qufei1993 / blog Goto Github PK
View Code? Open in Web Editor NEW五月君,一个疯狂输出干货的技术博主!欢迎关注公众号【编程界】共同学习与成长!
五月君,一个疯狂输出干货的技术博主!欢迎关注公众号【编程界】共同学习与成长!

















增删改查是业务的基础,也是使用最多和最广泛的,本文通过 MongoDB 客户端 mongo shell 来演示基本的增、删、改、查操作。
MongoDB 中插入数据使用 insert 关键字,相当于关系型数据中的 INSERT INTO。
向 demo_admin 表中插入数据,mongo 中使用 json 格式以键值对的方式插入数据,会自动创建一个 _id(ObjectID) 字段,在全局范围内不会重复。
db.user.insert({name: 'Jack'}) 写法类似于 JavaScript 中的语法,通过一个 for 循环插入数据。
for(i=0;i<10;i++) {
db.user.insert({name: 'Jack' + i})
}db.user.insertMany([{name: 'Jack'}, {name: 'Tom'}]) 在关系型数据库中插入数据,使用 INSERT INFO 关键字。
INSERT INTO user (name)
VALUES ('Jack');
MongoDB 中查询数据使用 find 关键字,相当于关系型数据中的 SELECT。
find 返回的是一个游标对象,需要遍历才能拿到结果,在终端经过了处理所以我们可以直接的看到结果,如果你是通过程序读取的,例如在 Node.js 中需要使用 toArray() 转为数组或使用异步迭代器遍历数据。
> db.user.find()
{ "_id" : ObjectId("61371542ffd35c79530231b6"), "name" : "Jack" }
{ "_id" : ObjectId("61371548ffd35c79530231b7"), "name" : "Jack0" }
{ "_id" : ObjectId("61371548ffd35c79530231b8"), "name" : "Jack1" }
{ "_id" : ObjectId("61371548ffd35c79530231b9"), "name" : "Jack2" }
{ "_id" : ObjectId("61371548ffd35c79530231ba"), "name" : "Jack3" }
{ "_id" : ObjectId("61371548ffd35c79530231bb"), "name" : "Jack4" }
{ "_id" : ObjectId("61371548ffd35c79530231bc"), "name" : "Jack5" }
{ "_id" : ObjectId("61371548ffd35c79530231bd"), "name" : "Jack6" }
{ "_id" : ObjectId("61371548ffd35c79530231be"), "name" : "Jack7" }
{ "_id" : ObjectId("61371548ffd35c79530231bf"), "name" : "Jack8" }
{ "_id" : ObjectId("61371548ffd35c79530231c0"), "name" : "Jack9" }Node.js 中可通过以下两种方式使用 find() 命令查询数据。
const users = await userColl.find().toArray();
console.log(users);
// 或以下方式
const users = await userColl.find();
for await (const user of users) {
console.log(user);
}> db.user.find({ name: 'Jack' })
{ "_id" : ObjectId("61371542ffd35c79530231b6"), "name" : "Jack" }> db.user.find({'$or': [{name: 'Tom'}, {name: 'Jack'}]})
{ "_id" : ObjectId("61371542ffd35c79530231b6"), "name" : "Jack" }> db.user.find().count()
11> db.user.find({'name': /^Jack/i})
// Node.js 可采用以下两种写法
{ name: new RegExp('Jack', 'i') }
{ name: { $regex: 'Jack' } } MongoDB 的投影可指定返回的字段,_id 默认返回,我们可以指定为不返回。
> db.user.find({ name: 'Jack' }, { _id: 0, name: 1 })skip(3):表示过滤掉前 3 条limit(2):显示 2 条结果sort({x:1}): 使用 x:1 递增排序 ASC,-1 时递减排序 DESC> db.user.find().skip(3).limit(2).sort({_id: -1});
{ "_id" : ObjectId("61371548ffd35c79530231bd"), "name" : "Jack6" }
{ "_id" : ObjectId("61371548ffd35c79530231bc"), "name" : "Jack5" }使用 findOne 查询单条数据,如果有多个符合条件的数据,也只会返回一条结果。注意 findOne() 返回的不是一个游标。
> db.user.findOne({'name': 'Jack'})
{ "_id" : ObjectId("61371542ffd35c79530231b6"), "name" : "Jack" }使用 update 更新数据,如果没有使用操作符(例如 $set)是全部字段更新,如果有字段没有指定更新成功之后以前的字段数据就没有了。
可有使用 updateOne 或 updateMany 这两个方法,需要指定操作符,都是指定的字段才会更新。
db.user.update(a, b, c, d);> db.user.update({"x":1},{"x":111})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })设置 c 值为 true,插入一条新的数据
> db.user.update({"y":999}, {"y":9999}, true)
WriteResult({
"nMatched" : 0,
"nUpserted" : 1,
"nModified" : 0,
"_id" : ObjectId("5a6e85a36c2de84d2e5a69d6")
})设置 c 值为 false,则不会插入数据
> db.user.update({"y":999},{"y":9999888}, false)
WriteResult({ "nMatched" : 0, "nUpserted" : 0, "nModified" : 0 })db.user.update({"a":2},{$set:{"a":222}},false,true);
db.user.update({"x":100},{$set:{"y":99}})updateOne/updateMany 这两个方法分别表示更新一条、更新多条,并且要跟随以下操作符,否则会报错。
db.user.updateOne({name: 'Jack', age: 18})
db.user.updateMany({name: 'Jack', info: 'info...'})例如,使用 update 对集合中的 orderNo 为 o111111 字段下的 userInfo 数组对象下的 cardNo 等于 123456789 这个对象中的 logs 字段和 status 字段(在更新的时候没有 status 字段将会创建) 进行日志更新。
{
"_id" : ObjectId("59546c5051eb690367d457fa"),
"orderNo" : "o111111"
"userInfo" : [
{
"name" : "o1111",
"cardNo" : "123456789",
"logs" : [
"2017-08-09 timeline ...",
]
}
...
]
},
...
}可以使用 $push 在找到 logs 数组后依次添加日志信息
let condition = {"orderNo":"o111111","userInfo.cardNo":"123456789"}
let update = {
$push: {
"passengers.$.logs": "2017-08-10 timeline1 ..."
}
}
db.collections.findOneAndUpdate(condition, update, { returnOriginal: false })也可以使用 $set 对某个字段进行更新
let condition = {"orderNo":"o111111","userInfo.cardNo":"123456789"}
let update = {
$set: {"passengers.$.status": "已更新"}
}
db.orderColl.updateOne(condition,update)需要注意的点是位置运算符 $ 只能在查询中使用一次,官方对于这个问题提出了一个方案 https://jira.mongodb.org/browse/SERVER-831 如果能在未来发布这将是非常有用的。如果,目前你需要在嵌套层次很深的情况下想对数组的内容进行修改可以采用 forEach() 方法操作,像下面这样:
db.post
.find({"answers.comments.name": "jeff"})
.forEach(function(post) {
if (post.answers) {
post.answers.forEach(function(answer) {
if (answer.comments) {
answer.comments.forEach(function(comment) {
if (comment.name === "jeff") {
comment.name = "joe";
}
});
}
});
db.post.save(post);
}
});删除操作需谨慎,数据一旦删除很难再恢复。
> db.demo_admin.remove({a:222})
WriteResult({ "nRemoved" : 1 })
返回 true 删除成功, false 删除失败。
> db.demo_admin.drop()
true

HTTPS 是建立在 SSL/TLS 传输层安全协议之上的一种 HTTP 协议,相当于 HTTPS = HTTP + SSL/TLS。第一篇文章 “HTTPS - 通俗易懂的阐述 HTTPS 协议,解决面试难题” 更多是理论上的一些阐述,能解决一些面试及常见问题,例如 “SSL/TLS” 的关系是什么?文中都有介绍。本文通过对一次 TLS 握手过程的数据抓包分析做为切入点,希望能进一步的帮助大家理解 HTTPS 原理。
TLS 是一种密码学协议,保证了两个端点之间的会话安全,一种最好的学习方法是使用抓包工具,捕获网络数据包,基于这些真实的数据包能够有一些直观的感受,例如:Wireshark,它可以捕获 HTTP、TCP、TLS 等各种网络协议数据包,是我们学习的好工具。
TLS 定义了四个核心子协议:握手协议 (handshake protocol)、密钥规格变更协议 (change cipher spec protocol)、应用数据协议 (application data protocol) 和警报协议 (alert protocol),这里最主要、最复杂是“握手协议”,协商对称密码就是在该协议中完成的。

参考 “网络协议那些事儿 - 如何抓包并破解 HTTPS 加密数据?”,本文是抓取的 www.imooc.com 网站数据包,基于 TLS v1.2 协议未对数据包做解密处理。

下图展示了 HTTPS 链接建立、TLS 握手协议里参数传递、证书验证、协商对称密钥的过程,更详细的内容,下文会介绍。

握手协议是 TLS 协议中最复杂的一部分,在这个过程中双方会协商链接参数(TLS 版本号、随机数等)并完成身份验证。里面可能会存在几种情况:完整握手,对服务器进行身份验证、恢复之前的会话采用的简短握手、对客户端和服务器都进行身份验证握手,下文以完整握手为例。
在建立 TCP 链接之后,每一个 TLS 链接都会以握手协议开始,完整握手是客户端与服务器之前未建立会话,在第一次会话时会经历一次完整的握手。
在一次新的握手协议中,客户端(浏览器)首先发出的一条消息是 “Client Hello”,告诉服务器我将给你传递这些数据:
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 223
Version: TLS 1.2 (0x0303)
Random: b0fcb3aca27c6de8b0e4f146b92d33f24e6a671e62f8f6f669aabbfc19bb4326
Session ID Length: 0
Cipher Suites Length: 92
Cipher Suites (46 suites)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 (0xc02c)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 (0xc028)
...“Server Hello” 是服务器在收到客户端 “Client Hello” 之后的一个回应,告诉客户端服务器的协议版本、服务器也会给出一个随机数 Random 用于后续生成密钥,Cipher Suite 是从客户端 “Client Hello” 消息的 Cipher Suites 里选择的一个密码套件。
Handshake Protocol: Server Hello
Handshake Type: Server Hello (2)
Length: 89
Version: TLS 1.2 (0x0303)
Random: 616d836f609800aaa1713462f61d50cc6472c45b54c0ac58dd52b9db4d555f6f
Session ID Length: 32
Session ID: 279fb99351526e29a4ce41af4cbff5575933e5c45dff7a2016a16cdf414f22c2
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
在 “Server Hello” 之后,服务器紧跟随着发出 “Certificate, Server Key Exchange, Server Hello Done” 这三个消息告知客户端。

证书信息,典型的 Certificate 消息用于携带服务器 X.509 证书链,一个接一个组合而成,主证书第一个,之后中间证书和根证书,服务器的公钥也包含在证书信息中。
Handshake Protocol: Certificate
Handshake Type: Certificate (11)
Length: 2781
Certificates Length: 2778
Certificates (2778 bytes)
Certificate Length: 1407
Certificate: 3082057b30820463a0030201020210040f1f824b17ca53814dc5c6f4c6a0a8300d06092a… (id-at-commonName=*.imooc.com)
Certificate Length: 1365
Certificate: 3082055130820439a003020102021007983603ade39908219ca00c27bc8a6c300d06092a… (id-at-commonName=RapidSSL TLS DV RSA Mixed SHA256 2020 CA-1,id-at-organizationName=DigiCert Inc,id-at-countryName=US)这个证书链在浏览器地址栏点击域名前面的 “小锁”,可看到如下信息,最上面是根证书、中间(RapidSSL)是中级证书颁发机构、*.imooc.com 这个是 CA 颁发给我们的域名证书。

“Server Key Exchange” 消息是携带密钥交换算法需要的额外数据,目的是计算主密钥需要的另一个值:“预主密钥(premaster secret)”。
不同的算法套件对应的消息内容也是不同的,下面 EC Diffie-Hellman(简称 ECDHE)就是密钥交换算法,这个对应 “Server Hello” 消息中选择的密码套件 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 中的 ECDHE
。
下面 Server Params 中的 Curve Type 表示曲线类型,本次选中的椭圆曲线名称为 named_curve:secp256r1,再确定基点 G,此时还会选择生成一个随机数做为服务端椭圆曲线的私钥,存放到本地,再根据基点 G 和椭圆曲线的私钥计算出椭圆曲线公钥(这里的椭圆曲线公/私钥都是临时的,只对本次链接生效),名字为 Pubkey 传递给客户端。
为了确保椭圆曲线公钥信息不被篡改,将 Server Params 与客户端和服务器随机值连在一起使用私钥签名,客户端从证书中获得服务器的公钥,就可验证是否来自服务器。客户端和服务器的随机值对于一次握手是唯一的,这也意味着攻击者无法重复利用该签名。
Handshake Protocol: Server Key Exchange
Handshake Type: Server Key Exchange (12)
Length: 329
EC Diffie-Hellman Server Params
Curve Type: named_curve (0x03)
Named Curve: secp256r1 (0x0017)
Pubkey Length: 65
Pubkey: 049c1c4eaa2ab8ae7b54482efc5d07e2b191174d804d660be07ded253c86f9bc5cd24f34…
Signature Algorithm: rsa_pkcs1_sha512 (0x0601)
Signature Hash Algorithm Hash: SHA512 (6)
Signature Hash Algorithm Signature: RSA (1)
Signature Length: 256
Signature: 5b9b1a750f0168f0a57852b4a77c14c351c5b97d7eb4a470fa8e3cf9e385cf7ac16f056f…不同的密钥交换算法,生成预主密钥的方式也不同,我们这里的示例以 ECDHE 为主,还有一种密钥交换算法是 RSA,它的密钥交换过程很简单,由客户端生成预主密钥,为 46 字节的随机数,使用服务器的公钥加密,经过“Client Key Exchange” 消息发送到服务端,服务端再用私钥就可解密出这个预主密钥。
基于 RSA 的密钥交换算法被认为存在严重的漏洞威胁,任何能够接触到私钥的人(例如,由于政治、贿赂、强行进入等)都可恢复预主密钥,进而构建相同的主密钥,最终密钥泄漏就可解密之前记录的所有流量了。这种密钥交换算法正在被支持前向保密保密的其它算法替代,例如,我们示例中的 ECDHE 算法在密钥交换时,每个链接使用的主密钥相互独立,如果出现问题也只是影响到当前会话,不能用于追溯解密任何其它的流量。
“Server Hello Done” 表示服务器已将握手消息需要的数据都发送完毕。之后就是等待客户端的回应。
Handshake Protocol: Server Hello Done
Handshake Type: Server Hello Done (14)
Length: 0“Client Key Exchange” 的消息也是携带密钥交换需要的额外数据,不过这一次是客户端发送给服务端的,Client Params 里面提供了客户端生成的临时椭圆曲线公钥信息。
Handshake Protocol: Client Key Exchange
Handshake Type: Client Key Exchange (16)
Length: 66
EC Diffie-Hellman Client Params
Pubkey Length: 65
Pubkey: 04c64110c2838d112d8fbc8a85a2c2b3b596e70d6ff9198330801df93ce9737432eeabe6…现在一次 TCP 往返结束了,客户端拿到了服务器的证书、Server Random、Server Params,现在客户端需要验证证书合法性和计算一些加密信息。
客户端收到服务器的响应信息,验证证书的合法性,可回顾上一节 深入浅出 HTTPS 原理篇。如果证书校验通过继续往下走。
上面也提了,在 “Server Key Exchange” 消息中,服务器对 Server Params 用私钥做了签名,客户端要从证书中获得服务器公钥,验证参数是否来自期望的服务器,这也是身份验证。
身份验证成功之后,得到 Server Params 参数,而 Server Params 参数里包含了 “服务器密钥交换消息” 中生成的临时公钥、secp256r1 椭圆曲线算法,现在客户端使用 secp256r1 算法用这个临时公钥和客户端自己生成的临时私钥相乘计算出预主密钥(premaster secret)。
现在客户端手里已经有了 Client Random、Server Random、Premaster Secret 三个随机参数,调用 PRF 伪随机函数函数生成 48 字节(384 位)主密钥。
master_secret = PRF(pre_master_secret, "master secret",
ClientHello.random + ServerHello.random)上面的主密钥并不是最终的会话密钥,最终的会话密钥使用 PRF 伪随机函数传入主密钥、客户端随机数、服务端随机数生成。
key_block = PRF(master_secret, "key expansion", server_random + client_random)这个最终的会话密钥包括:对称加密密钥(symmetric key)、消息认证码密钥(mac key)、初始化项量(iv key,只在必要时生成)。
当客户端完成密钥计算操作后,还要给服务器发送切换加密模式、验证会话密码消息。
“Change Cipher Spec” 消息表示客户端已生成加密密钥,并切换到加密模式。
TLSv1.2 Record Layer: Change Cipher Spec Protocol: Change Cipher Spec
Content Type: Change Cipher Spec (20)
Version: TLS 1.2 (0x0303)
Length: 1
Change Cipher Spec Message注意:“Change Cipher Spec” 不属于握手协议,它是另一种密钥规格变更协议。
这个是将之前所有的握手数据做一个摘要,再用最后协商好的对称加密算法对数据做加密,通过 “Encrypted Handshake Message” 消息发送到服务器进行校验,这个对称加密密钥是否成功。
TLSv1.2 Record Layer: Handshake Protocol: Encrypted Handshake Message
Content Type: Handshake (22)
Version: TLS 1.2 (0x0303)
Length: 60
Handshake Protocol: Encrypted Handshake Message服务器在收到客户端 “Client Key Exchange” 消息后,这时可以拿到 Client Random、Server Random、Client Params,先计算出预主密钥后,再分别计算出主密钥和最终的会话密钥,这块可参考客户端计算密钥一样的。

服务器发出 “Change Cipher Spec” 消息告诉客户端,服务端已生成密钥,请求客户端切换加密模式。
TLSv1.2 Record Layer: Change Cipher Spec Protocol: Change Cipher Spec
Content Type: Change Cipher Spec (20)
Version: TLS 1.2 (0x0303)
Length: 1
Change Cipher Spec Message“Encrypted Handshake Message” 这条消息也是服务器对握手的所有数据用协商好的对称加密算法加密,供客户端校验。
如果对抓取后的报文做解密,这里看到的是 “Finished” 消息。
TLSv1.2 Record Layer: Handshake Protocol: Encrypted Handshake Message
Content Type: Handshake (22)
Version: TLS 1.2 (0x0303)
Length: 40
Handshake Protocol: Encrypted Handshake Message整个握手过程完毕之后,我们会看到应用数据协议 “Application Data Protocol: http-over-tls”,之后我们的客户端/服务端建立一个安全通信隧道,就可以发送应用程序数据了。
TLSv1.2 Record Layer: Application Data Protocol: http-over-tls
Content Type: Application Data (23)
Version: TLS 1.2 (0x0303)
Length: 101
Encrypted Application Data: 1303136ee3f0e6daf0cb0e82d07fcca423c9cb2a26b29e332cdc604397f43c377df9805e…
[Application Data Protocol: http-over-tls]
XSS 攻击其中的一种类型是基于 DOM 型,攻击者很容易将包含恶意的 JavaScript 代码注入前端页面中,从而发起恶意攻击。
如今,很大一部分网站都在使用 React 进行开发,本文带大家了解 XSS 攻击是如何影响着我们的 React 应用程序,及如何避免应用程序受到 XSS 攻击。
如下所示,让我们先用 React 写一段存在 XSS 攻击的恶意代码,看它运行之后会发生什么?
const content = `<img onerror='alert("xss 😄");' src='xxx.png' /> Test XSS 攻击`;
class XSSTest extends React.Component {
render() {
return (
<div> { content } </div>
)
}
}当运行之后,浏览器为我们呈现的是一段字符串而不是被解析运行的 DOM。这是因为 React 中的 JSX 提供了防止注入攻击,在渲染所有的输入内容前,默认会进行转义,这些内容都会被转换成字符串输出到 DOM ,有效地防止 XSS 攻击。
如果想在我们的 DOM 上渲染 HTML 该怎么办?
dangerouslySetInnerHTML 是 React 解析含有 HTML 标记内容的一种方式,也是原生 DOM 元素 innerHTML 的替代方案,从这个命名 dangerously 也能看出是一个危险的 API,以此来警示用户,使用 dangerouslySetInnerHTML API 直接设置含有 HTML 标签的内容很容易遭到 XSS 攻击。
继续上面的示例,让我们做下修改。
const content = `<img onerror='alert("xss 😄");' src='xxx.png' /> Test XSS 攻击`;
class XSSTest extends React.Component {
render() {
return (
<div dangerouslySetInnerHTML={{ __html: content }}></div>
)
}
}运行上面代码之后,会出现以下界面,页面被 XSS 注入了。
有的时候在内容管理系统(CMS)中包含有 HTML 标记的内容,确实需要在页面展示,你应该做的是在解析前先通过一个工具函数处理掉内容中的恶意脚本。
通常这类工具函数不需要自己重新编写,社区已经有一些不错的解决方案,例如 github.com/leizongmin/js-xss这个工具,同时支持浏览器端、Node.js 服务端,可通过白名单策略控制允许的 HTML 标签和属性。
import xss from 'xss';
const content = xss(`<img onerror='alert("xss 😄");' src='xxx.png' /> Test XSS 攻击`);再次运行看下展现效果,发现当通过 xss() 工具函数包装处理之后,img 标签里的 onerror 属性被转义了。
除此之外还有一个用来处理含有恶意代码的工具 sanitize-html,默认有一些过滤策略,如果想获得更多内容,还需要自定义允许的标签和属性。
React 提供的 Refs 允许我们操作 DOM 节点或在 render() 方法中创建的 React 元素。
Refs 设计的应用场景是在媒体播放、焦点和文本选择,及实现动画与一些基于 DOM 的第三方库配合使用,例如结合 react-transition-group 实现动画在严格模式下必须使用 refs <CSSTransition nodeRef={React.createRef()} /> 否则会警告 findDOMNode is deprecated in StrictMode,这也是警告我们不要直接操作 DOM。
当 Refs 被过度滥用时,往往就会出现一些不可控的影响,如下例所示,通过创建的 xssTestRef 对象来操作 DOM 节点是有风险的,XSS 很容易被注入。
import React from 'react';
const content = `<img onerror='alert("xss 😄");' src='xxx.png' /> Test XSS 攻击`;
const xssTestRef = React.createRef();
class XSSTest extends React.Component {
componentDidMount() {
xssTestRef.current.innerHTML = content;
}
render() {
return (
<div ref={xssTestRef}>11</div>
)
}
}
export default XSSTest;为了更好的预防应用程序出现 XSS 攻击,我们要了解它是什么,什么情况下会发生,本文我们的讲解主要围绕 XSS 攻击的 DOM 类型来看,除此之外还有存储型,这涉及到服务端,关于 XSS 的详细介绍可参考这篇文章 Web 安全 - 跨站脚本攻击 XSS 三种类型及防御措施。
关于 XSS 攻击,在 React 中我们可以做这些防范措施:
本文开始,先提个问题:“MongoDB ObjectId() 生成的 id 是唯一的吗?”,答案在文中。
谈起分布式 ID,经常会聊到的一些方案是使用 Twitter 的 Snowflake 算法、UUID、数据库自增 ID 等。前些时间看了下 MongoDB ObjectId() 的实现原理,也不失为一种好的实现思路,正如标题所描述的,本文会给大家分享下在 MongoDB 中是如何实现的 “千万级” 分布式唯一 ID。
MongoDB 一开始的设计就是用来做为分布式数据库,插入数据时默认使用 _id 做为主键,下面这个 _id 就是 MongoDB 中开源的分布式系统 ID 算法ObjectId()生成的。
new ObjectId("632c6d93d65f74baeb22a2c9")关于其组成需要指出一个误区,网上很多介绍 MongoDB ObjectId() 的文章,都有这样一段描述:
// 过时的规则,现在已经不用 机器标识 + 进程号
// 一种猜测,现在大多应用容器化,在容器内有独立的进程空间,它的进程号永远可能都为 1,还有创建几台虚拟机,其中的 hostname 可能也都为 localhost
4 字节的时间戳 + 3 个字节机器标识码 + 2 个字节进程号 + 3 个字节自增数很长一段时间我也一直这样认为,直到前些时间看了源码之后,发现中间的 3 个字节机器标识码 + 2 个字节进程号已被替换为 5 个字节的进程唯一标识,之后翻阅了 MongoDB 官方文档 描述也确实如此。
// 当前 ObjectId 实现规则
4 字节的时间戳(单位:秒) + 5 个字节的进程唯一标识 + 3 个字节自增数这个组成规则反映出几个问题:
Math.pow(2, 24) - 1 = 16777215 个唯一 ID,因此文章开头我用了 “千万级” 描述,这已经够了,当下突破这个限制几乎不太可能。下面让我们开始实践,参考 源码 写一个最简化的 ObjectId(),真正理解它的实现原理。编程语言为 JavaScript,运行环境 Node.js。
实现会用到一些 Node.js 的系统模块 API 和运算符,每一步都会对用到的知识做一个讲解。
按照它的组成规则,分步实现,首先,创建一个自定义的类,这里我命名为 UniqueId,并初始化一个 12 Byte 的 Buffer。
Buffer 是 Node.js 中的一个系统模块,Buffer.alloc() 按照指定字节数创建一段连续的内存空间,用来处理二进制数据,默认使用 0 进行填充,也可以指定字符进行填充,参见 API Buffer.alloc(size[, fill[, encoding]])。
const kId = Symbol('id');
class UniqueId {
constructor() {
this[kId] = UniqueId.generate()
}
get id() {
return this[kId];
}
static generate() {
const buffer = Buffer.alloc(12);
return buffer;
}
}运行之后输出一个 0 填充的 12 Byte 的 buffer。
(new UniqueId()).id -> <Buffer 00 00 00 00 00 00 00 00 00 00 00 00>Date.now() 获取当前时间毫秒数,除以 1000 精确到秒,通过 Math.floor() 函数向下取整,取到一个整数。
buffer.writeUInt32BE()** 将一个无符号的 32 位整数以高位优先(大端写入)方式写入到 buffer 中**,32 位在这里占用的是 4 Byte,offset 设置为 0(默认 offset 就是 0),将时间戳写入到 buffer 的前 4 个字节。
const kId = Symbol('id');
class UniqueId {
constructor() {
this[kId] = UniqueId.generate()
}
get id() {
return this[kId];
}
static generate() {
const buffer = Buffer.alloc(12);
// 4-byte timestamp
+ const time = Math.floor(Date.now() / 1000);
+ buffer.writeUInt32BE(time, 0);
+ return buffer;
}
}运行之后可以看到 buffer 的前 4 个字节已被填充,对 Node.js Buffer 模块不太了解的,看到这个结果又迷惑了,buffer 里面存储的既不是二进制也不是十进制,到底是啥?
(new UniqueId()).id -> <Buffer 63 2e 90 c0 00 00 00 00 00 00 00 00>Node.js 中的 buffer 是用来处理二进制数据的,例如下面的 “2e” 二进制为 00101110,那么二进制方式在用户这一侧看起来显然不是很方便,Node.js buffer 中我们所看到的其实是内存实际存储的值,转换为了十六进制表示(00 ~ ff)。
记住一点:“计算机底层使用的二进制,如果是用来展示通常是 10 进制,编程用的时候会采用 16 进制,内存地址编码使用的就是 16 进制。” 内存管理这块想了解更多可参考这篇文章 为什么递归会造成栈溢出?探索程序的内存管理!https://github.com/qufei1993/blog/issues/44
如果想取到存进去的时间戳,使用 buffer.readUInt32BE(offset) 方法,默认 offset 为 0,从 0 位开始读取前 4 Byte。
中间 5 Byte 没有规定实现方式,保证进程唯一就好,使用 Node.js 系统模块 crypto 提供的 randomBytes() 方法生成一个长度为 5 的随机字节。
+ const crypto = require('crypto');
+ let PROCESS_UNIQUE = null;
const kId = Symbol('id');
class UniqueId {
constructor() {
this[kId] = UniqueId.generate()
}
get id() {
return this[kId];
}
static generate() {
const buffer = Buffer.alloc(12);
// 4-byte timestamp
const time = Math.floor(Date.now() / 1000);
buffer.writeUInt32BE(time, 0);
+ // 5-byte process unique
+ if (PROCESS_UNIQUE === null) {
+ PROCESS_UNIQUE = crypto.randomBytes(5);
+ }
+ buffer[4] = PROCESS_UNIQUE[0];
+ buffer[5] = PROCESS_UNIQUE[1];
+ buffer[6] = PROCESS_UNIQUE[2];
+ buffer[7] = PROCESS_UNIQUE[3];
+ buffer[8] = PROCESS_UNIQUE[4];
return buffer;
}
}最后 3 Byte 为自增数,是关键的一部分,在 1 秒钟内、进程标识唯一的情况下,一个 ObjectId() 能生成多少个不重复的 ID,由这 3 Byte 决定。
自增数不是简单的理解为 0、1、2... 这样依次生成的,实现步骤为:
Math.random() * 0xffffff 首先生成一个 3 Byte 的随机数做为起始值(这样也加大了产生重复的机率),声明在类的静态属性上(相当于 UniqueId.index = Math.random() * 0xffffff,0xffffff是一个十六进制数,等价于十进制的 16777215。**getInc()** 初始的随机数都会 +1,做为当前的随机自增数 inc,并做了取余操作,可以放心这个自增数永远都不会大于 16777215。11111111,转为 16 进制是 0xff,转为十进制是 255。现在我们知道了 buffer 中的一个字节所表达的 10 进制是不能大于 255 的,想实现一个字节存放的数不能大于 255 一个实现是做二进制与运算,本文用的也是这种方式,举个与运算的例子:16777215 二进制表示: 11111111 11111111 11111111
255(0xff)二进制表示: 00000000 00000000 11111111
与运算结果: 00000000 00000000 11111111
# 与运算是都为 1 则为 1,这里的结果最大是不会超过 255 的 **buffer[11] = inc & 0xff**),同理将 inc 向右偏移 8 位与 0xff 做与运算赋值给 buffer[10],inc 向右偏移 16 位与 0xff 做与运算赋值给 buffer[9]。const crypto = require('crypto');
let PROCESS_UNIQUE = null;
const kId = Symbol('id');
class UniqueId {
+ static index = Math.floor(Math.random() * 0xffffff);
constructor() {
this[kId] = UniqueId.generate()
}
get id() {
return this[kId];
}
+ static getInc() {
+ return (UniqueId.index = (UniqueId.index + 1) % 0xffffff);
+ }
static generate() {
const buffer = Buffer.alloc(12);
// 4-byte timestamp
const time = Math.floor(Date.now() / 1000);
buffer.writeUInt32BE(time, 0);
// 5-byte process unique
if (PROCESS_UNIQUE === null) {
PROCESS_UNIQUE = crypto.randomBytes(5);
}
buffer[4] = PROCESS_UNIQUE[0];
buffer[5] = PROCESS_UNIQUE[1];
buffer[6] = PROCESS_UNIQUE[2];
buffer[7] = PROCESS_UNIQUE[3];
buffer[8] = PROCESS_UNIQUE[4];
+ // 3-byte counter
+ const inc = UniqueId.getInc();
+ buffer[11] = inc & 0xff;
+ buffer[10] = (inc >> 8) & 0xff;
+ buffer[9] = (inc >> 16) & 0xff;
+ return buffer;
}
}以下为最终的生成结果,可以看到每个字节都被 1 个 16 进制数所填充。
(new UniqueId()).id -> <Buffer 63 33 01 c2 55 58 38 cf e0 be 75 46>本文从理论到实践,实现了一个自定义的 UniqueId(),这是一个最简化的 MongoDB ObjectId() 实现,代码量也不多,感兴趣的可以自己实现一遍,加深理解。
文章开头提到了一个问题 “MongoDB ObjectId() 生成的 id 是唯一的吗?” 答案即是 Yes 也是 No,在 1 秒钟内且进程唯一标识不重复的情况下,根据后 3 Byte 自增数可以得到生成的最大不重复 id 为 **2^24 - 1 = 16777215** 个唯一 ID。
最后,留一个问题,为什么 MongoDB ObjectId() 可以不用 new 就能生成一个 ID 呢?并且显示的结果和上面自定义的 UniqueId() 也不一样,关于 MongoDB ObjectId() 还有很多玩法,下一篇介绍。
console.log(ObjectId()); // 原生 ObjectId 输出结果:new ObjectId("633304ee48d18c808c6bb23a")
console.log(new UniqueId()); // 自定义 UniqueId 输出结果:UniqueId { [Symbol(id)]: <Buffer 63 33 04 ee f0 b2 b8 1f c3 15 53 2c> }
从 Callback 到 Promise 的 .then().then()... 也是在不断尝试去解决异步编程带来的回调嵌套、错误管理等问题,Promise 进一步解决了这些问题,但是当异步链多了之后你会发现代码会变成这样 .then().then()... 由原来的横向变成了纵向的模式,仍就存在冗余的代码,基于我们大脑对事物的思考,我们更倾向于一种近乎 “同步” 的写法来表达我们的异步代码,在 ES6 规范中为我们提供了 Generator 函数进一步改善我们的代码编写方式。
Generator 中文翻译过来我们可以称呼它为 “生成器”,它拥有函数的执行权,知道什么时候暂停、什么时候执行,这里还有一个概念协程,有些地方也看到过一些提问:“JavaScript 中有协程吗?” “Node.js 中有协程吗?” 这些问题正是本文讨论的,本节着重从概念上让大家做一些了解,认识到协程在 JavaScript 是怎么样的存在。
在了解协程之前,先看进程、线程分别是什么,分享一个笔者之前写的 Node.js 进阶之进程与线程 文中结合 Node.js 列举了一些示例,也是从一些基础的层面来理解。
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器(来自百科)。
我们启动一个服务、运行一个实例,就是开一个服务进程,例如 Java 里的 JVM 本身就是一个进程,Node.js 里通过 node app.js 开启一个服务进程,多进程就是进程的复制(fork),fork 出来的每个进程都拥有自己的独立空间地址、数据栈,一个进程无法访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信,进程之间才可数据共享。
Mac 系统自带的监控工具 “活动监视器” 也可看到效果。
Node.js 中我们通过 Cluster 模块创建多进程时为什么要根据 CPU 核心数?创建更多不好吗?在一个 CPU 核心的任何时间内只能执行一个进程。因此,当你 CPU 核心数有限时,创建过多的进程,CPU 也是忙不过来的。
Node.js 通过单线程 + 事件循环解决了并发问题。而我们使用 Node.js 利用 Cluster 模块根据 CPU 核心数创建多进程解决的是并行问题,假设我有 4 CPU 每个 CPU 分别对应一个线程并行处理 A、B、C、D 不同的任务,线程之间互不抢占资源。
一句话总结:进程之间数据完全隔离、由操作系统调度,自动切换上下文信息,属系统层级的构造。
线程是操作系统能够进行运算调度的最小单位,首先我们要清楚线程是隶属于进程的,被包含于进程之中。一个线程只能隶属于一个进程,但是一个进程是可以拥有多个线程的。
同一块代码,可以根据系统 CPU 核心数启动多个进程,每个进程都有属于自己的独立运行空间,进程之间是不相互影响的。同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage),线程又有单线程和多线程之分,具有代表性的 JavaScript、Java 语言。
线程共享进程的资源,可以由系统调度运行,可以自动完成线程切换,也许你会听到多线程编程、并发问题,首先,并发指的某个时间点多个任务队列对应到同一个 CPU 上运行,在任一时间点内也只会有一个任务队列在 CPU 上执行,这时就产生排队了。
为了解决这个问题,CPU 运行时间片会被分成多个 CPU 时间段,每个时间段给各个任务队列执行(对应多个线程),这样解决了一个任务如果造成阻塞,不会影响到其它的任务运行,同样线程是会自动切换的。
Node.js 是怎么解决的并发问题?Node.js 主线程是单线程的,核心通过事件循环,每次循环时取出任务队列中的可执行任务运行,没有多线程上下文切换,资源抢占问题,达到高并发成就。
一句话总结:线程之间大多数共享数据(各自的调用栈这些信息除外),由操作系统调用,自动切换上下文,系统层级的构造。
协程又称为微线程、纤程,英文 Coroutine。协程类似于线程,但是协程是协作式多任务的,而线程是抢占式多任务的。协程之间的调用不需要涉及任何系统调用,是语言层级的构造,可看作一种形式的控制流,有时候我们也会称它为用户态的轻量级线程。
协程一个特点是通过关键字 yield 调用其它协程,接下来每次协程被调用时,从协程上次 yield 返回的位置接着执行,这种通过 yield 协作转移执行权的操作,彼此没有调用者和被调用者的关系,是彼此平等对称的一种关系。
协程与线程两者的差异,可以看出 “同一时间如果有多个线程,但它们会都处于运行状态,线程是抢占式的,而协程同一时间运行的只有一个,其它的协程处于暂停状态,执行权由协程自己分配”。
协程也不是万能的,它需要配合异步 I/O 才能发挥最好的效果,对于操作系统而言是不知道协程的存在的,它只知道线程。需要注意,如果一个协程遇到了阻塞的 I/O 调用,这时会导致操作系统让线程阻塞,那么在这个线程上的其它协程也都会陷入阻塞。
一句话总结:协程共享数据,由程序控制完成上下文切换,语言层级的构造。
之前知乎上有个问题 “Node.js 真的有协程吗?” 协程在很多语言中都支持,只是每个实现略有差异,下图来自维基百科展示了支持协程的编程语言,可以看到 JavaScript 在 ECMAScript 6 支持,ECMAScript 7 之后通过 await 支持,Node.js 做为 JavaScript 在服务端的运行时,只要你的 Node.js 版本对应支持,就是可以的。
生成器(Generator)是协程的子集,也称为 “半协程”。差异在于,生成器只能把控制权交给它的调用者,完全协程有能力控制在它让位之后哪个协程立即接续它执行。在 JavaScript 里我们说的 Generator 函数就是 ES6 对协程的实现。
JavaScript 是一个单线程的语言,只能保持一个调用栈。在异步操作的回调函数里,一旦出错原始的调用栈早已结束,引入协程之后每个任务可以保持自己的调用栈,这样解决的一大问题是出错误时可以找到原始的调用栈。
看下生成器函数与普通函数有什么区别?首先普通函数通过栈实现的,举个例子,调用时是 A() -> B() -> C() 入栈,最后是 C() -> B() -> A() 这样一个顺序最后进入的先出栈执行。
生成器函数看似和普通函数相似,其实内部执行机制是完全不同的,生成器函数在内部执行遇到 yield 会交出函数的执行权给其它协程(此处类似 CPU 中断),转而去执行别的任务,在将来一段时间后等到执行权返回(生成器还会把控制权交给它的调用者),程序再从暂停的地方继续执行。
自 ES6 开始,通过 “Generator” 和 “yield” 表达式提供了无堆栈协程功能。
“无栈协程的秘密在于它们只能从顶级函数中挂起自己。对于其他所有函数,它们的数据都分配在被调用者堆栈上,因此从协程调用的所有函数必须在挂起协程之前完成。协程保留其状态所需的所有数据都在堆上动态分配。这通常需要几个局部变量和参数,其大小远小于预先分配的整个堆栈”。参考 coroutines-introduction
栈是一块连续的内存,能够从子函数产生的协程称为栈式,它们可以记住整个调用栈,这种也称为栈式协程。在 JavaScript 中我们只能从生成器函数内部暂停、恢复执行生成器函数。
下面示例 test1() 是生成器函数,但是 forEach 里面的匿名函数是一个普通的函数,就无法在内部使用 yield 关键字,运行时会抛出错误 “SyntaxError: Unexpected identifier”
function *test1() {
console.log('execution start');
['A', 'B'].forEach(function(item) {
yield item;
})
}例如,现在有两个生成器函数 test1()、test2(),还有 co 这个工具可以帮助我们自动的执行生成器函数。
const co = require('co');
function *test1() {
console.log('execution 1');
console.log(yield Promise.resolve(1));
console.log('execution 2');
console.log(yield Promise.resolve(2));
}
function *test2() {
console.log('execution a');
console.log(yield Promise.resolve('a'));
console.log('execution b');
console.log(yield Promise.resolve('b'));
}
co(test1);
co(test2);看下运行结果:
execution 1
execution a
1
execution 2
a
execution b
2
b“JavaScript 有协程吗?” JavaScript 中是在 ES6 后基于生成器函数(Generator)实现的,生成器只能把程序的执行权还给它的调用者,这种方式我们称为 “半协程”,而完全的协程是任何函数都可让暂停的协程执行。
基于生成器函数这种写法,如果去掉 yield 关键字,与我们普通的函数是相似的,以一种同步的方式来表达,解决了回调嵌套的问题,另外我们还可以通过 try...catch 做错误捕获,只不过我们还需要借助 CO 这样的模块,让生成器函数自动执行,这个问题在 ES7 中已经得到了更好地解决,我们可以通过 async/await 轻松的实现。

HTTPS 工作原理,之前也看过一些,但是对整体的一个完整流程和部分细节,还是处于一个模糊状态,之前也有一些疑问:“证书是怎么验证的?”、“TLS 握手过程是怎么样的?”、“对称密钥如何计算?”、“计算预主密钥随机数用了几个?” 等等,基于这些疑问,也花了一些时间才逐步了解的,基于自己的理解,做了一个 HTTPS 的系列文章,希望能帮助到有此疑问的读者朋友。
本文为系列的第一篇,带着一些问题逐步了解对称加密、非对称加密、数字证书、密钥协商等这些概念分别是什么、能做什么,一层一层揭开其神秘面纱。
在 HTTP 中数据之间的网络传输是明文的,很容易被中间人窃取、攻击,对数据进行伪造再发往服务器端,服务端接收到数据也无法判断数据的来源是否准确。

如果说为什么要使用 HTTPS?直白点就是 “HTTP 不安全”,无法准确的保证数据的机密性、真实性、完整性。
HTTPS 不是一种全新的协议,它是建立在 SSL/TLS 传输层安全协议之上的一种 HTTP 协议,相当于 HTTPS = HTTP + SSL/TLS,可保护用户计算机与网站服务器之间数据传输的完整性、机密性。
从 OSI 模型图上看主要是在应用层和传输层直接多了一个 SSL/TLS 协议。

这里最主要的部分 SSL/TLS 就是我们学习 HTTPS 的关键部分,SSL/TLS 做为一种安全的加密协议,其在不安全的基础设施之上为我们提供了安全的通信通道。
SSL/TLS 这个名字有时也会让人迷,现在我们所说的 SSL/TLS 一般特指 TLS 协议,不妨看下它的发展历史。
SSL 是 secure socket layer 的简称,中文为安全套接字层。最早由网景(Netscape)公司开发,该协议的第一个版本从未发布过。自 1994 年 11 月开始发布第二个版本,SSL 2 在开发上基本上没有与 Netscape 公司以外的安全专家商讨,这个版本被认为存在严重缺陷,这个版本最终也以失败告终。在 SSL2 失败后,Netscape 专注于 SSL 3 进行了完全重新的协议设计,于 1995 年发布,SSL 3 版的协议被沿用至今,只不过后来被改了名字 TLS 1.0,也许很多人并不知道。
1996 年 5 月,TLS 工作组成立,开始将 SSL 从 Netscape 公司迁移至 IETF,由于 Netscape 与 Microsoft 在 Web **权的争执,整个迁移工作也经历了一个漫长的过程,在 1999 年 1 月 IETF 组织将 SSL 进行了标准化 TLS 1.0 问世,前身就是 SSL 3。
TLS 是 transport layer security 的简称,中文为传输层安全协议。在 2006 年 4 月 TSL 1.1 版本发布,修复了一些关键的安全问题,添加对 CBC 攻击的保护(隐式 IV 被替换为显示 IV,更改分组密码模式中的填充错误)。
在 2008 年 8 月 TLS 1.2 版本发布,主要包括:增加 SHA-2 密码散列函数、AEAD 加密算法、TLS 扩展定义和 AES 密码组合。
2018 年 8 月 TLS 1.3 版本发布,对安全的加强、性能的提升也做了很多改变,例如,在安全上将 MD5、SHA-1 这些不安全或过时的算法移除,仅保留了少数算法 ECDHA、SHA-2 等。性能上在 TLS 握手过程中由之前的 2-RTT 握手改进为 1-RTT 握手并初步支持 0-RTT。
我们谈到 https 都知道它之所以安全是因为传输中对数据做了加密,首先了解下它选择了哪种加密方式来实现的。
对称加密是一种共享密钥的算法,客户端与服务端共用一把密钥,对数据做加密传输,如果密钥只有通信双方持有,不保证泄漏,那就可以保证安全。

现实世界中显然不是这样的,例如浏览器同服务器交互,服务器把共享密钥传输给浏览器,这个密钥在传输过程中怎么保证不被截取、篡改?
进一步提升安全系数,出现了 “非对称加密” 又称为 “公钥加密”,该算法拥有两个不对称的密钥,它的特性是使用公钥加密只有对应的私钥可解密,反之,私钥加密也只有对应的公钥才可解密。注意,私钥仅自己可见,对外暴露的是公钥。

非对称加密的安全性比对称加密要高,但是它需要更多的计算,不适用于数据量大的场景,通信速度没有了保证也不行的,TLS 加密算法并没有完全采用这种加密算法。
所谓 “取长补短”,TLS 在加密算法上结合了非对称加密和对称加密,我们这里称之为 “混合加密” 算法,使用非对称加密进行身份验证和共享密钥的协商,只用一次即可,后续的通信中使用对称密钥进行数据的传输。
除此之外,客户端和服务端交换公钥的过程,依然存在被窃听,经典的例子还是中间人攻击,因为公钥在传输的过程是可见的,中间人可以对客户端扮演服务端的角色或者对服务端扮演客户端的角色,依然可以对数据进行篡改,但是服务端无法判别来源是否可靠,问题仍然存在。
举一个例子:
这也不行那该怎么办?在这里使用 “混合加密” 从安全、性能上得到了一个平衡,使用非对称加密交换对称加密密钥,已实现了我们需要的机密性。
现在我们要解决下一个疑问:如何保证浏览器拿到的公钥是可信的?
例如,现实世界里,我们去银行办事,到柜台前你说我是张三,要办理业务,银行工作人员首先需要你出示证件,得证明你是真的张三,能证明自己的就是 “身份证” 了,由权威机构(现实世界里的公安局)颁发的大家都认可的证件。
那么网络世界里的公安局,就是我们常说的 CA,Certificate Authority,证书认证机构,我们也需要为网站申请数字证书。
证书是一个包含版本、序列号、签名算法、颁发者、有效期、公钥等的数字证书文件。我们的网站在使用 HTTPS 之前都会预先向 CA 机构申请一份数字证书,安装到自己的服务器上,之后浏览器发起请求,服务器就可以把这个数字证书返回到浏览器,这个过程中怎么保证数字证书不被修改呢?
公安局在颁发我们的身份证时有一定的防伪技术,同样 CA 在签发证书时也会对证书进行数字签名,保证证书的完整性。

摘要算法是一种单向的加密算法,也称为 “散列算法”,在加密数据时不需要提供密钥,加密之后的数据也不能进行逆向推算。
它能实现对一个大文件加密之后映射为一个小文件,好比一篇文章提取一段摘要,但如果原文发生改变,哪怕是增加或删除一个标点符号再次加密后的结果也会发生完全不同的变化,目前一些常用的摘要算法(MD5、SHA-1)被认为存在安全性问题,在 TLS 1.3 版本已经移除了,现在推荐的是 SHA-2,例如 SHA256。
CA 机构对明文数据会做一个摘要算法,生成一段不可逆向解密的 Hash value,这段 Hash value 不能明文传输,避免中间人在修改证书后把摘要算法也修改了。
数字签名,这个名字在现实世界也是如此,例如我给你一个证明,要证明是我给你的,最有效的办法就是签名、按手印,这个是没办法伪造的。
CA 也有一对自己的公私钥,结合上面摘要算法生成的 hash value,使用 CA 私钥加上这段 hash value 来生成数字签名,这个只有对应的公钥才可解密。
CA 将数字签名和我们申请的信息(服务器名称、公钥、主机名、权威机构的名称、信息等)整合到一块,生成数字证书,颁发给服务器。
下面是对 www.nodejs.red 这个域名截取的一张图。

有了数字证书,客户端和服务端在交互时就可使用非对称密钥来协商用于数据加密的对称加密密钥了。
我们在浏览器打开一个 HTTPS 协议的网址发起请求,在建立 TCP 链接之后,会发起 TLS 的握手协议,之后服务器会返回一系列消息,其中就包括证书消息。
证书的验证存在一个证书信任链问题,我们向 CA 申请的证书,通常是由中间证书机构颁发的。例如,www.nodejs.red 这个域名你会看到它的证书签发者是 “R3”,它是 Let's Encrypt 在 2020 年 11 月 20 日推出的一个免费证书,通过 R3 我们可以找到它的签发者是 “ISRG Root X1”,而 “ISRG Root X1” 没有了上级的签发者,现在会认为它是根证书。
下图展示的是 www.nodejs.red 这个域名网站的证书链关系。

在我们的操作系统中会预先安装一些权威机构的证书,浏览器信任的是根证书,如果根证书在本地,就用根证书 “ISRG Root X1” 公钥去验证 “ISRG Root X1” 这个中间证书机构是否可信,如果校验通过,再用 “ISRG Root X1” 去验证最终的实体证书 “www.nodejs.red” 是否可信任,如果通过就认为证书 “www.nodejs.red” 是可信的。
证书验证基本上都是这种模式,最终要找到本地安装的根证书,在反向的逐级验证,确认网站的签发者是可信的。如下图所示。

如果服务器返回的证书验证通过,浏览器就可获取到数字证书的明文、签名信息,做以下操作:

如果证书信息被篡改,没有证书私钥是不能改签名的,客户端收到证书之后对原文信息做个签名一比对就知道是否被篡改。
另一个问题,假设:“我们的证书被黑客用合法证书调包呢?”,证书的域名等信息是不能被篡改的,就算黑客调包换成了自己的合法证书,因为域名信息不一样,浏览器请求的时候一对比也可发现问题。
没有绝对的安全,如果黑客把自己的根证书安装在了你的计算机上,那么它就可以签发任意域名的虚假证书了,因此,遇到一些不可信的文件还是不要乱安装的好,保证根证书的安全。
上面浏览器向服务器发起请求,服务器返回证书,这个过程双方会交换两个参数,分别是客户端的随机数、服务端的随机数,用于生成主密钥,但是主密钥的生成还依赖一个预主密钥。
不同的密钥交换算法,生成预主密钥的方法也不同。一种密钥交换算法是 RSA,它的密钥交换过程很简单,由客户端生成预主密钥,为 46 字节的随机数,使用服务器的公钥加密,经过密钥交换消息发送到服务端,服务端再用私钥就可解密出这个预主密钥。
基于 RSA 的密钥交换算法被认为存在严重的漏洞威胁,任何能够接触到私钥的人(例如,由于政治、贿赂、强行进入等)都可恢复预主密钥,进而构建相同的主密钥,最终密钥泄漏就可解密之前记录的所有流量了。这种密钥交换算法正在被支持前向保密的其它算法替代,例如,ECDHE 算法在密钥交换时,每个链接使用的主密钥相互独立,如果出现问题也只是影响到当前会话,不能用于追溯解密任何其它的流量。
ECDHE 是临时椭圆曲线密钥交换算法,客户端和服务器会分别交换两个信息 Server Params、Client Params,在每次的链接中,都会生成一对新的临时公私钥。基于 ECDHE 算法客户端和服务端可分别计算出预主密钥(premaster secret)
这时客户端和服务端就分别拥有 Client Random、Server Random、Premaster Secret 三个随机数。
主密钥在 TLS v1.2 是通过一个伪随机函数 master_secret = PRF(pre_master_secret, "master secret", ClientHello.random + ServerHello.random) 计算出来的。
但主密钥并不是最终的会话密钥,最终的会话密钥使用 PRF 伪随机函数传入主密钥、客户端随机数、服务端随机数生成。
key_block = PRF(master_secret, "key expansion", server_random + client_random)这个最终的会话密钥包括:对称加密密钥(symmetric key)、消息认证码密钥(mac key)、初始化项量(iv key,只在必要时生成)
上面这些都是在 TLS 的握手协议中完成的,当握手完成之后,客户端/服务端建立一个安全通信隧道,就可以发送应用程序数据了。
协商对称加密密钥,这里面主要就是 TLS 的握手协议,这个过程很复杂,还有很多内容本篇最后没有详细的讲解,下图为笔者画的一个握手交互图,在下一篇文章中会通过 Wireshark 工具来抓取网络数据包做分析,做一个实战讲解,更深刻的理解 HTTPS 的原理。

平常写一些文档或者个人笔记时,Markdown 是我的第一个选择,因为它用起来真的很方便、简洁。那么今天要讲的 Docsify 是什么呢?
Docsify 是一个动态生成文档网站的工具。不同于 GitBook、Hexo 的地方是它不会生成将 .md 转成 .html 文件,所有转换工作都是在运行时进行。
这将非常实用,如果只是需要快速的搭建一个小型的文档网站,或者不想因为生成的一堆 .html 文件“污染” commit 记录,只需要创建一个 index.html 就可以开始写文档而且直接部署在 GitHub Pages。
安装脚手架工具 docsify-cli,安装过程中较慢的可以切换 npm 源为 cnpm
$ npm i docsify-cli -g
如果你正在用 Markdown 写一些 Blog 项目,那么也可以用你现在的项目,如果你没有,那么建议你在 Github 新建一个属于你的 Blog 项目,开始我们接下来的学习

注意这里的文件名约定为 docs 也是官方推荐,请按照规则设置,否则发到 Github 可能会出现一些问题
$ docsify init docs
Initialization succeeded! Please run docsify serve docs
执行完以上命令 docs 文件目录下会生成以下 3 个文件:
index.html:入口文件README.md:会做为主页内容渲染.nojekyll:用于阻止 GitHub Pages 会忽略掉下划线开头的文件docs 同级目录下执行以下命令,打开本地服务器,默认地址为:http://localhost:3000
$ docsify serve docs
Serving /Users/may/Nodejs-Roadmap/docs now.
Listening at http://localhost:3000
这里我以 Nodejs-Roadmap 项目做为介绍,以下为最终的效果,你也可以点击 https://www.nodejs.red/ 在线预览。

设置我们的封面图,需要两步,首先在 docs/index.html 文件中将设置 coverpage: true,之后创建 docs/_coverpage.md 文件
docs/index.html
<script>
window.$docsify = {
coverpage: true
}
</script>
<script src="//unpkg.com/docsify"></script>docs/_coverpage.md
<img width="160px" style="border-radius: 50%" bor src="https://nodejsred.oss-cn-shanghai.aliyuncs.com/nodejs_roadmap-logo.jpeg?x-oss-process=style/may">
# Nodejs技术栈
- 本文档是作者 @五月君 从事 Node.js 开发以来的学习历程,希望这些分享能帮助到正在学习、使用 Node.js 的朋友们,也真诚的希望能聚集所有 Node.js 爱好者,共建互帮互助的「Nodejs技术栈」交流平台。
[](https://github.com/qufei1993/Nodejs-Roadmap) [](https://github.com/qufei1993/Nodejs-Roadmap) [<img src="https://img.shields.io/static/v1.svg?label=%E6%85%95%E8%AF%BE&message=7k%20stars&color=ef151f">](https://www.imooc.com/u/2667395) [<img src="https://img.shields.io/badge/%E5%BE%AE%E4%BF%A1-%E5%85%AC%E4%BC%97%E5%8F%B7-brightgreen">](https://nodejsred.oss-cn-shanghai.aliyuncs.com/node_roadmap_wx.jpg?x-oss-process=style/may)
[GitHub](<https://github.com/qufei1993/Nodejs-Roadmap>)
[开始阅读](README.md)
支持两种方式,可以在 HTML 里设置,但是链接要以 #/ 开头,另外一种通过 Markdown 配置导航,我们这里用的也是后者
首先配置 loadNavbar: true,之后创建 docs/_navbar.md文件.
docs/index.html
<script>
window.$docsify = {
loadNavbar: true
}
</script>
<script src="//unpkg.com/docsify"></script>这里配置并不是很复杂,根据缩进生成对应的目录结构,注意目录的跳转链接是当前 (docs) 目录下的文件
docs/_navbar.md
* Introduction
* [简介](README.md)
* JavaScript
* [基础](/javascript/base.md)
* [This](/javascript/this.md)
...
以上示例生成效果,如下所示:


关于 docsify 定制化,可以看官方文档讲的也很详细 docsify 中文版,下面开始介绍如何将我们的 blog 项目通过 Github Pages 进行在线预览。
将我们搭建的 Blog 托管到 Github,可以实时访问,在项目的 Settings 里开启 GitHub Pages 功能。
选择 dcos 文件目录,如下所示:

因为我这里定制了域名,默认情况下你会看到类似于 Your site is ready to be published at https://github.com/qufei1993/Nodejs-Roadmap 这样的信息。
浏览器输入 https://qufei1993.github.io/Nodejs-Roadmap/ 即可访问,qufei1993 为您的用户名,Nodejs-Roadmap 为您的项目名称。
Gitalk 是一个基于 GitHub Issue 和 Preact 开发的评论插件。
以上 clientID 和 clientSecret 需要在你的 Github Applications 申请。
修改 docs/index.html 文件
<link rel="stylesheet" href="//unpkg.com/gitalk/dist/gitalk.css">
<script>
var gitalkConfig = {
clientID: 'XXXXXX',
clientSecret: 'XXXXXXX',
repo: 'Nodejs-Roadmap',
owner: 'q-angelo',
admin: ["q-angelo"],
distractionFreeMode: false
};
window.$docsify = {
plugins: [
function (hook, vm) {
hook.doneEach(function() {
var label, domObj, main, divEle, gitalk;
label = vm.route.path.split("/").pop();
domObj = Docsify.dom;
main = domObj.getNode("#main");
Array.apply(
null,
document.querySelectorAll("div.gitalk-container")
).forEach(function(ele) {
ele.remove();
});
divEle = domObj.create("div");
divEle.id = "gitalk-container-" + label;
divEle.className = "gitalk-container";
divEle.style = "width: " + main.clientWidth + "px; margin: 0 auto 20px;";
domObj.appendTo(domObj.find(".content"), divEle);
gitalk = new Gitalk(
Object.assign(gitalkConfig, { id: !label ? "home" : label })
);
gitalk.render("gitalk-container-" + label);
});
}
]
}
</script>
<script src="//unpkg.com/docsify/lib/docsify.min.js"></script>
<script src="//unpkg.com/gitalk/dist/gitalk.min.js"></script>看完本篇文章,如果你也刚好想搭建一个 Blog 写写文章,可以尝试下 Docsify,最好自己实践下。我在写作《Nodejs技术栈》 时也选择的 Docsify,用起来给人的感觉很简洁、方便。你也可以参考我的项目设置。
之前看了一篇关于 V8 是如何实现 sort() 方法的介绍,其中有点疑问就去 Github 上搜了源码,但是换到最新的版本后发现并没有找到相关的 JavaScript 版实现,心想或许是后来用 C++ 改了,查找了一番后来发现确实改了但不是 C++...
之前是用什么算法实现的,后来为什么要改,性能提升了多少,带着这些疑问透过 v8 源码探索 JavaScript 数组 sort() 方法的底层实现原理~
下面列举了一些数组排序算法在最好、最坏等情况下的复杂度,可以先了解下:
图片来源:https://www.bigocheatsheet.com/
JavaScript sort() 方法使用了 “原地算法” 这是一种基本上不需要额外辅助结构仅靠输出来覆盖输入的的一种算法操作。
通俗的讲数组会原地排序,原来的数组会改变,不会返回一个新的数组对象。
JavaScript 的 sort() 方法,如果你不清楚它的一些规则,有些执行结果看起来很不可思议。
例如下面示例,第一个执行结果看似正常是我们期望的,第二个为什么 a 跑到了最后?第三个为什么 2 跑到了 10 的后面?
这是因为 Array 的 sort() 方法如果不传入比较函数,默认会将所有的元素先转换为字符串在做排序。第二个是因为小写字母 a 的 ASCII 在大写字母之后。第三个同样也是因为先转为了字符串 '10'、'2' 因为字符 '1' 的 ASCII 要比 '2' 的 ASCII 小。
console.log(['B', 'A', 'C'].sort()); // [ 'A', 'B', 'C' ]
console.log(['B', 'a', 'C'].sort()); // [ 'B', 'C', 'a' ]
console.log([10, 2, 1].sort()); // [ 1, 10, 2 ]这些如果是新手上路,很容易入坑。
sort() 方法还可以接收一个高阶函数 compareFunction(a, b) 实现自定义排序,在内部排序时会按照该方法的返回值做排序。
compareFunction(a, b) 函数返回三个结果:
例如 [10, 2, 1] 如果想按升序排序,我们可以像下面这样写一个 compareFunction() 比较函数,简短点的写法还可以这样写 const compareFunction = (a, b) => a - b;如果想实现降序,相反的思维 (a, b) => b - a。
const numbers = [10, 2, 1];
const compareFunction = (a, b) => {
if (a < b ) {
return -1;
}
if (a > b ) {
return 1;
}
return 0;
}
numbers.sort(compareFunction);
console.log(numbers); // [ 1, 2, 10 ]当我们在研究 v8 某个版本的时候,如果需要写一些 demo 做验证最好本地 Node.js 环境的 v8 版本也要保持一致,否则有时候得到答案并非和你的预想一样,到最后查看发现是因为版本不一致导致的,就有点浪费时间了。
我将本地的 Node.js 版本切换为了 v10.22.1 对应的 v8 版本为 6.8.275.32-node.58 该版本的排序方法还是基于 JavaScript 来实现的,对应的 v8 源码在 https://github.com/v8/v8/blob/6.8.275.32/src/js/array.js。
代码略长,中间有部分会省略掉,只讲解一些重要的代码片段,例如某个算法的实现自己可以单独的做一些研究。
以下可以理解为在 global.Array 原型上定义 sort() 函数,接收比较函数(comparefn)做为参数调用内部的一个排序方法。
// https://github.com/v8/v8/blob/6.8.275.32/src/js/array.js#L826
DEFINE_METHOD(
GlobalArray.prototype,
sort(comparefn) {
return InnerArraySort(array, length, comparefn);
}
);InnerArraySort() 方法首先判断 comparefn() 方法如果不存在,对该函数做一些初始化,并且会将元素转化为字符串的形式排序,如果数组长度小于 2 就没必要排序了直接返回,下面重点来看 QuickSort() 方法
function InnerArraySort(array, length, comparefn) {
if (!IS_CALLABLE(comparefn)) {
if (x === y) return 0;
if (%_IsSmi(x) && %_IsSmi(y)) {
return %SmiLexicographicCompare(x, y);
}
x = TO_STRING(x);
y = TO_STRING(y);
if (x == y) return 0;
else return x < y ? -1 : 1;
}
if (length < 2) return array;
QuickSort(array, 0, num_non_undefined);
return array;
}QuickSort 是一个快速排序,但是里面不只是快速排序,也是有一些优化在的。
首先数组元素如果小于 10 时采用插入排序,插入排序在最好的情况下为 O(n),当 n 很小时插入排序是有着很高的性能的,甚至是会超过快排的。这是因为 QuickSort 在分区后需要递归调用两次,这个过程会产生函数栈空间的创建、销毁开销。
插入排序随着 n 变大也会退化为 O(n^2)。当 n > 10 又采用了快速排序,分别取出数组的第一个元素、最后一个元素、在选取一个中间值做为 pivot(轴元素)。
function QuickSort(a, from, to) {
var third_index = 0;
while (true) {
// Insertion sort is faster for short arrays.
if (to - from <= 10) {
InsertionSort(a, from, to);
return;
}
if (to - from > 1000) {
third_index = GetThirdIndex(a, from, to);
} else {
third_index = from + ((to - from) >> 1);
}
// Find a pivot as the median of first, last and middle element.
var v0 = a[from];
var v1 = a[to - 1];
var v2 = a[third_index];
...
}
};在快速排序中每轮选中设置一个中间值有些地方也称为基准值,小于基准值的放到左边,大于基准值的放到右边,之后在基准值的左边、右边再次递归操作,这种方法称为**分治法,**中间值选取,v8 采用了两条策略:
from + ((to - from) >> 1)所示。function GetThirdIndex(a, from, to) {
var t_array = new InternalArray();
// Use both 'from' and 'to' to determine the pivot candidates.
var increment = 200 + ((to - from) & 15);
var j = 0;
from += 1;
to -= 1;
for (var i = from; i < to; i += increment) {
t_array[j] = [i, a[i]];
j++;
}
t_array.sort(function(a, b) {
return comparefn(a[1], b[1]);
});
// 取中间元素,例如 t_array.length 等于 10,t_array.length >> 1 的返回结果为 5
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}在以往的 JavaScript v8 版本中排序使用的不是一个普通快速排序算法,v8 对它也是做了优化的。
如果元素小于 10 选择插入排序,这时候效率相对会更高,当元素大于 10 之后选择快速排序,快速排序本身是以一种递归的方式实现的,避免出现一边大、一边小,深度的递归,我们还要找到一个中间值做分区,使两边递归达到一个平衡,中间值的选取在 v8 中也采用了两种策略。
要更好的理解,需要先熟悉什么是插入排序、快速排序,在学习源码的过程中,可以看它是怎么做的,好的**是可以学习借鉴的。
Timsort 最早由蒂姆·彼得斯(Tim Peters)在 2002 年实现,最早应用于 Python 语言,后来在 Java SE7 也有应用,包括 v8 在 7.0 之后对于数组排序也使用的该算法,这是一个基于事实的,能较好地处理真实世界中各种各样的数据,因为现实中大多数真实数据集已经有很多元素是已经排好序了。
Timsort 算法里有一个术语 run 可以理解为数据的分区,也可以认为是一组已经排好序的小数组,要么是单调递增或单调递减,单调递增的 run 顺序不变,单调递减的可以简单地翻转成为一个新的 run,在排序过程中算法会根据输入数据的长度来决定一个 run 的最小长度(这个最小长度是根据数组长度动态变化的在 32~64 之间),当无法满足最小的 run 长度时使用插入算法生成一个 run。
每一个 run 都会在栈中被记录包括索引位置和长度,Timsort 仅合并连续的 run,如下图 A、B、C 分别代表一个数值,顺序是 B < A < C,Timsort 强调稳定性,且相邻的合并,A、C 中 A 最小,此时 B 就合并到它们中最小的一个,这样就有相当高的机率和相邻的 run 长度相近。
v8 7.0 之后你已经找不到数组 sort 方法的 JavaScript 版代码实现了,现在改为 V8 Torque 实现,Torque 是一门领域专用语言,具有类似 TypeScript 的语法,目前使用 CodeStubAssembler 做为其编译工具。
源码地址为 v8 github 项目下 /third_party/v8/builtins/array-sort.tq 文件。
看不懂的可以看下这个 JavaScript 版本实现的 timesort
以下代码来源 stackoverflow 上 https://stackoverflow.com/questions/15606290/how-to-use-timsort-in-javascript,也是笔者学习过程中找到的一些参考。
Array.prototype.timsort = function(comp){
var global_a=this
var MIN_MERGE = 32;
var MIN_GALLOP = 7
var runBase=[];
var runLen=[];
var stackSize = 0;
var compare = comp;
sort(this,0,this.length,compare);
/*
* The next two methods (which are package private and static) constitute the entire API of this class. Each of these methods
* obeys the contract of the public method with the same signature in java.util.Arrays.
*/
function sort (a, lo, hi, compare) {
if (typeof compare != "function") {
throw new Error("Compare is not a function.");
return;
}
stackSize = 0;
runBase=[];
runLen=[];
rangeCheck(a.length, lo, hi);
var nRemaining = hi - lo;
if (nRemaining < 2) return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
var initRunLen = countRunAndMakeAscending(a, lo, hi, compare);
binarySort(a, lo, hi, lo + initRunLen, compare);
return;
}
/**
* March over the array once, left to right, finding natural runs, extending short natural runs to minRun elements, and
* merging runs to maintain stack invariant.
*/
var ts = [];
var minRun = minRunLength(nRemaining);
do {
// Identify next run
var runLenVar = countRunAndMakeAscending(a, lo, hi, compare);
// If run is short, extend to min(minRun, nRemaining)
if (runLenVar < minRun) {
var force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLenVar, compare);
runLenVar = force;
}
// Push run onto pending-run stack, and maybe merge
pushRun(lo, runLenVar);
mergeCollapse();
// Advance to find next run
lo += runLenVar;
nRemaining -= runLenVar;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
mergeForceCollapse();
}
/**
* Sorts the specified portion of the specified array using a binary insertion sort. This is the best method for sorting small
* numbers of elements. It requires O(n log n) compares, but O(n^2) data movement (worst case).
*
* If the initial part of the specified range is already sorted, this method can take advantage of it: the method assumes that
* the elements from index {@code lo}, inclusive, to {@code start}, exclusive are already sorted.
*
* @param a the array in which a range is to be sorted
* @param lo the index of the first element in the range to be sorted
* @param hi the index after the last element in the range to be sorted
* @param start the index of the first element in the range that is not already known to be sorted (@code lo <= start <= hi}
* @param c comparator to used for the sort
*/
function binarySort (a, lo, hi, start, compare) {
if (start == lo) start++;
for (; start < hi; start++) {
var pivot = a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
var left = lo;
var right = start;
/*
* Invariants: pivot >= all in [lo, left). pivot < all in [right, start).
*/
while (left < right) {
var mid = (left + right) >>> 1;
if (compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
/*
* The invariants still hold: pivot >= all in [lo, left) and pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the first slot after them -- that's why this sort is stable.
* Slide elements over to make room to make room for pivot.
*/
var n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2:
a[left + 2] = a[left + 1];
case 1:
a[left + 1] = a[left];
break;
default:
arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
/**
* Returns the length of the run beginning at the specified position in the specified array and reverses the run if it is
* descending (ensuring that the run will always be ascending when the method returns).
*
* A run is the longest ascending sequence with:
*
* a[lo] <= a[lo + 1] <= a[lo + 2] <= ...
*
* or the longest descending sequence with:
*
* a[lo] > a[lo + 1] > a[lo + 2] > ...
*
* For its intended use in a stable mergesort, the strictness of the definition of "descending" is needed so that the call can
* safely reverse a descending sequence without violating stability.
*
* @param a the array in which a run is to be counted and possibly reversed
* @param lo index of the first element in the run
* @param hi index after the last element that may be contained in the run. It is required that @code{lo < hi}.
* @param c the comparator to used for the sort
* @return the length of the run beginning at the specified position in the specified array
*/
function countRunAndMakeAscending (a, lo, hi, compare) {
var runHi = lo + 1;
// Find end of run, and reverse range if descending
if (compare(a[runHi++], a[lo]) < 0) { // Descending
while (runHi < hi && compare(a[runHi], a[runHi - 1]) < 0){
runHi++;
}
reverseRange(a, lo, runHi);
} else { // Ascending
while (runHi < hi && compare(a[runHi], a[runHi - 1]) >= 0){
runHi++;
}
}
return runHi - lo;
}
/**
* Reverse the specified range of the specified array.
*
* @param a the array in which a range is to be reversed
* @param lo the index of the first element in the range to be reversed
* @param hi the index after the last element in the range to be reversed
*/
function /*private static void*/ reverseRange (/*Object[]*/ a, /*int*/ lo, /*int*/ hi) {
hi--;
while (lo < hi) {
var t = a[lo];
a[lo++] = a[hi];
a[hi--] = t;
}
}
/**
* Returns the minimum acceptable run length for an array of the specified length. Natural runs shorter than this will be
* extended with {@link #binarySort}.
*
* Roughly speaking, the computation is:
*
* If n < MIN_MERGE, return n (it's too small to bother with fancy stuff). Else if n is an exact power of 2, return
* MIN_MERGE/2. Else return an int k, MIN_MERGE/2 <= k <= MIN_MERGE, such that n/k is close to, but strictly less than, an
* exact power of 2.
*
* For the rationale, see listsort.txt.
*
* @param n the length of the array to be sorted
* @return the length of the minimum run to be merged
*/
function /*private static int*/ minRunLength (/*int*/ n) {
//var v=0;
var r = 0; // Becomes 1 if any 1 bits are shifted off
/*while (n >= MIN_MERGE) { v++;
r |= (n & 1);
n >>= 1;
}*/
//console.log("minRunLength("+n+") "+v+" vueltas, result="+(n+r));
//return n + r;
return n + 1;
}
/**
* Pushes the specified run onto the pending-run stack.
*
* @param runBase index of the first element in the run
* @param runLen the number of elements in the run
*/
function pushRun (runBaseArg, runLenArg) {
//console.log("pushRun("+runBaseArg+","+runLenArg+")");
//this.runBase[stackSize] = runBase;
//runBase.push(runBaseArg);
runBase[stackSize] = runBaseArg;
//this.runLen[stackSize] = runLen;
//runLen.push(runLenArg);
runLen[stackSize] = runLenArg;
stackSize++;
}
/**
* Examines the stack of runs waiting to be merged and merges adjacent runs until the stack invariants are reestablished:
*
* 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1] 2. runLen[i - 2] > runLen[i - 1]
*
* This method is called each time a new run is pushed onto the stack, so the invariants are guaranteed to hold for i <
* stackSize upon entry to the method.
*/
function mergeCollapse () {
while (stackSize > 1) {
var n = stackSize - 2;
if (n > 0 && runLen[n - 1] <= runLen[n] + runLen[n + 1]) {
if (runLen[n - 1] < runLen[n + 1]) n--;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
/**
* Merges all runs on the stack until only one remains. This method is called once, to complete the sort.
*/
function mergeForceCollapse () {
while (stackSize > 1) {
var n = stackSize - 2;
if (n > 0 && runLen[n - 1] < runLen[n + 1]) n--;
mergeAt(n);
}
}
/**
* Merges the two runs at stack indices i and i+1. Run i must be the penultimate or antepenultimate run on the stack. In other
* words, i must be equal to stackSize-2 or stackSize-3.
*
* @param i stack index of the first of the two runs to merge
*/
function mergeAt (i) {
var base1 = runBase[i];
var len1 = runLen[i];
var base2 = runBase[i + 1];
var len2 = runLen[i + 1];
/*
* Record the length of the combined runs; if i is the 3rd-last run now, also slide over the last run (which isn't involved
* in this merge). The current run (i+1) goes away in any case.
*/
//var stackSize = runLen.length;
runLen[i] = len1 + len2;
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
stackSize--;
/*
* Find where the first element of run2 goes in run1. Prior elements in run1 can be ignored (because they're already in
* place).
*/
var k = gallopRight(global_a[base2], global_a, base1, len1, 0, compare);
base1 += k;
len1 -= k;
if (len1 == 0) return;
/*
* Find where the last element of run1 goes in run2. Subsequent elements in run2 can be ignored (because they're already in
* place).
*/
len2 = gallopLeft(global_a[base1 + len1 - 1], global_a, base2, len2, len2 - 1, compare);
if (len2 == 0) return;
// Merge remaining runs, using tmp array with min(len1, len2) elements
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}
/**
* Locates the position at which to insert the specified key into the specified sorted range; if the range contains an element
* equal to key, returns the index of the leftmost equal element.
*
* @param key the key whose insertion point to search for
* @param a the array in which to search
* @param base the index of the first element in the range
* @param len the length of the range; must be > 0
* @param hint the index at which to begin the search, 0 <= hint < n. The closer hint is to the result, the faster this method
* will run.
* @param c the comparator used to order the range, and to search
* @return the int k, 0 <= k <= n such that a[b + k - 1] < key <= a[b + k], pretending that a[b - 1] is minus infinity and a[b
* + n] is infinity. In other words, key belongs at index b + k; or in other words, the first k elements of a should
* precede key, and the last n - k should follow it.
*/
function gallopLeft (key, a, base, len, hint, compare) {
var lastOfs = 0;
var ofs = 1;
if (compare(key, a[base + hint]) > 0) {
// Gallop right until a[base+hint+lastOfs] < key <= a[base+hint+ofs]
var maxOfs = len - hint;
while (ofs < maxOfs && compare(key, a[base + hint + ofs]) > 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs) ofs = maxOfs;
// Make offsets relative to base
lastOfs += hint;
ofs += hint;
} else { // key <= a[base + hint]
// Gallop left until a[base+hint-ofs] < key <= a[base+hint-lastOfs]
var maxOfs = hint + 1;
while (ofs < maxOfs && compare(key, a[base + hint - ofs]) <= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs) ofs = maxOfs;
// Make offsets relative to base
var tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
}
/*
* Now a[base+lastOfs] < key <= a[base+ofs], so key belongs somewhere to the right of lastOfs but no farther right than ofs.
* Do a binary search, with invariant a[base + lastOfs - 1] < key <= a[base + ofs].
*/
lastOfs++;
while (lastOfs < ofs) {
var m = lastOfs + ((ofs - lastOfs) >>> 1);
if (compare(key, a[base + m]) > 0)
lastOfs = m + 1; // a[base + m] < key
else
ofs = m; // key <= a[base + m]
}
return ofs;
}
/**
* Like gallopLeft, except that if the range contains an element equal to key, gallopRight returns the index after the
* rightmost equal element.
*
* @param key the key whose insertion point to search for
* @param a the array [] in which to search
* @param base the index of the first element in the range
* @param len the length of the range; must be > 0
* @param hint the index at which to begin the search, 0 <= hint < n. The closer hint is to the result, the faster this method
* will run.
* @param c the comparator used to order the range, and to search
* @return the int k, 0 <= k <= n such that a[b + k - 1] <= key < a[b + k]
*/
function gallopRight (key, a, base, len, hint, compare) {
var ofs = 1;
var lastOfs = 0;
if (compare(key, a[base + hint]) < 0) {
// Gallop left until a[b+hint - ofs] <= key < a[b+hint - lastOfs]
var maxOfs = hint + 1;
while (ofs < maxOfs && compare(key, a[base + hint - ofs]) < 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs) ofs = maxOfs;
// Make offsets relative to b
var tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
} else { // a[b + hint] <= key
// Gallop right until a[b+hint + lastOfs] <= key < a[b+hint + ofs]
var maxOfs = len - hint;
while (ofs < maxOfs && compare(key, a[base + hint + ofs]) >= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs) ofs = maxOfs;
// Make offsets relative to b
lastOfs += hint;
ofs += hint;
}
/*
* Now a[b + lastOfs] <= key < a[b + ofs], so key belongs somewhere to the right of lastOfs but no farther right than ofs.
* Do a binary search, with invariant a[b + lastOfs - 1] <= key < a[b + ofs].
*/
lastOfs++;
while (lastOfs < ofs) {
var m = lastOfs + ((ofs - lastOfs) >>> 1);
if (compare(key, a[base + m]) < 0)
ofs = m; // key < a[b + m]
else
lastOfs = m + 1; // a[b + m] <= key
}
return ofs;
}
/**
* Merges two adjacent runs in place, in a stable fashion. The first element of the first run must be greater than the first
* element of the second run (a[base1] > a[base2]), and the last element of the first run (a[base1 + len1-1]) must be greater
* than all elements of the second run.
*
* For performance, this method should be called only when len1 <= len2; its twin, mergeHi should be called if len1 >= len2.
* (Either method may be called if len1 == len2.)
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
function mergeLo (base1, len1, base2, len2) {
// Copy first run into temp array
var a = global_a;// For performance
var tmp=a.slice(base1,base1+len1);
var cursor1 = 0; // Indexes into tmp array
var cursor2 = base2; // Indexes int a
var dest = base1; // Indexes int a
// Move first element of second run and deal with degenerate cases
a[dest++] = a[cursor2++];
if (--len2 == 0) {
arraycopy(tmp, cursor1, a, dest, len1);
return;
}
if (len1 == 1) {
arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
return;
}
var c = compare;// Use local variable for performance
var minGallop = MIN_GALLOP; // " " " " "
outer:
while (true) {
var count1 = 0; // Number of times in a row that first run won
var count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run starts winning consistently.
*/
do {
if (compare(a[cursor2], tmp[cursor1]) < 0) {
a[dest++] = a[cursor2++];
count2++;
count1 = 0;
if (--len2 == 0) break outer;
} else {
a[dest++] = tmp[cursor1++];
count1++;
count2 = 0;
if (--len1 == 1) break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a huge win. So try that, and continue galloping until (if
* ever) neither run appears to be winning consistently anymore.
*/
do {
count1 = gallopRight(a[cursor2], tmp, cursor1, len1, 0, c);
if (count1 != 0) {
arraycopy(tmp, cursor1, a, dest, count1);
dest += count1;
cursor1 += count1;
len1 -= count1;
if (len1 <= 1) // len1 == 1 || len1 == 0
break outer;
}
a[dest++] = a[cursor2++];
if (--len2 == 0) break outer;
count2 = gallopLeft(tmp[cursor1], a, cursor2, len2, 0, c);
if (count2 != 0) {
arraycopy(a, cursor2, a, dest, count2);
dest += count2;
cursor2 += count2;
len2 -= count2;
if (len2 == 0) break outer;
}
a[dest++] = tmp[cursor1++];
if (--len1 == 1) break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0) minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len1 == 1) {
arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
} else if (len1 == 0) {
throw new Error("IllegalArgumentException. Comparison method violates its general contract!");
} else {
arraycopy(tmp, cursor1, a, dest, len1);
}
}
/**
* Like mergeLo, except that this method should be called only if len1 >= len2; mergeLo should be called if len1 <= len2.
* (Either method may be called if len1 == len2.)
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
function mergeHi ( base1, len1, base2, len2) {
// Copy second run into temp array
var a = global_a;// For performance
var tmp=a.slice(base2, base2+len2);
var cursor1 = base1 + len1 - 1; // Indexes into a
var cursor2 = len2 - 1; // Indexes into tmp array
var dest = base2 + len2 - 1; // Indexes into a
// Move last element of first run and deal with degenerate cases
a[dest--] = a[cursor1--];
if (--len1 == 0) {
arraycopy(tmp, 0, a, dest - (len2 - 1), len2);
return;
}
if (len2 == 1) {
dest -= len1;
cursor1 -= len1;
arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2];
return;
}
var c = compare;// Use local variable for performance
var minGallop = MIN_GALLOP; // " " " " "
outer:
while (true) {
var count1 = 0; // Number of times in a row that first run won
var count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run appears to win consistently.
*/
do {
if (compare(tmp[cursor2], a[cursor1]) < 0) {
a[dest--] = a[cursor1--];
count1++;
count2 = 0;
if (--len1 == 0) break outer;
} else {
a[dest--] = tmp[cursor2--];
count2++;
count1 = 0;
if (--len2 == 1) break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a huge win. So try that, and continue galloping until (if
* ever) neither run appears to be winning consistently anymore.
*/
do {
count1 = len1 - gallopRight(tmp[cursor2], a, base1, len1, len1 - 1, c);
if (count1 != 0) {
dest -= count1;
cursor1 -= count1;
len1 -= count1;
arraycopy(a, cursor1 + 1, a, dest + 1, count1);
if (len1 == 0) break outer;
}
a[dest--] = tmp[cursor2--];
if (--len2 == 1) break outer;
count2 = len2 - gallopLeft(a[cursor1], tmp, 0, len2, len2 - 1, c);
if (count2 != 0) {
dest -= count2;
cursor2 -= count2;
len2 -= count2;
arraycopy(tmp, cursor2 + 1, a, dest + 1, count2);
if (len2 <= 1) // len2 == 1 || len2 == 0
break outer;
}
a[dest--] = a[cursor1--];
if (--len1 == 0) break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0) minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len2 == 1) {
dest -= len1;
cursor1 -= len1;
arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2]; // Move first elt of run2 to front of merge
} else if (len2 == 0) {
throw new Error("IllegalArgumentException. Comparison method violates its general contract!");
} else {
arraycopy(tmp, 0, a, dest - (len2 - 1), len2);
}
}
/**
* Checks that fromIndex and toIndex are in range, and throws an appropriate exception if they aren't.
*
* @param arrayLen the length of the array
* @param fromIndex the index of the first element of the range
* @param toIndex the index after the last element of the range
* @throws IllegalArgumentException if fromIndex > toIndex
* @throws ArrayIndexOutOfBoundsException if fromIndex < 0 or toIndex > arrayLen
*/
function rangeCheck (arrayLen, fromIndex, toIndex) {
if (fromIndex > toIndex) throw new Error( "IllegalArgument fromIndex(" + fromIndex + ") > toIndex(" + toIndex + ")");
if (fromIndex < 0) throw new Error( "ArrayIndexOutOfBounds "+fromIndex);
if (toIndex > arrayLen) throw new Error( "ArrayIndexOutOfBounds "+toIndex);
}
}
// java System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
function arraycopy(s,spos,d,dpos,len){
var a=s.slice(spos,spos+len);
while(len--){
d[dpos+len]=a[len];
}
}以下两个微基准测试数据图来源于 v8 开发者博客(https://v8.dev/blog/array-sort)对 array sort 的介绍。
第一个图展示了用户提供的比较函数对各种元素类型进行排序的正常用例。
第二个图展示了在处理已完全排序的数组或具有已单向排列的子序列数组时 Timsort 对数组的影响。
在除了随机数的情况下,Timsort 的算法的表现会更好,正如前面说的这是一个基于事实的,能较好地处理真实世界中各种各样的数据,因为现实中大多数真实数据集已经有很多元素是已经排好序了。
What?在服务端写 React 组件?这看起来是一件不可思议的事情,首先在服务端,我们有很多的权限,例如访问文件系统、数据库等。如果在服务端写前端组件,是不是意味着 “前端可以直链数据库了?” 还有安全性可言吗?
本文代码示例基于 Next.js 框架,让我们先看一段代码示例,你可以先思考一个问题,这是服务端代码还是前端代码?
// src/app/home/page.tsx
import fs from 'fs/promises';
const DisplayText = async () => {
try {
const text = await fs.readFile('/xxx/my-next-app/text.txt', { encoding: 'utf8' });
console.log(text);
return <p>{text}</p>
} catch (err) {
return <p>{err.message}</p>
}
}
const Home = () => {
return <div>
<p>Hello Server Component</p>
{/* @ts-expect-error */}
<DisplayText />
</div>
}
export default Home;看到这段代码你的想法是什么?如果是前端组件代码,怎么会有 fs 模块呢?在前端是没有文件系统的,更不能访问本地的文件。如果是后端,看起来怎么还有前端的组件代码?
没什么神秘的,这是 React 中的 Server Component,简称 RSC。它是 React 提出的一种新型组件类型,以前我们编写组件的方式可以称为 Client Component。Server Component 它的渲染是在服务端完成之后通过网络请求交给客户端 React 做整合,如果运行时是 Node.js,在 Server Component 中就可以使用 Node.js 中的所有模块资源,访问数据库这些自然就可以了。
它安全吗?有些代码你可能只想在服务器上运行,例如在 Server Component 会有一些链接数据库读取数据的代码逻辑,但 JavaScript 模块可以在 Server Component 和 Client Component 之间实现共享,有时你会无意识地在 Client Component 中导入服务器端的代码,为了避免敏感的信息被暴露,在 Next.js 框架中,我们可以在文件头部添加一个 import 'server-only'; 语句,表示该模块只在服务器端使用。
React Server Component 带来了一种新的思维模式,我们要考虑为什么使用它?以下是它带来的一些好处:
useEffect(() => {}, []) 中请求 API 获取数据,做渲染,使用 Server Component 后可以减少这些请求。这里有一个重点是要与 SSR 区别开来。SSR 也是在服务端运行,使用它可以解决首屏加载、SEO 问题,它的工作方式是把整个应用程序打包为 html 然后返回到浏览器渲染。React Server Component 返回的是一个客户端可以解析的 React 结构,之后会在客户端同 Client Component 混合在做渲染。在 React Server Component 中还可以结合 Streaming、Suspense 允许服务器先返回页面的部分内容,待一些异步组件稍后就绪时再返回余下的内容,这也是其强大的一方面。
下例代码中,如果去掉 <Suspense> </Suspense>,React 会等待 <DisplayText /> 组件渲染完成,才会发送内容到浏览器。假设读取数据很慢,需要 5 秒中,此时页面就有 5 秒钟的等待。如果是 SSR 来处理,它的问题也是如此,会在这里等待,等所有的内容拼接完成后才会返回。
现在我们可以先让页面的其它部分先返回到浏览器渲染,Suspense 的 fallback 先渲染第一个版本,待 <DisplayText /> 组件就绪时渲染第二个版本。
import fs from 'fs/promises';
import { Suspense } from 'react';
+ const sleep = (ms: number) => new Promise((resolve, reject) => setTimeout(() => resolve(1), ms))
const DisplayText = async () => {
try {
+ await sleep(5000);
const text = await fs.readFile('/xxx/my-next-app/text.txt', { encoding: 'utf8' });
console.log(text);
return <p>{text}</p>
} catch (err) {
return <p>{err.message}</p>
}
}
const Home = () => {
return <div>
<p>Hello Server Component</p>
+ <Suspense fallback={<> Loading... </>}>
+ {/* @ts-expect-error */}
+ <DisplayText />
+ </Suspense>
</div>
}
export default Home;以下是运行后的预览效果,刚开始会显示 Loading...
大约 5 秒钟后,展示 <DisplayText /> 组件获取到的内容
Next.js 框架 App Router 路由默认开启 Server Component 模式,它认为在大多数情况下应该编写 Server Component 而不是 Client Component。对于开发者而言要有一个边界,来区分什么情况下应该使用 Server Component、什么情况下应该使用 Client Component。
上图是 Next.js 文档的一个描述,以下做了一些总结:
应该用 Server Component 的情况:
应该用 Client Component 的情况:
现在我们知道了 Server Component 有一些限制,当我们需要写一些具有交互性的组件时必须在 Client Component 内完成。
以下是一个 Server Component 引入 Client Component 的示例,它们在服务器上预渲染并在客户端上混合。
// src/app/home/page.tsx
import Count from './Count';
const Home = () => {
return <div>
...
<Count />
</div>
}
export default Home;Server Component 是默认的组件类型,如果要写 Client Component 需要先在文件顶部引入 'use client' 指令,定义 Client Component 和 Server Component 的边界。
// src/app/home/Count.tsx
'use client';
import { useState } from "react";
const btnStyle = { padding: '2px 5px', marginLeft: '10px' };
const Count = () => {
console.log('Client Component');
const [count, setCount] = useState(0);
return <div>
current count: {count}
<button style={{...btnStyle}} onClick={() => setCount(preCount => preCount + 1)}> + </button>
<button style={{...btnStyle}} onClick={() => setCount(preCount => preCount - 1)}> - </button>
</div>
};
export default Count;React Server Component 不是一个新的概念了,第一次提出是在 2020 年 12 月,它提出的这种 Server Component 编程范式,还是挺有趣的,值得学习下。
之前也是大致了解,最近看了一些 Next.js 相关的内容,在 2022 年底 Next.js 13 发布时整合了一些 React Server Component 相关的内容,并在 App Router 将 Server Component 做为默认的组件类型,这也是值得关注的一个地方。
在当前前后端分离的背景下,这种前后端写在一起的方式是不是和以前写 jade、ejs 这种类似?看似回到了以前,但 Server Component 也解决了一些问题,例如减少了 Bundle Size、请求的瀑布流等,并且在服务端也可以使用一些更成熟的 UI 库来写 Server Component。
Server Component 的到来,也看到了前端的边界在不断的扩大。学习一些 Node.js 和后端相关的知识也是必要的。
https://scastiel.dev/view-counter-react-server-components
https://nextjs.org/docs/getting-started/react-essentials
https://oldmo860617.medium.com/從-next-js-13-認識-react-server-components-37c2bad96d90
这是一个系列文章,你可以关注公众号「五月君」订阅话题《JavaScript 异步编程指南》获取最新信息。
Promise 是现代 JavaScript 比较重要的一个核心概念,也许你会疑问为什么会提到 Deferred?这个是什么?也许你之前没听过,其实我们现在的 Promise 就是由 Deferred 逐步演变而来形成了如今的一套规范 PromiseA+。
本节你可以跟随笔者一起来了解下这个 Deferred 是什么?对于你以后学习 Promise 我想是会有帮助的,并且对它的历史也会多一些了解、记忆也会更深刻。当今你不能保证所有系统都是使用 React、Vue 来写的,也许你会遇到一些使用 Jquery 写的系统,总不能不维护吧,当你看到它的 Ajax 请求时也知道这个东西是干嘛的,为什么要这样写。
Promise 曾经以多种形式存在于多种语言中,这个词最早由 C++ 工程师用在 Xanadu 项目中,随后被应用于 E 语言中,这又激发了 Python 人员的灵感,将它实现成为了 Twisted 框架的 Deffered 对象。
2007 年 Promise 赶上了 JavaScript 的流行大潮,当时 Twisted 的 Dojo 框架添加了一个名为 dojo.Deferred 对象。当时,相对成熟的 Dojo 在流行方面可以与初出茅庐的 Jquery 相媲美(争夺人气),虽然 Deferred 模式最早出现于 Dojo 代码中,但被广为所知却来源于 Jquery 1.5 版本,这也是 Jquery 中的一个重要的转折点,在这个版本之后引入了一个新的功能 Deferred,它彻底的改变了在 Jquery 中如何使用 Ajax,几乎重写了 Jquery 的 Ajax 部分。
在 2009 年时 Kris Zyp 有感于 dojo.deferred 的影响力,该模式被抽象为一个提议草案,发布在 CommonJS 规范中,后来又抽象出 Promise/A 规范,同年 Node.js 首次亮相。
Node.js 的早期迭代在非阻塞 API 中使用了 Promise。但是,在 2010 年 2 月,Node.js 早期的作者 Ryan Dahl 决定改为现在大家都熟悉的 callback(err, result),理由是 Promise 属于 “用户区” 更高级别构造,所以早期你会看到 Node.js 中的很多 API 都是 callback(err, result) 形式的,包括现在也还有,顺便在说明下 Ryan Dahl 早在 2012 年就已经离开了 Node.js 社区,之后一直由 Node.js 基金会管理,如今已经 2021 年了,Node.js 本身也发生了很多的变化,包括文件操作也为我们提供了基于 Promise 形式的 API,Stream 目前也很好的支持异步迭代,你不用在使用 callback 那种形式嵌套你的程序。
当时 Ryan Dahl 的决定为以 Node.js 为竞争目标的 Promise 实现创建了条件,例如 Q.js 曾一度很流行,是基于 Promise/A 规范相当简单的实现。Futures 是一个更广泛的工具包,其中包含 Async.js 之类的库中提供了许多流程控制功能。
在上一节,我们讲到了在早期我们都是通过使用回调(Callback)的形式向服务器发起网络请求,随后通过注册的回调函数拿到返回的数据,当时我们也提到了基于 Callback 的形式很容易造成回调函数嵌套、错误难以处理,现在我们看下早期 Jquery 中 Deferred 的解决方案是如何做的,与我们后面讲解的 Promise 有什么关联。
Jquery 1.5 之前的 ajax 书写方式:
// 返回的是 XHR 对象
$.ajax({
url: "http://openapi.xxxxxx.com/api",
success: function(){
console.log("success!");
},
error:function(){
console.log("failed!");
}
});Jquery 1.5 之后的 ajax 书写方式:
// 返回的是 Deferred 对象
$.ajax("http://openapi.xxxxxx.com/api")
.done(function(){ console.log("success1!"); })
.fail(function(){ console.log("failed1!"); })
.done(function(){ console.log("success2!"); })
.fail(function(){ console.log("failed2!"); })以链式的方式来写,极大的提高了阅读体验,相比回调嵌套确实解决了回调地狱问题,done() 是之前的 success() 方法,fail() 是之前 error() 方法。
了解 Promise 的应该能看出是不是有点感觉像?让我们在改造下,使用 .then() 的方式:
$.ajax("http://openapi.xxxxxx.com/api")
.then(function(){ console.log("success1!"); }, function(){ console.log("failed1!"); })
.then(function(){ console.log("success2!"); }, function(){ console.log("failed2!"); })是不是更像 Promise 了?
deferred 对象的执行将状态分为三个:未完成、已完成、已失败。调用 dtd.resolve() 是将执行状态变为已完成,会调用 done() 方法指定的回调函数。执行 dtd.reject() 是将执行状态变为已失败,会调用 fail() 方法指定的回调函数。
const wait = () => {
const dtd = $.Deferred();
const tasks = () => {
console.log('do something...')
dtd.resolve(); // 调用 Deferred 的执行状态为已完成
// 如果出错也可调用 dtd.reject();
}
setTimeout(tasks,5000);
return dtd;
}现在 wait 返回的就是一个 Deferred 对象了,可以使用链式操作。下面我们使用 dtd.then() 该方法就已经涵盖了 done() 和 fail() 方法。
const d = wait()
d.then(() => {
console.log('success1');
}, err => {
console.error('failed1')
})
.then(() => {
console.log('success2');
}, err => {
console.error('failed2')
})运行程序后,大约 5 秒钟我们的程序运行结果如下所示:
do something...
success1
success2现在还有一个问题,我可以在代码的尾部添加一行 d.resolve(); 这会改变程序的运行结果,这是因为我们在外部改变了执行状态。
const d = wait()
d.then(...); // 和上面一样,此处省略
d.resolve();
// 运行结果
success1
success2
do something...为了避免这种情况,jQuery 1.5 之后提供了 deferred.promise() 方法,作用是在 deferred 对象上返回 deferred 的 promise 对象,仅能使用与执行状态无关的方法,例如 dtd.then() 或 dtd.done()、dtd.fail() 方法。与执行状态有关的方法 dtd.resolve()、dtd.reject() 会被屏蔽。
const wait = () => {
...
return dtd.promise();
}Deferred 对象有 dtd.resolve()、dtd.reject() 这种与执行状态有关主动触发的函数,也有 dtd.then() 或 dtd.done()、dtd.fail() 这种被动监听的函数,这些函数都在一块,如上面例所示很容易出现在外部被篡改。解决方案是返回一个 dtd.promise() 对象,只能被动监听不能主动修改执行状态。
通过本文你应该会发现这和我们现在使用的 Promise/A+ 这种规范很相似,这也是 Promise/A+ 规范的前世。
本文会根据以下几个话题进行讨论与讲解,文中的目录不完全和这几个话题一致,但当你阅读完本文后,相信这些答案应该也有了,都在文中。
这样的写法 collection.find().toArray(),大家在学习 MongoDB 时应该见的也不少,它的原理是客户端驱动程序会自动把返回的所有数据一次性加载到应用程序内存中,理解起来相对简单些,如果数据量小是没问题的,在一些数据处理的场景中,具体有多少数据也许是未知的,有可能返回大量的数据,如果全部 hold 在内存,在服务端内存寸土寸金的地方,白白消耗服务内存不说,内存占用过高还可能造成服务 OOM。
MongoDB 里面的游标,有点类似于在 Node.js 里使用 Stream 处理文件数据,相比把整个文件读入内存在处理这种模式,Stream 带来的收益是很大的。
很形象的一个图,来源:https://www.cnblogs.com/vajoy/p/6349817.html
当我们使用 collection.find() 或 collection.aggregate() 返回的是一个指向该集合的指针,也称为游标(cursor),是不能直接访问数据的,只有当循环迭代这个游标时才会真正的从数据库集合读取数据。
在 Node.js 中使用很简单,只要支持 for await of 语法,即可遍历游标返回的数据集,和正常使用 for of 遍历数组很相似,区别是 for await of 遍历的数据源是异步的。当循环迭代开始时驱动程序会使用 getMore() 命令批量从数据库集合中获取一批数据先缓存起来,例如 Node.js MongoDB 驱动程序每次默认批量获取 1000 条(注意,第一次 getMore() 时实际请求是 101 条),取决于 batchSize 参数设置,待这批数据处理完成之后,在向 MongoDB Server 执行 getMore() 继续请求直到游标耗尽。
以下为 Node.js 中的两种使用示例,个人比较推荐 for await of 这种写法。方法二 while 循环这种写法在一个 MongoDB Node.js 驱动程序版本中存在一个 Bug 下文会介绍。
const userCursor = await collection.find();
// 如果没有返回数据,需要做一些特殊处理的,可以使用 userCursor.count() 或 userCursor.hasNext()
if (!await userCursor.count()) {
// TODO: 提前结束,做一些其它操作
return;
}
// 方法一:
for await (const user of userCursor) {
}
// 方法二:
while (await userCursor.hasNext()) {
const doc = userCursor.next();
}例如,数据库集合有 10000 条数据,每次批量获取 1000 条,I/O 消耗应该也为 10 次。终端链接至 MongoDB Server 设置 db.setProfilingLevel(0, { slowms: 0 })记录所有的操作日志,之后在打开 MongoDB Server 控制台日志,执行应用程序之后会看到如下日志信息,每次 getMore 都指向了同一个游标 ID getMore: 5098682199385946244。
如果需要修改 batchSize 结果的,通过 options 指定 batchSize 属性或调用 batchSize 方法都可以。
collection.find().batchSize(1100)
// 或以下方法
collection.find({}, {
batchSize: 1100
})切记不要将 batchSize 设置为 1,例如,10000 条数据每获取一条数据,客户端都将连接服务器读取,这将会产生 10000 次网络 IO,下图使用 mongostat 监控,展示了每秒查询游标时的 getMore 次数。
如果一个游标在一定时间内无人访问,超时之后会被回收,防止产生内存泄漏,启动时可通过 mongod --setParameter cursorTimeoutMillis=300000 参数设置,默认超时为 10 分钟,参见文档 cursorTimeoutMillis#Default: 600000 (10 minutes)。
例如,总共查询 10000 条数据,第一次 getmore() 默认批量获取 1000 条数据,如果在默认的 10 分钟内没有处理完成这 1000 条数据,游标会被关闭,待下次执行 getmore() 就会报错 cursor id 4011961159809892672 not found,一般称之为游标超时。
如有遇到游标超时,可通过调整 cursorTimeoutMillis 参数或减少 batchSize 数量选择适合于自己的程序配置,通常默认配置是不需要调整的。例如,在遍历游标数据时调了一个外部接口,由于接口超时导致的游标超时这种外部业务原因的,应先去优化业务本身,再考虑调整配置。
为了解决游标超时,你可能还见到过 cursor.addCursorFlag('noCursorTimeout', true) 这样的配置,这会禁用掉游标的超时限制,只有等到游标耗尽或手动关闭 cursor.close() 游标才可能被释放,禁用超时时间这种做法,很不推荐使用,每个游标都存在额外的内存占用消耗,如果因为疏忽忘记手动关闭游标导致的 MongoDB Server 内存泄漏就得不偿失了。
登陆 MongoDB 客户端,执行 db.serverStatus().metrics.cursor 命令,查看当前游标使用状态。如果真的出现游标导致的 MongoDB 服务器内存泄漏,以下几个数据指标,做为运维人员在排查问题时,会有帮助。
{
"timedOut" : NumberLong(4),
"open" : {
"noTimeout" : NumberLong(0),
"pinned" : NumberLong(0),
"total" : NumberLong(0)
}
}JavaScript 在 ES6 语法提供了一个功能叫迭代器,定义了一套统一的接口,只要实现了该接口的数据类型,都可使用 for of 关键词遍历,例如数组、Map、Set 类型等,这些类型上有一个方法 Symbol.iterator 返回的就是一个迭代器对象,迭代器对象的 next() 方法返回值包含了 vlaue、done 两个属性,如果 done 为 true 表示数据已遍历完成,但 Symbol.iterator 只支持同步的数据源。
而我们从数据库集合获取数据涉及到网络 I/O,这是一个异步的操作,Symbol.iterator 就无法支持了,在ECMAScript 2018 标准中提供了一个新的属性 Symbol.asyncIterator,这是一个异步迭代器,与 Symbol.iterator 不同的是 Symbol.asyncIterator 的 next() 方法返回的是一个包含 { value, done } 的 Promise 对象,如果一个对象设置了该属性,它就是异步可迭代对象,相应的我们可使用 for await...of 循环遍历数据。
下面看下 MonogoDB Node.js 驱动程序在 v4.2.2 版本中的实现,同样也提供了 Symbol.asyncIterator 接口,这也就是为什么我们可以使用 for await...of 循环遍历。
// mongodb/lib/cursor/abstract_cursor.js
class AbstractCursor extends mongo_types_1.TypedEventEmitter {
[Symbol.asyncIterator]() {
return {
next: () => this.next().then(value => value != null ? { value, done: false }: { value: undefined, done: true })
};
}
}在遍历游标的过程中,for 循环体内如果出现一些错误导致循环提前终止,这个时候游标并不会被立刻销毁,可以选择手动关闭游标或等待超过默认的游标超时时间后,游标也会被销毁。
如果设置了 noCursorTimeout 属性为永不超时,这个时候就一定记得要关闭游标,因此在上班也建议尽量不要做这个设置。
const userCursor = await collection.find();
try {
for await (const user of userCursor) {
// 可能抛出错误 throw new Error('124')
}
} catch (e) {
// 处理错误
} finally {
userCursor.close();
}使用 mongoose 和原生支持的 mongodb 模块还是有很多差异的,mongoose 的 find() 方法默认不会返回游标对象,需要在 find 后显示调用 cursor() 方法,且没有 cursor.count()、cursor.hasNext() 方法支持,对于一些想判断如果游标没有数据做一些特殊处理,处理起来不是很友好。
const userCursor = await User.find({}).cursor();
for await (const user of userCursor) {
}在 Node.js 群里,一个群友发来消息使用游标遇到了问题,后来也对这个问题做了一些查找和验证,下文会介绍,基于一个特定版本和特定的应用场景才会出现这个问题,放在这里也是希望用到的朋友能少踩一个坑。
MongoDB Node.js 驱动程序在 3.5.4 版本基于游标迭代查询数据时,如果用了 limit 限制返回的数据条目,并且使用 hasNext(),存在一个 Bug,首先是从返回的游标对象取出的 count 数不对,其次是遍历出的数据条目与实际 limit count 数对不上,如果 limit 为奇数还会收到 MongoError: Cursor is closed 错误。
如果需要调整每一次的 getMore() 数量,游标可以结合 batchSize 使用。为什么用了游标还要使用 limit?这个也可以思考下。
const userCursor = await collection.find({}).limit(5);
console.log('cursor count: ', await userCursor.count());
try {
while (await userCursor.hasNext()) {
const doc = await userCursor.next();
console.log(doc);
}
} catch (err) {
console.error(err.stack);
}
userCursor.close();mongodb@^3.5.4 版本输出结果:
cursor count: 10000
{ _id: 61d6590b92058ddefbac6a14, userID: 0 }
{ _id: 61d6590b92058ddefbac6a15, userID: 1 }
null
MongoError: Cursor is closed
at Function.create (/test/node_modules/mongodb/lib/core/error.js:43:12)
at Cursor.hasNext (/test/node_modules/mongodb/lib/cursor.js:197:24)
at file:///test/index.mjs:42:27
at processTicksAndRejections (internal/process/task_queues.js:93:5)
NPM 包 mongodb 受影响版本为 3.5.4 参见 issue jira.mongodb.org/browse/NODE-2483
NPM 包 mongoose 受影响版本为 5.9.4 参见 issue github.com/Automattic/mongoose/issues/8664

跨站请求伪造(Cross-Site Request Forgery,简称 CSRF)是一种冒充受信任用户在当前已登陆 Web 应用程序上执行非本意操作的攻击方式。
CSRF 攻击简单来说,是黑客通过一种技术手段诱骗用户浏览器访问一个曾经受信任的网站去执行一些非法操作。这利用了 Web 中用户身份验证的一个漏洞:“简单的身份验证只保证了请求是发自用户的浏览器,却不能验证请求本身是否为用户自愿发出的”。

假设 “五月君” 是某内容管理系统网站 www.codingmay.com 的管理员,拥有删除文章的操作权限。
/api/user/auth 登陆网站,此时网站会将该用户信息放入 cookie 中,用于后续身份验证。POST: /api/delete/article/:id 接口,传递文章 id 使用 POST 请求删除一篇文章。www.hacker.com 伪造了一个 CSRF 请求。www.hacker.com。修改本地 /etc/hosts 文件,模拟两个站点:www.codingmay.com 表示 “五月君” 要登陆的内容管理系统。www.hacker.com 这是 “黑客君” 模拟 CSRF 的网站。
另外一个知识点:由于在本地模拟,两个站点主机都使用的 localhost 通过 port 区分,而 cookie 的存储需要根据域名做区分,本示例中 cookie 存放在 www.codingmay.com 中。
127.0.0.1 www.codingmay.com
127.0.0.1 www.hacker.com使用 Node.js Express 框架和 pug 模版引擎模拟 CSRF 攻击,创建项目和安装依赖。
$ mkdir csrf-demo
$ cd mkdir csrf-demo
$ npm init
$ npm i express pug cookie-parser -S
$ mkdir codingmay hacker
# 最终的项目结构创建 codingmay/app.js 文件,设置服务端口为 3000,提供如下接口:
/user/auth:模拟用户授权,保存用户信息到 cookie 中,设置 cookie 过期时间为 10 分钟。/article/list:文章列表,授权成功跳转至该页面。/delete/article/:id:模拟删除文章,如果 cookie 不存在,提示未授权删除失败。// codingmay/app.js
const express = require('express')
const path = require('path')
const cookieParser = require('cookie-parser')
const app = express()
const PORT = 3000
const list = [{ title: 'JavaScript 异步编程指南', id: 1 }, { title: 'HTTPS 工作原理', id: 2 }];
app.use(cookieParser())
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug')
app.get('/user/auth', (req, res) => {
res.cookie('userId', 'user_001', { expires: new Date(Date.now() + 1000 * 60 * 10) }) // 过期时间 10 分钟
res.redirect(301, '/article/list')
});
app.get('/article/list', (req, res) => {
res.render('index', { title: 'xxx 内容管理系统', list})
});
app.post('/delete/article/:id', (req, res) => {
if (!req.cookies.userId) {
return res.status(401).send('Unauthorized')
}
list.splice(list.findIndex(item => item.id === Number(req.params.id)), 1)
res.json({ code: 'SUCCESS' })
});
app.listen(PORT, () => console.log(`Example app listening at http://localhost:${PORT}`))基于 pug 模版引擎,模拟简单的内容管理页面,在这个页面可查看和删除文章。
// codingmay/views/index.pug
html
head
title= title
body
ul
each data in list
//- [call onclick js function and pass param from pug](https://github.com/pugjs/pug/issues/2933)
li= data.title
button(onclick=`deleteArticle(${data.id})`)= "删除"
else
li= "没有文章了"
script.
async function deleteArticle(id) {
const response = await fetch(`/api/delete/article/${id}`, { method: 'POST' })
if (response.status === 401) {
return alert(`Delete article failed with message: ${response.statusText}`);
}
if (response.status === 200) {
alert(`Delete article success`);
location.reload();
return;
}
}创建 hacker/app.js 文件,设置服务端口为 4000,渲染页面。
// hacker/app.js
const express = require('express')
const path = require('path')
const app = express()
const PORT = 4000
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug')
app.get('/', (req, res) => {
res.render('index', { title: '黑客网站'})
});
app.listen(PORT, () => console.log(`Example app listening at http://localhost:${PORT}`))在黑客自己伪造的页面,自动触发请求,如何是 GET 请求就更好模拟了,<script src="">、<img src=""、<a href=""/> 这些标签本身不受同源策略限制,可直接发起请求。
有些网站服务端提供的接口为 POST,我们可构建一个隐藏的表单伪造 POST 请求,当用户 “五月君” 打开 “黑客君” 伪造的页面后,表单会自动提交,服务器在收到请求后执行删除文章操作。
// hacker/views/index.pug
html
head
title= title
body
form(action="http://www.codingmay.com:3000/api/delete/article/2", method="post")
input(type="hidden", name="id" value="2")
script.
document.forms[0].submit()通过一个 Gif 动图演示,如果不理解的,最好是能够跟着上面的 Demo 在本地实践下。

