Comments (6)
 albertz
commented on May 24, 2024
albertz
commented on May 24, 2024
Do you have statistics about the sequence length, esp when this happens? Is
it mostly for long sequences?
Am Di., 13. Nov. 2018, 17:04 hat Akshat Dewan <[email protected]>
geschrieben:
… Hi,
I trained models on around 1500h of audio data (Librispeech + WIPO
proprietary) and obtain good performance (around 18% on proprietary test
set).
But sometimes we encounter an issue when the coverage of the audio is very
low and lot of text (5-6 seconds) is missing. I just wanted to ask if
anyone of you has encountered similar challenges.
Best
Akshat
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#11>, or mute the
thread
<https://github.com/notifications/unsubscribe-auth/AADm_HUM59vv2GxSVDgqiYkKeT8I5A3qks5uuplFgaJpZM4YbTbk>
.
from returnn-experiments.
 akshatdewan
commented on May 24, 2024
akshatdewan
commented on May 24, 2024
The test sequences, like training sequences, are mostly between 1-15 sec long. (see histogram)
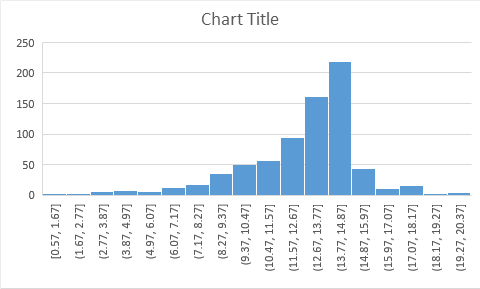
I do not have any statistic on the problematic segments though. However, I do have a feeling that it occurs for long segments. Do you think a solution could be to just reduce the length of the test sequences?
from returnn-experiments.
albertz
commented on May 24, 2024
So, to make it more clean again: You have some sequences which are longer (e.g. 14 secs), and they contain some text (about 6 secs) which you don't have in your reference transcription?
Noisy/incorrect training transcriptions can definitely be problematic for stable training.
Also, I observed that the attention model kind of learns like a linear alignment initially, and to detect silence. So any sequence which are far away from this pattern will be hard.
Some sort of curriculum learning, to exclude such bad sequences in the beginning of the training (first 20 epochs or so), will probably help to some extend.
from returnn-experiments.
akshatdewan
commented on May 24, 2024
Sorry, I guess I was not clear - for some longer test segments (e.g. 14.9 sec), the predicted sequence is missing a lot of text (5-6 seconds worth) as compared to the reference.
"Also, I observed that the attention model kind of learns like a linear alignment initially, and to detect silence. So any sequence which are far away from this pattern will be hard."
I thought that input and output sequences in S2T are always linearly aligned. Am I missing something here?
"Some sort of curriculum learning, to exclude such bad sequences in the beginning of the training (first 20 epochs or so), will probably help to some extend."
I currently do not have a mechanism to classify training segments as clean or noisy but I plan on working on it.
from returnn-experiments.
albertz
commented on May 24, 2024
I think you mean monotonic. Of course that is true for speech recognition (but e.g. not for translation).
But linear is not true. Linear means that e.g. the attention for the first output label should be at t=0, and for the last output label the attention should be at t=T, and for all other output labels, the attention should focus exactly linearly interpolated in between.
from returnn-experiments.
akshatdewan
commented on May 24, 2024
Thanks! I think I understand it better now. I will run some more experiments to see what can I do. Perhaps if I try to limit non-speech in my test segments, the "linearity" condition might get satisfied and coverage might improve.
from returnn-experiments.
Related Issues (20)
- local attention with unidirectional lstm not converging HOT 5
- Implement a unidirectional variant of local attention HOT 10
- Loading a saved Returnn model from its .meta file HOT 16
- query regarding LM data preprocessing HOT 2
- Reusing parameters inside rec layer HOT 5
- Training Configuration for TEDLIUMv2 HOT 3
- specAugment policy and schedules HOT 3
- Question about 2020-rnn-transducer HOT 16
- 2018-asr-attention/librispeech/attention/exp3.ctc.lm.config: target 'bpe' unknown HOT 3
- Question about 2018-asr-librispeech dev = get_dataset("dev", subset=3000) HOT 2
- loss nan and cost nan while running my own corpus using librispeech sets HOT 10
- Hierarchical layer name not captured correctly
- Problem with retrieving source layer from a hierarchical definition
- Multi Stage Training
- Questions on librispeech transformer lm HOT 10
- Transducer error in GetFilteredScoreOp HOT 4
- Big files in repo HOT 5
- Git commit/push rule to not allow big files HOT 3
- Could you please provide a script that could run lsh-attention for translation? HOT 4
- Assert Error when running 2022-lsh-attention HOT 7
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from returnn-experiments.