purplebamboo / blog Goto Github PK
View Code? Open in Web Editor NEWpurplebamboo的博客
purplebamboo的博客

































































































































































reactjs是目前比较火的前端框架,但是目前并没有很好的解释原理的项目。reactjs源码比较复杂不适合初学者去学习。所以本文通过实现一套简易版的reactjs,使得理解原理更加容易。包括:
声明:
所有实例源码都托管在github。点这里里面有分步骤的例子,可以一边看一边运行例子。
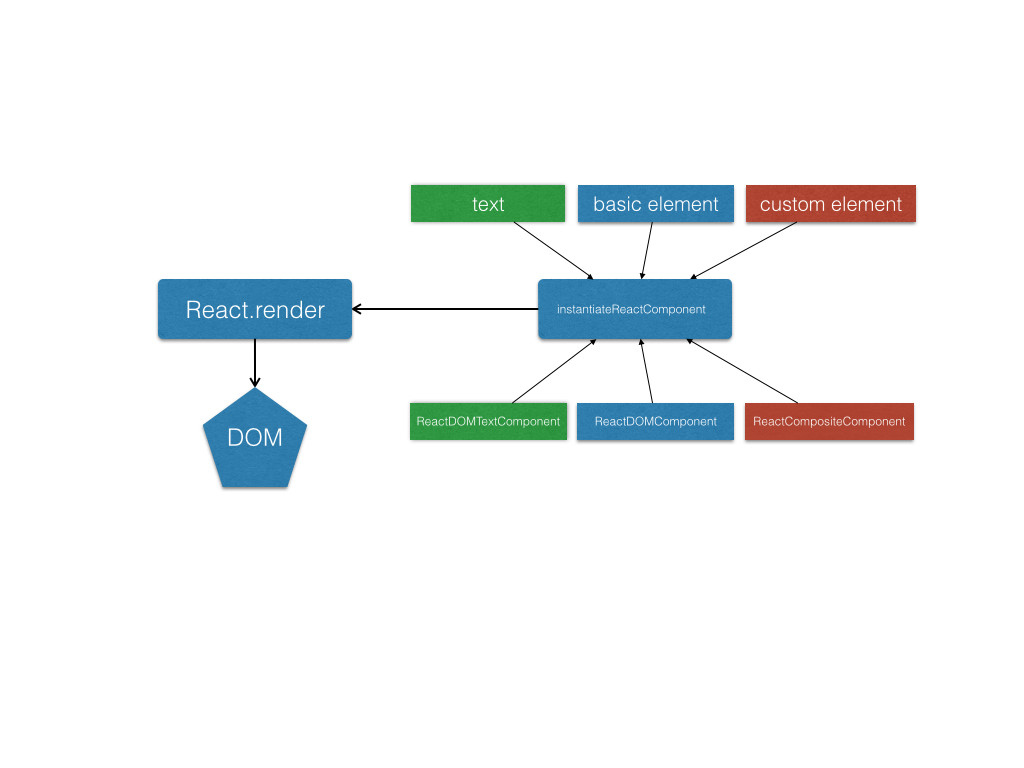
紧接上文,虚拟dom差异化算法(diff algorithm)是reactjs最核心的东西,按照官方的说法。他非常快,非常高效。目前已经有一些分析此算法的文章,但是仅仅停留在表面。大部分小白看完并不能了解(博主就是 = =)。所以我们下面自己动手实现一遍,等你完全实现了,再去看那些文字图片流的介绍文章,就会发现容易理解多了。
下面我们探讨下更新的机制。
一般在reactjs中我们需要更新时都是调用的setState。看下面的例子:
var HelloMessage = React.createClass({
getInitialState: function() {
return {type: 'say:'};
},
changeType:function(){
this.setState({type:'shout:'})
},
render: function() {
return React.createElement("div", {onclick:this.changeType},this.state.type, "Hello ", this.props.name);
}
});
React.render(React.createElement(HelloMessage, {name: "John"}), document.getElementById("container"));
/**
//生成的html为:
<div data-reactid="0" id="test">
<span data-reactid="0.0">hello world</span>
</div>
点击文字,say会变成shout
*/
点击文字,调用setState就会更新,所以我们扩展下ReactClass,看下setState的实现:
//定义ReactClass类
var ReactClass = function(){
}
ReactClass.prototype.render = function(){}
//setState
ReactClass.prototype.setState = function(newState) {
//还记得我们在ReactCompositeComponent里面mount的时候 做了赋值
//所以这里可以拿到 对应的ReactCompositeComponent的实例_reactInternalInstance
this._reactInternalInstance.receiveComponent(null, newState);
}可以看到setState主要调用了对应的component的receiveComponent来实现更新。所有的挂载,更新都应该交给对应的component来管理。
就像所有的component都实现了mountComponent来处理第一次渲染,所有的componet类都应该实现receiveComponent用来处理自己的更新。
所以我们照葫芦画瓢来给自定义元素的对应component类(ReactCompositeComponent)实现一个receiveComponent方法:
//更新
ReactCompositeComponent.prototype.receiveComponent = function(nextElement, newState) {
//如果接受了新的,就使用最新的element
this._currentElement = nextElement || this._currentElement
var inst = this._instance;
//合并state
var nextState = $.extend(inst.state, newState);
var nextProps = this._currentElement.props;
//改写state
inst.state = nextState;
//如果inst有shouldComponentUpdate并且返回false。说明组件本身判断不要更新,就直接返回。
if (inst.shouldComponentUpdate && (inst.shouldComponentUpdate(nextProps, nextState) === false)) return;
//生命周期管理,如果有componentWillUpdate,就调用,表示开始要更新了。
if (inst.componentWillUpdate) inst.componentWillUpdate(nextProps, nextState);
var prevComponentInstance = this._renderedComponent;
var prevRenderedElement = prevComponentInstance._currentElement;
//重新执行render拿到对应的新element;
var nextRenderedElement = this._instance.render();
//判断是需要更新还是直接就重新渲染
//注意这里的_shouldUpdateReactComponent跟上面的不同哦 这个是全局的方法
if (_shouldUpdateReactComponent(prevRenderedElement, nextRenderedElement)) {
//如果需要更新,就继续调用子节点的receiveComponent的方法,传入新的element更新子节点。
prevComponentInstance.receiveComponent(nextRenderedElement);
//调用componentDidUpdate表示更新完成了
inst.componentDidUpdate && inst.componentDidUpdate();
} else {
//如果发现完全是不同的两种element,那就干脆重新渲染了
var thisID = this._rootNodeID;
//重新new一个对应的component,
this._renderedComponent = this._instantiateReactComponent(nextRenderedElement);
//重新生成对应的元素内容
var nextMarkup = _renderedComponent.mountComponent(thisID);
//替换整个节点
$('[data-reactid="' + this._rootNodeID + '"]').replaceWith(nextMarkup);
}
}
//用来判定两个element需不需要更新
//这里的key是我们createElement的时候可以选择性的传入的。用来标识这个element,当发现key不同时,我们就可以直接重新渲染,不需要去更新了。
var _shouldUpdateReactComponent = function(prevElement, nextElement){
if (prevElement != null && nextElement != null) {
var prevType = typeof prevElement;
var nextType = typeof nextElement;
if (prevType === 'string' || prevType === 'number') {
return nextType === 'string' || nextType === 'number';
} else {
return nextType === 'object' && prevElement.type === nextElement.type && prevElement.key === nextElement.key;
}
}
return false;
}
不要被这么多代码吓到,其实流程很简单。
它主要做了什么事呢?首先会合并改动,生成最新的state,props然后拿以前的render返回的element跟现在最新调用render生成的element进行对比(_shouldUpdateReactComponent),看看需不需要更新,如果要更新就继续调用对应的component类对应的receiveComponent就好啦,其实就是直接当甩手掌柜,事情直接丢给手下去办了。当然还有种情况是,两次生成的element差别太大,就不是一个类型的,那好办直接重新生成一份新的代码重新渲染一次就o了。
本质上还是递归调用receiveComponent的过程。
这里注意两个函数:
另外可以看到这里还处理了一套更新的生命周期调用机制。
我们再看看文本节点的,比较简单:
ReactDOMTextComponent.prototype.receiveComponent = function(nextText) {
var nextStringText = '' + nextText;
//跟以前保存的字符串比较
if (nextStringText !== this._currentElement) {
this._currentElement = nextStringText;
//替换整个节点
$('[data-reactid="' + this._rootNodeID + '"]').html(this._currentElement);
}
}
没什么好说的,如果不同的话,直接找到对应的节点,更新就好了。
最后我们开始看比较复杂的浏览器基本元素的更新机制。
比如我们看看下面的html:
<div id="test" name="hello">
<span></span>
<span></span>
</div>想一下我们怎么以最小代价去更新这段html呢。不难发现其实主要包括两个部分:
所以更新代码结构如下:
ReactDOMComponent.prototype.receiveComponent = function(nextElement) {
var lastProps = this._currentElement.props;
var nextProps = nextElement.props;
this._currentElement = nextElement;
//需要单独的更新属性
this._updateDOMProperties(lastProps, nextProps);
//再更新子节点
this._updateDOMChildren(nextElement.props.children);
}
整体上也不复杂,先是处理当前节点属性的变动,后面再去处理子节点的变动
我们一步步来,先看看,更新属性怎么变更:
ReactDOMComponent.prototype._updateDOMProperties = function(lastProps, nextProps) {
var propKey;
//遍历,当一个老的属性不在新的属性集合里时,需要删除掉。
for (propKey in lastProps) {
//新的属性里有,或者propKey是在原型上的直接跳过。这样剩下的都是不在新属性集合里的。需要删除
if (nextProps.hasOwnProperty(propKey) || !lastProps.hasOwnProperty(propKey)) {
continue;
}
//对于那种特殊的,比如这里的事件监听的属性我们需要去掉监听
if (/^on[A-Za-z]/.test(propKey)) {
var eventType = propKey.replace('on', '');
//针对当前的节点取消事件代理
$(document).undelegate('[data-reactid="' + this._rootNodeID + '"]', eventType, lastProps[propKey]);
continue;
}
//从dom上删除不需要的属性
$('[data-reactid="' + this._rootNodeID + '"]').removeAttr(propKey)
}
//对于新的属性,需要写到dom节点上
for (propKey in nextProps) {
//对于事件监听的属性我们需要特殊处理
if (/^on[A-Za-z]/.test(propKey)) {
var eventType = propKey.replace('on', '');
//以前如果已经有,说明有了监听,需要先去掉
lastProps[propKey] && $(document).undelegate('[data-reactid="' + this._rootNodeID + '"]', eventType, lastProps[propKey]);
//针对当前的节点添加事件代理,以_rootNodeID为命名空间
$(document).delegate('[data-reactid="' + this._rootNodeID + '"]', eventType + '.' + this._rootNodeID, nextProps[propKey]);
continue;
}
if (propKey == 'children') continue;
//添加新的属性,或者是更新老的同名属性
$('[data-reactid="' + this._rootNodeID + '"]').prop(propKey, nextProps[propKey])
}
}属性的变更并不是特别复杂,主要就是找到以前老的不用的属性直接去掉,新的属性赋值,并且注意其中特殊的事件属性做出特殊处理就行了。
下面我们看子节点的更新,也是最复杂的部分。
ReactDOMComponent.prototype.receiveComponent = function(nextElement){
var lastProps = this._currentElement.props;
var nextProps = nextElement.props;
this._currentElement = nextElement;
//需要单独的更新属性
this._updateDOMProperties(lastProps,nextProps);
//再更新子节点
this._updateDOMChildren(nextProps.children);
}
//全局的更新深度标识
var updateDepth = 0;
//全局的更新队列,所有的差异都存在这里
var diffQueue = [];
ReactDOMComponent.prototype._updateDOMChildren = function(nextChildrenElements){
updateDepth++
//_diff用来递归找出差别,组装差异对象,添加到更新队列diffQueue。
this._diff(diffQueue,nextChildrenElements);
updateDepth--
if(updateDepth == 0){
//在需要的时候调用patch,执行具体的dom操作
this._patch(diffQueue);
diffQueue = [];
}
}就像我们之前说的一样,更新子节点包含两个部分,一个是递归的分析差异,把差异添加到队列中。然后在合适的时机调用_patch把差异应用到dom上。
那么什么是合适的时机,updateDepth又是干嘛的?
这里需要注意的是,_diff内部也会递归调用子节点的receiveComponent于是当某个子节点也是浏览器普通节点,就也会走_updateDOMChildren这一步。所以这里使用了updateDepth来记录递归的过程,只有等递归回来updateDepth为0时,代表整个差异已经分析完毕,可以开始使用patch来处理差异队列了。
所以我们关键是实现_diff与_patch两个方法。
我们先看_diff的实现:
//差异更新的几种类型
var UPATE_TYPES = {
MOVE_EXISTING: 1,
REMOVE_NODE: 2,
INSERT_MARKUP: 3
}
//普通的children是一个数组,此方法把它转换成一个map,key就是element的key,如果是text节点或者element创建时并没有传入key,就直接用在数组里的index标识
function flattenChildren(componentChildren) {
var child;
var name;
var childrenMap = {};
for (var i = 0; i < componentChildren.length; i++) {
child = componentChildren[i];
name = child && child._currentelement && child._currentelement.key ? child._currentelement.key : i.toString(36);
childrenMap[name] = child;
}
return childrenMap;
}
//主要用来生成子节点elements的component集合
//这边注意,有个判断逻辑,如果发现是更新,就会继续使用以前的componentInstance,调用对应的receiveComponent。
//如果是新的节点,就会重新生成一个新的componentInstance,
function generateComponentChildren(prevChildren, nextChildrenElements) {
var nextChildren = {};
nextChildrenElements = nextChildrenElements || [];
$.each(nextChildrenElements, function(index, element) {
var name = element.key ? element.key : index;
var prevChild = prevChildren && prevChildren[name];
var prevElement = prevChild && prevChild._currentElement;
var nextElement = element;
//调用_shouldUpdateReactComponent判断是否是更新
if (_shouldUpdateReactComponent(prevElement, nextElement)) {
//更新的话直接递归调用子节点的receiveComponent就好了
prevChild.receiveComponent(nextElement);
//然后继续使用老的component
nextChildren[name] = prevChild;
} else {
//对于没有老的,那就重新新增一个,重新生成一个component
var nextChildInstance = instantiateReactComponent(nextElement, null);
//使用新的component
nextChildren[name] = nextChildInstance;
}
})
return nextChildren;
}
//_diff用来递归找出差别,组装差异对象,添加到更新队列diffQueue。
ReactDOMComponent.prototype._diff = function(diffQueue, nextChildrenElements) {
var self = this;
//拿到之前的子节点的 component类型对象的集合,这个是在刚开始渲染时赋值的,记不得的可以翻上面
//_renderedChildren 本来是数组,我们搞成map
var prevChildren = flattenChildren(self._renderedChildren);
//生成新的子节点的component对象集合,这里注意,会复用老的component对象
var nextChildren = generateComponentChildren(prevChildren, nextChildrenElements);
//重新赋值_renderedChildren,使用最新的。
self._renderedChildren = []
$.each(nextChildren, function(key, instance) {
self._renderedChildren.push(instance);
})
var nextIndex = 0; //代表到达的新的节点的index
//通过对比两个集合的差异,组装差异节点添加到队列中
for (name in nextChildren) {
if (!nextChildren.hasOwnProperty(name)) {
continue;
}
var prevChild = prevChildren && prevChildren[name];
var nextChild = nextChildren[name];
//相同的话,说明是使用的同一个component,所以我们需要做移动的操作
if (prevChild === nextChild) {
//添加差异对象,类型:MOVE_EXISTING
diffQueue.push({
parentId: self._rootNodeID,
parentNode: $('[data-reactid=' + self._rootNodeID + ']'),
type: UPATE_TYPES.MOVE_EXISTING,
fromIndex: prevChild._mountIndex,
toIndex: nextIndex
})
} else { //如果不相同,说明是新增加的节点
//但是如果老的还存在,就是element不同,但是component一样。我们需要把它对应的老的element删除。
if (prevChild) {
//添加差异对象,类型:REMOVE_NODE
diffQueue.push({
parentId: self._rootNodeID,
parentNode: $('[data-reactid=' + self._rootNodeID + ']'),
type: UPATE_TYPES.REMOVE_NODE,
fromIndex: prevChild._mountIndex,
toIndex: null
})
//如果以前已经渲染过了,记得先去掉以前所有的事件监听,通过命名空间全部清空
if (prevChild._rootNodeID) {
$(document).undelegate('.' + prevChild._rootNodeID);
}
}
//新增加的节点,也组装差异对象放到队列里
//添加差异对象,类型:INSERT_MARKUP
diffQueue.push({
parentId: self._rootNodeID,
parentNode: $('[data-reactid=' + self._rootNodeID + ']'),
type: UPATE_TYPES.INSERT_MARKUP,
fromIndex: null,
toIndex: nextIndex,
markup: nextChild.mountComponent() //新增的节点,多一个此属性,表示新节点的dom内容
})
}
//更新mount的index
nextChild._mountIndex = nextIndex;
nextIndex++;
}
//对于老的节点里有,新的节点里没有的那些,也全都删除掉
for (name in prevChildren) {
if (prevChildren.hasOwnProperty(name) && !(nextChildren && nextChildren.hasOwnProperty(name))) {
//添加差异对象,类型:REMOVE_NODE
diffQueue.push({
parentId: self._rootNodeID,
parentNode: $('[data-reactid=' + self._rootNodeID + ']'),
type: UPATE_TYPES.REMOVE_NODE,
fromIndex: prevChild._mountIndex,
toIndex: null
})
//如果以前已经渲染过了,记得先去掉以前所有的事件监听
if (prevChildren[name]._rootNodeID) {
$(document).undelegate('.' + prevChildren[name]._rootNodeID);
}
}
}
}
我们分析下上面的代码,咋一看好多,好复杂,不急我们从入口开始看。
首先我们拿到之前的component的集合,如果是第一次更新的话,这个值是我们在渲染时赋值的。然后我们调用generateComponentChildren生成最新的component集合。我们知道component是用来放element的,一个萝卜一个坑。
注意flattenChildren我们这里把数组集合转成了对象map,以element的key作为标识,当然对于text文本或者没有传入key的element,直接用index作为标识。通过这些标识,我们可以从类型的角度来判断两个component是否是一样的。
generateComponentChildren会尽量的复用以前的component,也就是那些坑,当发现可以复用component(也就是key一致)时,就还用以前的,只需要调用他对应的更新方法receiveComponent就行了,这样就会递归的去获取子节点的差异对象然后放到队列了。如果发现不能复用那就是新的节点,我们就需要instantiateReactComponent重新生成一个新的component。
这里的flattenChildren需要给予很大的关注,比如对于一个表格列表,我们在最前面插入了一条数据,想一下如果我们创建element时没有传入key,所有的key都是null,这样reactjs在generateComponentChildren时就会默认通过顺序(index)来一一对应改变前跟改变后的子节点,这样变更前与变更后的对应节点判断(_shouldUpdateReactComponent)其实是不合适的。也就是说对于这种列表的情况,我们最好给予唯一的标识key,这样reactjs找对应关系时会更方便一点。
当我们生成好新的component集合以后,我们需要做出对比。组装差异对象。
对比老的集合和新的集合。我们需要找出涵盖四种情况,包括三种类型(UPATE_TYPES)的变动:
| 类型 | 情况 |
|---|---|
| MOVE_EXISTING | 新的component类型在老的集合里也有,并且element是可以更新的类型,在generateComponentChildren我们已经调用了receiveComponent,这种情况下prevChild=nextChild,那我们就需要做出移动的操作,可以复用以前的dom节点。 |
| INSERT_MARKUP | 新的component类型不在老的集合里,那么就是全新的节点,我们需要插入新的节点 |
| REMOVE_NODE | 老的component类型,在新的集合里也有,但是对应的element不同了不能直接复用直接更新,那我们也得删除。 |
| REMOVE_NODE | 老的component不在新的集合里的,我们需要删除 |
所以我们找出了这三种类型的差异,组装成具体的差异对象,然后加到了差异队列里面。
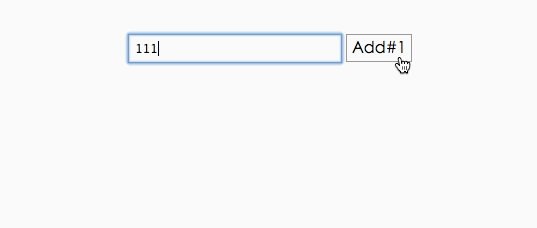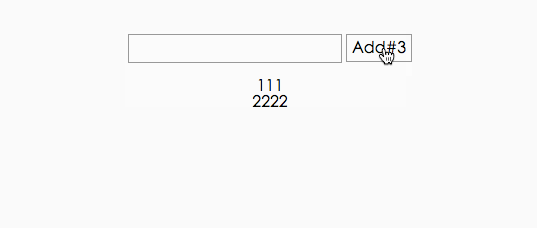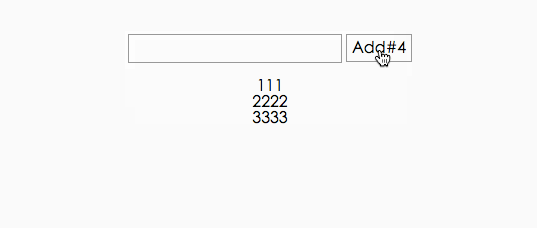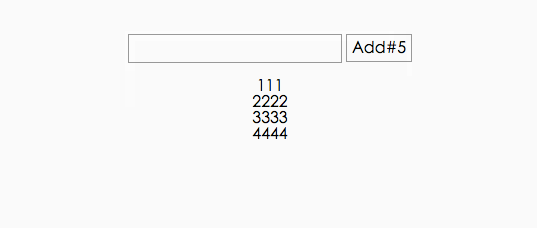
比如我们看下面这个例子,假设下面这些是某个父元素的子元素集合,上面到下面代表了变动流程:
数字我们可以理解为给element的key。
正方形代表element。圆形代表了component。当然也是实际上的dom节点的位置。
从上到下,我们的4 2 1里 2 ,1可以复用之前的component,让他们通知自己的子节点更新后,再告诉2和1,他们在新的集合里需要移动的位置(在我们这里就是组装差异对象加到队列)。3需要删除,4需要新增。
好了,整个的diff就完成了,这个时候当递归完成,我们就需要开始做patch的动作了,把这些差异对象实打实的反映到具体的dom节点上。
我们看下_patch的实现:
//用于将childNode插入到指定位置
function insertChildAt(parentNode, childNode, index) {
var beforeChild = parentNode.children().get(index);
beforeChild ? childNode.insertBefore(beforeChild) : childNode.appendTo(parentNode);
}
ReactDOMComponent.prototype._patch = function(updates) {
var update;
var initialChildren = {};
var deleteChildren = [];
for (var i = 0; i < updates.length; i++) {
update = updates[i];
if (update.type === UPATE_TYPES.MOVE_EXISTING || update.type === UPATE_TYPES.REMOVE_NODE) {
var updatedIndex = update.fromIndex;
var updatedChild = $(update.parentNode.children().get(updatedIndex));
var parentID = update.parentID;
//所有需要更新的节点都保存下来,方便后面使用
initialChildren[parentID] = initialChildren[parentID] || [];
//使用parentID作为简易命名空间
initialChildren[parentID][updatedIndex] = updatedChild;
//所有需要修改的节点先删除,对于move的,后面再重新插入到正确的位置即可
deleteChildren.push(updatedChild)
}
}
//删除所有需要先删除的
$.each(deleteChildren, function(index, child) {
$(child).remove();
})
//再遍历一次,这次处理新增的节点,还有修改的节点这里也要重新插入
for (var k = 0; k < updates.length; k++) {
update = updates[k];
switch (update.type) {
case UPATE_TYPES.INSERT_MARKUP:
insertChildAt(update.parentNode, $(update.markup), update.toIndex);
break;
case UPATE_TYPES.MOVE_EXISTING:
insertChildAt(update.parentNode, initialChildren[update.parentID][update.fromIndex], update.toIndex);
break;
case UPATE_TYPES.REMOVE_NODE:
// 什么都不需要做,因为上面已经帮忙删除掉了
break;
}
}
}_patch主要就是挨个遍历差异队列,遍历两次,第一次删除掉所有需要变动的节点,然后第二次插入新的节点还有修改的节点。这里为什么可以直接挨个的插入呢?原因就是我们在diff阶段添加差异节点到差异队列时,本身就是有序的,也就是说对于新增节点(包括move和insert的)在队列里的顺序就是最终dom的顺序,所以我们才可以挨个的直接根据index去塞入节点。
但是其实你会发现这里有个问题,就是所有的节点都会被删除,包括复用以前的component类型为UPATE_TYPES.MOVE_EXISTING 的,所以闪烁会很严重。其实我们再看看上面的例子,其实2是不需要记录到差异队列的。这样后面patch也是ok的。想想是为什么呢?
我们来改造下代码:
//_diff用来递归找出差别,组装差异对象,添加到更新队列diffQueue。
ReactDOMComponent.prototype._diff = function(diffQueue, nextChildrenElements){
。。。
/**注意新增代码**/
var lastIndex = 0;//代表访问的最后一次的老的集合的位置
var nextIndex = 0;//代表到达的新的节点的index
//通过对比两个集合的差异,组装差异节点添加到队列中
for (name in nextChildren) {
if (!nextChildren.hasOwnProperty(name)) {
continue;
}
var prevChild = prevChildren && prevChildren[name];
var nextChild = nextChildren[name];
//相同的话,说明是使用的同一个component,所以我们需要做移动的操作
if (prevChild === nextChild) {
//添加差异对象,类型:MOVE_EXISTING
。。。。
/**注意新增代码**/
prevChild._mountIndex < lastIndex && diffQueue.push({
parentId:this._rootNodeID,
parentNode:$('[data-reactid='+this._rootNodeID+']'),
type: UPATE_TYPES.REMOVE_NODE,
fromIndex: prevChild._mountIndex,
toIndex:null
})
lastIndex = Math.max(prevChild._mountIndex, lastIndex);
} else {
//如果不相同,说明是新增加的节点,
if (prevChild) {
//但是如果老的还存在,就是element不同,但是component一样。我们需要把它对应的老的element删除。
//添加差异对象,类型:REMOVE_NODE
。。。。。
/**注意新增代码**/
lastIndex = Math.max(prevChild._mountIndex, lastIndex);
}
。。。
}
//更新mount的inddex
nextChild._mountIndex = nextIndex;
nextIndex++;
}
//对于老的节点里有,新的节点里没有的那些,也全都删除掉
。。。
}可以看到我们多加了个lastIndex,这个代表最后一次访问的老集合节点的最大的位置。
而我们加了个判断,只有_mountIndex小于这个lastIndex的才会需要加入差异队列。有了这个判断上面的例子2就不需要move。而程序也可以好好的运行,实际上大部分都是2这种情况。
这是一种顺序优化,lastIndex一直在更新,代表了当前访问的最右的老的集合的元素。
我们假设上一个元素是A,添加后更新了lastIndex。
如果我们这时候来个新元素B,比lastIndex还大说明当前元素在老的集合里面就比上一个A靠后。所以这个元素就算不加入差异队列,也不会影响到其他人,不会影响到后面的path插入节点。因为我们从patch里面知道,新的集合都是按顺序从头开始插入元素的,只有当新元素比lastIndex小时才需要变更。其实只要仔细推敲下上面那个例子,就可以理解这种优化手段了。
这样整个的更新机制就完成了。我们再来简单回顾下reactjs的差异算法:
首先是所有的component都实现了receiveComponent来负责自己的更新,而浏览器默认元素的更新最为复杂,也就是经常说的 diff algorithm。
react有一个全局_shouldUpdateReactComponent用来根据element的key来判断是更新还是重新渲染,这是第一个差异判断。比如自定义元素里,就使用这个判断,通过这种标识判断,会变得特别高效。
每个类型的元素都要处理好自己的更新:
自定义元素的更新,主要是更新render出的节点,做甩手掌柜交给render出的节点的对应component去管理更新。
text节点的更新很简单,直接更新文案。
浏览器基本元素的更新,分为两块:
整个reactjs的差异算法就是这个样子。最核心的两个_shouldUpdateReactComponent以及diff,patch算法。
有了上面简易版的reaactjs,我们来实现一个简单的todolist吧。
var TodoList = React.createClass({
getInitialState: function() {
return {items: []};
},
add:function(){
var nextItems = this.state.items.concat([this.state.text]);
this.setState({items: nextItems, text: ''});
},
onChange: function(e) {
this.setState({text: e.target.value});
},
render: function() {
var createItem = function(itemText) {
return React.createElement("div", null, itemText);
};
var lists = this.state.items.map(createItem);
var input = React.createElement("input", {onkeyup: this.onChange.bind(this),value: this.state.text});
var button = React.createElement("p", {onclick: this.add.bind(this)}, 'Add#' + (this.state.items.length + 1))
var children = lists.concat([input,button])
return React.createElement("div", null,children);
}
});
React.render(React.createElement(TodoList), document.getElementById("container"));效果如下:
整个的流程是这样:
ReactCompositeComponent渲染自定义元素TodoList,调用getInitialState拿到初始值,然后使用ReactDOMComponent渲染render返回的div基本元素节点。div基本元素再一层层的使用ReactDOMComponent去渲染各个子节点,包括input,还有p。基本上,整个流程都梳理清楚了
这只是个玩具,但实现了reactjs最核心的功能,虚拟节点,差异算法,单向数据更新都在这里了。还有很多reactjs优秀的东西没有实现,比如对象生成时内存的线程池管理,批量更新机制,事件的优化,服务端的渲染,immutable data等等。这些东西受限于篇幅就不具体展开了。
reactjs作为一种解决方案,虚拟节点的想法比较新奇,不过个人还是不能接受这种别扭的写法。使用reactjs,就要使用他那一整套的开发方式,而他核心的功能其实只是一个差异算法,而这种其实已经有相关的库实现了。
最后再吐槽下前端真是苦命,各种新技术,各种新知识脑细胞不够用了。也难怪前端永远都缺人。
相关资料:
原文:http://blog.mgechev.com/2015/03/09/build-learn-your-own-light-lightweight-angularjs/
第一次翻译外文,就拿这篇作为第一次练习。加上一些自己的理解并且做了些删减。
正文开始:
我的实践经验证明有两种好方法来学习一项新技术。
在一些情况下第一种方式很难做到。比如,如果你为了理解kernel(linux内核)的工作原理而去重新实现一次它会很困难很慢。往往更有效的是你去实现一个轻量的版本,去除掉那些你没兴趣的技术细节,只关注核心功能。
第二种方法一般是很有效的,特别是当你具有一些相似的技术经验的时候。最好的证明就是我写的angularjs-in-patterns,对于有经验的工程师来说这是个对angular框架非常好的介绍。
不管怎么说,从头开始实现一些东西并且去理解代码使用的技术细节是非常好的学习方式。整个angularjs框架大概有20k行代码,其中有很多特别难懂的地方。这是很多聪明的程序员夜以继日的工作做出来的伟大的壮举。然而为了理解这个框架还有它主要的设计原则,我们可以仅仅简单的实现一个‘模型’。
我们可以通过下面这些步骤来实现这个模型:
这就是我在Lightweight AngularJS里面做的事情。
在开始阅读下面的内容之前,建议先了解下angularjs的基本用法,可以看这篇文章
下面是一些demo例子还有代码片段:
让我们开始我们的实现:
我们不完全实现angularjs的那套技术,我们就仅仅定义一部分的组件并且实现大部分的angularjs里面的时尚特性。可能会接口变得简单点,或者减少些功能特性。
我们会实现的angular的组件包括:
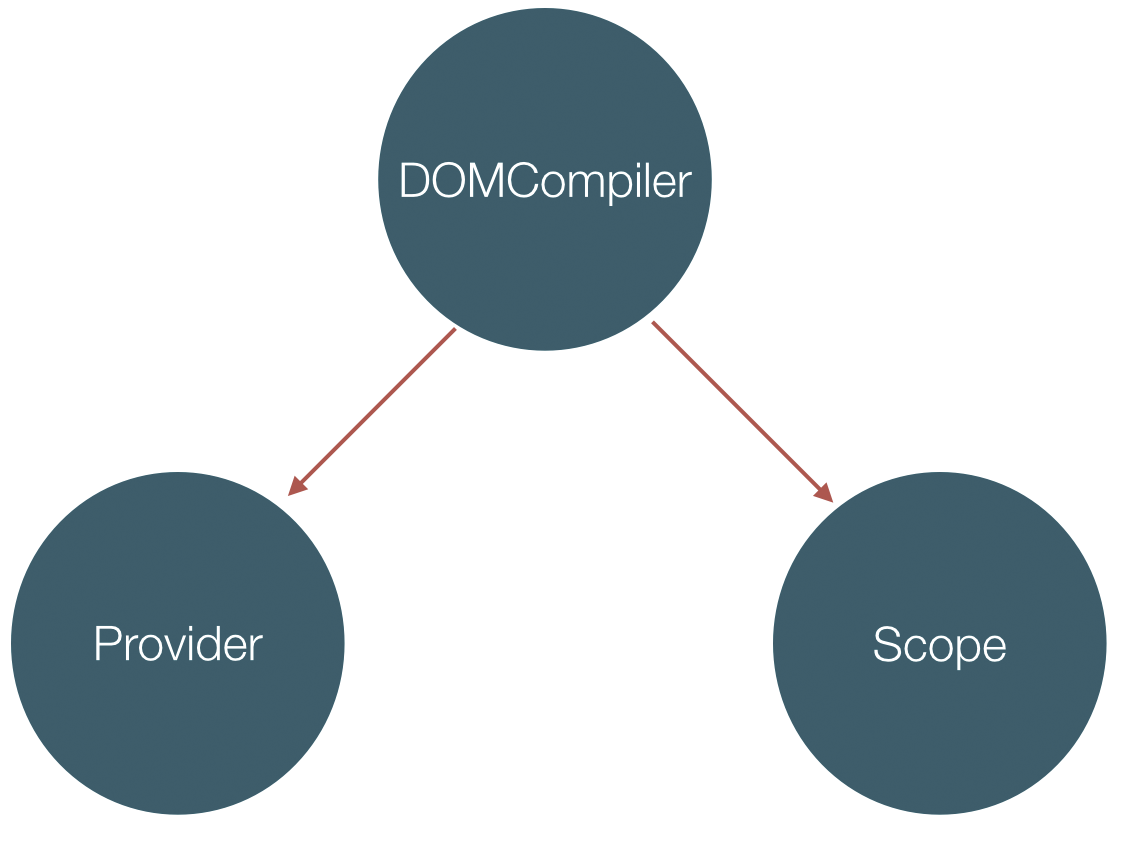
为了达到这些功能我们需要实现$compileservice(我们称之为DOMCompiler),还有$provider跟$injector(在我们的实现里统称为Provider)。为了实现双向绑定我们还要实现scope。
下面是Provider, Scope 跟 DOMCompiler 的依赖关系:
就像上面提到的,我们的Provider会包括原生angular里面的两个组件的内容:
他是一个具有如下功能特性的单列:
DOMCompiler也是一个单列,他会遍历dom树去查找对应的directives节点。我们这里仅仅支持那种用在dom元素属性上的directive。当DOMCompiler发现directive的时候会给他提供scope的功能特性(因为对应的directive可能需要一个新的scope)并且调用关联在它上面对应的逻辑代码(也就是link函数里面的逻辑)。所以这个组件的主要职责就是:
编译dom
我们的轻量级angular的最后一个主要的组件就是scope。为了实现双向绑定的功能,我们需要有一个$scope对象来挂载属性。我们可以把这些属性组合成表达式并且监控它们。当我们发现监控的某个表达式的值改变了,我们就调用对应的回调函数。
scope的职责:
下面本来还有些图论的讲解,但是认为意义不大,这边就略去了。
让我们开始实现我们的轻量版angular
正如我们上面说的,Provide会:
所以它具有下面这些接口:
组件的注册:
var Provider = {
_providers: {},
directive: function (name, fn) {
this._register(name + Provider.DIRECTIVES_SUFFIX, fn);
},
controller: function (name, fn) {
this._register(name + Provider.CONTROLLERS_SUFFIX, function () {
return fn;
});
},
service: function (name, fn) {
this._register(name, fn);
},
_register: function (name, factory) {
this._providers[name] = factory;
}
//...
