This project collects Wikipedia articles from a search term entered by the user and formats the data in a .docx document with images related to each section of the collected article.
This project is inspired by the Video Maker project by Filipe Deschamps
All the project is made with NodeJS and uses the following APIs:
- Wikipedia Parser API (from Algorithmia)
- Google Custom Search (from Google Cloud Platform)
- Natural Language Understanding (from IBM CLOUD)
You can use this app by running the index.js file and typing a search term, after this you just need to select a language and wait for the app end the process.
At the end of the process a folder will be created at the root of the project with the same name as the search term containing the .docx document and a folder with the images.
Por Hebert Lima
É necessário criar a sua chave de acesso para poder testar os robôs, pra isso você precisa acessar o site do Algorithmia, aqui não tem muito segredo, basta acessar e se cadastrar, depois de logar na sua conta, na Dashboard procure no menu Api Keys e copie.

vá até a pasta do projeto onde você clonou o repositório, navegue até a pasta credentials, dentro do arquivo algorithmia.json você irá colocar a API que copiou do site Algorithmia na estrutura abaixo:
{
"apiKey": "API_KEY_AQUI"
}Você precisa criar também as credenciais do Watson no site da IBM, também não tem segredo, basta se cadastrar, quando estiver logado no menu superior clique em Catálogo, depois dentro de IA procure por Natural Language Understanding

clicando nele na nova página vai aparecer um botão "criar" no final da página, uma vez que o serviço for criado, você será redirecionado para a página de gerenciamento do serviço que você acabou de criar, no menu lateral esquerdo procure por Credenciais de Serviços e depois clique em Auto-generated service credentials destacado abaixo, então copie as Credenciais:

Novamente, voltando na pasta do projeto ainda dentro da pasta credentials você ira encontrar um arquivo json com o nome nlu-watson.json e dentro desse arquivo você vai colar as credenciais que copiou anteriormente:
{
"apikey" : "...",
"iam_apikey_description" : "...",
"iam_apikey_name": "...",
"iam_role_crn": "...",
"iam_serviceid_crn": "...",
"url": "..."
}Antes de criarmos as api's que iremos utilizar é necessário vincular a nossa conta do Google com o Google Cloud Plataform, na página do Google Cloud Plataform você irá clicar no botão Faça uma Avaliação Gratuita:

em seguida marque a opção Termos e Condições

Ps.: É importante lembrar que alguns recursos do Google Cloud Plataform são Pagos, por esse motivo é necessário inserir as informações de pagamento, mas fique tranquilo porque iremos utilizar apenas os recursos Gratuitos

