smallpen1 / blog Goto Github PK
View Code? Open in Web Editor NEW学习总结
学习总结

首先看一个没有经过任何处理的🌰:
// 模拟一个输出的函数
function input(value) {
console.log(`输入的内容${value}`)
}
const ipt = document.getElementById('input')
ipt.addEventListener("keyup",function(e){
input(e.target.value)
})
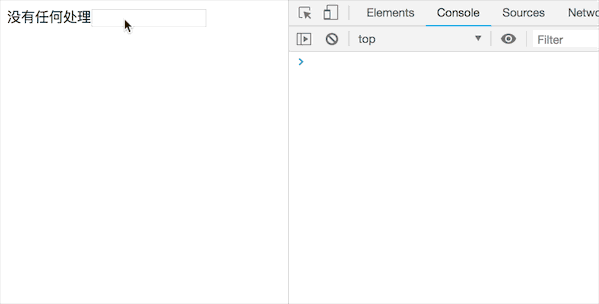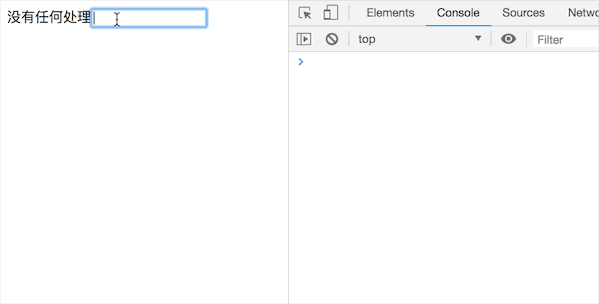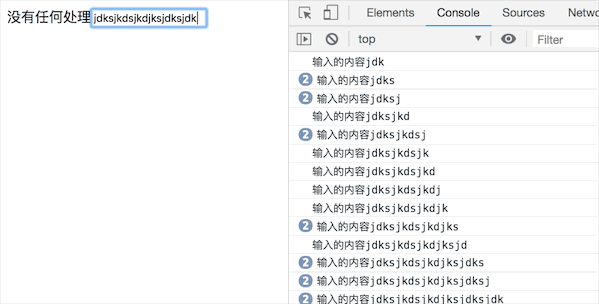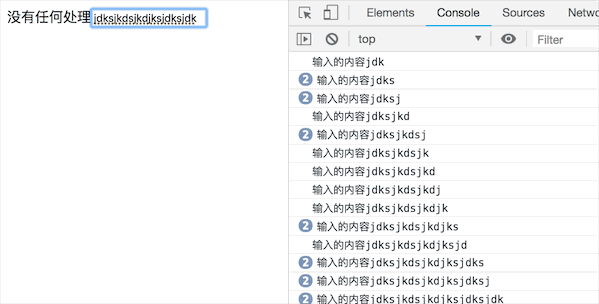
效果如下:
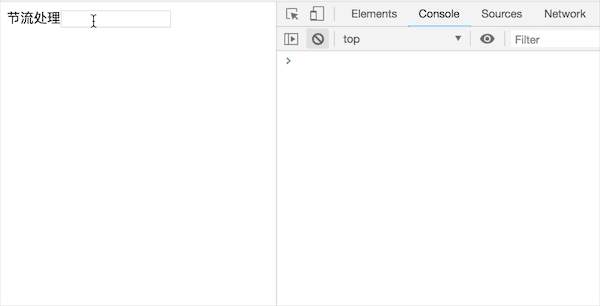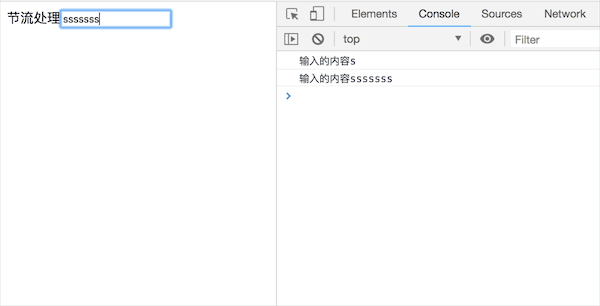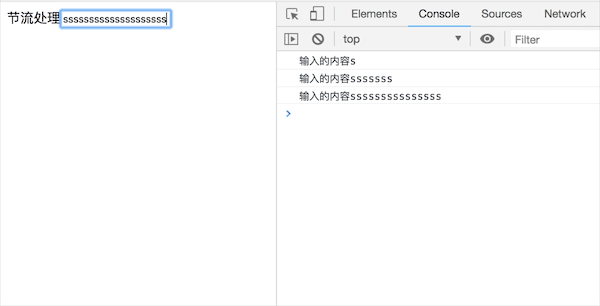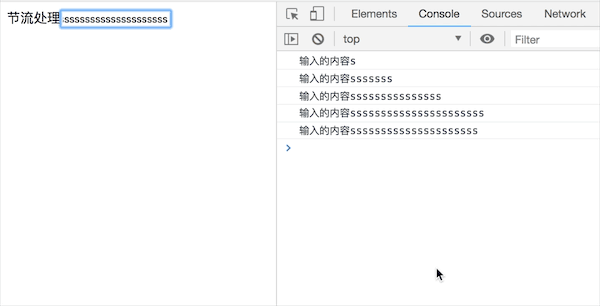
可以发现,只要按下键盘就会触发函数调用,这样在某些情况下会造成资源的浪费,在这些情况下,可能只需要在输入完成后做请求,比如身份验证等
首先看下效果:
由此可以看出来,当我们重新频繁的输入后,并不会立即调用方法,只有在经过指定的间隔内没有输入的情况下才会调用函数方法;
代码如下:
function input(value) {
console.log(`输入的内容${value}`)
}
const ipt = document.getElementById('input')
function debounce(fun,delay){
let timer ;
return function(args){
const that = this
clearTimeout(timer)
timer = setTimeout(function(){
fun.call(that,args)
},delay)
}
}
const debounceInput = debounce(input,500)
ipt.addEventListener("keyup",function(e){
debounceInput(e.target.value)
})
节流就是在规定的时间间隔呢,重复触发函数,只有一次是成功调用
先看下效果:
可以看到在一直输入的情况下每隔一段时间会触发一次函数
代码如下:
function input(value) {
console.log(`输入的内容${value}`)
}
const ipt = document.getElementById('input')
function throttle(fun,delay){
let last,timer;
return function(args){
const that = this
const now = +new Date()
if(last && now < last + delay){
clearTimeout(timer)
timer = setTimeout(function(){
fun.call(that,args)
},delay)
}else{
last = now
fun.call(that,args)
}
}
}
const throttleInput = throttle(input,1000)
ipt.addEventListener("keyup",function(e){
throttleInput(e.target.value)
})
1. 浮动
clear:both;清除浮动200px,中间设置100%margin-left:-100%,使left回到上一行的最左侧padding-left:200px;padding-right:200px;,给left和right腾出位置;padding的原因并不在最左侧,之前设置了定位,可以给left添加right:200px,使left回到最左侧margin-right:-200px;,使其回到第一行最好设置一个最小宽度防止页面变形
