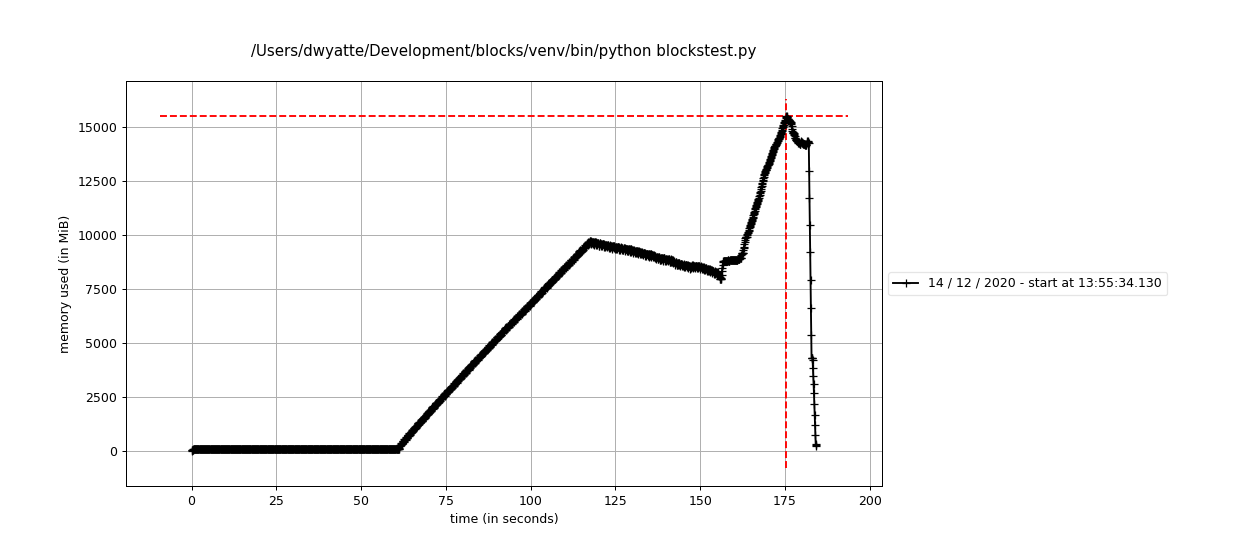
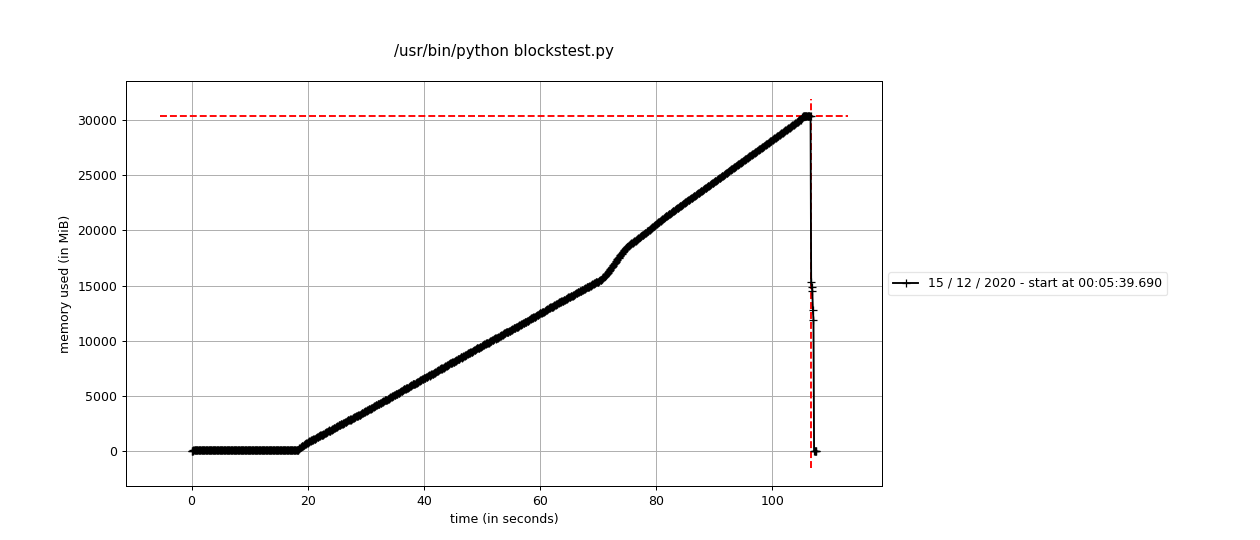
Unfortunately, there are some platform-dependent memory allocation issues that are likely out of blocks' control where Linux requires 2x the expected memory for blocks.assemble (see attached profiling).
