oap-project / raydp Goto Github PK
View Code? Open in Web Editor NEWRayDP provides simple APIs for running Spark on Ray and integrating Spark with AI libraries.
License: Apache License 2.0
RayDP provides simple APIs for running Spark on Ray and integrating Spark with AI libraries.
License: Apache License 2.0





































































































































Thanks to the author's efforts, this is a very good project.
I tried to run the following brief test program.
------------code-------------
import raydp
from raydp.torch import TorchEstimator
#start Spark job on Ray
spark = raydp.init_spark(
app_name = "example test",
num_executors = 3,
executor_cores = 3,
executor_memory="10GB"
)
##prepare the data
customers = [(1,'James',21,6), (2, "Liz",25,8), (3, "John", 31, 6),
(4, "Jennifer", 45, 7), (5, "Robert", 41, 5), (6, "Sandra", 45, 8)]
df = spark.createDataFrame(customers, ["cID", "name", "age", "grade"])
df.show()
import torch
##create model
model = torch.nn.Sequential(torch.nn.Linear(2, 1))
optimizer = torch.optim.Adam(model.parameters())
loss = torch.nn.MSELoss()
#config
estimator = TorchEstimator(
model = model,
optimizer = optimizer,
loss = loss,
num_workers = 3,
num_epochs = 5,
feature_columns = ["age"],
label_column = ["grade"]
)
print("before fit on spark, the type of model:", type(model))
estimator.fit_on_spark(df)
##get the trained model
pytorch_model = estimator.get_model()
------------code-------------
But when performing model training model.train() in training_operator.py, an error message was reported: AttributeError:'list' object has no attribute'train'.
--------error-----------
Traceback (most recent call last):
File "", line 1, in
File "/root/miniconda3/lib/python3.7/site-packages/raydp/torch/estimator.py", line 311, in fit_on_spark
train_ds, evaluate_ds, num_steps, profile, reduce_results, max_retries, info)
File "/root/miniconda3/lib/python3.7/site-packages/raydp/torch/estimator.py", line 284, in fit
info=info)
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/torch/torch_trainer.py", line 410, in train
num_steps=num_steps, profile=profile, info=info, dataset=dataset)
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/torch/worker_group.py", line 325, in train
success = check_for_failure(remote_worker_stats)
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/utils.py", line 244, in check_for_failure
finished = ray.get(finished)
File "/root/miniconda3/lib/python3.7/site-packages/ray/worker.py", line 1379, in get
raise value.as_instanceof_cause()
ray.exceptions.RayTaskError(AttributeError): ray::DistributedTorchRunner.train_epoch() (pid=54182, ip=10.3.68.117)
File "python/ray/_raylet.pyx", line 463, in ray._raylet.execute_task
File "python/ray/_raylet.pyx", line 415, in ray._raylet.execute_task.function_executor
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/torch/distributed_torch_runner.py", line 112, in train_epoch
num_steps=num_steps, profile=profile, info=info, iterator=iterator)
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/torch/torch_runner.py", line 140, in train_epoch
train_stats = self.training_operator.train_epoch(iterator, info)
File "/root/miniconda3/lib/python3.7/site-packages/ray/util/sgd/torch/training_operator.py", line 504, in train_epoch
model.train()
AttributeError: 'list' object has no attribute 'train'
--------error-----------
I was confused, and then executed output before mode.train( line 504 in training_operator.py): print(type(model)), and found that the output was: <class'list'>.
But I executed output after model = outer._model(line 174 in estimator.py): print(type(model)), and found that the output was: <class'torch.nn.modules.container.Sequential'>.
It seems that the type of model has changed.
But I cannot see the specific process of the change, can you help me solve it?
You can run the above program directly.
Looking forward to your reply~~
TL;DR:
How does one zero-copy convert a PySpark dataframe to a Modin dataframe?
I am currently searching for a way to manipulate PySpark dataframes without materializing them as a Pandas dataframe.
Since my experience with Ray has been quite good, I wonder whether it would be possible to solve this with Modin.
If yes, I think a raydp.modin module would be a perfect addition to this project :)
We can create and maintain a branch to support Ray 2.0.0-dev. Ray 2.0.0-dev java package is not available in Maven so users need to build Ray before building RayDP.
When I enable Java for Ray, I couldn't build it successfully on MacOS
cd oap-raydp/dev/.tmp_dir/ray/python
export RAY_INSTALL_JAVA=1
python3 setup.py -q bdist_wheel
The errors are:
INFO: Analyzed 2 targets (2 packages loaded, 484 targets configured).
INFO: Found 2 targets...
ERROR: /oap-raydp/dev/.tmp_dir/ray/BUILD.bazel:1818:10: C++ compilation of rule '//:libcore_worker_library_java.so' failed (Exit 1): cc_wrapper.sh failed: error executing command
and
Use --sandbox_debug to see verbose messages from the sandbox
In file included from src/ray/core_worker/lib/java/io_ray_runtime_object_NativeObjectStore.cc:17:
src/ray/core_worker/lib/java/jni_utils.h:341:20: error: loop variable 'item' is always a copy because the range of type 'const std::vector<bool>' does not return a reference [-Werror,-Wrange-loop-analysis]
1 error generated.
INFO: Elapsed time: 24.630s, Critical Path: 24.28s
INFO: 13 processes: 10 internal, 3 darwin-sandbox.
FAILED: Build did NOT complete successfully
Traceback (most recent call last):
File "setup.py", line 440, in <module>
setuptools.setup(
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/setuptools/__init__.py", line 165, in setup
return distutils.core.setup(**attrs)
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/core.py", line 148, in setup
dist.run_commands()
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/wheel/bdist_wheel.py", line 223, in run
self.run_command('build')
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/Users/dr6jl/anaconda3/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "setup.py", line 433, in run
return pip_run(self)
File "setup.py", line 342, in pip_run
build(True, BUILD_JAVA)
File "setup.py", line 299, in build
return bazel_invoke(
File "setup.py", line 185, in bazel_invoke
result = invoker([cmd] + cmdline, *args, **kwargs)
File "/Users/dr6jl/anaconda3/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['bazel', 'build', '--verbose_failures', '--', '//:ray_pkg', '//java:ray_java_pkg']' returned non-zero exit status 1.
If I disable Java, the wheel can be built. But in the examples, I couldn't run this:
ray.init(include_java=True)
I followed the README to install RayDP.
