remindmodel / remind Goto Github PK
View Code? Open in Web Editor NEWREMIND - REgional Model of INvestments and Development
License: Other
REMIND - REgional Model of INvestments and Development
License: Other




















































































































This branch has to be removed: https://github.com/remindmodel/remind/tree/cchrisgong-patch-1
Correct me if I'm wrong but, as far as I can tell, the following lines in the prepare function of our starting procedure don't work
# Make sure all MAGICC files have LF line endings, so Fortran won't crash
if (on_cluster)
system("find ./core/magicc/ -type f | xargs dos2unix -q")
They produce the following error in the log.txt file:
xargs: dos2unix: No such file or directory
The problem is that the system on the cluster nodes can't find the dos2unix command. We need to add the dos2unix executable to our $PATH (e.g. in /p/projects/rd3mod/tools), or remove the command. (Since it isn't working, as far as I can tell, and nobody is complaining, maybe it isn't necessary?)
- Start comment on sections with the initials of the programmer and the data of change (e.g. GL, 2011-06-07)
https://github.com/remindmodel/remind/blob/develop/tutorials/7_Advanced_ChangeCode.md
Nobody is doing that anymore, now most people now how to use git blame (at leas on github), right? Should we scrap that?
The idea used to be that a REMIND run can be used from its directory independent of all other REMIND code. Currently, that's not the case any more in at least two instances. I copied a run to a temporary directory for debugging and got this:
$ grep Error log.txt | sort | uniq
Error in fread("../../modules/35_transport/edge_esm/input/EDGEscenario_description.csv") :
Error in read.magpie("../../modules/11_aerosols/exoGAINS/input/ef_gains.cs4r")
So at least two files need to be included in
Lines 460 to 475 in be7a866
/home/giannou/REMIND/output/SSP2-PkBudg1100_2020-04-13_16.10.08/full.lst
We used to have the SVN/git version and the changes with respect to these reported in the run files, is this not the case any more? It was a very helpful feature.
Please indicate at the top of the file how it is used and which parameters or flags can be given.
Alternatively, one could use optparse and provide --help or --usage.
Lines 478 to 502 in 08e58ef
I don't see any point in (and am confused by) the OR (pe2se(enty,enty2,te) AND sameas(enty3,"cco2")) part. This would come into play for combinations of (pety,sety,te,"cco2") that are not present in emi2te yet have non-zero data in pm_emifac. This might happen if new data is included in ./core/input/generisdata_emi.put, but is not the case at the moment.
However, these entries would be excluded from the equation in any case, since it sums over emi2te, of which they are not a part. (Incidentally, this sum does nothing productive besides excluding the non-existent cases that were manually included.)
Do you have any idea what was the reasoning behind this? I will delete it, unless there's some foreseeable edge-case where this is necessary.
For Baseline scenarios -
For SDP scenarios -
General -
Status:
Right now, there is a variable in REMIND (v_shGreenH2) that defines the share of green hydrogen as all the hydrogen produced from electricity.
Issues:
Propositions:
When reporting.R is executed, the magicc reporting parts fail with
[1] "Executing reporting.R"
/p/tmp/aloisdir/remind-trunk/output/SDP-calibrate_2020-05-27_16.57.02/magicc
At line 1299 of file MAGICC_6005_v2_forJessicaGunnarElmar.F90 (unit = 42, file = 'MAGCFG_NMLYEARS.CFG')
Fortran runtime error: End of file
sh: climate_reporting_template.txt: No such file or directory
sed: can't read ../../../output/SDP-calibrate_2020-05-27_16.57.02/REMIND_climate_SDP-calibrate.mif: No such file or directory
cat: ../../../output/SDP-calibrate_2020-05-27_16.57.02/REMIND_climate_SDP-calibrate.mif: No such file or directory
Consequentially the EDGE Transport reporting is not executed (it comes after the magicc reporting in reporting.R) but a MIF file is produced so without checking the logs or looking for EDGE-T or MAGICC reporting, no error is evident.
https://github.com/remindmodel/remind/blob/develop/scripts/output/single/LCOEPlot.R
throws an error when called via "Rscript output.R"
After you select:
Rscript output.R > 2: Comparison across runs > 9: compareScenarios > and choose the scenario to be compared
It would be important to have the two following questions asking for additional user input:
(1) Please provide a file name prefix (press enter to none):
If the user type any string, this should be added to the beginning of the comparison scenario filenames. This is highly important when creating multiple comparison scenarios simultaneously.
