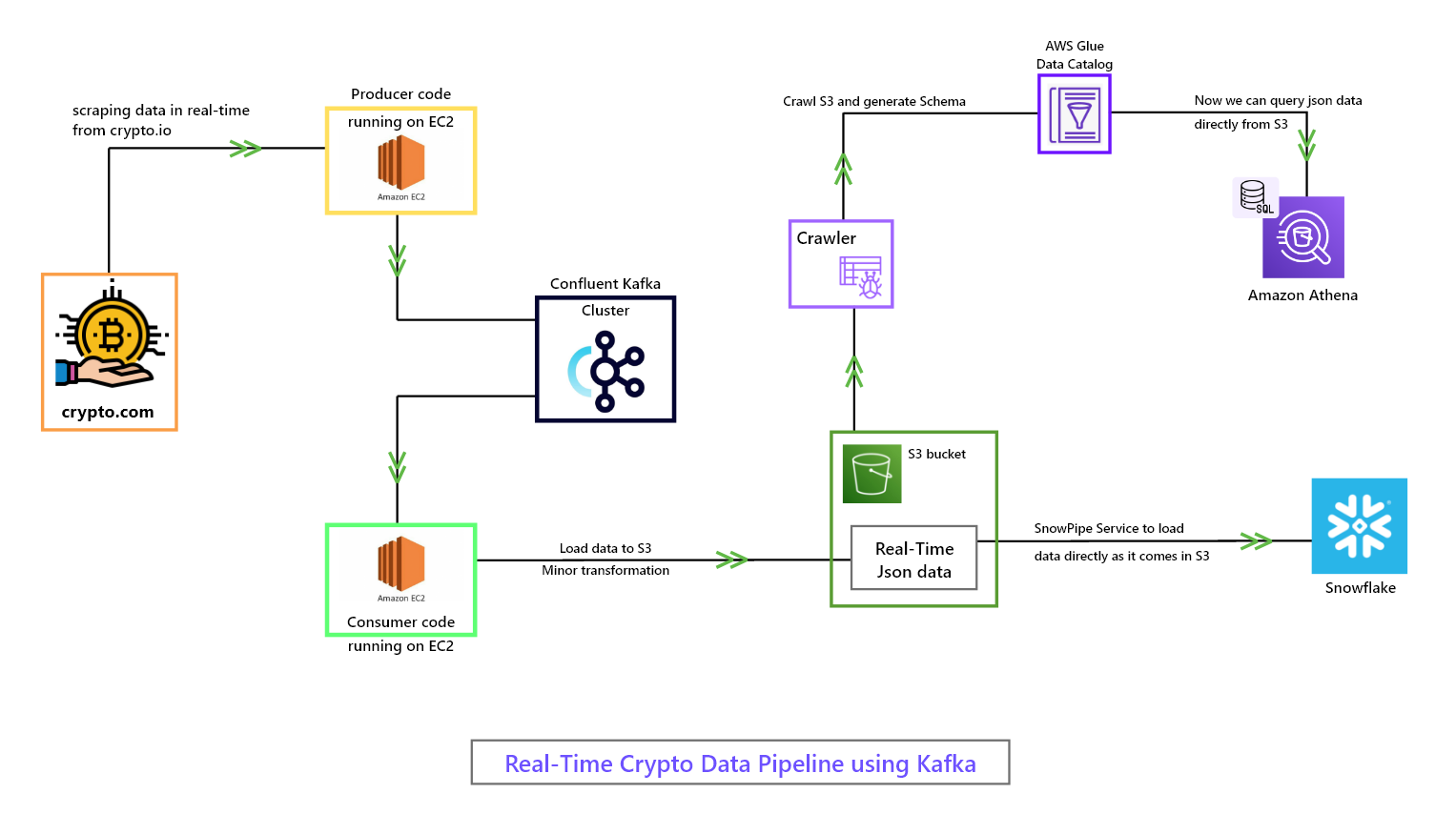
I am using confluent Kafka cluster to produce and consume scraped data.
In this project, I've created a real-time data pipeline that utilizes Kafka to scrape, process, and load data onto S3 in JSON format. With a producer-consumer architecture, I ensure that the data is in the right format for loading onto S3 by performing minor transformations while consuming it.
But that's not all - I've also used AWS crawler to crawl the data and generate a schema catalog. Athena utilizes this catalog, allowing me to query the data directly from S3 without loading it first. This saves time and resources and enables me to get insights from the data much faster!
Moreover, I've connected S3 with Snowflake using Snowpipe. As data is loaded onto S3, a SNS notification is sent to Snowpipe, which then automatically starts loading the data into Snowflake. This makes data loading a seamless and automated process, freeing up time for other important tasks.