[toc]
- 如何原地交换两个数
- 字符串之间保留一个空格之后将字符串翻转
- 找到字符串的最长无重复字符子串
- 最短回文串
- 最长回文子串长度
- 数组中重复的数据
- 1到n乱序排列的数据,少了其中一个,找出这个数
- 26进制字母求和
- 两个字符串最长公共子串
- ⼀个40亿的⽆序数字,请找出不存在的数字
- 盛最多水的容器
- 爬楼梯问题
- 接雨水
- 岛屿问题(高频)
- 力扣 221最大正方形
- 力扣 279 完全平方数
- 力扣 70 爬楼梯
- 力扣 121 买卖股票的最佳时机
- 力扣 62 不同路径
- 力扣 509 斐波那契数
- 力扣 485 最大连续1的个数
- 力扣 283 移动零
- 力扣 27 移除元素
- 力扣 933 最近的请求次数
- 力扣 225 用队列实现栈
- 力扣 622 设计循环队列
- 力扣 641 设计循环双端队列
- 两个有序数组合并
- 两个有序数组合并,返回合并之后的中位数
- 数组中值出现了一次的数字
- 寻找两个升序数组的第K大值
- 无序数组找中位数
- 多数组 笛卡尔积,例:['s',['a', 'b'], [1, 2], 'x'],输出:[["s","a",1,"x"],["s","a",2,"x"],["s","b",1,"x"],["s","b",2,"x"]]
- ⼀个很⼤的List,⾥⾯都是int类型,如何实现加和?因为电⾯,就说了⼀下思路
- 二叉树的右视图
- 二叉数中序遍历
- 判断二叉树是否为平衡二叉树
- 二叉树节点的公共祖先
- 二叉树的最大深度
- 通过中序遍历序列和先序序列恢复二叉树
- 二叉树的中序遍历和层次遍历
- 二叉树的后续遍历
- 接口怎么设计,需要实现方实现什么
- 怎么调用这个通用的排序方法
- 全排列
- 力扣 206 反转链表
- 力扣 203 移除链表元素
- 合并两个有序的单链表
- 链表奇递增 偶递减,整体递增
- 单链表逆序
- LRU缓存机制 (考虑并发访问)(高频) LRU实现--针对hash存储的方式,如何改进
- 单向链表排序
- 取单链表的倒数第K个结点
- ⼀个链表,输⼊k,⽐如k=3,翻转前3个链表值
- 字符串hash算法的实现
- 敏感词过滤
- 力扣 217 存在重复元素
- 力扣 389 找不同
- 力扣 496 下一个更大的元素
- 25匹马,每次只能比赛5组,最快几次找到前3名
- hash
- 字典树
- bitmap
- 布隆过滤器
- MapReduce
- 桶
- 亿级数据,每一行两列,如何按照第一列升序 第二列降序排列?数据分布不均或较为集中的情况又如何处理更好?
- 几十亿行数据,记录当天的抖音用户 uid 登录时间 登出时间 如何计算出日活峰值在哪个时间(精确到秒),以及持续了几秒。
- 力扣 20 有效的括号
- 力扣 496 下一个更大的元素
- 力扣 232 用栈实现队列
- 力扣 217 存在重复元素
- 力扣 705 设计哈希集合
- 力扣 215 数组中的第K个最大元素
- 力扣 692 前K个高频单词
- 力扣 141 环形链表
- 力扣 344 反转字符串
- 力扣 881 救生艇
- 力扣 704 二分查找
- 力扣 35 搜索插入位置
- 力扣 162 寻找峰值
- 力扣 74 搜索二维矩阵
- 力扣 210 课程表 II
- 力扣 207 课程表
- 力扣 208 实现Trie
- 力扣 720 词典中最长的单词
- 力扣 692 前K个高频单词
- 力扣 209 长度最小的子数组
- 力扣 1456 定长子串中元音的最大数目
- 力扣 509 斐波那契数
- 力扣 206 反转链表
- 力扣 344 反转字符串
- 力扣 687 最长同值路径
- 力扣 169 多数元素
- 力扣 53 最大子序和
- 力扣 22 括号生成
- 力扣 78 子集
- 力扣 77 组合
- 力扣 46 全排列
深度优先算法 DFS
| 力扣 938 | 二叉搜索树的范围和 | Range Sum of BST |
|---|---|
| 力扣 78 | 子集 | Subsets |
| 力扣 200 | 岛屿数量 | Number of Islands |
宽度优先算法 BFS
| 力扣 102 | 二叉树的层序遍历 | Binary Tree Level Order Traversal |
|---|---|
| 力扣 107 | 二叉树的层序遍历 II | Binary Tree Level Order Traversal II |
| 力扣 200 | 岛屿数量 | Number of Islands |
并查集 Union Find
| 力扣 200 | 岛屿数量 | Number of Islands |
|---|---|
| 力扣 547 | 省份数量 | Number of Provinces |
| 力扣 721 | 账户合并 | Accounts Merge |
贪心算法 Greedy
| 力扣 322 | 零钱兑换 | Coin Change |
|---|---|
| 力扣 1217 | 玩筹码 | Minimum Cost to Move Chips to The Same Position |
| 力扣 55 | 跳跃游戏 | Jump Game |
记忆化搜索 Memoization
| 力扣 509 | 斐波那契数 | Fibonacci Number |
|---|---|
| 力扣 322 | 零钱兑换 | Coin Change |
- zset的底层实现
- redis incr实现
- Redis 3.1 都⽤过哪些数据类型?分别介绍下使⽤场景?
-
分布式锁
单节点:`SET resource_name my_random_value NX PX 30000`该命令仅当 Key 不存在时(NX保证)set 值,并且设置过期时间 3000ms (PX保证),值 my_random_value 必须是所有 client 和所有锁请求发生期间唯一的释放锁:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
上述实现可以避免释放另一个client创建的锁,如果只有 del 命令的话,那么如果 client1 拿到 lock1 之后因为某些操作阻塞了很长时间,此时 Redis 端 lock1 已经过期了并且已经被重新分配给了 client2,那么 client1 此时再去释放这把锁就会造成 client2 原本获取到的锁被 client1 无故释放了,但现在为每个 client 分配一个 unique 的 string 值可以避免这个问题。至于如何去生成这个 unique string,方法很多随意选择一种就行了。
-
获取当前时间(毫秒数);
-
尝试顺序地在 N 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设置与 master 节点沟通的 timeout 大小,避免长时间和一个 fail 了的节点浪费时间;
-
当 client 在半数以上的实例成功申请到锁的时候,且它会计算申请锁消耗了多少时间,这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到,如果锁的持续时长(lock validity time)比流逝的时间多的话,那么锁就真正获取到了;
-
如果锁申请到了,那么锁真正的 lock validity time 应该是 origin(lock validity time) - 申请锁期间流逝的时间;
-
如果 client 申请锁失败了,那么它就会在少部分申请成功锁的 master 节点上执行释放锁的操作,重置状态。
由于 Redlock 算法中使用的各个实例没有同步的时钟,而且每个机器时钟可能也不准,简单的做法是对步骤 3 中的时间再减去一小段时间,从而缓解实际中各个机器间的时钟偏移(Clock Drift)。
如果一个 client 申请锁失败了,那么它需要稍等一会在重试避免多个 client 同时申请锁的情况,最好的情况是一个 client 需要几乎同时向 N个 实例 发起锁申请。另外就是如果 client 申请锁失败了它需要尽快在它曾经申请到锁的 实例上执行 unlock 操作,便于其他 client 获得这把锁,避免这些锁过期造成的时间浪费,当然如果这时候网络分区使得 client 无法联系上这些 实例,那么这种浪费就是不得不付出的代价了。
假设 Redis 没有持久性,当一个客户端获得了 5 个实例中的 3 个锁,若 3 个锁所在的实例 Down 掉了,实例再次启动时,其他的客户端也可以再次获得锁。
这个问题会因为开启了 Redis 的持久化而改观,对于 AOF 持久化(区别与 RDB 的二进制持久化,是文本持久化)。默认采用的是每秒钟通过
fsync落盘,这意味着会丢失一秒内的数据,如果需要更有安全保证的持久化,可以设置fsync=always,但对应的会损失一部分性能。更好的解决办法是在实例 Down 掉后延迟一个略长于锁合法时间的时间,这样就可以保证在实例启动起来时锁一定是过期的,从而无须以损失性能为代价而使用
fsync=always的持久化。Topic 中还提出了一个锁续约的概念,即客户端可初始时使用较小的锁有效时间,若时间超时仍操作仍未完成则通过 Lua 脚本来续期。
续约操作同获取锁的操作,如果能从多数的 Redis 实例中续约,则认为锁续约成功。
为了保证锁最终可以被释放,续约操作存在着一定的次数限制。
放锁操作很简单,就是依次释放所有节点上的锁就行了
针对 Redlock 的安全性问题,Martin Kleppmann 与作者 antirez 存在着一些争论。
Martin Kleppmann 提出使用分布式锁有两种目的:效率和正确性。
效率相关的应用主要在使得同一个运算不会被同时计算两次,如果在这种情况下使用多个实例的分布式锁,不如使用单机分布式锁实现。由于误判仅会增加计算量而并不影响正确性,所以可以使用 Master Slave 的方式来增加可用性。
正确性相关的质疑在两个方面:
- 由于无法保证锁在操作结束前一定不会结束,可能无法意识到自己的锁失效了,会导致同时有多个客户端持有锁并进行操作。
- 基于时间的假设是不可靠的。
针对第二点,Martin 举了两个例子,以下均以 5 个节点 A ~ E 和 2 个客户端为例。
- Redis 实例的时间无法保证不被修改,时间的修改可能导致锁的过期和异常:
- 客户端 1 从节点 A、B、C 上获取锁,节点 D、E 由于网络原因不可达。
- 节点 C 的时间跳变,锁过期了。
- 客户端 2 从节点 C、D、E 上获取了锁,由于网络原因,节点 A、B 不可达。
- 客户端 1、2 均认为它们拥有了锁。
- 即使时间不会跳变,进程停等也可能影响正确性:
- 客户端 1 从节点 A、B、C、D、E 上获取了锁。
- 当请求快抵达客户端 1 时,客户端 GC 进行了 stop-the-world 操作。
- 所有实例上的锁都过期了。
- 客户端 2 从节点 A、B、C、D、E 上获取了锁。
- 客户端 1 GC 结束了,同时获取了之前的请求信息。
- 客户端 1、2 均认为它们拥有了锁。
Martin 提出使用一种小 trick,使用类似的递增 ID 作为 fencing token 来保证每次锁内操作的正确性。在客户端每次请求中会检查 fencing token,如果依赖的是旧的 token,那么此操作会被拒绝并提示。
Martin 认为 Redlock 是一个 asynchronous model with unreliable failure detectors,依赖了不可靠的元素来保证其一致性,容错存在一个限度,超过限度则无法保证其正确性。GC 的 stop-the-world、网络的阻塞、换页等都会影响 Redlock 的效率或者正确性。
Martin 的结论是:如果仅是效率需求,使用单节点算法;如果需求正确性,通过 zookeeper 来实现锁,或者使用 fencing token 来保证安全性。
antirez 解释了目的是为了让人们找到单节点或者主备锁的替代品,从而在复杂度低以及高效的前提下使用锁。
针对正确性的第一点质疑,即锁内可能超时,antirez 认为分布式锁并不能提供强一致性的保证,只在没有别的办法控制共享资源时才会使用。
针对正确性的第二点质疑,对于第一个例子,提出 NTP 和手动修改时间导致的时间过大跃迁都可以被人工避免,其次也提出可以使用单调时间 API 来进行改进(不过好像至今没有更新);对于第二个例子,实际出现次数非常少,另可以通过在获取到锁之后检查获取锁之前后的本地时间来确定锁是否过期。
对于 fencing token,若操作之间存在着线性关系,则可更改为递增 id;如果没有线性关系,则可以每次操作前检查 Key 对应的随机 Value 来避免过期操作。
非常建议看下https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html 这篇文章。
翻译版 https://juejin.cn/post/6844904039218429960
1、锁误解除
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
2、超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
上述问题 解决办法:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
-
-
缓存雪崩
概念
规模的缓存失效情况的发生。 造成原因缓存服务宕机, 大量key 同时过期
解决方案
针对 缓存服务宕机的情况,只能采用增加副本情况,提高缓存稳定;针对key 同时过期,相对简单timeout+random()
如果出现缓存雪崩,主要应对方案服务治理,限流,资源隔离,熔断,降级。(详细点后面补充)
-
缓存击穿
零值处理?
