TensorFlow Extended (TFX) is an end-to-end platform for deploying production ML pipelines.

How it works
When you’re ready to move your models from research to production, use TFX to create and manage a production pipeline
When you’re ready to go beyond training a single model, or ready to put your amazing model to work and move it to production, TFX is there to help you build a complete ML pipeline.
A TFX pipeline is a sequence of components that implement an ML pipeline which is specifically designed for scalable, high-performance machine learning tasks. That includes modeling, training, serving inference, and managing deployments to online, native mobile, and JavaScript targets.
There are many great components in the pipeline. But for this tutorial I will focus on Tensorflow Serving. One of the most important and interesting component of TFX.
Machine Learning (ML) serving systems need to support model versioning (for model updates with a rollback option) and multiple models (for experimentation via A/B testing), while ensuring that concurrent models achieve high throughput on hardware accelerators (GPUs and TPUs) with low latency. TensorFlow Serving has proven performance handling tens of millions of inferences per second at Google.

TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. TensorFlow Serving makes it easy to deploy new algorithms and experiments, while keeping the same server architecture and APIs. TensorFlow Serving provides out of the box integration with TensorFlow models, but can be easily extended to serve other types of models.
-
Servables: Servables are the central abstraction in TensorFlow Serving. Servables are the underlying objects that clients use to perform computation (for example, a lookup or inference).
-
Loader: Loaders manage a servable's life cycle. The Loader API enables common infrastructure independent from specific learning algorithms, data or product use-cases involved. Specifically, Loaders standardize the APIs for loading and unloading a servable.
-
Source: Sources are plugin modules that find and provide servables. Each Source provides zero or more servable streams. For each servable stream, a Source supplies one Loader instance for each version it makes available to be loaded. (A Source is actually chained together with zero or more SourceAdapters, and the last item in the chain emits the Loaders.
-
Manager: Managers listen to Sources and track all versions. The Manager tries to fulfill Sources' requests, but may refuse to load an aspired version if, say, required resources aren't available.
What makes Tensorflow Serving is huge more advance than other web application framework like Python Flask or Django?
When deploying a machine learning model to production, we go through these steps:
-
Build web application (Flask, Django, ..)
-
Create API endpoint to handle the request and communicate with backend.
-
Load pretrain model
-
Pre-processing, predict
-
Return results to client
Example of a Python Flask app.py:
import os
import random
import string
from flask import Flask, request, render_template
import torch
import torch.nn.functional as F
import csv
import pandas as pd
from nltk.tokenize import sent_tokenize, word_tokenize
import numpy as np
app = Flask(__name__)
APP_ROOT = os.path.dirname(os.path.abspath(__file__))
IMAGES_FOLDER = "flask_images"
rand_str = lambda n: "".join([random.choice(string.ascii_letters + string.digits) for _ in range(n)])
model = None
word2vec = None
max_length_sentences = 0
max_length_word = 0
num_classes = 0
categories = None
@app.route("/")
def home():
return render_template("main.html")
@app.route("/input")
def new_input():
return render_template("input.html")
@app.route("/show", methods=["POST"])
def show():
global model, dictionary, max_length_word, max_length_sentences, num_classes, categories
trained_model = request.files["model"]
if torch.cuda.is_available():
model = torch.load(trained_model)
else:
model = torch.load(trained_model, map_location=lambda storage, loc: storage)
dictionary = pd.read_csv(filepath_or_buffer=request.files["word2vec"], header=None, sep=" ", quoting=csv.QUOTE_NONE,
usecols=[0]).values
dictionary = [word[0] for word in dictionary]
max_length_sentences = model.max_sent_length
max_length_word = model.max_word_length
num_classes = list(model.modules())[-1].out_features
if "classes" in request.files:
df = pd.read_csv(request.files["classes"], header=None)
categories = [item[0] for item in df.values]
return render_template("input.html")
@app.route("/result", methods=["POST"])
def result():
global dictionary, model, max_length_sentences, max_length_word, categories
text = request.form["message"]
document_encode = [
[dictionary.index(word) if word in dictionary else -1 for word in word_tokenize(text=sentences)] for sentences
in sent_tokenize(text=text)]
for sentences in document_encode:
if len(sentences) < max_length_word:
extended_words = [-1 for _ in range(max_length_word - len(sentences))]
sentences.extend(extended_words)
if len(document_encode) < max_length_sentences:
extended_sentences = [[-1 for _ in range(max_length_word)] for _ in
range(max_length_sentences - len(document_encode))]
document_encode.extend(extended_sentences)
document_encode = [sentences[:max_length_word] for sentences in document_encode][
:max_length_sentences]
document_encode = np.stack(arrays=document_encode, axis=0)
document_encode += 1
empty_array = np.zeros_like(document_encode, dtype=np.int64)
input_array = np.stack([document_encode, empty_array], axis=0)
feature = torch.from_numpy(input_array)
if torch.cuda.is_available():
feature = feature.cuda()
model.eval()
with torch.no_grad():
model._init_hidden_state(2)
prediction = model(feature)
prediction = F.softmax(prediction)
max_prob, max_prob_index = torch.max(prediction, dim=-1)
prob = "{:.2f} %".format(float(max_prob[0])*100)
if categories != None:
category = categories[int(max_prob_index[0])]
else:
category = int(max_prob_index[0]) + 1
return render_template("result.html", text=text, value=prob, index=category)
if __name__ == "__main__":
app.secret_key = os.urandom(12)
app.run(host="0.0.0.0", port=4555, debug=True)
Flask is fine only if you are planning to demo your model on local machine, but when deploy your model to production, there will be some issues:
-
Loading and Serving model are processing inside backend codebase. Everytime clients send a request to server, pretrain model is reloaded. For one single model, reload the pretrain model is acceptable but it will be impossible to load multiple complex models at the same time (eg: object detection + image alignment + object tracking)
-
Model version: There is no information about model version. Anytime you want to update your model, you need to create a new API endpoint to process or overwrite the old version.
## Example: Simple NN with Mnist datasaet
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
def make_model(input_shape=[28, 28, 1]):
model = tf_models.Sequential()
model.add(layers.InputLayer(input_shape=input_shape))
for no_filter in [16, 32, 64]:
model.add(layers.Conv2D(
no_filter,
kernel_size=(3, 3),
strides=(1, 1),
padding='same',
activation='relu',
))
model.add(layers.MaxPooling2D(
pool_size=(2, 2),
strides=(2, 2),
padding='same',
))
model.add(layers.BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
return model
model = make_model()
print(model.inputs, model.outputs, model.count_params())
# [<tf.Tensor 'input_1:0' shape=(?, 28, 28, 1) dtype=float32>]
# [<tf.Tensor 'dense_1/Softmax:0' shape=(?, 10) dtype=float32>]
# 156234
from tensorflow.keras.models import load_model
# fit model and save weight
model.fit(...)
model.save(...)
# load pretrained model
model = load_model('./temp_models/mnist_all.h5')# The export path contains the name and the version of the model
tf.keras.backend.set_learning_phase(0) # Ignore dropout at inference
export_path = './temp_models/serving/1'with tf.keras.backend.get_session() as sess:
tf.saved_model.simple_save(
sess,
export_path,
inputs={'input_image': model.input},
outputs={'y_pred': model.output})Export model by SaveModelBuilder method with custom MetaGraphDef. Custom tag-set or define assets (external file for serving)
from tensorflow.python.saved_model import builder as saved_model_builder
from tensorflow.python.saved_model import utils
from tensorflow.python.saved_model import tag_constants, signature_constants
from tensorflow.python.saved_model.signature_def_utils_impl import build_signature_def, predict_signature_def
from tensorflow.contrib.session_bundle import exporter
builder = saved_model_builder.SavedModelBuilder(export_dir_path)
signature = predict_signature_def(
inputs={
'input_image': model.inputs[0],
},
outputs={
'y_pred': model.outputs[0]
}
)
with K.get_session() as sess:
builder.add_meta_graph_and_variables(
sess=sess,
tags=[tag_constants.SERVING],
signature_def_map={'reid-predict': signature},
# or
# signature_def_map={signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: signature},
)
builder.save()import os
import tensorflow as tf
trained_checkpoint_prefix = './temp_models/model.ckpt-00001'
export_dir = os.path.join('./temp_models/serving', '1')
graph = tf.Graph()
with tf.compat.v1.Session(graph=graph) as sess:
# Restore from checkpoint
loader = tf.compat.v1.train.import_meta_graph(trained_checkpoint_prefix + '.meta')
loader.restore(sess, trained_checkpoint_prefix)
# Export checkpoint to SavedModel
builder = tf.compat.v1.saved_model.builder.SavedModelBuilder(export_dir)
builder.add_meta_graph_and_variables(sess,
[tf.saved_model.TRAINING, tf.saved_model.SERVING],
strip_default_attrs=True)
builder.save()-
File saved_model.pb and variables folder will be created:
- saved_model.pb: serialized model, stored graph info of the model and other metadata such as: signature, model inputs/outputs.
