muyunyun / blog Goto Github PK
View Code? Open in Web Editor NEWLife is a moment :notebook_with_decorative_cover:
Home Page: http://muyunyun.cn/blog
Life is a moment :notebook_with_decorative_cover:
Home Page: http://muyunyun.cn/blog















































































































































































项目地址: diana
为啥已经有如此多的前端工具类库还要自己造轮子呢?个人认为有以下几个观点吧:
抛开内部方法(写相应的专题效果可能会更好,所以这里先略过),下面分享一些开发 diana 库 时的一些心得:
├── LICENSE 开源协议
├── README-zh_en.md 英文说明文档
├── README.md 中文说明文档
├── coverage 代码覆盖率文件
├── docs 文档目录
│ └── static-parts
│ ├── index-end.html 静态文档目录结尾文件
│ └── index-start.html 静态文档目录开头文件
├── karma.conf.js karma 配置文件
├── lib
│ ├── diana.back.js 服务端引用入口
│ └── diana.js 浏览器引用入口
├── package.json
├── script
│ ├── build.js 构建文件
│ ├── check.js 结合 pre-commit 进行 eslint 校验
│ ├── tag-script.js 自动生成文档的标签
│ ├── web-script.js 自动生成文档
│ ├── webpack.browser.js 浏览器端 webpack 配置文件
│ └── webpack.node.js 服务器端 webpack 配置文件
├── snippets
├── src
│ ├── browser 浏览器端方法
│ ├── common 共用方法
│ ├── node node 端方法
│ └── util.js 库内通用方法
├── tag_database 文档标签
└── test 测试文件
├── browserTest
├── commonTest
├── index.js
└── nodeTest
目录结构也随着方法的增多在不停迭代当中,建议直接到库中查看最新的目录结构。
相应地,具体的方法会随着时间迭代,所以首先推荐查看文档,点击如下图的 Ⓢ 就能查看源码。
我们可以通过如下方法来判断模块当前是运行在 Node.js 还是浏览器中,然后使用不同的方式实现我们的功能。
// Only Node.JS has a process variable that is of [[Class]] process
const isNode = Object.prototype.toString.call(typeof process !== 'undefined' ? process : 0) === '[object process]'但如果用户使用了模块打包工具,这样做会导致 Node.js 与浏览器的实现方式都会被包含在最终的输出文件中。针对这个问题,开源社区提出了在 package.json 中添加 browser 字段的提议,目前 webpack 和 rollup 都已经支持这个字段了。
给 browser 字段提供一个文件路径作为在浏览器端使用时的模块入口,但需要注意的是,打包工具会优先使用 browser 字段指定的文件路径作为模块入口,所以你的 main 字段 和 module 字段会被忽略,但是这会导致打包工具不会优化你的代码。详细信息请参考这个问题。
在 diana 库 为了在不同环境中使用适当的文件,在 package.json 中进行了如下声明:
"browser": "lib/diana.js",
"main": "lib/diana.back.js", // 或者 "module": "lib/diana.back.js",这样一来,在 node 环境中,引用的是 lib/diana.back.js 文件,在浏览器环境中,引用的是 lib/diana.js 文件。然后就能愉快地在浏览器端和 node 端愉快地使用自己特有的 api 了。
另外为了使 diana 库 的打包文件兼容 node 端、以及浏览器端的引用,选择了 UMD 规范进行打包,那么为什么要选择 UMD 规范呢?让我们看下以下几种规范之间的异同:
CommonJs 是服务器端模块的规范,Node.js 采用了这个规范。这些规范涵盖了模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套接字、单元测试、服务器网关接口、包管理等。
根据 CommonJS 规范,一个单独的文件就是一个模块。加载模块使用 require 方法,该方法读取一个文件并执行,最后返回文件内部的 exports 对象。
CommonJS 加载模块是同步的。像 Node.js 主要用于服务器的编程,加载的模块文件一般都已经存在本地硬盘,所以加载起来比较快,不用考虑异步加载的方式,所以 CommonJS 规范比较适用。但如果是浏览器环境,要从服务器加载模块,这是就必须采用异步模式。所以就有了 AMD、CMD 解决方案。
// AMD 默认推荐的是
define(['./a', './b'], function(a, b) {
a.doSomething()
b.doSomething()
...
})// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
...
})UMD 是 AMD 和 CommonJS 的结合。因为 AMD 是以浏览器为出发点的异步加载模块,CommonJS 是以服务器为出发点的同步加载模块,所以人们想出了另一个更通用的模式 UMD,来解决跨平台的问题。
diana 库 选择了以 umd 方式进行输出,来看下 UMD 做了啥:
(function (root, factory) {
if (typeof exports === 'object' && typeof module === 'object') { // UMD 先判断是否支持 Node.js 的模块(exports)是否存在,存在则使用 CommonJS 模式
module.exports = factory()
} else if (typeof define === 'function' && define.amd) { // 接着判断是否支持 AMD(define是否存在),存在则使用 AMD 方式加载模块。
define([], factory)
} else if (typeof exports === 'object') { // CommonJS 的另一种形式
exports['diana'] = factory()
} else
root['diana'] = factory() // Window
})(this, function() {
return module
})单元测试的代码覆盖率统计,是衡量测试用例好坏的一个的方法。但凡是线上用的库,基本上都少不了高质量的代码覆盖率的检测。如下图为 diana 库的测试覆盖率展示。
可以看到覆盖率分为以下 4 种类型,
番外:github 上显示的覆盖率是根据行覆盖率来展示的。
最初的版本, 仅仅用到 mocha 进行测试 *.test.js 文件,然后在 codecov 得到测试覆盖率。
如果仅仅测试 es5、es6 的语法,其实用 mocha 就已经够用了,但是涉及到测试 Dom 操作的语法等就必须建立一个浏览器,在上面进行测试。karma 的作用其实就是自动帮我们建立一个测试用的浏览器环境。
为了让浏览器支持 Common.js 规范,中间用了 karma + browserify,尽管测试用例都跑通了,但是最后的代码覆盖率的文件里只有各个方法的引用路径。最后只能又回到 karma + webpack 来,这里又踩到一个坑,打包编译JS代码覆盖率问题,踩了一些坑后,终于实现了可以查看编译前代码的覆盖率。图如下:
通过这幅图我们能清晰地看到源代码中测试用例跑过各行代码的次数(左侧的数字),以及测试用例没有覆盖到的代码(图中红色所示)。然后我们就能改善相应的测试用例从而提高测试覆盖率。
配置文件,核心部分如下:
module.exports = function(config) {
config.set({
files: ['test/index.js'], // 需载入浏览器的文件
preprocessors: { // 预处理
'test/index.js': ['webpack', 'coverage']
},
webpack: {
module: {
rules: [{
test: /\.js$/,
use: { loader: 'sourcemap-istanbul-instrumenter-loader' }, // 这里用 istanbul-instrumenter-loader 插件的 0.0.2 版本,其它版本有坑~
exclude: [/node_modules/, /\.spec.js$/],
}],
}
},
coverageReporter: {
type: 'lcov', // 貌似只能支持这种类型的读取
dir: 'coverage/'
},
remapIstanbulReporter: { // 生成 coverage 文件
reports: {
'text-summary': null,
json: 'coverage/coverage.json',
lcovonly: 'coverage/lcov.info',
html: 'coverage/html/',
}
},
reporters: ['progress', 'karma-remap-istanbul'], // remap-isbanbul 也报了一个未找到 sourcemap 的 error,直接注释了 remap-istanbul 包的 CoverageTransformer.js 文件的 169 行,以后有机会再捣鼓吧。(心累)
...
})
}本文围绕 diana 库 对造轮子的意义,模块兼容性,测试用例进行了思考总结。后续会对该库流程自动化以及性能上做些分享。
该库参考学习了很多优秀的库,感谢 underscore、outils、ec-do、30-seconds-of-code 等库对我的帮助。
最后欢迎各位大佬在 issues 尽情吐槽。
跨域是日常开发中经常开发中经常会接触到的一个重难点知识,何不总结实践一番,从此心中对之了无牵挂。
之所以会出现跨域解决方案,是因为同源策略的限制。同源策略规定了如果两个 url 的协议、域名、端口中有任何一个不等,就认定它们跨源了。比如下列表格列出和 http://127.0.0.1:3000 比较的同源检测的结果,
| url | 结果 | 原因 |
|---|---|---|
| http://127.0.0.1:3000/index | 同源 | |
| https://127.0.0.1:3000 | 跨源 | 协议不同 |
| https://localhost:3000 | 跨源 | 域名不同 |
| http://127.0.0.1:3001 | 跨源 | 端口不同 |
那跨源有什么后果呢?归纳有三:不能获取 Cookie、LocalStorage、IndexedDB;不能获取 dom 节点;不能进行一般的 Ajax 通信;跨域解决方案的出现就是为了解决以上痛处。
提到 JSONP 跨域,不得不先提到 script 标签,和 img、iframe 标签类似,这些标签是不受同源策略限制的,JSONP 的核心就是通过动态加载 script 标签来完成对目标 url 的请求。
先来看一段 JSONP 调用的 Headers 部分,字段如下:
Request URL:http://127.0.0.1:3000/?callback=handleResponse
Request Method:GET
Status Code:200 OK
Remote Address:127.0.0.1:3000可以很鲜明地发现在 Request URL 中有一句 ?callback=handleResponse,这个 callback 后面跟着的 handleResponse 即回调函数名(可以任意取),服务端会接收到这个参数然后拼接成形如 handleResponse(JSON) 的形式返还给前端(这也是 JSONP == JSON with padding 的原因吧),如下图,这时候浏览器就会自动调用我们事先定义好的 handleResponse 函数。
前端代码示例:(源为 http://127.0.0.1:3001)
function handleResponse(res) {
console.log(res) // {text: "jsonp"}
}
const script = document.createElement('script')
script.src = 'http://127.0.0.1:3000?callback=handleResponse'
document.head.appendChild(script)服务端代码示例:(源为 http://127.0.0.1:3000)
const server = http.createServer((req, res) => {
if (~req.url.indexOf('?callback')) { // 简单处理 JSONP 跨域的时候
const obj = {
"text": 'jsonp',
}
const callback = req.url.split('callback=')[1]
const json = JSON.stringify(obj)
const build = callback + `(${json})`
res.end(build) // 这里返还给前端的是拼接好的 JSON 对象
}
});可以看出 JSONP 具有直接访问响应文本的优点,但是要想确认 JSONP 是否请求失败并不容易,因为 script 标签的 onerror 事件还未得到浏览器广泛的支持,此外它仅能支持 GET 方式调用。
CORS(Cross-Origin Resource Sharing) 可以理解为加强版的 Ajax,也是目前主流的跨域解决方案。它的核心**即前端与后端进行 Ajax 通信时,通过自定义 HTTP 头部设置从而决定请求或响应是否生效。
比如前端代码(url 为 http://127.0.0.1:3001)写了段 Ajax,代码如下:
const xhr = new XMLHttpRequest()
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
console.log('responseTesx:' + xhr.responseText)
}
}
}
xhr.open('get', 'http://127.0.0.1:3000', true)
xhr.send()因为端口不一致的关系这时候导致不同源了,这时候会在 Request Headers 中发现多了这么一行字段,
Origin: http://127.0.0.1:3001而且控制台中会报出如下错误:
Failed to load http://127.0.0.1:3000/: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://127.0.0.1:3001' is therefore not allowed access.这时候就需要在服务端设置字段 Access-Control-Allow-Origin,它的作用就是设置允许来自什么源的请求,如果值设置为 *,表明允许来自任意源的请求。服务端代码示例如下:
http.createServer((req, res) => {
res.setHeader('Access-Control-Allow-Origin', 'http://127.0.0.1:3001') // 设置允许来自 http://127.0.0.1:3001 源的请求
})CORS 分为简单请求以及非简单请求。可以这么区分,如果请求方法为 POST、GET、HEAD 时为简单请求,其它方法如 PUT、DELETE 等为非简单请求,如果是非简单请求的话,可以在 chrome 的 Network 中看到多了一次 Request Method 为 OPTIONS 的请求。如下图:
可以把这个请求称为预请求,用白话文翻译下,浏览器询问服务器,'服务器大哥,我这次要进行 PUT 请求,你给我发张通行证呗',服务器大哥见浏览器小弟这么殷勤,于是给了它发了张通行证,叫作 Access-Control-Allow-Methods:PUT,接着浏览器就能愉快地进行 PUT 请求了。服务端代码示例如下:
http.createServer((req, res) => {
res.setHeader('Access-Control-Allow-Origin', 'http://127.0.0.1:3001')
res.setHeader('Access-Control-Allow-Methods', 'http://127.0.0.1:3001')
})聊完简单请求和非简单请求的区别后,再来看看如何利用 CORS 实现 Cookie 的跨域传送,首先在服务器随意设置个 Cookie 值下发到浏览器,如果非跨域的情况下,浏览器再次请求服务器时就会带上服务器给的 Cookie,但是跨域的时候怎么办呢?不卖关子了,需在服务端设置 Access-Control-Allow-Credentials 字段以及在客户端设置 withCredentials 字段,两者缺一不可,代码如下:
前端代码示例:(源为 http://127.0.0.1:3001)
const xhr = new XMLHttpRequest()
...
xhr.withCredentials = true // 传 cookie 的时候前端要做的
xhr.open('get', 'http://127.0.0.1:3000', true)
xhr.send()服务端代码示例: (源为 http://127.0.0.1:3000)
const server = http.createServer((req, res) => {
res.setHeader('Access-Control-Allow-Origin', 'http://127.0.0.1:3001') // 必填:接受域的请求
res.setHeader('Set-Cookie', ['type=muyy']) // 下发 cookie
res.setHeader('Access-Control-Allow-Credentials', true) // ② 选填:是否允许浏览器传 cookie 到服务端,只能设置为 true
res.end('date from cors')
})至此介绍了几个比较关键 HTTP 头在 CORS 中的实践运用,更为详细的资料可以参阅 Cross-Origin Resource Sharing,最后概括下 CORS 的优缺点,优点是支持所有类型的 HTTP 方法,缺点是有些老的浏览器不支持 CORS。
在文章最开始提到过 iframe 标签也是不受同源策略限制的标签之一,hash + iframe 的跨域核心**就是,在 A 源中通过动态改变 iframe 标签的 src 的哈希值,在 B 源中通过 window.onhashchange 来捕获到相应的哈希值。思路不难直接上代码:
A 页面代码示例(源为 http://127.0.0.1:3000)
<body>
<iframe src="http://127.0.0.1:3001"></iframe>
<script>
const iframe = document.getElementsByTagName('iframe')[0]
iframe.setAttribute('style', 'display: none')
const obj = {
data: 'hash'
}
iframe.src = iframe.src + '#' + JSON.stringify(obj) // ① 关键语句
</script>
</body>B 页面代码示例(源为 http://127.0.0.1:3001)
window.onhashchange = function() { // ① 关键语句
console.log('来自 page2 的代码 ' + window.location.hash) // 来自 page2 的代码 #{"data":"hash"}
}刷新 A 页面,可以发现在控制台打印了如下字段,至此实现了跨域。
来自 page2 的代码 #{"data":"hash"}这种方式进行跨域优点是支持页面和页面间的通信,缺点也是只支持 GET 方法和单向的跨域通信。
为了实现跨文档传送(cross-document messaging),简称 XDM。HTML5 给出了一个 api —— postMessage,postMessage() 方法接收两个参数:发送消息以及消息接收方所在域的字符串。代码示例如下:
A 页面代码示例(源为 http://127.0.0.1:3000)
<body>
<iframe src="http://127.0.0.1:3001"></iframe>
<script>
const iframe = document.getElementsByTagName('iframe')[0]
iframe.setAttribute('style', 'display: none')
iframe.onload = function() { // 此处要等 iframe 加载完毕,后续代码才会生效
iframe.contentWindow.postMessage('a secret', 'http://127.0.0.1:3001')
}
</script>
</body>B 页面代码示例(源为 http://127.0.0.1:3001)
window.addEventListener('message', function(event) {
console.log('From page1 ' + event.data)
console.log('From page1 ' + event.origin)
}, false)刷新 A 页面,可以发现在控制台打印了如下字段,至此实现了跨域。
From page1 a secret
From page1 http://127.0.0.1:3000
这种跨域方式优点是是支持页面和页面间的双向通信,缺点也是只能支持 GET 方法调用。
WebSockets 属于 HTML5 的协议,它的目的是在一个持久连接上建立全双工通信。由于 WebSockets 采用了自定义协议,所以优点是客户端和服务端发送数据量少,缺点是要额外的服务器。基础的使用方法如下:
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = function() {
// 连接成功建立
}
ws.onmessage = function(event) {
// 处理数据
}
ws.onerror = function() {
// 发生错误时触发,连接中断
}
ws.onclose = function() {
// 连接关闭时触发
}当然一般我们会使用封装好 WebSockets 的第三方库 socket.io,这里具体就不展开了。
前文所述五种跨域实践的 demo 已上传至 cross-domain,前端环境基于 create-react-app 搭建,后端环境用 node 搭建。
当然跨域方式还有一些其他方式的实现,后续酌情慢慢填坑~
该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
接上一章 HOC 探索 抛出的问题 ———— react 中的 onChange 事件和原生 DOM 事件中的 onchange 表现不一致,举例说明如下:
// React 中的 onChange 事件
class App extends Component {
constructor(props) {
super(props)
this.onChange = this.onChange.bind(this)
}
onChange(e) {
console.log('键盘松开立刻执行')
}
render() {
return (
<input onChange={this.onChange} />
)
}
}
/*--------------分割线---------------*/
// 原生 DOM 事件中的 onchange 事件:<input id='test'>
document.getElementById('test').addEventListener('change', (e) => {
console.log('键盘松开以后还需按下回车键或者点下鼠标才会触发')
})我们来看下 React 的一个 issue React Fire: Modernizing React DOM。有两点信息和这篇文章的话题相关。
从这两点内容我们可以得知下面的信息:
React 实现了一套合成事件机制,也就是它的事件机制和原生事件间会有不同。比如它目前 onChange 事件其实对应着原生事件中的 input 事件。在这个 issue 中明确了未来会使用 onInput 事件替代 onChange 事件,并且会大幅度地简化合成事件。
有了以上信息后,我们对 onChange 事件(将来的 onInput 事件)的代码作如下更改:
function setAttribute(dom, attr, value) {
...
if (attr.match(/on\w+/)) { // 处理事件的属性:
let eventName = attr.toLowerCase().substr(2)
if (eventName === 'change') { eventName = 'input' } // 和现阶段的 react 统一
dom.addEventListener(eventName, value)
}
...
}区分自由组件以及受控组件在于表单的值是否由 value 这个属性控制,比较如下代码:
const case1 = () => <input /> // 此时输入框内可以随意增减任意值
const case2 = () => <input defaultValue={123} /> // 此时输入框内显示 123,能随意增减值
const case3 = () => <input value={123} /> // 此时输入框内显示 123,并且不能随意增减值case3 的情形即为简化版的受控组件。
题目可以换个问法:当 input 的传入属性为 value 时(且没有 onChange 属性),如何禁用用户的输入事件的同时又能获取焦点?
首先想到了 html 自带属性 readonly、disable,它们都能禁止用户的输入,但是它们不能满足获取焦点这个条件。结合前文 onChange 的实现是监听 input 事件,代码分为以下两种情况:
1.dom 节点包含 value 属性、onChange 属性
2.dom 节点包含 value 属性,不包含 onChange 属性
代码如下:
function vdomToDom(vdom) {
...
if (vdom.attributes
&& vdom.attributes.hasOwnProperty('onChange')
&& vdom.attributes.hasOwnProperty('value')) { // 受控组件逻辑
...
dom.addEventListener('input', (e) => {
changeCb.call(this, e)
dom.value = oldValue
})
...
}
if (vdom.attributes
&& !vdom.attributes.hasOwnProperty('onChange')
&& vdom.attributes.hasOwnProperty('value')) { // 受控组件逻辑
...
dom.addEventListener('input', (e) => {
dom.value = oldValue
})
...
}
...
}可以发现它们的核心都在这段代码上:
dom.addEventListener('input', (e) => {
changeCb.call(this, e)
dom.value = oldValue
})区别是当有 onChange 属性 时,能提供相应的回调函数 changeCb 通过事件循环机制改变表单的值。看如下两个例子的比较:
const App = () => <input value={123} />效果如下:
class App extends Component {
constructor() {
super()
this.state = { num: 123 }
this.change = this.change.bind(this)
}
change(e) {
this.setState({
num: e.target.value
})
}
render() {
return (
<div>
<input value={this.state.num} onChange={this.change} />
</div>
)
}
}这段代码中的 change 函数即上个段落所谓的 changeCb 函数,通过 setState 的事件循环机制改变表单的值。
效果如下:
至此,模拟了受控组件的实现。
const createLoginLayer = function () {
const div = document.createElement('div');
div.innerHTML = '登陆弹窗';
document.appendChild(div); // 改为document.body.appendChild(div)
return div
}
该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
使用 PureComponent 是优化 React 性能的一种常用手段,相较于 Component, PureComponent 会在 render 之前自动执行一次 shouldComponentUpdate() 函数,根据返回的 bool 值判断是否进行 render。其中有个重点是 PureComponent 在 shouldComponentUpdate() 的时候会进行 shallowEqual(浅比较)。
PureComponent 的浅比较策略如下:
对 prevState/nextState 以及 prevProps/nextProps 这两组数据进行浅比较:
1.对象第一层数据未发生改变,render 方法不会触发;
2.对象第一层数据发生改变(包括第一层数据引用的改变),render 方法会触发;
照着上述思路我们来实现 PureComponent 的逻辑
function PureComponent(props) {
this.props = props || {}
this.state = {}
isShouldComponentUpdate.call(this) // 为每个 PureComponent 绑定 shouldComponentUpdate 方法
}
PureComponent.prototype.setState = function(updater, cb) {
isShouldComponentUpdate.call(this) // 调用 setState 时,让 this 指向子类的实例,目的取到子类的 this.state
asyncRender(updater, this, cb)
}
function isShouldComponentUpdate() {
const cpState = this.state
const cpProps = this.props
this.shouldComponentUpdate = function (nextProps, nextState) {
if (!shallowEqual(cpState, nextState) || !shallowEqual(cpProps, nextProps)) {
return true // 只要 state 或 props 浅比较不等的话,就进行渲染
} else {
return false // 浅比较相等的话,不渲染
}
}
}
// 浅比较逻辑
const shallowEqual = function(oldState, nextState) {
const oldKeys = Object.keys(oldState)
const newKeys = Object.keys(nextState)
if (oldKeys.length !== newKeys.length) {
return false
}
let flag = true
for (let i = 0; i < oldKeys.length; i++) {
if (!nextState.hasOwnProperty(oldKeys[i])) {
flag = false
break
}
if (nextState[oldKeys[i]] !== oldState[oldKeys[i]]) {
flag = false
break
}
}
return flag
}测试用例用 在 React 上提的一个 issue 中的案例,我们期望点击增加按钮后,页面上显示的值能够加 1。
class B extends PureComponent {
constructor(props) {
super(props)
this.state = {
count: 0
}
this.click = this.click.bind(this)
}
click() {
this.setState({
count: ++this.state.count,
})
}
render() {
return (
<div>
<button onClick={this.click}>增加</button>
<div>{this.state.count}</div>
</div>
)
}
}然而,我们点击上述代码,页面上显示的 0 分毫不动!!!
揭秘如下:
click() {
const t = ++this.state.count
console.log(t === this.state.count) // true
this.setState({
count: t,
})
}当点击增加按钮,控制台显示 t === this.state.count 为 true, 也就说明了 setState 前后的状态是统一的,所以 shallowEqual(浅比较) 返回的是 true,致使 shouldComponentUpdate 返回了 false,页面因此没有渲染。
类似的,如下写法也是达不到目标的,留给读者思考了。
click() {
this.setState({
count: this.state.count++,
})
}那么如何达到我们期望的目标呢。揭秘如下:
click() {
this.setState({
count: this.state.count + 1
})
}感悟:小小的一行代码里蕴藏着无数的 bug。
高阶组件(Higher Order Component) 不属于 React API 范畴,但是它在 React 中也是一种实用的技术,它可以将常见任务抽象成一个可重用的部分。这个小节算是番外篇,会结合 cpreact(前文实现的类 react 轮子) 与 HOC 进行相关的实践。
它可以用如下公式表示:
y = f(x),
// x:原有组件
// y:高阶组件
// f():f() 的实现有两种方法,下面进行实践。
这类实现也是装饰器模式的一种运用,通过装饰器函数给原来函数赋能。下面例子在装饰器函数中给被装饰的组件传递了额外的属性 { a: 1, b: 2 }。
声明:下文所展示的 demo 均已在 cpreact 测试通过
function ppHOC(WrappedComponent) {
return class extends Component {
render() {
const obj = { a: 1, b: 2 }
return (
<WrappedComponent { ...this.props } { ...obj } />
)
}
}
}
@ppHOC
class B extends Component {
render() {
return (
<div>
{ this.props.a + this.props.b } { /* 输出 3 */ }
</div>
)
}
}要是将 { a: 1, b: 2 } 替换成全局共享对象,那么不就是 react-redux 中的 Connect 了么?