对于部分数据,可能数据库始终为空,这时应该设置空缓存(用不过期),避免每次请求都缓存 miss 直接打到 DB。
-
缓存穿透
singlefly
对关键字进行一致性 hash,使其某一个维度的 key 一定命中某个节点,然后在节点内使用互斥锁,保证归并回源,但是对于批量查询无解;
分布式锁
设置一个 lock key,有且只有一个人成功,并且返回,交由这个人来执行回源操作,其他候选者轮训 cache 这个 lock key,如果不存在去读数据缓存,hit 就返回,miss 继续抢锁;
队列
如果 cache miss,交由队列聚合一个key,来 load 数据回写缓存,对于 miss 当前请求可以使用 singlefly 保证回源,如评论架构实现。适合回源加载数据重的任务,比如评论 miss 只返回第一页,但是需要构建完成评论数据索引。
lease
通过加入 lease 机制,可以很好避免这两个问题,lease 是 64-bit 的 token,与客户端请求的 key 绑定,对于过时设置,在写入时验证 lease,可以解决这个问题;对于 thundering herd,每个key 10s 分配一次,当 client 在没有获取到 lease 时,可以稍微等一下再访问 cache,这时往往cache 中已有数据。(基础库支持 & 修改 cache 源码);
-
大key
就是一个key的value特别大,比如一个hashmap中存了超多k,v;或者一个列表key中存了超长列表,等等;
hashmap中有100w的k,v => 1s延迟;
1、删除大Key的时间复杂度: O(N), N代表大key里的值数量,因为redis是单线程一个个删;所 以删大key也会卡qps。查询突然很慢,qps降低;
2、数据倾斜,部分redis分片节点存储占用很高,
当版本<4.0
1、导出rdb文件分析: bgsave, redis-rdb-tool;
2、命令: redis-cli --bigkeys,找出最大的key;
3、自己写脚本扫描;
4、单个key查看: debug object key: 查看某个key序列化后的长度,每次看1个key的信息,比较没效率。
删除大Key:
分解删除操作:
list: 逐步ltrim;
zset: 逐步zremrangebyscore;
hset: hscan出500个,然后hdel删除;
set: sscan扫描出500个,然后srem删除;
依次类推;
当版本>=4.0
寻找大key
命令: memory usage
删除大key
lazyfree机制
unlink命令:代替DEL命令;
会把对应的大key放到BIO_LAZY_FREE后台线程任务队列,然后在后台异步删除;
1、实际开发中,不要超过10KB; hash、list、set、zset元素个数不要超过5000。
2、分治法,加一些key前缀\后置分解(如时间、哈希前缀、用户id后缀);
-
热key
1、预估热key,优势:简单,凭经验发现热 Key,提早发现提早处理;缺点:没有办法预测所有热 Key 出现,比如某些热点新闻事件,无法提前预测。
2、客户端进行收集,优势:方案简单,缺点:对客户端代码有一定入侵,或者需要对 SDK 工具进行二次开发;没法适应多语言架构,每一种语言的 SDK 都需要进行开发,后期开发维护成本较高。
3、在代理层进行收集,对使用方完全透明,能够解决客户端 SDK 的语言异构和版本升级问题;(具体代码麻烦写过的,补充下伪代码)
1、如果数据量不大的情况下,可以考虑local cache, app 定时更 新;
2、多 Key 设计: 使用多副本,减小节点热点的问题, 使用多副本 ms_1,ms_2,ms_3 每个节点保存一份数据,使得请求分散到多个节点,避免单点热点问题。注意问题:分片 一时爽,过期火葬场
3、多级缓存,同一个 key 在每一个 frontend cluster 都可能有一个 copy,这样会带来 consistency 的问题,但是这样能够降低 latency 和提高 availability。利用 MySQL Binlog 消息 anycast 到不同集群的某个节点清理或者更新缓存;
4、如果应用程序层可以忍受稍微过期一点的数据,针对这点可以进一步降低系统负载。当一个key 被删除的时候(delete 请求或者 cache 爆棚清空间了),它被放倒一个临时的数据结构里,会再续上比较短的一段时间。当有请求进来的时候会返回这个数据并标记为“Stale”。对于大部分应用场景而言,Stale Value 是可以忍受的。(不建议,需要修改redis源码)
-
redis超时是什么引起的
1、是否被网络、CPU 或内存(RAM)的限制?
1、 验证客户端和搭建 Redis-Server 的服务器支持的最大带宽是多少; 2、 验证是否被客户端或服务器上的 CPU 限制——这将导致请求等待 CPU 时间,从而超时。 3、当 Redis 数据量超过分配的内存(RAM)限制时,发生 Redis 锁死,导致超时。2、是否有命令(command)在 Redis 服务器上处理时,消耗很长时间?
长时间运行命令的例子有 mget 大量的键、keys* 或写得不好的 lua 脚本。可以运行 SlowLog 命令查看是否有请求花费比预期更长的时间。
3、redis 在RDB,AOF 时,fork 产生延迟
fork操作(在主线程中被执行)本身会引发延迟。在大多数的类unix操作系统中,fork是一个很消耗的操作,因为它牵涉到复制很多与进程相关的对象。而这对于分页表与虚拟内存机制关联的系统尤为明显。对于运行在一个linux/AMD64系统上的实例来说,内存会按照每页4KB的大小分页。为了实现虚拟地址到物理地址的转换,每一个进程将会存储一个分页表(树状形式表现),分页表将至少包含一个指向该进程地址空间的指针。所以一个空间大小为24GB的redis实例,需要的分页表大小为 24GB/4KB*8 = 48MB。 当一个后台的save命令执行时,实例会启动新的线程去申请和拷贝48MB的内存空间。这将消耗一些时间和CPU资源,尤其是在虚拟机上申请和初始化大块内存空间时,消耗更加明显。
4、swapping (操作系统分页)引起的延迟
redis实例的数据,或者部分数据可能就不会被客户端访问,所以系统可以把这部分闲置的数据置换到硬盘上。需要把所有数据都保存在内存中的情况是非常罕见的。一些进程会产生大量的读写I/O。因为文件通常都有缓存,这往往会导致文件缓存不断增加,然后产生交换(swap)。请注意,redis RDB和AOF后台线程都会产生大量文件。
5、透明大页(transport huge pages)引起的延迟
透明大页,默认是always,启用是为了可以管理更多的内存地址空间。可以使用never关闭,之后会使用系统软件的算法管理内存映射;通常linux会将透明大页开启,在fork被调用后,redis产生的延迟被用来持久化到磁盘。
1.fork被调用,共享内存大页的两个进程被创建
2.在一个系统比较活跃的实例里,部分循环时间运行需要几千个内存页,期间引起的copy-on-write 会消耗几乎所有的内存
3.这个将导致更大的延迟和使用更多的内存
因此,redis官方建议需要确保禁掉内存大页:
echo never > /sys/kernel/mm/transparent_hugepage/enabled1.查看前num条慢命令,这个所谓的慢是可以通过参数slowlog-log-slower-than设定的,默认10000us,也就是10ms
slowlog get num
2.查看当前实例中哪些key比较占空间(redis-cli的参数)
redis-cli --bigkeys3.查看redis相关的监控信息
info 相关命令(memory cpu replication stats clients)客户端连接数默认限制为10000,生产测试发现超过5000就会影响;total_commands_processed、instantaneous_ops_per_sec、net_io_in_per_sec、net_io_out_per_sec、total_commands、connected_clients、used_memory_human、used_memory_peak_human这些指标都需要关注下;
4.测试qps
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -d 250个并发链接,10000个请求,每个请求2kb。
-
redis是单线程的吗
Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
主要目的 解决并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
-
redis底层网络原理
别问,问就是reactor
-
redis为什么速度比较快
1.Redis 大部分操作是在内存上完成,并且采用了高效的数据结构如哈希表和跳表
2.Redis 采用多路复用,能保证在网络 IO 中可以并发处理大量的客户端请求,实现高吞吐率
-
redis的发布/订阅的原理
命令
SUBSCRIBE first second //订阅 first, second 两个topicPUBLISH second Hello //往topic second 写数据原理
-
数据缓存过期策略
在设置了过期时间的数据中进行淘汰,包括 volatile-random、volatile-ttl、volatile-lru、volatile-lfu(Redis 4.0 后新增)四种。
在所有数据范围内进行淘汰,包括 allkeys-lru、allkeys-random、allkeys-lfu(Redis 4.0 后新增)三种。
volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
volatile-random 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
volatile-lru 会使用 LRU 算法筛选设置了过期时间的键值对。
volatile-lfu 会使用 LFU 算法选择设置了过期时间的键值对。
-
redis内存淘汰策略(说说 redis 中到期删除是怎么实现的)
在设置某个key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。 优点:定时删除对内存是最友好的,能够保存内存的key一旦过期就能立即从内存中删除。 缺点:对CPU最不友好,在过期键比较多的时候,删除过期键会占用一部分 CPU 时间,对服务器的响应时间和吞吐量造成影响。设置该key 过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。优点:对 CPU友好,我们只会在使用该键时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查。
缺点:对内存不友好,如果一个键已经过期,但是一直没有使用,那么该键就会一直存在内存中,如果数据库中有很多这种使用不到的过期键,这些键便 永远不会被删除,内存永远不会释放。从而造成内存泄漏。
每隔一段时间,我们就对一些key进行检查,删除里面过期的key。优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好。
如果执行的太少,那又和惰性删除一样了,过期键占用的内存不会及时得到释放。
另外最重要的是,在获取某个键时,如果某个键的过期时间已经到了,但是还没执行定期删除,那么就会返回这个键的值,这是业务不能忍受的错 误。
-
redis 的删除策略。定时 定期 惰性 lru(LRU高频)
同上
-
持久化策略及其对比:RDB和AOF区别,AOF重写(如果数据量比较大都可能会造成redis 抖动)
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:
appendonly yes- 命令追加(append):将Redis的写命令追加到缓冲区aof_buf;
- 文件写入(write)和文件同步(sync):根据不同的同步策略将aof_buf中的内容同步到硬盘;
- 文件重写(rewrite):定期重写AOF文件,达到压缩的目的。
注意:
AOF 采用写后日志。
优势
1、可以避免对当前指令的阻塞;
2、可以避免出现记录错误日志。
劣势
1、 可能会对之后的指令造成阻塞;
2、 当未及时记录日志丢失数据
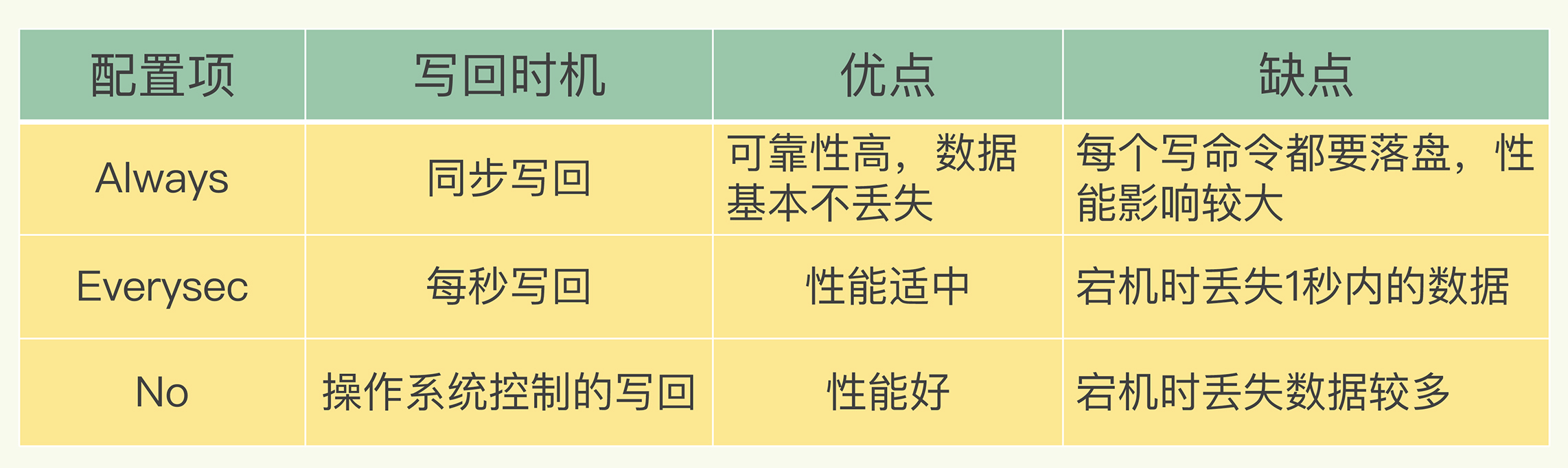
1、执行AOF重写请求。
如果当前进程正在执行AOF重写,请求不执行。
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再执行。
2、父进程执行fork创建子进程,开销等同于bgsave过程。
3.1、主进程fork操作完成后,继续响应其它命令。
所有修改命令依然写入AOF文件缓冲区并根据appendfsync策略同步到磁盘,保证原有AOF机制正确性。
3.2、由于fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据
由于父进程依然响应命令,Redis使用“AOF”重写缓冲区保存这部分新数据,防止新的AOF文件生成期间丢失这部分数据。
4、子进程依据内存快照,按照命令合并规则写入到新的AOF文件。
每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1、新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息。
5.2、父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3、使用新的AOF文件替换老的AOF文件,完成AOF重写。
AOF 重写
由后台子进程 bgrewriteaof 来完成,主要目的 避免阻塞主线程,导致数据库性能下降。
风险
1、fork子进程,fork这个瞬间一定是会阻塞主线程的;
2、如果父进程此时有写操作并且是已经存在的key, 则父进程就会真正copy这个key(COW), 如果这个key 是大key 的话就会导致copy 时间较长,产生阻塞风险;
AOF重写不复用AOF本身的日志,
1、防止与父进程产生文件竞争;
2、防止重写失败污染原AOF文件。
1、同时需要注意在rewriteAOF 时,会引起CPU 升高,原因需要扫描。
2、重写触发条件:通过配置自动触发, 触发条件文件大小和基准增量;2、手动触发 bgrewriteaof
save or bgsave1、Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(后面会详细介绍该命令)的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
2、父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
3、父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
4、子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
5、子进程发送信号给父进程表示完成,父进程更新统计信息
1、如果在执行 RDB 时,又触发RDB, 会等到第一次RDB 执行完之后,再执行。
2、如果在执行RDB时,有新数据写入时,RDB 并不会将新写入的数据进行持久化
3、在RDB 结束后,子进程内存退出,内存回收是怎样的?
1、 子进程指向的内存数据, 没有被父进程修改(cow),则归父进程持有;
2、如果在RDB 期间,父进程有对原数据修改对这部分key 进行了cow, 则在子进程退出时,这部分内存会被回收。
-
持久化机制,AOF、RDB具体区别有哪些?
优点:RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比,RDB最重要的优点之一是对性能的影响相对较小。
缺点:RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。此外,RDB文件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
与RDB持久化相对应,AOF的优点在于支持秒级持久化、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
-
redis主从复制过程

1)从服务器连接主服务器,发送SYNC命令; 2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令; 3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令; 4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照; 5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; 6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
-
Redis 主从同步机制是怎么样的,⽐如slave启动之后同步过程?
同上
-
redis的部署模式
- 单机
- 主从
- 主从 + sentinel
- redis cluster
-
Redis Cluster集群如何选主的?