};
Provider.DIRECTIVES_SUFFIX = 'Directive';
Provider.CONTROLLERS_SUFFIX = 'Controller';
译者注:看到这里容易对controller的包装一层有疑问,先忽略,看完invoke的实现后,下面我再给出解释。
上面的代码提供了一个针对注册组件的简单的实现。我们定义了一个私有属性_provides用来存储所有的组件的工厂函数。我们还定义了directive,service和controller这些方法。这些方法本质上内部会调用_register来实现。在controller方法里面我们简单的在给的工厂函数外面包装了一层函数,因为我们希望可以多次实例化同一个controller而不去缓存返回的值。在我们看了下面的get和ngl-controller方法实现后会对controller方法有更加清晰的认识。下面还剩下的方法就是:
var Provider = {
// ...
get: function (name, locals) {
if (this._cache[name]) {
return this._cache[name];
}
var provider = this._providers[name];
if (!provider || typeof provider !== 'function') {
return null;
}
return (this._cache[name] = this.invoke(provider, locals));
},
annotate: function (fn) {
var res = fn.toString()
.replace(/((\/\/.*$)|(\/\*[\s\S]*?\*\/))/mg, '')
.match(/\((.*?)\)/);
if (res && res[1]) {
return res[1].split(',').map(function (d) {
return d.trim();
});
}
return [];
},
invoke: function (fn, locals) {
locals = locals || {};
var deps = this.annotate(fn).map(function (s) {
return locals[s] || this.get(s, locals);
}, this);
return fn.apply(null, deps);
},
_cache: { $rootScope: new Scope() }
};
我们写了更多的逻辑,下面我们看看get的实现。
在get方法中我们先检测下一个组件是不是已经缓存在了私有属性_cache里面。
在invoke函数里,我们做的第一件事就是判断如果没有locals对象就赋值一个空的值。
这些locals对象 叫做局部依赖,什么是局部依赖呢?
在angularjs里面我们可以想到两种依赖:
全局依赖是我们使用factory,service,filter等等注册的组件。他们可以被所有应用里的其他组件依赖使用。但是$scope呢?对于每一个controller(具有相同执行函数的controller)我们希望拥有不同的scope,$scope对象不像$http,$resource,它不是全局的依赖对象,而是跟$delegate对象一样是局部依赖,针对当前的组件。
让我们呢回到invoke的实现上。通过合理的规避null,undefined这些值,我们可以获取到当前组件的依赖项的名字。注意我们的实现仅仅支持解析那种作为参数属性的依赖写法:
function Controller($scope, $http) {
// ...
}
angular.controller('Controller', Controller);一旦把controller的定义转换成字符串,我们就可以很简单的通过annotate里面的正则匹配出它的依赖项。但是万一controller的定义里面有注释呢?
function Controller($scope /* only local scope, for the component */, $http) {
// ...
}
angular.controller('Controller', Controller);
这边简单的正则就不起作用了,因为执行Controller.toString()也会返回注释,所以这就是我们为什么最开始要使用下面的正则先去掉注释:
.replace(/((\/\/.*$)|(\/\*[\s\S]*?\*\/))/mg, '').
当我们拿到依赖项的名称后,我们需要去实例化他们。所以我们使用map来循环遍历,挨个的调用get来获取实例。你注意到这边的问题了吗?
如果我们有个组件A,A依赖B和C。并且假设C依赖A?在这种情况下我们就会发生无止境的循环,也就是循环依赖。在这个实现里面我们不会处理这种问题,但是你应该小心点,尽量避免。
所以上面就是我们的provider的实现,现在我们可以这样注册组件:
Provider.service('RESTfulService', function () {
return function (url) {
// make restful call & return promise
};
});
Provider.controller('MainCtrl', function (RESTfulService) {
RESTfulService(url)
.then(function (data) {
alert(data);
});
});
然后我们可以这样执行MainCtrl:
var ctrl = Provider.get('MainCtrl' + Provider.CONTROLLERS_SUFFIX);
Provider.invoke(ctrl);译者注:
这边可以开始解释下上面的Provider里面controller方法里为啥要包装一层了。
首先我们注意到controller的调用方式是特殊的,Provider.get内部已经调用了一次invoke,但是我们还要再调用一次invoke才能执行MainCtrl的真正执行函数。这是因为我们包装了一层,导致_cache里面单列存储的是MainCtrl的执行函数。而不是执行函数的结果。
想想这才是合理的,因为MainCtrl可能会有多个调用,这些调用只有执行函数是一致的,但是执行函数的执行结果根据不同的scope环境是不一样的。换句话说对于controller来说 执行函数才是单列的,执行结果是差异的。如果我们不包装一层,就会导致第一次的执行结果会直接缓存,这样下次再使用MainCtrl的时候得到的值就是上一次的。
当然带来的问题就是我们需要get到执行函数后,再次调用invoke来获取结果。
这边的controller初始化,需要看下面的ngl-controller的实现,可以到时再回过头来看这边会理解的更清楚。
DOMCompiler的主要职责是:
编译dom
下面的这些接口就够了:
下面是对应的实现:
var DOMCompiler = {
bootstrap: function () {
this.compile(document.children[0],
Provider.get('$rootScope'));
},
compile: function (el, scope) {
//获取某个元素上的所有指令
var dirs = this._getElDirectives(el);
var dir;
var scopeCreated;
dirs.forEach(function (d) {
dir = Provider.get(d.name + Provider.DIRECTIVES_SUFFIX);
//dir.scope代表当前 directive是否需要生成新的scope
//这边的情况是只要有一个指令需要单独的scope,其他的directive也会变成具有新的scope对象,这边是不是不太好
if (dir.scope && !scopeCreated) {
scope = scope.$new();
scopeCreated = true;
}
dir.link(el, scope, d.value);
});
Array.prototype.slice.call(el.children).forEach(function (c) {
this.compile(c, scope);
}, this);
},
// ...
};
bootstrap的实现很简单。就是调用了一下compile,传递的是html的根节点,以及全局的$rootScope。
在compile里面的代码就很有趣了,最开始我们使用了一个辅助方法来获取某个节点上面的所有指令。我们后面再来看这个_getElDirectives的实现。
当我们获取到当前节点的所有指令后,我们循环遍历下并且使用Provider.get获取到对应的directive的工厂函数的执行返回对象。然后我们检查当前的directive是否需要一个新的scope,如果需要并且我们还没有为当前的节点初始化过新的scope对象,我们就执行scope.$new()来生成一个新的scope对象。这个对象会原型继承当前的scope对象。然后我们执行当前directive的link方法。最后我们递归执行子节点。因为el.children是一个nodelist对象,所以我们使用Array.prototype.slice.call将它转换成数组,之后对它递归调用compile。
再让我们看看_getElDirectives:
// ...
_getElDirectives: function (el) {
var attrs = el.attributes;
var result = [];
for (var i = 0; i < attrs.length; i += 1) {
if (Provider.get(attrs[i].name + Provider.DIRECTIVES_SUFFIX)) {
result.push({
name: attrs[i].name,
value: attrs[i].value
});
}
}
return result;
}
// ...
主要就是遍历当前节点el的所有属性,发现一个注册过的指令就把它的名字和值加入到返回的数组里。
好了,到这里我们的DOMCompiler就完成了,下面我们看看最后一个重要的组件:
为了实现脏检测的功能,于是scope可能是整个实现里面最复杂的部分了。在angularjs里面我们称为$digest循环。笼统的讲双向绑定的最主要原理,就是在$digest循环里面执行监控表达式。一旦这个循环开始调用,就会执行所有监控的表达式并且检测最后的执行结果是不是更当前的执行结果不同,如果angularjs发现他们不同,它就会执行这个表达式对应的回调函数。一个监控者就是一个对象像这样{ expr, fn, last }。expr是对应的监控表达试,fn是对应的回调函数会在值变化后执行,last是上一次的表达式的执行结果。
scope对象有下面这些方法:
让我们来深入的看看scope的实现:
function Scope(parent, id) {
this.$$watchers = [];
this.$$children = [];
this.$parent = parent;
this.$id = id || 0;
}
Scope.counter = 0;我们大幅度的简化了angularjs的scope。我们仅仅有一个监控者的列表,一个子scope对象的列表,一个父scope对象,还有个当前scope的id。我们添加了一个静态属性counter用来跟踪最后一个scope,并且为下一个scope对象提供一个唯一的标识。
我们来实现$watch方法:
Scope.prototype.$watch = function (exp, fn) {
this.$$watchers.push({
exp: exp,
fn: fn,
last: Utils.clone(this.$eval(exp))
});
};
在$watch方法中,我们添加了一个新对象到this.$$watchers监控者列表里。这个对象包括一个表达式,一个执行的回调还有最后一次表达式执行的结果last。因为我们使用this.$eval执行表达式得到的结果有可能是个引用,所以我们需要克隆一份新的。
下面我们看看如何新建scope,和销毁scope。
Scope.prototype.$new = function () {
Scope.counter += 1;
var obj = new Scope(this, Scope.counter);
//设置原型链,把当前的scope对象作为新scope的原型,这样新的scope对象可以访问到父scope的属性方法
Object.setPrototypeOf(obj, this);
this.$$children.push(obj);
return obj;
};
Scope.prototype.$destroy = function () {
var pc = this.$parent.$$children;
pc.splice(pc.indexOf(this), 1);
};
在destroy方法里,我们把当前scope对象从父级scope对象里的子scope对象列表(this.$$children)移除掉。
下面我们看看传说中的脏检测$digest的实现:
Scope.prototype.$digest = function () {
var dirty, watcher, current, i;
do {
dirty = false;
for (i = 0; i < this.$$watchers.length; i += 1) {
watcher = this.$$watchers[i];
current = this.$eval(watcher.exp);
if (!Utils.equals(watcher.last, current)) {
watcher.last = Utils.clone(current);
dirty = true;
watcher.fn(current);
}
}
} while (dirty);
for (i = 0; i < this.$$children.length; i += 1) {
this.$$children[i].$digest();
}
};
基本上我们一直循环运行检测一直到没有脏数据,默认情况下就是没有脏数据的。一旦我们发现当前表达式的执行结果跟上一次的结果不一样我们就任务有了脏数据,一旦我们发现一个脏数据我们就要重新执行一次所有的监控表达式。为什么呢?因为我们可能会有一些内部表达式依赖,所以一个表达式的结果可能会影响到另外一个的结果。这就是为什么我们需要一遍一遍的运行脏检测一直到所有的表达式都没有变化也就是稳定了。一旦我们发现数据改变了,我们就立即执行对应的回调并且更新对应的last值,并且标识当前有脏数据,这样就会再次调用脏检测。
然后我们会继续递归调用子scope对象的脏数据检测,一个需要注意的情况就是这边也会发生循环依赖:
function Controller($scope) {
$scope.i = $scope.j = 0;
$scope.$watch('i', function (val) {
$scope.j += 1;
});
$scope.$watch('j', function (val) {
$scope.i += 1;
});
$scope.i += 1;
$scope.$digest();
}
这种情况下我们就会看到:
最后一个方法是$eval.最好不要在生产环境里使用这个,这个是一个hack手段用来避免我们还需要自己做个表达式解析引擎。
// In the complete implementation there're
// lexer, parser and interpreter.
// Note that this implementation is pretty evil!
// It uses two dangerouse features:
// - eval
// - with
// The reason the 'use strict' statement is
// omitted is because of `with`
Scope.prototype.$eval = function (exp) {
var val;
if (typeof exp === 'function') {
val = exp.call(this);
} else {
try {
with (this) {
val = eval(exp);
}
} catch (e) {
val = undefined;
}
}
return val;
};
我们检测监控的表达式是不是一个函数,如果是的话我们就使用当前的上下文执行它。否则我们就通过with把当前的执行环境改成当前scope的上下文并且使用eval来得到结果。这个可以允许我们执行类似foo + bar * baz()的表达式,甚至是更复杂的。当然我们不会支持filters,因为他们是angularjs扩展的功能。
到目前为止使用已有的元素我们做不了什么。为了让它跑起来我们需要添加一些指令(directive)还有服务(service)。让我们来实现ngl-bind (ng-bind ), ngl-model (ng-model), ngl-controller (ng-controller) and ngl-click (ng-click)。括号里代表在angularjs里面的对应directive
ngl-bind
Provider.directive('ngl-bind', function () {
return {
scope: false,
link: function (el, scope, exp) {
el.innerHTML = scope.$eval(exp);
scope.$watch(exp, function (val) {
el.innerHTML = val;
});
}
};
});ngl-bind并不需要一个新的scope,它仅仅对当前节点添加了一个监控。当脏检测发现有了改变,回调函数就会把新的值赋值到innerHTML更新dom
ngl-model
我们的ng-model只会支持input框的改变检测,所以它的实现是这样:
Provider.directive('ngl-model', function () {
return {
link: function (el, scope, exp) {
el.onkeyup = function () {
scope[exp] = el.value;
scope.$digest();
};
scope.$watch(exp, function (val) {
el.value = val;
});
}
};
});
我们对当前的input框添加了一个onkeyup的监听,一旦当前input的值变化了,我们就调用当前scope对象的$digest脏检测循环。这样就可以保证这个改变会应用到所有scope的监控表达式。当值改变了我们就改变对应的节点的值。
ngl-controller
Provider.directive('ngl-controller', function () {
return {
scope: true,
link: function (el, scope, exp) {
var ctrl = Provider.get(exp + Provider.CONTROLLERS_SUFFIX);
Provider.invoke(ctrl, { $scope: scope });
}
};
});
我们需要针对每个controller生成一个新的scope对象,所以它的scope的值是true。我们使用Provide.get来获取到需要的controller执行函数,然后使用当前的scope来执行它。在controller里面我们可以给scope对象添加属性,我们可以使用ngl-bind/ngl-model绑定这些属性。一旦我们改变了属性值我们需要确保我们执行$digest脏检测来保证监控这些属性的表达式会执行。
ngl-click
在我们可以做一个有用的todo应用之前,这是我们最后要看的指令。
Provider.directive('ngl-click', function () {
return {
scope: false,
link: function (el, scope, exp) {
el.onclick = function () {
scope.$eval(exp);
scope.$digest();
};
}
};
});这里我们不需要新建个scope对象。我们需要的就是当用户点击按钮时执行当前ngl-click后面跟着的表达式并且调用脏检测。
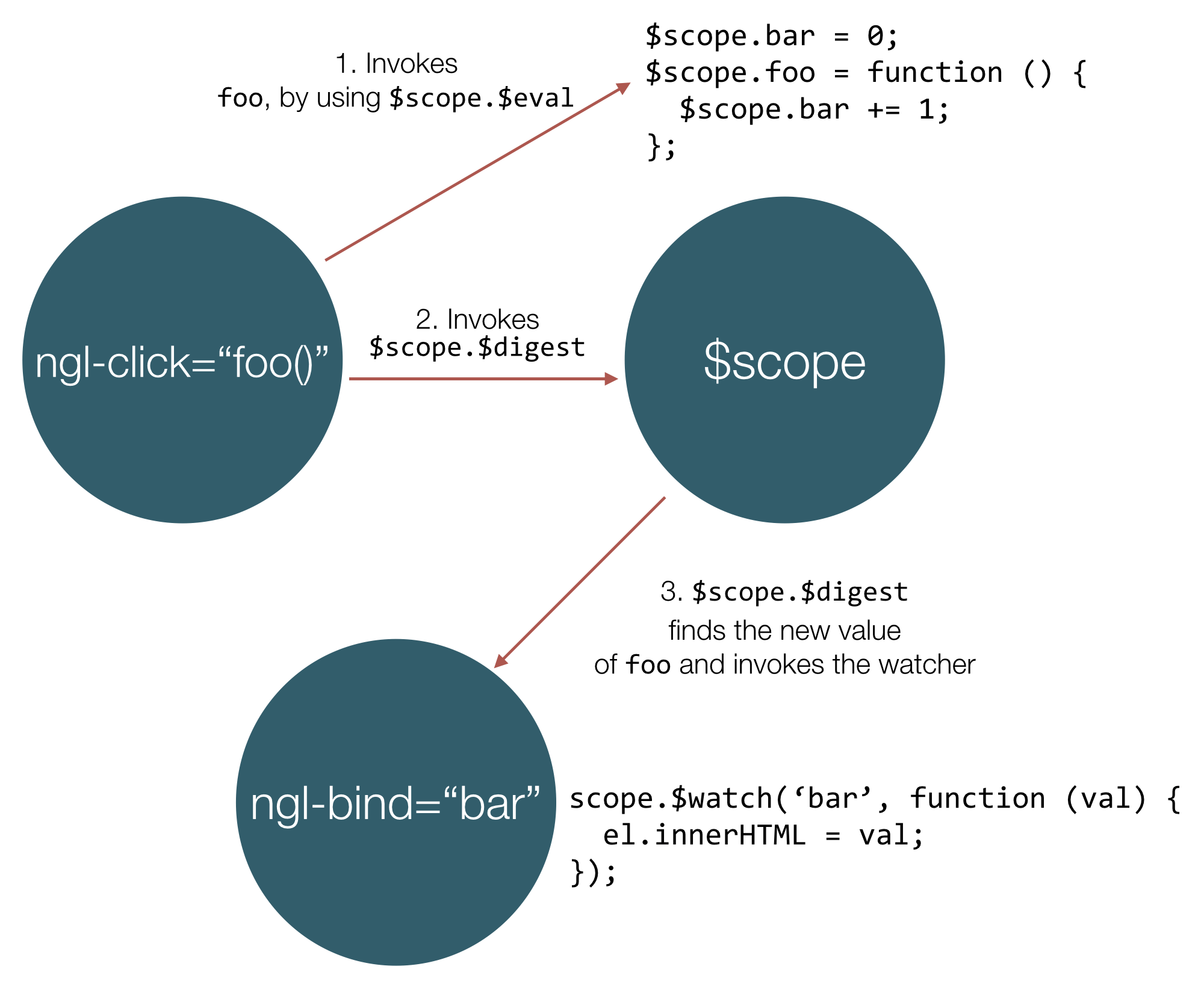
为了保证我们可以理解双向绑定是怎么工作的,我们来看个下面的例子:
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body ngl-controller="MainCtrl">
<span ngl-bind="bar"></span>
<button ngl-click="foo()">Increment</button>
</body>
</html>Provider.controller('MainCtrl', function ($scope) {
$scope.bar = 0;
$scope.foo = function () {
$scope.bar += 1;
};
});让我们看看使用这些会发生什么:
首先DOMCompiler会先发现我们的ngl-controller指令。然后会调用这个指令的link函数生成一个新的scope对象传递给controller的执行函数。我们增加了一个值为0的bar属性,还有一个叫做foo的方法,foo方法会不断增加bar。DOMCompiler会发现ngl-bind然后为bar添加监控。并且还发现了ngl-click同时添加click事件到按钮上。
一旦用户点击了按钮,foo函数就会通过$scope.$eval执行。使用的scope对象就是传递给MainCtrl的scope对象。这之后ngl-click会执行脏检测$scope.$digest。脏检测循环会遍历所有的监控表达式,发现bar的值变化了。因为我们添加了对应的回调函数,所以就执行它更新span的内容。
这个框架离实际的生产环境应用还有很大差距,但是它还是实现了不少功能:
跟在angular里面的运行方式差不多。这些可以帮助我们更容易理解angularjs。
但是你还是要记住的是不要把这些代码用在生产环境,最好还是直接使用bower install angular使用最新的anguar。
作为一个曾经辗转使用过java,php,ruby(ror)的小白,一见到nodejs就疯狂的迷恋上了。终于可以在服务端写js了。不过nodejs毕竟发展的时间太短,所以呢很多东西还不完善。比如我最近就遇到了比较麻烦的日志处理的问题。
曾几何时,我在使用php或者ruby的时候,日志啦,数据库orm啦这些东西都有很成熟的框架去自动帮你弄好。而nodejs现在最出名的koa实在是太简单纯粹了,只是帮你完成了中间件的结构,其他全部都撒手不管了。所以呢日志模块需要自己去找的。
##遇到的问题
首先我们看个例子:
var http = require('http');
var server = http.createServer(function (req, res) {
setTimeout(function(){
console.log("我开始打第一段日志了。。。");
res.write("处理中。。。");
},1000)
setTimeout(function(){
console.log("我要打第二段日志了。。。");
res.write("处理中。。。");
},5000)
setTimeout(function(){
console.log("日志打完了。。。");
res.end("请求结束。。。");
},10000)
}).listen(3000);
console.log('listening on port ' + 3000);
程序会针对每个请求打出一些日志,需要注意的是这些日志都是异步的。每个请求都要10秒才能结束。
运行程序后,我们再开两个终端前后运行:
curl http://localhost:3000
//你也可以用浏览器,开两个窗口访问
我们期待的效果应该是:
//第一个请求进来:
开始打第一段日志了。。。
我要打第二段日志了。。
。日志打完了。。。
//第二个请求进来:
开始打第一段日志了。。。
我要打第二段日志了。。。
日志打完了。。。
但是你会发现结果是:
我开始打第一段日志了。。。
我开始打第一段日志了。。。
我要打第二段日志了。。。
我要打第二段日志了。。。
日志打完了。。。
日志打完了。。。
你会发现发生了串行的现象,也就是第一个请求日志打了一半,第二个请求也开始打日志了。
试想一下,当我们的应用很大时,我们肯定是希望针对当前的一个请求的日志记录在一起的。这样才好方便排查某个请求的问题。如果不加处理的话,全是串行在一起。那完全就不知道错误属于哪个请求的。
##缘起
为什么会发生这种问题呢,这要从nodejs的请求模型开始聊起了。
首先单进程的ruby,php这类的服务是不会有这个问题的,因为他们都是同步机制,一个进程处理一个请求。注意这边强调的是单进程。比如我们在服务端开一个进程。当来了一个请求时,一个请求就使用其中的一个进程。再来一个请求怎么办呢?没办法,只能等着。等前面的请求结束了。你才可以进来。所以对于一个请求来说他是独享各种环境的,是不怕被其它请求打扰的。
而nodejs是单进程单线程异步处理所有的请求:
这边盗个图,出处这里。这篇文章很好的讲解了一些请求模型。
来了一个请求,nodejs就开始处理了,再来一个请求也可以使用这个进程。他们可以同时调用,这得益于nodejs本身的基于事件的异步编程模型。第一个请求过来了可能处理了一半下个请求就过来了。所以就会出现了我们上面的串行的问题。
我们上面说单进程的ruby,php是不会有这种问题的,因为一个进程一次只能处理一个请求。但是很不幸,一般使用ruby或者php的时候都是开启多个进程的,这样一个请求来了就去看有没有空闲的进程,有就使用,满了就等待。所以虽然 单个进程的模型不会有问题,但是多进程下的php,ruby模型如果一起写日志文件,还是会有这种请求之间竞争资源的问题。解决方案或是文件锁,或是使用内存记录最后一次性输出等等,这边就先不讨论。
另外,nodejs目前也具有了多进程的结构,就是使用cluster。比如四核的处理器我们就可以开四个进程来做负载均衡。当然这又跟ruby,php的进程模型是两码事了。
那么对于nodejs我们怎么处理呢?
很简单,我们只需要针对每个请求维护一个局部变量。等到当前请求结束的时候一次性的输出。
##针对koa的解决方案
由于项目使用koa架构,所以基于此我开发了个包来处理这样的日志的问题。koa很贴心的维护了一个针对每个请求的context对象。所以我们可以在这个对象上维护一个局部日志缓存,所有地方的输出日志都是先记录在这个缓存里等请求结束后再一次性输出到日志文件。
地址:https://github.com/purplebamboo/koa-logs-full
用来记录类似rails风格的日志。
##结语
结语还是要滴,nodejs还很不完善,但是正是因为不完善,作为开发人员才有很多东西可以去做去挑战。每踩到一个坑,去了解相应的实现就可以学到很多知识,对于前端来说是个很好的机遇。
最近做一个iframe上传的组件,需要限制上传文件的 高度宽度还有 大小。所以研究了下如何使用js获取这些信息。
网上的内容很多,不过很多解决方案都是有问题,下面进行些罗列和分析。
网上的几种解决方案
##第一种:
var image1 = new Image();
image1.dynsrc = path;
alert(image1.dynsrc); //这里路径显示真确
alert(image1.fileSize); //但是这里老是-1 为什么??
老是-1 是因为没有加载完,所以需要onload判断
dynsrc只有ie支持,但是连ie自己都给放弃了,经测试只有ie6支持。7,8都不行。
应该使用src属性。
var image = new Image();
image.onload =function(){
var width = image.width;
var height = image.height;
var fileSize = image.fileSize;
//alert(width+'======'+height+"====="+fileSize);
}
image.src = path;
改成这个后,测试 ie系列都支持,但是 在chrome等现代浏览器下是不行的,chrome这些浏览器 不允许读取本地的文件。
这边需要注意的是:最好将onload函数放在image.src = path 的前面,因为image对象下次加载时会优先读取缓存,onload放在后面可能会造成加载太快,来不及触发onload事件。
##第二种:
function getFileSize(filePath)
{
var fso = new ActiveXObject("Scripting.FileSystemObject");
alert("文件大小为:"+fso.GetFile(filePath).size);
}
没有测试 基本没有意义,会弹出安全提示
这种方法可以实现,也容易被开发人员想到,但是需要更改浏览器的安全设置,不然会报“Automation服务器不能创建对象”这个脚本错误。将浏览器的安全设置改为“中”,然后将ActiveX的设置设为启用就OK了,显然不能对用户做出什么要求,所以不推荐。
##第三种:
使用html5的 http://caniuse.com/fileapi
var f = document.getElementById("file").files[0];
var reader = new FileReader();
reader.onload = function (e) {
var data = e.target.result;
//加载图片获取图片真实宽度和高度
var image = new Image();
image.onload=function(){
var width = image.width;
var height = image.height;
alert(width+'======'+height+"====="+f.size);
};
image.src= data;
};
reader.readAsDataURL(f);
这是使用的html5技术,测试大部分现代浏览器都是可行的。
##第四种
经过查看开源组件的源码,发现了一种独特的写法,通过ie的滤镜实现读取文件的宽度高度
var input = self.input[0]
var temp_document = self.iframe[0].contentDocument || self.iframe[0].document;
input.select();
//确保IE9下,不会出现因为安全问题导致无法访问
input.blur();
var src = temp_document.selection.createRange().text;
var img = $('<img style="filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(sizingMethod=image);width:300px;visibility:hidden;" />').appendTo('body').getDOMNode();
img.filters.item('DXImageTransform.Microsoft.AlphaImageLoader').src = src;
var width = img.offsetWidth;
var height = img.offsetHeight;
$(img).remove();
此代码需要jquery选择器的支持。这种方法据说最稳定。
通过以上的分析,确定出一种最稳妥的跨浏览器的解决方案为
window.check=function(){
var input = document.getElementById("file");
if(input.files){
//读取图片数据
var f = input.files[0];
var reader = new FileReader();
reader.onload = function (e) {
var data = e.target.result;
//加载图片获取图片真实宽度和高度
var image = new Image();
image.onload=function(){
var width = image.width;
var height = image.height;
alert(width+'======'+height+"====="+f.size);
};
image.src= data;
};
reader.readAsDataURL(f);
}else{
var image = new Image();
image.onload =function(){
var width = image.width;
var height = image.height;
var fileSize = image.fileSize;
alert(width+'======'+height+"====="+fileSize);
}
image.src = input.value;
}
}
对应的html为:
<input id="file" type="file">
<input id="Button1" type="button" value="button" onclick="check()">
ps:
这个地址http://www.planeart.cn/?p=1121 使用一种方式可以很方便的提前获取 width和height 非常好
思路是,浏览器在图片未加载完时会通过http协议的header提前知道width和height,所以通过一个计时器,不停检测,快速的得到宽度高度。
代码如下:
// 更新:
// 05.27: 1、保证回调执行顺序:error > ready > load;2、回调函数this指向img本身
// 04-02: 1、增加图片完全加载后的回调 2、提高性能
/**
* 图片头数据加载就绪事件 - 更快获取图片尺寸
* @version 2011.05.27
* @author TangBin
* @see http://www.planeart.cn/?p=1121
* @param {String} 图片路径
* @param {Function} 尺寸就绪
* @param {Function} 加载完毕 (可选)
* @param {Function} 加载错误 (可选)
* @example imgReady('http://www.google.com.hk/intl/zh-CN/images/logo_cn.png', function () {
alert('size ready: width=' + this.width + '; height=' + this.height);
});
*/
var imgReady = (function () {
var list = [], intervalId = null,
// 用来执行队列
tick = function () {
var i = 0;
for (; i < list.length; i++) {
list[i].end ? list.splice(i--, 1) : list[i]();
};
!list.length && stop();
},
// 停止所有定时器队列
stop = function () {
clearInterval(intervalId);
intervalId = null;
};
return function (url, ready, load, error) {
var onready, width, height, newWidth, newHeight,
img = new Image();
img.src = url;
// 如果图片被缓存,则直接返回缓存数据
if (img.complete) {
ready.call(img);
load && load.call(img);
return;
};
width = img.width;
height = img.height;
// 加载错误后的事件
img.onerror = function () {
error && error.call(img);
onready.end = true;
img = img.onload = img.onerror = null;
};
// 图片尺寸就绪
onready = function () {
newWidth = img.width;
newHeight = img.height;
if (newWidth !== width || newHeight !== height ||
// 如果图片已经在其他地方加载可使用面积检测
newWidth * newHeight > 1024
) {
ready.call(img);
onready.end = true;
};
};
onready();
// 完全加载完毕的事件
img.onload = function () {
// onload在定时器时间差范围内可能比onready快
// 这里进行检查并保证onready优先执行
!onready.end && onready();
load && load.call(img);
// IE gif动画会循环执行onload,置空onload即可
img = img.onload = img.onerror = null;
};
// 加入队列中定期执行
if (!onready.end) {
list.push(onready);
// 无论何时只允许出现一个定时器,减少浏览器性能损耗
if (intervalId === null) intervalId = setInterval(tick, 40);
};
};
})();
调用例子
imgReady('http://www.google.com.hk/intl/zh-CN/images/logo_cn.png', function () {
alert('size ready: width=' + this.width + '; height=' + this.height);
});
这个月公司业务比较多,累死了,好久不写博客了。罪过罪过。花了段时间研究了下javascript的语法树,记录一下。虽然跟平时的写代码没有太多关系,但是了解下js的语法树结构还是有必要的。
在我还在上大学的时候,那时候参加软考,依稀的学过,作为一门语言。执行的时候大致需要经过以下过程:
词法分析=>语法分析=>语义分析=>中间代码生成=>优化代码=>代码生成
当然这是编译型的语言的一般步骤。
但是对于javascript这样的解释性语言,其实只有 前面的词法分析还有语法分析,词法分析就是挨个字符的去扫描源代码,把关键token识别出来。之后通过语法分析,建立上下文关系语法树ast(abstract syntax tree),解释器再根据语法树开始解释执行。所以会比c,c++这类的慢很多。
java是生成了一个jvm的中间代码。而php也是可以生成opcode来加快速度。当然其实最新的javascript解析引擎,比如V8也做了优化,会将部分js代码编译成目标代码。
关于语法树里面的各个节点的规范在这里可以看到:SpiderMonkey
SpiderMonkey是Mozilla项目的一部分,是一个用C语言实现的JavaScript脚本引擎
首先我们看一个简单的例子,有很多库还有工具可以解析出js的语法树。比如esprima,acorn。
esprima有个很赞的在线parse的web页面:http://esprima.org/demo/parse.html#
我们直接看个最简单的列子:
var a = 1,b=2;
/*解析后的语法树
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
},
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "b"
},
"init": {
"type": "Literal",
"value": 2,
"raw": "2"
}
}
],
"kind": "var"
}
]
}
*/
json格式的语法树,每个对象就是一个节点(Node)。可以看到每个节点都有一个type属性用来标识当前节点的类型。
Program类型,是语法树的根节点,只有一个。它具有body属性包括所有的语法节点。然后整个的var a = 1,b=2;是一个变量声明语句(VariableDeclaration)。这个语句里面有一些变量声明符(VariableDeclarator),这边就是a=1和b=2;变量声明符下面有两个属性,分别是id和init。也就是对应的左边的被赋值者和右边的值。Identifier与Literal都可以表示最小的单位,他们不再包含其他节点。
细细查看就会发现其实语法树并不复杂。也是一个包含的关系。下面按照节点的类型把各种节点都解释下:
什么是语句呢,粗俗点,可以加分号的,就代表一个语句结束了。
语句也分很多种语句:ExpressionStatement,IfStatement,BreakStatement等等等,详细的可以去规范里面看。
这种类型的后面都会跟上Statement。
看下面的例子:
/*ExpressionStatement*/
a = b;
/*ExpressionStatement*/
/*IfStatement*/
if(a==b){
....
