![]()
![]()
![]()
![]()

WHO announced that cardiovascular diseases is the top one killer over the world. There are seventeen million people died from it every year, especially heart disease. Prevention is better than cure. If we can evaluate the risk of every patient who probably has heart disease, that is, not only patients but also everyone can do something earlier to keep illness away.
There are thirteen features and one target as below:
-
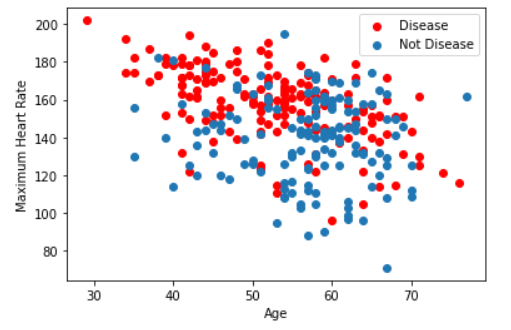
age: The person's age in years
-
sex: The person's sex (1 = male, 0 = female)
-
cp: The chest pain experienced (Value 1: typical angina, Value 2: atypical angina, Value 3: non-anginal pain, Value 4: asymptomatic)
-
trestbps: The person's resting blood pressure (mm Hg on admission to the hospital)
-
chol: The person's cholesterol measurement in mg/dl
-
fbs: The person's fasting blood sugar (> 120 mg/dl, 1 = true; 0 = false)
-
restecg: Resting electrocardiographic measurement (0 = normal, 1 = having ST-T wave abnormality, 2 = showing probable or definite left ventricular hypertrophy by Estes' criteria)
-
thalach: The person's maximum heart rate achieved
-
exang: Exercise induced angina (1 = yes; 0 = no)
-
oldpeak: ST depression induced by exercise relative to rest
-
slope: the slope of the peak exercise ST segment (Value 1: upsloping, Value 2: flat, Value 3: downsloping)
-
ca: The number of major vessels (0-3)
-
thal: A blood disorder called thalassemia (3 = normal; 6 = fixed defect; 7 = reversable defect)
-
target: Heart disease (0 = no, 1 = yes)
Libraries: NumPy pandas matplotlib sklearn seaborn








Our models work fine but best of them are KNN and Random Forest with 88.52% of accuracy. Let's look their confusion matrixes.

Feature endineering
Feature Scaling
Classification Models
Model Evaluation
If you have any feedback, please reach out at [email protected]
I am an AI Enthusiast and Data science & ML practitioner
![]()
![]()
![]()
![]()