改进上述 demo,我们就可以实现可插拔的受控组件,代码示意如下:
function ppDecorate(WrappedComponent) {
return class extends Component {
constructor() {
super()
this.state = {
value: ''
}
this.onChange = this.onChange.bind(this)
}
onChange(e) {
this.setState({
value: e.target.value
})
}
render() {
const obj = {
onChange: this.onChange,
value: this.state.value,
}
return (
<WrappedComponent { ...this.props } { ...obj } />
)
}
}
}
@ppDecorate
class B extends Component {
render() {
return (
<div>
<input { ...this.props } />
<div>{ this.props.value }</div>
</div>
)
}
}效果如下图:
这里有个坑点,当我们在输入框输入字符的时候,并不会立马触发 onChange 事件(我们想要让事件立即触发,然而现在要按下回车键或者点下鼠标才触发),在 react 中有个合成事件 的知识点,下篇文章会对 react 中的 onChange 事件为何和原生 DOM 事件中的 onchange 表现不一致进行探究揭秘。
顺带一提在这个 demo 中似乎看到了双向绑定的效果,但是实际中 React 并没有双向绑定的概念,但是我们可以运用 HOC 的知识点结合 setState 在 React 表单中实现伪双向绑定的效果。
继承反转的核心是:传入 HOC 的组件会作为返回类的父类来使用。然后在 render 中调用 super.render() 来调用父类的 render 方法。
在 《ES6 继承与 ES5 继承的差异》中我们提到了作为对象使用的 super 指向父类的实例。
function iiHOC(WrappedComponent) {
return class extends WrappedComponent {
render() {
const parentRender = super.render()
if (parentRender.nodeName === 'span') {
return (
<span>继承反转</span>
)
}
}
}
}
@iiHOC
class B extends Component {
render() {
return (
<span>Inheritance Inversion</span>
)
}
}在这个 demo 中,在 HOC 内实现了渲染劫持,页面上最终显示如下:
可能会有疑惑,使用
属性代理的方式貌似也能实现渲染劫持呀,但是那样做没有继承反转这种方式纯粹。
拼多多 - 商户前端团队(其它团队也可以帮推)
文章有描述错误的地方欢迎指正交流。
error:
const getSingle = function(fn) {
const result
return function() {
return result || result = fn.apply(this, arguments)
}
};
update:
const getSingle = function(fn) {
var result;
return function() {
if(result){
return result
}
return result = fn.apply(this, arguments)
}
};
Now I'm readding https://github.com/nusr/hacker-laws-zh.
webpack 可谓是让人欣喜又让人忧,功能强大但需要一定的学习成本。在探寻 webpack 插件机制前,首先需要了解一件有意思的事情,webpack 插件机制是整个 webpack 工具的骨架,而 webpack 本身也是利用这套插件机制构建出来的。因此在深入认识 webpack 插件机制后,再来进行项目的相关优化,想必会大有裨益。
先来瞅瞅 webpack 插件在项目中的运用
const MyPlugin = require('myplugin')
const webpack = require('webpack')
webpack({
...,
plugins: [new MyPlugin()]
...,
})那么符合什么样的条件能作为 webpack 插件呢?一般来说,webpack 插件有以下特点:
独立的 JS 模块,暴露相应的函数
函数原型上的 apply 方法会注入 compiler 对象
compiler 对象上挂载了相应的 webpack 事件钩子
事件钩子的回调函数里能拿到编译后的 compilation 对象,如果是异步钩子还能拿到相应的 callback
下面结合代码来看看:
function MyPlugin(options) {}
// 2.函数原型上的 apply 方法会注入 compiler 对象
MyPlugin.prototype.apply = function(compiler) {
// 3.compiler 对象上挂载了相应的 webpack 事件钩子 4.事件钩子的回调函数里能拿到编译后的 compilation 对象
compiler.plugin('emit', (compilation, callback) => {
...
})
}
// 1.独立的 JS 模块,暴露相应的函数
module.exports = MyPlugin这样子,webpack 插件的基本轮廓就勾勒出来了,此时疑问点有几点,
plugin.apply() 调用插件的。const webpack = (options, callback) => {
...
for (const plugin of options.plugins) {
plugin.apply(compiler);
}
...
}疑问 2:compiler 对象是什么呢?
疑问 3:compiler 对象上的事件钩子是怎样的?
疑问 4:事件钩子的回调函数里能拿到的 compilation 对象又是什么呢?
这些疑问也是本文的线索,让我们一个个探索。
compiler 即 webpack 的编辑器对象,在调用 webpack 时,会自动初始化 compiler 对象,源码如下:
// webpack/lib/webpack.js
const Compiler = require("./Compiler")
const webpack = (options, callback) => {
...
options = new WebpackOptionsDefaulter().process(options) // 初始化 webpack 各配置参数
let compiler = new Compiler(options.context) // 初始化 compiler 对象,这里 options.context 为 process.cwd()
compiler.options = options // 往 compiler 添加初始化参数
new NodeEnvironmentPlugin().apply(compiler) // 往 compiler 添加 Node 环境相关方法
for (const plugin of options.plugins) {
plugin.apply(compiler);
}
...
}终上,compiler 对象中包含了所有 webpack 可配置的内容,开发插件时,我们可以从 compiler 对象中拿到所有和 webpack 主环境相关的内容。
compilation 对象代表了一次单一的版本构建和生成资源。当运行 webpack 时,每当检测到一个文件变化,一次新的编译将被创建,从而生成一组新的编译资源。一个编译对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。
结合源码来理解下上面这段话,首先 webpack 在每次执行时会调用 compiler.run() (源码位置),接着追踪 onCompiled 函数传入的 compilation 参数,可以发现 compilation 来自构造函数 Compilation。
// webpack/lib/Compiler.js
const Compilation = require("./Compilation");
newCompilation(params) {
const compilation = new Compilation(this);
...
return compilation;
}再介绍完 compiler 对象和 compilation 对象后,不得不提的是 tapable 这个库,这个库暴露了所有和事件相关的 pub/sub 的方法。而且函数 Compiler 以及函数 Compilation 都继承自 Tapable。
事件钩子其实就是类似 MVVM 框架的生命周期函数,在特定阶段能做特殊的逻辑处理。了解一些常见的事件钩子是写 webpack 插件的前置条件,下面列举些常见的事件钩子以及作用:
| 钩子 | 作用 | 参数 | 类型 |
|---|---|---|---|
| after-plugins | 设置完一组初始化插件之后 | compiler | sync |
| after-resolvers | 设置完 resolvers 之后 | compiler | sync |
| run | 在读取记录之前 | compiler | async |
| compile | 在创建新 compilation 之前 | compilationParams | sync |
| compilation | compilation 创建完成 | compilation | sync |
| emit | 在生成资源并输出到目录之前 | compilation | async |
| after-emit | 在生成资源并输出到目录之后 | compilation | async |
| done | 完成编译 | stats | sync |
完整地请参阅官方文档手册,同时浏览相关源码 也能比较清晰地看到各个事件钩子的定义。
拿 emit 钩子为例,下面分析下插件调用源码:
compiler.plugin('emit', (compilation, callback) => {
// 在生成资源并输出到目录之前完成某些逻辑
})此处调用的 plugin 函数源自上文提到的 tapable 库,其最终调用栈指向了 hook.tapAsync(),其作用类似于 EventEmitter 的 on,源码如下:
// Tapable.js
options => {
...
if(hook !== undefined) {
const tapOpt = {
name: options.fn.name || "unnamed compat plugin",
stage: options.stage || 0
};
if(options.async)
hook.tapAsync(tapOpt, options.fn); // 将插件中异步钩子的回调函数注入
else
hook.tap(tapOpt, options.fn);
return true;
}
};有注入必有触发的地方,源码中通过 callAsync 方法触发之前注入的异步事件,callAsync 类似 EventEmitter 的 emit,相关源码如下:
this.hooks.emit.callAsync(compilation, err => {
if (err) return callback(err);
outputPath = compilation.getPath(this.outputPath);
this.outputFileSystem.mkdirp(outputPath, emitFiles);
});一些深入细节这里就不展开了,说下关于阅读比较大型项目的源码的两点体会,
要抓住一条主线索去读,忽视细节。否则会浪费很多时间而且会有挫败感;
结合调试工具来分析,很多点不用调试工具的话很容易顾此失彼;
结合上述知识点的分析,不难写出自己的 webpack 插件,关键在于想法。为了统计项目中 webpack 各包的有效使用情况,在 fork webpack-visualizer 的基础上对代码升级了一番,项目地址。效果如下:
插件核心代码正是基于上文提到的 emit 钩子,以及 compiler 和 compilation 对象。代码如下:
class AnalyzeWebpackPlugin {
constructor(opts = { filename: 'analyze.html' }) {
this.opts = opts
}
apply(compiler) {
const self = this
compiler.plugin("emit", function (compilation, callback) {
let stats = compilation.getStats().toJson({ chunkModules: true }) // 获取各个模块的状态
let stringifiedStats = JSON.stringify(stats)
// 服务端渲染
let html = `<!doctype html>
<meta charset="UTF-8">
<title>AnalyzeWebpackPlugin</title>
<style>${cssString}</style>
<div id="App"></div>
<script>window.stats = ${stringifiedStats};</script>
<script>${jsString}</script>
`
compilation.assets[`${self.opts.filename}`] = { // 生成文件路径
source: () => html,
size: () => html.length
}
callback()
})
}
}该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
而在现有 setState 逻辑实现中,每调用一次 setState 就会执行 render 一次。因此在如下代码中,每次点击增加按钮,因为 click 方法里调用了 10 次 setState 函数,页面也会被渲染 10 次。而我们希望的是每点击一次增加按钮只执行 render 函数一次。
export default class B extends Component {
constructor(props) {
super(props)
this.state = {
count: 0
}
this.click = this.click.bind(this)
}
click() {
for (let i = 0; i < 10; i++) {
this.setState({ // 在先前的逻辑中,没调用一次 setState 就会 render 一次
count: ++this.state.count
})
}
}
render() {
console.log(this.state.count)
return (
<div>
<button onClick={this.click}>增加</button>
<div>{this.state.count}</div>
</div>
)
}
}查阅 setState 的 api,其形式如下:
setState(updater, [callback])它能接收两个参数,其中第一个参数 updater 可以为对象或者为函数 ((prevState, props) => stateChange),第二个参数为回调函数;
确定优化思路为:将多次 setState 后跟着的值进行浅合并,并借助事件循环等所有值合并好之后再进行渲染界面。
let componentArr = []
// 异步渲染
function asyncRender(updater, component, cb) {
if (componentArr.length === 0) {
defer(() => render()) // 利用事件循环,延迟渲染函数的调用
}
if (cb) defer(cb) // 调用回调函数
if (_.isFunction(updater)) { // 处理 setState 后跟函数的情况
updater = updater(component.state, component.props)
}
// 浅合并逻辑
component.state = Object.assign({}, component.state, updater)
if (componentArr.includes(component)) {
component.state = Object.assign({}, component.state, updater)
} else {
componentArr.push(component)
}
}
function render() {
let component
while (component = componentArr.shift()) {
renderComponent(component) // rerender
}
}
// 事件循环,关于 promise 的事件循环和 setTimeout 的事件循环后续会单独写篇文章。
const defer = function(fn) {
return Promise.resolve().then(() => fn())
}此时,每点击一次增加按钮 render 函数只执行一次了。
在 react 中并不建议使用 ref 属性,而应该尽量使用状态提升,但是 react 还是提供了 ref 属性赋予了开发者操作 dom 的能力,react 的 ref 有 string、callback、createRef 三种形式,分别如下:
// string 这种写法未来会被抛弃
class MyComponent extends Component {
componentDidMount() {
this.refs.myRef.focus()
}
render() {
return <input ref="myRef" />
}
}
// callback(比较通用)
class MyComponent extends Component {
componentDidMount() {
this.myRef.focus()
}
render() {
return <input ref={(ele) => {
this.myRef = ele
}} />
}
}
// react 16.3 增加,其它 react-like 框架还没有同步
class MyComponent extends Component {
constructor() {
super() {
this.myRef = React.createRef()
}
}
componentDidMount() {
this.myRef.current.focus()
}
render() {
return <input ref={this.myRef} />
}
}React ref 的前世今生 罗列了三种写法的差异,下面对上述例子中的第二种写法(比较通用)进行实现。
首先在 setAttribute 方法内补充上对 ref 的属性进行特殊处理,
function setAttribute(dom, attr, value) {
...
else if (attr === 'ref') { // 处理 ref 属性
if (_.isFunction(value)) {
value(dom)
}
}
...
}针对这个例子中 this.myRef.focus() 的 focus 属性需要异步处理,因为调用 componentDidMount 的时候,界面上还未添加 dom 元素。处理 renderComponent 函数:
function renderComponent(component) {
...
else if (component && component.componentDidMount) {
defer(component.componentDidMount.bind(component))
}
...
}刷新页面,可以发现 input 框已为选中状态。
处理完普通元素的 ref 后,再来处理下自定义组件的 ref 的情况。之前默认自定义组件上是没属性的,现在只要针对自定义组件的 ref 属性做相应处理即可。稍微修改 vdomToDom 函数如下:
function vdomToDom(vdom) {
if (_.isFunction(vdom.nodeName)) { // 此时是自定义组件
...
for (const attr in vdom.attributes) { // 处理自定义组件的 ref 属性
if (attr === 'ref' && _.isFunction(vdom.attributes[attr])) {
vdom.attributes[attr](component)
}
}
...
}
...
}跑如下测试用例:
class A extends Component {
constructor() {
super()
this.state = {
count: 0
}
this.click = this.click.bind(this)
}
click() {
this.setState({
count: ++this.state.count
})
}
render() {
return <div>{this.state.count}</div>
}
}
class B extends Component {
constructor() {
super()
this.click = this.click.bind(this)
}
click() {
this.A.click()
}
render() {
return (
<div>
<button onClick={this.click}>加1</button>
<A ref={(e) => { this.A = e }} />
</div>
)
}
}效果如下:
Especially thank simple-react for the guidance function of this library. At the meantime,respect for preact and react
文章有描述错误的地方欢迎指正交流。
Python 是一门运用很广泛的语言,自动化脚本、爬虫,甚至在深度学习领域也都有 Python 的身影。作为一名前端开发者,也了解 ES6 中的很多特性借鉴自 Python (比如默认参数、解构赋值、Decorator等),同时本文会对 Python 的一些用法与 JS 进行类比。不管是提升自己的知识广度,还是更好地迎接 AI 时代,Python 都是一门值得学习的语言。
在 Python 中,最常用的能够直接处理的数据类型有以下几种:
除此之外,Python 还提供了列表[list]、字典[dict] 等多种数据类型,这在下文中会介绍。
与 JS 十分类似,python 也能实现不同数据类型间的强制与隐式转换,例子如下:
强制类型转换:
int('3') # 3
str(3.14) # '3.14'
float('3.14') # 3.14
# 区别于 JS 只有 Number 一种类型,Python 中数字中的不同类型也能相互强制转换
float(3) # 3.0
bool(3) # True
bool(0) # False隐式类型转换:
1 + 1.0 # 2.0
1 + False # 1
1.0 + True # 2.0
# 区别于 JS 的 String + Number = String, py 中 str + int 会报错
1 + '1' # TypeError: cannot concatenate 'str' and 'int' objects此外写代码的时候经常会需要判断值的类型,可以 使用 python 提供的 type() 函数获取变量的类型,或者使用 isinstance(x, type) 来判断 x 是否属于相应的 type 类型。
type(1.3) == float # True
isinstance('a', str) # True
isinstance(1.3, int) # False
isinstance(True, bool) # True
isinstance([], list) # True
isinstance({}, dict) # True集合是指包含一组元素的数据结构,有序集合即集合里面的元素是是按照顺序排列的,Python 中的有序集合大概有以下几类:list, tuple, str, unicode。
Python 中 List 类型类似于 JS 中的 Array,
L = [1, 2, 3]
print L[-1] # '3'
L.append(4) # 末尾添加元素
print L # [1, 2, 3, 4]
L.insert(0, 'hi') # 指定索引位置添加元素
print L # ['hi', 1, 2, 3, 4]
L.pop() # 末尾移除元素 L.pop(2) ?????? 2 ???
print L # ['hi', 1, 2, 3]tuple 类型是另一种有序的列表,中文翻译为“ 元组 ”。tuple 和 list 非常类似,但是,tuple 一旦创建完毕,就不能修改了。
t = (1, 2, 3)
print t[0] # 1
t[0] = 11 # TypeError: 'tuple' object does not support item assignment
t = (1)
print t # 1 t 的结果是整数 1
t = (1,) # 为了避免出现如上有歧义的单元素 tuple,所以 Python 规定,单元素 tuple 要多加一个逗号“,”
print t # (1,)Python 中的 dict 类型类似于 JS 中的 {} (最大的不同是它是没有顺序的), 它有如下特点:
d = {
'a': 1,
'b': 2,
'c': 3
}
print d # {'a': 1, 'c': 3, 'b': 2} 可以看出打印出的序对没有按正常的顺序打出
# 遍历 dict
for key,value in d.items():
print('%s: %s' % (key,value))
# a: 1
# c: 3
# b: 2有的时候,我们只想要 dict 的 key,不关心 key 对应的 value,而且要保证这个集合的元素不会重复,这时,set 类型就派上用场了。set 类型有如下特点:
s = set(['A', 'B', 'C', 'C'])
print s # set(['A', 'C', 'B'])
s.add('D')
print s # set(['A', 'C', 'B', 'D'])
s.remove('D')
print s # set(['A', 'C', 'B'])在介绍完 Python 中的有序集合和无序集合类型后,必然存在遍历集合的 for 循环。但是和其它语言的标准 for 循环不同,Python 中的所有迭代是通过 for ... in 来完成的。以下给出一些常用的迭代 demos:
索引迭代:
L = ['apple', 'banana', 'orange']
for index, name in enumerate(L): # enumerate() 函数把 ['apple', 'banana', 'orange'] 变成了类似 [(0, 'apple), (1, 'banana'), (2, 'orange')] 的形式
print index, '-', name
# 0 - apple
# 1 - banana
# 2 - orange迭代 dict 的 value:
d = { 'apple': 6, 'banana': 8, 'orange': 5 }
print d.values() # [6, 8, 5]
for v in d.values()
print v
# 6
# 8
# 5迭代 dict 的 key 和 value:
d = { 'apple': 6, 'banana': 8, 'orange': 5 }
for key, value in d.items()
print key, ':', value
# apple : 6
# banana: 8
# orange: 5Python 提供的切片操作符类似于 JS 提供的原生函数 slice()。有了切片操作符,大大简化了一些原来得用循环的操作。
L = ['apple', 'banana', 'orange', 'pear']
L[0:2] # ['apple', 'banana'] 取前 2 个元素
L[:2] # ['apple', 'banana'] 如果第一个索引是 0,可以省略
L[:] # ['apple', 'banana', 'orange', 'pear'] 只用一个 : ,表示从头到尾
L[::2] # ['apple', 'orange'] 第三个参数表示每 N 个取一个,这里表示从头开始,每 2 个元素取出一个来如果要生成 [1x1, 2x2, 3x3, ..., 10x10] 怎么做?方法一是循环:
L = []
for x in range(1, 11):
L.append(x * x)但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的 list:
# 把要生成的元素 x * x 放到前面,后面跟 for 循环,就可以把 list 创建出来
[x * x for x in range(1, 11)]
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]列表生成式的 for 循环后面还可以加上 if 判断(类似于 JS 中的 filter() 函数),示例如下:
[x * x for x in range(1, 11) if x % 2 == 0]
# [4, 16, 36, 64, 100]for 循环可以嵌套,因此,在列表生成式中,也可以用多层 for 循环来生成列表。
[m + n for m in 'ABC' for n in '123']
# ['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']JS 中 ES6 的 默认参数正是借鉴于 Python,用法如下:
def greet(name='World'):
print 'Hello, ' + name + '.'
greet() # Hello, World.
greet('Python') # Hello, Python.类似于 JS 函数中自动识别传入参数的个数,Python 也提供了定义可变参数,即在可变参数的名字前面带上个 * 号。
def fn(*args):
print args
fn() # ()
fn('a') # ('a',)
fn('a', 'b') # ('a', 'b')Python 解释器会把传入的一组参数组装成一个 tuple 传递给可变参数,因此,在函数内部,直接把变量 args 看成一个 tuple 就好了。
Python 中常用的函数 (map、reduce、filter) 的作用和 JS 中一致,只是用法稍微不同。
def f(x):
return x * x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) # [1, 4, 9, 16, 25, 36, 49, 64, 81]def f(x, y):
return x * y
reduce(f, [1, 3, 5]) # 15def is_odd(x):
return x % 2 == 1
filter(is_odd, [1, 4, 6, 7, 9, 12, 17]) # [1, 7, 9, 17]和 JS 的匿名函数不同的地方是,Python 的匿名函数中只能有一个表达式,且不能写 return。拿 map() 函数为例:
map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]) # [1, 4, 9, 16, 25, 36, 49, 64, 81]关键词 lambda 表示匿名函数,冒号前面的 x 表示函数参数,可以看出匿名函数 lambda x: x* x 实际上就是:
def f(x):
return x * x之前写过一些关于 JS 闭包的文章,比如 深入浅出JavaScript之闭包(Closure)、以及 读书笔记-你不知道的 JavaScript (上),Python 中闭包的定义和 JS 中的是一致的即:内层函数引用了外层函数的变量,然后返回内层函数。下面来看下 Py 中闭包之 for 循环经典问题:
# 希望一次返回3个函数,分别计算1x1,2x2,3x3:
def count():
fs = []
for i in range(1, 4):
def f():
return i * i
fs.append(f)
return fs
f1, f2, f3 = count() # 这种写法相当于 ES6 中的解构赋值
print f1(), f2(), f3() # 9 9 9老问题了,f1(), f2(), f3() 结果不应该是 1, 4, 9 吗,实际结果为什么都是 9 呢?
原因就是当 count() 函数返回了 3 个函数时,这 3 个函数所引用的变量 i 的值已经变成了 3。由于 f1、f2、f3 并没有被调用,所以,此时他们并未计算 i*i,当 f1 被调用时,i 已经变为 3 了。
要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。代码修改如下:
方法一: 可以理解为创建了一个封闭的作用域,i 的 值传给 j 之后,就和 i 没任何关系了。每次循环形成的闭包都存进了内存中。
def count():
fs = []
for i in range(1, 4):
def f(j):
def g(): # 方法一
return j * j
return g
r = f(i)
fs.append(r)
return fs
f1, f2, f3 = count()
print f1(), f2(), f3() # 1 4 9方法二:思路比较巧妙,用到了默认参数 j 在函数定义时可以获取到 i 的值,虽然没有用到闭包,但是和方法一有异曲同工之处。
def count():
fs = []
for i in range(1, 4):
def f(j = i): # 方法二
return j * j
fs.append(f)
return fs
f1, f2, f3 = count()
print f1(), f2(), f3() # 1 4 9ES6 的语法中的 decorator 正是借鉴了 �Python 的 decorator。decorator 本质上就是一个高阶函数,它接收一个函数作为参数,然后返回一个新函数。
那装饰器的作用在哪呢?先上一段日常项目中用 ts 写的网关代码:
@Post('/rider/detail') // URL 路由
@log() // 打印日志
@ResponseBody
public async getRiderBasicInfo(
@RequestBody('riderId') riderId: number,
@RequestBody('cityId') cityId: number,
) {
const result = await this.riderManager.findDetail(cityId, riderId)
return result
}可以看出使用装饰器可以极大地简化代码,避免每个函数(比如日志、路由、性能检测)编写重复性代码。
回到 Python 上,Python 提供的 @ 语法来使用 decorator,@ 等价于 f = decorate(f)。下面来看看 @log() 在 Python 中的实现:
# 我们想把调用的函数名字给打印出来
@log()
def factorial(n):
return reduce(lambda x,y: x*y, range(1, n+1))
print factorial(10)
# 来看看 @log() 的定义
def log():
def log_decorator(f):
def fn(x):
print '调用了函数' + f.__name__ + '()'
return f(x)
return fn
return log_decorator
# 结果
# 调用了函数 factorial()
# 3628800面向对象编程是一种程序设计范式,基本**是:用类定义抽象类型,然后根据类的定义创建出实例。在掌握其它语言的基础上,还是比较容易理解这块知识点的,比如从下面两种写法可以看出不同语言的语言特性间竟然有如此多的共性。
es6: (附:本文的主题是 python,所以只是初略展示下 js 中类的定义以及实例的创建,为了说明写法的相似性)
class Person {
constructor(name, age) {
this.name = name
this.age = age
}
}
const child1 = new Person('Xiao Ming', 10)Python: (核心要点写在注释中)
# 定义一个 Person 类:根据 Person 类就可以造成很多 child 实例
class Person(object):
address = 'Earth' # 类属性 (实例公有)
def __init__(self, name, age): # 创建实例时,__init__()方法被自动调用
self.name = name
self.age = age
def get_age(self): # 定义实例方法,它的第一个参数永远是 self,指向调用该方法的实例本身,其他参数和普通函数是一样的
return self.age
child1 = Person('Xiao Ming', 10)
child2 = Person('Xiao Hong', 9)
print child1.name # 'Xiao Ming'
print child2.get_age() # 9
print child1.address # 'Earth'
print child2.address # 'Earth'child 属于 Student 类,Student 类属于 People 类,这就引出了继承: 即获得了父类的方法属性后又能添加自己的方法属性。
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
class Student(Person):
def __init__(self, name, age, grade):
super(Student, self).__init__(name, age) # 这里也能写成 Person.__init__(self, name, age)
self.grade = grade
s = Student('Xiao Ming', 10, 90)
print s.name # 'Xiao Ming'
print s.grade # 90可以看到子类在父类的基础上又增加了 grade 属性。我们可以再来看看 s 的类型。
isinstance(s, Person)
isinstance(s, Student)可以看出,Python 中在一条继承链上,一个实例可以看成它本身的类型,也可以看成它父类的类型。
显示文件的头部内容,如果不指定参数默认显示 10 行
# 显示前 10 行内容
head README.md
# 或者显示多个文件
head README.md package.json
# -n 指定显示行数
head -n 100 README.md显示文件的末尾部分
# 默认显示末尾10行
tail README.md
# -n 指定显示末尾20行
tail -n 20 README.md# 显示当前目录列表
ls
# 显示目录列表的详细信息
ls -l
# 显示指定目录
ls ./src
# 可读性地显示目录列表详细信息, h means human-readable
ls -lh
# 列出所有文件包括隐藏文件
ls -a
# -F 可以显示类型,用以区分是文件还是目录
ls -F # 后缀为 ”/“ 代表是目录,”*“ 为可执行文件,没有则为文件
# -i 查看 inode 编号, 每一个文件或目录都有一个唯一的编号,这个数字由内核分配给文件系统中的每一个对象
ls -i
# 过滤文件列表, * 代表 0 个或多个字符, ? 代表一个字符
ls READ*显示当前路径
# pwd means pathname of the current working directory
pwd统计文件的行数、字数、字节数, 常见用于统计代码行数
# 统计行数
wc -l README.md
# 统计字数
wc -w README.md
# 统计字符数, 中文占两个字符, 英文占一个字符
wc -m README.md指定某个目录下查找文件
# 在当前目录递归搜索文件名为 README.md 文件
find . -name README.md
# 通过通配符进行查找, 必须用引号括着, 这里查找所有后缀为 .md 文件
find . -name "*.md"
find . -iname "*.md" # 忽略文件大小写
# 排除文件,只要加 ! , 排除掉所有 .md 后缀的文件
find . ! -name "*.md"
# 根据类型进行过滤搜索
# f 普通文件 d 目录
find . -type f
# 限定目录递归深度
find . -maxdepth 3 # 最大为3个目录
find . -mindepth 3 # 最小为3个目录
# 查找文件大小大于 25k 文件
find . -size +25k
# 查找 10 天前文件 -mtime 修改时间、 -ctime 创建时间、 -atime 访问时间
find . -mtime +10# 在当前目录下创建 temp 目录
mkdir temp
# 创建多层目录, p means parent
mkdir -p temp/temp2/temp3
# 基于权限创建, m means mode
mkdir -m 777 tempmore README.md
# 从第 10 行开始显示
more +10 README.md合并 N 个文件的列。
并不是纵向合并, 而是横向合并。
# 1.txt 和 2.txt 合并输出
paste 1.txt 2.txt
# 1.txt 2.txt 合并后保存为 3.txt
paste 1.txt 2.txt > 3.txt用于显示文件或目录的状态信息
16777220 8702541224 -rw-r--r-- 1 mac staff 0 15857 "Nov 1 13:02:02 2020" "Nov 1 13:02:02 2020" "Nov 1 13:02:02 2020" "Oct 25 18:48:15 2020" 4096 32 0 README.md强大的文本搜索工具, 被称为 Linux 命令三剑客。
# 从 README.md 文件中搜索 linux 关键字
grep "linux" README.md
grep "linux" README.md README2.md # 多个文件搜索
# 输出时高亮显示
grep "linux" README.md --color
# -o 只输出匹配部分
grep -o "linux" README.md --color
# -n 输出到匹配的行数
grep -n "linux" README.md
# -c 输出到匹配次数
grep -c "linux" README.md
# -r 递归目录文件搜索
grep -r "linux" ./src
# 使用 glob 风格表达式搜索
egrep "[0-9]" # 等价于 grep -E "[0-9]" README.md创建一个空文件, 如果文件存在只会修改文件的创建时间
touch README.md进入指定目录
# 进入当前 src 目录
cd src
# 回到上一次目录
cd -
# 返回上一级目录
cd ..
cd ../../.. # 返回多级
# 进入家目录
cd ~
cd # 或者不带任何参数
# 将上一个命令的参数作为cd参数使用
cd !$
# 模糊匹配目录,有时目录名很长一个一个敲效率就很低
# * 代表0个或多个字符, ? 代表一个字符
cd READ*删除指定目录或文件
使用此命令需要非常小心, 一但删除无法恢复
# 删除当前 1.txt 文件
rm 1.txt
# -i 删除前询问是否真的要删除,因为一旦删除无法恢复
rm -i README.md
# 这条命令比较常用, 强制删除目录或文件
# -r 如果是目录递归删除, -f 强制删除 不发出任何警告
rm -rf ./src拷贝文件或目录
# 将当前 README.md 文件拷贝到上一层
cp ./README.md ../README.md
# -a 将原文件属性一同拷贝, 修改时间、创建时间等
cp -a ./README.md ../README.md
# -r 用于递归拷贝目录
cp -r home ../home
# -i 如果目标文件存在会询问用户是否需要覆盖
cp -i README.md README.md查看指定整个文件内容
# 查看 README.md 文件所有内容
cat README.md
cat README.md README2.md # 或者一次性显示多个文件
# -n 每一行显示行号
cat -n README.md
# -b 只给有内容的行显示行号
cat -b README.mdmv 有 2 个用途:
# 将 README.md 重命名为 README-2.md, 如果 README-2.md 存在会直接覆盖。
mv README.md README-2.md
# 将 README.md 移动到上一层目录
mv README.md ../README.md
# -i 交互式操作,如果目标文件存在则进行询问是否覆盖
mv -i README.md ../README.mdopen 命令可在 linux / mac 具有可视化界面下进行文本编辑、打开应用程序等功能。
# 在mac下用Finder打开当前目录
open .