(2) Please choose the SLURM configuration for your submission (default: priority):
options:
1: SLURM priority
2: SLURM standby
This is highly important because the cluster is taking too long in the standby queue. If you are creating reportings by hand, there is a higher chance that this is one of your priorities.
When starting a testOneRegi run on the cluster by changing the config file instead of using the --testOneRegi flag to start.R, the run reports via email (subject, body is empty)
SLURM Job_id=16067591 Name=default Ended, Run time 00:09:58, OUT_OF_MEMORY
Checking the output, /p/tmp/aloisdir/remind/output/default_2020-04-16_10.30.13, everything seems to be fine (except MAGICC) but validation seems to fail. Log says
[1] "Executing reporting.R"
/p/tmp/aloisdir/remind/output/default_2020-04-16_10.30.13/magicc
At line 1299 of file MAGICC_6005_v2_forJessicaGunnarElmar.F90 (unit = 42, file = 'MAGCFG_NMLYEARS.CFG')
Fortran runtime error: End of file
sh: climate_reporting_template.txt: No such file or directory
sed: can't read ../../../output/default_2020-04-16_10.30.13/REMIND_climate_default.mif: No such file or directory
cat: ../../../output/default_2020-04-16_10.30.13/REMIND_climate_default.mif: No such file or directory
Joining, by = c("region", "tech", "rlf")
Joining, by = "opTimeYr"
Joining, by = "tech"
Joining, by = c("opTimeYr", "fuel")
Joining, by = c("region", "tech")
Joining, by = c("region", "tech")
Joining, by = c("region", "period", "tech")
Joining, by = "tech"
Joining, by = c("region", "period", "tech")
Joining, by = c("region", "period", "tech")
[1] "Executing validation.R"
/var/spool/slurmd/job16067591/slurm_script: line 4: 21304 Killed Rscript prepare_and_run.R
slurmstepd: error: Detected 1 oom-kill event(s) in step 16067591.batch cgroup.
REMIND version is 998771da3af9b243925161105ff86e5cd865b0d9, no changes to config apart from cfg$gms$optimization <- "testOneRegi" .
There is no package ncdf.
> download.packages('ncdf', './')
Warning in download.packages("ncdf", "./") :
no package 'ncdf' at the repositories
[,1] [,2]
> getOption('repos')
CRAN pik
"https://cran.rstudio.com" "https://rse.pik-potsdam.de/r/packages"
Why is it that full.log reports being at the 12th iteration whereas full.lst hasn't even started reporting the first one? Does anyone have an idea?
This run:
/p/tmp/giannou/sa2_updated/output/NDC_spvL_CDR_2020-05-12_20.12.24
has 3 subsequent runs:
$subsequentruns [1] "PkBudg1100_spvL_CDR" "PkBudg900_spvL_CDR" "PkBudg1300_spvL_CDR"
They weren't started when the run was finished and they don't start when I restart the basis-run with
Rscript start.R --restart from the mail folder.
Any idea what is going on here? I get no error message and in the log.txt file it looks as though the subsequent runs don't exist.
Other runs of mine had the same problem.
remind/tutorials/1_GettingREMIND.md
Lines 30 to 45 in 23fc5eb
remind depends on remulator, depends on magpie4, depends on moinput, depends on rhdf5. So the Bioconductor-stuff is needed as well.The calibration of fesob in the USA region does not reach the target, even after many iterations:
SDP:

SSP2:
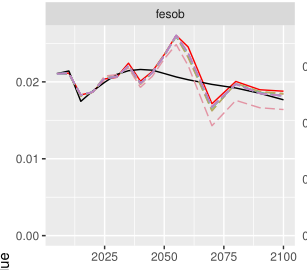
Behind the quantities, the prices of fesob show great variations, with sudden price drops or increases from one period to another.
In the calibration routine, the strong and sudden variations of prices are smoothed. This normally does not cause a problem, but if prices vary strongly, the difference between smoothed and original prices becomes important. Therefore the computed efficiencies (which make target quantities optimal at the smoothed prices) will not adapt so as to make the output quantities close to the target quantities (because smoothed prices are too far away from output prices). Removing the smoothing would help for fesos USA, but it would cause problems elsewhere. The real problem lies in the strong and sudden variations of prices, which I could not solve.
