Comments (36)
 pemami4911
commented on July 28, 2024
2
pemami4911
commented on July 28, 2024
2
@unnir Yep! That's the general framework. The critic helps to reduce the variance when updating the actor (policy) parameters
@ricgama I contacted the authors of Learning Combinatorial Optimization Algorithms Over Graphs, as they present some results comparing this to their proposed algorithm, and got the following reply about their attempt to replicate the results
"We also use single GPU card for PN-AC (as Hanjun mentioned we use K80 for experiments). It is indeed painful to make Bello et.al.’s method work on TSP2D. We carefully read their paper for many times, and used all the tricks they mentioned. We also found it not working at all, and tried to use exponential moving average as the critic, instead of a separate critic neural network. Finally it works (the loss goes down), but not as good as the performance reported in their paper."
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
1
Hey, thanks for the comments. I am currently in the process of getting results for experiments on the Travelling Salesman Problem, and in the process I've been improving the code quite a bit. As soon as I get some reasonable results that are comparable to those from the paper, I'll make a more detailed write-up (probably a blog post!). This was quite difficult to implement from scratch lol.
To do that, you'd just have to write a script that loads the model from a checkpoint (I have this code written in trainer.py, see line 112) and then takes the input string of numbers and passes it to the model, basically following the code I wrote in trainer.py for evaluating the model from line 250 onwards. Line 285 is an example of how to get the final result out.
from neural-combinatorial-rl-pytorch.
 unnir
commented on July 28, 2024
1
unnir
commented on July 28, 2024
1
I'm kindly asking to keep the discussion here, because it will be beneficial for all concerned.
from neural-combinatorial-rl-pytorch.
 ricgama
commented on July 28, 2024
1
ricgama
commented on July 28, 2024
1
@pemami4911 well, we are not alone :)
I think I can give it a try with exponential moving average...
Thanks
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
1
There's no ground truth in the RL case! So I am computing w.r.t the selected paths
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
1
Hmm.. I would just recommend using the reward function I have in tsp_task.py, which is the one from the paper. Basically just average tour length. With gradient clipping, it shouldn't cause any funny business during backprop. Check out issue #5 though-- it turns out our issue was not cloning the mask!
from neural-combinatorial-rl-pytorch.
unnir
commented on July 28, 2024
thank you for your answer and looking 👀 forward to your blog post!
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
Hello,
Very nice work. I'm also working on an implementation of the paper's solution to solve TSP in Pytorch. I've also implemented the Supervised learning version of Vinyals et al.
I've a question regarding your code: Why have you implemented an LSTM cell in the decoder, insted of using the Pytorch LSTM implementation?
Would you be interested in exchanging implementation ideas? If so I can send you an email...
Best regards,
Ricardo
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@ricgama I implemented the LSTM cell in the decoder myself to add the "glimpse" and "pointer" attention components manually. I took inspiration from https://github.com/MaximumEntropy/Seq2Seq-PyTorch/blob/master/model.py
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
ok, thanks for the reply. As I followed https://github.com/spro/practical-pytorch/tree/master/seq2seq-translation I've used an Pytorch cell for the decoder as well. I think it's the same only different programming style.
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
I'm not 100% sure, but I don't think it is the same. The attending and pointing mechanisms, as indicated in the paper, take as input both the encoder LSTM's hidden state (context, in the NCO for RL paper, ref) as well as the decoder hidden state at each time step of the decoder LSTM (the query). It looks like in that repo that the attention is only over the encoder hidden states. No clue as to how this would empirically affect performance without trying it.
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
My decoder class looks like this:
class Decoder(nn.Module):
def __init__(self, feactures_dim,hidden_size, n_layers=1):
super(Decoder, self).__init__()
self.W1 = Var(hidden_size, hidden_size)
self.W2 = Var(hidden_size, hidden_size)
self.b2 = Var(hidden_size)
self.V = Var(hidden_size)
self.W1g = Var(hidden_size, hidden_size)
self.W2g = Var(hidden_size, hidden_size)
self.b2g = Var(hidden_size)
self.Vg = Var(hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True, num_layers=n_layers)
def pointerAtt(self,di, enc_outputs):
w1e = torch.matmul(enc_outputs,self.W1)
w2h = (torch.matmul(di, self.W2) + self.b2).unsqueeze(1)
u = F.tanh(w1e + w2h)
a = torch.matmul(u, self.V)
a = F.log_softmax(a)
return a
def glimpseAtt(self,di, enc_outputs):
w1eg = torch.matmul(enc_outputs,self.W1g)
w2hg = (torch.matmul(di, self.W2g) + self.b2g).unsqueeze(1)
ug = F.tanh(w1eg + w2hg)
a = torch.matmul(ug, self.Vg)
a = F.softmax(a).unsqueeze(1)
att_state = torch.bmm(a,enc_outputs).squeeze(1)
return att_state
def forward(self, input, hidden, enc_outputs):
di = hidden[-1]
h = self.glimpseAtt(di, enc_outputs)
a = self.pointerAtt(h, enc_outputs)
res, hidden = self.gru(input, hidden)
return a, hidden
Maybe I'm wrong but I think that it does what you have described. What do you think?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
I see, you're calling forward repeatedly and passing the last decoder hidden state as input. Yeah that should be equivalent!