# 用默认应用程序打开文件
open README.md
# 用默认编辑器打开文件
open -e README.md
# 如果是一个URL用默认浏览器打开页面
open https://github.com/MuYunyun/blog.git
# 指定某个应用程序打开某个文件, 如果不指定文件默认直接打开程序
open -a /Applications/Google\ Chrome.app README.md在当前Shell环境中从指定文件读取和执行命令, 通常用于重新执行环境。
它有个别名 . 点操作符号。
# 等价 . ~/.bash_profile
source ~/.bash_profile实际上大部分开发者都没搞懂 source 命令。 可以把它理解为编程语言中的 import, java/python/js 都有这个,就是用来导入文件。
下面演示 source 用于 shell 脚本中
util.sh
#!/bin/bash
getName() {
echo "Linux"
}main.sh
#!/bin/bash
# 加载文件
source ./util.sh
# 这样就可以调用 util 文件中的函数了
echo $(getName)生成目录树结构, 通常用于描述项目结构。
# 递归当前目录下所有文件并生成目录树
tree
# -I 忽略某些目录
tree -I "node_modules"
# 只显示目录
tree -d
# 指定要递归的目录层级
tree -L 3将某一个文件在另外一个位置建立并产生同步的链接。当不同的 2 个目录需要同时引用某一个文件时此命令就派上用场了。
这个命令的应用场景: 比如 yarn link
理解: 文件系统博主理解: 比如在 mac 系统中装了个虚拟机, 虚拟机里面跑了另外一个 window 系统, 那此时 mac 和虚拟机里面的系统就是两个不同的文件系统。
# 默认创建硬链接,修改 README.md 内容, a.md 也会同步修改, 修改 a.md, README.md 也会同步修改
ln README.md a.md
# -s 创建软链接
ln -s README.md a.md # 如果删除了 README.md a.md 将失效
# -f 强制执行
ln -f README.md ./src/a.md查看文件类型, 比如文件、目录、二进制、符号链接等。
file README.md
README.md: HTML document text, UTF-8 Unicode text测试目标地址是否可连接、延迟度
# 测试 github.com 连通性, 按 ctrl + C 停止
ping github.com
# ping 5 次后断开
ping -c 5 github.com
# 每 5 秒 ping 一次
ping -i 5 github.com查找某个命令存储在哪个位置, 输出绝对路径, which 会在环境变量 $PATH 设置的目录里去查找。
注: 可以通过 echo $PATH 查看设置的目录.
which top # /usr/bin/top
# 打印多个命令
which ping top# 当前系统运行的天数,小时,分钟 (从上次开机起计算), 当前系统登录用户数。一分钟、5分钟、15分钟平均负载, 这 3 个值不能大于 CPU 个数,如果大于了说明系统负载高,性能低。
uptime # 13:25 up 2 days, 18:57, 7 users, load averages: 2.06 2.06 2.15打印系统信息
# 不带任何参数打印当前操作系统内核名称
uname # Darwin , 等价于 uname -s
# 打印系统所有信息, cloud-2.local: 网络节点主机名称, x86_64: 主机的硬件架构名称
uname -a # Darwin cloud-2.local 19.4.0 Darwin Kernel Version 19.4.0: Wed Mar 4 22:28:40 PST 2020; root:xnu-6153.101.6~15/RELEASE_X86_64 x86_64
# 打印主机的硬件架构名称
uname -m # x86_64配置或显示系统网卡的网络参数。
# 显示所有网络参数信息
ifconfig列出当前系统打开文件的工具
## 打印所有打开文件的的列表
lsof
# 查看指定端口被占用情况
lsof -i:8080设置命令别名,用于简化较长的命令。
# 列出所有已设置的别名
alias
# 删除所有别名
unalias -a
# 设置别名
alias ll='ls -l'ps 命令涵盖命令参数三大风格
前面加单破折线前面不加破折线前面加双破折线# 配合 grep 查询指定进程, -a means: all, -f means full
ps -af | grep nginx用于清除当前终端所有信息,本质上只是向后翻了一页,往上滚动还能看到之前的操作信息
注:效果等用于
command + K可以完全清除终端所有操作信息。
clearFor example, the root has React dir, the site should has a menu name called React.
yarn add seed
// perf
seed startAnd then you'll see the blog run in the localhost: 3000.
随着 ES6 和 TypeScript 中类的引入,在某些场景需要在不改变原有类和类属性的基础上扩展些功能,这也是装饰器出现的原因。
作为一种可以动态增删功能模块的模式(比如 redux 的中间件机制),装饰器同样具有很强的动态灵活性,只需在类或类属性之前加上 @方法名 就完成了相应的类或类方法功能的变化。
不过装饰器模式仍处于第 2 阶段提案中,使用它之前需要使用 babel 模块 transform-decorators-legacy 编译成 ES5 或 ES6。
在 TypeScript 的 lib.es5.d.ts 中,定义了 4 种不同装饰器的接口,其中装饰类以及装饰类方法的接口定义如下所示:
declare type ClassDecorator = <TFunction extends Function>(target: TFunction) => TFunction | void;
declare type MethodDecorator = <T>(target: Object, propertyKey: string | symbol, descriptor: TypedPropertyDescriptor<T>) => TypedPropertyDescriptor<T> | void;下面对这两种情况进行解析。
当装饰的对象是类时,我们操作的就是这个类本身。
@log
class MyClass { }
function log(target) { // 这个 target 在这里就是 MyClass 这个类
target.prototype.logger = () => `${target.name} 被调用`
}
const test = new MyClass()
test.logger() // MyClass 被调用由于装饰器是表达式,我们也可以在装饰器后面再添加提个参数:
@log('hi')
class MyClass { }
function log(text) {
return function(target) {
target.prototype.logger = () => `${text},${target.name} 被调用`
}
}
const test = new MyClass()
test.logger() // hello,MyClass 被调用在使用 redux 中,我们最常使用 react-redux 的写法如下:
@connect(mapStateToProps, mapDispatchToProps)
export default class MyComponent extends React.Component {}经过上述分析,我们知道了上述写法等价于下面这种写法:
class MyComponent extends React.Component {}
export default connect(mapStateToProps, mapDispatchToProps)(MyComponent)与装饰类不同,对类方法的装饰本质是操作其描述符。可以把此时的装饰器理解成是 Object.defineProperty(obj, prop, descriptor) 的语法糖,看如下代码:
class C {
@readonly(false)
method() { console.log('cat') }
}
function readonly(value) {
return function (target, key, descriptor) { // 此处 target 为 C.prototype; key 为 method;
// 原 descriptor 为:{ value: f, enumarable: false, writable: true, configurable: true }
descriptor.writable = value
return descriptor
}
}
const c = new C()
c.method = () => console.log('dog')
c.method() // cat可以看到装饰器函数接收的三个参数与 Object.defineProperty 是完全一样的,具体实现可以看 babel 转化后的代码,主要实现如下所示:
var C = (function() {
class C {
method() { console.log('cat') }
}
var temp
temp = readonly(false)(C.prototype, 'method',
temp = Object.getOwnPropertyDescriptor(C.prototype, 'method')) || temp // 通过 Object.getOwnPropertyDescriptor 获取到描述符传入到装饰器函数中
if (temp) Object.defineProperty(C.prototype, 'method', temp)
return C
})()再将再来看看如果有多个装饰器作用于同一个方法上呢?
class C {
@readonly(false)
@log
method() { }
}经 babel 转化后的代码如下:
desc = [readonly(false), log]
.slice()
.reverse()
.reduce(function(desc, decorator) {
return decorator(target, property, desc) || desc;
}, desc);可以清晰地看出,经过 reverse 倒序后,装饰器方法会至里向外执行。
javascript-decorators
Javascript 中的装饰器
JS 装饰器(Decorator)场景实战
修饰器
Babel
该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
在上一篇 JSX 和 Virtual DOM 中,解释了 JSX 渲染到界面的过程并实现了相应代码,代码调用如下所示:
import React from 'react'
import ReactDOM from 'react-dom'
const element = (
<div className="title">
hello<span className="content">world!</span>
</div>
)
ReactDOM.render(
element,
document.getElementById('root')
)本小节,我们接着探究组件渲染到界面的过程。在此我们引入组件的概念,组件本质上就是一个函数,如下就是一段标准组件代码:
import React from 'react'
// 写法 1:
class A {
render() {
return <div>I'm componentA</div>
}
}
// 写法 2:无状态组件
const A = () => <div>I'm componentA</div>
ReactDOM.render(<A />, document.body)<A name="componentA" /> 是 JSX 的写法,和上一篇同理,babel 将其转化为 React.createElement() 的形式,转化结果如下所示:
React.createElement(A, null)可以看到当 JSX 中是自定义组件的时候,createElement 后接的第一个参数变为了函数,在 repl 打印 <A name="componentA" />,结果如下:
{
attributes: undefined,
children: [],
key: undefined,
nodeName: ƒ A()
}
注意这时返回的 Virtual DOM 中的 nodeName 也变为了函数。根据这些线索,我们对之前的 render 函数进行改造。
function render(vdom, container) {
if (_.isFunction(vdom.nodeName)) { // 如果 JSX 中是自定义组件
let component, returnVdom
if (vdom.nodeName.prototype.render) {
component = new vdom.nodeName()
returnVdom = component.render()
} else {
returnVdom = vdom.nodeName() // 针对无状态组件:const A = () => <div>I'm componentsA</div>
}
render(returnVdom, container)
return
}
}至此,我们完成了对组件的处理逻辑。
在上个小节组件 A 中,是没有引入任何属性和状态的,我们希望组件间能进行属性的传递(props)以及组件内能进行状态的记录(state)。
import React, { Component } from 'react'
class A extends Component {
render() {
return <div>I'm {this.props.name}</div>
}
}
ReactDOM.render(<A name="componentA" />, document.body)在上面这段代码中,看到 A 函数继承自 Component。我们来构造这个父类 Component,并在其添加 state、props、setState 等属性方法,从而让子类继承到它们。
function Component(props) {
this.props = props
this.state = this.state || {}
}首先,我们将组件外的 props 传进组件内,修改 render 函数中以下代码:
function render(vdom, container) {
if (_.isFunction(vdom.nodeName)) {
let component, returnVdom
if (vdom.nodeName.prototype.render) {
component = new vdom.nodeName(vdom.attributes) // 将组件外的 props 传进组件内
returnVdom = component.render()
} else {
returnVdom = vdom.nodeName(vdom.attributes) // 处理无状态组件:const A = (props) => <div>I'm {props.name}</div>
}
...
}
...
}实现完组件间 props 的传递后,再来聊聊 state,在 react 中是通过 setState 来完成组件状态的改变的,在后面的 setState 优化 中会实现 setState 的异步逻辑,此处简单实现如下:
function Component(props) {
this.props = props
this.state = this.state || {}
}
Component.prototype.setState = function() {
this.state = Object.assign({}, this.state, updateObj) // 这里简单实现,后续篇章会深入探究
const returnVdom = this.render() // 重新渲染
document.getElementById('root').innerHTML = null
render(returnVdom, document.getElementById('root'))
}此时虽然已经实现了 setState 的功能,但是 document.getElementById('root') 节点写死在 setState 中显然不是我们希望的,我们将 dom 节点相关转移到 _render 函数中:
Component.prototype.setState = function(updateObj) {
this.state = Object.assign({}, this.state, updateObj)
_render(this) // 重新渲染
}自然地,重构与之相关的 render 函数:
function render(vdom, container) {
let component
if (_.isFunction(vdom.nodeName)) {
if (vdom.nodeName.prototype.render) {
component = new vdom.nodeName(vdom.attributes)
} else {
component = vdom.nodeName(vdom.attributes) // 处理无状态组件:const A = (props) => <div>I'm {props.name}</div>
}
}
component ? _render(component, container) : _render(vdom, container)
}在 render 函数中分离出 _render 函数的目的是为了让 setState 函数中也能调用 _render 逻辑。完整 _render 函数如下:
function _render(component, container) {
const vdom = component.render ? component.render() : component
if (_.isString(vdom) || _.isNumber(vdom)) {
container.innerText = container.innerText + vdom
return
}
const dom = document.createElement(vdom.nodeName)
for (let attr in vdom.attributes) {
setAttribute(dom, attr, vdom.attributes[attr])
}
vdom.children.forEach(vdomChild => render(vdomChild, dom))
if (component.container) { // 注意:调用 setState 方法时是进入这段逻辑,从而实现我们将 dom 的逻辑与 setState 函数分离的目标;知识点: new 出来的同一个实例
component.container.innerHTML = null
component.container.appendChild(dom)
return
}
component.container = container
container.appendChild(dom)
}让我们用下面这个用例跑下写好的 react 吧!
class A extends Component {
constructor(props) {
super(props)
this.state = {
count: 1
}
}
click() {
this.setState({
count: ++this.state.count
})
}
render() {
return (
<div>
<button onClick={this.click.bind(this)}>Click Me!</button>
<div>{this.props.name}:{this.state.count}</div>
</div>
)
}
}
ReactDOM.render(
<A name="count" />,
document.getElementById('root')
)效果图如下:
至此,我们实现了 props 和 state 部分的逻辑。
当没有使用 setState 更新 state 状态时,通常要结合 forceUpdate 一起使用,例子如下:
class B extends Component {
constructor(props) {
super(props)
this.state = {
count: {
value: 1
}
}
}
shouldComponentUpdate() { // 当使用 forceUpdate() 时,shouldComponentUpdate() 会失效
return false
}
click() {
this.state.count.value = ++this.state.count.value // 没有使用 setState 更新 state 状态时,通常要结合 forceUpdate 一起使用
this.forceUpdate()
}
render() {
return (
<div>
<button onClick={this.click.bind(this)}>Click Me!</button>
<div>{this.state.count.value}</div>
</div>
)
}
}这里要注意一个点当使用 forceUpdate() 时,shouldComponentUpdate() 会失效,下面我们来补充 forceUpdate() 的代码逻辑:
// force to update
Component.prototype.forceUpdate = function(cb) {
this.allowShouldComponentUpdate = false // 不允许 allowShouldComponentUpdate 执行
asyncRender({}, this, cb)
}相应的在 render.js 中加上 allowShouldComponentUpdate 的判断条件:
function renderComponent(component) {
if (component.base && component.shouldComponentUpdate && component.allowShouldComponentUpdate !== false) { // 加上 allowShouldComponentUpdate 的判断条件
const bool = component.shouldComponentUpdate(component.props, component.state)
if (!bool && bool !== undefined) {
return false // shouldComponentUpdate() 返回 false,则生命周期终止
}
}
...
}组件即函数;当 JSX 中是自定义组件时,经过 babel 转化后的 React.createElement(fn, ..) 后中的第一个参数变为了函数,除此之外其它逻辑与 JSX 中为 html 元素的时候相同;
此外我们将 state/props/setState 等 api 封装进了父类 React.Component 中,从而在子类中能调用这些属性和方法。
在下篇,我们会继续实现生命周期机制。
Especially thank simple-react for the guidance function of this library. At the meantime,respect for preact and react
该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
首先安装以下 babel 模块,其具体作用会在后文 JSX 和 虚拟 DOM 中提及
扩展延伸:babel 执行机制
"@babel/core": "^7.0.0",
"@babel/preset-env": "^7.0.0",
"@babel/preset-react": "^7.0.0",
"babel-loader": "v8.0.0-beta.0",同时 .babelrc 配置如下:
{
"presets": [
[
"@babel/preset-env",
{
"targets": "> 0.25%, not dead",
"useBuiltIns": "entry"
}
],
[
"@babel/preset-react",
{
"pragma": "cpreact.createElement" // 该参数传向 transform-react-jsx 插件,是前置的一个核心,后文有解释为什么使用 cpreact.createElement
}
]
]
}配置好 babel 后,接着提供两套打包工具的配置方案,读者可以自行选择。
webpack 拥有一个活跃的社区,提供了更为丰富的打包能力。
首先安装以下模块:
"webpack": "^4.17.2",
"webpack-cli": "^3.1.0",
"webpack-dev-server": "^3.1.8"
在根目录的 webpack.config.js 配置如下:
const webpack = require('webpack')
const path = require('path')
const rootPath = path.resolve(__dirname)
module.exports = {
entry: path.resolve(rootPath, 'test', 'index.js'),
mode: 'development',
devtool: 'inline-source-map',
devServer: {
contentBase: './dist'
},
output: {
filename: 'cpreact.js',
path: path.resolve(rootPath, 'dist'),
libraryTarget: 'umd'
},
module: {
rules: [{
test: /\.js$/,
loader: "babel-loader",
}]
},
}然后在 package.json 里加上如下配置:
"scripts": {
"start": "webpack-dev-server --open",
},
具体可以参照 0.4.3 版本
parcel 是一款上手极快的打包工具,使用其可以快速地进入项目开发的状态。在 package.json 加上如下配置,具体可以参照 0.1 版本
"scripts": {
"start": "parcel ./index.html --open -p 8080 --no-cache"
},
const element = (
<div className="title">
hello<span className="content">world!</span>
</div>
)JSX 是一种语法糖,经过 babel 转换结果如下,可以发现实际上转化成 React.createElement() 的形式:
扩展:babel执行机制
var element = React.createElement(
"div",
{ className: "title" },
"hello",
React.createElement(
"span",
{ className: "content" },
"world!"
)
);打印 element, 结果如下:
{
attributes: {className: "title"}
children: ["hello", t] // t 和外层对象相同
key: undefined
nodeName: "div"
}因此,我们得出结论:JSX 语法糖经过 Babel 编译后转换成一种对象,该对象即所谓的虚拟 DOM,使用虚拟 DOM 能让页面进行更为高效的渲染。
我们按照这种思路进行函数的构造:
const React = {
createElement
}
function createElement(tag, attr, ...child) {
return {
attributes: attr,
children: child,
key: undefined,
nodeName: tag,
}
}
// 测试
const element = (
<div className="title">
hello<span className="content">world!</span>
</div>
)
console.log(element) // 打印结果符合预期
// {
// attributes: {className: "title"}
// children: ["hello", t] // t 和外层对象相同
// key: undefined
// nodeName: "div"
// }上个小节介绍了 JSX 转化为虚拟 DOM 的过程,这个小节接着来实现将虚拟 DOM 转化为真实 DOM (页面上渲染的是真实 DOM)。
我们知道在 React 中,将虚拟 DOM 转化为真实 DOM 是使用 ReactDOM.render 实现的,使用如下:
import ReactDOM from 'react-dom'
ReactDOM.render(
element, // 上文的 element,即虚拟 dom
document.getElementById('root')
)接着来实现 ReactDOM.render 的逻辑:
const ReactDOM = {
render
}
/**
* 将虚拟 DOM 转化为真实 DOM
* @param {*} vdom 虚拟 DOM
* @param {*} container 需要插入的位置
*/
function render(vdom, container) {
if (typeof(vdom) === 'string') {
container.innerText = vdom
return
}
const dom = document.createElement(vdom.nodeName)
for (let attr in vdom.attributes) {
setAttribute(dom, attr, vdom.attributes[attr])
}
vdom.children.forEach(vdomChild => render(vdomChild, dom))
container.appendChild(dom)
}
/**
* 给节点设置属性
* @param {*} dom 操作元素
* @param {*} attr 操作元素属性
* @param {*} value 操作元素值
*/
function setAttribute(dom, attr, value) {
if (attr === 'className') {
attr = 'class'
}
if (attr.match(/on\w+/)) { // 处理事件的属性:
const eventName = attr.toLowerCase().splice(1)
dom.addEventListener(eventName, value)
} else if (attr === 'style') { // 处理样式的属性:
let styleStr = ''
let standardCss
for (let klass in value) {
standardCss = humpToStandard(klass) // 处理驼峰样式为标准样式
value[klass] = _.isNumber(+value[klass]) ? value[klass] + 'px' : value[klass] // style={{ className: '20' || '20px' }}>
styleStr += `${standardCss}: ${value[klass]};`
}
dom.setAttribute(attr, styleStr)
} else { // 其它属性
dom.setAttribute(attr, value)
}
}至此,我们成功将虚拟 DOM 复原为真实 DOM,展示如下:
另外配合热更新,在热更新的时候清空之前的 dom 元素,改动如下:
const ReactDOM = {
render(vdom, container) {
container.innerHTML = null
render(vdom, container)
}
}JSX 经过 babel 编译为 React.createElement() 的形式,其返回结果就是 Virtual DOM,最后通过 ReactDOM.render() 将 Virtual DOM 转化为真实的 DOM 展现在界面上。流程图如下:
如下是一个 react/preact 的常用组件的写法,那么为什么要 import 一个 React 或者 h 呢?
import React, { Component } from 'react' // react
// import { h, Component } from 'preact' // preact
class A extends Component {
render() {
return <div>I'm componentA</div>
}
}
render(<A />, document.body) // 组件的挂载该系列文章会尽可能的分析项目细节,具体的还是以项目实际代码为准。
Especially thank simple-react for the guidance function of this library. At the meantime,respect for preact and react
从一道简单的题目开始:
function* gen() {
const a = yield 1
console.log(a)
}为了让其能成功打印出 1,设计如下函数:
function step(gen) {
const it = gen()
let result
return function() {
result = it.next(result).value
}
}可进行如下调用
var a = step(gen)
a()
a() // 1从这个题目总结下规律
生成器中的 yield/next 除了控制能力外还有双向的消息通知能力:
function* foo(url) {
try {
const val = yield request(url)
console.log(val)
} catch (err) {
...
}
}
const it = foo('http://some.url.1')yield 后面跟着的语句执行完再进入暂停状态的,在如上代码中,当执行 it.next() 时,可以稍加转换为如下形式:
function* foo(url) {
try {
const promise = request(url) // 当执行 it.next() 时,这里是被执行的
const val = yield promise // 这里被暂停
console.log(val)
} catch (err) {
...
