![]()
![]()
![]()
![]()
Pruning Decision Trees

Overview:
Decision trees are tree data structures that are generated using learning algorithms for the purpose of Classification and Regression. One of the most common problem when learning a decision tree is to learn the optimal size of the resulting tree that leads to a better accuracy of the model. A tree that has too many branches and layers can result in overfitting of the training data.
Pruning a decision tree helps to prevent overfitting the training data so that our model generalizes well to unseen data. Pruning a decision tree means to remove a subtree that is redundant and not a useful split and replace it with a leaf node. Decision tree pruning can be divided into two types:
- pre-pruning
- post-pruning.
Pre-pruning:
Pre-pruning, also known as Early Stopping Rule, is the method where the subtree construction is halted at a particular node after evaluation of some measure. These measures can be the Gini Impurity or the Information Gain.
Pre-pruning has the advantage of being faster and more efficient as it avoids generating overly complex subtrees which overfit the training data. However, in pre-pruning, the growth of the tree is stopped prematurely by our stopping condition.
Post-pruning:
Post-pruning means to prune after the tree is built. You grow the tree entirely using your decision tree algorithm and then you prune the subtrees in the tree in a bottom-up fashion. You start from the bottom decision node and, based on measures such as Gini Impurity or Information Gain, you decide whether to keep this decision node or replace it with a leaf node. For example, say we want to prune out subtrees that result in least information gain. When deciding the leaf node, we want to know what leaf our decision tree algorithm would have created if it didn’t create this decision node.
Dataset:
Heart Disease UCI This database contains 76 attributes, but all published experiments refer to using a subset of 14 of them. In particular, the Cleveland database is the only one that has been used by ML researchers to this date. The "goal" field refers to the presence of heart disease in the patient. It is integer valued from 0 (no presence) to 4.
Data Fields:
- age
- sex
- chest pain type (4 values)
- resting blood pressure
- serum cholestoral in mg/dl
- fasting blood sugar > 120 mg/dl
- resting electrocardiographic results (values 0,1,2)
- maximum heart rate achieved
- exercise induced angina
- oldpeak = ST depression induced by exercise relative to rest
- the slope of the peak exercise ST segment
- number of major vessels (0-3) colored by flourosopy
- thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
Implementation:
Libraries: NumPy pandas sklearn Matplotlib tensorflow keras
Model results without pruning:
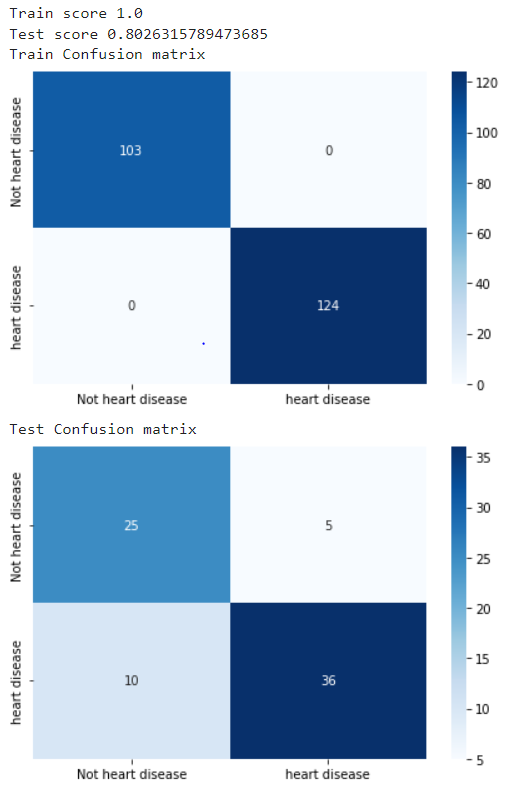
Following confudion matrix shows that in our train data we have 100% accuracy (100 % precison and recall). But in test data model is not well generalizing. We have just 75% accuracy. Over model is clearly overfitting. We will avoid overfitting through pruning. We will do cost complexity prunning.
Pre-Pruning:
Here, we can limit the growth of trees by setting constrains. We can limit parameters like max_depth , min_samples etc.
params = {'max_depth': [2,4,6,8,10,12],
'min_samples_split': [2,3,4],
'min_samples_leaf': [1,2]}
clf = tree.DecisionTreeClassifier()
gcv = GridSearchCV(estimator=clf,param_grid=params)
gcv.fit(x_train,y_train)
model = gcv.best_estimator_
model.fit(x_train,y_train)
y_train_pred = model.predict(x_train)
y_test_pred = model.predict(x_test)

Post-Pruning:
There are several post pruning techniques. Cost complexity pruning is one of the important among them.
Cost Complexity Pruning:
Decision trees can easily overfit. One way to avoid it is to limit the growth of trees by setting constrains. We can limit parameters like max_depth , min_samples etc. But a most effective way is to use post pruning methods like cost complexity pruning. This helps to improve test accuracy and get a better model.
Cost complexity pruning is all about finding the right parameter for alpha.We will get the alpha values for this tree and will check the accuracy with the pruned trees.
path = clf.cost_complexity_pruning_path(x_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
print(ccp_alphas)
[0. 0.00288708 0.00330396 0.00391581 0.00412996 0.00419574
0.00430739 0.00520069 0.0062653 0.00660793 0.00660793 0.00726872
0.00728816 0.00755192 0.00877322 0.00949077 0.00959373 0.01006923
0.01101322 0.01126221 0.01201442 0.01355942 0.0156278 0.0185022
0.02270545 0.0235234 0.03840245 0.14387775]
# For each alpha we will append our model to a list
clfs = []
for ccp_alpha in ccp_alphas:
clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(x_train, y_train)
clfs.append(clf)



We can see that now our model is not overfiting and performance on test data have improved.

Learnings:
Decision Trees Pruning Gini-Impurity Information-Gain
References:
Feedback
If you have any feedback, please reach out at [email protected]
🚀 About Me
Hi, I'm Pradnya! 👋
I am an AI Enthusiast and Data science & ML practitioner
![]()
![]()
![]()
![]()