1.当slave发现自己的master挂了 2.将自己记录的currentEpoch加1,并向其他节点请求投票给自己成为master 3.其他节点收到请求,只有master会回应,判断请求的合法性,并投票,可能会有多个slave请求,每个master只能投一票 4.slave收集master的投票 5.当slave收到的投票超过半数后就可以成为master 6.广播消息通知其他节点
1.当slave发现自己的master挂了并不会立即进行请求投票,会有一定的延时,确保其他的master也意识到当前的master挂了,否则master可能会拒绝投票
2.延时计算公式Delay=500ms+random(0-500)ms+Slave_rank* 100ms(slave_rank为复制数据的等级,等级越小表示复制数据越多也是为了保证能让拥有最新数据的slave最先发起选举)
Redis Cluster 使用了类似于 Raft 算法 term(任期)的概念称为 epoch(纪元),用来给事件增加版本号。Redis 集群中的纪元主要是两种:currentEpoch 和 configEpoch。
这是一个集群状态相关的概念,可以当做记录集群状态变更的递增版本号。每个集群节点,都会通过 server.cluster->currentEpoch 记录当前的 currentEpoch。
集群节点创建时,不管是 master 还是 slave,都置 currentEpoch 为 0。当前节点接收到来自其他节点的包时,如果发送者的 currentEpoch(消息头部会包含发送者的 currentEpoch)大于当前节点的currentEpoch,那么当前节点会更新 currentEpoch 为发送者的 currentEpoch。因此,集群中所有节点的 currentEpoch 最终会达成一致,相当于对集群状态的认知达成了一致。
currentEpoch作用在于,当集群的状态发生改变,某个节点为了执行一些动作需要寻求其他节点的同意时,就会增加 currentEpoch 的值。目前 currentEpoch 只用于 slave 的故障转移流程,这就跟哨兵中的sentinel.current_epoch 作用是一模一样的。当 slave A 发现其所属的 master 下线时,就会试图发起故障转移流程。首先就是增加 currentEpoch 的值,这个增加后的 currentEpoch 是所有集群节点中最大的。然后*slave A* 向所有节点发起拉票请求,请求其他 master 投票给自己,使自己能成为新的 master。其他节点收到包后,发现发送者的 currentEpoch 比自己的 currentEpoch 大,就会更新自己的 currentEpoch,并在尚未投票的情况下,投票给 slave A,表示同意使其成为新的 master。
这是一个集群节点配置相关的概念,每个集群节点都有自己独一无二的 configepoch。所谓的节点配置,实际上是指节点所负责的槽位信息。
每一个 master 在向其他节点发送包时,都会附带其 configEpoch 信息,以及一份表示它所负责的 slots 信息。而 slave 向其他节点发送包时,其包中的 configEpoch 和负责槽位信息,是其 master 的 configEpoch 和负责的 slot 信息。节点收到包之后,就会根据包中的 configEpoch 和负责的 slots 信息,记录到相应节点属性中。
configEpoch 主要用于解决不同的节点的配置发生冲突的情况。举个例子就明白了:节点A 宣称负责 slot 1,其向外发送的包中,包含了自己的 configEpoch 和负责的 slots 信息。节点 C 收到 A 发来的包后,发现自己当前没有记录 slot 1 的负责节点(也就是 server.cluster->slots[1] 为 NULL),就会将 A 置为 slot 1 的负责节点(server.cluster->slots[1] = A),并记录节点 A 的 configEpoch。后来,节点 C 又收到了 B 发来的包,它也宣称负责 slot 1,此时,如何判断 slot 1 到底由谁负责呢?
这就是 configEpoch 起作用的时候了,C 在 B 发来的包中,发现它的 configEpoch,要比 A 的大,说明 B 是更新的配置。因此,就将 slot 1 的负责节点设置为 B(server.cluster->slots[1] = B)。在 slave 发起选举,获得足够多的选票之后,成功当选时,也就是 slave 试图替代其已经下线的旧 master,成为新的 master 时,会增加它自己的 configEpoch,使其成为当前所有集群节点的 configEpoch 中的最大值。这样,该 slave 成为 master 后,就会向所有节点发送广播包,强制其他节点更新相关 slots 的负责节点为自己。
-
Redis Cluster 跟哨兵模式有什么区别吗?
都是高可用方案,但是哨兵模式下只有一台主节点,容易出现性能瓶颈,并且在数据量大后,同步数据需要Fork子进程,而拷贝页表的开销会很大,从而阻塞主进程,而Redis Cluster可以横向扩展,部署多主节点,解决单点写入性能瓶颈。另外redis cluster内置了哨兵。
-
Sentinel 哨兵模式是如何选主的?
如果一个 master 被认为 odown 了,而且 majority 数量的哨兵都允许主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个 slave 来,会考虑 slave 的一些信息:
- 跟 master 断开连接的时长
- slave 优先级
- 复制 offset
- run id
如果一个 slave 跟 master 断开连接的时间已经超过了
down-after-milliseconds的 10 倍,外加 master 宕机的时长,那么 slave 就被认为不适合选举为 master。(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state接下来会对 slave 进行排序:
- 按照 slave 优先级进行排序,slave priority 越低,优先级就越高。
- 如果 slave priority 相同,那么看 replica offset,哪个 slave 复制了越多的数据,offset 越靠后,优先级就越高。
- 如果上面两个条件都相同,那么选择一个 run id 比较小的那个 slave。
每次一个哨兵要做主备切换,首先需要 quorum 数量的哨兵认为 odown,然后选举出一个哨兵来做切换,这个哨兵还需要得到 majority 哨兵的授权,才能正式执行切换。
如果 quorum < majority,比如 5 个哨兵,majority 就是 3,quorum 设置为 2,那么就 3 个哨兵授权就可以执行切换。
但是如果 quorum >= majority,那么必须 quorum 数量的哨兵都授权,比如 5 个哨兵,quorum 是 5,那么必须 5 个哨兵都同意授权,才能执行切换。
哨兵会对一套 redis master+slaves 进行监控,有相应的监控的配置。
执行切换的那个哨兵,会从要切换到的新 master(salve->master)那里得到一个 configuration epoch,这就是一个 version 号,每次切换的 version 号都必须是唯一的。
如果第一个选举出的哨兵切换失败了,那么其他哨兵,会等待 failover-timeout 时间,然后接替继续执行切换,此时会重新获取一个新的 configuration epoch,作为新的 version 号。
哨兵完成切换之后,会在自己本地更新生成最新的 master 配置,然后同步给其他的哨兵,就是通过之前说的
pub/sub消息机制。这里之前的 version 号就很重要了,因为各种消息都是通过一个 channel 去发布和监听的,所以一个哨兵完成一次新的切换之后,新的 master 配置是跟着新的 version 号的。其他的哨兵都是根据版本号的大小来更新自己的 master 配置的。
-
redis哨兵选leader过程、槽相关、redis-cluster和codis扩展、
- 自动将数据进行分片,每个 master 上放一部分数据
- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的
在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。
16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,
gossip协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。集群元数据的维护有两种方式:集中式、Gossip 协议。redis cluster 节点间采用 gossip 协议进行通信。
集中式是将集群元数据(节点信息、故障等等)几种存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的
storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper(分布式协调的中间件)对所有元数据进行存储维护。redis 维护集群元数据采用另一个方式,
gossip协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。集中式的好处在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;不好在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip 好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打到所有节点上去更新,降低了压力;不好在于,元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
gossip 协议包含多种消息,包含
ping,pong,meet,fail等等。- meet:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。
redis-trib.rb add-node其实内部就是发送了一个 gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。
- ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。
- pong:返回 ping 和 meeet,包含自己的状态和其它信息,也用于信息广播和更新。
- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机啦。
ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。
每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。当然如果发现某个节点通信延时达到了
cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长,落后的时间太长了。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以cluster_node_timeout可以调节,如果调得比较大,那么会降低 ping 的频率。每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含
3个其它节点的信息,最多包含总节点数减 2个其它节点的信息。- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- redis cluster 的 hash slot 算法
来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。
致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。
在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
然而,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
redis cluster 有固定的 16384 个 hash slot,对每个
key计算 CRC16 值,然后对16384取模,可以获取 key 对应的 hash slot。redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过
hash tag来实现。任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。
redis cluster 的高可用的原理,几乎跟哨兵是类似的。
如果一个节点认为另外一个节点宕机,那么就是
pfail,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown。在
cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail。如果一个节点认为某个节点
pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail。对宕机的 master node,从其所有的 slave node 中,选择一个切换成 master node。
检查每个 slave node 与 master node 断开连接的时间,如果超过了
cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master。每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。
所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node
(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。从节点执行主备切换,从节点切换为主节点。
整个流程跟哨兵相比,非常类似,所以说,redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能。
-
![digraph pubsub { rankdir = LR; node [shape = record, style = filled]; edge [style = bold]; // keys pubsub [label = "pubsub_channels |<channel1> channel1 |<channel2> channel2 |<channel3> channel3 | ... |<channelN> channelN", fillcolor = "#A8E270"]; // clients blocking for channel1 client1 [label = "client1", fillcolor = "#95BBE3"]; client5 [label = "client5", fillcolor = "#95BBE3"]; client2 [label = "client2", fillcolor = "#95BBE3"]; null_1 [label = "NULL", shape = plaintext]; pubsub:channel1 -> client2; client2 -> client5; client5 -> client1; client1 -> null_1; // clients blocking for channel2 client7 [label = "client7", fillcolor = "#95BBE3"]; null_2 [label = "NULL", shape = plaintext]; pubsub:channel2 -> client7; client7 -> null_2; // channel client3 [label = "client3", fillcolor = "#95BBE3"]; client4 [label = "client4", fillcolor = "#95BBE3"]; client6 [label = "client6", fillcolor = "#95BBE3"]; null_3 [label = "NULL", shape = plaintext]; pubsub:channel3 -> client3; client3 -> client4; client4 -> client6; client6 -> null_3; }](https://redisbook.readthedocs.io/en/latest/_images/graphviz-241c988b86bb9bed6bf26537e654baaab4eef77b.svg)

-
如果Innodb没主键怎么办?
如果表中没有主键或者一个合适的的唯一索引,InnoDB内部会以一个包含行ID值的合成列生成一个隐藏的聚簇索引。表中的行是按照InnoDB分配的ID排序的。行ID是一个6字节的字段,随着一个新行的插入单调增加。因此,行ID顺序物理上是插入顺序
-
对 a b c 建索引,找 b c 时会不会走索引? 精准找 a 范围 b 精准 c 呢?
- 不会,根据最左匹配原则,不会命中abc联合索引。
- 不会,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
-
MySQL为什么是B + 树的结构,为什么不能是红⿊树呢,b+树和红黑树的区别(高频)
B+树与红黑树相比,在相同的的节点的情况下,B+树的高度远远小于红黑树的高度,Mysql的节点是按页存储的,页大小为16kb,假设主键ID为bigint,占8个byte,已知叶子节点是常驻内存的,那么4层的B+tree可容纳的数据大约为16亿条,而如果是红黑树,则树高为30层,优化的是磁盘IO,减少磁盘寻址次数。
-
innodb的B+树原理?如何做页分裂和页合并?查询时间复杂度?
-
B+树为B树的扩展,在B树的基础上,非叶子节点依旧保存索引,将数据行存放在叶子节点,保证了查询性能的稳定,并且将叶子节点通过指针连接起来,对范围查询更加友好。
-
为了保证分裂时并发数据的一致性,在进行分裂前会对索引内存对象加x-latch,同时对分裂的页加x-latch,因此分裂时所有其他操作都需要等待分裂完成。
分裂操作步骤:
- 确定分裂点记录
- 从索引的数据段分配一个新页,对这个页加x-latch
- 确定需要移动页中开始的第一个记录first+rec以及移动到的记录move_limit_
- 更新上层节点记录
- 将记录移动到新页中
- 将待插入的记录插入到页中
- 若上述插入操作失败,对页进行重新组织,然后重新进行插入操作
- 若上述操作失败,回到步骤1再次进行分裂操作
-
页合并
- 。。。
-
分情况,命中索引和未命中索引
- 命中索引
- 命中主键索引 = log(N)-1次磁盘IO (B+Tree查找)
- 命中普通索引 = 2 (log(N)-1)次磁盘IO (B+Tree查找) + 回表
- 未命中索引
- 全表扫描,由于叶子节点数据不在内存里,会频繁IO换入页
- 命中索引
-
-
为什么选择B+树实现索引?一般深度为多少?
因为B+Tree的树更加扁平,层高更加低矮,能尽量减少查找次数(磁盘IO) 一般深度为4,当深度为4时,主键索引使用bigint,可以大约存放17亿条数据 B+树的数据⻚,以及⻚⽬录相关
-
MySQL数据库底层实现结构?B+树结构,也讲了数据⻚,以及⻚⽬录相关的
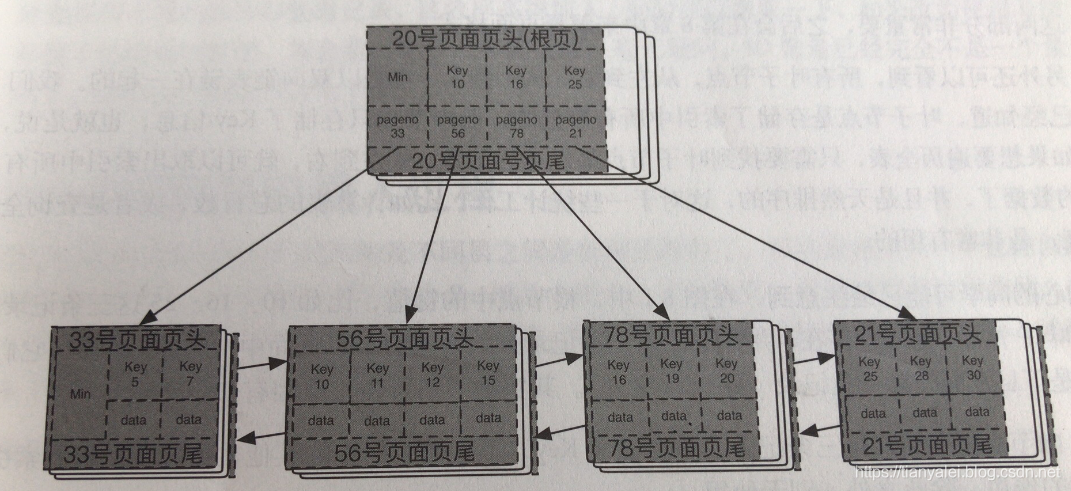
页,最小的存储单位。常见的页类型有数据页、undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页、未压缩的二进制大对象页、压缩的二进制大对象页,大小为16kb。
数据页的最左边位置会有一个Min记录,该记录由2部分组成,第一部分就是一个Min标记,代表这就是最小值;第二部分是一个pageNo指针,指向下一层中最左边的记录。
每一个page还会有一个最大记录和最小记录,用来标记该page的边界,便于查询。 做一次查询的耗时,每一层只需要一次内存级的二分查找,定位后就进入下一层,再一次二分查找。
-
索引的分类
- 聚簇索引
- 非聚簇索引
- 联合索引
- 唯一索引
- 前缀索引
- 全文索引
- hash索引
-
聚簇索引和非聚簇索引区别?如何避免回表查询?