}
}function* gen() {
yield 1
return 2
console.log('执行/不执行')
}
const it = gen()
it.next() // {value: 1, done: false}
it.next() // {value: 2, done: true}
it.next() // {value: undefined, done: true}总结:遇到 return,generator 函数结束中断,done 变为 true;
function* gen() {
yield 1
console.log('执行/不执行')
}
var it = gen()
it.throw(new Error('boom')) // Error: boom
it.next() // {value: undefined, done: true}总结:遇到 iterator 的 throw,generator 函数运行中断,done 变为 true;
Generator 是一个返回迭代器的函数,日后可以研究下 regenerator,目前简单食用如下:
function foo(url) {
var state
var val
function process(v) {
switch (state) {
case 1:
console.log('requesting:', url)
return request(url)
case 2:
val = v
console.log(val)
return
case 3:
var err = val
console.log('Oops:', err)
return false
}
}
return {
next: function(v) {
if (!state) {
state = 1
return {
done: false,
value: process()
}
} else if (state === 1) {
state = 2
return {
done: true,
value: process(v)
}
} else {
return {
done: true,
value: undefined
}
}
},
throw: function() {
if (state === 1) {
state = 3
return {
done: true,
value: process(e)
}
} else {
throw e
}
}
}
}
var it = foo('http://some.url.1')以 co 库来说,现在已经统一为 Generator + Promise 的调用方式,下面进行简单的模拟:
co(function* () {
const result = yield Promise.resolve(true)
console.log(result) // true
})// 简版 promise
function co(gen) {
const it = gen()
const step = function(data) {
const result = it.next(data)
if (result.done) {
return result.value
}
result.value.then((data) => {
step(data)
})
}
step()
}观察 co 库发现,co 函数后返回的是 promise,使用如下:
// 期待
co(function* () {
const result = yield Promise.resolve(true)
return result // 这里有个语法,it.next() 碰到 return 后,其值会变为 { value: result, done: true } 的形式
}).then((data) => {
console.log(data) // true
})我们再对其稍加改造,使之更加添近 co 库:
function co(gen) {
return new Promise((resolve, reject) => {
const it = gen()
let result
const step = function(fn) {
try {
result = fn()
} catch(e) {
return reject(e)
}
if (result.done) { return resolve(result.value) }
result.value.then((data) => {
step(() => it.next(data))
}, (err) => {
step(() => it.throw(err)) // 这里为了让抛错直接在 generator 消化,所以 step 内改传函数
})
}
step(() => it.next())
})
}文章有描述错误的地方欢迎指正交流。
"(()(" 返回 true
BasicSkill/基础篇/askself/answer.md
自定义事件,事件绑定addEventListener多了个s
然后事件派发应该是dispatchEvent
文中的案例代码已经上传到 TypeScript
TypeScript 并不是一个完全新的语言, 它是 JavaScript 的超集,为 JavaScript 的生态增加了类型机制,并最终将代码编译为纯粹的 JavaScript 代码。
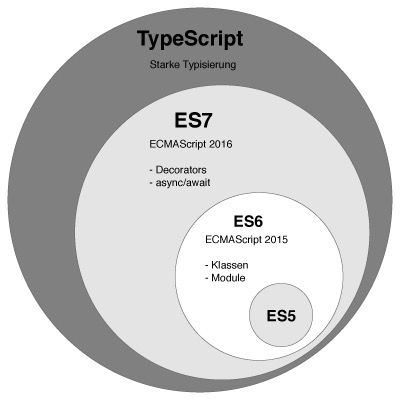
TypeScript 由 Microsoft(算上 Angular 2 的话加上 Google)开发和维护的一种开源编程语言。 它支持 JavaScript 的所有语法和语义,同时通过作为 ECMAScript 的超集来提供一些额外的功能,如类型检测和更丰富的语法。下图显示了 TypeScript 与 ES5,ES2015,ES2016 之间的关系。
JavaScript 是一门弱类型语言,变量的数据类型具有动态性,只有执行时才能确定变量的类型,这种后知后觉的认错方法会让开发者成为调试大师,但无益于编程能力的提升,还会降低开发效率。TypeScript 的类型机制可以有效杜绝由变量类型引起的误用问题,而且开发者可以控制对类型的监控程度,是严格限制变量类型还是宽松限制变量类型,都取决于开发者的开发需求。添加类型机制之后,副作用主要有两个:增大了开发人员的学习曲线,增加了设定类型的开发时间。总体而言,这些付出相对于代码的健壮性和可维护性,都是值得的。
此外,类型注释是 TypeScript 的内置功能之一,允许文本编辑器和 IDE 可以对我们的代码执行更好的静态分析。这意味着我们可以通过自动编译工具的帮助,在编写代码时减少错误,从而提高我们的生产力。
对 TypeScript 的简介到此,接下来对其特有的知识点进行简单概括总结。
我们可以给每个参数添加类型之后再为函数本身添加返回值类型。TypeScript 能够根据返回语句自动推断出返回值类型,因此我们通常省略它。下面函数 add, add2, add3 的效果是一样的,其中是 add3 函数是函数完整类型。
function add(x: string, y: string): string{
return "Hello TypeScript"
}
let add2 = function(x: string, y: string): string{
return "Hello TypeScript"
}
let add3: (x: string, y: string) => string = function(x: string, y: string): string{
return "Hello TypeScript"
}JavaScript 里,每个参数都是可选的,可传可不传。没传参的时候,它的值就是 undefined。 在 TypeScript 里我们可以在参数名旁使用 ? 实现可选参数的功能。 比如,我们想让 lastname 是可选的:
function buildName(firstName: string, lastname?: string){
console.log(lastname ? firstName + "" + lastname : firstName)
}
let res1 = buildName("鸣","人") // 鸣人
let res2 = buildName("鸣") // 鸣
let res3 = buildName("鸣", "人", "君") // Supplied parameters do not match any signature of call target.如果带默认值的参数出现在必须参数前面,用户必须明确的传入 undefined 值来获得默认值。 例如,我们重写上例子,让 firstName 是带默认值的参数:
function buildName2(firstName = "鸣", lastName?: string){
console.log(firstName + "" + lastName)
}
let res4 = buildName2("人") // 人
let res5 = buildName2(undefined, "人") // 鸣人传统的 JavaScript 程序使用函数和基于原型的继承来创建可重用的组件,但对于熟悉使用面向对象方式的程序员来讲就有些棘手,因为他们用的是基于类的继承并且对象是由类构建出来的。 从 ECMAScript 2015,也就是 ECMAScript 6 开始,JavaScript 程序员将能够使用基于类的面向对象的方式。 使用 TypeScript,我们允许开发者现在就使用这些特性,并且编译后的 JavaScript 可以在所有主流浏览器和平台上运行,而不需要等到下个 JavaScript 版本。
class Person{
name:string // 这个是对后文this.name类型的定义
age:number
constructor(name:string,age:number){
this.name = name
this.age = age
}
print(){
return this.name + this.age
}
}
let person:Person = new Person('muyy',23)
console.log(person.print()) // muyy23我们在引用任何一个类成员的时候都用了 this。 它表示我们访问的是类的成员。其实这本质上还是 ES6 的知识,只是在 ES6 的基础上多上了对 this 字段和引用参数的类型声明。
class Person{
public name:string // public、private、static 是 typescript 中的类访问修饰符
age:number
constructor(name:string,age:number){
this.name = name
this.age = age
}
tell(){
console.log(this.name + this.age)
}
}
class Student extends Person{
gender:string
constructor(gender:string){
super("muyy",23)
this.gender = gender
}
tell(){
console.log(this.name + this.age + this.gender)
}
}
var student = new Student("male")
student.tell() // muyy23male这个例子展示了 TypeScript 中继承的一些特征,可以看到其实也是 ES6 的知识上加上类型声明。不过这里多了一个知识点 —— 公共,私有,以及受保护的修饰符。TypeScript 里,成员默认为 public ;当成员被标记成 private 时,它就不能在声明它的类的外部访问;protected 修饰符与 private 修饰符的行为很相似,但有一点不同,protected 成员在派生类中仍然可以访问。
TypeScript 支持通过 getters/setters 来截取对对象成员的访问。 它能帮助你有效的控制对对象成员的访问。
对于存取器有下面几点需要注意的:
首先,存取器要求你将编译器设置为输出 ECMAScript 5 或更高。 不支持降级到 ECMAScript 3。 其次,只带有 get 不带有 set 的存取器自动被推断为 readonly。 这在从代码生成 .d.ts 文件时是有帮助的,因为利用这个属性的用户会看到不允许够改变它的值。
class Hello{
private _name: string
private _age: number
get name(): string {
return this._name
}
set name(value: string) {
this._name = value
}
get age(): number{
return this._age
}
set age(age: number) {
if(age>0 && age<100){
console.log("年龄在0-100之间") // 年龄在0-100之间
return
}
this._age = age
}
}
let hello = new Hello()
hello.name = "muyy"
hello.age = 23
console.log(hello.name) // muyyTypeScript 的核心原则之一是对值所具有的结构进行类型检查。在 TypeScript 里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
interface LabelValue{
label: string
}
function printLabel(labelObj: LabelValue){
console.log(labelObj.label)
}
let myObj = {
"label":"hello Interface"
}
printLabel(myObj)LabelledValue 接口就好比一个名字,它代表了有一个 label 属性且类型为 string 的对象。只要传入的对象满足上述必要条件,那么它就是被允许的。
另外,类型检查器不会去检查属性的顺序,只要相应的属性存在并且类型也是对的就可以。
带有可选属性的接口与普通的接口定义差不多,只是在可选属性名字定义的后面加一个 ? 符号。可选属性的好处之一是可以对可能存在的属性进行预定义,好处之二是可以捕获引用了不存在的属性时的错误。
interface Person{
name?:string
age?:number
}
function printInfo(info:Person){
console.log(info)
}
let info = {
"name":"muyy",
"age":23
}
printInfo(info) // {"name": "muyy", "age": 23}
let info2 = {
"name":"muyy"
}
printInfo(info2) // {"name": "muyy"}接口能够描述 JavaScript 中对象拥有的各种各样的外形。除了描述带有属性的普通对象外,接口也可以描述函数类型。定义的函数类型接口就像是一个只有参数列表和返回值类型的函数定义。参数列表里的每个参数都需要名字和类型。定义后完成后,我们可以像使用其它接口一样使用这个函数类型的接口。
interface SearchFunc{
(source: string, subString: string): boolean
}
let mySearch: SearchFunc
mySearch = function(source: string,subString: string){
return source.search(subString) !== -1
}
console.log(mySearch("鸣人","鸣")) // true
console.log(mySearch("鸣人","缨")) // false与使用接口描述函数类型差不多,我们也可以描述那些能够“通过索引得到”的类型,比如 a[10] 或 ageMap["daniel"]。 可索引类型具有一个索引签名,它描述了对象索引的类型,还有相应的索引返回值类型。 让我们看如下例子:
interface StringArray{
[index: number]: string
}
let MyArray: StringArray
MyArray = ["是","云","随","风"]
console.log(MyArray[2]) // 随与 C# 或 Java 里接口的基本作用一样,TypeScript 也能够用它来明确的强制一个类去符合某种契约。
我们可以在接口中描述一个方法,在类里实现它,如同下面的 setTime 方法一样:
interface ClockInterface{
currentTime: Date
setTime(d: Date)
}
class Clock implements ClockInterface{
currentTime: Date
setTime(d: Date){
this.currentTime = d
}
constructor(h: number, m: number) {}
}和类一样,接口也可以相互继承。 这让我们能够从一个接口里复制成员到另一个接口里,可以更灵活地将接口分割到可重用的模块里。
interface Shape{
color: string
}
interface PenStroke{
penWidth: number
}
interface Square extends Shape,PenStroke{
sideLength: number
}
let s = <Square>{}
s.color = "blue"
s.penWidth = 100
s.sideLength = 10TypeScript 与 ECMAScript 2015 一样,任何包含顶级 import 或者 export 的文件都被当成一个模块。
export interface StringValidator{
isAcceptable(s:string): boolean
}
var strReg = /^[A-Za-z]+$/
var numReg = /^[0-9]+$/
export class letterValidator implements StringValidator{
isAcceptable(s:string): boolean{
return strReg.test(s)
}
}
export class zipCode implements StringValidator{
isAcceptable(s: string): boolean{
return s.length == 5 && numReg.test(s)
}
}软件工程中,我们不仅要创建一致的定义良好的 API,同时也要考虑可重用性。 组件不仅能够支持当前的数据类型,同时也能支持未来的数据类型,这在创建大型系统时为你提供了十分灵活的功能。
在像 C# 和 Java 这样的语言中,可以使用泛型来创建可重用的组件,一个组件可以支持多种类型的数据。 这样用户就可以以自己的数据类型来使用组件。
如下代码,我们给 Hello 函数添加了类型变量 T ,T 帮助我们捕获用户传入的类型(比如:string)。我们把这个版本的 Hello 函数叫做泛型,因为它可以适用于多个类型。 代码中 output 和 output2 是效果是相同的,第二种方法更加普遍,利用了类型推论 —— 即编译器会根据传入的参数自动地帮助我们确定 T 的类型:
function Hello<T>(arg:T):T{
return arg;
}
let outPut = Hello<string>('Hello Generic');
let output2 = Hello('Hello Generic')
console.log(outPut);
console.log(outPut2);《你不知道的JavaScript》系列丛书给出了很多颠覆以往对JavaScript认知的点, 读完上卷,受益匪浅,于是对其精华的知识点进行了梳理。
作用域是一套规则,用于确定在何处以及如何查找变量。
JavaScript是一门编译语言。在传统编译语言的流程中,程序中一段源代码在执行之前会经历三个步骤,统称为“编译”。
var a = 2;会被分解为var、a、=、2、;作用域 分别与编译器、引擎进行配合完成代码的解析
对于 var a = 2 这条语句,首先编译器会将其分为两部分,一部分是 var a,一部分是 a = 2。编译器会在编译期间执行 var a,然后到作用域中去查找 a 变量,如果 a 变量在作用域中还没有声明,那么就在作用域中声明 a 变量,如果 a 变量已经存在,那就忽略 var a 语句。然后编译器会为 a = 2 这条语句生成执行代码,以供引擎执行该赋值操作。所以我们平时所提到的变量提升,无非就是利用这个先声明后赋值的原理而已!
对于 var a = 10 这条赋值语句,实际上是为了查找变量 a, 并且将 10 这个数值赋予它,这就是 LHS 查询。 对于 console.log(a) 这条语句,实际上是为了查找 a 的值并将其打印出来,这是 RHS 查询。
为什么区分 LHS 和 RHS 是一件重要的事情?
在非严格模式下,LHS 调用查找不到变量时会创建一个全局变量,RHS 查找不到变量时会抛出 ReferenceError。 在严格模式下,LHS 和 RHS 查找不到变量时都会抛出 ReferenceError。
作用域共有两种主要的工作模型。第一种是最为普遍的,被大多数编程语言所采用的词法作用域( JavaScript 中的作用域就是词法作用域)。另外一种是动态作用域,仍有一些编程语言在使用(比如Bash脚本、Perl中的一些模式等)。
词法作用域是一套关于引擎如何寻找变量以及会在何处找到变量的规则。词法作用域最重要的特征是它的定义过程发生在代码的书写阶段(假设没有使用 eval() 或 with )。来看示例代码:
function foo() {
console.log(a); // 2
}
function bar() {
var a = 3;
foo();
}
var a = 2;
bar()词法作用域让foo()中的a通过RHS引用到了全局作用域中的a,因此会输出2。
而动态作用域只关心它们从何处调用。换句话说,作用域链是基于调用栈的,而不是代码中的作用域嵌套。因此,如果 JavaScript 具有动态作用域,理论上,下面代码中的 foo() 在执行时将会输出3。
function foo() {
console.log(a); // 3
}
function bar() {
var a = 3;
foo();
}
var a = 2;
bar()对于函数表达式一个最熟悉的场景可能就是回调函数了,比如
setTimeout( function() {
console.log("I waited 1 second!")
}, 1000 )这叫作匿名函数表达式。函数表达式可以匿名,而函数声明则不可以省略函数名。匿名函数表达式书写起来简单快捷,很多库和工具也倾向鼓励使用这种风格的代码。但它也有几个缺点需要考虑。
始终给函数表达式命名是一个最佳实践:
setTimeout( function timeoutHandler() { // 我有名字了
console.log("I waited 1 second!")
}, 1000 )考虑以下代码:
a = 2;
var a;
console.log(a); // 2考虑另外一段代码
console.log(a); // undefined
var a = 2;我们习惯将 var a = 2; 看作一个声明,而实际上 JavaScript 引擎并不这么认为。它将 var a 和 a = 2 当作两个单独的声明,第一个是编译阶段的任务,而第二个是执行阶段的任务。
这意味着无论作用域中的声明出现在什么地方,都将在代码本身被执行前首先进行处理。可以将这个过程形象地想象成所有的声明(变量和函数)都会被“移动”到各自作用域的最顶端,这个过程称为提升。
可以看出,先有声明后有赋值。
再来看以下代码:
foo(); // TypeError
bar(); // ReferenceError
var foo = function bar() {
// ...
};这个代码片段经过提升后,实际上会被理解为以下形式:
var foo;
foo(); // TypeError
bar(); // ReferenceError
foo = function() {
var bar = ...self...
// ...
};这段程序中的变量标识符 foo() 被提升并分配给全局作用域,因此 foo() 不会导致 ReferenceError。但是 foo 此时并没有赋值(如果它是一个函数声明而不是函数表达式就会赋值)。foo()由于对 undefined 值进行函数调用而导致非法操作,因此抛出 TypeError 异常。另外即时是具名的函数表达式,名称标识符(这里是 bar )在赋值之前也无法在所在作用域中使用。
之前写过关于闭包的一篇文章深入浅出JavaScript之闭包(Closure)
要说明闭包,for 循环是最常见的例子。
for (var i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log(i);
}, i*1000 )
}正常情况下,我们对这段代码行为的预期是分别输出数字 1~5,每秒一次,每次一个。但实际上,这段代码在运行时会以每秒一次的频率输出五次6。
它的缺陷在于:根据作用域的工作原理,尽管循环中的五个函数是在各个迭代中分别定义的,但是它们都被封闭在一个共享的全局作用域中,因此实际上只有一个i。因此我们需要更多的闭包作用域。我们知道IIFE会通过声明并立即执行一个函数来创建作用域,我们来进行改进:
for (var i = 1; i <= 5; i++) {
(function() {
var j = i;
setTimeout( function timer() {
console.log(j);
}, j*1000 )
})();
}还可以对这段代码进行一些改进:
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout( function timer() {
console.log(j);
}, j*1000 )
})(i);
}在迭代内使用 IIFE 会为每个迭代都生成一个新的作用域,使得延迟函数的回调可以将新的作用域封闭在每个迭代内部,每个迭代中都会含有一个具有正确值的变量供我们访问。
我们使用 IIFE 在每次迭代时都创建一个新的作用域。换句话说,每次迭代我们都需要一个块作用域。我们知道 let 声明可以用来劫持块作用域,那我们可以进行这样改:
for (var i = 1; i <= 5; i++) {
let j = i;
setTimeout( function timer() {
console.log(j);
}, j*1000 )
}本质上这是将一个块转换成一个可以被关闭的作用域。
此外,for循环头部的 let 声明还会有一个特殊行为。这个行为指出每个迭代都会使用上一个迭代结束时的值来初始化这个变量。
for (let i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log(i);
}, i*1000 )
}之前写过一篇深入浅出JavaScript之this。我们知道this是在运行时进行绑定的,并不是在编写时绑定,它的上下文取决于函数调用时的各种条件。this的绑定和函数声明的位置没有任何关系,只取决于函数的调用方式。
来看下面这段代码的问题:
var obj = {
id: "awesome",
cool: function coolFn() {
console.log(this.id);
}
};
var id = "not awesome";
obj.cool(); // awesome
setTimeout( obj.cool, 100); // not awesomeobj.cool() 与 setTimeout( obj.cool, 100 ) 输出结果不一样的原因在于 cool() 函数丢失了同 this 之间的绑定。解决方法最常用的是 var self = this;
var obj = {
count: 0,
cool: function coolFn() {
var self = this;
if (self.count < 1) {
setTimeout( function timer(){
self.count++;
console.log("awesome?");
}, 100)
}
}
}
obj.cool(); // awesome?这里用到的知识点是我们非常熟悉的词法作用域。self 只是一个可以通过词法作用域和闭包进行引用的标识符,不关心 this 绑定的过程中发生了什么。
ES6 中的箭头函数引人了一个叫作 this 词法的行为:
var obj = {
count: 0,
cool: function coolFn() {
if (this.count < 1) {
setTimeout( () => {
this.count++;
console.log("awesome?");
}, 100)
}
}
}
obj.cool(); // awesome?箭头函数弃用了所有普通 this 绑定规则,取而代之的是用当前的词法作用域覆盖了 this 本来的值。因此,这个代码片段中的箭头函数只是"继承"了 cool() 函数的 this 绑定。
但是箭头函数的缺点就是因为其是匿名的,上文已介绍过具名函数比匿名函数更可取的原因。而且箭头函数将程序员们经常犯的一个错误给标准化了:混淆了 this 绑定规则和词法作用域规则。
箭头函数不仅仅意味着可以少写代码。本书的作者认为使用 bind() 是更靠得住的方式。
var obj = {
count: 0,
cool: function coolFn() {
if (this.count < 1) {
setTimeout( () => {
this.count++;
console.log("more awesome");
}.bind( this ), 100)
}
}
}
obj.cool(); // more awesome函数在执行的过程中,可以根据下面这4条绑定规则来判断 this 绑定到哪。
fn.apply( obj, arguments ))书中对4条绑定规则的优先级进行了验证,得出以下的顺序优先级:
如果你把 null 或者 undefined 作为 this 的绑定对象传入 call、apply 或者 bind,这些值在调用时会被忽略,实际应用的是默认规则。
什么时候会传入 null/undefined 呢?一种非常常见的做法是用 apply(..) 来“展开”一个数组,并当作参数传入一个函数。类似地,bind(..) 可以对参数进行柯里化(预先设置一些参数),如下代码:
function foo(a, b) {
console.log( "a:" + a + ", b:" + b );
}
// 把数组"展开"成参数
foo.apply(null, [2, 3]); // a:2, b:3
// 使用 bind(..) 进行柯里化
var bar = foo.bind( null, 2);
bar(3); // a:2, b:3其中 ES6 中,可以用 ... 操作符代替 apply(..) 来“展开”数组,但是 ES6 中没有柯里化的相关语法,因此还是需要使用 bind(..)。
使用 null 来忽略 this 绑定可能产生一些副作用。如果某个函数(比如第三库中的某个函数)确实使用了 this ,默认绑定规则会把 this 绑定到全局对象,这将导致不可预计的后果。更安全的做法是传入一个特殊的对象,一个 “DMZ” 对象,一个空的非委托对象,即 Object.create(null)。
function foo(a, b) {
console.log( "a:" + a + ", b:" + b );
}
var ø = Object.create(null);
// 把数组"展开"成参数
foo.apply( ø, [2, 3]); // a:2, b:3
// 使用 bind(..) 进行柯里化
var bar = foo.bind( ø, 2);
bar(3); // a:2, b:3JavaScript中的对象有字面形式(比如var a = { .. })和构造形式(比如var a = new Array(..))。字面形式更常用,不过有时候构造形式可以提供更多选择。
作者认为“JavaScript中万物都是对象”的观点是不对的。因为对象只是 6 个基础类型( string、number、boolean、null、undefined、object )之一。对象有包括 function 在内的子对象,不同子类型具有不同的行为,比如内部标签 [object Array] 表示这是对象的子类型数组。
首先看下这个对象:
let a = {
name: 'XiaoMing',
habits: ['a', 'b']
}从这个对象,先抛出下面几个概念:
对于 JSON 安全的对象(就是能用 JSON.stringify 序列号的字符串)来说,有一种巧妙的深复制方法:
var newObj = JSON.parse( JSON.stringify(someObj) )但是这个方法存在以下坑:
如果对象里面有循环引用,会抛错
不能复制对象里面的 Date、Function、RegExp
所有的构造函数会指向 Object
看下面这个对象:
function anotherFunction() { /*..*/ }
var anotherObject = {
c: true
};
var anotherArray = [];
var myObject = {
a: 2,
b: anotherObject, // 引用,不是复本!
c: anotherArray, // 另一个引用!
d: anotherFunction
};
anotherArray.push( myObject )如何准确地表示 myObject 的复制呢?
这个例子中除了复制 myObject 以外还会复制 anotherArray。这时问题就来了,anotherArray 引用了 myObject, 所以又需要复制 myObject,这样就会由于循环引用导致死循环。该如何解决呢?
可以查看在 diana 库中的实践。
相比于深复制,浅复制非常易懂并且问题要少得多,ES6 定义了 Object.assign(..) 方法来实现浅复制。 Object.assign(..) 方法的第一个参数是目标对象,之后还可以跟一个或多个源对象。它会遍历一个或多个源对象的所有可枚举的自由键并把它们复制到目标对象,最后返回目标对象,就像这样:
var newObj = Object.assign( {}, myObject );
newObj.a; // 2
newObj.b === anotherObject; // true
newObj.c === anotherArray; // true
newObj.d === anotherFunction; // trueJavaScript 有一些近似类的语法元素(比如 new 和 instanceof), 后来的 ES6 中新增了一些如 class 的关键字。但是 JavaScript 实际上并没有类。类是一种设计模式,JavaScript 的机制其实和类完全不同。
思考下面的代码:
function Foo() {
// ...
}
Foo.prototype.blah = ...;
var a = new Foo();我们如何找出� a 的“祖先”(委托关系)呢?
a instanceof Foo; // true (对象 instanceof 函数)Foo.prototype.isPrototypeOf(a); // true (对象 isPrototypeOf 对象)Object.getPrototypeOf(a) === Foo.prototype; // true (Object.getPrototypeOf() 可以获取一个对象的 [[Prototype]]) 链;a.__proto__ == Foo.prototype; // true来看下面的代码:
var foo = {
something: function() {
console.log("Tell me something good...");
}
};
var bar = Object.create(foo);
bar.something(); // Tell me something good...Object.create(..)会创建一个新对象 (bar) 并把它关联到我们指定的对象 (foo),这样我们就可以充分发挥 [[Prototype]] 机制的为例(委托)并且避免不必要的麻烦 (比如使用 new 的构造函数调用会生成 .prototype 和 .constructor 引用)。
Object.create(null) 会创建一个拥有空链接的对象,这个对象无法进行委托。由于这个对象没有原型链,所以 instanceof 操作符无法进行判断,因此总是会返回 false 。这些特殊的空对象通常被称作“字典”,它们完全不会受到原型链的干扰,因此非常适合用来存储数据。
我们并不需要类来创建两个对象之间的关系,只需要通过委托来关联对象就足够了。而Object.create(..)不包含任何“类的诡计”,所以它可以完美地创建我们想要的关联关系。
此书的第二章第6部分就把面对类和继承和行为委托两种设计模式进行了对比,我们可以看到行为委托是一种更加简洁的设计模式,在这种设计模式中能感受到Object.create()的强大。
来看一段 ES6中Class 的例子
class Widget {
constructor(width, height) {
this.width = width || 50;
this.height = height || 50;
this.$elem = null;
}
render($where){
if (this.$elem) {
this.$elem.css({
width: this.width + "px",
height: this.height + "px"
}).appendTo($where);
}
}
}
class Button extends Widget {
constructor(width, height, label) {
super(width, height);
this.label = label || "Default";
this.$elem = $("<button>").text(this.label)
}
render($where) {
super($where);
this.$elem.click(this.onClick.bind(this));
}
onClick(evt) {
console.log("Button '" + this.label + "' clicked!")
}
}除了语法更好看之外,ES6还有以下优点
但是 class 就是完美的吗?在传统面向类的语言中,类定义之后就不会进行修改,所以类的设计模式就不支持修改。但JavaScript 最强大的特性之一就是它的动态性,在使用 class 的有些时候还是会用到 .prototype 以及碰到 super (期望动态绑定然而静态绑定) 的问题,class 基本上都没有提供解决方案。
这也是本书作者希望我们思考的问题。
Nodejs板块中
简版 express.js 的实现 链接失效
koa的链接也失效了
在业务中一般 MVVM 框架一般都会配合上数据状态库(redux, mobx 等)一起使用,本文会通过一个小 demo 来讲述为什么会引人数据状态库。
传统 MVC 架构(如 JSP)在当今移动端流量寸土寸金的年代一个比较头疼的问题就是会进行大量的全局重复渲染。但是 MVC 架构是好东西,其对数据、视图、逻辑有了清晰的分工,于是前端 MVC 框架(比如 backbone.js) 出来了,对于很多业务规模不大的场景,前端 MVC 框架已经够用了,它也能做到前后端分离开发单页面应用,那么它的缺陷在哪呢?
拿 backbone.js 说,它的 Model 对外暴露了 set 方法,也就是说可以在不止一个 View 里修改同个 Model 的数据,然后一个 Model 的数据同时对应多个 View 的呈现,如下图所示。当业务逻辑过多时,多个 Model 和多个 View 就会耦合到一块,可以想到排查 bug 的时候会比较痛苦。
针对传统 MVC 架构性能低(多次全局渲染)以及前端 MVC 框架耦合度高(Model 和 View) 的痛处,MVVM 框架完美地解决了以上两点。可以参阅之前写的 MVVM 框架解析之双向绑定
假设有这么一个场景,在输入框中查询条件,点击查询,然后在列表中返回相应内容。如下图所示:
假设用 react 实现,思路大体是先调用查询接口,调用成功后将获取到的数据通过 setState 存进 list 中,列表显示部分代码如下:
const Decorate = (ListComponent) => class extends Component {
constructor() {
super()
this.state = { list: [] }
}
componentDidMount() {
fetch('./list.json')
.then((res) => res.json())
.then(result => this.setState({ list: result.data }))
}
render() {
return (
<ListComponent data={this.state.list} />
)
}
}接着往封装的 Decorate 组件里,传入无状态函数构建的 List 组件用来展示列表数据,代码如下:
function List(props) {
return (
<div>
{props.data.map(r =>
<p key={r.id}>{r.content}</p>
)}
</div>
)
}可以看到 List 组件相当于是 View 层,而封装的 Decorate 组件相当于是 Model 层。但是这么做还是把业务逻辑写进了组件当中。而我们期望的是能得到一个纯粹的 Model 层和 View 层。接着一起看看 Flux 架构模式是如何解决这个问题的。
Flux 架构模式的 4 个重要组成部分以及它们的关系如上图所示,下文会根据 dispatch,store, action, view 的顺序逐步揭开 Flux 架构模式的面纱。
从 Flux 的源码中可以看出 Dispacher.js 是其的核心文件,其核心是基于事件的发布/订阅模式完成的,核心源码如下:
class Dispatcher {
...