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@ricgama How is it going for you? I have yet to get results on TSP20. The hyperparameters mentioned in the paper don't seem to be working for me :(
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
Hello @pemami4911,
I’m still fighting with it. I’m testing first for n=10 as is an easier problem and I can obtain very good results with the supervised learning version. For the RL, the critic loss decreases very well but I guess that I still have a bug in my code because the tour distance stays practically the same…
Have you manage to train for a small n? For how many epochs?
Although I understand @unnir argument, I still think that via email we could improve our discussions about this, even exchanging emails between the 3. My email is [email protected].
Best regards,
Ricardo
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@ricgama Is there a particular difficulty with using Github issues for you? I find communicating via Issues quite nice actually.
Yeah for n=10, I tried halving the size of the network to 64 and batch sizes of 64, and for learning rates of ~3.5e-4 I was able to get a little bit of improvement. But for n=20, and for the most part for n=10, the tour length stays the same. I'm plotting the average negative-log likelihood of the selected tours, which helps to see whether it's learning something our not. On n=10, the NLL hangs at 15.10; on my best run, it dropped all the way down to ~5 for a little while, but the test tour length stayed around 5. I've been training the regular 128 dim network with lr 1e-3 on n=20 for about ~30 hours now (~850K minibatches of size 128) and the NLL has stayed flat and the tour length hasn't budged :/
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@ricgama are you setting the logits of the already selected nodes during decoding to -infty to ensure only valid tours are used?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@ricgama Also, did you do a distributed implementation? Or single-threaded on a GPU?
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
@pemami4911
1- Yes, I'm setting the logits to -inf
2- I have a single-thead on a GPU
I don't have any values for now, because I'm still trying to find the problem in the code.
Here it is my training plot for superfised version and n=10. At the end of 10 epochs I obtain:
true: 3.06973212456 predicted: 3.13004359636
on the Vinyals "Pointer Networks" paper test set.

from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
Ok, let me know if you find any bugs. Maybe I have a similar one then. I've tried to double and triple check how I implemented the equations, and it all seems right.
For the RL version, I call 1 epoch a random generation of 10,000 minibatches of size 128 of TSP2D graphs- basically, I randomly generate training data on the fly. I randomly generate 1000 test graphs at the beginning of a run and keep it the same thereafter; after each epoch, I shuffle this test set and evaluate the progress of my model. I hope this is correct but not 100% sure.
from neural-combinatorial-rl-pytorch.
unnir
commented on July 28, 2024
first, thank you for your answers, Patrick.
I'm trying to understand the architecture, and I found critic-actor system a bit confusing. So, I studied the topic and saw such picture:

Could please tell me if this picture is relevant to your implementation?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
and from Irwan Bello via email - "You can get to 6.3 average TSP50 tour length pretty easily (a few hours on a CPU). To get to 5.95, you will need to train longer, e.g 2 days with 8 gpus."
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
@pemami4911 One question: You calculate the negative-log likelihood with respect to the ground truth or to the selected path?
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
Hello,
For TSP you can have ground truth, especially for n=10. In RL you just don't train with it. Anyway, I was asking just to implement the same loss as you, so we can compare results.
Best regards
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
Hello,
@pemami4911 Do you have any progress?
