multiprocess\datastation\desktop\runner.ts:100:24)
at ChildProcess.<anonymous> (C:\Users\philn\multiprocess\datastation\desktop\panel\eval.ts:120:18)
at ChildProcess.emit (node:events:394:28)
at Process.ChildProcess._handle.onexit (node:internal/child_process:290:12)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.