NodeJs server to facilitate the analysis and serving of media (mainly video) files on a local server.
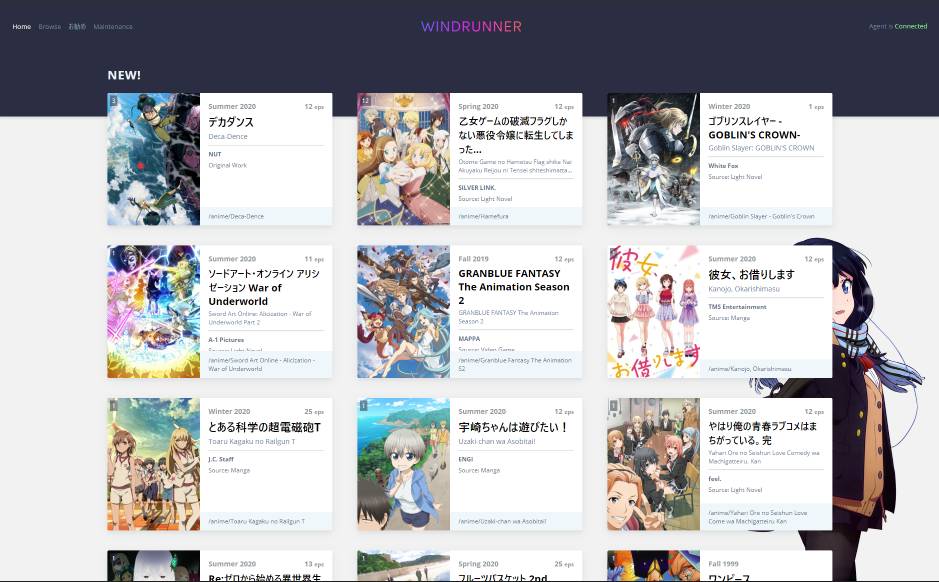 The server facilitates all calls for this web app!
The server facilitates all calls for this web app!
I wrote this as a simple way for me to access my network shared video files. It allows me to access and browse through my media as if it were another resource like youtube. The purpose is similar to plex (in fact I attempted to use plex first), however I disliked the fact that I would have to install plex clients on all my devices. I originally ran this on a raspberry pi and it was bare able to transcode the media on the fly for web playback. In the end I settled on writing my own.
The first version was rudientary and lacking in features. Essentially a glorified ls. The current repository is an updated version with many quality of life features that makes it a joy (for me) to use. We are able to:
- Browse shared directories
- Directory Metadata
- Analyze and fetch Metadata for (most) anime
- Video Metadata
- Video Thumbnail Generation
- Add folders to custom lists (favourites, recommended)
This is the server portion of the application.
I have run this on multiple debian based versions of linux. It does leverage the use of the *nix find command as well as ffmpeg. As long as these are in your PATH then there should not be many problems.
I have tested with WSL and mounted my network share manually (during development) using the following command.
sudo mount --verbose -t drvfs //server/folder/to/share /local/mount/point
To run this you'll need nodeJs (as this IS a node project). Almost any relatively modern version should work (I am on v12).
This project depends on several packages to provide additional functionality.
| Package | Purpose |
|---|---|
| koa | Web Server |
| axios | Sending web requests |
| imagemin | Minifying thumbnails |
| level | File persisted Key Value Store |
You will likely have to modify the config.json to set the application up properly. You can base yours off of the config.json.eg.
- API_VERSION: We can leave this as 2
- API_PORT: The port that we want the server to run on
- SHARE_PATH: Which folder to share (absolute path preferred)
- LOG_DIR: Log directory
- DB_PATH: Database Directory (for LevelDb)
- IMAGE_HOME: Where to store our images,
- SERIES_IMAGE_BASE: Where to store our images relating to series metadata, should be a sub directory of the images dir
- THUMBNAIL_BASE: Where to store our video thumbnails, should be a sub directory of the images dir
- MAX_THUMBNAILS: How many thumbnails to generate per file,
- MAX_CLI_WORKERS: Max Command line processes spawned at once,
- HEALTH_MONITOR_INTERVAL: How often to run health monitoring (set to -1 for off), this will log the executor process counts & waiting counts (for externally spawned tasks)
- ANI_LIST_RESTORE_FILE: Convenience file for restoring of previously loaded metadata, mainly so we don't hit the aniList api too hard on load
- NG_ROOT: Hosts the related angular project from this directory if specified
Run npm start to start everything up.
You can manage your node processes with a manager such as pm2 if you wish.
Thumbnail Generation is done via ffmpeg and spawned by node through child_process.exec or child_process.execFile. The generated files are minified into .webp using the imagemin package.
The AniList GraphQL API has been leveraged to retrieve most information regarding the various series. The application will try to guess the series based on the folder name. While not perfect, any mistakes can be corrected and manually set. The data retrieved is used to significantly enhance user experience by providing for airing times, series images, descriptions, studio etc etc.
The search is run via the *nix find command. Originally used for actually searching, this use case was quite rare in real world usage. Instead, it can be used to search through many files and folders and try to find the most recently changed files.
The executor is the main entry point for none nodeJs code execution in the program. This includes the searches and thumbnail generation. A priority queue is used to ensure UI dependant functions are executed with the highest priority whereas everything else is constrained with a timeout to prevent deadlocks from dead workers that have either errored out or stalled.

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
