nvidia-ai-iot / deepstream_tao_apps Goto Github PK
View Code? Open in Web Editor NEWSample apps to demonstrate how to deploy models trained with TAO on DeepStream
License: MIT License
Sample apps to demonstrate how to deploy models trained with TAO on DeepStream
License: MIT License



















































































































Hi,
I was working with deepstream-app before with face detection model and getting landmarks with user_meta.
Here , i can see in deepstream-faciallandmark-app, i can get face boxes with landmarks.
My question is how can i integrate gst-dsexample plugin with this? or any other way around?
Thanks.
Hi, I am attempting to build and run the Facial Landmark App. But encourtering the following problem. I am running this in the DeepStream 6 container image.
root@jn-dev-01:/opt/nvidia/deepstream/deepstream-6.0/deepstream_tao_apps/apps/tao_others/deepstream-faciallandmark-app# make
g++ -c -o deepstream_faciallandmark_app.o -fpermissive -Wall -Werror -DPLATFORM_TEGRA -I/opt/nvidia/deepstream/deepstream/sources/includes -I/opt/nvidia/deepstream/deepstream/sources/includes/cvcore_headers -I /usr/local/cuda-10.2/include `pkg-config --cflags gstreamer-1.0` -D_GLIBCXX_USE_CXX11_ABI=1 -Wno-sign-compare deepstream_faciallandmark_app.cpp
In file included from deepstream_faciallandmark_app.cpp:36:0:
/opt/nvidia/deepstream/deepstream/sources/includes/nvdsinfer_custom_impl.h:375:19: error: 'IPluginFactory' in namespace 'nvcaffeparser1' does not name a type
nvcaffeparser1::IPluginFactory *pluginFactory;
^~~~~~~~~~~~~~
/opt/nvidia/deepstream/deepstream/sources/includes/nvdsinfer_custom_impl.h:376:19: error: 'IPluginFactoryExt' in namespace 'nvcaffeparser1' does not name a type
nvcaffeparser1::IPluginFactoryExt *pluginFactoryExt;
^~~~~~~~~~~~~~~~~
/opt/nvidia/deepstream/deepstream/sources/includes/nvdsinfer_custom_impl.h:386:16: error: 'IPluginFactory' in namespace 'nvuffparser' does not name a type
nvuffparser::IPluginFactory *pluginFactory;
^~~~~~~~~~~~~~
/opt/nvidia/deepstream/deepstream/sources/includes/nvdsinfer_custom_impl.h:387:16: error: 'IPluginFactoryExt' in namespace 'nvuffparser' does not name a type
nvuffparser::IPluginFactoryExt *pluginFactoryExt;
^~~~~~~~~~~~~~~~~
Makefile:69: recipe for target 'deepstream_faciallandmark_app.o' failed
make: *** [deepstream_faciallandmark_app.o] Error 1
Running on an NVIDIA Jetson Nano
Hi all,
1- I want to know how the deep stream sdk can efficient for custom application, I know we can train the models with TLT on custom dataset and then deploy that model on deep stream, and that show me best result, but showing the results on screen isn’t enough in the business,maybe I want to crop the ROI and passed into another model, How flexible is it?
2- In my opinion, deep stream can’t efficient for custom business, is it possible to add this sdk into your project? If we want to when we see unknown object and the system active alarmed, is it possible? in my opinion, the deep stream sdk is only for to show the capability of that device not be expendable to custom project, right?
3- Suppose I trained a detection model (Face Detection) with TLT and deployed that model on deep stream and I want when the system see some people save some where, Is it possible in deep stream?
4- In the deep stream python apps, I see only ssdparser as detector, It is only supported that model? If I want to deploy detectnet_v2 detector Is it possible with python samples? If so, Is it work with ssdparserr sample?
5- Is it possible to use some plugins like tracker or decoder , … in custom python applications?
How to load yolov3/v4? Now I can't find ds-tlt in apps.
Hi!
I've managed to install the custom parsing plugins from the repo, and run the samples successfully.
However, when I try to run use these parsers for a model trained by me on TLT (SSD for person detection), It doesn't seem to show any detection.
Here's my trained model configuration. I'm only listing what's different from the sample configuration.
Architecture: SSD
Input dims: 3x1280x720
Num. classes: 1
I wonder if the plugins must be adapted to the specific configuration of the network (specially regarding the class numbers).
I have installed the custom libnvinfer plugin from TRTOSS and followed all the prerequisite material.
I was able to run frcnn but yolov3 yields an odd error, which goes as follows, despite using the -b option and setting batch-size=1 in the config file.
Warning: 'input-dims' parameter has been deprecated. Use 'infer-dims' instead.
Now playing: pgie_yolov3_tlt_config.txt
Opening in BLOCKING MODE
Opening in BLOCKING MODE
0:00:00.367867762 14858 0x559ac50b00 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1715> [UID = 1]: Trying to create engine from model files
ERROR: [TRT]: IPluginV2DynamicExt requires network without implicit batch dimension
Segmentation fault (core dumped)
My computer specification are:
Windows 10
cuda 10.1
cudnn 8.0.4
Nvidia geforce GTX 3080
tensorflow-gpu 2.3.0
tensorflow 2.3.0
I used this web(https://github.com/armaanpriyadarshan/Training-a-Custom-TensorFlow-2.x-Object-Detector) to install faster rcnn. When I trained faster RCNN, it appeared the question loss=Nan.
How do I pass out the object_list for each frame?Modify the post-handler?
I have trained a SSD model on TLT 2.0 and followed all the necessary steps mentioned to run on my Jetson Nano. I downloaded the open sourced Tensor RT for the batch tile plugin and successfully able to convert my .etlt file into an .engine file. Also, followed the steps to download the custom shared object library in this repo for custom bounding box parser.
Then, right before it begins to run inference on the video input - the deepstream app crashes with the following error below:
NvMMLiteOpen : Block : BlockType = 4
===== NVMEDIA: NVENC =====
NvMMLiteBlockCreate : Block : BlockType = 4
#assertion/home/nvidia/TensorRT/plugin/nmsPlugin/nmsPlugin.cpp,118
Aborted (core dumped)
Any information is greatly appreciated.
Hello. I have tested peopleSegNetV2 and peopleSegNet on a jetson Nano and on a jetson TX2.
I used a .jpg and a .h264 files from deepstream samples and as output I got black images and black videos without any detection.
I have TensorRT OSS plugin installed, deepstream 5.1, TensorRT 7.1.3, jetpack 4.5.1.
Using updated github files.
