Compatible with all the major/latest Tensorflow versions (from 1.14 to 2.4.0+).
![]()
pip install keras-tcnKeras Temporal Convolutional Network. [paper]
- Keras TCN
- TCNs exhibit longer memory than recurrent architectures with the same capacity.
- Constantly performs better than LSTM/GRU architectures on a vast range of tasks (Seq. MNIST, Adding Problem, Copy Memory, Word-level PTB...).
- Parallelism, flexible receptive field size, stable gradients, low memory requirements for training, variable length inputs...
 Visualization of a stack of dilated causal convolutional layers (Wavenet, 2016)
Visualization of a stack of dilated causal convolutional layers (Wavenet, 2016)
The usual way is to import the TCN layer and use it inside a Keras model. An example is provided below for a regression task (cf. tasks/ for other examples):
from tensorflow.keras.layers import Dense
from tensorflow.keras import Input, Model
from tcn import TCN, tcn_full_summary
batch_size, timesteps, input_dim = None, 20, 1
def get_x_y(size=1000):
import numpy as np
pos_indices = np.random.choice(size, size=int(size // 2), replace=False)
x_train = np.zeros(shape=(size, timesteps, 1))
y_train = np.zeros(shape=(size, 1))
x_train[pos_indices, 0] = 1.0
y_train[pos_indices, 0] = 1.0
return x_train, y_train
i = Input(batch_shape=(batch_size, timesteps, input_dim))
o = TCN(return_sequences=False)(i) # The TCN layers are here.
o = Dense(1)(o)
m = Model(inputs=[i], outputs=[o])
m.compile(optimizer='adam', loss='mse')
tcn_full_summary(m, expand_residual_blocks=False)
x, y = get_x_y()
m.fit(x, y, epochs=10, validation_split=0.2)In the example above, TCNs can also be stacked together, like this:
o = TCN(return_sequences=True)(i)
o = TCN(return_sequences=False)(o)A ready-to-use TCN model can be used that way (cf. tasks/ for the full code):
from tcn import compiled_tcn
model = compiled_tcn(...)
model.fit(x, y) # Keras model.TCN(nb_filters=64, kernel_size=2, nb_stacks=1, dilations=[1, 2, 4, 8, 16, 32], padding='causal', use_skip_connections=False, dropout_rate=0.0, return_sequences=True, activation='relu', kernel_initializer='he_normal', use_batch_norm=False, **kwargs)
nb_filters: Integer. The number of filters to use in the convolutional layers. Would be similar tounitsfor LSTM.kernel_size: Integer. The size of the kernel to use in each convolutional layer.dilations: List. A dilation list. Example is: [1, 2, 4, 8, 16, 32, 64].nb_stacks: Integer. The number of stacks of residual blocks to use.padding: String. The padding to use in the convolutions. 'causal' for a causal network (as in the original implementation) and 'same' for a non-causal network.use_skip_connections: Boolean. If we want to add skip connections from input to each residual block.return_sequences: Boolean. Whether to return the last output in the output sequence, or the full sequence.dropout_rate: Float between 0 and 1. Fraction of the input units to drop.activation: The activation used in the residual blocks o = activation(x + F(x)).kernel_initializer: Initializer for the kernel weights matrix (Conv1D).use_batch_norm: Whether to use batch normalization in the residual layers or not.kwargs: Any other arguments for configuring parent class Layer. For example "name=str", Name of the model. Use unique names when using multiple TCN.
3D tensor with shape (batch_size, timesteps, input_dim).
timesteps can be None. This can be useful if each sequence is of a different length: Multiple Length Sequence Example.
- if
return_sequences=True: 3D tensor with shape(batch_size, timesteps, nb_filters). - if
return_sequences=False: 2D tensor with shape(batch_size, nb_filters).