// 注册回调函数,
register(callback) {
var id = _prefix + this._lastID++;
this._callbacks[id] = callback;
}
// 当调用 dispatch 的时候会调用 register 中注册的回调函数
dispatch(payload) {
this._startDispatching(payload);
for (var id in this._callbacks) {
this._invokeCallback(id);
}
}
}回顾下之前的目的:让 Store 层变得纯粹。于是定义了一个变量 comments 用来专门存放列表数据,在了解 Dispatcher 的核心原理之后,当调用 dispatch(obj) 方法时,就可以把参数传递到事先注册的 register 函数中,代码如下:
// commentStore.js
let comments = []
const CommentStore = {
getComment() {
return comments
}
}
dispathcer.register((action) => { // 调用 Dispatcher 实例上的 register 函数
switch (action.type) {
case 'GET_LIST_SUCCESS': {
comments = action.comment
}
}
})以及 action 中的函数如下:
// commentAction.js
const commentAction = {
getList() {
fetch('./list.json')
.then((res) => res.json())
.then(result =>
dispathcer.dispatch({ // 调用 Dispatcher 实例上的 dispatch 函数
type: 'GET_LIST_SUCCESS',
comment: result.data
}))
}
}但是似乎少了点什么,当 GET_LIST_SUCCESS 成功后,发现还缺少通知到页面再次调用 CommentStore.getComment() 的能力,所以再次引用事件发布/订阅模式,这次使用了 Node.js 提供的 events 模块,对 commentStore.js 文件进行修改,修改后代码如下:
let comments = []
const CommentStore = Object.assign({}, EventEmitter.prototype, {
getComment() {
return comments
},
emitChange() {
this.emit('change')
},
addListener(callback) { // 提供给页面组件使用
this.on('change', callback)
}
})
appDispathcer.register((action) => {
switch (action.type) {
case 'GET_LIST_SUCCESS': {
comments = action.comment
CommentStore.emitChange() // 有了这行代码,也就有了通知页面再次进行调用 CommentStore.getComment 的能力
}
}
})剩下最后一步了,就是整合 store 和 action 进页面中,代码如下:
class ComponentList extends Component {
constructor() {
super()
this.state = {
comment: commentStore.getComment()
}
}
componentDidMount() {
commentStore.addListener(() => this.setState({ // 注册函数,上面已经提过,供 store 使用
comment: commentStore.getComment()
}))
}
render() {
return (
<div>
{this.state.comment.map(r =>
<p key={r.id}>{r.content}</p>
)}
</div>
)
}
}单纯以 mvvm 构建应用会发现业务逻辑以及数据都耦合在组件之中,引入了 Flux 架构模式后数据和业务逻辑得到较好的分离。但是使用 Flux 有什么缺点呢?在下篇 《聊聊 Redux 架构模式》中会进行分析,下回见。
本文实践案例已上传至 stateManage
系列博客,欢迎 Star

在业务中需要打印每一个 action 信息来调试,又或者希望 dispatch 或 reducer 拥有异步请求的功能。面对这些场景时,一个个修改 dispatch 或 reducer 代码有些乏力,我们需要一个可组合的、自由增减的插件机制,Redux 借鉴了 Koa 中 middleware 的**,利用它我们可以在前端应用中便捷地实现如日志打印、异步请求等功能。
比如在项目中,进行了如下调用后,redux 就集成了 thunk 函数调用以及打印日志的功能。
import thunk from 'redux-thunk'
import logger from '../middleware/logger'
const enhancer = applyMiddleware(thunk, logger), // 以 redux-thunk、logger 中间件为例介绍中间件的使用
const store = createStore(rootReducer, enhancer)下面追本溯源,来分析下源码。
export default function createStore(reducer, preloadedState, enhancer) {
// 通过下面代码可以发现,如果 createStore 传入 2 个参数,第二个参数相当于就是 enhancer
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
return enhancer(createStore)(reducer, preloadedState)
}
...
}由上述 createStore 源码发现,applyMiddleware 会进行 applyMiddleware(thunk, logger)(createStore)(reducer, preloadedState) 的调用。
export default function applyMiddleware(...middlewares) {
return createStore => (...args) => {
const store = createStore(...args)
let dispatch = store.dispatch
let chain = []
const middlewareAPI = {
getState: store.getState, // 调用 redux 原生方法,获取状态
dispatch: (...args) => dispatch(...args) // 调用 redux 原生 dispatch 方法
}
// 串行 middleware
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch // 返回加工过的 dispatch
}
}
}可以发现 applyMiddleware 的作用其实就是返回加工过的 dispatch,下面会着重分析 middlewares 是如何串行起来的以及 dispatch 是如何被加工的。
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)观察上述代码后发现每个 middleware 都会传入参数 middlewareAPI,来看下中间件 logger 的源码 以及 redux-thunk 的源码, 发现中间件接受的第一个参数正是 ({ dispatch, getState })
// logger 源码
export default ({ dispatch, getState }) => next => action => {
console.log(action)
return next(action) // 经 compose 源码分析,此处 next 为 Store.dispatch
}// redux-thunk 源码
export default ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch)
}
return next(action) // 此处 next 为 logger 中间件返回的 (action) => {} 函数
}接着上个小节,在 dispatch = compose(...chain)(store.dispatch) 中发现了 compose 函数,来看下 compose 的源码
export default function compose(...funcs) {
// ...
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}compose 源码中的 funcs.reduce((a, b) => (...args) => a(b(...args))) 算是比较重要的一句,它的作用是返回组合参数后的函数,比如 compose(f, g, h) 等价于 (...args) => f(g(h(...args))),效果图如下所示,调用 this.props.dispatch() 后,会调用相应的中间件,最终会调用 redux 原生的 store.dispatch(),并且可以看到中间件调用的形式类似数据结构中的栈(先进后出)。
拿上个小节提到的 logger、redux-thunk 中间件为例,其 middleware 的内部串行调用方式如下,从而完成了 dispatch 功能的增强(支持如 this.props.dispatch(func) 的调用以及日志功能)。具体可以看 项目中的运用
action => {
if (typeof action === 'function') {
return action(dispatch)
}
return (action => {
console.log(action)
return store.dispatch(action)
})(action)
}深入React技术栈
插件地址(集成Github、掘金、知乎、淘宝等搜索)
作为 Mac 上常年位居神器榜第一位的软件来说,Alfred 给我们带来的便利是不言而喻的,其中 workflow(工作流) 功不可没,在它上面可以轻松地查找任何 api;可以快速在豆瓣上搜到自己喜欢的电影、图书、音乐;可以快速把图片上传到图床 等等。
附上一张个人装着的插件的截图。Caffeinate 插件能在指定时间使电脑不黑屏;在 Dash 插件上能轻松查任何文档;Youdao Translate 插件比系统自带的翻译方便许多。插件也是因人而异,大家可以在 Workflow List 上逛逛,各取所需。
在用了别人的插件感觉高大上后,便萌发了也写一个插件的想法,计划把自己常逛的网站集合成一个插件,使用特定的缩略词便可快速进行搜索数据,又看了官方称可以使用 bash, zsh, PHP, Ruby, Python, Perl, Apple Script 开发 Alfred Workflow。于是我选择了 Node.js 作为开发语言,开发了一款 commonSearch, 开发完效果如下(集成了Github、掘金、知乎、淘宝等搜索)。
在开发前,得先对一些特定的操作步骤和知识点有一定的认知,这样开发时就基本上没有大碍了。
可以先参考 如何去写一个第三方的 workflow 的开始部分, 完成基本工作流的搭建,如下图是我搭建好的基本工作流连线。
在 Script 中,可以看到 /usr/local/bin/node common_search.js 相当于就是在调用该插件的时候起了一个 node 服务,后面的 1 是为了区分当前调用的是哪个搜索手动传入 common_search.js 的,{query} 则是用户查询的名称。
最初开发参考了 知乎搜索 这个项目,它是基于 cheerio 这个模块对请求到的网页数据进行分析爬取,但是引入了 cheerio 后,插件体积多了 2M 多,这对于一个插件来说太不友好了,所以这可能是 python 之类的语言更适合开发类似插件的原因吧(猜想:python 不需要引人第三方库就能进行爬虫),于是我开始选择提供 JSON API 的接口,比如找寻掘金返回数据的接口。首先打开 chrome 控制台,这可能对前端工程师比较熟悉了。
从而找到了掘金返回搜索数据的接口是 https://search-merger-ms.juejin.im/v1/search?query={query}&page=0&raw_result=false&src=web
接着愉快地使用 node 提供的 https 模块,这里有一个注意点,http.get() 回调中的 res 参数不是正文,而是 http.ClientResponse 对象,所以我们需要组装内容。
var options = {
host: 'search-merger-ms.juejin.im',
path: '/v1/search?query=' + encodeURI(keyword) + '&page=0&raw_result=false&src=web'
}
https.get(options, function (res) {
res.on('data', (chunk) => {
var content += chunk
}).on('end', function () {
var jsonContent = JSON.parse(content) && JSON.parse(content).d
var result_array = []
for (var i = 0; i < jsonContent.length; i++) {
if (jsonContent[i].user.jobTitle === '') {
result_array.push({
title:
subtitle:
arg:
icon: {
path: join(__dirname, 'xx.png'),
},
mods: {
cmd: {}
}
})
}
}
content = ''
console.log(JSON.stringify({
items: result_array
}))
})
})这种方法应该是最直接的调用 JSON API 的方案了,当然也可以引人第三方模块 request 后解析 JSON,示例如下:
var request = require('request')
var url = 'search-merger-ms.juejin.im/v1/search?query=' + encodeURI(keyword) + '&page=0&raw_result=false&src=web'
request.get({
url: url,
json: true,
headers: {'User-Agent': 'request'}
}, (err, res, data) => {
if (err) {
console.log('Error:', err);
} else if (res.statusCode !== 200) {
console.log('Status:', res.statusCode);
} else {
// data is already parsed as JSON:
console.log(data.html_url);
}
});还有一点要注意的是返回值的字段是固定的,具体可以参考它的官方解释,琢磨了好久才把 JS 中的 Icon 自定义的格式找出来。
title: 主标题
subtitle: 内容行
arg: 跳转链接
icons: 图标
mods:定制键盘按键的方法对于 Github、掘金、知乎、淘宝的搜索都是基于以上思路进行开发的,就是对于具体返回的 JSON 数据进行了不同处理,虽然粗糙,但也算完成了第一个 Alfred Workflow 插件的开发。
本文的知识点写的不是特别丰满,一是就是对开发这个插件的小结,另外就是抛砖引玉了,能让更多的小伙伴了解开发一个插件并不是难事,同时让更多的朋友开发出更多有意义,有趣的 alfred-workflow 插件也算是本文分享的一个初衷了。

度过在点我达两年欢快的时光,开启在拼多多的新的旅程。
Siren 是星巴克 Logo 上双尾女海妖的名字。本意是希望星巴克的咖啡就像 Siren 的歌声那样美妙, 除此之外它还有个引申意 —— 克制欲望。
18 年下半年的周末大多待在下城区金逸影城(也就是 18 年 VueConf 的举办地)的星巴克里看看书之类, 这家星巴克在喧嚣和安静之间保持了恰当好处, 坐在周围的可能是谈论艺术的大学教授,或者是带小朋友做作业的家长,又或者是看书的同学。自由、温馨,时间在这里可快可慢。
以下是对 18 年计划的 review
| flag | 完成情况 |
|---|---|
| 对知识点采取思维脑图的方式进行学习 | 创建了 blog 项目进行了知识点的整理输出 |
| 参与到一个千星 Star 的开源项目的改善,提高阅读源码的能力,阅读 6 本技术书籍,1 本非技术书籍 | 在开源项目的参与深度上有所欠缺, 书籍阅读指标基本达成 |
| 课外学习积累相关方面知识并尝试用到公司项目中 | 指标达成 |
| 避免讲话结巴,加强语言组织能力和逻辑能力,没想清楚问题之前不要轻易回答 | 沟通交流能力需持续加强 |
| 加强自控能力, 规定的时间做规定的事情,做到按时起睡,不晚于 8 点半起床 | 自控能力有所提高,按时起睡指标未达成 |
React.js 社区,提一次 prnode.js 文档感恩亦师亦友的愚安 boss, 以及给我帮助的点我达小伙伴们; 感激对我给予肯定的刃捷、明江前辈; 感激与我聊到凌晨的兵长兄; 感谢给我提供前行指引的死月、芙兰姐; 感谢掘金社区让我结识了小小倩、染陌、相学长等好友。感谢所有内推、面试过我的前辈, 让我认识到自己的不足。最后感谢所有杭州的朋友们,期待下次更好的遇见!
提到 Node.js, 我们脑海就会浮现异步、非阻塞、单线程等关键词,进一步我们还会想到 buffer、模块机制、事件循环、进程、V8、libuv 等知识点。本文起初旨在理顺 Node.js 以上易混淆概念,然而一入异步深似海,本文尝试基于 Node.js 的异步展开讨论,其他的主题只能日后慢慢补上了。(附:亦可以把本文当作是朴灵老师所著的《深入浅出 Node.js》一书的小结)。
Node.js 正是依靠构建了一套完善的高性能异步 I/O 框架,从而打破了 JavaScript 在服务器端止步不前的局面。
听起来异步和非阻塞,同步和阻塞是相互对应的,从实际效果而言,异步和非阻塞都达到了我们并行 I/O 的目的,但是从计算机内核 I/O 而言,异步/同步和阻塞/非阻塞实际上是两回事。
注意,操作系统内核对于 I/O 只有两种方式:阻塞与非阻塞。
调用阻塞 I/O 的过程:
调用非阻塞 I/O 的过程:
在此先引人一个叫作轮询的技术。轮询不同于回调,举个生活例子,你有事去隔壁寝室找同学,发现人不在,你怎么办呢?方法1,每隔几分钟再去趟隔壁寝室,看人在不;方法2,拜托与他同寝室的人,看到他回来时叫一下你;那么前者是轮询,后者是回调。
再回到主题,阻塞 I/O 造成 CPU 等待浪费,非阻塞 I/O 带来的麻烦却是需要轮询去确认是否完全完成数据获取。从操作系统的这个层面上看,对于应用程序而言,不管是阻塞 I/O 亦或是 非阻塞 I/O,它们都只能是一种同步,因为尽管使用了轮询技术,应用程序仍然需要等待 I/O 完全返回。
完成整个异步 I/O 环节的有事件循环、观察者、请求对象以及 I/O 线程池。
在进程启动的时候,Node 会创建一个类似于 whlie(true) 的循环,每一次执行循环体的过程我们称为 Tick。
每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在相关的回调函数,就执行他们。然后进入下一个循环,如果不再有事件处理,就退出进程。
伪代码如下:
while(ture) {
const event = eventQueue.pop()
if (event && event.handler) {
event.handler.execute() // execute the callback in Javascript thread
} else {
sleep() // sleep some time to release the CPU do other stuff
}
}每个 Tick 的过程中,如何判断是否有事件需要处理,这里就需要引入观察者这个概念。
每个事件循环中有一个或多个观察者,而判断是否有事件需要处理的过程就是向这些观察者询问是否有要处理的事件。
在 Node 中,事件主要来源于网络请求、文件 I/O 等,这些事件都有对应的观察者。
对于 Node 中的异步 I/O 而言,回调函数不由开发者来调用,在 JavaScript 发起调用到内核执行完 id 操作的过渡过程中,存在一种中间产物,它叫作请求对象。
请求对象是异步 I/O 过程中的重要中间产物,所有状态都保存在这个对象中,包括送入线程池等待执行以及 I/O 操作完后的回调处理
以 fs.open() 为例:
fs.open = function(path, flags, mode, callback) {
bingding.open(
pathModule._makeLong(path),
stringToFlags(flags),
mode,
callback
)
}fs.open 的作用就是根据指定路径和参数去打开一个文件,从而得到一个文件描述符。
从前面的代码中可以看到,JavaScript 层面的代码通过调用 C++ 核心模块进行下层的操作。
从 JavaScript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用,这是 Node 里经典的调用方式。
libuv 作为封装层,有两个平台的实现,实质上是调用了 uv_fs_open 方法,在 uv_fs_open 的调用过程中,会创建一个 FSReqWrap 请求对象,从 JavaScript 层传入的参数和当前方法都被封装在这个请求对象中。回调函数则被设置在这个对象的 oncomplete_sym 属性上。
req_wrap -> object_ -> Set(oncomplete_sym, callback)对象包装完毕后,在 Windows 下,则调用 QueueUserWorkItem() 方法将这个 FSReqWrap 对象推人线程池中等待执行。
至此,JavaScript 调用立即返回,由 JavaScript 层面发起的异步调用的第一阶段就此结束(即上图所注释的异步 I/O 第一部分)。JavaScript 线程可以继续执行当前任务的后续操作,当前的 I/O 操作在线程池中等待执行,不管它是否阻塞 I/O,都不会影响到 JavaScript 线程的后续操作,如此达到了异步的目的。
组装好请求对象、送入 I/O 线程池等待执行,实际上是完成了异步 I/O 的第一部分,回调通知是第二部分。
线程池中的 I/O 操作调用完毕之后,会将获取的结果储存在 req -> result 属性上,然后调用 PostQueuedCompletionStatus() 通知 IOCP,告知当前对象操作已经完成,并将线程归还线程池。
在这个过程中,我们动用了事件循环的 I/O 观察者,在每次 Tick 的执行过程中,它会调用 IOCP 相关的 GetQueuedCompletionStatus 方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到 I/O 观察者的队列中,然后将其当做事件处理。
I/O 观察者回调函数的行为就是取出请求对象的 result 属性作为参数,取出 oncomplete_sym 属性作为方法,然后调用执行,以此达到调用 JavaScript 中传入的回调函数的目的。
通过介绍完整个异步 I/O 后,有个需要重视的观点是 JavaScript 是单线程的,Node 本身其实是多线程的,只是 I/O 线程使用的 CPU 比较少;还有个重要的观点是,除了用户的代码无法并行执行外,所有的 I/O (磁盘 I/O 和网络 I/O) 则是可以并行起来的。
Node 是首个将异步大规模带到应用层面的平台。通过上文所述我们了解了 Node 如何通过事件循环实现异步 I/O,有异步 I/O 必然存在异步编程。异步编程的路经历了太多坎坷,从回调函数、发布订阅模式、Promise 对象,到 generator、asycn/await。趁着异步编程这个主题刚好把它们串起来理理。
对于刚接触异步的新人,很大几率会混淆回调 (callback) 和异步 (asynchronous) 的概念。先来看看维基的 Callback 条目:
In computer programming, a callback is any executable code that is passed as an argument to other code
因此,回调本质上是一种设计模式,并且 jQuery (包括其他框架)的设计原则遵循了这个模式。
在 JavaScript 中,回调函数具体的定义为:函数 A 作为参数(函数引用)传递到另一个函数 B 中,并且这个函数 B 执行函数 A。我们就说函数 A 叫做回调函数。如果没有名称(函数表达式),就叫做匿名回调函数。
因此 callback 不一定用于异步,一般同步(阻塞)的场景下也经常用到回调,比如要求执行某些操作后执行回调函数。讲了这么多让我们来看下同步回调和异步回调的例子:
同步回调:
function f2() {
console.log('f2 finished')
}
function f1(cb) {
cb()
console.log('f1 finished')
}
f1(f2) // 得到的结果是 f2 finished, f1 finished异步回调:
function f2() {
console.log('f2 finished')
}
function f1(cb) {
setTimeout(cb, 1000) // 通过 setTimeout() 来模拟耗时操作
console.log('f1 finished')
}
f1(f2) // 得到的结果是 f1 finished, f2 finished小结:回调可以进行同步也可以异步调用,但是 Node.js 提供的 API 大多都是异步回调的,比如 buffer、http、cluster 等模块。
事件发布/订阅模式 (PubSub) 自身并无同步和异步调用的问题,但在 Node 的 events 模块的调用中多半伴随事件循环而异步触发的,所以我们说事件发布/订阅广泛应用于异步编程。它的应用非常广泛,可以在异步编程中帮助我们完成更松的解耦,甚至在 MVC、MVVC 的架构中以及设计模式中也少不了发布-订阅模式的参与。
以 jQuery 事件监听为例
$('#btn').on('myEvent', function(e) { // 触发事件
console.log('I am an Event')
})
$('#btn').trigger('myEvent') // 订阅事件可以看到,订阅事件就是一个高阶函数的应用。事件发布/订阅模式可以实现一个事件与多个回调函数的关联,这些回调函数又称为事件侦听器。下面我们来看看发布/订阅模式的简易实现。
var PubSub = function() {
this.handlers = {}
}
PubSub.prototype.subscribe = function(eventType, handler) { // 注册函数逻辑
if (!(eventType in this.handlers)) {
this.handlers[eventType] = []
}
this.handlers[eventType].push(handler) // 添加事件监听器
return this // 返回上下文环境以实现链式调用
}
PubSub.prototype.publish = function(eventType) { // 发布函数逻辑
var _args = Array.prototype.slice.call(arguments, 1)
for (var i = 0, _handlers = this.handlers[eventType]; i < _handlers.length; i++) { // 遍历事件监听器
_handlers[i].apply(this, _args) // 调用事件监听器
}
}
var event = new PubSub // 构造 PubSub 实例
event.subscribe('name', function(msg) {
console.log('my name is ' + msg) // my name is muyy
})
event.publish('name', 'muyy')至此,一个简易的订阅发布模式就实现了。然而发布/订阅模式也存在一些缺点,创建订阅本身会消耗一定的时间与内存,也许当你订阅一个消息之后,之后可能就不会发生。发布-订阅模式虽然它弱化了对象与对象之间的关系,但是如果过度使用,对象与对象的必要联系就会被深埋,会导致程序难以跟踪与维护。
想象一下,如果某个操作需要经过多个非阻塞的 IO 操作,每一个结果都是通过回调,程序有可能会看上去像这个样子。这样的代码很难维护。这样的情况更多的会发生在 server side 的情况下。代码片段如下:
operation1(function(err, result1) {
operation2(result1, function(err, result2) {
operation3(result2, function(err, result3) {
operation4(result3, function(err, result4) {
callback(result4) // do something useful
})
})
})
})这时候,Promise 出现了,其出现的目的就是为了解决所谓的回调地狱的问题。让我们看下使用 Promise 后的代码片段:
promise()
.then(operation1)
.then(operation2)
.then(operation3)
.then(operation4)
.then(function(value4) {
// Do something with value4
}, function (error) {
// Handle any error from step1 through step4
})
.done()可以看到,使用了第二种编程模式后能极大地提高我们的编程体验,接着就让我们自己动手实现一个支持序列执行的 Promise。(附:为了直观的在浏览器上也能感受到 Promise,为此也写了一段浏览器上的 Promise 用法示例)
在此之前,我们先要了解 Promise/A 提议中对单个异步操作所作的抽象定义,定义具体如下所示:
Promise 的状态转化示意图如下:
除此之外,Promise 对象的另一个关键就是需要具备 then() 方法,对于 then() 方法,有以下简单的要求:
then() 方法的定义如下:
then(fulfilledHandler, errorHandler, progressHandler)有了这些核心知识,接着进入 Promise/Deferred 核心代码环节:
var Promise = function() { // 构建 Promise 对象
// 队列用于存储执行的回调函数
this.queue = []
this.isPromise = true
}
Promise.prototype.then = function (fulfilledHandler, errorHandler, progressHandler) { // 构建 Progress 的 then 方法
var handler = {}
if (typeof fulfilledHandler === 'function') {
handler.fulfilled = fulfilledHandler
}
if (typeof errorHandler === 'function') {
handler.error = errorHandler
}
this.queue.push(handler)
return this
}如上 Promise 的代码就完成了,但是别忘了 Promise/Deferred 中的后者 Deferred,为了完成 Promise 的整个流程,我们还需要触发执行上述回调函数的地方,实现这些功能的对象就叫作 Deferred,即延迟对象。
Promise 和 Deferred 的整体关系如下图所示,从中可知,Deferred 主要用于内部来维护异步模型的状态;而 Promise 则作用于外部,通过 then() 方法暴露给外部以添加自定义逻辑。
接着来看 Deferred 代码部分的实现:
var Deferred = function() {
this.promise = new Promise()
}
// 完成态
Deferred.prototype.resolve = function(obj) {
var promise = this.promise
var handler
while(handler = promise.queue.shift()) {
if (handler && handler.fulfilled) {
var ret = handler.fulfilled(obj)
if (ret && ret.isPromise) { // 这一行以及后面3行的意思是:一旦检测到返回了新的 Promise 对象,停止执行,然后将当前 Deferred 对象的 promise 引用改变为新的 Promise 对象,并将队列中余下的回调转交给它
ret.queue = promise.queue
this.promise = ret
return
}
}
}
}
// 失败态
Deferred.prototype.reject = function(err) {
var promise = this.promise
var handler
while (handler = promise.queue.shift()) {
if (handler && handler.error) {
var ret = handler.error(err)
if (ret && ret.isPromise) {
ret.queue = promise.queue
this.promise = ret
return
}
}
}
}
// 生成回调函数
Deferred.prototype.callback = function() {
var that = this
return function(err, file) {
if(err) {
return that.reject(err)
}
that.resolve(file)
}
}接着我们以两次文件读取作为例子,来验证该设计的可行性。这里假设第二个文件读取依赖于第一个文件中的内容,相关代码如下:
var readFile1 = function(file, encoding) {
var deferred = new Deferred()
fs.readFile(file, encoding, deferred.callback())
return deferred.promise
}
var readFile2 = function(file, encoding) {
var deferred = new Deferred()
fs.readFile(file, encoding, deferred.callback())
return deferred.promise
}
readFile1('./file1.txt', 'utf8').then(function(file1) { // 这里通过 then 把两个回调存进队列中
return readFile2(file1, 'utf8')
}).then(function(file2) {
console.log(file2) // I am file2.