Agora é a hora de criarmos um projeto que iremos vincular as Api's que vamos utilizar, para isso basta clicar no menu do topo da página "Selecionar projeto" e depois em "Novo Projeto":
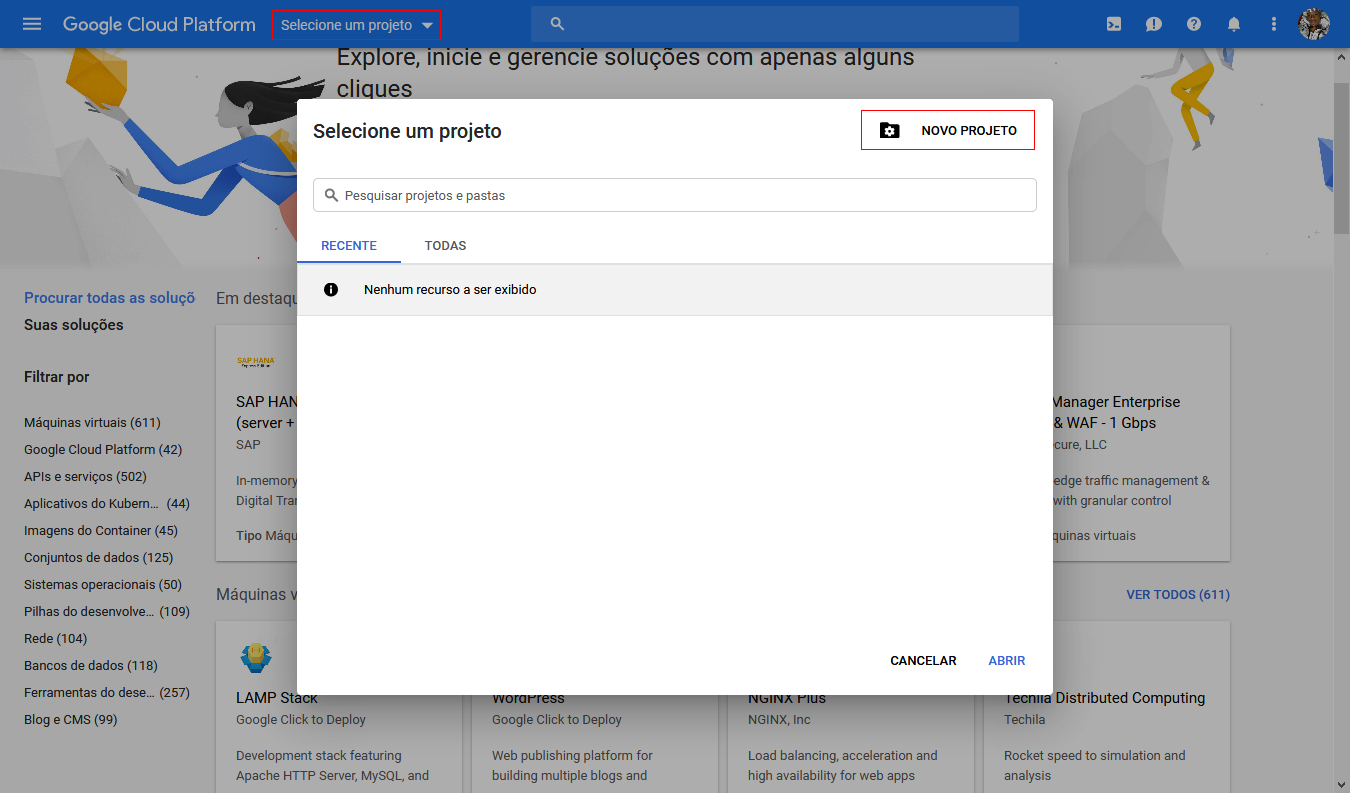
de um nome ao projeto e clique no botão criar:
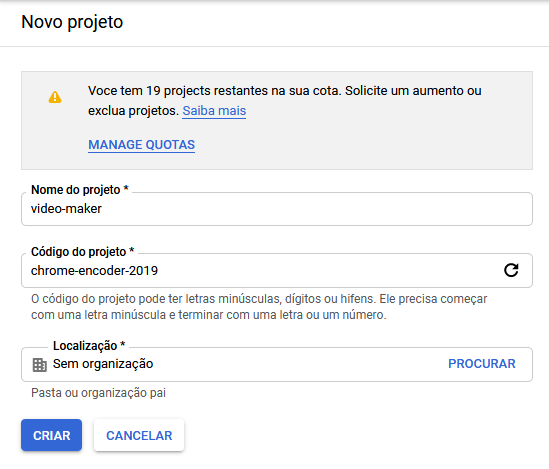
após isso o projeto começará a ser criado e assim que terminar um menu vai aparecer com o projeto que acabamos de criar então você irá seleciona-lo:
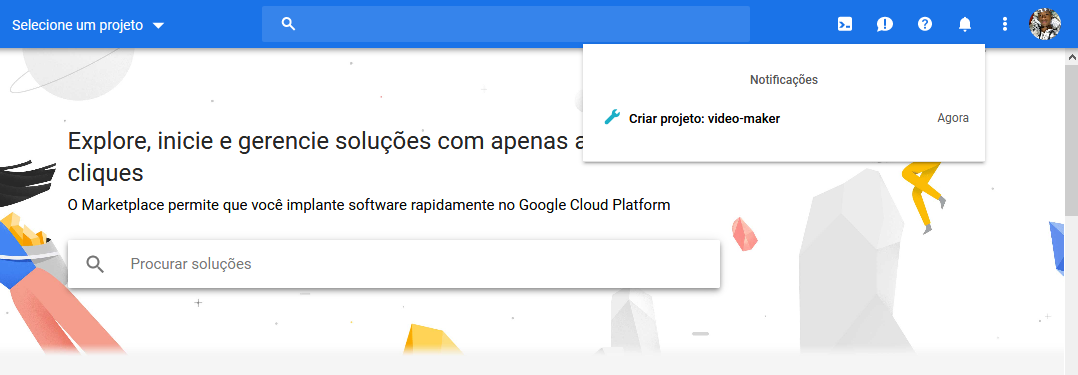