Deepstream sample apps works properly on the devices.
mero@Jetson-HC02:~/deepstream_tlt_apps$ export SHOW_MASK=1
mero@Jetson-HC02:~/deepstream_tlt_apps$ ./apps/tlt_segmentation/ds-tlt-segmentation -c configs/peopleSegNet_tlt/pgie_peopleSegNetv2_tlt_config.txt -i /opt/nvidia/deepstream/deepstream-5.1/samples/streams/sample_720p.jpg
Now playing: configs/peopleSegNet_tlt/pgie_peopleSegNetv2_tlt_config.txt
Opening in BLOCKING MODE
Opening in BLOCKING MODE
0:00:24.214130103 10905 0x557a39d640 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1702> [UID = 1]: deserialized trt engine from :/home/mero/deepstream_tlt_apps/models/peopleSegNet/peopleSegNetV2_resnet50.etlt_b1_gpu0_fp16.engine
INFO: [Implicit Engine Info]: layers num: 3
0 INPUT kFLOAT Input 3x576x960
1 OUTPUT kFLOAT generate_detections 100x6
2 OUTPUT kFLOAT mask_fcn_logits/BiasAdd 100x2x28x28
0:00:24.214316410 10905 0x557a39d640 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:1806> [UID = 1]: Use deserialized engine model: /home/mero/deepstream_tlt_apps/models/peopleSegNet/peopleSegNetV2_resnet50.etlt_b1_gpu0_fp16.engine
0:00:24.334049448 10905 0x557a39d640 INFO nvinfer gstnvinfer_impl.cpp:313:notifyLoadModelStatus:<primary-nvinference-engine> [UID 1]: Load new model:configs/peopleSegNet_tlt/pgie_peopleSegNetv2_tlt_config.txt sucessfully
Running...
NvMMLiteBlockCreate : Block : BlockType = 256
[JPEG Decode] BeginSequence Display WidthxHeight 1280x720
in videoconvert caps = video/x-raw(memory:NVMM), format=(string)RGBA, framerate=(fraction)1/1, width=(int)1280, height=(int)720
End of stream
Returned, stopping playback
[JPEG Decode] NvMMLiteJPEGDecBlockPrivateClose done
[JPEG Decode] NvMMLiteJPEGDecBlockClose done
Deleting pipeline
I wanted to ask if we need to install libnvinferplugin.so in DeepStream devel container too for TensorRT custom plugins to perform correctly in DeepStream.
Hi,
I am trying to clone the repository of the following project:
https://github.com/dws-pm/TorLAB.git
I've already installed git lfs but still get the same error.
How can I clone the repo?
Thanks in advance.
This gihub repo claims that the open sourced tensor RT (https://github.com/NVIDIA/TensorRT/tree/release/7.0) is not needed for faster rcnn, while the TLT getting started guide explicitly mentions it as a pre - requisite
Any information is helpful.
I used the following command and it loaded the engine successfully and then printed Running... but there is no result and it keeps running while there is only one image given.
./apps/ds-tlt -c configs/yolov4_tlt/pgie_yolov4_tlt_config.txt -i /home/images/img1.jpg -d -b 1
When doing git clone, i encounter this issue:
Git LFS: (0 of 10 files) 0 B / 338.10 MB
batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access.
error: failed to fetch some objects from 'https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps.git/info/lfs'
I have git-lsf installed, try to workaround by using git-lfs pull but it still fails.
I am trying to run the GazeNet TAO sample app on Jetson with following configuration:
NVIDIA Jetson AGX Xavier [16GB]
L4T 32.6.1 [ JetPack 4.6 ]
Ubuntu 18.04.5 LTS
Kernel Version: 4.9.253-tegra
CUDA 10.2.300
CUDA Architecture: 7.2
OpenCV version: 4.1.1
OpenCV Cuda: NO
CUDNN: 8.2.1.32
TensorRT: 8.0.1.6
Vision Works: 1.6.0.501
VPI: ii libnvvpi1 1.1.12 arm64 NVIDIA Vision Programming Interface library
Vulcan: 1.2.70
When I run the app with the command as mentioned in ReadME (with default sample config files)
./deepstream-gaze-app 2 /opt/nvidia/deepstream/deepstream-6.0/sources/deepstream_tao_apps/configs/facial_tao/sample_faciallandmarks_config.txt file:///home/nvidia/Pictures/face.jpg ./gazenet
It crashes with the following error:
Request sink_0 pad from streammux
Now playing: file:///home/nvidia/Pictures/face.jpg
Library Opened Successfully
Setting custom lib properties # 1
Adding Prop: config-file : ../../../configs/gaze_tao/sample_gazenet_model_config.txt
Inside Custom Lib : Setting Prop Key=config-file Value=../../../configs/gaze_tao/sample_gazenet_model_config.txt
0:00:03.325956146 22185 0x55a517f8f0 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<second-infer-engine1> NvDsInferContext[UID 2]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1900> [UID = 2]: deserialized trt engine from :/opt/nvidia/deepstream/deepstream-6.0/sources/deepstream_tao_apps/models/faciallandmark/faciallandmarks.etlt_b32_gpu0_int8.engine
INFO: [FullDims Engine Info]: layers num: 3
0 INPUT kFLOAT input_face_images:0 1x80x80 min: 1x1x80x80 opt: 32x1x80x80 Max: 32x1x80x80
1 OUTPUT kFLOAT softargmax/strided_slice_1:0 80 min: 0 opt: 0 Max: 0
2 OUTPUT kFLOAT softargmax/strided_slice:0 80x2 min: 0 opt: 0 Max: 0
0:00:03.326175740 22185 0x55a517f8f0 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<second-infer-engine1> NvDsInferContext[UID 2]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:2004> [UID = 2]: Use deserialized engine model: /opt/nvidia/deepstream/deepstream-6.0/sources/deepstream_tao_apps/models/faciallandmark/faciallandmarks.etlt_b32_gpu0_int8.engine
0:00:03.348156671 22185 0x55a517f8f0 INFO nvinfer gstnvinfer_impl.cpp:313:notifyLoadModelStatus:<second-infer-engine1> [UID 2]: Load new model:../../../configs/facial_tao/faciallandmark_sgie_config.txt sucessfully
0:00:03.348498992 22185 0x55a517f8f0 WARN nvinfer gstnvinfer.cpp:635:gst_nvinfer_logger:<primary-infer-engine1> NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::initialize() <nvdsinfer_context_impl.cpp:1161> [UID = 1]: Warning, OpenCV has been deprecated. Using NMS for clustering instead of cv::groupRectangles with topK = 20 and NMS Threshold = 0.5
0:00:03.384695424 22185 0x55a517f8f0 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<primary-infer-engine1> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1900> [UID = 1]: deserialized trt engine from :/opt/nvidia/deepstream/deepstream-6.0/sources/deepstream_tao_apps/models/faciallandmark/facenet.etlt_b1_gpu0_int8.engine
INFO: [Implicit Engine Info]: layers num: 3
0 INPUT kFLOAT input_1 3x416x736
1 OUTPUT kFLOAT output_bbox/BiasAdd 4x26x46
2 OUTPUT kFLOAT output_cov/Sigmoid 1x26x46
0:00:03.384832039 22185 0x55a517f8f0 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<primary-infer-engine1> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:2004> [UID = 1]: Use deserialized engine model: /opt/nvidia/deepstream/deepstream-6.0/sources/deepstream_tao_apps/models/faciallandmark/facenet.etlt_b1_gpu0_int8.engine
0:00:03.387896538 22185 0x55a517f8f0 INFO nvinfer gstnvinfer_impl.cpp:313:notifyLoadModelStatus:<primary-infer-engine1> [UID 1]: Load new model:../../../configs/facial_tao/config_infer_primary_facenet.txt sucessfully
Decodebin child added: source
Decodebin child added: decodebin0
Running...
Decodebin child added: nvjpegdec0
In cb_newpad
###Decodebin pick nvidia decoder plugin.