}
/*IfStatement*/
还是可以很容易看出来的。这其中有个特殊的语句,BlockStatement。说白了就是两个{}括号之间的内容称为一个BlockStatement。所以像if语句,switch语句等等都会有这样的一个子节点。因为他们都会跟花括号嘛。
具体的每个语句有哪些属性节点代表什么都可以在规范里面找到一目了然。
语句下面一般会包含表达式还有一些其他的杂项节点(后面会说)。比如赋值表达式(AssignmentExpression)
a = b
/*
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "AssignmentExpression",
"operator": "=",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Identifier",
"name": "b"
}
}
}
]
}
*/
可以看到表达式语句(ExpressionStatement)下面有一个赋值表达式(AssignmentExpression)。可以说表达式是语句的重要组成部件。
表达式也有很多中,比如ArrayExpression,FunctionExpression等等。具体每个表达式有哪些属性,每个属性可以是哪些类型的子节点,还是建议看下规范。
声明其实也可以不单独拿出来的,其实声明就可以当成语句。作为一种特殊的语句。
声明包括两个FunctionDeclaration,VariableDeclaration。
//FunctionDeclaration
function aa(){
}
//VariableDeclaration
var a = 1; //let const 也算,当然这是es6才支持的
然后这边要特别提到VariableDeclarator,它是VariableDeclaration下面附属的一个子节点,可以当作特殊的表达式吧。
字句包括SwitchCase,CatchClause分别指 try后面跟的 catch语句,还有switch后面的case语句。
switch(a){
/*SwitchCase*/
case 1:
var a = b;
/*SwitchCase*/
}
try{
}
/*CatchClause*/
catch(e)
{
}
/*CatchClause*/
这个其实是es6的内容了。es6支持一种非常酷炫的解构操作(Destructuring)。
可以参考这篇博客:http://odetocode.com/blogs/scott/archive/2014/09/11/features-of-es6-part-6-destructuring.aspx
或者ruanyifeng的书:http://es6.ruanyifeng.com/#docs/destructuring
简单的说就是可以这么做了:
var [a,b]=[1,2];
/*
a 1
b 2
*/
var {a,b}={a:1,b:2}
/*
a 1
b 2
*/
其中 [a,b]和{a,b}就分别代表ArrayPattern 和ObjectPattern。
这个例子是es6的,文章开头给的在线parse的地址不支持的,可以自己用acorn指定版本号跑个代码看看。
解析语法树就是这样的:
var [a,b]=[1,2];
/*
{
"type": "Program",
"body": [{
"type": "VariableDeclaration",
"declarations": [{
"id": {
"type": "ArrayPattern",//ArrayPattern
"elements": [{
"type": "Identifier",
"name": "a"
}, {
"type": "Identifier",
"name": "b"
}]
},
"init": {
"type": "ArrayExpression",
。。。
}
}],
"kind": "var"
}]
}
*/
var {a,b}={a:1,b:2}
/*
{
"type": "Program",
"body": [{
"type": "VariableDeclaration",
"declarations": [{
"type": "VariableDeclarator",
"id": {
"type": "ObjectPattern", //ObjectPattern
"properties": [{
"type": "Property",
"method": false,
"shorthand": true,
"computed": false,
"key": {
"type": "Identifier",
"name": "a"
},
"kind": "init",
"value": {
"type": "Identifier",
"name": "a"
}
}, {
"type": "Property",
"method": false,
"shorthand": true,
"computed": false,
"key": {
"type": "Identifier",
"name": "b"
},
"kind": "init",
"value": {
"type": "Identifier",
"name": "b"
}
}]
},
"init": {
"type": "ObjectExpression",
...
}
}],
"kind": "var"
}]
}
*/
杂项就是不在上面那些范围的东西。比如我们总是看见的最小组成元素Identifier,Literal。
Identifier与Literal都可以表示最小的单位,他们不再包含其他节点。
区别是Identifier是标识符一般我们使用的变量都是标识符。而Literal是文字,可以是正则表达式,字符串(也就是带引号的),null,数字等等。
看下面的对比:
var a = {
"aaa":b,
test:null
}
/*
b是Identifier
test是Identifier
“aaa”是Literal
null是Literal
*/
然后还有一堆的操作符:这些操作符都不能成为一个节点,而是直接作为一个值在语法树里面:
比如:
a = b
/*
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "AssignmentExpression",
"operator": "=",//直接作为一个值,而不是子节点
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Identifier",
"name": "b"
}
}
}
]
}
*/
有下面这些操作符:
一元运算符:"-" | "+" | "!" | "~" | "typeof" | "void" | "delete"
二元操作符: "==" | "!=" | "===" | "!=="
| "<" | "<=" | ">" | ">="
| "<<" | ">>" | ">>>"
| "+" | "-" | "*" | "/" | "%"
| "|" | "^" | "in"
| "instanceof" | ".."
逻辑操作符:"||" | "&&"
赋值操作符:"=" | "+=" | "-=" | "*=" | "/=" | "%="
| "<<=" | ">>=" | ">>>="
| "|=" | "^=" | "&="
自增自减操作符:"++" | "--"
最后还有些特殊的节点,比如ObjectExpression的property,VariableDeclaration的VariableDeclarator。我觉得都是可以归到这边的杂项的。
###结语
语法树的结构还是内容比较多的。不过只要了解节点的大概结构。还是可以很容易看懂语法树的。可以使用上面的在线解析语法树的工具没事试些简单的多对比对比,就可以很清楚了。
有人说知道语法树有什么用呢,其实还是很有用的。比如你要做代码压缩,语法高亮,关键字匹配,作用域判断。等等等都是最好先把代码解析成语法树之后再去各种操作的。我是因为有个需求需要修改js代码的结构,所以也是需要先把代码解析成语法树。当然仅仅解析还不够,还要提供api去遍历修改语法树。最好直接就是类似jQuery那样的api。这个就是另外一件事了,以后有空也记录下。
最近项目中发现个问题,就是javascript的String.fromCharCode对超过两个字节的unicode不能很好的返回对应的字。
测试如下:
String.fromCharCode('0x54c8') //正常返回"哈"
String.fromCharCode('0x20087') //应该返回"𠂇",但是此处返回了""
也就是说 只要超出了两个字节的unicode,js都没有很好的解析。
事实上,不仅仅是fromCharCode,javascript里面大部分字符处理函数都无法很好的处理超过两个字节的字符的问题。
##汉字的unicode区间
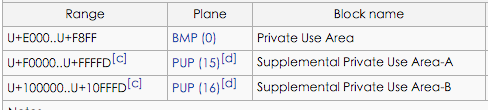
我们一直都认为汉字是双字节的,实际上根据unicode5.0规范。汉字的范围如下:
| Block名称 | 开始码位 | 结束码位 | 字符数 |
|---|---|---|---|
| CJK统一汉字 | 4E00 | 9FBB | 20924 |
| CJK统一汉字扩充A | 3400 | 4DB5 | 6582 |
| CJK统一汉字扩充B | 20000 | 2A6D6 | 42711 |
| CJK兼容汉字 | F900 | FA2D | 302 |
| CJK兼容汉字 | FA30 | FA6A | 59 |
| CJK兼容汉字 | FA70 | FAD9 | 106 |
| CJK兼容汉字补充 | 2F800 | 2FA1D | 542 |
可以看到 其中 CJK统一汉字扩充B的范围就不是双字节的。上面提到的"𠂇"就在这个范围里。当然大部分的汉字都是双字节的。
CJK统一汉字扩充B的汉字我们可以在这看到个大概:
http://www.chinesecj.com/code/ext-b.php
更加完整的unicode范围,可以参考这个文章,虽然年代有些久远。
##javascript的编码
javascript之所以会有这样的问题,是因为javascript使用了一种叫做UCS-2的编码方式。UCS-2编码只能处理两个字节的字符。而对于0x20087这种不止两个字节的,他会拆成两个双子节的字符。
对于上面的0x20087它会拆成两个双字节 0xd840 ,0xdc87。然后分别解析发现都是"",就造成了上面的现象。具体的转换公式为:
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
更加具体的javascript的编码历史,可以参考阮一峰的文章。
##es6的解决方案
在es6的规范里,已经针对这种双字节的问题做了处理,提供了几个方法:
String.fromCodePoint():从Unicode码点返回对应字符
String.prototype.codePointAt():从字符返回对应的码点
于是我们可以这样:
String.fromCodePoint('0x20087') //返回'𠂇'
('𠂇'.codePointAt(0)).toString(16) //返回20087
不过很显然支持性很一般。
mdn有相关的兼容处理,具体方法就是
fromCodePoint的实现:
if (!String.fromCodePoint) {
(function() {
var defineProperty = (function() {
// IE 8 only supports `Object.defineProperty` on DOM elements
try {
var object = {};
var $defineProperty = Object.defineProperty;
var result = $defineProperty(object, object, object) && $defineProperty;
} catch(error) {}
return result;
}());
var stringFromCharCode = String.fromCharCode;
var floor = Math.floor;
var fromCodePoint = function() {
var MAX_SIZE = 0x4000;
var codeUnits = [];
var highSurrogate;
var lowSurrogate;
var index = -1;
var length = arguments.length;
if (!length) {
return '';
}
var result = '';
while (++index < length) {
var codePoint = Number(arguments[index]);
if (
!isFinite(codePoint) || // `NaN`, `+Infinity`, or `-Infinity`
codePoint < 0 || // not a valid Unicode code point
codePoint > 0x10FFFF || // not a valid Unicode code point
floor(codePoint) != codePoint // not an integer
) {
throw RangeError('Invalid code point: ' + codePoint);
}
if (codePoint <= 0xFFFF) { // BMP code point
codeUnits.push(codePoint);
} else { // Astral code point; split in surrogate halves
// http://mathiasbynens.be/notes/javascript-encoding#surrogate-formulae
codePoint -= 0x10000;
highSurrogate = (codePoint >> 10) + 0xD800;
lowSurrogate = (codePoint % 0x400) + 0xDC00;
codeUnits.push(highSurrogate, lowSurrogate);
}
if (index + 1 == length || codeUnits.length > MAX_SIZE) {
result += stringFromCharCode.apply(null, codeUnits);
codeUnits.length = 0;
}
}
return result;
};
if (defineProperty) {
defineProperty(String, 'fromCodePoint', {
'value': fromCodePoint,
'configurable': true,
'writable': true
});
} else {
String.fromCodePoint = fromCodePoint;
}
}());
}
codePointAt的实现:
if (!String.prototype.codePointAt) {
(function() {
'use strict'; // needed to support `apply`/`call` with `undefined`/`null`
var codePointAt = function(position) {
if (this == null) {
throw TypeError();
}
var string = String(this);
var size = string.length;
// `ToInteger`
var index = position ? Number(position) : 0;
if (index != index) { // better `isNaN`
index = 0;
}
// Account for out-of-bounds indices:
if (index < 0 || index >= size) {
return undefined;
}
// Get the first code unit
var first = string.charCodeAt(index);
var second;
if ( // check if it’s the start of a surrogate pair
first >= 0xD800 && first <= 0xDBFF && // high surrogate
size > index + 1 // there is a next code unit
) {
second = string.charCodeAt(index + 1);
if (second >= 0xDC00 && second <= 0xDFFF) { // low surrogate
// http://mathiasbynens.be/notes/javascript-encoding#surrogate-formulae
return (first - 0xD800) * 0x400 + second - 0xDC00 + 0x10000;
}
}
return first;
};
if (Object.defineProperty) {
Object.defineProperty(String.prototype, 'codePointAt', {
'value': codePointAt,
'configurable': true,
'writable': true
});
} else {
String.prototype.codePointAt = codePointAt;
}
}());
}
有了上面的兼容处理,我们就可以很好的处理unicode与多字节字符之间的转换了。
##结语
作为10天设计出来的语言,javascript总是有这样那样的坑,实在是让人很无奈。总是要让人花一大堆时间擦屁股。
koa基于co实现,co又是使用了es6的generator特性,所以,没错这个特性支持很一般。
有下面几种办法体验generator:
##thunk函数
thunk函数是一个偏函数,执行它会得到一个新的只带一个回调参数的函数。下面我们对node的stat举个例子(其实是co官方的例子):
var fs = require('fs');
function size(file) {
return function(fn){
fs.stat(file, function(err, stat){
if (err) return fn(err);
fn(null, stat.size);
});
}
}
var getIndexSize = size("./index.js");
getIndexSize(function(size){
console.log(size);
})
size函数就是个典型的thunk函数了,执行size("./index.js")我们就会得到一个只有回调的新函数。co的异步解决方案需要建立在thunk的基础上。
使用co时,yield的经常是thunk函数,thunk函数可以使用一些方法转换,也有一些库支持,可以了解下thunkify 或者thunkify-wrap。
##最简单的co实现
我们先看下有了co我们会怎么编程:
co(function *(){
var a = yield size('.gitignore');
var b = yield size('package.json');
console.log(a);
console.log(b);
return [a,b];
})(function (err,args){
console.log("callback===args=======");
console.log(args);
})
//下面是结果,实际的数据根据你的文件会有不同
/*
12
1215
callback===args=======
[ 12, 1215 ]
*/
你会发现我们可以直接使用yield来直接获取 异步函数的值了。如果忽略yield关键字,完全就是同步编程了。再也不用考虑那一大堆回调了。co本质上也是一个thunk函数,接收一个generatorfunction作为参数,生成一个实际操作函数。这个实际操作函数可以接收一个callback来传入最后return的值。
下面我们就来实现最简单的co函数:
function co(fn) {
return function(done) {
var ctx = this;
var gen = fn.call(ctx);
var it = null;
function _next(err, res) {
it = gen.next(res);
if (it.done) {
done.call(ctx, err, it.value);
} else {
it.value(_next);
}
}
_next();
}
}
co本质上也是thunk函数,传入一个generatorFunction,它会自动帮你不停的调用对应generator的next函数,如果done为true代表generatorFunction函数执行完毕,就会把值传给回调函数。逻辑比较简单就不详细解释了。这边要注意_next函数的实现,注意11行,_next实际上会成为前面yield后面的函数的回调函数。
比如前面我们说的size('package.json')会返回一个带回调的函数a。于是调用就是yield a。这边11行it.value就会是这个a,会把_next作为回调执行a函数。
所以这边需要有个约定就是thunk函数的回调都要是function(err,res){}的格式,实际上这也是node实际的规范。
##进阶-yield后面跟array或者对象
上面我们实现了一个最简单的co函数,已经可以支持最基本的同步调用了,但是yield后面只能跟thunk函数的执行结果。我们这边还需要支持其他类型的yield值,比如一个数组或者对象。
我们要对co做些改进:
function co(fn) {
return function(done) {
var ctx = this;
var gen = fn.call(ctx);
var it = null;
function _next(err, res) {
it = gen.next(res);
if (it.done) {
done.call(ctx, err, it.value);
} else {
//new line
it.value = toThunk(it.value,ctx);
it.value(_next);
}
}
_next();
}
}
35行,我们增加了一行it.value = toThunk(it.value,ctx);用于对yield的值进行处理。
我们看下toThunk的实现:
function isObject(obj){
return obj && Object == obj.constructor;
}
function isArray(obj){
return Array.isArray(obj);
}
function toThunk(obj,ctx){
if (isObject(obj) || isArray(obj)) {
return objectToThunk.call(ctx, obj);
}
return obj;
}
toThunk主要就是用来判断yield返回的值的类型,如果是对象或者数组就会调用objectToThunk对返回值做处理。否则的话就会正常的返回。
下面我们重点看看objectToThunk的实现方式。
function objectToThunk(obj){
var ctx = this;
return function(done){
var keys = Object.keys(obj);
var results = new obj.constructor();
var length = keys.length;
var _run = function(fn,key){
fn.call(ctx,function(err,res){
results[key] = res;
--length || done(null, results);
})
}
foreach(var i in keys){
_run(Object[keys[i]],keys[i]);
}
}
}
其实这种类型的函数基本都是一个思路。都是将数组里面所有的thunk函数全部拿出来执行一次,通过记录下数组的长度,各个函数执行一次就对公用的长度变量减一,不需要关心各个函数的执行顺序,只要当其中一个函数发现变量变为0时,代表其他函数都执行好了,我是最后一个,于是就可以调用回调函数done了。
objectToThunk就是这种思路。
首先我们先解释下面这两句的意思:
var keys = Object.keys(obj);
var results = new obj.constructor();
这么写是为了通用性,Object.keys接收一个数组或者对象,返回key值。eg:
Object.keys([1,2,3,4]) //[ '0', '1', '2', '3' ]
Object.keys({"one":1,"two":2,"three":3}) //[ 'one', 'two', 'three' ]
然后new obj.constructor()这句,会根据obj的类型生成一个相关的空数组或者空对象。便于下面的赋值。这也是动态语言的优势。
之后我们定义了length变量,初始化为数组或者对象的属性长度。
然后就如上面的那个思路,挨个的使用_run执行每个函数,根据length来判断是否所有的函数都执行完毕了,执行完毕就调用回调函数done。
可以看到objectToThunk本质上也是一个thunk函数。这样 我们通过这层转换,使得数组里面的函数可以并行执行。
通过这层封装我们可以这么调用了:
co(function *(){
var a = size('.gitignore');
var b = size('package.json');
var r = yield [a,b];
return r;
})(function (err,args){
console.log("callback===args=======");
console.log(args);
})
/*
callback===args=======
[ 12, 1215 ]
*/
yield后面跟的数组,两个异步任务,将会并行执行,不在乎谁先结束,而是等最慢的一个执行完成后会得到返回值赋值给r。
有的时候,可能会发生数组里面还是数组的情况,我们需要深度遍历执行。所以我们需要对上面的_run函数做下改造:
var _run = function(fn,key){
//new line
fn = toThunk(fn);
fn.call(ctx,function(err,res){
results[key] = res;
--length || done(null, results);
})
}
只要加一句fn = toThunk(fn);就成功实现了深度遍历了。不得不说TJ的设计真是太强大。
这样 我们就可以这么调用了:
co(function *(){
var a = [size('.gitignore'), size('index.js')];
var b = [size('.gitignore'), size('index.js')];
var c = [size('.gitignore'), size('index.js')];
var d = yield [a, b, c];
console.log(d);
})()
##进阶-yield后面跟promise,或者generator或generatorFunction
co的强大之处在于,yield真的几乎什么都可以跟了。promise是我们经常使用的解决异步的东西。我们现在如果想要支持yield后面跟promise对象,只需要做点小改动就行。
首先在toThunk里面加点东西
function isPromise(obj) {
return obj && 'function' == typeof obj.then;
}
function toThunk(obj,ctx){
if (isObject(obj) || isArray(obj)) {
return objectToThunk.call(ctx, obj);
}
if (isPromise(obj)) {
return promiseToThunk.call(ctx, obj);
}
return obj;
}
是的,只需要加一个针对promise的判断就行了。然后通过promiseToThunk来转换promise。
promiseToThunk的实现也比较容易:
function promiseToThunk(promise){
return function(done){
promise.then(function(err,res){
done(err,res);
},done)
}
}
还是通过转换,转成一个只有一个回调参数的函数。
那我们怎么去支持yield后面跟generator呢?
如果yield后面跟generator,我们期待的理想的结果是,继续执行这个generator里面的断点。其实有点类似es6规范里面yield的delegating yiled,不清楚的可以去看上一篇博文。co相当于做了这么个扩展。
首先我们继续在toThunk里面加一个判断
function isGenerator(obj) {
return obj && 'function' == typeof obj.next && 'function' == typeof obj.throw;
}
function toThunk(obj,ctx){
if (isGenerator(obj)) {
return co(obj);
}
if (isObject(obj) || isArray(obj)) {
return objectToThunk.call(ctx, obj);
}
if (isPromise(obj)) {
return promiseToThunk.call(ctx, obj);
}
return obj;
}
如果是generator的话 我们就直接调用co去处理。有木有觉得奇怪之前明明说co只接受generatorFunction来着。
别急,让我们对co函数做点小改动:
function co(fn) {
return function(done) {
var ctx = this;
//old line
//var gen = fn.call(ctx);
//new line
var gen = isGenerator(fn) ? fn : fn.call(ctx);
var it = null;
function _next(err, res) {
it = gen.next(res);
if (it.done) {
done.call(ctx, err, it.value);
} else {
//new line
it.value = toThunk(it.value,ctx);
it.value(_next);
}
}
_next();
}
}
仅仅一个简单的判断,于是世界都清净了,突然就可以yield后面跟generator对象了,就支持深度调用了。虽然有点绕,不过代码真的是太精辟了。
同样的如果我们要支持yield后面跟generatorFunction的话,只需要在toThunk里面再加一个判断:
function isGeneratorFunction(obj) {
return obj && obj.constructor && 'GeneratorFunction' == obj.constructor.name;
}
function toThunk(obj,ctx){
if (isGeneratorFunction(obj)) {
return co(obj.call(ctx));
}
if (isGenerator(obj)) {
return co(obj);
}
if (isObject(obj) || isArray(obj)) {
return objectToThunk.call(ctx, obj);
}
if (isPromise(obj)) {
return promiseToThunk.call(ctx, obj);
}
return obj;
}
如果是generatorFunction,我们就先执行得到generator再调用co处理。一切就是这么简单。
完整的代码如下:
var fs = require("fs")
function size(file) {
return function(fn){
fs.stat(file, function(err, stat){
if (err) return fn(err);
fn(null, stat.size);
});
}
}
function co(fn) {
return function(done) {
var ctx = this;
//old line
//var gen = fn.call(ctx);
//new line
var gen = isGenerator(fn) ? fn : fn.call(ctx);
var it = null;
function _next(err, res) {
it = gen.next(res);
if (it.done) {
done.call(ctx, err, it.value);
} else {
//new line
it.value = toThunk(it.value,ctx);
it.value(_next);
}
}
_next();
}
}
function isGeneratorFunction(obj) {
return obj && obj.constructor && 'GeneratorFunction' == obj.constructor.name;
}
function isGenerator(obj) {
return obj && 'function' == typeof obj.next && 'function' == typeof obj.throw;
}
function isPromise(obj) {
return obj && 'function' == typeof obj.then;
}
function isObject(obj){
return obj && Object == obj.constructor;
}
function isArray(obj){
return Array.isArray(obj);
}
function promiseToThunk(promise){
return function(done){
promise.then(function(err,res){
done(err,res);
},done)
}
}
function objectToThunk(obj){
var ctx = this;
return function(done){
var keys = Object.keys(obj);
var results = new obj.constructor();
var length = keys.length;
var _run = function(fn,key){
fn = toThunk(fn);
fn.call(ctx,function(err,res){
results[key] = res;
--length || done(null, results);
})
}
for(var i in keys){
_run(obj[keys[i]],keys[i]);
}
}
}
function toThunk(obj,ctx){
if (isGeneratorFunction(obj)) {
return co(obj.call(ctx));
}
if (isGenerator(obj)) {
return co(obj);
}
if (isObject(obj) || isArray(obj)) {
return objectToThunk.call(ctx, obj);
}
if (isPromise(obj)) {
return promiseToThunk.call(ctx, obj);
}
return obj;
}
co(function *(){
var a = size('.gitignore');
var b = size('package.json');
var r = yield [a,b];
return r;
})(function (err,args){
console.log("callback===args=======");
console.log(args);
})
这份代码,是去除了co里面很多判断,错误处理之后的代码。用来理解原理更加简单。
##结语
什么都不说了,co这样的库。源码不看真的是损失。是在不得不佩服TJ大神的脑子。据说以前还是个搞设计的。有了co,再也不用担心异步回调了。妈妈再也不用担心“恶魔金字塔了”so happy。。。。
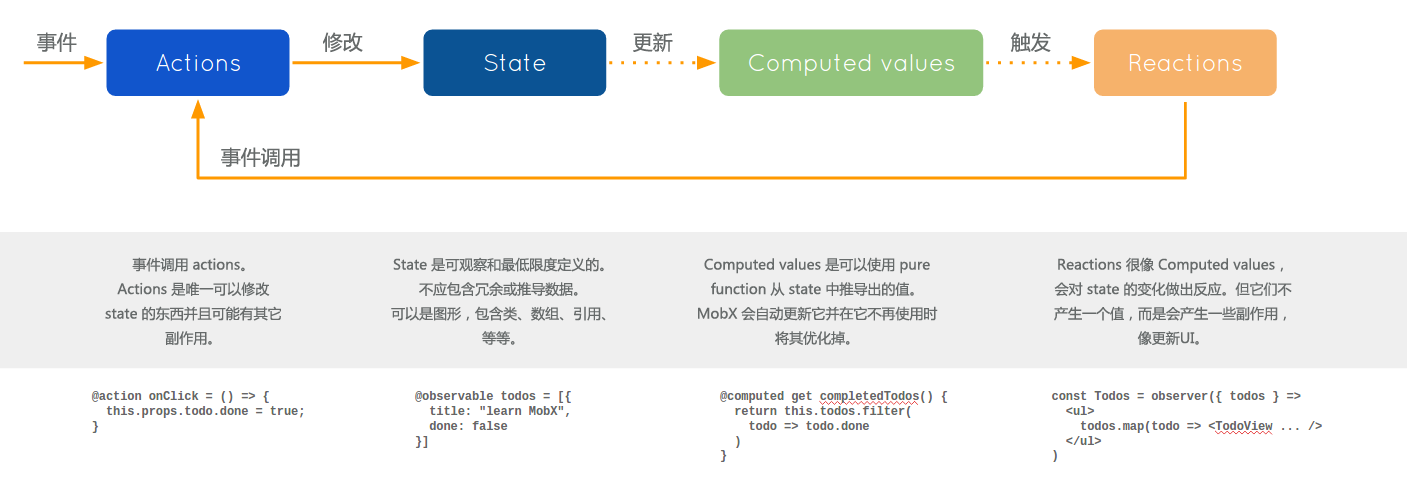
mobx是简单、可扩展的状态管理库。
mobx的核心是TFRP,透明的函数响应式编程(transparently applying functional reactive programming)
mobx认为任何源自应用状态的东西都应该自动地获得。
我们通过一个简单的计数器看mobx的实例。这边的例子不包含与react的结合。
import { observable, autorun } from 'mobx';
// let { observable, autorun } = mobx;
// 注入观察钩子
let counter = observable({number:0});
// 运行一次,建立依赖
autorun(() => {
console.log('number:' + counter.number)
});
setTimeout(function(){
counter.number ++
},100)
// 结果为:
// number:0
// number:1
在线编辑:https://jsfiddle.net/mweststrate/wv3yopo0/
两个概念:
其实粗略的可以想到原理:
mobx一个很大的特色是可以使用es7的注解增强可读性。我们先回顾下javascript的注解使用方式。虽然还没有完全定稿,不过可以使用babel转义使用。
参考: https://aotu.io/notes/2016/10/24/decorator/index.html
class Cat {
say() {
console.log("meow ~");
}
}
等价于:
function Cat() {}
Object.defineProperty(Cat.prototype, "say", {
value: function() { console.log("meow ~"); },
enumerable: false,
configurable: true,
writable: true
});
function isAnimal(target) {
target.isAnimal = true;
return target;
}
@isAnimal
class Cat {
...