- Regression (Many to one) e.g. adding problem
- Classification (Many to many) e.g. copy memory task
- Classification (Many to one) e.g. sequential mnist task
For a Many to Many regression, a cheap fix for now is to change the number of units of the final Dense layer.
- Receptive field = nb_stacks_of_residuals_blocks * kernel_size * last_dilation.
- If a TCN has only one stack of residual blocks with a kernel size of 2 and dilations [1, 2, 4, 8], its receptive field is 2 * 1 * 8 = 16. The image below illustrates it:
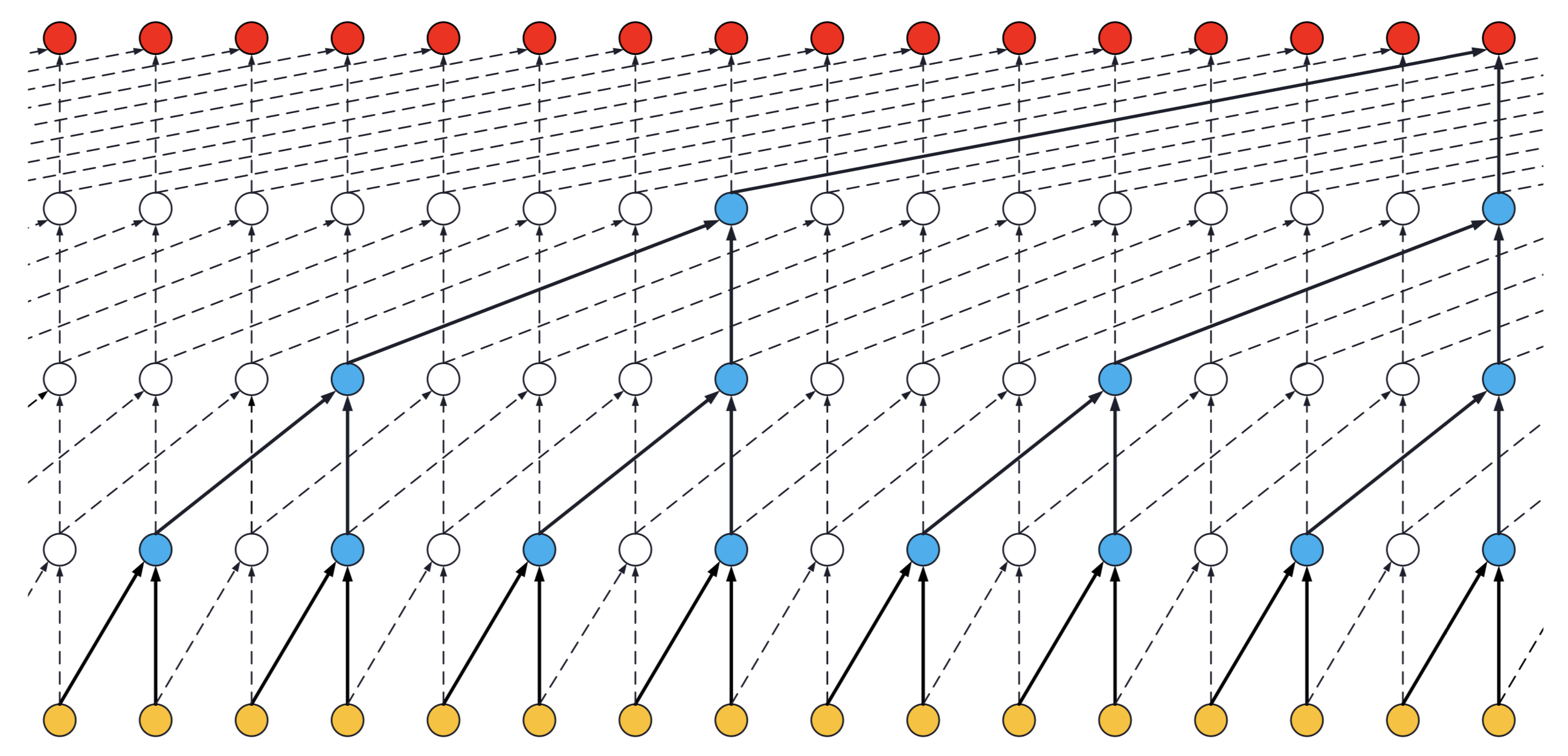 ks = 2, dilations = [1, 2, 4, 8], 1 block
ks = 2, dilations = [1, 2, 4, 8], 1 block
- If the TCN has now 2 stacks of residual blocks, wou would get the situation below, that is, an increase in the receptive field to 32:
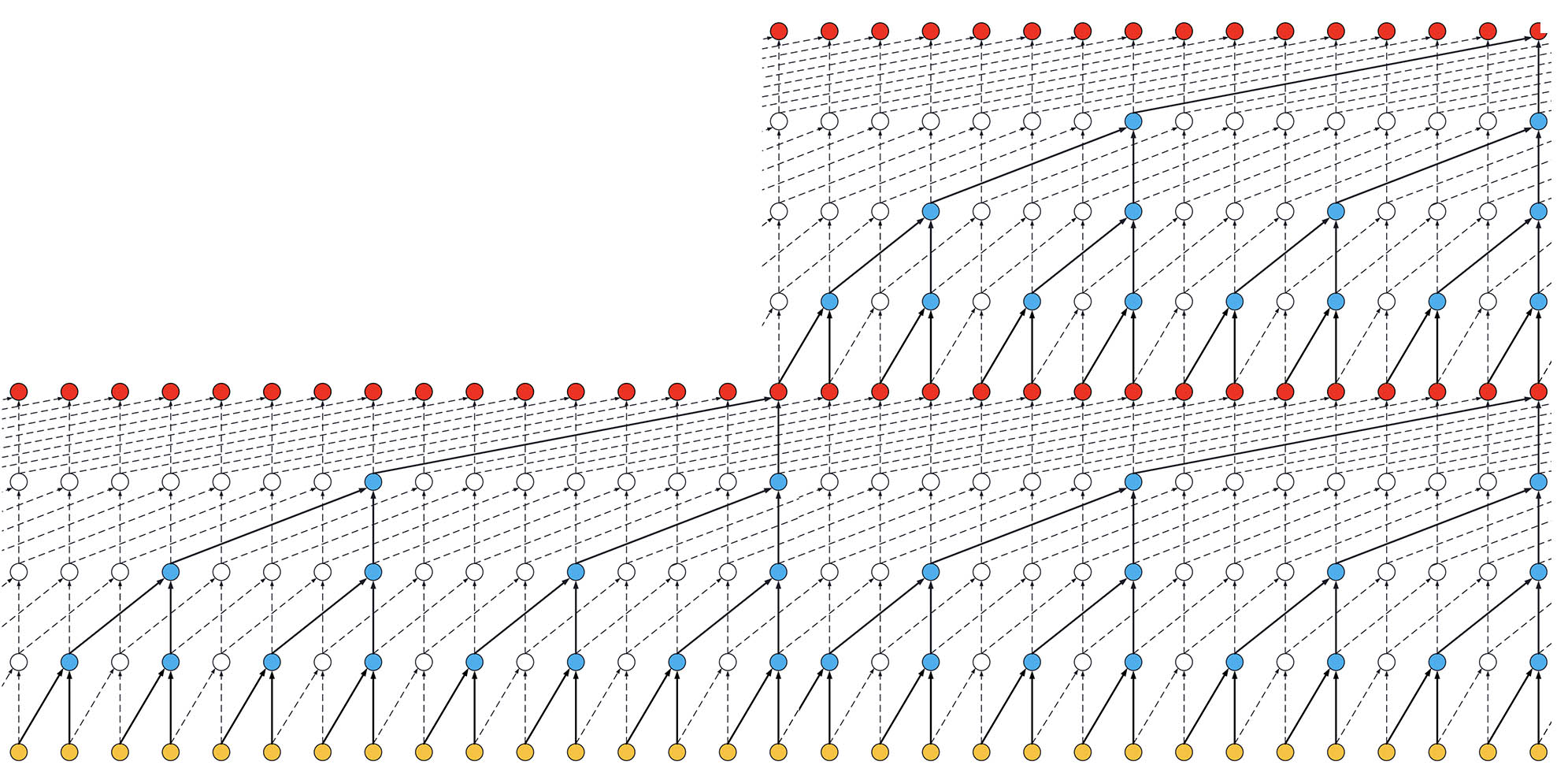 ks = 2, dilations = [1, 2, 4, 8], 2 blocks
ks = 2, dilations = [1, 2, 4, 8], 2 blocks
- If we increased the number of stacks to 3, the size of the receptive field would increase again, such as below:
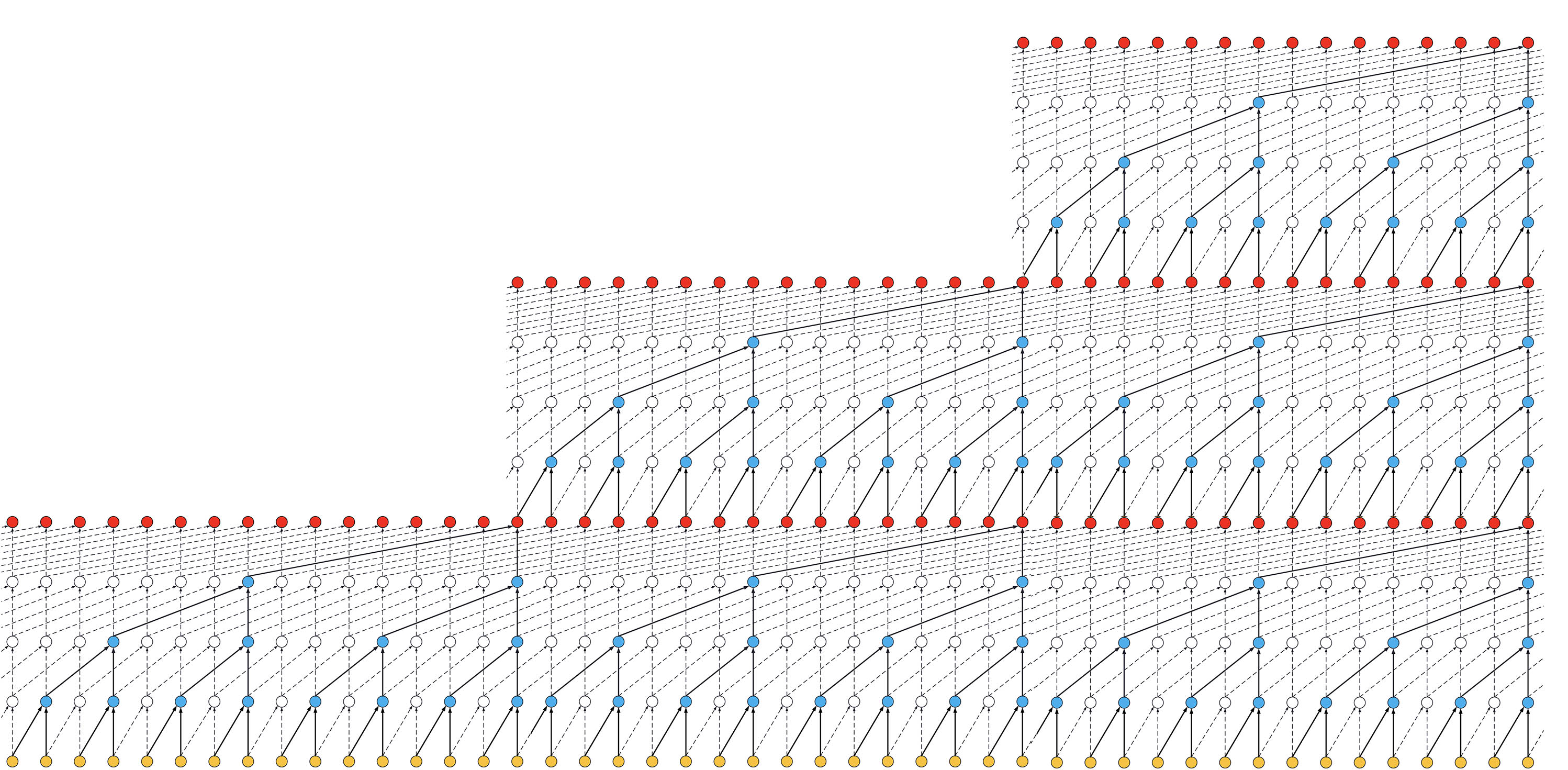 ks = 2, dilations = [1, 2, 4, 8], 3 blocks
ks = 2, dilations = [1, 2, 4, 8], 3 blocks
Thanks to @alextheseal for providing such visuals.
Making the TCN architecture non-causal allows it to take the future into consideration to do its prediction as shown in the figure below.
However, it is not anymore suitable for real-time applications.
 Non-Causal TCN - ks = 3, dilations = [1, 2, 4, 8], 1 block
Non-Causal TCN - ks = 3, dilations = [1, 2, 4, 8], 1 block
To use a non-causal TCN, specify padding='valid' or padding='same' when initializing the TCN layers.
Special thanks to: @qlemaire22
git clone [email protected]:philipperemy/keras-tcn.git
cd keras-tcn
virtualenv -p python3.6 venv
source venv/bin/activate
pip install -r requirements.txt # change to tensorflow if you dont have a gpu.
pip install . --upgrade # install it as a package.Note: Only compatible with Python 3 at the moment. Should be almost compatible with python 2.