- 聚簇索的叶子节点会存储数据行,而非聚簇索引也称为二级索引,叶子节点存储的是主键索引的值。
- 避免回表的方法:
- 使用索引下推,通过建立联合索引,在查询时,增加判断条件,如果索引刚好在判断条件里,不符合的节点会直接跳过
- 使用索引覆盖,通过建立联合索引,将返回的数据都包含在二级索引中了,不需要回表
- 尽量使用聚簇索引查询,直接打到叶子节点拿数据
-
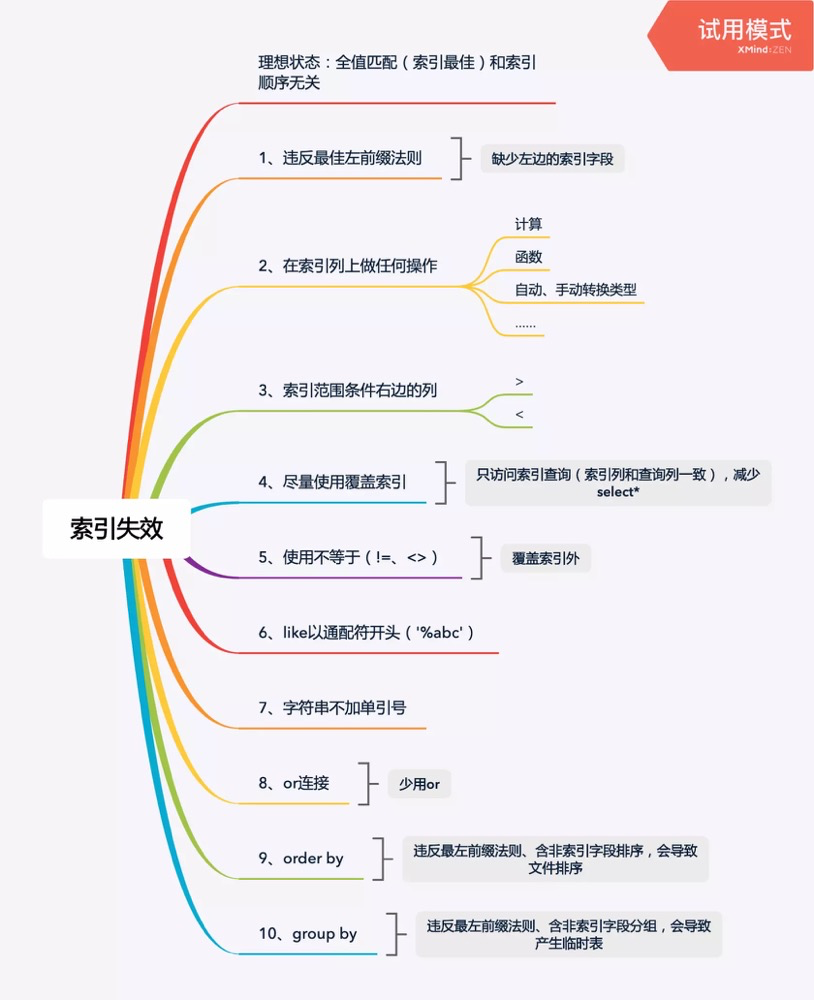
mysql数据的索引优化以及失效
-
最左前缀匹配原则,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
-
尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
-
索引列不能参与计算,保持列“干净”,否则无法使用索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大
-
尽量减少回表次数,可以使用索引下探和索引覆盖
-
尽量的扩展索引,不要新建索引
-
-
覆盖索引相关问题
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点:
-
索引项通常比记录要小,所以MySQL访问更少的数据。
-
索引都按值得大小存储,相对于随机访问记录,需要更少的I/O。
-
数据引擎能更好的缓存索引,比如MyISAM只缓存索引。
-
覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找了。
限制:
-
覆盖索引也并不适用于任意的索引类型,索引必须存储列的值。
-
Hash和full-text索引不存储值,因此MySQL只能使用BTree。
-
不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引。
-
如果要使用覆盖索引,一定要注意SELECT列表值取出需要的列,不可以SELECT * ,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
-
-
假设有⼀个表字段⼏⼗个,索引如何创建的?所有字段都能建吗?区分度、选择性、列基数
尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
-
索引覆盖的概念是什么, 索引覆盖的优点是什么?
索引覆盖的概念是,当正常查询命中索引时,会查询索引的B+Tree,直到找到索引的Value为主键索引的值,然后拿到主键索引的值再去主键索引中查询,最终得到结果,这存在一个回表, 也就是从普通索引回到主键索引的过程,如果我们避免此过程,可提高查询效率。具体通过复合索引来实现,如 select a from 表 where c = 1; 如果索引为c,虽然会命中索引,但会回表操作. 如果索引为c,a,执行引擎会直接从普通索引返回字段a的数据,避免了回表的性能开销
-
索引的最左前缀匹配是什么? 为什么不能直接使用复合索引的第二个索引?
是索引在执行查询的时候,如果是复合索引,并且查询的字段的顺序,刚好和复合索引的顺序一致,可以匹配上。例如select a from 表 where b = 1 and c = 2 and d = 3 ; 如果索引为 b,c,d ,则查询可以命中这个复合索引 如果查询为select a from 表 where b = 1 and c = 2; 一样可以,在存储索引数据时,是先按最左边的排序后,再依次向后排序,同理select a from 表 where b = 1; 一样可以命中索引 如果直接使用复合索引的后面的索引,如 select a from 表 where c = 2; 此时c列是乱序的,无法实现查询。
-
索引下推是什么?
有时候会出现这样的情况,复合索引是 b,c,d 而我们的查询条件是select a from 表 where b = 1 and c = 20 and e = "hello"; 此时由于最左匹配原则,可以匹配到 b这个字段,万幸的是没有走全表扫描, 但是也有问题,问题是字段e并不存在于 b,c,d 字段中,所以索引可以命中 b,c 但是,一旦命中b,会直接拿着索引的val回表,然后通过c 和 e 的值来过滤数据,我们发现其实c的值也在索引中,可以在索引里把c的值也过滤掉, 只回表查询过滤索引中不存在的字段e,这样减少了回表次数,提高了查询性能。
-
前缀索引是什么?
对字符串字段做索引的时候,如果做全量字符串的索引,当字符串长度很长的时候,存储成本较高,Mysql的前缀索引可以解决部分此问题 在设置索引的时候可以指定存储N位的前缀,虽然使得查询需要回表次数增加,但降低了存储成本,但是副作用也明显
-
前缀索引对覆盖索引的影响?
- 无法使用范围查询了,因为存储的是部分信息,范围查询必须回表
- 无法使用覆盖索引,既原本索引上的数据已经覆盖了所有的查询列的时候,本来会触发覆盖索引,直接返回不需要回表,但此时不行
-
字符串索引的最佳实践?
-
使用合理的前缀范围,通常可以对数据进行采样,比如count(distinc left(email,4)),多采样一些范围,找到区分度最高的范围作为前缀
-
如果字符串包含大量通用前缀,比如身份证的前6位在一个市内都是一样的时候,可以采取将数据倒排存储的,然后再使用前缀索引
-
如果区分度实在是不高,还可以采用hash存储的方式,新增一个字段,存储的值是crc(字段)的值,在查询的时候,直接通过crc(字段)精确查找
-
-
数据库中的乐观锁悲观锁
悲观锁
就是对于数据的处理持悲观态度,总认为会发生并发冲突,获取和修改数据时,别人会修改数据。所以在整个数据处理过程中,需要将数据锁定。悲观锁的实现,通常依靠数据库提供的锁机制实现,比如mysql的排他锁,select .... for update来实现悲观锁。注意,mysql中的行级锁是基于索引的,如果sql没有走索引,那将使用表级锁把整张表锁住。悲观锁在并发控制上采取的是先上锁然后再处理数据的保守策略,虽然保证了数据处理的安全性,但也降低了效率。
乐观锁
就是对数据的处理持乐观态度,乐观的认为数据一般情况下不会发生冲突,只有提交数据更新时,才会对数据是否冲突进行检测。如果发现冲突了,则返回错误信息给用户,让用户自已决定如何操作。乐观锁的实现不依靠数据库提供的锁机制,需要我们自已实现,实现方式一般是记录数据版本,一种是通过版本号,一种是通过时间戳。给表加一个版本号或时间戳的字段,读取数据时,将版本号一同读出,数据更新时,将版本号加1。当我们提交数据更新时,判断当前的版本号与第一次读取出来的版本号是否相等。如果相等,则予以更新,否则认为数据过期,拒绝更新,让用户重新操作。
-
排他锁(x锁)
排他锁(x锁),共享锁(s锁)都属于行锁,加锁方式为:
x:select ... for update
s:select lock in share mode
x锁,是事务T对数据A加上x锁时,只允许事务T读取和修改数据A
s锁,是事务T对数据A加上s锁时,其他事务只能再对数据A加s锁,而不能加x锁,直到T释放A上的s锁
-
什么是死锁,如何避免
死锁
是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
如何避免死锁
-
设置等待锁的超时时间,一般默认50s,但是不建议改小,因为容易误伤
-
mysql自带的默认启动的死锁检测,会在新加入事务后,检测是否因为当前事务的加入,出现死锁,如果出现死锁,则回滚其中之一的事务,结束死锁
那等待超时处理死锁的机制什么?有什么局限?
一般50s后会自动失败回滚,局限性就是不怎么好把我这个超时时间的设置,设置小了误伤,设置大了死锁问题影响严重当新事务加入,并产生锁竞争的时候,会检查当前与该锁有关的事务,查看是否出现死锁。如果不对并发量做控制,短时间内大量争抢同一行级锁的死锁事务进来后,由于死锁检测会在每个事务都循环每个其他冲突的事务,导致CPU忙于做死锁检测,降低吞吐率
-
-
间隙锁坏处,如何避免
什么是间隙锁
间隙锁就是在索引中,给每个索引之间的间隙加锁, 相较于行锁,或者表锁,还是有区别的,普通锁的冲突是指锁与锁之间的冲突,如读锁和写锁冲突,写锁和写锁冲突 而间隙锁的冲突是指: (给加了间隙锁的区间插入一条数据这个操作)
间隙锁坏处
当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定值范围内的任何数据,在某些场景下这可能会针对性造成很大的危害。
如何避免
todo
-
说说这些间隙锁的底层实现 ( 我真的学不动了 )
- undo log
- redo log
- binlog
- mysql的主从复制过程?
- mysql的大表优化方式
-
什么是事务? 什么是事务隔离?
事务是一串连续的操作,并且这一串连续的操作,视作一个整体操作,要么一起成功,要么一起失败,所谓的"原子操作"
事务隔离是指 不同的事务在并发操作同一行数据时,由于事务隔离的存在,使得互相读取的数据不一样,事务之间的并发操作互不影响
-
事务隔离的实现
innodb下,通过给每个字段加上回滚段来实现数据行的版本控制,从而实现不同的事务之间看到的数据是不一样的,俗称MVCC设计模式
-
如何解决事务二次查询,数据不受其他正常写入事务的改变
在readCommited 隔离级别下,是在每次sql执行的时候,建立视图,当其他事务修改时,第二次执行sql,会读取到其他事务已经提交的数据,因为会二次创建视图。 在readRepeatAble 隔离级别下,视图是在事务开启的时候简历的,当二次执行查询sql时,不会再次创建视图,因此其他事务在此期间提交的修改,不会影响当前事务的数据查询操作。
-
mysql事务的隔离级别?处理什么问题的(脏读、幻读、不可重复读)(高频)
标准SQL定义的隔离级别
读未提交
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
读提交
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
可重复读
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
串行化
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
为了处理以下问题
脏读
事务A修改了字段X的值,还未提交,事务B读取到了未提交的X的值
不可重复读
幻读
幻读是在事务中查询相同范围内的数据,前后两次查询结果不一致。出现的前提条件是:1 RR隔离级别下 2.仅指新插入的行,修改不算
幻读带来的问题?
两个问题,1:破坏了行锁的语义(比如 select * from t where val = 5 for update,原本意思是要把所有val值 = 5的行都锁住, 但是如果同时有其他事务,将原本val不等于5的行 update t set val = 5 where id = 0时,事务A中只锁住了事务启动时val = 5的行,并没有锁住id=0的行) 2:破坏了binlog日志文件的执行顺序,如果只给查询到的行加锁,会导致binlog的日志执行顺序和数据库中数据不一致
- 数据库的ACID原理和各个隔离级别,实现原理?
- Innodb 默认是哪个隔离级别
- 说说 innodb 如何避免各种读的
- 说说 mvcc 的底层实现
- 从学生表中查询每个班的分数的前3名
- 写一条sql统计, 统计当天访问量前10的ip ip visit_time url 102.12.12.1 2020-03-25 10:10:10
- kafka使用场景
- Kafka如何保证消息可靠,Kafak为什么那么快
- Kafka 4.1 ⽣产端是如何发送⼀条消息到Broker的?
- 4.2 具体可以调整哪些参数提升吞吐量?
- 4.3 消费端发⽣rebalance的过程是怎样的?
- ⽐如有⼀个新的consumer加⼊ 到了Group中是个什么流程?
- RabbitMQ如何保证⾼可⽤的?queue数据在节点之间如何同步的?死信队列 如何实现的?