Line # Mem usage Increment Occurences Line Contents
============================================================
30 86.297 MiB 86.297 MiB 1 @profile
31 def assemble(
32 path: str,
33 cgroups: Optional[Sequence[cgroup]] = None,
34 rgroups: Optional[Sequence[rgroup]] = None,
35 read_args: Any = {},
36 cgroup_args: Dict[cgroup, Any] = {},
37 merge: str = "inner",
38 filesystem: FileSystem = GCSFileSystem(),
39 ) -> pd.DataFrame:
74 86.438 MiB 0.141 MiB 1 grouped = _collect(path, cgroups, rgroups, filesystem)
75
76 # ----------------------------------------
77 # Concatenate all rgroups
78 # ----------------------------------------
79 86.438 MiB 0.000 MiB 1 frames = []
80
81 731.676 MiB -3327.988 MiB 2 for group in grouped:
82 86.438 MiB 0.000 MiB 1 datafiles = grouped[group]
83 86.438 MiB 0.000 MiB 1 args = read_args.copy()
84 86.438 MiB 0.000 MiB 1 if group in cgroup_args:
85 args.update(cgroup_args[group])
86 4059.664 MiB -184418.691 MiB 403 frames.append(pd.concat(read_df(d, **args) for d in datafiles))
87
88 # ----------------------------------------
89 # Merge all cgroups
90 # ----------------------------------------
91 731.691 MiB 0.016 MiB 1 df = _merge_all(frames, merge=merge)
92
93 # ----------------------------------------
94 # Delete temporary files
95 # ----------------------------------------
96 731.746 MiB 0.016 MiB 201 for file in datafiles:
97 731.746 MiB 0.039 MiB 200 if hasattr(file.handle, "name"):
98 tmp_file_path = file.handle.name
99 if os.path.exists(tmp_file_path):
100 os.remove(file.handle.name)
101 731.754 MiB 0.008 MiB 1 return df
Line # Mem usage Increment Occurences Line Contents
============================================================
30 104.570 MiB 104.570 MiB 1 @profile
31 def assemble(
32 path: str,
33 cgroups: Optional[Sequence[cgroup]] = None,
34 rgroups: Optional[Sequence[rgroup]] = None,
35 read_args: Any = {},
36 cgroup_args: Dict[cgroup, Any] = {},
37 merge: str = "inner",
38 filesystem: FileSystem = GCSFileSystem(),
39 ) -> pd.DataFrame:
74 104.805 MiB 0.234 MiB 1 grouped = _collect(path, cgroups, rgroups, filesystem)
75
76 # ----------------------------------------
77 # Concatenate all rgroups
78 # ----------------------------------------
79 104.805 MiB 0.000 MiB 1 frames = []
80
81 30356.867 MiB 0.000 MiB 2 for group in grouped:
82 104.805 MiB 0.000 MiB 1 datafiles = grouped[group]
83 104.805 MiB 0.000 MiB 1 args = read_args.copy()
84 104.805 MiB 0.000 MiB 1 if group in cgroup_args:
85 args.update(cgroup_args[group])
86 30356.867 MiB 30248.691 MiB 403 frames.append(pd.concat(read_df(d, **args) for d in datafiles))
87
88 # ----------------------------------------
89 # Merge all cgroups
90 # ----------------------------------------
91 30356.867 MiB 0.000 MiB 1 df = _merge_all(frames, merge=merge)
92
93 # ----------------------------------------
94 # Delete temporary files
95 # ----------------------------------------
96 30356.867 MiB 0.000 MiB 201 for file in datafiles:
97 30356.867 MiB 0.000 MiB 200 if hasattr(file.handle, "name"):
98 tmp_file_path = file.handle.name
99 if os.path.exists(tmp_file_path):
100 os.remove(file.handle.name)
101 30356.867 MiB 0.000 MiB 1 return df