Distill-BERT-Textgen
Research code for ACL 2020 paper: "Distilling Knowledge Learned in BERT for Text Generation".
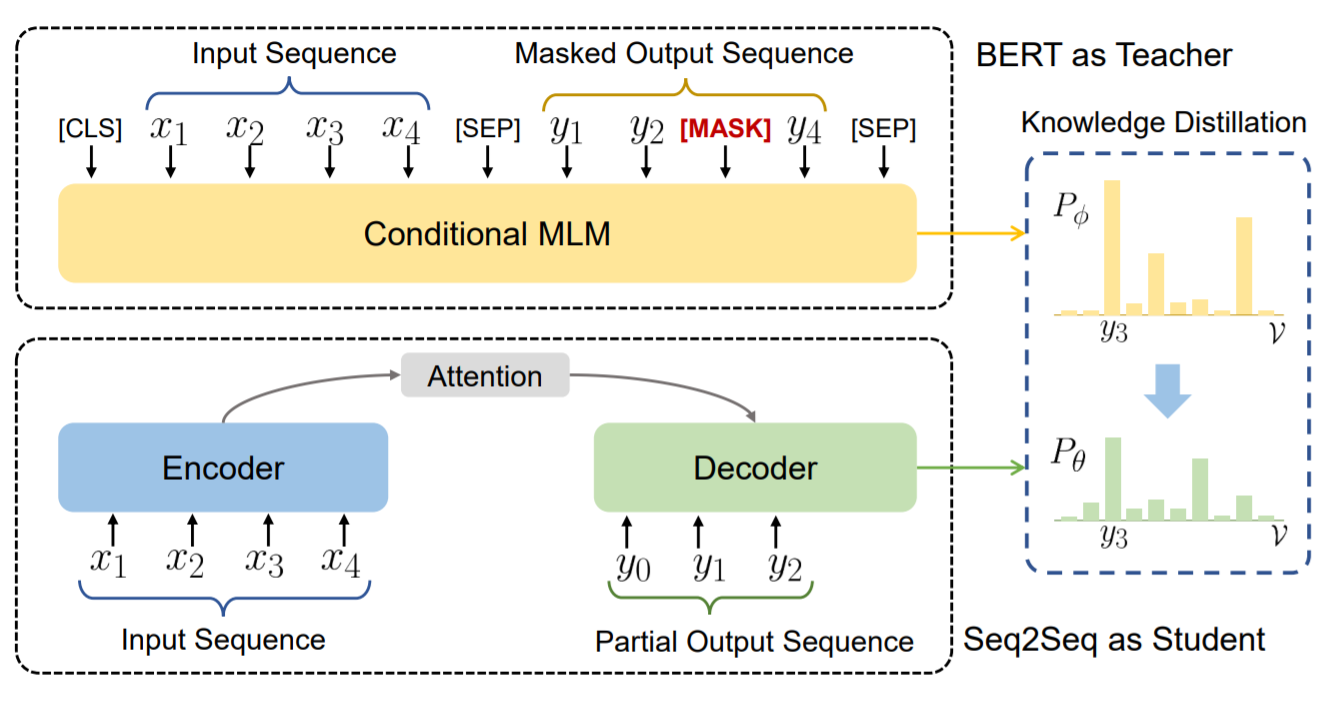
This repository contains the code needed to reproduce our IWSLT De-En experiments.
Setting Up
This repo is tested on Ubuntu 18.04 machine with Nvidia GPU. We do not plan to support other OS or CPU-only machines.