- kafka的offset怎么管理
- 消息队列消费端的推和拉有什么区别
- MQ队列⽤了哪些,Kafka,那⾦融场景下,Kafka如何保证消息不丢失?ack = -1,Leader-->ISR写⼊所有的follower
-
TCP和UDP的区别,TCP三次握手?SEQ 是干什么的?两次握手行不行? TCP Fast Open了解么,TCP的拥塞控制是怎么做的
不知道
自己查去
序列号
- 序列号(Sequence Number)字段标识了TCP发送端到TCP接收端的数据流的一个字节,该字节代表着包含该序列号的报文段的数据中的第一个字节
第一、二次握手后,服务端并不知道客户端的接收能力以及自己的发送能力是否正常。而在第三次握手时,服务端收到了客户端对第二次握手作的回应。从服务端的角度,我在第二次握手时的响应数据发送出去了,客户端接收到了。所以,我的发送能力是正常的。而客户端的接收能力也是正常的。
-
syn flood攻击(低频)
最基本的DoS攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。syn flood属于Dos攻击的一种。
如果恶意的向某个服务器端口发送大量的SYN包,则可以使服务器打开大量的半开连接,分配TCB(Transmission Control Block), 从而消耗大量的服务器资源,同时也使得正常的连接请求无法被相应。当开放了一个TCP端口后,该端口就处于Listening状态,不停地监视发到该端口的Syn报文,一 旦接收到Client发来的Syn报文,就需要为该请求分配一个TCB,通常一个TCB至少需要280个字节,在某些操作系统中TCB甚至需要1300个字节,并返回一个SYN ACK命令,立即转为SYN-RECEIVED即半开连接状态。系统会为此耗尽资源。
-
tcp 拥塞策略(高频)(RBB)
-
CLOSE_WAIT
CLOSE_WAIT:被动关闭连接的一方,有一个中间状态,即CLOSE_WAIT
CLOSE_WAIT很多,表示说要么是你的应用程序写的有问题,没有合适的关闭socket;要么是说,你的服务器CPU处理不过来(CPU太忙)或者你的应用程序一直睡眠到其它地方(锁,或者文件I/O等等),你的应用程序获得不到合适的调度时间,造成你的程序没法真正的执行close操作
-
TIME_WAIT(高频)
TIME_WAIT 主动调用socket的close操作的一方,最终会进入TIME_WAIT状态
第一,防止前一个连接【五元组,我们继续 180.172.35.150:45678, tcp, 180.97.33.108:80 为例】上延迟的数据包或者丢失重传的数据包,被后面复用的连接【前一个连接关闭后,此时你再次访问百度,新的连接可能还是由180.172.35.150:45678, tcp, 180.97.33.108:80 这个五元组来表示,也就是源端口凑巧还是45678】错误的接收(异常:数据丢了,或者传输太慢了)
第二,确保连接方能在时间范围内,关闭自己的连接。其实,也是因为丢包造成的
这个定义,更多的是一种保障(IP数据包里的TTL,即数据最多存活的跳数,真正反应的才是数据在网络上的存活时间),确保最后丢失了ACK,被动关闭的一方再次重发FIN并等待回复的ACK,一来一去两个来回。内核里,写死了这个MSL的时间为:30秒(RFC里建议的MSL其实是2分钟,但是很多实现都是30秒),所以TIME_WAIT的即为1分钟:
timewait/close_wait 强烈看下这个链接 https://mp.weixin.qq.com/s/8WmASie_DjDDMQRdQi1FDg
-
如何解决tcp的粘包问题,tcp的拆包粘包怎么处理?
自定以协议中包含 包体长度
-
如何理解网络模型(重点epoll , select 的区别。 实现非阻塞 connect, 使用select)
-
tcp的send函数返回一定代表数据从网卡发送出去了么?我说只是发送到了内核缓冲区。又问这个缓冲区也是属于该进程的么?回答是。又继续问,一个数据接收过程发生了几次用户态到内核态的拷贝?
- 说说CDN的架构,缓存的实现, 用户的访问流程,调度是怎么选择机房的
- DSN 查询过程,递归查询和迭代查询的区别
- HTTP协议的发展,HTTP缓存实现方式,跟HTTP缓存相关的头部字段,HTTP 302了解么
- HTTP和HTTPS有什么区别、HTTPS的访问流程、CA中心是什么,确定加密协议过程
- http的状态码含义:502 504区别 301 302区别,分析一下系统 502 和504 可能的原因(线上各类排错)
- http2的优势
- http header有哪些部分
- 长连接 http长连接和websocket对比
- 长轮询和短轮询了解吗
- rpc和http优劣
- session cookie区别,分别存哪里?跨域问题如何解决
- 进程、线程和协程的区别?
- 栈和堆的特点?那个效率更高效?
- 进程间通信方式?哪种方式最快?为什么共享内存要比socket快? 我说了共享内存最快,面试官接着问为什么比socket快,我说了socket走网络,面试官继续问,要是本地回环呢?我想到socket涉及到用户态内核态数据拷贝,而共享内存采用mmap就可以。
- 线程间通信方式有哪些?线程通信跟线程同步有何区别?
- Linux最基本的两个锁是什么?说一下各自的特点
- nginx反向代理怎么配置
- nginx平滑重启什么原理
- sync.map、sync.pool、sync.once 的原理
- sync.pool 如果采用该方案实现连接池,会不会出现连接断开情况?
-
goroutine(协程)和线程是什么关系,goroutine是如何调度的?
- goroutine 和thead 之间的区别
- 概念上:
- Goroutines 在同一个用户地址空间里并行独立执行 functions
- thread 则是操作系统能够进行运算调度的最小单位
- 内存上:
- 创建一个 goroutine 的栈内存消耗为 2 KB(Linux AMD64 Go v1.4后),运行过程中,如果栈空间不够用,会自动进行扩容
- 创建一个 thread 为了尽量避免极端情况下操作系统线程栈的溢出,默认会为其分配一个较大的栈内存( 1 - 8 MB 栈内存,线程标准 POSIX Thread),而且还需要一个被称为 “guard page” 的区域用于和其他 thread 的栈空间进行隔离。而栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有溢出的风险
- 销毁时:
- goroutine 可以理解为用户态级别的线程,由go runtime 进行管理,销毁成本较低
- thread 销毁则需要进行内核级交互, 成本较高
- 调度时:
- goroutine切换完全在用户空间进行,相比线程切换做的事情更少
- 线程切换涉及特权模式切换,需要在内核空间完成
- 具体:
- 协程切换只涉及基本的CPU上下文切换,所谓的 CPU 上下文,就是一堆寄存器,里面保存了 CPU运行任务所需要的信息:从哪里开始运行栈顶的位置,当前栈帧在哪,以及其它的CPU的中间状态或者结果。goroutine 切换就是把当前的 CPU 寄存器状态保存起来,然后将需要切换进来的协程的 CPU 寄存器状态加载的 CPU 寄存器上就 ok 了
- 而线程的调度只有拥有最高权限的内核空间才可以完成,所以线程的切换涉及到用户空间和内核空间的切换,除了和协程相同基本的 CPU 上下文,还有线程私有的栈和寄存器等。
- 扩展问题, 可能会涉及到 操作系统中的 什么是用户态和内核态,还有就是系统调度?
- 用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
- 内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
- 系统调度:这是用户态进程主动要求切换到内核态的一种方式。
- 协程切换只涉及基本的CPU上下文切换,所谓的 CPU 上下文,就是一堆寄存器,里面保存了 CPU运行任务所需要的信息:从哪里开始运行 栈顶的位置,当前栈帧在哪,以及其它的CPU的中间状态或者结果。goroutine 切换就是把当前的 CPU 寄存器状态保存起来, 然后将需要切换进来的协程的 CPU 寄存器状态加载的 CPU 寄存器上就 ok 了;