}
console.log(Cat.isAnimal); // true
等价于:
Cat = isAnimal(function Cat() { ... });
function readonly(target, name, descriptor) {
discriptor.writable = false;
return discriptor;
}
class Cat {
@readonly
say() {
console.log("meow ~");
}
}
var kitty = new Cat();
kitty.say = function() {
console.log("woof !");
}
kitty.say() // meow ~
等价于:
function Cat() { ... }
let descriptor = {
value: function() {
console.log("meow ~");
},
enumerable: false,
configurable: true,
writable: true
};
descriptor = readonly(Cat.prototype, "say", descriptor) || descriptor;
Object.defineProperty(Cat.prototype, "say", descriptor);
所以属性注解拿到的是 prototype,name,descriptor
于是我们看下,注解写法的计数器例子
import { observable, autorun,computed } from 'mobx';
class Counter {
@observable number = 0;
@computed get msg() {
return 'number:' + this.number
}
}
var store = new Counter()
// 运行一次,建立依赖
autorun(() => {
console.log(store.msg)
});
// 做出改动
setTimeout(function(){
store.number ++
},100)
多了几个概念:
@computed 的执行,也会进行依赖收集。import { observer } from 'react-mobx';
import React, { Component } from 'react';
import { observable, autorun,computed } from 'mobx';
class Counter {
@observable number = 0;
@computed get msg() {
return 'number:' + this.number
}
}
var store = new Counter()
@observer
class App extends Component {
render() {
return (<div>
{ store.msg } <br />
<button onClick={this.handleInc}> + </button>
<button onClick={this.handleDec}> - </button>
</div>);
}
handleInc() {
store.number ++ ;
}
handleDec() {
store.number -- ;
}
}
ReactDOM.render(<App />, document.getElementById('root'));
@observer是一个注解,本质上是用 mobx.autorun 包装了组件的 render 函数以确保任何组件渲染中使用的数据变化时都可以强制刷新组件
mobx之前一个比较大的问题是可以随意修改store,后来引入了 action解决这个问题。
action做了这几个事情:
例子改写:
import { observer } from 'react-mobx';
import React, { Component } from 'react';
import { observable, autorun,computed } from 'mobx';
class Counter {
@observable number = 0;
@computed get msg() {
return 'number:' + this.number
}
@action increment: () => {
this.number ++
}
@action decrement: () => {
this.number --
}
}
var store = new Counter()
@observer
class App extends Component {
render() {
return (<div>
{ store.msg } <br />
<button onClick={this.handleInc}> + </button>
<button onClick={this.handleDec}> - </button>
</div>);
}
handleInc() {
store.increment();
}
handleDec() {
store.decrement();
}
}
ReactDOM.render(<App />, document.getElementById('root'));
这样就比较安全了。
至此,mobx的整个流程就出来了:
mobx的哲学:
类似redux这样的粗粒度的订阅很容易出现超额订阅的问题:
view() {
if (count === 0) {
return a;
} else {
return b;
}
}
基于 redux 的方案,我们必须同时监听 count, a 和 b 。在 counte === 0 的时候,b 如果修改了,也会触发 view 。而这个时候的 b 其实是无意义的。
view() {
todos[0].title
}
基于 redux,我们通常会订阅 todos,这样 todos 的新增、删除都会触发 view 。其实这里真正需要监听的是 todos 第一个元素的 title 属性是否有修改。
与之对应的mobx的运行时依赖,可以做到最小力度。
import { observable, autorun } from 'mobx';
const counter = observable(0);
const foo = observable(0);
const bar = observable(0);
autorun(() => {
if (counter.get() === 0) {
console.log('foo', foo.get());
} else {
console.log('bar', bar.get());
}
});
bar.set(10); // 不触发 autorun
counter.set(1); // 触发 autorun
foo.set(100); // 不触发 autorun
bar.set(100); // 触发 autorun
执行结果:
foo 0
bar 10
bar 100
vue其实跟mobx做的事情类似。
Redux 与 MobX 的不同主要集中于以下几点:
mobx的工程例子:
https://github.com/gothinkster/realworld
mobx 不需要自己管理订阅,可以像vue那样直接帮你解析出依赖,数据流修改起来很自然。而redux的数据流更清晰,一个完整的数据流闭环规范,小项目使用mobx感觉会像vue那样很简单快速,但是大项目还是像redux那样更清晰。目前mobx的社区也没有redux活跃,缺少一些最佳实践。目前来看redux还是react下最合适的选择。
相关引用:
koa基于co实现,co又是使用了es6的generator特性,所以,没错这个特性支持很一般。
有下面几种办法体验generator:
##koa简介与使用
koa是基于generator与co之上的新一代的中间件框架。虽然受限于generator的实现程度。。但是它的优势却不容小觑。
使用方式:
var koa = require('koa');
var app = koa();
//添加中间件1
app.use(function *(next){
var start = new Date;
console.log("start=======1111");
yield next;
console.log("end=======1111");
var ms = new Date - start;
console.log('%s %s - %s', this.method, this.url, ms);
});
//添加中间件2
app.use(function *(){
console.log("start=======2222");
this.body = 'Hello World';
console.log("end=======2222");
});
app.listen(3000);
/*
start=======1111
start=======2222
end=======2222
end=======1111
GET / - 10
start=======1111
start=======2222
end=======2222
end=======1111
GET /favicon.ico - 5
*/
这就是官方的例子,运行后访问localhost:3000,控制台会打印这些东西。
访问首页会有两个请求,一个是网站小图标favicon.ico,一个是首页。我们只需要看第一个请求。
首先我们使用var app = koa();获得一个koa对象。
之后我们可以使用app.use()来添加中间件。use函数接受一个generatorFunction。这个generatorFunction就是一个中间件。generatorFunction有一个参数next。这个next是下一个中间件generatorFunction的对应generator对象。
比如上面的代码第7行next就是下面添加第二个中间件的generatorFunction的对应generator。
yield next;代表调用下一个中间件的代码。
对于上面的例子。
一个请求会先执行第一个中间件的:
var start = new Date;
console.log("start=======1111");
遇到yield next;的时候会转过去执行后来的中间件的代码也就是:
console.log("start=======2222");
this.body = 'Hello World';
console.log("end=======2222");
等下一级中间件执行完毕后才会继续执行接下来的:
console.log("end=======1111");
var ms = new Date - start;
console.log('%s %s - %s', this.method, this.url, ms);
说白了yield next;的作用就是我们之前提到过的delegating yield的功能,只不过这边是通过co支持的,而不是使用的原生的。
通过这种中间件机制,我们可以对一个请求的之前与之后做出处理。这种**其实在java里面已经很出名了。java框架Spring的 Filter过滤器就是这个概念。这种编程方式叫做面向切面编程。
有了这种next的机制 我们只需要关心写各种中间件,就可以很容易的把应用搭建起来了。
##一步一步实现koa
###简单例子
首先我们写一个最简单的hello word网页。
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');
官方标准例子,相当简单。不过毫无扩展性。
###简单改良
我们进行下改良:
var http = require('http');
function Application (){
this.context = {};
this.context['res'] = null;
}
var app = Application.prototype;
function respond(){
this.res.writeHead(200, {'Content-Type': 'text/plain'});
this.res.end(this.body);
}
app.use = function(fn){
this.do = fn;
}
app.callback = function(){
var fn = this.do;
var that = this;
return function(req,res){
that.context.res = res;
fn.call(that.context);
respond.call(that.context);
}
}
app.listen = function(){
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
//调用
var appObj = new Application();
appObj.use(function(){
this.body = "hello world!";
})
appObj.listen(3000);
咋看一下,这么多代码,感觉好复杂,但是应该注意到的是我们实际使用时只要写:
function(){
this.body = "hello world!";
}
我们称之为中间件。
解释下上面这段代码,appObj.listen的时候调用http.createServer创建一个server实例。通过this.callback()得到一个标准回调函数。callback是一个高阶函数,返回一个新的执行函数。在执行函数里,我们首先将http请求的res对象保存下来。之后调用存储的this.do函数。this.do函数就是我们之前使用appObj.use添加的,也就是我们的中间件函数。最后调用respond。在respond里我们完成通用的处理代码。
###使用中间件队列
当然 我们这个还不完善,作为中间件应该可以添加多个,并且顺序执行。
我们需要一种机制,实现上面说的面向切面编程的效果。我们做一些改进:
var http = require('http');
function Application (){
this.context = {};
this.context['res'] = null;
this.middleware = [];
}
var app = Application.prototype;
var respond = function(next){
console.log("start app....");
next();
this.res.writeHead(200, {'Content-Type': 'text/plain'});
this.res.end(this.body);
}
var compose = function(){
var that = this;
var handlelist = Array.prototype.slice.call(arguments,0);
var _next = function(){
if((handle = handlelist.shift()) != undefined){
handle.call(that.context,_next);
}
}
return function(){
_next();
}
}
app.use = function(fn){
//this.do = fn;
this.middleware.push(fn)
}
app.callback = function(){
var mds = [respond].concat(this.middleware);
var fn = compose.apply(this,mds);
var that = this;
return function(req,res){
that.context.res = res;
fn.call(that.context);
//respond.call(that.context);
}
}
app.listen = function(){
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
//调用
var appObj = new Application();
appObj.use(function(next){
this.body = "hello world!";
next();
})
appObj.use(function(){
this.body += "by me!!";
})
appObj.listen(3000);
这样实现了可以使用use添加多个中间件的功能,并且respond我们也作为一个中间件放在了最前。为什么放在最前面在下面再分析。
use的时候我们将所有的中间件存起来。在app.callback里面通过compose对所有的中间件进行一次“编译”,返回一个启动函数fn。
我们看下compose的实现:
function compose(handlelist){
var that = this;
var handle = null;
var _next = function(){
if((handle = handlelist.shift()) != undefined){
handle.call(that.context,_next);
}
}
return function(){
_next();
}
}
compose也是一个高阶函数,它内部定义了一个_next函数,用于不停的从队列中拿中间件函数执行,并且传入_next的引用,这样每个中间件函数都可以在自己内部调用下一个中间件。compose会返回一个启动函数,就是初始调用_next()。这样一个由中间件组成的,一层层的操作就开始了。注意这边的调用顺序,一个中间件的代码,"next"关键字之前的会先执行,之后会跳入下一个中间件执行"next"关键字之前的代码,一直跳下去,一直到最后一个,开始返回执行"next"关键字下面的代码,然后又一层层的传递回来。实现了一种先进入各种操作,之后再出来再各种操作,相当于每个中间件都有个前置代码区和后置代码区。这就是面向切面编程的概念。
执行过程如下图:
所以我们才把respond放在了中间件最前面。
这其实是之前connect的大致实现方式,通过这种尾触发的机制,实现这种顺序流机制。
###使用generator和co改进
我们的主要目的是探讨koa的实现。我们需要做的是使用generator和co对上面做些改进。
我们希望这样,每个中间件都是一个generatorFunction。有了co的支持后,在中间件里面我们可以直接使用yield,操作各种异步任务,可以直接yield下一个中间件generatorFunction的generator对象。实现顺序流机制。
如果实现了,我们以respond为例改造:
function *respond(next){
console.log("start app....");
yield next;
this.res.writeHead(200, {'Content-Type': 'text/plain'});
this.res.end(this.context.body);
}
respond本身变为一个generatorFunction,我们只需要通过yield next去调用下一个中间件。在这个中间件里面,我们可以随意使用co提供的异步操作机制。
要实现这个,我们只需要对compose做一个改造:
require "co"
function compose(handlelist,ctx) {
return co(function * () {
var prev = null;
var i = handlelist.length;
while (i--) {
prev = handlelist[i].call(ctx, prev);
}
yield prev;
})
}
compose仍然用来返回一个启动函数。
我们首先对中间件队列从后遍历,挨个的获取对应的generator对象,同时将后面的generator对象传递给前面中间件的generatorFunction。这样就形成了一个从前往后的调用链,每个中间件都保存着下一个中间件的generator的引用。
最后我们使用co生成一个启动函数。
co(function *(){
yield gen;
})
通过前面的co的源码分析,我们知道co接收一个generatorFunction,生成一个回调函数,执行这个回调函数就会开始执行里面的yield。这个回调函数显然就是个启动函数。当co引擎遇到yield gen;的时候,又会开始执行这个gen的代码,一个个的执行下去。实现切面编程。
在koa的源码里,其实不是
yield gen;而是yield *gen;其实功能是一样的,差别在于前者是co引擎支持的,后者是es6的generator规范原生支持的。原生的在某些情况下性能更好,koa官方是不推荐在中间件里面直接使用yield *next;的,直接使用yield next;,co会为你完成一切。
全部代码如下:
var co = require('co');
var http = require('http');
function Application() {
this.context = {};
this.context['res'] = null;
this.middleware = [];
}
var app = Application.prototype;
function compose(handlelist,ctx) {
return co(function * () {
var prev = null;
var i = handlelist.length;
while (i--) {
prev = handlelist[i].call(ctx, prev);
}
yield prev;
})
}
function *respond(next) {
console.log("start app....");
yield next;
this.res.writeHead(200, {
'Content-Type': 'text/plain'
});
this.res.end(this.body);
}
app.use = function(fn) {
//this.do = fn;
this.middleware.push(fn)
}
app.callback = function() {
var fn = compose.call(this, [respond].concat(this.middleware),this.context);
var that = this;
return function(req, res) {
that.context.res = res;
fn.call(that.context);
//respond.call(that.context);
}
}
app.listen = function() {
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
//调用
var appObj = new Application();
appObj.use(function *(next) {
this.body = "hello world!";
yield next;
})
appObj.use(function *(next) {
this.body += "by me!!";
})
appObj.listen(3000);
##结语
整个koa分析系列到这就完了,koa必将成为未来流行的框架之一,目前我们部门已经尝试着在一些地方使用了。node还不成熟,koa更是一种前瞻性的东西,但是总要有人去尝试才行。技术日新月异,前端再也不是只会切切页面就行了。
koa基于co实现,co又是使用了es6的generator特性,所以,没错这个特性支持很一般。
有下面几种办法体验generator:
##核心代码分析
之前写过一篇co的源码分析文章,但是不久之后co就发生了重大变化,就是完全抛弃了thunk风格的函数。全部转用promise。于是,找了个时间我再次看了下源码。简单记录下。
本文假设你已经熟悉了es6里面promise的基本用法。如果不是特别清楚的可以参考下面几篇文章:
co4.0全部采用promise来实现。下面我们分析下代码。
首先co的用法发生了改变:
co(function* () {
var result = yield Promise.resolve(true);
return result;
}).then(function (value) {
console.log(value);
}, function (err) {
console.error(err.stack);
});可以看到co还是接受了一个generatorFunction作为参数,实际上参数如果是一个generator对象也是可以的。如果是generatorFunction,co内部会帮你执行生成对应的generator对象。
不同的是co不再返回一个thunk函数,而是返回了一个promise对象。
yield后面推荐的也是promise对象,而不是thunk函数了。
我们看下实现:
function co(gen) {
var ctx = this;
//如果是generatorFunction,就执行 获得对应的generator对象
if (typeof gen === 'function') gen = gen.call(this);
//返回一个promise
return new Promise(function(resolve, reject) {
//初始化入口函数,第一次调用
onFulfilled();
//成功状态下的回调
function onFulfilled(res) {
var ret;
try {
//拿到第一个yield返回的对象值ret
ret = gen.next(res);
} catch (e) {
//出错直接调用reject把promise置为失败状态
return reject(e);
}
//开启调用链
next(ret);
}
function onRejected(err) {
var ret;
try {
//抛出错误,这边使用generator对象throw。这个的好处是可以在co的generatorFunction里面使用try捕获到这个异常。
ret = gen.throw(err);
} catch (e) {
return reject(e);
}
next(ret);
}
function next(ret) {
//如果执行完成,直接调用resolve把promise置为成功状态
if (ret.done) return resolve(ret.value);
//把yield的值转换成promise
//支持 promise,generator,generatorFunction,array,object
//toPromise的实现可以先不管,只要知道是转换成promise就行了
var value = toPromise.call(ctx, ret.value);
//成功转换就可以直接给新的promise添加onFulfilled, onRejected。当新的promise状态变成结束态(成功或失败)。就会调用对应的回调。整个next链路就执行下去了。
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
//否则说明有错误,调用onRejected给出错误提示
return onRejected(new TypeError('You may only yield a function, promise, generator, array, or object, '
+ 'but the following object was passed: "' + String(ret.value) + '"'));
}
});
}
function isPromise(obj) {
return 'function' == typeof obj.then;
}核心代码主要是onFulfilled与next的实现。
我们先不考虑错误处理看下执行流程。也先不看toPromise的实现。假定我们只是yield一个promise对象。
例子:
co(function* () {
var a = yield Promise.resolve('传给a的值');
var b = yield Promise.resolve('传给b的值');
return b;
}).then(function (value) {
console.log(value);
}, function (err) {
console.error(err.stack);
});
假设:
Promise.resolve('传给a的值');生成的叫做promise对象A。Promise.resolve('传给b的值');生成的叫做promise对象B。onFulfilled作为入口函数。
yield Promise.resolve('传给a的值');然后停住。拿到了返回值`{value:'promise对象A',done:false}。yield Promise.resolve('传给b的值');停住。不同的是这次调用onFulfilled会传递res的值。通过gen.next(res)会把res也就是resolve的值赋值给a。然后继续这个过程,一直到最后return的时候。
//co包裹的generatorFunction return后 ret.done为true。这个时候就可以resole `Co生成的promise对象`了。
if (ret.done) return resolve(ret.value);这样整个调用链就执行下去了。可以看到主要是使用promise的then方法添加onfullied操作函数,来实现自动调用gen.next()。
##co的错误处理
co的错误处理主要使用onRejected实现,基本逻辑跟onFulfilled差不多,这边主要说一下gen.throw(err);的原理。
generator对象的一个特性是可以在generatorFunction外面抛出异常,在generatorFunction里面捕获到这个异常。
function *test(){
try{
yield 'a'
yield 'b'
}catch(e){
console.log('内部捕获:')
console.log(e)
}
}
var g = test()
g.next()
g.throw('外面报错消息')
/*结果
*内部捕获:
*外面报错消息
*
*/当我们运行gen.next()的时候,会运行到yield 'a'这一句。这一句正好在内部的try范围内,因此g.throw('外面报错消息')这个抛出的错误会被捕获到。
如果我们不调用gen.next()或者连续调用三次gen.next()。代码执行不在try的范围,这个时候去gen.throw错误就不会被内部捕获到。
所以co里面用了这个特性,可以让你针对某一个或多个yield加上try,catch代码。
co发现某个内部promise报错就会调用onRejected然后调用gen.throw抛出错误。
如果你不处理错误,co就调用reject(err)传递给包装后的co返回的promise对象。这样你就可以在co(*fn).catch 拿到这个错误。
##toPromise的实现
我们看下toPromise的代码:
function toPromise(obj) {
if (!obj) return obj;
//是promise就直接返回
if (isPromise(obj)) return obj;
//如果是generator对象或者generatorFunction就直接用co包一层,最后会返回一个包装好的promise。
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
//如果是thunk函数就调用thunkToPromise转换
if ('function' == typeof obj) return thunkToPromise.call(this, obj);
//是数组就使用arrayToPromise转换
if (Array.isArray(obj)) return arrayToPromise.call(this, obj);
//是对象就使用objectToPromise转换
if (isObject(obj)) return objectToPromise.call(this, obj);
return obj;
}主要就是各种判断,把不同类型的yield值转换成一个promise对象。
前面几个都很简单不说了。
thunkToPromise比较简单如下:
function thunkToPromise(fn) {
var ctx = this;
//主要就是新new一个promise对象,在thunk的回调里resolve这个promise对象
return new Promise(function (resolve, reject) {
fn.call(ctx, function (err, res) {
//错误就调用reject抛出错误
if (err) return reject(err);
//对多个参数的支持
if (arguments.length > 2) res = slice.call(arguments, 1);
resolve(res);
});
});
}arrayToPromise也比较容易:
function arrayToPromise(obj) {
//直接调用Promise的静态方法包装一个新的promise对象。然后对于每个value调用toPromise进行递归的包装
return Promise.all(obj.map(toPromise, this));
}
objectToPromise会稍微绕一点:
function objectToPromise(obj){
//小技巧,生成一个跟obj一样类型的克隆空对象
var results = new obj.constructor();
//拿到 对象的所有key,返回key的集合数组
var keys = Object.keys(obj);
var promises = [];
//遍历所有值
for (var i = 0; i < keys.length; i++) {
var key = keys[i];
//递归调用
var promise = toPromise.call(this, obj[key]);
//如果转换后是promise对象,就异步的去赋值
if (promise && isPromise(promise)) defer(promise, key);
//如果不能转换,说明是纯粹的值。就直接赋值
else results[key] = obj[key];
}
//监听所有队列里面的promise对象,等所有的promise对象成功了,代表都赋值完成了。就可以调用then,返回结果results了。
return Promise.all(promises).then(function () {
return results;
});
function defer(promise, key) {
//先占位
results[key] = undefined;
//把当前promise加入待监听promise数组队列
promises.push(promise.then(function (res) {
//等当前promise变成成功态的时候赋值
results[key] = res;
}));
}
}objectToPromise的主要思路是循环递归遍历对象的值
##结语
整个分析到这就结束了,新版的co代码非常清晰也更加容易理解。不过完全抛弃thunk不知道TJ大神怎么想的。好像目前的koa还是使用的老的co来实现的。不管怎么说,还是值得看一看的。
koa基于co实现,co又是使用了es6的generator特性,所以,没错这个特性支持很一般。
有下面几种办法体验generator:
##generator的es6规范。
什么是generator?generator是javascript1.7的内容,是 ECMA-262 在第六个版本,即我们说的 Harmony 中所提出的新特性。
首先我们先定义一个generatorFunction:
function* start() {
var a = yield 'start';
console.log(a);
var b = yield 'running';
console.log(b);
var c = yield 'end';
console.log(c);
return 'over';
}
console.log(start.constructor.name) //"GeneratorFunction"
带有 *的函数声明即代表是一个GeneratorFunction,GeneratorFunction里面可以使用yield关键字,可以理解为在当前位置设置断点。
下面我们获得一个generator并且使用它
var it = start();
console.log(it.next());//Object {value: "start", done: false}
console.log(it.next(22));//22 object {value: 'running', done: false}
console.log(it.next(333));//333 Object {value: 'end', done: false}
console.log(it.next(444));//444 Object {value: "over", done: true}
通过执行GeneratorFunction我们可以得到一个generator对象也就是it。it对象有一个next方法。
当我们执行start()的时候,start里面的代码并没有执行。当我们第一次调用it.next()的时候代码会执行到第一个yield声明的地方。也就是var a = yield 'start';,注意这边只是执行到了赋值语句的右边yield部分,换句话说var a =这个赋值语句还没有执行。
此时it.next()返回的是一个对象,value是yield语句的值,这个值可以是字符串,函数,对象等等等,done代表当前的GeneratorFunction是否执行完毕。
也许你注意到了我们后来调用了it.next(22)给next传了一个参数。这个时候var a =赋值语句开始执行,实际上此时yield 'start'返回的就是22,也就是我们传的参数。一直执行到yield 'running';代码再次断点停住了。next方法的参数会成为上一个yield的返回值。
最后当执行到return 'over';的时候,next(444)返回的对象的done为true,代表整个代码执行完毕。
es6的generator的规范可以点这里,可惜由于本身generator还没有正式定稿,所以一直在修改中.前面的wiki也没有更新。目前来说wiki里面提到的send和close方法都已经移除了。变更记录可以在v8的issue里找到。https://code.google.com/p/v8/issues/detail?id=2715
##进阶知识:generator的Delegating yield
Delegating yield是generator的进阶内容。代表一个代理的yield。
前面提到yield后面的值可以是函数,对象,等等。其实yield后面还可以这么用。
function* run() {
console.log("step in child generator")
var b = yield 'running';
console.log(b);
console.log("step out child generator")
}
var runGenerator = run();
function* start() {
var a = yield 'start';
console.log(a);
yield *runGenerator;
var c = yield 'end';
console.log(c);
return 'over';
}
var it = start();
console.log(it.next());//Object {value: "start", done: false}
console.log(it.next(22));//22 step in child generator object {value: 'running', done: false}
console.log(it.next(333));//333 step out child generator Object {value: 'end', done: false}
console.log(it.next(444));//444 Object {value: "over", done: true}
yield后面可以跟 *anothergenerator,这样当前的断点就会进入到anothergenerator的generatorfunction里面,等子generator全部执行完后再回来继续执行。这个其实有点类似递归的意思。
其实说白了上面的代码跟之前的是等价的。yield*generator其实相当于把子generator的generatorfunction的代码混入了进来。
另外子generatorfunction的return值会做为yield*generator的返回值。
实例如下:
function* run() {
console.log("step in child generator");
return "child over";
var b = yield 'running';
console.log(b);
console.log("step out child generator")
}
var runGenerator = run();
function* start() {
var a = yield 'start';
console.log(a);
var childValue = yield *runGenerator;
console.log("childValue=="+childValue);
var c = yield 'end';
console.log(c);
return 'over';
}
var it = start();
console.log(it.next());
//Object {value: "start", done: false}
console.log(it.next(22));
//22
//step in child generator
//childValue==child over
//Object {value: "end", done: false}
console.log(it.next(333));
//333 Object {value: "over", done: true}
简单的测试,子generator的generatorFunction里面如果有return的话,下面的断点就不再起作用,而是提前返回,并且return的值 作为代理调用的返回值。
##结语
generator是es6的一个新特性,支持还不是很好,但是这并不影响它的成名,因为通过它可以很好的解决javascript的“恶魔”回调问题。基本generator的功能都介绍了。通过设置断点,我们将可以很好的将回调解放出来,目前比较知名的就是TJ的co库了,下篇,我将按照co的原理实现异步编程的一个简陋库。
好久不写文章了,罪过罪过,最近一直在忙iconfont改版的事情,各种焦头烂额。今天做了次iconfont的分享,所以整理下,发一篇水文。
主要给大家同步下iconfont的字体生成原理,以及解答下使用上的一些比较常见的问题
iconfont技术早就不是什么新技术了,我们iconfont.cn也已经做了快三年了。后来陆陆续续的来了很多新同学,可能只知道用这个,却不知道它内部的原理,这里给大家同步下,知道了原理可以更好的去使用。
首先前端都知道我们可以定义web上面文字的fontfamily。
css:
.test{
font-size: 16px;
font-family: '微软雅黑';
}
html:
<span class="test">iconfont字体原理</span>但是这种情况下我们只能用系统默认的一些字体,限制比较大。比如微软雅黑就是windows下面才有。
其实css是可以自定义字体的,所以我们可以加载自己的字体。
使用 @font-face 定义一个字体family:
css:
@font-face {
font-family: 'iconfont';
src: url('//at.alicdn.com/t/font_1453702746_9938898.eot'); /* IE9*/
src: url('//at.alicdn.com/t/font_1453702746_9938898.eot?#iefix') format('embedded-opentype'), /* IE6-IE8 */
url('//at.alicdn.com/t/font_1453702746_9938898.woff') format('woff'), /* chrome、firefox */
url('//at.alicdn.com/t/font_1453702746_9938898.ttf') format('truetype'), /* chrome、firefox、opera、Safari, Android, iOS 4.2+*/
url('//at.alicdn.com/t/font_1453702746_9938898.svg#iconfont') format('svg'); /* iOS 4.1- */
}
.test{
font-size: 16px;
font-family: 'iconfont';
}
html:
<span class="test">iconfont字体原理</span>
这样我们就可以用自定义字体渲染这些文字了。
每一个字都有对应的unicode。比如我们在web上输入我跟输入我是一样的。浏览器会自动帮你找到对应的图形去渲染。
当然因为兼容性的问题,不同的浏览器需要加载不同格式的字体,所以我们要同时支持四种字体。
我们来看下一个字体的样子。
我们可以通过一些软件打开字体,比如fontforge,fontlab。
比如下面的方正大草字体:
我们打开看下:
可以看到我这个字对应的的图形就是我们在网页上看到的样子。另外注意左上角的unicode。是6211,也就是我们的另一种表现形式。
再双击可以看到我这个图形的样子:
其实就是一些路径。而这个路径可以用ai,ps,sketch等等来画,画完粘贴到这里。
所以我们就可以做一些事情了,我们可以去改造字体,把一个字对应的图形换成我们设计师设计的样子,处理好兼容性就成了我们iconfont的1.0。
当年iconfont1.0是怎样的流程呢:
由设计师手动修改ttf字体对应的图形,我们人工转换出另外四种字体。
这样前台就可以用unicode去引用,就是我们第一代的iconfont的原理。这个成本有点大。
其实我们注意到里面有个svg的字体。你用文本编辑器打开会发现他是xml格式的,每个字的图形对应了一个路径。这个路径就是我们svg里面的path对应的序列。
好了于是我们有了一个全新的思路,由设计师上传svg,我们存储下来,然后大家自由组合,由平台拼出对应的svg字体,然后再转换到不同的其他格式的字体。
这里面的难点主要在,我们要分析svg。转换出对应的path序列。用户上传的svg格式太多,大小不一。要做各种转换,这里不展开了。
这就是我们的iconfont2.0,也就是目前线上跑的版本。
当然这一切都封装好了,做了一个工具库,font-carrier。
语法比较简单,可以直接往一个字体里面添加svg,也可以拿到某个字对应的svg,最终导出四种兼容字体。
知道了原理,以后大家调试就比较简单了,直接自己打开对应的svg字体,去看看你们对应的unicode的图形是不是有问题就行了,下面我们说说使用上一些常见的问题。
下面就可能会遇到的一些问题,做些简单的解答。
iconfont.cn平台给出的font-face定义默认都是 iconfont的fontfamily,建议大家改掉,避免与其他项目字体(比如引用的公共组件里面的字体)冲突。
unicode其实没有特别的规定。
字体有几个私有平面:
很早以前我们使用的五位数的,结果现在chrome支持不太好,后面建议大家使用第一个平面里的。
这样用的好处是,字体没有加载的时候,显示的是一个框 口。而不是乱码。
这是个艰难的决定。一脸无辜.jpg
中文字体没有严格意义上的基线。我们参考了方正字体的基线:
中间的线是baseline,这个就是0这条线。对于一个字体来说,可以设置上边界(ascent)跟下边界(descent)。比如我们iconfont设置的是812,-212。
所以如果我们的图标这么设计:
那么是可以基本对齐的。
但是我们发现用户上传图标时喜欢撑满整个框:
可以想像下,这种图标跟字体一起展现,就会变得偏下了。
所以在支付宝的要求下,我们修改了基线。当我们把下偏移量设置的比较小,这样基线相对就会在比较下面的位置。 这样就算用户上传的图标撑满也没关系了,因为普通的汉子是差不多三分之一,我们迁就一下,偏少一点,这样基本就能对齐了。
于是带来了一群不明真相的群众的吐槽。但是又不得不做这个事情。
有的时候设计师设计的icon会有多余的点,也可能当前上传的svg边界太大,于是导致我们的整个字体被撑开。
表现如下:
可以看到由于最左边的icon把字体撑开了。导致大家展示除了问题,表现在页面上是:
注意看里面的阴影,由于被撑开,导致它的边界是不对的。我们删掉这个图标再生成字体就好了。
当然这里还有各种问题,字体清晰度,icon上传svg规范问题,字体跨域问题,锯齿问题等等。这些平台基本都可以内部优化掉了,就不展开了。
iconfont解决了我们以前大量使用图片带来的种种问题,但是也有自身的各种缺陷。比如不支持多色就是一个最大的致命伤,另外在不同浏览器下的表现不同,需要做各种兼容。
不久的将来iconfont应该会被svg symbol技术替换。可以参考这篇文章。
淘积木目前接入了webfont,直接用svg当作字体展现,实时预览,也是一种新的突破。
iconfont.cn平台目前也在做相关的改造,期待带来新一轮的字体使用方式变革。
reactjs是目前比较火的前端框架,但是目前并没有很好的解释原理的项目。reactjs源码比较复杂不适合初学者去学习。所以本文通过实现一套简易版的reactjs,使得理解原理更加容易。包括:
声明:
所有实例源码都托管在github。点这里里面有分步骤的例子,可以一边看一边运行例子。
前端的发展特别快,经历过jQuery一统天下的工具库时代后,现在各种框架又开始百家争鸣了。angular,ember,backbone,vue,avalon,ploymer还有reactjs,作为一个前端真是稍不留神就感觉要被淘汰了,就在去年大家还都是angularjs的粉丝,到了今年又开始各种狂追reactjs了。前端都是喜新厌旧的,不知道最后这些框架由谁来一统天下,用句很俗的话说,这是最好的时代也是最坏的时代。作为一个前端,只能多学点,尽量多的了解他们的原理。
reactjs的代码非常绕,对于没有后台开发经验的前端来说看起来会比较吃力。其实reactjs的核心内容并不多,主要是下面这些:
下面我们将一点点的来实现一个简易版的reactjs,实现上面的那些功能,最后用这个reactjs做一个todolist的小应用,看完这个,或者跟着敲一遍代码。希望让大家能够更好的理解reactjs的运行原理。
我们先从渲染hello world开始吧。
我们看下面的代码:
<script type="text/javascript">
React.render('hello world',document.getElementById("container"))
</script>
/**
对应的html为
<div id="container"></div>
生成后的html为:
<div id="container">
<span data-reactid="0">hello world</span>
</div>
*/假定这一行代码,就可以把hello world渲染到对应的div里面。
我们来看看我们需要为此做些什么:
//component类,用来表示文本在渲染,更新,删除时应该做些什么事情
function ReactDOMTextComponent(text) {
//存下当前的字符串
this._currentElement = '' + text;
//用来标识当前component
this._rootNodeID = null;
}
//component渲染时生成的dom结构
ReactDOMTextComponent.prototype.mountComponent = function(rootID) {
this._rootNodeID = rootID;
return '<span data-reactid="' + rootID + '">' + this._currentElement + '</span>';
}
//component工厂 用来返回一个component实例
function instantiateReactComponent(node){
if(typeof node === 'string' || typeof node === 'number'){
return new ReactDOMTextComponent(node)
}
}
React = {
nextReactRootIndex:0,
render:function(element,container){
var componentInstance = instantiateReactComponent(element);
var markup = componentInstance.mountComponent(React.nextReactRootIndex++);
$(container).html(markup);
//触发完成mount的事件
$(document).trigger('mountReady'); }
}
代码分为三个部分:
文本类型的节点,在渲染,更新,删除时应该做什么操作,这边暂时只用到渲染,另外两个可以先忽略nextReactRootIndex作为每个component的标识id,不断加1,确保唯一性。这样我们以后可以通过这个标识找到这个元素。
可以看到我们把逻辑分为几个部分,主要的渲染逻辑放在了具体的componet类去定义。React.render负责调度整个流程,这里是调用instantiateReactComponent生成一个对应component类型的实例对象,然后调用此对象的mountComponent获取生成的内容。最后写到对应的container节点中。
可能有人问,这么p大点功能,有必要这么复杂嘛,别急。往下看才能体会这种分层的好处。
我们知道reactjs最大的卖点就是它的虚拟dom概念,我们一般使用React.createElement来创建一个虚拟dom元素。
虚拟dom元素分为两种,一种是浏览器自带的基本元素比如 div p input form 这种,一种是自定义的元素。
这边需要说一下我们上节提到的文本节点,它不算虚拟dom,但是reacjs为了保持渲染的一致性。文本节点是在外面包了一层span标记,也给它配了个简化版component(ReactDOMTextComponent)。
这节我们先讨论浏览器的基本元素。
在reactjs里,当我们希望在hello world外面包一层div,并且带上一些属性,甚至事件时我们可以这么写:
//演示事件监听怎么用
function hello(){
alert('hello')
}
var element = React.createElement('div',{id:'test',onclick:hello},'click me')
React.render(element,document.getElementById("container"))
/**
//生成的html为:
<div data-reactid="0" id="test">
<span data-reactid="0.0">click me</span>
</div>
//点击文字,会弹出hello的对话框
*/上面使用React.createElement创建了一个基本元素,我们来看看简易版本React.createElement的实现:
//ReactElement就是虚拟dom的概念,具有一个type属性代表当前的节点类型,还有节点的属性props
//比如对于div这样的节点type就是div,props就是那些attributes
//另外这里的key,可以用来标识这个element,用于优化以后的更新,这里可以先不管,知道有这么个东西就好了
function ReactElement(type,key,props){
this.type = type;
this.key = key;
this.props = props;
}
React = {
nextReactRootIndex:0,
createElement:function(type,config,children){
var props = {},propName;
config = config || {}
//看有没有key,用来标识element的类型,方便以后高效的更新,这里可以先不管
var key = config.key || null;
//复制config里的内容到props
for (propName in config) {
if (config.hasOwnProperty(propName) && propName !== 'key') {
props[propName] = config[propName];
}
}
//处理children,全部挂载到props的children属性上
//支持两种写法,如果只有一个参数,直接赋值给children,否则做合并处理
var childrenLength = arguments.length - 2;
if (childrenLength === 1) {
props.children = $.isArray(children) ? children : [children] ;
} else if (childrenLength > 1) {
var childArray = Array(childrenLength);
for (var i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
props.children = childArray;
}
return new ReactElement(type, key,props);
},
render:function(element,container){
var componentInstance = instantiateReactComponent(element);
var markup = componentInstance.mountComponent(React.nextReactRootIndex++);
$(container).html(markup);
//触发完成mount的事件
$(document).trigger('mountReady');
}
}createElement只是做了简单的参数修正,最终返回一个ReactElement实例对象也就是我们说的虚拟元素的实例。
这里注意key的定义,主要是为了以后更新时优化效率,这边可以先不管忽略。
好了有了元素实例,我们得把他渲染出来,此时render接受的是一个ReactElement而不是文本,我们先改造下instantiateReactComponent:
function instantiateReactComponent(node){
//文本节点的情况
if(typeof node === 'string' || typeof node === 'number'){
return new ReactDOMTextComponent(node);
}
//浏览器默认节点的情况
if(typeof node === 'object' && typeof node.type === 'string'){
//注意这里,使用了一种新的component
return new ReactDOMComponent(node);
}
}我们增加了一个判断,这样当render的不是文本而是浏览器的基本元素时。我们使用另外一种component来处理它渲染时应该返回的内容。这里就体现了工厂方法instantiateReactComponent的好处了,不管来了什么类型的node,都可以负责生产出一个负责渲染的component实例。这样render完全不需要做任何修改,只需要再做一种对应的component类型(这里是ReactDOMComponent)就行了。
所以重点我们来看看ReactDOMComponent的具体实现:
//component类,用来表示文本在渲染,更新,删除时应该做些什么事情
function ReactDOMComponent(element){
//存下当前的element对象引用
this._currentElement = element;
this._rootNodeID = null;
}
//component渲染时生成的dom结构
ReactDOMComponent.prototype.mountComponent = function(rootID){
//赋值标识
this._rootNodeID = rootID;
var props = this._currentElement.props;
var tagOpen = '<' + this._currentElement.type;
var tagClose = '</' + this._currentElement.type + '>';
//加上reactid标识
tagOpen += ' data-reactid=' + this._rootNodeID;
//拼凑出属性
for (var propKey in props) {
//这里要做一下事件的监听,就是从属性props里面解析拿出on开头的事件属性的对应事件监听
if (/^on[A-Za-z]/.test(propKey)) {
var eventType = propKey.replace('on', '');
//针对当前的节点添加事件代理,以_rootNodeID为命名空间
$(document).delegate('[data-reactid="' + this._rootNodeID + '"]', eventType + '.' + this._rootNodeID, props[propKey]);
}
//对于children属性以及事件监听的属性不需要进行字符串拼接
//事件会代理到全局。这边不能拼到dom上不然会产生原生的事件监听
if (props[propKey] && propKey != 'children' && !/^on[A-Za-z]/.test(propKey)) {
tagOpen += ' ' + propKey + '=' + props[propKey];
}
}
//获取子节点渲染出的内容
var content = '';
var children = props.children || [];
var childrenInstances = []; //用于保存所有的子节点的componet实例,以后会用到
var that = this;
$.each(children, function(key, child) {
//这里再次调用了instantiateReactComponent实例化子节点component类,拼接好返回
var childComponentInstance = instantiateReactComponent(child);
childComponentInstance._mountIndex = key;
childrenInstances.push(childComponentInstance);
//子节点的rootId是父节点的rootId加上新的key也就是顺序的值拼成的新值
var curRootId = that._rootNodeID + '.' + key;
//得到子节点的渲染内容
var childMarkup = childComponentInstance.mountComponent(curRootId);
//拼接在一起
content += ' ' + childMarkup;
})
//留给以后更新时用的这边先不用管
this._renderedChildren = childrenInstances;
//拼出整个html内容
return tagOpen + '>' + content + tagClose;
}
我们增加了虚拟dom reactElement的定义,增加了一个新的componet类ReactDOMComponent。
这样我们就实现了渲染浏览器基本元素的功能了。
对于虚拟dom的渲染逻辑,本质上还是个递归渲染的东西,reactElement会递归渲染自己的子节点。可以看到我们通过instantiateReactComponent屏蔽了子节点的差异,只需要使用不同的componet类,这样都能保证通过mountComponent最终拿到渲染后的内容。
另外这边的事件也要说下,可以在传递props的时候传入{onClick:function(){}}这样的参数,这样就会在当前元素上添加事件,代理到document。由于reactjs本身全是在写js,所以监听的函数的传递变得特别简单。
这里很多东西没有考虑,比如一些特殊的类型input select等等,再比如img不需要有对应的tagClose等。这里为了保持简单就不再扩展了。另外reactjs的事件处理其实很复杂,实现了一套标准的w3c事件。这里偷懒直接使用jQuery的事件代理到document上了。
上面实现了基本的元素内容,我们下面实现自定义元素的功能。
随着前端技术的发展浏览器的那些基本元素已经满足不了我们的需求了,如果你对webcomponents有一定的了解,就会知道人们一直在尝试扩展一些自己的标记。
reactjs通过虚拟dom做到了类似的功能,还记得我们上面element.type只是个简单的字符串,如果是个类呢?如果这个类恰好还有自己的生命周期管理,那扩展性就很高了。
如果对生命周期等概念不是很理解的,可以看看我以前的另一片文章:javascript组件化
我们看下reactjs怎么使用自定义元素:
var HelloMessage = React.createClass({
getInitialState: function() {
return {type: 'say:'};
},
componentWillMount: function() {
console.log('我就要开始渲染了。。。')
},
componentDidMount: function() {
console.log('我已经渲染好了。。。')
},
render: function() {
return React.createElement("div", null,this.state.type, "Hello ", this.props.name);
}
});
React.render(React.createElement(HelloMessage, {name: "John"}), document.getElementById("container"));
/**
结果为:
html:
<div data-reactid="0">
<span data-reactid="0.0">say:</span>
<span data-reactid="0.1">Hello </span>
<span data-reactid="0.2">John</span>
</div>
console:
我就要开始渲染了。。。
我已经渲染好了。。。
*/React.createElement接受的不再是字符串,而是一个class。
React.createClass生成一个自定义标记类,带有基本的生命周期:
对reactjs稍微有点了解的应该都可以明白上面的用法。
我们先来看看React.createClass的实现:
//定义ReactClass类,所有自定义的超级父类
var ReactClass = function(){
}
//留给子类去继承覆盖
ReactClass.prototype.render = function(){}
React = {
nextReactRootIndex:0,
createClass:function(spec){
//生成一个子类
var Constructor = function (props) {
this.props = props;
this.state = this.getInitialState ? this.getInitialState() : null;
}
//原型继承,继承超级父类
Constructor.prototype = new ReactClass();
Constructor.prototype.constructor = Constructor;
//混入spec到原型
$.extend(Constructor.prototype,spec);
return Constructor;
},
createElement:function(type,config,children){
...