Got error when running ./build.sh
+ python setup.py bdist_wheel
File "setup.py", line 31
JARS_PATH = glob.glob(os.path.join(CORE_DIR, f"target/raydp-*.jar"))
^invalid syntax
I have:
Then I just manually re-run the python setup.py and it seems ok:
python setup.py bdist_wheel
And I copied all wheels in dist/
ls
pyspark-3.0.0-py2.py3-none-any.whl spark
raydp-0.1.dev0-py2.py3-none-any.whl
And installed RayDP and PySpark with pip:
pip install raydp-0.1.dev0-py2.py3-none-any.whl
pip install pyspark-3.0.0-py2.py3-none-any.whl
Then I run the following code on terminal:
import ray
import os
import pandas as pd, numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from pyspark.sql.functions import *
import raydp
from raydp.torch.estimator import TorchEstimator
from raydp.utils import random_split
ray.init()
app_name = "NYC Taxi Fare Prediction with RayDP"
num_executors = 4
cores_per_executor = 1
memory_per_executor = "1GB"
spark = raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
Got this error:
>>> spark = raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
File descriptor limit 256 is too low for production servers and may result in connection errors. At least 8192 is recommended. --- Fix with 'ulimit -n 8192'
2020-11-30 11:56:36,039 INFO services.py:1169 -- View the Ray dashboard at http://127.0.0.1:8265
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/jars/ray_dist.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/jars/spark-unsafe_2.12-3.0.0.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2020-11-30 11:56:40 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/usr/local/Cellar/apache-spark/3.0.1/libexec/jars/spark-unsafe_2.12-3.0.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Exception in thread "main" org.apache.spark.SparkException: Master must either be yarn or start with spark, mesos, k8s, or local
at org.apache.spark.deploy.SparkSubmit.error(SparkSubmit.scala:936)
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:238)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:871)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Error in sys.excepthook:
Traceback (most recent call last):
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/worker.py", line 856, in custom_excepthook
ray.state.state.add_worker(worker_id, worker_type, worker_info)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/state.py", line 733, in add_worker
return self.global_state_accessor.add_worker_info(
AttributeError: 'NoneType' object has no attribute 'add_worker_info'
Original exception was:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/raydp/context.py", line 121, in init_spark
return _global_spark_context.get_or_create_session()
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/raydp/context.py", line 69, in get_or_create_session
self._spark_session = spark_cluster.get_spark_session(
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/raydp/spark/ray_cluster.py", line 64, in get_spark_session
spark_builder.appName(app_name).master(self.get_cluster_url()).getOrCreate()
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/sql/session.py", line 186, in getOrCreate
sc = SparkContext.getOrCreate(sparkConf)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/context.py", line 371, in getOrCreate
SparkContext(conf=conf or SparkConf())
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/context.py", line 128, in __init__
SparkContext._ensure_initialized(self, gateway=gateway, conf=conf)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/context.py", line 320, in _ensure_initialized
SparkContext._gateway = gateway or launch_gateway(conf)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/pyspark/java_gateway.py", line 105, in launch_gateway
raise Exception("Java gateway process exited before sending its port number")
Exception: Java gateway process exited before sending its port number
We can add RayMLDataset to simplify how to create MLDataset from a Spark dataframe. For example: torch_ds = RayMLDataset(spark_df, ...).to_torch(…)
We may keep create_ml_dataset_from_spark for compatibility.
I'm following the example at: examples/pytorch/pytorch_nyctaxi.ipynb
Got this error when execute the raydp.init_spark
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<ipython-input-4-cb3a24832a0a> in <module>
4 cores_per_executor = 1
5 memory_per_executor = "2GB"
----> 6 spark = raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
~/anaconda3/lib/python3.8/site-packages/raydp/context.py in init_spark(app_name, num_executors, executor_cores, executor_memory, configs)
120 _global_spark_context = _SparkContext(
121 app_name, num_executors, executor_cores, executor_memory, configs)
--> 122 return _global_spark_context.get_or_create_session()
123 else:
124 raise Exception("The spark environment has inited.")
~/anaconda3/lib/python3.8/site-packages/raydp/context.py in get_or_create_session(self)
67 if self._spark_session is not None:
68 return self._spark_session
---> 69 spark_cluster = self._get_or_create_spark_cluster()
70 self._spark_session = spark_cluster.get_spark_session(
71 self._app_name,
~/anaconda3/lib/python3.8/site-packages/raydp/context.py in _get_or_create_spark_cluster(self)
61 if self._spark_cluster is not None:
62 return self._spark_cluster
---> 63 self._spark_cluster = RayCluster()
64 return self._spark_cluster
65
~/anaconda3/lib/python3.8/site-packages/raydp/spark/ray_cluster.py in __init__(self)
37 super().__init__(None)
38 self._app_master_bridge = None
---> 39 self._set_up_master(None, None)
40 self._spark_session: SparkSession = None
41
~/anaconda3/lib/python3.8/site-packages/raydp/spark/ray_cluster.py in _set_up_master(self, resources, kwargs)
43 # TODO: specify the app master resource
44 self._app_master_bridge = RayClusterMaster()
---> 45 self._app_master_bridge.start_up()
46
47 def _set_up_worker(self, resources: Dict[str, float], kwargs: Dict[str, str]):
~/anaconda3/lib/python3.8/site-packages/raydp/spark/ray_cluster_master.py in start_up(self, popen_kwargs)
48 self._set_properties()
49 self._host = ray.services.get_node_ip_address()
---> 50 self._create_app_master(extra_classpath)
51 self._started_up = True
52
~/anaconda3/lib/python3.8/site-packages/raydp/spark/ray_cluster_master.py in _create_app_master(self, extra_classpath)
156 if self._started_up:
157 return
--> 158 self._app_master_java_bridge.startUpAppMaster(extra_classpath)
159
160 def get_master_url(self):
~/anaconda3/lib/python3.8/site-packages/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
~/anaconda3/lib/python3.8/site-packages/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o0.startUpAppMaster.
: java.lang.NoSuchMethodError: java.nio.ByteBuffer.flip()Ljava/nio/ByteBuffer;
at io.ray.api.id.JobId.fromInt(JobId.java:47)
at io.ray.runtime.gcs.GcsClient.nextJobId(GcsClient.java:186)
at io.ray.runtime.RayNativeRuntime.start(RayNativeRuntime.java:105)
at io.ray.runtime.DefaultRayRuntimeFactory.createRayRuntime(DefaultRayRuntimeFactory.java:38)
at io.ray.api.Ray.init(Ray.java:42)
at io.ray.api.Ray.init(Ray.java:28)
at org.apache.spark.deploy.raydp.AppMasterJavaBridge.startUpAppMaster(AppMasterJavaBridge.scala:41)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Hi,
I am trying to specify custom jars in the spark init using the spark.jars.packages for example:
spark = raydp.init_spark(
"Sample APP",
1,
2,
"2G",
{
"spark.jars.packages": "com.ibm.stocator:stocator:1.1.3"
})
The jar is download but seems that it isn't propagated to the driver/executer class path so I get class java.lang.ClassNotFoundException
if I use spark.jars with a local jar then things work fine.
Have you seen the same behaviour?
Hi there, I am continuing to enjoy using this project, it's great!
I wish to have a heterogeneous clusters where I have some GPU worker nodes, a few CPU-heavy worker nodes for HPO jobs, and many smaller instances for Spark jobs. I know that it's possible to declare custom resource markers on nodes in Ray. However, I don't think I see a way to get raydp to request those custom resources. Am I missing something, or is this not possible?