- variables: store serialized variables of the graph (learned weight)
-
Tensorflow Serving manage the model version control by folder name. I.e: version 1 is folder 1
temp_models/serving/1
>├── saved_model.pb
>└── variables
>├── variables.data-00000-of-00001
>└── variables.index
-
Use
save_model_clito showsaved_model.pbmetadatabash saved_model_cli show --dir temp_models/serving/1 --tag_set serve --signature_def serving_default -
Result
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input_image'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 28, 28, 1)
name: input_1:0
The given SavedModel SignatureDef contains the following output(s):
outputs['pred'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: dense_1/Softmax:0
Method name is: tensorflow/serving/predict-
Test output with 1 sample
saved_model_cli run --dir temp_models/serving/1/ --tag_set serve --signature_def serving_default --input_exprs "input_image=np.zeros((1, 28, 28, 1))" -
Output
#output
Result for output key y_pred:
[[1.5933816e-01 1.6137624e-01 4.8642698e-05 8.6862819e-05 2.8394745e-05
1.3426773e-03 2.7080998e-03 6.2681846e-03 1.3640945e-02 6.5516180e-01]- Tensorflow Serving support both gRPC and http. To make the request to tensorflow server via gRPC, we need to install
tensorflow_model_serverand libtensorflow-serving-api
echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && \
curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
# step 2
apt-get update && apt-get install tensorflow-model-server
# or apt-get upgrade tensorflow-model-server
# step 3
pip install tensorflow-serving-api - Run the server:
tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=mnist-serving --model_base_path=/home/thuc/project/tensorflow/temp_models/serving- Save_model folder structure. I.e: home/thuc/project/tensorflow/temp_models/serving with 2 diffirent version
temp_models/serving
├── 1
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── 2
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
...
4 directories, 6 files
#Code to request Restful API
from sklearn.metrics import accuracy_score, f1_score
print(x_test.shape)
# (10000, 28, 28, 1)
def rest_infer(imgs,
model_name='mnist-serving',
host='localhost',
port=8501,
signature_name="serving_default"):
"""MNIST - serving with http - RESTful API
"""
if imgs.ndim == 3:
imgs = np.expand_dims(imgs, axis=0)
data = json.dumps({
"signature_name": signature_name,
"instances": imgs.tolist()
})
headers = {"content-type": "application/json"}
json_response = requests.post(
'http://{}:{}/v1/models/{}:predict'.format(host, port, model_name),
data=data,
headers=headers
)
if json_response.status_code == 200:
y_pred = json.loads(json_response.text)['predictions']
y_pred = np.argmax(y_pred, axis=-1)
return y_pred
else:
return None
y_pred = rest_infer(x_test)
print(
accuracy_score(np.argmax(y_test, axis=-1), y_pred),
f1_score(np.argmax(y_test, axis=-1), y_pred, average="macro")
)
# result
# 0.9947 0.9946439344333233gRPC example, default port=8500, require: model_name, signature_name,host, port, input_name, output_name
# With gRPC, default port = 8500, code require: model_name, signature_name, host, port, input_name, output_name
import numpy as np
import copy
import tensorflow as tf
import cv2
import grpc
import matplotlib.pyplot as plt