},
render:function(element,container){
...
}
}
可以看到createClass生成了一个继承ReactClass的子类,在构造函数里调用this.getInitialState获得最初的state。
为了演示方便,我们这边的ReactClass相当简单,实际上原始的代码处理了很多东西,比如类的mixin的组合继承支持,比如componentDidMount等可以定义多次,需要合并调用等等,有兴趣的去翻源码吧,不是本文的主要目的,这里就不详细展开了。
我们这里只是返回了一个继承类的定义,那么具体的componentWillmount,这些生命周期函数在哪里调用呢。
看看我们上面的两种类型就知道,我们是时候为自定义元素也提供一个componet类了,在那个类里我们会实例化ReactClass,并且管理生命周期,还有父子组件依赖。
好,我们老规矩先改造instantiateReactComponent
function instantiateReactComponent(node){
//文本节点的情况
if(typeof node === 'string' || typeof node === 'number'){
return new ReactDOMTextComponent(node);
}
//浏览器默认节点的情况
if(typeof node === 'object' && typeof node.type === 'string'){
//注意这里,使用了一种新的component
return new ReactDOMComponent(node);
}
//自定义的元素节点
if(typeof node === 'object' && typeof node.type === 'function'){
//注意这里,使用新的component,专门针对自定义元素
return new ReactCompositeComponent(node);
}
}很简单我们增加了一个判断,使用新的component类形来处理自定义的节点。我们看下
ReactCompositeComponent的具体实现:
function ReactCompositeComponent(element){
//存放元素element对象
this._currentElement = element;
//存放唯一标识
this._rootNodeID = null;
//存放对应的ReactClass的实例
this._instance = null;
}
//用于返回当前自定义元素渲染时应该返回的内容
ReactCompositeComponent.prototype.mountComponent = function(rootID){
this._rootNodeID = rootID;
//拿到当前元素对应的属性值
var publicProps = this._currentElement.props;
//拿到对应的ReactClass
var ReactClass = this._currentElement.type;
// Initialize the public class
var inst = new ReactClass(publicProps);
this._instance = inst;
//保留对当前comonent的引用,下面更新会用到
inst._reactInternalInstance = this;
if (inst.componentWillMount) {
inst.componentWillMount();
//这里在原始的reactjs其实还有一层处理,就是 componentWillMount调用setstate,不会触发rerender而是自动提前合并,这里为了保持简单,就略去了
}
//调用ReactClass的实例的render方法,返回一个element或者一个文本节点
var renderedElement = this._instance.render();
//得到renderedElement对应的component类实例
var renderedComponentInstance = instantiateReactComponent(renderedElement);
this._renderedComponent = renderedComponentInstance; //存起来留作后用
//拿到渲染之后的字符串内容,将当前的_rootNodeID传给render出的节点
var renderedMarkup = renderedComponentInstance.mountComponent(this._rootNodeID);
//之前我们在React.render方法最后触发了mountReady事件,所以这里可以监听,在渲染完成后会触发。
$(document).on('mountReady', function() {
//调用inst.componentDidMount
inst.componentDidMount && inst.componentDidMount();
});
return renderedMarkup;
}
实现并不难,ReactClass的render一定是返回一个虚拟节点(包括element和text),这个时候我们使用instantiateReactComponent去得到实例,再使用mountComponent拿到结果作为当前自定义元素的结果。
应该说本身自定义元素不负责具体的内容,他更多的是负责生命周期。具体的内容是由它的render方法返回的虚拟节点来负责渲染的。
本质上也是递归的去渲染内容的过程。同时因为这种递归的特性,父组件的componentWillMount一定在某个子组件的componentWillMount之前调用,而父组件的componentDidMount肯定在子组件之后,因为监听mountReady事件,肯定是子组件先监听的。
需要注意的是自定义元素并不会处理我们createElement时传入的子节点,它只会处理自己render返回的节点作为自己的子节点。不过我们在render时可以使用this.props.children拿到那些传入的子节点,可以自己处理。其实有点类似webcomponents里面的shadow dom的作用。
上面实现了三种类型的元素,其实我们发现本质上没有太大的区别,都是有自己对应component类来处理自己的渲染过程。
大概的关系是下面这样。
于是我们发现初始化的渲染流程都已经完成了。
整个初次渲染的流程基本就分析完毕了。看看我们目前的进展,事件监听做了,虚拟dom有了。基本的组件生命周期也有了。我们这个小玩具已经可以简单跑跑了。下篇文章我们将一起去实现reactjs的更新机制,看看它最核心的diff算法是怎么回事。
promise最早是在commonjs社区提出来的,当时提出了很多规范。比较接受的是promise/A规范。后来人们在这个基础上。提出了promise/A+规范,也就是实际上的业内推行的规范。es6也是采用的这种规范。
promise/A规范在这里
不过规范这种东西看着比较晦涩。下面具体说说promise的用法。
##规范里的定义
什么是promise呢,说白了就是一个承诺,我承诺你叫我做的事情我将来会去做,不过要等我能去做的时候。
一个promise对象有三种状态,预备状态(pending),成功态(fulfilled),失败态(rejected)。
我们看下promise对象的构造函数:
var promise = new Promise(function(resolve, reject) {
//if(报错){
//reject(new Error('promise出错啦。。'))
//}
//某个异步操作,比如ajax请求
setTimeout(function(){
resolve('异步请求结束了。。变成完成态')
},1000)
});
promise对象初始状态一般是预备状态,并且promise对象的状态转换只能是预备状态到成功态或者预备状态到失败态。
##promise对象的then方法
我们可以使用promise对象的then方法往这个对象里面添加回调函数。调用方式为:
promise.then(onFulfilled, onRejected)then接受一个成功回调,还有失败回调。都是可选参数。
当promise对象是预备状态这些函数不会立即执行。而是等待。
当promise对象变成了成功态会调用onFulfilled,参数为resolve传递的值。
变成失败态则会调用onRejected,参数为reject传递的值。
因为then返回一个promise对象。所以支持链式调用:
promise.then(onFulfilled, onRejected).then(onFulfilled, onRejected)then负责往promise对象里添加函数,随便添加多少。
例子:
//onRejected可以为null也可以省略
promise.then(function(prevValue){
console.log('resolve的值:'+prevValue)
return "我是传递给第二个回调的参数"
},null).then(function(value){
console.log('报告:'+ value)
console.log('我是最后一个')
})
/*
*结果
resolve的值:异步请求结束了。。变成完成态
报告:我是传递给第二个回调的参数
我是最后一个
*/可以看到一直等到前面的异步操作结束了,后面的才会执行。
此外如果onFulfilled返回一个新的promise对象,那么之后的then添加的操作函数会被托管给新的promise对象。然后之后的操作函数执不执行就由新的promise对象说了算了。
比如:
promise.then(function(prevValue){
console.log('resolve的值:'+prevValue)
var newPromise = new Promise(function(resolve,reject){
setTimeout(function(){
resolve('2秒后,新的promise变成完成态')
},2000)
})
//返回新的promise
console.log('返回一个promise,开始托管。')
return newPromise
},null).then(function(value){
console.log('报告:'+ value)
console.log('我是最后一个')
})
/*
*结果
resolve的值:异步请求结束了。。变成完成态
返回一个promise,开始托管。
报告:2秒后,新的promise变成完成态
我是最后一个
*/##promise对象的catch方法
用来捕获上一个then方法里面reject过来的错误,说白了就是一种特殊的then
promise.catch(function(error) {
console.log('发生错误!', error);
});
//等价于
promise.then(null,function(error) {
console.log('发生错误!', error);
});##Promise的类方法resolve和reject
Promise.resolve
接受的参数如果是promise对象就直接返回。
如果是一个非promise,但具有then方法的对象就会尝试转换成一个成功状态的promise对象。
如果是个不具有then方法的值就传递给下一个onFulfilled函数,并且生成一个处于成功状态的promise对象。
Promise.reject
接受的参数如果是promise对象就直接返回。
如果是一个非promise,但具有then方法的对象就会尝试转换成一个失败状态的promise对象。
如果是个不具有then方法的值就传递给下一个onRejected函数。并且生成一个处于失败状态的promise对象。
var a = Promise.resolve(true)
//same as
var a = new Promise(function(resolve,reject){
//立即变成成功状态
resolve(true)
})
var b = Promise.reject(true)
//same as
var b = new Promise(function(resolve,reject){
//立即变成失败状态
reject(true)
})
//使用Promise.resolve转换不标准的jQuery的promise对象
var promise = Promise.resolve($.get('http://www.taobao.com'));##Promise的类方法all和race
Promise.all用来包装一系列的promise对象返回一个包装后的promise对象,比如我们称之为A。
var a = new Promise(function(resolve,reject){})
var b = Promise.resolve(true)
Promise.all([a,b])Promise.race也是用来包装一系列的promise对象返回一个包装后的promise对象,比如我们称之为B。跟all不同的是,只要有一个对象变成了成功状态(fulfilled),B就会变成成功状态。
Promise.race([a,b])all是一种与的关系,而race是一种或的关系。
##Promise的类方法defer使用
其实除了在构造函数里面使用resolve,reject去改变一个promise对象的状态外,我们还有另外一种方式。那就是defer。
例子:
promise.then(function(val){
var d = Promise.defer()
setTimeout(function(){
d.resolve('2秒后,新的promise变成完成态')
//d.reject('err')
},2000)
//返回自己的promise对象
return d.promise
})Promise.defer()生成一个defer对象。这个对象d具有一个promise对象属性。d.resolve会把管理的promise变成完成态,同理d.reject会将管理的promise变成失败态。
整个promise的用法就说完了。
其实A+规范中只定义了then函数的具体细节,而promise状态的改变都是前人的经验慢慢积累后总结出的一套使用方式
参考链接:
作为一名前端工程师,写组件的能力至关重要。虽然javascript经常被人嘲笑是个小玩具,但是在一代代大牛的前仆后继的努力下,渐渐的也摸索了一套组件的编写方式。
下面我们来谈谈,在现有的知识体系下,如何很好的写组件。
比如我们要实现这样一个组件,就是一个输入框里面字数的计数。这个应该是个很简单的需求。
我们来看看,下面的各种写法。
为了更清楚的演示,下面全部使用jQuery作为基础语言库。
嗯 所谓的入门级写法呢,就是完完全全的全局函数全局变量的写法。(就我所知,现在好多外包还是这种写法)
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>test</title>
<script src="http://code.jquery.com/jquery-1.9.1.min.js"></script>
<script>
$(function() {
var input = $('#J_input');
//用来获取字数
function getNum(){
return input.val().length;
}
//渲染元素
function render(){
var num = getNum();
//没有字数的容器就新建一个
if ($('#J_input_count').length == 0) {
input.after('<span id="J_input_count"></span>');
};
$('#J_input_count').html(num+'个字');
}
//监听事件
input.on('keyup',function(){
render();
});
//初始化,第一次渲染
render();
})
</script>
</head>
<body>
<input type="text" id="J_input"/>
</body>
</html>
这段代码跑也是可以跑的,但是呢,各种变量混乱,没有很好的隔离作用域,当页面变的复杂的时候,会很难去维护。目前这种代码基本是用不了的。当然少数的活动页面可以简单用用。
让我们对上面的代码作些改动,使用单个变量模拟命名空间。
var textCount = {
input:null,
init:function(config){
this.input = $(config.id);
this.bind();
//这边范围对应的对象,可以实现链式调用
return this;
},
bind:function(){
var self = this;
this.input.on('keyup',function(){
self.render();
});
},
getNum:function(){
return this.input.val().length;
},
//渲染元素
render:function(){
var num = this.getNum();
if ($('#J_input_count').length == 0) {
this.input.after('<span id="J_input_count"></span>');
};
$('#J_input_count').html(num+'个字');
}
}
$(function() {
//在domready后调用
textCount.init({id:'#J_input'}).render();
})
这样一改造,立马变的清晰了很多,所有的功能都在一个变量下面。代码更清晰,并且有统一的入口调用方法。
但是还是有些瑕疵,这种写法没有私有的概念,比如上面的getNum,bind应该都是私有的方法。但是其他代码可以很随意的改动这些。当代码量特别特别多的时候,很容易出现变量重复,或被修改的问题。
于是又出现了一种函数闭包的写法:
var TextCount = (function(){
//私有方法,外面将访问不到
var _bind = function(that){
that.input.on('keyup',function(){
that.render();
});
}
var _getNum = function(that){
return that.input.val().length;
}
var TextCountFun = function(config){
}
TextCountFun.prototype.init = function(config) {
this.input = $(config.id);
_bind(this);
return this;
};
TextCountFun.prototype.render = function() {
var num = _getNum(this);
if ($('#J_input_count').length == 0) {
this.input.after('<span id="J_input_count"></span>');
};
$('#J_input_count').html(num+'个字');
};
//返回构造函数
return TextCountFun;
})();
$(function() {
new TextCount().init({id:'#J_input'}).render();
})这种写法,把所有的东西都包在了一个自动执行的闭包里面,所以不会受到外面的影响,并且只对外公开了TextCountFun构造函数,生成的对象只能访问到init,render方法。这种写法已经满足绝大多数的需求了。事实上大部分的jQuery插件都是这种写法。
上面的写法已经可以满足绝大多数需求了。
但是呢,当一个页面特别复杂,当我们需要的组件越来越多,当我们需要做一套组件。仅仅用这个就不行了。首先的问题就是,这种写法太灵活了,写单个组件还可以。如果我们需要做一套风格相近的组件,而且是多个人同时在写。那真的是噩梦。
在编程的圈子里,面向对象一直是被认为最佳的编写代码方式。比如java,就是因为把面向对象发挥到了极致,所以多个人写出来的代码都很接近,维护也很方便。但是很不幸的是,javascript不支持class类的定义。但是我们可以模拟。
下面我们先实现个简单的javascript类:
var Class = (function() {
var _mix = function(r, s) {
for (var p in s) {
if (s.hasOwnProperty(p)) {
r[p] = s[p]
}
}
}
var _extend = function() {
//开关 用来使生成原型时,不调用真正的构成流程init
this.initPrototype = true
var prototype = new this()
this.initPrototype = false
var items = Array.prototype.slice.call(arguments) || []
var item
//支持混入多个属性,并且支持{}也支持 Function
while (item = items.shift()) {
_mix(prototype, item.prototype || item)
}
// 这边是返回的类,其实就是我们返回的子类
function SubClass() {
if (!SubClass.initPrototype && this.init)
this.init.apply(this, arguments)//调用init真正的构造函数
}
// 赋值原型链,完成继承
SubClass.prototype = prototype
// 改变constructor引用
SubClass.prototype.constructor = SubClass
// 为子类也添加extend方法
SubClass.extend = _extend
return SubClass
}
//超级父类
var Class = function() {}
//为超级父类添加extend方法
Class.extend = _extend
return Class
})()这是拿John Resig的class简单修改了下。
这边只是很简陋的实现了类的继承机制。如果对类的实现有兴趣可以参考我另一篇文章javascript oo实现
我们看下使用方法:
//继承超级父类,生成个子类Animal,并且混入一些方法。这些方法会到Animal的原型上。
//另外这边不仅支持混入{},还支持混入Function
var Animal = Class.extend({
init:function(opts){
this.msg = opts.msg
this.type = "animal"
},
say:function(){
alert(this.msg+":i am a "+this.type)
}
})
//继承Animal,并且混入一些方法
var Dog = Animal.extend({
init:function(opts){
//并未实现super方法,直接简单使用父类原型调用即可
Animal.prototype.init.call(this,opts)
//修改了type类型
this.type = "dog"
}
})
//new Animal({msg:'hello'}).say()
new Dog({msg:'hi'}).say()
使用很简单,超级父类具有extend方法,可以继承出一个子类。子类也具有extend方法。
这边要强调的是,继承的父类都是一个也就是单继承。但是可以通过extend实现多重混入。详见下面用法。
有了这个类的扩展,我们可以这么编写代码了:
var TextCount = Class.extend({
init:function(config){
this.input = $(config.id);
this._bind();
this.render();
},
render:function() {
var num = this._getNum();
if ($('#J_input_count').length == 0) {
this.input.after('<span id="J_input_count"></span>');
};
$('#J_input_count').html(num+'个字');
},
_getNum:function(){
return this.input.val().length;
},
_bind:function(){
var self = this;
self.input.on('keyup',function(){
self.render();
});
}
})
$(function() {
new TextCount({
id:"#J_input"
});
})
这边可能还没看见class的真正好处,不急我们继续往下。
可以看到,我们的组件有些方法,是大部分组件都会有的。
当然这也是一种约定俗成的规范了。如果大家全部按照这种风格来写代码,开发大规模组件库就变得更加规范,相互之间配合也更容易。
这个时候面向对象的好处就来了,我们抽象出一个Base类。其他组件编写时都继承它。
var Base = Class.extend({
init:function(config){
//自动保存配置项
this.__config = config
this.bind()
this.render()
},
//可以使用get来获取配置项
get:function(key){
return this.__config[key]
},
//可以使用set来设置配置项
set:function(key,value){
this.__config[key] = value
},
bind:function(){
},
render:function() {
},
//定义销毁的方法,一些收尾工作都应该在这里
destroy:function(){
}
})base类主要把组件的一般性内容都提取了出来,这样我们编写组件时可以直接继承base类,覆盖里面的bind和render方法。
于是我们可以这么写代码:
var TextCount = Base.extend({
_getNum:function(){
return this.get('input').val().length;
},
bind:function(){
var self = this;
self.get('input').on('keyup',function(){
self.render();
});
},
render:function() {
var num = this._getNum();
if ($('#J_input_count').length == 0) {
this.get('input').after('<span id="J_input_count"></span>');
};
$('#J_input_count').html(num+'个字');
}
})
$(function() {
new TextCount({
//这边直接传input的节点了,因为属性的赋值都是自动的。
input:$("#J_input")
});
})可以看到我们直接实现一些固定的方法,bind,render就行了。其他的base会自动处理(这里只是简单处理了配置属性的赋值)。
事实上,这边的init,bind,render就已经有了点生命周期的影子,但凡是组件都会具有这几个阶段,初始化,绑定事件,以及渲染。当然这边还可以加一个destroy销毁的方法,用来清理现场。
此外为了方便,这边直接变成了传递input的节点。因为属性赋值自动化了,一般来说这种情况下都是使用getter,setter来处理。这边就不详细展开了。
有了base应该说我们编写组件更加的规范化,体系化了。下面我们继续深挖。
还是上面的那个例子,如果我们希望输入字的时候超过5个字就弹出警告。该怎么办呢。
小白可能会说,那简单啊直接改下bind方法:
var TextCount = Base.extend({
...
bind:function(){
var self = this;
self.get('input').on('keyup',function(){
if(self._getNum() > 5){
alert('超过了5个字了。。。')
}
self.render();
});
},
...
})
的确也是一种方法,但是太low了,代码严重耦合。当这种需求特别特别多,代码会越来越乱。
这个时候就要引入事件机制,也就是经常说的观察者模式。
注意这边的事件机制跟平时的浏览器那些事件不是一回事,要分开来看。
什么是观察者模式呢,官方的解释就不说了,直接拿这个例子来说。
想象一下base是个机器人会说话,他会一直监听输入的字数并且汇报出去(通知)。而你可以把耳朵凑上去,听着他的汇报(监听)。发现字数超过5个字了,你就做些操作。
所以这分为两个部分,一个是通知,一个是监听。
假设通知是 fire方法,监听是on。于是我们可以这么写代码:
var TextCount = Base.extend({
...
bind:function(){
var self = this;
self.get('input').on('keyup',function(){
//通知,每当有输入的时候,就报告出去。
self.fire('Text.input',self._getNum())
self.render();
});
},
...
})
$(function() {
var t = new TextCount({
input:$("#J_input")
});
//监听这个输入事件
t.on('Text.input',function(num){
//可以获取到传递过来的值
if(num>5){
alert('超过了5个字了。。。')
}
})
})fire用来触发一个事件,可以传递数据。而on用来添加一个监听。这样组件里面只负责把一些关键的事件抛出来,至于具体的业务逻辑都可以添加监听来实现。没有事件的组件是不完整的。
下面我们看看怎么实现这套事件机制。
我们首先抛开base,想想怎么实现一个具有这套机制的类。
//辅组函数,获取数组里某个元素的索引 index
var _indexOf = function(array,key){
if (array === null) return -1
var i = 0, length = array.length
for (; i < length; i++) if (array[i] === item) return i
return -1
}
var Event = Class.extend({
//添加监听
on:function(key,listener){
//this.__events存储所有的处理函数
if (!this.__events) {
this.__events = {}
}
if (!this.__events[key]) {
this.__events[key] = []
}
if (_indexOf(this.__events,listener) === -1 && typeof listener === 'function') {
this.__events[key].push(listener)
}
return this
},
//触发一个事件,也就是通知
fire:function(key){
if (!this.__events || !this.__events[key]) return
var args = Array.prototype.slice.call(arguments, 1) || []
var listeners = this.__events[key]
var i = 0
var l = listeners.length
for (i; i < l; i++) {
listeners[i].apply(this,args)
}
return this
},
//取消监听
off:function(key,listener){
if (!key && !listener) {
this.__events = {}
}
//不传监听函数,就去掉当前key下面的所有的监听函数
if (key && !listener) {
delete this.__events[key]
}
if (key && listener) {
var listeners = this.__events[key]
var index = _indexOf(listeners, listener)
(index > -1) && listeners.splice(index, 1)
}
return this;
}
})
var a = new Event()
//添加监听 test事件
a.on('test',function(msg){
alert(msg)
})
//触发 test事件
a.fire('test','我是第一次触发')
a.fire('test','我又触发了')
a.off('test')
a.fire('test','你应该看不到我了')
实现起来并不复杂,只要使用this.__events存下所有的监听函数。在fire的时候去找到并且执行就行了。
这个时候面向对象的好处就来了,如果我们希望base拥有事件机制。只需要这么写:
var Base = Class.extend(Event,{
...
destroy:function(){
//去掉所有的事件监听
this.off()
}
})
//于是可以
//var a = new Base()
// a.on(xxx,fn)
//
// a.fire()是的只要extend的时候多混入一个Event,这样Base或者它的子类生成的对象都会自动具有事件机制。
有了事件机制我们可以把组件内部很多状态暴露出来,比如我们可以在set方法中抛出一个事件,这样每次属性变更的时候我们都可以监听到。
到这里为止,我们的base类已经像模像样了,具有了init,bind,render,destroy方法来表示组件的各个关键过程,并且具有了事件机制。基本上已经可以很好的来开发组件了。
我们还可以继续深挖。看看我们的base,还差些什么。首先浏览器的事件监听还很落后,需要用户自己在bind里面绑定,再然后现在的TextCount里面还存在dom操作,也没有自己的模板机制。这都是需要扩展的,于是我们在base的基础上再继承出一个richbase用来实现更完备的组件基类。
主要实现这些功能:
我们看下我们实现richbase后怎么写组件:
var TextCount = RichBase.extend({
//事件直接在这里注册,会代理到parentNode节点,parentNode节点在下面指定
EVENTS:{
//选择器字符串,支持所有jQuery风格的选择器
'input':{
//注册keyup事件
keyup:function(self,e){
//单向绑定,修改数据直接更新对应模板
self.setChuckdata('count',self._getNum())
}
}
},
//指定当前组件的模板
template:'<span id="J_input_count"><%= count %>个字</span>',
//私有方法
_getNum:function(){
return this.get('input').val().length || 0
},
//覆盖实现setUp方法,所有逻辑写在这里。最后可以使用render来决定需不需要渲染模板
//模板渲染后会append到parentNode节点下面,如果未指定,会append到document.body
setUp:function(){
var self = this;
var input = this.get('parentNode').find('#J_input')
self.set('input',input)
var num = this._getNum()
//赋值数据,渲染模板,选用。有的组件没有对应的模板就可以不调用这步。
self.render({
count:num
})
}
})
$(function() {
//传入parentNode节点,组件会挂载到这个节点上。所有事件都会代理到这个上面。
new TextCount({
parentNode:$("#J_test_container")
});
})
/**对应的html,做了些修改,主要为了加上parentNode,这边就是J_test_container
<div id="J_test_container">
<input type="text" id="J_input"/>
</div>
*/
看下上面的用法,可以看到变得更简单清晰了:
下面我们看下richebase的实现:
var RichBase = Base.extend({
EVENTS:{},
template:'',
init:function(config){
//存储配置项
this.__config = config
//解析代理事件
this._delegateEvent()
this.setUp()
},
//循环遍历EVENTS,使用jQuery的delegate代理到parentNode
_delegateEvent:function(){
var self = this
var events = this.EVENTS || {}
var eventObjs,fn,select,type
var parentNode = this.get('parentNode') || $(document.body)
for (select in events) {
eventObjs = events[select]
for (type in eventObjs) {
fn = eventObjs[type]
parentNode.delegate(select,type,function(e){
fn.call(null,self,e)
})
}
}
},
//支持underscore的极简模板语法
//用来渲染模板,这边是抄的underscore的。非常简单的模板引擎,支持原生的js语法
_parseTemplate:function(str,data){
/**
* http://ejohn.org/blog/javascript-micro-templating/
* https://github.com/jashkenas/underscore/blob/0.1.0/underscore.js#L399
*/
var fn = new Function('obj',
'var p=[],print=function(){p.push.apply(p,arguments);};' +
'with(obj){p.push(\'' + str
.replace(/[\r\t\n]/g, " ")
.split("<%").join("\t")
.replace(/((^|%>)[^\t]*)'/g, "$1\r")
.replace(/\t=(.*?)%>/g, "',$1,'")
.split("\t").join("');")
.split("%>").join("p.push('")
.split("\r").join("\\'") +
"');}return p.join('');")
return data ? fn(data) : fn
},
//提供给子类覆盖实现
setUp:function(){
this.render()
},
//用来实现刷新,只需要传入之前render时的数据里的key还有更新值,就可以自动刷新模板
setChuckdata:function(key,value){
var self = this
var data = self.get('__renderData')
//更新对应的值
data[key] = value
if (!this.template) return;
//重新渲染
var newHtmlNode = $(self._parseTemplate(this.template,data))
//拿到存储的渲染后的节点
var currentNode = self.get('__currentNode')
if (!currentNode) return;
//替换内容
currentNode.replaceWith(newHtmlNode)
self.set('__currentNode',newHtmlNode)
},
//使用data来渲染模板并且append到parentNode下面
render:function(data){
var self = this
//先存储起来渲染的data,方便后面setChuckdata获取使用
self.set('__renderData',data)
if (!this.template) return;
//使用_parseTemplate解析渲染模板生成html
//子类可以覆盖这个方法使用其他的模板引擎解析
var html = self._parseTemplate(this.template,data)
var parentNode = this.get('parentNode') || $(document.body)
var currentNode = $(html)
//保存下来留待后面的区域刷新
//存储起来,方便后面setChuckdata获取使用
self.set('__currentNode',currentNode)
parentNode.append(currentNode)
},
destroy:function(){
var self = this
//去掉自身的事件监听
self.off()
//删除渲染好的dom节点
self.get('__currentNode').remove()
//去掉绑定的代理事件
var events = self.EVENTS || {}
var eventObjs,fn,select,type
var parentNode = self.get('parentNode')
for (select in events) {
eventObjs = events[select]
for (type in eventObjs) {
fn = eventObjs[type]
parentNode.undelegate(select,type,fn)
}
}
}
})
主要做了两件事,一个就是事件的解析跟代理,全部代理到parentNode上面。另外就是把render抽出来,用户只需要实现setUp方法。如果需要模板支持就在setUp里面调用render来渲染模板,并且可以通过setChuckdata来刷新模板,实现单向绑定。
有了richbase,基本上组件开发就没啥问题了。但是我们还是可以继续深挖下去。
比如组件自动化加载渲染,局部刷新,比如父子组件的嵌套,再比如双向绑定,再比如实现ng-click这种风格的事件机制。
当然这些东西已经不属于组件里面的内容了。再进一步其实已经是一个框架了。实际上最近比较流行的react,ploymer还有我们的brix等等都是实现了这套东西。受限于篇幅,这个以后有空再写篇文章详细分析下。
鉴于有人跟我要完整代码,其实上面都列出来了。好吧 那我就再整理下,放在github了包含具体的demo,请点这里。不过仅仅作为理解使用最好不要用于生产环境。如果觉得有帮助就给我个star吧。
模板是每个前端工作者都会接触到的东西,近几年前端的工程化,发展的如火如荼。从基本的字符串拼接到字符串模板,再到现在各种框架给出的“伪模板”解决方案,前端模板经历了种种变革。
下面就不同时期的模板做一下回顾。
本文假定读者已经对
underscore,mustache,angularjs,reactjs等技术有了一定的了解。否则请先看看相关资料了解下。
提到模板,不得不提到每个前端都会经历的字符串拼接的阶段。
看下面这段代码:
<ul id="test">
</ul>
<script>
var students = [{
name:'张三',
age:'19'
},{
name:'李四',
age:'17'
},{
name:'王五',
age:'21'
}]
var htmlArray = [],tmplStr
for(var i=0;i<students.length;i++){
tmplStr = '<li>'
tmplStr += '姓名:'+ students[i].name +'年龄:' + students[i].age
tmplStr += '</li>'
htmlArray.push(tmplStr)
}
document.getElementById('test').innerHTML = htmlArray.join(' ')
</script>代码逻辑很简单,将一份数据循环拼接好字符串最后组装好html字符串塞到页面上。
可以看到这种写法,模板部分跟逻辑部分很容易耦合在一起,非常的不清晰,可读性也很差。在大规模项目中是不建议这么用的。
因为上面的写法有太多的缺点,所以先辈们开始实现基本的模板引擎。实现展示与逻辑的分离。
比较典型的是underscore类型的模板,它其实很简单,就是把一个基本的模板语法转换成一个可执行的javascript代码。
我们看下上面的功能使用underscore的语法怎么写:
<ul id="test">
</ul>
<script>
var students = [{
name:'张三'
},{
name:'李四'
},{
name:'王五'
}]
var tmpl = '<% for(var i=0;i<students.length;i++){ %> 姓名: <% students[i].name %> <% } %>'
//假设template可以实现类似underscore的语法
var tplCompile = template(tmpl) //先生成执行函数
document.getElementById('test').innerHTML = tplCompile(students)//执行渲染
</script>template,作为实现了underscore功能的函数,传入一个模板还有一份数据,就可以把模板渲染出来。
这样写的好处是,实现了模板与字符串逻辑的分离。ui层,也就是渲染逻辑看起来会比较清晰。
下面我们来看看如何实现一个最基本的template:
function template(tpl){
//用来匹配出我们的特殊语法
var tplReg = /<%([^%>]+)?%>/g
var match;
var cursor=0;
var regOut = /(^( )?(if|for|else|switch|case|break|{|}))(.*)?/g;
//需要拼接的代码,这里注意with的用法,用来使渲染的数据应用在模板里
var code = 'var codes=[];\nwith(renderData){\n';
var addLine = function(line,js){
//普通文本,这时候加上一个双引号就可以了
if(!js){
code += 'codes.push("' + line.replace(/"/g, '\\"') + '");\n'
return
}
//特殊语法特殊处理
//对于有js特殊逻辑比如for,if这种代码,不适用push。直接打出。
if(regOut.test(line)){
code += line + '\n';
}else{
//普通的特殊语法,跟上面的普通的文本唯一的区别就是少了双引号,这样以后执行时就会是变量。
code += 'codes.push(' + line + ');\n'
}
}
//通过正则不停的去匹配特殊语法
while(match = tplReg.exec(tpl)) {
//截取前面的普通文本
addLine(tpl.slice(cursor, match.index)); //普通文本
//将当前的特殊语法加入
addLine(match[1],true); //特殊逻辑
cursor = match.index + match[0].length; //更新游标
}
//末尾可能还剩下些语法
addLine(tpl.substr(cursor, tpl.length - cursor)); //剩下的代码
code += '};return codes.join("")';
code = code.replace(/[\r\t\n]/g, '')
var compileFn = function(data){
//使用function执行拼好的代码,将data传到函数里。
return new Function('renderData',code)(data);
}
return compileFn
}实现很简单,主要就是通过正则替换,拼凑出最终的js执行语句,然后使用function来执行得到结果。
我们通过tplReg这个正则匹配出所有的<% ... %>特殊语法,addLine负责生成javascript可执行语句。
addLine添加的语句需要分三种情况:
姓名:这种文本。这个时候直接push到codes里面就行,最后会原样输出。这边需要加上双引号代表是个普通字符串。students[i].name,这种时候直接push到codes里面,跟上面不同的是,这时不需要加双引号,这样最后这些codes执行时就会把它作为变量去处理。for(var i=0;i<students.length;i++){这种带for的最后拼接好codes后,使用function一次执行得到最终渲染好的字符串。
当然我们这边的实现超级简陋,仅供参考原理。实际的模板还需要考虑缓存,兼容性,xss等等。
字符串模板使用很广泛,也踊跃出了若干实现。mustache,Underscore templates,Dust.js等等,前端真的是能折腾。如果有选择困难症,可以看看这里:http://garann.github.io/template-chooser/
这个阶段的模板或多或少都是相同的原理。
这在很长一段时间里对于前端工程师来说已经够用了。通过模板的dsl,很好的实现了前端逻辑与ui的分离。
但是随着前端的发展,特别是富客户端应用的兴起。单纯的字符串模板已经很难满足需求了。
比如一个学生个人信息界面,分为个人姓名,还有个人成绩两块。
<div>个人信息:</div>
<div id="test">
</div>
<script>
var student = {
name:'张三',
score:89
}
var tmpl = '<div>姓名: <% name %> </div><div>成绩: <% score %> </div>'
//假设template方法可以实现underscore的语法
document.getElementById('test').innerHTML = template(tmpl)(student)
</script>如果我们初次渲染后需要去更新成绩。我们期待的情况肯定是只更新成绩,个人姓名不要重复刷新。这对于普通字符串模板是做不到的。只能自己使用dom操作去修改,而这样就违背了我们的初衷,逻辑又跟展现耦合变的不可控了。
实际情况会更复杂,页面内容更多,需要局部刷新的地方更多,这里为了方便,只举一个最简单的例子。
如果不自己使用dom操作,还希望用模板,那么每次要改点东西都需要整个页面全部重新渲染,在通过innerHTML一次性更新。
我们其实是需要一种局部刷新的东西,在初次渲染后仍然保持模板与dom的联系。通过一些方法,只改变页面中的一小部分html。差异化的去更新。其实是一种innerHTML的优化。
我们团队很久之前就做了这方面的尝试,可以先看下我们是怎么用的:
<script>
var student = {
name:'张三',
score:89
}
//注意下面的模板里面多了 tpl-name="sc" tpl-key="score"
var tmpl = '<div>姓名: <% name %> </div><div tpl-name="sc" tpl-key="score">成绩: <% score %> </div>'
//第一次渲染,会自动绑定到test的div上
var node = render('test', tmpl, student)
//如果我们需要更新成绩只需要调用setChunkData来局部刷新页面
node.setChunkData(score,100)
</script>首先我们会在需要更新的局部dom上打上标签tpl-name="sc" tpl-key="score",代表这里的dom第二次渲染需要依赖score这个变量,并且这个局部模板有了唯一标识sc。然后当我们需要更新成绩的时候只需要调用node.setChunkData(score,100)就可以找到依赖score这个变量对应的dom并且自动使用局部模板去刷新页面了。
可以看到这样带来了不少好处,我们可以继续享受模板带来的便利性,也可以局部刷新页面中的某个区块。而这一切都是建立在数据上的,我们的逻辑处理永远在数据这一层,面向数据编程。而渲染,局部渲染都会自动帮忙完成。
那么达到这样的功能我们需要做什么呢?