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>圣杯布局</title>
<link rel="stylesheet" href="">
</head>
<style type="text/css" media="screen">
/**
圣杯布局要求
1.header和footer各自占领屏幕所有宽度,高度固定。
2.中间的container是一个三栏布局。
3.三栏布局两侧宽度固定不变,中间部分自动填充整个区域。
4.中间部分的高度是三栏中最高的区域的高度。
*/
body {
min-width: 600px;
}
.header, .footer {
width: 100%;
height: 100px;
background: #ccc;
}
.footer {
clear: both;
}
.container {
padding: 0 200px;
}
.container .column {
float: left;
position: relative;
height: 400px;
}
#left {
width: 200px;
right: 200px;
background: pink;
margin-left: -100%;
}
#right {
width: 200px;
background: red;
margin-right: -200px;
}
#center {
width: 100%;
background: blue;
}
</style>
<body>
<div class="header">header</div>
<div class="container">
<div id="center" class="column">center</div>
<div id="left" class="column">left</div>
<div id="right" class="column">right</div>
</div>
<div class="footer">footer</div>
</body>
</html>
2. flex弹性布局
display:flex;flex:1;<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>圣杯布局-flex</title>
</head>
<style>
body{
min-width: 600px;
}
.header,.footer{
width: 100%;
height: 100px;
background: #ccc;
}
.container{
display: flex;
}
.container .column{
height: 400px;
}
#left{
width: 200px;
background: pink;
}
#center{
flex: 1;
background: blue;
}
#right{
width: 200px;
background: red;
}
</style>
<body>
<div class="header">header</div>
<div class="container">
<div id="left" class="column">left</div>
<div id="center" class="column">center</div>
<div id="right" class="column">right</div>
</div>
<div class="footer">footer</div>
</body>
</html>
首先我们需要了解javascript的变量作用域。
我们都知道变量的作用域有两种:全局变量和局部变量。
先看一个🌰
var n=999;
function f1(){
console.log(n);
}
f1(); // 999
我们可以发现,函数内部可以直接读取全局变量。
再看一个🌰
function f1(){
var n=999;
}
console.log(n); // error
而函数外部无法读取函数内部的局部变量。这里有一个地方需要注意,函数内部声明变量的时候,一定要使用var等命令。如果不用,你实际上声明的是一个全局变量!