from tensorflow_serving.apis import predict_pb2, prediction_service_pb2_grpc
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
# model_name
request.model_spec.name = "mnist-serving"
# signature name, default is `serving_default`
request.model_spec.signature_name = "serving_default"
def grpc_infer(imgs):
"""MNIST - serving with gRPC
"""
if imgs.ndim == 3:
imgs = np.expand_dims(imgs, axis=0)
request.inputs["input_image"].CopyFrom(
tf.contrib.util.make_tensor_proto(
imgs,
dtype=np.float32,
shape=imgs.shape
)
)
try:
result = stub.Predict(request, 10.0)
result = result.outputs["y_pred"].float_val
result = np.array(result).reshape((-1, 10))
result = np.argmax(result, axis=-1)
return result
except Exception as e:
print(e)
return None
y_pred = grpc_infer(x_test)
print(
accuracy_score(np.argmax(y_test, axis=-1), y_pred),
f1_score(np.argmax(y_test, axis=-1), y_pred, average="macro")
)
# result
# 0.9947 0.9946439344333233- Benchmark inference time between gRPC and RESTful API, with 1 request
# http
start = time.time()
y_pred = rest_infer(x_test[0])
print("Inference time: {}".format(time.time() - start))
# >>> Inference time: 0.0028078556060791016
# gRPC
start = time.time()
y_pred = grpc_infer(x_test[0])
print("Inference time: {}".format(time.time() - start))
# >>> Inference time: 0.0012249946594238281- Inference time with 10000 MNIST sample
start = time.time()
y_pred = rest_infer(x_test)
print(">>> Inference time: {}".format(time.time() - start))
>>> Inference time: 6.681854248046875
start = time.time()
y_pred = grpc_infer(x_test)
print(">>> Inference time: {}".format(time.time() - start))
>>> Inference time: 0.3771860599517822- gRPC has almost 18 times faster with 10000 Mnist sample request
- With more complicate model or model with multiple input, output, gRPC perform even more faster than http
- Example: Face verification system. We will have 2 images as inputs, the system will parse the result if 2 images are show the same person or not
- Model: Siamese network
- Input: 2 images as inputs
- Output: 1 verification result
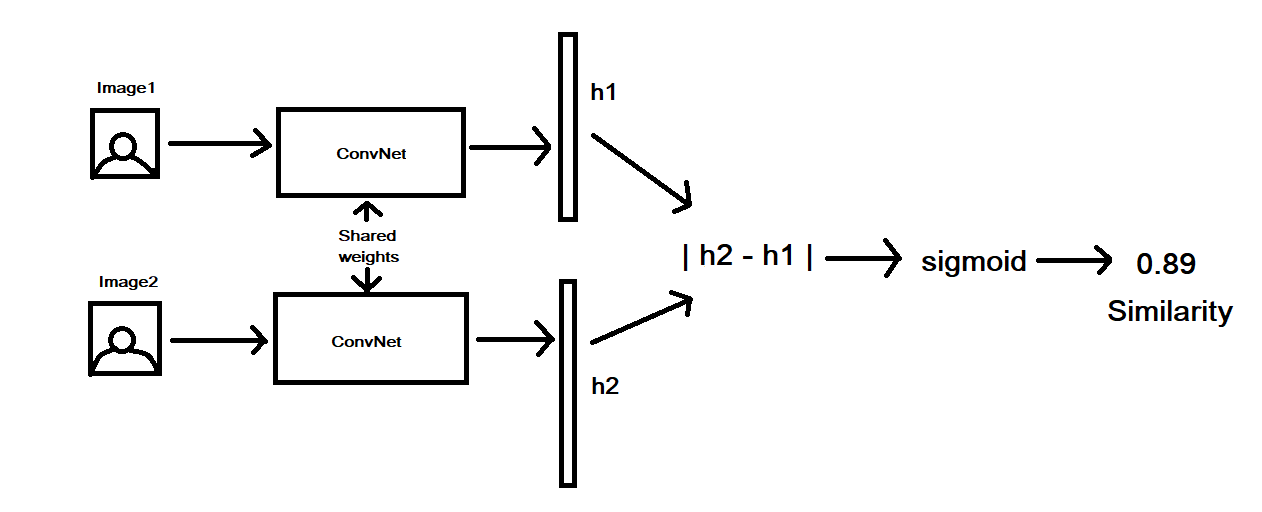
from tensorflow.keras.models import load_model
model = load_model('sianet.h5')
print(model.inputs, model.outputs)
# output
# <tf.Tensor 'input_6:0' shape=(?, 64, 32, 3) dtype=float32>,
# <tf.Tensor 'input_7:0' shape=(?, 64, 32, 3) dtype=float32>],
# <tf.Tensor 'dense_2/Sigmoid:0' shape=(?, 1) dtype=float32>])#Convert to .pb format
import tensorflow.keras.backend as K
def export_pb(export_dir_path, model):
builder = saved_model_builder.SavedModelBuilder(export_dir_path)
signature = predict_signature_def(
inputs={
'img1': model.inputs[0],
'img2': model.inputs[1]
},
outputs={
'predict': model.outputs[0]
}
)
with K.get_session() as sess:
builder.add_meta_graph_and_variables(
sess=sess,
tags=[tag_constants.SERVING],
signature_def_map={'signature-reid': signature}
)
builder.save()!tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=siamese-reid --model_base_path=relative-path-to-model-version
!curl localhost:8501/v1/models/siamese-reiddef _grpc_client_request(
img1,
img2,
host='localhost',
port=8500,
img1_name='img1',
img2_name='img2',
model_spec_name='siamese-reid',
model_sig_name='signature-reid',
timeout=10
):
host = host.replace("http://", "").replace("https://", "")
channel = grpc.insecure_channel("{}:{}".format(host, port))