})最后可以看到控制台输出 I am file2,验证成功~,这个案例的完整代码可以点这里查看,并建议使用 node-inspector 进行断点观察,(这段代码里面有些逻辑确实很绕,通过断点调试就能较容易理解了)。
从 Promise 链式调用可以清晰地看到队列(先进先出)的知识,其有如下两个核心步骤:
至此,实现了 Promise/Deferred 的完整逻辑,Promise 的其他知识未来也会继续探究。
尽管 Promise 一定程度解决了回调地狱的问题,但是对于喜欢简洁的程序员来说,一大堆的模板代码 .then(data => {...}) 显得不是很友好。所以爱折腾的开发者们在 ES6 中引人了 Generator 这种数据类型。仍然以读取文件为例,先上一段非常简洁的 Generator + co 的代码:
co(function* () {
const file1 = yield readFile('./file1.txt')
const file2 = yield readFile('./file2.txt')
console.log(file1)
console.log(file2)
})可以看到比 Promise 的写法简洁了许多。后文会给出 co 库的实现原理。在此之前,先归纳下什么是 Generator。可以把 Generator 理解为一个可以遍历的状态机,调用 next 就可以切换到下一个状态,其最大特点就是可以交出函数的执行权(即暂停执行),让我们看如下代码:
function* gen(x) {
yield (function() {return 1})()
var y = yield x + 2
return y
}
// 调用方式一
var g = gen(1)
g.next() // { value: 1, done: false }
g.next() // { value: 3, done: false }
g.next() // { value: undefined, done: true }
// 调用方式二
var g = gen(1)
g.next() // { value: 1, done: false }
g.next() // { value: 3, done: false }
g.next(10) // { value: 10, done: true }由此我们归纳下 Generator 的基础知识:
next() 指令启动。yield 处停止。并返回一个 {value: AnyType, done: Boolean} 对象,value 是这次执行的结果,done 是迭代是否结束。并等待下一次的 next() 指令。上一个 yield 语句的返回值。另外我们注意到,上述代码中的第一种调用方式中的 y 值是 undefined,如果我们真想拿到 y 值,就需要通过 g.next(); g.next().value 这种方式取出。可以看出,Generator 函数将异步操作表示得很简洁,但是流程管理却不方便。这时候用于 Generator 函数的自动执行的 co 函数库 登场了。为什么 co 可以自动执行 Generator 函数呢?我们知道,Generator 函数就是一个异步操作的容器。它的自动执行需要一种机制,当异步操作有了结果,能够自动交回执行权。
两种方法可以做到这一点:
co 函数库其实就是将两种自动自动执行器(Thunk 函数和 Promise 对象),包装成一个库。使用 co 的前提条件是,Generator 函数的 yield 命令后面,只能是 Thunk 函数或者是 Promise 对象。下面分别用以上两种方法对 co 进行一个简单的实现。
在 JavaScript 中,Thunk 函数就是指将多参数函数替换成单参数的形式,并且其只接受回调函数作为参数的函数。Thunk 函数的例子如下:
// 正常版本的 readFile(多参数)
fs.readFile(filename, 'utf8', callback)
// Thunk 版本的 readFile(单参数)
function readFile(filename) {
return function(callback) {
fs.readFile(filename, 'utf8', callback);
};
}在基于 Thunk 函数和 Generator 的知识上,接着我们来看看 co 基于 Thunk 函数的实现。(附:代码参考自co最简版实现)
function co(generator) {
return function(fn) {
var gen = generator()
function next(err, result) {
if(err) {
return fn(err)
}
var step = gen.next(result)
if (!step.done) {
step.value(next) // 这里可以把它联想成递归;将异步操作包装成 Thunk 函数,在回调函数里面交回执行权。
} else {
fn(null, step.value)
}
}
next()
}
}用法如下:
co(function* () { // 把 function*() 作为参数 generator 传入 co 函数
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
console.log(file1) // I'm file1
console.log(file2) // I'm file2
return 'done'
})(function(err, result) { // 这部分的 function 作为 co 函数内的 fn 的实参传入
console.log(result) // done
})上述部分关键代码已进行注释,下面对 co 函数里的几个难点进行说明:
var step = gen.next(result), 前文提到的一句话在这里就很有用处了:next方法可以带一个参数,该参数就会被当作上一个yield语句的返回值;在上述代码的运行中一共会经过这个地方 3 次,result 的值第一次是空值,第二次是 file1.txt 的内容 I'm file1,第三次是 file2.txt 的内容 I'm file2。根据上述关键语句的提醒,所以第二次的内容会作为 file1 的值(当作上一个yield语句的返回值),同理第三次的内容会作为 file2 的值。step.value(next), step.value 就是前面提到的 thunk 函数返回的 function(callback) {}, next 就是传入 thunk 函数的 callback。这句代码是条递归语句,是这个简易版 co 函数能自动调用 Generator 的关键语句。建议亲自跑一遍代码,多打断点,从而更好地理解,代码已上传github。
基于 Thunk 函数的自动执行中,yield 后面需跟上 Thunk 函数,在基于 Promise 对象的自动执行中,yield 后面自然要跟 Promise 对象了,让我们先构建一个 readFile 的
Promise 对象:
function readFile(fileName) {
return new Promise(function(resolve, reject) {
fs.readFile(fileName, function(error, data) {
if (error) reject(error)
resolve(data)
})
})
}在基于前文 Promise 对象和 Generator 的知识上,接着我们来看看 co 基于 Promise 函数的实现:
function co(generator) {
var gen = generator()
function next(data) {
var result = gen.next(data) // 同上,经历了 3 次,第一次是 undefined,第二次是 I'm file1,第三次是 I'm file2
if (result.done) return result.value
result.value.then(function(data) { // 将异步操作包装成 Promise 对象,用 then 方法交回执行权
next(data)
})
}
next()
}用法如下:
co(function* generator() {
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
console.log(file1.toString()) // I'm file1
console.log(file2.toString()) // I'm file2
})这一部分的代码上传在这里,通过观察可以发现基于 Thunk 函数和基于 Promise 对象的自动执行方案的 co 函数设计思路几乎一致,也因此呼应了它们共同的本质 —— 当异步操作有了结果,自动交回执行权。
看上去 Generator 已经足够好用了,但是使用 Generator 处理异步必须得依赖 tj/co,于是 asycn 出来了。本质上 async 函数就是 Generator 函数的语法糖,这样说是因为 async 函数的实现,就是将 Generator 函数和自动执行器,包装进一个函数中。伪代码如下,(注:其中 automatic 的实现可以参考 async 函数的含义和用法中的实现)
async function fn(args){
// ...
}
// 等同于
function fn(args) {
return automatic(function*() { // automatic 函数就是自动执行器,其的实现可以仿照 co 库自动运行方案来实现,这里就不展开了
// ...
})
}接着仍然以上文的读取文件为例,来比较 Generator 和 async 函数的写法差异:
// Generator
var genReadFile = co(function*() {
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
})
// 改用 async 函数
var asyncReadFile = async function() {
var file1 = await readFile('./file1.txt')
var file2 = await 1 // 等同于同步操作(如果跟上原始类型的值)
}总体来说 async/await 看上去和使用 co 库后的 generator 看上去很相似,不过相较于 Generator,可以看到 Async 函数更优秀的几点:
开发中,我们或多或少地接触了设计模式,但是很多时候不知道自己使用了哪种设计模式或者说该使用何种设计模式。本文意在梳理常见设计模式的特点,从而对它们有比较清晰的认知。
看完了上述设计模式后,把它们的关键词特点罗列出来,以后提到某种设计模式,进而联想相应的关键词和例子,从而心中有数。
| 设计模式 | 特点 | 案例 |
|---|---|---|
| 单例模式 | 一个类只能构造出唯一实例 | 创建菜单对象 |
| 策略模式 | 根据不同参数可以命中不同的策略 | 动画库里的算法函数 |
| 代理模式 | 代理对象和本体对象具有一致的接口 | 图片预加载 |
| 迭代器模式 | 能获取聚合对象的顺序和元素 | each([1, 2, 3], cb) |
| 发布-订阅模式 | PubSub | 瀑布流库 |
| 命令模式 | 不同对象间约定好相应的接口 | 按钮和命令的分离 |
| 组合模式 | 组合模式在对象间形成一致对待的树形结构 | 扫描文件夹 |
| 模板方法模式 | 父类中定好执行顺序 | 咖啡和茶 |
| 享元模式 | 减少创建实例的个数 | 男女模具试装 |
| 职责链模式 | 通过请求第一个条件,会持续执行后续的条件,直到返回结果为止 | if else 优化 |
| 中介者模式 | 对象和对象之间借助第三方中介者进行通信 | 测试结束告知结果 |
| 装饰者模式 | 动态地给函数赋能 | 天冷了穿衣服,热了脱衣服 |
| 状态模式 | 每个状态建立一个类,状态改变会产生不同行为 | 电灯换挡 |
| 适配者模式 | 一种数据结构改成另一种数据结构 | 枚举值接口变更 |
| 观察者模式 | 当观察对象发生变化时自动调用相关函数 | vue 双向绑定 |
*《JavaScript设计模式与开发实践》
下面函数singleton.getInstance里面!this.instance,this指向的是singleton。
观察基于 create-react-doc 搭建的文档站点, 发现网页代码光秃秃的一片(见下图)。这显然是单页应用 (SPA) 站点的通病 —— 不利于文档被搜索引擎搜索 (SEO)。
难道 SPA 站点就无法进行 SEO 了么, 那么 Gatsby、nuxt 等框架又为何能作为不少博主搭建博客的首选方案呢, 此类框架赋能 SEO 的技术原理是什么呢? 在好奇心的驱动下, 笔者尝试对 creat-react-doc 进行赋能 SEO 之旅。
在实践之前, 先从理论上分析为何单页应用不能被搜索引擎搜索到。核心在于 爬虫蜘蛛在执行爬取的过程中, 不会去执行网页中的 JS 逻辑, 所以隐藏在 JS 中的跳转逻辑也不会被执行。
查看当前 SPA 站点打包后的代码, 除了一个根目录 index.html 外, 其它都是注入的 JS 逻辑, 因此浏览器自然不会对其进行 SEO。
此外, 搜索引擎详优化是一门较复杂的学问。如果你对 SEO 优化比较陌生, 建议阅读搜索引擎优化 (SEO) 新手指南 一文, Google 搜索中心给出了全面的 17 个最佳做法, 以及 33 个应避免的做法, 这也是笔者近期在实践的部分。
在轻文档站点的背景前提下, 我们暂不考虑 SSR 方案。
对市面上文档站点的 SEO 方案调研后, 笔者总结为如下四类:
静态模板渲染方案以 hexo 最为典型, 此类框架需要指定特定的模板语言(比如 pug)来开发主题, 从而达到网页内容直出的目的。
404 重定向方案的原理主要是利用 GitHub Pages 的 404 机制进行重定向。比较典型的案例有 spa-github-pages、sghpa。
但是遗憾的是 2019 年 Google 调整了爬虫算法, 因此此类重定向方案在当下是无利于 SEO 的。spa-github-pages 作者也表示如果需要 SEO 的话, 使用 SSG 方案或者付费方案 Netlify。
SSG 方案全称为 static site generator, 中文可译为路由静态化方案。社区上 nuxt、Gatsby 等框架赋能 SEO 的技术无一例外可以归类此类 SSG 方案。
以 nuxt 框架为例, 在约定式路由的基础上, 其通过执行 nuxt generate 命令将 vue 文件转化为静态网页。
例子:
-| pages/
---| about.vue/
---| index.vue/静态化后变成:
-| dist/
---| about/
-----| index.html
---| index.html经过路由静态化后, 此时的文档目录结构可以托管于任何一个静态站点服务商。
经过上文对 SSG 方案的分析, 此时 SPA 站点的优化关键已经跃然纸上 —— 静态化路由。相较于 nuxt、Gatsby 等框架存在约定式路由的限制, create-react-doc 在目录结构上的组织灵活自由。它的建站理念是文件即站点, 同时它对存量 markdown 文档的迁移也十分便捷。
以 blog 项目结构为例, 其文档结构如下:
-| BasicSkill/
---| basic/
-----| DOM.md
-----| HTML5.md静态化后应该变成:
-| BasicSkill/
---| basic/
-----| DOM
-------| index.html
-----| HTML5
-------| index.html经过调研, 该构思与 prerender-spa-plugin 预渲染方案一拍即合。预渲染方案的原理可以见如下图:
至此技术选型定下为使用预渲染方案实现 SSG。
create-react-doc 在预渲染方案实践的步骤简单概况如下(完整改动可见 mr):
export default function RouterRoot() {
return (
- <HashRouter>
+ <BrowserRouter>
<RoutersContainer />
- </HashRouter>
+ </BrowserRouter>
)
}预渲染环境, 同时对路由进行环境匹配。其主要解决了资源文件与主域名下的子路径的对应关系。过程比较曲折, 感兴趣的同学可以见 issue。const ifProd = env === 'prod'
+ const ifPrerender = window.__PRERENDER_INJECTED && window.__PRERENDER_INJECTED.prerender
+ const ifAddPrefix = ifProd && !ifPrerender
<Route
key={item.path}
exact
- path={item.path}
+ path={ifAddPrefix ? `/${repo}${item.path}` : item.path}
render={() => { ... }}
/>官方版本当前未支持 webpack 5, 详见 issue, 同时笔者存在对预渲染后执行回调的需求。因此当前 fork 了一份版本 出来, 解决了以上问题。
经过上述步骤的实践, 终于在 SPA 站点中实现了静态化路由。
SEO 优化至此, 来看下站点优化前后 FP、FCP、LCP 等指标数据的变化。
以 blog 站点为例, 优化前后的指标数据如下(数据指标统计来自未使用梯子访问 gh-pages):
优化前: 接入预渲染方案前, 首次绘制(FP、FCP) 的时间节点在 8s 左右, LCP 在 17s 左右。
优化后: 接入预渲染方案后, 首次绘制时间节点在 1s 之内开始, LCP 在 1.5s 之内。
对比优化前后: 首屏绘制速度提升了 8 倍, 最大内容绘制速度提升 11 倍。本想优化 SEO, 结果站点性能优化的方式又 get 了一个。
在完成预渲染实现站点路由静态化后, 距离 SEO 的目标又近了一步。暂且抛开 SEO 优化细节, 单刀直入 SEO 核心腹地 站点地图。
站点地图 Sitemap 格式与各字段含义简单说明如下:
<?xml version="1.0" encoding="utf-8"?>
<urlset>
<!-- 必填标签, 这是具体某一个链接的定义入口,每一条数据都要用 <url> 和 </url> 包含在里面, 这是必须的 -->
<url>
<!-- 必填, URL 链接地址,长度不得超过 256 字节 -->
<loc>http://www.yoursite.com/yoursite.html</loc>
<!-- 可以不提交该标签, 用来指定该链接的最后更新时间 -->
<lastmod>2021-03-06</lastmod>
<!-- 可以不提交该标签, 用这个标签告诉此链接可能会出现的更新频率 -->
<changefreq>daily</changefreq>
<!-- 可以不提交该标签, 用来指定此链接相对于其他链接的优先权比值,此值定于 0.0-1.0 之间 -->
<priority>0.8</priority>
</url>
</urlset>上述 sitemap 中, lastmod、changefreq、priority 字段对 SEO 没那么重要, 可以见 how-to-create-a-sitemap
根据上述结构, 笔者开发了 create-react-doc 的站点地图生成包 crd-generator-sitemap, 其逻辑就是将预渲染的路由路径拼接成上述格式。
使用方只需在站点根目录的 config.yml 添加如下参数便可以在自动化发版过程中自动生成 sitemap。
seo:
google: true将生成的站点地图往 Google Search Console 中提交试试吧,
最后验证下 Google 搜索站点优化前后效果。
优化前: 只搜索到一条数据。
优化后: 搜索到站点地图中声明的位置数据。
至此使用 SSG 优化 SPA 站点实现 SEO 的完整流程完整实现了一遍。后续便剩下参照 搜索引擎优化 (SEO) 新手指南 做一些 SEO 细节方面的优化以及支持更多搜索引擎了。
本文从 SPA 站点实现 SEO 作为切入点, 先后介绍了 SEO 的基本原理, SEO 在 SPA 站点中的 4 种实践案例, 并结合 create-react-doc SPA 框架进行完整的 SEO 实践。
瀑布流布局中的图片有一个核心特点 —— 等宽不定等高,瀑布流布局在国内网网站都有一定规模的使用,比如pinterest、花瓣网等等。那么接下来就基于这个特点开始瀑布流探索之旅。
首先我们定义好一个有 20 张图片的容器,
<body>
<style>
#waterfall {
position: relative;
}
.waterfall-box {
float: left;
width: 200px;
}
</style>
</body>
<div id="waterfall">
<img src="images/1.png" class="waterfall-box">
<img src="images/2.png" class="waterfall-box">
<img src="images/3.png" class="waterfall-box">
<img src="images/4.png" class="waterfall-box">
<img src="images/5.png" class="waterfall-box">
<img src="images/6.png" class="waterfall-box">
...
</div>由于未知的 css 知识点,丝袜最长的妹子把下面的空间都占用掉了。。。
接着正文,假如如上图,每排有 5 列,那第 6 张图片应该出现前 5 张图片哪张的下面呢?当然是绝对定位到前 5 张图片高度最小的图片下方。
那第 7 张图片呢?这时候把第 6 张图片和在它上面的图片当作是一个整体后,思路和上述是一致的。代码实现如下:
Waterfall.prototype.init = function () {
...
const perNum = this.getPerNum() // 获取每排图片数
const perList = [] // 存储第一列的各图片的高度
for (let i = 0; i < perNum; i++) {
perList.push(imgList[i].offsetHeight)
}
let pointer = this.getMinPointer(perList) // 求出当前最小高度的数组下标
for (let i = perNum; i < imgList.length; i++) {
imgList[i].style.position = 'absolute' // 核心语句
imgList[i].style.left = `${imgList[pointer].offsetLeft}px`
imgList[i].style.top = `${perList[pointer]}px`
perList[pointer] = perList[pointer] + imgList[i].offsetHeight // 数组最小的值加上相应图片的高度
pointer = this.getMinPointer(perList)
}
}细心的朋友也许发现了代码中获取图片的高度用到了 offsetHeight 这个属性,这个属性的高度之和等于图片高度 + 内边距 + 边框,正因为此,我们用了 padding 而不是 margin 来设置图片与图片之间的距离。此外除了offsetHeight 属性,此外还要理解 offsetHeight、clientHeight、offsetTop、scrollTop 等属性的区别,才能比较好的理解这个项目。css 代码简单如下:
.waterfall-box {
float: left;
width: 200px;
padding-left: 10px;
padding-bottom: 10px;
}至此完成了瀑布流的基本布局,效果图如下:
实现了初始化函数 init 以后,下一步就要实现对 scroll 滚动事件进行监听,从而实现当滚到父节点的底部有源源不断的图片被加载出来的效果。这时候要考虑一个点,是滚动到什么位置时触发加载函数呢?这个因人而异,我的做法是当满足 父容器高度 + 滚动距离 > 最后一张图片的 offsetTop 这个条件,即橙色线条 + 紫色线条 > 蓝色线条时触发加载函数,代码如下:
window.onscroll = function() {
// ...
if (scrollPX + bsHeight > imgList[imgList.length - 1].offsetTop) {// 浏览器高度 + 滚动距离 > 最后一张图片的 offsetTop
const fragment = document.createDocumentFragment()
for(let i = 0; i < 20; i++) {
const img = document.createElement('img')
img.setAttribute('src', `images/${i+1}.png`)
img.setAttribute('class', 'waterfall-box')
fragment.appendChild(img)
}
$waterfall.appendChild(fragment)
}
}因为父节点可能自定义节点,所以提供了对监听 scroll 函数的封装,代码如下:
proto.bind = function () {
const bindScrollElem = document.getElementById(this.opts.scrollElem)
util.addEventListener(bindScrollElem || window, 'scroll', scroll.bind(this))
}
const util = {
addEventListener: function (elem, evName, func) {
elem.addEventListener(evName, func, false)
},
}resize 事件的监听与 scroll 事件监听大同小异,当触发了 resize 函数,调用 init 函数进行重置就行。
既然以开发插件为目标,不能仅仅满足于功能的实现,还要留出相应的操作空间给开发者自行处理。联想到业务场景中瀑布流中下拉加载的图片一般都来自 Ajax 异步获取,那么加载的数据必然不能写死在库里,期望能实现如下调用(此处借鉴了 waterfall 的使用方式),
const waterfall = new Waterfall({options})
waterfall.on("load", function () {
// 此处进行 ajax 同步/异步添加图片
})观察调用方式,不难联想到使用发布/订阅模式来实现它,关于发布/订阅模式,之前在 Node.js 异步异闻录 有介绍它。其核心**即通过订阅函数将函数添加到缓存中,然后通过发布函数实现异步调用,下面给出其代码实现:
function eventEmitter() {
this.sub = {}
}
eventEmitter.prototype.on = function (eventName, func) { // 订阅函数
if (!this.sub[eventName]) {
this.sub[eventName] = []
}
this.sub[eventName].push(func) // 添加事件监听器
}
eventEmitter.prototype.emit = function (eventName) { // 发布函数
const argsList = Array.prototype.slice.call(arguments, 1)
for (let i = 0, length = this.sub[eventName].length; i < length; i++) {
this.sub[eventName][i].apply(this, argsList) // 调用事件监听器
}
}接着,要让 Waterfall 能使用发布/订阅模式,只需让 Waterfall 继承 eventEmitter 函数,代码实现如下:
function Waterfall(options = {}) {
eventEmitter.call(this)
this.init(options) // 这个 this 是 new 的时候,绑上去的
}
Waterfall.prototype = Object.create(eventEmitter.prototype)
Waterfall.prototype.constructor = Waterfall继承方式的写法吸收了基于构造函数继承和基于原型链继承两种写法的优点,以及使用 Object.create 隔离了子类和父类,关于继承更多方面的细节,可以另写一篇文章了,此处点到为止。
为了防止 scroll 事件触发多次加载图片,可以考虑用函数防抖与节流实现。在基于发布-订阅模式的基础上,定义了个 isLoading 参数表示是否在加载中,并根据其布尔值决定是否加载,代码如下:
let isLoading = false
const scroll = function () {
if (isLoading) return false // 避免一次触发事件多次
if (scrollPX + bsHeight > imgList[imgList.length - 1].offsetTop) { // 浏览器高度 + 滚动距离 > 最后一张图片的 offsetTop
isLoading = true
this.emit('load')
}
}
proto.done = function () {
this.on('done', function () {
isLoading = false
...
})
this.emit('done')
}这时候需要在调用的地方加上 waterfall.done, 从而告知当前图片已经加载完毕,代码如下:
const waterfall = new Waterfall({})
waterfall.on("load", function () {
// 异步/同步加载图片
waterfall.done()
})项目简陋,不足之处在所难免,欢迎留下你们宝贵的意见。
写博客有三个层次,第一层次是借鉴居多的博文,第二层次是借鉴后经过消化后有一定量产出的博文,第三层次是原创好文居多的博文。在参考了大量前辈搭建hexo的心得后,此文尽量把一些别人未提到的点以及比较好用的点给提出来。所以你在参考本文的时候,应该已经过完了hexo。本文有以下内容:
项目压缩也叫代码丑化, 分别对 html、css、js、images进行优化,即把重复的代码合并,把多余的空格去掉,用算法把 images 进行压缩。压缩后的博客,加载速度会有较大的提升,自然能留住更多游客。
蛮多朋友使用了gulp对博客进行压缩,这也是一个办法,但在社区逛了下,找到了一个比较好用的模块hexo-all-minifier,这个模块集成了对 html、css、js、image 的优化。安装上此模块后,只要在根目录下的_config.yml文件中加上如下字段就可对博客所有内容进行压缩。
html_minifier:
enable: true
ignore_error: false
exclude:
css_minifier:
enable: true
exclude:
- '*.min.css'
js_minifier:
enable: true
mangle: true
output:
compress:
exclude:
- '*.min.js'
image_minifier:
enable: true
interlaced: false
multipass: false
optimizationLevel: 2
pngquant: false
progressive: false也许你会数次更改文章题目或者变更文章发布时间,在默认设置下,文章链接都会改变,不利于搜索引擎收录,也不利于分享。唯一永久链接才是更好的选择。
安装
npm install hexo-abbrlink --save在站点配置文件中查找代码permalink,将其更改为:
permalink: posts/:abbrlink/ # “posts/” 可自行更换这里有个知识点:
百度蜘蛛抓取网页的规则: 对于蜘蛛说网页权重越高、信用度越高抓取越频繁,例如网站的首页和内页。蜘蛛先抓取网站的首页,因为首页权重更高,并且大部分的链接都是指向首页。然后通过首页抓取网站的内页,并不是所有内页蜘蛛都会去抓取。
搜索引擎认为对于一般的中小型站点,3层足够承受所有的内容了,所以蜘蛛经常抓取的内容是前三层,而超过三层的内容蜘蛛认为那些内容并不重要,所以不经常爬取。出于这个原因所以permalink后面跟着的最好不要超过2个斜杠。
然后在站点配置文件中添加如下代码:
# abbrlink config
abbrlink:
alg: crc32 # 算法:crc16(default) and crc32
rep: hex # 进制:dec(default) and hex可选择模式:
看了好些博客,支付宝的收款码和微信的收款码都是分开的,且是没有美化过的二维码,让人打赏的欲望自然就下降了。来看一下我的赞赏二维码(支持微信和支付宝支付哟)
实现这个酷炫二维码的流程如下:
讲生成的图片pay.png放到根目录的source文件中,并在主题配置文件中加上
alipay: /pay.png修改文件next/source/css/_common/components/post/post-reward.styl,然后注释其中的函数wechat:hover和alipay:hover,如下:
/* 注释文字闪动函数
#wechat:hover p{
animation: roll 0.1s infinite linear;
-webkit-animation: roll 0.1s infinite linear;
-moz-animation: roll 0.1s infinite linear;
}
#alipay:hover p{
animation: roll 0.1s infinite linear;
-webkit-animation: roll 0.1s infinite linear;
-moz-animation: roll 0.1s infinite linear;
}
*/博主用的是next主题,别的主题目录结构可能不太一样,但是整个框架是一样的,生成方式是一样的,所以引用方式也是相同的
\themes\next\source\js\src文件目录下\themes\next\layout目录下的布局文件_layout.swig<script type="text/javascript" src="/js/src/js文件名.js"></script>
添加外部css样式和引用自定义js代码是一样的,在对应css文件夹内添加自定义外部css样式文件,然后在layout文件中添加引用即可。也可以在\themes\next\source\css\_custom\custom.styl文件中进行样式的添加。
这个模块借鉴了@小胡子哥。根据上面的自定义JS和CSS的知识点不难实现歌单模块以及播放器。效果如下图:
核心代码在\themes\next\source\js\src\music\nmlist中,点击看源码,其核心思路就是通过jsonp的方式对定义好的歌单进行调用。
在调试的过程中,发现了小胡子哥代码的一个bug:当点击一个专辑暂停后,再点击其他的专辑,这时候点击暂停、播放的控制逻辑有错误。经过排查在nmlist.js文件中的bind方法中加上了$("#nmPlayer").removeAttr("data-paused")解决了这个bug。
再接着玩的话,可以给播放器加上歌词的功能。这里有一篇相关文章, 有机会可以去把玩一番。
有一个问题,如果我电脑坏了怎么办,因为在github中的我们github.io项目是只有编译后的文件的,没有源文件的,也就是说,如果我们的电脑坏了,打不开了,我们的博客就不能进行更新了,所以我们要把我们的源文件也上传到github上。这个时候我可以选择新建一个仓库来存放源文件,也可以把源文件 push 到 user.github.io 的其他分支。我选择了后者。
创建两个分支:master 与 muyy,(这个muyy分支就是存放我们源文件的分支,我们只需要更新muyy分支上的内容据就好,master上的分支hexo编译的时候会更新的)
然后我们再初始化仓库,重新对我们的代码进行版本控制
git init
git remote add origin <server><server>是指在线仓库的地址。origin是本地分支,remote add操作会将本地仓库映射到云端
.gitignore文件作用是声明不被git记录的文件,blog根目录下的.gitignore是hexo初始化带来的,可以先删除或者直接编辑,对hexo不会有影响。建议.gitignore内添加以下内容:
/.deploy_git
/public
/_config.yml.deploy_git是hexo默认的.git配置文件夹,不需要同步
public内文件是根据source文件夹内容自动生成,不需要备份,不然每次改动内容太多
即使是私有仓库,除去在线服务商员工可以看到的风险外,还有云服务商被攻击造成泄漏等可能,所以不建议将配置文件传上去
依次执行
git add .
git commit -m "..."
git push origin muyy在markdown中写blog的朋友,想必这点是最烦恼的吧,一般来说都要手动上传图片到七牛云,再把链接写到markdown中。逛了逛社区,有人用phthon实现一个自动上传的脚本,但是我觉得还不是特别方便,这时在github上找到一个一键贴图工具qiniu-image-tool,它支持本地文件、截图、网络图片一键上传七牛云并返回图片引用。Mac 是基于 Alfred 的,其 windows 也有相应版本windows版本。
按照其要求配置好以后,用截图软件截图后,或者本地图片后 copy,然后直接按设置好的 command+option+v,然后在图片成功上传到七牛云图床上,剪贴板上也有相应的连接。

通常我们把hexo托管在github,但是毕竟github是国外的,访问速度上还是有点慢,所以想也部署一套在国内的托管平台,目前gitcafe已经被coding收购了,所以就决定部署到coding。但是coding有个不好的地方就是访问自定义域名的站点时,不充值的话会有广告跳转页,所以我现在也是处于观望的态度,先把coding的环境代码也先布置好,等它哪一天广告跳转页没了,就把域名指过去。
这里只介绍 coding 上面如何创建项目,以及把本地 hexo 部署到 coding 上面
把获取到了ssh配置_config.yml文件中的deploy下,如果是第一次使用 coding 的话,需要设置SSH公钥,生成的方法可以参考coding帮助中心, 其实和 github 配置一模一样的。
本地打开 id_rsa.pub 文件,复制其中全部内容,填写到SSH_RSA公钥key下的一栏,公钥名称可以随意起名字。完成后点击“添加”,然后输入密码或动态码即可添加完成。
添加后,在git bash命令输入:
ssh -T git@git.coding.net如果得到下面提示就表示公钥添加成功了:
Coding.net Tips : [Hello ! You've conected to Coding.net by SSH successfully! ]想要同时部署到2个平台,就要修改博客根目录下面的_config.yml文件中的deploy如下
根据Hexo官方文档需要修改成下面的形式
deploy:
type: git
message: [message]
repo:
github: <repository url>,[branch]
gitcafe: <repository url>,[branch]所以我是这样的
deploy:
- type: git
repo:
github: https://github.com/MuYunyun/MuYunyun.github.io.git,master
coding: git@git.coding.net:muyunyun/muyunyun.git,master最后使用部署命令就能把博客同步到coding上面:
hexo deploy -g将代码上传至coding之后我们就要开启pages服务了,在pages页面我们只需要将部署来源选择为master分支,然后将自定义域名填写我们自己购买的域名就可以了
现在要实现国内的走coding,海外的走github,只要配置2个CNAME就行。域名解析如下:
不久前年会主题征集活动中,我提交的主题是《在路上》,和骑手们一样,我们亦不是在路上呢?
