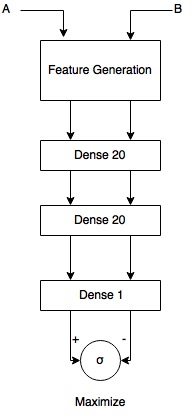
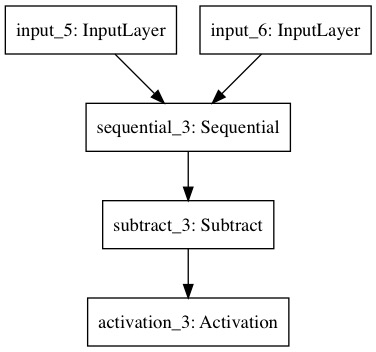
Below is part of the log. Can you please help to identify the cause?
Thanks.
........
........
INFO:tensorflow:Number of queries: 622450
INFO:tensorflow:Number of documents in total: 9436717
INFO:tensorflow:Number of documents discarded: 0
INFO:tensorflow:Loading data from /home/Downloads/train.tsv
INFO:tensorflow:Number of queries: 298651
INFO:tensorflow:Number of documents in total: 4519591
INFO:tensorflow:Number of documents discarded: 0
INFO:tensorflow:Loading data from /home/Downloads/evaluation.tsv
INFO:tensorflow:Number of queries: 298651
INFO:tensorflow:Number of documents in total: 4519591
INFO:tensorflow:Number of documents discarded: 0
INFO:tensorflow:Using config: {'_model_dir': '/tmp/output', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': 1000, '_save_checkpoints_secs': None, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f4fa0320d30>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
WARNING:tensorflow:Estimator's model_fn (<function make_groupwise_ranking_fn.._model_fn at 0x7f4fa032a620>) includes params argument, but params are not passed to Estimator.
INFO:tensorflow:Not using Distribute Coordinator.
INFO:tensorflow:Running training and evaluation locally (non-distributed).
INFO:tensorflow:Start train and evaluate loop. The evaluate will happen after every checkpoint. Checkpoint frequency is determined based on RunConfig arguments: save_checkpoints_steps 1000 or save_checkpoints_secs None.
INFO:tensorflow:Skipping training since max_steps has already saved.
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Use groupwise dnn v2.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2019-01-04-15:25:52
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/output/model.ckpt-100
Traceback (most recent call last):
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1334, in _do_call
return fn(*args)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1319, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1407, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Assign requires shapes of both tensors to match. lhs shape= [18,256] rhs shape= [136,256]
[[{{node save/Assign_18}} = Assign[T=DT_FLOAT, _class=["loc:@group_score/dense/kernel"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](group_score/dense/kernel, save/RestoreV2:18)]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1546, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 929, in run
run_metadata_ptr)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1152, in _run
feed_dict_tensor, options, run_metadata)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1328, in _do_run
run_metadata)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1348, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Assign requires shapes of both tensors to match. lhs shape= [18,256] rhs shape= [136,256]
[[node save/Assign_18 (defined at /home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py:323) = Assign[T=DT_FLOAT, _class=["loc:@group_score/dense/kernel"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](group_score/dense/kernel, save/RestoreV2:18)]]
Caused by op 'save/Assign_18', defined at:
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 338, in
tf.app.run()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 329, in main
train_and_eval()
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 323, in train_and_eval
estimator.evaluate(input_fn=test_input_fn, hooks=[test_hook])
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 478, in evaluate
return _evaluate()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 467, in _evaluate
output_dir=self.eval_dir(name))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 1591, in _evaluate_run
config=self._session_config)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/evaluation.py", line 271, in _evaluate_once
session_creator=session_creator, hooks=hooks) as session:
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 921, in init
stop_grace_period_secs=stop_grace_period_secs)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 643, in init
self._sess = _RecoverableSession(self._coordinated_creator)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1107, in init
_WrappedSession.init(self, self._create_session())
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1112, in _create_session
return self._sess_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 800, in create_session
self.tf_sess = self._session_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 557, in create_session
self._scaffold.finalize()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 213, in finalize
self._saver = training_saver._get_saver_or_default() # pylint: disable=protected-access
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 886, in _get_saver_or_default
saver = Saver(sharded=True, allow_empty=True)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1102, in init
self.build()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1114, in build
self._build(self._filename, build_save=True, build_restore=True)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1151, in _build
build_save=build_save, build_restore=build_restore)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 789, in _build_internal
restore_sequentially, reshape)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 459, in _AddShardedRestoreOps
name="restore_shard"))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 428, in _AddRestoreOps
assign_ops.append(saveable.restore(saveable_tensors, shapes))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 119, in restore
self.op.get_shape().is_fully_defined())
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/ops/state_ops.py", line 221, in assign
validate_shape=validate_shape)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/ops/gen_state_ops.py", line 61, in assign
use_locking=use_locking, name=name)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py", line 488, in new_func
return func(*args, **kwargs)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3274, in create_op
op_def=op_def)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1770, in init
self._traceback = tf_stack.extract_stack()
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [18,256] rhs shape= [136,256]