Com o projeto criado agora é hora de habilitarmos e configurarmos a Api, você irá clicar no menu lateral esquerdo no topo navegar até API's e Serviços > Bibliotecas:
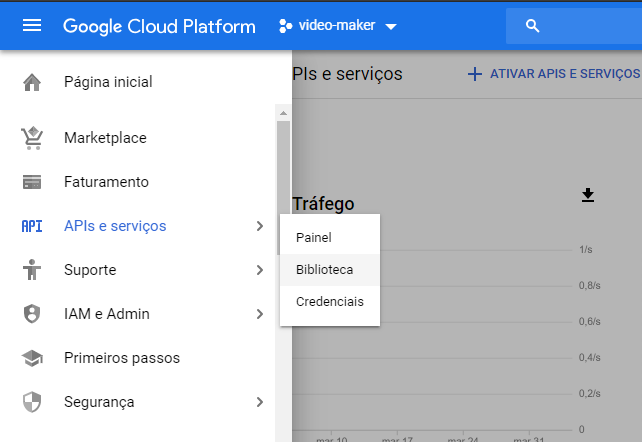
no campo de pesquisa basta procurar por Custom Search API, clicar em Ativar, e aguardar até a ativação da api:
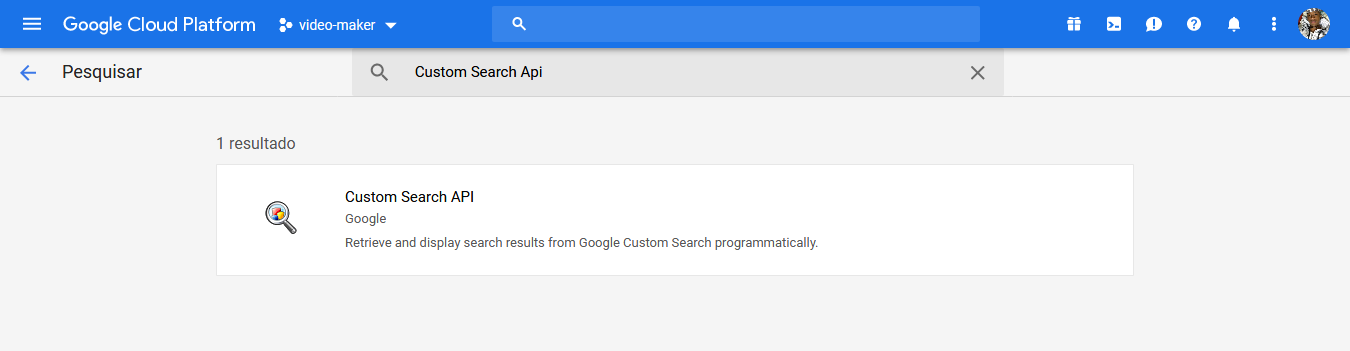
Após a ativação vai aparecer uma mensagem solicitando a criação das credenciais da API, então basta você clicar em Criar Credenciais:

