This repo is a collection of public resources to help you to grab technical skills in data science fields through practical projects.
Currently, this repo includes topics of:
- Data Wrangling Scenarios - Data Analysis: basic pandas queries that helps quickly answer business problems
- Regression Scenarios - Demand Forecasting: projects using Tree-based Models, Time Series, and other Regression Models to predict future demand/sales based on historical data
- Model Interpretation - Shapley value: helps identify feature importance and to what extend each feature is affecting final prediction
- Classification Scenarios - Propensity Scoring; Regression to Classification
- Recommender System - Collaborative Filtering; Content-based Recommendation
- Causal Inference - Predict and understand the causal effects of these interventions
Ready? Let's have fun with real-world data challenges!
| Topic | Project |
|---|---|
| Demand Forecasting | Bike demand forecast based on features such as timing and weather indicators |
| Demand Forecasting | Item-level demand forecasting for different stores based on trend only |
| Basic Pandas | Lego Data - basic pandas |
| Data Visualization | Pandas + ployly html reports |
| RFM Analytics | RFM Analysis based on order data |
| Model Interpretation | Boston house price - shapley value of features affecting house prices |
| Recommender System | Content Based + Collaborative Filtering + Deep Learning |
| Classification | In which time range would the customer made their next purchase |
| Causal Inference | Hotel Cancellation Causality Analysis using DoWhy Package |
It's one of the most classic scenario of how regression models solving real-world requests. The companies need a scientific way to anticipate future sales, thus avoid issues including but not limit to:
- Out-of-stock and understocking leads to lost of sales, extra refillment cost
- Overstocking leads to cost of inventory, low turnover, and high working capital
- Preoccupied supply team refrain from focusing on value-added work
The following datasets and solutions are included regarding this topic:
-
Bike demand forecast based on features such as timing and weather indicators
-
Item-level demand forecasting for different stores based on trend only
-
Demand Forecasting for a Sports Apparel Company
Differentiators:
- Applied models that works best for short, mid, and long-term demand forecasting
- Reconstructed data for anomaly periods
-
Demand Planning for a Retail & Wholeselling Company
Differentiators:
- Considered external factors such as holidays, temperature
- Models were generated for 1500 loops for each SKU each week before finding an optimum
Not all projects requires Machine Learning, but definitely requireds Data Analysis.
No matter encounter with what kind of data, it's always important to first have a basic understanding of the data.
It's recommended to use pandas-profiling to quickly screen the basic condition of data, then use visualizations (histograms, box plots, scatter plots) to make deep dives on distributions and correlation among features. Crucial features are often found during EDA process, and otherwise would never be found or thought of if jumped into modelling process directly.
The following datasets and solutions are included regarding this topic:
Although the main focus of ML projects is to make as much accurate predictions as possible, model interpretability, as a intermediate output, is more important than the result.
The following datasets and solutions are included regarding this topic:
Methodology is quite similar to regression problems.
Currently we haven't cover a lot in this scenario.
This section is waiting to be updated.
Feel free to add scenarios that you feel like worth sharing :)
Classic recommender system consists of two types: collaborative filtering and content-based filtering.

Advantages
- No need for data on other users, thus no cold-start or sparsity problems.
- Can recommend to users with unique tastes.
- Can recommend new & unpopular items.
- Can provide explanations for recommended items by listing content-features that caused an item to be recommended (in this case, movie genres)
Disadvantages
- Finding the appropriate features is hard.
- Does not recommend items outside a user's content profile.
- Unable to exploit quality judgments of other users.
Advantages
-
No domain knowledge necessary
- We don't need domain knowledge because the embeddings are automatically learned.
-
Serendipity
- The model can help users discover new interests. In isolation, the ML system may not know the user is interested in a given item, but the model might still recommend it because similar users are interested in that item.
-
Great starting point
- To some extent, the system needs only the feedback matrix to train a matrix factorization model. In particular, the system doesn't need contextual features. In practice, this can be used as one of multiple candidate generators.
Disadvantages
-
Cannot handle fresh items
- The prediction of the model for a given (user, item) pair is the dot product of the corresponding embeddings. So, if an item is not seen during training, the system can't create an embedding for it and can't query the model with this item. This issue is often called ** the cold-start problem**
-
Hard to include side features for query/item
- Side features are any features beyond the query or item ID. For movie recommendations, the side features might include country or age. Including available side features improves the quality of the model. Although it may not be easy to include side features in WALS, a generalization of WALS makes this possible.
In our daily lives, cause & result happens everywhere. Take the following picture as an example, 'Getting up late' would definitely affect whether one would be late for schools. However, there might be other confounders having an impact on the final outcome, such as traffic accident & heavy rain.

