paddlepaddle / models Goto Github PK
View Code? Open in Web Editor NEWOfficially maintained, supported by PaddlePaddle, including CV, NLP, Speech, Rec, TS, big models and so on.
License: Apache License 2.0
Officially maintained, supported by PaddlePaddle, including CV, NLP, Speech, Rec, TS, big models and so on.
License: Apache License 2.0



































































































































































































































I am trying to train ds2 on THCHS30 which is a mandarin dataset. A phenomenon is that we encounter error explosion easily when batch_size is big liking 64, 128 or 256. I try to clip the error to 1000 when inf appears. The clipping operation is very tricky, I catch inf and clip in paddle/v2/trainer.py as following:
cost_sum = out_args.sum()
import math
if (math.isinf(cost_sum)): cost_sum = 1000.0
cost = cost_sum / len(data_batch)We can train ds2 normally after adding the clipping operation. I have tried to train the model using batch_shuffle_clipped provider and instance_shuffle provider. The learning curves are as following:
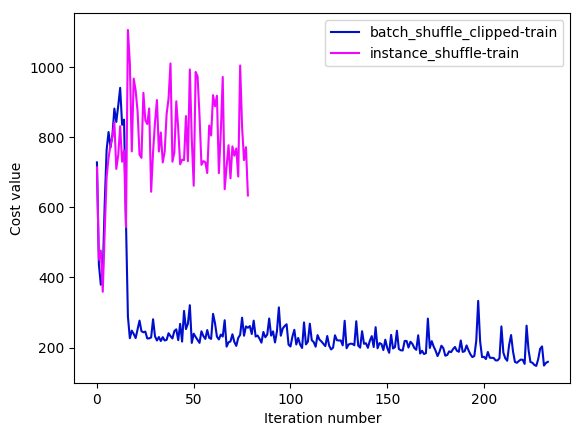
As we can see, instance_shuffle converges badly and I abandon this configuration after training several iterations. The batch_shuffle_clipped configuration looks like converging very slowly when the training cost goes down to 170~. The key settings of above experiments are:
| setting | value |
|---|---|
| batch_size | 64 |
| trainer_count | 4 |
| num_conv_layers | 2 |
| adam_learning_rate | 0.0005 |
I also product another experiment on a tiny dataset which only contains 128 samples (first 128). Training data and validation data both use the tiny dataset. Training settings are same with above. Following are the learning curves:

From the figure above we can learn that the convergence is very unstable and slow. There exists a unreasonable gap between training curve and validation curve. Since the training data and validation data are same, the difference of two curves should be minor. Will figure out the reason of the anomalies.
Maybe
the idea of external memory originates from NTM.
In this example, we would like to show how to add external memory to a NMT model. Please refer to this configuration file written in old PaddlePaddle API.
The example must include the training and generating process.
Please directly use the wmt14 dataset.
Please pull your codes and doc to the mt_with_external_memory directory.
@lcy-seso
Don't understand how to add prediction logic in the task.
In this example, we would like to show how to do LTR task in PaddlePaddle. Usually, there are three ways:
The example also must include how to predict. Note that in LTR task, training and testing network is different.
I suggest to use movielens dataset.
Please pull your codes and docs into the ltr directory.
Goals of example configuration files are twofold:
Example configuration file is a kind of documentations to some extent, which shows how to use layers/pre-defined small networks in PaddlePaddle through examples. It is expected to be more lightweight than PaddleBook.
Backup of configuration files for newly developed layers/modules. Every time, if anyone adds a new layer into PaddlePaddle, or add a new pre-defined network into the paddle python package, he must have written a test configuration file. This test configuration file is also a good example to show how to use his new layer/network for other users.
In this example, we would like to show how to use NCE in PaddlePaddle, which is useful when training language model with a large vocabulary.
The example must include a training and a predicting process.
Please consider to use the following data for training and add these datasets into paddle.dataset package.
Note that the dataset is also used in this task, please consider to share the data processing work.
Please pull your codes and docs into the nce_cost directory.
In this example, we would like to show how to do image classification task in PaddlePaddle. We need to provide several classic configuration, AlexNet, VGG, GoogleNet, ResNet. It's betther to provide GoogleNet-v3/v4, identity-mapping-ResNet, but it doesn't matter if they are not provided in the first version.
Reference configuration:
DataSet:
I don't have permission to revise it.