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Create PredictRequest ProtoBuf from image data
request = predict_pb2.PredictRequest()
request.model_spec.name = model_spec_name
request.model_spec.signature_name = model_sig_name
# img1
img_arr1 = np.expand_dims(img1, axis=0)
request.inputs[img1_name].CopyFrom(
tf.contrib.util.make_tensor_proto(
img_arr1,
dtype=np.float32,
shape=[*img_arr1.shape]
)
)
# img2
img_arr2 = np.expand_dims(img2, axis=0)
request.inputs[img2_name].CopyFrom(
tf.contrib.util.make_tensor_proto(
img_arr2,
dtype=np.float32,
shape=[*img_arr2.shape]
)
)
print(img_arr1.shape, img_arr2.shape)
start = time.time()
# Call the TFServing Predict API
predict_response = stub.Predict(request, timeout=timeout)
print(">>> Inference time: {}'s".format(time.time() - start))
return predict_responseimg_size = (64, 32)
img1_fp = 'path-to-img1'
img2_fp = 'path-to-img2'
# preprocess images
img1 = preprocess_reid(img1_fp, img_size)
img2 = preprocess_reid(img2_fp, img_size)
# parse result
result = _grpc_client_request(img1, img2)
pred = np.array(result.outputs['predict'].float_val)
pred = (pred >= 0.5).astype(int)
print(pred)
# [1]
- Object Detection model and Image Segmentation are the model with very complex output. Usually the model output flatten, normalize array content lot of coordinator, bounding-boxes, detection-boxes, detection classes, detection score, num_detections and a lot more information. First, I will go through Object Detection with ssd-mobilenet-v2 model: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
ssd_mobilenet_v2_coco_2018_03_29/
├── checkpoint
├── frozen_inference_graph.pb
├── model.ckpt.data-00000-of-00001
├── model.ckpt.index
├── model.ckpt.meta
└── saved_model
├── saved_model.pb
└── variables
!saved_model_cli show --dir /home/thuc/Downloads/pretrained_models/ssd_mobilenet_v2_coco_2018_03_29/saved_model/1 --all# output
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['inputs'] tensor_info:
dtype: DT_UINT8
shape: (-1, -1, -1, 3)
name: image_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['detection_boxes'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 100, 4)
name: detection_boxes:0
outputs['detection_classes'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 100)
name: detection_classes:0
outputs['detection_scores'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 100)
name: detection_scores:0
outputs['num_detections'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: num_detections:0
Method name is: tensorflow/serving/predict- Model outputs include:
- Signature: signature_def['serving_default']
- Model input: dtype: int8, 3 channels, undefined input dimension
- Model output: - detection_boxes: shape: (-1, 100, 4) - detection_classes: shape: (-1, 100) - detection_scores: shape: (-1, 100) - num_detections: shape: (-1)
#start tensorflow_model_server
!tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=ssd-mbv2-coco --model_base_path=/home/thuc/Downloads/ssd_mobilenet_v1_coco_2018_01_28/saved_model/test_img = "/home/thuc/Downloads/cat.jpg"
img = cv2.imread(test_img)[:, :, ::-1]
img_arr = np.expand_dims(img, axis=0)
# init channel
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = "ssd-mbv2-coco"
request.model_spec.signature_name = "serving_default"
request.inputs["inputs"].CopyFrom(
tf.contrib.util.make_tensor_proto(