- 而线程的调度只有拥有最高权限的内核空间才可以完成,所以线程的切换涉及到用户空间和内核空间的切换,除了和协程相同基本的 CPU 上下文,还有线程私有的栈和寄存器等。 扩展问题, 可能会涉及到 操作系统中的 什么是用户态和内核态,还有就是系统调度? 用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。 内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。参考链接 https://www.cnblogs.com/gtblog/p/12155109.html https://www.zhihu.com/question/308641794
- 概念上:
- goroutine 和thead 之间的区别
-
go gmp 调度模型实现。从早期1.x版本演进到1.14,做了哪些大改变? time.sleep阻塞时,网络请求阻塞时,调用系统方法时,GMP怎么流转的?
-
谁负责来标记抢占? 有如下代码 go func(){ for{}}() 死循环,能否被抢占?1.14版本前会有什么问题?
-
go 调度模型。发生网络io.会怎么调度。发生阻塞的IO会怎么调度。epoll
-
select和epoll的区别
-
如何控制goroutine并发数?
-
for(i<1000000;i++){go fun(){ …time.sleep(10秒)}()} 同时启动100万协程。会有什么问题?影响面: 如(gc 检查,死锁检查) 怎么解决?
-
是否有必要使用协程池?好坏处?举个使用场景
-
实现一个并发模型。生产者消费者
-
go 读写锁和互斥锁的区别和使用场景
-
sync.RWMutex :由Mutex + atomic 实现, sync/rwmutex.go
特点:抢占式读写锁,写锁之后,读锁加不上;
-
写写时需要引入Mutex 注意点:知道读写锁 纯读或者 读多写少的情况下,性能差别不是太大,大概几倍,在一些场景下,可以考虑使用Mutex代替RWMutex, 毕竟RWMutex 编码还是比较复杂的。相信我多数面试官没有压测过。
-
-
chan 底层实现 、 make(chan struct {}) 和 make(chan bool) 在chan的源码实现上有什么区别,chan,什么时候会panic
- 循环队列+mutex(注意下 no buffer 的在读取时的优化,其他大概回答下 );make(chan, 1) 和make(chan) 的区别 。 顺便可以说下channel 的优雅关闭 注意点:在有等待的receiver 时,发送方会越过channel buffer 直接将数据copy 到receiver 。 源码解析 参考 https://github.com/cch123/golang-notes/blob/master/channel.md
- 第二个问题: 大概是问struct{} 在go内部做了优化,不占用内存;其他类型(int, bool, ptr)都需要64位(bool 待定)。可以不具体回答字节数
- chan,什么时候会panic write to close(chan)
-
有缓冲channel和无缓冲channel区别?
-
map 底层实现&sync.Map的区别
1. 原理参考:https://tonybai.com/2020/11/10/understand-sync-map-inside-through-examples/ 源码解析: https://github.com/cch123/golang-notes/blob/master/sync.md -
golang 的map 插入顺序和输出顺序是一样的吗?
随机输出, 原因 考虑map 扩容时,原来同一个bucket 的key,扩容后,有可能落到其他位置上。
-
go内存分配
1.go 内存管理借鉴了TCMalloc
3.使用span 机制来减少内存碎片,每个span至少为一个page(8KB),每个span用于一个范围的内存分配需求.比如16-32 byte使用分配32byte的span,112-128 使用分配128byte的span;
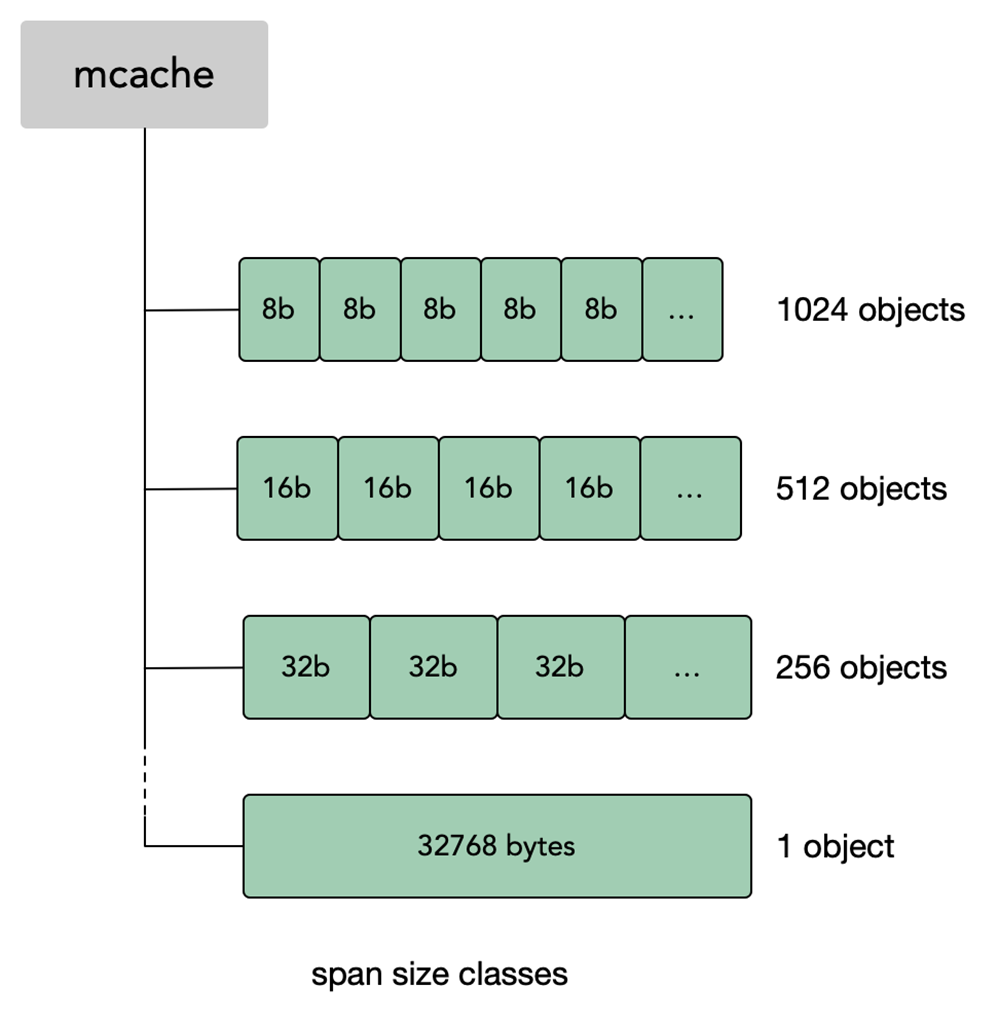
4.一共有67个size范围,8byte-32KB,每个size 有两种类型(scan 和noscan, 表示分配的对象是否包含指针);
5.多层cache 来减少分配的冲突,per-P 无所的mcache,全局67*2个对应不同size的span的后备mcentral,全局1个mheap;
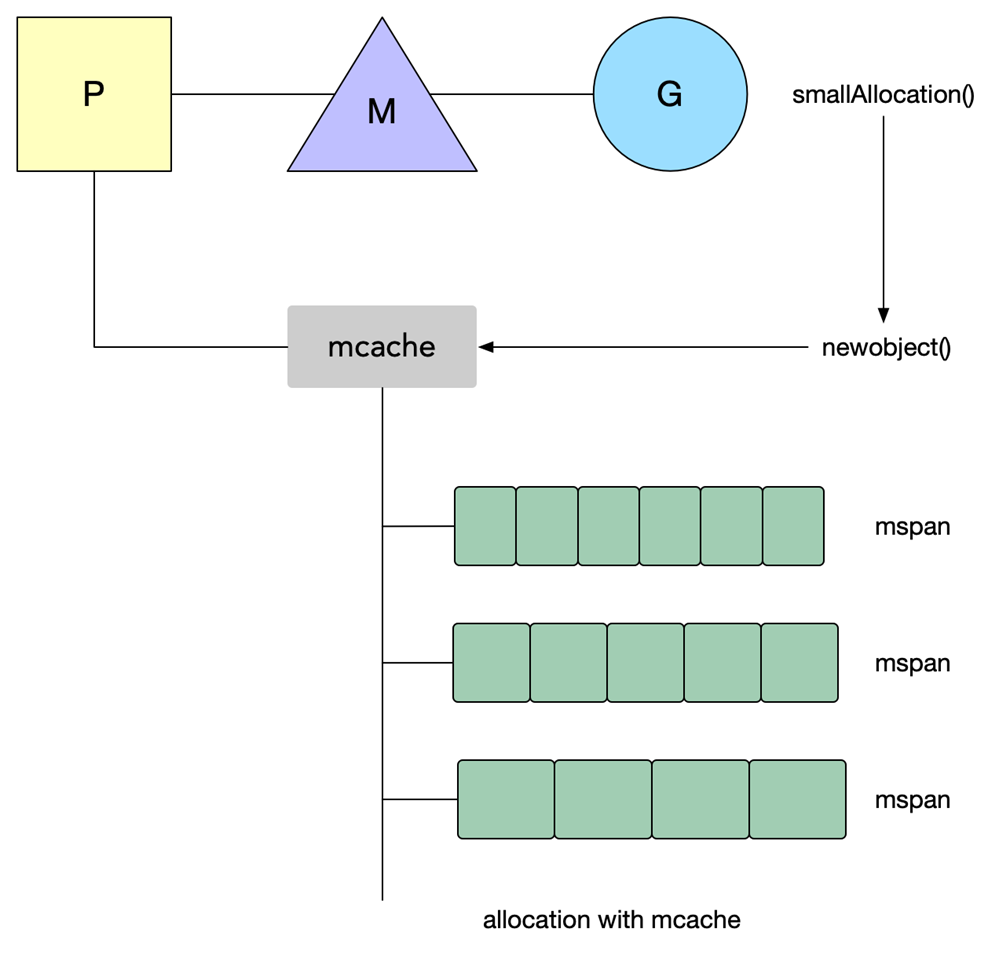
6.mheap中以treap的结构维护空闲连续page.归还内存到heap时,连续地址会进行合并(想一下伙伴系统)
7.stack 分配也是多层次和多class的;
8.对象由GC进行回收.sysmon会定时把空余的内存归还给系统
特点:
使用一小块一小块的连续内存页,进行分配某个范围大小的内存需求,比如某个连续8KB专门用于分配17-24字节,以此减少内存碎片, 线程拥有一定的cache, 可用于无锁分配,同时Go对于GC后回收的内存页, 并不是马上归还给操作系统, 而是会延迟归还, 用于满足未来的内存需求。
1.10 及以前
1.11及以后
mspan
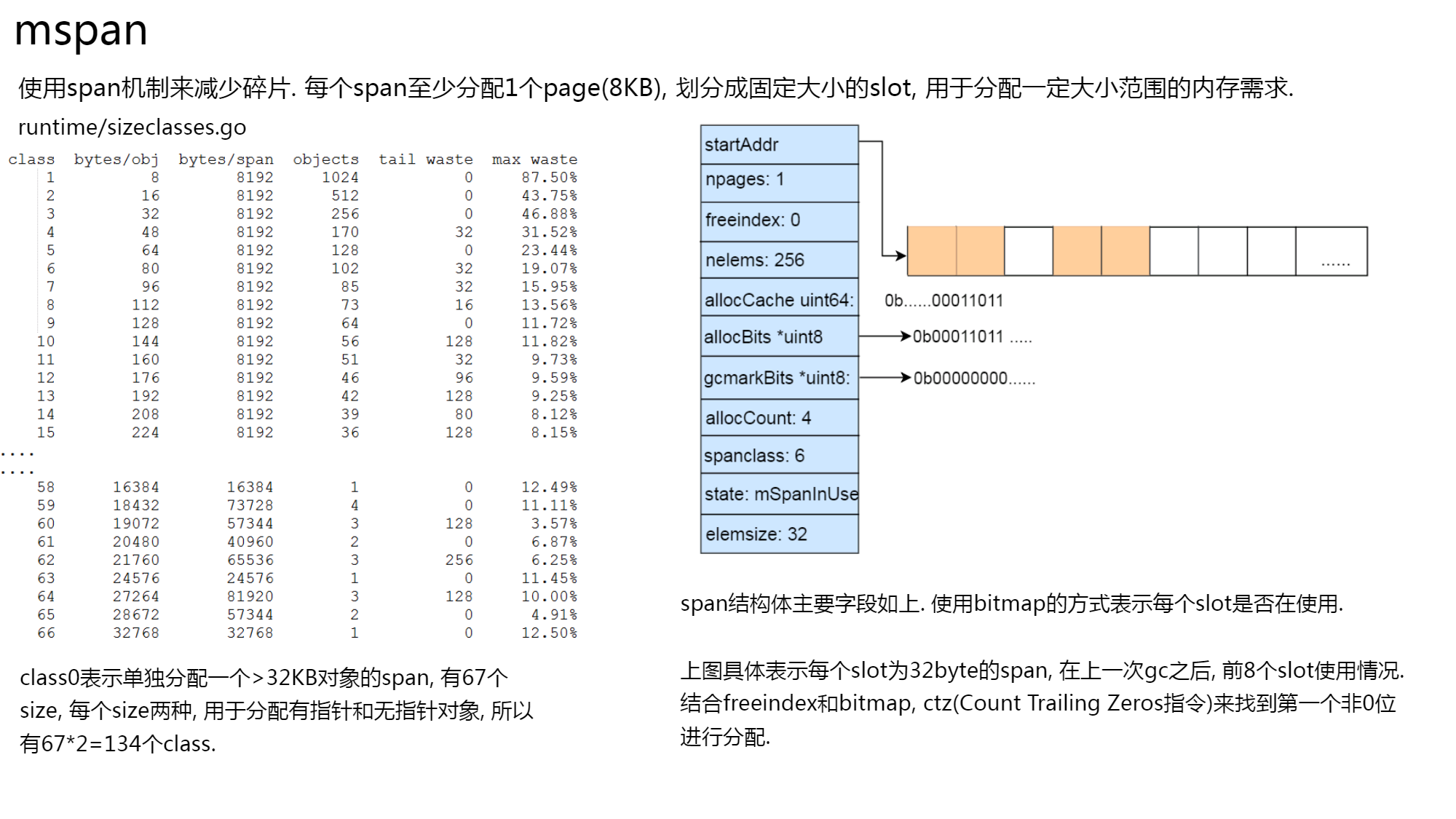
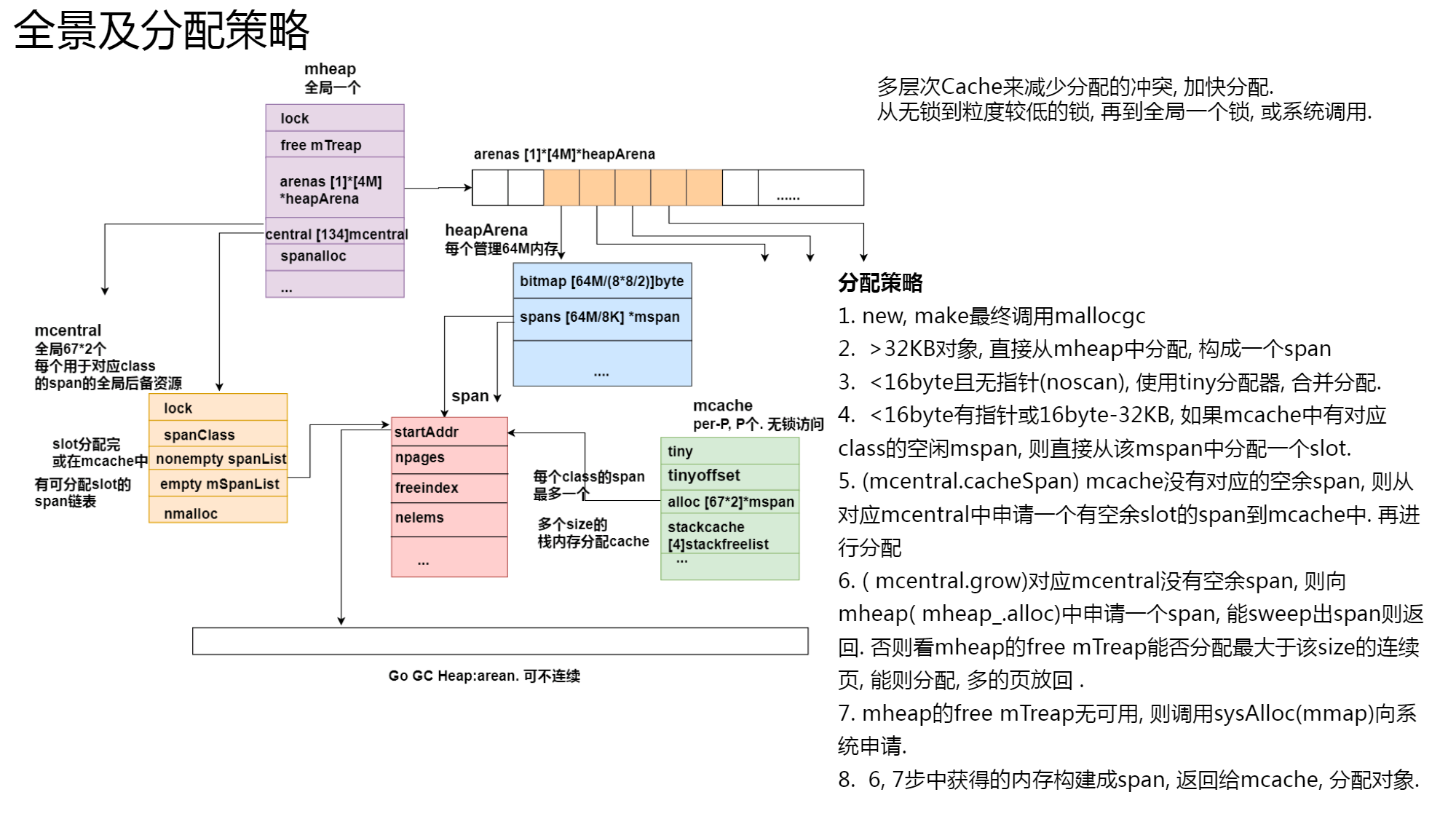
简而言之
一般小对象使用mspan 进行分配;大对象则直接由mheap分配内存。
1.Go在程序启动时,会向操作系统申请一块大内存,由mheap 全局管理(现在Go版本不需要连续地址了,所以不会申请一大堆地址);
2.Go 内存管理的基本单元是 mspan,每种 mspan 可以分配特定大小的 object
3.mcache, mcentral, mheap 是 Go 内存管理的三大组件,mcache 管理线程在本地缓存的 mspan;mcentral 管理全局的 mspan 供所有线程
-
go 内存分配,大小对象内存分配区别?多级分配的优点是什么?

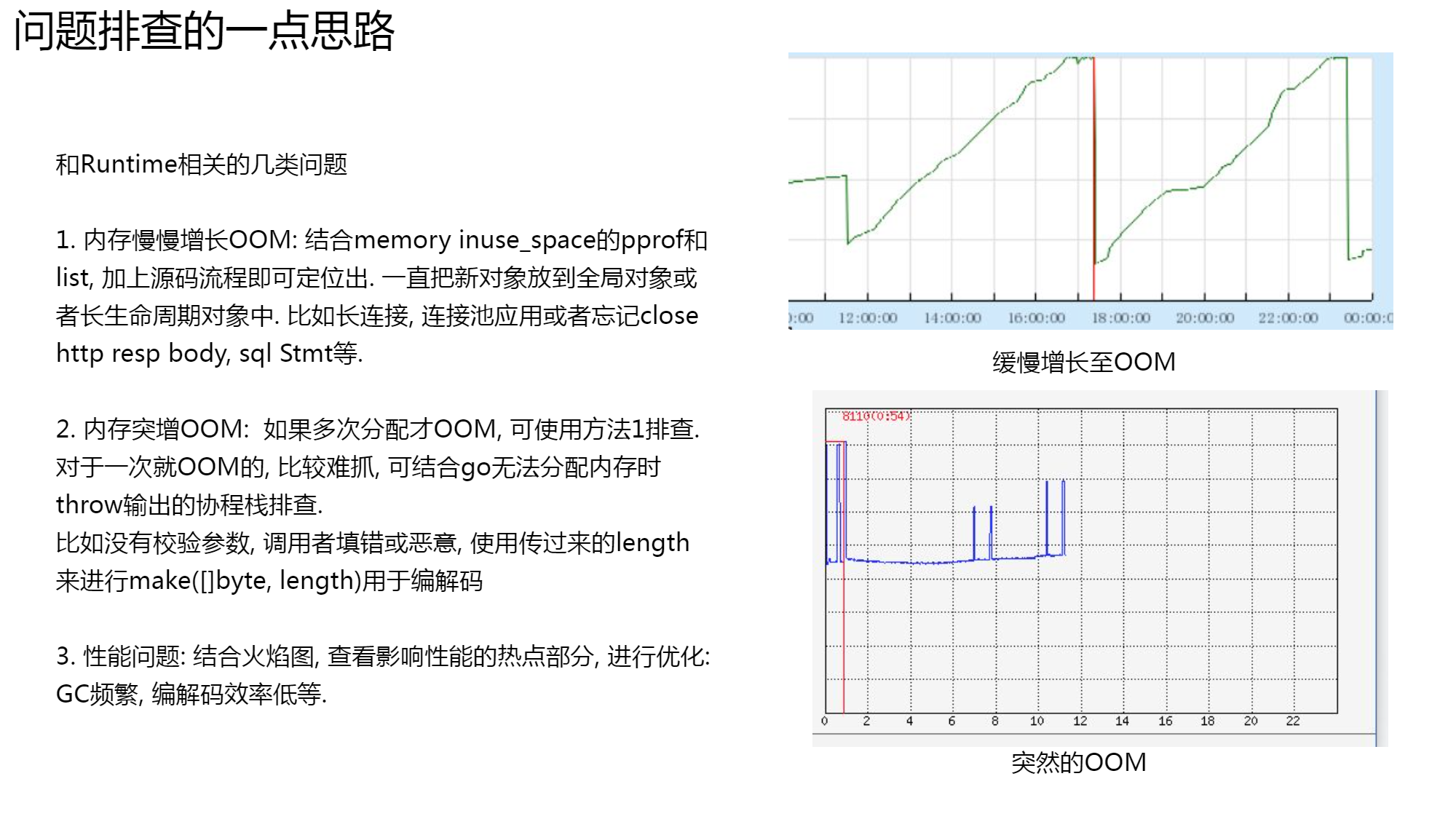
Go 没法使用工作线程的本地缓存 mcache 和全局中心缓存 mcentral 上管理超过32KB的内存分配,
所以对于那些超过32KB的内存申请,会直接从堆上(mheap)上分配对应的数量的内存页(每页大小是8KB)给程序。
-
go内存泄漏
1. 内存泄漏场景: https://gfw.go101.org/article/memory-leaking.html 有兴趣可以看下这个: https://xargin.com/logic-of-slice-memory-leak/ -
内存对齐,说说为什么要内存对齐,原理原因
- 原因:比如 intel 32位cpu,每个总线周期都是从偶地址开始读取32位的内存数据,如果数据存放地址不是从偶数开始,则可能出现需要两个总线周期才能读取到想要的数据,因此需要在内存中存放数据时进行对齐。参考https://www.zhihu.com/question/27862634
-
go gc的实现与触发机制
1. 实现: https://github.com/yifhao/share/blob/master/gopher%20meetup-%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BAGolang%20Runtime-yifhao-%E5%AE%8C%E6%95%B4%E7%89%88.pdf 2. 触发: 1. 主动触发 通过调用 runtime.GC 来触发 GC,此调用阻塞式地等待当前 GC 运行完毕; 2. 被动触发,分为两种方式: 使用系统监控,当超过两分钟没有产生任何 GC 时,强制触发 GC。 使用步调(Pacing)算法,其核心**是控制内存增长的比例。 -
interface 底层实现,怎么判空?
