An advanced task flow management on top of Celery.






Is this project helpful? Send me a simple warm message!
Last stable release: Selinon 1.3.0
An advanced flow management above Celery (an asynchronous distributed task queue) written in Python3, that allows you to:
- Dynamically schedule tasks based on results of previous tasks
- Group tasks into flows in simple YAML configuration files
- Schedule flows from other flows (even recursively)
- Store results of tasks in your storages and databases transparently, validate results against defined JSON schemas
- Do redeployment respecting changes in the YAML configuration files without purging queues (migrations)
- Track flow progress via the build-in tracing mechanism
- Complex per-task or per-flow failure handling with fallback tasks or fallback flows
- No DAG limitation in your flows
- Selectively pick tasks in your flow graphs that should be executed respecting task dependencies
- Make your deployment easy to orchestrate using orchestration tools such as Kubernetes
- Highly scalable Turing complete solution for big data processing pipelines
- And (of course) much more... check docs
Let's explain Selinon using a YouTube video (click to redirect to YouTube).

This tool is an implementation above Celery that enables you to define flows and dependencies in flows, schedule tasks based on results of Celery workers, their success or any external events. If you are not familiar with Celery, check out its homepage www.celeryproject.org or this nice tutorial.
Selinon was originally designed to take care of advanced flows in one of Red Hat products, where it already served thousands of flows and tasks. Its main aim is to simplify specifying group of tasks, grouping tasks into flows, handle data and execution dependencies between tasks and flows, easily reuse tasks and flows, model advanced execution units in YAML configuration files and make the whole system easy to model, easy to maintain and easy to debug.
By placing declarative configuration of the whole system into YAML files you can keep tasks as simple as needed. Storing results of tasks in databases, modeling dependencies or executing fallback tasks/flows on failures are separated from task logic. This gives you a power to dynamically change task and flow dependencies on demand, optimize data retrieval and data storage from databases per task bases or even track progress based on events traced in the system.
Selinon was designed to serve millions of tasks in clusters or data centers orchestrated by Kubernetes, OpenShift or any other orchestration tool, but can simplify even small systems. Moreover, Selinon can make them easily scalable in the future and make developer's life much easier.
Selinon is serving recipes in a distributed environment, so let's make a dinner!
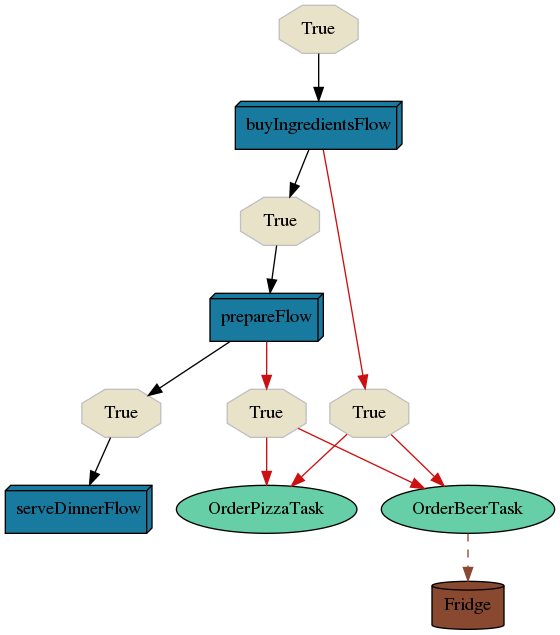
If we want to make a dinner, we need to buy ingredients. These ingredients are bought in buyIngredientsFlow. This flow consists of multiple tasks, but let's focus on our main flow. Once all ingredients are bought, we can start preparing our dinner in prepareFlow. Again, this flow consists of some additional steps that need to be done in order to accomplish our future needs. As you can see, if anything goes wrong in mentioned flows (see red arrows), we make a fallback to pizza with beer which we order. To make beer cool, we place it to our Fridge storage. If we successfully finished prepareFlow after successful shopping, we can proceed to serveDinnerFlow.
Just to point out - grey nodes represent flows (which can be made of other flows or tasks) and white (rounded) nodes are tasks. Conditions are represented in hexagons (see bellow). Black arrows represent time or data dependencies between our nodes, grey arrows pinpoint where results of tasks are stored.
For our dinner we need eggs, flour and some additional ingredients. Moreover, we conditionally buy a flower based on our condition. Our task BuyFlowerTask will not be scheduled (or executed) if our condition is False. Conditions are made of predicates and these predicates can be grouped as desired with logical operators. You can define your own predicates if you want (default are available in selinon.predicates). Everything that is bought is stored in Basket storage transparently.
Let's visualise our buyIngredientsFlow:

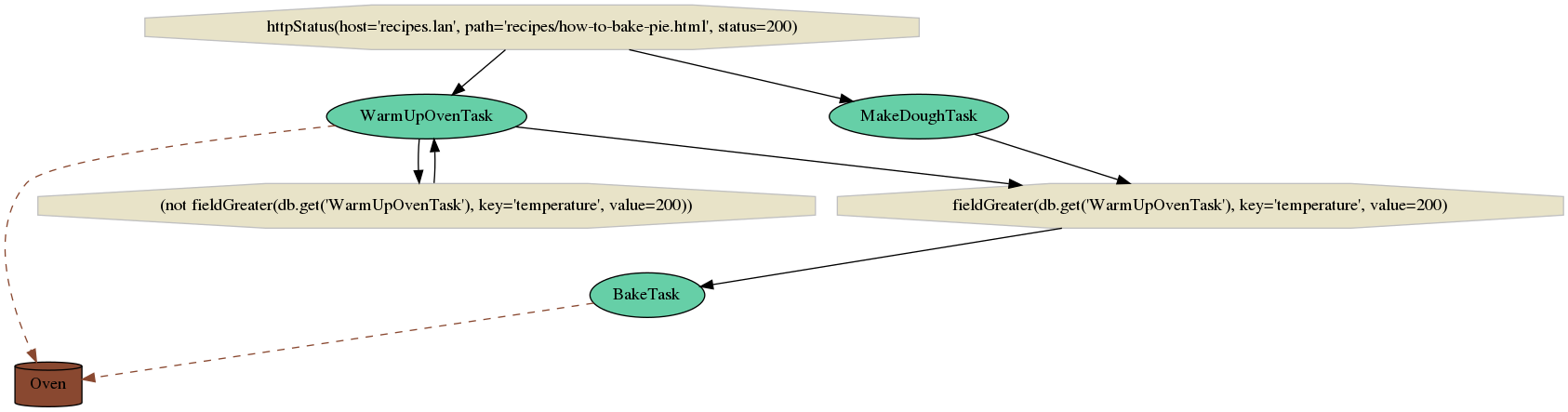
As stated in our main flow after buying ingredients, we proceed to dinner preparation but first we need to check our recipe that is hosted at http://recipes.lan/how-to-bake-pie.html. Any ingredients we bought are transparently retrieved from defined storage as defined in our YAML configuration file. We warm up our oven to expected temperature and once the temperature is reached and we have finished with dough, we can proceed to baking.
Based on the description above, our prepareFlow will look like the following graph:
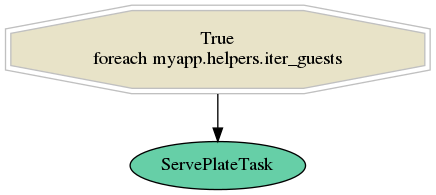
Once everything is done we serve plates. As we want to serve plates for all guests we need to make sure we schedule N tasks of type ServePlateTask. Each time we run our whole dinner flow, number of guests may vary so make sure no guest stays hungry. Our serveDinnerFlow would look like the following graph:
This example demonstrates very simple flows. The whole configuration can be found here. Just check it out how you can easily define your flows! You can find a script that visualises graphs based on the YAML configuration in this repo as well.
The example was intentionally simplified. You can also parametrize your flows, schedule N tasks (where N is a run-time evaluated variable), do result caching, placing tasks on separate queues in order to be capable of doing fluent system updates, throttle execution of certain tasks in time, propagate results of tasks to sub-flows etc. Just check documentation for more info.
A live demo with few examples can be found here. Feel free to check it out.
$ pip3 install selinonAvailable extras:
- celery - needed if you use Celery
- mongodb - needed for MongoDB storage adapter
- postgresql - needed for PostgreSQL storage adapter
- redis - needed for Redis storage adapter
- s3 - needed for S3 storage adapter
- sentry - needed for Sentry support
Extras can be installed via:
$ pip3 install selinon[celery,mongodb,postgresql,redis,s3,sentry]Feel free to select only needed extras for your setup.



























































































