Thanks!
Hi I was able to run raydp on my laptop and on K8S (by initializing a single node ray cluster, e.g., ray.init()),
but on K8S, if I run raydp by connecting to a multi-node existing ray cluster, e.g., ray.init(address="auto"), I got the errors, and ray head will crash.
Here is my test code:
import ray,raydp
ray.init(address="auto")
raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
(base) root@ray-head-7f4bc4b6df-nx697:/ray-raydp# python spark_init.py 1
2020-12-23 13:14:59,426 INFO worker.py:655 -- Connecting to existing Ray cluster at address: 10.40.1.13:6379
number of workers:1
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/ray-raydp/ray/python/ray/jars/ray_dist.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/anaconda3/lib/python3.7/site-packages/pyspark/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
(pid=raylet) [2020-12-23 13:15:01,006 C 35 35] worker_pool.cc:952: Check failed: state != states_by_lang_.end() Required Language isn't supported.
(pid=raylet) [2020-12-23 13:15:01,006 E 35 35] logging.cc:414: *** Aborted at 1608758101 (unix time) try "date -d @1608758101" if you are using GNU date ***
(pid=raylet) [2020-12-23 13:15:01,006 E 35 35] logging.cc:414: PC: @ 0x0 (unknown)
(pid=raylet) [2020-12-23 13:15:01,006 E 35 35] logging.cc:414: *** SIGABRT (@0x23) received by PID 35 (TID 0x7f14e82f7800) from PID 35; stack trace: ***
(pid=raylet) [2020-12-23 13:15:01,006 E 35 35] logging.cc:414: @ 0x556a2af32d97 google::(anonymous namespace)::FailureSignalHandler()
(pid=raylet) [2020-12-23 13:15:01,007 E 35 35] logging.cc:414: @ 0x7f14e85293c0 (unknown)
(pid=raylet) [2020-12-23 13:15:01,007 E 35 35] logging.cc:414: @ 0x7f14e834218b gsignal
(pid=raylet) [2020-12-23 13:15:01,007 E 35 35] logging.cc:414: @ 0x7f14e8321859 abort
(pid=raylet) [2020-12-23 13:15:01,007 E 35 35] logging.cc:414: @ 0x556a2a9e00ad _ZN3ray6RayLogD2Ev.cold
(pid=raylet) [2020-12-23 13:15:01,009 E 35 35] logging.cc:414: @ 0x556a2aa66a3c ray::raylet::WorkerPool::GetStateForLanguage()
(pid=raylet) [2020-12-23 13:15:01,010 E 35 35] logging.cc:414: @ 0x556a2aa6e003 ray::raylet::WorkerPool::RegisterDriver()
(pid=raylet) [2020-12-23 13:15:01,012 E 35 35] logging.cc:414: @ 0x556a2aac9096 ray::raylet::NodeManager::ProcessRegisterClientRequestMessage()
(pid=raylet) [2020-12-23 13:15:01,014 E 35 35] logging.cc:414: @ 0x556a2aadcce2 ray::raylet::NodeManager::ProcessClientMessage()
(pid=raylet) [2020-12-23 13:15:01,014 E 35 35] logging.cc:414: @ 0x556a2aa29625 _ZNSt17_Function_handlerIFvSt10shared_ptrIN3ray16ClientConnectionEElRKSt6vectorIhSaIhEEEZNS1_6raylet6Raylet12HandleAcceptERKN5boost6system10error_codeEEUlS3_lS8_E0_E9_M_invokeERKSt9_Any_dataOS3_OlS8_
(pid=raylet) [2020-12-23 13:15:01,015 E 35 35] logging.cc:414: @ 0x556a2ae81792 ray::ClientConnection::ProcessMessage()
(pid=raylet) [2020-12-23 13:15:01,016 E 35 35] logging.cc:414: @ 0x556a2ae7eabc boost::asio::detail::reactive_socket_recv_op<>::do_complete()
(pid=raylet) [2020-12-23 13:15:01,016 E 35 35] logging.cc:414: @ 0x556a2b26b701 boost::asio::detail::scheduler::do_run_one()
(pid=raylet) [2020-12-23 13:15:01,017 E 35 35] logging.cc:414: @ 0x556a2b26ce41 boost::asio::detail::scheduler::run()
(pid=raylet) [2020-12-23 13:15:01,019 E 35 35] logging.cc:414: @ 0x556a2b26f4bb boost::asio::io_context::run()
(pid=raylet) [2020-12-23 13:15:01,020 E 35 35] logging.cc:414: @ 0x556a2a9fbdc2 main
(pid=raylet) [2020-12-23 13:15:01,020 E 35 35] logging.cc:414: @ 0x7f14e83230b3 __libc_start_main
(pid=raylet) [2020-12-23 13:15:01,022 E 35 35] logging.cc:414: @ 0x556a2aa1189e _start
ERROR:root:Exception while sending command.
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.7/site-packages/py4j/java_gateway.py", line 1207, in send_command
raise Py4JNetworkError("Answer from Java side is empty")
py4j.protocol.Py4JNetworkError: Answer from Java side is empty
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.7/site-packages/py4j/java_gateway.py", line 1033, in send_command
response = connection.send_command(command)
File "/root/anaconda3/lib/python3.7/site-packages/py4j/java_gateway.py", line 1212, in send_command
"Error while receiving", e, proto.ERROR_ON_RECEIVE)
py4j.protocol.Py4JNetworkError: Error while receiving
An error occurred while calling o0.startUpAppMaster
ERROR:py4j.java_gateway:An error occurred while trying to connect to the Java server (127.0.0.1:25333)
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.7/site-packages/py4j/java_gateway.py", line 977, in _get_connection
connection = self.deque.pop()
IndexError: pop from an empty deque
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.7/site-packages/py4j/java_gateway.py", line 1115, in start
self.socket.connect((self.address, self.port))
ConnectionRefusedError: [Errno 111] Connection refused
Hey there, it looks like Ray's Java API made a backwards incompatible change in December (ray-project/ray#10762).
Because RayConfig.instance() was removed, spark_init() breaks at runtime.
I'm can contribute the change, but wanted to check if this is something the RayDP team is interested in first.
We need to add code style check for both python and java.
Hi @buaazhwb, can you pick this issue?
In [3]: import raydp
In [4]: spark = raydp.init_spark(
...: app_name = "example test",
...: num_executors = 3,
...: executor_cores = 3,
...: executor_memory="5GB")
with jinfo:
VM Flags:
Non-default VM flags: -XX:CICompilerCount=18 -XX:InitialHeapSize=2147483648 -XX:MaxHeapSize=32210157568 -XX:MaxNewSize=10736369664 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=715653120 -XX:OldSize=1431830528 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
The -XX:MaxHeapSize=32210157568 is not correctly. It seems like the ray java actor has not set the VM flags correctly.
Currently, we serialize the pandas DataFrame and store it into ray object store in spark pandas udf, then get the object from ray (zero-copy) and deserialize back to pandas DataFrame in the TorchTrainer. For each block of data, we have to do:
So, we need serialize/deserialize and two times memory copy. This is not efficient.