Once keras-tcn is installed as a package, you can take a glimpse of what's possible to do with TCNs. Some tasks examples are available in the repository for this purpose:
cd adding_problem/
python main.py # run adding problem task
cd copy_memory/
python main.py # run copy memory task
cd mnist_pixel/
python main.py # run sequential mnist pixel taskReproducible results are possible on (NVIDIA) GPUs using the tensorflow-determinism library. It was tested with keras-tcn by @lingdoc and he got reproducible results.
The task consists of feeding a large array of decimal numbers to the network, along with a boolean array of the same length. The objective is to sum the two decimals where the boolean array contain the two 1s.
 Adding Problem Task
Adding Problem Task
782/782 [==============================] - 154s 197ms/step - loss: 0.8437 - val_loss: 0.1883
782/782 [==============================] - 154s 196ms/step - loss: 0.0702 - val_loss: 0.0111
782/782 [==============================] - 153s 195ms/step - loss: 0.0053 - val_loss: 0.0038
782/782 [==============================] - 154s 196ms/step - loss: 0.0035 - val_loss: 0.0027
782/782 [==============================] - 153s 196ms/step - loss: 0.0030 - val_loss: 0.0065
782/782 [==============================] - 151s 193ms/step - loss: 0.0027 - val_loss: 0.0018
782/782 [==============================] - 152s 194ms/step - loss: 0.0025 - val_loss: 0.0036
782/782 [==============================] - 153s 196ms/step - loss: 0.0024 - val_loss: 0.0018
782/782 [==============================] - 152s 194ms/step - loss: 0.0023 - val_loss: 0.0016
782/782 [==============================] - 152s 194ms/step - loss: 0.0014 - val_loss: 3.7456e-04
782/782 [==============================] - 153s 196ms/step - loss: 9.4740e-04 - val_loss: 7.0205e-04
782/782 [==============================] - 152s 194ms/step - loss: 6.9630e-04 - val_loss: 3.7180e-04
The copy memory consists of a very large array:
- At the beginning, there's the vector x of length N. This is the vector to copy.