在看一张图,如下所示,这是在黑客伪造的网站上发起的请求信息,且 Cookie 是浏览器自动为我们获取带上的。

CSRF 攻击的特点是利用受害者已登陆网站的凭证,冒充受害者在第三方网站发起操作,这里攻击者只能使用 cookie,而不能获取。针对性的提出防范策略:
HTTP 请求头包含一个 Referer 字段标明了请求来源于哪个地址,在处理敏感数据请求时应位于同一域名下,该包含了 URL 路径,除此之外还有一个 Origin 字段包含了域名信息。
我们可以优先判断 Origin 字段,再根据具体情况选择性的判断 Referer 字段。
// codingmay/app.js
app.post('/api/delete/article/:id', (req, res) => {
if (req.get('Origin').indexOf('www.codingmay.com') < 0) {
return res.json({ code: 'ERROR', message: 'origin error' })
}
});上面示例中我们在黑客伪造的网站 www.hacker.com 上引导发出的 Cookie 称为第三方 Cookie。为了减少安全风险,可设置 Cookie 的 SameSite 属性用来限制发送第三方 Cookie。
Cookie 的 SameSite 属性有三个值:
<form method="GET">)、链接 (<a></a>)、预加载(<link rel="prerender"/>) 这三种情况下会发送 Cookie 信息。// codingmay/app.js
app.get('/user/auth', (req, res) => {
res.cookie('userId', 'user_001', {
expires: new Date(Date.now() + 1000 * 60 * 10),
sameSite: 'strict' // 设置为严格模式,完全禁止第三方 Cookie
})
});解决 CSRF 攻击另一个常用的解决方案是 CSRF Token 验证,第一步是浏览器向服务器请求时,服务器返回一个随机 Token。
// codingmay/app.js
const jwt = require('jsonwebtoken')
const secretKey = 'secret_123456'
app.get('/article/list', (req, res) => {
const token = jwt.sign({
userId: 'user_001',
now: Date.now()
}, secretKey, {
expiresIn: '1h'
});
res.render('index', { title: 'xxx 内容管理系统', token, list})
});浏览器将该 Token 以隐藏形式植入页面中,当需要请求数据时,携带上 Token 信息,最好的方式是放在 Headers 请求头中,让请求发生跨域。此处为了简单测试,放在 query 传递。
html
head
title= title
body
span(id='token' data-token= token)
script.
async function deleteArticle(id) {
const tokenElement = document.getElementById('token')
const token = tokenElement.dataset.token;
const response = await fetch(`/api/delete/article/${id}?token=${token}`, { method: 'POST' })
...
}服务器对传递的 Token 信息增加验证,现在从第三方网站发起的请求,即便取到 Cookie,也很难取到 CSRF Token 值,进一步增强安全性。
// codingmay/app.js
app.post('/api/delete/article/:id', async (req, res) => {
try {
const decode = await jwt.verify(req.query.token, secretKey);
console.log(decode);
} catch (err) {
console.error(err);
return res.json({ code: 'ERROR' })
}
...
});Node.js 中有一个中间件 expressjs/csurf 也可用来预防 CSRF 攻击。
又一年金三银四到来,似乎 “面向手撕代码面试” 已经成为一些公司的必备面试之一了,之所以有这个感触是因为笔者和你一样也层经历过,当被面试手写代码时,刚开始自信心爆棚,忽然有种提笔就来的感觉,上来就是一顿写、一顿画,然后写完又删。。。如果是在纸上应该就是反复的涂画了,因为没有经过一些思考,没有好的思路,最后的结果就是漏洞百出、相当的不顺利了,之后吐槽:“什么年代了?一个库就搞定了,还手写代码?”。
社区已经有一些现成的库了,为什么还要手写?当然这并不是必须的,谈一点自己的思考,在实际的开发过程中,也会去优先选择一些优秀的库,并不会到处造轮子,否则也会增加维护的成本。
为什么有时候大家会谈论 “CURD 工程师 / API 工程师”?如果只会 API 调用,哪怕它的实现很简单,也是不知道的,如果能在工作中多一些思考,对一些自己经常使用的东西多一些学习和思考,一方面能加深自己的理解、例如 Promise 的 resolve 函数不执行会发生什么?之前写过一个并发请求控制的实现 “实现浏览器中的最大请求并发数控制” 核心的也是利用的 Promise 这一点。另一方面了解其背后实现,也可以反思是否有待优化的空间,优秀的项目不都是不断的总结、迭代优化的吗?
在写代码时,变量名定义、函数或接口设计、代码可读性和细节处理这些点也可体现出一个面试者的代码水平和习惯。在平常的工作中要养成一个良好的习惯,不要只是为了面试而面试。
不论是手写/机写代码,所谓的 “手撕代码” 并非最终目的,做为一个面试官也不要只把最后的运行结果来做为最终评估,可以更多关注下其实现的一些思路。
笔者日常看到一些库或文章对于感兴趣的点,会记录下来,尝试着去写下,也才有大家看到的 “某某 API 是如何实现?” 本文中,归纳了 10 个 JavaScript 相关的问题分享给大家,希望能对您有所帮助!Good Luck!
之前写过多种实现思路参考:http://www.imooc.com/article/247303 推荐以下方式,实现思路:
/**
* 数组降维
* @param { Array } arr
* @returns { Array } 返回一个处理完成的数组
*/
function arrReduction(arr) {
return arrReductionRecursive(arr, []); // {1}
}
/**
* 数组降维递归调用
* @param { Array } arr
*/
function arrReductionRecursive(arr, result=[]) { // {2}
arr.forEach(item => { // {3}
item instanceof Array ?
arrReductionRecursive(item, result) // {4}
:
result.push(item); // {5}
})
return result; // {6}
}
// 测试
const arr = [[0, 1], [2, [4, [6, 7]]]];
console.log('arrReduction: ', arrReduction(arr)); // [ 0, 1, 2, 4, 6, 7 ]实现思路:
/**
* 数组/对象数组去重
* @param { Array } arr 待去重的数组
* @param { String } name 如果是对象数组,为要过滤的依据 key
* @returns { Array }
*/
function unique (arr=[], name='') {
if ((arr[0] instanceof Object) && !name) { // {1}
throw new Error('对象数组请传入需要过滤的属性!');
}
const hash = {};
return arr.reduce((prev, current) => {
let key; // {2}
if (!name) {
key = current; // {3}
} else if (current.hasOwnProperty(name)) {
key = current[name]; // {4}
} else {
key = Math.random(); // {5} 保证其它 key 不受影响
}
if (!(Object.prototype.toString.call(key) === '[object Number]')) { // {6}
key += '_';
}
hash[key] ? '' : hash[key] = true && prev.push(current); // {7}
return prev; // {8}
}, []);
}
let arr = [1, 2, 2, 3, '3', 4];
arr = [{ a: 1 }, { b: 2 }, { b: 2 }]
arr = [{ a: 1 }, { a: 1 }, { b: 2 }]
console.log(unique(arr, 'a'));一种更简单的 ES6 新的数据结构 Set,因为 Set 能保证集合中的元素是唯一的,可以利用这个特性,但是支持有限,对象数组这种就不支持咯
let arr = [1, 2, 2, 3, '3', 4];
[...new Set(arr)] // [ 1, 2, 3, '3', 4 ]深拷贝与浅拷贝区别:前者深拷贝遇到复杂类型对象、数组之后会切断与原先对象的引用,进行层层拷贝,保证两者互不影响,而浅拷贝遇到对象、数组之后拷贝的是其引用。
实现思路:
/**
* 深拷贝
* @param { Object|Array|Function } elements
* @returns { Object|Array|Function } newElements
*/
function deepClone(elements) {
if (!typeCheck(elements, 'Object')) { // {1}
throw new Error('必须为一个对象')
}
return deepCloneRecursive(elements); // {2}
}
/**
* 深度拷贝递归调用
* @param { Object|Array|Function } elements
*/
function deepCloneRecursive(elements) {
const newElements = typeCheck(elements, 'Array') ? [] : {}; // {3}
for (let k in elements) { // {4}
// {5}
if (typeCheck(elements[k], 'Object') || typeCheck(elements[k], 'Array')) {
newElements[k] = deepCloneRecursive(elements[k]);
} else {
newElements[k] = elements[k];
}
}
return newElements; // {6}
}
/**
* 类似检测 | 辅助函数
* @param {*} val 值
* @param { String } type 类型
* @returns { Boolean } true|false
*/
function typeCheck(val, type) {
return Object.prototype.toString.call(val).slice(8, -1) === type;
}
// 测试
const obj = { a: 1, b: { c: [], d: function() {} }};
const obj2 = deepClone(obj);
obj.b.c.push('a');
obj.b.d = [];
console.log(obj); // { a: 1, b: { c: [ 'a' ], d: [] } }
console.log(obj2); // { a: 1, b: { c: [], d: [Function: d] } }介绍另外一种简单的方法:使用 JSON 进行序列化和反序列化
const obj = { a: 1, b: { c: [], d: function() {} }};
const obj2 = JSON.parse(JSON.stringify(obj));
console.log(obj); // { a: 1, b: { c: [], d: [Function: d] } }
console.log(obj2); // { a: 1, b: { c: [] } }上面运行结果发现函数 d 没有了,因为在 JSON 的标准中有规定仅支持 object, array, number, or string 四个数据类型,或 false, null, true 这三个值,解析时对于其它类型的编码都会被默认转换掉。
JavaScript 在语言层面没有直接提供类似 Java 或其它的语言中的 sleep() 线程沉睡功能,也许你会看到如下代码:
function sleep(seconds) { // 不可取
const start = new Date();
while (new Date() - start < seconds) {}
}
sleep(10000); // 10 秒钟运行之后如上图所示,CPU 暴涨,因为 JavaScript 是单线程的,这样 CPU 资源都会为这段代码服务,这是一种阻塞操作,不是线程睡眠,另外也会破坏事件循环调度,导致其它任务无法执行。
正确写法推荐以下代码,通过 setTimeout 来控制延迟执行。
/**
* 延迟函数
* @param { Number } seconds 单位秒
*/
function sleep(seconds) {
return new Promise(resolve => {
setTimeout(function() {
resolve(true);
}, seconds)
})
}
async function test() {
console.log('hello');
await sleep(5000);
console.log('world! 5 秒后输出');
}
test();ECMA262 草案提供了 Atomics.wait API 来实现线程睡眠,它会真正的阻塞事件循环,阻塞线程直到超时。
该方法 Atomics.wait(Int32Array, index, value[, timeout]) 会验证给定的 Int32Array 数组位置中是否仍包含其值,在休眠状态下会等待唤醒或直到超时,返回一个字符串表示超时还是被唤醒。
同样的因为我们的业务是工作在主线程,避免在主线程中使用,在 Node.js 的工作线程中可以根据实际需要使用。
/**
* 真正的阻塞事件循环,阻塞线程直到超时,不要在主线程上使用
* @param {Number} ms delay
* @returns {String} ok|not-equal|timed-out
*/
function sleep(ms) {
const valid = ms > 0 && ms < Infinity;
if (valid === false) {
if (typeof ms !== 'number' && typeof ms !== 'bigint') {
throw TypeError('ms must be a number');
}
throw RangeError('ms must be a number that is greater than 0 but less than Infinity');
}
return Atomics.wait(int32, 0, 0, Number(ms))
}
sleep(3000)通过 N-API 写 C/C++ 插件的方式实现,参见笔者的这个项目 https://github.com/qufei1993/easy-sleep 里面也包含了上述各方法的实现。
这个名次第一次听到时感觉好神秘、好高大上,其实明白之后也就没那么复杂了,下面让我们一块揭秘这个神秘的柯里画函数是什么!
接收函数作为参数的函数称为高阶函数,柯里化是高阶函数中的一种特殊写法。
函数柯里化是一把接受多个参数的函数转化为最初只接受一个参数且返回接受余下的参数返回结果的新函数。
常见的面试题是这样 add(1)(2)(3) 计算 1 + 2 +3 的和,下面也是一种函数柯里化的写法,但自由度不高,如果我在增加一个参数呢,例如 add(1, 2)(3)
function add(a) {
return function(b) {
return function(c) {
return a + b + c;
}
}
}
console.log(add(1)(2)(3)); // 6函数柯里化具备更加强大的能力,因此,我们要去想办法实现一个柯里化的通用式,上面例子中我们使用了闭包,但是代码是重复的,所以我们还需要借助递归来实现。
实现思路:
/**
* add 函数
* @param { Number } a
* @param { Number } b
* @param { Number } c
*/
function addFn(a, b, c) { // {1}
return a + b + c;
}
/**
* 柯里化函数
* @param { Function } fn
* @param { ...any } args 记录参数
*/
function curry(fn, ...args) { // {2}
if (args.length < fn.length) { // {3}
return function() { // {4}
let _args = Array.prototype.slice.call(arguments); // {5}
return curry(fn, ...args, ..._args); // {6} 上面得到的结果为数组,进行解构
}
}
return fn.apply(null, args); // {7}
}
// curry 函数简写如下,上面写法可能更易理解
// const curry = (fn, ...args) => args.length < fn.length ?
// (..._args) => curry(fn, ...args, ..._args)
// :
// fn.call(null, ...args);
// 柯里化 add 函数
const add = curry(addFn); // {8}
console.log(add(1)(2)(3)); // 6
console.log(add(1, 2)(3)); // 6
console.log(add(1)(2, 3)); // 6自定义 _new() 方法,模拟 new 操作符实现原理,共分为以下 3 步骤:
/**
* 实现一个 new 操作符
* @param { Function } fn 构造函数
* @param { ...any } args
* @returns { Object } 构造函数实例
*/
function _new(fn, ...args) {
// {1} 以构造器的 prototype 属性为原型,创建新对象
// 以下两行代码等价于
// const obj = Object.create(fn.prototype)
const obj = {}; // {1.1} 创建一个新对象 obj
obj.__proto__ = fn.prototype; // {1.2} 新对象的 __proto__ 指向构造函数的 prototype,实现继承
// {2} 改变 this 指向,将新的实例 obj 和参数传入给构造函数 fn 执行
const result = fn.apply(obj, args);
// {3} 返回实例,如果构造器没有手动返回对象,则返回第一步创建的对象
return typeof result === 'object' ? result : obj;
}将构造函数 Person 与行参传入我们自定义 _new() 方法,得到实例 zhangsan,使用 instanceof 符号检测与使用 new 是一样的。
function Person(name, age) {
this.name = name;
this.age = age;
}
const zhangsan = _new(Person, '张三', 20);
const lisi = new Person('李四', 18)
console.log(zhangsan instanceof Person, zhangsan); // true Person { name: '张三', age: 20 }
console.log(lisi instanceof Person, lisi); // true Person { name: '李四', age: 18 }function Person() {}
const p1 = new Person();
const n1 = new Number()
console.log(p1 instanceof Person) // true
console.log(n1 instanceof Person) // false
console.log(_instanceof(p1, Person)) // true
console.log(_instanceof(n1, Person)) // false
function _instanceof(L, R) {
L = L.__proto__;
R = R.prototype;
while (true) {
if (L === null) return false;
if (L === R) return true;
L = L.__proto__;
}
}/*
* 实现一个自己的 call 方法
*/
Function.prototype.mayJunCall = function(context) {
// {1} 如果 context 不存,根据环境差异,浏览器设置为 window,Nodejs 设置为 global
context = context ? context : globalThis.window ? window : global;
const fn = Symbol(); // {2} 上下文定义的函数保持唯一,借助 ES6 Symbol 方法
context[fn] = this; // {3} this 为需要执行的方法,例如 function test(){}; test.call(null) 这里的 this 就代表 test() 方法
const args = [...arguments].slice(1); // {4} 将 arguments 类数组转化为数组
const result = context[fn](...args) // {5} 传入参数执行该方法
delete context[fn]; // {6} 记得删除
return result; // {7} 如果该函数有返回值,将结果返回
}
// 测试
name = 'lisi';
const obj = {
name: 'zs'
};
function test(age, sex) {
console.log(this.name, age, sex);
}
test(18, '男'); // lisi 18 男
test.mayJunCall(obj, 18, '男'); // zs 18 男与上面模拟 call 函数的实现类似,唯一的区别在于 apply 接受数组做为参数传递,因此刚开始要做下参数校验,如果参数传了且不为数组,抛出一个 TypeError 错误。
/**
* 实现一个自己的 apply 方法
*/
Function.prototype.mayJunApply = function(context) {
let args = [...arguments].slice(1); // 将 arguments 类数组转化为数组
if (args && args.length > 0 && !Array.isArray(args[0])) { // 参数校验,如果传入必须是数组
throw new TypeError('CreateListFromArrayLike called on non-object');
}
context = context ? context : globalThis.window ? window : global;
const fn = Symbol();
context[fn] = this;
args = args.length > 0 ? args[0] : args; // 因为本身是一个数组,此时传值了就是 [[0, 1]] 这种形式
const result = context[fn](...args);
delete context[fn];
return result
}bind 的实现与 call、apply 不同,但也没那么复杂,首先 bind 绑定之后并不会立即执行,而是会返回一个新的匿名函数,只有我们手动调用它才会执行。
另外 bind 可以分为两部接收:
function test(age, sex) {
console.log(`name: ${this.name}, age: ${age}, sex: ${sex}`);
}
const fn = test.mayJunBind(obj, 20); // 进行 bind 调用fn('男') // 传入第二个参数以下为实现 bind 的模式实现,最后还是调用了 apply 实现了上下文的绑定
/**
* 实现一个自己的 bind 方法
*/
Function.prototype.mayJunBind = function(context) {
const that = this; // 保存当前调用时的 this,因为 bind 不是立即执行
const firstArgs = [...arguments].slice(1); // 获取第一次绑定时的参数
return function() {
const secondArgs = [...arguments]; // 获取第二次执行时的参数
const args = firstArgs.concat(secondArgs); // 两次参数拼接
return that.apply(context, args); // 将函数与 context 进行绑定,传入两次获取的参数 args
}
}/**
* 实现 map 函数
* map 的第一个参数为回调,第二个参数为回调的 this 值
*/
Array.prototype.mayJunMap = function(fn, thisValue) {
const fnThis = thisValue || [];
return this.reduce((prev, current, index, arr) => {
prev.push(fn.call(fnThis, current, index, arr));
return prev;
}, []);
}
const arr1 = [undefined, undefined];
const arr2 = [undefined, undefined].mayJunMap(Number.call, Number);
const arr3 = [undefined, undefined].mayJunMap((element, index) => Number.call(Number, index));
// arr2 写法等价于 arr3
console.log(arr1) // [ undefined, undefined ]
console.log(arr2) // [ 0, 1 ]
console.log(arr3) // [ 0, 1 ]Array.prototype.mayJunReduce = function(cb, initValue) {
const that = this;
for (let i=0; i<that.length; i++) {
initValue = cb(initValue, that[i], i, that);
}
return initValue;
}
const arr = [1, 2, 3];
const arr1 = arr.mayJunReduce((prev, current) => {
console.log(prev, current);
prev.push(current)
return prev;
}, [])
console.log(arr1)这是一个经典的面试问题了,我将它放了最后,不废话直接上代码,共分为 5 部份完成,实现思路如下,理清了 Promise 的实现原理,很多问题自然就迎刃而解了。
主要在构造函数里做一些初始化操作
/**
* 封装一个自己的 Promise
*/
class MayJunPromise {
constructor(fn) {
// {1} 初始化一些默认值
this.status = 'pending'; // 一个 promise 有且只有一个状态 (pending | fulfilled | rejected)
this.value = undefined; // 一个 JavaScript 合法值(包括 undefined,thenable,promise)
this.reason = undefined; // 是一个表明 promise 失败的原因的值
this.onResolvedCallbacks = []; // {2}
this.onRejectedCallbacks = []; // {3}
// {4} 成功回调
let resolve = value => {
if (this.status === 'pending') {
this.status = 'fulfilled'; // 终态
this.value = value; // 终值
this.onResolvedCallbacks.forEach(itemFn => {
itemFn()
});
}
}
// {5} 失败回调
let reject = reason => {
if (this.status === 'pending') { // 状态不可逆,例如 resolve(1);reject('err'); 第二个 reject 就无法覆盖
this.status = 'rejected'; // 终态
this.reason = reason; // 终值
this.onRejectedCallbacks.forEach(itemFn => itemFn());
}
}
try {
// {6} 自执行
fn(resolve, reject);
} catch(err) {
reject(err); // {7} 失败时捕获
}
}
}/**
* 封装一个自己的 Promise
*/
class MayJunPromise {
...
/**
* 一个 promise 必须提供一个 then 方法以访问其当前值、终值和据因
* @param { Function } onFulfilled 可选,如果是一个函数一定是在状态为 fulfilled 后调用,并接受一个参数 value
* @param { Function } onRejected 可选,如果是一个函数一定是在状态为 rejected 后调用,并接受一个参数 reason
* @returns { Promise } 返回值必须为 Promise
*/
then(onFulfilled, onRejected) {
// {8} 值穿透,把 then 的默认值向后传递,因为标准规定 onFulfilled、onRejected 是可选参数
// 场景:new Promise(resolve => resolve(1)).then().then(value => console.log(value));
onFulfilled = Object.prototype.toString.call(onFulfilled) === '[object Function]' ? onFulfilled : function(value) {return value};
onRejected = Object.prototype.toString.call(onRejected) === '[object Function]' ? onRejected : function(reason) {throw reason};
// {9} then 方法必须返回一个 promise 对象
const promise2 = new MayJunPromise((resolve, reject) => {
// {10}
if (this.status === 'fulfilled') { // 这里的 this 会继承外层上下文绑定的 this
// {10.1} Promise/A+ 规定:确保 onFulfilled、onRejected 在下一轮事件循环中被调用
// 可以使用宏任务 (setTimeout、setImmediate) 或微任务(MutationObsever、process.nextTick)
setImmediate(() => {
try {
// {10.2} Promise/A+ 标准规定:如果 onFulfilled 或 onRejected 返回的是一个 x,那么它会以 [[Resolve]](promise2, x) 处理解析
const x = onFulfilled(this.value);
// 这里定义解析 x 的函数为 resolveMayJunPromise
resolveMayJunPromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
}
// {11}
if (this.status === 'rejected') {
setImmediate(() => {
try {
const x = onRejected(this.reason)
resolveMayJunPromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
}
// {12}
// 有些情况无法及时获取到状态,初始值仍是 pending,例如:
// return new Promise(resolve => { setTimeout(function() { resolve(1) }, 5000) })
// .then(result => { console.log(result) })
if (this.status === 'pending') {
this.onResolvedCallbacks.push(() => {
setImmediate(() => {
try {
const x = onFulfilled(this.value);
resolveMayJunPromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
});
this.onRejectedCallbacks.push(() => {
setImmediate(() => {
try {
const x = onRejected(this.reason)
resolveMayJunPromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
});
}
});
return promise2;
}
}声明函数 resolveMayJunPromise(),Promise 解决过程是一个抽象的操作,在这里可以做到与系统的 Promise 或一些遵循 Promise/A+ 规范的 Promise 实现相互交互,以下代码建议跟随 Promise/A+ 规范进行阅读,规范上面也写的很清楚。
注意:在实际编码测试过程中规范 [2.3.2] 样写还是有点问题,你要根据其它的 Promise 的状态值进行判断,此处注释掉了,建议使用 [2.3.3] 也是可以兼容的 。
/**
* Promise 解决过程
* @param { Promise } promise2
* @param { any } x
* @param { Function } resolve
* @param { Function } reject
*/
function resolveMayJunPromise(promise2, x, resolve, reject){
// [2.3.1] promise 和 x 不能指向同一对象,以 TypeError 为据因拒绝执行 promise,例如:
// let p = new MayJunPromise(resolve => resolve(1))
// let p2 = p.then(() => p2); // 如果不做判断,这样将会陷入死循环
if (promise2 === x) {
return reject(new TypeError('Chaining cycle detected for promise'));
}
// [2.3.2] 判断 x 是一个 Promise 实例,可以能使来自系统的 Promise 实例,要兼容,例如:
// new MayJunPromise(resolve => resolve(1))
// .then(() => new Promise( resolve => resolve(2)))
// 这一块发现也无需,因为 [2.3.3] 已经包含了
// if (x instanceof Promise) {
// // [2.3.2.1] 如果 x 是 pending 状态,那么保留它(递归执行这个 resolveMayJunPromise 处理程序)
// // 直到 pending 状态转为 fulfilled 或 rejected 状态
// if (x.status === 'pending') {
// x.then(y => {
// resolveMayJunPromise(promise2, y, resolve, reject);
// }, reject)
// } else if (x.status === 'fulfilled') { // [2.3.2.2] 如果 x 处于执行态,resolve 它
// x.then(resolve);
// } else if (x.status === 'rejected') { // [2.3.2.3] 如果 x 处于拒绝态,reject 它
// x.then(reject);
// }
// return;
// }
// [2.3.3] x 为对象或函数,这里可以兼容系统的 Promise
// new MayJunPromise(resolve => resolve(1))
// .then(() => new Promise( resolve => resolve(2)))
if (x != null && (x instanceof Promise || typeof x === 'object' || typeof x === 'function')) {
let called = false;
try {
// [2.3.3.1] 把 x.then 赋值给 then
// 存储了一个指向 x.then 的引用,以避免多次访问 x.then 属性,这种预防措施确保了该属性的一致性,因为其值可能在检索调用时被改变。
const then = x.then;
// [2.3.3.3] 如果 then 是函数(默认为是一个 promise),将 x 作为函数的作用域 this 调用之。
// 传递两个回调函数作为参数,第一个参数叫做 resolvePromise (成功回调) ,第二个参数叫做 rejectPromise(失败回调)
if (typeof then === 'function') {
// then.call(x, resolvePromise, rejectPromise) 等价于 x.then(resolvePromise, rejectPromise),笔者理解此时会调用到 x 即 MayJunPromise 我们自己封装的 then 方法上
then.call(x, y => { // [2.3.3.3.1] 如果 resolvePromise 以值 y 为参数被调用,则运行 [[Resolve]](promise, y)
if (called) return;
called = true;
resolveMayJunPromise(promise2, y, resolve, reject);
}, e => { // [2.3.3.3.2] 如果 rejectPromise 以据因 r 为参数被调用,则以据因 r 拒绝 promise
if (called) return;
called = true;
reject(e);
});
} else {
// [2.3.3.4 ] 如果 then 不是函数,以 x 为参数执行 promise
resolve(x)
}
} catch(e) { // [2.3.3.2] 如果取 x.then 的值时抛出错误 e ,则以 e 为据因拒绝 promise
if (called) return;
called = true;
reject(e);
}
} else {
resolve(x);
}
}Promise 提供了一个测试脚本,进行正确性验证。
npm i -g promises-aplus-tests
promises-aplus-tests mayjun-promise.js同时需要暴露出一个 deferred 方法。
MayJunPromise.defer = MayJunPromise.deferred = function () {
let dfd = {}
dfd.promise = new MayJunPromise((resolve,reject)=>{
dfd.resolve = resolve;
dfd.reject = reject;
});
return dfd;
}
module.exports = MayJunPromise;Promise/A+ 规范中只提供了 then 方法,但是我们使用的 catch、Promise.all、Promise.race 等都可以在 then 方法的基础上进行实现
class MayJunPromise {
constructor(fn){...}
then(){...},
/**
* 捕获错误
* @param { Function } onRejected
*/
catch(onRejected) {
return this.then(undefined, onRejected);
}
}
/**
* 仅返回成功态,即 status = fulfilled
*/
MayJunPromise.resolve = function(value) {
return (value instanceof Promise || value instanceof MayJunPromise) ? value // 如果是 Promise 实例直接返回
: new MayJunPromise(resolve => resolve(value));
}
/**
* 仅返回失败态,即 status = rejected
*/
MayJunPromise.reject = function(value) {
return (value instanceof Promise || value instanceof MayJunPromise) ? value : new MayJunPromise(reject => reject(value));
}
/**
* MayJunPromise.all() 并行执行
* @param { Array } arr
* @returns { Array }
*/
MayJunPromise.all = function(arr) {
return new MayJunPromise((resolve, reject) => {
const length = arr.length;
let results = []; // 保存执行结果
let count = 0; // 计数器
for (let i=0; i<length; i++) {
MayJunPromise.resolve(arr[i]).then(res => {
results[i] = res;
count++;
if (count === length) { // 全部都变为 fulfilled 之后结束
resolve(results);
}
}, err => reject(err)); // 只要有一个失败,就将失败结果返回
}
});
}
/**
* MayJunPromise.race() 率先执行,只要一个执行完毕就返回结果;
*/
MayJunPromise.race = function(arr) {
return new MayJunPromise((resolve, reject) => {
for (let i=0; i<arr.length; i++) {
MayJunPromise.resolve(arr[i])
.then(result => resolve(result), err => reject(err));
}
})
}Promise.all 同时将请求发出,假设我现在有上万条请求,势必会造成服务器的压力,如果我想限制在最大并发 100 该怎么做?例如,在 Chrome 浏览器中就有这样的限制,Chrome 中每次最大并发链接为 6 个,其余的链接需要等待其中任一个完成,才能得到执行,下面定义 allByLimit 方法实现类似功能。
/**
* 并发请求限制
* @param { Array } arr 并发请求的数组
* @param { Number } limit 并发限制数
*/
MayJunPromise.allByLimit = function(arr, limit) {
const length = arr.length;
const requestQueue = [];
const results = [];
let index = 0;
return new MayJunPromise((resolve, reject) => {
const requestHandler = function() {
console.log('Request start ', index);
const request = arr[index].then(res => res, err => {
console.log('Error', err);
return err;
}).then(res => {
console.log('Number of concurrent requests', requestQueue.length)
const count = results.push(res); // 保存所有的结果
requestQueue.shift(); // 每完成一个就从请求队列里剔除一个
if (count === length) { // 所有请求结束,返回结果
resolve(results);
} else if (count < length && index < length - 1) {
++index;
requestHandler(); // 继续下一个请求
}
});
if (requestQueue.push(request) < limit) {
++index;
requestHandler();
}
};
requestHandler()
});
}测试,定义一个 sleep 睡眠函数,模拟延迟执行
/**
* 睡眠函数
* @param { Number } ms 延迟时间|毫秒
* @param { Boolean } flag 默认 false,若为 true 返回 reject 测试失败情况
*/
const sleep = (ms=0, flag=false) => new Promise((resolve, reject) => setTimeout(() => {
if (flag) {
reject('Reject ' + ms);
} else {
resolve(ms);
}
}, ms));
MayJunPromise.allByLimit([
sleep(1000),
sleep(1000),
sleep(1000),
sleep(5000, true),
sleep(10000),
], 3).then(res => {
console.log(res);
})
// 以下为运行结果
Request start 0
Request start 1
Request start 2
Number of concurrent requests 3
Request start 3
Number of concurrent requests 3
Request start 4
Number of concurrent requests 3
Error Reject 5000
Number of concurrent requests 2
Number of concurrent requests 1
[ 1000, 1000, 1000, 'Reject 5000', 10000 ]co 是一个自动触发调度 next 的函数
/**
* 定义一个生成器函数 test
*/
function *test() {
yield 1;
const second = yield Promise.resolve(2);
// console.log('second', second);
const third = yield 3;
// console.log('third', third);
return 'ok!';
}
const gen = test();
console.log(gen.next()) // { value: 1, done: false }
console.log(gen.next()) // { value: Promise { 2 }, done: false }
console.log(gen.next()) // { value: 3, done: false }
console.log(r.next()) // { value: 'ok!', done: true }自定义一个 co 函数自动触发 next 函数
/**
* 自定义 CO 函数实现
* @param { Generator } gen 生成器函数
*/
function mayJunCo(gen) {
return new Promise((resolve, reject) => {
function fn(data) {
const { value, done } = gen.next(data);
// 如果 done 为 true 递归到尾结束
if (done) return resolve(value);
// 否则递归 fn 函数自动执行迭代器
Promise.resolve(value).then(fn, reject);
}
return fn();
})
}
mayJunCo(test()).then(console.log)ECMAScript 是 JavaScript 要实现的一个语言标准,通常缩写为 ES。自从 ES6 之后 JavaScript 多出了很多新特性,当开始学习这些新特性时,不可避免的会看到这些术语:“ES6、ES7、ES8、ECMAScript 2018、ECMAScript 2019...” 等等很多。很多时候让人困惑或混淆,例如 ES6 其实等价于 ES2015,这个 ES2015 代表的是当时发表的年份,ES2016 发布的称为 ES7,依次类推,ES2023 可以称为 ES14 了~
本文根据最新已完成的提案,按照时间倒序列出 ES2013 ~ ES2016 之间新增的语言特性。
ES2023 新特性目前有两条:Array find from last、Hashbang Grammar,也都处于 stage 4 阶段,预计 2023 年发布。
新增两个方法: .findLast()、.findLastIndex() 从数组的最后一个元素开始查找,可以同 find()、findIndex() 做一个对比。
const arr = [{ value: 1 }, { value: 2 }, { value: 3 }, { value: 4 }];
// find vs findLast
console.log(arr.find(n => n.value % 2 === 1)); // { value: 1 }
console.log(arr.findLast(n => n.value % 2 === 1)); // { value: 3 }
// findIndex vs findLastIndex
console.log(arr.findIndex(n => n.value % 2 === 1)); // 0
console.log(arr.findLastIndex(n => n.value % 2 === 1)); // 2如下所示,在 index.js 脚本文件里编写 JS 代码,如果要正确的执行,需要在控制台输入 node index.js。
console.log("JavaScript");如果直接执行 ./index.js 脚本文件会得到以下报错:
$ ./index.js
./index.js: line 1: syntax error near unexpected token `"JavaScript"'
./index.js: line 1: `console.log("JavaScript");' 很正常,因为我们并没有指定使用何种解释器来执行上述脚本文件。Hashbang 语法是用来指定脚本文件的解释器是什么,语法规则是在脚本文件头部增加一行代码:#!/usr/bin/env node。
// #!/usr/bin/env node
console.log("JavaScript");注意,还需修改脚本文件的权限 chmod +x index.js,否则执行会报 permission denied: ./index.js 错误。
允许在类最外层声明类成员,参考 https://github.com/tc39/proposal-class-fields。
class Person {
name = 'Tom'
}私有化类成员:支持私有实例、私有静态类型字段、私有方法。
class Person {
#privateField1 = 'private field 1'; // 私有字段赋初值
#privateField2; // 默认 undefined
static #privateStaticField3 = 'private static field 3'
constructor(value) {
this.#privateField2 = value; // 实例化时为私有字段赋值
}
#toString() {
console.log(this.#privateField1, this.#privateField2, InstPrivateClass.#privateStaticField3);
}
print() {
this.#toString()
}
}
const p = new Person('private field 2')
p.print()使用 in 操作符检测某一实例是否包含要检测的私有字段。
class Person {
#name = 'Ergonomic brand checks for Private Fields';
static check(obj) {
return #name in obj;
}
}以前 await 必须随着 async 一起出现,只有在 async 函数内才可用。当需要在一些文件顶部进行初始化的场景中使用时就有不支持了,顶级 await 可以解决这个问题,但它仅支持 ES Modules。
let jQuery;
try {
jQuery = await import('https://cdn-a.com/jQuery');
} catch {
jQuery = await import('https://cdn-b.com/jQuery');
}以前的正则表达式支持 3 个修饰符:/i(忽略大小写)、/g(全局匹配)、/m(多行),当执行正则表达式的 exec() 方法时,新增一个 /d 修饰符,它会返回一个 indices 属性,包含了匹配元素的开始、结束位置索引。
const str = 'ECMAScript_JavaScript'
const regexp = /sc/igd // 忽略大小全局匹配并返回匹配元素的开始、结束位置索引
console.log(regexp.exec(str).indices) // [ 4, 6 ]
console.log(regexp.exec(str).indices) // [ 15, 17 ]根据指定索引获取数组元素,不同的是它支持传递负数,例如 -1 获取最后一个元素。
const arr = ['a', 'b', 'c']
console.log(arr.at(0));
console.log(arr.at(-1)); // 等价于 arr[arr.length - 1]Object.hasOwn() 提供了一种更安全的方法来检查对象是否具有自己的属性,适用于检查所有的对象。Object.prototype.hasOwnProperty() 方法遇到 obj = null这种情况会报错,参见以下示例:
const person = Object.create({ name: 'Tom' })
person.age = 18;
console.log(Object.hasOwn(person, 'name')); // false
console.log(Object.hasOwn(person, 'age')); // true
// 遇到这种情况 hasOwnProperty 会报错
const p1 = null
console.log(p1.hasOwnProperty('name')); // TypeError: Cannot read properties of null (reading 'hasOwnProperty')Error Cause 是由阿里巴巴提出的一个提案,为 Error 构造函数增加了一个 options,可设置 cause 的值为任意一个有效的 JavaScript 值。
例如,自定义错误 message,将错误原因赋给 cause 属性,传递给下一个捕获的地方。
try {
await fetch().catch(err => {
throw new Error('Request failed', { cause: err })
})
} catch (e) {
console.log(e.message);
console.log(e.cause);
}类的静态初始化块是在类中为静态成员提供了一个用于做初始化工作的代码块。
class C {
static x = 'x';
static y;
static z;
static {
try {
const obj = doSomethingWith(this.x);
this.y = obj.y;
this.z = obj.z;
} catch (err) {
this.y = 'y is error';
this.z = 'z is error';
}
}
}replaceAll() 用于替换正则表达式或字符串的所有匹配项,之前的 replace() 只会匹配一个。
console.log('JavaScript'.replaceAll('a', 'b')); // JbvbScriptPromise.any() 接收一个 Promise 数组做为参数,返回第一个执行成功的 Promise,如果全部执行失败将返回一个新的异常类型 AggregateError,错误信息会以对象数组的形式放入其中。
const delay = (value, ms) => new Promise((resolve, reject) => setTimeout(() => resolve(value), ms));
const promises = [
delay('a', 3000),
delay('b', 2000),
delay('c', 4000),
];
Promise.any(promises)
.then(res => console.log(res)) // b
.catch(err => console.error(err.name, err.message, err.errors)) // 全部失败时返回:AggregateError All promises were rejected [ 'a', 'b', 'c' ]数字分隔符可以让大数字看起来也容易理解。
const budget = 1_000_000_000_000;
console.log(budget === 10 ** 12); // true结合了逻辑运算符 &&、||、?? 和逻辑表达式 =。
// "Or Or Equals" (or, the Mallet operator :wink:)
a ||= b; // a || (a = b);
// "And And Equals"
a &&= b; // a && (a = b);
// "QQ Equals"
a ??= b; // a ?? (a = b);能够拿到一个对象的弱引用,而不会阻止该对象被垃圾回收。例如 ref 弱引用了 obj,尽管持有了 obj 对象的引用,但也不会阻止垃圾回收 obj 这个对象,如果是强引用则不行。
参考 https://github.com/tc39/proposal-weakrefs
const obj = { a: 1 };
const ref = new WeakRef(obj)
console.log(ref.deref());String.prototype.matchAll() 会返回正则匹配的所有字符串及其位置,相比于 String.prototype.match() 返回的信息更详细。
const str = 'JavaScript'
const regexp = /a/g
console.log([...str.matchAll(regexp)]);
// Output:
[
[ 'a', index: 1, input: 'JavaScript', groups: undefined ],
[ 'a', index: 3, input: 'JavaScript', groups: undefined ]
]动态导入意思是当你需要该模块时才会进行加载,返回的是一个 Promise 对象。只有在 ES Modules 模块规范下才支持。
// index-a.mjs
export default {
hello () {
console.log(`hello JavaScript`);
}
}
// index-b.mjs
import('./index-a.mjs').then(module => {
module.default.hello(); // hello JavaScript
})import.meta 指当前模块的元数据。一个广泛支持的属性是 import.meta.url,以字符串形式输出当前模块的文件路径。
BigInt 是新增的一种描述数据的类型,用来表示任意大的整数。因为原先的 JavaScript Number 类型能够表示的最大整数位 Math.pow(2, 53) - 1,一旦超出就会出现精度丢失问题。详情可参考笔者之前的这篇文章 JavaScript 浮点数之迷下:大数危机 https://github.com/qufei1993/blog/issues/10。
9007199254740995 // 会出现精度丢失
9007199254740995n // BigInt 表示方式一
BigInt('9007199254740995') // BigInt 表示方式二Promise.allSettled() 会等待所有的 Promise 对象都结束后在返回结果。
const delay = (value, ms, isReject) => new Promise((resolve, reject) => setTimeout(() => isReject ? reject(new Error(value)) : resolve(value), ms));
const promises = [
delay('a', 3000),
delay('b', 2000, true),
];
Promise.allSettled(promises)
.then(res => console.log(res))
// Output:
[
{ status: 'fulfilled', value: 'a' },
{
status: 'rejected',
reason: Error: b
at Timeout._onTimeout (/index.js:1:108)
at listOnTimeout (node:internal/timers:564:17)
at process.processTimers (node:internal/timers:507:7)
}
]JavaScript 可以运行在不同的环境,浏览器为 window、Node.js 为 global。为了能够统一全局环境变量,引入了 globalThis。
window === globalThis // 浏览器环境
global === globalThis // Node.js 环境ECMA-262 规范没有规定 for (a in b) ... 的遍历顺序,部分原因是所有引擎都有自己特殊的实现,现在很难就 for-in 完整顺序规范达成一致,但规范了一些供参考的实现行为,详情参考 this list of interop semantics。
可选链是一个很好的语法,使用 ?. 表示,能避免一些常见类型错误。
const obj = null;
obj.a // TypeError: Cannot read properties of null (reading 'a')
obj?.a // 使用可选链之后就不会报错了,会输出 undefined空值合并语法使用 ?? 表示,和 || 这个语法类似,不同的是 ?? 有明确的规定,只有当左侧的值为 null 或 undefined 时才会返回右侧的值,例如,左侧是 0 也会认为是合法的。
const a = 0
a || 1 // 1
a ?? 1 // 0try {
throw new Error('this is not a valid')
} catch {
console.error(`error...`);
}创建 Symbol 对象时可以传入一个描述做为参数。如下所示,使用 symbol.description 可方便的获取到这个描述。
const symbol = Symbol('Hello World')
symbol.description函数也可以执行 toString() 方法,它会返回定义的函数体代码,包含注释。
const fn = (a, b) => {
// return a + b value
const c = a + b;
return c;
}
console.log(fn.toString()); Object.fromEntries() 方法会把键值对列表转换为对象。同 Object.entries() 相反。
const arr = [ [ 'name', 'foo' ], [ 'age', 18 ] ];
const obj = Object.fromEntries(arr);
console.log(obj); // { name: 'foo', age: 18 }
console.log(Object.entries(obj)); // [ [ 'name', 'foo' ], [ 'age', 18 ] ]ES2019 之前有一个 trim() 方法会默认消除前后空格。新增的 trimStart()、trimEnd() 方法分别用来指定消除前面、后面空格。
' JavaScript '.trim() // 'JavaScript'
' JavaScript '.trimStart() // 'JavaScript '
' JavaScript '.trimEnd() // ' JavaScript'flat(depth) 可以实现数组扁平化,传入的 depth 参数表示需要扁平化的数组层级。
[['a'], ['b', 'bb'], [['c']]].flat(2) // [ 'a', 'b', 'bb', 'c' ]flatMap() 方法是 map() 和 flat() 方法的结合,该方法只能展开一维数组。
[['a'], ['b', 'bb'], [['c']]].flatMap(x => x) // [ 'a', 'b', 'bb', [ 'c' ] ]ES2019 之前 JSON 字符串中不支持 \u2028(行分隔符)、\u2029(段落分隔符) 字符,否则 JSON.parse() 会报错,现在给予了支持。
const json = '"\u2028"';
JSON.parse(json);防止 JSON.stringify 返回格式错误的 Unicode 字符串,参考 https://2ality.com/2019/01/well-formed-stringify.html
异步迭代在 Node.js 中用的会多些,使用 for-await-of 遍历异步数据。例如使用 MongoDB 查询数据返回值默认为一个游标对象,避免了一次性把数据读入应用内存,详情参考 #31。
const userCursor = userCollection.find();
for await (const data of userCursor) { ... }Promise.finally 能保证无论执行成功或失败都一定被执行,可以用来做一些清理工作。
const connection = { open: () => Promise.resolve() }
connection
.open()
.then()
.catch()
.finally(() => {
console.log('clear connection');
})正则命名组捕获使用符号 ?<name> 表示,对匹配到的正则结果按名称访问。
const regexp = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/u;
const result = regexp.exec('2023-01-01');
console.log(result.groups); // { year: '2023', month: '01', day: '01' }Rest 参数语法使用 ... 表示,会将所有未明确的参数表示为一个数组。
const fn = (a, ...rest) => {
console.log(a, rest); // 1 [ 2, 3 ]
}
fn(1, 2, 3);展开操作符(Spread)也使用 ... 表示,将一个数组内容转换为参数传递给函数。
const fn = (a, ...rest) => {
console.log(a, rest); // 1 [ 2, 3 ]
}
fn(...[1, 2, 3]);展开操作符另一个常用的场景是用来做对象的浅拷贝。
const obj = { a: 1 }
const newObj = { ...obj, b: 2 }“Lifting template literal restriction” 翻译过来为 “解除模版字符串限制”,这个要结合 ES6 中的 “带标签的模版字符串” 来理解。
以下代码执行时,解析器会去查找有效的转义序列,例如 Unicode 字符以 "\u" 开头,例如 \u00A9,以下 "\unicode" 是一个非法的 Unicode 字符,在之前就会得到一个 SyntaxError: malformed Unicode character escape sequence 错误。ES2018 中解除了这个限制,当遇到不合法的字符时也会正常执行,得到的是一个 undefined,通过 raw 属性还是可以取到原始字符串。
function latex(strings, ...exps) {
console.log(strings); // [ undefined ]
console.log(strings.raw); // [ 'latex \\unicode' ]
}
latex`latex \unicode`;Object.values() 返回一个对象的所有值,同 Object.keys() 相反。
const obj = { name: 'Tom', age: 18 }
console.log(Object.values(obj)); // [ 'Tom', 18 ]Object.entries() 返回一个对象的键值对。
const obj = { name: 'Tom', age: 18 }
for (const [key, value] of Object.entries(obj)) {
console.log(key, value);
}
// Output
// name Tom
// age 18两个字符串补全方法 .padStart()、.padEnd() 分别在字符串的头部、尾部进行按目标长度和指定字符进行填充。
console.log('a'.padStart(5, '1')); // 1111a
console.log('a'.padEnd(5, '2')); // a2222异步函数 async/await 现在开发必备了,无需多讲。
async function fn() { ... }
try {
await fn();
} catch (err) {} Object.getOwnPropertyDescriptors() 方法用来获取一个对象的所有自身属性的描述符。
const obj = {
name: 'Tom',
run: () => ``,
};
console.log(Object.getOwnPropertyDescriptors(obj));
// {
// name: {
// value: 'Tom',
// writable: true,
// enumerable: true,
// configurable: true
// },
// run: {
// value: [Function: run],
// writable: true,
// enumerable: true,
// configurable: true
// }
// }支持在函数声明及调用时末尾增加逗号而不报 SyntaxError 错误。
function add(a, b,) {
return a + b;
}
add(1, 2,)Shared memory and atomics,“共享内存和原子” 又名 “共享数组缓冲区”,可以在主线程和多个工作线程间共享对象的字节,能更快的在多个工作线程间共享数据、除 postMessage() 多了一种数据传输方式。
多线程间的内存共享会带来一个后端常遇见的问题 “竞态条件”,提案提供了全局变量 Atomics 来解决这个问题。详情参考 ES proposal: Shared memory and atomics
当判断一个数组中是否包含指定值时,使用 includes() 会很实用。
['a', 'b'].includes('a') // true** 是求幂运算符,左侧是基数、右侧是指数。等价于之前的 Math.pow() 函数。
2 ** 3 // 8
Math.pow(2, 3) // 8最后关于 ES2015,也就是常说的 ES6 更新的内容是比较多的,不在这里赘述,推荐一个资料给有需要的朋友 https://es6.ruanyifeng.com/。
对于前端构建工具 Webpack、babel、eslint 等的每一次升级,就像刚刚经历一场地震似得,最不想面对的就是处理各种 API 的不兼容性,有时还会出现一些奇奇怪怪的问题,为什么还要升呢?并不是为了给自己找事,还是要讲究投入产出比的,也就是最终的收益是要大于产出比的。
前段在团队内部对 Webpack v5 带来的一些新特性做一些 Research,相较于一些项目的构建工具版本(Webpack v3)做了一个对比,在构建效率这块是有质的飞跃的,同样相对于 Webpack v4 也是有很大提升的。
本文是本次升级过程中的实践(踩坑)记录,分享一些值得关注的功能、一些重大的改变、遇到的一些 NPM 组建兼容性问题,希望能给予读者朋友一些参考和帮助。
先上一张脑图,涵盖本文主题!
基于一些项目做了一些测试,首次构建相较于之前提速将近 2 倍多,二次构建差不多 2s 左右,效果更显著,修改文件后的增量构建,差不多也在几秒钟可完成,整体构建效率提升还是很明显的,除此之外打包后的文件大小也比之前小了一些,但之间的差距不是特别的大,重点还是构建效率大幅提升。
构建效率上之所以有这么大的性能提升,这与它的基于文件系统的持久化缓存是有很大帮助的,下文会讲解。内部的项目数据就不便再这里展示了,文末提供了一些来自社区的实践,也可以看到一些数据对比。
下面,基于之前 Research 时写的一些 Demo 可以对比下使用了持久化缓存在初次构建、二次无文件改动构建、增量构建三种情况下的效率对比,也可以显著的看到一些效果。
Webpack5 在生产环境下默认使用自带的 TerserPlugin 插件(无需安装)来做代码压缩,这个插件也被认为是在代码压缩方面性能是较好的。无需再借助 UglifyjsPlugin、ParallelUglifyPlugin 这些插件了。
如果你使用的是 webpack4 版本需要手动安装 yarn add terser-webpack-plugin -D 并将插件添加到生产环境的配置文件中。
以下是使用示例,在 Webpack v5 的生产环境默认开启。
const TerserPlugin = require("terser-webpack-plugin");
module.exports = {
optimization: {
minimize: true,
minimizer: [new TerserPlugin()],
},
};支持做一些自定义的配置:文件过滤、并发运行等,详细参见 Webpack 文档 TerserWebpackPlugin。
os.cpus().length - 1。module.exports = {
optimization: {
minimize: true,
minimizer: [
new TerserPlugin({
test: /\.js(\?.*)?$/i,
include: /\/includes/,
exclude: /\/excludes/,
parallel: true
// more ...
}),
],
},
};CSS 压缩之前先做的一项工作是 CSS 和 JS 文件分离,如果是从 Webpack v3 升级到 v5 会遇到一些问题,之前使用的是 extract-text-webpack-plugin 在 webpack v5 会收到废弃提醒,建议使用 **MiniCssExtractPlugin** 这个插件,本插件基于 webpack v4 的新特性(模块类型)构建。
与 extract-text-webpack-plugin 相比,拥有这些特性:异步加载、没有重复的编译(性能提升)、更容易使用、特别针对 CSS 开发。
下面是一个配置,这里还有些优化,生产模式使用 mini-css-extract-plugin 插件分离 JS/CSS 文件实现并行加载,而开发环境选择 style-loader 它可以使用多个标签将 CSS 插入到 DOM 中,并且反应会更快。
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
module: {
rules: [
{
test: /\.css$/i,
use: [
devMode ? 'style-loader' : MiniCssExtractPlugin.loader,
'css-loader'
],
},
],
},
plugins: [new MiniCssExtractPlugin()],
};关于 CSS 分割插件的更详细配置 Webpack 文档 mini-css-extract-plugin。
生产环境我们使用 mini-css-extract-plugin 插件分离 CSS 文件,如果你在 CSS 里引用了图片,可能会遇到为什么打包后 CSS 里引用的图片加载时 404 了?
在 Webpack 的 output 选项中有一个 publicPath 配置,它指定了应用程序中所有资源的基础路径。
module.exports = {
output: {
publicPath: 'auto'
}
}Webpack loader 的 options 选项中也有一个 publicPath 配置,为 CSS 内的图片、文件等外部资源指定一个自定义的公共路径,**默认值为 ****output.publicPath**。如果出现打包后 CSS 内图片 404 的可以检查下这里的配置是否有问题。
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
module: {
rules: [
{
test: /\.css$/i,
use: [
devMode ? 'style-loader' : {
loader: MiniCssExtractPlugin.loader,
options: {
publicPath: '../'
}
},
],
},
],
},
plugins: [new MiniCssExtractPlugin()],
};CSS 压缩之前会使用 optimize-css-assets-webpack-plugin 这个插件,在 webpack v5 之后推荐使用 css-minimizer-webpack-plugin 这个插件。
const CssMinimizerPlugin = require('css-minimizer-webpack-plugin');
module.exports = {
optimization: {
minimizer: [
new CssMinimizerPlugin(),
],
},
};之前通过 cache-loader、babel-loader?cacheDirectory 在配置 cacheDirectory:true 实现将编译结果写入磁盘或者通过 hard-source-webpack-plugin 插件。
Webpack5 自带缓存能力,会缓存生成的 webpack module 和 chunk,对于二次构建有了很大的性能提升。通过 cache 属性配置,分为内存和文件两种缓存方式,默认在生产环境是禁用的,需自行开启。
当在开发环境默认设置为 memory,基于内存的缓存,除了下面的方式配置外,也可通过 cache: true 配置。
module.exports = {
cache: {
type: 'memory'
},
};基于内存的缓存,只有在服务运行中,才有效,每次的单独构建是利用不了缓存的,webpack5 对于缓存另一个比较好的功能是提供了基于文件系统的持久化缓存。
基于文件系统的持久化缓存无论在单独构建或连续构建(可以指热更新操作)中都可应用,首先它会查看内存缓存,如果未命中,则降级到文件系统缓存。
应用很简单,设置 type:filesystem。默认情况下它位于 node_modules/.cache/webpack/ 目录,我们还可以通过 name 属性修改它的名称,例如,我们通过不同的环境 NODE_ENV 来区别不同环境的缓存。
当 type 设置为 filesystem 后,有很多属性是可以配置的,参见 Webpack 文档 cache。
module.exports = {
cache: {
type: 'filesystem',
buildDependencies: {
config: [__filename],
},
name: `${ process.env.NODE_ENV || 'development'}-cache`
}
}基于内存的缓存每一次重新运行都是一次新的构建。需要注意的是持久化缓存,当你修改了文件或传递了一些参数,发现最终展现的效果没有被更改,通常这与持久化缓存的缓存策略相关。
出于性能考虑,缓存会跳过 node_modules 认为这会极大降低 webpack 执行速度,建议是不要手动编辑 node_modules。通常也不会这么干直接去修改 node_modules。
有些操作也会使缓存失效,例如:当 NPM 升级 loader、plugin、更改配置等。
Webpack 提供了 buildDependencies、name、version 三种方式可以使构建缓存失效。
buildDependencies 指定构建过程中受影响的代码依赖,默认为 webpack/lib,当 node_modules 中的 webpack 或其依赖项发生任何变化,当前的缓存即失效。
还有一个是指定的配置文件 config: [__filename] 或配置文件的依赖项发生变化,也会失效。
module.exports = {
cache: {
type: 'filesystem',
buildDependencies: {
defaultWebpack: ["webpack/lib/"],
config: [__filename],
},
name: `${ process.env.NODE_ENV || 'development'}-cache`
}
}如果是把构建工具封装为一个单独的工具包,类似于 react-scripts 这种的,理论上每次升级工具包,就需要重新编译的,之前在一次本地测试时发现工具包升级后缓存没有失效,如果出现这种情况的可以在 cache 里加上 version 配置指向 package.json 里的 version。
module.exports = {
cache: {
type: 'filesystem',
version: `${packageJson.version}`
}
}有时配置文件或者代码没有修改,但是会依赖于命令行传递值想使缓存失效,同样也可在 version 上加上这些命令行传递的值做为版本控制。
module.exports = {
cache: {
type: 'filesystem',
version: `${process.env.CLI_VALUE}`
}
}当 version 依赖于多个值时,可以将多个值做个 md5 生成一串唯一的字符串做为版本也可。
name 属性比较好的是可以保存多个缓存目录,例如通过 process.env.NODE_ENV 区分不同的环境。
module.exports = {
cache: {
type: 'filesystem',
name: `${ process.env.NODE_ENV || 'development'}-cache`
}
}持久化缓存这块也有很多的东西可以讲,详情参见 [译] webpack 5 之持久化缓存。
Webpack 5 新增了长期缓存算法,以确定性的方式为模块和分块分配短的(3 或 5 位)数字 ID,这是包大小和长期缓存之间的一种权衡,生产环境默认开启以下配置。在减小文件打包大小同时也利于浏览器长期缓存(不会因为删除或新增一个模块而导致大量缓存文件失效)。
// production default
module.exports = {
optimization: {
moduleIds: 'deterministic',
chunkIds: 'deterministic'
mangleExports: 'deterministic'
}
}Webpack v4 及之前的 moduleId 默认是自增的,例如 0.xxx.js、1.xxx.css、2.xxx.js 如果更改模块数量(即使内容没有变化),也会导致模块文件重新发生改变,不利于长期缓存。
不同的版本也提供了不同的解决方案,webpack v4 之前使用 HashedModuleIdsPlugin 插件覆盖默认的模块 ID 规则,在 webpack v4 中可以配置 optimization.moduleIds = 'hashed' 解决。这几种方案都是使用模块路径生成的 hash 做为 moduleId。
Webpack v5 生产环境默认 optimization.moduleIds='deterministic' 无需更改。
webpack v4 及之前的 chunkId 默认也是递增的,如果在 entry 配置中新增或删除一个元素,chunkId 也会随着递增或递减。
webpack v4 之前使用 NamedChunksPlugin 插件覆盖默认的 chunkId 规则,在 webpack v4 中可以配置 optimization.chunkIds = 'named' 解决。
Webpack v5 生产环境默认 optimization.chunkIds='deterministic' 无需更改。
另外,当使用 [contenthash] 时,webpack5 将使用真正的文件内容做为哈希值,这个类似于协商缓存 Etag,不一样的是还有一些优化,如果你只是删除了代码中的一些注释或重新命名变量,而这种情况代码逻辑是没有修改的,这些变化在压缩后是不可见的,不会导致 [contenthash] 也发生变化。
如果是从 webpack v3 升级到 v5 的,HashedModuleIdsPlugin、NamedChunksPlugin 这些插件是可以去掉的,webpack v5 环境默认开启新的算法,无需再配置。
参考文档 Webpack release 日志记录 — 重大变更:长期缓存。
Webpack v5 内置了资源模块(assert),用来处理资源文件(图片、字体等),在之前是通过配置额外的 loader,例如 raw-loader、file-loader、url-loader 实现的。
下面是一段 webpack v4 及之前版本的资源文件处理配置,当匹配的文件大小如果小于 limit 限制,将其处理成 data URI 内联到 bundle 中,否则生成文件(使用 file-loader)输出到目录中,url-loader 内置了 file-loader 对文件的处理。
{
test: /\.(jpe?g|png|gif|svg)$/,
use: [
{
loader: 'url-loader',
options: {
limit: 1024 * 10
}
}
]
},Webpack v5 不再需要安装 url-loader 处理资源文件,内置了资源模块类型,通过 type 定义,用来替换之前需要额外配置 loader 的方式。
Rule.parser.dataUrlCondition.maxSize 自动的在 asset/resource、asset/inline 之间做选择,小于该大小指定的文件视为 inline 模块类型,否则视为 resource 模块类型。下面是一个示例,大于 4kb 的输出到目录 static 中。
{
test: /\.(png|jpe?g|gif|svg|eot|ttf|woff|woff2)$/i,
type: "asset",
parser: {
dataUrlCondition: {
maxSize: 4 * 1024 // 4kb
}
},
generator: {
filename: 'static/[hash][ext][query]'
}
},参考文档 Webpack 文档 Assert module。
tree-shaking 是一个术语,翻译为中文为 “树摇”,想想一下一颗长满果子的树木,其中有些已经熟透了,当摇晃树木时是不是一部分会被摇掉。
图片来源:https://cdn.pixabay.com/photo/2019/05/16/23/39/apple-tree-4208594_1280.jpg
对于我们代码层面来说,那些上下文未引用的 JavaScript 代码,也可以通过工具移除(“摇掉”),实现打包体积的优化。
在这种情况下,可以删除未使用的变量 b,生产环境默认开启。
// inner.js
export const a = 1;
export const b = 2;
// module.js
export * as inner from './inner';
// user.js
import * as module from './module';
console.log(module.inner.a);Webpack v5 还增加了模块导出和引用之间的依赖关系分析,通过配置 optimization.innerGraph 控制,生产环境默认开启。
以下示例,something 只有在使用 test 导出时才会使用。
import { something } from './something';
function usingSomething() {
return something;
}
export function test() {
return usingSomething();
}新增 CommonJS 模块的导出和引用之间的依赖分析,下例,可以删除未使用的变量 b。
// inner.js
exports.a = 1;
exports.b = 2;
// module.js
exports.inner = require('./inner');
// user.js
const module = require('./module');
console.log(module.inner.a);之前在团队内部,基于 webpack 这些构建工具封装了适合团队内部的构建工具模块,是通过 API 调用的,有些问题还是要注意下。
调用 webpack() 创建一个 compiler 实例,之后调用 run() 方法执行,需要注意的是在完成之后记得关闭 compiler,这样低优先级的工作(比如持久缓存)就有机会完成,否则,有时候会发现每次都是重新构建没有利用上缓存。
下例中的 stats 参数可以获取到代码编译过程产生的错误和警告、计时信息、module 和 chunk 信息,如果想达到 cli 环境下的日志输出格式,调用 stats.toString() 方法即可。
const compiler = webpack(config);
return new Promise((resolve, reject) => {
compiler.run((err, stats) => {
if (err) {
return reject(err);
}
console.log(stats.toString({
chunks: false,
colors: true
}));
compiler.close(closeErr => {
if (closeErr) {
console.log(chalk.red(`compiler close failed with message ${closeErr.message}`));
}
});
return resolve(stats);
});
});与生产环境 API 调用不同,开发环境我们需要热更新,在创建一个 compiler 后需要调用 webpack-dev-server 插件。
还有个问题是 devServer 中的配置选项将被忽略,但可以将配置选项作为第二个参数传入。
const compiler = webpack(config);
const devServerOptions = Object.assign({}, config.devServer, {
port: port,
host: DEFAULT_HOST,
open: true,
});
const server = new WebpackDevServer(compiler, devServerOptions);
server.listen(port, DEFAULT_HOST);参考文档 Webpack 文档 Node.js API 接口。
从 webpack 5 开始,使用 Web Workers 代替 worker-loader,这种语法也是为了实现不使用 bundler 就可以运行代码。
Web Worker 是解决一些密集型的任务,例如一些加解密、图片处理等一些耗时的计算任务可以放置于工作线程处理,处理完毕在通知到主线程,在处理的过程不会影响用户在界面上的一些其它操作。
// index.js
const worker = new Worker(new URL('./worker-calculate.js', import.meta.url));
worker.postMessage({
question:
'The Answer to the Ultimate Question of Life, The Universe, and Everything.',
});
worker.onmessage = ({ data: { answer } }) => {
console.log(answer);
};
// worker-calculate.js
self.onmessage = ({ data: { question } }) => {
self.postMessage({
answer: 42,
});
};Web Workers 可以在浏览器中的原生 ECMAScript 模块中使用,也可以用于 Node.js 中,如果采用 ESM 模块规范,Node.js 需要 >= 12.17.0。
import { Worker } from 'worker_threads';
new Worker(new URL('./worker.js', import.meta.url));Node.js 通过 worker_threads 模块提供支持,在 Node.js 中如果你使用 CommonJS 规范在 v10.0.5 版本就已经支持了。
const { Worker } = require('worker_threads');更多详情参考 webpack 文档 Web Workers。
如果是从 webpack v3.x 升级的,会发现之前的热更新方式会报如下错误。
Error: Cannot find module 'webpack/bin/config-yargs'
Webpack v5 使用 webpack serve 启动开发环境,解决这个问题就是重新安装 webpack-cli、还有 webpack-dev-server 也是需要安装的。
// For webpack-cli 3.x:
"scripts": { "start:dev": "webpack-dev-server" }
// For webpack-cli 4.x:
"scripts": { "start:dev": "webpack serve" }问题参考 cannot-find-module-webpack-bin-config-yargs。
可能会遇到以下错误:
TypeError: compiler.plugin is not a function
at InterpolateHtmlPlugin.apply (/Users/qufei/Documents/code/f-designer-tool-webpack5-test/node_modules/react-dev-utils/InterpolateHtmlPlugin.js:25:14)
单独安装插件 yarn add -D interpolate-html-plugin 替换 InterpolateHtmlPlugin = require('react-dev-utils/interpolate-html-plugin'); 为 const InterpolateHtmlPlugin = require('interpolate-html-plugin');
最后确保 InterpolateHtmlPlugin 出现在插件列表中的 HtmlWebpackPlugin 之后。
当开启 HMR 的时候使用该插件会显示模块的相对路径,该插件已废弃,在 Webpack4 中建议设置为 optimization.namedModules,但是在 Webpack5 也被废弃,如果需要请改为 optimization.moduleIds: 'named',在 Webpack5 中的建议是 “请考虑将 optimization.moduleIds 和 optimization.chunkIds 从你 webpack 配置中移除。使用默认值会更合适,因为它们会在 production 模式 下支持长效缓存且可以在 development 模式下进行调试。” 参见 https://webpack.docschina.org/migrate/5/#clean-up-configuration
Webpack5 移除了 Node.js 模块的 Polyfills,更专注于前端模块兼容。认为这会在构建时给 bundle 附加庞大的 Polyfills,大部分情况下也并非必须的,如果你的模块或你安装的第三方模块引用了 cypto、process 这些模块,就会看到报错。
process is not a function
xxx is not a function
参考 automatic-nodejs-polyfills-removed,对于 webpack v5,可以从 webpack.config.js 的相应插件部分引用 process/browser。
参考 webpack-bundle-js-uncaught-referenceerror-process-is-not-defined。
const webpack = require('webpack')
module.exports = {
plugins: [
// fix "process is not defined" error:
// (do "npm install process" before running the build)
new webpack.ProvidePlugin({
process: 'process/browser',
}),
]
}new WatchMissingNodeModulesPlugin(),
// 运行之后报错
// TypeError: compiler.plugin is not a function
// at WatchMissingNodeModulesPlugin.apply (/Users/xxx/node_modules/react-dev-utils/WatchMissingNodeModulesPlugin.js:20:14)这个错误是在 Webpack 4 upgrade PR,升级 react-dev-utils yarn add react-dev-utils -D。
之前在使用 eslint 代码检查时,如果有用到 eslint 不支持的试验性特性时会需要用到 babel-eslint,但是这个项目已经废弃了,到官网会看到这样一句话:
babel-eslint is now @babel/eslint-parser. This package will no longer receive updates.
现在推荐使用 @babel/eslint-parser 代替。
experiments.topLevelAwait 配置支持,这对于文件头部初始化资源很有用,无需让 await 必须在 async 里面。参考 Webpack v5 配置#experiments。experiments.syncWebAssembly 配置即可,这个功能也属于试验性支持。👨🎓:使用了 React,你可能不需要 Redux,但你需要了解它!
👩🎓:既然不需要,为什么需要了解?
👨🎓:不了解你怎么知道不需要呢?
👩🎓:这话没毛病,学它!
Redux 是一个可预测的状态管理容器,也是 react 中最流行的一个状态管理工具,无论是工作或面试只要你使用了 react 都需要掌握它。核心理念是在全局维护了一个状态,称为 store,为应用系统提供了全局状态管理的能力,使得跨组件通信变得更简单。
Redux 抽象程度很高,关注的是 “哲学设计”,开发者最关心的是 “如何实现”,做为初学者尽管看了官网 API 介绍但面对实际项目时还是发现无从入手,特别是面对一些新名词 store、state、action、dispatch、reducer、middlwware 时,有些小伙伴表示我就认识 state...
本篇在介绍一些 Redux 的概念后会重构上一节 useReducer + useContext 实现的 Todos,介绍如何在 React 中应用 Redux,从实践中学习。
Redux 通过一系列规范约定来约束应用程序如何根据 action 来更新 store 中的状态,下图展示了 Redux 数据流转过程,也是 Redux 的主要组成部分:
图片来源:redux application data flow
在 reducer 纯函数中不允许直接修改 state 对象,每次都应返回一个新的 state。原生 JavaScript 中我们要时刻记得使用 ES6 的扩展符 ... 或 Object.assign() 函数创建一个新 state,但是仍然是一个浅 copy,遇到复杂的数据结构我们还需要做深拷贝返回一个新的状态,总之你要保证每次都返回一个新对象,一方面深拷贝会造成性能损耗、另一方面难免会忘记从而直接修改原来的 state。
Immutable 数据一旦创建,对该数据的增、删、改操作都会返回一个新的 immutable 对象,保证了旧数据可用同时不可变。
Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。参考 Immutable 详解及 React 中实践
请看下面动画:
在本文中整个 redux store 状态树都采用的是 Immutable 数据对象,同时使用时也应避免与普通的 JavaScript 对象混合使用,从下面例子中可以学习到一些常用的 API 使用,更详细的介绍参考官网文档 immutable-js.com/docs。
React + Redux 项目的组织结构,在第一次写项目时也犯了困惑,你如果在社区中搜索会发现很多种声音,例如,按类型划分(类似于 MVC 这样按不同的角色划分)、页面功能划分、Ducks(将 actionTypes、actionCreators、reducer 放在一个文件里),这里每一种的区别也可以单独写篇文章讨论了,本节采用的方式是按页面功能划分,也是笔者刚开始写 React + Redux 时的一种目录组织方式。没有最佳的方式,选择适合于你的方式。
按照一个页面功能对应一个文件夹划分,pages/todos 文件夹负责待办事项功能,如果页面复杂可在页面组件内创建一个 pages/todos/components 文件夹,redux 相关的 action、reducer 等放在 page/todos/store 文件夹中。
src/
├── App.css
├── App.js
├── index.css
├── index.js
├── components
├── pages
│ └── todos
│ ├── components
│ │ ├── Todo.jsx
│ │ └── TodoAdd.jsx
│ ├── index.jsx
│ └── store
│ ├── actionCreators.js
│ ├── constants.js
│ ├── index.js
│ └── reducer.js
├── reducers
│ └── todos-reducer.js
├── routes
│ └── index.js
└── store
├── index.js
└── reducer.jsView 层我们定义为 “展示组件”,负责 UI 渲染,至于渲染时用到的数据如何获取交由后面的容器组件负责。以下 Todo、TodoAdd、Todos 三个组件中使用到的数据都是从 props 属性获取,后面容器组件链接 React 与 Redux 时会再讲。
组件位置src/pages/todos/components/Todo.jsx
import { useState } from "react";
/**
* Todo component
* @param {Number} props.todo.id
* @param {String} props.todo.content
* @param {Function} props.editTodo
* @param {Function} props.removeTodo
* @returns
*/
const Todo = ({ todo, editTodo, removeTodo }) => {
console.log('Todo render');
const [isEdit, setIsEdit] = useState(false);
const [content, setContent] = useState(todo.get('content'));
return <div className="todo-list-item">
{
!isEdit ? <>
<div className="todo-list-item-content">{todo.get('content')}</div>
<button className="btn" onClick={() => setIsEdit(true)}> 编辑 </button>
<button className="btn" onClick={() => removeTodo(todo.get('id'))}> 删除 </button>
</> : <>
<div className="todo-list-item-content">
<input className="input" value={content} type="text" onChange={ e => setContent(e.target.value) } />
</div>
<button className="btn" onClick={() => {
setIsEdit(false);
editTodo(todo.get('id'), content);
}}> 更新 </button>
<button className="btn" onClick={() => setIsEdit(false)}> 取消 </button>
</>
}
</div>
}
export default Todo;组件位置src/pages/todos/components/TodoAdd.jsx
import { useState } from "react";
import { actionCreators } from '../store';
/**
* Add todo component
* @param {Function} props.addTodo
* @returns
*/
const TodoAdd = ({ addTodo }) => {
console.log('TodoAdd render');
const [content, setContent] = useState('');
return <div className="todo-add">
<input className="input" type="text" onChange={e => setContent(e.target.value)} />
<button className="btn btn-lg" onClick={() => addTodo(content)}>
添加
</button>
</div>
};
export default TodoAdd;组件位置src/pages/todos/index.jsx。
import { useEffect } from "react";
import { actionCreators } from './store';
import Todo from './components/Todo';
import TodoAdd from './components/TodoAdd';
/**
* Todos component
* @param {Number} todos[].id
* @param {String} todos[].content
* @param {Function} getTodos
* @returns
*/
const Todos = ({ todos, getTodos }) => {
console.log('Todos render');
useEffect(() => {
getTodos();
}, []); // eslint-disable-line react-hooks/exhaustive-deps
return <div className="todos">
<h2 className="todos-title"> Todos App </h2>
<p className="todos-desc"> React + Redux 实现 todos </p>
<TodoAdd />
<div className="todo-list">
{
todos.map(todo => <Todo key={todo.get('id')} todo={todo} />)
}
</div>
</div>
}
export default Todos;一个 React + Redux 的应用程序中只有一个 store,是应用程序的唯一数据源,类似于在我们应用中抽象出一个状态树,与组件一一关联。这也是一种集中式管理应用状态的方式,也是和 React hooks 提供的 useState/useReducer 一个重大区别之处。
通过 redux 的 createStore() 方法创建 store,支持预设一些初始化状态。
代码位置src/store/index.js。
import { createStore, compose } from 'redux';
import reducer from './reducer';
const store = createStore(reducer, /* preloadedState, */);
export default store;当应用复杂时我们通常会拆分出多个子 reducer 函数,每个 reducer 处理自己负责的 state 数据。例如,按页面功能划分项目结构,每个页面/公共组件都可以维护自己的 reducer。
有了拆分,对应还有组合,redux 为我们提供了 combineReducers 函数用于合并多个 reducer。因为我们的 state 是一个 Immutable 对象,而 redux 提供的 combineReducers 只支持原生 JavaScript 对象,不能操作 Immutable 对象,我们还需要借助另外一个中间件 **redux-immutable** 从 state 取出 Immutable 对象。
可以为 reducer 函数指定不同的 key 值,这个 key 值在组件从 store 获取 state 时会用到,下文 “容器组件链接 React 与 Redux” 中会使用到。
代码位置src/store/reducer.js。
import { combineReducers } from 'redux-immutable';
import { reducer as todosReducer } from '../pages/todos/store';
import { reducer as otherComponentReducer } from '../pages/other-component/store';
const reducer = combineReducers({
todosPage: todosReducer,
otherComonpent: otherComponentReducer, // 其它组件的 reducer 函数,在这里依次写
});
export default reducer;代码位置:src/pages/todos/store/index.js。
import * as constants from './constants';
import * as actionCreators from './actionCreators';
import reducer from './reducer';
export {
reducer,
constants,
actionCreators,
};代码位置:src/pages/todos/store/constants.js。
export const TODO_LIST = 'todos/TODO_LIST';
export const TODO_LIST_ADD = 'todos/TODO_LIST_ADD';
export const TODO_LIST_EDIT = 'todos/TODO_LIST_EDIT';
export const TODO_LIST_REMOVE = 'todos/TODO_LIST_REMOVE';action 是 store 唯一的信息来源,action 的数据结构要能清晰描述实际业务场景,通常 type 属性是必须的,描述类型。我的习惯是放一个 payload 对象,描述类型对应的数据内容。
一般会通过 action creator 创建一个 action。例如,以下为一个获取待办事项列表的 action creator,这种写法是同步的。
function getTodos() {
return {
type: 'TODO_LIST',
payload: {}
}
}在实际的业务中,异步操作是必不可少的,而 store.dispatch 方法只能处理普通的 JavaScript 对象,如果返回一个异步 function 代码就会报错。通常需要结合 redux-thunk 中间件使用,实现思路是** action creator 返回的异步函数先经过 redux-thunk 处理,当真正的请求响应后,在发送一个 dispatch(action) 此时的 action 就是一个普通的 JavaScript 对象了**。
Redux 的中间件概念与 Node.js 的 Web 框架 Express 类似,通用的逻辑可以抽象出来做为一个中间件,一个请求先经过中间件处理后 -> 到达业务处理逻辑 -> 业务逻辑响应之后 -> 响应再到中间件。redux 里的 action 好比 Web 框架收到的请求。
代码位置:src/store/index.js。修改 store 文件,引入中间件使得 action 支持异步操作。
import { createStore, compose, applyMiddleware } from 'redux'; // 导入 compose、applyMiddleware
import chunk from 'redux-thunk'; // 导入 redux-thunk 包
import reducer from './reducer';
const store = createStore(reducer, /* preloadedState, */ compose(
applyMiddleware(chunk),
));
export default store;创建本次 todos 需要的 action creator,实际业务中增、删、改、查我们会调用服务端的接口查询或修改数据,为了模拟异步,我们简单点使用 Promise 模拟异步操作。
代码位置:src/pages/todos/store/actionCreators.js。
import { TODO_LIST, TODO_LIST_ADD, TODO_LIST_REMOVE, TODO_LIST_EDIT } from './constants';
const randomID = () => Math.floor(Math.random() * 10000);
// 获取待办事项列表
export const getTodos = () => async dispatch => {
// 模拟 API 异步获取数据
const todos = await Promise.resolve([
{
id: randomID(),
content: '学习 React',
},
{
id: randomID(),
content: '学习 Node.js',
}
]);
const action = {
type: TODO_LIST,
payload: {
todos
}
};
dispatch(action);
}
// 添加待办事项
export const addTodo = (content) => async dispatch => {
const result = await Promise.resolve({
id: randomID(),
content,
});
const action = {
type: TODO_LIST_ADD,
payload: result
};
dispatch(action);
}
// 编辑待办事项
export const editTodo = (id, content) => async dispatch => {
const result = await Promise.resolve({ id, content });
const action = {
type: TODO_LIST_EDIT,
payload: result,
};
dispatch(action);
}
// 移除待办事项
export const removeTodo = id => async dispatch => {
const result = await Promise.resolve({ id });
const action = {
type: TODO_LIST_REMOVE,
payload: result,
};
dispatch(action);
}reducer 根据 action 的响应决定怎么去修改 store 中的 state。编写 reducer 函数没那么复杂,倒要切记该函数始终为一个纯函数,应避免直接修改 state。reducer 纯函数要保证以下两点:
(previousState, action) => newState。需要注意一点是在第一次调用时 state 为 undefined,这时需使用 initialState 初始化 state。
代码位置:src/pages/todos/store/reducer.js。
import { fromJS } from 'immutable';
import { TODO_LIST, TODO_LIST_ADD, TODO_LIST_REMOVE, TODO_LIST_EDIT } from './constants';
export const initialState = fromJS({
todos: [],
});
const reducer = (state = initialState, action = {}) => {
switch (action.type) {
case TODO_LIST: {
return state.merge({
todos: state.get('todos').concat(fromJS(action.payload.todos)),
});
}
case TODO_LIST_ADD: {
return state.set('todos', state.get('todos').push(fromJS({
id: action.payload.id,
content: action.payload.content,
})));
}
case TODO_LIST_EDIT: {
return state.merge({
todos: state.get('todos').map(item => {
if (item.get('id') === action.payload.id) {
const newItem = { ...item.toJS(), content: action.payload.content };
return fromJS(newItem);
}
return item;
})
})
}
case TODO_LIST_REMOVE: {
return state.merge({
todos: state.get('todos').filter(item => item.get('id') !== action.payload.id),
})
}
default: return state;
}
};
export default reducer;Redux 做为一个状态管理容器,本身并没有与任何 View 层框架绑定,当在 React 框架中使用 Redux 时需安装 react-redux npm i react-redux -S 库。
react-redux 提供的 connect 函数,可以把 React 组件和 Redux 的 store 链接起来生成一个新的容器组件(这里有个经典的设计模式 “高阶组件”),数据如何获取就是容器组件需要负责的事情,在获取到数据后通过 props 属性传递到展示组件,当展示组件需要变更状态时调用容器组件提供的方法同步这些状态变化。
总结下来,容器组件需要做两件事:
// 创建容器组件代码示例
import { connect } from 'react-redux';
import ExampleComponent from './ExampleComponent'
const mapStateToProps = (state) => ({ // 从全局状态取出数据映射到展示组件的 props
todos: state.getIn(['todosComponent', 'todos']),
});
const mapDispatchToProps = (dispatch) => ({ // 把展示组件变更状态需要用到的方法映射到展示组件的 props 上。
getTodos() {
dispatch(actionCreators.getTodos());
},
});
export default connect(mapStateToProps, mapDispatchToProps)(ExampleComponent);上例,当 redux store 中的 state 变化时,对应的 mapStateToProps 函数会被执行,如果 mapStateToProps 函数新返回的对象与之前对象浅比较相等(此时,如果是类组件可以理解为 shouldComponentUpdate 方法返回 false),展示组件就不会重新渲染,否则重新渲染展示组件。
展示组件与容器组件之间的关系可以自由组合,可以单独创建一个 container 文件,来包含多个展示组件,同样也可以在展示组件里包含容器组件。在我们的示例中,也比较简单是在展示组件里返回一个容器组件,下面开始修改我们展示组件。
组件位置src/pages/todos/components/Todo.jsx。
在我们的 Todo 组件中,参数 todo 是由上层的 Todos 组件传递的这里并不需要从 Redux 的 store 中获取 state,只需要修改状态的函数就可以了,connect() 函数第一个参数 state 可以省略,这样 state 的更新也就不会引起该组件的重新渲染了。
import { connect } from 'react-redux';
const Todo = ({ todo, editTodo, removeTodo }) => {...} // 中间代码省略
const mapDispatchToProps = (dispatch) => ({
editTodo(id, content) {
dispatch(actionCreators.editTodo(id, content));
},
removeTodo(id) {
dispatch(actionCreators.removeTodo(id));
}
});
export default connect(null, mapDispatchToProps)(Todo);组件位置src/pages/todos/components/TodoAdd.jsx。
import { connect } from 'react-redux';
const TodoAdd = ({ addTodo }) => {...}; // 中间代码省略
const mapDispatchToProps = (dispatch) => ({
addTodo(content) {
dispatch(actionCreators.addTodo(content));
},
});
export default connect(null, mapDispatchToProps)(TodoAdd);组件位置src/pages/todos/components/Todos.jsx。
import { connect } from 'react-redux';
const Todos = ({ todos, getTodos }) => { ... } // 中间代码省略
const mapStateToProps = (state) => ({
todos: state.getIn(['todosPage', 'todos']),
});
const mapDispatchToProps = (dispatch) => ({
getTodos() {
dispatch(actionCreators.getTodos());
},
});
export default connect(mapStateToProps, mapDispatchToProps)(Todos);有了 Page 相应的也有路由,创建 MyRoutes 组件,代码位置 src/routes/index.js。
import {
BrowserRouter, Routes, Route
} from 'react-router-dom';
import Todos from '../pages/todos';
const MyRoutes = () => {
return (
<BrowserRouter>
<Routes>
<Route path="/todos" element={<Todos />} />
</Routes>
</BrowserRouter>
);
};
export default MyRoutes;通过 react-redux 的 connect 函数创建的容器组件可以获取 redux store,那么有没有想过容器组件又是如何获取的 redux store?
在 React 状态管理 - Context 一篇中介绍过,使用 React.createContext() 方法创建一个上下文(MyContext),之后通过 MyContext 提供的 Provider 组件可以传递 value 属性供子组件使用。react-redux 也提供了一个 Provider 组件,正是通过 context 传递 store 供子组件使用,所以我们使用 redux 时,一般会把 Provider 组件做为根组件,这样被 Provider 根组件包裹的所有子组件都可以获取到 store 中的存储的状态。
创建 App.js 组件,组件位置:src/app.js。
import { Provider } from 'react-redux';
import store from './store';
import Routers from './routes';
const App = () => (
<Provider store={store}>
<Routers />
</Provider>
);
export default App;介绍一个在开发过程中调试 Redux 应用的一款浏览器插件 Redux DevTools extension,可以实时显示当前应用的 action 触发、state 变更记录。
该插件目前支持 Chrome 浏览器、Firefox 浏览器、Electron,安装方法参考 redux-devtools-extension installation。
代码位置src/store/index.js。 修改 store 文件,在非生产环境优先使用调试插件提供的 compose 函数。
const composeEnhancers = (
process.env.NODE_ENV !== 'production' &&
typeof window !== 'undefined' &&
window.__REDUX_DEVTOOLS_EXTENSION_COMPOSE__
) || compose;
const store = createStore(reducer, /* preloadedState, */ composeEnhancers(
applyMiddleware(chunk),
));如下所示,每次 action 触发及修改的状态都可以记录到。
上一节 React 状态管理 - useState/useReducer + useContext 实现全局状态管理 提出了 Context 一旦某个属性发生变化,依赖于该上下文的组件同样也会重新渲染。Redux 内部对应用性能是做了优化的,当组件的数据没有发生变化时是不会重新渲染的。
在写 Redux 过程中,你会体会到它关注的 “哲学问题”,有一套自己的流程,你需要理解什么是唯一数据源、不可变、函数式编程**。
为了保持保持应用的状态为只读原则,无论何时我们都不能直接修改应用状态,必须先发送一个 action 描述修改行为,由 store 交给 reducer 纯函数修改应用的状态。
有时一个简单的修改行为,就需要编写 actionCreator、reducer 等 “样板代码”,站在开发者 “如何简单使用” 角度,会感觉过于繁琐。但是,这一看似繁琐的修改流程也正是 Redux 状态管理流程中的核心概念。在大型复杂项目的应用状态管理中,一个流程清晰、职责范围明确的数据层框架会使应用代码变的思路清晰、易于测试、团队协作。每个状态管理框架都有其优缺点,利于弊,看你怎么看待了。
在 Redux 基础之上又衍生了 redux-toolbox 来优化项目的状态管理,解决了一些 Redux 的配置复杂、样板代码太多、需要添加多个依赖包等问题,具体怎么样呢?关注 “编程界” 下一讲介绍。
Generator 是 ES6 对协程的实现,提供了一种异步编程的解决方案,和 Promise 一样都是线性的模式,相比 Promise 在复杂的业务场景下避免了 .then().then() 这样的代码冗余。
曾经一直认为 Generator 是一种过渡的解决方案,并没有过多的去了解它,后来在一些项目中还会看到它的身影,基于它还可以做很多有意思的事情,在不了解的情况下,你无法准确预知它的一些行为能够导致什么问题。
例如,Node.js 的可读流对象在 v10.0.0 版本已试验性的支持了异步迭代器,当监听来自可读流的数据时无需在基于事件和回调的方式 on('data', callback),可以方便的使用 for...await...of 异步迭代,看过源码会发现在它的内部实现中是用的异步生成器函数来生成的异步迭代器。还有目前的 Async/Await 是一种更好的异步解决方案,在下一节我们会讲,本质上还是基于 Generator 的语法糖。
如果想更好的理解 JavaScript 的异步编程,学习下 Generator 是没错的~
形式上 Generator 函数与普通函数没太大区别,两个特点:一是 function 关键字与函数名之间使用 * 号表达,二是内部使用使用 yield 表达式。
function *test() {
yield 'A';
yield 'B';
yield 'C';
}如果是普通函数,当 test() 后函数会立即执行,而生成器函数调用后函数不会立即执行,会给我们返回一个迭代器对象。
调用 next() 从函数头部或上一次暂停的地方执行,直到遇到下一个 yield 表达式暂停或 return 终止,当遇到 yield 表达式暂停后,想要继续执行下去,需接着调用 next() 恢复执行。
next() 返回 yield 表达式值,当 done 为 true 时迭代完成。
const gen = test();
gen.next() // { value: 'A', done: false }
gen.next() // { value: 'B', done: false }
gen.next() // { value: 'C', done: false }
gen.next() // { value: undefined, done: false }使用 return() 方法返回给定的值,可以强行终止,即使生成器还没有运行完毕。
const gen = test();
gen.next() // { value: 'A', done: false }
gen.next() // { value: 'B', done: false }
gen.return('termination'); // { value: 'termination', done: true }
gen.next() // { value: undefined, done: true }gen.return() 相当于将 yield 语句替换为了 return 表达式 **yield 'B' 相当于 return 'termination'**。
生成器函数返回的迭代器对象还有一个 throw() 方法,在函数体外抛出错误,在函数体内捕获。需要注意 throw() 方法抛出的错误要被内部捕获,必须至少执行过一次 next() 方法。
function *test() {
yield 'A';
try {
yield 'B';
} catch (err) {
console.error('内部错误', err); // 内部错误 unknown mistake
}
yield 'C';
}
const gen = test();
gen.next()
gen.next() // { value: 'B', done: false }
gen.throw('unknown mistake')
console.log(gen.next()); // { value: undefined, done: true }gen.throw() 相当于将 yield 语句替换为了 throw 表达式 **yield 'B' 相当于 throw 'unknown mistake'**。
yield 表达式本身自己没有值,返回 undefined,可以通过 next() 方法将上一个 yield 表达式的值做为参数传入。
下面我们将上面示例改下每一个 yiled 依赖前一个 yield 表达式的返回值。
function *test() {
const res1 = yield 'A';
const res2 = yield res1 + 'B';
const res3 = yield res2 + 'C';
return res3;
}如果按照上面 gen.next() 不传入参数,结果只会拿到 undefined。
以下第一次调用 gen2.next() 拿到返回值为 A,第二次调用 next() 时传入第一次的返回值,test() 函数内部 res1 就可取到第一次 yield 表达式的值,后面执行一样。
因为 next() 传入的是第一次 yield 表达式的返回值,所以第一次在调用 next() 方法时无需传入参数。
const gen2 = test();
const res1 = gen2.next(); // { value: 'A', done: false }
const res2 = gen2.next(res1.value) // { value: 'AB', done: false }
const res3 = gen2.next(res2.value) // { value: 'ABC', done: false }
const res = gen2.next(res3.value); // { value: 'ABC', done: true }
console.log(res);gen.next 相当于将 yield 语句替换为了一个表达式值,例如 gen.next('A') 可以这样理解 const res2 = yield res1 + 'B'** 相当于 **const res2 = 'A' + 'B'。
迭代器是通过 next() 方法实现可迭代协议的任何一个对象,该方法返回 value 和 done 两个属性,其中 value 属性是当前成员的值,done 属性表示遍历是否结束。
生成器函数在最初调用时会返回一种称为 Generator 的迭代器,这样可以通过 for...of 遍历。
function *test() {
yield 'A';
yield 'B';
yield 'C';
return 'D';
}
const gen = test();
for (const item of gen) {
console.log(item); // A B C
}有个点需要注意下,for...of 只遍历到最后一个 yield 关键字,最后一个 return 'D' 忽略掉了,如果使用 next() 是会处理 return 语句的。
Generator 用于实现状态机还是比较简单的,也是 JavaScript 里面高级的用法。例如,我们使用 A、B、C 三种状态去描述一个事物,状态之间是一种有序循环的,总是 A-B-C-A-B... 永远跑不出第 4 种状态。
const state = function* (){
while(1){
yield 'A';
yield 'B';
yield 'C';
}
}
const status = state();
setInterval(() => {
console.log(status.next().value) // A B C A B C A B...
}, 1000)
在 Promise 小节中我们基于 Promise 做了一次改造,你可以回头去看下,下面我们使用 Generator 改造后看下差别是什么?
下例,去掉 yield 关键字和我们使用正常的普通函数没什么区别,为了使 Generator 迭代器对象能够自动执行,还要借助外部模块 co 实现。
co(function *() {
const files = yield fs.readdir(rootDir);
for (const filname of files) {
const file = path.resolve(rootDir, filname);
const stats = yield fs.lstat(file);
if (stats.isFile()) {
const chunk = yield fs.readFile(file);
console.log(chunk.toString());
}
}
});生成器是一个强大的通用控制结构,不像普通函数那样调用之后就直接运行到结束,在程序运行过程中当遇到 yield 关键字它可以使其保持暂停状态,直到将来某个时间点继续恢复执行。
在 ES6 中它的最大价值就是管理我们的异步代码,但是还不是很完美,我们不得不借助类似与 co 这样的工具来使我们的生成器函数自动调用 next() 方法运行。不过,在 ES7 到来之后,这一切都过去了,通过 Async/Await 可以更好的管理我们的异步任务。
在一些优秀的开源框架,如 Angular、Nest.js、Midway 中会看到一种常见的写法 @符号 + 方法名,做为一个只有 JavaScript 经验的开发者第一次看到这种写法还是感觉挺新奇的。
一个 @符号开头 + 方法名,这种写法正是 JavaScript 中的装饰器 Decorators,它附加在我们定义的类、类方法、类字段、类访问器、类自动访问器上,在不改变原对象基础上,为我们的程序增强一些功能,例如逻辑复用、代码解耦。
如下所示 @executionTime 是我们实现的装饰器函数,它会记录被修饰方法的执行耗时,下文中我们会进行详细的介绍。
class Person {
@executionTime
run() {}
}关于 JavaScript 装饰器,已经提案很多年了,尽管提案还未进入最后阶段,得益于 TypeScript 和 babel,我们可以在一些框架中提前使用到该技术。 先了解下装饰器的最新动态,及在 TypeScript、babel 中的支持程度。
一个好消息是 2022-03 JavaScript 装饰器提案终于进入到 stage 3 了,这已经是到了候选阶段了,该阶段会接收使用者的反馈并对提案完善,离最终的 stage 4 最近的一个阶段了。查看进入到 TC39 提案的一些语法,参考这里阅读更多 ECMAScript proposals。
一个提案进入到 stage 3 之后,TypeScript 就会去实现它。装饰器是一个特殊的存在,目前 TypeScript 中的装饰器实现还是基于第一版装饰器的提案(这在早期对 TypeScript 也是一个卖点了),和现在 stage 3 中的提案存在很大的差别。
做为用户可能会担心,会不会出现不兼容的情况?兼容肯定是要的,旧版也不会立马废弃,现在是通过 --experimentalDecorators、--emitDecoratorMetadata 两个配置开启装饰器,stage 3 的提案离最终已经很近了,要么默认开启,要么在增加一个新的配置开启,对使用者来说也许不会有太大的差异,对于库的开发者 目前 TS 装饰器和 JS 最新的装饰器提案实现已经不是一回事了,有很多问题需要考虑。
在可预见的未来,TypeScript 下个版本 5.0 大概率会实现新版装饰器,参考 TypeScript 接下来的 5.0 版本迭代计划,里面提到了 “实现更新后的 JavaScript 装饰器提案”。
babel 也一直在跟进 JavaScript 装饰器提案,最新的 stage 3 版本也已实现,算是支持的比较好的了,通过 @babel/plugin-proposal-decorators 插件提供支持,装饰器不同阶段的提案 babel 都有实现,如下所示:
2022-03:在 2022 年 3 月的 TC39 会议上就 Stage 3 达成共识的提案版本。阅读更多相关信息tc39/proposal-decorators@8ca65c046d。2021-12:2021 年 12 月提交给 TC39 的提案版本。阅读更多相关信息 tc39/proposal-decorators@d6c056fa06。2018-09:最初提升到第 2 阶段的提案版本,于 2018 年 9 月提交给 TC39。阅读更多相关信息tc39/proposal-decorators@7fa580b40f。legacy:最初的第 1 阶段提案,阅读更多相关信息 wycats/javascript-decorators@e1bf8d41bf。下文用到的所有的代码会用 babel 编译,接下来让我们先搭建一个支持装饰器的运行环境。
babel 7.19.0 版本已支持 stage 3 装饰器,安装的 babel 大于此即可。
创建一个项目 decorators-demo
$ mkdir decorators-demo
$ cd decorators-demo
$ npm init安装 babel 依赖
npm i @babel/core @babel/cli @babel/preset-env @babel/plugin-proposal-decorators -D创建一个名为 .babelrc 的新文件配置 babel
{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"node": "current"
}
}
]
],
"plugins": [
["@babel/plugin-proposal-decorators", { "version": "2022-03" }] // 这个地方要配置,因为当前默认的版本不是最新的
]
}编辑 package.json scripts 命令
"scripts": {
"build": "babel index.js -d dist",
"start": "npm run build && node dist/index.js"
}类装饰器修饰的是定义的类本身,我们可以为它添加属性、方法。类装饰器类型签名如下所示,第一个参数 value 就是被修饰的类。
类型签名如下所示:
type ClassDecorator = (value: Function, context: {
kind: "class";
name: string | undefined;
addInitializer(initializer: () => void): void;
}) => Function | void;例如,再不改变原始代码的情况下,借助外部组件使用类装饰器为 Person 类扩展一个方法 run。
function addRunMethod(value, { kind, name }) {
if (kind === "class") {
return class extends value {
constructor(...args) {
super(...args);
}
run() {
console.log(`Add a run method for ${this.name}`);
}
}
}
}
@addRunMethod
class Person {
constructor(name) {
this.name = name
}
}
const p1 = new Person('Tom')
p1.run()
const p2 = new Person('Jack')
p2.run()以上我们是通过继承被修饰的类并返回一个新的子类方式来扩展一个新方法。我们定义的类装饰器函数 addRunMethod 第一个参数既然是被修饰的类本身,因此我们还可以通过原型方式来扩展一个新的方法或属性。
function addRunMethod(value, { kind }) {
if (kind === "class") {
value.prototype.run = function () {
console.log(`Add a run method for ${this.name}`);
}
}
}类方法装饰器接收一个被修饰的方法做为第一个参数,并可以选择返回一个新方法替换原始的方法。类型签名如下所示:
type ClassMethodDecorator = (value: Function, context: {
kind: "method";
name: string | symbol;
access: { get(): unknown };
static: boolean;
private: boolean;
addInitializer(initializer: () => void): void;
}) => Function | void;下面从一个记录方法执行耗时的例子,做个不用装饰器与用装饰器的前后效果对比。日常开发工作中我们可能会有类似的需求:“记录一个方法的执行时间,便于后续做些性能优化”。
下面定义了一个 Person 类,有一个 run(跑步) 方法,如果已经吃过饭了,他就有更多的力气,跑的就会快些,否则就会跑的慢些。sleep 方法是为了辅助做些延迟测试。
const sleep = ms => new Promise(resolve => setTimeout(() => resolve(1), ms));
class Person {
async run(isEat) {
const start = Date.now();
if (isEat) {
await sleep(1000 * 1);
console.log(`execution time: ${Date.now() - start}`);
return `I can run fast.`;
}
await sleep(1000 * 5);
console.log(`execution time: ${Date.now() - start}`);
return `I can't run any faster.`;
}
}
const p = new Person();
console.log(await p.run(true))上面代码暴露出两个问题:
接下来使用类方法装饰器改写以上示例,类方法装饰器第一个参数为被装饰的函数,可以返回一个新函数来代替被装饰的方法, 类型签名如下所示:
type ClassMethodDecorator = (value: Function, context: {
kind: "method";
name: string | symbol;
access: { get(): unknown };
static: boolean;
private: boolean;
addInitializer(initializer: () => void): void;
}) => Function | void;以下声明一个 **@executionTime** 装饰器函数,该函数包装原始函数,并在调用前后记录函数执行耗时。
现在的代码逻辑看起来是不是清晰了很多?通过装饰器函数扩展了原有的功能,但并没有修改原始函数内容,如果哪天想去掉计算函数执行耗时这段逻辑,也容易的多了。
const sleep = ms => new Promise(resolve => setTimeout(() => resolve(1), ms));
function executionTime(value, context) {
const { kind, name } = context;
if (kind === 'method') {
return async function (...args) { // 返回一个新方法,代替被装饰的方法
const start = Date.now();
const result = await value.apply(this, args);
console.log(`CALL method(${name}) execution time: ${Date.now() - start}`);
return result;
};
}
}
class Person {
@executionTime
async run(isEat) {
if (isEat) {
await sleep(1000 * 1); // 1 minute
return `I can run fast.`;
}
await sleep(1000 * 5); // 5 minute
return `I can't run any faster.`;
}
}
const p = new Person();
console.log(await p.run(true))注意,类的构造函数不支持装饰器,尽管构造函数看起来像方法,但实际上不是方法。
下面代码直接执行 p.run() 是没问题的,但是将 p.run 提取为一个方法再执行,此时函数内的 this 执行就发生变化了,会被指向为 undefined,单独运行 run() 方法后就会出现 TypeError: Cannot read properties of undefined (reading '#name') 错误。
class Person {
#name
constructor(name) {
this.#name = name;
}
async run() {
console.log(`My name is ${this.#name}`);
}
}
const p = new Person('Tom');
const run = p.run;
run()装饰器上下文对象上提供了一个 [添加初始化逻辑 addInitializer()](https://github.com/tc39/proposal-decorators#adding-initialization-logic-with-addinitializer) 方法,可以调用此方法将初始化函数与类或类元素相关联,该方法在类实例化时会触发,允许用户在初始化时添加一些额外的逻辑。
例如,在这里我们可以声明一个 @bind 装饰器在 addInitializer() 方法触发时将类方法绑定到类实例,解决 this 绑定问题。
function bind(value, context) {
const { kind, name, addInitializer } = context;
if (kind === 'method') {
addInitializer(function () {
this[name] = value.bind(this);
});
}
}
class Person {
...
@bind
async run() {
console.log(`My name is ${this.#name}`);
}
}对于某些在今后版本会被移除的 API,可以通过定义一个 @deprecated 的装饰器,用于 API 将要废弃的消息提醒。
const DEFAULT_MSG = 'This function will be removed in future versions.';
function deprecated(value, context) {
const { kind, name } = context;
if (kind === 'method') {
return function (...args) {
console.warn(`DEPRECATION ${name}: ${DEFAULT_MSG}`);
const result = value.apply(this, args);
return result;
};
}
}
class Person {
@deprecated
hello() {
console.log(`Hello world!`);
}
}
const p = new Person()
p.hello()类访问器装饰器与类方法装饰器相似,区别地方在于上下文 context 对象的 kind 属性为 getter、setter。
类型签名如下所示:
type ClassGetterDecorator = (value: Function, context: {
kind: "getter" | "setter";
name: string | symbol;
access: { get(): unknown } | { set(value: unknown): void };
static: boolean;
private: boolean;
addInitializer(initializer: () => void): void;
}) => Function | void;下例,实现一个 @logged 装饰器 追踪函数被调用的前后记录,细看是不是同上面我们自定义的类方法装饰器 @executionTime 很相似。
function logged(value, context) {
const { kind, name } = context;
if (kind === 'method' || kind === 'getter' || kind === 'setter') {
return function (...args) { // 返回一个新方法,代替被装饰的方法
console.log(`starting ${name} with arguments ${args.join(", ")}`);
const result = value.apply(this, args);
console.log(`ending ${name}`);
return result;
};
}
}
class Person {
#name
constructor(name) {
this.#name = name;
}
@logged
get name() {
return this.#name;
}
@logged
set name(name) {
this.#name = name;
}
}
const p = new Person('Tom')
p.name = 'Jack'
p.name让我们先抛开装饰器的概念,了解下 accessor 是什么?
类自动访问器(Auto-Accessors)是 ECMAScript 将要推出的一个新功能,目前 TC39 提案为 stage 1。通过 accessor 关键词在类属性前定义。
class Person {
accessor name = 'Tom';
}类自动访问器相当于在类原型上定义了 getter、setter,大致等价于以下行为:
class Person {
#name = 'Tom';
get name() {
return this.#name;
}
set name(name) {
this.#name = name;
}
}自动访问器装饰器接收的第一个参数 value 包含了在类原型上定义的访问器对象 get、set,第二参数 context 对象上的 kind 属性为 accessor。
自动访问器装饰器允许拦截对属性的访问,在进行一些包装之后,返回一个新的 **get**、**set**** 方法,还支持返回一个 **init** 函数,用于更改初始值**
类型签名如下所示:
type ClassAutoAccessorDecorator = (
value: {
get: () => unknown;
set(value: unknown) => void;
},
context: {
kind: "accessor";
name: string | symbol;
access: { get(): unknown, set(value: unknown): void };
static: boolean;
private: boolean;
addInitializer(initializer: () => void): void;
}
) => {
get?: () => unknown;
set?: (value: unknown) => void;
init?: (initialValue: unknown) => unknown;
} | void;实现一个 @readOnly 装饰器,确保被装饰的属性在第一次初始化后可以变为只读的,如果未被初始化不允许访问该属性,给一个错误提示。
const UNINITIALIZED = Symbol('UNINITIALIZED');
function readOnly(value, context) {
const { get, set } = value;
const { name, kind } = context;
if (kind === 'accessor') {
return {
init(initialValue) {
return initialValue || UNINITIALIZED;
},
get() {
const value = get.call(this);
if (value === UNINITIALIZED) {
throw new TypeError(
`Accessor ${name} hasn’t been initialized yet`
);
}
return value;
},
set(newValue) {
const oldValue = get.call(this);
if (oldValue !== UNINITIALIZED) {
throw new TypeError(
`Accessor ${name} can only be set once`
);
}
set.call(this, newValue);
},
};
}
}
class Person {
@readOnly
accessor name = 'Tom';
}
const p = new Person()
console.log(p.name);
// p.name = 'Jack' // TypeError: Accessor name can only be set once类字段装饰器接收到的第一个参数 value 为 undefined,我们不能更改字段的名称。通过返回函数,我们可以接收字段的初始值并返回一个新的初始值。
类型签名如下:
type ClassFieldDecorator = (value: undefined, context: {
kind: "field";
name: string | symbol;
access: { get(): unknown, set(value: unknown): void };
static: boolean;
private: boolean;
}) => (initialValue: unknown) => unknown | void;声明一个 @Multiples() 装饰器,接收一个倍数,将字段初始值翻倍处理并返回。
function multiples(mutiple) {
return (value, { kind, name }) => {
if (kind === 'field') {
return initialValue => initialValue * mutiple;
}
}
}
class Person {
@multiples(3)
count = 2;
}
const p = new Person();
console.log(p.count); // 6Logger 是我们的基础类,Person 类似于我们的业务类。以下代码耦合的一点是 Person 与 Logger 产生了直接依赖,对于 Person 类只需要使用 Logger 实例,不需要把 Logger 实例化也放到 Person 类中。接下来我们要解决的是如何将两个依赖模块之间的初始化信息解耦。
class Logger {
info(...args) {
console.log(...args);
}
}
class Person {
logger = new Logger();
run() {
this.logger.info('Hi!', 'I am running.')
}
}
const p = new Person();
p.run();依赖注入是将 “依赖” 注入给调用方,而不是让调用方直接获得依赖,在程序运行过程中由专门的组件负责 “依赖” 的实例化。
接下来,使用装饰器和依赖注册表实现依赖注入。
const assert = require('assert');
const { registry, inject } = createRegistry();
@registry.register('logger')
class Logger {
info(...args) {
console.log(new Date().toLocaleString(), ...args);
}
}
class Person {
@inject logger;
run() {
this.logger.info('Hi!', 'I am running.')
}
}
const p = new Person();
p.run();
assert.equal(p.logger, registry.getInstance('logger'));下面是核心方法 createRegistry() 的实现,参考了 JavaScript metaprogramming with the 2022-03 decorators API 的一个示例,下面主要用到了类装饰器、类字段装饰器。
function createRegistry() {
const classMap = new Map();
const instancesMap = new Map();
const registry = {
register(registerName) {
return (value, { kind }) => {
if (kind === 'class') {
classMap.set(registerName, value)
}
}
},
getInstance(name) {
if (instancesMap.has(name)) {
return instancesMap.get(name);
}
const TargetClass = classMap.get(name);
if (!TargetClass) {
throw new Error(`Unregistered dependencies with register name: ${name}`);
}
const instance = new TargetClass();
instancesMap.set(name, instance);
return instance;
},
}
return {
registry,
inject: (_value, {kind, name}) => {
if (kind === 'field') {
return () => registry.getInstance(name);
}
}
};
}装饰器在未了解之前,给人一种神秘的感觉,了解之后会发现它的语法并没有那么复杂。它的一个优点是在不改变原有代码的基础之上允许我们来扩展一些新功能。
装饰器只适用于类,不支持函数。函数相对类来说,更容易做一些修饰,例如我们可以使用高阶函数做一些包装。
装饰器可以应用于,类、类字段、类方法、类访问器、类自动访问器(这是类的一个新成员)。掌握了装饰器的使用之后,再去看像 Nest.js、Angular 等这些框架时对于 @expression 这种语法,不会再陌生了。
在了解了装饰器后,下一步让我们在详细了解下什么是 IoC(控制反转)、DI(依赖注入)。
在 JavaScript 中浮点数运算时经常出现 0.1+0.2=0.30000000000000004 这样的问题,除了这个问题之外还有一个不容忽视的大数危机(大数处理丢失精度问题),也是近期遇到的一些问题,做下梳理同时理解下背后产生的原因和解决方案。
在开始本节之前,希望你能事先了解一些 JavaScript 浮点数的相关知识,在上篇文章 JavaScript 浮点数之迷:0.1 + 0.2 为什么不等于 0.3? 中很好的介绍了浮点数的存储原理、为什么会产生精度丢失(建议事先阅读下)。
IEEE 754 双精确度浮点数(Double 64 Bits)中尾数部分是用来存储整数的有效位数,为 52 位,加上省略的一位 1 可以保存的实际数值为
Math.pow(2, 53) // 9007199254740992
Number.MAX_SAFE_INTEGER // 最大安全整数 9007199254740991
Number.MIN_SAFE_INTEGER // 最小安全整数 -9007199254740991 只要不超过 JavaScript 中最大安全整数和最小安全整数范围都是安全的。
例一
当你在 Chrome 的控制台或者 Node.js 运行环境里执行以下代码后会出现以下结果,What?为什么我定义的 200000436035958034 却被转义为了 200000436035958050,在了解了 JavaScript 浮点数存储原理之后,应该明白此时已经触发了 JavaScript 的最大安全整数范围。
const num = 200000436035958034;
console.log(num); // 200000436035958050例二
以下示例通过流读取传递的数据,保存在一个字符串 data 中,因为传递的是一个 application/json 协议的数据,我们需要对 data 反序列化为一个 obj 做业务处理。
const http = require('http');
http.createServer((req, res) => {
if (req.method === 'POST') {
let data = '';
req.on('data', chunk => {
data += chunk;
});
req.on('end', () => {
console.log('未 JSON 反序列化情况:', data);
try {
// 反序列化为 obj 对象,用来处理业务
const obj = JSON.parse(data);
console.log('经过 JSON 反序列化之后:', obj);
res.setHeader("Content-Type", "application/json");
res.end(data);
} catch(e) {
console.error(e);
res.statusCode = 400;
res.end("Invalid JSON");
}
});
} else {
res.end('OK');
}
}).listen(3000)运行上述程序之后在 POSTMAN 调用,200000436035958034 这个是一个大数值。

