silab-bonn / beam_telescope_analysis Goto Github PK
View Code? Open in Web Editor NEWBeam Telescope Analysis (BTA) is a testbeam analysis software written in Python (and C++)
License: MIT License
Beam Telescope Analysis (BTA) is a testbeam analysis software written in Python (and C++)
License: MIT License













using the latest anaconda 2.7 environment the execution of setup.py fails with following message:
beam_telescope_analysis/cpp/analysis_functions.cpp:629:10: fatal error: 'ios' file not found
#include "ios"
All packages from requirements.txt are installed
Issues in detector alignments of "transposed" detectors were observed with the Kalman Filter Alignment resulting in diverging alignment parameters.
A transposition results into the following possible euler angles ('xyz'):
None of these starting values results into a successful alignment using the KFA.
The proposed solution is either to:
NB: The problem seems to be a rotation of alpha or beta by +- pi. The Alignment of heavily rotated devices could be confirmed
Browsing the code, I noticed usage of Cython functions for histogramming and array operations. Maybe those can be ported to numba to remove the cython/cpp dependency, making this project pure python.
If this is considered useful, I am willing to do a speed comparison and provide a PR when I find the time.
Install requirements for Numba and PyLandau cannot be fulfilled simultaneously at the moment. Numba requires numpy<1.22,>=1.18, but PyLandau requires numpy>=1.22.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
Successfully installed numpy-1.22.3 pylandau-2.2.0 scipy-1.8.0
numba 0.55.1 requires numpy<1.22,>=1.18, but you have numpy 1.22.3 which is incompatibleUsing pip install -e . or python setup.py develop in Conda on macOS Catalina (10.15.5) results in an error:
beam_telescope_analysis/cpp/analysis_functions.cpp:642:10: fatal error: 'ios' file not found
#include "ios"
^~~~~
1 warning and 1 error generated.
error: command 'gcc' failed with exit status 1
can be worked around by providing a CFLAG to pip :
CFLAGS='-stdlib=libc++' pip install -e .
Using reduce_events() on the merged data file throws the following error:
Traceback (most recent call last):
File "telescope.py", line 237, in <module>
run_analysis(hit_files=hit_files)
File "telescope.py", line 144, in run_analysis
max_events=500000)
File "/home/silab/git/beam_telescope_analysis/beam_telescope_analysis/tools/storage_utils.py", line 75, in wrapper
ret_val = func(*args, **kwargs)
File "/home/silab/git/beam_telescope_analysis/beam_telescope_analysis/tools/data_selection.py", line 131, in reduce_events
logging.info('Reducing events for node %s', node.name)
File "/home/silab/miniconda3/envs/bta/lib/python2.7/site-packages/tables/group.py", line 839, in __getattr__
return self._f_get_child(name)
File "/home/silab/miniconda3/envs/bta/lib/python2.7/site-packages/tables/group.py", line 711, in _f_get_child
self._g_check_has_child(childname)
File "/home/silab/miniconda3/envs/bta/lib/python2.7/site-packages/tables/group.py", line 398, in _g_check_has_child
% (self._v_pathname, name))
tables.exceptions.NoSuchNodeError: group ``/arguments`` does not have a child named ``name``
It should probabaly be checked if the node is a group and in that case just copy it.
From scipy version 1.7.3 to 1.8.0 a bug fix for scipy.stats.binned_statistics_2d was released (see here and here). This change affects the output of the result analysis (histogram entries are properly calculated now) and yield a failing unit test (edge bins of histogram are different)
E AssertionError: False is not true : Comparing files /home/runner/work/beam_telescope_analysis/beam_telescope_analysis/beam_telescope_analysis/testing/fixtures/Efficiency_regions_result.h5 and tmp_test_res_output/Efficiency_regions.h5: FAILED
E Node /DUT3/Region_0/count_in_pixel_hits_2d_hists:
E Difference (close):
E
E Not equal to tolerance rtol=1e-05, atol=1e-08
E
E Mismatched elements: 28 / 100 (28%)
E Max absolute difference: 963.