function f1(){
n=999;
}
console.log(n); // 999
出于种种原因,我们有时候需要得到函数内的局部变量。但是正常情况下,这是办不到的,只有通过变通方法才能实现。
function f1(){
n=999;
function f2(){
alert(n); // 999
}
}
可以在函数内部再定义一个函数。在上面的例子种我们看到,函数f2包裹在函数f1的内部,这是函数f1内的局部变量对于f2都是可见的,但是反过来,f2内的局部变量对f1依旧是不可见的。这就是Javascript语言特有的“链式作用域”结构
子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
既然f2可以读取f1的局部变量,那么我们可以把f2设置返回值,就可以在外部读取局部变量。
function f1(){
var n = 999
function f2(){
alert(n)
}
return f2
}
var result = f1()
result() // 999
我的理解是,闭包就是能够读取函数内部变量的函数。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
function f1(){
var n = 999
nadd = function(){
n+=1
}
function f2(){
alert(n)
}
return f2
}
var result = f1()
result() // 999
nadd()
result() // 1000
在这段代码中,result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在内存中,并没有在f1调用后被自动清除。
造成这样的原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
而另外的nadd函数前面没有加入任何关键字,所以他是一个全局变量,其次这个nadd是一个匿名函数,而这个匿名函数本身也是一个闭包,他的主要功能就是set,可以在函数外部对函数内部进行操作
因为闭包会造成垃圾回收机制失效,变量会一直保存在内存中,容易造成内存泄露,所以在退出函数之前,将不使用的局部变量全部删除。
堆(stack) 动态分配内存,大小不定,不会自动释放。存放引用类型的值
栈 自动分配内存,大小固定,且会自动释放,存放基本类型的值
基本类型:存放在栈内存中的简单数据段,数据大小确定,内存空间大小可以分配。数据类型有5种: Number,Null,Undefined,Boolean,String 。
引用类型:存放在堆内存中的对象,变量实际保存的是一个指针,这个指针指向另一个位置。每个空间大小不一样,要根据情况开进行特定的分配。
当我们需要访问引用类型(如对象,数组,函数等)的值时,首先从栈中获得该对象的地址指针,然后再从堆内存中取得所需的数据。
基本类型和引用类型最大的区别是传值和传址的区别
var a = [1,2,3,4]
var b = a // 传址 ,对象中传给变量的数据是引用类型的,会存储在堆中;
var c = a[0] //传值,把对象中的属性/数组中的数组项赋值给变量,这时变量C是基本数据类型,存储在栈内存中;改变栈中的数据不会影响堆中的数据
b[3] = 5
console.log(a) // [1,2,3,5]
console.log(b) // [1,2,3,5]
c = 6
console.log(c) // 6
console.log(a) // [1,2,3,5]
从上面我们可以得知,当我改变b中的数据时,a中数据也发生了变化;但是当我改变c的数据值时,a却没有发生改变。
因为a是数组,属于引用类型,它赋予给b的时候传的是栈中的地址(相当于新建了一个不同名“指针”),而不是堆内存中的对象。而c仅仅是从a堆内存中获取的一个数据值,并保存在栈中。所以b修改的时候,会根据地址回到a堆中修改,c则直接在栈中修改,并且不能指向a堆内存中。
前面已经提到,在定义一个对象或数组等引用类型的值时,变量存放的往往只是一个地址。当我们使用对象拷贝时,如果属性是对象或数组时,这时候我们传递的也只是一个地址。因此子对象在访问该属性时,会根据地址回溯到父对象指向的堆内存中,即父子对象发生了关联,两者的属性值会指向同一内存空间。
var a = {
s1:'111111'
}
function copy(data){
var c = {}
for (var i in data) {
c[i] = data[i]
}
return c
}
a.s2 = ['火影','死神']
var b = copy(a)
b.s3 = '33333'
console.log(a) // {s1:'111111',s2:['火影','死神']}
console.log(b) // {s1:'111111',s2:['火影','死神'],s3:'33333'}
a对象中s1属性是字符串,s2属性是数组。a拷贝到b,属性均顺利拷贝。给b对象新增一个字符串类型的属性s3时,b能正常修改,而a中无定义。说明子对象的s3(基本类型)并没有关联到父对象中,所以undefined。
但是,若修改的属性变为对象或数组时,那么父子对象之间就会发生关联。从以上弹出结果可知,我对b对象进行修改,a、b的s2属性值(数组)均发生了改变。其在内存的状态。
b.s2.push("数码宝贝");
console.log(a.s2) // ['火影','死神','数码宝贝']
console.log(b.s2) // ['火影','死神','数码宝贝']
如果不希望父子对象之间产生关联的话可以用深拷贝。
上面的问题可以用递归方法解决
var a = {
s1:'111111'
}
function copy(data,c){
var c = c || {}
for (var i in data) {
if(typeof data[i] === 'object'){
console.log(data[i].constructor === Array)
c[i] = (data[i].constructor === Array) ? [] : {};
copy(data[i],c[i])
}else{
c[i] = data[i]
}
}
return c
}
a.s2 = ['火影','死神']
var b = copy(a)
b.s3 = '33333'
a.s2.push('数码宝贝')
console.log(a) // {s1:'111111',s2:['火影','死神','数码宝贝']}
console.log(b) // {s1:'111111',s2:['火影','死神'],s3:'33333'}
跨域就是向不同协议、域名、端口的地址发送请求的过程,之所以出现这样的问题是受到浏览器同源策略的影响。可能你会觉得这样不是影响我们正常的开发造成麻烦是个累赘,但他的存在却是给我们带来安全的保障,隔离来自黑客的攻击。
这里就不得不提 CSRF
CSRF,又称跨站请求伪造,指非法网站挟持用户cookie在已登陆网站上实施非法操作的攻击,这是基于使用cookie在网站免登和用户信息留存的实用性。正常免登陆流程如下:
1. 首先进入网站,向后端发送登录请求。
2.后端对登录信息就行校验,判断信息是否正确。
3.待信息判断无误后,后端会给浏览器发送一个request,并在request-header中添加一个set-cookie字段。
4.浏览器将request进行展示操作,并对header存到cookie中。
5.当关闭页面再重进进入后,浏览器自动将cookie信息放入request-header中。
假如我们登录 *宝网站,并在浏览器中留下来登录等重要信息,当用户又进入什么澳门赌场网站,那么这个网站可能用浏览器设置的cookie信息自动向 *宝发送请求。
这样可能就会信息泄露或者严重的可能财产损失。
对于需要安全性的网站来说,同源策略是完全有必要的。
这算一个很早就用的解决方案,利用script进行数据的请求。因为script进行数据请求不受同源策略的限制,所以可以通过script来进行请求跨域数据,后端再将对应的结果利用jsonp的格式进行返回
🌰代码:
<script>
function callback(result){
// 返回的结果
}
</script>
<script src="www.baidu.com/ajax/jsonp.php?jsoncallback=callback">
</script>
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求
CORS又分为简单请求和预检请求
简单请求就是不会触发cors预检的请求
application/x-www-form-urlencoded、 multipart/form-data、 text/plain后端适配: 在respones header中添加Access-Control-Allow-Origin
Access-Control-Allow-Origin代表允许发送请求的源,参数可以是固定的白名单ip,也可以用通配符"*",代表接受所有请求。不过有种特殊情况是不能使用通配符的,就是前端请求header中含有withCredentials,withCredentials:true是跨域请求想要携带cookie必须加入的headers配置
预检请求就是在跨域的时候设置了对应的需要预检的内容,结果上会在普通跨域请求前添加了个options请求,用来检查前端headers的修改是否在后端允许范围内。 触发预检请求在跨域开发中会碰到的主要情况如下:
预检请求就需要后端设置更多的respones headers了,常用如下:
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
除此之外,后端还需要设置对OPTIONS请求的判断:
if (req.method == 'OPTIONS') {
res.send(200);
} else {
next();
}
1.本地代理
2.node中间件
可以在webpack中配置
"proxy": {
"/api": {
"target": "http://127.0.0.1:8988/",
"changeOrigin": true,
"pathRewrite": { "^/api" : "" }
}
}
/api代表代理的路径名,target代表代理的地址,changeOrigin代表更改发出源地址为target,pathRewrite代表路径重写,别的脚手架直接加载webpack配置文件即可
可以用express + http-proxy-middleware
设置全局的路由拦截
app.all('*', function (req, res, next) {
res.header('Access-Control-Allow-Origin', '*');
if (req.method == 'OPTIONS') {
res.send(200);
} else {
next();
}
})
再设置对应代理逻辑
var options = {
target: 'https://xxxx.xxx.xxx/abc/req',
changeOrigin: true,
pathRewrite: (path,req)=>{
return path.replace('/api','/')
}
}
app.use('/api', proxy(options));``
**jsonp**和**CORS**:
- json只支持get请求,无法支持复杂的请求
- jsonp出现错误的时候,很难去进行错误识别与处理,cors可以正常错误捕捉
- jsonp的兼容性比较高,而cors在旧版ie中需要寻找对应的替代方案
reduce() 方法接收一个函数作为累加器,reduce 为数组中的每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,接受四个参数:初始值(上一次回调的返回值),当前元素值,当前索引,原数组
语法:arr.reduce(callback,[initialValue])
callback:函数中包含四个参数
- previousValue (上一次调用回调返回的值,或者是提供的初始值(initialValue))
- currentValue (数组中当前被处理的元素)
- ndex (当前元素在数组中的索引)
- array (调用的数组)
initialValue (作为第一次调用 callback 的第一个参数。)
const arr = [1, 2, 3, 4, 5]
const sum = arr.reduce((pre, item) => {
return pre + item
}, 0)
console.log(sum) // 15
以上回调被调用5次,每次的参数详见下表
| callback | previousValue | currentValue | index | array | return value |
|---|---|---|---|---|---|
| 第1次 | 0 | 1 | 0 | [1, 2, 3, 4, 5] | 1 |
| 第2次 | 1 | 2 | 1 | [1, 2, 3, 4, 5] | 3 |
| 第3次 | 3 | 3 | 2 | [1, 2, 3, 4, 5] | 6 |
| 第4次 | 6 | 4 | 3 | [1, 2, 3, 4, 5] | 10 |
| 第5次 | 10 | 5 | 4 | [1, 2, 3, 4, 5] | 15 |
使用reduce方法可以完成多维度的数据叠加。
计算总成绩,且学科的占比不同
const scores = [
{
subject: 'math',
score: 88
},
{
subject: 'chinese',
score: 95
},
{
subject: 'english',
score: 80
}
];
const dis = {
math: 0.5,
chinese: 0.3,
english: 0.2
}
const sum = scores.reduce((pre,item) => {
return pre + item.score * dis[item.subject]
},0)
console.log(sum) // 88.5
递归利用reduce处理tree树形
var data = [{
id: 1,
name: "办公管理",
pid: 0,
children: [{
id: 2,
name: "请假申请",
pid: 1,
children: [
{ id: 4, name: "请假记录", pid: 2 },
],
},
{ id: 3, name: "出差申请", pid: 1 },
]
},
{
id: 5,
name: "系统设置",
pid: 0,
children: [{
id: 6,
name: "权限管理",
pid: 5,
children: [
{ id: 7, name: "用户角色", pid: 6 },
{ id: 8, name: "菜单设置", pid: 6 },
]
}, ]
},
];
const arr = data.reduce(function(pre,item){
const callee = arguments.callee
pre.push(item)
if(item.children && item.children.length > 0) item.children.reduce(callee,pre);
return pre;
},[]).map((item) => {
item.children = []
return item
})
console.log(arr)
利用reduce来计算一个字符串中每个字母出现次数
const str = 'jshdjsihh';
const obj = str.split('').reduce((pre,item) => {
pre[item] ? pre[item] ++ : pre[item] = 1
return pre
},{})
console.log(obj) // {j: 2, s: 2, h: 3, d: 1, i: 1}
cookie的大小现在在4k左右,主要用来保存登录信息,比如记住登录密码等功能。
localStorage是HTML5标准中新加入的技术
sessionStorage与localStorage接口类似,但保存数据的生命周期不同,而 sessionStorage 是一个前端的概念,它只是可以将一部分数据在当前会话中保存下来,刷新页面数据依旧存在。但当页面关闭后,sessionStorage 中的数据就会被清空。
| 特性 | cookie | localStorage | sessionStorage |
|---|---|---|---|
| 生命周期 | 一般由服务器生成,可设置失效时间。如果在浏览器端生成,默认关闭即失效 | 除非被清除否则永久保存 | 仅在当前会话下有效,关闭页面或浏览器即清除 |
| 存放数据大小 | 4k左右 | 5M左右 | 5M左右 |
| 与服务器端通信 | 每次会携带到HTTP头中,如果使用cookie保存过多数据会带来性能问题 | 仅浏览器端保存,不参与与服务器间的通信 | 仅浏览器端保存,不参与与服务器间的通信 |
| 易用性 | 需要程序员进行封装 | 源生接口可以接受,亦可再次封装来对Object和Array有更好的支持 | 源生接口可以接受,亦可再次封装来对Object和Array有更好的支持 |
需要注意的是,不是什么数据都适合放在 Cookie、localStorage 和 sessionStorage 中的。使用它们的时候,需要时刻注意是否有代码存在 XSS 注入的风险。因为只要打开控制台,你就随意修改它们的值,也就是说如果你的网站中有 XSS 的风险,它们就能对你的 localStorage 肆意妄为。所以千万不要用它们存储你系统中的敏感数据。
localStorage和sessionStorage都具有相同的操作方法,例如setItem、getItem和removeItem等。
setItem存储value
localStorage.setItem('size',8) sessionStorage('key','value')
getItem获取value
var size = localStorage.getItem('size') var value = sessionStorage.getItem('key')
removeItem删除key
localStorage.removeItem('size') sessionStorage.removeItem('key')
clear清除所有的key/value
localStorage.clear() sessionStorage.clear()
我们都知道call apply bind都可以改变函数调用的this指向。那么它们三者有什么区别呢?