0:00:03.417211615 22185 0x55a5158d40 WARN nvvideoconvert gstnvvideoconvert.c:3098:gst_nvvideoconvert_transform:<source_nvvidconv> error: Memory Compatibility Error:Input surface gpu-id doesnt match with configured gpu-id for element, please allocate input using unified memory, or use same gpu-ids OR, if same gpu-ids are used ensure appropriate Cuda memories are used
0:00:03.417257217 22185 0x55a5158d40 WARN nvvideoconvert gstnvvideoconvert.c:3098:gst_nvvideoconvert_transform:<source_nvvidconv> error: surface-gpu-id=604095472,source_nvvidconv-gpu-id=0
0:00:03.417366983 22185 0x55a5158d40 ERROR nvvideoconvert gstnvvideoconvert.c:3484:gst_nvvideoconvert_transform: buffer transform failed
ERROR from element source_nvvidconv: Memory Compatibility Error:Input surface gpu-id doesnt match with configured gpu-id for element, please allocate input using unified memory, or use same gpu-ids OR, if same gpu-ids are used ensure appropriate Cuda memories are used
Error details: /dvs/git/dirty/git-master_linux/deepstream/sdk/src/gst-plugins/gst-nvvideoconvert/gstnvvideoconvert.c(3098): gst_nvvideoconvert_transform (): /GstPipeline:pipeline/GstBin:source-bin-00/Gstnvvideoconvert:source_nvvidconv:
surface-gpu-id=604095472,source_nvvidconv-gpu-id=0
Returned, stopping playback
Deserializing engine from: ./gazeinfer_impl/../../../../models/gazenet/gazenet_facegrid.etlt_b8_gpu0_fp16.engineThe logger passed into createInferRuntime differs from one already provided for an existing builder, runtime, or refitter. TensorRT maintains only a single logger pointer at any given time, so the existing value, which can be retrieved with getLogger(), will be used instead. In order to use a new logger, first destroy all existing builder, runner or refitter objects.
Average fps 0.000233
Totally 0 faces are inferred
Deleting pipeline
I successfully installed deepstream -5.0 on my Jetson Nano. I have also trained a faster rcnn model using TLT 2.0 and generated the appropriate .engine file.
My goal is to deploy it using deepstream 5.0, i am following the instructions here to install the respective pre requisites:
https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/#intg_fasterrcnn_model
The 2 pre requsities were installing the custom parsers which i successfully did using this repository (the metropolis documentation mentioned a link to gitlab which is broken) and the other one is downloading the Tensor RT open source to get the custom plugins specifically: cropandresize plugin and the proposal plugin.
So, I am trying to install this as mentioned onto my jetson nano:
https://github.com/NVIDIA/TensorRT
It is not installing at all; any help is greatly appreciated.
Hello, I tried to run the mrcnn example, but I couldn't get bounding boxes and masks as shown in https://developer.nvidia.com/blog/training-instance-segmentation-models-using-maskrcnn-on-the-transfer-learning-toolkit/
When running mrcnn, I got no error and the output is just the original input video. I am using Deepstream 5.0 GA docker.
Hi
I tried to follow the instructions right HERE to build the plugin on Jetson, here is my environment
Device: Jetson Nano
JetPack: 4.4
TensorRT: 7.1.3
CUDA: 10.2
I upgraded CMake to 3.13.5, and got an error while runring the following command under the path "~/TensorRT/build"
/usr/local/bin/cmake .. -DGPU_ARCHS="53 62 72" -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=pwd/out
Here is the error
Building for TensorRT version: 7.1.3, library version: 7
-- The CUDA compiler identification is unknown
CMake Error at CMakeLists.txt:46 (project):
No CMAKE_CUDA_COMPILER could be found.Tell CMake where to find the compiler by setting either the environment
variable "CUDACXX" or the CMake cache entry CMAKE_CUDA_COMPILER to the full
path to the compiler, or to the compiler name if it is in the PATH.-- Configuring incomplete, errors occurred!
See also "/home/jetbot/TensorRT/build/CMakeFiles/CMakeOutput.log".
See also "/home/jetbot/TensorRT/build/CMakeFiles/CMakeError.log".
Does anyone know the possible root cuases? Thanks in Advance.
Going through the README here -> https://github.com/NVIDIA-AI-IOT/deepstream_tao_apps/tree/master/apps/tao_others/deepstream-gaze-app
I believe I have all the prerequisites in order, however I am unable to make gazeiner_impl
jn@jn-ds6:~/deepstream_tao_apps/apps/tao_others/deepstream-gaze-app/gazeinfer_impl$ make
-fPIC -DDS_VERSION="6.0.0" -I /usr/local/cuda-10.2/include -I ../../../includes -I /opt/nvidia/deepstream/deepstream/sources/gst-plugins/gst-nvdsvideotemplate/includes -I /opt/nvidia/deepstream/deepstream/sources/includes -I /opt/nvidia/deepstream/deepstream/sources/includes/cvcore_headers -I ../../deepstream-faciallandmark-app -I ../ -pthread -I/usr/include/gstreamer-1.0 -I/usr/include/orc-0.4 -I/usr/include/gstreamer-1.0 -I/usr/include/glib-2.0 -I/usr/lib/aarch64-linux-gnu/glib-2.0/include
g++ -c -o gazeinfer.o -fPIC -DDS_VERSION=\"6.0.0\" -I /usr/local/cuda-10.2/include -I ../../../includes -I /opt/nvidia/deepstream/deepstream/sources/gst-plugins/gst-nvdsvideotemplate/includes -I /opt/nvidia/deepstream/deepstream/sources/includes -I /opt/nvidia/deepstream/deepstream/sources/includes/cvcore_headers -I ../../deepstream-faciallandmark-app -I ../ -pthread -I/usr/include/gstreamer-1.0 -I/usr/include/orc-0.4 -I/usr/include/gstreamer-1.0 -I/usr/include/glib-2.0 -I/usr/lib/aarch64-linux-gnu/glib-2.0/include gazeinfer.cpp
gazeinfer.cpp:42:10: fatal error: nvdscustomlib_base.hpp: No such file or directory
#include "nvdscustomlib_base.hpp"
^~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Makefile:69: recipe for target 'gazeinfer.o' failed
make: *** [gazeinfer.o] Error 1
Running JetPack 4.5.1 and DeepStream 6 EA.
From this table, TRT_OSS_CHECKOUT_TAG is empty, so I guess I should use: git clone https://github.com/nvidia/TensorRT but with an empty tag, it will pull TRT 8.0.X instead of TRT 7.2.X. So what tag should I use for DS 5.1?
like the yolov4's detection custom parse function implemented in this repo, its output is not identity to the tao output. I know it is because the yolov4 parse need a ratio param, which is computed from frame_original_h, frame_original_w, network_input_w and network_input_w, but in current detection parse function interface, the frame_orignal_h and orignal_w can not be obtained yet.
So, I think the current detection parse function interface should fix this bug like to add feild like frame_orignal_h and frame_orignal_w in the NvDsInferNetworkInfo struct.
current:
typedef struct
{
/** Holds the input width for the model. /
unsigned int width;
/* Holds the input height for the model. /
unsigned int height;
/* Holds the number of input channels for the model. /
unsigned int channels;
} NvDsInferNetworkInfo;
after added:
typedef struct
{
/* Holds the input width for the model. /
unsigned int width;
/* Holds the input height for the model. /
unsigned int height;
/* Holds the number of input channels for the model. */
unsigned int channels;
unsigned int frame_orignal_h;
unsigned int frame_orignal_w;
} NvDsInferNetworkInfo;
Hi all,
I want to run deepstream_test_1.ipynb on PC has ubuntu 18.04,
in the import pyds, I get that error.
I trained a resnet34_yolov4 model with tlt and tested the exported model inference via the yolov4 Jupiter notebook and it works fine. However, when testing with deepstream, the model output is completely wrong. The output is very small dimensions (x,y values of < 10 and w,h values of < 1 (always almost 0 or a very small number)) with wrong classes predictions. Is this caused by the custom batched NMS functions?