以下为输出结果,发现没有经过 JSON 序列化的一切正常,当程序执行 JSON.parse() 之后,又发生了精度问题,这又是为什么呢?JSON 转换和大数值精度之间又有什么猫腻呢?
未 JSON 反序列化情况: {
"id": 200000436035958034
}
经过 JSON 反序列化之后: { id: 200000436035958050 }这个问题也实际遇到过,发生的方式是调用第三方接口拿到的是一个大数值的参数,结果 JSON 之后就出现了类似问题,下面做下分析。
先了解下 JSON 的数据格式标准,Internet Engineering Task Force 7159,简称(IETF 7159),是一种轻量级的、基于文本与语言无关的数据交互格式,源自 ECMAScript 编程语言标准.
https://www.rfc-editor.org/rfc/rfc7159.txt 访问这个地址查看协议的相关内容。
我们本节需要关注的是 “一个 JSON 的 Value 是什么呢?” 上述协议中有规定必须为 object, array, number, or string 四个数据类型,也可以是 false, null, true 这三个值。
到此,也就揭开了这个谜底,JSON 在解析时对于其它类型的编码都会被默认转换掉。对应我们这个例子中的大数值会默认编码为 number 类型,这也是造成精度丢失的真正原因。
在前后端交互中这是通常的一种方案,例如,对订单号的存储采用数值类型 Java 中的 long 类型表示的最大值为 2 的 64 次方,而 JS 中为 Number.MAX_SAFE_INTEGER (Math.pow(2, 53) - 1),显然超过 JS 中能表示的最大安全值之外就要丢失精度了,最好的解法就是将订单号由数值型转为字符串返回给前端处理,这是再和一个供应商对接过程中实实在在遇到的一个坑。
Bigint 是 JavaScript 中一个新的数据类型,可以用来操作超出 Number 最大安全范围的整数。
创建 BigInt 方法一
一种方法是在数字后面加上数字 n
200000436035958034n; // 200000436035958034n创建 BigInt 方法二
另一种方法是使用构造函数 BigInt(),还需要注意的是使用 BigInt 时最好还是使用字符串,否则还是会出现精度问题,看官方文档也提到了这块 github.com/tc39/proposal-bigint#gotchas--exceptions 称为疑难杂症
BigInt('200000436035958034') // 200000436035958034n
// 注意要使用字符串否则还是会被转义
BigInt(200000436035958034) // 200000436035958048n 这不是一个正确的结果检测类型
BigInt 是一个新的数据类型,因此它与 Number 并不是完全相等的,例如 1n 将不会全等于 1。
typeof 200000436035958034n // bigint
1n === 1 // false运算
BitInt 支持常见的运算符,但是永远不要与 Number 混合使用,请始终保持一致。
// 正确
200000436035958034n + 1n // 200000436035958035n
// 错误
200000436035958034n + 1
^
TypeError: Cannot mix BigInt and other types, use explicit conversionsBigInt 转为字符串
String(200000436035958034n) // 200000436035958034
// 或者以下方式
(200000436035958034n).toString() // 200000436035958034与 JSON 的冲突
使用 JSON.parse('{"id": 200000436035958034}') 来解析会造成精度丢失问题,既然现在有了一个 BigInt 出现,是否使用以下方式就可以正常解析呢?
JSON.parse('{"id": 200000436035958034n}');运行以上程序之后,会得到一个 SyntaxError: Unexpected token n in JSON at position 25 错误,最麻烦的就在这里,因为 JSON 是一个更为广泛的数据协议类型,影响面非常广泛,不是轻易能够变动的。
在 TC39 proposal-bigint 仓库中也有人提过这个问题 github.comtc39/proposal-bigint/issues/24 截至目前,该提案并未被添加到 JSON 中,因为这将破坏 JSON 的格式,很可能导致无法解析。
BigInt 的支持
BigInt 提案目前已进入 Stage 4,已经在 Chrome,Node,Firefox,Babel 中发布,在 Node.js 中支持的版本为 12+。
BigInt 总结
我们使用 BigInt 做一些运算是没有问题的,但是和第三方接口交互,如果对 JSON 字符串做序列化遇到一些大数问题还是会出现精度丢失,显然这是由于与 JSON 的冲突导致的,下面给出第三种方案。
通过一些第三方库也可以解决,但是你可能会想为什么要这么曲折呢?转成字符串大家不都开开心心的吗,但是呢,有的时候你需要对接第三方接口,取到的数据就包含这种大数的情况,且遇到那种拒不改的,业务总归要完成吧!这里介绍第三种实现方案。
还拿我们上面 大数处理精度丢失问题复现 的第二个例子进行讲解,通过 json-bigint 这个库来解决。
知道了 JSON 规范与 JavaScript 之间的冲突问题之后,就不要直接使用 JSON.parse() 了,在接收数据流之后,先通过字符串方式进行解析,利用 json-bigint 这个库,会自动的将超过 2 的 53 次方类型的数值转为一个 BigInt 类型,再设置一个参数 storeAsString: true 会将 BigInt 自动转为字符串。
const http = require('http');
const JSONbig = require('json-bigint')({ 'storeAsString': true});
http.createServer((req, res) => {
if (req.method === 'POST') {
let data = '';
req.on('data', chunk => {
data += chunk;
});
req.on('end', () => {
try {
// 使用第三方库进行 JSON 序列化
const obj = JSONbig.parse(data)
console.log('经过 JSON 反序列化之后:', obj);
res.setHeader("Content-Type", "application/json");
res.end(data);
} catch(e) {
console.error(e);
res.statusCode = 400;
res.end("Invalid JSON");
}
});
} else {
res.end('OK');
}
}).listen(3000)再次验证会看到以下结果,这次是正确的,问题也已经完美解决了!
JSON 反序列化之后 id 值: { id: '200000436035958034' }本文提出了一些产生大数精度丢失的原因,同时又给出了几种解决方案,如遇到类似问题,都可参考。还是建议大家在系统设计时去遵循双精度浮点数的规范来做,在查找问题的过程中,有看到有些使用正则来匹配,个人角度还是不推荐的,一是正则本身就是一个耗时的操作,二操作起来还要查找一些匹配规律,一不小心可能会把返回结果中的所有数值都转为字符串,也是不可行的。
v8.dev/features/bigint
github.com/tc39/proposal-bigint
en.wikipedia.org/wiki/Double-precision_floating-point_format
在 JavaScript 中 ES6 之前我们使用函数(构造器函数)和基于原型来创建一个自定义的类,但这种方式总会让人产生困惑,特别是习惯了 Java、PHP 等面向对象编程的同学来说更加难以理解。
面向对象编程的基本单位是对象,但对象又是由类实例化的,所以我们第一步需要先知道怎么去声明一个类。
类的声明使用 class 关键词,类名与变量、函数等命名规则类似,这里要首写字母大写,类名后跟上一对花括号可以理解为的类的主体,类的主体三部分组成:成员属性、构造函数、成员方法。
class 类名 {
成员属性:
构造函数:
成员方法:
}在类中可以直接声明变量,也称为成员属性,另外在类中声明成员属性我们还可以使用关键词 private、public、protected 来修饰:
class Person {
age: number; // age 等价于 public age
private sex: string;
protected phone: number;
}构造函数用于类的初始化,可以声明哪些字段是必传的,哪些字段是非必传的。
构造函数参数中 public name: string 相当于如下形式:
class Person {
public name: string
constructor(public name: string) {
this.name = name;
}
}在构造函数内部,可以为之前声明的成员属性做赋值。
class Person {
...
constructor(public name: string, age: number, sex: string, phone?: number) {
this.age = age;
this.sex = sex;
this.phone = phone;
}
}在类中直接声明函数称为成员方法,注意这里的函数是不需要加 function 关键词的,成员方法要和对象有关联,例如 eat 方法(每个都需要吃饭的),另外方法也可以使用 public、private、protected 等关键词声明。
class Person {
...
public eat() {
const info = this.info();
console.log(`${info} eat...`);
}
private info() {
return `${this.name} ${this.age} ${this.sex} ${this.phone}`;
}
}什么是对象?只要能用属性、方法描述的事物我们都可以声明为一个类,然后对这个类实例化出对象使用。
上面我们抽象了一个类 Person,但是在程序中我们不是直接使用的类,而是通过抽象出来的类来实例化一个或多个对象为我们所使用。
实例化一个对象主要使用 new 关键词,后面跟上需要实例的类。
const zhangsan = new Person('张三', 18, '男');
const lisi = new Person('李四', 20, '男', 18800000000);
zhangsan.eat(); // 张三 18 男 undefined eat...
lisi.eat(); // 李四 20 男 18800000000 eat...static 可以用来将类成员属性、成员方法标识为静态的。
static 关键词修饰的类成员属性、成员方法是属于类的与类实例对象无关,且在多个对象之间是共享的。
下例定义了静态属性 language 为 chinese,最后实例化了两个对象,其中 language 可以使用类名来调用,且在两个对象间是共享的。
class Person {
static language: string = 'chinese';
constructor(public name: string) {}
info() {
console.log(`我叫: ${this.name}, 我说: ${Person.language}`);
}
}
const zhangsan = new Person('张三');
zhangsan.info(); // 我叫: 张三, 我说: chinese
const lisi = new Person('李四');
lisi.info(); // 我叫: 李四, 我说: chinese对象的成员属性或方法如果没有被封装,实例化后在外部就可通过引用获取,对于用户 phone 这种数据,是不能随意被别人获取的。
封装性做为面向对象编程重要特性之一,它是把类内部成员属性、成员方法统一保护起来,只保留有限的接口与外部进行联系,尽可能屏蔽对象的内部细节,防止外部随意修改内部数据,保证数据的安全性。
用 private 关键词修饰类的成员属性和成员方法来实现对成员的封装,封装后的成员对象仅能在类的内部被访问。
下面我们使用 private 关键词对 Person 类部分成员进行封装,能够被外部访问的只有 info 方法。
class Person {
private name: string;
private phone: string;
constructor(name: string, phone: string) {
this.name = name;
this.phone = phone;
}
public info() {
console.log(`我是 ${this.name} 手机号 ${this.formatPhone()}`)
}
private formatPhone() {
return this.phone.replace(/(\d{3})\d{4}(\d{3})/, '$1****$2');
}
}
const zhangsan = new Person('张三', '18800000000');
zhangsan.info();使用 private 修饰过后的成员属性或方法在外部将会无法访问,如果需要访问,我们可以设置公有方法返回私有属性,这里你也可以做一些条件限制。
class Person {
private name: string;
private phone: string;
constructor(name: string, phone: string) {
this.name = name;
this.phone = phone;
}
public getName() {
return this.name;
}
...
}
const zhangsan = new Person('张三', '18800000000');
console.log(zhangsan.getName()); // 张三已存在的用来派生新类的类成为基类,又可称为超类。新派生的类称为派生类或子类。
在 C++ 中一个派生类可以继承多个基类,有单继承、多继承。在 TypeScript、Java、PHP 中都是只可继承自一个基类,只有单继承。
下图展示一个关于 Person 基类被继承的示意图:
创建基类 Person 一个成员属性 name,一个成员方法 eat。
class Person {
protected name: string;
constructor(name: string) {
this.name = name;
}
eat() {
console.log('eat...');
}
}创建派生类 Student,通过关键词 extends 继承于基类 Person,实现一个自定义的 study 方法。
class Student extends Person {
study() {
this.eat();
console.log(`${this.name} 开始学习...`);
}
}创建派生类 Work,通过关键词 extends 继承于基类 Person,实现一个自定义的 work 方法。
class Work extends Person {
work() {
super.eat();
console.log(`${this.name} 开始工作...`);
}
}上面创建的两个子类 Student、Work 都有自己单独的方法,学生要学习,工人要工作,但是在开始之前都要先吃饱饭吧。
下面我们测试下这个实例。
const s1 = new Student('张三');
s1.study();
// eat...
// 张三 开始学习...
const w1 = new Work('李四');
w1.work();
// eat...
// 李四 开始工作...我们不能定义重名的函数,也无法在同一个类中定义重名的方法,但是在派生类中我们可以重写在基类中同名的方法。
class Student extends Person {
constructor(name: string) { super(name); }
eat() {
console.log('今天作业有点多,再加一块肉!');
super.eat();
}
study() {
this.eat();
console.log(`${this.name} 开始学习...`);
}
}
const s1 = new Student('张三');
s1.study();
// 今天作业有点多,再加一块肉!
// eat...
// 张三 开始学习...注意:如果派生类中写了 constructor() 方法,必须在 this 之前调用 super 方法,它会调用基类的构造函数。
接口多继承实现
上面讲了在 TS 中类之间只能实现单继承,但是在接口里是可以实现单继承和多继承的。
interface Person1 {
nickname: string;
}
interface Person2 {
age: number;
}
interface Person3 extends Person1, Person2 {
sex: string;
}
function study(obj: Person3) {
console.log(obj.nickname, obj.age, obj.sex);
}
study({ nickname: 'may', age: 20, sex: 'man' });接口继承类
接口可以通过 extends 关键词继承一个类,如果类成员包含实现,则不会被继承其实现。
class Person1 {
nickname: string;
test(): string {
return 'Hello';
}
}
interface Person2 extends Person1 {
age: number;
}
class Study implements Person2 {
nickname: string;
age: number;
constructor(nickname: string, age: number) {
this.nickname = nickname;
this.age=age;
}
test(): string {
console.log(this.nickname, this.age)
return 'Hi';
}
}
const lisi = new Study('李四', 20);
console.log(lisi.test());多态性是面向对象编程的三大特性之一,可以让具有继承关系的不同类对象,使用相同的函数名完成不同的功能,通俗的讲:一个子类可以修改、重写父类中定义的相同名称的方法,父类可以使用抽象类或接口来定义相应的规范。
抽象类是一种特殊的类,使用 abstract 关键词修饰,一般不会直接被实例化。
抽象类中的成员属性或方法如果没有用 abstract 关键词修饰,可以包含实现细节。如果使用 abstract 关键词修饰,则只能定义,实现必须要在派生类中去做。
abstract class Person {
abstract name: string;
eat(): void {
console.log('eat...')
}
abstract walk(): void;
}
class Student extends Person {
name: string;
walk(): void {
console.log('walk...');
}
}
const zhangsan = new Student();
zhangsan.eat(); // eat...
zhangsan.walk(); // walk...接口是一种特殊的抽象类,与之抽象类不同的是,接口没有具体的实现,只有定义,通过 interface 关键词声明。
在继承的时候说过,TypeScript 中只能单继承,但是在接口这里,是可以实现多个接口的。
class 类名 implements Interface1, Interface2 {
...
}以下是一个接口的示例:
interface Person {
name: string;
phone?: string;
}
interface Student {
diploma(): void;
}
class HighSchool implements Student, Person {
name: string;
diploma(): void {
console.log('高中生 ...');
}
}
class University implements Student, Person {
name: string;
diploma(): void {
console.log('大学生 ...')
}
}一个经典的例子,电脑的 USB 接口,我们可以插上鼠标、键盘、U 盘等设备,来为其扩展不同的功能,每个设备的功能是不同的,但是 USB 接口的规范遵守的是统一的,这也就是我们所讲的多态性,通过声明抽象类或接口定义规范,子类重写和父类名称相同的方法,实现自己的功能。
// 定义USB 接口规范
interface USB {
run(): void;
}
// 实现一个 USB 规范的键盘设备
class UKey implements USB {
run(): void {
console.log('USB 规范的键盘设备');
}
}
// 实现一个 USB U 盘设备
class UDisk implements USB {
run(): void {
console.log('USB 规范的 U 盘设备');
}
}
// 计算机类
class Computer {
useUSB(usb: USB) {
usb.run();
}
}
const computer = new Computer();
computer.useUSB(new UKey()); // USB 规范的键盘设备
computer.useUSB(new UDisk()); // USB 规范的 U 盘设备大学期间自学了 PHP 开发,当时印象比较深刻的一本书是 “细说 PHP”,书中的面向对象这节印象还是比较深刻的,讲的很好,在学习 TypeScript 面向对象的封装、继承、多态特性时很多概念都是相通的,对于理解给予了很大帮助。
译者:五月君
作者:ayooluwa-isaiah
原文:https://blog.appsignal.com/2022/02/09/an-introduction-to-deno-is-it-better-than-nodejs.html
Deno 是一个类似于 Node.js 的 JavaScript 和 TypeScript 运行时,基于 Rust 和 JavaScript V8 引擎构建。 它由 Node.js 创始人 Ryan Dahl 创建,以弥补他在 2009 年最初设计和发布 Node.js 时所犯的错误。
Ryan's 有关 Node.js 的遗憾在 2018 年 JSConf EU 上著名的演讲 “我对 Node.js 遗憾的十件事” 有充分的记录。总而言之,他感叹缺乏对安全性的关注、通过 node_modules 解析模块、浏览器工作方式的各种偏差以及其他问题,他开始在 Deno 中修复这些错误。
在本文中,我们将讨论 Deno 的创建原因以及它与 Node.js 相比的优缺点。还将对 Deno 的怪癖(quirks)和功能做一个实用概述,以便您决定它是否适合于您的下一个项目。
Deno 做为一个独立的、自包含的二进制文件没有任何依赖。你可以通过多种方式安装 Deno,具体取决于你的操作系统。最简单的方法是下载并执行一个 shell 脚本,如下所示:
# Linux and macOS
$ curl -fsSL https://deno.land/x/install/install.sh | sh
# Windows PowerShell
$ iwr https://deno.land/x/install/install.ps1 -useb | iex一旦你为你的操作系统执行了适当的命令,Deno CLI 二进制文件将会下载到你的计算机。根据你选择的安装方法,你需要添加这个二进制文件位置到你的 PATH。
你可以在 Bash 中添加以下行到你的 $HOME/bash_profile 文件来执行此操作。你可能需要开启一个新的 shell 会话来使更改生效。
export DENO_INSTALL="$HOME/.deno"
export PATH="$DENO_INSTALL/bin:$PATH"运行以下命令,验证 Deno 的安装版本。如果这个 CLI 已经下载成功并且添加到您的 PATH,控制台应该会打印输出 Deno 版本信息。
$ deno --version
deno 1.14.2 (release, x86_64-unknown-linux-gnu)
v8 9.4.146.16
typescript 4.4.2如果你的 Deno 版本已过时,可以通过 upgrade 子命令升级到最新的 release 版本。
$ deno upgrade
Looking up latest version
Found latest version 1.14.2
Checking https://github.com/denoland/deno/releases/download/v1.14.2/deno-x86_64-unknown-linux-gnu.zip
31.5 MiB / 31.5 MiB (100.0%)
Deno is upgrading to version 1.14.2
Archive: /tmp/.tmpfdtMXE/deno.zip
inflating: deno
Upgraded successfully接下来,编写一个常用的 Hello world 程序来验证是否可以正常工作。可以为你的 Deno 项目创建一个目录并在该目录下创建一个 index.ts 文件放入以下代码:
function hello(str: string) {
return `Hello ${str}!`;
}
console.log(hello("Deno"));在 deno run 子命令后将文件名做为参数执行,如果输出 “Hello Deno!”,意味着你已经成功的安装了 Deno。
$ deno run index.ts
Check file:///home/ayo/dev/deno/index.ts
Hello Deno!要了解 Deno CLI 提供的其它功能及选项,使用 --help 标志:
$ deno --helpDeno 相较于 Node.js 的一大卖点是它对 TypeScript 的一流支持。
正如你所看到的,除了安装 Deno CLI 之外,你不需要做任何的事情让它来工作。与其前身一样,使用 V8 引擎运行时来解析解释和执行 JavaScript 代码,但它还在其可执行文件中使用 TypeScript 编译器以实现对 TypeScript 的支持。
在后台,TypeScript 代码被检查和编译。生成的 JavaScript 代码会缓存在文件系统上的一个目录中,可以再次执行而无需从头编译。你可以使用 deno info 检查缓存目录位置和其它包含 Deno 管理文件的目录。
在使用 TypeScript 时 Deno 不需要任何配置,但如果你想调整 TypeScript 编译器解析代码的方式,你可以提供一个 JSON 文件指定 TypeScript 的编译选项。尽管 tsconfig.json 是用 TSC 编译时的一个常见选择方式,但是 Deno 团队建议使用 deno.json 因为其它特定于 Deno 的配置选项也可以放置在这里。
请注意 Deno 不支持所有的 TypeScript 编译选项。在 Deno 的文档中提供了一个完整的可用的的选项和它们的默认值。对于 Deno 的示例配置文件如下所示:
{
"compilerOptions": {
"checkJs": true,
"noImplicitReturns": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
"noUncheckedIndexedAccess": true
}
}在撰写本文时,Deno 不会自动检测 deno.json 文件,因此必须通过 --config 标志指定它。然后,这个功能计划在未来的一个版本发布。
$ deno run --config deno.json index.ts当 Deno CLI 遇到类型错误时,它会停止脚本编译并以非 0 状态码退出终止。你可以通过以下方式绕错错误:
在错误发生的地方使用
//@ts-ignore或//@ts-expect-error// @ts-nocheck在一个文件的开始忽略所有的错误。
Deno 还提供了一个 --no-check 标志来完全禁用类型检查。这有助于防止 TypeScript 编译器在快速迭代问题时减慢你的速度。
$ deno run --no-check index.tsDeno 以成为 JavaScript 和 TypeScript 的安全运行时而骄傲。它维护安全性部分的方式是通过权限功能完成的。为了演示权限功能在 Deno 中的工作方式,添加以下脚本到您的 index.ts 文件。这个脚本会从 disease.sh 获取最新的全球 Covid-19 统计数据。
async function getCovidStats() {
try {
const response = await fetch("https://disease.sh/v3/covid-19/all");
const data = await response.json();
console.table(data);
} catch (err) {
console.error(err);
}
}
getCovidStats();当你尝试执行脚本时,它应该显示 PermissionDenied 错误:
$ deno run index.ts
PermissionDenied: Requires net access to "disease.sh", run again with the --allow-net flag
# PermissionDenied:需要对 “disease.sh” 的网络访问,使用 --allow-net 标志再次运行。上面的错误消息表明脚本没有给予网络访问权限,它建议在命令中包含 --allow-net 标志以授予访问权限。
$ deno run --allow-net index.ts
┌────────────────────────┬───────────────┐
│ (idx) │ Values │
├────────────────────────┼───────────────┤
│ updated │ 1633335683059 │
│ cases │ 235736138 │
│ todayCases │ 32766 │
│ deaths │ 4816283 │
│ todayDeaths │ 670 │
│ recovered │ 212616434 │
│ todayRecovered │ 51546 │
│ active │ 18303421 │
│ critical │ 86856 │
│ casesPerOneMillion │ 30243 │
│ deathsPerOneMillion │ 617.9 │
│ tests │ 3716763329 │
│ testsPerOneMillion │ 473234.63 │
│ population │ 7853954694 │
│ oneCasePerPeople │ 0 │
│ oneDeathPerPeople │ 0 │
│ oneTestPerPeople │ 0 │
│ activePerOneMillion │ 2330.47 │
│ recoveredPerOneMillion │ 27071.26 │
│ criticalPerOneMillion │ 11.06 │
│ affectedCountries │ 223 │
└────────────────────────┴───────────────┘你可以提供一个以逗号分隔的主机名或 IP 地址的允许列表做为 --allow-net 的参数,以便脚本仅可以访问指定的网站,而不是授予脚本访问所有网站的权限(如上所示)。如果脚本尝试链接不在允许列表中的列,Deno 将会阻止它的链接,并且脚本将会执行失败。
$ deno run --allow-net='disease.sh' index.ts这个功能是 Deno 对 Node.js 的改进之一,任何脚本都可以通过网络访问任何资源。读取和写入文件系统也存在类似的权限。如果一个脚本需要执行任一任务,你需要分别指定 --allow-read 和 --allow-write 权限。两个标志允许你为脚本设置特定可访问的目录,以便文件系统的其它部分免受篡改。Deno 还提供了一个 --allow-all 标志,如果需要,可以为一个脚本开启所有的安全敏感功能。
Deno 的主要目标之一是尽可能与 Web 浏览器兼容。 这反映在它使用 Web 平台 API,而不是为某些操作创建特定于 Deno 的 API。 例如,我们在上一节中看到了 Fetch API 的实际应用。 这是一个在浏览器中使用的确切 Fetch API,在必要时有一些偏差以说明 Deno 中独特的安全模型(这些更改大多无关紧要)。
Deno 的在线文档中列出了所有已实现的浏览器 API。
Deno 管理依赖方式可能是它与 Node.js 的最大不同之处。
Node.js 使用 npm 或 yarn 之类的包管理器将第三方包从 npm 注册表下载到 node_modules 目录和 package.json 文件以跟踪项目的依赖关系。Deno 摒弃了这些机制,转而采用更加以浏览器为中心的方式来使用第三方包:URLs。
这里有一个使用 Deno web 应用程序框架 Oka 来创建基础 web server 的示例:
import { Application } from "https://deno.land/x/oak/mod.ts";
const app = new Application();
app.use((ctx) => {
ctx.response.body = "Hello Deno!";
});
app.addEventListener("listen", ({ hostname, port, secure }) => {
console.log(`Listening on: http://localhost:${port}`);
});
await app.listen({ port: 8000 });Deno 使用 ES 模块,与 Web 浏览器中使用的模块系统相同。只要引用的脚本(模块)导出方法或其它值,就可以从绝对路径或相对路径导入模块。值得注意的是,文件扩展名必须始终存在,无论您是从绝对路径还是相对路径导入。
虽然您可以从任何 URL 导入模块,但许多专门为 Deno 构建的第三方模块都通过 **deno.land/x** 进行缓存。每次发布模块的新版本时,它都会自动缓存在该位置并使其不可变,以便模块的特定版本内容保持不变。
假设您运行上一个片段中的代码。在这种情况下,它将下载模块及其所有依赖项并将它们缓存在本地 DENO_DIR 环境变量指定的目录中(默认应为 $HOME/.cache/deno)。下次程序运行时,将不会再次下载,因为所有依赖项都已缓存在本地。这类似于 Go 模块系统的工作方式。
$ deno run --allow-net index.ts
Download https://deno.land/x/oak/mod.ts
Warning Implicitly using latest version (v9.0.1) for https://deno.land/x/oak/mod.ts
Download https://deno.land/x/oak@v9.0.1/mod.ts
. . .对于生产应用程序,Deno 创建者建议检查您的依赖性已进入代码版本控制系统,以确保持续可用(即时模块的源代码不可用,无论处于何原因)。将 DENO_DIR 环境变量指向项目中的本地目录(例如 vendor),您可以将其提交给 Git。
例如,下面的命令会将脚本的所有依赖项下载到项目中的 vendor 目录中。 随后,您可以提交该文件夹以在您的生产服务器中一次将其全部拉下。 您还需要将 DENO_DIR 变量设置为从服务器上的 vendor 目录中读取,而不是重新下载它们。
$ DENO_DIR=$PWD/vendor deno cache index.ts # Linux and macOS
$ $env:DENO_DIR="$(get-location)\vendor"; deno cache index.ts # Windows PowerShellDeno 还支持对依赖项进行版本控制,以确保可重现的构建。 目前,我们已经从 https://deno.land/x/oak/mod.ts 导入了 Oak。 这始终会下载最新版本,将来可能与您的程序不兼容。 当你第一次下载模块时,它还会导致 Deno 产生警告:
Warning Implicitly using latest version (v9.0.1) for https://deno.land/x/oak/mod.ts最佳实践是引用一个特定版本,如下所示:
import { Application } from 'https://deno.land/x/[email protected]/mod.ts';如果您在代码库的许多文件中引用一个模块,升级它可能会变得乏味,因为您必须在许多地方更新 URL。 为了规避这个问题,Deno 团队建议将您的外部依赖项导入到一个集中的 deps.ts 文件中,然后重新导出它们。 这是一个 deps.ts 示例文件,它从 Oak 库中导出我们需要的内容。
export { Application, Router } from "https://deno.land/x/[email protected]/mod.ts";然后在您的应用程序代码中,您可以按如下方式导入它们:
import { Application, Router } from "./deps.ts";此时,更新一个模块变得很简单,只需将 deps.ts 文件中的 URL 更改为指向新版本即可。
Deno 提供了标准库(stdlib)旨在成为 Go 标准库的松散端口(译者注:这里原句为 “aims to be a loose port of Go's standard library”)。标准中包含的模块由 Deno 团队审核并随着每一次 Deno release 而更新。提供标准库的目的是让您立即创建有用的 Web 应用程序,而不需要任何第三方包(这是 Node.js 生态系统中的规范)。
你可能会发现一些有帮助的第三方模块,示例如下:
这是一个示例(取自 Deno 官方文档)它取自 Deno 标准库中的 HTTP 模块用于创建一个基本的 Web Server。
import { listenAndServe } from "https://deno.land/[email protected]/http/server.ts";
const addr = ":8080";
const handler = (request: Request): Response => {
let body = "Your user-agent is:\n\n";
body += request.headers.get("user-agent") || "Unknown";
return new Response(body, { status: 200 });
};
console.log(`HTTP webserver running. Access it at: http://localhost:8080/`);
await listenAndServe(addr, handler);通过以下命令开启这个服务:
$ deno run --allow-net index.ts
HTTP webserver running. Access it at: http://localhost:8080/在不同终端,通过以下命令访问这个正在运行的服务。
$ curl http://localhost:8080
Your user-agent is:
curl/7.68.0请注意,标准库中的模块当前标记为不稳定(如版本号所示)。 这意味着您不应该仅仅依赖它们来进行严肃的生产应用程序。
不可否认 Node.js 成功的主要原因是可以在项目下载使用大量的 NPM 包。如果你正在考虑切换到 Deno,你也许想知道是否要放弃所有你知道且喜爱的 NPM 包。
最简单的答案是 “不”。如果某些 NPM 包依赖于 Node.js API,您可能无法在 Deno 中使用它们(特别是如果 Deno 的 Node.js 兼容层不支持特定 API),但许多 NPM 包可以通过 CDN 在 Deno 中使用,例如 esm.sh 和 skypack.dev。这两个 CDN 都将 NPM 包作为 ES 模块提供,即使包的作者没有专门针对 Deno 进行设计,也可以随后在 Deno 脚本中使用这些包。
这是一个在 Deno 脚本中从 Skypack 到入 NPM 包的示例:
import dayjs from "https://cdn.skypack.dev/[email protected]";
console.log(`Today is: ${dayjs().format("MMMM DD, YYYY")}`);$ deno run index.ts
Today is: October 05, 2021为确保 Deno 可以发现与包关联的类型,请确保在使用 Skypack CDN 时在包 URL 的末尾添加 ?dts后缀。 这会使 Skypack 设置 X-TypeScript-Types 标头,以便 Deno 可以自动发现与包关联的类型。Esm.sh 默认包含此标头,但您可以通过在包 URL 末尾添加 ?no-check 后缀来选择退出。
import dayjs from "https://cdn.skypack.dev/[email protected]?dts";Deno CLI 附带了几个有价值的工具,可以提高开发人员的使用体验。 与 Node.js 一样,它带有一个 REPL(交互式解析器),您可以使用 deno repl 访问它。
$ deno repl
Deno 1.14.2
exit using ctrl+d or close()
> 2+2
4它还有一个内置的文件观察器,可以与它的几个子命令一起使用。 例如,您可以使用 --watch 标志将 deno run 配置为在文件更改后自动重建和重新启动程序。 在 Node.js 中,这个功能一般是通过一些第三方包来实现的,比如 nodemon。
$ deno run --allow-net --watch index.ts
HTTP webserver running. Access it at: http://localhost:8080/
Watcher File change detected! Restarting!
HTTP webserver running. Access it at: http://localhost:8080/使用 Deno 1.6,您可以通过 compile 子命令将脚本编译为不需要安装 Deno 的独立可执行文件(您可以在 Node.js 中使用 pkg 执行相同操作)。 您还可以通过 --target 标志为其他平台(交叉编译)生成可执行文件。 编译脚本时,您必须指定其运行所需的权限。
$ deno compile --allow-net --output server index.ts
$ ./server
HTTP webserver running. Access it at: http://localhost:8080/请注意,通过此过程生成的二进制文件非常庞大。 在我的测试中,deno compile 为一个简单的 “Hello world” 程序生成了一个 83MB 的二进制文件。 然而,Deno 团队目前正在努力减少文件大小以使其更易于管理。
发布 Deno 程序的另一种方法是通过 bundle 子命令将其打包到单个 JavaScript 文件中。 该文件包含程序的源代码及其所有依赖项,可以通过 deno run 执行,如下所示。
$ deno bundle index.ts index.bundle.js
Check file:///home/ayo/dev/demo/deno/index.js
Bundle file:///home/ayo/dev/demo/deno/index.js
Emit "index.bundle.js" (7.39KB)
$ deno run --allow-net index.bundle.js
HTTP webserver running. Access it at: http://localhost:8080/
Deno 附带的另外两个很棒的工具是内置的 linter (deno lint) 和 formatter (deno fmt)。 在 Node.js 生态系统中,linting 和格式化代码通常分别由 ESLint 和 Prettier 处理。
使用 Deno 时,您不再需要安装任何东西或编写配置文件来获取 JavaScript、TypeScript 和其他支持的文件格式的 linting 和格式化。
Deno 内置了对 JavaScript 和 TypeScript 代码的单元测试支持。当您运行 deno test 时,它会自动检测任何以 _test.ts 或 .test.ts 结尾的文件(也支持其他文件扩展名)并在其中执行任何定义的测试。
要编写您的第一个测试,请创建一个 index_test.ts 文件并使用以下代码填充它:
import { assertEquals } from "https://deno.land/[email protected]/testing/asserts.ts";
Deno.test("Multiply two numbers", () => {
const ans = 2 * 2;
assertEquals(ans, 4);
});Deno 提供了用于创建单元测试的 Deno.test 方法。它将测试的名称作为其第一个参数。它的第二个参数是测试运行时执行的函数。
还有第二种风格接受一个对象而不是两个参数。除了测试名称和功能之外,它还支持其他属性来配置测试是否应该运行或如何运行。
Deno.test({
name: "Multiply two numbers",
fn() {
const ans = 2 * 2;
assertEquals(ans, 4);
},
});assertEquals() 方法来自标准库中的测试模块,它提供了一种轻松检查两个值是否相等的方法。
继续运行测试:
$ deno test
test Multiply two numbers ... ok (8ms)
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out (37ms)选择编程语言或环境的主要考虑因素之一是它与编辑器和 IDE 的集成。 在 Deno 1.6 中,内置语言服务协议(deno lsp) 被添加到运行时以提供以下功能:
以及任何支持语言服务协议 (LSP) 的编辑器的其他语言智能。 你可以在 Deno 的在线文档中了解有关在编辑器中设置 Deno 支持的更多信息。
在本文中,我们考虑了 Deno 运行时的许多方面,以及它是对 Node.js 的升级的方式。
关于 Deno 及其生态系统还有很多话要说,但对于考虑将 Deno 用于新项目的 Node.js 开发人员来说,这应该是一个有用的介绍。 Deno 第三方软件包的可用性较低是它明显不足的一个方面,因为它在现实世界中由于年龄太小而没有像 Node.js 那样经过实战测试(Deno 1.0 于 2020 年 5 月发布)。
比较 Node.js 和 Deno 之间的性能可以发现,在大多数情况下,它们在同一个范围内,尽管在少数情况下 Node.js 表现出更出色的性能。随着 Deno 变得更加成熟,所测得的差异势必会有所改善。
在选择 Node.js 和 Deno 时,同样重要的是要记住,Deno 提供的一些好处也可以在第三方包的帮助下在 Node.js 中使用。因此,如果您对 Deno 只有一两点欣赏,那么您很可能在 Node.js 中也可获得类似的结果,尽管不是那么无缝。
感谢阅读,祝您编码愉快!
某些场景下,对于数据隐私会有较高的要求,例如,用户系统的个人信息(身份证、手机号)、医患系统的患者信息等,怎么用技术手段安全的保护这些敏感数据是我们开发人员需要考虑的问题。
本篇文章,将介绍 MongoDB 的客户端字段级加密功能,英文全称为 Client-Side Field Level Encryption,在有些地方会看到简称为 CSFLE,代表的是一个意思,下文有些地方也会这样称呼。
该功能允许开发人员将数据保存到 MongoDB 服务器之前选择性的指定数据字段进行加密,这些加密/解密操作都是事先在客户端完成,与服务器通信时完全是加密的,最终只有配置了 CSFLE 客户端才能读取和写入敏感数据字段。
文末列举了几个使用中的常见错误原因,如有遇到类似错误可以做为参考。
MongoDB Server 选择:MongoDB 客户端字段级加密分为自动加密、手动加密两种类型,自动加密社区版是不支持的,需要 MongoDB Server 4.2 企业版 或 MongoDB Atlas,学习使用推荐 MongoDB Atlas,它是在云服务器中托管的 MongoDB 服务器,不需要安装,且提供了免费的入门套餐是够我们学习使用了。
驱动兼容性:使用支持 CSFLE 功能的 Node.js MongoDB 驱动程序,3.4+ 以上版本是支持的,快速入门。
libmongocrypt:客户端字段级加密依赖 libmongocrypt,它是 MongoDB 驱动程序实现客户端加密/解密的核心组件,对应的 Node.js NPM 包为 mongodb-client-encryption,需要注意这个包依赖于 libbson 和 libmongocrypt C 库,需要 C++ 工具链,但是做为 Node.js Addons 插件,其已经利用 prebuild 在 CI 期间做了模块的预先编译,直接 npm i mongodb-client-encryption 安装即可,如果网络环境问题链接不上 github.com 可能就很麻烦了需要手动构建、编译,因为对模块的预先编译是放在 Github 上的。
mongocryptd:客户端加密必须要 mongocryptd 进程启动才能正常工作,刚开始一直遇到一个问题: MongoError: BSON field 'insert.jsonSchema' is an unknown field. This command may be meant for a mongocryptd process. 貌似就是因为 mongocryptd 进程没有启动导致的。在 MongoDB Server 企业版中包含 mongocryptd 这个组件的,解决办法也很简单就是本机安装下企业版,尽管我们这里使用的是 MongoDB Atlas 也要安装的,安装方法参考 docs.mongodb.com/manual/tutorial/install-mongodb-enterprise-on-os-x。
做一些初始化工作,安装依赖、配置文件、创建一个常规的 MongoDB client。
mkdir nodejs-mongodb-client-encryption
cd nodejs-mongodb-client-encryption
npm init
npm i mongodb mongodb-client-encryption -S创建一个 index.js 文件,核心代码逻辑都在该文件编写,
// index.js
const base64 = require('uuid-base64');
const { MongoClient, Binary } = require('mongodb');
const { ClientEncryption } = require('mongodb-client-encryption');
const fs = require('fs');
// 配置
const config = {
connectionString: '${替换为自己的 MongoDB 链接字符串}',
keyVaultDb: 'encryption', // encryption 表示密钥保管数据库
keyVaultCollection: '__keyVault', // __keyVault 表示集合
keyVaultNamespace: `encryption.__keyVault`, // 密钥库命名空间
keyAltNames: 'test-data-key',
masterKeyPath: 'master-key.txt'
}
const LOCAL_MASTER_KEY = fs.readFileSync(config.masterKeyPath); // 读取本地主密钥
const kmsProviders = { // 指定 KMS 提供程序设置
local: {
key: LOCAL_MASTER_KEY,
},
};/**
* 获取常规 Mongo 客户端
* @param {String} connectionString
* @returns
*/
function getRegularClient(connectionString) {
const client = new MongoClient(connectionString, {
useNewUrlParser: true,
useUnifiedTopology: true,
});
return client.connect();
}MongoDB 驱动程序自动加密/解密时需要访问事先创建的数据加密密钥,而这个密钥经过程序的处理会存储在密钥保管数据库的集合中,以下是创建一个数据加密密钥的交互图。
创建 MongoDB 数据加密密钥还需要另外一个称为 “主密钥” 的密钥进行加密,下图展示了创建主密钥的流程:
主密钥的存储,生产环境 MongoDB 官方的推荐是使用密钥管理服务(KMS):亚马逊网络服务 KMS、Azure 密钥保管库、谷歌云平台密钥管理,更多内容可阅读 客户端字段级加密:使用 KMS 存储主密钥。
学习为目的,简单方便些可使用本地密钥提供程序存储主密钥,这种方式不安全,不适合生产。
创建一个脚本文件 create-master-key.js,生成一个 96 字节的密钥文件,并写入到本地文件系统的 master-key.txt 文件中。
// create-master-key.js
const fs = require('fs');
const crypto = require('crypto');
try {
fs.writeFileSync('master-key.txt', crypto.randomBytes(96));
} catch (err) {
console.error(err);
}客户端使用如下配置发现主密钥,local 表示的是使用本地主密钥。
const LOCAL_MASTER_KEY = fs.readFileSync(config.masterKeyPath); // 读取本地主密钥
const kmsProviders = { // 指定 KMS 提供程序设置
local: {
key: LOCAL_MASTER_KEY,
},
};写一个函数 getOrCreateDataKey 分别传入创建的常规 client、上面指定的 KMS 程序配置,该方法目的是获取一个数据密钥,如果不存在则创建,实现为以下几个步骤:
/**
* 获取或创建数据加密密钥
* 如果已存在 dataKey 则返回,否则创建一条 dataKey
*/
async function getOrCreateDataKey(regularClient, kmsProviders) {
// 在密钥保管库集合的 keyAltNames 字段上先设置索引
await regularClient
.db(config.keyVaultDb)
.collection(config.keyVaultCollection)
.createIndex("keyAltNames", {
unique: true,
partialFilterExpression: {
keyAltNames: {
$exists: true
}
}
});
// 检查是否已创建数据加密密钥
const dataKeyInfo = await regularClient
.db(config.keyVaultDb)
.collection(config.keyVaultCollection)
.findOne({
keyAltNames: {
$in: [config.keyAltNames]
}
});
if (dataKeyInfo) { // 存在立即返回
return dataKeyInfo['_id'].toString("base64");
}
// 创建一条新的数据密钥
const encryption = new ClientEncryption(regularClient, {
keyVaultNamespace: config.keyVaultNamespace,
kmsProviders,
});
const dataKey = await encryption.createDataKey('local', {
keyAltNames: [config.keyAltNames]
});
return dataKey.toString('base64');
}调用编写好的方法,验证下数据加密密钥是否创建成功。
(async () => {
let regularClient;
try {
// 创建常规 MongoDB 客户端
regularClient = await getRegularClient(config.connectionString);
// 获取数据加密密钥
const base64DataKeyId = await getOrCreateDataKey(regularClient, kmsProviders);
} catch (err) {
console.error(err);
regularClient.close();
}
})();我使用 Robo 3T 链接的 Atlas 集群,如果一切正常,你会看到在 encryption.__keyVault 集合中有如下一条密钥记录,_id 字段就是为我们需要的数据加密密钥,使用 Base64 格式编码。
Node.js 驱动程序使用 JSON Schema 定义集合需要加密的字段,文档类型定义使用 BSON 类型。
/**
* 使用 JSON Schema 定义集合需要加密的字段
* @param {String} base64DataKeyId
* @returns
*/
function getSchemaMap(base64DataKeyId) {
// 使用 JSON Schema 指定加密字段
const userJsonSchema = {
bsonType: 'object',
encryptMetadata: {
keyId: [new Binary(Buffer.from(base64DataKeyId, 'base64'), 4)]
},
properties: {
phone: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Deterministic'
}
},
password: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Random'
}
},
emergencyContact: {
bsonType: 'object',
properties: {
phone: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Deterministic'
}
},
}
}
}
}
// 将 JSON 模式映射到集合上
const schemaMap = {
'test.users': userJsonSchema
};
return schemaMap;
}在有了数据加密密钥、JSON Schema 之后可以创建一个支持 CSFLE 的 Mongo client,该客户端和 MongDB 服务器交互,读取/写入带有加密字段的数据。
下图展示了客户端应用程序和驱动程序为写入字段级加密数据的一个步骤:
下图展示了客户端应用程序和驱动程序为读取加密后字段进行解密操作的一个过程:
创建 CSFLE 的 mongo client 与常规 mongo client 相比较,需要多传入 autoEncryption 对象,以下参数含义分别为:
function getCSFLEClient(schemaMap, kmsProviders) {
const secureClient = new MongoClient(config.connectionString, {
useNewUrlParser: true,
useUnifiedTopology: true,
monitorCommands: true,
autoEncryption: {
bypassAutoEncryption: true,
keyVaultNamespace: config.keyVaultNamespace,
kmsProviders,
schemaMap
}
});
return secureClient.connect();
}
(async () => {
try {
const regularClient = await getRegularClient(config.connectionString);
const base64DataKeyId = await getOrCreateDataKey(regularClient, kmsProviders);
const schemaMap = getSchemaMap(base64DataKeyId);
const csfleClient = await getCSFLEClient(schemaMap, kmsProviders);
// 执行读写操作
} catch (err) {
console.error(err);
}
})();在拥有 CSFLE 客户端后,执行一些读写操作,创建一条用户记录,下面的代码和我们常规的读写操作没什么区别,并且 phone 这个字段虽然是经过加密的,我们仍可使用该字段做为索引,更新/查找数据。
(async () => {
try {
// ...
const db = csfleClient.db('test');
const userColl = db.collection('users');
const doc = {
name: '小张',
phone: '18800030009',
password: '123456',
emergencyContact: {
name: '小李',
phone: '16600260023'
}
};
const query = { phone: doc.phone };
await userColl.updateOne(query, { $set: doc }, { upsert: true });
const result = await userColl.findOne(query);
console.log(result);
} catch (err) {
console.error(err);
}
})();当成功插入一条记录之后,在 Robo 3T 工具查询该集合,可以看到需要的字段都已经做了加密,尽管我是一个管理员能够查看数据,也无法查看这些隐私数据。
只能通过程序正确的创建了 CSFLE 的客户端才能读取出解密后的数据。
文中示例测试时常见的几个错误,可以做为参考。
遇到 Authentication failed 错误,基本上都是连接字符串的账号密码或权限错误,使用 MongoDB Atlas 的需要检查下数据库的访问权限配置
MongoServerError: bad auth : Authentication failed.
...
ok: 0,
code: 8000,
codeName: 'AtlasError',
[Symbol(errorLabels)]: Set(0) {}
}下面的报错很简单就是服务器链接不上。需要注意的是文中创建加密客户端还会去链接本地安装的 MongoDB 企业版 Server,在本地启动 MongoDB 企业版 Server 时需要指定下端口 bin/mongod --dbpath data --logpath logs/mongo.log --port 27020。
MongoServerSelectionError: connect ECONNREFUSED 127.0.0.1:27020
at Timeout._onTimeout (/Users/***********/nodejs-mongodb-client-encryption/node_modules/mongodb/lib/sdam/topology.js:318:38)
at listOnTimeout (internal/timers.js:554:17)
at processTimers (internal/timers.js:497:7) {
reason: TopologyDescription {
type: 'Unknown',
servers: Map(1) { 'localhost:27020' => [ServerDescription] },
stale: false,
compatible: true,
heartbeatFrequencyMS: 10000,
localThresholdMS: 15,
logicalSessionTimeoutMinutes: undefined
},
code: undefined,
[Symbol(errorLabels)]: Set(0) {}
}在刚开始的环境要求里有提到过 mongocryptd 进程,它会在这里检查 JSON Schema 中定义的加密指令,也就是 getCSFLEClient() 传入的 schemaMap 参数,如果 mongocryptd 进程没有启动,这里会一直报错。
以下是我最开始一直遇到的一个问题,解决办法很简单:
autoEncryption.bypassAutoEncryption=true 会自动生成 mongocryptd 进程。writeError occurred: MongoError: BSON field 'insert.jsonSchema' is an unknown field. This command may be meant for a mongocryptd process.
at MessageStream.messageHandler (/Users/quzhenfei/Documents/study/node_modules/mongodb/lib/cmap/connection.js:268:20)
at MessageStream.emit (events.js:314:20)
at processIncomingData (/Users/quzhenfei/Documents/study/node_modules/mongodb/lib/cmap/message_stream.js:144:12)
at MessageStream._write (/Users/quzhenfei/Documents/study/node_modules/mongodb/lib/cmap/message_stream.js:42:5)
at writeOrBuffer (_stream_writable.js:352:12)
at MessageStream.Writable.write (_stream_writable.js:303:10)
at TLSSocket.ondata (_stream_readable.js:713:22)
at TLSSocket.emit (events.js:314:20)
at addChunk (_stream_readable.js:303:12)
at readableAddChunk (_stream_readable.js:279:9) {
operationTime: Timestamp { _bsontype: 'Timestamp', low_: 1, high_: 1632613160 },
ok: 0,
code: 4662500,
codeName: 'Location4662500',
'$clusterTime': {
clusterTime: Timestamp { _bsontype: 'Timestamp', low_: 1, high_: 1632613160 },
signature: { hash: [Binary], keyId: [Long] }
}
}MongoDB 提供的客户端字段级自动加密,对于有数据隐私需要加密保护的还是很方便的,在配置了 CSFLE 客户端后应用程序在读写操作时和常规的客户端读写操作是没有差别的,唯一的阻碍可能是仅企业版支持。
文中我们将主密钥存储放在了本地的文件系统中,这在本地测试环境是可以的,但是生产环境不要用这种方式,因为任何能够访问您本地文件系统主密钥的人都可以读取您的数据加密密钥,建议放在更安全的地方,例如密钥管理系统(KMS)。
完整代码:
// create-master-key.js
const fs = require('fs');
const crypto = require('crypto');
try {
fs.writeFileSync('master-key.txt', crypto.randomBytes(96));
} catch (err) {
console.error(err);
}
// index.js
const { MongoClient, Binary } = require('mongodb');
const { ClientEncryption } = require('mongodb-client-encryption');
const fs = require('fs');
// 配置
const config = {
connectionString: 'mongodb://localhost:27017',
keyVaultDb: 'encryption', // encryption 表示密钥保管数据库
keyVaultCollection: '__keyVault', // __keyVault 表示集合
keyVaultNamespace: `encryption.__keyVault`, // 密钥库命名空间
keyAltNames: 'test-data-key',
masterKeyPath: 'master-key.txt'
}
const LOCAL_MASTER_KEY = fs.readFileSync(config.masterKeyPath); // 读取本地主密钥
const kmsProviders = { // 指定 KMS 提供程序设置
local: {
key: LOCAL_MASTER_KEY,
},
};
/**
* 获取常规 Mongo 客户端
* @param {String} connectionString
* @returns
*/
function getRegularClient(connectionString) {
const client = new MongoClient(connectionString, {
useNewUrlParser: true,
useUnifiedTopology: true,
});
return client.connect();
}
/**
* 获取或创建数据加密密钥
* 如果已存在 dataKey 则返回,否则创建一条 dataKey
*/
async function getOrCreateDataKey(regularClient, kmsProviders) {
await regularClient
.db(config.keyVaultDb)
.collection(config.keyVaultCollection)
.createIndex("keyAltNames", {
unique: true,
partialFilterExpression: {
keyAltNames: {
$exists: true
}
}
});
// 检查是否已创建数据加密密钥
const dataKeyInfo = await regularClient
.db(config.keyVaultDb)
.collection(config.keyVaultCollection)
.findOne({
keyAltNames: {
$in: [config.keyAltNames]
}
});
if (dataKeyInfo) { // 存在立即返回
return dataKeyInfo['_id'].toString("base64");
}
// 创建一条新的数据密钥
const encryption = new ClientEncryption(regularClient, {
keyVaultNamespace: config.keyVaultNamespace,
kmsProviders,
});
const dataKey = await encryption.createDataKey('local', {
keyAltNames: [config.keyAltNames]
});
return dataKey.toString('base64');
}
/**
* 使用 JSON Schema 定义集合需要加密的字段
* @param {String} base64DataKeyId
* @returns
*/
function getSchemaMap(base64DataKeyId) {
// 使用 JSON Schema 指定加密字段
const userJsonSchema = {
bsonType: 'object',
encryptMetadata: {
keyId: [new Binary(Buffer.from(base64DataKeyId, 'base64'), 4)]
},
properties: {
phone: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Deterministic'
}
},
password: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Random'
}
},
emergencyContact: {
bsonType: 'object',
properties: {
phone: {
encrypt: {
bsonType: 'string',
algorithm: 'AEAD_AES_256_CBC_HMAC_SHA_512-Deterministic'
}
},
}
}
}
}
// 将 JSON 模式映射到集合上
const schemaMap = {
'test.users': userJsonSchema
};
return schemaMap;
}
function getCSFLEClient(schemaMap, kmsProviders) {
const secureClient = new MongoClient(config.connectionString, {
useNewUrlParser: true,
useUnifiedTopology: true,
monitorCommands: true,
autoEncryption: {
bypassAutoEncryption: true,
keyVaultNamespace: config.keyVaultNamespace,
kmsProviders,
schemaMap
}
});
return secureClient.connect();
}
(async () => {
try {
// 创建常规 MongoDB 客户端
const regularClient = await getRegularClient(config.connectionString);
// 获取数据密钥
const base64DataKeyId = await getOrCreateDataKey(regularClient, kmsProviders);
// 使用 JSON Schema 定义集合需要加密的字段
const schemaMap = getSchemaMap(base64DataKeyId);
// 创建加密 MongoDB 客户端
const csfleClient = await getCSFLEClient(schemaMap, kmsProviders);
const db = csfleClient.db('test');
const userColl = db.collection('users');
const doc = {
name: '小张',
phone: '18800030009',
password: '123456',
emergencyContact: {
name: '小李',
phone: '16600260023'
}
};
const query = { phone: doc.phone };
await userColl.updateOne(query, { $set: doc }, { upsert: true });
const result = await userColl.findOne(query);
console.log('user information after decrypteduser info: ', result);
} catch (err) {
console.error(err);
}
})();Git 当下最流行的版本管理工具,结合自己工作中的实际应用做了以下梳理,如果您在使用中还有其它问题欢迎评论留言。
git init 初始化本地仓库git add -A . 来一次添加所有改变的文件git add -A 表示添加所有内容git add . 表示添加新文件和编辑过的文件不包括删除的文件git add -u 表示添加编辑或者删除的文件,不包括新添加的文件git commit -m '版本信息' 提交的版本信息描述git status 查看状态git push -u origin master 推送到远程仓库看git pull 拉取远程仓库代码到本地git branch -av 查看每个分支的最新提交记录git branch -vv 查看每个分支属于哪个远程仓库git reset --hard a3f40baadd5fea57b1b40f23f9a54a644eebd52e 代码回归到某个提交记录git branch -a git branch dev git checkout -b devgit branchgit checkout devgit branch -d devgit push origin :devgit branch -m oldBranch newBranchgit remote rm origin 先删除git remote add origin 仓库地址 链接到到远程git仓库git remote set-url origin 仓库地址git pull命令首先从远程的origin的master主分支下载最新的版本到origin/master分支上
git fetch origin master
比较本地的master分支和origin/master分支的差别
git log -p master..origin/master
进行合并
git merge origin/master
首先要与origin master建立连接:git remote add origin [email protected]:XXXX/nothing2.git
切换到其中某个子分支:git checkout -b dev origin/dev
可能会报这种错误:
fatal: Cannot update paths and switch to branch 'dev' at the same time.
Did you intend to checkout 'origin/dev' which can not be resolved as commit?
原因是你本地并没有dev这个分支,这时你可以用 git branch -a 命令来查看本地是否具有dev分支
我们需要:git fetch origin dev 命令来把远程分支拉到本地
然后使用:git checkout -b dev origin/dev 在本地创建分支dev并切换到该分支
最后使用:git pull origin dev 就可以把某个分支上的内容都拉取到本地了
如何解决 failed to push some refs to git
git pull --rebase origin master 进行代码合并git push -u origin master 即可完成代码上传If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=origin/<branch> master
指定当前当前工作目录工作分支,跟远程仓库分支之间的联系
git branch --set-upstream master origin/master
获取 git pull 最新代码报以下错误:
fatal: refusing to merge unrelated histories
git pull之后加上可选参数 --allow-unrelated-histories 强制合并
git pull origin master --allow-unrelated-histories
使用钩子pre-commit,提交代码提示如下错误:
$ git commit -m '.'
sh: eslint: command not found
pre-commit:
pre-commit: We've failed to pass the specified git pre-commit hooks as the `fix`
pre-commit: hook returned an exit code (1). If you're feeling adventurous you can
pre-commit: skip the git pre-commit hooks by adding the following flags to your commit:
pre-commit:
pre-commit: git commit -n (or --no-verify)
pre-commit:
pre-commit: This is ill-advised since the commit is broken.
pre-commit:.git/hooks 文件夹,找到 pre-commit.sample 文件,将以下代码替换到文件中,或者,npm install pre-commit --save 也可以,这个命令会自动执行以下操作。#!/bin/bash
TSLINT="$(git rev-parse --show-toplevel)/node_modules/.bin/tslint"
for file in $(git diff --cached --name-only | grep -E '\.ts$')
do
git show ":$file" | "$TSLINT" "$file"
if [ $? -ne 0 ]; then
exit 1
fi
donepre-commit.sample文件名修改为pre-commit。.gitignore 规则不生效的解决办法
把某些目录或文件加入忽略规则,按照上述方法定义后发现并未生效,原因是.gitignore只能忽略那些原来没有被追踪的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的。那么解决方法就是先把本地缓存删除(改变成未被追踪状态),然后再提交:
git rm -r --cached . 或者 git rm -r README.md
git add .
git commit -m 'update .gitignore'
当我了解事件循环时,尝试去找一些规范来学习,但是查遍 EcmaScript 或 V8 发现它们没有这个东西的定义,例如,在 v8 里有的是执行栈、堆这些信息。确实,事件循环不在这里。
后来才逐渐的了解到,当在浏览器环境中,关于事件循环相关定义是在 HTML 标准中,之前 HTML 规范由 whatwg 和 w3c 制定,两个组织都有自己的不同,2019 年时两个组织签署了一项协议 就 HTML 和 DOM 的单一版本进行合作,最终,HTML、DOM 标准最终由 whatwg 维护。
本文的讲解主要也是以 whatwg 标准为主,在 HTML Living Standard Event loops 中,这个规范定义了浏览器内核该如何的去实现它。
为了协调事件、用户交互、脚本、渲染、网络等,用户代理必须使用本节描述的事件循环。 每个代理有一个关联的事件循环,它对每个代理是唯一的。
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents must use event loops as described in this section. Each agent has an associated event loop, which is unique to that agent.
从这个定义也可看出,事件循环主要是用来协调事件、网络、JavaScript 等之间的一个运行机制,我们以 JavaScript 为出发点来看下它们之间是如何交互的。
事件循环中有一个重要的概念任务队列,它决定了任务的执行顺序。
规范 8.1.6.3 处理模型 定义了事件循环的处理模式,当一个事件循环存在,它就会不断的执行以下步骤:
这些概念很晦涩难懂,简单总结下:
看到一个图,描述一次事件循环的过程,差不多就是这个意思,主要呢,还是这三个阶段:Task、Microtask、Render 下文会展开的讨论。
图片来源:https://pic2.zhimg.com/80/v2-38e53b9df2d13e9470c31101bb82dbb1_1440w.jpg
之前也看过很多文章关于事件循环的介绍,**大多会把 “Task” 当作 “Marcotask” 也就是宏任务来介绍,但是在规范中没有所谓的 “Marcotask”,**因为规范里没有这个名词,所以我在这个标题上特意加了个括号,有很多的叫法,也有称为外部队列的,这其实是一个意思,如果你是学习事件循环的新朋友可能就会有疑问,为什么我搜索不到关于这个的解释。
下文我会继续使用规范中的名词 “任务队列” 来表达。
任务队列是一个任务的集合。事件循环有一个或多个任务队列,事件循环做的第一步是从选择的队列中获取第一个可运行的任务,而不是出列第一个任务。
传统的队列(Queue)是一个先进先出的数据结构,总是排在第一个的先执行,而这里的队列里面会包含一些类似于 setTimeout 这样延迟执行的任务,所以,在规范中有这样一句话:“Task queues are sets, not queues(翻译为任务队列是一个集合,不是队列)”。
任务队列的 任务源 主要包括以下这些:
document.body = aNewBodyElement;。例如,当 User agent 有一个管理鼠标和键盘事件的任务队列和另一个其它任务源相关的任务队列,在事件循环中相比其它任务,它会多出四分之三的时间来优先执行鼠标和键盘事件的任务队列,这样使得其它任务源的任务队列在能够得到处理的情况下用户交互相关的任务可以得到更高优先级的处理,这也是提高了用户的体验。
每个事件循环有一个微任务队列,它不是一个 task queue,两者是独立的队列。
微任务是一个简短的函数,当创建该函数的函数执行后,并且 JavaScript 执行上下文栈为空,而控制权尚未交还给事件循环之前触发。
当我们在一个微任务里通过 queueMicrotask(callback) 继续向微任务队列中创建更多的任务,对于事件循环来说,它仍会持续调用微任务直至队列为空。
const log = console.log;
let i = 0;
log('sync run start');
runMicrotask();
log('sync run end');
function runMicrotask() {
queueMicrotask(() => {
log("microtask run, i = ", i++);
if (i > 10) return;
runMicrotask();
});
}上面这段代码很简单,在主线程调用了 runMicrotask() 函数,该函数内部使用 queueMicrotask() 创建了微任务并且递归调用,微任务的触发是在执行栈为空时才执行,因为里面递归调用每次都会生成新的微任务,事件循环也是在微任务执行完毕才执行 Task Queue 里面的 setTimeout 回调。
sync run start
sync run end
microtask run, i = 0
microtask run, i = 1
microtask run, i = 2
microtask run, i = 3
microtask run, i = 4
microtask run, i = 5
microtask run, i = 6
microtask run, i = 7
microtask run, i = 8
microtask run, i = 9
microtask run, i = 10
通过这个示例,也可看到当调度大量的微任务也会导致和同步任务相同的性能缺陷,后面的任务得不到执行,浏览器的渲染工作也会被阻止。微任务这里的队列才是真正的队列。
在以往我们创建一个微任务很简单,可以创建一个立即 resolve 的 Promise,每次都需要创建一个 Promise 实例,同时也带来了额外的内存开销,另外 Promise 中抛出的错误是一个非标准的 Error,如果未正常捕获通常会得到这样一个错误 UnhandledPromiseRejectionWarning:。
使用 Promise 创建一个微任务。
const p = new Promise((resolve, reject) => {
// reject('err')
resolve(1);
});
p.then(() => {
log('Promise microtask.')
});现在 Window 对象上提供了 queueMicrotask() 方法以一种标准的方式,可以安全的引入微任务,而无需使用额外的技巧,它提供了一种标准的异常。
使用 queueMicrotask() 创建一个微任务。
queueMicrotask(() => {
log('queueMicrotask.');
});在我们写业务功能时,一个功能或方法内涉及多个异步调度的任务也是很常见的,基于 Promise 我们很熟悉,还可以使用 Async/Await 以一种同步线性的思维来书写代码。而 queueMicrotask 需要传递一个回调函数,当层级多了很容易出现嵌套。
重点是大多数情况下我们也不需要去创建微任务,过多的滥用也会造成性能问题,也许在做一些类似创建框架或库时可能需要借助微任务来达到某些功能。这里我想到了一个经常问的面试题 “实现一个 Promise” 这个在实现时也许可以采用 queueMicrotask(),在《JavaScript 异步编程》的源码系列,会再看到这个问题。
Microtask 总结一句话来讲就是:“它是在当前执行栈尾部下一次事件循环前执行”,需要注意的是,事件循环在处理微任务时,如果微任务队列不为空,就会继续执行微任务,例如,使用递归不停的增加新的微任务,这就很糟糕了。
微任务所包含的任务源没有明确的定义,通常包括这几个:Promise.then()、Object.observe(已废弃)、MutaionObserver、queueMicrotask。
渲染是事件循环中另一个很重要的阶段,这里有一个关于 浏览器工作原理 的讲解很好,整个渲染过程,理解下来主要是下面几个步骤,其中 Layout、 **Paint **这些词在下面的示例还会再次看到。
图片来源:https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/webkitflow.png
做一个测试,使用 queueMicrotask 创建一个微任务,在自定义的 runMicrotask() 函数内部递归调用了 10 次,每一次里我都希望来回变换 container 这个 div 的背景色,另外还放置了一个 setTimeout 属于 Task queue 这个是让大家顺便看下 Task queue 在事件循环中的执行顺序。
<div id="container" style="width: 200px; height: 200px; background-color: red; font-size: 100px; color: #fff;">
0
</div>
<script>
let i = 0;
const container = document.getElementById('container');
setTimeout(() => {});
runMicrotask();
function runMicrotask() {
queueMicrotask(() => {
if (i > 10) return;
container.innerText = i;
container.style.backgroundColor = i % 2 === 0 ? 'blue' : 'red';
runMicrotask();
});
}
</script>通过 Chrome 的 Performance 记录,运行过程,首先看下 Frame 只有一个,直接渲染出了最后的结果,如果按照上例,我们可能会觉得应该是在每个微任务执行时都会有一次渲染 blue -> red -> blue -> ...
再看一个更详细的执行过程,可以看到在执行脚步执行后,首先运行的是微任务,对应的是我们代码 runMicrotask() 函数,下图紫色的是 Layout,Paint 是渲染绘制能够看到就是在运行完所有的微任务之后执行的,在之后是下一次事件循环最后执行了 Task Queue Timer。
根据事件循环处理模式规范中的描述,渲染是在一次事件循环的微任务结束之后运行,上例差不多验证了这个结果,这个时候有个疑问:“为什么不是在每一次微任务结束之后执行,当你把 queueMicrotask 替换成 setTimeout 也是一样的,不会在每次事件中都去执行”。
规范中还有这样一段描述,得到一个信息是:在每一次的事件循环结束后不一定会执行渲染。
每一轮的事件循环如果没有阻塞操作,这个时间是很快的,考虑到硬件刷新频率限制和性能原因的 user agent 节流,浏览器的更新渲染不会在每次事件循环中被触发。如果浏览器试图达到每秒 60Hz 的刷新率,也简称 60fps(60 frame per second),这时绘制一个 Frame 的间隔为 16.67ms(1000/60)。如果在 16ms 内有多次 DOM 操作,也是不会渲染多次的。
如果浏览器无法维持 60fps 就会降低到 30fps、4fps 甚至更低。
如果想在每次事件循环中或微任务之后执行一次绘制,可以通过 requestAnimationFrame 重新渲染。
requestAnimationFrame 是浏览器 window 对象下提供的一个 API,它的应用场景是告诉浏览器,我需要运行一个动画。该方法会要求浏览器在下次重绘之前调用指定的回调函数更新动画。
修改上述示例,加上 requestAnimationFrame() 方法。
function runMicrotask() {
queueMicrotask(() => {
requestAnimationFrame(() => {
if (i > 10) return;
container.innerText = i;
container.style.backgroundColor = i % 2 === 0 ? 'blue' : 'red';
i++;
runMicrotask();
});
});
}运行之后如下所示,每一次的元素改变都得到了重新绘制。
放大其中一个看看任务的执行情况,requestAnimationFrame 也可以看作一个任务,可以看到它在运行之后执行微任务。
事件循环中 Render 阶段可能在一次事件循环中运行,也可能在多次事件循环后运行。它会受到浏览器的刷新频率影响,如果是 60fps 那就是每间隔 16.67ms 执行一次,另一方面当浏览器认为更新渲染对用户没有影响的情况下,也会认为这不是一次必要的渲染。
总的来说它的机制和浏览器是相关的,了解即可,不用特别的纠结。
浏览器中事件循环主要由 Task、Microtask、Render 三个阶段组成,Task、Microtask 是我们会用到的比较多的,无论是网络请求、还是 DOM 操作、Promise 这些大致都划分为这两类任务,每一轮的事件循环都会检查这两个任务队列里是否有要执行的任务,等 JavaScript 上下文栈空后,先情况微任务队列里的所有任务,之后在执行宏任务,而 Render 则不是必须的,它受浏览器的一些因素影响,并不一定在每次事件循环中执行。