E Max relative difference: 963.
E x: array([[9.300e+01, 3.000e+00, 1.100e+01, 9.000e+00, 3.200e+02, 1.160e+02,
E 1.200e+01, 2.000e+00, 2.500e+02, 2.000e+00],
E [2.000e+00, 3.280e+02, 1.200e+01, 1.000e+01, 2.000e+00, 1.000e+00,...
E y: array([[9.300e+01, 3.000e+00, 1.100e+01, 9.000e+00, 3.200e+02, 1.160e+02,
E 1.200e+01, 2.000e+00, 4.000e+00, 2.480e+02],
E [2.000e+00, 3.280e+02, 1.200e+01, 1.000e+01, 2.000e+00, 1.000e+00,...This can be reproduced using this minimal working example (adopted from here)
import scipy.stats as st
import matplotlib.pyplot as plt
import numpy as np
arr = []
size = 8
for i in range(size):
arr += [1-0.1**i]
bins = np.linspace(0,1,10)
hist_dd = st.binned_statistic_dd(arr,
np.ones(len(arr)), bins=[bins],
statistic='count')
plt.hist(arr, bins=bins, label='hist')
plt.plot(np.linspace(0.05,0.95,9), hist_dd[0], marker='o', label='binned_statistic_dd')
plt.legend()
plt.show()The result of the histogram using scipy.stats.binned_stats_2d with scipy version 1.7.3 leads to a different result compared to numpy histogram and is fixed with scipy version 1.8.0.
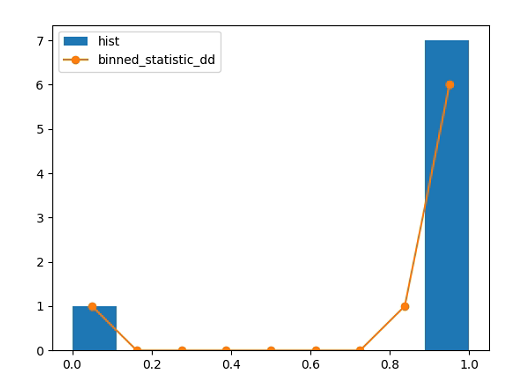

Note: It was confirmed (locally) that the unit test do not fail with BTA installed with scipy version 1.7.3.
Calculation of the in-pixel resolution (also done in line 2316) for the in-pixel efficiency map is only correct for quadratic pixels. efficiency_regions_in_pixel_hist-extent = [x_lim_lower, x_lim_upper, y_lim_lower, y_lim_upper] contains the plot range information of the in-pixel plot.
For non-quadratic pixels the currently implemented method (np.diff(efficiency_regions_in_pixel_hist_extent)[:-1] = [x_lim_lower - x_lim_upper, x_lim_upper - y_lim_lower]) results in a wrong maximum range in y/row direction. Instead I propose to use np.diff(efficiency_regions_in_pixel_hist_extent)[::len(efficiency_regions_in_pixel_hist_extent) - 2] as the resulting array only contains the differences of lower_limit - upper_limit for both x and y direction.
Please crosscheck the proposed solution for quadratic pixel geometries.
For a fresh checkout in master, running examples/fei4_telescope.py I get following error:
File "/home/niko/git/beam_telescope_analysis/beam_telescope_analysis/examples/fei4_telescope.py", line 17, in
from beam_telescope_analysis import dut_alignment
File "/home/niko/git/beam_telescope_analysis/beam_telescope_analysis/dut_alignment.py", line 7, in
from collections import Iterable
ImportError: cannot import name 'Iterable' from 'collections' (/home/niko/anaconda3/envs/tba_env/lib/python3.10/collections/init.py)
I am running on conda with python 3.10.5
Apparently collections was changed in a recent python update, and Iterables has now to be imported from collections.abc:
Todos:
With updating to numpy 1.24.0 (see release information) numpy finally expired the deprecation for ragged/inhomogeneous (see here). For the voronoi plots we are generating in the efficiency plotting e.g. here we are using matplotlib.patches which needs a ragged array of the form [[x, y], height, width] as input see here for matplotlib.patches documentation. This will cause the script to fail for latest numpy versions.