If training texts are end of white space, sentences generated by decoder should be end of white space too. In such situation, we need a post processing logic to re-calculate a LM score after replacing white space by end token.
add data augmentation part for DeepSpeech2(inclued noise_speech, impuls_response eg)
noise_speech, impuls_response, resampler, speed_perturb, online_bayesias_normalization.convolve, add_noise, normalizerThe computation of probabilities in CTC beam search involves the addition and multiplication of very small numbers. To make sure the numerical stability, many other implementations first convert the probabilities into log format, then execute the operation.
In the Deep Speech 2 project, we implement two versions of beam search decoder, computing probability in the original and log form respectively. Currently, we use the the former for which is found to have a bit benefit in efficiency. But we also care about the numerical stability, so we have an independent test to compare the two decoders with the ctc beam search decoder in TensorFlow.
Run test_ctc_beam_search_decoder.py, the outputs look like

When the length of input probability list is limited to several hundreds, the two decoders get almost the same scores and decoding results. Hence we believe that the numerical stability may be not a problem in the decoder right now, but we will be careful about it all the way.
GAN is one of some of the old examples that haven't merged into PaddlePaddle yet. Here is the original pull request: PaddlePaddle/book#30. We are going to merge it into PaddlePaddle first.
GAN will be a good example to enhance PaddlePaddle's control flow of sub-graphs in the entire network during training.
In this example, we would like to show how to use scheduled sampling for seq2seq task.
Please refer to this configuration file written in old PaddlePaddle API.
The example must include the training and the generating process.
Please pull your codes and docs into the scheduled_sampling directory.
@lcy-seso huber_cost is used error ,connect to issue #10
##example
import paddle.v2 as paddle
import paddle.v2.dataset.uci_housing as uci_housing
def main():
# init
paddle.init(use_gpu=False, trainer_count=1)
# network config
x = paddle.layer.data(
name='x',
type=paddle.data_type.dense_vector(13))
y_predict = paddle.layer.fc(
input=x,
size=1,
act=paddle.activation.Linear())
y = paddle.layer.data(
name='y',
type=paddle.data_type.dense_vector(1))
cost = paddle.layer.huber_cost(input=y_predict, label=y)
# create parameters
parameters = paddle.parameters.create(cost)
# create optimizer
optimizer = paddle.optimizer.Momentum(momentum=0)
trainer = paddle.trainer.SGD(
cost=cost, parameters=parameters, update_equation=optimizer)
feeding = {'x': 0, 'y': 1}
# event_handler to print training and testing info
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "Pass %d, Batch %d, Cost %f" % (
event.pass_id, event.batch_id, event.cost)
if isinstance(event, paddle.event.EndPass):
result = trainer.test(
reader=paddle.batch(uci_housing.test(), batch_size=2),
feeding=feeding)
print "Test %d, Cost %f" % (event.pass_id, result.cost)
# training
trainer.train(
reader=paddle.batch(
paddle.reader.shuffle(uci_housing.train(), buf_size=500),
batch_size=2),
feeding=feeding,
event_handler=event_handler,
num_passes=30)
if name == 'main':
main()