2008 年 8 月 TLS v1.2 发布,时隔 10 年,TLS v1.3 于 2018 年 8 月发布,在性能优化和安全性上做了很大改变,同时为了避免新协议带来的升级冲突,TLS v1.3 也做了兼容性处理,通过增加扩展协议来支持旧版本的客户端和服务器。
TLS v1.2 支持的加密套件很多,在兼容老版本上做的很全,里面有些加密强度很弱和一些存在安全漏洞的算法很可能会被攻击者利用,为业务带来潜在的安全隐患。TLS v1.3 移除了这些不安全的加密算法,简化了加密套件,对于服务端握手过程中也减少了一些选择。
性能优化一个显著的变化是简化了 TLS 握手阶段,由 TLS v1.2 的 2-RTT 缩短为 1-RTT,同时在第一次建立链接后 TLS v1.3 还引入了 0-RTT 概念。
密钥协商在 TLS v1.2 中需要客户端/服务端双方交换随机数和服务器发送完证书后,双方各自发送 “Clent/Server Key Exchange” 消息交换密钥协商所需参数信息。在安全性上,TLS v1.3 移除了很多不安全算法,简化了密码套件,现在已移除了 “Clent/Server Key Exchange” 消息,在客户端发送 “Client Hello” 消息时在扩展协议里携带支持的椭圆曲线名称、临时公钥、签名信息。服务器收到消息后,在 “Server Hello” 消息中告诉客户端选择的密钥协商参数,由此可少了一次消息往返(1-RTT)。
Client Server
Key ^ ClientHello
Exch | + key_share*
| + signature_algorithms*
| + psk_key_exchange_modes*
v + pre_shared_key* -------->
ServerHello ^ Key
+ key_share* | Exch
+ pre_shared_key* v
{EncryptedExtensions} ^ Server
{CertificateRequest*} v Params
{Certificate*} ^
{CertificateVerify*} | Auth
{Finished} v
<-------- [Application Data*]
^ {Certificate*}
Auth | {CertificateVerify*}
v {Finished} -------->
[Application Data] <-------> [Application Data]
The basic full TLS handshake当访问之前访问过的站点时,客户端可以通过利用先前会话中的 预共享密钥 (PSK) 将第一条消息上的数据发送到服务器,实现 “零往返时间(0-RTT)”。
Client Server
ClientHello
+ early_data
+ key_share*
+ psk_key_exchange_modes
+ pre_shared_key
(Application Data*) -------->
ServerHello
+ pre_shared_key
+ key_share*
{EncryptedExtensions}
+ early_data*
{Finished}
<-------- [Application Data*]
(EndOfEarlyData)
{Finished} -------->
[Application Data] <-------> [Application Data]
Message Flow for a 0-RTT Handshake以一次客户端/服务端完整的 TLS 握手为例,通过抓包分析看下 TLS v1.3 的握手过程。下图是抓取的 www.zhihu.com 网站数据报文,且对报文做了解密处理,否则 “Change Cipher Spec” 报文后的数据都已经被加密是分析不了的。抓包请参考 “网络协议那些事儿 - 如何抓包并破解 HTTPS 加密数据?”。

TLS v1.3 握手过程如下图所示:

握手开始客户端告诉服务端自己的 Random、Session ID、加密套件等。
除此之外,TLS v1.3 需要关注下 “扩展协议”,TLS v1.3 通过扩展协议做到了 “向前兼容“,客户端请求的时候告诉服务器它支持的协议、及一些其它扩展协议参数,如果老版本不识别就忽略。
下面看几个主要的扩展协议:
Transport Layer Security
TLSv1.3 Record Layer: Handshake Protocol: Client Hello
Version: TLS 1.0 (0x0301)
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Version: TLS 1.2 (0x0303)
Random: 77f485a55b836cbaf4328ea270082cdf35fd8132aa7487eae19997c8939a292a
Session ID: 8d4609d9f0785880eb9443eff3867a63c23fb2e23fdf80d225c1a5a25a900eee
Cipher Suites (16 suites)
Cipher Suite: Reserved (GREASE) (0x1a1a)
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
Extension: signature_algorithms (len=18)
Extension: supported_groups (len=10)
Supported Groups (4 groups)
Supported Group: Reserved (GREASE) (0xcaca)
Supported Group: x25519 (0x001d)
Supported Group: secp256r1 (0x0017)
Supported Group: secp384r1 (0x0018)
Extension: key_share (len=43)
Type: key_share (51)
Key Share extension
Client Key Share Length: 41
Key Share Entry: Group: Reserved (GREASE), Key Exchange length: 1
Key Share Entry: Group: x25519, Key Exchange length: 32
Group: x25519 (29)
Key Exchange Length: 32
Key Exchange: 51afc57ca38df354f6d4389629e222ca2654d88f2800cc84f8cb74eefd473f4b
Extension: supported_versions (len=11)
Type: supported_versions (43)
Supported Versions length: 10
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)服务端收到客户端请求后,返回选定的密码套件、Server Random、选定的椭圆曲线名称及对应的公钥(Server Params)、支持的 TLS 版本。
这次的密码套件看着短了很多 TLS_AES_256_GCM_SHA384,其中用于协商密钥的参数是放在 key_share 这个扩展协议里的。
TLSv1.3 Record Layer: Handshake Protocol: Server Hello
Content Type: Handshake (22)
Handshake Protocol: Server Hello
Handshake Type: Server Hello (2)
Version: TLS 1.2 (0x0303)
Random: 1f354a11aea2109ba22e26d663a70bddd78a87a79fed85be2d03d5fc9deb59a5
Session ID: 8d4609d9f0785880eb9443eff3867a63c23fb2e23fdf80d225c1a5a25a900eee
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Compression Method: null (0)
Extensions Length: 46
Extension: supported_versions (len=2)
Supported Version: TLS 1.3 (0x0304)
Extension: key_share (len=36)
Type: key_share (51)
Key Share extension
Key Share Entry: Group: x25519, Key Exchange length: 32
Group: x25519 (29)
Key Exchange: ac1e7f0dd5a4ee40fd088a8c00113178bafb2df59e0d6fc74ce77452732bc44d服务端此时拿到了 Client Random、Client Params、Server Random、Server Params 四个参数,可优先计算出预主密钥。在 TLS v1.2 中是经历完第一次消息往返之后,客户端优先发起请求。
在计算出用于对称加密的会话密钥后,服务端发出 Change Cipher Spec 消息并切换到加密模式,之后的所有消息(证书、证书验证)传输都会加密处理,也减少了握手期间的明文传递。
除了 Certificate 外,TLS v1.3 还多了个 “Certificate Verify” 消息,使用服务器私钥对握手信息做了一个签名,强化了安全措施。
Transport Layer Security
TLSv1.3 Record Layer: Handshake Protocol: Certificate
TLSv1.3 Record Layer: Handshake Protocol: Certificate Verify
Handshake Protocol: Certificate Verify
Signature Algorithm: rsa_pss_rsae_sha256 (0x0804)
Signature Hash Algorithm Hash: Unknown (8)
Signature Hash Algorithm Signature: Unknown (4)
Signature length: 256
Signature: 03208990ec0d4bde4af8e2356ae7e86a045137afa5262ec7c82d55e95ba23b6eb5876ebb…
TLSv1.3 Record Layer: Handshake Protocol: Finished
Handshake Protocol: Finished
Verify Data客户端获取到 Client Random、Client Params、Server Random、Server Params 四个参数计算出最终会话密钥后,也会发起 “Certificate Verify”、“Finished” 消息,当客户端和服务端都发完 “Finished” 消息后握手也就完成了,接下来就可安全的传输数据了。

事件循环是一种控制应用程序的运行机制,在不同的运行时环境有不同的实现,上一节讲了浏览器中的事件循环,它们有很多相似的地方,也有着各自的特点,本节讨论下 Node.js 中的事件循环。
Node.js 做为 JavaScript 的服务端运行时,主要与网络、文件打交道,没有了浏览器中事件循环的渲染阶段。
在浏览器中有 HTML 规范来定义事件循环的处理模型,之后由各浏览器厂商实现。Node.js 中事件循环的定义与实现均来自于 Libuv。
Libuv 围绕事件驱动的异步 I/O 模型而设计,最初是为 Node.js 编写的,提供了一个跨平台的支持库。下图展示了它的组成部分,Network I/O 是网络处理相关的部分,右侧还有文件操作、DNS,底部 epoll、kqueue、event ports、IOCP 这些是底层不同操作系统的实现。
图片来源:http://docs.libuv.org/en/v1.x/_images/architecture.png
当 Node.js 启动时,它会初始化事件循环,处理提供的脚本,同步代码入栈直接执行,异步任务(网络请求、文件操作、定时器等)在调用 API 传递回调函数后会把操作转移到后台由系统内核处理。目前大多数内核都是多线程的,当其中一个操作完成时,内核通知 Node.js 将回调函数添加到轮询队列中等待时机执行。
下图左侧是 Node.js 官网对事件循环过程的描述,右侧是 Libuv 官网对 Node.js 的描述,都是对事件循环的介绍,不是所有人上来都能去看源码的,这两个文档通常也是对事件循环更直接的学习参考文档,在 Node.js 官网介绍的也还是挺详细的,可以做为一个参考资料学习。

右侧更详细的描述了,在事件循环迭代前,先去判断循环是否处于活动状态(有等待的异步 I/O、定时器等),如果是活动状态开始迭代,否则循环将立即退出。
下面对每个阶段分别讨论。
首先事件循环进入定时器阶段,该阶段包含两个 API setTimeout(cb, ms)、setInterval(cb, ms) 前一个是仅执行一次,后一个是重复执行。
这个阶段检查是否有到期的定时器函数,如果有则执行到期的定时器回调函数,和浏览器中的一样,定时器函数传入的延迟时间总比我们预期的要晚,它会受到操作系统或其它正在运行的回调函数的影响。
例如,下例我们设置了一个定时器函数,并预期在 1000 毫秒后执行。
const now = Date.now();
setTimeout(function timer1(){
log(`delay ${Date.now() - now} ms`);
}, 1000);
setTimeout(function timer2(){
log(`delay ${Date.now() - now} ms`);
}, 5000);
someOperation();
function someOperation() {
// sync operation...
while (Date.now() - now < 3000) {}
}当调用 setTimeout 异步函数后,程序紧接着执行了 someOperation() 函数,中间有些耗时操作大约消耗 3000ms,当完成这些同步操作后,进入一次事件循环,首先检查定时器阶段是否有到期的任务,定时器的脚本是按照 delay 时间升序存储在堆内存中,首先取出超时时间最小的定时器函数做检查,如果 **nowTime - timerTaskRegisterTime > delay** 取出回调函数执行,否则继续检查,当检查到一个没有到期的定时器函数或达到系统依赖的最大数量限制后,转移到下一阶段。
在我们这个示例中,假设执行完 someOperation() 函数的当前时间为 T + 3000:
定时器阶段完成后,事件循环进入到 pending callbacks 阶段,在这个阶段执行上一轮事件循环遗留的 I/O 回调。根据 Libuv 文档的描述:大多数情况下,在轮询 I/O 后立即调用所有 I/O 回调,但是,某些情况下,调用此类回调会推迟到下一次循环迭代。听完更像是上一个阶段的遗留。
idle, prepare 阶段是给系统内部使用,idle 这个名字很迷惑,尽管叫空闲,但是在每次的事件循环中都会被调用,当它们处于活动状态时。这一块的资料介绍也不是很多。略...
poll 是一个重要的阶段,这里有一个概念观察者,有文件 I/O 观察者,网络 I/O 观察者等,它会观察是否有新的请求进入,包含读取文件等待响应,等待新的 socket 请求,这个阶段在某些情况下是会阻塞的。
在阻塞 I/O 之前,要计算它应该阻塞多长时间,参考 Libuv 文档上的一些描述,以下这些是它计算超时时间的规则:
如果以上情况都没有,则采用最近定时器的超时时间,或者如果没有活动的定时器,则超时时间为无穷大,poll 阶段会一直阻塞下去。
很简单的一段代码,我们启动一个 Server,现在事件循环的其它阶段没有要处理的任务,它会在这里等待下去,直到有新的请求进来。
const http = require('http');
const server = http.createServer();
server.on('request', req => {
console.log(req.url);
})
server.listen(3000);结合阶段一的定时器,在看个示例,首先启动 app.js 做为服务端,模拟延迟 3000ms 响应,这个只是为了配合测试。再运行 client.js 看下事件循环的执行过程:
setTimeout run after 1003 ms。// client.js
const now = Date.now();
setTimeout(() => log(`setTimeout run after ${Date.now() - now} ms`), 1000);
someAsyncOperation();
function someAsyncOperation() {
http.get('http://localhost:3000/api/news', () => {
log(`fetch data success after ${Date.now() - now} ms`);
});
}
// app.js
const http = require('http');
http.createServer((req, res) => {
setTimeout(() => { res.end('OK!') }, 3000);
}).listen(3000);当 poll 阶段队列为空时,并且脚本被 setImmediate() 调度过,此时,事件循环也会结束 poll 阶段,进入下一个阶段 check。
check 阶段在 poll 阶段之后运行,这个阶段包含一个 API setImmediate(cb) 如果有被 setImmediate 触发的回调函数,就取出执行,直到队列为空或达到系统的最大限制。
拿 setTimeout 和 setImmediate 对比,这是一个常见的例子,基于被调用的时机和定时器可能会受到计算机上其它正在运行的应用程序影响,它们的输出顺序,不总是固定的。
setTimeout(() => log('setTimeout'));
setImmediate(() => log('setImmediate'));
// 第一次运行
setTimeout
setImmediate
// 第二次运行
setImmediate
setTimeout但是一旦把这两个函数放入一个 I/O 循环内调用,setImmediate 将总是会被优先调用。因为 setImmediate 属于 check 阶段,在事件循环中总是在 poll 阶段结束后运行,这个顺序是确定的。
fs.readFile(__filename, () => {
setTimeout(() => log('setTimeout'));
setImmediate(() => log('setImmediate'));
})在 Libuv 中,如果调用关闭句柄 uv_close(),它将调用关闭回调,也就是事件循环的最后一个阶段 close callbacks。
这个阶段的工作更像是做一些清理工作,例如,当调用 socket.destroy(),'close' 事件将在这个阶段发出,事件循环在执行完这个阶段队列里的回调函数后,检查循环是否还 alive,如果为 no 退出,否则继续下一次新的事件循环。
在浏览器的事件循环中,把任务划分为 Task、Microtask,在 Node.js 中是按照阶段划分的,上面我们介绍了 Node.js 事件循环的 6 个阶段,给用户使用的主要是 timer、poll、check、close callback 四个阶段,剩下两个由系统内部调度。这些阶段所产生的任务,我们可以看做 Task 任务源,也就是常说的 “Macrotask 宏任务”。
通常我们在谈论一个事件循环时还会包含 Microtask,Node.js 里的微任务有 Promise、还有一个也许很少关注的函数 queueMicrotask,它是在 Node.js v11.0.0 之后被实现的,参见 PR/22951。
Node.js 中的事件循环在每一个阶段执行后,都会检查微任务队列中是否有待执行的任务。
Node.js 在 v11.x 前后,每个阶段如果即存在可执行的 Task 又存在 Microtask 时,会有一些差异,先看一段代码:
setImmediate(() => {
log('setImmediate1');
Promise.resolve('Promise microtask 1')
.then(log);
});
setImmediate(() => {
log('setImmediate2');
Promise.resolve('Promise microtask 2')
.then(log);
});在 Node.js v11.x 之前,当前阶段如果存在多个可执行的 Task,先执行完毕,再开始执行微任务。基于 v10.22.1 版本运行结果如下:
setImmediate1
setImmediate2
Promise microtask 1
Promise microtask 2在 Node.js v11.x 之后,当前阶段如果存在多个可执行的 Task,先取出一个 Task 执行,并清空对应的微任务队列,再次取出下一个可执行的任务,继续执行。基于 v14.15.0 版本运行结果如下:
setImmediate1
Promise microtask 1
setImmediate2
Promise microtask 2在 Node.js v11.x 之前的这个执行顺序问题,被认为是一个应该要修复的 Bug 在 v11.x 之后并修改了它的执行时机,和浏览器保持了一致,详细参见 issues/22257 讨论。
Node.js 中还有一个异步函数 process.nextTick(),从技术上讲它不是事件循环的一部分,它在当前操作完成后处理。如果出现递归的 process.nextTick() 调用,这将会很糟糕,它会阻断事件循环。
如下例所示,展示了一个 process.nextTick() 递归调用示例,目前事件循环位于 I/O 循环内,当同步代码执行完成后 process.nextTick() 会被立即执行,它会陷入无限循环中,与同步的递归不同的是,它不会触碰 v8 最大调用堆栈限制。但是会破坏事件循环调度,setTimeout 将永远得不到执行。
fs.readFile(__filename, () => {
process.nextTick(() => {
log('nextTick');
run();
function run() {
process.nextTick(() => run());
}
});
log('sync run');
setTimeout(() => log('setTimeout'));
});
// 输出
sync run
nextTick将 process.nextTick 改为 setImmediate 虽然是递归的,但它不会影响事件循环调度,setTimeout 在下一次事件循环中被执行。
fs.readFile(__filename, () => {
process.nextTick(() => {
log('nextTick');
run();
function run() {
setImmediate(() => run());
}
});
log('sync run');
setTimeout(() => log('setTimeout'));
});
// 输出
sync run
nextTick
setTimeoutprocess.nextTick 是立即执行,setImmediate 是在下一次事件循环的 check 阶段执行。但是,它们的名字着实让人费解,也许会想这两个名字交换下比较好,但它属于遗留问题,也不太可能会改变,因为这会破坏 NPM 上大部分的软件包。
在 Node.js 的文档中也建议开发者尽可能的使用 setImmediate(),也更容易理解。
Node.js 事件循环分为 6 个阶段,每个阶段都有一个 FIFO(先进先出)队列执行回调函数,这几个阶段之间执行的优先级顺序还是明确的。
事件循环的每一个阶段,有时还会伴随着一些微任务而运行,这里以 Node.js v11.x 版本为分界线会有一些差异,文中也都有详细的介绍。
在上一篇介绍了浏览器的事件循环机制,本篇又详细的介绍了 Node.js 中的事件循环机制,留给大家一个思考问题,结合自己的理解,总结下浏览器与 Node.js 中事件循环的一些差异,这个也是常见的一个面试题,欢迎在留言区讨论。
在 Cnode 上看到的两篇事件循环相关文章,推荐给大家,文章很精彩,评论也更加精彩。
使用 React Hooks 时函数组件应用的比较多,当遇到组件重复渲染问题不像类组件可以使用生命周期函数 shouldComponentUpdate 或 extends React.PureComponent 解决重复渲染问题。
例如,一个父组件 Home 中渲染了子组件 List,同时 Home 组件还有一个计数器组件,每次点击 count 都会加 1,遇到类似的场景就会出现子组件重复渲染问题,这是因为 React 中当父组件的一个状态改变后,无论和子组件是否有关,子组件都会受到影响进行重新渲染,这也是 React 中默认的一个行为。
函数组件中的解决方案是使用 React.memo() 函数,将需要优化的函数组件传入即可。
import React, { useEffect, useState } from "react";
// 未使用 memo:const List = ({ dataList }) => {
const List = React.memo(({ dataList }) => {
console.log("List 渲染");
return (
<div>
{dataList.map((item) => (
<h2 key={item.id}> {item.title} </h2>
))}
</div>
);
});
const Home = () => {
const [count, setCount] = useState(0);
const [dataList, setDataList] = useState([]);
useEffect(() => {
const list = [
{ title: "React 性能优化", id: 1 },
{ title: "Node.js 性能优化", id: 2 },
];
setDataList(list);
}, []);
return (
<div>
<button type="button" onClick={() => setCount(count + 1)}>
count: {count}
</button>
<List dataList={dataList} />
</div>
);
};
export default Home;下图对比了使用 React.memo() 前后的效果。
函数React.memo() 还提供了第二个参数 propsAreEqual,用来自定义控制对比过程。
// React.memo() 的 TypeScript 类型描述
function memo<T extends ComponentType<any>>(
Component: T,
propsAreEqual?: (
prevProps: Readonly<ComponentProps<T>>,
nextProps: Readonly<ComponentProps<T>>
) => boolean
): MemoExoticComponent<T>;一是 React.memo 对普通的引用类型是无效的。例如,在 List 组件增加 user 属性,即使使用了 React.memo() ,每次点击 count, List 组件还会重复渲染。
const Home = () => {
const user = {name: '哈哈'};
...
return (
<div>
<List dataList={dataList} user={user} />
</div>
);
};与 React.memo() 结合使用时,普通引用类型对象需要通过 useMemo、useState 处理,来避免组件的重复渲染。
const user = useMemo(() => ({ name: "哈哈" }), []);
const [user] = useState({ name: "哈哈" });还有一种情况是函数组中包括了一些 Hooks 例如 useState、useContext,当上下文发生变化时,组件也同样会重新渲染,React.memo 在这里仅比较 props。上面例子中,如果把 button 组件放到 List 组件里,每次点击,List 也还是会被重新渲染。
const List = React.memo(({ dataList }) => {
console.log("List 渲染");
const [count, setCount] = useState(0);
return (
<div>
<button type="button" onClick={() => setCount(count + 1)}>
List count: {count}
</button>
{dataList.map((item) => (
<h2 key={item.id}> {item.title} </h2>
))}
</div>
);
});React.memo() 是一个高阶组件,接收一个组件并返回一个新组件。它会记忆组件上次的 Props,同下次需要更新的 Props 做 “浅对比”,如果相同就不做更新,只有在不同时才会重新渲染。如果你的组件存在一些耗时的计算,每次重新渲染对页面性能显然是糟糕的,这时 React.memo() 对你来说也许是一个好的选择。并不是所有的组件都要引入 React.memo(),自身浅对比这个过程也会有一些消耗,如果没有特殊需求,也不一定非要使用。
一天 “小张” 接到一个需求 “一旦用户登陆认证成功之后,后续的请求可以携带一个令牌,无需再次身份认证”。
这时 “小张” 咨询了资深搬砖工程师 “小李”,凭借多年的搬砖经验,同事 “小李” 说到:HTTP 协议是无状态的,在第一次登陆认证成功后,下一次请求时,服务器也不知道请求者的身份信息。通常有两种实现方式:
“小张” 听完后,连忙说到第二种听着不错哦,搜索了一些相关文章介绍之后就开始了愉快的代码编写。完成之后提交了代码给同事 “小李” 做 code review,做为资深搬砖工程师的 “小李”,一眼看出了问题:“怎么能在 JWT 生成的 token 里放用户密码呢!JWT 默认是明文的,不能存储隐私信息”。
“小张” 不解,反问道:怎么会是明文呢,加密之后的数据我看了的,是一堆乱码啊,下面是打印的 token 信息。
// jwt 签名后生成的 token
"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6IuW8oOS4iSIsInBhc3N3b3JkIjoxMjM0NTYsImlhdCI6MTY2MTg2OTQxMX0.3-60HUf_cKIo44hWUviNzqdUoUGngGQfrqffg0A6uqM"“小李” 通过一段 Node.js 代码展示了如何解密出 JWT 签名后的 token 数据。
此时的 “小张” 陷入了沉思,顿时心里产生了两个疑问🤔️:
带着这两个疑问,下一步让我们一块了解下 JWT 的原理。
JWT 全称 JSON Web Token,是一种基于 JSON 的数据对象,通过技术手段将数据对象签名为一个可以被验证和信任的令牌(Token)在客户端和服务端之间进行安全的传输。
JWT Token 由三部分组成:header(头信息)、payload(消息体)、signature(签名),之间用 . 链接,构成如下所示:
Header 部分由 JSON 对象 { typ, alg } 两部分构成,使用 base64url(header) 算法转为字符串:
JWTHS256,支持的算法为 ['RS256', 'RS384', 'RS512', 'ES256', 'ES384', 'ES512', 'HS256', 'HS384', 'HS512', 'none']Payload 部分为消息体,用来存储需要传输的数据,同样也是一个 JSON 对象使用base64url(payload) 算法转为字符串,JWT 提供了 7 个可选字段供选择,也可以自定义字段:
Signature 是对 Header、Payload 两部分数据按照指定的算法做了一个签名,防止数据被篡改。 需要指定一个 sceret,产生签名的公式如下:
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
your-256-bit-secret
)生成签名后,将 header.payload.signature 三部分链接在一起,形成一个令牌(token)返回给客户端。
这就是 JWT 的原理,了解之后并没有那么神秘,回答上面的几个问题。
header、payload 部分是使用 base64 算法进行的编码,并没有被加密,自然也可以被解码。但注意这里的 base64 算法有点不一样的地方在于,token 可能会被放在 url query 中传输,URL 里面有三个特殊字符会被替换。下面是 JWT 中 base64url 的实现方式:
// https://github1s.com/auth0/node-jws/blob/HEAD/lib/sign-stream.js#L9-L16
function base64url(string, encoding) {
return Buffer
.from(string, encoding)
.toString('base64')
.replace(/=/g, '')
.replace(/\+/g, '-')
.replace(/\//g, '_');
}还需要注意 payload 对象放置的内容越多,base64 之后的字符串就越大,同理签名后的 token 也一样。
数据一旦被篡改,到服务端也会认证失败的,服务端在生成签名时有一个重要的参数是 secret,只要保证这个密钥不被泄漏,就没问题,就算篡改也是无效的。
在 Node.js 中使用 JWT 需要用到 jsonwebtoken 这个库,API 很简单,主要用到两个方法:
const crypto = require('node:crypto');
const jwt = require('jsonwebtoken');
const secret = crypto.createHmac('sha256', 'abcdefg')
.update('')
.digest('hex');
const payload = {
"username": "张三",
"password": 123456,
iat: 1516239022
};
const token = jwt.sign(payload, secret)
const result = jwt.verify(token, secret)JWT 由服务端生成可以存储在客户端,对服务端来说是无状态的,可扩展性好。
上文我们也讲了 JWT 中传输数据的 payload 默认是使用 base64 算法进行的编码,看似一串乱码,实则是没有加密,因此不要将涉及到安全、用户隐私的数据存放在 payload 中,如果要存放也请先自己进行加密。
一旦 token 泄漏,任何人都可以使用,为了减少 token 被盗用,尽可能的使用 HTTPS 协议传输,token 的过期时间也要设置的尽可能短。
防止数据被篡改,服务端密钥(secret)很重要,一定要保管好。
在编程中使用递归,如果没有控制好代码的执行边界或过多层级的递归调用,就会造成栈溢出错误,就像下面展示的这段错误堆栈。
RangeError: Maximum call stack size exceeded
at fn (/xxx/test.js:2:3)
at fn (/xxx/test.js:7:10)函数运行会有一个执行栈,每次调用会做入栈操作,保存一些局部变量、函数参数、当前程序的运行状态等,这些信息都会保存在栈空间里,而栈空间的存储是一段连续的内存地址,有大小限制。
以下是一段递归调用的简单示例。
function fn(i) {
i--;
if (i < 1) {
return;
}
return fn(i);
}
fn(20000);以下通过 gif 动图展示了上述代码的执行过程,当在主线程上调用 fn 函数后,不断的做压栈操作,而栈空间也在不断的增加,直到达到最大的栈空间限制,程序报错 “Maximum call stack size exceeded”。
解决递归造成的栈溢出问题,一种方法是可以使用 JavaScript 中的异步任务,也是借助了事件循环机制。宏任务有 setTimeout、Node.js 环境下的 setImmediate,微任务有 Promise、queueMicrotask。
修改代码,在 setTimeout 函数里递归调用。
function fn(i) {
i--;
if (i < 1) {
return;
}
setTimeout(function() {
fn(i);
}, 0);
}
fn(20000);运行效果如下所示:
当首次调用 fn(2000) 时,创建一个调用栈,函数内部调用 setTimeout 函数后会立即返回,当前的调用栈就结束了,传入的回调 **function() { fn(i) }** 还没有执行,主线程不会在这里等待,也不会形成层层嵌套的调用链。
定时器函数由宿主环境实现,当将来的某个时间点计时器时间到达后,宿主环境会将 timer 函数封装为一个事件放入 “任务队列” 中,事件循环检测到任务队列有可执行的任务,就拿出来执行,之后再次调用 fn(i) 创建新的调用栈,反复循环。
还可以通过微任务实现,微任务有个缺点是当调度大量的微任务时虽然不会导致调用栈溢出,但也会导致和同步任务相同的性能缺陷,后面的任务得不到执行,浏览器的渲染工作也会被阻止,直到所有的微任务执行完毕。
这个问题通过结合异步任务来解决递归造成的栈溢出问题,也可以做为事件循环的一个例子来学习,更好的掌握同步任务、异步之间的调度关系。
在程序中使用递归还是要谨慎的,若控制不好边界,很容易造成 “栈溢出”。除了改为异步任务调用外,还可将递归改为循环迭代、尾递归优化等。
重构这本书中,介绍的一些技巧、方法,对改善即有的代码设计有一定的帮助。另一方面,掌握了这些重构方法之后对你的编码能力也会有一个显著的提升。
孟子的《尽心章句下》中有这样一句话 :“尽信书,不如无书”,意思是读者要有独立思考精神,读书时应该加以分析,辩证的看待问题。在重构这本书中,介绍的重构方法多达将近上百种,不要一上来就被这么多的介绍给吓的退缩,找到适合于自己的才是最重要的,如果你是一个拥有多年编程经验的开发者,更要带着自己的理解去阅读。
当人们只为短期目的修改代码时,可能并没有很好理解架构的整体设计,当越难看出代码所表达的设计意图时就越难保护其设计,代码结构也会逐渐流失。
例如,产品经理告诉你,现在客户提出了一个新需求,很着急,希望尽快完成并上线。做这块的人,也许是一个并不了解该模块原有功能设计的人,也许是一个老队友,无奈于 “时间紧”、“任务重” 怎么办呢?顾不上先设计在开发了,先完成再说,一旦有第一次,就很有可能会产生第二次,周而复始,会发现代码结构越来越难以维护。
我想这种例子,在你身边也许经历过,当面对一些遗留系统的代码时,可能心里也会想 “这写的都是什么啊!”
我们编写代码,很大程度上都在与计算机对话,告诉它我们的代码指令以及该做出何种响应,那么我们编程的对象只是计算机吗?
不,这里往往忽略另外一个对象,我们编写的代码除了计算机外,还有其他读者。因为在一段时间后,会有其他编程人员来阅读这段代码并作出修改,我们每个人都可能成为这个未来的读者,这个是我们系统得以长久维护的一个重要对象。
在每一次的产品新版本迭代时,可能会遇到以前的结构不能满足,需要做一些调整,有时我们会吐槽为什么之前没考虑到呢?现在却要花时间调整它。
在开始代码之前,我们需要先完成软件的设计与架构,这很重要但也不要 “过度设计”,软件永远不应该被视为 “完成”,每当有新功能时,软件就应该做出相应的改变,最后会发现重构是一个长期的过程。
内部质量良好的模块划分,我们只需要了解代码库的一小部分,就可以容易的找出要修改的地方,是可以提高编程速度的。
当遇到一段糟糕的代码,你可能需要花费更多的时间去思考如何将新功能加入现有的代码库,一不小心还容易引入 bug,修复起来也困难,这份负担会拖累你的开发进度,并且以后的新功能也会越来越难以加入,最后实在难以维护 “我们就重构它吧”。
重构的意义在于让代码有着一个良好的模块划分,让未来的读者更易于理解、提高之后的开发效率。
“重构风险太大,可能引入 bug”,如果你有这个担忧,是正常的,重构的目的是为了让代码更易于理解,但也不能破坏现有的运行状态。
大多数情况下,我们想重构,得先有可以自测试的代码,哪怕是一个看似很小的改动,这会让重构更加可靠,这也是为什么在开发中我们会强调单元测试的重要性。因此,一开始时,团队有必要投入一定的精力和时间在一些测试工作上,这对于新功能添加也会多一层安全保证。
关于重构,一部分人认为需要安排一段时间来专门做这件事,这个投入成本是很大的,需要团队达成共识,在大多数情况下你的项目也不会给你计划这么多时间允许你做。有这样一句话:“种一棵树最好的时间是十年前,其次是现在”,同样大多数的重构也可在添加新功能、修复 bug 时去做,重构不一定是推翻重来。
书中这一部分称为代码的坏味道,这些是我们在编程中需要警惕的一些规则,很容易造成代码结构流失,不易后期维护。
a、b 这种随意的命名要避免。当你花了很长时间还是想不到一个好的名字,也许背后隐藏着更深的设计问题。重构方法是本书的重点,每个重构方法都围绕动机、做法、范例三部分进行介绍,书中你会看到作者的做法很谨慎,分小步一点一点重构、验证,以至于有时会感觉些许 “啰嗦”,但这种小步前进确实会减少出错,不可否认它是一种好的工作方式。
下文我会摘选一些认为在以往编程经历中对自己有帮助的代码编写方法。
“提炼函数” 是最常用的重构之一,在一些面向对象编程语言中是 “提炼方法”。何时提炼?有三种不同的观点:
这里我们主要讨论 “将意图与实现分开”,如果你需要花时间浏览一段代码才能弄清楚它的意图时,那么就应该将其提炼到一个函数中,下次再读到这段代码时,根据调用的函数名一眼即可看到函数的用途,无需关心函数体内的具体实现是怎么样的。
优化前示例:
function printOwing(invoice) {
// calculate outstanding
let outstanding = 0;
for (const order of invoice.orders) {
outstanding += order.amount;
}
// print details
console.log(`name: ${invoice.customer}`);
console.log(`amount: ${outstanding}`);
}优化后示例:
function printOwing(invoice) {
const outstanding = calculateOutstanding(invoice);
printDetails(invoice, outstanding);
function calculateOutstanding(invoice) {
let result = 0;
for (const order of invoice.orders) {
result += order.amount;
}
return result;
}
function printDetails(invoice, outstanding) {
console.log(`name: ${invoice.customer}`);
console.log(`amount: ${outstanding}`);
}
}创建一个新函数提炼我们的代码,根据函数的意图(做什么)来对它命名。原先需要在一段代码的顶部写一段注释描述它做什么,经过函数提炼之后,通过调用函数名称已经知道了它的意图,此时可以不用注释。
这里有个很多人都容易犯难的问题:“如何更好的命名?”,一个改进函数名称的好办法是:“先写一句注释描述函数的用途,再把这句注释变为函数名称”,变量命名也同样如此。但是英语也是一部分人的硬伤,总不能用中文给函数命名吧,建议先用一句简洁的中文描述,之后在借助一些工具翻译为英文,“这也不失为提升英语的一种方式”。
“内联函数” 是 “提炼函数” 的反向重构,一个函数的内部实现和它的函数名称同样清晰可读,这种情况下直接使用其中的代码,去掉这个函数。
优化前示例:
function getRating(driver) {
return moreThanFiveLateDeliveries(driver) ? 2 : 1;
}
function moreThanFiveLateDeliveries(driver) {
return driver.numberOfLateDeliveries > 5;
}优化后示例:
function getRating(driver) {
return driver.numberOfLateDeliveries > 5 ? 2 : 1;
}当一个表达式非常复杂而难以阅读时,分解表达式、提炼变量也许是个不错的选择。
优化前示例:
// base price(底价)、quantity discount(折扣)、shipping(运费)
function price(order) {
// price is base price - quantity discount + shipping
return order.quantity * order.itemPrice -
Math.max(0, order.quantity - 500) * order.itemPrice * 0.05 +
Math.min(order.quantity * order.itemPrice * 0.1, 100);
}优化后示例:
function price(order) {
const basePrice = order.quantity * order.itemPrice;
const quantityDiscount = Math.max(0, order.quantity - 500) * order.itemPrice * 0.05;
const shiping = Math.min(basePrice * 0.1, 100);
return basePrice - quantityDiscount + shiping;
}在一个函数内部,变量能给表达式提供有意义的名字,如上例所示,看起来清晰明了,函数内的注释也可以删除掉了。
“内联变量” 是 “提炼变量” 的反向重构。变量是个好东西,但有时当表达式更具表现力时,无需在对表达式提炼变量。
优化前示例:
const basePrice = order.basePrice;
return basePrice > 1000;优化后示例:
return order.basePrice > 1000;对于所有可变的数据,如果作用域超出单个函数,就可考虑将其封装为一个函数进行访问,优点是对变量的修改不会散落在各个地方,可监控数据的变化情况,添加一些修改前的验证或后续逻辑处理也是很方便的。数据作用域越大,封装就越重要,面向对象编程中强调数据的私有(private)背后也是同样的原理。
// 优化前示例:
let defaultOwner = { firstName: 'Martin', lastName: 'Fowler' }; // 全局变量中保存的数据
spaceship.owner = defaultOwner; // 使用地方平平无奇
defaultOwner = { firstName: 'Rebecca', lastName: 'Parsons' }; // 更新数据上面代码带来两个隐患:
以下是优化后示例:
// defaultOwner.js
let defaultOwner = { firstName: 'Martin', lastName: 'Fowler' };
export function getDefaultOwner() { return { ...defaultOwner } }; // 个人编码习惯不同,这里有些人可能不喜欢 get 前缀,
export function setDefaultOwner(arg) { defaultOwner = arg };“重构” 可以把一些复杂的东西分解为较简单的小块。随着对问题的理解,会发现在原先做法之外,有更简单的解决方案,此时就可改变原先的算法。
// 优化前示例:
function foundPerson(people) {
for (let i=0; i<people.length; i++) {
if (people[i] === 'Don') return 'Don';
if (people[i] === 'John') return 'John';
if (people[i] === 'Kent') return 'Kent';
}
return '';
}
// 优化后示例:
function foundPerson(people) {
const condidates = ['Don', 'John', 'Kent'];
return people.find(p => candidates.includes(p)) || '';
}经常会看到一些身兼多职的循环,只因可以只循环一次。拆分循环能让每个循环更容易理解,每次修改时也只需要理解修改的那块代码行为。
但这会让许多程序员感到不安的是它会迫使程序执行多次循环。在 “重构” 本书中的建议是先重构让代码结构变得清晰,再进行下一步优化。实际情况下即使处理的列表数据更多一些,循环本身也很少成为性能瓶颈。
优化前示例:
let averageAge = 0;
let totalSalary = 0;
for (const p of people) {
averageAge += p.salary
totalSalary += p.salary
}
averageAge = averageAge / people.length先移动语句微调代码顺序,让存在关联的东西一起出现,可以使代码更容易理解。
let totalSalary = 0;
for (const p of people) {
totalSalary += p.salary
}
let averageAge = 0;
for (const p of people) {
averageAge += p.salary
}
averageAge = averageAge / people.length进一步优化,还可以提炼函数,将每个循环提炼到单独的函数中,这要根据实际的情况进行选择。以上示例相对简单, 还可以使用 “以管道取代循环” 做进一步重构,如今的编程语言都提供了更好的语言结构来处理迭代结果,不一定非要使用循环。集合管道就是这样的一种技术,允许使用一组运算来描述集合的迭代过程,JavaScript 中这类运算很多,常见的非map 和 filter 莫属,还有 reduce、find、some 等。
const totalSalary = people.reduce((total, p) => total + p.salary, 0);
const averageAge = people.reduce((total, p) => total + p.age, 0) / people.length;数据结构对于帮助阅读者理解很重要,在本书中介绍了一种专门的 “重构” 手法:“重新组织数据”。
将一个变量用于多个不同的用途,这是催生混乱和 bug 的温床,遇到这种情况可通过 “拆分变量” 方式将不同的用途分开,一个变量只做一件事,同时记得给变量起一个有意义的名字。这个问题看似简单,也是一个常犯的错误。
// 一个变量承担了两件不同的事情
let temp = 2 * (height + width)
console.log(temp)
temp = height * with
console.log(temp)
// 每个变量只承担一个责任
const perimeter = 2 * (height + width)
console.log(perimeter)
const area = height * with
console.log(area)可变数据是软件中最大的错误源头之一,应尽可能把可变数据限制在最小范围。例如,有些变量可以很容易的计算出来,此时就可考虑去掉这些变量,避免原数据更改时忘记更新派生变量。
// 优化前
get production() { return this._production };
applyAdjustment(anAdjustment) {
this._adjustments.push(anAdjustment);
this._production += anAdjustment.amount;
}
// 优化后
get production() {
return this._adjustments
.reduce((sum, d) => sum + d.amount, 0)
};
applyAdjustment(anAdjustment) {
this._adjustments.push(anAdjustment);
}条件逻辑占据了程序的大部分,如果处理不当也会加大程序的复杂度。一个复杂的条件逻辑,应尽可能的去简化它,提高代码的可读性。这个重构手法称为 “简化条件逻辑”。
例如,要计算购买某样商品的总价(总价 = 数量 * 单价),而该商品在夏季单价计算同其它季节存在差别。下面是优化前代码示例:
// 优化前
if (!aDate.isBefore(plan.summerStart) && !aDate.isAfter(plan.summerEnd)) {
charge = quantity * plan.summerRate;
} else {
charge = quantity * plan.regularRate + plan.regularServiceCharge
}当条件逻辑复杂不易理解时,可以采用 “分解条件表达式” 方式,提炼条件判断为一个新的函数并取一个有意义的名字。根据实际情况也可以提炼为一个变量,包括每一个条件分支都可以做提炼。
// 优化后
if (summer()) {
charge = quantity * plan.summerRate;
} else {
charge = quantity * plan.regularRate + plan.regularServiceCharge
}
function summer() {
!aDate.isBefore(plan.summerStart) && !aDate.isAfter(plan.summerEnd)
}当发现有一串条件检查,最终行为都一致,这种情况下,应该使用 “逻辑或” 或 “逻辑与” 将它们合并为一个表达式。
// 优化前
function disabilityAmount(anEmployee) {
if (anEmployee.seniority < 2) return 0;
if (anEmployee.monthsDisabled > 12) return 0;
if (anEmployee.isPartTime) return 0;
// compute the disability amount
}
// 优化后
function disabilityAmount(anEmployee) {
if (isNotEligibleForDisability()) return 0;
// compute the disability amount
}
function isNotEligibleForDisability() {
return anEmployee.seniority < 2
|| anEmployee.monthsDisabled > 12
|| anEmployee.isPartTime;
}使用条件逻辑,还应注意不必要的深层 if...else 嵌套,尽可能的扁平化处理,当该条件为真时立刻从函数中返回。这样能保持代码结构的清晰整洁,一口气就能看得出该函数是做什么的。
// 优化前
function getPayAmount() {
let result;
if (isDead) {
result = deadAmount();
} else {
if (isSeparated) {
result = separatedAmount();
} else {
if (isRetired) {
result = retiredAmount();
} else {
result = normalPayAmount();
}
}
}
}
// 优化后
function getPayAmount() {
if (isDead) return deadAmount();
if (isSeparated) return separatedAmount();
if (isRetired) return retiredAmount();
return normalPayAmount();
}在一些复杂的条件逻辑编程中除了 if...else 你可能还会见到过使用 **switch...case**,在一组数据类型中,根据每个类型处理各自的条件逻辑,对于这种情况,“重构” 这本书中提出了一种 “以多态取代条件表达式” 的重构手法。
多态是面向对象编程中的一个关键特性,这种重构手法是针对 switch 语句中的每个分支逻辑创建一个类,用多态这一特性来承载各个类型特有的行为。
这种重构手法在笔者以往的项目中是没有使用过的,但也不失为一种有趣的思路,可以探索下。
// 优化前
function plumages(birds) {
return new Map(birds.map(b => [b.name, plumage(b)]));
}
function plumage(bird) {
switch (bird.type) {
case 'EuropeanSwallow':
return 'average';
case 'AfricanSwallow':
return (bird.numberOfCoconuts > 2) ? 'tired' : 'average';
case 'NorwegianBlueParrot':
return (bird.voltage > 100) ? 'scorched' : 'beautiful';
default:
return 'unknown';
}
}
// 优化后
function plumages(birds) {
return new Map(birds
.map(b => createBird(b))
.map(b => [b.name, plumage]));
}
function createBird(bird) {
switch (bird.type) {
case 'EuropeanSwallow':
return new EuropeanSwallow(bird);
case 'AfricanSwallow':
return new AfricanSwallow(bird);
case 'NorwegianBlueParrot':
return new NorwegianBlueParrot(bird);
default:
return new Bird(bird);
}
}
class Bird {
constructor(birdObject) {
Object.assign(this, birdObject);
}
get plumage() {
return 'unknown';
}
}
class AfricanSwallow extends Bird {
get plumage() {
return 'average';
}
}
class EuropeanSwallow extends Bird {
get plumage() {
return this.numberOfCoconuts > 2 ? 'tired' : 'average';
}
}
class NorwegianBlueParrot extends Bird {
get plumage() {
return this.voltage > 100 ? 'scorched' : 'beautiful';
}
}任何有返回值的函数,都不应该有看得到的副作用。保持了修改和查询的分离,当某个函数只返回一个值时,可以在任意地方调用它,后续对该函数的测试也会变的容易多。
以下示例,检查一群人中是否混进了恶棍(miscreant),如果是则返回恶棍名字并拉响警报。
// 优化前
function alertForMiscreant(people) {
for (const p of people) {
if (p === 'Don') {
setOfAlarms();
return 'Don';
}
if (p === 'John') {
setOfAlarms();
return 'John'
}
}
return '';
}
// 优化后
function findMiscreant(people) {
for (const p of people) {
if (p === 'Don') {
return 'Don';
}
if (p === 'John') {
return 'John'
}
}
return '';
}
function alertForMiscreant(people) {
if (findMiscreant(people) !== '') setOfAlarms();
}当调用者需要一个新对象时,很多编程语言都提供了构造函数专门用于对象的初始化。也不是所有的场景都用构造函数就是好的,例如工厂函数相比构造函数有更多的灵活性。工厂函数的实现内部可以调用构造函数,也可以是其它的实现方式。
// Class Employee (员工)
constructor() {
this._name = name;
this._typeCode = typeCode;
}
get name() { return this._name }
get type() { return Employee.legalTypeCodes[this._typeCode] }
static get legalTypeCodes() { return { E: 'Engineer', M: 'Manager'... } }
// 调用方:类的方式
const candidate = new Employee(document.name, document.empType); // 类的方式一
const leadEngineer = new Employee(document.leadEngineer, 'E'); // 类的方式二
// 调用方:工厂函数
// 例如上面示例中 “类的方式二” 如果不想以字面量的形式传入类型码,可以再新建一个工厂函数
const leadEngineer = createEngineer(document.leadEngineer);
function createEngineer(name) {
return new Employee(name, 'E');
}以前当谈及 “重构” 时,想到的会是我们要推翻重来吗?读完本书后改了这一观点,重构不是推倒重来,它可以在不改变外部条件的情况下,小步前进,有条不紊的改善既有代码的设计。
如果你是一个经验丰富的程序,书中的一些重构方法会让你感到熟悉,例如,文中笔者列举的一些重构方法有些平常也在这样做,只是没想过原来它还可以有这样一个名字,当看到这些示例后也更坚定了自己的一些做法。也会有些不是很理解,它也需要你带着实践去理解。在不同的时间、环境下阅读都会带来不一样的启发。
React 是一个用于构建用户界面的 JavaScript 库,解决了视图 UI 层问题。但是对于状态管理却没有给出一个好的解决方案,状态大致分为:反映 UI 变化的状态、本地创建的状态、服务器返回的数据状态等,面对社区众多的状态管理库,做为初学者不知道如何更好的选择。
本系列文章 “React 状态管理” 也是希望能帮助到大家了解不同状态管理方案(React 官方本身提供的及社区的一些库)能做的事情有哪些及优略点。
本篇先从 React 本身提供的组件状态管理开始。React 的组件状态分为类组件时代的 this.state 和当下函数组件的 useState/useReducer() hooks API 管理数据状态。
类组件将组件内所有的状态放在一个 state 中管理:this.state 获取状态数据、this.setState() 更新状态数据。
import React from 'react';
class State extends React.Component {
constructor() {
super();
this.state = {
count: 0,
}
}
render() {
return <div>
<p>count: {this.state.count}</p>
<button onClick={() =>
this.setState({ count: this.state.count + 1 })
}> 类组件计数 </button>
</div>
}
}
export default State;React 16.8 发布后,函数组件成为热门选择,组件状态使用 useState() 函数,相比类组件状态拆分的更细并且每次更新状态变量都是替换而不是合并。
如果更新依赖于先前的状态,可以将函数传递给 setState,并返回一个更新后的值 setState(preState => newState)。 熟悉 Redux 的朋友看起来也许不陌生,该函数是不是更像一个 reducer 函数?
Example:useState 实现计数器增、减、重置。
import { useState } from 'react';
const State = () => {
const [count, setCount] = useState(0);
return <div>
<p>计数器 count: {count}</p>
<button onClick={() => setCount(count + 1)}> 增 </button>
<button onClick={() => setCount(preCount => preCount - 1)}> 减 </button>
<button onClick={() => setCount(0)}> 重置 </button>
</div>
}
export default State;刚开始看到 useReducer 时,还联想和 Redux 之间有什么关系?需要注意的是和 Redux 完全不是一个东西,useReducer 是 React Hooks 提供的一个 API,如果熟悉 Redux 可能看起来会更熟悉。
useReducer 是 useState 的替代方案,主要用来处理一些逻辑比较复杂的 state 或 下一个 state 依赖于前一个 state 等。
Example:使用 useReducer 重写上面的计数器示例,可以和上面的 useState 做一个对比。
import { useReducer } from "react"
const COUNT_INCREMENT = 'COUNT_INCREMENT';
const COUNT_DECREMENT = 'COUNT_DECREMENT';
const COUNT_RESET = 'COUNT_RESET';
const initialState = {
count: 0,
};
const reducer = (state, action) => {
switch (action.type) {
case COUNT_INCREMENT:
return { count: state.count + 1 };
case COUNT_DECREMENT:
return { count: state.count - 1 };
case COUNT_RESET:
return { count: initialState.count };
default:
return state;
}
};
const State = () => {
const [state, dispatch] = useReducer(reducer, initialState);
return <div>
<p>计数器 count: {state.count}</p>
<button onClick={() => dispatch({ type: COUNT_INCREMENT })}> 增 </button>
<button onClick={() => dispatch({ type: COUNT_DECREMENT })}> 减 </button>
<button onClick={() => dispatch({ type: COUNT_RESET })}> 重置 </button>
</div>
}
export default State;使用 useReducer 实现一个稍微复杂点的功能,例如 Todos,有创建、更新、移除待办事项功能,你可以试想下如果换做 useState 该怎么处理?会不会更麻烦?
在 src/reducers 目录下实现 reducer 需要的逻辑,定义的 initialState 变量、reducer 函数都是为 useReducer 这个 Hook 做准备的,这里的 reducer 函数是一个纯函数。
// src/reducers/todos-reducer.jsx
export const TODO_LIST_ADD = 'TODO_LIST_ADD';
export const TODO_LIST_EDIT = 'TODO_LIST_EDIT';
export const TODO_LIST_REMOVE = 'TODO_LIST_REMOVE';
const randomID = () => Math.floor(Math.random() * 10000);
export const initialState = {
todos: [{ id: randomID(), content: 'todo list' }],
};
const reducer = (state, action) => {
switch (action.type) {
case TODO_LIST_ADD: {
const newTodo = {
id: randomID(),
content: action.payload.content
};
return {
todos: [ ...state.todos, newTodo ],
}
}
case TODO_LIST_EDIT: {
return {
todos: state.todos.map(item => {
const newTodo = { ...item };
if (item.id === action.payload.id) {
newTodo.content = action.payload.content;
}
return newTodo;
})
}
}
case TODO_LIST_REMOVE: {
return {
todos: state.todos.filter(item => item.id !== action.payload.id),
}
}
default: return state;
}
}
export default reducer;下面进行待办事项组件开发,细分为 TodoAdd、Todo、Todos 三个组件,在 Todos 组件内使用 useReducer 获取组件需要的状态(state)和更新状态的方法(dispatch)。
添加、更新、删除待办事项行为分别在 TodoAdd、Todo 组件中,以下我们使用的是 React 推荐的 组合组件模式,可以通过 props 从父组件传递数据到子组件。
import { useReducer, useState } from "react";
import reducer, { initialState, TODO_LIST_ADD, TODO_LIST_EDIT, TODO_LIST_REMOVE } from "../../reducers/todos-reducer";
const TodoAdd = ({ dispatch }) => {
const [content, setContent] = useState('');
return <>
<input type="text" onChange={e => setContent(e.target.value)} />
<button onClick={() => {
dispatch({ type: TODO_LIST_ADD, payload: { content } })
}}>
添加
</button>
</>
};
const Todo = ({ todo, dispatch }) => {
const [isEdit, setIsEdit] = useState(false);
const [content, setContent] = useState(todo.content);
return <div>
{
!isEdit ? <>
<span>{todo.content}</span>
<button onClick={() => setIsEdit(true)}> 编辑 </button>
<button onClick={() => dispatch({ type: TODO_LIST_REMOVE, payload: { id: todo.id } })}> 删除 </button>
</> : <>
<input value={content} type="text" onChange={ e => setContent(e.target.value) } />
<button onClick={() => {
setIsEdit(false);
dispatch({ type: TODO_LIST_EDIT, payload: { id: todo.id, content } })
}}> 更新 </button>
<button onClick={() => setIsEdit(false)}> 取消 </button>
</>
}
</div>
}
const Todos = () => {
const [state, dispatch] = useReducer(reducer, initialState);
return <>
<TodoAdd dispatch={dispatch} />
{
state.todos.map(todo => <Todo
key={todo.id}
todo={todo}
dispatch={dispatch}
/>)
}
</>
}
export default Todos;useState 适合定义一些单一的状态,useReducer 适合逻辑比较复杂的 state。
一个好的经验法则是:“如果状态是基本的数据类型(字符串、数值型、布尔型)可以选择 useState,如果是数组或对象等其它复杂的类型或复杂逻辑时最好选择 useReducer”。
但是两者都是组件的状态管理,当多个组件协同工作时不得不面对组件间 “数据通信” 问题。
React 组件数据状态流转是一个 “单项数据流” 的理念。简单的组件可以通过 props 传递数据状态,当组件过多时,层层 Props 传递的方式显的就有点过于繁琐了,不易维护。
全局跨组件之间状态共享还需要其它方案,React 官方为我们提供了 Context,具体怎么样呢?下篇文章介绍。
知乎上看到的一个问题:“ES6 中的 symbol 类型在实际开发中用得多吗?”,以前在学习 ES6 时也有此疑问,这个 Symbol 是干嘛的?有什么应用场景?
Symbol 在实际开发中用的不多,在看一些类库的实现时有看到相关使用,下面分享下关于 Symbol 的几个使用场景。
使用 Symbol 做为私有属性,最早知道这个是在 Egg 源码中学习到的,看一段相关的代码片段:
// https://github.com/eggjs/egg/blob/3.0.0/lib/core/base_context_logger.js#L22
const CALL = Symbol('BaseContextLogger#call');
class BaseContextLogger {
[CALL](method, args) {
// ...
this.ctx.logger[method](...args);
}
}在 JavaScript 中为了实现私有属性,之前常用的一种方式是命名规范约定,方法名以 _ 开始。
Symbol 出现之后看到的一个相对较多的场景是用它来模式私有属性、方法。这对一些 for...in、Object.getOwnPropertyNames() 操作是可以隐藏掉这些属性,但是 ES6 中的 Symbol 和强类型语言中的 private 相比并不完全是私有的,仍然能通过 Object.getOwnPropertySymbols()、Reflect.ownKeys() 操作枚举到这些属性进行访问。
使用 MongoDB Node.js 驱动程序生成一个 id,当执行 ObjectId()或 new ObjectId() 时总会按照固定格式输出,如下所示:
new ObjectId("632c6d93d65f74baeb22a2c9")没了解实现之前,看起来总归是有些神秘的,如果自己写一个类并实现自定义输出信息该怎么做呢?带着好奇之心看了下源码实现:
// https://github.com/mongodb/js-bson/blob/v4.4.0/src/objectid.ts#L343
class ObjectId {
toHexString(): string {
const hexString = this.id.toString('hex');
return hexString;
}
[Symbol.for('nodejs.util.inspect.custom')](): string {
return this.inspect();
}
inspect(): string {
return `new ObjectId("${this.toHexString()}")`;
}
}Symbol.for(str) 是新建一个以该字符串为名称的值,并注册到全局,如果已注册过,就直接返回。与 Symbol() 区别简单理解是,Symbol() 调用 100 次会返回 100 个不同 Symbol 值,Symbol.for(str) 调用 100 次返回的 Symbol 值都是相同的。
Node.js util 模块实现了 util.inspect.custom 方法用于声明自定义检查函数,这里个人理解更像一个钩子函数,在 nodejs/node#20821 PR 中已支持将 util.inspect.custom 做为公共符号,实现了不用加载 util 模块就可在任何地方使用它,这里用的就是 Symbol.for()。
JavaScript 中的 Array、Set、Map 数据类型都可被 for...of 所遍历。如果面试官说:“实现一个可以被 for...of 所遍历的对象” 这个该怎么实现呢?
Symbol 提供了 Symbol.iterator 方法,该方法返回一个迭代器对象,目前 Array、Set、Map 这些数据结构默认具有 Symbol.iterator 属性,而对象 Object 是没有的,如下所示:
console.log([][Symbol.iterator]()); // Object [Array Iterator] {}
console.log((new Map())[Symbol.iterator]()); // [Map Entries] { }
console.log((new Set())[Symbol.iterator]()); // [Set Iterator] { }
console.log({}[Symbol.iterator]); // undefined Symbol.iterator 是迭代协议标准中的一部分:可迭代器协议,它定义了哪些值可以被遍历到。要成为可迭代器对象,必须实现 @@iterator 方法,可通过常量 Symbol.iterator 访问(到这里是不是发现,原来常使用的 Array 类型竟和 Symbol 也有联系啊
迭代协议标准的另一部分是:迭代器协议 ,它定义了产生一系列值的的标准方式。通过定义 next() 方法实现,这里不做详细阐述,参见文档。
了解了 Symbol.iterator 和迭代协议规则实现一个可被遍历的对象并不难。
const range = {
start: 0,
end: 3,
[Symbol.iterator]: function() { return this },
next: function() {
if (this.start > this.end) {
return { value: undefined, done: true }
}
return { value: this.start++, done: false }
}
}
for (const id of range) {
console.log(id); // 0,1,2,3
}除了 Symbol.iterator 还有 Symbol.asyncIterator,这个在 Node.js 后端中有一些使用场景。
Symbol 的详细介绍,推荐两个学习资源:

“0.1 + 0.2 = ?” 这个问题,你要是问小学生,他也许会立马告诉你 0.3。但是在计算机的世界里就没有这么简单了,做为一名程序开发者在你面试时如果有人这样问你,小心陷阱喽!
你可能在哪里见过 “0.1 + 0.2 = 0.30000000000000004” 但是知道这背后真正的原理吗?是只有 JavaScript 中存在吗?带着这些疑问本文将重点梳理这背后的原理及浮点数在计算机中的存储机制。
注意: 发现对于 Markdown 公式不支持,可以在 微信端链接打开阅读
以下是一些基础的,可能被你所忽略的知识,了解它很有用,因为这些基础知识在我们的下文讲解中都会应用到,如果你已掌握了它,可以跳过本节。
1. 计算机的内部是如何存储的?一个浮点数 float a = 1 会存储成 1.0 吗?
计算机内部都是采用二进制进行表示,即 0 1 编码组成。在计算机中是没有 1.0 的,它只认 0 1 编码。
2. 1bit 可以存储多少个整数?8bit 可以存储多少个整数?
N 个 bit 可以存储的整数是 2 的 N 次方个。8bit 为 2 的 8 次方($2^{8}=256$)。
3. 了解下科学计数法,下文讲解会用到
在日常生活中遇到一个比较的大的数字,例如全国总人口数、每秒光速等,在物理上用这些大数表达很不方便,通常可以采用科学计数法表达。
以下为 10 进制科学计数法表达式,底数为 10 ,其中 1≤|a|<10,n 为整数
例如,0.1 的科学计数法表示为
在 IEEE 754 标准中也类似,只不过它是以一个二进制数来表示,底数为 2,以下为 0.1 的二进制表达式:
4. 十进制小数如何转二进制?
十进制小数转二进制,小数部分,乘 2 取整数,若乘之后的小数部分不为 0,继续乘以 2 直到小数部分为 0 ,将取出的整数正向排序。
例如: 0.1 转二进制
0.1 * 2 = 0.2 --------------- 取整数 0,小数 0.2
0.2 * 2 = 0.4 --------------- 取整数 0,小数 0.4
0.4 * 2 = 0.8 --------------- 取整数 0,小数 0.8
0.8 * 2 = 1.6 --------------- 取整数 1,小数 0.6
0.6 * 2 = 1.2 --------------- 取整数 1,小数 0.2
0.2 * 2 = 0.4 --------------- 取整数 0,小数 0.4
0.4 * 2 = 0.8 --------------- 取整数 0,小数 0.8
0.8 * 2 = 1.6 --------------- 取整数 1,小数 0.6
0.6 * 2 = 1.2 --------------- 取整数 1,小数 0.2
...
最终 0.1 的二进制表示为 0.00110011... 后面将会 0011 无限循环,因此二进制无法精确的保存类似 0.1 这样的小数。那这样无限循环也不是办法,又该保存多少位呢?也就有了我们接下来要重点讲解的 IEEE 754 标准。
IEEE 754 是 IEEE 二进制浮点数算术标准的简称,在这之前各家计算机公司的各型号计算机,有着千差万别的浮点数表示方式,这对数据交换、计算机协同工作造成了极大不便,该标准的出现则解决了这一乱象,目前已成为业界通用的浮点数运算标准。
IEEE 754 常用的两种浮点数值的表示方式为:单精确度(32位)、双精确度(64位)。例如, C 语言中的 float 通常是指 IEEE 单精确度,而 double 是指双精确度。
这里重点讲解下双精确度(64位)(JS 中使用),单精确度(32 位)同理。
在 JavaScript 中不论小数还是整数只有一种数据类型表示,这就是 Number 类型,其遵循 IEEE 754 标准,使用双精度浮点数(double)64 位(8 字节)来存储一个浮点数(所以在 JS 中 1 === 1.0)。其中能够真正决定数字精度的是尾部,即
根据 IEEE 754 标准,任意二进制数 V 都可用如下公式表示:
符号位的作用是什么?你可能会有此疑惑,在计算机中一切万物都以二进制表示,那么二进制中又以 0 1 存储,你可能想用负号(-)表示负数,对不起这是不支持的,为了表示负数通常把最高位当作符号位来表示,这个符号位就表示了正负数,0 表示正数(+),1 表示负数(-)。
顺便抛出几个问题
1. 计算机的世界中是否有减法?1 - 1 是如何实现的?
2. 十进制数 1 的二进制为 0000 0001,-1 对应的二进制是什么?用 1000 0001 表示 -1 对吗?
IEEE 754 规定,在计算机内部保存 M 时,默认这个数的第一位总是 1,因此可以被舍去,只保存后面部分,这样可以节省 1 位有效数字,对于双精度 64 位浮点数,M 为 52 位,将第一位的 1 舍去,可以保存的有效数字为 52 + 1 = 53 位。
在双精确度浮点数下二进制数公式 V 演变如下所示:
E 为一个无符号整数,在双精度浮点数中 E 为 11 位,取值范围为
中间值: 由于科学计数法中的 E 是可以出现负数的,IEEE 754 标准规定指数偏移值的固定值为
正负范围: 双精确度 64 位中间值为 1023,负数为 [0, 1022] 正数为 [1024, 2047]。
双精确度浮点数下二进制数公式 V 最终演变如下所示:
不知道怎么转换的,参考上面 先修知识 的 十进制小数转二进制
0.000110011001100110011(0011) // 0011 将会无限循环
任何一个数都可以用科学计数法表示,0.1 的二进制科学计数法表示如下所示:
以上结果类似于十进制科学计数法表示:
0.1 的二进制表示如下所示:
3.1 符号位
由于 0.1 为整数,所以符号位 S = 0
3.2 指数位
E = -4,实际存储为 -4 + 1023 = 1019,二进制为 1111111011,E 为 11 位,最终为 01111111011
3.3 尾数位
在 IEEE 754 中,循环位就不能在无限循环下去了,在双精确度 64 位下最多存储的有效整数位数为 52 位,会采用 就近舍入(round to nearest)模式(进一舍零) 进行存储
11001100110011001100110011001100110011001100110011001 // M 舍去首位的 1,得到如下
1001100110011001100110011001100110011001100110011001 // 0 舍 1 入,得到如下
1001100110011001100110011001100110011001100110011010 // 最终存储
3.4 最终存储结果
0 01111111011 1001100110011001100110011001100110011001100110011010

