- Spotify Web API
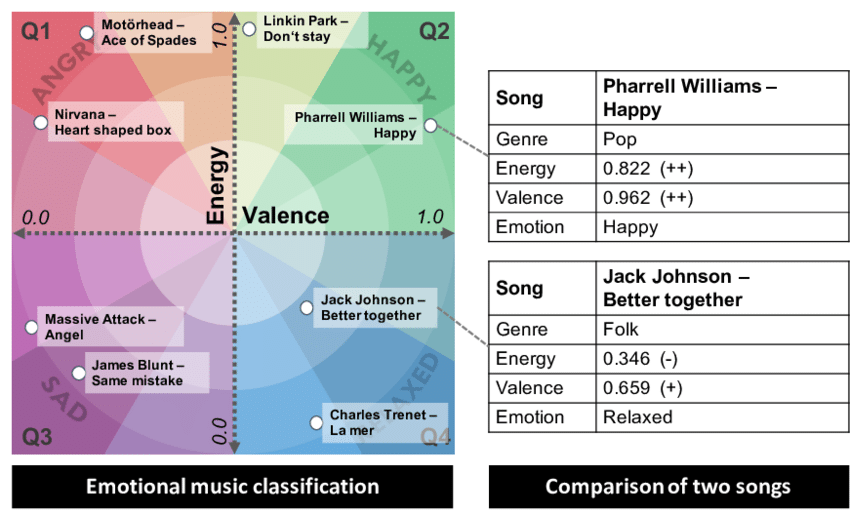
from the feature the system only uses valence and energy. 2. With this the Valence-Arousal Plane, a well known psychological models can be built, that can display all dimensins of mood. The model is it is widely adopted because it strikes a great balance between complexity and predictive power.
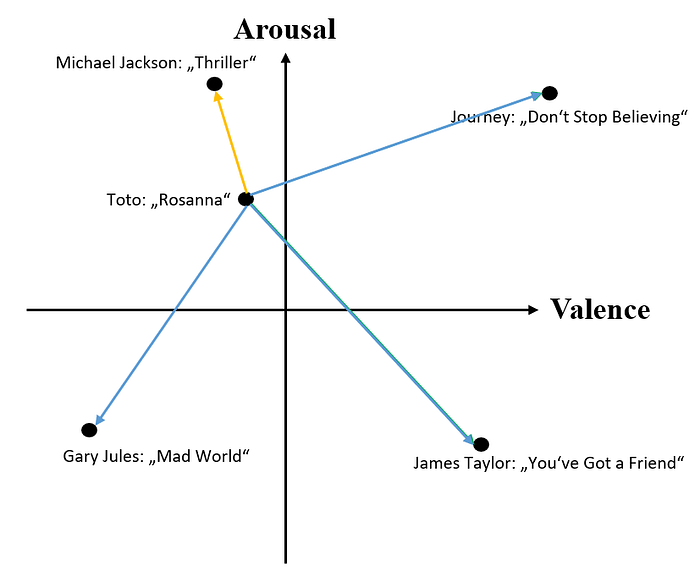
- Vector Distance Model for recommendations:
- Each track can be seen as a vector
- The tracks can be connected through vectors as well
- Tracks with similar vibe = connecting vecktor has lowest length
- -> connect find all the vectors (arrows) connecting a given track with all the other tracks (t2-t1), apply sqrt(a²+b²) to find the norm and take the arrow with the lowest norm/length.
- this can be implemented as: def distance(p1, p2): distance_x = p2[0]-p1[0] distance_y = p2[1]-p1[1] distance_vec = [distance_x, distance_y] norm = (distance_vec[0]**2 + distance_vec[1]2)(1/2) return norm or just use numpy.linalg.norm(p2-p1)
- Authorization with Spotify Client ID and Client Secret.
- Get all of Spotify’s 120 genre labels using <sp.recommendation_genre_seeds()> and set the number of recommendations per genre to 100
- Fetch a dataset of songs from spotify. The system draws 100 tracks from over 120 genres, resulting in a track database of around 12000 tracks with music from various styles.
- For each of these tracks, crawl metadata and audio information and store them in the <data_dict>
- Transform the dictionary to a pandas dataframe, drop duplicate id’s and export the dataframe to working directory: df = pd.read_csv("valence_arousal_dataset.csv")
- Read in the dataframe
- Combine Valence and Mood to a vector
- Use the above generated data to create a recommendation system:
- Crawl the input track’s “valence” and “energy” values from the Spotify API
- Compute the distances between the input track and ALL other tracks in our reference dataset.
- Sort the reference tracks from lowest to highest distance.
- Return the n least distant tracks.
- Tekore for authorization
- pandas
- tqdm