- At the end, N+1 9s are present. The first 9 is seen as a delimiter.
- In the middle, only 0s are there.
The idea is to copy the content of the vector x to the end of the large array. The task is made sufficiently complex by increasing the number of 0s in the middle.
 Copy Memory Task
Copy Memory Task
118/118 [==============================] - 17s 143ms/step - loss: 1.1732 - accuracy: 0.6725 - val_loss: 0.1119 - val_accuracy: 0.9796
118/118 [==============================] - 15s 125ms/step - loss: 0.0645 - accuracy: 0.9831 - val_loss: 0.0402 - val_accuracy: 0.9853
118/118 [==============================] - 15s 125ms/step - loss: 0.0393 - accuracy: 0.9856 - val_loss: 0.0372 - val_accuracy: 0.9857
118/118 [==============================] - 15s 125ms/step - loss: 0.0361 - accuracy: 0.9858 - val_loss: 0.0344 - val_accuracy: 0.9860
118/118 [==============================] - 15s 125ms/step - loss: 0.0345 - accuracy: 0.9860 - val_loss: 0.0335 - val_accuracy: 0.9864
118/118 [==============================] - 15s 125ms/step - loss: 0.0325 - accuracy: 0.9867 - val_loss: 0.0268 - val_accuracy: 0.9886
118/118 [==============================] - 15s 125ms/step - loss: 0.0268 - accuracy: 0.9885 - val_loss: 0.0206 - val_accuracy: 0.9908
118/118 [==============================] - 15s 125ms/step - loss: 0.0228 - accuracy: 0.9900 - val_loss: 0.0169 - val_accuracy: 0.9933
The idea here is to consider MNIST images as 1-D sequences and feed them to the network. This task is particularly hard because sequences are 28*28 = 784 elements. In order to classify correctly, the network has to remember all the sequence. Usual LSTM are unable to perform well on this task.
 Sequential MNIST
Sequential MNIST
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0949 - accuracy: 0.9706 - val_loss: 0.0763 - val_accuracy: 0.9756
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0831 - accuracy: 0.9743 - val_loss: 0.0656 - val_accuracy: 0.9807
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0752 - accuracy: 0.9763 - val_loss: 0.0604 - val_accuracy: 0.9802
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0685 - accuracy: 0.9785 - val_loss: 0.0588 - val_accuracy: 0.9813
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0624 - accuracy: 0.9801 - val_loss: 0.0545 - val_accuracy: 0.9822
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0603 - accuracy: 0.9812 - val_loss: 0.0478 - val_accuracy: 0.9835
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0566 - accuracy: 0.9821 - val_loss: 0.0546 - val_accuracy: 0.9826
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0503 - accuracy: 0.9843 - val_loss: 0.0441 - val_accuracy: 0.9853
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0486 - accuracy: 0.9840 - val_loss: 0.0572 - val_accuracy: 0.9832
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0453 - accuracy: 0.9858 - val_loss: 0.0424 - val_accuracy: 0.9862
Testing is based on Tox.
pip install tox
tox
- https://github.com/locuslab/TCN/ (TCN for Pytorch)
- https://arxiv.org/pdf/1803.01271.pdf (An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling)
- https://arxiv.org/pdf/1609.03499.pdf (Original Wavenet paper)
- https://github.com/Baichenjia/Tensorflow-TCN (Tensorflow Eager implementation of TCNs)
@misc{KerasTCN,
author = {Philippe Remy},
title = {Temporal Convolutional Networks for Keras},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/philipperemy/keras-tcn}},
}

![dependabot-preview[bot] avatar](https://avatars.githubusercontent.com/in/2141?v=4 "dependabot-preview[bot]")