Further more, there could be much more complicated obstacles:
- confounders might affect each other
- confounders might be unobserved
Given these into consideration, finding the true effect of 'getting up late' would be very hard.
Luckily, Dr.Pengfei found a package called Dowhy that could help solve this issue.
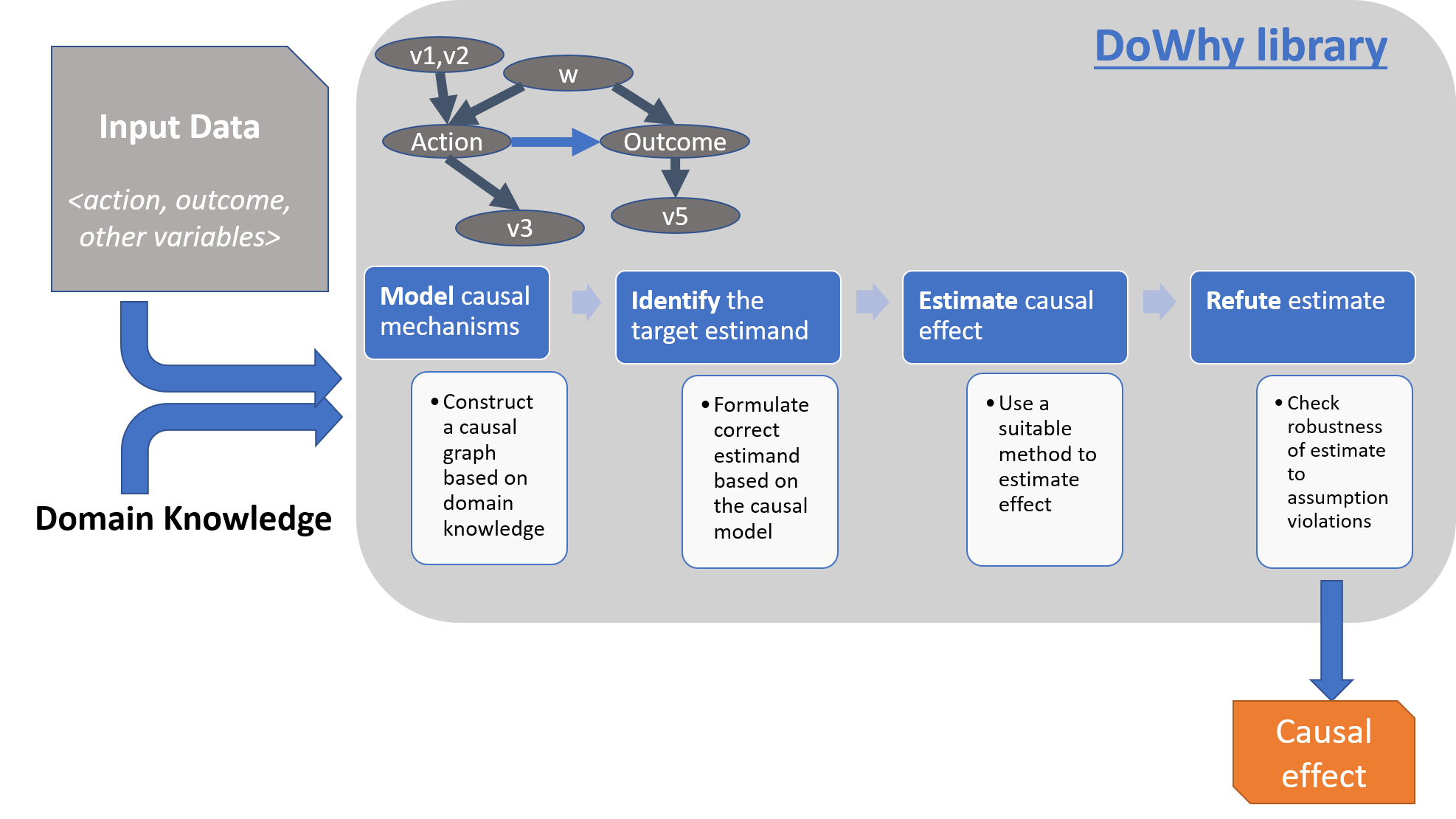
Dowhy follows a 4 steps rule to find causal inference:
- Model a causal problem
- Identify a target estimand under the model
- Estimate causal effect based on the identified estimand
- Refute the obtained estimate
We would cover more details in here. Basically, we feed in the data as well as the causal relationships among all variables.
We then pointed out treatment & outcome specifically. Such relationships are visualized in a graph that looks like below:

DoWhy would then take into account all of the complicate relationships and give an output as below.

In the example above, Dowhy gives the final verdict of how much the treatment (assign a different room) would affect the outcome (whether the customer would cancel the reservation).
Original links of resources in this repo are listed below:
| Topic | Author | Project Desription | Note |
|---|---|---|---|
| Data Analysis | Joao Correia | RFM Analysis | Simple way to quick segment customers based on Recency, Frequency, and Monetory |
| Data Analysis | Keith Galli | Lego Theme Analysis | How to conduct basic pandas manipulation |
| Model Interpretation | Vytautas Bielinskas | Shap Value of Ad's | Examples to explain equation of calculating shap value |
| Model Interpretation | Ajay Halthor | Shap Value of features affecting house price | Performed shap calculation and visualization on house price regression model |
| Causal Inference | Siddharth Dixit | Hotel Cancellation Causality Analysis | Utilize Python's DoWhy package to find causal inference on hotel cancellation |
| Recommender System | James Le | Movie Recommender System | Based on MovieLens 1M dataset, Developed Recommender System include: Content-Based and Collaborative Filtering, SVD Model (Deep Learning) |
| Classification | Barış Karaman | In which time range would the customer made their next purchase | Based on UCI Online Retail Data, construct a classification model to predict in which time range would the customer make the next purchase |
