In this repository, I implemented Gradient Boosting Trees using XGBoost to predict customer churn. The "Churn-modeling" dataset was downloaded from Kaggle.
Customer retention is very important for businesses, as a customer lost rarely returns. One lost customer is greater than $100 lost for a business per year. So it is important for businesses to analyze the customer churn and take measures to retain the customers.
In this project, I downloaded Kaggle's "Churn-modeling" dataset and implemented Gradient Boosted Trees using library XGBoost. XGBoost gained a lot of popularity as it helped data scientists win competition on Kaggle. I will not go in its theory here. It can be learnt online. XGBoost library though is very simple to use.
We have 14 columns in our dataset i.e. RowNumber, CustomerId, Surname, CreditScore, Geography, Gender, Age, Tenure, Balance, NumOfProducts, HasCrCard, IsActiveMember, EstimatedSalary, Exited. Exited is binary, it tells whether customer exited business i.e. 1 or not i.e. 0.
We dont need Row Number, Surname and CustomerId column so we drop them.
I use LabelEncoder in scikit-learn to encode the columns Geography and Gender as they are categorical and algorithms take data in numbers.
I use Standard Scaler in scikit-learn to scale the Credit Score, Age, Balance, Tenure, NumOfProducts, EstimatedSalary columns so that they have mean 0 and standard deviation 1. It is proven to increase the algorithm's performance when the data is normalized or scaled.
Finally the data is split into 80:20 train data : test data.
I use XGBoost algorithm with following parameters to train my data:
xgb_model = XGBClassifier(learning_rate=0.1,base_score=0.8,max_depth=3,n_estimators=400,gamma=0.001) xgb_model.fit(x_train,y_train,eval_metric=["auc","error"],verbose=True)
Tuning XGBoost model gives 87.1% prediction accuracy. Following is classification report for the model performance. It is seen that recall for 0 (customer retained) is 97% but recall for 1 (customer exited) is 41% which is poor. The reason for that is that we have 7963 data samples for 0 (customer retained) in dataset 2037 samples for 1 (customer exitted) in dataset. Hence dataset is imbalanced. We need more samples for 1 (customers exited) so that our model does not give biased predictions. Right now it is biased in favor of 0 (customer retained).

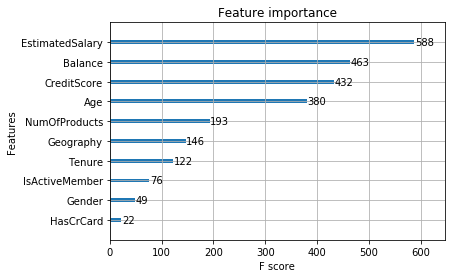
We can also check which features in our data are more dominant for decision making. It is seen that Estimated Salary is the most dominant factor to determine customer churn.
By doing this project, I got to learn about Gradient Boosted Trees and XGBoost library to implement on real-life business problem of predicting customer churn. I will use this knowledge to solve further problems with machine learning and gradient boosted trees.