Procure por Custom Search API no dropdown e clique em "Preciso de quais credenciais?"
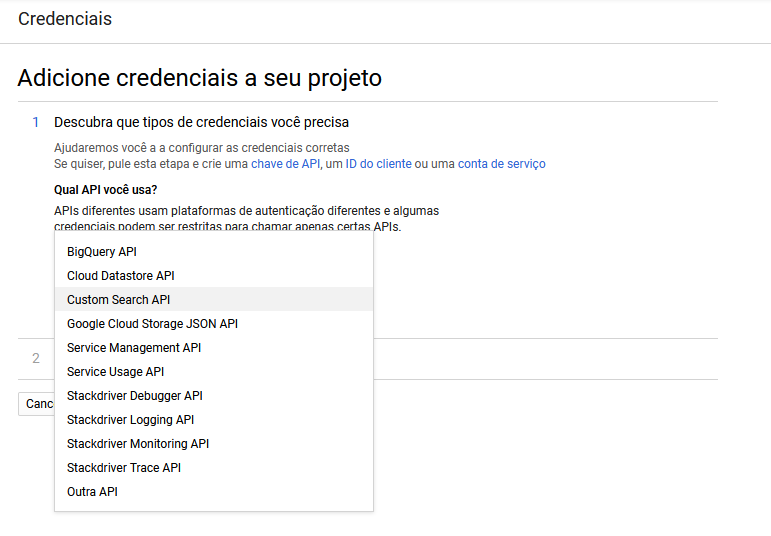
Após isso irá aparecer sua Api Key, você vai copia-la e clicar no botão concluir, voltando a pasta do projeto você vai navegar até credentials e irá criar um novo arquivo chamado google-custom-search.json com o conteúdo abaixo:
{
"apiKey": "API_KEY_AQUI"
}
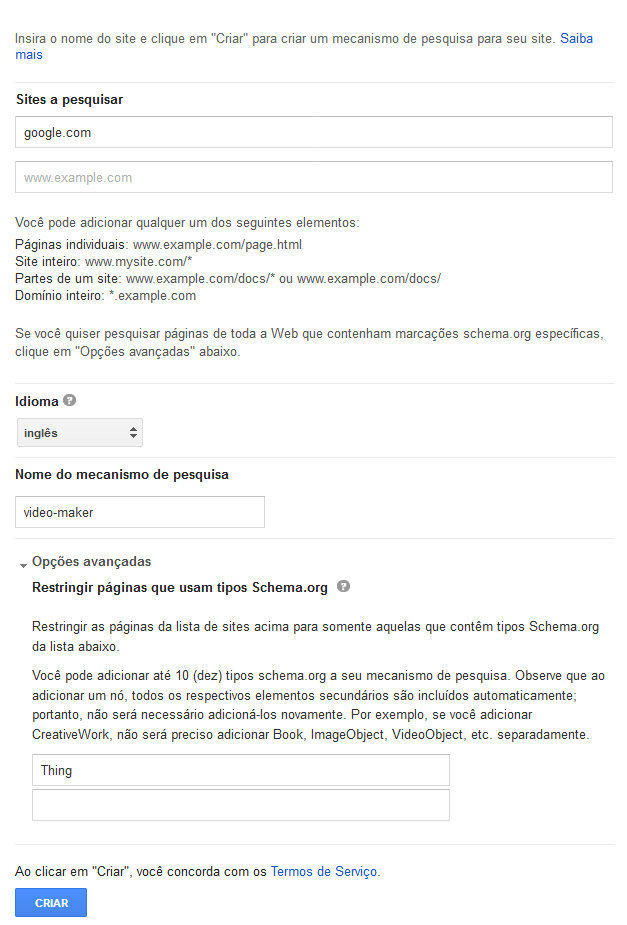
Agora iremos configurar o nosso motor de busca personalizado do google, para isso você vai acessar o Custom Search Engine, e irá informar o site a pesquisar coloque google.com, irá selecionar o idioma que preferir, e por fim clique em Opções avançadas e para o esquema iremos utilizar o mais genérico Thing, pronto tudo preenchido você irá clicar em criar:
PS.: Para saber mais sobre o schema acesse schema.org.
Ps.: Caso não apareça a opção para selecionar o Schema você poderá selecionar no Painel de Controle clicando em Configurações avançadas na parte inferior da tela. Veja a seguir
Agora basta clicar em Painel de Controle na nova tela nós iremos habilitar a opção Pesquisa de imagens e depois iremos clicar no botão Copiar para área de transferência"
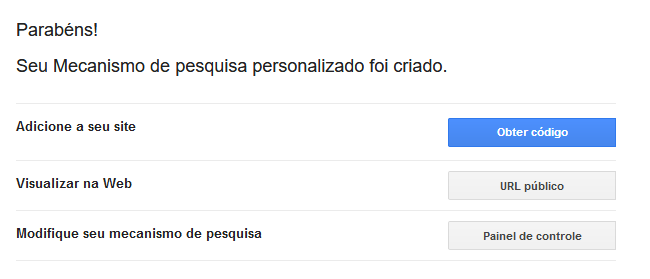
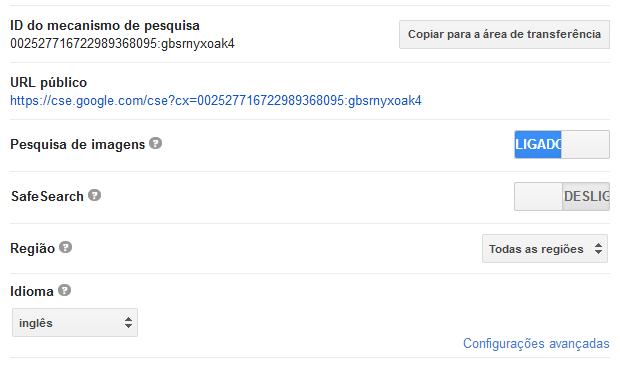
Voltando no arquivo google-custom-search.json iremos criar uma nova propriedade e iremos colar o código identificador do mecanismo de busca que criamos, identificado por searchEngine, no final irá ficar assim:
{
"apiKey": "API_KEY_AQUI",
"searchEngine": "ID_MECANISMO_DE_BUSCA"
}
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")