恰逢踏入社会一年之际写下第一篇年终总结,百感交集,有初融入团队的喜悦、有独自完成需求的兴奋、有一次次团建的畅饮也有过为自己能力不足的懊恼以及与好友离别的感伤。
通过这篇总结,希望能记录些琐事,并给 2018 年的自己定下 promise。
按捺不住走出校园的兴奋,走入我达新世界的大门。当时未进公司的时候,在朋友圈中看到的小伙伴们的照片,当时心中一阵惊叹,"这么帅!!要拖后腿了",不曾想到后来几个月和每个人发生的故事,已然成为生命中不可或缺的色彩了。时隔一年当再次回味这张照片时,似乎里面藏着初心。
春节结束后公司如期举行了年会,我在倒数第二个节目中独奏了二胡~,前端部门的年会中奖率也是全公司最高的,一度让其他部门的人说是改了脚本o(╯□╰)o。运气也是实力的一部分吧,不过我没有中奖。再接着是为期 15 天的小黑屋封闭式开发快递模块,这也是我第一次感觉到了挫败感,让林师傅帮填了好多坑。期间李开复老师来参观我们公司,我也跑去趁了张合照。同时迎来了陪我渡过短暂岁月的小伙伴虾球。一只可爱的猫咪。现在在新主人家过得很好。
在往后的一段时间,前端部门内部进行了更细致的分工划分,我被划分到了直营业务组,主要负责 batman(客服关系系统) 以及 hawkeye(运维系统)的开发与维护,期间经历了并参与了 batman、hawkeye 的技术栈迭代,从老鹰眼的 reflux 到 redux,以及 batman 网关独立抽离成一个 ts 项目。为了更好的熟悉 react 全家桶的工作流程,五月份的时候在仿照 batman 和 hawkeye 写了个 demo,现在收获了几百的 Star,也算今年的一大收获吧。o(╯□╰)o
下面谈谈今年在做项目的收获和成长:
谈完收获再来谈谈不足:
分享一位同行的博客中让我感慨良多的话:行远自迩,登高自卑。在写这篇总结前我曾以为这句话是说当你登高的途中看到比你站在更高更远处的人的时候会产生自卑感,现在不经莞尔一笑,风起于青萍之末,浪成于微澜之间,那些让我高高仰望的人不正是有着一颗常人难能企及的大毅力和大心脏吗?而我呢,希望能离那群人能近一点是一点吧。想到现在负责的项目名为 batman,突然谐音想到了 better-man。新年计划做一个让别人靠得住的 better-man。
今年刷了好多动漫,整体偏热血、玄幻类型,也入了 B 站刷了几部小清新动漫,如四月是你的谎言、宝石之国~,和朋友一起刷了几部有意义的电影,比如爱乐之城、寻梦环游记~;另外从 4 月份开始使用网易云音乐来,累计听了七八千首歌吧,基本码代码的时候都会带着耳机~,以英文歌、民谣为主,我的歌单如下;
在游戏方面发挥稳定,王者荣耀上了最强王者以及为团队拿下个冠军,不过感觉花了太多时间在上面,浪费了不少原定的计划~,不过也算是青春的成长吧。公司年假即将会去曼巴玩上一段时间,也将算是我第一次出国。
看书方面主要是技术类的,大概阅读了 6、7 本,这个比较尴尬了,看书看得慢而且看过的知识点也不是完全吃透了,新年期待改善。个人产出方面也比较低产,翻译文章和原创文章加起来十几篇~,我把它们集合在了 blog这个项目里。不过也有值得高兴的事,搭建了自己的博客,并且写文章的深度自己感觉有所提高(虽然依然菜)。然后很遗憾的是今年的技术交流会一场也没参加成,怪自己的消息不灵通加上水平的不足。
这部分是对自己打算要成为一个 better-man 的一个 promise 吧。就结合文章中提到的不足点进行相应的改善(自己想到解决方案的先记下来了),也就是新年的计划。望监督。
| problen | flag |
|---|---|
| 知识点碎片化 | 对已有的知识点进行思维脑图的整理,对将来的知识点也采取思维脑图的方式进行学习 |
| 知识面广度和深度欠缺 | 参与到一个千星 Star 的开源项目的改善,提高阅读源码的能力,阅读 6 本技术书籍,阅读 1 本非技术书籍 |
| 项目优化方面没有用心 | 课外学习积累相关方面知识并尝试用到公司项目中 |
| 没去成技术交流会 | 带有目的性地参加 1 到 2 场前端技术交流会 |
| 沟通能力不足 | 避免讲话结巴,加强语言组织能力和逻辑能力,没想清楚问题之前不要轻易回答 |
| 效率不足 | 加强自己的自控能力,规定的时间做规定的事情,做到按时起睡,不晚于 8 点半起床 |
It need run yarn build && yarn deploy every time after update some document in blog, with ability of Github actions, the steps can be reduced.
function arrToValue (arr) {
const tmpArray = Array.prototype.toString
Array.prototype.toString = function () {
return this.join(',')
}
let result = arr + ''
Array.prototype.toString = tmpArray
return result
}
和下面代码返回结果是一样的,有什么区别吗?
console.log(['a', ['b', 'c'], 2, ['d', 'e', 'f', ['m', 'n']], 'g', 3, 4].join(','));
const 声明一个变量必须要赋初始值的啊
该系列文章在实现 cpreact 的同时理顺 React 框架的核心内容
先来回顾 React 的生命周期,用流程图表示如下:
该流程图比较清晰地呈现了 react 的生命周期。其分为 3 个阶段 —— 生成期,存在期,销毁期。
因为生命周期钩子函数存在于自定义组件中,将之前 _render 函数作些调整如下:
// 原来的 _render 函数,为了将职责拆分得更细,将 virtual dom 转为 real dom 的函数单独抽离出来
function vdomToDom(vdom) {
if (_.isFunction(vdom.nodeName)) { // 为了更加方便地书写生命周期逻辑,将解析自定义组件逻辑和一般 html 标签的逻辑分离开
const component = createComponent(vdom) // 构造组件
setProps(component) // 更改组件 props
renderComponent(component) // 渲染组件,将 dom 节点赋值到 component
return component.base // 返回真实 dom
}
...
}我们可以在 setProps 函数内(渲染前)加入 componentWillMount,componentWillReceiveProps 方法,setProps 函数如下:
function setProps(component) {
if (component && component.componentWillMount) {
component.componentWillMount()
} else if (component.base && component.componentWillReceiveProps) {
component.componentWillReceiveProps(component.props) // 后面待实现
}
}而后我们在 renderComponent 函数内加入 componentDidMount、shouldComponentUpdate、componentWillUpdate、componentDidUpdate 方法
function renderComponent(component) {
if (component.base && component.shouldComponentUpdate) {
const bool = component.shouldComponentUpdate(component.props, component.state)
if (!bool && bool !== undefined) {
return false // shouldComponentUpdate() 返回 false,则生命周期终止
}
}
if (component.base && component.componentWillUpdate) {
component.componentWillUpdate()
}
const rendered = component.render()
const base = vdomToDom(rendered)
if (component.base && component.componentDidUpdate) {
component.componentDidUpdate()
} else if (component && component.componentDidMount) {
component.componentDidMount()
}
if (component.base && component.base.parentNode) { // setState 进入此逻辑
component.base.parentNode.replaceChild(base, component.base)
}
component.base = base // 标志符
}测试如下用例:
class A extends Component {
componentWillReceiveProps(props) {
console.log('componentWillReceiveProps')
}
render() {
return (
<div>{this.props.count}</div>
)
}
}
class B extends Component {
constructor(props) {
super(props)
this.state = {
count: 1
}
}
componentWillMount() {
console.log('componentWillMount')
}
componentDidMount() {
console.log('componentDidMount')
}
shouldComponentUpdate(nextProps, nextState) {
console.log('shouldComponentUpdate', nextProps, nextState)
return true
}
componentWillUpdate() {
console.log('componentWillUpdate')
}
componentDidUpdate() {
console.log('componentDidUpdate')
}
click() {
this.setState({
count: ++this.state.count
})
}
render() {
console.log('render')
return (
<div>
<button onClick={this.click.bind(this)}>Click Me!</button>
<A count={this.state.count} />
</div>
)
}
}
ReactDOM.render(
<B />,
document.getElementById('root')
)页面加载时输出结果如下:
componentWillMount
render
componentDidMount
点击按钮时输出结果如下:
shouldComponentUpdate
componentWillUpdate
render
componentDidUpdate
在 react 中,diff 实现的思路是将新老 virtual dom 进行比较,将比较后的 patch(补丁)渲染到页面上,从而实现局部刷新;本文借鉴了 preact 和 simple-react 中的 diff 实现,总体思路是将旧的 dom 节点和新的 virtual dom 节点进行了比较,根据不同的比较类型(文本节点、非文本节点、自定义组件)调用相应的逻辑,从而实现页面的局部渲染。代码总体结构如下:
/**
* 比较旧的 dom 节点和新的 virtual dom 节点:
* @param {*} oldDom 旧的 dom 节点
* @param {*} newVdom 新的 virtual dom 节点
*/
function diff(oldDom, newVdom) {
...
if (_.isString(newVdom)) {
return diffTextDom(oldDom, newVdom) // 对比文本 dom 节点
}
if (oldDom.nodeName.toLowerCase() !== newVdom.nodeName) {
diffNotTextDom(oldDom, newVdom) // 对比非文本 dom 节点
}
if (_.isFunction(newVdom.nodeName)) {
return diffComponent(oldDom, newVdom) // 对比自定义组件
}
diffAttribute(oldDom, newVdom) // 对比属性
if (newVdom.children.length > 0) {
diffChild(oldDom, newVdom) // 遍历对比子节点
}
return oldDom
}下面根据不同比较类型实现相应逻辑。
首先进行较为简单的文本节点的比较,代码如下:
// 对比文本节点
function diffTextDom(oldDom, newVdom) {
let dom = oldDom
if (oldDom && oldDom.nodeType === 3) { // 如果老节点是文本节点
if (oldDom.textContent !== newVdom) { // 这里一个细节:textContent/innerHTML/innerText 的区别
oldDom.textContent = newVdom
}
} else { // 如果旧 dom 元素不为文本节点
dom = document.createTextNode(newVdom)
if (oldDom && oldDom.parentNode) {
oldDom.parentNode.replaceChild(dom, oldDom)
}
}
return dom
}对比非文本节点,其思路为将同层级的旧节点替换为新节点,代码如下:
// 对比非文本节点
function diffNotTextDom(oldDom, newVdom) {
const newDom = document.createElement(newVdom.nodeName);
[...oldDom.childNodes].map(newDom.appendChild) // 将旧节点下的元素添加到新节点下
if (oldDom && oldDom.parentNode) {
oldDom.parentNode.replaceChild(oldDom, newDom)
}
}对比自定义组件的思路为:如果新老组件不同,则直接将新组件替换老组件;如果新老组件相同,则将新组件的 props 赋到老组件上,然后再对获得新 props 前后的老组件做 diff 比较。代码如下:
// 对比自定义组件
function diffComponent(oldDom, newVdom) {
if (oldDom._component && (oldDom._component.constructor !== newVdom.nodeName)) { // 如果新老组件不同,则直接将新组件替换老组件
const newDom = vdomToDom(newVdom)
oldDom._component.parentNode.insertBefore(newDom, oldDom._component)
oldDom._component.parentNode.removeChild(oldDom._component)
} else {
setProps(oldDom._component, newVdom.attributes) // 如果新老组件相同,则将新组件的 props 赋到老组件上
renderComponent(oldDom._component) // 对获得新 props 前后的老组件做 diff 比较(renderComponent 中调用了 diff)
}
}遍历对比子节点的策略如下:
在 cpreact 的代码实现中,1 的目的降低了空间复杂度(避免了更深层次的遍历);2 的目的目前看来是少了一次新老类型的判断消耗。
代码如下:
// 对比子节点
function diffChild(oldDom, newVdom) {
const keyed = {}
const children = []
const oldChildNodes = oldDom.childNodes
for (let i = 0; i < oldChildNodes.length; i++) {
if (oldChildNodes[i].key) {
keyed[oldChildNodes[i].key] = oldChildNodes[i]
} else { // 如果不存在 key,则优先找到节点类型相同的元素
children.push(oldChildNodes[i])
}
}
let newChildNodes = newVdom.children
if (isArray(newVdom.children[0])) { // https://github.com/MuYunyun/cpreact/issues/9
newChildNodes = newVdom.children[0]
}
for (let i = 0; i < newChildNodes.length; i++) {
let child = null
if (keyed[newChildNodes[i].key]) {
child = keyed[newChildNodes[i].key]
keyed[newChildNodes[i].key] = undefined
} else { // 对应上面不存在 key 的情形
// 在新老节点相同位置上寻找相同类型的节点进行比较;如果不满足上述条件则直接将新节点插入;
if (children[i] && isSameNodeType(children[i], newChildNodes[i])) {
child = children[i]
children[i] = undefined
} else if (children[i] && !isSameNodeType(children[i], newChildNodes[i])) { // 不是相同类型,直接替代掉
children[i].replaceWith(newChildNodes[i])
continue
}
}
const result = diff(child, newChildNodes[i])
// 如果 child 为 null
if (result === newChildNodes[i]) {
oldDom.appendChild(vdomToDom(result))
}
}
}在生命周期的小节中,componentWillReceiveProps 方法还未跑通,稍加修改 setProps 函数即可:
/**
* 更改属性,componentWillMount 和 componentWillReceiveProps 方法
*/
function setProps(component, attributes) {
if (attributes) {
component.props = attributes // 这段逻辑对应上文自定义组件比较中新老组件相同时 setProps 的逻辑
}
if (component && component.base && component.componentWillReceiveProps) {
component.componentWillReceiveProps(component.props)
} else if (component && component.componentWillMount) {
component.componentWillMount()
}
}来测试下生命周期小节中最后的测试用例:
Especially thank simple-react for the guidance function of this library. At the meantime,respect for preact and react
研究 Promise 的动机大体有以下几点:
对其 api 的不熟悉以及对实现机制的好奇;
很多库(比如 fetch)是基于 Promise 封装的,那么要了解这些库的前置条件得先熟悉 Promise;
要了解其它更为高级的异步操作得先熟悉 Promise;
基于这些目的,实践了一个符合 Promise/A+ 规范的 repromise
本札记系列总共三篇文章,作为之前的文章 Node.js 异步异闻录 的拆分和矫正。
在实现一个符合 Promise/A+ 规范的 promise 之前,先了解下 Promise/A+ 核心,想更全面地了解可以阅读 Promise/A+规范
Promise.resolve() 括号内有 4 种情况
/* 跟 Promise 对象 */
Promise.resolve(Promise.resolve(1))
// Promise {state: "resolved", data: 1, callbackQueue: Array(0)}
/* 跟 thenable 对象 */
var thenable = {
then: function(resolve, reject) {
resolve(1)
}
}
Promise.resolve(thenable)
// Promise {state: "resolved", data: 1, callbackQueue: Array(0)}
/* 普通参数 */
Promise.resolve(1)
// Promise {state: "resolved", data: 1, callbackQueue: Array(0)}
/* 不跟参数 */
Promise.resolve()
// Promise {state: "resolved", data: undefined, callbackQueue: Array(0)}相较于 Promise.resolve(),Promise.reject() 原封不动地返回参数值
对于 Promise.all(arr) 来说,在参数数组中所有元素都变为决定态后,然后才返回新的 promise。
// 以下 demo,请求两个 url,当两个异步请求返还结果后,再请求第三个 url
const p1 = request(`http://some.url.1`)
const p2 = request(`http://some.url.2`)
Promise.all([p1, p2])
.then((datas) => { // 此处 datas 为调用 p1, p2 后的结果的数组
return request(`http://some.url.3?a=${datas[0]}&b=${datas[1]}`)
})
.then((data) => {
console.log(msg)
})对于 Promise.race(arr) 来说,只要参数数组有一个元素变为决定态,便返回新的 promise。
// race 译为竞争,同样是请求两个 url,当且仅当一个请求返还结果后,就请求第三个 url
const p1 = request(`http://some.url.1`)
const p2 = request(`http://some.url.2`)
Promise.race([p1, p2])
.then((data) => { // 此处 data 取调用 p1, p2 后优先返回的结果
return request(`http://some.url.3?value=${data}`)
})
.then((data) => {
console.log(data)
})通过下面这个案例,提供回调函数 Promise 化的思路。
function foo(a, b, cb) {
ajax(
`http://some.url?a=${a}&b=${b}`,
cb
)
}
foo(1, 2, function(err, data) {
if (err) {
console.log(err)
} else {
console.log(data)
}
})如上是一个传统回调函数使用案例,只要使用 Promise.wrap() 包裹 foo 函数就对其完成了 promise 化,使用如下:
const promiseFoo = Promise.wrap(foo)
promiseFoo(1, 2)
.then((data) => {
console.log(data)
})
.catch((err) => {
console.log(err)
})Promise.wrap 的实现逻辑也顺带列出来了:
Promise.wrap = function(fn) {
return funtion() {
const args = [].slice.call(arguments)
return new Promise((resolve, reject) => {
fn.apply(null, args.concat((err, data) => {
if (err) {
reject(err)
} else {
resolve(data)
}
}))
})
}
}这几个 api 比较简单,合起来一起带过
Promise.resolve(1)
.then((data) => {console.log(data)}, (err) => {console.log(err)}) // 链式调用,可以传一个参数(推荐),也可以传两个参数
.catch((err) => {console.log(err)}) // 捕获链式调用中抛出的错误 || 捕获变为失败态的值
.done() // 能捕获前面链式调用的错误(包括 catch 中),可以传两个参数也可不传事件循环:同步队列执行完后,在指定时间后再执行异步队列的内容。
之所以要单列事件循环,因为代码的执行顺序与其息息相关,此处用 setTimeout 来模拟事件循环;
下面代码片段中,① 处执行完并不会马上执行 setTimeout() 中的代码(③),而是此时有多少次 then 的调用,就会重新进入 ② 处多少次后,再进入 ③
excuteAsyncCallback(callback, value) {
const that = this
setTimeout(function() {
const res = callback(value) // ③
that.excuteCallback('fulfilled', res)
}, 4)
}
then(onResolved, onRejected) {
const promise = new this.constructor()
if (this.state !== 'PENDING') {
const callback = this.state === 'fulfilled' ? onResolved : onRejected
this.excuteAsyncCallback.call(promise, callback, this.data) // ①
} else {
this.callbackArr.push(new CallbackItem(promise, onResolved, onRejected)) // ②
}
return promise
}this.callbackArr.push() 中的 this 指向的是 ‘上一个’ promise,所以类 CallbackItem 中,this.promise 存储的是'下一个' promise(then 对象)。
class Promise {
...
then(onResolved, onRejected) {
const promise = new this.constructor()
if (this.state !== 'PENDING') { // 第一次进入 then,状态是 RESOLVED 或者是 REJECTED
const callback = this.state === 'fulfilled' ? onResolved : onRejected
this.excuteAsyncCallback.call(promise, callback, this.data) // 绑定 this 到 promise
} else { // 从第二次开始以后,进入 then,状态是 PENDING
this.callbackArr.push(new CallbackItem(promise, onResolved, onRejected)) // 这里的 this 也是指向‘上一个’ promise
}
return promise
}
...
}
class CallbackItem {
constructor(promise, onResolve, onReject) {
this.promise = promise // 相应地,这里存储的 promise 是来自下一个 then 的
this.onResolve = typeof(onResolve) === 'function' ? onResolve : (resolve) => {}
this.onReject = typeof(onRejected) === 'function' ? onRejected : (rejected) => {}
}
...
}实践的更多过程可以参考测试用例。有好的意见欢迎交流。
根基真的很重要!
var a = true;
setTimeout(function(){
a = false;
}, 100)
while(a){
console.log('while执行了')
}评语: 这是一个很有迷惑性的题目,不少人认为100ms之后,由于a变成了false,所以while就中止了,实际不是这样,因为JS是单线程的,所以进入while循环之后,没有「时间」(线程)去跑定时器了,所以这个代码跑起来是个死循环!
function foo() {
console.log('foo');
Promise.resolve().then(foo);
}
foo();
function bar() {
console.log('bar');
setTimeout(bar);
}
bar();function Foo() {
getName = function () { console.log(1) }
return this
}
Foo.getName = function () { console.log(2) }
Foo.prototype.getName = function () { console.log(3) }
var getName = function () { console.log(4) }
function getName () { console.log(5) }
Foo.getName()
getName()
Foo().getName()
getName()
new Foo.getName()
new Foo().getName()
new new Foo().getName()
// 2
// 4 考察变量提升
// 1 ※考察作用域
// 1
/* 后面三个考察运算符顺序 */
// 2
// 3
// 3用到的优先级: 对象访问 > 带参数的 new > 函数调用 > 不带参数的 new
再来一个日常经常写的代码片段:
var a = 1
a = a++
a ?
var b = 1
b = ++b
b ?回过头发现和优先级并无太大关系, 应该和运算符本身有关系。
输入: ['a', ['b', 'c'], 2, ['d', 'e', 'f'], 'g', 3, 4]
输出: a, b, c, 2, d, e, f, g, 3, 4
function convert(arr) {
return arr.toString()
}题目: 驼峰转化。将
fontSize转化为font-size。
function turnCamel(literal) {
return literal.replace(/[A-Z]/g, (match) => {
return '-' + match.toLowerCase()
})
}如果考虑首字母的话, 可以先 slice 一份出来再进行操作。
题目: 字符串中第一个出现一次的字符。eg: go => g; google => l
function find(str) {
for (let i of str) {
const reg = new RegExp(i, 'g')
if (str.match(reg).length === 1) {
return i
}
}
}题目: 将 1234567 变成 1,234,567, 即千分位标注
function SplitThousand(number) {
return (number).toLocaleString()
}正则:
function SplitThousand(str) {
return str.replace(/\d{1,3}(?=(\d{3})+$)/g, (value) => {
return value + ','
})
}题目,请写出下面的代码执行结果
var str = 'google';
var reg = /o/g;
console.log(reg.test(str))
console.log(reg.test(str))
console.log(reg.test(str))true
true
false解答:reg 执行完 test 会发生改变,观察如下:
console.log(reg.test(str), reg.lastIndex) // true 2
console.log(reg.test(str), reg.lastIndex) // true 3
console.log(reg.test(str), reg.lastIndex) // false 0数据结构在开发中是一种编程**的提炼,无关于用何种语言开发或者是哪种端开发。下列将笔者涉猎到的与前端相关的数据结构案例作如下总结:
| 数据结构 | 案例 |
|---|---|
| 栈 | FILO: 其它数据结构的基础,redux/koa2 中间件机制 |
| 队列 | FIFO:其它数据结构的基础 |
| 链表 | React 16 中的 Fiber 的优化 |
| 集合 | 对应 JavaScript 中的 Set |
| 字典 | 对应 JavaScript 中的 Map |
| 哈希表 | 一种特殊的字典,可以用来存储加密数据 |
| 树 | DOM TREE / HTML TREE / CSS TREE |
| 图 | 暂时没遇到,不过里面的 BFS/DFS 蛮常见 |
个人首页增加最近新增的前 10 篇文章列表
使用React技术栈搭建一个后台管理系统最初是为了上手公司的业务,后来发现这个项目还能把平时遇到的有趣的demo给整合进去。此文尝试对相关的技术栈以及如何在该项目中引人Redux进行分析。
小模块展示:
redux在项目中的运用demo展示
├── build.js 项目打包后的文件
├── config webpack配置文件
│ ├──...