python train.py
prepare vocab...
Segmentation fault
train.txt 1.8GB - chinese UTF-8 Unicode text
cat /proc/meminfo |grep MemTotal
MemTotal: 4048124 kB
Currently, dependencies installation is always failed in CI, since some complex requirements is lack of well tested installing process. I try to settle this problem by following the below solutions:
In this example, we would like to show how the three addressing mechanism in NTM.
Please refer to this configuration file written in old PaddlePaddle API.
The example must include the training and the generating process.
Please pull your codes and docs into the ntm_addressing_mechanism directory.
1.add data augmentor class for DeepSpeech2(inclued speed_change, resample, online bayesias_noline)
2.NosieAugmentor and ImpulseResaponseAugmentor will be added later
There are several new python modules added in deep speech project. These modules should be tested before merging. Since some scripts need PaddlePaddle running environment, so I expand the .travis.yml to support docker. There are several rules when writing unit test scripts.
test*.py.The ctc beam search in DS2, or prefix beam search consists of appending candidate characters to prefixes and repeatedly looking up the n-gram language model. Both the two processes are time-consuming, and bring difficulty in parameters tuning and deployment.
A proven effective way is to prune the beam search. Specifically, in extending prefix only the fewest number of characters whose cumulative probability is at least p need to be considered, instead of all the characters in the vocabulary. When p is taken 0.99 as recommended by the DS2 paper, about 20x speedup is yielded in English transcription than that without pruning, with very little loss in accuracy. And for the Mandarin, the speedup ratio is reported to be up to 150x.
Due to pruning, the tuning of parameters gets more efficiently. There are two important parameters alpha and beta in beam search, associated with language model and word insertion respectively. With a more acceptable speed, alpha and beta can be searched elaborately. And the relation between WER and the two parameters turns out to be:

With the optimal parameters alpha=0.26 and beta=0.1 as shown in above figure, currently the beam search decoder has decreased WER to 13% from the best path decoding accuracy 22%.
how to
models code &document Cannot find in PaddlePaddle Documents
In this example, we would like to show how the do regression task in PaddlePaddle.
Please refer to this configuration file written in old PaddlePaddle API.
Note that, currently PaddlePaddle provides two regression costs: mse and huber loss. Please consider adding an example for huber loss.
Please pull your codes and docs into the regressoin directory.
F0606 AverageOptimizer.h:76 Check failed: numUpdates_ > prevNumUpdate_(0 vs.0)
FYI image

fix:
add parameter max_average_window=10000
model_average=paddle.optimizer.ModelAverage(average_window=0.5, max_ average_window=10000)
We are now working on a CTR model trained by PaddlePaddle.
The model structure mainly follows the paper Wide & Deep Learning for Recommender Systems.
Add Deep Structured Semantic Model(DSSM)
学习两个句子之间的相关性
After merging PR #74, we have seen such abnormal learning curve:

