![]()
This project is deprecated without any replacement. If you are interested into fully automated and transparent distribution of funding within open source please contact the main developers.
LibreSelery is a command line tool to distribute funding in free and open source projects. With a new funding model, it offers transparent, automated and adaptable compensation of contributors. The aim is to replace the middleman in donation distribution as far as possible with a free and transparent algorithm. Unlike most other donation systems LibreSelery only offers a decentralized tool and not a platform.



This project is funded by LibreSelery itself. If you actively contribute to this repository, you will receive a small amount of cryptocurrency from the donation pool to your public email address on GitHub.
![]()
- Attract new developers by sharing donations with your dependency tree.
- Strengthen the bond with existing developers.
- Reward the contributors keeping the project up to date.
- Attract new donors by distributing donations to the people actually working on the project.
LibreSelery is a simple command line tool that runs upon any GitHub hosted project manually or automated by continuous integration. It works with a donation pool containing cryptocurrency in a wallet. With each run a small amount is taken from the donation pool and is distributed to the project's contributors and dependencies. The project owner has the freedom to customize the distribution but it is done openly in-front of the community.
It is designed to run in a continuous integration pipeline like GitHub Actions. Donation transactions are automatically handled and transaction details are published for transparency into the wiki of your repository. Even the donation website is automatically created in your Wiki.
Donations are divided between contributors based on public and transparent metrics. The metrics can be configured per repository and are based on the following weights:
- Uniform Weight: Everyone who contributed a minimum number of commits to the main branch is considered
- Activity Weight: Everyone who contributed in the last X commits
- Service Weight: Everyone who contributed to successful pull requests based on issues in the last X commits (not implemented yet #132)
The amount distributed to each contributor is calculated from an accumulation of these weights. It is sent via the cryptocurrency market API to the public email address of the git platform user profile. You can even configure the compensation of contributors from your own dependencies, therefore donating money back to open source platforms which play an integral role in your project.
The weights calculations are under active development and will be extended in the future in cooperation with the community. We always listen to concerns and actively seek options for fair and appropriate measures of payout weights. The goal is a system that is fair and recognizes the contributions made without being susceptible to abuse. Furthermore the issue of 'morality' is still open and any issues, concerns or ideas, regarding the following questions, are always welcome:
- Which metric should give contributions more weight than others?
- How can we design metrics, which do represent and reward more helpful contributors?
- Feedback on how we can improve the metrics.

LibreSelery ...
- is configured based on the selery.yml file and runs as a GitHub Action on your project.
- is triggered with every push on the main branch by the GitHub Action worflow file that is part of your project repository.
- gathers contributor information about the target project via the GitHub and Libraries.io API.
- filters out contributors with a hidden email address in the GitHub profile and below the minimum contribution limit. LibreSelery will not send emails to the git commit email addresses in order to avoid spam.
- creates custom funding distribution weights based on the contribution rating of various projects: Minimum contribution, activity, ...
- adds the weights to the combined weight used for different distribution splitting behaviors.
- distributes the funding between the contributors based on the selected split behavior.
- pays out cryptocurrency to the selected contributor's email addresses via the Coinbase API. Contributors without a Coinbase account will receive an email to claim the donation.
- automatically generates a donation and transaction visualization website in your GitHub wiki.
- Transparent payout of GitHub project contributors with every push you make to your main (master) branch.
- Minimal changes to your GitHub project as shown in the seleryaction to adapt LibreSelery with just a few steps.
- Detailed transaction history is regenerated in your github wiki every time you run LibreSelery.
- User defined payout configuration by the selery.yml.
- Dependency scanning for most languages to include developers of your dependencies using Libraries.io.
- The funding is distributed via Coinbase. Other payment methods like Uphold are currently work in progress.
- Donators can see transparent payout logs in GitHub Action.
- Self-hosted donation website for secure donations is automatically stored in the Wiki of your repository.
- Simulate the funding distribution for your repository without actually transferring payout to see how the distribution would look like.
- Automated plot generation on how much was paid out to which developer.
- Add additional dependencies from your runtime and development environment to the
tooling_repos.ymllike Docker or Linux that LibreSelery is not able to find out based on your repository information. - Splitting Strategies:
- full split - All contributors receive a payout according to their weight.
- random split - X contributors are randomly picked using the weight as probability.
![]()
Since the project is in its early stages the amount of funding on your wallet should therefore be limited.
Use the template seleryaction to integrate LibreSelery into any GitHub project. Starting with GitHub Actions integration is the easiest way for newcomers and people without Linux knowledge.