img_arr,
dtype=np.uint8,
shape=img_arr.shape
)
)
result = stub.Predict(request, 10.0)- Use function provided by TF Object Dectection API: https://github.com/tensorflow/models/tree/master/research/object_detection/utils
- File map label by TF API: https://github.com/tensorflow/models/blob/master/research/object_detection/data/mscoco_label_map.pbtxt
- Because the detection output of Tensorflow-serving has been flatten and normalize to [0,1] so we need to convert back to original coordinator value in order to visualize on output image
import copy
from object_detection.utils import visualization_utils as vis_util
from object_detection.utils import label_map_util
boxes = result.outputs['detection_boxes'].float_val
classes = result.outputs['detection_classes'].float_val
scores = result.outputs['detection_scores'].float_val
no_dets = result.outputs['num_detections'].float_val
print(boxes)
# output
[0.05715984106063843, 0.4511566460132599, 0.9412486553192139, 0.9734638929367065, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 .........label_map = label_map_util.load_labelmap("/home/thuc/Downloads/mscoco_label_map.pbtxt")
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
img_ = copy.deepcopy(img)
image_vis = vis_util.visualize_boxes_and_labels_on_image_array(
img_,
np.reshape(boxes, [len(boxes) // 4,4]),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=2,
max_boxes_to_draw=12,
min_score_thresh=0.9,
skip_scores=False,
skip_labels=False,
skip_track_ids=False
)
plt.imshow(image_vis)
- Tensorflow Serving support serving multiple model and automatic reload the newest version of each model.
- We need to create
serving.configwith the model_path are absolute path:
model_config_list {
config {
name: 'model-1'
base_path: 'path-to-model1'
model_platform: "tensorflow",
model_version_policy {
specific {
versions: 1
}
}
}
config {
name: 'model-2'
base_path: 'path-to-model2'
model_platform: "tensorflow",
model_version_policy {
specific {
versions: 1
}
}
}
config {
name: 'model-3'
base_path: 'path-to-model3'
model_platform: "tensorflow",
model_version_policy {
specific {
versions: 1
}
}
}
}#start tensorflow_model_server
!tensorflow_model_server --port=8500 --rest_api_port=8501 --model_config_file=./temp_models/serving.config-
Server side
Model without Server-side batching
-
Model with server-side Batching

max_batch_size { value: 32 }
batch_timeout_micros { value: 5000 }
#with max_batch_size is number of batch-size, i.e batch-size=32
#batch_timeout_micros. Maximum timeout to create the batch-size 32Add batching_parameter.txt to docker container
!tensorflow_model_server --port=8500 --rest_api_port=8501 \
--model_name=mnist-serving \
--model_base_path=/home/thuc/phh_workspace/temp_models/serving \
--enable_batching=true \
--batching_parameters_file=/home/thuc/phh_workspace/temp_models/batching_parameters.txt- Pull docker image and test
# step 1
docker pull tensorflow/serving
# step 2
docker run --rm -p 8500:8500 -p 8501:8501 --mount type=bind,source=/home/thuc/phh_workspace/temp_models/serving,target=/models/mnist-serving -e MODEL_NAME=mnist-serving -t tensorflow/serving
# with config file
docker run --rm -p 8500:8500 -p 8501:8501 --mount type=bind,source=/home/thuc/phh_workspace/temp_models/serving,target=/models/mnist-serving --mount type=bind,source=/home/thuc/phh_workspace/temp_models/serving.config,target=/models/serving.config -t tensorflow/serving --model_config_file=/models/serving.config