Array的构造器用于创建新的数组,推荐使用对象字面量创建数组
// 使用构造器
var a = Array()
// 使用对象字面量
var b = [];
Array.isArray用来判断变量是否是数组类型。在ES5提供该方法之前,我们至少有如下5种方式去判断一个值是否数组:
var a = []
// 1.基于instanceof
a instanceof Array;
// 2.基于constructor
a. constructor === Array;
// 3.基于Object.prototype.isPrototypeOf
Array.protopyte.isPrototypeOf(a)
//4.基于Object.prototype.toString
Object.prototype.toString.call(a) === "[object Array]"
以上,除了Object.prototype.toString外,其它方法都不能正确判断变量的类型。
使用Array.isArray则非常简单,如下:
Array.isArray([]) //true
Array.isArray({0: 'a', length: 1}) //false
通过Object.prototype.toString判断值类型,Array.isArray的polyfill
if (!Array.isArray){
Array.isArray = function(arg){
return Object.prototype.toString.call(arg) === "[object Array]"
};
}
继承的常识告诉我们,js中所有的数组方法均来自于Array.prototype,和其他构造函数一样,你可以通过扩展 Array 的 prototype 属性上的方法来给所有数组实例增加方法。
其实Array.prototype本身也是一个数组
Array.isArray(Array.prototype) // true
cosnole.log(Array.prototype.length) // 0
数组提供了很多方法,主要分成三种。一种是会改变自身值得,一种是不会改变自身值得,还有就是遍历方法。
基于ES6,改变自身值的方法一共有9个,分别为pop、push、reverse、shift、sort、splice、unshift,以及两个ES6新增的方法copyWithin 和 fill。
pop() 方法删除一个数组中的最后的一个元素,并且返回这个元素。
var array = ["cat", "dog", "chicken", "mouse"];
var item = array.pop()
console.log(array) // ["cat", "dog", "chicken"]
console.log(item) // 'mouse'
push()方法添加一个或者多个元素到数组末尾,并且返回数组新的长度。
var array = ["cat", "dog", "chicken"];
var item = array.push("mouse")
console.log(array) // ["cat", "dog", "chicken","mouse"]
console.log(item) // 4
reverse()方法颠倒数组中元素的位置,第一个会成为最后一个,最后一个会成为第一个,该方法返回对数组的引用。
var array = [1,2,3,4,5];
var array2 = array.reverse();
console.log(array); // [5,4,3,2,1]
console.log(array2===array); // true
shift()方法删除数组的第一个元素,并返回这个元素。
var array = [1,2,3,4,5];
var item = array.shift();
console.log(array); // [2,3,4,5]
console.log(item); // 1
unshift() 方法用于在数组开始处插入一些元素(就像是栈底插入),并返回数组新的长度。
var array = ["red", "green", "blue"];
var length = array.unshift("yellow");
console.log(array); // ["yellow", "red", "green", "blue"]
console.log(length); // 4
sort()方法对数组元素进行排序,并返回这个数组。
语法:arr.sort([comparefn])
comparefn是可选的,如果省略,数组元素将按照各自转换为字符串的Unicode(万国码)位点顺序排序,例如”Boy”将排到”apple”之前。当对数字排序的时候,25将会排到8之前,因为转换为字符串后,”25”将比”8”靠前。
var array = ["apple","Boy","Cat","dog"];
var array2 = array.sort();
console.log(array); // ["Boy", "Cat", "apple", "dog"]
console.log(array2 == array); // true
array = [10, 1, 3, 20];
var array3 = array.sort();
console.log(array3); // [1, 10, 20, 3]
如果指明了comparefn,数组将按照调用该函数的返回值来排序。若 a 和 b 是两个将要比较的元素:
function compare(a, b){
return a-b;
}
splice()方法用新元素替换旧元素的方式来修改数组。它是一个常用的方法,复杂的数组操作场景通常都会有它的身影,特别是需要维持原数组引用时,就地删除或者新增元素,splice是最适合的。
语法:arr.splice(start,deleteCount[, item1[, item2[, …]]])
start 指定从哪一位开始修改内容。如果超过了数组长度,则从数组末尾开始添加内容;如果是负值,则其指定的索引位置等同于 length+start (length为数组的长度),表示从数组末尾开始的第 -start 位。
deleteCount 指定要删除的元素个数,若等于0,则不删除。这种情况下,至少应该添加一位新元素,若大于start之后的元素总和,则start及之后的元素都将被删除。
itemN 指定新增的元素,如果缺省,则该方法只删除数组元素。
返回值 由原数组中被删除元素组成的数组,如果没有删除,则返回一个空数组。
var array = ["apple","boy"];
var splices = array.splice(1,1);
console.log(array); // ["apple"]