[[node save/Assign_18 (defined at /home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py:323) = Assign[T=DT_FLOAT, _class=["loc:@group_score/dense/kernel"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](group_score/dense/kernel, save/RestoreV2:18)]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 338, in
tf.app.run()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 329, in main
train_and_eval()
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 323, in train_and_eval
estimator.evaluate(input_fn=test_input_fn, hooks=[test_hook])
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 478, in evaluate
return _evaluate()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 467, in _evaluate
output_dir=self.eval_dir(name))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 1591, in _evaluate_run
config=self._session_config)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/evaluation.py", line 271, in _evaluate_once
session_creator=session_creator, hooks=hooks) as session:
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 921, in init
stop_grace_period_secs=stop_grace_period_secs)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 643, in init
self._sess = _RecoverableSession(self._coordinated_creator)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1107, in init
_WrappedSession.init(self, self._create_session())
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1112, in _create_session
return self._sess_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 800, in create_session
self.tf_sess = self._session_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 566, in create_session
init_fn=self._scaffold.init_fn)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/session_manager.py", line 288, in prepare_session
config=config)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/session_manager.py", line 202, in _restore_checkpoint
saver.restore(sess, checkpoint_filename_with_path)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1582, in restore
err, "a mismatch between the current graph and the graph")
tensorflow.python.framework.errors_impl.InvalidArgumentError: Restoring from checkpoint failed. This is most likely due to a mismatch between the current graph and the graph from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Assign requires shapes of both tensors to match. lhs shape= [18,256] rhs shape= [136,256]
[[node save/Assign_18 (defined at /home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py:323) = Assign[T=DT_FLOAT, _class=["loc:@group_score/dense/kernel"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](group_score/dense/kernel, save/RestoreV2:18)]]
Caused by op 'save/Assign_18', defined at:
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 338, in
tf.app.run()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 329, in main
train_and_eval()
File "/home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py", line 323, in train_and_eval
estimator.evaluate(input_fn=test_input_fn, hooks=[test_hook])
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 478, in evaluate
return _evaluate()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 467, in _evaluate
output_dir=self.eval_dir(name))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/estimator/estimator.py", line 1591, in _evaluate_run
config=self._session_config)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/evaluation.py", line 271, in _evaluate_once
session_creator=session_creator, hooks=hooks) as session:
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 921, in init
stop_grace_period_secs=stop_grace_period_secs)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 643, in init
self._sess = _RecoverableSession(self._coordinated_creator)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1107, in init
_WrappedSession.init(self, self._create_session())
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 1112, in _create_session
return self._sess_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 800, in create_session
self.tf_sess = self._session_creator.create_session()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 557, in create_session
self._scaffold.finalize()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py", line 213, in finalize
self._saver = training_saver._get_saver_or_default() # pylint: disable=protected-access
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 886, in _get_saver_or_default
saver = Saver(sharded=True, allow_empty=True)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1102, in init
self.build()
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1114, in build
self._build(self._filename, build_save=True, build_restore=True)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1151, in _build
build_save=build_save, build_restore=build_restore)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 789, in _build_internal
restore_sequentially, reshape)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 459, in _AddShardedRestoreOps
name="restore_shard"))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 428, in _AddRestoreOps
assign_ops.append(saveable.restore(saveable_tensors, shapes))
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 119, in restore
self.op.get_shape().is_fully_defined())
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/ops/state_ops.py", line 221, in assign
validate_shape=validate_shape)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/ops/gen_state_ops.py", line 61, in assign
use_locking=use_locking, name=name)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py", line 488, in new_func
return func(*args, **kwargs)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3274, in create_op
op_def=op_def)
File "/tmp/tfr/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1770, in init
self._traceback = tf_stack.extract_stack()
InvalidArgumentError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a mismatch between the current graph and the graph from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Assign requires shapes of both tensors to match. lhs shape= [18,256] rhs shape= [136,256]
[[node save/Assign_18 (defined at /home/Downloads/ranking/./bazel-bin/tensorflow_ranking/examples/tf_ranking_libsvm_py_binary.runfiles/org_tensorflow_ranking/tensorflow_ranking/examples/tf_ranking_libsvm.py:323) = Assign[T=DT_FLOAT, _class=["loc:@group_score/dense/kernel"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](group_score/dense/kernel, save/RestoreV2:18)]]