- Install Docker.
- Clone LibreSelery and build your Container.
cd ~
git clone https://github.com/protontypes/libreselery.git
cd libreselery
docker build -t libreselery .- Clone your target repository.
cd ~
git clone <target_repository>- Create a token file for your user, where you store API keys and secrets. The scope of your github token should not include any additional permissions beyond the standard minimum scope. Find out more about how to create GitHub tokens here.
mkdir -p ~/.libreselery/secrets ~/.libreselery/results/public
touch ~/.libreselery/secrets/tokens.env-
Copy a selery.yml into your <target_repository>.
-
Libreselery currently supports Coinbase. To enable valid payouts using Coinbase:
- Create a dedicated Coinbase account with limited amounts. Coinbase does not support sending emails to yourself. That's why you should use a dedicated email address when you are the owner of the Coinbase account and contributor of the project. Otherwise LibreSelery will skip these payouts.
- Buy some cryptocurrency. See the price list for transferring money into the Coinbase account.
- Configure the access control settings of the automated Coinbase wallet.
- Never transfer or store large values with automated cryptocurrency wallets. Use recurring automated buys to recharge you wallet on a regular base to avoid financial and security risks. Coinbase does not charge for transferring cryptocurrency from one Coinbase wallet to another.
- Add your Coinbase API keys and secrets to the newly created file (
~/.libreselery/tokens.env). Never store these tokens in a public repository. Replace XXXXX with the Coinbase and Libraries.io tokens to get started without creating an actual accounts for these APIs.
COINBASE_TOKEN=<your_coinbase_token>
COINBASE_SECRET=<your_coinbase_secret>
GITHUB_TOKEN=<your_github_tokens>
LIBRARIES_API_KEY=<your_libaries_io_tokens>- If you don't have a Coinbase account, the payouts can be simulated. To enable simulation mode:
- Set
simulation: Trueandinclude_dependencies: Falsein yourselery.ymlin your <target_repository>. - Adjust and test different configurations in
selery.ymlaccording to your requirements. - LibreSelery just needs API tokens from GitHub in simulation mode. Edit the
~/.libreselery/tokens.envas follows:
COINBASE_TOKEN=XXXXX
COINBASE_SECRET=XXXXX
GITHUB_TOKEN=<your_github_tokens>
LIBRARIES_API_KEY=XXXXX- Make the token file read only.
chmod 400 ~/.libreselery/secrets/tokens.env- Send cryptocurrency to weighted random product contributors with a valid visible email address on GitHub:
env $(cat ~/.libreselery/secrets/tokens.env) ./run.sh <target_repository>- Install the Python and Ruby dependencies on your machine.
sudo apt update && sudo apt install git ruby ruby-dev curl python3-pip- Install LibreSelery and Python dependencies.
cd ~
git clone https://github.com/protontypes/libreselery.git
cd libreselery
pip3 install .- Ensure that
$HOME/.local/binis in$PATH. Check the output ofecho $PATH. If it does not contain.local/binadd the following line to your dotfile for example~/.bashrc.
export PATH=$HOME/.local/bin:$PATH-
Follow Step 3 to 9 of the Running with Docker instructions. They should not differ at this steps.
-
Run LibreSelery on your target project and enjoy fresh Selery.
env $(cat ~/.libreselery/secrets/tokens.env) selery run -d ~/<target_repository> -r ~/.libreselery/results/
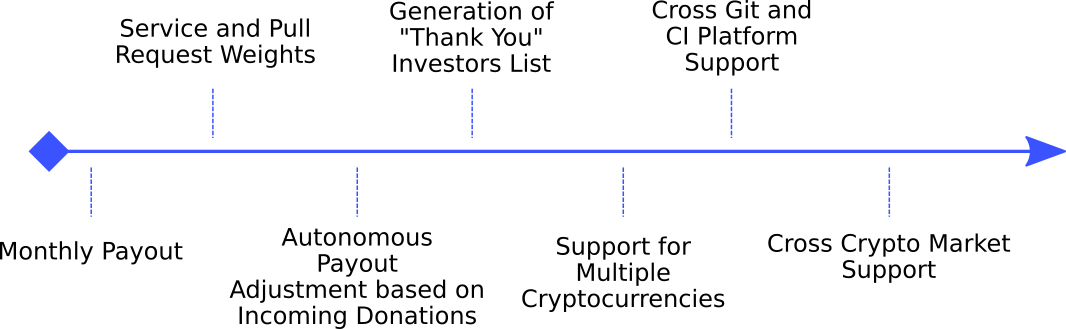
LibreSelery is going to support multiple APIs and assets in the near future like:
- GitHub
- Gitlab
- Savannah
- Libraries.io
- Coinbase
- Uphold
- GNU Taler
What about Goodhart's Law? ("any measure which becomes a metric ceases to be a useful measure")
Solving this problem that is one of the core challenges of LibreSelery. We combine multiple weights calculated based on different project data. Via the GitHub API we can even create weights based on projects activity like merging, code review, issue creation, etc... By the accumulation of all weights, we try to avoid rewarding just one behavior. One of the most important metrics will be how much pull requests X have been solved based on the Y issues. We also have a minimum contribution limit that you can adjust for your project. By making all payments transparent, everyone involved can see what the distribution looked like in the past. In principle, every company has metrics for the distribution of funds. Unfortunately, these are often very non-transparent. In contrast, we try to solve the whole thing with the community. That is why our architecture allows you to add more and more weights. These weights can be balanced between each other depending on your project and community. There will never be one ideal metric that can determine the performance of totally different people. We even have a simulator on our roadmap to fine tune the weights.