binaryconvert.com/convert_double.html?decimal=048046049
上面我们讲解了浮点数 0.1 采用 IEEE 754 标准的存储过程,0.2 也同理,可以自己推理下,0.1、0.2 对应的二进制分别如下所示:
S E M
0 01111111011 1001100110011001100110011001100110011001100110011010 // 0.1
0 01111111100 1001100110011001100110011001100110011001100110011010 // 0.2
浮点数加减首先要判断两数的指数位是否相同(小数点位置是否对齐),若两数指数位不同,需要对阶保证指数位相同。
对阶时遵守小阶向大阶看齐原则,尾数向右移位,每移动一位,指数位加 1 直到指数位相同,即完成对阶。
本示例,0.1 的阶码为 -4 小于 0.2 的阶码 -3,故对 0.1 做移码操作
// 0.1 移动之前
0 01111111011 1001100110011001100110011001100110011001100110011010
// 0.1 右移 1 位之后尾数最高位空出一位,(0 舍 1 入,此处舍去末尾 0)
0 01111111100 100110011001100110011001100110011001100110011001101(0)
// 0.1 右移 1 位完成
0 01111111100 1100110011001100110011001100110011001100110011001101
尾数右移 1 位之后最高位空出来了,如何填补呢?涉及两个概念:
两个尾数直接求和
0 01111111100 1100110011001100110011001100110011001100110011001101 // 0.1
+ 0 01111111100 1001100110011001100110011001100110011001100110011010 // 0.2
= 0 01111111100 100110011001100110011001100110011001100110011001100111 // 产生进位,待处理
或者以下方式:
0.1100110011001100110011001100110011001100110011001101
+ 1.1001100110011001100110011001100110011001100110011010
10.0110011001100110011001100110011001100110011001100111
由于产生进位,阶码需要 + 1,对应的十进制为 1021,此时阶码为 1021 - 1023(64 位中间值)= -2,此时符号位、指数位如下所示:
S E
= 0 01111111101
尾部进位 2 位,去除最高位默认的 1,因最低位为 1 需进行舍入操作(在二进制中是以 0 结尾的),舍入的方法就是在最低有效位上加 1,若为 0 则直接舍去,若为 1 继续加 1
100110011001100110011001100110011001100110011001100111 // + 1
= 00110011001100110011001100110011001100110011001101000 // 去除最高位默认的 1
= 00110011001100110011001100110011001100110011001101000 // 最后一位 0 舍去
= 0011001100110011001100110011001100110011001100110100 // 尾数最后结果
IEEE 754 中最终存储如下:
0 01111111101 0011001100110011001100110011001100110011001100110100
最高位为 1,得到的二进制数如下所示:
2^-2 * 1.0011001100110011001100110011001100110011001100110100
转换为十进制如下所示:
0.30000000000000004
这显然不是的,这在大多数语言中基本上都会存在此问题(大都是基于 IEEE 754 标准),让我们看下 0.1 + 0.2 在一些常用语言中的运算结果。
JavaScript
推荐一个用于任意精度十进制和非十进制算术的 JavaScript 库 github.com/MikeMcl/bignumber.js
console.log(.1 + .2); // 0.30000000000000004
// bignumber.js 解决方案
const BigNumber = require('bignumber.js');
const x = new BigNumber(0.1);
const y = 0.2
console.log(parseFloat(x.plus(y)));Python
Python2 的 print 语句会将 0.30000000000000004 转换为字符串并将其缩短为 “0.3”,可以使用 print(repr(.1 + .2)) 获取所需要的浮点数运算结果。这一问题在 Python3 中已修复。
# Python2
print(.1 + .2) # 0.3
print(repr(.1 + .2)) # 0.30000000000000004
# Python3
print(.1 + .2) # 0.30000000000000004Java
Java 中使用了 BigDecimal 类内置了对任意精度数字的支持。
System.out.println(.1 + .2); // 0.30000000000000004
System.out.println(.1F + .2F); // 0.3推算 0.1 + 0.2 为什么不等于 0.3 这个过程是乏味和有趣并存的,因为它很难理解,但是一旦你掌握了它,能让你更深刻的认识到其中的存储、运算机制,从而理解结果为什么是 0.30000000000000004。
最后做个总结,由于计算机底层存储都是基于二进制的,需要事先由十进制转换为二进制存储与运算,这整个转换过程中,类似于 0.1、0.2 这样的数是无穷尽的,无法用二进制数精确表示。JavaScript 采用的是 IEEE 754 双精确度标准,能够有效存储的位数为 52 位,所以就需要做舍入操作,这无可避免的会引起精度丢失。另外我们在 0.1 与 0.2 相加做对阶、求和、舍入过程中也会产生精度的丢失。
“Give me a promise, I will not go anywhere, just stand here and wait for you.”
“给我一个承诺,我哪里都不会去,就在原地等你。” 这句话形式 Promise 还挺有意思的,文中我会在提及!
随着 ES6 标准的出现,给我们带来了一个新的异步解决方案 Promise。目前绝大多数 JavaScript 新增的异步 API 无论是在浏览器端还是 Node.js 服务端都是基于 Promise 构建的,以前基于 Callback 形式的也有解决方案将其转为 Promise。
看过笔者上一节对 “Promise 前世 Deferred 的讲解”,对于本章学习相对会更轻松一些,介绍来我们还是先了解下 Promise/A+ 规范,更好的理解下 Promise 的一些**和规则。
Promise 是一个对象用来表示异步操作的结果,我们没有办法同步的知道它的结果,但是这个结果可以用来表示未来值,将来的某个时间点我们可以拿到该值,它可能成功,也可能失败,也会一直等待下去(这个请看下文 “无法取消的承诺”)。
在 Promise A+ 规范中有一些专业的术语,先了解下:
这些概念在我们想要更深入的了解 Promise 是需要的,例如,我们实现一个自己的 Promise 最好也是按照这种规范去做,本节我们主要将 Promise 的基础使用,后面也会在异步进阶里去讲 Promise 的实现原理,实现一个自己的 Promise 对象。
一个 Promise 在被创建出来时是一个等待态,最后要么成功、要么失败这个状态是不能够逆转的:
这几个状态流转就像一个状态机,通过这个图也可看到状态只能从 Pending -> Fulfilled 或 Pending -> Rejected
目前有些 API 直接是基于 Promise 的形式,例如 Fetch API 从网络获取数据。
fetch('http://example.com/movies.json')
.then(function(response) {
// TODO
});举一个 Node.js 的示例,例如 fs.readFile() 这个 API 默认是 callback 的形式,如果要转为 Promise 也很方便。
fs.readFile('xxx', function(err, result) {
console.error('Error: ', err);
console.log('Result: ', result);
});new Promise() 是创建一个新的 Promise 对象,之后我们可以在里面使用 resolve、reject 返回结果信息。
const readFile = filename => new Promise((resolve, reject) => {
fs.readFile(filename, (err, file) => {
if (err) {
reject(err);
} else {
resolve(file);
}
})
});
readFile('xxx')
.then(result => console.log(result))
.catch(err => console.log(err));Node.js util 模块提供了很多工具函数。为了解决回调地狱问题,Nodejs v8.0.0 提供了 promisify 方法可以将 Callback 转为 Promise 对象。
笔者之前也曾写过一篇解析 “Node.js 源码解析 util.promisify 如何将 Callback 转为 Promise”
const { promisify } = require('util');
const readFilePromisify = util.promisify(fs.readFile); // 转为 Promise
readFilePromisify('xxx')
.then(result => console.log(result))
.catch(err => console.log(err));除此之外 Node.js fs 模块的 fs.promises API 提供了一组备用的异步文件系统的方法,它们返回 Promise 对象而不是使用回调。
API 可通过 require('fs').promises 或 require('fs/promises') 访问。
const fsPromises = require('fs/promises');
fsPromises('xxx')
.then(result => console.log(result))
.catch(err => console.log(err));Promise 实例提供了两种错误捕获的方式:一是 Promise.then() 方法传入第二个参数,另一种是 Promise 实例的 catch() 方法。
const ajax = function(){
console.log('promise 开始执行');
return new Promise(function(resolve,reject){
setTimeout(function(){
reject(`There's a mistake`);
},1000);
});
}
ajax()
.then(function(){
console.log('then1');
return Promise.resolve();
}, err => {
console.log('then1里面捕获的err: ', err);
})
.then(function(){
console.log('then2');
return Promise.reject(`There's a then mistake`);
})
.catch(err => {
console.log('catch里面捕获的err: ', err);
});
// 输出
// promise开始执行
// then1里面捕获的err: There's a mistake
// then2
// catch里面捕获的err: There's a then mistakePromise.all() 以数组的形式接收多个 Promise 实例,内部好比一个 for 循环执行传入的多个 Promise 实例,当所有结果都成功之后返回结果,执行过程中一旦其中某个 Promise 实例发生 reject 就会触发 Promise.all() 的 catch() 函数。
以下示例,加载 3 张图片,如果全部成功之后渲染结果到页面中。
function loadImg(src){
return new Promise((resolve,reject) => {
let img = document.createElement('img');
img.src = src;
img.onload = () => {
resolve(img);
}
img.onerror = (err) => {
reject(err)
}
})
}
function showImgs(imgs){
imgs.forEach(function(img){
document.body.appendChild(img)
})
}
Promise.all([
loadImg('http://www.xxxxxx.com/uploads/1.jpg'),
loadImg('http://www.xxxxxx.com/uploads/2.jpg'),
loadImg('http://www.xxxxxx.com/uploads/3.jpg')
]).then(showImgs)在 Promise 链式调用中,任意时刻都只有一个任务执行,下一个任务要等待这个任务完成之后才能执行,如果现在我有两个或以上的任务,之间没有顺序依赖关系,希望它们能够并行执行,这样可以提高效率,此时就可以选择 Promise.all()。
Promise.race() 只要其中一个 Promise 实例率先发生改变,其它的将不在响应。好比短跑比赛,我只想知道第一是谁,当第一个人跨越终点线之后,我的目的就达到了。
还是基于上面的示例,只要有一个图片加载完成就直接添加到页面。
function showImgs(img){
let p = document.createElement('p');
p.appendChild(img);
document.body.appendChild(p);
}
Promise.race([
loadImg('http://www.xxxxxx.com/uploads/1.jpg'),
loadImg('http://www.xxxxxx.com/uploads/2.jpg'),
loadImg('http://www.xxxxxx.com/uploads/3.jpg')
]).then(showImgs)Promise 在执行后最终结果要么成功进入 then,要么失败 进入 catch。也许某些时候我们需要一个总是能够被调用的回调,以便做一些清理工作,ES7 新加入了 finally 也许是你不错的选择。
Promise.finally() 在 Node.js 10.3.0 版本之后支持。
const p = Promise.resolve();
p
.then(onSuccess)
.catch(onFailed)
.finally(cleanup);Promise.any() 接收一个数组作为参数,可传入多个 Promise 实例,只要其中一个 Promise 变为 Fulfilled 状态,就返回该 Promise 实例,只有全部 Promise 实例都变为 Rejected 拒绝态,Promise.any() 才会返回 Rejected。
Promise.any() 在 Node.js 15.14.0 版本之后支持。
Promise.any([
Promise.reject('FAILED'),
Promise.resolve('SUCCESS1'),
Promise.resolve('SUCCESS2'),
]).then(result => {
console.log(result); // SUCCESS1
});Promise.allSettled() 与 Promise.all() 类似,不同的是 Promise.allSettled() 执行完成不会失败,它会将所有的结果以数组的形式返回,我们可以拿到每个 Promise 实例的执行状态和结果。
Promise.allSettled() 在 Node.js 12.10.0 版本之后支持。
Promise.allSettled([
Promise.reject('FAILED'),
Promise.resolve('SUCCESS1'),
Promise.resolve('SUCCESS2'),
]).then(results => {
console.log(results);
});
// [
// { status: 'rejected', reason: 'FAILED' },
// { status: 'fulfilled', value: 'SUCCESS1' },
// { status: 'fulfilled', value: 'SUCCESS2' }
// ]刚开始引用了一句话 “Give me a promise, I will not go anywhere, just stand here and wait for you.” 就好比一个小伙子对一个心仪的姑娘说:“给我一个承诺,我哪里都不会去,就在原地等你”。
好比我们的程序,创建了一个 Promise 对象 promise,并为其注册了完成和拒绝的处理函数,因为一些原因,我们没有给予它 resolve/reject,这个时候 promise 对象将会一直处于 Pending 等待状态。我们也无法从外部取消。如果 then 后面还有业务需要处理,也将会一直等待下去,当我们自己去包装一个 Promise 对象时要尽可能的避免这种情况发生。
const promise = new Promise((resolve, reject) => {
// 没有 resolve 也没有 reject
});
console.log(promise); // Promise {<pending>}
promise
.then(() => {
console.log('resolve');
}).catch(err => {
console.log('reject');
});这是我们之前在讲解 JavaScript 异步编程指南 Callback 一节写的例子:
fs.readdir('/path/xxxx', (err, files) => {
if (err) {
// TODO...
}
files.forEach((filename, index) => {
fs.lstat(filename, (err, stats) => {
if (err) {
// TODO...
}
if (stats.isFile()) {
fs.readFile(filename, (err, file) => {
// TODO
})
}
})
})
});Node.js 的 fs 模块为我们提供了 promises 对象,现在解决了深层次嵌套问题,这个问题还有更优雅的写法,在之后的 Async/Await 章节我们会继续介绍。
const fs = require('fs').promises;
const path = require('path');
const rootDir = '/path/xxxx';
fs.readdir('/path/xxxx')
.then(files => {
files.forEach(checkFileAndRead);
})
.catch(err => {
// TODO
});
function checkFileAndRead(filename, index) {
const file = path.resolve(rootDir, filename);
return fs.lstat(file)
.then(stats => {
if (stats.isFile()) {
return fs.readFile(file);
}
})
.then(chunk => {
// TODO
})
.catch(err => {
// TODO
})
}Promise 是很好的,它解决了 callback 形式的回调地狱、难以管理的错误处理问题, Promise 提供了一种链式的以线性的方式(.then().then().then()...)来管理我们的异步代码,这种方式是可以的,解决了我们一些问题,但是并非完美,在 Async/Await 章节你会看到关于异步编程问题更好的解决方案,但是 Promise 是基础,请掌握它。
ES7 之后引入了 Async/Await 解决异步编程,这种方式在 JavaScript 异步编程中目前也被称为 “终极解决方案”。
函数声明时在 function 关键词之前使用 async 关键字,内部使用 await 替换了 Generator 中的 yield,语义上比起 Generator 中的 * 号也更明确。
在执行时相比 Generator 而言,Async/Await 内置执行器,不需要 co 这样的外部模块,程序语言本身实现是最好的,使用上也更简单。
以下是基于 Generator 一讲中的一个例子做了改造,在第二个 await 后面,使用 Promise 封装了下,它本身是支持跟一个 Promise 对象的,这个时候它会等待当 Promise 状态变为 Fulfilled 才会执行下一步,当 Promise 未能正常执行 resolve/reject 时那就意味着,下面的也将得不到执行。
await 后面还可跟上基本类型:数值、字符串、布尔值,但这时也会立即转成 Fulfilled 状态的 Promise。
async function test() {
const res1 = await 'A';
const res2 = await Promise.resolve(res1 + 'B');
const res3 = await res2 + 'C';
return res3;
}
(async () => {
const res = await test(); // ABC
})();如果 await 后面的 Promise 返回一个错误,需要 try/catch 做错误捕获,若有多个 await 操作也可都放在一起。这种情况,假如第一个 await 后面的 Promise 报错,第二个 await 是不会执行的。
这和普通函数操作基本上是一样的,不同的是对于异步函数我们需要加上 await 关键字。
(async () => {
try {
await fetch1(url);
await fetch2(url);
} catch (err) {
// TODO
}
})();也要注意 await 必须写在 async 函数里,否则会报错 SyntaxError: await is only valid in async functions and the top level bodies of modules。
// 错误的操作
(() => {
await 'A';
})();这样写也是不行的,在 “协程” 一讲中也提过类似的示例,只不过当时是基于 yield 表达式,async/await 实际上是 Generator 函数的一种语法糖,内部机制是一样的,forEach 里面的匿名函数是一个普通的函数,运行时会被看作是一个子函数,栈式协程是从子函数产生的,而 ES6 中实现的协程属于无堆栈式协程,只能从生成器内部生成。以下代码在运行时会直接失败。
(async () => {
['B', 'C'].forEach(item => {
const res = await item;
console.log(res);
})
})();想通过 await 表达式正常运行,就要避免使用回调函数,可以使用遍历器 for...of。
(async () => {
for (const item of ['B', 'C']) {
const res = await item; // B C
}
})();当我们拥有多个异步请求,且不必顺序执行时,可以在 await 表达式后使用 Promise.all(),这是一个很好的实践。
(async () => {
await Promise.all([
fetch(url1),
fetch(ur2)
])
})();通过这个示例可以看出,async/await 也还是基于 Promise 的。
上面讲解的使用 Async/Await 都是基于单次运行的异步函数,在 Node.js 中我们还有一类需求它来自于连续的事件触发,例如,基于流式 API 读取数据,常见的是注册 on('data', callback) 事件和回调函数,但是这样我们不能利用常规的 Async/Await 表达式来处理这类场景。
异步迭代器与同步迭代器不同的是,一个可迭代的异步迭代器对象具有 [Symbol.asyncIterator] 属性,并且返回的是一个 Promise.resolve({ value, done }) 结果。
实现异步迭代器比较方便的方式是使用声明为 async 的生成器函数,可以使我们像常规函数中一样去使用 await,以下展示了 Node.js 可读流对象是如何实现的异步可迭代,只列出了核心代码,异步迭代器笔者也有一篇详细的文章介绍,很精彩,感兴趣的可以看看 探索异步迭代器在 Node.js 中的使用。
// for await...of 循环会调用
Readable.prototype[SymbolAsyncIterator] = function() {
...
const iter = createAsyncIterator(stream);
return iter;
};
// 声明一个创建异步迭代器对象的生成器函数
async function* createAsyncIterator(stream) {
...
try {
while (true) {
// stream.read() 从内部缓冲拉取并返回数据。如果没有可读的数据,则返回 null
// readable 的 destroy() 方法被调用后 readable.destroyed 为 true,readable 即为下面的 stream 对象
const chunk = stream.destroyed ? null : stream.read();
if (chunk !== null) {
yield chunk; // 这里是关键,根据迭代器协议定义,迭代器对象要返回一个 next() 方法,使用 yield 返回了每一次的值
}
...
}
} catch (err) {
}
}Node.js Stream 模块的可读流对象在 v10.0.0 版本试验性的支持了 [Symbol.asyncIterator] 属性,可以使用 for await...of 语句遍历可读流对象,在 v11.14.0 版本以上已 LTS 支持,这使得我们从流中读取连续的数据块变的很方便。
const fs = require('fs');
const readable = fs.createReadStream('./hello.txt', { encoding: 'utf-8' });
async function readText(readable) {
let data = '';
for await (const chunk of readable) {
data += chunk;
}
return data;
}
(async () => {
try {
const res = await readText(readable);
console.log(res); // Hello Node.js
} catch (err) {
console.log(err.message);
}
})();使用 **for await...of** 语句遍历 readable,如果循环中因为 break 或 throw 一个错误而终止,则这个 Stream 也将被销毁。
根据 async 函数语法规则,await 只能出现在 async 异步函数内。对于异步资源,之前我们必须在 async 函数内才可使用 await,这对一些在文件顶部需要实例化的资源可能会不好操作。
在 Node.js v14.x LTS 发布后,已支持顶级 Await 我们可以方便的在文件顶部对这些异步资源做一些初始化操作。
我们可以像下面这样来写,但这种模式也只有在 ES Modules 中才可用。
import fetch from 'node-fetch';
const res = await fetch(url)JavaScript 编程中大部分操作都是异步编程,Async/Await 可以已同步的方式来书写我们的代码,但是实际执行其还是异步的,这种被方式目前也称为异步编程的终极解决方案。
MongoDB 是一个文档型数据库,支持的数据结构非常松散,可以存储比较复杂的数据类型,查询语句可以使用 JavaScript 编写,其支持的 JSON 数据模型对 Node.js/JavaScript 开发者很友好。
MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引,它的特点还有很多,请看下面介绍。
MongoDB 分为社区版本、企业版本两种类型,学习使用选择社区版本就够了 www.mongodb.com/download-center/community 这是 MongoDB 的下载中心,选择需要下载的版本和操作系统。MongoDB 的稳定版本都是偶数的,生产环境选择要注意。
Mac 系统可通过 Homebrew 安装 MongoDB 还是相对较简单的,如果 Homebrew 遇到被墙无法安装的,可尝试下 MacPorts 这个工具。
$ brew update # 更新 Homebrew 数据包
$ brew install mongodb # 安装 MongoDB
下面是下载安装包解压的方式安装,Mac 上也可通过这种方式,下载相对应的 Mac 系统的 tgz 版本即可。
$ wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu1604-4.2.2.tgz
$ tar -xvf mongodb-linux-x86_64-ubuntu1604-4.2.2.tgz
$ mv mongodb-linux-x86_64-ubuntu1604-4.2.2 mongodb-4.2.2
$ export PATH=$PATH:./data/soft/mongodb-4.2.2/bin # 注意,这个是你自己电脑上的安装路径
上面 export PATH= 这个命令在关闭当前终端之后就无效了,这个时候你网上搜索 MongoDB 安装后如何配置全局环境变量 大多会得到类似以下答案:
vim ~/.bash_profile
export PATH=$PATH:./data/soft/mongodb-4.2.2/bin # 这个还是你自己电脑上的 mongodb 路径
source ~/.bash_profile完事之后,也许很幸运成功了,但也可能失败了,原因是一些系统默认的终端是 bash 所以按照上面的配置是没问题的,但是如果你使用的是 zsh 那就要对 .zshrc 的配置文件做修改,按照上面流程,再来一遍:
vim ~/.zshrc
export PATH=$PATH:./data/soft/mongodb-4.2.2/bin # 这个还是你自己电脑上的 mongodb 路径
source ~/.zshrc查看 MongoDB 版本,初步校验是否安装成功,出现以下信息则是正确的。
$ mongo --version
MongoDB shell version v4.2.2
通过 --dbpath 参数自定义目录路径,若省略 --dbpath 参数,将会使用系统默认的数据目录 (/data/db),--dbpath 指定的目录是用来存放 MongoDB 数据库的地方。
$ mongod --dbpath <自定义的目录路径>
执行完以上命令之后,会开启 MongoDB 服务,默认监听的端口为 27017 看到类似以下日志信息,启动成功。
$ mongod --dbpath ./data
YYYY-MM-DDTHH:mm:ss.943+0800 I NETWORK [listener] Listening on 127.0.0.1
YYYY-MM-DDTHH:mm:ss.943+0800 I NETWORK [listener] waiting for connections on port 27017
YYYY-MM-DDTHH:mm:ss.944+0800 I SHARDING [LogicalSessionCacheReap] Marking collection config.transactions as collection version: <unsharded>
YYYY-MM-DDTHH:mm:ss.023+0800 I SHARDING [ftdc] Marking collection local.oplog.rs as collection version: <unsharded>以上我们搭建的是一个单机版的数据库,后面的文章中会介绍使用复制集搭建 MongoDB 服务器集群,下面还有一种更简单的方案在云端快速的开启一个 MongoDB 集群。
MongoDB Atlas cloud 是一个运行在云端的数据库,无需安装、配置,也无需在我们的机器上安装 Mongo 服务,只需要一个 URL 即可访问数据库,还提供了非常酷的 UI 界面,易于使用。最重要的一点对于我们初学者来说它提供了免费使用,最大限制为 512 MB,这对于小型项目是足够的。
之前在一篇 Serverless 的文章中有介绍如何开启一个 MongoDB Atlas cloud 集群,有详细的步骤介绍,可以看看这篇文章 使用 ServerLess, Nodejs, MongoDB Atlas cloud 构建 REST API。
以下是一个创建好的数据库集群,标注了几个地方可以看到有说明是 Replica Set 3 节点的,提供了链接方式,可以注册一个账号体验下。
终端链接到 MongoDB Server 主要通过客户端的 mongo 命令链接,在安装好 MongoDB 服务器之后,客户端的 mongo 命令通常就已经安装了。
如果本地没有该命令,也可安装 brew install mongosh 使用 mongosh 替代 mongo。
打开本地控制台输入命令 mongo 连接到 mongodb 服务器,也可以指定 IP 和 PORT
$ mongo --host 127.0.0.1 --port 27017
看到以下信息链接成功,会显示 mongodb 的版本号、链接地址,默认端口号为 27017
$ mongo --host 127.0.0.1 --port 27017
MongoDB shell version v4.2.6
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("8e2f9799-473f-48e9-84cf-3515480f084f") }
MongoDB server version: 4.2.6MongoDB Atlas cloud 可以生成一段终端的链接字符串,为了安全,需要配置 IP 白名单和创建一个用户,链接成功如下所示:
$ mongo "mongodb+srv://cluster0.******.mongodb.net/test" --username admin
MongoDB shell version v4.2.6
Enter password:
connecting to: mongodb://cluster0-shard-00-02.******.mongodb.net:27017,cluster0-shard-00-00.******.mongodb.net:27017,cluster0-shard-00-01.******.mongodb.net:27017/test?authSource=admin&compressors=disabled&gssapiServiceName=mongodb&replicaSet=Cluster0-shard-0&ssl=true
Implicit session: session { "id" : UUID("bfe6c53b-accb-4f51-93e1-d849c099a9c4") }
MongoDB server version: 4.4.8
MongoDB Enterprise Cluster0-shard-0:PRIMARY>在客户端想快速的查看或检索一些数据,图形化工具有很多的便利之处的,推荐一个工具 Robo 3T,官网地址:robomongo.org/ 自行下载,链接示例如下所示,上面是复制集的链接方式,下面是直链方式。
还有一个工具是 MongoDB 自带的 www.mongodb.com/try/download/compass。
应用程序以 Node.js 为例,可以使用 MongoDB 的 Node.js 驱动 mongodb 或 mongoose 这个模块,都可以。
我们在客户端每创建一个链接,MongoDB 的 Node.js 驱动都会在后台维护一个链接池,在应用层我们创建一个实例就可以了,可采用单例模式防止创建过多链接。
const MongoClient = require("mongodb").MongoClient;
const dbConnectionUrl = 'mongodb+srv://:<password>@cluster0-xxx.mongodb.net/test?retryWrites=true&w=majority';
// const dbConnectionUrl = 'mongodb://localhost:27017/test';
let dbInstance = null
async function getMongoInstance() {
try {
if (dbInstance) {
return dbInstance;
}
dbInstance = await MongoClient.connect(dbConnectionUrl);
console.log("[MongoDB connection] SUCCESS");
return dbInstance;
} catch (err) {
console.log(`[MongoDB connection] ERROR: ${err.message}`);
throw err;
}
}
getMongoInstance()推荐几个 MongoDB 学习资源,可以做为学习过程中的参考资料,有收费的也有免费的,也都是笔者在学习、工作中看过的一些资料,如果你有其它的学习资源欢迎留言区推荐。
现代的前端开发、Node.js 后端开发中 NPM 包管理是最基础也是最关键的一部分,本文将从一个问题开始,阐述 NPM 版本控制的工作原理,我相信这是每一个使用了 NPM 的开发人员都应该熟悉的知识。
事情的经过是前一天测试还一切正常,第二天部署时却提示 yarn 安装依赖失败,下面是本地复现的结果,如下图所示:
一个明显的提示是 [email protected] 这个依赖不再支持 Node.js 14.20.1 以下版本,但是项目的 dependencies 中也没有指定这个包啊,了解 MongoDB 的同学应该知道 bson 是 Mongo 实现的一个类 JSON 的二进制存储格式。
为了一探究竟,执行 yarn --ignore-engines 先忽略这个引擎检测,看下 yarn.lock 文件中 bson 的依赖关系。
mongoose@^5.3.0 是项目中的依赖,实际安装后使用的版本为 5.13.5,之后又依赖了 @types/mongodb,问题来了,这里竟然使用了 @types/bson: * 要知道在 NPM 的版本号规则里 * 号是不会锁定版本的,每次都会升级为最新版本,也就是最后的 bson: 5.0.0。
查了下 bson 这个库的 CHANGELOG 发现其在 2023-01-31 号发布了 5.0.0,要求 Node.js 版本必须大于 14.20.1,上面报错显然当前版本不满足。
库的版本升级很正常,了解 NPM 版本号规则的同学应该知道 “bson: 5.0.0 ” 这是一个大版,会存在不向前兼容的情况,这里的问题在于 @types/mongodb 直接使用了 @types/bson: *,每次安装都会升级到最新,是有点不讲 “码德”,这里是个坑,NPM 上查了 @types/mongodb 这个包,发现已经被废弃了,如下图所示:
mongoose 这个包的影响版本为:mongoose 5.11 ~ 5.13.15。
这里先抛出一个问题:“为什么安装时使用的 mongoose@^5.3.0 安装成功后却变成了 5.13.15”?
在发布 NPM 模块新版本时,建议遵循 “语义版本控制” 考虑使用这样的版本号x.y.z 控制,如下所示:
版本号规则:
在发布 NPM 包时建议从 1.0.0 开始,例如:
语义化版本号的几种表示方法:
^1.1.2:^ 是 NPM 安装后的默认符号,保持高版本不升级,次版本、补丁版本升级到最新,例如:^1.1.2 等价于 1.1.2 >= ^1.1.2 < 2.0.0。~1.1.3:波浪符 ~ 只会升级补丁版本,例如:~1.1.3 等价于 1.1.3 >= ~1.1.3 <1.2.0。1.1.3:不加任何符号表示锁定了这个版本,不会进行任何升级。* 或 "":* 号或者空字符 "",不会锁定版本,每次都会升级到最新版本,前面提的问题就是这个导致的。1.0.0-alpha.1:使用 alpha、rc 等标识的表示该版本是一个预发布版本,该版本可能无法满足预期的兼容性需求,正式环境不要用。v1.0.0:在一些版本控制的系统中通常用 v 表示版本号,例如 git tag v1.0.0,但它并不是语义化版本号。了解了语义化版本号规则后,应该要知道上面提出的一个问题:“为什么安装时使用的 mongoose@^5.3.0 安装成功后却变成了 5.13.15”,因为版本号前加 ^ 符号,它表示的是第一位保持不变、最后两位升级到最新。
考虑一个问题,项目第一次添加一个模块的依赖是 ^1.2.3,过了两周另一个同事需要修这个项目,此时依赖已经更新到 1.3.0 他在重新安装后就会得到最新的版本,这会带来一个问题,每个人得到依赖版本不一致,该如何确保团队成员的依赖版本都是一致呢?
解决依赖版本不一致的问题一种方法是 “固定依赖版本”,但在实际做法中这种很少见,大多数时候没有意识到一个问题 “安全修复”,通过版本号前加 ^ 或 ~ 符号我们可以得到补丁版本错误修复、向前兼容的小版本新功能。
解决依赖版本不一致的另一种方法是通过 lock 文件(NPM 中的 package-lock.json 或 yarn 中的 yarn.lock )来解决同一个项目团队成员之间依赖版本不一致的问题,在使用 npm 或 yarn 安装之前会先检查 lock 文件上的版本,并来安装它们,有必要将 lock 文件推送至 git 仓库。
如果需要将依赖项更新到指定范围的最新版本,只需要执行 npm update 命令,该命令会遵循语义化版本控制对依赖进行升级,同时也会更新 lock 文件。
在 《JavaScript 异步编程指南》的上个模块中,我主要讲解了异步编程的基本应用,在这个模块系列中我想来聊聊事件循环,英文称为 EventLoop。
相信这个名字对于参加过 JavaScript 面试的同学(包括前端或后端 Node.js)而言不会陌生。
讨论事件循环的文章很多,成系列的倒不是很多见,我将事件循环放在《JavaScript 异步编程指南》系列的第二个模块展开讨论,也是希望能够对 JavaScript 异步编程有个更深刻的理解。
JavaScript 这门编程语言,既可以在客户端浏览器上运行,也可以在服务端 Node.js 上运行。我想以一种自己理解的角度来讲,所以上来不会直接去讲浏览器中的 EventLoop 或 Node.js 中的 EventLoop。
事件循环中的一些概念,无论是在浏览器或 Node.js 中我们去学习事件循环时,这些都是通用的,了解这些概念对于后面的学习也会相对轻松些。
单线程、调用栈、堆、队列、Eventloop 这些词通过可视化界面描述看起来就像下图展示的,但是它们之间的关系是怎么样呢?接下来我会分别的去介绍。
JavaScript 是单线程的,此时,是否有疑问为什么是单线程呢?多线程处理效率不是更高吗?
需要从浏览器说起,在浏览器环境中对于 DOM 操作,试想如果多个线程来对同一个 DOM 操作,一个线程添加 DOM 而另一个线程删除 DOM 那这结果到底是删除还是添加呢?是不是就乱了呢?那也就意味着对于 DOM 的操作只能是单线程,避免 DOM 渲染冲突。
在浏览器环境中 UI 渲染线程和 JavaScript 执行引擎是互斥的,一方在执行时都会导致另一方被挂起。
上面说了既然 JavaScript 是单线程的,那么同一时间只能处理一件事情,对于高并发大量请求不是会造成程序阻塞吗?
答案是 No,解决阻塞等待的方案就是异步,例如,程序发起一次网络请求或文件请求不必同步等待响应结果,真正处理这些任务由另外的线程实现,待有结果了再通知到 JavaScript 主线程,在 JavaScript 中正是通过单线程加事件循环实现的,同时也避免了多线程上下文切换,资源抢占问题,达到更好的高并发成就。
另外,HTML5 提出了 Web Worker 标准,Node.js 提供了 worker_threads 模块,允许我们在服务中创建多个线程,但是这些都没改变 JavaScript 单线程的本质,这些创建线程属于子线程还是由主线程来管理。
栈是一种先进后出的数据结构,JavaScript 是一个单线程的编程语言,每次只能运行一段代码,有且只有一个调用栈。
JavaScript 中所有的任务可以归为两种:同步任务与异步任务。
我们先看第一种,同步任务在主线程上排队执行,形成一个由若干个帧组成的调用栈(Call Stack)。
下例,当调用 hello() 函数时,第一个帧被创建压入栈中,该函数又调用了 intro() 函数,第二个帧被创建并压入栈中,位于 hello() 之上。此时 intro() 函数中没有在调用其它函数了,按照栈的后进先出的规则,intro() 函数开始执行直到完成第二个帧从栈中弹出,之后开始执行 hello() 函数,执行完毕之后,第一个帧从栈中弹出,栈也就被清空了。
function intro() {
console.log('My name is codingMay!');
}
function hello() {
intro();
console.log('Hello');
}
hello();通过动图的方式展示下运行结果。
在开发中,还有一个问题也是不可避免的,在某些场景下程序会抛出一些错误信息,也许是显示的错误定义,也许是意外的未知错误。
我们对示例做下改造,让 intro() 抛出一个 Error 对象,在 Chrome 控制台运行之后,错误信息从 intro、Hello 再到匿名函数,把整个错误的调用栈都打印出来了。这是一个同步调用,上下文信息是有关联的,程序能够跟踪到下一行要执行的一些代码。
你可能还听过一个问题 “内存泄漏”,下面左侧就是一个例子,hello() 函数递归调用自身,代码没有设置边界,hello() -> hello() -> ... 程序一直这样运行下去,调用栈不断的增加数据,直到超过栈的最大空间限制,程序会报一个错误 VM356:4 Uncaught RangeError: Maximum call stack size exceeded。
思考一个问题 “上面的递归代码怎么改造才能不触发栈溢出?前提是还是递归调用。”
JavaScript 在执行时所有的数据会存放在内存里,像函数、函数变量、参数等这些已知数据占用空间的存在于内存区域的栈中,代码执行过程中创建的对象,存在于堆中,也是内存中的另外一块区域。
在 JavaScript 中当调用栈有东西还在执行时,我们的程序也不会空闲去执行其它的操作,试想,如果调用栈出现一些很耗时的任务,如果是用在客户端用户会看到页面被卡住了,如果是用在服务端会造成接口响应很慢,也就没有并发优势了,这是很糟糕的一件事,我们不能让 JavaScript 主线程阻塞。
修改下上面的示例,在 inrto() 方法里加上 setTimeout 延迟执行,看下程序的执行是怎么样的?
function intro() {
setTimeout(function timer() {
console.log('My name is codingMay!');
}, 8000)
}
function hello() {
intro();
console.log('Hello');
}
hello(); 上述代码,intro() 函数内部执行了 setTimeout 定时器函数,这个是异步的,我们的 JavaScript 主线程不会在这里等待,会立即返回。setTimeout 第一个参数我们传入的 timer 这个是我们需要执行的代码,这里 timer 通常也是我们说的回调函数。
注:Web Apis 这个是由宿主环境提供的 API,这里也有单独的线程来实现,例如定时器就是由宿主环境实现的。
setTimeout 不是由 JavaScript 引擎实现的,这个是由 JavaScript 程序所运行的宿主环境提供的,理解这个概念也不难,在客户端我们的宿主环境就是浏览器,如果在服务端就是 Node.js。当计时器时间到了之后,宿主环境会将 timer 函数封装为一个事件放入 “队列”,队列是一个先进先出的数据结构。
接下来执行队列里的任务就是 EventLoop 了~
EventLoop 从这个名字上也可以看出它是一个持续循环的过程,它会检查当前调用栈是否为空,只有在当前调用栈为空后进入下一个 Loop,如果任务队列有任务,取出执行,如果任务队列为空,它会同步地等待消息到达。
按照如下类似方式来实现:
while (queue.waitForMessage()) {
queue.processNextMessage(); // 同步地等待消息到达
}通过一个 Gif 完整的展示其运行效果,稍微有点灰,因为上传过程中被压缩了。
学习 Rust 之前,在知乎等平台也看到过一些回答,认为 Rust 学习曲线陡峭、难学,个人觉得如果有些 C/C++ 的基础其实学起来也还好,只不过 Rust 有很多独有的概念,这一点是和现有很多主流语言是不同的,需要花点时间看下。
本文是笔者在 Rust 学习过程中所记录的,在掘金看到了 Rust 技术征文,整理出这份基础的不完全入门指南,也希望能帮助一些学习 Rust 的朋友。
一个脑图概括本文所有知识点。
Rust 语言是 Mozilla 员工 Craydon Hoare 在 2006 年创建的一个业余项目,2012 年 Mozilla 宣布推出基于 Rust 语言开发的以内存安全性、 并发性为首要原则的新浏览器引擎 Servo 这也是其首个完整的大型项目。
2015 年发布首个 Rust v1.0 版本,这是第一个重要的里程碑,近期在过去的 2020 年由于疫情原因,Mozilla 宣布裁员,涉及到一些 Rust 项目和 Rust 社区中的活跃成员,这对外界对于 Rust 猜测又增加了更多不确定性。
今年的 2 月 9 号,Rust 基金会 https://foundation.rust-lang.org/ 宣布成立,从 Mozilla 脱离出来,目前的基金会董事成员包括:亚马逊、Google、微软、Mozilla 和国内的华为,由五大科技巨头支持,对 Rust 来说总归是好事,可以为这门语言促进更好的发展,也有着更好的前景,社区看到的一句话:“Go 是当下,Rust 是未来”。
let a = 1; 声明一个变量,看似给 JavaScript 一样的,Rust 中类型推断的结果可能是这样的 let a: i32 = 1;如果你不想在本地电脑上安装,想尽快尝试下 Rust 可通过其提供的在线代码编辑器。
如果使用 MacOS、Linux 或其它的类 Unix 系统,可以下载 Rustup 安装 Rust,Rustup 即是一个 Rust 安装器又是一个版本管理工具。
终端运行如下命令,根据提示完成即可。
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shRust 目前的升级很频繁,如果你已安装很长一段时间,可通过 rustup update 命令更新最新版本。
$ rustup update$ rustc --version
rustc 1.50.0 (cb75ad5db 2021-02-10)Rust 的所有工具存在于 ~/.cargo/bin 目录下,正常情况下安装时会配置环境变量,但是由于不同平台、shell 之间存在的差异,可能会存在一些问题,导致在终端未重启或用户未重新登陆之前,rustup 对环境变量的修改不生效,如果存在问题 rustc --version 命令就会执行失败。
$ rustup self uninstall在 Windows 平台上,通过下载可执行应用程序 rustup-init.exe 安装。
Rust 支持多种编辑器 VS CODE、SUBLIME TEXT 3、ATOM、INTELLIJ IDEA、ECLIPSE、VIM、EMACS、GEANY。
以笔者常用的 VS CODE 做一个介绍。
推荐两个 Rust 的 VS CODE 插件: rust-analyzer、rust。
创建一个项目 cargo new hello-rust
查看目录结构 tree -a
├── .gitignore
├── Cargo.toml
└── src
└── main.rs看下 Cargo.toml 的内容,这个类似于 Node.js 中的 package.json 声明了项目所需的信息,对于 Rust 项目来说就是声明了 Cargo 编译程序包所需的元数据,以 .toml 文件格式编写。
TOML 一种新的配置文件格式。
[package]
name = "hello-rust"
version = "0.1.0"
authors = ["五月君 <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]主程序 main.rs 使用 function 的简写 fn 声明了一个函数,注意,里面 println! 后面加上了符号 ! 并不是一个函数,而是一个宏。
fn main() {
println!("Hello, rust!");
}编译我们的 Rust 项目,之后会在 target/debug/ 目录下生成编译好的文件,如下所示:
$ cargo build
$ target/debug/hello-rust
Hello, rust!Rust 的 Release 编译模式,如下所示:
$ cargo build --release
$ target/release/hello-rust
Hello, rust!开发阶段每次编译再执行,你可能会感觉很麻烦,Rust 允许我们使用 cargo run 直接编译运行,该命令会自动帮我们做编译操作,如下所示:
$ cargo run
Compiling hello-rust v0.1.0 (/Users/xxxx/study/hello-rust)
Finished dev [unoptimized + debuginfo] target(s) in 1.00s
Running `target/debug/hello-rust`
Hello, rust!Rust 使用 let 声明一个变量,通常来说变量将是可变的,但是在 Rust 中默认设置的变量是预设不可变的,这也是 Rust 推动你能充分利用其提供的安全性来写程序的方式之一,Rust 中鼓励你多多使用不可变的,当然如果你明确知道该变量是可变得,也是可以的。
以下我们声明的变量 num 并没有明确其类型,这也是 Rust 的特性之一类型推断
fn main() {
let num = 1;
num = 2;
println!("num {}", num);
}运行之后会得到一个 cannot assign twice to immutable variable 'num' 错误,这在编译器阶段就是不会通过的。
在变量名称前加上 mut 关键字,表明该变量是可变的。
fn main() {
let mut num = 1;
println!("num {}", num);
num = 2;
println!("num {}", num);
}常量使用 const 声明,之后是不可变的,在声明时必须指定变量类型,这也是与 let 的不同,还需注意的是常量名称一定要大写,否则编译阶段也是会报错的。
fn main() {
const NUM: i8 = 1;
println!("num {}", NUM);
}一个变量只有在其作用域内是生效的。下例,变量 y 在花括号内即它的块级作用域内是有效的,当离开花括号如果想在外部打印,会报 cannot find value y in this scope 错误。
fn main() {
let x = 1;
{
let y = 2; // y 在此处开始有效
println!("y {}", y);
} // 此作用域结束,y 不再有效
println!("x {} y {}", x, y);
// println!("x {}", x);
}Rust 是一个静态数据类型的语言,这意味着在编译时它就要知道变量的类型。
Rust 包含四种基本数据类型分别为:整形、浮点型、布尔型、字符型。
Rust 里的整型又分为带符号的整型(signed)和非带符号整型(unsigned),两者之间的区别是数字是否是负数。
带符号整型的安全存储范围为
非带符号整型的安全存储范围为 0 到
isize 和 usize 是根据系统架构决定的,例如带符号整型,如果系统是 64 位,类型为 i64,如果系统是 32 位,类型为 i32。
| 长度 | 带符号整型 | 非带符号整型 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| 系统架构 | isize | usize |
Rust 的浮点型提供了两种数据类型 f32、f64,分别表示为 32 位与 64 位,默认情况下是 64 位。
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
println!("x: {}, y: {}", x, y); // x: 2, y: 3
}和大多数编程语言一样,Rust 中的布尔型包含两个值:true 和 false。
fn main() {
let x = true; // bool
let y: bool = false; // bool
}Rust 中的字符型为一个 Unicode 码,大小为 4 bytes,char 类型使用单引号包括。
fn main() {
let x = 'x';
let y = '😊';
println!("x: {}, y: {}", x, y); // x: x, y: 😊
}复合类型可以组合多个数值为一个类别,复合类型包含两种:元组(tuples)和数组(arrays)。
元组是将多个不同数值组合为一个复合类型的常见方法,元组拥有固定长度,一旦声明无法更改。
我们通过解构的方式,分别从声明的元组中取出数据,如下例所示:
fn main() {
let tup: (i32, f64, char) = (1, 1.01, '😊');
let (x, y, z) = tup;
println!("x: {}, y: {}, z: {}", x, y, z); // x: 1, y: 1.01, z: 😊
}除此之外我们还可通过数值的索引来访问元组中的数据。
fn main() {
let tup: (i32, f64, char) = (1, 1.01, '😊');
let x = tup.0;
let y = tup.1;
let z = tup.2;
println!("x: {}, y: {}, z: {}", x, y, z); // x: 1, y: 1.01, z: 😊
}与元组不同的是数组中的所有元素类型必须一致,Rust 中的 Array 与其它语言不太一样,因为其 Array 的长度是固定的和元组一样。
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
println!("a[0]: {}, a[4]: {}", a[0], a[1]); // a[0]: 1, a[4]: 2
}Rust 中的 if 语句必须接收一个布尔值,不像 JavaScript 这门语言会自动转换,还可以省略括号。
fn main() {
let number = 1;
if number < 2 {
println!("true"); // true
} else {
println!("false");
}
}如果预期不是一个布尔值,编译阶段就会报错。
fn main() {
let number = 1;
if number {
println!("true");
}
}运行之后,报错如下:
cargo run
Compiling hello-rust v0.1.0 (/Users/xxxxx/study/hello-rust)
error[E0308]: mismatched types
--> src/main.rs:3:8
|
3 | if number {
| ^^^^^^ expected `bool`, found integer
error: aborting due to previous error在 let 中使用 if 表达式,注意 if else 分支的数据类型要一致,因为 Rust 是静态类型,需要在编译期间确定所有的类型。
fn main() {
let condition = true;
let num = if condition { 1 } else { 0 };
println!("num: {}", num); // 1
}loop 表达式会无限的循环执行代码块,如果想终止循环,可配合 break 语句使用。
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("result: {}", result); // 20
}使用 while 可以加上条件判断决定是否还要循环多少次,如果条件为 true 继续循环,条件为 false 则退出循环。
fn main() {
let mut counter = 3;
while counter != 0 {
println!("counter: {}", counter);
counter -= 1;
}
println!("end");
}使用 for 循环遍历集合元素,例如在访问一个数组时,增加了程序的安全性不会出现超出数组大小或读取长度不足的情况。
fn main() {
let arr = ['a', 'b', 'c'];
for element in arr.iter() {
println!("element: {}", element);
}
println!("end");
}在 Rust 中使用 for 循环的另一种方式。
fn main() {
for number in (1..4).rev() {
println!("number:{}", number);
}
println!("end");
}在 Rust 代码中函数随处可见,例如我们使用的 main 函数,关于函数的几个特点总结如下:
-> 后声明返回类型,默认情况下返回最后一个表达式,注意不要有分号 ;;。fn main() {
let res1 = multiply(2, 3);
let res2 = add(2, 3);
print!("multiply {}, add {} \n", res1, res2);
}
fn multiply(x: i32, y: i32) -> i32 {
x * y
}
fn add(x: i32, y: i32) -> i32 {
return x + y;
}结构体是一种自定义数据类型,它由一系列属性组成(这个属性拥有自己的属性和值),结构体是数据的集合,就像面向对象编程语言中一个无方法的轻量级类,因为 Rust 本身不是一门面向对象的语言,合理的使用结构体可以使我们的程序更加的结构化。
使用 struct 关键字定义一个结构体,创建一个结构体实例也很简单,如下例所示:
struct User {
username: String,
age: i32
}
fn main() {
// 创建结构体实例 user1
let user1 = User {
username: String::from("五月君"),
age: 18
};
print!("我是: {}, 永远 {}\n", user1.username, user1.age); // 我是: 五月君, 永远 18
}方法与函数类似,使用 fn 关键字声明,拥有参数和返回值,不同的是方法在结构体的上下文中定义,方法的第一个参数始终为 self 表示调用该方法的结构体实例。
改写上面的结构体示例,在结构体 User 上定义一个方法 info 打印信息,这里用到一个关键字 impl,它是 implementation 的缩写。
struct User {
username: String,
age: i32
}
impl User {
fn info(self) {
print!("我是: {}, 永远 {}\n", self.username, self.age);
}
}
fn main() {
let user1 = User {
username: String::from("五月君"),
age: 18
};
user1.info();
}enum Language {
Go,
Rust,
JavaScript,
}#[derive(Debug)]
enum OpenJS {
Nodejs,
React
}
enum Language {
JavaScript(OpenJS),
}#[derive(Debug)]
enum IpAddrKind {
V4,
V6,
}
#[derive(Debug)]
struct IpAddr {
kind: IpAddrKind,
address: String,
}
fn main() {
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
println!("{:#?} \n {:#?} \n", home, loopback);
}Rust 提供的匹配模式允许将一个值与一系列的模式比较,并根据匹配的模式执行相应的代码块,使用表达式 match 表示。
举一个例子,我们可以定义一个 Language 枚举,代表编程语言,之后定义一个函数 get_url_by_language 根据语言获取一个对应的地址,match 表达式的结果就是这个函数的结果。看起来有点像 if 表达式,但是 if 只能返回 true 或 false,match 表达式可以返回任何类型。
这个示例分为三个小知识点:
Go 匹配,因为这个分支我们仅需要返回一个值,可以不使用大括号。Rust 匹配,这次我们需要在分支中执行多行代码,可以使用大括号。JavaScript 匹配,这次我们想对匹配的模式绑定一个值,可以修改枚举的一个成员来存放数据,这种模式称为绑定值的模式。#[derive(Debug)]
enum OpenJS {
Nodejs,
React
}
enum Language {
Go,
Rust,
JavaScript(OpenJS),
}
fn get_url_by_language (language: Language) -> String {
match language {
Language::Go => String::from("https://golang.org/"),
Language::Rust => {
println!("We are learning Rust.");
String::from("https://www.rust-lang.org/")
},
Language::JavaScript(value) => {
println!("Openjs value {:?}!", value);
String::from("https://openjsf.org/")
},
}
}
fn main() {
print!("{}\n", get_url_by_language(Language::JavaScript(OpenJS::Nodejs)));
print!("{}\n", get_url_by_language(Language::JavaScript(OpenJS::React)));
print!("{}\n", get_url_by_language(Language::Go));
print!("{}\n", get_url_by_language(Language::Rust));
}Option 是 Rust 系统定义的一个枚举类型,它有两个变量:None 表示失败、Some(value) 是元组结构体,封装了一个范型类型的值 value。
fn something(num: Option<i32>) -> Option<i32> {
match num {
None => None,
Some(value) => Some(value + 1),
}
}
fn main() {
let five = Some(5);
let six = something(five);
let none = something(None);
println!("{:?} {:?}", six, none);
}Rust 匹配模式还有一个概念**匹配是穷尽的,**上例中 None => None 是必须写的,否则会报 pattern None not covered 错误,编译阶段就不会通过的。
| 符号实现多值匹配。..= 符号实现范围匹配,注意,之前是使用 ... 现在该方式已废弃。_ 符号是匹配穷进行,Rust 要检查所有被覆盖的情况。fn main() {
let week_day = 0;
match week_day {
1 ..= 4 => println!("周一至周四过的好慢啊..."),
5 => println!("哇!今天周五啦!"),
6 | 0 => println!("这两天是周末,休息啦!"),
_ => println!("每周只有 7 天,请输入正确的值...")
};
}我们想仅在 Some(value) 匹配时做些处理,其它情况不想考虑,为了满足 match 表达式穷进性的要求,还要在写上 _ => () 来匹配其它的情况,类似代码多了显然繁琐。
fn main() {
let five = Some(5);
match five {
Some(value) => println!("{}", value),
_ => ()
}
}只针对一种模式做匹配处理的场景下,可以使用 if let 语法,可以更少的代码来写,如下所示:
fn main() {
let five = Some(5);
if let Some(value) = five {
println!("{}", value + 1);
}
}所有权是 Rust 的核心特色之一,它让 Rust 无需垃圾回收即可保证内存安全。我们先记住这样一句话: 在 Rust 里每一个值都有一个唯一的所有者,如果当我们对这个值做一个赋值操作,那么这个值的所有权也将发生转移,当所有者离开作用域,这个值也会随之被销毁。
对许多人来说这是一个全新的概念,在接下来我们慢慢来了解它。
也不得不说下目前的内存管理方式, 一类是类似于 C 语言这样的需要手动分配、释放内存,在 C 语言中可以使用 malloc/free 这两个函数,手动管理内存如果出现遗漏释放、过早释放、重复释放等这些问题也是最容易制造 Bug 的。 **另一类是类似于 JavaScript、Java 这类的高级语言由垃圾回收机制自动管理内存, **你不需要担心有什么内容会忘记释放,也不需要担心过早的释放。
Rust 采用了第三种方式,通过所有权系统管理内存,编译器在编译时会根据一系列规则做检查,如果出现错误,例如堆上的一个值其所在的变量 x 被赋值给一个新的变量 y,如果此后的程序还在使用 x,就会报错,因为一个值只有一个所有者,下文 "复杂数据类型 — 移动" 这个小节会讲到这个示例。
基本数据类型,类似于 i32、char 这些的长度都是固定已知的,程序可以轻松的分配一定的内存给它,且它们都是存储在栈上在离开所在的作用域时也会被移除栈。对于一些复杂的数据类型,例如 String 它的长度在编写时是未知的,成勋运行过程中是有可能改变它的长度的,这个类型就存储在堆上。
类似 String 类型的数据它的过程是这样的:
看一段小示例:
fn main() {
let s1 = String::from("hello");
print!("{}", s1); // hello
}如下图所示, 左侧是存储在栈上的数据,ptr 指向存放字符串内容的指针,len 是 s1 内容使用了多少字节的内存,capacity 是容量表示从操作系统获取了多少字节的内存。 右侧是存储在堆上的数据。
当我们执行 String::from("hello") 时,这是第一步操作,实现请求所需的内存。在变量 s1 离开作用域后会被自动释放掉,这是第二步操作,但这块不需要开发者手动操作,Rust 会为我们调用一个特殊的函数 drop,在这里 String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop。
声明基本数据类型 x 将其赋值给变量 y,由于这是一个已知固定大小的值,因此被放入了栈中,赋值的过程也是一个拷贝的过程,现在栈中既有 x 也有 y,程序是可以正常执行的。
fn main() {
let x: i32 = 5;
let y: i32 = x;
print!("x {}, y {}", x, y); // x 5, y 5
}接下来让我们看一个复杂数据类型的赋值,和上面的示例类似,不过这次使用的 String 类型。
fn main() {
let s1 = String::from("hello");
let s2 = s1;
print!("s1 {}, s2 {}", s1, s2);
}运行之后,报错如下:
$ cargo run
Compiling hello-rust v0.1.0 (/Users/xxx/study/hello-rust)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:4:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 | print!("s1 {}, s2 {}", s1, s2);
| ^^ value borrowed here after moveString 类型的数据存储在堆上,那么赋值时也并不会在堆上拷贝一份,如果真的是拷贝在运行时过程中一旦堆上数据比较大这对性能的影响也是很大的。
为了确保安全,Rust 在这种场景下有一个值得注意的细节,**当尝试拷贝被分配的内存时,Rust 会使第一个变量无效,这个过程在 Rust 中称为移动,**可以看作 s1 被移动到了 s2 当 s2 离开作用域时,它就会自动释放自己的内存,这里也再次证明一点,在 Rust 同一时间每一个值仅有一个所有者。
基本数据类型存储在栈上,赋值就是一个拷贝的过程,在堆上的数据当你需要拷贝时,也是可以通过一个 clone 的通用函数实现的。
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
print!("s1 {}, s2 {}", s1, s2); // s1 hello, s2 hello
}将值传递给函数与变量赋值类似,值的所有权会发生变化,如下示例所示,外层 s1 处是会报错的,这在编译阶段会报 borrow of moved value: s1 错误。
fn main() {
let s1 = String::from("hello"); // s1 进入作用域
dosomething(s1); // s1 的值移动到函数 dosomething 里
print!("s1: {}", s1); // s1 在这里就不再有效了
}
fn dosomething(s: String) { // s 进入作用域
print!("dosomething->s: {}", s);
}// s 离开作用域会被自动释放掉解决这个问题的一个办法是转移函数返回值的所有权。
fn main() {
let s1 = String::from("hello");
let s = dosomething(s1);
print!("s1: {} \n", s);
}
fn dosomething(s: String) -> String {
print!("dosomething->s: {} \n", s);
s
}但是这样实现起来难免啰嗦,还可以通过 引用 简单的实现。
符号 & 表示引用,&s1 为我们创建一个指向值 s1 的引用,但并不拥有它,所有权没有发生转移。
fn main() {
let s1 = String::from("hello");
dosomething(&s1);
print!("s1: {} \n", s1); // s1: hello
}
fn dosomething(s: &String) {
print!("dosomething->s: {} \n", s);
} // s 离开作用域,但其没有拥有引用值的所有权,这里也不会发生什么...引用也许还可以理解,那么借用又是什么呢?在 Rust 中我们获取引用做为函数的参数称为 借用,这里就需要注意了,预设变量默认是不可变的,想修改引用的值还需使用可变引用,在特定作用域中数据有且只有一个可变引用,好处是在编译时即可避免数据竞争。
fn main() {
let mut s1 = String::from("hello");
dosomething(&mut s1);
print!("s1: {} \n", s1); // s1: hello 五月君
}
fn dosomething(s: &mut String) {
s.push_str(" 五月君");
print!("dosomething->s: {} \n", s); // dosomething->s: hello 五月君
}范型是对具体类型的一种抽象,常用在强类型编程语言中,高效的处理重复概念。例如我们定义一个函数,参数可能有多种类型的值传递,那么就不能用具体的类型来声明,可以在编写代码时使用范型来指定类型,在实例化时做为参数指明这些类型。
为了开启比较功能,我们要使用到 trial 标准库中定义的 std::cmp::PartialOrd
fn largest<T: std::cmp::PartialOrd>(a: T, b: T) -> T {
if a > b {
a
} else {
b
}
}
fn main() {
let res1 = largest(1, 2);
let res2 = largest(1.1, 2.1);
print!("res1: {}, res2: {} \n", res1, res2);
}fn add<T: std::ops::Add>(a: T, b: T) -> <T>::Output {
a + b
}
fn main() {
let res1 = add(1, 2);
let res2 = add(1.1, 2.1);
print!("res1: {}, res2: {}", res1, res2);
}我们通常使用 T 来标识一个范型,例如我们定义一个坐标结构体,x、y 可能同时是不同的类型,这样就需要定义两个范型参数。也要尽可能的避免在参数中定义太多的范型参数,这会让代码看起来很难阅读和理解。
struct Point<T1, T2> {
x: T1,
y: T2
}
fn main() {
let res1 = Point { x:1, y: 2};
let res2 = Point { x:1.1, y: 2.1};
let res3 = Point { x:1, y: 2.1};
}必须在 impl 后声明范型 T,对应我们的示例因为有多个范型参数,所以就是 T1、T2。
struct Point<T1, T2> {
x: T1,
y: T2
}
impl<T1, T2> Point<T1, T2> {
fn x(&self) -> &T1 { &self.x }
fn y(&self) -> &T2 { &self.y }
}
fn main() {
let res = Point { x:1, y: 2.1};
print!("res.x: {}, res.y: {} \n", res.x(), res.y());
}Option 和 Result 这两个枚举都拥有范型,由 Rust 标准库提供。
enum Option<T> {
Some(T),
None,
}
enum Result<T, E> {
Ok(T),
Err(E),
}以 Resut 举例,如果我们读取一个环境变量,成功时触发 Ok 函数,失败时触发 Err 函数。
fn main() {
match std::env::var("HOME") {
Ok(data) => print!("Data: {}", data),
Err(err) => print!("Error: {}", err)
}
}
fn main() {
match std::env::var("xxxx") {
Ok(data) => print!("Data: {}", data),
Err(err) => print!("Error: {}", err) // Error: environment variable not found
}
}trait 是告诉 Rust 编译器某种类型具有哪些可以与其它类型共享的功能,抽象的定义共享行为,简单来说就是把方法的签名放在一起,定义实现某一目的所必须的一组行为。与其它语言的接口(Interface)类似,也还有些区别。
创建文件 person.rs 使用 trait 定义行为 Person,例如,每个人都有一个简单的介绍,在大括号内声明实现这个 trail 行为所需要的签名方法。
注意,trait 定义的类型里只有方法签名,没有具体实现,每一个方法签名独占一行,以 ; 结尾,pub 代表公用的,可被外部其它模块调用。
pub trait Person {
fn intro(&self) -> String;
}实现 trait 定义的行为,使用 impl 后跟自定义的 trait,for 后跟自定义的结构体,大括号内编写实现 Person 这个行为类型声明的方法签名,这点看起来和其它面向对象编程语言中的 Interface 相似。
format!() 是格式化为一个字符串返回。
pub struct Worker {
pub name: String,
pub age: i32
}
impl Person for Worker {
fn intro(&self) -> String {
format!("My name is {}, age {}, is a worker", self.name, self.age)
}
}在 main.rs 中引入 person.rs 模块。
mod 关键字用来加载需要引入的文件为我们的模块,use 表示加载 person 这个模块定义的 trait 和结构体。
mod person;
use person::{ Person, Worker };
fn main() {
let may_jun = Worker {
name: String::from("五月君"),
age: 20
};
println!("{}", may_jun.intro());
}可以为 trait 中某些签名方法提供默认的行为,这样当某个特定的类型实现 trait 时,可以选择保留或重载签名方法提供的默认行为。
修改 person.rs,当为方法提供默认行为之后,无法在 Worker 中再次定义 intro 方法了,但是可以在 Worker 实例后调用。
pub trait Person {
fn intro_author(&self) -> String;
fn profession(&self) -> String;
fn intro(&self) -> String {
format!("我的个人简介:{}, 职业 {}", self.intro_author(), self.profession())
}
}
pub struct Worker {
pub name: String,
pub age: i32
}
impl Person for Worker {
fn intro_author(&self) -> String {
format!("姓名: {} 年龄: {}", self.name, self.age)
}
fn profession(&self) -> String {
format!("打工人")
}
}把 trait 做为参数,例如定义 intro 方法,传入的 item 需要是实现了 Person 这个 trait 的参数类型,这样我们可以直接调用 Person 这个 trait 上定义的 intro() 方法。
pub fn print_intro (item: impl Person) {
println!("pub fn print_intro {}", item.intro());
}修改 main.rs 引入 person.rs 文件里定义的 print_intro() 执行时传入实现了 Person 这个 trait 的结构体类型。
mod person;
use person::{ Person, Worker, print_intro };
fn main() {
let may_jun = Worker {
name: String::from("五月君"),
age: 20
};
println!("{}", may_jun.intro());
print_intro(may_jun);
}可以定义实现了某个 trait 的类型为返回值,与上面的例子结合使用,修改 main.rs 文件。
fn returns_intro () -> impl Person {
Worker {
name: String::from("五月君"),
age: 20
}
}
print_intro(returns_intro());Trait Bounds 适用于复杂的场景,例如方法参数中定义多个实现了 trait 的类型。
pub fn print_intro (item1: impl Person, item2: impl Person) {}Trait Bounds 与范型参数声明在一起,改写上面的例子如下所示:
pub fn print_intro<T: Person> (item1: T, item2: T) {}以上仅是关于 Rust 一些基础知识、独有概念的一些介绍,篇幅有限也还有很多内容没有写,欢迎关注【五月君】后续也会继续分享。
对 Rust 感兴趣的朋友推荐去看看《The Rust Programming Language》这本书,官方开源的 Rust 教程,写的挺好,也有中文版的翻译,想看视频的可以上 bilibili 搜索下 Rust 入门,有几个视频版本的讲解基本上也是参考的这本书,重点还是要多思考、多实践。
社区上会看到一些话题:“Rust 可能取代 C 语言吗?”,Rust 提供了系统编程的能力,从能力上来讲 C 的一些实现 Rust 也是有能力去做的,但是 C/C++ 这个地位是很难被取代的,生态已经很大了,也并不是所有的项目都需要重写,也是有成本在的生态、人员等也不是一蹴而就的。
编程语言只是工具,为我们实现某些业务或功能的编程工具,不要盲目互吹或黑某一门语言,例如某乎上经常看到的 “xxxx 年了,xxx 凉了吗?”,多学习不同编程语言背后的设计**、优势与劣势,磨练技艺、突破自我、适时选择。
JavaScript 异步编程中回调是最常用和最基础的实现模式。回调就是函数,一般我们也会称它为 Callback,相信这对于 JavaScript 开发者不会陌生,而函数在 JavaScript 中属于一等公民,可以将函数传递给方法作为实参调用。
这种编程模式对于习惯同步思维的人来说很难理解,一般我们的大脑对事物的理解是同步的、线性的,在异步编程中它是一种相反的模式,你会看到代码的编写顺序与实际执行顺序并不是我们预期的,因为它们的编写与实际执行顺序也许没有什么直接的关系,特别是在处理一些复杂的业务场景时,掌握不好异步编程,通常也会写出糟糕的代码。
在笔者组建的技术交流群中,有时候大家提问一些问题,当看到一大堆 Callback 嵌套的代码时,感觉就很糟糕,顿时很难让人在有耐心去看它,这种模式它不会给予我们很友好的阅读体验,有时看到了我会说你先把代码书写逻辑整理下,也许问题就出在这里!
谈回调也少不了一个概念 “事件”,在使用 JavaScript 操作 DOM、网络请求或在 Node.js 中更多的是一种事件驱动的模型,由事件触发执行我们的回调。
例如,我们为 定时器 API 其传入一个函数,让其在将来某个时间之后执行。我们可以通过 setTimeout 或 setInterval 实现,前一个 setTimeout 是仅执行一次,后一个 setInterval 是间隔指定时间后重复执行。
这两个 API 在浏览器、Node.js 环境中使用都是一样的。
function fn() {
// do something...
}
setTimeout(fn, 1000);
setInterval(fn, 1000);发起一个请求从另一端获取数据,这也是异步中很常见的一个操作,在客户端早期我们可以使用 XMLHttpRequest发起 HTTP 请求并异步处理服务器返回的响应。
const httpRequest = new XMLHttpRequest();
httpRequest.open('GET', 'http://openapi.xxx.com/api');
httpRequest.send();
httpRequest.onreadystatechange = function() {
if (httpRequest.readyState === XMLHttpRequest.DONE) {
if (httpRequest.status === 200) {
alert(httpRequest.responseText);
} else {
alert('There was a problem with the request.');
}
}
};现在浏览器端有了一个新的 API fetch() 取代了复杂且名字容易误导人的 XMLHttpRequest,因为这个虽然名字带了 XML 但和 XML 没关系,fetch() API 完全基于 Promise 可以方便的让你编写代码从网络获取数据,简单看一下:
fetch('http://example.com/movies.json')
.then(function(response) {
return response.json();
})
.then(function(myJson) {
console.log(myJson);
});Node.js 中也定义了一些网络相关的 API,Node.js 提供的 HTTP/HTTPS 模块可以帮助我们在 Node.js 客户端向服务端请求数据
const http = require('http');
function sendRequest() {
const req = http.request({
method: 'GET',
host: '127.0.0.1',
port: 3010,
path: '/api'
}, res => {
let data = '';
res.on('data', chunk => data += chunk.toString());
res.on('end', () => {
console.log('response body: ', data);
});
});
req.on('error', console.error);
req.end();
}
sendRequest();这种方式来写还是有点繁琐的,在实际的业务开发中我们使用一些功能完备的 HTTP 请求模块,例如 node-fetch、nodejs/undici、axios 等,这些工具都是可以基于 Promise 的形式。
Node.js 做为一个服务端启动,我们还可以使用 HTTP 模块,如下方式启动一个 Server:
const http = require('http');
http.createServer((req, res) => {
req.on('data', chunk => {
// TODO
});
req.on('end', () => res.end('ok!'))
req.on('error', () => ...)
}).listen(3010);客户端下的 JavaScript 我们可以获取指定的 DOM 元素,为特定类型的事件注册回调函数,当用户移动鼠标或移动触摸板、按下键盘时,浏览器会生成相应的事件并调用我们事先注册的回调函数,这些都是由事件驱动的。
下例,通过 addEventListener() 函数为事件注册回调函数。相对来说 DOM 事件在互相依赖、多级依赖嵌套的场景较少些,但是在 Node.js 里面你可能会遇到很多。
<button id="btn"> 点我哦 </button>
<script>
const btn = document.getElementById('btn');
// 单击时触发
btn.addEventListener('click', event => console.log('click!'));
// 鼠标移入触发
btn.addEventListener('mouseover', event => console.log('mouseover!'));
// 鼠标移出触发
btn.addEventListener('mouseout', event => console.log('mouseout!'));
</script>Node.js 作为 JavaScript 的服务端运行时,大部分的 API 都是异步的,大家可能也听过 Node.js 比较擅长 I/O 密集型任务,这与它的单线程、基于事件驱动模型、异步 I/O是有关系的,它无需像多线程程序那样为每一个请求创建额外的线程、省掉了线程创建、销毁、上下文切换等开销。
它通过主循环加事件触发的方式执行程序,事件循环会不停地处理网络/文件 IO 事件,每一次的事件循环就是检查,检查是否有待处理的事件,如果有就取出事件及关联的回调函数,如果有传入 JavaScript 回调函数,传递到业务逻辑层执行,也许回调函数里还会在发起一次新的 I/O 请求,整个程序不断的通过事件循环调度执行。
也许你听过这样一句话:“它的优秀之处并非原创,它的原创之处并不优秀。” 异步 I/O 并非 Node.js 原创,但 Node.js 却是第一个成功的平台,Node.js 2009 年出现之前,JavaScript 在服务端近乎空白。例如,文件 API 在 Node.js 中默认就是异步的,也就是它的标准库 I/O 本身给你提供的就是非阻塞的,它没有任何的历史包袱。
谈到异步 I/O 必然少不了异步编程,早期我们的很多程序中都充斥着 Callback 风格的代码,包括 Node.js 提供的 API 大多数也是,大家都遵循一个默认的规则 “错误优先的回调函数”。
例如,下面 API 第一个参数为 err 如果有错误就是一个 Error 对象,否则就为 null,这也是一种默认的约定。
fs.readFile(filename, (err, file) => {
// TODO
})现在 Node.js 的一些系统模块已经为我们提供了一些工具可以方便的将 callback 转换为 Promise 的工具,或者文件模块我们可以通过 fs.promises 直接引入基于 Promise 版本的 API,这些编程方法我们会在后续章节 Promise 篇幅里讲。
当我们在 Node.js 中有时需要处理一些复杂的业务场景,有些需要多级依赖,如果以 callback 形式很容易造成函数嵌套过深,例如下面示例很容易写出回调地狱、冗余的代码,这也是早期 Node.js 被人诟病比较多的地方。包括现在前段在群里仍然还有看到有些提问题的,写出类似于下面嵌套的代码,确实要改下了。
fs.readdir('/path/xxxx', (err, files) => {
if (err) {
// TODO...
}
files.forEach((filename, index) => {
fs.lstat(filename, (err, stats) => {
if (err) {
// TODO...
}
if (stats.isFile()) {
fs.readFile(filename, (err, file) => {
// TODO
})
}
})
})
});异步编程 Callback 的形式一个难点是上面说的容易出现回调地狱的例子,另外一方面是异常的处理很麻烦,在一些同步的代码中我们可以像下面示例这样使用 try/catch 捕获错误。
try {
doSomething(...);
} catch(err) {
// TODO
}这种方式在一些异步方法面前显得无能为力,上面我们写的回调嵌套的示例,如果我们对 fs.readFile() 做 try/catch 捕获,当我们调用 fs.readFile 并为其注册回调函数这个步骤对应异步 I/O 中是提交请求,而 callback 函数会被存放起来,等到下一个事件循环到来 callback 才会被取出执行,这个时间是将来的某个时间点,而 try/catch 是同步的,捕获不到这个错误的。
下面因为我对一个 null 对象做了非法操作,这时程序会给我们报一个 TypeError: Cannot read property 'a' of null 错误,在 Java 中可以称它为空指针异常。
类似于这样的一个错误如果没有被捕获到,在单进程的应用程序中必然会导致进程退出,无关语言。
try {
fs.readFile(filename, (err, file) => {
const obj = null
obj.a;
// TODO
})
} catch () {
// TODO
}有时候也会听大家说为什么我的 Node.js 程序老是崩溃?也有人说 Node.js 弱爆了(这个我曾经听过一个架构师这样说过...)如果程序这样写,就算你用的 Java 照样崩溃。
在延伸一点,Node.js 的 Process 对象为我们提供了两个事件可以用来捕获程序中出现的未捕获异常,方便程序优雅退出,这是笔者之前写的一篇文章,可以看看如何处理 Node.js 中出现的未捕获异常?
process.on('uncaughtException', fn);
process.on('unhandledRejection', fn);异步编程中 Callback 是比较早的模式,也是异步编程的基础,但是随着业务的发展、复杂度的上升,基于 Callback 的模式已经不能满足我们的需求了,就像我们的大脑对事物的思考,需要一种同步的、顺序的方式表达异步编程**。
“办法总比困难多”,解决问题的方案还是很多的,目前的 JavaScript 中已有一些更高级、强大的异步编程模式,在本系列中会逐步的讲解。
原文发表于 JavaScript 异步编程指南 — 事件与回调函数 Callback 这是一个系列文章,你可以关注公众号「五月君」订阅话题《JavaScript 异步编程指南》获取最新的信息。如有疑问或更好的建议也可以添加我的微信 codingMay 一起讨论。
TypeScript 是 JavaScript 的超集,JavaScript 能够做的事情,它都可以做且还增加了很多功能,例如静态类型、增强的面向对象编程能力等。
本文是笔者日常学习、使用 TypeScript 过程中自己记录的一些知识点,现在总结分享给大家。包含了做为初学者在学习 TypeScript 时应关注的核心知识,在掌握了这些知识点后,就是在项目中的灵活应用,文末推荐了一个基于 TypeScript 的前后端项目,做为学习可参考(文末阅读原文查看)。
下图为本文概览:
近些年 TypeScript 在前端圈备受推崇,正在被越来越多的前端开发者所接受,包括在 Node.js 后端开发中同样如此。
下面从几份开发者报告调查数据看 TypeScript 的发展现状。
本报告来源于 https://tsh.io/state-of-frontend/#report 调查面比较广泛。来自 125 个国家的 3703+ 前端开发者及 19 位前端专家参与了该次调查。
关于 TypeScript ,过去一年里有将近 84.1% 的参与者表示使用过。
对于 TypeScript 前景描述,近 43% 开发者表示 “TypeScript 将超越 JavaScript 成为新的前端标准” 还是比较看好的。
下面来看一份来国内的 Node.js 2021 年度开发者调查报告 https://nodersurvey.github.io/reporters。
从 “代码转译” 角度调研,有 47.5% 的开发者使用了 TypeScript。在 Node.js 后端框架中 Nest.js 最近几年也是一个热门选择,该框架一个特点是完全基于 TypeScript,受到了更多开发者的青睐。
还有一些其它的调查报告数据,例如 2021 年 Stack Overflow 调查者报告、Google 搜索量趋势,NPM 下载量趋势 从上面可以看出 TypeScript 近几年的发展趋势还是很快的。
现在的你可能还在考虑要不要学习 TypeScript,但在将来也许会是每个前端开发者、Node.js 开发者必备的技能。
做为一个初学者刚开始使用 TypeScript 时,你无法在使用一些 JavaScript 的思维来编码,下面的一部分观点也许是每一个 TypeScript 初学者都会遇到的疑问。
TypeScript 不能被浏览器或 Node.js 和 Deno 这些运行时所理解,最终要编译为 JavaScript 执行,我们需要一个 compiler 做编译。另外你可能会想到在 Deno 中不是可以直接写 TypeScript 吗,本质上 Deno 也不是直接运行的 TypeScript,同样需要先编译为 JavaScript 来运行。
想尝试一下而不想本地安装的,可以看看以下这两个在线工具:
tsc 是将 TypeScript 代码编译为 JavaScript 代码,全局安装 npm install -g typescript 即可得到一个 tsc 命令,之后通过 tsc hello.ts 编译 typescript 文件。
// 编译前 hello.ts
const message: string = 'Hello Nodejs';
// 编译后 hello.js
var message = 'Hello Nodejs';与 tsc 不同的是 ts-node 是编译 + 执行。可以在开发时使用 ts-node,生产环境使用 tsc 编译。
# 安装全局依赖
$ npm install -g typescript
$ npm install -g ts-node
# 运行
$ ts-node hello.ts使用 CRA、Vite 这种库创建出来的前端 TS 项目、及后端 Nest.js 这样的框架,默认都是支持 TypeScript 的,一些基础的 tsconfig.json 配置文件,也都帮你配置好了。
TypeScript 编译时会使用 tsconfig.json 文件做为配置文件,该配置所在的项目会被认为是根目录。
使用 npx tsc --init 命令快速创建一个 tsconfig.json 配置文件,具体的配置可参考 文档。
TypeScript 除了包含 JavaScript 已有的 string、number、boolean、symbol、bigint、undefined、null、array、object 数据类型之外,还包括 tuple、enum、any、unknown、never、void、范型概念及类型声明符号 ineterface、type。
在参数名称后面使用冒号指定参数类型,同时也可在类型后面赋默认值,const 声明的变量必须要赋予默认值否则 IDE 编译器会提示错误,let 则不是必须的。
对于一些基础的数据类型,如果后面有值,TS 可以自动进行类型推断,不需要显示声明,例如 const nickname: string = '五月君' 等价于 const nickname = '五月君'。
const nickname: string = '五月君'; // 字符串
const age: number = 20; // Number 类型
const man: boolean = true; // 布尔型
let hobby: string; // 字符串仅声明一个变量
let a: undefined = undefined; // undefined 类型
let b: null = null; // null 类型,TS 区分了 undefined、null
let list: any[] = [1, true, "free"]; // 不需要类型检查器检测直接通过编译阶段检测的可以使用 any,但是这样和直接使用 JavaScript 没什么区别了
let c: any;
c = 1;
c = '1';数组(Array)通常用来表示所有元素类型相同的集合,也可以使用数组泛型:Array<element type> 允许这个集合中存在多种类型。
const list1: number[] = [1, 2, 3];
const list2: Array<number|string> = [1, '2', 3];元组(Tuple)允许一个已知元素数量的数组中各元素的类型可以是不同的,通常是事先定义好的不能被修改,元组的定义和赋值必须要一一对应。
const list1: [number, string, boolean] = [1, '2', true]; // 正确
const list2: [number, string, boolean] = [1, 2, true]; // 元素 2 会报错,不能将类型 "number" 分配给类型 "string"元组更严格一些,不可出现越界操作,例如 list1 只有三个元素,下标从 0 ~ 2,如果执行 list1[3] 就会报错,如下所示,这在数组操作中是不会出现报错的。
list1[3]
Tuple type '[number, string, boolean]' of length '3' has no element at index '3'.可选参数使用 “?” 符号声明,可选参数、函数参数的默认值需要声明在必选参数之后。函数也可以声明返回值类型,在某些情况下不需要显示声明,能够自动推断出返回值类型。
当一个函数没有返回值时用 void 表示,在 JavaScript 中一个函数没有返回值,它的结果也等同于 undefined。
// 定义函数返回值为空
// 给传入的参数定义类型
// 给传入的参数赋予默认值
const fn = function(content: string='Hello', nickname?: string): void {
console.log(content, nickname);
}
fn(); // Hello undefined
fn('Hello', '五月君'); // Hello 五月君
// 指定函数的返回值为 string
function fn(): string {
return 'str';
}
// 根据传入的参数可以自动推断类型
const add = (a: number, b: number) => {
return a + b;
}俗话说:“一入 any 深似海,从此类型是路人”,any 不会做任何类型检查,下面这段代码运行之后肯定会报 TypeError: value.toLocaleLowerCase is not a function 错误,并且这种错误只能在运行时才会发现,应尽可能的避免使用 any,否则就失去了使用 TypeScript 的意义。
const fn = (value: any) => {
value.toLocaleLowerCase();
}
fn(1);unknown 也表示任何值,相比于 any 它更加严谨,在使用上会有很多限制。
下面代码在编译时 fn1 函数会报错 TSError: ⨯ Unable to compile TypeScript: Object is of type 'unknown'。
const fn1 = (value: unknown) => {
value.toLocaleLowerCase(); // 编译失败
}
const fn2 = (value?: unknown) => {
return typeof value === 'string'; // 编译通过
}
fn1(1); fn2(1);不对 unknown 声明的类型做任何取值操作,是没问题的,正如上例的 fn2 函数。这个时候就有疑问了,既然什么都不能操作,有什么应用场景呢?
unknown 的意义在于我们可以结合 “类型守卫” 在声明的函数或其它块级作用域内获取精确的参数类型。这样在运行时也能避免出现类型错误这种常见问题。
例如,想对一个数组执行 length 操作时,首先通过 Array.isArray 进一步精确参数的类型之后,在做一些操作。
const fn = (value?: unknown) => {
if (Array.isArray(value)) {
return value.length; // 编译通过
}
}使用 is 关键词自定义类型守卫 {参数名称} is {参数类型},这个意思是告诉 TypeScript 函数 isString() 返回的是一个 string 类型。
function isString(str: unknown): str is string {
return typeof str === 'string';
}
const fn = (value?: unknown) => {
if (isString(value)) {
return value.toLocaleLowerCase(); // 编译通过
}
}例如,react-query 这个库返回的 error 默认为 unknown 类型,如果在 render 时直接这样写 <p>${error.message}<p>是不行的,一个解决方案是拿到错误后用类型守卫处理,如下所示:
const isError = (error: unknown): error is Error => {
return error instanceof Error;
};
<p>Error: {isError(error) && error.message}</p>另外一种方案是在调用它的 Api 时直接传入一个 Error 对象:useMutation<TResponse, Error, string>()
枚举定义了一组相关值的集合,通过描述性的常量声明使代码更具可读性。默认情况下枚举将字符串的值存储为从 0 开始的数字,也可以显示声明为字符串。
enum OrderStatus {
CREATED, // 0
CANCELLED, // 1
COMPLETED, // 2
}
enum OrderStatus {
CREATED = 'created',
CANCELLED = 'cancelled',
COMPLETED = 'completed',
}交叉类型:是将多个类型合并为一个类型,使用符号 & 表示。例如,将 TPerson & TWorker 合并为一个新的类型 User。
interface TPerson {
name: string,
age: number,
}
interface TWorker {
jobTitle: string,
}
type User = TPerson & TWorker;
const user: User = {
name: 'Tom',
age: 18,
jobTitle: 'Developer'
}注意,声明类型时不要与系统的关键词冲突,例如上例中的 Worker 尽管使用 interface 声明时没有提示报错,但使用时会有提示,因此才改为 TWorker。
联合类型:表示一个变量通常由多个类型组成,这之间是一种或的关系,使用 | 符号声明。意思是 id 即可以是 string 也可以是 number 类型。
let id: string | number;类型别名:给一个类型起一个新名字。如果另外一个字段和 id 一样也是由相同的多个类型组成,就要用到类型别名了,使用 type 关键字将多个基本类型声明为一个自定义的类型,这种是 interface 替代不了的。
type StringOrNumber = string | number;
let id: StringOrNumber;
let no: StringOrNumber;TypeScript 中使用 class、interface、type 关键词均可声明类型。class 声明的是一个类对象,这个好理解,容易迷惑的地方在于 interface 和 type 两者分别该用于何处。
// class 声明类型
class Person {
nickname: string;
age: number;
}
// interface 声明类型
interface Person {
nickname: string;
age: number;
}
// type 声明类型
type Person = {
nickname: string;
age: number;
}interface 和 type 非常相似,大多数情况下 interface 的特性都可以使用 type 实现。但两者还是有些区别:
从概念上每个人都有不同的理解,对于团队来说无论使用哪一个,都应该保持好统一的规范。在 TypeScript 官网文档中也提到了 如果不清楚该使用哪一个,请使用 interface 直到您需要 type。
鸭子类型在程序设计中是动态类型的一种风格,它的关注点在于对象的行为能做什么,而不是关注对象所属的类型。这个概念的名字源自一个 “鸭子测试”,可以解释为 :
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
下例,使用 interface 定义了两个类型 Duck、Bird,它们都有共同的特征 “走路”,于是对两个类型分别定义了 walk() 方法。test() 方法中期望的 value 类型为 Duck,但实际调用时传的 value 是 Bird,在 TypeScript 中是可以编译通过的。
interface Duck {
walk: () => void;
}
interface Bird {
walk: () => void;
}
const test = (value: Duck) => {
value.walk(); // 输出 “bird” 测试通过
}
const value: Bird = {
walk: () => {
console.log('bird');
}
}
test(value);TypeScript 的鸭子类型是面向接口编程,虽然我们的例子 Duck、Bird 类型不一样,但是都有共同的接口,是可以编译通过的,对于面向对象编程的语言,例如 Java 就不行了。
在参数和返回类型未知的情况下,可以使用范型来传递类型,保证组件内的类型安全。
一个有用的场景是用范型定义接口返回对象。例如,接口返回值 Result 对象,每一个接口返回的 data 是不一样的,这时 Result 对象的 data 属性就适合用范型作为类型进行传递。
interface Result<T> = {
code: string;
message: string;
data: T;
}
interface User = {
userId: string;
}
const users: Result<User[]> = { // 获取用户列表接口返回值
code: 'SUCCESS',
message: 'Request success',
data: [
{
userId: '123',
}
]
}
const userInfo: Result<User> = { // 获取用户详情接口返回值
code: 'SUCCESS',
message: 'Request success',
data: {
userId: '123',
}
}在函数内部使用范型变量时,存在类型约束,不能随意操作它的属性。例如下例,需要事先定义范型 T 拥有 length 属性。
type TLenght = {
length: number;
}
function fn<T extends TLenght>(val: T) {
if (val.length) {
// do something
}
}
fn('hello') // 5
fn([1, 2]) // 2
fn({ length: 3 }) // 3范型定义也可以有多个。例如,swap 函数交换两个变量。
Utility type(实用类型) 不是一种新的类型,基于类型别名实现的一个工具集的自定义类型。包括:Parameters<T>、Omit<T,K>。
Parameters<T>:接收一个范型 T,这个 T 是一个 Function,将会提取这个函数的返回值为 tuple。
例如,两个函数 fn2 的参数同 fn1 相等,这时使用 Parameters 就很合适。
const fn1 = (name: string, age: number) => {}
const fn2 = (...[name, age]: Parameters<typeof fn1>) => {
console.log(name, age);
}
fn2('五月君', 18);Pritial<T>:将范型 T 的所有属性变为可选。例如,user1 我必须写 name、age,而 user2 就不用了,现在都变为选填了,只填写需要的数据。
interface Person {
name: string,
age: number,
}
const user1: Person = { name: '五月君', age: 18 };
const user2: Partial<Person> = {};实现原理:实用 keyof 关键词取出 T 的所有的属性,遍历过程为每个属性加了一个 ? 符号,也就表示可选的。
type Partial<T> = {
[P in keyof T]?: T[P];
};Pick<T,K>:选取范型 T 中指定的部分属性,如果需要选出多个属性,用联合类型指定。
const user: Pick<Person, 'name'> = { name: '五月君' };实现原理:首先校验第二个类型 K 的属性必须在第一个类型 T 里面,之后遍历传入的联合类型 K,形成一个新的类型。
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};Omit<T,K>:与 Pick 相反,将第一个范型 T 中的部分属性删除,如果要删除多个属性,用联合类型指定需要删除的属性。
const user: Omit<Person, 'age'> = { name: '五月君'}
// const user: Omit<Person, 'name' | 'age'> = {}实现原理:Omit 使用了 Pick 和 Exclude 组合来实现的,这个地方有点绕:
T extends U ? never : T 这块的判断是,如果类型匹配,返回 never 就什么也没有,不匹配则返回。我们的例子中,age 类型匹配没有返回,返回的是未匹配的 name。/**
* Exclude from T those types that are assignable to U
*/
type Exclude<T, U> = T extends U ? never : T;
type Omit<T, K extends keyof any> = Pick<T, Exclude<keyof T, K>>;
// 下面两个是等价的
const user: Omit<Person, 'name' | 'age'> = {}
// 等价于
const user: Pick<Person, Exclude<'name' | 'age', 'age'>> = { name: '五月君' }ES6 时代为 JavaScript 增加了 class “语法糖”,可以方便的去定义一个类并通过 extends 关键词实现继承,尽管 ES6 中的 class 本质上仍是基于原型链实现的,但代码编写方式看起来简洁多了(以 class 关键词进行的面向对象编程)。
和其它的面向对象编程语言相比较,会发现 JavaScript 中的 class 少了好多功能。一个常见需求是不能私有化类成员,为了达到这个目的,通常有几种做法:在属性或方法前加上 _ 表示私有化,这属于命名规则约束、使用 symbol 的唯一性实现私有化。
TypeScript 中增强了面向对象的编程能力,具备类的访问权限控制、接口、模块、类型注解等功能。
对象的成员属性或方法如果没有被封装,实例化后在外部就可通过引用获取,对于用户 phone 这种数据,是不能随意被别人获取的。
封装性做为面向对象编程重要特性之一,它是把类内部成员属性、成员方法统一保护起来,只保留有限的接口与外部进行联系,尽可能屏蔽对象的内部细节,防止外部随意修改内部数据,保证数据的安全性。
同传统的面向对象编程语言类似,TypeScript 提供了 3 个关键词 public、private、protected 控制类成员的访问权限。
class Person {
public name: string; // 属性 “name” 可以被外部调用
protected email: string; // 属性“email”受保护,只能在类“Person”及其子类中访问
private phone: string; // 属性“phone”为私有属性,只能在类“Person”中访问。
constructor(name: string, email: string, phone: string) {
this.name = name;
this.email = email;
this.phone = phone;
}
public info() {
console.log(`我是 ${this.name} 手机号 ${this.formatPhone()}`)
}
private formatPhone() { // 方法 “formatPhone” 为私有属性,只能在类“Person”中访问。
return this.phone.replace(/(\d{3})\d{4}(\d{3})/, '$1****$2');
}
}接口是一种特殊的抽象类,与抽象类不同的是,接口没有具体的实现,只有定义,通过 interface 关键词声明。
TypeScript 对接口的定义是这样的:
TypeScript 的核心原则之一是对值所具有的结构进行类型检查。 它有时被称做 “鸭式辨型法” 或 “结构性子类型化”。 在 TypeScript 里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
TypeScript 中只能单继承,但可以实现多个接口。
interface Person {
name: string;
phone?: string;
}
interface Student {
diploma(): void;
}
class HighSchool implements Student, Person {
name: string;
diploma(): void {
console.log('高中');
}
}
class University implements Student, Person {
name: string;
diploma(): void {
console.log('大学本科')
}
}面向对象程序设计概念不止这些,参见这篇文章 #41。
最终要不要用 TypeScript,还要结合项目规模、维护周期、团队成员多方面看,以下为个人的一些理解:
文章开头我们看了一些 TypeScript 社区发展现状调研报告,从目前使用情况、发展趋势看,已然成为前端开发者的必备技能之一。如果你还在犹豫要不要学习 TypeScript,那我建议你在时间允许的情况,开始做一些尝试吧。
下面从个人角度,总结一些建议:
useReducer 是 useState 的替代方案,用来处理复杂的状态或逻辑。当与其它 Hooks(useContext)结合使用,有时也是一个好的选择,不需要引入一些第三方状态管理库,例如 Redux、Mobx。
在本文结束时,您将了解:
Context 解决了跨组件之间的通信,也是官方默认提供的一个方案,无需引入第三方库,适用于存储对组件树而言是全局的数据状态,并且不要有频繁的数据更新。例如:主题、当前认证的用户、首选语言。
使用 React.createContext 方法创建一个上下文,该方法接收一个参数做为其默认值,返回 MyContext.Provider、MyContext.Consumer React 组件。
const MyContext = React.createContext(defaultValue);MyContext.Provider 组件接收 value 属性用于传递给子组件(使用 MyContext.Consumer 消费的组件),无论嵌套多深都可以接收到。
<MyContext.Provider value={color: 'blue'}>
{children}
</MyContext.Provider>将我们的内容包装在 MyContext.Consumer 组件中,以便订阅 context 的变更,类组件中通常会这样写。
<MyContext.Consumer>
{value => <span>{value}</span>}}
</MyContext.Consumer>以上引入不必要的代码嵌套也增加了代码的复杂性,React Hooks 提供的 useContext 使得访问上下文状态变得更简单。
const App = () => {
const value = useContext(newContext);
console.log(value); // this will return { color: 'black' }
return <div></div>
}以上我们对 Context 做一个简单了解,更多内容参考官网 Context、useContext 文档描述,下面我们通过两个例子来学习如何使用 useContext 管理全局状态。
本节的第一个示例是使用 React hooks 的 useState 和 useContext API 实现暗黑主题切换。
在 ThemeContext 组件中我们定义主题为 light、dark。定义 ThemeProvider 在上下文维护两个属性:当前选择的主题 theme、切换主题的函数 toggleTheme()。
通过 useContext hook 可以在其它组件中获取到 ThemeProvider 维护的两个属性,在使用 useContext 时需要确保传入 React.createContext 创建的对象,在这里我们可以自定义一个 hook useTheme 便于在其它组件中直接使用。
代码位置:src/contexts/ThemeContext.js。
import React, { useState, useContext } from "react";
export const themes = {
light: {
type: 'light',
background: '#ffffff',
color: '#000000',
},
dark: {
type: 'dark',
background: '#000000',
color: '#ffffff',
},
};
const ThemeContext = React.createContext({
theme: themes.dark,
toggleTheme: () => {},
});
export const ThemeProvider = ({ children }) => {
const [theme, setTheme] = useState(themes.dark);
const context = {
theme,
toggleTheme: () => setTheme(theme === themes.dark
? themes.light
: themes.dark)
}
return <ThemeContext.Provider value={context}>
{ children }
</ThemeContext.Provider>
}
export const useTheme = () => {
const context = useContext(ThemeContext);
return context;
};创建一个 AppProviders,用来组装创建的多个上下文。代码位置:src/contexts/index.js。
import { ThemeProvider } from './ThemeContext';
const AppProviders = ({ children }) => {
return <ThemeProvider>
{ children }
</ThemeProvider>
}
export default AppProviders;在 App.js 文件中,将 AppProviders 组件做为根组件放在最顶层,这样被包裹的组件都可以使用 AppProviders 组件提供的属性。
代码位置:src/App.js。
import AppProviders from './contexts';
import ToggleTheme from './components/ToggleTheme';
import './App.css';
const App = () => (
<AppProviders>
<ToggleTheme />
</AppProviders>
);
export default App;在 ToggleTheme 组件中,我们使用自定义的 useTheme hook 访问 theme 对象和 toggleTheme 函数,以下创建了一个简单主题切换,用来设置背景颜色和文字颜色。
代码位置:src/components/ToggleTheme.jsx。
import { useTheme } from '../contexts/ThemeContext'
const ToggleTheme = () => {
const { theme, toggleTheme } = useTheme();
return <div style={{
backgroundColor: theme.background,
color: theme.color,
width: '100%',
height: '100vh',
textAlign: 'center',
}}>
<h2 className="theme-title"> Toggling Light/Dark Theme </h2>
<p className="theme-desc"> Toggling Light/Dark Theme in React with useState and useContext </p>
<button className="theme-btn" onClick={toggleTheme}>
Switch to { theme.type } mode
</button>
</div>
}
export default ToggleTheme;示例代码地址:https://github.com/qufei1993/react-state-example/tree/usestate-usecontext-theme。
使用 useReducer 和 useContext 完成一个 Todos。这个例子很简单,可以帮助我们学习如何实现一个简单的状态管理工具,类似 Redux 这样可以跨组件共享数据状态。
在 src/reducers 目录下实现 reducer 需要的逻辑,定义的 initialState 变量、reducer 函数都是为 useReducer 这个 Hook 做准备的,在这个地方需要都导出下,reducer 函数是一个纯函数,了解 Redux 的小伙伴对这个概念应该不陌生。
// src/reducers/todos-reducer.jsx
export const TODO_LIST_ADD = 'TODO_LIST_ADD';
export const TODO_LIST_EDIT = 'TODO_LIST_EDIT';
export const TODO_LIST_REMOVE = 'TODO_LIST_REMOVE';
const randomID = () => Math.floor(Math.random() * 10000);
export const initialState = {
todos: [{ id: randomID(), content: 'todo list' }],
};
const reducer = (state, action) => {
switch (action.type) {
case TODO_LIST_ADD: {
const newTodo = {
id: randomID(),
content: action.payload.content
};
return {
todos: [ ...state.todos, newTodo ],
}
}
case TODO_LIST_EDIT: {
return {
todos: state.todos.map(item => {
const newTodo = { ...item };
if (item.id === action.payload.id) {
newTodo.content = action.payload.content;
}
return newTodo;
})
}
}
case TODO_LIST_REMOVE: {
return {
todos: state.todos.filter(item => item.id !== action.payload.id),
}
}
default: return state;
}
}
export default reducer;定义 TodoContext 导出 state、dispatch,结合 useContext 自定义一个 useTodo hook 获取信息。
// src/contexts/TodoContext.js
import React, { useReducer, useContext } from "react";
import reducer, { initialState } from "../reducers/todos-reducer";
const TodoContext = React.createContext(null);
export const TodoProvider = ({ children }) => {
const [state, dispatch] = useReducer(reducer, initialState);
const context = {
state,
dispatch
}
return <TodoContext.Provider value={context}>
{ children }
</TodoContext.Provider>
}
export const useTodo = () => {
const context = useContext(TodoContext);
return context;
};// src/contexts/index.js
import { TodoProvider } from './TodoContext';
const AppProviders = ({ children }) => {
return <TodoProvider>
{ children }
</TodoProvider>
}
export default AppProviders;在 TodoAdd、Todo、Todos 三个组件内分别都可以通过 useTodo() hook 获取到 state、dispatch。
import { useState } from "react";
import { useTodo } from "../../contexts/TodoContext";
import { TODO_LIST_ADD, TODO_LIST_EDIT, TODO_LIST_REMOVE } from "../../reducers/todos-reducer";
const TodoAdd = () => {
console.log('TodoAdd render');
const [content, setContent] = useState('');
const { dispatch } = useTodo();
return <div className="todo-add">
<input className="input" type="text" onChange={e => setContent(e.target.value)} />
<button className="btn btn-lg" onClick={() => {
dispatch({ type: TODO_LIST_ADD, payload: { content } })
}}>
添加
</button>
</div>
};
const Todo = ({ todo }) => {
console.log('Todo render');
const { dispatch } = useTodo();
const [isEdit, setIsEdit] = useState(false);
const [content, setContent] = useState(todo.content);
return <div className="todo-list-item">
{
!isEdit ? <>
<div className="todo-list-item-content">{todo.content}</div>
<button className="btn" onClick={() => setIsEdit(true)}> 编辑 </button>
<button className="btn" onClick={() => dispatch({ type: TODO_LIST_REMOVE, payload: { id: todo.id } })}> 删除 </button>
</> : <>
<div className="todo-list-item-content">
<input className="input" value={content} type="text" onChange={ e => setContent(e.target.value) } />
</div>
<button className="btn" onClick={() => {
setIsEdit(false);
dispatch({ type: TODO_LIST_EDIT, payload: { id: todo.id, content } })
}}> 更新 </button>
<button className="btn" onClick={() => setIsEdit(false)}> 取消 </button>
</>
}
</div>
}
const Todos = () => {
console.log('Todos render');
const { state } = useTodo();
return <div className="todos">
<h2 className="todos-title"> Todos App </h2>
<p className="todos-desc"> useReducer + useContent 实现 todos </p>
<TodoAdd />
<div className="todo-list">
{
state.todos.map(todo => <Todo key={todo.id} todo={todo} />)
}
</div>
</div>
}
export default Todos;上面代码实现需求是没问题,但是存在一个性能问题,如果 Context 中的某个熟悉发生变化,所有依赖该 Context 的组件也会被重新渲染,观看以下视频演示:
示例代码地址:https://github.com/qufei1993/react-state-example/tree/usereducer-usecontext-todos。
useState/useReducer 管理的是组件的状态,如果子组件想获取根组件的状态一种简单的做法是通过 Props 层层传递,另外一种是把需要传递的数据封装进 Context 的 Provider 中,子组件通过 useContext 获取来实现全局状态共享。
Context 对于构建小型应用程序时,相较于 Redux,实现起来会更容易且不需要依赖第三方库,同时还要看下适用场景。在官网也有说明,适用于存储对组件树而言是全局的数据状态,并且不要有频繁的数据更新(例如:主题、当前认证的用户、首选语言)。
以下是使用 Context 会遇到的几个问题:
<ThemeProvider> <UserProvider> ... </UserProvider> </ThemeProvider> 是不是有点之前 “callback 回调地狱” 的意思了。 这里有个解决思路是创建一个 store container,参考 The best practice to combine containers to have it as "global" state、Apps with many containers。在我们实际的 React 项目中没有一个 Hook 或 API 能解决我们所有的问题,根据应用程序的大小和架构来选择适合于您的方法是最重要的。
介绍完 React 官方提供的状态管理工具外,下一节介绍一下社区状态管理界的 “老大哥 Redux”。
为了进一步增强 Web 的安全性,出现了内容安全策略(Content Security Policy,缩写 CSP),配置好策略后,就算黑客发现安全漏洞也无法注入恶意脚本。
CSP 实施的是白名单策略,服务器告诉客户端哪些资源可加载和执行,不符合条件的会被阻止,是阻止 XSS 攻击的一种有效解决方案。
CSP 使用分为两种,一是设置 HTTP Response Headers Content-Security-Policy: "script-src 'self';" 响应头。
另一种是网页的 标签 <meta http-equiv="Content-Security-Policy" content="script-src 'self';" /> 标签设置
Content-Security-Policy 内容由不容的指令组成,详情参考 Content-Security-Policy。
结合 Demo 做演示,进一步理解 CSP 的应用。结合上一讲 “Web 安全 - 跨站脚本攻击 XSS 三种类型及防御措施” XSS 例子做改造,首先设置 CSP 响应头如下:
app.get('/', (req, res) => { // app.js
res.set('Content-Security-Policy', "script-src 'self' https;")
})修改 views/index.pug 模版,加载一个 JS 脚本。
html
head
title= title
script(src="https://www.nodejs.red/index.js")
body
h= message运行之后,在控制台得到如下错误提示,意思是我们设置的 CSP 策略为只有当前域的 JS 文件且是 HTTPS 协议才可加载,www.nodejs.red 显然此时是非法的。
为了解决这个问题,需要修改 CSP 策略,允许能够加载 www.nodejs.red 域下的 JS 文件。
app.get('/', (req, res) => { // app.js
res.set('Content-Security-Policy', "script-src www.nodejs.red 'self' https;")
})除此之外,根据我们上面设置的 CSP 策略,如果想在控制台通过 document.write("<script> console.log(111) </script>") 写入一段脚本代码,浏览器也会为阻止,无法执行。
有没有想过一个问题:“如何在 CSP 策略里允许一段脚本可加载?”,细心的同学可能发现报错日志中有这样一句话 a hash ('sha256-9JfoB1vAaB60i4F+k48fZHFrPLMI73jH+c94nYGoDEk=') ,我们也可对可信任的脚本使用 sha256 算法计算出 hash 值([<hash-algorithm>-<base64-value>](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy/script-src)),设置到 CSP 的响应头中。
注意,生成 hash 时不要包含 <script> 标签,以 Node.js 为例:
const crypto = require('crypto')
const getHash = (code, algorithm = 'sha256') =>
`${algorithm}-${crypto.createHash(algorithm).update(code, 'utf8').digest("base64")}`
const hash = getHash(`console.log('Hello 五月君')`);
app.get('/', (req, res) => {
res.set('Content-Security-Policy', `script-src '${hash}' www.nodejs.red 'self' https;`)
})CSP 除了用来防止 XSS 攻击,还可上报攻击记录,report-uri 指定上报的服务器地址,浏览器会以 POST 请求 application/csp-report 协议将攻击记录放在 body 中发送至服务器。
res.set('Content-Security-Policy', `script-src 'self' https; report-uri /csp/report;`)内容安全策略 CSP 还可使用 Content-Security-Policy-Report-Only 响应头仅用来上报违规记录,不限制执行。
res.set('Content-Security-Policy-Report-Only', `script-src 'self' https; report-uri /csp/report;`)
在任何编程语言中,掌握内存管理都是很重要的,一方面对于操作系统而言内存是有限制的,另外一方面内存变化也会影响我们的程序执行效率。
选择基于 C 语言来学习,也是因为我们可以借助一些工具。例如,使用 gdb 方便的调试我们的程序,从每一步的调试,来看程序的运行变化。
在本文开始前,先列出几个问题,读者朋友可以先思考下,也是本讲你能学到的一些知识点,如下:
简单列举一些基础知识点,这些是接下来会用到的。
问题解答:我们的 32 位操作系统能够管理的内存是多大?对应 64 位又是如何?
32 位操作系统的地址总线是 32 位,也就是寻址空间是 32 位,因为内存是按照字节寻址的,每个字节可以理解成对应一个地址编号,如下所示,可以是全 0 的,也可以是全 1 的。
00000000 00000000 00000000 00000000
........ ........ ........ ........
11111111 11111111 11111111 1111111132 位操作系统能分配的地址编号数是 
最终,我们 32 位操作系统最多可管理的内存是 4 GB。
注: 1024Byte = 1KB | 1024KB = 1MB | 1024MB = 1GB。
**内存的访问是比磁盘驱动器快的多了,因此 4GB 肯定也不满足不了需求了,随之而来的是现在的 64 位操作系统,理论上它所能管理的内存空间为 **
内存是交由操作系统管理,它会给我们的内存做编号、用户内存与操作系统内存隔离。在 64 位的操作系统上,我们能够使用的是前面的 48 位,0x0000000000000000 ~ 0x00007FFFFFFFFFFF,而内核态在用户态最后一位上加 1 就是 0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF。
问题解答:内存空间一般划分为哪几个段,每个段存储都存储哪些东西?
通过上图可以清楚的看到,我们的内存是有划分的,一份为系统的内核空间,另外一部分为用户空间,与我们程序相关的主要看下用户空间部分,将内存划分为:栈、堆、数据段、代码段,每个里面分别存储的是什么?下面会分别介绍,答案就在里面。
代码段保存我们代码编译后的机器码,代码段的内存地址也是最小的,下例,以 0x4 开头,你可以先记住这个值,在后面介绍的其它段里,可以比较下内存大小。
(gdb) p &swap
$11 = (void (*)(int *, int *)) 0x40052d <swap>
(gdb) p &main
$12 = (int (*)()) 0x400559 <main>数据段保存静态变量、常量和一些全局变量,以下是一段示例,两个函数分别定义了静态变量 count 和执行了全局变量 globalCount。
#include <stdio.h>
int globalCount = 0;
int add(int x, int y) {
static int count = 0;
count++;
globalCount++;
return x + y;
}
int sub(int x, int y) {
static int count = 0;
count++;
globalCount++;
return x + y;
}
int main() {
int a = 6;
int b = 3;
int s1 = add(a, b);
int s2 = sub(a, b);
printf("s1=%d s2=%d", s1, s2);
}通过 gdb 调试看下,分别在 add 函数里打印了静态变量 count 和全局变量 globalCount 的内存地址。
静态变量 count 是声明在函数内部的,因此两次打印出来的地址也是不一样的,自然两个是不会相互影响的,全局变量可以看到内存地址是一样的,因此在任意一个函数里修改,值都会发生变化。
0x601038、0x60103c、0x601040 每次递增 4 个字节,可以看到它们的内存地址是连续递增的,数据段的内存地址以 0x6 开头是大于代码段的。
add (x=6, y=3) at main2.c:5
5 count++;
(gdb) p &count
$1 = (int *) 0x60103c <count.2181>
(gdb) p &globalCount
$2 = (int *) 0x601038 <globalCount>
sub (x=6, y=3) at main2.c:11
11 count++;
(gdb) p &count
$3 = (int *) 0x601040 <count.2186>
(gdb) p &globalCount
$4 = (int *) 0x601038 <globalCount>数据段还有一种称为 “BSS” 段,表示未初始化或初始化为 0 的所有全局变量或静态变量,static int a 或全局变量 int a 称为 “未初始化数据段”。
关于初始化数据段与未初始化数据段,这里有篇文章讲的也很好,可以参考 https://zhuanlan.zhihu.com/p/62208277。
栈寄存器段,指向包含当前程序栈的段,这些都是临时的信息。例如:局部变量、函数参数、返回值和当前程序运行状态等都存在于栈中,随着这些临时变量对应的作用域完成之后,也会被弹出栈。
以下为一段 C 语言代码示例,通过 swap 函数交换两个变量。
// main.c
#include <stdio.h>
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int a = 2;
int b = 3;
swap(&a, &b);
printf("a=%d b=%d", a, b);
}先使用 gcc 编译我们的源代码 gcc -g main.c -o main.out,之后使用 gdb 调试。
问题解答:为什么说栈是一块连续的内存空间?
在 C 语言里一个整型的数据大小为 4 个字节(指针类型另有规定,后面会讲),整型变量 a 存储的内存地址为 0x7fffffffe35c 也即首地址,按照 4 Byte 推算应该是 0x7fffffffe35c、0x7fffffffe35d、0x7fffffffe35e、0x7fffffffe35f。整型变量 b 的内存地址为 0x7fffffffe358 同样按照 4 Byte 推算应该是 0x7fffffffe358、0x7fffffffe359、0x7fffffffe35a、0x7fffffffe35b 也就是加上 4 个字节正好相邻于变量 a,因此我们还可以在确认一个问题是:“栈是一块连续的内存区域”。
通过一个图,相对直观的感受下。
这时可能会产生一个疑问,为什么创建变量顺序是 a、b 而分配的内存地址确是递减的顺序?
这涉及到栈的存储结构,栈是先进后出的,栈顶的地址是由系统预先设置好的,由栈顶入栈随后每次内存地址呈递减的方式依次分配,当还有新元素时就继续压栈,最先入栈的最后出栈,也可理解为栈底对应高地址、栈顶对应低地址。
(gdb) p &a
$1 = (int *) 0x7fffffffe35c
(gdb) p &b
$2 = (int *) 0x7fffffffe358使用 gdb 调试进入 swap 函数,这两个参数 a、b 我们定义为指针类型,可以看到它的值为外层整型变量 a 和 b 的内存地址。
swap 函数里的指针类型变量 a 与 b 也是有内存地址的,可以打印出来看下。同样的可以看出,这两个内存地址之间相差 8 个字节,也就号符合指针类型的定义,在 64 位系统下一个指针占用 8 个字节,当然大学课本上你可能看到过 1 个指针占用 4 个字节,那是针对的 32 位系统。
swap (a=0x7fffffffe35c, b=0x7fffffffe358) at main.c:3
3 int temp = *a;
(gdb) p &a
$1 = (int **) 0x7fffffffe328
(gdb) p &b
$2 = (int **) 0x7fffffffe320目前处于代码的第 3 行,swap 函数里指针变量 a 存储的是外层传入的变量 a 的内存地址,如何获取该值呢?那么在 C 语言中通过运算符 * 号可以取到一个内存地址对应的值,也就是“解引用”。
(gdb) p *a
$3 = 2接下来执行 2 两步,程序停留在第 5 行,可以看到 a 的值由 2 变为了 3,为什么 swap 函数能交换两个变量的值,也正是因为我们在这里通过指针修改了传进来的两个变量的内存地址。
(gdb) n
4 *a = *b;
(gdb) n
5 *b = temp;
(gdb) p *a
$4 = 3通过 bt 可以打印当前函数调用栈的所有信息,左侧有一个 #0、#1 的序号,0 就是目前的栈顶,因为我们这个程序很简单,程序入口函数 main() 就是我们的栈底,而当前执行的 swap() 函数就是我们的栈顶,也是当前程序所在的位置。
(gdb) bt
#0 swap (a=0x7fffffffe35c, b=0x7fffffffe358) at main.c:5
#1 0x0000000000400582 in main () at main.c:11栈是有内存大小限制的,Linux 或 Mac 下我们可通过 ulimit -s 命令查看,结果为:8192 # stack size (kbytes) ,Linux 下用户默认的栈空间大小为 8MB。
写递归时,通常要控制好边界,避免出现无限递归,递归的层级也不要太深,尽量不要在栈上定义太大的数据。一段递归调用的程序如下所示:
#include <stdio.h>
void call()
{
int a[2048];
printf("hello call! \n");
call();
}
int main(int argc, char *argv[]) {
call();
}gdb 调试之后得到如下错误信息:
Program received signal SIGSEGV, Segmentation fault.
0x000000000040053d in call () at a.c:6bt -n 从栈底打印 n 条信息,最下面为我们的 main 函数,除此之外可以看到 call() 总共递归调用了 1022 次,因为最上面序号是从 0 开始的。
(gdb) bt -5
#1018 0x000000000040054c in call () at a.c:7
#1019 0x000000000040054c in call () at a.c:7
#1020 0x000000000040054c in call () at a.c:7
#1021 0x000000000040054c in call () at a.c:7
#1022 0x0000000000400567 in main (argc=1, argv=0x7fffffffe458) at a.c:10问题解答:为什么递归会造成栈溢出?
当我们递归一个函数时,这个时候每一次的递归运行都会做压栈操作,栈是一种先进后出的数据结构,系统也是有最大的空间限制的,Linux 下用户默认的栈空间大小为 8MB,当栈的存放容量超出这个限制之后,通常我们的程序会得到栈溢出得到错误。
留一个问题大家思考下🤔:通过上面我们知道了递归层级太深会导致栈溢出,这是因为系统会有栈空间大小限制的,笔者平常使用 JavaScript 相会多一些,如果是在 JavaScript 中遇到这种问题怎么解决?不知道也没关系,笔者最近在写一个系列文章 《JavaScript 异步编程指南》可以带你一起深入了解这个问题。
模拟这个问题很简单,创建一个过大的字符数组。
#include<stdio.h>
int main()
{
char str[8192 * 1024];
int size = sizeof(str);
printf("size: %d\n", size);
}通过 gdb 调试,会得到一个 “Segmentation fault” 通常也称为段错误,指的是访问的内存超出了系统给程序设定的内存空间,一般包括:不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址、栈溢出等。
Program received signal SIGSEGV, Segmentation fault.
0x000000000040054e in main () at index.c:7解决这种问题,继续往下看~
堆段由开发者手动申请分配和释放,也称动态内存分配。在 C 语言中可以使用系统提供的函数 malloc() 和 free() 申请和释放内存。
继续拿上面 “字符数组栈溢出” 这个示例,现在改成在堆中创建内存,这时仅在栈中保存指针变量 str 的地址,真正数据存放于堆中,也就不会出现栈溢出问题了。
#include <stdio.h>
#include <malloc.h>
int main()
{
char *str = (char *)malloc(8192 * 1024);
if (str == NULL) {
printf("Heap memory application failed.");
return 0;
}
printf("Heap memory application successed.");
free(str);
str = NULL;
return 0;
}进入 gdb 调试,代码停留在第 5 行,在未分配堆内存之前,打印 str 可以看到是没有值的,而 &str 取的是该变量在栈空间的内存地址 0x7fffffffe368,这不是一回事,这是该变量的值。
再次执行,创建堆内存,代码停留在第 12 行 free(str) 打印 str 得到 0x7ffff720c010 这时候堆内存已分配成功。
现在让我们做释放操作,代码停留在 14 行,打印 str 可以看到值已被释放。
# 未分配
Temporary breakpoint 1, main () at b.c:5
5 char *str = (char *)malloc(8192 * 1024);
(gdb) p str
$1 = 0x0
(gdb) p &str
$2 = (char **) 0x7fffffffe368
(gdb) n
# 已分配
6 if (str == NULL) {
(gdb) n
10 printf("Heap memory application successed.");
(gdb) n
# 释放
12 free(str);
(gdb) p str
$3 = 0x7ffff720c010 ""
(gdb) n
13 str = NULL;
(gdb) n
14 return 0;
(gdb) p str
$4 = 0x0
(gdb) p &str
$5 = (char **) 0x7fffffffe368本文也是笔者在之前学习过程中的总结,近期又稍微整理下,发出来也是希望能与大家共同的分享、交流。
通过本文,几个场景的知识点:栈与堆的区别、为什么递归会造成栈溢出,类似于这种常见的问题,希望读者朋友能够掌握。
最后,欢迎大家关注公众号【编程界】一起学习新知识!

