
See the ModelDB frontend in action:
ModelDB is an end-to-end system to manage machine learning models. It ingests models and associated metadata as models are being trained, stores model data in a structured format, and surfaces it through a web-frontend for rich querying. ModelDB can be used with any ML environment via the ModelDB Light API. ModelDB native clients can be used for advanced support in spark.ml and scikit-learn.
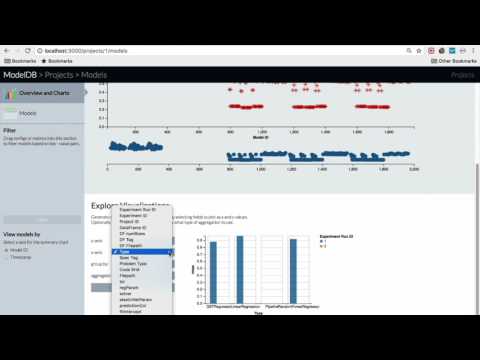
The ModelDB frontend provides rich summaries and graphs showing model data. The frontend provides functionality to slice and dice this data along various attributes (e.g. operations like filter by hyperparameter, group by datasets) and to build custom charts showing model performance.

ModelDB Frontend Projects Summary Page

ModelDB Graph for Model Metrics

ModelDB Configurable Graph Parameters
ModelDB's Light API can be used with any ML environment to sync model metrics and metadata or even entire config files by calling a few functions (e.g. see here and here respectively).
Alternatively, ModelDB native clients for spark.ml and scikit-learn can be used to perform automatic, fine-grained logging. Unlike the Light API, native clients do not require the user to explicitly provide model data to ModelDB. The native clients can automatically extract relevant pieces of model data as the model is being built and sync them with ModelDB. Incorporating ModelDB into a scikit-learn / spark.ml workflow is as simple as appending Sync or _sync to relevant methods in the respective libraries. See samples for spark.ml here and those for scikit-learn here.
- ModelDB client: See how ModelDB can be integrated into different ML workflows
- ModelDB frontend: See how ModelDB can visualize model data and results
2017.02.08: ModelDB publicly available! Try it out and contribute.
If you have Docker Compose installed, you can bring up a ModelDB server with just a couple commands.
To run ModelDB with Docker, but without Docker Compose, see detailed instructions.
-
Clone the repo
git clone https://github.com/mitdbg/modeldb
-
Build and run ModelDB
cd [path_to_modeldb] docker-compose up
The error was resolved by running the docker-compose command prefixing it with “sudo”. This created containers for Mongo(27017:27017), frontend(6543:6543) and backend(3000:3000).-Satyam Note by default ModelDB will listen on localhost:3000.
Watch a video of the setup and installation process here.
-
Clone the repo
git clone https://github.com/mitdbg/modeldb
-
Install dependencies
ModelDB requires Linux or MacOS. The code below shows how you can install the dependencies on each of them. A detailed list of all the dependencies with the recommended and required versions can be found here.
Depending on the client you're using, we assume you have the following already installed:
- scikit-learn client:
- Python 2.7 or Python 3.5.1**
- pip
- scikit-learn 0.17**
- spark.ml client:
- Java 1.8+
- Spark 2.0.0**
(**) = Python 3.5.1+ is only compatible with thrift 0.10.0+
On OSX, we also assume that you have homebrew installed.
On Mac OSX:
# Use homebrew to install the dependencies brew install sqlite brew install maven brew install node brew install sbt # for spark.ml client only brew install mongodb # ModelDB works only with Thrift 0.9.3 and 0.10.0. Python 3 is only compatible with thrift 0.10.0 If you do not have thrift installed, install via brew. `brew install thrift` pip install -r [path_to_modeldb]/client/python/requirements.txt
On Linux:
apt-get update sudo apt-get install sqlite sudo apt-get install maven sudo apt-get install sbt # for spark.ml client only sudo apt-get install nodejs # may need to symlink node to nodejs. "cd /usr/bin; ln nodejs node" sudo apt-get install -y mongodb-org # further instructions here: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/ # install thrift. [path_to_thrift] is the installation directory # ModelDB works with thrift 0.9.3 and 0.10.0. The following instructions are for 0.9.3 cd [path_to_thrift] wget http://mirror.cc.columbia.edu/pub/software/apache/thrift/0.9.3/thrift-0.9.3.tar.gz tar -xvzf thrift-0.9.3.tar.gz cd thrift-0.9.3 ./configure make export PATH=[path_to_thrift]/:$PATH pip install -r [path_to_modeldb]/client/python/requirements.txt