console.log(splices); // ["boy"] ,可见是从数组下标为1的元素开始删除,并且删除一个元素,由于itemN缺省,故此时该方法只删除元素
array = ["apple","boy"];
splices = array.splice(2,1,"cat");
console.log(array); // ["apple", "boy", "cat"]
console.log(splices); // [], 可见由于start超过数组长度,此时从数组末尾开始添加元素,并且原数组不会发生删除行为
array = ["apple","boy"];
splices = array.splice(-2,1,"cat");
console.log(array); // ["cat", "boy"]
console.log(splices); // ["apple"], 可见当start为负值时,是从数组末尾开始的第-start位开始删除,删除一个元素,并且从此处插入了一个元素
array = ["apple","boy"];
splices = array.splice(-3,1,"cat");
console.log(array); // ["cat", "boy"]
console.log(splices); // ["apple"], 可见即使-start超出数组长度,数组默认从首位开始删除
array = ["apple","boy"];
splices = array.splice(0,3,"cat");
console.log(array); // ["cat"]
console.log(splices); // ["apple", "boy"], 可见当deleteCount大于数组start之后的元素总和时,start及之后的元素都将被删除
不会改变自身的方法一共有9个,分别为concat、join、slice、toString、toLocateString、indexOf、lastIndexOf、未标准的toSource以及ES7新增的方法includes。
concat() 方法将传入的数组或者元素与原数组合并,组成一个新的数组并返回。
语法:arr.concat(value1, value2, …, valueN)
var array = [1, 2, 3];
var array2 = array.concat(4,[5,6],[7,8,9]);
console.log(array2); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(array); // [1, 2, 3], 可见原数组并未被修改
若concat方法中不传入参数,那么将基于原数组浅复制生成一个一模一样的新数组(指向新的地址空间)。
join() 方法将数组中的所有元素连接成一个字符串。
语法:arr.join([separator = ‘,’]) separator可选,缺省默认为逗号。
var array = ['We', 'are', 'Chinese'];
console.log(array.join()); // "We,are,Chinese"
console.log(array.join('+')); // "We+are+Chinese"
console.log(array.join('')); // "WeareChinese"
slice() 方法将数组中一部分元素复制存入新的数组对象,并且返回这个数组对象。
语法:arr.slice([start[, end]])
参数 start 指定复制开始位置的索引,end如果有值则表示复制结束位置的索引(不包括此位置)。
如果 start 的值为负数,假如数组长度为 length,则表示从 length+start 的位置开始复制,此时参数 end 如果有值,只能是比 start 大的负数,否则将返回空数组。
slice方法参数为空时,同concat方法一样,都是复制生成一个新数组。
toString() 方法返回数组的字符串形式,该字符串由数组中的每个元素的 toString() 返回值经调用 join() 方法连接(由逗号隔开)组成。
语法: arr.toString()
var array = ['Jan', 'Feb', 'Mar', 'Apr'];
var str = array.toString();
console.log(str); // Jan,Feb,Mar,Apr
indexOf() 方法用于查找元素在数组中第一次出现时的索引,如果没有,则返回-1。
语法:arr.indexOf(element, fromIndex=0)
element 为需要查找的元素。
fromIndex 为开始查找的位置,缺省默认为0。如果超出数组长度,则返回-1。如果为负值,假设数组长度为length,则从数组的第 length + fromIndex项开始往数组末尾查找,如果length + fromIndex<0 则整个数组都会被查找。
indexOf使用严格相等(即使用 === 去匹配数组中的元素)。
var array = ['abc', 'def', 'ghi','123'];
console.log(array.indexOf('def')); // 1
console.log(array.indexOf('def',-1)); // -1 此时表示从最后一个元素往后查找,因此查找失败返回-1
console.log(array.indexOf('def',-4)); // 1 由于4大于数组长度,此时将查找整个数组,因此返回1
console.log(array.indexOf(123)); // -1, 由于是严格匹配,因此并不会匹配到字符串'123'
astIndexOf() 方法用于查找元素在数组中最后一次出现时的索引,如果没有,则返回-1。并且它是indexOf的逆向查找,即从数组最后一个往前查找。
语法:arr.lastIndexOf(element, fromIndex=length-1)
element 为需要查找的元素。
fromIndex 为开始查找的位置,缺省默认为数组长度length-1。如果超出数组长度,由于是逆向查找,则查找整个数组。如果为负值,则从数组的第 length + fromIndex项开始往数组开头查找,如果length + fromIndex<0 则数组不会被查找。
同 indexOf 一样,lastIndexOf 也是严格匹配数组元素。
includes() 方法基于ECMAScript 2016(ES7)规范,它用来判断当前数组是否包含某个指定的值,如果是,则返回 true,否则返回 false。
语法:arr.includes(element, fromIndex=0)
element 为需要查找的元素。
fromIndex 表示从该索引位置开始查找 element,缺省为0,它是正向查找,即从索引处往数组末尾查找。
var array = [-0, 1, 2];