We can leverage pyarrow to exchange the data between pandas DataFrame <--> ray object store <--> pandas DataFrame. With pyarrow:
pandas DataFrame convert to/back pyarrow Table in zero-copy mode seems only works for limited data types, however, deep learning frameworks only support number like type. This should work.
To run the NYC Taxi Fare Prediction using PyTorch example, 'x.squeeze(1)' need to be changed to 'return x' (in the NYC model definition). I'm using PyTorch version 1.4.0.
I submit a simple spark example to RayCluster on Kubernetes and meet this problem.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Traceback (most recent call last):
File "raydp-spark.py", line 15, in <module>
executor_memory='1G')
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/context.py", line 122, in init_spark
return _global_spark_context.get_or_create_session()
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/context.py", line 68, in get_or_create_session
spark_cluster = self._get_or_create_spark_cluster()
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/context.py", line 62, in _get_or_create_spark_cluster
self._spark_cluster = SparkCluster()
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/spark/ray_cluster.py", line 32, in __init__
self._set_up_master(None, None)
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/spark/ray_cluster.py", line 38, in _set_up_master
self._app_master_bridge.start_up()
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/spark/ray_cluster_master.py", line 55, in start_up
self._set_properties()
File "/home/ray/anaconda3/lib/python3.7/site-packages/raydp/spark/ray_cluster_master.py", line 144, in _set_properties
options["ray.node-ip"] = node.node_ip_address
AttributeError: 'NoneType' object has no attribute 'node_ip_address'
Looks like ray.worker.global_worker.node return None and _set_properties failed afterwards.
I am new to ray and not sure if this is a RayDP issue or Ray environment issue?
I follow ray instruction and use Ray operator to spin up an example cluster in my environment.
apiVersion: batch/v1
kind: Job
metadata:
generateName: raydp-spark-
namespace: ray
spec:
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: ray
image: seedjeffwan/ray:0.1
imagePullPolicy: Always
command: [ "/bin/bash", "-c", "--" ]
args:
- "wget https://gist.githubusercontent.com/Jeffwan/e10c08dcd4aa2751c361e136896bc35f/raw/9d7a8558290768b042f85695aa509aa35874571f/raydp-spark.py &&
python raydp-spark.py"
resources:
requests:
cpu: 100m
memory: 256Mi
import os
import ray
import raydp
HEAD_SERVICE_IP_ENV = "EXAMPLE_CLUSTER_RAY_HEAD_SERVICE_HOST"
HEAD_SERVICE_CLIENT_PORT_ENV = "EXAMPLE_CLUSTER_RAY_HEAD_SERVICE_PORT_CLIENT"
head_service_ip = os.environ[HEAD_SERVICE_IP_ENV]
client_port = os.environ[HEAD_SERVICE_CLIENT_PORT_ENV]
ray.util.connect(f"{head_service_ip}:{client_port}")
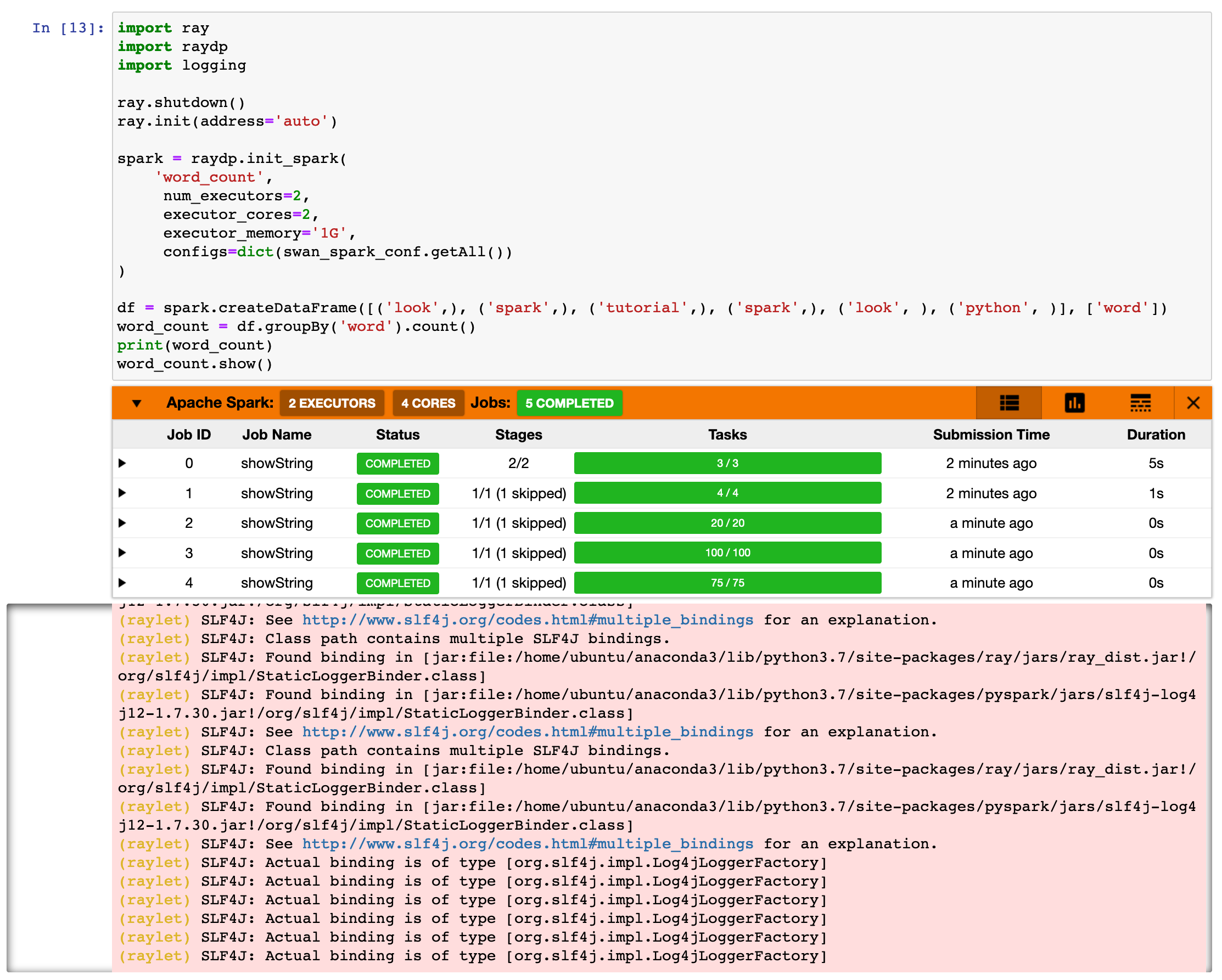
spark = raydp.init_spark('word_count',
num_executors=2,
executor_cores=2,
executor_memory='1G')
df = spark.createDataFrame([('look',), ('spark',), ('tutorial',), ('spark',), ('look', ), ('python', )], ['word'])
df.show()
word_count = df.groupBy('word').count()
word_count.show()
raydp.stop_spark()
For now, user can only obtain predictions by getting the model and then predicting
Refactor Dataset API into multiple subclasses:
Eg:
GeneralDataset
import raydp
general_ds: GeneralDataset = raydp.from_generator(data_generator, num_shards)
# data process
...
def create_torch_ds(ds: GeneralDataset):
#...
return torch.data.Dataset(...)
torch_ds = general_ds.to_torch(create_torch_ds)
estimator.fit(torch_ds)TextDataset
import raydp
text_ds: TextDataset = raydp.read_parquet(...)