-
底层实现
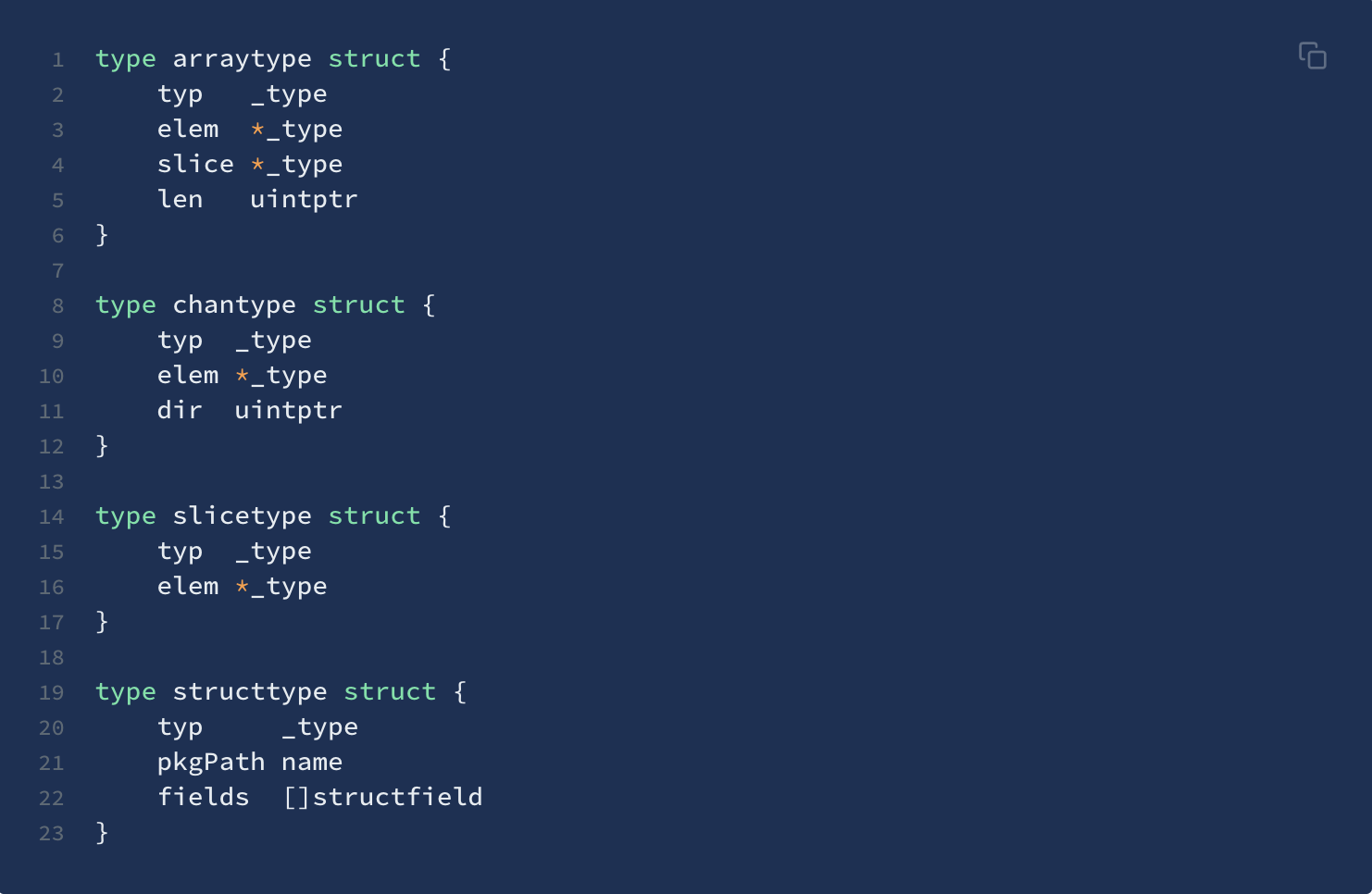
- 接口有两种底层结构,分别是:
iface和eface,区别在于iface描述的接口包含方法,而eface则是不包含任何方法的空接口:interface{}。 iface内部维护两个指针,tab指向一个itab实体, 它表示接口的类型以及赋给这个接口的实体类型。data则指向接口具体的值,一般而言是一个指向堆内存的指针。_type字段描述了实体的类型,包括内存对齐方式,大小等;inter字段则描述了接口的类型。fun字段放置和接口方法对应的具体数据类型的方法地址,实现接口调用方法的动态分派,一般在每次给接口赋值发生转换时会更新此表,或者直接拿缓存的 itab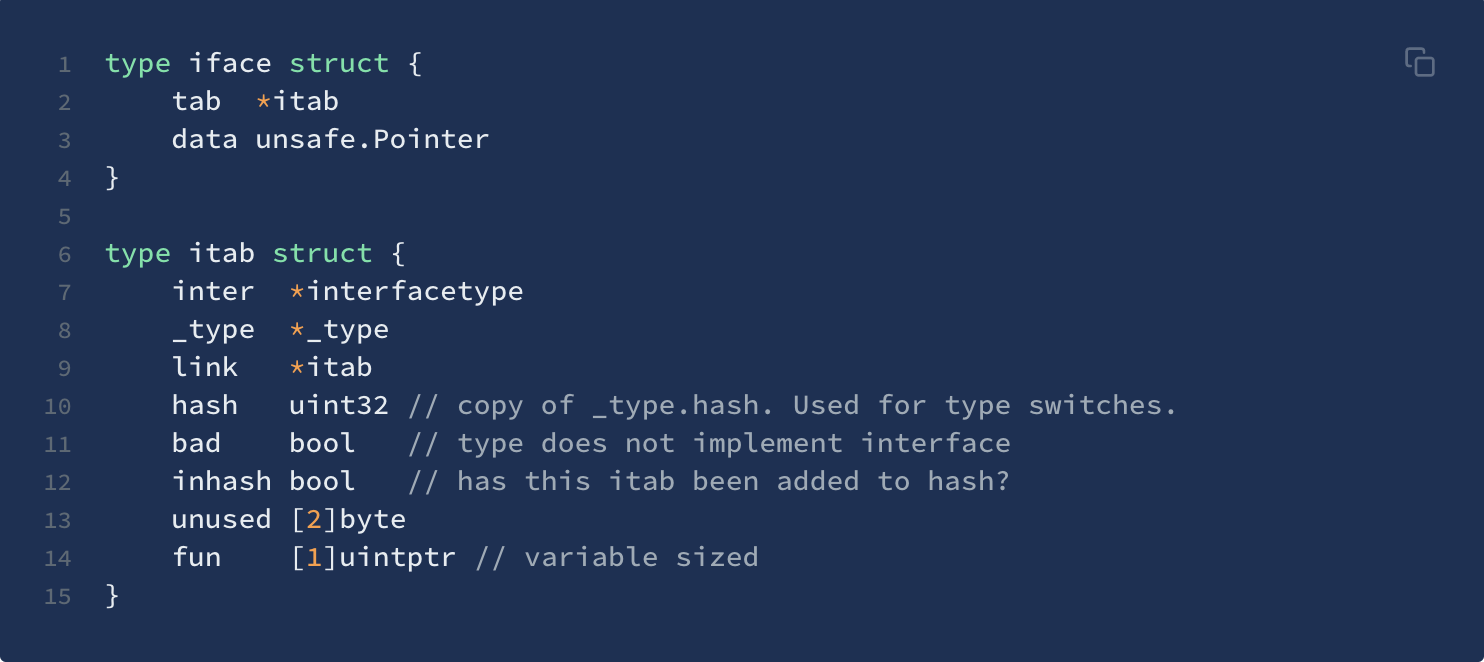

interfacetype类型,它描述的是接口的类型,它包装了_type类型,_type实际上是描述 Go 语言中各种数据类型的结构体。我们注意到,这里还包含一个mhdr字段,表示接口所定义的函数列表,pkgpath记录定义了接口的包名
- 看下
_type结构体,Go 语言各种数据类型都是在_type字段的基础上,增加一些额外的字段来进行管理的 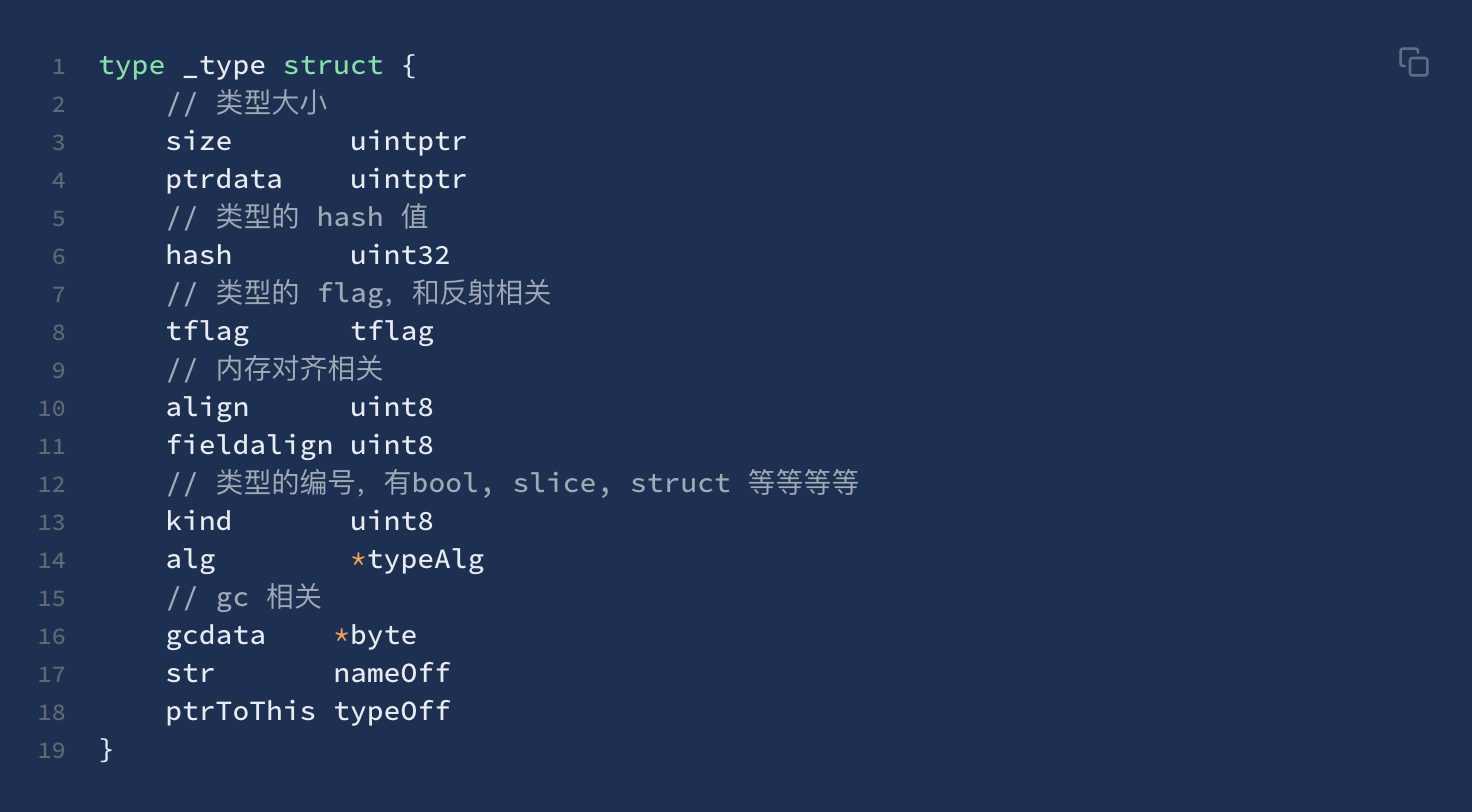
- 接口有两种底层结构,分别是:
-
接口判空
**接口值的零值是指
动态类型和动态值都为nil。**当仅且当这两部分的值都为nil的情况下,这个接口值就才会被认为接口值 == nil -
接口小技巧
- 编译器自动检测类型是否实现接口 ,
var _ io.Writer = (*myWriter)(nil),赋值语句会发生隐式地类型转换,在转换的过程中,编译器会检测等号右边的类型是否实现了等号左边接口所规定的函数。
- 编译器自动检测类型是否实现接口 ,
-
-
slice的底层实现
-
slice 是一个结构体,包含三个字段:长度、容量、底层数组。
-
底层数据结构是数组,slice 是对数组的封装,它描述一个数组的片段,可以通过下标来访问单个元素。
-

-
slice在进行append的时候,如果容量不够,会发生扩容,通常情况下,将新的容量将扩大为原始容量的2倍。如果原先的容量超过1024,则按1.25倍来进行扩容。 slice 是一个结构体,包含三个字段:长度、容量、底层数组。底层数据结构是数组,slice 是对数组的封装,它描述一个数组的片段,可以通过下标来访问单个元素。
-
slice在进行append的时候,如果容量不够,会发生扩容,通常情况下,将新的容量将扩大为原始容量的2倍。如果原先的容量超过1024,则按1.25倍来进行扩容。
-
小TIPS:在对slice进行扩容的时候,由于做了内存对齐的操作,实际容量是要大于1.25倍的
-
-
slice 和 array的区别?