tpl-key这样的标签,我们需要特殊处理,把子模板记录下来,并且记录tpl-name,作为对应。我们看一个最简单的实现(基于上面的template增强而来):
//此函数依赖上面的template函数
var render = function(id, tpl,data){
//初次渲染,直接使用以前的template函数
document.getElementById(id).innerHTML = template(tpl)(data)
//下面都是局部渲染需要的逻辑
var tpls = []//存放局部刷新的模板
//解析模板,找到局部模板 这边的getSubTpls可以先不管,只需要知道返回结果为:
//[{name:'sc',key:score,tpl:'<span>成绩:</span> <% score %> '}]
tpls = getSubTpls(tpl)
//用于根据依赖的key找到对应的那些模板
function getChunkTpl(key){
var results = []
for(var i= tpls.length-1;i>-1;i--){
if(tpls[i].key === key){
results.push(tpls[i])
}
}
return results
}
return {
setChunkData:function(key,value){
var subData = {}
subData[key] = value
var subNode
var subTpls = getChunkTpl(key) //匹配到对应的局部模板,可能有多个
for(var i=0;i<subTpls.length;i++){
//这里为了图方便直接用querySelector了
subNode = document.querySelector('[tpl-name="' + subTpls[i].name + '"]')
//渲染好,刷新局部dom
subNode.innerHTML = template(subTpls[i].tpl)(subData)
}
}
}
}
基本实现了我们需要的功能,逻辑上也不复杂,提前准备好局部模板,在setChunkData时通过key找出对应的局部模板还有dom节点,这样就可以达到局部刷新的目的。
下面看下getSubTpls的实现,这个如果不感兴趣可以直接跳过,毕竟已经是过时的技术了。
//这个方法是用来获取一个tag下面的字符串
//getTagInnerHtml('<div><span></span><div id='1'></div></div>',div,0,0)
//可以匹配出<span></span><div id='1'></div>
function getTagInnerHtml(tpl, tag, s_pos, offset) {
var s_tag = '<' + tag
var e_tag = '</' + tag + '>'
var s_or_pos = s_pos + offset
var e_pos = s_pos
var e_next_pos = s_pos
s_pos = tpl.indexOf(s_tag, s_pos)
var s_next_pos = s_pos + 1
while (true) {
s_pos = tpl.indexOf(s_tag, s_next_pos);
e_pos = tpl.indexOf(e_tag, e_next_pos);
if (s_pos == -1 || s_pos > e_pos) {
break
}
s_next_pos = s_pos + 1
e_next_pos = e_pos + 1
}
return {
html: tpl.substring(s_or_pos, e_pos)
}
}
function getSubTpls(tpl){
//用来匹配带有标签的tag的正则
var tplTagReg = /<([\w]+)\s+[^>]*?tpl-name=["\']([^"\']+)["\']\s+[^>]*?tpl-key=["\']([^"\']+)["\']\s*[^>]*?>/g
var match,tagInfo
var tpls = []
while(match = tplTagReg.exec(tpl)) {
tagInfo = getTagInnerHtml(tpl,match[1],match.index,match[0].length)
tpls.push({
name:match[2],
key:match[3],
tpl: tagInfo.html
})
}
return tpls
}
关键是getTagInnerHtml的实现,由于javascript没有平衡组的概念,所以不得不写这么一长串的处理逻辑,具体参考
http://lf-6666.blog.163.com/blog/static/3123705200942155416430/
http://thx.github.io/brix-core/articles/tpl-3/
至此基本功能就完成了。在一段时间里也够用了。
实际的代码,需要处理的问题更多,需要处理好父子级局部模板,多个数据并列依赖等等问题,由于已经是过时的技术了,这里就不详细展开了,有兴趣的可以到这里了解。
但是其实还是有些显而易见的问题:
setChunkData私有方法,需要到模板找到对应的依赖数据,需要自己去把握逻辑这个时候我们渐渐发现字符串模板已经走到头了。面对日新月异的前端开发,尤其是单页应用,普通的字符串模板已经不能满足需求了。
因为字符串模板的种种缺陷,在新的大时代背景下,尤其是前端各种框架的井喷时代。各种各样的框架实现了很多很有意思的东西,跳出了传统字符串模板的概念,但是的确实现了模板的功能。这个时候已经不适合称之为模板了。
我们先想想,我们上面探索局部刷新时遇到了什么问题。
首先我们需要保持跟模板的联系,这样我们下次需要局部刷新时才能找到对应的节点。比如我们上面是通过在dom节点上打标来实现的。
其次我们需要监听数据的变化,我们上面是直接使用私有方法setChunkData来通知引擎数据变化了,可以开始更新了。这样其实很不好,需要我们关注太多的东西。
另外如果我们多次调用setChunkData,那么就会渲染多次,除了最后一次前面的渲染都是没有必要的,所以我们还需要个批量更新的东西,前面的那些改动不需要真实的反应到dom上。
事实上,目前的主流框架虽然已经脱离了模板的范畴,但是也是紧紧围绕这几个方面来实现的。
当然目前还兴起了双向绑定的热潮,不过在传统的字符串模板里是难以实现的。
下面我们大概介绍下主流的几个框架的是如何实现模板功能的,具体分为下面这几点:
angularjs带来了很多前端界的新概念,指令,脏检测,filter等等等。
我们看下angularjs的大致图形
几个概念:
三个大模块:
Provider:
DOMCompiler:
Scope:
怎么串起来:
<span ng-bind="a + 'hello'"></span>我们看看ng-bind这个指令的实现:
Provider.directive('ng-bind', function () {
return {
link: function (el, scope, exp) {
//初次渲染的逻辑
el.innerHTML = scope.$eval(exp);
//添加一个观察者,当在下一次脏检测发现数据改变时就执行回调逻辑
scope.$watch(exp, function (val) {
el.innerHTML = val;
});
}
};
});初始化时:DOMCompiler遍历dom节点,找到指令定义,执行link,写dom。并且通过scope的方法增加watcher观察者。
更新时:调用scope的digest,这个时候会遍历所有watchers,拿新的值跟旧的值做对比,如果不同就执行回调。
所以对于我们这边的简单例子来说,第一次初始化时,通过link函数我们第一次使用innerHTML来渲染dom。同时添加了一个watcher,这样在框架下次脏检测时,检测到数据变化就会调用回调里的逻辑,这里就是重新innerHTML。
具体可以看看这篇文章了解下它内部的渲染逻辑。
当然这里只是给出了最简单的实现,其实这类模板的难点在于for,if这种指令的实现。这里受限于篇幅就不详细展开了。
所以,angular的局部刷新,就是通过指令的私有逻辑来实现的。提出了一些比较好玩的概念。
我们再对比下之前说的那几个点:
如何监听数据的变化:通过脏检测,用户在代码中调用scope.$digest()方法,在angularjs里面框架会在某些时候帮你调用。脏检测会负责遍历scope上面的所有观察者watcher。对比表达式的上一次值与现在的值,如果发现数据变化就会调用添加的回调逻辑。
如何渲染更新页面定位节点位置:通过指令,本身已经有了dom引用,一些特殊情况,会使用注释节点做占位符。
如何实现双向绑定:实现model指令,监听数据改变后先修改data数据,之后调用digest来一次脏检测更新就行了。
如何实现批量更新:脏检测本身就是批量的,因为是一次性调用digest才开始统一检查数据变化。
vue在学习angular的基础上,做了些精简还有优化。vue只负责处理view,其实是模板+组件方案+动画。我们这里主要看他的模板方面的原理
原理其实类似,也是有指令还有watcher的概念,只是去掉了scope,去掉了脏检测而是使用get set来做数据的变化监听。
首先你需要先了解下defineProperty,这个特性,可以达到在你对一个属性读或者写的时候写上自己的钩子函数。
整个原理是这样:
可以看到跟angular不同的地方主要在于,指令职责更细,另外有暴力的全部watcher检测,变成了通过set的钩子来指向性的找到对应的watcher做数据变更检测。所以在更新性能上会明显优于脏检测。
具体原理可以参考:http://cn.vuejs.org/guide/reactivity.html
还有:http://jiongks.name/blog/vue-code-review/
其实这些缺点也都是angular会有的缺点,可以说vue已经解决了大部分的angular会有的问题。不过为了使用defineproperties放弃了支持ie8,对于国内的环境来说,ie8还是难以割舍。
reactjs创造性的提出了虚拟dom的概念,完全改变了前端的开发方式
react,其实就是虚拟dom与真实dom的互动。
最上面的text,basic element,custom element都是我们通常说的virtual dom。我们先不管红色的自定义组件节点custom element。
每一个virtual dom都有一个对应的Component来管理。Component具有两个方法:mountComponent还有receiveComponent分别负责处理初次渲染还有更新的逻辑。
react初次渲染就是拼接出字符串。每种virtual dom会调用自己的Component对应的mountComponent来得到渲染之后的内容。比如对于text就直接返回个span包裹的文本,对于basic element,需要先处理自身属性,再调用子节点对应的Component的mountComponent,最后全部拼接好,一次性的innerHTMl到页面上。
更新的时候,react里面一般是通过setState来赋予一个新的值,这样内部再调用receiveComponent来处理逻辑。对于basic element,就是先更新属性,再去更新子节点。这里有套算法,能复用的就直接调用子节点的receiveComponent。否则就是一次重新的mountComponent渲染(diff,patch)。对于text节点,直接是innerHTML更新。
具体原理参考:http://purplebamboo.github.io/2015/09/15/reactjs_source_analyze_part_one/
如何监听数据的变化:很原始的get set(setState),跟我们最上面的setChunkData类似
如何渲染更新页面定位节点位置:不需要直接引用真实dom,引用虚拟dom就行。虚拟dom根据id来跟真实dom一一对应。
如何实现双向绑定:原生不支持双向绑定,不过有插件形式的替代方案。
如何实现批量更新:执行方法时会包裹一个batchUpdate。这样所有的setState会执行完以后再统一去diff。
不管是 angularjs,vuejs,或者是reactjs,总感觉用起来不是那么顺手,原因是我们已经习惯了传统意义上的模板写法。所以这种dom based的模板总会有这样那样的限制,导致我们不能很顺畅的去开发。
上面这几种,目前我是比较喜欢vue的设计理念的,但是它也有着我们难以接受的缺点。不能说vue不优秀,只是的确不适合我们的业务。
那么我们是不是可以改造下,是否可以结合virtual dom 跟 指令的优势?
vue的指令是直接操作dom的,如果加一层virtual dom,实现大部分dom方法。让指令引用virtual dom,由virtual dom来操作真实dom。这样其实就可以解决掉vue的大部分问题。
我们可以先把模板解析成一个ast(抽象语法树)结构的虚拟dom树。然后去解析这个树,分析出各种依赖信息。这比vue直接使用原生dom会好很多。
指令不会直接跟dom打交道,而是跟虚拟dom打交道。
对于初次的渲染来说,各个指令会调用虚拟dom的方法,此时虚拟dom知道是初次渲染,所以只会更新自己,而不会修改真实的dom。在最后全部执行好后,一次性的innerHTML到页面中。有点跟react类似?
而更新的时候,仍然是指令的逻辑,只不过这个时候虚拟dom不仅仅会更新自身,也会同时更新真实的dom。
可以看到因为加了一层虚拟dom,解决了很多问题。
我们的基本原理还是vue的原理,但是通过一层中间虚拟dom层。我们可以做到:
所以 我做了pat,在vue的基础上加上vd的概念,当然还支持了ie8等等,为了支持业务做了一些改动。
一句话概括pat:
listener(defineProperties/dirtycheck) + directive + virtual dom
地址:http://purplebamboo.github.io/pat/doc/views/index.html
与目前主要的框架相比,pat具有以下特点:
目前的前端界各种框架满天飞,但是都或多或少的有所缺陷。有句话说的好,没有最完美的方案只有最适合的自己的方案。
在这样的背景下作为一个前端遇到问题该怎么办呢,我认为可以先找开源技术,但是当开源技术不能满足自己的需求时。可以在开源技术的基础上修改加上自己的东西从而更好的解决问题。
其实把模板解析成ast已经有很多框架在做了。都是看重了virtual dom的优势。比如下面这些:
总之前端的轮子真的太多了,但是无外乎那些解决方案,我们要做的就是了解这些方案,找到合适自己的,当没有特别合适的就拿一个加以改造解决自己的问题(于是又会造个轮子= =)。
javascript一直被人诟病的就是异步操作,总是带来很多的callback形成所谓的恶魔金字塔。传统意义上的前端浏览器开发遇到的还不多,
在后端nodejs开发时,这种情况经常遇到。如何处理这种异步操作,已经成为了一个合格的前端的必修课。下面整理一下最近了解过的各种异步编程知识。
##一个生活例子
假设还有1秒钟就到下班的点了,胖子虽然急着回家,但是也只能等着。
两件事:
第一件,下班。我们用个函数模拟下:
function offWork(callback){
console.log("上班ing。。。")
setTimeout(function(){
console.log("下班了。。。")
callback();
},1000);
}
第二件,回家。模拟如下:
function backHome(callback){
setTimeout(function(){
console.log("到家了!!!")
callback();
},1000);
console.log("回家ing。。。")
}
下班是1秒之后才发生的事情。所以 我们是不能这么干的。
offWork()
backHome()
还没下班,胖子就回家了。这样就等着被骂吧。
所以我们只能乖乖的投降,慢慢的等待。于是就有了下面这样的写法。
offWork(function(){
backHome()
})
恩看起来还不错。。是吧
但是,回家后还要吃饭,而且回家也是需要时间的。。吃饭后还要看睡觉,吃饭也是需要时间的,于是在javascript里面,我们就变成了这样写。
offWork(function(){
backHome(function(){
eatFood(function(){
sleep(function(){
。。。。
})
})
})
})
这就是恶魔金字塔问题了。
所以callback虽然可以简单的解决异步调用问题。但是异步一多,就会让人无法忍受,我们需要一些新的方式。下面就介绍几种目前比较火的方式。
##事件发布订阅方式
这种方式使用一种观察者的设计模式
不知道什么是观察者模式的可以先去补补23种设计模式。建议通过java这些比较成熟的语言来了解这些模式。javascript虽然也可以实现,但个人觉得不适合初学者很好的理解。
所谓的观察者模式,是定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新。
说白了,就是我们平时使用的事件机制。
为了更好的理解。首先我们实现一个最简单的事件监听程序。
var Observer = function(){
this._callbacks = {};
this._fired = {};
};
Observer.prototype.addListener = function(eventname, callback) {
this._callbacks[eventname] = this._callbacks[eventname] || [];
this._callbacks[eventname].push(callback);
return this;
}
Observer.prototype.removeListener = function(eventname,callback){
var cbs = this._callbacks,cbList,cblength;
if(!eventname) return this;
if(!callback){
cbs[eventname] = [];
}else{
cbList = cbs[eventname];
if (!cbList) return this;
cblength = cbList.length;
for (var i = 0; i < cblength; i++) {
if (callback === cbList[i]) {
cbList.splice(i, 1);
break;
}
}
}
}
Observer.prototype.fire = function(eventname,data){
var cbs = this._callbacks,cbList,i,l;
if(!cbs[eventname]) return this;
cbList = cbs[eventname];
if (cbList) {
for (i = 0, l = cbList.length; i < l; i++) {
cbList[i].apply(this,Array.prototype.slice.call(arguments, 1));
}
}
}
可以看到原来很简单,将事件对应的处理函数储存起来,fire的时候拿出来调用。这样一个简单的事件监听就弄好了,当然这只是个非常简陋的原型。= =就不要在意太多细节了。
现在我们可以这么写了:
var observer = new Observer();
observer.addListener('backHomed',function(){
//eatFood(function(){
//.....
//});
})
observer.addListener('offworked',function(){
backHome(function(){
observer.fired('backHomed');
});
})
offWork(function(){
observer.fire('offworked');
})
可以看到,事件监听极大的减少了各个任务之间的耦合。有效的解决了恶魔金字塔的问题。but,看着还是好刺眼啊。代码组织起来还是很吃力。
我们需要做点什么,改造下任务函数再加点扩展。扩展之后我们可以这么调用:
var observer = new Observer();
observer.queue([offWork,backHome],function(data){
console.log("eating");
});
我们看下queue的扩展代码:
Observer.prototype.queue = function(queue,callback){
var eventName = '';
var index= 0;
var data = [];
var self = this;
var task = null;
var _getFireCb = function(ename){
return function(val){
val = val || null;
self.fire(ename,val);
}
}
var _next = function(){
if((task = queue.shift()) != undefined){
eventName = 'queueEvent' + index++;
self["addListener"](eventName, function(val){
data.push(val);
_next();
})
task.call(this,_getFireCb(eventName));
}else{
callback.apply(null, [data]);
}
}
_next();
}
实现思路是这样的,从队列里挨个的取出task,增加事件监听,自动生成callback注入,这样task执行完后会fire一下。监听的回调函数里再调用_next拿出下个task重复流程。
有的时候我们对于顺序并不看重,比如对于吃饭这个问题,a,b,c吃饭,只要三个人都吃完了就可以去结账了。他们谁先吃完我们都不用管,如果按照上面的思路,就得a先吃,a吃完b吃,b吃完再c吃。白白浪费很多时间,我们需要发挥异步的优势,采用并行的执行方式。所以有了下面的when扩展。
function aEat(callback){
setTimeout(function(){
console.log("a吃完了。。。")
callback();
},1000);
}
function bEat(callback){
setTimeout(function(){
console.log("b吃完了。。。")
callback();
},1000);
}
var observer = new Observer();
observer.when("a-eat-ok","b-eat-ok",function(data){
console.log("结账");
});
aEat(function(){
observer.fired('a-eat-ok');
})
bEat(function(){
observer.fired('b-eat-ok');
});
我们看下when的实现方式:
Observer.prototype.when = function(){
var events,callback,i,l,self,argsLength;
argsLength = arguments.length;
events = Array.prototype.slice.apply(arguments, [0, argsLength - 1]);
callback = arguments[argsLength - 1];
if (typeof callback !== "function") {
return this;
}
self = this;
l = events.length;
var _isOk = function(){
var data = [];
var isok = true;
for (var i = 0; i < l; i++) {
if(!self._fired.hasOwnProperty(events[i])||!self._fired[events[i]].hasOwnProperty("data")){
isok = false;
break;
}
var d = self._fired[events[i]].data;
data.push(d);
}
if(isok) callback.apply(null, [data]);
}
var _bind =function(key){
self["addListener"](key, function(data){
self._fired[key] = self._fired[key] || {};
self._fired[key].data = data;
_isOk();
})
}
for(i=0;i<l;i++){
_bind(events[i]);
}
return this;
}
这段代码。其实不难,也是基于上面的事件基础上实现的。实现方法主要是对所有的事件进行监听。每个事件触发后,都会去检查其他事件是否都已经触发完毕了。如果发现都触发了就调用回调函数。当然这个扩展只适合不讲究顺序的并行执行情况。
上面的例子大部分参考eventproxy的实现,有兴趣的人可以去了解一下。
##Promise 和 Defferred
Promise是一种规范,Promise都拥有一个叫做then的唯一接口,当Promise失败或成功时,它就会进行回调。它代表了一种可能会长时间运行而且不一定必须完成的操作结果。这种模式不会阻塞和等待长时间的操作完成,而是返回一个代表了承诺的(promised)结果的对象。Defferred就是之后来处理回调的对象。二者紧密不可分割。
如果有了promise,我们可以这么调用上面的例子:
function start(){
var d = new Deffered();
offWork(function(){
d.resolve('done----offWork');
})
return d.promise;
}
start().then(function(){
var d = new Deffered();
backHome(function(){
d.resolve('done----backhome');
})
return d.promise;
}).then(function(){
/** var d = new Deffered();
eatFood(function(){
d.resolve('done----eatFood');
})
return d.promise;**/
console.log('eating');
})
看起来清晰多了吧。通过then可以很方便的按顺序链式调用。
下面我们来实现一个基础的promise:
var Deffered = function(){
this.promise = new Promise(this);
this.lastReturnValue = '';
}
Deffered.prototype.resolve = function(obj){
var handlelist = this.promise.queue;
var handler = null;
//var returnVal = obj;
if(obj) this.lastReturnValue = obj;
this.promise.status = 'resolved';
while((handler = handlelist.shift()) != undefined){
if (handler&&handler.resolve) {
this.lastReturnValue = handler.resolve.call(this,this.lastReturnValue);
if (this.lastReturnValue && this.lastReturnValue.isPromise) {
this.lastReturnValue.queue = handlelist;
return;
}
}
}
}
Deffered.prototype.reject = function(obj){
var handlelist = this.promise.queue;
var handler = null;
//var returnVal = obj;
if(obj) this.lastReturnValue = obj;
this.promise.status = 'rejected';
while((handler = handlelist.shift()) != undefined){
if (handler&&handler.reject) {
this.lastReturnValue = handler.reject.call(this,this.lastReturnValue);
if (this.lastReturnValue && this.lastReturnValue.isPromise) {
this.lastReturnValue.queue = handlelist;
return;
}
}
}
}
var Promise = function(_deffered){
this.queue = [];
this.isPromise = true;
this._d = _deffered;
this.status = 'started';//three status started resolved rejected
}
Promise.prototype.then = function(onfulled,onrejected){
var handler = {};
var _d = this._d;
var status = this.status;
if (onfulled) {
handler['resolve'] = onfulled;
}
if (onrejected) {
handler['reject'] = onrejected;
}
this.queue.push(handler);
if (status == 'resolved') _d.resolve();
if (status == 'rejected') _d.reject();
return this;
}
首先我们先看promise部分,Promise有三种状态。未完成(started),已完成(resolved),失败(rejected)。Promise只能是由未完成往 另外两种状态转变,而且不可逆。
我们先是定义了一个队列,用来存放所有的回调函数包括正确完成的回调(onfulled)和失败的回调(onrejected)。
this.isPromise = true;用来表明是一个promise对象。
this._d = _deffered;是用来存储与这个promise对象对应的deffered对象的。
deffered对象一般具有resolve还有reject方法分别代表开始执行队列里handle相应的回调。
promise有一个then方法,用来声明完成的函数,还有失败的函数。
this.queue.push(handler);
if (status == 'resolved') _d.resolve();
if (status == 'rejected') _d.reject();
这段代码先是将回调对象储存起来,后面的两个判断,是用来当一个promise对象已经不是未完成时直接调用then添加的回调。
下面我们看下Deffered对象,首先有个promise对象的引用。还有个lastReturnValue,这个是用来储存promise队列里面的handle回调的返回值的。
我们重点看下Deffered.prototype.resolve:
Deffered.prototype.resolve = function(obj){
var handlelist = this.promise.queue;
var handler = null;
//var returnVal = obj;
obj && this.lastReturnValue = obj;
this.promise.status = 'resolved';
while((handler = handlelist.shift()) != undefined){
if (handler&&handler.resolve) {
this.lastReturnValue = handler.resolve.call(this,this.lastReturnValue);
if (this.lastReturnValue && this.lastReturnValue.isPromise) {
this.lastReturnValue.queue = handlelist;
return;
}
}
}
}
还记得我们怎么调用的吗?
没错,我们先要创建一个deffered对象,之后返回他的promise对象。通过then,我们给这个promise添加了很多的异步正确完成回调。同时这些回调也返回自己的promise对象。此时backHome对应的deffered对象关联的promise里面已经通过then添加了很多回调函数。但是并未执行。
在start函数里面当backhome完成时 我们执行了d.resolve('done----backhome');
这个 时候调用了backHome对应的deffered对象的resolve。
while((handler = handlelist.shift()) != undefined){
if (handler&&handler.resolve) {
this.lastReturnValue = handler.resolve.call(this,this.lastReturnValue);
if (this.lastReturnValue && this.lastReturnValue.isPromise) {
this.lastReturnValue.queue = handlelist;
return;
}
}
}
backHome对应的deffered对象的resolve里面开始循环调用回调队列里的函数。同时backHome对应的deffered对象关联的promise的状态已经变成了已完成。
请注意下面这个判断:
if (this.lastReturnValue && this.lastReturnValue.isPromise) {
this.lastReturnValue.queue = handlelist;
return;
}
当then添加的是一个普通非异步函数时。就会继续取出队列的函数执行。但是当添加的函数也返回了一个promise,这时候话语权就要交给这个新的promise了,当前队列的执行就要停下来,同时将当前的操作函数队列赋值给新的peomise的队列,完成交接。之后就又是一个新的promise从未完成到另外状态的过程了,只有新的promise被resolve或者reject了,下面的才会继续执行下去。
可以看到通过promise和deffered,事件的声明和调用完全分开了。一个负责管理函数一个负责调用。非常灵活优雅。
promise与很多开源库实现了,比较出名的是when.js,Q,有兴趣的可以去了解下。
##尾触发机制
这是connect中间件使用的方式,可以串行处理异步代码。当然这只是一种实现思路,不具备通用性,所有任务都需要一个next参数。我们需要对前面的代码做些小改造。
function offWork(data,next){
console.log("上班ing。。。")
setTimeout(function(){
console.log("下班了。。。")
next('传给下个任务的数据');
},1000);
}
function backHome(data,next){
console.log('上个任务传过来的数据为:'+data);
setTimeout(function(){
console.log("到家了!!!")
next('传给下个任务的数据');
},1000);
console.log("回家ing。。。")
}
App = {
handles:[],
use:function(handle){
if(typeof handle == 'function')
App.handles.push(handle);
},
next:function(data){
var handlelist = App.handles;
var handle = null;
var _next = App.next;
if((handle = handlelist.shift()) != undefined){
handle.call(App,data,_next);
}
},
start:function(data){
App.next(data);
}
}
每个任务,都必须有两个参数,next是一个函数引用,等当前任务结束时,需要手动调用next,就可以启动下一个任务的运行,当然可以通过next(data)传一些数据给下一个任务。任务的第一个参数就是上一个任务调next的时候传过来的数据。
于是我们可以这么调用了:
App.use(offWork);
App.use(backHome);
App.start();
显然调用过程非常直观,这个方式的缺点就是需要对每个任务进行相应的改造。而且只能是串行的执行,不能很好的发挥异步的优势。
##wind.js
还有种比较知名的方式,是国内的程序员老赵的wind.js,它使用了一种完全不同的异步实现方式。前面的所有方式都要改变我们正常的编程习惯,但是wind.js不用。它提供了一些服务函数使得我们可以按照正常的思维去编程。
下面是一个简单的冒泡排序的算法:
var compare = function (x, y) {
return x - y;
}
var swap = function (a, i, j) {
var t = a[i]; a[i] = a[j]; a[j] = t;
}
var bubbleSort = function (array) {
for (var i = 0; i < array.length; i++) {
for (var j = 0; j < array.length - i - 1; j++) {
if (compare(array[j], array[j + 1]) > 0) {
swap(array, j, j + 1);
}
}
}
}
很简单就不讲解了,现在的问题是我们如果要做一个动画,一点点的展示这个过程呢。
于是我们需要给compare加个延时,并且swap后重绘数字展现。
可javascript是不支持sleep这样的休眠方法的。如果我们用setTimeout模拟,又不能保证比较的顺序的正确执行。
可是有了windjs后我们就可以这么写:
var compareAsync = eval(Wind.compile("async", function (x, y) {
$await(Wind.Async.sleep(10)); // 暂停10毫秒
return x - y;
}));
var swapAsync = eval(Wind.compile("async", function (a, i, j) {
$await(Wind.Async.sleep(20)); // 暂停20毫秒
var t = a[i]; a[i] = a[j]; a[j] = t;
paint(a); // 重绘数组
}));
var bubbleSortAsync = eval(Wind.compile("async", function (array) {
for (var i = 0; i < array.length; i++) {
for (var j = 0; j < array.length - i - 1; j++) {
// 异步比较元素
var r = $await(compareAsync(array[j], array[j + 1]));
// 异步交换元素
if (r > 0) $await(swapAsync(array, j, j + 1));
}
}
}));
注意其中最终要的几个辅助函数:
这样上面的代码就可以很容易的理解了。compare,swap都被弄成了异步函数,然后使用$await等待他们的执行完毕。可以看到跟我们之前的写法比起来,实现思路几乎一样,只是多了些辅助函数。相当的创新。
windjs的实现原理,暂时没怎么看,这是一种预编译的思路。之后有空看看也来实现一个简单的demo。
什么是generator?generator是javascript1.7的内容,是 ECMA-262 在第六个版本,即我们说的 Harmony 中所提出的新特性。所以,没错这个特性支持很一般。
有下面几种办法体验generator:
function* start() {
var a = yield 'start';
console.log(a);
var b = yield 'running';
console.log(b);
var c = yield 'end';
console.log(c);
return 'over';
}
var it = start();
console.log(it.next(11));//Object {value: "start", done: false}
console.log(it.next(22));//22 object {value: 'running', done: false}
console.log(it.next(333));//333 Object {value: 'end', done: false}
console.log(it.next(444));//444 Object {value: "over", done: true}
其实很好理解,function* functionname() {用来声明一个generator function。通过执行generator function我们得到一个generator,也就是it。
当我们调用it.next(11)的时候,代码会执行到var a = yield 'start';然后断点。注意这个时候还没有进行对a的赋值,这个时候it.next(11)返回一个对象有两个属性,value代表yield返回的东西,可以是值也可以是函数。done代表当前generator有没有结束。
当我们调用 it.next(22)的时候,代码开始执行到var b = yield running;。此时你发现打出了22,没错a的值被赋为22,也就是说next里面的参数会作为上一个yield的返回值。
一直到调用it.next(444),代码一直执行到return,这个时候 函数的返回值就作为 next返回对象的value值,也就是我们的over。
这就是generator的全部内容了
详细的可以参考这边的MDN的介绍,猛戳这里
那我们如何将它应用在我们的异步代码上呢?
实际上TJ大神已经做了这件事,编写了一个CO的库。
我们简单探讨下CO的原理
假设我们需要知道小胖回家的总时间。
有了co框架后 我们可以这么完成我们上面的代码:
function offWork(callback){
console.log("上班ing。。。")
setTimeout(function(){
console.log("下班了。。。")
callback(1);
},1000);
}
function backHome(callback){
setTimeout(function(){
console.log("到家了!!!")
callback(2);
},2000);
console.log("回家ing。。。")
}
co(function* () {
var a;
a = yield offWork;
console.log(a);
a = yield backHome;
console.log(a);
})(function(data) {
console.log(data);
})
//结果为:
/*
上班ing。。。
下班了。。。
1
回家ing。。。
到家了!!!
2
2
*/
co函数接收一个generatorfunction作为参数,生成一个实际操作函数。这个实际操作函数可以接收一个callback来传入最后一个异步任务的回调值。
可以看到我们可以直接使用a = yield offWork;来获取异步函数offwork的返回值。真的是太赞了,而且我们可以提供一个回调用来接收最后回调的值,这边就是backHome回调的值。
下面我们来实现这个函数:
function *co(generatorFunction){
var generator = generatorFunction();
return function(cb){
var iterator = null;
var _next = function (args){
iterator = generator.next(args);
if(iterator.done){
cb&&cb(args);
}else{
iterator.value(_next);
}
}
_next();
}
}
代码很简单,就是不停的调用generator的next,当next返回的对象的done属性不为空时就执行返回的异步函数。注意那边args的传递。
可以看到短短几行就实现了这个功能,当然实际的co框架比这个复杂的多,这边只是实现了最基础的原理。
使用co时,yield的必须是thunk函数,thunk函数就是那种参数只有一个callback的函数,这个可以使用一些方法转换,也有一些库支持,可以了解下thunkify 或者thunkify-wrap。
这边给个简单的普通nodejs读文件函数到thunk函数的转换。
function read(file) {
return function(fn){
fs.readFile(file, 'utf8', fn);
}
}
//于是可以这么用
co(function* () {
var a;
a = yield read('.gitignore');
})(function(data) {
})
##结语
javascript是一门短时间内就创出的语言,虽然很灵活,但是很容易写出糟糕的代码。异步编程,在性能问题上尤其是io处理上是它的优势,但是同时也是它的劣势,大部分人都无法很好的组织异步代码。于是就出现了一大堆的库,来给它擦屁股。不得不说人类的智慧是无限的。上面这么多的异步流程库的实现就是很好的例子,没有最好的语言,只有最合适的。也没有最好的异步实现方式,关键是找到合适的。
除了上面介绍的这些实现异步编程的思路以外,其实还有很多优秀的实现方式,以后有空再研究下step,async等等的实现方式。
最近需要做这样一个需求,就是一个接口请求,服务器端执行时间比较长,过了好久才会返回内容,这个体验是很不好的。在浏览器端就会感觉浏览器死掉了。
优化方案就是给前端浏览器一些提示,所以需要一种实时的进度条一样的东西。告诉用户,当前到底执行到什么程度了。
首先以一个简单的例子来大概说明下问题,你去餐厅一屁股坐下来点完菜,菜要7秒种才能上来。(这边假设7秒已经很长时间了):
为了更容易理解,我们尽量使用原生的node代码实现。
服务端代码:
var http = require('http');
var fs = require('fs');
var url = require('url');
http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
if(path === '/api'){
//调用的接口点菜
//这是个需要7秒才能完成的任务
setTimeout(function() {
res.end('心好累,7秒后菜才好了。。。');
}, 7000);
}
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
console.log('Server listening on port 3000');
前端 index.html代码:
<!DOCTYPE html>
<html>
<head>
<title>长连接测试</title>
<script type="text/javascript" src='http://lib.sinaapp.com/js/jquery/1.7.2/jquery.min.js'></script>
<script type="text/javascript">
function _start(node){
$(node).attr('disabled','disabled');
/*后面前端代码基本只修改这边的其他的不变*/
/*修改区域开始*/
$.ajax({
url: "/api",
async: false,
success:function(data){
$('body').append('<div>'+data+'</div>');
}
})
/*修改区域结束*/
}
</script>
</head>
<body>
我就是个打酱油的。。
<button onclick="_start(this)">点菜</button>
</body>
</html>
我们以一个setTimeout来模拟一个7秒才能完成的任务.