For Linux, you can also refer to this script.
- scikit-learn client:
-
Build
ModelDB is composed of three components: the ModelDB server, the ModelDB client libraries, and the ModelDB frontend.
In the following, [path_to_modeldb] refers to the directory into which you have cloned the modeldb repo and [thrift_version] is 0.9.3 or 0.10.0 depending on your thrift version (check by running
thrift -version).# run the script to set up the sqlite and the mongodb databases that modeldb will use # this also starts mongodb # ***IMPORTANT NOTE: This clears any previous modeldb databases. This should only be done once.*** cd [path_to_modeldb]/server/codegen ./gen_sqlite.sh """SQLite is a public domain, open-source project. It is what is called an “embedded” database which means the DB engine runs as part of your app. MySQL is also open-source but is owned by Oracle. MySQL is a database server so you have to install it somewhere and then connect to it from your app. They serve two totally different purposes. SQLite is often used for an app to maintain its own data. For example, a web browser might use SQLite to store its bookmarks. An email client might use SQLite to store email messages locally. A database server such as MySQL is used to store data that is typically accessed by multiple users and apps. """ This removes jar files which are already present (specially from sqlite). Then, it creates a directory "jars". jOOQ is a simple way to integrate the SQL language into Java in a way that allows for developers to write safe and quality SQL fast and directly in Java such that they can again focus on their business. #wget stands for "web get". It is a command-line utility which downloads files over a network. #Downloads some jar files. # build and start the server cd .. ./start_server.sh [thrift_version] & # NOTE: if you are building the project in eclipse, you may need to uncomment the pluginManagement tags in pom.xml located in the server directory Thrift is a framework for developing services in multiple programming languages. So, you only need this if you are considering supporting multiple programming languages in an IT system. Used for building API. # build or pip install the scikit-learn client library pip install modeldb -- or -- cd [path_to_modeldb]/client/python ./build_client.sh # build spark.ml client library cd [path_to_modeldb]/client/scala/libs/spark.ml ./build_client.sh # start the frontend cd [path_to_modeldb]/frontend ./start_frontend.sh & # the frontend will now be available in http://localhost:3000/ # ****** For server shutdown ****** # Kill server # Shutdown mongodb server mongo --eval "db.getSiblingDB('admin').shutdownServer()"
After incorporating ModelDB into your models, follow these steps to run and view them in ModelDB.
-
Make sure the server is running.
Each time you use ModelDB, the server, including MongoDB for the database, must be up and running.
# start the server cd [path_to_modeldb]/server ./start_server.sh [thrift_version] & # make sure mongodb is running. if not running, execute the commands below # cd codegen # mkdir -p mongodb # mongod --dbpath mongodb
-
Run your models instrumented with ModelDB as shown above.
-
View, visualize, and query your models.
You can view all these models in http:localhost:3000/ by starting the frontend.
cd [path_to_modeldb]/frontend ./start_frontend.sh &
More comprehensive documentation on ModelDB, including answers to FAQ, will be available soon in the wiki. Information about the server documentation can be found in the docs folder. For other questions, don't hesitate to contact us.
Questions? Bugs? We're happy to talk about all things ModelDB! Reach out to modeldb at lists.csail.mit.edu or post in the ModelDB Google Group.
Contributions are welcome! Please read this to get started.


