# data process
...
torch_ds = text_ds.to_torch(...)
estimator.fit(torch_ds)ImageDataset
import raydp
img_ds: ImageDataset = raydp.read_imgs(...)
# data process
...
torch_ds = img_ds.to_torch(...)
estimator.fit(torch_ds)We don't need to calculate accuracy in the evaluation of torch estimator, since we have no idea whether it's a regression or a classification task.
I was using very simple code:
import ray
import raydp
ray.init()
spark = raydp.init_spark(app_name="RayDP example", num_executors=2, executor_cores=2, executor_memory="4GB")
My laptop is MacBook (Big Sur). Tried Ray nightly and 1.2. PySpark 3.0.1. Tried Java 11 and 15.
Got the below error:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/ray/jars/ray_dist.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/pyspark/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Exception in thread "main" py4j.Py4JNetworkException
at py4j.GatewayServer.startSocket(GatewayServer.java:788)
at py4j.GatewayServer.start(GatewayServer.java:763)
at py4j.GatewayServer.start(GatewayServer.java:746)
at org.apache.spark.deploy.raydp.AppMasterEntryPoint$.main(AppMasterEntryPoint.scala:39)
at org.apache.spark.deploy.raydp.AppMasterEntryPoint.main(AppMasterEntryPoint.scala)
Caused by: java.net.BindException: Address already in use
at java.base/sun.nio.ch.Net.bind0(Native Method)
at java.base/sun.nio.ch.Net.bind(Net.java:550)
at java.base/sun.nio.ch.Net.bind(Net.java:539)
at java.base/sun.nio.ch.NioSocketImpl.bind(NioSocketImpl.java:643)
at java.base/java.net.ServerSocket.bind(ServerSocket.java:396)
at py4j.GatewayServer.startSocket(GatewayServer.java:786)
... 4 more
In function save_to_ray, the pandas udf type "MAP_ITER" is not supported in spark 3.0
def save_to_ray(df: Any) -> BlockSet:
...
@pandas_udf(return_type, PandasUDFType.MAP_ITER)
def save(batch_iter):```
Hi ,
First of all thanks for this implementation which is of great use .
I am a beginner to this , facing below issue when i am trying to execute raydp on minikube with cpu 10 and memory 10GB
Is there any explict memory that needs to be set , because for any action execution in spark i get the following issue
21/04/07 05:02:09 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
Any help is greatly appreciated 👍
I am running the PyTorch_nyctaxi example on a node with 80 CPUs, each with 20 physical cores. If I set the number of executors to a number larger than 16 and the number of workers in TorchEstimator to more than 20, the code won't run and I would get resource unavailable errors, such as these ones:
(raylet) terminate called after throwing an instance of 'std::system_error'
(raylet) what(): Resource temporarily unavailable
2021-02-26 11:42:09,982 WARNING worker.py:1090 -- The node with node id e7d998b5c895816e6446685482cb0392ad76245a8dab474562b232d9 has been marked dead because the detector has missed too many heartbeats from it. This can happen when a raylet crashes unexpectedly or has lagging heartbeats.
Obviously, I am utilizing a small portion of the computing resources I have available on the node. I do not specify the num_cpus to use in ray.init(), so it should automatically detect all 80.
Any idea why is this happening?
Hi,
I'm trying to use raydp with Ray client mode and I found the below issue as a guide.
#130
The issue suggests I should instantiate SparkSession within Ray worker's context, but as I tried it, an error occurred telling me that raydp is not installed on worker nodes.
Is this intended? Should I install raydp pacakges on all Ray worker nodes?
It seems like there are multiple versions of SLF4J coming from Ray and PySpark, which lead to the following error being shown:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/ubuntu/anaconda3/lib/python3.7/site-packages/ray/jars/ray_dist.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/ubuntu/anaconda3/lib/python3.7/site-packages/pyspark/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
I'm using raydp in conjunction with the sparkmonitor project, which displays a progress bar for spark jobs, and this warning generates a lot of output which pollutes the results. Any suggestions for how to suppress this output or prevent it from happening in the first place?
This line of code fails:
spark = raydp.init_spark(app_name="RayDP example",
num_executors=2,
executor_cores=2,
executor_memory="4GB")
I am getting the following errors (linux server with a standalone Spark cluster):
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/internal/Logging
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:468)
at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.apache.spark.deploy.raydp.AppMasterEntryPoint.main(AppMasterEntryPoint.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.internal.Logging
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 13 more
Traceback (most recent call last):
File "/home/guryaniv/try_raydp_simple.py", line 4, in
spark = raydp.init_spark(app_name="RayDP example", num_executors=2, executor_cores=2, executor_memory="4GB")
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/context.py", line 122, in init_spark
return _global_spark_context.get_or_create_session()
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/context.py", line 68, in get_or_create_session
spark_cluster = self._get_or_create_spark_cluster()
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/context.py", line 62, in _get_or_create_spark_cluster
self._spark_cluster = SparkCluster()
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/spark/ray_cluster.py", line 31, in init
self._set_up_master(None, None)
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/spark/ray_cluster.py", line 37, in _set_up_master
self._app_master_bridge.start_up()
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/spark/ray_cluster_master.py", line 52, in start_up
self._gateway = self._launch_gateway(extra_classpath, popen_kwargs)
File "/opt/anaconda3/envs/raydp/lib/python3.6/site-packages/raydp/spark/ray_cluster_master.py", line 115, in _launch_gateway
raise Exception("Java gateway process exited before sending its port number")
Exception: Java gateway process exited before sending its port number
To run the code I am using spark-submit with the spark master:
spark-submit --master spark://:7077 raydp_example.py
Support set placement group for Spark cluster.