运行后,访问:localhost:3000我们会看到index.html的内容,点击点菜按钮,会ajax请求/api的内容。7秒后我们才能看到内容。体验非常不好。我们需要改进下,在任务执行的过程中提前返回数据通知浏览器给些进度提示。
要实现这个需求,就我知道的有下面这些技术:
这是一种最古老,最简单粗暴的方式。轮询说白了就是不停的用ajax发请求问服务器,当前执行到什么程度了。
就好像你去餐厅一屁股坐下来点完菜,菜一直没上来,然后你每5秒种就叫服务员跑到厨房问下厨师菜几分熟了。
所以一般我们的做法是前端:
var interId = null;
//先调用耗时接口,就是你开始点菜
$.ajax({
url: "/api",
success:function(data){
//成功后,就可以取消轮询了。
clearInterval(interId);
$('body').append('<div>'+data+'</div>');
}
})
//使用轮询去查状态,开始叫服务员去问菜烧到几分熟了
function queryPercent(){
$.ajax({
url: "/pencent",
success:function(pencent){
$('body').append('<div>当前进度'+pencent+'</div>');
}
})
}
interId = setInterval(queryPercent,500)
后端一般是这样:
var http = require('http');
var fs = require('fs');
var url = require('url');
//定义一个菜几分熟的变量,在实际运用中,可能是针对不同请求存储在数据库中的。
//这边为了简单直接放在全局
var percent = '0%';
http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
//查看菜几分熟了
if(path === '/pencent'){
res.end(percent);
}
//调用的接口点菜
if(path === '/api'){
percent = '0%';
//5分熟的时候更新下状态
setTimeout(function() {
percent = '50%';
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
res.end('心好累,7秒后菜才好了。。。');
}, 7000);
}
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
console.log('Server listening on port 3000');
主要就是/api这个接口会更新一个全局的进度变量,这样我们可以再开一个接口,给前端不停的轮询请求查看进度。就是每500毫秒就让服务员去问一次。
结果是:
当前进度0%
当前进度0%
当前进度0%
当前进度0%
当前进度0%
当前进度0%
当前进度50%
当前进度50%
当前进度50%
当前进度50%
当前进度50%
当前进度50%
当前进度50%
心好累,7秒后菜才好了。。。
这样的缺点是很明显的,浪费很多请求。造成很多不必要的开销。
上面是额外开了个接口获取进度,而如果我们使用了长连接技术。可以不需要/pencent这个接口。
长连接说白了,就是浏览器跟服务器发一个请求,这个请求一直不断开,而服务器程序每过一段时间就返回一段数据。达到一种分块读取的效果。有数据就提前返回,而不用等所有数据都准备好了再返回。
这项技术的实现,归功于http1.1实现的 Transfer-Encoding: chunked。
当你设置了这个 http头。服务器的数据就不会整体的返回,而是一段一段的返回。可以参考这段wiki
nodejs原生支持分块读取,默认就打开了Transfer-Encoding: chunked。我们调用res.write(data)就会提前将数据分块返回给浏览器端。而在php里面 不仅需要改写header还要调用flush来提前响应。
我们修改下服务端代码:
var http = require('http');
var fs = require('fs');
var url = require('url');
http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
//调用的接口点菜
if(path === '/api'){
//5分熟的时候更新下状态
setTimeout(function() {
//提前响应数据
res.write('当前进度50%');
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
res.end('心好累,7秒后菜才好了。。。');
}, 7000);
}
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
console.log('Server listening on port 3000');
如果这时候你直接使用浏览器访问http://localhost:3000/api就会发现数据已经是一点一点的出来的了。
当然我们需要程序化的调用,前端使用分下面几种方式:
XMLHttpRequest其实有一个状态readyState = 3标识数据正在传输中。因此我们可以这样:
var lastIndex = 0;
var query = new XMLHttpRequest();
query.onreadystatechange = function () {
if (query.readyState === 3) {
//每次返回的数据responseText会包含上次的数据,所以需要手动substring一下
var info = query.responseText.substring(lastIndex);
$('body').append('<div>'+info+'</div>');
lastIndex = query.responseText.length;
}
}
query.open("GET", "/api", true);
query.send(null);
上面的代码我在chrome下面测试通过,显然这东西兼容性很差,ie什么的就不要指望了。
这也是一种曾经流行的方式,特点就是兼容性比较好。我们知道我们之前直接访问http://localhost:3000/api,页面上已经会一点点的出来数据了。我们可以在服务器端在数据外面包一层script标记,这样就可以调用前端页面上的函数,达到一种分段处理数据的目的。
首先改造下核心的服务端代码:
//调用的接口点菜
if(path === '/api'){
//这边一定要设置为text/html; charset=UTF-8,不然就不会有分段效果
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
//5分熟的时候更新下状态
setTimeout(function() {
res.write('<script> top.read("当前进度50%") </script>');
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
res.end('<script> top.read("心好累,7秒后菜才好了。。。") </script>');
}, 7000);
}
可以看到我们在数据外面包了一层script标签还有方法。
然后前端代码,使用一个隐藏的iframe来加载接口:
window.read = function(info){
$('body').append('<div>'+info+'</div>');
}
$('body').append('<iframe style="display:none" src="/api"></iframe>');
当iframe加载时,一块块加载,加载一块就会调用父iframe的read方法。这样就达到了一点点提示的目的。
实际上这也是bigpie这种技术的主要实现方式,只不过不需要iframe,直接在当前页面更新视图就好了。这边就不扯了。
另外按照这个原理,这边我还尝试了下 动态插入script的方式,但是发现不管怎样都不会有分段调用的过程,应该是浏览器会等js全部加载完之后才会执行里面的代码。
总之这种方式实现了一个接口分段返回信息的功能,但是只是单向的服务端传输,不存在可操作性。
这是后来比较流行的一种方式,Facebook,Plurk都曾经使用过。这个技术被称为服务器推送技术。其实原理也很简单,就是一个请求过去了,不要马上返回,等数据有更新了,再返回。这样可以减少很多无意义的请求。
跟上面的polling的对比就是,轮询是每5秒就去问一次,不管状态有没有更新。而长轮询是服务员跑过去问了,但是状态没更新就先不回去,因为回去了再跑过来是没意义的。所以就等状态更新后再返回告诉客人,熟到几分了。
比如上面的例子,只有5分熟的时候才会更新状态,所以如果用轮询的方式,可能来来回回好几趟,但是返回的结果一直都是0%.完全没有意义。
我们把上面的改造成长轮询:
前端js:
//先调用耗时接口,就是你开始点菜
$.ajax({
url: "/api",
success:function(data){
$('body').append('<div>'+data+'</div>');
}
})
//叫服务员去问菜烧到几分熟了,状态更新了再回来告诉我,没到100%就立即再去问。
function queryPercent(){
$.ajax({
url: "/pencent",
success:function(pencent){
$('body').append('<div>当前进度'+pencent+'</div>');
if (pencent != '100%') {
queryPercent();
}
}
})
}
queryPercent();
服务端改造为:
var http = require('http');
var fs = require('fs');
var url = require('url');
//定义一个菜几分熟的变量,在实际运用中,可能是针对不同请求存储在数据库中的。
//这边为了简单直接放在全局
var percent = '0%';
var isPencentUpate = false;
http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
//查看菜几分熟了
if(path === '/pencent'){
//实际应用中这边最好使用事件机制。否则只是把轮询放到了后端而已。
var tId = setInterval(function(){
if (isPencentUpate){
isPencentUpate = false;
clearInterval(tId);
res.end(percent);
}
},100);
}
//调用的接口点菜
if(path === '/api'){
percent = '0%';
//5分熟的时候更新下状态
setTimeout(function() {
isPencentUpate = true;
percent = '50%';
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
isPencentUpate = true;
percent = '100%';
res.end('心好累,7秒后菜才好了。。。');
}, 7000);
}
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
console.log('Server listening on port 3000');
结果为:
当前进度50%
心好累,7秒后菜才好了。。。
当前进度100%
/pencent的请求只会发两次,只在服务端程序发现状态变更的时候请求才会返回数据。也就是一种主动推送的概念。
这种技术,不仅减少了请求,而且弥补了上面长连接的不可交互的弊端。但是因为一直维持着一个连接会比较占用资源。特别是对php,ruby这种一个请求一个进程的模型来说是硬伤,不过node没有这个问题。基于事件的请求模型使他天生就适合这种方式。
虽然苹果放弃了flash,虽然越来越多的前端放弃flash转投h5的怀抱,但是不得不承认,有的时候flash还是可以实现很多功能。
主要是,使用javascript跟flash通信,用flash提供的XMLSocket来实现。但是这种毕竟已经越来越被淘汰了,这边就不展开细讲了。
另外据说还有种使用更小众的Java Applet的socket接口来实现的。这个也不考虑了。早就淘汰了n年的东西了。
上面提到的插件方式,说白了都是使用javascript借助别人的socket实现。万幸的是html5已经提出了websocket的概念,javascript也可以在浏览器端实现socket了。虽然ie系列肯定不支持,但是我们还是有必要了解下。
说了这么多,我们先要科普下socket。socket也叫做套接字,提供了一种面向tcp、udp的编程方式。我们知道http协议是无状态的一次请求型的。只有浏览器端发起请求才能建立一次会话。而socket可以建立双向的通信。
首先我们撇开浏览器,看下nodejs里面的socket用法:
我们先建立一个socket服务端(server.js):
var net = require('net');
var server = net.createServer(function(c) { //'connection' listener
console.log('server connected');
//这边的c是一个net.Socket实例,本质上是一个可读可写流。
c.on('end', function() {
console.log('server disconnected');
});
//这边调用write,客户端那边可以使用data监听到数据
c.write('客户端你好!\r\n');
c.write('客户端你幸苦了!\r\n');
//调用end同时会触发客户端那边的实例的end事件
c.end();
//客户端那边写过来的数据可以使用data事件获取到。
c.on('data', function(data) {
console.log(data.toString());
});
});
server.listen(8124, function() { //'listening' listener
console.log('server bound');
});
运行它
我们建立个socket客户端去连接这个服务端(client.js):
var net = require('net');
var client = net.connect({port: 8124},function() {
//'connect' listener
console.log('client connected');
//写数据到服务端
client.write('服务端你好!\r\n');
});
//获取服务器端写过来的数据
client.on('data', function(data) {
console.log(data.toString());
//client.end();
});
client.on('end', function() {
console.log('client disconnected');
});
运行client.js
服务端会打出
server bound
server connected
服务端你好!
server disconnected
客户端会打出:
client connected
客户端你好!
客户端你幸苦了!
client disconnected
这就是很简单的一个socket程序,可以看到这是一种双工通信。服务端可以写数据到客户端,客户端也可以写数据到服务端。相当的简洁高效。通过上面的例子我们可以理解socket的通信方式。
而我们现在需要的是一个服务端的socket不停的更新菜的信息,以及一个浏览器的客户端socket接受信息给用户展示。我们该怎么实现html5的socket呢:
可能第一反应就是服务端就用上面说的那个socket写法好了嘛。这是不对的,因为html5的socket协议跟这个node原生的socket是不同的,所以是不能结合使用的。详细websocket的介绍可以看这里,我们需要使用nodejs实现websocket draft-76的协议才行。万幸的是,社区里面已经有很成熟的模块:ws。这个就是个实现了websocket协议的服务端socket库。
首先安装ws:
npm install --save ws
服务端代码:
var http = require('http');
var fs = require('fs');
var url = require('url');
var net = require('net');
http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
var WebSocketServer = require('ws').Server
, wss = new WebSocketServer({ port: 8124 });
wss.on('connection', function connection(ws) {
//5分熟的时候更新下状态
setTimeout(function() {
ws.send('当前进度50%');
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
ws.send('心好累,7秒后菜才好了。。。');
}, 7000);
});
客户端代码:
var read = function(info){
$('body').append('<div>'+info+'</div>');
}
var websocket = new WebSocket("ws://127.0.0.1:8124/");
websocket.onmessage = function(evt){
read(evt.data);
}
当然我这边只用到了简单的服务端给浏览器发消息。并不是真正的双工通信。不过可以看到,这种写法真的是最优雅的。
上面的那么多写法,都是前人的各种经验,奈何兼容性总是欠缺,于是socket.io出来了。集大成者,兼容处理了上面的所有方式。他会按照这个顺序来挨个的尝试:
WebSocket
flash socket
XHR Polling 长连接
XHR 分段读取
Iframe 分段读
JSONP Polling 轮询
另外它同时封装了前端浏览器跟nodejs部分的api。使socket调用更加简单方便,并且可以跟普通的http请求结合在一起。
它分为两个库,一个客户端js,一个服务端nodejs库
我们看下有了socket.io我们的编码方式。
先安装服务端socket.ionpm install socket.io
服务端代码:
var http = require('http');
var fs = require('fs');
var url = require('url');
var net = require('net');
var server = http.createServer(function (req, res) {
var path = url.parse(req.url).pathname;
if(path === '/'){
//不是ajax接口,直接返回前端的html内容
var indexStr = fs.readFileSync('index.html');
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
res.end(indexStr);
}
}).listen(3000);
//将server对象托管给socket.io
var io = require('socket.io')(server);
//监听connection事件
io.on('connection', function(socket){
//5分熟的时候更新下状态
setTimeout(function() {
//fire一个pencent事件,这样可以在客户端监听这个事件获取数据
io.emit('pencent', '当前进度50%');
}, 3500);
//这是个需要7秒才能完成的任务
setTimeout(function() {
io.emit('pencent', '心好累,7秒后菜才好了。。。');
}, 7000);
});
前端js代码:
<!DOCTYPE html>
<html>
<head>
<title>长连接测试</title>
<script src="https://cdn.socket.io/socket.io-1.2.0.js"></script>
<script type="text/javascript" src='http://lib.sinaapp.com/js/jquery/1.7.2/jquery.min.js'></script>
<script type="text/javascript">
function _start(node){
$(node).attr('disabled','disabled');
var socket = io('http://localhost:3000');
socket.on('pencent', function(data){
$('body').append('<div>'+data+'</div>');
});
}
</script>
</head>
<body>
我就是个打酱油的。。
<button onclick="_start(this)">点菜</button>
</body>
</html>
可以看到使用socket.io直接就可以用事件的方式来传递消息了,非常的简单优雅,socket.io的底层也是使用的ws来实现的websocket协议,在这个上面再封装了事件机制,同时对于低级浏览器会做降级处理使用上面说的几种技术一个个的尝试。当然我没有看过socket.io的源码,这只是猜测。之后有空还是要详细看下源码,应该还有很多东西可以挖掘。
上面的总结探索都是网上各种查资料,再自己写例子实验出来的,感谢下面这些文章:
[1] 使用Node.JS构建Long Polling应用程序
[2] 基于 HTTP 长连接的“服务器推”技术
[3] Socket 通讯
[4] Browser 與 Server 持續同步的作法介紹
因为一个简单的需求,上网找资料。一下子牵扯出了好多知识点,不得不感慨程序员这行真是学习永无止尽。下次有空再详细看下socket.io的详细实现,相信又是一大堆新的知识。
发布在 http://purplebamboo.github.io/2015/09/15/reactjs_source_analyze_part_two/ 写得非常好,但是存在两个问题
但凡是比较成熟的服务端语言,都会有模块或者包的概念。模块化开发的好处就不用多说了。由于javascript的运行环境(浏览器)的特殊性。js很早之前一直都没有模块的概念。经过一代代程序猿们的努力。提供了若干的解决方案。
为了解决模块化的问题。早期的程序员会把代码放到某个变量里。做一个最简单的命名空间的划分。
比如一个工具模块:util
var util = {
_prefix:'我想说:',
log:function(msg){ console.log(_prefix +msg)}
/*
其他工具函数
*/
}这样所有的工具函数都托管在util这个对象变量里,极其简陋的弄了个伪命名空间。这样的局限性很大,因为我们可以随意修改。util不存在私有的属性。_prefix这个私有属性,后面可以随意修改。而我们很难定位到到底在哪边被修改了。
后来,一些程序员想到了方法解决私有属性的问题,有了下面这种写法:
var util = (function(window){
var _prefix = '我想说:';
return {
log:function(msg){ console.log(_prefix +msg)}
}
})(window)主要使用了匿名函数立即执行的技巧,这样 _prefix 是一个匿名函数里面的局部变量,外面无法修改。但是log这个函数里面又因为闭包的关系可以访问到_prefix。只把公用的方法暴露出去。
这是后来模块划分的主要技巧,各大库比如jQuery,都会在最外层包裹这样一个匿名函数。
但是这只是在同一个文件里面的技巧,如果我们把util单独写到一个文件util.js。而我们程序的主代码是main.js那我们需要在页面里面一起用script标签引入:
<script src="main.js"></script>
<script src="util.js"></script>这会有不少问题,最典型的比如如果我们的main.js如下:
util.log('我是模块主代码,我加载好了')这个就执行不了,因为我们的util.js是在main.js后面引入的。所以执行main.js的内容的时候util还没定义呢。
不止这个问题,再比如如果引入了其他的js文件,并且也定义了util这个变量。就会混乱。
node作为javascript服务端的一种应用场景,加入了文件模块的概念,主要是实现的CommonJS规范。
后来一些程序员就想,服务端可以有文件模块。浏览器端为什么就不可以呢。但是CommonJS规范是设计给服务端语言用的,不适合浏览器端的js。
于是出现了amd规范,并且在这个基础上出现了实现amd规范的库requirejs。
后来国内的大神玉伯由于多次给requirejs提建议(比如用时定义)一直不被采纳。于是另起炉灶制作了seajs。慢慢的也沉淀出了seajs的cmd规范。
关于模块规范的具体历史,可以参考:seajs/seajs#588
两个规范差别并不是很大,可能由于写node习惯了,个人更喜欢cmd的编写方式。
首先我们看看基于cmd规范(其实就是seajs)后我们怎么写代码:
//util.js
define(function(require, exports, module){
var _prefix = '我想说:';
module.exports = {
log:function(msg){ console.log(_prefix +msg)}
}
})
///main.js
define(function(require, exports, module){
var util = require('util')
util.log('我是模块主代码,我加载好了')
})
///index.html
<html>
<head>
<script src="seajs.js"></script>
</head>
<body>
<script type='text/javascript'>
seajs.use(["main"])
</script>
</body>
</html>seajs的书写风格跟node很像。
seajs会自动帮你加载好模块的文件,并且正确的处理依赖关系。于是前端终于也可以使用模块化的开发方式了。
下面我们来实现一个简单的cmd模块加载器程序,也可以当作是seajs的核心源码分析。
cmd模块规定一个模块一个文件,当我们require('util')的时候需要找到对应的文件,一般会加上根路径。默认情况下加载模块的根路径就是seajs.js所在目录。如何获取这个目录地址呢?我们只要在seajs.js里面写上:
var loadderDir = (function(){
//使用正则获取一个文件所在的目录
function dirname(path) {
return path.match(/[^?#]*\//)[0]
}
//拿到引用seajs所在的script节点
var scripts = document.scripts
var ownScript = scripts[scripts.length - 1]
//获取绝对地址的兼容写法
var src = ownScript.hasAttribute ? ownScript.src :ownScript.getAttribute("src", 4)
return dirname(src)
})()这边有两个小技巧:
scripts[scripts.length - 1]拿到引用seajs.js的那个script节点引用。getAttribute("src", 4)的方式获取绝对地址。参考这里。ie67下没有 hasAttribute属性,所以就有了获取绝对地址的兼容写法。模块加载是建立在文件加载器基础上的。在浏览器环境下我们可以通过动态生成script标记的方式,加载js。我们写一个简单js文件加载器:
var head = document.getElementsByTagName("head")[0]
var baseElement = head.getElementsByTagName("base")[0]
;function request(url,callback){
var node = document.createElement("script")
var supportOnload = "onload" in node
if (supportOnload) {
node.onload = function() {
callback()
}
}else {
node.onreadystatechange = function() {
if (/loaded|complete/.test(node.readyState)) {
callback()
}
}
}
node.async = true
node.src = url
//ie6下如果有base的script节点会报错,
//所以有baseElement的时候不能用`head.appendChild(node)`,而是应该插入到base之前
baseElement ? head.insertBefore(node, baseElement) : head.appendChild(node)
}
主要就是动态生成一个script节点加载js,监听事件触发回调函数,没什么难度,算是一个工具函数,给下面的模块使用。
终于到了重头戏。我们需要引入一个模块类的概念。util,main这些都是一个模块。模块有自己的依赖,有自己的状态。
我们先定义一个模块类:
function Module(uri,deps){
this.uri = uri
this.dependencies = deps || []
this.factory = null
this.status = 0
// 哪些模块依赖我
this._waitings = {}
// 我依赖的模块还有多少没加载好
this._remain = 0
}1.uri代表当前模块的地址,一般是使用baseUrl(就是上面的loadderDir)+ id + '.js'
2.dependencies是当前模块依赖的模块。
3.factory就是我们定义模块时define的参数function(require, exports, module){}
4.status代表当前模块的状态,我们先定义下面这些状态:
var STATUS = Module.STATUS = {
// 1 - 对应的js文件正在加载
FETCHING: 1,
// 2 - js加载完毕,并且已经分析了js文件得到了一些相关信息,存储了起来
SAVED: 2,
// 3 - 依赖的模块正在加载
LOADING: 3,
// 4 - 依赖的模块也都加载好了,处于可执行状态
LOADED: 4,
// 5 - 正在执行这个模块
EXECUTING: 5,
// 6 - 这个模块执行完成
EXECUTED: 6
}5._waitings存放着依赖我的模块实例集合,_remain则代表我还有多少依赖模块是处于不可用,也就是上面的小于LOADED的状态。
这个的作用是什么呢?
是这样的,比如A模块依赖B,C模块。那么A模块装载的时候会先去通知B,C模块把自己(A)加入到他们的_waitings里面。当B模块装载好了,就可以通过遍历B自己的_waitings去更新依赖它的模块比如A的_remain值。B发现更新后A的_remain后不为0,就什么也不做。直到C也好了,C更新下A的_remain值发现为0了,就会调用A的完成回调了。
如果B,C有自己的依赖模块也是一样的原理。
而如果一个模块没有依赖的模块,就会立即进入完成状态,然后通知依赖它的模块更新_remain值。他们处于最底端,往上一级级的去更新状态。
模块相互之间的通知机制就是这样,那么状态是如何变化的呢。
我们给模块增加一些原型方法:
//用于加载当前模块所在文件
//加载前状态是STATUS.FETCHING,加载完成后状态是SAVED,加载完后调用当前模块的load方法
Module.prototype.fetch = function(){}
//用于装载当前模块,装载之前状态变为STATUS.LOADING,主要初始化依赖的模块的加载情况。
//看一下依赖的模块有多少没有达到SAVED的状态,赋值给自己的_remain。另外对还没有加载的模块设置对应的_waitings,增加对自己的引用。
//挨个检查自己依赖的模块。发现依赖的模块都加载完成,或者没有依赖的模块就直接调用自己的onload
//如果发现依赖模块还有没加载的就调用它的fetch让它去加载。如果已经是加载完了,也就是SAVED状态的。就调用它的load
Module.prototype.load = function() {}
//当模块装载完,也就是load之后会调用此函数。会将状态变为LOADED,并且遍历自己的_waitings,找到依赖自己的那些模块,更新相应的_remain值,发现为0的话就调用对应的onload。
//onload调用有两种情况,第一种就是一个模块没有任何依赖直接load后调用自己的onload.
//还有一种就是当前模块依赖的模块都已经加载完成,在那些加载完成的模块的onload里面会帮忙检测_remain。通知当前模块是否该调用onload
//这样就会使用上面说的那套通知机制,当一个没有依赖的模块加载好了,会检测依赖它的模块。发现_remain为0,就会帮忙调用那个模块的onload函数
Module.prototype.onload = function() {}
/*===========================================*/
/*****下面的几个跟上面的通知机制就没啥关系了*****/
/*===========================================*/
//exec用于执行当前模块的factory
//执行前为STATUS.FETCHING 执行后为STATUS.EXECUTED
Module.prototype.exec = function(){}
//这是一个辅助方法,用来获取格式化当前依赖的模块的地址。
//比如上面就会把 ['util'] 格式化为 [baseUrl(就是上面的loadderDir)+ util + '.js']
Module.prototype.resolve = function(){}
//实例生成方法,所有的模块都是单例的,get用来获得一个单例。
Module.get = function(){}是不是感觉有点晕,没事我们一个个来看。
我们先把辅助函数实现下:
//存储实例化的模块对象
cachedMods = {}
//根据uri获取一个对象,没有的话就生成一个新的
Module.get = function(uri, deps) {
return cachedMods[uri] || (cachedMods[uri] = new Module(uri, deps))
}
//进行id到url的转换,实际情况会比这个复杂的多,可以支持各种配置,各种映射。
function id2Url(id){
return loadderDir + id + '.js'
}
//解析依赖的模块的实际地址的集合
Module.prototype.resolve = function(){
var mod = this
var ids = mod.dependencies
var uris = []
for (var i = 0, len = ids.length; i < len; i++) {
uris[i] = id2Url(ids[i])
}
return uris
}实现fetch之前我们先实现全局函数define。
fetch会生成script节点加载模块的具体代码。
还记得我们上面模块定义的写法吗?都是使用define来定义一个模块。define的主要任务就是生成当前模块的一些信息,给fetch使用。
define的实现:
var REQUIRE_RE = /"(?:\\"|[^"])*"|'(?:\\'|[^'])*'|\/\*[\S\s]*?\*\/|\/(?:\\\/|[^\/\r\n])+\/(?=[^\/])|\/\/.*|\.\s*require|(?:^|[^$])\brequire\s*\(\s*(["'])(.+?)\1\s*\)/g
var SLASH_RE = /\\\\/g
//工具函数,解析依赖的模块
function parseDependencies(code) {
var ret = []
code.replace(SLASH_RE, "")
.replace(REQUIRE_RE, function(m, m1, m2) {
if (m2) {
ret.push(m2)
}
})
return ret
}
function define (factory) {
//使用正则分析获取到对应的依赖模块
deps = parseDependencies(factory.toString())
var meta = {
deps: deps,
factory: factory
}
//存到一个全局变量,等后面fetch在script的onload回调里获取。
anonymousMeta = meta
}
这边为了尽量展现原理,去掉了很多兼容的代码。
比如其实define是支持function (id, deps, factory)这种写法的,这样就可以提前写好模块的id和deps,这样就不需要通过正则去获取依赖的模块了。一般写的时候只写factory,上线时会使用构建工具生成好deps参数,这样可以避免压缩工具把require关键字压缩掉而导致依赖失效。性能上也会更好。
另外,为了兼容ie下面的script标签不一定触发的问题。这边其实有个getCurrentScript()的方法,用于获取当前正在解析的script节点的地址。这边略去,有兴趣的可以去源码里看看。
function getCurrentScript() {
//主要原理就是在ie6-9下面可以查看script.readyState === "interactive"来判断当前节点是否处于加载状态
var scripts = head.getElementsByTagName("script")
for (var i = scripts.length - 1; i >= 0; i--) {
var script = scripts[i]
if (script.readyState === "interactive") {
return script
}
}
下面是fetch的实现:
Module.prototype.fetch = function() {
var mod = this
var uri = mod.uri
mod.status = STATUS.FETCHING
//调用工具函数,异步加载js
request(uri, onRequest)
//保存模块信息
function saveModule(uri, anonymousMeta){
//使用辅助函数获取模块,没有就实例化个新的
var mod = Module.get(uri)
//保存meta信息
if (mod.status < STATUS.SAVED) {
mod.id = anonymousMeta.id || uri
mod.dependencies = anonymousMeta.deps || []
mod.factory = anonymousMeta.factory
mod.status = STATUS.SAVED
}
}
function onRequest() {
//拿到之前define保存的meta信息
if (anonymousMeta) {
saveModule(uri, anonymousMeta)
anonymousMeta = null
}
//调用加载函数
mod.load()
}
}fetch完成后会调用load方法。
我们看下load的实现:
Module.prototype.load = function() {
var mod = this
// If the module is being loaded, just wait it onload call
if (mod.status >= STATUS.LOADING) {
return
}
mod.status = STATUS.LOADING
//拿到解析后的依赖模块的列表
var uris = mod.resolve()
//复制_remain
var len = mod._remain = uris.length
var m
for (var i = 0; i < len; i++) {
//拿到依赖的模块对应的实例
m = Module.get(uris[i])
if (m.status < STATUS.LOADED) {
// Maybe duplicate: When module has dupliate dependency, it should be it's count, not 1
//把我注入到依赖的模块里的_waitings,这边可能依赖多次,也就是在define里面多次调用require加载了同一个模块。所以要递增
m._waitings[mod.uri] = (m._waitings[mod.uri] || 0) + 1
}
else {
mod._remain--
}
}
//如果一开始就发现自己没有依赖模块,或者依赖的模块早就加载好了,就直接调用自己的onload
if (mod._remain === 0) {
mod.onload()
return
}
//检查依赖的模块,如果有还没加载的就调用他们的fetch让他们开始加载
for (i = 0; i < len; i++) {
m = cachedMods[uris[i]]
if (m.status < STATUS.FETCHING) {
m.fetch()
}
else if (m.status === STATUS.SAVED) {
m.load()
}
}
}
Module.prototype.onload = function() {
var mod = this
mod.status = STATUS.LOADED
//回调,预留接口给之后主函数use使用,这边先不管
if (mod.callback) {
mod.callback()
}
var waitings = mod._waitings
var uri, m
//遍历依赖自己的那些模块实例,挨个的检查_remain,如果更新后为0,就帮忙调用对应的onload
for (uri in waitings) {
if (waitings.hasOwnProperty(uri)) {
m = cachedMods[uri]
m._remain -= waitings[uri]
if (m._remain === 0) {
m.onload()
}
}
}
}这样整个通知机制就结束了。
模块onload之后代表已经处于一种可执行状态。seajs不会立即执行模块代码,只有你真正require了才会去调用模块的exec去执行。这就是用时定义。
Module.prototype.exec = function () {
var mod = this
if (mod.status >= STATUS.EXECUTING) {
return mod.exports
}
mod.status = STATUS.EXECUTING
var uri = mod.uri
//这是会传递给factory的参数,factory执行的时候,所有的模块已经都加在好处于可用的状态了,但是还没有执行对应的factory。这就是cmd里面说的用时定义,只有第一次require的时候才会去获取并执行
function require(id) {
return Module.get(id2Url(id)).exec()
}
function isFunction (obj) {
return ({}).toString.call(obj) == "[object Function]"
}
// Exec factory
var factory = mod.factory
//如果factory是函数,直接执行获取到返回值。否则赋值,主要是为了兼容define({数据})这种写法,可以用来发jsonp请求等等。
var exports = isFunction(factory) ?
factory(require, mod.exports = {}, mod) :
factory
//没有返回值,就使用mod.exports的值。看到这边你受否明白了,为什么我们要返回一个函数的时候,直接exports = function(){}不行了呢?因为这边取的是mod.exports。exports只是传递过去的指向{}的一个引用。你改变了这个引用地址,却没有改变mod.exports。所以当然是不行的。
if (exports === undefined) {
exports = mod.exports
}
mod.exports = exports
mod.status = STATUS.EXECUTED
return exports
}上面这套东西已经完成了整个模块之间的加载执行依赖关系了。但是还缺少一个入口。
这时候就是seajs.use出场的时候了。seajs.use用来加载一些模块。比如下面:
seajs.use(["main"])其实我们可以把它当作一个主模块,use的后面那些比如main就是它的依赖模块。而且这个主模块比较特殊,他不需要经过加载的过程,直接可以从load装载开始,于是use的实现就很简单了:
seajs = {}
seajs.use = function (ids, callback) {
//生成一个带依赖的模块
var mod = Module.get('_use_special_id', ids)
//还记得上面我们在onload里面预留的接口嘛。这边派上用场了。
mod.callback = function() {
var exports = []
//拿到依赖的模块地址数组
var uris = mod.resolve()
for (var i = 0, len = uris.length; i < len; i++) {
//执行依赖的那些模块
exports[i] = cachedMods[uris[i]].exec()
}
//注入到回调函数中
if (callback) {
callback.apply(global, exports)
}
}
//直接使用load去装载。
mod.load()
}于是整个流程就变成了这样:
主入口函数use直接生成一个模块,直接load。然后建立好依赖关系。通过上面那套通知机制,从下到上一个个的触发模块的onload。然后主函数里面调用依赖模块的exec去执行,然后一层层的下去,每一层都可以通过require来执行对应的factory。整个过程就是这样。
又是一个因为js本身的缺陷,然后后人擦屁股的事情。这样的例子已经数不胜数了。js真是让人又爱又恨。总之有了模块加载器,让js有了做大规模富客户端应用的能力。是前端工业化开发不可缺少的一环。
作为一个DOTA小菜鸟,一直羡慕各路大神的从零单排,在DOTA上是单排不了了。所以就只能代码上单排了。这个系列准备写一些各种知识的从零开始到深入原理的过程。记录学到的知识。
这篇文章就介绍下gulp实战。
gulp是基于node的stream之上的,所以在介绍gulp之前。需要先介绍下nodejs里面流的概念。
以前第一次接触流还是写java的时候,那时候文件都是流。现在node里面也有了流的概念。
这里可以把读文件比作搬水桶,没有流的话我们读文件是一次性把水桶里面的水都搬走,而有了流就相当于我们搞了个管道。让水一点点的流出来。然后后面要处理的时候,我们也可以一点点的去处理。比如一个文件非常大的时候,一次性的读到内存是很消耗性能的。这时候我们就可以使用流一点点的取,一点点的处理,最后再一点点的写到文件里面。
node里面最典型的http请求就是一个流。读文件也可以以流的形式。所有的流都继承了EventEmitter,所以都可以使用简单的事件机制。
比如一个简单的文件读取流:
var stream = fs.createReadStream('ex.txt');
//阶段性的触发data事件,像流水一样,每次出来一点点数据
stream.on('data',function(chunk){
console.log(chunk);
})
//全部读取完毕后触发end事件
stream.on('end',function(chunk){
console.log('done');
})
node里面有四种类型的流:Readable,Writable,Duplex,Transform
1.Readable 可读流
上面的createReadStream就是生成了一个可读流。
一个可读流分为两种模式:流动模式和暂停模式。流动模式就是数据会自动往外读取。暂停模式是默认的模式,代表数据不会自动往外读。
当处于暂停模式时我们必须使用stream.read(size)来主动读取数据。一直到没有数据的时候会返回null;
也可以开启流动模式,有三种方法:
(1) 监听data事件,就像我们上面的使用那样。没有数据会触发end事件
(2) 使用pipe,会自动开启。pipe代表把当前流写入到一个可写流(见下面介绍)里面。比如我们可以这样:
var readStream = fs.createReadStream('a.txt');
var writeStream = fs.createWriteStream('b.txt');
readStream.pipe(writeStream);
//这样 a.txt的内容就会自动写入到 b.txt里面。
(3)使用stream.resume()来开启流动模式,有时我们不需要监听data事件来获取获取数据,只是想要监听end事件,这时候就可以使用这个来开启流动模式。
2.Writable 可写流,
比如createWriteStream就是返回一个可写流。用于接受一个可读流的写入。就好像是在两个缸直接加了条管道。
可写流也支持一些方法。
首先就像我们上面做的那样我们可以 writeStream.pipe(writeStream);直接把一个可读流接到一个可写流上面。
当然有的时候我们可以自己手动去写数据。
writeStream.write(data, encoding, callback);用于向可写流里面写数据。如果数据量太大,处理不过来会返回false。这个时候先不要写数据了。我们可以监听 drain事件,代表处理完毕可以继续写数据了。
另外调用writeStream.end(chunk, encoding, callback);来表示写数据完毕。
3.Transform 转换流,同时可读可写,他可以接受一个流然后做一系列的操作后再输出处理后的流。相当于一个中转站。你可以想象为,它的左边是一个可写流接受可读流的写入。进行处理后,它的右边是个可读流,给下一个转换流处理或者给下一个可写流。所以我们可以这么用readStream.pipe(transformStream).pipe(writeStream);
4.Duplex 双工流,也是同时可读可写。可以作为可读流也可以作为可写流,典型的例子是socket,zlib的使用。这边的gulp涉及不到就不详细展开了。简单来说就是可以这么用 duplexStream.pipe(transformStream).pipe(duplexStream);
上面的可读流可写流我们都是直接用的系统自带的,其实我们是可以自己创建一个自定义流对象的。node提供了下面各自对应的父类函数。我们需要自定义自己的流类来继承这些基类并且实现对应的方法。
| 模式 | 父类名 | 需要继承的方法 | 解释 |
|---|---|---|---|
| Reading only | require('stream').Readable | _read | 每次可读流开始读数据的时候就会调用_read来获取数据,在_read里面可以调用this.push(data)来将数据输出到流。如果data是null就代表没数据了 |
| Writing only | require('stream').Writable | _write | 每次可写流写数据的时候就会调用_write来写数据,我们可以决定这些数据去哪 |
| Reading and writing | require('stream').Duplex | _read, _write | 双工流可以同时继承这两个函数,表现出上面的样子 |
| Operate on written data, then read the result | require('stream').Transform | _transform, _flush | Transform(chunk, encoding, callback)用于处理上一个可读流过来的数据,chunk就是数据,可以在Transform中多次使用this.push(data)来将数据写到下一个流,调用callback结束当前转换。_flush(callback)是在数据全部读完后会调用,在_flush里面也可以调用push和callback结束转换。 |
这边与下面gulp最相关的就是转换流,我们以一个例子来说明主要的用法。
var Transform = require('stream').Transform;
util.inherits(TestStream, Transform);
function TestStream(options) {
Transform.call(this, options);
}
TestStream.prototype._transform = function(chunk, encoding, cb) {
this.push(chunk+'|');
cb();
};
TestStream.prototype._flush = function(cb) {
cb('end');
};
//于是可以使用 readStream.pipe(new TestStream()).pipe(writeStream);
其他模式的都差不多一个用法,总之就是继承父类再实现相对应的接口。
默认情况下上面四种构造函数实例化后都是使用的string或者buffer来传递数据的。其实 在使用new实例化对象的时候支持objectMode参数。如果这个参数为true。那么我们调用this.push的时候就可以传入一个对象。这样后面的流去分段读的时候每次都会只读取一个对象。有了这个特性,我们就可以在不同的流之间以对象为单位进行数据转换了。
前端经过这几年的发展已经越来越向工业化的道路发展了。java有ant,ruby有rake。而前端比较出名的任务工具就要属grunt和gulp了。说白了这两个工具就是可以自定义任务脚本,然后使用命令行去执行这些任务。包括打包,压缩,开个服务器等等等都可以实现。
###入门使用
首先我们安装gulp:
npm install -g gulp
记得使用全局安装,这样我们就具有了gulp这个命令。
下面我们需要在项目根目录新建一个gulpfile.js,这个是任务的定义的地方。
我们看一个简单的gulpfile.js:
var gulp = require('gulp');
var less = require('gulp-less');
gulp.task('less',[], function () {
gulp.src('./public/css/*.less')
.pipe(less({}))
.pipe(gulp.dest('./public/css/'));
});
这边引用了gulp-less,所以不要忘了 npm install gulp-less --save
less就是官方的一个插件,用于将less格式的文件解析为css。可以看到这边less({})其实就是返回了一个转换流。
gulp.task用于定义一个新的任务。
第一个参数是这个任务的名称是less.