# step 3 - testing with curl
curl localhost:8501/v1/models/mnist-serving
# output
# return OK
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}Build a web API with Python Flask, tensorflow-serving-api, docker/docker compose and preprocessing data using gRPC
- Preprocessing, gRPC request
import base64
import cv2
import numpy as np
import grpc
from protos.tensorflow_serving.apis import predict_pb2
from protos.tensorflow_serving.apis import prediction_service_pb2_grpc
from protos.tensorflow.core.framework import (
tensor_pb2,
tensor_shape_pb2,
types_pb2
)
def convert_image(encoded_img, to_rgb=False):
if isinstance(encoded_img, str):
b64_decoded_image = base64.b64decode(encoded_img)
else:
b64_decoded_image = encoded_img
img_arr = np.fromstring(b64_decoded_image, np.uint8)
img = cv2.imdecode(img_arr, cv2.IMREAD_COLOR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = np.expand_dims(img, axis=-1)
return img
def grpc_infer(img):
channel = grpc.insecure_channel("10.5.0.5:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = "mnist-serving"
request.model_spec.signature_name = "serving_default"
if img.ndim == 3:
img = np.expand_dims(img, axis=0)
tensor_shape = img.shape
dims = [tensor_shape_pb2.TensorShapeProto.Dim(size=dim) for dim in tensor_shape]
tensor_shape = tensor_shape_pb2.TensorShapeProto(dim=dims)
tensor = tensor_pb2.TensorProto(
dtype=types_pb2.DT_FLOAT,
tensor_shape=tensor_shape,
float_val=img.reshape(-1))
request.inputs['input_image'].CopyFrom(tensor)
try:
result = stub.Predict(request, 10.0)
result = result.outputs["y_pred"].float_val
result = np.array(result).reshape((-1, 10))
result = np.argmax(result, axis=-1)
return result
except Exception as e:
print(e)
return None- API endpoint, handle request, parse result
import json
from flask import Flask, request
from utils import grpc_infer, convert_image
app = Flask(__name__)
@app.route('/api/mnist', methods=['POST'])
def hello():
encoded_img = request.values['encoded_image']
img = convert_image(encoded_img)
result = grpc_infer(img)
return json.dumps(
{
"code": 200,
"result": result.tolist()
}
)
if __name__ == '__main__':
app.run(debug=True, host="10.5.0.4", port=5000)- Dockerfile
FROM ubuntu:16.04
RUN apt-get update
RUN apt-get install -y python3-pip python3-dev libglib2.0-0 libsm6 libxrender1 libxext6 \
&& cd /usr/local/bin \
&& ln -s /usr/bin/python3 python \
&& pip3 install --upgrade pip
RUN mkdir /code
WORKDIR /code
COPY requirements.txt /code/requirements.txt
RUN pip3 install -r requirements.txt- Docker compose
version: '2'
services:
web:
container_name: mnist_api
build: .
restart: always
volumes:
- .:/code
command: bash -c "python3 serve.py"
ports:
- "5000:5000"
networks:
mynet:
ipv4_address: 10.5.0.4
tf-serving:
image: tensorflow/serving
restart: always
ports:
- "8500:8500"
- "8501:8501"
volumes:
- ./serving:/models
- ./serving_docker.config:/models/serving_docker.config
command: --model_config_file=/models/serving_docker.config
networks:
mynet:
ipv4_address: 10.5.0.5
networks:
mynet:
driver: bridge
ipam:
config:
- subnet: 10.5.0.0/16
gateway: 10.5.0.1- Build image
# step 1
!docker-compose build
# step 2
!docker-compose up- Test API with Postman, data input as base64