HTTPS 是 SSL/TLS 协议之上的 HTTP 协议,现在我们使用的主要是 TLS v1.2、TLS v1.3,如果想深入的了解 TLS 协议的细节,客户端与服务端是如何交互的,最好的学习方法是使用抓包工具,捕获网络数据包,基于这些真实的数据包能够有一些直观的感受。例如:Wireshark,它可以捕获 HTTP、TCP、TLS 等各种网络协议数据包,是我们学习的好工具。
但是 HTTPS 在握手过程中,密钥规格变更协议发送之后所有的数据都已经加密了,有些细节也就看不到了,如果常规的使用 Wireshark 这些工具是无法捕获到解密后的数据的,下面让我们先从 TLS v1.2 开始。
tcpdump 是一个 Unix/Linux 下的网络数据采集分析工具,也是我们常说的抓包工具。另一个与之类似的是 Wireshark,两者区别是 Wireshark 提供了客户端图形界面化展示,更多的用在客户端,而 tcpdump 是一个命令行工具,可用于服务端抓取数据输出到指定文件,并且 tcpdump 输出的 .cap 文件是可以被 Wireshark 解析的。
我通常更喜欢在命令抓取数据,让我们一起看看两者结合如何使用,首先我们用 tcpdump 抓取一个网络数据包。
en0,需要注意 localhost 不会走这个网络接口,通过 ifconfig 命令在本机查看。host www.imooc.com and port 443:过滤指定地址、端口的数据(这里之所以抓取 immoc 是因为看了下其 TLS 协议是 v1.2,协议不同抓包的结果也是不同的,下面会介绍 TLS v1.3)。# 首先监视指定的地址
sudo tcpdump -i en0 -v 'host www.imooc.com and port 443' -w imooc-https.cap
# 再打开一个终端发起请求,响应成功后关闭
curl https://www.imooc.com/结合 Wireshark 工具使用,菜单栏选择 “File” -> “Open” 打开生成的数据报文,可看到类似下面的输出信息。

现在我们没有解密抓取的 HTTPS 数据,在 TLS v1.2 握手阶段 Certificate 消息这个时候还是明文传递的,在 Change Cipher Spec 协议发送之后所有数据都是加密传输。其实,TLS v1.2 如果我们不做 HTTPS 解密处理,握手阶段也是可以做一些分析的,接下来的 TLS v1.3 又待如何呢?
TLS v1.3 协议相较于 TLS v1.2 要复杂些,要考虑客户端/服务器(网站)是否同时支持 TLS v1.3?抓包工具是否支持?如何解密 HTTPS 加密后的数据?
现在已经有很多网站支持 TLS 1.3 协议了,例如 Github、知乎等。抓包之前,最好还是先验证下客户端与服务器是否都支持 TLS 1.3,如果仅一端支持还是会降级为 TLS 1.2 协议或更低的协议支持。
浏览器、OpenSSL 等的 TLS 支持情况请参考 https://wiki.mozilla.org/Security/Server_Side_TLS。
之前我通过 Chrome 浏览器测试 TLS 1.3 一直都很好用,但当我在终端使用 **curl** --tlsv1.3 [https://www.github.com](https://www.github.com) 命令时,却报错 curl: (4) LibreSSL was built without TLS 1.3 support,这与 curl 版本有关,参考文章 Curl with TLSv1.3 and openSSL on macOS。
验证**网站(服务端)**的 TLS 1.3 支持情况,在 Chrome 开发者工具 -> Security 模块查看。

以 Github 网站为例,终端执行以下命令,开启抓包准备,之后浏览器输入 https://github.com 抓取数据。
$ sudo tcpdump -i en0 -v 'host www.github.com and port 443' -w github-tls1-3.cap
$ curl https://www.github.com以下为常规方法抓取到的数据,在 Change Cipher Spec 协议之后的数据都已做加密处理,像握手过程中的 Certificate、Finished 这些消息是看不到的,此时看不到完整的握手过程是怎么样的。

解密 HTTPS 数据,需要借助 Wireshark 的功能实现,目前有两种方式:基于 RSA 密钥协商算法在 Wireshark 中配置服务器私钥、会话级别的密钥文件。
Wireshark 中配置服务器私钥这种方式需要获取到证书中携带公钥对应的服务器私钥,然而这种方式仅在协商密钥为 RSA 算法时生效,它不具有前向安全保护,一旦拿到服务器私钥如果黑客记录了之前的会话是可以破解的,RSA 协商密钥算法在 TLS v1.3 已经废除了。
密钥日志文件是 Firefox、Chrome 和 curl 等应用程序在设置 SSLKEYLOGFILE 环境变量时生成的文本文件,它们的底层库(NSS、OpenSSL 或 boringssl)会将每次会话密钥写入文件,随后可以在 Wireshark 中配置此文件实现解密。
不同的操作系统和不同的浏览器操作上会有区别,可以参考这篇介绍 : Decrypt SSL traffic with the SSLKEYLOGFILE environment variable on Firefox or Google Chrome using Wireshark。
本文以 Mac 系统,Chrome 浏览器介绍。在本地 Home 目录下创建一个 sslkeylog.log 文件,之后在终端以命令方式打开 Chrome 浏览器,携带 --ssl-key-log-file。
$ touch ~/sslkeylog.log
$ /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --ssl-key-log-file=/Users/{user}/sslkeylog.log注意:--ssl-key-log-file 后面的路径,最开始我是用的相对路径 ~/sslkeylog.log 运行之后一直失败,错误信息提示无法加载密钥日志文件 ~/sslkeylog.log。后来解决方法是改成了绝对路径 --ssl-key-log-file=/Users/{user}/sslkeylog.log 加载密钥日志文件。
[10270:259:1106/140033.195135:ERROR:network_service_instance_impl.cc(738)] Failed opening SSL key log file: ~/sslkeylog.logWireshark 选择 “Preferences” -> “Protocols” -> “TLS”,配置预主密钥日志文件路径。

之后,Wireshark 配置好过滤规则,可以抓包了。

以下为我抓取的 www.zhihu.com 网站完整握手过程信息。

防抖和节流都是应用在高频事件触发场景中,例如 **scroll(滚动加载、回到顶部)**、**input(联想输入)** 事件等。防抖和节流核心实现**是在事件和函数之间增加了一个控制层,达到延迟执行的功能,目的是防止某一时间内频繁执行一些操作,造成资源浪费。
事件与函数之间的控制层通常有两种实现方式:一是使用定时器,每次事件触发时判断是否已经存在定时器,是本文我们实现的方式。另外一种是记录上一次事件触发的时间戳,每次事件触发时判断当前时间戳距离上次执行的时间戳之间的一个差值(deplay - (now - previous)),是否达到了设置的延迟时间。
下图是通过一个可视化工具 debounce_throttle 截取的一个效果图,展示了移动鼠标事件在常规操作、防抖处理(debounce)、**节流处理(throttle)**三种情况下的一个对比。
防抖是在事件触的指定时间后执行回掉函数,如果指定时间内再次触发事件,按照最后一次重新计时。
生活场景示例:公交车到站点后,师傅不会上一个人就立马关闭车门起步,会等待最后一个人上去了或车上人已经满了,才会关闭车门起步。
例如搜索框联想提示,当我们输入数据后,可能会请求接口获取数据,如果没有做任何处理,当在输入开始时就会不断的触发接口请求,这中间必然会造成资源的浪费,如果这样频繁操作 DOM 也是不可取的。
// Bad code
<html>
<body>
<div> search: <input id="search" type="text"> </div>
<script>
const searchInput = document.getElementById("search");
searchInput.addEventListener('input', ajax);
function ajax(e) { // 模仿数据查询
console.log(`Search data: ${e.target.value}`);
}
</script>
</body>
</html>上面这段代码我们没有做过任何优化,使用 ajax() 方法模拟数据请求,让我们看下执行效果。

如果是调用的真实接口,从输入的那一刻起就会不停掉用服务端接口,浪费不必要的性能,还很容易触发接口的限流措施,例如 Github 提供的 API 会有每小时最大请求数限制。
让我们实现一个防抖函数(**debounce****)**优化下上面的代码。**原理是通过标记,判断指定的时间内是否存在多次调用,当存在多次调用时清除掉上一次的定时器,重新开始计时,在指定的时间内如果没有再次调用,就执行传入的回调函数 ****fn**。
function debounce(fn, ms) {
let timerId;
return (...args) => {
if (timerId) {
clearTimeout(timerId);
}
timerId = setTimeout(() => {
fn(...args);
}, ms);
}
}这对于搜索场景是比较合适的,我们希望以最后一次输入结果为准,修改最开始的联想输入示例。
const handleSearchRequest = debounce(ajax, 500)
searchInput.addEventListener('input', handleSearchRequest);这次就好多了,当连续输入停顿时以最后一次的输入接口为准请求接口,避免了不停的刷新接口。
适当的时候记得要清除事件,例如 React 中,我们在组件挂载时监听 input,同样的组件卸载时也要清除对应的事件监听器函数。
componentDidMount() {
this.handleSearchRequest = debounce(ajax, 500)
searchInput.addEventListener('input', this.handleSearchRequest);
}
componentWillUnmount() {
searchInput.removeEventListener('input', this.handleSearchRequest);
}节流是在事件触发后,在指定的间隔时间内执行回调函数。
生活场景示例:当我们乘坐地铁时,列车总是按照指定的间隔时间每 5 分钟(也许是其它时间)这样运行,当时间到达之后,列车就要开走了。
例如,页面有很多个列表项,当我们向下滚动之后希望出现一个 Top 按钮 点击之后能够回到顶部,这时我们需要获取滚动位置与顶部的距离判断是否展示 Top 按钮。
<body>
<div id="container"></div>
<script>
const container = document.getElementById('container');
window.addEventListener('scroll', handleScrollTop);
function handleScrollTop() {
console.log('scrollTop: ', document.body.scrollTop);
if (document.body.scrollTop > 400) {
// 处理展示按钮操作
} else {
// 处理不展示按钮操作
}
}
</script>
</body>可以看到,如果不加任何处理,滚动一下可能就会触发上百次,每次都去做处理,显然是白白浪费性能的。
实现一个简单的节流(throttle)函数,与防抖很相似,区别的地方是,这里通过标志位判断是否已经被触发,当已经触发后,再进来的请求直接结束掉,直到上一次指定的间隔时间到达且回调函数执行之后,再接受下一个处理。
function throttle(fn, ms) {
let flag = false;
return (...args) => {
if (flag) return;
flag = true;
setTimeout(() => {
fn(...args)
flag = false;
}, ms);
}
}改造下上面的示例,再来看看执行结果。
const handleScrollTop = throttle(() => {
console.log('scrollTop: ', document.body.scrollTop);
// todo:
}, 500);
window.addEventListener('scroll', handleScrollTop);与上面 “常规滚动到顶部示例” 做对比,现在效果已经好多了。
以 React 为例,组件挂载时我们监听 window 的 scroll 事件,在组件卸载时记得要移除对应的事件监听器函数。如果组件卸载时忘记移除,原先 A 页面引入了 ScrollTop 组件,单页面应用跳转到 B 页面后,虽然 B 页面没有引入 ScrollTop 组件,但是也会受到影响,因为该事件已经在 window 全局对象注册了,另外这样也存在内存泄漏。
class ScrollTop extends PureComponent {
componentDidMount() {
this.handleScrollTop = throttle(this.props.updateScrollTopValue, 500);
window.addEventListener('scroll', this.handleScrollTop);
}
componentWillUnmount() {
window.removeEventListener('scroll', this.handleScrollTop);
}
// ...
}requestAnimationFrame 是浏览器提供的一个 API,它的应用场景是告诉浏览器,我需要运行一个动画。该方法会要求浏览器在下次重绘之前调用指定的回调函数更新动画。这个 API 在 JavaScript 异步编程指南 - 探索浏览器中的事件循环机制 中有讲过。
它会受到浏览器的刷新频率影响,如果是 60fps 那就是每间隔 16.67ms 执行一次,如果在 16.67ms 内有多次 DOM 操作,也是不会渲染多次的。
当浏览器的刷新频率为 60fps 时等价于 throttle(fn, 16.67)。在使用时需要先处理下,不能让它立即执行,由事件触发。
const handleScrollTop = () => requestAnimationFrame(() => {
console.log('scrollTop: ', document.body.scrollTop);
// todo:
});
window.addEventListener('scroll', handleScrollTop);requestAnimationFrame 这个是浏览器的 API,在 Node.js 中是不支持的。
社区中一些 JavaScript 的工具集框架,也都提供了防抖与节流的支持,例如 underscorejs、lodash。
刚开始有提到,另外一种实现方式是记录上一次事件触发的时间戳,每次事件触发时判断当前时间戳距离上次执行的时间戳之间的一个差值,来判断是否达到了设置的延迟时间,以 underscorejs throttle 实现为例,只保留部分代码示例,一个关键代码片段是 remaining = wait - (_now - previous)。
// https://github.com/jashkenas/underscore/blob/master/modules/throttle.js#L23
export default function throttle(func, wait, options) {
var timeout, context, args, result;
var previous = 0;
var throttled = function() {
var _now = now();
if (!previous && options.leading === false) previous = _now;
var remaining = wait - (_now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = _now;
result = func.apply(context, args);
if (!timeout) context = args = null;
}
};
return throttled;
}防抖是在事件触的指定时间后执行回掉函数,如果指定时间内再次触发事件,按照最后一次重新计时。节流是在事件触发后的间隔时间内执行回调函数。这两个概念在前端开发中都是会遇到的,选择合理的方案解决实际问题。
防抖与节流还不是太理解的,对着文中的示例自己实践下,有什么疑问在留言区提问。
关键字日点击数,网站的外链关系,网站的内容质量,关键字的竞争力,当时百度排名规则的重点侧向等等众多因素影响排名
正常情况日点击关键字的量大于关键字指数效果比较好.(因为点击量只是排名规则的其中一个因素,如果在不清楚自己网站与竞争对手的差距的情况下,只有完全强化某个排名因素才会明显的影响排名,既为什么点击量要大于指数)
如果想快速提升排名,建议把搜索引擎点爆,比如指数100的关键字,每天点击量大于1000,这样效果非常明显,比较适合暴力产品.(大家都知道第一页与第二页的流量是相差很多的,所有竞争力度也相差很多,这就是为什么要点爆才容易上首页一原因)
提高搜索引擎用户体验来提高整站的权重,建议点击大量关键字,包括子页面关键字排名点击,并且配合外链,软文等优化,这样是非常不错的,适合长久发展的网站一般设置正常,需要等待百度对关键字的更新,正常情况百度1-7天会有更新,所以排名需要等待1-7天才能提升.
搜索点击量越大关键字的指数也就越高,当指数提升之后随之网站的权重也会提升!站长工具一般1个月更新百度指数,当站长工具更新后,既可以查到网站的权重提升!如果无法在百度中查看指数,请登入软件--我的点击管理--开通百度指数就可以提升百度权重!
网页优化可以说是从 Title 开始的。在搜索结果中,每个抓取内容的第一行显示的文字就是该页的Title,同样在浏览器中打开一个页面,地址栏上方显示的也是该页的 Title。因此, Title 可谓一个页面的核心。对 Title 的书写要注意以下问题:
title 简短精炼,高度概括,含有关键词,而不是只有一个网站名称。但关键词不宜过多,不要超过 3 个词组。
前7个字对搜索引擎最重要,因此关键词位置尽量靠前,总字数不超过30 个汉字。
标题title文字长度多少字节最合适? 每个搜索引擎是不同的,以下是各搜索引擎收录字节数,注意2个字节等于一个汉字。 更谨慎的说法是,title不要超过25个汉字
百度:60个字节。
谷歌:66个字节。
搜搜:66个字符。
雅虎:64个字节。
微软:46个字节。
114:45个字符。
搜狗:56个字符。
有道:56个字符。
关于网站优化,个人认为遵守一条原则 “内容为王,外链为后”,下面是之前优化过的一个案例:

XSS(Cross Site Scripting)是一种代码注入方式的跨站脚本攻击,为了与层叠样式表 CSS 区分,而简称 XSS。起因通常是由于黑客往 HTML、DOM 中插入了网站没有校验的恶意脚本,当用户浏览时,浏览器无法确认这些脚本是正常的还是注入的页面内容,当执行到这些恶意脚本时就会对用户进行 cookie 窃取、监听用户行为收集信息发往黑客服务器、会话劫持和修改页面 DOM 恶意攻击等。
恶意脚本的注入方式,归纳起来有三种类型:存储型 XSS 攻击、反射型 XSS 攻击、基于 DOM XSS 攻击。
存储型 XSS 攻击是将恶意代码存储到网站服务器,如果出现漏洞传播速度、影响范围较为广泛,常见于社区、论坛等带有内容保存的系统中。
首先黑客利用网站漏洞将恶意代码发送至服务器,而服务器未经校验就保存了,其他用户通过浏览器向网站服务器请求内容,浏览器解析恶意代码并执行,黑客的意图就成功了,接下来黑客可以通过脚本读取用户信息上传到黑客自己的服务器,或做一些其它的非法操作。
反射型 XSS 攻击是将恶意代码拼接在 URL 处,常见于网站搜索、跳转等,一个特点是需要黑客诱导用户点击 URL 实现代码注入。
假设黑客在 URL 处拼接一段恶意代码,当请求到达网站服务端后,从 URL 取出这段恶意代码,如果不做任何处理直接拼接在 HTML 处返回,浏览器收到内容解析执行,混淆在正常内容中的恶意代码也会被执行。
不同于存储型,反射型是请求到达网站服务器后,不会存储到数据库。
使用 Node.js Express 框架和 pug 模版引擎模拟反射型 XSS 攻击,加深理解。
首先,创建一个项目 xss-reflection-type 并安装 express、pug 两个依赖。
$ mkdir xss-reflection-type
$ cd xss-reflection-type
$ npm init
$ npm i express pug -S
创建 app.js,这是我们的服务端,渲染模版数据返回。
// app.js
const express = require('express')
const path = require('path')
const app = express()
const PORT = 3000
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug')
app.get('/', (req, res) => {
res.set('Set-Cookie', ['a=111'])
res.render('index', { title: 'Hey', message: req.query.message })
})
app.listen(PORT, () => console.log(`Example app listening at http://localhost:${PORT}`))
模版路径为 views/index.pug,body 里面接收消息。
注意,使用 pug 模版引擎默认情况下,所有的属性都经过转义(即把特殊字符转换成转义序列)来防止诸如跨站脚本攻击之类的攻击方式。
为了模拟 XSS 攻击,在模版渲染过程中我们先不对消息内容做转义,使用 != 代替 =,**你要知道这是不安全的,正常情况推荐你使用 ****=**。如果使用的 EJS 可以用 <%- 代替 <%= 实现不做转义处理。
// views/index.pug
html
head
title= title
body
h1!= message
运行 app.js 后,浏览器输入 http://localhost:3000/?message=<script>var cookie = document.cookie; alert(我是 XSS 攻击,你中招了 😄, cookie: ${cookie})</script> 回车后,页面上会弹出如下提示框。
DOM XSS 攻击不涉及网站服务器,通常是由于前端页面不严谨的代码产生的安全漏洞,导致注入了恶意代码。
例如,在使用 .innerHTML、document.write()、document.outerHTML 这些能够修改页面结构的 API 时要注意防范恶意代码,尽量使用 .textContent、.setAttribute() 等。
例如,黑客构造带有恶意代码的 URL 诱导用户打开 http://www.xxx.com/index.html/?content=<script>alert('我是 DOM 型 XSS 攻击')</script>,浏览器收到请求后解析之行,如果使用 document.write() 未经转义输出,就可能遭到攻击。
<!DOCTYPE html>
<html>
<body>
<script>
document.write('content: ' + decodeURIComponent(location.search));
</script>
</body>
</html>为了防止 XSS 攻击,我们需要验证用户的输入,做到有效检测。对输出的数据做编码,防止恶意脚本注入成功在浏览器端之行。
<script> 转义为 <script>。推荐一个库 js-xss,用于对用户输入的内容进行过滤,以避免遭受 XSS 攻。
最近在一个 React 项目中,使用到了 socket.io 处理即时消息,这里面有几点容易被忽视的问题,例如:在 React 单页面应用中如何防止出现多个 socket 实例、在任意的的组件内如何方便的取到 socket 实例、对于某个事件不要随着页面切换出现多个监听器。
在本文中,将会给大家分享下我在 React 中使用 Socket.io 客户端的一些经验,希望对此有疑惑的朋友给予一些帮助,也许你会有一些更好的实现方式,欢迎交流!
本文的实现方式是使用状态管理工具保存 socket 实例,供子组件使用,如果使用了 React Hooks,可以用其提供的 useContext API,实现起来也很简单。
// contexts/socket.tsx
import { createContext, ReactNode, useContext } from 'react';
import io, { Socket } from 'socket.io-client';
const SOCKET_URL = 'ws://localhost:8080';
export const socket = io(SOCKET_URL, {
transports: ['websocket'],
});
const SocketContext = createContext<Socket>(socket);
SocketContext.displayName = 'SocketContext';
export const SocketProvider = ({ children }: { children: ReactNode }) => (
<SocketContext.Provider value={socket}>{children}</SocketContext.Provider>
);
export const useSocket = () => {
const context = useContext(SocketContext);
return context;
};
// contexts/index.tsx
import { ReactNode } from 'react';
import { SocketProvider } from './Socket';
const AppContextProviders = ({ children }: { children: ReactNode }) => (
<SocketProvider>{children}</SocketProvider>
);
export default AppContextProviders;有关 useContext 介绍可参考之前的文章 React 状态管理 - useState/useReducer + useContext 实现全局状态管理,其中 const socket = io(SOCKET_URL),有些朋友可能就有疑问了,为什么不执行下 **socket.connect()** 呢?
socket.io 客户端默认是自动链接的,如果声明了 **autoConnect** 属性为 false,则需要手动执行下链接。
以上,在页面第一次加载时会初始化 socket,解决了第一个问题:“React 单页面应用中如何防止出现多个 socket 实例”。
在项目的 App.js 文件中引入我们自定义的 Providers,将 AppProviders 组件做为根组件放在最顶层,这样被包裹的组件都可以使用 AppProviders 组件提供的属性。也解决了第二个问题:“在任意的的组件内如何方便的取到 socket 实例”。
import AppProviders from './contexts';
import './App.css';
const App = () => (
<AppProviders>
...
</AppProviders>
);
export default App;useEffect() 是 React 内置的一个 Hook,如果第二个参数依赖项数组为空,那么传入的第一个函数在该组件内只会执行一次,依赖项数组只要有一个状态被更新,useEffect() 传入的第一个函数也将会被执行。
还需要注意的是 useEffect() 传入的第一个函数,它又返回的函数在函数组件卸载时被调用,通常我们会用 useEffect() 模拟类组件的 componentDidMount、componentWillUnmount 行为。
在组件卸载时,使用 socket.off() 移除事件监听器,实际上这可以预防内存泄漏,同时也解决了最开始提的第三个问题: “对于某个事件不要随着页面切换出现多个监听器”。
import { useEffect } from 'react';
import { useSocket } from '../../contexts/Socket';
const ComponentA = () => {
const socket = useSocket();
useEffect(() => {
// componentDidMount
socket.on('message', handleMessage); // 监听消息
return () => {
// componentWillUnmount
socket.off('message', handleMessage);
};
}, [socket]);
return ();
};
export default ComponentA;在我们的组件 B 中,也可以使用自定义的 useSocket Hook 获取最开始初始化的 socket 实例,但这并不会产生一个新的 socket 实例。
import { useEffect } from 'react';
import { useSocket } from '../../contexts/Socket';
const ComponentB = () => {
const socket = useSocket();
const handleSendMessage = () => {
socket.emit('compress', data); // 发送消息
}
return <div>
// ...
<button onClick={handleSendMessage}>Send message</button>
</div>;
};
export default ComponentB;以上介绍,感兴趣的可以 “阅读原文” 看看这个项目 https://github.com/qufei1993/compressor,里面有使用 socket.io 的代码片段,包括客户端和服务端。
以前如果使用 CSS-in-JS 编写项目样式文件,优先会考虑 styled-components,它的特点是使用模版字符串编写样式组件,使用方便、上手简单。一个被反对的声音主要是 styled-components 采用了运行时机制,增加了产物的体积也担心运行时的开销带来一些性能损耗问题。
前段时间在个人项目中(访问 https://github.com/qufei1993/compressor 查看这个项目)使用了 Vanilla Extract,不同于其它 CSS-in-JS 方案,它可以在编译时期编译出 CSS 样式文件,实现了零运行时且支持 TypeScript。
下文,将为您介绍 Vanilla Extract 的特点及应用。
Vanilla Extract 是一个新的 CSS-in-JS 库,用来编写 CSS 样式文件,于 2021 年开源,在年度全球 CSS 报告中荣登 CSS-in-JS 满意度榜首。
Vanilla Extract 是一个通用的库,没有绑定在任何 JavaScript 框架上,你可以在 React、Vue、Angular... 等框架中来使用它,但在这之前你需要先让自己的构建工具能够支持它。
Vanilla Extract 目前已经为最流行的前端构建工具做了集成,包括:webpack、esbuild、Vite 等。
本文以在 Vite 中使用为例,首先需要安装 @vanilla-extract/css、@vanilla-extract/vite-plugin 两个库。@vanilla-extract/css 是我们样式开发中主要用到的库。
npm install @vanilla-extract/css @vanilla-extract/vite-plugin之后将 vanillaExtractPlugin 插件添加到 vite 配置中。对 CSS 的编译和处理主要是通过该插件完成的,在编写样式文件时,文件名要以 **.css.ts** 结尾。
// vite.config.ts
import { defineConfig } from 'vite';
import { vanillaExtractPlugin } from '@vanilla-extract/vite-plugin';
export default defineConfig({
plugins: [vanillaExtractPlugin()],
});使用 TypeScript 是 Vanilla Extract 的核心,使得 Vanilla Extract 能够准确的定位到样式所在的位置,实现了在构建时生成所有的样式,就像 SaaS、Less 那样,也是与其它 CSS in JS 方案(Styled Components 和 Emotion)不同的地方。
使用 TypeScript 编写 CSS 样式的另一个好处是,带来了样式的类型安全,如果编写了错误的值,在编译时就会给我们报错。在编码的过程中编辑器也会给我们一些样式提示。
介绍一些日常开发常用的样式 API 在 vanilla extract 中是如何编写的,@vanilla-extract/css 库的 style() 方法是常用的基础 API。
样式文件需要以 **.css.ts** 结尾,CSS 样式属性名编写采用驼峰式,和正常写 CSS 样式区别也不是很大。
// styled.css.ts
import { style } from '@vanilla-extract/css';
export const todoList = style({
marginTop: '20px',
background: '#ccc',
});
export const todoInfo = style({
paddingTop: '10px',
});之后在我们的 App 组件内,导入样式文件,为标签的 className 属性赋值 value 就可以了,使用方式和其它的 CSS-in-JS 库还是有区别的,例如 styled-component 样式是以组件的方式来编写和使用的。
// app.tsx
import * as styled from './styled.css';
const App = () => {
return <>
<ul className={styled.todoList}>
<li className={styled.todoInfo}>学习 React 开发</li>
<li className={styled.todoInfo}>学习 Node.js 开发</li>
</ul>
</>
}vanilla extract 支持一些伪类选择器、子选择器、媒体查询、**@supports**以及引用 style() 函数创建的其它类。
export const todoInfo = style({
paddingTop: '10px',
// 伪类选择器
':hover': {
color: 'red',
},
selectors: {
// 选择自身的最后一个元素
'&:last-child': {
paddingBottom: '10px',
},
// 选择器还可以包含对其他作用域类名称的引用,这会改变 todoList 这个类的背景颜色
[`${todoList} &`]: {
background: 'yellow',
},
},
// 媒体查询
'@media': {
'screen and (min-width: 568px)': {
color: 'blue',
},
},
'@supports': {
// 摘自官网示例
'(display: grid)': {
display: 'grid',
},
},
});文档中有声明:为了提高可维护性,每个样式块只能针对单个元素。意思也就是说你不能直接对其子元素或兄弟元素做调整,例如,如下需求:
.todo-list > li { // 期望的写法
color: green !important;
}
export const todoList = style({
marginTop: '20px',
background: '#ccc',
'& > li': { // 错误的实现
color: green !important;
}
});Vanilla Extract 提供了 GlobalStyle() API 用于在全局范围内定位当前元素的子节点。这里你不需要担心重复问题,Vanilla Extract 具有局部范围的类名,就像 CSS Module 那样,不存在类名冲突的风险。
import { style, globalStyle } from '@vanilla-extract/css';
export const todoList = style({ ... });
// 对局部作用类名的样式设置
globalStyle(`${todoList} > li`, {
color: 'green !important',
});Vanilla Extract 全局样式不支持嵌套,有些情况可能需要调用 globalStyle() 函数多次来设置样式。
globalStyle('html, body', {
margin: 0
});
globalStyle('a', {
color: 'blue',
});
globalStyle('a:hover', {
color: 'red',
});样式组合,就像父类和子类的继承关系,将样式的通用部分抽象出来。
import { style } from '@vanilla-extract/css';
const base = style({ padding: 12 });
export const primary = style([
base,
{ background: 'blue' }
]);
export const secondary = style([
base,
{ background: 'aqua' }
]);CSS 变量有时也被称作 CSS 自定义属性,当定义一个 CSS 变量后,可以在整个网站的样式文件中重复使用。
例如,在一个网站开发中,可能会有很多重复的值,比如 color,用原生的 CSS 编写如下所示:
**--** 声明一个自定义属性,属性值则可以是任何有效的 CSS 值,注意属性名是大小写敏感的。**var()**函数访问一个自定义的 CSS 变量。// css 变量声明与使用
:root {
--blue-color: blue;
}
.one {
color: var(--blue-color);
}
.two {
color: var(--blue-color);
}
// javascript 操作 css
element.style.getPropertyValue("--blue-color");// 获取一个 Dom 节点上的 CSS 变量
getComputedStyle(element).getPropertyValue("--blue-color");// 获取任意 Dom 节点上的 CSS 变量
element.style.setProperty("--blue-color", jsVar + 4);// 修改一个 Dom 节点上的 CSS 变量vanilla extract 没有重复造轮子,而是大量使用了浏览器内置的原生 CSS 变量功能。由于 vanilla extract 具有局部作用域的类名,另一个好处是能够在样式块内限定 CSS 变量的范围。
当应用程序具有单一的全局主题时,推荐使用 createGlobalTheme 方法,使用也不复杂,直接看文档即可。
有时我们的应用程序会存在多个主题的情况,例如 “暗黑模式”,首先需要做的是使用 createGlobalThemeContract() 方法创建一个主题契约,这些 key 的值可以先设置为 null,这也是确保创建的主题能有正确的 key。之后将 “主题契约” 返回的值做为 createTheme() 方法的第一个参数传入。
import { createTheme, createThemeContract } from '@vanilla-extract/css';
const colors = createThemeContract({
color: null,
backgroundColor: null,
});
export const lightTheme = createTheme(colors, {
color: '#000000',
backgroundColor: '#ffffff',
});
export const darkTheme = createTheme(colors, {
color: '#ffffff',
backgroundColor: '#000000',
});
export const vars = { colors };上面的 createTheme() 方法返回的值是一个类名,可以应用于 HTML 标签的 className 中来声明 CSS 变量,在应用需要获取 CSS 样式的根标签中,设置这个类名。
import { darkTheme, lightTheme } from './styles/theme.css';
import { useState } from 'react';
const App = () => {
const [isDarkTheme, setIsDarkTheme] = useState(false);
return (
<div id="app" className={isDarkTheme ? darkTheme : lightTheme}>
<button
type="button"
onClick={() => setIsDarkTheme((currentValue) => !currentValue)}
>
Switch to {isDarkTheme ? 'light' : 'dark'} theme
</button>
</div>
);
};**上面代码片段中,以一个简单的 Demo 来展示如何应用主题,想做的体验好一点的,还可以通过监听系统主题的方式设置默认的主题颜色,参考项目 **https://github.com/qufei1993/compressor/blob/main/client/src/hooks/index.ts#L27。
export const useSystemTheme = () => {
const [name, setName] = useState<TThemeName>(Theme.Light);
useEffect(() => {
if (window.matchMedia('(prefers-color-scheme: dark)').matches) {
setName(Theme.Dark);
} else {
setName(Theme.Light);
}
window
.matchMedia('(prefers-color-scheme: dark)')
.addEventListener('change', (event: MediaQueryListEvent) => {
if (event.matches) {
setName(Theme.Dark);
} else {
setName(Theme.Light);
}
});
}, []);
return {
name,
isDarkMode: name === Theme.Dark,
isLightMode: name === Theme.Light,
};
};切换主题按钮,可以看到在 CSS 样式表中会包含以下两个主题的 CSS 变量。
在组件样式中使用声明好的主题变量,vars 是 theme.css.ts 文件中导出的变量。
import { style } from '@vanilla-extract/css';
import { vars } from '../../styles/theme.css';
export const todoList = style({
marginTop: '20px',
backgroundColor: vars.colors.backgroundColor,
color: vars.colors.color,
});让我们看下效果,就像直接写原生 CSS 变量一样,使用 var 获取 CSS 变量,而不是直接的值替换。
在本文中,我们主要介绍了 Vanilla Extract 的一些特点及在 React 中的应用,不同于其它任何的 CSS-in-JS 方案,它的样式不是在 JavaScript 运行时生成的,而是在编译阶段已经完成。
Vanilla Extract 是一个新的 CSS-in-JS,尽管目前在使用率上远不及它的竞争对手,但在 2021 年全球 CSS 满意度调查中还是位列榜首的,也是一个可以关注的技术。
本文我们也只介绍了它的皮毛,更多使用参考以下链接,可以去官网阅读更多,笔者最近写的一个项目,CSS 方案也用的该框架,感兴趣的可关注下 https://github.com/qufei1993/compressor。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.








































































































































{kind=link}
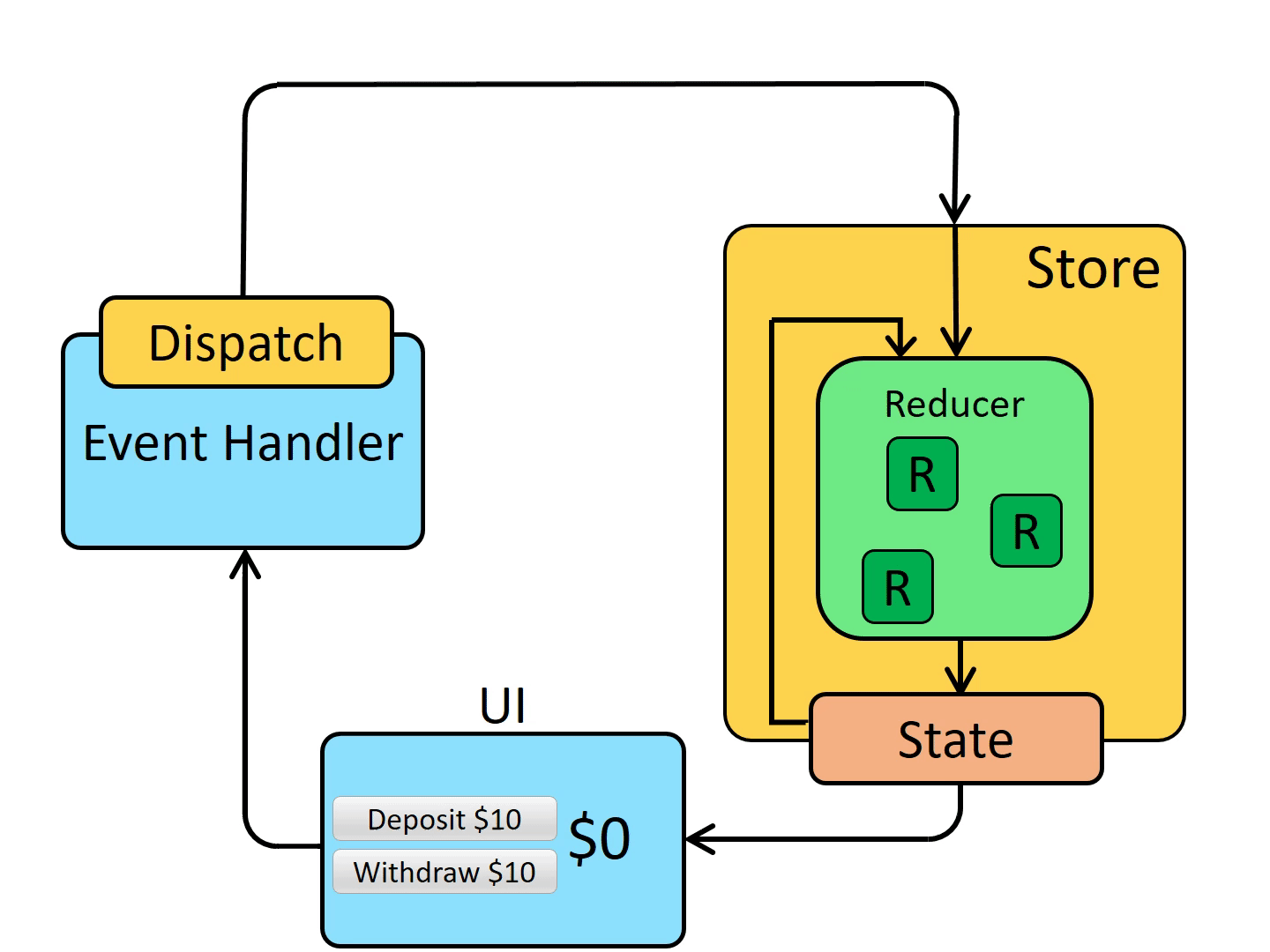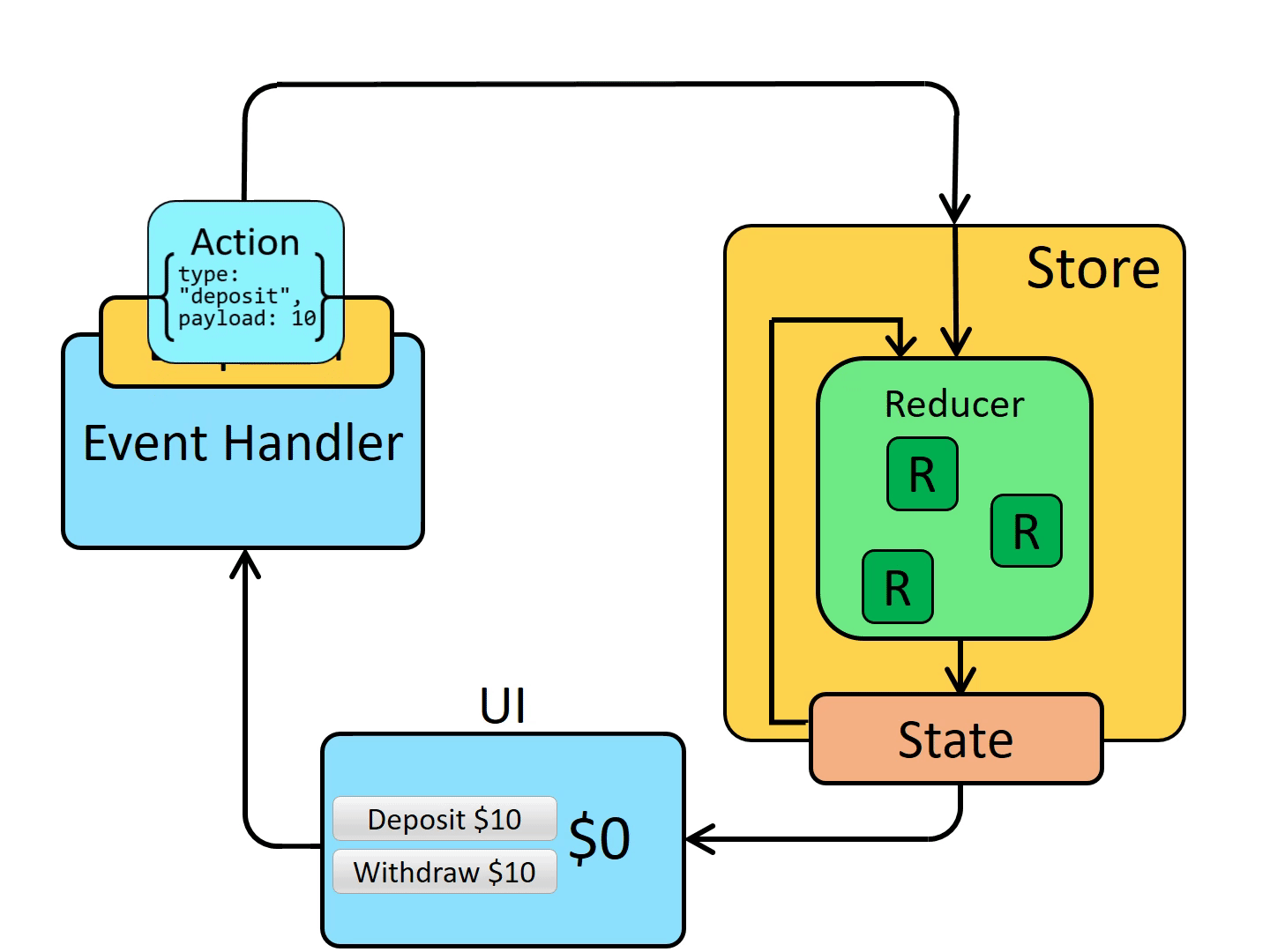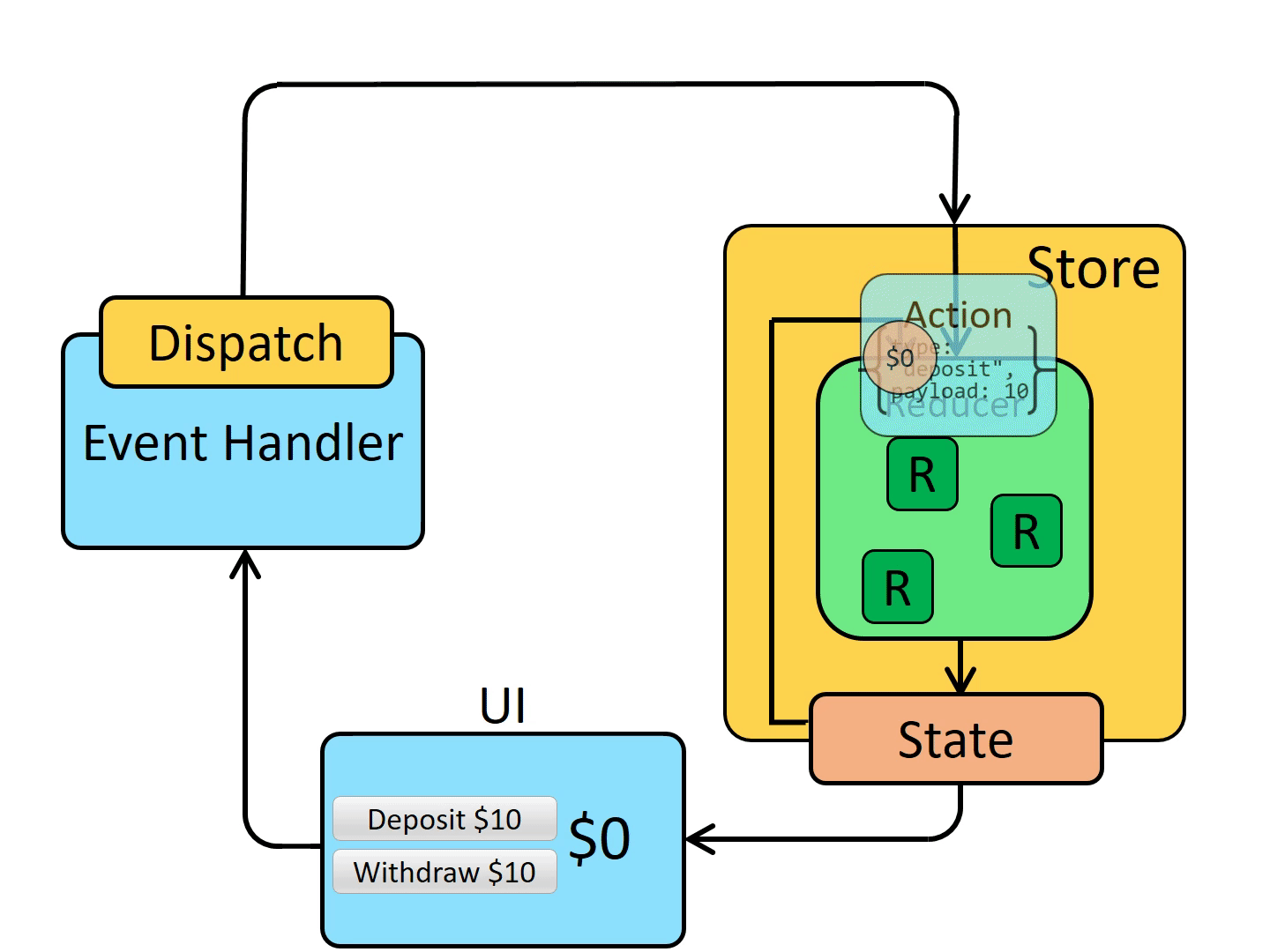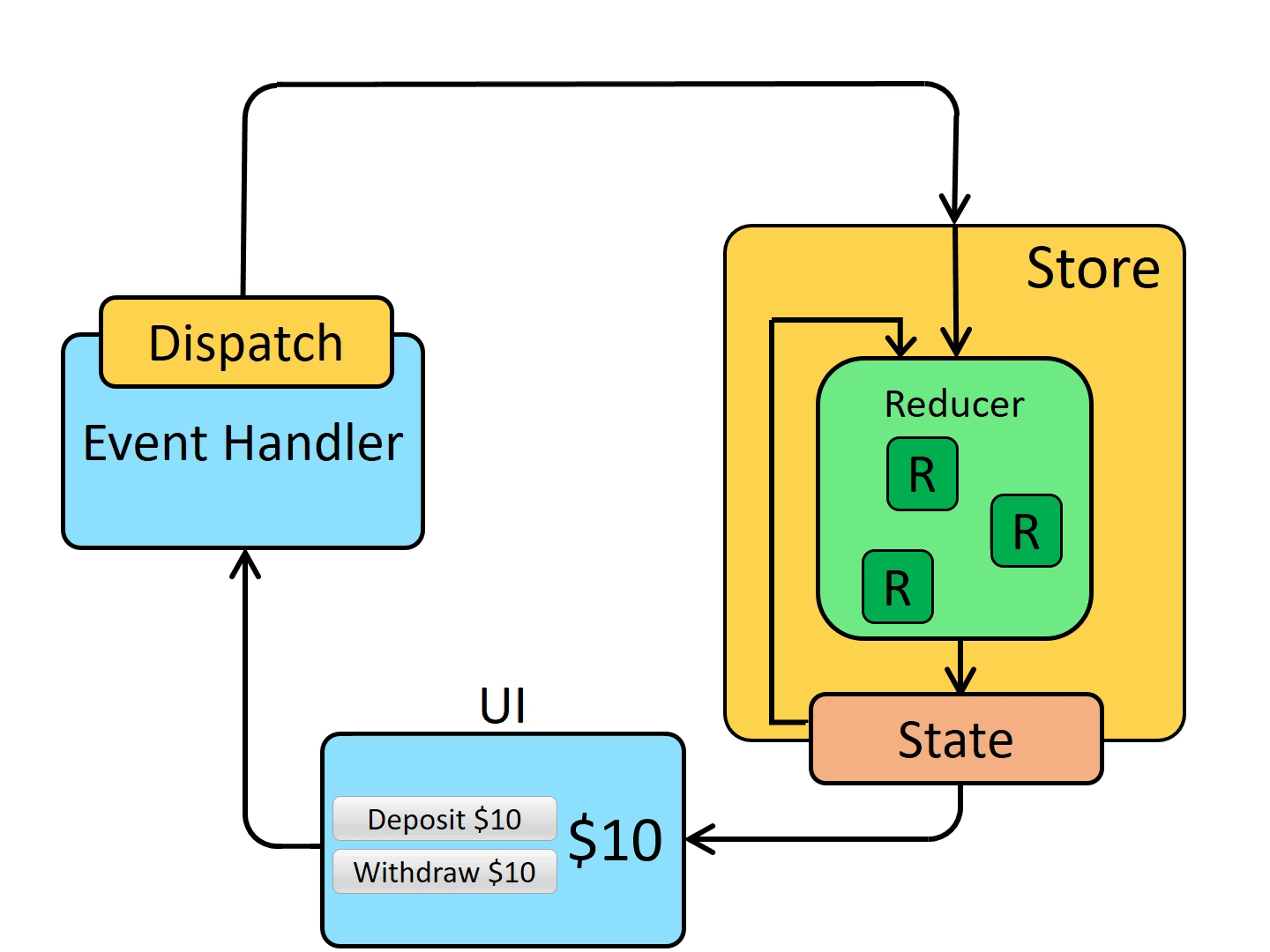{kind=link}
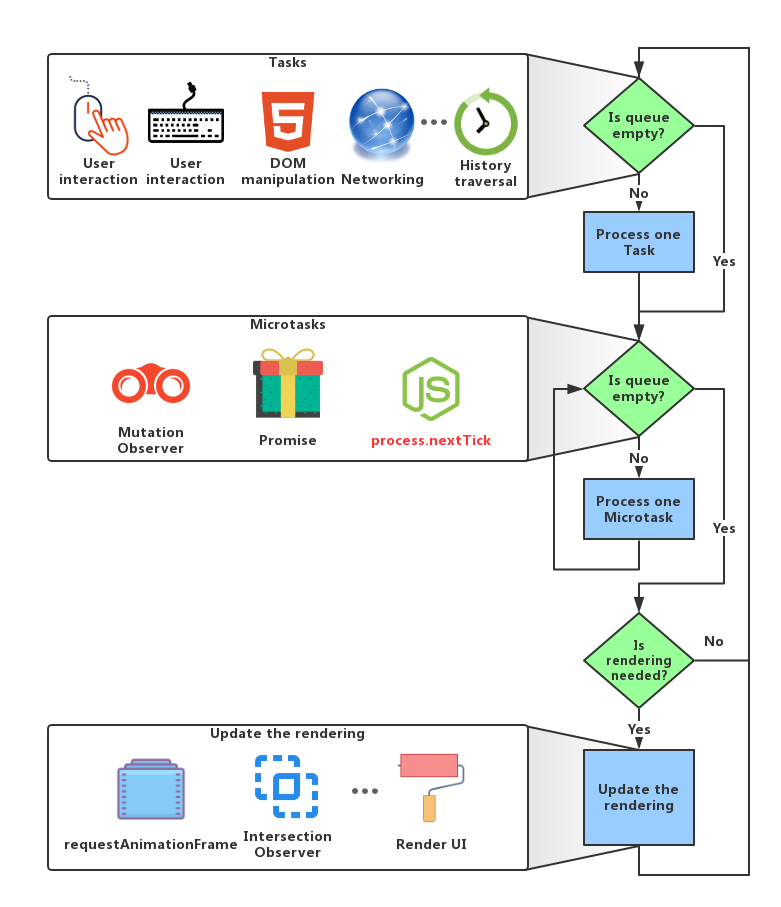{kind=link}
{kind=link}
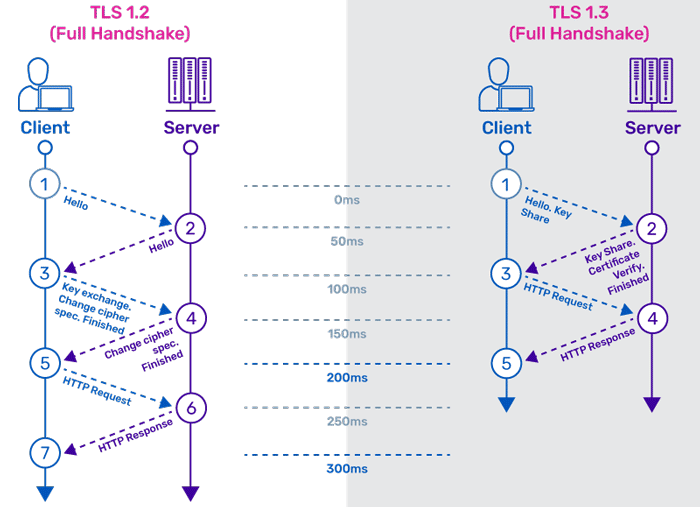{kind=link}
{kind=link}