第二个可选参数是当前任务依赖的其他任务,启动当前任务会同时挨个启动依赖的任务。
第三个可选参数是任务的具体执行函数。
gulp.src用于读取文件,转换为流的形式。写入下一个转换流。参数为glob标识,或者多个标识组成的数组
什么是glob呢?
说白了就是支持那种类似正则一样的标识手法,比如*.less就代表所有以less结尾的文件。
另外我们经常在unix类型的系统里面使用 ls *.less 也是使用的golb标识。
gulp主要使用的是node-glob来解析glob的,所以可以去那边看一下支持的写法。
gulp.dest执行返回一个转换流,用于接受可读流然后写到对应的文件里面。接受一个文件夹地址作为参数。
于是我们定义了一个起始输入流,还有最后面的转换流。使用了less在半路上处理中间的流。想要其他的插件也只需要中间多pipe一个就行了。只有src还有dest会有磁盘读写,而且职责清晰,每个人对经过的流都做些操作再丢给下一个处理。这就像车间流水线一样,每个阶段都有相应的处理程序对原材料加工。所以效率相当高效。
最后我们在命令行里调用:
gulp less
这样就会把./public/css/下面的所有less文件解析为对应文件名的css。
gulp还支持两个接口
一个是watch用于监控文件变化:接受glob标识,还有相对应的执行任务数组
gulp.task('watch_less', function () {
gulp.watch(['./public/css/*.less'], ['less']);
});
//运行gulp watch_less 会监听所有的less文件,发生改变就会调用less任务。
还有一个是run用于手动调用任务,不过即将被废弃了,慎用。
gulp.task('test',[less],function(){
gulp.run('watch_less');
})
//在运行完less后 运行watch_less持续监听文件
刚开始接触gulp的人肯定会被他的异步机制搞晕。在grunt里面因为后面一个脚本的读入文件都是依赖前一个脚本的产出文件的,所以他们是串行的,因此任务会一个个的去执行。
但是在gulp里所有任务都是并行同步执行的。比如我们上面的例子:
gulp.task('test',[less],function(){
gulp.run('watch_less');
})
//在运行完less后 运行watch_less持续监听文件
我们是希望 运行完less,再去运行watch_less,但是在gulp里面这两个任务是同时并行执行的。这会给我们造成困扰,这个时候我们需要对依赖的任务做一些处理。使得依赖的任务做完了再去执行当前任务的执行函数。
gulp有三种方式:
1.直接返回一个流
gulp.task('watch_less', function () {
return gulp.watch(['./public/css/*.less'], ['less']);
});
//是的只要加一个return就好了
2.直接返回一个promise
比如我们再定义一个异步的任务
gulp.task('test_async', function () {
var Q = require('q');
var deferred = Q.defer();
// do async stuff
setTimeout(function () {
deferred.resolve();
}, 1);
return deferred.promise;
});
3.使用回调callback
task的执行函数其实都有个回调,我们只需要在异步队列完成的时候调用它就好了。
gulp.task('test_async', function (cb) {
// do async stuff
setTimeout(function () {
cb()
}, 1);
});
所以只要依赖的任务是上面三种情况之一,就能保证当前任务在依赖任务执行完成后再执行。这边需要注意的是依赖的任务相互之间还是并行的。需要他们按顺序的话。记得给每个依赖的任务也配置好依赖关系。
好了基本上gulp的入门使用就介绍完了。
###gulp vs grunt
grunt由于是基于文件读写的,前一个任务做完写好文件,下个任务再去读文件进行操作。所以频繁的磁盘io读写会很浪费性能。而且由于grunt的输入输出格式没有统一规范化,导致目前线上的各种库的入口文件还有出口文件配置五花八门,而且职责混乱。越来越被人诟病。
于是gulp出来了。基于node的stream机制,最大程度的减少了磁盘io消耗。所有的插件具有了统一的入口,插件都是在流的中间对输入流操作,输出更改过的流给下一个插件。并且每个人只做自己的事,职责分明。
当然grunt出来的比较早,所以官方社区的插件比较多。gulp的插件还没那么多。不过未来gulp肯定是主流,目前我们团队的项目基本都在望gulp上迁移了。
gulp的原理其实很简单,如果去查看它的源码,你就会发现他就像用乐高积木搭建起来的一样。都是已经很成熟的一个个模块组合在一起的。
主要有两大模块支撑着gulp.
第一个就是一个任务依赖队列的库。orchestrator.主要实现了task方法,还有解决任务依赖关系。这个没啥好说的
第二个就是一个文件转换系统。vinyl-fs.主要实现了src,dst还有watch。watch功能就不说了使用的glob-watcher。src内置了glob的功能,前面已经解释过了。
src会将匹配到的路径全部生成一个对应的开启Object Mode的可读流。传递的对象为vinyl,如下参数:
{
cwd: cwd,
base: base,
stat: 使用 fs.Stats得到的结果
path: 文件路径,
contents: 文件的内容
}
之后再把所有的可读流合并成一个可读流,使用的是ordered-read-streams
然后传递给一个转换流,也就是我们之后会编写的插件。处理完再写入到一个dst生成的转换流里面,写入文件。整个过程就结束了。
由于dst是一个转换流,所以可以继续pipe到其他的插件上。
终于到了最后一步了,我们可以自己编写插件了。通过前面的解释其实已经很清楚了,我们只要实现一个转换流就好了。为了避免写那么一大堆的继承的东西我们可以使用一些库,比如through2,比如through-gulp
于是我们可以写个最简单的插件,比如我写的这个简单的将html文件内容打包成cmd,amd的模块。方便线上跨域调用的插件。
/**
* 用于将html代码打包成cmd,amd规范可以使用的模块。这样可以跨域使用。
*/
var through = require('through-gulp');
function viewComile() {
//through(transformFunction, flushFunction) through 接受两个参数对应前面的_transform, _flush。返回一个生成好的开启object mode的转换流
var stream = through(function(file, encoding,callback) {
var htmlStr,jsStr;
//拿到内容
htmlStr = file.contents.toString();
/******逻辑开始*****/
//各种逻辑,处理htmlStr,略
/******逻辑结束*****/
//改写文件内容
file.contents = new Buffer(htmlStr);
//给下一个流
this.push(file);
callback();
});
return stream;
};
module.exports = viewComile;
一个插件就弄好了,至于后续是发到npm上还是放在本地目录,就随便了。
可以直接放在本地,调用的时候就可以:
var rename = require('gulp-rename');
var viewCompile = require('./task/gulp-view-compile.js');
gulp.task('viewcompile', function () {
gulp.src('./public/views/**/*.html')
.pipe(viewCompile())
.pipe(rename(function (path) {
path.extname = ".js";
}))
.pipe(gulp.dest('build/views/'))
});
当然也可以封装成npm包。比如上面的插件我最后封装在了这里,可以到这里面看看详细用法。
写文章好累,一个知识点总是串联着其他的知识点,想要重头开始理一边的确很吃力,不过相应的带来的收获也是巨大的
很久很久以前,我还是个phper,第一次接触javascript觉得好神奇。跟传统的oo类概念差别很大。记得刚毕业面试,如何在javascript里面实现class一直是很热门的面试题,当前面试百度就被问到了,当年作为一个小白只是网上随便搜搜应付了下。= =现在发现当时知道的还是太少太少。今天整理了下javascript的oo实现,发现知道的越多,越发现知识真是无穷无尽。
javascript虽然没有class的概念,但是它的函数却是可以new出来一个对象的。所以一个最简单的class就可以用function来模拟出来。
function Animal(name){
this.name = name;
this.run = function(){
console.log(this.name + "is running!!");
}
}
var pet = new Animal("pet");
pet.run();//petis running!!这样 pet就有了属性,有了方法,不过这种写法毫无继承性,扩展性。比如我们要实现个dog类,只能把属性方法再写一遍。而且每个new出来的对象都有自己的方法,造成资源浪费。
在javascript里面有个原型链的概念,每一个函数都有一个prototype对象属性。这样通过这个函数new出来的对象会自动具有__proto__属性指向函数的prototype对象。说白了所有的实例对象都会共用一个prototype对象,并且调用一个属性或者方法时在自己上面找不到,就会找__proto__对象有没有,之后一直往上追溯一直到找到为止。具体表现为:
function Animal(name){
this.name = name;
}
Animal.prototype.run = function(){
console.log(this.name + "is running!!");
}
var a = new Animal("a");
var b = new Animal("b");
console.log(Animal.prototype) //Animal {}
console.log(Animal.prototype instanceof Object) //true prototype是个对象
console.log(Animal.prototype.constructor == Animal)//true
console.log(a.__proto__ == Animal.prototype) //true __proto__在new的时候会自动加载在实例对象上。在现代浏览器里可以看到
console.log(b.__proto__ == Animal.prototype) //true
console.log(a.__proto__.__proto__) //Object {} 最后会找到最上面的boject对象
console.log(a.__proto__.run == a.run) //true
console.log(a.__proto__.run == Animal.prototype.run) //true所以,在prototype对象上定义的方法会被所有实例共享,这不就是复用吗?
于是有了基于原型链的继承的写法:
function Animal(name){
this.name = name;
}
Animal.prototype.run = function(){
console.log(this.name + "is running!!");
}
function Dog(name){
//调用父类的构造函数,通过改变this指向将属性赋值到新的实例对象
Animal.call(this,name);
}
Dog.prototype = new Animal();
var dog = new Dog("dog");
dog.run();//dog is running!!可以看到我们将Animal的实例对象暂且叫做a,作为 Dog的prototype,这样 Dog的实例对象dog的__proto__指向Dog的prototype也就是a,a的__proto__再指向Animal的prototype对象,这个对象上有run方法。于是我们调用dog.run()的时候会一层层的往上追溯一直找到run方法执行。于是通过原型链我们就让 Dog继承了Animal的方法run。
需要注意的是,如果在子类的prototype对象上也有run方法,就会覆盖父类的,因为查找时在自己上面就找到了,就不会向上回溯了。
上面是原型链方法的继承。而属性我们则是通过调用父类的构造函数来赋值的。因为属性不能所有的实例都公用,应该每个人都有自己的一份,所以不能放在原型上。
上面就是原始时代最简单的类继承了。
这个时代javascript变得比较重要了,作为非常有用的特性,oo开始被很多人研究。
首先上面的那种简单oo实现方式,其实是有很多问题的。
1.没有实现传统oo该有的super方法来调用父类方法。
作为oo,怎么能没有super呢。作为我们前端界宗师一般的人物。Douglas 有一篇经典文章。不过貌似有很多问题。国内的玉伯分析过。在这里
最后Douglas总结出来:
我编写 JavaScript 已经 8 个年头了,从来没有一次觉得需要使用 uber 方法。在类模式中,super 的概念相当重要;但是在原型和函数式模式中,super 的概念看起来是不必要的。现在回顾起来,我早期在 JavaScript 中支持类模型的尝试是一个错误。
2.直接将父类实例作为子类的原型,简单粗暴造成多余的原型属性。还有construct的问题。
这个问题主要是之前代码里面这一句造成的:
Dog.prototype = new Animal();
//var dog = new Dog("dog");
//console.log(dog.__proto__) Animal {name: undefined}执行new Animal()就会执行animal的构造函数,就会在Dog.prototype生成多余的属性值,这边是name。而一般属性值为了复用是不能放在原型对象上的。并且由于dog有自己的name属性,原型上的是多余的。
还有construct的问题。
console.log(dog.constructor == Animal) //true
console.log(dog.constructor == Dog) //false显然这不是我们希望看到的。
所以我们要对上面做些改良:
var F = function(){};
F.prototype = Animal.prototype;
Dog.prototype = new F();
Dog.prototype.constructor = Dog;我们可以封装下:
function objCreate(prototype){
var F = function(){};
F.prototype = prototype;
return new F();
}
function inherit(subclass,parentclass){
subclass.prototype = objCreate(parentclass.prototype);
subclass.prototype.constructor = subclass;
}于是继承可以写成:
function Animal(name){
this.name = name;
}
Animal.prototype.run = function(){
console.log(this.name + "is running!!");
}
function Dog(name){
//调用父类的构造函数,通过改变this指向将属性赋值到新的实例对象
Animal.call(this,name);
}
inherit(Dog,Animal);
var dog = new Dog("dog");
dog.run();//dog is running!!当年大学毕业面试,也就到这个程度了。 = =
这个时代,各种javascript类库像雨后春笋般涌现了出来。
上面最后给出的方案,使用起来还是很不便,比如需要自己手动维护在构造函数里调用父类构造函数。同时继承写法对不了接原理的比较容易出错。
这个时候涌现了一大堆的类库的实现:
1.首先有些类库决定跳出传统oo的思维。不一定非要实现传统oo的继承。归根到底我们是为了复用。于是出现了很多轻量级的复用方式。
比如jquery的extend:http://api.jquery.com/jQuery.extend/
还有kissy的mix:http://docs.kissyui.com/1.3/docs/html/api/seed/kissy/mix.html?highlight=mix#seed.KISSY.mix
还有kissy的argument:http://docs.kissyui.com/1.3/docs/html/api/seed/kissy/augment.html
还有很多很多,说白了都是对象级别上的混入达到复用的地步。大部分情况下已经足够了。
2.当然还是有人对类的继承有需求的。
下面我们看下kissy的extend的实现方式。其他类库实现方式类似,kissy的我觉得算是比较有代表性了。为了演示,做了些小修改。
//这个就是我们之前实现的方法,为了演示做了些改动主要是处理了construct的问题
function objCreate(prototype,construct){
var F = function(){};
F.prototype = prototype;
var newPro = new F();
newPro.construct = construct;//维护构造函数的改变
return newPro;
}
//mix是个辅助方法,这边给个最简单的实现,其实kissy里面的复杂的多。这边不考虑深度遍历等等,只是最简单的实现。
function mix(r, s) {
for (var p in s) {
if (s.hasOwnProperty(p)) {
r[p] = s[p]
}
}
}
//下面是kissy的实现r代表子类 s代表父类,px代表最后会混入子类原型上的属性,sx代表会混入子类函数上面的属性,也就是可以当做静态方法。
//http://docs.kissyui.com/1.3/docs/html/api/seed/kissy/extend.html?highlight=extend#seed.KISSY.extend
function extend (r, s, px, sx) {
if (!s || !r) {
return r;
}
var sp = s.prototype,
rp;
//针对父类生成一个原型。跟之前我们写的一致
rp = createObject(sp, r);
//不是简单的直接复制原型对象,而是先把以前原型的方法跟要继承的合并之后再一起赋值
r.prototype = S.mix(rp, r.prototype);
//为子类增加superclass属性,指向一个父类对象,这样就可以调用父类的方法了。这边是实现比较巧妙的地方
r.superclass = createObject(sp, s);
//下面就是往原型还有函数上混入方法了
// add prototype overrides
if (px) {
S.mix(rp, px);
}
// add object overrides
if (sx) {
S.mix(r, sx);
}
return r;
}有了kissy的extend我们可以这么用:
function Animal(name){
this.name = name;
}
Animal.prototype.run = function(){
console.log(this.name + "is running!!");
}
function Dog(name){
//Animal.call(this,name);
//因为kissy的封装 这边可以这么用
Dog.superclass.construct.call(this,name);
}
extend(Dog,Animal,{
wang:function(){
console.log("wang wang!!")
}
})
var dog = new Dog("dog");
dog.run();//dog is running!!
dog.wang();//wang wang!!相对之前的变得清晰了很多,也更易用了。
前面的写法,目前虽然还是有很多人用,不过也渐渐过时了。上面的写法还是不够清晰,定义属性,方法都很分散,也没有多继承,等特性。我们需要像传统oo一样具有一个类工厂,可以生成一个类,属性都定义在里面。同时具有继承的方法。
而随着javascript成为前端唯一的语言,一代代大神前仆后继。终于开始涌现出了各种神奇的写法,下面罗列下一些我觉得特别好的实现,加上原理注释。
作为jquery的作者。John Resig在博客里记录了一种class的实现,原文在此
调用方法:
var Person = Class.extend({
init: function(isDancing){
this.dancing = isDancing;
},
dance: function(){
return this.dancing;
}
});
var Ninja = Person.extend({
init: function(){
this._super( false );
},
dance: function(){
// Call the inherited version of dance()
return this._super();
},
swingSword: function(){
return true;
}
});
var p = new Person(true);
p.dance(); // => true
var n = new Ninja();
n.dance(); // => false
n.swingSword(); // => true
// Should all be true
p instanceof Person && p instanceof Class &&
n instanceof Ninja && n instanceof Person && n instanceof Class源码解读:
/* Simple JavaScript Inheritance
* By John Resig http://ejohn.org/
* MIT Licensed.
*/
// Inspired by base2 and Prototype
(function(){
//initializing是为了解决我们之前说的继承导致原型有多余参数的问题。当我们直接将父类的实例赋值给子类原型时。是会调用一次父类的构造函数的。所以这边会把真正的构造流程放到init函数里面,通过initializing来表示当前是不是处于构造原型阶段,为true的话就不会调用init。
//fnTest用来匹配代码里面有没有使用super关键字。对于一些浏览器`function(){xyz;}`会生成个字符串,并且会把里面的代码弄出来,有的浏览器就不会。`/xyz/.test(function(){xyz;})`为true代表浏览器支持看到函数的内部代码,所以用`/\b_super\b/`来匹配。如果不行,就不管三七二十一。所有的函数都算有super关键字,于是就是个必定匹配的正则。
var initializing = false, fnTest = /xyz/.test(function(){xyz;}) ? /\b_super\b/ : /.*/;
// The base Class implementation (does nothing)
// 超级父类
this.Class = function(){};
// Create a new Class that inherits from this class
// 生成一个类,这个类会具有extend方法用于继续继承下去
Class.extend = function(prop) {
//保留当前类,一般是父类的原型
//this指向父类。初次时指向Class超级父类
var _super = this.prototype;
// Instantiate a base class (but only create the instance,
// don't run the init constructor)
//开关 用来使原型赋值时不调用真正的构成流程
initializing = true;
var prototype = new this();
initializing = false;
// Copy the properties over onto the new prototype
for (var name in prop) {
// Check if we're overwriting an existing function
//这边其实就是很简单的将prop的属性混入到子类的原型上。如果是函数我们就要做一些特殊处理
prototype[name] = typeof prop[name] == "function" &&
typeof _super[name] == "function" && fnTest.test(prop[name]) ?
(function(name, fn){
//通过闭包,返回一个新的操作函数.在外面包一层,这样我们可以做些额外的处理
return function() {
var tmp = this._super;
// Add a new ._super() method that is the same method
// but on the super-class
// 调用一个函数时,会给this注入一个_super方法用来调用父类的同名方法
this._super = _super[name];
// The method only need to be bound temporarily, so we
// remove it when we're done executing
//因为上面的赋值,是的这边的fn里面可以通过_super调用到父类同名方法
var ret = fn.apply(this, arguments);
//离开时 保存现场环境,恢复值。
this._super = tmp;
return ret;
};
})(name, prop[name]) :
prop[name];
}
// 这边是返回的类,其实就是我们返回的子类
function Class() {
// All construction is actually done in the init method
if ( !initializing && this.init )
this.init.apply(this, arguments);
}
// 赋值原型链,完成继承
Class.prototype = prototype;
// 改变constructor引用
Class.prototype.constructor = Class;
// 为子类也添加extend方法
Class.extend = arguments.callee;
return Class;
};
})();相当简单高效的实现方式,super的实现方式非常亮
源地址:https://github.com/jneen/pjs
pjs的一大亮点是支持私有属性,他的类工厂传递的是函数不是对象。
调用方式:
//可以生成一个可继承的对象,P接收一个函数,这个函数会传入生成后的class的原型。
var Animal = P(function(animal) {
animal.init = function(name) { this.name = name; };
animal.move = function(meters) {
console.log(this.name+" moved "+meters+"m.");
}
});
//继承Animal。后面的snake,animal分别是前面Snake和Animal的原型。程序直接把这些对象暴露给你了。于是灵活度很高。
var Snake = P(Animal, function(snake, animal) {
snake.move = function() {
console.log("Slithering...");
animal.move.call(this, 5);
};
});
var Horse = P(Animal, function(horse, animal) {
//真正的私有属性,外面没法调用到
var test = "hello world";
horse.move = function() {
console.log(test);
console.log("Galloping...");
//调用父类的方法,so easy!!
animal.move.call(this, 45);
};
});
//工厂方式生成对象,可以不用new
var sam = Snake("Sammy the Python")
, tom = Horse("Tommy the Palomino")
;
sam.move()
tom.move()源码解读:
var P = (function(prototype, ownProperty, undefined) {
return function P(_superclass /* = Object */, definition) {
// handle the case where no superclass is given
if (definition === undefined) {
definition = _superclass;
_superclass = Object;
}
//最后返回的类就是这个,也就是我们需要的子类。这个类可以用new生成实例,也可以直接调用生成实例
function C() {
//判断,是new的话this instanceof C就是true。否则我们自己手动new一下Bare。Bare就是为了实现这种类工厂的生成类的方式
var self = this instanceof C ? this : new Bare;
self.init.apply(self, arguments);
return self;
}
//这个就是用来实现不用new生成类的方式
function Bare() {}
C.Bare = Bare;
//将父类的原型赋值给Bare
//这边prototype就是个字符串“prototype”变量,主要为了压缩字节少点,所以作者还单独传成变量进来 = =
var _super = Bare[prototype] = _superclass[prototype];
//再生成这个空函数的实例赋值给C,Bare的原型,同时在C.p存下来
//这样C,Bare都公用一个原型
var proto = Bare[prototype] = C[prototype] = C.p = new Bare;
var key;
//改变constructor指向
proto.constructor = C;
//上面几部其实还是实现的通用的继承实现方式,新建个空函数,将父类的原型赋给这个空函数再生成实例赋值给子类的原型。万变不离其宗。原理都一样
//增加extend方法。这是个语法糖,本质上还是调用P来实现,只不过第一个参数是调用者C
C.extend = function(def) { return P(C, def); }
//下面是最关键的地方,写的有点绕。这边分为这几步
//传入definition 执行 function(def){}
// 执行C.open = C
// return C.open 其实就是 renturn C 返回最终的生成类
return (C.open = function(def) {
if (typeof def === 'function') {
// call the defining function with all the arguments you need
// extensions captures the return value.
//是函数的话就传入 一些属性包括子类原型,父类原型,子类构造函数,父类构造函数
def = def.call(C, proto, _super, C, _superclass);
}
// 如果是对象,就直接混入到原型
if (typeof def === 'object') {
for (key in def) {
if (ownProperty.call(def, key)) {
proto[key] = def[key];
}
}
}
//确保有init函数
if (!('init' in proto)) proto.init = _superclass;
return C;
})(definition);
}
})('prototype', ({}).hasOwnProperty);
这是支付宝的库阿拉蕾的实现,我觉得是最不错的一种方式:
源地址:https://github.com/aralejs/class/blob/master/class.js
// The base Class implementation.
function Class(o) {
//这个判断用来支持 将一个已有普通类转换成 阿拉蕾的类
if (!(this instanceof Class) && isFunction(o)) {
//原理是给这个函数增加extend,implement方法
return classify(o)
}
}
//用来支持 commonjs的模块规范。
module.exports = Class
// Create a new Class.
//
// var SuperPig = Class.create({
// Extends: Animal,
// Implements: Flyable,
// initialize: function() {
// SuperPig.superclass.initialize.apply(this, arguments)
// },
// Statics: {
// COLOR: 'red'
// }
// })
//
//
//用于创建一个类,
//第一个参数可选,可以直接创建时就指定继承的父类。
//第二个参数也可选,用来表明需要混入的类属性。有三个特殊的属性为Extends,Implements,Statics.分别代表要继承的父类,需要混入原型的东西,还有静态属性。
Class.create = function(parent, properties) {
//创建一个类时可以不指定要继承的父类。直接传入属性对象。
if (!isFunction(parent)) {
properties = parent
parent = null
}
properties || (properties = {})
//没有指定父类的话 就查看有没有Extends特殊属性,都没有的话就用Class作为父类
parent || (parent = properties.Extends || Class)
properties.Extends = parent
// 子类构造函数的定义
function SubClass() {
// 自动帮忙调用父类的构造函数
parent.apply(this, arguments)
// Only call initialize in self constructor.
//真正的构造函数放在initialize里面
if (this.constructor === SubClass && this.initialize) {
this.initialize.apply(this, arguments)
}
}
// Inherit class (static) properties from parent.
//parent为Class就没必要混入
if (parent !== Class) {
//将父类里面的属性都混入到子类里面这边主要是静态属性
mix(SubClass, parent, parent.StaticsWhiteList)
}
// Add instance properties to the subclass.
//调用implement将自定义的属性混入到子类原型里面。遇到特殊值会单独处理,真正的继承也是发生在这里面
//这边把属性也都弄到了原型上,因为这边每次create或者extend都会生成一个新的SubClass。所以倒也不会发生属性公用的问题。但是总感觉不大好
implement.call(SubClass, properties)
// Make subclass extendable.
//给生成的子类增加extend和implement方法,可以在类定义完后,再去继承,去混入其他属性。
return classify(SubClass)
}
//用于在类定义之后,往类里面添加方法。提供了之后修改类的可能。类似上面defjs实现的open函数。
function implement(properties) {
var key, value
for (key in properties) {
value = properties[key]
//发现属性是特殊的值时,调用对应的处理函数处理
if (Class.Mutators.hasOwnProperty(key)) {
Class.Mutators[key].call(this, value)
} else {
this.prototype[key] = value
}
}
}
// Create a sub Class based on `Class`.
Class.extend = function(properties) {
properties || (properties = {})
//定义继承的对象是自己
properties.Extends = this
//调用Class.create实现继承的流程
return Class.create(properties)
}
//给一个普通的函数 增加extend和implement方法。
function classify(cls) {
cls.extend = Class.extend
cls.implement = implement
return cls
}
// 这里定义了一些特殊的属性,阿拉蕾遍历时发现key是这里面的一个时,会调用这里面的方法处理。
Class.Mutators = {
//这个定义了继承的真正操作代码。
'Extends': function(parent) {
//这边的this指向子类
var existed = this.prototype
//生成一个中介原型,就是之前我们实现的objectCreat
var proto = createProto(parent.prototype)
//将子类原型有的方法混入到新的中介原型上
mix(proto, existed)
// 改变构造函数指向子类
proto.constructor = this
// 改变原型 完成继承
this.prototype = proto
//为子类增加superclass属性,这样可以调用父类原型的方法。
this.superclass = parent.prototype
},
//这个有点类似组合的概念,支持数组。将其他类的属性混入到子类原型上
'Implements': function(items) {
isArray(items) || (items = [items])
var proto = this.prototype, item
while (item = items.shift()) {
mix(proto, item.prototype || item)
}
},
//传入静态属性
'Statics': function(staticProperties) {
mix(this, staticProperties)
}
}
// Shared empty constructor function to aid in prototype-chain creation.
function Ctor() {
}
// 这个方法就是我们之前实现的objectCreat,用来使用一个中介者来处理原型的问题,当浏览器支持`__proto__`时可以直接使用。否则新建一个空函数再将父类的原型赋值给这个空函数,返回这个空函数的实例
var createProto = Object.__proto__ ?
function(proto) {
return { __proto__: proto }
} :
function(proto) {
Ctor.prototype = proto
return new Ctor()
}
// Helpers 下面都是些辅助方法,很简单就不说了
// ------------
function mix(r, s, wl) {
// Copy "all" properties including inherited ones.
for (var p in s) {
//过滤掉原型链上面的属性
if (s.hasOwnProperty(p)) {
if (wl && indexOf(wl, p) === -1) continue
// 在 iPhone 1 代等设备的 Safari 中,prototype 也会被枚举出来,需排除
if (p !== 'prototype') {
r[p] = s[p]
}
}
}
}
var toString = Object.prototype.toString
var isArray = Array.isArray || function(val) {
return toString.call(val) === '[object Array]'
}
var isFunction = function(val) {
return toString.call(val) === '[object Function]'
}
var indexOf = Array.prototype.indexOf ?
function(arr, item) {
return arr.indexOf(item)
} :
function(arr, item) {
for (var i = 0, len = arr.length; i < len; i++) {
if (arr[i] === item) {
return i
}
}
return -1
}
万变不离其宗,本质上还是我们之前的继承方式,只是在上面再封装一层,更加清晰,明白了。
还有很多很多的实现,这边就不一一列举了。
其实 es6已经开始重视emcsript的oo实现了。不过还没定案,就算定案了,也不知道嘛时候javascript会实现。再加上一大堆浏览器的跟进。不知道什么时候才能用的上。不过了解下最新的规范还是很有必要的。
目前nodejs里面已经实现了 inherite方法用来实现类继承,类似我们上面的那种实现。
而es6(harmony)实现了class关键字用来创建类,并且具有类该有的一系列方法。如下:
class Monster {
// The contextual keyword "constructor" followed by an argument
// list and a body defines the body of the class’s constructor
// function. public and private declarations in the constructor
// declare and initialize per-instance properties. Assignments
// such as "this.foo = bar;" also set public properties.
constructor(name, health) {
public name = name;
private health = health;
}
// An identifier followed by an argument list and body defines a
// method. A “method” here is simply a function property on some
// object.
attack(target) {
log('The monster attacks ' + target);
}
// The contextual keyword "get" followed by an identifier and
// a curly body defines a getter in the same way that "get"
// defines one in an object literal.
get isAlive() {
return private(this).health > 0;
}
// Likewise, "set" can be used to define setters.
set health(value) {
if (value < 0) {
throw new Error('Health must be non-negative.')
}
private(this).health = value
}
// After a "public" modifier,
// an identifier optionally followed by "=" and an expression
// declares a prototype property and initializes it to the value
// of that expression.
public numAttacks = 0;
// After a "public" modifier,
// the keyword "const" followed by an identifier and an
// initializer declares a constant prototype property.
public const attackMessage = 'The monster hits you!';
}可以看到具有了传统oo里面的大部分关键字,私有属性也得到了支持。
继承也很容易:
class Base {}
class Derived extends Base {}
//Here, Derived.prototype will inherit from Base.prototype.
let parent = {};
class Derived prototype parent {}原文在这里:http://h3manth.com/content/classes-javascript-es6
虽然es6已经实现了正规的class关键字。不过等到真正能用上也不知道是何年马月了。不过规范提供了方向,在es6还没出来之前,n多大神前仆后继实现了自己的class方式,分析源码可以学到的还是很多,仅仅一个类的实现就可以抠出这么多的类容,程序员还是应该多探索,不能只停留在表面。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.