I followed the commands inside:
Deepstream 5.0/samples/configs/tlt_pretrained_model/README
mkdir -p ../../models/tlt_pretrained_models/mrcnn&& \
wget https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps/blob/master/models/mrcnn/mask_rcnn_resnet50.etlt?raw=true \
-O ../../models/tlt_pretrained_models/mrcnn/mask_rcnn_resnet50.etlt && \
wget https://raw.githubusercontent.com/NVIDIA-AI-IOT/deepstream_tlt_apps/master/models/mrcnn/cal.bin \
-O ../../models/tlt_pretrained_models/mrcnn/cal.bin
To download maskrcnn model files but it gives an 404 error, github link on this blogpost also redirects to https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps/tree/master/models/mrcnn
when i visited the page i got to know these files are not commited to master branch yet.
Also these files are present in temp branch so i tried to modify the link to make it work but it only downloads 11kb of data.
Something issue with github LFS files.
Please review the README instructions.
Hi
I want to run sample of detectnet_v2_tlt on jetson nano.
my jetson has:
jetpack 4.4 DP
TensorRT 7.1
Cuda 10.2
I installed Deep stream with this way :
$ sudo tar -xvpf deepstream_sdk_v5.0.0_jetson.tbz2 -C /
$ cd /opt/nvidia/deepstream/deepstream-5.0
$ sudo ./install.sh
$ sudo ldconfig
I follow all the commnad in the repo except TRT OS.
when I run this cammand I get this error:
./deepstream-custom -c pgie_detectnet_v2_tlt_config.txt -i sample_720p.h264
nvbuf_utils: Could not get EGL display connection
One element could not be created. Exiting.
Environment:
Device: Tesla T4
Cuda Version: 10.2
Tensorrt version: 7.0
Docker image: docker pull nvcr.io/nvidia/deepstream:5.0-20.07-triton
Models downloaded from: https://nvidia.box.com/shared/static/i1cer4s3ox4v8svbfkuj5js8yqm3yazo.zip
Command:
./ds-tlt -c /opt/nvidia/deepstream/deepstream-5.0/samples/deepstream_tlt_apps/configs/yolov3_tlt/pgie_yolov3_tlt_config.txt -i /opt/nvidia/deepstream/deepstream-5.0/samples/streams/sample_720p.h264 -b 2
Output Error:
WARNING: Overriding infer-config batch-size (1) with number of sources (2)
Now playing: /opt/nvidia/deepstream/deepstream-5.0/samples/deepstream_tlt_apps/configs/yolov3_tlt/pgie_yolov3_tlt_config.txt
0:00:00.737391560 396 0x563947a11610 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1715> [UID = 1]: Trying to create engine from model files
ERROR: ../nvdsinfer/nvdsinfer_func_utils.cpp:33 [TRT]: UffParser: Validator error: FirstDimTile_2: Unsupported operation _BatchTilePlugin_TRT
parseModel: Failed to parse UFF model
ERROR: tlt/tlt_decode.cpp:274 failed to build network since parsing model errors.
ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:797 Failed to create network using custom network creation function
ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:862 Failed to get cuda engine from custom library API
0:00:00.944565439 396 0x563947a11610 ERROR nvinfer gstnvinfer.cpp:613:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1735> [UID = 1]: build engine file failed
Segmentation fault (core dumped)

I have also followed:
https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps/tree/master/TRT-OSS/Jetson
But still the error persists:
ERROR: …/nvdsinfer/nvdsinfer_model_builder.cpp:1523 Deserialize engine failed because file path: /opt/nvidia/deepstream/deepstream-5.1/sources/deepstream_python_apps/apps/deepstream-imagedata-multistream/yolov3_resnet18.etlt_b1_gpu0_fp16.engine open error
0:00:11.954855314 2771 0x22e4ac0 WARN nvinfer gstnvinfer.cpp:616:gst_nvinfer_logger: NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1691> [UID = 1]: deserialize engine from file :/opt/nvidia/deepstream/deepstream-5.1/sources/deepstream_python_apps/apps/deepstream-imagedata-multistream/yolov3_resnet18.etlt_b1_gpu0_fp16.engine failed
0:00:11.954914143 2771 0x22e4ac0 WARN nvinfer gstnvinfer.cpp:616:gst_nvinfer_logger: NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:1798> [UID = 1]: deserialize backend context from engine from file :/opt/nvidia/deepstream/deepstream-5.1/sources/deepstream_python_apps/apps/deepstream-imagedata-multistream/yolov3_resnet18.etlt_b1_gpu0_fp16.engine failed, try rebuild
0:00:11.954933439 2771 0x22e4ac0 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1716> [UID = 1]: Trying to create engine from model files
ERROR: …/nvdsinfer/nvdsinfer_func_utils.cpp:33 [TRT]: UffParser: Could not read buffer.
parseModel: Failed to parse UFF model
ERROR: tlt/tlt_decode.cpp:274 failed to build network since parsing model errors.
ERROR: …/nvdsinfer/nvdsinfer_model_builder.cpp:797 Failed to create network using custom network creation function
ERROR: …/nvdsinfer/nvdsinfer_model_builder.cpp:862 Failed to get cuda engine from custom library API
0:00:12.046943291 2771 0x22e4ac0 ERROR nvinfer gstnvinfer.cpp:613:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1736> [UID = 1]: build engine file failed
Segmentation fault (core dumped)
Please help.
Hi, does Deepstream support m3u8 live stream video as input? If yes, how to build the pipeline to capture and decode input?
I want to run frcnn model from model/frcnn/faster_rcnn_resnet10.etlt. However when I run with command ./deepstream-custom -c pgie_frcnn_tlt_config.txt -i ./sample_720p.h264 ,error happend.
nvidia@nvidia-X10SRA:~/zongxp/tlt/deepstream_tlt_apps$ ./deepstream-custom -c pgie_frcnn_tlt_config.txt -i ../deepstream_tlt_apps_bak/sample_720p.h264 Now playing: pgie_frcnn_tlt_config.txt 0:00:00.528579923 10118 0x55ae34a35b00 INFO nvinfer gstnvinfer.cpp:602:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1591> [UID = 1]: Trying to create engine from model files parseModel: Failed to open TLT encoded model file /home/nvidia/zongxp/tlt/deepstream_tlt_apps/./models/frcnn/faster_rcnn_resnet10.etlt ERROR: tlt/tlt_decode.cpp:274 failed to build network since parsing model errors. ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:797 Failed to create network using custom network creation function ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:862 Failed to get cuda engine from custom library API 0:00:00.529707445 10118 0x55ae34a35b00 ERROR nvinfer gstnvinfer.cpp:596:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1611> [UID = 1]: build engine file failed Segmentation fault (core dumped)
I have no changed anything, and my env is cuda10.2,trt 7.0
Hello,
1- This repo only work on jetpack 4.4 and deepstream 5.0 and TLT 2.0?
2- For Detectnet-V2 , is it possible to run multi-stream RTSP support? HOW?
3- If I want to run other codes along with deep stream, I want to do multi-stream RTSP decoding with HW deocer of jetson nano and pass some RTPS decoded to deep stream your repo and some RTSP decoded to my own python code for other progressing, Is is possible? I want to do this with docker.
4- In the models folder, only bin and etlt file existed, Is it enough for running? and If I want to put my training models ones of six-models but different input size and dataset, Is it possible to run with this repo codes related to its model?
5- Deep stream accept both TensorRT engine file and etlt file, but the TensorRT engine file is hardware dependent. Which mode has high FPS in inference?