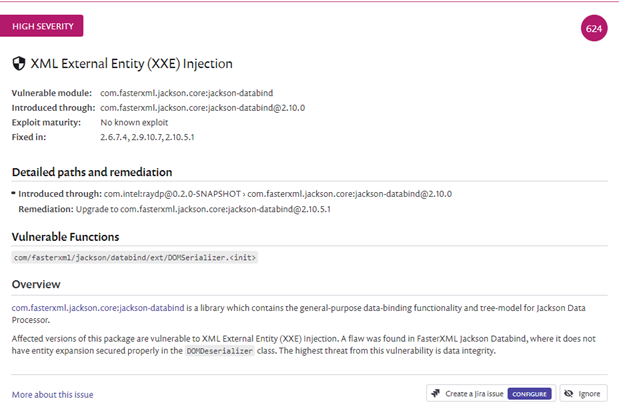
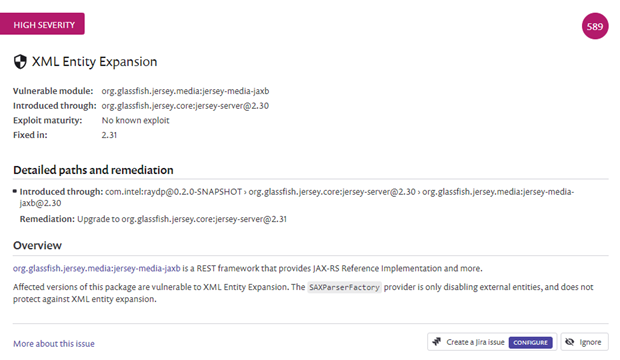
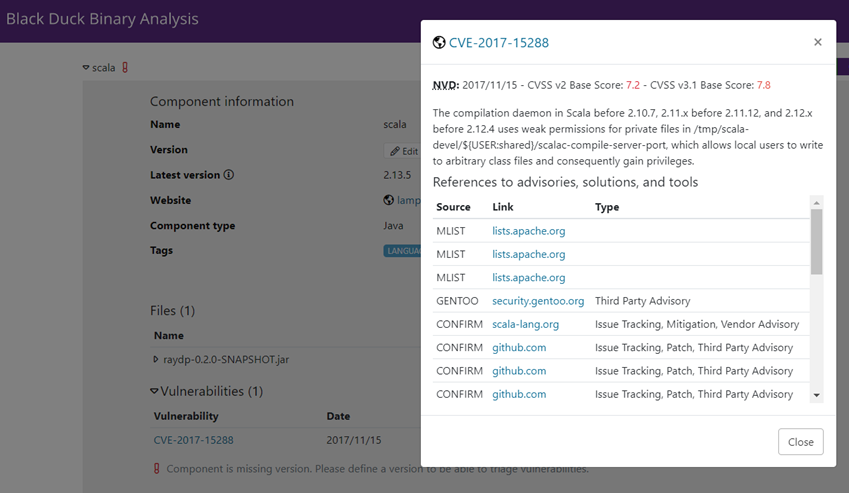
Hi there,
I'm trying to use RayDP on an EC2 Ray cluster. It took me some time to figure out how to access S3 correctly. The solution involved downloading a custom version of Spark (with Hadoop 3), and then downloading some AWS jars:
# Install a custom version of PySpark which plays nicely with S3
wget 'https://mirrors.ocf.berkeley.edu/apache/spark/spark-3.0.2/spark-3.0.2-bin-hadoop3.2.tgz'
tar -xvzf spark-3.0.2-bin-hadoop3.2.tgz
pushd spark-3.0.2-bin-hadoop3.2/python/
python setup.py sdist
pip install dist/pyspark-3.0.2.tar.gz
popd
# Install the Spark-on-Ray project
pip install raydp-nightly
# Get the S3 connector for Spark
pushd "$(python -c 'import os, pyspark; print(os.path.dirname(pyspark.__file__))')/jars"
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar
wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.375/aws-java-sdk-bundle-1.11.375.jar
popd
As a result of this, I am able to use the S3A connector to do things like spark.read.parquet("s3a://....."). This connector automatically figures credentials from the head node's instance role, so no explicit authentication is needed.
However, when I try to do the same in an auto-scaling cluster, the worker nodes are not able to get the credentials. The following error shows up:
Py4JJavaError: An error occurred while calling o166.json.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 71 in stage 0.0 failed 4 times,
most recent failure: Lost task 71.3 in stage 0.0 (TID 88, 172.31.38.110, executor 12):
java.nio.file.AccessDeniedException: <<BUCKET_NAME>>: org.apache.hadoop.fs.s3a.auth.NoAuthWithAWSException:
No AWS Credentials provided by SimpleAWSCredentialsProvider EnvironmentVariableCredentialsProvider
InstanceProfileCredentialsProvider : com.amazonaws.SdkClientException: The requested metadata is not
found at http://xxx.xxx.xxx.xxx/latest/meta-data/iam/security-credentials/
I guess this problem is related to this one: ray-project/ray#3115.
However, I am wondering if there's any workaround specific to RayDP that could help with this issue.
Ideally, we could get the best performance when the time of data loading overlap with forward+backward time. This is a little similar to LR scheduling. We could use the history metrics to determine the reasonable processes number for data loading. This could also be added to Horovod.
Hi, are there any plans to automatically publish conda-forge packages beside of pip packages?
Setting spark version to 3.1.0+ in pom.xml of core will result in this:
[ERROR] /home/lzhi/Projects/raydp/core/src/main/scala/org/apache/spark/scheduler/cluster/raydp/RayCoarseGrainedSchedulerBackend.scala:196: error: method doRequestTotalExecutors overrides nothing.
[ERROR] Note: the super classes of class RayCoarseGrainedSchedulerBackend contain the following, non final members named doRequestTotalExecutors:
[ERROR] protected def doRequestTotalExecutors(resourceProfileToTotalExecs: Map[org.apache.spark.resource.ResourceProfile,Int]): scala.concurrent.Future[Boolean]
[ERROR] override protected def doRequestTotalExecutors(requestedTotal: Int): Future[Boolean] = {
The following erros are just error prints. It is a bug in ray and will be fixed in future.
2020-12-01 20:44:59,081 ERROR worker.py:977 -- Possible unhandled error from worker: ray::ParallelIteratorWorker.par_iter_next_batch() (pid=24362, ip=192.168.3.6)
File "python/ray/_raylet.pyx", line 464, in ray._raylet.execute_task
File "python/ray/_raylet.pyx", line 419, in ray._raylet.execute_task.function_executor
File "/Users/xianyang/miniconda3/envs/torch/lib/python3.7/site-packages/ray/util/iter.py", line 1158, in par_iter_next_batch
batch.append(self.par_iter_next())
File "/Users/xianyang/miniconda3/envs/torch/lib/python3.7/site-packages/ray/util/iter.py", line 1152, in par_iter_next
return next(self.local_it)
StopIterationhttps://github.com/oap-project/raydp/blob/master/examples/pytorch_dlrm.ipynb
This example's markdown format not correct,
"cell_type": "raw" => "cell_type": "markdown",
What:
https://github.com/Intel-bigdata/oap-raydp/search?q=dynamic suggests that dynamic executor allocation may be added later.
Are there plans to add this, are there fundamental challenges in the ray context for supporting this?
Hi there! I'm trying to figure out how to put together a proper Spark config in an auto-scaling cluster.
I'm trying something very simple:
import ray
import raydp
ray.init(address='auto')
spark = raydp.init_spark(
'word_count',
num_executors=16,
executor_cores=5,
executor_memory='1G'
)
I'm running this with an autoscaling config that starts with a single m4.16xlarge node (64 cores, 160GB RAM) and can auto-scale a few more worker nodes. However, I'm seeing the following error from the autoscaler:
Demands:
{'memory': 20.0, 'CPU': 5.0}: 4+ pending tasks/actors
2021-03-12 23:24:25,447 WARNING resource_demand_scheduler.py:642 -- The autoscaler could
not find a node type to satisfy the request: [{'CPU': 5.0, 'memory': 20.0}, {'CPU': 5.0, 'memory': 20.0},
{'CPU': 5.0, 'memory': 20.0}, {'CPU': 5.0, 'memory': 20.0}]. If this request is related to placement
groups the resource request will resolve itself, otherwise please specify a node type with the
necessary resource https://docs.ray.io/en/master/cluster/autoscaling.html#multiple-node-type-autoscaling.