console.log(array.includes(+0)); // true
console.log(array.includes(1)); // true
console.log(array.includes(2,-4)); // true
从上面可以看到,includes似乎忽略了 -0 与 +0 的区别,这不是问题,因为JavaScript一直以来都是不区分 -0 和 +0 的。
既然有了indexOf方法,为什么又造一个includes方法,arr.indexOf(x)>-1不就等于arr.includes(x)?看起来是的,几乎所有的时候它们都等同,唯一的区别就是includes能够发现NaN,而indexOf不能。
var array = [NaN];
console.log(array.includes(NaN)); // true
console.log(arra.indexOf(NaN)); // -1
基于ES6,不会改变自身的方法一共有12个,分别为forEach、every、some、filter、map、reduce、reduceRight 以及ES6新增的方法entries、find、findIndex、keys、values。
forEach() 方法指定数组的每项元素都执行一次传入的函数,返回值为undefined。
语法:arr.forEach(fn, thisArg)
fn 表示在数组每一项上执行的函数,接受三个参数:
hisArg 可选,用来当做fn函数内的this对象。
var array = [1, 3, 5];
var obj = {name:'cc'};
var sReturn = array.forEach(function(value, index, array){
array[index] = value * value;
console.log(this.name); // cc被打印了三次
},obj);
console.log(array); // [1, 9, 25], 原数组改变了
console.log(sReturn); // undefined
every() 方法使用传入的函数测试所有元素,只要其中有一个函数返回值为 false,那么该方法的结果为 false;如果全部返回 true,那么该方法的结果才为 true。因此 every 方法存在如下规律:
some() 方法刚好同 every() 方法相反,some 测试数组元素时,只要有一个函数返回值为 true,则该方法返回 true,若全部返回 false,则该方法返回 false。
filter() 方法使用传入的函数测试所有元素,并返回所有通过测试的元素组成的新数组。它就好比一个过滤器,筛掉不符合条件的元素。
语法:arr.filter(fn, thisArg)
var array = [18, 9, 10, 35, 80];
var array2 = array.filter(function(value,index,array) => {
return value > 20;
});
console.log(array2) // [35,80]
即 Array.prototype.map,该方法只支持数组。map() 方法遍历数组,使用传入函数处理每个元素,并返回函数的返回值组成的新数组。
语法:arr.map(fn, thisArg)
var array = [-1, -4, 9];
var roots = array.map(Math.abs);//map包裹方法名
console.log(roots) // [1,4,9]
var array = [1, 4, 9];
var doubles = array.map(function(num) {//map包裹方法实体
return num * 2;
});
console.log(doubles) // [2,8,18]
reduce() 方法接收一个方法作为累加器,数组中的每个值(从左至右) 开始合并,最终为一个值。
语法:arr.reduce(fn, initialValue)
fn 表示在数组每一项上执行的函数,接受四个参数:
当 fn 第一次执行时:
var array = [1, 2, 3, 4,5];
var s = array.reduce(function(previousValue, value, index, array){
return previousValue * value;
},1);
console.log(s); // 120
以上回调被调用5次,每次的参数和返回见下表:
| callback | previousValue | currentValue | index | array | return value |
|---|---|---|---|---|---|
| 第1次 | 1 | 1 | 0 | [1,2,3,4,5] | 1 |
| 第2次 | 1 | 2 | 1 | [1,2,3,4,5] | 2 |
| 第3次 | 2 | 3 | 2 | [1,2,3,4,5] | 6 |
| 第4次 | 6 | 4 | 3 | [1,2,3,4,5] | 24 |
| 第5次 | 24 | 5 | 4 | [1,2,3,4,5] | 120 |
和其他所有对象一样,字符串实例的所有方法均来自String.prototype。以下是它的属性特性:
| writable | false |
|---|---|
| enumerable | false |
| configurable | false |
可见,字符串属性不可编辑,任何试图改变它属性的行为都将抛出错误。
String.prototype共有两个属性:
charAt() 方法返回字符串中指定位置的字符。
语法:str.charAt(index)
index 为字符串索引(取值从0至length-1),如果超出该范围,则返回空串。
console.log("Hello, World".charAt(8)); // o
charCodeAt() 返回指定索引处字符的 Unicode 数值。
语法:str.charCodeAt(index)
index 为一个从0至length-1的整数。如果不是一个数值,则默认为 0,如果小于0或者大于字符串长度,则返回 NaN。
concat() 方法将一个或多个字符串拼接在一起,组成新的字符串并返回。
语法:str.concat(string2, string3, …)
concat 的性能表现不佳,强烈推荐使用赋值操作符(+或+=)代替 concat。”+” 操作符大概快了 concat 几十倍。
match() 方法用于测试字符串是否支持指定正则表达式的规则,即使传入的是非正则表达式对象,它也会隐式地使用new RegExp(obj)将其转换为正则表达式对象。
语法:str.match(regexp)
该方法返回包含匹配结果的数组,如果没有匹配项,则返回 null。
该方法并不改变调用它的字符串本身,而只是返回替换后的字符串.