[Environment]
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 15110 MBytes (15843721216 bytes)
(40) Multiprocessors, ( 64) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 179 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
[Command]
./deepstream-custom -c pgie_yolov3_tlt_config.txt -i /home/topsci/workspace/test/test1.jpg
[Output]
Now playing: pgie_yolov3_tlt_config.txt
0:00:00.427745155 18888 0x55d0613cf030 INFO nvinfer gstnvinfer.cpp:602:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1591> [UID = 1]: Trying to create engine from model files
ERROR: ../nvdsinfer/nvdsinfer_func_utils.cpp:31 [TRT]: UffParser: UFF buffer empty
parseModel: Failed to parse UFF model
ERROR: tlt/tlt_decode.cpp:274 failed to build network since parsing model errors.
ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:797 Failed to create network using custom network creation function
ERROR: ../nvdsinfer/nvdsinfer_model_builder.cpp:862 Failed to get cuda engine from custom library API
0:00:00.488408775 18888 0x55d0613cf030 ERROR nvinfer gstnvinfer.cpp:596:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1611> [UID = 1]: build engine file failed
Segmentation fault (core dumped)
If run the code below,will directory of pwd be created?
git clone -b release/6.0 https://github.com/nvidia/TensorRT cd TensorRT/ git submodule update --init --recursive
I created the directory of pwd after running below code.
Then I continue run the code below.
export TRT_SOURCE=pwd cd $TRT_SOURCE mkdir -p build && cd build cmake .. -DGPU_ARCHS=61 -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=pwd/out -DCUDA_VERSION=10.0
It shows below.
Building for TensorRT version: 6.0.1.0, library version: 6.0.1
-- Targeting TRT Platform: x86_64
-- CUDA version set to 10.0
-- cuDNN version set to 7.5
-- Protobuf version set to 3.0.0
-- Found CUDA: /usr/local/cuda-10.0 (found suitable version "10.0", minimum required is "10.0")
-- Using libprotobuf /DATA/hhyang/tools/TensorRT/build/third_party.protobuf/lib/libprotobuf.a
-- ========================= Importing and creating target nvinfer ==========================
-- Looking for library nvinfer
-- Library that was found nvinfer_LIB_PATH-NOTFOUND
-- ========================= Importing and creating target nvuffparser ==========================
-- Looking for library nvparsers
-- Library that was found nvparsers_LIB_PATH-NOTFOUND
-- Protobuf proto/trtcaffe.proto -> proto/trtcaffe.pb.cc proto/trtcaffe.pb.h
-- /DATA/hhyang/tools/TensorRT/build/parsers/caffe
Summary
-- CMake version : 3.13.5
-- CMake command : /home/hhyang/cmake/bin/cmake
-- System : Linux
-- C++ compiler : /usr/bin/g++
-- C++ compiler version : 5.4.0
-- CXX flags : -Wno-deprecated-declarations -DBUILD_SYSTEM=cmake_oss -Wall -Wno-deprecated-declarations -Wno-unused-function -Wno-unused-but-set-variable -Wnon-virtual-dtor
-- Build type : Release
-- Compile definitions : _PROTOBUF_INSTALL_DIR=/DATA/hhyang/tools/TensorRT/build;ONNX_NAMESPACE=onnx2trt_onnx
-- CMAKE_PREFIX_PATH :
-- CMAKE_INSTALL_PREFIX : /usr/lib/aarch64-linux-gnu/..
-- CMAKE_MODULE_PATH :
-- ONNX version : 1.3.0
-- ONNX NAMESPACE : onnx2trt_onnx
-- ONNX_BUILD_TESTS : OFF
-- ONNX_BUILD_BENCHMARKS : OFF
-- ONNX_USE_LITE_PROTO : OFF
-- ONNXIFI_DUMMY_BACKEND : OFF
-- Protobuf compiler :
-- Protobuf includes :
-- Protobuf libraries :
-- BUILD_ONNX_PYTHON : OFF
-- GPU_ARCH defined as 61. Generating CUDA code for SM 61
-- Found TensorRT headers at /DATA/hhyang/tools/TensorRT/include
-- Find TensorRT libs at /DATA/hhyang/tools/TensorRT-6.0.1.5/lib/libnvinfer.so;/DATA/hhyang/tools/TensorRT-6.0.1.5/lib/libnvinfer_plugin.so
-- Adding new sample: sample_char_rnn
-- - Parsers Used: none
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_dynamic_reshape
-- - Parsers Used: onnx
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_fasterRCNN
-- - Parsers Used: caffe
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_googlenet
-- - Parsers Used: caffe
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_int8
-- - Parsers Used: caffe
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_int8_api
-- - Parsers Used: onnx
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_mlp
-- - Parsers Used: caffe
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_mnist
-- - Parsers Used: caffe
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_mnist_api
-- - Parsers Used: caffe
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_movielens
-- - Parsers Used: uff
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_movielens_mps
-- - Parsers Used: uff
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_nmt
-- - Parsers Used: none
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_onnx_mnist
-- - Parsers Used: onnx
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_plugin
-- - Parsers Used: caffe
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_reformat_free_io
-- - Parsers Used: caffe
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_ssd
-- - Parsers Used: caffe
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_uff_fasterRCNN
-- - Parsers Used: uff
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_uff_maskRCNN
-- - Parsers Used: uff
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: sample_uff_mnist
-- - Parsers Used: uff
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_uff_plugin_v2_ext
-- - Parsers Used: uff
-- - InferPlugin Used: OFF
-- - Licensing: opensource
-- Adding new sample: sample_uff_ssd
-- - Parsers Used: uff
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Adding new sample: trtexec
-- - Parsers Used: caffe;uff;onnx
-- - InferPlugin Used: ON
-- - Licensing: opensource
-- Configuring done
-- Generating done
-- Build files have been written to: /DATA/hhyang/tools/TensorRT/build
`
Things seems going in the right direction. But when I run the below code, the error occured!
make nvinfer_plugin -j$(nproc)
make[3]: *** No rule to make target 'nvinfer_LIB_PATH-NOTFOUND', needed by 'plugin/CMakeFiles/nvinfer_plugin.dir/cmake_device_link.o'. Stop.
CMakeFiles/Makefile2:283: recipe for target 'plugin/CMakeFiles/nvinfer_plugin.dir/all' failed
make[2]: *** [plugin/CMakeFiles/nvinfer_plugin.dir/all] Error 2
CMakeFiles/Makefile2:295: recipe for target 'plugin/CMakeFiles/nvinfer_plugin.dir/rule' failed
make[1]: *** [plugin/CMakeFiles/nvinfer_plugin.dir/rule] Error 2
Makefile:238: recipe for target 'nvinfer_plugin' failed
make: *** [nvinfer_plugin] Error 2
I can't figure out the reason.
Ang suggestion will be appreciate!
Thank you for your patient.
hi,
I have followed the steps described to install TensorRT OSS and deepstream-tlt-apps on my Nano (TRT 7.0, DeepStream 5.0 and CUDA 10.2, JetPack 4.4) and both the libraries were built successfuly and updated the .so file libnvinfer_plugin.so.7.0.0.1 to the folder /usr/lib/aarch64-linux-gnu/. However when I tried to run the example application for frcnn (./deepstream-custom -c pgie_frcnn_tlt_config.txt -i $DS_SRC_PATH/samples/streams/sample_720p.h264). Model engine has been created successfully but I still get the following error:
#assertion .../TensorRT/plugin/common/kernels/proposalKernel.cu,709 Aborted (core dumped)
Complete output infomation shows below:
Now playing: pgie_frcnn_tlt_config.txt
Opening in BLOCKING MODE
0:00:00.312834850 7163 0x5589b21e70 INFO nvinfer gstnvinfer.cpp:602:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1591> [UID = 1]: Trying to create engine from model files
INFO: [TRT]: Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
INFO: [TRT]: Detected 1 inputs and 3 output network tensors.