Solids, and especially solids in buildings, are one of the most problematic energy carriers in the calibration, because there are many equations and fixings which constrain their development, and prices. I list some of the constraints and equations I played around with in the following. Unfortunately, this has not helped solving the price issue for fesob/i USA so far. Prices of fesob and fesoi should normally be equal. There are several reasons why it need not be the case.
q_limitBiotrmod: this equation is in core/equations.gms . It is supposed to prevent that all solids are provided by biomass in the long term, at least for industry. In practice, this equation says that (modern biomass in B and I)-(solids in B)<2*(coal in B and I). The equation is less stringent in the short term (5 instead of 2). This equation, if at the boundary, can lead to a difference in prices of fesob and fesoi.q_inconvPenCoalSolids, now q02_inconvPenCoalSolids, in modules/02_welfare/utilitarian/equations.com. Local air pollution for coal. But in practice, the penalty applies to (coal for B and I) – (solids in I). So this equation can also lead to a difference in prices of fesob and fesoi.vm_deltaCap.fx (biotr): in most scenarios biotr follows a fixed trajectory. But it cannot be suspected to cause variations in fesob/i prices as biotr is 0 in the USA.In addition, I have tried to fix fesob and fesoi to their 2025 target quantity: the idea is to provoke an infeasibility that could point to the original problem (for early periods it is usually related to capacities). There was no infeasibility.
Instead of looking directly for the source of the problem, another option to solve the calibration issue could be track back from which version on the problem occurs. This would require making a calibration of several versions of the model. But this option is a rather expensive way of solving the issue, and it could probably only work if the problem arises from a significant change and not from an accumulation of small changes.
The current default version is non-optimal. Is there some work-in-progress going on?
Hi,
I downloaded the latest release and tried to run this model. It threw an error while trying to download and distribute input data. The error message looks like:
Load data..
Following files not found:
rev5.961_690d3718e151be1b450b394c1064b1c5_remind.tgz
My understanding is it tries to download the above tgz file from somewhere. But where is the file stored?
And according to the README, the input data is not part of this project. But do we provide any example data for me to understand the structure and the format of the input data?
Many thanks!
path_gdx_bau is not included in the default configuration
remind/config/scenario_config.csv
Line 1 in 46de327
start.RLine 84 in 46de327
Warning messages:
1: In is.na(isettings$path_gdx_bau) :
is.na() applied to non-(list or vector) of type 'NULL'
Shouldn't it be included in the default configuration (even if empty)?
We might want to change this
tl;dr: EDGE-Transport needs to stop messing with the past like a naughty time traveller. ;)
I'm pretty confident I found the origin of the infeasibilities having to do with geohdr capacity in the first free time step.
Ultimately, it is caused by EDGE_transport.R modifying the values of p35_fe2es
remind/modules/35_transport/edge_esm/presolve.gms
Lines 13 to 19 in 547ba8f
fulldata.gdx, which becomes the input_ref.gdx for the next run, where they are loaded, overwriting the data from ./modules/35_transport/edge_esm/input/fe2es.cs4r.remind/modules/35_transport/edge_esm/datainput.gms
Lines 50 to 54 in 547ba8f
Then, different pm_fe2es values change the result of initialcap2, specifically v05_INIcap0/pm_cap0, which trickles down to change the vintage capital structure of geohdr through pm_cap0 → s05_aux_tot_prod → s05_aux_prod_remaining → p05_aux_prod_thisgrade → p05_aux_cap_distr → p05_aux_cap → sm_tmp → vm_capDistr.fx:
remind/modules/05_initialCap/on/preloop.gms
Lines 145 to 182 in 547ba8f
Then, depending on region and scenario settings, it is possible that (a) CONOPT is in a weird spot it can't find out of (my Npi run) or (b) the modified vintage capacity is so high that capacity × capacity factor exceeds pm_dataren(regi,"maxprod",rlf,te) (FelixNSW run) – which isn't a problem for the fixed time-steps, asq_limitProd` is defined only over the free ones.
@LaviniaBaumstark @dklein-pik @giannou (In lieu of a RSE github team):
I think it's problematic that a run, that is supposed to be fixed on a different run up to some point, has a different vintage structure. I was always puzzled by the fact that initialcap2 is run for every run. This seems not only to be the case for geohdr, but other technologies too. Small thing that doesn't show up in the results (vm_cap is still the same), but this bug wouldn't happened without initialcap2 running again, although its results should be the same in any case.