-
Prerequisite
-
you also need to follow this to run docker without sudo
-
nvidia-driver (we tested on version 418)
# reference installation command on Ubuntu sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update sudo apt install nvidia-driver-418 -
clone this repo and its submodule (we use a modified version of OpenNMT-py)
git clone --recursive [email protected]:ChenRocks/Distill-BERT-Textgen.git
Users can potentially setup non-docker environment following the
Dockerfileto install python packages and other dependencies. However, to guarantee reproducibility, it is safest to use our official docker image and we will not provide official support/troubleshooting if you do not use dockerized setup. (If you absolutely need non-docker install, feel free to discuss in github issue with other users and contribution is welcome.) -
-
Downloading Data and Preprocessing
- Run the following command to download raw data and then preprocess
and then you should see <data_folder> populated with files of the following structure.
source scripts/setup.sh <data_folder>
├── download │ ├── de-en │ └── de-en.tgz ├── dump │ └── de-en │ ├── DEEN.db.bak │ ├── DEEN.db.dat │ ├── DEEN.db.dir │ ├── DEEN.train.0.pt │ ├── DEEN.valid.0.pt │ ├── DEEN.vocab.pt │ ├── dev.de.bert │ ├── dev.en.bert │ ├── ref │ ├── test.de.bert │ └── test.en.bert ├── raw │ └── de-en └── tmp └── de-en
- Run the following command to download raw data and then preprocess
Usage
First, launch the docker container
source launch_container.sh <data_folder> <output_folder>This will mount <data_folder>/dump (contains preprocessed data), <output_folder> (store experiment outputs),
and the repo itself (so that any code you change is reflected inside the container).
All following commands in this section should be run inside the docker container.
To exit the docker environment, type exit or press Ctrl+D.
-
Training
- C-MLM finetuning
python run_cmlm_finetuning.py --train_file /data/de-en/DEEN.db \ --vocab_file /data/de-en/DEEN.vocab.pt \ --valid_src /data/de-en/dev.de.bert \ --valid_tgt /data/de-en/dev.en.bert \ --bert_model bert-base-multilingual-cased \ --output_dir /output/<exp_name> \ --train_batch_size 16384 \ --learning_rate 5e-5 \ --valid_steps 5000 \ --num_train_steps 100000 \ --warmup_proportion 0.05 \ --gradient_accumulation_steps 1 \ --fp16 - Extract teacher soft label
# extract hidden states of teacher python dump_teacher_hiddens.py \ --bert bert-base-multilingual-cased \ --ckpt /output/<exp_name>/ckpt/model_step_100000.pt \ --db /data/de-en/DEEN.db --output /data/de-en/targets/<teacher_name> # extract top-k logits python dump_teacher_topk.py --bert_hidden /data/de-en/targets/<teacher_name>
- Seq2Seq training with KD
python opennmt/train.py \ --bert_kd \ --bert_dump /data/de-en/targets/<teacher_name> \ --data_db /data/de-en/DEEN.db \ -data /data/de-en/DEEN \ -config opennmt/config/config-transformer-base-mt-deen.yml \ -learning_rate 2.0 \ -warmup_steps 8000 \ --kd_alpha 0.5 \ --kd_temperature 10.0 \ --kd_topk 8 \ --train_steps 100000 \ -save_model /output/<kd_exp_name>
- C-MLM finetuning
-
Inference and Evaluatation
The following command will translate the dev split using the 100k step checkpoint, with beam size 5 and length penalty 0.6.
./run_mt.sh /output/<kd_exp_name> 100000 dev 5 0.6
Usually the BLEU score correlates well with the accuracy in validation. The results will be stored at
/output/<kd_exp_name>/output/.
Misc
- We test on a single Nvidia Titan RTX GPU, which has 24GB of RAM. If you encounter OOM, try decrease batch size and increase gradient accumulation.
- If you have a multi-GPU machine, use
CUDA_VISIBLE_DEVICESto sepcify GPU you want to use before launching the docker container. Otherwise it will use GPU 0 only. - Feel free to ask questions and discuss in the github issues.
Citation
If you find this work helpful to your research, please consider citing:
@inproceedings{chen2020distilling,
title={Distilling Knowledge Learned in BERT for Text Generation},
author={Chen, Yen-Chun and Gan, Zhe and Cheng, Yu and Liu, Jingzhou and Liu, Jingjing},
booktitle={ACL},
year={2020}
}