0:00:36.675326788 7163 0x5589b21e70 INFO nvinfer gstnvinfer.cpp:602:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1624> [UID = 1]: serialize cuda engine to file: /home/iot/Downloads/deepstream_tlt_apps-master/models/frcnn/faster_rcnn_resnet10.etlt_b1_gpu0_fp16.engine successfully
INFO: [Implicit Engine Info]: layers num: 4
0 INPUT kFLOAT input_image 3x272x480
1 OUTPUT kFLOAT proposal 300x4x1
2 OUTPUT kFLOAT dense_regress_td/BiasAdd 300x16x1x1
3 OUTPUT kFLOAT dense_class_td/Softmax 300x5x1x1
0:00:36.733242280 7163 0x5589b21e70 INFO nvinfer gstnvinfer_impl.cpp:311:notifyLoadModelStatus: [UID 1]: Load new model:pgie_frcnn_tlt_config.txt sucessfully
Running...
NvMMLiteBlockCreate : Block : BlockType = 256
[JPEG Decode] BeginSequence Display WidthxHeight 1280x720
#assertion/home/iot/Downloads/TensorRT/plugin/common/kernels/proposalKernel.cu,709
Aborted (core dumped)
Any information will be appreciated, thanks a lot.
I deployed TensorRT based model trained with TLT on Triton.
How should I format my input data to match input of FRCNN net?
Hi, I am new to using learning transfer tools, I have a problem installing TRT-OSS / Jetson / README.md during command execution
/usr/ local/bin/cmake .. -DGPU_ARCHS = "53 62 72" -DTRT_LIB_DIR = /usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER = /usr/bin/gcc -DTRT_BIN_DIR = pwd /out
it throws me the following error:
Configuring incomplete, errors occurred!
See also "/home/dlinano/TensorRT/build/CMakeFiles/CMakeOutput.log".
See also "/home/dlinano/TensorRT/build/CMakeFiles/CMakeError.log".
Could you help me to solve it?
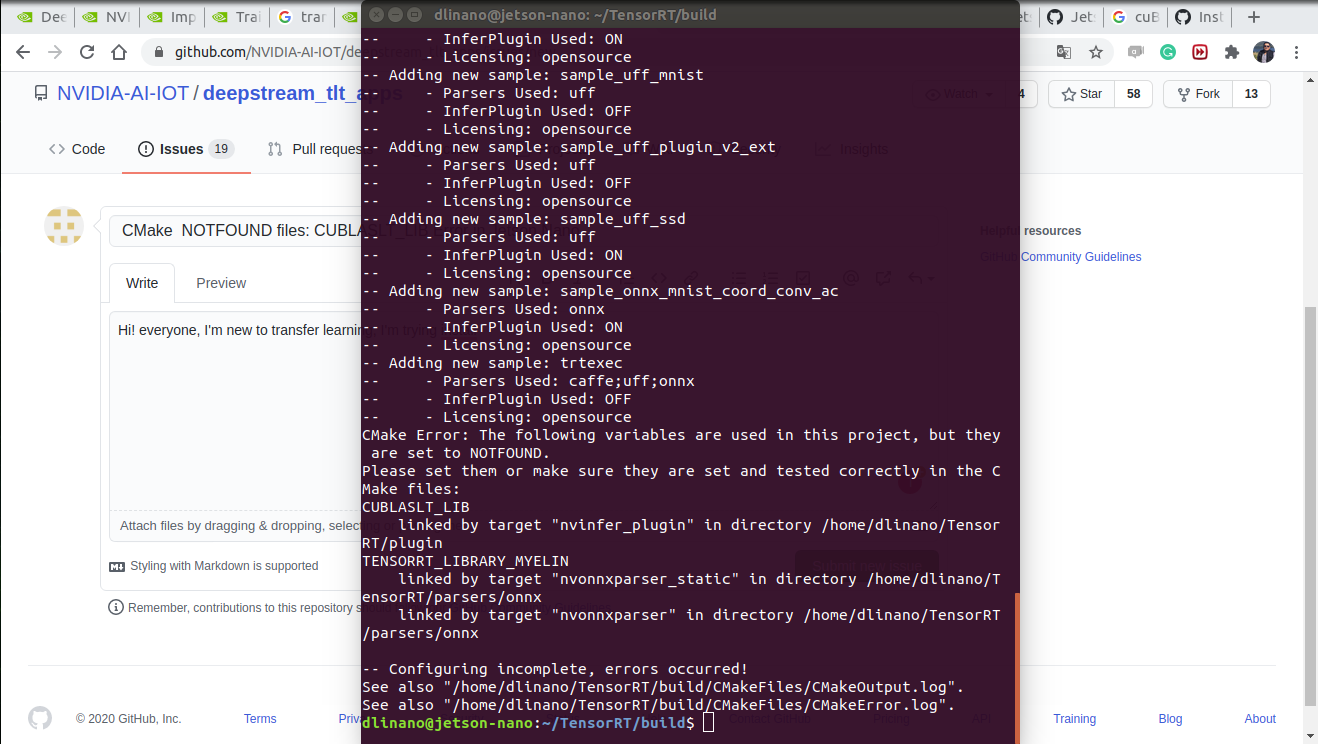
hi,
I've followed the steps to build the app, and directly download the libnvinfer_plugin.so.8.0.1 from:

after i run the detection app, always got an error, could you help:
./ds-tao-detection -c ../../configs/frcnn_tao/pgie_frcnn_tao_config.txt -i /opt/nvidia/deepstream/deepstream/samples/streams/sample_720p.h264 -d
Now playing: ../../configs/frcnn_tao/pgie_frcnn_tao_config.txtUsing winsys: x11
Opening in BLOCKING MODE
0:00:00.353550568 8168 0x5576ab4aa0 WARN nvinfer gstnvinfer.cpp:635:gst_nvinfer_logger: NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::initialize() <nvdsinfer_context_impl.cpp:1161> [UID = 1]: Warning, OpenCV has been deprecated. Using NMS for clustering instead of cv::groupRectangles with topK = 20 and NMS Threshold = 0.5
0:00:00.354951181 8168 0x5576ab4aa0 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1914> [UID = 1]: Trying to create engine from model files
WARNING: INT8 not supported by platform. Trying FP16 mode.
NvDsInferCudaEngineGetFromTltModel: Failed to open TLT encoded model file /home/shao/deepstream_tao_apps/configs/frcnn_tao/../../models/frcnn/frcnn_kitti_resnet18.epoch24_trt8.etlt
ERROR: Failed to create network using custom network creation function
ERROR: Failed to get cuda engine from custom library API
0:00:01.622621061 8168 0x5576ab4aa0 ERROR nvinfer gstnvinfer.cpp:632:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1934> [UID = 1]: build engine file failed
terminate called after throwing an instance of 'nvinfer1::InternalError'
what(): Assertion mRefCount > 0 failed.
Aborted (core dumped)
The model file provided for SSD uses resnet-18 as backbone. I want to use Mobilenet_v1 as backbone. Please let me know how to do the same.