-
相同点:
- 都可以通过下标访问
-
不同点:
-
数组元素个数固定不能修改,slice元素个数不固定
-
切片可以扩容
-
初始化方法不一样,切片使用make创建
-
-
-
[]byte{} string 的区别
- string底层结构为指向byte数组的指针+len
- byte切片可以改变元素,而string由于底层是数组,无法修改
- 对string的修改操作需要重新开辟内存,旧数组会被GC回收,有性能问题
-
new和make的区别(高频)
- new返回的是指向type的指针,指向分配类型的内存地址;make直接返回的是type类型值
- new只有一个type参数,type可以是任意类型数据; make可以有多个参数,但是只能是slice,map,或者chan
- new返回的指针指向的地址值为类型的0值;make返回的是非零值的实例
-
reflect 的使用
reflect 是指在运行时动态的调整对象的方法和属性
1.变量包括(type, value)两部分,理解这一点就知道为什么 nil != nil。
2.type 包括 static type 和concrete type. 简单的说 static type 是在编码时可以看见的类型(int、string),
concrete type 是runtime 系统看见的类型。
3.类型断言是否能成功,取决于变量的concrete type。比如一个 reader变量如果它的concrete type也实现了write方法的话,
它也可以被类型断言为writer.
// TypeOf returns the reflection Type that represents the dynamic type of i. // If i is a nil interface value, TypeOf returns nil. func TypeOf(i interface{}) Type { eface := *(*emptyInterface)(unsafe.Pointer(&i)) return toType(eface.typ) }
对于reflect.TypeOf, 传参是一个空接口类型, 返回值是一个reflet.Type 非空接口类型type Type interface { //对齐边界 Align() int // 如果是 struct 的字段,对齐后占用的字节数 FieldAlign() int // 方法 Method(int) Method // 通过名称获取方法 MethodByName(string) (Method, bool) // 获取类型方法集里导出的方法个数 NumMethod() int // 类型名称 Name() string // 返回类型所在包的路径 PkgPath() string // 返回类型的大小,和 unsafe.Sizeof 功能类似 Size() uintptr // 返回类型的字符串表示形式 String() string // 返回类型的类型值 Kind() Kind // 类型是否实现了接口 u Implements(u Type) bool // 是否可以赋值给 u AssignableTo(u Type) bool // 是否可以类型转换成 u ConvertibleTo(u Type) bool // 类型是否可以比较 Comparable() bool // many others...... }
以下面代码为例,说明下reflect.TypeOf 原理:
type Eggo struct{ Name string } func(e *Eggo)A(){ println("A") } func(e *Eggo)B(){ println("B") } func main(){ a := Eggo{Name:"eggo"} t := reflect.TypeOf(a) println(t.Name(), t.NumMethod()) }
1、从函数调用栈来看, 下图所示 main 函数栈帧中有两个局部变量: Eggo 类型的a, reflect.Type 类型的t ,临时变量, 返回值,参数空间;
临时空间
前文提到 go 语言中传参都是值拷贝, 参数空间中的值应该是a的值拷贝,由于参数空间是空接口类型,需要一个地址,但是go 语言中传参都是值拷贝,所以不论
reflect.Typeof对a 做什么样的修改都不能作用到 原变量a的身上, 如果直接拷贝a的地址,则不符合go 语言的值拷贝语义, 所以不能直接将a的地址copy到参数空间中。为了解决这个问题,go 在编译期间增加了一个临时变量作为a的拷贝,这样就可以在参数空间使用这个临时变量的地址。通过传递拷贝后变量的地址, 来实现传值的语义。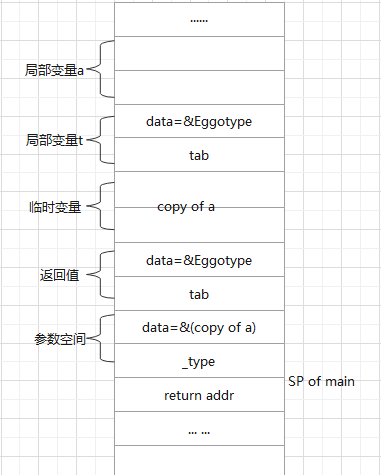
2、查看
func TypeOf源码不难发现func TypeOf(i interface{}) Type { eface := *(*emptyInterface)(unsafe.Pointer(&i)) return toType(eface.typ) } type emptyInterface struct { typ *rtype word unsafe.Pointer } // nonEmptyInterface is the header for an interface value with methods. type nonEmptyInterface struct { // see ../runtime/iface.go:/Itab itab *struct { ityp *rtype // static interface type typ *rtype // dynamic concrete type hash uint32 // copy of typ.hash _ [4]byte fun [100000]unsafe.Pointer // method table } word unsafe.Pointer }
reflec.TypeOf函数之后会将runtime.eface 类型的参数, 转换成reflect.emptyInterface类型(在源码中,两者的结构是一样的),并给赋值给eface,在源码中由于*rtype 类型实现了Type接口。最终转换成如下图所显示: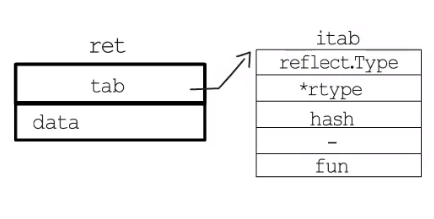
ret 为非空接口格式
iface,itab这里接口类型inter自然是reflect.Type, 动态类型_type是*rtype,fun对应的类型方法对应的就是eface.typ实现的相关方法。// interface 相关的代码 //eface 空接口类型 type eface struct { //空接口 _type *_type //类型信息 data unsafe.Pointer //指向数据的指针(go语言中特殊的指针类型unsafe.Pointer类似于c语言中的void*) } // iface 表示 non-empty interface 的数据结构 type iface struct { tab *itab data unsafe.Pointer } type itab struct { inter *interfacetype // 接口自身的元信息 _type *_type // 具体类型的元信息 link *itab bad int32 hash int32 // _type里也有一个同样的hash,此处多放一个是为了方便运行接口断言 fun [1]uintptr // 函数指针,指向具体类型所实现的方法 }
3、回到列子中,
reflect.TypeOf(a)返回值 一个reflect.Type和*rtype组合 对应的itab指针和一个Eggo类型元数据地址。所以通过reflect.TypeOf拿到的就是a中非空接口变量t。比如t.Name(),t.NumMethod()调用的这些方法就回去Eggotype指向的Eggo类型元数据查找相关信息。func ValueOf(i interface{}) Value { if i == nil { return Value{} } // TODO: Maybe allow contents of a Value to live on the stack. // For now we make the contents always escape to the heap. It // makes life easier in a few places (see chanrecv/mapassign // comment below). escapes(i) return unpackEface(i) }
1、
escapes(i)表示reflect.ValueOf函数会显示的将参数指向的变量逃逸到堆上;2、以下面代码为例
func main(){ a := "eggo" v := reflect.ValueOf(a) v.SetString("new eggo") // panic: reflect.Value.SetString using unaddressable value println(a) }
上述想修改变量a 中的值为“new eggo”, 画出main 的栈帧如下图所示:
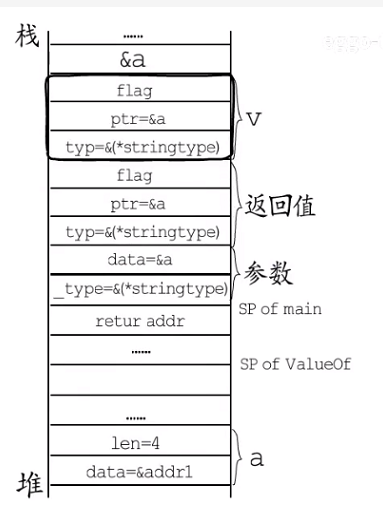
- 函数栈中:一个局部变量a 和局部类型v, 编译阶段会增加一个临时变量作为a 的拷贝,
ValueOf返回值空间,以及参数空间。 - 参数这里
data指向a的拷贝,_type指向string类型元数据;ValueOf返回值,这里typ等于参数的的一个字段,ptr等于参数的第二个字段, 处理flag 标记; - 接下来通过v 调用SetString 时,因为ptr 指向a 的拷贝而不是a,而修改这样一个用户都不知道的临时变量,没有任何意义。会出现panic()。
3、为了能够修改变量a 中值 这里需要反射a的指针
func main(){ a := "eggo" v := reflect.ValueOf(a) v = v.Elem() v.SetString("new eggo") // panic: reflect.Value.SetString using unaddressable value println(a) }
这样
valueof函数参数指向的变量就是a。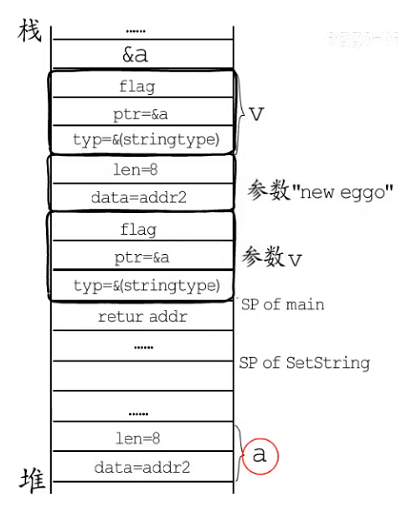
1.上图 在main 函数栈帧中,局部变量a就逃逸到堆上,栈上只留一个地址, 然后是局部变量v, 返回值和参数;
2.参数这里
_type指向*string类型元数据,data 指向a,valueof 返回值赋值给局部变量v;3.调用v 点
Elem()方法, 会拿到v.ptr指向的变量a,并包装成reflect.Value类型的返回值,返回值中类型是string, 地址是指向堆上的a,然后这个返回值会被赋给V - 函数栈中:一个局部变量a 和局部类型v, 编译阶段会增加一个临时变量作为a 的拷贝,
-
map 底层实现sync.Map的区别
- Map底层实现 1.
- sync.Map的底层实现 1.
- 区别 1.
-
Context 的使用,用法,有无父子关系?怎么去做并发控制?底层实现(高频)
-
context 的使用,context是否并发安全?
-
defer关键字的作用, 多个defer的调用顺序?
-
go panic 的机制。defer,recover的结合使用(golang的panic怎么理解,怎么处理,recover 一般怎么处理)
-
讲一下Golang 空结构体
-
go timer底层的实现 . 时间调度可以用哪些数据结构来实现?( 如 回答 时间轮: nginx 。最小堆: go timer 链表等 )
-
init函数如何使用?
-
go 性能问题的定位( pprof,各项指标)
-
逃逸分析能做什么?如何进行逃逸分析?
- 如何设计一个秒杀系统
- trace了解吗
- 实时战力前100排行榜怎么设计(考察redis 使用)
- rank系统怎么设计
- 有10亿用户,让你设计一个社区架构。包括点赞 发帖 删帖 的积分架构、期间一直在追问设计合不合理
- 给你1亿个URL 。爬取信息。会遇到什么问题?从 CPU 磁盘 网络 等方面。这个聊了很多。
- 描述 推送架构设计
- 线上熔断降级怎么做的
- 全站Push 的 运营误操作如何防止
- 亿级帖子,对应的评论表如何设计
- 设计一个短连(一个长的url地址,转为一个短的)
- 设计一个高可用的稳定的并发模型处理HTTP请求
- 一致性hash算法
- 限流策略
- 高并发的生产者消费者模式
- 编码过程中你比较注意哪一些
- 你负责的系统中,你一般关注哪些点,怎么保证你关注的点不出问题
- 实现MapReduce中的Map,例如: cat file.txt | ./go-reader -cmd "${cmd} " > result.txt
- go-reader为接受cat file.txt的输入lines,将lines给${cmd}处理,最后输出结果
- 进程间怎么通信,go-reader要考虑协程池吗,为什么
- 不用定时任务的方式,实现一条消息定时发送或者任务到点执行
- 说说定时任务系统怎么做的,什么是一个任务,一个任务的生命周期是什么样的
- 设计一个高并发、高可用的架构
- 读比较多怎么设计
- 写比较多怎么设计
- 服务的负载均衡怎么做
- MySQL 怎么部署,读写分离怎么做
- MySQL索引是什么,什么数据结构,MyISAM与InnoDB索引的区别,假设有一张表,有a,b两个索引,索引会怎么选择?(a,b) 是联合索引时会怎么选择
- MySQL的事物,有什么特征,ACID是怎么实现的,隔离级别有几种,MVCC是怎么实现的,乐观锁,悲观锁
- 缓存的热Key和大Key怎么处理
- 简单说说kafka的架构,我要实现消息的顺序消费怎么办
- 分布式事务了解
- 分布式事务讲⼀下?结合项⽬想讲的可靠消息⼀致性实现⽅案 + 最⼤努⼒送达通知⽅案,最后也提到了单应⽤多DB(JPA)、TCC事务以及适⽤场景。
- 分布式锁
- 缓存和数据库⼀致性如何保证的?谈到了分布式锁,那详细讲讲分布式锁实现?redis setnx、redisson、zookeeper
- 介绍平滑负载均衡算法,实现
- 对比 mysql redis http 连接池的实现
- [ ]