I think the problem with my training is in the mask. I've tried it on the supervised model and it also stopped learning. I've changed the mask function to
def apply_mask(self, probs, mask, prev_idxs):
if mask is None:
mask = Variable(torch.ones(probs.size())).cuda()
maskk = mask.clone()
# to prevent them from being reselected.
if prev_idxs is not None:
# set most recently selected idx values to 0
for i,j in zip(range(probs.size(0)),prev_idxs.data):
maskk[i,j[0]] = 0
masked= maskk*probs
# renormalize
probs = F.normalize(masked,p=1,dim=1)
return probs, maskk
but now the loss blows up to nan. Any suggestions?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
I had loss going to NaN when there was (what I believe to be) a race condition occurring when the decoder would select an invalid tour by sampling a city that it had just selected. You can check out my decode_stochastic function- I added a hack to check if it was trying to do this, at which point it resamples a new city
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
I implemented the exponential moving average critic but it didn’t seem to fix anything
from neural-combinatorial-rl-pytorch.
ricgama
commented on July 28, 2024
I'm almost sure that the problem is on the mask but still haven't figured out how to fix it. I guess that if the mask is properly done it will work on supervised learning as in RL...
What do you think?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
Yeah, if the mask is not implemented properly it will affect both the SL and RL cases. That was one of the trickier parts to get right I think
from neural-combinatorial-rl-pytorch.
unnir
commented on July 28, 2024
Hi,
a quick one, I implemented my custom reward function with range (-inf,1], where 1 is the best score. Do you think it a good idea to have a negative reward? Or should I change my range to [0,1] ?
I'm trying to use your code...
from neural-combinatorial-rl-pytorch.
unnir
commented on July 28, 2024
I just download the latest version of the code from the GitHub, and it seems to me something has changed there and not in a good way...
I did a test with the sorting task and got this:

Shortly, the framework is stacked:
Validation overall avg_reward: 0.10000000149
Validation overall reward var: 0.0
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
Thanks for pointing this out, I haven’t tested on the sorting task in a while- I’ll take a look soon
from neural-combinatorial-rl-pytorch.
 yhyu13
commented on July 28, 2024
yhyu13
commented on July 28, 2024
Hi, my name is Yohan. I am also implementing combinatory optimization with RL, but in tensorflow. The Google Drive downloading functionality and the TSP dataset you created are helpful.
I've question on the x-axis of the 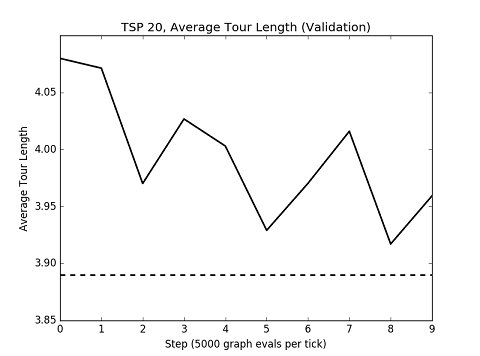
Could you explain what is per tick? Also, the dashed line indicates the optimal solution baseline, right?
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
Per tick means that “0” = 5000, “1” = 10,000, ... , “9” = 50,000.
The dashed line represents the results from Bello et al.
EDIT: Also, I should point out that the Google drive dataset is for the supervised learning scenario; for RL, you need to be generating your data on the fly (since you need a lot more graphs to learn with RL than SL!)
from neural-combinatorial-rl-pytorch.
pemami4911
commented on July 28, 2024
@unnir Just had to flip the sign of the sorting reward! Check out the latest commit on the master branch. Since for sorting, you want to maximize reward (in TSP, you minimize). Also updated it so you generate a new training set every epoch, but sorting converges after only a few steps
from neural-combinatorial-rl-pytorch.
 quheng54
commented on July 28, 2024
quheng54
commented on July 28, 2024
Hello, your code has benefited me a lot. Do you have a program with a knapsack problem? I look forward to your help.My emai is [email protected]
from neural-combinatorial-rl-pytorch.
Related Issues (17)
- TSP_20 task reward function HOT 1
- beam search
- plot_reward.py: reward_csv?
- n_epochs > 1 : multinomial sampling error probs<0 HOT 1
- Why is the progress bar not moving in line for batch_id, sample_batch in enumerate(tqdm(training_dataloader, disable=args['disable_progress_bar'])):?
- Meet lots of Deprecated warning with higher version of Pytorch. Do you have any idea? HOT 1
- Subset selection
- request return 400
- a question in the mwm2D problem
- how to define a grouped knapsack task?
- How to run the program
- Error when executing main.sh
- is this project still open?
- mask HOT 35
- RuntimeError HOT 2
- variable length inputs HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from neural-combinatorial-rl-pytorch.