Hi,
I have followed the steps described to install TensorRT OSS and deepstream-tlt-apps on my Xavier (TRT 7.0, DeepStream 5.0 and CUDA 10.2) and both the libraries were built successfuly. However when I tried to run the example application for frcnn I get the following error:
**_./deepstream-custom -c pgie_frcnn_tlt_config.txt -i $DS_SRC_PATH/samples/streams/sample_720p.h264
Now playing: pgie_frcnn_tlt_config.txt
Opening in BLOCKING MODE
Opening in BLOCKING MODE
0:00:00.239738191 12739 0x558ded24f0 INFO nvinfer gstnvinfer.cpp:602:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1591> [UID = 1]: Trying to create engine from model files
ERROR: [TRT]: UffParser: UFF buffer empty
parseModel: Failed to parse UFF model
ERROR: failed to build network since parsing model errors.
ERROR: Failed to create network using custom network creation function
ERROR: Failed to get cuda engine from custom library API
0:00:01.450726826 12739 0x558ded24f0 ERROR nvinfer gstnvinfer.cpp:596:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1611> [UID = 1]: build engine file failed
Bus error (core dumped)_**
Any suggestions on how I can fix the error ?
-Dilip.
Systems GPU_ARCHS => 75 (x =7, y= 5)
and the plugin that is already present in /usr/lib/x86_64-linux-gnu => libnvinfer_plugin.so, libnvinfer_plugin.so.7, libnvinfer_plugin.so.7.0.0
Generated files : libnvinfer_plugin.so libnvinfer_plugin.so.7.0.0 libnvinfer_plugin.so.7.0.0.1
The question is:
Do I need to move the plugin that is already present "libnvinfer_plugin.so.7.0.0" and back it up (or backup all the libnvinfer_plugin.so*)? It is confusing because it is mentioned in the readme to back up libnvinfer_plugin.so.7.x.y(x=7,y=5) which is not here !!
There are the lib files generated => libnvinfer_plugin.so, libnvinfer_plugin.so.7.0.0 and libnvinfer_plugin.so.7.0.0.1. Which one of the generated files to copy(or to copy all) to '/usr/lib/x86_64-linux-gnu' and as what libnvinfer_plugin.so.7.0.0 or libnvinfer_plugin.so.7.7.5.. It's not that clear from the README.
Is there any docker container or something available to develop apps with the deep stream?
I am running the notebook YOLO example of TLT Version 2 release in the tlt docker. I have successfully trained, pruned, and retrained the YOLO-restnet18. The results of FP32’s are fine but when I executed the tlt-export (int8) command as shown in the notebook:
!tlt-export yolo -m $USER_EXPERIMENT_DIR/experiment_dir_retrain/weights/yolo_resnet18_epoch_$EPOCH.tlt \ -o $USER_EXPERIMENT_DIR/FFxport/yolo_resnet18_8epoch_$EPOCH.etlt \ -e $SPECS_DIR/yolo_retrain_resnet18_kitti.txt \ -k $KEY \ --cal_image_dir $USER_EXPERIMENT_DIR/data/training/image_2 \ --data_type int8 \ --batch_size 1 \ --batches 10 \ --cal_cache_file $USER_EXPERIMENT_DIR/FFxport/cal.bin \ --cal_data_file $USER_EXPERIMENT_DIR/FFxport/cal.tensorfile
The warning message popped up:
Using TensorFlow backend.
2020-05-12 02:09:02,221 [INFO] /usr/local/lib/python2.7/dist-packages/iva/yolo/utils/spec_loader.pyc: Merging specification from /workspace/examples/yolo/specs/yolo_retrain_resnet18_kitti.txt
2020-05-12 02:09:05,844 [INFO] /usr/local/lib/python2.7/dist-packages/iva/yolo/utils/spec_loader.pyc: Merging specification from /workspace/examples/yolo/specs/yolo_retrain_resnet18_kitti.txt
NOTE: UFF has been tested with TensorFlow 1.14.0.
WARNING: The version of TensorFlow installed on this system is not guaranteed to work with UFF.
Warning: No conversion function registered for layer: BatchedNMS_TRT yet.
Converting BatchedNMS as custom op: BatchedNMS_TRT
Warning: No conversion function registered for layer: ResizeNearest_TRT yet.
Converting upsample1/ResizeNearestNeighbor as custom op: ResizeNearest_TRT
Warning: No conversion function registered for layer: ResizeNearest_TRT yet.
Converting upsample0/ResizeNearestNeighbor as custom op: ResizeNearest_TRT
Warning: No conversion function registered for layer: BatchTilePlugin_TRT yet.
Converting FirstDimTile_2 as custom op: BatchTilePlugin_TRT
Warning: No conversion function registered for layer: BatchTilePlugin_TRT yet.
Converting FirstDimTile_1 as custom op: BatchTilePlugin_TRT
Warning: No conversion function registered for layer: BatchTilePlugin_TRT yet.
Converting FirstDimTile_0 as custom op: BatchTilePlugin_TRT
DEBUG [/usr/lib/python2.7/dist-packages/uff/converters/tensorflow/converter.py:96] Marking [‘BatchedNMS’] as outputs
2020-05-12 02:09:22,062 [WARNING] modulus.export._tensorrt: Calibration file /workspace/tlt-experiments/yolo/export/cal.bin exists but is being ignored.
[TensorRT] INFO: Detected 1 inputs and 4 output network tensors.
[TensorRT] WARNING: Current optimization profile is: 0. Please ensure there are no enqueued operations pending in this context prior to switching profiles
[TensorRT] INFO: Starting Calibration with batch size 1.
DEPRECATED: This variant of get_batch is deprecated. Please use the single argument variant described in the documentation instead.
[TensorRT] INFO: Calibrated batch 0 in 0.101843 seconds.
[TensorRT] INFO: Calibrated batch 1 in 0.0926203 seconds.
[TensorRT] INFO: Calibrated batch 2 in 0.0919941 seconds.
[TensorRT] INFO: Calibrated batch 3 in 0.0910869 seconds.
[TensorRT] INFO: Calibrated batch 4 in 0.0929871 seconds.
[TensorRT] INFO: Calibrated batch 5 in 0.0934323 seconds.
[TensorRT] INFO: Calibrated batch 6 in 0.099967 seconds.
[TensorRT] INFO: Calibrated batch 7 in 0.104515 seconds.
[TensorRT] INFO: Calibrated batch 8 in 0.0996476 seconds.
[TensorRT] INFO: Calibrated batch 9 in 0.0921785 seconds.
[TensorRT] WARNING: Tensor BatchedNMS is uniformly zero; network calibration failed.
[TensorRT] WARNING: Tensor BatchedNMS_1 is uniformly zero; network calibration failed.
[TensorRT] WARNING: Tensor BatchedNMS_2 is uniformly zero; network calibration failed.
[TensorRT] INFO: Post Processing Calibration data in 3.91784 seconds.
[TensorRT] INFO: Calibration completed in 37.7898 seconds.
2020-05-12 02:09:59,897 [WARNING] modulus.export._tensorrt: Calibration file /workspace/tlt-experiments/yolo/export/cal.bin exists but is being ignored.
[TensorRT] INFO: Writing Calibration Cache for calibrator: TRT-7000-EntropyCalibration2
2020-05-12 02:09:59,897 [INFO] modulus.export._tensorrt: Saving calibration cache (size 9237) to /workspace/tlt-experiments/yolo/export/cal.bin
[TensorRT] WARNING: Rejecting int8 implementation of layer BatchedNMS due to missing int8 scales, will choose a non-int8 implementation.
[TensorRT] INFO: Detected 1 inputs and 4 output network tensors
It looks like I did not make it in generating an int8 implementation for calibration but I am not sure what is going on with the warnings and any solution to it. I google-searched several forums but noting related to TLT version 2.