So far I have not found a way to fix this other than limiting numpy<1.24.0. Maybe matplotlib will adapt to this (not so new) numpy version soon?
The fit range is taken from the histogram range, which is not useful in my opinion. With a very broad range, the fit errors vanish. When fitting a Gaussian, maybe only a range relative to the RMS should be used.
Move testing to Github actions.
With commit 9e2289a a wrong use of np.resize was implemented. np.resize fills additionally added entries in the new array by repeating elements of the original one (see here). This can lead to wrong histograms in the final step of the analysis. The correct way of resizing in this case is array.resize(shape) as this method complements the original array with zeros (if needed).
In /tools/geometry_utils.py in the function get_line_intersection_with_plane is a small bug in line 132. One can just remove the raise.
Adding other columns is a bit cumbersome. Right now it is enforced to use certain columns.
Solution:
Add required ordered dictionary with input and output names and dtypes.
With python 3.7 scipys binned statistics has change behavior
In result_analysis.py L. 261 binned_statistics is called with values = None causing a TypeError:
TypeError: ufunc 'isfinite' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
What is new is that values is checked with np.isfinite()
scipy.stats._binned_statistic.py L. 518
if not np.isfinite(values).all() or not np.isfinite(sample).all:
this check can not be performed on None type.
The analysis_tools.py file contains a function get_data() to download data from a sciebo repository, e.g for examples or unit tests.
This introduces the dependency on the requests package which is no needed for any normal usage, but imported and therefore required. Maybe get_data() should be moved to its on file under beam_telescope_analysis/testing?
For the master the package "requests" is neeed. This is not listed in the requirements in the readme
If Kalman Filter is used performance is low, because all tracks with minimum 3 hits are fitted.
Solution:
If Kalman Filter is used, use Linear Fit for tracks with # hits smaller than minimum track hits.
When executing the example scripts with Python3, one gets the following error (it works with Python2):
Traceback (most recent call last):
File "/home/gianna/anaconda3/lib/python3.6/site-packages/numpy/core/function_base.py", line 117, in linspace
num = operator.index(num)
TypeError: 'numpy.float64' object cannot be interpreted as an integerDuring handling of the above exception, another exception occurred:Traceback (most recent call last):
File "eutelescope.py", line 349, in
run_analysis(hit_files=hit_files)
File "eutelescope.py", line 130, in run_analysis
select_reference_dut=0)
File "/home/gianna/beam_telescope_analysis/beam_telescope_analysis/dut_alignment.py", line 257, in prealign
accumulator, theta, rho, theta_edges, rho_edges = analysis_utils.hough_transform(hough_data, theta_res=0.1, rho_res=1.0, return_edges=True)
File "/home/gianna/beam_telescope_analysis/beam_telescope_analysis/tools/analysis_utils.py", line 919, in hough_transform
thetas = np.linspace(-90.0, 0.0, np.ceil(90.0 / theta_res) + 1)
File "<array_function internals>", line 6, in linspace
File "/home/gianna/anaconda3/lib/python3.6/site-packages/numpy/core/function_base.py", line 121, in linspace
.format(type(num)))
TypeError: object of type <class 'numpy.float64'> cannot be safely interpreted as an integer.
The default chunk size in the fit_tracks function exceeds RAM usage on a 16 GB machine. Many computers still run on 16 GB, so I would propose to change the default chunk size to 500000, but I am open for a discussion.
Many code blocks in plotting and result analysis are identical (plotting of 1-D, 2-D histograms, calculating/creating histograms, ....). With a few "generic" helper functions, lines of code could be massively reduced and the code could be more readable.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.