语法:str.replace( regexp | substr, newSubStr | function[, flags] )
var a = "what is this? before";
var b = a.replace("before","after"); // "what is this? after"
search() 方法用于测试字符串对象是否包含某个正则匹配,相当于正则表达式的 test 方法,且该方法比 match() 方法更快。如果匹配成功,search() 返回正则表达式在字符串中首次匹配项的索引,否则返回-1。
**
注意:search方法与indexOf方法作用基本一致,都是查询到了就返回子串第一次出现的下标,否则返回-1,唯一的区别就在于search默认会将子串转化为正则表达式形式,而indexOf不做此处理,也不能处理正则。
**
var str = "abcdefg";
console.log(str.search(/[d-g]/)); // 3
search() 方法不支持全局匹配(正则中包含g参数)
slice() 方法提取字符串的一部分,并返回新的字符串。
语法:str.slice(start, end)
首先 end 参数可选,start可取正值,也可取负值。
取正值时表示从索引为start的位置截取到end的位置(不包括end所在位置的字符,如果end省略则截取到字符串末尾)。
取负值时表示从索引为 length+start 位置截取到end所在位置的字符。
split() 方法把原字符串分割成子字符串组成数组,并返回该数组。
语法:str.split(separator, limit)
两个参数均是可选的,其中 separator 表示分隔符,它可以是字符串也可以是正则表达式。如果忽略 separator,则返回的数组包含一个由原字符串组成的元素。如果 separator 是一个空串,则 str 将会被分割成一个由原字符串中字符组成的数组。limit 表示从返回的数组中截取前 limit 个元素,从而限定返回的数组长度。
var str = "today is a sunny day";
console.log(str.split()); // ["today is a sunny day"]
console.log(str.split(" ")); // ["today", "is", "a", "sunny", "day"]
substr() 方法返回字符串指定位置开始的指定数量的字符。
语法:str.substr(start[, length])
start 表示开始截取字符的位置,可取正值或负值。取正值时表示start位置的索引,取负值时表示 length+start位置的索引。
length 表示截取的字符长度。
var str = "Yesterday is history. Tomorrow is mystery. But today is a gift.";
console.log(str.substr(47)); // today is a gift.
substring() 方法返回字符串两个索引之间的子串。
语法:str.substring(indexA[, indexB])
indexA、indexB 表示字符串索引,其中 indexB 可选,如果省略,则表示返回从 indexA 到字符串末尾的子串。
substring 要截取的是从 indexA 到 indexB(不包含)之间的字符,符合以下规律:
var str = "Get outside every day. Miracles are waiting everywhere.";
console.log(str.substring(1,1)); // ""
console.log(str.substring(0)); // Get outside every day. Miracles are waiting everywhere.
console.log(str.substring(-1)); // Get outside every day. Miracles are waiting everywhere.
console.log(str.substring(0,100)); // Get outside every day. Miracles are waiting everywhere.
console.log(str.substring(22,NaN)); // Get outside every day.
javascript是基于原型的继承。
每一个函数都有一个prototype属性,所以通过new出来的新的实例都有一个proto属性,指向这个函数的prototype,每当代码读取某个对象的某个属性时,都会执行一次搜索。搜索首先在对象实例本身开始,如果实例中找到了具有给定名字的属性,则返回属性的值;如果没有找到,则继续搜索指针指向的原型对象,在原型对象中查找具有给定名字的属性。
function Person(){
}
Person.prototype.name = '小明'
var person1 = new Person()
var person2 = new Person()
person1.name = '小红'
console.log(person1.name) // 小红 --来自实例
console.log(person2.name) // 小明 --来自原型
delete person1.name
console.log(person1.name) // 小明 --来自原型
prototype[显示原型]prototype是显示原型属性,只有函数拥有该属性。每个函数创建之后都会拥有该属性,这个属性指向的是函数的原型对象
prototype是一个指针,指向一个对象。比如Array.prototype就是指向Array这个函数的原型对象。
我们现在写一个function Person(){}函数。
当写一个Person这个方法,他会自动创建prototype指针属性(指向原型对象)。而被指向的原型对象自动获得constructor(构造函数)。其中constructor指向Person。
Person.prototype.constructor === Person // true
一个函数的原型对象的构造函数是这个函数本身
__proto__[隐式原型]__proto__其实是指向了
[[prototype]],但是[[prototype]]是内部属性,我们并不能直接访问,所以使用__proto__来访问。
定义:
__proto__指向了创建该对象的构造函数的显示原型。
我们发现上面Person.prototype含有一个属性__proto__。
如果打印该属性会发现__proto__指向Object.prototype。
作用
显示原型:用于实现基于原型的继承与属性的共享。
隐式原型:构成原型链,同样用于基于原型的继承。
当我们使用new操作符时,生成的实例对象拥有了__proto__属性。即在 new 的过程中,新对象被添加了__proto__ 并且链接到构造函数的原型上。
new 的过程:
setTimeout(() => {
// callback
},1000)
优点:解决同步问题
缺点:回调地狱,不能捕获到错误
其中回调地狱的问题在于:
ajax('x',() => {
//callback
ajax('x2',() => {
//callback
ajax('x3',() => {
//callback
})
})
})
promise解决了callback产生的问题
promise实现链式调用,每次then后返回的都是全新的promise,如果我们在then中return,return的结果会被Promise.resolve()包装
优点:解决回调地狱问题
缺点:无法取消Promise,错误需要回调函数来捕获
async,await是异步的终极解决方案
优点:代码清晰,不用写过多的then链,同时也处理了回调地狱问题
缺点:await将异步代码改造成同步代码,如果多个异步操作没有依赖性而使用await会降低性能
async function test(){
await fetch('x1')
await fetch('x2')
await fetch('x3')
}
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.