I appreciate your help! Thanks!
Hi,
I followed the installation steps and been trying to run the yolov3 demo on the NX, but I am getting the following error log:
Warning: 'input-dims' parameter has been deprecated. Use 'infer-dims' instead.
Now playing: pgie_yolov3_tlt_config.txt
Opening in BLOCKING MODE
Opening in BLOCKING MODE
0:00:00.303902873 15849 0x559a818900 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1715> [UID = 1]: Trying to create engine from model files
ERROR: [TRT]: IPluginV2DynamicExt requires network without implicit batch dimension
Segmentation fault (core dumped)
I just flashed the device with a fresh Jetpack 4.4.1
Hi,
Configurations
Hardware: NVIDIA Jetson Xavier NX
DeepStream: 5.0
Jetpack: 4.4
Issue
I am trying to run peopleSegNet model but there is no output either displaying or storing. I have tried to debug the code, it is predicting the mask and classes but the inference is not displaying any frame.
There is a black screen coming as the output.
I have used the FRCNN Detector, which is working perfectly in displaying and storing the inference.
How to measure inference time for a single frame? I'm using SSD model.
Essentially, I want to print 2 timestamps. One, before nvinfer is executed. Another, after nvinfer is executed.
Please show me how to do so.
Hello. I have modified the jetson deepstream_app_source1_mrcnn.txt config file to use the mask_rcnn_resnet50.etlt file from the models linked in this repo's README. But when I try to run deepstream against that model, I get the error:
ERROR: [TRT]: UffParser: Validator error: multilevel_propose_rois: Unsupported operation _MultilevelProposeROI_TRT
the full output is:
deepstream-app -c deepstream_app_source1_mrcnn.txt
Using winsys: x11
ERROR: Deserialize engine failed because file path: /opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models/../../models/tlt_pretrained_models/mrcnn/mask_rcnn_resnet50.etlt_b1_gpu0_int8.engine open error
0:00:01.157964011 21695 0x556aa94a30 WARN nvinfer gstnvinfer.cpp:616:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1690> [UID = 1]: deserialize engine from file :/opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models/../../models/tlt_pretrained_models/mrcnn/mask_rcnn_resnet50.etlt_b1_gpu0_int8.engine failed
0:00:01.158108114 21695 0x556aa94a30 WARN nvinfer gstnvinfer.cpp:616:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:1797> [UID = 1]: deserialize backend context from engine from file :/opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models/../../models/tlt_pretrained_models/mrcnn/mask_rcnn_resnet50.etlt_b1_gpu0_int8.engine failed, try rebuild
0:00:01.158157396 21695 0x556aa94a30 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1715> [UID = 1]: Trying to create engine from model files
ERROR: [TRT]: UffParser: Validator error: multilevel_propose_rois: Unsupported operation _MultilevelProposeROI_TRT
parseModel: Failed to parse UFF model
ERROR: failed to build network since parsing model errors.
ERROR: Failed to create network using custom network creation function
ERROR: Failed to get cuda engine from custom library API
0:00:01.984863191 21695 0x556aa94a30 ERROR nvinfer gstnvinfer.cpp:613:gst_nvinfer_logger:<primary_gie> NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1735> [UID = 1]: build engine file failed
I am using Jetpack 4.4 with Deepstream 5.0 and Tensorrt 7.1.3.0. Is this supposed to work? Thanks!
Hi guys,
I want to know this repo for detectnet_v2 is support for multi-stream rtsp? If so, How?
and How I can to get outputs of the network, is it possible?
Is it possible to add tracker of deepstream into this pipeline?
when I run :./deepstream-custom -c pgie_yolov3_tlt_config.txt -i $DS_SRC_PATH/samples/streams/sample_720p.h264
Warning: 'input-dims' parameter has been deprecated. Use 'infer-dims' instead.
Now playing: pgie_yolov3_tlt_config.txt
Opening in BLOCKING MODE
Opening in BLOCKING MODE
0:00:00.206458755 10991 0x559c739b00 INFO nvinfer gstnvinfer.cpp:619:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1715> [UID = 1]: Trying to create engine from model files
ERROR: [TRT]: UffParser: Validator error: FirstDimTile_2: Unsupported operation _BatchTilePlugin_TRT
parseModel: Failed to parse UFF model
ERROR: failed to build network since parsing model errors.
ERROR: Failed to create network using custom network creation function
ERROR: Failed to get cuda engine from custom library API
0:00:01.417451184 10991 0x559c739b00 ERROR nvinfer gstnvinfer.cpp:613:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1735> [UID = 1]: build engine file failed
Segmentation fault (core dumped)
What is the reason for this problem and how to solve it?
Hello. I have tested peopleSegNetv2 con a jetson nano and it's working as expected, but on a jetson TX2 the network is not generating any detection over the input image. Threre are no output labels using SHOW_MASK=1 or SHOW_MASK=0. Other models are working fine, I have tested SSD succesfully.
Jetpack 4.5.1,Deepstream 5.1, TensorRT 7.1.3, TRT OSS plugin built with -DGPU_ARCHS="62".
Using latest github files.
mero-jetson@Jetson-TX2:~/deepstream_tlt_apps$ export SHOW_MASK=1
mero-jetson@Jetson-TX2:~/deepstream_tlt_apps$ ./apps/tlt_detection/ds-tlt-detection -c configs/peopleSegNet_tlt/pgie_peopleSegNetv2_tlt_config.txt -i /opt/nvidia/deepstream/deepstream-5.1/samples/streams/sample_720p.jpg
Output image:

Hi,
I tested bodypose2d example. Its running fine.
i modified it so that dsexample plugin can be used along with it.
When i enable dsexample plugin, i found no data inside "batch_meta->frame_meta_list" loop. Total detected objects are 0.
I can see the API "nvds_add_2dpose_meta" is being used to attach the user_meta data in each object and followed by "nvds_add_obj_meta_to_frame" API to attach the obj data to frame. But why i am not getting any data in dsexample plugin?
Thanks.
I installed nvidia deepstream-5.0 sdk and I'm trying to build this repo, but I have a problem. After setting the DS_SRC_PATH and CUDA_VER, I can't build it. Here's some logs:
make[1]: Entering directory '/home/rockefella09/deepstream_tlt_apps/nvdsinfer_customparser_dssd_tlt'
g++ -o libnvds_infercustomparser_dssd_tlt.so nvdsinfer_custombboxparser_dssd_tlt.cpp -I/opt/nvidia/deepstream/deepstream/sour
ces/includes -I/usr/local/cuda-10.2/include -Wall -std=c++11 -shared -fPIC -Wl,--start-group -lnvinfer -lnvparsers -L/usr/loc
al/cuda-10.2/lib64 -lcudart -lcublas -Wl,--end-group
In file included from nvdsinfer_custombboxparser_dssd_tlt.cpp:14:0:
/opt/nvidia/deepstream/deepstream/sources/includes/nvdsinfer_custom_impl.h:128:10: fatal error: NvCaffeParser.h: No such file
or directory
#include "NvCaffeParser.h"
^~~~~~~~~~~~~~~~~
compilation terminated.
Makefile:41: recipe for target 'libnvds_infercustomparser_dssd_tlt.so' failed
make[1]: *** [libnvds_infercustomparser_dssd_tlt.so] Error 1
make[1]: Leaving directory '/home/rockefella09/deepstream_tlt_apps/nvdsinfer_customparser_dssd_tlt'
Makefile:68: recipe for target 'deepstream-custom' failed
make: *** [deepstream-custom] Error 2
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.