Build a GUI Interface which provides the user the facility to send the requests to the server. The server downloads the content based on the request and stores it temporarily in its own memory for a fixed time interval. The user will have the flexibility to see the content downloaded and indexed by the server and download it at his own convenience.
Let us suppose that if you want to download a large software or movie (GBs of data) but because of bandwidth being distributed among your friends, you would have to wait hours for such a huge data to get downloaded, as you will not be having enough bandwidth.One alternative to this problem is to stay awake at odd timings (3AM - 4AM) to download the data, which is very difficult and also unhealthy. Other solution may be to keep your laptop 'ON' all night. Which is also not desirous because it is not good for life of laptop. Both of these solutions require a lot of effort.With our software, we would simply send the request to the local server to download the data. The local server would schedule the downloading when the traffic is less on local network and will store the downloaded content in its own memory. Thereby, this method would not affect the browsing speed of your friends at the time when they want. You can sleep comfortably at night without keeping your laptop 'ON' all the time. At your convenience, you would be able to see the content downloaded by the server which is properly indexed. Thus you would have the flexibility to download the data as per your ease as well as at high speed provided by the intranet.
If two or more users are requesting same file to be downloaded via internet then server will have to download it once and then it can provide the same file to all the users. Indexing will provide future downloads of the same file as well as the downloading of content requested by your friends. As intranet speed is greater than internet speed file transfer will be at much higher speeds.
First of all to download any data from web we need a URL for that data. The URL constitutes a reference to the resource for the data. It is displayed in navigation bar of the browser. We can copy the URL from this navigation bar. We are building an extension to the Chrome browser which takes the URL from user to download the data and gives him choice to save data in preferred filename.
Phase1: When user wants to download some data he can click on the Chrome Extension Icon. Clicking on which will open a popup window. User can input the URL in the given text field and he/she can give preferred file name to save data under that name. To start download he/she can click on the download button below it.
CHROME BROWSER EXTENSION: There are three files in the folder DownManager.crx namely
icon.jpg (This is the icon displayed in extension) manifest.json (This is manifesto file contains information about extension we created such as version number, purpose, browser actions)popup.html (This html file displays a popup on clicking the extension)
The chrome extension shot is

Now user do not have to worry about anything else. Here comes the role of our layering design pattern, one script will call other, each have independent functionality and can be developed separately while providing easy interface to upper layer scripts. We will now see what is happening on server side.
Phase2:
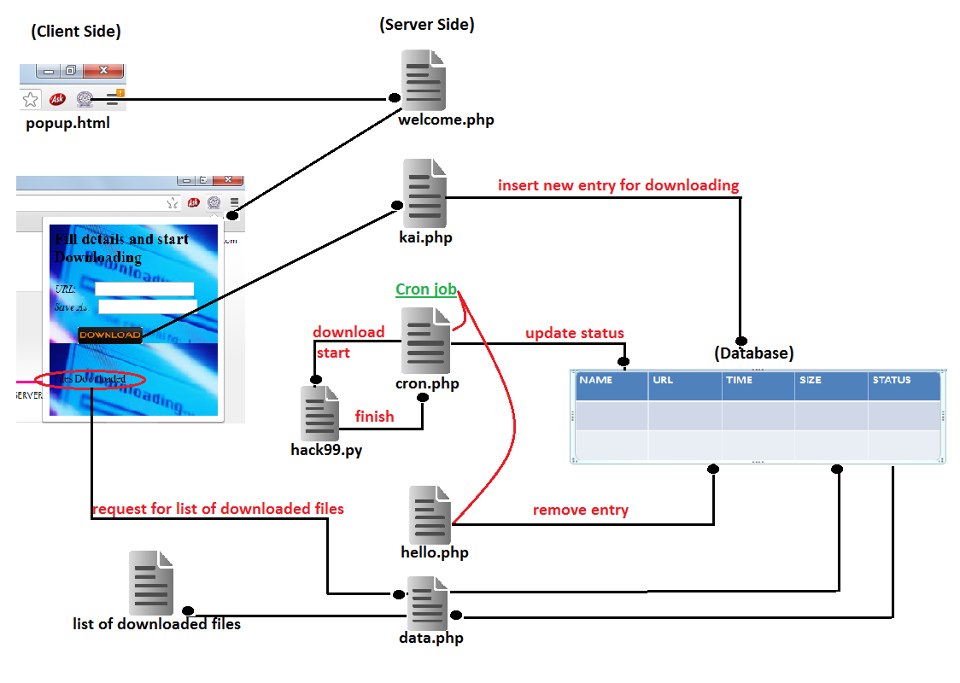
When popup.html is opened it calls the address of server requesting file Welcome.php, it also defines the size of popup that is going to be open.Now at server side script welcome.php comes in role, which displays the background image of popup, two text fields one for URL and other for File name under which data is suppose to be save, one submit button with name download on it, one link for accessing all the files that are already present in server.
Phase3:
When user fills this form and presses Download button URL and Filename is sent to the script Database.php. Database.php script finds out the size of data to be downloaded and current date.Now Database.php connects to the database which is present at server and verifies whether same URL is present in database or not. If same URL is present in database then it says that File already present on server else it enters a new entry in database corresponding to the new URL which is name of file, URL, size, date when it is requested and status. Status is kept as 0, which means file is not downloaded yet.
Phase4:
At server side using cron tab we can initiate any process any specific time automatically, for this purpose we have to update entry in cron file. If we want some process to automate at specific time then we have to define at what time we want process to start and we have to write corresponding execution command. So we have updated two entries one for cron.php which pick one entry from database that is suppose to be downloaded and other for Delete_file.php which removes older entries, we will discuss both of them one by one below.So when cron initiates cron.php it picks one entry from database in FCFS manner and pass URL of that entry to Download.py. Download.py file takes the URL and saves the file under the filename provided by user in same directory in which hack99.py is present.After finishing download by Download.py, cron.php updates the database by updating corresponding status entry of downloaded file by 1, which means file is completed downloading. hello.php file checks that if a file is older than a prespecified time then it removes that file from memory of server and also corresponding database entry.
Data.php shows the downloaded files whenever user ask for it. It traverse the database and list those.
The Schematic Diagram of project is
Currently we are searching file only on the basis of URL we can improve our search by searching file on the basis of URL, File size and File name in database.
We have to deal with the issue of when and which file to delete for that we can check the left memory space in server if it is less than some particular value then we can delete some file.
Any further idea, bug report or patch is welcome.
Simply fork the repo and clone it to your local machine and start contributing.
A tutorial on How to contribute to a Project on GitHub.