Find more information on this discussion in our issue board: #159 #132
Since LibreSelery is only a tool and not a platform, we do not and cannot charge any fees. Only buying and selling cryptocurrency on Coinbase has fees. Transactions between Coinbase wallets have no fees.
Yes, you can do that. But please try to avoid spamming people with emails. Every payout results in an email. To disable notification emails, set send_email_notification: False. Users without a Coinbase account on their github profile email address will still receive emails. Sending cryptocurrency between Coinbase wallets is for free. The Coinbase API allows you to send a minimum of 0.000001 BTC.
Coinbase Help:
We do not charge for transferring cryptocurrency from one Coinbase wallet to another
Let's assume you have a small donation that you want to distribute within a larger project. full_split could cause your transaction to fall below the allowed limit of 0.000001 BTC. Not many people in your project may have a Coinbase account. Only few people would open an account for 10 cents. With the random distribution, individual donors are randomly selected based on their weight and receive a larger donation. Over a longer period of time, the same distribution should emerge as it would with the full_split distribution.
After 30 days, any cryptocurrency sent via email that has not been claimed by the recipient will be returned to the sender.
Coinbase Officially Supported Countries:
You can always use Paypal as a transaction bridge. Find more information on the the Paypal integration into Coinbase here
The Coinbase referral program lets you earn a bonus for each successful referral registered to your account! If your friend visits coinbase.com/trade and initiates a buy or sell of $100 USD or more (or 100 USD equivalent of your domestic currency) within 180 days of opening his or her account, you both will receive a 10 USD (or 10 USD equivalent of your domestic currency) referral bonus when the order completes. Orders can take up to 4 business days to complete. [...] You can also send funds to an email address. This will register as a referral as well.
LibreSelery is working on a way to make even this referral income transparent for the sending account.
How does this work from the legal side in the context of people partly funded by third-party sources, being employed in academics, or people working in industries?
LibreSelery will send the donation to the public email address of your GitHub account. In case the email address is a business or academics address you need to talk to your organization about what to do with the donation. If you have entered a private e-mail address here, you can accept donations at your own discretion. We consider your project contribution as privately done that has not already been rewarded.
Certainly we are funded by LibreSelery with our donation website. The usage and development of LibreSelery will always be free and without any charges. If you want to support us by using LibreSelery on a regular base you just need to add us to the tooling_repos.yml of your project. The donations are distributed among the developers of LibreSelery, how else?
Those who have contributed to the master branch receive emails with cryptocurrency from Coinbase. Only git profiles with emails on the GitHub profile page will be considered. Find out more in the contribution guide or look into the good first issue labels to get into the project with some first simple tasks.
For further information please contact us at team_at_protontypes.eu, join our Gitter chat or check out our wiki. The organisation behind LibreSelery is protontypes. We are building an "Open Accelerator for Free and Sustainable Innovation" based on LibreSelery. Find out more on https://protontypes.eu/.

Artwork by Miriam Winter and undraw















































































































































