2021-03-12 23:24:25,559 INFO autoscaler.py:305 --
======== Autoscaler status: 2021-03-12 23:24:25.559754 ========
Node status
---------------------------------------------------------------
Healthy:
1 ray-legacy-head-node-type
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
60.0/64.0 CPU
11.72/163.184 GiB memory
0.00/50.977 GiB object_store_memory
Demands:
{'memory': 20.0, 'CPU': 5.0}: 4+ pending tasks/actors
I guess I have 2 questions about this:
Thanks for all the awesome work!
I am playing raydp inside head pod on k8s.
import ray
import raydp
# connect to the cluster
ray.init(address='auto')
2021-04-08 15:26:01,060 INFO worker.py:654 -- Connecting to existing Ray cluster at address: 192.168.13.21:6379
{'node_ip_address': '192.168.13.21', 'raylet_ip_address': '192.168.13.21', 'redis_address': '192.168.13.21:6379', 'object_store_address': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/plasma_store', 'raylet_socket_name': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/raylet', 'webui_url': '0.0.0.0:8265', 'session_dir': '/tmp/ray/session_2021-04-08_15-02-34_751440_101', 'metrics_export_port': 49804, 'node_id': 'adb6bbd4e36d880a70ee156fd05895c0b8a4bad92e88f14a733b035c'}
ray.nodes()
[{'NodeID': 'bbf00a25f2fc5fecb28245c63b57d18700e5819532233dbc0bc1d936', 'Alive': True, 'NodeManagerAddress': '192.168.13.22', 'NodeManagerHostname': 'example-cluster-ray-worker-jr8js', 'NodeManagerPort': 41061, 'ObjectManagerPort': 43811, 'ObjectStoreSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/plasma_store', 'RayletSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/raylet', 'MetricsExportPort': 50616, 'alive': True, 'Resources': {'memory': 3006477107.0, 'CPU': 2.0, 'object_store_memory': 1273641369.0, 'bar': 1.0, 'foo': 1.0, 'node:192.168.13.22': 1.0}}, {'NodeID': 'adb6bbd4e36d880a70ee156fd05895c0b8a4bad92e88f14a733b035c', 'Alive': True, 'NodeManagerAddress': '192.168.13.21', 'NodeManagerHostname': 'example-cluster-ray-head-xnk64', 'NodeManagerPort': 35547, 'ObjectManagerPort': 45743, 'ObjectStoreSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/plasma_store', 'RayletSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/raylet', 'MetricsExportPort': 49804, 'alive': True, 'Resources': {'memory': 3006477107.0, 'node:192.168.13.21': 1.0, 'CPU': 2.0, 'object_store_memory': 1273423872.0}}, {'NodeID': '02df037ac63f257c289e1d16762cadff26c9f8b0e5714738416c09f9', 'Alive': True, 'NodeManagerAddress': '192.168.13.23', 'NodeManagerHostname': 'example-cluster-ray-worker-5rknz', 'NodeManagerPort': 42665, 'ObjectManagerPort': 36957, 'ObjectStoreSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/plasma_store', 'RayletSocketName': '/tmp/ray/session_2021-04-08_15-02-34_751440_101/sockets/raylet', 'MetricsExportPort': 64861, 'alive': True, 'Resources': {'memory': 3006477107.0, 'object_store_memory': 1273514803.0, 'foo': 1.0, 'node:192.168.13.23': 1.0, 'bar': 1.0, 'CPU': 2.0}}]
Ray environment is correct, however, it encounter some issues when I use raydp.
Seems Java run time is not compatible with current ray.
Java Version: openjdk 11.0.10 2021-01-19
Ray Cluster: 2.0.0-dev
Raydp: 0.2.0
spark = raydp.init_spark("K8S test", num_executors=2, executor_cores=1, executor_memory="512M")
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
.....
2021-04-08 15:27:23 ERROR Inbox:94 - An error happened while processing message in the inbox for RAY_APP_MASTER
java.lang.NoSuchMethodError: 'io.ray.api.call.ActorCreator io.ray.api.call.ActorCreator.setJvmOptions(java.lang.String)'
at org.apache.spark.raydp.AppMasterJavaUtils.createExecutorActor(AppMasterJavaUtils.java:47)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.org$apache$spark$deploy$raydp$RayAppMaster$RayAppMasterEndpoint$$requestNewExecutor(RayAppMaster.scala:190)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.$anonfun$schedule$1(RayAppMaster.scala:177)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:158)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.org$apache$spark$deploy$raydp$RayAppMaster$RayAppMasterEndpoint$$schedule(RayAppMaster.scala:176)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint$$anonfun$receive$1.applyOrElse(RayAppMaster.scala:104)
at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75)
at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
Exception in thread "dispatcher-event-loop-1" java.lang.NoSuchMethodError: 'io.ray.api.call.ActorCreator io.ray.api.call.ActorCreator.setJvmOptions(java.lang.String)'
at org.apache.spark.raydp.AppMasterJavaUtils.createExecutorActor(AppMasterJavaUtils.java:47)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.org$apache$spark$deploy$raydp$RayAppMaster$RayAppMasterEndpoint$$requestNewExecutor(RayAppMaster.scala:190)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.$anonfun$schedule$1(RayAppMaster.scala:177)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:158)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint.org$apache$spark$deploy$raydp$RayAppMaster$RayAppMasterEndpoint$$schedule(RayAppMaster.scala:176)
at org.apache.spark.deploy.raydp.RayAppMaster$RayAppMasterEndpoint$$anonfun$receive$1.applyOrElse(RayAppMaster.scala:104)
at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:213)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75)
at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
action doesn't get any resources. It keeps waiting here. I can confirm that my cluster has enough resources. I think this is still related to spark session initialization
>>> spark.range(0, 100).count()
21/04/08 15:28:52 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
21/04/08 15:29:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
21/04/08 15:29:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
...