In any case, preserving the 2005 values of pm_fe2es at the ./modules/35_transport/edge_esm/input/fe2es.cs4r levels should fix this.
Evidence/notes using the failed DeepEl3 Npi run as an example: /p/tmp/pehl/Remind_DeepEl/output/TraInd-Npi_2020-11-27_16.06.51
$ gdxdiff input_ref.gdx non_optimal.gdx id=pm_cap0,pm_EN_demand_from_initialcap2,pm_cesdata,pm_shFeCes,pm_fe2es,pm_cf,pm_data,pm_prodCouple,p35_fe2es,EDGE_scenario
GDXDIFF 31.1.1 r4b06116 Released May 16, 2020 LEG x86 64bit/Linux
File1 : input_ref.gdx
File2 : non_optimal.gdx
Id : pm_cap0 pm_EN_demand_from_initialcap2 pm_cesdata pm_shFeCes pm_fe2es pm_cf pm_data pm_prodCouple p35_fe2es EDGE_scenario
Summary of differences:
pm_cap0 Data are different
pm_cf Data are different
pm_data Data are different
pm_EN_demand_from_initialcap2 Data are different
pm_fe2es Data are different
pm_shFeCes Data are different
Output: diffile.gdx
GDXDiff finished
$ dumpgdx diffile.gdx vm_deltaCap "CHA.*geohdr.*L\>" | head
1995 CHA geohdr 1 dif1 L 8.2494690248504E-8
1995 CHA geohdr 1 dif2 L 8.24965476551363E-8
2000 CHA geohdr 1 dif1 L 1.42715686791135E-6
2000 CHA geohdr 1 dif2 L 1.42718900101742E-6
2015 CHA geohdr 1 dif1 L 0.000906719440325381
2015 CHA geohdr 1 dif2 L 0.000906719440325381
2020 CHA geohdr 1 dif1 L 3.4181901481737E-5
2020 CHA geohdr 1 dif2 L 3.4181901481737E-5
2030 CHA geohdr 1 dif1 L 0.000100553100549173
2030 CHA geohdr 1 dif2 L 0.000100553067898506
$ dumpgdx diffile.gdx pm_cap0 "CHA.*geohdr"
CHA geohdr dif1 1.49901612654113E-5
CHA geohdr dif2 1.4990498775921E-5
$ dumpgdx diffile.gdx pm_fe2es "2005.*CHA"
2005 CHA te_espet_pass_sm dif1 32.7810653744073
2005 CHA te_espet_pass_sm dif2 32.7803397536317
2005 CHA te_esdie_pass_sm dif1 72.8208842393301
2005 CHA te_esdie_pass_sm dif2 72.6703864713621
2005 CHA te_eselt_pass_sm dif1 274.077206442013
2005 CHA te_eselt_pass_sm dif2 276.29708722215
2005 CHA te_esh2t_pass_sm dif1 64.7583317381968
2005 CHA te_esh2t_pass_sm dif2 64.742052256529
2005 CHA te_esgat_pass_sm dif1 66.8262951982073
2005 CHA te_esgat_pass_sm dif2 67.1300018776568
2005 CHA te_esdie_frgt_sm dif1 35.041588297353
2005 CHA te_esdie_frgt_sm dif2 34.9779610388119
2005 CHA te_eselt_frgt_sm dif1 226.082090011469
2005 CHA te_eselt_frgt_sm dif2 226.082090011469
2005 CHA te_esh2t_frgt_sm dif1 33.3906087857954
2005 CHA te_esh2t_frgt_sm dif2 33.391690768669
2005 CHA te_esgat_frgt_sm dif1 13.2919587450842
2005 CHA te_esgat_frgt_sm dif2 13.3447480682688
Any chance these can be formulated otherwise? We don't want hard-coded regions, right?
remind/modules/21_tax/on/datainput.gms
Line 192 in 8b57bef
remind/modules/21_tax/on/datainput.gms
Line 261 in 8b57bef

by not decompressing levs.gms.gz, margs.gms.gz, and fixings.gms.gz.