The figure plots the training cost. Notice that in the tails of the curve, there are many spikes, exactly locating at the first batch of each epoch.
Besides, it is not easy to reproduce the phenomenon in a small dataset.
Not supported
Refactor the whole data preprocessor for DeepSpeech2 (e.g. re-design classes, re-organize dir, add augmentation interfaces etc.):
AudioSegment, SpeechSegment, TextFeaturizer, AudioFeaturizer, SpeechFeaturizer etc.AugmentorBase, AugmentationPipeline, VolumePerturbAugmentor etc., to make it easier to add more data augmentation models.DataGenerator. Add FeatureNormalizer. -compute_mean_std.py for users to create mean_std file before training.data directory into datasets and data_utils.We are planning to build Deep Speech 2 (DS2) [1], a powerful Automatic Speech Recognition (ASR) engine, on PaddlePaddle. For the first-stage plan, we have the following short-term goals:
Intensive system optimization and low-latency inference library (details in [1]) are not yet covered in this first-stage plan.
We roughly break down the project into 14 tasks:
DenseScanner in dataprovider_converter.py, etc.ctc_error_evaluator(CER) to support WER.Tasks parallelizable within phases:
| Roadmap | Description | Parallelizable Tasks |
|---|---|---|
| Phase I | Basic model & components | Task 1 ~ Task 8 |
| Phase II | Standard model & benchmarking & profiling | Task 9 ~ Task 12 |
| Phase III | Documentations | Task13 ~ Task14 |
Issue for each task will be created later. Contributions, discussions and comments are all highly appreciated and welcomed!
Improve audio featurizer by adding e.g. resampling, db_normalization, and random shift, as suggested in speech_dl codes.
Add multi-threading support for DS2 data generator, to accelerate the training.
In this example, we would like to show how to use hsigmoid to training word embedding for large vocabulary.
Please refer to this example provided by @reyoung. Note that this example is not for word embedding training exactly. You‘d better learn and then modify it.
The example must include the training and the predicting process.
Please pull your codes and docs into the word_embedding directory.
In future, we may add more configuration for models with a large vocabulary.
A part of model code:
firstword = paddle.layer.data(
name="firstw", type=paddle.data_type.integer_value(dict_size))
secondword = paddle.layer.data(
name="secondw", type=paddle.data_type.integer_value(dict_size))
thirdword = paddle.layer.data(
name="thirdw", type=paddle.data_type.integer_value(dict_size))
fourthword = paddle.layer.data(
name="fourthw", type=paddle.data_type.integer_value(dict_size))
nextword = paddle.layer.data(
name="fifthw", type=paddle.data_type.integer_value(dict_size))
Efirst = wordemb(firstword)
Esecond = wordemb(secondword)
Ethird = wordemb(thirdword)
Efourth = wordemb(fourthword)
contextemb = paddle.layer.concat(input=[Efirst, Esecond, Ethird, Efourth])
hidden1 = paddle.layer.fc(input=contextemb,
size=hiddensize,
act=paddle.activation.Sigmoid(),
layer_attr=paddle.attr.Extra(drop_rate=0.5),
bias_attr=paddle.attr.Param(learning_rate=1),
param_attr=paddle.attr.Param(
initial_std=1. / math.sqrt(embsize * 8),
learning_rate=1))
predictword = paddle.layer.fc(input=hidden1,
size=dict_size,
bias_attr=paddle.attr.Param(learning_rate=1),
act=paddle.activation.Softmax())
The part of inference code:
embsize = 32
hiddensize = 256
N = 5
def main():
paddle.init(use_gpu=False, trainer_count=3)
word_dict = paddle.dataset.imikolov.build_dict()
dict_size = len(word_dict)
_, prediction, _= nnlm(hiddensize, embsize, dict_size)
#with gzip.open("model_params.tar.gz", 'r') as f:
# parameters.from_tar(f)
parameters = paddle.parameters.Parameters.from_tar(gzip.open("model_params.tar.gz", 'r'))
infer_data = []
infer_label_data = []
cnt = 0
for item in paddle.dataset.imikolov.test(word_dict, N)():
infer_data.append((item[:4]))
infer_label_data.append(item[4])
cnt += 1
if cnt == 100:
break
predictions = paddle.infer(
output_layer = prediction,
parameters = parameters,
input = infer_data
)
for i, prob in enumerate(predictions):
print prob, infer_label_data[i]
if __name__ == '__main__':
main()
10 elements ahead of item[:4]:
[(2, 1063, 95, 353), (1063, 95, 353, 5), (95, 353, 5, 335), (353, 5, 335, 51), (5, 335, 51, 2072), (335, 51, 2072, 6), (51, 2072, 6, 319), (2072, 6, 319, 2072), (6, 319, 20, 5), (319, 2072, 5, 0)]
In this example, we would like to show how to use nested sequence, which is one of the most amazing things in PaddlePaddle.
We would like to show how to use the nested sequence in the following task:
About dataset:
Please pull your codes and docs into the nested_sequence directory.
caffe2paddle.py which can be used to convert most of Caffe's model.In this example, we would like to show how to train:
Besides, we would like to show how to generate sequence from:
In the generation process, please consider the following two situations:
Please consider to use the following data for training and add these datasets into paddle.dataset package.
Please pull your codes and docs into the language_model directory.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.