│ ├──webpack.config.dev.js 开发环境配置
│ ├──webpack.config.prod.js 生产环境配置
├── node_modules node模块目录
├── public
│ └──index.html
├── scripts
│ ├── build.js 打包项目文件
│ ├── start.js 启动项目文件
│ └── test.js 测试项目文件
├── src
│ ├── client 汇聚(入口)目录
│ ├── common 核心目录
│ │ ├── actions redux中的action
│ │ ├── components 通用功能组件
│ │ ├── container 通用样式组件
│ │ ├── images
│ │ ├── pages 页面模块
│ │ ├── reducers redux中的reducer
│ │ ├── utils 工具类
│ │ │ ├── config.js 通用配置
│ │ │ ├── menu.js 菜单配置
│ │ │ └── ajax.js ajax模块(日后用到)
│ │ └── routes.js 前端路由
│ └── server 服务端目录(日后用到)
│ └── controller
├── .gitignore
├── package.json
├── README.md
└── yarn.lock
项目的初始结构和构造原因已罗列如上,由于过些日子会引人ts,所以项目结构必然还会改动,但肯定基于这基本雏形扩展的。
下面对目录结构作以下说明
| container | component | |
|---|---|---|
| 目的 | 如何工作(数据获取,状态更新) | 如何显示(样式,布局) |
| 是否在 Redux 数据流中 | 是 | 否 |
| 读取数据 | 从 Redux 获取 state | 从 props 获取数据 |
| 修改数据 | 向 Redux 派发 actions | 从 props 调用回调函数 |
| 实现方式 | 向react-redux生成 | 手写 |
虽然用到的技术栈众多,但是自己也谈不上熟练运用,多半是边查API边用的,所以只罗列些自己用相关的技术栈解决的点;
4月的时候 create-react-app 还是基于 webpack(1.x) 构建的,5月27号升到了webpack(2.6),于是我也进行了 webpack 的版本升级。
babel-plugin-import 是一个用于按需加载组件代码和样式的 babel 插件,使用此插件后,在引人 antd 相应模块就能实现按需引人,在config/webpack.config.dev.js 文件中作如下修改:
{
test: /\.(js|jsx)$/,
include: paths.appSrc,
loader: require.resolve('babel-loader'),
options: {
plugins: [
"transform-decorators-legacy", // 引人 ES7 的装饰器 @
['import', [{ libraryName: 'antd', style: true }]],
],
cacheDirectory: true,
},
},首先引人 less-loader 来加载 less 样式,同时修改 config/webpack.config.dev.js 文件
test: /\.less$/,
use: [
require.resolve('style-loader'),
require.resolve('css-loader'),
{
loader: require.resolve('postcss-loader'),
options: {
ident: 'postcss', //https://webpack.js.org/guides/migrating/#complex-options
plugins: () => [
require('postcss-flexbugs-fixes'),
autoprefixer({
browsers: [
'>1%',
'last 4 versions',
'Firefox ESR',
'not ie < 9', // React doesn't support IE8 anyway
],
flexbox: 'no-2009',
}),
],
},
},
{
loader: require.resolve('less-loader'),
options: {
modifyVars: { "@primary-color": "#1DA57A" }, // 这里利用了 less-loader 的 modifyVars 来进行主题配置, 变量和其他配置方式可以参考 [配置主题](https://ant.design/docs/react/customize-theme-cn) 文档。
},
},
],
},用到了 gh-pages ,使用 npm run deploy 一键发布到自己的gh-pages上,姑且把gh-pages当成生产环境吧,所以在修改config/webpack.config.dev.js 文件的同时也要对 config/webpack.config.prod.js 作出一模一样的修改。
alias: {
'react-native': 'react-native-web',
components: path.resolve(__dirname, '..') + '/src/common/components',
container: path.resolve(__dirname, '..') + '/src/common/container',
images: path.resolve(__dirname, '..') + '/src/common/images',
pages: path.resolve(__dirname, '..') + '/src/common/pages',
utils: path.resolve(__dirname, '..') + '/src/common/utils',
data: path.resolve(__dirname, '..') + '/src/server/data',
actions: path.resolve(__dirname, '..') + '/src/common/actions',
reducers: path.resolve(__dirname, '..') + '/src/common/reducers',
},配置了引用路径的缩写后,就可以在任意地方如这样引用,比如
import Table from 'components/table'antd是(蚂蚁金服体验技术部)经过大量的项目实践和总结,沉淀出的一个中台设计语言 Ant Design,使用者包括蚂蚁金服、阿里巴巴、口碑、美团、滴滴等一系列知名公司,而且我从他们的设计理念也学到了很多关于UI、UX的知识。
该项目采用的是antd最新的版本2.10.0,由于2.x的版本和1.x的版本还是相差蛮大的,之前参考的项目(基于1.x)改起来太费劲,所以在组件那块就干脆自己重新封装了一遍。这部分知识点建议多看文档,官方更新还是非常勤快的。
react-router 4.x和2.x的差异又是特别的大,召唤文档,网上基本上都还是2.x的教程,看过文档之后,反正简而言之其就是要让使用者更容易上手。印象最深的是以前嵌套路由写法在4.x中写到同层了。如下示例他们的效果是相同的。
2.x:
<Route path="/" component={App}>
<Route path="/aaaa" component={AAAA} />
<Route path="/bbbb" component={BBBB} />
</Route>4.x:
<Route path="/" component={App} />
<Route path="/aaaa" component={AAAA} />
<Route path="/bbbb" component={BBBB} />fetch 使用比较简单,基本的 promise 用法如下
fetch(url).then(response => response.json())
.then(data => console.log(data))
.catch(e => console.log("Oops, error", e))此外还能这样用
try {
let response = await fetch(url);
let data = await response.json();
console.log(data);
} catch(e) {
console.log("Oops, error", e);
}但是其简洁的特点是为了让我们可以自定义其扩展,还是其本身就还不完善呢?我在调用 JSONP 的请求时,发现其不支持对 JSONP 的调用,所幸社区还是很给力地找到了 fetch-jsonp 这个模块,实现了对百度音乐接口调用。fetch-jsonp使用也和 fetch 类似,代码如下
fetchJsonp(url,{method: 'GET'})
.then((res) =>res.json())
.then((data) => {})使用了redux也已经有段时日了,我对redux的定义就是更好的管理组件的状态,一旦应用的逻辑复杂起来,各种组件状态、界面耦合起来,就容易出岔子,redux就是为了解决这个而诞生的,让我们可以更多地关注UI层,而降低对状态的关注。
画了一幅比较简陋的图来说明 redux 的大致流程,假设首先通过鼠标点击页面上的按钮触发了一个行为(action),这时我们叫了一辆出租车 dispatch() 将这个 action 带到了终点站 store。这时候 store 就会通过 reducer 函数返回一个新的状态 state,从而改变 UI 显示。之前也写了篇深入Redux架构
下面通过把 代办事项 这个demo运用到后台管理系统中来讲解 Redux 在其中的运用。
首先,在入口目录创建 store
const store = createStore(rootReducer)
ReactDOM.render(
<Provider store={store}>
{ routes }
</Provider>,
document.getElementById('root')
);接着,我使用了 redux-actions 这个模块。使用 redux-actions 的好处是能简化大量对 action 的声明,以及能简化 reducer 的写法。
代办事项的 actions 文件片段(拿展示全部任务、已完成任务、未完成任务的 action 举例):
import { createAction } from 'redux-actions'
export const setVisibility = createAction('SET_VISIBILITY')没使用 redux-actions 时,actions 写法如下,可看出着实麻烦了不少,
export const setVisibility = (filter) => {
return {
type: "SET_VISIBILITY",
filter
}
}相应的代办事项的 reducers 文件片段:
export const setVisibility = handleActions({
'SET_VISIBILITY'(state, action) {
return { ...state, ...action.payload}
}
}, 'SHOW_ALL')使用 redux-actions 后,只要进行如下调用,reducers文件里的SET_VISIBILITY的 action 就能捕获到SHOW_ALL这个状态。
import { setVisibility } from 'actions/todoList'
@connect(
(state) => ({
setVisibility: state.setVisibility, // 这个 setVisibility 是取自 reducers 的
})
)
dispatch(this.props.dispatch(setVisibility('SHOW_ALL')))connect 来自 react-redux,这里的 @ 是 ES7里的装饰器的用法,使用它之后又能减少不少的代码量,原来还要写 mapStateToProps、mapDispatchToProps。
计划在该项目把平时工作、学习中遇到的react案例抽离成demo展现出来,所以以后还会多出一些模块。另外过段时间会在该项目中引人 typescript,如果还有精力的话,可以在这个项目上折腾下网关层。喜欢这个项目的话,点我 Star。
贴士:这篇文章主要是针对 vue 的双向绑定实现,React 中其实并没有双向绑定这一说。
近年来前端一个明显的开发趋势就是架构从传统的 MVC 模式向 MVVM 模式迁移。在传统的 MVC 下,当前前端和后端发生数据交互后会刷新整个页面,从而导致比较差的用户体验。因此我们通过 Ajax 的方式和网关 REST API 作通讯,异步的刷新页面的某个区块,来优化和提升体验。
在 MVVM 框架中,View(视图) 和 Model(数据) 是不可以直接通讯的,在它们之间存在着 ViewModel 这个中间介充当着观察者的角色。当用户操作 View(视图),ViewModel 感知到变化,然后通知 Model 发生相应改变;反之当 Model(数据) 发生改变,ViewModel 也能感知到变化,使 View 作出相应更新。这个一来一回的过程就是我们所熟知的双向绑定。
MVVM 框架的好处显而易见:当前端对数据进行操作的时候,可以通过 Ajax 请求对数据持久化,只需改变 dom 里需要改变的那部分数据内容,而不必刷新整个页面。特别是在移动端,刷新页面的代价太昂贵。虽然有些资源会被缓存,但是页面的 dom、css、js 都会被浏览器重新解析一遍,因此移动端页面通常会被做成 SPA 单页应用。由此在这基础上诞生了很多 MVVM 框架,比如 React.js、Vue.js、Angular.js 等等。
模拟 Vue 的双向绑定流,实现了一个简单的 MVVM 框架,从上图中可以看出虚线方形中就是之前提到的 ViewModel 中间介层,它充当着观察者的角色。另外可以发现双向绑定流中的 View 到 Model 其实是通过 input 的事件监听函数实现的,如果换成 React(单向绑定流) 的话,它在这一步交给状态管理工具(比如 Redux)来实现。另外双向绑定流中的 Model 到 View 其实各个 MVVM 框架实现的都是大同小异的,都用到的核心方法是 Object.defineProperty(),通过这个方法可以进行数据劫持,当数据发生变化时可以捕捉到相应变化,从而进行后续的处理。
一般会这样调用 Mvvm 框架
const vm = new Mvvm({
el: '#app',
data: {
title: 'mvvm title',
name: 'mvvm name'
},
})但是这样子的话,如果要得到 title 属性就要形如 vm.data.title 这样取得,为了让 vm.title 就能获得 title 属性,从而在 Mvvm 的 prototype 上加上一个代理方法,代码如下:
function Mvvm (options) {
this.data = options.data
const self = this
Object.keys(this.data).forEach(key =>
self.proxyKeys(key)
)
}
Mvvm.prototype = {
proxyKeys: function(key) {
const self = this
Object.defineProperty(this, key, {
get: function () { // 这里的 get 和 set 实现了 vm.data.title 和 vm.title 的值同步
return self.data[key]
},
set: function (newValue) {
self.data[key] = newValue
}
})
}
}实现了代理方法后,就步入主流程的实现
function Mvvm (options) {
this.data = options.data
// ...
observe(this.data)
new Compile(options.el, this)
}observer 的职责是监听 Model(JS 对象) 的变化,最核心的部分就是用到了 Object.defineProperty() 的 get 和 set 方法,当要获取 Model(JS 对象) 的值时,会自动调用 get 方法;当改动了 Model(JS 对象) 的值时,会自动调用 set 方法;从而实现了对数据的劫持,代码如下所示。
let data = {
number: 0
}
observe(data)
data.number = 1 // 值发生变化
function observe(data) {
if (!data || typeof(data) !== 'object') {
return
}
const self = this
Object.keys(data).forEach(key =>
self.defineReactive(data, key, data[key])
)
}
function defineReactive(data, key, value) {
observe(value) // 遍历嵌套对象
Object.defineProperty(data, key, {
get: function() {
return value
},
set: function(newValue) {
if (value !== newValue) {
console.log('值发生变化', 'newValue:' + newValue + ' ' + 'oldValue:' + value)
value = newValue
}
}
})
}运行代码,可以看到控制台输出 值发生变化 newValue:1 oldValue:0,至此就完成了 observer 的逻辑。
观测到变化后,我们总要通知给特定的人群,让他们做出相应的处理吧。为了更方便地理解,我们可以把订阅当成是订阅了一个微信公众号,当微信公众号的内容有更新时,那么它会把内容推送(update) 到订阅了它的人。
那么订阅了同个微信公众号的人有成千上万个,那么首先想到的就是要 new Array() 去存放这些人(html 节点)吧。于是就有了如下代码:
// observer.js
function Dep() {
this.subs = [] // 存放订阅者
}
Dep.prototype = {
addSub: function(sub) { // 添加订阅者
this.subs.push(sub)
},
notify: function() { // 通知订阅者更新
this.subs.forEach(function(sub) {
sub.update()
})
}
}
function observe(data) {...}
function defineReactive(data, key, value) {
var dep = new Dep()
observe(value) // 遍历嵌套对象
Object.defineProperty(data, key, {
get: function() {
if (Dep.target) { // 往订阅器添加订阅者
dep.addSub(Dep.target)
}
return value
},
set: function(newValue) {
if (value !== newValue) {
console.log('值发生变化', 'newValue:' + newValue + ' ' + 'oldValue:' + value)
value = newValue
dep.notify()
}
}
})
}初看代码也比较顺畅了,但可能会卡在 Dep.target 和 sub.update,由此自然而然地将目光移向 watcher,
// watcher.js
function Watcher(vm, exp, cb) {
this.vm = vm
this.exp = exp
this.cb = cb
this.value = this.get()
}
Watcher.prototype = {
update: function() {
this.run()
},
run: function() {
// ...
if (value !== oldVal) {
this.cb.call(this.vm, value) // 触发 compile 中的回调
}
},
get: function() {
Dep.target = this // 缓存自己
const value = this.vm.data[this.exp] // 强制执行监听器里的 get 函数
Dep.target = null // 释放自己
return value
}
}从代码中可以看到当构造 Watcher 实例时,会调用 get() 方法,接着重点关注 const value = this.vm.data[this.exp] 这句,前面说了当要获取 Model(JS 对象) 的值时,会自动调用 Object.defineProperty 的 get 方法,也就是当执行完这句的时候,Dep.target 的值传进了 observer.js 中的 Object.defineProperty 的 get 方法中。同时也一目了然地在 Watcher.prototype 中发现了 update 方法,其作用即触发 compile 中绑定的回调来更新界面。至此解释了 Observer 中 Dep.target 和 sub.update 的由来。
来归纳下 Watcher 的作用,其充当了 observer 和 compile 的桥梁。
1 在自身实例化的过程中,往订阅器(dep) 中添加自己
2 当 model 发生变动,dep.notify() 通知时,其能调用自身的 update 函数,并触发 compile 绑定的回调函数实现视图更新
最后再来看下生成 Watcher 实例的 compile.js 文件。
首先遍历解析的过程有多次操作 dom 节点,为提高性能和效率,会先将跟节点 el 转换成 fragment(文档碎片) 进行解析编译,解析完成,再将 fragment 添加回原来的真实 dom 节点中。代码如下:
function Compile(el, vm) {
this.vm = vm
this.el = document.querySelector(el)
this.fragment = null
this.init()
}
Compile.prototype = {
init: function() {
if (this.el) {
this.fragment = this.nodeToFragment(this.el) // 将节点转为 fragment 文档碎片
this.compileElement(this.fragment) // 对 fragment 进行编译解析
this.el.appendChild(this.fragment)
}
},
nodeToFragment: function(el) {
const fragment = document.createDocumentFragment()
let child = el.firstChild // △ 第一个 firstChild 是 text
while(child) {
fragment.appendChild(child)
child = el.firstChild
}
return fragment
},
compileElement: function(el) {...},
}这个简单的 mvvm 框架在对 fragment 编译解析的过程中对 {{}} 文本元素、v-on:click 事件指令、v-model 指令三种类型进行了相应的处理。
Compile.prototype = {
init: function() {
if (this.el) {
this.fragment = this.nodeToFragment(this.el) // 将节点转为 fragment 文档碎片
this.compileElement(this.fragment) // 对 fragment 进行编译解析
this.el.appendChild(this.fragment)
}
},
nodeToFragment: function(el) {...},
compileElement: function(el) {...},
compileText: function (node, exp) { // 对文本类型进行处理,将 {{abc}} 替换掉
const self = this
const initText = this.vm[exp]
this.updateText(node, initText) // 初始化
new Watcher(this.vm, exp, function(value) { // 实例化订阅者
self.updateText(node, value)
})
},
compileEvent: function (node, vm, exp, dir) { // 对事件指令进行处理
const eventType = dir.split(':')[1]
const cb = vm.methods && vm.methods[exp]
if (eventType && cb) {
node.addEventListener(eventType, cb.bind(vm), false)
}
},
compileModel: function (node, vm, exp) { // 对 v-model 进行处理
let val = vm[exp]
const self = this
this.modelUpdater(node, val)
node.addEventListener('input', function (e) {
const newValue = e.target.value
self.vm[exp] = newValue // 实现 view 到 model 的绑定
})
},
}在上述代码的 compileTest 函数中看到了期盼已久的 Watcher 实例化,对 Watcher 作用模糊的朋友可以往上回顾下 Watcher 的作用。另外在 compileModel 函数中看到了本文最开始提到的双向绑定流中的 View 到 Model 是借助 input 监听事件变化实现的。
本文记录了些阅读 mvvm 框架源码关于双向绑定的心得,并动手实践了一个简版的 mvvm 框架,不足之处在所难免,欢迎指正。
function quickSort(arr) {
if (arr.length === 0) {
return []
}
const basicValue = arr[Math.floor((arr.length - 1) / 2)] // 随意取,这里取中间
const left = []
const right = []
for (let i = 0; i < arr.length; i++) {
if (arr[i] < basicValue) {
left.push(arr[i])
}
if (arr[i] > basicValue) {
right.push(arr[i])
}
}
return quickSort(left).concat(basicValue, quickSort(right))
}当arr[i]的值等于basicValue时 这个值就被过滤掉了
React是最受欢迎的客户端 JavaScript 框架,但你知道吗(可以试试),你可以使用 React 在服务器端进行渲染?
假设你已经在客户端使用 React 构建了一个事件列表 app。该应用程序使用了您最喜欢的服务器端工具构建的API。几周后,用户告诉您,他们的页面没有显示在 Google 上,发布到 Facebook 时也显示不出来。 这些问题似乎是可以解决的,对吧?
您会发现,要解决这个问题,需要在初始加载时从服务器渲染 React 页面,以便来自搜索引擎和社交媒体网站的爬虫工具可以读取您的标记。有证据表明,Google 有时会执行 javascript 程序并且对生成的内容进行索引,但并不总是的。因此,如果您希望确保与其他服务(如Facebook,Twitter)有良好的SEO兼容性,那么始终建议使用服务器端渲染。
在本教程中,我们将逐步介绍服务器端的呈现示例。包括围绕与API交流的React应用程序的共同路障。
在本教程中,我们将逐步向您介绍服务器端的渲染示例。包括围绕着 APIS 交流一些在服务端渲染 React 应用程序的共同障碍。
可能您的团队谈论到服务端渲染的好处是首先会想到 SEO,但这并不是唯一的潜在好处。
更大的好处如下:服务器端渲染能更快地显示页面。使用服务器端渲染,您的服务器对浏览器进行响应是在您的 HTML 页面可以渲染的时候,因此浏览器可以不用等待所有的 JavaScript 被下载和执行就可以开始渲染。当浏览器下载并执行页面所需的 JavaScript 和其他资源时,不会出现 “白屏” 现象,而 “白屏” 这是在完全有客户端呈现的 React 网站中可能发生的情况。
接下来让我们来看看如何将服务器端渲染添加到一个基本的客户端渲染的使用Babel和Webpack的React应用程序中。我们的应用程序将增加从第三方 API 获取数据的复杂性。我们在GitHub上提供了相关代码,您可以在其中看到完整的示例。
提供的代码中只有一个 React 组件,`hello.js`,这个文件将向 ButterCMS 发出异步请求,并渲染返回的 JSON 列表的博文。ButterCMS 是一个基于API的博客引擎,可供个人使用,因此它非常适合测试现实生活中的用例。启动代码中连接着一个 API token,如果你想使用你自己的 API token 可以使用你的 GitHub 账号登入 ButterCMS。
import React from 'react';
import Butter from 'buttercms'
const butter = Butter('b60a008584313ed21803780bc9208557b3b49fbb');
var Hello = React.createClass({
getInitialState: function() {
return {loaded: false};
},
componentWillMount: function() {
butter.post.list().then((resp) => {
this.setState({
loaded: true,
resp: resp.data
})
});
},
render: function() {
if (this.state.loaded) {
return (
<div>
{this.state.resp.data.map((post) => {
return (
<div key={post.slug}>{post.title}</div>
)
})}
</div>
);
} else {
return <div>Loading...</div>;
}
}
});
export default Hello;启动器代码中包含以下内容:
要使应用运行,请先克隆资源库:
git clone ...
cd ..
安装依赖:
npm install
然后启动服务器:
npm run start
浏览器输入 http://localhost:8000 可以看到这个 app: (这里译者进行补充,package.json 里的 start 命令改为如下:"start": webpack-dev-server --watch)
如果您查看渲染页面的源代码,您将看到发送到浏览器的标记只是一个到 JavaScript 文件的链接。这意味着页面的内容不能保证被搜索引擎和社交媒体平台抓取:
接下来,我们将实现服务器端渲染,以便将完全生成的HTML发送到浏览器。如果要同时查看所有更改,请查看GitHub上的差异。
To get started, we'll install Express, a Node.js server side application framework:
开始前,让我们安装 Express,一个 Node.js 的服务器端应用程序框架:
npm install express --save
我们要创建一个渲染我们的 React 组件的服务器:
import express from 'express';
import fs from 'fs';
import path from 'path';
import React from 'react';
import ReactDOMServer from 'react-dom/server';
import Hello from './Hello.js';
function handleRender(req, res) {
// 把 Hello 组件渲染成 HTML 字符串
const html = ReactDOMServer.renderToString(<Hello />);
// 加载 index.html 的内容
fs.readFile('./index.html', 'utf8', function (err, data) {
if (err) throw err;
// 把渲染后的 React HTML 插入到 div 中
const document = data.replace(/<div id="app"><\/div>/, `<div id="app">${html}</div>`);
// 把响应传回给客户端
res.send(document);
});
}
const app = express();
// 服务器使用 static 中间件构建 build 路径
app.use('/build', express.static(path.join(__dirname, 'build')));
// 使用我们的 handleRender 中间件处理服务端请求
app.get('*', handleRender);
// 启动服务器
app.listen(3000);让我们分解下程序看看发生了什么事情...
handleRender 函数处理所有请求。在文件顶部导入的 ReactDOMServer 类提供了将 React 节点渲染成其初始 HTML 的 renderToString() 方法
ReactDOMServer.renderToString(<Hello />);这将返回 Hello 组件的 HTML ,我们将其注入到 index.html 的 HTML 中,从而生成服务器上页面的完整 HTML 。
const document = data.replace(/<div id="app"><\/div>/,`<div id="app">${html}</div>`);To start the server, update the start script in package.json and then run npm run start:
要启动服务器,请更新 `package.json` 中的起始脚本,然后运行 npm run start :
"scripts": {
"start": "webpack && babel-node server.js"
},
浏览 http://localhost:3000 查看应用程序。瞧!您的页面现在正在从服务器渲染出来了。但是有个问题,
如果您在浏览器中查看页面源码,您会注意到博客文章仍未包含在回复中。这是怎么回事?如果我们在Chrome中打开网络标签,我们会看到客户端上发生API请求。
虽然我们在服务器上渲染了 React 组件,但是 API 请求在 componentWillMount 中异步生成,并且组件在请求完成之前渲染。所以即使我们已经在服务器上完成渲染,但我们只是完成了部分。事实上,React repo 有一个 issue,超过 100 条评论讨论了这个问题和各种解决方法。
要解决这个问题,我们需要在渲染 Hello 组件之前确保 API 请求完成。这意味着要使 API 请求跳出 React 的组件渲染循环,并在渲染组件之前获取数据。我们将逐步介绍这一步,但您可以在GitHub上查看完整的差异。
To move data fetching before rendering, we'll install react-transmit:
要在渲染之前获取数据,我们需安装 react-transmit:
npm install react-transmit --save
React Transmit 给了我们优雅的包装器组件(通常称为“高阶组件”),用于获取在客户端和服务器上工作的数据。
这是我们使用 react-transmit 后的组件的代码:
import React from 'react';
import Butter from 'buttercms'
import Transmit from 'react-transmit';
const butter = Butter('b60a008584313ed21803780bc9208557b3b49fbb');
var Hello = React.createClass({
render: function() {
if (this.props.posts) {
return (
<div>
{this.props.posts.data.map((post) => {
return (
<div key={post.slug}>{post.title}</div>
)
})}
</div>
);
} else {
return <div>Loading...</div>;
}
}
});
export default Transmit.createContainer(Hello, {
// 必须设定 initiallVariables 和 ftagments ,否则渲染时会报错
initialVariables: {},
// 定义的方法名将成为 Transmit props 的名称
fragments: {
posts() {
return butter.post.list().then((resp) => resp.data);
}
}
});我们已经使用 Transmit.createContainer 将我们的组件包装在一个高级组件中,该组件可以用来获取数据。我们在 React 组件中删除了生命周期方法,因为无需两次获取数据。同时我们把 render 方法中的 state 替换成 props,因为 React Transmit 将数据作为 props 传递给组件。
为了确保服务器在渲染之前获取数据,我们导入 Transmit 并使用 Transmit.renderToString 而不是 ReactDOM.renderToString 方法
import express from 'express';
import fs from 'fs';
import path from 'path';
import React from 'react';
import ReactDOMServer from 'react-dom/server';
import Hello from './Hello.js';
import Transmit from 'react-transmit';
function handleRender(req, res) {
Transmit.renderToString(Hello).then(({reactString, reactData}) => {
fs.readFile('./index.html', 'utf8', function (err, data) {
if (err) throw err;
const document = data.replace(/<div id="app"><\/div>/, `<div id="app">${reactString}</div>`);
const output = Transmit.injectIntoMarkup(document, reactData, ['/build/client.js']);
res.send(document);
});
});
}
const app = express();
// 服务器使用 static 中间件构建 build 路径
app.use('/build', express.static(path.join(__dirname, 'build')));
// 使用我们的 handleRender 中间件处理服务端请求
app.get('*', handleRender);
// 启动服务器
app.listen(3000);重新启动服务器浏览到 http://localhost:3000。查看页面源代码,您将看到该页面现在完全呈现在服务器上!
我们做到了!在服务器上使用 React 可能很棘手,尤其是从 API 获取数据时。幸运的是,React社区正在蓬勃发展,并创造了许多有用的工具。如果您对构建在客户端和服务器上渲染的大型 React 应用程序的框架感兴趣,请查看 Walmart Labs 的 Electrode 或 Next.js。或者如果要在 Ruby 中渲染 React ,请查看 AirBnB 的 Hypernova 。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.