Lines 696 to 702 in c67cc61
default_2020-01-08_14.13.34 run, 2020/USA
vm_co2capture 2020 USA cco2 ico2 ccsinje 1 L 0.00304342219022761
v_co2capturevalve 2020 USA L 0.00194586349440526
vm_co2CCS 2020 USA cco2 ico2 ccsinje 1 L 0.00109755869582235
vm_emiTeDetail 2020 USA * * * cco2 L 0.00036196011504294
vm_ccs_cdr 2020 USA cco2 ico2 ccsinje * L 0
vm_emiIndCCS 2020 USA * L 0.00268146207518457
vm_co2capture = vm_co2CCS + v_co2capturevalve and
vm_co2CCS = vm_emiTeDetail + vm_ccs_cdr + vm_emiIndCCS
So CO2 captured in industry gets vented. I'm not entirely sure what the purpose of v_co2capturevalve is
Line 293 in c67cc61
Lines 18 to 21 in 3dc3519
Could we release these limits on CONOPT?
I'm mainly interested in reslim for Nash, because the REMIND-EU calibration has shown to need more time to find a feasible solution (at least three and a half hours). I don't think limiting reslim is useful (anymore).
NA. But if it doesn't, having it keep going may give me a feasible (unconverged) .gdx from which to start a new run. (Worked for me a lot for initial calibrations of new parametrisations.)solve iteration or even Nash iteration, but will just waste eleven iterations trying again from the beginning, without informing the user who could then intervene.The non-Nash reslim (eleven days) isn't really different from the default (317 years) – most runs will get cancelled well before, and if not (Negishi?), users are likely to check in on them.
Same argument for iterlim. 1e6 is a random number that is not qualitatively different from the default (2e9).
Compilation error: pm_taxCO2eqHist not defined
Todo: either mark as incompatible, or add definition to the tax=off module

enty used to be "energy type" and encompass primary, secondary, and final energy (pety, sety, fety). Now it includes useful energy, a gazillion emissions, peog as an oil-and gas aggregate, as well as the good and perm tradable assets.
Is there a legitimate case where they all have to be in the same set? Because that's blowing up all the variables and parameters involved and is quite confusing from time to time.

out-of-the-box REMIND run with module piam/1.10 loaded fails with error message:
Error in setNames(pop[regi, , ] * log(1000 * cons[regi, , ] * (1 - (c_damage * :
dims [product 19] do not match the length of object [0]
Calls: mbind -> reportMacroEconomy -> setNames
after the 1st iteration, when running exoGAINSAirpollutants.R
Installing the latest R version, GAMS version, and following the documentation through on Mac brings the following error when running source('start.R'):
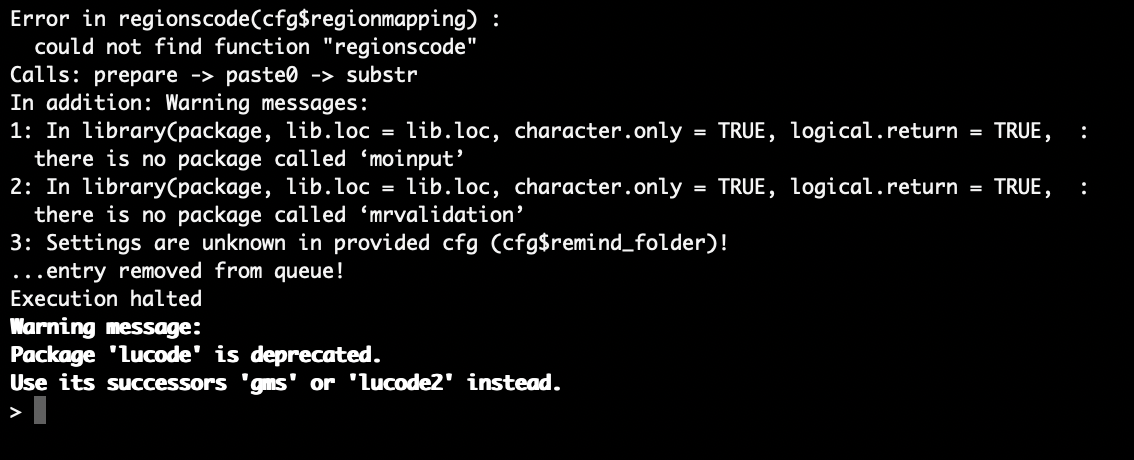
I've recreated this on two separate Mac machines. If I'm able to sort it out I'll post here, but any ideas or solutions would be a great help.
due to the renaming of log.txt to $JOBNAME.out in 285f5c2
There should be a facility to document values in generisdata, as REMIND results are quite sensitive to these assumptions. One possibility would be to start from a YAML file and generate the .prn, thereby ensuring the presence of some documentation string (ideally containing a reference).
..is a waste of resources. Maybe a two-step process is needed, like the one we had before?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.