Hi,
while trying out the example "Titanic survival prediction with RayDp", I ran into the following problem when running the step:
app_name = "Titanic survival prediction with RayDp" num_executors = 2 cores_per_executor = 1 memory_per_executor = "1GB" spark = raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
Py4JJavaError Traceback (most recent call last)
<ipython-input-3-478be455a428> in <module>
3 cores_per_executor = 1
4 memory_per_executor = "1GB"
----> 5 spark = raydp.init_spark(app_name, num_executors, cores_per_executor, memory_per_executor)
/usr/local/lib/python3.8/dist-packages/raydp/context.py in init_spark(app_name, num_executors, executor_cores, executor_memory, configs)
120 _global_spark_context = _SparkContext(
121 app_name, num_executors, executor_cores, executor_memory, configs)
--> 122 return _global_spark_context.get_or_create_session()
123 except:
124 _global_spark_context = None
/usr/local/lib/python3.8/dist-packages/raydp/context.py in get_or_create_session(self)
66 if self._spark_session is not None:
67 return self._spark_session
---> 68 spark_cluster = self._get_or_create_spark_cluster()
69 self._spark_session = spark_cluster.get_spark_session(
70 self._app_name,
/usr/local/lib/python3.8/dist-packages/raydp/context.py in _get_or_create_spark_cluster(self)
60 if self._spark_cluster is not None:
61 return self._spark_cluster
---> 62 self._spark_cluster = SparkCluster()
63 return self._spark_cluster
64
/usr/local/lib/python3.8/dist-packages/raydp/spark/ray_cluster.py in __init__(self)
29 super().__init__(None)
30 self._app_master_bridge = None
---> 31 self._set_up_master(None, None)
32 self._spark_session: SparkSession = None
33
/usr/local/lib/python3.8/dist-packages/raydp/spark/ray_cluster.py in _set_up_master(self, resources, kwargs)
35 # TODO: specify the app master resource
36 self._app_master_bridge = RayClusterMaster()
---> 37 self._app_master_bridge.start_up()
38
39 def _set_up_worker(self, resources: Dict[str, float], kwargs: Dict[str, str]):
/usr/local/lib/python3.8/dist-packages/raydp/spark/ray_cluster_master.py in start_up(self, popen_kwargs)
54 self._set_properties()
55 self._host = ray._private.services.get_node_ip_address()
---> 56 self._create_app_master(extra_classpath)
57 self._started_up = True
58
/usr/local/lib/python3.8/dist-packages/raydp/spark/ray_cluster_master.py in _create_app_master(self, extra_classpath)
162 if self._started_up:
163 return
--> 164 self._app_master_java_bridge.startUpAppMaster(extra_classpath)
165
166 def get_master_url(self):
/usr/local/lib/python3.8/dist-packages/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/usr/local/lib/python3.8/dist-packages/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o0.startUpAppMaster.
: java.lang.RuntimeException: Failed to initialize Ray runtime.
at io.ray.api.Ray.init(Ray.java:27)
at org.apache.spark.deploy.raydp.AppMasterJavaBridge.startUpAppMaster(AppMasterJavaBridge.scala:41)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: Failed to initialize ray runtime
at io.ray.runtime.DefaultRayRuntimeFactory.createRayRuntime(DefaultRayRuntimeFactory.java:43)
at io.ray.api.Ray.init(Ray.java:38)
at io.ray.api.Ray.init(Ray.java:25)
... 12 more
Caused by: java.lang.RuntimeException: Failed to get address info. Output: null
at io.ray.runtime.runner.RunManager.getAddressInfoAndFillConfig(RunManager.java:90)
at io.ray.runtime.RayNativeRuntime.start(RayNativeRuntime.java:88)
at io.ray.runtime.DefaultRayRuntimeFactory.createRayRuntime(DefaultRayRuntimeFactory.java:39)
... 14 more
Caused by: java.io.IOException: Cannot run program "python": error=2, No such file or directory
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at io.ray.runtime.runner.RunManager.runCommand(RunManager.java:105)
at io.ray.runtime.runner.RunManager.getAddressInfoAndFillConfig(RunManager.java:80)
... 16 more
Caused by: java.io.IOException: error=2, No such file or directory
at java.lang.UNIXProcess.forkAndExec(Native Method)
at java.lang.UNIXProcess.<init>(UNIXProcess.java:247)
at java.lang.ProcessImpl.start(ProcessImpl.java:134)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1029)
... 18 more
I checked the closed issues before, and I already changed my JDK version to
openjdk version "1.8.0_282"
OpenJDK Runtime Environment (build 1.8.0_282-8u282-b08-0ubuntu1~20.04-b08)
OpenJDK 64-Bit Server VM (build 25.282-b08, mixed mode)
Can you please help me?
Thank you!
I was able to run all the steps following the pytorch example, until:
# Train the model
estimator.fit_on_spark(train_df, test_df)
Got this error:
2020-12-01 00:03:26,525 WARNING worker.py:1031 -- Failed to unpickle actor class 'DistributedTorchRunner' for actor ID 62223d8501000000. Traceback:
Traceback (most recent call last):
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/function_manager.py", line 494, in _load_actor_class_from_gcs
actor_class = pickle.loads(pickled_class)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/util/sgd/__init__.py", line 1, in <module>
from ray.util.sgd.torch import TorchTrainer
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/util/sgd/torch/__init__.py", line 12, in <module>
from ray.util.sgd.torch.torch_trainer import (TorchTrainer,
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/util/sgd/torch/torch_trainer.py", line 13, in <module>
from ray.tune import Trainable
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/tune/__init__.py", line 2, in <module>
from ray.tune.tune import run_experiments, run
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/tune/tune.py", line 13, in <module>
from ray.tune.ray_trial_executor import RayTrialExecutor
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/tune/ray_trial_executor.py", line 15, in <module>
from ray.tune.durable_trainable import DurableTrainable
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/tune/durable_trainable.py", line 5, in <module>
from ray.tune.syncer import get_cloud_sync_client
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/ray/tune/syncer.py", line 90, in <module>
class SyncConfig:
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 958, in dataclass
return wrap(_cls)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 950, in wrap
return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 800, in _process_class
cls_fields = [_get_field(cls, name, type)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 800, in <listcomp>
cls_fields = [_get_field(cls, name, type)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 659, in _get_field
if (_is_classvar(a_type, typing)
File "/Users/dr6jl/anaconda3/lib/python3.8/site-packages/dataclasses.py", line 550, in _is_classvar
return type(a_type) is typing._ClassVar
AttributeError: module 'typing' has no attribute '_ClassVar'
I'm using raydp in ray's client mode, trying to submit a raydp operation with ray.remote,
it works during the initial test, but when I re-run this code, it doesn't print anything, which seems failed quitely.
import ray
import raydp
import logging
example_cluster = "xxx.xxx.xxx.xxx:50051" # set this to your ray client address
try:
ray.util.connect(example_cluster)
logging.info(f"Connected to pre-provisioned cluster:{example_cluster}")
except Exception as e:
logging.info(f"Error in client connection:{e}")
pass
class SparkOp:
def __init__(self):
self.spark = None
self.started = False
def start(self, config= None):
try:
#todo: pass user config into init_spark
self.spark = raydp.init_spark('word_count',
num_executors=2,
executor_cores=1,
executor_memory='1G')
self.started = True
except Exception as e:
logging.info(f"starting spark failed:{e}")
self.started = False
def run(self, input_data=None):
if not self.started:
self.start()
logging.info("starting spark now...")
if not self.started:
logging.info("spark is not started, exit")
return
try:
df = self.spark.createDataFrame([('look',), ('spark',), ('tutorial',), ('spark',), ('look', ), ('python', )], ['word'])
df.show()
word_count = df.groupBy('word').count()
word_count.show()
logging.info("returnning dataframe")
#todo: add support for RayFlow Tensor Cache
#return df.collect()
except Exception as e:
logging.info(f"running spark job failed:{e}, stopping spark now")
self.stop()
def stop(self):
raydp.stop_spark()
spark = ray.remote(SparkOp).remote()
ray.get(spark.run.remote())
ray.get(spark.stop.remote())
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.